Алгоритм быстрого нахождения похожих изображений / Хабр
Недавно наткнулся на статью, размещенную на Хабрахабре, посвященную сравнению изображений «Выглядит похоже». Как работает перцептивный хэш. Так как я сам достаточно долго занимался этой тематикой (являюсь автором программы AntiDupl), то мне захотелось поделиться здесь своим опытом по данному вопросу. В статье я приведу два варианта алгоритма сравнения похожих изображений — базовый и улучшенный. Все они были проверены автором на практике в рамках указанного выше проекта. Изложение мое будет вестись без строгих доказательств, сложных формул и специальной математической терминологии. Надеюсь, что читатели простят меня за это.
Мера схожести изображений
При сравнении похожих изображений первым встает вопрос: что считать мерой схожести изображений? Очевидно, что это величина имеет значение обратное различию изображений друг от друга. Следственно нужно выбрать некую метрику, характеризующую различие изображений друг от друга. Тогда схожими изображениями будут считаться изображения, отличие между которыми меньше некоторого порога. Для изображений с одинаковыми габаритами, обычно такой мерой различия служит среднеквадратическое отклонение пикселей одного изображения от другого. Хотя конечно, нам ни что не мешает выбрать другую метрику, например усредненную абсолютную разность пикселей изображений друг от друга.
Следственно нужно выбрать некую метрику, характеризующую различие изображений друг от друга. Тогда схожими изображениями будут считаться изображения, отличие между которыми меньше некоторого порога. Для изображений с одинаковыми габаритами, обычно такой мерой различия служит среднеквадратическое отклонение пикселей одного изображения от другого. Хотя конечно, нам ни что не мешает выбрать другую метрику, например усредненную абсолютную разность пикселей изображений друг от друга.
Картинки разных размеров
Вопрос несколько усложняется, если нужно сравнить изображения разных размеров. Однако достаточно очевидным решением этой проблемы является приведение всех изображений к одинаковому размеру. Остается выбрать это размер — если выбрать его слишком маленьким, то очевидно, что различия между изображениями тогда будут нивелироваться, и у нас будет много ложно положительных срабатываний. При слишком большом размере неоправданно повышается ресурсоёмкость алгоритма сравнения.
Основные шаги
Итак, простейший вариант алгоритма сравнения похожих изображений будет включать в себя следующие шаги:
- Приведение всех изображений к одному размеру (возьмем для определенности размер 32х32).
- Отбрасыванию цветовой информации (преобразование в серое изображение).
- Нахождение среднеквадратической разности для каждой пары уменьшенных серых изображений.
- Сравнение полученной среднеквадратической разности с некоторым порогом.
Здесь порог определяет меру схожести изображений. Так если выбрать порогом 0%, то алгоритм найдет только полностью идентичные изображения.
Недостатки базового алгоритма
К недостаткам данного алгоритма, можно отнести его плохую чувствительность при сравнении слабо контрастных изображений, а также изображений без крупномасштабных особенностей (контурные рисунки, изображения текста). Слабая чувствительность объясняется тем, что при уменьшении исходного изображения до размера 32х32, как правило все такие изображения становятся не различимыми друг от друга. 13 операций, что может занять существенное время даже на современном железе.
13 операций, что может занять существенное время даже на современном железе.
Как уже было сказано, у данной базовой реализации алгоритма две проблемы — невысокая точность на изображениях без крупномасштабных особенностей и квадратичная зависимость времени исполнения от общего числа изображений. Первая проблема достаточно специфична и характерна для довольно узкого круга изображений, потому далее мы сосредоточимся на решении второй проблемы. Очевидно, что данный алгоритм хорошо распараллеливается и векторизуется. Однако, в рамках данной статьи мне хотелось бы остановиться не на программной, а на алгоритмической оптимизации данного алгоритма.
Соотношение сторон
Визуально одинаковые изображения, как правило, обладают близкими соотношениями ширины и высоты. Отсюда логичный вывод — сравнивать только изображения с близкими соотношениями сторон. На практике, большинство изображений в одной коллекции, как правило, имеет одинаковое соотношение сторон (например — 3:4), но имеет разную ориентацию (вертикальную или горизонтальную).
Предварительное сравнение
Первый самый очевидный шаг: если мы один раз уменьшили изображение, то почему бы не сделать это снова? Делаем из картинки 32х32 картинку размером 4х4, где каждая точка уменьшенного изображения представляет собой усредненную яркость соответствующей части исходного изображения размером 8х8. Можно математически строго доказать, что среднеквадратическая разность для этого уменьшенного изображения будет не больше, чем среднеквадратическая разность исходного изображения. Следовательно, мы можем путем предварительного сравнения уменьшенных изображений размером 4х4 создать своеобразный фильтр, который будет отсеивать большую часть кандидатов на полноценное сравнение (при условии, что в выборке большая часть изображений относительно уникальны).
i[0] = (p[0][0] + p[0][1] + p[1][0] + p[1][1])/4,
который представляет собой среднюю яркость нашего изображения. Фактически, это изображение, уменьшенное до размера 1х1. Среднеквадратическая разность исходных изображений, будет не меньше, чем разность их интенсивностей. Таким образом, если порог для сравнения изображений имеет значение t, то все возможные кандидаты на сравнение должны иметь среднюю яркость в диапазоне от i[0] — t до i[0] + t. Фактически, если мы отсортируем все изображения по индексу i[0], то можем проводить сравнение со значительно меньшим числом изображений — 2*t/255. Не сложно подсчитать, что для типичного порога в 5% — имеем теоретический выигрыш в 10 раз. Практически, выигрыш будет меньше, так как статистическое распределение изображений по средней яркости не равномерно в диапазоне [0.
Многомерное индексирование изображений
Помимо средней яркости i[0], из изображения размером 2×2 можно построить еще 3 дополнительных индекса:
i[1] = 128 + (p[0][0] — p[0][1] + p[1][0] — p[1][1])/4,
i[2] = 128 + (p[0][0] + p[0][1] — p[1][0] — p[1][1])/4,
i[3] = 128 + (p[0][0] — p[0][1] — p[1][0] + p[1][1])/4,
которые имеют простой физический смысл: индекс i[1] показывает на сколько левая часть изображения ярче чем правая, i[2] — на сколько верхняя часть ярче нижней, а i[3] — на сколько отличаются диагонали изображения. По всем этим индексам можно также отсортировать изображения, как и по первому, причем все возможные кандидаты на сравнение будут лежать в диапазонах от i[j] — t до i[j] + t. Т.е. в четырехмерном пространстве, образованном этими индексами область поиска будет представлять 4-х мерный куб со стороной 2*t и центром с координатами, образованными индексами искомого изображения.
Основные этапы улучшенного алгоритма
И так, можно обобщить наши рассуждения и привести основные шаги, которые необходимо сделать в рамка алгоритма быстрого сравнения изображений.
- Приведение всех изображений к одному размеру (32х32) и отбрасывание цветовой информации.
- Нахождение уменьшенного изображения для предварительного сравнения размером 4х4.
- Построение n-мерного индекса изображения на основании изображения для предварительного сравнения.
 2). Также стоит отметить, что на практике для реализации сортировки по n-мерному индексному пространству приходится организовывать n-мерный массив со списками изображений, лежащих в определенном диапазоне индексов. Что вносит дополнительные накладные расходы и делает неоправданным использование индексирования большой размерности, а также не эффективность такого индексирования для небольших коллекций изображений.
2). Также стоит отметить, что на практике для реализации сортировки по n-мерному индексному пространству приходится организовывать n-мерный массив со списками изображений, лежащих в определенном диапазоне индексов. Что вносит дополнительные накладные расходы и делает неоправданным использование индексирования большой размерности, а также не эффективность такого индексирования для небольших коллекций изображений.В целом, если суммировать все улучшения, которые применяются в улучшенном варианте алгоритма, то получаем выигрыш на 3-4 порядка по сравнению с базовой реализацией. Тесты на больших коллекциях изображений показывают, что это действительно так. Так непосредственно сравнение изображений друг с другом занимает порядка 30 сек на одноядерном процессоре для коллекции 100 тысяч изображений. На практике, скорость сравнения становится несущественным фактором в общем процессе поиска изображений — ведь их еще нужно найти, считать с диска и сформировать уменьшенные изображения (хотя конечно последние два пункта можно выполнять только 1 раз, так как очевидно, что уменьшенные изображения весом всего по 1000 байт целесообразно сохранять для повторного использования).
Надеюсь, что читателей заинтересовало мое изложение. Возможно, даже кому-то показалось полезным. Жду отзывов.
C момента написания данной статьи прошло достаточно много времени. Я решил сделать небольше дополнение к ней. В рамках проекта Simd был написан класс на C++ ImageMatcher, который реализует алгоритм, описанный в данной статье. Приятного использования!
Python. Как сравнить фотографии? — Machine learning на vc.ru
Наверняка у каждого из Вас есть большой домашний архив фотографий, а в нем лежат собственные снимки и фотографии, которыми с Вами поделились родственники. Просматривая свою фототеку, Вы наткнулись на дубли и тут же возник вопрос – сколько же еще таких? В этой статье я поделюсь тем, как я решал свою задачу по поиску одинаковых фотографий.
27 256 просмотров
Совсем недавно у меня появилась интересная задача – необходимо было найти одинаковые фотографии на разных объектах недвижимости. Т.
е. к объектам недвижимости расположенных с разным местоположением крепилась одна и та же фотография, может ошибочно, может специально, но такие объекты надо было найти. И я хотел бы поделиться тем, как я решал эту задачу. Для примера у Вас может быть домашняя фототека.Инструменты
Посмотрев просторы интернета, первым делом на глаза мне попалась библиотека OpenCV, эта библиотека имеет интерфейсы на различных языках, среди которых Python, Java, C++ и Matlab. Мне стало интересно, есть ли у Python стандартная библиотека для работы с изображениями и вот она – Pillow. Это форк PIL, которая успешно развивается и был принят в качестве замены оригинальной библиотеки. Свой выбор я остановил на ней.
Решение задачи
Начнем работу с библиотекой, и попробуем открыть файл и показать его.
from PIL import Image #указываем необходимое имя файла im=Image.open(‘cbcf449ffc010b9f958d611e787fa48092ac31841.jpg’) # Покажет нам изображение. im.show()
Данный скрипт откроет нам изображение.
Почитав документацию, я нашел функцию, которая по пикселям сравнивает два изображения и выдает разницу. Функция называется difference и находится в модуле ImageChops. Что бы показать принцип работы функции, для примера возьмем фотографию и добавим на нее какой-нибудь текст:from PIL import Image, ImageChops image_1=Image.open(’06ebe74e5dfc3bd7f5e480cf611147bac45c33d2.jpg’) image_2=Image.open(’06ebe74e5dfc3bd7f5e480cf611147bac45c33d2_text.jpg’) result=ImageChops.difference(image_1, image_2) result.show() #Вычисляет ограничивающую рамку ненулевых областей на изображении. print(result.getbbox()) # result.getbbox() в данном случае вернет (0, 0, 888, 666) result.save(‘result.jpg’)
result.show() вернет разницу в пикселях. Так же прошу обратить внимание на result.getbbox(), функция либо вернет рамку где расходятся пиксели, либо вернет None если картинки идентичны. Если мы сравним первую картинку саму с собой, то получим полностью черное изображение.
Напишем простенькую функцию по сравнению двух картинок:
def difference_images(img1, img2): image_1 = Image.
open(img1)
image_2 = Image.open(img2)
result=ImageChops.difference(image_1, image_2).getbbox()
if result==None:
print(img1,img2,’matches’)
returnТеперь необходимо подумать над алгоритмом перебора имеющихся изображений.
path=’images/’ #Путь к папке где лежат файлы для сравнения imgs=os.listdir(path) check_file=0 #Проверяемый файл current_file=0 #Текущий файл while check_file<len(imgs): if current_file==check_file: current_file+=1 continue difference_images(path+imgs[current_file], path+imgs[check_file]) current_file+=1 if current_file==len(imgs): check_file+=1 current_file=check_file
Данный алгоритм перебирает все файлы в папке и сравнивает их между собой исключая проверку между собой и файлы, которые уже были проверены на совпадение.
А если файлов для сравнения очень много и их обработка очень долгая? Можно пойти двумя способами:
- Создать миниатюры и работать с ними.
- Запустить нашу обработку в несколько потоков.
Первый способ простой, в нашу функцию difference_images добавляем несколько строк:
def difference_images(img1, img2): image_1 = Image.open(img1) image_2 = Image.open(img2) size = [400,300] #размер в пикселях image_1.thumbnail(size) #уменьшаем первое изображение image_2.thumbnail(size) #уменьшаем второе изображение #сравниваем уменьшенные изображения result=ImageChops.difference(image_1, image_2).getbbox() if result==None: print(img1,img2,’matches’) return
Второй способ уже сложнее и более интересный, потому что нужно будет управлять и потоками, и очередями, так же нужно будет переписать часть кода. Для этого нам понадобятся следующие библиотеки threading и Queue (подробней можно почитать в интернете), ниже приведен готовый код с внесенными изменениями, я постарался прокомментировать все действия что бы было понятно:
class diff_image(threading.Thread): #класс по сравнению картинок. «»»Потоковый обработчик»»» def __init__(self, queue): «»»Инициализация потока»»» threading.
Thread.__init__(self)
self.queue = queue
def run(self):
«»»Запуск потока»»»
while True:
# Получаем пару путей из очереди
files = self.queue.get()
# Делим и сравниваем
self.difference_images(files.split(‘:’)[0],files.split(‘:’)[1])
# Отправляем сигнал о том, что задача завершена
self.queue.task_done()
def difference_images(self, img1, img2):
image_1 = Image.open(img1)
image_2 = Image.open(img2)
size = [400,300] #размер в пикселях
image_1.thumbnail(size) #уменьшаем первое изображение
image_2.thumbnail(size) #уменьшаем второе изображение
result=ImageChops.difference(image_1, image_2).getbbox()
if result==None:
print(img1,img2,’matches’)
return
def main(path):
imgs=os.listdir(path) #Получаем список картинок
queue = Queue()
# Запускаем поток и очередь
for i in range(4): # 4 — кол-во одновременных потоков
t = diff_image(queue)
t. setDaemon(True)
t.start()
# Даем очереди нужные пары файлов для проверки
check_file=0
current_file=0
while check_file<len(imgs):
if current_file==check_file:
current_file+=1
continue
queue.put(path+imgs[current_file]+’:’+path+imgs[check_file])
current_file+=1
if current_file==len(imgs):
check_file+=1
current_file=check_file
# Ждем завершения работы очереди
queue.join()
if __name__ == «__main__»:
path=’images/’
main(path)Резюме
В результате мы получили готовый алгоритм для поиска одинаковых картинок, а так же постарались ускорить обработку файлов двумя способами. Завершив свою задачу, я обнаружил 1227 совпадений в выборке из 6616 картинок.
Надеюсь, моя статья была полезна. Спасибо за внимание.
Сравнение изображений — быстрый алгоритм
Ниже приведены три подхода к решению этой задачи (и много других).
Первый — это стандартный подход в компьютерном зрении, сопоставление ключевых точек.
Это может потребовать некоторых базовых знаний для реализации и может быть медленным.Второй метод использует только элементарную обработку изображений, потенциально быстрее первого и прост в реализации. Однако, несмотря на то, что он выигрывает в понятности, ему не хватает надежности — сопоставление не работает на масштабированных, повернутых или обесцвеченных изображениях.
Третий метод одновременно быстрый и надежный, но потенциально его труднее всего реализовать.
Сопоставление ключевых точек
Лучше, чем выбрать 100 случайных точек, выбрать 100 важных точек. Некоторые части изображения содержат больше информации, чем другие (особенно по краям и углам), и именно их вы захотите использовать для интеллектуального сопоставления изображений. Погуглите «извлечение ключевых точек» и «сопоставление ключевых точек», и вы найдете немало академических статей по этому вопросу. В наши дни ключевые точки SIFT, возможно, являются самыми популярными, поскольку они могут сопоставлять изображения в разных масштабах, поворотах и освещении.
Некоторые реализации SIFT можно найти здесь. 92m), где n — количество ключевых точек на каждом изображении, а m — количество изображений в базе данных. Некоторые хитрые алгоритмы могут быстрее находить наиболее близкое совпадение, например деревья квадрантов или разбиение двоичного пространства.Альтернативное решение: Метод гистограммы
Еще одно менее надежное, но потенциально более быстрое решение — построить гистограммы признаков для каждого изображения и выбрать изображение с гистограммой, наиболее близкой к гистограмме входного изображения. Я реализовал это как старшекурсник, и мы использовали 3 гистограммы цвета (красный, зеленый и синий) и две гистограммы текстуры, направление и масштаб. Я дам подробности ниже, но я должен отметить, что это хорошо работало только для сопоставления изображений, ОЧЕНЬ похожих на изображения базы данных. Повторно масштабированные, повернутые или обесцвеченные изображения могут не работать с этим методом, но небольшие изменения, такие как обрезка, не нарушат алгоритм
Вычисление цветных гистограмм очень просто — просто выберите диапазон для сегментов гистограммы и для каждого диапазона подсчитайте количество пикселей с цветом в этом диапазоне.
Например, рассмотрим «зеленую» гистограмму и предположим, что мы выбрали 4 сегмента для нашей гистограммы: 0–63, 64–127, 128–191 и 192–255. Затем для каждого пикселя мы смотрим на значение зеленого и добавляем значение в соответствующее ведро. Когда мы закончим подсчет, мы разделим сумму каждой корзины на количество пикселей во всем изображении, чтобы получить нормализованную гистограмму для зеленого канала.Для гистограммы направления текстуры мы начали с определения границ изображения. Каждая краевая точка имеет вектор нормали, указывающий в направлении, перпендикулярном ребру. Мы квантовали угол вектора нормали в один из 6 сегментов между 0 и PI (поскольку ребра имеют 180-градусную симметрию, мы преобразовали углы между -PI и 0, чтобы они были между 0 и PI). После подсчета количества краевых точек в каждом направлении у нас есть ненормализованная гистограмма, представляющая направление текстуры, которую мы нормализовали, разделив каждое ведро на общее количество краевых точек в изображении.
Чтобы рассчитать гистограмму масштаба текстуры, для каждой точки края мы измерили расстояние до ближайшей точки края в том же направлении. Например, если граничная точка А имеет направление 45 градусов, алгоритм проходит в этом направлении, пока не найдет другую граничную точку с направлением 45 градусов (или в пределах разумного отклонения). После вычисления этого расстояния для каждой граничной точки мы выводим эти значения на гистограмму и нормализуем ее путем деления на общее количество граничных точек.
Теперь у вас есть 5 гистограмм для каждого изображения. Чтобы сравнить два изображения, вы берете абсолютное значение разницы между каждым сегментом гистограммы, а затем суммируете эти значения. Например, чтобы сравнить изображения A и B, мы должны вычислить
|A.green_histogram.bucket_1 - B.green_histogram.bucket_1|
для каждого сегмента на зеленой гистограмме, и повторите для других гистограмм, а затем просуммируйте все результаты. Чем меньше результат, тем лучше совпадение.
Повторите для всех изображений в базе данных, и победит совпадение с наименьшим результатом. Вы, вероятно, захотите иметь порог, выше которого алгоритм делает вывод, что совпадений не найдено.Третий вариант — ключевые точки + деревья решений
Третий подход, который, вероятно, намного быстрее, чем два других, заключается в использовании семантических текстовых лесов (PDF). Это включает в себя извлечение простых ключевых точек и использование деревьев решений коллекции для классификации изображения. Это быстрее, чем простое сопоставление ключевых точек SIFT, поскольку позволяет избежать дорогостоящего процесса сопоставления, а ключевые точки намного проще, чем SIFT, поэтому извлечение ключевых точек происходит намного быстрее. Однако он сохраняет инвариантность метода SIFT к вращению, масштабу и освещению, что является важной особенностью, которой не хватало методу гистограмм.
Обновление :
Моя ошибка — статья Semantic Texton Forests посвящена не сопоставлению изображений, а маркировке регионов.
Первоначальная статья, в которой проводится сопоставление, — это: Распознавание ключевых точек с использованием рандомизированных деревьев. Кроме того, приведенные ниже документы продолжают развивать идеи и представляют собой современное состояние техники (ок. 2010 г.):- Быстрое распознавание ключевых точек с использованием случайных папоротников — быстрее и более масштабируемо, чем Lepetit 06
-
КРАТКОЕ ОПИСАНИЕ: Двоичные надежные независимые элементарные функции— менее надежный, но очень быстрый — я думаю, что цель здесь — сопоставление в реальном времени на смартфонах и других портативных устройствах
python — Алгоритм сравнения изображений
спросил
Изменено 3 года, 10 месяцев назад
Просмотрено 62к раз
Я пытаюсь сравнить изображения друг с другом, чтобы выяснить, отличаются ли они.
Сначала я попытался провести корреляцию значений RGB по методу Пирсона, который также работает неплохо, если только изображения не немного смещены. Поэтому, если у меня есть 100% идентичные изображения, но одно немного сдвинуто, я получаю плохое значение корреляции.Есть предложения по улучшению алгоритма?
Кстати, я говорю о сравнении тысячи изображений…
Редактировать: Вот пример моих снимков (микроскопический):
im1:
im2:
im3:
im1 и im2 одинаковые, но немного смещены/обрезаны, im3 должен быть распознан как совершенно другое…
Редактировать: Проблема решена с помощью предложений Питера Хансена! Работает очень хорошо! Спасибо всем ответам! Некоторые результаты можно найти здесь http://labtools.ipk-gatersleben.de/image%20comparison/image%20comparision.pdf
- python
- изображение
- обработка изображений
- сравнить
- компьютерное зрение
4
Аналогичный вопрос был задан год назад и получил множество ответов, в том числе один относительно пикселизации изображений, который я собирался предложить как минимум в качестве шага предварительной квалификации (поскольку это довольно быстро исключит очень непохожие изображения).
Там также есть ссылки на еще более ранние вопросы, на которые есть еще больше ссылок и хороших ответов.
Вот реализация, использующая некоторые идеи с Scipy, используя ваши три изображения выше (сохраненные как im1.jpg, im2.jpg, im3.jpg соответственно). Окончательный вывод показывает, что im1 сравнивается с самим собой в качестве базовой линии, а затем каждое изображение сравнивается с другими.
>>> импортировать scipy как sp >>> из scipy.misc импортировать imread >>> из scipy.signal.signaltools импортировать корреляцию2d как c2d >>> >>> по умолчанию получить(я): ... # получить изображение JPG в виде массива Scipy, RGB (3 слоя) ... данные = imread('im%s.jpg' % i) ... # преобразовать в оттенки серого, используя W3C luminance calc ... данные = sp.inner(данные, [299, 587, 114]) / 1000,0 ... # нормализовать согласно http://en.wikipedia.org/wiki/Cross-correlation ... вернуть (данные - data.mean()) / data.std() ... >>> im1 = получить(1) >>> im2 = получить(2) >>> im3 = получить(3) >>> im1. shape
(105, 401)
>>> im2.shape
(109, 373)
>>> im3.shape
(121, 457)
>>> c11 = c2d(im1, im1, mode='same') # базовый уровень
>>> c12 = c2d(im1, im2, режим='такой же')
>>> c13 = c2d(im1, im3, режим='такой же')
>>> c23 = c2d(im2, im3, режим='такой же')
>>> c11.max(), c12.max(), c13.max(), c23.max()
(42105.00000000259, 39898.103896795357, 16482.883608327804, 15873.465425120798)
Итак, обратите внимание, что im1 по сравнению с самим собой дает результат 42105, im2 по сравнению с im1 не за горами, но im3 по сравнению с любым другим дает меньше половины этого значения. Вам придется поэкспериментировать с другими изображениями, чтобы увидеть, насколько хорошо это может работать и как вы можете его улучшить.
Длительное время выполнения… несколько минут на моей машине. Я бы попробовал некоторую предварительную фильтрацию, чтобы не тратить время на сравнение очень непохожих изображений, возможно, с помощью трюка «сравнить размер файла jpg», упомянутого в ответах на другой вопрос, или с пикселизацией.
Тот факт, что у вас есть изображения разного размера, усложняет ситуацию, но вы не предоставили достаточно информации о степени разделки, которую можно было бы ожидать, поэтому трудно дать конкретный ответ, учитывающий это.11
Я сделал это со сравнением гистограммы изображения. Мой основной алгоритм был таким:
- Разделить изображение на красный, зеленый и синий
- Создайте нормализованные гистограммы для красного, зеленого и синего каналов и объедините их в вектор
(r0...rn, g0...gn, b0...bn), где n — количество «сегментов», 256 должно хватит - вычесть эту гистограмму из гистограммы другого изображения и вычислить расстояние
вот какой-то код с
numpyиpilr = numpy.asarray(im.convert("RGB", (1,0,0,0, 1,0,0,0, 1,0 ,0,0))) g = numpy.asarray(im.convert("RGB", (0,1,0,0, 0,1,0,0, 0,1,0,0)) b = numpy.asarray(im.convert("RGB", (0,0,1,0, 0,0,1,0, 0,0,1,0)) hr, h_bins = numpy. histogram(r, bins=256, new=True, normed=True)
hg, h_bins = numpy.histogram(g, bins=256, new=True, normed=True)
hb, h_bins = numpy.histogram(b, bins=256, new=True, normed=True)
гист = numpy.array ([час, час, час]). ravel ()
если у вас есть две гистограммы, вы можете получить расстояние следующим образом:
diff = hist1 - hist2 расстояние = numpy.sqrt (numpy.dot (diff, diff))
Если два изображения идентичны, расстояние равно 0, чем больше они расходятся, тем больше расстояние.
Для меня это работало достаточно хорошо для фотографий, но не работало с графикой, такой как тексты и логотипы.
1
Вам действительно нужно уточнить вопрос, но, глядя на эти 5 изображений, кажется, что все организмы ориентированы одинаково. Если это всегда так, вы можете попробовать выполнить нормализованную взаимную корреляцию между двумя изображениями и принять пиковое значение в качестве степени сходства.
Я не знаю нормализованной кросс-корреляционной функции в Python, но есть похожая функция fftconvolve(), и вы можете самостоятельно выполнить круговую кросс-корреляцию:0003a = asarray(Image.open('c603225337.jpg').convert('L')) b = asarray(Image.open('9b78f22f42.jpg').convert('L')) f1 = rfftn(a) f2 = rfftn(b) г = f1 * f2 с = irfftn(g)Это не будет работать так, как написано, поскольку изображения имеют разные размеры, а выходные данные вообще не взвешиваются и не нормализуются.
Расположение пикового значения выходных данных указывает на смещение между двумя изображениями, а величина пика указывает на сходство. Должен быть способ взвесить/нормализовать его, чтобы можно было отличить хорошее совпадение от плохого. 9
Что касается производительности, если все изображения имеют одинаковый размер, если я хорошо помню, пакет FFTW создал специализированную функцию для каждого размера ввода FFT, поэтому вы можете получить хороший прирост производительности, повторно используя один и тот же код.
.. I не знаю, основан ли numpy на FFTW, но если это не так, возможно, вы могли бы попытаться немного исследовать его.Вот у вас есть прототип… вы можете немного поиграть с ним, чтобы увидеть, какой порог соответствует вашим изображениям.
импорт изображения импортировать numpy импорт системы деф основной(): img1 = Image.open(sys.argv[1]) img2 = Image.open(sys.argv[2]) если img1.size != img2.size или img1.getbands() != img2.getbands(): возврат -1 с = 0 для band_index, диапазон в enumerate(img1.getbands()): m1 = numpy.fft.fft2(numpy.array([p[band_index] для p в img1.getdata()]).reshape(*img1.size)) m2 = numpy.fft.fft2(numpy.array([p[band_index] для p в img2.getdata()]).reshape(*img2.size)) s += numpy.sum(numpy.abs(m1-m2)) печать с если __name__ == "__main__": sys.exit(основной())Другим способом может быть размытие изображений, а затем вычитание значений пикселей из двух изображений. Если разница не равна нулю, то можно сдвинуть одно из изображений на 1 пиксель в каждую сторону и сравнить снова, если разница меньше, чем на предыдущем шаге, можно повторить сдвиг в сторону градиента и вычитание до тех пор, пока разница ниже определенного порога или снова возрастает.
Это должно работать, если радиус ядра размытия больше смещения изображений.Кроме того, вы можете попробовать некоторые из инструментов, которые обычно используются в рабочем процессе фотографии для смешивания нескольких экспозиций или создания панорам, таких как Pano Tools.
8
Я давно прошел курс обработки изображений и помню, что при сопоставлении я обычно начинал с создания изображения в оттенках серого, а затем повышал резкость краев изображения, чтобы вы видели только края. Затем вы (программное обеспечение) можете сдвигать и вычитать изображения, пока разница не станет минимальной.
Если эта разница больше установленного вами порога, изображения не равны, и вы можете перейти к следующему. Затем можно анализировать изображения с меньшим порогом.
Я думаю, что в лучшем случае вы можете радикально сократить количество возможных совпадений, но вам нужно будет лично сравнить возможные совпадения, чтобы определить, действительно ли они равны.
Я не могу показать код, так как это было давно, и я использовал Khoros/Cantata для этого курса.
Во-первых, корреляция — очень требовательная к ЦП и довольно неточная мера сходства. Почему бы просто не использовать сумму квадратов различий между отдельными пикселями?
Простое решение, если максимальное смещение ограничено: сгенерировать все возможные смещенные изображения и найти наиболее подходящее. Убедитесь, что вы вычисляете переменную сопоставления (т. е. корреляцию) только для подмножества пикселей, которые могут сопоставляться во всех сдвинутых изображениях. Кроме того, ваш максимальный сдвиг должен быть значительно меньше размера ваших изображений.
Если вы хотите использовать некоторые более продвинутые методы обработки изображений, я предлагаю вам взглянуть на SIFT, это очень мощный метод, который (во всяком случае, теоретически) может правильно сопоставлять элементы в изображениях независимо от перевода, поворота и масштаба.
Я думаю, вы могли бы сделать что-то вроде этого:
Измерить сдвиг несложно.
- Возьмите область (скажем, около 32×32) в сравнительном изображении.
- Сдвинуть на x пикселей по горизонтали и на y пикселей по вертикали.
- Вычислите SAD (сумма абсолютной разницы) по отношению к исходное изображение
- Сделайте это для нескольких значений x и y в небольшом диапазоне (-10, +10)
- Найдите место, где разница минимальна
- Выберите это значение в качестве вектора движения сдвига
Примечание:
Если SAD становится очень высоким для всех значений x и y, то вы в любом случае можете предположить, что изображения сильно различаются и измерение сдвига не требуется.
2
Чтобы импорт работал правильно на моем Ubuntu 16.04 (по состоянию на апрель 2017 г.), я установил python 2.7 и эти:
sudo apt-get install python-dev sudo apt-get установить libtiff5-dev libjpeg8-dev zlib1g-dev libfreetype6-dev liblcms2-dev libwebp-dev tcl8.
6-dev tk8.6-dev python-tk
sudo apt-get установить python-scipy
sudo pip установить подушку
Затем я изменил импорт Snowflake на эти:
import scipy as sp из scipy.ndimage импортировать imread из scipy.signal.signaltools импортировать correct2d как c2d
Как здорово, что сценарий Снежинки сработал у меня 8 лет спустя!
Предлагаю решение, основанное на показателе сходства Жаккара на гистограммах изображения. См.: https://en.wikipedia.org/wiki/Jaccard_index#Weighted_Jaccard_similarity_and_distance
Вы можете вычислить разницу в распределении цветов пикселей. Это действительно довольно инвариантно к переводам.
из импорта изображения PIL.Image от ввода списка импорта def jaccard_similarity (im1: изображение, im2: изображение) -> float: """Вычислите сходство между двумя изображениями. Сначала для каждого изображения извлекается гистограмма распределения пикселей. Затем сходство между гистограммами сравнивается с использованием взвешенного индекса сходства Жаккара, определяемого как: Jподобие = сумма (мин (b1_i, b2_i)) / сумма (макс (b1_i, b2_i) где b1_i и b2_i — i-я ячейка гистограммы изображений 1 и 2 соответственно.
Два изображения должны иметь одинаковое разрешение и количество каналов (глубину).
См.: https://en.wikipedia.org/wiki/Jaccard_index.
Где его еще называют ружицким подобием."""
если im1.size != im2.size:
поднять Exception("Изображения должны иметь одинаковый размер. Найдено {} и {}".format(im1.size, im2.size))
n_channels_1 = len(im1.getbands())
n_channels_2 = len(im2.getbands())
если n_channels_1 != n_channels_2:
поднять Exception("Изображения должны иметь одинаковое количество каналов. Найдено {} и {}".format(n_channels_1, n_channels_2))
утверждать n_channels_1 == n_channels_2
сумма_мин = 0
сумма_макс = 0
hi1 = im1.histogram() # тип: List[int]
hi2 = im2.histogram() # тип: List[int]
# Так как два изображения имеют одинаковое количество каналов, они должны иметь одинаковое количество бинов на гистограмме.
утверждать len(hi1) == len(hi2)
для b1, b2 в zip (hi1, hi2):
мин_b = мин (b1, b2)
сумма_мин += мин_б
max_b = макс (b1, b2)
sum_maxs += max_b
jaccard_index = сумма_минут/сумма_максимум
вернуть jaccard_index
Что касается среднеквадратичной ошибки, то индекс Жаккара всегда находится в диапазоне [0,1], что позволяет сравнивать изображения разных размеров.
Затем вы можете сравнить два изображения, но после масштабирования до одинакового размера! Или количество пикселей придется как-то нормализовать. Я использовал это:
import sys из skincare.common.utils импортировать jaccard_similarity импорт PIL.Image из PIL.Image импортировать изображение файл1 = sys.argv[1] файл2 = sys.argv[2] im1 = PIL.Image.open(file1) # тип: Изображение im2 = PIL.Image.open(file2) # тип: Изображение print("Изображение 1: режим={}, размер={}".format(im1.mode, im1.size)) print("Изображение 2: режим={}, размер={}".format(im2.mode, im2.size)) если im1.size != im2.size: print("Изменение размера изображения 2 до {}".format(im1.size)) im2 = im2.resize (im1.size, resample = PIL.Image.BILINEAR) j = jaccard_similarity (im1, im2) print("Индекс сходства Жаккара = {}".format(j))Тестирование на ваших изображениях:
$ python CompareTwoImages.py im1.jpg im2.jpg Изображение 1: режим = RGB, размер = (401, 105) Изображение 2: режим = RGB, размер = (373, 109) Изменение размера изображения 2 до (401, 105) Индекс подобия Жаккара = 0,7238955686269157 $ python CompareTwoImages.
 2). Также стоит отметить, что на практике для реализации сортировки по n-мерному индексному пространству приходится организовывать n-мерный массив со списками изображений, лежащих в определенном диапазоне индексов. Что вносит дополнительные накладные расходы и делает неоправданным использование индексирования большой размерности, а также не эффективность такого индексирования для небольших коллекций изображений.
2). Также стоит отметить, что на практике для реализации сортировки по n-мерному индексному пространству приходится организовывать n-мерный массив со списками изображений, лежащих в определенном диапазоне индексов. Что вносит дополнительные накладные расходы и делает неоправданным использование индексирования большой размерности, а также не эффективность такого индексирования для небольших коллекций изображений.
 е. к объектам недвижимости расположенных с разным местоположением крепилась одна и та же фотография, может ошибочно, может специально, но такие объекты надо было найти. И я хотел бы поделиться тем, как я решал эту задачу. Для примера у Вас может быть домашняя фототека.
е. к объектам недвижимости расположенных с разным местоположением крепилась одна и та же фотография, может ошибочно, может специально, но такие объекты надо было найти. И я хотел бы поделиться тем, как я решал эту задачу. Для примера у Вас может быть домашняя фототека. Почитав документацию, я нашел функцию, которая по пикселям сравнивает два изображения и выдает разницу. Функция называется difference и находится в модуле ImageChops. Что бы показать принцип работы функции, для примера возьмем фотографию и добавим на нее какой-нибудь текст:
Почитав документацию, я нашел функцию, которая по пикселям сравнивает два изображения и выдает разницу. Функция называется difference и находится в модуле ImageChops. Что бы показать принцип работы функции, для примера возьмем фотографию и добавим на нее какой-нибудь текст: open(img1)
image_2 = Image.open(img2)
result=ImageChops.difference(image_1, image_2).getbbox()
if result==None:
print(img1,img2,’matches’)
return
open(img1)
image_2 = Image.open(img2)
result=ImageChops.difference(image_1, image_2).getbbox()
if result==None:
print(img1,img2,’matches’)
return
 Thread.__init__(self)
self.queue = queue
def run(self):
«»»Запуск потока»»»
while True:
# Получаем пару путей из очереди
files = self.queue.get()
# Делим и сравниваем
self.difference_images(files.split(‘:’)[0],files.split(‘:’)[1])
# Отправляем сигнал о том, что задача завершена
self.queue.task_done()
def difference_images(self, img1, img2):
image_1 = Image.open(img1)
image_2 = Image.open(img2)
size = [400,300] #размер в пикселях
image_1.thumbnail(size) #уменьшаем первое изображение
image_2.thumbnail(size) #уменьшаем второе изображение
result=ImageChops.difference(image_1, image_2).getbbox()
if result==None:
print(img1,img2,’matches’)
return
def main(path):
imgs=os.listdir(path) #Получаем список картинок
queue = Queue()
# Запускаем поток и очередь
for i in range(4): # 4 — кол-во одновременных потоков
t = diff_image(queue)
t.
Thread.__init__(self)
self.queue = queue
def run(self):
«»»Запуск потока»»»
while True:
# Получаем пару путей из очереди
files = self.queue.get()
# Делим и сравниваем
self.difference_images(files.split(‘:’)[0],files.split(‘:’)[1])
# Отправляем сигнал о том, что задача завершена
self.queue.task_done()
def difference_images(self, img1, img2):
image_1 = Image.open(img1)
image_2 = Image.open(img2)
size = [400,300] #размер в пикселях
image_1.thumbnail(size) #уменьшаем первое изображение
image_2.thumbnail(size) #уменьшаем второе изображение
result=ImageChops.difference(image_1, image_2).getbbox()
if result==None:
print(img1,img2,’matches’)
return
def main(path):
imgs=os.listdir(path) #Получаем список картинок
queue = Queue()
# Запускаем поток и очередь
for i in range(4): # 4 — кол-во одновременных потоков
t = diff_image(queue)
t. setDaemon(True)
t.start()
# Даем очереди нужные пары файлов для проверки
check_file=0
current_file=0
while check_file<len(imgs):
if current_file==check_file:
current_file+=1
continue
queue.put(path+imgs[current_file]+’:’+path+imgs[check_file])
current_file+=1
if current_file==len(imgs):
check_file+=1
current_file=check_file
# Ждем завершения работы очереди
queue.join()
if __name__ == «__main__»:
path=’images/’
main(path)
setDaemon(True)
t.start()
# Даем очереди нужные пары файлов для проверки
check_file=0
current_file=0
while check_file<len(imgs):
if current_file==check_file:
current_file+=1
continue
queue.put(path+imgs[current_file]+’:’+path+imgs[check_file])
current_file+=1
if current_file==len(imgs):
check_file+=1
current_file=check_file
# Ждем завершения работы очереди
queue.join()
if __name__ == «__main__»:
path=’images/’
main(path) Это может потребовать некоторых базовых знаний для реализации и может быть медленным.
Это может потребовать некоторых базовых знаний для реализации и может быть медленным. Некоторые реализации SIFT можно найти здесь. 92m), где n — количество ключевых точек на каждом изображении, а m — количество изображений в базе данных. Некоторые хитрые алгоритмы могут быстрее находить наиболее близкое совпадение, например деревья квадрантов или разбиение двоичного пространства.
Некоторые реализации SIFT можно найти здесь. 92m), где n — количество ключевых точек на каждом изображении, а m — количество изображений в базе данных. Некоторые хитрые алгоритмы могут быстрее находить наиболее близкое совпадение, например деревья квадрантов или разбиение двоичного пространства. Например, рассмотрим «зеленую» гистограмму и предположим, что мы выбрали 4 сегмента для нашей гистограммы: 0–63, 64–127, 128–191 и 192–255. Затем для каждого пикселя мы смотрим на значение зеленого и добавляем значение в соответствующее ведро. Когда мы закончим подсчет, мы разделим сумму каждой корзины на количество пикселей во всем изображении, чтобы получить нормализованную гистограмму для зеленого канала.
Например, рассмотрим «зеленую» гистограмму и предположим, что мы выбрали 4 сегмента для нашей гистограммы: 0–63, 64–127, 128–191 и 192–255. Затем для каждого пикселя мы смотрим на значение зеленого и добавляем значение в соответствующее ведро. Когда мы закончим подсчет, мы разделим сумму каждой корзины на количество пикселей во всем изображении, чтобы получить нормализованную гистограмму для зеленого канала.
 Повторите для всех изображений в базе данных, и победит совпадение с наименьшим результатом. Вы, вероятно, захотите иметь порог, выше которого алгоритм делает вывод, что совпадений не найдено.
Повторите для всех изображений в базе данных, и победит совпадение с наименьшим результатом. Вы, вероятно, захотите иметь порог, выше которого алгоритм делает вывод, что совпадений не найдено. Первоначальная статья, в которой проводится сопоставление, — это: Распознавание ключевых точек с использованием рандомизированных деревьев. Кроме того, приведенные ниже документы продолжают развивать идеи и представляют собой современное состояние техники (ок. 2010 г.):
Первоначальная статья, в которой проводится сопоставление, — это: Распознавание ключевых точек с использованием рандомизированных деревьев. Кроме того, приведенные ниже документы продолжают развивать идеи и представляют собой современное состояние техники (ок. 2010 г.): Сначала я попытался провести корреляцию значений RGB по методу Пирсона, который также работает неплохо, если только изображения не немного смещены. Поэтому, если у меня есть 100% идентичные изображения, но одно немного сдвинуто, я получаю плохое значение корреляции.
Сначала я попытался провести корреляцию значений RGB по методу Пирсона, который также работает неплохо, если только изображения не немного смещены. Поэтому, если у меня есть 100% идентичные изображения, но одно немного сдвинуто, я получаю плохое значение корреляции.
 shape
(105, 401)
>>> im2.shape
(109, 373)
>>> im3.shape
(121, 457)
>>> c11 = c2d(im1, im1, mode='same') # базовый уровень
>>> c12 = c2d(im1, im2, режим='такой же')
>>> c13 = c2d(im1, im3, режим='такой же')
>>> c23 = c2d(im2, im3, режим='такой же')
>>> c11.max(), c12.max(), c13.max(), c23.max()
(42105.00000000259, 39898.103896795357, 16482.883608327804, 15873.465425120798)
shape
(105, 401)
>>> im2.shape
(109, 373)
>>> im3.shape
(121, 457)
>>> c11 = c2d(im1, im1, mode='same') # базовый уровень
>>> c12 = c2d(im1, im2, режим='такой же')
>>> c13 = c2d(im1, im3, режим='такой же')
>>> c23 = c2d(im2, im3, режим='такой же')
>>> c11.max(), c12.max(), c13.max(), c23.max()
(42105.00000000259, 39898.103896795357, 16482.883608327804, 15873.465425120798)
 Тот факт, что у вас есть изображения разного размера, усложняет ситуацию, но вы не предоставили достаточно информации о степени разделки, которую можно было бы ожидать, поэтому трудно дать конкретный ответ, учитывающий это.
Тот факт, что у вас есть изображения разного размера, усложняет ситуацию, но вы не предоставили достаточно информации о степени разделки, которую можно было бы ожидать, поэтому трудно дать конкретный ответ, учитывающий это. histogram(r, bins=256, new=True, normed=True)
hg, h_bins = numpy.histogram(g, bins=256, new=True, normed=True)
hb, h_bins = numpy.histogram(b, bins=256, new=True, normed=True)
гист = numpy.array ([час, час, час]). ravel ()
histogram(r, bins=256, new=True, normed=True)
hg, h_bins = numpy.histogram(g, bins=256, new=True, normed=True)
hb, h_bins = numpy.histogram(b, bins=256, new=True, normed=True)
гист = numpy.array ([час, час, час]). ravel ()
 Я не знаю нормализованной кросс-корреляционной функции в Python, но есть похожая функция fftconvolve(), и вы можете самостоятельно выполнить круговую кросс-корреляцию:0003
Я не знаю нормализованной кросс-корреляционной функции в Python, но есть похожая функция fftconvolve(), и вы можете самостоятельно выполнить круговую кросс-корреляцию:0003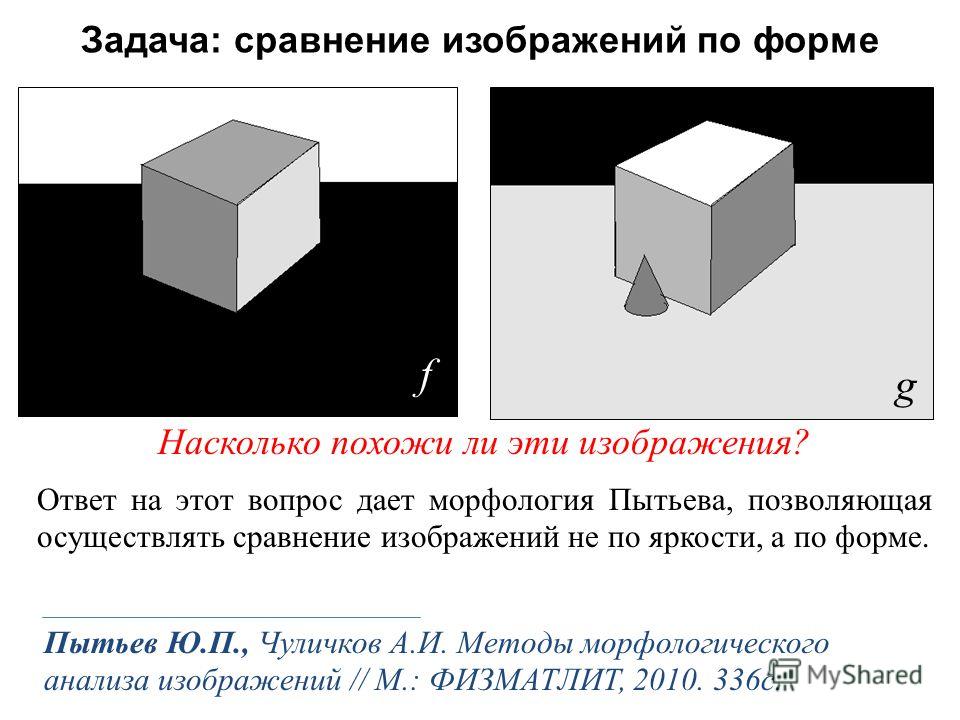 .. I не знаю, основан ли numpy на FFTW, но если это не так, возможно, вы могли бы попытаться немного исследовать его.
.. I не знаю, основан ли numpy на FFTW, но если это не так, возможно, вы могли бы попытаться немного исследовать его. Это должно работать, если радиус ядра размытия больше смещения изображений.
Это должно работать, если радиус ядра размытия больше смещения изображений.

 6-dev tk8.6-dev python-tk
sudo apt-get установить python-scipy
sudo pip установить подушку
6-dev tk8.6-dev python-tk
sudo apt-get установить python-scipy
sudo pip установить подушку
 Два изображения должны иметь одинаковое разрешение и количество каналов (глубину).
См.: https://en.wikipedia.org/wiki/Jaccard_index.
Где его еще называют ружицким подобием."""
если im1.size != im2.size:
поднять Exception("Изображения должны иметь одинаковый размер. Найдено {} и {}".format(im1.size, im2.size))
n_channels_1 = len(im1.getbands())
n_channels_2 = len(im2.getbands())
если n_channels_1 != n_channels_2:
поднять Exception("Изображения должны иметь одинаковое количество каналов. Найдено {} и {}".format(n_channels_1, n_channels_2))
утверждать n_channels_1 == n_channels_2
сумма_мин = 0
сумма_макс = 0
hi1 = im1.histogram() # тип: List[int]
hi2 = im2.histogram() # тип: List[int]
# Так как два изображения имеют одинаковое количество каналов, они должны иметь одинаковое количество бинов на гистограмме.
утверждать len(hi1) == len(hi2)
для b1, b2 в zip (hi1, hi2):
мин_b = мин (b1, b2)
сумма_мин += мин_б
max_b = макс (b1, b2)
sum_maxs += max_b
jaccard_index = сумма_минут/сумма_максимум
вернуть jaccard_index
Два изображения должны иметь одинаковое разрешение и количество каналов (глубину).
См.: https://en.wikipedia.org/wiki/Jaccard_index.
Где его еще называют ружицким подобием."""
если im1.size != im2.size:
поднять Exception("Изображения должны иметь одинаковый размер. Найдено {} и {}".format(im1.size, im2.size))
n_channels_1 = len(im1.getbands())
n_channels_2 = len(im2.getbands())
если n_channels_1 != n_channels_2:
поднять Exception("Изображения должны иметь одинаковое количество каналов. Найдено {} и {}".format(n_channels_1, n_channels_2))
утверждать n_channels_1 == n_channels_2
сумма_мин = 0
сумма_макс = 0
hi1 = im1.histogram() # тип: List[int]
hi2 = im2.histogram() # тип: List[int]
# Так как два изображения имеют одинаковое количество каналов, они должны иметь одинаковое количество бинов на гистограмме.
утверждать len(hi1) == len(hi2)
для b1, b2 в zip (hi1, hi2):
мин_b = мин (b1, b2)
сумма_мин += мин_б
max_b = макс (b1, b2)
sum_maxs += max_b
jaccard_index = сумма_минут/сумма_максимум
вернуть jaccard_index

