ОБЗОР СОВРЕМЕННЫХ МЕТОДОВ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
В настоящее время использование баз данных (БД) и информационных систем стало обязательным элементом осуществления деятельности каждой организации или предприятия. Проекты, в рамках реализации которых выполняется обработка данных, представляют собой немалую часть всех проектов в области информационных технологий. В процессе создания таких систем решаются задачи проектирования баз данных различных типов. Решение таких задач означает повышение степени вероятности того, что проектируемая информационная система будет отвечать определенным функциональным и информационным требованиям с учетом заданных ограничений.
В связи с этим большую актуальность приобретает освоение принципов построения и эффективного применения соответствующих технологий и программных продуктов.
Основными подходами к проектированию систем БД являются восходящий метод и нисходящий метод проектирования. Суть первого способа заключается в структурном проектировании снизу—вверх. В данном процессе на основе описания частей осуществляется попытка получения целого, адекватно отображающего предметную область.
Этапы проектирования БД методом «восходящего» проектирования представлены на рисунке 1.
При использовании восходящего подхода на первом этапе происходит выявление свойств объектов (атрибутов сущностей) предметной области. Проводится анализ связей между свойствами, на основании которого свойства объединяются в таблицы (реляционные отношения).
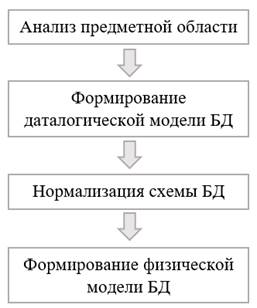
Рисунок 1. Этапы проектирования БД методом «восходящего» проектирования
Во избежание различных аномалий, которые могут произойти при добавлении, обновлении или удалении данных из-за их избыточности, следует провести процесс нормализации каждой схемы отношения. Отношения должны быть преобразованы к виду, отвечающему требованиям 3НФ. В связи с большим количеством операций по нормализации метод восходящего проектирования также носит второе название – метод нормализации.
«Нормализация — это процесс организации данных в базе данных, включающий создание таблиц и установление отношений между ними в соответствии с правилами, которые обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и несогласованные зависимости» [2].
Для успешного проведения нормализации (до 3НФ) необходимо выполнить ряд операций, представленных на рисунке 2. На первом этапе нормализации происходит сбор сырых данных, определение атрибутов. Затем данные представляются в виде схем реляционных отношений. На втором этапе изучается семантика данных, определяется первичный ключ и функциональные зависимости между атрибутами. Третий этап – это поиск и удаление транзитивных зависимостей.
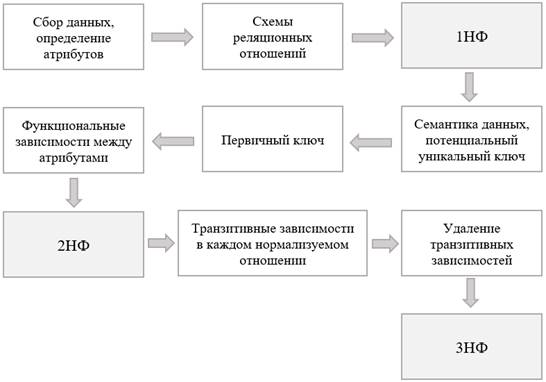
Рисунок 2. Этапы нормализации
Восходящий метод проектирования применяют в распределенных БД при интеграции спроектированных локальных баз данных.
Для проектирования сложных БД преимущественно применяется нисходящий подход. При таком подходе работа начинается с подготовки моделей данных, содержащих несколько высокоуровневых сущностей и связей. После этого производятся нисходящие уточнения низкоуровневых сущностей, связей и атрибутов, относящихся к ним.
Этапы проектирования БД методом «нисходящего» проектирования представлены на рисунке 3.
Нисходящий подход используется в концепции метода проектирования «сущность-связь». В основе метода лежат три элемента: сущность, атрибут, связь. Работа начинается с выявления сущностей и связей между ними.
В результате строится иерархическая схема, которая отражает состав и взаимоподчиненность отдельных функций.
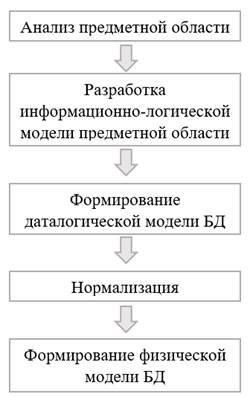
Рисунок 3. Этапы проектирования БД методом «нисходящего» проектирования
Процесс построения баз данных методом «сущность-связь» включает в себя три этапа: концептуальное, логическое и физическое проектирование [1].
Концептуальное проектирование БД – это процесс, результатом которого является создание модели имеющейся информации. Модель строится вне зависимости от любых физических аспектов ее представления. Такая модель данных формируется на основе информации, определенной в перечне требований пользователей. Особенности физической реализации (тип СУБД, язык программирования, тип вычислительной платформы и т.д.) на данном этапе не учитываются.
На этапе логического проектирования БД происходит выбор модели организации данных, на основе которой создается модель используемой информации. Далее в концептуальную модель вносятся изменения и дополнения, и происходит преобразование в логическую модель данных. Созданная модель должна учитывать особенности организации данных в целевой СУБД (например, реляционная модель).
На данном этапе должна быть определена целевая СУБД (реляционная, сетевая, иерархическая или объектно-ориентированная), так как построение логической модели происходит с учетом выбранной модели организации данных. С помощью метода нормализации происходит проверка правильности модели. Нормализация исключает избыточность данных, которая может привести к различным аномалиям в процессе обновления данных. Поддержка всех транзакций, которые необходимы пользователям, также должна обеспечиваться логической моделью.
Физическое проектирование БД – это процесс, включающий в себя определение способов реализации и разработку описания конкретной реализации БД. В ходе данной стадии проектирования создается набор реляционных таблиц, определяется организация файлов и способы доступа к ним, а также анализируются ограничения целостности и разрабатываются средства защиты проектируемой БД.
В таблице 1 приводится сравнение методов проектирования по нескольким критериям.
Таблица 1.
Сравнение методов проектирования БД
Критерии | Восходящее проектирование | Нисходящее проектирование |
Степень описания семантики (смысла) предметной области | Низкая1 | Высокая |
Вероятность появления ошибок в последующей работе АИС | Высокая | Низкая2 |
Степень формализации процесса (возможность автоматизации процесса) | Отсутствует | Высокая |
Объем трудозатрат при приведении ДЛМ БД к заданной НФ | Очень большой | Небольшой |
1 – начальная модель не предусматривают возможность описания полного смысла предметной области.
2 – при условии качественного проектирования.
Каждый метод проектирования имеет свои преимущества и недостатки. При нисходящем проектировании элементы еще не определены, информация об их свойствах предположительна. При восходящем проектировании элементы проектируются раньше системы, поэтому предположительный характер будут иметь требования к системе. И в том, и в другом случае возможно несоответствие оптимальным техническим результатам.
Список литературы:
- Дейт К.Дж. Введение в системы баз данных, 8-е издание.: Пер. с англ. – М.: Издательский дом «Вильяме», 2005. 1328с.
- Описание основных приемов нормализации базы данных // Microsoft. [электронный ресурс] – Режим доступа. – URL: https://support.microsoft.com/ru-ru/help/283878/description-of-the-database-normalization-basics (дата обращения: 27.05.2017).
sibac.info
Автоматизированные средства проектирования баз данных Обзор и классификация Case-технологий
Проект студента группы
С-1
Й Курс
Исполнитель
Вельхиев Асланбек Хизирович
Преподаватель Тангиев И.М.
Год.
1. Введение……………………………………………………………….3
Глава 1. Теоретическая часть
Основные понятия и определения баз данных
Модели баз данных
Иерархическая
Сетевая
Реляционная
Анализ предметной области
Автоматизированные средства проектирования баз данных Обзор и классификация Case-технологий
Глава 2. Практическая часть
Этапы проектирования баз данных
2.2. Концептуальная модель “Сущность-связь”
Физическая модель базы данных
Хранимые процедуры и триггеры
Заключение
Литература
Приложения
Введение
За последние двадцать лет значительно возрос объём и оборот информации во всех сферах жизнедеятельности человека: экономической, финансовой, политической, духовной. И процесс накопления, обработки и использования знаний постоянно ускоряется. Учёные утверждают, что каждые десять лет количество информации увеличивается вдвое. В связи с этим возникает необходимость использования автоматических средств, позволяющих эффективно хранить, обрабатывать и распределять накопленные данные.
Исходя из современных требований, предъявляемых к качеству работы финансового звена крупного предприятия, нельзя не отметить, что эффективная работа его всецело зависит от уровня оснащения компании информационными средствами на базе компьютерных систем.
Актуальность данного проекта заключается в следующем: во-первых, компьютерный учет имеет свои особенности и радикально отличается от обычного. Компьютер не только облегчает учет, сокращая время, требующееся на оформление документов и обобщение накопленных данных для анализа хода производственной деятельности, необходимого для управления ею. Во-вторых, отчеты о положении в производстве, получаемые с помощью компьютера, можно получить и без него – никакой особой математики в компьютере не содержится – но на расчеты уйдет столько времени, что они уже ни на что не будут нужны; или ими придется занять такое количество расчетчиков, что на их зарплату уйдет значительно больше, чем будет получено прибыли в результате их расчетов.
Программное обеспечение для работы с базами данных используется на персональных компьютерах уже довольно давно. К сожалению, эти программы либо были элементарными диспетчерами хранения данных и не имели средств разработки приложений, либо были настолько сложны и трудны, что даже хорошо разбирающиеся в компьютерах люди избегали работать с ними до тех пор, пока не получали полных, ориентированных на пользователя приложений.
Основное преимущество автоматизации — это сокращение избыточности хранимых данных, а следовательно, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте, увеличение степени достоверности информации и увеличение скорости обработки информации; излишнее количество внутренних промежуточных документов, различных журналов, папок, заявок и т.д., повторное внесение одной и той же информации в различные промежуточные документы. Также значительно сокращает время автоматический поиск информации, который производится из специальных экранных форм, в которых указываются параметры поиска объекта.
Информационная система позволит избавить сотрудника от рутинной
повседневной работы по выписке расходных накладных. Так как раньше
документы выписывались в ручную, в которых указывались повторяющиеся реквизиты, а также большой перечень номенклатуры – это занимало много времени. Автоматизация позволит значительно сократить время.
Чтобы сделать отчет, необходимо собрать нужные данные путем поиска их в соответствующих документах, если это отчет за год, то необходимо будет просмотреть все документы за этот год, на что уйдет огромное количество времени. При выведении итогов по отчету необходима огромная точность в расчетах, что не всегда получается даже у специалиста своего дела. Эти и многие другие задачи сможет решить проектируемая информационная система.
При поиске нужного объекта (суммы, документа, количества), если не будет известен документ, в котором его искать, нужно будет перелистать всю кипу документов и просмотреть каждую позицию. Автоматизация позволит сделать выборку по этой позиции и значительно сократит объем подходящих документов или сведет к одному единственному искомому документу.
За счет сокращения времени на выполнение долгих рутинных работ, можно повысить трудоемкость сотрудника, который может теперь выполнять не только свою работу, но и взять на себя ряд других обязанностей.
Создание собственной автоматизированной системы позволит учесть все особенности, т.е. разрабатывается только то, что нужно, и как нужно.
Глава 1. Теоретическая часть
Основные понятия и определения баз данных
База данных – совокупность связанных данных, организованных по определенным правилам, предусматривающих общие принципы описания, хранения и манипулирования независимо от прикладных программ.
Система управления базами данных (СУБД) – приложение, обеспечивающее создание, хранение, обновление и поиск информации в базах данных. СУБД осуществляют взаимодействие между базой данных и пользователями системы, а также между базой данных и прикладными программами, реализующими определенные функции
обработки данных.
Система баз данных – совокупность одной или нескольких баз данных и комплекса информационных, программных и технических средств, обеспечивающих накопление, обновление, корректировку и многоаспектное использование данных в интересах
пользователей.
Свойства БД.: Само документированность. База данных
должна иметь словарь данных – специальное отведенное место в базе данных, которое используется для хранения информации об архитектуре базы данных, о хранимых процедурах, о пользовательских привилегиях, и др. Независимость данных от программ. Структура данных должна быть независима от программ, которые использующих эти данные, чтобы данные можно было добавлять или перестраивать без изменения программ. Целостность данных. Определяет корректность данных и их непротиворечивость. Для обеспечения целостности накладывают ограничения целостности.
Модели баз данных
Иерархическая
Сетевая
Реляционная
Иерархическая модель представляет данные в виде иерархииОсновной принцип иерархической модели — иерархическая структура данных. Это означает, что каждая запись в базе данных может иметь сколько угодно потомков, но только одного родителя. Модель ориентирована на описание объектов, находящихся между собой в отношении подчинения. Например, структура кадров некоторой организации. Организация состоит из отделов, каждый отдел имеет руководителя
и сотрудников. Другой пример: объект «колесо» является составной частью
объекта «автомобиль». Между автомобилем и колесом имеется связь, смысл
которой можно озвучить следующим образом: объект «автомобиль» включает в
себя несколько объектов «колесо».
Сетевая модель представляет собой развитие иерархической. Модель позволяет описывать более сложные виды взаимоотношений между данными. Однако расширение возможностей достигается за счет большей сложности реализации самой модели и трудности манипулирования данными. Сетевой принцип организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь только одного предка; в сетевой структуре данных потомок может иметь любое число предков. К недостатку сетевой модели можно отнести низкое быстродействие и высокие требования к памяти
В реляционной модели данные представляются в виде таблиц, состоящих из строк и столбцов. Каждая строка таблицы — информация об одном конкретном объекте, столбцы содержат свойства этого объекта. Взаимоотношения между объектами задаются с помощью связей между столбцами таблиц. Широкое распространение получили БД, имеющие табличную структуру. В таких БД все данные хранятся в различных таблицах и физически не связаны между собой. Разработчик должен сам продумать, каким образом объединить эти данные при извлечении их из БД. Координация осуществляется путем установления связей между таблицами. В Microsoft Access используется реляционная модель данных. Основные определения. Как уже говорилось выше, реляционная база данных состоит из множества таблиц. В этих таблицах столбцы называются полями
или атрибутами, а строки — записями или кортежами. Поля образуют структуру базы данных, а записи составляют информацию, которая в ней содержится Непременным правилом создания таблицы в СУБД является строгое определение
содержимого самой таблицы. В ее ячейках может храниться только фактическая, и только неизменяемая информация — в ячейках базовых таблиц принципиально не может быть вычисляемых значений. Создание базы данных всегда начинается с разработки структуры ее таблиц. Структура должна быть такой, чтобы при работе с базой требовалось вводить в нее как можно меньше данных. Если ввод каких-то данных приходится повторять неоднократно, базу делают из нескольких связанных таблиц. Структуру каждой таблицы разрабатывают отдельно. Если данные в разных записях начинают повторяться, это может говорить о том, что
база имеет плохую структуру. Для того чтобы связи между таблицами работали надежно, и по записи из одной таблицы можно было однозначно найти записи в другой таблице, надо предусмотреть в таблице уникальные поля. Уникальное поле — это поле, значения в котором не могут повторяться. Если ни одно поле таблицы не приемлемо в качестве уникального, его можно создать искусственно. Существует понятие ключевого поля. При создании структуры таблиц одно поле
(или одну комбинацию полей) можно назначить ключевым. С ключевыми полями
СУБД работает особо. Она проверяет их уникальность и быстрее выполняет
сортировку по таким полям. Ключевое поле – очевидный кандидат для создания связей. Иногда ключевое поле называют первичным ключом. В реляционных базах данных важную роль играет еще один ключ — внешний ключ. Внешний ключ — это поле одной таблицы, которое ссылается на первичный ключ другой таблицы
Реляционная модель на сегодняшний день наиболее распространена. Она достаточно универсальна и проста в проектировании.
Анализ предметной области
Анализ предметной области — это первый шаг этапа системного анализа, с которого начинается разработка программной системы. Разработчики должны научиться:
· понимать язык, на котором говорят заказчики;
· выявить цели их деятельности;
· определить набор решаемых ими задач;
· определить набор сущностей, с которыми приходится иметь дело при решении этих задач.
Анализом предметной области занимаются системные аналитики или бизнес-аналитики. Они передают полученные ими знания другим членам проектной команды, сформулировав их на более понятном разработчикам языке. Для передачи этих знаний обычно служит некоторый набор моделей, в виде графических схем и текстовых документов.
Первым этапом проектирования БД любого типа является анализ предметной области, который заканчивается построением концептуальной схемы (информационной структуры).
На этом этапе анализируются запросы пользователей, выбираются информационные объекты и их характеристики, которые определяют содержание проектируемой БД. На основе проведенного анализа структурируется предметная область.
Анализ предметной области разбивается на три фазы:
· анализ концептуальных требований и информационных потребностей;
· выявление информационных объектов и связей между ними;
· построение концептуальной модели предметной области и проектирование концептуальной схемы БД.
Первая фаза анализа предметной области представляют собой список запросов, которые разработчик получает в диалоге с будущими пользователями этой БД.
Вторая фаза анализа предметной области состоит в выборе информационных объектов, задании необходимых свойств для каждого объекта, выявлении связей между объектами, определении ограничений, накладываемых на информационные объекты, типы связей между ними, характеристики информационных объектов.
Заключительная фаза анализа предметной области состоит в проектировании ее информационной структуры или концептуальной модели. Концептуальная модель включает описания объектов и их взаимосвязей, выявляемых в результате анализа данных. Концептуальная модель применяется для структурирования предметной области с учетом информационных интересов пользователей системы. Она является представлением точки зрения пользователя на предметную область и должна быть стабильной т.е. неизменной. Хотя возможно ее наращивание и включение дополнительных данных.
Автоматизированные средства проектирования баз данных Обзор и классификация Case-технологий
Проектирования БД является сложным итерационным процессом. Автоматизировать данный процесс можно с помощью современных CASE-средств (средств автоматизации проектирования). CASE-средства позволяют ускорить и облегчить разработку, повысить качество создаваемых БД. Многие из CASE-средств имеют систему управления коллективной работой над проектом. Современные CASE-средства позволяют создавать синтаксические модели базы данных на этапах 4 и 5, исходя из инфологической модели предметной области, построенной человеком (проектировщиком БД) на этапе 2. Очевидно, что этапы 1 и 3 полностью не формализуются. Этап 2 допускает лишь частичную автоматизацию, поскольку только человек способен построить в своей голове инфологическую модель предметной области, а лишь потом для описания этой модели применить соответствующие CASE-средства. Термин CASE (Computer Aided Software Engineering) дословно переводится как разработка программного обеспечения с помощью компьютера. В настоящее время этот термин получил более широкий смысл, означающий автоматизацию разработки информационных систем. CASE-средства обеспечивают наглядное описание информационных процессов и инфологической модели предметной области, генерацию и анализ вариантов логических и физических моделей базы данных, создание приложений и т.п. Современная CASE-индустрия объединяет сотни известных фирм и компаний. В настоящее время практически все серьезные проекты осуществляются с использованием CASE-средств. Общее число распространяемых на рынке программных продуктов CASE-средств составляет
порядка 500 наименований. По ориентации на этапы проектирования выделяют следующие типы CASE-средств: инструменты анализа и моделирования предметной области; средства проектирования баз данных; средства разработки приложений. По степени независимости от СУБД различают независимые и встроенные CASE-средства. После построения проекта БД начинается процесс реализации этого проекта, т. е. создание БД. Создание БД и дальнейшая ее эксплуатация традиционно осуществляется с помощью специальных программного обеспечения которое называют по-разному: диспетчер базы данных (database manager), сервер базы данных (database server) или, что более привычно, система управления базами данных, СУБД (DataBase Management System — DBMS).
Рекомендуемые страницы:
Воспользуйтесь поиском по сайту:
megalektsii.ru
Руководство по проектированию реляционных баз данных (1-3 часть из 15) [перевод] / Habr
Перевод цикла из 15 статей о проектировании баз данных.Информация предназначена для новичков.
Помогло мне. Возможно, что поможет еще кому-то восполнить пробелы.
Руководство по проектированию баз данных.
1. Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о проекте вашей базы данных. Хороший проект базы данных, как было сказано ранее, обеспечит целостность данных и простоту их обслуживания.
Структурированный язык запросов (SQL).
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван Структурированный язык запросов или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка. Ниже приведен пример запроса на выборку данных и его результат.
SQL – большая тема для повествования и его рассмотрение выходит за рамки данного руководства. Данная статья строго сфокусирована на изложении процесса проектирования баз данных. Позднее, в отдельном руководстве, я расскажу об основах SQL.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь», как на рисунке (Пример взят из MySQL Workbench).
Примеры.
В качестве примеров в руководстве я использовал ряд приложений.
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров – MySQL. MySQL – наиболее популярная РСУБД и она бесплатна.
Утилита для администрирования БД.
После установки MySQL вы получаете только интерфейс командной строки для взаимодействия с MySQL. Лично я предпочитаю графический интерфейс для управления моими базами данных. Я часто использую SQLyog. Это бесплатная утилита с графическим интерфейсом. Изображения таблиц в данном руководстве взяты оттуда.
Визуальное моделирование.
Существует отличное бесплатное приложение MySQL Workbench. Оно позволяет спроектировать вашу базу данных графически. Изображения диаграмм в руководстве сделаны в этой программе.
Проектирование независимо от РСУБД.
Важно знать, что хотя в данном руководстве и приведены примеры для MySQL, проектирование баз данных независимо от РСУБД. Это значит, что информация применима к реляционным базам данных в общем, не только к MySQL. Вы можете применить знания из этого руководства к любым реляционным базам данных, подобным Mysql, Postgresql, Microsoft Access, Microsoft Sql or Oracle.
В следующей части я коротко расскажу об эволюции баз данных. Вы узнаете откуда взялись базы данных и реляционная модель данных.
2. История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.
Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.
Выше приведен пример того, как такой файл мог бы выглядеть. Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок ‘Database Design Tutorial’, то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова ‘Database Design Tutorial’ и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или “запись” содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок (title) и его категория (category).
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию. Это намного быстрее, чем поиск по файлу строка за строкой, подобно тому, как это делает программа в текстовом файле.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
— Oracle – используется преимущественно для профессиональных, больших приложений.
— Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
— Mysql – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
— IBM – имеет ряд РСУБД, наиболее известна DB2.
— Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
В следующей части я расскажу кое-что о характеристиках реляционных баз данных.
3. Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом. Зачастую, первичный ключ это автоматически увеличиваемое (автоинкрементное) число (1,2,3,4 и т.д). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки (записи) другой таблицы, тем самым, связывая эти записи вместе.
Используя структурированный язык запросов (SQL), данные из разных таблиц, которые связаны ключом, могут быть выбраны за один раз. Для примера вы можете создать запрос, который выберет все заказы из таблицы заказов (orders), которые принадлежат пользователю с идентификатором (id) 3 (Mike) из таблицы пользователей (users). О ключах мы поговорим далее, в следующих частях.
Столбец id в данной таблице является первичным ключом. Каждая запись имеет уникальный первичный ключ, часто число. Столбец usergroup (группы пользователей) является внешним ключом. Судя по ее названию, она видимо ссылается на таблицу, которая содержит группы пользователей.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.
Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
— ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
— ввод индекса региона с длинной этого самого индекса в сотню символов
— создание пользователей с одним и тем же именем
— создание пользователей с одним и тем же адресом электронной почты
— ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN. Как и упоминалось ранее, SQL в данном руководстве обсуждаться не будет. Я сосредоточусь на проектировании баз данных.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Как говорилось ранее, проектирование базы данных – это вопрос идентификации данных, их связи и помещение результатов решения данного вопроса на бумагу (или в компьютерную программу). Проектирование базы данных независимо от РСУБД, которую вы собираетесь использовать для ее создания.
В следующей части подробнее рассмотрим первичные ключи.
habr.com
Тема 5. Средства автоматизированного проектирования структур баз данных.
Подход создания базы данных и входящих в нее таблиц с помощью SQL-конструкций можно применить при конструировании небольших информационных систем, но создание больших баз данных, содержащих сотни и тысячи таблиц и сложные связи между ними, возможно только при использовании CASE-средств. Вручную очень трудно разработать и представить графически структуру системы, проверить ее на полноту и непротиворечивость, отслеживать версии и выполнять модификации.
В данной теме рассмотрим создание концептуальной и физической моделей, а затем их использование для создания и модификации структуры базы данных с помощью современных CASE-средств.
Концептуальное моделирование структуры данных
Широкое распространение реляционных СУБД и их использование в самых разнообразных приложениях показывает, что реляционная модель данных достаточна для моделирования предметных областей. Однако проектирование реляционной базы данных в терминах отношений на основе механизма нормализации часто представляет собой очень сложный и неудобный для проектировщика процесс. Это обусловлено некоторой ограниченностью реляционной модели данных, которая особенно ярко проявляется в следующих аспектах:
реляционная модель не предоставляет достаточных средств для представления смысла данных. Проектировщик должен независимым от модели способом представлять семантику реальной предметной области. Примером данного ограничения может служить представление ограничений целостности;
в ряде случаев предметную область трудно моделировать на основе плоских таблиц. Сложности могут возникнуть на начальной стадии проектирования при описании предметной области в виде одной (возможно, даже ненормализованной) таблицы;
хотя весь процесс проектирования происходит на основе учета зависимостей, реляционная модель не содержит никаких средств для представления этих зависимостей;
несмотря на то что процесс проектирования начинается с выделения некоторых объектов (сущностей) предметной области, существенных для приложения, и выявления связей между этими сущностями, реляционная модель данных не предлагает какого-либо аппарата для разделения сущностей и связей.
Концептуальные модели данных
Для преодоления ограничений реляционной модели и обеспечения потребности проектировщиков баз данных в более удобных и мощных средствах моделирования предметной области проектирование баз данных обычно выполняется не в терминах реляционной модели, ас использованием концептуальных моделей предметной области.
Обычно различают концептуальные модели двух видов:
объектно-ориентированные модели, в которых сущности реального мира представляются в виде объектов, а не записей реляционных таблиц;
семантические модели, отражающие значения реальных сущностей и отношений.
Объектно-ориентированную модель можно рассматривать как результат объединения семантической модели данных и объектно-ориентированного языка программирования.
Несмотря на то, что в последнее время все большее распространение получают объектно-ориентированные модели, не снижается и значение семантических моделей. Концептуальное моделирование баз данных на основе семантических моделей поддерживается во всех известных CASE-средствах (например, таких как ERWin и Power Designer). Кроме того, семантические модели более просты для понимания, особенно при проектировании сравнительно небольших баз данных.
Как и реляционная модель, любая развитая семантическая модель данных включает структурную, манипуляционную и целостную части. Главным назначением семантических моделей является обеспечение возможности выражения семантики данных.
Цель семантического моделирования — обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому семантическую модель данных пытаются строить по аналогии с естественным языком (последний не может быть использован в чистом виде из-за сложности компьютерной обработки текстов и неоднозначности любого естественного языка). Основными конструктивными элементами семантических моделей являются сущности, связи между ними и их свойства (атрибуты). Модель «сущность-связь»
Одной из наиболее популярных семантических моделей данных является модель «сущность-связь» (часто называемая также ER-моделью — по первым буквам английских слов Entity (сущность) и Relation (связь)).
На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена Ченом в 1976г. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в CASE-средствах, предназначенных для автоматизированного проектирования реляционных баз данных.
Для моделирования структуры данных используются ER-диаграммы (диаграммы «сущность-связь»), которые в наглядной форме представляют связи между сущностями. В соответствии с этим ER-диаграммы получили распространение в CASE-системах, поддерживающих автоматизированное проектирование реляционных баз данных. Наиболее распространенными являются диаграммы, выполненные в соответствии со стандартом IDEF1X, который используют наиболее популярные CASE-системы (в частности, ERwin, Design/IDEF, Power Designer).
Основными понятиями ER-диаграммы являются сущность, связь и атрибут.
studfile.net
Case технологии в проектировании баз данных
Библиографическая ссылка:
Гайфуллов Р.Р. Case технологии в проектировании баз данных // Портал научно-практических публикаций [Электронный ресурс]. URL: http://portalnp.ru/2014/06/2067 (дата обращения: 26.11.2019)
Гайфуллов Руслан, студент 2 курса, специальность прикладная информатика ФГБОУ ВПО Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «МГТУ имени Носова»
Аннотация
В данной статье дается определение базы данных. Дальше рассматриваются типы данных в базах данных, и их использование при проектировании баз данных. Потом дается определение Case технологий. А в конце, рассказывается о Case технологиях в проектирования баз данных
CASE technologies in database design
Gayfullov Ruslan, 2nd year student, specialty Applied Informatics, FSBEI HPE “MSTU of a name Nosov”
Аnnotation
In this article provides a definition database. Further describes the types of data in databases and their use in database design. Then provides a definition database. And in the end, tells about case technologies in database design.
ЧТО ТАКОЕ БАЗЫ ДАННЫХ
Базы данных (БД) – множество связанных друг с другом данных, которые организуются со схемой БД для удобной работы с ними пользователя.
Определение из Википедии: Базы данных – множество документов в объективной форме, систематизированных для поиска и обработки с помощью ЭВМ (это электронная вычислительная машина).
База данных – множество данных, хранящихся согласно схеме данных, манипуляция с которыми происходит по правилам средств манипулирования данных.
База данных – сведения, хранящиеся неким упорядоченным способом.
ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ
Этап проектирования базы данных — процесс создания проекта баз данных, нужной для поддержки функционирования предприятия и способствующей достижению его целей.
Проектирование баз данных – процесс создания схемы БД, а также определение нужных ограничений целостности.
Основные задачи:
— Хранение в БД всей нужной информации.
— Возможность получить данные по всем нужным запросам.
— Уменьшение избыточности и дублирования данных.
— Обеспечение целостности и дублирования данных
ЭТАПЫ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
Проектирование БД осуществляется в 3 этапа: концептуальное (инфологическое), логическое (даталогическое), физическое.
Концептуальное проектирование – процесс создания конечной (инфологической) модели данных предприятия (абстрактной структуры баз данных) посредством моделирования данных без учета физических условий (оборудование и программное обеспечение).
Концептуальное (инфологическое) проектирование – создание семантической модели предметной области (информационная модель самого высокого уровня абстракции). Эта модель создаётся без ориентации на СУБД и модель данных. Концептуальная модель БД состоит из описания информационных объектов (понятий предметной области) со связями меж ними и описания ограничений целостности, то есть требований к допускаемым значением данных связей меж ними.
Логическое проектирование – перенесение проекта на внутреннюю модель СУБД (это система управления БД).
Логическое (даталогическое) проектирование – это создание схемы БД с помощью реляционной модели данных.
Даталогическая модель – это набор схем отношений с указанием первичных ключей и связей меж отношениями, являющихся внешними ключами.
Физическое проектирование – это создание схемы БД для конкретно для нужной системы управления БД (например, Access).
Есть еще один вариант этапов проектирования БД:
1 этап: постановка задачи
2 этап: Анализ предметной области.
3 этап: Создание модели.
4 этап: Выбор способов представления информации и программного инструментария.
5 этап: Создание компьютерной модели объекта.
6 этап: Работа с созданной базой данных.
ЧТО ТАКОЕ CASE ТЕХНОЛОГИИ
CASE – инструментарий системных аналитиков для проектирования и разработки. Цель CASE средств – отделить процессы проектирование от программирования. CASE технологии (Computer Aided Software Engineering) совокупность методологий анализа, проектирования, разработки, сопровождения сложных систем программного обеспечения(ПО), поддержанные комплексом взаимоувязанных средств автоматизации. CASE – инструменты и методы программной инженерии для проектирования ПО, обеспечивающее создание высококачественных программ, отсутствие ошибок, а также простоту обслуживания программных продуктов. Также CASE является множеством методов и средств проектирования информационных средств при помощи CASE инструментов.
Case технологии – это методология проектирования ИС и набор инструментов, при помощи которых можно в наглядно смоделировать предметную область, а также проанализировать модель на разных этапах разработки и проектирования, а также разработать приложение с учетом потребностей пользователей.
Средства автоматизации разработки программ – это инструменты для автоматизации процессов проектирования и разработки ПО для системного аналитика, а также разработчика программного обеспечения и программиста. Изначально, Case средствами считали только инструменты, с помощью которых упрощались самые трудоемкие процессы анализа и проектирования, но позже Case средствами стали считать еще и как программные средства поддержки жизненных циклов ПО.
Основной целью CASE технологий является разделение процессов проектирования программных продуктов и кодирования и следующих за ним процессов разработки, а также максимальная автоматизация процесса разработки. Поэтому имеются два совершенно разных подхода к проектированию: структурный и объектно-ориентированный.
Структурный подход предлагает декомпозицию (разделение) задачи на функции, требующие автоматизации. Функции в свою очередь делятся на подфункции, задачи и процедуры. А в конце создается иерархия функций в определенном порядке передающая информацию меж функциями
Также подход использует общепринятые методологии, моделируя разные информационные системы, а именно
SADT (Structured Analysis and Design Technique), DFD (Data Flow Diagrams), а также ERD (Entity Relationship Diagrams).
Есть три основные модели в этом подходе:
функциональные, информационные и динамические
Этот подход реализуют Bpwin, Erwin, Business Studio, IBM WebSphere business modeler и Sybase Power Designer.
В объектно-ориентированном подходе основной инструмент – это язык UML – унифицированный язык моделирования, который может визуализировать и документировать объектно-ориентированные системы, ориентированные на разработку ПО. UML имеет систему разных диаграмм для построения представления о проектируемой системе.
Этот подход реализуют Rational Rose и ARIS.
Case умеет анализировать и программировать программные средства, проектировать интерфейс, документировать, а также производить структурный код на каком-нибудь языке программирования.
Case инструменты делятся на типы и категории:
Типы (здесь отражается функциональная ориентация на разные процессы жизненного цикла разработки ПО и совпадает с составом компонент крупных интегрированных Case систем):
средства анализа, созданные для создания и анализа модели предметной области(Bpwin (logical works).
средства для анализа и проектирования, которые поддерживают самые известные методологии проектирования, создавая с их помощью проектные спецификации. В качестве выхода здесь спецификации компонентов и интерфейсов системы, архитектура систем, алгоритмы м структуры данных.
средства проектирования БД, моделирующие данные и генерирующие схемы БД (на SQL) для систем управления базами данных. Это Erwin (Logic works) и DataBase Designer (Oracle) и Designer/2000.
средства разработки приложений (Developer/2000), Delphi).
средства реинжиниринга, анализирующие программные коды и схемы БД, а также формирование с их помощью разных моделей и проектных спецификаций. Средства анализа схем БД и формирование ERD имеют Designer/2000, Erwin. При анализе программных кодов самыми известными являются объектно-ориентированные Case средства, помогающие проводить реинжиниринг программ на языке С++ (Rational Rose).
Вспомогательные типы
средства планирования и управления проектом (Microsoft Project).
средства конфигурационного управления (PVCS (Intersolv)).
средства тестирования (Quality Works (Segue Software)).
средства документирования (SoDA (Rational Software)).
CASE ТЕХНОЛОГИИ В ПРОЕКТИРОВАНИИ БАЗ ДАННЫХ
В качестве Case технологии я рассмотрю Erwin
На всех стадиях разработки БД, Erwin показывает структуру и основные элементы создаваемой базы данных. Это инструмент разработки, в автоматическом режиме создающий таблицы, а также генерирующий тысячи строк текста хранимых процедур и триггеров для систем управления базами данных. Erwin ускоряет создание приложений для обработки данных.
С Erwin проектирование БД легче. Для этого надо создается графическую E-R модель (объект-отношение), которая удовлетворяет требованиям к данным, а также вводятся бизнес-правила, создавая логическую модель, отображающую элементы, атрибуты, отношения и группировки. Erwin может манипулировать атрибутами при помощи их буксировки, вносить изменения, а также нормализовать во время создания БД. Можно редактировать прямо на диаграммах. Это означает внесение изменений в модель, не открывая специальных диалоговых окон. При помощи отчетов, которые формируются системой, проверяется правильность созданной БД.
Erwin не только инструмент для «рисования», но и автоматизирует проектирование. Ссылочная целостность БД обеспечивается автоматическим переносом ключей. Создающиеся в Erwine модели данных могут редактироваться, просматриваться и распечатываться разными способами. А при помощи RPTwin (имеющей графический интерфейс и умеющей формировать отчеты) и средства для просмотра настраиваемыми режимами, обеспечивающими контроль отображения содержимого отчетов, можно реализовать одинаковые стандарты проектирования и отображения настроек для всех моделей.
Erwin средство для быстрого создания БД. Erwin оптимизирует модель для соответствия физическим характеристикам нужной БД. Так же Erwin самостоятельно согласует логическую и физическую схемы и преобразовывает логические конструкции (например, многие ко многим) в их реализацию на физическом уровне. Реализация и прямого и обратного инжиниринга в Erwin достигается при помощи естественной динамической связи между моделью и базой данных. При помощью этой связи Erwin самостоятельно создает таблицы, представления, индексы, правила поддержания целостности ссылок (первичных и внешних ключей), устанавливает значения по умолчанию, а также ограничения для доменов/столбцов. В Erwine целостность ссылок обеспечивают множество оптимизированных шаблонов триггеров, а также мощный макроязык, при помощи которого создаются свои триггеры и хранимые процедуры. Для точной оценки и характера роста базы данных или хранилища имеются средства расчёта объема, облегчающие эффективное распределение ресурсов системы и планирование мощности.
БД проектируется и создается без написания SQL-предложений. Так как физическая схема формируется на основе описательной логической модели, создаваемая БД будет полностью задокументировано. Также возможен обратный инжиниринг имеющихся БД с помощью построения модели непосредственно на основе ее таблиц. Erwin поддерживает Oracle, Microsoft SQL Server, Sybase, Informix и другие. Одна и та же модель может использоваться для проектирования нескольких БД (или переноса приложения с платформы одной системы управления БД на другую.
Источники
- Википедия: Базы данных
- определение БД
- Проектирование баз данных
- Этапы проектирования БД
- CASE
- Реферат Case средства
- Википедия: Erwin
- сайт про Erwin
Количество просмотров публикации: —
portalnp.ru
Проектирование Базы Данных. Лучшие практики / OTUS. Онлайн-образование corporate blog / Habr
В преддверии старта очередного потока по курсу «Базы данных» подготовили небольшой авторский материал с важными советами по конструированию БД. Надеемся данный материал будет полезен для вас.Базы данных повсюду: от простейших блогов и директорий до надежных информационных систем и крупных социальных сетей. Не настолько важно, простая или сложная база данных, насколько существенно спроектировать ее правильно. Когда база спроектирована бездумно и без четкого понимания цели, она не просто не эффективна, но и дальнейшая работа с базой будет реальным мучением, непроходимым лесом для пользователей. Вот несколько советов по конструированию базы данных, которые помогут создать полезный и простой в использовании продукт.
1. Определите, для чего таблица и какова ее структура
Сегодня такие методы разработки, как Scrum или RAD (быстрая разработка приложения), помогают ИТ-командам быстро разрабатывать базы данных. Однако, в погоне за временем очень велик соблазн погрузиться сразу в построение базы, смутно представляя, в чем же сама цель, какие должны быть конечные результаты.
Как будто команда нацелена на эффективную, скоростную работу, но это мираж. Чем дальше и быстрее погружаться вглубь проекта, тем больше потребуется времени, чтобы выявить и изменить ошибки в проекте базы.
Поэтому первое, что нужно решить — это определить цель для вашей базы данных. Для какого типа приложения разрабатывается база? Пользователь будет лишь работать с записями и нужно уделить внимание транзакциям или его больше интересует аналитика данных? Где база должна быть развернута? Будет ли она отслеживать поведение клиентов или же просто управлять отношениями между ними?
Чем раньше команда проектирования ответит на эти вопросы, тем мягче, плавнее пройдет процесс проектирования базы данных.
2. Какие данные выбрать для хранения?
Планируйте наперед. Мысли о том, что в будущем будет делать сайт или система, для которых проектируется база данных. Важно выходить за рамки простых требований технического задания. Только пожалуйста, не начинайте размышлять сразу обо всех возможных типах данных, которые когда-либо будет хранить пользователь. Лучше подумайте о том, смогут ли пользователи писать посты, загружать документы или фотографии или обмениваться сообщениями. Если это так, то в базе нужно выделить место под них.
Работайте с командой, департаментом или организацией, для которых в будущем будет поддерживаться проектируемая база. Общайтесь с людьми разных уровней, от специалистов по работе с клиентами до глав отделов. Так с помощью обратной связи вы получите четкое представление о требованиях компании.
Неизбежно потребности пользователей в рамках даже одного департамента будут конфликтовать. Если вы столкнетесь с этим, не бойтесь опереться на собственный опыт и найти компромисс, который устроит все стороны и будет удовлетворять конечной цели БД. Будьте уверенны: в будущем вам прилетит +100500 в карму и гора печенек.
3. Моделируйте данные с осторожностью
Есть несколько ключевых моментов, на которые стоит обратить внимание при моделировании данных. Как мы уже ранее говорили, от назначения базы данных зависит, какие методы использовать при моделировании. Если мы проектируем базу данных для оперативной обработки записей (OLTP), иными словами для их создания, редактирования и удаления, то используем моделирование транзакций. Если же база данных должна быть реляционной, то лучше всего применять многомерное моделирование.
Во время моделирования строятся концептуальные (CDM), физические (PDM) и логические (LDM) модели данных.
Концептуальные модели описывают сущности и типы данных, которые они включают, а также отношения между ними. Делите ваши данные на логические куски — так намного проще жить.
Главное — мера, не переусердствуйте.
Если сущность очень сложно классифицировать одним словом или фразой, то пришло время использовать подтипы (дочерние сущности).
Если же сущность ведет собственную жизнь, имеет атрибуты, которые описывают ее поведение и ее вид, а также отношения с другими объектами, то смело можно использовать не только подтип, но и супертип ( родительская сущность).
Если пренебречь этим правилом, другие разработчики запутаются в вашей модели и не до конца будут понимать данные и правила, как их собирать.
Реализуются концептуальные модели с помощью логических. Эти модели словно дорожная карта для проектирования физической базы данных. В логической модели выделяются сущности бизнес-данных, определяются типы данных, статус ключа правила, которые регулируют отношения между данными.
Затем Логическая модель данных сопоставляется с выбранной заранее платформой СУБД (системы управления базами данных) и получается Физическая модель. Она описывает способ физического хранения данных.
4. Используйте подходящие типы данных
Применение неправильного типа данных может привести к менее точным данным, трудностям в объединении таблиц, синхронизации атрибутов и к раздуванию размеров файлов.
Чтобы гарантировать целостность информации, атрибут должен содержать только приемлемые для него типы данных. Если в базу данных вносится возраст, то убедитесь, что в колонке хранятся целые числа из максимум 3 цифр.
Создавайте минимум пустых столбцов со значением NULL. Если вы создаете все столбцы как NULL, это грубая ошибка. Если же вам нужен пустой столбец для исполнения конкретной бизнес-функции, когда данные неизвестны или еще не имеют смысла, то смело создавайте. Ведь мы же не можем заранее заполнить столбцы “Дата смерти” или “Дата увольнения”, мы же не предсказатели тыкать пальцем в небо :-).
Большинство софта для моделирования (ER/Studio, MySQL Workbench, SQL DBM, gliffy.com) данных позволяет создавать прототипы областей данных. Так гарантируется не только правильный тип данных, логика приложения и хорошая производительность, но также и обязательное задание значения.
5. Предпочитайте естественное
Когда вы решаете, какой столбец в таблице выбрать в качестве ключа, всегда обращайте внимание, какие поля может редактировать пользователь. Никогда не выбирайте их в качестве ключа — плохая идея. Произойти может все что угодно, а вы должны гарантировать уникальность.
Лучше всего использовать естественный, или бизнес, ключ (natural key). Он имеет смысловое значение, так вы избежите дублирования в базе данных.
Если только бизнес-ключ не уникален (имя, фамилия, должность) и повторяется в разных строках таблицы или он должен изменяться, то первичным ключом стоит назначить сгенерированный искусственный, суррогатный ключ (artificial key).
6. Нормализуйте в меру
Чтобы эффективно организовать данные в БД, необходимо следовать набору рекомендаций и нормализовать базу данных. Существует пять нормальных форм, которым нужно следовать.
С помощью нормализации вы избежите избыточности и обеспечите целостность данных, использующихся в приложении или на сайте.
Как всегда, всего должно быть в меру, даже нормализации. Если в БД слишком много таблиц с одинаковыми уникальными ключами, то вы увлеклись и чрезмерно нормализовали базу данных. Излишняя нормализация негативно влияет на производительность базы данных.
7. Тестируйте пораньше, тестируйте почаще
Тестовый план и надлежащее тестирование должны быть частью проектирования базы данных.
Лучше всего тестировать базу данных путем Continuous Integration (непрерывной интеграции). Моделируйте сценарий “Один день из жизни базы данных” и проверяйте, все ли граничные случаи обрабатываются, какие взаимодействия пользователей вероятны. Чем раньше вы найдете баги, тем больше сэкономите и времени, и денег.
Это всего лишь семь советов, с помощью которых вы можете спроектировать отличную базу данных по производительности и эффективности. Если будете следовать им, вы избежите большинства головных болей в будущем. Эти советы — всего лишь верхушка айсберга в моделировании базы данных. Существует огромное число лайфхаков. Какими пользуетесь вы?
habr.com
Обзор программных средств для реализации базы данных
В настоящее время в мире используется достаточно большое количество универсальных промышленных СУБД. Проведен обзор наиболее распространенные СУБД.
В настоящее время в мире используется достаточно большое количество универсальных промышленных СУБД. Среди них можно выделить несколько несомненных лидеров, как по уровню развития технологий, так и по объему рынка — они вместе занимают более 90% мирового рынка СУБД. Это СУБД первого эшелона — Oracle, Microsoft SQL Server, MySQL, Microsoft Access и IBM DB2, в последнее время быстро становится популярна система с открытым кодом PostgreSQL. Список СУБД второго эшелона довольно велик, сюда относят такие СУБД, как Sybase, Informix, Ingress, Adabas, Interbase, Progress, Cache, Linter, Firebird, Teradata и т д.
Рассмотрим более подробно наиболее распространенные СУБД.
1. СУБД Oracle одна из наиболее мощных современных СУБД, предназначенных для реализации баз данных уровня корпорации, что предъявляет серьезные требования к серверу. Oracle может работать в большинстве операционных систем: Windows-NT, -2000, Linux, UNIX, AIX, Nowell Netware.
Использование Oracle в качестве СУБД дает возможность выбора языка программирования. Традиционно для этого используется язык PL/SQL, но можно использовать и гораздо более мощный язык программирования Java.
Oracle полностью располагает мощными и удобными средствами администрирования не только одного сервера, но и группы серверов, расположенных в разных частях планеты.
Основными преимуществами Oracle можно считать поддержку баз данных очень большого объема (до 64 Гбайт), мощные средства разработки и администрирования, поддержку многопроцессорности и двух языковых сред, а также интеграцию с Web. Вместе с этим программа предъявляет серьезные аппаратные требования и высокую цену.
2. СУБД MS SQL Server-2000 предлагает широкий спектр услуг администрирования и легко масштабируется. Это позволяет использовать ее в информационных системах для среднего бизнеса и больших компьютерных информационных системах (КИС).
В основе платформы MS SQL Server используется среда Windows. Главное преимущество программы тесная интеграция с программными продуктами от Microsoft и возможность экспорта/импорта данных в большинство распространенных форматов данных, что позволяет использовать MS SQL Server как центральное хранилище данных.
3. СУБД Borland Interbase содержит все, что требуется от СУБД, предназначенной для нужд малого и среднего бизнеса. К тому же начиная с версии 6.0 программа стала бесплатной, что тоже существенно. Программа нетребовательна к аппаратной части. Borland Interbase поддерживается платформами Windows и Linux, а также UNIX, NetBSD, FreeBSD.
Популярные языки программирования от Borland, как Delphi, Kylix и C++ Builder, поставляются с компонентами, позволяющими работать с данной СУБД. Именно это позволяет достичь очень высокого быстродействия программы.
4. СУБД MySQL получила широкое распространение в качестве средства работы с базами данных в Интернете. Программа совершенно нетребовательна к ресурсам сервера, на котором работает, очень быстрая и к тому же совершенно бесплатная: исходные коды и дистрибутивы для различных платформ доступны на сайте в Интернете. Изначально программа была ориентирована на операционную систему Linux, но сейчас уже существуют версии программы для операционных систем Windows, UNIX, NetBSD, FreeBSD, AIX. В последнее время программа завоевывает популярность у пользователей Macintosh с использованием операционной системой Mac OSX.
5. СУБД MS Access используется для решения локальных офисных задач с ограниченным объемом данных и формирование отчетов по результатам работы, при этом отчеты могут быть представлены в стандартном для офисных приложений виде.
MS Access одновременно является и средой разработки на двух языках программирования (Visual Basic и сильно усеченный диалект SQL), и CASE-средством, а также мощным и наглядным средством создания отчетов по результатам работы.
Программмное обеспечение позволяет создавать программы, состоящие из одного файла, содержащего как текст программы, так и реляционную базу данных сложной структуры. Access легко интегрируется с другими решениями от Microsoft. Это позволяет использовать ее как клиентскую часть информационного комплекса в связке с MS SQL Server, выступающей в качестве серверной части.
Успех Access заключается в прекрасной реализации продукта, рассчитанного как на начинающего, так и квалифицированного пользователя. В настоящее время это самая популярная настольная система управления базами данных.
В Microsoft Access присутствует язык программирования Visual Basic, который позволяет создавать массивы, свои типы данных, контролировать работу приложений. Также имеется один из самых лучших наборов визуальных средств разработки и представления информации среди аналогичных программных продуктов.
Вся работа с базой данных осуществляется через окно контейнера базы данных. Отсюда осуществляется доступ ко всем объектам: таблицам, запросам, формам, отчетам, макросам, модулям. Встроенный язык запросов SQL позволяет максимально гибко работать с данными и значительно ускоряет доступ к внешним данным.
Access воспринимает большое количество форматов данных, включая файловые структуры других СУБД. В приложение можно импортировать из текстовых файлов или электронных таблиц и экспортировать в них, предоставлять прямой доступ и обновлять файлы Paradox, FoxPro и других баз данных (БД).
Преимуществом Access является наличие средств проектирования приложения БД без знания языка программирования. Работа в Access начинается с определения реляционных таблиц и полей, предназначенных для хранения данных. Сразу после этого с помощью форм, отчетов, макросов и VBA можно определять действия над этими данными. Формы и отчеты используются для вывода на экран и дополнительных вычислений при работе с таблицами. В случае разработки более сложного приложения можно использовать язык Visual Basic.
Архитектура Access называет объектами все, что может иметь имя. В базе данных основными объектами являются таблицы, запросы, формы, отчеты, макросы и модули. В целом термин «база данных» обычно относится только к файлам, в которых хранятся данные, в Access же база включает все объекты, связанные с хранимыми данными, в том числе и те, которые определяются для автоматизации работы. Основными компонентами СУБД Access являются:
- Таблица — содержит информацию об объектах. Поля (столбцы) хранят характеристики объектов, а каждая запись (строка) содержит сведения об объекте.
- Запрос — фиксирует нужные данные из одной или нескольких таблиц. Для запроса можно использовать запрос по образцу или инструкцию SQL -запросы на выборку и обновление данных.
- Форма — отражает требования к данным таблиц или запросов. Формы можно распечатать. С помощью формы можно запустить макрос или VBA.
- Отчет — объект форматирования, вычисления итогов и печати данных.
- Макрос — описание действий Access в ответ на событие. Макрос открывает другую форму, может проверять поля при изменении его содержимого, открывать таблицы, запросы, просмотр или печать, запустить другой макрос или процедуру VBA
- Модуль — программа на языке Visual Basic для приложений, обнаружевает ошибки, которые не обнаруживает макрос. Модули могут быть независимыми объектами, содержащими функции, вызываемые из любого приложения или отчета для реакции на события.
В таблицах хранятся данные. Используя формы, можно выводить данные на экран или изменять их. Формы и отчеты получают данные как непосредственно из таблиц, так и через запросы. Для выполнения вычислений запросы могут использовать встроенные функции или функции, созданные с помощью Visual Basic для приложений.
События в формах или отчетах могут запускать макросы или процедуры VBA. Событие — любое изменение состояния объекта Access, например открытие формы, закрытие формы, ввод новой строки в форму, изменение содержимого текущей записи или элемента управления. Для обработки события можно создать макрос или процедуру VBA, с помощью которых можно предусмотреть реакцию на любое действие пользователя, вплоть до нажатия определенных клавиш во время ввода данных. С помощью макросов и модулей можно изменять ход выполнения приложения; открывать, фильтровать и изменять данные в формах и отчетах; выполнять запросы и создавать новые таблицы. Используя VBA, можно создавать, модифицировать и удалять любой объект Access, обрабатывать данные по строкам и по столбцам или каким-либо другим способом. Можно также вызывать процедуры из библиотек динамической компоновки Windows, чтобы использовать в приложении не только встроенные в Access функции, но и возможности Windows.
Таким образом, для разработки базы данных наиболее целесообразно использовать Microsoft Access.
novainfo.ru