Читайте про Страницы пагинации в нашем словаре SEO терминов
Страницами пагинации называют определенные страницы каталога, где присутствует список статей или товаров, которые не поместились на самых первых страницах раздела и категории. Как правило, это вторая, третья и остальные страницы, кроме первой. Почти всегда располагается в нижней области интернет-ресурса, хотя можно размещать и сверху.
Правила настройки пагинации
На многих страницах пагинации происходит частичное дублирование текстового контента. Это же относится и к мета-тегам. Но такое решение не только существенно ухудшает показатели внутренней оптимизации, но и негативно влияет на релевантность главных посадочных интернет-страниц в отношении пользовательских запросов через поисковики. Конечно же, подобные площадки будут намного хуже ранжироваться в выдаче поиска.
При этом существует и другая серьезная проблема, которую не всегда учитывают. Поисковые роботы посещают ресурс, а затем анализируют его. Но количество и глубина просматриваемых страниц могут иметь ограничения, зависящие не только от частоты обновления материалов, но и траста. При этом наличие частичных дублей снижает вероятность индексирования необходимых страниц, так как бот впустую тратит драгоценные переходы.
Поисковые роботы посещают ресурс, а затем анализируют его. Но количество и глубина просматриваемых страниц могут иметь ограничения, зависящие не только от частоты обновления материалов, но и траста. При этом наличие частичных дублей снижает вероятность индексирования необходимых страниц, так как бот впустую тратит драгоценные переходы.
Неактуальные методы оптимизации страниц пагинации
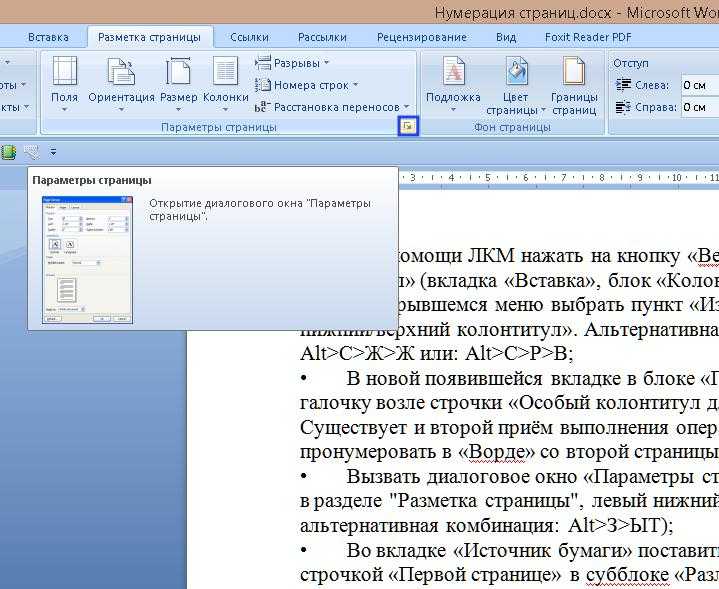
Скрытие страниц пагинации при помощи robots.txt
Нет необходимости редактировать код интернет-ресурса, что делает данный способ быстровыполнимым. Благодаря маске директивы в robots.txt есть возможность быстро закрыть нумерованные страницы. Но конкретная директива напрямую связана с вариантом реализации подобных страниц площадки.
 Вот только придется достаточно долго ждать, когда из индекса все-таки исчезнут страницы, попавшие туда ранее. Робот (поисковая система) увидит директиву с запретом в данном файле, а потом просто проигнорирует такую страницу. Могут возникнуть неприятности с индексированием товарных страниц пагинации, располагающихся в файле robots.txt.
Вот только придется достаточно долго ждать, когда из индекса все-таки исчезнут страницы, попавшие туда ранее. Робот (поисковая система) увидит директиву с запретом в данном файле, а потом просто проигнорирует такую страницу. Могут возникнуть неприятности с индексированием товарных страниц пагинации, располагающихся в файле robots.txt.
Использование <meta name=»robots» content=»noindex, follow»>
Как и в предыдущем методе страницы пагинации будут запрещены для индексации. Но есть отличия:
- Робот сможет беспрепятственно переходить по страницам пагинации и индексировать все ссылки на них, что решает проблему индексации карточек товаров.
- Попавшие в индекс страницы пагинации при переобходе будут удалены из индекса.
Но у этого метода тоже есть свои минусы:
- Теряются ссылочные свойства
- Не подходит для больших статей, разбитых на страницы, т.

Пагинация с тегом rel = «canonical» на начальную страницу
Чуть ли не самое распространенное решение для борьбы с дублирующимися страницами пагинации в поисковом индексе. Причем такой метод действительно является эффективным. Но он существенно затрудняет индексирование товаров, которые находятся на страницах пагинации.
В органическом поиске этот метод плохо влияет на ранжирование. Причины такие же, как в предыдущем методе.
А с недавних пор Гугл причислил настройку ссылок канонического типа, располагающихся на самой начальной странице категории, к наиболее частым ошибкам. В Google заявляют, что каноникал используется для дублированного контента, в то время как страницы пагинации дублями не являются.
Теги Prev/Next
Ранее использование этих указаний было идеальным способом для Google. Но в 2019 году поисковик заявил об отказе от их использования. Яндекс не учитывал их и ранее.
Но в 2019 году поисковик заявил об отказе от их использования. Яндекс не учитывал их и ранее.
Прогрессивные способы оптимизации страниц пагинации
Создание цельной страницы без пагинации
Как говорится нет пагинации – нет проблем. Для обоих поисковиков это будет лучшим способом, имеющим ряд преимуществ:
- Пользователя удобнее смотреть весь контент сразу, чем переключаться между страницами.
- Сохраняются все свойства и не возникает проблем с индексацией.
- Улучшение ранжирования. Поисковики любят, когда страница решает максимальное количество проблем пользователей, за что могут поднять ее в выдаче.
Но, как и везде, существует несколько минусов:
- Скорость загрузки для большого количества контента может значительно упасть, что ухудшит поведенческие факторы (увеличит количество отказов), и таким образом негативно скажется на ранжировании.

Оставить все как есть
Как ни странно, но это вполне работает, и даже рекомендуется Гуглом, как нормальное решение проблемы. Поисковый гигант мотивирует это верой в свои алгоритмы, которые по их словам могут сами разобраться в данной ситуации.
Но есть одно НО. Часто некоторые страницы признаются дублями и вылетают из индекса.
Поэтому чтобы способ стал не просто нормальным, а хорошим необходимо внести некоторые доработки. Для любого типа сайта нужно уникализировать мета-теги. Проще всего это сделать добавив в title и description страниц пагинации номера страниц (например, «стр.- 4»).
 Это актуально для интернет-магазинов, в которых текст повторяется на каждой странице. Необходимо оставить его только на той странице, которую вы хотите видеть в индексе (обычно первая).
Это актуально для интернет-магазинов, в которых текст повторяется на каждой странице. Необходимо оставить его только на той странице, которую вы хотите видеть в индексе (обычно первая).
Что выбрать?
При выборе способа лучше отталкиваться от вашей конкретной ситуации и приоритетной поисковой системы. Прогрессивные методы подойдут для обоих поисковиков, но сложны в реализации при отсутствии навыков, поэтому потребуют привлечения хорошей компании по продвижению сайтов.
Правильная индексация страниц пагинации — Офтоп на vc.ru
Что такое пагинация
8849 просмотров
Пагинация (pagination, пейджинг, листинг) происходит от слов «page» и «navigation» и в буквальном смысле означает «постраничную навигацию». Вывод массива данных (например товаров в категории интернет-магазина) с разбиением на несколько страниц.
Если показывать все товары на одной странице, то при большом количестве их загрузка может занять много времени и замедлить работу браузера.
Нужно ли закрывать ее от индексации
Однозначно — не нужно. Но для того чтобы пагинация не вредила продвижению сайта, необходимо выполнить определенные настройки.
К сожалению, на момент написания заметки ни в одной CMS данный функционал не реализован полноценно, что заставляет проводить доработки и вносить правки в логику работы. Если этого не сделать, то
страницы-пагинации будут дублировать контент, заголовки и мета-теги первой страницы, а поисковые системы, как известно, негативно относятся к дублям на сайте.
Отношение к пагинации у Яндекса и Google
В своем блоге Яндекс советует использовать атрибут rel=»canonical» тега <link>, в котором в качестве канонического адреса необходимо указывать первую страницу. В поиске будет участвовать только она одна, но остальные страницы будут посещаться поисковым роботом, с которых он перейдет на страницы товаров.
Google же предлагает три варианта реализации:
- Ничего не делать и положиться на алгоритм Google — он сам выберет страницу с наиболее релевантным содержимым.
- В атрибуте rel=»canonical» в качестве канонической указать страницу «Показать все», на которой выводились бы все товары категории.
- Указать логическую связь между страницами пагинации с помощью атрибутов rel=»next» и rel=»prev» для тега <link>.
Первый вариант отметаем сразу, так как в Яндексе будет полный беспорядок.
Второй вариант имеет право на жизнь, что подтверждается представителем Яндекса в одном из обсуждений «Клуба о поиске Яндекса». Но если на вашем сайте в категории огромное количество товаров, которые будут выведены на одной странице, это может создать сложности для индексации и верного восприятия содержимого страницы. К тому же, таким образом вы даете понять поисковикам, что именно эту страницу необходимо ранжировать, а значит в поиске будет появляться именно она, и при переходе на нее пользователи будут долго ждать полной загрузки.
Третий вариант отлично работает для Google, но, к сожалению, данные атрибуты не воспринимаются Яндексом, и без дополнительных настроек будет неразбериха, как и при первом варианте.
Как правильно реализовать индексацию пагинации
Чтобы найти компромисс между рекомендациями Яндекса и Google, мы в своей работе придерживаемся следующих правил:
- Страницы пагинации открыты для индексации (исключение составляют страницы вида пагинация+сортировка и пагинация+фильтрация, если для фильтрации не предусмотрен корректно реализованный функционал смарт-фильтра).
- Текст с описанием категории выводится только на первой странице. На второй, третьей и так далее страницах он не выводится (не скрывается в display:none, а именно не выводится). Это актуально для интернет-магазинов и неактуально, например, для раздела статей или новостей — в этом случае у разделов не бывает описаний, а в качестве контента выступают превью статей/новостей.
- Первая страница должна быть доступна только по адресу без префикса пагинации. Например, в Bitrix пагинация по умолчанию строится с помощью GET-параметров, которые имеют вид PAGEN_1=N, где N — номер страницы пагинации. Допустим, первая страница категории имеет вид /catalog/category/, вторая — /catalog/category/?PAGEN_1=2, третья — /catalog/category/?PAGEN_1=3 и так далее. В этом случае важно, чтобы первая страница НЕ была доступна по адресу /catalog/category/?PAGEN_1=1 (это можно настроить с помощью 301-редиректов и правильного построения ссылок в навигационной цепочке).
- Мета-теги и заголовок Title не должны дублироваться. Например, если для первой страницы задан оптимизированный title, то для страниц пагинации его можно строить по шаблону «%name% — страница N», где %name% — название категории, а N — номер страницы пагинации.
- Используем атрибуты rel=»next» и rel=»prev» тега <link> — для Google это будет плюсом, для Яндекса вреда не принесет.


Можно заметить, что мы не во всем следуем официальным рекомендациям поисковиков, и вот почему:
- Указание в качестве канонической страницы вида «Показать все» для больших каталогов неприемлемо, как описывалось выше.
- Указание в качестве канонической первой страницы категории создаст трудности для Google — это не вписывается ни в одну рекомендацию и может создать проблемы при индексации и верном восприятии сайта.
- Задание уникальных мета-тегов и заголовков в совокупности с различными выводимыми товарами делает страницы пагинации уже не дубликатами — на каждой из них свой контент. По этой же причине связывать их через rel=»canonical» становится нелогично.
- Благодаря оптимизированным мета-тегам, заголовкам и описанию, в поиске приоритет всегда будет отдаваться первой странице категории. Однако если возникнет ситуация, что в выдаче Яндекса ее место займет какая-либо страница пагинации, это можно расценивать как сигнал о переоптимизации страницы, что упрощает обнаружение данного фильтра.

Такой подход позволяет избежать всех проблем, связанных с индексацией страниц пагинации.
Ждите новые заметки в блоге или ищите на нашем сайте.
Пагинация SEO | Самые популярне методы настройки пагинации | Блог msystem.com.ru
Крупные коммерческие ресурсы за время своей работы «обрастают» огромным количеством карточек, статей, изображений и прочей сопутствующей информацией, структура и логика которой, зачастую понятна только администрации этих гигантов. Упорядочить контент призвана пагинация – инструмент, позволяющий не перегружать содержимым одну страницу, тем самым ускоряя её загрузку и общее юзабилити ресурса. Игнорирование проблемы оборачивается частичными дублями и снижением позиций в поисковой выдаче.
Тема злободневная и точно одна из самых комментируемых в СЕО-среде. Если отталкиваться от технической сути, то пагинация SEO – это настройка нумерации, позволяющая разделить содержимое каталога на страницы. Существует теория, что некорректная настройка пагинации, сказывается на глубине сканирования каталога поисковыми ботами. В индексацию попадают только две первые страницы.
В индексацию попадают только две первые страницы.
Как правило, на коммерческих сайтах (интернет магазинах), а также досках объявлений пагинация выглядит следующим образом
Существует как минимуму три вида пагинации
- Перечень номеров веб-страниц, каждый из которых выступает ссылкой.
- Список позиций, в котором группа цифр переводит пользователя к месту с разыскиваемым материалом.
- Буквенные подборки: товарные карточки группируются по буквам вместо цифр.
Обсуждаемый в этой статье инструмент решает несколько задач. Как уже было сказано выше, ускоряет загрузку, плюс, упрощает поиск необходимой информации, придает дизайну логически-завершенную архитектуру. Если подытожить вступление, то пользователям нравится этот инструмент, прежде всего, за возможность быстрого и точного подбора данных.
Настройка пагинации: какие методы мы рекомендуем?
Так как оптимизация критична при оценке поисковыми ботами, логичным будет отталкиваться от рекомендаций Google и Яндекс.
А чем больше ссылок на ваш сайт будет поступать с качественных, схожих по тематике сайтов, тем выше будут ваши позиции в органической выдаче.
rel=”canonical” со всех страниц на первую (она же основная)
Вот, что рекомендует американская корпорация: не вносить изменений, либо же установить кнопку «Показать все». Второй метод довольно популярен, так как поощряется Google и в целом нравится большинству пользователей, но имеет некоторые минусы: требует высокой скорость загрузки содержимого, работает не со всеми CMS системами.
Пошаговая настройка пагинации в данном случае выглядит так:
- Создаем страницу «Показать все»;
- через тег canonical указываем, что она является канонической;
- в поле HEAD размещаем ссылку rel=”canonical”, которая приводит пользователя на «Показать все».
То есть суть настройки сводится к тому, что каноническая страница, это первая страница. Относительно недавно поисковик Яндекс также включил поддержку атрибута rel=”canonical”.
Rel=”prev”/”next”
Значения «rel=»prev»» и «rel=»next»» дают понять поисковым роботам Google, что страницы связаны друг с другом структурно. Для реализации идеи применяются HTTP-заголовки или HTML-ссылки. Минусом этого метода выступает тот факт, что Яндекс не понимает приведенные атрибуты, поэтому индексацию приходится закрывать вручную, применяя мета-теги «noindex/nofollow». Если говорить о позитивных моментах, то они заключаются в повышении позиций по низкочастотным запросам, а ведь именно такие запросы трансформируются в покупательскую конверсию.
Иногда оптимизация страниц пагинации и вовсе не требует от пользователя знаний кода. Так, для блогов на движке WordPress эту задачу решили, что называется по умолчанию. Даже без корректировки настроек пользователю доступны переходы к следующему и предыдущему посту. Изменить базовые возможности допускается посредством плагинов:
- WP-PageNavi
- Infinite-Scroll
- Faster Pagination
- Alphabetic Pagination
Конечно, пагинация на сайте не может ограничиваться плагинами, ведь в отличие от блога коммерческому ресурсу требуется установить более сложные структурные связи.
Краткий перечень методов настройки пагинации
Весь перечень методов настройки пагинации приведем в формате удобного запоминающегося списка. О наиболее популярных мы уже рассказали выше.
- Первая страница – каноническая. Составные ресурсы пагинации открыты для сканирования, но не попадают в индекс поисковиков. Атрибут canonical указывается только на главной.
- Все страницы индексируются и сканируются. Каноническая – только первая.
- Сканируются все, в индексе только первая. Все переходы ведут на неё.
- Сканируются и индексируются все. Каждая является канонической. В коде каждой страницы canonical указывает на себя.
- Вся структура сканируется, индексируется, canonical указывает на первую. Атрибуты prev/next не используются.
- В индексе только первая, сканируются все. Атрибуты предыдущая/следующая не применяются.
Независимо от того, какое направление будет принято за приоритетное, необходимо учесть несколько нюансов. Первое – размер страницы и количество ссылок имеет значение.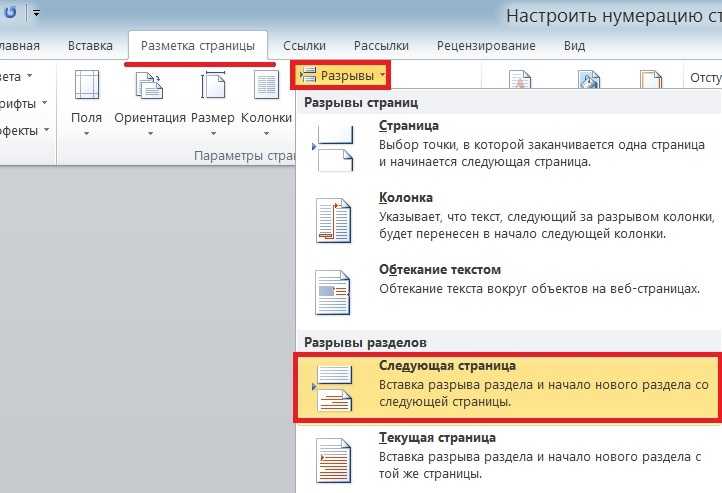 Говоря проще, оптимизация страницы сайта это поиск баланса. Нельзя делать страницу слишком короткой (менее 20-и элементов). Оптимальный объем: от 20-и до 100 элементов. Второе – оформление пагинации. Если это нумерованный подход, то пользователь должен сразу понимать, на какой именно по счету странице находится. Третий момент – подгонка под мобильную версию пользования обязательна!
Говоря проще, оптимизация страницы сайта это поиск баланса. Нельзя делать страницу слишком короткой (менее 20-и элементов). Оптимальный объем: от 20-и до 100 элементов. Второе – оформление пагинации. Если это нумерованный подход, то пользователь должен сразу понимать, на какой именно по счету странице находится. Третий момент – подгонка под мобильную версию пользования обязательна!
Что не рекомендуется использовать при оптимизации структуры сайта?
Мы не рекомендуем делать две вещи: пускать все на самотек, закрывать от индексации все страницы пагинации, кроме первой. Если ничего не предпринимать, в процессе усложнения структуры, начнут возникать дубли текстового контента, страниц. Из-за этого в индекс могут попасть адреса с плохой оптимизацией, а продвигаемые страницы «выпадут» из ТОПа.
Нет желания углубляться в технические дебри самостоятельно? Достаточно заказать услуги поискового продвижения у профессионалов. Мы всегда рады помочь. Первичный аудит в подарок.
Оцените статью
Средняя оценка 0 / 5. Количество оценок: 0
Количество оценок: 0
Оценок пока нет. Поставьте оценку первым.
Личный помощник
Ведет дела в рамках услуги поисковая рекламаПогружается в специфику работы, но при этом умеет донести информацию доступным способомСвязывается с заказчиком минимум раз в неделю для передачи отчетов, обсуждения результатов
Обсудить проект
Разбиение на страницы · Bootstrap
- Обзор
- Работа с иконками
- Отключенное и активное состояния
- Размер
- Выравнивание
Документация и примеры для отображения нумерации страниц, указывающей на то, что ряд связанного контента существует на нескольких страницах.
Обзор
Мы используем большой блок связанных ссылок для разбиения на страницы, благодаря чему ссылки трудно пропустить и их легко масштабировать, обеспечивая при этом большие области охвата. Разбивка на страницы создается с помощью HTML-элементов списка, поэтому программы чтения с экрана могут объявить количество доступных ссылок. Используйте обертку
Используйте обертку , чтобы идентифицировать его как раздел навигации для программ чтения с экрана и других вспомогательных технологий.
Кроме того, поскольку страницы, вероятно, имеют более одного такого раздела навигации, рекомендуется предоставить описательную метку арии для , чтобы отразить ее назначение. Например, если компонент разбивки на страницы используется для перехода между набором результатов поиска, подходящей меткой может быть aria-label="Страницы результатов поиска" .
Работа с иконками
Хотите использовать значок или символ вместо текста для некоторых ссылок на страницы? Не забудьте обеспечить надлежащую поддержку чтения с экрана с aria атрибуты и утилита .. sr-only
sr-only
Ссылки на страницы настраиваются для различных обстоятельств. Используйте .disabled для ссылок, которые кажутся неактивными, и .active для указания текущей страницы.
В то время как класс .disabled использует событий указателя: нет до попробуйте отключить функцию ссылки s, это свойство CSS еще не стандартизировано и не учитывает навигацию с помощью клавиатуры. Таким образом, вы всегда должны добавлять tabindex="-1" для отключенных ссылок и используйте пользовательский JavaScript, чтобы полностью отключить их функциональность.
При желании вы можете поменять местами активные или отключенные привязки для или опустить привязку в случае стрелок вперед/назад, чтобы удалить функцию щелчка и предотвратить фокус клавиатуры при сохранении предполагаемых стилей.
Размеры
Хотите увеличить или уменьшить количество страниц? Добавьте . или  pagination-lg
pagination-lg .pagination-sm для дополнительных размеров.
Выравнивание
Измените выравнивание компонентов пагинации с помощью утилит flexbox.
Примеры разбивки на страницы CSS
❮ Предыдущая Далее ❯
Узнайте, как создать адаптивную нумерацию страниц с помощью CSS.
Простая нумерация страниц
Если у вас есть веб-сайт с большим количеством страниц, вы можете добавить нумерация страниц на каждой странице:
Пример
.pagination {
отображение: встроенный блок;
}
.pagination a {
цвет:
черный;
с плавающей запятой: слева;
отступ: 8 пикселей
16 пикселей;
украшение текста: нет;
}
Попробуйте сами »
Active and Hoverable Pagination
Выделить текущую страницу с помощью .active класс и используйте :hover селектор для изменения цвета каждой ссылки на страницу при наведении на них указателя мыши:
Пример
.pagination a.active {
background-color:
#4CAF50;
цвет: белый;
}
.pagination a:hover:not(.active) {background-color: #ddd;}
Попробуйте сами »
Закругленные активные и наводимые кнопки
Добавьте свойство border-radius , если вам нужна закругленная «активная» и «зависающая» кнопка:
Пример
. pagination a {
pagination a {
border-radius: 5px;
}
.pagination a.active {
border-radius: 5px;
}
Попробуйте сами »
Hoverable Transition Effect
Добавьте свойство transition к ссылкам на страницы, чтобы создать эффект перехода при наведении:
Пример
.pagination a {
transition: background-color .3s;
}
Попробуйте сами »
Разбиение на страницы с границами
Используйте свойство border , чтобы добавить границы к разбивке на страницы:
/* Серый */
}
Попробуйте сами »
Закругленные границы
Совет: Добавьте закругленные границы к первой и последней ссылке в нумерация страниц:
Пример
.pagination a:first-child {
border-top-left-radius:
5 пикселей;
border-bottom-left-radius: 5px;
}
. pagination
a:last-child {
pagination
a:last-child {
border-top-right-radius: 5px;
border-bottom-right-radius: 5px;
}
Попробуйте сами »
Пробел между ссылками
Совет: Добавьте свойство margin , если вы не хотите группировать ссылки страниц:
Пример:
. pagination a 4 пикселя; /* 0 для верха и дно. Смело меняйте */
}
Попробуйте сами »
Размер страницы
Измените размер страницы с помощью свойства font-size :
}
Попробуйте сами »
Разбивка по центру
Чтобы отцентрировать разбивку на страницы, оберните вокруг нее элемент-контейнер (например,
text-align:center Пример
90 {0141.90 {0141.90}0103 выравнивание текста: по центру;
}
Попробуйте сами »
Другие примеры
Пример
Попробуйте сами »
Панировочные сухари
Главная- Картинки
- Лето 15
- Италия
Другой вариант нумерации страниц — так называемые «хлебные крошки»:
Пример
ul. breadcrumb {
padding: 8px 16px;
стиль списка: нет;
background-color: #eee;
}
ul.breadcrumb li {display: inline;}
ul.breadcrumb li+li:before {
отступ: 8px;
цвет: черный;
content: «/\00a0»;
}
Попробуйте сами »
❮ Предыдущая
Далее ❯
НОВИНКА
Мы только что запустили
Видео W3Schools
Узнать
ВЫБОР ЦВЕТА
КОД ИГРЫ
Играть в игру
Top Tutorials
Учебное пособие по HTML
Учебное пособие по CSS
Учебное пособие по JavaScript
Учебное пособие
Учебное пособие по SQL
Учебное пособие по Python
Учебное пособие по W3.CSS
Учебное пособие по Bootstrap
Учебное пособие по PHP
Учебное пособие по Java
Учебное пособие по C++
Учебное пособие по jQuery
Справочник по HTML
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3. CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
Основные примеры
Примеры HTML
Примеры CSS
Примеры JavaScript
Примеры инструкций
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
4 FORUM |
О W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Copyright 1999-2022 Refsnes Data. Все права защищены.
W3Schools работает на основе W3.CSS.
Полное руководство по передовому опыту
Разбивка сайта на страницы — хитрый оборотень. Он используется в самых разных контекстах: от отображения элементов на страницах категорий до архивов статей, слайд-шоу галереи и тем форума.
Для специалистов по SEO это не вопрос , если вам придется иметь дело с нумерацией страниц, это вопрос , когда .
В определенный момент роста веб-сайтам необходимо разделить контент на ряд составных страниц для взаимодействия с пользователем (UX).
Наша работа заключается в том, чтобы помочь поисковым системам сканировать и понимать взаимосвязь между этими URL-адресами, чтобы они индексировали наиболее релевантную страницу.
С течением времени передовые методы SEO обработки разбиения на страницы эволюционировали. Попутно многие мифы преподносились как факты. Но не больше.
Эта статья будет:
- Развенчайте мифы о том, что нумерация страниц вредит поисковой оптимизации.
- Представить оптимальный способ управления нумерацией страниц.
- Просмотрите неправильно понятые или некачественные методы обработки разбиения на страницы.
- Узнайте, как отслеживать влияние нумерации страниц на KPI.
Как нумерация страниц может повредить SEO
Вы, наверное, читали, что нумерация страниц вредна для SEO.
Однако в большинстве случаев это связано с отсутствием правильной обработки пагинации, а не с наличием самой пагинации.
Давайте посмотрим на предполагаемые недостатки нумерации страниц и на то, как преодолеть проблемы SEO, которые это может вызвать.
Разбивка на страницы приводит к дублированию содержимого
Исправить, если разбивка на страницы была реализована неправильно, например, на странице «Просмотреть все» и страницах с разбивкой на страницы без правильного rel=canonical или если вы создали страницу=1 в дополнение к своей корневой странице.
Неверно, если у вас оптимизированная для SEO нумерация страниц. Даже если ваши теги h2 и метатеги одинаковы, фактическое содержимое страницы отличается. Так что это не дублирование.
Да, это нормально. Полезно получать отзывы о повторяющихся заголовках и описаниях, если вы случайно используете их на совершенно разных страницах, но для серий с разбивкой на страницы это нормально и ожидается, что вы будете использовать одно и то же.
— 🍌 John 🍌 (@JohnMu) 13 марта 2018 г.
Разбиение на страницы создает разреженный контент слишком мало контента на каждой странице.
Неверно, когда вы ставите желание пользователя легко потреблять ваш контент выше доходов от баннерной рекламы или искусственно завышенных просмотров страниц. Разместите на каждой странице UX-дружественный объем контента.
Пагинация ослабляет сигналы ранжирования
Верно. Пагинация приводит к тому, что внутренний вес ссылок и другие сигналы ранжирования, такие как обратные ссылки и социальные сети, распределяются между страницами.
Но может быть минимизирован с помощью с использованием разбиения на страницы только в тех случаях, когда подход с одностраничным контентом может привести к ухудшению взаимодействия с пользователем (например, страницы категорий электронной торговли). И на таких страницах, добавляя как можно больше элементов, не замедляя страницу до заметного уровня, чтобы уменьшить количество разбитых на страницы страниц.
Пагинация использует бюджет сканирования
Исправьте, если вы разрешаете Google сканировать страницы с разбивкой на страницы. И есть несколько случаев, когда вы хотели бы использовать этот бюджет.
Например, для робота Googlebot, который будет перемещаться по разбивке на страницы URL-адресов для доступа к страницам с более глубоким содержанием.
Часто неверно, когда вы устанавливаете для параметра обработки страницы Google Search Console значение «Не сканировать» или устанавливаете запрет в файле robots.txt, если вы хотите сохранить бюджет сканирования для более важных страниц.
Управление разбивкой на страницы в соответствии с передовыми методами SEO
Используйте доступные для сканирования ссылки привязки
Чтобы поисковые системы могли эффективно сканировать страницы с разбивкой на страницы, на сайте должны быть ссылки с атрибутами href на эти URL-адреса с разбивкой на страницы.
Убедитесь, что ваш сайт использует для внутренних ссылок на страницы с разбивкой на страницы. Не загружайте якорные ссылки с разбивкой на страницы или атрибут href через JavaScript.
Кроме того, вы должны указать взаимосвязь между URL-адресами компонентов в разбивке на страницы с помощью атрибутов rel=»next» и rel=»prev».
Да, даже после печально известного твита Google о том, что они вообще больше не используют эти атрибуты ссылок.
Весенняя уборка!
Когда мы оценили наши сигналы индексации, мы решили отказаться от rel=prev/next.
Исследования показывают, что пользователям нравится одностраничный контент, стремитесь к нему, когда это возможно, но многостраничный контент также подходит для Google Поиска. Знайте и делайте то, что лучше для *ваших* пользователей! #весна идет pic.twitter.com/hCODPoKgKp
— Веб-мастера Google (@googlewmc) 21 марта 2019 г.
Вскоре после этого Илья Григорик пояснил, что rel=»next» / «prev» все еще может быть ценным.
нет, используйте нумерацию страниц. позвольте мне переформулировать это. Googlebot достаточно умен, чтобы найти вашу следующую страницу, просматривая ссылки на странице, нам не нужен явный сигнал «предыдущая, следующая». и да, есть и другие веские причины (например, a11y), по которым вы можете или должны добавить их.
— Илья Григорик (@igrigorik) 22 марта 2019 г.
Google — не единственная поисковая система в городе. Вот мнение Бинга по этому вопросу.
Мы используем rel prev/next (как и большинство разметки) в качестве подсказок для обнаружения страниц и понимания структуры сайта. На данный момент мы не объединяем страницы в индексе на их основе и не используем предыдущее/следующее в модели ранжирования. https://t.co/ZwbSZkn3Jf
— Frédéric Dubut (@CoperniX) 21 марта 2019 г.
Дополните rel=»next» / «prev» ссылкой на себя rel=»canonical». Таким образом, /category?page=4 должен иметь отношение rel=”canonical” к /category?page=4.
Это уместно, поскольку нумерация страниц изменяет содержимое страницы, а также мастер-копию этой страницы.
Если у URL есть дополнительные параметры, включите их в ссылки rel=»prev» / «next», но не включайте их в rel=»canonical».
Например:
Это укажет на четкую взаимосвязь между страницами и предотвратит возможность дублирования контента.
Распространенные ошибки, которых следует избегать:
- Размещение атрибутов ссылки в содержимом
. Они поддерживаются поисковыми системами только в разделе вашего HTML. - Добавление ссылки rel=»prev» на первую страницу (также известную как корневая страница) в серии или ссылки rel=»next» на последнюю. Для всех остальных страниц в цепочке должны присутствовать оба атрибута ссылки.
- Остерегайтесь канонического URL корневой страницы. Скорее всего, на ?page=2 ссылка rel=prev должна указывать на каноническую, а не на ?page=1.
Код серии из четырех страниц будет выглядеть примерно так:
- Один тег пагинации на корневой странице, указывающий на следующую страницу серии.
-
- Два тега пагинации на странице 2.
-
-
- Два тега пагинации на странице 3.
-
- Один тег разбиения на страницы на странице 4, последней странице в разбивке на страницы.
-
-
Изменение элементов страницы с разбивкой на страницы
Джон Мюллер прокомментировал: «Мы не относимся к нумерации страниц по-разному. Мы относимся к ним как к обычным страницам».
Значение Страницы с разбивкой на страницы не распознаются Google как ряд страниц, объединенных в одну часть контента, как они рекомендовали ранее. Каждая страница с разбивкой на страницы может конкурировать с корневой страницей за ранжирование.
Чтобы побудить Google вернуть корневую страницу в поисковой выдаче и предотвратить появление предупреждений «Повторяющиеся метаописания» или «Повторяющиеся теги заголовков» в Google Search Console, внесите простые изменения в свой код.
Если корневая страница имеет формулу:
Последовательные страницы с разбивкой на страницы могут иметь формулу:
Эти заголовки URL-адресов с разбивкой на страницы и метаописание намеренно неоптимальны, чтобы отговорить Google от отображения этих результатов, а не корневой страница.
Если даже с такими изменениями страницы с разбивкой на страницы ранжируются в поисковой выдаче, попробуйте другие традиционные тактики SEO на странице, такие как:
- Деоптимизируйте теги h2 страницы с разбивкой на страницы.
- Добавить полезный текст на странице на корневую страницу, но не на страницы с разбивкой на страницы.
- Добавить изображение категории с оптимизированным именем файла и тегом alt на корневую страницу, но не на страницы с разбивкой на страницы.
Не включать страницы с разбивкой на страницы в XML-карты сайта
Хотя URL-адреса с разбивкой на страницы технически индексируются, они не являются приоритетом SEO для расходования краулингового бюджета.
Таким образом, им не место в вашей XML-карте сайта.
Обработка параметров разбивки на страницы в Google Search Console
Если у вас есть выбор, запустите разбиение на страницы с помощью параметра, а не статического URL-адреса. Например:
example.com/category?page=2 вместо example.com/category/page-2
Хотя нет никакого преимущества в использовании одного перед другим для целей ранжирования или сканирования, исследования показали, что Googlebot угадывает шаблоны URL-адресов на основе динамических URL-адресов. Таким образом, увеличивается вероятность быстрого обнаружения.
С другой стороны, это может потенциально вызвать ловушки сканирования, если сайт отображает пустые страницы для догадок, которые не являются частью текущей серии с разбивкой на страницы.
Например, серия состоит из четырех страниц.
URL-адреса с содержанием заканчиваются на www.example.com/category?page=4
Если Google угадывает www.example.com/category?page=7 и загружается действующая, но пустая страница, бот тратит время на сканирование бюджета и потенциально потеряться в бесконечном количестве страниц.
Убедитесь, что код состояния HTTP 404 отправляется для всех страниц с разбивкой на страницы, которые не являются частью текущей серии.
Еще одним преимуществом параметрического подхода является возможность настроить параметр в Google Search Console на «Разбивка на страницы» и в любое время изменить сигнал Google для сканирования «Все URL» или «Нет URL», в зависимости от того, как вы хотите использовать краулинговый бюджет. Разработчик не нужен!
Никогда не сопоставляйте содержимое страницы с разбивкой на страницы с идентификаторами фрагментов (#), поскольку оно недоступно для сканирования или индексации и, следовательно, не подходит для поисковых систем.
Неправильно понятые, устаревшие или просто неверные SEO-решения для разбитого на страницы контента
Ничего не делать
Google считает, что Googlebot достаточно умен, чтобы найти следующую страницу по ссылкам, поэтому ему не нужен явный сигнал.
По сути, SEO-специалистам нужно обрабатывать разбиение на страницы, ничего не делая.
Хотя в этом утверждении есть доля правды, ничего не делая, вы рискуете своим SEO.
Многие сайты видели, как Google выбирает страницу с разбивкой на страницы для ранжирования над корневой страницей для поискового запроса.
Всегда важно дать краулерам четкие указания, как вы хотите, чтобы они индексировали и отображали ваш контент.
Канонизировать до страницы «Просмотреть все»
Страница «Просмотреть все» была задумана так, чтобы содержать все содержимое страницы компонента на одном URL-адресе.
Все страницы с разбивкой на страницы имеют ссылку rel=»canonical» на страницу «Просмотреть все» для консолидации сигналов ранжирования.
Аргумент здесь в том, что пользователи предпочитают просматривать всю статью или список элементов категорий на одной странице, если она быстро загружается и удобна в навигации.
Идея заключалась в том, что если ваша серия с разбивкой на страницы имеет альтернативную версию «Просмотреть все», которая предлагает лучший пользовательский интерфейс, поисковые системы предпочтут эту страницу для включения в результаты поиска, а не страницу соответствующего сегмента цепочки разбиения на страницы.
В связи с чем возникает вопрос — зачем вообще страницы разбиты на страницы?
Давайте сделаем это просто.
Если вы можете предоставить свой контент по одному URL-адресу, предлагая удобный пользовательский интерфейс, нет необходимости в нумерации страниц или версии «Просмотреть все».
Если вы не можете, например, страница категории с тысячами продуктов была бы смехотворно большой и загружалась бы слишком долго, тогда разбивайте на страницы. «Просмотреть все» — не лучший вариант, поскольку он не обеспечивает хорошего пользовательского опыта.
Использование rel=»next» / «prev» и версии View All не дает четких указаний поисковым системам и приводит к путанице у сканеров.
Не делай этого.
Канонизировать до первой страницы
Распространенной ошибкой является указание rel=»canonical» всех результатов с разбивкой на страницы на корневую страницу серии.
Некоторые плохо информированные специалисты по поисковой оптимизации предлагают использовать это как способ консолидировать полномочия по всему набору страниц на корневой странице, но это дезинформация.
Неправильная канонизация корневой страницы может ввести поисковые системы в заблуждение, заставив их думать, что у вас есть только одна страница результатов.
После этого робот Googlebot не будет индексировать страницы, расположенные дальше по цепочке, и не будет принимать сигналы к контенту, связанному с этими страницами.
Вы не хотите, чтобы ваши страницы с подробным содержимым выпадали из индекса из-за плохой обработки пагинации.
Каждая страница в серии с разбивкой на страницы должна иметь каноническую ссылку на себя, если только вы не используете страницу «Просмотреть все».
Неправильное использование rel=canonical может привести к тому, что робот Googlebot просто проигнорирует ваш сигнал.
Страницы с разбивкой на страницы Noindex
Классическим методом решения проблем с нумерацией страниц был тег robots noindex для предотвращения индексации содержимого страниц поисковыми системами.
Использование только тега noindex для обработки разбиения на страницы приведет к игнорированию любых сигналов ранжирования от страниц-компонентов.
Однако более серьезная проблема с этим методом заключается в том, что длительное отсутствие индекса на странице в конечном итоге приведет к тому, что Google будет использовать nofollow для ссылок на этой странице.
Это может привести к удалению из индекса содержимого, связанного со страницами с разбивкой на страницы.
Разбиение на страницы и бесконечная прокрутка или Загрузить больше
Более новая форма обработки разбивки на страницы:
- Бесконечная прокрутка, , где содержимое предварительно загружается и добавляется непосредственно на текущую страницу пользователя по мере прокрутки вниз.
- Загрузить еще , где содержимое отображается при нажатии кнопки «Просмотреть больше».
Пользователи оценили эти подходы, но Googlebot? Не так много.
Робот Googlebot не имитирует такие действия, как прокрутка страницы вниз или щелчок, чтобы загрузить больше. Это означает, что без посторонней помощи поисковые системы не смогут эффективно сканировать весь ваш контент.
Чтобы оптимизировать SEO, преобразуйте бесконечную прокрутку или загрузите больше страниц в эквивалентную постраничную серию, основанную на сканируемых якорных ссылках с атрибутами href, которые доступны даже при отключенном JavaScript.
Когда пользователь прокручивает или щелкает, используйте JavaScript для адаптации URL-адреса в адресной строке к странице компонента с разбивкой на страницы.
Кроме того, реализуйте pushState для любого действия пользователя, похожего на щелчок или активное перелистывание страницы. Вы можете проверить эту функциональность в демо, созданном Джоном Мюллером.
По сути, вы по-прежнему применяете рекомендации SEO, рекомендованные выше, вы просто добавляете дополнительные функциональные возможности для взаимодействия с пользователем.
Препятствовать или блокировать сканирование страницы с разбиением на страницы
Некоторые специалисты по поисковой оптимизации рекомендуют вообще избегать проблемы обработки разбивки на страницы, просто блокируя Google от сканирования URL-адресов с разбивкой на страницы.
В таком случае вам понадобятся хорошо оптимизированные XML-карты сайта, чтобы страницы, связанные с помощью нумерации страниц, могли быть проиндексированы.
Есть три способа заблокировать сканеры:
- Беспорядочный способ : Добавьте nofollow ко всем ссылкам, которые ведут на страницы с разбивкой на страницы.
- Более чистый способ : Используйте запрет в файле robots.txt.
- Способ, не требуемый разработчиком : установите для параметра страницы с разбивкой на страницы значение «Разбивает на страницы», чтобы Google мог сканировать «Нет URL-адресов» в Google Search Console.
Используя один из этих методов, чтобы запретить поисковым системам сканировать URL-адреса с разбивкой на страницы, вы:
- Запретите поисковым системам распознавать сигналы ранжирования страниц с разбивкой на страницы.
- Предотвратить передачу внутренних ссылок со страниц с разбивкой на страницы на страницы с целевым содержимым.
- Запретить Google обнаруживать ваши целевые страницы контента.
Очевидным преимуществом является то, что вы экономите на краулинговом бюджете.
Здесь нет однозначного правильного или неправильного ответа. Вам нужно решить, что является приоритетом для вашего сайта.
Лично я, если бы мне нужно было установить приоритет краулингового бюджета, я бы сделал это с помощью обработки разбивки на страницы в Google Search Console, так как она имеет оптимальную гибкость, чтобы изменить ваше мнение.
Отслеживание влияния разбиения на страницы на KPI
Итак, теперь вы знаете, что делать, как отследить эффект оптимизации обработки разбивки на страницы?
Во-первых, соберите контрольные данные, чтобы понять, как ваша текущая обработка пагинации влияет на SEO.
Источники ключевых показателей эффективности могут включать:
- Файлы журнала сервера для количества обходов страниц с разбивкой на страницы.
- Сайт: оператор поиска (например, site:example.com inurl:page), чтобы понять, сколько страниц с разбивкой на страницы проиндексировал Google.
- Консоль поиска Google Отчет Search Analytics, отфильтрованный по страницам, содержащим нумерацию страниц, чтобы понять количество показов.
- Отчет о целевых страницах Google Analytics , отфильтрованный по URL-адресам с разбивкой на страницы для понимания поведения на сайте.
Если вы видите проблему, из-за которой поисковые системы сканируют страницы вашего сайта, чтобы добраться до вашего контента, вы можете изменить ссылки на страницы.
После того, как вы запустили передовой метод работы с разбиением на страницы, повторно посетите эти источники данных, чтобы оценить успех ваших усилий.
 breadcrumb {
breadcrumb { padding: 8px 16px;
стиль списка: нет;
background-color: #eee;
}
отступ: 8px;
цвет: черный;
content: «/\00a0»;
}
Видео W3Schools
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3.
 CSS
CSS Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
W3Schools работает на основе W3.CSS.
 Он используется в самых разных контекстах: от отображения элементов на страницах категорий до архивов статей, слайд-шоу галереи и тем форума.
Он используется в самых разных контекстах: от отображения элементов на страницах категорий до архивов статей, слайд-шоу галереи и тем форума.

Да, это нормально. Полезно получать отзывы о повторяющихся заголовках и описаниях, если вы случайно используете их на совершенно разных страницах, но для серий с разбивкой на страницы это нормально и ожидается, что вы будете использовать одно и то же.
— 🍌 John 🍌 (@JohnMu) 13 марта 2018 г.
 И на таких страницах, добавляя как можно больше элементов, не замедляя страницу до заметного уровня, чтобы уменьшить количество разбитых на страницы страниц.
И на таких страницах, добавляя как можно больше элементов, не замедляя страницу до заметного уровня, чтобы уменьшить количество разбитых на страницы страниц.
Весенняя уборка!
Когда мы оценили наши сигналы индексации, мы решили отказаться от rel=prev/next.
Исследования показывают, что пользователям нравится одностраничный контент, стремитесь к нему, когда это возможно, но многостраничный контент также подходит для Google Поиска. Знайте и делайте то, что лучше для *ваших* пользователей! #весна идет pic.twitter.com/hCODPoKgKp
— Веб-мастера Google (@googlewmc) 21 марта 2019 г.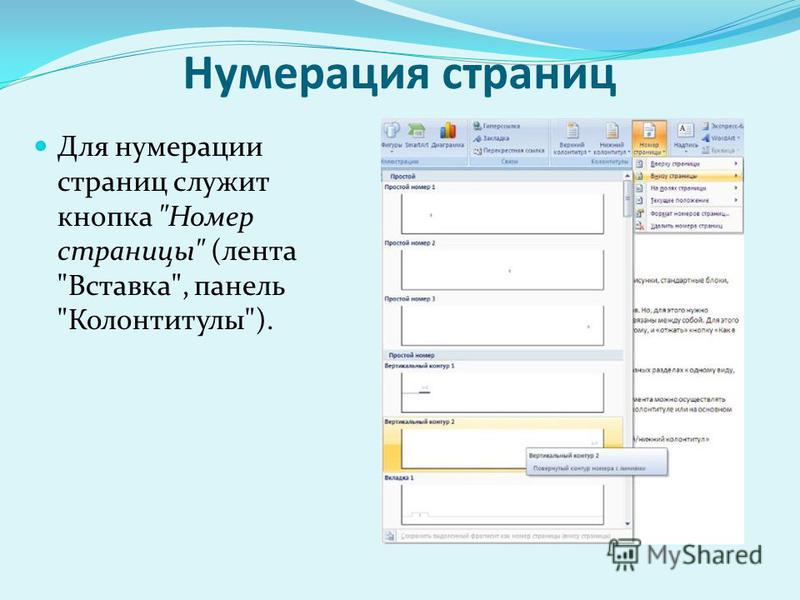
Вскоре после этого Илья Григорик пояснил, что rel=»next» / «prev» все еще может быть ценным.
нет, используйте нумерацию страниц. позвольте мне переформулировать это. Googlebot достаточно умен, чтобы найти вашу следующую страницу, просматривая ссылки на странице, нам не нужен явный сигнал «предыдущая, следующая». и да, есть и другие веские причины (например, a11y), по которым вы можете или должны добавить их.
— Илья Григорик (@igrigorik) 22 марта 2019 г.
Мы используем rel prev/next (как и большинство разметки) в качестве подсказок для обнаружения страниц и понимания структуры сайта. На данный момент мы не объединяем страницы в индексе на их основе и не используем предыдущее/следующее в модели ранжирования. https://t.co/ZwbSZkn3Jf
— Frédéric Dubut (@CoperniX) 21 марта 2019 г.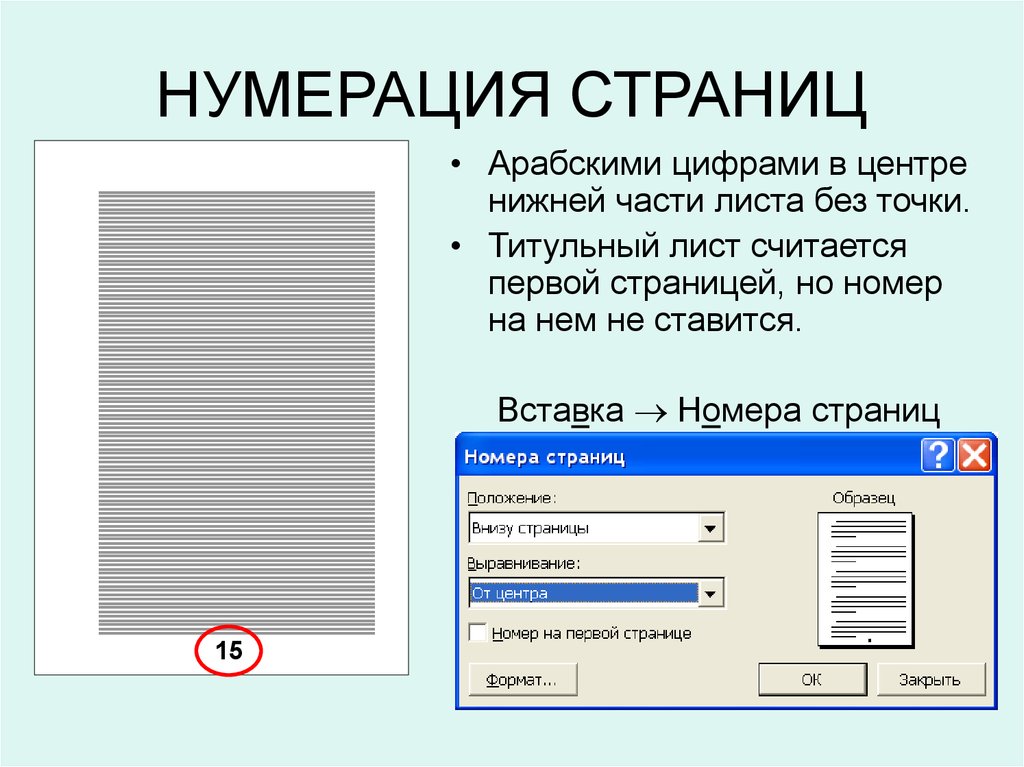
. Они поддерживаются поисковыми системами только в разделе вашего HTML. Для всех остальных страниц в цепочке должны присутствовать оба атрибута ссылки.
Для всех остальных страниц в цепочке должны присутствовать оба атрибута ссылки. серии из четырех страниц будет выглядеть примерно так:
example.com/category?page=2 вместо example.com/category/page-2