Обзор систем управления базами данных (СУБД) для систем контроля и управления доступом (СКУД)
Пивоваров Семён
Руководитель отдела разработки ПО Parsec
Любая современная сетевая СКУД нуждается в базе данных, так как является по своей сути информационной системой, предназначенной для хранения, обработки и анализа информации о происходящих на защищаемом объекте событиях. Также в СКУД должны храниться настройки оборудования, коды карт и личные данные пользователей, уровни доступа и другая нужная информация.
Источник:
статья была опубликована в журнале «Технологии Защиты» № 1, 2014
(обновлена 14 мая 2020 года)
Терминология
Частая ошибка многих специалистов по безопасности — некорректное использование термина «база данных» (БД) вместо термина «система управления базами данных» (СУБД). Давайте разберёмся, что к чему.
База данных — представленная в объективной форме совокупность самостоятельных материалов, систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины.
Система управления базами данных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
То есть, упрощённо, «база данных» — это сами данные, представленные в виде совокупности файлов на дисках, с которыми как раз работает «система управления базами данных» (СУБД) — программный продукт, имеющий средства для создания, наполнения, модификации и поиска по базам данных.
Разработчики различных приложений, в том числе и разработчики СКУД, работают именно с СУБД и выбирают СУБД под свои нужды.
Требования к СУБД, применяемым в СКУД
Какие же особенные требования следует предъявить к СУБД, используемой в СКУД с точки зрения пользователя?
- Во-первых — надёжность: никакие данные не должны пропасть! Сбои должны быть минимизированы и не должны приводить к потерям данных, базы должны быть надёжно защищены от несанкционированного доступа, на режимных объектах могут потребоваться функции шифрования данных, необходимо также обеспечивать регулярное резервное копирование баз данных и возможность восстановления из архива при необходимости.

- Во-вторых — производительность: СУБД должна обеспечивать приемлемый уровень производительности для решения возложенных на неё задач.
- В-третьих, на мой взгляд, это уверенность в том, что СУБД будет поддерживаться производителем, и вы не останетесь один на один с проблемой в случае какого-то серьёзного сбоя или сложной ситуации.

Виды СУБД
СУБД на данный момент существует великое множество и классифицируются они по разным признакам. Но мы не будем останавливаться в данной статье на всём многообразии этих типов, опустим перспективные и экзотические технологии типа объектно-ориентированных и иерархических СУБД. Стандартом де-факто в современных информационных системах являются реляционные СУБД, в которых данные хранятся в табличном виде, о них мы и будем говорить. Так чем же различаются все эти системы? Перечислю ключевые параметры важные как для разработчиков, так и для пользователей системы.
Способы доступа к БД
- Клиент-серверные СУБД
- Файл-серверные СУБД
- Встраиваемые СУБД
В клиент-серверных СУБД (Microsoft SQL Server, Oracle, Firebird, PostgreSQL, InterBase, MySQL и др.
- Вся обработка данных ведётся в одном месте, на сервере, в том же месте, где хранятся (обычно) данные.
- К файлам данных имеет доступ только один сервер, одна система — это сама СУБД.
- Приложения-клиенты посылают запросы на обработку и получение данных из СУБД и получают ответы.
- Приложения-клиенты не имеют непосредственного доступа к файлам данных.
Все промышленные СУБД на данный момент являются именно клиент-серверными.
В файл-серверных СУБД (Paradox, Microsoft Access, FoxPro, dBase и др.), наоборот,
- Приложения имеют общий доступ ко всем файлам базы данных (хранящимся обычно в каком-то разделяемом файловом хранилище) и совместно обрабатывают эти данные.
- Каждое приложение самостоятельно обрабатывает данные.
На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком. Проблема в том, что файл-серверные СУБД не имеют многих преимуществ клиент-серверных, таких как кэширование данных, параллелизм запросов, высокая производительность и обладают рядом недостатков (сложности с поддержанием целостности базы, восстановлением, блокировками и т.д.), что приводит в свою очередь к пониженной надёжности и производительности. Состояние базы в файловых СУБД необходимо постоянно отслеживать и проводить операции по её «лечению» с помощью встроенных или сторонних утилит.
Проблема в том, что файл-серверные СУБД не имеют многих преимуществ клиент-серверных, таких как кэширование данных, параллелизм запросов, высокая производительность и обладают рядом недостатков (сложности с поддержанием целостности базы, восстановлением, блокировками и т.д.), что приводит в свою очередь к пониженной надёжности и производительности. Состояние базы в файловых СУБД необходимо постоянно отслеживать и проводить операции по её «лечению» с помощью встроенных или сторонних утилит.
Встраиваемые СУБД (SQLite, Firebird Embedded, Microsoft SQL Server Compact и др.)
- Поставляются в составе готового программного продукта, не требуя процедуры самостоятельной установки.
- Предназначены для локального хранения данных приложения и не рассчитаны на коллективное использование в сети.
Встраиваемая бесплатная СУБД SQLite широко используется в известной мобильной ОС Android, разработанной в компании Google, и во многих мобильных приложениях.
Схема лицензирования
- Бесплатные СУБД
- Коммерческие промышленные СУБД (большинство производителей предлагают также бесплатную ограниченную версию)
Файл-серверные и встраиваемые СУБД практически все являются бесплатными, из бесплатных клиент-серверных СУБД наиболее известные: Firebird, PostgreSQL и MySQL.
Чисто коммерческий продукт, разработанный компанией Borland: СУБД InterBase. Ранее у этой СУБД была бесплатная версия с открытым исходным кодом: InterBase 6.0, но проект InterBase 6.0 Open Source Edition перестал поддерживаться компанией Borland. В 2001 году группа энтузиастов создала отдельный Open source проект СУБД Firebird, упомянутой выше, который получил широкую известность и множество поклонников среди разработчиков.
Большинство производителей промышленных СУБД дают возможность пользоваться бесплатными редакциями своих продуктов, которые являются урезанными по функционалу и по производительности вариантами полнофункциональной версии СУБД.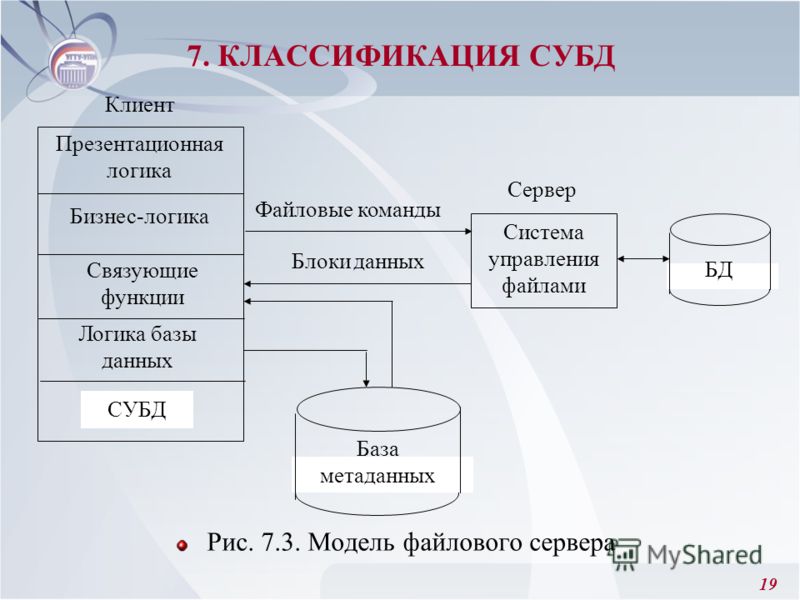
Сравнение свободных и коммерческих СУБД
Свободные СУБД
+
- Менее требовательны к железу.
- Богатый функционал.
- Хорошая производительность.
- Надежность.
−
- Проект в любой момент может закрыться, т.к. поддерживается энтузиастами.
- Сложнее найти грамотного специалиста для обслуживания.
Коммерческие СУБД
+
- Высокая производительность.
- Масштабируемость.
- Надёжность.
- Поддерживаемость.
- Задокументированность.
- Встроенные инструменты для разработки и администрирования.
−
- Требовательность к ресурсам.
- Высокая цена.
В приведённой ниже таблице приведены ограничения наиболее часто используемых бесплатных редакций промышленных СУБД.
| Компания-производитель | Бесплатные версии | Ограничения |
| Microsoft | SQL Server 2005/2008 Express Edition | Размер базы данных — до 4 Гб, количество баз не ограничено, использует не более 1 Гб оперативной памяти и только 1 процессор (ядро) на многопроцессорных и многоядерных машинах. Поддерживаемые платформы: только Windows 2005 — только x86, 2008 — x86 и x64. |
| SQL Server 2008 R2/2012/2014/2016/2017/2019 Express Edition | Размер базы данных — до 10 Гб, количество баз не ограничено, использует не более 1 Гб оперативной памяти и только 1 процессор (ядро) на многопроцессорных и многоядерных машинах. Поддерживаемые платформы: только Windows x86 и x64. | |
| Oracle | Oracle Database 11g Express Edition, (Oracle Database XE) |
Суммарно до 11Гб пользовательских данных, использует не более 1Гб оперативной памяти и только 1 процессор (ядро) на многопроцессорных и многоядерных машинах. Поддерживаемые платформы: Windows x86, Linux x64. Поддерживаемые платформы: Windows x86, Linux x64.
|
| IBM | IBM DB2 Express-C | Размер базы не ограничен, используется до 4Гб оперативной памяти и до 2-х процессоров. Поддерживаемые платформы: Windows x86 и x64, Linux x86 и x64, Unix x86 и x64, Solaris x86 и x64, Mac OS X |
При превышении максимального размера базы запись в БД прекратится, но эту проблему легко предотвратить. В основном, объём требуется для хранения постоянно накапливающихся в системе событий, остальные данные (настройки контроллеров, данные субъектов доступа, уровни доступа и т.п.) относительно статичны и только на сверхкрупных системах могут превысить ограничения бесплатных Express-версий. Необходимо настроить средствами вашей СУБД процедуру периодического удаления старых событий из БД. Во многих СКУД эти процедуры предусмотрены разработчиками и их надо просто настроить.
Что касается ограничений по производительности: если система небольшая, не подразумевает больших нагрузок на СУБД, спокойно можно ограничиться бесплатной редакцией, её будет более чем достаточно. Если же задача накладывает повышенные требования на подсистему СУБД: большое количество пользователей в системе, большой трафик событий и поток обновлений данных в системе (объекты с большим количеством временных посетителей) и высокие требования к глубине архива событий, то всегда можно перейти с бесплатной редакции на коммерческий вариант, оплатив необходимую лицензию.
СУБД в СКУД
В таблице ниже приведены данные из открытых источников относительно типа применяемой СУБД в популярных в России системах контроля и управления доступом.
| Производитель | СКУД | СУБД |
| Parsec | ParsecNET 3 |
Microsoft SQL Server (в поставке 2012 Express, заявлена поддержка версий 2008 R2 и выше) — центральная БД; SQLite — локальные базы рабочих станций.
|
| Elsys | Бастион 2 | Oracle (в поставке 11g Express), заявлена поддержка версий Oracle 12с, Oracle SE2, также может использоваться СУБД PostgreSQL 10 или Postgres Pro |
| Perco | S20 | Firebird 2.0 |
| НВП Болид | Орион ПРО |
Microsoft SQL Server (в поставке 2012 Express), заявлена поддержка версий 2008/2012/2014 |
| РусГард | RusGuard | Microsoft SQL Server (в поставке 2014 Express), заявлена поддержка версий 2014/2016 |
| Равелин ЛТД | Gate | Microsoft Access |
| ПромАвтоматика Сервис | Сфинкс | MySQL |
| Кодос | ИКБ Кодос | Firebird |
| TSS | Семь Печатей | Firebird |
| Bosсh |
Access PE |
Microsoft SQL Server (рекомендуется версия 2014 Express Edition) |
| Honeywell | Pro-Watch | Microsoft SQL Server 2012/2014/2016 |
| Siemens | SiPass | Microsoft SQL Server 2000 |
| ААМ Системз | Apacs 3000 |
Firebird 2.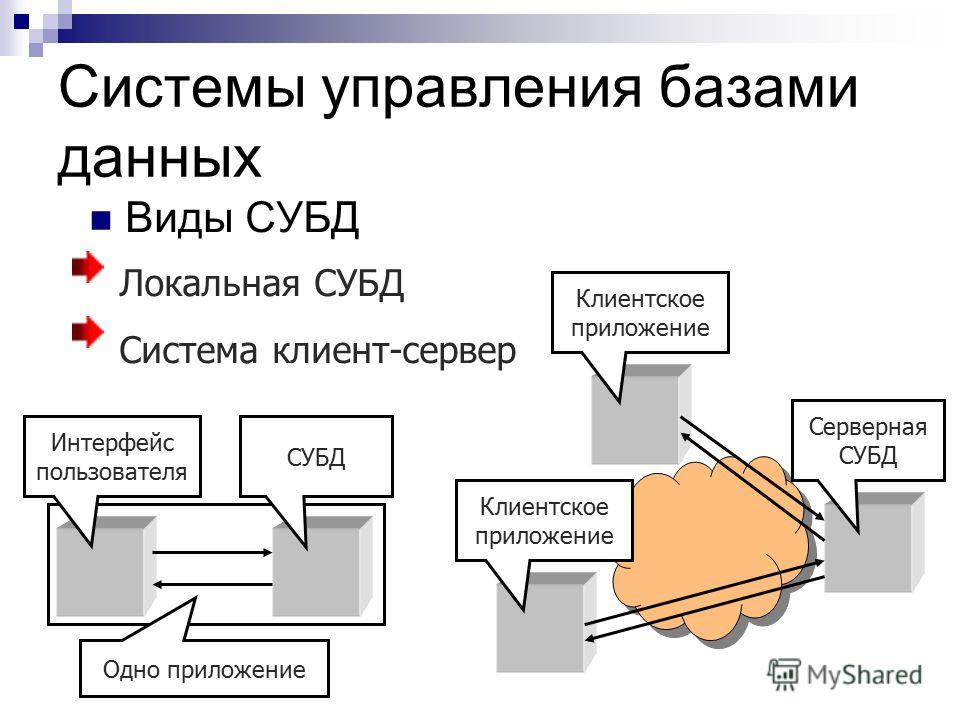 5 (входит в комплект поставки), поддерживается также Microsoft SQL Server 2017 5 (входит в комплект поставки), поддерживается также Microsoft SQL Server 2017 |
| Lyrix |
Borland Interbase 2007 (в комплекте поставки), поддержка Oracle 10g и Microsoft SQL Server 2005 |
Как видно, большинство производителей СКУД поставляют бесплатную версию промышленной клиент-серверной СУБД Microsoft SQL Server Express Edition и свободную (бесплатную) кроссплатформенную СУБД Firefird (примерно 50 на 50).
Конкретный выбор той или иной СУБД — дело вкуса и предпочтений каждого производителя, благо — выбор есть. При выборе разработчики учитывают также вопросы удобства и простоты администрирования, наличие встроенных бесплатных инструментов для администрирования и разработки.
СУБД для СКУД помимо высокой надёжности и производительности должна быть удобной и недорогой в поддержке. Разработчики СКУД прекрасно понимают, что даже на крупных объектах зачастую нет выделенных специалистов для обслуживания СКУД, обладающих навыками администрирования СУБД, поэтому стараются включать в свои продукты функции, облегчающие и автоматизирующие процессы обслуживания базы данных.
Прежде всего — резервное копирование БД, основа основ, которая позволяет администратору системы спокойно спать. Все СУБД имеют собственные средства для создания резервных копий, но хорошим тоном считается, когда функция резервного копирования интегрирована в продукт и администратору необходимо лишь включить/настроить её и периодически проверять функционирование.
Вторая частая проблема — восстановление данных после сбоя. Здесь опять же на выручку приходит свежая резервная копия, но если её нет, или критично восстановление всех возможных данных, то потребуются дополнительные усилия. К счастью, в промышленных СУБД (чего не скажешь о старых файловых СУБД типа Paradox) такие явления происходят нечасто, их может вызвать разве что «умирающий» жёсткий диск или сбой электропитания. В этом случае потребуются услуги специалиста-администратора СУБД, который сможет с помощью встроенных в любую серьёзную СУБД инструментов восстановить максимум из возможного. Также следует учесть, что некоторые производители СКУД в рамках технической поддержки оказывают услуги по восстановлению баз.
Также следует учесть, что некоторые производители СКУД в рамках технической поддержки оказывают услуги по восстановлению баз.
Рекомендации
- При выборе СКУД обратите внимание на то, какая СУБД поставляется совместно с системой.
- Если вы эксплуатируете СКУД, то выясните, какая СУБД в ней используется.
- Оцените трафик данных и нагрузку в вашей системе, чтобы определиться с требуемыми аппаратными ресурсами сервера СУБД и нужной редакцией СУБД (проконсультируйтесь у производителя вашей СКУД при необходимости).
- Если в вашей СКУД используется Express-версия Microsoft SQL Server или Oracle, то необходимо задаться вопросом: «Насколько нам хватит бесплатного объёма базы?». Настройте периодическое удаление из базы старых событий средствами СКУД (если таковые имеются) либо же рассмотрите вопрос о миграции на платную неограниченную версию СУБД.
- Настройте резервное копирование баз данных средствами СКУД или же средствами СУБД и регулярно проверяйте его выполнение.
- Найдите специалиста по СУБД (администратора), к которому можно будет обратиться в случае повреждения базы данных, узнайте в технической поддержке производителя СКУД возможность предоставления такого рода услуг.

Хотите узнать больше?
Пройдите бесплатный курс «Основы систем контроля и управления доступом» в Академии Parsec. На курсе будут рассмотрены основные компоненты СКУД, их назначение и принципы работы, основные термины, необходимые для понимая устройства и специфики работы систем контроля доступа. По окончании курса вы получите сертификат.
Конфигуратор СКУД
Автоматический подбор оборудования и программного обеспечения профессиональной системы контроля доступа Перейти к подборуОпределение СУБД. Что такое система управления базами данных?
Представим, что в ваше распоряжение попала какая-либо база данных. Она содержит очень полезные, для вас или кого-то ещё, сведения. Однако вы ничего не сможете с ней сделать!
Однако вы ничего не сможете с ней сделать! Можно попытаться открыть её текстовым редактором и извлечь часть данных. Но это будет лишь набор данных в непонятном для вас порядке. Ещё меньше пользы вы получите из БД, если она будет зашифрована. Отсюда возникает вопрос — с помощью чего была создана структура базы данных, и как потом с ней работать?
Оказывается, с одной стороны всё значительно проще, а с другой стороны — гораздо сложнее, чем вы себе представляете. Поясню, что для работы с определенным типом и моделью базы данных используется та или иная программа. В информатике их называют системой управления базами данных.
Cистема управления базами данных
Cистема управления базами данных
Дадим определение системы управления базами данных.
Система управления базами данных (СУБД) представляет собой комплекс языковых и программных средств, которые обеспечивают управление созданием и использованием баз данных.
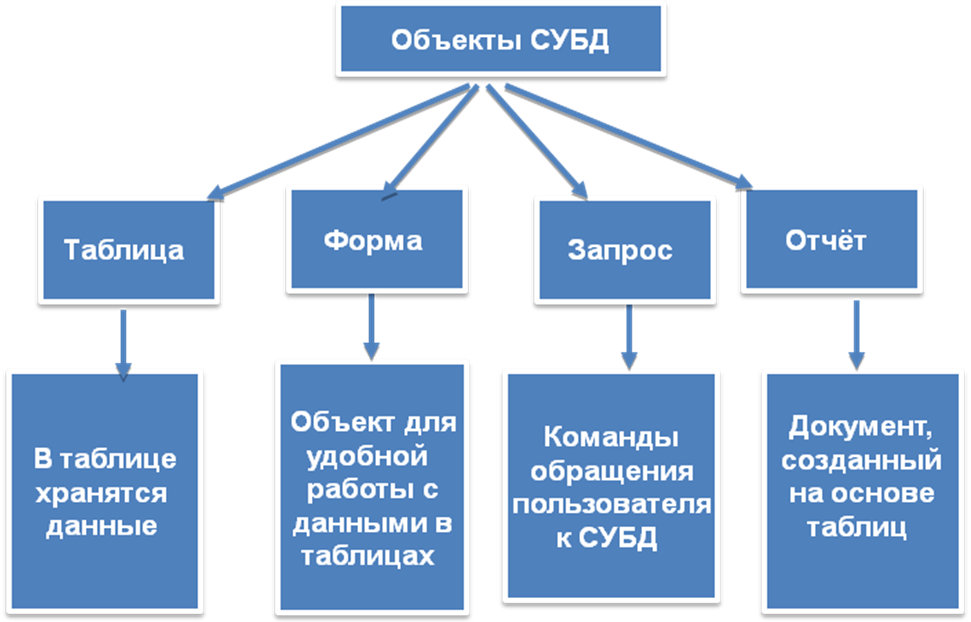
Современная СУБД состоит из:
- ядра — части программ СУБД, отвечающих за управление данными в памяти и журнализацию
- Процессора языка базы данных, обеспечивающего оптимизацию запросов на извлечение и изменение данных, и создание БД
- Подсистемы поддержки времени исполнения, интерпретирующую программы манипуляции данными, которые создают интерфейс пользователя СУБД
- Сервисных программ (внешних утилит), которые обеспечивают прочие возможности по обслуживанию информационных систем.
Так как через СУБД осуществляют все процессы, применимые к базам данных, следовательно, лучше будет выделить только её основные возможности.
Основными функциями СУБД являются
- Управление данными, хранящимися во внешней памяти
- Управление данными, загруженными в оперативную память с использованием дискового кэша
- Журнализация событий и изменений, резервное копирование и восстановление БД после сбоев
- поддержка языков обращения с БД (язык определения данных, язык манипулирования данными).
Кстати, по этой теме вы можете скачать презентацию в PowerPoint.
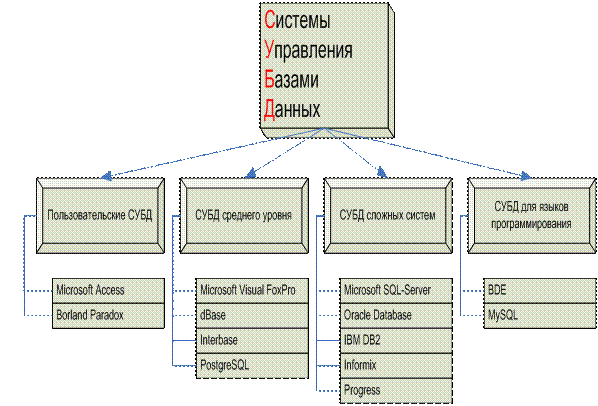
Классификации СУБД
Существует несколько признаков, по которым можно классифицировать СУБД.
СУБД по модели данных бывают:
- Иерархические СУБД
- Сетевые СУБД
- Реляционные СУБД
- Объектно-ориентированные СУБД
- Объектно-реляционные СУБД
В настоящее время в серьезных проекта используются 2 последних типа.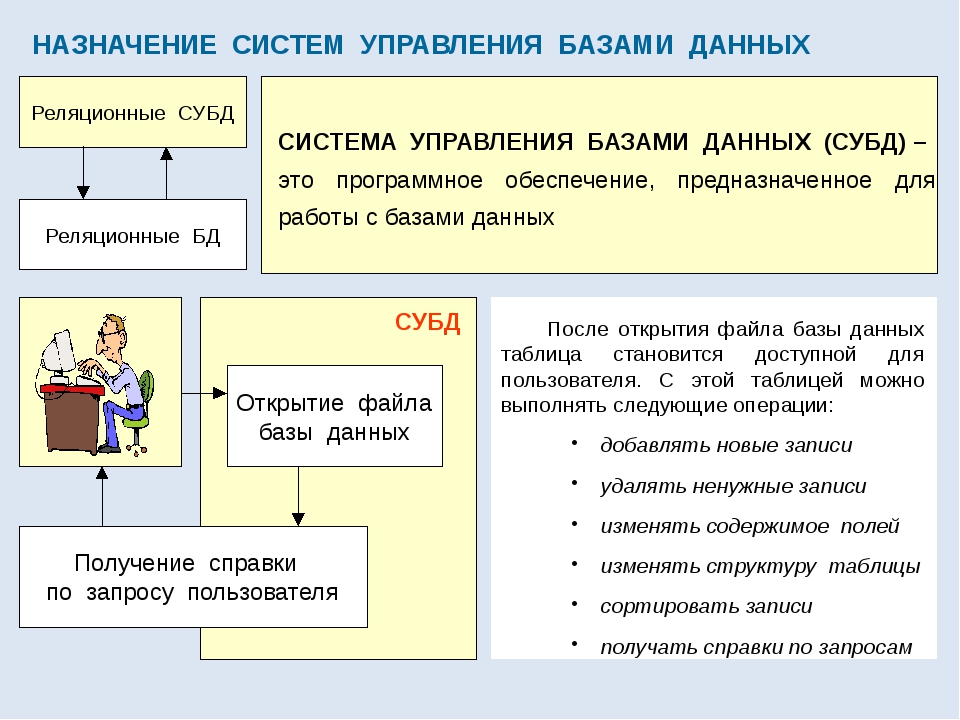
СУБД по степени распределённости
- Локальные (СУБД размещается только на одном компьютере)
- Распределённые (части СУБД могут размещаться на 2-х и более компьютерах).
Наверняка, вам будет полезным тест по СУБД, который есть на нашем проекте.
По способу доступа к БД
Файл-серверные СУБД
В них файлы с данными расположены централизованно на специальном файл-сервере. СУБД же должны быть расположены на каждом клиенте (рабочей станции). Доступ СУБД к данным производится посредством локальной сети. Поддержка синхронизации чтений и обновлений осуществляется за счет временных блокировок затребованных файлов.
Плюсом этой архитектуры можно назвать низкую нагрузку на файловый сервер.
К минусам же: высокая загрузка трафиком локальной сети; сложность или невозможность централизованного управления; нельзя обеспечить такие важные характеристики как надёжность, доступность и безопасность. Файл-серверные СУБД используют в локальных приложениях; в системах с малой интенсивностью обработки данных и небольшими пиковыми нагрузками на базу данных.
Файл-серверные СУБД используют в локальных приложениях; в системах с малой интенсивностью обработки данных и небольшими пиковыми нагрузками на базу данных.
Сейчас её при создании крупной информационной системы не используют.
Примеры файл-серверных СУБД:
- dBase,
- FoxPro,
- Microsoft Access,
- Paradox,
- Visual FoxPro.
Клиент-серверные СУБД
Клиент-серверная СУБД расположена на сервере вместе с базой данных и осуществляет доступ к БД исключительно в монопольном режиме. Все запросы на обработку данных клиентских приложений и станций обрабатываются централизованно.
Недостатком такого типа СУБД можно назвать повышенные требования к серверу.
Достоинствами: более низкую загрузку локальной сети; преимущества централизованного управления; поддержку высокой надёжности, доступности и безопасности.
Примеры клиент-серверных СУБД:
- Caché,
- Firebird,
- IBM DB2,
- Informix,
- Interbase,
- MS SQL Server,
- MySQL, Oracle,
- PostgreSQL,
- Sybase Adaptive Server Enterprise,
- ЛИНТЕР.

Встраиваемые СУБД
Это вид СУБД, который может выступать лишь в качестве составной части определенного программного комплекса, без необходимости процедуры отдельной установки. Такой вид СУБД может быть использован для локального хранения данных своего приложения и не рассчитан на коллективное использование в компьютерной сети. Физически же это зачастую реализуется в виде подключаемой библиотеки. Со стороны приложения доступ к данным происходит посредством SQL-запросов либо через специальный программный интерфейс.
Примеры встраиваемых СУБД:
- Firebird Embedded,
- BerkeleyDB,
- Microsoft SQL Server Compact,
- OpenEdge,
- SQLite,
- ЛИНТЕР.
Для рассмотрения лишь части основных возможностей и внутреннего устройства любой СУБД требуется один или несколько отдельных учебных курсов.
Список литературы по теме:
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. C. J. Date Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с.
 — М.: Финансы и статистика, 2002. — 800 с.
— М.: Финансы и статистика, 2002. — 800 с.Файловая система NTFS Что такое информация?
Типы СУБД — Платформа CUBA. Руководство по разработке приложений
3.3.2. Типы СУБД
Тип используемой СУБД определяется свойствами приложения cuba. dbmsType и (опционально) cuba.dbmsVersion, которые влияют на поведение механизмов, зависящих от типа базы данных.
dbmsType и (опционально) cuba.dbmsVersion, которые влияют на поведение механизмов, зависящих от типа базы данных.
Платформа «из коробки» поддерживает следующие СУБД:
| cuba.dbmsType | cuba.dbmsVersion | JDBC driver | |
|---|---|---|---|
HSQLDB | hsql | org.hsqldb.jdbc.JDBCDriver | |
PostgreSQL 8.4+ | postgres | org.postgresql.Driver | |
Microsoft SQL Server 2005 | mssql | 2005 | net.sourceforge.jtds.jdbc.Driver |
Microsoft SQL Server 2008 | mssql | com.microsoft.sqlserver.jdbc.SQLServerDriver | |
Microsoft SQL Server 2012+ | mssql | 2012 | com. |
Oracle Database 11g+ | oracle | oracle.jdbc.OracleDriver | |
MySQL 5.6+ | mysql | com.mysql.jdbc.Driver | |
MariaDB 5.5+ | mysql | org.mariadb.jdbc.Driver |
 microsoft.sqlserver.jdbc.SQLServerDriver
microsoft.sqlserver.jdbc.SQLServerDriverТаблица ниже описывает рекомендованное соответствие типов данных между атрибутами сущностей в Java и колонками таблиц различных СУБД. Эти типы автоматически выбираются Studio при генерации скриптов создания и обновления БД, и для них гарантируется работоспособность всех механизмов платформы.
| Java | HSQL | PostgreSQL | MS SQL Server | Oracle | MySQL | MariaDB |
|---|---|---|---|---|---|---|
UUID | varchar(36) | uuid | uniqueidentifier | varchar2(32) | varchar(32) | varchar(32) |
Date | timestamp | timestamp | datetime | timestamp | datetime(3) | datetime(3) |
java. | timestamp | date | datetime | date | date | date |
java.sql.Time | timestamp | time | datetime | timestamp | time(3) | time(3) |
BigDecimal | decimal(p, s) | decimal(p, s) | decimal(p, s) | number(p, s) | decimal(p, s) | decimal(p, s) |
Double | double precision | double precision | double precision | float | double precision | double precision |
Long | bigint | bigint | bigint | number(19) | bigint | bigint |
Integer | integer | integer | integer | integer | integer | integer |
Boolean | boolean | boolean | tinyint | char(1) | boolean | boolean |
String (limited) | varchar(n) | varchar(n) | varchar(n) | varchar2(n) | varchar(n) | varchar(n) |
String (unlimited) | longvarchar | text | varchar(max) | clob | longtext | longtext |
byte[] | longvarbinary | bytea | image | blob | longblob | longblob |
 sql.Date
sql.DateКак правило, всю работу по преобразованию данных между БД и кодом Java выполняет слой ORM совместно с соответствующим JDBC драйвером. Это означает, что при работе с данными через DataManager, EntityManager и запросы на JPQL никакой ручной конвертации выполнять не нужно — вы просто используете типы Java, перечисленные в левой колонке таблицы.
Это означает, что при работе с данными через DataManager, EntityManager и запросы на JPQL никакой ручной конвертации выполнять не нужно — вы просто используете типы Java, перечисленные в левой колонке таблицы.
При использовании native SQL через EntityManager.createNativeQuery() или через QueryRunner для разных типов СУБД некоторые типы данных в Java коде будут отличаться от приведенных. В первую очередь это касается атрибутов типа UUID — только драйвер PostgreSQL возвращает значения соответствующих колонок в этом типе, для других серверов это будет String. Для обеспечения независимости кода от используемой СУБД рекомендуется конвертировать типы параметров и результатов запросов с помощью интерфейса DbTypeConverter.
Системы управления базами данных
Основные функции СУБД
Создание базы данных, ее хранение, обеспечение доступа пользователей к данным осуществляются с помощью специальных программных инструментов – систем управления базами данных.
Определение 1
Система управления базами данных (СУБД) – это комплекс языковых и программных средств, обеспечивающих создание, хранение и совместное использование баз данных.
Основными функциями СУБД являются:
- Ведение словаря данных. Словарем данных называется информация, позволяющая описывать данные, хранящиеся в базах. В словарь данных входят названия, типы и размеры элементов данных, названия связей, ограничения целостности данных.
- Поддержка многопользовательского режима. В случае, когда с базой данных работает несколько пользователей, СУБД должна гарантировать корректность обновления данных разными пользователями.
- Восстановление баз данных после сбоев. СУБД ведет журнал, куда поступает информация обо всех изменениях в базах данных. Восстановление после сбоев происходит на основании данных, зафиксированных в журнале.
- Управление доступом к данным. СУБД позволяет создавать пользователей и давать им различные права доступа к данным. На основании прав доступа производится контроль.
- Поддержка целостности данных.
 СУБД позволяет создавать пользователей и давать им различные права доступа к данным. На основании прав доступа производится контроль.
СУБД позволяет создавать пользователей и давать им различные права доступа к данным. На основании прав доступа производится контроль.Определение 2
Целостностью данных называется соответствие данных логике той модели данных, на которой основана СУБД и всем накладываемым на данные ограничениям.
СУБД должна постоянно контролировать выполнение этих ограничений.
- Поддержка транзакций.
Определение 3
Транзакцией называется последовательность операций, которая должна быть либо выполнена целиком, либо отменена.
Пример 1
Допустим, необходимо выполнить следующую последовательность действий:
- Определить сумму на счете №1.
- Вычислить 10% от этой суммы.
- Уменьшить сумму на счете №1 на полученное значение.
- Увеличить сумму на счете №2 на это же значение.
Если на любом из этих шагов произойдет сбой в системе, то в лучшем случае не произойдет перевод денег со счета №1, на счет №2. А в худшем деньги будут сняты со счета №1, но на счет №2 не попадут. Поэтому эти четыре операции должны быть оформлены транзакцией. В случае сбоя, система должна вернуться в то состояние, в котором она была до выполнения шага 1.
Кроме перечисленных функций различные СУБД могут обладать рядом дополнительных.
Классификация СУБД
Самым важным признаком, по которому классифицируются СУБД, является модель данных. Как и модели данных СУБД бывают следующих видов:
- Иерархические. Самыми известными иерархическими СУБД является IMS и Cache . Модель удобна для хранения структур, которые являются иерархическими по своей природе. Иерархической является, например, структура предприятия с подчиненными подразделениями. Однако, большинство предметных областей не соответствуют иерархической структуре. Потому иерерхические СУБД не популярны и используются в основном в устаревших ИС.
- Сетевые. Известными представителями этого класса являются IDMS и CronosPRO. Данная модель является усовершенствованием иерархической. Высокая сложность и жесткость структуры базы данных также снижают популярность этого класса СУБД;
- Реляционные. На сегодняшний день реляционные базы данных и СУБД являются стандартом де-факто. Чаще всего, когда речь идет о базе данных, то подразумевается именно реляционная. На рынке ПО существует много представителей этого класса СУБД: MS SQL SERVER,IBM DB2, MySQL, PostgreSQL и т.д. ;
- Постреляционные. Постреляционная модель основана на тех же принципах, что и реляционная, но без учета требования неделимости данных. Их достоинством является более высокая скорость работы, а недостатком – сложности в обеспечении целостности данных. Типичным представителем являются СУБД uniVerse и UniData;
- No sql (нереляционные). Модель no sql отличается простотой и гибкостью. Она позволяет добавлять элементы данных в таблицы без предварительного объявления об изменении структуры. Наиболее известные представители MongoDB и CouchDB.
- Объектные. Этот класс СУБД хранит данные в виде объектов. Такой подход очень удобен для предметных областей со сложной структурой. Недостатком является необходимость использовать процедурные языки для доступа к данным. К современным объектным СУБД относятся POET, Jasmine, Versant, O2, ODB-Jupiter.
- Объектно-реляционные. Некоторые производители СУБД совмещают в своих продуктах реляционную и объектную модели. К таким «гибридам» относятся Informix Universal Server и Oracle8 Universal Data Server
- Многомерные. Если реляционная модель хранит данные в двумерных таблицах, то многомерная позволяет добавлять дополнительные измерения. В результате данных хранятся не в таблицах, а в гиперкубах. Многомерные СУБД используются в задачах анализа данных. На многомерной технологии основаны СУБД jBASE, EssBase.

 Она позволяет добавлять элементы данных в таблицы без предварительного объявления об изменении структуры. Наиболее известные представители MongoDB и CouchDB.
Она позволяет добавлять элементы данных в таблицы без предварительного объявления об изменении структуры. Наиболее известные представители MongoDB и CouchDB.
Реляционные базы данных и NoSQL-хранилища
Базы данных нужны для хранения данных и их обработки. Бывают реляционные (SQL) и NoSQL системы управления базами данных.
Реляционные базы данных (SQL)
Наиболее распространенными базами данных являются реляционные или SQL — данные в них хранятся во взаимосвязаанных таблицах. Типичные представители SQL СУБД: MySQL / MariaDB, PostgreSQL, MSSQL и Oracle. Первые две — бесплатны и для сайтов используются чаще всего. Вторые две — платные и реже используются в веб-проектах (чаще они применяются в корпоративных приложениях). По сути, для обычных проектов в техническом плане нет существенной разницы какую базу использовать, но в экономическом плане выгоднее использовать самую распространенную MySQL или чуть менее распространенную в простых проектах PostgreSQL — больше разработчиков, ниже стоимость поддержки и разработки.
Базы данных и хранилища NoSQL
Есть еще так называемые NoSQL базы данных и хранилища — MongoDB, CouchDB, Redis, Memcached, Cassandra, Scylla, которые значительно моложе реляционных баз данных, а также существенно отличаются от них по структуре хранения и механикам работы с данными.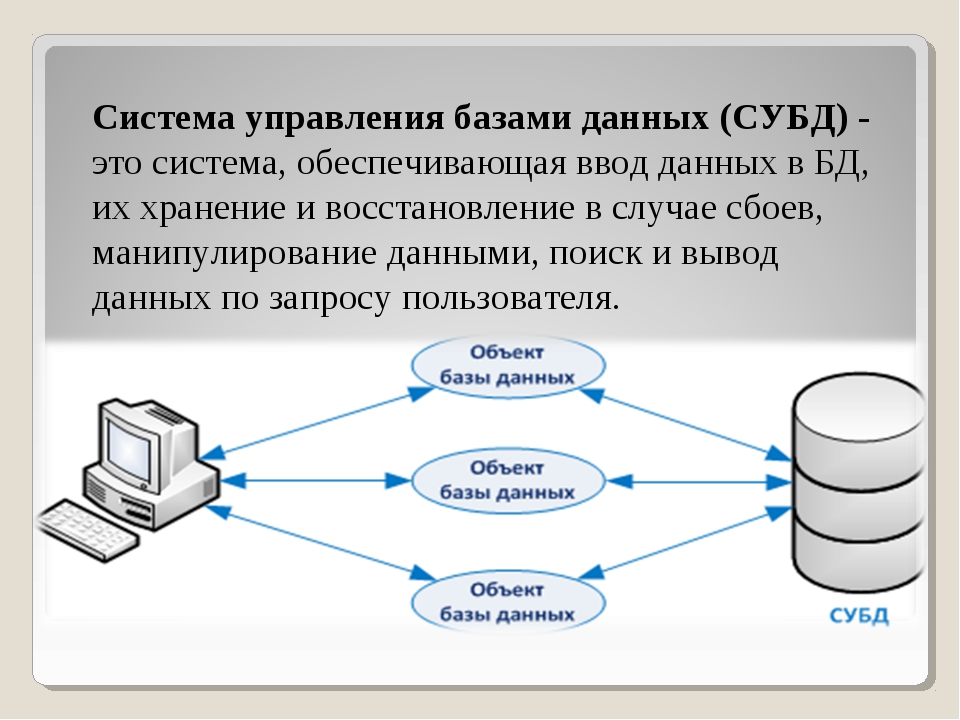 NoSQL СУБД применяются чаще не для хранения всех данных приложения, а лишь для решения специфических задач (журналирование, кэширование, очереди заданий, распределённое хранение данных) и поэтому менее распространены в простых проектах.
NoSQL СУБД применяются чаще не для хранения всех данных приложения, а лишь для решения специфических задач (журналирование, кэширование, очереди заданий, распределённое хранение данных) и поэтому менее распространены в простых проектах.
Рекомендации
В качестве основного хранилища предпочтительнее использовать реляционную СУБД. Для обычных проектов проще использовать MySQL или PostgreSQL, так как на простых операциях не очень заметна разница между различными реляционными базами данных. Хотя обычно мы склоняемся к использованию PostgreSQL. Однако, если проект предусматривает сложную логику обработки данных, то выбор базы стоит производить исходя из технических характеристик.
Как правило, выбор системы управления сайтом, фреймворка или даже языка программирования уже в какой-то мере обуславливает выбор базы данных для проекта. Например, системы управления сайтами на PHP обычно полноценно поддерживает в качестве БД только MySQL, а продукты от Microsoft, как правило, используют в одной связке (например, .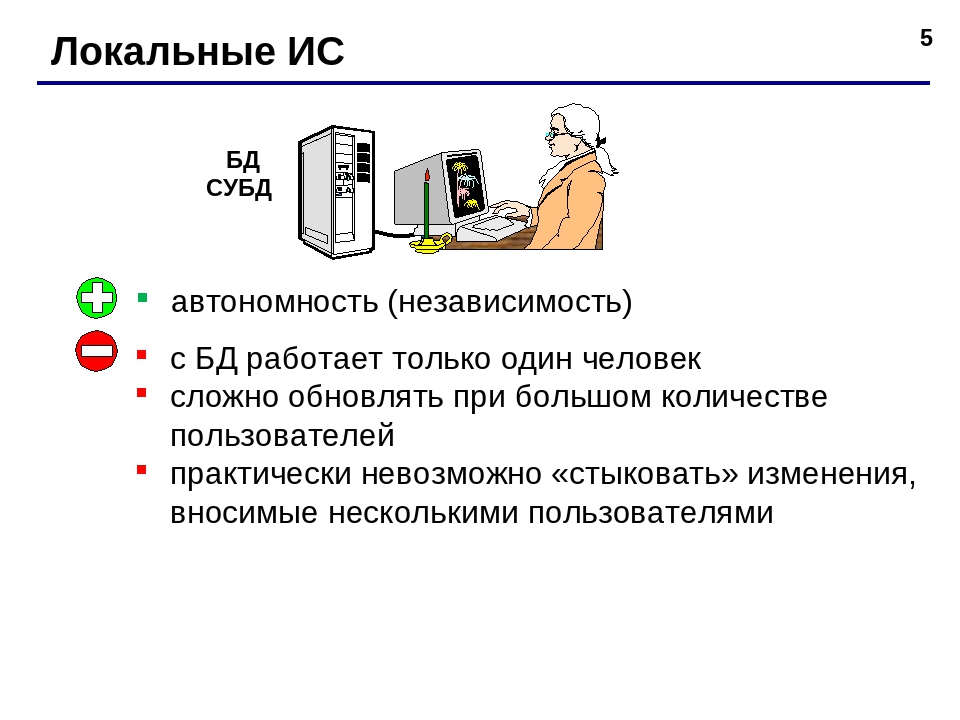 NET + MSSQL).
NET + MSSQL).
Нереляционные СУБД лучше применять там, где их использование позволит увеличить скорость работы приложения, но нет необходимости в обеспечении сверхнадёжного хранения данных.
Типы данных в СУБД—Справка | ArcGIS Desktop
При создании таблицы или добавлении поля в таблицу базы геоданных поля создаются с конкретным типом данных. Типы данных представляют собой классификации, которые позволяют определить возможные значения, операции, которые могут быть выполнены для этих данных, а также каким образом данные этого поля будут храниться в базе данных.
При импорте данных одного типа в поле, имеющее другой тип данных, вам нужно понимать, что является эквивалентами типов данных при их переносе между ArcSDE и вашей системой управления базами данных (СУБД), поскольку это может влиять на содержание данных. Точно так же, при создании новых наборов данных в ArcGIS полезно знать, что является эквивалентами типов данных при их переносе между ArcGIS и вашей СУБД.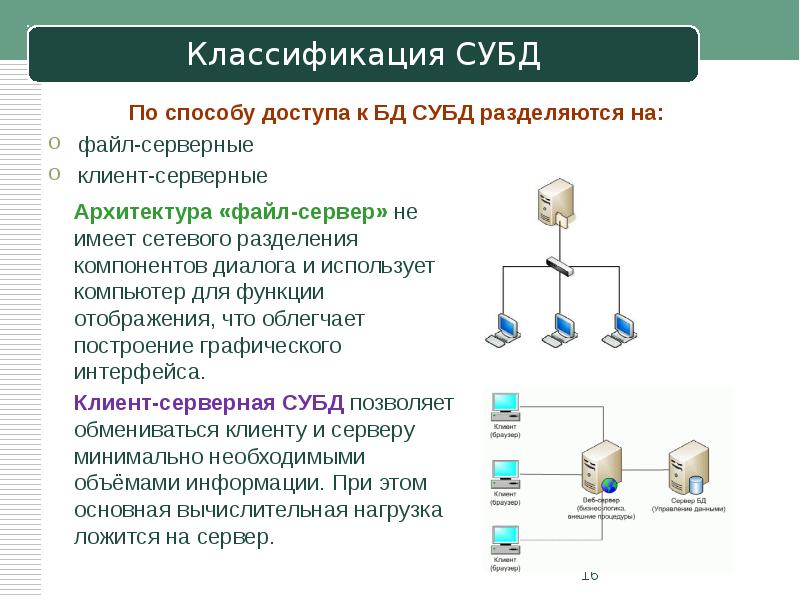 Например, если вы добавите столбец с плавающей точкой (float) в созданный класс пространственных объектов, то в базе данных SQL Server это будет соответствовать столбцу с численным (numeric) типом данных.
Например, если вы добавите столбец с плавающей точкой (float) в созданный класс пространственных объектов, то в базе данных SQL Server это будет соответствовать столбцу с численным (numeric) типом данных.
Примечание:
Перемещение данных из одной базы данных в другую может вызывать преобразование типов данных.
Подробнее о конвертации данных из одного типа в другой
Типы данных файловой базы геоданных представляют собой типы данных ArcGIS. Однако среди продуктов СУБД типы данных могут различаться. В расположенных ниже разделах содержится информация о том, каким образом происходит преобразование типов данных СУБД в типы данных ArcGIS.
Типы данных Access
При создании класса пространственных объектов или таблицы в ArcGIS для каждого столбца существует возможность выбора 11 различных типов данных. Эти типы данных преобразуются в типы данных Access, как указано в расположенной ниже таблице.
| Тип данных ArcGIS | Тип данных Access | Примечания |
|---|---|---|
OBJECTID | Длинное целое (Long Integer) | OBJECTID является полем AutoNumber. |
SHORT INTEGER | Целое (Integer) | |
LONG INTEGER | Длинное целое (Long Integer) | |
FLOAT | Одинарной точности (Single) | |
DOUBLE | Двойной точности (Double) | |
TEXT | Текст (Text) | |
DATE | Дата/Время (Date/Time) | |
BLOB | Объект OLE* | |
GUID | Число (Number) | Replication ID, возможны повторы |
GEOMETRY | Объект OLE* | |
RASTER | Длинное целое (Long Integer) |

*Объекты связывания и встраивания (OLE) представляют собой объекты, которые были созданы в других приложениях и сейчас связаны с Microsoft Access или встроены в него. В данном случае, типы данных Большой двоичный объект (BLOB) и Геометрия (GEOMETRY) не существуют в Access, поэтому объект ArcGIS связывается с базой данных Access.
В данном случае, типы данных Большой двоичный объект (BLOB) и Геометрия (GEOMETRY) не существуют в Access, поэтому объект ArcGIS связывается с базой данных Access.
Типы данных в системах управления базами данных и многопользовательских базах геоданных
При создании класса объектов или таблицы в базе данных или многопользовательской базе геоданных с помощью ArcGIS для каждого столбца существует возможность выбора одного из одиннадцати различных типов данных. Выбор используемого типа зависит от типа СУБД, к которой выполняется подключение. Для получения информации о том, каким образом происходит преобразование типов данных СУБД в типы данных ArcGIS, см. раздел Типы данных, поддерживаемых в ArcGIS.
Связанные разделы
история, виды, примеры, применение Big Data
NoSQL – это подход к реализации масштабируемого хранилища (базы) информации с гибкой моделью данных, отличающийся от классических реляционных СУБД. В нереляционных базах проблемы масштабируемости (scalability) и доступности (availability), важные для Big Data, решаются за счёт атомарности (atomicity) и согласованности данных (consistency) [1].
NoSQL-базы оптимизированы для приложений, которые должны быстро, с низкой временной задержкой (low latency) обрабатывать большой объем данных с разной структурой [2]. Таким образом, нереляционные хранилища непосредственно ориентированы на Big Data. Однако, идея баз данных такого типа зародилась гораздо раньше термина «большие данные», еще в 80-е годы прошлого века, во времена первых компьютеров (мэйнфреймов) и использовалась для иерархических служб каталогов. Современное понимание NoSQL-СУБД возникло в начале 2000-х годов, в рамках создания параллельных распределённых систем для высокомасштабируемых интернет-приложений, таких как онлайн-поисковики [1].
Вообще термин NoSQL обозначает «не только SQL» (Not Only SQL), характеризуя ответвление от традиционного подхода к проектированию баз данных. Изначально так называлась опенсорсная база данных, созданная Карло Строззи, которая хранила все данные как ASCII-файлы, а вместо SQL-запросов доступа к данным использовала шелловские скрипты [3]. В начале 2000-х годов Google построил свою поисковую систему и приложения (GMail, Maps, Earth и прочие сервисы), решив проблемы масштабируемости и параллельной обработки больших объёмов данных. Так была создана распределённые файловая и координирующая системы, а также колоночное хранилище (column family store), основанное на вычислительной модели MapReduce. После того, как корпорация Google опубликовала описание этих технологий, они стали очень популярны у разработчиков открытого программного обеспечения. В результате этого был создан Apache Hadoop и запущены основные связанные с ним проекты. Например, в 2007 году другой ИТ-гигант, Amazon.com, опубликовав статьи о своей высокодоступной базе данных Amazon DynamoDB. Далее в эту гонку NoSQL- технологий для управления большими данными включилось множество корпораций: IBM, Facebook, Netflix, eBay, Hulu, Yahoo! и другие ИТ-компаний со своими проприетарными и открытыми решениями [1].
Изначально так называлась опенсорсная база данных, созданная Карло Строззи, которая хранила все данные как ASCII-файлы, а вместо SQL-запросов доступа к данным использовала шелловские скрипты [3]. В начале 2000-х годов Google построил свою поисковую систему и приложения (GMail, Maps, Earth и прочие сервисы), решив проблемы масштабируемости и параллельной обработки больших объёмов данных. Так была создана распределённые файловая и координирующая системы, а также колоночное хранилище (column family store), основанное на вычислительной модели MapReduce. После того, как корпорация Google опубликовала описание этих технологий, они стали очень популярны у разработчиков открытого программного обеспечения. В результате этого был создан Apache Hadoop и запущены основные связанные с ним проекты. Например, в 2007 году другой ИТ-гигант, Amazon.com, опубликовав статьи о своей высокодоступной базе данных Amazon DynamoDB. Далее в эту гонку NoSQL- технологий для управления большими данными включилось множество корпораций: IBM, Facebook, Netflix, eBay, Hulu, Yahoo! и другие ИТ-компаний со своими проприетарными и открытыми решениями [1].
Все NoSQL решения принято делить на 4 типа:
- Ключ-значение (Key-value) – наиболее простой вариант хранилища данных, использующий ключ для доступа к значению в рамках большой хэш-таблицы [4]. Такие СУБД применяются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в масштабируемых Big Data системах, включая игровые и рекламные приложения, а также проекты интернета вещей (Internet of Things, IoT), в т.ч. индустриального (Industrial IoT, IIoT). Наиболее известными представителями нереляционных СУБД типа key-value считаются Oracle NoSQL Database, Berkeley DB, MemcacheDB, Redis, Riak, Amazon DynamoDB, которые поддерживают высокую разделяемость, обеспечивая беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД [2].
- Документно-ориентированное хранилище, в котором данные, представленные парами ключ-значение, сжимаются в виде полуструктурированного документа из тегированных элементов, подобно JSON, XML, BSON и другим подобным форматам [4]. Такая модель хорошо подходит для каталогов, пользовательские профилей и систем управления контентом, где каждый документ уникален и изменяется со временем [2]. Поэтому чаще всего документные NoSQL-СУБД используются в CMS-системах, издательском деле и документальном поиске. Самые яркие примеры документно-ориентированных нереляционных баз данных – это CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML [1].
- Колоночное хранилище, которое хранит информацию в виде разреженной матрицы, строки и столбцы которой используются как ключи. В мире Big Data к колоночным хранилищам относятся базы типа «семейство столбцов» (Column Family). В таких системах сами значения хранятся в столбцах (колонках), представленных в отдельных файлах. Благодаря такой модели данных можно хранить большое количество атрибутов в сжатом виде, что ускоряет выполнение запросов к базе, особенно операции поиска и агрегации данных [4]. Наличие временных меток (timestamp) позволяет использовать такие СУБД для организации счётчиков, регистрации и обработки событий, связанных со временем: системы биржевой аналитики, IoT/IIoT-приложения, систему управления содержимым и т.д. Самой известной колоночной базой данных является Google Big Table, а также основанные на ней Apache HBase и Cassandra. Также к этому типу относятся менее популярные ScyllaDB, Apache Accumulo и Hypertable [1].
- Графовое хранилище представляют собой сетевую базу, которая использует узлы и рёбра для отображения и хранения данных [4]. Поскольку рёбра графа являются хранимыми, его обход не требует дополнительных вычислений (как соединение в SQL). При этом для нахождения начальной вершины обхода необходимы индексы. Обычно графовые СУБД поддерживают ACID-требования и специализированные языки запросов (Gremlin, Cypher, SPARQL, GraphQL и т.д.) [1]. Такие СУБД используются в задачах, ориентированных на связи: социальные сети, выявление мошенничества, маршруты общественного транспорта, дорожные карты, сетевые топологии [3]. Примеры графовых баз: InfoGrid, Neo4j, Amazon Neptune, OrientDB, AllegroGraph, Blazegraph, InfiniteGraph, FlockDB, Titan, ArangoDB.

 Благодаря такой модели данных можно хранить большое количество атрибутов в сжатом виде, что ускоряет выполнение запросов к базе, особенно операции поиска и агрегации данных [4]. Наличие временных меток (timestamp) позволяет использовать такие СУБД для организации счётчиков, регистрации и обработки событий, связанных со временем: системы биржевой аналитики, IoT/IIoT-приложения, систему управления содержимым и т.д. Самой известной колоночной базой данных является Google Big Table, а также основанные на ней Apache HBase и Cassandra. Также к этому типу относятся менее популярные ScyllaDB, Apache Accumulo и Hypertable [1].
Благодаря такой модели данных можно хранить большое количество атрибутов в сжатом виде, что ускоряет выполнение запросов к базе, особенно операции поиска и агрегации данных [4]. Наличие временных меток (timestamp) позволяет использовать такие СУБД для организации счётчиков, регистрации и обработки событий, связанных со временем: системы биржевой аналитики, IoT/IIoT-приложения, систему управления содержимым и т.д. Самой известной колоночной базой данных является Google Big Table, а также основанные на ней Apache HBase и Cassandra. Также к этому типу относятся менее популярные ScyllaDB, Apache Accumulo и Hypertable [1]. Обычно графовые СУБД поддерживают ACID-требования и специализированные языки запросов (Gremlin, Cypher, SPARQL, GraphQL и т.д.) [1]. Такие СУБД используются в задачах, ориентированных на связи: социальные сети, выявление мошенничества, маршруты общественного транспорта, дорожные карты, сетевые топологии [3]. Примеры графовых баз: InfoGrid, Neo4j, Amazon Neptune, OrientDB, AllegroGraph, Blazegraph, InfiniteGraph, FlockDB, Titan, ArangoDB.
Обычно графовые СУБД поддерживают ACID-требования и специализированные языки запросов (Gremlin, Cypher, SPARQL, GraphQL и т.д.) [1]. Такие СУБД используются в задачах, ориентированных на связи: социальные сети, выявление мошенничества, маршруты общественного транспорта, дорожные карты, сетевые топологии [3]. Примеры графовых баз: InfoGrid, Neo4j, Amazon Neptune, OrientDB, AllegroGraph, Blazegraph, InfiniteGraph, FlockDB, Titan, ArangoDB.По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами:
- линейная масштабируемость – добавление новых узлов в кластер увеличивает общую производительность системы [1];
- гибкость, позволяющая оперировать полуструктирированные данные, реализуя, в. т.ч. полнотекстовый поиск по базе [2];
- возможность работать с разными представлениями информации, в т. ч. без задания схемы данных [1];
- высокая доступность за счет репликации данных и других механизмов отказоустойчивости, в частности, шаринга – автоматического разделения данных по разным узлам сети, когда каждый сервер кластера отвечает только за определенный набор информации, обрабатывая запросы на его чтение и запись. Это увеличивает скорость обработки данных и пропускную способность приложения [5].
- производительность за счет оптимизации для конкретных видов моделей данных (документной, графовой, колоночной или «ключ‑значение») и шаблонов доступа [2];
- широкие функциональные возможности – собственные SQL-подобные языки запросов, RESTful-интерфейсы, API и сложные типы данных, например, map, list и struct, позволяющие обрабатывать сразу множество значений [2].
 ч. без задания схемы данных [1];
ч. без задания схемы данных [1];Обратной стороной вышеуказанных достоинств являются следующие недостатки:
- ограниченная емкость встроенного языка запросов [5]. Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
- сложности в поддержке всех ACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того, что NoSQL-СУБД вместо CAP-модели (согласованность, доступность, устойчивость к разделению) скорее соответствуют модели BASE (базовая доступность, гибкое состояние и итоговая согласованность) [1]. Впрочем, некоторые нереляционные СУБД пытаются обойти это ограничение с помощью настраиваемых уровней согласованности, о чем мы рассказывали на примере Cassandra. Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции [1]. Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
- сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных, ориентированной на конкретный случай [5];
- недостаток специалистов по NoSQL-базам по сравнению с реляционными аналогами [5].
 Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill. Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.Подводя итог описанию основных аспектов нереляционных СУБД, стоит отметить некоторую некорректность запроса «NoSQL vs SQL» в связи с разными архитектурными подходами и прикладными задачами, на которые ориентированы эти ИТ-средства. Традиционные SQL-базы отлично справляются с обработкой строго типизированной информации не слишком большого объема. Например, локальная ERP-система или облачная CRM. Однако, в случае обработки большого объема полуструктурированных и неструктурированных данных, т.е. Big Data, в распределенной системе следует выбирать из множества NoSQL-хранилищ, учитывая специфику самой задачи. В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь. А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS.
В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь. А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS.
Источники
- https://ru.wikipedia.org/wiki/NoSQL
- https://aws.amazon.com/ru/nosql/
- https://ru.bmstu.wiki/NoSQL
- https://tproger.ru/translations/types-of-nosql-db/
- https://habr.com/ru/sandbox/113232/
Related Entries
Введение в SubD (Subdivision Surface Modeling) в Rhino3d v7
В этом видео Фил Кук из Simply Rhino рассматривает SubD, или Subdivision Surface Modeling, который разрабатывается для Rhino v7.
Традиционно объекты SubD основаны на сетке и хорошо подходят для более приближенных типов моделирования, таких как моделирование персонажей и создание гладких органических форм, которые управляются приблизительным образом.
Rhino SubD представляют собой высокоточные сплайновые поверхности и, таким образом, вносят определенный уровень точности в процесс создания сложных форм произвольной формы.В то время как традиционное «push-pull» редактирование ребер, граней и вершин в SubD включено, все команды поверхности Rhino, такие как Loft, Revolve, Sweep 1 & 2 и Extrude, теперь производят прямой вывод SubD.
Точно так же кривая контрольной точки и интерполированная кривая имеют параметры «SubD Friendly», которые позволяют создавать точные поверхности SubD из компоновки кривой аналогичным методом, который можно использовать для моделирования NURBS, но с преимуществом присущей гладкости поверхностей SubD.
Видео начинается с изучения поверхностей SubD и их сравнения с NURBS, прежде чем перейти к рассмотрению некоторых примеров того, как и почему можно использовать SubD вместе с традиционным рабочим процессом NURBS в Rhino.
Посмотрите видео «Введение в инструменты SubD в Rhino v7»:
 youtube.com/embed/RIbsNurVdb0?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/RIbsNurVdb0?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> Введение в инструменты SubD в стенограмме видео Rhino v7.
Мы сделали стенограмму видео для всех, кто хотел бы следить за видео по сценарию.
Смотрите стенограмму видео здесь:
Это Фил из Simply Rhino, и сегодня я хотел бы взглянуть на моделирование SubD, которое является новым в Rhino v7.
Здесь я использую незавершенную версию программного обеспечения, поэтому некоторые функции могут быть доработаны к моменту поставки продукта.
Что такое SubD?
Итак, прежде всего, что такое SubD? Поверхности SubD или SubDivision — это новый тип объекта внутри Rhino. Если мы вернемся к версии 6, у нас будут NURBS-объекты и сетки. Проще говоря, NURBS-поверхности можно рассматривать как непрерывное описание, в данном случае, искривленного объема. В зависимости от степени и компоновки контрольных точек NURBS-кривые и поверхности могут иметь постоянный радиус или могут использоваться для описания кривизны непрерывных форм произвольной формы.
В зависимости от степени и компоновки контрольных точек NURBS-кривые и поверхности могут иметь постоянный радиус или могут использоваться для описания кривизны непрерывных форм произвольной формы.
могут только аппроксимировать геометрию кривой.Если мы посмотрим на пример сетчатой сферы, то только вершины сетки касаются условной сферы. Края сетки экстраполируются из этих вершин путем отслеживания прямого пути через пары точек, а затем между тремя или четырьмя ребрами сетки создаются плоские грани сетки.
Если вы какое-то время пользовались Rhino3d, возможно, вы знакомы с такими плагинами, как T-Splines и Clayoo. Благодаря им в Rhino появился рабочий процесс SubD, но, что особенно важно, он был основан на сетке. Итак, лежащая в основе геометрия представляла собой сетку, которая была сглажена для приближения кривизны непрерывной поверхности или полигональной поверхности.
Новые объекты SubD в Rhino основаны на сплайнах. Таким образом, как и в случае с объектами Rhino NURBS, они обеспечивают непрерывное описание геометрии кривой.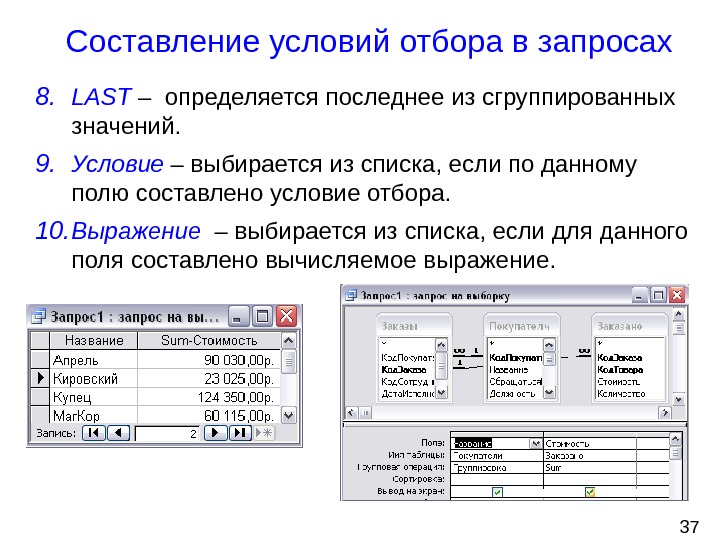 Это означает, что геометрия SubD может быть точно создана в Rhino, и это преодолевает одну из основных критических замечаний в отношении рабочих процессов SubD на основе сетки, которые часто рассматриваются как приблизительные.
Это означает, что геометрия SubD может быть точно создана в Rhino, и это преодолевает одну из основных критических замечаний в отношении рабочих процессов SubD на основе сетки, которые часто рассматриваются как приблизительные.
Rhino могут быть созданы несколькими способами. Команды Surface, такие как Loft, Revolve, Sweep1, Sweep2 и Extrude, позволяют создавать выходные данные SubD.У команд Curve есть опции, дружественные к SubD, и, конечно же, есть ряд примитивов. Существуют также рабочие процессы, в которых сетки могут быть преобразованы в объекты SubD. Наконец, объекты SubD Rhino могут быть без потерь преобразованы в объекты NURBS.
Сравнение геометрии SubD Rhino с NURBS в Rhino3d v7
Итак, чем же SubD отличается от NURBS и зачем они нам нужны?
Давайте посмотрим на первую часть этого вопроса и сравним открытую и закрытую поверхность NURBS с открытой и закрытой поверхностью SubD.
Слева у меня деформируемая сфера степени 3 и плоская поверхность степени 3, а справа их эквиваленты в SubD. Теперь нам не нужно беспокоиться о предмете степени с объектами SubD, но в целом они аналогичны непрерывным поверхностям кривизны степени 3.
Теперь нам не нужно беспокоиться о предмете степени с объектами SubD, но в целом они аналогичны непрерывным поверхностям кривизны степени 3.
С закрытой поверхностью NURBS я могу включать контрольные точки, выбирать некоторые из этих контрольных точек и плавно настраивать форму. Я могу сделать то же самое с объектом SubD, но я также могу использовать выбор подпараметров, который в Windows (сочетание клавиш) Shift, Control и щелчок левой кнопкой мыши, и я могу выбрать одну или несколько граней или один или несколько краев для настройки форма плавно.
Хотя поверхности SubD в основном гладкие, я могу добавить к ним складки, и это делается путем выбора ребер, и здесь я могу выбрать подобъект и дважды щелкнуть его, чтобы выбрать границу ребра, а затем, как только я выбрал эти ребра, я может добавить им складку. Складки также можно удалить с помощью команды удаления складок.
Возможно, самая большая разница между NURBS и SubD заключается в том, как мы добавляем локальное управление в поверхность. Если я просто смотрю на поверхность NURBS для начала, если я хочу добавить в эту область какой-то локальный элемент управления, тогда мне нужно будет добавить строки и столбцы контрольных точек.Итак, я сделаю это, например, перейдя к редактированию, контрольным точкам и вставке узла, и я вставлю несколько узлов в направлении U. Затем я нажму тумблер и вставлю несколько узлов в направлении V. Таким образом, это даст мне более плотную область контрольных точек здесь, но поскольку контрольные точки должны быть добавлены по всей области поверхности, другими словами, от края до края в направлении U или V, тогда I ‘ м, добавляя сложности этой части поверхности и этой части поверхности. Тем не менее, это дает мне возможность добавлять локальные детали на поверхность вот так.
Если я просто смотрю на поверхность NURBS для начала, если я хочу добавить в эту область какой-то локальный элемент управления, тогда мне нужно будет добавить строки и столбцы контрольных точек.Итак, я сделаю это, например, перейдя к редактированию, контрольным точкам и вставке узла, и я вставлю несколько узлов в направлении U. Затем я нажму тумблер и вставлю несколько узлов в направлении V. Таким образом, это даст мне более плотную область контрольных точек здесь, но поскольку контрольные точки должны быть добавлены по всей области поверхности, другими словами, от края до края в направлении U или V, тогда I ‘ м, добавляя сложности этой части поверхности и этой части поверхности. Тем не менее, это дает мне возможность добавлять локальные детали на поверхность вот так.
Если мы посмотрим на SubD, то с помощью SubD я могу разделить эту поверхность на SubDivide. Итак, я могу выбрать лицо, а затем я могу использовать команду SubDivide для SubDivide это лицо, и я могу продолжать добавлять больше SubDivisions по мере продвижения, а затем я могу выбрать одно из этих лиц и переместить его вверх, чтобы получить свой локальный контроль .
Если я хочу вставить края более контролируемым образом, а не просто разделить целую область, я могу использовать команду InsertEdge, скопировать край и вставить его.А если я хочу переместить край, я могу использовать команду SlideEdge.
Команда InsertEdge имеет пропорциональный режим, двусторонний режим и абсолютный режим, и здесь вы можете увидеть разницу между абсолютным и пропорциональным режимами. Точно так же, когда я перемещаю края с помощью команды SlideEdge, я могу выбрать два края и одновременно перемещать их внутрь и наружу, и для этого у меня также есть пропорциональный и абсолютный режимы.
Основное различие между тем, как работают NURBS и SubD, заключается в том, что с NURBS у вас есть концепция либо одной поверхности, либо полиповерхности, которая представляет собой более чем одну поверхность, соединенную вместе частично или полностью совпадающими край.Итак, используя эту метафору, я могу взять шесть поверхностей, имеющих общие совпадающие края, и объединить их в твердую замкнутую поли-поверхность.
Не существует концепции полигональной поверхности с SubD, поэтому для воспроизведения такой формы в SubD нам нужна единственная поверхность SubD со складками по краям.
Тем не менее, существует рабочий процесс, который позволяет нам моделировать NURBS-полигональную поверхность в SubD, и это идет с оговоркой, заключающейся в том, что каждая из отдельных составляющих поверхностей полиповерхности должна быть неотрезанной.Если это так, то мы можем взорвать нашу поли-поверхность и использовать инструмент преобразования в SubD. Важно, чтобы параметр «Угол» здесь говорил «да», чтобы мы могли сохранить эти острые углы отдельных поверхностей. Теперь у нас будет шесть отдельных поверхностей SubD, и мы сможем соединить их вместе с помощью инструмента соединения. Опять же, у нас будет выбор, что делать с краями. У нас могут быть гладкие края или загнутые края. Здесь я выбрал загнутые края, и если мы посмотрим на свойства объекта, вы увидите, что у меня закрытый SubD, и если я хочу удалить складки с этих трех краев здесь, я просто выбираю их и использую RemoveCrease орудие труда.
Теперь мы скоро вернемся к объекту, похожему на этот, и рассмотрим альтернативу рабочему процессу NURBS в SubD.
Зачем использовать объекты SubD в рабочем процессе Rhino3d?
Итак, теперь мы немного знаем, что такое объекты SubD, давайте перейдем ко второй части вопроса: зачем они нам?
Один из ответов на этот вопрос заключается в том, что моделирование поверхностей SubDivision действительно полезно в ситуациях, когда моделирование в NURBS затруднено или проблематично.Простым примером этого является Y-ветвь. Это довольно легко смоделировать в NURBS, но становится сложнее, если ветви имеют, как в этом примере, разные диаметры, или расположение ветвей каким-либо образом неодинаково. Есть ряд методов, которые мы можем использовать в NURBS, но явным недостатком большинства из них является то, что если мы хотим произвести итерации или уточнения формы, это может занять много времени, потому что мы должны заботиться не только о контролировать форму, а также согласовывать непрерывность на разных поверхностях.
SubDivision дает нам более простую альтернативу. Здесь я преобразовал три трубки в объекты SubD, поэтому давайте рассмотрим быстрый подход. В примере NURBS я использовал SplitEdge, а затем BlendSurf для создания переходов сбоку от Y-образной формы. В SubD я могу использовать команду Bridge для аналогичного эффекта.
Теперь мне не нужно разделять эти кромки, потому что я могу выбрать отдельные сегменты кромок, поэтому я собираюсь перейти к моей команде Мост, я собираюсь выбрать одну половину большой трубы и есть четыре отдельных секции, а затем соответствующие четыре сегмента меньшей трубки.И затем, Enter приведет меня к параметрам команды. Я могу выбрать количество сегментов, и я собираюсь сказать, что хочу здесь четыре сегмента, и у меня есть ползунок, чтобы контролировать, насколько прямолинейна эта геометрия, и я приму это значение. Я могу управлять этой формой позже, если захочу ее скорректировать.
Затем я повторю процесс с другой стороны Y-ветви. Итак, я снова перехожу к команде «Мост», выбираю четыре сегмента, выбираю те же четыре сегмента здесь и оставляю параметры как предыдущие.
Итак, я снова перехожу к команде «Мост», выбираю четыре сегмента, выбираю те же четыре сегмента здесь и оставляю параметры как предыдущие.
В примере NURBS я построил эту верхнюю поверхность перед построением передней поверхности, но я могу сделать это наоборот в примере SubD, и снова я могу использовать команду Bridge для создания вершины Y. тот же процесс, что и предыдущий, и я принимаю этот результат.
Хорошо, теперь у нас есть стороны Y-образной формы, и все, что мне нужно сделать, это закрыть это отверстие. Теперь я хочу сделать это структурированным способом, сохраняющим некоторую регулярность топологии.Итак, еще раз я собираюсь использовать команду Bridge, но сейчас я собираюсь соединить пары ребер, и теперь я хочу уменьшить количество сегментов до одного, и я могу их исправить. Хорошо, я хочу соединить мост здесь и здесь. Ладно, как видите, у меня осталось четыре дырки. Я повторю процесс внизу, а затем все, что мне нужно сделать, это заполнить эти дыры, и есть команда под названием FillSubDHole, которую я могу использовать для этого. Опять же, если я дважды щелкну здесь границу, она просто выделит всю дыру.Я могу выбрать все сразу, войти и вот результат. И вы можете видеть, как это дает мне действительно хорошую топологию. Я пропустил здесь дыру, так что давайте заполним ее.
Опять же, если я дважды щелкну здесь границу, она просто выделит всю дыру.Я могу выбрать все сразу, войти и вот результат. И вы можете видеть, как это дает мне действительно хорошую топологию. Я пропустил здесь дыру, так что давайте заполним ее.
Давайте посмотрим на это сейчас с картой окружения. Итак, мы видим, что все гладко. Но вы можете видеть, что у нас есть немного звездного неба здесь, прямо там. Итак, давайте посмотрим, как мы можем это уменьшить. Итак, что я собираюсь рассмотреть, это взять это преимущество и удалить его, и я думаю, что это просто даст мне гораздо более плавный переход от этого момента к этому краю.Я повторю процесс на обратной стороне, и давайте взглянем на это с картой окружения. Итак, мы видим, что сейчас звездный час выглядит лучше.
Теперь большое преимущество заключается в том, что если я хочу начать играть с этой формой, например, если я хочу, возможно, нажать здесь форму Y, именно здесь мы получаем большое преимущество SubD . Итак, я собираюсь включить жевательную резинку и просто вдавить это лицо внутрь. Я собираюсь отключить объектные привязки, чтобы я случайно не привязывалась к чему-либо, и теперь вы можете видеть, что, когда я вдавливаю эту грань или эту пару ребер, как движутся смежные ребра и грани с этим.
Я собираюсь отключить объектные привязки, чтобы я случайно не привязывалась к чему-либо, и теперь вы можете видеть, что, когда я вдавливаю эту грань или эту пару ребер, как движутся смежные ребра и грани с этим.
Итак, вся идея поверхности SubD заключается в том, что она по своей сути гладкая. Итак, это в некотором смысле аналогично поверхности степени 3. Таким образом, он по своей сути гладкий, если, конечно, мы не укажем никаких складок. Итак, все, что мне нужно, это форма этих объектов. Мне не нужно чрезмерно беспокоиться о плавности. И снова, если мы видим здесь яркие моменты, мы можем использовать тот же процесс, что и раньше, для удаления этих маленьких краев, чтобы улучшить форму.Итак, теперь это выглядит красиво и гладко.
Другой способ, которым мы можем использовать команду «Мост» аналогичным образом для смешивания поверхностей, — это создать переход между этими двумя открытыми краями. Итак, я воспользуюсь командой «Мост», дважды щелкните здесь, чтобы выбрать весь цикл, дважды щелкните, чтобы выбрать здесь весь цикл, нажмите Enter, чтобы перейти к предварительному просмотру. Я добавлю сегментацию и немного поиграю с этим значением прямолинейности. Итак, у нас есть красивый плавный переход между этими двумя поверхностями. И снова, большое преимущество SubD в том, что весь этот объект здесь рассматривается как одна кривизна непрерывной поверхности.Итак, если я хочу отрегулировать форму локально, например, чтобы сделать эту асимметричную, скажем, я хочу подтолкнуть эту область вверх, я могу это сделать, хорошо, и мне совсем не нужно беспокоиться о гладкости Вот. Мне может потребоваться посмотреть, что здесь происходит, и вставить и удалить некоторые края или поставить здесь другое ограничение. Итак, чтобы форма не менялась слишком сильно здесь, я мог бы вставить здесь край, дважды щелкнуть для всего цикла ребер и добавить сюда больше контроля, и это будет означать, что это изменение формы будет происходить немного быстрее не влияет на эту область.
Я добавлю сегментацию и немного поиграю с этим значением прямолинейности. Итак, у нас есть красивый плавный переход между этими двумя поверхностями. И снова, большое преимущество SubD в том, что весь этот объект здесь рассматривается как одна кривизна непрерывной поверхности.Итак, если я хочу отрегулировать форму локально, например, чтобы сделать эту асимметричную, скажем, я хочу подтолкнуть эту область вверх, я могу это сделать, хорошо, и мне совсем не нужно беспокоиться о гладкости Вот. Мне может потребоваться посмотреть, что здесь происходит, и вставить и удалить некоторые края или поставить здесь другое ограничение. Итак, чтобы форма не менялась слишком сильно здесь, я мог бы вставить здесь край, дважды щелкнуть для всего цикла ребер и добавить сюда больше контроля, и это будет означать, что это изменение формы будет происходить немного быстрее не влияет на эту область.
Итак, вы можете видеть, что в этом примере SubD дает нам средство для создания плавного набора переходов между этими различными ветвями.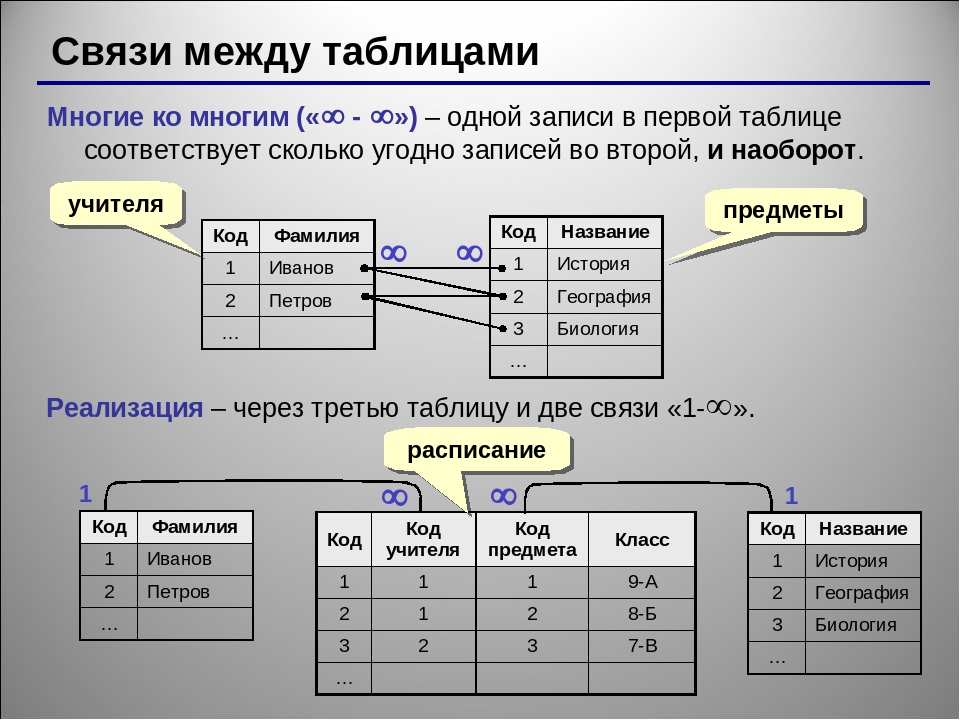 Это было бы сложно смоделировать и, конечно же, трудно настроить, если бы мы смотрели на это исключительно как на геометрию NURBS.
Это было бы сложно смоделировать и, конечно же, трудно настроить, если бы мы смотрели на это исключительно как на геометрию NURBS.
SubD с точностью! Rhino v7 меняет игру.
Рабочий процесс SubD может быть очень полезен для разработки стилей поверхностей. Не только быстрые аппроксимации, но и качественные, хорошо топологизированные поверхности, которые можно использовать для окончательных данных.
В этой модели мыши большая часть формы была создана как SubD перед преобразованием в NURBS, где она затем была разделена на секции перед добавлением более мелких деталей.
Так же, как и при моделировании NURBS-поверхности, управление топологией и поддержание простоты необходимы для создания поверхностей хорошего качества.
Итак, давайте начнем с создания дружественных к SubD кривых и построения поверхностей непосредственно из них с помощью команд поверхности Rhino.
Поверхностные команды Rhino «Кривая контрольной точки»
Если мы сначала посмотрим на кривую контрольной точки, то мы можем включить опцию SubD. Это фиксирует степень на 3. Если я визуализирую контрольные точки открытой кривой SubD, то я увижу две скрытые ограниченные контрольные точки, которые находятся между первыми двумя и последними двумя выбранными точками.
Это фиксирует степень на 3. Если я визуализирую контрольные точки открытой кривой SubD, то я увижу две скрытые ограниченные контрольные точки, которые находятся между первыми двумя и последними двумя выбранными точками.
Если мы теперь посмотрим на интерполированную кривую, там будет гораздо более прямая связь с точками редактирования в кривых, поддерживающих SubD, и если я создам интерполированную кривую через точки редактирования моей первой кривой, мы увидим, что две кривые идентичны .
Итак, возвращаясь к верхней поверхности мыши, поверхность слева — это то, как я хотел бы, чтобы выглядела исходная поверхность SubD, прежде чем я заполню стороны, чтобы получить поверхность справа.
В классе Simply Rhino Intermediate / Advanced много обсуждается важность топологии при создании поверхностей NURBS, так как если топология правильная, то форма почти сама себя отсортирует и ее можно будет правильно скорректировать. Итак, здесь, как и в случае с NURBS, важна схема кривой. Сначала я нарисовал большую синюю кривую как кривую контрольной точки, удобную для SubD, а затем меньшую синюю кривую — это масштабированная и скорректированная версия этой кривой. Затем создаются красные кривые поперечного сечения с помощью интерполированной дружественной кривой SubD, которая проходит через конечные точки синих кривых. Это дает мне компоновку кривой, которую я могу выделить синими или красными кривыми и получить поверхность SubD, которая фактически совпадает с компоновкой кривой.
Сначала я нарисовал большую синюю кривую как кривую контрольной точки, удобную для SubD, а затем меньшую синюю кривую — это масштабированная и скорректированная версия этой кривой. Затем создаются красные кривые поперечного сечения с помощью интерполированной дружественной кривой SubD, которая проходит через конечные точки синих кривых. Это дает мне компоновку кривой, которую я могу выделить синими или красными кривыми и получить поверхность SubD, которая фактически совпадает с компоновкой кривой.
На этом этапе стороны формы все еще открыты, и у нас есть несколько способов закрыть их, которые в полной мере используют тот факт, что поверхности SubD по своей природе гладкие или имеют непрерывную кривизну.
Rhino’s Surface Commands «Мост»
Прежде всего, я могу использовать команду «Мост» с соответствующей прямолинейностью и количеством сегментов, а затем я могу использовать команду под названием стежок, чтобы закрыть две оставшиеся пары кромок.
Итак, давайте взглянем на это. Я собираюсь использовать Bridge в первую очередь, чтобы соединить этот край и этот край, но я использую его очень похоже на то, как мы использовали бы BlendSurf, если бы я использовал форму NURBS.Итак, я собираюсь установить два сегмента и немного поиграть с прямолинейностью здесь, а затем закрыть эти два края здесь и эти два края здесь, я собираюсь использовать Stitch. Собираемся выбрать первые две пары ребер, вторые две пары ребер. Это закроет их. Я могу скользить вверх или вниз по этим краям. Я могу выбрать здесь первое или второе. Первый будет здесь, второй — здесь, и средний будет их серединой. Итак, я просто потяну это вверх, а затем у меня получится складка, которую я могу удалить с помощью RemoveCrease, и теперь у меня есть приятная гладкая форма, которая поддерживает обычную топологию, которую я инициировал с помощью макета кривой.
Альтернативой этому подходу могло бы быть закрытие стороны формы одной или несколькими гранями SubD.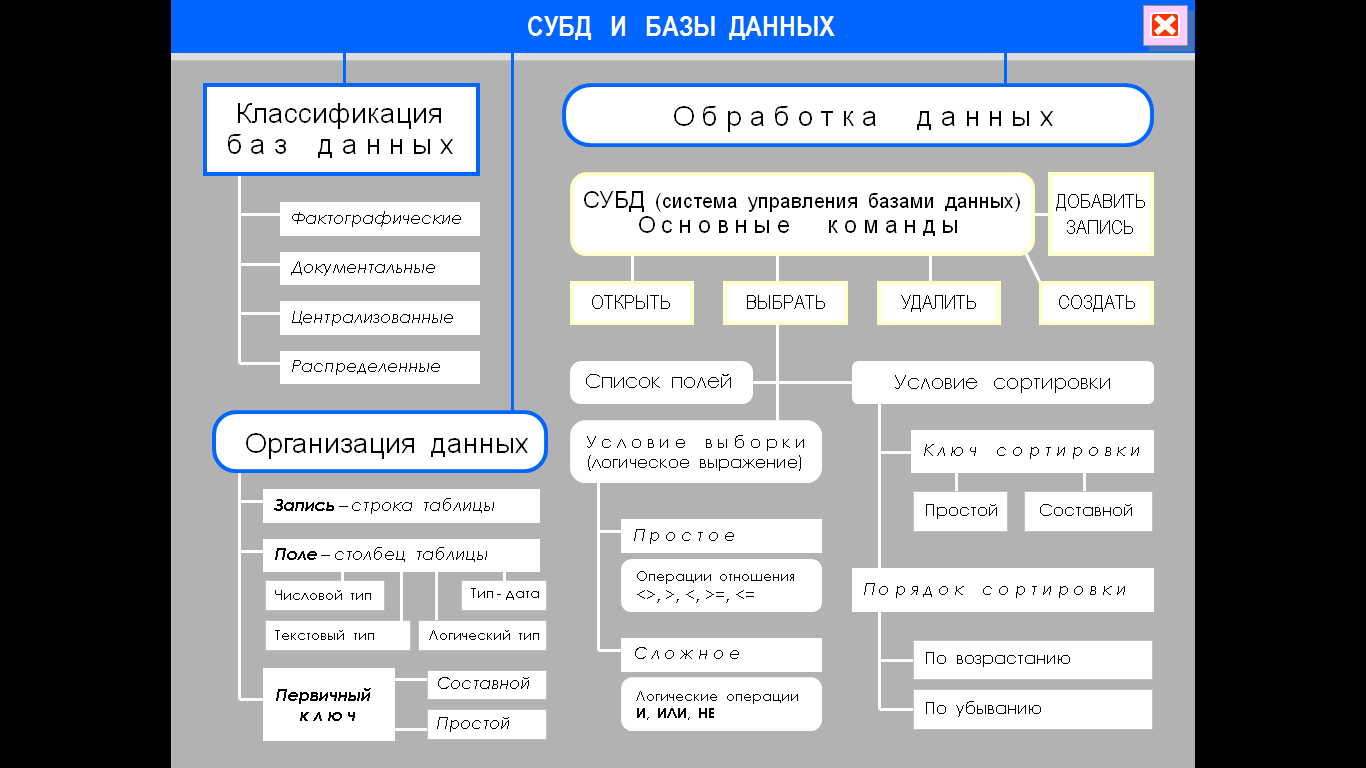 Это трудно визуализировать с помощью SubD в его гладкой форме. Итак, я собираюсь использовать команду SubDDisplayToggle, которая визуализирует плоские грани через контрольные точки, а не гладкую форму, интерполированную через точки редактирования. Сейчас для этого нет значка, так что это моя самодельная иконка. Поэтому, если вы смотрите это видео с более поздним выпуском версии 7, бета-версией или в процессе разработки, вы наверняка не увидите этого значка.
Это трудно визуализировать с помощью SubD в его гладкой форме. Итак, я собираюсь использовать команду SubDDisplayToggle, которая визуализирует плоские грани через контрольные точки, а не гладкую форму, интерполированную через точки редактирования. Сейчас для этого нет значка, так что это моя самодельная иконка. Поэтому, если вы смотрите это видео с более поздним выпуском версии 7, бета-версией или в процессе разработки, вы наверняка не увидите этого значка.
Хорошо, теперь я собираюсь использовать команду под названием SingleSubDFace, и я собираюсь привязаться к точке вершины здесь, а затем я могу присоединить единственную грань к остальной части SubD. Здесь есть гладкий или мятый вариант. Я собираюсь выбрать плавное, а затем переключить отображение обратно, и мы увидим результат. Итак, это дает мне немного другую топологию, чем раньше, и более прямой участок здесь.
Преимущество работы в этом прямоугольном режиме состоит в том, что форма очень просто выражается как прямые линии между точками вершин. Итак, если я хотел создать здесь две грани сбоку от формы, я могу очень просто нарисовать здесь пару линий, которые, если хотите, дадут мне цель, где разместить мои грани SubD. Итак, снова я могу привязаться к вершинам здесь, и теперь я могу создать две отдельные грани, которые я могу присоединить к остальной части SubD. Как и раньше, я использую параметр сглаживания для соединения, а затем снова могу переключить отображение на плавное. Я удалю эти кривые, и тогда мы сможем увидеть форму.
Итак, если я хотел создать здесь две грани сбоку от формы, я могу очень просто нарисовать здесь пару линий, которые, если хотите, дадут мне цель, где разместить мои грани SubD. Итак, снова я могу привязаться к вершинам здесь, и теперь я могу создать две отдельные грани, которые я могу присоединить к остальной части SubD. Как и раньше, я использую параметр сглаживания для соединения, а затем снова могу переключить отображение на плавное. Я удалю эти кривые, и тогда мы сможем увидеть форму.
Итак, как и в случае с объектами NURBS, я могу использовать сами контрольные точки для редактирования формы, и здесь я просто хочу немного вытянуть эту нижнюю точку, чтобы добавить немного кривизны к этому нижнему краю.Итак, я сделаю это ограничение для C-плоскости, направления Y, и я просто немного вытащу это, просто чтобы дать мне небольшую кривизну на этом нижнем крае. Опять же, как и NURBS, помогает, если эта точка, эта точка и эта точка выровнены, потому что они поддерживают регулярность формы. Итак, если мы посмотрим на эту форму сейчас, с нашей картой окружающей среды, особенно если мы используем люминесцентную лампу, мы увидим, что у нас действительно хорошая прогрессия формы здесь, и это действительно связано с простой топологией или компоновкой. лиц СУБ.
Итак, если мы посмотрим на эту форму сейчас, с нашей картой окружающей среды, особенно если мы используем люминесцентную лампу, мы увидим, что у нас действительно хорошая прогрессия формы здесь, и это действительно связано с простой топологией или компоновкой. лиц СУБ.
Теперь с SubD мы не ограничены использованием четырехсторонних граней, и ограничение здесь — это мой выбор, потому что я знаю, что последующий рабочий процесс будет включать преобразование в NURBS, а NURBS, конечно, имеет четырехстороннюю топологию.
Я просто немного изменю форму, настроив SubD, и воспользуюсь для этого манипулятором жевательной резинки. Теперь, если я редактирую лица, неплохо настроить жевательную резинку так, чтобы она была выровнена по объекту, потому что тогда, если я выберу подобъект лица, синее направление здесь будет указывать в нормальном направлении этой поверхности, и если я выберу пару поверхностей, то это будет среднее нормальное направление этих поверхностей.
Если я собираюсь редактировать края, иногда мне лучше ограничить манипулятор, в данном случае плоскостью C, чтобы я мог быть уверен, что перемещаю эти края по одной линии, в данном случае с помощью Y ось C-плоскости, и я собираюсь использовать здесь значок масштаба и просто слегка сдвинуть эти края внутрь, а затем выдвинуть эти два края наружу, просто чтобы дать мне отступ в стороне формы мыши.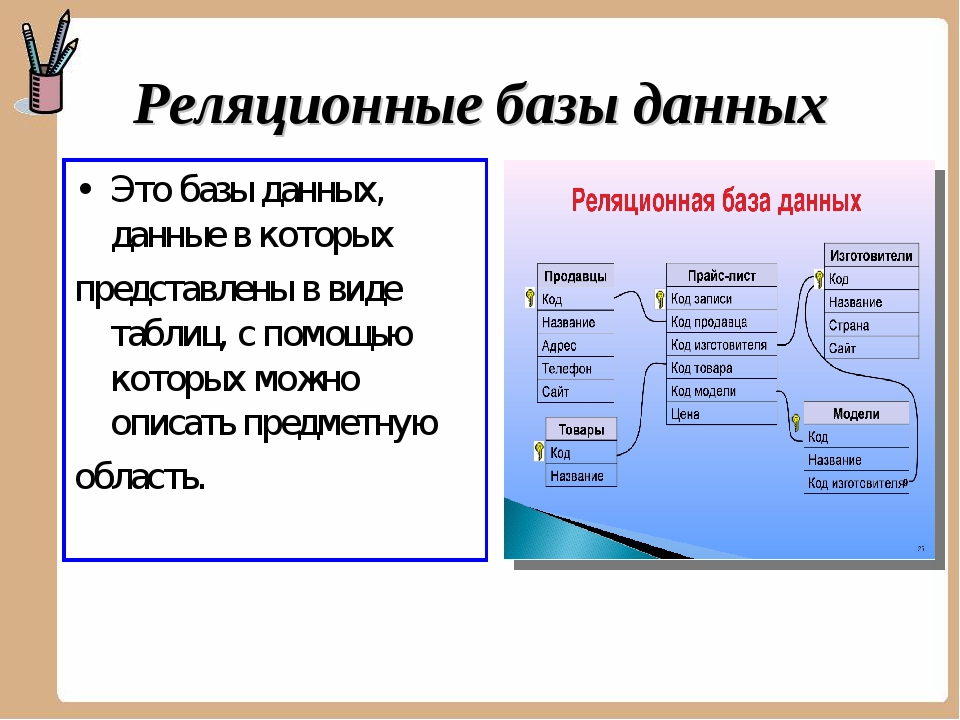 Что-то вроде этого. И затем я просто хочу сделать спину немного более округлой, когда я увижу это сверху, поэтому я смогу сделать это, выбрав эти два лица здесь.Извините, эти два края здесь и тянут их вперед. Итак, я снова выберу их для перемещения по оси X плоскости C. Итак, я просто потащу их вперед. Вы можете видеть, как это округляется.
Что-то вроде этого. И затем я просто хочу сделать спину немного более округлой, когда я увижу это сверху, поэтому я смогу сделать это, выбрав эти два лица здесь.Извините, эти два края здесь и тянут их вперед. Итак, я снова выберу их для перемещения по оси X плоскости C. Итак, я просто потащу их вперед. Вы можете видеть, как это округляется.
Теперь это должно сохранить топологию и форму, но опять же, неплохо было бы просто свериться с картой окружения, чтобы убедиться, что у нас все еще есть хорошее очертание формы. Итак, когда я доволен формой, я могу преобразовать ее в многоуровневую поверхность NURBS с помощью инструмента ConvertToNurbs, и когда я это сделаю, у меня есть возможность удалить входной объект, т.е.е. SubD, или нет, и в этом случае я собираюсь выбрать «нет», чтобы я мог сравнить NURBS и поли-поверхность друг с другом. Итак, я просто использую свой фильтр здесь, чтобы отфильтровать поли-поверхность, чтобы я мог выбрать SubD и переместить его в сторону, и теперь мы можем видеть поли-поверхность слева и SubD справа.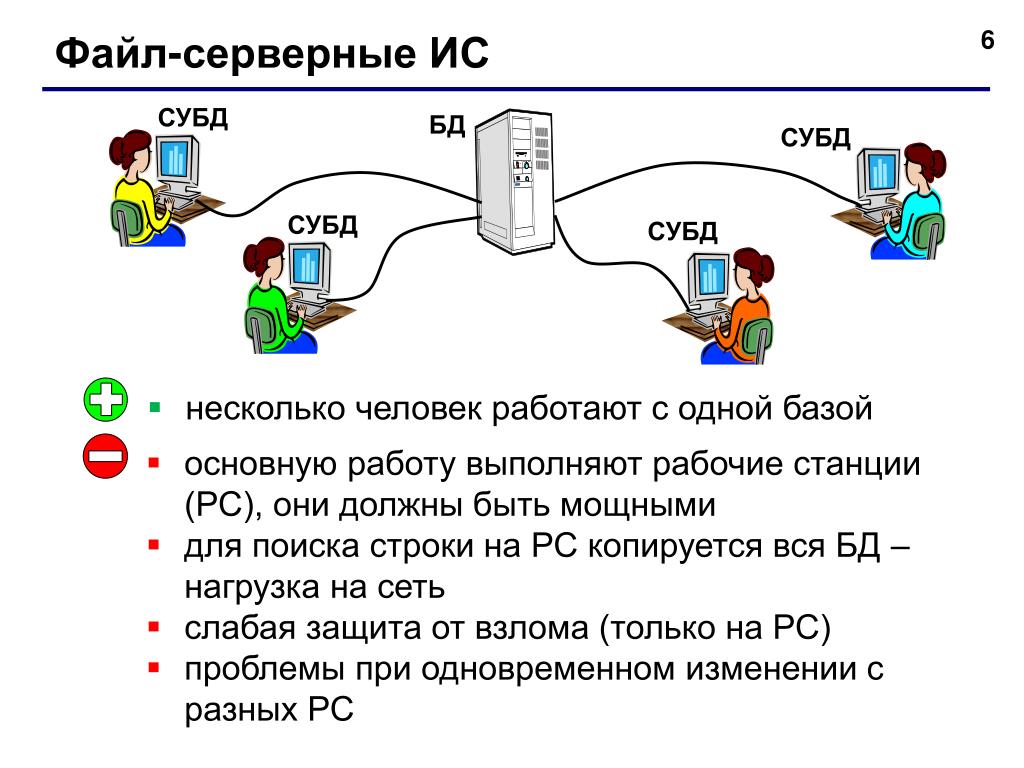 .
.
Теперь, когда мы используем преобразование NURBS, каждая грань на SubD становится участком поверхности на поли-поверхности. Но преемственность между ними и общая форма должны быть одинаковыми.Итак, здесь вы можете видеть, что у нас одинаковое разрешение формы для NURBS и SubD.
Итак, двигаясь дальше, я выдавил нижнюю половину мыши SubD, продублировав границу полигональной поверхности, затем соединил выдавливание с полигональной поверхностью и создал между ними кромку перехода, а затем скругление вдоль нижней части. мыши. На этом этапе у меня была сплошная поли-поверхность, которую я мог затем обычным способом начать разделять, пока не получил большинство основных компонентов, к которым я мог затем применить материалы и текстуры.
Другая стратегия разработки формы в SubD — рассмотреть возможность использования контрольной точки или положения вершин и начать с метафоры квадратного, а не гладкого объекта SubD. Это рабочий процесс, с которым вы, возможно, знакомы, если у вас есть опыт работы с Clayoo или T-Splines.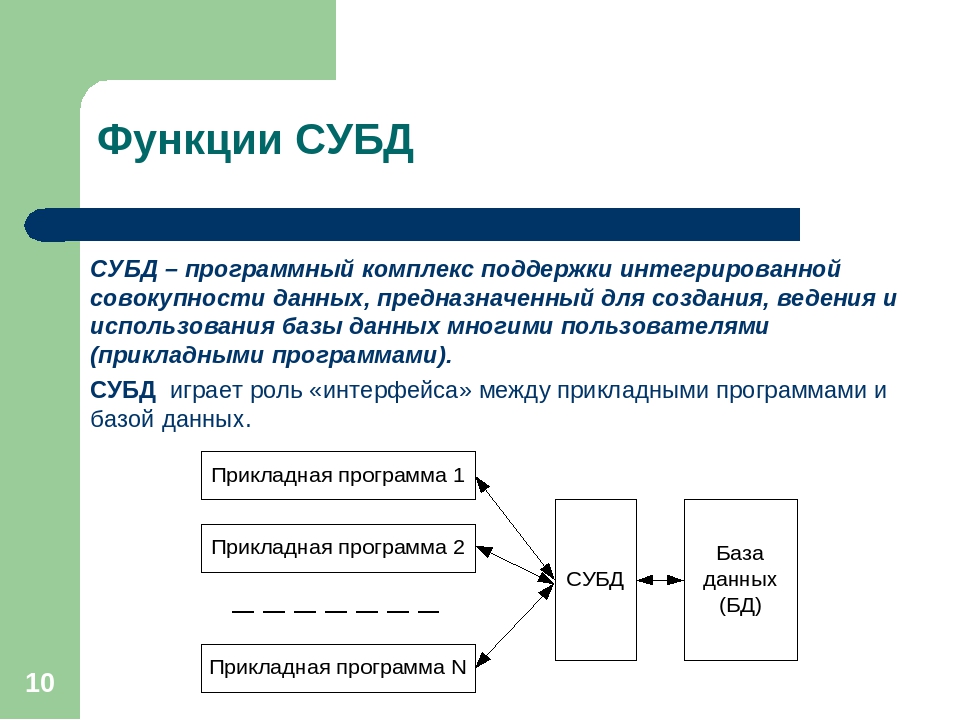
Итак, здесь, например, я мог бы начать с создания серии линий, которые определяют компоновку контрольной точки моей желаемой формы. Затем я могу перейти к инструментам создания сетки и использовать инструмент, называемый сеткой из линий.Здесь я могу указать, что я хочу рассматривать не более четырех сторон для каждой грани, и я могу выбрать все эти линии за один раз и нажать Enter, и у меня будет закрытый объект-сетка. Теперь этот закрытый объект сетки будет таким же, как квадратная версия SubD, которую я хочу создать. Итак, теперь я могу выбрать сетку и запустить этот инструмент ConvertToSubD. А пока я выберу удалить ввод, да. Здесь важно, чтобы опция интерполировать точки говорила «нет», потому что я не хочу интерполировать точки.Я хочу использовать здесь макет контрольной точки, и складки и углы тоже скажут нет. Это мой квадратный дисплей SubD, и если я сгладю его, мы увидим форму.
Ранее в видео я рассматривал создание эквивалента полигональной поверхности с острыми краями в виде одного объекта SubD / объекта со складками. Очень часто в NURBS-моделировании правильным способом создания скруглений, переходов или переходных поверхностей является запуск с контролируемых острых краев, и очень часто эта геометрия лучше подходит для рабочего процесса NURBS.Однако повторение и корректировка результатов может занять много времени.
Очень часто в NURBS-моделировании правильным способом создания скруглений, переходов или переходных поверхностей является запуск с контролируемых острых краев, и очень часто эта геометрия лучше подходит для рабочего процесса NURBS.Однако повторение и корректировка результатов может занять много времени.
Rhino3d v7 представляет усовершенствованную команду смешивания краев, которая позволяет устанавливать задние углы в сложных условиях, например, если мне нужны три разных номинальных радиуса на этих смешанных краях.
Итак, давайте сначала посмотрим на рабочий процесс NURBS. Итак, я перейду к Solid, FilletEdge и BlendEdge и выберу свой первый радиус, который я хочу быть 20 мм, затем мой следующий радиус, который будет 60 мм, и, наконец, вертикальный угол, который я хочу быть 50 мм.Теперь в предварительном просмотре вы увидите, что команда BlendEdge теперь создает эти углы смещения, что является большим улучшением по сравнению со стандартным способом создания углов в Rhino v6.
Проблема все еще возникает, если мы хотим перебрать эти углы и поиграть с радиусами, потому что на данный момент нам нужно будет продолжать повторно запускать команду и отменять и повторять предыдущий результат. Итак, мы можем смоделировать этот тип угла как SubD. Итак, если мы начнем с той же или подобной топологии, то я собираюсь просто отметить точечным объектом, где начинается и прекращается слияние, а также контрольную точку для этого угла, а затем я собираюсь переместить эти точки и привязать их к SubD.Затем, что я могу сделать со своим SubD здесь, чтобы смоделировать этот угол, который даст мне что-то, с чем гораздо легче играть и настраивать, тогда я могу удалить складку на этом крае, этом крае и этом крае, и затем я могу использовать команду «Сдвинуть края», чтобы сдвинуть эти края и привязать к этим точкам. Теперь, когда я делаю это и привязываюсь к точкам, это макет контрольной точки, который я на самом деле перемещаю сюда, я привязываюсь к этому краю. Итак, если вы посмотрите на квадратный объект, вы увидите, что именно там находятся эти края, тогда как это интерполяция формы, плавная интерполяция.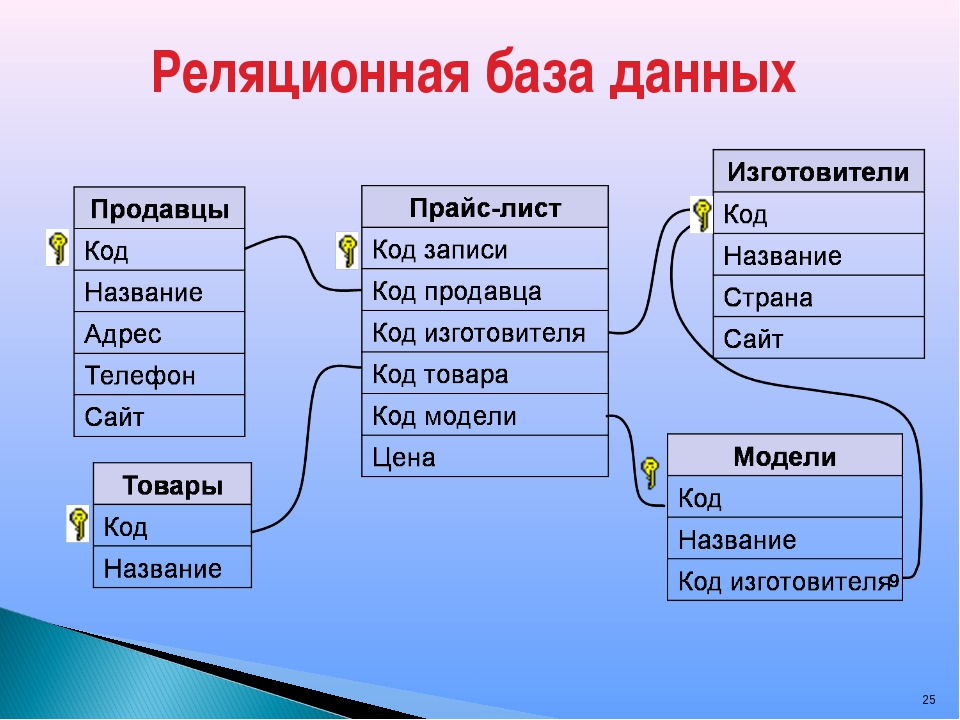 Итак, я просто продолжу сдвигать эти края, они довольно близко, но я все равно их сдвину. Если я посмотрю на оба из них вместе с картой окружения, вы увидите, что результаты похожи. Фактически, эквивалент SubD здесь может быть немного лучше в том смысле, что он контролирует этот край.
Итак, я просто продолжу сдвигать эти края, они довольно близко, но я все равно их сдвину. Если я посмотрю на оба из них вместе с картой окружения, вы увидите, что результаты похожи. Фактически, эквивалент SubD здесь может быть немного лучше в том смысле, что он контролирует этот край.
Итак, это пример того, как мы можем использовать SubD для создания быстрых итераций дизайна, даже если мы можем смоделировать конечный результат как поверхности NURBS.
Учебники по Rhino 7 SubD [McNeel Wiki]
Резюме: Rhino 7 включает новый тип геометрии Sub-D для более гибкого моделирования.SubD от Rhino точны и воспроизводимы. Это позволяет преобразовать наш SubD в NURBS для изготовления.
Традиционно объекты SubD основаны на сетке и хорошо подходят для более приближенных типов моделирования, таких как моделирование персонажей и создание гладких органических форм. Однако объекты Rhino SubD представляют собой высокоточные сплайновые поверхности и, таким образом, вносят определенный уровень точности в процесс создания сложных форм произвольной формы.
Однако объекты Rhino SubD представляют собой высокоточные сплайновые поверхности и, таким образом, вносят определенный уровень точности в процесс создания сложных форм произвольной формы.
Перейдите в обсуждение Rhino SubD, чтобы присоединиться к разговору об этом новом инструменте.Вы можете скачать Rhino 7 Eval, чтобы попробовать SubD уже сегодня.
Введение в SubD в Rhino 7
Видео начинается с изучения поверхностей SubD и их сравнения с NURBS, прежде чем перейти к рассмотрению некоторых примеров того, как и почему можно использовать SubD вместе с традиционным рабочим процессом NURBS в Rhino. Фил Кук из SimplyRhino рассматривает SubD, или Subdivision Surface Modeling, который разрабатывается для Rhino v7. (37 минут) SimplyRhino — самый популярный реселлер Rhino3D в Великобритании, они предлагают профессиональное обучение и поддержку для Rhino и всех ключевых Rhino. плагины.
Изучение SubD в Rhino 7 WIP
Знаете ли вы, что в Rhino 7 WIP есть инструменты SubD? Присоединитесь к Брайану Джеймсу в этом видео, где он исследует использование инструментов создания и редактирования SubD, которые в настоящее время добавлены в V7. (8 минут)
(8 минут)
Моделирование вилки, понимание основных элементов управления SubD
| Брайан Джеймс рассматривает различные методы выбора и рабочий процесс моделирования, характерные для поверхностей Rhino 7 SubD.Это отличное видео для понимания того, как вместе использовать инструменты SubD в Rhino (10 минут) |
Начало работы с SubD — блокировка модели
| Быстрая демонстрация техники Paperdoll для создания модели SubD в Rhino v7. Идеально подходит для пользователей, которые никогда раньше не использовали Subd. |
Моделирование раковины SubD с помощью Rhino 7
| В этом видео показано, как смоделировать мягкую прямоугольную форму с помощью поверхностей SubD в Rhino 7. |
Моделирование мыши с помощью SubD
В руководстве используется простой формат файлов GIF и имен команд, чтобы показать нам общий процесс создания корпуса мыши MX Master 3. Отличный способ познакомиться с новыми инструментами SubD в Rhino 7. Отличный способ познакомиться с новыми инструментами SubD в Rhino 7. |
Моделирование рамки для монет в Rhino 7 SubD
| Узнайте, как использовать новую команду QuadRemesh и инструменты SubD в Rhino3D для моделирования оправы ювелирной монеты.Моделирование SubD — одна из новых возможностей Rhino. Вы можете быстро лепить и редактировать плавные переходы. (5 минут) |
| В этом коротком видео Джузеппе Массони показывает нам, как можно быстро превратить сферу SubD в собаку. Он использует простые техники выталкивания и вытягивания на гранях подразделения и контрольных точках сети, используя Gumball. Вы также заметите возможность добавлять складки. (1 минута) |
Новая команда SubD Reflect, симметричная копия
В этом коротком руководстве Джузеппе Массони быстро знакомит нас с 7 новой командой Rhino: Reflect.Эта команда позволяет сделать симметричную копию объекта, сохраняя при этом плавное соединение между зеркальными копиями.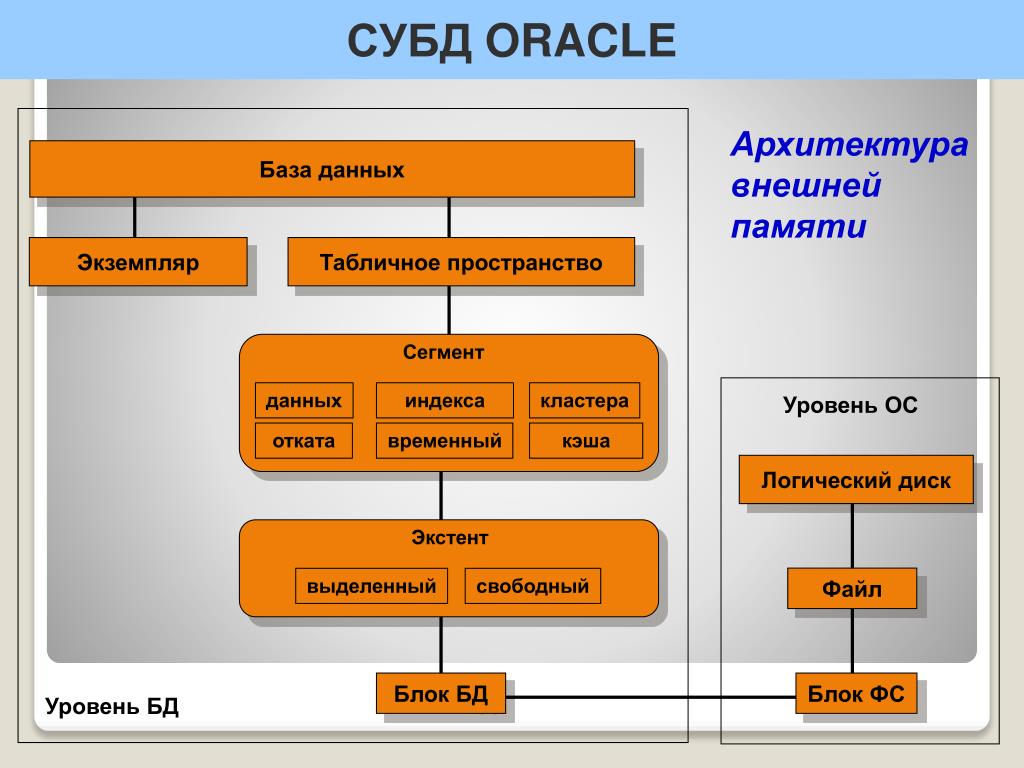 Очень необходимый инструмент для скульптинга SubD. (1 минута) Очень необходимый инструмент для скульптинга SubD. (1 минута) |
| How to Rhino рассматривает версию Rhino 7 Work in Progress и новые инструменты SubD, которые находятся на хорошем пути к замене плагина T-splines для Rhino 5, который был королем моделирования SubD. В этом уроке мы рассмотрим несколько простых методов с использованием этих новых инструментов моделирования Rhino, чтобы создать концептуальный проект, разработанный @archihab. |
Обратный инжиниринг поверхностей с SubD
| Используя rhino v7 wip, это видео показывает комбинацию quadremesh и SubD для преобразования мешей в nurbs. (59’47 “) |
Компонент Sub D Rhino Grasshopper
Из How to Rhino youtube channel, пройдитесь по основным манипуляциям с компонентом Sub-D как в Rhino, так и в Grasshopper, а также как быстро редактировать произвольную геометрию.Этот конкретный проект, который был использован в качестве вдохновения, разработан Даниэлем Видригом для конкурса Duhamel Competition в Германии. (9’31 ”) (9’31 ”) |
Rhino wip 7 subdivision «append»
| Джорджио Гуриоли показывает, как использовать команду «Добавить» с геометрией Rhino 7 SubD. (6 минут) |
QuadRemesh в SubD в Rhino 7 WIP
| Вот видео-введение в новую команду QuadRemesh в Rhino 7 WIP (работа в процессе).Понимание рабочего процесса между Quadremesher и SubD является ключевым. (8 минут) |
Использование моделей Tsplines в Rhino v7 wip
| Вот видео-введение в использование ваших старых моделей Tsplines в Rhino v7 WIP (работа в процессе). Ключевым моментом является экспорт ваших Tsplines в режиме Box. (7:26 минут) |
Использование поверхности для извлечения для разделения СУБД на несколько частей
| быстрое видео, показывающее, как разбить модели СУБД на несколько частей с помощью извлечения поверхности (46 секунд) |
Плавные края сложной скульптурной формы
Используйте QuadRemesh с опцией SubD для сглаживания острых краев сложных многоповерхностей. (5:16 минут) (5:16 минут) |
Таймлапс с ручным утюгом
| Полная замедленная съемка ручного утюга. (26:01 минут) |
Коробка против плавного режима
| Быстрая демонстрация использования режима box vs smooth в SubD. (6:35 минут) |
Замедленная съемка роботов-рыбок
| Полная замедленная съемка персонажа-робота-рыбы. (47:24 минут) |
Замедленная съемка концептуального велосипеда, сборка
| Полное время сборки концептуального мотоцикла.(46:00 минут) |
Подразделение Поверхностей
Обзор
Поверхности подразделения — это обычный примитив моделирования, который приобрел популярность в анимация и визуальные эффекты за последние десятилетия.
Как следует из названия, поверхности подразделения — это по сути поверхности .
Более конкретно, поверхности подразделения представляют собой кусочно-параметрических поверхностей , определенных на сетки произвольной топологии — обе концепции, которые будут описаны в разделах которые следуют.
Subdivision — это и операция, которую можно применить к полигональной сетке для ее уточнения, и математический инструмент, который определяет нижележащую гладкую поверхность, на которую повторное деление сетки сходится. Явное подразделение просто применить некоторое количество раз, чтобы обеспечить более гладкую сетку, и эта простота исторически привела к появлению множества инструментов представляя форму таким образом. Напротив, получение гладкой поверхности, которая в конечном итоге определяет форму — его «предельная поверхность» — значительно сложнее, но обеспечивает большую точность и гибкость.Эти различия привели к путанице в том, как некоторые инструменты выставить поверхности подразделения.
Конечная цель состоит в том, чтобы все инструменты использовали поверхности подразделения как истинные примитивы поверхности. Таким образом, здесь делается упор не на подразделение, а на природу.
поверхности, которая является результатом этого. Помимо обеспечения последовательной реализации
подразделение — тот, который включает в себя ряд широко используемых расширений функций — значительный
Ценность OpenSubdiv в том, что он делает поверхность ограничения более доступной.
Таким образом, здесь делается упор не на подразделение, а на природу.
поверхности, которая является результатом этого. Помимо обеспечения последовательной реализации
подразделение — тот, который включает в себя ряд широко используемых расширений функций — значительный
Ценность OpenSubdiv в том, что он делает поверхность ограничения более доступной.
С момента своего появления OpenSubdiv вызвал интерес со стороны пользователей и разработчиков. с широким спектром навыков, интересов и опыта. Этот документ предназначен для представления поверхностей подразделения с точки зрения полезной при использовании OpenSubdiv. Одна из его целей — предоставить обзор высокого уровня для тех, кто с меньшим опытом работы с алгоритмами или математикой подразделения. Другой состоит в том, чтобы предоставить обзор набора функций, доступных в OpenSubdiv, и представьте эти возможности с помощью терминологии, используемой OpenSubdiv (поскольку большая часть ее перегружен).
Кусочно-параметрические поверхности
Кусочно-параметрические поверхности, пожалуй, наиболее широко используемое геометрическое представление
в промышленном дизайне, развлечениях и многих других областях. Многие объекты, с которыми мы работаем
в повседневной жизни — автомобили, мобильные телефоны, ноутбуки — все было спроектировано и визуализировано
как кусочно-параметрические поверхности, прежде чем эти проекты были одобрены и реализованы.
Многие объекты, с которыми мы работаем
в повседневной жизни — автомобили, мобильные телефоны, ноутбуки — все было спроектировано и визуализировано
как кусочно-параметрические поверхности, прежде чем эти проекты были одобрены и реализованы.
Кусочно-параметрические поверхности — это, в конечном счете, просто наборы более простых примитивов моделирования. называемые патчами.Пятна представляют собой «кусочки» большей поверхности во многом точно так же, как грань или многоугольник составляют часть многоугольной сетки.
Параметрические патчи
Патчи — это строительные блоки кусочно-гладких поверхностей и множество различных видов патчи эволюционировали, чтобы удовлетворить потребности геометрического моделирования. Два наиболее эффективных и общие патчи показаны ниже:
Патч одинарный бикубический B-Spline | Одинарная бикубическая нашивка Безье |
Патчи состоят из набора точек или вершин, которые влияют на прямоугольный кусок гладкого
поверхность (встречаются также треугольные пятна).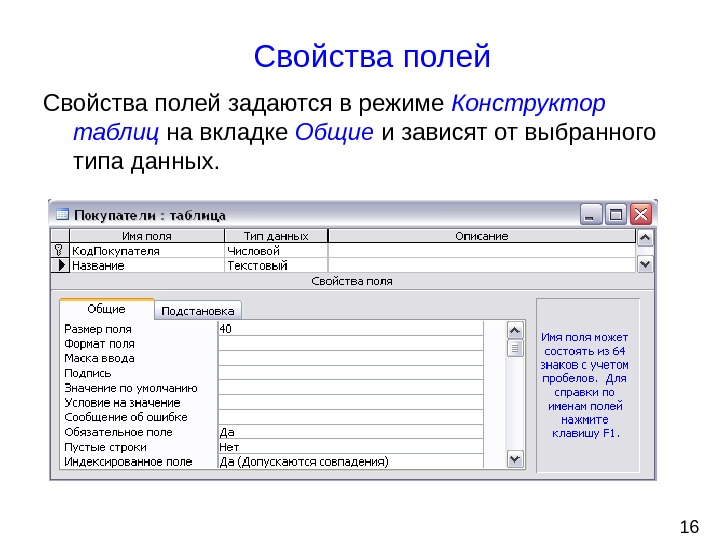 Этот прямоугольник «параметризован» двумя
направлений, превращая простой двухмерный прямоугольник в трехмерную поверхность:
Этот прямоугольник «параметризован» двумя
направлений, превращая простой двухмерный прямоугольник в трехмерную поверхность:
(u, v) 2D домен патча | Отображение из (u, v) в (x, y, z) |
Точки, которые контролируют форму поверхности, обычно называются контрольными. точек или контрольных вершин, а также набор всего набора, определяющий патч как сетка управления, корпус управления, клетка управления или просто корпус, клетка, и т.п.Для краткости мы будем часто использовать термин «клетка», который нам нужен. в общем позже.
Итак, патч состоит из двух объектов: его контрольных точек и поверхности. затронутые ими.
Способ воздействия контрольных точек на поверхность — вот что делает различные типы
патчи уникальные. Даже участки, определяемые одинаковым количеством точек, могут иметь разные
поведение. Обратите внимание, что все 16 точек патча B-Spline выше относительно далеки от
поверхность, которую они определяют по сравнению с аналогичным патчем Безье. Два патча в
этот пример фактически представляет собой точно такой же кусок поверхности — каждый с набором
контрольных точек, оказывающих на него различное воздействие. С математической точки зрения каждый элемент управления
точка имеет связанную с ней «базисную функцию», которая влияет на поверхность в конкретном
способ, когда перемещается только эта точка:
Два патча в
этот пример фактически представляет собой точно такой же кусок поверхности — каждый с набором
контрольных точек, оказывающих на него различное воздействие. С математической точки зрения каждый элемент управления
точка имеет связанную с ней «базисную функцию», которая влияет на поверхность в конкретном
способ, когда перемещается только эта точка:
Базисная функция бикубического B-сплайна | Бикубическая функция на основе Безье |
Именно эти базовые функции часто приводят к именам различных патчей.
У этих различных свойств контрольных точек патчей есть свои плюсы и минусы. которые становятся более очевидными, когда мы собираем участки в кусочки поверхности.
Кусочные поверхности
Кусочно-параметрические поверхности представляют собой наборы патчей.
Для прямоугольных участков один из простейших способов создания коллекции — определить набор патчей с использованием прямоугольной сетки контрольных точек:
Покусочная B-шлицевая поверхность | Кусочная поверхность Безье |
Обратите внимание, что мы можем перекрывать точки соседних участков B-сплайна. Это перекрытие
означает, что перемещение одной контрольной точки влияет на несколько патчей, но также обеспечивает
что эти исправления всегда проходят гладко (это было намерением дизайна, а не
для других типов патчей). Смежные пятна Безье имеют общие точки только на своих границах
и согласование точек на этих границах, чтобы поверхность оставалась гладкой.
возможно, но неудобно. Это делает B-шлицы более подходящим представлением поверхности.
для интерактивного моделирования, но патчи Безье служат и многим другим полезным целям.
Это перекрытие
означает, что перемещение одной контрольной точки влияет на несколько патчей, но также обеспечивает
что эти исправления всегда проходят гладко (это было намерением дизайна, а не
для других типов патчей). Смежные пятна Безье имеют общие точки только на своих границах
и согласование точек на этих границах, чтобы поверхность оставалась гладкой.
возможно, но неудобно. Это делает B-шлицы более подходящим представлением поверхности.
для интерактивного моделирования, но патчи Безье служат и многим другим полезным целям.
Более сложная B-шлицевая поверхность:
Часть более сложной поверхности B-Spline |
Так же, как заплатка состояла из клетки и поверхности, то же самое теперь верно и для коллекция. Управляющая клетка управляется дизайнером, и поверхность каждого отображаемых исправлений, чтобы они могли оценить его эффект.
Произвольная топология
Кусочные поверхности, обсуждаемые до сих пор, были ограничены коллекциями патчей. над регулярными сетками контрольных точек.В прямоугольном корпусе есть определенная простота.
параметрические поверхности, которые привлекательны, но представление поверхности, которое поддерживает
У произвольной топологии есть много других преимуществ.
над регулярными сетками контрольных точек.В прямоугольном корпусе есть определенная простота.
параметрические поверхности, которые привлекательны, но представление поверхности, которое поддерживает
У произвольной топологии есть много других преимуществ.
Прямоугольные параметрические поверхности получили широкое распространение, несмотря на их топологию. ограничения, и их популярность продолжается и сегодня в некоторых областях. Часто сложные объекты нужно много таких поверхностей, чтобы представить их, и для собрать их эффективно, включая «сшивание» нескольких поверхностей вместе или вырезание отверстия в них («обрезка»).Это сложные методы, и хотя они эффективны в в одних контекстах (например, промышленный дизайн) они становятся громоздкими в других (например, анимация и визуальные эффекты).
Одиночная многоугольная сетка может представлять формы с гораздо большей сложностью, чем одиночная
прямоугольная кусочная поверхность, но ее граненый характер со временем становится проблемой.
Поверхности подразделения сочетают топологическую гибкость полигональных сеток с лежащая в основе гладкость кусочно-параметрических поверхностей.Так же, как прямоугольник кусочно параметрические поверхности имеют набор контрольных точек (его клетка хранится в виде сетки) и нижележащая поверхность, поверхности подразделения также имеют набор контрольных точек (его клетка хранится в виде сетки) и нижележащая поверхность (часто называемая ее «пределом»). поверхность »).
Обычные и нестандартные элементы
Сетка содержит вершины и грани, которые образуют клетку для нижележащего поверхность, и топология этой сетки может быть сколь угодно сложной.
В областях, где грани и вершины сетки соединяются, образуя прямоугольную форму.
сеток, предельная поверхность становится одной из прямоугольных кусочно-параметрических
ранее упомянутые поверхности. Эти области сетки называются «регулярными»:
они обеспечивают поведение, знакомое по использованию аналогичных прямоугольных поверхностей и
их предельная поверхность относительно проста.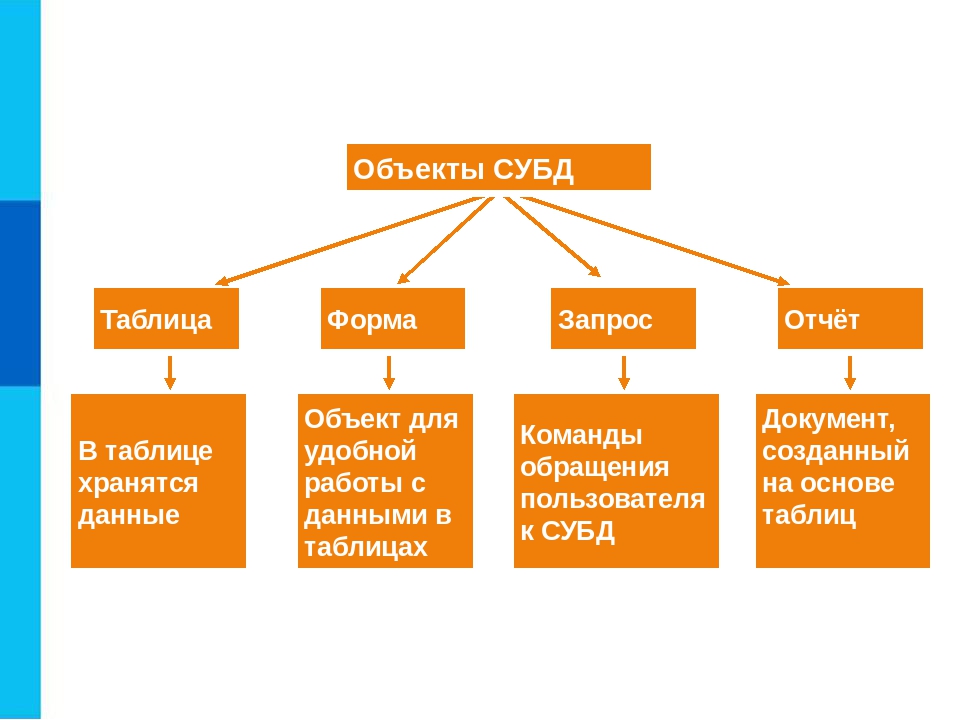 Все остальные области
считаются «нерегулярными»: они обеспечивают желаемую топологическую гибкость и
менее знакомы (и в некоторых случаях менее предсказуемы) и их предельная поверхность
может быть намного сложнее.
Все остальные области
считаются «нерегулярными»: они обеспечивают желаемую топологическую гибкость и
менее знакомы (и в некоторых случаях менее предсказуемы) и их предельная поверхность
может быть намного сложнее.
Необычные черты бывают разных форм. Наиболее широко упоминается экстраординарная вершина, то есть вершина, которая в случае четырехугольного подразделения схема, подобная Catmull-Clark, не имеет четырех инцидентных лиц.
Неправильная вершина и инцидент лица | Регулярные и нерегулярные районы поверхность |
Наличие этих неровностей делает ограничивающую поверхность вокруг них аналогично нерегулярные, т.е.е. его нельзя представить так просто, как для обычных регионы.
Стоит отметить, что неправильные области уменьшаются в размерах и становятся более «изолированными». как подразделение применяется. Лицо с множеством необычных вершин вокруг него делает поверхность очень сложной, и выделение этих функций — способ помочь справиться с этой сложностью:
Две вершины валентности-5 рядом | Изоляция разделена один раз | Изоляция разделенная дважды |
Обычно необходимо провести какое-то локальное деление на этих участках.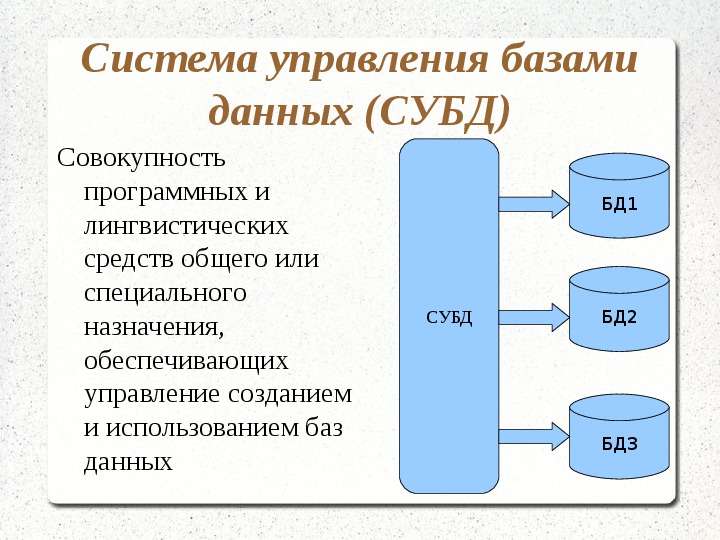 чтобы разбить эти части поверхности на более мелкие, более управляемые части, и
термин «адаптивное подразделение функций» стал популярным в последние годы для описания
этот процесс.Делается ли это явно или неявно, глобально или локально,
что наиболее важно, так это то, что для каждого
лицо — хотя и потенциально сложное в необычных чертах — которое может
оцениваться во многом так же, как прямоугольные кусочные поверхности.
чтобы разбить эти части поверхности на более мелкие, более управляемые части, и
термин «адаптивное подразделение функций» стал популярным в последние годы для описания
этот процесс.Делается ли это явно или неявно, глобально или локально,
что наиболее важно, так это то, что для каждого
лицо — хотя и потенциально сложное в необычных чертах — которое может
оцениваться во многом так же, как прямоугольные кусочные поверхности.
Патчи штатных регионов | Пятна неправильной области |
Поддержание гладкой поверхности на этих неровных участках является основным преимуществом
поверхностей подразделения, как сложность полученных поверхностей, так и их
качество — причина использовать их с осторожностью.Когда топология в значительной степени нерегулярна,
его поверхность требует более высокой стоимости, поэтому неровности сводятся к минимуму
выгодно. А в некоторых случаях качество поверхности, т.е.
гладкость неровных поверхностей может привести к нежелательным артефактам.
А в некоторых случаях качество поверхности, т.е.
гладкость неровных поверхностей может привести к нежелательным артефактам.
Произвольная многоугольная сетка часто не является хорошей клеткой для подразделения, независимо от насколько хороша эта полигональная сетка.
Как и в случае прямоугольных кусочно-параметрических поверхностей, клетка должна иметь форму воздействуют на нижележащую поверхность, которую он должен представлять.Увидеть Советы по моделированию для связанных рекомендаций.
Немногообразная топология
Так как клетка поверхности подразделения хранится в сетке, и часто манипулируют в том же контексте, что и многоугольные сетки, тема многообразия противопоставление немногообразной топологии заслуживает некоторого внимания.
Существует множество определений или описаний того, что отличает многообразие
сетка из той, которой нет.
Они варьируются от кратких, но абстрактных математических определений до наборов
примеры, показывающие многообразные и неоднородные сетки — все имеют свое значение
и соответствующая аудитория. Следующее определение не является строгим, но служит
хорошо для иллюстрации большинства локальных топологических конфигураций, которые вызывают сетку
быть неоднородным.
Следующее определение не является строгим, но служит
хорошо для иллюстрации большинства локальных топологических конфигураций, которые вызывают сетку
быть неоднородным.
Представьте, что вы «стоите» на гранях меша и «ходите» вокруг каждой вершины. в очереди. Предполагая правый порядок намотки граней, встаньте сбоку от лицо в положительном нормальном направлении. И при ходьбе шагай через каждую падающая кромка в направлении против часовой стрелки к следующей падающей грани.
Для внутренней вершины:
- начало в углу любой падающей грани
- пройти вокруг вершины через каждое инцидентное ребро к следующей невидимой грани; повторить
- , если вы вернетесь с того места, где начали, и какие-либо грани или кромки инцидентов не были посещены, сетка разветвленная
Аналогично для граничной вершины:
- начать с угла грани, содержащей переднюю граничную кромку
- пройти вокруг вершины через каждое инцидентное ребро к следующей невидимой грани; повторить
- , если вы дойдете до другого граничного ребра и ни одна граница или граница не были посещены, сетка разветвленная
Если вы можете таким образом обойти все вершины и не встретить ни одного не-многообразия
особенности, сетка, вероятно, многообразна.
Очевидно, что если вершина не имеет граней, нечего ходить и этот тест не может быть успешным, так что снова не многообразие. Все грани вокруг вершины также должны быть в одном ориентация, в противном случае две смежные грани имеют нормали в противоположных направлениях и сетка будет считаться неоднородной, поэтому мы действительно должны включить это ограничение при переходе к следующему лицу быть более строгим.
Рассмотрите возможность обхода указанных вершин следующих неоднородных сеток:
Кромки с более чем 2 гранями | Грани с общей вершиной, но без ребер |
Как упоминалось ранее, многие инструменты не поддерживают неразборные сетки, а в
некоторые контексты, например.г. 3D-печати их следует категорически избегать. Иногда
коллекторная сетка может быть желательна и в конечном итоге усилена, но сетка
могут временно стать не многообразными из-за определенной последовательности моделирования
операции.
Вместо того, чтобы поддерживать или защищать использование неоднородных сеток, OpenSubdiv стремится быть устойчивым к наличию не многообразных функций, чтобы упростить использования своих клиентов — избавляя их от необходимости топологического анализа определить, можно или нельзя использовать OpenSubdiv.Хотя правила подразделения не так хорошо стандартизированы в областях, где сетка неоднородна, OpenSubdiv в большинстве случаев предоставляет простые правила и разумную предельную поверхность.
Поверхность вокруг краев с более чем 2 инцидентами лица | Поверхность для граней, имеющих общую вершину, но не края |
Как и в случае правильных и неправильных черт, поскольку каждое лицо имеет
соответствующий кусок поверхности, связанный с ним — будь то локально многообразие или
нет — можно сказать, что термин «произвольная топология» включает немногообразную топологию.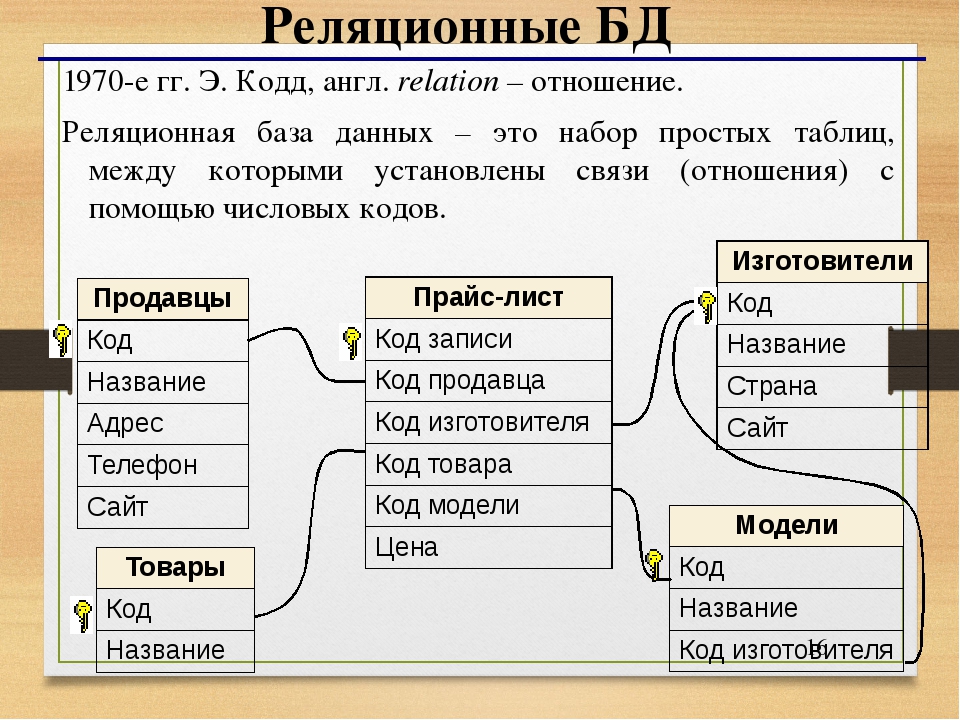
Подразделение против тесселяции
Предыдущие разделы иллюстрируют поверхности подразделения как кусочно параметрические поверхности произвольная топология. Как кусочно-параметрические поверхности они состоят из обоймы и подстилающая поверхность, определяемая этой клеткой.
Для отображения поверхностей подразделения используются два метода: разделение и тесселяция. Оба имеют свое законное использование, но между ними есть важное различие:
- подразделение работает на клетке и производит усовершенствованную клетку
- мозаика работает на поверхности и производит дискретизацию этой поверхности
Существование и относительная простота алгоритма подразделения позволяет легко
применять повторно, чтобы приблизить форму поверхности, но в результате
изящная клетка, это приближение не всегда очень точное. По сравнению с
клетка, уточненная до другого уровня, или мозаика, в которой используются точки, оцениваемые напрямую
на предельной поверхности расхождения могут сбивать с толку.
По сравнению с
клетка, уточненная до другого уровня, или мозаика, в которой используются точки, оцениваемые напрямую
на предельной поверхности расхождения могут сбивать с толку.
Подразделение
Подразделение — это процесс, который дает название «поверхности подразделения», но это не так. уникальный для них. Будучи кусочно-параметрическими поверхностями, давайте сначала посмотрим на подразделение в контекст более простых параметрических патчей, которые их составляют.
Subdivision — это особый случай уточнения , который является ключом к успеху некоторых из
Наиболее широко используемые типы параметрических участков и их совокупные поверхности.Поверхность может
быть «доработанным», когда существует алгоритм, позволяющий ввести больше контрольных точек при сохранении формы поверхности точно такой же, как . Для интерактивности и дизайна
целей, это позволяет дизайнеру вводить большее разрешение для более точного управления без
внесение нежелательных побочных эффектов в форму. Для более аналитических целей это позволяет
поверхность должна быть разбита на части, часто адаптивно, при сохранении верности
оригинальная форма.
Для более аналитических целей это позволяет
поверхность должна быть разбита на части, часто адаптивно, при сохранении верности
оригинальная форма.
Одна из причин, почему так широко используются как B-сплайн, так и патчи Безье, заключается в том, что они оба можно доработать.Единое подразделение — процесс разделения каждого из патчей в одном или обоих направлениях — это частный случай уточнения, который эти типы патчей поддерживают:
Поверхность B-Spline и ее обойма | Клетка разделенная 1x | Клетка, разделенная на 2 части |
В случаях, показанных выше для B-шлицев, равномерно очищенные сепараторы производят одинаковые
ограничить поверхность как оригинал (предоставляется в большем количестве штук).Так что будет справедливо сказать, что оба
однородные B-шлицы и поверхности Безье являются поверхностями деления.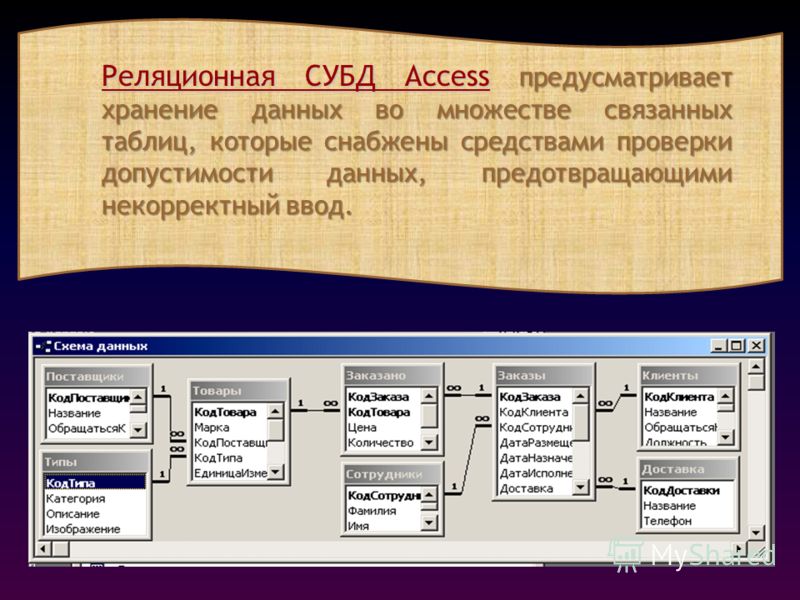
Поверхность предела остается прежней со многими другими контрольными точками (примерно в 4 раза с каждой итерация подразделения), и эти точки находятся ближе к поверхности (но не на ней). Это может возникнуть соблазн использовать эти новые контрольные точки для представления поверхности, но с использованием тех же количество точек, оцениваемых в соответствующих равномерно распределенных параметрических точках на поверхность обычно более простая и эффективная.
Обратите внимание, что точки клетки обычно не имеют нормальных векторов, связанных с их, хотя мы можем явно оценить нормали для произвольных мест на поверхности, просто как мы делаем для позиции. Таким образом, если клетка отображается в виде заштрихованной поверхности, векторы нормалей на каждом контрольных точек должны быть изобретены. И положение, и нормали точек на поэтому более тонкая клетка — оба приближения.
То же верно и для более общих поверхностей подразделения. Subdivision уточнит сетку
произвольной топологии, но полученные точки не будут лежать на предельной поверхности и любой нормальной
векторы, созданные из этих точек и связанные с ними, будут только приближениями к тем
предельной поверхности.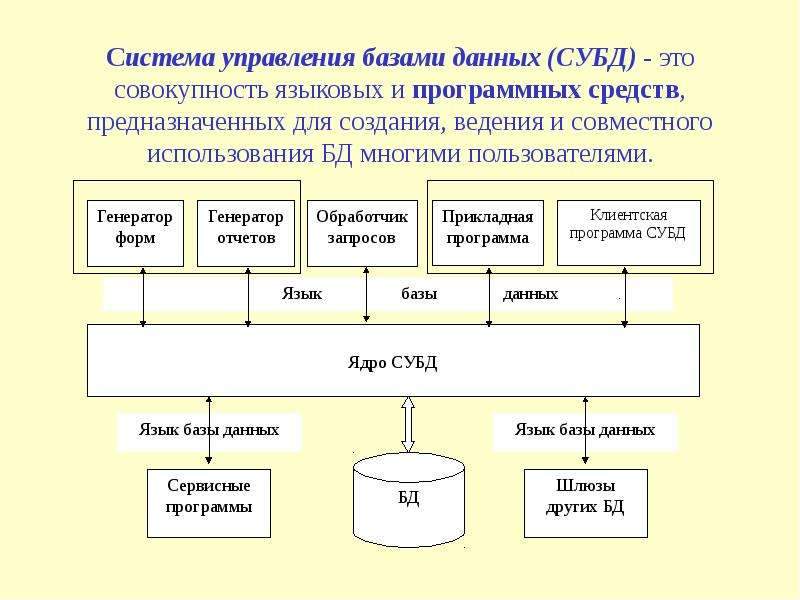
Тесселяция
Нет необходимости использовать подразделение для аппроксимации параметрической поверхности, когда ее можно вычисляется напрямую, то есть может быть тесселирован. Мы можем оценивать в произвольных местах на поверхности и соедините полученные точки, чтобы сформировать тесселяцию — дискретизацию предельная поверхность — это намного более гибко, чем результаты, полученные от равномерного подразделения:
Равномерная (3×3) мозаика B-сплайна поверхность | Адаптивная к кривизне мозаика B-сплайна поверхность |
Для простой параметрической поверхности прямая оценка предельной поверхности также проста,
но для более сложных поверхностей разбиения произвольной топологии это не так.Отсутствие четкого понимания взаимосвязи предельной поверхности и
cage исторически приводил к тому, что многие приложения избегали тесселяции.
Стоит отметить, что подразделение можно использовать для создания тесселяции, даже если предельная поверхность недоступна для прямой оценки. Рекурсивный характер подразделения приводит к формулам, которые позволяют вычислить точку на предельной поверхности, которая соответствует каждой точке клетки. Этот процесс часто называют «привязкой». или «толкать» концы клетки на ограничительную поверхность.
Разделены на 1x и привязаны к ограничивающей поверхности | Разделены на 2 части и привязаны к ограничивающей поверхности |
Поскольку конечный результат
связный набор точек на предельной поверхности, это образует мозаику предела
поверхность, и мы рассматриваем его как отдельный процесс для подразделения (хотя он действительно использует
из него). Тот факт, что такая тесселяция могла быть достигнута с помощью подразделения, является
неотличимы от конечного результата — та же тесселяция может так же легко иметь
были сгенерированы путем оценки предельных участков клетки равномерно 2x, 4x, 8x и т. д.вместе
каждый край.
д.вместе
каждый край.
Что использовать?
Subdivision, несомненно, полезен для создания более мелких клеток для манипулирования поверхностью, но тесселяция предпочтительнее для отображения поверхности, когда участки доступны для прямой оценки. Было время, когда глобальное усовершенствование преследовалось ограниченными круги как способ быстрой оценки параметрических поверхностей вдоль изопараметрических линий, но оценка исправлений, то есть тесселяция, обычно преобладает.
Значительная путаница возникла из-за того, как использовались эти две техники и
представлен при отображении формы в приложениях конечного пользователя.Можно утверждать, что если
приложение отображает представление поверхности, удовлетворяющее ее
целей, то нет необходимости обременять пользователя дополнительной терминологией и
выбор. Но когда два изображения одной и той же поверхности значительно отличаются между
два приложения, отсутствие какого-либо объяснения или контроля приводит к путанице.
Пока приложения выбирают разные способы отображения поверхности, мы ищем баланс между простотой и контролем. Поскольку разбитые точки не лежат на пределе поверхность, важно дать понять пользователям, когда вместо этого используется подразделение тесселяции.Это особенно верно в случаях, когда клетка и поверхности отображаются в том же стиле, поскольку для пользователей нет визуальной подсказки, чтобы сделать это различие.
Данные сетки и топология
Способность поверхностей подразделения поддерживать произвольную топологию приводит к использованию сетки для хранения как топологии клетки, так и значений данных, связанных с ее контрольные точки, то есть его вершины. Форма сетки или поверхность подразделения это результат комбинации топологии сетки и положения данные, связанные с его вершинами.
При работе с сетками есть преимущества отделения топологии от данных,
и это даже более важно при работе с поверхностями подразделения. Форма»
упомянутое выше — это не только форма сетки (в данном случае клетки), но и
иметь форму изысканной клетки или предельной поверхности. Наблюдая за ролями, которые оба
данные и топология играют в таких операциях, как подразделение и оценка, значительная
преимущества могут быть получены путем управления данными, топологией и соответствующими вычислениями
соответственно.
Наблюдая за ролями, которые оба
данные и топология играют в таких операциях, как подразделение и оценка, значительная
преимущества могут быть получены путем управления данными, топологией и соответствующими вычислениями
соответственно.
В то время как основное назначение поверхностей подразделения состоит в использовании данных о местоположении, связанных с вершины для определения гладкой непрерывной предельной поверхности, во многих случаях непозиционные данные связаны с сеткой. Эти данные часто могут быть интерполированы плавно, как и положение, но часто предпочтительно интерполировать его линейно или даже сделать прерывистым по краям сетки. Координаты текстуры и цвет общие примеры здесь.
Кроме позиции, которая назначена и связана с вершинами, нет
ограничения на то, как произвольные данные могут или должны быть связаны или интерполированы.Текстура
координаты, например, могут быть назначены для создания полностью гладкой предельной поверхности
как положение, линейно интерполированное по граням или даже прерывистое между
их.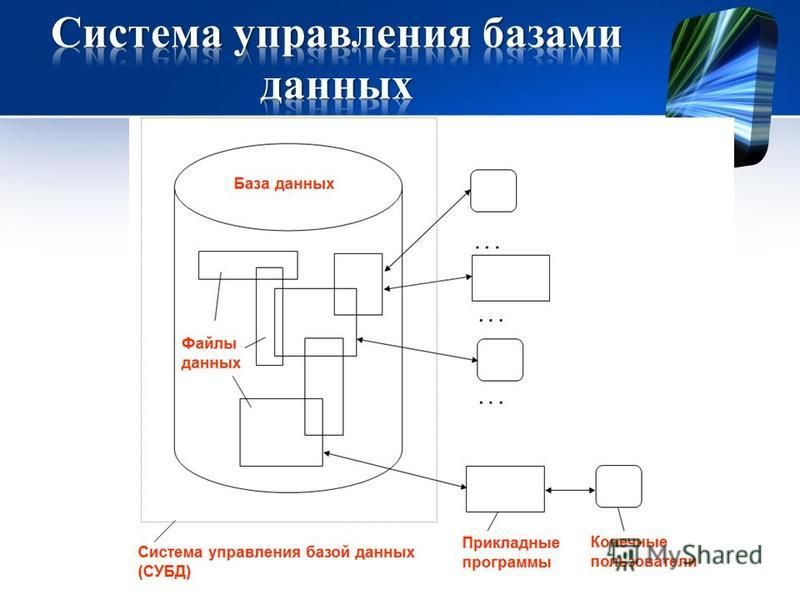 Однако следует учитывать последствия — как с точки зрения управления данными.
и производительность — которые описаны ниже как терминология и методы, используемые для
достижения каждого определены.
Однако следует учитывать последствия — как с точки зрения управления данными.
и производительность — которые описаны ниже как терминология и методы, используемые для
достижения каждого определены.
Отделение данных от топологии
Хотя топология сеток, используемых для хранения поверхностей подразделения, произвольно сложна и переменная топология параметрических участков, составляющих его предельную поверхность: простой и фиксированный.Бикубический B-сплайн и патчи Безье определяются простым 4×4 сетка контрольных точек и набор базовых функций для каждой точки, которые вместе сформировать получившуюся поверхность.
Для такого патча положение в заданном параметрическом местоположении является результатом
сочетание данных о местоположении, связанных с его контрольными точками, и весов
соответствующие базисные функции ( весов — значения оцененных базисных функций
в параметрической локации). Топология и базисные функции остаются прежними, поэтому мы
может использовать веса независимо от данных. Если позиции управления
изменения точек, мы можем просто рекомбинировать новые данные о местоположении с весами, которые мы
просто использовали и применяем ту же комбинацию.
Если позиции управления
изменения точек, мы можем просто рекомбинировать новые данные о местоположении с весами, которые мы
просто использовали и применяем ту же комбинацию.
| Фиксированная топология параметрического патча и двух форм, получаемых из двух наборов позиций. | ||
Аналогично, для кусочной поверхности положение в заданном параметрическом местоположении является
результат одного патча, содержащего это параметрическое местоположение, оцененное в заданном
должность.Участвующие контрольные точки — это подмножество контрольных точек, связанных с
именно этот патч. Если топология поверхности фиксирована, то же самое и топология
коллекции пятен, составляющих эту поверхность. Если позиции тех
контрольные точки меняются, мы можем рекомбинировать новые данные о местоположении с теми же весами для
подмножество точек, связанных с патчем.
| Более сложная, но фиксированная топология поверхности и двух форм, получаемых из двух наборов позиций. | ||
Это верно для кусочной поверхности произвольной топологии. Независимо от того, насколько сложен топология, пока она остается фиксированной (т.е. отношения между вершинами, ребрами и лиц не меняется (или какие-либо другие настройки, влияющие на правила подразделения)), применяются те же методы.
Это всего лишь один пример значения разделения вычислений, связанных с топологией, от те, которые связаны с данными. И подразделение, и оценку можно разделить на этапы. включая топологию (вычисление весов) и раздельное объединение данных.
Три формы, полученные в результате трех наборов позиций для сетки фиксированной топологии. | ||
Когда топология фиксирована, огромная экономия возможна за счет предварительного вычисления информации связанных с топологией и организацией данных, связанных с контрольными точками в способ, который можно эффективно с ним комбинировать. Это ключ к пониманию некоторых методы, используемые для обработки поверхностей подразделения.
Для сетки произвольной топологии контрольными точками подстилающей поверхности являются вершины и связанные с ними данные о положении наиболее знакомы. Но нет ничего это требует, чтобы контрольные точки патча представляли положение — то же самое методы применяются независимо от типа задействованных данных.
Вершины и изменяющиеся данные
Самая типичная и основная операция — это оценка положения на поверхности, т.е.
оценить нижележащие участки предельной поверхности, используя положения (x, y, z) в
вершины сетки.Учитывая параметрическое (u, v) расположение на одном таком участке, не зависящие от данных
метод оценки сначала вычисляет веса, а затем объединяет позиции вершин (x, y, z)
в результате получается позиция (x, y, z) в этом месте. Но веса и их сочетание
может применяться к любым данным в вершинах, например цвет, координаты текстуры или что-то еще
еще.
Но веса и их сочетание
может применяться к любым данным в вершинах, например цвет, координаты текстуры или что-то еще
еще.
Данные, связанные с вершинами, которые интерполированы таким образом, включая положение, называются быть «вершинными» данными или иметь «вершинную» интерполяцию.Указание других данных как «вершина» данные приведут к тому, что они будут плавно интерполированы точно так же (с использованием точно тот же вес), что и позиция. Итак, чтобы сделать простую 2D-проекцию поверхности для координаты текстуры, будут использоваться 2D-значения, соответствующие позициям (x, y).
Если вместо этого требуется линейная интерполяция данных, связанных с вершинами, данные называются
быть «меняющимися» данными или иметь «изменяющуюся» интерполяцию. Здесь нелинейная оценка
пятна, определяющие гладкую предельную поверхность, игнорируются, а веса для простых линейных
используется интерполяция.Это обычный выбор текстурных координат для оценки
текстуры без бикубических пятен дешевле в вычислительном отношении. Линейный
интерполяция не обеспечивает гладкости, необходимой для истинной проекции между
вершины, но и вершина, и переменная интерполяция имеют свое применение.
Линейный
интерполяция не обеспечивает гладкости, необходимой для истинной проекции между
вершины, но и вершина, и переменная интерполяция имеют свое применение.
Спроецированная текстура с плавной интерполяцией из данных вершины | Спроецированная текстура с линейной интерполяцией по разным данным |
Поскольку вершины и различные данные связаны с вершинами (уникальное значение, присвоенное к каждому), полученная поверхность будет непрерывной — кусочно гладкой в случае вершинные данные и кусочно-линейные в случае варьирования.
Данные и топология с изменяющимся лицом
Чтобы поддерживать неоднородность данных на поверхности, в отличие от вершинных и переменных данных, должно быть несколько значений, связанных с вершинами, ребрами и / или гранями, чтобы разрыв существовать.
Разрывы становятся возможными путем присвоения значений углам граней, аналогично
способу присвоения вершин углам граней при определении
топология сетки. Вспоминая назначение вершин граням:
Вспоминая назначение вершин граням:
Индексы вершин присваиваются всем углам каждой грани как часть построения сетки и часто называют гранями-вершинами отдельной грани или сетки.Все грани-вершины, которые имеют один и тот же индекс вершины, будут связаны этой вершиной и будут иметь общие те же данные вершины, связанные с ним.
Путем присвоения граням-вершинам другого набора индексов — индексов, не относящихся к вершины, но некоторый набор данных, который будет связан с углами каждой грани — углы которые совместно используют одну и ту же вершину, больше не должны иметь одно и то же значение данных, и данные могут быть прерывистые между гранями:
Этот метод связывания значений данных с гранями-вершинами сетки называется
назначение данных с изменяющимся лицом для интерполяции с изменением лица.Интерполированное значение
будет непрерывно изменяться в пределах грани (то есть участок предельной поверхности, связанный
с гранью), но не обязательно через ребра или вершины, общие с соседними
лица.
Непересекающиеся УФ-области с изменяющейся гранью, примененные к предельной поверхности |
Комбинация связывания значений данных не с вершинами (контрольными точками) но углы лица и возникающие в результате разрывы, зависящие от данных, делают этот подход значительно более сложным, чем вершинный или вариативный.Добавленный сложность данных сама по себе является причиной использовать их только при необходимости, т.е. когда разрывы желательны и присутствуют.
Отчасти сложность работы с данными с изменяющимся лицом и интерполяцией заключается в
которые можно определить при интерполяции. Если данные непрерывны,
интерполяция может быть такой же гладкой, как нижележащая предельная поверхность вершины
данные или просто линейные, как достигается с различными данными.
Если данные прерывистые — по внутренним краям и вокруг вершин —
разрывы создают границы для данных и разделяют нижележащую поверхность на
непересекающиеся области. Интерполяцию по этим границам также можно задать как
гладкими или линейными по ряду причин (многие из которых имеют историческую основу).
Интерполяцию по этим границам также можно задать как
гладкими или линейными по ряду причин (многие из которых имеют историческую основу).
Более полное описание различных вариантов линейной интерполяции с изменением граней данные и интерполяция даны позже. Эти параметры позволяют обрабатывать данные как либо вершина, либо переменная, но с добавлением разрывов.
При интерполяции с изменяющимся лицом важно помнить, что каждый набор данных может иметь свои собственные разрывы — это приводит к тому, что каждый набор данных имеет уникальные топология и размер.
Топология, указанная для сбора данных с разными лицами, называется канал и является уникальным для интерполяции с изменением лица. В отличие от вершинных и различных
интерполяция, которая связывает значение данных с вершиной, количество значений в
канал с изменяющейся гранью не фиксируется количеством вершин или граней. Номер
индексы, присвоенные граням-углам, будут одинаковыми для всех каналов, но число
уникальных значений, на которые ссылаются эти индексы, не может. Мы можем воспользоваться
общая топология сетки в областях, где данные непрерывны, но мы теряем некоторые из них
преимущества вокруг разрывов. Это приводит к более высокой сложности и стоимости.
канала с изменяющимся лицом по сравнению с вершиной или изменяющимися данными. Если топология для
канал фиксирован, однако аналогичные методы могут быть применены для вычисления коэффициента
связаны с топологией, чтобы можно было эффективно обрабатывать изменения данных.
Мы можем воспользоваться
общая топология сетки в областях, где данные непрерывны, но мы теряем некоторые из них
преимущества вокруг разрывов. Это приводит к более высокой сложности и стоимости.
канала с изменяющимся лицом по сравнению с вершиной или изменяющимися данными. Если топология для
канал фиксирован, однако аналогичные методы могут быть применены для вычисления коэффициента
связаны с топологией, чтобы можно было эффективно обрабатывать изменения данных.
Схемы и опции
В то время как предыдущие разделы описывали поверхности подразделения в более общих терминах, этот В разделе описывается ряд общих вариантов (часто называемых расширениями , от до алгоритмы подразделения) и способы их представления в OpenSubdiv.
Количество и характер расширений здесь значительно усложняют то, что в противном случае
довольно простые алгоритмы подразделения. Исторически приложения поддерживали либо
подмножество или имели разные реализации одной и той же функции. OpenSubdiv стремится к
обеспечить последовательную и эффективную реализацию этого набора функций.
OpenSubdiv стремится к
обеспечить последовательную и эффективную реализацию этого набора функций.
Учитывая различное представление некоторых из этих функций в других местах, выбранное название by OpenSubdiv.
Схема деления
OpenSubdiv предоставляет два хорошо известных типа подразделения поверхности — Catmull-Clark (часто упоминается короче «Catmark») и Loop subdivision.Катмулл-Кларк более широко используется и подходит для четырехкомпонентных сеток, тогда как Loop предпочтительнее (и требует) чисто триангулированных сетки.
Множество примеров из предыдущих разделов проиллюстрировали более популярные модели Catmull-Clark схема. Для примера Loop:
Правила интерполяции границ
Правила граничной интерполяции управляют тем, как подразделение и предельная поверхность ведут себя для граней рядом с граничными ребрами и вершинами.
Следующие варианты доступны через перечисление Sdc :: Options :: VtxBoundaryInterpolation :
| Режим | Поведение |
|---|---|
| VTX_BOUNDARY_NONE | По умолчанию интерполяция границ не применяется; грани границы помечены как отверстия, так что граница вершины продолжают поддерживать прилегающий интерьер грани, но нет поверхности, соответствующей границе лица сформированы; граничные грани можно выборочно интерполирован путем повышения резкости всех граничных кромок, вершины грани |
| VTX_BOUNDARY_EDGE_ONLY | Последовательность граничных вершин определяет гладкую кривую до которой проходит граничная поверхность по граничным граням |
| VTX_BOUNDARY_EDGE_AND_CORNER | Аналогично только краю, но плавная кривая приводит к граница сделана для интерполяции угловых вершин (вершины ровно с одной инцидентной гранью) |
На примере сетки:
На практике редко используют граничную интерполяцию вообще — эта функция
его использование, позволяющее легко соединять отдельные сетки, реплицируя
вершины вдоль границ, но это использование ограничено. Учитывая глобальный характер
настройки, обычно предпочтительнее явно сделать отверстия на граничных поверхностях
в местах стыковки поверхностей из отдельных сеток, а не заточка
ребра для интерполяции желаемых границ везде.
Учитывая глобальный характер
настройки, обычно предпочтительнее явно сделать отверстия на граничных поверхностях
в местах стыковки поверхностей из отдельных сеток, а не заточка
ребра для интерполяции желаемых границ везде.
Оставшиеся варианты «только кромка» и «кромка и угол» затем различаются исключительно по тому, является ли поверхность в угловых вершинах гладкой или острой.
Правила интерполяции с изменяющимся лицом
Правила интерполяции с изменяющимся лицом управляют тем, как данные с изменяющимся лицом интерполируются как в внутри областей с изменяющимся лицом (гладких или линейных) и на границах, где прерывистый (ограниченный быть линейным или «закрепленным» рядом способов).Где топология непрерывна и интерполяция выбрана гладкой, поведение интерполяция с изменением граней будет соответствовать интерполяции вершин.
Варианты интерполяции с изменяющейся гранью обычно доступны в контексте UV
для координат текстуры, и ряд имен для таких вариантов эволюционировали в разных
приложения на протяжении многих лет. Варианты, предлагаемые OpenSubdiv, охватывают широкий спектр популярных
Приложения. Элемент получил название линейная интерполяция с изменяющейся гранью, а не граница обычно используется интерполяция — чтобы подчеркнуть, что ее можно применить
ко всей поверхности (а не только к границам), и что эффекты должны сделать поверхность
вести себя более линейно по-разному.
Варианты, предлагаемые OpenSubdiv, охватывают широкий спектр популярных
Приложения. Элемент получил название линейная интерполяция с изменяющейся гранью, а не граница обычно используется интерполяция — чтобы подчеркнуть, что ее можно применить
ко всей поверхности (а не только к границам), и что эффекты должны сделать поверхность
вести себя более линейно по-разному.
Для перечисления Sdc :: Options :: FVarLinearInterpolation доступны следующие варианты — порядок здесь с применением все более линейных ограничений:
| Режим | Поведение |
|---|---|
| FVAR_LINEAR_NONE | везде гладкая сетка гладкая |
| FVAR_LINEAR_CORNERS_ONLY | линейная интерполяция (заострение или штифт) только углов |
| FVAR_LINEAR_CORNERS_PLUS1 | CORNERS_ONLY + заточка стыков 3-х и более областей |
| FVAR_LINEAR_CORNERS_PLUS2 | CORNERS_PLUS1 + заточка дротиков и вогнутых углов |
| FVAR_LINEAR_BOUNDARIES | линейная интерполяция по всем граничным кромкам и углам |
| FVAR_LINEAR_ALL | линейная интерполяция везде (границы и внутренняя часть) |
Эти правила не могут сделать интерполяцию данных с изменяющимся лицом более плавной, чем
то из вершин. Наличие резких особенностей сетки, созданной
значения резкости, правила граничной интерполяции или сама схема разделения
(например, билинейный) имеют приоритет.
Наличие резких особенностей сетки, созданной
значения резкости, правила граничной интерполяции или сама схема разделения
(например, билинейный) имеют приоритет.
Все режимы интерполяции с изменяющимся лицом, проиллюстрированные в УФ-пространстве с помощью простого 4×4 сетка четырехугольников, сегментированная на три УФ-области (предполагалось расположение контрольных точек интерполяцией в случае FVAR_LINEAR_ALL):
(Для тех, кто знаком, эта форма и назначенные ей наборы UV доступны для проверки в фигуре «catmark_fvar_bound1» примера OpenSubdiv и фигурах регрессии.)
Полуострые складки
Так же, как некоторые типы параметрических поверхностей поддерживают дополнительные элементы управления влияют на складки по границам между элементами поверхности, OpenSubdiv предоставляет дополнительные значения резкости или «веса», связанные с ребрами и вершинами для добиться аналогичных результатов по произвольной топологии.
Установка максимального значения резкости (в данном случае 10 — число, выбранное для
исторические причины) эффективно изменяет правила подразделения, так что границы
между кусочно-гладкими поверхностями бывают бесконечно резкими или прерывистыми.
Но поскольку у реальных поверхностей никогда не бывает бесконечно острых краев, особенно при достаточно близком рассмотрении часто предпочтительнее установить резкость ниже этого значения, что делает складку «полуострой». Постоянное значение веса присваивается последовательности ребер, связанных ребер, поэтому позволяет создавать функции, подобные скруглениям и переходам, без добавления дополнительных рядов вершин (хотя эта техника все еще имеет свои достоинства):
Диапазон значений резкости от 0 до 10, при этом значение 0 (или меньше) не влияет на поверхность и значение 10 (или более), делающее объект полностью резким.
Следует отметить, что бесконечно острые складки действительно касаются друг друга.
разрывов на поверхности, подразумевая, что геометрические нормали также
прерывистый там. Следовательно, перемещение по нормали, скорее всего, приведет к разрыву
раздвиньте поверхность по складке. Если вы действительно хотите сместить поверхность на
складку, возможно, лучше сделать складку полуострой.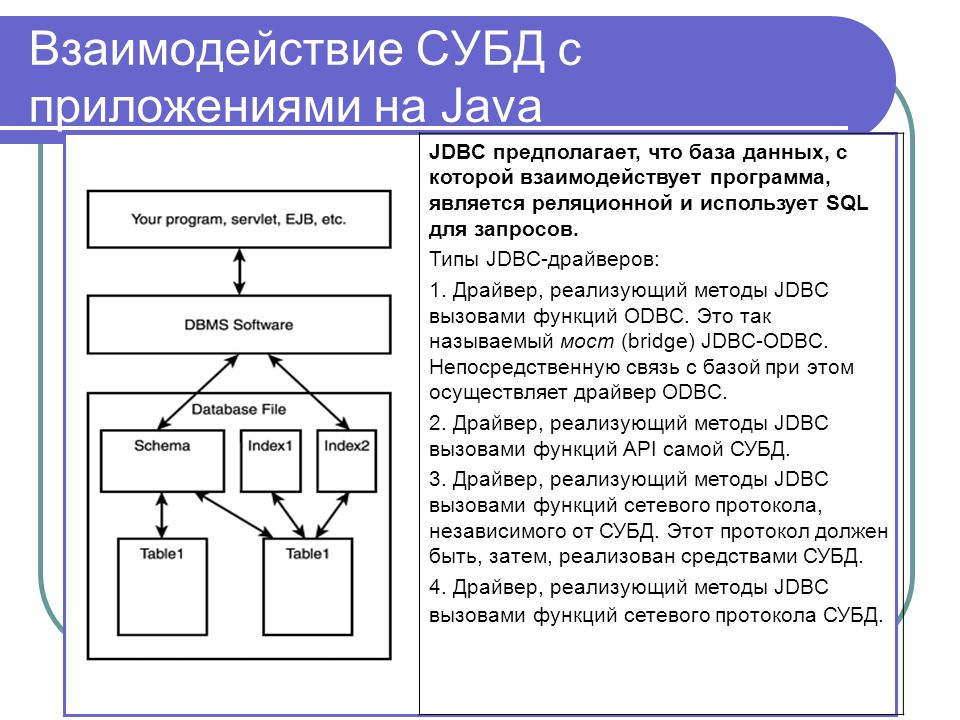
Другие опции
В то время как предыдущие параметры представляют функции, доступные в большом количестве инструментов и форматы моделирования, существует несколько других, признание и принятие которых более ограничено.В некоторых случаях они предлагают улучшения нежелательного поведения подразделения. алгоритмы, но их эффекты далеки от идеала.
Учитывая как их ограниченную эффективность, так и отсутствие признания, эти варианты должны быть использовать с осторожностью.
Правило Чайкина
«Правило Чайкина» — это разновидность метода полуострого биговки, который пытается улучшить вид складок вдоль последовательности соединенных краев, когда резкость значения различаются. Этот выбор изменяет подразделение значений резкости с помощью Чайкина. алгоритм подразделения кривой для учета всех значений резкости краев вокруг общего вершина при определении резкости дочерних ребер.
Метод сгиба может быть установлен с использованием значений, определенных в перечислении. Sdc :: Options :: CreasingMethod :
Sdc :: Options :: CreasingMethod :
| Режим | Поведение |
|---|---|
| CREASE_UNIFORM | Нанесите обычные полуострые складки |
| CREASE_CHAIKIN | Применить полуострую складку «Чайкина» |
Пример интерполяции смежных полуострых складок:
Правило «деления треугольника»
Правило деления треугольников — это правило, добавленное к схеме Катмалла-Кларка, которое изменяет поведение на треугольных гранях, чтобы улучшить нежелательную поверхность артефакты, которые часто возникают на таких участках.
| Режим | Поведение |
|---|---|
| TRI_SUB_CATMARK | Вес схемы Catmark по умолчанию |
| TRI_SUB_SMOOTH | Гири «Гладкий треугольник» |
Пример цилиндра:
Это правило было установлено эмпирическим путем, чтобы треугольники делились более плавно. Однако это правило нарушает то прекрасное свойство, что две отдельные сетки могут быть
соединяются плавно, перекрывая их границы; я.е. когда есть треугольники
на любой границе невозможно бесшовно соединить сетки
Однако это правило нарушает то прекрасное свойство, что две отдельные сетки могут быть
соединяются плавно, перекрывая их границы; я.е. когда есть треугольники
на любой границе невозможно бесшовно соединить сетки
Подразделение моделирования
Создано 31 марта 2011 г., 15:17
Подразделение моделирования — это метод цифрового трехмерного моделирования, используемый для создания чистых моделей с масштабируемыми деталями, которые хорошо выглядят при визуализации. В той или иной степени он используется почти во всех отраслях, где работают цифровые художники. Говоря это, часто художник или инструмент выбирают, какую технику моделирования использовать.Другие популярные методы — это моделирование на уровне полигонов, моделирование Нурбса и цифровая скульптура.
Техника и последующее искусство моделирования с подразделениями возникли более или менее естественно из-за нескольких аспектов или явлений в том, как обычно отображается цифровое искусство. Два основных примера того, что это метод по умолчанию, с помощью которого вычисляются нормали вершин, и способ, которым работает подразделение Катмулла – Кларка (в честь которого названа техника).
Два основных примера того, что это метод по умолчанию, с помощью которого вычисляются нормали вершин, и способ, которым работает подразделение Катмулла – Кларка (в честь которого названа техника).
Пример подразделения модели
Вершина — это точка в пространстве, где встречаются различные линии (или ребра).Их можно рассматривать как углы геометрических фигур. Когда компьютер отображает фигуру на экране, есть два варианта. Либо он может визуализировать каждый многоугольник (или грань) этой формы как плоскую поверхность и выполнять расчеты освещения на основе этого, либо он может попытаться визуализировать некоторую сглаженную версию той же формы. Нам часто нужен второй вариант, и именно здесь используются нормали вершин.
Если вместо того, чтобы смотреть на нормали граней (направление, в котором указывает грань), средство визуализации смотрит на нормали вершин (направление, указывающее угол), тогда оно может интерполировать (своего рода усреднение) это направление по треугольной грани, это рендеринг, придавая ему плавный вид. Фактически, для любого треугольника видеокарты специально разработаны так, чтобы иметь возможность очень быстро выполнять эту интерполяцию нормалей из трех вершин в каждом углу. Это то, что происходит во всей трехмерной компьютерной графике, от «Властелина колец» до Quake II.
Фактически, для любого треугольника видеокарты специально разработаны так, чтобы иметь возможность очень быстро выполнять эту интерполяцию нормалей из трех вершин в каждом углу. Это то, что происходит во всей трехмерной компьютерной графике, от «Властелина колец» до Quake II.
Но, прежде чем мы сможем выполнить эту интерполяцию, мы должны определить фактические нормали вершин, которые будут использоваться. По-настоящему найти направление, в котором указывает вершина, невозможно (у нее нет поверхности, следовательно, нет нормали), но обычно мы просто усредняем нормали граней для всех граней, прикрепленных к этой вершине — и используем это как приближение для нормального.
Это позволяет нам визуализировать гладкие поверхности, используя угловую геометрию (и фиксированное количество полигонов), но за это приходится платить. Во многих случаях это работает не совсем так, как ожидалось, и может привести к визуальным артефактам или участкам освещения, которые выглядят странно. Они возникают из-за проблем с аппроксимацией нормалей вершин, а также с вычислениями интерполяции по треугольникам. Но с хорошей сеткой эти артефакты можно свести к минимуму или даже преодолеть, и здесь на помощь приходит моделирование с разбиением.
В компьютерной графике есть новые термины практически для всего. Я, наверное, уже подбросил вам несколько новых, которые я здесь пересмотрю, но как только вы освоитесь с ними, все станет намного проще объяснить. Причина, по которой некоторые из этих вещей имеют имена, также станет очевидной позже.
- Вершина — точка в пространстве, где встречаются края, угол фигуры.
- Ребро — соединение между двумя вершинами.
- Многоугольник — грань трехмерной формы, соединяющая несколько вершин посредством ребер.
- Сетка — Набор многоугольников, форма в трехмерном пространстве. Также называется моделью или телом.
- Треугольник — многоугольник с ровно тремя вершинами.
- Quad — многоугольник с четырьмя вершинами.
- N-Gon — многоугольник с пятью или более вершинами.
- Полюс — Вершина с тремя выходящими из нее ребрами.
- N-Pole — Вершина с пятью или более ребрами, выходящими из нее.
Спрашивать, что делает хорошую сетку, почти то же самое, что спрашивать, что делает хорошую картину. Как и на большинство других вещей в жизни, на этот простой ответ нет, и, по правде говоря, хорошее моделирование действительно требует практики. Когда вы хорошо разбираетесь в подразделении, вы можете почувствовать, что делает хороший меш, и это будет видно, когда вы его визуализируете. Тем не менее, есть некоторые рекомендации, которым вы можете следовать, которые сведут к минимуму визуальные артефакты и сделают вашу жизнь намного проще.Вот некоторые из основных. (Здесь стоит отметить, что эти руководящие принципы также применимы почти ко всему созданию сетки и никоим образом не относятся к моделированию с разбиением.)
Избегайте треугольников и полюсов
Треугольники и полюса можно рассматривать как две стороны одной медали. Они часто являются причиной странных артефактов сглаживания, поэтому их следует по возможности избегать. Однако полностью избежать их просто невозможно; любая сетка потребует их некоторое количество.Часто их ставят с целью минимизировать их действие. Есть два основных способа сделать это: либо разместить их на относительно плоской поверхности, либо «спрятать» их в плотно закрытых участках сетки. У человеческих персонажей это часто делается в подмышках, паху, суставах или вообще в любом месте с естественными складками на поверхности.
Полюса и треугольники «спрятаны» на плоской части ключа
Избегайте N-угольников и N-полюсов
Это действительно очень похоже на предыдущий пункт, и они скрыты с использованием тех же методов.Обычно люди стараются избегать этого больше, чем треугольников или полюсов. В основном это связано с тем, что их сложнее моделировать, и тем фактом, что чем больше количество ребер, входящих в полюс, или количество сторон грани, тем более странными становятся проблемы сглаживания.
Попробуйте построить сетку в основном из четырехугольников
Этот момент часто кажется новичкам немного вводящим в заблуждение. Например, если у вас есть какие-то знания о графике, вы знаете, что модели в любом случае визуализируются только с использованием треугольников — все квадраты превращаются в треугольники перед визуализацией, обычно путем соединения ребра между двумя ближайшими вершинами.Таким образом, попытка построить сетку в основном из четырехугольников может показаться излишней и глупой. Но на самом деле создание меша с учетом квадратов — это самый простой способ избежать всех других плохих вещей, которые могут вызвать визуальные артефакты.
Не только это, но есть много-много причин, по которым работать с четырехугольными сетками проще, чем с другими беспорядочными и перепутанными сетками. Их легче анимировать, проще оснастить и легче выполнять практически любую другую задачу, которую вы можете с ними выполнить.
Видео, показывающее убедительные примеры артефактов подразделения
Распределите вершины равномерно
Новички часто ошибаются, когда в процессе создания сетки с четырьмя квадратами набивают кучу избыточных ребер, вершин и деталей. В этом нет необходимости, да и со временем рендеринга это не будет хорошо выглядеть. Что происходит, когда у вас есть сетка, состоящая из продолговатых, а не квадратов, вы получаете массу длинных тонких треугольников во время рендеринга.Это вызовет проблемы при интерполяции и, как правило, будет плохо выглядеть. Слишком тонкие пучки создают на сетке что-то похожее на жесткие швы, что во многих случаях нежелательно.
Также можно расположить вершины так, чтобы плотность увеличивалась в областях с большим количеством деталей. Это придаст вашей сетке дополнительную четкость там, где это необходимо, и не будет тратить полигоны в другом месте.
Хорошо расположенная головка
Внимание к телу, форме и потоку
Еще одна ошибка новичка — зацикливаться на создании четырехугольной сетки и в результате получить что-то, что действительно не соответствует моделируемому объекту.При моделировании вы должны представить, что края, которые вы размещаете, повторяют контуры объекта. Если вы моделируете что-то органическое, например человеческое тело, края должны повторять движение мускулов, выпуклостей, изгибов и складок. Это поможет с анимацией, манипуляциями и настройкой вашей сетки.
Использование формы над квадратом
Также стоит отметить, что этот момент является самым важным. В то время как другие рекомендации уменьшают количество артефактов, они обычно считаются эстетическим выбором и облегчают построение модели, а не исправляют ее окончательный вид.
Начинайте медленно, веселитесь
Моделирование подразделений — это продвинутая техника. Это не то, что можно освоить за один сеанс. Если вы чувствуете, что ведете битву с моделированием подразделений, значит, вы делаете это неправильно. Начните с малого, получайте удовольствие и гордитесь тем, что вы создаете! Намного легче научиться моделированию подразделений, когда вы чувствуете, что вам нравится.
Subdivision — это процесс, который сглаживает сетку, добавляя больше полигонов и вершин, сохраняя форму.Четырехугольник будет сглажен на четыре четырехугольника, которые будут продолжать следовать контуру меша. Этот процесс используется во многих вещах, от рендеринга до цифровой скульптуры. По сути, это то, что позволяет вам строить сетки с управляемым количеством полигонов, прежде чем использовать подразделение, чтобы сделать его настолько гладким, насколько это визуально необходимо.
Сапоги сетчатые
Сапоги гладкие
Subdivision, как и вычисление нормалей вершин, не идеален.Вы получаете артефакты во многом одинаковыми способами. Кроме того, любые артефакты из нормалей вершин в исходной сетке (на одном уровне подразделения) останутся после разделения (на следующем уровне подразделения). В том, как это работает, есть прекрасная симметрия. При подразделении треугольники становятся полюсами, а N-угольники становятся северными полюсами. Обратное тоже верно. Полюса становятся треугольниками, а северные полюса становятся N-угольниками. Из-за этого квадраты — единственное, что подразделяется «идеально», и поэтому наличие квадратов в вашей сетке во всех ключевых местах, которые определяют форму и гладкость поверхности, имеет важное значение.
Видео, объясняющее, как работает подразделение.
Все, что я сказал выше, применимо практически к любой технике моделирования. Они могут показаться про рендеринг в целом. Но моделирование с разбиением на части действительно можно рассматривать как процесс моделирования, в котором все эти идеи находятся в вашем уме. Идея состоит в том, чтобы следовать этим правилам и моделировать их соответствующим образом. На форумах подразделений вы не увидите конца разговорам о поляках, N-Gons и прочем.Сторонники других техник склонны просто жить с этим.
Вторая часть моделирования сабдивов как методики — это инструменты. Часто программы моделирования, классифицируемые как «составители моделей с разбиением», предоставляют вам множество расширенных инструментов, помогающих с моделированием сабдивов. Они часто позволяют быстро переключаться между уровнями подразделения, позволяя предварительно просмотреть сетку и увидеть, как она выглядит после сглаживания.
Они также используют концепцию «концевых петель» и «кромочных колец», которые представляют собой наборы ребер, соединенных в линию (для петель) или параллельно (для колец).Обычно существует простой способ их выбора, добавления, удаления и изменения. Эти две вещи являются важной концепцией в моделировании подразделений, так как в конечном итоге они определяют ход и форму вашей модели.
И, наконец, при моделировании с разбиением часто бывает принято сначала сосредоточиться на определении формы и тела, а затем на разбиении и использовании дополнительных многоугольников, чтобы добавить больше деталей и глубины. Это в некоторой степени похоже на метод традиционной рисования, при котором сначала используются большие мазки кисти, задолго до того, как будут добавлены какие-либо реальные детали.Как и в обычной живописи, это имеет те же преимущества и часто приводит к лучшему восприятию тела, формы и пропорций.
Коробка для моделирования
Количество хороших ресурсов по моделированию подразделов сократилось, но хороший список можно найти здесь:
Вы начинаете здесь
Он расскажет вам все, что я вам сказал, и многое другое.
Хотя на самом деле, если вы новичок в 3D-моделировании в целом, безусловно, лучший способ действий — просто загрузить пакет моделирования и немного повеселиться.Мой любимый (и один из самых простых в освоении) — Wings3d. Это бесплатный, легкий и открытый исходный код, поэтому, если вам нравится возиться со своими недавно приобретенными знаниями, загрузите его и попробуйте. Удачного моделирования!
Законы о территориальных единицах — Закон о общинном жилищном строительстве
Во многих штатах действуют законы, регулирующие продажу застройщиками участков земли покупателям. Точно так же, как законы о ценных бумагах предназначались для защиты инвесторов от потери денег в инвестиционных схемах, правила о подразделениях предназначены для защиты покупателей от потери денег в результате покупки собственности в рамках проекта с общими интересами, который управлялся ненадлежащим образом с финансовой или иной точки зрения.
Законы, предназначенные для защиты покупателей подразделяемой собственности, несколько неудобно применять, когда покупатель является частью группы людей, которые также застраивали и продают землю. Юридические обручи, через которые приходится преодолевать такие группы, могут показаться невероятно высокими, учитывая, что обручи были разработаны для отношений, в которых разработчик может даже не знать покупателя.
В Калифорнии, где есть пять или более единиц в проекте кондоминиума, кооперативе, запланированной застройке, проекте общественной квартиры или совместной аренде, проект должен пройти долгий и дорогостоящий процесс утверждения в Департаменте недвижимости штата (DRE ) до того, как единицы в проекте можно будет продать или, в случае проектов кооперативов и общественных квартир, сдать в аренду.При утверждении проекта DRE проверяет запланированное разделение собственности, обеспечивает четкое право собственности на землю, изучает предлагаемые регулирующие документы и должен быть удовлетворен тем, что все необходимые услуги (коммунальные услуги, дороги и т. Д.) Предоставляются для каждой единицы. DRE также изучает бюджеты и определяет, подвергнет ли структура финансирования проекта слишком большой риск покупателей в случае, если другой покупатель не сможет произвести выплаты по ипотеке. DRE в конечном итоге создает так называемый публичный отчет по проекту, который служит набором раскрываемой информации, которая будет предоставлена любому, кто купит объект. 1
Во многих штатах 2 действуют законы, регулирующие деятельность ассоциаций, таких как ассоциации домовладельцев и ассоциаций владельцев кондоминиумов, созданные для управления правами собственности и неразделенными интересами на землю. В сообществе, где владение или аренда единицы сочетается с безраздельной долей в собственности, например, в кондоминиуме или кооперативе, и / или где Условия, Соглашения и Ограничения (CC&R) предусматривают общую схему управления для права собственности в районе, возможно, потребуется придерживаться определенных правил, касающихся структуры и деятельности ассоциации сообщества.Такие законодательные акты, как правило, устанавливают минимальные стандарты для процедур соблюдения, требований к уведомлению, кворума, количества голосов, необходимых для принятия определенных предложений, процедур выборов, требований для принятия повышенных оценок или специальных оценок, средств правовой защиты в случае невыплаты, использования залогового права в качестве механизма для принуждение и так далее. Такой устав может также налагать ограничения на права ассоциаций определять, как собственность может или не может использоваться. Например, Калифорния 3 и Флорида 4 приняли законы, запрещающие общественным ассоциациям делать газоны обязательными, и позволяющие жителям создавать засухоустойчивые ландшафты.Закон штата Колорадо запрещает ассоциациям домовладельцев запрещать использование веревок для одежды и солнечных батарей. 5
Единый закон о кондоминиумах (UCA) 6 и Единый закон о планируемых сообществах (UPCA) 7 являются примерами нормативных актов об общественных объединениях, и эти законы были приняты в некоторых штатах. В Калифорнии применимый закон называется законом Дэвиса-Стирлинга. Эти законы устанавливают обязательные процедуры или обязательные минимумы, которые могут иметь преимущественную силу перед правилами, установленными в руководящих документах ассоциации.В других случаях эти законы устанавливают правила по умолчанию, которые будут применяться, когда руководящие документы ассоциации умалчивают.
Раздел земли | Округ Огаста, VA
В округе Огаста есть два типа подразделений: второстепенное подразделение и основное подразделение. Второстепенное подразделение — это раздел имущества не более чем на два лота. Любое подразделение, которое создает более двух лотов, является крупным подразделением. Исключительный участок для членов семьи — это тип второстепенного участка, с помощью которого собственники могут создавать участки без необходимого участка дороги.
Второстепенное подразделение:
Незначительное подразделение — это раздел имущества, при котором один земельный участок делится на два участка. Этот тип подразделения в основном выполняется в районе общего сельскохозяйственного районирования и может быть выполнен, выполнив следующие шаги:
- Попросите геодезиста выселить желаемый участок
- Восемь копий таблички должны быть представлены в отдел развития сообщества с оплатой 100 долларов, одобрением VDOT для входа и одобрением Департамента здравоохранения для размещения дренажного поля
- Плата обычно рассматривается в течение десяти рабочих дней и либо утверждается, либо отклоняется.
- В случае одобрения владелец собственности обязан доставить табличку в окружной суд округа Огаста и зарегистрировать ее.
- В случае отказа планшет возвращается инспектору для внесения необходимых изменений
Если у вас есть какие-либо вопросы по поводу этого процесса, обращайтесь в Департамент общественного развития.
Исключение для членов семьи:
Участок, наделенный исключениями для членов семьи, является исключением из обычных правил мелкого разделения, позволяющих владельцам собственности создавать участки без дороги. Постановление о зонировании округа Огаста требует, чтобы участки дороги имели ширину не менее 50 футов на улице общего пользования. Если требование 50 футов не может быть выполнено, вы можете создать участок и передать его ближайшему члену семьи. Согласно Постановлению о зонировании, член семьи может быть:
- Супруга
- Родной брат
- Дети
- Внук
- Дедушка или бабушка
- Пасынок
Начиная с 1 января 2007 г. земельный участок для членов семьи должен оставаться в собственности на срок не менее трех лет.
Главное подразделение:
Основные подразделения позволяют создавать сразу несколько новых лотов, при этом требуется больше шагов, чем при выполнении второстепенного подразделения. Чтобы завершить крупное подразделение, необходимо предпринять следующие шаги:
- Отправить предварительную таблицу с указанием предлагаемых лотов и общественных улучшений на утверждение
- Общественная или частная вода и канализация должны быть доступны для обслуживания того количества участков, которое вы хотите создать
- Отправьте планы строительства всех общественных улучшений (улицы, водопровод, канализация, ливневая канализация, памятники и т. Д.))
- Для улучшения инфраструктуры также требуется оценка инженера
- Вы должны подготовить юридические документы и внести залог до того, как будет подписана окончательная плата за подразделение
- В дополнение к рассмотрению Департаментом общественного развития предварительная площадка, планы строительства и окончательная площадка будут рассмотрены прокурором округа, пожарно-спасательной службой округа Огаста, Управлением службы округа Огаста, Департаментом транспорта Вирджинии и Вирджинией. Департамент здравоохранения, если применимо
Контрольный список шагов, которые необходимо выполнить в процессе основного подразделения, можно найти здесь.Соответствующие сборы указаны в главе 19 «Сборы».
Постановление о подразделениях содержит более подробную информацию о процессах крупных и второстепенных подразделений. Если у вас есть вопросы, обращайтесь в Департамент общественного развития.
Subdivision Surface Modifier — Руководство Blender
Модификатор Subdivision Surface (часто сокращается до «Subdiv») используется для разделения граней сетки на более мелкие, что придает ей гладкий вид. Он позволяет создавать сложные гладкие поверхности при моделировании простых сеток с малым числом вершин.Это позволяет избежать необходимости сохранять и поддерживать огромные объемы данных, и придает объекту плавный «органичный» вид.
Как и любой модификатор, порядок выполнения (позиция в стеке модификаторов) имеет важное значение для результатов.
Имейте в виду, что эта операция отличается от сопутствующей операции, Плавное затенение. Вы можете увидеть разницу между ними на изображении сетки ниже.
Уровни разделения от 0 до 3, без плавного затенения и с ним.
Подсказка
Модификатор Subdivision Surface не позволяет редактировать новую разбитую геометрию без ее применения, но модификатор Multiresolution делает (в режиме Sculpt Mode).
Опции
Модификатор Subdivision Surface.
- Catmull-Clark
Параметр по умолчанию, разделяет и сглаживает поверхности. Согласно его странице в Википедии, «произвольно выглядящая формула была выбрана Катмаллом и Кларком на основе эстетического внешнего вида получаемые поверхности, а не математический вывод ».
- Простой
Разделяет только поверхности без сглаживания (аналогично оператору Subdivide в режиме редактирования).Может использоваться, например, для увеличения разрешения базовой сетки при использовании карт смещения.
- Уровни Окно просмотра, рендеринг
Количество уровней подразделения, отображаемых в окне просмотра 3D или окончательном рендере.
Предупреждение
Более высокие уровни подразделения приводят к большему количеству вершин, что означает более высокое потребление памяти (как системная оперативная память, так и видеопамять для отображения). Это может привести к зависанию или сбою Blender, если недостаточно памяти.
Подсказка
Правильная комбинация этих настроек позволит вам сохранить быстрое и легкое приближение ваша модель при взаимодействии с ней в 3D Viewport, но используйте более качественную версию при визуализации.
Будьте осторожны, не устанавливайте подразделения Viewport выше, чем подразделения Render , это будет означать, что качество в 3D Viewport будет выше, чем качество визуализации.
- Оптимальное отображение
При визуализации каркаса этого объекта провода новых разделенных краев будут пропущены (отображает только края исходной геометрии).
Продвинутый
- Использовать предельную поверхность
Размещает вершины на поверхности, которые могут быть созданы с помощью бесконечного уровни подразделения (максимально гладкая форма).
- Качество
Если параметр Использовать предельную поверхность включен, это свойство управляет насколько точно расположены вершины на предельной поверхности (относительно их теоретического положения бесконечно разделенной сетки). Его можно уменьшить, чтобы повысить производительность.
Использование более высоких значений не обязательно означает реальное улучшение качества, идеальные результаты могут быть достигнуты задолго до максимального значения Качество .
Примечание
Это значение может повлиять на точность складывания кромок; Использование более высокого значения Качество позволит более широкий диапазон значений складки для точной работы.
- UV Smooth
Управляет тем, как сглаживание деления применяется к UV.
- Нет
UV остаются без изменений.
- Keep Corners
UV-островки сглажены, но их границы остаются неизменными.
- Все
UV и их границы сглажены.
- Сглаживание границ
Управляет сглаживанием открытых границ (и углов).
- Все
Сглаженные границы, включая углы.
- Сохранить углы
Границы гладкие, но углы остаются острыми.
- Использовать складки
Использовать значения складок со взвешенными краями, хранящиеся в краях, для управления их гладкостью.
- Использовать пользовательские нормали
Интерполирует существующие пользовательские нормали результирующего меша.
Сочетания клавиш
Чтобы быстро добавить модификатор Subdivision Surface к одному или нескольким объектам, выберите объект (ы) и нажмите Ctrl - 1 .Это добавит модификатор Subdivision Surface с Viewport subdivisions, установленным на 1. Вы также можете использовать другие номера, например Ctrl - 2 , Ctrl - 3 и т. Д. чтобы добавить модификатор с таким количеством подразделений. Добавление модификатора Subdivision Surface таким образом не изменит Render subdivisions.
Если объект уже имеет модификатор Subdivision Surface , это просто изменит его уровень подразделения вместо добавления другого модификатора.
Контроль
Подразделение Catmull-Clark закругляет края, и часто это не то, что вам нужно. Есть несколько решений, позволяющих управлять подразделением.
Утяжеленная кромка загибает
Утяжеленные складки кромок для поверхностей разделения позволяют изменить способ модификатор Subdivision Surface разделяет геометрию на части, чтобы края выглядели гладкими или резкими.
Разделенный куб со загнутыми краями.
Толщина сгиба выбранных краев может быть изменена на панели Transform , боковой панели 3D Viewport.Специальный инструмент в виде шкалы Shift - E также можно использовать для регулировки веса складки. Более высокое значение делает кромку «более прочной» и более устойчивой к эффекту сглаживания поверхностей разделения.
Петли кромочные
Subdivision Level 2 куб, то же самое с дополнительным контуром ребер и то же самое с шестью дополнительными петлями ребер.
Модификатор Subdivision Surface демонстрирует, почему хорошая чистая топология так важна. Как вы можете видеть на рисунке, это оказывает сильное влияние на куб по умолчанию.Пока вы не добавите дополнительные петли (например, Loop Cut и Slide), форма почти неузнаваема, как куб.
Сетка с преднамеренной топологией имеет хорошее размещение краевых петель, что позволяет размещать больше петель (или их удаление), чтобы контролировать резкость / гладкость результирующей сетки.
Известные ограничения
Несмежные нормали
Система подразделенияBlender создает красивые гладкие разделенные меши, но любое разделенное лицо (то есть любое маленькое лицо, созданное алгоритмом из одной грани исходной сетки), имеет общую нормальную ориентацию исходного лица.
Сравнение хороших нормалей и плохих нормалей. | Изображение слева, вид сбоку. |
Резкие обычные изменения могут привести к некрасивым черным выбоинам, даже если эти перевернутые нормали не являются проблемой для самой формы.
Быстрый способ исправить это — использовать Blender’s Операция «Пересчет нормалей» в режиме редактирования.
Если у вас все еще есть уродливые черные выбоины, вам придется вручную перевернуть нормали.
.