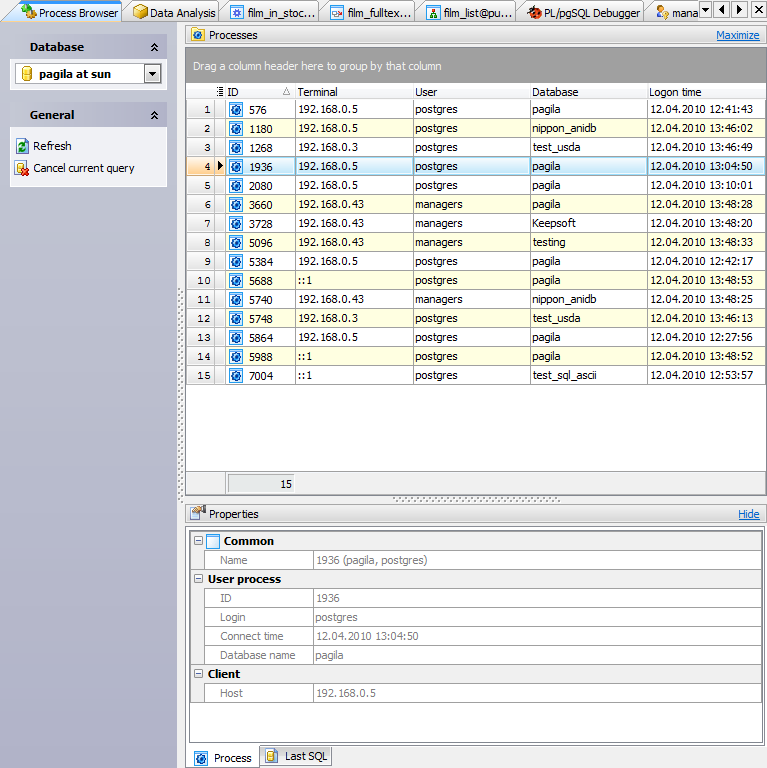
PostgreSQL — объектно-реляционная система управления базами данных
PostgreSQL — это популярная свободная объектно-реляционная система управления базами данных. PostgreSQL базируется на языке SQL и поддерживает многочисленные возможности.
Преимущества PostgreSQL:- поддержка БД неограниченного размера;
- мощные и надёжные механизмы транзакций и репликации;
- расширяемая система встроенных языков программирования и поддержка загрузки C-совместимых модулей;
- наследование;
- легкая расширяемость.
- Нет ограничений на максимальный размер базы данных
- Нет ограничений на количество записей в таблице
- Нет ограничений на количество индексов в таблице
- Максимальный размер таблицы — 32 Тбайт
- Максимальный размер записи — 1,6 Тбайт
- Максимальный размер поля — 1 Гбайт
- Максимум полей в записи250—1600 (в зависимости от типов полей)
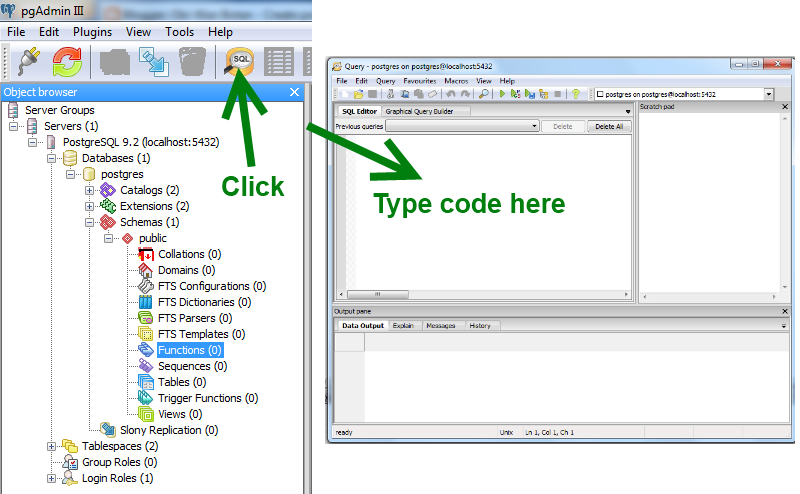
Функции в PostgreSQL являются блоками кода, исполняемыми на сервере, а не на клиенте БД. Хотя они могут писаться на чистом SQL, реализация дополнительной логики, например, условных переходов и циклов, выходит за рамки собственно SQL и требует использования некоторых языковых расширений. Функции могут писаться с использованием различных языков программирования. PostgreSQL допускает использование функций, возвращающих набор записей, который далее можно использовать так же, как и результат выполнения обычного запроса. Функции могут выполняться как с правами их создателя, так и с правами текущего пользователя. Иногда функции отождествляются с хранимыми процедурами, однако между этими понятиями есть различие.
Хотя они могут писаться на чистом SQL, реализация дополнительной логики, например, условных переходов и циклов, выходит за рамки собственно SQL и требует использования некоторых языковых расширений. Функции могут писаться с использованием различных языков программирования. PostgreSQL допускает использование функций, возвращающих набор записей, который далее можно использовать так же, как и результат выполнения обычного запроса. Функции могут выполняться как с правами их создателя, так и с правами текущего пользователя. Иногда функции отождествляются с хранимыми процедурами, однако между этими понятиями есть различие.
Триггеры в PostgreSQL определяются как функции, инициируемые DML-операциями. Например, операция INSERT может запускать триггер, проверяющий добавленную запись на соответствия определённым условиям. При написании функций для триггеров могут использоваться различные языки программирования. Триггеры ассоциируются с таблицами. Множественные триггеры выполняются в алфавитном порядке.
Механизм правил в PostgreSQL представляет собой механизм создания пользовательских обработчиков не только DML-операций, но и операции выборки. Основное отличие от механизма триггеров заключается в том, что правила срабатывают на этапе разбора запроса, до выбора оптимального плана выполнения и самого процесса выполнения. Правила позволяют переопределять поведение системы при выполнении SQL-операции к таблице.
Индексы в PostgreSQL следующих типов: B-дерево, хэш, R-дерево, GiST, GIN. При необходимости можно создавать новые типы индексов, хотя это далеко не тривиальный процесс.
Многоверсионность поддерживается в PostgreSQL — возможна одновременнуя модификация БД несколькими пользователями с помощью механизма Multiversion Concurrency Control (MVCC). Благодаря этому соблюдаются требования ACID, и практически отпадает нужда в блокировках чтения.
Расширение PostgreSQL для собственных нужд возможно практически в любом аспекте. Есть возможность добавлять собственные преобразования типов, типы данных, домены (пользовательские типы с изначально наложенными ограничениями), функции (включая агрегатные), индексы, операторы (включая переопределение уже существующих) и процедурные языки.
Есть возможность добавлять собственные преобразования типов, типы данных, домены (пользовательские типы с изначально наложенными ограничениями), функции (включая агрегатные), индексы, операторы (включая переопределение уже существующих) и процедурные языки.
Наследование в PostgreSQL реализовано на уровне таблиц. Таблицы могут наследовать характеристики и наборы полей от других таблиц (родительских). При этом данные, добавленные в порождённую таблицу, автоматически будут участвовать (если это не указано отдельно) в запросах к родительской таблице.
Использование в веб-проектах
В разработке простых сайтов PostgreSQL используется несколько реже, чем MySQL / MariaDB, но всё же эта пара с заметным отрывом опережает по частоте использования остальные системы управления базами данных. При этом в разработке сложных сайтов и веб-приложений PostgreSQL опережает по использованию MySQL и MariaDB. Большинство фреймворков (например, Ruby on Rails, Yii, Symfony, Django) поддерживают использование PostgreSQL в разработке.
Россияне в два раза ускорили СУБД PostgreSQL
| Поделиться В новом релизе СУБД Postgres Pro Enterprise, созданной на основе популярного международного проекта с открытым исходным кодом PostgreSQL, отечественным разработчикам удалось добиться вдвое более высокой производительности по сравнению с базовой версией.Новый релиз Postgres Pro Enterprise
Российская компания Postgres Professional («Постгрес профессиональный») объявила о выпуске новой версии промышленной системы управления базами данных (СУБД) Postgres Pro Enterprise, предназначенной для высоконагруженных систем.
СУБД Postgres Pro Enterprise 11, по заявлению представителей компании, способна выдержать нагрузку до 10 тыс.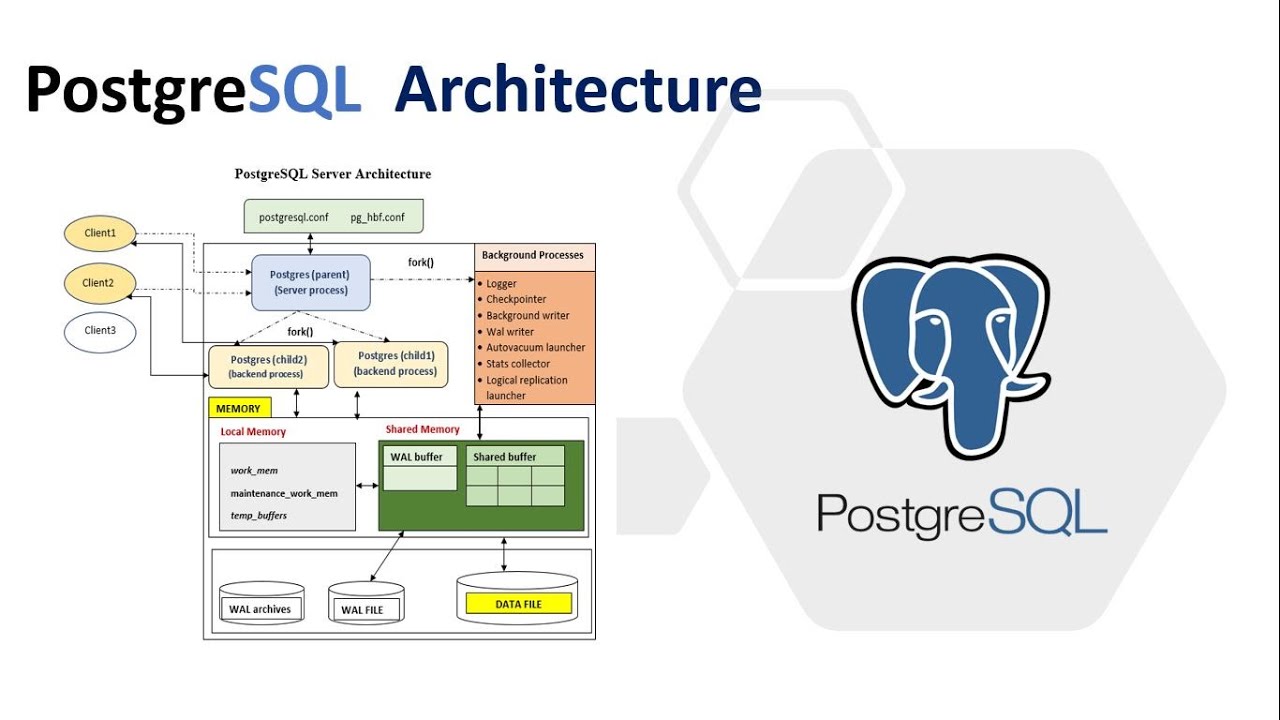
Postgres Pro Enterprise, базирующаяся на свободной СУБД PostgreSQL, входит в Единый реестр отечественного ПО Минкомсвязи. Продукт нашел применение в информационных системах ФНС, Минфина, «Газпромнефти». В марте 2019 г. CNews рассказывал о планах Федеральной таможенной службы отказаться от СУБД Oracle в пользу продукта Postgres Professional.
Ключевые изменения
В новую версию Postgres Pro Enterprise 11 добавлен экспериментальный встроенный пулер соединений, позволяющий, как утверждают разработчики, на порядок увеличить число одновременно работающих с базой данных пользователей. Ускорено создание индексов и индексный поиск по JSON, добавлены покрывающие индексы. Кроме того, ряд улучшений коснулся оптимизации SQL-запросов, секционирования таблиц и параллельного исполнения запросов.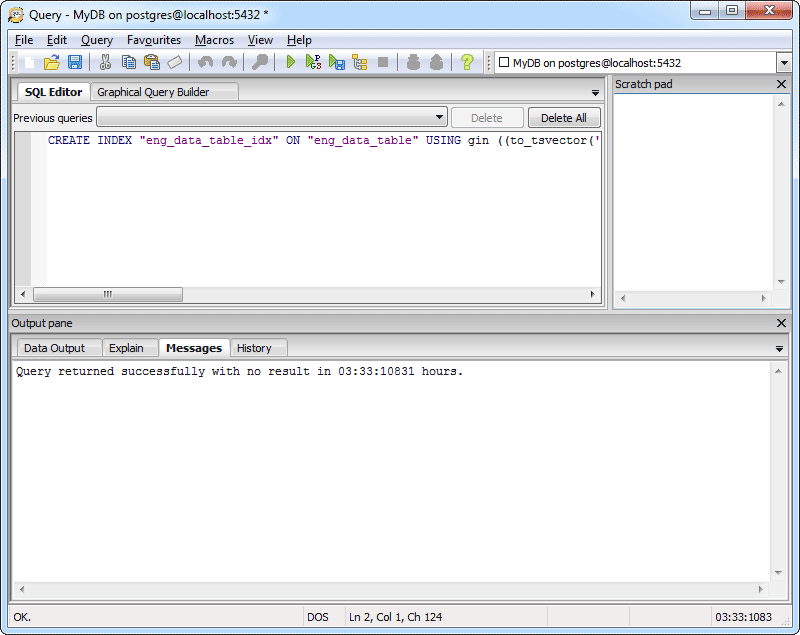
Кроме того, расширены возможности оконных функций до полного покрытия стандарта SQL:2011. Добавлена поддержка управления транзакциями во встроенных процедурных языках.
В число особых возможностей Postgres Pro Enterprise входят встроенный планировщик заданий, поддержка автономных транзакций и мультимастер-кластер. По сравнению со стандартным кластером PostgreSQL конструкции ведущий-ведомый в мультимастер-кластере все узлы являются ведущими. Такой подход упрощает построение и эксплуатацию отказоустойчивой конфигурации, а также позволяет проводить обновление версий СУБД без остановки системы. В Postgres Pro Enterprise 11 модуль мультимастера обновлен с целью повышения надежности и сокращения системных требований.
Postgres Pro Enterprise 11 включает поддержку расширенного управления доступом, в том числе на уровне отдельных записей. Также добавлена поддержка семейства криптографических функций SHA2 (sha224, sha256, sha384 и sha512) с целью повышения надежности хранения хешей паролей.
Краткая история Postgres Pro и PostgreSQL
Postgres Pro Enterprise – это российская коммерческая система управления базами данных для крупных клиентов, базирующаяся на свободной СУБД PostgreSQL. Возможности СУБД расширены за счет доработки ядра и включают компрессию данных на уровне блоков, 64-битный счетчик транзакций и прочие функции.
Как пандемия изменила подходы к организации рабочего пространства
БизнесСУБД сертифицирована ФСТЭК, поэтому может применяться для защиты информации, в ГИС и АСУ до первого класса защищенности, а также обеспечения до первого уровня защищенности персональных данных в ИС, для которых к актуальным отнесены угрозы первого, второго или третьего типа.
Российский продукт разработан компанией Postgres Professional, созданной в начале 2015 г. Учредителями выступили ведущие на тот момент разработчики PostgreSQL Олег Бартунов, Федор Сигаев, Александр Коротков, разработчик Иван Панченко, а также инвестор проекта Антон Сушкевич, основатель интегратора «Энвижн груп».
На фото: генеральный директор Postgres Professional Олег Бартунов (в центре)
Основа отечественной Postgres Pro Enterprise – PostgreSQL — реляционная СУБД, написанная одноименным сообществом разработчиков. Разработка PostgreSQL восходит к проекту POSTGRES, который стартовал в Калифорнийском университете в Беркли, США, в 1986 г. Проект спонсировали американские госведомства, в том числе Министерство обороны США. Разработкой руководил
POSTGRES использовалась в области анализа финансовых данных и работы с реактивными двигателями. На нем работали базы данных наблюдений за астероидами и медицинской информации, а также ряд геоинформационных систем. В 1993 г. разработку системы прекратили, последней версией стала 4.2.
В 1994 г. Эндрю Ю (Andrew Yu) и Джолли Чен (Jolly Chen) модифицировали POSTGRES, добавив в него интерпретатор языка SQL. Система получила название Postgres95 и стала распространяться с открытым кодом.
Система получила название Postgres95 и стала распространяться с открытым кодом.
В 1996 г. проект был переименован в PostgreSQL. В этот же период была восстановлена нумерация версий, восходящая к POSTGRES. Если Postgres95 фокусировался на поиске проблем в серверном коде, то PostgreSQL — на расширении функциональности.
Дмитрий Степанов
Решения на СУБД PostgreSQL – КОРУС Консалтинг
Описание
Система управления базами данных PostgreSQL уже давно используется специалистами в высоконагруженных средах.
СУБД PostgreSQL оценивается ИТ-экспертами, как решение, не уступающее по своим функциональным характеристикам проприетарного ПО от ведущих западных разработчиков.
Преимущества СУБД PostgreSQL
- Высокая производительность и отказоустойчивость баз данных.
- Широкий спектр встроенных языков программирования с возможностью расширения и загрузки совместимых модулей.
- Простота масштабирования и тиражирования.
- Открытое программное обеспечение, прекрасно удовлетворяющее требованиям политики импортозамещения.
Миграция на СУБД PostgreSQL
- Анализ имеющихся прикладных систем на базе Oracle, MS SQL, DB2 и определение сложности их миграции с коммерческих СУБД на PostgreSQL.
- Определение архитектуры нового решения и требований к доработкам прикладных систем.
- Внедрение СУБД PostgreSQL в соответствии с техническим заданием.
Промышленные решения на СУБД PostgreSQL
- Проектирование и участие в создании критичных высоконагруженных систем с использованием СУБД PostgreSQL.

- Определение архитектуры СУБД и ее настроек для решения поставленной задачи.
- Внедрение СУБД в соответствии с проектом.

СУБД Postgres Pro доступна в трёх вариантах: Standard, Certified, Enterprise.
Системы управления базами данных «Postgres Professional»
Call-Центр
Санкт-Петербург:
Бесплатно по всей РФ:
Время работы Call-Центра:
Пн-Пт: с 09:00 до 19:00
Пятница: с 9:00 до 18:00
Сб, Вск — выходные дни
Точки самовывоза
Москва
117335 г.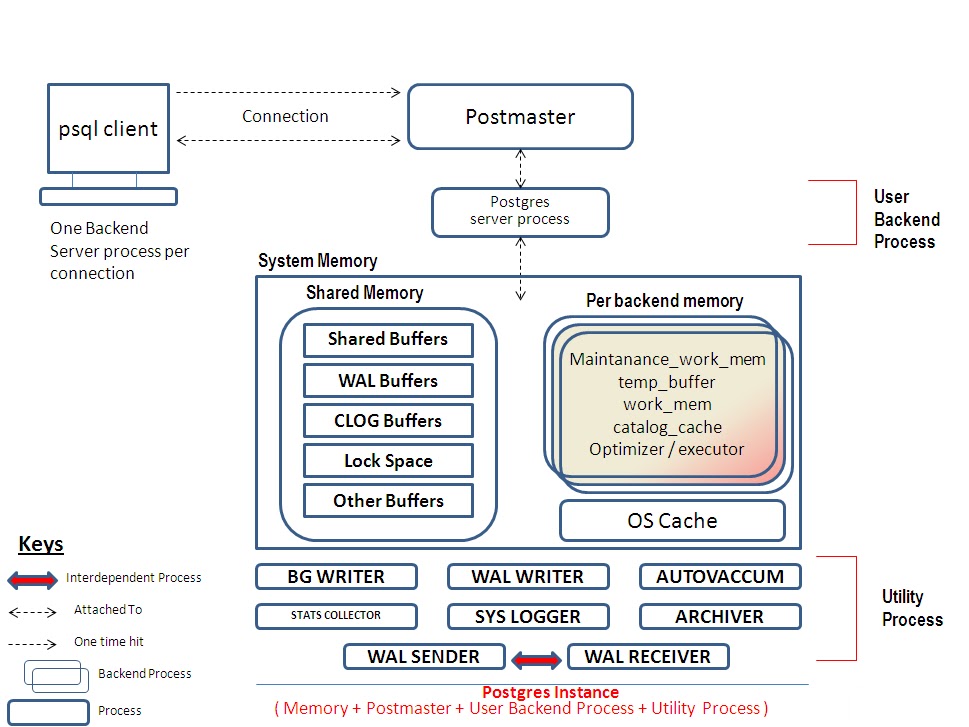
Время работы:
Пн-Пт: с 09:00 до 19:00
Пятница: с 9:00 до 18:00
Сб, Вск — выходные дни
Санкт-Петербург
196084, г. Санкт-Петербург, ул. Малая Митрофаньевская, д.4, лит. А, офис 401
Пн-Пт: с 09:00 до 19:00
Пятница: с 9:00 до 18:00
Сб, Вск — выходные дни
Услуги и поддержка
Отзывы ЯндексМаркет:
Мы в соц. сетях:
сетях:
СУБД PostgreSQL — Джино • Хостинг
PostgreSQL — высокопроизводительная и надежная СУБД (Система Управления Базами Данных). На данный момент не все CMS и блоговые движки по-умолчанию поддерживают эту СУБД в качестве хранилища своих данных, но если вы столкнетесь с необходимостью использовать PostgreSQL в своих проектах, то всегда сможете подключить соответствующую услугу в разделе «Хостинг / Услуги» контрольной панели.
При подключении услуги вы можете выбрать несколько вариантов дискового пространства под PostgreSQL, от 25 до 80 Гб. Для начала большинству пользователей подойдет минимальный вариант — 25 Гб, однако это значение при необходимости можно в любой момент увеличить.
Базы данных PostgreSQL на хостинге «Джино» размещаются на высокопроизводительных SSD-накопителях. Это позволило существенно увеличить скорость работы динамических сайтов по сравнению с аналогичными сайтами, чьи базы данных располагаются на традиционных жестких магнитных дисках.
Это позволило существенно увеличить скорость работы динамических сайтов по сравнению с аналогичными сайтами, чьи базы данных располагаются на традиционных жестких магнитных дисках.
При подключении данной услуги автоматически создается одна база данных (БД), ее имя совпадает с логином аккаунта. Через контрольную панель в разделе «Хостинг / Управление / Управление PostgreSQL» вы можете создавать дополнительные БД, все они будут иметь имена вида логин_имяБД, а их количество зависит от подключенного варианта услуги. Создавать БД прямым SQL-запросом (CREATE DATABASE …) нельзя.
По умолчанию имя пользователя автоматически созданной БД и его пароль также совпадают с логином и паролем аккаунта, однако в целях безопасности мы настоятельно рекомендуем сразу же сменить пароль пользователя БД, чтобы сделать их разными. Сменить пароль можно в контрольной панели в разделе «Хостинг / Управление / Управление PostgreSQL».
По умолчанию доступ к базам данных вашего аккаунта возможен только с того же сервера, на котором этот аккаунт находится. Если же вам нужно обращаться к БД извне (например, для использования PostgreSQL-менеджеров на локальном компьютере), то вы можете открыть доступ для отдельных IP-адресов или подсетей класса C — это делается в разделе «Хостинг / Управление / Управление PostgreSQL / Доступ по IP». Для удаленного подключения к PostgreSQL используйте домен postgresql.логин.myjino.ru, где логин — ваш логин на «Джино».
Если же вам нужно обращаться к БД извне (например, для использования PostgreSQL-менеджеров на локальном компьютере), то вы можете открыть доступ для отдельных IP-адресов или подсетей класса C — это делается в разделе «Хостинг / Управление / Управление PostgreSQL / Доступ по IP». Для удаленного подключения к PostgreSQL используйте домен postgresql.логин.myjino.ru, где логин — ваш логин на «Джино».
Настройка приложений
Для того, чтобы ваши приложения или скрипты могли использовать БД, их надо соответствующим образом настроить. Это делается в конфигурационном файле приложения, который обычно называется config.php, configuration.php или т. п. Для настройки скрипта впишите в этот файл следующие параметры:
- Имя сервера (хост) или сокет: /var/run/postgresql
- Имя пользователя БД: совпадает с логином или имеет вид логин_имяпользователяБД (см. выше)
- Пароль: пароль к вашей БД (см. выше)
- Имя БД: совпадает с логином или имеет вид логин_имяБД (см. выше)
 выше)
выше)Postgres Pro Enterprise для 1С:Предприятие — лицензия, русская версия, цена
Сколько стоит купить лицензию, варианты поставки
- Артикул: PPC-86-LIC
- НДС: Не облагается
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания:
Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу. Поддержка на 12 месяцев входит в стоимость.
- Платформа: Linux/Windows
- Тип лицензии: Постоянная
- Тип покупателя: Коммерческая
- Доступна оплата картой
 Поддержка на 12 месяцев входит в стоимость.
Поддержка на 12 месяцев входит в стоимость.- Артикул: SUP-PPC-86-1
- НДС: 20 % (включен в стоимость)
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии:
12 мес.
- Тип покупателя: Коммерческая
- Доступна оплата картой
- Артикул: SUP-PPC-86-2
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии:
24 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
- Артикул: SUP-PPC-86-3
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии:
36 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
- Артикул: SUP-PPC-86-4
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии:
48 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
- Артикул: SUP-PPC-86-5
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии:
60 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
- Артикул: PPC-86-LIC-1Y
- НДС: Не облагается
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания:
Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу. Включает техническую поддержку на срок действия лицензии.
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии: 12 мес.
- Тип покупателя: Коммерческая
- Доступна оплата картой
 Включает техническую поддержку на срок действия лицензии.
Включает техническую поддержку на срок действия лицензии.- Артикул: PPC-86-LIC-2Y
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу. Включает техническую поддержку на срок действия лицензии.
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии: 24 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
- Артикул: PPC-86-LIC-3Y
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу. Включает техническую поддержку на срок действия лицензии.
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии: 36 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
- Артикул: PPC-86-LIC-4Y
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу. Включает техническую поддержку на срок действия лицензии.
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии: 48 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
- Артикул: PPC-86-LIC-5Y
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Учитываются аппаратные ядра или виртуальные ядра, выделенные виртуальному серверу. Включает техническую поддержку на срок действия лицензии.
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии: 60 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
- Артикул: PPC-SRV-LIC
- НДС: Не облагается
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: На каждый аппаратный сервер или виртуальную машину на которой запускается СУБД требуется отдельная лицензия. Дополнительно требуется приобрести лицензии на то количество пользователей которое работает с платформой 1С. Поддержка на 12 месяцев входит в стоимость.
- Платформа: Linux/Windows
- Тип лицензии: Постоянная
- Тип покупателя: Коммерческая
- Доступна оплата картой
- Артикул: PPC-USR-1
- НДС: Не облагается
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Необходимо приобрести лицензии на то число пользователей, что и на платформе 1С:Предприятие. Пользовательские лицензии приобретаются на все серверы работающие с платформой. Если вы организуете кластер СУБД, то на каждый сервер кластера необходимо приобрести столько лицензий пользователей, сколько их куплено на 1С: предприятие. Поддержка на 12 месяцев входит в стоимость.
- Платформа: Linux/Windows
- Тип лицензии: Постоянная
- Тип покупателя: Коммерческая
- Доступна оплата картой
- Артикул: SUP-PPC-SRV-LIC
- НДС: 20 % (включен в стоимость)
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Приобретается на 2-й и последующие годы эксплуатации
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии: 12 мес.
- Тип покупателя: Коммерческая
- Доступна оплата картой
- Артикул: SUP-PPC-USR-1
- НДС: 20 % (включен в стоимость)
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Приобретается на 2-й и последующие годы эксплуатации
- Платформа: Linux/Windows
- Тип лицензии: Временная
- Срок действия лицензии: 12 мес.
- Тип покупателя: Коммерческая
- Доступна оплата картой
Мы используем файлы cookies для сбора информации с целью улучшения нашего сайта. Вы можете принять или отказаться от использования файлов cookies, нажав на кнопки ниже, а также можете ознакомиться с нашей Политикой использования файлов cookies. Опция «отказаться» применяется по умолчанию при отсутствии выбора.
‘; html += ‘Подтвердите свое согласие с условиями политики конфиденциальности
‘; html += »; html += »; html += »; html += ‘PostgreSQL
PostgreSQL — одна из систем управления базами данных, которую поддерживает платформа в клиент-серверном варианте работы.
При этом Фирма «1С», занимаясь поддеркой PostgreSQL, выпускает PostgreSQL от 1С.
Свежие версии PostgreSQL от 1С публикуются на портале 1С в разделе «1С:Обновление программ».
Публикуются готовые к использованию сборки PostgreSQL от 1С с патчами, обеспечивающими совместимость с платформой 1С:Предприятие, а также значительно повышающими производительность PostgreSQL при работе в типовых сценариях использования продуктов фирмы «1С».
Кроме того публикуется исходный код патчей и инструкция по сборке PostgreSQL.
На ресурсе 1С:ИТС публикуются методики и инструкции по настройке и использованию PostgreSQL.
Также вы можете принять участие в бета-тестировании новых версий PostgreSQL от 1С. Вы получите квалифицированную поддержку инженеров фирмы «1С», возможность внести реальный вклад и получить более качественную версию PostgreSQL, работающую именно на ваших сценариях в вашей системе.
Ключевые особенности PostgreSQL от 1С:
- включает патчи с оптимизациями, выполненными разработчиками платформы 1С:Предприятия, которые учитывают особенности работы платформы 1С:Предприятие и типовых решений фирмы «1С»;
- бесплатное использование PostgreSQL от 1С в промышленных коммерческих системах;
- квалифицированная поддержка инженеров фирмы «1С»;
- возможность бесплатного участия в пилотных проектах по переходу на PostgreSQL от 1С;
- публикуется как в готовом для использования виде, так и в исходном коде;
- используется в системах тестирования продуктов фирмы «1С» перед их выпуском;
- обучение на официальных курсах в УЦ 1С: «Подготовка к 1С:Эксперту по технологическим вопросам. Применение методик», «Эксплуатация крупных информационных систем»;
- используется фирмой «1С» в своих высоконагруженных коммерческих проектах, например, 1С:Fresh.
PostgreSQL: Документация: 11: 16.4. Процедура установки
--with-extra-version = STRING Добавьте STRING к номеру версии PostgreSQL. Вы можете использовать это, например, чтобы пометить двоичные файлы, созданные из невыпущенных моментальных снимков Git или содержащие пользовательские исправления, дополнительной строкой версии, такой как git describe идентификатор или номер выпуска пакета распространения.
--with-includes = СПРАВОЧНИКИ КАТАЛОГИ — это список каталогов, разделенных двоеточиями, которые будут добавлены в список, который компилятор будет искать в файлах заголовков. Если у вас есть дополнительные пакеты (такие как GNU Readline), установленные в нестандартном месте, вы должны использовать эту опцию, а также, возможно, соответствующую опцию --with-libraries .
Пример: --with-includes = / opt / gnu / include: / usr / sup / include .
--with-libraries = КАТАЛОГ КАТАЛОГИ — это список каталогов, разделенных двоеточиями, для поиска библиотек. Вам, вероятно, придется использовать эту опцию (и соответствующую опцию --with-includes ), если у вас установлены пакеты в нестандартных местах.
Пример: --with-libraries = / opt / gnu / lib: / usr / sup / lib .
--enable-nls [= ЯЗЫКИ ] Включает поддержку родного языка (NLS), то есть возможность отображать сообщения программы на языке, отличном от английского. LANGUAGES — это необязательный разделенный пробелами список кодов языков, которые вы хотите поддерживать, например --enable-nls = 'de fr' .(Пересечение между вашим списком и набором фактически предоставленных переводов будет вычислено автоматически.) Если вы не укажете список, будут установлены все доступные переводы.
Чтобы использовать эту опцию, вам потребуется реализация Gettext API; см. выше.
--with-pgport = НОМЕР Установите НОМЕР в качестве номера порта по умолчанию для сервера и клиентов.Значение по умолчанию — 5432. Порт всегда можно изменить позже, но если вы укажете его здесь, то и сервер, и клиенты будут иметь одинаковые значения по умолчанию, скомпилированные по умолчанию, что может быть очень удобно. Обычно единственная веская причина для выбора значения, отличного от значения по умолчанию, — это если вы собираетесь запускать несколько серверов PostgreSQL на одном компьютере.
- с Perl Создайте серверный язык PL / Perl.
- с питоном Создайте серверный язык PL / Python.
- с-tcl Создайте серверный язык PL / Tcl.
--with-tclconfig = КАТАЛОГ Tcl устанавливает файл tclConfig.sh , который содержит информацию о конфигурации, необходимую для создания модулей, взаимодействующих с Tcl. Этот файл обычно автоматически находится в известном месте, но если вы хотите использовать другую версию Tcl, вы можете указать каталог, в котором его искать.
--with-gssapi Сборка с поддержкой аутентификации GSSAPI. Во многих системах система GSSAPI (обычно являющаяся частью установки Kerberos) не установлена в месте, которое ищется по умолчанию (например, / usr / include , / usr / lib ), поэтому вы должны использовать опции --with-includes и --with-libraries в дополнение к этой опции. configure проверит наличие необходимых файлов заголовков и библиотек, чтобы убедиться, что ваша установка GSSAPI достаточна, прежде чем продолжить.
--with-krb-srvnam = НАИМЕНОВАНИЕ Имя по умолчанию участника службы Kerberos, используемое GSSAPI. postgres — значение по умолчанию. Обычно нет причин менять это, если у вас нет среды Windows, и в этом случае он должен быть установлен в верхний регистр POSTGRES .
- с LLVM Сборка с поддержкой JIT-компиляции на основе LLVM (см. Главу 32).Для этого необходимо установить библиотеку LLVM. Минимальная необходимая версия LLVM в настоящее время — 3.9.
llvm-config будет использоваться для поиска необходимых параметров компиляции. llvm-config , а затем llvm-config- $ major- $ minor для всех поддерживаемых версий, будет выполняться поиск по PATH . Если это не приведет к получению правильного двоичного файла, используйте LLVM_CONFIG , чтобы указать путь к правильному llvm-config . Например
./ configure ... --with-llvm LLVM_CONFIG = '/ путь / к / llvm / bin / llvm-config'Для поддержки
LLVM требуется совместимый компилятор clang (при необходимости указывается с использованием переменной среды CLANG ) и рабочий компилятор C ++ (при необходимости указывается с помощью переменной среды CXX ).
- с icu Сборка с поддержкой библиотеки ICU.Для этого необходимо установить пакет ICU4C. Минимальная необходимая версия ICU4C в настоящее время — 4.2.
По умолчанию для поиска необходимых параметров компиляции будет использоваться pkg-config. Это поддерживается для ICU4C версии 4.6 и более поздних. Для более старых версий или если pkg-config недоступен, переменные ICU_CFLAGS и ICU_LIBS можно указать для configure , как в этом примере:
./configure ... --with-icu ICU_CFLAGS = '- I / some / where / include' ICU_LIBS = '- L / some / where / lib -licui18n -licuuc -licudata'
(Если ICU4C находится в пути поиска по умолчанию для компилятора, вам все равно нужно указать непустую строку, чтобы избежать использования pkg-config, например, ICU_CFLAGS = '' .)
- с openssl Сборка с поддержкой SSL (зашифрованных) соединений. Для этого необходимо установить пакет OpenSSL. configure проверит наличие необходимых файлов заголовков и библиотек, чтобы убедиться, что вашей установки OpenSSL достаточно, прежде чем продолжить.
--with-pam с поддержкой PAM (подключаемых модулей аутентификации).
- с-bsd-auth Сборка с поддержкой аутентификации BSD. (Фреймворк BSD Authentication в настоящее время доступен только в OpenBSD.)
- с-ldap Build с поддержкой LDAP для аутентификации и поиска параметров соединения (дополнительную информацию см. В Разделе 34.17 и Разделе 20.10). В Unix для этого требуется установить пакет OpenLDAP.В Windows используется библиотека WinLDAP по умолчанию. configure проверит наличие необходимых файлов заголовков и библиотек, чтобы убедиться, что вашей установки OpenLDAP достаточно, прежде чем продолжить.
- с системой Сборка с поддержкой сервисных уведомлений systemd. Это улучшает интеграцию, если двоичный файл сервера запускается под systemd, но в противном случае не влияет; см. Раздел 18.3 для получения дополнительной информации.Для использования этой опции необходимо установить libsystemd и связанные файлы заголовков.
- без строки чтения Запрещает использование библиотеки Readline (а также libedit). Эта опция отключает редактирование командной строки и историю в psql, поэтому не рекомендуется.
--with-libedit-preferred Поддерживает использование библиотеки libedit под лицензией BSD, а не Readline под лицензией GPL.Этот параметр имеет значение, только если у вас установлены обе библиотеки; по умолчанию в этом случае используется Readline.
- с Bonjour Сборка с поддержкой Bonjour. Для этого требуется поддержка Bonjour в вашей операционной системе. Рекомендуется для macOS.
--with-uuid = БИБЛИОТЕКА Создайте модуль uuid-ossp (который предоставляет функции для генерации UUID), используя указанную библиотеку UUID. БИБЛИОТЕКА должна быть одной из:
bsdдля использования функций UUID, имеющихся во FreeBSD, NetBSD и некоторых других системах, основанных на BSDe2fsдля использования библиотеки UUID, созданной проектомe2fsprogs; эта библиотека присутствует в большинстве систем Linux и в macOS, а также может быть получена для других платформ.osspдля использования библиотеки OSSP UUID
--with-ossp-uuid Устаревший эквивалент --with-uuid = ossp .
- с-libxml Сборка с libxml2, включающая поддержку SQL / XML. Для этой функции требуется Libxml2 версии 2.6.23 или более поздней.
Чтобы определить необходимые параметры компилятора и компоновщика, PostgreSQL запросит pkg-config , если он установлен и знает о libxml2. В противном случае будет использована программа xml2-config , установленная libxml2, если она будет найдена.Использование pkg-config является предпочтительным, поскольку он лучше справляется с установками с несколькими архитектурами.
Чтобы использовать установку libxml2 в необычном месте, вы можете установить переменные среды, связанные с pkg-config (см. Ее документацию), или установить переменную среды XML2_CONFIG так, чтобы она указывала на программу xml2-config , принадлежащую в установку libxml2 или установите переменные XML2_CFLAGS и XML2_LIBS .(Если установлен pkg-config , то, чтобы изменить его представление о том, где находится libxml2, вы должны либо установить XML2_CONFIG , либо установить для XML2_CFLAGS и XML2_LIBS непустые строки.)
- с-libxslt Используйте libxslt при сборке модуля xml2. xml2 полагается на эту библиотеку для выполнения XSL-преобразований XML.
--disable-float4-byval Отключить передачу значений float4 «по значению», вместо этого они будут передаваться «по ссылке».Эта опция снижает производительность, но может потребоваться для совместимости со старыми пользовательскими функциями, написанными на C и использующими соглашение о вызовах «версии 0». Лучшее долгосрочное решение — обновить любые такие функции, чтобы использовать соглашение о вызовах «версии 1».
--disable-float8-byval Отключить передачу значений float8 «по значению», вместо этого они будут передаваться «по ссылке». Эта опция снижает производительность, но может потребоваться для совместимости со старыми пользовательскими функциями, написанными на C и использующими соглашение о вызовах «версии 0».Лучшее долгосрочное решение — обновить любые такие функции, чтобы использовать соглашение о вызовах «версии 1». Обратите внимание, что этот параметр влияет не только на float8, но также на int8 и некоторые связанные типы, такие как timestamp. На 32-битных платформах --disable-float8-byval является значением по умолчанию, и нельзя выбирать --enable-float8-byval .
--with-segsize = SEGSIZE Установите размер сегмента в гигабайтах.Большие таблицы делятся на несколько файлов операционной системы, размер каждого из которых равен размеру сегмента. Это позволяет избежать проблем с ограничениями размера файлов, которые существуют на многих платформах. Размер сегмента по умолчанию, 1 гигабайт, безопасен для всех поддерживаемых платформ. Если ваша операционная система поддерживает «большие файлы» (а в настоящее время большинство из них поддерживает), вы можете использовать сегмент большего размера. Это может быть полезно для уменьшения количества файловых дескрипторов, используемых при работе с очень большими таблицами. Но будьте осторожны и не выбирайте значение больше, чем поддерживается вашей платформой и файловыми системами, которые вы собираетесь использовать.Другие инструменты, которые вы, возможно, захотите использовать, например tar, также могут установить ограничения на размер файла, который можно использовать. Рекомендуется, хотя и не обязательно, чтобы это значение было степенью 2. Обратите внимание, что для изменения этого значения требуется initdb.
--with-blockize = BLOCKSIZE Установите размер блока в килобайтах. Это единица хранения и ввода-вывода в таблицах. Значение по умолчанию 8 килобайт подходит для большинства ситуаций; но в особых случаях могут быть полезны другие значения.Значение должно быть степенью двойки от 1 до 32 (килобайт). Обратите внимание, что для изменения этого значения требуется initdb.
--with-wal-blockize = BLOCKSIZE Установите размер блока WAL в килобайтах. Это единица хранения и ввода-вывода в журнале WAL. Значение по умолчанию 8 килобайт подходит для большинства ситуаций; но в особых случаях могут быть полезны другие значения. Значение должно быть степенью двойки от 1 до 64 (килобайт).Обратите внимание, что для изменения этого значения требуется initdb.
- отключение спин-блокировок Разрешить успешную сборку, даже если PostgreSQL не поддерживает спин-блокировку ЦП для платформы. Отсутствие поддержки спин-блокировки приведет к снижению производительности; поэтому этот параметр следует использовать только в том случае, если сборка прерывается и сообщает вам, что платформа не поддерживает спин-блокировку. Если эта опция необходима для сборки PostgreSQL на вашей платформе, сообщите о проблеме разработчикам PostgreSQL.
- отключение сильного случайного Разрешить успешную сборку, даже если PostgreSQL не поддерживает сильные случайные числа на платформе. Источник случайных чисел необходим для некоторых протоколов аутентификации, а также для некоторых подпрограмм в модуле pgcrypto. --disable-strong-random отключает функциональность, которая требует криптографически стойких случайных чисел, и заменяет слабый генератор псевдослучайных чисел для генерации значений соли аутентификации и ключей отмены запроса.Это может сделать аутентификацию менее безопасной.
- отключение безопасности потока Отключить потокобезопасность клиентских библиотек. Это не позволяет параллельным потокам в программах libpq и ECPG безопасно контролировать свои личные дескрипторы подключения.
--with-system-tzdata = СПРАВОЧНИК PostgreSQL включает собственную базу данных часовых поясов, которая требуется для операций с датой и временем.Эта база данных часовых поясов фактически совместима с базой данных часовых поясов IANA, предоставляемой многими операционными системами, такими как FreeBSD, Linux и Solaris, поэтому повторная установка будет излишней. Когда используется эта опция, база данных часовых поясов, предоставляемая системой в DIRECTORY , используется вместо той, которая включена в исходный дистрибутив PostgreSQL. КАТАЛОГ должен быть указан как абсолютный путь. / usr / share / zoneinfo — вероятный каталог в некоторых операционных системах.Обратите внимание, что процедура установки не обнаружит несоответствия или ошибочных данных часового пояса. Если вы используете эту опцию, вам рекомендуется запустить регрессионные тесты, чтобы убедиться, что данные часового пояса, на которые вы указали, правильно работают с PostgreSQL.
Этот вариант в основном предназначен для распространителей двоичных пакетов, которые хорошо знают свою целевую операционную систему. Основное преимущество использования этой опции заключается в том, что пакет PostgreSQL не нужно обновлять при изменении любого из многих местных правил перехода на летнее время.Еще одно преимущество состоит в том, что PostgreSQL может быть более просто скомпилирован, если файлы базы данных часовых поясов не нужно создавать во время установки.
- без злиб Запрещает использование библиотеки Zlib. Это отключает поддержку сжатых архивов в pg_dump и pg_restore. Эта опция предназначена только для тех редких систем, где эта библиотека недоступна.
- включить-отладку Компилирует все программы и библиотеки с отладочными символами.Это означает, что вы можете запускать программы в отладчике для анализа проблем. Это значительно увеличивает размер установленных исполняемых файлов, а на компиляторах, отличных от GCC, это обычно также отключает оптимизацию компилятора, вызывая замедление. Однако наличие доступных символов чрезвычайно полезно для решения любых проблем, которые могут возникнуть. В настоящее время этот вариант рекомендуется для производственных установок, только если вы используете GCC. Но он всегда должен быть включен, если вы занимаетесь разработкой или запускаете бета-версию.
- включить покрытие При использовании GCC все программы и библиотеки скомпилированы с помощью инструментов тестирования покрытия кода. При запуске они создают файлы в каталоге сборки с метриками покрытия кода. За дополнительными сведениями обратитесь к Разделу 33.5. Эта опция предназначена только для использования с GCC и при разработке.
- включить профилирование При использовании GCC все программы и библиотеки скомпилированы, чтобы их можно было профилировать.При выходе из серверной части будет создан подкаталог, содержащий файл gmon.out для использования при профилировании. Эта опция предназначена только для использования с GCC и при разработке.
- включить-cassert Разрешает утверждение . проверяет на сервере, что проверяет наличие многих условий «не может произойти». Это бесценно для целей разработки кода, но тесты могут значительно замедлить работу сервера.Кроме того, включение тестов не обязательно повысит стабильность вашего сервера! Проверки утверждений не классифицируются по степени серьезности, поэтому то, что может быть относительно безвредной ошибкой, все равно приведет к перезапуску сервера, если она вызовет сбой утверждения. Этот параметр не рекомендуется для производственного использования, но вы должны включить его для разработки или при запуске бета-версии.
- включить-зависит Включает автоматическое отслеживание зависимостей.С этой опцией make-файлы настраиваются таким образом, что все затронутые объектные файлы будут перестроены при изменении любого файла заголовка. Это полезно, если вы занимаетесь разработкой, но это просто лишние накладные расходы, если вы собираетесь скомпилировать и установить только один раз. В настоящее время эта опция работает только с GCC.
- включить-dtrace Компилирует PostgreSQL с поддержкой инструмента динамической трассировки DTrace. См. Раздел 28.5 для получения дополнительной информации.
Чтобы указать на программу dtrace , можно установить переменную среды DTRACE . Это часто бывает необходимо, потому что dtrace обычно устанавливается в каталоге / usr / sbin , который может отсутствовать в пути.
Дополнительные параметры командной строки для программы dtrace можно указать в переменной среды DTRACEFLAGS . В Solaris, чтобы включить поддержку DTrace в 64-битный двоичный файл, необходимо указать DTRACEFLAGS = "- 64" для настройки.Например, используя компилятор GCC:
./configure CC = 'gcc -m64' --enable-dtrace DTRACEFLAGS = '- 64' ...
Использование компилятора Sun:
./configure CC = '/ opt / SUNWspro / bin / cc -xtarget = native64' --enable-dtrace DTRACEFLAGS = '- 64' ...
- испытания с возможностью отпирания Включите тесты с помощью инструментов Perl TAP. Для этого требуется установка Perl и модуль Perl IPC :: Run .См. Раздел 33.4 для получения дополнительной информации.
Сравнение MySQL и PostgreSQL. Выбрать subd между mysql, postgresql, mariadb и mssql? Сравнение производительности ms sql server и postgresql
Скажем честно, хотя 1С Предприятие совместимо со многими СУБД, на самом деле 99 процентов работают либо в MS SQL, либо в бесплатном PostgreSQL.
Иными словами, эти два «недешевых» завоевали рынок клиент-серверной 1С.
И можно смело предположить, что если компания не работает в MS SQL, то, скорее всего, они просто используют PostgreSQL.
Соответственно, Postgres имеет смысл сравнивать только с MS SQL.
Сегодня много пишут как о MS SQL, так и о PostgreSQL, но обычно объективно их не сравнивают.
В этой статье мы разберем основные технические моменты бесплатного PostgreSQL, сравнив его с MS SQL.
Что позволит вам в будущем сделать лучший выбор и быть готовым к различным «сюрпризам» или, что вернее, к «особенностям» работы в этой бесплатной СУБД.
Оценим все как есть, не добавляя Постгресу тех достоинств, которых у него нет и не приукрашивая платный MS.
Сразу отвечу на вопрос, волнующий многих новичков!
ДА! MS SQL работает быстрее PostgreSQL, это факт! И тому есть ряд причин!
Возможно, я сразу кого-то разочаровал, а возможно, вы не согласны с этим утверждением, прошу прощения, но сама физика этой бесплатной СУБД не позволяет ей опередить MS SQL, особенно если речь идет о такой связке, как «Monster» 1С »и PostgreSQL .
Подобные рассуждения часто встречаются на различных конференциях и семинарах, посвященных этой СУБД. Никто ничего не скрывает и не отрицает; факт есть факт.
Однако производительность PostgreSQL достаточно хороша для пользователей, чтобы мог комфортно работать в 1С.
Будь то десяток пользователей или даже несколько сотен одновременно работающих в 1С Предприятие.
Почему «Монстр 1С»?
Вот так 1С видит PostgreSQL без установки каких-либо специальных патчей и расширений.
Да как говорится из коробки, скачав раздачу PostgreSQL на оф. сайт, вы не сможете использовать его для работы совместно с 1С. 1С будет жутко тормозить и просто остановится, откажется работать.
Почему это происходит и зачем нужны патчи?
Дело в том, что 1С Предприятие создает в процессе своей работы огромное количество временных таблиц, можно говорить о тысячах таблиц в секунду, а если взять, например, регистр «Срез последних» — «Остатки». и обороты », вполне может быть и миллион строк.
Дело в том, что по умолчанию (без «патчей») PostgreSQL не считает статистику по этим большим временным таблицам, то есть оптимизатор запросов, ориентирующийся на данные из статистики (а, как вы помните, пусто, есть нечего считать), грубо говоря, делает выбор по методу SELECT * который конечно будет работать очень и очень медленно!
Отсюда и грандиозные тормоза в 1С!
Конечно, это далеко не все проблемы, которые нужно решить, чтобы PostgreSQL нормально работал в тандеме с 1С.Нам понадобятся другие «патчи» и специальные расширения, а после 15-20 пользователей — все больше и больше. настройки в «конфиге»
Да, на самом деле все выглядит намного сложнее, чем я описал выше, но именно так, если сильно упростить, будет выглядеть основная проблема медленной работы 1С с PostgreSQL.
Второе, что мне сильно не нравится в PostgreSQL, — это отсутствие многопоточности в рамках одного запроса по сравнению с MS SQL.
(Начиная с версии 9.6, мы сделали первую попытку распараллелить запросы, но пока не получается, иногда эффект обратный). но за попытку 5!)
Что конечно влияет на производительность, чтобы вы понимали простыми словами —
PostgreSQL может остановить ваш 48-ядерный сервер одним большим запросом!
Все просто, в одном запросе нет распараллеливания потоков, а один большой запрос «загружает» только одно ядро.
Да, если запросов много, то все ядра загрузятся и все будет нормально работать.
И чуть не забыл сравниваем PostgreSQL с MS SQL Standard, а не Express!
Express хоть и может использоваться в коммерческих целях, но имеет ряд ограничений.
, например, 10 ГБ на базу, использование одного процессора, 1 ГБ ОЗУ,
делает использование такого продукта практически нереальным для работы в 1С Предприятие.
Разве что у вас очень маленькая база и всего пара пользователей (да и то тормозов СУБД на 1 Гбайт очень мало).
Итак, сравним PostgreSQL с популярной версией Standard.
СКРИПТЫ !!!
PostgreSQL — это в первую очередь скрипты по сравнению с MS SQL, большинство операций приходится выполнять вручную, да, конечно, вы можете установить некоторые базовые вещи через интерфейс, но я подчеркиваю, что базовый, и шаг влево — это шаг справа, и вам нужно написать скрипт или BASH в Linux или cmd, powershell в Windows.
Просмотр и анализ трассировок с помощью SQL Server Profiler.
Хорошо известный SQL Server Profiler отсутствует в PostgreSQL, и под словом «отсутствует» я представлю полностью, увы, в PostgreSQL ничего подобного нет.
Есть, конечно, утилиты, позволяющие, если успеешь перехватить запрос или выставить в отладчике точку останова 1С, получить что-то и посмотреть, но по сравнению с Profiler, как говорится, даже близко не было.
Вы можете настроить журнал, а затем перебирать его все — но надолго!
Вот пример:
Программист 1С пытается отладить какой-то большой запрос, это занимает много времени, например 30 минут, и поэтому в PostgreSQL, чтобы данные попали в журнал, этот запрос нужно выполнить! Представляете, сколько времени можно отлаживать такой запрос?
Находясь в MS SQL, вы можете прервать выполнение запроса и проанализировать его в профилировщике, так как он уже будет там, но со статусом «сбой».
По типу «резервных копий» Postgres не имеет себе равных!
Здесь у вас будет инкрементная резервная копия, полная резервная копия и непрерывное архивирование WAL.
По сути, есть частичное резервное копирование и частичное восстановление данных.
Настроить непрерывное архивирование и восстановление на определенный момент времени (Восстановление на момент времени (PITR)) .
Также репликация , доступная изначально в PostgreSQl без каких-либо «патчей» утилит и дополнений!
- Каскадная репликация
- Потоковая репликация
- Синхронная репликация
- Непрерывное архивирование на резервном сервере
Все это есть, уже изначально в PostgreSQl и, конечно, не в «экспрессе» и недоступно в версии MS SQL Standard.
Чтобы получить все вышеперечисленное в MS SQL, вам нужно купить очень дорогой MS SQL Enterprise, который сейчас стоит около 15 000 долларов.
Чего не хватает по сравнению с MS SQL?
НЕТ дифференциальной «резервной копии»
Да, в PostgreSQl нет дифференциального «бэкапа», но есть разные аналоги инкрементных «бэкапов».
Например, инкрементное резервное копирование на уровне блоков.
ЕСТЬ раздел TABLESPACE, который уже по умолчанию поддерживает 1С!
Которого, кстати, нет в MS SQL!
Например, вы можете настроить, на каком диске у вас будут «индексы» и на каком диске будет располагаться «таблица», это очень удобно при планировании ИТ-инфраструктуры, когда речь идет о больших базах 1С.ONLINE_ANALYZE для пересчета статистики. То же самое и с файлом * dt.
Используя PostgreSQl, вам редко понадобится REINDEX!
Фактически, его следует использовать только тогда, когда есть подозрение, что целостность базы данных была нарушена.
Можно делать «бэкапы» за исключением таблиц!
Например, у вас в компании работает несколько программистов 1С, они гарантированно делают себе бэкапы, создают «бэкапы» для дальнейшего развития.
В результате страдают пользователи, тормозит база данных при создании большой «бэкапа», особенно если в этой базе есть такие вещи, как различные вложения, архивы, документы из писем. Такие файловые таблицы легко могут содержать сотни гигабайт. И их также можно исключить в PostgreSQl, создав «резервную копию», тем самым небольшую и со всеми функциональными возможностями одновременно.
Таким образом мы лишний раз не загружаем сетевые устройства, не засоряем канал, тратим гораздо меньше времени на создание такой «резервной копии».
В конце концов выигрывают все! И пользователи, и программисты, и администраторы спят спокойно.
В этой статье мы разобрали только основные отличия PostgreSQl от MS SQL (есть и другие), но определимся с выбором в пользу той или иной СУБД, статья должна помочь!
Успех, коллега!
П.С. Сейчас работаю над новым курсом «1С и PostgreSQL» (уже на стадии записи, ждите, скоро!)
С уважением, Богдан.
В ожидании моего выступления на PGCONF.На конференции RUSSIA 2015 я поделюсь некоторыми наблюдениями о важных различиях между MySQL и PostgreSQL. Этот материал будет полезен всем тем, кого уже не устраивают возможности и особенности MySQL, а также тем, кто делает первые шаги в Postgres. Конечно, не стоит рассматривать этот пост как исчерпывающий список отличий, но его будет достаточно, чтобы принять решение в пользу конкретной СУБД.
Тема моего выступления — «Асинхронная репликация без цензуры, или почему PostgreSQL завоюет мир», а репликация — одна из самых болезненных тем для загруженных проектов, использующих MySQL.Проблем много — правильность работы, стабильность работы, производительность — и на первый взгляд они кажутся не связанными друг с другом. Если мы посмотрим в историческом контексте, мы получим интересный вывод: репликация MySQL имеет так много проблем, потому что она не была продумана, и точкой невозврата была поддержка механизма хранения (подключаемых модулей) без ответа на вопросы «что делать с журналом?» и «как разные механизмы хранения могут участвовать в репликации». В 2004 году в списке рассылки PostgreSQL пользователь попытался «найти» механизм хранения в исходном коде PostgreSQL и был очень удивлен, что его там не оказалось.Во время обсуждения кто-то предложил добавить эту функцию в PostgreSQL, и один из разработчиков ответил: «Ребята, если мы это сделаем, у нас будут проблемы с репликацией и транзакциями между движками».Проблема в том, что многие системы управления хранением … часто используют собственные WAL и PITR. Некоторые также занимаются управлением буфером, блокировкой и репликацией / нагрузкой. Итак, как вы говорите, сложно сказать, где должен быть абстрагирован интерфейсссылка на это письмо в списке рассылки postgresql
.
Прошло более 10 лет, и что мы видим? MySQL имеет неприятные проблемы с транзакциями между таблицами различных механизмов хранения, а MySQL имеет проблемы с репликацией.За последнее десятилетие PostgreSQL разработал подключаемые типы данных, индексы и репликацию — то есть преимущество MySQL было нивелировано, в то время как архитектурные проблемы MySQL остаются и затрудняют жизнь. MySQL 5.7 попытался решить проблему производительности репликации путем ее распараллеливания. Поскольку рабочий проект очень чувствителен к производительности репликации из-за своего масштаба, я попытался проверить, улучшилось ли оно. Я обнаружил, что параллельная репликация в 5.7 медленнее, чем однопоточная в 5.5, и только в некоторых случаях примерно такая же.Если вы в настоящее время используете MySQL 5.5 и хотите перейти на более новую версию, имейте в виду, что миграция невозможна для высоконагруженных проектов, поскольку репликация просто перестанет работать.
После разговора о высокой нагрузке Oracle обратила внимание на тест, который я разработал, и сказал, что они попытаются исправить проблему; недавно мне даже написали, что смогли увидеть параллелизм в своих тестах, и прислали настройки. Если не ошибаюсь, с 16 потоками было небольшое ускорение по сравнению с однопоточной версией.К сожалению, я пока не повторял свои тесты на предоставленных настройках — в частности, потому что с такими результатами наши проблемы по-прежнему остаются актуальными.
Точные причины снижения производительности неизвестны. Было несколько предположений — например, Кристиан Нельсен, один из разработчиков MariaDB, написал в своем блоге, что могут быть проблемы со схемой производительности, с синхронизацией потоков. Из-за этого наблюдается 40% регресс, который виден на обычных тестах.Разработчики Oracle это опровергают, и я даже был уверен, что его не существует, видимо, я вижу какую-то другую проблему (а их сколько?).
В репликации MySQL проблемы с механизмом хранения усугубляются выбранным уровнем репликации — они логичны, а в PostgreSQL — физические. В принципе, у логической репликации есть свои преимущества, она позволяет делать более интересные вещи, я также упомяну об этом в своем докладе. Но PostgreSQL даже в рамках своей физической репликации уже сводит на нет все эти преимущества.Другими словами, почти все в MySQL уже можно сделать в PostgreSQL (или это будет возможно в ближайшем будущем).
Есть небольшая надежда на реализацию низкоуровневой физической репликации в MySQL. Проблема в том, что вместо одного журнала (как в PostgreSQL) их два или четыре, в зависимости от того, как вы его считаете. PostgreSQL просто фиксирует запросы, они попадают в журнал, и этот журнал используется при репликации. Репликация PostgreSQL очень стабильна, поскольку в ней используется тот же журнал, что и для операций переключения при отказе.Этот механизм написан давно, хорошо протестирован и оптимизирован.
В MySQL ситуация иная. У нас есть отдельный журнал InnoDB и журнал репликации, и нам нужно фиксировать и там, и там. И это двухфазная фиксация между журналами, которая по определению является медленной. То есть мы не можем просто взять и сказать, что мы повторяем транзакцию из журнала InnoDB — мы должны выяснить, что это за запрос, и запустить его заново. Даже если это логическая репликация на уровне строк, эти строки необходимо искать в индексе.И вам не только нужно проделать много работы, чтобы выполнить запрос — он снова будет записан в ваш журнал InnoDB на реплике, что явно не очень хорошо для производительности.
В PostgreSQL в этом смысле архитектура гораздо более продумана и реализована лучше. Недавно компания анонсировала функцию под названием «Логическое декодирование», которая позволяет делать всевозможные интересные вещи, которые очень сложно сделать в физическом журнале. В PostgreSQL это надстройка поверх логического декодирования, позволяющая работать с физическим журналом так, как если бы он был логическим.Именно эта функциональность скоро устранит все преимущества репликации MySQL, за исключением, возможно, размера журнала — репликация MySQL на основе операторов победит, — но репликация MySQL на основе операторов имеет совершенно дикие проблемы в самых неожиданных местах, и не стоит считать это хорошим решением (об этом я тоже расскажу в своем отчете).
Кроме того, есть триггерная репликация для PostgreSQL — это Tungsten, что позволяет делать то же самое. Репликация триггеров работает следующим образом: триггеры устанавливаются, заполняют таблицы или записывают файлы, результат отправляется на реплику и там применяется.Насколько мне известно, именно через Tungsten происходит миграция с MySQL на PostgreSQL и наоборот. В MySQL логическая репликация работает прямо на уровне движка, и теперь это невозможно сделать иначе.
PostgreSQL имеет гораздо лучшую документацию. Формально в MySQL он даже есть, но может быть сложно понять значение отдельных опций. Вроде написано, что они делают, но чтобы понять, как их правильно настроить, нужно пользоваться неофициальной документацией, поищите статьи на эту тему.Часто нужно разбираться в архитектуре MySQL, без этого понимания настройки выглядят как какое-то волшебство.Например, Percona снимала это так: они вели блог о производительности MySQL, и в этом блоге было много статей, посвященных конкретным аспектам эксплуатации MySQL. Это принесло бешеную популярность, привело клиентов к консалтингу, позволило привлечь ресурсы для начала разработки собственного форка Percona-Server. Существование и актуальность блога производительности MySQL доказывают, что официальной документации просто недостаточно.
PostgreSQL имеет практически все ответы в документации. С другой стороны, я слышал много критики при сравнении документации PostgreSQL со «зрелым» Oracle. Но на самом деле это очень важный показатель. Никто вообще не пытается сравнивать MySQL со взрослым Oracle — это было бы смешно и нелепо — и PostgreSQL уже начинает довольно серьезно сравнивать, сообщество PostgreSQL слышит эту критику и работает над улучшением продукта. Это говорит о том, что по своим возможностям и производительности он начинает конкурировать с такой мощной системой, как Oracle, на которой работают операторы мобильной связи и банки, в то время как MySQL остается в нише веб-сайтов.А гигантские проекты, которые выросли до большого объема данных, и пользователи страдают от MySQL, постоянно сталкиваясь с его ограничениями и архитектурными проблемами, которые нельзя исправить, затрачивая разумное количество времени и усилий.
Примером таких больших проектов на PostgreSQL является 1С: PostgreSQL поставляется в качестве опции вместо Microsoft SQL, а Microsoft SQL — действительно фантастическая СУБД, одна из самых мощных. PostgreSQL может заменить MS SQL и попытаться заменить его MySQL… давайте пожалеем эту сцену, как написал Марк Твен.
PostgreSQL соответствует стандартам SQL-92, SQL-98, SQL-2003 (реализованы все разумные его части) и уже работает над SQL-2011. Это очень круто. Для сравнения: MySQL даже не поддерживает SQL-92. Кто-то может сказать, что в MySQL эта цель просто не была поставлена разработчиками. Но нужно понимать, что разница между версиями стандарта не в небольших изменениях — это новый функционал. То есть в тот момент, когда MySQL сказал: «Мы не будем следовать стандарту», они не просто внесли некоторые небольшие изменения, которые затрудняют поддержку MySQL, они также закрыли путь к реализации многих необходимых и важных функций.Хорошего оптимизатора пока нет. Оптимизация — это то, что PostgreSQL называет «парсером» плюс нормализации. В MySQL это просто план выполнения запросов без разделения. И MySQL все еще далек от поддержки стандартов, поскольку на них ложится бремя обратной совместимости. Да, хотят, но через пять лет, может быть, у них что-то будет. В PostgreSQL все это уже есть. С точки зрения вы просто сравнение администрирования не в пользу PostgreSQL.MySQL намного проще администрировать. И не потому, что в этом смысле он лучше продуман, а просто умеет делать гораздо меньше. Соответственно настроить его проще.MySQL имеет проблемы со сложными запросами. Например, MySQL не умеет спускать группировку на отдельные части union all. Разница между двумя запросами — в нашем примере группировка по отдельным таблицам и объединение всех из вышеперечисленных работала в 15 раз быстрее, чем объединение всех и последующая группировка, хотя оптимизатор должен привести к обоим запросам один и тот же эффективный план выполнения запроса.Придется генерировать такие запросы вручную, то есть тратить время разработчиков на то, что должна делать база.
«Простота» MySQL проистекает, как вы можете видеть выше, из чрезвычайно плохих функций — MySQL просто работает хуже и требует больше времени и усилий во время разработки. Напротив, PostrgreSQL имеет гистограммы и обычный оптимизатор, и он будет эффективно выполнять такие запросы. Но если есть гистограммы, то есть их настройки — хотя бы размер ведра. Вам нужно знать о настройках и в некоторых случаях их изменять — следовательно, вам нужно понимать, что это за настройка, за что она отвечает, уметь распознавать такие ситуации и видеть, как выбирать оптимальные параметры.
Редко бывает, что навыки PostrgreSQL могут мешать, а не помогать. В 95% случаев все работает хорошо — лучше, чем MySQL — и один глупый запрос выполняется намного медленнее. Или все работает хорошо, а потом вдруг (с точки зрения пользователя) по мере роста проекта некоторые запросы стали плохо работать (данных стало больше, был выбран другой план выполнения запроса). Скорее всего, чтобы это исправить, нужно просто запустить анализ или немного подправить настройки. Но нужно знать, что и как делать.Как минимум, вам нужно прочитать документацию PostgreSQL по этой теме, но по какой-то причине они не любят читать документацию. Может потому, что MySQL мало помогает? 🙂
Подчеркну, PostgreSQL в этом смысле ничем не хуже, просто позволяет отложить проблемы, а MySQL сразу их сбрасывает, а на их решение приходится тратить время и деньги. В этом смысле MySQL всегда работает стабильно плохо, и даже на этапе разработки люди принимают во внимание эти особенности: они все делают максимально простым способом.Это касается только производительности, точнее, методов ее достижения и ее предсказуемости. С точки зрения правильности и удобства PostgreSQL на голову выше MySQL.
Чтобы определиться с выбором между MySQL и PostgreSQL для конкретного проекта, вам сначала нужно ответить на другие вопросы.Во-первых, какой опыт у команды? Если вся команда имеет 10-летний опыт работы с MySQL и нужно как можно быстрее приступить к работе, то не факт, что стоит менять знакомый инструмент на незнакомый.Но если сроки не критичны, то стоит попробовать PostgreSQL.
Во-вторых, нельзя забывать о проблемах эксплуатации. Если у вас нет сильно загруженного проекта, то с точки зрения производительности разницы между этими двумя СУБД нет. С другой стороны, PostgreSQL имеет еще одно важное преимущество: он более строгий, выполняет больше проверок за вас, дает меньше возможностей для ошибок, и это огромное преимущество в будущем. Например, в MySQL вам нужно написать свои собственные инструменты для проверки обычной ссылочной целостности базы данных.И даже это может быть проблемой. В этом смысле PostgreSQL — более мощный инструмент, более гибкий и более приятный для разработки. Но это во многом зависит от опыта разработчика.
Подводя итог: если у вас простой интернет-магазин, нет денег на админа, нет серьезных амбиций вырасти в большой проект и есть опыт работы с MySQL, то берите MySQL. Если вы рассчитываете, что проект будет популярным, если он большой, его будет сложно переписать, если у него сложная логика и взаимосвязи между таблицами — возьмите PostgreSQL.Даже из коробки он будет работать на вас, поможет в разработке, сэкономит время, и вам будет легче расти.
Сложно найти организацию, которая не использует учетные системы от 1С — даже в мегахолдингах, где давно внедрены SAP или OEBS, они практически всегда используются в той или иной сфере. Отрадно, что российское прикладное программное обеспечение стало де-факто стандартом для наших компаний, но есть одна тонкость: использование Microsoft SQL Server в качестве СУБД стало де-факто стандартом для самой «1С: Предприятия».
Среди практикующих 1С-никнеймы наиболее распространено мнение, что без коммерческих СУБД от американских производителей ничего хорошего из этого не выйдет, мол, несколько сотен пользователей неизбежно потребуют установки базы данных на MS SQL, Oracle Database или IBM DB2 в этот случай. Мнения известных нам практиков разошлись по поводу работы в условиях свободы PostgreSQL, но в диапазоне от «совсем не работает» до «подходит для нескольких десятков пользователей, не более».
Таким скромным оценкам был и ряд правдоподобных объяснений: активное использование механизмами временных таблиц платформами 1С (которые в Postgres реализованы слишком «честно» — с транзакционным DDL, всеми возможностями восстановления) и особенностями работы. с текстовыми данными (в то время как в области многоязычных текстов ванильный Postgres, опять же, слишком консервативен, используя не самые производительные системные библиотеки) и ряд других менее значимых аспектов.
Но мы втайне верили в Postgres, тем более что сборка анонсировала решение всех тех проблем, которые скептики использовали для оправдания выбора коммерческой СУБД. Кроме того, нам было важно получить показатели назначения программно-аппаратного комплекса — машины базы данных для СУБД, построенной на базе санкционированного безопасного оборудования и программного обеспечения, разработанного IBS совместно с Postgres Professional.
Из реплицированных приложений наиболее очевидным приложением для такой машины, конечно же, будут системы 1С.А результаты проведенных бенчмарков полностью перевели нас из разряда «тайных верующих» (и даже сомневающихся) в разряд «убежденных»: теперь можно смело сказать, что 1С: Предприятие версии 8.3 на сборке PostgreSQL EE 1.5 для Skala-CP / PostgreSQL работает лучше, чем MS SQL 2012 на том же оборудовании со всеми возможными оптимизациями.
Итак, некоторые подробности экспериментов. Что касается тестирования производительности, то в 1С все систематично и научно — есть типовая конфигурация «Стандартный нагрузочный тест», на которой запускается бенчмарк, постепенно добавляя в нагрузку новых пользователей, пока приложение не станет достаточно отзывчивым для комфортной работы.(Точнее, пользователи добавляются до тех пор, пока стандартная оценка производительности приложения Apdex не упадет ниже порога 0,85, и максимальное количество таких эффективных пользователей является результатом теста.)
Мы использовали версию 8.3.9.1850 1С: Предприятие, стандартная загрузка тест в версии 2.0.17.36. Изначально было решено не давать Postgres скидок: делаем максимальную оптимизацию под MS SQL на узле из комплекса Skala-CP / PostgreSQL (ставим Windows на «голый металл», настраиваем по всем канонам, ибо скорости — мы делаем ramdisk для временных таблиц), а затем — мы возвращаем тот же узел в комплекс Skala-CP, сворачиваем Linux и Postgres Pro EE и запускаем тот же тест только на нем (без кластерных чипов, имеющихся в сложный).
Тест первый: начинаем со 100 рабочих мест, нагрузка 50/50 — половина форм документов, половина отчетов. Тест второй: начало 400, нагрузка 70/30. MS SQL «доработал» в первом тесте на 360 пользователей, во втором — на 540, причем работа с локальным вводом-выводом стала ограничителем в обоих прогонах, несмотря на то, что процессор был загружен в среднем всего на 30%. Postgres Pro в первом тесте достиг 440 рабочих станций, а во втором — до 660, а на сервере базы данных все упиралось в процессор, который берет более 90% нагрузки на «максимальных пользователей».
Для 1С, где количество одновременных пользователей является наиболее проблемным ограничивающим фактором, это замечательный результат, а главное, он говорит о том, что эти важнейшие российские прикладные системы не только могут работать без западных коммерческих СУБД, но даже могут это делать. намного лучше.
Содержимое серии:
1. История разработки MySQL и PostgreSQL
История MySQL началась в 1979 году с небольшой компании, возглавляемой Монти Видениусом. В 1996 году вышел первый выпуск 3.11 появился под Solaris с публичной лицензией. Затем MySQL был перенесен на другие операционные системы, появилась специальная коммерческая лицензия. В 2000 году с добавлением интерфейса, подобного Berkeley DB, база данных стала транзакционной. Репликация была добавлена примерно в то же время. В 2001 году версия 4.0 добавила движок InnoDB к существующему MyISAM, который ввел кэширование и повысил производительность. В 2004 году вышла версия 4.1, в которой появились подзапросы, частичная индексация для MyISAM и юникод.В версии 5.0 2005 года появились хранимые процедуры, курсоры, триггеры, представления. Бизнес-тенденции в MySQL развиваются: в 2009 году MySQL стал товарным знаком Oracle.
История postgres началась в 1977 году с базы данных Ingress.
В 1986 году в Университете Беркли, Калифорния, он был переименован в PostgreSQL.
В 1995 году postgres стал открытой базой данных. Появился интерактивный psql.
Postgres95 был переименован в PostgreSQL версии 6.0 в 1996 году.
Postgres имеет несколько сотен разработчиков по всему миру.
2. Архитектура MySQL и PostgreSQL
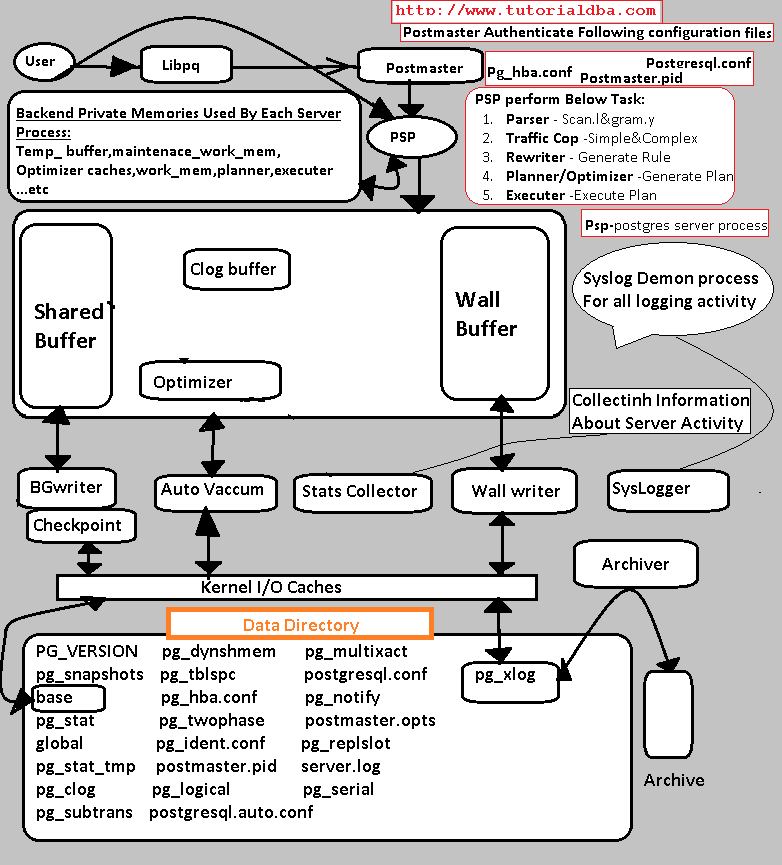
PostgreSQL — унифицированный сервер баз данных с единым механизмом хранения. Postgres использует модель клиент-сервер.
Для каждого клиента на сервере создается новый процесс (не поток!). Сервер использует семафоры для работы с такими клиентскими процессами.
Запрос клиента проходит следующие этапы.
- Подключить.
- Анализ: проверяется правильность запроса и создается дерево запроса.Парсер основан на базовых утилитах Unix yacc и lex.
- Перепишите: берется дерево запросов и проверяется наличие правил, которые есть в системных каталогах. Каждый раз пользовательский запрос переписывается в запрос, который обращается к таблицам базы данных.
- Оптимизатор: для каждого запроса создается план запроса, который передается исполнителю. Смысл плана в том, что он перечисляет все возможные варианты получения результата (использовать ли индексы, объединения и т. Д.), И выбирается самый быстрый вариант.
- Выполнение запроса: исполнитель рекурсивно проходит по дереву и извлекает результат, используя сортировку, объединения и т. Д., И возвращает строки. Postgres — объектно-реляционная база данных, каждая таблица в ней представляет класс, между таблицами реализовано наследование. Реализованы стандарты SQL92 и SQL99.
Транзакционная модель построена на основе так называемого мультиверсионного управления параллелизмом (MVCC), что обеспечивает максимальную производительность. Ссылочная целостность обеспечивается наличием первичного и вторичного ключей.
MySQL имеет два уровня — внешний слой sql и внутренний набор механизмов, из которых чаще всего используется механизм InnoDb, поскольку он наиболее полно поддерживает ACID.
Стандарт SQL92 реализован.
С модульной точки зрения код MySQL можно разделить на следующие модули.
- Инициализация сервера.
- Диспетчер подключений.
- Менеджер потоков.
- Обработчик команд.
- Аутентификация.
- Парсер.
- Оптимизатор.
- Табличный менеджер. Двигатели
- (MyISAM, InnoDB, MEMORY, Berkeley DB).
- Лесозаготовка.
- Репликация.
- Сетевой API.
- Core API.
Порядок модулей следующий: сначала загружается первый модуль, который считывает параметры командной строки, файлы конфигурации, выделяет память, инициализирует глобальные структуры, загружает системные таблицы и передает управление диспетчеру соединений.
Когда клиент подключается к базе, управление передается диспетчеру потоков, который создает поток (не процесс!) Для клиента, и его аутентификация проверяется.
Клиентские запросы в зависимости от их типа на верхнем уровне обрабатываются четвертым модулем (диспетчером). Запросы будут регистрироваться 11-м модулем. Команда передается парсеру, проверяется кеш. Далее запрос может перейти к оптимизатору, модулю таблицы, модулю репликации и т. Д. В результате данные возвращаются клиенту через диспетчер потоков.
Самый важный код находится в файле sql / mysqld.cc. Он содержит основные функции, которые не изменились с версии 3.22: init_common_variables () init_thread_environment () init_server_components () grant_init () // sql / sql_acl.cc init_slave () // sql / slave.cc get_options () handle_connections_soewthreadth () handle_one_connection () check_connection () ac_connection () sql_acl.cc create_random_string () // sql / password.cc check_user () // sql / sql_parse.cc mysql_parse () // sql / sql_parse.cc (dispatch_command) Query_cache :: store_query () // sql / sql_cache.cc JOIN :: optimize () // sql / sql_select.cc open_table () // sql / sql_base.cc mysql_update () // sql / sql_update.cc mysql_check_table () // sql / sql_table.cc
Заголовок sql / sql_class.h определяет базовые классы: Query_arena, Statement, Security_context , Классы Open_tables_state, THD. Объект класса THD является дескриптором потока и является аргументом большого количества функций.
3. Сравнение MySQL и PostgreSQL: сходства и различия
Стандарт ACID
Стандарт ACID основан на атомарности, целостности, изоляции и надежности.Эта модель используется для обеспечения целостности данных. Это реализуется на основе транзакции. PostgreSQL полностью совместим с ACID. Для полной поддержки ACID в MySQL нужно в конфиге установить default-storage-engine = innodb.
Производительность
Базы данных часто оптимизируются в зависимости от среды, в которой они работают. Обе базы имеют разные технологии для повышения производительности. Исторически сложилось так, что MySQL начинался с расчетом на скорость, а PostgreSQL с самого начала разрабатывался как база данных с множеством настроек и соответствия стандартам.PostgreSQL имеет ряд настроек для повышения скорости доступа:
- частичных индексов;
- сжатие данных;
- выделение памяти;
- улучшенный кеш.
MySQL частично поддерживает частичные индексы в InnoDB. Если мы возьмем движок MySQL ISAM, он окажется быстрее на плоских запросах, при этом нет блокировок вставок, поддержки транзакций, внешнего ключа.
Сжатие
PostgreSQL лучше выполняет сжатие и распаковку данных, позволяя хранить больше данных на диске.В этом случае данные сжатия считываются с диска быстрее.
Сжатие MySQL для разных движков частично поддерживается, частично нет, и это зависит от конкретной версии конкретного движка.
В многопроцессорной системе PostgreSQL имеет приоритет над MySQL. Даже сами разработчики MySQL признают, что их движок в этом плане не так хорош.
Типы данных
MySQL: использует типы TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB для хранения двоичных данных, которые различаются по размеру (до 4 ГБ).
Символ: четыре типа — TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT.
PostgreSQL: Поддерживает движок пользовательских данных с командой CREATE TYPE, тип BOOLEAN, геометрические типы.
Символ: ТЕКСТ (ограничение — максимальный размер строки).
Существует тип BLOB для хранения двоичных данных, которые хранятся в файловой системе. Столбцы таблицы можно определить как многомерный массив переменной длины. Объектно-реляционное расширение: структура таблицы может быть унаследована от другой таблицы.
Хранимые процедуры
И PostgreSQL, и MySQL поддерживают хранимые процедуры.PostgreSQL придерживается стандарта Oracle PL / SQL, MySQL — IBM DB2. MySQL поддерживает расширение SQL для написания функций на C / C ++ начиная с версии 5.1. PostgreSQL: PL / PGSQL, PL / TCL, PL / Perl, SQL, C для написания хранимых процедур.
Ключи
И PostgreSQL, и MySQL поддерживают уникальность первичного и внешнего ключей. MySQL не поддерживает проверочные ограничения, плюс частично реализованы вторичные ключи. PostgreSQL: полная реализация плюс поддержка ON DELETE CASCADE и ON UPDATE CASCADE.
Триггеры
MySQL: элементарная поддержка. PostgreSQL: декларативные триггеры: SELECT, INSERT, DELETE, UPDATE, INSTEAD OF; процедурные триггеры: CONSTRAINT TRIGGER. События: ДО или ПОСЛЕ INSERT, DELETE, UPDATE.
Автоинкремент
MySQL: в таблице может быть только один такой столбец, который необходимо проиндексировать. PostgreSQL: тип данных SERIAL.
Репликация
Поддерживается как в MySQL, так и в PostgreSQL. PostgreSQL имеет модульную архитектуру и репликация идет отдельными модулями:
- Slony-I — основной механизм репликации в postgres, падение производительности в квадратичной зависимости от количества серверов;
Репликация PostgreSQL выполняется на основе триггера и работает медленнее, чем в MySQL.Репликацию планируется добавить в ядро начиная с версии 8.4.
В MySQL репликация включена в ядро и имеет две разновидности, начиная с версии 5.1:
- SBR — репликация на основе операторов;
- RBR — репликация на основе строк.
Первый тип основан на регистрации записей в двоичном журнале, второй — на регистрации изменений. Начиная с версии 5.5 MySQL поддерживает так называемую полусинхронную репликацию, при которой главный сервер (главный) сбрасывает данные на другой сервер (подчиненный) при каждой фиксации.Механизм NDB выполняет полную синхронную двухфазную репликацию.
Транзакции
MySQL: только для InnoDB. Поддерживает SAVEPOINT, ROLLBACK TO SAVEPOINT. Уровни блокировки: уровень таблицы (MyISAM). PostgreSQL: Поддерживается плюс уровни фиксации чтения и изоляции. ROLLBACK, ROLLBACK TO SAVEPOINT поддержка. Уровни блокировки: уровень строки, уровень таблицы.
Уровни привилегий
PostgreSQL: привилегии могут быть назначены пользователю или группе пользователей.
Экспорт-импорт данных
MySQL: набор утилит экспорта: mysqldump, mysqlhotcopy, mysqlsnapshot.Импорт из текстовых файлов, html, dbf. PostgreSQL: экспорт — утилита pg_dump. Импорт между базами данных и файловой системой.
Вложенные запросы
Доступны как в MySQL, так и в PostgreSQL, но MySQL может быть неэффективным.
Индексирование
Хеширование индексов: в MySQL — частичное, в PostgreSQL — полное. Полнотекстовый поиск: в MySQL — частичный, в PostgreSQL — полный. Частичные индексы: не поддерживаются в MySQL, поддерживаются в PostgreSQL. Многоколоночные индексы: MySQL ограничен 16 столбцами, PostgreSQL — 32.Индексы выражений: MySQL эмулирует, PostgreSQL заполнен. Неблокирующий индекс создания: частичный в MySQL, полный в PostgreSQL.
Разбиение на разделы
MySQL поддерживает горизонтальное разделение: диапазон, список, хэш, ключ, составное разделение. PostgreSQL поддерживает ДИАПАЗОН и СПИСОК. Автоматическое разбиение таблиц и индексов.
Автоматическое восстановление после сбоя
MySQL: частичное для InnoDB — вам нужно вручную сделать резервную копию. PostgreSQL: предварительная запись в журнал (WAL).
Механизмы хранения данных
PostgreSQL поддерживает один механизм — систему хранения Postgres. В MySQL 5.1 их несколько:
- MyISAM — используется для хранения системных таблиц;
- InnoDB — максимальное соответствие ACID, хранит данные с первичными ключами, кеширует вставки, поддерживает сжатие с версии 5.1 — см. Атрибут ROW_FORMAT = COMPRESSED;
- NDB Cluster — движок, ориентированный на память, кластерная архитектура с использованием синхронной репликации;
- АРХИВ — поддерживает сжатие, не использует индексы;
- , а также: MERGE, MEMORY (HEAP), CSV.
InnoDB разработан InnoBase, дочерней компанией Oracle. В 6 версии должны появиться два двигателя — Мария и Сокол. Falcon — это движок на основе транзакций ACID.
Лицензирование
PostgreSQL: BSD (Распространение программного обеспечения Беркли) с открытым исходным кодом. MySQL: GPL (Стандартная общественная лицензия GNU) или коммерческая. MySQL — это продукт с открытым исходным кодом. Postgres — проект с открытым исходным кодом.
Заключение
Подводя итог, можно сказать следующее: MySQL и PostgreSQL — две из самых популярных баз данных с открытым исходным кодом в мире.Каждая база имеет свои особенности и отличия. Если вам нужно быстрое хранилище для простых запросов с минимальной настройкой, я бы порекомендовал MySQL. Если вам нужно надежное хранилище для большого количества данных с возможностью расширения, репликации, полностью соответствующее современным стандартам языка SQL, я бы предложил использовать PostgreSQL.
Мы обсудим проблемы конфигурации MySQL и PostgreSQL.
Ресурсы для загрузки
static.content.url = http: //www.site/developerworks/js/artrating/
Zone = Open source, Linux
ArticleID = 779830
ArticleTitle = MySQL & PostgreSQL, Part 1: Comparative анализ
Реляционные базы данных используются давно.Они стали популярными благодаря системам управления, которые настолько хорошо реализуют реляционную модель, что это лучший способ работы с данными, особенно для критически важных приложений и сервисов.
MySQL существует уже давно и зарекомендовал себя как отличное решение, Postgresql появился на рынке примерно в то же время, но предоставляет множество интересных функций и возможностей, благодаря которым быстро набирает популярность. В этой статье мы попытаемся сравнить MySQL и Postgresql, сравним основные различия между этими системами, узнаем, как они работают, и попытаемся понять, какая система лучше всего подойдет для вашего проекта.
Базы данныхпредназначены для структурированного хранения и быстрого доступа к различным данным. Каждая база данных, помимо самих данных, должна иметь определенную модель работы, согласно которой будет производиться обработка данных. Для управления базами данных используются СУБД или системы управления базами данных, к таким программам относятся MySQL и Postgresql.
Системы управления реляционными базами данных позволяют размещать данные в таблицах, связывая строки из разных таблиц и, таким образом, связывая разные, логически объединенные данные.Прежде чем вы сможете сохранять данные, вам необходимо создать таблицы определенного размера и указать тип данных для каждого столбца. Столбцы представляют поля данных, а сами данные расположены в строках. И системы управления базами данных, и MySQL vs Postgresql являются реляционными. Далее мы более подробно рассмотрим, чем отличаются эти две программы. А теперь перейдем к более подробному рассмотрению.
Рассказ
MySQL
Разработка MySQLначалась еще в 90-х годах. Первый внутренний выпуск базы данных состоялся в 1995 году.За это время к разработке программы были привлечены несколько компаний. Разработка была начата шведской компанией MySQL AB, которую приобрела Sun Microsystems, фактически перешедшая в собственность Oracle. На данный момент с 2010 года развивается Oracle.
Postgresql
РазработкаPostrgresql началась еще в 1986 году в стенах Калифорнийского университета в Беркли. Разработка длилась почти восемь лет, затем проект был разделен на две части: коммерческую базу данных IIlustra и полностью бесплатный проект Postrgesql, который разрабатывают энтузиасты.
Хранение данных
MySQL
MySQL — реляционная база данных, для хранения данных в таблицах используются различные движки, но работа с движками скрыта в самой системе. Движок не влияет на синтаксис запросов и их выполнение. Поддерживаются такие основные движки, как MyISAM, InnoDB, MEMORY, Berkeley DB. Они отличаются друг от друга способом записи данных на диск, а также методами чтения.
Postgresql
Postgresql — это объектно-реляционная база данных, работающая только на одном механизме хранения.Все таблицы представлены в виде объектов, их можно наследовать, а все действия с таблицами производятся с помощью объективно ориентированных функций. Как и в MySQL, все данные хранятся на диске в специально отсортированных файлах, но структура этих файлов и их записей сильно различается.
Стандарт SQL
Независимо от используемой системы управления базами данных, SQL является стандартизированным языком выполнения запросов. И он поддерживается всеми решениями, даже MySQL или Postgresql. Стандарт SQL был разработан в 1986 году, и за это время было выпущено несколько версий.
MySQL
MySQL не поддерживает все новые функции стандарта SQL. Разработчики выбрали этот путь развития, чтобы MySQL оставался простым в использовании. Компания старается соответствовать стандартам, но не за счет простоты. Если функция может улучшить удобство использования, разработчики могут реализовать ее как расширение независимо от стандарта.
Postgresql
Postgresql — проект с открытым исходным кодом, он разработан командой энтузиастов, и разработчики стараются максимально соответствовать стандарту SQL и внедрять все новейшие стандарты.Но все это ведет в ущерб простоте. Postgresql очень сложен и из-за этого не так популярен, как MySQL.
Возможности обработки
Другие различия между postgresql и mysql вытекают из предыдущего абзаца, это возможности и ограничения обработки данных. Естественно, соответствие новым стандартам предоставляет новые возможности.
MySQL
При выполнении запроса MySQL загружает весь ответ сервера в память клиента; при больших объемах данных это может быть не очень удобно.По сути, Postgresql превосходит Mysql по функциям, какие из них мы рассмотрим позже.
Postgresql
Postgresql поддерживает использование курсоров для навигации по полученным данным. Вы получаете только указатель, весь ответ сохраняется в памяти сервера базы данных. Этот указатель может сохраняться между сеансами. Он поддерживает построение индексов сразу для нескольких столбцов таблицы. Кроме того, индексы могут быть разных типов, кроме хеша и b-дерева, доступны GiST и SP-GiST для работы с городами, GIN для текстового поиска, BRIN и Bloom.
Postgresql поддерживает регулярные выражения в запросах, рекурсивных запросах и наследовании таблиц. Однако есть несколько ограничений, например, вы можете добавить новое поле только в конец таблицы.
Производительность
Базы данных должны быть оптимизированы для среды, в которой вы будете работать. Исторически MySQL был ориентирован на максимальную производительность, в то время как Postgresql был разработан как база данных с широкими возможностями настройки и совместимая со стандартами. Но со временем Postgresql получил множество улучшений и оптимизаций.
MySQL
В большинстве случаев для организации работы с базой данных в MySQL используется таблица InnoDB, эта таблица представляет собой B-дерево с индексами. Индексы позволяют очень быстро извлекать данные с диска, а для этого потребуется меньше дисковых операций. Но сканирование дерева требует поиска двух индексов, что и так медленно. Все это означает, что MySQL будет быстрее Postgresql только при использовании первичного ключа.
Postgresql
Все заголовки таблиц Postgresql находятся в памяти.Вы не можете создать таблицу, в которой не хватает памяти. Записи таблицы отсортированы по индексу, поэтому вы можете быстро их получить. Для большего удобства вы можете применить несколько индексов к одной и той же таблице.
В целом PostgreSQL работает быстрее, за исключением использования первичных ключей. Давайте посмотрим на некоторые тесты с разными операциями:
Типы данных
Одно из преимуществ обеих баз данных — поддерживаемые типы данных, которые вы можете использовать. Поскольку оба решения пытаются соответствовать синтаксису SQL, они имеют похожие наборы, но все же в чем-то отличаются.
MySQL
MySQL поддерживает следующие типы данных:
- TINYINT : очень маленький целый .;
- МАЛЕНЬКОЕ: маленькое целое;
- MEDIUMINT: целиком среднего размера;
- INT: целиком нормального размера;
- BIGINT: большое целое;
- FLOAT: Число с плавающей запятой одинарной точности со знаком;
- DOUBLE, DOUBLE PRECISION, REAL: Число с плавающей запятой двойной точности со знаком
- DECIMAL, NUMERIC: число с плавающей запятой со знаком;
- ДАТА: дата;
ДАТА: комбинация даты и времени; - TIMESTAMP: отметка времени ;
- ВРЕМЯ: раз;
ГОД: год в формате ГГ или ГГГГ; - CHAR : строка фиксированного размера, дополненная справа пробелами до максимальной длины;
- VARCHAR: строка переменной длины;
- TINYBLOB, TINYTEXT: двоичные или текстовые данные с максимальной длиной 255 символов;
- BLOB, TEXT : двоичные или текстовые данные с максимальной длиной 65535 символов;
- MEDIUMBLOB, MEDIUMTEXT: текстовые или двоичные данные;
- LONGBLOB, LONGTEXT: текстовых или двоичных данных, максимальная длина данных 4294967295 символов;
- ENUM: передача;
- НАБОР: компл.
Postgresql
Поддерживаемые типы полей в Postgresql сильно различаются, но они позволяют записывать одни и те же данные:
- bigint: 8-байтовое целое число со знаком;
- bigserial : 8-байтовое целое число с автоматическим приращением;
- бит: двоичная строка фиксированной длины;
- переменные биты: двоичная строка переменной длины;
- логическое: флаг;
- коробка: прямоугольник на плоскости;
- байт : двоичные данные;
- различный символ: символьная строка фиксированной длины;
- символ:
- cidr: сетевой адрес IPv4 или IPv6;
- круг: круг на плоскости;
- дата : дата в календаре;
- двойная точность: число двойной точности с плавающей запятой;
- inet: Интернет-адрес IPv4 или IPv6;
- целое число : 4-байтовое целое число со знаком;
- интервал: период;
- линия: бесконечная прямая на плоскости;
- lseg: сегмент на плоскости;
- macaddr: MAC-адрес;
- деньги: денежное выражение;
- путь: геометрический путь на плоскости;
- точка: геометрическая точка на плоскости;
- многоугольник: многоугольник на плоскости;
- вещественное: число одинарной точности с плавающей запятой;
- smallint: двухбайтовое целое число;
- последовательный: автоматически увеличивающееся четырехбитное целое число;
- текст: символьная строка переменной длины;
- время : время суток;
- отметка времени: дата и время;
- tsquery : текстовый поисковый запрос;
- цвектор: текстовый поиск документа;
- uuid : уникальный идентификатор;
- xml: Данные XML.
Как видите, в Postgresql больше типов данных, и они более разнообразны, есть типы полей для определенных типов данных, которых нет в MySQL. Разница между MySQL и Postgresql очевидна.
Разработка
Оба проекта имеют открытый исходный код, но развиваются по-разному. Не всем нравится разработка MySQL. И в этом сравнение mysql и postgresql дает много различий.
MySQL
База данных MySQL разрабатывается Oracle, и ходят слухи, что компания намеренно препятствует разработке движка.Было много ответвлений проекта, в том числе вилка MariaDB от исходного разработчика MySQL. Тем не менее, развитие остается медленным.
Postgresql
Как упоминалось в начале статьи, разработка началась в Университете Беркли. Затем перешла в коммерческую компанию. В настоящее время программа разрабатывается независимой группой программистов и советом нескольких компаний. Новые версии выходят довольно активно и получают все новые и новые функции.
выводы
В этой статье мы провели сравнение mysql и postgresql, рассмотрели основные различия между обеими системами управления базами данных и попытались понять, что лучше postgresql или mysql. В целом Postgresql — лучший с точки зрения возможностей, но он сложен и применим не везде. MySQL проще, но в нем отсутствуют некоторые интересные функции. Какую базу данных вы выберете для своего проекта? Почему именно она? Напишите в комментариях!
Для завершения видео с описанием возможностей и перспектив Postgresql:
Как мне подключиться с помощью psql к subd внутри контейнера докеров? — Просить.pro
Добрый день, у меня PostgresSQL работает внутри контейнера докеров, и я хочу подключиться к нему с помощью утилиты psql:
sudo psql -h localhost -p 5432 -U postgres -d мастер
, но что-то идет не так, и при аутентификации я постоянно получаю сообщение об ошибке:
FATAL: ошибка аутентификации пароля для пользователя postgres
Я запускаю все это на Ubuntu 19.10 через docker-compose:
версия: «3.4 "
сети:
default_network:
ipam:
config:
- подсеть: 18.129.0.0/16
Сервисы:
postgres:
изображение: postgres: 11
сети:
- default_network
порты:
- $ {DB_EXTERNAL_PORT}: $ {DB_INTERNAL_PORT}
среда:
POSTGRES_DB: $ {DB_NAME}
POSTGRES_USER: $ {USER}
POSTGRES_PASSWORD: $ {PASSWORD}
тома:
- ./db_data:/var/lib/postgresql/data и, соответственно, переменные окружения:
DB_NAME = мастер
ПОЛЬЗОВАТЕЛЬ = postgres
ПАРОЛЬ = postgres
DB_EXTERNAL_PORT = 5432
DB_INTERNAL_PORT = 5432 Было бы смешно, если бы действительно была ошибка при вводе пароля, но я не мог ошибиться 15 раз подряд, включая копипаст.Заранее спасибо тому, кто не проходит мимо, подозреваю, что ошибка в том, что при подключении к контейнеру нужно авторизоваться под конкретным пользователем linux, но я не уверен.
UPD:
Забыл посмотреть логи контейнера
ПОДРОБНЕЕ: роль «postgres» не существует.
, но, тем не менее, как роль может не существовать, если она указана в POSTGRES_USER или действительно существует роль под ролью?
UPD 1:
Пользователь существует, и код Python может легко подключиться к базе данных, когда он находится в соседнем контейнере в той же подсети.Очевидно, я не настроил конфигурацию разрешений, найденную в файле pg_hba.conf. postgrespro.ru
Осталось понять, к какому адресному пространству принадлежит локальный хост для содержимого контейнера.
Дайджест новостей из мира PostgreSQL. Новогодний (сокращенный) выпуск №13 / Sudo Null IT News
Продолжаем знакомить вас с самыми интересными новостями о PostgreSQL. В этом новогоднем выпуске мы не будем утомлять вас длинным списком новостей.С Новым Годом!
Релизы
pgAdmin4 3.6 В этой версии добавлено
:
- из панели свойств вы можете удалить несколько объектов одновременно;
- можно импортировать и экспортировать в определения сервера из базы данных и в базу данных конфигурации.
pgpoolAdmin 4.0.2
можно скачать здесь, а также множество предыдущих версий.
dbForge Studio для PostgreSQL v2.0
На этот раз devart выпустила Studio со стандартной версией, функциональность которой не включена в бесплатную версию Express. 30 дней можно использовать стандартную версию бесплатно. О различиях между Standard и Express можно прочитать здесь.
VOPS-2.0
Выпущена новая версия расширения PostgreSQL для Postgres Professional для эффективного выполнения векторных операций.
pg_probackup 2.0.25
Новая версия утилиты для резервного копирования и восстановления, также из Postgres Professional
pgCluu 2.9 A
новую версию этой программы Perl для аудита производительности кластеров с PostgreSQL можно скачать здесь. pgCluu собирает статистику не только по СУБД, но и по системным ресурсам кластера.
postgres_dba 4.0
Выпущена новая версия утилиты Николая Самохвалова для администрирования PostgreSQL. В нем три новых отчета: список расширений, настройка параметров PostgreSQL и Vacuum: что сейчас происходит.И, конечно же, доработки и исправления.
Education
Учебник «Основы технологии баз данных»
Следуя руководству «PostgreSQL. Основы языка SQL »первая часть учебника Б.А. Новикова Основы технологии баз данных. Учебник можно приобрести в издательстве DMK Press, интернет-магазинах ozon.ru, Labirint.ru и розничных книжных сетях. В формате PDF первую часть книги можно бесплатно загрузить с веб-сайта Postgres Professional .Вторая часть книги готовится к печати. Учебник охватывает теорию баз данных, методы и алгоритмы, используемые при реализации СУБД, а также их особенности в системе PostgreSQL.
Статьи и блоги
Тестирование PostgreSQL с Linux HugePages
Ибрар Ахмед (Ибрар Ахмед) делится в блоге Percona результатами тестирования PostgreSQL с Linux HugePages . Тестирование проводилось на 2-сокетной машине с SSD с использованием pgbench .В статье описаны как параметры операционной системы, так и параметры PostgreSQL 11.
Threaded Postgres
Брюс Момджиан (Брюс Момджян) в своем блоге рассказывает о впечатляющей экспериментальной работе Константин Книжник ( Postgres Professional ). Это попытки перейти от процессов к потокам. Преимущества начинают сказываться, когда количество одновременных запросов превышает сотню. Развитием этих работ может стать разработка комплексного съемника.
Конференции
FOSDEM PGDay 2019
Однодневная конференция состоится в столице Бельгии 1 февраля.
PgConf.Russia 2019
Конференция пройдет 4-6 февраля на факультете Экономика МГУ. С программой конференции можно ознакомиться здесь.
Prague PostgreSQL Developer Day 2019
P2D2 2019 в Праге пройдет 13-14 февраля.
Подпишитесь на канал postgresso!
Свои идеи и пожелания присылайте по электронной почте: news_channel @ postgrespro.ru
Предыдущие выпуски: 12, 11 (специальные), 10, 9, 8, 7, 6, 5, 4, 3, 2, 1
| | Эта публикация цитируется в 4 научных статьях (всего в 4 статьях) Динамическая компиляция выражений в SQL-запросах для PostgreSQL E.Ю. Шарыгин а , Бучацкий Р.А. а , Скворцов Л.В. б , Жуйков Р.А. а , Мельник Д.М. а а Институт системного программирования РАН Аннотация: В последние годы, по мере роста производительности и емкости основной и внешней памяти, производительность систем управления базами данных (СУБД) по определенным типам запросов в большей степени определяется необработанной скоростью процессора.В настоящее время PostgreSQL использует интерпретатор для выполнения SQL-запросов. Это приводит к накладным расходам, вызванным косвенными вызовами функций-обработчиков и проверок во время выполнения, которых можно было бы избежать, если бы запрос был скомпилирован в собственный код «на лету», то есть точно в срок (JIT) скомпилирован: во время выполнения известна конкретная структура таблицы, а также типы данных и встроенные функции, используемые в запросе, а также сам запрос. Это особенно важно для сложных запросов, производительность которых зависит от ЦП. Мы разработали расширение PostgreSQL, которое реализует JIT-компиляцию SQL-запросов с использованием инфраструктуры компилятора LLVM.В этой статье мы покажем, как реализовать JIT-компиляцию для ускорения оператора последовательного сканирования (SeqScan), а также выражений в предложениях WHERE. Мы описываем некоторые важные оптимизации, которые возможны только при динамической компиляции, такие как предварительное вычисление смещения атрибутов кортежа только для атрибутов, используемых запросом. Мы также обсуждаем ремонтопригодность нашего расширения, то есть автоматизацию трансляции бэкэнд-функций PostgreSQL в LLVM IR, используя один и тот же исходный код как для нашего JIT-компилятора, так и для существующего интерпретатора.В настоящее время с помощью LLVM JIT мы достигаем пятикратного ускорения синтетических тестов по сравнению с исходным интерпретатором PostgreSQL. Ключевые слова: PostgreSQL, LLVM, динамическая компиляция, своевременная компиляция, движки системы управления базами данных, языки запросов. DOI: https://doi.org/10.15514/ISPRAS-2016-28(4)-13 Полный текст: PDF-файл (635 kB) Образец цитирования: Э.Ю. Шарыгин, Р.А. Бучацкий, Л.В. Скворцов, Р.А. Жуйков, Д.М. Мельник, “Динамическая компиляция выражений в SQL-запросах для PostgreSQL”, Труды ИСП РАН, 28: 4 (2016), 217–240 Цитирование в формате AMSBIB Варианты соединения: Цитирование статей в Google Scholar: Русские цитаты,
Цитаты на английском языке Эта публикация цитируется в следующих статьях:
|
|
| |
Эта статья цитируется в научной статье 1 (всего в статье 1 ) Математические основы компьютерной безопасности Подходы к формальному моделированию контроля доступа в PostgreSQL в рамках DP-модели MROSL с.Девянин Н.А. ab a Академия криптографии Российской Федерации, Москва Аннотация: PostgreSQL широко используется в проверенных операционных системах. Следовательно, необходимо разработать научные подходы к реализации безопасности контроля доступа в PostgreSQL. Во-первых, необходимо проанализировать управление доступом на основе ролей (RBAC), изначально реализованное в PostgreSQL.Во-вторых, мы должны изучить обязательный контроль доступа (MAC) и обязательный контроль целостности (MIC) на практике разработки доверенных операционных систем. Теперь обязательная сущностно-ролевая DP-модель (MROSL DP-модель) становится научной основой политики контроля доступа в ОС семейства Linux, например, в ОС Astra Linux Special Edition. Эта модель включает RBAC, MAC и MIC. Модель также имеет иерархическую структуру, что позволяет дополнять модель новыми элементами без ее полной обработки.Кроме того, модель была подтверждена инструментами дедуктивной верификации как правильная. В статье представлены подходы, которые предлагаются для построения новых уровней в рамках иерархического представления DP-модели MROSL, связанной с контролем доступа в PostgreSQL. При этом первый этап моделирования ориентирован на RBAC из-за существенных различий между принципами управления доступом в ОС Astra Linux Special Edition и PostgreSQL. Ключевые слова: компьютерная безопасность, формальная модель, контроль доступа, PostgreSQL. DOI: https://doi.org/10.17223/2226308X/11/29 Полный текст: PDF-файл (399 kB) УДК: 004.94 Образец цитирования: П. Н. Девянин, “Подходы к формальному моделированию управления доступом в PostgreSQL в рамках DP-модели MROSL”, Прикл. Дискр. Мат. Приложение.2018. 11, 95–99 Цитирование в формате AMSBIB Варианты соединения: Цитирование статей в Google Scholar: Русские цитаты,
Цитаты на английском языке Эта публикация цитируется в следующих статьях:
|
| |
Ошибка установления соединения 1c 8.3. Установка ms sql server subd
Серверная связка 1С: Предприятие и PostgreSQL — вторая по популярности среди инсталляций 1С и наиболее часто используемое решение на платформе Linux.В отличие от развертываний на основе Windows и MSSQL, где сложно заставить его не работать, развертывания на основе Linux чреваты ловушками для неопытного администратора. Часто бывает так, что вроде бы все сделано правильно, но ошибка следует за ошибкой. Сегодня мы рассмотрим самые типичные.
общая информация
Прежде чем приступить к поиску ошибок установки и вообще приступить к внедрению серверной версии 1С: Предприятия, было бы неплохо освежить свои представления о том, как это работает:
В небольших развертываниях сервер 1С и сервер СУБД обычно объединены на одном физическом сервере, что немного сужает диапазон возможных ошибок.В нашем случае мы рассмотрим ситуацию, когда серверы находятся на разных машинах. В нашей тестовой лаборатории мы развернули следующую схему:
В нашем распоряжении два сервера под управлением Ubuntu 12.04 x64, на одном из них установлена 1С: Предприятие версии 8.3, на другом PostgreSQL 9.04 от Ethersoft, а также клиент под управлением Windows. Напоминаем, что клиент работает только с сервером 1С, который, в свою очередь, формирует необходимые запросы к серверу СУБД. Никаких запросов от клиента к серверу управления базой данных не происходит .
ВАЖНО: пользователь postgres не аутентифицирован (Ident)
Эта ошибка возникает, когда серверы распределены по разным компьютерам из-за неправильно настроенной аутентификации в локальной сети. Чтобы исключить open /var/lib/pgsql/data/pg_hba.conf , найдите строку:
Host all all 192.168.31.0/24 identity
и приведите ее к форме:
Host all all 192.168.31.0 / 24 md5
где 192.168.31.0/24 — радиус действия вашей локальной сети.Если такой строки нет, ее нужно создать в разделе IPv4 локальных подключений .
Сервер базы данных не найден.
не может преобразовать имя хоста «NAME» в адрес: временный сбой в разрешении имен
На первый взгляд, ошибка понятна: клиент не может разрешить имя сервера СУБД, типичная ошибка для небольших сетей, где нет локального DNS-сервера. В качестве решения добавьте запись в файл hosts на клиенте, которая не дает результата…
А теперь вспомним сказанное чуть ранее. Клиент сервера СУБД — это сервер 1С, а не клиентский ПК, поэтому запись должна быть добавлена в файл на сервере 1С: Предприятия / etc / hosts на платформе Linux или на платформе Windows.
Аналогичная ошибка возникнет, если вы забыли добавить запись типа A для сервера СУБД на локальный DNS-сервер.
Произошла ошибка при выполнении операции с информационной базой.
адрес_сервера = ИМЯ descr = 11001 (0x00002AF9): Этот хост неизвестен.
Как и предыдущая, эта ошибка возникает из-за неправильного разрешения клиентом имени сервера. На этот раз это был клиентский компьютер. В качестве решения добавьте в файл / etc / hosts на платформе Linux или в C: \ Windows \ System32 \ drivers \ etc \ hosts на платформе Windows запись вида:
192.168.31.83SRV-1C-1204
где вы указываете адрес и имя вашего сервера 1С: Предприятия. При использовании локального DNS добавьте A запись для сервера 1С.
Ошибка СУБД: БАЗА ДАННЫХ не используется
Гораздо более серьезная ошибка, которая указывает на то, что вы установили версию PostgreSQL, несовместимую с 1С: Предприятием или допустили грубые ошибки при установке, например, не установили все необходимые зависимости, в частности библиотеку libICU .
Если у вас есть достаточный опыт администрирования систем Linux, вы можете попробовать установить необходимые библиотеки и повторно инициализировать кластер СУБД.В противном случае PostgreSQL лучше переустановить, не забыв удалить содержимое папки / var / lib / pgsql .
Также эта ошибка может возникать при использовании сборок 9.1.x и 9.2.x [электронная почта защищена] , подробности см. Ниже.
Ошибка СУБД:
ОШИБКА: не удалось загрузить библиотеку «/usr/lib/x86_64-linux-gnu/postgresql/fasttrun.so»
Довольно специфическая ошибка, специфичная для сборок 9.1.x и 9.2.x [email protected] , также может привести к предыдущей ошибке.Причина кроется в неисправленной ошибке в библиотеке fasttrun.so. Решение — откатиться на сборку 9.0.x [email protected] .
Ошибка СУБД
ОШИБКА: тип «mvarchar» не существует для символа 31
Возникает, если база данных была создана без помощи системы «1С: Предприятие». Помните, что для работы с 1С базы данных нужно создавать только средствами платформы 1С: через консоль
или через лаунчер 1С.
Сервер базы данных не найден
ВАЖНО: пользователь postgres не аутентифицирован (по паролю)
Очень простая ошибка. Неверный пароль суперпользователя СУБД postgres. Есть два решения: запомнить пароль или сменить его. Во втором случае потребуется изменить пароль в свойствах всех существующих информационных баз с помощью оснастки Администрирование серверов 1С Предприятия .
Сервер базы данных не найден
FATAL: база данных «NAME» не существует
Еще одна очень простая ошибка.Его смысл сводится к тому, что указанной базы данных не существует. Чаще всего это происходит из-за ошибки в указании названия базы. Следует помнить, что информационная база 1С в кластере и база данных СУБД — два разных объекта и могут иметь разные названия. Также помните, что системы Linux чувствительны к регистру и для них unf83 и UNF83 два разных имени.
Включите JavaScript для просмотраПри подключении к серверу 1С из консоли получаем:
Ошибка сервера или соединение было прервано администратором
Ошибка формата потока
При запуске базы данных SQL получаем error:
Произошла ошибка на сервере или соединение было прервано администратором.
Ошибка формата потока
Итак, исходные данные:
Недавно установленная Windows 7 Professional x64, все обновления и т. Д. (Проблема возникает как на Server 2008, так и на 2008R2)
Установлен сервер 1С x64 (пробовал тоже 32бит)
Все работает до перезагрузки. После перезагрузки при попытке подключения к базе данных в SQL или открытии кластера в консоли 1С получаем тряску со следующими картинками:
При подключении к серверу 1С из консоли получаем:
Ошибка подключения к 1С: Предприятию 8.2 сервер:
Ошибка сервера или соединение было прервано администратором
Ошибка формата потока
При запуске базы данных SQL получаем ошибку:
Ошибка при работе с информационной базой.
Произошла ошибка на сервере или соединение было прервано администратором.
Ошибка формата потока
Чтобы иметь возможность запускать БД и подключаться к кластеру из консоли, помогло только:
1.Остановка службы сервера 1С: Предприятия 8.2
2. Удаление процессов rmngr.exe rphost.exe (происходит сбой при завершении работы rmngr.exe).
3. Очистка каталога C: \ Program Files \ 1cv82 \ srvinfo \ reg_1541 \ snccntx (для 32-битного сервера C: \ Program Files (x86) \ 1cv82 \ srvinfo \ reg_1541 \ snccntx)
4. Запуск службы сервера 1С: Предприятия 8.2
Однако в процессе работы с конфой SQL можно было неожиданно отловить аварийное отключение 1Sky с последующим получением тех же ошибок.
Было протестировано:
1. разные релизы, разные серверы,
2. разные пользователи: System, Administrator, USR1CV82.
3. форсирование полных прав этих пользователей на каталоги C: \ Program Files \ 1cv82 \ (для 32-битного сервера C: \ Program Files (x86) \ 1cv82 \) с наследованием дочерним объектам.
4. Десятки перезагрузок и не только.
Однако причина была гораздо более неожиданной!
Разыменование в Windows 7 (Server 2008, 2008R2, возможно 2012)
Попробуйте проверить связь с компьютером по имени.То, что вы увидите, определит применимость моего решения.
Это легко сделать:
1. Запустите командную строку (Win + R, введите cmd и нажмите OK)
2. В командной строке введите команду «Ping», пробел и имя вашего компьютера. А именно не его IP-адрес. Нажмите Enter.
3. Если система начинает пинговать себя через адрес типа fabc: de12: 3456: 7890: ABCD: EF98: 7654: 3210 или другой IP-адрес, отличный от вашего
Добро пожаловать в частный клуб разыменования бугофичей Windows 7.
В основе проблемы лежит то, что сервер 1С не может идентифицировать себя по имени.
Но отображение вашего IP-адреса как IPv6 — одна из наиболее частых причин этой ошибки.
Другой причиной может быть периодическое подключение к другой сети (скажем, VPN), когда создается новый интерфейс, и Windows снова начинает разыменование себя «неправильно».
Ниже я опишу два решения для обхода этой «особенности».
Хочу сначала вас предупредить:
Все действия с компьютером вы выполняете на свой страх и риск.
Номер варианта 1 Добавьте ваш компьютер и его IP-адрес в хосты
1. Вам нужно найти файл hosts в папке C: \ Windows \ System32 \ drivers \ etc. Если вы не видите файл Hosts в этой папке, значит, он просто скрыт. Затем можно нажать клавишу ALT и в появившемся меню выбрать «Сервис» — «Параметры папки» — «Просмотр» и снять там стоит галочка «Скрыть защищенные системные файлы». Еще можно установить переключатель «Показывать скрытые файлы, папки, диски», тогда в целом все будет видно.(После манипуляций с Hosts рекомендую вернуть галочку на исходное место, чтобы случайно что-то не зацепить в будущем)
2. Откройте этот файл в Блокноте и добавьте в конец строку типа 192.168.0.1 Server (IP-адрес PCName). Сохраните и закройте файл.
3. Попробуйте снова пропинговать ваш компьютер, используя это имя. Если вы снова не видите IP, что-то пошло не так … Возможно, антивирус вернул старую версию файла (Каспер любит это) или что-то еще.
В общем, вам нужно добиться правильного адреса при пинге через имя.
Пытаясь опередить остальной мир, Windows 7 не только помещает IPv6 во все интерфейсы сразу, но также делает его по умолчанию при разыменовании. Однако сегодня этот протокол мало кто использует, и поэтому его можно / нужно отключить. Помните, что снятие галочки с протокола IPv6 в интерфейсе сетевой карты ничего не даст!
- Щелкните Win + R, напишите regedit и нажмите Enter. Откроется редактор реестра.
- Если вам будет предложено разрешение, щелкните в диалоговом окне Контроль учетных записей пользователей кнопку Продолжить .
- Найдите и выберите следующий подраздел реестра:
HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Services \ Tcpip6 \ Parameters \
- Дважды щелкните элемент DisabledComponents , чтобы изменить параметр DisabledComponents .
Если параметр DisabledComponents отсутствует, его необходимо создать.Для этого:- Находясь в ветви Parameters, в меню Edit выбираем пункт Create a , а затем — DWORD Parameter (32 bit) .
- Введите DisabledComponents и нажмите Enter.
Хочу напомнить, что оба решения не являются панацеей и действительно не позволяют обойти ошибку, а также не устранить ее причину.
Вопрос: Ошибка Com при обработке Заполните
Здравствуйте.
8.2 Retail 1.
Подключаюсь к 8.1 Не типичная конференция.
Я подключаюсь к базе данных через com и пытаюсь создать документ, но при вызове «CreateDocument ()» или «GetObject ()» возникает ошибка процедуры ProcessingFillings … см. Рис.
Я пробую то же самое в самой базе 8.1, но ошибки нет, и я тоже не вхожу в Filling Processing.
В чем может быть косяк?
Ответ: turboq , криво написанный модуль документов!
Добавлено через 5 минут
Она не называется! Он пытается скомпилировать! Но поскольку при подключении через ComConnector DialogueModeQuestion НЕ СУЩЕСТВУЕТ, модуль документа не может быть скомпилирован.
Для таких случаев, когда необходимо реализовать работу с диалогом в объектном модуле, используются инструкции препроцессору
Это не ваша вина, а ошибка модуля документа в базе данных, к которой вы подключаетесь .
В базе код выполняется на клиенте и в диалоговом режиме Вопрос в том, значит все происходит без ошибок
Используйте для подключения не ComConnector, V8.Application, тогда у вас будет доступ к интерфейсным вещам
Добавлено после 5 минут
================================================= ================================================== ====================
из описания внешнего подключения (SP) Выделено жирным шрифтом то, что вам следует прочитать о ComConnections
Описание :
В целом работа с 1С: Предприятием 8 через внешнее подключение аналогична работе с 1С: Предприятием в режиме Сервера Автоматизации.Основные отличия заключаются в следующем:
- В случае Сервера Автоматизации запускается полноценное приложение 1С: Предприятие 8, а в случае внешнего подключения — относительно небольшой внутрипроцессный COM-сервер.
- При работе через внешнее подключение недоступны функциональные возможности, так или иначе связанные с организацией пользовательского интерфейса 1С: Предприятия 8;
- При работе внешнего подключения модуль управляемого приложения (обычный модуль приложения) конфигурации 1С: Предприятия 8 не используется.Его роль при работе с внешним подключением выполняет модуль внешнего подключения.
- Более быстрое установление соединения, поскольку нет необходимости создавать отдельный процесс операционной системы, и все действия выполняются внутри вызывающего процесса;
- Более быстрый доступ к свойствам и методам объектов 1С: Предприятия, так как для организации звонка не требуется организация межпроцессного взаимодействия;
- Меньше потребление ресурсов операционной системы.
- создается диспетчер COM-соединений, с помощью которого устанавливается соединение;
- выполняется вызов метода Connect диспетчера COM-соединений. Метод Connect возвращает внешнее подключение к информационной базе 1С: Предприятия 8;
- внешнее соединение используется для доступа к разрешенным методам, свойствам и объектам информационной базы, с которой установлено соединение.
Внешнее соединение обеспечивает полный доступ к своему глобальному контексту. Следовательно, внешнее соединение может иметь в качестве своих методов: системные константы, значения указанных в конфигураторе объектов объектов, доступ к которым осуществляется с помощью менеджеров (например, константы, перечисления, справочники, документы, журналы документов, отчеты, обработки, графики типов характеристик, планы счетов, планы видов расчетов, регистры), а также переменные, объявленные в модуле внешнего подключения с ключевым словом Export.
Наличие:
Система «1С: Предприятие», помимо файловой, может работать с информационными базами в клиент-серверной версии. В последнем случае понимается архитектура, состоящая из нескольких программных уровней, схематично показанных на рисунке ниже.
- Клиентские приложения, тонкие клиенты и веб-клиенты — это «1С: Предприятие» в различных режимах запуска, с которыми работает конечный пользователь. Для клиентских приложений и тонких клиентов требуются компьютеры пользователей (или на них), для веб-клиента достаточно веб-браузера.
- Кластер серверов «1С: Предприятие» — это набор рабочих процессов, запущенных на одном или нескольких компьютерах, и список информационных баз, которые находятся в этом кластере. Вся работа объектов приложения осуществляется в кластере серверов, выполняется подготовка к отображению форм (чтение объектов информационной базы, заполнение данных форм, расположение элементов и т. Д.) И командного интерфейса, формируются отчеты, выполняются фоновые задачи. Клиенты отображают только информацию, подготовленную в кластере серверов.Кроме того, на сервере кластера 1С: Предприятия хранятся служебные файлы, а также журнал информационной базы.
- Сервер баз данных — на сервере баз данных осуществляется непосредственное хранение и работа с данными, предоставляемыми одной из следующих систем управления базами данных (СУБД), поддерживаемых системой 1С: Предприятие:
- Microsoft SQL Server, начиная с Microsoft SQL Server 2000 и выше;
- PostgrageSQL, начиная с версии 8.1;
- IBM DB2, начиная с версии 9.1;
- Oracle Database 10g Release 2 или выше.
- Веб-сервер требуется только для веб-клиентов и одного из вариантов тонкого клиента. Обеспечивает взаимодействие данных типов подключения с серверным кластером 1С: Предприятия.
Также стоит отметить, что каждый программный уровень не обязательно должен располагаться на отдельном физическом компьютере. Кластер серверов может располагаться на одном компьютере с сервером базы данных, веб-сервером и т. Д. Например, в небольших организациях часто встречается следующая структура работы:
В этой статье я опишу установку сервера 1С: Предприятия версии 8.3.4.389 (для остальных версий платформы 1С: Предприятия 8.1, 8.2 и 8.3 действия аналогичны) на одном компьютере под управлением Windows Server 2008 (R2) или Windows Server 2012 (R2). Microsoft SQL Server 2008 (R2) или Microsoft SQL Server 2012 будет рассматриваться как СУБД. Для этого нам понадобится:
- Компьютер, отвечающий системным требованиям для установки сервера 1С: Предприятия и с установленной на нем ОС или.
- Компьютер для сервера базы данных, также работающий под управлением ОС или (может быть компьютер из пункта 1).
- Права локального администратора на обоих компьютерах.
- Дистрибутив для установки сервера 1С: Предприятия 8.
- Лицензия на ПО или ключ защиты HASP4 Net для сервера 1С: Предприятия.
- Дистрибутив для установки Microsoft SQL Server 2008 (R2) или Microsoft SQL Server 2012.
2. Установка СУБД MS SQL Server
Установите СУБД MS SQL Server на компьютер, который служит сервером базы данных. Для работы с системой 1С: Предприятия достаточно установить следующие компоненты:
- Службы ядра СУБД
- Инструменты управления — Базовые
- Инструменты управления — Полные.
Параметры сортировки выберите « Cyrillic_General_CI_AS ». Подробно об установке систем
3. Настройка брандмауэра Windows для работы СУБД
Если сервер БД и кластерный сервер 1С: Предприятия расположены на разных физических компьютерах, необходимо настроить Брандмауэр Windows на сервере БД, чтобы сервер 1С: Предприятия мог работать с СУБД, а именно открывать входящие соединения по порт 1433 (для экземпляра SQL Server по умолчанию).
- Я подробно писал о настройке брандмауэра Windows для Microsoft SQL Server 2008 (R2) / 2012.
4. Добавление пользователя в MS SQL Server
Далее добавляем в MS SQL Server отдельного пользователя, под которым будут подключаться базы данных сервера 1С: Предприятия. Этот пользователь также будет владельцем этих баз данных. Добавленный пользователь должен быть авторизован на сервере с использованием пароля и иметь набор ролей: dbcreator , processadmin, public … Подробности о добавлении пользователя в
- Microsoft SQL Server 2008 (R2) Я написал. Я написал
- Microsoft SQL Server 2012.
5. Установка сервера 1С: Предприятия
Перейдем к установке файлов сервера 1С: Предприятия и запуску соответствующей службы. Для установки необходим дистрибутив технологической платформы «1С: Предприятие». Из списка поставляемых дистрибутивов подходят следующие:
- Технологическая платформа 1С: Предприятие для Windows — позволяет установить 32-битный сервер «1С: Предприятие»
- Сервер 1С: Предприятия (64-бит) для Windows — позволяет установку как 32-битных, так и 64-битных серверов 1С: Предприятия
(Также существует расширенная версия КОРП сервера 1С: Предприятие 8.3, подробности на сайте 1С)
Откройте каталог с установочными файлами сервера 1С: Предприятия и запустите файл setup.exe .
Запущен помощник по установке системы 1С: Предприятие. На первой странице нажмите « Далее ».
На следующей странице нужно выбрать те компоненты, которые будут установлены, нам понадобятся компоненты:
- Сервер 1С: Предприятие — серверные компоненты «1С: Предприятие»
- Администрирование сервера 1С: Предприятия 8 — дополнительные компоненты для администрирования серверного кластера 1С: Предприятия
Остальные компоненты (список компонентов может зависеть от конкретного дистрибутива), в зависимости от необходимости, также могут быть установлены на этом компьютере.Сделав выбор, нажмите « Далее ».
Выберите язык интерфейса, который будет использоваться по умолчанию, и нажмите « Далее ».
Если сервер 1С: Предприятия установлен как служба Windows (а в большинстве случаев он должен быть установлен), рекомендую сразу создать отдельного пользователя, из-под которого будет запускаться созданная служба. Для этого
- Оставить флаг « Установить сервер 1С: Предприятия как службу Windows (рекомендуется) »;
- Переводим соответствующий переключатель на « Создать пользователя USR1CV8 ».
- Введите пароль для создаваемого пользователя 2 раза. По умолчанию пароль должен соответствовать политике паролей Windows. Подробнее об этом можно прочитать:
- Для Microsoft Windows Server 2008 (R2) -;
- для Microsoft Windows Server 2012 -.
Также можно выбрать существующего пользователя для запуска сервера 1С: Предприятия. В этом случае выбранный пользователь должен иметь следующие права:
- Войти как услуга
- Вход в систему как пакетное задание
- Пользователи журнала производительности.
Также пользователь должен обязательно дать необходимые права на каталог служебных файлов сервера (по умолчанию C: \ Program Files \ 1cv8 \ srvinfo для 64-битных и C: \ Program Файлы (x86) \ 1cv8 \ srvinfo для 32-битного сервера).
Автоматически созданный пользователь USR1CV8 будет иметь все вышеперечисленные права.
После заполнения соответствующих параметров нажмите « Далее ».
И наконец, нажимаем « Установить », чтобы начать установку.Это скопирует файлы выбранных компонентов, создаст файлы конфигурации, зарегистрирует компоненты программы, создаст ярлыки и запустит сервис сервера 1С: Предприятия.
По завершении установки помощник предложит установить драйвер защиты — HASP Device Driver. При использовании лицензии на ПО для сервера 1С: Предприятия установка драйвера не требуется. Сохраняем или снимаем флажок « Установить драйвер защиты » И нажимаем « Далее ».
Ошибки, которые проявляются при работе с программными продуктами, часто делают невозможным их использование. А отсутствие специальных знаний для понимания алгоритмов работы также порождает невозможность диагностики и устранения возникающих сбоев. В этой статье рассмотрим проблему «Сервер 1С: Предприятие не найден, как исправить запуск агента-сервера?»
Устранить проблему в работе 1С можно несколькими способами.
Возникающие ошибки имеют разные входы и выходы, их можно отсортировать по уровням возникновения:
- Некорректное прописывание кодов разработчиками самой one-eski;
- Ошибки программистов, модифицирующих (изменяющих) продукт применительно к требованиям (задачам) конкретного пользователя;
- Сбои, вызванные ошибками в работе кеш-памяти, чаще всего озадачивают программистов;
Что касается ошибки «Сервер 1С: Предприятия не найден», то отнести ее к одному из названных нереально, так как такое уведомление является указанием пользователю не выполнять какое-то необходимое действие для работы программы. .
Исправляем — запускаем сервер
Итак — ситуация, которой посвящена данная публикация, возникает, когда служба агент-сервер либо отключена, либо остановлена. Отметим, что, как правило, причины этого остаются неясными (кто признан).
Эта служба работает двумя способами: как приложение или как служба. Давайте посмотрим, как это сделать в обоих случаях:
Как приложение
Чтобы запустить его как приложение, выполните команду:
В этом случае указываются порт, диапазоны портов, уровень и каталог (в их настройках) .Если эти параметры не указаны, их значения будут установлены программой «по умолчанию».
Как сервис
Когда при первой установке 1С сервисом был выбран вариант запуска, то он регистрируется и в дальнейшем должен запускаться автоматически (при каждом запуске операционной системы).
Если агент изначально был установлен приложением, то вы можете вручную зарегистрировать его и запустить. Произойдет это по команде (не забываем про параметры):
ragent.exe -instsrvc -usr ‹укажите имя› -pwd ‹укажите пароль›
Port ‹для порта› -regport ‹для порта› -range ‹диапазоны портов›
Seclev ‹желаемый уровень› -d ‹указывает каталог›
Результатом регистрации будет создание новой Услуги (в данном случае для 1С версии 8.3 для 64-бит):
Для памяти
Для удаления (отмены регистрации) услуги:
Стоп:
Сейчас Вы знаете все о причинах возникновения проблемы «Сервер 1С: Предприятия не обнаружен» и о том, что нужно делать при ее появлении.