СУБД: что это, виды, структура, функции
Разбираемся с тем, как устроены эти системы и какие примеры использования СУБД существуют.
- Что такое СУБД
- Для чего нужны СУБД
- Из чего состоят системы управления базами данных
- Основные виды СУБД
- Примеры современных СУБД
- Что нужно запомнить о СУБД
Что такое СУБД
СУБД — это система управления базами данных. Первые СУБД появились ещё в 1970-х, и сегодня их используют в каждой второй компании: от небольших интернет-магазинов до Facebook, Google и Amazon.
Чтобы управлять базами данных и находить нужную информацию, запросы к ним пишут на специальных языках. Самый популярный из них — SQL (от англ. Structured Query Language — «язык структурированных запросов»).
Так СУБД применяют на практике: пользователи отправляют через них SQL-запросы к базам данных и в ответ получают нужные данные
База без СУБД — просто набор данных, с которым ничего нельзя сделать, как КамАЗ без кабины. Технически это машина: можно заливать бензин и масло, менять детали. Но водитель с таким камазом не сможет ничего делать. Стоит только добавить кабину, то есть систему управления, и всё меняется: можно ехать, рулить и поворачивать. Так и СУБД позволяет управлять и пользоваться данными.
Технически это машина: можно заливать бензин и масло, менять детали. Но водитель с таким камазом не сможет ничего делать. Стоит только добавить кабину, то есть систему управления, и всё меняется: можно ехать, рулить и поворачивать. Так и СУБД позволяет управлять и пользоваться данными.
Материал по теме:
Что такое DevOps: зачем он нужен, где применяется и в чём его плюсы и минусы
Для чего нужны СУБД
При помощи СУБД можно создавать, объединять, удалять информацию в базах данных, предоставлять к ним доступ определённым пользователям и защищать от взлома.
Основные функции СУБД:
● Создание баз данных, изменение, удаление и объединение их по определённым признакам.
● Хранение данных, в том числе больших массивов, в структурированном виде и нужном формате.
● Защита данных от взлома и нежелательных изменений при помощи распределённого доступа: когда разным группам пользователей доступны разный объём и сегменты данных.
● Выгрузка и сортировка данных по заданным фильтрам при помощи SQL-запросов.
● Поддержка целостности баз данных, резервное копирование и восстановление после сбоёв.
Системы управления БД нужны специалистам, которые работают с данными в IT:
● Разработчикам приложений и сайтов, чтобы хранить и обрабатывать данные о пользователях, транзакциях и содержимом каталога.
Например, при разработке приложения для фитнес-клуба данные пользователей складывают в огромную таблицу типа Excel, где указаны имя, дата рождения, данные об абонементе, записи и отмены тренировок и так далее. Если БД организована правильно, то будет намного проще «расшарить» приложение при открытии нового филиала фитнес-клуба или — в случае блокировки приложения — создать новое без потери данных клиентов, а значит, и без потери денег для бизнеса.
● Аналитикам данных и специалистам по Data Science, чтобы извлекать нужные данные для исследований, формировать отчёты и строить прогнозы. В любом смартфоне система способна узнавать лица людей на фотографиях и группировать изображения.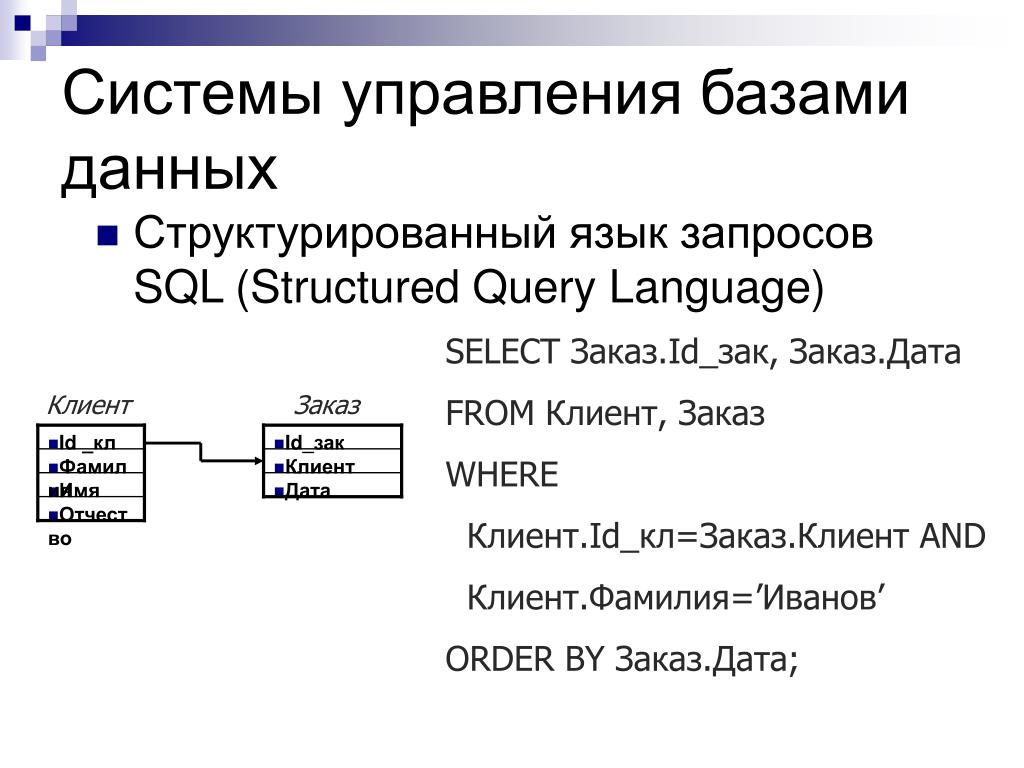 Это происходит благодаря обучению компьютеров на миллионах изображений, данные о которых хранятся в СУБД.
Это происходит благодаря обучению компьютеров на миллионах изображений, данные о которых хранятся в СУБД.
● DevOps-инженерам, чтобы автоматизировать процесс разработки и внедрения продукта на основе данных и отчётов. Агрегировать и анализировать отчёты пользователей вручную практически невозможно, а СУБД позволяют автоматизировать, например, разработку новой версии ПО или собирать данные об ошибках при разработке нового приложения.
Разобраться, как устроены СУБД и какими они бывают, можно на курсе «SQL для работы с данными и аналитики». Специалисты-практики научат составлять простейшие запросы и пользоваться популярными СУБД для бизнеса и аналитики.
Научитесь работать с SQL
Попробуйте себя в роли аналитика, даже если нет опыта работы с базами данных и html, и сделайте 2 бизнес-проекта по реальным требованиям заказчика за 1,5 месяца обучения. Начните с бесплатной вводной части курса «SQL для работы с данными и аналитики».
Из чего состоят системы управления базами данных
Вот главные элементы, которые есть в каждой СУБД, и их функции:
● Ядро. Это основа всей системы, которая отвечает за хранение и обработку баз данных. В ядре фиксируются все изменения: добавление, удаление или исправление целых баз и отдельных ячеек.
Это основа всей системы, которая отвечает за хранение и обработку баз данных. В ядре фиксируются все изменения: добавление, удаление или исправление целых баз и отдельных ячеек.
Так выглядит структура СУБД: когда кто-то отправляет запрос к базе данных, он проходит через специальное ПО, процессор языка запросов и ядро, а потом тот же путь проходят результаты в виде данных
● Процессор, или компилятор. Обрабатывает запросы к базам данных на внутренних языках и SQL, преобразуя их в нужные команды и передавая результаты.
● Программные средства, или утилиты. С их помощью пользователи вводят запросы, а администраторы баз данных настраивают доступ и другие параметры.
● Базы данных. То, где хранятся данные, организованные особым образом, иногда — в зашифрованном виде. Если это реляционные базы, то данные представлены в виде таблиц, связанных с друг другом. Если объектные — в виде объектов: блоков информации с определёнными свойствами и параметрами.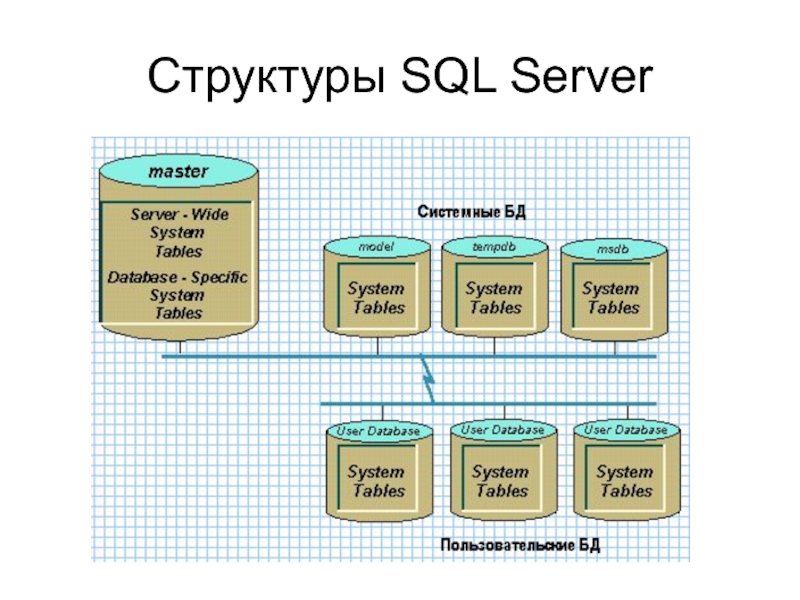
К примеру, чтобы составить меню собственной кофейни, для начала нужно изучить, что продают конкуренты и откуда заказывают продукты, а потом собрать все данные в одном месте. На выходе получатся базы данных:
— С напитками и их ингредиентами: например, миндальный капучино состоит из кофе, молока и миндального сиропа.
— С поставщиками, которые поставляют продукты и расходные материалы: стаканчики, трубочки, салфетки.
Если эти базы структурировать нужным образом, будет легко рассчитать, во сколько обойдётся кокосовый латте, у кого выгоднее брать сырьё и расходные материалы и по какой цене продавать готовый кофе. Как работают базы данных и где используются в бизнесе, наглядно и на примерах объяснили в статье.
Узнайте больше про работу с базами данных и SQL
Скачайте нашу памятку с основными SQL-командами, чтобы они всегда были под рукой
Основные виды СУБД
СУБД можно классифицировать по разным параметрам:
Хранение баз данных:
● Локальные.
Все элементы системы и баз данных находятся на одном сервере, как правило внутри компании.
● Распределённые.
Элементы находятся на разных серверах, в том числе облачных.
Многие современные СУБД поддерживают как локальное, так и распределённое применение или позволяют подключить дополнительные модули для распределённого доступа.
Хранение и обработка данных и запросов:
● Клиент-серверные.
СУБД и базы данных размещены на одном сервере, к которому обращаются с запросами разные пользователи. Получить доступ к данным через этот сервер можно с любого компьютера, специального ПО для этого не требуется. Например, если это база данных интернет-магазина, где покупатели ищут разные товары.
Примеры: Firebird, MS SQL Server, Oracle, PostgreSQL.
● Файл-серверные.
Базы данных хранятся на одном файл-сервере, а СУБД — на каждом устройстве, с которого отправляются запросы к БД. Чтобы пользователь мог получить доступ к данным, у него на компьютере должна быть установлена и настроена СУБД. Такие системы используют для локальных корпоративных сервисов: например, CRM, где хранятся данные о клиентах компании и документообороте.
Такие системы используют для локальных корпоративных сервисов: например, CRM, где хранятся данные о клиентах компании и документообороте.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
● Встраиваемые.
Локальные СУБД, которые встраиваются в приложение как отдельный модуль и используются для управления данными только внутри него.
Примеры: OpenEdge, SQLite, Microsoft SQL Server Compact.
Язык запросов:
● СУБД с поддержкой SQL — самого распространённого и универсального языка структурированных запросов к базам данных.
Примеры: MySQL, Microsoft SQL Server, PostgreSQL.
● NoSQL — нереляционные СУБД, которые поддерживают другие языки запросов, основанные на языках программирования: например, JavaScript. Такие СУБД встречаются там, где нужно работать с большими данными или архивами документов с огромным количеством разных связей.
Примеры: Oracle NoSQL Database.
Структура и организация данных:
● Реляционные.
Данные представлены в виде таблиц, связанных между собой сквозными параметрами. У каждой строки есть уникальный идентификатор, или ключ. Это позволяет легко находить нужные данные и связывать их между собой.
Примеры: MySQL, PostgreSQL.
● Ключ-значение.
Те, где для хранения данных используют уникальный идентификатор из двух частей — ключ и значение, — который присваивается каждой единице данных.
Примеры: Redis, Memcached.
● Документные.
СУБД для баз данных, где хранятся документы со структурированным текстом и особым синтаксисом. Это могут быть архивы, каталоги или журналы действий, логи для сайтов и приложений.
Примеры: Amazon DocumentDB, CouchDB, MongoDB.
● Графовые.
СУБД, которые работают с базами данных, где в качестве единицы информации выступают взаимосвязи, аналогичные тем, что есть между родственниками или людьми со схожими интересами. Такие базы часто используют в соцсетях или рекомендательных сервисах.
Примеры: Amazon Neptune, Neo4j, InfoGrid.
● Колоночные.
Эти СУБД похожи на реляционные, только данные здесь представлены в виде колонок, каждая из которых аналогична отдельной таблице.
Примеры: SAP IQ, Google Bigtable, Vertica.
Примеры современных СУБД
PostgreSQL
Клиент-серверная реляционная СУБД, которая обладает значительной функциональностью и производительностью, при этом доступна бесплатно. Она также подходит для масштабных проектов с большими массивами данных и высокой нагрузкой.
В качестве основного языка запросов используется SQL, но СУБД также поддерживает его расширения на базе языков программирования: PL/Perl, PL/Python и PL/Java. Одно из главных преимуществ PostgreSQL в том, что здесь нет ограничений по размеру баз данных и числу записей в таблицах.
Интерфейс СУБД PostgreSQL
На курсе «SQL для работы с данными и аналитики» студенты учатся решать рабочие задачи с помощью популярных СУБД, чтобы принимать решения на основе данных и структурировать их в больших массивах.
Реляционная СУБД клиент-серверного типа, которая подходит для средних и небольших команд или проектов. Программа для работы с базами данных обладает простым и удобным интерфейсом и доступна для свободного пользования, поддерживает множество разных форматов таблиц и постоянно расширяет свои возможности.
СУБД работает онлайн с высокой скоростью и позволяет хранить до 50 млн единиц данных. Однако её функциональность всё же уже, чем у PostgreSQL. MySQL используют для хранения и управления данными сайтов и интернет-магазинов, среди которых Facebook, Twitter, Alibaba, Wikipedia. Она также может работать в комбинации с другими популярными СУБД.
Интерфейс MySQL
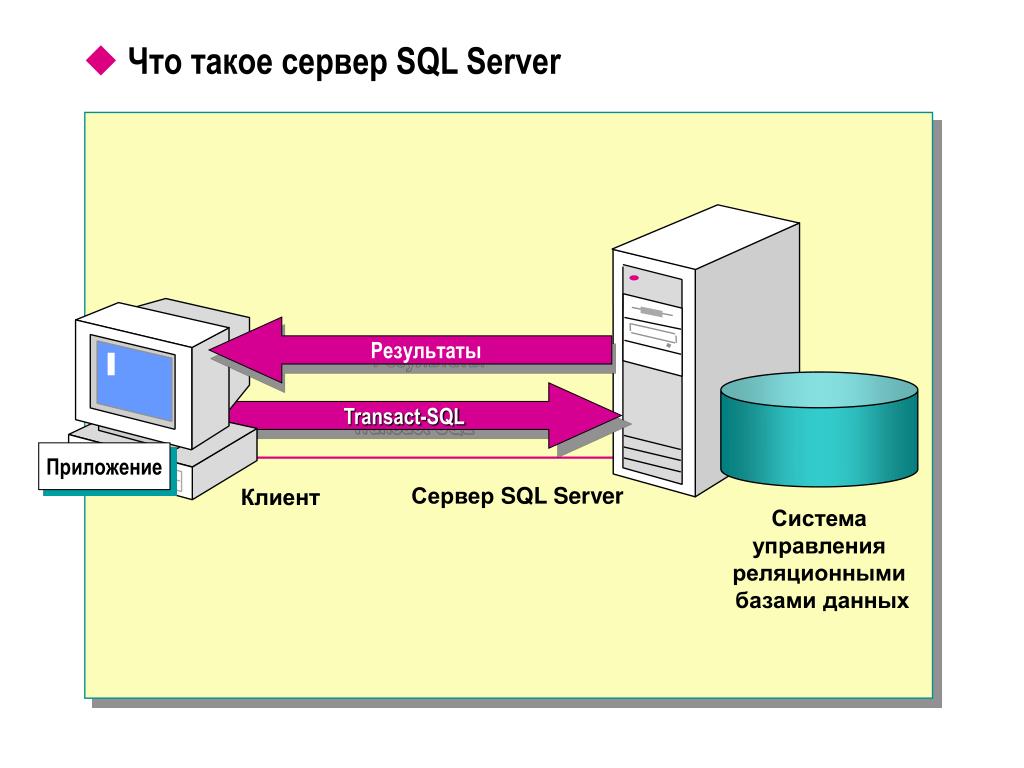
Microsoft SQL Server
Реляционная СУБД, расширенную платную версию которой используют в крупных компаниях. Бесплатная версия Express подходит для небольших проектов с объёмом данных до 10 Гб.
Система позволяет автоматизировать рутинные задачи: например, изменить размер файла или управлять памятью. Здесь удобно хранить данные со сложной структурой и быстро находить нужное за счёт простого поиска.
Здесь удобно хранить данные со сложной структурой и быстро находить нужное за счёт простого поиска.
В систему можно выгружать данные из других программ Microsoft (например, Access и Excel), а также вносить изменения в режиме онлайн. Для запросов в СУБД используется расширение SQL T-SQL (Transact-SQL).
Интерфейс MS SQL Server
MongoDB
Документная система управления NoSQL, где данные хранятся в виде JSON-файлов (от англ. JavaScript Object Notation), то есть текстовых документов в формате, основанном на JavaScript. Его же СУБД поддерживает в качестве языка запросов вместо SQL.
Вместо таблиц, как это принято в реляционных СУБД, в MongoDB данные хранятся в виде коллекций, то есть групп документов. Это бесплатная программа для работы с БД с открытым кодом, которая позволяет хранить любые данные, если их перевести в формат JSON. Такие свойства делают её практически универсальной и легко масштабируемой.
Эта СУБД подходит для работы с большими данными разных типов и из множества разных источников. Данные автоматически распределяются между разными базами так, чтобы оптимизировать нагрузку и ускорить обработку запросов. MongoDB используют для хранения локальных данных такие компании, как Google, Facebook, Twitter, IBM, Forbes, а также многие интернет-магазины.
Данные автоматически распределяются между разными базами так, чтобы оптимизировать нагрузку и ускорить обработку запросов. MongoDB используют для хранения локальных данных такие компании, как Google, Facebook, Twitter, IBM, Forbes, а также многие интернет-магазины.
Интерфейс MongoDB
SQLite
Компактная СУБД, которая подходит для небольших проектов. Она состоит из одного файла и встраивается в IT-инфраструктуру в виде библиотеки, не задействуя серверы и специальные службы. Все базы данных хранятся на одном устройстве.
SQLite подходит для небольших сайтов и приложений с ограниченным трафиком и объёмом данных, а также сервисов, где нужно прочитать или сохранить файлы на диск. СУБД работает на компьютерах, смартфонах, ТВ, приставках и беспилотниках, не требует администрирования и поддержки. В качестве языка запросов здесь используется С.
Интерфейс SQLIte
Что нужно запомнить о СУБД
● При помощи СУБД можно собирать, хранить, защищать базы данных, управлять ими. А ещё предоставлять распределённый доступ: чтобы разным группам пользователей были доступны разные объёмы данных и операции с ними.
А ещё предоставлять распределённый доступ: чтобы разным группам пользователей были доступны разные объёмы данных и операции с ними.
● СУБД нужны всем, кто работает с данными: интернет-магазинам, банкам, маркетологам, исследователям, разработчикам игр и приложений.
● Чтобы работать с СУБД, нужно освоить основы языка запросов (самый популярный и универсальный — SQL). Для некоторых СУБД пригодятся также языки программирования: JavaScript, Python, C++.
● Есть разные виды и классификации СУБД: по структуре баз данных, формату файлов, языку запросов и способу размещения системы.
● На рынке десятки различных СУБД, но самых популярных не больше десяти. Среди них можно выбрать ту, которая отвечает задачам, условиям и бюджету: по масштабу проекта и объёму данных, способу установки и размещения, доступности (платная или бесплатная). Чем масштабнее и дороже СУБД, тем больше у неё возможностей и выше уровень защиты данных.
Статью подготовили:
Поделиться
Читать также:
Как работают базы данных в IT: разбор на примерах
Читать статью
Как устроен язык SQL и почему он так востребован
Читать статью
Учитесь на майских и получайте скидку 7%. Пройдите первый бесплатный урок с 1 по 14 мая и получите промокод на скидку.
Пройдите первый бесплатный урок с 1 по 14 мая и получите промокод на скидку.
Какую СУБД выбрать и почему? (Статья 1) / Хабр
Это первый выпуск в серии статей про СУБД, в рамках которых буду достаточно простыми словами давать информацию про то, что сейчас есть на рынке баз данных, и что выбрать для решения своих задач.
Заметил, что когда спрашиваешь кого-нибудь, особенно на собеседовании, какие типы СУБД существуют, то первое что вспоминают многие – это реляционные базы данных, и NoSQL, а вот про разновидности часто забывают или не могут сформулировать их отличие. Поэтому начнем с простого перечисления наиболее используемых.
Реляционные
Ключ-значение
Документные
Графовые
Колоночные
Тем, кому не хочется долго читать, может сразу перейти на итоговую таблицу.
Нужно обязательно сделать ремарку, что некоторые крупные производители, имеют в своем арсенале несколько типов СУБД, как в виде отдельных продуктов, так и в виде внутренней реализации. Например, у Oracle на самом деле чего только нет, начиная с классической реляционной СУБД, продолжая с отдельным продуктом Oracle NoSQL Database, который может использоваться и как документная, и как колоночная, и как ключ-значение. Отдельное решение от того же Oracle, Autonomous Data Warehouse – это уже специализированное решение для хранилищ данных. Еще один отдельный продукт от Oracle – Oracle Graph Server для работы с графами, и еще много другого. Этому можно посвятить отдельную серию статей.
Например, у Oracle на самом деле чего только нет, начиная с классической реляционной СУБД, продолжая с отдельным продуктом Oracle NoSQL Database, который может использоваться и как документная, и как колоночная, и как ключ-значение. Отдельное решение от того же Oracle, Autonomous Data Warehouse – это уже специализированное решение для хранилищ данных. Еще один отдельный продукт от Oracle – Oracle Graph Server для работы с графами, и еще много другого. Этому можно посвятить отдельную серию статей.
Реляционные СУБД
Начнем по порядку, классические, реляционные СУБД чаще всего используются для построения решений OLTP (Online Transaction Processing). В таких решениях СУБД работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом от системы требуется минимальное время отклика, а так же возможность, при определенных условиях, отменить любые изменения выполняемых в рамках транзакции. Если вы строите систему, в рамках которой требуется хранить значительное количество сущностей (таблиц), с различными типами связей между ними (один-к-одному, один-к-многим, многие-ко-многим), то это скорее всего про реляционные СУБД.
Наиболее известные СУБД такого типа — Oracle, Microsoft SQL, PostgreSQL, MySQL.
Когда выбирать реляционную СУБД
Один из основных признаков, который говорит о том что нужно выбирать реляционную СУБД – это высокая нормализация данных. Дополнительными признаками будет необходимость обработки большого кол-ва коротких транзакций, с большей долей операций на вставку
Когда не выбирать реляционную СУБД
Если предполагается хранить не структурируемые данные, или наоборот очень простые структуры типа ключ-значение, то лучше посмотреть в сторону документных СУБД и специализированных СУБД типа ключ-значение соответственно.
Так же один из признаков, что имеет смысл подумать не о реляционных СУБД, это такой факт как необходимость часто обновлять значения в одних и тех же строках. Обычно это обходится «дорого» в реляционных СУБД, и нужно применять «продвинутую магию» что бы делать это корректно.
Конечно, тут есть много «но», или «а если очень хочется», и других ситуаций, когда данные рекомендации можно игнорировать. Это нормально, особенно когда за дело берется эксперт, который знает как это сделать.
Это нормально, особенно когда за дело берется эксперт, который знает как это сделать.
СУБД типа ключ-значение
Наверное один из самых простых типов СУБД. В упрощенном виде, это некая таблица с уникальным ключом и собственно связанным с ним значением, в котором может быть что угодно. Чаще всего такие СУБД используют для кэширования, т.к. они очень быстро работают, а это и не сложно, когда есть уникальный ключ, и запрос возвращает только одно значение. У некоторых представителей данных СУБД есть возможность работать полностью в памяти, а так же есть возможность задавать срок жизни записи, после истечения которого, записи будут автоматически удаляться.
Наиболее известные СУБД такого типа — Redis и Memcached.
Когда выбирать СУБД ключ-значение
Если СУБД будет использоваться для кэширования данных или для брокеров сообщений, то это очень подходящий тип. Так же, такая СУБД хорошо подходит для баз где нужно хранить достаточно простые структуры, и иметь к ним очень быстрый доступ.
Когда не выбирать СУБД ключ-значение
Если вы предполагаете хранить в базе данных много сущностей (таблиц), а у сущностей будут сложные структуры с разными типами данных. Так же, если вы предполагаете делать из этой таблицы сложные запросы которые возвращают множества строк.
Документные СУБД
Документные или документно-ориентированные СУБД — это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ — структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название «документо-ориентированная» подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Когда выбирать документную СУБД
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Когда не выбирать документную СУБД
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.
Графовые СУБД
Графовые СУБД — специфичный тип, предназначены для работы с графами, с их узлами, свойствами, и произвольными отношениями между узлами.
Очень простой пример, это организация связей в различного типа социальных сетях, где нужно хранить связи между пользователями (узлами) по разным критериям (родственные связи, коллеги, общие интересы).
Известные представители этого типа субд — Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid.
Когда выбирать графовые СУБД
Точно стоит обратить внимание на графовые СУБД, если строите какое-то подобие социальной сети, или реализуете систему оценок и рекомендаций. Ну и во всех случаях когда вы хорошо понимаете что такое графы, и для чего это нужно.
Когда не выбирать графовые СУБД
Практически во всех остальных случаях, кроме указанных выше, лучше воздержаться от использования графовых СУБД.
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся «построчно», это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся «поколоночно», т.е. колонка — это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД — Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД — это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
Итоги
Важное замечание – не пытайтесь сразу все задачи решить в рамках одной СУБД. Это более чем нормально иметь несколько разных типов СУБД. Так же, не пытайтесь сразу определиться с производителем СУБД, или связать свою жизнь с одним конкретным брендом.
При выборе типа СУБД следует, прежде всего, исходить из типа решаемых задач, типов обрабатываемых данных, перспектив роста и масштабирования.
Обращайте так же внимание на популярность и наличие широкого круга разработчиков и средств разработки – это даст вам возможность, при необходимости, найти ответ на возникший вопрос быстро.
В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей.
Итак, в таблице представленной ниже, кратко собрано то, что описано выше в статье.
Тип СУБД | Когда выбирать | Примеры популярных СУБД |
Реляционные | Нужна транзакционность; высокая нормализация; большая доля операций на вставку | Oracle, MySQL, Microsoft SQL Server, PostgreSQL |
Ключ-значение | Задачи кэширования и брокеры сообщений | Redis, Memcached |
Документные | Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON | CouchDB, MongoDB, Amazon DocumentDB |
Графовые | Задачи подобные социальным сетям; системы оценок и рекомендаций | Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid |
Колоночные | Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов | Vertica, ClickHouse, Google BigTable, Sybase \ SAP IQ, InfoBright, Cassandra |
Надеюсь данная статья оказалась полезной.
В следующих статьях посмотрим на выбор между облачными и on-premise СУБД, платными и бесплатными, и многое другое.
подзапросов и подтаблиц в SQL и VB
Поиск
Введение
Добро пожаловать в сегодняшнюю статью. Сегодня я хочу продемонстрировать, что такое подзапросы и подтаблицы и как их использовать в Visual Basic.
Прежде чем вы сможете приступить к внутренней работе сегодняшней темы, вам потребуется некоторая справочная информация.
Базы данных
Базы данных могут быть дружественными существами, если вы знаете, как правильно их использовать; они также могут стать очень плохими, особенно если вы не знаете, как правильно их использовать. Единственной функцией базы данных является хранение информации, отсюда и название: база данных. Знание того, как правильно хранить внутри них, требует практики и тщательного планирования.
База данных состоит из следующих объектов:
- Таблицы
- Запросы
- просмотров
- Хранимые процедуры
- Функции
Таблицы
Таблицы являются основными строительными блоками любой базы данных. Здесь будет храниться вся информация. Таблица состоит из строк (записей) и столбцов (полей). Строка или запись содержит всю информацию, относящуюся к одной теме. Столбец или поле — это когда-то часть информации.
SQL
Язык структурированных запросов (SQL) — это язык программирования, используемый для создания баз данных, извлечения информации из баз данных и хранения информации в базах данных. В предыдущей статье я говорил о термине «база данных», поэтому, если вы еще не читали его, прочтите здесь. Если вы впервые слышите термин SQL, загляните сюда.
Чтобы извлечь любую информацию из любой базы данных, нам нужно написать запрос SQL. Запрос можно объяснить как запрос информации, которую он затем представляет в конечном итоге. Теперь, как я уже говорил, вся информация базы данных хранится внутри таблиц. Эти таблицы содержат всю информацию, которая была сохранена. Мы должны написать запрос, чтобы получить эту информацию и предоставить ее пользователю.
Теперь, как я уже говорил, вся информация базы данных хранится внутри таблиц. Эти таблицы содержат всю информацию, которая была сохранена. Мы должны написать запрос, чтобы получить эту информацию и предоставить ее пользователю.
Запросы
Простейшая форма запроса будет выглядеть следующим образом:
SELECT * FROM TableName
Это даст вам все данные, хранящиеся в этой конкретной таблице. Помните, что в некоторых таблицах могут быть миллионы записей, поэтому в этом случае этот простой запрос может дать вам все миллионы записей. Обычно в этом нет особой необходимости. Обычно при извлечении информации возникает какое-то условие. Запрос с условием будет выглядеть следующим образом:
SELECT * FROM TableName WHERE Field = Value
Запрос, подобный приведенному выше, теперь может возвращать только определенную информацию. Позвольте мне использовать банк в качестве примера. С любым банком они имеют дело с миллионами клиентов. У многих из этих клиентов могут быть одинаковые фамилии или даже одинаковые полные имена. Любой клиент банка может иметь более одного типа счета. Теперь, принимая все это во внимание, запрос на возврат всей информации конкретному человеку может быть проблематичным. Если бы условий не было, это заставило бы вас очень долго стоять в банковской очереди, пока бедный кассир перебирает всю информацию только для того, чтобы найти нужного человека с правильной информацией.
Любой клиент банка может иметь более одного типа счета. Теперь, принимая все это во внимание, запрос на возврат всей информации конкретному человеку может быть проблематичным. Если бы условий не было, это заставило бы вас очень долго стоять в банковской очереди, пока бедный кассир перебирает всю информацию только для того, чтобы найти нужного человека с правильной информацией.
Мы можем пойти дальше и написать запрос, подобный следующему:
SELECT * FROM TableName WHERE Field1 = Value1 И Поле2 > Значение2 ИЛИ Поле3 < Значение3
Теперь все становится сложнее, так как здесь мы имеем дело с более чем одним значением поля и более чем одним условием. Приведенный выше запрос может быть переведен на непрофессиональный язык и означает:
Выберите все данные из таблицы с именем TableName , где Column1 равен Value1 И Column2 больше Value2 ИЛИ Column3 меньше Value3.
SELECT * FROM Table1, Table2, Table3 ГДЕ Таблица1.Поле1 = Значение1 И Таблица2.Поле2 > Значение2 ИЛИ Таблица3.Поле3 < Значение3
 Поле1 = Значение1
И Таблица2.Поле2 > Значение2
ИЛИ Таблица3.Поле3 < Значение3
Поле1 = Значение1
И Таблица2.Поле2 > Значение2
ИЛИ Таблица3.Поле3 < Значение3
Этот код SQL извлекает определенные данные из трех разных таблиц на основе различных заданных условий.
Подзапросы
Ознакомьтесь со следующими ссылками:
- https://technet.microsoft.com/en-us/library/ms189575%28v=sql.105%29.aspx?f=255&MSPPError=- 2147217396
- https://technet.microsoft.com/en-us/library/ms187638%28v=sql.105%29.aspx
- https://technet.microsoft.com/en-us/library/ms175838%28v=sql.105%29.aspx
Вот пример:
ВЫБЕРИТЕ
Таблица1.Поле1, Таблица1.Поле2,
(ВЫБЕРИТЕ Поле1 ИЗ Таблицы2
ГДЕ Таблица2.Поле = Таблица1.Поле)
AS [Код],
(ВЫБЕРИТЕ Поле2 ИЗ Таблицы3
ГДЕ Таблица3.Поле = Таблица1.Поле)
АС [Курс]
ИЗ Таблицы1
Предыдущий запрос выбирает два поля из таблицы. Затем он использует подзапрос для выбора соответствующего поля из вторичной таблицы, а затем из третьей таблицы. Итак, как видите, подзапрос — очень полезный инструмент для извлечения данных из других таблиц без необходимости соединения. Для получения дополнительной информации о
Для получения дополнительной информации о
- https://technet.microsoft.com/en-us/library/ms191517%28v=sql.105%29.aspx
- https://technet.microsoft.com/en-us/library/ms191472%28v=sql.105%29.aspx
Подтаблицы
Прочитайте здесь, чтобы получить представление о подтаблицах.
Ниже приведен пример:
ВЫБОР
[Поле 1], [Поле 2], [Поле 3], [Поле 4]
ОТ
(ВЫБИРАТЬ
Table1.Field1 AS [Поле 1],
Table1.Field2 AS [Поле 2],
((ВЫБРАТЬ поле1 ИЗ таблицы2
ГДЕ Таблица2.Поле = Таблица1.Поле))
АС [Поле 3],
((ВЫБРАТЬ поле2 ИЗ таблицы2
ГДЕ Таблица2.Поле = Таблица1.Поле))
АС [поле 4]
ИЗ Таблицы1
) КАК [ГРУППИРОВАТЬ ТАБЛИЦУ]
ГДЕ [GROUPEDTABLE].Field1 = 'ЗНАЧЕНИЕ'
СГРУППИРОВАТЬ ПО [Поле 1], [Полю 2], [Полю 3],
[Поле 4]
В приведенном выше примере подтаблица создается в основном для целей группировки. Группировка в данном случае означает, что когда у вас есть большие группы похожих данных, вы можете сгруппировать их в соответствии с их значениями.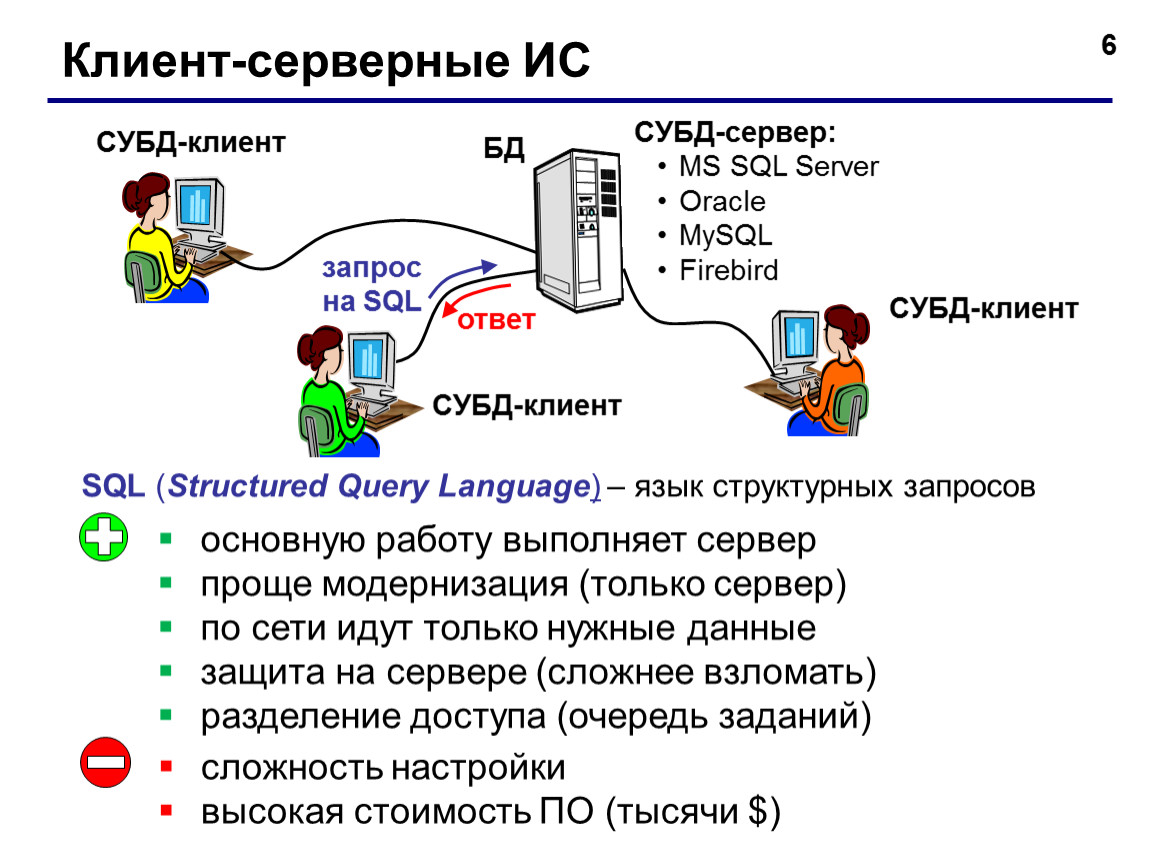 В приведенном выше случае вся избыточная информация должна была быть отброшена.
В приведенном выше случае вся избыточная информация должна была быть отброшена.
Лучшим примером было бы использование агрегатной функции, такой как Sum, для суммирования всей информации, таким образом предоставляя только рассчитанные итоги из подтаблицы. Для получения дополнительной информации об агрегатных функциях прочитайте здесь.
Наш проект
Используйте SQL Server для создания базы данных, а затем создайте три таблицы, как показано на рис. 1. Вы также можете добавлять информацию во все таблицы по своему усмотрению.
Рисунок 1: Таблицы базы данных
Если вы не знаете, как создать базу данных или таблицы базы данных, я предлагаю вам прочитать здесь для получения дополнительной информации.
Создайте новый запрос и добавьте в него один из следующих кодов:
SELECT
Сведения о студенте.Имя, Сведения о студенте.Фамилия,
(ВЫБЕРИТЕ НАЧАЛЬНЫЙ 1 Код Курса ИЗ Сведения о Курсе
ГДЕ CourseDetails.StudentID = StudentDetails. StudentNumber)
AS [Код],
(ВЫБЕРИТЕ TOP 1 CourseName ИЗ CourseDetails
ГДЕ CourseDetails.StudentID = StudentDetails.StudentNumber)
АС [Курс]
ОТ Сведения о студенте
ВЫБИРАТЬ
CourseDetails.CourseCode, CourseDetails.CourseName,
(ВЫБЕРИТЕ НАЧАЛЬНОЕ 1 Имя ИЗ StudentDetails
ГДЕ StudentDetails.StudentNumber = CourseDetails.StudentID)
AS [Код],
(ВЫБЕРИТЕ ТОП 1 Фамилию ИЗ Сведения о студенте
ГДЕ StudentDetails.StudentNumber = CourseDetails.StudentID)
АС [Курс]
ОТ КурсДетали

Это код для наших подзапросов. Создайте еще один запрос и добавьте в него следующий код для подтаблицы:
SELECT
[Код темы], [Описание темы], [Код] AS [Код курса], [Курс]
ОТ
(ВЫБИРАТЬ
SubjectDetails.SubjectCode AS [Код темы],
SubjectDetails.SubjectDescription AS [Описание темы],
((ВЫБЕРИТЕ TOP 1 CourseCode ИЗ CourseDetails
ГДЕ CourseDetails.CourseID = SubjectDetails.CourseID))
AS [Код],
((ВЫБРАТЬ TOP 1 CourseName ИЗ CourseDetails
ГДЕ CourseDetails. CourseID = SubjectDetails.CourseID))
АС [Курс]
ОТ ТемыДетали
) КАК [CD]
ГДЕ [CD].Code = 'VB'
СГРУППИРОВАТЬ ПО [Код], [Курс], [Код темы], [Описание темы]
 CourseID = SubjectDetails.CourseID))
АС [Курс]
ОТ ТемыДетали
) КАК [CD]
ГДЕ [CD].Code = 'VB'
СГРУППИРОВАТЬ ПО [Код], [Курс], [Код темы], [Описание темы]
CourseID = SubjectDetails.CourseID))
АС [Курс]
ОТ ТемыДетали
) КАК [CD]
ГДЕ [CD].Code = 'VB'
СГРУППИРОВАТЬ ПО [Код], [Курс], [Код темы], [Описание темы]
Создайте новый VB Project , добавьте Datagridview в форму и добавьте в него следующий код:
Imports System.Data.SqlClient
Форма публичного класса1
'переменные
Dim con As SqlConnection = _
Новое SqlConnection("Источник данных=HTG\ _
Тест;AttachDbFilename= _
|DataDirectory|\MyDB.mdf;Встроенная безопасность=Истина; _
Время ожидания подключения = 30; Экземпляр пользователя = True").
Dim cmd как SqlCommand
Dim myDA как SqlDataAdapter
Dim myDataSet как набор данных
Private Sub Form1_Load (отправитель ByVal As System.Object, _
ByVal e As System.EventArgs) Обрабатывает MyBase.Load
ПоказатьПодзапрос1()
Конец сабвуфера
'Привязать базу данных к DataGridView
Общедоступная подпрограмма ShowSubQuery1()
cmd = New SqlCommand("ВЫБЕРИТЕ Сведения о Студенте. Имя, _
StudentDetails.Surname, (SELECT TOP 1 CourseCode _
ОТ CourseDetails, ГДЕ CourseDetails.StudentID = _
StudentDetails.StudentNumber) AS [Код], _
(ВЫБЕРИТЕ TOP 1 CourseName FROM CourseDetails _
ГДЕ CourseDetails.StudentID = StudentDetails.StudentNumber) _
AS [Курс] FROM StudentDetails», кон)
Если con.State = ConnectionState.Closed, тогда con.Open()
myDA = новый SqlDataAdapter (cmd)
мой набор данных = новый набор данных ()
myDA.Fill(myDataSet, "MyTable")
DataGridView1.DataSource = myDataSet.Tables("MyTable").DefaultView
Конец сабвуфера
'Привязать таблицу к DataGridView
Общедоступная подтаблица ShowSubTable()
cmd = New SqlCommand("SELECT [Код темы], [Описание темы], _
[Код] AS [Код курса], [Курс] _
ОТ (ВЫБЕРИТЕ SubjectDetails.SubjectCode _
AS [Код темы], SubjectDetails.SubjectDescription _
AS [Описание темы], ((ВЫБРАТЬ TOP 1 CourseCode _
ОТ CourseDetails, ГДЕ CourseDetails. CourseID = _
SubjectDetails.CourseID)) AS [Код], ((SELECT TOP 1 CourseName _
ОТ CourseDetails, ГДЕ CourseDetails.CourseID = _
SubjectDetails.CourseID)) AS [Курс] FROM SubjectDetails) _
КАК [CD] ГДЕ [CD].Code = 'VB' СГРУППИРОВАТЬ ПО [Код], [Курс], _
[Код темы], [Описание темы]", con)
Если con.State = ConnectionState.Closed, тогда con.Open()
myDA = новый SqlDataAdapter (cmd)
мой набор данных = новый набор данных ()
myDA.Fill(myDataSet, "MyTable")
DataGridView1.DataSource = myDataSet.Tables("MyTable").DefaultView
Конец сабвуфера
' Получить/выбрать записи
Private Sub Button1_Click (отправитель ByVal As System.Object, _
ByVal e As System.EventArgs) Обрабатывает Button1.Click
cmd = New SqlCommand("SELECT CourseDetails.CourseCode, _
CourseDetails.CourseName, (SELECT TOP 1 Name _
ОТ StudentDetails ГДЕ StudentDetails.StudentNumber = _
CourseDetails.StudentID) AS [Имя], (SELECT TOP 1 Фамилия _
ОТ StudentDetails ГДЕ StudentDetails. StudentNumber = _
+/CourseDetails.StudentID) AS [Фамилия] FROM CourseDetails", con)
Если con.State = ConnectionState.Closed, тогда con.Open()
Dim sdr As SqlDataReader = cmd.ExecuteReader()
Пока sdr.Read = True
MessageBox.Show(sdr.Item("CourseCode") & " " & sdr.Item("Имя"))
Конец пока
sdr.Закрыть()
Конец сабвуфера
Private Sub Button2_Click (отправитель как объект, e как EventArgs) _
Ручки Button2.Click
ПоказатьПодтаблицу()
Конец класса SubEnd


 StudentNumber = _
+/CourseDetails.StudentID) AS [Фамилия] FROM CourseDetails", con)
Если con.State = ConnectionState.Closed, тогда con.Open()
Dim sdr As SqlDataReader = cmd.ExecuteReader()
Пока sdr.Read = True
MessageBox.Show(sdr.Item("CourseCode") & " " & sdr.Item("Имя"))
Конец пока
sdr.Закрыть()
Конец сабвуфера
Private Sub Button2_Click (отправитель как объект, e как EventArgs) _
Ручки Button2.Click
ПоказатьПодтаблицу()
Конец класса SubEnd
StudentNumber = _
+/CourseDetails.StudentID) AS [Фамилия] FROM CourseDetails", con)
Если con.State = ConnectionState.Closed, тогда con.Open()
Dim sdr As SqlDataReader = cmd.ExecuteReader()
Пока sdr.Read = True
MessageBox.Show(sdr.Item("CourseCode") & " " & sdr.Item("Имя"))
Конец пока
sdr.Закрыть()
Конец сабвуфера
Private Sub Button2_Click (отправитель как объект, e как EventArgs) _
Ручки Button2.Click
ПоказатьПодтаблицу()
Конец класса SubEnd
Сначала я создал соединение с таблицей SQL Server и сохранил его в переменной con.
Во всех различных подразделах я использовал функцию SQLCommand для заполнения строки запроса SQL, и оттуда связанные данные загружаются в адаптеры данных, которые загружают полученные данные в Datagridview.
Заключение
Как видите, работать с подзапросами и подтаблицами в SQL и VB не так уж и сложно. До следующего раза, до свидания.
Необходимо прочитать
sql - Способ поиска уникальных значений из таблицы по определенному столбцу
Задавать вопрос
спросил
Изменено 4 года, 11 месяцев назад
Просмотрено 72 раза
Вот таблица, состоящая из данных, как показано ниже:
StandardName|Имя пользователя |RType ------------|-------------|-------- Департамент |Отдел | Позиция Дивизия | Дивизия | Сущность Дивизия | Дивизия | Позиция Завод |Завод | Сущность Раздел |Раздел | Позиция Подраздел |Подраздел| Сущность Подраздел |Подраздел | Позиция Подраздел |Подраздел | Позиция Единица | Единица | Сущность
Я хочу, чтобы все StandardName и UserName сопровождались Rtype = 'Entity', а в случае Rtype = 'Position' он получит только StandardName, которые не связаны с RType 'Entity'
Для этого я сделал запрос вроде этот
SELECT DISTINCT u.
 StandardName, u.UserName, ISNULL (e.RType, 'позиция') AS RType
от (
SELECT DISTINCT StandardName,UserName
из Table1 AS ee, где RType = 'Entity'
СОЮЗ
SELECT DISTINCT StandardName, UserName
из Table1 AS pp, где RType = 'position'
) ты
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ (
выберите Имя пользователя, Стандартное имя, RType
из таблицы 1, ГДЕ RType = 'Сущность'
) e on e.StandardName = u.StandardName
ЗАКАЗАТЬ ПО Rtype
StandardName, u.UserName, ISNULL (e.RType, 'позиция') AS RType
от (
SELECT DISTINCT StandardName,UserName
из Table1 AS ee, где RType = 'Entity'
СОЮЗ
SELECT DISTINCT StandardName, UserName
из Table1 AS pp, где RType = 'position'
) ты
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ (
выберите Имя пользователя, Стандартное имя, RType
из таблицы 1, ГДЕ RType = 'Сущность'
) e on e.StandardName = u.StandardName
ЗАКАЗАТЬ ПО Rtype
Затем выводится
StandardName|Имя пользователя |RType ------------|-------------|-------- Дивизия | Дивизия | Сущность Завод |Завод | Сущность Подраздел |Подраздел| Сущность Подраздел |Подраздел | Сущность Единица | Единица | Сущность Департамент |Отдел | Позиция Раздел |Раздел | Позиция Подраздел |Подраздел | Позиция
Здесь, в случае 'SubDivision', он появляется два раза, тогда как для RType 'Entity' он должен появиться один раз.
Ожидаемый результат должен быть --
StandardName|Имя пользователя |RType ------------|-------------|-------- Дивизия | Дивизия | Сущность Завод |Завод | Сущность Подраздел |Подраздел| Сущность Единица | Единица | Сущность Департамент |Отдел | Позиция Раздел |Раздел | Позиция Подраздел |Подраздел | Позиция
Ссылка SQLFIDDLE
- sql
- sql-сервер
- база данных
1
Это оператор sql, переведенный из ваших требований:
-- дайте мне все, что является сущностью
выберите StandardName, UserName, RType
из таблицы 1
где RType = 'Сущность'
союз
-- и все, что не имеет сущности-входа
выберите StandardName, UserName, RType из Table1 как k
где rtype = 'Позиция' и не существует (
выберите 1
из таблицы1 как t
где t. стандартное имя = k.стандартное имя
и t.rtype = 'Сущность'
)
 стандартное имя = k.стандартное имя
и t.rtype = 'Сущность'
)
стандартное имя = k.стандартное имя
и t.rtype = 'Сущность'
)
не содержит ваших "отличий", но вы получаете результат:
StandardName UserName RType ---------------------------------------- Подразделение Подразделение Сущность Завод Завод Сущность Подразделение Подразделение Субъект Единица измерения Должность отдела Раздел Положение раздела Положение подраздела подраздела
У вас нет дубликатов «Объект» -записи - так что никаких особых требований не требуется.
Это запрос определения приоритета. Метод Патрика — хороший метод, особенно когда есть только два типа.
Другой метод использует row_number() :
select e.StandardName, e.Username, e.RType
из (выберите e.*,
row_number() над (раздел по StandardName
порядок (случай RType, когда «Сущность», затем 1, когда «Позиция», затем 2, иначе 3 заканчиваются)
) как последовательность
от сотрудников е
) е
где последовательность = 1;
Для каждого StandardName вам нужна строка с 'Entity', но если она не существует, строка с 'Position'.