|
Навигация: Главная Случайная страница Обратная связь ТОП Интересно знать Избранные Топ: Определение места расположения распределительного центра: Фирма реализует продукцию на рынках сбыта и имеет постоянных поставщиков в разных регионах. Увеличение объема продаж… Эволюция кровеносной системы позвоночных животных: Биологическая эволюция – необратимый процесс исторического развития живой природы… Комплексной системы оценки состояния охраны труда на производственном объекте (КСОТ-П): Цели и задачи Комплексной системы оценки состояния охраны труда и определению факторов рисков по охране труда… Интересное: Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны… Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является… Дисциплины: Автоматизация Антропология Археология Архитектура Аудит Биология Бухгалтерия Военная наука Генетика География Геология Демография Журналистика Зоология Иностранные языки Информатика Искусство История Кинематография Компьютеризация Кораблестроение Кулинария Культура Лексикология Лингвистика Литература Логика Маркетинг Математика Машиностроение Медицина Менеджмент Металлургия Метрология Механика Музыкология Науковедение Образование Охрана Труда Педагогика Политология Правоотношение Предпринимательство Приборостроение Программирование Производство Промышленность Психология Радиосвязь Религия Риторика Социология Спорт Стандартизация Статистика Строительство Теология Технологии Торговля Транспорт Фармакология Физика Физиология Философия Финансы Химия Хозяйство Черчение Экология Экономика Электроника Энергетика Юриспруденция |
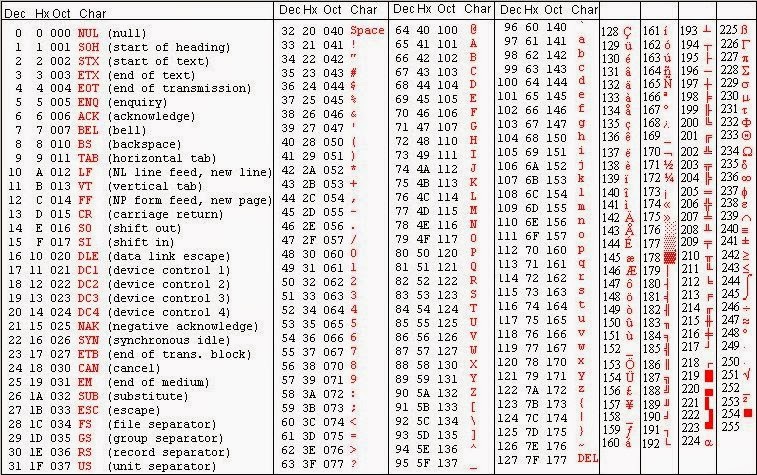
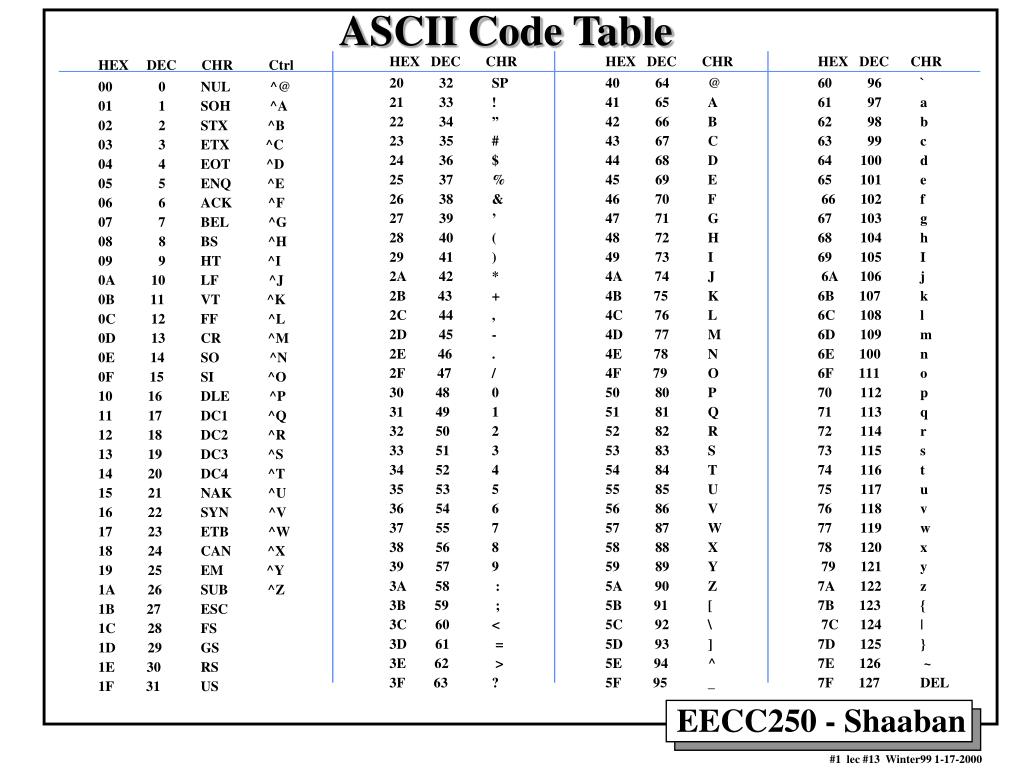
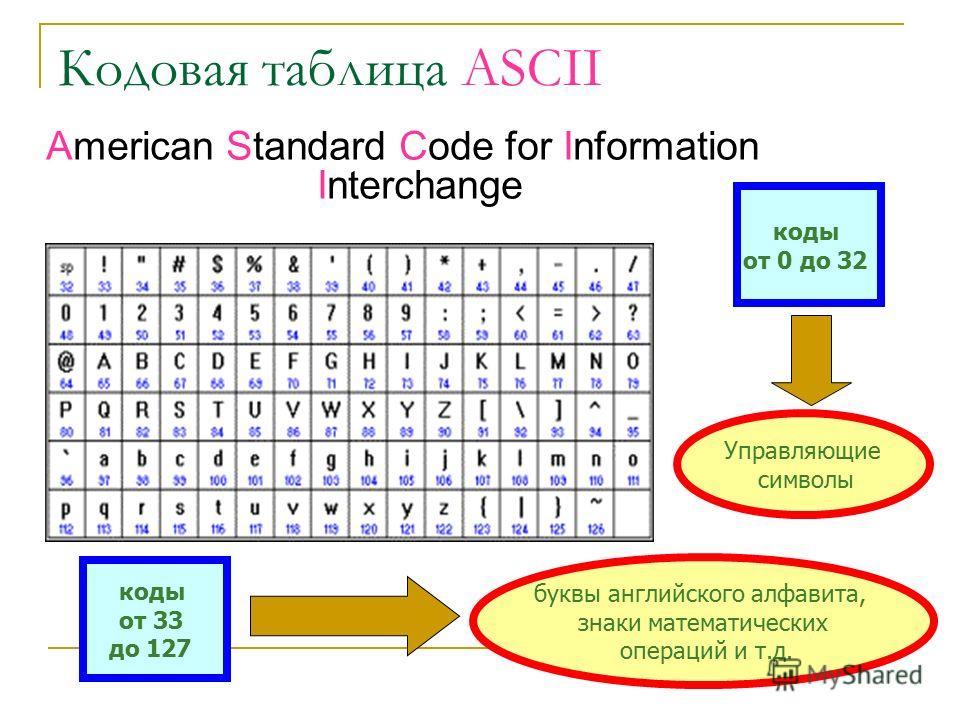
Стр 1 из 5Следующая ⇒ Кодирование текстовой информации Всякий текст состоит из символов — букв, цифр, знаков препинания, которые человек различает по начертанию. В программировании наиболее часто используются однобайтовые кодировки, в которых код каждого символа занимает ровно 1 байт (или 8 бит). Общее количество различных символов в таком случае составляет 256. Кодировка ASCII Наиболее распространенной системой байтового кодирования является система (таблица) ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией), созданная в 1963 году. В своей первоначальной версии это система семибитного кодирования. В таблице ASCII всего 256 позиций. Каждому двоичному коду от 0 до 255 в таблице ставится в соответствие один символ. Сама таблица делится на две части. Первая часть с 0-го по 127-й символ называется основной таблицей ASCII и является неизменной для всех стран. Первые 32 символа в основной таблице являются управляющими. Среди них есть символы, не имеющие изображения, например, «подача стандартного звукового сигнала» (код 7), «перевод строки» (код 10) и т.п. Другие символы основной таблицы являются «изображаемыми». Начиная с 33-его (пробела с кодом 32) по 127 символ в таблице закодированы знаки препинания, цифры и английские буквы – как строчные, так и заглавные. Таблица ASCII — первая неизменная часть:
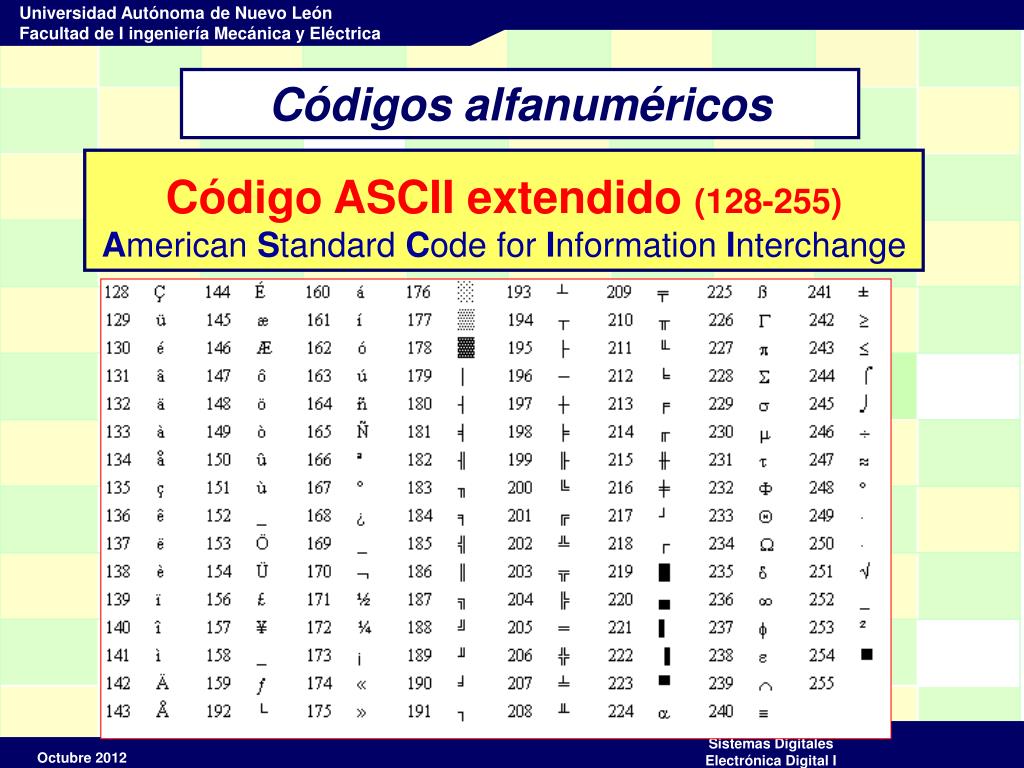
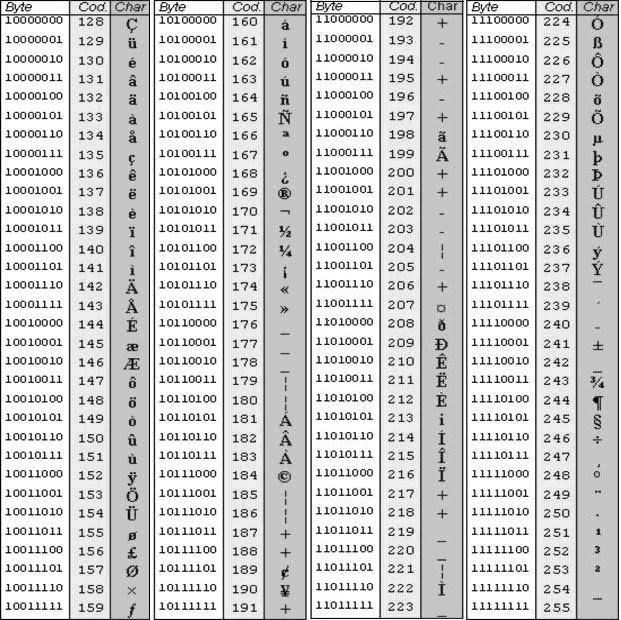
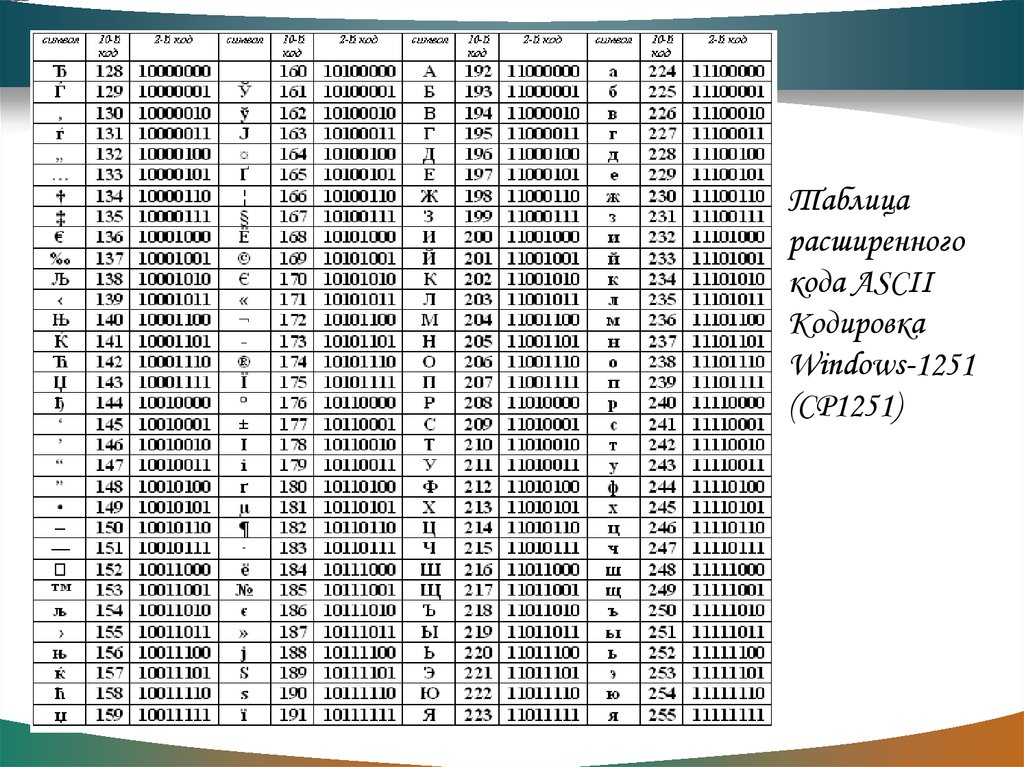
Вторая часть – до 255-го символа – называется расширенной таблицей ASCII, она уникальна для каждой страны, так как в этой части хранятся символы, специфичные для этой страны, например буквы национального алфавита. Пример второй части кодовой таблицы для русской кодировки СР-866:
Кодировка UNICODE К концу 1980-х годов стандартом стали 8-битные коды, при этом существовало множество разных 8-битных кодировок и постоянно появлялись все новые. Это объяснялось как постоянным расширением круга поддерживаемых языков, так и стремлением создать кодировку, частично совместимую с какой-нибудь другой (характерный пример — появление альтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437). В результате появилась необходимость решения нескольких задач:
Было признано необходимым создание единой «широкой» кодировки фиксированной ширины. Использование 32-битных кодов казалось слишком расточительным, поэтому было решено использовать 16-битные коды. Первая версия «Юникода» представляла собой кодировку с фиксированным размером кода в 16 бит, общее число кодов в ней было 2 Полная 32-битная таблица «Юникод» включает символы практически всех современных письменностей. С академическими целями в эту кодировочную таблицу добавлены многие исторические письменности, в том числе: руны, древнегреческая письменность, египетские иероглифы, клинопись, письменность майя, этрусский алфавит. В «Юникоде» представлен широкий набор математических и музыкальных символов, а также пиктограмм.
RGB-модель
В компьютере для хранения изображений и вывода их на монитор используется цветовая RGB-модель ( CMYK-модель Базовыми цветами CMYK-модели (Cyan – Magenta – Yellow – blac Главной причиной появления CMYK-модели является различие в принципах формирования цвета при его воспроизведении на мониторах и при печати. Основные цвета CMYK-модели подобраны так, чтобы соответствующие краски поглощали свет в достаточно узкой области спектра: голубая краска сильно поглощает красный цвет, пурпурная – зеленый, а желтая – синий. В идеальном случае голубого, пурпурного и желтого цветов было бы достаточно для формирования на бумаге любого цвета. Однако реально существующие краски не идеальны, они не могут поглотить цветовые компоненты полностью. Если нанести все три краски на бумагу, то вместо чисто-черного получится темно-серый цвет. Поэтому, чтобы скорректировать цветовую гамму, используют четвертую краску – черную . Пространство цветовой модели CMYK также можно представить единичным кубом, где плотность закраски (или яркость базовых цветов) – это вещественные числа в диапазоне от 0 до 1.
Цветовая модель HSB Модель HSB (Hue – Saturation – Brightness) описывает цветовое пространство через такие характеристики цвета, как цветовой оттенок, насыщенность и яркость.
В модели HSB цвет описывается тройкой чисел (цветовой оттенок, яркость, насыщенность). Рассмотрим ряд цветов: красный, темно-красный, красновато-черный, алый, розовый, бледно-розовый. В модели HSB эти цвета – производные от красного цвета и отличаются друг от друга только яркостью и насыщенностью красного оттенка.
Чтобы использовать математическую модель HSB для компьютерного представления графической информации, надо, как и для моделей RGB и CMYK, непрерывно изменяемые значения компонент цвета представить в дискретной форме. В операционной системе Windows каждая из HBS-характеристик описывается одним байтом, то есть шкала значений разделена на 256 уровней.
Звук
Основными параметрами любой волны и звуковой в частности, является частота и амплитуда колебаний. Частота звука измеряется в герцах (Гц, количество колебаний в секунду). Амплитуда звуковых колебаний характеризует воспринимаемую громкость звука и называется звуковым давлением или силой звука. Абсолютную величину звукового давления измеряют в единицах давления паскалях (Па). Человеческое ухо может воспринимать огромный разброс значений амплитуды звуковой волны. Порог слышимости – самые слабые различимые человеческим ухом звуки – имеют амплитуду колебаний около 20 мкПа. Самые сильные звуки, которые еще не травмируют органы слуха, могут иметь амплитуду до 200 Па. Звуковая волна такой силы называется болевым порогом. В силу строения человеческого уха увеличение амплитуды в десятки раз человеком воспринимается как незначительное увеличением силы звука. Поэтому на практике для измерения амплитуды звука обычно используется адаптированная для человека логарифмическая шкала децибелов. Эта шкала работает с относительной силой звука, или уровнем звука. Уровень звука определяют как логарифм отношения абсолютной величины звукового давления к величине порога слышимости, скорректированный с помощью специального коэффициента: L= 20lg(Pзв/Pпс), где L – это величина звука, измеряемая в децибелах (дБ). Приведем некоторые значения уровней звука:
Понятие звукозаписи Люди давно научились записывать различные звуки и потом воспроизводить их. С появлением компьютеров люди захотели хранить звук в компьютере и воспроизводить его с помощью ЭВМ. Однако аналоговая запись не подошла для такого хранения. В компьютере используется только цифровая форма записи звука. При цифровой записи звук необходимо подвергнуть подготовительным процедурам, а именно временной дискретизации и квантованию. Дискредитация выполняется для того, чтобы от бесконечного количества информации, которое содержит звук, перейти к конечному количеству информации. При цифровой звукозаписи значения амплитуды звукового сигнала измеряются не непрерывно, а через равные небольшие промежутки времени (временная дискретизация) и записываются с некоторой точностью, то есть округляются до некоторого значения – уровня, на которые предварительно разбивается диапазон всех возможных значений (квантование). Из-за этих процедур цифровая запись, в отличие от аналоговой, несет двойное искажение. Во-первых, теряется информация о реальном значении амплитуд в моменты времени между замерами, а во-вторых, сами измеренные значения записываются с некоторой точностью. В компьютер приходит не сам звук, а электрический сигнал, снимаемый с какого-либо устройства: микрофона, преобразующего звуковое давление в электрические колебания, магнитофона, радио, эхолота или любого другого устройства, вырабатывающего электрические сигналы. Электрические сигналы переводятся в цифровую запись способом импульсно-кодовой модуляции.
Импульсно-кодовая модуляция Импульсно-кодовая модуляция (англ.
Процесс получения цифровой формы звука называют оцифровкой. Преобразование аналоговой информации, получаемой от различных источников, производится в специальных устройствах – аналого-цифровых преобразователях. Сигнал, полученный от микрофона или другого устройства, можно образно представить в виде графика кривой. Для преобразования кривая разбивается на несколько равных участков, и значение сигнала на границе каждого участка (в опорных точках) заносится в память компьютера. При обратном преобразовании, которое реализуется в цифроаналоговом преобразователе (ЦАП), сигнал «восстанавливается» по тем значениям, которые зафиксированы в памяти компьютера. Качество восстановленного сигнала во многом зависит от способа разбиения. Второй причиной серьезного искажения сигнала может быть количество битов, отведенных для записи значения сигнала. Если для записи отведено только 4 бита, то можно записать только 16 уровней, для высококачественной записи необходимо использовать 1 байт (256 уровней) или 2 байта и выше. Этот параметр преобразования характеризуется разрядностью преобразования. Количество бит, которые используются для записи номеров подуровней, называется глубиной кодирования звука. Импульсное кодирование по сути можно сравнить с растровым представлением изображения: · структура звука при таком способе кодирования не анализируется, так же как и структура изображения при растровом представлении; · время (в графических изображениях – пространство) изначально разбивается на небольшие области, и в пределах каждой области параметры звука (изображения) считаются постоянными.
Растровое представление изображений не требует хранения координат каждого пикселя. Аналогично при сохранении импульсного представления звука один раз сохраняются параметры оцифровки (глубина кодирования, частота дискретизации и длительность звукового фрагмента), а затем требуется сохранять только номера подуровней единым потоком. Очевидно, что если увеличивать частоту дискретизации и глубину кодирования, то впоследствии можно будет более точно восстановить форму звукового сигнала. Однако, при повышении таким образом качества записи ее объем будет увеличиваться. Поэтому возникает вопрос, какими должны быть частота дискретизации и глубина кодирования, чтобы получить оптимальное соотношение объема файла и качества воспроизводимого звука. В 1928 году американский инженер и ученый Гарри Найквист высказал утверждение, что частота дискретизации должна в два или более раз превышать максимальную частоту измеряемого сигнала. В 1933 году советский ученый В. А. Котельников и независимо от него Клод Шеннон сформулировали и доказали теорему о том, при каких условиях и как по дискретным значениям можно восстановить форму непрерывного сигнала.
Формат MIDI В 80-х годах прошлого века появились электронные музыкальные инструменты – синтезаторы, способные воспроизводить не только звуки многих существующих музыкальных инструментов, но и абсолютно новые звуки. Было разработано соглашение о системе команд универсального синтезатора, получившее название стандарта MIDI (от англ. Musical Instrument Digital Interface). Запись музыкального произведения в формате MIDI – последовательность закодированных сообщений синтезатору. MIDI-команды делают запись музыкальной информации более компактной, чем испульсное кодирование. Если сравнить способы представления графической и звуковой информации, то запись звука в виде MIDI-команд соответствует векторному представлению изображения. Записанные звуковые файлы можно редактировать, то есть вырезать, копировать и вставлять фрагменты из других файлов. Кроме того, можно увеличивать или уменьшать громкость, применять различные звуковые эффекты (эхо, уменьшение или увеличение скорости воспроизведения, воспроизведение в обратном направлении и другое), а также накладывать файлы друг на друга (микшировать). Кодирование текстовой информации Всякий текст состоит из символов — букв, цифр, знаков препинания, которые человек различает по начертанию. В программировании наиболее часто используются однобайтовые кодировки, в которых код каждого символа занимает ровно 1 байт (или 8 бит). Общее количество различных символов в таком случае составляет 256. Кодировка ASCII Наиболее распространенной системой байтового кодирования является система (таблица) ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией), созданная в 1963 году. В своей первоначальной версии это система семибитного кодирования. В таблице ASCII всего 256 позиций. Каждому двоичному коду от 0 до 255 в таблице ставится в соответствие один символ. Сама таблица делится на две части. Первая часть с 0-го по 127-й символ называется основной таблицей ASCII и является неизменной для всех стран. Первые 32 символа в основной таблице являются управляющими. Среди них есть символы, не имеющие изображения, например, «подача стандартного звукового сигнала» (код 7), «перевод строки» (код 10) и т.п. Другие символы основной таблицы являются «изображаемыми». Начиная с 33-его (пробела с кодом 32) по 127 символ в таблице закодированы знаки препинания, цифры и английские буквы – как строчные, так и заглавные. Таблица ASCII — первая неизменная часть:
Вторая часть – до 255-го символа – называется расширенной таблицей ASCII, она уникальна для каждой страны, так как в этой части хранятся символы, специфичные для этой страны, например буквы национального алфавита. Пример второй части кодовой таблицы для русской кодировки СР-866:
12345Следующая ⇒ Папиллярные узоры пальцев рук — маркер спортивных способностей: дерматоглифические признаки формируются на 3-5 месяце беременности, не изменяются в течение жизни… Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций… Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции… Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ — конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой… |


 Причем даже в одной и той же стране расширенная часть кодировочной таблицы может быть разной, в зависимости от производителя программного обеспечения.
Причем даже в одной и той же стране расширенная часть кодировочной таблицы может быть разной, в зависимости от производителя программного обеспечения.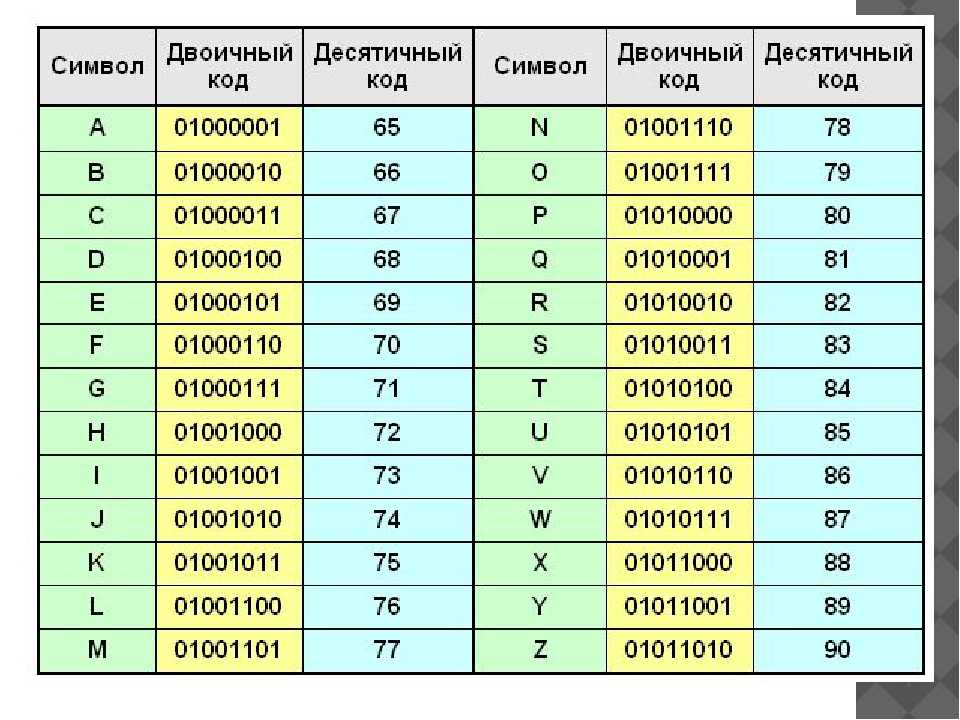
 Как известно из курса физики, смешением красного, зеленого и синего можно синтезировать все остальные цвета, поэтому эти три цвета принимаются в качестве базисных. Пространство цветовой модели RGB можно представить единичным кубом, где интенсивности (яркости) базовых цветов образуют оси координат и их значения – это вещественные числа в диапазоне от 0 до 1.
Как известно из курса физики, смешением красного, зеленого и синего можно синтезировать все остальные цвета, поэтому эти три цвета принимаются в качестве базисных. Пространство цветовой модели RGB можно представить единичным кубом, где интенсивности (яркости) базовых цветов образуют оси координат и их значения – это вещественные числа в диапазоне от 0 до 1.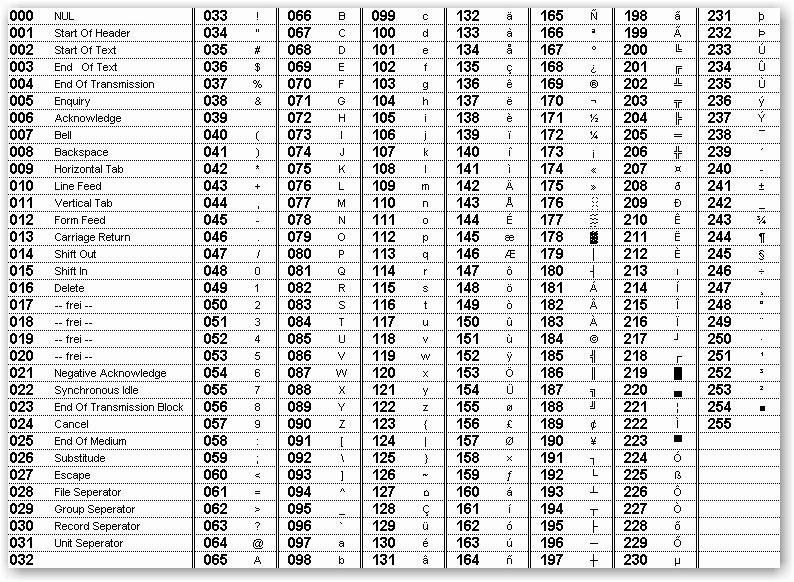 Если вы возьмете краски и смешаете красную и зеленую краску, то в действительности получите темно-коричневую краску, а не желтую, как ожидалось (и как это предполагается в RGB-модели). Все дело в том, что когда мы смотрим на изображение на экране монитора, то видим излучаемый свет, а вот когда рассматриваем картинки на бумаге, то видим свет отраженный.
Если вы возьмете краски и смешаете красную и зеленую краску, то в действительности получите темно-коричневую краску, а не желтую, как ожидалось (и как это предполагается в RGB-модели). Все дело в том, что когда мы смотрим на изображение на экране монитора, то видим излучаемый свет, а вот когда рассматриваем картинки на бумаге, то видим свет отраженный.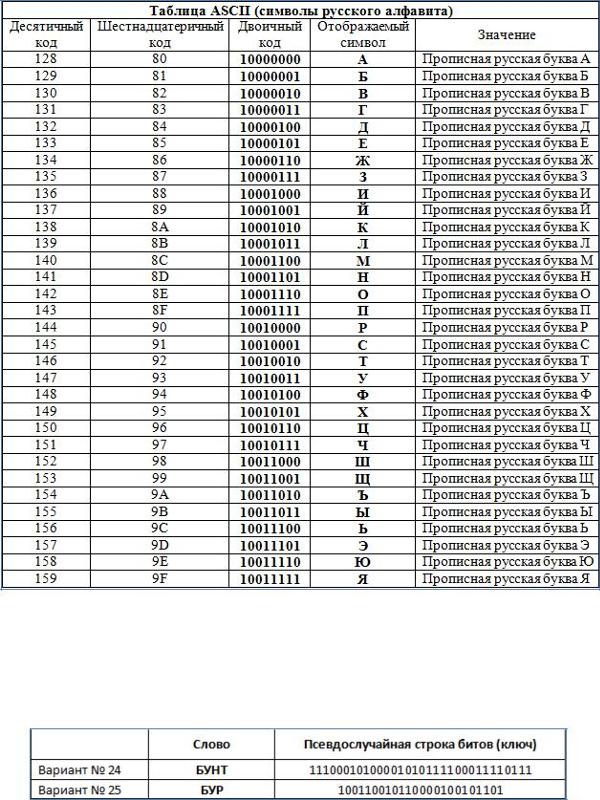
 Такое описание цвета (в отличие от моделей RGB и CMYK) очень точно передают субъективное восприятие цвета человеком, а не технические особенности воспроизведения цветов.
Такое описание цвета (в отличие от моделей RGB и CMYK) очень точно передают субъективное восприятие цвета человеком, а не технические особенности воспроизведения цветов. Человеческое ухо способно воспринимать звук в достаточно широком диапазоне частот: от 16 Гц до 20кГц. В нетехнических областях (например, в музыке) вместо термина частота используют термин тон.
Человеческое ухо способно воспринимать звук в достаточно широком диапазоне частот: от 16 Гц до 20кГц. В нетехнических областях (например, в музыке) вместо термина частота используют термин тон.
 Сам процесс сохранения информации о параметрах звуковых волн называется звукозаписью. Сначала люди освоили аналоговые способы записи и хранения звуковой информации. При аналоговой записи на носителе размещается непрерывный «слепок» звуковой волны. Например, на музыкальные пластинки наносится непрерывная канавка, изгибы которой повторяют амплитуду и частоту звука, на магнитофонной ленте параметры звука сохраняются в виде намагниченности рабочей поверхности, намагниченность поверхности непрерывно изменяется, повторяя параметры звука.
Сам процесс сохранения информации о параметрах звуковых волн называется звукозаписью. Сначала люди освоили аналоговые способы записи и хранения звуковой информации. При аналоговой записи на носителе размещается непрерывный «слепок» звуковой волны. Например, на музыкальные пластинки наносится непрерывная канавка, изгибы которой повторяют амплитуду и частоту звука, на магнитофонной ленте параметры звука сохраняются в виде намагниченности рабочей поверхности, намагниченность поверхности непрерывно изменяется, повторяя параметры звука.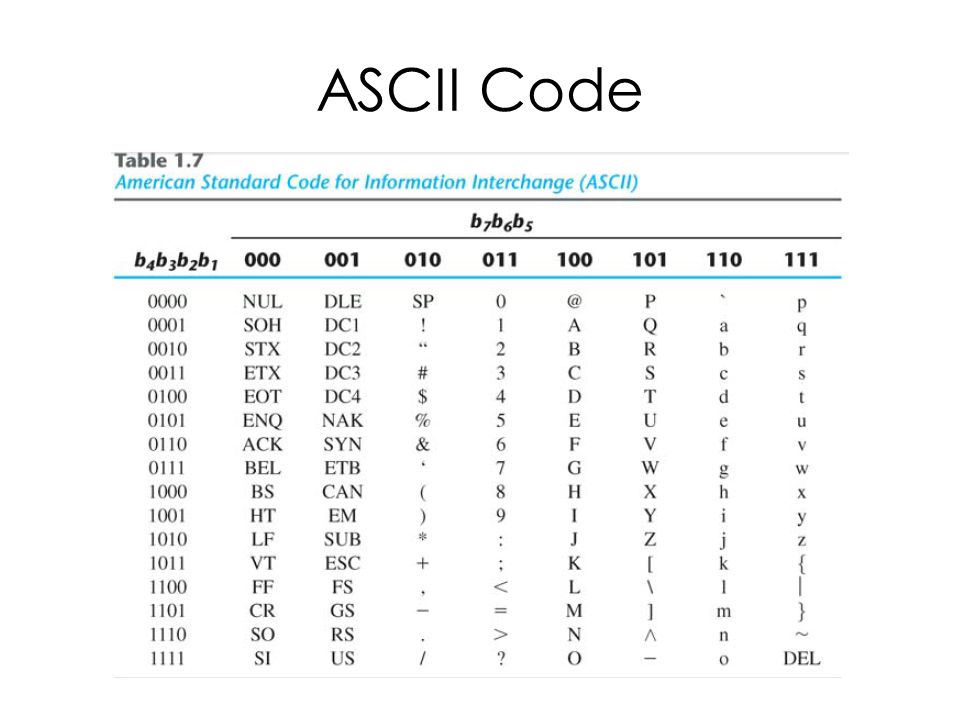
 Pulse Code Modulation, PCM) заключается в том, что звуковая информация хранится в виде значений амплитуды, взятых в определенные моменты времени ( измерения проводятся «импульсами»).
Pulse Code Modulation, PCM) заключается в том, что звуковая информация хранится в виде значений амплитуды, взятых в определенные моменты времени ( измерения проводятся «импульсами»).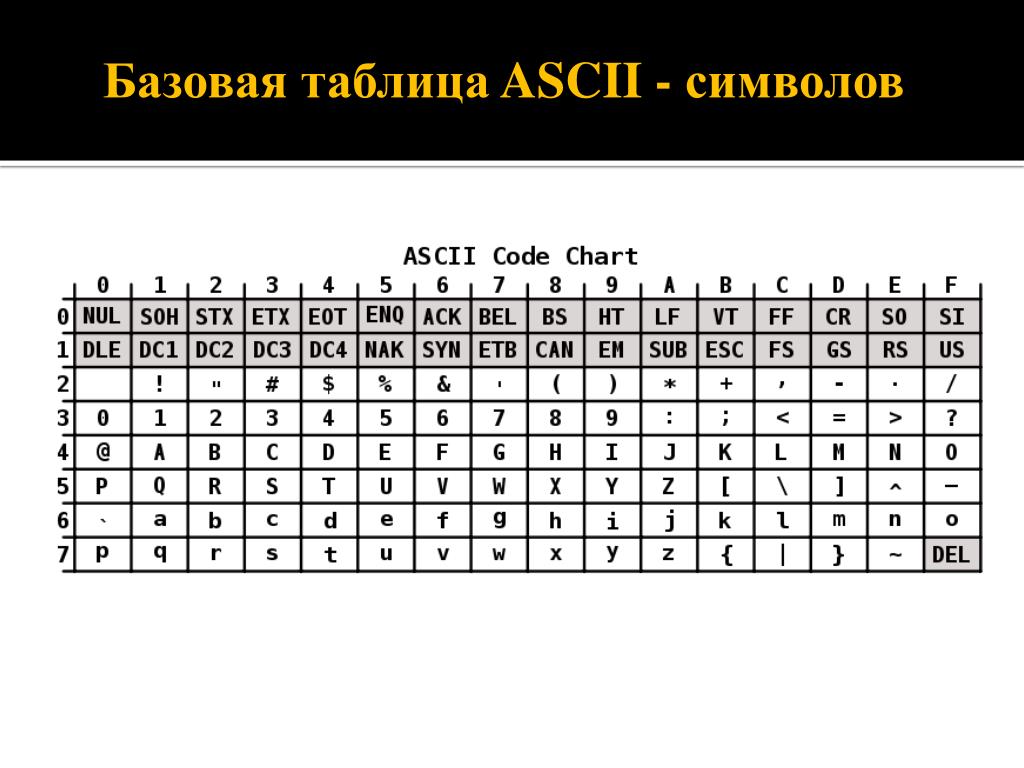 Чем чаще расположены опорные точки, тем меньше будет искажен восстановленный сигнал, но при этом выше затраты ресурсов памяти. Количество интервалов разбиения, размещенных на промежутке длительностью в одну секунду, характеризуется частотой дискретизации.
Чем чаще расположены опорные точки, тем меньше будет искажен восстановленный сигнал, но при этом выше затраты ресурсов памяти. Количество интервалов разбиения, размещенных на промежутке длительностью в одну секунду, характеризуется частотой дискретизации.
 Эта теорема носит название всех трех ученых, или нейтрально называется Теоремой об отсчетах. Результат применения этой теоремы – частота дискретизации должна быть как минимум вдвое выше частоты сигнала. Теорема доказана для сигналов с непрерывными частотными характеристиками и бесконечной длительностью. Поэтому для оцифровки реальных звуковых сигналов (конечных по времени) частоту дискретизации выбирают с небольшим запасом.
Эта теорема носит название всех трех ученых, или нейтрально называется Теоремой об отсчетах. Результат применения этой теоремы – частота дискретизации должна быть как минимум вдвое выше частоты сигнала. Теорема доказана для сигналов с непрерывными частотными характеристиками и бесконечной длительностью. Поэтому для оцифровки реальных звуковых сигналов (конечных по времени) частоту дискретизации выбирают с небольшим запасом.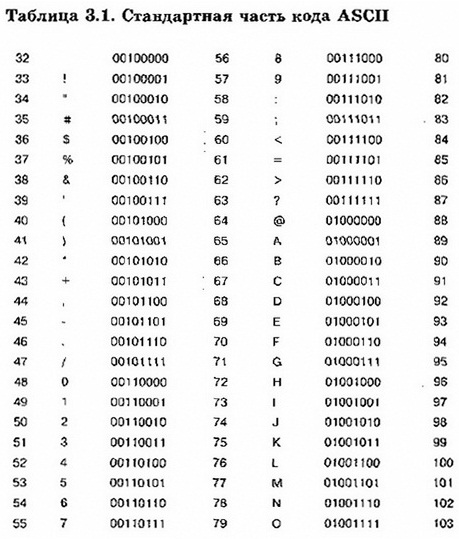 Сообщение может быть командой (нажать или отпустить определенную клавишу, изменить высоту или тембр звучания), описанием параметров воспроизведения (например, силы давления на клавиатуру) или управляющим сообщением (включение полифонического режима).
Сообщение может быть командой (нажать или отпустить определенную клавишу, изменить высоту или тембр звучания), описанием параметров воспроизведения (например, силы давления на клавиатуру) или управляющим сообщением (включение полифонического режима). Для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются так называемые кодовые (кодировочные) таблицы, в которых каждому коду ставится в соответствие изображение символа.
Для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются так называемые кодовые (кодировочные) таблицы, в которых каждому коду ставится в соответствие изображение символа. Она ограничивалась одним естественным алфавитом (английским), цифрами и набором различных символов, включая «символы пишущей машинки» (привычные знаки препинания, знаки математических действий и др.) и «управляющие символы». В следующей версии фирма IBM перешла на расширенную 8-битную кодировку.
Она ограничивалась одним естественным алфавитом (английским), цифрами и набором различных символов, включая «символы пишущей машинки» (привычные знаки препинания, знаки математических действий и др.) и «управляющие символы». В следующей версии фирма IBM перешла на расширенную 8-битную кодировку. Причем даже в одной и той же стране расширенная часть кодировочной таблицы может быть разной, в зависимости от производителя программного обеспечения.
Причем даже в одной и той же стране расширенная часть кодировочной таблицы может быть разной, в зависимости от производителя программного обеспечения.Кодировка символов и Юникод (для разработчиков)
Перевод статьи «What Every Developer Must Know About Encoding and Unicode».
Если вы пишете международное приложение, в котором будут использоваться разные языки, вы должны разбираться в кодировке символов. Впрочем, эту статью стоит почитать, даже если вам просто любопытно, как слова выводятся на экран.
Я расскажу краткую историю кодировки символов (и о том, сколь мало она была стандартизирована), а затем чуть подробнее остановлюсь на том, чем мы пользуемся в настоящее время.
Введение в кодирование символов
Компьютер понимает только двоичный код. То есть только нули и единицы. Каждая из этих цифр — один бит. Восемь таких цифр (нулей и/или единиц) — один байт.
В конечном итоге все в компьютере сводится к двоичному коду: языки программирования, движения мыши, ввод текста и все слова на экране.
Но если весь текст, который вы читаете, тоже был в форме нулей и единиц, то как же произошло его превращение в понятные человеку слова? Чтобы в этом разобраться, давайте вернемся к истокам.
Краткая история кодировки
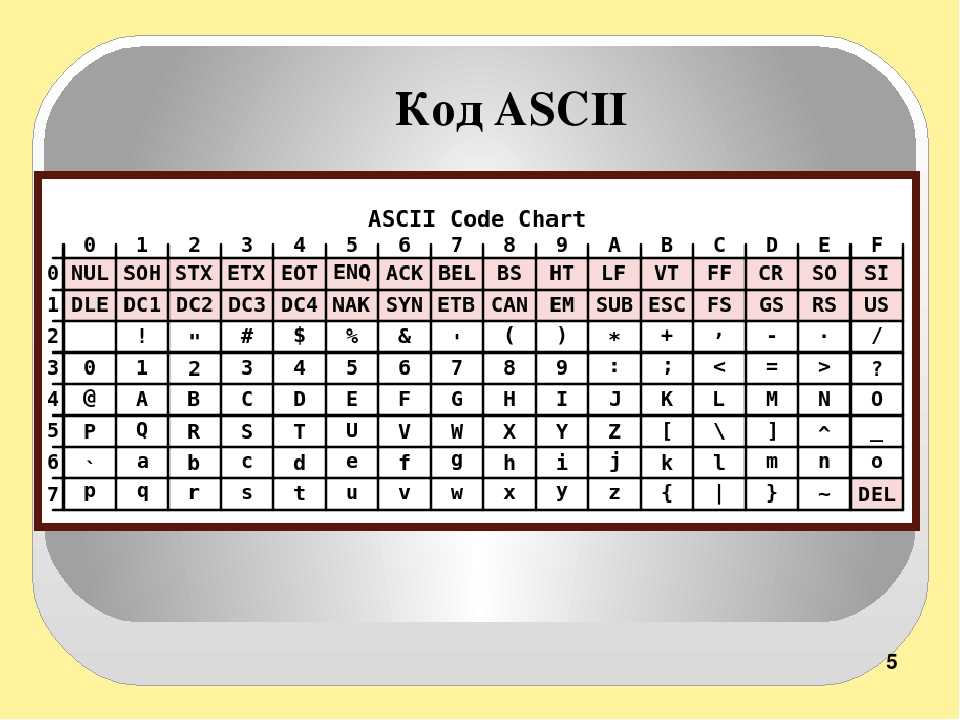
На заре интернета в нем все было исключительно на английском. Нам не приходилось беспокоиться о символах, которых в английском языке просто нет. Для сопоставления всех нужных символов с числовыми кодами использовалась таблица ASCII (American standard code for information interchange).
Нам не приходилось беспокоиться о символах, которых в английском языке просто нет. Для сопоставления всех нужных символов с числовыми кодами использовалась таблица ASCII (American standard code for information interchange).
Получаемый компьютером двоичный код:
01001000 01100101 01101100 01101100 01101111 00100000 01110111 01101111 01110010 01101100 01100100
при помощи ASCII переводился в «Hello world».
Одного байта (8 бит) вполне хватало, чтобы уникально закодировать любой символ английского языка, а также некоторое количество управляющих символов. Часть этих управляющих символов использовалась для телетайпов, которые были довольно распространены в то время. Сейчас, впрочем, не используются ни телетайпы, ни эти символы.
Что из себя представляют управляющие символы? Например, управляющий символ с кодом 7 (111 в двоичной системе) служит для подачи компьютером звукового сигнала. Символ с кодом 8 (1000 в двоичной системе) перемещает позицию печати на один символ назад (например, для наложения одного символа на другой или для стирания предшествующего символа). Символ с кодом 12 (1100 в двоичной системе) отвечает за очистку экрана терминала.
Символ с кодом 12 (1100 в двоичной системе) отвечает за очистку экрана терминала.
В то время компьютеры использовали 8 бит для одного байта (хотя так было не всегда), так что проблем не было. Это позволяло закодировать все управляющие символы, все цифры и буквы английского алфавита, да еще и свободные коды оставались! Дело в том, что 1 байт может принимать 256 (0 — 255) разных значений. То есть потенциально можно было закодировать 255 символов, а в ASCII их было всего 127. Так что 128 кодов оставались неиспользованными.
Давайте посмотрим на саму таблицу ASCII. Все символы алфавита в верхнем и нижнем регистре, а также цифры получили двоичные коды. Первые 32 символа таблицы — управляющие, они не имеют графического отображения.
Как видите, символы кончаются кодом 127. У нас осталось свободное место в таблице.
Проблемы с ASCII
При помощи кодов 128-255 можно было бы закодировать еще какие-нибудь символы. Люди задумались, какими именно символами лучше заполнить таблицу.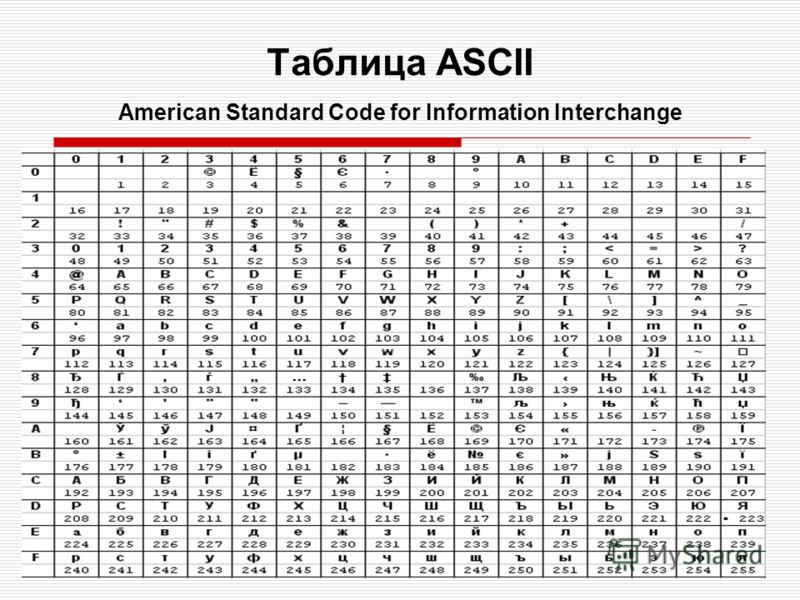 Но у всех были разные идеи на этот счет.
Но у всех были разные идеи на этот счет.
Американский институт национальных стандартов (American national standards institute, ANSI) разметил, за какие символы должны отвечать коды 0-127 (т. е., те, которые уже были размечены ASCII). Но остальные коды остались открытыми.
Примечание: не путайте ANSI (институт) и ASCII (таблица).
Назначение кодов 0-127 никто не оспаривал. Проблема была в том, что делать с оставшимися.
В первых компьютерах IBM коды ASCII 128-255 представляли следующие символы:
Но в других компьютерах было по-другому. И буквально каждый производитель стремился по-своему применить свободные коды из конца таблицы ASCII.
Эти разные варианты концовок таблицы ASCII назывались кодовыми страницами.
Что такое кодовые страницы ASCII?
Пройдя по ссылке, вы найдете коллекцию из более чем 465 различных кодовых страниц! Как видите, даже для одного языка существовали разные кодовые страницы. Например, для греческого и китайского есть по нескольку кодовых страниц.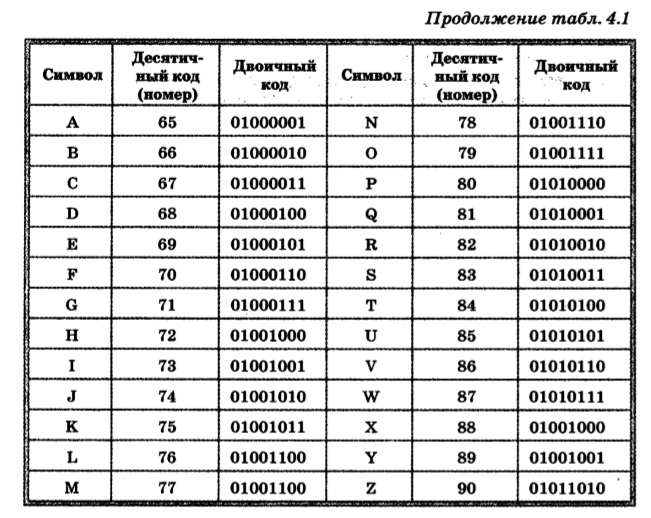
Но как же, черт побери, все это стандартизировать? Как работать с несколькими языками? А с одним языком, но разными кодовыми страницами? А с не-английским языком?
В китайском языке больше 100 тысяч различных символов. Даже если бы мы договорились отдать под символы китайского языка все оставшиеся коды, их бы все равно не хватило.
Выглядело все это довольно плохо. Для этой проблемы даже придумали отдельный термин: mojibake (на японском это слово означает «трансформация символа»).
Это неправильно декодированный текст, в котором символы систематически заменяются другими, причем часто — даже из других систем письменности.
Пример mojibakeС ума сойти…
Вот именно! У нас не было ни единого шанса надежно обмениваться данными.
Интернет — всего лишь огромная сеть компьютеров по всему миру. Представьте, что было бы, если бы каждая страна самостоятельно определяла стандарты кодировки. Тогда компьютеры в Греции нормально выводили бы только греческий язык, а в США — только английский.
ASCII не подходила для использования в реальном мире. Чтобы интернет был всемирным, нам нужно было что-то менять. Ну, или вечно работать с сотнями кодовых страниц.
���Если только вам������, конечно, не ���нравится ��� расшифровывать такие абзацы.�֎֏0590��׀ׁׂ׃ׅׄ׆ׇ
И тут пришел Юникод
Юникод (Unicode) иногда называют UCS — универсальным набором символов (Universal Coded Character Set), и даже ISO/IEC 10646. Но Юникод — наиболее распространенное название.
Юникод состоит из множества кодовых пунктов (code points, по сути — шестнадцатеричные числа), связанных с символами. Коллекция кодовых пунктов называется набором символов. Вот этот набор — и есть Юникод.
Люди проделали огромную работу, назначив коды всем символам всех языков, а мы можем просто пользоваться результатами их труда. Отображение кодов выглядит так:
"Hello World" U+0048 : LATIN CAPITAL LETTER H U+0065 : LATIN SMALL LETTER E U+006C : LATIN SMALL LETTER L U+006C : LATIN SMALL LETTER L U+006F : LATIN SMALL LETTER O U+0020 : SPACE [SP] U+0057 : LATIN CAPITAL LETTER W U+006F : LATIN SMALL LETTER O U+0072 : LATIN SMALL LETTER R U+006C : LATIN SMALL LETTER L U+0064 : LATIN SMALL LETTER D
U+ указывает на то, что это стандарт Unicode, а номер — число, в которое переведен двоичный код для данного символа. В Юникоде используется шестнадцатеричная система — просто потому, что в нее проще переводить двоичный код. Впрочем, вам не придется делать это вручную, так что можно не волноваться.
В Юникоде используется шестнадцатеричная система — просто потому, что в нее проще переводить двоичный код. Впрочем, вам не придется делать это вручную, так что можно не волноваться.
Вот ссылка на ресурс, где вы можете впечатать в форму любой символ и получить его кодировку в Юникод. Или же можете просмотреть все 143859 символов здесь. В таблице можно увидеть, из какой части света происходит каждый символ!
Просто для ясности подобью итоги. В настоящее время у нас есть большой словарь кодовых пунктов с отображением на символы. Это очень большое множество символов. Н
Наконец, переходим к последнему ингредиенту.
Unicode Transform Format (UTF)
UTF («Формат преобразования Юникода») — это способ представления Юникод. Кодировки UTF определены стандартом Юникод и позволяют закодировать любой нужный нам кодовый пункт Юникод.
Есть несколько разных видов UTF-стандартов. Они отличаются количеством байтов, используемых для кодирования одного кодового пункта. В UTF-8 используется один байт на кодовый пункт, в UTF-16 — 2 байта, в UTF-32 — 4 байта.
Поскольку кодировок так много, как понять, какую использовать? Есть такая вещь как маркер последовательности байтов (англ. Byte order mark, BOM) Это двубайтный маркер в начале файла, который говорит о том, какая кодировка используется в этом файле.
UTF-8 — самая распространенная кодировка в интернете. В HTML5 она определена как предпочтительная для новых документов. Поэтому я уделю ей особое внимание.
Даже по диаграмме 2012 года видно, что UTF-8 становится самой распространенной кодировкой.Диаграмма от W3 показывает, насколько интенсивно используется UTF-8 на сайтахЧто такое кодировка UTF-8 и как она работает?
UTF-8 кодирует кодовые пункты Юникод 0-127 в одном байте (т. е. так же, как в ASCII). Это значит, что если вы для своей программы использовали кодировку ASCII, а ваши пользователи используют UTF-8, они не заметят никакой разницы. Все будет нормально работать.
Просто обратите внимание, насколько это классно. Нам нужно было начать внедрять и повсеместно использовать UTF-8 и при этом сохранить обратную совместимость с ASCII. Это удалось сделать, UTF-8 ничего не ломает.
Это удалось сделать, UTF-8 ничего не ломает.
В названии кодировки заложено указание на количество бит (8 бит = 1 байт), которые используются для одного кодового пункта. Но есть символы Юникод, для хранения которых требуется по нескольку байтов (раньше было до 6, теперь — до 4, в зависимости от символа). Именно это имеется в виду, когда говорят, что UTF-8 — кодировка переменной длины (см. UTF-32, — прим. ред.).
Тут все зависит от языка. Символ английского алфавита — 1 байт. Европейская латиница, иврит, арабские символы представляются 2 байтами. Для китайских, японских, корейских символов и символов других азиатских языков используются 3 байта.
Чтобы символ мог занимать больше одного байта, есть битовая комбинация, идентифицирующая знак продолжения. Она сообщает о том, что этот символ продолжается в нескольких последующих байтах. Таким образом, для английского языка вы по-прежнему будете использовать по одному байту на символ, но сможете составить и документ, содержащий символы на других языках.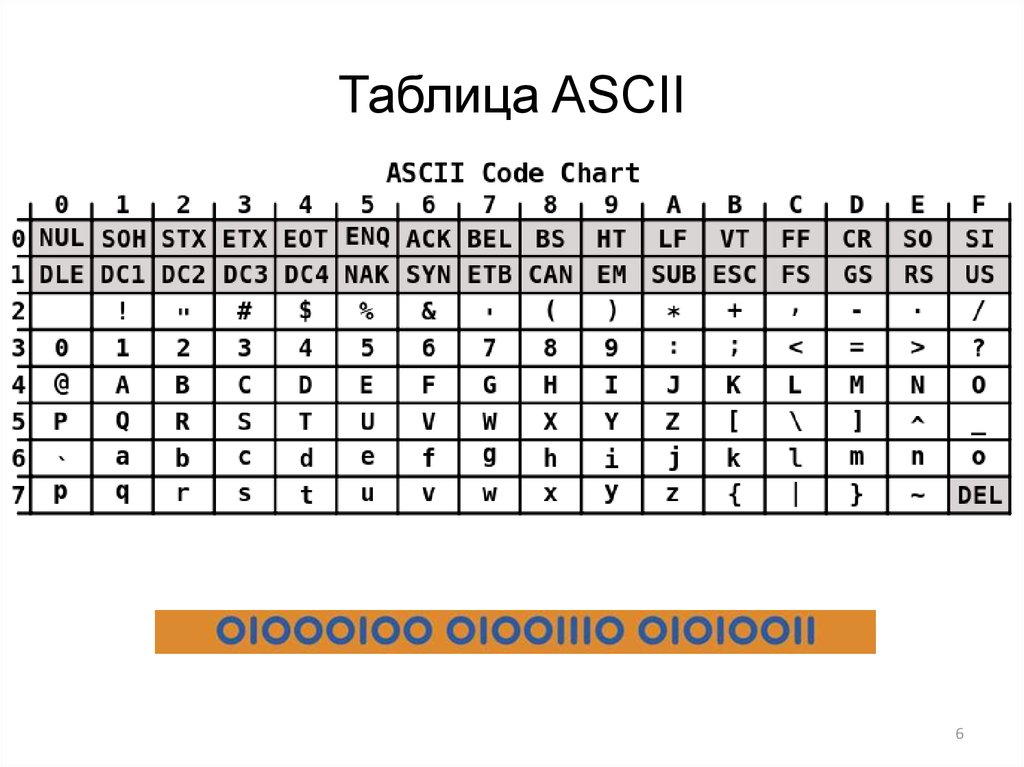
Радостно сознавать, что теперь у нас полное согласие по части того, как кодировать шумерскую клинопись, а также смайлики!
Если описать весь процесс в общих чертах, то:
- сначала вы читаете BOM, чтобы узнать кодировку,
- затем расшифровываете файл в кодовые пункты Юникод,
- затем представляете символы из набора Юникод в символы, которые отрисовываются на экране.
Еще немного о UTF
Помните, что кодировка это ключ. Если я пошлю совершенно неправильную кодировку, вы не сможете ничего прочесть. Имейте это в виду, отсылая или получая данные. Зачастую в постоянно используемых нами инструментах это абстрагировано, но программист должен понимать, что происходит под капотом.
Как мы указываем кодировку? Поскольку HTML написан на английском и практически все кодировки прекрасно справляются с английскими символами, мы можем указать кодировку прямо сверху, в разделе <head>.
<html lang="en"> <head> <meta charset="utf-8"> </head>
Это важно сделать в самом начале <head>, потому что если будет использована не та кодировка, парсинг HTML может начаться заново.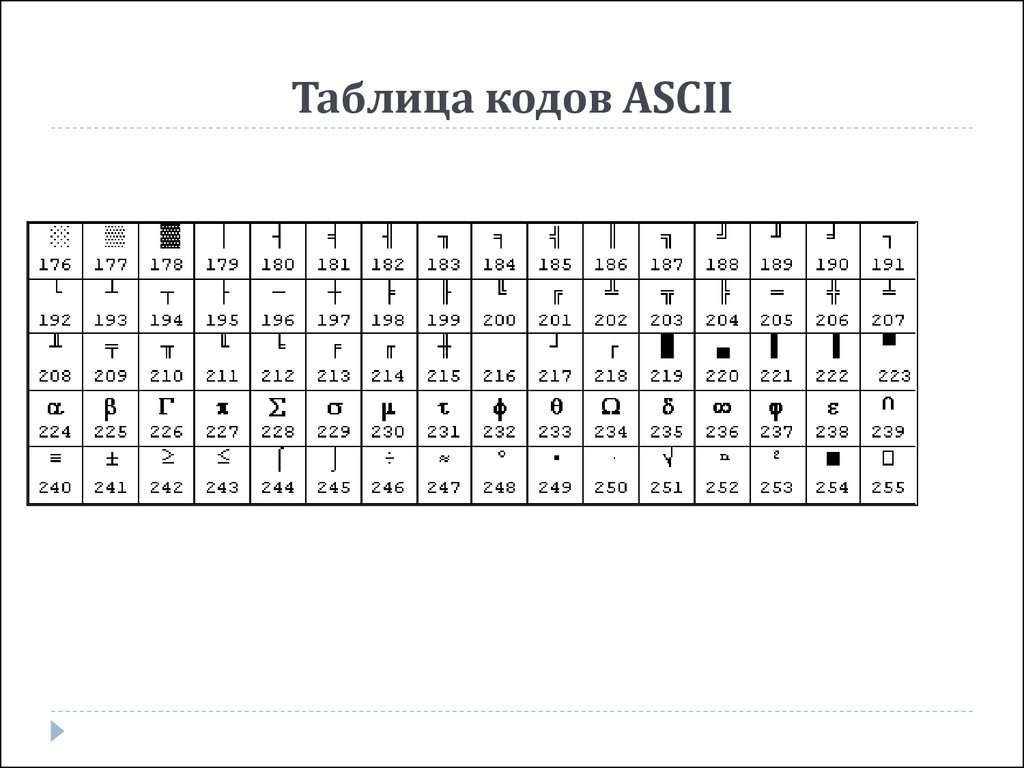
Мы также можем получить кодировку из заголовка Content-Type в HTTP-запросе или ответе.
В спецификации HTML5 есть любопытный способ угадать кодировку, если HTML-документ не содержит соответствующего тега, — BOM sniffing («вынюхивание BOM»). В этом случае кодировка определяется по маркеру последовательности байтов, который мы упоминали ранее.
Это все?
Работа над Юникодом продолжается. Как в любом стандарте, мы можем что-то добавлять, удалять, вносить предложения. Никакая спецификация никогда не считается окончательно завершенной.
Обычно бывает 1-2 релиза Юникода в год, найти их можно здесь.
Недавно мне попалась статья об очень интересном баге: Twitter неверно рендерил русские символы Юникода.
Если вы дочитали до сюда, — снимаю шляпу. Я знаю, информации много.
Советую также выполнить «домашнее задание».
Посмотрите, как могут ломаться сайты из-за неправильной кодировки. Я использовал вот это расширение Google Chrome для смены кодировки и пробовал читать разные страницы.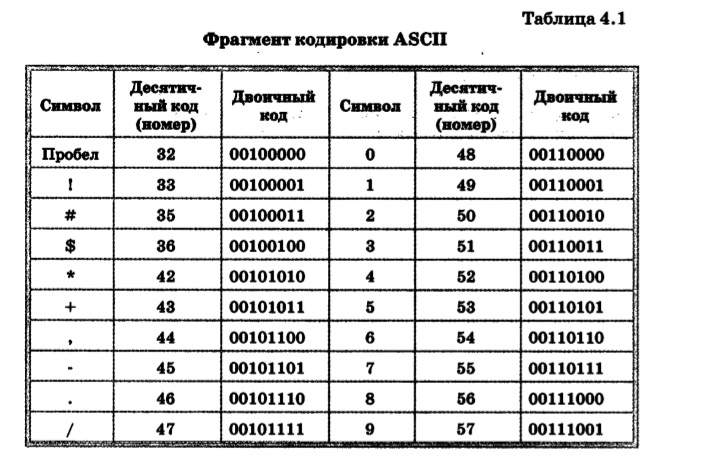 Текст был совершенно непонятен. Попробуйте прочесть эту статью, например. Зайдите на Википедию. Посмотрите на Mojibake своими глазами.
Текст был совершенно непонятен. Попробуйте прочесть эту статью, например. Зайдите на Википедию. Посмотрите на Mojibake своими глазами.
Это поможет вам проникнуться важностью кодировок.
Заключение
Название этой статьи — дань уважения статье Джоела Спольски, которая познакомила меня с кодировкой и многими концепциями, о которых я и не подозревал. Именно после прочтения этой статьи я углубился в тему кодировки. Также я очень многое почерпнул из этого источника.
Изучая информацию и пытаясь упростить свою статью, я узнал о Майкле Эверсоне. С 1993 года он предложил больше 200 изменений в Юникод и добавил в стандарт тысячи символов. В 2003 году он был одним из ведущих контрибьюторов предложений в Юникод. Своим современным видом Юникод (а значит, и вообще интернет) во многом обязан именно Майклу Эверсону.
Надеюсь, у меня получилось сделать хороший обзор того, зачем нам нужны кодировки, какие проблемы они решают и что случается, если с кодировкой происходит сбой.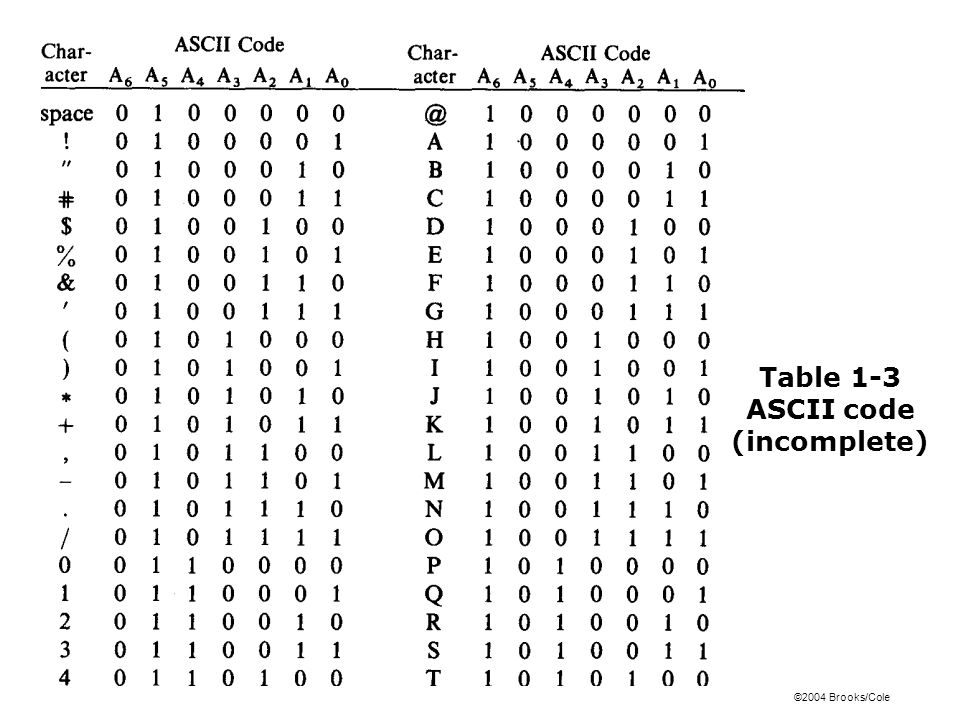
ASCII Значение Символ Шестнадцатеричный, 26 английских букв, разное, угол, текст png
ASCII Значение Символ Шестнадцатеричный, 26 английских букв, разное, угол, текст pngтеги
- разное,
- угол,
- текст,
- прямоугольник,
- другие,
- компьютерная программа,
- число,
- с,
- целое число,
- точка,
- подпись,
- квадрат,
- линия,
- шестнадцатеричное,
- площадь,
- aSCII,
- base64,
- двоичный код,
- двоичное число,
- бит,
- черный и белый,
- символ,
- символКодировка,
- значение,
- png,
- прозрачный,
- бесплатная загрузка
Об этом PNG
- Размер изображения
- 940x654px
- Размер файла
- 134.1KB
- MIME тип
- Image/png
изменить размер PNG
ширина(px)
высота(px)
Лицензия
Некоммерческое использование, DMCA Contact Us
 org/ImageGallery» align=»middle»>
org/ImageGallery» align=»middle»> 12KB
12KB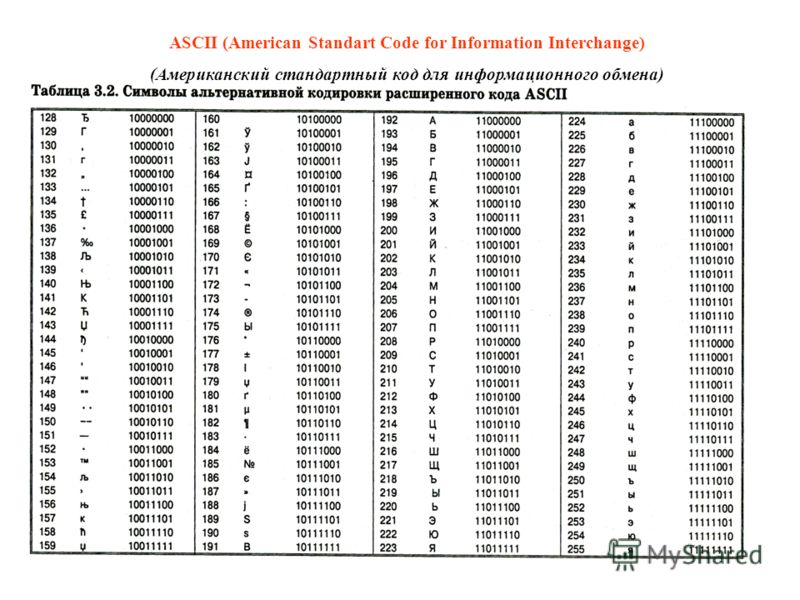 org/ImageObject»> ASCII шестнадцатеричный двоичный код Таблица символов, двоичный код зеленого цвета, угол, мебель, текст png
1280x851px
227.52KB
org/ImageObject»> ASCII шестнадцатеричный двоичный код Таблица символов, двоичный код зеленого цвета, угол, мебель, текст png
1280x851px
227.52KB org/ImageObject»> QR-код Сканеры штрих-кода, СКАН, разное, угол, текст png
1024x1024px
8.74KB
org/ImageObject»> QR-код Сканеры штрих-кода, СКАН, разное, угол, текст png
1024x1024px
8.74KB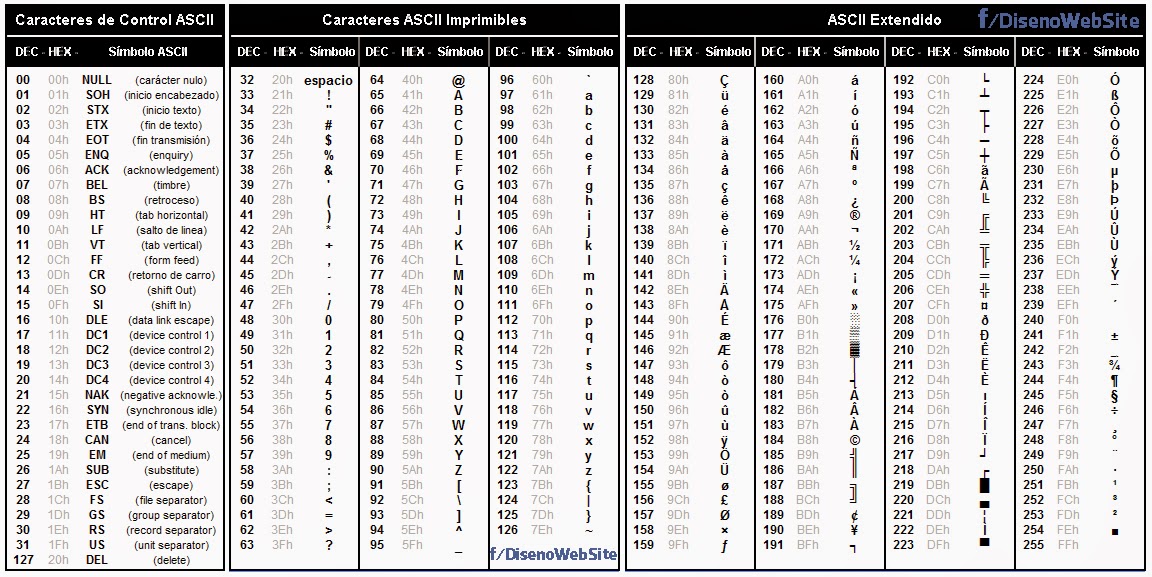 78KB
78KB 05MB
05MB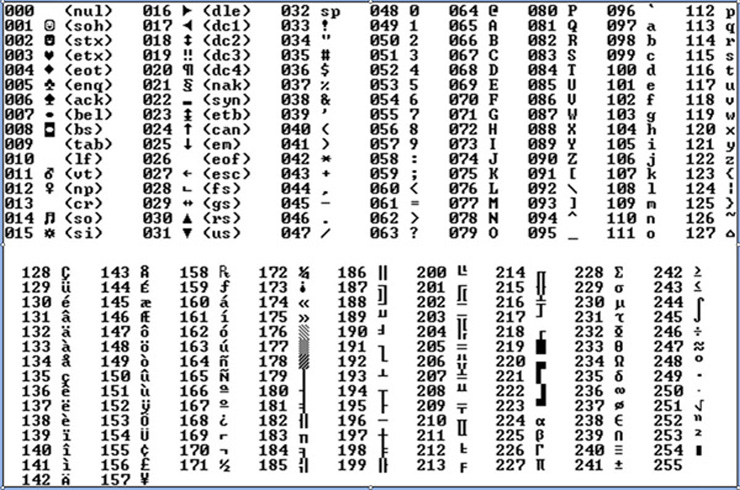 org/ImageObject»> QR-код Сканеры штрих-кода Data Matrix, другие, текст, прямоугольник, другие png
1056x1056px
6.75KB
org/ImageObject»> QR-код Сканеры штрих-кода Data Matrix, другие, текст, прямоугольник, другие png
1056x1056px
6.75KB 67KB
67KB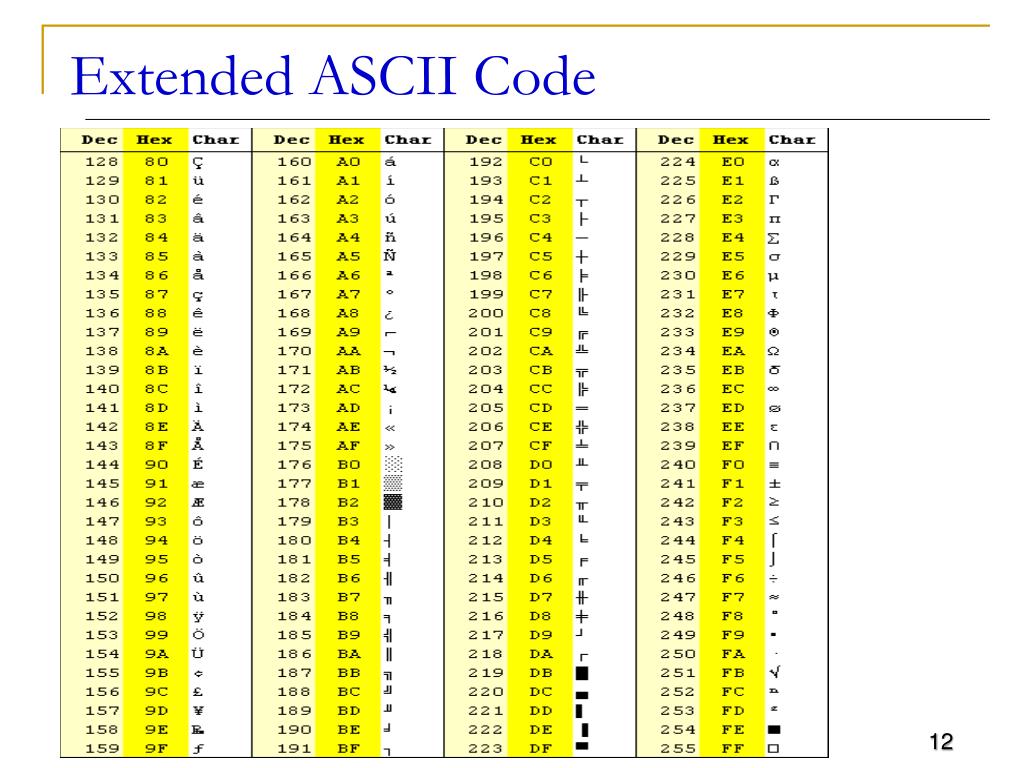 org/ImageObject»> Пазлы Frozen Bubble Tangram, пазл, Разное, угол, текст png
1697x2400px
110.62KB
org/ImageObject»> Пазлы Frozen Bubble Tangram, пазл, Разное, угол, текст png
1697x2400px
110.62KB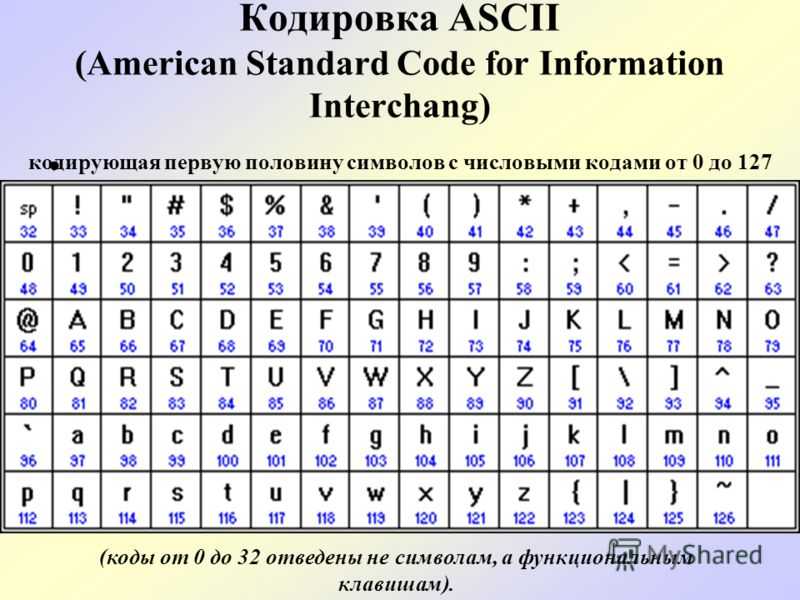 12MB
12MBс десятичным, двоичным и шестнадцатеричным преобразованием Таблица символов
ASCII с преобразованием десятичного, двоичного и шестнадцатеричного Таблица символов ASCII с десятичными, двоичными и шестнадцатеричными преобразованиямиASCII расшифровывается как «Американский стандартный код для обмена информацией».
| Имя персонажа | Символ | Код | Десятичный | Двоичный | Шестигранник | ||
| Нуль | НУЛ | Контр@ | 0 | 00000000 | 00 | ||
| Начало заголовка | СОХ | Контроллер А | 1 | 00000001 | 01 | ||
| Начало текста | СТХ | Ctrl B | 2 | 00000010 | 02 | ||
| Конец текста | ЕТХ | Клавиша C | 3 | 00000011 | 03 | ||
| Конец передачи | ЕОТ | Ctrl D | 4 | 00000100 | 04 | ||
| Запрос | ENQ | Ctrl E | 5 | 00000101 | 05 | ||
| Подтверждение | ПОДТВЕРЖДЕНИЕ | Ctrl F | 6 | 00000110 | 06 | ||
| Звонок | Бел | Ctrl G | 7 | 00000111 | 07 | ||
| Заднее пространство | БС | Управл. | 8 | 00001000 | 08 | ||
| Горизонтальная вкладка | ВКЛАДКА | Контрол I | 9 | 00001001 | 09 | ||
| Перевод строки | НЧ | Ctrl J | 10 | 00001010 | 0А | ||
| Вертикальный выступ | ВТ | Ctrl K | 11 | 00001011 | 0Б | ||
| Подача бумаги | ТФ | Контроллер L | 12 | 00001100 | 0С | ||
| Возврат каретки | ЧР | Контроллер M | 13 | 00001101 | 0D | ||
| Выход на смену | СО | Контр. | 14 | 00001110 | 0Е | ||
| Смена | СИ | Ctrl O | 15 | 00001111 | 0F | ||
| Выход из строки данных | ДЛЭ | Контр. П | 16 | 00010000 | 10 | ||
| Управление устройством 1 | DC1 | Ctrl Q | 17 | 00010001 | 11 | ||
| Управление устройством 2 | DC2 | Ctrl R | 18 | 00010010 | 12 | ||
| Управление устройством 3 | DC3 | Ctrl S | 19 | 00010011 | 13 | ||
| Управление устройством 4 | DC4 | Ctrl T | 20 | 00010100 | 14 | ||
| Отрицательное подтверждение | НАК | Управл. | 21 | 00010101 | 15 | ||
| Синхронный холостой ход | СИН | Управл. V | 22 | 00010110 | 16 | ||
| Конец передачи Блок | ЭТБ | Панель управления W | 23 | 00010111 | 17 | ||
| Отмена | МОЖЕТ | Ctrl X | 24 | 00011000 | 18 | ||
| Конец среды | ЭМ | Управл Y | 25 | 00011001 | 19 | ||
| Заместитель | SUB | Ctrl Z | 26 | 00011010 | 1А | ||
| Побег | ESC | Управл [ | 27 | 00011011 | 1Б | ||
| Разделитель файлов | ФС | Ctrl \ | 28 | 00011100 | 1С | ||
| Разделитель групп | ГС | Контр] | 29 | 00011101 | 930 | 00011110 | 1Е |
| Разделитель блоков | США | Контр _ | 31 | 00011111 | 1F | ||
| Космос | 32 | 00100000 | 20 | ||||
| Восклицательный знак | ! | Смена 1 | 33 | 00100001 | 21 | ||
| Двойная кавычка | » | Смена ‘ | 34 | 00100010 | 22 | ||
| Знак фунта/числа | # | Смена 3 | 35 | 00100011 | 23 | ||
| Знак доллара | $ | Смена 4 | 36 | 00100100 | 24 | ||
| Знак процента | % | Смена 5 | 37 | 00100101 | 25 | ||
| Амперсанд | и | Смена 7 | 38 | 00100110 | 26 | ||
| Одиночная кавычка | ‘ | ‘ | 39 | 00100111 | 27 | ||
| Левая скобка | ( | Смена 9 | 40 | 00101000 | 28 | ||
| Правая скобка | ) | Смена 0 | 41 | 00101001 | 29 | ||
| Звездочка | * | Смена 8 | 42 | 00101010 | 2А | ||
| Плюс | + | Сдвиг = | 43 | 00101011 | 2Б | ||
| Запятая | , | , | 44 | 00101100 | 2К | ||
| Дефис/знак минус | — | — | 45 | 00101101 | 2D | ||
| Период | . | . | 46 | 00101110 | 2Е | ||
| Косая черта | / | / | 47 | 00101111 | 2Ф | ||
| Нулевая цифра | 0 | 0 | 48 | 00110000 | 30 | ||
| Одна цифра | 1 | 1 | 49 | 00110001 | 31 | ||
| Две цифры | 2 | 2 | 50 | 00110010 | 32 | ||
| Три цифры | 3 | 3 | 51 | 00110011 | 33 | ||
| Четыре цифры | 4 | 4 | 52 | 00110100 | 34 | ||
| Пятизначный | 5 | 5 | 53 | 00110101 | 35 | ||
| Шестизначный | 6 | 6 | 54 | 00110110 | 36 | ||
| Семизначный | 7 | 7 | 55 | 00110111 | 37 | ||
| Восьмизначный | 8 | 8 | 56 | 00111000 | 38 | ||
| Девять цифр | 9 | 9 | 57 | 00111001 | 39 | ||
| Двоеточие | : | Смена ; | 58 | 00111010 | 3А | ||
| Точка с запятой | ; | ; | 59 | 00111011 | 3Б | ||
| Знак «меньше» | < | Смена, | 60 | 00111100 | 3С | ||
| Знак равенства | = | = | 61 | 00111101 | 3D | ||
| Знак «больше чем» | > | Смена . | 62 | 00111110 | 3Е | ||
| Знак вопроса | ? | Смена / | 63 | 00111111 | 3F | ||
| У знака | @ | Смена 2 | 64 | 01000000 | 40 | ||
| Капитал А | А | Смена А | 65 | 01000001 | 41 | ||
| Капитал Б | Б | Смена В | 66 | 01000010 | 42 | ||
| Капитал С | С | Смена С | 67 | 01000011 | 43 | ||
| Капитал Д | Д | Смена Д | 68 | 01000100 | 44 | ||
| Капитал Э | Е | Сдвиг E | 69 | 01000101 | 45 | ||
| Капитал Ф | Ф | Сдвиг F | 70 | 01000110 | 46 | ||
| Капитал Г | Г | Сдвиг G | 71 | 01000111 | 47 | ||
| Капитал Н | Н | Переключение H | 72 | 01001000 | 48 | ||
| Капитал I | я | Смена I | 73 | 01001001 | 49 | ||
| Капитал Дж | Дж | Сдвиг J | 74 | 01001010 | 4А | ||
| Капитал К | К | Смена К | 75 | 01001011 | 4Б | ||
| Капитал Л | Л | Сдвиг L | 76 | 01001100 | 4С | ||
| Капитал М | М | Сдвиг М | 77 | 01001101 | 4D | ||
| Капитал N | Н | Смена N | 78 | 01001110 | 4Е | ||
| Капитал О | О | Переключение O | 79 | 01001111 | 4F | ||
| Капитал П | Р | Сдвиг П | 80 | 01010000 | 50 | ||
| Капитал К | Q | Переключение Q | 81 | 01010001 | 51 | ||
| Капитал Р | Р | Сдвиг Р | 82 | 01010010 | 52 | ||
| Капитал С | С | Сдвиг S | 83 | 01010011 | 53 | ||
| Капитал Т | Т | Сдвиг Т | 84 | 01010100 | 54 | ||
| Капитал У | У | Сдвиг U | 85 | 01010101 | 55 | ||
| Капитал В | В | Сдвиг V | 86 | 01010110 | 56 | ||
| Капитал Вт | Вт | Переключение W | 87 | 01010111 | 57 | ||
| Капитал Х | Х | Сдвиг Х | 88 | 01011000 | 58 | ||
| Капитал Y | Д | Сдвиг Y | 89 | 01011001 | 59 | ||
| Капитал Z | З | Сдвиг Z | 90 | 01011010 | 5А | ||
| Кронштейн левый | [ | [ | 91 | 01011011 | 5Б | ||
| Обратная косая черта | \ | \ 9 | Смена 6 | 94 | 01011110 | 5Е | |
| Подчеркивание | _ | Смена — | 95 | 01011111 | 5F | ||
| Обратная цитата | ` | ` | 96 | 01100000 | 60 | ||
| Строчная А | и | А | 97 | 01100001 | 61 | ||
| Нижний регистр B | б | Б | 98 | 01100010 | 62 | ||
| Строчная C | с | С | 99 | 01100011 | 63 | ||
| Строчный D | д | Д | 100 | 01100100 | 64 | ||
| Строчная Е | и | Е | 101 | 01100101 | 65 | ||
| Нижний регистр F | ф | Ф | 102 | 01100110 | 66 | ||
| Строчная G | г | Г | 103 | 01100111 | 67 | ||
| Нижний регистр Н | ч | Н | 104 | 01101000 | 68 | ||
| Строчная I | я | я | 105 | 01101001 | 69 | ||
| Строчная J | к | Дж | 106 | 01101010 | 6А | ||
| Строчная К | к | К | 107 | 01101011 | 6Б | ||
| Строчный L | л | Л | 108 | 01101100 | 6С | ||
| Строчная М | м | М | 109 | 01101101 | 6D | ||
| Нижний регистр N | п | Н | 110 | 01101110 | 6Е | ||
| Строчный O | или | О | 111 | 01101111 | 6F | ||
| Строчная буква P | р | Р | 112 | 01110000 | 70 | ||
| Строчный Q | q | Q | 113 | 01110001 | 71 | ||
| Строчный R | р | Р | 114 | 01110010 | 72 | ||
| Строчные S | с | С | 115 | 01110011 | 73 | ||
| Строчная Т | т | Т | 116 | 01110100 | 74 | ||
| Строчная U | и | У | 117 | 01110101 | 75 | ||
| Строчная буква V | v | В | 118 | 01110110 | 76 | ||
| Строчные буквы W | ш | Вт | 119 | 01110111 | 77 | ||
| Строчный X | х | Х | 120 | 01111000 | 78 | ||
| Строчная буква Y | г | Д | 121 | 01111001 | 79 | ||
| Строчный Z | я | З | 122 | 01111010 | 7А | ||
| Левая скоба | { | Сдвиг [ | 123 | 01111011 | 7Б | ||
| Вертикальная перекладина | | | Смена \ | 124 | 01111100 | 7С | ||
| Правая скоба | } | Смена ] | 125 | 01111101 | 7Д | ||
| Тильда | ~ | Смена ` | 126 | 01111110 | 7Е | ||
| Дельта | Д | 127 | 01111111 | 7F |
 H
H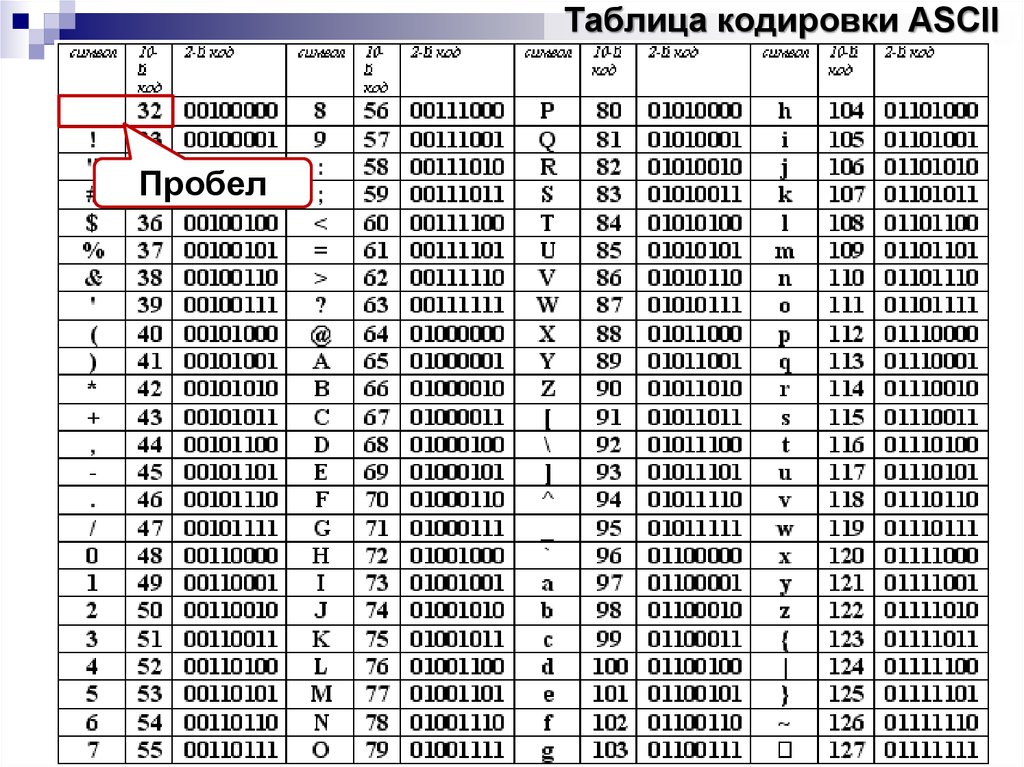 N
N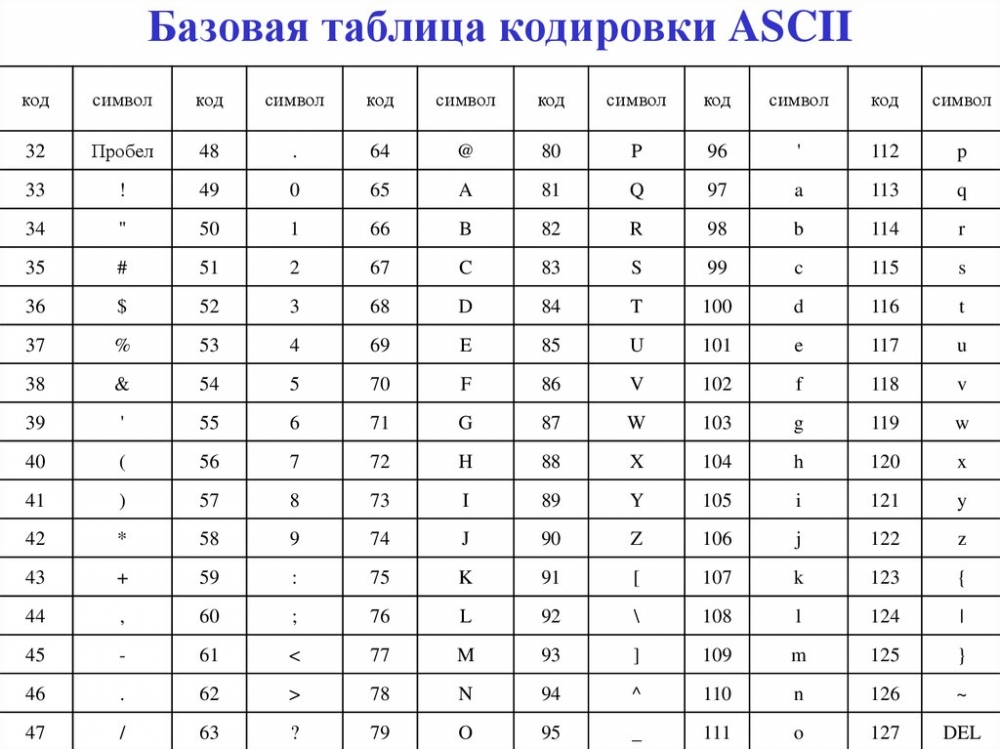 U
U
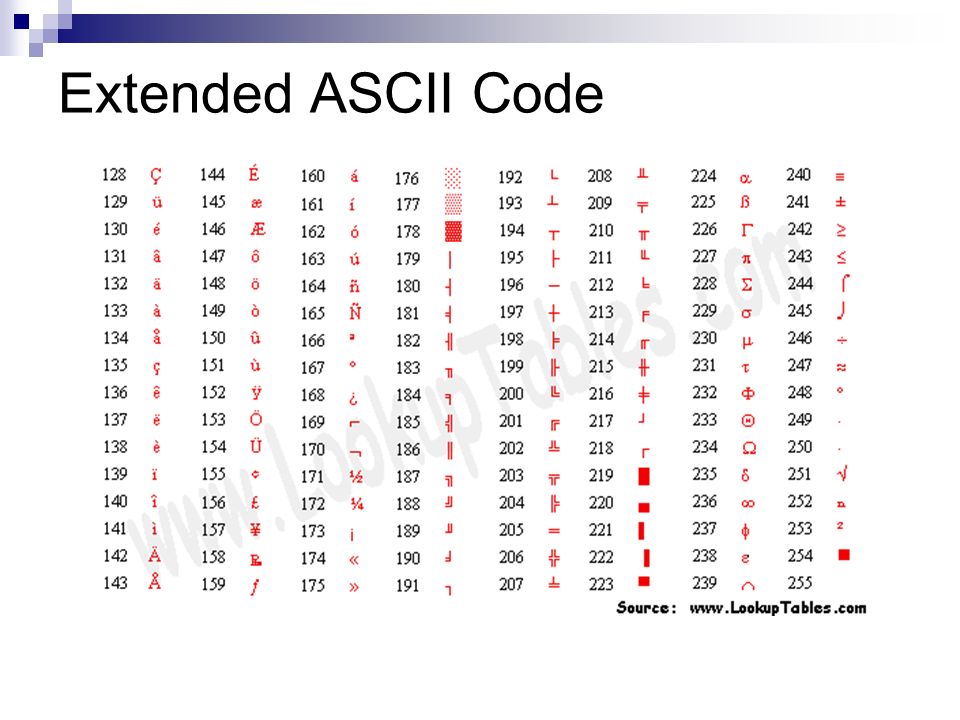
Таблица ASCII 0-127 | LEARN.
 PARALLAX.COM
PARALLAX.COMТаблица ASCII для символов 0-127. ASCII означает американский стандарт обмена кодовой информацией. Многие ПК и многие микроконтроллеры, включая BASIC Stamp, Propeller и Ardunio, используют этот код для присвоения номера функции клавиатуры. Некоторые числа соответствуют действиям клавиатуры, таким как курсор вверх, курсор вниз, пробел или удаление. Остальные числа соответствуют печатным буквам и символам.
Числа 32–126 соответствуют символам, которые могут отображаться в терминале отладки BASIC Stamp, последовательном терминале Parallax для пропеллера, последовательном мониторе Arduino и ЖК-дисплеях Parallax Serial. Это также удобный справочник для отправки текстовых строк между беспроводными устройствами. Некоторые устройства могут по-разному реагировать на кодовые числа 0–31, а также могут использовать специальные символы 128–255 (не показаны).
| Декабрь | Шестнадцатеричный | Символ | Имя/Функция | декабрь | Шестнадцатеричный | Символ | декабрь | Шестнадцатеричный | Символ | декабрь | Шестнадцатеричный | Символ | |||
| 0 | 00 | НУЛ | Нуль | 32 | 20 | пробел | 64 | 40 | @ | 96 | 60 | ` | |||
| 1 | 01 | СОХ | Начало заголовка | 33 | 21 | ! | 65 | 41 | А | 97 | 61 | и | |||
| 2 | 02 | СТХ | Начало текста | 34 | 22 | » | 66 | 42 | Б | 98 | 62 | б | |||
| 3 | 03 | ЕТХ | Конец текста | 35 | 23 | # | 67 | 43 | С | 99 | 63 | в | |||
| 4 | 04 | ЕОТ | Конец передачи | 36 | 24 | $ | 68 | 44 | Д | 100 | 64 | д | |||
| 5 | 05 | ENQ | Запрос | 37 | 25 | % | 69 | 45 | Е | 101 | 65 | и | |||
| 6 | 06 | ПОДТВЕРЖДЕНИЕ | Подтвердить | 38 | 26 | и | 70 | 46 | Ф | 102 | 66 | ф | |||
| 7 | 07 | бел | Звонок | 39 | 27 | ‘ | 71 | 47 | Г | 103 | 67 | г | |||
| 8 | 08 | БС | Возврат | 40 | 28 | ( | 72 | 48 | Х | 104 | 68 | ч | |||
| 9 | 09 | НТ | Горизонтальная вкладка | 41 | 29 | ) | 73 | 49 | я | 105 | 69 | и | |||
| 10 | 0А | ЛФ | Перевод строки | 42 | 2А | * | 74 | 4А | Дж | 106 | 6А | и | |||
| 11 | 0Б | ВТ | Вертикальный выступ | 43 | 2Б | + | 75 | 4Б | К | 107 | 6Б | к | |||
| 12 | 0С | ФФ | Подача бланка | 44 | 2С | , | 76 | 4С | л | 108 | 6С | л | |||
| 13 | 0D | КР | Возврат каретки | 45 | 2D | — | 77 | 4Д | М | 109 | 6Д | м | |||
| 14 | 0Е | СО | Смена | 46 | 2Е | .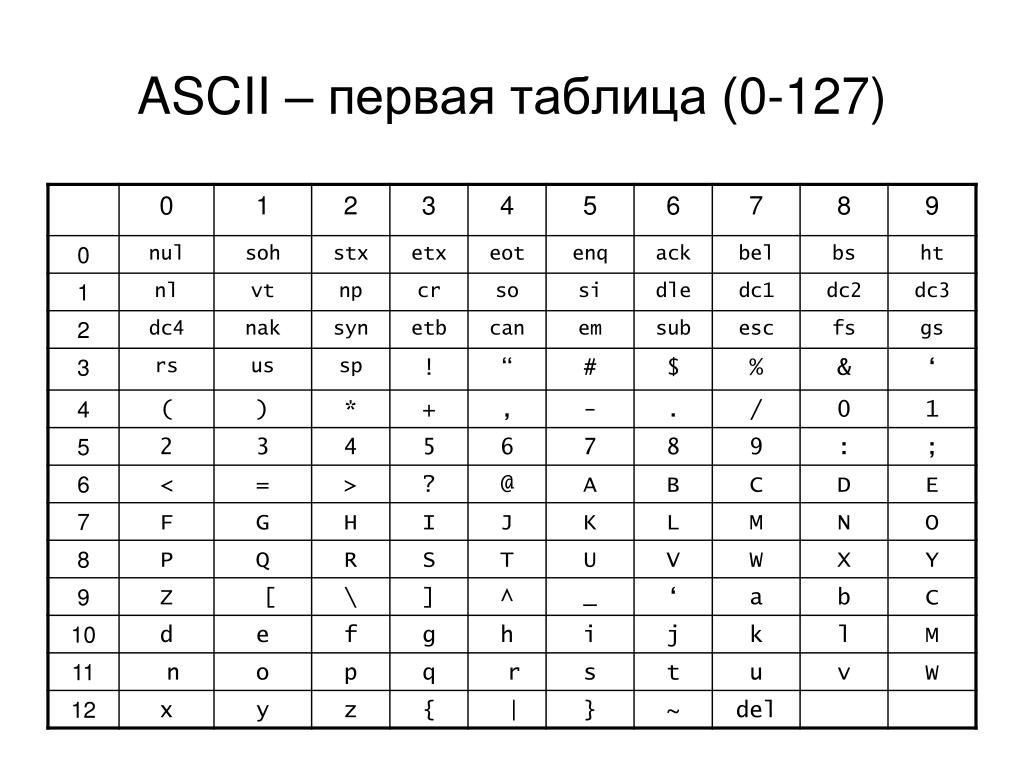 | 78 | 4Е | Н | 110 | 6Е | п | |||
| 15 | 0Ф | СИ | Shift In | 47 | 2F | / | 79 | 4F | О | 111 | 6Ф | или | |||
| 16 | 10 | ДЛЭ | Выход из строки данных | 48 | 30 | 0 | 80 | 50 | Р | 112 | 70 | р | |||
| 17 | 11 | ДС1 | Управление устройством 1 | 49 | 31 | 1 | 81 | 51 | Вопрос | 113 | 71 | д | |||
| 18 | 12 | ДС2 | Управление устройством 2 | 50 | 32 | 2 | 82 | 52 | Р | 114 | 72 | р | |||
| 19 | 13 | ДС3 | Управление устройством 3 | 51 | 33 | 3 | 83 | 53 | С | 115 | 73 | с | |||
| 20 | 14 | ДС4 | Управление устройством 4 | 52 | 34 | 4 | 84 | 54 | Т | 116 | 74 | т | |||
| 21 | 15 | НАК | Без подтверждения | 53 | 35 | 5 | 85 | 55 | У | 117 | 75 | и | |||
| 22 | 16 | СИН | Синхронный холостой ход | 54 | 36 | 6 | 86 | 56 | В | 118 | 76 | против | |||
| 23 | 17 | ЭТБ | Завершить блок передачи | 55 | 37 | 7 | 87 | 57 | Вт | 119 | 77 | с | |||
| 24 | 18 | МОЖЕТ | Отмена | 56 | 38 | 8 | 88 | 58 | х | 120 | 78 | х | |||
| 25 | 19 | ЭМ | Конец среды | 57 | 39 | 9 | 89 | 59 | Д | 121 | 79 | и | |||
| 26 | 1А | СУБ | Замена | 58 | 3А | : | 90 | 5А | З | 122 | 7А | г | |||
| 27 | 1Б | ЕСК | Побег | 59 | 3Б | ; | 91 | 5Б | [ | 123 | 7Б | { | |||
| 28 | 1С | ФС | Разделитель файлов | 60 | 3С | < | 92 | 5С | \ | 124 | 7С | | | |||
| 29 | 1Д | ГС | Разделитель групп | 61 | 3D | = | 93 | 5Д | ] | 125 | 7Д | } | |||
| 30 | 1Э | РС | Разделитель записей 9 | 126 | 7Е | ~ | |||||||||
| 31 | 1F | США | Разделитель блоков | 63 | 3F | ? | 95 | 5F | _ | 127 | 7Ф | удалить |
ASCII
ASCII Стандартный 7-битный код ASCII для текста восходит к 1967 году, когда почти все пользователи компьютеров говорили по-английски. 7-битный код дает только 128 уникальных символов. Unicode использует 16 бит и включает в себя наборы символов многих языков. (Коды ASCII включают первые 128 символов Unicode). Исходный код ASCII, показанный здесь, до сих пор широко используется текстовыми редакторами, такими как Блокнот, и в таких приложениях, как HTML и электронная почта.
7-битный код дает только 128 уникальных символов. Unicode использует 16 бит и включает в себя наборы символов многих языков. (Коды ASCII включают первые 128 символов Unicode). Исходный код ASCII, показанный здесь, до сих пор широко используется текстовыми редакторами, такими как Блокнот, и в таких приложениях, как HTML и электронная почта.| Код США ASCII | |||||||||||||
| Непечатный символы | Печать символов | Печать символов | |||||||||||
| Символ | декабрь | Двоичный | Шестнадцатеричный | Символ | декабрь | Двоичный | Шестнадцатеричный | Символ | декабрь | Двоичный | Шестнадцатеричный | ||
| ноль | 0 | 0000000 | 00 | пробел | 32 | 0100000 | 20 | Р | 80 | 1010000 | 50 | ||
| сох | 1 | 0000001 | 01 | ! | 33 | 0100001 | 21 | В | 81 | 1010001 | 51 | ||
| стх | 2 | 0000010 | 02 | » | 34 | 0100010 | 22 | Р | 82 | 1010010 | 52 | ||
| эткс | 3 | 0000011 | 03 | # | 35 | 0100011 | 23 | С | 83 | 1010011 | 53 | ||
| эот | 4 | 0000100 | 04 | $ | 36 | 0100100 | 24 | Т | 84 | 1010100 | 54 | ||
| enq | 5 | 0000101 | 05 | % | 37 | 0100101 | 25 | У | 85 | 1010101 | 55 | ||
| подтверждение | 6 | 0000110 | 06 | и | 38 | 0100110 | 26 | В | 86 | 1010110 | 56 | ||
| бел | 7 | 0000111 | 07 | ‘ | 39 | 0100111 | 27 | Вт | 87 | 1010111 | 57 | ||
| бс | 8 | 0001000 | 08 | ( | 40 | 0101000 | 28 | х | 88 | 1011000 | 58 | ||
| 9 | 0001001 | 09 | ) | 41 | 0101001 | 29 | Д | 89 | 1011001 | 59 | |||
| левый | 10 | 0001010 | 0А | * | 42 | 0101010 | 2А | З | 90 | 1011010 | 5А | ||
| вт | 11 | 0001011 | 0Б | + | 43 | 0101011 | 2Б | [ | 91 | 1011011 | 5Б | ||
| и далее | 12 | 0001100 | 0С | , | 44 | 0101100 | 2С | \ | 92 | 1011100 | 5С | ||
| кр | 13 | 0001101 | 0D | — 9 | 94 | 1011110 | 5Е | ||||||
| и | 15 | 0001111 | 0Ф | / | 47 | 0101111 | 2F | _ | 95 | 1011111 | 5F | ||
| или | 16 | 0010000 | 10 | 0 | 48 | 0110000 | 30 | ` | 96 | 1100000 | 60 | ||
| дк1 | 17 | 0010001 | 11 | 1 | 49 | 0110001 | 31 | и | 97 | 1100001 | 61 | ||
| DC2 | 18 | 0010010 | 12 | 2 | 50 | 0110010 | 32 | б | 98 | 1100010 | 62 | ||
| дк3 | 19 | 0010011 | 13 | 3 | 51 | 0110011 | 33 | в | 99 | 1100011 | 63 | ||
| дк4 | 20 | 0010100 | 14 | 4 | 52 | 0110100 | 34 | д | 100 | 1100100 | 64 | ||
| нет | 21 | 0010101 | 15 | 5 | 53 | 0110101 | 35 | и | 101 | 1100101 | 65 | ||
| син | 22 | 0010110 | 16 | 6 | 54 | 0110110 | 36 | ф | 102 | 1100110 | 66 | ||
и т. | |||||||||||||