Теория компиляции
Проекты выполняются в течении всего курса и сдаются в конце. В некоторых проектах возможна командная работа — об этом написано явно в спецификации. Ссылки на спецификации проектов ниже.
Проект: компилятор процедурного языка Проект: интерпретатор языка PostScript для 2D графики Книги и материалы по разработке компиляторов А что такое Compiler Driver? А что такое Compiler Frontend? А что такое Compiler Backend? Конечные автоматы Калькулятор на основе рекурсивного спуска Abstract Syntax Tree Сердце современных фронтендов компиляторов — абстрактное синтаксическое дерево (Abstract Syntax Tree, AST).


Примеры ко всем статьям ищите в репозитории примеров в каталоге chapter_3
Изучаем LLVM, виртуальный ассемблер LLVM-IR, генерируем машинный код. Все примеры в этой серии статей основаны на C++14, генераторе кода Lemon или библиотеках проекта LLVM.
 Знакомит с примерами и утилитами в составе LLVM.
Архитектура Backend компилятора
Статья рассматривает архитектуру бекенда и связывает понятия Abstract Syntax Tree, «промежуточный код» и «машинный код».
Минимальный транслятор, основанный на LLVM
В данной статье описан пример минимального компилятора, бекенд которого основан на LLVM. Транслятор умеет превращать исходный код с функциями и выражениями в промежуточный код на языке LLVM-IR, который затем можно скомпилировать вручную.
Особенности языка C и C-style кода
Знакомит с примерами и утилитами в составе LLVM.
Архитектура Backend компилятора
Статья рассматривает архитектуру бекенда и связывает понятия Abstract Syntax Tree, «промежуточный код» и «машинный код».
Минимальный транслятор, основанный на LLVM
В данной статье описан пример минимального компилятора, бекенд которого основан на LLVM. Транслятор умеет превращать исходный код с функциями и выражениями в промежуточный код на языке LLVM-IR, который затем можно скомпилировать вручную.
Особенности языка C и C-style кодаТеория и практика Java: Динамическая компиляция и измерение производительности
 В данной статье серии Теория и практика Java Brian Goetz объясняет несколько из множества причин, по которым динамическая компиляция может усложнить тест производительности. http://www-128.ibm.com/developerworks/java/library/j-jtp12214/
В данной статье серии Теория и практика Java Brian Goetz объясняет несколько из множества причин, по которым динамическая компиляция может усложнить тест производительности. http://www-128.ibm.com/developerworks/java/library/j-jtp12214/Ведущий консультант, Quiotix
21 Dec, 2004
Содержание
1 Динамическая компиляция — краткая история
2 Так какое отношение все это имеет к тесту производительности?
3 Удаление «мертвого» кода
4 Тренировка
5 Динамическая деоптимизация
6 Заключение
7 Ресурсы
8 Об авторах
Динамическая компиляция — краткая история
Процесс компиляции Java-приложения отличается от процесса компиляции статически компилируемых языков программирования, подобных С или С++. Статический компилятор преобразует исходный код непосредственно в машинные инструкции, которые могут быть выполнены на целевой платформе. Различные аппаратные платформы требуют применения различных компиляторов.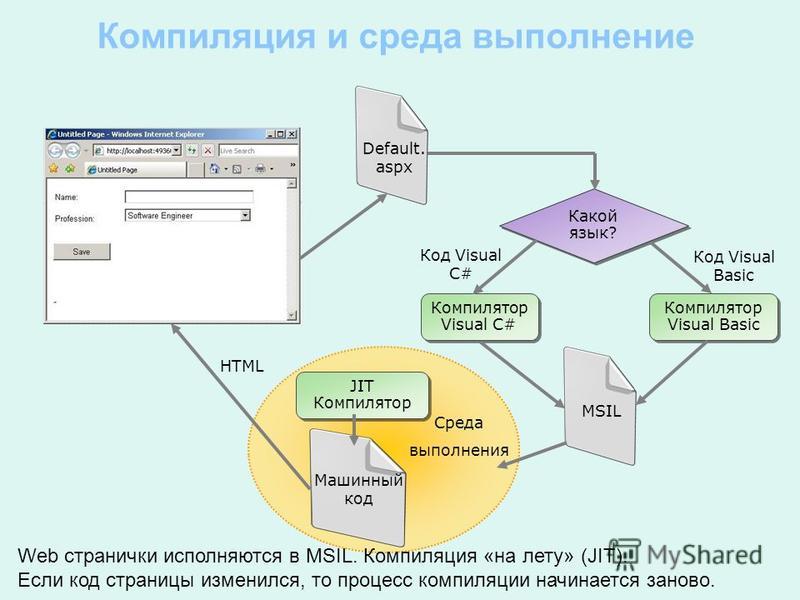
Первые поколения JVM были полностью интерпретируемыми. JVM интерпретировала байткод вместо компиляции его в машинный код и выполнения машинного кода. Этот подход, естественно, не предлагал наилучшей возможной производительности, поскольку система больше времени тратила на выполнение интерпретатора, а не самой программы.
Just-in-time (оперативная) компиляция
 Этот подход дает возможность программам стартовать быстрее, поскольку не требуется длительная фаза компиляции перед возможным началом исполнения кода.
Этот подход дает возможность программам стартовать быстрее, поскольку не требуется длительная фаза компиляции перед возможным началом исполнения кода.Использование JIT выглядело многообещающим, но существуют недостатки. JIT-компиляция устранила накладные расходы интерпретации (за счет некоторого дополнительного замедления запуска), но уровень оптимизации кода по некоторым причинам был посредственным. Во избежание значительного замедления при запуске Java-приложений JIT-компилятор должен быть быстрым, т.е. он не может тратить много времени на оптимизацию. И первые JIT-компиляторы были консервативны в создании встроенных предположений, поскольку они не знали, какие классы могут быть загружены позднее.
С технической точки зрения JIT-виртуальная машина компилирует каждый байткод перед его выполнением. Термин JIT часто используется для обозначения любой динамической компиляции байткода в машинный код, даже когда возможна интерпретация байткода.
Динамическая компиляция HotSpot
Исполняющий процесс HotSpot объединяет интерпретацию, профилирование и динамическую компиляцию. Вместо преобразования всех байткодов в машинный код HotSpot начинает работу как интерпретатор и компилирует только «горячий» код, то есть код, выполняющийся наиболее часто. Во время выполнения он собирает данные анализа. Эти данные используются для определения фрагментов кода, выполняющихся достаточно часто и заслуживающих компиляции. Компиляция только часто исполняемого кода имеет несколько преимуществ: не тратится время на компиляцию кода, выполняющегося редко, таким образом, компилятор может тратить больше времени на оптимизацию «горячего» кода, поскольку он знает, что время будет потрачено не зря. Кроме того, откладывая компиляцию, компилятор имеет доступ к данным анализа, которые могут быть использованы для улучшения оптимизации, например, встраивать ли вызов конкретного метода.
Вместо преобразования всех байткодов в машинный код HotSpot начинает работу как интерпретатор и компилирует только «горячий» код, то есть код, выполняющийся наиболее часто. Во время выполнения он собирает данные анализа. Эти данные используются для определения фрагментов кода, выполняющихся достаточно часто и заслуживающих компиляции. Компиляция только часто исполняемого кода имеет несколько преимуществ: не тратится время на компиляцию кода, выполняющегося редко, таким образом, компилятор может тратить больше времени на оптимизацию «горячего» кода, поскольку он знает, что время будет потрачено не зря. Кроме того, откладывая компиляцию, компилятор имеет доступ к данным анализа, которые могут быть использованы для улучшения оптимизации, например, встраивать ли вызов конкретного метода.
HotSpot поставляется с двумя компиляторами: клиентским и серверным. По умолчанию используется клиентский компилятор. Вы можете выбрать серверный компилятор, указав параметр -server при запуске JVM. Серверный компилятор оптимизирован для повышения пиковой скорости работы и предназначен для «долгоиграющих» серверных приложений. Клиентский компилятор оптимизирован для уменьшения времени начального запуска приложения и занимаемого объема памяти, реализует менее сложную оптимизацию, чем серверный компилятор, и, следовательно, требует меньше времени для компиляции.
Серверный компилятор оптимизирован для повышения пиковой скорости работы и предназначен для «долгоиграющих» серверных приложений. Клиентский компилятор оптимизирован для уменьшения времени начального запуска приложения и занимаемого объема памяти, реализует менее сложную оптимизацию, чем серверный компилятор, и, следовательно, требует меньше времени для компиляции.
Серверный компилятор HotSpot может выполнять впечатляющее число видов оптимизации. Среди них множество стандартных видов оптимизации, имеющихся в статических компиляторах, например, выведение кода из тела циклов, общее удаление подвыражения, развертка цикла, удаление проверки диапазона, удаление «мертвого» кода, анализ движения данных, а также множество оптимизаций, обычно не применяющихся в статических компиляторах, например, принудительное встраивание вызовов виртуальных методов.
Непрерывная перекомпиляция
Еще одна интересная особенность HotSpot — компиляция не осуществляется по принципу «все или ничего». Code path компилируется в машинный код после интерпретации его определенное количество раз. Но JVM продолжает анализ и может перекомпилировать код заново с более высоким уровнем оптимизации, если решит, что code path является особенно «горячим» или последующий анализ данных показал возможность дополнительной оптимизации. JVM может перекомпилировать одни и те же байткоды много раз при выполнении одиночного приложения. Для получения более подробной информации о работе компилятора попробуйте вызвать JVM с флагом
Code path компилируется в машинный код после интерпретации его определенное количество раз. Но JVM продолжает анализ и может перекомпилировать код заново с более высоким уровнем оптимизации, если решит, что code path является особенно «горячим» или последующий анализ данных показал возможность дополнительной оптимизации. JVM может перекомпилировать одни и те же байткоды много раз при выполнении одиночного приложения. Для получения более подробной информации о работе компилятора попробуйте вызвать JVM с флагом -XX:+PrintCompilation, который заставляет компилятор (клиентский или серверный) каждый раз во время своей работы выводить на экран короткое сообщение.
Замещение в стеке
Первая версия HotSpot выполняла компиляцию по одному методу в каждый момент времени. Метод считался «горячим», если он выполнял итерации цикла, превышающие определенное количество раз (10000 в первой версии HotSpot). Это определялось назначением каждому методу счетчика и увеличением его значения каждый раз при выполнении обратного перехода. Однако после компиляции метода переключение на компилированную версию не производилось до тех пор, пока не происходил выход из метода и повторный вход — компилированная версия могла использоваться только для последовательных вызовов. В результате этого в некоторых ситуациях компилированная версия вообще никогда не использовалась, например, в случае программы, выполняющей интенсивные вычисления и в которой все вычисления производятся одинарным вызовом метода. В такой ситуации вычисляющий метод может быть скомпилирован, но компилированный код ни разу не использоваться.
Однако после компиляции метода переключение на компилированную версию не производилось до тех пор, пока не происходил выход из метода и повторный вход — компилированная версия могла использоваться только для последовательных вызовов. В результате этого в некоторых ситуациях компилированная версия вообще никогда не использовалась, например, в случае программы, выполняющей интенсивные вычисления и в которой все вычисления производятся одинарным вызовом метода. В такой ситуации вычисляющий метод может быть скомпилирован, но компилированный код ни разу не использоваться.
Более свежие версии HotSpot используют технологию, называемую on-stack replacement (OSR), для разрешения переключения от интерпретируемого кода к компилированному (или замены одной версии компилированного кода другой) в середине цикла.
Так какое отношение все это имеет к тесту производительности?
Я обещал вам статью о тестах производительности и измерении производительности, но пока вы только получили урок по истории и пересказ белых книг HotSpot от Sun. Причиной такого длительного отступления является то, что без понимания процесса динамической компиляции практически невозможно правильно писать или интерпретировать тесты производительности для Java-классов. (Это сделать довольно непросто даже при глубоком понимании динамической компиляции и JVM-оптимизации.)
Причиной такого длительного отступления является то, что без понимания процесса динамической компиляции практически невозможно правильно писать или интерпретировать тесты производительности для Java-классов. (Это сделать довольно непросто даже при глубоком понимании динамической компиляции и JVM-оптимизации.)
Писать микротесты производительности для Java-программы намного сложнее, чем для C-программы.
Традиционным способом определения того, что Вариант А быстрее Варианта Б, является написание маленького теста производительности, часто называемого микротестом производительности. Это очень благоразумно. Научный метод требует независимого исследования! Увы. Написание (и интерпретация) тестов производительности является намного более трудной и запутанной задачей для языков с динамической компиляцией, чем для языков со статической компиляцией. Ничего нет плохого в попытке узнать что-либо о производительности определенной конструкции путем написания программы, ее использующей. Но в большинстве случаев написанные на Java микротесты не покажут вам того, что вы думали получить.
Но в большинстве случаев написанные на Java микротесты не покажут вам того, что вы думали получить.
Что касается программ, написанных на C, вы можете многое узнать о характеристиках производительности программы, даже не запуская ее, а просто посмотрев на откомпилированный машинный код. Сгенерированные компилятором инструкции представляют собой реальные машинные команды, которые будут выполняться, а их временные характеристики в общем случае достаточно хорошо понятны. (Существуют патологические примеры, производительность которых намного хуже, чем можно было бы ожидать от просмотра машинного кода, по причине отсутствия постоянного предсказания ветвлений или отсутствия кэша. Но в большинстве случаев вы можете много узнать о производительности C-программы, просмотрев ее машинный код.)
Если компилятор собирается оптимизировать фрагмент кода и удалить его, поскольку считает его несущественным (обычная ситуация с тестами производительности, которые в действительности ничего не делают), вы можете увидеть это в сгенерированном машинном коде — фрагмента не будет. И вы обычно не должны запускать C-программу на длительное время, перед тем как сделать определенные выводы о ее производительности.
И вы обычно не должны запускать C-программу на длительное время, перед тем как сделать определенные выводы о ее производительности.
С другой стороны, HotSpot JIT периодически перекомпилирует Java-байткод в машинный код при выполнении вашей программы, и эта перекомпиляция может выполняться в неожиданное время после накопления определенного количества данных для анализа, при загрузке новых классов или при выполнении code path, еще не переведенных в разряд загруженных классов. Измерения времени при постоянной перекомпиляции могут быть совершенно не точными и обманчивыми, и очень часто нужно выполнять Java-код довольно продолжительное время (я видел анекдотические ситуации повышения производительности после часов или даже дней, прошедших с момента запуска программы) до получения полезных данных о производительности.
Удаление «мертвого» кода
Одной из проблем написания хорошей тестовой программы является удаление оптимизирующим компилятором «мертвого» кода — кода, не влияющего на результат выполнения программы. Программы тестов производительности часто не выполняют вывод каких-либо результатов на экран; это означает, что некоторый или весь ваш код может быть оптимизирован и удален без вашего ведома, и с этого момента вы будете тестировать не то что думаете. В частности, многие микротесты работают намного лучше, будучи запущенными с параметром
Программы тестов производительности часто не выполняют вывод каких-либо результатов на экран; это означает, что некоторый или весь ваш код может быть оптимизирован и удален без вашего ведома, и с этого момента вы будете тестировать не то что думаете. В частности, многие микротесты работают намного лучше, будучи запущенными с параметром -server вместо -client, не потому что серверный компилятор быстрее (хотя чаще всего так и есть), а потому что серверный компилятор более приспособлен к оптимизации фрагментов «мертвого» кода. К сожалению, такая оптимизация «мертвого» кода, ускоряющая работу вашей тестовой программы (возможно оптимизируя ее полностью), не работает также хорошо с программой, которая что-то реально делает.
Странный результат
Листинг 1 содержит пример кода теста производительности с ничего не делающим блоком, который был взят из теста для измерения производительности параллельных потоков, но вместо этого измеряет что-то совершенно другое. (Этот пример был позаимствован из отличной презентации JavaOne 2003 «The Black Art of Benchmarking». См. раздел Ресурсы.)
(Этот пример был позаимствован из отличной презентации JavaOne 2003 «The Black Art of Benchmarking». См. раздел Ресурсы.)
Листинг 1. Тест производительности, искаженный непреднамеренным «мертвым» кодом
public class StupidThreadTest {
public static void doSomeStuff() {
double uselessSum = 0;
for (int i = 0; i < 1000; i++) {
for (int j = 0; j < 1000; j++) {
uselessSum += (double) i + (double) j;
}
}
}
public static void main(String[] args) throws InterruptedException {
doSomeStuff();
int nThreads = Integer.parseInt(args[0]);
Thread[] threads = new Thread[nThreads];
for (int i = 0; i < nThreads; i++)
threads[i] = new Thread(new Runnable() {
public void run() {
doSomeStuff();
}
});
long start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++)
threads[i]. start();
start();
for (int i = 0; i < threads.length; i++)
threads[i].join();
long end = System.currentTimeMillis();
System.out.println("Time: " + (end - start) + "ms");
}
} start();
start();Метод doSomeStuff() предназначен для порождения выполняющих какое-то действие потоков. Мы можем оценить планируемые издержки для нескольких потоков времени исполнения StupidThreadBenchmark. Однако компилятор может определить, что весь код в doSomeStuff является «мертвым», и оптимизировать его путем удаления, поскольку uselessSum никогда не используется. Как только код внутри цикла удаляется, может удалиться также и сам цикл, оставив doSomeStuff полностью пустым. В таблице 1 показана производительность StupidThreadBenchmark на клиенте и на сервере. Обе JVM показывают линейную зависимость от количества потоков. Легко может быть выдвинуто ошибочное предположение о том, что JVM сервера в 40 раз быстрее JVM клиента. В действительности происходит следующее — серверный компилятор выполняет более полную оптимизацию и может обнаружить, что
В действительности происходит следующее — серверный компилятор выполняет более полную оптимизацию и может обнаружить, что doSomeStuff содержит полностью «мертвый» код. В то время как многие программы действительно ускоряются на JVM сервера, ускорение, которое видите вы — это просто измерение плохо написанного теста производительности, а не блестящая производительность JVM сервера. Но если вы были невнимательны, можно довольно легко перепутать одно с другим.
Таблица 1. Производительность StupidThreadBenchmark в клиентской и серверной JVM
| Количество потоков | Время работы JVM клиента | Время работы JVM сервера |
| 10 | 43 | 2 |
| 100 | 435 | 10 |
| 1000 | 4142 | 80 |
| 10000 | 42402 | 1060 |
Оптимизация (т.е. удаление) «мертвого» кода также является проблемой при тестировании компилированных статически приложений. Однако определить удаление компилятором большого фрагмента вашего кода в таких приложениях намного легче. Вы можете посмотреть на сгенерированный машинный код и обнаружить отсутствие части вашей программы. При использовании же динамически компилируемых языков эта информация не является для вас легкодоступной.
Однако определить удаление компилятором большого фрагмента вашего кода в таких приложениях намного легче. Вы можете посмотреть на сгенерированный машинный код и обнаружить отсутствие части вашей программы. При использовании же динамически компилируемых языков эта информация не является для вас легкодоступной.
Тренировка
При измерении производительности идиомы Х вы, обычно, хотите измерить производительность ее компилированной, а не интерпретируемой, версии. (Вы хотите знать, насколько быстро X будет работать.) Для этого перед началом измерений времени выполнения необходима «тренировка» JVM — выполнение вашего действия достаточное количество раз, для того чтобы компилятор имел достаточно времени и заменил интерпретируемый код компилированным.
Для первых JIT и динамических компиляторов без замещения в стеке существовала простая формула измерения компилированной производительности метода: выполнить определенное количество вызовов метода, запустить таймер, затем выполнить метод определенное дополнительное количество раз. Если число тренировочных вызовов превышало порог срабатывания процедуры компиляции метода, фактически измеренные вызовы относились к компилированному коду, а все издержки компиляции должны были проявиться до начала измерения.
С современными динамическими компиляторами это сделать значительно труднее. Компилятор запускается в менее предсказуемое время, JVM по своему желанию переключает код с интерпретируемой версии на компилированную, а один и тот же code path при выполнении может быть компилирован и перекомпилирован более одного раза. Если вы не определите время этих событий, они могут серьезно исказить результаты ваши х измерений.
На рисунке 1 показаны некоторые из возможных искажений из-за непредсказуемой динамической компиляции. Допустим, вы собираетесь измерить 200000 итераций цикла и компилированный код в 10 раз быстрее интерпретируемого. Если компиляция запускается за 200000 итераций, вы измеряете только интерпретируемую производительность (шкала времени (a)). Если компиляция запускается за 100000 итераций, общее время выполнения состоит из времени выполнения 100000 интерпретируемых итераций плюс время компиляции (которое вы не хотите учитывать) плюс время выполнения компилируемых итераций (шкала времени (b)). Если компиляция запускается за 20000 итераций, общее время состоит из 20000 интерпретируемых итераций плюс время компиляции плюс 180000 компилированных итераций (шкала времени (c)). Поскольку вы не знаете,когда запускается компилятор, а также время компиляции, результат измерений может сильно искажаться. В зависимости от времени компиляции и того, насколько компилируемый код быстрее интерпретируемого, небольшие изменения количества итераций могут привести к большим различиям в измерении «производительности».
Итак, какого объема тренировки достаточно? Вы не знаете. Лучшее, что можно сделать — запустить ваш тест с параметром -XX:+PrintCompilation, найти причину запуска компилятора, затем реструктуризировать вашу программу измерения производительности так, чтобы вся компиляция происходила до начала измерений и не вызывалась в середине измерительного цикла.
Не забывайте о сборке мусора
Как вы уже видели, для получения точных результатов измерения нужно выполнить тестирующий код даже большее количество раз, чем было бы достаточно для тренировки JVM. С другой стороны, если тестирующий код производит любое размещение объектов (почти каждый код это делает), из них создается мусор и со временем должен будет запуститься сборщик мусора. Это еще один элемент, который может сильно исказить результаты измерений — небольшое изменение количества итераций может означать работу сборщика мусора, который искажает измерение «времени итерации».
Если запустить тест с параметром -verbose:gc, то можно определить время, затрачиваемое на сборку мусора, и соответственно скорректировать данные измерений. Еще лучше запустить программу на очень длительное время, гарантируя инициирование большого числа сборок мусора для более точной компенсации действий по размещению объектов и сборке мусора.
Динамическая деоптимизация
Многие из стандартных типов оптимизаций могут быть выполнены только в «основном блоке», так что встраивание вызовов методов часто является очень важным для достижения хорошей оптимизации. При встраивании вызовов методов устраняются не только накладные расходы при вызове методов, но и предоставляется больший основной блок компилятору для оптимизации с реальной возможностью оптимизации «мертвого кода».
Листинг 2 представляет пример типа оптимизации, разрешаемой через встраивание. Метод outer() вызывает inner() с аргументом null, который приводит к тому, что inner() не выполняет никаких действий. Но, встраивая вызов к inner(), компилятор может обнаружить, что ветвление else в inner() является «мертвым» кодом и может оптимизировать проверку и ветвление else путем удаления, что может в свою очередь дать возможность оптимизировать (удалить) вызов к inner() полностью. Если бы inner() не был бы встроен, такая оптимизация не была бы возможна.
public class Inline {
public final void inner(String s) {
if (s == null)
return;
else {
// выполнить что-то действительно сложное
}
}
public void outer() {
String s = null;
inner(s);
}
}К сожалению, виртуальные функции ставят препятствие для встраивания, а виртуальные функции в Java больше распространены, чем в C++. Допустим, компилятор пытается оптимизировать вызов doSomething() в следующем коде:
Foo foo = getFoo();
foo.doSomething();
Из этого фрагмента кода компилятор не может с уверенностью определить, какая версия doSomething() будет выполнена: реализованная в классе Foo, или в субклассе Foo. Есть несколько ситуаций, когда ответ очевиден (например, если Foo указан как final или doSomething() определен как final-метод в Foo), но чаще всего компилятор должен догадываться. Со статическим компилятором, который компилирует один класс в данный момент времени, нам бы не повезло. Но динамический компилятор может использовать глобальную информацию для принятия лучшего решения. Допустим, что не существует в данном приложении расширяющих Foo загруженных классов. Эта ситуация больше похожа на тот случай, когда doSomething() являлся final-методом Foo — компилятор может преобразовать вызов виртуального метода в прямую передачу (уже улучшение) и, далее, может также выполнить встраивание doSomething(). (Преобразование вызова виртуального метода в прямой вызов метода называется мономорфным преобразованием вызова.)
Подождите секунду — классы могут быть загружены динамически. Что произойдет если компилятор выполнит такую оптимизацию, а затем загрузится класс, расширяющий Foo? Более того, что если это будет сделано внутри метода генератора getFoo(), и getFoo() возвратит экземпляр нового субкласса Foo? Не будет ли сгенерированный код ошибочным? Да, будет. Но JVM понимает это и сделает недействительным сгенерированный код, основанный на теперь уже неверном предположении, и возвратится к интерпретации (или перекомпилирует неверный code path).
В результате компилятор может принять решение о принудительном встраивании для достижения более высокой производительности, затем отменить это решение, если оно более не основывается на верных предположениях. Фактически эффективность такой оптимизации заключается в том, что добавление ключевого слова final к не переопределенным методам (совет для повышения производительности из старой литературы) дает очень мало для улучшения реальной производительности.
Странный результат
В листинге 3 приведен шаблон кода, в котором объединены неправильная тренировка, мономорфное преобразование вызова и деоптимизация, что приводит к полностью бессмысленным, но легко интерпретируемым результатам:
Листинг 3. Результаты тестовой программы искажены мономорфным преобразованием вызова и последовательной деоптимизацией
public class StupidMathTest {
public interface Operator {
public double operate(double d);
}
public static class SimpleAdder implements Operator {
public double operate(double d) {
return d + 1.0;
}
}
public static class DoubleAdder implements Operator {
public double operate(double d) {
return d + 0.5 + 0.5;
}
}
public static class RoundaboutAdder implements Operator {
public double operate(double d) {
return d + 2.0 - 1.0;
}
}
public static void runABunch(Operator op) {
long start = System.currentTimeMillis();
double d = 0.0;
for (int i = 0; i < 5000000; i++)
d = op.operate(d);
long end = System.currentTimeMillis();
System.out.println("Time: " + (end - start) + " ignore:" + d);
}
public static void main(String[] args) {
Operator ra = new RoundaboutAdder();
runABunch(ra); // неправильная попытка тренировки
runABunch(ra);
Operator sa = new SimpleAdder();
Operator da = new DoubleAdder();
runABunch(sa);
runABunch(da);
}
} StupidMathTest сначала пытается выполнить тренировку (безуспешно), затем измеряет время выполнения SimpleAdder, DoubleAdder и RoundaboutAdder с результатами, отображенными в таблице 2. Похоже, что намного быстрее добавить 1 к double, добавив 2 и отняв 1, чем просто добавив 1 сразу же. И немного быстрее добавить 0.5 дважды, чем добавить 1. Возможно ли такое? (Ответ: нет.)
Таблица 2. Бессмысленные и обманчивые результаты StupidMathTest
| Method | Runtime |
| SimpleAdder | 88ms |
| DoubleAdder | 76ms |
| RoundaboutAdder | 14ms |
Что здесь произошло? После цикла тренировки RoundaboutAdder и runABunch() компилируются, и компилятор выполняет мономорфное преобразование вызова с Operator и RoundaboutAdder, так что первый проход выполняется довольно быстро. Во втором проходе (SimpleAdder) компилятор должен выполнить деоптимизацию и откат к диспетчеризации виртуального метода, так что второй проход выполняется медленнее благодаря неспособности оптимизировать (удалить) вызов виртуальной функции, время тратится на перекомпиляцию. На третьем проходе (DoubleAdder) выполняется меньше перекомпиляции, поэтому он работает быстрее. (В действительности компилятор собирается провести свертывание констант в RoundaboutAdder и DoubleAdder, генерируя точно такой же код, что и SimpleAdder. То есть, если существует разница во время выполнения, она не зависит от арифметического кода.) Какой проход выполнится первый, он и будет самым быстрым.
Итак, какой мы можем сделать вывод из этого «теста производительности»? Практически никакого, за исключением того, что тестирование производительности динамически компилируемых языков программирования является намного более коварным процессом, чем вы могли бы представить.
Заключение
Результаты приведенных здесь примеров были настолько очевидно ошибочными, что было ясно — должно происходить еще нечто. Даже меньшие эффекты могут легко исказить результаты ваших программ тестирования производительности без включения вашего детектора «Что-то здесь не то». И хотя здесь представлены распространенные источники искажений микротестов производительности, существует множество других источников. Мораль этой истории: вы не всегда измеряете то, что думаете. Фактически, вы обычно не измеряете то, что думаете. Будьте очень осторожны с результатами любых измерений производительности, в которые не были вовлечены реальные программы на длительный период времени.
Ресурсы
Ссылки по теме
Jikes Research Virtual Machine
Overview of the IBM Just-in-Time Compiler
Java theory and practice series
Об авторах
Brian Goetz является профессиональным разработчиком программного обеспечения более чем 17 лет. Он — главный консультант в Quiotix, компании по разработке программного обеспечения и консультациям в Los Altos, Calif., и работает в нескольких экспертных группах JCP. Ищите опубликованные и готовящиеся им статьи в популярных отраслевых публикациях.
Теория компиляторов
Пользователи также искали:
алгоритм сети — ульмана, автомата, регулярному, выражение, регулярное, выражению, детерминизация автомата, рв в нка, преобразования, преобразование, преобразование нка в дка, построение, автомату, детерминизация, синтез, конечного, Алгоритм, Сети, регулярное выражение дка, регулярное выражение по автомату, Ульмана, правила, Алгоритм Сети — Ульмана, правила преобразования рв в ка, базовый блок, вышка, тура, Базовый, базовый, паспорт,
…
НОУ ИНТУИТ | Теория и реализация языков программирования
Форма обучения:
дистанционная
Стоимость самостоятельного обучения:
бесплатно
Доступ:
свободный
Документ об окончании:
Уровень:
Профессионал
Длительность:
22:52:00
Выпускников:
713
Качество курса:
4.45 | 4.29
В курсе излагаются основные разделы теории разработки компиляторов. Рассматриваются такие средства автоматизации процесса разработки трансляторов, как LEX, YACC, СУПЕР, методы генерации оптимального кода.
Сделана попытка на протяжении всего изложения провести единую «атрибутную» точку зрения на процесс разработки компилятора.
Теги: beta, FPA, objective-c, YACC, автоматы, алгоритмы, анализ, внутренняя вершина, вычисления, дерево вывода, компиляторы, левая рекурсия, нетерминал, подцепочка, поиск, программирование, процедуры, регулярное множество, регулярные выражения, статическая цепочка, трансляторы, указатели, функция расстановки, элементыДополнительные курсы
2 часа 30 минут
—
Введение
В данной лекции рассматривается место компилятора в программном обеспечении, который составляет существенную часть программного обеспечения ЭВМ. Приведены основные понятия, рассмотрена структура компилятора согласно фазам его действия.—
Языки и их представление
В данной лекции рассматривается понятие языков и их представление. Приведены такие определения, как алфавит, цепочка, грамматика, машина Тьюринга. Также приведены примеры практической реализации основных понятий в теории программирования.—
Лексический анализ
В данной лекции приводится понятие лексического анализа. Рассмотрены основные задачи лексического анализа, приведены основные определения, такие как регулярное множество, конечный автомат, конфигурация, лексический анализатор. Также приведены примеры решения задач, связанных с лексическим анализом.—
Синтаксический анализ
В данной лекции рассматривается понятие синтаксического анализа. Приводятся определения понятий упорядоченного графа, дерева вывода, автомата с магазинной памятью и его конфигурации. Приведены примеры задач, алгоритмов и доказательства теорем синтаксического анализа.—
Элементы теории перевода
В данной лекции рассматривается теория перевода. Рассматриваются несколько формализмов для определения переводов: преобразователи с магазинной памятью, схемы синтаксически управляемого перевода и атрибутные грамматики. Приведены основные понятия, примеры решения задач и доказательства теорем.—
Проверка контекстных условий
В данной лекции рассматривается проверка контекстных условий. Приведены определения понятий компоненты программы, области действия и области видимости, основных действий со средой. Также приведены примеры программного кода и решения задач.—
Организация таблиц символов
В данной лекции рассматривается организация таблиц символов. Рассмaтриваются некоторые основные способы организации таблиц символов в компиляторе: таблицы идентификаторов, таблицы расстановки, двоичные деревья и реализация блочной структуры. Приведены также примеры программного кода и графическая интерпретация таблиц символов и идентификаторов.—
Промежуточное представление программы
В данной лекции рассматривается промежуточное представление программы, которое предназначено прежде всего для удобства генерации кода и/или проведения различных оптимизаций. Рассматриваются часто используемые формы промежуточного представления такие, как ориентированный граф (в частности, абстрактное синтаксическое дерево, в том числе атрибутированное), трехадресный код (в виде троек или четверок), префиксная и постфиксная запись. Также рассмотрена виртуальная Java-машина и ее команды. Приведены основные понятия, графическая интерпретация промежуточного представления программ и части программного кода.—
Генерация кода
В данной лекции рассматривается генерация кода, задачей которой является построение для программы на входном языке эквивалентной машинной программы. Рассматривается действие модели машины, осуществляющей генерацию кода. Приведены основные понятия и части программного кода.—
Системы автоматизации построения трансляторов
В данной лекции рассматриваются системы автоматизации построения трансляторов на примере систем автоматизации построения трансляторов СУПЕР и YACC. Приведены структуры этих систем, основные термины и определения и части программного кода реализации систем автоматизации построения трансляторов.—
Сергей Михайлович Салибекян | репетитор на profi.ru (информатика, программирование, ЕГЭ по информатике, ОГЭ по информатике, языки программирования).
Имеется опыт преподавания различных дисциплин, в том числе информатики, программирования, моделирования, теории компиляции, теории формальных языков, теории автоматов, схемотехники, математической логики, теории алгоритмов, теории информации и кодирования, теории вероятностей, исследования операций, теории графов, вычислительной математики, технологии программирования. Являлся научным руководителем более 30 дипломных работ студентов.
Программирую на языках C, C++, C#, BASIC, PASCAL, Python, Web-разработкой не занимаюсь.
Веду активную научную деятельность в области ИТ: компьютерных архитектур, теории вычислительных процессов, параллельных вычислительных процессов (более 50 печатных работ).
Имеется серьезный опыт в создании программного обеспечения (постановка задачи, написание кода, тестирование и отладка). Поэтому знаю множество полезных приемов, о которых не пишут в книжках, и которые можно постичь только на практике.
Обучение программированию строю на теоретической базе дискретной математики и теории алгоритмов (теоретический материал даю в максимально простой и понятной форме, без всяческих «наворотов»). Такая база позволяет «сцементировать» знания ученика в данной области, ведь основа программирования — знание математики, а язык программирования — только инструмент. Стараюсь развить у ученика творческие способности: приемы активизации творчества, приемы решения нестандартных задач.
Большое внимание уделяю вопросам качества и скорости создания программы: как не допустить ошибку во время создания программы, где чаще всего могут появиться ошибки, как быстро обнаружить ошибку, как правильно выбрать оптимальный алгоритм, как выбрать эффективную методику создания программы и т.д. Также занимаюсь психологическими проблемами, снижающими эффективность программирования у ученика: невнимательность, психологические зажимы, быстрое забывание уже приобретенных знаний, страх перед экзаменом, психологический настрой на неудачу.
При подготовке к ОГЭ и ЕГЭ основная моя задача — не натаскать ученика на решение задач определенного типа, а дать полноценную теоретическую базу. Такая база делает знания целостными, отчего они хорошо запоминаются. Для ЕГЭ отработано множество стандартных приемов решения задач, что существенно повышает скорость решения, а также снижает вероятность совершения ошибки на экзамене.
С удовольствием берусь помочь в решении нестандартных задач. Имеется небольшой опыт подготовки учеников к олимпиадам по информатике и программированию.
Достаточно свободно читаю английский научно-технический текст.
Инструменты для поиска JIT-компилятора — Cryptoworld
Поскольку JIT-компиляция по сути является формой динамической компиляции, она позволяет использовать такие технологии, как адаптивная оптимизация и динамическая перекомпиляция. Это позволяет JIT-компиляции работать лучше, чем статическая. Интерпретация и JIT-компиляция особенно подходят для динамических языков программирования, в то время как среда выполнения обрабатывает привязку позднего типа и гарантирует безопасность выполнения.
С легкой руки Microsoft .NET стала сегодня одной из самых популярных платформ программирования. Большое количество инструментов, библиотек и документации обеспечивает легкость входа даже для самых начинающих программистов, а наиболее продвинутая кроссплатформенная оптимизация делает его одним из основных стандартов для написания коммерческого программного обеспечения. В результате для этой платформы было создано множество инструментов взлома и обратного проектирования. Среди них dnSpy, ILspy, ILdasm, Dile, SAE и многие другие.
Задача для реверсоров упрощается тем, что по умолчанию скомпилированная программа фактически содержит свой источник: имена символов сохраняются явно, а кроссплатформенный IL-псевдокод легко восстанавливается до исходных синтаксических конструкций C # или VB, из которых он был получен. во время компиляции. Соответственно, взломать такую программу для начинающего хакера — одно удовольствие: достаточно загрузить ее в dnSpy, и вот она, на блюдечке в исходном коде, даже раскрашенная для удобства в приятные цвета. Отлаживайте и редактируйте как хотите, как будто вы сами написали эту программу!
Теория
Конечно, производители программного обеспечения терпеть не могут такое положение вещей, и в следующем раунде противостояния хакеров и протекторов было разработано множество инструментов для предотвращения восстановления исходного кода из сборки IL. Грубо говоря, все эти инструменты используют три основных принципа:
- сокрытие (шифрование, компрессия и так далее) .NET-метаданных и IL-кода с восстановлением только в краткий миг JIT-компиляции;
- обфускация IL-кода, то есть преднамеренное запутывание его логики, борьба с читаемостью текстовых строк и имен символов, чтобы понять логику работы восстановленного IL-кода было сложнее;
- комбинация двух предыдущих категорий.
Сегодняшняя беседа будет о методах первой категории. По сути, самый простой и наиболее требовательный способ защитить программу от ILDasm — это скомпилировать ее с атрибутом SupressIldasmAttribute. Конечно, это защита от честных людей, так как такой набор отлично определяется как .NET-приложение, декомпилированное другими инструментами, и этот атрибут убирается из полутона в CFF Explorer или, при большом умении, в простом HEX-редакторе. Более интересно поместить метаданные в обычное собственное приложение, которое на лету генерирует и запускает сборку .NET.
В данном случае никакие детекторы не распознают в ней .NET, если предварительно не обучены этому трюку, а декомпиляторы и отладчики, которые не сразу увидели метаданные в программе, остановятся при загрузке. Вы можете попробовать исследовать такое приложение с помощью dnSpy, но если его прервать, то вряд ли удастся получить и отследить код дальше, что делает такую отладку бесполезной. Что делать в этом случае?
Простейший способ — использовать утилиту MegaDumper (или даже ее более продвинутую версию ExtremeDumper). Если .NET сформирован и запущен по всем правилам, то он правильно распознается упомянутыми утилитами как .NET-процесс, и при нажатии кнопки дампа .NET он загружается как стандартное .NET-приложение. Правда, далеко не факт, что он будет запущен. Чтобы привести его в метательную форму, вам нужно будет выполнить определенные движения тела в зависимости от продвинутости протектора. Однако метаданные .NET и IL в такой сборке будут доступны для декомпиляции и анализа. Проверить это можно, открыв сборку, например, в CFF Explorer. Однако я специально сделал оговорку «если». Попробуем разобраться, почему это может не сработать.
Я постараюсь в двух словах вкратце напомнить принцип работы .NET-приложения для тех, кто забыл про железо. Хотя сборка состоит из метаданных и кросс-платформенного кода IL, она не интерпретируется при запуске приложения, а скорее компилируется в высокооптимизированный собственный целевой процессор и код целевой операционной системы. Это делается непосредственно при однократной загрузке блока кода, после чего будет выполнен уже скомпилированный нативный код метода. Сам процесс называется JIT-компиляцией. То есть, если вы завершите программу в произвольное время в отладчике, таком как x64dbg, то процесс будет завершен именно тогда, когда выполняется этот временно скомпилированный машинный код.
Конечно, его можно отследить, отладить и отменить, но целесообразность этого вызывает сомнения. Нас интересует другой подход — захват и выгрузка уже восстановленного фрагмента IL перед его компиляцией в JIT. Логика заключается в том, что если мы хотим сделать это вручную, мы должны найти исходную точку входа JIT-компилятора в отладчике. Самый простой способ — найти метод SystemDomain :: Execute в clr.dll (или mscorwks.dll для более старых версий .NET). Обычно для таких вещей рекомендуется использовать WinDbg и его расширение SOS, но в качестве примера я покажу вам, как это сделать в x64dbg.
Поиск JIT-компилятора
Таким образом, после загрузки необходимого приложения в отладчик мы неприятно удивлены, обнаружив, что библиотека clr.dll отсутствует в списке отладочных символов. Это значит, что вам нужно будет скачать его дополнительно, найдя глубоко в недрах подкаталогов системной папки Windows. После нахождения и загрузки clr.dll (по пути будут загружены несколько библиотек) мы снова с раздражением обнаруживаем, что метод SystemDomain :: Execute не находится в правильном списке экспорта. Что ж, к счастью, x64dbg предлагает отличную возможность загрузить символы отладки прямо с сервера Microsoft — для этого вам нужно щелкнуть правой кнопкой мыши на clr.dll и выбрать соответствующий пункт из контекстного меню.
Обождав определенное время, мы увидим, что список в правой части окна отладчика значительно увеличился и в нем уже присутствует необходимый метод SystemDomain :: Execute. Ставим на него точку останова и запускаем программу. На момент остановки этого метода метаданные dotnet обычно уже расшифрованы, разархивированы и могут быть выгружены в файл даже с помощью MegaDumper или Scylla из самого отладчика. Однако и этого может быть недостаточно. Попробуем копнуть немного глубже и перейдем к исходному JIT-компилятору.
Для этого найдем и загрузим вышеописанным способом библиотеку clrjit., а также отладочные символы к ней. Находим в них следующий метод:
private: virtual enum CorJitResult __stdcall CILJit::compileMethod(class ICorJitInfo *,struct CORINFO_METHOD_INFO *,unsigned int,unsigned char * *,unsigned long *)
Это желаемая точка входа для JIT-компилятора, который переводит код IL в машинно-зависимый. К сожалению (или к счастью), этот метод можно переопределить с помощью функции GetJit самого модуля clrjit.dll, которую используют протекторы, внедряя в компилятор свой собственный модуль расшифровки кода IL. К нашему удовольствию, они не могут полностью заменить компилятор на собственный, потому что в этом случае им придется переписывать всю платформу .NET с нуля, с полной поддержкой различных операционных систем и процессоров. То есть в какой-то момент расшифрованный код будет передан найденному нами собственному компилятору. Там мы его примем живым и невредимым. Поставим точку останова на этот метод и запустим программу.
После того как программа остановится, попробуем проанализировать параметры на стеке. Для этого снова вспомним теорию. В терминах языка С описание данного метода выглядит вот так:
CorJitResult (__stdcall * compileMethod) {
struct ICorJitCompiler *pThis, /* IN */
struct ICorJitInfo *comp, /* IN */
struct CORINFO_METHOD_INFO *info, /* IN */
unsigned /* CorJitFlag */ flags, /* IN */
BYTE **nativeEntry, /* OUT */
ULONG *nativeSizeOfCode /* OUT */
Третий сверху стека адрес (аккурат над двойным словом flags, которые обычно равны FFFFFFFF) — указатель на структуру CORINFO_METHOD_INFO. Эта структура содержит данные о блоке IL-кода, которым описывается компилируемый метод. Снова покурив мануалы, находим описание этой структуры:
struct CORINFO_METHOD_INFO {
CORINFO_METHOD_HANDLE ftn;
CORINFO_MODULE_HANDLE scope;
BYTE * ILCode;
unsigned ILCodeSize;
unsigned short maxStack;
unsigned short EHcount;
CorInfoOptions options;
CORINFO_SIG_INFO args;
CORINFO_SIG_INFO locals;
};
Перейдя по ссылке в дампе, мы увидим, что третье двойное слово в начале структуры действительно является указателем на IL-код метода, а четвертое — это размер блока. Конечно, расшифровывать каждый метод в отладчике таким образом своими руками довольно сложно. Однако теперь мы знаем, как это делается, и, если хотите, мы можем отменить всю предыдущую последовательность действий, которую протектор внедрил в нее с помощью блока кода. В конце концов, вы можете вставить свой код между протектором и собственным компилятором и реализовать свой собственный дампер для каждой новой защиты.
Проверка на практике
Попытаемся применить данный метод для случайного приложения. Когда приложение загружается в отладчик или декомпилятор, оно предоставляет почти всем методам пустое тело, состоящее из команды ret или ldnull / ret. То же самое происходит в секции Main, но .cctor относится к вызову внешней DLL, где быстрая проверка показывает упоминание AgileDotNetRT.dll. Действительно, в определении защиты таким образом не может быть никаких сомнений. Начинаем копаться в программе со всеми имеющимися у нас инструментами.
Деобфускаторы не могут справиться с программой на лету, дамп с использованием MegaDumper и ExtreamDumper не добавляет данные, отображаемые в теле метода. ManagedJitter тоже не помогает — словом, все инструменты под рукой оказались бессильны. Забегая вперед, я замечаю, что существует версия дампера специально для Agile: SimpleMSILDecryptorForAgile, которая основана на принципе внедрения собственного кода в clrjit, упомянутом выше, но мы постараемся добраться до нее по-своему.
После тестирования всех методов загружаем нашу программу в x64dbg и, как описано выше, устанавливаем точку останова на CILJit :: compileMethod. Часто точка останова работает нормально, хотя скомпилированный код методов, представленных на входе, ничем не отличается от исходного, который мы видели в декомпиляторе. И вдруг, счастье заканчивается, программа молча завершается. Кажется, что Agile оправдывает свою репутацию, активно борясь с отладчиком.
Можно было бы побороться и с анти-отладчиком, но сейчас наша задача несколько иная, и мы не отвлекаемся на такие мелочи. Временно отключите точку останова и перезапустите приложение — оно запускается нормально. Что ж, анти-отладчику нравятся только активные точки останова внутри clrjit, что не может не радовать. Мы прерываем программу и повторно включаем точку останова в методе compileMethod — к счастью, программа не совершает самоубийства. Значит, проверка идет не постоянно, а в некоторых ключевых точках, это тоже обнадеживает.
Рассмотрим подробнее, на чем именно мы остановились. Да, вызов clrjit :: CompileMethod из той же пользовательской библиотеки DLL. Мы смотрим на стек вызовов, откуда мы пришли. К счастью для нас, только одно вложение выше — это вызов функции защиты, внедренной из clr.dll. Мы нашли вход и выход дешифратора кода IL. Давайте установим на них две точки останова, потому что анти-отладчик борется только с вырезками из исходного clrjit :: CompileMethod, после чего мы перезапускаем программу. Попутно заносим в журнал значения CORINFO_METHOD_INFO * info и BYTE * ILCode при входе и выходе из инъекции.
Так как все точки останова находятся вне clrjit, анти-отладчик нас больше не беспокоит. С момента запуска внедренного компилятора он дважды простаивает — исходный IL-код переносится в исходную компиляцию без изменений. А вот третий уже интересен: указатель на ILCode в информационной структуре заменен новым блоком памяти размером 0x100000, который, в принципе, уже можно выгрузить для исследования. Оставим это за рамками нашей статьи, остановимся лишь на паре моментов.
Сначала проверим, какой метод подменил протектор. На самом деле задача не так проста, как может показаться. Структуры, предоставленные записи CompileMethod, содержат только параметры скомпилированного блока кода, но нет ни указателя на имя метода, ни даже его индекса в таблице методов. Но это нужно будет сделать, если мы хотим написать собственный дампер. Прямой метод — использовать следующий метод интерфейса ICorStaticInfo:
virtual const char* getMethodName(
CORINFO_METHOD_HANDLE ftn, /* IN */
const char **moduleName /* OUT */
) = 0;
Сюда включены параметр comp и дескриптор метода ftn, но это сложно сделать с помощью отладчика, поэтому давайте немного схитрим. Дело в том, что дескриптор ftn (первое двойное слово в структуре CORINFO_METHOD_INFO) при использовании в качестве указателя указывает на одно слово — индекс метода в метаданных .NET модуля EXE. В нашем примере это 0x23 = 35.
Откройте CFF Explorer и найдите метод Main. В оригинале он занимает 1 байт ret, но на выходе он поправился до 0x1A байт . Попутно мы нашли форк в коде, отфильтровывая внешние методы, которые передаются в пути исходному компилятору без изменений, а также сам код преобразования и замены:
730B902E | mov ecx,dword ptr ds:[edx+C]
730B9031 | mov dword ptr ss:[ebp-190],ecx
730B9037 | cmp dword ptr ss:[ebp-19C],0
730B903E | je 730B90BF <-----------------------
730B9040 | mov eax,dword ptr ss:[ebp-18C]
730B9046 | push eax
730B9047 | mov ecx,dword ptr ss:[ebp-48]
730B904A | push ecx
730B904B | lea edx,dword ptr ss:[ebp-3C]
730B904E | push edx
730B904F | mov ecx,dword ptr ss:[ebp-4]
730B9052 | call 730B1361
730B9057 | push 1C
730B9059 | push 0
730B905B | call dword ptr ds:[<&GetProcessHeap>]
730B9061 | push eax
730B9062 | call dword ptr ds:[<&RtlAllocateHeap>]
730B9068 | mov dword ptr ss:[ebp-38],eax
730B906B | mov eax,dword ptr ss:[ebp-3C]
730B906E | push eax
730B906F | mov ecx,dword ptr ss:[ebp-38]
730B9072 | push ecx
730B9073 | call 730B1104
730B9078 | mov eax,dword ptr ss:[ebp+10]
730B907B | mov dword ptr ss:[ebp-1A0],eax
730B9081 | mov eax,dword ptr ss:[ebp+10]
730B9084 | mov ecx,dword ptr ss:[ebp-38]
735D9087 | mov edx,dword ptr ds:[ecx+C]
735D908A | mov dword ptr ds:[eax+8],edx <-- edx-указатель на новый IL-код метода Main
Заключение
Во время выполнения приложения расшифрованные разделы присутствуют в памяти процесса. Программы Dotnet обычно нуждаются в двух секциях для анализа: .text, который содержит метаданные и код IL, и .rsrc с ресурсами. Попробуем найти эти участки в памяти процесса. В качестве маски поиска в разделе .text возьмем, например, имя потока «#Strings», содержащего список строк со служебной информацией: имена классов, методы и атрибуты. Есть много экземпляров этого типа (по количеству загруженных библиотек .NET). Мы фильтруем их по заголовкам метаданных .NET и по Assembly.Name определяем имя модуля. Вы можете использовать строку манифеста для поиска раздела ресурсов, например <assembly xmlns =. Мы определяем членство в разделе, найденном по ProductName.
Таким образом, у нас есть два расшифрованных жизненно важных раздела. Приклеивая к ним PE-заголовок и настраивая в нем допустимые размеры, мы получаем EXE-файл, который, хотя и не запускается, отлично загружается в декомпиляторы и деобфускаторы для дальнейшего анализа кода. Теоретически исполняемый файл можно даже заставить работать, запускать с помощью одного из инструментов, которые легко найти в Интернете.
Click to rate this post!
[Total: 0 Average: 0]Граф потока управления — в теории компиляции
2. Терминология
Приведённые ниже термины часто используются при работе с графами потока управления.
Edge направленное ребро или дуга, соединяющее блоки графа. Entry block, входной блок, стартовый блок блок, с которого начинается любой путь. Exit block, выходной блок блок, которым заканчивается любой путь. Back edge ребро, указывающее на предыдущий блок, то есть блок, который бы был пройден раньше в процессе обхода графа в глубину. Critical edge ребро, исходящее из блока с несколькими исходящими рёбрами и входящее в блок с несколькими входящими рёбрами. Abnormal edge ребро, исходящее из одного блока и не входящее в другой блок из-за невозможности вычисления последнего. Возникает, например, после преобразования конструкции обработки исключений. Такие рёбра мешают оптимизациям. Impossible edge, ложное ребро ребро, добавленное в граф исключительно ради сохранения свойства графа о постдоминировании выходного блока над любым другим блоком. Это ребро не может быть пройдено. Dominator, доминатор, обязательный предшественник Блок M называется доминирующим над блоком N, если любой путь от входного блока к блоку N проходит через блок M. Входной блок доминирует над всеми остальными блоками графа. Postdominator, постдоминатор Блок M называется постдоминирующим над блоком N, если любой путь от N к выходному блоку проходит через блок M. Выходной узел постдоминирует над всеми блоками графа. Immediate dominator, непосредственный доминатор Блок M называется непосредственно доминирующим блок N, если блок M доминирует блок N, и не существует иного промежуточного блока P, который бы доминировался блоком M и доминировал над блоком N. Другими словами, M — последний доминатор в любых путях от входного блока к блоку N. У каждого блока кроме входного есть единственный непосредственный доминатор. Immediate postdominator, непосредственный постдоминатор аналог термина непосредственный доминатор, но для постдоминатора. Dominator tree, дерево доминаторов вспомогательная структура данных типа дерево, содержащая информацию об отношениях доминирования. Ветка от блока M к блоку N создаётся тогда и только тогда, когда блок M является непосредственным доминатором N. Структура данных является деревом, поскольку любой блок имеет уникального непосредственного доминатора. Корнем дерева является входной узел. Для построения используется эффективный алгоритм Lengauer-Tarjan’s. Postdominator tree, дерево постдоминаторов аналог дерева доминаторов, но для постдоминаторов. Корнем дерева является выходной блок. Loop header, заголовок цикла, точка входа цикла блок, соединённый ребрами со всеми блоками тела цикла. Блок доминирует над всеми узлами тела цикла. Loop pre-header, предзаголовок цикла блок, соединённый ребром с блоком loop header ; непосредственный доминатор для точки входа цикла. Пусть блок M — точка входа цикла. Для некоторых фаз оптимизации выгодно, чтобы блок M был разделён на два блока: M pre предзаголовок цикла и M loop заголовок цикла. После разделения блока M его содержимое и обратные рёбра переносятся в блок M loop, а остальные рёбра — в блок M pre ; затем создаётся новое ребро, соединяющее блок M pre с блоком M loop ; таким образом блок M pre становится непосредственным доминатором блока M loop. Блок M pre не будет содержать кода, пока некоторые оптимизации, например, вынос инвариантов англ. англ. loop-invariant code motion, не пополнят его содержимое.Произошла ошибка при настройке пользовательского файла cookie
Этот сайт использует файлы cookie для повышения производительности. Если ваш браузер не принимает файлы cookie, вы не можете просматривать этот сайт.
Настройка вашего браузера для приема файлов cookie
Существует множество причин, по которым cookie не может быть установлен правильно. Ниже приведены наиболее частые причины:
- В вашем браузере отключены файлы cookie. Вам необходимо сбросить настройки своего браузера, чтобы он принимал файлы cookie, или чтобы спросить, хотите ли вы принимать файлы cookie.
- Ваш браузер спрашивает вас, хотите ли вы принимать файлы cookie, и вы отказались. Чтобы принять файлы cookie с этого сайта, используйте кнопку «Назад» и примите файлы cookie.
- Ваш браузер не поддерживает файлы cookie. Если вы подозреваете это, попробуйте другой браузер.
- Дата на вашем компьютере в прошлом. Если часы вашего компьютера показывают дату до 1 января 1970 г., браузер автоматически забудет файл cookie. Чтобы исправить это, установите правильное время и дату на своем компьютере.
- Вы установили приложение, которое отслеживает или блокирует установку файлов cookie. Вы должны отключить приложение при входе в систему или проконсультироваться с системным администратором.
Почему этому сайту требуются файлы cookie?
Этот сайт использует файлы cookie для повышения производительности, запоминая, что вы вошли в систему, когда переходите со страницы на страницу. Чтобы предоставить доступ без файлов cookie потребует, чтобы сайт создавал новый сеанс для каждой посещаемой страницы, что замедляет работу системы до неприемлемого уровня.
Что сохраняется в файле cookie?
Этот сайт не хранит ничего, кроме автоматически сгенерированного идентификатора сеанса в cookie; никакая другая информация не фиксируется.
Как правило, в файле cookie может храниться только информация, которую вы предоставляете, или выбор, который вы делаете при посещении веб-сайта. Например, сайт не может определить ваше имя электронной почты, пока вы не введете его. Разрешение веб-сайту создавать файлы cookie не дает этому или любому другому сайту доступа к остальной части вашего компьютера, и только сайт, который создал файл cookie, может его прочитать.
Введение в дизайн компилятора — GeeksforGeeks
Введение в дизайн компилятора
Компилятор — это программное обеспечение, которое преобразует программу, написанную на языке высокого уровня (исходный язык), в язык низкого уровня (объектный / целевой / машинный язык).
- Кросс-компилятор , который работает на машине «A» и создает код для другой машины «B». Он способен создавать код для платформы, отличной от той, на которой работает компилятор.
- Преобразователь исходного кода в исходный код или транскомпилятор или транспилятор — это компилятор, который переводит исходный код, написанный на одном языке программирования, в исходный код другого языка программирования.
Системы обработки языков (с использованием компилятора) —
Мы знаем, что компьютер — это логическая совокупность программного и аппаратного обеспечения. Аппаратное обеспечение знает язык, который нам трудно понять, следовательно, мы склонны писать программы на языке высокого уровня, который нам гораздо проще понять и поддерживать в мыслях.Теперь эти программы проходят серию преобразований, чтобы их можно было легко использовать на машинах. Вот здесь и пригодятся системы языковых процедур.
- Язык высокого уровня — Если программа содержит директивы #define или #include, такие как #include или #define, она называется HLL. Они ближе к людям, но далеки от машин. Эти (#) теги называются директивами препроцессора. Они указывают препроцессору, что делать.
- Препроцессор — Препроцессор удаляет все директивы #include, включая файлы, называемые включением файлов, и все директивы #define, используя расширение макроса. Он выполняет включение файлов, увеличение, макрообработку и т. Д.
- Язык ассемблера — Ни в двоичной форме, ни в высоком уровне. Это промежуточное состояние, которое представляет собой комбинацию машинных инструкций и некоторых других полезных данных, необходимых для выполнения.
- Ассемблер — Для каждой платформы (Аппаратное обеспечение + ОС) у нас будет ассемблер.Они не универсальны, так как для каждой платформы у нас есть одна. Вывод ассемблера называется объектным файлом. Он переводит язык ассемблера в машинный код.
- Интерпретатор — Интерпретатор преобразует язык высокого уровня в машинный язык низкого уровня, как компилятор. Но они разные по тому, как они читают ввод. Компилятор за один раз считывает входные данные, выполняет обработку и выполняет исходный код, тогда как интерпретатор делает то же самое построчно. Компилятор сканирует всю программу и переводит ее в машинный код, тогда как интерпретатор переводит программу по одному оператору за раз.Интерпретируемые программы обычно медленнее скомпилированных.
- Код перемещаемой машины — Он может быть загружен в любой момент и может быть запущен. Адрес в программе будет таким, что он будет сотрудничать для движения программы.
- Загрузчик / компоновщик — Он преобразует перемещаемый код в абсолютный код и пытается запустить программу, что приводит к запущенной программе или сообщению об ошибке (а иногда может произойти и то, и другое). Компоновщик загружает множество объектных файлов в один файл, чтобы сделать его исполняемым.Затем загрузчик загружает его в память и выполняет.
Этапы компиляции —
Есть два основных этапа компиляции, которые, в свою очередь, состоят из множества частей. Каждый из них использует результаты предыдущего уровня и работают согласованно.
Этап анализа — Промежуточное представление создается из данного исходного кода:
- Лексический анализатор
- Анализатор синтаксиса
- Семантический анализатор
- Генератор промежуточного кода
Лексический анализатор делит программу на « tokens », синтаксический анализатор распознает« предложения »в программе, используя синтаксис языка, а семантический анализатор проверяет статическую семантику каждой конструкции.Генератор промежуточного кода генерирует «абстрактный» код.
Фаза синтеза — Эквивалентная целевая программа создается из промежуточного представления. Он состоит из двух частей:
- Code Optimizer
- Code Generator
Code Optimizer оптимизирует абстрактный код, а конечный генератор кода переводит абстрактный промежуточный код в конкретные машинные инструкции.
GATE CS Corner Questions
Выполнение следующих вопросов поможет вам проверить свои знания.Все вопросы задавались в GATE в предыдущие годы или в пробных тестах GATE. Настоятельно рекомендуется попрактиковаться в них.
- GATE CS 2011, вопрос 1
- GATE CS 2011, вопрос 19
- GATE CS 2009, вопрос 17
- GATE CS 1998, вопрос 27
- GATE CS 2008, вопрос 85
- GATE CS 1997, вопрос 8
- GATE CS 2014 (набор 3), вопрос 65
- GATE CS 2015 (набор 2), вопрос 29
Ссылки —
Введение в компиляцию — viden.io
slideshare
Летняя школа языков программирования в Орегоне
Программа состоит из 80-минутных лекций, представленных международными признанные лидеры в области языков программирования и исследований формального мышления.
Логические отношения — Амаль Ахмед
Основы теории категорий — Стив Awodey
Конспект лекций
Доказательства как процессы — Роберт Констебль
Поляризация и фокусировка — Пьер-Луи Курьен
Основы теории типов — Роберт Харпер
Студенты должны быть знакомы с
Нордстроем, Петерссон и Смит. Программирование в теории типов Мартина-Лёфа .
Кроме того, студенты могут почитать:
Монады и все такое — Джон Хьюз
Проверка компилятора — Ксавье Леруа
Безопасность на основе языка — Эндрю Майерс
Основы теории доказательств — Фрэнк Пфеннинг
Основы программного обеспечения в Coq — Бенджамин Пирс
Chaos Theory — 11 Years Of Chaos (сборник по сбору средств)
Прежде всего, я хотел бы начать с поздравления Куналу Сингхалу , основателю и руководителю семейства Chaos Theory .С самого начала промоушен был образцом левой музыкальной сцены, и это неудивительно, если учесть повсеместность и трудовую этику его динамичного фронтмена; Кунал вездесущ на концертах, в музыкальных магазинах, на музыкальных площадках. Он идет туда, где звучит музыка, и наклеивает на нее наклейку. Этот парень настоящий мудрец, если вы хотите найти новую классную группу или площадку для игры, он уже более десяти лет ищет, впитывая эти знания, как губка.
Сочиняя для Echoes And Dust и будучи заядлым музыкальным ботаником, я не часто могу найти новые крутые группы для прослушивания. Кунал находит лучшие новые звуки со всего мира.Он давал концерты с постоянно развивающейся, но неизменно прекрасной и трудолюбивой командой, и хотя некоторые лица приходили и уходили, я хотел бы особо поблагодарить давнего члена команды, Алана Прайда, еще одного замечательного защитника андеграундной музыки. .
Я думаю, что если бы Куналу было что сказать здесь, это, вероятно, было бы поблагодарить бывших членов команды, таких как: звукорежиссер Питер Юнг, дизайнеры Лу Стеатон-Притчард (Реми Мели) и Дорота Санковска (Сагуи), видеооператоры Крис Пурди (Riff Underground) , Адам Харрис и Алек Мейнард (Magic Theater Films), разносторонний Себ Талл, а также многие другие хорошие яйца и нынешние участники, в том числе: веб-разработчик Тереза Киннертова, писатель и художественный куратор Наталья Джорук, член команды и подкастер Шахин Нанако Комацу и все Оккупанты, Крис Вуд и Мел Аль-Шейх.Не говоря уже о некоторых выдающихся фотографах Chaos Theory за эти годы, включая Саймона Калласа, Луиса Родригеса, Хосе Рамона Камааньо, Райана Уитвелла, Кристофера Маклеода, Анжелику Ле Маршан и Магду Кампань.
Для этого действительно нужна деревня, а объединение сообществ — это то, к чему всегда стремилась теория Хаоса. Привлечение внимания групп, концертных площадок и артистов везде, где это возможно, и частое участие в благотворительных мероприятиях… и я не имею в виду только готовность Кунала выступать в качестве ди-джея практически на любом мероприятии.Промоутеры — неотъемлемая часть музыкальной экосистемы, без промоутеров, у нас не было бы невероятной живой музыки, к которой мы привыкли до жизни в условиях изоляции. Они направляют группы напрямую к соответствующей аудитории и помогают им донести информацию. Не говоря уже о том, что они платят группам, чтобы они могли выжить, работая с площадками, чтобы музыка оставалась прекрасным релизом, который мы знаем и любим.
Что подводит меня к этому релизу, если вы купите этот альбом, вы поможете сохранить Chaos Theory в живых, а также поможете спасти The Black Heart от закрытия (из-за доходов от альбома, идущих на их сбор средств), и вы будет поддерживать андерграундные группы.Каждая группа, которую вы когда-либо любили, дожила до многих лет, имея сначала промоутера, который их поддерживал, и места, где они были организованы, и привлекала к себе всеобщее внимание. Если вы можете дать ответ, сейчас самое время.
Побывал на одном из ежегодных фестивалей празднования дня рождения Chaos Theory (вы можете посмотреть обзор здесь: https://echoesanddust.com/2018/02/long-live-chaos-theory-8-years-of -chaos /) Я могу сказать вам по опыту, что нас лишили одного из величайших ежегодных музыкальных событий года.Я надеюсь, что если вы читаете это, вам это тоже больно, но, по крайней мере, у нас есть следующая лучшая вещь в этом сборнике. Он включает в себя сочетание новых / неизданных треков, а также заметные предложения от широкого спектра отличных групп, которые ранее выступали на концертах этой акции.
Ниже приводится краткое изложение некоторых из моих любимых выборов из сборника, чтобы они имели для меня смысл в то время. A Sweet Niche «La Cuisine (версия для живого биг-бэнда)» моментально покорила меня.При первом прослушивании он напомнил мне постджазовый стиль The Comet is Coming с его мелодичной медной секцией, но по ходу трека он превратился в удивительный гибрид, который я бы назвал ArcTanGent Whiplash . Действительно охуенно крутой трек, обязательно нужно послушать больше этой группы.
Еще один отличный постджазовый трек на сборнике — «Fire From Frozen Cloud» Five The Heirophant . Саксофонист чертовски невероятен, атмосфера и зацепки, которые этот инструмент создает в главной мелодии, не имеют себе равных.Мне нравится сочетание латуни и металлической конструкции внизу. Определенно мое главное открытие этого выпуска, настолько раздражающее, что Кунал предлагал мне их раньше, и я так и не добрался до них. Глупый я. Абсолютно круто. Не могу достаточно разрекламировать это. Я легко могу увидеть, как эти два художника сносят крышу с дома на одном из мероприятий Chaos Theory Jazz Market . Но, говоря о The Jazz Market, я вспоминаю еще одну запоминающуюся коллекцию тематических вечеров из акции: The Facemelter .
Одним из моих любимых фейслифтеров на компиляции был ‘Locking Stumps’ Boss Keloid , кажется, на него повлияли прото-гранжевые группы, такие как Jesus Lizard и The Melvins, но есть намек на классический рок и хэви-метал. / трэш, а также хардкор. Действительно хорошее сочетание. Я действительно думаю, что это могло бы звучать немного менее влажно и немного резче, но это просто потому, что мне нравится музыка, которая кажется, будто кто-то скальпирует меня и заглушает шум в моем мозгу. Тем не менее, чертовски круто, отличный рифф, жесткая игра на ударных и хорошо исполненные вокальные гармонии. Casual Nun , предлагающий мне «A Light Plague (Radio Edit)», — это действительно совершенно другой звук для группы, в основном из-за ясности вокала Василия Шако, который обычно звучит с использованием эффектов. Похоже, если бы Metallica была хороша. Или у меня был отличный певец, а не дерьмовый певец и популярная группа. Это песня из их альбома Resort for Dead Desires , который я рецензировал для Echoes and Dust, но в то время не особо выделял трек.
Еще один палящий трек, который мне действительно понравился, — это «Hy-Brasil» Kylver .Мне нравится ритм, который в нем очень захватывающий, клавиши тоже действительно классные. Трек кажется чем-то средним между ужасом и металлом, и я люблю обе эти вещи. Риффы тоже на высоте, группа определенно заслуживает знамени Facemelter от Chaos Theory. Награда за лучший трек определенно достается могучему Årabrot с его рычащим пост-металлическим отстойным джинглом «The World Must Be Destroyed». Броское и запоминающееся предложение. Хотя это еще не все мрачно и обреченно, «Absurdly Ineffective Barricade» — это забавно названная и безжалостно неистовая запись Yowie в сборник.Мне нравится, насколько насыщен трек, кажется, что все играют столько, сколько могут и так быстро, как могут. В нем есть что-то в духе Oneida, и песня, очевидно, передает более беззаботный подход к тяжелому.
Говоря о сердцах, с этой коллекцией, пожертвованной The Black Heart, я хотел бы поговорить о группе, которую я видел, разрушившей дом в другом большом лондонском клубе The Lexington, и эта группа — Mammoth Weed Wizard Bastard . Я имел честь получать деньги в качестве сотрудника бара за просмотр этого концерта Chaos Theory, и они действительно поразили меня.«Yn Ol I Annwn» — отличный пример их работы. К сожалению, в результате пандемии The Lexington, такие как The Black Heart и The Windmill, полагаются на краудфандинг, чтобы остаться в живых, поэтому, если вы можете позволить себе, пожалуйста, поддержите эти места и сохраните экосистему групп, промоутеров и площадок. Выньте один кусок пазла, и все они рухнут.
Еще несколько групп, которые вызывают у меня ностальгию по выступлениям Chaos Theory в этом выпуске: Flies Are Spies From Hell и The Fierce and The Dead , слушая их треки здесь, словно машина времени в хорошие времена.То же самое и с волшебником дарк-эмбиента Metalogue , который пост-техно рассматривает этот жанр и дает завораживающие результаты. Prisa Mata также выделяется мне как еще одна классическая группа Chaos Theory, и их трек «Crooked Tress» настолько потрясает голову, что я почти чувствую, как длинные вьющиеся волосы Кунала бьются о меня в яме, пока слушаю его.
Наконец, я хотел бы взглянуть на некоторые из странных и замечательных предложений, которые я обнаружил в этом сборнике 11 Years Of Chaos .Будь то индастриал из Riotmiloo ‘Vile Butterfly (Chaos Theory Mix)’ или мрачная синтвейв-атмосфера ‘Blackwood’ Томаса Рэгсдейла , есть канал темной, левосторонней и временами готической музыки. это проходит через историю Chaos Theory, как будто они проползают в ночь после долгой ночи в Электроударках. Есть два трека, которые настолько мрачно готичны, что оба напомнили мне об отчаянном превосходстве Dead Can Dance, и это Black Orchids ‘‘ Lament ‘, который звучит для меня так, как я себе представляю, если бы Dead Can Танцы сделали гибель, и я думаю, это должно означать, что основатель Echoes And Dust Дэн Солтер должен их любить? Определенно один поклонникам дарквейва понравится.
И, во-вторых, Drekka ‘Call To Prayer’, еще одно удивительное открытие для меня в более эмбиентной части компиляции. Зловещий вокал и глубокая постановка создают мощную манящую атмосферу, и я не могу дождаться, чтобы глубже погрузиться в этих ребят. Последний странный и замечательный трек, который я хочу сделать кавер, — это «Cold» Scald , действительно наркотический, бредовый трек. Перкуссия звучит как пожар на сервере, атмосфера отличная, но огонь горит ярче всего. Действительно классное музыкальное произведение.
В целом, неудивительно, что в этом выпуске много действительно отличных песен, и я очень рад найти новые группы, которые стоит попробовать. 11 Years Of Chaos — отличный пример безупречного чутья Chaos Theory на таланты из рога изобилия групп, сольных исполнителей и продюсеров. Пожалуйста, помогите им поддержать себя и The Black Heart, купив этот релиз: без площадок, промоутеров и групп , музыки нет, она настолько проста и симбиотична.
The Fierce & The Dead и другие функции в новом сборнике по сбору средств по теории Хаоса
The Fierce & The Dead, Sumer, Thumpermonkey, Maud The Moth и Kylver — лишь некоторые из представителей группы, представленных на новом сборнике по сбору средств от лондонских промоутеров Chaos Theory.
11 Years Of Chaos , который выходит завтра, включает в себя совершенно новые работы Aphexia, Five The Hierophant, Riotmiloo, Scald и Thomas Ragsdale, неизданную концертную запись The Fierce & The Dead, специальные отредактированные Thumpermonkey и Metalogue и неизданный кавер Мод The Moth.
10% выручки пойдет на кампанию #SaveTheBlackHeart, а остальная часть будет поделена между художниками и Chaos Theory, чтобы инвестировать в другие способы продвижения, несмотря на влияние коронавируса и Brexit.
«В канун Нового года я думал о том, как нам повезло, что мы провели фестиваль 10 Years Of Chaos в The Dome и Boston Music Room, концерт с Insect Ark и Evi Vine в Electrowerkz, концерт с Бриджит Хэндли, Hi — Взаимность и Шама Рахман в The Harrison, а также вечера ди-джеев в The Dev и Signature Brew Taproom — все в 2020 году, пока мир не перестал вращаться », — говорит Кунал Сингал из Chas Theory.
«Благодарность, которую я почувствовал, что нам удалось втиснуть эти впечатления, смешанные с подавляющим отсутствием звуков и лиц на каждом мероприятии, довела меня до слез. Я скучаю по суб-басу из громких звуковых систем на площадках, и я скучаю по сообществу что я считал само собой разумеющимся, я увижу на следующем концерте. Это был финансово и эмоционально неустойчивый год, но, надеюсь, этот сборник напомнит людям об огромном круге музыкантов, которых еще предстоит открыть.
«Группа из нас участвующие в Chaos Theory, собираются использовать деньги, вырученные от этого альбома, для разработки новых способов поддерживать связи между артистами и фанатами со всего мира.Брексит или нет, но мы одно сообщество. Я не могу дождаться, чтобы в будущем разделить со всеми вами одну и ту же парную атмосферу на концерте ».
11 Years Of Chaos доступен на странице группового лагеря Chaos Theory.
Econometrics: Making Theory Count — Back to Basics Compilation Book
Компиляция «Назад к основам» | Финансы и развитие | PDF версия
I. Общая картинаСпрос и предложение: почему рынки тикают
Когда покупатели и продавцы собираются вместе, ключевым результатом является цена
Ирена Асмундсон
Для экономистов рынок определяется тем, как спрос и предложение соединяются, чтобы определить цену.Спрос и предложение, в свою очередь, определяются технологиями и условиями, в которых работают люди. С одной стороны, рынок может быть заполнен большим количеством практически идентичных продавцов и покупателей (например, рынок шариковых ручек). С другой стороны, может быть только один продавец и один покупатель (как в случае, если я хочу обменять свой стол на ваше одеяло).
Идеальная конкуренция
Экономисты сформулировали модели для объяснения различных типов рынков.Самым фундаментальным из них является совершенная конкуренция, при которой существует большое количество идентичных поставщиков и потребителей одного и того же продукта, покупатели и продавцы могут найти друг друга бесплатно, и никакие препятствия не препятствуют выходу на рынок новых поставщиков. В условиях совершенной конкуренции никто не может повлиять на цены. Обе стороны принимают рыночную цену как данность, а рыночная цена — это цена, при которой нет ни избыточного предложения, ни избыточного спроса. Поставщики будут продолжать производство до тех пор, пока они могут продать товар по цене, превышающей их затраты на производство еще одного товара (предельные издержки производства).Покупатели будут продолжать покупать до тех пор, пока удовлетворение, которое они получают от потребления, превышает цену, которую они платят (предельная полезность потребления). Если цены вырастут, на рынок будут привлечены дополнительные поставщики. Предложение будет увеличиваться до тех пор, пока снова не будет достигнута рыночная цена. Если цены упадут, поставщики, которые не в состоянии покрыть свои расходы, выбывают.
Экономисты обычно объединяют количество, которое поставщики готовы производить по каждой цене, в уравнение, называемое кривой предложения.Чем выше цена, тем больше вероятность того, что поставщики произведут продукцию. И наоборот, покупатели склонны покупать больше товара, чем ниже его цена. Уравнение, описывающее количество, которое потребители готовы купить по каждой цене, называется кривой спроса.
Кривые спроса и предложения могут быть нанесены на график с ценами на вертикальной оси и количествами на горизонтальной оси. Обычно считается, что предложение имеет тенденцию к увеличению: по мере роста цен поставщики готовы производить больше. Обычно считается, что спрос имеет тенденцию к снижению: при более высоких ценах потребители покупают меньше.Точка пересечения двух кривых представляет собой рыночную цену, при которой спрос и предложение совпадают (см. Диаграмму).
Цены могут меняться по многим причинам (технологии, предпочтения потребителей, погодные условия). Связь между спросом и предложением на товар (или услугу) и изменением цены называется эластичностью. Неэластичные товары относительно нечувствительны к изменениям цены, тогда как эластичные товары очень чувствительны к цене. Классическим примером неэластичного блага (по крайней мере, в краткосрочной перспективе) является энергия.Потребителям требуется энергия, чтобы добираться до работы и с работы, а также для обогрева своих домов. В краткосрочной перспективе им может быть трудно или невозможно купить более энергоэффективные автомобили или дома. С другой стороны, спрос на многие товары очень чувствителен к цене. Подумайте о стейке. Если цена на стейк вырастет, потребители могут быстро купить более дешевый кусок говядины или переключиться на другое мясо. Стейк — эластичный товар.
Конечно, большинство рынков несовершенно; они не состоят из неограниченного числа покупателей и продавцов практически идентичных товаров, обладающих совершенными знаниями.На другом конце спектра совершенной конкуренции находится монополия. В монополии есть один поставщик товара, которому нет простой замены. Поставщик не принимает рыночную цену как данность. Вместо этого его может установить монополист. (Двойник монополии — монопсония, в которой есть только один покупатель, обычно правительство, хотя может быть много поставщиков.)
Препятствия для конкуренции
В ситуациях монополии обычно существует препятствие — естественное или юридическое — для потенциальных конкурентов.Например, коммунальные предприятия часто являются монополиями. Для двух компаний водоснабжения было бы неэффективно управлять водосборными бассейнами, согласовывать права пользования и прокладывать трубы до домохозяйств. Но у потребителей нет другого выбора, кроме как покупать у монополиста, и доступ может быть недоступен для некоторых. В результате правительства обычно регулируют деятельность таких монополий, чтобы гарантировать, что они не будут злоупотреблять своей рыночной властью, устанавливая слишком высокие цены. В обмен на разрешение компании работать в качестве единственного поставщика могут быть требования по минимальному количеству услуг, которые должны предоставляться каждому, или ограничение по ценам, которые могут взиматься.Эти ограничения обычно позволяют компаниям возмещать фиксированные затраты.
Монополисты не могут не обращать внимания на спрос, который, как и при совершенной конкуренции, варьируется в зависимости от цены. Разница в том, что в условиях совершенной конкуренции производитель удовлетворяет лишь часть общего спроса, в то время как монополист получает выгоду от кривой спроса всего рынка. Таким образом, нерегулируемый монополист может решить производить количество, которое максимизирует его прибыль — почти всегда по более высокой цене и в меньших количествах, чем на совершенно конкурентном рынке.
В условиях совершенной конкуренции фирма с более низкими затратами может снизить свою цену и привлечь достаточно клиентов, чтобы компенсировать потерянный доход от существующих продаж. Предположим, фирма зарабатывает 5 центов за единицу, продав 1000 единиц, или 50 долларов, на общем рынке в 100 000 единиц. Если он снизит цену на 1 цент и получит дополнительные 1000 единиц продаж, его прибыль составит 80 долларов при новом уровне продаж в 2000 единиц.
Только один продавец
Но монополист контролирует все продажи — в данном случае 100 000 единиц по никель за акцию, что дает прибыль в размере 5 000 долларов.Снижение цены может увеличить общий объем продаж, но, вероятно, этого недостаточно, чтобы компенсировать потерю выручки от существующих продаж. Скажем, он снизил цену (и прибыль с продажи) на копейки, что привело к увеличению спроса на 1000 единиц. Это добавило бы 40 долларов к выручке. Но монополист также потеряет пенни прибыли с каждой из 100 000 единиц, которые он продал, или 1 000 долларов.
Ключевым результатом монополии являются цены и прибыль, которые выше, чем при совершенной конкуренции, и предложение, которое часто ниже.Существуют и другие типы рынков, на которых покупатели и продавцы обладают большей рыночной властью, чем при совершенной конкуренции, но меньше, чем при монополии. В этих случаях цены выше, а производство ниже, чем в случаях совершенной конкуренции. Например, если у авиакомпании была информация о том, насколько вы оценили рейс, потому что она знала, что вы собираетесь на свадьбу друга, она бы знала, что может получить более высокую цену.
Спрос и предложение также могут зависеть от самого продукта. В условиях совершенной конкуренции все производители производят, а покупатели ищут один и тот же продукт или близкие аналоги.В условиях монополии покупателям не хватает простых заменителей. Однако разнообразие допускает замену между типами. Например, рынок помидоров включает больше, чем просто подбор покупателей и продавцов идеализированных помидоров. Потребители могут захотеть разные типы, и производители могут ответить. Участники рынка могут конкурировать с существующим производителем, применяя ту же технологию производства, но вместо этого они могут вводить новые сорта (вишня, бифштекс, семейные реликвии), чтобы удовлетворить разные вкусы. В результате производители имеют ограниченную рыночную власть по установлению цен, когда рынки конкурентоспособны, но продукты дифференцированы.Тем не менее, разновидности продуктов могут заменять друг друга, даже если это несовершенно, поэтому цены не могут быть такими высокими, как в монополиях.
Временная монополия
Сложности возникают, когда основные характеристики, отличающие один продукт от другого, дороги в создании, но дешевы для имитации — например, книги, лекарства, компьютерное программное обеспечение. Написание книги может быть трудным, но печать копии имеет низкие маржинальные затраты. Потребители могут покупать много книг, но если одна из них станет популярной, у конкурентов появится стимул подорвать издателя и продать свои собственные экземпляры.Чтобы позволить автору и издателю возместить фиксированные затраты, правительства часто предоставляют автору и издателю временную монополию на эту книгу (так называемое авторское право). Цена превышает предельные издержки производства, но авторское право побуждает авторов продолжать писать, а издателей производить и продавать книги, обеспечивая будущее предложение.
Обсуждаемые здесь рыночные структуры — это несколько способов, по которым спрос и предложение могут различаться в зависимости от контекста. Технологии производства, предпочтения потребителей и трудности с подбором продавцов и покупателей — вот некоторые из факторов, влияющих на рынки, и все они играют роль в определении рыночной цены.
ИРЕНА АСМУНДСОН — главный экономист Департамента финансов Калифорнии и бывший сотрудник МВФ.
Технология Prolog для рассуждений по умолчанию: теория доказательств и методы компиляции
Abstract
Цель этой работы — показать, как технология Prolog может использоваться для эффективной реализации ответов на запросы в логике по умолчанию. Идея состоит в том, чтобы перевести теорию по умолчанию вместе с запросом в программу на Прологе и запрос на Пролог таким образом, чтобы исходный запрос выводился из теории по умолчанию, если и только если запрос Пролога выводится из программы Пролог.Чтобы соответствовать целенаправленному поиску доказательства этого подхода, мы сосредотачиваемся на теориях по умолчанию, поддерживающих локальные процедуры доказательства, на примере так называемых полумонотонных теорий по умолчанию. Хотя это не отражает общих теорий по умолчанию в интерпретации Рейтера, но в альтернативных ».
Для теоретического обоснования мы нашли методы компиляции, основанные на нисходящей процедуре доказательства, основанной на исключении модели. Мы показываем, как понятие доказательства исключения модели может быть уточнено, чтобы захватить доказательства по умолчанию, и как стандартные методы реализации и улучшения средств доказательства теорем исключения модели (регулярность, леммы) могут быть адаптированы и расширены до рассуждений по умолчанию.Этот интегрированный подход позволяет нам перенести концепции, необходимые для обработки значений по умолчанию, из базового исчисления в результирующие методы компиляции.
Этот метод доказательства теорем по умолчанию дополняется модельным подходом к пошаговой проверке согласованности. Мы показываем, что для решающей задачи проверки непротиворечивости может быть полезно сохранение моделей, чтобы ограничить внимание к в конечном итоге необходимым проверкам непротиворечивости. Это поддерживается концепцией лемм по умолчанию, которые позволяют дополнительно избежать избыточности.
Ключевые слова
Рассуждения по умолчанию
Автоматизированные рассуждения
Логика по умолчанию
Устранение модели
PTTP
Проверка согласованности на основе моделей
Рекомендуемые статьи Цитирующие статьи (0)
Просмотреть аннотациюРекомендуемые статьи