НОУ ИНТУИТ | Лекция | Типы данных в языке С++
< Лекция 1 || Лекция 2: 1234 || Лекция 3 >
Аннотация: В лекции рассматриваются понятие типов данных в языках программирования, приводится классификация типов данных в С++, излагаются особенности представления базовых типов и операций над ними, рекомендации и правила выполнения операции преобразования базовых типов в С++.
Ключевые слова: представление, пользовательский тип, переменная, вычисление выражения, тип данных, объект, проверка допустимости, язык программирования, базовый тип, стандарт языка, сложный тип, производный тип, спецификатор, диапазон, short, sign, unsigned, базовый тип данных, integer, описание переменной, время выполнения, определение, асимметрия, целочисленный тип, значение, операции, декремент, инкремент, целый тип, восьмеричная система счисления, точность, бит, экспонента, мантисса, таблица кодировки, таблица символов, ASCII, байт, Unicode, константы, слово, истина, ложь, единица, логический тип, синтаксис, именованная константа, память, параметр функции, нетипизированный указатель, определение функции, операция приведения, ENUM, сообщение об ошибке, операнд, приведение типов, тип переменной, явное преобразование, потеря информации, hour, автоматическое преобразование, знаковый бит, потеря точности, производный тип данных, управляющая последовательность, входные данные, числовой тип, вещественное число, линейная программа, высказывание, mx/s, символьные типы
Основная цель любой программы состоит в обработке каких-либо данных, например, чисел или текстов. Данные могут быть различного вида или типа и, в зависимости от этого, с ними можно выполнять разные действия.
В любом языке программирования каждая константа, переменная, результат вычисления выражения или функции должны иметь определенный тип данных.
Тип данных – это множество допустимых значений, которые может принимать тот или иной объект, а также множество допустимых операций, которые применимы к нему. В современном понимании тип также зависит от внутреннего представления информации.
 Тип данных определяет:
Тип данных определяет:- внутреннее представление данных в памяти компьютера;
- объем памяти, выделяемый под данные;
- множество (диапазон) значений, которые могут принимать величины этого типа;
- операции и функции, которые можно применять к данным этого типа.
Исходя из данных характеристик, необходимо определять тип каждой величины, используемой в программе для представления объектов. Обязательное описание типа позволяет компилятору производить проверку допустимости различных конструкций программы. От выбора типа величины зависит последовательность машинных команд, построенная компилятором.
Классификация типов данных в С++
Современные языки программирования, как правило, могут иметь набор простых типов, являющихся встроенными в данный язык программирования, и средства для создания производных типов.
Объектно-ориентированные языки программирования позволяют определять типы класса.
Реализация простых типов данных заключается в способе представления значений данного типа в компьютере и в наборе операций, поддерживаемых для данного типа.
Тип данных определяет размер памяти, выделяемой под переменную данного типа при ее создании. Язык программирования C++ поддерживает следующие типы данных (рис. 1.1).
- Базовые типы. Базовые типы предопределены стандартом языка, указываются зарезервированными ключевыми словами и характеризуются одним значением. Их не надо определять и их нельзя разложить на более простые составляющие без потери сущности данных. Базовые типы объектов создают основу для построения более сложных типов.
- Производные типы.
 Производные типы задаются пользователем, и переменные этих типов создаются как с использованием базовых типов, так и типов классов.
Производные типы задаются пользователем, и переменные этих типов создаются как с использованием базовых типов, так и типов классов. - Типы класса. Экземпляры этих типов называются объектами.
 Производные типы задаются пользователем, и переменные этих типов создаются как с использованием базовых типов, так и типов классов.
Производные типы задаются пользователем, и переменные этих типов создаются как с использованием базовых типов, так и типов классов.Существует четыре спецификатора типа данных, уточняющих внутреннее представление и диапазон базовых типов:
| short (короткий) | длина |
| long (длинный) | |
| signed (знаковый) | знак (модификатор) |
| unsigned (беззнаковый) |

Целочисленный (целый) тип данных (тип int)
Переменные данного типа применяются для хранения целых чисел (integer). Описание переменной, имеющей тип int, сообщает компилятору, что он должен связать с идентификатором (именем) переменной количество памяти, достаточное для хранения целого числа во время выполнения программы.
Границы диапазона целых чисел, которые можно хранить в переменных типа int, зависят от конкретного компьютера, компилятора и операционной системы (от реализации). Для 16-разрядного процессора под него отводится 2 байта, для 32-разрядного – 4 байта.
Для внутреннего представления знаковых целых чисел характерно определение знака по старшему биту (0 – для положительных, 1 – для отрицательных). Поэтому число 0 во внутреннем представлении относится к положительным значениям. Следовательно, наблюдается асимметрия границ целых промежутков.
Следовательно, наблюдается асимметрия границ целых промежутков.
В целочисленных типах для всех значений определены следующий и предыдущий элементы. Для максимального следующим значением будет являться минимальное в этом же типе, предыдущее для минимального определяется как максимальное значение. То есть целочисленный диапазон условно можно представить сомкнутым в кольцо. Поэтому определены операции декремента для минимального и инкремента для максимального значений в целых типах.
От количества отводимой под объект памяти зависит множество допустимых значений, которые может принимать объект:
- short int – занимает 2 байта, следовательно, имеет диапазон от –32 768 до +32 767;
- int – занимает 4 байта, следовательно, имеет диапазон от –2 147 483 648 до +2 147 483 647;
- long long int – занимает 8 байтов, следовательно, имеет диапазон от –9 223 372 036 854 775 808 до +9 223 372 036 854 775 807.
 intuit.ru/2010/edi»>
long int – занимает 4 байта, следовательно, имеет диапазон от –2 147 483 648 до +2 147 483 647;
intuit.ru/2010/edi»>
long int – занимает 4 байта, следовательно, имеет диапазон от –2 147 483 648 до +2 147 483 647;Модификаторы signed и unsigned также влияют на множество допустимых значений, которые может принимать объект:
- unsigned short int – занимает 2 байта, следовательно, имеет диапазон от 0 до 65 535;
- unsigned int – занимает 4 байта, следовательно, имеет диапазон от 0 до 4 294 967 295;
- unsigned long int – занимает 4 байта, следовательно, имеет диапазон от 0 до 4 294 967 295;
- unsigned long long int – занимает 8 байтов, следовательно, имеет диапазон от 0 до 18 446 744 073 709 551 615.

Например:
unsigned int b; signed int a; int c; unsigned d; signed f;
Приведем несколько правил, касающихся записи целочисленных значений в исходном тексте программ.
- Нельзя пользоваться десятичной точкой. Значения 26 и 26.0 одинаковы, но 26.0 не является значением типа int.
- Нельзя пользоваться запятыми в качестве разделителей тысяч. Например, число 23,897 следует записывать как 23897.
- Целые значения не должны начинаться с незначащего нуля. Он применяется для обозначения восьмеричных или шестнадцатеричных чисел, так что компилятор будет рассматривать значение 011 как число 9 в восьмеричной системе счисления.
На практике рекомендуется использовать основной целый тип, то есть тип int. Данные основного целого типа практически всегда обрабатываются быстрее, чем данные других целых типов. Короткий тип short подойдет для хранения больших массивов чисел с целью экономии памяти при условии, что значения элементов не выходят за предельные границы для этих типов. Длинные типы необходимы в ситуации, когда не достаточно типа int.
Данные основного целого типа практически всегда обрабатываются быстрее, чем данные других целых типов. Короткий тип short подойдет для хранения больших массивов чисел с целью экономии памяти при условии, что значения элементов не выходят за предельные границы для этих типов. Длинные типы необходимы в ситуации, когда не достаточно типа int.
Вещественный (данные с плавающей точкой) тип данных (типы float и double)
Для хранения вещественных чисел применяются типы данных float (с одинарной точностью) и double (с двойной точностью). Смысл знаков «+» и «-» для вещественных типов совпадает с целыми. Последние незначащие нули справа от десятичной точки игнорируются. Поэтому варианты записи +523.5, 523.5 и 523.500 представляют одно и то же значение.
Для представления вещественных чисел используются два формата:
В большинстве случаев используется тип double, он обеспечивает более высокую точность, чем тип float. Максимальную точность и наибольший диапазон чисел достигается с помощью типа long double.
Максимальную точность и наибольший диапазон чисел достигается с помощью типа long double.
Величина с модификатором типа float занимает 4 байта. Из них 1 бит отводится для знака, 8 бит для избыточной экспоненты и 23 бита для мантиссы. Отметим, что старший бит мантиссы всегда равен 1, поэтому он не заполняется, в связи с этим диапазон модулей значений переменной с плавающей точкой приблизительно равен от 3.14E–38 до 3.14E+38.
Величина типа double занимает 8 байтов в памяти. Ее формат аналогичен формату float. Биты памяти распределяются следующим образом: 1 бит для знака, 11 бит для экспоненты и 52 бита для мантиссы. С учетом опущенного старшего бита мантиссы диапазон модулей значений переменной с двойной точностью равен от 1.7E–308 до 1.7E+308.
Величина типа long double аналогична типу double.
Например:
float a, b; double x, y; long double z;
Дальше >>
< Лекция 1 || Лекция 2: 1234 || Лекция 3 >
Что такое типы данных и зачем они нужны?
Предполагается, что Вы всё ещё помните с прошлого шага, что такое переменная. Если не помните, вернитесь и посмотрите. А мы продолжаем.
Если не помните, вернитесь и посмотрите. А мы продолжаем.
Кроме имени и области в памяти, любая переменная имеет такую важную характеристику как тип данных, которые будут храниться в этой переменной. Постараюсь пояснить.
Как уже говорилось ранее, программы работают с различными данными, а не только с числами. И если для человека записи «x=3», «x=3.0» и «x = три» несут одинаковую смысловую нагрузку, то для компьютера это не так очевидно. Мы понимаем, что в каждой из этих записей говорится, что х равен трём. Компьютер же пока не настолько умен, чтобы это осознать. Ему нужно точно знать, с какими данными он будет работать. И дело даже не в том, число это или слово, ему важно даже то, целое это число или вещественное. Поэтому все переменные имеют дополнительную характеристику — тип данных.
Наверное, вам известно, что в памяти компьютера все числа хранятся в виде последовательности 0 и 1. Так вот, для того чтобы записать любое число только ноликами и единичками существуют определённые правила. Эти правила довольно сильно отличаются для целых чисел и для вещественных чисел. В памяти компьютера числа «3» и «3.0» будут записаны совершенно по-разному. Для тех, кто заинтересовался представлением чисел в памяти компьютера, в конце урока я дам ссылки на дополнительные материалы по этой теме.
Эти правила довольно сильно отличаются для целых чисел и для вещественных чисел. В памяти компьютера числа «3» и «3.0» будут записаны совершенно по-разному. Для тех, кто заинтересовался представлением чисел в памяти компьютера, в конце урока я дам ссылки на дополнительные материалы по этой теме.
Кроме того, зачастую компьютеры гораздо быстрее и лучше могут производить различные действия с целыми числами, чем с вещественными. Если вы не забросите этот курс, то на одном из следующих уроков мы в этом убедимся. Раньше, когда компьютеры занимали целую комнату, это была безусловная истина, а теперь этот факт уже нужно проверять.
Подведём итог. Каждая переменная должна иметь конкретный тип данных. И в эту переменную можно сохранить данные только этого типа.
Возвращаясь к аналогии с ящиками, можем думать, что существуют различные ящики. Одни ящики подходят только для целых чисел, другие — только для вещественных чисел, третьи — только для хранения букв. И нельзя в ящик для букв положить вещественное число. Точнее положить можно, но тогда ваша программа работать не будет. Очень важно следить за этим делом и не путать мух с котлетами. Порядок должен быть в этом деле.
И нельзя в ящик для букв положить вещественное число. Точнее положить можно, но тогда ваша программа работать не будет. Очень важно следить за этим делом и не путать мух с котлетами. Порядок должен быть в этом деле.
Ниже выписаны некоторые (не все!) базовые типы данных, которые есть в языке Си, и которые вы будете использовать в ваших программах чаще всего.
- целые числа – тип int,
- вещественные числа – тип double
- и символы – тип char.
Для вещественных чисел есть ещё тип float. Он в некотором смысле хуже типа double. Две основные причины: у типа float меньше диапазон хранимых чисел, меньше точность (примерно 7 знаков после запятой, против 15 у типа double). Про точность у нас ещё будет пример в третьем уроке.
Есть и другие типы данных, но мы пока о них говорить не будем, чтобы не забивать свою память различными нюансами, которые на начальном этапе не так уж важны.
Важно другое. Необходимо понимать, что тип данных для переменной нужно выбирать в зависимости от того, что мы собираемся в этой переменной хранить. Например, если бы мы считали количество посещений какой-то страницы на сайте, то для этого мы использовали переменную типа int, а вот для хранения курса доллара целые числа уже бы не подошли. Думаю, у банка возникли бы серьёзные проблемы после использования такой программы.
Например, если бы мы считали количество посещений какой-то страницы на сайте, то для этого мы использовали переменную типа int, а вот для хранения курса доллара целые числа уже бы не подошли. Думаю, у банка возникли бы серьёзные проблемы после использования такой программы.
типов данных в C | Типы данных C
Обзор
Типы данных в C (или в любом другом языке программирования) очень важно изучить и понять, прежде чем вы начнете писать программу.
Они необходимы для хранения различных типов данных, таких как целые числа, символы, десятичные дроби, строки или даже определяемые пользователем.
Зачем нужны типы данных в C
Мы знаем, что компьютеры хранят все данные в виде двоичных чисел, и каждому из них выделяется память. Теперь предположим, что вы хотите создать программу для хранения вашего имени, возраста и номера телефона. Без упоминания типов данных ваш компьютер не сможет различить ваше имя, возраст и номер телефона и будет относиться к ним одинаково, выделяя одну и ту же память и сохраняя их в одном наборе переменных.
Возраст состоит из 2-3 цифр, а номер телефона состоит как минимум из 10 цифр, но компьютеры будут выделять одну и ту же память для них обоих, что приведет к большому расходу памяти.
Чтобы справиться с такими сценариями, мы назначаем типы данных для каждой переменной, чтобы избежать путаницы или потери памяти.
Что такое типы данных в C
Тип данных — это атрибут данных, который сообщает компилятору C, какой тип данных содержит переменная.
Может быть целым числом, числом с плавающей запятой (десятичное), символьным, логическим (истина/ложь) и т. д.
Формально мы используем типы данных для указания типа данных, которые хранятся в наших переменных.
Обычно в C существует два типа типов данных:
a. Первичные типы данных или основные типы данных б. Вторичные типы данных
A. Первичные типы данных или базовые типы данных
Это самые основные типы данных, и все другие типизированные данные являются производными или создаются только из них. Он содержит целое число, плавающую точку и char.
Он содержит целое число, плавающую точку и char.
Четыре основных типа первичных/базовых типов данных:
- Целое число
- Поплавок
- Символ
- Пустота
Теперь они далее классифицируются как короткие, длинные, двойные, длинные двойные, знаковые и беззнаковые типы данных в C.
Прежде чем обсуждать это, давайте сначала разберемся, что означают короткие, длинные, знаковые и беззнаковые типы данных в C.
SHORT AND LONG
Они используются для определения объема памяти, выделяемого компилятором. В случае короткого целого это обычно 2 байта, а в длинном — 4 байта.
SIGNED AND UNSIGNED
Это также относится только к выделению памяти, но другим способом. В случае со знаком int учитываются как отрицательные, так и положительные числа. Но в unsigned int мы можем представлять только положительные числа. Теперь, поскольку диапазон значений уменьшается без знака, он может представлять более высокие значения в той же перспективе памяти.
Давайте разберемся на примере. Тип данных Integer состоит из 2-байтовой памяти.
1 байт = 8 бит 2 байта = 16 бит 9(16 бит)= 65536
В случае типа данных unsigned int есть только положительные числа, а поскольку ноль также входит в число положительных чисел, поэтому unsigned int может принимать значения от 0 до 65535.
Теперь рассмотрим случай знакового типа данных, он имеет как положительные, так и отрицательные числа. Таким образом, общая длина текущей памяти делится на две равные половины (65536/2= 32768), одна половина для представления положительных чисел (от 0 до 32767), а другая половина для представления отрицательных чисел (от -1 до -32768).
Это применимо ко всем другим типам данных, таким как float char и т. д.
Теперь аналогичным образом вы можете найти диапазон значений всех типов данных, таких как float, char, double и т. д.
Просто возьмите ручку и бумагу и найдите диапазон подписанного символа, беззнакового символа, подписанного поплавка и беззнакового поплавка.
Надеюсь, вам понравилось упражнение!!!
LONG AND LONG DOUBLE
В основном используются с десятичными числами. Используя эти префиксы, мы можем увеличить диапазон значений, представленных в float. Float имеет размер 4 байта, double — 8 байтов, а long double — 10 байтов. 98). Объем памяти зависит от использования префиксов (надеюсь, вы помните это упражнение, которое мы сделали выше).
Вывод
2. ТИП ДАННЫХ INT В C
Он используется для хранения целочисленных значений и требует памяти в соответствии со значением целого числа, которое мы хотим сохранить.
Размер int зависит от компилятора. Например, 32-битные компиляторы имеют int как 4 байта, но 64-битные компиляторы (которые мы используем сейчас) имеют int как 8 байтов.
И поскольку размер варьируется, диапазон значений, которые могут хранить целые числа, также варьируется от компилятора к компилятору. 9(4*8) длина значения, которая составляет 4,29,49,67,296, т. е. числа от 0 до 4,29,49,67,296 могут быть представлены с использованием числа с плавающей запятой.
е. числа от 0 до 4,29,49,67,296 могут быть представлены с использованием числа с плавающей запятой.
Вывод
Размер различных типов данных на моем компьютере (64-разрядный). Используя аналогичную программу, вы можете найти размер в своем собственном компиляторе. (Вы делаете это упражнение, чтобы развеять все свои сомнения относительно размера!!)
Вывод:
4. VOID
Это специальный тип, известный как пустой тип данных, который используется для указания того, что данная переменная не имеет никакого типа. . Это в основном используется при определении функций, в которых мы не хотим возвращать какое-либо значение.
Ниже приведены данные о размере типа данных на основе 32-битного компилятора и 64-битного компилятора.
В основном они бывают двух типов:
- ПОЛЬЗОВАТЕЛЬСКИЕ ТИПЫ ДАННЫХ
- ТИП ПРОИЗВОДНЫХ ДАННЫХ
1. ПОЛЬЗОВАТЕЛЬСКИЕ ТИПЫ ДАННЫХ В C
Эти типы данных определяются пользователем в соответствии с их удобством. Если пользователь чувствует потребность в типе данных, который не предопределен в библиотеке C, он создает свой собственный.
Если пользователь чувствует потребность в типе данных, который не предопределен в библиотеке C, он создает свой собственный.
1. СТРУКТУРА
Структура — это определяемый пользователем тип данных в C, где мы можем хранить значения нескольких типов данных.
Например, если вы хотите хранить информацию о студентах колледжа, где у каждого студента будет имя, номер броска и оценки. Но совместное управление данными одного учащегося (строка, целое число и переменная с плавающей запятой) для учащегося невозможно ни с одним из типов данных, которые мы обсуждали до сих пор. Теперь для этого мы используем другой тип данных, известный как структура.
Допустим, я создаю структуру учеников с такими полями, как имя, номер списка и оценки. Теперь для каждого ученика я могу создать переменную структуры, в которой будут храниться данные этого конкретного ученика. И я могу получить к нему доступ, когда захочу.
2. UNION
Union очень похож на структуру, поскольку он также используется для хранения значений нескольких типов данных.
Единственная разница между структурой и объединением заключается в том, что в объединении выделение пространства равно максимальному объему памяти, требуемому типом данных.
Предположим, у нас есть две переменные, одна типа float (4 байта) и одна типа char (1 байт). Теперь для структуры потребуется 5 байт памяти (4 байта с плавающей запятой в 1 байте char), а для объединения потребуется 4 байта (4 байта с плавающей запятой, что является максимальным среди всех переменных).
3. TYPEDEF
Это ключевое слово в C, которое используется для присвоения нового имени любому типу данных.
Например, иногда утомительно вводить полное имя типа данных, теперь вы можете указать короткое имя, используя typedef, т. е. если вы хотите записать unsigned long int в краткой форме как INT, то вы можете использовать typedef как:
typedef unsigned long int ul; ул i1, i2;
4. ENUM
Enum — это определяемый пользователем тип данных, который используется для того, чтобы сделать программу более читабельной и понятной. Он используется для присвоения текстовых значений целочисленным значениям.
Он используется для присвоения текстовых значений целочисленным значениям.
Он в основном использует метод индексации и присваивает текстовые значения соответствующему значению индекса.
На приведенном ниже рисунке 0 будет присвоено январю, 1 — февралю, 3 — апрелю и так далее.
ВЫВОД:
2. ПРОИЗВОДНЫЕ ТИПЫ ДАННЫХ
Производные типы данных — это типы данных, которые формируются путем объединения одного или нескольких примитивных типов данных или базовых типов данных в C. Например, могут быть некоторые случаи, когда примитивных типов данных нам недостаточно. Например, если мы хотим сохранить номер телефона, мы можем использовать целое число, но что, если мы хотим сохранить номера телефонов всех студентов в колледже. Создание переменных для каждого из них не является оптимальным способом.
Чтобы оптимально справляться с такими ситуациями, в C есть несколько производных типов данных, которые мы можем использовать по своему усмотрению.
- МАССИВ
- СТРОКА
- УКАЗАТЕЛЬ
- ФУНКЦИИ
1. МАССИВ
Массив — производный тип данных, который используется для хранения данных того же типа в смежной области памяти. Мы можем хранить любые типы данных, начиная от int, float, double, char и заканчивая указателем, строкой и структурой. То есть мы можем сделать массив примитивных, пользовательских или производных типов данных.
Массив обеспечивает произвольный доступ, то есть мы можем получить значение любого элемента массива, используя значение его индекса. На изображении, показанном выше, вы можете видеть, как элементы хранятся в массиве (непрерывно) и как выполняется индексация (начинается с 0, а не с 1). То есть 9Доступ к элементу осуществляется с использованием индекса 8.
Например, если вы хотите сохранить все свои оценки. Вы можете использовать целочисленный массив. И затем вы можете получить доступ к своим оценкам, просто используя его индекс. Давайте разберемся с этим через код. (Если внимательно следить за кодом, доступ к элементу с индексом i осуществляется с помощью arr[i])
Давайте разберемся с этим через код. (Если внимательно следить за кодом, доступ к элементу с индексом i осуществляется с помощью arr[i])
Вывод
Мы также можем создать массив структур.
Ввод
Вывод
2. СТРОКА
Строка представляет собой массив символов. Разница между обычным массивом символов и строкой заключается в том, что строка содержит значение «\0» в конце, указывающее, что это конец строки, в то время как в простом массиве символов это не требуется.
‘\0’ — это специальный символ, известный как символ NULL, который используется для обозначения завершения строки.
В C существует множество способов инициализировать строку. На изображении, показанном выше, вы можете видеть, как символы хранятся внутри строки. Да, это соответствует свойству индексирования массива, поэтому строка также известна как массив символов. Обратите внимание на «\0» (NULL) в конце строки.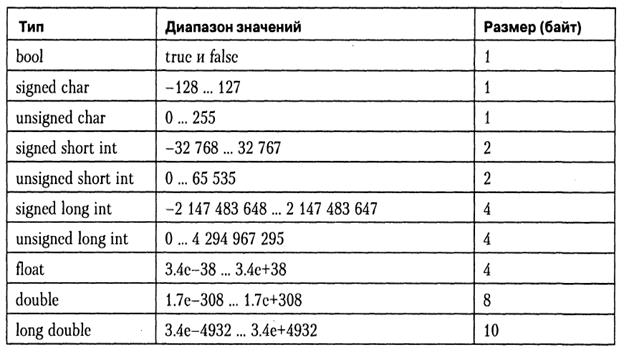 Это означает конец строки.
Это означает конец строки.
Выход
Мы можем просмотреть каждый символ строки, используя его длину или используя ‘\0’. Давайте посмотрим, как:
Вывод
3. УКАЗАТЕЛЬ
Указатель — это особый тип данных. Он уникален тем, что, в отличие от других типов данных, не хранит нормальные значения в переменных. Вместо этого переменная-указатель хранит адрес памяти определенного места в памяти компьютера. Указатели также считаются типом переменных и требуют выделения памяти для хранения своих значений. Размер памяти, выделяемой указателю, определяется архитектурой компьютера и используемой операционной системой. В 32-битной системе размер указателя обычно составляет 4 байта, а в 64-битной системе размер указателя обычно составляет 8 байт. Важно отметить, что тип данных указателя всегда совпадает с типом данных переменной, адрес которой он хранит.
Теперь небольшой вопрос к вам, ребята: почему все указатели имеют одинаковый размер? Ответ скрыт в обсуждении выше.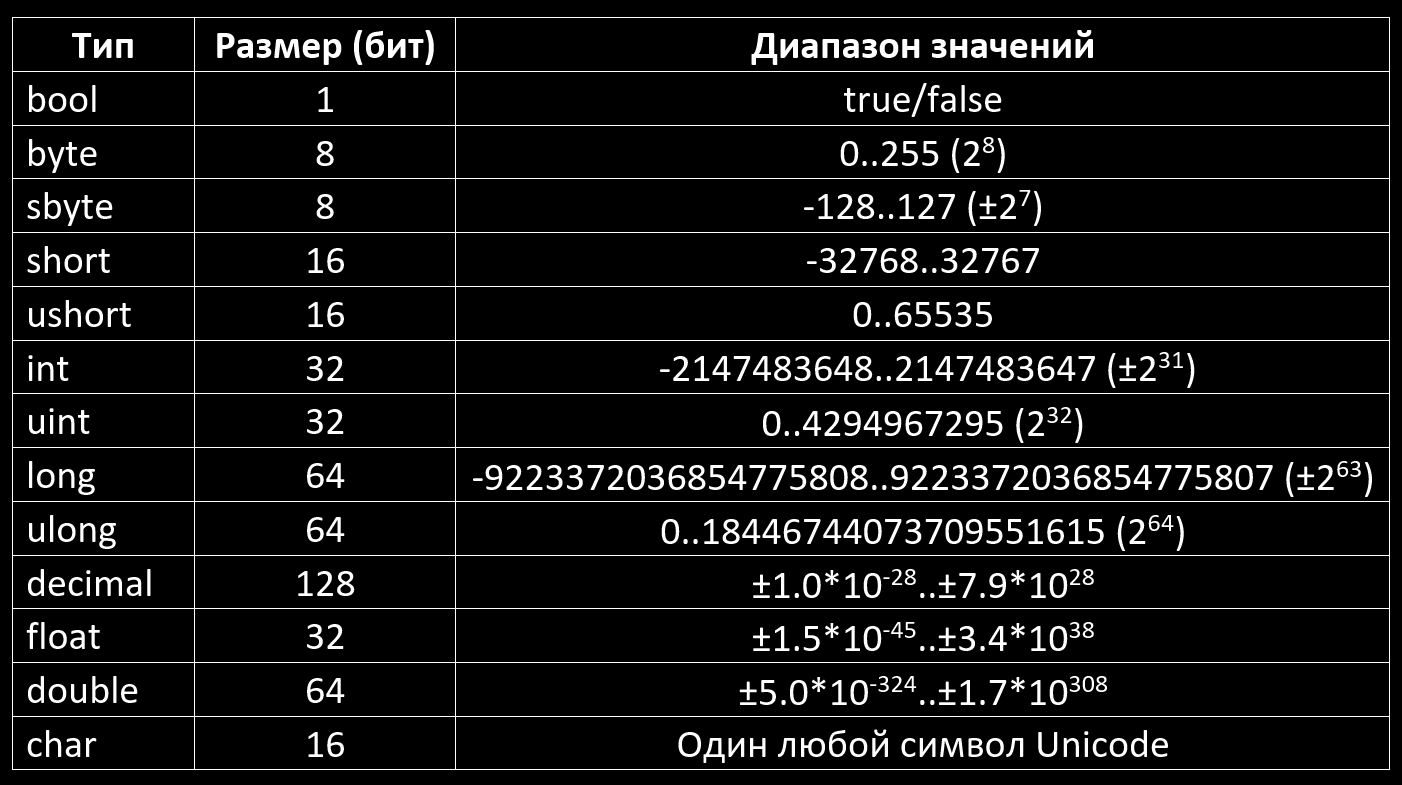 Если вы не поняли, просто перечитайте!!
Если вы не поняли, просто перечитайте!!
Теперь мы можем выполнять две основные операции с помощью указателей. Во-первых, мы можем сохранить адрес переменной, что называется инициализацией, а во-вторых, мы можем получить значение по этому адресу, что называется разыменованием. «&» используется для инициализации, а «*» — для разыменования.
Теперь давайте посмотрим, как это реализовано на самом деле. Ниже приведен простой код для увеличения значения целого числа с помощью переменной-указателя.
Вы также можете понять эту концепцию из графического изображения, приведенного ниже.
4. ФУНКЦИИ
Функции в C или любом другом языке программирования относятся к набору инструкций, которые при выполнении в заданном порядке выполняют определенную задачу. Задание может быть таким, как поиск максимального элемента, сортировка элементов, перестановка элементов и т. д.
Давайте рассмотрим сценарий, в котором вы хотите подсчитать общие оценки всех учащихся. Теперь писать код сложения каждый раз для каждого ученика — не оптимальный путь. Существует ли какой-либо способ, с помощью которого мы просто должны написать код добавления один раз и можем использовать его в любое время, когда захотим?? Ответ ДА!!!
Теперь писать код сложения каждый раз для каждого ученика — не оптимальный путь. Существует ли какой-либо способ, с помощью которого мы просто должны написать код добавления один раз и можем использовать его в любое время, когда захотим?? Ответ ДА!!!
Чтобы справиться с подобными ситуациями, мы используем функцию, которая выполняет желаемую задачу для пользователя (в данном случае функция суммирования).
В каждой программе на C есть функция main, все остальные функции объявлены только там.
Помимо основной функции, пользователь сам решает, сколько функций он хочет добавить.
Объявление функции на C
Ниже приведен код суммы двух чисел, введенных пользователем:
Вывод
В двух словах, тип данных используется для определения типа данных, которые содержит переменная. Это может быть примитивный (простой) тип, такой как целое число, символ, число с плавающей запятой или вторичный (немного сложный), такой как структура, объединение, массив, указатель и т. д.
д.
Мы можем использовать любой предопределенный тип данных, как того требует наша программа, или мы можем просто создайте свой собственный тип данных (массив, структура, объединение), если мы не найдем подходящего предопределенного типа данных.
Теперь мы почти обсудили все типы данных, которые вам потребуются во время вашего путешествия по программированию на языке C. Вам может показаться ошеломляющим узнать о стольких типах данных. Но очень важно знать об этих типах данных.
И когда вы начнете их использовать, вам станет удобнее.
Заключение
В этой статье мы узнали:
- Различные категории, по которым мы можем различать типы данных, то есть первичные и вторичные.
- Мы разобрались с различными первичными типами данных, включая целое число, символ, число с плавающей запятой, пустоту.
- Мы также узнали, как использовать вторичные типы данных, такие как пользовательские типы данных и производные типы данных.

Понимание типов данных и модификаторов в C
Основные понятия C
В этом уроке мы изучим основы типов данных и модификаторов в программировании на C и то, как они используются при объявлении переменных для ограничения типа и длины данных, хранящихся в памяти компьютера.
Что такое тип данных
В программировании на C тип данных используется для указания типа данных, которые могут храниться в переменной во время или после ее объявления. Всякий раз, когда переменная определяется в C, компилятор выделяет часть памяти для этой переменной в зависимости от типа данных, с которым она объявлена. C поддерживает следующие типы данных, указанные ниже.
- Краткое имя Целое число тип данных int .
- Краткое наименование Плавающая тип данных с плавающей запятой .
- Краткое имя Двойной тип данных двойной .
- Краткое имя Символ тип данных char .

Что такое модификаторы типа данных
Модификаторы типа данных в программе C используются с целым, двойным и Символьные типы данных для изменения длины данных типа Integer, Double или Character. может держать. Модификаторы типа данных, доступные в C:
- подписано — Это модификатор по умолчанию для типа данных int и char , если модификатор не указан. указано. В нем говорится, что пользователь может хранить отрицательные или положительные значения.
- без знака — Он используется для типов данных int и char . Он говорит, что пользователь может хранить только положительные значения.
- короткий — Это ограничивает пользователя для хранения небольших значений int и занимает 2 байта памяти. в каждой операционной системе. Его можно использовать только для целочисленного типа данных.
- длинный — Это можно использовать для увеличения размера типов данных int или double для
еще 2 байта.

В таблице ниже приведены измененные размеры и диапазон встроенных типов данных в C
| Тип данных | Размер для хранения | Диапазон | Спецификатор формата |
| короткое целое | 2 байта | от -32 768 до 32 767 | %HD |
| короткое целое без знака | 2 байта | от 0 до 65 535 | %ху |
| целое число без знака | 4 байта | от 0 до 4 294 967 295 | % |
| Целое число | 4 байта | -2 147 483 648 до 2 147 483 647 | %д |
| длинное целое | 4 байта | -2 147 483 648 до 2 147 483 647 | 963)-1%lld |
| без знака длинное длинное целое | 8 байт | от 0 до 18 446 744 073 709 551 615 | %llu |
| символ | 1 байт | от -128 до 127 | %с |
| беззнаковый символ | 1 байт | от 0 до 255 | %с |
| поплавок | 4 байта | от 1. |