Встроенные типы (C++) | Microsoft Learn
- Статья
- Чтение занимает 5 мин
Встроенные типы (также называемые фундаментальными типами) задаются стандартом языка C++ и встроены в компилятор. Встроенные типы не определены в файле заголовка. Встроенные типы делятся на три основные категории: целочисленные, с плавающей запятой и void. Целочисленные типы представляют целые числа. Типы с плавающей запятой могут указывать значения, которые могут иметь дробные части. Большинство встроенных типов рассматриваются как отдельные типы компилятором. Однако некоторые типы являются синонимами или рассматриваются как эквивалентные типы компилятором.
Тип void
Тип void описывает пустой набор значений. Переменная типа void не может быть указана. Этот void тип используется в основном для объявления функций, которые не возвращают значения или объявляют универсальные указатели на нетипизированные или произвольные типизированные данные. Любое выражение можно явно преобразовать или привести к типу void. Однако такие выражения можно использовать только в следующих операторах и операндах:
в операторе выражения (Дополнительные сведения см. в разделе «Выражения».)
в левом операнде оператора запятой (Дополнительные сведения см. в разделе «Оператор запятой».)
во втором и третьем операндах условного оператора (
? :). (Дополнительные сведения см. в разделе «Выражения» с условным оператором.)
std::nullptr_t
Ключевое слово nullptr является константой std::nullptr_tтипа NULL-указателя, которая может быть преобразована в любой необработанный тип указателя. Для получения дополнительной информации см.
Для получения дополнительной информации см. nullptr.
Тип Boolean
Тип bool может иметь значения true и false. Размер bool типа зависит от реализации. Дополнительные сведения о реализации для конкретной корпорации Майкрософт см. в разделе «Размеры встроенных типов «.
Символьные типы
Тип char — это тип представления символов, который эффективно кодирует члены базового набора символов выполнения. Компилятор C++ обрабатывает переменные типа char, signed charи unsigned char как переменные разных типов.
Для конкретной корпорации Майкрософт: переменные типа char действуют так int , как будто по умолчанию из типа signed char , если /J только не используется параметр компиляции.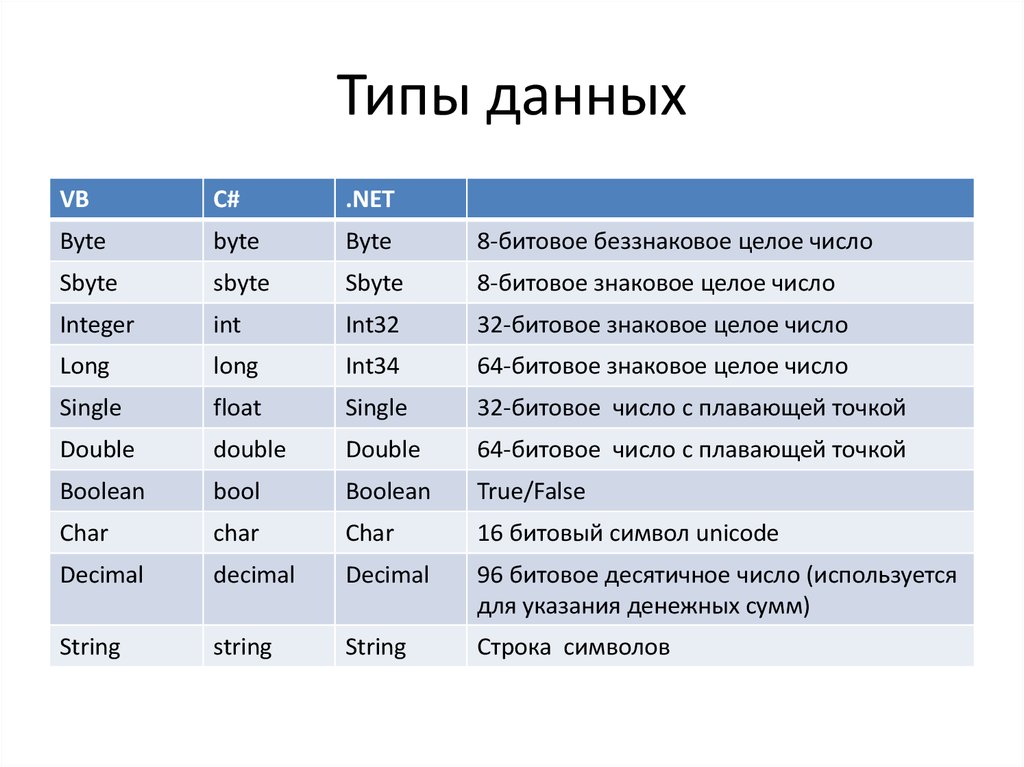 В этом случае они рассматриваются как тип
В этом случае они рассматриваются как тип unsigned char и действуют без int расширения знака.
Переменная типа wchar_t — это расширенный или многобайтовый тип символов. L Используйте префикс перед символом или строковым литералом для указания типа расширенных символов.
Корпорация Майкрософт: по умолчанию wchar_t это собственный тип, но можно использовать /Zc:wchar_t- для определения wchar_t типаunsigned short. __wchar_t — синоним для машинного типа wchar_t для систем Майкрософт.
Тип char8_t используется для представления символов UTF-8. Он имеет то же представление, что unsigned charи компилятор, но рассматривается как отдельный тип компилятора. Новый
Новый char8_t тип в C++20. Для конкретнойchar8_t корпорации Майкрософт: для использования требуется /std:c++20 параметр компилятора или более поздней версии (например/std:c++latest).
Тип char16_t используется для представления символов UTF-16. Он должен быть достаточно большим, чтобы представить любую единицу кода UTF-16. Он обрабатывается компилятором как отдельный тип.
Тип char32_t используется для представления символов UTF-32. Он должен быть достаточно большим, чтобы представлять любую единицу кода UTF-32. Он обрабатывается компилятором как отдельный тип.
Типы с плавающей запятой
Типы с плавающей запятой используют представление IEEE-754 для обеспечения приближения дробных значений по широкому диапазону величин. В следующей таблице перечислены типы с плавающей запятой в C++ и относительные ограничения на размеры типов с плавающей запятой. Эти ограничения налагаются стандартом C++ и не зависят от реализации Майкрософт. Абсолютный размер встроенных типов с плавающей запятой не указан в стандарте.
Эти ограничения налагаются стандартом C++ и не зависят от реализации Майкрософт. Абсолютный размер встроенных типов с плавающей запятой не указан в стандарте.
| Тип | Содержимое |
|---|---|
float | Тип float является наименьшим типом с плавающей запятой в C++. |
double | double — это тип с плавающей запятой, размер которого больше или равен размеру типа float, но меньше или равен размеру типа long double. |
long double | long doubledouble. |
Для конкретнойlong double корпорации Майкрософт: представление и double идентично.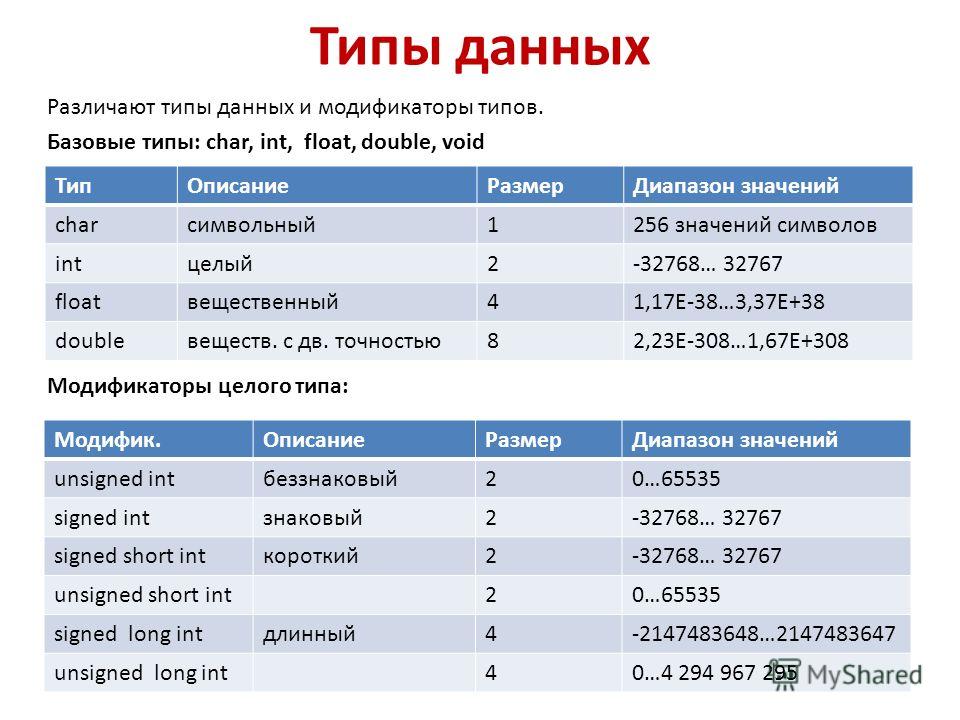
long double Однако и double рассматриваются как отдельные типы компилятором. Компилятор Microsoft C++ использует 4-байтовые представления IEEE-754 с плавающей запятой. Дополнительные сведения см. в описании представления с плавающей запятой IEEE.
Целочисленные типы
Тип int — это базовый целочисленный тип по умолчанию. Он может представлять все целые числа по диапазону реализации.
Целочисленное представление со знаком — это представление, которое может содержать как положительные, так и отрицательные значения. Он используется по умолчанию или при наличии ключевого signed слова-модификатора. Ключевое unsigned слово модификатора указывает неподписаемое представление, которое может содержать только неотрицательных значений.
Модификатор размера задает ширину в битах используемого целочисленного представления. Язык поддерживает
Язык поддерживает shortи longlong long модификаторы. Тип short должен быть не менее 16 бит в ширину. Тип long должен иметь ширину не менее 32 бит. Тип long long должен быть не менее 64 бит. Стандарт задает связь размера между целочисленными типами:
1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)
Реализация должна поддерживать как минимальные требования к размеру, так и отношение размера для каждого типа. Однако фактические размеры могут различаться между реализациями. Дополнительные сведения о реализации для конкретной корпорации Майкрософт см. в разделе «Размеры встроенных типов «.
Ключевое int слово может быть пропущено при signedunsignedуказании модификаторов размера или размера. Модификаторы и
Модификаторы и int тип, если они присутствуют, могут отображаться в любом порядке. Например, short unsigned и unsigned int short ссылаться на тот же тип.
Синонимы целочисленного типа
Следующие группы типов считаются синонимами компилятора:
short,short int,signed short,signed short intunsigned short,unsigned short intint,signed,signed intunsigned,unsigned intlong,long int,signed longsigned long intunsigned long,unsigned long intlong long,long long int,signed long long,signed long long intunsigned long long,unsigned long long int
Типы целых чисел, зависящие от Майкрософт, включают определенные ширины__int8, __int16__int32и __int64
 Эти типы могут использовать модификаторы
Эти типы могут использовать модификаторы signed и unsigned модификаторы. Тип данных __int8 аналогичен типу char, __int16 — типу short, __int32 — типу int, а __int64 — типу long long.Размеры встроенных типов
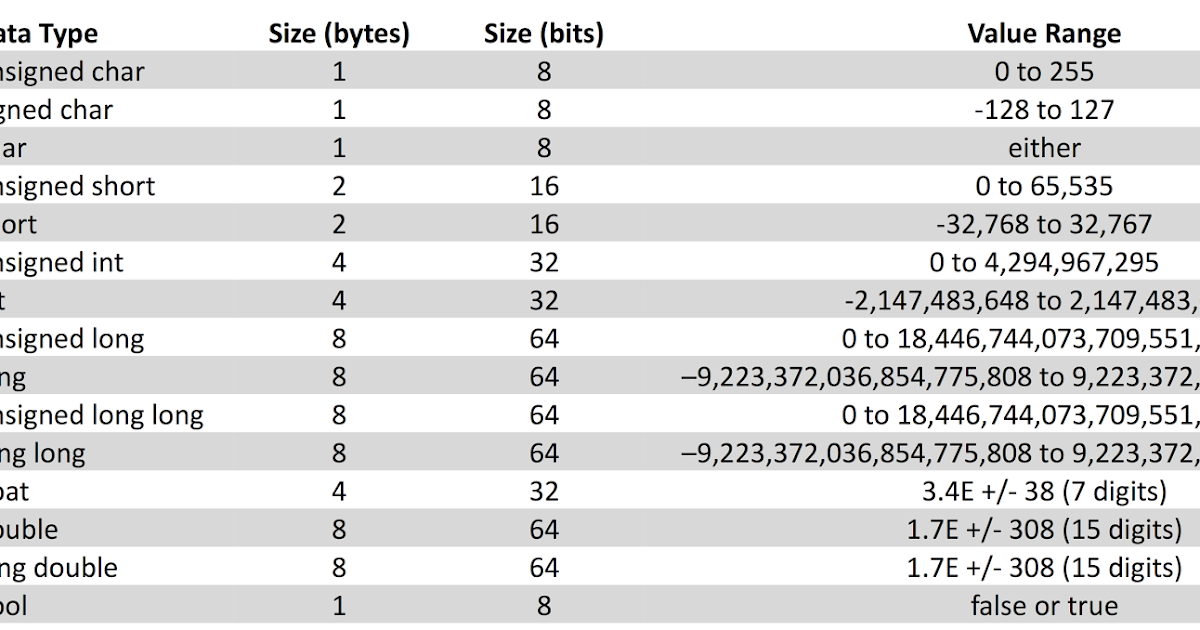
Большинство встроенных типов имеют определенные реализацией размеры. В следующей таблице перечислены объем хранилища, необходимый для встроенных типов в Microsoft C++. В частности, long 4 байта даже в 64-разрядных операционных системах.
| Тип | Размер |
|---|---|
bool, char, char8_t, unsigned char, signed char, __int8 | 1 байт |
char16_t, __int16, short, unsigned short, wchar_t, __wchar_t | 2 байта |
char32_t, float, __int32, int, unsigned int, long, unsigned long | 4 байта |
double, __int64, long double, long long, unsigned long long | 8 байт |
Сведения о диапазоне типов данных см.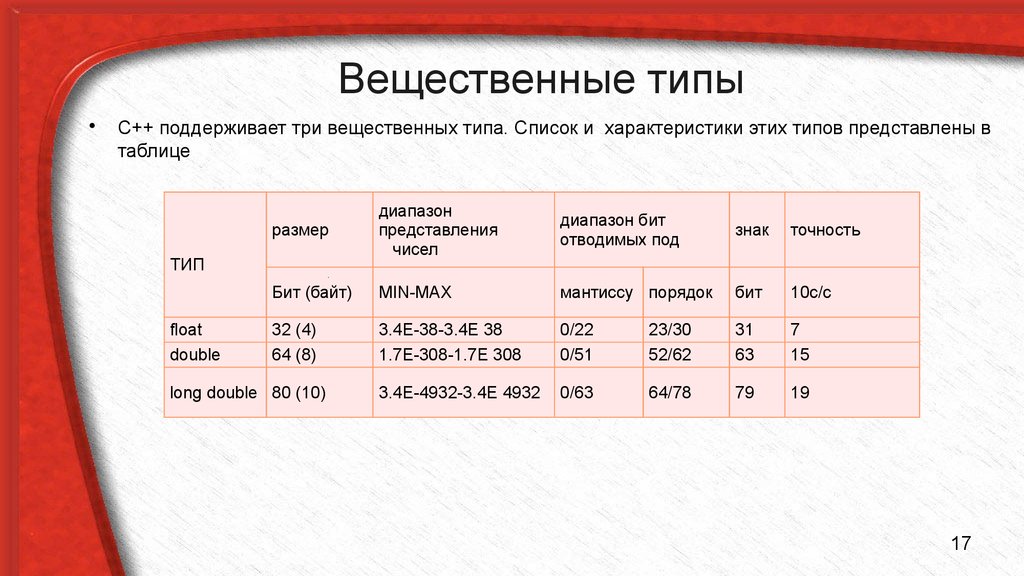 в сводке по диапазону значений каждого типа.
в сводке по диапазону значений каждого типа.
Дополнительные сведения о преобразовании типов см. в разделе «Стандартные преобразования».
См. также раздел
Диапазоны типов данных
Глава 1 Типы данных | Визуализация и анализ географических данных на языке R
Программный код главы
1.1 Типы данных
Тип данных — это класс данных, характеризуемый членами класса и операциями, которые могут быть к ним применены1. С помощью типов данных мы можем представлять привычные нам сущности, такие как числа, строки и т.д. В языке R существует 5 базовых типов данных:
complex | комплексные числа |
character | символьный (строки) |
integer | целые числа |
logical | логические (булевы) |
numeric | числа с плавающей точкой |
Помимо этого есть тип Date, который позволяет работать с датами.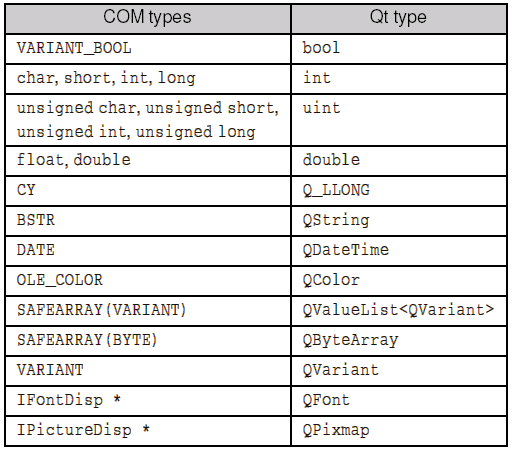 3
## [1] 8
2 ** 3
## [1] 8
3
## [1] 8
2 ** 3
## [1] 8
Результат деления по умолчанию имеет тип с плавающей точкой:
5 / 3 ## [1] 1.666667 5 / 2.5 ## [1] 2
Если вы хотите чтобы деление производилось целочисленным образом (без дробной части) необходимо использовать оператор
5 %/% 3 ## [1] 1
Остаток от деления можно получить с помощью оператора %%:
5 %% 3 ## [1] 2
Вышеприведенные арифметические операции являются бинарными, то есть требуют наличия двух чисел. Числа называются “операндами”. Отделять операнды от оператора пробелом или нет — дело вкуса. Однако рекомендуется все же отделять, так как это повышает читаемость кода. Следующие два выражения эквивалентны. Однако сравните простоту их восприятия:
5%/%3 ## [1] 1
5 %/% 3 ## [1] 1
Как правило, в настоящих программах числа в явном виде встречаются лишь иногда. Вместо этого для их обозначения используют переменные. В вышеприведенных выражениях мы неоднократно использовали число 3.
=a = 5 b = 3
Чтобы вывести значение переменной на экран, достаточно просто ввести его:
a ## [1] 5 b ## [1] 3
Мы можем выполнить над переменными все те же операции что и над константами:
a + b ## [1] 8 a - b ## [1] 2 a / b ## [1] 1.666667 a %/% b ## [1] 1 a %% b ## [1] 2
Легко меняем значение второй переменной с 3 на 4 и выполняем код заново.
b = 4 a + b ## [1] 9 a - b ## [1] 1 a / b ## [1] 1.25 a %/% b ## [1] 1 a %% b ## [1] 1
Нам пришлось изменить значение переменной только один раз в момент ее создания, все последующие операции остались неизменны, но их результаты обновились!
Новую переменную можно создать на основе значений существующих переменных:
c = b d = a+c
Посмотрим, что получилось:
c ## [1] 4 d ## [1] 9
Вы можете комбинировать переменные и заданные явным образом константы:
e = d + 2.5 e ## [1] 11.5
 5
e
## [1] 11.5
5
e
## [1] 11.5Противоположное по знаку число получается добавлением унарного оператора - перед константой или переменной:
f = -2 f ## [1] -2 f = -e f ## [1] -11.5
Операция взятия остатка от деления бывает полезной, например, когда мы хотим выяснить, является число четным или нет. Для этого достаточно взять остаток от деления на 2. Если число является четным, остаток будет равен нулю. В данном случае c равно 4, d равно 9:
c %% 2 ## [1] 0 d %% 2 ## [1] 1
1.1.1.1 Числовые функции
Прежде чем мы перейдем к рассмотрению прочих типов данных и структур данных нам необходимо познакомиться с функциями, поскольку они встречаются буквально на каждом шагу. Понятие функции идентично тому, к чему мы привыкли в математике. Например, функция может называться Z, и принимать 2 аргумента: x и y. В этом случае она записывается как Z(x,y). Чтобы получить значение функции, необходимо подставить некоторые значения вместо x и y в скобках.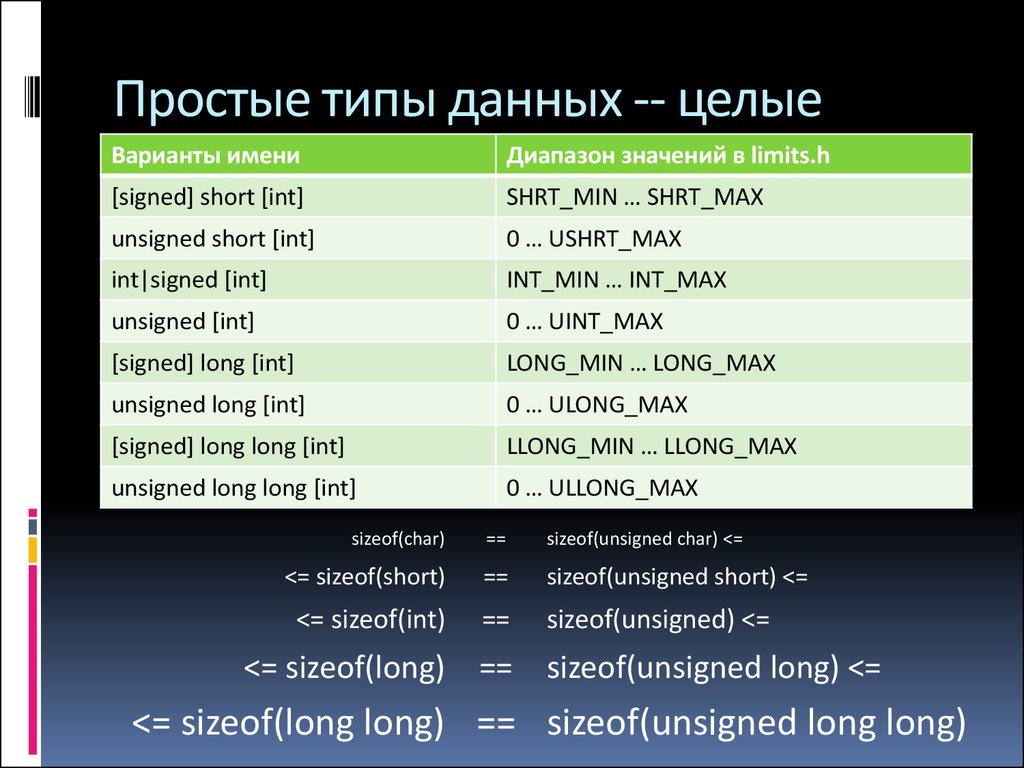 Нас даже может не интересовать, как фактически устроена функция внутри, но важно понимать, что именно она должна вычислять. С созданием функций мы познакомимся позднее.
Нас даже может не интересовать, как фактически устроена функция внутри, но важно понимать, что именно она должна вычислять. С созданием функций мы познакомимся позднее.
Важнейшие примеры функций — математические. Это функции взятия корня sqrt(x), модуля abs(x), округления round(x, digits), натурального логарифма abs(x), тригонометрические функции sin(x), cos(x), tan(x), обратные к ним asin(y), acos(y), atan(y) и многие другие. Основные математические функции содержатся в пакете base, который по умолчанию доступен в среде R и не требует подключения.
В качестве аргумента функции можно использовать переменную, константу, а также выражения:
sqrt(a) ## [1] 2.236068 sin(a) ## [1] -0.9589243 tan(1.5) ## [1] 14.10142 abs(a + b - 2.5) ## [1] 6.5
Вы также можете легко вкладывать функции одна в одну, если результат вычисления одной функции нужно подставить в другую:
sin(sqrt(a)) ## [1] 0.
 7867491
sqrt(sin(a) + 2)
## [1] 1.020331
7867491
sqrt(sin(a) + 2)
## [1] 1.020331Также как и с арифметическими выражениями, результат вычисления функции можно записать в переменную:
b = sin(sqrt(a)) b ## [1] 0.7867491
Если переменной b ранее было присвоено другое значение, оно перезапишется. Вы также можете записать в переменную результат операции, выполненной над ней же. Например, если вы не уверены, что a — неотрицательное число, а вам это необходимо в дальнейших расчетах, вы можете применить к нему операцию взятия модуля:
b = sin(a) b ## [1] -0.9589243 b = abs(b) b ## [1] 0.9589243
1.1.2 Строки
Строки — также еще один важнейший тип данных. Чтобы создать строковую переменную, необходимо заключить текст строки в кавычки:
s = "В историю трудно войти, но легко вляпаться (М.Жванецкий)" s ## [1] "В историю трудно войти, но легко вляпаться (М.Жванецкий)"
Строки состоят из символов, и, в отличие от некоторых других языков, в R нет отдельного типа данных для объекта, которых хранит один символ (в C++ для этого используется тип char). Поэтому при создании строк вы можете пользоваться как одинарными, так и двойными кавычками:
Поэтому при создании строк вы можете пользоваться как одинарными, так и двойными кавычками:
s1 = "Это строка" s1 ## [1] "Это строка" s2 = 'Это также строка' s2 ## [1] "Это также строка"
Иногда бывает необходимо создать пустую строку (например, чтобы в нее далее что-то добавлять). В этом случае просто напишите два знака кавычек, идущих подряд без пробела между ними:
s1 = "" # это пустая строка s1 ## [1] "" s2 = '' # это также пустая строка s2 ## [1] "" s3 = ' ' # а это не пустая, тут есть пробел s3 ## [1] " "
Длину строки в символах можно узнать с помощью функции nchar()
nchar(s) ## [1] 56 nchar(s1) ## [1] 0 nchar(s3) ## [1] 1
Чтобы извлечь из строки подстроку (часть строки), можно использовать функцию substr(), указав ей номер первого и последнего символа:
substr(s, 3, 9) # извлекаем все символы с 3-го по 9-й ## [1] "историю"
В частности, зная длину строки, можно легко извлечь последние \(k\) символов:
n = nchar(s) k = 7 substr(s, n - k, n) ## [1] "анецкий)"
Строки можно складывать так же как и числа. Эта операция называется конкатенацией. В результате конкатенации строки состыковываются друг с другом и получается одна строка. В отличие от чисел, конкатенация производится не оператором
Эта операция называется конкатенацией. В результате конкатенации строки состыковываются друг с другом и получается одна строка. В отличие от чисел, конкатенация производится не оператором +, а специальной функцией paste(). Состыковываемые строки нужно перечислить через запятую, их число может быть произвольно
s1 = "В историю трудно войти," s2 = "но легко вляпаться" s3 = "(М.Жванецкий)"
Посмотрим содержимое подстрок:
s1 ## [1] "В историю трудно войти," s2 ## [1] "но легко вляпаться" s3 ## [1] "(М.Жванецкий)"
А теперь объединим их в одну:
s = paste(s1, s2) s ## [1] "В историю трудно войти, но легко вляпаться" s = paste(s1, s2, s3) s ## [1] "В историю трудно войти, но легко вляпаться (М.Жванецкий)"
Настоящая сила конкатенации проявляется когда вам необходимо объединить в одной строке некоторое текстовое описание (заранее известное) и значения переменных, которые у вас вычисляются в программе (заранее неизвестные). Предположим, вы нашли в программе что максимальная численность населения в Детройте пришлась на 1950 год и составила 1850 тыс. человек. Найденный год записан у вас в переменную
Предположим, вы нашли в программе что максимальная численность населения в Детройте пришлась на 1950 год и составила 1850 тыс. человек. Найденный год записан у вас в переменную year, а население в переменную pop. Вы их значения пока что не знаете, они вычислены по табличным данным в программе. Как вывести эту информацию на экран “человеческим” образом? Для этого нужно использовать конкатенацию строк.
Условно запишем значения переменных, как будто мы их знаем
year = 1950 pop = 1850
s1 = "Максимальная численность населения в Детройте пришлась на" s2 = "год и составила" s3 = "тыс. чел" s = paste(s1, year, s2, pop, s3) s ## [1] "Максимальная численность населения в Детройте пришлась на 1950 год и составила 1850 тыс. чел"
Обратите внимание на то что мы конкатенировали строки с числами. Конвертация типов осуществилась автоматически. Помимо этого, функция сама вставила пробелы между строками.
Функция
paste()содержит параметрsep, отвечающий за символ, который будет вставляться между конкатенируемыми строками.sep = " ", то есть, между строками будет вставляться пробел. Подобное поведение желательно не всегда. Например, если после переменной у вас идет запятая, то между ними будет вставлен пробел. В таком случае при вызовеpaste()необходимо указатьsep = "", то есть пустую строку:paste(... sep = ""). Вы также можете воспользоваться функциейpaste0(), которая делает [почти] то же самое, что иpaste(..., sep = ""), но избавляет вас от задания параметраsep.
 По умолчанию
По умолчанию 1.1.3 Даты и длительности
Для работы с временными данными в R существуют специальные типы. Чаще всего используются даты, указанные с точностью до дня. Такие данные имеют тип Date, а для их создания используется функция as.Date(). В данном случае точка — это лишь часть названия функции, а не какой-то особый оператор. В качестве аргумента функции необходимо задать дату, записанную в виде строки. Запишем дату рождения автора (можете заменить ее на свою):
Запишем дату рождения автора (можете заменить ее на свою):
birth = as.Date('1986/02/18')
birth
## [1] "1986-02-18"Сегодняшнюю дату вы можете узнать с помощью специальной функции Sys.Date():
current = Sys.Date() current ## [1] "2022-08-23"
Даты можно вычитать. Результатом выполнения. Например, узнать продолжительность жизни в днях можно так:
livedays = current - birth livedays ## Time difference of 13335 days
Вы также можете прибавить к текущей дате некоторое значение. Например, необходимо узнать, какая дата будет через 40 дней:
current + 40 ## [1] "2022-10-02"
Имея дату, вы можете легко извлечь из нее день, месяц и год. Существуют специальные функции для этих целей (описанные в главе 8), но прямо сейчас вы можете сделать это сначала преобразовав дату в строку, а затем выбрав из нее подстроку, соответствующую требуемой компоненте даты:
cdate = as.character(current) substr(cdate, 1, 4) # Год ## [1] "2022" substr(cdate, 6, 7) # Месяц ## [1] "08" substr(cdate, 9, 10) # День ## [1] "23"
Более подробно о преобразованиях типов, аналогичных функции as., используемой в данном примере, рассказано далее в настоящей главе.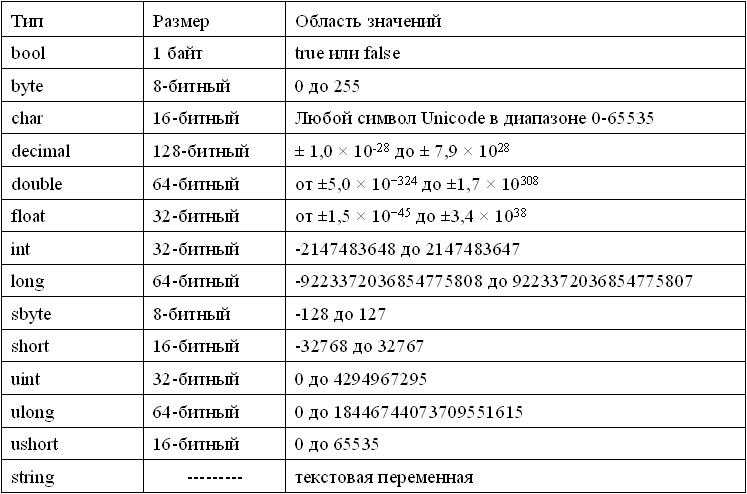 character()
character()
1.1.4 Время и периоды
1.1.5 Логические
Логические переменные возникают там, где нужно проверить условие. Переменная логического типа может принимать значение TRUE (истина) или FALSE (ложь). Для их обозначения также возможны более компактные константы T и F соответственно.
Следующие операторы приводят к возникновению логических переменных:
- РАВНО (
==) — проверка равенства операндов - НЕ РАВНО (
!=) — проверка неравенства операндов - МЕНЬШЕ (
<) — первый аргумент меньше второго - МЕНЬШЕ ИЛИ РАВНО (
<=) — первый аргумент меньше или равен второму - БОЛЬШЕ (
>) — первый аргумент больше второго - БОЛЬШЕ ИЛИ РАВНО (
>=) — первый аргумент больше или равен второму
Посмотрим, как они работают:
a = 1 b = 2 a == b ## [1] FALSE a != b ## [1] TRUE a > b ## [1] FALSE a < b ## [1] TRUE
Если необходимо проверить несколько условий одновременно, их можно комбинировать с помощью логических операторов. Наиболее популярные среди них:
Наиболее популярные среди них:
- И (
&&) — проверка истинности обоих условий - ИЛИ (
||) — проверка истинности хотя бы одного из условий - НЕ (
!) — отрицание операнда (истина меняется на ложь, ложь на истину)
c = 3 (b > a) && (c > b) ## [1] TRUE (a > b) && (c > b) ## [1] FALSE (a > b) || (c > b) ## [1] TRUE !(a > b) ## [1] TRUE
Более подробно работу с логическими переменными мы разберем далее при знакомстве с условным оператором if.
1.2 Манипуляции с типами
1.2.1 Определение типа данных
Определение типа данных осуществляется с помощью функции class() (см. раздел Диагностические функции во Введении)
class(1)
## [1] "numeric"
class(0.5)
## [1] "numeric"
class(1 + 2i)
## [1] "complex"
class("sample")
## [1] "character"
class(TRUE)
## [1] "logical"
class(as.Date('1986-02-18'))
## [1] "Date"В вышеприведенном примере видно, что R по умолчанию “повышает” ранг целочисленных данных до более общего типа чисел с плавающей точкой, тем самым закладываясь на возможность точного деления без остатка. Если вы хотите, чтобы данные в явном виде интерпретировались как целочисленные, их нужно принудительно привести к этому типу. Операторы преобразования типов рассмотрены ниже.
Если вы хотите, чтобы данные в явном виде интерпретировались как целочисленные, их нужно принудительно привести к этому типу. Операторы преобразования типов рассмотрены ниже.
1.2.2 Преобразование типов данных
Преобразование типов данных осуществляется с помощью функций семейства as(d, type), где d — это входная переменная, а type — название типа данных, к которому эти данные надо преобразовать (см. таблицу в начале главы). Несколько примеров:
k = 1 print(k) ## [1] 1 class(k) ## [1] "numeric" l = as(k, "integer") print(l) ## [1] 1 class(l) ## [1] "integer" m = as(l, "character") print(m) ## [1] "1" class(m) ## [1] "character" n = as(m, "numeric") print(n) ## [1] 1 class(n) ## [1] "numeric"
Для функции as() существуют обертки (wrappers), которые позволяют записывать такие преобразования более компактно и выглядят как as.<dataype>(d), где datatype — название типа данных:
k = 1 l = as.
 integer(k)
print(l)
## [1] 1
class(l)
## [1] "integer"
m = as.character(l)
print(m)
## [1] "1"
class(m)
## [1] "character"
n = as.numeric(m)
print(n)
## [1] 1
class(n)
## [1] "numeric"
d = as.Date('1986-02-18')
print(d)
## [1] "1986-02-18"
class(d)
## [1] "Date"
integer(k)
print(l)
## [1] 1
class(l)
## [1] "integer"
m = as.character(l)
print(m)
## [1] "1"
class(m)
## [1] "character"
n = as.numeric(m)
print(n)
## [1] 1
class(n)
## [1] "numeric"
d = as.Date('1986-02-18')
print(d)
## [1] "1986-02-18"
class(d)
## [1] "Date"Если преобразовать число c плавающей точкой до целого, то дробная часть будет отброшена:
as.integer(2.7) ## [1] 2
После преобразования типа данных, разумеется, к переменной будут применимы только те функции, которые определены для данного типа данных:
a = 2.5 b = as.character(a) b + 2 ## Error in b + 2: нечисловой аргумент для бинарного оператора nchar(b) ## [1] 3
1.2.3 Проверка типов данных и пустых значений
Для проверки типа данных можно использовать функции семейства is.<datatype>:
is.integer(2.7)
## [1] FALSE
is.numeric(2.7)
## [1] TRUE
is.character('Привет!')
## [1] TRUEОсобое значение имеют функции проверки пустых переменных (имеющих значение NA — not available), которые могут получаться в результате несовместимых преобразований или соответствовать пропускам в исходных данных:
as.
 integer('Привет!')
## [1] NA
is.na(as.integer('Привет!'))
## [1] TRUE
integer('Привет!')
## [1] NA
is.na(as.integer('Привет!'))
## [1] TRUE1.3 Ввод и вывод данных в консоли
1.3.1 Ввод данных
Для ввода данных через консоль можно воспользоваться функцией readline(), которая будет ожидать пользовательский ввод и нажатие клавиши Enter, после чего вернет введенные данные в виде строки. Предположим, пользователь вызывает эту функцию и вводит с клавиатуры 1024:
a = readline()
Выведем результат на экран:
a ## [1] "1024"
Функция
readline()всегда возвращает строку, поэтому если вы ожидаете ввод числа, полученное значение необходимо явным образом преобразовать к числовому типу.
Весьма полезной особенностью readline() является возможность указания строки запроса (чтобы пользователь понимал, что от него хотят). Строку запроса можно указать при вызове функции:
lat = readline('Введите широту точки:')
## Введите широту точки:
## 54
lat
## [1] "54"1.
 3.2 Вывод данных
3.2 Вывод данныхДля вывода данных в консоль можно воспользоваться тремя способами:
- Просто напечатать название переменной с новой строки (не работает при запуске программы командой
Source) - Вызвать функцию
print() - Вызвать функцию
cat() - Заключить выражение в круглые скобки
()
Первый способ мы уже регулярно использовали ранее в настоящей главе. Следует обратить внимание на то, что он хорош для отладки программы, но выглядит некрасиво в рабочих программах, поскольку просто печатая название переменной с новой строки вы как бы явно не говорите о том, что хотите вывести ее значение в консоль, а лишь подразумеваете это. Более того, если скрипт запускается командой Source, данный метод вывода переменной просто не сработает, интерпретатор его проигнорирует.
Поэтому после отладки следует убрать из программы все лишние выводы в консоль, а оставшиеся (действительно нужные) оформить с помощью функций print() или cat(). 10))
## [1] «2 в степени 10 равно 1024»
print(paste(«Сегодняшняя дата — «, Sys.Date()))
## [1] «Сегодняшняя дата — 2022-08-23»
10))
## [1] «2 в степени 10 равно 1024»
print(paste(«Сегодняшняя дата — «, Sys.Date()))
## [1] «Сегодняшняя дата — 2022-08-23»
Функция cat() отличается от print() следующими особенностями:
-
cat()выводит значение переменной, и не печатает ее измерения и внешние атрибуты типа двойных кавычек вокруг строки. Это означает, чтоcat()можно использовать и для записи данных в файл (на практике этим мало кто пользуется, но знать такую возможность надо). -
cat()принимает множество аргументов и может осуществлять конкатенацию строк аналогично функции paste() -
cat()не возвращает никакого значений, в то время какprint()возвращает значение, переданное ей в качестве аргумента. -
cat()можно использовать только для атомарных типов данных. Для классов (таких как Date) она будет выводит содержимое объекта, которое может не совпадать с тем, что пользователь ожидает вывести
Например:
cat(a)
## 1024
cat(b)
## Fourty winks in progress
cat("2 в степени 10 равно", 2^10)
## 2 в степени 10 равно 1024
cat("Сегодняшнаяя дата -", Sys. Date())
## Сегодняшнаяя дата - 19227 Date())
## Сегодняшнаяя дата - 19227
Date())
## Сегодняшнаяя дата - 19227Можно видеть, что в последнем случае cat() напечатала отнюдь не дату в ее привычном представлении, а некое число, которое является внутренним представлением даты в типе данных Date. Такие типы данных являются классами объектов в R, и у них есть своя функция print(), которая и выдает содержимое объекта в виде, который ожидается пользователем. Поэтому пользоваться функцией cat() надо с некоторой осторожностью.
Заключительная возможность — вывод с помощью заключения выражения в круглые скобки — очень удобна на стадии отладки программы. При этом переменная, которая создается в выражении, остается доступной в программе:
(a = rnorm(5)) # сгенерируем 5 случайных чисел, запишем их в переменную a и выведем на экран ## [1] -3.740944 2.263287 -1.012359 1.370046 -1.102049 (b = 2 * a) # переменная a доступна, ее можно использовать и далее для вычислений ## [1] -7.481888 4.526573 -2.024718 2.
 740092 -2.204099
740092 -2.2040991.4 Условный оператор
Проверка условий позволяет осуществлять так называемое ветвление в программе. Ветвление означает, что при определенных условиях (значениях переменных) будет выполнен один программный код, а при других условиях — другой. В R для проверки условий используется условный оператор if — else if — else следующего вида:
if (condition) {
statement1
} else if (condition) {
statement2
} else {
statement3
}Сначала проверяется условие в выражении if (condition), и если оно истинно, то выполнится вложенный в фигурные скобки программный код statement1, после чего оставшиеся условия не будут проверяться. Если первое условие ложно, программа перейдет к проверке следующего условия else if (condition). Далее, если оно истинно, то выполнится вложенный код statement2, если нет — проверка переключится на следующее условие и так далее. Заключительный код statement3, следующий за словом else, выполнится только если ложными окажутся все предыдущие условия.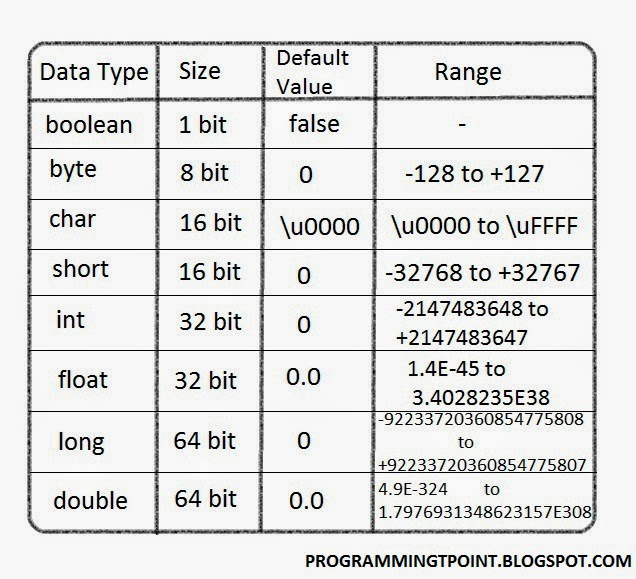
Конструкций
else ifможет быть произвольное количество, конструкцииifиelseмогут встречаться в условном операторе только один раз, в начале и конце соответственно. При этом условный оператор может состоять только из конструкцииif, аelse ifиelseне являются обязательными.
Например, сгенерируем случайное число, округлим его до одного знака после запятой и проверим относительно нуля:
(a = round(rnorm(1), 1))
## [1] -0.1
if (a < 0) {
cat('Получилось отрицательное число!')
} else if (a > 0) {
cat('Получилось положительное число!')
} else {
cat('Получился нуль!')
}
## Получилось отрицательное число!Условия можно использовать, в частности, для того чтобы обрабатывать пользовательский ввод в программе. Например, охарактеризуем положение точки относительно Полярного круга:
phi = as.numeric(readline('Введите широту вашей точки:'))Пользователь вводит 68, а мы оцениваем результат:
if (!is.
 na(phi)) { # проверяем, является ли введенное значение числом
if (abs(phi) >= 66.562 && abs(phi) <= 90) { # выполняем проверку на заполярность
cat('Точка находится в Заполярье')
} else {
cat('Точка не находится в Заполярье')
}
} else {
cat('Необходимо ввести число!') # оповещаем о некорректном вводе
}
## Точка находится в Заполярье
na(phi)) { # проверяем, является ли введенное значение числом
if (abs(phi) >= 66.562 && abs(phi) <= 90) { # выполняем проверку на заполярность
cat('Точка находится в Заполярье')
} else {
cat('Точка не находится в Заполярье')
}
} else {
cat('Необходимо ввести число!') # оповещаем о некорректном вводе
}
## Точка находится в Заполярье1.5 Оператор переключения
Оператор переключения (switch) является удобной заменой условному оператору в тех случаях, когда надо вычислить значение переменной в зависимости от значения другой переменной, которая может принимать ограниченное (заранее известное) число значений. Например:
name = readline('Введите название федерального округа:')Пользователь вводит:
Приволжский
# Определим центр в зависимости от названия:
capital = switch(name,
'Центральный' = 'Москва',
'Северо-Западный' = 'Санкт-Петербург',
'Южный' = 'Ростов-на-Дону',
'Северо-Кавказский' = 'Пятигорск',
'Приволжский' = 'Нижний Новгород',
'Уральский' = 'Екатеринбург',
'Сибирский' = 'Новосибирск',
'Дальневосточный' = 'Хабаровск')
print(capital)
## [1] "Нижний Новгород"1.
 6 Прерывание программы
6 Прерывание программыВ процессе выполнения программы могут возникнуть ситуации, при которых дальнейшее выполнение программы невозможно или недопустимо. Например, пользователь вместо числа ввёл в консоли букву. Хорошим тоном разработчика в данном случае будет не пускать ситуацию на самотёк и ждать пока программа сама споткнется и выдаст системное сообщение об ошибке, а обработать некорректный ввод сразу, сообщить об этом пользователю и остановить программу явным образом.
Прервать выполнение программы можно разными способами. Рассмотрим две часто используемые для этого функции:
-
stop(...)выводит на экран объекты, перечисленные через запятую в...и завершает выполнение программы. При ручном вызове этой функции в...целесообразно передать текстовую строку с сообщением о причине остановки программы. Вызовstop()происходит обычно после проверки некоторого условия операторомif-else. -
stopifnot(.? 2) # возведем в квадрат и выведем на экран, если все ОКВывод программы в случае ввода строки
abcбудет следующим:## Error in eval(expr, envir, enclos): Введенная строка не является числом
1.7 Технические детали
Когда вы присваиваете значение переменной другой переменной, копирования не происходит. Оба имени будут ссылаться на один и тот же объект, до тех пор, пока через одно из имен не будет предпринята попытка модифицировать объект. Это можно легко проверить с помощью функции
tracemem():a = 1 b = a cat('a:', tracemem(a), '\n') ## a: <0x7fca5b0295f0> cat('b:', tracemem(b), '\n') ## b: <0x7fca5b0295f0> a = 2 cat('a:', tracemem(a), '\n') # объект скопирован в другую область памяти ## a: <0x7fca5b0292e0> cat('b:', tracemem(b), '\n') ## b: <0x7fca5b0295f0>Подобное поведение называется copy-on-modify. Оно позволяет экономить на вычислениях в случае, когда копия и оригинал остаются неизменными.
Аналогичное правило применяется когда вы копируете структуры данных, такие как векторы, списки и фреймы данных (см. Главу 2). Более подробно см. параграф 2.3 в (Wickham 2019).1.8 Краткий обзор
Для просмотра презентации щелкните на ней один раз левой кнопкой мыши и листайте, используя кнопки на клавиатуре:
Презентацию можно открыть в отдельном окне или вкладке браузере. Для этого щелкните по ней правой кнопкой мыши и выберите соответствующую команду.
1.9 Контрольные вопросы и упражнения
1.9.1 Вопросы
- Какие типы данных поддерживаются в R? Каковы их англоязычные наименования?
- Что такое переменная?
- Какой оператор используется для записи значения в переменную?
- С помощью какой функции можно узнать тип переменной?
- С помощью какого семейства функций можно преобразовывать типы переменных?
- Можно ли использовать ранее созданное имя переменной для хранения новых данных другого типа?
- Можно ли записать в переменную результат выполнения выражения, в котором она сама же и участвует?
- Какая функция позволяет прочитать пользовательский ввод с клавиатуры в консоли? Какой тип данных будет иметь возвращаемое значение?
- Какую функцию можно использовать для вывода значения переменной в консоль? Чем отличается использование этой функции от случая, когда вы просто пишете название переменной в строке программы?
- Какой символ является разделителем целой и дробной части при записи чисел с плавающей точкой?
- Что такое операторы и операнды? Приведите примеры бинарных и унарных операторов. , **
- Как проверить, является ли число четным?
- Как определить количество символов в строке?
- Как называется операция состыковки нескольких строк и с помощью какой функции она выполняется? Как добиться того, чтобы при этом не добавлялись пробелы между строками?
- С помощью какой функции можно создать дату из строки?
- Как извлечь из даты год? Месяц? День?
- Какая функция позволяет получить дату сегодняшнего дня?
- Можно ли складывать даты и числа? Если да, то в каких единицах измерения будет выражен результат?
- Какова краткая форма записи логических значений
TRUEиFALSE? - Каким числам соответствуют логические значения
TRUEиFALSE? - Сколько операндов должно быть верно, чтобы оператор логического И (
&&) принял значениеTRUE? Что можно сказать в этом отношении об операторе ИЛИ (||)? - Можно ли применять арифметические операции к логическим переменным? Что произойдет, если прибавить или вычесть из числа
aзначениеTRUE? А если заменитьTRUEнаFALSE? - Что такое условный оператор и для каких сценариев обработки данных необходимы условные операторы?
- Перечислите ключевые слова, которые могут быть использованы для организации условных операторов
- При каких сценариях целесообразно использовать оператор переключения?
Запишите условие проверки неравенства чисел
aиbне менее чем тремя способами.Напишите программу, которая запрашивает в консоли целое число и определяет, является ли оно чётным или нечетным. Программа должна предварительно определить, является ли введенное число а) числом и б) целым числом.
Подсказка: результат конвертации строки в целое число и число с плавающей точкой отличается. Вы можете использовать это для проверки, является ли введенное число целым.
Напишите программу, которая считывает из консоли введенную пользователем строку и выводит в консоль количество символов в этой строке. Вывод оформите следующим образом:
"Длина введенной строки равняется ... символам", где вместо многоточия стоит вычисленная длина.В программе в виде переменных задайте координаты населенного пункта А (
x1, y1), а также дирекционный уголDи расстояниеLдо населенного пункта B. Напишите код, который определяет координаты населенного пункта B (x2, y2).Функция
atan2()позволяет найти математический азимут (полярный угол), если известны координаты вектора между двумя точками. Используя эту функцию, напишите программу, которая вычисляет географический азимут между точками А (x1, y1) и B (x2, y2). Координаты точек задайте в виде переменных непосредственно в коде.Математический азимут отсчитывается от направления на восток против часовой стрелки. Географический азимут отсчитывается от направления на север по часовой стрелке).
- signed
- unsigned
- short
- long
 2) # возведем в квадрат и выведем на экран, если все ОК
2) # возведем в квадрат и выведем на экран, если все ОК Аналогичное правило применяется когда вы копируете структуры данных, такие как векторы, списки и фреймы данных (см. Главу 2). Более подробно см. параграф 2.3 в (Wickham 2019).
Аналогичное правило применяется когда вы копируете структуры данных, такие как векторы, списки и фреймы данных (см. Главу 2). Более подробно см. параграф 2.3 в (Wickham 2019). , **
, **1.
 9.2 Упражнения
9.2 Упражнения Напишите код, который определяет координаты населенного пункта B (
Напишите код, который определяет координаты населенного пункта B (| Самсонов Т.Е. Визуализация и анализ географических данных на языке R. М.: Географический факультет МГУ, 2022. DOI: 10.5281/zenodo.901911 |
Введение
2 Структуры данных
C++ — Типы данных
При написании программы на любом языке вам нужно использовать различные переменные для хранения различной информации. Переменные — это не что иное, как зарезервированные ячейки памяти для хранения значений. Это означает, что при создании переменной вы сохраняете некоторое пространство в памяти.
Переменные — это не что иное, как зарезервированные ячейки памяти для хранения значений. Это означает, что при создании переменной вы сохраняете некоторое пространство в памяти.
Вы можете хранить информацию различных типов данных, таких как символ, широкий символ, целое число, плавающая точка, двойная плавающая точка, логическое значение и т. Д. На основе типа данных переменной операционная система выделяет память и решает, что можно сохранить в зарезервированная память.
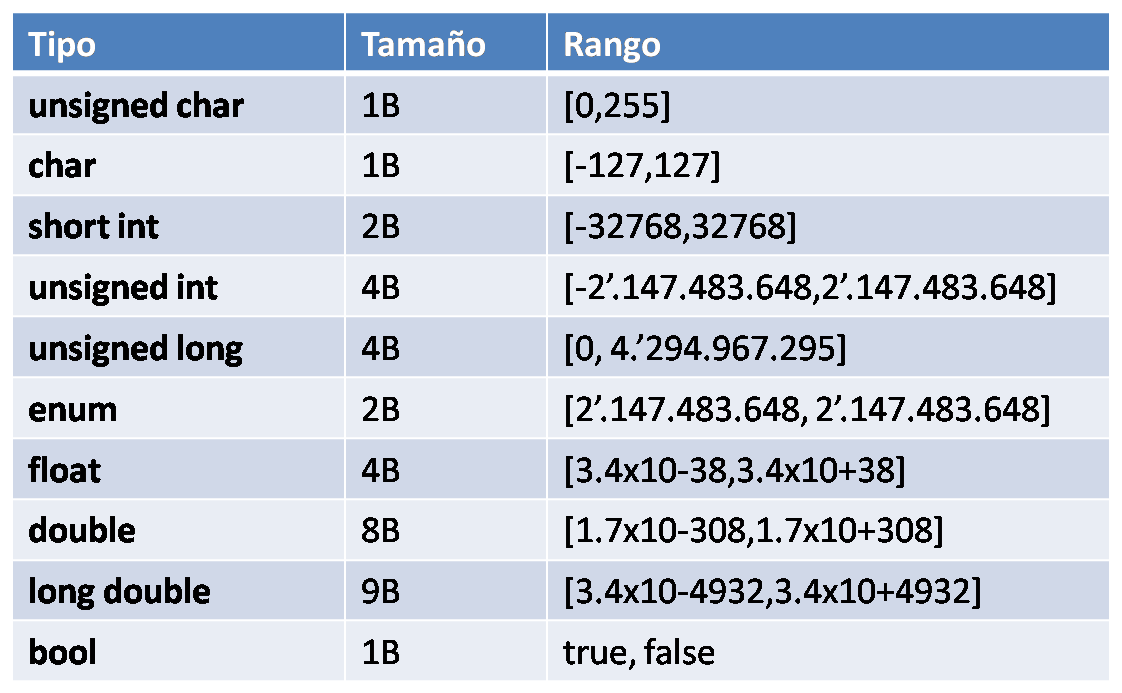
Примитивные встроенные типы
C ++ предлагает программисту богатый набор встроенных, а также пользовательских типов данных. В следующих таблицах перечислены семь основных типов данных C ++:
| Type | Keyword |
|---|---|
| Boolean | bool |
| Character | char |
| Integer | int |
| Floating point | float |
| Double floating point | double |
| Valueless | void |
| Wide character | wchar_t |
Некоторые из основных типов могут быть изменены с использованием одного или нескольких модификаторов этого типа:
В следующей таблице показан тип переменной, объем памяти, который требуется для хранения значения в памяти, и то, что является максимальным и минимальным значением, которое может быть сохранено в таких переменных.
| Type | Typical Bit Width | Typical Range |
|---|---|---|
| char | 1byte | -127 to 127 or 0 to 255 |
| unsigned char | 1byte | 0 to 255 |
| signed char | 1byte | -127 to 127 |
| int | 4bytes | -2147483648 to 2147483647 |
| unsigned int | 4bytes | 0 to 4294967295 |
| signed int | 4bytes | -2147483648 to 2147483647 |
| short int | 2bytes | -32768 to 32767 |
| unsigned short int | Range | 0 to 65,535 |
| signed short int | Range | -32768 to 32767 |
| long int | 4bytes | -2,147,483,648 to 2,147,483,647 |
| signed long int | 4bytes | same as long int |
| unsigned long int | 4bytes | 0 to 4,294,967,295 |
| float | 4bytes | +/- 3. 4e +/- 38 (~7 digits) 4e +/- 38 (~7 digits) |
| double | 8bytes | +/- 1.7e +/- 308 (~15 digits) |
| long double | 8bytes | +/- 1.7e +/- 308 (~15 digits) |
| wchar_t | 2 or 4 bytes | 1 wide character |
Размер переменных может отличаться от размера, указанного в приведенной выше таблице, в зависимости от компилятора и компьютера, который вы используете. Ниже приведен пример, который даст правильный размер различных типов данных на вашем компьютере.
#include <iostream>
using namespace std;
int main() {
cout << "Size of char : " << sizeof(char) << endl;
cout << "Size of int : " << sizeof(int) << endl;
cout << "Size of short int : " << sizeof(short int) << endl;
cout << "Size of long int : " << sizeof(long int) << endl;
cout << "Size of float : " << sizeof(float) << endl;
cout << "Size of double : " << sizeof(double) << endl;
cout << "Size of wchar_t : " << sizeof(wchar_t) << endl;
return 0;
}В этом примере используется endl , который вводит символ новой строки после каждой строки, а оператор << используется для передачи нескольких значений на экран. Мы также используем оператор sizeof () для получения размера различных типов данных.
Мы также используем оператор sizeof () для получения размера различных типов данных.
Когда приведенный выше код компилируется и выполняется, он производит следующий результат, который может варьироваться от машины к машине:
Size of char : 1
Size of int : 4
Size of short int : 2
Size of long int : 4
Size of float : 4
Size of double : 8
Size of wchar_t : 4Декларации typedef
Вы можете создать новое имя для существующего типа с помощью typedef. Ниже приведен простой синтаксис для определения нового типа с использованием typedef:
typedef type newname; Например, следующее говорит компилятору, что ногами является другое имя для int:
typedef int feet;Теперь следующая декларация совершенно легальна и создает целочисленную переменную, называемую расстоянием:
feet distance;Перечисленные типы
Перечислимый тип объявляет необязательное имя типа и набор из нуля или более идентификаторов, которые могут использоваться как значения типа. Каждый перечислитель является константой, тип которой является перечислением. Для создания перечисления требуется использование ключевого слова enum . Общий вид типа перечисления:
Каждый перечислитель является константой, тип которой является перечислением. Для создания перечисления требуется использование ключевого слова enum . Общий вид типа перечисления:
enum enum-name { list of names } var-list; Здесь enum-name — это имя типа перечисления. Список имен разделяется запятой. Например, следующий код определяет перечисление цветов, называемых цветами, и переменной c цвета типа. Наконец, c присваивается значение «blue».
enum color { red, green, blue } c;
c = blue;По умолчанию значение первого имени равно 0, второе имя имеет значение 1, а третье — значение 2 и т. Д. Но вы можете указать имя, определенное значение, добавив инициализатор. Например, в следующем перечислении зеленый будет иметь значение 5.
enum color { red, green = 5, blue };Здесь blue будет иметь значение 6, потому что каждое имя будет больше, чем предыдущее.
Понимание типов данных C — char, int, float, double и void
Как следует из названия, тип данных определяет используемый тип данных.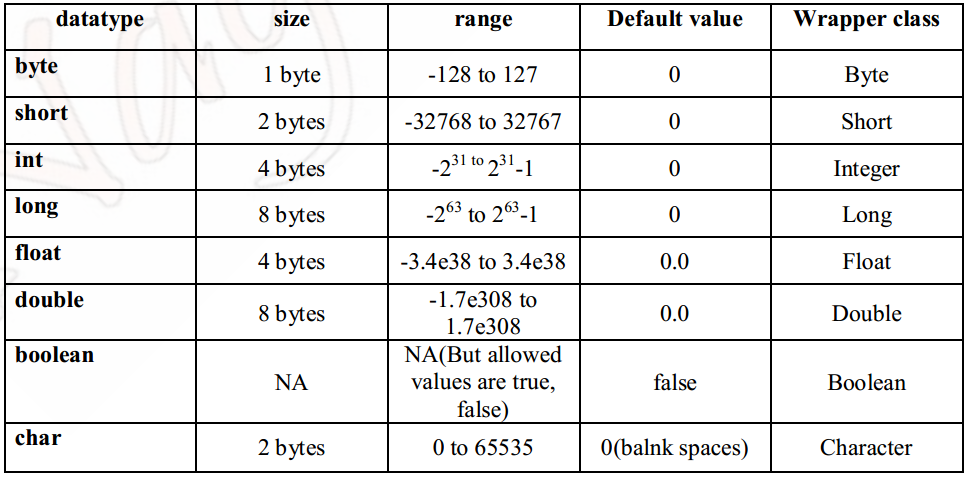 Всякий раз, когда мы определяем переменную или используем какие-либо данные в программе на языке C, мы должны указать тип данных, чтобы компилятор знал, какой тип данных ожидать.
Всякий раз, когда мы определяем переменную или используем какие-либо данные в программе на языке C, мы должны указать тип данных, чтобы компилятор знал, какой тип данных ожидать.
Например, вы можете использовать число , например 1 , 2 , 100 , или число с десятичной точкой , например 99.95 , 10.5 или текст , например «Studytonight» , все эти значения по-разному обрабатываются компилятором языка C , следовательно, мы используем типы данных для определения типа данных, используемых в любом программа.
Каждый тип данных занимает некоторое количество памяти, имеет диапазон значений и набор операций, которые он позволяет выполнять над собой. В этом руководстве мы объяснили различные типы данных, используемые в языке C. Примеры кода см. в руководстве по использованию типов данных C.
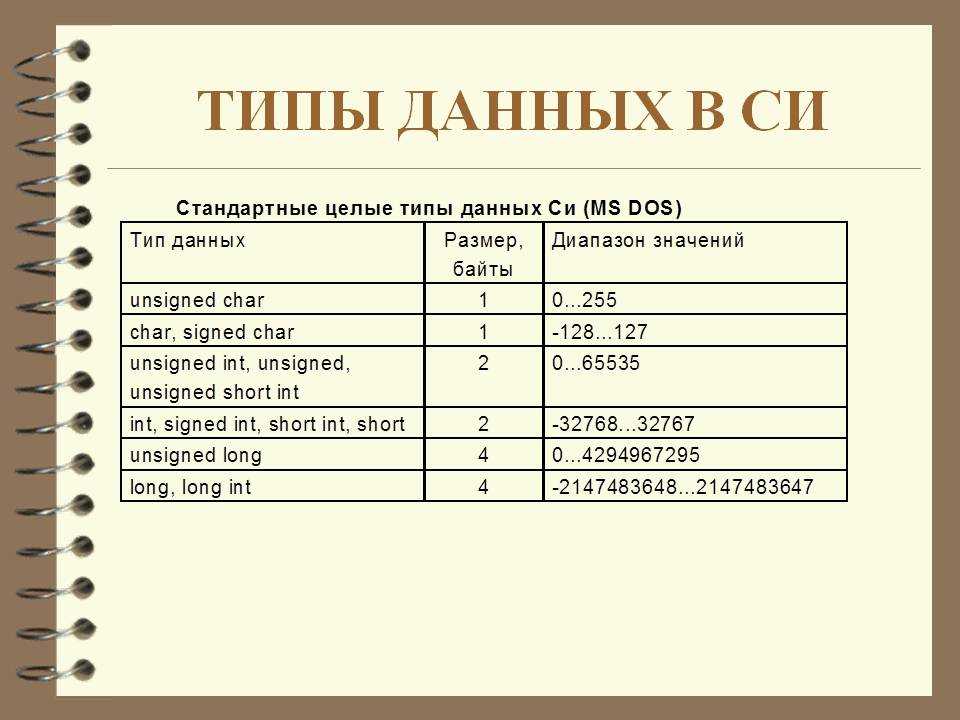
Типы данных в C
В общем, существует 5 различных категорий типов данных в языке C, а именно:
| Тип | Пример |
|---|---|
| Базовый | символов, целое число, число с плавающей запятой, двойное число. |
| Производный | Массив, структура, объединение и т. д. |
| Перечень | перечислений |
| Болт типа | правда или ложь |
| пустота | Пустое значение |
Первичные типы данных в C
Язык C имеет 5 основных (первичных или примитивных) типов данных, это:
Символ: Мы используем ключевое слово
charдля символьного типа данных. Он используется для хранения однобитовых символов и занимает 1 байт памяти. Мы можем хранить алфавиты от AZ (и az) и цифры 0-9, используяchar. Например,символа = 'а'; символ б = 'А'; символ с = '0'; символ д = 0; // ошибка
Для типа данных
charнеобходимо заключить наши данные в одинарных кавычках . Мы можем выполнять операции сложения и вычитания над символами, но значение ASCII не должно превышать 127.Целое число: Мы используем ключевое слово
intдля целочисленного типа данных. Тип данныхintиспользуется для хранения не дробных чисел, которые включают положительные, отрицательные и нулевые значения. Диапазон int составляет от -2 147 483 648 до 2 147 483 647 , и он занимает 2 или 4 байта памяти, в зависимости от используемой системы. Например,инт а = 5550; интервал b = -90, интервал с = 0; инт д = -0,5; // неверно
Мы можем выполнять сложение, вычитание, деление, умножение, побитовые операции и операции по модулю над
intтип данных.С плавающей запятой: Мы используем ключевое слово
floatдля типа данных с плавающей запятой.floatиспользуется для хранения десятичных чисел . Он занимает 4 байта памяти и находится в диапазоне от 1e-37 до 1e+37 . Например,с плавающей запятой а = 0,05; поплавок b = -0,005. поплавок с = 1; // оно станет c = 1.000000 из-за приведения типов
Мы можем выполнять операции сложения, вычитания, деления и умножения на
тип данных с плавающей запятой.Double: Мы используем ключевое слово
doubleдля двойного типа данных.doubleиспользуется для хранения десятичных чисел . Он занимает 8 байт памяти и находится в диапазоне от 1e-37 до 1e+37 .двойное а = 10,09; двойной б = -67,9;
doubleимеет большую точность, чемflaot, поэтомуdoubleдает более точные результаты по сравнению споплавок. Мы можем выполнять операции сложения, вычитания, деления и умножения с типом данныхdouble.Недействительно: Это означает отсутствие значения. Этот тип данных в основном используется, когда мы определяем функции. Тип данных
voidиспользуется, когда функция ничего не возвращает. Он занимает 0 байт памяти. Мы используем ключевое словоvoidдля типа данных void.недействительная функция () { //здесь будет ваш код }
 Мы можем выполнять операции сложения и вычитания над
Мы можем выполнять операции сложения и вычитания над  Он занимает 4 байта памяти и находится в диапазоне от 1e-37 до 1e+37 . Например,
Он занимает 4 байта памяти и находится в диапазоне от 1e-37 до 1e+37 . Например,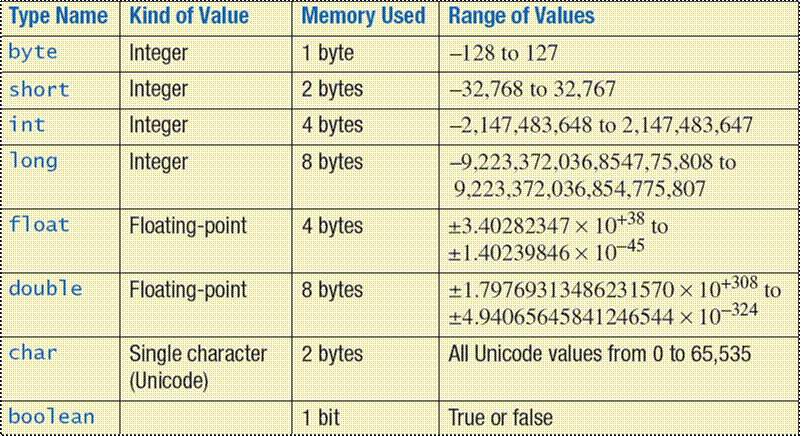
Каждый тип данных имеет размер , определенный в битах/байтах , и имеет диапазон для значений, которые могут содержать эти типы данных.
Размер различных типов данных в C
Размер различных типов данных зависит от типов компилятора и процессора, короче говоря, это зависит от компьютера, на котором вы используете язык C, и версии компилятора C, которую вы используете. установили.
символ 1 байт
Тип данных char имеет размер 1 байт или 8 бит .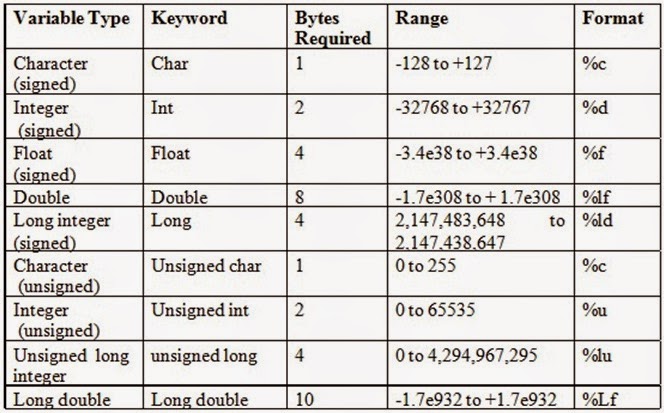 Это в основном то же самое и не зависит от используемого процессора или компилятора.
Это в основном то же самое и не зависит от используемого процессора или компилятора.
int может быть 2 байта/4 байта
Существует очень простой способ запомнить размер для типа данных int . Размер типа данных int обычно равен длине слова среды выполнения программы. Проще говоря, для 16-битной среды , int это 16 бит или 2 байта , а для 32-битной среды , int это 32 бита или 4 байта .
float имеет размер 4 байта
Тип данных float имеет размер 4 байта или 32 бита . Это тип данных одинарной точности , который используется для хранения десятичных значений. Он используется для хранения больших значений.
float — более быстрый тип данных по сравнению с double , потому что тип данных double работает с очень большими значениями, поэтому он медленный.
double имеет размер 8 байтов
Тип данных double имеет размер 8 байтов или 64 бита . Он может хранить значения, которые в раза удваивают размер того, что тип данных float может хранить , поэтому он называется double .
В 64 битах 1 бит для знака представления, 11 бит для экспоненты , а остальные 52 бита используются для мантиссы .
Тип данных double может содержать примерно от 15 до 17 цифр , до и после запятой.
void равен 0 байтам
Тип данных void ничего не означает, поэтому он не имеет размера.
Прежде чем перейти к диапазону значений для этих типов данных, необходимо изучить еще одну важную концепцию, а именно Модификаторы типов данных .
Модификаторы типа данных C:
В языке C существует 4 модификатора типа данных , которые используются вместе с основными типами данных для их дальнейшей категоризации.
Например, если вы говорите, что есть детская площадка, это может быть парк, детская площадка или стадион, но если вы конкретизируете и говорите, что есть площадка для игры в крикет или футбольный стадион, точнее.
Точно так же в языке C есть модификаторы, чтобы сделать первичные типы данных более конкретными .
Модификаторы:
подписано
без знака
длинный
короткий
Как следует из названия, знаковые и беззнаковые используются для представления знаковых (+ и -) и беззнаковых (только +) значений для любого типа данных. И длинные и короткие влияют на диапазон значений для любого типа данных.
Например, signed int , unsigned int , short int , long int и т. д. — все допустимые типы данных в языке C.
д. — все допустимые типы данных в языке C.
длинное длинное число = 123456789987654321; // мы не можем сохранить такое большое значение, используя тип данных int.
Теперь посмотрим диапазон для разных типов данных, сформированный в результате 5 первичных типов данных вместе с указанными выше модификаторами.
C Тип данных Диапазон значений
В таблице ниже у нас есть диапазон для различных типов данных в языке C.
| Тип | Типовой размер в битах | Минимальный диапазон | Спецификатор формата |
|---|---|---|---|
символ | 8 | от -127 до 127 | %с |
без знака символ | 8 | от 0 до 255 | %с |
подписанный символьный | 8 | от -127 до 127 | %с |
внутр. | 16 или 32 | -32 767 до 32 767 | %d , %i |
без знака целое число | 16 или 32 | от 0 до 65 535 | %u |
подписанный инт | 16 или 32 | То же, что и целое число | %d , %i |
короткий целый | 16 | -32 767 до 32 767 | %HD |
без знака короткий целочисленный | 16 | от 0 до 65 535 | %ху |
подписанный короткий инт | 16 | То же, что и короткое целое | %HD |
длинный целый | 32 | -2 147 483 647 до 2 147 483 647 | %ld , %li |
длинный длинный целый | 64 | -(2 63 — 1) до 2 63 — 1 (Добавлено стандартом C99) | %lld , %lli |
подписанный длинный целочисленный | 32 | То же, что и длинное целое | %ld , %li |
беззнаковые длинные целые | 32 | от 0 до 4 294 967 295 | %лу |
без знака длинный длинный целый | 64 | 2 64 — 1 (Добавлен стандартом C99) | %llu |
поплавок | 32 | От 1E-37 до 1E+37 с точностью до шести цифр | %f |
двойной | 64 | От 1E-37 до 1E+37 с точностью до десяти цифр | %лд |
длинный двойной | 80 | От 1E-37 до 1E+37 с точностью до десяти цифр | %Lf |
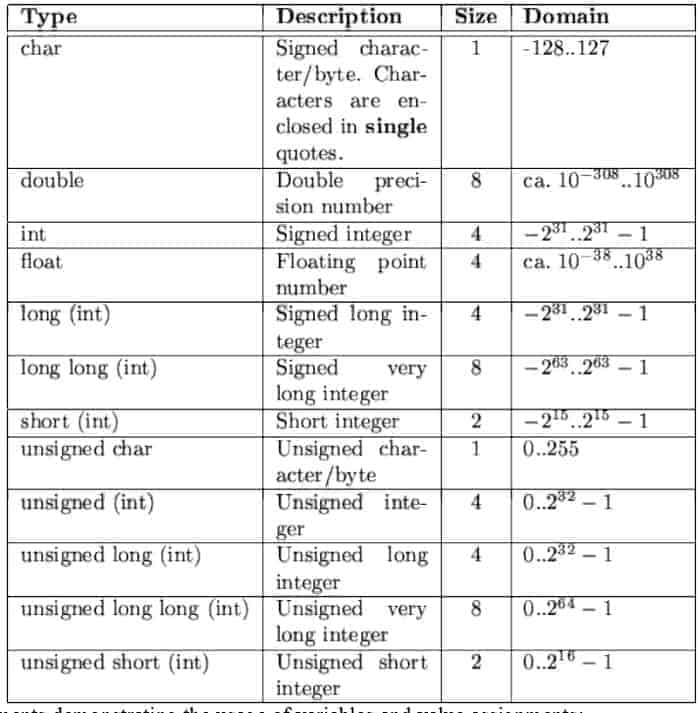
Как видно из таблицы выше, при различных сочетаниях типа данных и модификаторов меняется диапазон значений.
Когда мы хотим напечатать значение любой переменной с любым типом данных, мы должны использовать спецификатор формата в операторе printf() .
Что произойдет, если значение выйдет за пределы допустимого диапазона?
Ну, если вы попытаетесь присвоить любому типу данных значение, превышающее допустимый диапазон значений, то компилятор языка Си выдаст ошибку. Вот простой пример кода, чтобы показать это:
#includeинтервал основной () { // допустимое значение до 65535 беззнаковое короткое целое x = 65536; вернуть 0; }
предупреждение: большое целое неявно усекается до беззнакового типа [-Woverflow] 9
Код запуска →
Когда модификатор типа используется без какого-либо типа данных , тип данных int устанавливается в качестве типа данных по умолчанию. SO, USIGNED означает USIGNED INT , Подписано .
Что означает
со знаком и без знака значит?Это немного сложно объяснить, но давайте попробуем.
Проще говоря, модификатор без знака означает все положительные значения , а модификатор со знаком означает как положительные, так и отрицательные значения .
Когда компилятор получает числовое значение, он преобразует это значение в двоичное число, что означает комбинацию 0 и 1. Например, 32767 в двоичном виде равно 01111111 11111111 и 1 в двоичном формате — это 01 (или 0001) , 2 — это 0010 и так далее.
В случае целого числа со знаком бит старшего разряда или первая цифра слева (в двоичном формате) используется как флаг знака . Если флаг знака равен 0 , число положительное , а если 1 , число отрицательное .
И поскольку один бит используется для отображения того, является ли число положительным или отрицательным, следовательно, для представления самого числа на один бит меньше, следовательно, диапазон меньше.
Для со знаком int , 11111111 11111111 означает -32 767 и поскольку первый бит является флагом знака , чтобы пометить его как отрицательное число, а остальные представляют число. Тогда как в случае unsigned int , 11111111 11111111 означает 65,535 .
Производные типы данных в C
Хотя существует 5 основных типов данных, в языке C также есть несколько производных типов данных, которые используются для хранения сложных данных.
Производные типы данных — это не что иное, как первичные типы данных, но немного искаженные или сгруппированные вместе, такие как массив , структура , объединение , и указатели . Они подробно обсуждаются позже.
Они подробно обсуждаются позже.
Заключение:
В следующем уроке мы узнаем о переменных, и там вы узнаете фактическое использование типов данных с примерами кода человека. Итак, давайте двигаться дальше.
- ← Назад
- Далее →
Что такое double в C?
Переменная типа double — это 64-битный плавающий тип данных.
Par ailleurs, Сколько байтов занимает двойное число в C?
Типы с плавающей запятой
| Тип | Размер хранилища | Точность |
|---|---|---|
| поплавок | 4 байта | 6 знаков после запятой |
| двойной | 8 байт | 15 знаков после запятой |
| длинный двойной | 10 байт | 19 знаков после запятой |
Ainsi Что такое long double в C? В C и родственных языках программирования long double относится к . тип данных с плавающей запятой, который часто более точен, чем двойная точность , хотя стандарт языка требует, чтобы он был по крайней мере таким же точным, как double .
тип данных с плавающей запятой, который часто более точен, чем двойная точность , хотя стандарт языка требует, чтобы он был по крайней мере таким же точным, как double .
Что такое float и double в C? Float — это 32-битный тип данных с плавающей запятой. 1 бит для знака, 8 бит для экспоненты, 23 бит для значения или мантиссы. Double — это 64-битный тип данных с плавающей запятой. 1 бит для знака, 11 бит для экспоненты, 52 бит для значения или мантиссы. Для переменной с плавающей запятой требуется 4 байта памяти.
Или, что такое двойное число 4?
Двойное число 4 равно 8 .
Таблица материалов
Каков размер типа данных double?Типы и размеры данных
| Имя типа | 32-бит Размер | 64-бит Размер |
|---|---|---|
| поплавок | 4 байта | 4 байта |
| двойной | 8 байт | 8 байт |
| длинный двойной | 16 байт | 16 байт |
Также возможно, что размер целого числа составляет 32 бита или 4 байта для 64-битного процессора .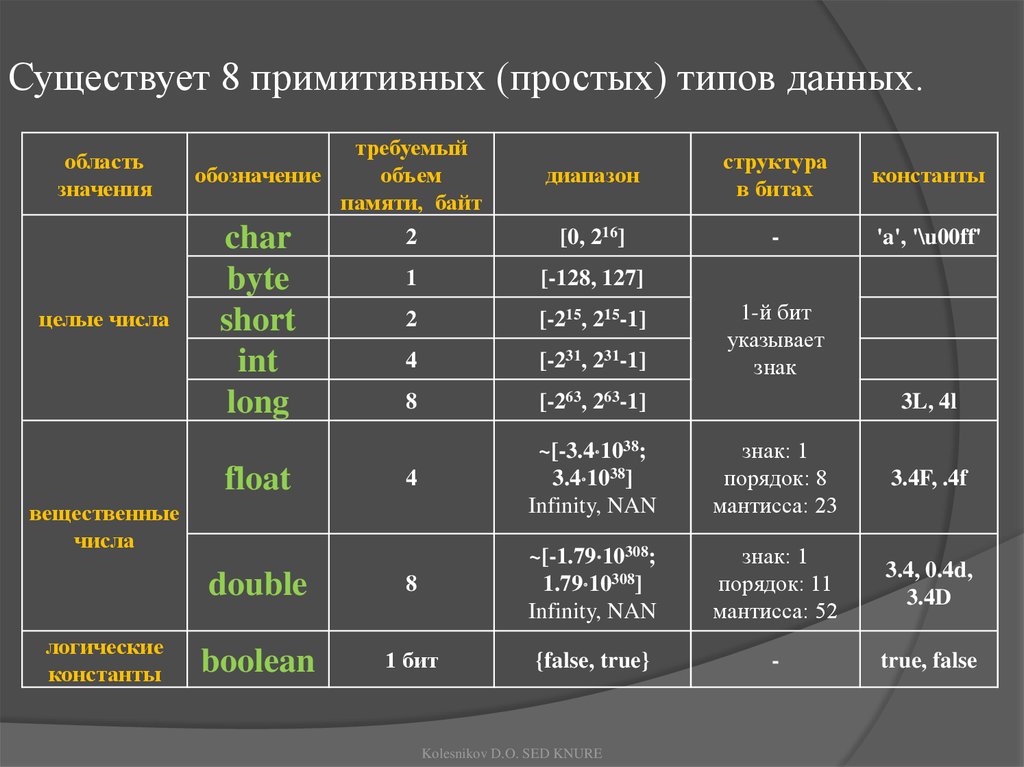 Это полностью зависит от типа компилятора.
Это полностью зависит от типа компилятора.
…
Размер первичных типов данных.
| Тип | Диапазон | Размер (в байтах) |
|---|---|---|
| целое число без знака | от 0 до 65535 | 2 |
| знаковое целое число или целое число | -32 768 до +32767 | 2 |
| короткое целое без знака | 0 до 65535 | 2 |
Типы данных в C
| Тип данных | Память (байт) | Диапазон |
|---|---|---|
| беззнаковый символ | 1 | от 0 до 255 |
| поплавок | 4 | |
| двойной | 8 | |
| длинный двойной | 16 |
• 28 июня 2021 г.
Можем ли мы использовать long double в C?%Lf Спецификатор формата для long double
%lf и %Lf играют разные роли в printf.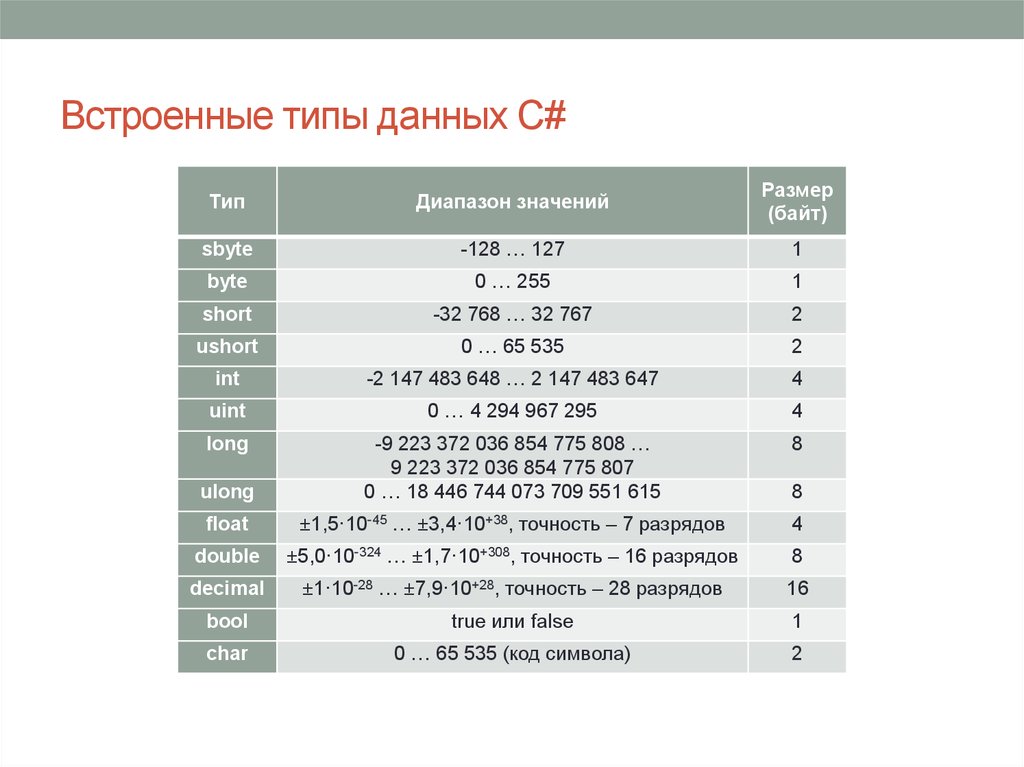 Итак, мы должны использовать спецификатор формата %Lf для вывода длинного двойного значения .
Итак, мы должны использовать спецификатор формата %Lf для вывода длинного двойного значения .
Длинный двойник обычно использует только 10 байт , но из-за выравнивания может фактически занимать 12 или 16 (в зависимости от компилятора и опций) байтов в структуре. 10-байтовая двойная длина обеспечивает 64-битную мантисса; это очень удобно, когда вы хотите хранить 64-битные целые числа с плавающей запятой без потери точности.
Что вы используете для double в C?Мы можем напечатать значение типа double, используя спецификаторы формата %f и %lf , потому что printf обрабатывает значения float и double одинаково. Таким образом, мы можем использовать как %f, так и %lf для вывода двойного значения.
Что означает %f C?Спецификаторы формата в C
| Спецификатор | Используется для |
|---|---|
| %f | число с плавающей запятой для чисел с плавающей запятой |
| %u | целое беззнаковое десятичное число |
| %е | число с плавающей запятой в экспоненциальном представлении |
| %Е | число с плавающей запятой в экспоненциальном представлении |
• 22 янв.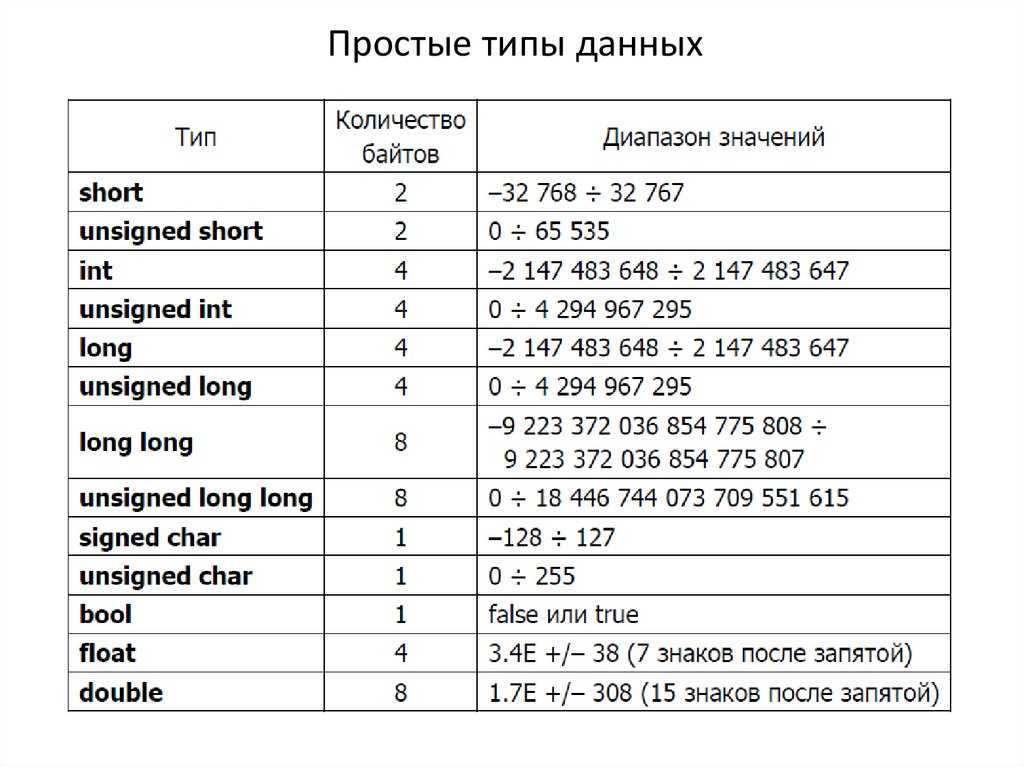 2020
2020
%lf является правильным спецификатором формата для double .
Какая строка формата для double в C?Спецификаторы формата в C
| Спецификатор формата | Тип |
|---|---|
| %лф | Двойной |
| %Lf | Длинный двойной |
| %лу | Беззнаковое целое или беззнаковое длинное |
| %lli или %lld | Длинный длинный |
• 18 июня 2019 г.
Сколько удвоится число 8?Двойная 8 это 16 .
Сколько удвоится число 3?Двойное число 3 равно 6 .
Сколько удвоится число 18? Знаете ли вы, что числа, кратные 18, состоят из чисел, которые удваивают кратные 9? Кроме того, математически 18 — это единственное число, сумма написанных цифр которого (1 + 8 = 9) равна половине самого себя (18/9 = 2).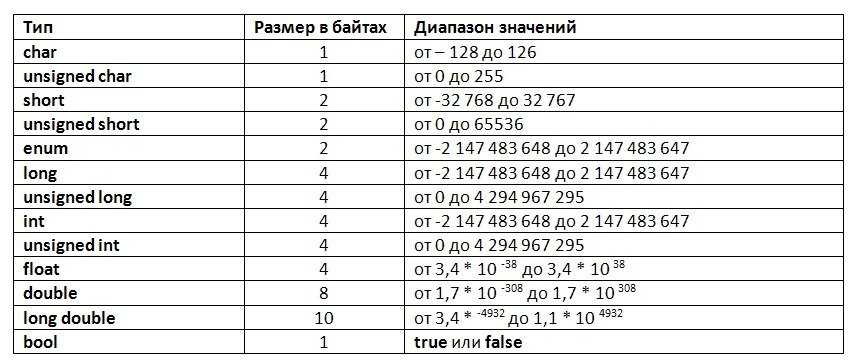
…
Кратность 18.
| 1. | Чему равно число , кратное 18 ? |
|---|---|
| 4. | Часто задаваемые вопросы о числах, кратных 18 |
| 5. | Сложные вопросы |
double: Тип данных double — это 64-битный IEEE 754 с плавающей запятой двойной точности . Его диапазон значений выходит за рамки этого обсуждения, но указан в разделе Типы, форматы и значения с плавающей запятой Спецификации языка Java. Для десятичных значений этот тип данных обычно используется по умолчанию.
Что такое тип double? Двойные ( с плавающей запятой двойной точности ) переменные хранятся в виде 64-битных (8-байтовых) чисел с плавающей запятой IEEE со значениями от: -1,79769313486231E308 до -4,94065645841247E-324 для отрицательных значений. От 4,94065645841247E-324 до 1,79769313486232E308 для положительных значений.
Например, для хранения годовой зарплаты генерального директора компании , более точным выбором будет double. Все тригонометрические функции, такие как sin, cos, tan, математические функции, такие как sqrt, возвращают двойные значения.
. . Этот метод преобразования данных также называется преобразованием типа или приведением типа. Приведение типов позволяет изменять тип данных, а не сами данные. C++ поддерживает приведение типов для всех типов данных. В этой статье будет обсуждаться один метод приведения типов: преобразование типа данных int в тип данных double. Мы рассмотрим различные подходы, которые просто преобразуют тип данных int в double.
Две категории преобразования в C++
Неявное преобразование типов
Неявное преобразование типов выполняется спонтанно.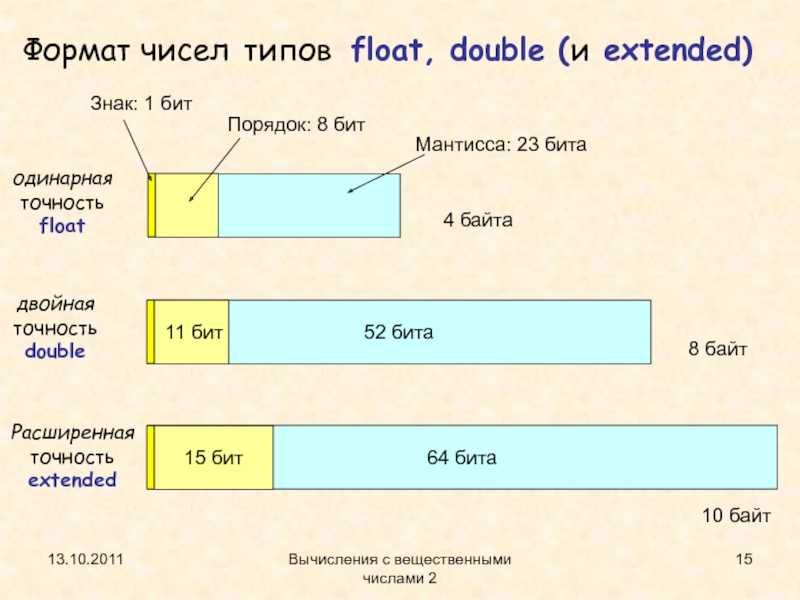 В этом преобразовании пользователь не имеет никаких входных данных, и компилятор выполняет преобразование полностью самостоятельно. Когда в выражении много типов данных, часто выполняется преобразование. Однако при такой форме преобразования существует риск потери данных, потери знаков или переполнения данных.
В этом преобразовании пользователь не имеет никаких входных данных, и компилятор выполняет преобразование полностью самостоятельно. Когда в выражении много типов данных, часто выполняется преобразование. Однако при такой форме преобразования существует риск потери данных, потери знаков или переполнения данных.
Явное преобразование типов
Тип Explicit определяется пользователем и иногда называется «приведением типов». В зависимости от потребностей пользователь переводит или конвертирует данные одного типа данных в другой. Эти типы преобразований более безопасны.
Пример 1
В следующем примере показана работа неявного преобразования типа, при котором int преобразуется в тип данных double. Программа запускается из заголовочных файлов. У нас есть два заголовочных файла в разделе заголовков. Затем идет основная функция реализации кода. В основной функции мы определили переменную как «IntNumber» целочисленного типа данных и инициализировали ее целым значением.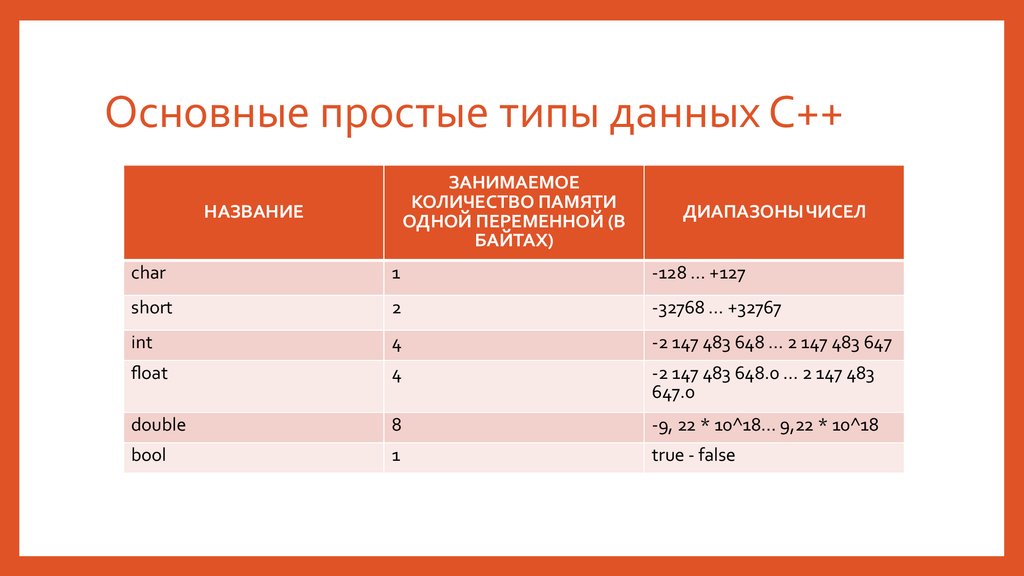
Аналогично, мы создали еще одну переменную как «DoubleNumber» с типом данных double, но она не инициализирована. Теперь нам нужно преобразовать значение типа данных int в значение типа данных double. Итак, мы присвоили переменной int «IntNumer» переменную типа double «DoubleNumber». Этот подход представляет собой неявное преобразование типов. Значения типа данных int и типа данных double будут напечатаны с помощью команды C++ cout.
Прежде чем присвоить переменной double значение int, компилятор автоматически преобразует его в double. Как видно на изображении, int не может включать десятичное значение, а цифры после запятой в этом примере усекаются.
Пример 2
Мы видели преобразование int в double в предыдущем примере. Теперь мы преобразуем double в int, что также выполняется посредством неявного преобразования.
На первом этапе мы включили файлы пространств имен iostream и std. Затем мы вызвали основную функцию программы, где объявили переменную целочисленного типа данных «IntVal». Кроме того, мы объявили еще одну переменную с типом данных double как «DoubleVal» и инициализировали ее двойным значением, так как она содержит десятичную часть. Для преобразования мы присвоили переменную double переменной int. Значение неявного преобразования типа будет напечатано на экране консоли при выполнении программы.
Кроме того, мы объявили еще одну переменную с типом данных double как «DoubleVal» и инициализировали ее двойным значением, так как она содержит десятичную часть. Для преобразования мы присвоили переменную double переменной int. Значение неявного преобразования типа будет напечатано на экране консоли при выполнении программы.
Вы можете увидеть значение double и преобразование данных типа double в данные типа int в качестве вывода.
Пример 3
Как видно из предыдущего примера, преобразование из одного типа данных в другой чревато потерей данных. Это происходит, когда данные большего типа преобразуются в данные меньшего типа. Чтобы преодолеть проблему потери данных, мы выполнили явное преобразование типов. Явное приведение типов выполняется посредством приведения типов в стиле C. Как следует из названия, он предпочитает форму приведения на языке C. Литая нотация — это еще один термин для этого.
Программа начинается с раздела заголовков, который включает файлы C++. На следующем шаге создается основная функция, в которой переменная определяется как «IntNumber» с типом данных «int» и сохраняет целочисленное значение. Другая переменная объявлена как «DoubleNumber» с типом данных «double».
На следующем шаге создается основная функция, в которой переменная определяется как «IntNumber» с типом данных «int» и сохраняет целочисленное значение. Другая переменная объявлена как «DoubleNumber» с типом данных «double».
Затем мы использовали метод приведения типов в стиле C, который использует нотацию типа double с переменной int и присваивает ее двойной переменной «DoubleNumber». Эти значения будут напечатаны с помощью команды C++ cout.
Десятичная часть усекается, так как тип данных int не имеет типа данных.
Пример 4
Функция записи может также перемещать данные между различными типами данных. Следующая программа использует приведение стилей функций для преобразования int в тип данных double.
У нас есть основная функция, в которой мы создали переменную типа данных int как «Integer_x» и инициализировали ее числовым значением «20». Переменная типа double также определяется как «Double_y». Затем мы использовали приведение типов функций для преобразования данных типа int в тип double.