Хронология релизов MySQL — какой выбрать?
 История версий MySQL поможет разобраться в том, с какой именно версией сервера вам лучше работать. А если вы уже давно пользуетесь ею, наверняка будет интересно вспомнить, как развивалась эта система.
История версий MySQL поможет разобраться в том, с какой именно версией сервера вам лучше работать. А если вы уже давно пользуетесь ею, наверняка будет интересно вспомнить, как развивалась эта система.
- Версия 3.23 (2001). Этот релиз MySQL считается первым по-настоящему жизнеспособным вариантом для широкого применения. В этом варианте MySQL еще не сильно превосходила язык запросов на основе неструктурированных файлов, но MyISAM была представлена в качестве замены ISAM — более старой и гораздо более ограниченной подсистемы хранения. Также стала доступна подсистема InnoDB, но из-за своей новизны она не была включена в стандартный двоичный дистрибутив. Чтобы использовать InnoDB, нужно было скомпилировать сервер самостоятельно. В версии 3.23 были добавлены полнотекстовая индексация и репликация. Последняя была призвана стать той самой отличительной особенностью, которая сделала бы MySQL известной в качестве базы данных, по большей части управляемой через Интернет.
- Версия 4.0 (2003). Появилась новая синтаксическая функция поддержки работы команд
UNIONиDELETEс несколькими таблицами. Репликация была переписана для использования двух потоков на реплике вместо одного потока, который выполнял всю работу и нес убытки от переключения задачи. InnoDB была запущена как стандартная составляющая сервера с полным набором отличительных характеристик, таких как строковая блокировка, внешние ключи и т. д. Кэширование запросов было введено в версии 4.0 (и с тех пор не изменилось). Также была представлена поддержка SSL-соединений. - Версия 4.1 (2005). Были добавлены дополнительные функции синтаксиса запросов, включая подзапросы и команду
INSERT ON DUPLICATE KEY UPDATE. Начала поддерживаться кодировка UTF-8. Появились новый двоичный протокол и поддержка предварительно подготовленных операторов. - Версия 5.0 (2006). В этой версии появилось несколько «корпоративных» функций: представления, триггеры, хранимые процедуры и хранимые функции. Подсистема хранения данных ISAM полностью удалена, введены новые подсистемы хранения, например Federated.
- Версия 5.1 (2008). Этот релиз стал первым после того, как Sun Microsystems поглотила MySQL АВ; работа над ним продолжалась более пяти лет, В версии 5.1 были представлены сегментирование, построчная репликация и разнообразные API для плагинов, включая API подключаемой подсистемы хранения. Подсистема хранения BerkeleyDB, первая транзакционная подсистема хранения в MySQL, удалена, а некоторые другие, такие как Federated, устарели. Кроме того, компания Oracle, которая к этому моменту уже владела Innobase Оy, выпустила подключаемую подсистему хранения InnoDB.
- Версия 5.5 (2010). MySQL 5.5 была первой версией, выпущенной после того как Oracle поглотила Sun (и, следовательно, MySQL). Основное внимание было уделено улучшению производительности, масштабируемости, репликации, сегментированию и поддержке Microsoft Windows, внесено и множество других улучшений. InnoDB стала подсистемой хранения, установленной по умолчанию, а многие устаревшие функции, настройки и параметры были удалены. Добавлены база данных
- Версия 5.6 (2013). MySQL 5.6 приобрела множество новых функций, в том числе впервые за многие годы появились значительные улучшения оптимизатора запросов, больше плагинов
PERFORMANCE_SCHEMA. В то время как версия MySQL 5.5 в основном стремилась улучшить и исправить базовые функции и содержала немного нововведений, MySQL 5.6 нацелена на серьезное улучшение работы сервера и повышение производительности. - Версия 6.0 (отменена). Версия 6.0 вносит путаницу из-за перекрывающейся нумерации. Она была анонсирована во время разработки версии 5.1. Ходили слухи о большом количестве новых функций, таких как резервные онлайн-копии и внешние ключи на уровне сервера для всех подсистем хранения, улучшение механизма подзапросов и поддержка пула потоков. Этот релиз был отменен, и Sun возобновила разработку версии 5.4, которая в итоге была выпущена как версия 5.5. Многие из возможностей версии 6.0 реализованы в версиях 5.5 и 5.6.
- Версия 8.0 (2018). Основные возможности версии 8.0 хорошо изложены в статье на нашем портале.
Давайте подведем итоги исторического обзора MySQL: на раннем этапе жизненного цикла она стала прорывной технологией. Несмотря на ограниченные функциональные возможности и второсортные функции, ее отличительные особенности и низкая стоимость сделали ее революционной новинкой, которая взорвала Интернет. В ранних версиях 5.x MySQL попыталась выйти на корпоративный рынок с такими функциями, как представления и хранимые процедуры, но они были нестабильны и содержали ошибки, поэтому не все шло как по маслу. Если вдуматься, то поток исправлений ошибок, допущенных в MySQL 5.0, не иссяк вплоть до релиза 5.0.50, a MySQL 5.1 была ненамного лучше. Выпуск релизов 5.0 и 5.1 был отложен, а поглощения, произведенные Sun и Oracle, заставили многих наблюдателей понервничать. Но, на наш взгляд, развитие идет полным ходом: версия MySQL 5.5 стала релизом самого высокого качества в истории MySQL, Oracle сделала MySQL гораздо более удобной для корпоративных клиентов, а версия 5.6 обещает значительные улучшения функциональности и производительности.
Говоря о производительности, неплохо было бы продемонстрировать базовый эталонный тест изменения производительности сервера с течением времени. Мы решили не тестировать версии старше 4.1, потому что сейчас редко можно встретить 4.0 и более старые. Кроме того, очень сложно сравнивать эталонные тесты разных версий по причинам, о которых вы подробнее прочтете в следующей главе. Мы получили массу удовольствия, создавая метод эталонного тестирования, который будет работать одинаково со всеми тестируемыми версиями сервера, и нам потребовалось предпринять множество попыток, прежде чем мы достигли успеха. В табл. 1. показано количество транзакций в секунду для нескольких уровней конкурентного доступа.
Таблица 1. Эталонный тест блокировки «только для чтения» нескольких версий MySQL
|
Потоки |
MySQL 4.1 |
MySQL 5.0 |
MySQL 5.1 |
MySQL 5.1 c InnoDB |
MySQL 5.5 |
MySQL 5.6 |
1 |
686 |
640 |
596 |
594 |
531 |
526 |
|
2 |
1307 |
1221 |
1140 |
1139 |
1077 |
1019 |
|
4 |
2275 |
2168 |
2032 |
2043 |
1938 |
1831 |
|
8 |
3879 |
3746 |
3606 |
3681 |
3523 |
3320 |
|
16 |
4374 |
4527 |
4393 |
6131 |
5881 |
5573 |
|
32 |
4591 |
4864 |
4698 |
7762 |
7549 |
7139 |
|
64 |
4688 |
5078 |
4910 |
7536 |
7269 |
6994 |
На рис. 1. изображен график, который представляет результаты в более наглядном виде.
Прежде чем интерпретировать результаты, следует немного рассказать о самом эталонном тесте. Мы запускали его на машине Cisco UCS С250 с двумя шестиядерными процессорами, каждый из которых имеет два аппаратных потока. Сервер содержит 384 Гбайт ОЗУ, но мы провели тест с объемом данных 2,5 Гбайт, поэтому настроили для MySQL пул буферов размером 4 Гбайт. Эталонным тестом была стандартная рабочая нагрузка «только для чтения» SysBench, причем все данные были в InnoDB, хранились в оперативной памяти и зависели только от быстродействия центрального процессора. Мы провели 60-минутный тест для каждой точки замера, измеряя пропускную способность каждые 10 секунд и используя 900 секунд измерений после прогрева и стабилизации сервера для получения окончательных результатов.
Теперь, глядя на результаты, мы можем заметить две основные тенденции. Во-первых, версии MySQL, которые включают плагин InnoDB, намного лучше работают при более высокой степени конкурентности, то есть они более масштабируемы.
Этого следовало ожидать, так как нам известно, что предыдущие версии серьезно ограничены в плане поддержки конкурентности. Во-вторых, более новые версии MySQL медленнее старых при однопоточных рабочих нагрузках, чего вы, возможно, и не ожидали. Но это легко объяснить, отметив, что нагрузка «только для чтения» — очень простая рабочая нагрузка. Новые версии серверов имеют более сложную грамматику SQL и множество других функций и улучшений, которые позволяют производить более сложные запросы, но также требуют дополнительных издержек для простых запросов, которые мы как раз и использовали в эталонном тесте. Старые версии сервера проще и, следовательно, имеют преимущество при выполнении простых запросов.

Рис. 1. Эталонный тест блокировки «только для чтения» нескольких версий MySQL
Мы хотели показать вам более сложный эталонный тест чтения/записи (например, ТРС-С) с более высокой степенью конкурентности, но не смогли сделать это для большого количества столь разных версий сервера. И можем сказать, что в целом новые версии сервера имеют более высокую и более стабильную производительность при сложных нагрузках, особенно при высокой степени конкурентности, и с большим набором данных.
MySQL 8.0 еще слишком сырая и по ней накоплено мало статистики. Ее следует использовать только тогда, когда Вам необходимы новые функции этой версии, описанные по ссылке в статье выше.
Какую версию лучше использовать вам? Это зависит от особенностей вашего бизнеса больше, чем от технических потребностей. В идеале вы должны ориентироваться на самую новую из доступных версий, но, конечно, можете подождать до тех пор, пока не появится новейшая версия с первыми исправлениями ошибок. Если вы только разрабатываете приложение, то есть еще не выпустили его, можете задуматься о его создании в следующей версии, чтобы максимально отсрочить обновление и увеличить жизненный цикл.
Вас заинтересует / Intresting for you:

Другие статьи автора:
oracle-patches.com
Как узнать версию MySQL?
Получить версию бд можно как из консоли, так и средствами языка mySQL.
Версия из консоли UNIX
Тут все просто. Получаем версию из консоли.
mysql -V выведет что то вроде: mysql Ver 15.1 Distrib 5.5.56-MariaDB, for Linux (x86_64) using readline 5.1
mysql -V выведет что то вроде: mysql Ver 15.1 Distrib 5.5.56-MariaDB, for Linux (x86_64) using readline 5.1 |
Версия из SQL консоли
Как получить версию mySQL не из unix консоли, а средствами самого sql. Рассмотрим полезные команды.
Во первых, можно обратиться к значению переменной @@version;
Если у вас используется продукт от Oracle, т.е. оригинальная mySQL, то вы получите однозначное значение версии. Но из-за вопросов лицензирования сейчас широко используется MariaDB, которая обеспечивает точное соответствие с API и командами MySQL, но распространяется под GNU GPL (лицензия на свободное программное обеспечение).
Потому вы скорее всего получите следующий результат:
+——————+ | @@version | +——————+ | 10.0.24-MariaDB | +——————+ 1 row in set (0.00 sec)
+——————+ | @@version | +——————+ | 10.0.24-MariaDB | +——————+ 1 row in set (0.00 sec) |
Тоже самое вы получите и выполнив команду:
Очевидно это не то, что нам нужно, т.к. не ясно какая версия у mySQL.
Тогда можно попробовать команду статуса или прочитать глобальные переменные:
Первой строкой в ответе будет показана версия (вроде такой):
mysql Ver 15.1 Distrib 5.5.56-MariaDB, for Linux (x86_64) using readline 5.1
mysql Ver 15.1 Distrib 5.5.56-MariaDB, for Linux (x86_64) using readline 5.1 |
Здесь 5.5.56 — это как раз соответствие с оракловcкой версией mysql. После 5.5-й версии MariaDB стали нумеровать свои версии иначе, чем MySQL, т.к. они поддерживают не все новые фичи которые реализованы в MySQL 5.6.
Давайте заглянем еще и в глобальные переменные:
MariaDB [(none)]> show global variables like ‘%vers%’; +—————————+——————+ | Variable_name | Value | +—————————+——————+ | innodb_version | 5.6.28-76.1 | | protocol_version | 10 | | slave_type_conversions | | | thread_pool_oversubscribe | 3 | | version | 10.0.24-MariaDB | | version_comment | MariaDB Server | | version_compile_machine | x86_64 | | version_compile_os | Linux | | version_malloc_library | system | +—————————+——————+ 9 rows in set (0.00 sec)
MariaDB [(none)]> show global variables like ‘%vers%’; +—————————+——————+ | Variable_name | Value | +—————————+——————+ | innodb_version | 5.6.28-76.1 | | protocol_version | 10 | | slave_type_conversions | | | thread_pool_oversubscribe | 3 | | version | 10.0.24-MariaDB | | version_comment | MariaDB Server | | version_compile_machine | x86_64 | | version_compile_os | Linux | | version_malloc_library | system | +—————————+——————+ 9 rows in set (0.00 sec) |
Здесь версия mysql никак не обнаруживается, но зато мы можем узнать версию innodb.
Данная запись опубликована в 03.09.2018 16:15 и размещена в mySQL. Вы можете перейти в конец страницы и оставить ваш комментарий.
shra.ru
Тест производительности MySQL: MySQL 5.7 против MySQL 8.0
MySQL 8.0 принес огромные изменения и модификации, которые были выдвинуты Oracle MySQL Team. Физические файлы были изменены. Например, * .frm, * .TRG, * .TRN и * .par больше не существуют. Было добавлено множество новых функций, таких как CTE (общие табличные выражения), оконные функции, невидимые индексы, регулярные выражения (или регулярные выражения) – последнее было изменено и теперь обеспечивает полную поддержку Unicode и является многобайтовой безопасностью. Словарь данных также изменился. Теперь он включен в словарь транзакционных данных, в котором хранится информация об объектах базы данных. В отличие от предыдущих версий, словарные данные хранились в файлах метаданных и нетранзакционных таблицах. Безопасность была улучшена с новым дополнениемcaching_sha2_password, который теперь является аутентификацией по умолчанию, заменяющей mysql_native_password, и предлагает большую гибкость, но ужесточенную защиту, которая должна использовать либо защищенное соединение, либо незашифрованное соединение, поддерживающее обмен паролями с использованием пары ключей RSA.Со всеми этими классными функциями, улучшениями, улучшениями, которые предлагает MySQL 8.0, наша команда заинтересовалась, чтобы определить, насколько хорошо работает текущая версия MySQL 8.0, особенно учитывая, что наша поддержка версий MySQL 8.0.x в ClusterControl находится в процессе (так что следите за обновлениями). на этом. В этом посте не будут обсуждаться возможности MySQL 8.0, но мы намерены сравнить его производительность с MySQL 5.7 и посмотреть, как она улучшилась.
Настройка сервера и среды
Для этого теста мы намерены использовать минимальную настройку для производства с использованием следующей среды AWS EC2:
- Тип экземпляра: t2.xlarge instance
- Хранилище: gp2 (SSD-хранилище с минимальной 100 и максимальной 16000 IOPS)
- vCPUS: 4
- Память: 16 ГБ
- MySQL 5.7 версия: MySQL Community Server (GPL) 5.7.24 Версия
- MySQL 8.0: MySQL Community Server – GPL 8.0.14
Есть несколько переменных, которые мы установили для этого теста, а именно:
- innodb_max_dirty_pages_pct = 90 ## Это значение по умолчанию в MySQL 8.0.
- innodb_max_dirty_pages_pct_lwm = 10 ## Это значение по умолчанию в MySQL 8.0
- innodb_flush_neighbors = 0
- innodb_buffer_pool_instances = 8
- innodb_buffer_pool_size = 8GiB
Остальные переменные, устанавливаемые здесь для обеих версий (MySQL 5.7 и MySQL 8.0), уже настроены ClusterControl для своего шаблона my.cnf.
Кроме того, пользователь, которого мы здесь использовали, не соответствует новой аутентификации MySQL 8.0, которая использует caching_sha2_password. Вместо этого обе версии сервера используют mysql_native_password, а переменная innodb_dedicated_server имеет значение OFF (по умолчанию), что является новой функцией MySQL 8.0.
Чтобы упростить жизнь, мы настроили узел версии MySQL 5.7 Community с ClusterControl с отдельного узла, затем удалили узел в кластере и выключили узел ClusterControl, чтобы сделать узел MySQL 5.7 бездействующим (без трафика мониторинга). Технически, оба узла MySQL 5.7 и MySQL 8.0 неактивны, и через них никакие активные соединения не проходят, так что это по сути чистый тест бенчмаркинга.
Используемые команды и сценарии
Для этой задачи sysbench используется для тестирования и моделирования нагрузки для двух сред. Вот следующие команды или сценарий, используемые в этом тесте:
sb-prepare.sh
#!/bin/bash
host=$1 #host192.168.10.110 port=3306 user='sysbench' password='@MysqP@66w0rd' table_size=500000 rate=20 ps_mode='disable' sysbench /usr/share/sysbench/oltp_read_write.lua --db-driver=mysql --threads=1 --max-requests=0 --time=3600 --mysql-host=$host --mysql-user=$user --mysql-password=$password --mysql-port=$port --tables=10 --report-interval=1 --skip-trx=on --table-size=$table_size --rate=$rate --db-ps-mode=$ps_mode prepare
sb-run.sh
#!/usr/bin/env bash
host=$1
port=3306
user="sysbench"
password="@MysqP@66w0rd"
table_size=100000
tables=10
rate=20
ps_mode='disable'
threads=1
events=0
time=5
trx=100
path=$PWD
counter=1
echo "thread,cpu" > ${host}-cpu.csv
for i in 16 32 64 128 256 512 1024 2048;
do
threads=$i
mysql -h $host -e "SHOW GLOBAL STATUS" >> $host-global-status.log
tmpfile=$path/${host}-tmp${threads}
touch $tmpfile
/bin/bash cpu-checker.sh $tmpfile $host $threads &
/usr/share/sysbench/oltp_read_write.lua --db-driver=mysql --events=$events --threads=$threads --time=$time --mysql-host=$host --mysql-user=$user --mysql-password=$password --mysql-port=$port --report-interval=1 --skip-trx=on --tables=$tables --table-size=$table_size --rate=$rate --delete_inserts=$trx --order_ranges=$trx --range_selects=on --range-size=$trx --simple_ranges=$trx --db-ps-mode=$ps_mode --mysql-ignore-errors=all run | tee -a $host-sysbench.log
echo "${i},"`cat ${tmpfile} | sort -nr | head -1` >> ${host}-cpu.csv
unlink ${tmpfile}
mysql -h $host -e "SHOW GLOBAL STATUS" >> $host-global-status.log
done
python $path/innodb-ops-parser.py $host
mysql -h $host -e "SHOW GLOBAL VARIABLES" >> $host-global-vars.log
Таким образом, скрипт просто подготавливает схему sbtest и заполняет таблицы и записи. Затем он выполняет чтение/запись нагрузочных тестов, используя скрипт /usr/share/sysbench/oltp_read_write.lua. Сценарий сбрасывает глобальное состояние и переменные MySQL, собирает данные об использовании процессора и анализирует операции строки InnoDB, обработанные сценарием innodb-ops-parser.py. Затем сценарии генерируют файлы * .csv на основе выгруженных журналов, которые были собраны во время теста, затем мы использовали электронную таблицу Excel, чтобы сгенерировать график из файлов * .csv.
Теперь перейдем к результатам графика!
Операции со строками в InnoDB
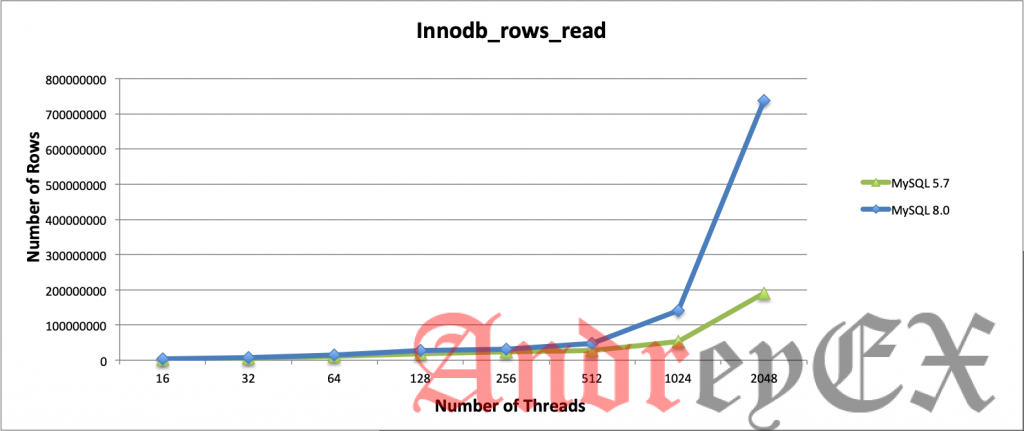
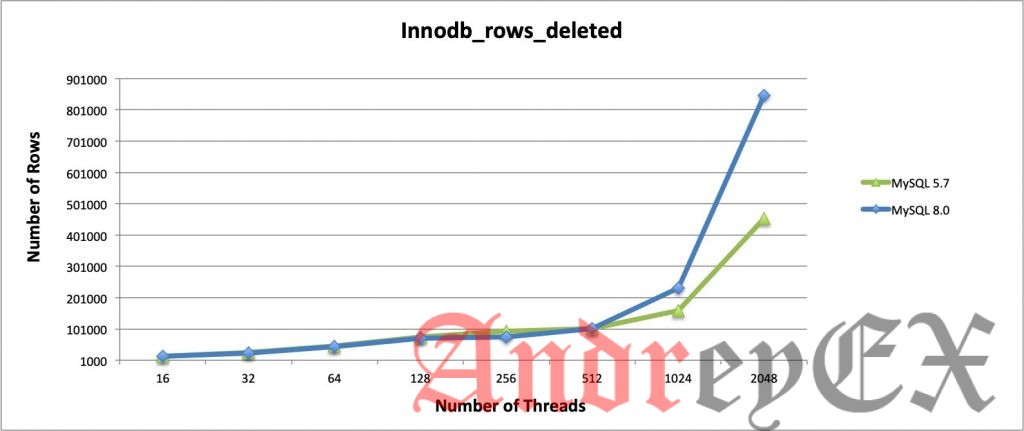
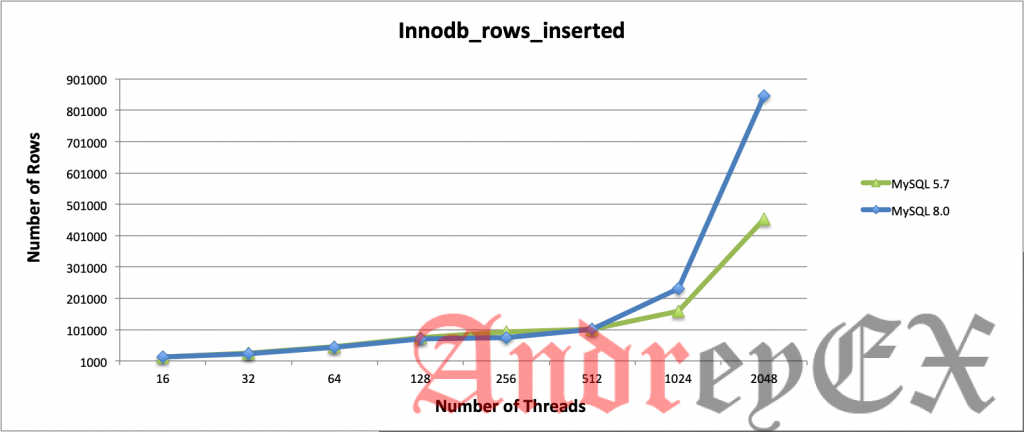
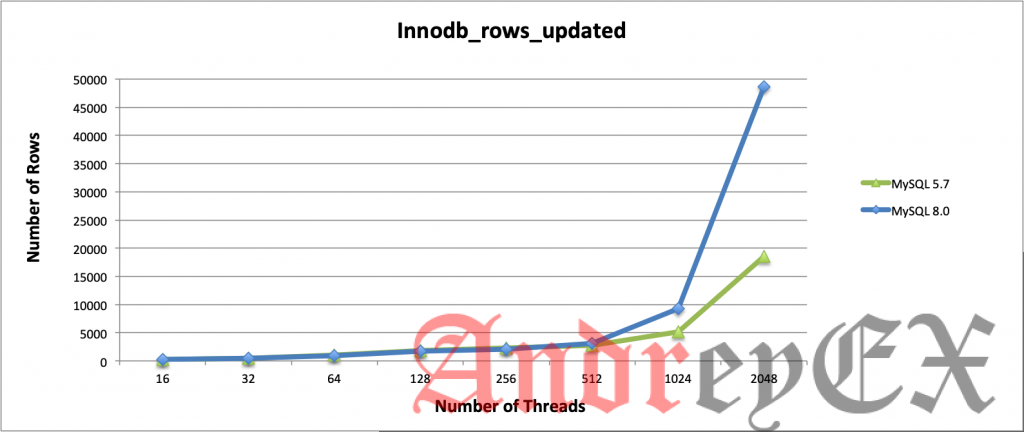
В основном здесь мы извлекли только строковые операции InnoDB, которые выполняют выбор (чтение), удаление, вставку и обновление. Когда количество потоков увеличивается, MySQL 8.0 значительно превосходит MySQL 5.7! Обе версии не имеют каких-либо конкретных изменений конфигурации, но только заметные переменные, которые мы установили. Таким образом, обе версии в значительной степени используют значения по умолчанию.
Интересно, что в отношении заявлений MySQL Server Team о производительности операций чтения и записи в новой версии графики указывают на значительное улучшение производительности, особенно на сервере с высокой нагрузкой. Представьте разницу между MySQL 5.7 и MySQL 8.0 для всех операций с строками InnoDB, есть большая разница, особенно когда количество потоков увеличивается. MySQL 8.0 показывает, что он может работать эффективно независимо от его рабочей нагрузки.
Обработанные транзакции
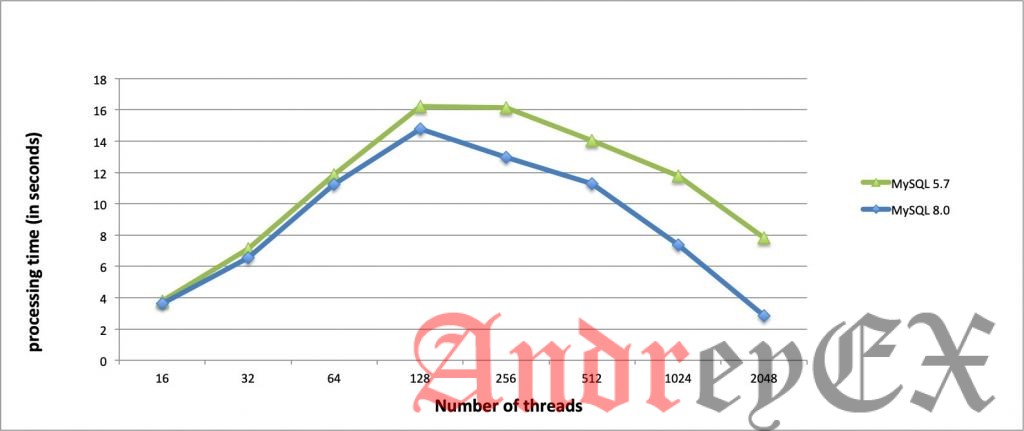
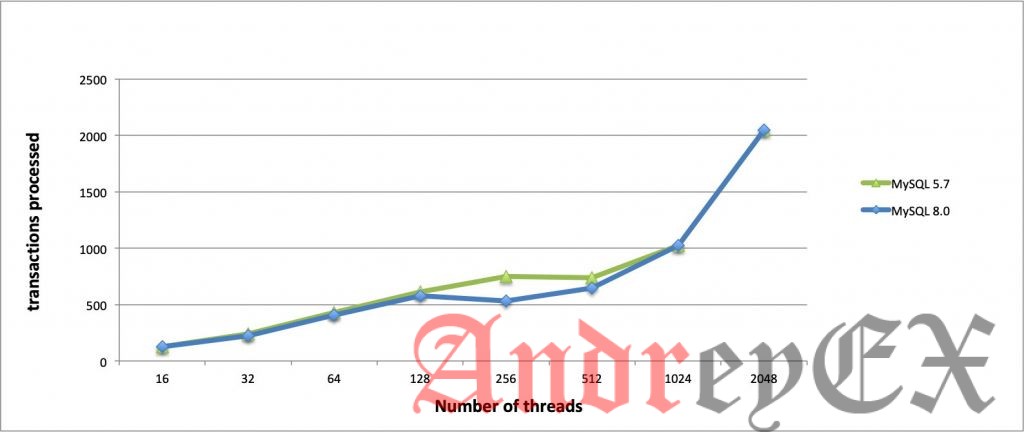
Как показано на графике выше, производительность MySQL 8.0 снова показывает огромную разницу во времени, необходимом для обработки транзакций. Чем ниже, тем лучше он работает, а значит быстрее обрабатывать транзакции. Обработанные транзакции (второй график) также показывают, что оба числа транзакций не отличаются друг от друга. Это означает, что обе версии выполняют почти одинаковое количество транзакций, но отличаются тем, насколько быстро они могут завершиться. Хотя мы могли бы сказать, что MySQL 5.7 все еще может справляться с большими нагрузками при более низкой нагрузке, но можно ожидать, что реалистичная нагрузка, особенно в производстве, будет выше, особенно в самый загруженный период.
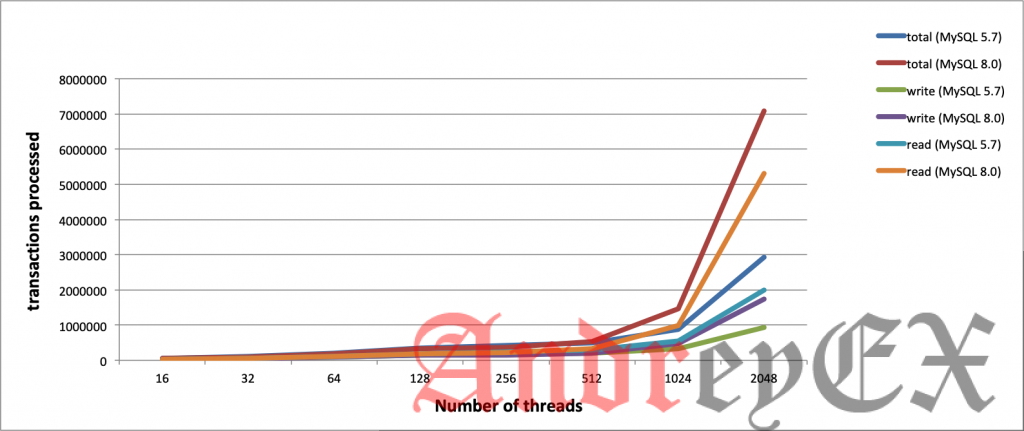
Приведенный выше график все еще показывает транзакции, которые он смог обработать, но отделяет чтение от записи. Тем не менее, на графиках есть выбросы, которые мы не включили, так как они представляют собой небольшие кусочки результата, которые искажают график.
MySQL 8.0 показывает большие улучшения, особенно для чтения. Он показывает свою эффективность в записи особенно для серверов с высокой рабочей нагрузкой. Некоторая отличная дополнительная поддержка, которая влияет на производительность MySQL для операций чтения в версии 8.0, – это возможность создавать индексы в порядке убывания (или прямого сканирования индекса). Предыдущие версии имели только сканирование по возрастанию или обратному индексу, и MySQL должен был выполнять сортировку файлов, если требовался сортировка по убыванию (если нужна сортировка файлов, вы можете проверить значение max_length_for_sort_data). Нисходящие индексы также позволяют оптимизатору использовать многостолбцовые индексы, когда наиболее эффективный порядок сканирования смешивает восходящий порядок для некоторых столбцов и нисходящий порядок для других. Смотрите здесь для более подробной информации.
Ресурсы процессора
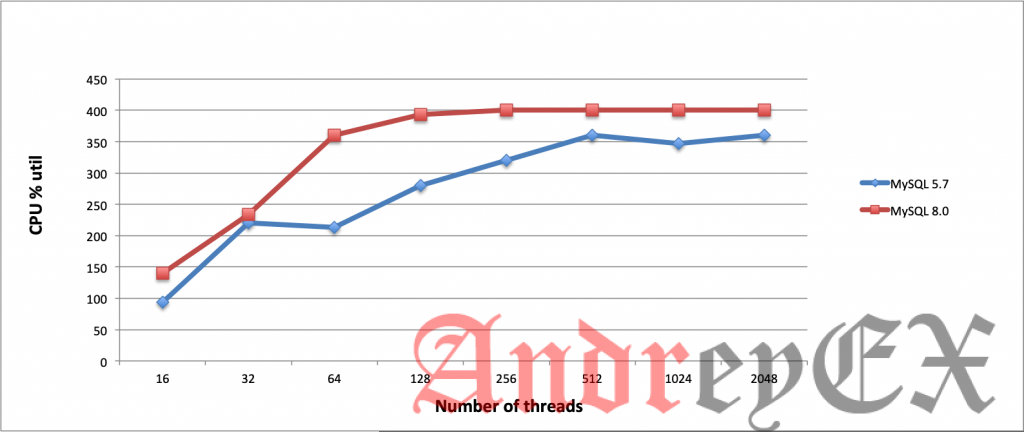
Во время этого бенчмаркинга мы решили использовать некоторые аппаратные ресурсы, в частности, загрузку процессора.
Позвольте нам сначала объяснить, как мы используем ресурсы ЦП здесь во время бенчмаркинга. sysbench не включает в себя коллективную статистику для аппаратных ресурсов, использованных или используемых в процессе, когда вы сравниваете базу данных. Из-за этого мы создали флаг, создав файл, подключившись к целевому хосту через SSH, а затем собрав данные из команды top в Linux и проанализировав их во время сна на секунду, а затем собрали снова. После этого возьмите самое значительное увеличение использования ЦП для процесса mysqld, а затем удалите файл флага.
Итак, давайте снова поговорим о графике, кажется, что он показывает, что MySQL 8.0 потребляет много ресурсов процессора. Больше, чем MySQL 5.7. Однако, возможно, придется иметь дело с новыми переменными, добавленными в MySQL 8.0. Например, эти переменные могут повлиять на ваш сервер MySQL 8.0:
- innodb_log_spin_cpu_abs_lwm = 80
- innodb_log_spin_cpu_pct_hwm = 50
- innodb_log_wait_for_flush_spin_hwm = 400
- innodb_parallel_read_threads = 4
Переменные с их значениями оставлены значениями по умолчанию для этого теста. Первые три переменные обрабатывают ЦП для повторного ведения журнала, что в MySQL 8.0 было улучшением из-за перепроектирования того, как InnoDB записывает в журнал REDO. Переменная innodb_log_spin_cpu_pct_hwm имеет привязку к процессору, что означает, что она будет игнорировать другие ядра процессора, если mysqld прикреплен только к 4 ядрам, например. Для параллельных потоков чтения в MySQL 8.0 добавлена новая переменная, для которой вы можете настроить количество используемых потоков.
Однако мы не стали углубляться в эту тему. Могут быть способы повышения производительности за счет использования функций, предлагаемых MySQL 8.0.
Заключение
Есть множество улучшений, которые присутствуют в MySQL 8.0. Результаты тестирования показывают, что произошло впечатляющее улучшение не только в управлении рабочими нагрузками чтения, но также и в высокой рабочей нагрузке чтения/записи по сравнению с MySQL 5.7.
Переходя к новым функциям MySQL 8.0, похоже, что он использует преимущества самых современных технологий не только в программном обеспечении (например, значительное улучшение для Memcached, удаленное управление для лучшей работы DevOps и т. д.), Но и также в оборудовании. Например, замена latin1 на UTF8MB4 в качестве кодировки символов по умолчанию. Это будет означать, что для этого потребуется больше дискового пространства, поскольку UTF8 требуется 2 байта для символов, не входящих в US-ASCII. Хотя в этом тесте не использовался новый метод аутентификации с caching_sha2_password, это не повлияет на производительность, если он использует шифрование. После аутентификации он сохраняется в кеше, что означает, что аутентификация выполняется только один раз. Поэтому, если вы используете одного пользователя для своего клиента, это не будет проблемой и будет более безопасным, чем предыдущие версии.
Поскольку MySQL использует самое современное аппаратное и программное обеспечение, он меняет свои переменные по умолчанию.
В целом, MySQL 8.0 эффективно доминирует над MySQL 5.7.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
andreyex.ru
Анонсирован стабильный релиз MySQL 5.6 / Habr
5 февраля компания Oracle анонсировала выпуск стабильного релиза MySQL версии 5.6. В новой версии проделана огромная работа. Основные усилия были направлены на повышение производительности, масштабируемости и гибкости. Масштабным по значимости изменениям подвергся движок InnoDB.К ключевым улучшения можно отнести: поддержка средств полнотекстового поиска, возможность доступа к данным через memcached API, увеличена производительность работы при интенсивной записи данных, а также увеличена масштабируемость при обработке большого числа одновременных запросов.
Еще одним новшеством версии 5.6 является возможность исполнения DDL-операций (Data Definition Language) без перевода СУБД в офлайн и прерывания доступа к таблицам. Администраторы получают возможность производить операции связанные с сбросом схемы, добавлением или удалением столбцов данных или переименованием столбцов без отключения СУБД. Ранее подобные возможности были доступны только в NoSQL-продуктах.
В сравнении с версией 5.5 новинка теперь может работать на 48-ядерных серверах, против 32-ядерных в MySQL 5.5
Немного подробнее о ключевых возможностях:
- Реализован интерфейс для прямого доступа к таблицам InnoDB в стиле NoSQL-систем с использованием API, манипулирующего парами ключ/значение и совместимого с memcached.
- Появилась возможность создания в InnoDB полнотекстовых индексов для организации быстрого поиска по словоформам среди текстового контента, хранимого в таблицах InnoDB. Ранее полнотекстовый поиск был доступен только для таблиц MyISAM.
- Повышение эффективности оптимизатора запросов, оптимизация процесса выбора результирующего набора значений, сортировки и выполнения запроса. Новые оптимизации Index Condition Pushdown (ICP) и Batch Key Access (BKA) позволяют до 280 раз увеличить пропускную способность выполнения некоторых запросов. Увеличена эффективность выполнения запросов вида «SELECT… FROM single_table… ORDER BY non_index_column [DESC] LIMIT [M,]N;». Увеличена производительность запросов «SELECT… LIMIT N» выводящих только часть строк из большой выборки.
- Расширены средства диагностики работы оптимизатора, добавлена поддержка EXPLAIN для операций INSERT, UPDATE и DELETE. Результаты работы EXPLAIN теперь могут быть выведены в формате JSON. Новый режим трассировки оптимизатора позволяет проследить за каждым принятым решением в процессе оптимизации запроса.
- Дополнительные оптимизации выполнения подзапросов, при которых вложенные запросы вида «SELECT… FROM table1 WHERE… IN (SELECT… FROM table2 …))» транслируются в более оптимальное представление на стадии до непосредственного выполнения запроса, например, заменяются на более эффективный JOIN.
- Расширение реализации системы диагностики PERFORMANCE_SCHEMA, предоставляющей низкоуровневые средства для мониторинга за выполнением запросов и различными событиями при работе СУБД. PERFORMANCE_SCHEMA позволяет детально оценить узкие места при выполнении длительных запросов, а также представить сводную статистику, сгруппированную по запросам, нитям, пользователям, хостам и объектам.
- Улучшена реализация движка InnoDB, отмечается рост производительности при выполнении транзакций и при активности с преобладанием операций чтения данных — в некоторых ситуациях ускорение достигает 230%.
- Режим отложенной репликации, позволяющий реплицировать данные не сразу, а с определённой задержкой, что позволяет обеспечить защиту от ошибок оператора (например, случайное удаление содержимого таблиц).
- Увеличение максимального размера файлов с логами изменений (InnoDB Redo Log) с 4 Гб до 2 Тб.
- Улучшение безопасности: поддержка указания параметров аутентификации в файле .mylogin.cnf в зашифрованном виде; добавление плагина sha256_password для хранения хэшей паролей с использованием алгоритма SHA-256; добавление в таблицу mysql.user поля со временем истечения действия пароля; новая SQL-функций VALIDATE_PASSWORD_STRENGTH() для оценки надёжности пароля.
- Поддержка запуска сервера в режиме только для чтения (опция —innodb-read-only, только для InnoDB).
- Поддержка указания дробных значений секунд в функциях TIME, DATETIME и TIMESTAMP для указания микросекунд.
- Прекращена поддержка опций «—log», «—log-slow-queries», «—one-thread», «—safe-mode», «—skip-thread-priority», «—table-cache».
Более подробно ознакомится с новшествами вы можете на соответствующей странице.
В связи с данным релизом становится более интересным соперничество MySQL и MariaDB, которая в последнее время стремительно вытесняет MySQL из дистрибутивов. На данный момент это произошло в Fedora и OpenSUSE.
Страница загрузки
MySQL 5.6 Reference Manual
habr.com
Практический опыт обновления MySQL 5.7 до версии 8.0 / Habr
Недавно мы обновили свои сервера с MySQL 5.7 на 8.0.
Оставим за рамками этой статьи зачем и какие новые плюшки появились в MySQL 8.0, а вместо этого расскажем о том, с какими сложностями мы столкнулись в процессе обновления.
Во-первых, перед обновлением стоит посмотреть на список изменений и поправить свой конфиг-файл.
Как минимум, удалены следующие параметры:
innodb_file_format, innodb_file_format_check, innodb_file_format_max,innodb_large_prefix
query_cache_limit, query_cache_min_res_unit, query_cache_size, query_cache_type, query_cache_wlock_invalidate.
В параметре sql_mode удалён в частности NO_AUTO_CREATE_USER — что особенно важно, т.к. в MySQL 5.7 он был включен по-умолчанию.
Инструкция по in-place upgrade есть у Percona. И в общем случае можно следовать ей, однако нам удалось так обновить только один кластер, у остальных попытка такого обновления заканчивалась неудачно с подобной ошибкой:
2019-06-22T05:04:18.510888Z 1 [ERROR] [MY-011014] [Server] Found partially upgraded DD. Aborting upgrade and deleting all DD tables. Start the upgrade process again.
2019-06-22T05:04:23.115018Z 0 [ERROR] [MY-010020] [Server] Data Dictionary initialization failed.
2019-06-22T05:04:23.115655Z 0 [ERROR] [MY-010119] [Server] Aborting
Поэтому остальные кластеры мы обновляли путем поднятия нового пустого инстанса и восстановления дампа БД с предыдущей версии.
Чтобы сделать такое, во-первых, потребуется дамп БД. И тут поджидает опасность #1 — сделанный стандартным образом дамп:
mysqldump -u root -p --hex-blob --default-character-set=utf8mb4 --all-databases --triggers --routines --events > dump.sqlне восстанавливается, выдавая ошибку:
ERROR 3554 (HY000) at line 15915: Access to system table 'mysql.innodb_index_stats' is rejected.
Описание есть в багтрекере MySQL (со статусом Not a bug :), там же есть и совет как делать дамп, чтобы его таки можно было восстановить:
mysqldump -u root -p --hex-blob --default-character-set=utf8mb4 --all-databases --triggers --routines --events --ignore-table=mysql.innodb_index_stats --ignore-table=mysql.innodb_table_stats > dump.sqlНо при попытке использовать такой дамп, если в нём присутствовали триггеры (а у нас они были), может поджидать опасность #2, в виде вот такой ошибки:
ERROR 1231 (42000) at line 54: Variable 'sql_mode' can't be set to the value of 'NO_AUTO_CREATE_USER'
Причина этого в том, как MySQL использует sql_mode для триггеров, а именно: MySQL сохраняет значение sql_mode для триггера в момент его создания и выполняет его потом всегда с этим значением. И соответственно сохраняет это значение в дамп.
Описание этого в справке:
dev.mysql.com/doc/refman/8.0/en/create-trigger.html
MySQL stores the sql_mode system variable setting in effect when a trigger is created, and always executes the trigger body with this setting in force, regardless of the current server SQL mode when the trigger begins executing.
Что же нам делать? Мы просто с помощью sed вырезали NO_AUTO_CREATE_USER из готового дампа. Подобной командой:
sed "s/50003 SET sql_mode = 'STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER/50003 SET sql_mode = 'STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO/g" dump.sql > dump2.sql
После этого дамп успешно восстанавливается, но нас поджидает опасность #3 (вполне ожидаемая правда) — системные таблицы восстановлены в состоянии от версии 5.7 и в логах у нас следующие ошибки:
[ERROR] [MY-013143] [Server] Column count of mysql.user is wrong. Expected 51, found 45. The table is probably corruptedПо опыту работы с прошлыми версиями это лечится запуском mysql_upgrade — но начиная с версии 8.0.16 — это не работает, т.к. mysql_upgrade объявлен deprecated и ничего не делает.
Теперь, чтобы вызвать обновление системных таблиц, необходимо запустить MySQL с опцией upgrade=FORCE.
На свежей ubuntu это можно сделать следующим образом:
systemctl set-environment MYSQLD_OPTS="--upgrade=FORCE"После чего перезапустить MySQL. Ну и после успешного обновления удалить её:
systemctl unset-environment MYSQLD_OPTShabr.com
Переход на MySQL 5.6, а стоит ли? / Habr
После выхода новой версии MySQL в начале этого года, многие задумались о том стоит ли на неё переходить с более старых версий. Чтобы ответить на этот вопрос для себя, вначале необходимо понять, а что именно даст этот переход. В этой статье я постараюсь осветить новые, важные для меня, фичи, которые были включены в дистрибутив новой версии, анализ их производительности и работоспособность новой версии, а так же необходимость что-то менять в коде в связи в переписанным оптимизатором. Так как объем изменений действительно очень велик, для каждого пункта дам ссылку на оригинальную статью по тестирования производительности и исключу из описания воду.Начнем с самого интересного — расширения оптимизатора
Index Condition Pushdown (ICP) — данная оптимизация производится, если мы получаем доступ к данным в таблице с использованием составного индекса. Если условие на первую часть ключа может быть применено явно, а условие на оставшуюся часть ключа явно применено быть не может к примеру:
keypart1 = 1— предикат доступа,keypart2 like ‘%value%’— предикат фильтрации,- или же наложить на обе части ключа range условие
keypart1 between a and b— предикат доступа,keypart2 between c and d— предикат фильтрации (полное использование индекса для данного типа запросов в качестве предиката доступа вMySQLдо сих пор не реализовано),
то ранее сервер
MySQL, после применения предиката доступа, сделал бы переключение на storage engine и, прочитав строку таблицы, применил бы второе условие. С использованием данной опции, этого переключения не будет, конечно если сам storage engine поддерживает ICP, на данный момент это MyISAM и InnoDB, и применение предиката фильтрации будет произведено исключительно на основании данных индекса. В плане будет стоять Using index condition.Согласно тестированию производительность при запросе данных из кэша составит порядка 30-50 процентов, при работе же с подсистемой ввода вывода возможно ускорение до 100 раз.
Multi Range Read (MRR) — при проведение
Range Scan с использованием вторичных ключей, для уменьшения количества произвольных дисковых чтений, вначале считываем все необходимые данные из индекса, затем производим сортировку по ROWID, и только после этого читаем данные по первичному ключу. В плане, что несомненно замечательно, будет стоять Using MRR. Данная операция является балковой. Т.е. применяя предикаты доступа по вторичному ключу — заполняем доступный буфер, и только после этого производим сортировку и чтение данных. Тут уж либо повезло и данные близко друг к другу либо нет. Для распределенных таблиц ситуация ещё лучше но это выходит за рамки этой статьи. В чистом виде данный алгоритм может быть применен при выполнении запроса по одной таблице. В сочетании с Batch Key Access (BKA) он так же заметно позволяет ускорить и операции джойнов. По умолчанию флаг BKA выключен, его значение, как и любое значение флагов оптимизатора можно посмотреть выполнив запрос SELECT @@optimizer_switch. При включение BKA необходимо провести проверки ваших запросов на разных значениях параметра join_buffer_size так как именно этот параметр будет использован для вычисления максимального размера буфера. При применении этого замечатльного алгоритма в плане запроса мы увидим Using join buffer (Batched Key Access). Более детальное освещение темы тут. Согласно результатам тестирования данная оптимизация может давать значительные ускорения только при условии ввода вывода и работы с диском. В этом случае вы можете получить 10-ти кратное ускорение только с MRR. В ряде других синтетических тестов были получены ускорения до 280 раз, при совместном использовании MRR и BKA. При работе же исключительно с памятью, ускорения вы не получите, что вполне логично, так как данная операция призвана оптимизировать исключительно ввод вывод.File Sort Optimization — сортировка по неиндексированной колонке стала значительно более производительна, при соблюдении некоторых условий. Раньше при выполнении данного вида сортировки единственно возможным вариантом была сортировка слиянием. Грубо говоря, данные полученные в результате запроса сохранялись во временную таблицу. После этого для данной таблицы производилась сортировка и возвращались записи удовлетворяющие условию
LIMIT. Как видно данный алгоритм не очень производителен, особенно если у вас много запросов, возвращающих малое количество строк. Для того чтобы оптимизировать ввод вывод алгоритм был изменен на следующий. Если количество записей полученных в результате выполнения запроса полностью помещается в sort_buffer_size, при сканировании таблицы создается очередь. Данная очередь является упорядоченной, и заполняется сразу в момент получения очередной строки результата запроса. Размер очереди N (или M + N если использована конструкция LIMIT M, N). При переполнении очереди лишние данные с конца выкидываются. Таким образом окончание сортировки производится одновременно с окончанием результата запроса, и полностью отсуствуют обращения ко временной таблице. Оптимизатор самостоятельно выбирает стратегию для проведения сортировки. Очередь будет использовна в том случае, когда необходимо больше загрузить процессор, сортировка слиянием когда доступна система ввода вывода.При проведении синтетических тестов было получено ускорение в 4 раза. Но так же необходимо понимать что данная оптимизация позволяет снизить нагрузку на подсистему ввода вывода, что положительно скажется на работе всего инстанса.
Subqueries optimisation
postpone materialization — в основном она касается ускорения построения плана запроса. Ранее при выполнении команды EXPLAIN подзапросы используемые в секции FROM материализовались для получения по ним статистических данных. Т.е. фактически производилось выполнение данных запросов на БД. Сейчас эта операция не производится, и получить план запроса стало возможно не нагружаю инстанс БД. Однако и время выполнения запросов так же может быть ускорено, к примеру если имеется 2 материализуемых представления в секции FROM и первое не вернуло ни одной записи то 2-ое не будет выполнено. Так же во время выполнения запроса, MySQL может самостоятельно проиндексировать полученную материализованную таблицу, если сочтет это необходимым. semi-join transformation — полусоединение может быть использовано для получения данных только из одной таблицы, на основании данных другой таблицы, во всех БД классическим примером является конструкция EXISTS. Использования этой оптимизации стало возможно и для конструкции IN которая раньше работала из рук вон плохо. Для того чтобы применение этой оптимизации стало возможно необходимо чтобы подзапрос удовлетворял следующим условиям: отсутствие UNION, отсутствие GROUP BY и HAVING, отсутствие ORDER BY с ограничением LIMIT (по отдельности данные конструкции могут быть использованы). Так же необходимо чтобы количество подзапросов не превышало максимальное количество таблиц допустимое для JOIN, так как в противном случае MySQL не сможет переписать данный запрос. Оптимизация достигается через переписывание запроса в SEMI JOIN или же через представление подзапроса в качестве VIEW в конструкции FROM и использование оптимизаций для postpone materialization описанных выше. Дублирующие записи из финального результата удаляются следующими способами:- при помощи помещения уникальных результатов финального запроса во временную таблицу (
Start temporaryиEnd temporaryв колонке планаExtra) - при помощи применения критерия “первый найденный” на этапе сканирования таблицы из подзапроса (
FirstMatch(tbl_name)в колонке планаExtra) - при помощи применения оптимизации Loose Index Scan (
LooseScan(m..n)где m и n — части ключа используемые для данной оптимизации)
При материализации и последующем индексировании подзапроса в колонке
select_type плана запроса будет стоять MATERIALIZED. Для понимания как именно был переписан запрос можно использовать стандартную команду EXPLAIN EXTENDED. Таким образом вы всегда поймете, как именно был переписан ваш запрос, и была ли применена оптимизация.Как вы понимаете переписывание криво написанных запросов (раньше за такие запросы я бы оторвал руки, сейчас это стало простительным) может дать просто бешеный прирост производительности, так что проводить тесты на
table pullout (вынос подзапроса из условия WHERE в условие FROM) практически лишено смысла, ибо и 1000-и кратный прирост производительности там будет не предел, однако если все ваши запросы написаны корректно, то можете не ждать чего-то экстраординарного от данного вида оптимизаций.Статичная статистика для
InnoDBНаконец-то свершилось. Не знаю откуда, из
Google, Percona или же из самого Oracle, но в MySQL появилась возможность исключить из построения плана запроса динамический семплинг. Теперь статистика по таблицам и индексам хранится в персистных таблицах. Данный метод сбора статистики включен по умолчанию. При обновление более 10% данных в таблице, статистика по ней пересобирается автоматически (конечно же это можно изменить). Так же сбор статистики можно запустить принудительно командой ANALYSE. Для принудительного сброса статистики, когда оптимизатор беспрецендентно тупит, можно вызвать команду FLUSH TABLE. Что именно собирается можно наглядно посмотреть в новых таблицах mysql.innodb_index_stats, mysql.innodb_table_stats. Это конечно не продвинутые оракляные гистограммы, но прогресс на лицо. Теперь планы стали более стабильны с одной стороны, а с другой у администраторов БД появилось новое развлечение: подадай когда статистика в таблице стала неактуальна, найди время простоя, угадай объем семплинга и пересчитай её, тем более как следует из блога разработчиков, статистику можно менять ручками, путем прямых апдейтов. Так же хотелось бы заметить что у меня при проведении тестов, сборщик статистики, видимо работающий в фоновом потоке, не успевал обрабатывать данные. Статистика на протяжении долгого времени оставалась пустой, пока я не запускал её анализ вручную. Анализ статистики для конкретной партиции запустить невозможно по этому приходилось проводить анализ всей партиционированной таблицы, что конечно же не очень удобно. Такая же ситуация возникает если провести активный DML и положить базу. Данные будут — статистики нет. Но думаю это исключительные ситуации и штатной работе базы данных они мешать не будут.В качестве вывода по оптимизатору считаю нелишним заметить, что оптимизатор Maria DB 5.5 по заключению специалистов является более навороченным, однако в версии MySQL 5.6 ряд аналогичных оптимизаций позволяет добиться более высокой производительности.
Больше мьютексов хороших и разных
Как всем хорошо известно MySQL не достаточно хорошо масштабируется на большое количество процессоров при большом количестве одновременно выполняемых транзакций. Причиной всему внутренние блокировки, в частности
kernel mutex, а так же принципиальные проблемы при работе с памятью в многоядерной архитектуре. Kernel mutex, удерживаемый на время копирования списка активных транзакций, был разделен на несколько мьютексов, для неблокирущих и блокирующий транзакций, блокировок, ожиданий блокировок и т.д. Так же была решена проблема false sharing’а, когда одно ядро подгружало необходимые ему неизменяемые данные, а другое необходимые ему изменяемые в одном cacheline, и как результат данные для первого ядра все время вымывались из кэша. Теперь для ряда критических объектов введено выравнивание в 64 байта.Согласно блогам разработчиков
MySQL стал масштабироваться на 50% лучше для read only транзакций. А прирост производительности при увеличении количества активных сессий составил до 600% по сравнению с предыдущей версией. При проведении независимых нагрузочных тестов, до 16 одновременных сессий — скорость работы не изменилась, выше — до 100% для смешанных транзакций на чтение запись и до 300% для транзакций read-only.Оптимизация сброса UNDO
Теперь стало возможно сбрасывать UNDO параллельно. Для этого необходимо выставить параметр
innodb_purge_threads в значени больше 1. Экспериментировать с этим параметром на промышленной БД будет разумно только тем, кто параллельно удаляет много данных из партиционированных таблиц. Улучшения производительности для тех кто не использует партиционирование или использует партиции для причин отличных от параллельного DML, к примеру архивирование, при котором DML операции производятся только с одной партицией, не будет, так как при сбросе данных вы повисните на блокировке dict_index_t::lock. Для них рекомендуется, как и раньше, просто выделить сброс данных в один, отдельный от основного, поток.Оптимизация сброса грязных блоков
Как известно сброс грязных блоков из памяти одно из самых проблемных мест для любой версионной базы данных. Сброс необходимой части блоков на диск может быть осуществлен либо главным
InnoDB Master Thread, и тогда будут ждать все, или, как в основном и бывает фоновым потоком, команду на сброс которому подаст конкретная сессия, и тогда эта сессия зависнет на неопределенное время, а остальные сесси заблокированы не будут. Для избежания проблем как в первом так и во втором случае был создан отдельный тред названный page_cleaner. Детальную информацию чем занят данный поток можно посмотреть тутselect name, comment from information_schema.innodb_metrics where name like 'buffer_flush_%';
Теперь сброс блоков действительно стал выполняться асинхронно. Если вы решите поиграть параметрами сброса блоков рекомендую так же обратить внимание на новые параметры оптимизации
LRU flush так как данные параметры, согласно заключению разработчиков MySQL, могут косвенно влиять друг на друга.Сброс блоков был одаптирован под SSD диски. Эта туманная фраза обозначает следующее. Как мы знаем кэширование блоков происходит страницами. 64 страницы образуют экстент. Соседями приянто называть эти самые последовательные страницы в рамках одного экстента. Раньше
InnoDB при изменении страниц пытался набрать целый экстент для сброса данных на диск для оптимизации ввода вывода, так как для HDD один мегабайт является оптимальным размером, что позволяет выполнить операцию за одно обращение к диску. Для SSD возможен размер сброса всего 4 килобайта, так что набирать что либо лишено смысла. В добавок сбрасывать неизмененные страницы тоже лишено смысла. Так что обладателям новомодного железа можно поиграть с параметром. В качестве вывода не лишне было бы заметить результаты вот этого теста.
Как видно из графиков при работе с кэшем новая версия с оптимизированным сбросом, проигрывает
MySQL 4.0.30 (причины выбора столько древней версии мне не известны) при малом количестве сессий, зато показывает на порядок лучший результат при масштабировании.При работе же с файловой системой результаты не столько впечатляющие и обе версии иду ноздря в ноздрю и MySQL 5.6 местами даже проигрывает. Однако согласно заключению автора, при выходе
5.6.12, данный недостаток будет устранен, и производительность скакнет в 3 раза. Т.е. для тех у кого проблемы с большим вводом выводом и активный сброс буферов на диски, стоит подождать выхода следующей версии, будет вам счастье.InnoDB: ALTER TABLE… ONLINE
Все дифирамбы данной технологии можно смело охарактеризовать двумя словами — банальная реклама. Согласно заявлениям разработчиков данная команда была переписана чуть более чем полностью однако получить от этого какие-то существенные преимущества у команды
InnoDB-engine не вышло. В online выполняется всего лишь ограниченное число крайне редкий операций, да ещё и с ограничениями. Понять что операция прошла online очень легко. В результате выполнения запроса вы получитеQuery OK, 0 rows affected
И так что же можно:
Ну вот собственно и все. Как видно из описания возможности предоставленные нам крайне скудны, будем надеяться, что в будущем ситуация улучшиться и изменения больших таблиц можно будет проводить без танцев с бубном, которые связаны с полным копированием таблицы при выполнении любой (с
MySQL 5.6 читаем любой за исключением 5-ти) DDL команды.Партиционирование
Был существенно переработан партиционный движок. Теперь выбор партиций на обработку выполняется раньше чем открытие таблиц и установка блокировок. Вот анализ ввода вывода при тривиальном запросе по партиционному ключу.
select count(1)
from part_table
where partition_key = 190110;
+----------+
| count(1) |
+----------+
| 500 |
+----------+
1 row in set (0.50 sec)
Ввод вывод и пул буферов
select count(distinct file_name) file_name_count,
sum(sum_number_of_bytes_read) sum_number_of_bytes_read,
min(substring_index(file_name, '/', -1)) min_file_name,
max(substring_index(file_name, '/', -1)) max_file_name
from performance_schema.file_summary_by_instance
where file_name like '%part_table%.ibd' and count_read + count_write > 0
order by 1;
-- Server version: 5.5
+-----------------+--------------------------+------------------------------------+------------------------------------+
| file_name_count | sum_number_of_bytes_read | min_file_name | max_file_name |
+-----------------+--------------------------+------------------------------------+------------------------------------+
| 1024 | 107692032 | part_table#P#part_table_184609.ibd | part_table#P#part_table_190110.ibd |
+-----------------+--------------------------+------------------------------------+------------------------------------+
-- Server version: 5.6
+-----------------+--------------------------+------------------------------------+------------------------------------+
| 1 | 98304 | part_table#P#part_table_190110.ibd | part_table#P#part_table_190110.ibd |
+-----------------+--------------------------+------------------------------------+------------------------------------+
select min(table_name) min_table_name,
max(table_name) max_table_name,
count(distinct table_name) file_name_count,
sum(data_size) pool_size
from information_schema.innodb_buffer_page
where table_name like '%part_table%';
-- Server version: 5.5
+--------------------------------------+--------------------------------------+-----------------+-----------+
| min_table_name | max_table_name | file_name_count | pool_size |
+--------------------------------------+--------------------------------------+-----------------+-----------+
| test/part_table#P#part_table_184609 | test/part_table#P#part_table_190110 | 1024 | 26567424 |
+--------------------------------------+--------------------------------------+-----------------+-----------+
-- Server version: 5.6
+--------------------------------------+--------------------------------------+-----------------+-----------+
| Partition `part_table_190110` | Partition `part_table_190110` | 1 | 32048 |
+--------------------------------------+--------------------------------------+-----------------+-----------+
Как видно в отличии от версии 5.5 статистика анализируется не по всем партициям указанной таблицы, а только по той которая соответствует условию. Что исключает подгрузку остальных партиций в буферный пул.
По блокировкам ничего пока не понятно, так как очень сильно поменялся сам алгоритм парсинга и ожидания выполнения запроса, из того что бросается в глаза, самый горячий мьютекс
wait/synch/mutex/mysys/THR_LOCK::mutex ранее блокируемый для каждой партиции стал использоваться гораздо реже, т.е. при запросе по одной партиции он блокируется не столько раз сколько всего партиций в данной таблице умножить на два, а всего один, что несомненно большой плюс. Других блокировок с похожим агрессивным поведением мне найти пока не удалось. Судя по всему проблемы движка указанные в посте были устранены (для получения списка партиций, без самостоятельного их ведения, можно использовать таблицу mysql.innodb_table_stats, запись в нее добавляется в момент создания партиции, реальна статистика появляется позднее). Так же из приятного можно отметить повышение ограничения на максимально возможное количество партиций для одной таблицы. Так как нареканий к движку, лично у меня, больше не осталось, не лишне заметить, что партиции созданы для параллельной обработки, ждем hint parallel(n) для партиционированных таблиц.Архивирование и восстановление
В новой версии было добавлено сразу две очень ожидаемые фичи для InnoDB:
EXCHANGE PARTITIONALTER TABLE part_table EXCHANGE PARTITION p1 WITH TABLE non_part_table;
Все стандартно: таблицы должны иметь полностью идентичную структуру, включая индексы и
storage engine, так же необходимо чтобы данные в непартиционированной таблице не выходили за пределы обмениваемой партиции. Transportable TablespacesКак вы знаете просто так подменить
.ibd файл и ожидать что у вас появятся данные — не прокатит. Так как необходимо учесть: REDO логи, словарь данных, системные колонки, метаданные табличного пространства и наверное ещё много чего. Для таких манипуляций теперь предусмотрено ряд комманд:на БД экспорта
—
FLUSH TABLES table_one, table_two FOR EXPORT;— копируем
.ibd и сгенерированный файл конфигурации из директории БДна БД импорта
— создаем пустую таблицу аналогичной структуры
—
ALTER TABLE table_one DISCARD TABLESPACE;— копируем
.ibd и сгенерированный файл конфигурации в директорию БД—
ALTER TABLE table_one IMPORT TABLESPACE;Операции выполняется за счет словаря данных, а значит максимально быстро.
Performance Schema
Схемы диагностики производительности была заметно улучшена. Во первых её работа стала в три раза быстрее, т.е. просадка производительности при её включении теперь составляет не 10% а всего 3.5%, что позволило делать её включенной по умолчанию. По мимо этого теперь в схеме не 17 таблиц как ранее, а 52. Изменений как вы понимаете очень много, и если описывать их всех потребуется отдельная статья, по этому выделю лишь ключевые, по моему мнению, полезности откинув настройку и введение.
- стало можно трейсить непосредственно запросы
show tables like '%statements%'; +----------------------------------------------------+ | Tables_in_performance_schema (%statements%) | +----------------------------------------------------+ | events_statements_current | | events_statements_history | | events_statements_history_long | | events_statements_summary_by_account_by_event_name | | events_statements_summary_by_digest | | events_statements_summary_by_host_by_event_name | | events_statements_summary_by_thread_by_event_name | | events_statements_summary_by_user_by_event_name | | events_statements_summary_global_by_event_name | +----------------------------------------------------+ 9 rows in set (0.01 sec) - трассировка выполняется на уровне строк как для постоянных таблиц так и для временных (хотя у меня почему то объектов с
object_type= 'TEMPORARY TABLE'в схемах нет, вероятно что-то не сумел настроить, но персистные таблицы все присутствуют)select digest_text, sum_rows_affected, sum_rows_sent, sum_rows_examined from events_statements_summary_by_digest; +---------------------------------------+-------------------+---------------+-------------------+ | digest_text | sum_rows_affected | sum_rows_sent | sum_rows_examined | +---------------------------------------+-------------------+---------------+-------------------+ | SHOW VARIABLES | 0 | 4410 | 4410 | ... | SET NAMES utf8 | 0 | 0 | 0 | +---------------------------------------+-------------------+---------------+-------------------+ 48 rows in set (0.00 sec) - ожидания можно смотреть целиком по всей сессии
show tables like '%by_thread%'; +---------------------------------------------------+ | Tables_in_performance_schema (%by_thread%) | +---------------------------------------------------+ | events_stages_summary_by_thread_by_event_name | | events_statements_summary_by_thread_by_event_name | | events_waits_summary_by_thread_by_event_name | +---------------------------------------------------+ 3 rows in set (0.00 sec) - можно мониторить временные таблицы, при чем как их создание в оперативной памяти, так и на диске, что позволит найти наиболее затратные запросы и выставить для них параметры сессии индивидуально
select digest_text, sum_created_tmp_disk_tables, sum_created_tmp_tables from events_statements_summary_by_digest; +--------------------------------------------------------+-----------------------------+------------------------+ | digest_text | sum_created_tmp_disk_tables | sum_created_tmp_tables | +--------------------------------------------------------+-----------------------------+------------------------+ | SHOW VARIABLES | 0 | 10 | ... | SELECT `routine_schema` , `specific_name` FROM INF... | 2 | 2 | ... | SHOW TABLE STATUS FROM `performance_schema` LIKE | 0 | 52 | +--------------------------------------------------------+-----------------------------+------------------------+ 49 rows in set (0.00 sec) - больше конкретики, данные привели в удобоваримый вид, схема стала понятнее и проще
show tables like 'table%waits%sum%'; +-------------------------------------------------+ | Tables_in_performance_schema (table%waits%sum%) | +-------------------------------------------------+ | table_io_waits_summary_by_index_usage | | table_io_waits_summary_by_table | | table_lock_waits_summary_by_table | +-------------------------------------------------+ 3 rows in set (0.01 sec)
Для заинтересовавшихся могу порекомендовать вот это, думаю вебинар будет полезен как для начинающих, так и для знакомых с этой схемой с версии 5.5, так как изменений очень много. Так же от себя добавлю, что, так как схема теперь включена по умолчанию её настройки очень скромны. К примеру в основной таблице для 5.5
events_waits_history_long всего 100 записей, а так как все эти параметры статические и их изменение требует перезапуск инстанса, то лучше заранее определится с вашими настройками.Заключение
В качестве заключения позволю себе привести вывод Петра Зайцева озвученный в его недавней статье. По итогам синтетических тестов
MySQL 5.6 медленнее предыдущей версии MySQL 5.5 на 7.5-11 процентов при нагрузке в один поток и на 11-26 процентов при нагрузке в 64 потока, что в корне разнится с официальной версией. Т.е. все переписали оптимально, но получить прирост производительности не смогли. При всех оптимизациях озвученных выше, вывод просто феноменален, но конечно же вам лучше проверить вашу среду самостоятельно. К примеру для нас критическим местом является вызов процедур. Для этого мы пользуемся самописным открытым фреймворком, из разработчиков на хабре присутствует esinev, jbdc-proc. Замер попугаев выглядит следующим образом.Как видно прирост производительности на наших серверах мы не получаем, даже наоборот наблюдается падение попугаев до 20%, однако, устанавливая новую версию, мы получаем большое количество средств диагностики, которые позволят нам легче находить узкие места. Помимо этого уже сейчас понятно, что MySQL идет в верном направлении, и подождав пару версий, чтобы убедиться в стабильности, мы планируем подъем версии.
habr.com
выбираем замену для популярной СУБД — «Хакер»
Содержание статьи
Что будет теперь, когда ненавистная и даже глубоко противная истинным сторонникам открытого софта компания Oracle купила многострадальную Sun, а заодно и наш с тобой любимый MySQL? Конец легендарного продукта? Может быть. Но уже сейчас есть куда более функциональные и полностью совместимые разработки!
MySQL, он же просто «мускул». Бьюсь об заклад, что это единственная СУБД, которая по умолчанию доступна на твоем хостинге. Любимые движки для форума и блога работают на ней. Это фактически стандарт де-факто для любого веб-продукта. Да и в своих проектах ты, вероятнее всего, используешь именно ее. В Сети миллионы сайтов осуществляют запросы и сохраняют данные в БД с помощью MySQL. И все было просто и понятно до тех пор, пока компанию Sun вместе с ее любимым мускулом неожиданно не купила корпорация Oracle. Учитывая, что основным продуктом последней является мощнейшая СУБД с одноименным названием, сообщество сильно тревожилось о дальнейшей судьбе MySQL. И не напрасно. Компания Oracle, конечно же, выступила с заявлением, что все в порядке: проект по-прежнему будет развиваться. Но многим верится в это с трудом. Ведь даже быстрый выпуск версии 5.5, которую многие так ждали, не дал положительных результатов: старые баги как были, так и остались. Разве ж это дело? Но параллельно с оригинальным MySQL уже давно развиваются альтернативные проекты, которые совместимы с оригинальной СУБД, но во многом даже превосходят ее. И об этом мы сейчас и поговорим.
Движок БД — что это такое?
Если немного упростить понятия, то база данных — это обертка вокруг движка хранения данных. Она занимается приемом запросов и управлением ими, кэшированием и прочими обслуживающими функциями, обеспечивая работу с низкоуровневым API движка. Последний, в свою очередь, собственно и хранит данные (на диске или в памяти), работает с операционной системой и обеспечивает выдачу нужных выборок по запросу от сервера. Если раньше СУБД (связка «сервер + движок») была монолитная, то теперь во всех системах используется структура с плагинами. Движок в такой организации является просто модулем, а сам сервер не зависит от системы хранения данных. В последних редакциях классического MySQL также используется плагинная архитектура. Поэтому встроенный движок InnoDB (правда, обычно устаревшей версии) можно легко заменить на модуль другого проекта, который часто будет лучше. В альтернативных мускулу разработках, в том числе MariaDB или Drizzle, все движки изначально выполнены как плагины. Попробую кратко пробежаться по современным движкам хранения данных в MySQL-совместимых СУБД.
- InnoDB — основной движок для мускула, который с версии 5.5 наконец-то сделали дефолтным. Поддерживает транзакции, репликацию, построчную блокировку. Достаточно устойчив к сбоям.
- MyISAM — очень проблемный движок, плохо переносящий крах сервера. Не поддерживает транзакции, но зато может похвастаться полнотекстовыми индексами и быстротой работы. Долгое время был стандартным для всех версий MySQL, а потому до сих пор является самым популярным.
- Aria — замена для MyISAM с поддержкой транзакций и улучшенной работой с памятью. Движок гарантирует целостность данных и при этом не уступает в скорости MyISAM.
- CVS — специализированный движок на случай, когда требуется хранить и обрабатывать большие массивы строковых данных, разделяемых запятой.
- Federated/FederatedX — этот движок специализируется на прозрачном разнесении данных по нескольким серверам (физическим) на уровне таблицы.
- PBXT — призванный заменить InnoDB новый движок, в котором реализованы полная поддержка транзакций, многоверсионность, автоматическая обработка дедлоков. Движок оптимизирован для большого количества одновременных транзакций.
- Blackhole — служебный движок, представляющий собой, по сути, /dev/null для СУБД и фактически не производящий никаких записей на диск. Используется для репликации.
- Archive — движок, который максимально быстро работает на запись. Используется в тех случаях, когда необходимо хостить большие массивы данных. Для эффективности хранения используется сжатие, что приводит к медлительности во время выборок. Движок хорошо подходит для долговременного хранения логов и другой служебной информации.
- XtraDB — расширенная и исправленная в некоторых проблемных местах InnoDB от компании Percona.
- MERGE — схожий с Federated движок для разнесения данных в одной таблице на несколько разных.
- MEMORY — движок, использующийся для хранения данных не на диске, а в памяти. Информация из базы доступна только во время работы сервера, но это дает колоссальный прирост в производительности.
- BlitzDB — еще одна замена для MyISAM с хорошей производительностью за счет встроенного построчного кэширования и автоматического восстановления после сбоев. Движок не поддерживает транзакции.
- NDB — движок для кластера, обладающий, впрочем, кучей проблем и удручающе плохой производительностью.
- Falcon — легендарный движок от компании MySQL AB, разрабатываемый еще со времен Sun, когда было принято решение заменить оракловский InnoDB.
- SphinxSE — полнотекстовый движок от создателя поискового сервера Sphinx. Лучший вариант для полнотекстового поиска и индексации по правилам русского языка. Легко оперирует терабайтами данных, обеспечивая при этом все возможности современной БД.
Важная вещь — совместимость
Итак, мы взялись за непростую задачу — найти замену для MySQL. Но если менять, то на что? Только не беги с криками «Да отстой ваш мускул — бери слона, то есть PostgreSQL». Не выйдет! Сейчас столько кода написано с поддержкой MySQL, что переписать или искать замену — себе дороже. Причем в прямом смысле — часто уложиться в рамки разумных финансовых затрат просто невозможно. Хорошо, если речь идет о простецком форуме или блоге (обычно в них реализована поддержка сразу нескольких систем). Но что если это что-то самописное или заточенное под возможности именно MySQL? Тут все ох как непросто. Так что наша задача — сохранить мускулы (то есть полную совместимость с MySQL), но прокачать их так, чтобы не зависеть от старшего тренера и его стероидов.
Разработчики и идеологи самого MySQL далеко не дураки и сами предвидели ситуацию, что после поглощения сложно будет всем. Некоторые из них решили даже покинуть компанию и основать свои проекты, прихватив тогда еще свободные коды мускула. Благодаря этому сейчас есть несколько интересных продуктов, основанных на коде оригинального сервера, но с большими доработками и изменениями во всем, куда только удалось дотянуться разработчикам. Первым делом энтузиасты освободились от бремени движка InnoDB, правами на который уже давно обладает все тот же самый Oracle. На замену ему выкатили несколько движков, которые стали доступными в MariaDB.
Архитектура MySQL — теперь уже как пособие по устройству некогда великой СУБД
MariaDB
История этого сервера уходит в далекий 2008 год, когда один из главных разработчиков MySQL, осознавая, что сильно связан поставленными работодателем рамками, уволился и основал свою компанию, которая занялась исправлением родовых травм MySQL. Я говорю о дефолтном движке MyISAM, который необходимо было менять, и критических багах, на исправление которых уходило неприемлемое количество времени. Что получилось у создателей MariaDB? Замечательный продукт, который на уровне протокола, формата файлов и языка SQL идентичен с оригинальной версией MySQL. Это предоставляет возможность безболезненного перехода: без потери данных или изменения логики работы имеющегося кода.
«Но какие бонусы я получу от перехода?», — спросишь ты. Взамен мы получаем большую скорость работы и новые фичи, которых, возможно, вообще никогда не будет в мускуле. Например, интегрированный в сам сервер поисковый движок Sphinx, который не придется ставить отдельно, расширенные возможности по бэкапу и управлению данными и так далее.
Надо сказать, что многие очень крупные компании (в том числе такие звери, как Google и Facebook) давно используют MariaDB. По сети гуляет специальный набор патчей, которые после наложения на исходные коды оригинального мускула решают многие проблемы. Однако не жди их появления в официальном сервере — если за столько лет не сподобились, то вряд ли в следующей версии решатся. Разработчики MariaDB же пока свободны от корпоративных правил и маркетинговых ограничений, поэтому новые патчи и исправления багов принимаются достаточно быстро.
Если оригинальный мускул держится на двух китах — движках хранения данных InnoDB и MyISAM, то MariaDB использует свои собственные, выступающие продвинутыми заменителями. Движок Aria пришел на замену MyISAM и на деле куда более производителен благодаря построчному кэшированию и оптимизированному формату упаковки данных. Если оригинальный MyISAM был быстр за счет отказа от транзакций, что означало возможную потерю данных, то Aria одновременно и производителен, и безопасен. За счет улучшенных форматов для хранения информации MariaDB существенно быстрее восстанавливается после сбоев, не требуя отдельных процедур проверки данных после краха. Принадлежащий Oracle движок InnoDB заменен на XtraDB, разработку другой компании в области БД Percona. Последняя известна своими сборками MySQL с интегрированными патчами от Гугла и Фейсбука, а также расширенными инструментами администрирования. Команда имеет необычную историю (подробнее ты можешь прочитать во врезке) и сейчас активно занимается созданием нового мускула. Для обратной совместимости с MySQL движок XtraDB в MariaDB даже называется точно так же, то есть InnoDB. Но надо понимать, что на самом деле сохранилось только название, дабы не смущать софт непривычными идентификаторами.
Первым проектом молодой компании Oracle была разработка по заказу разведчиков учетной системы, за которую на конкурсе другие компании запрашивали под $2 000 000, а молодой Ларри Элисон заносчиво указал сумму всего в $300 000. Стоит ли говорить, что проект был провален, зато компания получила стартовый капитал и начала свое восхождение.
Дополнительные движки
Об XtraDB стоит поговорить более детально: по мнению многих специалистов это номер один в мире движок для БД. Более того, он обставляет оракловский InnoDB, как маленького :). Ключевая фича — долгожданная поддержка многоядерных и многопроцессорных систем, чем ну никак не хочет (или не может?) похвастаться MySQL. Патчи от Google давно решили эту проблему, но, как всегда, их не удосужились включить в оригинальный движок, поэтому MySQL с точки зрения производительности плетется далеко позади по любым бенчмаркам. Разработчики XtraDB значительно улучшили стратегию использования дискового I/O, что раньше ограничивало производительность из-за тормозов со сбросом данных на диск из кэша. Соответствующими опциями теперь можно тонко управлять из настроек, что позволяет особо продвинутым админам подтюнить производительность демона самому, не обращаясь к дорогим специалистам по базам данных. Тем более, что из коробки доступна детальная статистика по работе движка, что сводит на нет потребность в дорогом коммерческом софте для анализа производительности базы данных. Нужна лишь одна команда SHOW ENGINE INNODB STATUS. И немаловажный момент — скорость восстановления после сбоя: если уж он и случился, восстановление будет не просто быстрым, а почти реактивным, зачастую до десяти раз быстрее, чем в MySQL. А также множество других мелочей: буферы для записей, адаптивные чекпоинты и увеличенное число открытых транзакций. Все это позволит серверу хорошо чувствовать себя в очень нагруженных условиях.
Если тебе и этого не хватает, и ты киваешь головой в сторону Firebird или PosgreSQL, намекая, что там есть и полная поддержка транзакционной модели и даже MVCC (Multiversion Concurrency Control — конкурентная модель данных на базе версионности, что позволяет без блокировок производить обновление и чтение одной и той же строки данных) — расслабься. В MariaDB доступен движок PBXT, который в некоторых ситуациях еще более крут, чем все вышеперечисленные. Правда, тут сразу стоит сказать, что он не такой универсальный и его нужно уметь готовить! PBXT в основном заточен под большое количество транзакций, которые пишут или изменяют данные, поддерживает быстрый откат и умеет сам разрешать сложные ситуации с блокировками и дедлоками. Например, если хочешь сделать хранилище логов, то у тебя будет огромное количество операций записи в таблицу, но сравнительно мало чтения. В то же время, если кто-то все-таки захочет сделать выборку из БД, он получит максимально свежие данные, не мешая при этом записи новых. И для совсем уж извращенцев есть движок FederatedX, умеющий распределять таблицу данных на несколько физических серверов, а также OQGRAPH, оптимизированный для хранения иерархических структур, графов и деревьев. Подход, идеально подходящий для создания клона Facebook и ВКонтакте, где требуется работать с социальным графом отношений между людьми, что плоховато вписывается в типичную модель баз данных.
Cloud Computing
Разработчики другого проекта — Drizzle — пошли по немного другому пути и решили вообще переосмыслить место базы данных в инфраструктуре типичного проекта. Вспомнили, что сейчас модно: cloud computing, Google Proto Buffers, масштабируемость, многоядерность и прочее. И подумали: база данных также должна двигаться вместе с современными технологиями, а не плестись в конце, вне зависимости от того, что на ней крутится — блоговый движок или крупная корпоративная CRM-система. Под шумок было решено упростить функционал оригинальной MySQL, выкинув тянущиеся из релиза в релиз возможности, которые в действительности мало кому нужны. Система утратила поддержку UNIX-сокетов (это хотя и спорное, но вполне допустимое решение ввиду направленности на облачные среды) и версию для Windows. В Drizzle нет никаких служебных баз и многих других привычных вещей. Но что же тогда есть?
Drizzle благодаря простой микроядерной и плагинной архитектуре умеет многое
А есть архитектура с микроядром, в которое вынесены все основные операции и поддержка протоколов, а также система плагинов, позволяющая расширить систему в любую сторону и на любую глубину. В качестве одной из основных системных компонент используется бинарный протокол от Google — Protocol Buffer. С его помощью описываются как таблицы, так и данные, он же применяется и для репликации. Основной упор в разработке сделан на максимальную поддержку многопоточности и многопроцессорности, так что масштабируемость — это основное достижение разработчиков. Реализована поддержка как стандартного MySQL-протокола, так и собственного варианта — через библиотеку libdrizzle и драйвера для большинства популярных языков, включая Perl, PHP, Python и Lua. При желании можно использовать клиентскую библиотеку и без самого сервера: в этом случае ты получишь эффективный асинхронный доступ к любимому MySQL. Поскольку эта же компания разработала и систему Gearman, то в Drizzle есть встроенная поддержка логирования в распределенной среде, нативное кэширование в memcache и даже такие продвинутые возможности, как репликация через системы сообщений типа RabbitMQ (используется в том числе новомодная технология WebSocket). В качестве основного движка хранения данных в Drizzle используется особая версия InnoDB, значительно переработанная и дополненная набором сторонних патчей. Также доступны движки XtraDB и PBXT. Если первые версии Drizzle основывались на MySQL 5.0, то теперь от оригинальной СУБД осталось немногое. Это почти полностью переписанный код с минимальной оглядкой на бывших родственников. На данный момент разработка Drizzle пребывает в активном состоянии, и к весне планируется первый стабильный релиз.
NoSQL-тренд
Ты наверняка знаешь о новомодном тренде NoSQL. По сути, это отказ от традиционного сервера базы данных с его таблицами и SQL-запросами и уход к самой простой схеме хранения данных «ключ-значение» (key-value). Для реализации последнего часто используются продвинутые типы данных вроде списков/хэшей (в Redis) или, например, формата JSON (в MongoDB). Но что мешает скрестить удава и ежа, используя, с одной стороны, всю мощь и годами отработанную технологию баз данных и их движков, а с другой — упрощенный протокол и отказ от громоздкой прослойки в виде обработки SQL-языка запросов? Суровым наследникам самураев не помешало ничего: японские парни из Yoshinori Matsunobu сделали плагин HandlerSocket, превращающий стандартный движок InnoDB в продвинутое NoSQL-хранилище, не мешая при этом работе обычного SQL. Скорость работы впечатляет: до 750 000 операций в секунду! Неудивительно, что компания Percona сразу же взяла на вооружение этот плагин, включив его в свои сборки сервера. Круто! Но, с другой стороны, как еще если не костылем можно назвать решение, которое имитирует то, что у нормальной БД типа Drizzle реализовано прямо из коробки в силу внутренней архитектуры?
Делаем выводы
Если ты обеспокоен развитием MySQL, тебе не нравится политика Oracle и ты справедливо опасаешься, что завтра тебя обяжут платить за функционал, который еще вчера был бесплатен, посмотри вокруг. Сообщество отреагировало на покупку MySQL как на начало заката технологии, некогда выведшей современный веб на недостижимую высоту благодаря стеку LAMP (Linux-Apache-MySQL-PHP). Ключевые разработчики начали развитие собственных форков, некоторые из которых уже сейчас на голову превосходят старый MySQL. За ними стоят многие знаковые фигуры и открытое сообщество. Сделав все по уму, разработчики умудрились оставить 100% внешней совместимости с приложениями и протоколами. Поэтому все желающие поставить новый сервер не окажутся у разбитого корыта: данные сохранятся, а приложения не придется переписывать. Многие вообще не заметят разницы, кроме возросшей скорости работы и надежности.
Уже сейчас ты можешь заменить свой сервер баз данных, так что имеющиеся приложения даже не почувствуют разницы, получив при этом гораздо большую скорость работы, надежность и массу недоступных в оригинальном мускуле фишек. MariaDB с набором движков — отличный вариант для старта. Ну а если ты задумал грандиозный проект с большим количеством серверов и гигабайтами данных, посмотри на Drizzle. Как программный продукт и как сервер баз данных он является очень перспективной разработкой, которая обязательно выстрелит уже в этом году. Если же хочется стабильности и поддержки самыми лучшими специалистами по базам данных — не бойся отвернуться от Oracle и пойти к Perconа. Ребята раздают бесплатно свою версию СУБД — исправляя, насколько это возможно, баги и добавляя фичи для увеличения производительности оригинального MySQL, не нарушая при этом совместимости. Ты все еще сидишь на стареньком мускуле? Тогда мы идем к тебе!
Links
xakep.ru