База данных. Понятие базы данных. Виды баз данных. Объекты для работы с базами данных. Типы данн (стр. 1 из 3)
Федеральное агентство по образованию
Государственное Общеобразовательное Учреждение
Среднепрофессионального Обучения
«Тульский экономический колледж»
По дисциплине «Информатика»
На тему: «База данных. Понятие базы данных. Виды баз данных. Объекты для работы с базами данных. Типы данных в базах и таблицах Access. Основные элементы и понятия баз данных»
Подготовила студентка 2 курса
группы 216-БП
Храмова Анна
Проверил преподаватель:
Васильева И.В.
Щёкино,2007
С О Д Е Р Ж А Н И Е:
1. Введение………………………………………………………….……2
2. Понятие базы данных………………………………………………..3
3. Виды базы данных………………………………………….………4-5
Виды базы данных………………………………………….………4-5
4. Объекты для работы с базами данных……………………………6-7
5. Типы данных в базах………………………………………………….8
6. Типы данных в таблицах Access……………………………………9
7. Основные элементы и понятия баз данных…………………..10-15
8. Тест…………………………………………………………….…16-17
9. Ответы на тест…………………………………………………….…18
10. Вопросы для самопроверки……………………………………….19
11. Список используемой литературы……………………………….20
12. Презентация……………………………………………………21-33
13. Рецензия………………………………………………..…………..34
В В Е Д Е Н И Е:
Мы познакомились с работой Excel и знаем, что это приложение создано специально для решения задач обработки табличных данных.
Существуют системы (приложения) для решения иных классов задач. В частности, очень большую роль играют сейчас программы (приложения, системы), цепь которых – хранение данных и выдача данных по запросу пользователя.
Использование ЭВМ именно для решения этого класса задач становится всё более массовым явлением.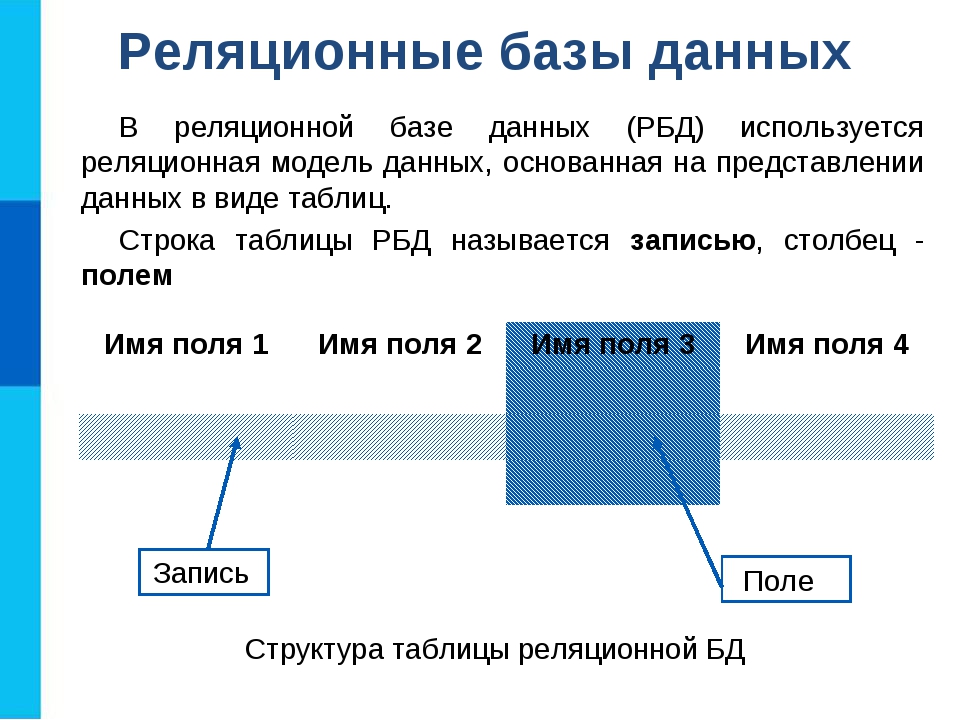
Смело можно сказать, что такие задачи и необходимость их решения существуют в любой фирме, на любом предприятии.
Основное понятие для подобного круга задач – база данных. Так называется файл или группа файлов стандартной структуры, служащая для хранения данных.
Для разработки программ, систем программ, работающих с базами данных, используются специальные средства – системы управления базами данных (СУБД).
СУБД включает, как правило, специальный язык программирования и все прочие средства, необходимые для разработки указанных программ.
В настоящее время наиболее известными СУБД являются FOXPRO и ACCESS. Последняя входит в состав профессионального пакета MS Office 97.
Это современные системы с большими возможностями, предназначенные для разработки сложных программных комплексов, и знакомство с ними для пользователя ЭВМ исключительно полезно, но в рамках настоящего пособия осуществить его затруднительно.
Понятие базы данных
База данных (БД) – это совокупность массивов и файлов данных, организованная по определённым правилам, предусматривающим стандартные принципы описания, хранения и обработки данных независимо от их вида.
База данных (БД) – совокупность организованной информации, относящейся к определённой предметной области, предназначенная для длительного хранения во внешней памяти компьютера и постоянного применения.
Виды БД:
1.Фактографическая – содержит краткую информацию об объектах некоторой системы в строго фиксированном формате;
2.Документальная – содержит документы самого разного типа: текстовые, графические, звуковые, мультимедийные;
3.Распределённая – база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть;
4.Централизованная – база данных, хранящихся на одном компьютере;
5.Реляционная – база данных с табличной организацией данных.
Одно из основных свойств БД – независимость данных от программы, использующих эти данные.
Работа с базой данных требует решения различных задач, основные из них следующие:
Создание базы, запись данных в базу, корректировка данных, выборка данных из базы по запросам пользователя.
Задачи этого списка называются стандартными.
Следующее понятие, связанное с базой данных: программа для работы с базой данных – это программа, которая обеспечивает решение требуемого комплекса задач. Любая подобная программа должна уметь решать все задачи стандартного набора.
База данных в разных системах имеет различную структуру.
В ПВЭМ обычно используются реляционные БД – в таких базах файл является по структуре таблицей. В ней столбцы называются полями, строки – записями.
В БД содержатся банные некоторого множества объктов. Каждая запись содержит данные одного объекта. Каждая такая БД определяется именем файла, списком полей, шириной полей. Например, БД Школа (Ученик, Класс, Адрес).
Примером БД может служить расписание движения поездов или автобусов. Здесь каждая строчка – запись отражает данные строго одного объекта. База включает поля: номер рейса, маршрута следования, время отправления и т.д.
Классическим примером БД является и телефонный справочник. Запрос к базе данных – это предписание, указывающее, какие данные пользователь желает получить из базы.
Запрос к базе данных – это предписание, указывающее, какие данные пользователь желает получить из базы.
Некоторые запросы могут представлять собой серьёзную задачу, для решения которой потребляется составлять сложную программу. Например, запрос к базе – автобусному расписанию: определить разницу в среднем интервале отправления автобусов из Ростова в Таганрог и из Ростова в Шахты.
Объекты для работы с базами данных
Для создания приложения, позволяющего просматривать и редактировать базы данных, нам потребуется три звена:
• набор данных
• источник данных
• визуальные элементы управления
В нашем случае эта триада реализуется в виде:
• Table
• DataSource
• DBGrid
Table подключается непосредственно к таблице в базе данных. Для этого нужно установить псевдоним базы в свойстве DataBaseName и имя таблицы в свойстве TableName, а затем активизировать связь: свойство Active = true.
Однако, поскольку Table является невизуальным компонентом, хотя связь с базой и установлена, пользователь не в состоянии увидеть какие – либо данные. Поэтому необходимо добавить визуальные компоненты, отображающие эти данные. В нашем случае это сетка DBGrid. Сетка сама по себе «не знает», какие данные ей нужно отображать, её нужно подключить к Table, что и делается через компонент – посредник DataSource.
А зачем нужен компонент – посредник? Почему бы сразу не подключаться к Table?
Допустим, несколько визуальных компонентов – таблица, поля ввода и т.п. подключены к таблице. А нам нужно быстро переключить их все на другую подобную таблицу. С DataSource это сделать несложно — достаточно просто поменять свойство DataSet, а вот без DataSource пришлось бы менять указатели у каждого компонента.
Приложения баз данных – нить, связывающая БД и пользователя:
БД – набор данных – источник данных – визуальные компоненты – пользователь
Набор данных:
• Table (таблица, навигационный доступ)
• Query (запрос, реляционный доступ)
Визуальные компоненты:
• Сетки DBGrid, DBCtrlGrid
• Навигатор DBNavigator
• Всяческие аналоги Lable, Edit и т. д.
д.
• Компоненты подстановки
Типы данных в базах
В Access можно определить следующие типы полей:
• Текстовый – текстовая строка; максимальная длина задаётся параметром «размер», но не может быть больше 255
• Поле МЕМО – текст длиной до 65535 символов
• Числовой – в параметре «Размер поля» можно задать поле: байт, целое, дейсвительное и т.п.
• Дата/время – поле, хранящее данные о времени.
• Денежный – специальный формат для финансовых нужд, по сути являющийся числовым
• Счётчик – автоинкрементное поле. При добавлении новой записи внутренний счётчик таблицы увеличивается на единицу и записывается в данное поле новой записи. Таким образом, значения этого поля гарантированно различны для разных записей. Тип предназначен для ключевого поля
• Логический – да или нет, правда или ложь, включен или выключен
• Объект OLE – в этом поле могут храниться документы, картинки, звуки и т. п. Поле является частным случаем BLOB – полей (Binary Large Object), встречающихся в различных базах данных
п. Поле является частным случаем BLOB – полей (Binary Large Object), встречающихся в различных базах данных
• Гиперссылка – используется для хранения ссылок на ресурсы Интернета. Встречается не во всех форматах баз данных. К примеру, такого типа нет в dBase и Paradox
• Подстановка
Типы данных в таблицах Access:
• Текстовый
• Поле МЕМО
• Числовой
• Дата\время
• Денежный
• Счётчик
• Логический
• Объект OLE
• Гиперссылка
Не надо забывать про индексы.
Связывать таблицы.
Связь с обеспечением целостности контролирует каскадное удаление и модификацию данных.
Монопольный доступ к БД нужен для того, чтобы производить в ней фундаментальные изменения.
Основные понятия и элементы баз данных
…………. | ………. | ………….. | ||
|
|
|
|
|
|
|
|
|
| Использование |
| Одна строка текста (до 255 символов) | |||
Memo | Текст, состоящий из нескольких строк, которые затем можно будет просмотреть при помощи полос прокрутки (до 65 535 символов) | |||
Числовой | Различные числовые данные (имеет несколько форматов: целое, длинное целое, с плавающей точкой) | |||
Дата \ Время | Дата и время в одном из предлагаемых БД форматов | |||
Денежный | Денежные суммы, хранящиеся с 8 знаками в десятичной части. | |||
Счетчик | Уникальное длинное целое, создаваемое БД для каждой новой записи | |||
Логические | Логические данные, имеющие значения Истина или Ложь | |||
Объект OLE | Картинки, диаграммы и другие объекты OLE из приложений Windows |

 .
.
 В целой части каждые три разряда разделяются запятой.
В целой части каждые три разряда разделяются запятой.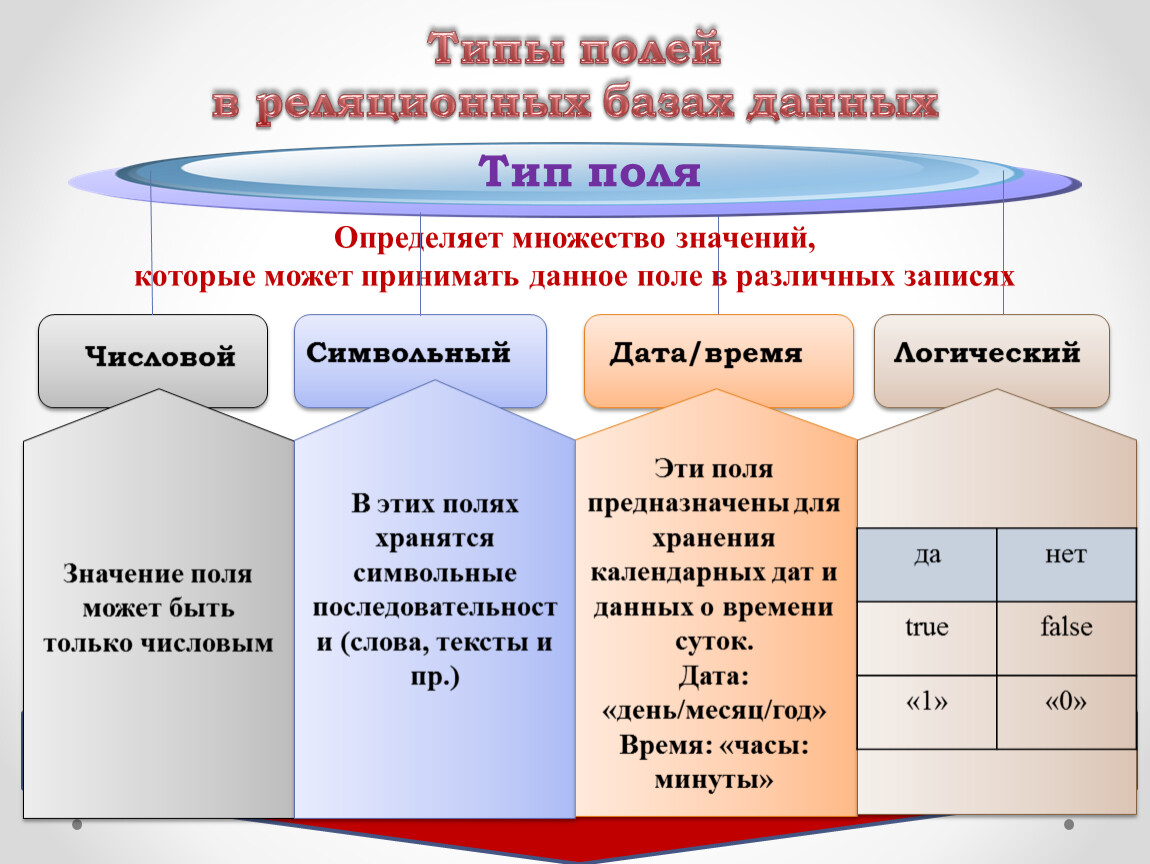 , паспорт).
, паспорт).Профессиональные базы данных, информационные справочные и поисковые системы
- Белорусский государственный университет физической культуры
- Национальный университет физического воспитания и спорта Украины
- Узбекский государственный институт физической культуры
Научно-поисковые системы:
1. Web of Science – самая авторитетная в мире база данных по научному цитированию Института научной информации (Institute of ScientificInformation – ISI). База данных научного цитирования Web of Science состоит из трех разделов:
Web of Science – самая авторитетная в мире база данных по научному цитированию Института научной информации (Institute of ScientificInformation – ISI). База данных научного цитирования Web of Science состоит из трех разделов:
- Science Citation Index Expanded (База по Естественным Наукам). Охват 5 866 журналов. Глубина поиска с 1945 года.
- Social Sciences Citation Index (База по Социальным Наукам). Охват 1 747 журналов. Глубина поиска с 1956 года.
- Arts and Humanities Citation Index (База по Искусству и Гуманитарным Наукам). Охват 1 135 журналов. Глубина поиска с 1975 года.
Зайдя в конкретную БД, можно посмотреть полный перечень журналов (ViewJournallist), список всех переименованных журналов (ViewJournalchanges), выбрать поиск журналов по категориям (Viewsubjectcategory), поиск отдельного журнала по названию, части названия или ISSN (Search).
С сайта science.thomsonreuters.com можно загрузить 3 тематических списка журналов, включенных в эту базу, в формате pdf.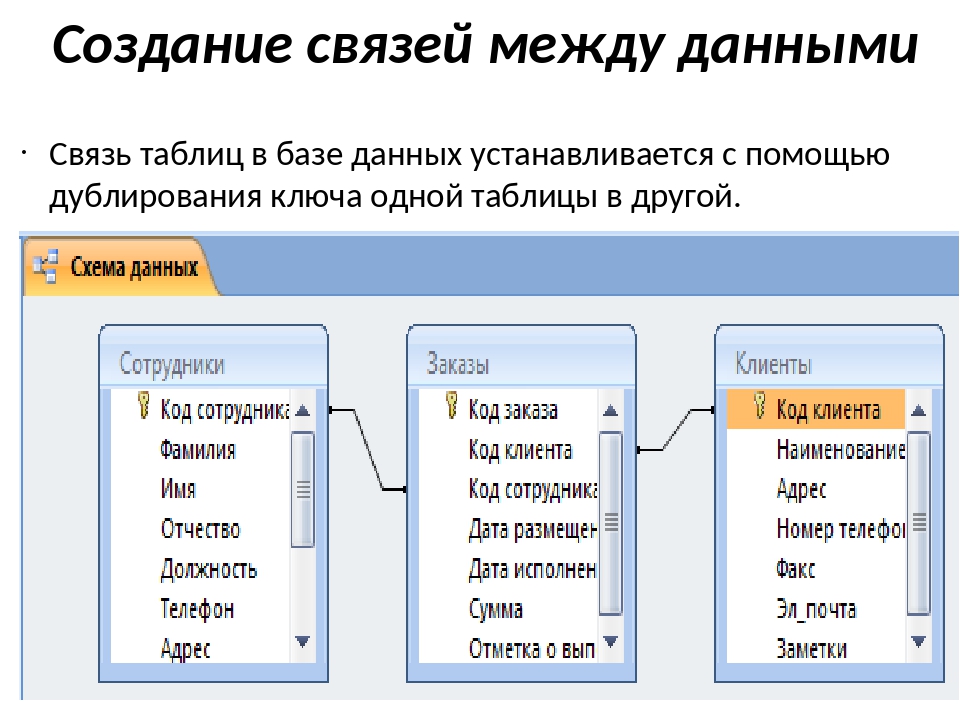
Проверить, индексируется ли журнал в БД Web of Science (без показателей цитируемости журнала) можно перейдя по ссылке http://ip-science.thomsonreuters.com/mjl .
Список журналов: http://wokinfo.com/russian/editors/
2. Scopus — это крупнейшая в мире единая мультидисциплинарная реферативная база данных, представляющая уникальную систему оценки частоты цитирования. Scopus индексирует более 15 тыс. наименований публикаций, включая около 300 российских журналов. Ежедневно обновляемая база данных Scopus включает записи вплоть до середины шестидесятых годов. Оценка частоты цитирования осуществляется с разбивкой по отдельным авторским статьям, годам их публикации.
Каталог журналов, включенных в базу данных Scopus опубликован на аналитическом портале SCImagoJournal&CountryRank (SJR) .
На данном портале можно выбрать перечень журналов в конкретной научной области и направлении, по интересующей тематике, стране издания ( http://www.scimagojr. com/journalrank.php), осуществить поиск журнала по его названию ( http://www.scimagojr.com/journalsearch.php), посмотреть импакт-фактор журнала и др. Обновляется два раза в год.
com/journalrank.php), осуществить поиск журнала по его названию ( http://www.scimagojr.com/journalsearch.php), посмотреть импакт-фактор журнала и др. Обновляется два раза в год.
Перечень журналов, индексирующихся в Scopus представлен на сайте компании Elsevier, на сайте можно скачать файл с перечнем в формате Exel (Viewthe Scopus titlelist). На русскоязычном информационном сайте компании представлен список российских журналов, входящих базу данных Scopus.
ПЕРЕЧЕНЬ ЖУРНАЛОВ РОССИИ, ВКЛЮЧЕННЫХ В БД SCOPUS (по состоянию на март 2014 г.) scopus_po_sostoyaniyu_na_mart_2014_g.xls
3. Scirus . Универсальная научная поисковая система. Осуществляет полнотекстовый поиск по статьям журналов большинства крупных иностранных издательств (порядка 17 млн. статей), статьям в крупных архивах статей и препринтов, научным ресурсам Internet (более 250 млн. проиндексированных страниц). Многократно признавалась лучшей специализированной поисковой системой
4. Google Scholar Поисковая система по научной литературе. Включает статьи крупных научных издательств, архивы препринтов, публикации на сайтах университетов, научных обществ и других научных организаций. Ищет статьи в том числе и на русском языке. Что не маловажно, рассчитывает индекс цитирования публикаций и позволяет находить статьи, содержащие ссылки на те, что уже найдены.
Включает статьи крупных научных издательств, архивы препринтов, публикации на сайтах университетов, научных обществ и других научных организаций. Ищет статьи в том числе и на русском языке. Что не маловажно, рассчитывает индекс цитирования публикаций и позволяет находить статьи, содержащие ссылки на те, что уже найдены.
5. Google Books Поиск книг и просмотр их содержания.
6. Science ResearchPortal Научная поисковая система, осуществляющая полнотекстовый поиск в журналах многих крупных научных издательств, таких как Elsevier, Highwire, IEEE, Nature, Taylor&Francis и др. Ищет статьи и документы в открытых научных базах данных: Directory of Open Access Journals, Library of Congress Online Catalog, Science.gov и Scientific News.
7. Medline Поиск по статьям медицинской тематики. Созданная национальной медицинской библиотекой США эта база данных включает статьи из более 3900 медицинских и биологических журналов, издающихся в 71 стране мира. Практически тематика намного шире только медицинской, поскольку в базу данных попадают статьи из всех журналов, в которых подобная статья может появиться (например, PhysicalReview E). HighWirePress + Medline
HighWirePress + Medline
HighWirePress это большое хранилище научных журналов, предоставляющих бесплатный полнотекстовый доступ к своим статьям (968 журналов, 1.39 млн. статей). Данная поисковая система позволяет осуществлять полнотекстовый поиск в этих журналах + поиск в Medline. Бесплатные статьи можно тут же скачать e-PrintArXive
Лос-Аламосский архив электронных публикаций. Это коллекция копий статей по физике, математике, нелинейной динамике, computerscience. Цель создания — свободный обмен научной информацией. Сознательные авторы размещают здесь свои статьи до опубликования, а иногда и вовсе без этого. Содержит поисковую систему по тематическим разделам SciNet — Science search
Рекламирует себя как первая из научных поисковых систем. Совмещена с каталогом научных ресурсов.
8. Britannica-EBooks Collection
Энциклопедии, справочники, словари:
Правовые базы данных:
Библиотеки
таблицы, формы, запросы, отчеты (11 класс) Информатика и ИКТ
Системы управления базами данных (СУБД).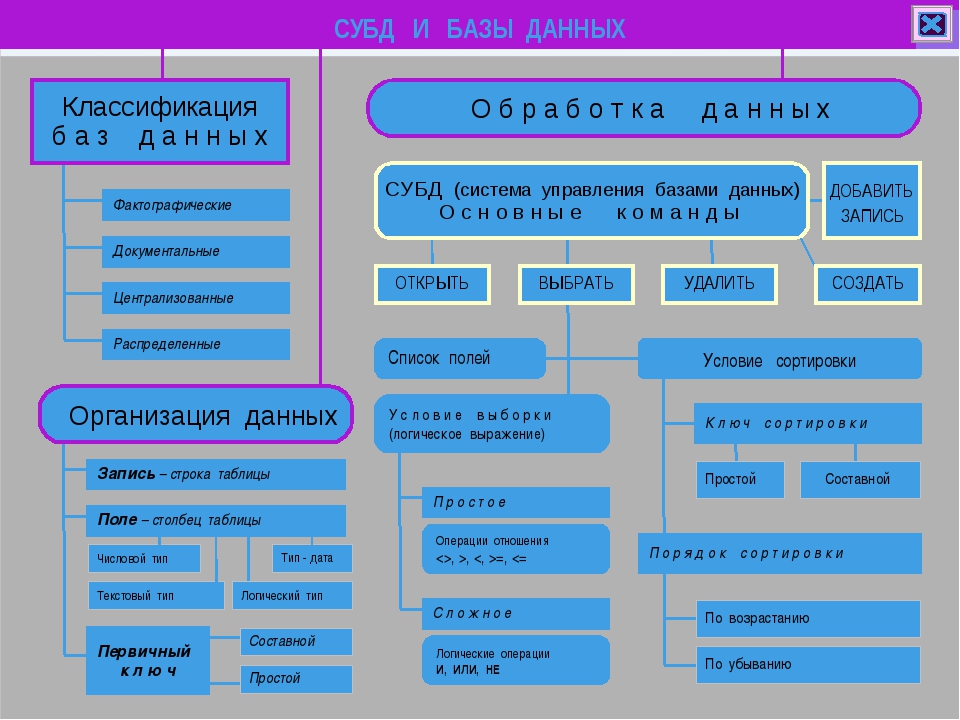
Развитие информационных технологий привело к созданию компьютерных баз данных. Создание баз данных, а также операции поиска и сортировки данных выполняются специальными программами — системами управления базами данных (СУБД). Таким образом, необходимо различать собственно базы данных (БД), которые являются упорядоченными наборами данных, и системы управления базами данных (СУБД) — программы, управляющие хранением и обработкой данных.
Система управления базами данных (СУБД) — это программа, позволяющая создавать базы данных, а также обеспечивающая обработку (сортировку) и поиск данных.
В СУБД Microsoft Access и OpenOffice Base используется стандартный для операционных систем многооконный интерфейс, но в отличие от других приложений, не многодокументный. Единовременно может быть открыта только одна база данных, содержащая обязательное окно базы данных и окна для работы с объектами базы данных. В каждый момент времени одно из окон является активным и в нем курсором отмечается активный объект.
Окно базы данных — один из главных элементов интерфейса СУБД. Здесь систематизированы все объекты базы данных: таблицы, запросы, формы, отчеты.
Таблицы.
В базах данных вся информация хранится в двумерных таблицах. Это базовый объект базы данных, все остальные объекты создаются на основе существующих таблиц (производные объекты). Каждая строка в таблице – запись базы данных, а столбец — поле. Запись содержит набор данных об одном объекте, а поле — однородные данные обо всех объектах.
Запросы.
В СУБД запросы являются важнейшим инструментом. Главное предназначение запросов — это отбор данных на основании заданных условий.
Формы.
Формы позволяют отображать данные, содержащиеся только в одной записи. При помощи форм можно добавлять в таблицы новые данные, а также редактировать или удалять существующие. Форма может содержать рисунки, графики и другие внедренные объекты.
Отчеты.
Они предназначены для печати данных, содержащихся в таблицах и запросах, в красиво оформленном виде.
Существует достаточно много различных СУБД, но для первого знакомства мы рекомендуем СУБД OpenOffice Base.
Контрольные вопросы:
- Какую функцию выполняют СУБД?
- Можно ли открыть в СУБД несколько разных баз данных?
- Какие основные объекты входят в СУБД, и какие функции они выполняют?
Содержание
Основные подходы к изучению темы «Базы данных» в школьном курсе информатики
В статье рассматриваются особенности преподавания в школьном курсе информатики темы «Базы данных». Проводятся обзоры существующих учебно-методических комплексов по информатике, в которые включена данная тема и на их анализе даются общие рекомендации.
На протяжении всей своей многовековой истории, человечество накопило большое количество знаний, информации. Для осуществления ее обработки автоматизированным способом используются особые структуры названные «Базы данных». Сегодня «Базы данных» стали частью большинства современных информационных систем, которые функционируют на основе их накопления и обработки. Именно поэтому, появляется необходимость познакомить учащихся с данным понятием, и сформировать у них набор знаний, умений и навыков работы, с блоками структурированных данных. Этот вопрос становится одним из ключевых и наиболее сложных современного курса информатики средней школы, и требует особенного отношения при его изучении. В первую очередь это связано с глобальностью понятия «Базы данных», как вида информационных систем. Во вторую очередь – как осуществлять практическое применение программных продуктов обрабатывающих базы данных.
Теоретическое обоснование внедрения в учебные программы школ тем связанных с использованием в практической деятельности баз данных выполнил В.Э. Фрейнман. Исследования по методике преподавания раздела «Базы данных» при изучении основ информатики провели С.В. Лаптева, Н.В. Сазонова и другие. Методические указания по обучению технологии работы с базами данных приведены так же в исследованиях М.К. Куликова, Т.А. Никифоровой, И.И. Сильванович, Н.В. Софроновой, Е.А. Глушихиной.
В Федеральном государственном образовательном стандарте среднего (полного) общего образования указано, что предметные результаты на базовом уровне должны быть ориентированы на формирование умений формализации и структурирования информации, умений выбирать способ представления данных в соответствии с поставленной задачей – таблицы, схемы, графики, диаграммы, с использованием соответствующих программных средств обработки данных.
В разделе информатика (базовый уровень) по отношению к теме «Базы данных» замечено, что изучение предметной области должно обеспечить «понятия о базах данных и средствах доступа к ним, умений работать с ними».
Основной целью изучения темы «Базы данных» в школьном курсе информатики является формирование знаний, умений и навыков создания баз данных с помощью компьютера.
Выделим основные задачи: обеспечить прочное и сознательное овладение учащимися основами знаний о методах и средствах хранения и переработки информации современном обществе; научить использовать технологии баз данных для решения практических задач из различных предметных областей; закрепить и углубить знания по информатике через рассмотрение алгоритмических проблем, лежащих в основе методов поиска и обработки информации; привить практические навыки использования компьютера как инструмента учебной и практической деятельности.
Как результат, отметим, что данная тема концентрирует в себе достаточно большой теоретический и практический материал, применяемый для эффективного решения задач связанных с базами данных и их приложений.
Изучение данной темы должно способствовать получению учащимися следующих результатов:
Личностные результаты: формирование ответственного отношения к учению, готовности и способности обучающихся к саморазвитию и самообразованию на основе мотивации к обучению и познанию; формирование целостного мировоззрения, соответствующего современному уровню развития науки и общественной практики; формирование коммуникативной компетентности в процессе образовательной, учебно-исследовательской, творческой и других видов деятельности.
Метапредметные результаты: владение основами самоконтроля, самооценки, принятия решений и осуществления осознанного выбора в учебной и познавательной деятельности; умение определять понятия, создавать обобщения, устанавливать аналогии, классифицировать, самостоятельно выбирать основания и критерии для классификации, устанавливать причинно-следственные связи; строить логическое рассуждение, умозаключение (индуктивное, дедуктивное и по аналогии) и делать выводы; умение создавать, применять и преобразовывать знаки и символы, модели и схемы для решения учебных и познавательных задач; формирование и развитие компетентности в области использования информационно-коммуникационных технологий.
Предметные результаты: умение использовать логические значения, операции и выражения с ними; формально выполнять алгоритмы, описанные с использованием конструкций ветвления (условные операторы) и повторения (циклы), вспомогательных алгоритмов, простых и табличных величин; умение использовать готовые прикладные компьютерные программы и сервисы в выбранной специализации, работать с описаниями программ и сервисами; навыки выбора способа представления данных в зависимости от постановленной задачи.
Формирование у учащихся навыков рациональной обработки информации и навыков целенаправленного использования компьютера для решения учебных, творческих и исследовательских задач осуществляется постепенно на протяжении всей темы.
Важно при работе с подаче в разных формах изучаемого материала учитывать возрастные особенности подростков.
В подростковом возрасте, с 11-12 лет, вырабатывается формальное мышление. Подросток уже может рассуждать, не связывая себя с конкретной ситуацией; ориентироваться на одни лишь общие посылы независимо от воспринимаемой реальности. Иными словами, подросток может действовать в логике рассуждения. Кризис 13 лет совпадает с переломом развития при переходе от школьного к пубертатному возрасту.
Мы можем констатировать, что именно в 9 классе возрастные особенности развития учащихся позволяют в полной мере усвоить учебный материал «Базы данных» в школьном курсе информатики.
На основе проведенного анализа научной литературы были определены возрастные психолого-педагогические особенности личности учащегося в 9 классе: быстрое развитие специальных способностей, сформированность умственных способностей, развитие самосознания. Все выявленные особенности указывают на потенциальную возможность освоения ими тем связанных с описанием функционирования баз данных.
Проанализируем подходы к изучению данной темы, сравнив УМК И.Г.Семакина, Н.Д. Угриновича и Л.Л. Босовой.
Так, И.Г. Семакин предлагает в 9 классе в курсе информатики изучение раздела «Хранение и обработка информации в базах данных». На изучение отводится 10 часов, из них 2 контрольные работы. При раскрытии темы автор подчеркивает актуальность умения работы с большими объемами информации, структурирования ее, важность таких умений у современного специалиста в области информационных технологий, мотивируя тем самым учащихся на более внимательное и глубокое изучение темы.
Предложена схема изложения учебного материала: основные понятия, система управления базами данных, создание и заполнении баз данных, условия выбора и простые логические выражения, условия выбора и сложные логические выражения, сортировка добавление и удаление записей.
Практические работы на компьютере предполагают работу с готовой базой данных: открытие, просмотр, простейшие приемы поиска и сортировки; формирование запросов на поиск с простыми условиями поиска; логические величины, операции, выражения; формирование запросов на поиск с составными условиями поиска; сортировка таблицы по одному и нескольким ключам; создание однотабличной базы данных; ввод, удаление и добавление записей.
М.К. Куликова предлагает следующий подход к почасовому разбиению темы: 1-й урок. Введение в тему «Информационные системы. Их классификация»; 2-й урок. Структуры данных. Табличный способ организации данных. Его достоинства. Иерархическая структура. Практическая работа по теме; 3-й урок. Анализ предметной области. Анализ данных. Основные понятия БД; 4-й урок. Основные объекты БД. Реляционные БД. СУБД ACCESS; 5-й урок. Этапы создания БД. Совместная разработка БД; 6-й урок. Построение логических выражений. Создание запросов к БД; 7й урок. Выбор темы проектной работы. Разработка контрольной учебной БД; 8-й урок. Защита проектной работы.
В УМК И.Д. Угриновича, тема «Базы данных» раскрывается в 9 и 11х классах. 9-й класс – темы: Базы данных в электронных таблицах; Представление базы данных в виде таблицы и формы; Сортировка и поиск данных в электронных таблицах; Практическая работа. «Сортировка и поиск данных в электронных таблицах». На первой ступени происходит первоначальное знакомство с ключевыми понятиями, описываются области использования баз данных, обосновывается актуальность данного приложения. Автор предлагает изучение темы «Представление базы данных в виде таблицы и формы». Функцию простой СУБД выполняют электронные таблицы. Работать можно с программой Excel (Microsoft Office), либо с электронным процессором Calc (OpenOffice, LibreOffice).
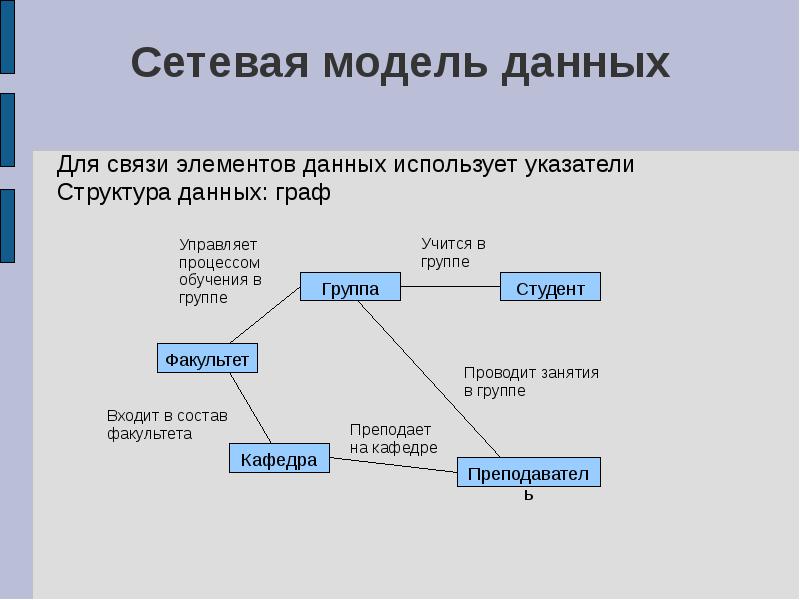
В 11-м классе более глубоко рассмотрены вопросы: Базы данных, Системы управления базами данных (СУБД), Иерархичные и сетевые базы данных. Учащиеся осваивают технологии создания таблиц, форм и запросов в приложении Microsoft Office Access.
Изучение темы «Базы данных» автор Л.Л. Босова разделяет следующим образом: База данных как модель предметной области; Система управления базами данных. Отметим, что УМК данного автора отличается качественным учебно-методическим и дидактическими материалами к урокам: методические рекомендации проведения уроков, рабочие тетради, презентации к каждому уроку, интерактивный задачник (раздел «Реляционные структуры данных»).
Таким образом, все отмеченные исследования рассматривают различные аспекты методики изучения систем управления базами данных (СУБД) в рамках школьной информатики. Однако базовый курс информатики в силу ограниченности своего объема требует от педагога четкой, универсальной методики изложения учебного материала.
Жуки (Coleoptera) и колеоптерологи Большой информационный сайт о жуках и тех, кто их изучает. Поддерживается ЗИН РАН. | |
Позвоночные животные России Информационная поисковая система по биоразнообразию позвоночных животных России. Интегрированная база данных позвоночных животных России включает виды и подвиды 295 пресноводных рыб, 29 – земноводных, 84 – пресмыкающихся, 739 – птиц и 310 – млекопитающих. Система поддерживалась в 2002–2009 гг., на настоящий момент, видимо, не обновляется. | |
Биоразнообразие России Ресурс разработан в БИН РАН в сотрудничестве с Зоологическим институтом РАН в рамках проекта «Информационная система по биоразнообразию России» Основными задачами были Основными задачами были апробация созданных классификаторов растений, грибов и лишайников в ранге от отдела до семейства,а также совмещение образцов классификаторов в иерархическую систему от отдела до рода. Последнее обновление системы состоялось в 2007 г. | |
Биоразнообразие Алтае-Саянского экорегиона Ресурс о биоразнообразии Алтае-Саянского региона, который включает территорию России, Монголии, Китая и Казахстана. Данные в GBIF | |
Информационно-аналитическая система по фиторазнообразию Байкальской Сибири Веб-интерфес базы данных, которую ведут сотрудники Сибирского института физиологии и биохимии растений СО РАН совместно с разработчиками из Института динамики систем и теории управления имени В.М. Матросова СО РАН (Иркутск) | |
Флора Байкальской Сибири Основой для Информационной системы «Флора Байкальской Сибири» послужил «Конспект флоры Иркутской области: сосудистые растения», опубликованный в 2008 г. Список видов был дополнен растениями, которые произрастают в Бурятии и Забайкальском крае, но отсутствуют в Иркутской области. | |
| ARCTOA Проект «Флора Мхов России» Основные задачи проекта: 1) таксономические ревизии групп мхов, встречающихся в России. |
CRIS (Cryptogamic Russian Information System) Информационная система CRIS — это инструмент для внесения, хранения, организации и вывода данных по биоразнообразию криптогамных организмов. Целями CRIS является: обеспечние иследователей инструментарием гербарной работы, а также организации и анализа данных по своей группе по всем возможным источникам; накопление первичной информации о биоразнообразии цианопрокариот,грибов, лишайников и мохообразных,хранящихся в гербарных коллекциях,и обеспечение свободного и удобного доступа к ним. Данные в GBIF | |
Он-лайн база данных находок редкого лишайника Lobaria pulmonaria на территории России Ресурс посвящен изучению распространения охраняемого лесного лишайника лобарии легочной (Lobaria pulmonaria (L.) Hoffm.) на территории России. Данные не обновлялись с 2018 г. Данные в GBIF | |
Биоразнообразие Двукрылых насекомых комплекса гнусa европейского Северо-Востока России Информационная система (ИС) служит для хранения и накопления данных о биоразнообразии двукрылых насекомых комплекса «гнус» на Европейском Северо-Востоке России. Для каждого вида кровососущих насекомых в базе данных хранится следующая информация: тип ареала (по Городкову, 1984), диагностические признаки, биология и экология, эпидемиологическое значение, точки сборов на территории Европейского северо-востока России (включая карты-схемы), фотографии насекомых и список литературы. В ИС имеется возможность поиска литературы по семейству, виду, автору, году издания и теме. | |
Охотничье-промысловые звери и птицы Республики Коми Для каждого вида животных в базе данных хранится: ареал и местообитания (включая карты-схемы), период размножения (период гона для млекопитающих, период насиживания для птиц), продолжительность беременности (для млекопитающих), плодовитость, тип питания, эпидемиологическое значение (перечень возможных болезней и паразитов для вида), практическое значение (хозяйственное значение, эпидемиологическое значение, биоценотическое значение), численность (плотность населения ос/кв.км), изображения (фотографии и рисунки) животных, изображения следов. | |
База данных «Список видов сосудистых растений Магаданской области» Основные литературные источники – «Флора Магаданской области» (Хохряков, 1985) и сводка «Сосудистые растения Советского Дальнего Востока» (1985-1996), «Флора российского Дальнего Востока: Дополнения и изменения к изданию «Сосудистые растения советского Дальнего Востока». Т. 1-8 (1985-1996), «Флора и растительность Магаданской области (конспект сосудистых растений и очерк растительности)» (Беркутенко и др., 2010), учтены и неопубликованные пока материалы сотрудников лаборатории ботаники. Последнее обновление в мае 2020 г. | |
Информационная система «Флора Костромской области» Цель проекта – показать разнообразие видов растений, произрастающих в Костромской области и разнообразие природных ландшафтов. Сайт представляет собой электронный атлас растений, произрастающих в настоящее время на территории Костромской области. Здесь собраны фотографии и другие сведения как об аборигенных видах, так и о сорных, рудеральных и заносных видах. | |
| … | Информационная система «Рыбы Приморья» (на ноябрь 2020 сайт на реконструкции) |
Классификация таблиц в реляционных базах данных по признакам целостности и избыточности данных
Содержание статьи
Обоснование статьи и некоторые ключевые понятия;
1. Справочники и связки;
1.1. Виды таблиц;
1.2. Виды справочников;
1.3. Виды связок;
2. Обобщение классификации;
2.1. Классификация в табличном виде;
2.2. Классификация в схематичном виде;
3. Некоторые комментарии по применению классификации;
3.1. Применение классификации при нормализации таблиц;
Заключение.
Обоснование статьи и некоторые ключевые понятия
Очень часто присутствовал на обучении дисциплине «Базы данных». Обучался когда-то сам… Как-то даже пришлось проводить целый курс для друзей и знакомых. Во время обучения мною было замечено, что трудности возникают уже на этапе понимания таблиц и того, как ими пользоваться. Многие просто не могли и не могут разработать простейшие базы данных. После более детального рассмотрения такого понятия как таблицы и маленькой классификации, трудности восприятия таблиц в реляционных базах данных почти всегда исчезают. Итак!
В данной статье будет рассмотрена маленькая классификация таблиц по признакам целостности и избыточности. Что это значит? Это значит, что будут приведены примеры с описанием, какую структуру таблиц можно делать, чтобы предотвращать (пытаться предотвращать) избыточность и добиваться целостности в реляционных базах данных.
Для понимания дадим краткие определения целостности и избыточности данных:
Целостность данных – это свойство способности по одним данным восстанавливать другие, при этом не теряя семантическое единство этих данных и отношения между ними (между данными).
Избыточность данных – это состояние базы данных, при котором в таблицах присутствуют лишние данные.
Целостность данных может быть нарушена в результате операций модификации данных. Если в базе данных запрещены операции удаления и обновления, то целостность может быть нарушена только в результате операции добавления, а также неправильно написанных скриптов по отображению данных.
1. Справочники и связки
1.1. Виды таблиц
Немного углубимся в маленькую классификацию таблиц по видам их структуры. Разделим таблицы на два общих вида. Первым видом будут таблицы-справочники, вторым таблицы-связки.
Рисунок 1. Справочники и связки
Информацию в таблицах можно разделить на два вида. На информацию, которая описывает объекты (субъекты), связи и информацию, которая описывает действия, процессы, события, иное.
В справочниках содержатся сведения об объектах и субъектах, связях. В связках содержатся сведения о действиях, процессах, событиях и так далее.
В связках хранятся данные, взятые из таблиц справочников. Поскольку невыгодно повторять одни и те же данные при описании объектов (субъектов) и при описании их взаимодействия, данные об объектах (субъектах) заносятся в справочники, а в таблицах-связках не хранятся данные объектов (субъектов) в чистом виде, а лишь ссылки на них (внешний ключ). Таким образом, в связках хранятся данные по взаимодействию объектов (субъектов) и ссылки на самих объектов (субъектов) (внешний ключ). Эти «ссылки» являются первичными ключами в таблицах справочниках. Но об этом потом…
Отличие справочника от связки выражается в том, что таблицы-справочники могут быть самостоятельными и независимыми (то есть, при чтении данных некоторых справочников можно в целом понять семантику), а таблицы-связки практически никогда.
1.2. Виды справочников
Справочники могут подразделяться на несколько видов. Это статичные, статично-динамичные и динамичные справочники. Разумеется, вряд ли можно назвать абсолютно статичный справочник, так как в этом мире может измениться всё. Или почти всё.
Статичный справочник – справочник, данные об объектах, субъектах, связях в котором либо никогда не подвергаются модификации после первичной модификации, либо настолько редко подвергаются модификации, что этим можно пренебречь.
Примером таких справочников могут служить список месяцев с названиями и номерами, список дней недели, список времён года, список океанов и так далее…
| Номер | Наименование |
| 1 | Январь |
| 2 | Февраль |
| 3 | Март |
| 4 | Апрель |
| 5 | Май |
| 6 | Июнь |
| 7 | Июль |
| 8 | Август |
| 9 | Сентябрь |
| 10 | Октябрь |
| 11 | Ноябрь |
| 12 | Декабрь |
Таблица 1. Пример статичных справочников
Статично-динамичный справочник – справочник, в котором хранятся данные о связях, если связи носят справочный характер. В таком справочнике могут быть внешние ключи.
Наиболее удачным примером будет таблица с такими медицинскими данными, как вес. Список человек, вес которых измеряется, изменяется не так часто. А вот данные по их весу могут меняться каждый день. Статично-динамичные справочники являются единственными справочниками, где осознанно можно повторять любую информацию. Ещё одним примером может быть справочник окладов по должностям (по коду должности).
| Код должности | Оклад | Дата обновления |
| 1001 | 12 000 | 05.02.2015 |
| 1002 | 17 000 | 01.02.2015 |
| 1003 | 11 500 | 01.02.2015 |
| 1004 | 25 450 | 01.02.2015 |
| 1005 | 10 000 | 01.02.2015 |
| 1006 | 6 000 | 04.02.2015 |
Таблица 2. Пример статично-динамичных справочников
Динамичные справочники – это таблицы, данные об объектах, субъектах, связях в которых меняются часто и используются в других таблицах. От статичных справочников отличаются только частотой модификации в них данных.
Примером таких таблиц могут быть списки проектов. На самом деле, данные об открытии или закрытии проектов могут находиться в самом справочнике проектов, что в большинстве случаев неправильно и нарушает целостность. С другой стороны, если хранить историю изменений по открытию и закрытию (приостановке) проектов, то можно получить избыточность данных. Целостность и избыточность данных будут бороться с друг другом ещё долго, также как и зима с летом.
| Код проекта | Проект | Нормативный срок выполнения | Дата добавления | Пользователь |
| PT102 | Покраска окон | 15 | 03.01.2014 | 1547 |
| PT103 | Установка дверей | 10 | 04.01.2014 | 9874 |
| PT587 | Проверка пожарных кранов | 2 | 04.01.2014 | 1456 |
| PT588 | Замена люков | 3 | 02.01.2014 | 0147 |
| PT133 | Очистка каналов | 11 | 09.02.2015 | 1547 |
Таблица 3. Пример динамичных справочников
Рисунок 2. Виды справочников
1.3. Виды связок
Таблицы-связки можно разделить на два вида.
Это справочник-связка (сразу же уточним, что справочник-связка справочником не является, назван так, потому что в нём существуют поля, которые образуют справочник, но в справочник выделены быть не могут). Таблица, в которой хранятся внешние ключи, данные, которые не являются справочными и поля, содержащие данные, которые образуют справочник, но не могут быть выделены в отдельную таблицу-справочник.
Примером справочника-связки будет являться таблица платёжных транзакций. Или таблица с данными о футбольном матче.
| Код транзакции | Плательщик | Получатель | Сумма | Дата | Комментарий |
| EEVS-doodi4 | 100045 | 57457 | -10 000 | 25.07.2014 | На сапоги |
| UDFD-ioeed9 | 455780 | 10024 | -900 | 24.06.2014 | NULL |
| PEDD-jdksl4 | 144770 | 56698 | -6980 | 01.01.2015 | NULL |
| FDFE-keiiii0 | 447757 | 1 | 120 | 08.07.2014 | NULL |
Таблица 4. Пример справочника-связки
И связка (да, просто связка). Это таблица в которой хранятся только внешние ключи и данные, которые нельзя отнести к справочным, например дата или значения логических полей.
Примером связки будет являться таблица автоматического логирования терминала обработки данных.
Кстати, легко догадаться, что связки почти нигде не используются, поскольку чаще всего находятся данные, которые могут быть записаны в базу, но не содержаться в справочниках, поэтому невозможно сопоставить им внешний ключ.
| Код | Код клиента | Показания счётчика | Месяц |
| 2334 | 35643 | 50 | 01.01.2015 |
| 2335 | 235673 | 49 | 01.01.2015 |
| 2335 | 436345 | 56 | 01.01.2015 |
| 2335 | 574733 | 24 | 01.01.2015 |
Таблица 5. Пример связки
Необходимо пояснить, что это за поля, которые образуют справочник, но не могут быть выделены в отдельную таблицу-справочник. Примером таких полей являются поля «комментарий», «жалоба», «описание», «предложение». Словом, если приводить популярный пример, то поле «сообщение» в таблице базы данных любой социальной сети…
Рисунок 3. Виды связок
2. Обобщение классификации
2.1. Классификация в табличном виде
| Вид таблицы | Описание | Примеры | Плюсы (+) | Минусы(-) |
| Статичный справочник | Таблица. Данные из неё берутся для других таблиц. Из справочника в других таблицах можно использовать только первичный ключ. В статичном справочнике должна содержаться информация, которая либо вообще не изменяется, либо изменяется так редко, что этим можно принебречь. На статичный справочник ссылаются (внешний ключ), когда нужно получить названия, обозначения, нормы, количественные или качественные показатели. Иное. | Справочник (наименований и номеров) месяцев. Справочник складов и цехов предприятия. Справочник правил игры. |
Иногда заменяет системные функции СУБД, позволяет более гибко работать с некоторыми данными. В случае, если меняется редко изменяемая информация, предостерегает от серьёзных последствий. | Использование таблицы с любой структурой может замедлять работу, в случае, если таблица заменяет системное хранилише. Приходится писать дополнительные функции и обработки для данной таблицы, которые не всегда правильно оптимизированны. В некоторых случаях невозможно оптимизировать. |
| Статично-динамичный справочник | Таблица. Данные из неё берутся для других таблиц. Из справочника в других таблицах нельзя использовать внешний ключ этого справочника, однако можно использовать первичный ключ. | Справочник окладов по должностям. Справочник (размеров обуви, веса, роста, размера головы) физиологических параметров. Справочник (менеджеров, компаний) содержащий компании и менеджеров, которые эти компании обслуживают и учитывают. | Позволяет проводить гибкую нормализацию по схеме «Справочник-связка» = «Связка»+«Статично-динамичный справочник». | Справочник, выделенный из справочника-связки, никуда не девается и не имеет никакой реляционной связи, которая позволила бы ему превратиться в статичный или динамичный справочник. А значит, всегда избыточен. |
| Динамичный справочник | Таблица. Данные из неё берутся часто для других таблиц. Из справочника в других таблицах можно использовать только первичный ключ. В динамичном справочнике должна содержаться информация, которая часто изменяется. | Справочник клиентов. Справочник поставщиков. Справочник контрагентов. Справочник менеджеров компании. Справочник работников. Справочник студентов. | Позволяет хранить динамичные данные, при этом давая возможность однозначно ссылаться на них. | Чаще всего накопительного типа и не делим, что создаёт определённую избыточность. |
| Справочник-связка | Таблица. Данные из неё не могут содержаться в других таблицах, но на основе них могут быть созданы данные в других таблицах. | Платёжные транзакции. Продажи. Межзаводские перемещения. График перевозок. | Позволяет проводить гибкую нормализацию по схеме «Справочник-связка» = «Связка»+«Статично-динамичный справочник». | Справочник-связка после нормализации превращается в связку и сводит избыточность данных к минимуму, не затрагивая целостность, однако не делим и при архивировании в текущей таблице не подлежит оптимизации. |
| Связка | Таблица. Данные из неё не могут содержаться в других таблицах, но на основе них могут быть созданы данные в других таблицах. Таблица не может содержать кортежей, значения атрибутов в которых являются неделимыми и не уникальными. | Автоматический лог ошибок в программе. Лог запроса сервера. Результаты трассировок. Отчёты о выгрузке и загрузке компонентов. Автоматические отчёты системы безопасности. | Связка сводит избыточность данных к минимуму, не затрагивая целостность. | Накапливаясь, является неделимой таблицей. Сложно оптимизировать. |
Таблица 6. Классификация
2.2. Классификация в схематичном виде
Рисунок 4. Схема классификации таблиц в реляционных базах данных по признакам целостности и избыточности данных
3. Некоторые комментарии по применению классификации
3.1. Применение классификации при нормализации таблиц
Процесс нормализации, если не учитывать некоторые этапы (Но учитывать результаты этих этапов!) — это обычное «дробление» таблиц на более мелкие таблицы с созданием реляционной связи между ними непосредственно или через промежуточные таблицы (связь «Многие ко многим»). Под реляционной связью может не всегда пониматься реляционное отношение!
Преобразование динамичного или статичного справочника в статично-динамичный справочник, а справочника-связки в связку, как и статично-динамичного справочника в справочник-связку — это ни что иное, как дробление таблиц. То есть, преобразование одного вида таблиц в другой через показанную выше классификацию в целях избежания избыточности данных — так можно определить нормализацию (один из вариантов определения).
Для примера. Пусть имеется база данных, в которой единственная операция по модификации данных — это добавление. В таком случае становится неэффективным каждый раз при изменении какого либо отдельного атрибута сущности, «копировать» остальные значения атрибутов уже в другой кортеж. В этом случае используются NULL или же создание статично-динамичного справочника, где описывается ряд атрибутов одной семантики или один атрибут, а дублируется лишь внешний ключ с первичным ключом последовательности. Этот же метод может использоваться в традиционной схеме модификации данных с обновлением и удалением данных.
Заключение
Данная классификация была создана мной на основе наблюдений при проектировании баз данных, а также исходя из прочитанной теории по проектированию в реляционных СУБД. Моим друзьям и знакомым, изучающим дисциплину «базы данных» и занимающимся проектированием баз данных, и мне эта классификация достаточно серьёзно упростила «жизнь» и позволила во многих ситуациях заранее выбрать наиболее подходящий и, как оказывалось потом, правильный вид таблицы для хранения в ней тех или иных данных.
Классификация может быть расширена разделением существующих видов в ней на подвиды (возможно, даже, добавлением новых видов). Также эта классификация показала, что лучше в некоторых ситуациях не использовать тот или иной вид таблиц. Некоторые виды таблиц из данной классификации лучше использовать реже (динамичные справочники). А некоторые пытаться заменить на другие (справочники-связки на связки).
Надеюсь, кому ни будь ещё поможет эта классификация при освоении дисциплины «Базы данных» и при проектировании баз данных в реляционных СУБД.
СУБД | Типы баз данных
Существуют различные типы баз данных, используемых для хранения различных типов данных:
1) Централизованная база данных
Это тип базы данных, в которой данные хранятся в централизованной системе баз данных. Это облегчает пользователям доступ к сохраненным данным из разных мест через несколько приложений. Эти приложения содержат процесс аутентификации, позволяющий пользователям безопасно получать доступ к данным. Примером централизованной базы данных может быть Центральная библиотека, которая содержит центральную базу данных каждой библиотеки в колледже / университете.
Преимущества централизованной базы данных
- Это снизило риск управления данными, то есть манипулирование данными не повлияет на основные данные.
- Согласованность данных поддерживается, поскольку он управляет данными в центральном репозитории.
- Он обеспечивает лучшее качество данных, что позволяет организациям устанавливать стандарты данных.
- Это менее затратно, потому что меньше поставщиков требуется для обработки наборов данных.
Недостатки централизованной базы данных
- Размер централизованной базы данных велик, что увеличивает время отклика для выборки данных.
- Обновить такую обширную систему баз данных непросто.
- Если произойдет какой-либо сбой сервера, все данные будут потеряны, что может быть огромной потерей.
2) Распределенная база данных
В отличие от централизованной системы баз данных, в распределенных системах данные распределяются между различными системами баз данных организации. Эти системы баз данных связаны через каналы связи. Такие ссылки помогают конечным пользователям легко получить доступ к данным. Примеры распределенной базы данных: Apache Cassandra, HBase, Ignite и т. Д.
Далее мы можем разделить систему распределенных баз данных на:
- Однородный DDB: Те системы баз данных, которые работают в одной операционной системе, используют один и тот же прикладной процесс и имеют одинаковые аппаратные устройства.
- Гетерогенный DDB: Те системы баз данных, которые выполняются в разных операционных системах под разными процедурами приложений и содержат разные аппаратные устройства.
Преимущества распределенной базы данных
- В распределенной базе данных возможна модульная разработка, то есть система может быть расширена за счет включения новых компьютеров и их подключения к распределенной системе.
- Отказ одного сервера не повлияет на весь набор данных.
3) Реляционная база данных
Эта база данных основана на реляционной модели данных, которая хранит данные в форме строк (кортеж) и столбцов (атрибутов) и вместе формирует таблицу (отношение).Реляционная база данных использует SQL для хранения, обработки и обслуживания данных. Э.Ф. Кодд изобрел базу данных в 1970 году. Каждая таблица в базе данных содержит ключ, который делает данные уникальными по сравнению с другими. Примеры реляционных баз данных: MySQL, Microsoft SQL Server, Oracle и т. Д.
Свойства реляционной базы данных
Существует четыре общеизвестных свойства реляционной модели, известных как свойства ACID, где:
A означает атомарность: Это гарантирует, что операция с данными завершится либо успешно, либо с ошибкой.Он следует стратегии «все или ничего». Например, транзакция будет либо зафиксирована, либо прервана.
C означает Согласованность: Если мы выполняем какую-либо операцию над данными, ее значение до и после операции должно быть сохранено. Например, баланс счета до и после транзакции должен быть правильным, т.е. он должен оставаться сохраненным.
Я имею в виду Изоляция: Могут существовать одновременные пользователи для одновременного доступа к данным из базы данных.Таким образом, изоляция между данными должна оставаться изолированной. Например, когда несколько транзакций происходят одновременно, эффекты одной транзакции не должны быть видны другим транзакциям в базе данных.
D означает надежность: Он гарантирует, что после завершения операции и фиксации данных изменения данных останутся постоянными.
4) База данных NoSQL
Non-SQL / Not Only SQL — это тип базы данных, который используется для хранения большого количества наборов данных.Это не реляционная база данных, поскольку она хранит данные не только в табличной форме, но и несколькими способами. Он появился, когда возросла потребность в создании современных приложений. Таким образом, NoSQL представила широкий спектр технологий баз данных в ответ на потребности. Далее мы можем разделить базу данных NoSQL на следующие четыре типа:
- Хранилище «ключ-значение»: Это простейший тип хранилища базы данных, в котором каждый отдельный элемент хранится в виде ключа (или имени атрибута), содержащего его значение вместе.
- Документно-ориентированная база данных: Тип базы данных, используемый для хранения данных в виде документа, подобного JSON. Это помогает разработчикам хранить данные, используя тот же формат модели документа, который используется в коде приложения.
- Графические базы данных: Он используется для хранения огромных объемов данных в графоподобной структуре. Чаще всего сайты социальных сетей используют базу данных графов.
- Хранилища с широкими столбцами: Это похоже на данные, представленные в реляционных базах данных.Здесь данные хранятся в больших столбцах вместе, а не в строках.
Преимущества базы данных NoSQL
- Это обеспечивает хорошую производительность при разработке приложений, поскольку не требуется хранить данные в структурированном формате.
- Это лучший вариант для управления и обработки больших наборов данных.
- Обеспечивает высокую масштабируемость.
- Пользователи могут быстро получить доступ к данным из базы данных с помощью пары «ключ-значение».
5) Облачная база данных
Тип базы данных, в которой данные хранятся в виртуальной среде и выполняются на платформе облачных вычислений.Он предоставляет пользователям различные сервисы облачных вычислений (SaaS, PaaS, IaaS и т. Д.) Для доступа к базе данных. Существует множество облачных платформ, но лучшие варианты:
- Веб-сервисы Amazon (AWS)
- Microsoft Azure
- Каматера
- PhonixNAP
- ScienceSoft
- Google Cloud SQL и т. Д.
6) Объектно-ориентированные базы данных
Тип базы данных, использующий объектно-ориентированную модель данных для хранения данных в системе баз данных.Данные представлены и хранятся как объекты, похожие на объекты, используемые в объектно-ориентированном языке программирования.
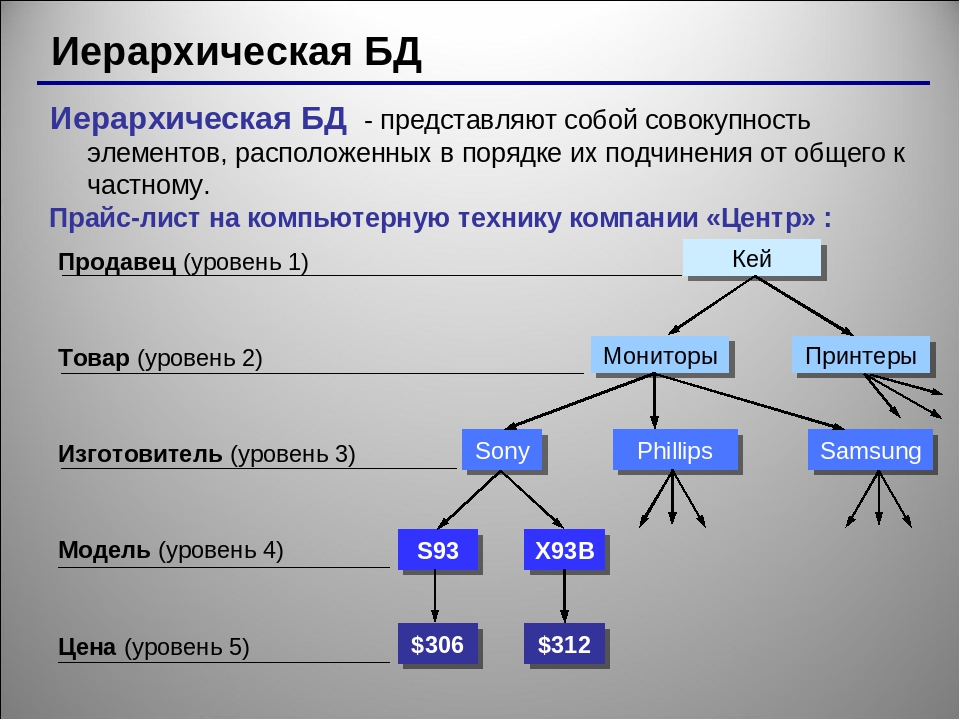
7) Иерархические базы данных
Это тип базы данных, в которой хранятся данные в виде узлов отношений родитель-потомок. Здесь данные упорядочиваются в виде древовидной структуры.
Данные сохраняются в виде записей, связанных ссылками. Каждая дочерняя запись в дереве будет содержать только одного родителя. С другой стороны, каждая родительская запись может иметь несколько дочерних записей.
8) Сетевые базы данных
Это база данных, которая обычно следует сетевой модели данных. Здесь данные представлены в виде узлов, соединенных между собой связями. В отличие от иерархической базы данных, он позволяет каждой записи иметь несколько дочерних и родительских узлов для формирования обобщенной структуры графа.
9) Персональная база данных
Сбор и хранение данных в системе пользователя определяет персональную базу данных. Эта база данных в основном предназначена для одного пользователя.
Преимущество личной базы данных
- Проста и удобна в обращении.
- Занимает меньше места для хранения, так как имеет небольшие размеры.
10) Операционная база данных
Тип базы данных, которая создает и обновляет базу данных в реальном времени. Он в основном предназначен для выполнения и обработки ежедневных операций с данными в нескольких компаниях. Например, организация использует оперативные базы данных для управления ежедневными транзакциями.
11) Корпоративная база данных
Крупные организации или предприятия используют эту базу данных для управления огромным объемом данных. Это помогает организациям увеличивать и улучшать свою эффективность. Такая база данных обеспечивает одновременный доступ пользователям.
Преимущества корпоративной базы данных:
- Несколько процессов поддерживаются в базе данных Enterprise.
- Позволяет выполнять параллельные запросы в системе.
Что такое база данных? | Определение, использование и информация
GCSE Введение в базы данных (14-16 лет)
- Редактируемая презентация урока в PowerPoint
- Редактируемые раздаточные материалы для исправлений
- Глоссарий, охватывающий ключевую терминологию модуля
- Тематические интеллектуальные карты для визуализации ключевых понятий
- Печатные карточки, помогающие учащимся активнее вспоминать и повторять на основе уверенности
- Викторина с сопровождающим ключом для проверки знаний и понимания модуля
A-level Введение в базы данных (16-18 лет)
- Редактируемая презентация урока в PowerPoint
- Редактируемые раздаточные материалы для исправлений
- Глоссарий, охватывающий ключевую терминологию модуля
- Тематические интеллектуальные карты для визуализации ключевых понятий
- Печатные карточки, помогающие учащимся активнее вспоминать и повторять на основе уверенности
- Викторина с сопровождающим ключом ответа для проверки знаний и понимания модуля
Система управления базами данных (СУБД)
База данных — это любой набор информации, систематизированный для быстрого поиска и извлечения с помощью компьютера.Базы данных предназначены для предоставления средств для изменения, удаления, хранения и поиска данных в связи с различными операциями. Система управления базой данных (СУБД) использует запросы для извлечения информации из базы данных.
База данных может быть сохранена как один файл или как группа файлов. Различные устройства хранения могут содержать базу данных. Данные в этих файлах можно разделить на записи, каждая из которых содержит поля. Поля являются основной сущностью хранилища данных, и каждое поле содержит информацию об атрибуте сущности, определенной базой данных.Записи также классифицируются по таблицам, которые содержат информацию о взаимосвязях между полями. Хотя термин «база данных» используется для обозначения любого набора данных в компьютерных файлах, база данных обычно должна обеспечивать функциональность перекрестных ссылок. Пользователи могут искать, сортировать и выбирать поля из различных записей для создания отчета с использованием ключевых слов и критериев поиска, среди других механизмов сортировки и фильтрации.
Записи и файлы базы данных должны быть систематизированы для обеспечения возможности извлечения данных.Запросы — это основной метод, который пользователи используют для получения информации. Мощная СУБД может определять новые отношения из базовых, предоставляемых таблицами, и использовать их для генерации запросов. Например, пользователь вводит строку символов, после чего компьютер просматривает базу данных и выводит различные места, в которых появляются символы поиска. Пользователь может выполнить поиск по всем записям, в которых имя человека — «Джон».
Пользователи большой базы данных должны иметь возможность легко и в любое время манипулировать содержащейся в ней информацией.Крупные организации, вероятно, разработают множество независимых файлов со связанными и перекрывающимися данными. Их задачи обработки данных связывают данные из нескольких файлов. Для поддержки этих различных требований были созданы различные типы СУБД.
Данные во многих базах данных содержат тексты документов на естественном языке. Цифровые базы данных содержат информацию о финансах, научных результатах, статистике и технических данных, в то время как небольшие базы данных могут управляться на персональных компьютерах и использоваться пользователями дома.Базы данных в последнее время становятся все более важными в деловой жизни. Теперь они обычно предназначены для интеграции с другими офисными приложениями, такими как электронные таблицы и финансовые программы.
Типы баз данных
Централизованная база данных
- К этой базе данных могут получить доступ пользователи из разных мест. Центральная база данных сохраняет данные и программы и отправляет их в центральный вычислительный центр для обработки.
Операционная база данных
- Это основная форма базы данных, которая содержит информацию о деятельности предприятия.Эти базы данных организованы для маркетинговых, производственных и других бизнес-целей.
База данных конечных пользователей
- Это база данных, совместно используемая пользователями и предназначенная для использования конечными пользователями, например менеджерами различных отделов. Эта база данных представляет собой сводку задействованной информации для простоты использования.
Коммерческая база данных
- Это база данных, в которой хранится информация, необходимая внешним пользователям.Однако для конечных пользователей неэффективно поддерживать такую базу данных самостоятельно. Коммерческие базы данных — это платная услуга для пользователя, так как базы данных зависят от конкретной темы. Доступ предоставляется по коммерческим ссылкам. Некоторые коммерческие базы данных предлагаются на компакт-дисках, что позволяет снизить стоимость связи.
Персональная база данных
- Персональные базы данных хранятся на персональных компьютерах. Они содержат информацию, предназначенную для использования ограниченным числом пользователей.
Распределенная база данных
- Эти базы данных используют данные из общих баз данных. Соответствующие данные распределяются между различными сайтами в рассматриваемой организации. Поскольку сайты связаны друг с другом, весь набор данных составляет базу данных организации.
В настоящее время существуют хранилища данных, в которых отдельные базы данных объединяются в электронном виде. Эти хранилища данных анализируются с помощью программного обеспечения интеллектуального анализа данных и широко используются в бизнесе и государственных учреждениях.
COMP_SCI 339: Знакомство с базами данных | Компьютерные науки
Предлагаемый квартал
Зима : 3: 30-4: 50 Вт ; РоджерсВесна : 3: 30-4: 50 Вт ; Rogers
Предварительные требования
Студенты должны завершить COMP_SCI 214 & (COMP_SCI 213 или COMP_ENG 205) или быть студентами CS Grad (MS или PhD), чтобы зарегистрироваться на этот курс.Описание
Модели данных и проектирование баз данных. Моделирование реального мира: структуры, ограничения и операции. Отношение сущности к моделированию данных (включая сетевое иерархическое и объектно-ориентированное), упор на реляционную модель. Использование существующих систем баз данных для внедрения информационных систем.
- Spring Раздел: Студенты должны быть знакомы с программированием на Java до прохождения этого курса.
- Этот курс удовлетворяет требованиям к системному охвату.
ИНСТРУКТОР КУРСА: Профессор Роджерс (зима и весна)
КООРДИНАТОРЫ КУРСА: Проф. Питер Динда и проф. Дженни Роджерс
НЕОБХОДИМЫЕ УЧЕБНИКИ :
- Гектор Гарсия-Молина, Джеффри Д. Уллман, Дженнифер Д. Видом, Системы баз данных: Полная книга, 2-е издание, Прентис Холл, 2009 г. (проф. Динда)
- Рамакришнан, Рагху и Йоханнес Герке. «Системы управления базами данных.», 3-е издание. Нью-Йорк: McGraw-Hill, 2002; ISBN-10: 0072465638, ISBN-13: 978-0072465631 (зима и весна; проф. Роджерс)
РЕКОМЕНДУЕМЫЕ ДОПОЛНИТЕЛЬНЫЕ УЧЕБНИКИ :
- Джо Селко, SQL for Smarties: Advanced SQL Programming, 5th edition, Morgan Kaufman, 2014. (Полезно) (Проф. Динда)
- Том Кристиансен, Брайан д Фой, Ларри Уолл, Джон Орвант, Programming Perl, 4-е издание, O’Reilly and Associates, 2012.(Полезно) (Проф. Динда)
- Знакомство с концепциями дискретной математики, такими как теория множеств (например, COMP_SCI 212/310) (Winter & Spring; Prof. Rogers)
- Опыт объектно-ориентированного программирования, предпочтительно с Java (Winter & Spring; Prof. Rogers)
- Предпосылки использования системы контроля версий исходного кода, особенно git (Winter & Spring; Prof. Rogers)
ЦЕЛИ КУРСА: Этот курс знакомит с основными концепциями, лежащими в основе моделирования данных и систем баз данных с использованием систем управления реляционными базами данных (СУБД, в частности Oracle), языка структурированных запросов (SQL) и веб-приложений (Perl DBI inCGI) в качестве примеров.Студенты также знакомятся с внутренним устройством СУБД.
ЦЕЛИ КУРСА:
Учеников:
- Как моделировать домены и данные с помощью модели сущность-связь
- Как разработать нормализованную схему в реляционной модели данных
- Как реализовать схемы с помощью SQL
- Как обеспечить согласованность и безопасность данных с использованием свойств ACID (транзакций) современной СУБД
- Как запрашивать данные с помощью SQL
- Как подключиться к современной РСУБД из современного языка программирования
- Как такие интерфейсы используются для создания веб-приложений
- Как СУБД обеспечивает быстрый доступ к данным с помощью индексов и как индексы реализуются
- Как СУБД управляет хранилищем и иерархией хранилища
- Как СУБД оптимизирует и выполняет запросы с использованием реляционной алгебры, теоретическая основа систем баз данных
- Как СУБД реализует транзакции
- Актуальные темы
ПОДРОБНЫЕ ТЕМЫ КУРСА:
- Введение в веб-приложения на базе баз данных
- Веб-системы, CGI и другие модели приложений
- Введение в Perl
- Введение в SQL и ACID
- Водопад против спиральных моделей развития
- Модель данных сущность-связь
- Принципы проектирования
- Ссылочная целостность и другие ограничения
- Реляционная модель данных
- Схемы и ключи
- Функциональные и многозначные зависимости
- Нормализация и нормальные формы
- Преобразование схем ER в реляционные схемы
- Реляционная алгебра
- Пакеты и наборы
- Базовые операторы
- Присоединяется к
- Группировка
- Выражения и ограничения (утверждения)
- Эквивалентные выражения и оптимизация
- SQL в деталях
- Запись ограничений
- Расширенные типы данных
- Регулярные выражения
- Пустые значения и 3-значная логика
- Индексы
- Просмотры
- транзакции
- Триггеры
- Безопасность (контроль доступа, атаки SQL-инъекций)
- Системы хранения и записи
- Диски и RAID
- Планировка записи / управление свободным пространством
- Управление буфером
- индексы B-Tree
- B + Дерево
- Реализации запросов и соединений
- Хеш-индексы
- Расширяемое хеширование
- Линейное хеширование
- Реализации запросов и соединений
- Bitmap индексы
- Реализации запросов и соединений
- Краткое введение в реализацию транзакции
- Ведение журнала (отменить, повторить, повторить / отменить)
- Блокировка (тупиковая, упорядоченная, двухфазная блокировка)
ДОМАШНЕЕ ЗАДАНИЕ:
1.Модель данных Entity-Relationship
2. Реляционная модель данных
3. Реляционная алгебра
ЛАБОРАТОРНЫХ ПРОЕКТОВ:
- Расширение веб-приложения на основе базы данных
- Разработка реализации веб-приложения на базе базы данных
- Реализация компонента СУБД
СОРТА :
- 50% Проекты
- 10% Домашнее задание
- 20% Среднесрочная перспектива
- 20% Окончательный
Что такое СУБД? Определение системы управления базами данных
Система управления базами данных (СУБД) — это системное программное обеспечение для создания и управления базами данных.СУБД позволяет конечным пользователям создавать, защищать, читать, обновлять и удалять данные в базе данных. СУБД, наиболее распространенный тип платформы управления данными, по сути, служит интерфейсом между базами данных и конечными пользователями или прикладными программами, обеспечивая единообразную организацию данных и легкость доступа к ним.
Что делает СУБД?СУБД управляет данными; механизм базы данных позволяет получать доступ, блокировать и изменять данные; а схема базы данных определяет логическую структуру базы данных.Эти три основополагающих элемента помогают обеспечить параллелизм, безопасность, целостность данных и единообразные процедуры администрирования данных. Типичные задачи администрирования базы данных, которые поддерживает СУБД, включают управление изменениями, мониторинг и настройку производительности, безопасность, а также резервное копирование и восстановление. Большинство систем управления базами данных также отвечают за автоматический откат и перезапуск, а также за регистрацию и аудит активности в базах данных и приложениях, которые к ним обращаются.
СУБД обеспечивает централизованное представление данных, к которым могут получить доступ несколько пользователей из разных мест под контролем.СУБД может ограничивать, какие данные видит конечный пользователь, а также то, как этот конечный пользователь может просматривать данные, обеспечивая множество представлений одной схемы базы данных. Конечные пользователи и программное обеспечение не должны понимать, где физически расположены данные или на каком типе носителя они хранятся, поскольку СУБД обрабатывает все запросы.
СУБД может обеспечивать независимость как логических, так и физических данных. Это означает, что он может защитить пользователей и приложения от необходимости знать, где хранятся данные, или от беспокойства об изменениях физической структуры данных.Пока программы используют интерфейс прикладного программирования (API) для базы данных, предоставляемой СУБД, разработчикам не придется изменять программы только потому, что в базу данных были внесены изменения.
В системе управления реляционными базами данных (СУБД), наиболее широко используемом типе СУБД, этим API является SQL, стандартный язык программирования для определения, защиты и доступа к данным.
Какие компоненты СУБД?СУБД — это сложная часть системного программного обеспечения, которая состоит из нескольких интегрированных компонентов, которые обеспечивают согласованную управляемую среду для создания, доступа и изменения данных в базах данных.Эти компоненты включают следующее:
Структура СУБД- Складской двигатель. Этот базовый элемент СУБД используется для хранения данных. СУБД должна взаимодействовать с файловой системой на уровне операционной системы (ОС) для хранения данных. Он может использовать дополнительные компоненты для хранения данных или взаимодействия с фактическими данными на уровне файловой системы.
- Каталог метаданных. Каталог метаданных, который иногда называют системным каталогом или словарем базы данных, функционирует как репозиторий всех созданных объектов базы данных.При создании баз данных и других объектов СУБД автоматически регистрирует информацию о них в каталоге метаданных. СУБД использует этот каталог для проверки запросов пользователей на данные, и пользователи могут запрашивать в каталоге информацию о структурах базы данных, существующих в СУБД. Каталог метаданных может включать в себя информацию об объектах базы данных, схемах, программах, безопасности, производительности, коммуникации и другие подробности среды о базах данных, которыми он управляет.
- Язык доступа к базе данных. СУБД также должна предоставлять API для доступа к данным, обычно в форме языка доступа к базе данных. Это используется для доступа и изменения данных, но также может использоваться для создания объектов базы данных, а также для защиты и авторизации доступа к данным. SQL — это пример языка доступа к базе данных.
- Движок оптимизации. СУБД может также предоставлять механизм оптимизации, который используется для анализа языковых запросов доступа к базе данных и превращения их в действенные команды для доступа к данным и их изменения.
- Управляющий замками. Этот важный компонент СУБД управляет одновременным доступом к одним и тем же данным. Блокировки необходимы для того, чтобы несколько пользователей не пытались одновременно изменять одни и те же данные.
- Лог-менеджер. СУБД записывает все изменения, внесенные в данные, управляемые СУБД. Запись изменений называется журналом, и компонент диспетчера журналов СУБД используется для обеспечения эффективного и точного ведения записей журнала. СУБД использует диспетчер журналов во время выключения и запуска для обеспечения целостности данных, а также взаимодействует с утилитами базы данных для создания резервных копий и выполнения восстановлений.
- Утилиты данных. СУБД также предоставляет набор утилит для управления и контроля операций с базой данных. Примеры утилит базы данных включают реорганизацию, статистику выполнения, резервное копирование и копирование, восстановление, проверку целостности, загрузку данных, выгрузку данных и восстановление базы данных.
Популярные модели баз данных и системы управления включают следующее:
- РСУБД адаптируется к большинству вариантов использования, но продукты РСУБД уровня 1 могут быть довольно дорогими.
- СУБД NoSQL хорошо подходит для слабо определенных структур данных, которые могут развиваться со временем, но могут потребовать большего участия приложения для управления схемой.
- Система управления базами данных в памяти (IMDBMS) обеспечивает более быстрое время отклика и лучшую производительность, но может потреблять больше ресурсов.
- Система управления базами данных по столбцам (CDBMS) хорошо подходит для хранилищ данных, которые имеют большое количество схожих элементов данных.
- Облачная система управления базами данных построена и доступна через облако, и поставщик облачных услуг несет ответственность за предоставление и обслуживание СУБД.
Преимущества использования СУБД
Одним из самых больших преимуществ использования СУБД является то, что она позволяет конечным пользователям и прикладным программистам одновременно получать доступ к одним и тем же данным и использовать их при управлении целостностью данных. Данные лучше защищены и поддерживаются, когда их можно использовать совместно с СУБД вместо создания новых итераций одних и тех же данных, хранящихся в новых файлах для каждого нового приложения. СУБД представляет собой центральное хранилище данных, к которому несколько пользователей могут получить доступ контролируемым образом.
Централизованное хранение и управление данными в СУБД обеспечивает следующее:
- абстракция и независимость данных;
- безопасность данных;
- блокирующий механизм для одновременного доступа;
- — эффективный обработчик, позволяющий сбалансировать потребности нескольких приложений, использующих одни и те же данные;
- возможность быстрого восстановления после сбоев и ошибок;
- сильные возможности целостности данных;
- ведение журнала и аудит деятельности;
- простой доступ с использованием стандартного API; и
- единых процедур администрирования данных.
Еще одно преимущество СУБД состоит в том, что администраторы баз данных (DBA) могут использовать ее для создания логической структурированной организации данных. СУБД обеспечивает экономию на масштабе для обработки больших объемов данных, поскольку она оптимизирована для таких операций.
СУБД также может предоставлять множество представлений одной схемы базы данных. Представление определяет, какие данные видит пользователь и как этот пользователь видит данные. СУБД обеспечивает уровень абстракции между концептуальной схемой, определяющей логическую структуру базы данных, и физической схемой, описывающей файлы, индексы и другие физические механизмы, используемые базой данных.СУБД позволяет пользователям гораздо проще модифицировать системы при изменении бизнес-требований. Администратор базы данных может добавлять новые категории данных в базу данных, не нарушая работу существующей системы, тем самым изолируя приложения от того, как данные структурированы и хранятся.
Однако СУБД должна выполнять дополнительную работу, чтобы обеспечить эти преимущества, что приводит к накладным расходам. СУБД будет использовать больше памяти и ЦП, чем простая система хранения файлов, а разные типы СУБД потребуют разных типов и уровней системных ресурсов.
Недостатки СУБДВозможно, самым большим недостатком является стоимость оборудования, программного обеспечения и персонала, необходимых для работы корпоративной СУБД, такой как SQL Server, Oracle или IBM Db2. Аппаратное обеспечение обычно представляет собой высокопроизводительный сервер со значительным объемом настроенной памяти в сочетании с большими дисковыми массивами для хранения данных. Программное обеспечение включает в себя саму СУБД, которая стоит дорого, а также инструменты для программирования и тестирования, а также для администраторов баз данных, позволяющие управлять, настраивать и администрировать.
С точки зрения персонала, использование СУБД требует найма штата администратора БД, обучения разработчиков правильному использованию СУБД и, возможно, найма дополнительных системных программистов для управления установкой и интеграции СУБД в ИТ-инфраструктуру. Решение проблемы дополнительной сложности также является проблемой при реализации СУБД.
СУБД — это сложное программное обеспечение, которое требует глубоких знаний для правильной реализации и управления. Но СУБД взаимодействует со многими другими ИТ-компонентами, такими как ОС, системы обработки транзакций, языки программирования и сетевое программное обеспечение.Обеспечение правильной конфигурации и эффективности такой сложной настройки может быть трудным и вызвать снижение производительности или даже сбои в работе системы.
Сценарии использования СУБДЛюбое приложение, требующее большого количества данных, к которым должны обращаться несколько пользователей или заказчиков, является кандидатом на использование СУБД. Большинство средних и крупных организаций могут извлечь выгоду из использования СУБД, потому что у них больше потребностей в совместном использовании данных и параллелизме, и они могут легче преодолевать проблемы стоимости и сложности.
Примеры использования клиентами технологии СУБД включают следующее:
- Большинство коммерческих авиакомпаний полагаются на СУБД для приложений с большим объемом данных, таких как планирование планов полетов и управление бронированием рейсов клиентов.
- Приложения включают в себя хранение информации о клиентах, информации о счете, отслеживание транзакций по счету, включая снятие средств и депозиты, а также отслеживание платежей по кредитам. Банкоматы — хороший пример банковской системы, которая использует СУБД для отслеживания и управления этой деятельностью.
- Производство и управление цепочками поставок. Производственные компании также используют СУБД для отслеживания и управления запасами на складах. СУБД также можно использовать для управления данными для приложений управления цепочкой поставок, которые отслеживают поток товаров и услуг, включая перемещение и хранение сырья, незавершенного производства и готовой продукции от точки происхождения до точки. потребления.
- СУБД управляют продажами для любого типа организации.Это включает в себя хранение информации о продуктах, клиентах и продавцах, а также запись продаж, отслеживание выполнения и ведение информации об истории продаж.
- Человеческие ресурсы. СУБД также упрощает организациям отслеживание и управление информацией о сотрудниках в приложении для управления персоналом. Это включает в себя управление данными сотрудников, такими как адреса, номера телефонов, сведения о зарплате, расчет заработной платы и создание чеков.
Действительно, организации, которым необходимо хранить данные и получать к ним доступ позже для ведения бизнеса, имеют жизнеспособный вариант использования для развертывания СУБД.
Изменения в способах создания, продажи и обслуживания СУБДК 2019 году технологии СУБД с открытым исходным кодом быстро набирали обороты. Фактически, Gartner прогнозировал, что базы данных с открытым исходным кодом будут составлять 10% от общих расходов на программное обеспечение баз данных в этом году из-за более широкого внедрения на предприятиях. Большинство основных ИТ-организаций используют программное обеспечение с открытым исходным кодом в некоторых из своих критически важных операций. Эта тенденция дополняет две другие: приобретение поставщиков баз данных с открытым исходным кодом более крупными конкурентами и расширение рынка облачных услуг баз данных.
В 2019 году Gartner также заявил, что облачные базы данных являются движущей силой роста рынка СУБД, назвав облако «платформой по умолчанию для управления данными». В связи с растущим переходом к облаку многочисленные поставщики СУБД представили услуги управляемых облачных баз данных, которые предлагают освободить ИТ-команды и группы управления данными от многих задач, необходимых для развертывания, настройки и администрирования систем баз данных.
Еще одна растущая тенденция — это то, что Gartner называет гибридной транзакционной аналитической обработкой (HTAP).Это означает использование одной СУБД для обеспечения как обработки транзакций, так и аналитики, не требуя отдельной СУБД для каждой из них. Чтобы поддержать эту тенденцию, все больше поставщиков СУБД создают гибридные системы баз данных, которые предоставляют несколько механизмов баз данных в рамках одной СУБД. Большинство гибридных СУБД предоставляют сочетание реляционных и нескольких механизмов и API NoSQL. Примеры включают Altibase, Microsoft Azure Cosmos DB и DataStax Enterprise.
Далее: после выбора СУБД где ее разместить ?
История систем управления базами данныхПервая СУБД была разработана в начале 1960-х годов, когда Чарльз Бахман создал навигационную СУБД, известную как интегрированное хранилище данных (IDS).Вскоре после этого IBM разработала систему управления информацией (IMS), иерархическую СУБД, разработанную для мэйнфреймов IBM, которая до сих пор используется многими крупными организациями.
Следующее крупное достижение произошло в 1971 году, когда был выпущен стандарт конференции / комитета по языкам систем данных (CODSYL). Интегрированная система управления базами данных (IDMS) — это коммерческая реализация подхода к базе данных сетевой модели, разработанного CODASYL.
Но рынок СУБД изменился навсегда, поскольку реляционная модель данных стала популярной.Представленная Эдгаром Коддом из IBM в 1970 году в его основополагающей статье «Реляционная модель данных для больших общих банков данных», СУБД вскоре стала отраслевым стандартом. Первой СУБД была Ingres, разработанная в Калифорнийском университете в Беркли группой под руководством Майкла Стоунбрейкера. В то же время IBM работала над своим проектом System R по разработке СУБД.
Позже, в 1979 году, была выпущена первая успешная коммерческая СУБД Oracle. Через несколько лет за ним последовали IBM Db2, Sybase SQL Server и многие другие.
В 1990-х годах, когда объектно-ориентированное (ОО) программирование стало популярным, на рынок вышло несколько ОО-систем баз данных, но они так и не завоевали большую долю рынка. Позже, в 1990-х годах, был придуман термин NoSQL. В течение следующего десятилетия несколько типов новых нереляционных СУБД — включая ключ / значение, граф, документ и хранилище широких столбцов — были сгруппированы в категорию NoSQL.
Сегодня на рынке СУБД доминируют СУБД, но популярность систем баз данных NoSQL продолжает расти.
4 примера приложения базы данных
Благодаря настраиваемой онлайн-базе данных организации позиционируют себя для оптимизации затрат и повышения конкурентоспособности. Конечно, команда Kohezion считает, что программное обеспечение для онлайн-баз данных — лучший инструмент для создания приложений баз данных. Нетехнические люди, которым необходимо обрабатывать важные данные, как если бы они были экспертами, могут легко использовать Kohezion. В нашем продукте сочетаются все преимущества классических продуктов для баз данных с простотой использования электронной таблицы Excel, чтобы предложить вам настраиваемое, но доступное решение.Однако необходимо поискать другие примеров приложения базы данных, чтобы принять правильное решение для своего бизнеса.
Когда дело доходит до баз данных, легко потеряться во множестве определений. Если у вас кружится голова от таких слов, как SQL, запросы, таблицы и записи, я здесь, чтобы помочь вам во всем разобраться. Чтобы лучше понять, что такое Kohezion и как создавать приложения для баз данных, давайте сначала рассмотрим три других примера приложения для баз данных: системы управления базами данных на основе SQL, системы управления базами данных NoSQL / NewSQL и электронные таблицы Excel.Сначала я объясню, что такое база данных. Затем я изучу основные типы доступных баз данных и языков баз данных, включая плюсы и минусы каждого из них, а также примеры того, как их можно использовать. В заключение я объясню, что такое Kohezion и как он вписывается в мир баз данных.
Что такое база данных?
В самом простом выражении база данных — это совокупность информации, называемой здесь данными, которая хранится на сервере. Вы организовываете данные таким образом, чтобы рядовой пользователь мог извлекать, управлять и редактировать их значительными способами.Эти данные могут быть чем-то очень простым, например, личной информацией о клиентах или покупателях. Это также может быть инвентарь, продажи, звонки или что-то еще, что нужно отслеживать. Пользователь сам решает, какой формат и какие данные нужно агрегировать.
Когда вы используете базу данных, вы храните данные не на жестком диске вашего компьютера, а где-то в облаке на сервере. Используя систему управления базами данных (СУБД), вы выполняете вызовы / запросы для получения информации. Эта часть называется back-end.Для последовательного представления данных пользователю веб-разработчики создают веб-сайт и простые в использовании приложения для баз данных. Эта часть называется front-end.
Даже если существует множество других моделей баз данных, таких как иерархические и сетевые модели, реляционная модель базы данных является наиболее распространенной. Модель реляционной базы данных была разработана в начале 1970-х годов и до сих пор остается наиболее распространенной моделью. Вы храните данные в отношениях, принимая форму таблиц, состоящих из столбцов (полей) и строк (записей / элементов).Для доступа и взаимодействия с данными, содержащимися в реляционной базе данных, ее пользователю необходимо использовать систему управления реляционной базой данных (RDBMS). Несмотря на то, что есть другие примеры приложения базы данных, наиболее распространенным языком, используемым для запросов и управления реляционными базами данных, является SQL (язык структурированных запросов).
Читайте также: Онлайн-база данных, соответствующая HIPAA
Быстро и легко, вы создаете свои собственные приложения
Чтобы создавать собственные приложения для баз данных, вам не нужны навыки программирования.Если вы можете эффективно использовать Интернет и такой инструмент, как Word или Excel, у вас более чем достаточно навыков для создания собственных приложений. В качестве дополнительного бонуса создание приложения занимает от 30 до 60 минут. Допустим, вам нужно два-три приложения для управления вашими данными. Вы можете все подготовить до обеда.
Если вы переносите данные из электронных таблиц в облако, вы даже можете создать свое приложение, импортировав свои данные в свою учетную запись. Каждый столбец вашей электронной таблицы становится полем в вашем приложении.Все, что вам нужно сделать, это немного настроить здесь и там, чтобы он выглядел хорошо, и все готово.
Не беспокойтесь, если у вас нет уже имеющихся данных, приложение с нуля также легко создать. Кроме того, не беспокойтесь о том, чтобы приспособить свои потребности к фиксированному шаблону. С помощью программного обеспечения для онлайн-баз данных вы можете создать именно то, что вам нужно.
Сетки или календари, вы выбираете, как вы хотите видеть свои данные
Некоторые приложения, такие как клиенты или потенциальные клиенты, лучше обслуживаются за счет отображения в сетке при выполнении поиска.В таблице вы можете отсортировать данные в алфавитном порядке из любого существующего поля, например, фамилии вашего контакта или его названия компании.
С другой стороны, приложения, такие как задачи или любое другое приложение, основанное на дате или поле даты / времени, выиграют от отображения в календаре. Это позволяет быстро увидеть, что должно произойти в текущий день, неделю или месяц.
Если вам нужен еще более удобный способ просмотра данных в календаре, используйте функцию настраиваемого календаря с несколькими проектами для создания календарей, в которые вы добавляете несколько поисковых запросов.Например, вы можете увидеть все свои текущие задачи, встречи, запланированные звонки и даты продления контрактов в одном удобном календаре.
Нарезайте данные и создавайте собственные поисковые запросы
После создания приложений и проектов вы начнете вводить данные в свою учетную запись. Вскоре вы обнаружите, что часто хотите видеть определенные подмножества данных за раз. Например, вы можете захотеть увидеть все задачи, назначенные конкретному пользователю, или все встречи, запланированные на следующие семь дней.Для этого создайте собственный поиск.
Вы можете создавать поисковые запросы на разных уровнях в своей учетной записи. Создавайте поисковые запросы на уровне приложения, чтобы увидеть их во всех проектах, созданных на основе этого конкретного приложения. Вы можете сделать это, когда информация, к которой вам нужно получить доступ, также находится только в этом конкретном проекте. Каждый пользователь может даже создавать свои собственные поисковые запросы на своей панели инструментов. С помощью функции настраиваемого поиска вы можете быть уверены, что можете получить эффективный доступ к своим данным.
Разрешение на основе ролей, вы управляете своими пользователями и их разрешениями
Когда вы вводите все свои данные в одну учетную запись, вы можете беспокоиться о безопасности и доступности данных внутри вашей команды.Мы понимаем, что не все пользователи созданы равными. Вот почему все учетные записи включают функцию безопасности на основе ролей. Первым делом вам нужно создать всех нужных вам пользователей. Если у вас много пользователей, вы можете даже создать группы пользователей, чтобы облегчить назначение разрешений.
После того, как ваши пользователи и группы пользователей созданы, вы можете назначить определенные разрешения для каждого из них. Разрешения, которые вы можете назначить, охватывают множество различных сценариев. На уровне учетной записи вы можете сделать пользовательский проект, отчет, безопасность, шаблон и / или администратором расписания.Вы решаете в соответствии со своими потребностями. Затем на уровне проекта вы можете разрешить каждому пользователю создавать, удалять, редактировать и / или просматривать элементы, при условии, что они станут невидимыми пользователем или администратором проекта только для этого проекта.
Всякий раз, когда вам нужно внести изменения в ваших пользователей, группы пользователей или их разрешения, вы можете отредактировать все вышеперечисленное всего несколькими щелчками мыши в течение нескольких секунд, не вызывая технического специалиста. Вы — хозяин своей учетной записи.
1 — SQL: классический
Из всех наших примеров приложения базы данных SQL — это язык, который большинство ИТ-специалистов используют для взаимодействия с реляционными базами данных.Эти взаимодействия называются транзакциями. Чтобы быть эффективными и точными, транзакции должны быть ACID (атомарными, согласованными, изолированными, долговечными). Атомарный означает, что транзакция — все или ничего. Под согласованностью понимается тот факт, что база данных должна оставаться в согласованном состоянии до и после транзакции. Изоляция означает, что все транзакции должны быть независимыми друг от друга. Под долговечностью понимается тот факт, что вы не можете отменить транзакцию после того, как пользователь был уведомлен об успешной транзакции.
Лучший пример, который я могу найти для объяснения SQL и его свойств ACID, — это банковская система. Допустим, я хочу перевести средства со своего счета на счет мужа. Будет серия звонков или запросов на перевод денег с одного счета на другой. Он должен ответить и завершить все звонки, чтобы завершить транзакцию. Если вызов не удался, он не завершит транзакцию, и мы оба сохраним свои деньги (атомарно). Эта транзакция (согласованность) не повлияет на информацию в каждом из наших аккаунтов.Каждый вызов базы данных будет связан только с нашей транзакцией (изоляцией). Наконец, как только транзакция будет успешной, мы не сможем ее отменить (стойкость).
Самыми известными СУБД, использующими SQL для создания баз данных и запросов к ним, являются IBM DB2, Oracle, Microsoft Access и MySQL. Примеры баз данных на основе SQL, которые граждане используют каждый день, включают банковские системы, компьютеризированные медицинские записи и онлайн-магазины, и это лишь некоторые из них.
Плюсы SQL
- Хорошо известный язык существует уже более 40 лет.
- Отличное решение для хранения данных (серверы, а не жесткий диск!)
- Позволяет запрашивать всю базу данных
- Лучшее решение для структурированных данных и транзакционных нужд
- Разрешает отношения между таблицами
- Доступен многим пользователям одновременно
Минусы SQL
- Необходимость глубоких знаний в области программирования: крутая кривая обучения
- Плохо спроектированная база данных обращается к плохо управляемым данным
- Кто-то скажет, что SQL нелегко масштабировать
- Не лучшее решение при экспоненциальном росте данных (напр.социальные сети)
2 — NoSQL / NewSQL: хипстеры
NoSQL больше относится к тому, чем он является, чем к тому, чем он является. Это приложение базы данных относится к языковой системе, не использующей SQL. Он в основном используется для неструктурированных данных в ситуациях, когда требуется способность базы данных быстро принимать (создавать) или получать (получать) большие объемы данных. NoSQL предлагает большую гибкость с альтернативными моделями данных (например, нереляционные данные, неструктурированные документы).Хорошо то, что он не всегда беспокоится о доступе к данным в реальном времени. Возможно, вы обращаетесь к старой версии данных, поскольку она еще не обновлялась. По сравнению с другими примерами приложения базы данных, оно намного менее жесткое, чем транзакционная структура SQL, но может стать намного более запутанным! Он определенно не принимает во внимание свойства ACID SQL. Наиболее известные системы NoSQL включают MongoDB, Couchbase и Redis.
NewSQL можно отнести к современным языкам реляционных баз данных.Они основаны на модели реляционной базы данных и языке запросов SQL, но обеспечивают лучшую согласованность. Некоторые из них предлагают надежные гарантии ACID.
Платформы социальных сетей, такие как Facebook, Twitter или Instagram, являются лучшими примерами использования NoSQL и NewSQL. Для этого требуется способность очень быстро обрабатывать огромные объемы данных, но (в большинстве случаев) не требуются свойства ACID.
Плюсы NoSQL / NewSQL
- Очень быстро (NoSQL)
- Не требует фиксированных схем таблиц (NoSQL)
- Масштабирование по горизонтали (NoSQL)
- Более высокая согласованность (NewSQL)
- Возможна полная поддержка транзакций (NewSQL)
Минусы NoSQL / NewSQL
- Не транзакционный / ACID (NoSQL)
- Может запутаться (NoSQL)
- Не предлагает столько инструментов разработки, сколько SQL (NewSQL)
Это было всего лишь краткое введение в новейшие языки.Если вы хотите узнать больше о NoSQL и NewSQL, щелкните здесь или здесь.
3 — Excel: базы данных или электронные таблицы?
Вернемся к реляционным базам данных. Исходя из предположения, что реляционные базы данных имеют форму таблиц, состоящих из столбцов и строк, является ли Excel базой данных? Если вы хотите по-настоящему занимательного обсуждения, задайте этот вопрос группе программистов. Я предлагаю вам бежать в другом направлении, так как это может стать действительно уродливым!
Большинство из нас согласятся, что даже если Excel и его электронные таблицы могут быть чрезвычайно полезными, они не являются базами данных.Если посмотреть объективно, Excel создает электронные таблицы. Электронные таблицы на самом деле представляют собой таблицы, состоящие из столбцов и строк. Это формат таблицы, который сбивает людей с толку и заставляет думать, что электронные таблицы — это реляционные базы данных. Мы уже договорились о том, что базы данных используются для управления данными. Электронные таблицы не заходят так далеко и в основном используются для хранения и анализа данных. Тем не менее, это благородное упоминание в наших примерах приложения базы данных.
Плюсы использования Excel
- Простота использования
- Краткая кривая обучения
- Навыки программирования не требуются
- Идеально для числовых данных
- Идеально подходит для управления небольшими пулами данных
- Отлично подходит для анализа данных
- Недорогое решение
Минусы использования Excel
- Статический
- Только один пользователь может обновлять данные одновременно
- Значительные электронные таблицы со временем станут сложнее управлять, что приведет к ошибкам в данных
- Одно действие может где-то сломать что-то, даже если пользователи этого не осознают
- Данные, хранящиеся на вашем компьютере (жесткий диск), по сравнению с базами данных (серверами)
4 — Какое место на этой картинке занимает Кохецион?
Kohezion — это онлайн-база данных программного обеспечения.В нем сочетаются все преимущества классических баз данных с простотой использования электронной таблицы Excel, что позволяет разрабатывать приложения для баз данных. Из всех наших примеров приложения базы данных Kohezion является наиболее настраиваемым, но простым в использовании решением.
Серверная частьKohezion использует язык SQL и разрешает транзакции ACID, но не требует от пользователей использования или понимания SQL. Это то, что называется базой данных конечных пользователей, поскольку пользователям разрешено создавать свои собственные приложения без программирования.Затем они могут вводить данные, нарезать и нарезать их с помощью расширенных функций поиска, создавать мощные отчеты или даже связывать приложения друг с другом по принципу «один ко многим». Сводные таблицы значительно облегчают эту задачу. Но что такое сводная таблица? Создание одного в Excel требует времени и терпения, а с Kohezion вы можете использовать простой инструмент перетаскивания и суммировать большие объемы данных за считанные минуты. Это очень мощный инструмент для управления данными, не тратя много денег и не полагаясь на программистов.
Плюсы Кохезиона
- Навыки программирования не требуются
- Легко учиться
- Приложения для самостоятельной работы с базами данных
- Высокая масштабируемость
- Транзакционный, соблюдает свойства ACID
- Может использоваться многими пользователями одновременно
- Предлагает множество функций для доступа к данным (отчеты, календари, информационные панели и т. Д.).
- Данные хранятся в облаке
Минусы Кохезиона
- Никакой язык программирования не может быть использован
- Только онлайн
- База данных конечных пользователей, не может использоваться для классической разработки
Kohezion — также лучший вариант, если вам нужна база данных, которая управляет личной медицинской информацией.Прочтите эту статью, если хотите получить дополнительную информацию об облачной базе данных, совместимой с HIPAA.
Надеюсь, эта статья помогла вам понять, что такое базы данных, системы управления базами данных и языки. С этими примерами приложения базы данных вы теперь лучше подготовлены, чтобы принять обоснованное решение о том, какой инструмент лучше всего подойдет для ваших нужд управления данными. Если вы хотите узнать больше о Kohezion и о том, как создавать собственные приложения для баз данных, закажите бесплатную 30-минутную встречу с членом нашей команды.Мы хотели бы считать вас довольным пользователем Kohezion.
Что такое СУБД? Определение и часто задаваемые вопросы
Определение СУБД
Система управления базами данных (СУБД) — это программное обеспечение, предназначенное для хранения, извлечения, определения и управления данными в базе данных.
Часто задаваемые вопросы
Что такое СУБД?
Программное обеспечение СУБД в основном функционирует как интерфейс между конечным пользователем и базой данных, одновременно управляя данными, механизмом базы данных и схемой базы данных, чтобы облегчить организацию и управление данными.
Хотя функции СУБД сильно различаются, функции и возможности СУБД общего назначения должны включать: доступный пользователю каталог с описанием метаданных, систему управления библиотекой СУБД, абстракцию и независимость данных, безопасность данных, ведение журнала и аудит активности, поддержку параллелизма и транзакций. , поддержка авторизации доступа, поддержка доступа из удаленных мест, поддержка восстановления данных СУБД в случае повреждения и обеспечение соблюдения ограничений, обеспечивающих соответствие данных определенным правилам.
Методика проектирования схемы базы данных, предназначенная для повышения ясности в организации данных, называется нормализацией. Нормализация в СУБД изменяет существующую схему для минимизации избыточности и зависимости данных путем разделения большой таблицы на более мелкие таблицы и определения взаимосвязи между ними. Вывод СУБД — это встроенный пакет SQL в СУБД, который позволяет пользователю отображать отладочную информацию и вывод, а также отправлять сообщения из подпрограмм, пакетов, блоков PL / SQL и триггеров.Первоначально Oracle разработала пакет DBMS File Transfer, который предоставляет процедуры для копирования двоичного файла в базе данных или для передачи двоичного файла между базами данных.
Система управления базой данных функционирует за счет использования системных команд, сначала получая инструкции от администратора базы данных в СУБД, а затем соответственно инструктируя систему, либо извлекать данные, либо изменять данные, либо загружать существующие данные из системы. Популярные примеры СУБД включают облачные системы управления базами данных, системы управления базами данных в памяти (IMDBMS), системы управления столбцовыми базами данных (CDBMS) и NoSQL в СУБД.
РСУБД против СУБД
Система управления реляционными базами данных (РСУБД) относится к набору программ и возможностей, которые предназначены для того, чтобы позволить пользователю создавать, обновлять и администрировать реляционную базу данных, которая характеризуется структурированием данных в логически независимые таблицы. Существует несколько функций, которые отличают реляционную СУБД от СУБД, в том числе:
- Структура : там, где данные структурированы в иерархической форме в СУБД, данные структурируются в табличной форме в СУБД.
- Емкость пользователя : СУБД способна работать с несколькими пользователями. СУБД может одновременно управлять только одним пользователем.
- Требования к программному и аппаратному обеспечению : РСУБД предъявляет повышенные требования к программному и аппаратному обеспечению.
- Управляемые программы : СУБД поддерживает базы данных в компьютерной сети и на жестких дисках системы. РСУБД управляет отношениями между включенными в нее таблицами данных.
- Объем данных : СУБД способна управлять небольшими объемами данных, а СУБД может управлять неограниченным объемом данных.
- Распределенные базы данных : СУБД не поддерживает распределенные базы данных, в то время как СУБД поддерживает.
- Реализация ACID : РСУБД основывает структуру своих данных на модели ACID (атомарность, согласованность, изоляция и долговечность).
Разница между данными и информацией в СУБД
Данные — это необработанные, необработанные, неорганизованные факты, которые кажутся случайными и еще не несут никакого значения или смысла. Информация относится к данным, которые были организованы, интерпретированы и контекстуализированы человеком или машиной таким образом, чтобы иметь актуальность и цель.
Информация — это отфильтрованные данные, которые были сделаны систематизированными и полезными и считаются более надежными и ценными для исследователей, поскольку был проведен надлежащий анализ и уточнение. СУБД занимается манипулированием данными в базе данных.
Различия между моделями данных в СУБД
Модель данных — это абстрактная модель, которая организует элементы данных, документирует способ хранения и извлечения данных, стандартизирует то, как различные элементы данных соотносятся друг с другом и со свойствами реальных сущностей. , и разрабатывает ответы, необходимые для требований информационной системы.Существует три основных типа моделей данных СУБД: реляционные, сетевые и иерархические.
- Реляционная модель данных : данные организованы в виде логически независимых таблиц.
- Сетевая модель данных : Все объекты организованы в графическом представлении.
- Иерархическая модель данных : данные организованы в древовидную структуру.
Другие модели данных включают сущностные отношения, базы записей, объектно-ориентированные, объектные отношения, полуструктурированные, ассоциативные, контекстные и плоские модели данных.Архитектура системы баз данных в СУБД подразделяется на одноуровневую, в которой СУБД является единственной сущностью, в которой пользователь непосредственно сидит в СУБД и использует ее, или на многоуровневую, в которой почти все компоненты независимы и могут быть изменены независимо.
Особенности системы управления распределенными базами данных
Распределенная база данных — это совокупность связанных данных в нескольких взаимосвязанных базах данных, которые логически взаимосвязаны, но физически хранятся в нескольких физических местах.Распределенные базы данных подразделяются на однородные, в которых все физические местоположения используют одно и то же оборудование и запускают одни и те же операционные системы и приложения, или гетерогенные, в которых каждое местоположение может иметь разные данные, программное обеспечение и структуру оборудования.
Распределенная система управления базами данных (DDBMS) относится к централизованному приложению, которое функционирует для создания распределенных баз данных и управления ими, синхронизации базы данных через регулярные промежутки времени и обеспечения прозрачных механизмов доступа для пользователя, обеспечения универсального применения изменений данных, поддержания безопасности данных и целостность базы данных, к которой могут обращаться одновременно несколько пользователей, и используется в приложениях, обрабатывающих большие объемы данных.
Чем СУБД отличается от традиционной файловой системы?
Традиционная файловая система относится к ранним попыткам компьютеризации ручной файловой системы. Файловые системы обычно используют запоминающие устройства, такие как CD-ROM или жесткий диск, для хранения и организации компьютерных файлов и данных внутри с целью облегчения доступа.
Традиционная файловая система стоит недорого, идеально подходит для небольшой системы с меньшим количеством частей, очень низкими затратами на проектирование, изолированными данными и имеет простую систему резервного копирования, но она небезопасна, имеет недостаточную гибкость и множество ограничений, а также имеет недостатки целостности.
Преимущества СУБД перед традиционной файловой системой: удобство для больших систем, возможность совместного использования данных, гибкость, целостность данных и сложная система резервного копирования. Требования к безопасности данных СУБД основаны на использовании маскирования, токенизации, шифрования, списков управления доступом, разрешений, межсетевых экранов и виртуальных частных сетей, что делает хранение данных и выполнение запросов в СУБД гораздо более безопасным вариантом, чем в традиционной файловой системе.
Предлагает ли OmniSci решение СУБД?
Аналитическая платформа — это решение, предназначенное для компенсации недостатков системы управления реляционными базами данных, работающее в тандеме с различными методами обработки данных для удовлетворения растущих потребностей пользователей в крупных отраслях, ориентированных на данные.В то время как большая часть сегодняшних данных теперь обогащена геолокацией, геопространственные процессы в инструментах ГИС становятся слишком медленными для сегодняшних объемов данных. OmniSci устраняет этот разрыв, делая возможности геопространственного интеллекта (GEOINT) первоклассным гражданином нашей платформы ускоренной аналитики.
Книги по информатике @ Amazon.com
Базы данных
Базы данных, типы, и реляционная модель : Третий манифест
C.J. Дате
Хью Дарвен
Базы данных, типы и реляционная модель: третий манифест — это предложение для будущего направления систем управления данными и базами данных (СУБД). Он обеспечивает точное формальное определение абстрактной модели данных, которую следует рассматривать как основу для проектирования СУБД и языка баз данных.
Предлагаемый фундамент представляет собой эволюционный шаг, а не революционный; он основан на реляционной модели данных Теда Кодда и на исследованиях, основанных на работе Кодда.Он также включает точную и исчерпывающую спецификацию метода определения типов данных, включая исчерпывающую модель наследования типов, основанную на специализации по ограничению (в отличие от метода «расширения» подтипов в объектно-ориентированных языках). Таким образом, он не только переопределяет реляционную модель в современных терминах и разъясняет ее там, где пояснение казалось необходимым, но также обращается к ортогональной проблеме типов данных, от существования которых зависит реляционная модель.Поэтому он предлагается в качестве прочной основы для СУБД будущего и является обязательным к прочтению как для студентов, так и для специалистов по базам данных.
Новое в третьем издании
- Вводный обзор реляционной модели и теории типов, представленных в Манифесте , чтобы сделать книгу более подходящей для образовательных целей и более автономной
- Полный набор упражнений с решениями, доступными онлайн для инструкторов
- Улучшения в Tutorial D, языке, используемом в книге в иллюстративных целях (по крайней мере, одна реализация этого языка, Rel, теперь доступна для учебных целей бесплатно)
- Все обсуждения SQL обновлены до уровня текущего стандарта SQL: 2003
- Поддерживающий веб-сайт: www.thethirdmanifesto.com
- Обширный набор приложений, в том числе одно по все еще спорной теме обновления представлений
Хью Дарвен работал в отделах разработки программного обеспечения IBM с 1967 по 2004 год. В своей карьере он участвовал в разработке СУБД, а в период 1978–1982 годов был одним из главных архитекторов продукта IBM под названием Business System 12, продукта, который точно отражал принципы реляционной модели.Он был активным участником разработки международных стандартов SQL с 1988 года. Он является лектором и консультантом по разработке курсов в Уорикском и Открытом университетах, оба в Великобритании. , исследователь и консультант, специализирующийся на системах реляционных баз данных. Он был одним из первых, кто осознал фундаментальную важность новаторской работы Кодда над реляционной моделью. Он был
С.Дж. Дэйт — независимый автор, лектор, исследователь и консультант, специализирующийся на системах реляционных баз данных. Активный член сообщества баз данных более 30 лет, Дэйт посвятил большую часть своей карьеры изучению, расширению и разъяснению теории и практики реляционных технологий. Он также участвовал в техническом планировании продуктов IBN SQL / DS и DB2, а его книга An Introduction to Database Systems разошлась по всему миру более чем полмиллиона копий.
Хью Дарвен занимается разработкой программного обеспечения с 1967 года в качестве сотрудника IBM United Kingdom Ltd.