Модели баз данных
СУБД используют различные модели баз данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.
Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами.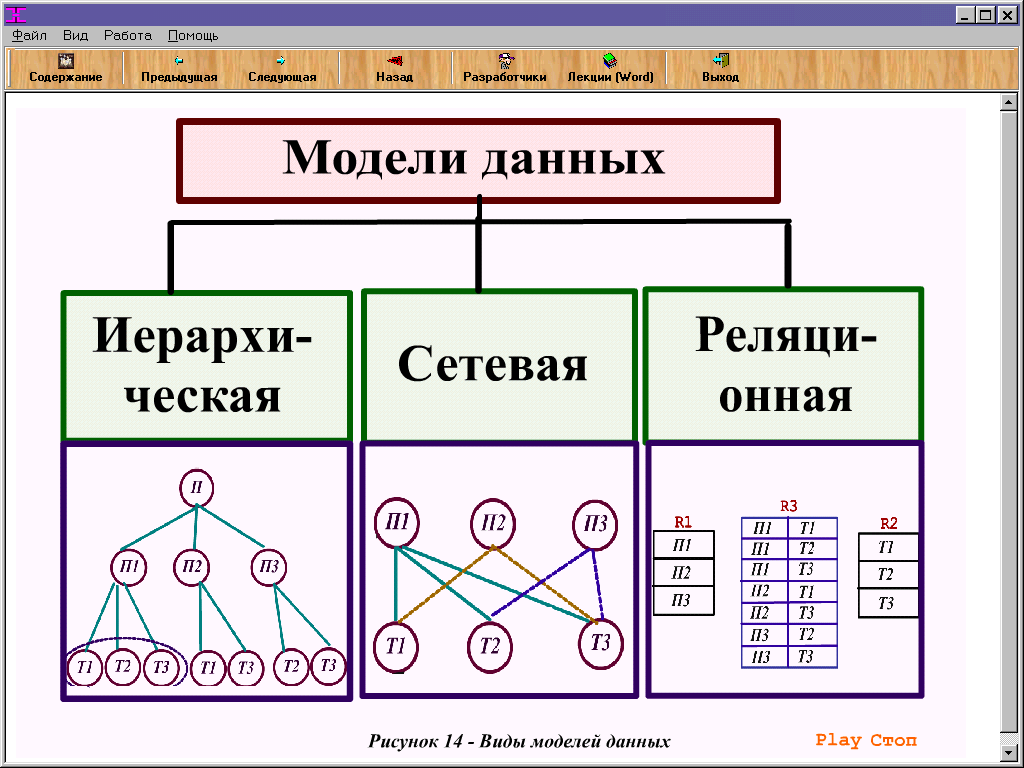 И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.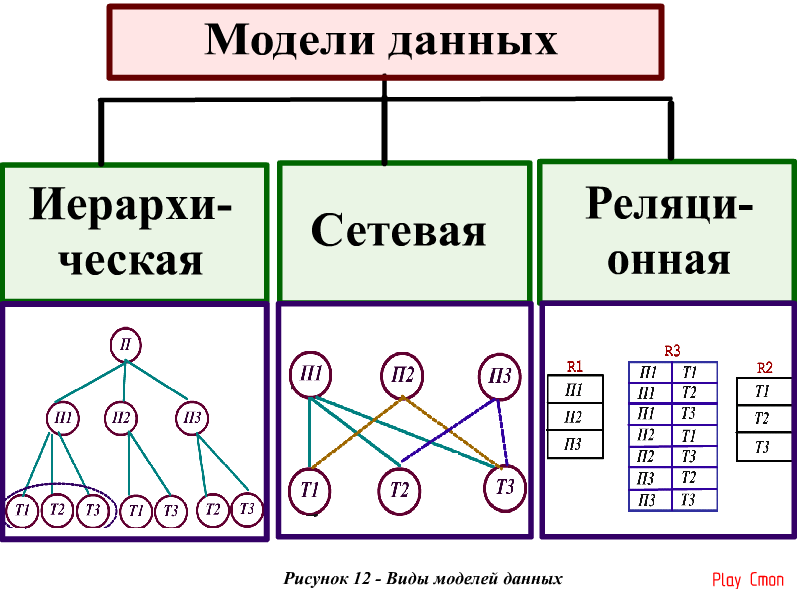
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД. Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
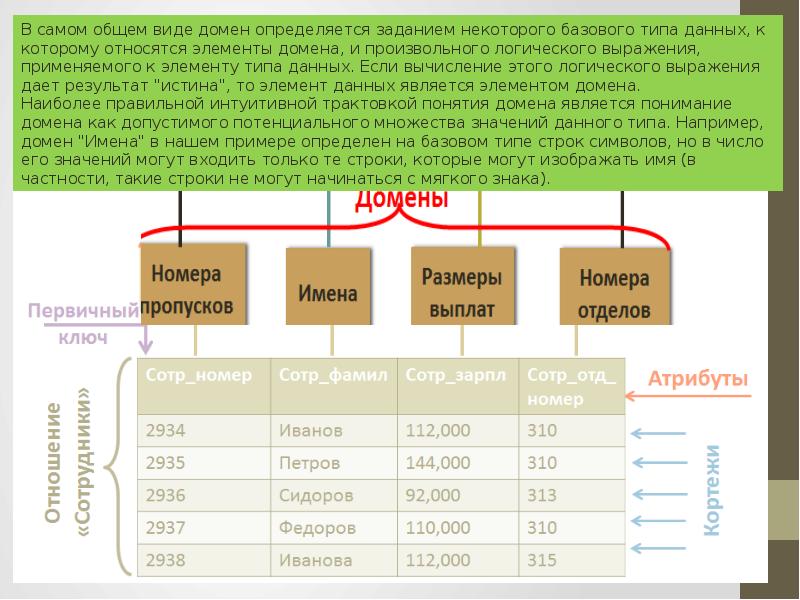
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.

- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.

Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта.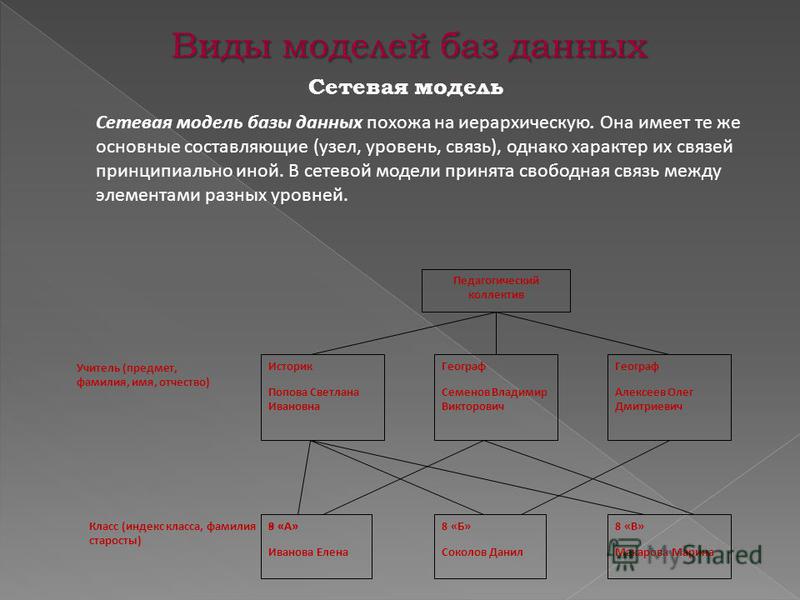 Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.

А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.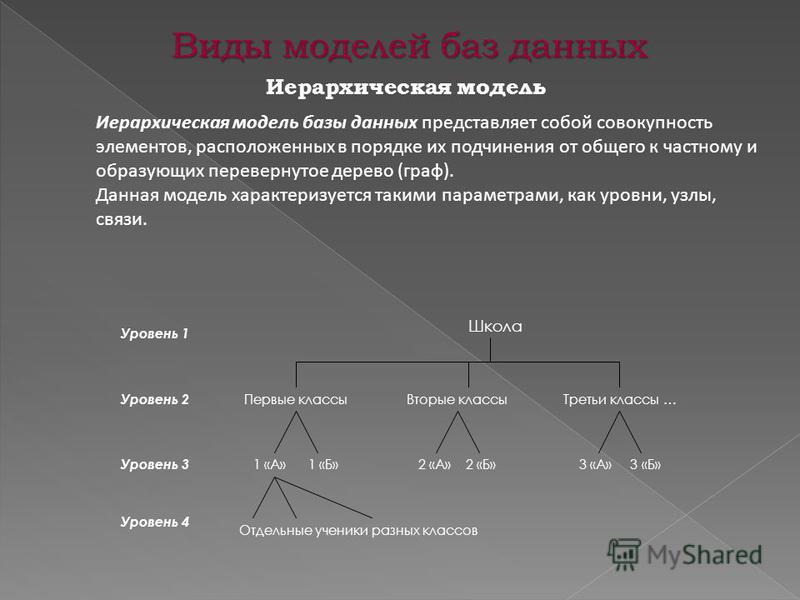
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Данная публикация является переводом статьи «Types of Database Models | Database Management System» , подготовленная редакцией проекта.
Модели баз данных
СУБД используют различные модели баз данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату.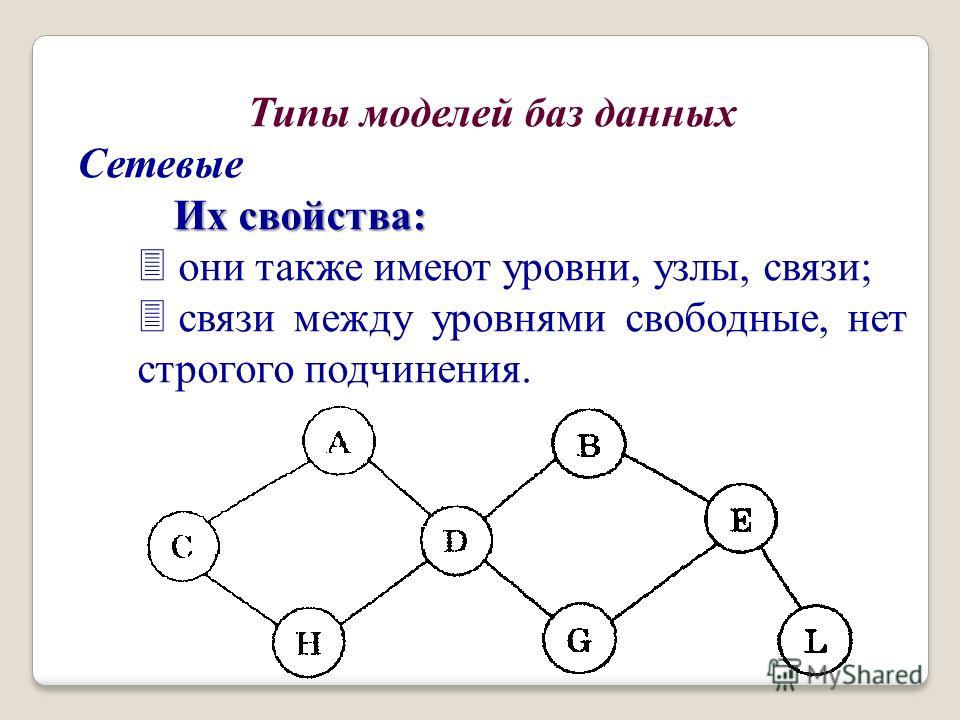 Организация также может хранить информацию о его детях, их имена и даты рождения.
Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.

Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.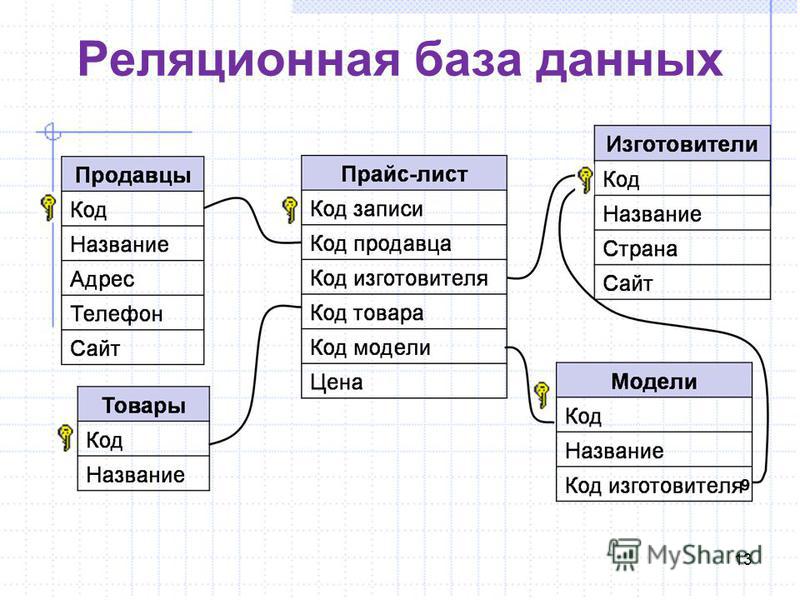
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД.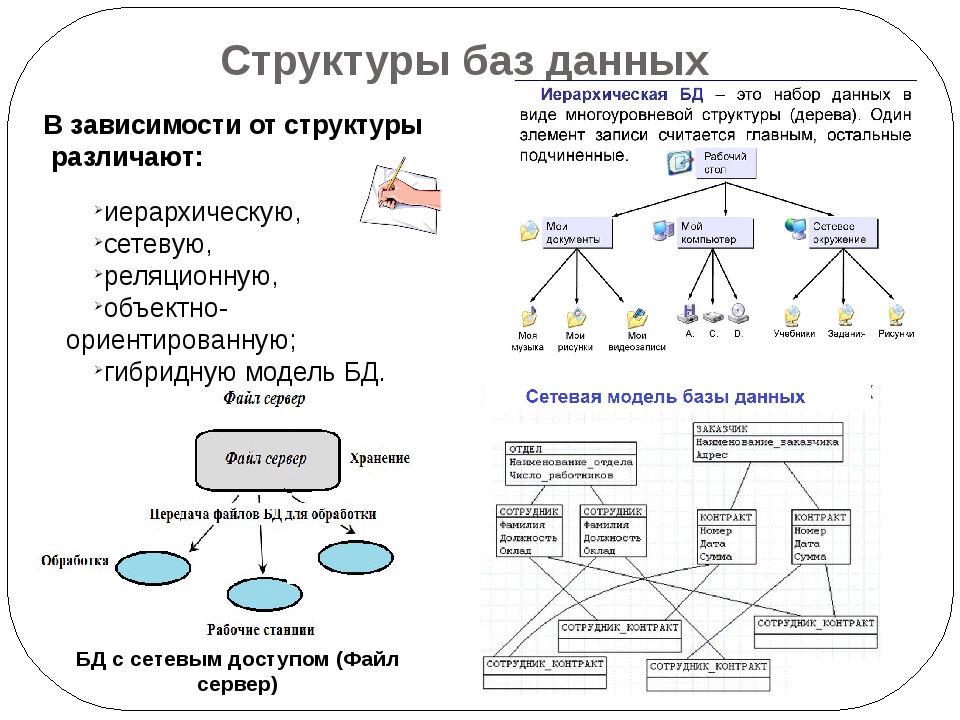 Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.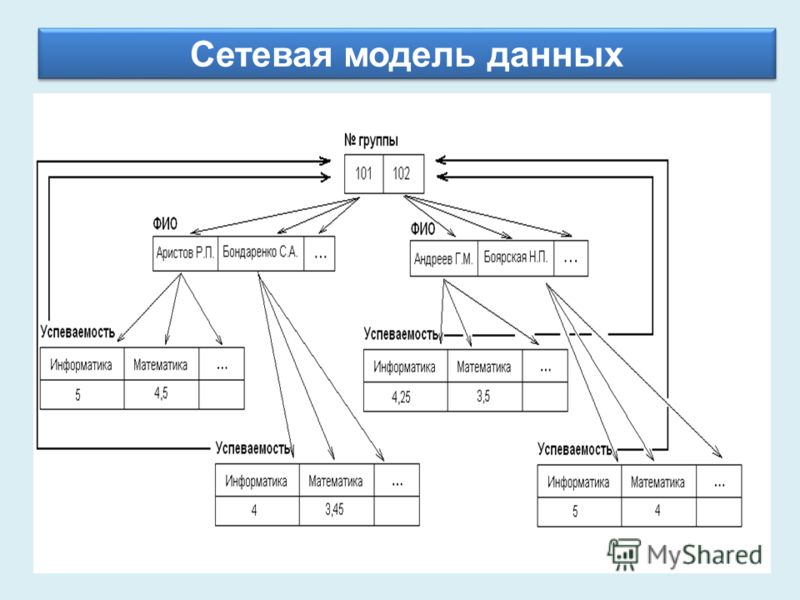
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим».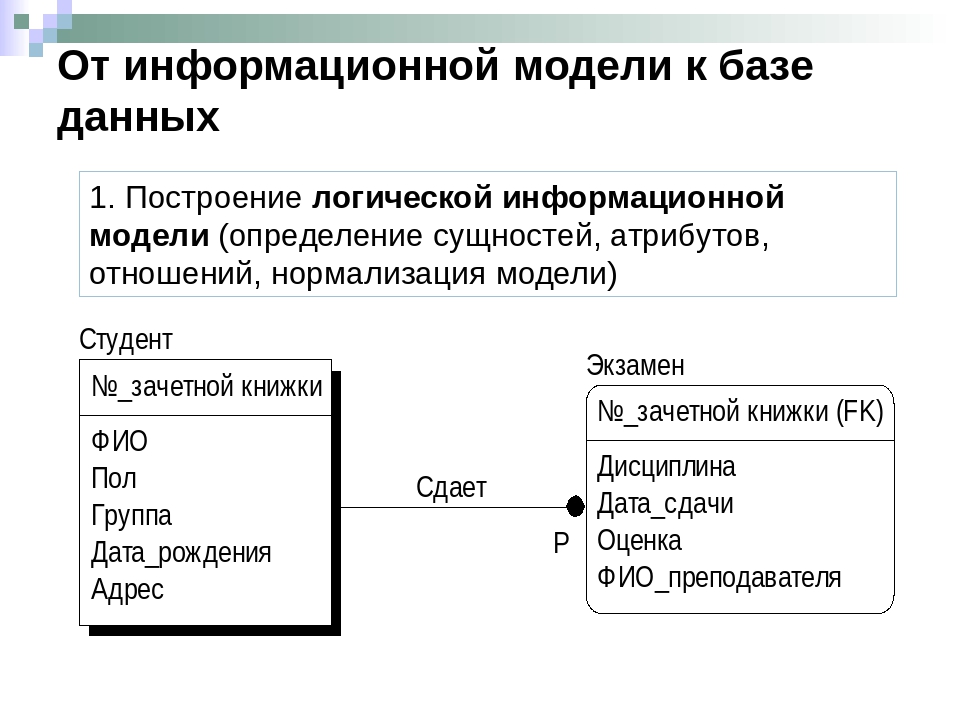 Но быстро становится слишком сложной и неудобной для управления.
Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
 То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.

Данная публикация является переводом статьи «Types of Database Models | Database Management System» , подготовленная редакцией проекта.
Основные модели баз данных — Разные уроки по Программированию
1) Иерархическая — представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней, структура запись-потомок должна иметь в точности одного предка.В 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM. Это была первая иерархически база данных благодаря которой определили ряд фундаментальных понятий в теории систем баз данных, которые и до сих пор являются основополагающими для сетевой модели данных.
Такая форма используется:
a.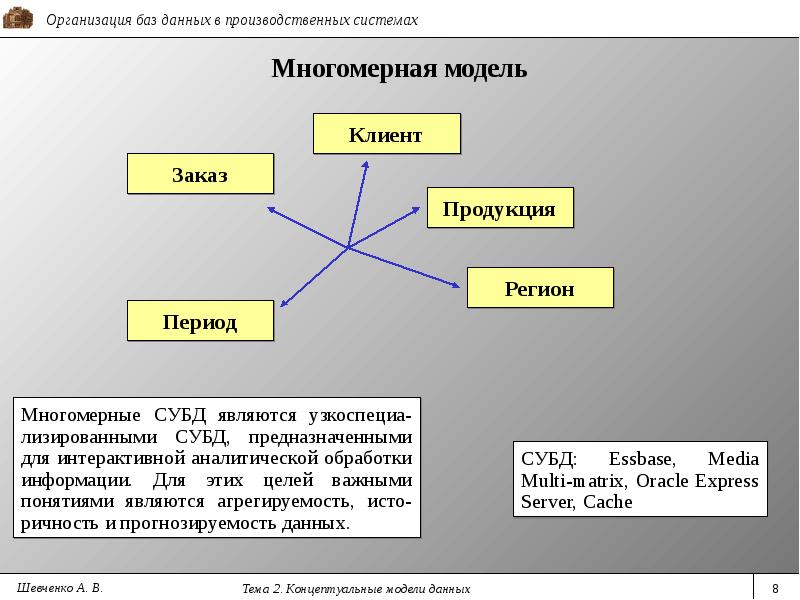 Серверы каталогов, такие, как LDAP и Active Directory (допускают чёткое представление в виде дерева)
Серверы каталогов, такие, как LDAP и Active Directory (допускают чёткое представление в виде дерева)
b. файловые, база настроек Windows WMI и Реестр Windows.
2) Сетевая — являющаяся расширением иерархического подхода, сетевой структуре данных у потомка может иметься любое число предков.
Такая модель данных используется:
1) в графических системах для формирования 3D изображений.
2) в системах пространственной координации объектов.
3) Реляционная — данные в базе данных представляют собой набор отношений. Отношения (таблицы) отвечают определенным условиям целостности. Реляционная модель данных поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения
и уровня базы данных.
Такая форма используется:
a. Oracle
b. MS SQL, MY SQL
c. Potgresql
d. MS Access
4) Объектная и объектно-ориентированная – Данные в таких базах представляют из себя объекты с определенными наборами свойств и методов и поведения.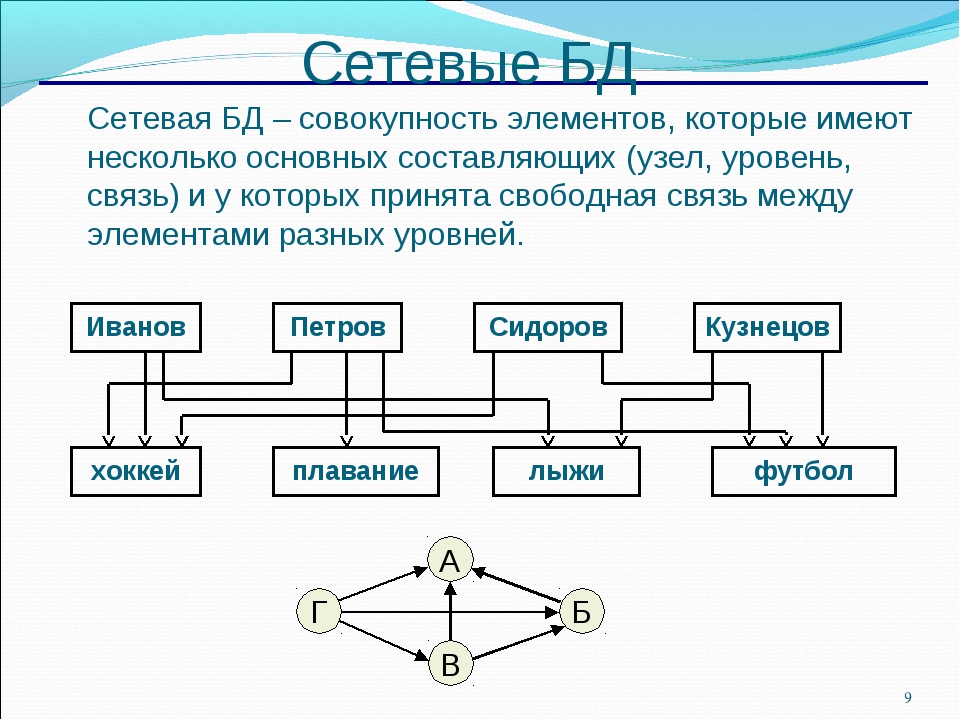 Отношения данных объектов строятся на основе обобщения свойств и методов и поведения различных объектов по отношению друг к другу.
Отношения данных объектов строятся на основе обобщения свойств и методов и поведения различных объектов по отношению друг к другу.
Данную модель данных используют:
1. Jasmine (компания Computer Associates) — Одна из известнейших объектных баз
2. Versant (разработка Versant Technologies) — использовалась в основном для разработки телекоммуникаций
3. POET (компания POET Software) — компактная объектная база данных. Которая поддерживает программные интерфейсы C++, Java, Visual Basic
4. ObjectStore PSE (разработка компании ObjectDesign) — Модули объектов Java
Модели и типы данных
Понятие данных и модели данных
Обобщенные категории «данные» и «модель данных» являются одними из основополагающих в концепции баз данных.
Определение 1
Данные (применимо к базам данных) – это набор конкретных значений, параметров, которые характеризуют ситуацию, условие, объект или другие факторы.
Пример 1
Например, данными является объект Иванов Иван Иванович, условие женат/не женат и т. д.
д.
Данные сами по себе не имеют определенной структуры. Они становятся информацией в том случае, когда пользователь им задаст определенную структуру, т.е. осознает их смысловое содержание. Таким образом, центральным понятием в базах данных является модель. Однозначно определить этот термин невозможно. Каждый автор определяет это понятие с некоторыми различиями. Выделим общее в этих определениях.
Определение 2
Модель данных
Классификация моделей данных
При трехуровневой архитектуре понятие модели данных относится к каждому уровню. Физическая модель данных использует категории, которые касаются организации внешней памяти и структур хранения в данной операционной среде. Сегодня в качестве физических моделей используют разные методы размещения данных, которые основаны на файловых структурах: файлы прямого и последовательного доступа, индексные файлы и инвертированные файлы, файлы, использующие разные методы хеширования, взаимосвязанные файлы.
Модели данных, которые используются на концептуальном уровне, вызывают наибольший интерес. Внешние модели по отношению к ним называют подсхемами и ими используются те же абстрактные категории, что и в концептуальных моделях данных.
При проектировании баз данных имеет место еще один уровень, который им предшествует.
Определение 3
Модель этого уровня выражает информацию о предметной области в таком виде, который не зависит от используемой СУБД. Такие модели называются
Инфологические модели данных используют на ранних стадиях проектирования с целью описать структуры данных при разработке приложения, а даталогические модели уже поддерживает конкретная СУБД.
Определение 4
Документальные модели данных представляют собой слабо структурированную организацию информации, которая ориентирована зачастую на свободные форматы текстов на естественном языке и документов.
Модели, которые основаны на языках разметки документов, прежде всего связаны со стандартным общим языком разметки – SGML (Standard Generalized Markup Language), утвержденным ISO как стандарт еще в 1980-х гг. Язык SGML применяется для создания других языков разметки, им определяется допустимый набор тегов (ссылок), их атрибуты и внутренняя структура документа. Контроль правильности использования тегов выполняется с помощью DTD-описаний (специальный набор правил). Из-за сложности SGML используется в основном для описания синтаксиса других языков (наиболее известный из них HTML) и напрямую с SGML-документами работали немногие приложения.
Язык HTML, более простой и удобный, предоставляет возможность определить оформление элементов документа и содержит набор инструкций – тегов, с помощью которых выполняется разметка. Команды HTML прежде всего предназначены для управления выводом содержимого документа на экран программы-клиента.
Более мощным, гибким и удобным языком гипертекстовой разметки является XML.
XML (Extensible Markup Language) является языком разметки, который описывает целый класс объектов данных – XML-документов. Его используют для описания грамматики других языков и как средство контроля правильности составления документов. Т.е. XML не содержит никаких тегов, а просто определяет порядок их создания.
Основой тезаурусных моделей является принцип организации словарей, которые содержат определенные языковые конструкции и правила их взаимодействия в определенной грамматике.
Такие модели эффективно используют в системах-переводчиках, особенно многоязыковых.
Дескрипторные модели являются самыми простыми из документальных моделей. Их широко применяли на ранних стадиях использования документальных БД. Каждому документу соответствовал дескриптор – описатель, который обладал жесткой структурой и описывал документ соответственно тем характеристикам, которые необходимы для работы с документами.
Данные, которые хранятся в БД, описываются моделью данных, которая поддерживается СУБД. К классическим относятся модели данных:
К классическим относятся модели данных:
- иерархическая;
- сетевая;
- реляционная.
В последнее время разработаны и активно внедряются модели данных:
- постреляционная;
- многомерная;
- объектно-ориентированная.
Ведется разработка всевозможных систем, основанных на других моделях данных, которые расширяют известные модели. К ним можно отнести ориентированные
Модели данных. Виды моделей данных бд
Классификация баз данных.
По технологии обработки данных базы данных подразделяются на централизованные и распределенные.
Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределённый доступ к такой базе.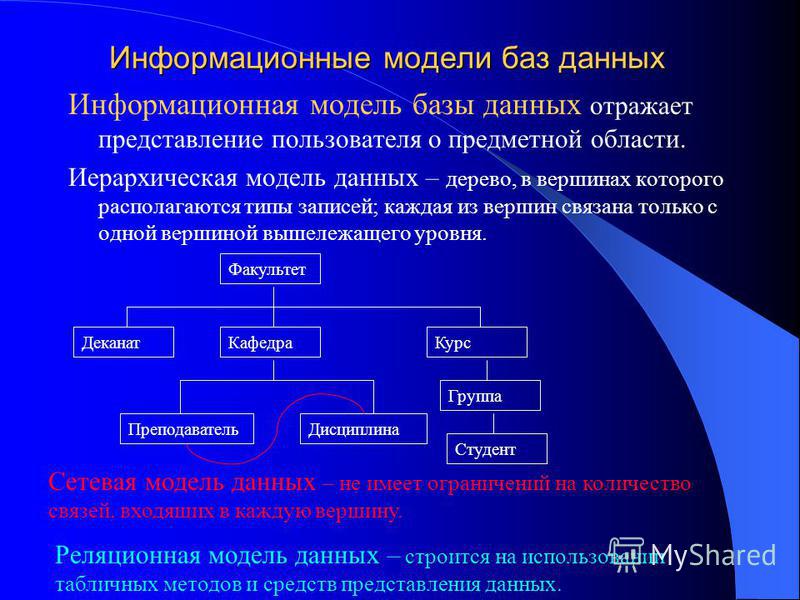 Такой способ использования баз данных часто применяют в локальных сетях ПК.
Такой способ использования баз данных часто применяют в локальных сетях ПК.
Распределённая база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределённой базой данных (СУРБД).
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным (сетевым) доступом.
Ядром любой модели базы данных является модель данных.
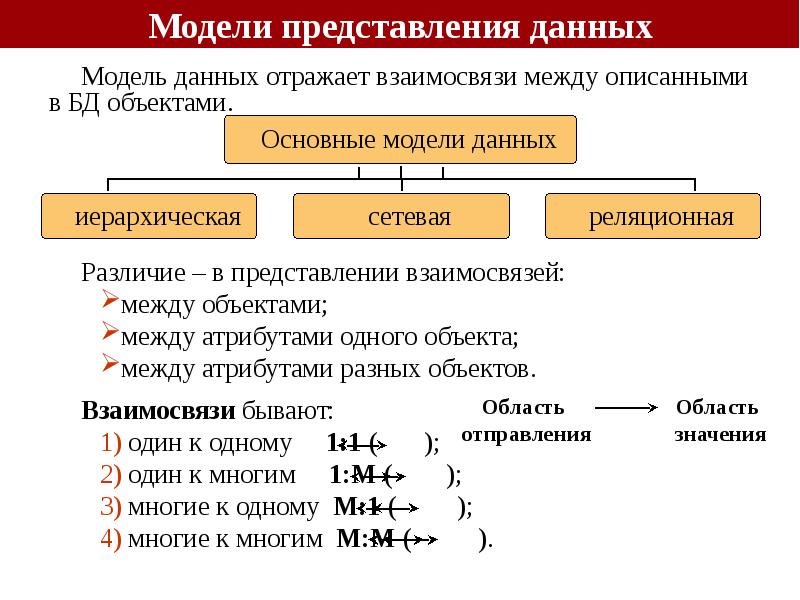
Модель данных — совокупность структур данных и операций их обработки. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
На сегодняшний день существует три основных подхода к построению баз данных: иерархический, сетевой и реляционный.
Исторически первой появилась Иерархическая модель данных. Иерархическая модель данных строится по принципу иерархии типов объектов, т. е. один тип объекта является главным, а остальные подчиненными.
е. один тип объекта является главным, а остальные подчиненными.
Данные представлены в виде деревьев. Две вершины дерева связаны отношением подчиненности. Дерево обязательно содержит одну вершину, которая не имеет главных. Такая вершина называется корнем. В данном случае это вершина 3. Вершины, которые не имеют подчиненных называются листьями, на рисунке это 1, 2, 5, 7, 8, 9.
Рис.1. Иерархическая модель данных
Вершина дерева хранит данные, характеризующие некоторый объект и несколько связей с подчиненными вершинами.
Между главными и подчиненными объектами установлено отношение «один ко многим». Для каждого подчиненного типа объекта может быть только один исходный тип объекта.
Главная вершина — Отдел — содержит информацию о названии, бюджете и телефоне отдела. Отдел имеет подчиненную вершину Руководитель с информацией Фамилия, Год рождения, Разряд и несколько подчиненных вершин сотрудники, каждый сотрудник характеризуется Фамилией, Адресом и т.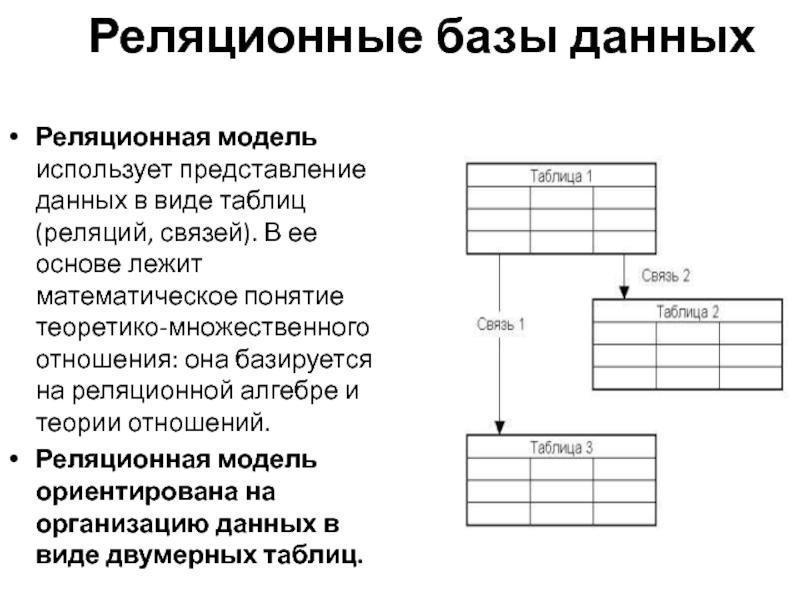
Сетевая модель данных.
Сетевая модель является обобщением иерархической модели данных. Любой объект может быть главным и подчиненным. Каждый объект может участвовать в любом числе взаимодействий. Единственное ограничение — отношение подчиненности не может вернуться обратно к вершине, с которой оно начиналось.
Рис.2. Сетевая модель данных
Отдел содержит информацию: Название, Бюджет, Телефон и связи с Руководителем и несколькими Сотрудниками. Руководитель характеризуется Датой вступления в должность, Годом рождения, Разрядом. Сотрудники характеризуются фамилией, Адресом. Вершина Руководитель связана с одной из вершин Сотрудников, в ней хранятся Фамилия и Адрес руководителя.
Сотрудники характеризуются фамилией, Адресом. Вершина Руководитель связана с одной из вершин Сотрудников, в ней хранятся Фамилия и Адрес руководителя.
Реляционная модель данных.
В реляционной модели данных объекты и взаимодействия между ними представляются с помощью таблиц. Каждая таблица должна иметь первичный ключ — поле или комбинацию полей, которая единственным образом идентифицирует каждую строку таблицы.
В настоящее время реляционная модель данных является наиболее популярной. На ее идеологии построены СУБД FoxPro, Access, Visual C++ и д.р.
Возможные операции в реляционной базе данных: создание таблиц и связей, изменение структуры таблиц, добавление, удаление и изменения записей, поиск данных, отбор данных из одной или нескольких таблиц и т.д.
Работа с реляционными базами данных основана на реляционной алгебре.
Различают
три основные
модели базы
данных —
это иерархическая, сетевая и реляционная.
Эти модели отличаются между собой по
способу установления связей между
данными.
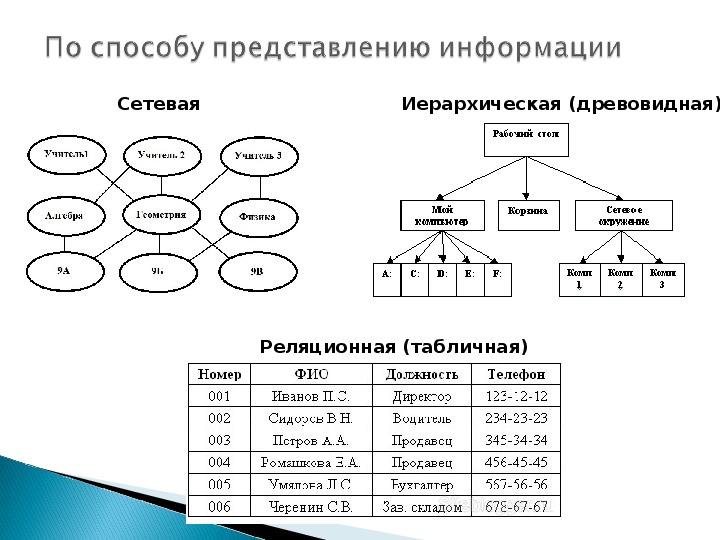
8.1. Иерархическая модель базы данных
Иерархические модели баз данных исторически возникли одними из первых. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений «предок-потомок «. Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных — невозможность реализовать отношения «многие-ко-многим «, а также ситуации, когда запись имеет несколько предков.
Иерархические базы данных . Иерархические базы данных графически могут быть представлены как перевернутое дерево , состоящее из объектов различных уровней. Верхний уровень (корень дерева ) занимает один объект , второй — объекты второго уровня и так далее.
Между
объектами существуют связи,
каждый объект может
включать в себя несколько объектов
более низкого уровня. Такие объекты
находятся в отношении предка (объект ,
более близкий к корню) к потомку
(объект более
низкого уровня), при этомобъект -предок
может не иметь потомков или иметь их
несколько, тогда как объект —потомок обязательно
имеет только одного предка. Объекты,
имеющие общего предка, называются
близнецами.
Такие объекты
находятся в отношении предка (объект ,
более близкий к корню) к потомку
(объект более
низкого уровня), при этомобъект -предок
может не иметь потомков или иметь их
несколько, тогда как объект —потомок обязательно
имеет только одного предка. Объекты,
имеющие общего предка, называются
близнецами.
Рис. 6. Иерархическая база данных
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа ), групповоеотношение , база данных .
Атрибут (элемент данных) | Наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем. |
Запись | Именованная совокупность атрибутов. |
Групповое отношение | — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры. |
 Использование записей позволяет за
одно обращение к базе получить некоторую
логически связанную совокупность
данных. Именно записи изменяются,
добавляются и удаляются. Тип записи
определяется составом ее
атрибутов. Экземпляр
записи —
конкретная запись с конкретным
значением элементов.
Использование записей позволяет за
одно обращение к базе получить некоторую
логически связанную совокупность
данных. Именно записи изменяются,
добавляются и удаляются. Тип записи
определяется составом ее
атрибутов. Экземпляр
записи —
конкретная запись с конкретным
значением элементов.Пример. Рассмотрим
следующую модель данных предприятия
(см. рис.
7): предприятие состоит из отделов,
в которых работают сотрудники. В каждом
отделе может работать несколько
сотрудников, но сотрудник не может
работать более чем в одном отделе. Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. 7 (а) (Для простоты полагается, что имеются только две дочерние записи). Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик — контракты с ним — сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК (НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. 7b). Рис. 7. Пример иерархической БД |
Из этого примера видны недостатки иерархических БД :
Частично
дублируется информация между
записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие
записи называют парными), причем
виерархической
модели данных не
предусмотрена поддержка соответствия
между парными записями.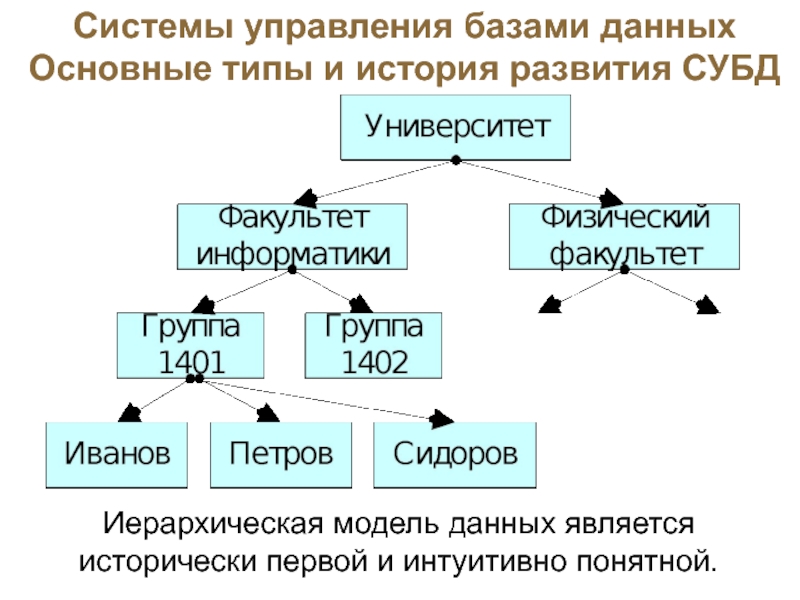
Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних.
Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение , в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ — дочерней (рис. 7 c). Таким образом, мы опять вынуждены дублировать информацию.
Иерархическая структура предполагаета неравноправие между данными — одни жестко подчинены другим. Подобные структуры, безусловно, четко удовлетворяют требованиям многих, но далеко не всех реальных задач.
Иерархические базы данных имеют форму деревьев с дугами-связями и узлами-элементами данных. Иерархическая структура предполагала неравноправие между данными — одни жестко подчинены другим. Подобные структуры, безусловно, четко удовлетворяют требованиям многих, но далеко не всех реальных задач.
2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель. Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных.
Во-первых , все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель — единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково — таблицами . Правда, такой подход усложняет понимание смысла хранящейся в базе данных информации, и, как следствие, манипулирование этой информацией.
Избежать трудностей манипулирования позволяет второй элемент модели — реляционно-полный язык (отметим, что язык является неотъемлемой частью любой модели данных, без него модель не существует). Полнота
языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры
или реляционного исчисления
( полнота
последних доказана математически Э.Ф. Коддом). Более того, язык должен описывать любой запрос
в виде операций с таблицами, а не с их строками. Одним из таких языков является SQL
.
Полнота
языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры
или реляционного исчисления
( полнота
последних доказана математически Э.Ф. Коддом). Более того, язык должен описывать любой запрос
в виде операций с таблицами, а не с их строками. Одним из таких языков является SQL
.
Третий элемент реляционной модели требует от реляционной модели поддержания некоторых ограничений целостности . Одно из таких ограничений утверждает, что каждая строка в таблице должна иметь некий уникальный идентификатор , называемый первичным ключом. Второе ограничение накладывается на целостность ссылок между таблицами. Оно утверждает, что атрибуты таблицы, ссылающиеся на первичные ключи других таблиц, должны иметь одно из значений этих первичных ключей.
4. Объектно-ориентированная модель. Новые области использования вычислительной техники, такие как научные исследования, автоматизированное проектирование и автоматизация
учреждений, потребовали от баз данных способности хранить и обрабатывать новые объекты — текст, аудио- и видеоинформацию, а также документы. Основные трудности объектно-ориентированного моделирования
данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая , не существует. В большой степени, поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных
в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности.
Несмотря на преимущества объектно-ориентированных систем — реализация сложных типов данных
, связь
с языками программирования и т.п. — на ближайшее время превосходство реляционных СУБД
гарантировано.
Основные трудности объектно-ориентированного моделирования
данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая , не существует. В большой степени, поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных
в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности.
Несмотря на преимущества объектно-ориентированных систем — реализация сложных типов данных
, связь
с языками программирования и т.п. — на ближайшее время превосходство реляционных СУБД
гарантировано.
Рассмотрим более подробно эти модели данных далее.
Иерархическая модель базы данных
Иерархические базы данных
— самая ранняя модель представления сложной структуры данных. Информация
в иерархической базе организована по принципу древовидной структуры, в виде отношений «предок- потомок
«. Каждая запись
может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных
— невозможность реализовать отношения » многие-ко-многим
«, а также ситуации, когда запись
имеет несколько предков.
Каждая запись
может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных
— невозможность реализовать отношения » многие-ко-многим
«, а также ситуации, когда запись
имеет несколько предков.
Иерархические базы данных . Иерархические базы данных графически могут быть представлены как перевернутое дерево , состоящее из объектов различных уровней. Верхний уровень ( корень дерева ) занимает один объект , второй — объекты второго уровня и так далее.
Между объектами существуют связи, каждый объект
может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка ( объект
, более близкий к корню) к потомку ( объект
более низкого уровня), при этом объект
-предок может не иметь потомков или иметь их несколько, тогда как объект
— потомок
обязательно имеет только одного предка. Объекты, имеющие общего предка, называются близнецами.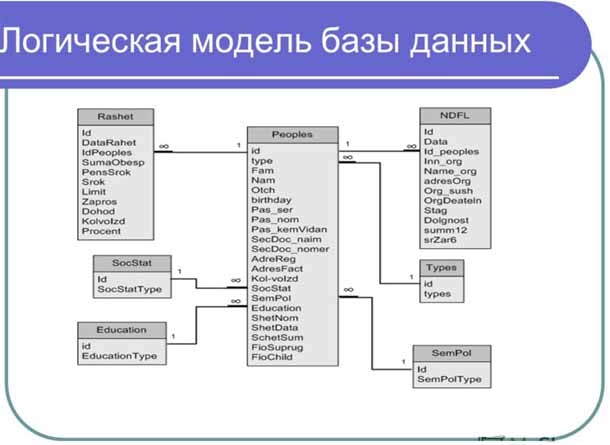
Иерархической базой данных является Каталог папок Windows , с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол . На втором уровне находятся папки Мой компьютер , Мои документы, Сетевое окружение и Корзина , которые являются потомками папки Рабочий стол , а между собой является близнецами. В свою очередь , папка Мой компьютер является предком по отношению к папкам третьего уровня -папкам дисков ( Диск 3,5(А:), (С:), (D:), (Е:), (F:)) и системным папкам ( сканер , bluetooth и.т.д.) — на рис. 4.1 .
Рис.
4.1.
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись ( группа ), групповое отношение , база данных .
| Атрибут (элемент данных) | — наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем. |
| Запись | — именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи — конкретная запись с конкретным значением элементов. |
| Групповое отношение | — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры. |
Корневая запись каждого дерева обязательно должна содержать ключ
с уникальным значением. Ключи некорневых записей должны иметь уникальное значение
только в рамках группового отношения. Каждая запись
идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой, по иерархическому пути.
Ключи некорневых записей должны иметь уникальное значение
только в рамках группового отношения. Каждая запись
идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой, по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей — вершинами ( диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись .
Пример
Рассмотрим следующую модель данных предприятия (см. рис. 4.2): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления
персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис.
4.2 (а) (Для простоты полагается, что имеются только две дочерние записи).
Это отношение показано на рис.
4.2 (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик — контракты с ним — сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК (НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (
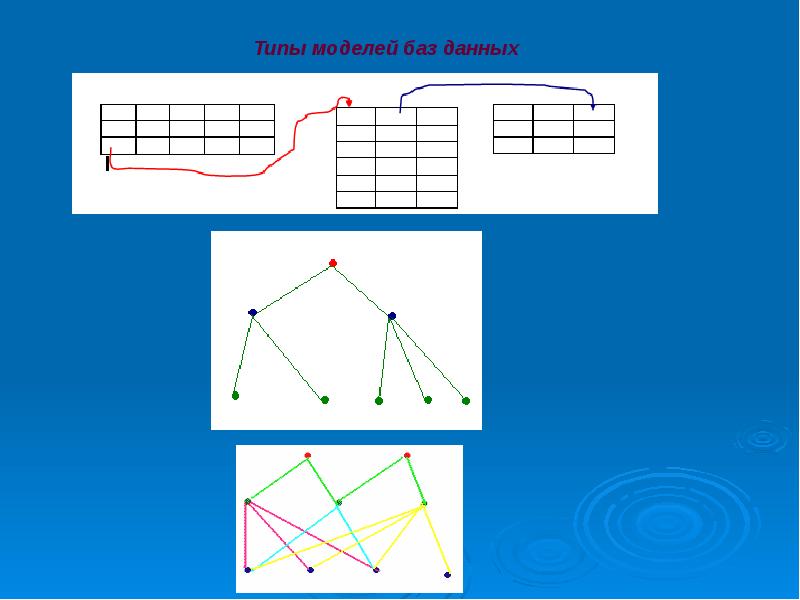
Типы моделей баз данных
СУБД используют различные модели данных . Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Иерархическая модель
В иерархической модели элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией
» (Information Management System ) компании IMB
— пример иерархической СУБД.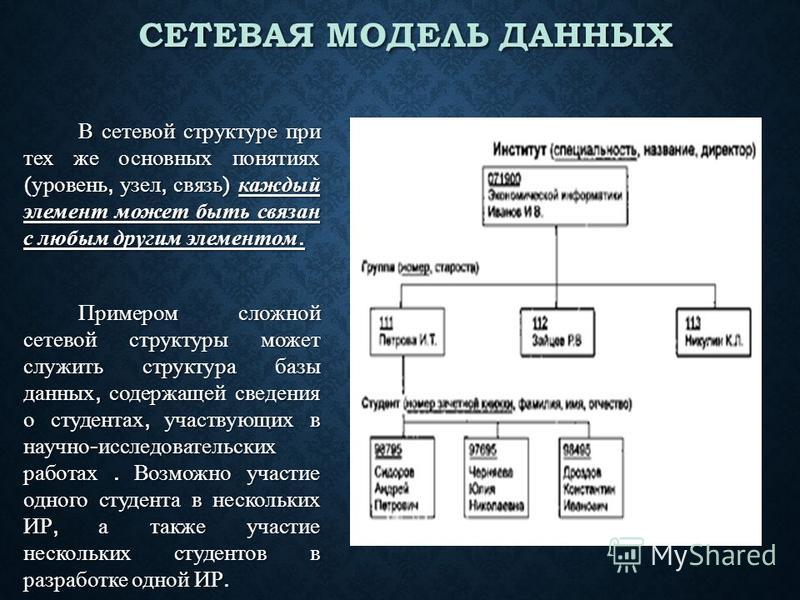
Иерархическая модель организует данные в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних ) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей » — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок » вида 1:N . Это достигается путём использования древовидной структуры — она «позаимствована » из математики, как и теория множеств, используемая в реляционной модели.
Иерархические системы баз данных
Рассмотрим в качестве примера иерархической модели данных
организацию, хранящую информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.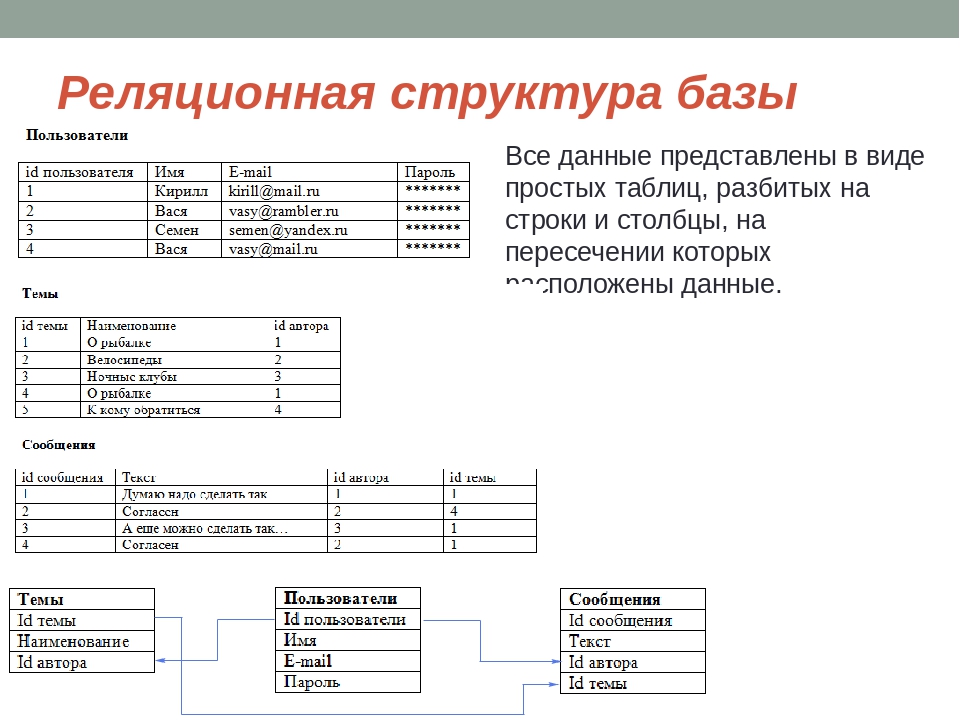
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. В иерархической базе данных отношение «родитель-потомок » — это отношение «один ко многим ». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок »:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Схема иерархической базы данных состоит из нескольких иерархических схем.
Сетевая модель
В сетевой модели данных
у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков.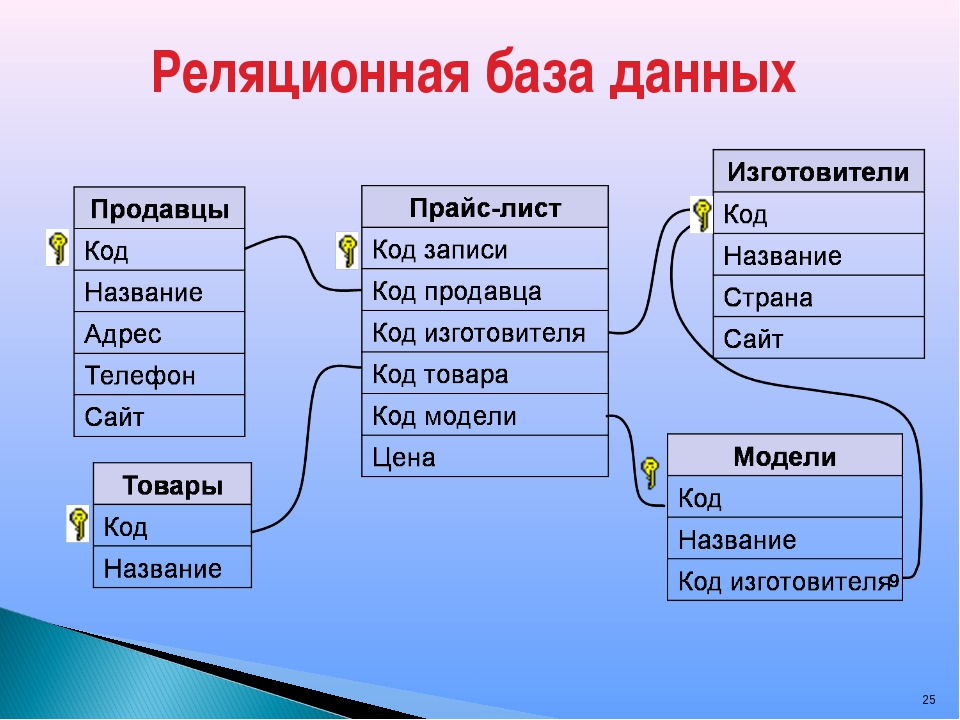 Записи в такой модели связаны списками с указателями. IDMS
(«Интегрированная система управления данными
») от компании Computer Associates international Inc.
— пример сетевой СУБД.
Записи в такой модели связаны списками с указателями. IDMS
(«Интегрированная система управления данными
») от компании Computer Associates international Inc.
— пример сетевой СУБД.
Иерархическая модель структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I . Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL ).
Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL ).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец », имени набора и типа «запись-член ». Запись подчинённого уровня («запись-член ») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец ») также может быть «членом » или «владельцем » в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records , то есть «перекрёстные записи ). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем
» (от него отходит «стрелка» связи
), и один или более типов записи являются «членами
» (на них указывает «стрелка»
). Обычно в наборе существует отношение 1:М
, но разрешено и отношение 1:1
. Сетевая модель данных CODASYL
основана на математической теории множеств.
Обычно в наборе существует отношение 1:М
, но разрешено и отношение 1:1
. Сетевая модель данных CODASYL
основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
Реляционная модель
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений ) , состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных
нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД. Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle
, Sybase
, DB2
, Ingres
, Informix
и MS-SQL Server
.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более ».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN
для выбора связанных записей двух таблиц, сопоставив значения полей.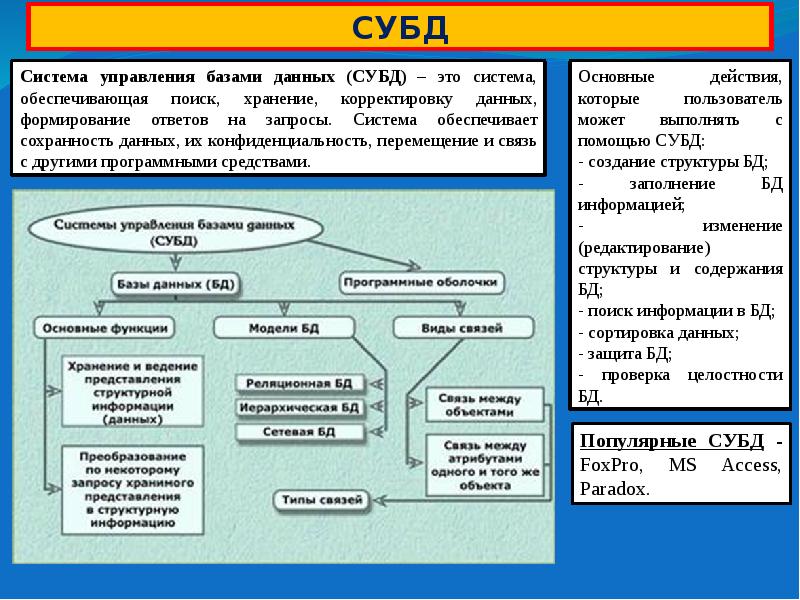
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы » может содержать пары «ID-покупателя » и «код-товара ». А в таблице «Товар » могут быть пары «код-товара » и «цена ». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара » этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Сравнение трёх моделей
Первая модель данных, иерархическая, имеет древовидную структуру («родитель-потомок »), и поддерживает только отношения типа «один к одному » или «один ко многим ». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка ) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных
, имеет более гибкую структуру, чем иерархическая, и поддерживает отношения «многие ко многим
». Но быстро становится слишком сложной и неудобной для управления.
Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
«Один к одному»
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел .
У каждого менеджера может быть только один отдел, и наоборот.
«Один ко многим»
В моделях данных отношение одного объекта с несколькими.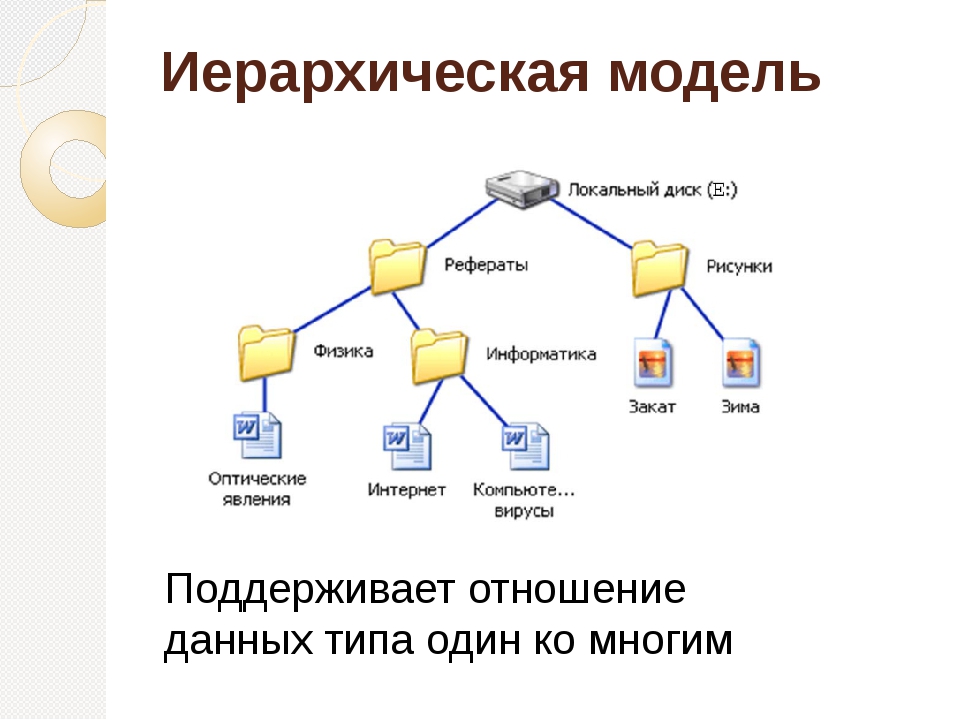 Например, Сотрудник -> Отдел
.
Например, Сотрудник -> Отдел
.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
«Многие ко многим»
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект .
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
Модели организации данных. Сетевые, реляционные, иерархические модели.
Ядром любой базы данных является модель данных. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных — это совокупность структур данных и операций их обработки. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
Виды моделей данных БД
Иерархическую модель БД изображают в виде дерева. Элементы дерева вершины представляют совокупность данных, например логические записи.
Иерархическая модель представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое по структуре дерево (граф).
К основным понятиям иерархической структуры относятся уровень, узел и связь. Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину, не подчиненную никакой другой вершине и находящуюся на самом верхнем — первом уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т. д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один иерархический путь от корневой записи.
Сетевые модели БД соответствуют более широкому классу объектов управления, хотя требуют для своей организации и дополнительных затрат.
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
Реляционная модель БД представляет объекты и взаимосвязи между ними в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. На этой модели базируются практически все современные СУБД. Эта модель более понятна, «прозрачна» для конечного пользователя организации данных.
Реляционная модель данных объекты и связи между ними представляет в виде таблиц, при этом связи тоже рассматриваются как объекты. Все строки, составляющие таблицу в реляционной базе данных, должны иметь первичный ключ. Все современные средства СУБД поддерживают реляционную модель данных.
Эта модель характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
1. Каждый элемент таблицы соответствует одному элементу данных.
2. Все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип и длину.
3. Каждый столбец имеет уникальное имя.
4. Одинаковые строки в таблице отсутствуют;
5. Порядок следования строк и столбцов может быть произвольным.
Вконтакте
Одноклассники
Google+
Модели данных в СУБД | Введение
Вступление
Модели данных используются, чтобы показать, как данные связаны и хранятся в системе. Модели данных в основном представляют отношения между данными. Модель в основном представляет собой высокоуровневое представление между атрибутами и сущностями. Три основные модели данных в системе управления базами данных — это реляционная, сетевая и иерархическая. Но в настоящее время существует множество моделей данных, которые используются в разных реализациях. здесь мы обсудим различные типы моделей данных в СУБД.
Различные типы моделей данных в СУБД
Используются различные типы моделей данных в СУБД:
- Плоская модель данных
- Модель сущности-отношения
- Модель отношений
- Запись базовой модели
- Модель сети
- Иерархическая модель
- Объектно-ориентированная модель данных
- Модель отношений объекта
- Полуструктурированная модель
- Ассоциативная модель
- Модель данных контекста
Ниже приводится подробное описание вышеуказанных моделей баз данных.
Плоская модель данных:
Плоская модель данных — это первая введенная традиционная модель данных, в которой данные хранятся в одной плоскости. Это очень старая модель, которая не очень научна.
Модель данных отношений сущностей:
Структура модели данных отношений сущностей основана на впечатлении от сущностей реального мира и существующих отношений между ними. В процессе проектирования сценария реального мира в модель базы данных наборы сущностей создаются вначале, а затем модель зависит от двух нижеприведенных важных вещей, которые представляют собой сущности, состоящие из атрибутов и отношений, существующих между сущностями. Сущность содержит реальное свойство с именем attribute. Атрибуты определяются набором значений, известных как домены. Например, в офисе сотрудник — это объект, офис — это база данных, идентификатор сотрудника, имя — это атрибуты. Логическая связь между различными объектами известна как отношения между ними.
Модель реляционных данных:
Наиболее популярной и широко используемой моделью данных является реляционная модель данных. Модель данных позволяет хранить данные в таблицах, называемых отношением. Отношения нормализуются, а нормализованные значения отношений известны как атомарные значения. Каждая из строк отношения называется кортежем, который содержит уникальное значение. Атрибутами являются значения в каждом из столбцов, которые принадлежат одному домену.
Модель сетевых данных:
В сетевой модели данных все объекты организованы в графических представлениях. На графике может быть несколько частей, в которых можно получить доступ к объектам.
Иерархическая модель данных:
Иерархическая модель основана на иерархических отношениях родитель-потомок. В этой модели есть один родительский объект с несколькими дочерними объектами. Вверху должна быть только одна сущность, которая называется root. Например, организация является родительской сущностью, называемой root, и имеет несколько дочерних сущностей, таких как клерк, сотрудник и многие другие.
Объектно-ориентированная модель данных:
Объектно-ориентированная модель данных является одной из наиболее развитых моделей данных, которая содержит видео, графические файлы и аудио. Он состоит из части данных и методов в виде инструкций системы управления базами данных.
База данных Модель данных:
Модель данных на основе записей используется для определения общего дизайна базы данных. Эта модель данных содержит различные типы типов записей. Каждый из типов записей имеет фиксированную длину и фиксированное количество полей.
Объектно-реляционная модель данных:
Объектно-реляционная модель данных является мощной моделью данных, но для проектирования объектно-реляционных данных модель очень сложна. Эта модель дает эффективные результаты и широко применяется в огромных приложениях, поэтому некоторую часть проблемы сложности можно игнорировать из-за этого. Он также предлагает такие функции, как работа с другими моделями данных. Используя объектно-реляционную модель данных, мы можем работать и с реляционной моделью.
Полуструктурированная модель данных:
Полуструктурированная модель данных — это модель данных с самоописанием. Данные, хранящиеся в этой модели, обычно связаны со схемой, которая содержится в свойстве данных, известном как свойство самоописания.
Ассоциативная модель данных:
Ассоциативная модель данных следует принципу разделения данных между объектами и ассоциацией. Следовательно, модель делит данные для всех сценариев реального мира на сущности и ассоциации.
Модель данных контекста:
Модели данных контекста очень гибкие, так как содержат набор из нескольких моделей данных. Это набор моделей данных, таких как реляционная модель, сетевая модель, полуструктурированная модель, объектно-ориентированная модель. Таким образом, благодаря универсальному дизайну этой модели базы данных могут быть выполнены различные типы задач. В результате добавлена поддержка различных типов пользователей, которые могут различаться в зависимости от взаимодействия пользователей в базе данных. Модель данных контекста привела к революционным изменениям в отрасли благодаря правильной обработке соответствующих данных. Основная функция моделей данных в системе управления базами данных помогает пользователям использовать и создавать базы данных. Существует несколько типов моделей данных в зависимости от того, какая структура нужна пользователям, и на основании этого мы можем выбирать модели данных в системе управления базами данных.
Вывод — модели данных в СУБД
Моделирование данных — это метод разработки модели данных для хранения данных в базе данных. Это обеспечивает согласованное соглашение об именах и различные другие функции безопасности для поддержания качества данных. Благодаря моделированию данных для таблиц и различных первичных и внешних ключей, а также хранимых процедур в базе данных определяется правильная структура Существует три основных модели моделирования данных: концептуальная, логическая и физическая. Концептуальная модель используется для установления сущностей, атрибутов и отношений. Логическая модель данных должна определять структуру элементов данных и устанавливать отношения между ними. Наконец, физическая модель используется для указания базисно-ориентированной реализации модели. Основным мотивом проектирования модели данных является обеспечение правильного и точного представления объектов, предоставленных функциональной группой. Основным недостатком моделирования базы данных является то, что минимальное изменение в структуре может привести к изменению всего приложения.
Рекомендуемые статьи
Это было руководство по моделям данных в СУБД. Здесь мы обсудили Основные понятия и различные типы моделей данных в СУБД. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше —
- Введение в СУБД
- Что такое большие данные
- Преимущества СУБД
- Вопросы интервью с СУБД
- Различные операции, связанные с кортежами
Лекция 10, ч.1. Базы данных и их разновидности · Курс лекций «Тестирование програмного обеспечения»
База данных (БД) –это совокупность массивов и файлов данных, организованная по определённым правилам, предусматривающим стандартные принципы описания, хранения и обработки данных независимо от их вида.
Основные классификации баз данныхСуществует огромное количество разновидностей баз данных, отличающихся по различным критериям. Основные из них:
- Классификация по модели данных
Центральным понятием в области баз данных является понятие модели.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
Виды:
Иерархическая.
Объектная и объектно-ориентированная.
Объектно-реляционная.
Реляционная.
Сетевая.
Функциональная.
1) Иерархическая база данных – каждый объект, при таком хранение информации, представляется в виде определенной сущности, то есть у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть документ в формате XML или файловая система компьютера.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть базы данных, имеющие иерархическую структуру умеют очень быстро выбирать запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию. Здесь можно привести первый пример из жизни: компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути, являются объектами иерархической структуры), но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.
На изображении Вы можете увидеть структуру иерархической базы данных. В самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы находящиеся на одном уровне называются братьями или соседними элементами. Соответственно, чем ниже уровень элемента, тем вложенность этого элемента больше.
Объектные базы данных — это модель работы с объектными данными.
Такая модель баз данных, несмотря на то, что она существует уже много лет, считается новой. И её создание открывает большие перспективы, в связи с тем, что использование объектной модели баз данных легко воспринимается пользователем, так как создается высокий уровень абстракции. Объектная модель идеально подходит для трактовки такого рода объектных данных как изображение, музыка, видео, разного вида текст.
Объектно-ориентированная база данных (ООБД) — база данных, в которой данные моделируются в виде объектов, их атрибутов, методов и классов.
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
2) Объектно-реляционные СУБД объединяют в себе черты реляционной и объектной моделей. Их возникновение объясняется тем, что реляционные базы данных хорошо работают со встроенными типами данных и гораздо хуже — с пользовательскими, нестандартными. Когда появляется новый важный тип данных, приходится либо включать его поддержку в СУБД, либо заставлять программиста самостоятельно управлять данными в приложении.
Не всякую информацию имеет смысл интерпретировать в виде цепочек символов или цифр. Представим себе музыкальную базу данных. Песню, закодированную в виде аудиофайла, можно поместить в текстовое поле большого размера, но как в таком случае будет ли осуществляться текстовый поиск?
3) Реляционная(или табличная) БД содержит перечень объектов одного типа, т.е. объектов с одинаковым набором свойств.
Такую базу удобно представлять в виде двумерной таблицы (или, чаще всего, нескольких связанных между собой таблиц).
Примером такой таблицы может служить БД «Учащиеся», представляющая собой перечень объектов (учеников), каждый из которых имеет фамилию, имя, отчество, дату рождения, класс, номер личного дела и др.
Столбцы такой таблицы называют полями; каждое поле характеризуется своим именем (названием соответствующего свойства объекта) и типом данных, которые это поле может хранить. Каждое поле обладает определенным набором свойств (размер, формат и т. п.). Т. о., поле БД — это столбец таблицы, содержащий значения определенного свойства объектов.
Строки таблицы являются записями. Записи разбиты на поля. Каждая строка таблицы содержит запись об одном единственном объекте, включая все его свойства.
В каждой таблице должно быть хотя бы одно ключевое поле, содержимое которого уникально для любой записи в этой таблице. Значения ключевого поля однозначно определяют каждую запись в таблице. В приведенном выше примере ключевым полем может являться поле «Номер личного дела». Очень часто в качестве ключевого поля используется поле, содержащее данные типа счетчик.
4) Сетевые базы данных являются своеобразной модификацией иерархических баз данных. Если Вы внимательно смотрели на изображение выше, то наверняка обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть элементов стоящих выше него. Для большей наглядности и понимания структуры сетевых баз данных обратите внимание на изображение:
Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но сейчас нас не особо интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML.
5) Функциональные базы данных используются для решения аналитических задач: финансовое моделирование и управление производительностью. Функциональная база данных или функциональная модель отличается от реляционной модели. Функциональная модель также отличается от других аналогично названных концепций, включая модель функциональной базы данных DAPLEX и базы данных функциональных языков.
Функциональная модель является частью категории оперативной аналитической обработки (OLAP электронной таблице,), поскольку она включает многомерное иерархическое объединение. Но она выходит за рамки OLAP, требуя ориентирования ячейки, подобно тому, где ячейки могут быть введены или рассчитаны как функции других ячеек. Также, как и в электронных таблицах, данная модель поддерживает интерактивные вычисления, в которых значения всех зависимых ячеек автоматически обновляются каждый раз, когда изменяется значение ячейки.
- Классификация по содержимому
Примеры:
Географическая.
Историческая.
Научная.
Мультимедийная.
Клиентская.
- Классификация по степени распределённости:
Централизованная или сосредоточенная (англ. centralized database): БД, которая полностью поддерживается на одном компьютере.
Распределённая (англ. distributed database): БД, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
Фрагментированная или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
Тиражированная (англ. replicated database): методом распределения данных является тиражирование.
- Классификация БД по среде физического хранения:
БД во вторичной памяти (традиционные): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — это, как правило, жёсткий диск. В оперативную память СУБД помещает лишь кэш и данные для текущей обработки.
БД в оперативной памяти (in-memory databases): все данные находятся в оперативной памяти.
БД в третичной памяти (tertiary databases): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило, на основе магнитных лент или оптических дисков. Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
SQL
SQL — язык структурированных запросов, основной задачей которого является предоставление простого способа считывания и записи информации в базу данных.
Функции языка SQL:
- Организация данных – создание и изменение структуры баз данных.
- Чтение данных.
- Обработка данных – удаление, добавление и корректировка данных.
- Управление доступа к данным – предоставление привилегий (ограничение возможностей) пользователю для чтения и изменения данных.
- Совместное использование данных — координация общего пользования данных многими пользователями.
- Целостность данных – защита данных от разрушения при сбое системы или других обстоятельствах.
Большинство современных СУБД построено на реляционной модели данных. Для получения информации из отношений (таблиц) базы данных в качестве языка манипулирования данными в теоретическом плане используется язык SQL
СУБД — система управления базами данных, совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных
Основные функции СУБД:
Управление данными во внешней памяти (на дисках).
Управление данными в оперативной памяти с использованием дискового кэша.
Журнализация изменений, резервное копирование и восстановление базы данных после сбоев.
Поддержка языков БД (язык определения данных, язык манипулирования данными).
Типы данных в SQL
Каждый столбец в таблице базы данных должен иметь имя и тип данных.
SQL разработчики должны решить, какие типы данных будут храниться внутри каждого столбца таблицы при создании таблицы SQL. Тип данных представляет собой метку и ориентир для SQL, чтобы понять, какой тип данных, как ожидается, внутри каждого столбца, а также определяет, как SQL будут взаимодействовать с хранимыми данными.
В следующей таблице перечислены общие типы данных в SQL:
SQL Data Type — Краткий справочник в разрезе БД
Тем не менее, различные базы данных предлагают различные варианты для определения типа данных.
В следующей таблице приведены некоторые из общих названий типов данных между различными платформами баз данных:
Что такое модель базы данных
Множество других моделей баз данных использовались или используются до сих пор.
Модель перевернутого файла
База данных, построенная с использованием перевернутой файловой структуры, предназначена для облегчения быстрого полнотекстового поиска. В этой модели содержимое данных индексируется как серия ключей в таблице подстановки, значения которой указывают на расположение связанных файлов. Эта структура может обеспечить почти мгновенную отчетность, например, по большим данным и аналитике.
Эта модель используется системой управления базами данных ADABAS компании Software AG с 1970 года и поддерживается до сих пор.
Плоская модель
Плоская модель — это самая ранняя и простая модель данных. Он просто перечисляет все данные в одной таблице, состоящей из столбцов и строк. Чтобы получить доступ к данным или управлять ими, компьютер должен прочитать весь плоский файл в память, что делает эту модель неэффективной для всех наборов данных, кроме самых маленьких.
Многомерная модель
Это разновидность реляционной модели, разработанная для облегчения улучшенной аналитической обработки.В то время как реляционная модель оптимизирована для онлайн-обработки транзакций (OLTP), эта модель предназначена для онлайн-аналитической обработки (OLAP).
Каждая ячейка в базе данных измерений содержит данные об измерениях, отслеживаемых базой данных. Визуально это похоже на набор кубиков, а не на двухмерные таблицы.
Полуструктурированная модель
В этой модели структурные данные, обычно содержащиеся в схеме базы данных, встроены в сами данные. Здесь различие между данными и схемой в лучшем случае нечеткое.Эта модель полезна для описания систем, таких как определенные веб-источники данных, которые мы рассматриваем как базы данных, но не можем ограничить их схемой. Это также полезно для описания взаимодействия между базами данных, которые не придерживаются одной и той же схемы.
Контекстная модель
Эта модель может включать элементы из других моделей баз данных по мере необходимости. Он объединяет элементы объектно-ориентированных, полуструктурированных и сетевых моделей.
Ассоциативная модель
Эта модель разделяет все точки данных в зависимости от того, описывают ли они сущность или ассоциацию.В этой модели сущность — это все, что существует независимо, тогда как ассоциация — это то, что существует только по отношению к чему-то еще.
Ассоциативная модель структурирует данные в два набора:
- Набор элементов, каждый с уникальным идентификатором, именем и типом
- Набор ссылок, каждая с уникальным идентификатором и уникальными идентификаторами источник, глагол и цель. Сохраненный факт имеет отношение к источнику, и каждый из трех идентификаторов может относиться либо к ссылке, либо к элементу.
К другим, менее распространенным моделям баз данных относятся:
- Семантическая модель, которая включает в себя информацию о том, как хранимые данные соотносятся с реальным миром
- База данных XML, которая позволяет задавать данные и даже сохранять их в формате XML
- Именованный graph
- Triplestore
Типы баз данных | Модели базы данных
База данных : База данных — это организованный набор взаимосвязанных данных, хранящихся в компьютере.
Важность базы данных:
• Это дает нам высокоэффективный метод для легкой обработки большого количества различных типов данных.
• Он позволяет систематически хранить большие объемы данных, и эти данные легко и эффективно и точно извлекать, фильтровать, сортировать и обновлять.
Типы модели базы данных
Модель базы данных: Он определяет логическую структуру базы данных и в основном определяет, каким образом данные могут храниться, организовываться и обрабатываться.
Существует четыре общих типа модели базы данных, которые полезны для разных типов данных или информации.В зависимости от ваших конкретных потребностей можно использовать одну из этих моделей.
1. Иерархические базы данных.
2. Сетевые базы данных.
3. Реляционные базы данных.
4. Объектно-ориентированные базы данных.
1. Иерархические базы данных
Это одна из старейших моделей баз данных, разработанных IBM для системы управления информацией. В иерархической модели базы данных данные организованы в древовидную структуру. Простым языком мы можем сказать, что это набор организованных данных в древовидной структуре.
Этот тип модели базы данных в настоящее время используется редко. Его структура подобна дереву с узлами, представляющими записи, и ветвями, представляющими поля. Реестр Windows, используемый в Windows XP, является примером иерархической базы данных. Параметры конфигурации хранятся в виде древовидных структур с узлами.
На следующем рисунке показана обобщенная структура модели иерархической базы данных, в которой данные хранятся в виде древовидной структуры (данные представлены или хранятся в корневом узле, родительском узле и дочернем узле).
На следующем рисунке показан пример иерархической модели базы данных для системы управления университетом. Этот тип базы данных использует отношения «родитель-потомок» для хранения данных.
Интернет-обучение MSBI
Преимущества
• Модель позволяет легко добавлять и удалять новую информацию.
• Доступ к данным наверху Иерархии осуществляется очень быстро.
• Он хорошо работал с линейными носителями данных, такими как ленты.
• Это хорошо относится ко всему, что работает через отношения «один ко многим». Например; есть президент с множеством менеджеров ниже них, и у этих менеджеров есть много служащих ниже них, но у каждого служащего есть только один менеджер.
Недостатки
• Он требует, чтобы данные многократно сохранялись во многих различных объектах.
• Сегодня больше не используются линейные носители данных, такие как ленты.
• Для поиска данных СУБД должна пройти через всю модель сверху вниз до тех пор, пока не будет найдена необходимая информация, что делает запросы очень медленными.
• Эта модель поддерживает только отношения «один ко многим», отношения «многие ко многим» не поддерживаются.
Концепции баз данных и SQL
2. Сетевые базы данных
Это похоже на модель иерархической базы данных, из-за которой ее часто называют модифицированной версией иерархической базы данных. Модель сетевой базы данных организовала данные больше как граф и может иметь более одного родительского узла. Сетевая модель — это модель базы данных, задуманная как гибкий способ представления объектов и их отношений.
Преимущество
• Сетевая модель концептуально проста и удобна в разработке.
• Сетевая модель может представлять избыточность данных более эффективно, чем в иерархической модели.
• Сетевая модель может обрабатывать отношения «один ко многим» и «многие ко многим», что действительно помогает в моделировании реальных ситуаций.
• Доступ к данным проще и гибче, чем в иерархической модели.
• Сетевая модель лучше, чем иерархическая, в том, что она изолирует программы от сложных деталей физического хранилища.
Недостаток:
• Все записи ведутся с использованием указателей, поэтому вся структура базы данных становится очень сложной.
• Операции вставки, удаления и обновления любой записи требуют настройки большого количества указателей.
• Внести структурные изменения в базу данных очень сложно.
3. Реляционная база данных
Реляционная база данных разработана Э. Ф. Коддом в 1970 году. Различные программные системы, используемые для поддержки реляционных баз данных, известны как система управления реляционными базами данных (СУБД).В этой модели данные организованы в виде строк и столбцов, то есть двумерных таблиц, и связь поддерживается путем хранения общего поля. Он состоит из трех основных компонентов.
В реляционной модели широко используются три ключевых термина, такие как отношения, атрибуты и домены. Отношение не что иное, как таблица со строками и столбцами. Именованные столбцы отношения называются атрибутами, и, наконец, домен — это не что иное, как набор значений, которые могут принимать атрибуты.На следующем рисунке представлен обзор рациональной модели базы данных.
Терминология, используемая в реляционной модели
• Кортеж: каждая строка в таблице называется кортежем.
• Мощность отношения: количество кортежей в отношении определяет его мощность. В этом случае отношение имеет мощность 4.
• Степень отношения: каждый столбец в кортеже называется атрибутом. Количество атрибутов в отношении определяет его степень.Отношение на рисунке имеет степень 3.
Ключи связи —
• Первичный ключ — это ключ, который однозначно идентифицирует таблицу. У него нет нулевых значений.
• Внешний ключ — он относится к первичному ключу некоторой другой таблицы. Он разрешает только те значения, которые появляются в первичном ключе таблицы, на которую он ссылается.
Вот некоторые примеры реляционной базы данных.
Oracle: Oracle Database обычно называют Oracle RDBMS или просто Oracle.Это многомодельная система управления базами данных, производимая и продаваемая Oracle Corporation.
MySQL: MySQL — это система управления реляционными базами данных (СУБД) с открытым исходным кодом, основанная на языке структурированных запросов (SQL). MySQL работает практически на всех платформах, включая Linux, UNIX и Windows.
Microsoft SQL Server: Microsoft SQL Server — это СУБД, которая поддерживает широкий спектр приложений для обработки транзакций, бизнес-аналитики и аналитики в корпоративных ИТ-средах.
PostgreSQL: PostgreSQL, часто просто Postgres, представляет собой систему управления объектно-реляционными базами данных (ORDBMS) с упором на расширяемость и соответствие стандартам.
DB2: DB2 — это СУБД, предназначенная для эффективного хранения, анализа и извлечения данных.
В следующих таблицах показан образец модели реляционной базы данных для банковской среды, в которой данные, связанные с банком, хранятся в виде двухмерных таблиц.
Преимущество
• Реляционная модель — одна из самых популярных моделей баз данных.
• В реляционной модели изменения в структуре базы данных не влияют на доступ к данным.
• Редактирование любой информации в виде таблиц, состоящих из строк и столбцов, намного проще для понимания.
• Реляционная база данных поддерживает концепцию независимости данных и независимости от структуры, что значительно упрощает проектирование, обслуживание, администрирование и использование базы данных по сравнению с другими моделями.
• Здесь мы можем написать сложный запрос для доступа или изменения данных из базы данных.
• Легче поддерживать безопасность по сравнению с другими моделями.
Недостатки
• Отображение объектов в реляционной базе данных очень сложно.
• В модели отношений отсутствует объектно-ориентированная парадигма.
• Целостность данных трудно обеспечить с помощью реляционной базы данных.
• Реляционная модель не подходит для огромной базы данных, но подходит для небольшой базы данных.
• Накладные расходы на оборудование, которые делают его дорогостоящим.
• Простота дизайна может привести к плохому дизайну.
• Система реляционных баз данных скрывает сложности реализации и детали физического хранения данных от пользователей.
4. Объектно-ориентированные базы данных
База данных объектов — это система, в которой информация представлена в форме объектов, используемых в объектно-ориентированном программировании. Объектно-ориентированные базы данных отличаются от реляционных баз данных, ориентированных на таблицы. Объектно-ориентированная модель данных основана на концепции объектно-ориентированного языка программирования, которая сейчас широко используется. Наследование, полиморфизм, перегрузка. Идентификация объектов, инкапсуляция и сокрытие информации с помощью методов, обеспечивающих интерфейс для объектов, являются одними из ключевых концепций объектно-ориентированного программирования, нашедших применение при моделировании данных.Объектно-ориентированная модель данных также поддерживает богатую систему типов, включая структурированные типы и типы коллекций.
На следующем рисунке показана разница между отношениями и объектно-ориентированной моделью базы данных.
На следующем рисунке показан пример объектно-ориентированной модели.
Преимущества
• База данных объектов может обрабатывать различные типы данных, в то время как реляционная база данных обрабатывает отдельные данные. В отличие от традиционных баз данных, таких как иерархические, сетевые или реляционные, объектно-ориентированные базы данных могут обрабатывать различные типы данных, например изображения, голосовое видео, включая текст, числа и так далее.
• Объектно-ориентированные базы данных обеспечивают возможность повторного использования кода, моделирование реального мира, а также повышенную надежность и гибкость.
• Объектно-ориентированная база данных имеет низкие затраты на обслуживание по сравнению с другой моделью, потому что большинство задач в системе инкапсулированы, их можно повторно использовать и включать в новые задачи.
Интернет-обучение MSBI
Недостатки
• Не существует универсально определенной модели данных для ООСУБД, и большинству моделей не хватает теоретической основы.
• По сравнению с СУБД использование ООСУБД все еще относительно ограничено.
• Отсутствует поддержка безопасности в OODBMS, которые не обеспечивают адекватных механизмов безопасности.
• Система более сложная, чем у традиционных СУБД.
моделей баз данных в СУБД | Studytonight
Модель базы данных определяет логический дизайн и структуру базы данных и определяет способ хранения, доступа и обновления данных в системе управления базами данных. Хотя реляционная модель является наиболее широко используемой моделью базы данных, существуют и другие модели:
- Иерархическая модель
- Сетевая модель
- Модель отношения сущностей
- Реляционная модель
Иерархическая модель
Эта модель базы данных организует данные в древовидную структуру с одним корнем, с которой связаны все остальные данные.Иерархия начинается с данных Root и расширяется как дерево, добавляя дочерние узлы к родительским узлам.
В этой модели дочерний узел будет иметь только один родительский узел.
Эта модель эффективно описывает многие реальные отношения, такие как указатель книги, рецепты и т. Д.
В иерархической модели данные организованы в древовидную структуру с одним отношением «один ко многим» между двумя разными типами данных, например, на одном факультете может быть много курсов, много профессоров и, конечно же, много студентов.
Сетевая модель
Это расширение иерархической модели. В этой модели данные организованы больше как граф, и им разрешено иметь более одного родительского узла.
В этой модели базы данных данные более связаны, поскольку в этой модели базы данных устанавливается больше взаимосвязей. Кроме того, поскольку данные более связаны, доступ к ним также становится проще и быстрее. Эта модель базы данных использовалась для сопоставления отношений данных «многие ко многим».
Это была наиболее широко используемая модель базы данных до появления реляционной модели.
Модель отношения сущностей
В этой модели базы данных отношения создаются путем разделения интересующего объекта на сущность и его характеристик на атрибуты.
Различные сущности связаны отношениями.
МоделиE-R определены для представления взаимосвязей в наглядной форме, чтобы их было легче понять различным заинтересованным сторонам.
Эта модель хороша для разработки базы данных, которую затем можно превратить в таблицы в реляционной модели (поясняется ниже).
Давайте возьмем пример. Если нам нужно разработать школьную базу данных, то Student будет объектом с атрибутами , имя, возраст, адрес и т. Д. Поскольку Address обычно сложен, это может быть еще один объект с атрибутами название улицы, пин-код, город и т. Д., И между ними будет связь.
Отношения также могут быть разных типов. Чтобы подробнее узнать о диаграммах E-R, щелкните ссылку.
Реляционная модель
В этой модели данные организованы в двухмерные таблицы , , и связь поддерживается путем хранения общего поля.
Эта модель была представлена Э. Ф. Коддом в 1970 году, и с тех пор она является наиболее широко используемой моделью базы данных, фактически, можно сказать, единственной моделью базы данных, используемой во всем мире.
Базовая структура данных в реляционной модели — это таблицы. Вся информация, относящаяся к определенному типу, хранится в строках этой таблицы.
Следовательно, таблицы также известны как отношений в реляционной модели.
В следующих руководствах мы узнаем, как создавать таблицы, нормализовать их для уменьшения избыточности данных и как использовать язык структурированных запросов для доступа к данным из таблиц.
Глава 4 Типы моделей данных — Проектирование базы данных — 2-е издание
Эдриен Ватт и Нельсон Энг
Концептуальные модели данных высокого уровня
Концептуальные модели данных высокого уровня предоставляют концепции для представления данных способами, близкими к тому, как люди воспринимают данные.Типичным примером является модель отношений сущностей, в которой используются такие основные концепции, как сущности, атрибуты и отношения. Сущность представляет собой объект реального мира, такой как сотрудник или проект. У объекта есть атрибуты, которые представляют такие свойства, как имя, адрес и дата рождения сотрудника. Отношение представляет собой ассоциацию между объектами; например, сотрудник работает над многими проектами. Между сотрудником и каждым проектом существуют отношения.
Логические модели данных на основе записей
Логические модели данных на основе записей предоставляют концепции, понятные пользователям, но не слишком далеки от способа хранения данных в компьютере.Три хорошо известных модели данных этого типа — это реляционные модели данных, сетевые модели данных и иерархические модели данных.
- Реляционная модель представляет данные в виде отношений или таблиц. Например, в системе членства в Science World каждое членство состоит из множества членов (см. Рис. 2.2 в главе 2). Идентификатор членства, дата истечения срока действия и адресная информация — это поля в членстве. Среди участников — Микки, Минни, Майти, Дор, Том, Кинг, Человек и Лось.Каждая запись называется экземпляром таблицы членства.
- Сетевая модель представляет данные как типы записей. Эта модель также представляет собой ограниченный тип отношения «один ко многим», называемый набором типа , как показано на рисунке 4.1.
- Иерархическая модель представляет данные в виде иерархической древовидной структуры. Каждая ветвь иерархии представляет собой ряд связанных записей.Рисунок 4.2 показывает эту схему в нотации иерархической модели.
Ключевые термины
иерархическая модель : представляет данные в виде иерархической древовидной структуры
экземпляр : запись в таблице
сетевая модель : представляет данные как типы записей
отношение : еще один термин для таблицы
реляционная модель : представляет данные в виде отношений или таблиц
установить тип : ограниченный тип отношения «один ко многим»
Упражнения
- Что такое модель данных?
- Что такое концептуальная модель данных высокого уровня?
- Что такое организация? Атрибут? Отношения?
- Перечислите и кратко опишите общие модели логических данных на основе записей.
Атрибуция
Эта глава Database Design является производной копией Database System Concepts от Nguyen Kim Anh под лицензией Creative Commons Attribution License 3.0 лицензии
Адриенн Ватт написала следующий материал:
- Ключевые термины
- Упражнения
Что такое модель данных в СУБД и каковы ее типы?
Что такое модель данных в СУБД и каковы ее типы?
Модель данных Модель данныхдает нам представление о том, как будет выглядеть окончательная система после ее полной реализации.Он определяет элементы данных и отношения между элементами данных. Модели данных используются, чтобы показать, как данные хранятся, подключаются, доступны и обновляются в системе управления базами данных. Здесь мы используем набор символов и текста для представления информации, чтобы члены организации могли общаться и понимать ее. Хотя в настоящее время используется много моделей данных, реляционная модель является наиболее широко используемой. Помимо реляционной модели, существует множество других типов моделей данных, которые мы подробно изучим в этом блоге.Вот некоторые из моделей данных в СУБД:
- Иерархическая модель
- Сетевая модель
- Модель отношений сущностей
- Реляционная модель
- Объектно-ориентированная модель данных
- Объектно-реляционная модель данных
- Плоская модель данных
- Полу -Структурированная модель данных
- Ассоциативная модель данных
- Модель контекстных данных
Иерархическая модель
Иерархическая модель была первой моделью СУБД. Эта модель организует данные в иерархической древовидной структуре.Иерархия начинается с корня, который имеет корневые данные, а затем расширяется в виде дерева, добавляющего дочерний узел к родительскому узлу. Эта модель легко представляет некоторые реальные отношения, такие как рецепты еды, карта сайта веб-сайта и т. Д. Пример: Мы можем представить отношения между обувью, представленной на веб-сайте покупок, следующим образом:
Особенности иерархической модели
- Отношение «один ко многим»: Данные здесь организованы в виде древовидной структуры, в которой отношения «один ко многим» устанавливаются между типами данных.Кроме того, от родителя к любому узлу может быть только один путь. Пример: В приведенном выше примере, если мы хотим перейти к узлу кроссовки , у нас есть только один путь к нему, то есть через узел мужской обуви.
- Отношения родитель-потомок: Каждый дочерний узел имеет родительский узел, но родительский узел может иметь более одного дочернего узла. Наличие нескольких родителей не допускается.
- Проблема удаления: Если родительский узел удален, дочерний узел удаляется автоматически.
- Указатели: Указатели используются для связи родительского узла с дочерним узлом и используются для навигации между сохраненными данными. Пример: В приведенном выше примере узел « обувь » указывает на два других узла: узел « женская обувь » и узел « мужская обувь ».
Преимущества иерархической модели
- Переход по древовидной структуре очень простой и быстрый.
- Любое изменение в родительском узле автоматически отражается на дочернем узле, поэтому целостность данных сохраняется.
Недостатки иерархической модели
- Сложные отношения не поддерживаются.
- Поскольку он не поддерживает более одного родителя дочернего узла, поэтому, если у нас есть некоторые сложные отношения, когда дочерний узел должен иметь два родительских узла, это не может быть представлено с помощью этой модели.
- При удалении родительского узла автоматически удаляется дочерний узел.
Сетевая модель
Эта модель является расширением иерархической модели.Это была самая популярная модель до реляционной модели. Эта модель аналогична иерархической модели, с той лишь разницей, что у записи может быть более одного родителя. Он заменяет иерархическое дерево графом. Пример: В приведенном ниже примере мы видим, что у учащегося узла есть два родителя, то есть отдел CSE и библиотека. Раньше это было невозможно в иерархической модели.
Особенности модели сети
- Возможность объединения большего количества взаимосвязей: В этой модели, поскольку существует больше взаимосвязей, данные становятся более взаимосвязанными.Эта модель имеет возможность управлять отношениями «один к одному», а также отношениями «многие ко многим».
- Множество путей: Поскольку существует больше связей, к одной и той же записи может быть несколько путей. Это делает доступ к данным быстрым и простым.
- Циклический связанный список: Операции с сетевой моделью выполняются с помощью кольцевого связанного списка. Текущая позиция поддерживается с помощью программы, и эта позиция позволяет перемещаться по записям в соответствии с отношениями.
Преимущества сетевой модели
- Доступ к данным можно получить быстрее по сравнению с иерархической моделью. Это связано с тем, что данные более связаны в сетевой модели, и может быть несколько путей для достижения определенного узла. Таким образом, к данным можно получить доступ разными способами.
- Поскольку существует связь «родитель-потомок», сохраняется целостность данных. Любое изменение в родительской записи отражается в дочерней записи.
Недостатки сетевой модели
- По мере того, как необходимо обрабатывать все больше и больше взаимосвязей, система может усложняться.Итак, для работы с моделью пользователь должен иметь подробные знания о модели.
- Любые изменения, такие как обновление, удаление, вставка, очень сложны.
Модель отношений сущностей
Модель отношений сущностей или просто модель ER — это диаграмма модели данных высокого уровня. В этой модели мы представляем реальную проблему в наглядной форме, чтобы заинтересованные стороны могли ее понять. Разработчикам также очень легко понять систему, просто взглянув на диаграмму ER.Мы используем диаграмму ER как визуальный инструмент для представления модели ER. Диаграмма ER состоит из следующих трех компонентов:
- Сущности: Сущность — это реальная вещь. Это может быть человек, место или даже концепция. Пример: Учителя, студенты, курс, здание, кафедра и т. Д. Являются некоторыми из объектов системы управления школой.
- Атрибуты: Сущность содержит реальное свойство, называемое атрибутом. Это характеристики этого атрибута. Пример: Учитель сущности имеет такое свойство, как идентификатор учителя, зарплата, возраст и т. Д.
- Отношение: Отношение сообщает, как связаны два атрибута. Пример: Преподаватель работает на кафедре.
Пример:
На приведенной выше диаграмме это Учитель и Департамент. Атрибуты сущности Учитель : Имя Учителя, Идентификатор учителя, Возраст, Зарплата, Номер мобильного телефона.Атрибуты объекта Department entity: Dept_id, Dept_name. Два объекта связаны с помощью отношения. Здесь каждый преподаватель работает на кафедру.
Особенности модели ER
- Графическое представление для лучшего понимания: Это очень легко и просто понять, поэтому разработчики могут использовать его для общения с заинтересованными сторонами.
- Диаграмма ER: Диаграмма ER используется как визуальный инструмент для представления модели.
- Дизайн базы данных: Эта модель помогает разработчикам баз данных создавать базу данных и широко используется при проектировании баз данных.
Преимущества модели ER
- Просто: Концептуально модель ER очень легко построить. Если мы знаем взаимосвязь между атрибутами и сущностями, мы можем легко построить диаграмму ER для модели.
- Эффективное средство коммуникации : Эта модель широко используется разработчиками баз данных для передачи своих идей.
- Простое преобразование в любую модель : Эта модель хорошо соответствует реляционной модели и может быть легко преобразована в реляционную модель путем преобразования модели ER в таблицу. Эта модель также может быть преобразована в любую другую модель, такую как сетевая модель, иерархическая модель и т. Д.
Недостатки модели ER
- Нет отраслевого стандарта для обозначений: Нет отраслевого стандарта для разработки модели ER. Таким образом, один разработчик может использовать нотации, которые не понятны другим разработчикам.
- Скрытая информация: Некоторая информация может быть потеряна или скрыта в модели ER. Поскольку это представление высокого уровня, есть вероятность, что некоторые детали информации могут быть скрыты.
Реляционная модель
Реляционная модель — наиболее широко используемая модель. В этой модели данные хранятся в виде двухмерной таблицы. Вся информация хранится в виде строк и столбцов. Основная структура реляционной модели — это таблицы.Итак, таблицы также называются отношениями в реляционной модели. Пример: В этом примере у нас есть таблица сотрудников.
Особенности реляционной модели
- Кортежи : Каждая строка в таблице называется кортежем. Строка содержит всю информацию о любом экземпляре объекта. В приведенном выше примере каждая строка содержит всю информацию о любом конкретном человеке, например, первая строка содержит информацию о Джоне.
- Атрибут или поле: Атрибуты — это свойство, которое определяет таблицу или отношение. Значения атрибута должны быть из одного домена. В приведенном выше примере у нас есть разные атрибуты сотрудника , такие как Salary, Mobile_no и т. Д.
Преимущества реляционной модели
- Simple: Эта модель более проста по сравнению с сетевой и иерархической моделью .
- Масштабируемость: Эту модель можно легко масштабировать, поскольку мы можем добавить столько строк и столбцов, сколько захотим.
- Структурная независимость: Мы можем вносить изменения в структуру базы данных без изменения способа доступа к данным. Когда мы можем вносить изменения в структуру базы данных, не влияя на способность СУБД получать доступ к данным, мы можем сказать, что структурная независимость достигнута.
Недостатки модели Relatinal
- Накладные расходы на оборудование: Для того, чтобы скрыть сложности и упростить работу пользователя, эта модель требует более мощных компьютеров и устройств хранения данных.
- Плохой дизайн: Поскольку реляционная модель очень проста в разработке и использовании. Таким образом, пользователям не нужно знать, как хранятся данные, чтобы получить к ним доступ. Такая простота проектирования может привести к разработке плохой базы данных, которая замедлится при росте базы данных.
Но все эти недостатки незначительны по сравнению с преимуществами реляционной модели. Этих проблем можно избежать с помощью правильной реализации и организации.
Объектно-ориентированная модель данных
Реальные проблемы более точно представлены с помощью объектно-ориентированной модели данных.В этой модели и данные, и отношения представлены в единой структуре, известной как объект. Мы можем хранить аудио, видео, изображения и т. Д. В базе данных, что было невозможно в реляционной модели (хотя вы можете хранить аудио и видео в реляционной базе данных, рекомендуется не хранить в реляционной базе данных). В этой модели еще два объекта связаны посредством ссылок. Мы используем эту ссылку, чтобы связать один объект с другими объектами. Это можно понять на примере, приведенном ниже.
В приведенном выше примере у нас есть два объекта Сотрудник и Отдел.Все данные и отношения каждого объекта содержатся как единое целое. Такие атрибуты, как Name, Job_title сотрудника и методы, которые будут выполняться этим объектом, хранятся как единый объект. Два объекта связаны через общий атрибут, то есть Department_id, и связь между ними будет осуществляться с помощью этого общего идентификатора.
Объектно-реляционная модель
Как следует из названия, это комбинация как реляционной модели, так и объектно-ориентированной модели.Эта модель была создана, чтобы заполнить пробел между объектно-ориентированной и реляционной моделями. У нас может быть много дополнительных функций, например, мы можем создавать сложные типы данных в соответствии с нашими требованиями, используя существующие типы данных. Проблема с этой моделью в том, что это может быть сложно и трудно справиться. Итак, требуется правильное понимание этой модели.
Модель плоских данных
Это простая модель, в которой база данных представлена в виде таблицы, состоящей из строк и столбцов.Чтобы получить доступ к каким-либо данным, компьютер должен прочитать всю таблицу. Это делает режимы медленными и неэффективными.
Полуструктурированная модель
Полуструктурированная модель — это развитая форма реляционной модели. Мы не можем различать данные и схему в этой модели. Пример: Веб-источники данных, которые мы не можем различить между схемой и данными веб-сайта. В этой модели некоторые объекты могут иметь отсутствующие атрибуты, а другие могут иметь дополнительный атрибут.Эта модель дает гибкость в хранении данных. Это также придает гибкость атрибутам. Пример: Если мы сохраняем какое-либо значение в любом атрибуте, то это значение может быть либо атомарным значением, либо набором значений.
Ассоциативная модель данных
Ассоциативная модель данных — это модель, в которой данные разделены на две части. Все, что имеет независимое существование, называется сущностью , а отношения между этими сущностями называются ассоциацией .Данные, разделенные на две части, называются элементами и ссылками.
- Элемент : Элементы содержат имя и идентификатор (некоторое числовое значение).
- Ссылки: Ссылки содержат идентификатор, источник, глагол и тему.
Пример : Допустим, у нас есть заявление «Чемпионат мира по футболу будет проходить в Лондоне с 30 мая 2020 года». В этих данных необходимо сохранить две ссылки:
- Чемпионат мира по футболу проводится в Лондоне.Источник здесь — «чемпионат мира», глагол «является», а цель — «Лондон».
- … от 30 мая 2020 г. Источник здесь — предыдущая ссылка, глагол — «от», а цель — «30 мая 2020 г.».
Это представлено с помощью следующей таблицы:
Модель данных контекста
Модель данных контекста — это совокупность нескольких моделей. Он состоит из таких моделей, как сетевая модель, реляционные модели и т. Д. Используя эту модель, мы можем выполнять различные типы задач, которые невозможно выполнить с использованием одной только модели.
Это все о различных моделях данных СУБД. Надеюсь, вы узнали что-то новое сегодня.
Поделитесь этим блогом с друзьями, чтобы распространять знания. Посетите наш канал YouTube, чтобы узнать больше. Вы можете прочитать больше блогов здесь.
Продолжайте учиться 🙂
Команда AfterAcademy!
Модели систем управления базами данных (СУБД) — видео и стенограмма урока
Плоский файл
Самый простой способ организовать данные — это плоский файл .Вы можете думать об этом как об одной таблице с большим количеством записей и полей. Все, что вам нужно, хранится в этой таблице или в плоском файле.
Представьте себе базу данных клиентов. Все, что вы хотите знать о клиентах, хранится в одной этой таблице. Вы начинаете с единой записи для каждого клиента. Клиент размещает заказ, и вы вводите его в одно из полей. Таким образом вы продолжаете вводить заказы клиентов.
Что, если тот же покупатель разместит второй заказ? Вы вводите это как новую запись в таблице или добавляете поле к существующей записи для этого клиента?
На этот вопрос нет однозначного ответа.Ключевым моментом здесь является то, что плоский файл довольно ограничен, поскольку он предоставляет очень мало с точки зрения структуры. На самом деле это настолько просто, что можно поспорить, что это вообще не СУБД. Однако лучше начать с идеи плоского файла, и тогда вы увидите, насколько альтернативные модели более гибкие и эффективные.
Иерархическая СУБД
В иерархической СУБД один элемент данных подчинен другому. Это называется отношением родитель-потомок . Иерархическая модель данных упорядочивает данные в древовидной структуре.
Одно из правил иерархической базы данных состоит в том, что родитель может иметь несколько дочерних элементов, но у дочернего элемента может быть только один родитель. Например, представьте себе интернет-магазин, в котором продается много разных товаров. Весь каталог продуктов будет относиться к родительскому элементу , а различные типы продуктов, таким как книги, электроника и т. Д., Будут относиться к дочернему элементу . У каждого типа продукта могут быть свои дочерние категории. Например, книги можно разделить на художественную и научную.Каждую из этих категорий можно разбить на подкатегории. Вы можете продолжить, перечислив отдельных авторов, а затем отдельные названия книг.
Это довольно простой способ представления данных, но он очень эффективен. Эта модель лучше всего подходит для данных, которые по своей природе являются иерархическими. Многие наборы данных нелегко организовать таким образом и требуют более сложного подхода. Например, в случае каталога продуктов, что, если книга попадает в более чем одну категорию? Или, что, если один автор написал несколько книг, но также выпустил аудио-компакт-диск с одной из своих книг? Вот где ломается иерархическая модель.
Сетевая СУБД
В сетевой СУБД каждый элемент данных может быть связан со многими другими. Структура базы данных похожа на график. Это похоже на иерархическую модель, а также обеспечивает древовидную структуру. Однако у ребенка может быть более одного родителя. В примере с каталогом товаров книга может относиться к нескольким категориям. Структура сетевой базы данных становится больше похожа на паутину связанных элементов.
Например, рассмотрим организацию с базой данных сотрудников.Для каждого сотрудника есть разные данные, такие как его имя, адрес, номер телефона, номер социального страхования и должность. Разным подразделениям организации требуются разные уровни доступа. Например, отдел кадров должен иметь доступ к информации о социальном обеспечении для каждого сотрудника, чтобы он мог позаботиться о налоговых вычетах и назначить льготы. Это в некоторой степени конфиденциальная информация, поэтому другим отделам не нужен доступ к этой части базы данных.Все фрагменты данных связаны в сеть, которая реализует эти правила.
Хотя концептуально относительно простая, эта структура базы данных может быстро стать очень сложной.
Реляционная СУБД
В реляционной СУБД все данные организованы в виде таблиц . Эта модель СУБД появилась в 1970-х годах и стала наиболее широко используемым типом СУБД. Эта модель используется в большинстве программных СУБД, разработанных за последние несколько десятилетий. В таблице каждая строка представляет собой запись , также называемую объектом .Каждый столбец представляет собой поле , также называемое атрибутом объекта.
Реляционная СУБД использует несколько таблиц для организации данных. Взаимосвязи используются для связывания различных таблиц вместе. Отношения создаются с использованием поля, которое однозначно идентифицирует каждую запись. Например, для таблицы книг вы можете использовать номер ISBN, поскольку не существует двух книг с одинаковым ISBN. Для таблицы авторов вы должны создать уникальный идентификатор автора, чтобы идентифицировать каждого отдельного автора.
Рассмотрим реляционную базу данных книг и авторов. Первая таблица — это таблица авторов. Каждый автор идентифицируется уникальным идентификатором автора, а таблица также содержит его имя и контактную информацию. Вторая таблица — таблица книг. Каждая книга идентифицируется своим номером ISBN, а таблица также содержит название книги, издателя и идентификатор автора, связанный с автором книги.
Реляционная база данных настолько эффективна, что вы можете связать эти таблицы вместе.В этом примере для этого вы должны использовать поле ID автора. Например, вы можете хранить несколько книг, написанных одним автором или несколькими авторами для одной и той же книги. Подробная информация по каждому автору и каждой книге сохраняется только один раз и не дублируется в обеих таблицах. Тем не менее, вся необходимая информация может быть доступна с помощью связи таблиц.
Объектно-ориентированная СУБД
Предыдущие модели СУБД работают в основном с текстом и числами. Объектно-ориентированные базы данных могут обрабатывать многие новые типы данных, такие как изображения, аудио и видео.Эти элементы данных представляют собой объекты , , хранящиеся в базе данных.
Если у вас есть данные, которые аккуратно помещаются в строки и столбцы, например база данных клиентов с именами, адресами, почтовыми индексами и т. Д., Реляционная СУБД обычно наиболее подходит. С другой стороны, если у вас есть библиотека мультимедийных файлов, объектно-ориентированная СУБД будет работать лучше.
Вы по-прежнему можете создавать табличные представления ваших данных. Например, вы можете представить свою видеотеку в виде таблицы со списком ваших видеороликов с указанием их длины, отсортированных по дате записи.
Рассмотрим базу данных для всех медицинских изображений, собранных в больнице, таких как рентгеновские снимки, компьютерная томография и электрокардиограммы. Наиболее подходящим способом организации этих данных была бы объектно-ориентированная база данных. Каждое изображение будет объектом, и это будет с тегом с использованием типа изображения, имени пациента, имени врача, запросившего обследование, техника, проводившего обследование, и т. Д.
различные модели не полностью исключают друг друга.Например, система управления объектно-реляционной базой данных объединяет элементы обеих моделей. Он использует реляционную модель для описания ассоциаций между таблицами данных, но позволяет хранить мультимедийные объекты.
В случае с больницей, вы можете использовать реляционную модель для создания базы данных записей пациентов и сохранения всех изображений в виде объектов. Пометив каждое изображение тегом, вы можете связать записи пациента с изображениями по мере необходимости.
Краткое содержание урока
Существует ряд различных моделей систем управления базами данных.Плоские файлы похожи на одну очень большую таблицу. Это работает только для очень простых данных.
Иерархические базы данных используют отношения родитель-потомок в древовидной структуре. Это работает только для данных, которые по своей природе являются иерархическими.
Сетевые базы данных больше похожи на структуру паутины с многочисленными сетевыми связями между элементами данных. Это быстро становится очень сложным.
Реляционные базы данных организуют данные в виде таблиц, которые связаны между собой с помощью отношений таблиц.Это, безусловно, наиболее широко используемая модель базы данных, поскольку она очень эффективна.
Объектно-ориентированные базы данных хорошо подходят для хранения мультимедийных данных в виде объектов вместо использования табличной структуры.
Результаты обучения
По завершении этого урока вы сможете:
- Проводить различия между различными типами систем управления базами данных (СУБД)
- Опишите ограничения плоских файлов и иерархических баз данных
- Поймите, как могут усложняться сетевые базы данных
- Объясните, почему реляционные базы данных являются наиболее часто используемой СУБД
- Понять способы, которыми объектно-ориентированные базы данных вмещают мультимедийные данные
Как разрабатывать базы данных с использованием различных моделей
В основе моделирования баз данных лежит идея разработки структуры базы данных, которая определяет, как можно получить доступ к хранимой информации, ее категоризацию и манипулирование.Это сама основа проектирования базы данных, а конкретная используемая модель данных определяет диаграмму базы данных и общие усилия по разработке. Прочтите, чтобы узнать, почему моделирование является инженерной необходимостью, а также узнать о некоторых из наиболее популярных методов моделирования данных.
Моделирование баз данных 101
По сути, база данных должна быть простой в использовании и обеспечивать безопасную целостность данных. Сильная модель базы данных также позволит использовать различные способы управления, контроля и организации хранимой информации для эффективного выполнения нескольких ключевых задач.На этапе проектирования схемы базы данных предоставят необходимую документацию по связям данных, которые облегчают функциональность базы данных.
Типы методов моделирования баз данных
Ниже приведен список наиболее распространенных методов моделирования баз данных. Обратите внимание, что в зависимости от типа данных и потребностей конечного пользователя при доступе к базе данных можно использовать несколько моделей для создания более сложной структуры базы данных. Конечно, в любом сценарии создание диаграмм базы данных потребовалось бы для установления и поддержания высоких операционных стандартов.К счастью, готовые инструменты для построения диаграмм и дизайна, такие как Creately, могут упростить эту задачу.
Из нижеперечисленных моделей реляционная модель является наиболее часто используемой моделью для большинства проектов баз данных. Но в некоторых особых случаях могут быть более выгодными другие модели. К счастью, поддержка всех моделей 🙂.
- Реляционная модель : основанная на математической теории, эта модель базы данных выводит хранение и поиск информации на новый уровень, поскольку она предлагает способ поиска и понимания различных отношений между данными.Изучая, как различные переменные могут изменить взаимосвязь между данными, можно получить новые перспективы, поскольку представление информации изменяется за счет сосредоточения внимания на различных атрибутах или областях. Эти модели часто можно найти в системах бронирования авиабилетов или в банковских базах данных.
Метод реляционного проектирования, самый популярный метод проектирования баз данных
- Графическая модель : Графическая модель — еще одна набирающая популярность модель. Эти базы данных созданы на основе теории графов и используют узлы и ребра для представления данных.Структура несколько похожа на объектно-ориентированные приложения. Базы данных графиков, как правило, легче масштабировать и обычно быстрее работают с ассоциативными наборами данных.
- Иерархическая модель : Подобно общей организационной схеме, используемой для организации компаний, эта модель базы данных имеет такой же древовидный вид и часто используется для структурирования XML-документов. С точки зрения эффективности данных это идеальная модель, в которой данные содержат вложенную и отсортированную информацию, но она может быть неэффективной, если данные не имеют восходящей ссылки на основную точку данных или тему.Эта модель хорошо работает для системы управления информацией о сотрудниках в компании, которая стремится ограничить или назначить использование оборудования определенным лицам и / или отделам.
Иерархический метод, самая первая модель проектирования базы данных
- Сетевая модель : Используя записи и наборы, эта модель использует подход отношения «один ко многим» для записей данных. Несколько ветвей выделяются для структур нижнего уровня и ветвей, которые затем соединяются несколькими узлами, которые представляют структуры более высокого уровня в информации.Этот метод моделирования базы данных обеспечивает эффективный способ извлечения информации и организации данных таким образом, чтобы их можно было просматривать различными способами, обеспечивая средства повышения производительности бизнеса и времени реакции. Это жизнеспособная модель для планирования автомобильных, железнодорожных или инженерных сетей.
Модель сети, в которой узел может иметь несколько родительских узлов
- Размерная модель : Это адаптация реляционной модели, которая часто используется в сочетании с ней, добавляя «измерение» фактов к точкам данных.Эти факты можно использовать в качестве меры для других данных, чтобы определить, как размер группы или время группы повлияли на определенные результаты. Это может помочь бизнесу принимать более эффективные стратегические решения и помочь им узнать свою целевую аудиторию. Эти модели могут быть полезны организациям, занимающимся анализом продаж и прибыли.
- Объектно-реляционная модель : Эти модели создали совершенно новый тип базы данных, которая сочетает в себе дизайн базы данных с прикладной программой для решения конкретных технических проблем, используя лучшее из обоих миров.На сегодняшний день объектные базы данных все еще нуждаются в доработке для достижения большей стандартизации. Реальные приложения этой модели часто включают технические или научные области, такие как инженерия и молекулярная биология.
Схемы базы данных и выбор модели
Независимо от того, какой метод моделирования базы данных вы выберете, крайне важно разработать связанные диаграммы для визуализации желаемого потока и функциональности, чтобы база данных была спроектирована наиболее эффективным и действенным способом.