Профилирование Python-программ и анализ их производительности / Хабр
Профилирование — это неотъемлемая часть любых работ по оптимизации кода или производительности программ. Любой опыт, любые знания в сфере оптимизации производительности, которые уже у вас есть, не принесут особой пользы в том случае, если вы не знаете о том, где их применить. В результате оказывается, что поиск узких мест приложений может помочь в деле решения проблем производительности, поможет сделать это быстро и приложив не слишком много усилий.
В этом материале мы обсудим инструменты и методы работы, которые способны обнаруживать и конкретизировать проблемы с производительностью кода, связанные и с ресурсами процессора, и с потреблением памяти. Здесь же мы поговорим о том, как реализовывать (почти безо всяких усилий) простые механизмы, позволяющие бороться с проблемами производительности. Эти механизмы используются в тех случаях, когда даже точно просчитанные изменения кода больше не позволяют улучшить ситуацию.
Идентификация узких мест
В деле оптимизации производительности программ лениться — это хорошо. Вместо того чтобы пытаться понять то, какая именно часть кодовой базы замедляет приложение, можно просто воспользоваться инструментами профилирования кода. Они позволят найти те места приложения, на которые стоит обратить внимание, такие, которые нуждаются в более глубоком исследовании.
Самый распространённый инструмент, который используют для этих целей Python-разработчики — это cProfile. Это — стандартный модуль, который способен измерять время выполнения функций.
Рассмотрим следующую функцию, которая возводит (медленно) e в степень X:
# some-code.py from decimal import * def exp(x): getcontext().prec += 2 i, lasts, s, fact, num = 0, 0, 1, 1, 1 while s != lasts: lasts = s i += 1 fact *= i num *= x s += num / fact getcontext().prec -= 2 return +s exp(Decimal(3000))
Исследуем этот медленный код с помощью
python -m cProfile -s cumulative some-code.py 1052 function calls (1023 primitive calls) in 2.765 seconds Ordered by: cumulative timek ncalls tottime percall cumtime percall filename:lineno(function) 5/1 0.000 0.000 2.765 2.765 {built-in method builtins.exec} 1 0.000 0.000 2.765 2.765 some-code.py:1(<module>) 1 2.764 2.764 2.764 2.764 some-code.py:3(exp) 4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:986(_find_and_load) 4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:956(_find_and_load_unlocked) 4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:650(_load_unlocked) 3/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap_external>:842(exec_module) 5/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:211(_call_with_frames_removed) 1 0.000 0.000 0.001 0.001 decimal.py:2(<module>) .
..
 py
1052 function calls (1023 primitive calls) in 2.765 seconds
Ordered by: cumulative timek
ncalls tottime percall cumtime percall filename:lineno(function)
5/1 0.000 0.000 2.765 2.765 {built-in method builtins.exec}
1 0.000 0.000 2.765 2.765 some-code.py:1(<module>)
1 2.764 2.764 2.764 2.764 some-code.py:3(exp)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:986(_find_and_load)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:956(_find_and_load_unlocked)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:650(_load_unlocked)
3/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap_external>:842(exec_module)
5/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:211(_call_with_frames_removed)
1 0.000 0.000 0.001 0.001 decimal.py:2(<module>)
.
py
1052 function calls (1023 primitive calls) in 2.765 seconds
Ordered by: cumulative timek
ncalls tottime percall cumtime percall filename:lineno(function)
5/1 0.000 0.000 2.765 2.765 {built-in method builtins.exec}
1 0.000 0.000 2.765 2.765 some-code.py:1(<module>)
1 2.764 2.764 2.764 2.764 some-code.py:3(exp)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:986(_find_and_load)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:956(_find_and_load_unlocked)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:650(_load_unlocked)
3/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap_external>:842(exec_module)
5/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:211(_call_with_frames_removed)
1 0.000 0.000 0.001 0.001 decimal.py:2(<module>)
.
Тут мы воспользовались опцией -s cumulative для сортировки выходных данных по суммарному времени, затраченному на выполнение каждой из функций. Это упрощает поиск проблемных участков кода. Видно, что почти всё время (примерно 2,764 секунды) в ходе одного сеанса выполнения программы было потрачено в функции
Профилирование подобного рода может принести пользу, но его, к сожалению, не всегда достаточно. cProfile снабжает нас информацией лишь о вызовах функций, но не об отдельных строках кода. Если вызвать какую-то особую функцию, вроде append, в разных местах, то сведения обо всех её вызовах будут собраны в одной строке отчёта cProfile. То же самое относится и к скриптам, вроде того, который мы исследовали выше. Он содержит единственную функцию, которая вызывается лишь один раз, в результате у
Иногда такая роскошь, как локальная отладка проблемного кода, программисту не доступна. Или бывает так, что нужно проанализировать проблему с производительностью, что называется, «на лету», когда она возникает в продакшн-окружении. В таких ситуациях можно воспользоваться пакетом
Или бывает так, что нужно проанализировать проблему с производительностью, что называется, «на лету», когда она возникает в продакшн-окружении. В таких ситуациях можно воспользоваться пакетом py-spy. Это — профилировщик, способный исследовать программы, которые уже запущены. Например — приложения, работающие в продакшне, или на любой удалённой системе:
pip install py-spy python some-code.py & [1] 1129587 ps -A -o pid,cmd | grep python ... 1129587 python some-code.py 1130365 grep python sudo env "PATH=$PATH" py-spy top --pid 1129587
В этом фрагменте кода мы сначала устанавливаем py-spy, а потом, в фоне, запускаем программу, которая выполняется длительное время. Это приводит к автоматическому показу идентификатора процесса (PID), но если мы его не знаем, можно, для его выяснения, воспользоваться командой ps. И, наконец, мы запускаем py-spy в режиме top, передавая ему PID. Это ведёт к выводу данных, очень похожих на те, что выводит Linux-утилита top.
Тут, правда, в нашем распоряжении оказывается не так много данных, так как скрипт представляет собой всего лишь одну функцию, выполняющуюся длительное время. Но в реальных случаях, вероятнее всего, подобный отчёт будет содержать сведения о многих функциях, совместно использующих процессорное время. А это может помочь несколько прояснить ситуацию с существующими проблемами производительности программы.
Более глубокое исследование кода
Профилировщики, о которых мы только что говорили, должны помочь вам в деле обнаружения функций, которые вызывают проблемы, связанные с производительностью. Но если это не приведёт к обнаружению конкретных строк кода, которые надо доработать, это значит, что мы можем обратиться к профилировщикам, которые позволяют исследовать программы на более глубоком уровне.
Первый из таких инструментов представлен пакетом line_profiler. Он, как можно судить по его названию, может использоваться для выяснения того, сколько времени уходит на выполнение каждой конкретной строки кода:
# https://github.0 5.0 0.0 getcontext().prec -= 2 14 1 2.0 2.0 0.0 return +s
 com/pyutils/line_profiler
pip install line_profiler
kernprof -l -v some-code.py # Это может занять некоторое время...
Wrote profile results to some-code.py.lprof
Timer unit: 1e-06 s
Total time: 13.0418 s
File: some-code.py
Function: exp at line 3
Line # Hits Time Per Hit % Time Line Contents
3 @profile
4 def exp(x):
5 1 4.0 4.0 0.0 getcontext().prec += 2
6 1 0.0 0.0 0.0 i, lasts, s, fact, num = 0, 0, 1, 1, 1
7 5818 4017.0 0.7 0.0 while s != lasts:
8 5817 1569.0 0.3 0.0 lasts = s
9 5817 1837.0 0.3 0.0 i += 1
10 5817 6902.0 1.2 0.1 fact *= i
11 5817 2604.0 0.4 0.0 num *= x
12 5817 13024902.0 2239.1 99.9 s += num / fact
13 1 5.
com/pyutils/line_profiler
pip install line_profiler
kernprof -l -v some-code.py # Это может занять некоторое время...
Wrote profile results to some-code.py.lprof
Timer unit: 1e-06 s
Total time: 13.0418 s
File: some-code.py
Function: exp at line 3
Line # Hits Time Per Hit % Time Line Contents
3 @profile
4 def exp(x):
5 1 4.0 4.0 0.0 getcontext().prec += 2
6 1 0.0 0.0 0.0 i, lasts, s, fact, num = 0, 0, 1, 1, 1
7 5818 4017.0 0.7 0.0 while s != lasts:
8 5817 1569.0 0.3 0.0 lasts = s
9 5817 1837.0 0.3 0.0 i += 1
10 5817 6902.0 1.2 0.1 fact *= i
11 5817 2604.0 0.4 0.0 num *= x
12 5817 13024902.0 2239.1 99.9 s += num / fact
13 1 5.
Библиотека line_profiler распространяется вместе с интерфейсом командной строки kernprof (названным так в честь Роберта Керна), который используется для организации эффективного анализа результатов тестовых прогонов программ. Передача нашего кода этой утилите приводит к созданию опции -v), подобный показанному выше. Тут чётко видны места функции, на выполнение которых уходит больше всего времени. Это очень сильно помогает в деле поиска и исправления проблем с производительностью. В выходных данных можно заметить декоратор @profile, добавленный к функции exp. Это — необходимое дополнение, которое позволяет line_profiler узнать о том, какую именно функцию в файле мы хотим изучить.
Но даже если построчно проанализировать функцию, первоисточник проблем с производительностью можно и не обнаружить. Например, такое бывает в том случае, если в конструкциях while или if используются условия, составленные из множества выражений. В подобных случаях имеет смысл переписать проблемные фрагменты, разбить одну строку кода на несколько. Это позволит получить более полные и понятные результаты анализа.
Если же вы — по-настоящему ленивый разработчик (как я), и чтение текстового вывода в интерфейсе командной строки — это для вас уже слишком — тогда вот вам ещё один инструмент — pprofile, ещё одном построчном профилировщике, создатели которого черпали вдохновение из кода line_profiler. Этот профилировщик генерирует тепловую карту для строк/областей кода, выполнение которых занимает основную долю времени выполнения программы:
pip install py-heat pyheat some-code.Тепловая карта, построенная с помощью pyheat
 py --out image_file.png
py --out image_file.pngУчитывая простоту кода нашего примера, отчёт, выводимый на экран с помощью kernprof, который мы видели, выглядит достаточно понятным. Но вышеприведённая тепловая карта ещё лучше идентифицирует узкое место нашей функции.
До сих пор мы говорили лишь о профилировании, имеющем отношение к ресурсам процессора. Но то, как программа пользуется CPU, не всегда является тем, что волнует разработчика. Оперативная память — дешёвый ресурс, поэтому программисты обычно не задумываются о её использовании. По крайней мере — до тех пор, пока программа не исчерпает доступную память.
Даже если ваша программа не попала в ситуацию, когда ей не хватает памяти, всё равно, то, как приложение пользуется памятью, стоит исследовать. Сделать это можно для того чтобы узнать, можно ли оптимизировать код с прицелом на экономию памяти, или можно ли дать программе больше памяти ради повышения её производительности. Для анализа использования памяти можно воспользоваться инструментом memory_profiler. Он похож на уже известный вам
Он похож на уже известный вам line_profiler:
# https://github.com/pythonprofilers/memory_profiler pip install memory_profiler psutil psutil is needed for better memory_profiler performance python -m memory_profiler some-code.py Filename: some-code.py Line # Mem usage Increment Occurrences Line Contents 15 39.113 MiB 39.113 MiB 1 @profile 16 def memory_intensive(): 17 46.539 MiB 7.426 MiB 1 small_list = [None] * 1000000 18 122.852 MiB 76.312 MiB 1 big_list = [None] * 10000000 19 46.766 MiB -76.086 MiB 1 del big_list 20 46.766 MiB 0.000 MiB 1 return small_list
Это испытание мы проводим на другом фрагменте кода.
Функция memory_intensive создаёт и уничтожает большие Python-списки. На её примере мы способны оценить ту пользу, которую может принести нам memory_profiler в деле анализа использования памяти. Так же, как и при
Так же, как и при kernprof-профилировании, функцию надо оснастить декоратором @profile. Он позволит memory_profiler узнать о том, какой именно код мы хотим профилировать.
Тут видно, что для обычного списка, содержащего значения None, было выделено более 100 МиБ памяти. Анализируя эти данные, правда, надо учитывать то, что они отражают не реальное использование памяти, а то, сколько памяти было выделено при выполнении каждой из строк функции. В данном случае это значит, что переменные, хранящие списки, на самом деле, не занимают столько памяти. Здесь отражён лишь тот факт, что Python-объекты list, вероятнее всего, выделяют память с запасом, чтобы подстроиться под ожидаемый рост объёма данных, которые могут попасть в список.
Как мы уже видели, Python-списки часто потребляют сотни мегабайт или даже гигабайты памяти. Быстро улучшить ситуацию можно, прибегнув к оптимизации, которая заключается в переходе на обычные объекты array. Они эффективнее хранят данные примитивных типов, вроде
Они эффективнее хранят данные примитивных типов, вроде int или float. Кроме того, можно ограничить использование памяти, выбирая типы с меньшей точностью, применяя параметр typecode. Воспользуйтесь командой help(array) чтобы посмотреть таблицу, в которой перечислены доступные варианты типов и их требования к памяти.
Если же даже подобные инструменты, дающие точную и детализированную информацию, не позволяют найти узкие места кода, можно попытаться дизассемблировать код и выйти на реальный байт-код, используемый интерпретатором Python. А если и дизассемблирование не помогает решить имеющуюся проблему — тогда полезным может оказаться выяснение и понимание того, какие операции выполняются в недрах Python при вызове некоей функции. Вооружившись знаниями, полученными в ходе таких исследований, в будущем вы сможете писать более производительный код.
Дизассемблированный вариант кода можно сгенерировать, воспользовавшись встроенным модулем dis, передав функцию методу dis.. Он сгенерирует и выведет список инструкций байт-кода, выполняемого при вызове функции. dis(...)
dis(...)
from math import e def exp(x): return e**x # math.exp(x) import dis dis.dis(exp)
В этом материале мы всё время исследовали очень медленную реализацию возведения e в степень X. Выше же представлена простейшая функция, которая решает эту задачу с высокой скоростью. Теперь мы можем сравнить результаты дизассемблирования быстрой и медленной функций. Результаты их дизассемблирования окажутся совершенно различными. Их изучение делает ещё более очевидным тот факт, что одна функция гораздо медленнее другой.
Вот как выглядит быстрая функция:
2 0 LOAD_GLOBAL 0 (e)
2 LOAD_FAST 0 (x)
4 BINARY_POWER
6 RETURN_VALUEА вот — наша старая функция, которая работает медленно:
4 0 LOAD_GLOBAL 0 (getcontext)
2 CALL_FUNCTION 0
4 DUP_TOP
6 LOAD_ATTR 1 (prec)
8 LOAD_CONST 1 (2)
10 INPLACE_ADD
12 ROT_TWO
14 STORE_ATTR 1 (prec)
5 16 LOAD_CONST 2 ((0, 0, 1, 1, 1))
18 UNPACK_SEQUENCE 5
20 STORE_FAST 1 (i)
22 STORE_FAST 2 (lasts)
24 STORE_FAST 3 (s)
26 STORE_FAST 4 (fact)
28 STORE_FAST 5 (num)
6 >> 30 LOAD_FAST 3 (s)
32 LOAD_FAST 2 (lasts)
34 COMPARE_OP 3 (!=)
36 POP_JUMP_IF_FALSE 80
. ..
100 RETURN_VALUE ..
100 RETURN_VALUE
..
100 RETURN_VALUEДля того чтобы лучше разобраться в том, что именно тут происходит — рекомендую взглянуть на этот ответ со StackOverflow, в котором раскрывается смысл столбцов, по которым распределены эти данные.
Подходы к решению проблем
Тот, кто занимается оптимизацией программы, рано или поздно доведёт её до такого состояния, когда изменения в коде или в алгоритмах начнут давать совсем небольшие улучшения. В этот момент хорошо будет обратить внимание на внешние инструменты, способные дать дополнительный прирост производительности.
Верный способ улучшить скорость работы кода заключается в компиляции его в виде C-программы. Это можно сделать, воспользовавшись различными инструментами. Например — PyPy или Cython. Первый из них — это JIT-компилятор, который можно использовать как непосредственную замену CPython. Он может дать, не требуя никаких усилий от программиста, значительный рост производительности кода. Его применение вполне может стать достойным решением некоей проблемы с производительностью. Для того чтобы воспользоваться PyPy — достаточно загрузить соответствующий архив, распаковать его и запустить с помощью PyPy свой код:
Для того чтобы воспользоваться PyPy — достаточно загрузить соответствующий архив, распаковать его и запустить с помощью PyPy свой код:
# Загрузить архив можно с https://www.pypy.org/download.html tar -xjf pypy3.8-v7.3.7-linux64.tar.bz2 cd pypy3.8-v7.3.7-linux64/bin ./pypy some-code.py
Просто чтобы доказать то, что благодаря PyPy можно, не прилагая особых усилий, сразу же улучшить производительность программы, устроим небольшое испытание скрипта, запущенного с помощью CPython и PyPy:
time python some-code.py real 0m2,861s user 0m2,841s sys 0m0,016s time pypy some-code.py real 0m1,450s user 0m1,422s sys 0m0,009s
PyPy, помимо вышеозначенных плюсов, отличается ещё и тем, что для его использования не нужно вносить в код никаких изменений. Он, кроме того, поддерживает все встроенные модули и функции Python.
Всё это звучит просто замечательно, но использование PyPy означает необходимость идти на кое-какие компромиссы. Этот инструмент поддерживает проекты, нуждающиеся в C-привязках, такие, как numpy, но это создаёт значительную дополнительную нагрузку на систему, что сильно замедляет соответствующие библиотеки, сводя на нет другие улучшения производительности. PyPy, кроме того, не решает проблем с производительностью в ситуациях, когда применяются внешние библиотеки, или в случаях, когда речь идёт о работе с базами данных. И, аналогично, если речь идёт о программах, производительность которых привязана к подсистеме ввода/вывода, не стоит ожидать значительной выгоды от применения PyPy.
PyPy, кроме того, не решает проблем с производительностью в ситуациях, когда применяются внешние библиотеки, или в случаях, когда речь идёт о работе с базами данных. И, аналогично, если речь идёт о программах, производительность которых привязана к подсистеме ввода/вывода, не стоит ожидать значительной выгоды от применения PyPy.
Если PyPy вам не помогает — можете попробовать Cythoh. Это — компилятор, который использует C-подобные аннотации типов (не подсказки по типам, применяемые в Python) для создания компилируемых модулей расширения Python. Cython, кроме прочего, использует AOT-компиляцию, что может дать значительный прирост производительности благодаря уходу от холодного запуска приложений. Но использование Cython требует переработки существующего кода с использованием особого синтаксиса, что приводит к усложнению программ.
Если вы не против перейти на Python-синтаксис, немного отличающийся от обычного, тогда вам, возможно, интересно будет взглянуть на prometeo — встраиваемый язык, отражающий специфику конкретной предметной области, основанный на Python. Он, в частности, ориентирован на научные вычисления. Программы, написанные на
Он, в частности, ориентирован на научные вычисления. Программы, написанные на prometeo, транспилируются в чистый C-код. Их производительность сравнима со скоростью работы программ, изначально написанных на C.
Если же ни одно из представленных тут решений не позволит вам выйти на нужный уровень производительности, тогда вам, возможно, стоит писать свой оптимизированный код на C или Fortran, а для вызова этого кода из Python использовать EFI. Среди библиотек, которые способны вам в этом помочь, можно отметить ctypes и cffi для языка C, и f2py для Fortran.
Итоги
Первое правило оптимизации заключается в том, чтобы ничего не оптимизировать. Если же вам действительно это нужно — оптимизируйте то, что имеет смысл оптимизировать. Используйте инструменты для профилирования кода, о которых мы говорили — это позволит вам избежать пустой траты времени на улучшение малозначимых фрагментов программ. Ещё, занимаясь оптимизацией, полезно создавать воспроизводимые тесты производительности для улучшаемого фрагмента кода. Это позволит оценить реальное воздействие оптимизаций на производительность.
Это позволит оценить реальное воздействие оптимизаций на производительность.
Эта статья нацелена на то, чтобы помочь всем желающим в поиске источников проблем с производительностью. Но вот исправление таких проблем — это уже совсем другая история. Кое-какие идеи на эту тему можно найти в одной из моих предыдущих статей, посвящённой методам значительного ускорения Python-кода.
О, а приходите к нам работать? 😏Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
Как ускорить приложения на Python
На Python пишут как десктопные программы, так и высокопрофессиональные web-приложения. Он является интерпретируемым языком и благодаря этому можно использовать продвинутые инструменты. Например, интроспекцию и метапрограммирование.
Но Python накладывает и некоторые ограничения, одно из них — снижение скорости работы по сравнению с программами, написанными на компилируемых языках программирования (C++ и др).
Андрей Смирнов
Python-разработчик, преподаватель по финансовой грамотности в Московской школе программистов (МШП)
В статье я разберу интересный кейс, чтобы проанализировать и ускорить имеющийся код на Python.
Исходные данные (демо-приложение)
Сразу же скажу, что мы не будем погружаться в пучину хардкорной отладки и продираться сквозь десяток уровней вызовов функций в стеке и сложные алгоритмические конструкции. Причина проста: все методы, которые я покажу сегодня, прекрасно воспроизводятся на простом коде и после этого тиражируются на любые масштабные проекты.
А в качестве стартового кода мы возьмём задачу: имеется магазин, продающий определенные товары. Товар характеризуется тремя величинами: название, цена, валюта. Необходимо реализовать хранилище товаров, заполнить его некими товарами.
На языке Python такая задача решается быстро:
Сразу отмечу, что я взял достаточно большой размер списка с данными для того, чтобы программа выполнялась такое количество времени, которое позволит не искать дельту в тысячных долях секунды.
Профилирование
Казалось бы, необходимо оптимизировать код, но как понять, что именно необходимо менять? Для этого нужно собрать с приложения определённые метрики, показывающие, насколько хорошо оно работает.
Процесс сбора этих метрик называется профилированием приложения. Проводить процесс профилирования можно как по времени работы, так и по памяти.
Профилирование по времени
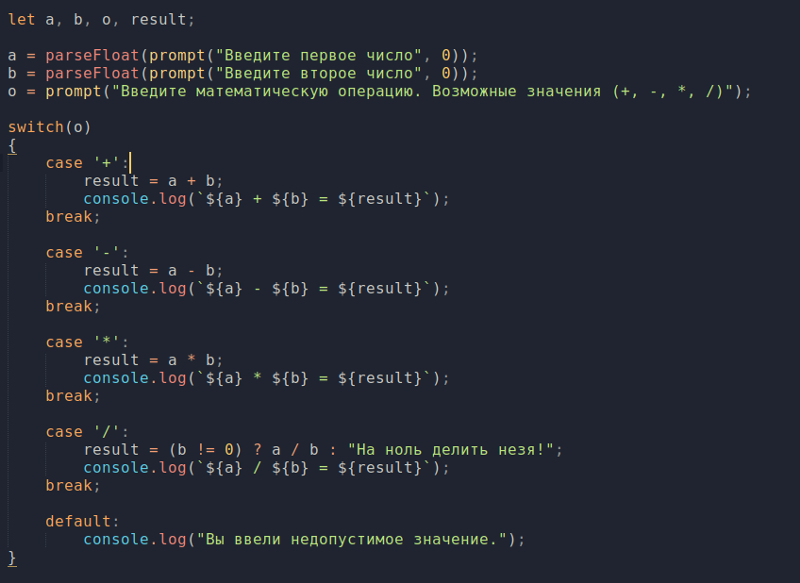
Сначала добавим в нашу программу измерение скорости её работы. Для этого в Python есть специальная функция time, находящаяся в одноименном модуле. Идея использования этой функции очень проста: мы изменяем текущее время в начале работы программы и в конце. Далее считаем дельту, которая будет являться длительностью работы программы.
Идея использования этой функции очень проста: мы изменяем текущее время в начале работы программы и в конце. Далее считаем дельту, которая будет являться длительностью работы программы.
И ещё несколько пунктов, которые обязательно нужно сказать про этот код:
- В ходе профилирования нет смысла измерять время работы кода, ответственного за ввод данных с клавиатуры, чтение из файла, получение данных из сетевого хранилища и т.д. Эти операции априори будут медленными из-за низкой скорости передачи данных по сравнению с аналогичной скоростью в передачи данных в ОЗУ компьютера. Если вы понимаете, что проблема низкой скорости кроется в коде ввода данных, тогда его нужно профилировать отдельно от основной программы.
- Одна и та же программа, запущенная два раза, практически никогда не выдаст идентичное время выполнения. Это происходит из-за того, что программа выполняется в операционной системе, в которой постоянно работают фоновые процессы. И чаще всего отключить все лишние процессы невозможно. В таком случае, чтобы минимизировать их влияние, достаточно всего лишь запустить программу многократно и посчитать среднее время выполнения (что и сделано в коде).
 В таком случае, чтобы минимизировать их влияние, достаточно всего лишь запустить программу многократно и посчитать среднее время выполнения (что и сделано в коде).
В таком случае, чтобы минимизировать их влияние, достаточно всего лишь запустить программу многократно и посчитать среднее время выполнения (что и сделано в коде).Этот код при запуске показал следующие тайминги:
Сразу можно заметить, что отклонение по времени доходит до половины секунды. Запускал код я на системе со следующей конфигурацией:
- Intel Core i7-7700HQ
- 16Gb RAM
- KUbuntu 22.04
Ещё немного про профилирование по времени и сразу же первая оптимизация
Если у вас “тормозит” программа, в которой сотни и тысячи строк кода и сама архитектура этого кода состоит их множества функций и классов, тогда использовать замер таймингов в том виде, в котором я написал выше, будет крайне неудобно.
Но эта проблема решаема с помощью встроенного в Python средства профилирования, идеально подходящего для такой ситуации — утилиты cProfile. Она способна не просто запустить код и рассчитать время его работы, но и рассчитать время работы каждого отдельного метода (включая даже низкоуровневые методы создания списков, выделения памяти, добавления объектов и т. д.).
д.).
Для того, чтобы запустить cProfile, не требуется менять код. Достаточно просто запустить программу на исполнение с подключением дополнительного модуля:
python3 -m cProfile main.py
В таком случае вся программа выполнится и после неё будет выведена детальная информация о времени выполнения каждой функции:
Сразу же есть две мысли:
- Наличие любого дополнительного профилировщика замедляет программу. Это происходит, потому что любой профилировщик добавляет свой исполняемый код, благодаря которому и собирается статистика выполнения. В результате этого среднее время выполнения нашей программы увеличилось с 2.46 до 3.26 секунд.
- Сразу же можно заметить, что больше всего раз вызывается метод list.append, который добавляет новый объект в список. И именно на этом месте появляется идея для оптимизации: если мы заранее знаем, что объектов будет добавляться именно три миллиона, что мешает нам создать заранее список такого размера?
Попробуем изменить код так, чтобы список создавался сразу:
Запустим его также с использованием cProfile. И что же мы видим?
И что же мы видим?
Среднее время уменьшилось до 2.06 секунд, и это со включённым профилировщиком. А без него будет так вообще 1.66! И всё путём простейшей оптимизации.
Профилирование по памяти
Также сразу же добавим в наш код профилирование по памяти, так как очень интересно узнать “сколько же занимает в памяти три миллиона товаров”. Для подсчёта памяти будем использовать библиотеку pympler.
И такой код при размере хранилища в три миллиона товаров показал следующие результаты:
Размер хранилища: 176000864 байт или 167.85 мегабайт
Вы можете заметить, что я убрал из кода подсчёт по времени. Причина проста: pympler для подсчёта количества занимаемой памяти проходит по всем имеющимся структурам данных, и во время подсчёта скорость выполнения увеличивается раз в пять, делая профилирование по времени неоправданным.
А теперь, когда мы достаточно знаем о поведении нашего приложения (и во времени, и в памяти) — приступим к его последовательной оптимизации.
Способы оптимизации
Оптимизация структур данных
Начнём мы с несколько нестандартной оптимизации, а именно — залезем внутрь нашего объекта товара и основательно там покопаемся.
Сейчас объект представлен в виде обыкновенного класса. Давайте подумаем, а возможно ли здесь использовать какую-нибудь иную структуру данных, которая построена на основе класса, но имеет дополнительный функционал? И такая структура есть, она называется датакласс. Правда, сразу стоит оговориться, что обычный датакласс является небольшой надстройкой над обычным классом, в которой разработчики языка чётко указали, какие будут поля и какие они будут иметь типы данных. А нам будет интересен датакласс с фиксированными полями, в который невозможно добавить новые поля.
Почему это важно? Для того, чтобы иметь возможность добавлять и удалять поля в рантайме, в классах питона реализована структура словаря __dict__. А это, в свою очередь, далеко не всегда является необходимым функционалом.
Поэтому, если сформировать чёткую структуру данных (а чаще всего для хранения больших объёмов данных используются как раз жёстко определённые структуры), то после этого можно убрать функционал динамического добавления полей, и в таком случае объекты будут работать быстрее.
Реализуем эту идею (для этого определим кортеж __slots__).
Если этот код запустить и проверить время выполнения, то мы получим ускорение в среднем на 25 процентов
А если директиву __slots__ указать в коде, который мы профилировали по памяти, то результаты получатся ещё более сногсшибательными:
Размер хранилища: 80000504 байт или 76.29 мегабайт
То есть, путём отказа от динамического добавления элементов мы сразу уменьшили расходы памяти нашего приложения вдвое!
И на этом мы не остановимся.
Оптимизация интерпретатора
Следующая оптимизация, которая может помочь нам в достижении нашей цели — замена интерпретатора Python на интерпретатор PyPy.
Согласно определению из Википедии, PyPy — это интерпретатор языка Python, написанный на языке Python. Однако в него встроен трассирующий JIT-компилятор, способный преобразовывать код на Python в машинный код прямо во время выполнения программы. Эта особенность позволяет ему существенно ускорить процесс исполнения программы без каких либо изменений кода.
Установим pypy следующей командой:
sudo apt install pypy3
А после этого запустим код с его помощью:
pypy3 main.py
Результаты говорят сами за себя: скомпилированный код априори выполняется намного быстрее, нежели интерпретируемый код.
Время исполнения уменьшилось ещё на 68%. И для такого запуска абсолютно не потребовалось менять исходный код.
Справедливости ради нужно заметить, что за счёт глубинной оптимизации некоторые сторонние библиотеки, которыми вы можете пользоваться, не смогут запуститься в pypy. И для них придётся искать аналоги. Но самые популярные библиотеки (такие как twisted, django, numpy, scikit-learn и другие) им полностью поддерживаются и работоспособны.
А как ещё можно оптимизировать?
В мире существуют и другие способы оптимизации, но они уже относятся к категории радикальных, подразумевающих кардинальное изменение структуры кода и (или) даже языка программирования. Среди них:
- изменение структуры хранимых данных со списка объектов на pandas. DataFrame.
- добавление строгой типизации и адаптация кода под компилятор cython
- распараллеливание программы на потоки при помощи Nvidia CUDA.
- И, наконец, если затраты от потерь производительности существенно превышают затраты от кардинальной переработки кода, можно попробовать переписать критичные части кода на языке C++ и оформить их в виде библиотеки, функции из которой можно запустить из Python-кода.
 DataFrame.
DataFrame.Итоги
Итак, в ходе нашего увлекательного путешествия мы
- написали код
- измерили его производительность (по памяти и по времени)
- оптимизировали его несколько раз
- результаты в виде графиков приведены ниже.
В каждом из случаев получилось улучшить измеряемый показатель производительности более чем в два раза, так что считаю, что цель достигнута.
Благодарю за внимание.
Как проверить время выполнения скрипта Python?
В этой статье мы обсудим, как проверить время выполнения скрипта Python.
В Python существует множество модулей Python, таких как модуль time, timeit и datetime, которые могут хранить время выполнения определенного раздела программы. Манипулируя или получая разницу между временем начала и окончания выполнения определенного раздела, мы можем рассчитать время, необходимое для выполнения раздела.
Для вычисления разницы во времени можно использовать следующие методы:
- Модуль времени Python предоставляет различные функции, связанные со временем. Этот модуль относится к стандартным служебным модулям Python. метод time.time() модуля Time используется для получения времени в секундах с начала эпохи. Обработка високосных секунд зависит от платформы.
- Модуль Python datetime определяет функцию, которая в основном может использоваться для получения текущего времени и даты. сейчас() 9Функция 0011 Возвращает текущую локальную дату и время, которые определены в модуле datetime.
- Python Модуль timeit запускает фрагмент кода n раз (значение по умолчанию — 1000000), чтобы получить статистически наиболее релевантное измерение времени выполнения кода.

Проверка времени выполнения Python с помощью модуля time-3. Мы можем проверить время, увеличив количество вычислений с использованием тех же алгоритмов.
Python3
импорт время
начало = time.time()
a = 0 для i в Диапазон ( 1000 ): a + = (i * * 100 9004 1 )
конец = время.время()
print ( "Время выполнения вышеуказанной программы:" , (конец - начало) * 10 * * 3 , "мс" ) |
Выход: 90 003
Время выполнения вышеуказанной программы: 0,77056884765625 мсПример 2: Измерение времени, необходимого для сегмент кода путем суммирования времени, необходимого на итерацию
Проверка времени выполнения программы для различного количества вычислений. Мы видим общую тенденцию к увеличению времени вычислений при увеличении числа выполнений. Однако он может не показывать какой-либо линейный тренд или фиксированные приращения.
Мы видим общую тенденцию к увеличению времени вычислений при увеличении числа выполнений. Однако он может не показывать какой-либо линейный тренд или фиксированные приращения.
Python3
импорт время
для j в ряд ( 100 , 5501 , 100 9 0041 ): начало = 0041 a = 0 для i в диапазон (j): a + = (i * * 100 ) end = time.
печать (f "Итерация: {j}\tЗатраченное время: {(конец-начало)*10**3:.03f}мс" ) |
 time()
time() Вывод: 9 0003
Итерация: 100 Затраченное время: 0,105 мс Итерация: 200 Затраченное время: 0,191 мс Итерация: 300 Затраченное время: 0,291 мс Итерация: 400 Затраченное время: 0,398 мс Итерация: 500 Затраченное время: 0,504 мс Итерация: 600 Затраченное время: 0,613 мс Итерация: 700 Затраченное время: 0,791 мс ... Итерация: 5400 Затраченное время: 6,504 мс Итерация: 5500 Затраченное время: 6,630 мс
Объяснение: Здесь мы усекли вывод для наглядности. Но если мы сравним итерации от 100 до 700, то они меньше 1 мс. Но ближе к концу цикла каждая итерация занимает ~ 7 мс. Таким образом, время увеличивается по мере увеличения количества итераций. Обычно это связано с тем, что внутренний цикл повторяется большее количество раз в зависимости от каждой внешней итерации.
Использование модуля DateTime для проверки времени выполнения
Использование модуля datetime в Python и функции datetime.now() для записи метки времени начала и окончания экземпляра и поиска разницы для получения времени выполнения кода.
Python3
из datetime импорт datetime 9000 3
a = 0 для i в диапазоне ( 1000 ): 9 0040 a + = (i * * 100 )
конец = datetime.now()
td = (конец - start). * 10 * * 3 печать 9 0042 |
 total_seconds()
total_seconds() Вывод:
Время выполнения вышеуказанной программы: 0,766 мс
Использование
timeit 90 Модуль 011 проверяет время выполненияЭто даст нам время выполнения любой программы . Этот модуль предоставляет простой способ найти время выполнения небольших фрагментов кода Python. Он предоставляет метод timeit() , чтобы сделать то же самое. Функция модуля timeit.timeit(stmt, setup, timer, number) принимает четыре аргумента:
- stmt — утверждение, которое вы хотите измерить; по умолчанию это «пройти».
- setup — это код, который вы запускаете перед запуском stmt; по умолчанию это «пройти». Обычно мы используем это для импорта необходимых модулей для нашего кода.
- таймер, который является объектом timeit.Timer; обычно имеет разумное значение по умолчанию, так что вам не о чем беспокоиться.
- Число, которое представляет собой количество выполнений, которые вы хотели бы запустить stmt.

Пример 1. Использование timeit во фрагменте кода Python для измерения времени выполнения
Python3
импорт timeit
mysetup 9004 1 = "из математического импорта sqrt"
mycode =
exec_time = timeit.timeit(stmt = мой код, настройка = mysetup, номер = 1000000 ) * 10 * * 3 печать (f «Время выполнения вышеуказанной программы: {exec_time:. ) |
 03f} мс»
03f} мс» Вывод:
Время выполнения вышеуказанной программы: 71,161 мс
Пример 2: Использование timeit из командной строки для измерения времени выполнения
Мы можем измерить время, затрачиваемое простыми операторами кода без необходимости писать новые файлы Python, используя timeit CLI-интерфейс.
time поддерживает различные входные данные командной строки. Здесь мы отметим несколько наиболее распространенных аргументов:
- -s [–setup] : Код установки для запуска перед выполнением оператора кода.
- -n [–число ]: количество раз выполнения инструкции.
- – p [–process] : Измерьте время выполнения кода вместо времени настенных часов.
- Оператор : операторы кода для проверки времени выполнения, взятые в качестве позиционного аргумента.
timeit Оператор командной строки:
python -m timeit -s "import random" "l = [x**9 for x in range(random.
 randint(1000, 1500))]"
randint(1000, 1500))]" Вывод:
500 циклов, лучший из 5: 503 использовано на цикл
Как получить время выполнения программы Python
В этой статье мы научимся рассчитывать время, необходимое программе для выполнения в Python . Мы также будем использовать некоторые встроенные функции с некоторыми пользовательскими кодами. Давайте сначала быстро рассмотрим, как выполнение программы влияет на время в Python.
Программисты, должно быть, часто сталкивались с ошибкой «Превышено время» при создании программных сценариев. Чтобы решить эту проблему, мы должны оптимизировать наши программы, чтобы они работали лучше. Для этого нам может понадобиться знать, сколько времени требуется программе для ее выполнения. Давайте обсудим различные функции, поддерживаемые Python, для расчета времени работы программы в Python 9.0010 .
Время выполнения программы Python может быть непоследовательным в зависимости от следующих факторов:
- Одна и та же программа может быть оценена с использованием разных алгоритмов
- Время работы зависит от алгоритма
- Время работы зависит от реализации
- Время работы зависит от компьютера
- Время работы непредсказуемо из-за небольших входных данных
Расчет времени выполнения с помощью функции time()
Мы вычисляем время выполнения программы, используя функцию time.. Он импортирует модуль  time()
time() time , который можно использовать для получения текущего времени. В приведенном ниже примере сохраняется время начала до выполнения цикла for, а затем сохраняется время окончания после выполнения строки печати. Разница между временем окончания и временем начала и будет временем выполнения программы. Функция time.time() лучше всего используется на *nix.
время импорта
#время начала
начало = время.время()
для i в диапазоне (3):
распечатать("Привет")
# время окончания
конец = время.время()
# общее время
print("Время выполнения программы - ", end-start)
Привет
Привет
Привет
Время выполнения программы 1.430511474609375e-05
Рассчитать время выполнения с помощью функции timeit()
Мы вычисляем время выполнения программы, используя функцию timeit() . Он импортирует модуль timeit . Результатом является время выполнения в секундах. Это предполагает, что ваша программа запускается как минимум за десятую долю секунды.
Это предполагает, что ваша программа запускается как минимум за десятую долю секунды.
В приведенном ниже примере создается переменная и весь код, включая импорт, заключен в тройные кавычки. Код теста действует как строка. Теперь мы вызываем функция time.timeit() . Функция timeit() принимает тестовый код в качестве аргумента, выполняет его и записывает время выполнения. Значение числового аргумента установлено равным 100 циклам.
время импорта
код_теста = """
а = диапазон (100000)
б = []
для я в:
б. добавить (я + 2)
"""
total_time = timeit.timeit(test_code, число=200)
print("Время выполнения программы -", total_time)
Время выполнения программы 4.26646219700342
Рассчитать время выполнения с помощью функции time.clock()
Еще одна функция модуля time для измерения времени выполнения программы — функция time.clock() . time.clock() измеряет время процессора в системах Unix, а не время стены. Эта функция в основном используется для целей сравнительного анализа или алгоритмов синхронизации.
Эта функция в основном используется для целей сравнительного анализа или алгоритмов синхронизации. time.clock() может возвращать чуть более высокую точность, чем time.time() . Он возвращает время процессора, что позволяет нам вычислить только время, используемое этим процессом. Лучше всего использовать в Windows.
время импорта
t0= время.часы()
распечатать("Привет")
t1 = время.часы() - t0
print("Время истекло: ", t1 – t0) Прошло # секунд ЦП (с плавающей запятой)
Привет
Прошедшее время: -0,02442
Примечание:
time.clock() «Устарело, начиная с версии 3.3». Поведение этой функции зависит от платформы. Вместо этого мы можем использовать perf_counter() или process_time() в зависимости от требований или иметь четко определенное поведение.
time.perf_counter() — возвращает значение (в долях секунды) счетчика производительности, т. е. часы с самым высоким доступным разрешением для измерения короткой продолжительности. Он включает время, прошедшее во время сна, и является общесистемным.
часы с самым высоким доступным разрешением для измерения короткой продолжительности. Он включает время, прошедшее во время сна, и является общесистемным.
time.process_time() — Возвращает значение (в долях секунды) суммы системного и пользовательского процессорного времени текущего процесса. Он не включает время, прошедшее во время сна. Например,
начало = время.процесс_время() ... сделай что-нибудь прошедшее = (time.process_time() - начало) 90 159Рассчитать время выполнения с помощью функции datetime.now()
Мы вычисляем прошедшее время, используя
datetime.datetime.now()из модуляdatetime, доступного в Python. Он не превращает скрипт в многострочную строку, как вtimeit(). Это решение медленнее, чемtimeit(), поскольку вычисление разницы во времени включено во время выполнения. Результат представлен в виде дней, часов, минут и т. д.В приведенном ниже примере текущее время сохраняется перед любым выполнением в переменной.
datetime.datetime.now()после выполнения программы, чтобы найти разницу между временем окончания и начала выполнения.импорт даты и времени start = datetime.datetime.now() список1 = [4, 2, 3, 1, 5] список1.sort() конец = datetime.datetime.now() печать (конец-начало)
0:00:00.000007Вычислить время выполнения с помощью %%time
Мы используем
%%time 9Команда 0042 для расчета времени, затраченного программой. Эта команда в основном предназначена для пользователей, которые работают с Jupyter Notebook . Это будет фиксировать только время стены конкретной ячейки.%%время [ x**2 для x в диапазоне (10000)] 90 159Почему timeit() — лучший способ измерить время выполнения кода Python?
1. Вы также можете использовать
time.clock()в Windows иtime.time()в Mac или Linux. Однакоtimeit()будет автоматически использовать либоtime.
 Затем вызовите
Затем вызовите 