Яндекс Вордстат — полное руководство по работе с сервисом
СоветыИщем ключи, прогнозируем показы и многое другое
Как работать с Вордстатом новичкам Как работать с операторами в Вордстате Какие запросы собирать бизнесу Приёмы работы с Вордстатом Полезные бесплатные расширения для работы с Яндекс.Wordstat Особенности использования Яндекс.Wordstat
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Благодаря Вордстату можно получить информацию о точном количестве запросов определенных ключевых слов в поисковой системе Яндекса.
- Собрать семантику для SEO и контекстной рекламы.
- Найти тему статьи для блога или поста в сообществе.
- Спрогнозировать количество показов в контекстной рекламе.
- Оценить динамику и сезонность товара или услуги.
- Найти перспективные регионы для продажи товаров и услуг.
В этой статье я расскажу, как и в каких ситуациях использовать Яндекс.Вордстат с примерами.
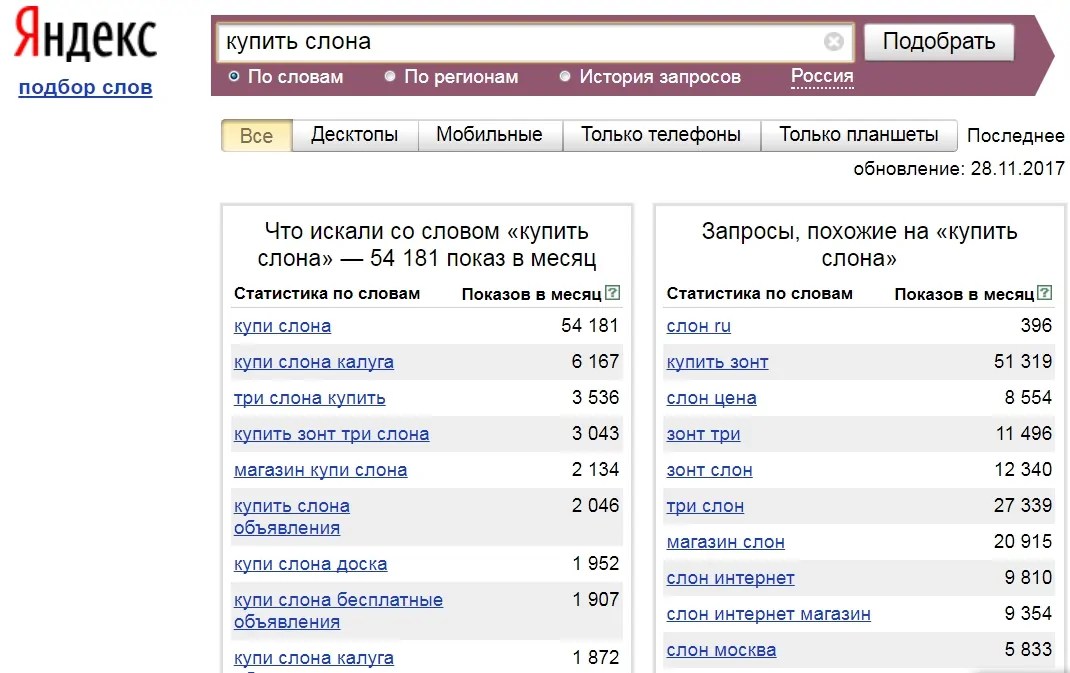
Как работать с Вордстатом новичкамПеред началом работы с сервисом авторизуйтесь или зарегистрируйтесь в Яндексе. В поисковой строке стартовой страницы введите запрос или ключевое слово и нажмите «Подобрать».
В левом столбце отображаются словоформы искомого слова, а также запросы, которые включены в основной ключевик. В правом — похожие запросы вашей тематики или слова.
По умолчанию Вордстат показывает прогноз показов в интернете на всех устройствах. В настройках можно выбрать условия «Десктопы», «Мобильные», «Только телефоны» или «Только планшеты». Для этого воспользуйтесь меню под поисковой строкой.
Для этого воспользуйтесь меню под поисковой строкой.
Более глубоко можно изучить статистику запросов по регионам. Для этого воспользуемся настройкой «Регионы». От выбора страны или отдельного города будет меняться статистика показов ключевого слова.
В статистике по регионам есть две колонки: «Показов в месяц» и «Региональная популярность». «Показов в месяц» отражает, сколько раз показывались страницы для конкретного региона. При просмотре статистики по всем регионам нужно учитывать их вложенность. Например, данные по Москве включены в данные по Центральному региону, а Центральный регион включен в Россию.
«Региональная популярность» показывает популярность запросов в конкретном регионе от общего количества. Популярность запроса выше 100% означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный.
Ещё один инструмент Яндекс.Wordstat — «История запросов». Он позволяет оценить динамику и сезонность поискового запроса. Соответствующая вкладка доступна под поисковой строкой сервиса. Здесь же можно выбрать настройки региона и устройств показа.
Здесь же можно выбрать настройки региона и устройств показа.
Абсолютное количество показов отражает число фактических показов ключевого слова. Относительные — число запросов относительно всех поисковых запросов за это время.
Как работать с операторами в ВордстатеЕсли вводить запрос, состоящий из двух и более слов, Wordstat покажет общую статистику показов по словам в запросе. Например, для фразы «заказать кровать» будут показаны все запросы, в которых есть эти слова: «заказать деревянную кровать», «заказать детскую кровать», «заказать двухэтажную кровать» и пр.
Поэтому при сборе точной семантики для контекстной рекламы и SEO, рекомендую использовать операторы.
Операторы позволяют уточнять пользовательские запросы в интернете и показывать в Яндекс.Wordstat только релевантную частотность.
Оператор « » (кавычки)
Заключение запроса в кавычки уточнит статистику показов только по заданным словам, но без учёта их порядка и окончания.
Без использования оператора кавычки
С использованием оператора кавычки
Оператор + (плюс)
Знак плюса ставят перед стоп-словами и предлогами для точного их включения. По умолчанию они не учитываются.
Без использования оператора плюс
С использованием оператора плюс
Оператор — (минус)
Минус ставится перед каждым словом, которое нужно удалить из статистики. Это те слова, которые точно нерелевантны аудитории или бизнесу. Минусовать можно сразу несколько слов.
Без использования оператора минус
С использованием оператора минус
Оператор ! (восклицательный знак)
Знак восклицания фиксирует словоформу запроса или окончание слов, однако порядок слов может нарушаться.
Без использования оператора знак восклицания
С использованием оператора знак восклицания
Операторы иногда используют одновременно. Например, чтобы узнать точное число запросов указанной фразы в интернете. Для этого используем операторы кавычки и знак восклицания.
Оператор [ ] (квадратные скобки)
С помощью квадратных скобок можно закрепить порядок слов в запросе. При этом дополнительные слова и изменение окончаний фразы не ограничивается.
Без использования оператора квадратные скобки
С использованием оператора квадратные скобки
Оператор | (или)
Употребляется для сравнения статистики показов нескольких фраз одновременно. Например, для поиска запросов по нужным ключам из ассортимента магазина.
Какие запросы собирать бизнесуЧтобы продавать товары или услуги, нужно продвигаться по коммерческим запросам. К таким относятся, например, поисковые фразы со словами «купить», «заказать», «интернет-магазин» и т. д.
Если таких слов нет в запросе, скорее всего, он будет информационным. В этом случае пользователь вряд ли будет мотивирован на покупку — он будет просто собирать информацию.
Поэтому страницы с товарами и услугами лучше продвигать через коммерческие запросы. А вот блоги — через информационные, чтобы получать больше трафика.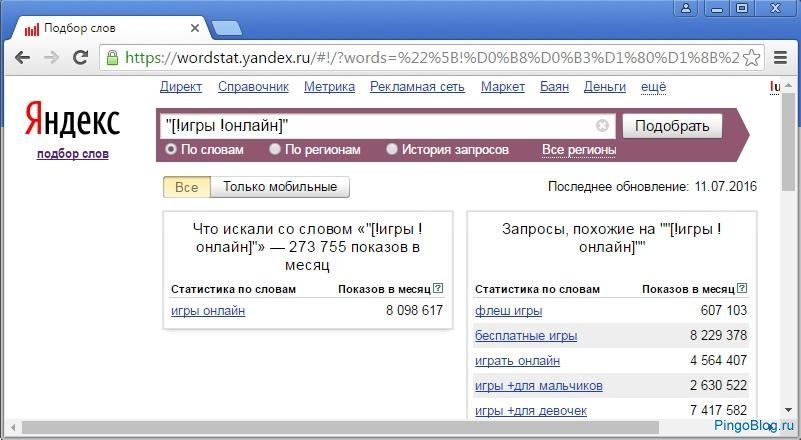
Вообще тема довольно большая и сложная, поэтому стоит изучить отдельные статьи по теме в блоге Unisender:
Как составить семантическое ядро сайта
Гид по SEO. Как оптимизировать сайт и сколько это стоит
Как ChatGPT изменит поиск и SEO
Приёмы работы с ВордстатЕщё несколько приёмов по работе с операторами разберём на примерах.
Ищем точное число показов с учётом словоформы и порядка слов. Для этого используем операторы «кавычки», «знак восклицания» и «квадратные скобки» одновременно.
Ищем несколько запросов с учётом минус-фраз. Для этого используем оператор «или» и «минус».
Ищем запросы с заданным количеством слов. Для этого вводим в Wordstat ключевое слово в кавычках несколько раз. В ответ сервис подберет запросы именно с таким количеством слов. Например, в запросе “unisender unisender unisender” будет три слова, а в “unisender unisender” — два.
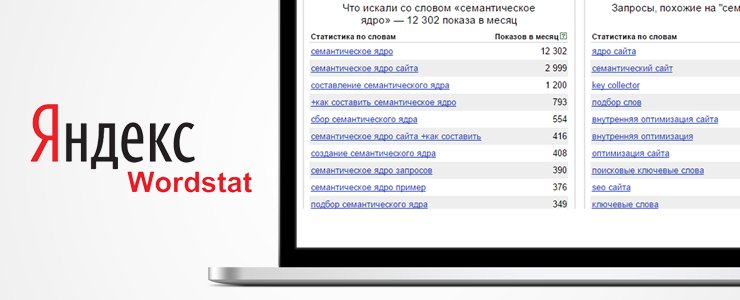
Полезные бесплатные расширения для работы с Яндекс. Wordstat
WordstatЕсть два полезных и бесплатных расширения.
Yandex Wordstat Helper
Сайт. arcticlab.ru/yandex-wordstat-helper
Расширение работает в Mozilla Firefox, Google Chrome и Яндекс.Браузере. С его помощью можно добавлять нужные ключи в отдельную форму и сортировать их по алфавиту, популярности или времени добавления в список. Но с большим количество ключей работать неудобно: придется кликать по каждому, просто скопировать и добавить их в форму не получится.
Yandex Wordstat Assistant
Сайт. https://semantica.in/tools/yandex-wordstat-assistant
Работает в Google Chrome, Яндекс.Браузер, Opera, Mozilla Firefox. Оно позволяет добавлять полученные запросы в отдельную форму, из которой потом можно переносить все в таблицу. В этой же форме можно отсортировать запросы по убыванию или по возрастанию. Расставить их в алфавитном порядке, по порядку добавления в список или по частотности.
Особенности использования Яндекс.WordstatКоличество показов ≠ количеству потенциальных посетителей вашего сайта. Их будет намного меньше.
Их будет намного меньше.
Операторы помогают уточнять запросы, делать более точный прогноз. Помните про вложенность.
С помощью «Истории запросов» оценивается сезонность товаров или услуг. Но операторы там не действуют.
Данные на вкладке «История запросов» просматриваются в абсолютных и относительных цифрах. Абсолютное значение — это число фактических показов ключевого слова. Относительное значение — число запросов относительно всех поисковых запросов за это время.
Есть ограничения на число предоставляемых данных: не более 50 результатов на страницу и не более 40 страниц. Максимально можно собрать 2 000 запросов.
Если семантическое ядро большое, вручную работать с Вордстатом не вариант. Тогда нужен один из профессиональных сервисов для подбора ключевых слов.
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
 Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала. Оставляя свой email, я принимаю Политику конфиденциальности
Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала. Оставляя свой email, я принимаю Политику конфиденциальностиинтерфейс, операторы, сбор семантики и частоты — Топвизор–Журнал

Эта статья для тех, кто никогда не пользовался Вордстатом Яндекса или думает, что пользуется им неправильно. Покажем, какие данные с его помощью получать, что они значат и как помогут в продвижении сайта.
Если вы SEO-специалист, то почувствуете, что чего-то не хватает… Скорее всего, не хватает вашего комментария с полезным советом по работе с Вордстатом. Поделитесь опытом – иногда это полезнее статьи.
Как работает Яндекс.Вордстат и откуда берёт данныеЛюди заходят в Яндекс каждый день и ищут кому что надо: заказать пиццу, официальный сайт городского ЗАГСа, бывает ли аллергия на доберманов и т. д. Какие-то запросы ищут чаще, например, «заказать пиццу». Какие-то реже, например, про аллергию. На каждый запрос формируется выдача, в которой показываются подходящие страницы сайтов. Вот она:
Выдача в Яндексе по запросу «как заказать пиццу»Яндекс собирает статистику по тому, сколько раз в месяц люди искали тот или иной запрос. И эту статистику можно посмотреть в инструменте «Яндекс.Вордстат» или, по-другому, «Подбор слов Яндекса».
И эту статистику можно посмотреть в инструменте «Яндекс.Вордстат» или, по-другому, «Подбор слов Яндекса».
Поскольку каждый сайт именно «показывается» по определённому запросу, то статистика формируется по «показам» – сколько показов выдачи было по этому запросу за последние 30 дней. Но специалисты называют эту метрику «Частота». Чем выше частота запроса, тем он популярнее.
Можно сделать вывод, что если продвигать сайт по запросам с самой высокой частотой, то на сайт придёт больше трафика. Но всё не так просто.
Что нужно знать о Частоте в Яндекс.Вордстате1. По умолчанию в Вордстате вы видите значение общей частоты. Это значит, что инструмент показывает вам все возможные запросы, которые включают в себя введённое вами слово в любом числе, падеже, склонении. Слова в запросах могут быть расставлены в любом порядке и к ним могут быть добавлены дополнительные слова. Поэтому общая частота обычно показывает самые высокие цифры.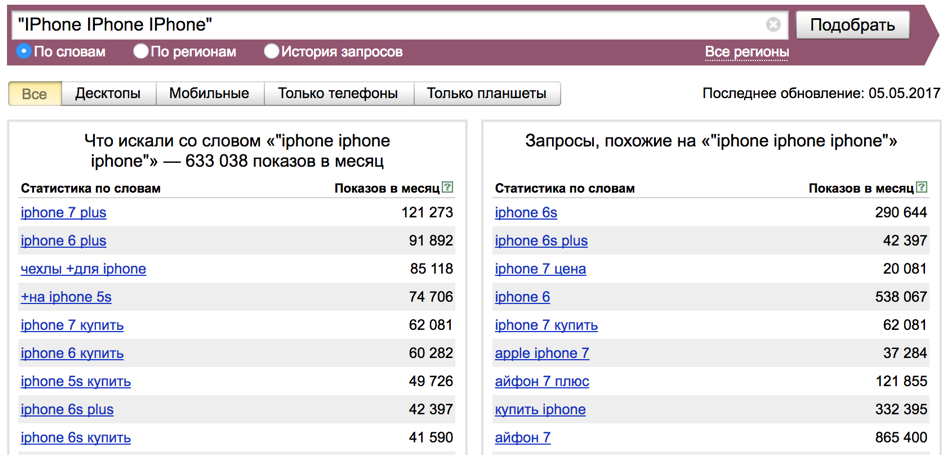 Например, запрос “заказать пиццу” имеет частоту 496 778, но это вовсе не значит, что именно такой запрос пользователи искали полмиллиона раз.
Например, запрос “заказать пиццу” имеет частоту 496 778, но это вовсе не значит, что именно такой запрос пользователи искали полмиллиона раз.
2. Частота запроса в первой строке левого столбца включает в себя частоты всех вариаций запроса, которые указаны на остальных строках. В примере выше частота запроса “заказать пиццу” 496 778 – это сумма частот всех запросов, указанных ниже.
Из чего складывается частота запроса «заказать пиццу»3. Мы можем смотреть частоту конкретного запроса или частоту запросов, содержащих конкретные слова, используя специальные операторы для Вордстата. Это пригодится, если нужно посмотреть точные цифры и спрогнозировать потенциальный трафик.
4. Если ничего не настраивать, то Вордстат показывает частоту по всем регионам в целом. Но можно посмотреть цифры отдельно по каждому региону.
5. Чем меньше слов в запросе – тем выше будет частота. Чем больше вы добавляете слов, тем больше уточняете запрос. Запросы из четырёх и более слов называются «запросы с длинным хвостом» или «longtail-запросы». Частота длинных запросов обычно ниже, потому что их реже ищут.
Частота длинных запросов обычно ниже, потому что их реже ищут.
Разберём все нюансы подробнее и расскажем, как правильно подбирать запросы для продвижения через Вордстат.
Виды запросов в ВордстатеПо частоте
В первую очередь, запросы в инструменте делятся по Частоте: высокочастотные, среднечастотные и низкочастотные. Сокращённо их обозначают ВЧ-, СЧ- и НЧ-запросы.
Нельзя точно обозначить границы частоты, при которой запрос считается высоко- или низкочастотным. Это зависит от тематики. Например, сравним запрос “заказать пиццу” и “купить водолазку”:
Сравнение запросов “заказать пиццу” и “купить водолазку”В случае с пиццей самый высокочастотный запрос имеет частоту почти 500 тыс., а с водолазкой – около 50 тыс.
Поэтому высокочастотными запросами для запроса “заказать пиццу” можно считать запросы с частотой выше 10 000, а для запроса “купить водолазку” от 3 000. Среднечастотными будут запросы от 2000 до 10 000 для пиццы и от 500 до 3000 для водолазки. Остальные запросы считаются низкочастотными.
Остальные запросы считаются низкочастотными.
Это примерные цифры. Строго установленной градации нет, в каждом случае специалист сам решает, какие запросы в его тематике распределить на ВЧ, СЧ и НЧ.
В продвижении используются запросы с любой частотой. Нельзя сказать, что какие-то запросы лучше, а какие-то хуже для SEO. Но на эти данные нужно ориентироваться, чтобы понять, какое количество трафика может принести страница, если оптимизировать её по тому или иному запросу.
Например, считается, что низкочастотные запросы – это те, которые пользователи реже всего ищут в поиске. Поэтому если страница оптимизирована под низкочастотные запросы, нельзя ожидать, что она принесёт полмиллиона трафика с поиска.
По типу
Кроме частоты нужно обратить внимание и на классификацию самих запросов. Даже если у запроса высокая частота, это не значит, что он подходит для продвижения.
Все запросы делятся на такие типы:
- Общие. Обычно состоят из одного слова, поэтому до конца не понятно, что именно искал пользователь по этому запросу.
 Например, Холодильник, Шуба, Книга. У этих запросов будет очень высокая частота, но для продвижения их не используют. Например, в запрос “Шуба” будет входить и “купить норковую шубу”, и “химчистка шуб”, и “сельдь под шубой”, и “шуба авито”. Если на вашем сайте нет услуги по химчистке шуб или вы не кулинарный блог, то большая часть запросов окажется для вас не подходящими.
Например, Холодильник, Шуба, Книга. У этих запросов будет очень высокая частота, но для продвижения их не используют. Например, в запрос “Шуба” будет входить и “купить норковую шубу”, и “химчистка шуб”, и “сельдь под шубой”, и “шуба авито”. Если на вашем сайте нет услуги по химчистке шуб или вы не кулинарный блог, то большая часть запросов окажется для вас не подходящими. - Информационные.
- Транзакционные. Запросы с намерением совершить какую-то покупку: “Заказать услуги SEO”, “Купить холодильник двухкамерный” и т. д. Это коммерческие запросы – по ним пользователь планирует потратить деньги, то есть совершить транзакцию.
- Навигационные. Запросы с названиями конкретной компании, сервиса или сайта.
- Мультимедийные. Запросы, которые содержат такие слова, как “смотреть”, “фото”, “слушать” и т. д. По ним поисковая система покажется документы, аудиофайлы, видео.
- Брендовые. Запросы содержат названия брендов. Например, “Nissan официальный сайт” или “Uniqlo одежда”. Такие запросы пересекаются с навигационными запросами.
 Например, Холодильник, Шуба, Книга. У этих запросов будет очень высокая частота, но для продвижения их не используют. Например, в запрос “Шуба” будет входить и “купить норковую шубу”, и “химчистка шуб”, и “сельдь под шубой”, и “шуба авито”. Если на вашем сайте нет услуги по химчистке шуб или вы не кулинарный блог, то большая часть запросов окажется для вас не подходящими.
Например, Холодильник, Шуба, Книга. У этих запросов будет очень высокая частота, но для продвижения их не используют. Например, в запрос “Шуба” будет входить и “купить норковую шубу”, и “химчистка шуб”, и “сельдь под шубой”, и “шуба авито”. Если на вашем сайте нет услуги по химчистке шуб или вы не кулинарный блог, то большая часть запросов окажется для вас не подходящими. 
Ещё запросы делятся на геозависимые и геонезависимые. При геонезависимых запросах пользователю неважно результаты какого региона будут в выдаче. Например, когда кто-то ищет “рецепт пиццы”, ему всё равно повар из какого региона этот рецепт выложил. А при геозависимых запросах регион важен. Например, “доставка пиццы”. Скорее всего пользователь хочет заказать пиццу, поэтому важно, чтобы в результатах поиска были рестораны того же региона, что и у него.
Заметьте, что указание региона не имеет значения для определения геозависимости запроса: “новости тула” – не геозависимый запрос. Геозависимость определяет поисковая система сама на основании множества факторов, в том числе местного номера телефона и адреса компании.
Геозависимость определяет поисковая система сама на основании множества факторов, в том числе местного номера телефона и адреса компании.
Но если в запросе пользователь укажет конкретный город, то сайты этого города получат приоритет в выдаче. Например, если из Москвы мы будем вводить запрос “адвокат волгоград”, то получим в выдаче результаты из волгограда, но запрос не будет считаться геозависимым.
Сам Вордстат не делит запросы на какие-либо типы, а только показывает список возможных запросов с их частотой. Тогда почему мы об этом говорим? Потому что это поможет вам подобрать правильные запросы для сайта с помощью Вордстата.
Как искать подходящие для продвижения запросы
Сначала определяемся с тематикой сайта. Она подскажет ориентировочные запросы, которые стоит искать в Яндекс.Вордстат.
Представим, что мы планируем продвигать сайт по продаже холодильников. Запросами-ориентирами будут “холодильник”, “новый холодильник”, “холодильник купить”. По ним можно оценить спрос на конкретные модели и марки, посмотреть, какие характеристики холодильников ищут люди и отобрать подходящие запросы. Их них формируется семантическое ядро – набор запросов, по которым сайт будет показываться в поиске.
Их них формируется семантическое ядро – набор запросов, по которым сайт будет показываться в поиске.
Например, вот поиск по слову “холодильник”:
Запросы по слову «холодильник»Для магазина холодильников нужно искать транзакционные запросы, потому что ваша цель – найти людей, которые хотят купить холодильник, то есть потратить деньги. Если магазин не новый и люди о нём знают, то возможно, они будут искать сайт по брендовым и навигационным запросам – их тоже стоит учесть.
Магазин холодильников – это коммерческий сайт. По коммерческим запросам в поиске обычно высокая конкуренция, потому что магазинов, которые продают холодильники, очень много. Так что если у вас маленький магазин, то продвижение по высокочастотным запросам скорее всего не принесёт результатов. Первую страницу выдачи займут крупные магазины вроде МВидео, Яндекс.Маркет, Ситилинк. А по данным исследований, только полпроцента людей переходят дальше первой страницы поиска. Возможно, в продвижении больше помогут средне- и низкочастотные запросы.
Дополнительный источник информации – правая колонка Вордстат или «Запросы, похожие на…». Тут можно найти тематические запросы, которые тоже интересны аудитории:
Похожие запросы на запрос «холодильник»Если кликнуть на любой запрос в правой колонке, то Вордстат покажет все запросы, которые искали с этими словами и запросы, похожие на него:
Запросы, которые искали с запросом из правой колонки и похожие запросыОператоры Вордстата: как найти запросы с нужными словами
Чтобы помочь нам в поиске запросов, Вордстат придумал специальные операторы.
Оператор «+»
Например, иногда мы хотим найти запросы, содержащие конкретные слова или союзы, чтобы уточнить, что ищут пользователи. Для этого используется оператор «+». Порядок слов не фиксируется, но мы увидим все запросы, в которых встречается и слово “холодильник”, и слово “как” одновременно.
Попробуем найти все запросы со словом “как”:
Запросы со словом “как”Второй пример – найдём запросы с союзом «для»:
Запросы с союзом “для”Как видим, запросы перепутались: тут и “для холодильника” и “холодильник для”.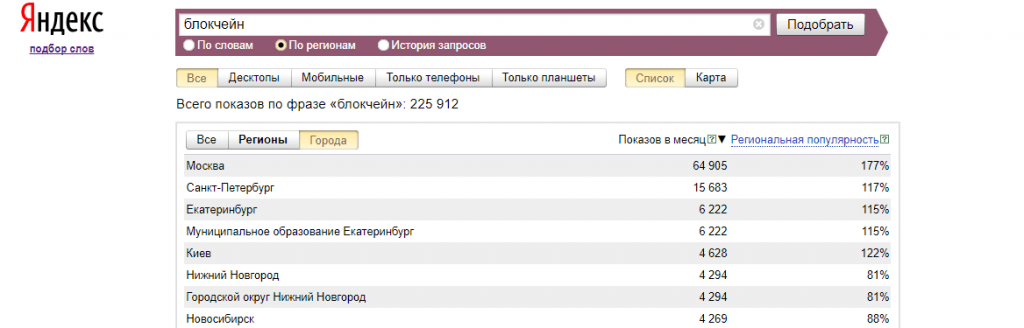 Если отбирать вручную, то можно потратить много времени. Поэтому пригодятся и другие операторы.
Если отбирать вручную, то можно потратить много времени. Поэтому пригодятся и другие операторы.
Оператор «!»
Это оператор фиксирует форму слова. С его помощью Вордстат покажет запросы, в которых слово упоминается именно в той форме, числе, падеже, которое ввели мы. Чтобы найти запросы, где холодильник упоминается в единственном числе, именительном падеже, добавим к нему оператор «!». Порядок слов по прежнему не фиксируется, поэтому если пользователь вводит запрос неточно, например “для холодильник”, то такие запросы тоже будут в списке:
Запросы с оператором «!»Оператор «[]»
Чтобы зафиксировать и порядок слов, используется оператор «[]» – квадратные скобки. Так мы получим чистые результаты:
Запросы с зафиксированным порядком словОператор «““»
Если нам нужно найти запросы, содержащие только конкретные слова без хвостов, то используется оператор “кавычки”. Например, если мы хотим посмотреть запрос только по фразе “купить холодильник” без каких-либо хвостов. При этом порядок слов и форма слова не важны:
При этом порядок слов и форма слова не важны:
Оператор «(|)»
Если мы хотим найти запросы с несколькими дополнительными словами, то используется оператор «(|)». Через черту перечисляются дополнительные слова.
Этот оператор отличается от оператора «+». Если вы напишете в ряд все дополнительные слова через +, например: холодильник +купить +недорого +бу – то Вордстат будет искать запросы, в которых одновременно содержатся сразу 4 слова в любой форме и порядке: «холодильник купить недорого бу».
А при использовании оператора «(|)» Вордстат будет искать запросы которые содержат одновременно “холодильник купить” или “холодильник недорого” или “холодильник бу”:
Как найти запросы с несколькими дополнительными словамиБонус
Представьте, что ищите запросы, состоящие из трёх слов. Вы знаете, что в них точно должны быть слова “купить” и “холодильник”, а третье слово может быть любым. Чтобы найти запросы с такими вводными, просто продублируйте последнее слово и ограничьте количество слов – используйте оператор «““»:
Как найти запросы, в которых несколько слов зафиксированы, а другие слова – нетТо же самое можно делать с любым количеством слов, дублируя последнее слово несколько раз:
Как сделать то же самое с любым количеством словПробуйте разные комбинации операторов, чтобы получить нужный результат. Например, зафиксируйте часть запроса и добавьте дополнительное слово:
Например, зафиксируйте часть запроса и добавьте дополнительное слово:
Так вы сможете найти все возможные запросы для сайта и изучить спрос.
Подробнее про операторы – в справке Яндекса.
Как смотреть точную частоту запроса
Мы уже говорили, что по умолчанию Вордстат показывает нам общую частоту запросов – включающую все возможные вариации. Благодаря этому, мы сможем собрать список запросов, которые нам подходят. Но чтобы спрогнозировать возможный трафик по ним, нужно знать точную частоту – сколько на самом деле людей ищут тот или иной запрос.
В этом нам тоже помогут операторы. Самую точную частоту можно определить, если зафиксировать порядок слов, форму слов и количество слов:
Как найти самую точную частоту в ВордстатЕсли количество слов в запросе неважно, но важен их порядок, то убирайте оператор «““». Если, наоборот, важно количество слов, но не их порядок, убирайте оператор «[]»
Но это ещё не всё. Даже при отображении самой точной частоты Вордстат по умолчанию показывает данные по всем регионам мира.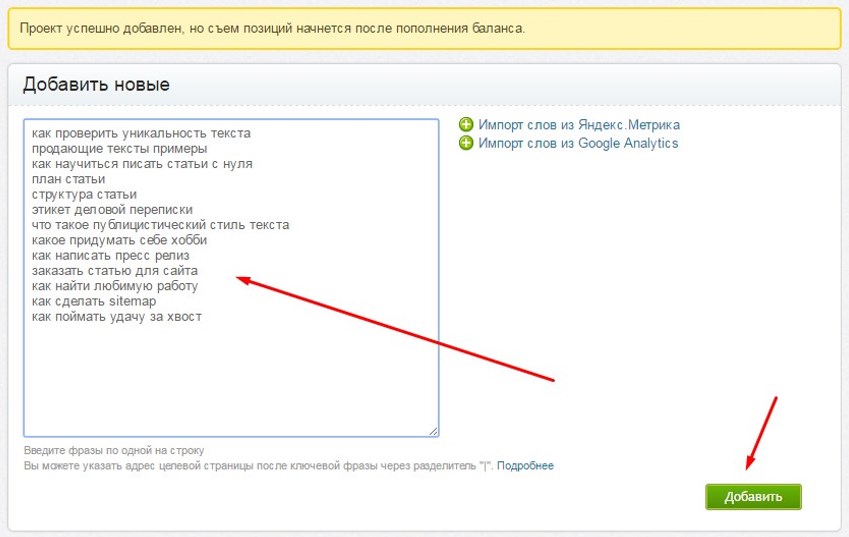 Если вы хотите оценить спрос в конкретном регионе, это нужно настроить.
Если вы хотите оценить спрос в конкретном регионе, это нужно настроить.
Настройка региона
Для того, чтобы смотреть статистику запросов в нужной стране или городе, в системе существует фильтр выдачи по регионам:
Фильтр выдачи по регионамПравда, в нём самом нет поиска, поэтому, чтобы посмотреть частоту, например, в Казани, нужно знать, что она находится в Поволжье, в республике Татарстан:
Как уточнить фильтр по регионамСтавим галочку, нажимаем кнопку «Выбрать» и смотрим частоту запросов:
Результат фильтрации по регионамЧто ещё можно смотреть в Яндекс.Вордстат
1. Частоту по Десктопной и Мобильной выдаче по отдельности: Десктопы (Компьютеры), Телефоны и Планшеты.
Как посмотреть Частоту по Десктопной и Мобильной выдачеПомогает оценить, по каким запросам высокий мобильный трафик и с каких устройств пользователи чаще ищут запросы. По этому показателю, например, можно принять решение о разработке адаптивной версии сайта.
2. Статистику запроса и популярность запроса по регионам и городам.
Региональная популярность указывается в процентах. Если больше 100 % – интерес в регионе повышен, если меньше – понижен. В интерфейсе Вордстата можно отсортировать регионы по показам или по популярности нажимая на «Показы» или «Региональная популярность» соответственно:
Как отсортировать регионы по показам или по популярностиРегиональная популярность помогает оценить, какая тема в каком регионе более и менее популярна.
3. Историю запросов. Этот раздел позволяет отслеживать динамику изменения популярности запроса по неделям и месяцам за два года:
Как посмотреть историю запросаВкладка «История запросов» – это полезные данные по сезонности запроса. Сезонность показывает, как изменяется спрос на товар или услугу в зависимости от времени года, месяца или каких-то знаковых событий. Повышенный спрос – это активность потенциальных покупателей. Зная сезонность, специалист может спрогнозировать увеличение или снижение трафика по запросу, определить знаковые в тематике события.
Например, на графике выше мы видим закономерность – запрос “холодильник купить” становится более популярным в июле. Так было в 2020 и в 2021 году:
Где посмотреть данные по сезонности запросаКак собрать Вордстат автоматически в Топвизоре
В Вордстате есть ценные для специалистов данные. Но все их приходится собирать вручную, что занимает много времени. Из-за ручного сбора можно упустить важную семантику. Поэтому в Топвизоре есть инструмент, который поможет собрать все подходящие запросы для сайта из Вордстата за 5 минут.
Зарегистрируйтесь, создайте проект и перейдите в инструмент «Поисковые запросы», а затем в «Подбор ключевых слов»:
Как перейти к подбору ключевых слов в ТопвизореВведите ориентировочные запросы. Например, “холодильник”, “новый холодильник”, “холодильник купить” и соберите запросы из Яндекса в нужном регионе. Если отметить галочку напротив «+ «с этим искали»» , то одновременно Топвизор соберёт и похожие запросы из правой колонки Вордстата.
Чтобы позже выбирать из собранных запросов нужные, удобнее объединить их в одну группу с помощью галочки «Собрать все данные в одну группу»:
Как выставить настройки для подбора ключевых словТопвизор поддерживает те же операторы Вордстата. В поле «Поисковые запросы» можно вводить запросы с любыми операторами и собрать более точную семантику:
При вводе запросов Топвизор поддерживает те же операторы ВордстатаВ результате вы получите список всех запросов, из которых по фильтру можно выбрать нужные. По нажатию Enter все выбранные по фильтру запросы перемещаются в одну группу:
Как с помощью фильтра выбрать нужные запросыПосле того, как вы отберёте нужные запросы, нужно проверить их частоту в нужных регионах. Для этого сначала добавьте нужные регионы для Яндекса в Настройках:
Как выбрать регионы для проверки частоты в ТопвизореПосле этого проверьте нужную частоту, учитывая операторы в инструменте «Поисковые запросы»:
Где проверить частотуСамая точная частота будет по запросу “[!Частота]”:
Как проверить самую точную частоту в ТопвизореТо, на что в Вордстате вы бы потратили один день, в Топвизоре займёт 5 минут. Но всё-таки Топвизор – это не только сбор данных из Вордстат.
Но всё-таки Топвизор – это не только сбор данных из Вордстат.
Что есть в Топвизоре, чего нет в Вордстате
- Автоматический сбор и группировка запросов. В Вордстате всё нужно делать вручную: вбивать запросы по одному, просматривать список (иногда это 40 страниц), обращать внимание на похожие запросы, чтобы не упустить интересные, собирать всё в Excel, не забывая про частоту. В Топвизоре это один клик.
- Одновременный сбор всех нужных частот для каждого запроса. В Вордстате придётся вводить один и тот же запрос с разными операторами и фиксировать частоту в Excel. Учитывая, что частота обновляется раз в месяц, то собранные данные быстро устареют. В Топвизоре все виды частоты можно собрать одновременно и обновлять по необходимости за 5 минут.
- Фильтрация запросов по нужному слову. В Подборе слов Яндекса вам приходится отбирать запросы вручную или фильтрами Excel. В Топвизоре вы просто выбираете нужное слово и все запросы с ним отправляются в отдельную группу.
- Просмотр всех запросов, по которым продвигается конкурент. Топвизор покажет страницы и запросы, которые приносят трафик, полный список запросов для каждой страницы + похожие запросы, с помощью которых можно получить даже больше трафика, чем получают конкуренты. Отчёт можно построить по всему сайту или по каждой отдельной странице. Вордстат такое не умеет.
Чтобы в Топвизоре посмотреть посмотреть запросы, по которым продвигаются ваши конкуренты, переходите в «Анализ конкурентов». Данные из отчёта можно выгрузить в таблицу или сразу в проект, чтобы работать с ними дальше: Как выгрузить запросы, по которым продвигаются конкуренты
- Нет капчи и лимитов – работайте комфортно и без ограничений!
На основе данных из Вордстата можно собирать запросы, по которым сайт будет виден в поиске и контекстной рекламе, и прогнозировать возможный трафик.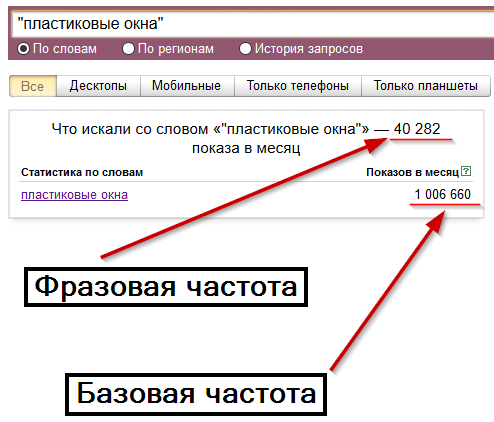 Но если вы хотите больше – используйте возможности Топвизора.
Но если вы хотите больше – используйте возможности Топвизора.
Новый алгоритм поиска Яндекса на основе искусственного интеллекта Палех
Недавно Яндекс объявил о своем новом алгоритме поиска Палех, который улучшает то, как Яндекс понимает значение каждого поискового запроса, используя свои глубокие нейронные сети в качестве фактора ранжирования среди других. В конечном счете, новый алгоритм помогает Яндексу улучшить результаты поиска по всем направлениям, но особенно для поисковых запросов с длинным хвостом.
Как известно большинству читателей State of Digital, поисковые запросы с длинным хвостом классифицируются по запросам, которые поисковая машина обрабатывает очень редко. Существует корреляция между редкостью запроса и его длиной. Как правило, чем короче запрос, тем он чаще встречается, а чем длиннее, тем реже. Такие запросы часто бывают разговорными и подробно описывают что-то, когда пользователь не знает точную фразу или слово, но пытается объяснить поисковику.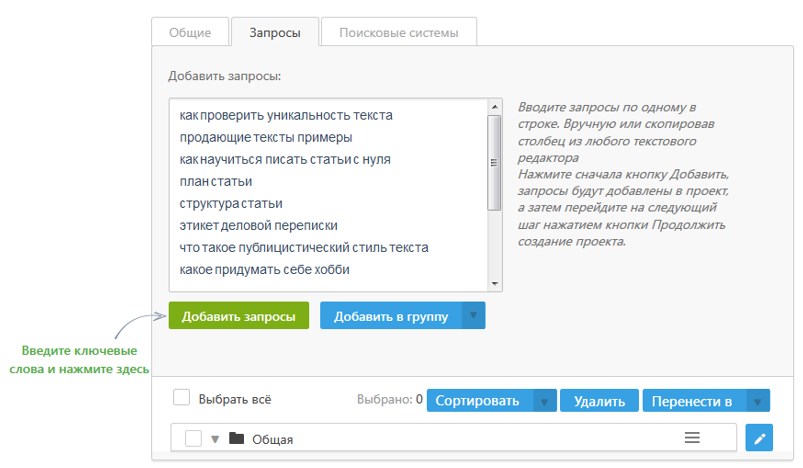 Например, написать описание фильма, не зная названия, например, «фильм о парне, выращивающем картошку на какой-то планете».
Например, написать описание фильма, не зная названия, например, «фильм о парне, выращивающем картошку на какой-то планете».
Эти длинные запросы заставляют поисковые системы полностью понять цель запроса, чтобы предлагать наиболее релевантные результаты поиска. Поисковые системы более легко предлагают результаты поиска на основе сходства слов в запросе схожести и релевантности слов в результатах. Проблема запросов с более длинным хвостом заключается в том, что они не так легко совпадают для релевантных синонимов слов, и по этим редким запросам гораздо меньше данных.
Однако запросы с длинным хвостом и результаты поиска можно лучше всего сопоставить, найдя и соединив сходство значений. Яндекс решил внедрить передовой искусственный интеллект, чтобы улучшить поиск совпадений между запросами и результатами, лучше понимая цель запроса, а не сходство самих слов.
Как компания, специализирующаяся на машинном обучении, Яндекс исторически внедрял машинное обучение в 70% своих продуктов и услуг, начиная с поиска. Совсем недавно с Палехом поисковая команда Яндекса научила свои нейронные сети видеть связи между запросом и документом, даже если они не содержат общих слов.
Совсем недавно с Палехом поисковая команда Яндекса научила свои нейронные сети видеть связи между запросом и документом, даже если они не содержат общих слов.
Этот новый алгоритм был назван в честь российского города Палех из-за жар-птицы на его гербе с длинным хвостом. Яндекс назвал все свои поисковые алгоритмы именами городов России и выбрал Палех, основываясь на символе длинного хвоста и влиянии этого алгоритма на запросы с длинным хвостом.
В этом блоге рассказывается о динамике машинного обучения, лежащей в основе последнего поискового алгоритма Яндекса Палех, и о том, что отличает его от других способов использования глубоких нейронных сетей для ранжирования в веб-поиске.
Что такое машинное обучение? Что такое нейронные сети? Машинное обучение — это именно то, что оно самообучается, создавая связи из шаблонов входных данных. Как говорит Яндекс, «машина, которая может учиться, — это машина, которая может принимать собственные решения на основе входных алгоритмов, эмпирических данных и опыта».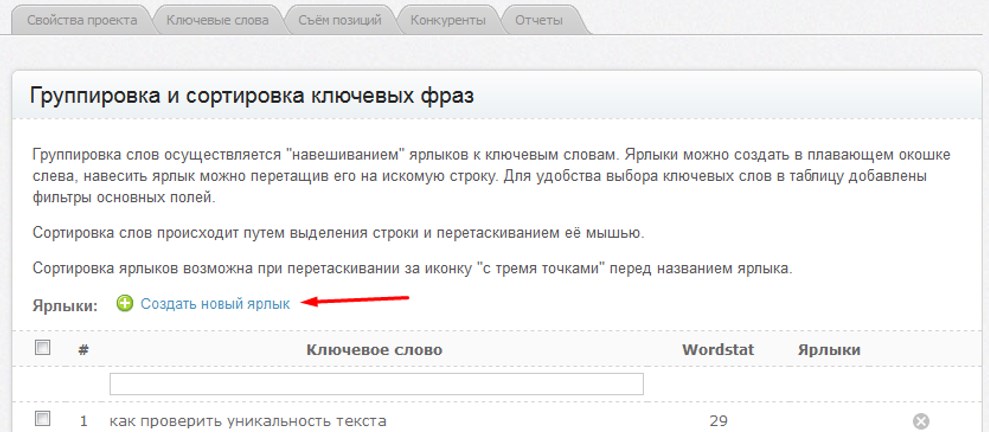 Как только цель поставлена, модели обучаются для достижения этой цели на основе обучающих образцов. Машина учится создавать правила, которые со временем совершенствуются по мере того, как она обрабатывает больше данных. На результаты алгоритма влияют миллионы факторов, которые оказываются гораздо более сложными, чем способность человека обрабатывать или программировать.
Как только цель поставлена, модели обучаются для достижения этой цели на основе обучающих образцов. Машина учится создавать правила, которые со временем совершенствуются по мере того, как она обрабатывает больше данных. На результаты алгоритма влияют миллионы факторов, которые оказываются гораздо более сложными, чем способность человека обрабатывать или программировать.
Нейронные сети — это метод машинного обучения, созданный по образцу нейронов в человеческом мозгу и предназначенный для решения задач, подобных человеческому мозгу. Нейронные сети основаны на реальных числах и могут быть обучены находить отношения в наборе данных после обработки входных данных и распознавания закономерностей. Их можно обучить анализировать изображения, звук или текст, и они применяются для различных целей, таких как распознавание изображений, перевод текста или ранжирование в веб-поиске.
Как Яндекс научил свои нейросети лучше понимать запросы? Яндекс обучил свои нейронные сети с помощью модели семантического отображения, которая сводит информацию к числам, группирует их на основе значения содержания, проецирует группы на семантическую карту, а затем находит совпадения между группами на основе их близости на карте. Как правило, семантическое отображение находит связи между двумя разными объектами, помещая их в одно и то же семантическое пространство и подтверждая их связи на основе их близости друг к другу. В этом случае ранжирования веб-страниц два объекта, которые проверяются на наличие связей, — это поисковые запросы и документы или заголовки просканированных страниц.
Как правило, семантическое отображение находит связи между двумя разными объектами, помещая их в одно и то же семантическое пространство и подтверждая их связи на основе их близости друг к другу. В этом случае ранжирования веб-страниц два объекта, которые проверяются на наличие связей, — это поисковые запросы и документы или заголовки просканированных страниц.
Прежде чем что-то случилось с сопоставлением, поисковая группа сначала должна была обучить алгоритм, предоставив ему примеры пар запросов и соответствующих заголовков веб-страниц. Этот обучающий набор предоставил нейронным сетям базовое понимание связей, которые поисковая команда Яндекса хотела установить.
Поскольку компьютеры лучше работают с числами, а не со словами, Яндекс затем преобразовал миллиарды поисковых запросов и просканированных страниц в числа. Затем эти числа нужно было организовать так, чтобы за ними стоял смысл. Произвольный набор слов не имеет реального понятия или значения. Только очень определенные наборы слов имеют смысл вместе, и существуют миллионы возможных контекстов. Алгоритм находит небольшие подмножества слов, заполненных по смыслу, но это по-прежнему приводит к миллионам возможностей, поэтому числа должны быть сгруппированы. Таким образом, используя метод, называемый уменьшением размерности, матрица сжимает длинный список слов в группу из 300, а затем помещает ее в 300-мерный вектор. Слова могут быть совершенно разными, но если они попадают в один и тот же вектор, то и значение у них похожее. То же самое делается для заголовков просканированных страниц.
Алгоритм находит небольшие подмножества слов, заполненных по смыслу, но это по-прежнему приводит к миллионам возможностей, поэтому числа должны быть сгруппированы. Таким образом, используя метод, называемый уменьшением размерности, матрица сжимает длинный список слов в группу из 300, а затем помещает ее в 300-мерный вектор. Слова могут быть совершенно разными, но если они попадают в один и тот же вектор, то и значение у них похожее. То же самое делается для заголовков просканированных страниц.
Затем эти семантические векторы используются для поиска совпадений на основе их близости. Каждый запрос и заголовок проверяются, чтобы увидеть, насколько близка проекция размерности заголовка к запросу на карте. Точно так же, как слова выглядят в поисковой системе, векторы тоже.
Чтобы упростить объяснение, давайте предположим, что мы имеем дело с двумерным пространством, поэтому числа рассматриваются как точки на координатной плоскости. Затем заданный запрос и заголовок веб-страницы отображаются на координатной плоскости. Затем можно измерить расстояние между точками запроса и заголовком веб-страницы, чтобы решить, насколько документ релевантен запросу. Чем ближе две точки, тем более релевантен запрос документу.
Затем можно измерить расстояние между точками запроса и заголовком веб-страницы, чтобы решить, насколько документ релевантен запросу. Чем ближе две точки, тем более релевантен запрос документу.
Помещая запрос в семантический вектор с заголовком веб-страницы, поисковая система понимает, что запрос и заголовок веб-страницы имеют смысл, даже если они не имеют похожих слов. Раньше алгоритмы были более ограничены поиском сходства на основе синонимов и понятий. Например, обувь и ботинки или концепция бренда Kayak и настоящего каяка. Однако, как люди, мы знаем, что запросы с длинным хвостом могут не включать слова, совпадающие с похожими словами или понятиями. Используя нейронные сети, поисковая система может найти сходство не только слов, но и значений. Из-за того, что запросы с длинным хвостом обычно требуют результатов, основанных на значении, и для этих редких запросов меньше данных, семантическое отображение заполняет пробел.
Яндекс также включает другие цели для обучения своих нейронных сетей. Эти цели включают предсказание длинных кликов, CTR и модели «кликать или не кликать». Вместо того, чтобы просто использовать одну из своих лучших моделей нейронных сетей, Яндекс включает пять. Сравнивая преимущества включения всех своих моделей, поисковая команда Яндекса отмечает гораздо более точные результаты поиска. Используя все свои предыдущие факторы ранжирования плюс свою лучшую модель нейронной сети, Яндекс добился улучшения на 1% по длинным хвостовым запросам. Применяя все свои предыдущие факторы ранжирования и пять моделей нейронных сетей, это улучшение удваивается и приводит к повышению точности запросов с длинным хвостом на 2%.
Что Яндекс планирует делать с этим в будущем? Яндекс научил свои нейросети видеть заголовки документов, но поисковая команда в настоящее время работает над проверкой текстового содержания. При этом поисковая система Яндекса сможет выдавать еще более точные результаты после более детального изучения того, соответствует ли содержание просканированных страниц заданному запросу. На сегодняшний день другие поисковые системы с аналогичной технологией проверяют только заголовки.
При этом поисковая система Яндекса сможет выдавать еще более точные результаты после более детального изучения того, соответствует ли содержание просканированных страниц заданному запросу. На сегодняшний день другие поисковые системы с аналогичной технологией проверяют только заголовки.
Яндекс также работает над внедрением модели с большим количеством просканированных страниц. В настоящее время модель просматривает сотни документов, которые уже отфильтрованы в топ результатов поиска Яндекса. Поисковая команда Яндекса работает над оптимизацией модели на более ранней стадии поиска, чтобы в конечном итоге она охватила миллиарды документов. Чем больше документов сможет включить Яндекс, тем точнее будут результаты поиска.
Помимо общего повышения точности результатов поиска Яндекса, это в целом поможет Яндексу лучше понимать разговорные запросы в будущем.
Что это означает для SEO? По мере того, как Яндекс совершенствует свою способность обрабатывать диалоговые запросы, остальным SEO-специалистам и онлайн-маркетологам также придется адаптироваться к этому. Как всегда в SEO, несколько факторов ранжирования имеют значение, и трудно сказать, какие из них имеют наибольшее значение. Однако в конечном итоге качественный контент для пользователя всегда был в центре внимания поисковой команды Яндекса. Палех этого не изменит. SEO-специалисты по-прежнему должны учитывать, что нужно пользователю, не сосредотачиваясь на отдельных ключевых словах и не практикуя наполнение ключевыми словами. Пока веб-мастера предоставляют контент, который поможет пользователям Яндекса, машинное обучение Яндекса распознает его.
Как всегда в SEO, несколько факторов ранжирования имеют значение, и трудно сказать, какие из них имеют наибольшее значение. Однако в конечном итоге качественный контент для пользователя всегда был в центре внимания поисковой команды Яндекса. Палех этого не изменит. SEO-специалисты по-прежнему должны учитывать, что нужно пользователю, не сосредотачиваясь на отдельных ключевых словах и не практикуя наполнение ключевыми словами. Пока веб-мастера предоставляют контент, который поможет пользователям Яндекса, машинное обучение Яндекса распознает его.
Пользователи Яндекса могут быть уверены, что передовая технология машинного обучения Яндекса будет предоставлять им все более и более релевантные результаты поиска по мере того, как будет обрабатываться больше данных. Поскольку поисковая команда Яндекса успешно обучила Палеха, пользователи могут рассчитывать на взаимодействие с окном поиска Яндекса с гораздо более сложными запросами.
Теги
AI (11) искусственный интеллект (6) поисковик (5) SEO (451) yandex (26)Управление группами поисковых запросов
Üzgünüz, bu belge Türkçe diline henüz çevrilmedi.
Sayfada belgenin varsayılan dili gösterilmektedir: İngilizce .
24.03.2021 для повышения качества данных мы улучшили фильтрацию запросов роботов в отчетах по поисковым фразам в Яндекс.Вебмастере. Это может привести к значительным корректировкам значений кликов и показов, что не указывает на наличие проблем на сайте. Эти изменения не влияют на результаты поиска.
Управление группами запросов в Яндекс.Вебмастере позволяет:Узнайте, по каким поисковым запросам страницы вашего сайта отображаются в результатах поиска и какие страницы отображаются по этим запросам.
Просмотр сводки статуса сайта в результатах поиска.
Добавьте свои поисковые запросы в Яндекс.Вебмастер.
Отслеживание сводной статистики по поисковым запросам.
Сформируйте группы запросов для получения подробной информации на странице статистики поисковых запросов.
Отображение ссылки на сайт в результатах поиска Яндекса по какому-либо запросу. Возможное наличие ссылки на второй и последующих страницах результатов поиска не считается показом, если пользователь не открывал страницу.
Возможное наличие ссылки на второй и последующих страницах результатов поиска не считается показом, если пользователь не открывал страницу.
Клик пользователя на сайте на странице результатов поиска Яндекса.
\n «}}»>, Позиция сайта — это место на странице результатов поиска Яндекса со ссылкой, ведущей на ваш сайт. В течение дня сайт может занимать разные позиции по одним и тем же поисковым запросам, поэтому Яндекс.Вебмастер показывает среднее значение за весь день.»}}»>, а Отношение количества кликов по сниппету к количеству его показы измеряются в процентах. Этот показатель определяет эффективность сайта'фрагмент страницы.»}}»>. Это средние значения за последние 7 дней, доступные на странице статистики поисковых запросов. Вы можете отслеживать данные по поисковым запросам и по URL-адресам страниц, которые отображаются по этим запросам.- Группы запросов
- Загрузка собственных запросов
- Фильтрация запросов
- FAQ
По умолчанию в Яндекс. Вебмастере доступно несколько групп запросов:
Вебмастере доступно несколько групп запросов:
Все запросы — список поисковых запросов, по которым ваш сайт попал в топ-50 поисковой выдачи Яндекса.
Uploaded — Поисковые запросы, добавленные вручную.
Сохранено — Специальная группа. Позволяет отслеживать данные по определенным запросам (например, отслеживать изменение позиций по ключевым фразам). Информация о запросах из этой группы доступна на странице Статистика поисковых запросов.
Вы можете добавить свои группы запросов, которые вы используете чаще всего.
Примечание. Вы можете добавить до 500 запросов в одну группу (и до 1000 запросов в группу Сохраненные). Для одного сайта можно создать до 100 групп.
Для создания группы необходимо скопировать поисковые запросы из списка всех запросов. Это можно сделать несколькими способами:
- Создать группу при копировании
Выберите группу Все запросы и отметьте нужные запросы.
Внизу страницы нажмите кнопку Копировать выбранные поисковые запросы в группу.
В появившемся окне введите название группы и нажмите кнопку Сохранить. Новая группа отображается в списке групп запросов.
В списке Группа запросов нажмите кнопку создания группы.
В появившемся окне введите название группы и нажмите кнопку Сохранить. Новая группа отображается в списке групп запросов.
Выберите группу Все запросы и отметьте нужные запросы.
Внизу страницы нажмите кнопку Копировать выбранные поисковые запросы в группу.
В появившемся окне выберите название группы из выпадающего списка и нажмите кнопку Сохранить. Запросы отображаются в выбранной группе.
Выберите группу Все запросы и отметьте нужные запросы.
Внизу страницы нажмите кнопку Копировать выбранные поисковые запросы в группу.
Запросы отображаются в группе Сохраненные.

.png) Запросы отображаются в группе Сохраненные.
Запросы отображаются в группе Сохраненные.- Пример группировки по ключевой фразе
- [мобильные телефоны]
- [сенсорные телефоны]
- [интернет-магазин телефонов]
- [купить мобильный телефон]
- [купить Samsung телефон]
- [салон сотовой связи]
Представьте, что вы продвигаете интернет-магазин по продаже телефонов. Вас интересуют запросы о моделях мобильных телефонов, производителях, покупке и характеристиках:
Вы можете отфильтровать эти запросы по слову «телефон», создать группу и посмотреть статистику.
Если вы только что создали новую группу, статистика для этой группы отображаться не будет. Подождите несколько дней, пока данные соберутся.
При необходимости вы можете управлять созданной группой, нажав :
Переименовать.
Удалить.
Если у группы есть фильтр, его можно сохранить для другой группы.
Вы можете добавить запросы, отсутствующие в списке. Вы можете загружать фразы в группу Сохраненные и в группы, созданные вручную.
Вы можете загружать фразы в группу Сохраненные и в группы, созданные вручную.
Примечание. Вы можете загрузить до 10 000 запросов на сайт.
Существует несколько способов загрузки запросов:
В виде текста.
С файлом .txt.
Примечание. Количество запросов (строк) в тексте или в текстовом файле может быть до 500.
После того, как вы загрузили фразы, они отображаются в той группе, в которую вы их добавили. Список фраз будет автоматически отфильтрован по добавленному вручную значению. В этом режиме вы можете удалить добавленный запрос. Чтобы просмотреть все фразы в группе, выберите значение фильтра по фильтру.
Также добавленные запросы отображаются в группе Загруженные.
Запросы можно фильтровать по параметрам (например, количество показов в результатах поиска, количество кликов, текст запроса и т. д.).
Например, отфильтруем запросы по адресу страницы и сформируем список запросов, для которых сниппет страницы — это блок информации о документе, который отображается в результатах поиска. Фрагмент включает заголовок, описание или аннотацию документа, а также может содержать дополнительную информацию о сайте. Узнать больше»}}»> отображается в результатах поиска:
Фрагмент включает заголовок, описание или аннотацию документа, а также может содержать дополнительную информацию о сайте. Узнать больше»}}»> отображается в результатах поиска:
Щелкните ссылку Добавить фильтр.
Выберите фильтр URL-адресов из раскрывающегося списка и выберите значение «Содержит». Введите часть URL в поле (например, /category/).
Нажмите кнопку Фильтр.
По умолчанию в списке отображаются запросы. Чтобы отобразить URL-адреса страниц в списке, щелкните URL-адрес.
Вы можете сохранить указанный фильтр в существующей группе или создать для него новую группу, нажав кнопку Сохранить.
Вы можете применить несколько фильтров для выбора запросов из списка. Фильтры добавляются с помощью оператора «И». Таким образом, каждая фраза в результатах соответствует сразу всем условиям.
Дополнительно в текстовом фильтре Запрос можно указать условия с помощью оператора «ИЛИ», используя символ «|» символ.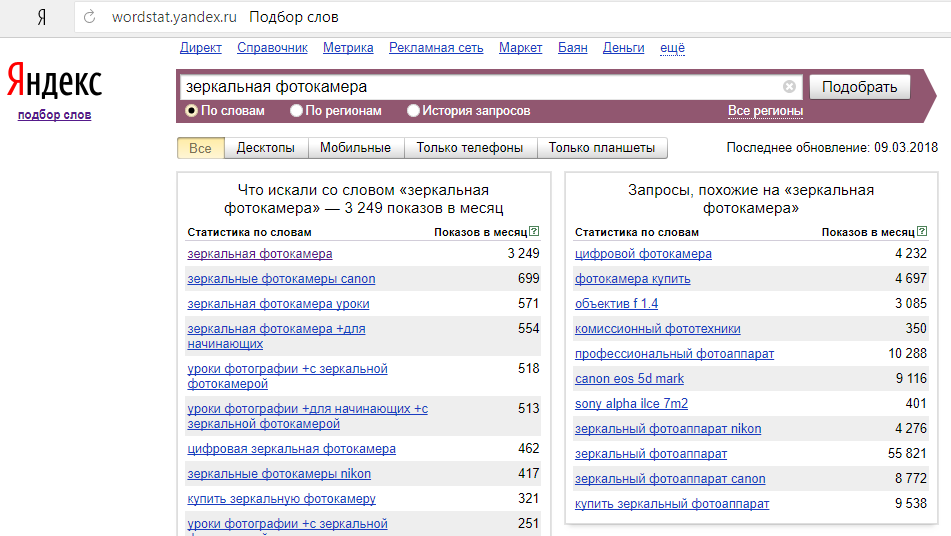 Например, если ввести вебмастер|Яндекс, в результате будут показаны фразы, содержащие хотя бы одно слово, указанное в фильтре.
Например, если ввести вебмастер|Яндекс, в результате будут показаны фразы, содержащие хотя бы одно слово, указанное в фильтре.
- Почему рейтинг сайта резко упал?
Это может быть связано с изменениями в алгоритмах ранжирования: время от времени добавляются новые факторы ранжирования, удаляются устаревшие, меняется вес факторов.
Кроме того, качество сайта влияет на его позиции в результатах поиска. Проверьте сайт на наличие ограничений на странице Диагностика сайта в Яндекс.Вебмастере.
За какой период отображается информация?Позиция на странице Управление группами запросов — это средняя позиция сайта по заданному запросу за последние 7 дней, доступная на странице статистики поисковых запросов.
Чтобы просмотреть информацию о группе запросов за определенный период времени, выберите время и группу запросов на странице Статистика.
Нет данных о поисковых запросах. Почему? На странице отображается информация о запросах, по которым сайт чаще всего попадал в топ-50 позиций в поисковой выдаче.