Роботы Яндекса — «robots.txt» для Яндекса, директива «Host», HTML-тег «noindex», IP-адреса роботов Яндекса — Robots.Txt по-русски
Методы управления поведением робота Яндекса
Читайте в отдельной статье: методы управления поведением робота.
Виды роботов Яндекса
- Yandex/1.01.001 (compatible; Win16; I) — основной индексирующий робот
- Yandex/1.01.001 (compatible; Win16; P) — индексатор картинок
- Yandex/1.01.001 (compatible; Win16; H) — робот, определяющий зеркала сайтов
- Yandex/1.02.000 (compatible; Win16; F) — робот, индексирующий пиктограммы сайтов (favicons)
- Yandex/1.03.003 (compatible; Win16; D) — робот, обращающийся к странице при добавлении ее через форму «Добавить URL»
- Yandex/1.03.000 (compatible; Win16; M) — робот, обращающийся при открытии страницы по ссылке «Найденные слова»
- YaDirectBot/1.0 (compatible; Win16; I) — робот, индексирующий страницы сайтов, участвующих в Рекламной сети Яндекса
- YandexBlog/0.99.101 (compatible; DOS3.30,B) – робот, индексирующий xml-файлы для поиска по блогам.
- YandexSomething/1.0 – робот, индексирующий новостные потоки партнеров Яндекс-Новостей.
- Bond, James Bond (version 0.07) — робот, заходящий на сайты из подсети Яндекса. Официально никогда не упоминался. Ходит выборочно по страницам. Referer не передает. Картинки не загружает. Судя по повадкам, робот занимается проверкой сайтов на нарушения – клоакинг и пр.
IP-адреса роботов Яндекса
IP-адресов, с которых «ходит» робот Яндекса, много, и они могут меняться. Список адресов не разглашается.
Кроме роботов у Яндекса есть несколько агентов-«простукивалок», которые определяют, доступен ли в данный момент сайт или документ, на который стоит ссылка в соответствующем сервисе.
- Yandex/2.01.000 (compatible; Win16; Dyatel; C) — «простукивалка» Яндекс.Каталога. Если сайт недоступен в течение нескольких дней, он снимается с публикации. Как только сайт начинает отвечать, он автоматически появляется в Каталоге.
- Yandex/2.01.000 (compatible; Win16; Dyatel; Z) — «простукивалка» Яндекс.Закладок. Ссылки на недоступные сайты помечаются серым цветом.
- Yandex/2.01.000 (compatible; Win16; Dyatel; D) — «простукивалка» Яндекс.Директа. Она проверяет корректность ссылок из объявлений перед модерацией. Никаких автоматических действий не предпринимается.
- Yandex/2.01.000 (compatible; Win16; Dyatel; N) — «простукивалка» Яндекс.Новостей. Она формирует отчет для контент-менеджера, который оценивает масштаб проблем и, при необходимости, связывается с партнером.
Директива Host
User-agent: Yandex
Disallow: /cgi-bin
Host: www.site.ru
либо
User-agent: Yandex
Disallow: /cgi-bin
Host: site.ru
в зависимости от того что для вас оптимальнее.
Вот цитата из ЧаВо Яндекса:
Мой сайт показывается в результатах поиска не под тем именем. Как это исправить?
Скорее всего, ваш сайт имеет несколько зеркал, и робот выбрал как основное не то зеркало, которое хочется вам. Есть несколько решений:
- удалите зеркала вашего сайта;
- на всех зеркалах, кроме того, которое вы хотите выбрать основным, разместите файл robots.txt, полностью запрещающий индексацию сайта, либо выложите на зеркалах robots.txt с директивой Host;
- разместите на главных страницах неосновных зеркал тег <meta name=»robots» content=»noindex, nofollow»>, запрещающий их индексацию и обход по ссылкам;
- измените код главных страниц на неосновных зеркалах так, чтобы все (или почти все) ссылки с них вглубь сайта были абсолютными и вели на основное зеркало.
В случае реализации одного из вышеперечисленных советов ваше основное зеркало будет автоматически изменено по мере обхода робота.
Интересная информация об обработке директивы Host из ответов А. Садовского на вопросы оптимизаторов:
Вопрос: Когда планируется своевременное соблюдение директивы Host: в robots.txt? Если сайт индексируется как www.site.ru, когда указано Host: site.ru уже после того, как robots.txt был размещен 1–2 недели, то при этом сайт с www и без www не склеивается более 1–2 месяца и в Яндексе существуют одновременно 2 копии частично пересекающихся сайтов (один 550 страниц, другой 150 страниц, при этом 50 страниц одинаковых). Прокомментируйте, пожалуйста, проблемы с работой «зеркальщика».
Ответ: Расширение стандарта robots.txt, введенное Яндексом, директива Host — это не команда считать зеркалами два любых сайта, это указание, какой сайт из группы, определенных автоматически как зеркала, считать главным. Следовательно, когда сайты будут идентифицированы как зеркала, директива Host сработает.
HTML-тег <noindex>
Робот Яндекса поддерживает тег noindex, который запрещает роботу Яндекса индексировать заданные (служебные) участки текста. В начале служебного фрагмента ставится <noindex>, а в конце — </noindex>, и Яндекс не будет индексировать данный участок текста.
Тег работает аналогично мета-тегу noindex, но распространяется только на контент, заключенный внутри тега в формате:
<noindex>текст, индексирование которого нужно запретить</noindex>
Тег noindex не чувствителен к вложенности (может находиться в любом месте html-кода страницы). При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<!––noindex––>текст, индексирование которого нужно запретить<!––/noindex––>
Ссылки по теме
Описание робота Яндекса на сайте Яндекса
Очень интересная запись о роботах на (не)?Путевых заметках
Яндекс и robots.txt – ньюансы
Яндекс накосячил с соблюдением стандарта файла robots.txt
Форма для добавления URL сайта в индекс
Robots.txt глазами Яндекса (Анализ robots.txt)
robotstxt.org.ru
Поисковые роботы Google и Яндекса
Просматривая логи сервера, иногда можно наблюдать чрезмерный интерес к сайтам со стороны поисковых роботов. Если боты полезные (например, индексирующие боты ПС) — остается лишь наблюдать, даже если увеличивается нагрузка на сервер. Но есть еще масса второстепенных роботов, доступ которых к сайту не обязателен. Для себя и для вас, дорогой читатель, я собрал информацию и переделал ее в удобную табличку.
Кто такие поисковые роботы
Поисковый бот, или как еще их называют, робот, краулер, паук — ни что иное, как
Использование имен пауков в robots.txt
Как видим, любой серьезный проект, связанный с поиском контента, имеет своих пауков. И иногда остро стоит задача ограничить доступ некоторым паукам к сайту или его отдельным разделам. Это можно сделать через файл robots.txt в корневой директории сайта. Подробнее про настройку роботса я писал ранее, рекомендую ознакомиться.
Обратите внимание — файл robots.txt и его директивы могут быть проигнорированы поисковыми роботами. Директивы являются лишь рекомендациями для ботов.
Задать директиву для поискового робота можно, используя секцию — обращение к юзер-агенту этого робота. Секции для разных пауков разделяются одной пустой строкой.
User-agent: Googlebot Allow: /
User-agent: Googlebot Allow: / |
Выше приведен пример обращения к основному поисковому роботу Google.
Изначально я планировал добавить в таблицу записи о том, как идентифицируют себя поисковые боты в логах сервера. Но так как для SEO эти данные имеют мало значения и для каждого токена агента может быть несколько видов записей, было решено обойтись только названием ботов и их предназначением.
Поисковые роботы Google
| User-agent | Функции |
|---|---|
| Googlebot | Основной краулер-индексатор страниц для ПК и оптимизированных для смартфонов |
| Mediapartners-Google | Робот рекламной сети AdSense |
| APIs-Google | Агент пользователя APIs-Google |
| AdsBot-Google | Проверяет качество рекламы на веб-страницах, предназначенных для ПК |
| AdsBot-Google-Mobile | Проверяет качество рекламы на веб-страницах, предназначенных для мобильных устройств |
| Googlebot-Image (Googlebot) | Индексирует изображения на страницах сайта |
| Googlebot-News (Googlebot) | Ищет страницы для добавления в Google Новости |
| Googlebot-Video (Googlebot) | Индексирует видеоматериалы |
| AdsBot-Google-Mobile-Apps | Проверяет качество рекламы в приложениях для устройств Android, работает по тем же принципам, что и обычный AdsBot |
Поисковые роботы Яндекс
| User-agent | Функции |
|---|---|
| Yandex | |
| YandexBot | Основной индексирующий робот |
| YandexDirect | Скачивает информацию о контенте сайтов-партнеров РСЯ |
| YandexImages | Индексирует изображения сайтов |
| YandexMetrika | Робот Яндекс.Метрики |
| YandexMobileBot | Скачивает документы для анализа на наличие верстки под мобильные устройства |
| YandexMedia | Робот, индексирующий мультимедийные данные |
| YandexNews | Индексатор Яндекс.Новостей |
| YandexPagechecker | Валидатор микроразметки |
| YandexMarket | Робот Яндекс.Маркета; |
| YandexCalenda | Робот Яндекс.Календаря |
| YandexDirectDyn | Генерирует динамические баннеры (Директ) |
| YaDirectFetcher | Скачивает страницы с рекламными объявлениями для проверки их доступности и уточнения тематики (РСЯ) |
| YandexAccessibilityBot | Cкачивает страницы для проверки их доступности пользователям |
| YandexScreenshotBot | Делает снимок (скриншот) страницы |
| YandexVideoParser | Паук сервиса Яндекс.Видео |
| YandexSearchShop | Скачивает YML-файлы каталогов товаров |
| YandexOntoDBAPI | Робот объектного ответа, скачивающий динамические данные |
Другие популярные поисковые боты
| User-agent | Функции |
|---|---|
| Baiduspider | Спайдер китайского поисковика Baidu |
| Cliqzbot | Робот анонимной поисковой системы Cliqz |
| AhrefsBot | Поисковый бот сервиса Ahrefs (ссылочный анализ) |
| Genieo | Робот сервиса Genieo |
| Bingbot | Краулер поисковой системы Bing |
| Slurp | Краулер поисковой системы Yahoo |
| DuckDuckBot | Веб-краулер ПС DuckDuckGo |
| facebot | Робот Facebook для веб-краулинга |
| WebAlta (WebAlta Crawler/2.0) | Поисковый краулер ПС WebAlta |
| BomboraBot | Сканирует страницы, задействованные в проекте Bombora |
| CCBot | Краулер на основе Nutch, который использует проект Apache Hadoop |
| MSNBot | Бот ПС MSN |
| Mail.Ru | Краулер поисковой системы Mail.Ru |
| ia_archiver | Скраппит данные для сервиса Alexa |
| Teoma | Бот сервиса Ask |
Поисковых ботов очень много, я отобрал только самых популярных и известных. Если есть боты, с которыми вы сталкивались по причине агрессивного и настойчивого сканирования сайтов, прошу в комментариях указать это, я добавлю их также в таблицу.
sky-fi.info
Что такое роботы поисковики Яндекса и Google
Роботы поисковики Google
Основной механизм индексации контента WWW у Google носит название Googlebot. Его механизм настроен так, чтобы ежедневно изучать миллиарды страниц с целью поиска новых или измененных документов. При этом бот сам определяет, какие страницы сканировать, а какие — игнорировать.
Для этого краулера важное значение имеет наличие на сайте файла Sitemap, предоставляемого владельцем ресурса. Сеть компьютеров, обеспечивающая его функционирование настолько мощна, что бот может делать запросы к страницам вашего сайта раз в пару секунд. А настроен бот так, чтобы за один заход проанализировать большее количество страниц, чтобы не вызывать нагрузку на сервер. Если работа сайта замедляется от частых запросов паука, скорость сканирования можно изменить, настроив в Search Console. При этом повысить скорость сканирования, к сожалению, нельзя.
Бота Google можно попросить повторно просканировать сайт. Для этого необходимо открыть Search Console и найти функцию Добавить в индекс, которая доступна пользователям инструмента Просмотреть как Googlebot. После сканирования появится кнопка Добавить в индекс. При этом Google не гарантирует индексацию всех изменений, поскольку процесс связан с работой «сложных алгоритмов».
Боты Google также представляются определенным user-agent. Например, Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) — индексирующий Googlebot. Googlebot-Image/1.0 — Google картинки.
Заблокировать доступ Googlebot к всему сайту или его каталогам можно с помощью все того же файла robots.txt. Например, «прочитав» в файле код
User-agent: googlebot
Disallow: /books/
паук откажется от индексации каталога books. Боты Google полностью подчиняются «Стандарту исключений для роботов».
Чтобы понять, как пауки Google видят ваш сайт (с учетом запретов), рекомендуется воспользоваться инструментом Сканер Google для сайтов. И почувствовать себя ботом.
arazuvaev.ru
Индексация страниц и разделов сайта поисковыми роботами Яндекс
41.4KКоличество ресурсов, проиндексированных поисковыми системами, постоянно растет. Чтобы ресурс мог попасть в базу поисковой системы, поисковику, как минимум, необходимо сообщить о существовании вашего ресурса. Узнать о нем поисковик может двумя способам:
- если вы зарегистрируетесь в поисковой системе;
- либо перейдя на ваши страницы по ссылке с ресурсов, уже проиндексированных системой.
После этого поисковый робот будет время от времени возвращаться на ваши страницы, обновляя информацию о них. Постоянная индексация ресурса – один из важнейших элементов в работе поисковых систем. От того, каким образом и в каких поисковых системах проиндексирован ваш сайт, будет зависеть конечный результат продвижения в той или иной поисковой системе.
Успешная индексация сайта роботами поисковых систем – это то, чего вы должны обязательно добиться на начальном этапе продвижения. О том, какими способами добиться корректной индексации сайта, какие сложности могут возникнуть при подготовительной работе, а также о том, как устроены поисковые системы, роботы которых будут обрабатывать ваши страницы, пойдет речь в данном мастер-классе.
Процесс индексации мы будем рассматривать на примере поисковой системы Яндекс. Это вполне логично, поскольку пользователей, владеющих русским языком, используют именно эту поисковую системы для поиска необходимой информации.
Говоря об индексации, прежде всего, следует рассказать о том, кто ее осуществляет непосредственно, то есть о роботах поисковых систем. На вопрос: “а что такое робот поисковой системы и что он делает?”. Яндекс отвечает следующим образом: «Робот (англ. crawler) хранит список URL, которые он может проиндексировать, и регулярно выкачивает соответствующие им документы. Если при анализе документа робот обнаруживает новую ссылку, он добавляет ее в свой список. Таким образом, любой документ или сайт, на который есть ссылки, может быть найден роботом, а значит, и поиском Яндекса».
Обладая знаниями о них, вы с легкостью сможете подготовить ваш сайт для успешной индексации. Индексация сайта происходит следующим образом: роботы-индексаторы посещают страницы и вносят их содержимое в базу документов, доступных для поиска.
Яндекс появился в 1996 году. Но не в качестве поисковой системы, а в виде нескольких обособленных продуктов. Например, Яndex.Site – программа, производящая поиск на сайте, Яndex.CD – программа поиска документов на сd-диске.
Сама же поисковая система возникла осенью 1997 года. 23 сентября на выставке Softool Яндекс был официально представлен уже в качестве полнофункциональной поисковой системы Интернета. С тех пор объем Рунета непрерывно возрастал, что вынуждало совершенствовать алгоритмы индексирования и поиска информации.
Поэтому в 1999 году был создан новый поисковый робот, который помимо значительного увеличения скорости индексации позволил пользователям искать информацию по разным зонам документа – в URL, в заголовках, в ссылках и т.п.
Сейчас официально анонсировано 11 роботов Яндекса, каждый из которых специализируется на определенной задаче.
- Yandex/1.01.001 (compatible; Win16; I) – основной индексирующий робот Яндекса. Это самый важный робот, функция которого – поиск и индексирование информации, найденной на просторах российского Интернета. Для всех SEO-специалистов важно отслеживать появление на своих сайтах в первую очередь этого робота-индексатора. Обычно робот заходит со следующих ip-адресов: 213.180.206.4, 213.180.206.1, 213.180.216.4, 213.180.206.248, 213.180.216.28. Поэтому, увидев в логах своего сайта заветное слово yandex, обратите свое внимание на ip-адрес, потому как в интернете сейчас существует достаточное большое количество сервисов тестирования сайта, которые позволяют заходить на странички, представляясь как user agent: Yandex/1.01.001 (compatible; Win16; I) Может оказаться, что вовсе и не Яндекс посетил Ваш сайт.
- Yandex/1.01.001 (compatible; Win16; P) — индексатор картинок, которые впоследствии будут доступны в поиске Яндекс. Картинки (http://images.yandex.ru). Для поисковой системы самым простым путем определения, соответствует ли картинка запросу пользователя, является анализ тега alt. Второй путь, который как и первый скорее всего использует сервис Яндекс.Картинки – анализ имени файла. Например, посмотрите на лотосы на странице (http://en.npftravel.ru/news/issue_117.html). Ни одного упоминания слова «лотос» в теле документа, однако картинка все-таки была найдена по запросу «лотос» благодаря тому, что файл имеет имя lotos.jpg.
- Yandex/1.01.001 (compatible; Win16; H) – робот, определяющий зеркала сайтов. Задача этого робота – определение степени схожести двух документов. Если документы очень похожи друг на друга, в результатах выдачи Яндекс, скорее всего, покажет только один сайт, в этом собственно и заключается процесс зазеркаливания. То есть сайт-зеркало представляет собой ничто иное, как полную копию сайта.
- Yandex/1.03.003 (compatible; Win16; D) – робот, определяющий доступность страницы для индексации при добавлении ее через форму «Добавить URL».
- Yandex/1.03.000 (compatible; Win16; M) – робот, посещающий страницу при ее открытии по ссылке «Найденные слова», ниже сниппета.
- YaDirectBot/1.0 (compatible; Win16; I) – робот, индексирующий страницы сайтов, участвующих в рекламной сети Яндекса.
- Yandex/1.02.000 (compatible; Win16; F) – робот, индексирующий иконки сайтов (favicons), которые показываются потом в результатах поиска слева от ссылки на найденный сайт.
Процесс индексации документа роботами поисковых систем, как правило, начинается с добавления сайта в форму на специальной странице. Для Яндекса это страница https://webmaster.yandex.ru/. Здесь требуется ввести лишь адрес сайта, никаких дополнительных данных вносить не требуется. В Рамблере, например, требуется указывать еще название сайта, дать краткое описание регистрируемого сайта и контактное лицо.
Если сайт добавляется впервые, то Яндекс выдаст сообщение:
«Адрес http://example.com успешно добавлен. По мере обхода робота он будет проиндексирован и станет доступным для поиска».
Если сайт уже посещался роботом-индексатором, то появится сообщение:
«Документ http://example.com/ уже проиндексирован и доступен для поиска.
Вы можете посмотреть, какие страницы сайта http://example.com/ доступны в Яндексе к настоящему времени (* страниц)».
После добавления нового сайта через форму, его тут же посетит робот Yandex/1.03.003 (compatible; Win16; D). Он определит доступность сайта для индексирования, а также установит, удовлетворяет ли сайт требованиям Яндекса, основным из которых является «русскоязычность» ресурса. Поэтому, как пример, может возникнуть такая ситуация:
«Адрес http://www.example.com/ не был внесен в базу Яндекса, так как сайт http://www.example.com/ находится вне доменов стран СНГ, при этом наш робот не смог распознать в нем русский текст».
Если же все хорошо, то в логах сайта можно будет обнаружить строку:
213.180.206.223 — [18/Jul/2006:10:22:08 +0400] «GET /robots.txt HTTP/1.1» 404 296 «-» «Yandex/1.03.003 (compatible; Win16; D)»
213.180.206.223 — [18/Jul/2006:10:22:08 +0400] «GET / HTTP/1.1» 200 2674 «-» «Yandex/1.03.003 (compatible; Win16; D)»
Видно, что сначала робот обратился к файлу robots.txt (его в данном случае просто не существует) чтобы определить, не запрещен ли сайт к индексации. Затем уже обратился к главной странице.
После добавления сайта на странице https://webmaster.yandex.ru/ менее чем через два дня сайт посетит робот-индексатор Yandex/1.01.001 (compatible; Win16; I). И еще через некоторое время сайт будет доступен для поиска в Яндексе.
То что Ваш сайт проиндексировался – это еще полдела, гораздо важнее научиться грамотно управлять индексацией. Подумайте, какие бы вы хотели видеть страницы вашего сайта в выдаче поисковых систем: какие из них будут полезны пользователю, а какие из них не несут никакой смысловой нагрузки и используются исключительно как техническая информация, к примеру.
Желательно закрыть от индексации административный раздел сайта, директории /images/ (если она названа таким образом), где хранится графическая информация. Владельцам интернет-маагазинов следует закрыть служебные станицы, например, те страницы сайта, через которые осуществляется непосредственная покупка того или иного продукта и т.д. Приняв данные меры, во-первых, вы будете уверены в том, что роботы проиндексируют именно ту информацию, которая на самом деле важна, во-вторых, облегчите роботу роботам, которые не будут посещать все страницы сайта.
Файл robots.txt является самым популярным инструмент, посредством которого вы сможете эффективно управлять индексацией вашего сайта. Крайне прост в эксплуатации, не требует специальных навыков. По большому счету, нужен только для того, чтобы запрещать индексацию страниц или разделов сайта для той или иной поисковой системы.
Файл /robots.txt предназначен для указания всем поисковым роботам, как индексировать информационные сервера.
Синтаксис файла позволяет задавать запретные области индексирования, как для всех, так и для определённых, роботов.
К файлу robots.txt предъявляются специальные требования, не выполнение которых может привести к неправильному считыванию информации роботом поисковой системы или вообще к недееспособности данного файла.
Основные требования:
- все буквы в названии файла должны быть прописными, т. е. должны иметь нижний регистр: robots.txt – правильно, Robots.txt или ROBOTS.TXT – не правильно;
- файл robots.txt должен создаваться в текстовом формате. При копировании данного файла на сайт, ftp-клиент должен быть настроен на текстовый режим обмена файлами;
- файл robots.txt должен быть размещен в корневом каталоге сайта.
Файл robots.txt обязательно включает в себя две директивы: «User-agent» и «Disallow». Некоторые поисковые системы поддерживают еще и дополнительные записи. Так, например, поисковая система Яндекс использует директиву «Host» для определения основного зеркала сайта.
Каждая запись имеет свое предназначение и может встречаться несколько раз, в зависимости от количества закрываемых от индексации страниц или (и) директорий и количества роботов, к которым Вы обращаетесь.
Полностью пустой файл robots.txt эквивалентен его отсутствию, что предполагает разрешение на индексирование всего сайта.
Директива «User-agent»
Запись «User-agent» должна содержать название поискового робота. Пример записи «User-agent», где обращение происходит ко всем поисковым системам без исключений и используется символ «*»:
Пример записи «User-agent», где обращение происходит только к роботу поисковой системы Яндекс:
Робот каждой поисковой системы имеет своё название. Существует два основных способа узнать эти названия:
- На сайтах многих поисковых систем присутствует специализированный раздел «помощь веб-мастеру» (на Яндексе он тоже есть http://webmaster.yandex.ru/faq.xml), в котором часто указываются названия поисковых роботов.
- При просмотре логов веб-сервера, а именно при просмотре обращений к файлу robots.txt, можно увидеть множество имён, в которых присутствуют названия поисковых систем или их часть. Поэтому Вам остается лишь выбрать нужное имя и вписать его в файл robots.txt.
Названия основных роботов популярных поисковых систем:
Google – «googlebot»;
Яндекса – «Yandex»;
Рамблера – «StackRambler»;
Yahoo! – «Yahoo! Slurp»;
MSN – «msnbot».
Директива «Disallow»
Директива «Disallow» должна содержать предписания, которые указывают поисковому роботу из записи «User-agent», какие файлы или (и) каталоги индексировать запрещено.
Рассмотрим различные примеры записи «Disallow».
Пример1. Сайт полностью открыт для индексирования:
Пример 2. Для индексирования запрещен файл «page.htm», находящийся в корневом каталоге и файл «page2.htm», располагающийся в директории «dir»:
Disallow: /page.htm Disallow: /dir/page2.htm
Пример 3. Для индексирования запрещены директории «cgi-bin» и «forum» и, следовательно, всё содержимое данной директории:
Disallow: /cgi-bin/ Disallow: /forum/
Возможно закрытие от индексации ряда документов и (или) директорий, начинающихся с одних и тех же символов, используя только одну запись «Disallow». Для этого необходимо прописать начальные одинаковые символы без закрывающей наклонной черты.
Пример 4. Для индексирования запрещены директория «dir», а так же все файлы и директории, начинающиеся буквами «dir», т. е. файлы: «dir.htm», «direct.htm», директории: «dir», «directory1», «directory2» и т. д:
Некоторые поисковые системы разрешают использование регулярных выражений в записи «Disallow». Так, например, поисковая система Google поддерживает в записи «Disallow» символы «*» (означает любую последовательность символов) и «$» (окончание строки). Это позволяет запретить индексирование определенного типа файлов.
Пример 5. Запрет индексации файлов с расширением «htm»:
Директива «Host»
Директива «Host» необходима для определения основного зеркала сайта, то есть, если сайт имеет зеркало, то с помощью директивы «Host» можно выбрать url того сайта, под которым проиндексируется ваш сайт. В противном случае поисковая система выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
В целях совместимости с поисковыми роботами, которые при обработке файла robots.txt не воспринимают директиву Host, необходимо добавлять ее непосредственно после записей Disallow.
Пример 6. www.site.ru – основное зеркало:
Оформление комментариев в файле robots.txt
Любая строка в robots.txt, начинающаяся с символа «#», считается комментарием. Разрешено использовать комментарии в конце строк с директивами, но некоторые роботы могут неправильно распознать данную строку.
Пример 7. Комментарий находится на одной строке вместе с директивой:
Disallow: /cgi-bin/ #комментарий
Желательно размещать комментарий на отдельной строке.
С помощью мета-тегов тоже можно управлять индексацией страниц сайта. Мета-теги должны находиться в заголовке HTML-документа (между тегами и ).
Наиболее полезные МЕТА-теги, которые помогут поисковикам правильно индексировать страницы вашего сайта:
- управление индексацией страниц для поисковых роботов. В данном случае, указывает поисковому роботу, чтобы он не индексировал все страницы.
- необходим для поисковых систем, чтобы определить релевантна ли страница данному запросу.
- повышает вероятность нахождения страницы поисковиком по выбранному запросу (ам).
- управление индексацией страницы для поисковых роботов. Определяет частоту индексации. В данном случае указывается, что ваш документ является динамичным и роботу следует индексировать его регулярно.
Есть теги, которые непосредственно к индексации не относятся, но выполняют также важную роль дл удобства работы пользователя с сайтом:
- контроль кэширования для HTTP/1.0. Не позволяет кэшировать страницы.
- определение задержки в секундах, после которой браузер автоматически обновляет документ или происходит редирект.
- указывает, когда информация на документе устареет, и браузер должен будет взять новую копию, а не грузить из кэша.
Есть еще один мета-тег revisit-after, по поводу использования, которого ходило раньше много слухов, что он может заставить роботы поисковых систем посещать сайт с определенной периодичностью, однако специалисты Яндекс официально опровергли это.
Нет гарантии, что поисковые системы учитывают содержимое мета-тегов, индексируя сайт. Тем более нет гарантии, что эта информация будет учитываться при ранжировании сайта в выдаче. Но мета-теги полезны тем, что при индексации страниц позволяют поисковикам получить необходимую информацию о ресурсе.
Для того, чтобы прописать их не нужно много времени, поэтому старайтесь ввести максимально полную мета-информацию о странице.
Работая в сфере поискового продвижения сайтов, приходится сталкиваться с проблемами индексирования сайтов поисковыми системами, временных «выпадений» некоторых страниц сайтов, и, как следствие, потерей позиций по ключевым словам. Происходит это, в подавляющем большинстве случаев, из-за ошибок веб-мастеров.
Ведь далеко не все понимают, что, на первый взгляд, даже незначительная ошибка или упущение может привести к «значительным» последствиям – потере позиций в выдаче поисковых систем. Далее будет рассмотрен список проблем, с которыми Вы можете столкнуться при индексации.
Проблема. Робот поисковой системы получает одну и ту же страницу с разными идентификаторами сессий. Поисковая система «видит» это как разные страницы. Тоже самое происходит и с динамическими страницами.
Описание. На некоторых сайтах существуют динамические страницы с различным порядком параметров, например index.php?id=3&show=for_print и index.php?show=for_print&id=3.
Для пользователей – это одна и та же страница, а для поисковых систем – страницы разные. Также можно привести пример со страницей сайта: «версия для печати» с адресом, например index.htm?do=print и самой главной страницей index.htm. По структуре и текстовому наполнению эти страницы практически одинаковы. Однако для поисковой системы – это разные страницы, которые будут «склеены», и, вместо, например, продвигаемой главной страницы в выдаче поисковика будет страница «для печати».
Схожая проблема возникает при использовании, по умолчанию, ссылок на директорию и на файл в директории, например /root/ и /root/index.htm. Для пользователей она решается использованием директивы «DirectoryIndex /index.htm» файла .htaccess, либо настройками сервера. Поисковые машины же решают данную проблему сами: с течением времени «склеивают» индексную страницу с «корнем» директории.
Один из видов динамических страниц – страницы с идентификаторами сессий. На сайтах, где принято использовать идентификаторы сессий, каждый посетитель при заходе на ресурс получает уникальный параметр &session_id=. Это парамет добавляется к адресу каждой посещаемой страницы сайта. Использование идентификатора сессии обеспечивает более удобный сбор статистики о поведении посетителей сайта. Механизм сессий позволяет сохранять информацию о пользователе при переходе от одной страницы сайта к другой, чего не позволяет делать протокол HTTP. Идентификатор хранится у пользователя в куки или добавляется как параметр в адрес страницы.
Однако, так как роботы поисковых систем не принимают куки, идентификатор сессии добавляется в адрес страницы, при этом робот может найти большое количество копий одной и той же страницы с разными идентификаторами сессий. Проще говоря, для поискового робота страница с новым адресом – это новая страница, при каждом заходе на сайт, робот будет получать новый идентификатор сессии, и, посещая те же самые страницы, что и раньше, будет воспринимать их как новые страницы сайта.
Известно, что поисковые системы имеют алгоритмы «склейки» страниц с одинаковым содержанием, поэтому сайты, использующие идентификаторы сессий, все же будут проиндексированы. Однако индексация таких сайтов затруднена. В некоторых случаях она может пройти некорректно, поэтому использование на сайте идентификаторов сессий не рекомендуется.
Решение. Что касается динамических страниц, то нужно закрывать страницы «версия для печати» и другие дубликаты в файле robots.txt, либо с помощью атрибута мета-тега noindex. Другое решение — заранее создавать функционал сайта, который бы не генерировал динамические страницы с различным порядком параметров.
Что касается идентификаторов сессий, то решение данной проблемы простое — прописать с .htaccess следующие команды:
php_flag session.use_trans_sid Off php_flag session.use_only_cookie On php_flag session.auto_start On
Проблема. Ошибки в обработке 404 статуса сервером, когда вместо 404 кода (страница не существует), сервер отдает код 200 и стандартную страницу ошибки.
Описание. Обрабатывать 404 ошибку можно по-разному, но смысл остается один. Основной и самый простой вариант обработки данной ошибки – создание страницы, например 404.htm и запись в файле .htaccess «ErrorDocument 404 /404.htm». Однако так поступают не все веб-мастера, многие настраивают сервер на выдачу главной страницы сайта при 404 ошибке. Вот здесь-то и спрятан «подводный камень». В случае некорректных настроек сервера, для страницы с ошибкой 404 (т.е. в данном случае отданной главной), сервер возвращает 200 OK. Таким образом, можно получить стопроцентный дубликат главной страницы, вследствие чего робот поисковика может «склеить» ее с любой другой страницей сайта.
Решение. Выход из данной проблемы таков: грамотная настройка сервера и обработка 404 кода через файл .htaccess путем создания отдельной страницы под обработку ошибки.
Проблема. Размещение материалов сайта на других сайтах, а, как следствие, – «склеивание» и потеря позиций.
Описание. Описание данной проблемы заключено в ее названии, и в современном Интернете всем хорошо известно, что плагиат – это «воровство» контента и «присваивание» авторских прав, а, с точки зрения поисковой оптимизации, – это еще и проблемы с индексацией сайта в виде появления дублей его страниц.
Решение. Решение проблемы здесь одно – письмо с жалобой о нарушении авторских прав, хостеру сайта-плагиатора, предварительно предупредив, конечно, виновного в том, что он поступает незаконно.
Неиндексация некоторых элементов страницы может быть вызвана несколькими причинами:
- Текст заключен в тег . Это специальный тег, запрещающий индексацию текста роботу Яндекса.
- Текст расположен в скрипте, т.е между тегами
- Текст расположен в комментариях
- Очень маленький размер страницы (Яндекс не индексирует файлы меньше 1 кб)
- Ресурс не содержит русский текст (опять же, это касательно Яндекса)
Каждому, кто ведет в Интернете серьезный проект, необходимо понимать, как роботы поисковых систем. Знание о том, когда робот приходит на сайт, что индексирует, что не индексирует, позволит избежать многих проблем, прежде всего технических, уже на стадии создания сайта и далее – при его сопровождении.
Чтобы не задаваться вопросом, почему в очередной раз сайт пропал из выдачи по некоторому запросу, прежде всего, стоит проанализировать, а что же на данный момент проиндексировал робот на сайте? Не могло оказаться так, что некоторая информация стала недоступна роботу по тем или иным причинам?
Знание основ индексирования документа позволит правильно произвести регистрацию ресурса в поисковой системе и грамотно осуществлять его дальнейшее продвижение, чтобы пользователи всегда находили Ваш сайт на просторах Интернета.
www.internet-technologies.ru
| Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) — основной индексирующий робот. |
| Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4 (compatible; YandexBot/3.0; +http://yandex.com/bots) — индексирующий робот. |
| Mozilla/5.0 (compatible; YandexAccessibilityBot/3.0; +http://yandex.com/bots) — скачивает страницы для проверки их доступности пользователям, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4 (compatible; YandexMobileBot/3.0; +http://yandex.com/bots) — робот, определяющий страницы с версткой, подходящей под мобильные устройства, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (compatible; YandexDirectDyn/1.0; +http://yandex.com/bots — робот генерации динамических баннеров, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36 (compatible; YandexScreenshotBot/3.0; +http://yandex.com/bots) — робот, делающий снимок страницы, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots) — индексатор Яндекс.Картинок. |
| Mozilla/5.0 (compatible; YandexVideo/3.0; +http://yandex.com/bots) — индексатор Яндекс.Видео. |
| ozilla/5.0 (compatible; YandexVideoParser/1.0; +http://yandex.com/bots) — индексатор Яндекс.Видео, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (compatible; YandexMedia/3.0; +http://yandex.com/bots) — робот, индексирующий мультимедийные данные. |
| Mozilla/5.0 (compatible; YandexBlogs/0.99; robot; +http://yandex.com/bots) — робот поиска по блогам, индексирующий комментарии постов. |
| Mozilla/5.0 (compatible; YandexFavicons/1.0; +http://yandex.com/bots)— робот, индексирующий пиктограммы сайтов (favicons). |
| Mozilla/5.0 (compatible; YandexWebmaster/2.0; +http://yandex.com/bots)— робот сервиса Яндекс.Вебмастер. |
| Mozilla/5.0 (compatible; YandexPagechecker/1.0; +http://yandex.com/bots)— робот, обращающийся к странице при валидации микроразметки через форму Валидатор микроразметки. |
| Mozilla/5.0 (compatible; YandexImageResizer/2.0; +http://yandex.com/bots) — робот мобильных сервисов. |
| Mozilla/5.0 (compatible; YandexAdNet/1.0; +http://yandex.com/bots) — робот Рекламной сети Яндекса. |
| Mozilla/5.0 (compatible; YandexDirect/3.0; +http://yandex.com/bots) — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (compatible; YaDirectFetcher/1.0; Dyatel; +http://yandex.com/bots) — скачивает целевые страницы рекламных объявлений для проверки их доступности и уточнения тематики. Это необходимо для размещения объявлений в поисковой выдаче и на сайтах-партнерах. При обходе сайта робот не использует файл robots.txt, поэтому игнорирует директивы, установленные для него. |
| Mozilla/5.0 (compatible; YandexCalendar/1.0; +http://yandex.com/bots) — робот Яндекс.Календаря, используется для синхронизации с другими календарями, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (compatible; YandexSitelinks; Dyatel; +http://yandex.com/bots) — «простукивалка» быстрых ссылок, используется для проверки доступности страниц, определившихся в качестве быстрых ссылок. |
| Mozilla/5.0 (compatible; YandexMetrika/2.0; +http://yandex.com/bots) — робот Яндекс.Метрики, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (compatible; YandexNews/4.0; +http://yandex.com/bots) — робот Яндекс.Новостей; |
| Mozilla/5.0 (compatible; YandexNewslinks; +http://yandex.com/bots) — «простукивалка» Яндекс.Новостей, используется для проверки ссылок из новостных материалов. |
| Mozilla/5.0 (compatible; YandexCatalog/3.0; +http://yandex.com/bots) — «простукивалка» Яндекс.Каталога, используется для временного снятия с публикации недоступных сайтов в Каталоге. |
| Mozilla/5.0 (compatible; YandexAntivirus/2.0; +http://yandex.com/bots) — антивирусный робот, который проверяет страницы на наличие опасного кода. |
| Mozilla/5.0 (compatible; YandexMarket/1.0; +http://yandex.com/bots) — робот Яндекс.Маркета. |
| Mozilla/5.0 (compatible; YandexVertis/3.0; +http://yandex.com/bots) — робот поисковых вертикалей. |
| Mozilla/5.0 (compatible; YandexForDomain/1.0; +http://yandex.com/bots) — Робот почты для домена, используется при проверке прав на владение доменом. |
| Mozilla/5.0 (compatible; YandexBot/3.0; MirrorDetector; +http://yandex.com/bots) — робот, определяющий зеркала сайтов; |
| Mozilla/5.0 (compatible; YandexSpravBot/1.0; +http://yandex.com/bots) — робот Яндекс.Справочника. |
| Mozilla/5.0 (compatible; YandexSearchShop/1.0; +http://yandex.com/bots) — робот, который регулярно скачивает YML-файлы каталогов товаров (по инициативе пользователей), которые часто располагаются в запрещенных для индексации каталогах.Особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36 (compatible; YandexMedianaBot/1.0; +http://yandex.com/bots) — робот сервиса Яндекс.Медиана, особым образом интерпретирует robots.txt. |
| Mozilla/5.0 (compatible; YandexOntoDB/1.0; +http://yandex.com/bots) — робот объектного ответа. |
| Mozilla/5.0 (compatible; YandexOntoDBAPI/1.0; +http://yandex.com/bots) — робот объектного ответа, скачивающий динамические данные, особым образом интерпретирует robots.txt. |
info-effect.ru
Robots.txt — Как создать правильный robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
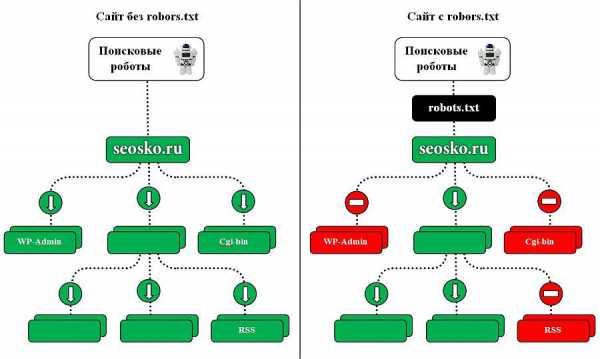
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
Для конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: *
Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
seogio.ru
Поисковые роботы Яндекс и Google
Москва г. Москва, ул. Нобеля 7, п. 56 +7 (800) 700-59-30

Поисковым роботом называется специальная программа какой-либо поисковой системы, которая предназначена для занесения в базу (индексирования) найденных в Интернете сайтов и их страниц. Также используются названия: краулер, паук, бот, automaticindexer, ant, webcrawler, bot, webscutter, webrobots, webspider.
Принцип работы
Поисковый робот — это программа браузерного типа. Он постоянно сканирует сеть: посещает проиндексированные (уже известные ему) сайты, переходит по ссылкам с них и находит новые ресурсы. При обнаружении нового ресурса робот процедур добавляет его в индекс поисковика. Поисковый робот также индексирует обновления на сайтах, периодичность которых фиксируется. Например, обновляемый раз в неделю сайт будет посещаться пауком с этой частотой, а контент на новостных сайтах может попасть в индекс уже через несколько минут после публикации. Если на сайт не ведет ни одна ссылка с других ресурсов, то для привлечения поисковых роботов ресурс необходимо добавить через специальную форму (Центр вебмастеров Google, панель вебмастера Яндекс и т.д.).
Виды поисковых роботов
Пауки Яндекса:
- Yandex/1.01.001 I — основной бот, занимающийся индексацией,
- Yandex/1.01.001 (P) — индексирует картинки,
- Yandex/1.01.001 (H) — находит зеркала сайтов,
- Yandex/1.03.003 (D) — определяет, соответствует ли страница, добавленная из панели вебмастера, параметрам индексации,
- YaDirectBot/1.0 (I) — индексирует ресурсы из рекламной сети Яндекса,
- Yandex/1.02.000 (F) — индексирует фавиконы сайтов.
Пауки Google:
- Робот Googlebot — основной робот,
- Googlebot News — сканирует и индексирует новости,
- Google Mobile — индексирует сайты для мобильных устройств,
- Googlebot Images — ищет и индексирует изображения,
- Googlebot Video — индексирует видео,
- Google AdsBot — проверяет качество целевой страницы,
- Google Mobile AdSense и Google AdSense — индексирует сайты рекламной сети Google.
Другие поисковики также используют роботов нескольких видов, функционально схожих с перечисленными.
wiki.rookee.ru