MySQL. Просмотр запросов в реальном времени
Дата 30.05.2021 Автор Alex Рубрика Сервер
В Linux существует команда «watch», которая позволяет запускать команды, стоящие после неё с определённым интервалом. Так можно почти в реальном времени отследить значения в выводе. К сожалению, иногда её неудобно или невозможно использовать для просмотра запросов MySQL. Но это ещё можно делать через mysqladmin.
Для просмотра всех исполняемых запросов из очереди в MySQL можно выполнить команду:
SELECT * FROM information_schema.processlist;
Но запросы часто выполняются намного быстрее секунды. Поэтому придётся запускать команду раз десять, чтобы поймать хотя бы один запрос, который находится в процессе выполнения. И чтобы не молотить пальцами по клавиатуре, можно воспользоваться утилитой «mysqladmin», запустив её с параметром «processlist» и некоторыми другими:
mysqladmin -h ip_адрес -P порт -u польз.
—verbose -p -i 1 processlist

Разберём все ключи mysqladmin в этой команде:
- -h — задаёт адрес сервера (хоста) с базой данных. По умолчанию «localhost».
- -P — указывает порт сервера, который прослушивается базой данных. По умолчанию «3306».
- -u — содержит имя пользователя базы данных, от имени которого надо выполнять запросы. По умолчанию «root».
- -p — заставляет mysqladmin запоминать введённый пароль, чтобы не переспрашивал. Можно не использовать, если пароль указан в файле «.my.conf», в домашней папке пользователя.
- -i
- —verbose — выводит полную информацию о запросе. Иначе SQL строка запроса будет обрезаться, чтобы таблица вошла в терминал по ширине.
При запуске этой команды в терминале будет каждую секунду появляться таблица, из которой можно узнать информацию о каждом запросе в очереди:
- id запроса
- Имя пользователя
- Имя базы данных
- Хост (ip адрес)
- Тип команды
- Время исполнения
- SQL строку запроса
- Размер ответа
Чтобы завершить повисший запрос можно воспользоваться командой kill, которой передаётся id запроса (который узнаётся из первого столбца таблицы «processlist»):
mysqladmin -h ip_адрес -P порт -u польз.
kill id_запроса
 kill id_запроса
kill id_запросаМетки: MySQL
Оптимизация запросов MySQL профилированием на примере
Существует два подхода к профилированию запросов, соответствующие двум вопросам, упомянутым в этой статье. Можно профилировать весь сервер, основываясь на том, какие запросы в наибольшей степени его загружают. (Если вы начали с верхнего уровня, с профилирования на уровне приложений, то, возможно, уже знаете, какие запросы требуют внимания.) Затем, как только настроите конкретные запросы для оптимизации, можете углубиться в их профилирование по отдельности, определяя, какие подзадачи значительнее увеличивают их время отклика.
Профилирование рабочей нагрузки сервера MySQL
Подход к профилированию на уровне сервера очень полезен, потому что он может помочь вам проверить сервер на предмет неэффективных запросов.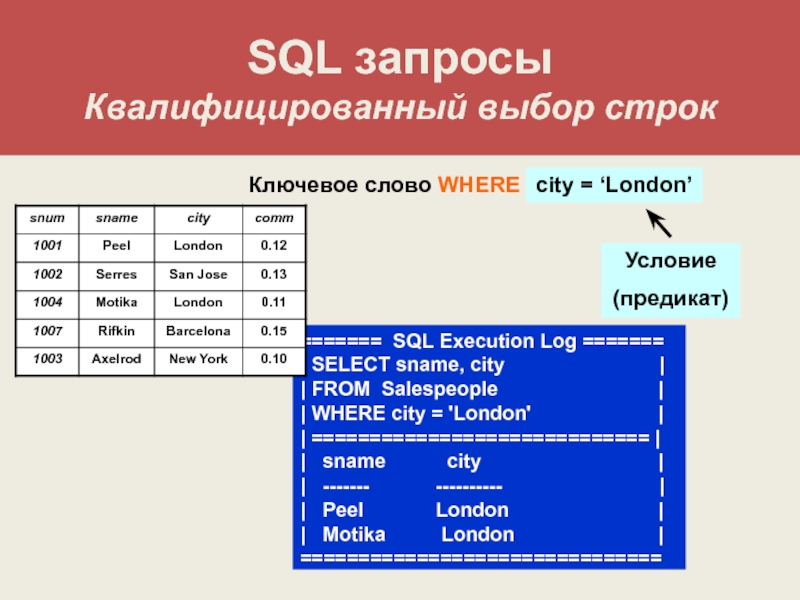 Обнаружение и исправление этих запросов позволит улучшить производительность приложения в целом, а также выявить конкретные проблемы. Вы можете снизить общую нагрузку на сервер, тем самым уменьшится конкуренция за совместно используемые ресурсы и увеличится скорость выполнения всех запросов (побочный эффект). Снижение нагрузки на сервер способно помочь вам отложить обновления и другие затратные мероприятия или избежать их, кроме того, вы можете обнаружить и устранить проблемы, связанные с результатами, неприемлемыми для пользователя, такими как выбросы (аномальные результаты измерений).
Обнаружение и исправление этих запросов позволит улучшить производительность приложения в целом, а также выявить конкретные проблемы. Вы можете снизить общую нагрузку на сервер, тем самым уменьшится конкуренция за совместно используемые ресурсы и увеличится скорость выполнения всех запросов (побочный эффект). Снижение нагрузки на сервер способно помочь вам отложить обновления и другие затратные мероприятия или избежать их, кроме того, вы можете обнаружить и устранить проблемы, связанные с результатами, неприемлемыми для пользователя, такими как выбросы (аномальные результаты измерений).
С каждой следующей версией в MySQL появляется все больше инструментов, и если такая тенденция сохранится, скоро в MySQL будут великолепные инструменты для измерения наиболее важных аспектов ее производительности. Но что касается профилирования запросов и поиска самых затратных из них, нам не нужна вся эта сложность. Необходимый инструмент существует уже довольно давно. Это так называемый журнал медленных запросов.
Фиксация запросов MySQL в журнал
В MySQL журнал медленных запросов изначально предназначался для фиксации только медленных запросов, но для целей профилирования необходима регистрация всех запросов. При этом нам требуется более тонкая детализация времени отклика, чем в MySQL 5.0 и ранних версиях. В этих версиях минимальный временной интервал равнялся 1 секунде. К счастью, прежние ограничения уже неактуальны.
В MySQL 5.1 и более поздних версиях журнал медленных запросов расширен так, что переменную сервера long_query_time можно установить равной нулю, зафиксировав все запросы, а время отклика на запрос детализировано с дискретностью 1 микросекунда. Если вы используете Percona Server, этот функционал доступен уже в версии 5.0, кроме того, Percona Server дает намного больший контроль над содержимым журнала и фиксацией запросов.
В существующих версиях MySQL у журнала медленных запросов наименьшие издержки и наибольшая точность измерения времени выполнения запроса. Если вас беспокоит дополнительный ввод/вывод, вызываемый этим журналом, то не тревожьтесь. Мы провели эталонное тестирование и выяснили, что при нагрузках, связанных с вводом/выводом, издержки незначительны. (На самом деле это лучше видно в ходе работ, нагружающих процессор.) Более актуальной проблемой является заполнение диска. Убедитесь, что вы установили смену журнала для журнала медленных запросов, если он включен постоянно. Либо оставьте его выключенным и включайте только на определенное время для получения образца рабочей нагрузки.
Если вас беспокоит дополнительный ввод/вывод, вызываемый этим журналом, то не тревожьтесь. Мы провели эталонное тестирование и выяснили, что при нагрузках, связанных с вводом/выводом, издержки незначительны. (На самом деле это лучше видно в ходе работ, нагружающих процессор.) Более актуальной проблемой является заполнение диска. Убедитесь, что вы установили смену журнала для журнала медленных запросов, если он включен постоянно. Либо оставьте его выключенным и включайте только на определенное время для получения образца рабочей нагрузки.
У MySQL есть и другой тип журнала запросов — общий журнал, но он не так полезен для анализа и профилирования сервера. Запросы регистрируются по мере их поступления на сервер, поэтому журнал не содержит информации о времени отклика или о плане выполнения запроса. MySQL 5.1 и более поздние версии поддерживают также ведение журнала запросов к таблицам, однако это не самая удачная идея. Данный журнал сильно влияет на производительность: хотя MySQL 5. 1 в журнале медленных запросов отмечает время запросов с точностью до 1 микросекунды, медленные запросы к таблице регистрируются с точностью до 1 секунды. Это не очень полезно.
1 в журнале медленных запросов отмечает время запросов с точностью до 1 микросекунды, медленные запросы к таблице регистрируются с точностью до 1 секунды. Это не очень полезно.
Percona Server регистрирует в журнале медленных запросов значительно более подробную информацию, чем MySQL. Здесь отмечается полезная информация о плане выполнения запроса, блокировке, операциях ввода/вывода и многом другом. Эти дополнительные биты данных добавлялись медленно, поскольку мы столкнулись с различными сценариями оптимизации, которые требовали более подробных сведений о том, как запросы выполняются и где происходят затраты времени. Мы также упростили администрирование. Например, добавили возможность глобально контролировать порог long_query_time для каждого соединения, поэтому вы можете заставить их запускать или останавливать журналирование своих запросов, когда приложение использует пул соединений или постоянные соединения, но не можете сбросить переменные уровня сеанса.
В целом это легкий и полнофункциональный способ профилирования сервера и оптимизации его запросов.
Допустим, вы не хотите регистрировать запросы на сервере или по какой-то причине не можете делать этого, например не имеете доступа к серверу. Мы сталкивались с такими ограничениями, поэтому разработали две альтернативные методики и добавили их в инструмент pt-query-digest пакета Percona Toolkit. Первая методика подразумевает постоянное отслеживание состояния с помощью команды SHOW FULL PROCESSLIST с параметром —processlist. При этом отмечается, когда запросы появляются и исчезают. В некоторых случаях этот метод довольно точен, но он не может зафиксировать все запросы. Очень короткие запросы могут проскочить и завершиться, прежде чем инструмент их заметит.
Второй метод состоит в фиксировании сетевого трафика TCP и его проверки, а затем декодирования протокола «клиент/сервер MySQL» (MySQL client/server protocol). Вы можете использовать утилиту tcpdump для записи трафика на диск, а затем — pt-query-digest с параметром --type=tpcdump для декодирования и анализа запросов. Это гораздо более точная методика, которая зафиксирует все запросы. Методика работает даже с расширенными протоколами, такими как бинарный протокол, используемый для создания и выполнения подготовленных операторов на стороне сервера, и сжатый протокол. Можно также использовать MySQL Proxy со скриптом журналирования, но в практике это нам редко встречалось.
Это гораздо более точная методика, которая зафиксирует все запросы. Методика работает даже с расширенными протоколами, такими как бинарный протокол, используемый для создания и выполнения подготовленных операторов на стороне сервера, и сжатый протокол. Можно также использовать MySQL Proxy со скриптом журналирования, но в практике это нам редко встречалось.
Анализ журнала запросов
Мы рекомендуем по крайней мере время от времени фиксировать в журнале медленных запросов все запросы, выполняемые на сервере, и анализировать их. Запишите запросы, сделанные в течение репрезентативного периода времени, например за час пикового трафика. Если рабочая нагрузка однородна, достаточно будет минуты или даже меньше для нахождения плохих запросов, которые следует оптимизировать.
Не стоит просто открывать журнал и смотреть в него — это пустая трата времени и денег. Сначала создайте профиль и, если это необходимо, просмотрите конкретные выборки в журнале. Лучше всего начинать с верхнего уровня и двигаться вниз, в противном случае, как упоминалось ранее, вы можете деоптимизировать процесс.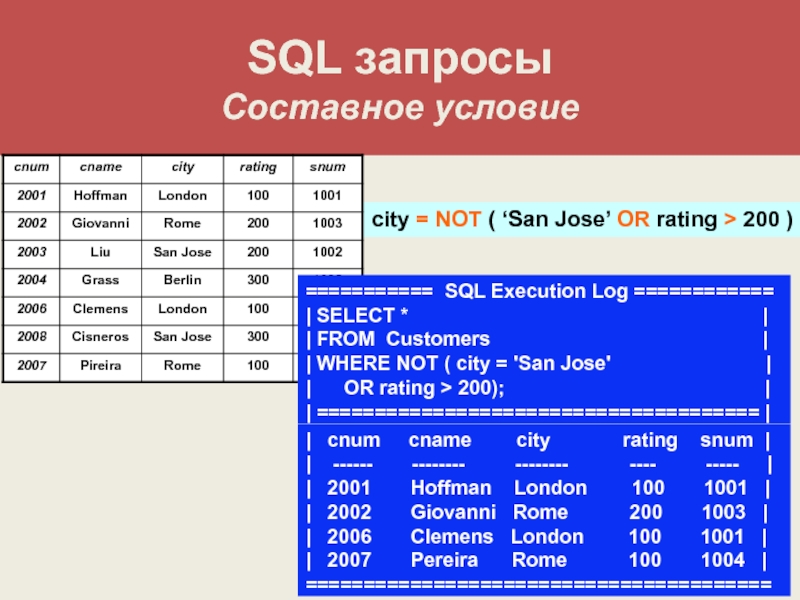
Для создания профиля из журнала медленных запросов требуется хороший инструмент анализа журналов. Мы предлагаем утилиту pt-query-digest
По умолчанию вы просто выполняете утилиту, передаете ей файл журнала медленных запросов в качестве аргумента, и она сама выполняет нужные действия. Утилита выводит профиль запросов в журнале, а затем выбирает важные классы запросов и выдает подробный отчет по каждому из них. В отчете есть десятки мелочей, облегчающих вашу жизнь. Мы продолжаем активно развивать этот инструмент, поэтому лучше прочитать документацию для последней версии, чтобы узнать о ее функциональности.
Приведем краткий обзор отчета
# Profile # Rank Query ID Response time Calls R/Call V/M Item # ==== ================== ================ ===== ====== ===== ======= # 1 0xBFCF8E3F293F6466 11256.
 3618 68.1% 78069 0.1442 0.21 SELECT InvitesNew?
# 2 0x620B8CAB2B1C76EC 2029.4730 12.3% 14415 0.1408 0.21 SELECT StatusUpdate?
# 3 0xB90978440CC11CC7 1345.3445 8.1% 3520 0.3822 0.00 SHOW STATUS
# 4 0xCB73D6B5B031B4CF 1341.6432 8.1% 3509 0.3823 0.00 SHOW STATUS
# MISC 0xMISC 560.7556 3.4% 23930 0.0234 0.0 <17 ITEMS>
3618 68.1% 78069 0.1442 0.21 SELECT InvitesNew?
# 2 0x620B8CAB2B1C76EC 2029.4730 12.3% 14415 0.1408 0.21 SELECT StatusUpdate?
# 3 0xB90978440CC11CC7 1345.3445 8.1% 3520 0.3822 0.00 SHOW STATUS
# 4 0xCB73D6B5B031B4CF 1341.6432 8.1% 3509 0.3823 0.00 SHOW STATUS
# MISC 0xMISC 560.7556 3.4% 23930 0.0234 0.0 <17 ITEMS>Здесь показано чуть больше деталей, чем раньше. Во-первых, каждый запрос имеет идентификатор, который является хеш-подписью его цифрового отпечатка. Цифровой отпечаток — это нормализованная каноническая версия запроса с удаленными литералами и пробелами, переведенная в нижний регистр (обратите внимание, что запросы 3 и 4 кажутся одинаковыми, но у них разные отпечатки). Инструмент также объединяет таблицы с похожими именами в каноническую форму. Вопросительный знак в конце имени таблицы invitesNew означает, что к имени таблицы был добавлен идентификатор сегмента данных (шарда), а инструмент удалил его, так что запросы к таблицам, сделанные с похожими целями, объединены вместе.
Еще один появившийся здесь столбец — отношение рассеяния к среднему значению V/M. Этот показатель называется индексом рассеяния. У запросов с более высоким индексом рассеяния сильнее колеблется время выполнения, и они, как правило, являются хорошими кандидатами на оптимизацию. Если вы укажете параметр --explain в утилите pt-query-digest, то к таблице будет добавлен столбец с кратким описанием плана запроса
Наконец, в нижней части есть дополнительная строка, показывающая наличие 17 других типов запросов, которые инструмент не счел достаточно важными для отдельной строки, и сводная статистика по ним. При задании параметров --limit и --outliers инструмент не будет сворачивать несущественные запросы в одну финальную строку. _ |
# Time range: 2008-09-13 21:51:55 to 22:45:30
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 63 78069
# Exec time 68 11256s 37us 1s 144ms 501ms 175ms 68ms
# Lock time 85 134s 0 650ms 2ms 176us 20ms 57us
# Rows sent 8 70.18k 0 1 0.92 0.99 0.27 0.99
# Rows examine 8 70.84k 0 3 0.93 0.99 0.28 0.99
# Query size 84 10.43M 135 141 140.13 136.99 0.10 136.99
# String:
# Databases production
# Hosts
# Users fbappuser
# Query_time distribution
# 1us
# 10us #
# 100us ####################################################
# 1ms ###
# 10ms ################
# 100ms ################################################################
# 1s #
# 10s+
# Tables
# SHOW TABLE STATUS FROM `production ` LIKE’InvitesNew82’\G
# SHOW CREATE TABLE `production `.
_ |
# Time range: 2008-09-13 21:51:55 to 22:45:30
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 63 78069
# Exec time 68 11256s 37us 1s 144ms 501ms 175ms 68ms
# Lock time 85 134s 0 650ms 2ms 176us 20ms 57us
# Rows sent 8 70.18k 0 1 0.92 0.99 0.27 0.99
# Rows examine 8 70.84k 0 3 0.93 0.99 0.28 0.99
# Query size 84 10.43M 135 141 140.13 136.99 0.10 136.99
# String:
# Databases production
# Hosts
# Users fbappuser
# Query_time distribution
# 1us
# 10us #
# 100us ####################################################
# 1ms ###
# 10ms ################
# 100ms ################################################################
# 1s #
# 10s+
# Tables
# SHOW TABLE STATUS FROM `production ` LIKE’InvitesNew82’\G
# SHOW CREATE TABLE `production `.
Вверху отчета содержится множество метаданных, в том числе: как часто выполняется запрос, его средняя конкурентность и смещение (в байтах) до того места, где в файле журнала находится запрос с наихудшей производительностью. Существует табличная распечатка числовых метаданных, включая статистику, такую как, например.стандартное отклонение.
Затем представлена гистограмма времени отклика. Любопытно, что, как вы видите под строкой Query_time distribution, у гистограммы этого запроса два пика. Обычно запрос выполняется за сотни миллисекунд, но есть также значительный всплеск числа запросов, которые были выполнены на три порядка быстрее. Если бы этот журнал был создан в пакете Percona Server, в журнале запросов был бы более богатый набор параметров. Как следствие, мы могли бы проанализировать запросы вдоль и поперек, чтобы понять, почему это происходит.
Наконец, раздел деталей отчета заканчивается небольшими вспомогательными фрагментами для облегчения копирования и вставки команд в командную строку, а также проверки схемы и статуса упомянутых таблиц и включает образец запроса EXPLAIN. Образец содержит все литералы, а не «отпечатки пальцев», поэтому это реальный запрос. На самом деле это экземпляр запроса, у которого было худшее время выполнения в нашем примере.
После выбора запросов, которые вы хотите оптимизировать, можете использовать этот отчет, чтобы быстро проверить выполнение запроса. Мы постоянно пользуемся этим инструментом, и потратили много времени на то, чтобы сделать его максимально эффективным и полезным. Настоятельно рекомендуем подружиться с ним. Возможно, в скором времени MySQL будет лучше оснащена встроенными инструментами профилирования, но на момент написания этой статьи нет инструментов лучше, чем журналирование запросов с помощью журнала медленных запросов или использование
Настоятельно рекомендуем подружиться с ним. Возможно, в скором времени MySQL будет лучше оснащена встроенными инструментами профилирования, но на момент написания этой статьи нет инструментов лучше, чем журналирование запросов с помощью журнала медленных запросов или использование tcpdump и запуск полученного журнала с помощью утилиты pt-query-digest.
Профилирование отдельных запросов
После того как вы определили запрос для оптимизации, можете углубиться в него и определить, почему он требует столько времени и как его оптимизировать. Современные методики оптимизации запросов будут описаны в последующих моих блогах вместе с необходимыми для их использования предварительными сведениями. Сейчас наша цель — просто показать, как измерить то, что делает запрос, и сколько времени требует каждый этап. Эти знания помогут вам определить, какие методики оптимизации использовать.
К сожалению, большинство инструментов в MySQL не очень полезны для профилирования запросов.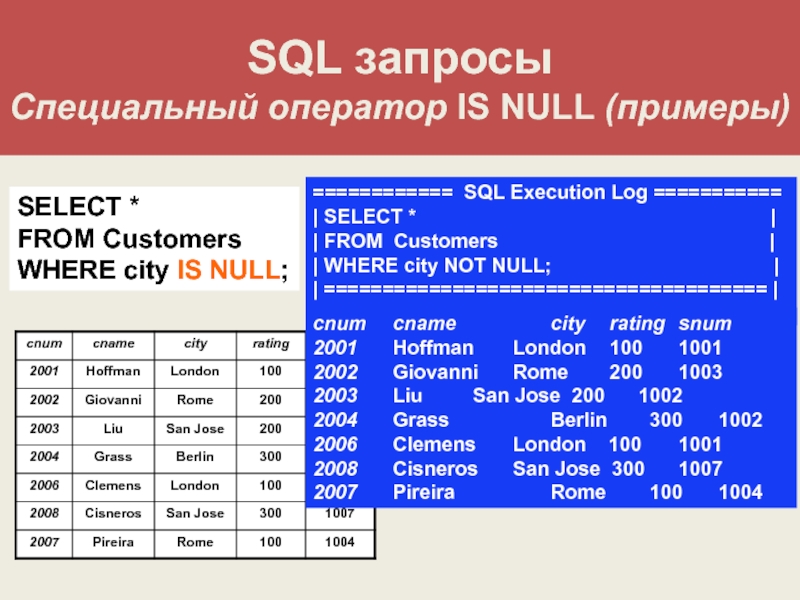 Ситуация меняется, но на момент написания этого блога большинство производственных серверов не поддерживают новейших функций профилирования. Поэтому при их использовании в практических целях мы сильно ограничены командами
Ситуация меняется, но на момент написания этого блога большинство производственных серверов не поддерживают новейших функций профилирования. Поэтому при их использовании в практических целях мы сильно ограничены командами SHOW STATUS, SHOW PROFILE и изучением отдельных записей в журнале медленных запросов (если у вас есть Percona Server — в стандартной системе MySQL в журнале нет дополнительной информации). Мы продемонстрируем все три метода на примере одного и того же запроса и покажем, что вы можете узнать о его выполнении в каждом случае.
Команда SHOW PROFILE
Команда SHOW PROFILE появилась благодаря Джереми Коулу (Jeremy Cole). Она включена в MySQL 5.1 и более поздние версии. Это единственный реальный инструмент профилирования запросов, доступный в GA-релизе MySQL на момент написания блога. Профилирование по умолчанию отключено, но его можно включить во время сеанса, установив значение переменной сервера:
mysql> SET profiling = 1;После этого всякий раз, когда вы посылаете выражение на сервер, он будет замерять прошедшее время и еще некоторые данные, когда запрос будет переходить из одного состояния выполнения в другое. Эта команда имеет довольно широкий функционал и была спроектирована так, что может иметь еще больше, но в следующих релизах она, по всей видимости, будет заменена или вытеснена Performance Schema. Несмотря на это, наиболее полезной функцией данной команды является создание профиля работы, выполняемой сервером во время реализации выражения.
Эта команда имеет довольно широкий функционал и была спроектирована так, что может иметь еще больше, но в следующих релизах она, по всей видимости, будет заменена или вытеснена Performance Schema. Несмотря на это, наиболее полезной функцией данной команды является создание профиля работы, выполняемой сервером во время реализации выражения.
Каждый раз, когда вы отправляете запрос на сервер, он записывает информацию профилирования во временную таблицу и присваивает выражению целочисленный идентификатор, начиная с 1. Приведем пример профилирования представления, включенного в базу данных Sakila:
mysql> SELECT * FROM sakila.nicer_but_slower_film_list;
[query results omitted]
997 rows in set (0.17 sec)Запрос возвратил 997 строк примерно через 1/6 секунды. Посмотрим, что выдаст команда SHOW PROFILES (обратите внимание на множественное число):
mysql> SHOW PROFILES;
+----------+------------+-------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-------------------------------------------------+
| 1 | 0. 16767900 | SELECT * FROM sakila.nicer_but_slower_film_list |
+----------+------------+-------------------------------------------------+ 16767900 | SELECT * FROM sakila.nicer_but_slower_film_list |
+----------+------------+-------------------------------------------------+
16767900 | SELECT * FROM sakila.nicer_but_slower_film_list |
+----------+------------+-------------------------------------------------+Первое, что мы видим, — то, что время отклика запроса показано с большей точностью, чем принято. Двух десятичных знаков точности, как показано в клиенте
MySQL, часто недостаточно, когда вы работаете с быстрыми запросами. Теперь посмотрим на профиль для этого запроса:
mysql> SHOW PROFILE FOR QUERY 1;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000082 |
| Opening tables | 0.000459 |
| System lock | 0.000010 |
| Table lock | 0.000020 |
| checking permissions | 0.000005 |
| checking permissions | 0.000004 |
| checking permissions | 0.000003 |
| checking permissions | 0.000004 |
| checking permissions | 0.000560 |
| optimizing | 0. 000054 |
| statistics | 0.000174 |
| preparing | 0.000059 |
| Creating tmp table | 0.000463 |
| executing | 0.000006 |
| Copying to tmp table | 0.090623 |
| Sorting result | 0.011555 |
| Sending data | 0.045931 |
| removing tmp table | 0.004782 |
| Sending data | 0.000011 |
| init | 0.000022 |
| optimizing | 0.000005 |
| statistics | 0.000013 |
| preparing | 0.000008 |
| executing | 0.000004 |
| Sending data | 0.010832 |
| end | 0.000008 |
| query end | 0.000003 |
| freeing items | 0.000017 |
| removing tmp table | 0.000010 |
| freeing items | 0.000042 |
| removing tmp table | 0.001098 |
| closing tables | 0.000013 |
| logging slow query | 0.000003 |
| logging slow query | 0.000789 |
| cleaning up | 0. 000007 |
+----------------------+----------+ 000054 |
| statistics | 0.000174 |
| preparing | 0.000059 |
| Creating tmp table | 0.000463 |
| executing | 0.000006 |
| Copying to tmp table | 0.090623 |
| Sorting result | 0.011555 |
| Sending data | 0.045931 |
| removing tmp table | 0.004782 |
| Sending data | 0.000011 |
| init | 0.000022 |
| optimizing | 0.000005 |
| statistics | 0.000013 |
| preparing | 0.000008 |
| executing | 0.000004 |
| Sending data | 0.010832 |
| end | 0.000008 |
| query end | 0.000003 |
| freeing items | 0.000017 |
| removing tmp table | 0.000010 |
| freeing items | 0.000042 |
| removing tmp table | 0.001098 |
| closing tables | 0.000013 |
| logging slow query | 0.000003 |
| logging slow query | 0.000789 |
| cleaning up | 0.
000054 |
| statistics | 0.000174 |
| preparing | 0.000059 |
| Creating tmp table | 0.000463 |
| executing | 0.000006 |
| Copying to tmp table | 0.090623 |
| Sorting result | 0.011555 |
| Sending data | 0.045931 |
| removing tmp table | 0.004782 |
| Sending data | 0.000011 |
| init | 0.000022 |
| optimizing | 0.000005 |
| statistics | 0.000013 |
| preparing | 0.000008 |
| executing | 0.000004 |
| Sending data | 0.010832 |
| end | 0.000008 |
| query end | 0.000003 |
| freeing items | 0.000017 |
| removing tmp table | 0.000010 |
| freeing items | 0.000042 |
| removing tmp table | 0.001098 |
| closing tables | 0.000013 |
| logging slow query | 0.000003 |
| logging slow query | 0.000789 |
| cleaning up | 0. 000007 |
+----------------------+----------+
000007 |
+----------------------+----------+Профиль позволяет следить за каждым шагом выполнения запроса и видеть, сколько прошло времени. Обратите внимание, что не очень легко просмотреть выведенный результат и найти, где затраты времени были максимальными: он сортируется в хронологическом порядке. Однако нас интересует не порядок, в котором выполнялись операции, — мы просто хотим знать, каковы были затраты времени на них. К сожалению, отсортировать вывод с помощью ORDER BY нельзя. Давайте перейдем к использованию команды SHOW PROFILE для запроса связанной таблицы INFORMATION_SCHEMA и формата, который выглядит как просмотренные нами ранее профили:
Так намного лучше! Теперь мы видим, что причина, по которой этот запрос так долго выполнялся, заключалась в копировании данных во временную таблицу, на что затрачено более половины общего времени. Возможно, придется переписать этот запрос так, чтобы он не использовал временную таблицу или хотя бы делал это более эффективно. Следующий крупный потребитель времени, отправка данных, фактически является своеобразной кладовкой, которая может включать в себя любое количество различных действий сервера, в том числе поиск совпадающих строк в соединении и т. д. Трудно сказать, сможем ли мы здесь что-то сэкономить. Обратите внимание на то, что результат сортировки занимает недостаточно много времени, чтобы его можно было оптимизировать. Это довольно типично, поэтому призываем вас не тратить время на «настройку буферов сортировки» и подобные мероприятия.
Следующий крупный потребитель времени, отправка данных, фактически является своеобразной кладовкой, которая может включать в себя любое количество различных действий сервера, в том числе поиск совпадающих строк в соединении и т. д. Трудно сказать, сможем ли мы здесь что-то сэкономить. Обратите внимание на то, что результат сортировки занимает недостаточно много времени, чтобы его можно было оптимизировать. Это довольно типично, поэтому призываем вас не тратить время на «настройку буферов сортировки» и подобные мероприятия.
Как обычно, хотя профиль помогает нам определить, какие виды деятельности вносят наибольший вклад в затраченное на выполнение запроса время, он не говорит нам, почему это происходит. Чтобы узнать, почему потребовалось столько времени для копирования данных во временную таблицу, нам пришлось бы углубиться в этот процесс и создать профиль выполняемых подзадач.
Команда SHOW STATUS
Команда SHOW STATUS MySQL возвращает множество счетчиков. Существует глобальная область действия сервера для счетчиков, а также область сеанса, которая специфична для конкретного соединения. Например, счетчик Queries в начале вашего сеанса равен нулю и увеличивается каждый раз, когда вы делаете запрос. Выполнив команду
Существует глобальная область действия сервера для счетчиков, а также область сеанса, которая специфична для конкретного соединения. Например, счетчик Queries в начале вашего сеанса равен нулю и увеличивается каждый раз, когда вы делаете запрос. Выполнив команду SHOW GLOBAL STATUS (обратите внимание на добавление ключевого слова GLOBAL), вы увидите общее количество запросов, полученных с момента его запуска. Области видимости разных счетчиков различаются — счетчики, которые не имеют области видимости на уровне сеанса, отображаются в SHOW STATUS, маскируясь под счетчики сеансов, и это может ввести в заблуждение. Учитывайте это при использовании данной команды. Как говорилось ранее, подбор должным образом откалиброванных инструментов является ключевым фактором успеха. Если вы пытаетесь оптимизировать что-то, что можете наблюдать только в конкретном соединении с сервером, измерения, которые «засоряются» всей активностью сервера, вам не помогут. В руководстве по MySQL есть отличное описание всех переменных, имеющих как глобальную, так и сеансовую область видимости.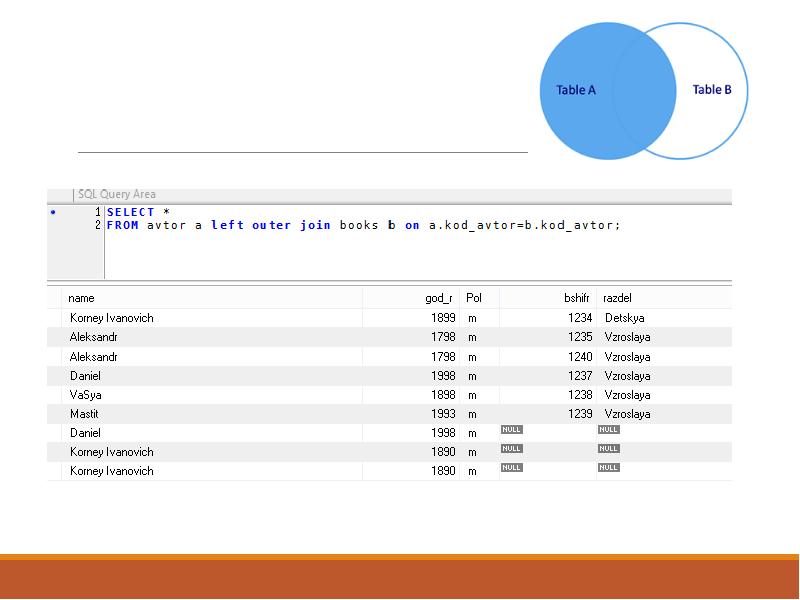
SHOW STATUS может быть полезным инструментом, но на самом деле его применение — это не профилирование. Большинство результатов команды SHOW STATUS — всего лишь счетчики. Они сообщают вам, как часто протекали те или иные виды деятельности, например чтение из индекса, но ничего не говорят о том, сколько времени на это было затрачено. В команде SHOW STATUS есть только один счетчик, который показывает время, израсходованное на операцию (Innodb_row_lock_time), но он имеет лишь глобальную область видимости, поэтому вы не можете использовать его для проверки работы, выполненной в ходе сеанса.
Хотя команда SHOW STATUS не предоставляет информацию о затратах времени, тем не менее иногда может быть полезно использовать ее после выполнения запроса для просмотра значений некоторых счетчиков. Вы можете сделать предположение о том, какие типы затратных операций выполнялись и как они могли повлиять на время запроса. Наиболее важными счетчиками являются счетчики обработчиков запросов и счетчики временных файлов и таблиц. А сейчас приведем пример сброса счетчиков состояния сеанса до нуля, выбора из использованного нами ранее представления и просмотра счетчиков:
А сейчас приведем пример сброса счетчиков состояния сеанса до нуля, выбора из использованного нами ранее представления и просмотра счетчиков:
mysql> SET @query_id = 1;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT STATE, SUM(DURATION) AS Total_R,
-> ROUND(
-> 100 * SUM(DURATION) /
-> (SELECT SUM(DURATION)
-> FROM INFORMATION_SCHEMA.PROFILING
-> WHERE QUERY_ID = @query_id
-> ), 2) AS Pct_R,
-> COUNT(*) AS Calls,
-> SUM(DURATION) / COUNT(*) AS "R/Call"
-> FROM INFORMATION_SCHEMA.PROFILING
-> WHERE QUERY_ID = @query_id
-> GROUP BY STATE
-> ORDER BY Total_R DESC;
+----------------------+----------+-------+-------+--------------+
| STATE | Total_R | Pct_R | Calls | R/Call |
+----------------------+----------+-------+-------+--------------+
| Copying to tmp table | 0. 090623 | 54.05 | 1 | 0.0906230000 |
| Sending data | 0.056774 | 33.86 | 3 | 0.0189246667 |
| Sorting result | 0.011555 | 6.89 | 1 | 0.0115550000 |
| removing tmp table | 0.005890 | 3.51 | 3 | 0.0019633333 |
| logging slow query | 0.000792 | 0.47 | 2 | 0.0003960000 |
| checking permissions | 0.000576 | 0.34 | 5 | 0.0001152000 |
| Creating tmp table | 0.000463 | 0.28 | 1 | 0.0004630000 |
| Opening tables | 0.000459 | 0.27 | 1 | 0.0004590000 |
| statistics | 0.000187 | 0.11 | 2 | 0.0000935000 |
| starting | 0.000082 | 0.05 | 1 | 0.0000820000 |
| preparing | 0.000067 | 0.04 | 2 | 0.0000335000 |
| freeing items | 0.000059 | 0.04 | 2 | 0.0000295000 |
| optimizing | 0.000059 | 0.04 | 2 | 0.0000295000 |
| init | 0.000022 | 0.01 | 1 | 0.0000220000 |
| Table lock | 0. 000020 | 0.01 | 1 | 0.0000200000 |
| closing tables | 0.000013 | 0.01 | 1 | 0.0000130000 |
| System lock | 0.000010 | 0.01 | 1 | 0.0000100000 |
| executing | 0.000010 | 0.01 | 2 | 0.0000050000 |
| end | 0.000008 | 0.00 | 1 | 0.0000080000 |
| cleaning up | 0.000007 | 0.00 | 1 | 0.0000070000 |
| query end | 0.000003 | 0.00 | 1 | 0.0000030000 |
+----------------------+----------+-------+-------+--------------+ 090623 | 54.05 | 1 | 0.0906230000 |
| Sending data | 0.056774 | 33.86 | 3 | 0.0189246667 |
| Sorting result | 0.011555 | 6.89 | 1 | 0.0115550000 |
| removing tmp table | 0.005890 | 3.51 | 3 | 0.0019633333 |
| logging slow query | 0.000792 | 0.47 | 2 | 0.0003960000 |
| checking permissions | 0.000576 | 0.34 | 5 | 0.0001152000 |
| Creating tmp table | 0.000463 | 0.28 | 1 | 0.0004630000 |
| Opening tables | 0.000459 | 0.27 | 1 | 0.0004590000 |
| statistics | 0.000187 | 0.11 | 2 | 0.0000935000 |
| starting | 0.000082 | 0.05 | 1 | 0.0000820000 |
| preparing | 0.000067 | 0.04 | 2 | 0.0000335000 |
| freeing items | 0.000059 | 0.04 | 2 | 0.0000295000 |
| optimizing | 0.000059 | 0.04 | 2 | 0.0000295000 |
| init | 0.000022 | 0.01 | 1 | 0.0000220000 |
| Table lock | 0.
090623 | 54.05 | 1 | 0.0906230000 |
| Sending data | 0.056774 | 33.86 | 3 | 0.0189246667 |
| Sorting result | 0.011555 | 6.89 | 1 | 0.0115550000 |
| removing tmp table | 0.005890 | 3.51 | 3 | 0.0019633333 |
| logging slow query | 0.000792 | 0.47 | 2 | 0.0003960000 |
| checking permissions | 0.000576 | 0.34 | 5 | 0.0001152000 |
| Creating tmp table | 0.000463 | 0.28 | 1 | 0.0004630000 |
| Opening tables | 0.000459 | 0.27 | 1 | 0.0004590000 |
| statistics | 0.000187 | 0.11 | 2 | 0.0000935000 |
| starting | 0.000082 | 0.05 | 1 | 0.0000820000 |
| preparing | 0.000067 | 0.04 | 2 | 0.0000335000 |
| freeing items | 0.000059 | 0.04 | 2 | 0.0000295000 |
| optimizing | 0.000059 | 0.04 | 2 | 0.0000295000 |
| init | 0.000022 | 0.01 | 1 | 0.0000220000 |
| Table lock | 0. 000020 | 0.01 | 1 | 0.0000200000 |
| closing tables | 0.000013 | 0.01 | 1 | 0.0000130000 |
| System lock | 0.000010 | 0.01 | 1 | 0.0000100000 |
| executing | 0.000010 | 0.01 | 2 | 0.0000050000 |
| end | 0.000008 | 0.00 | 1 | 0.0000080000 |
| cleaning up | 0.000007 | 0.00 | 1 | 0.0000070000 |
| query end | 0.000003 | 0.00 | 1 | 0.0000030000 |
+----------------------+----------+-------+-------+--------------+
000020 | 0.01 | 1 | 0.0000200000 |
| closing tables | 0.000013 | 0.01 | 1 | 0.0000130000 |
| System lock | 0.000010 | 0.01 | 1 | 0.0000100000 |
| executing | 0.000010 | 0.01 | 2 | 0.0000050000 |
| end | 0.000008 | 0.00 | 1 | 0.0000080000 |
| cleaning up | 0.000007 | 0.00 | 1 | 0.0000070000 |
| query end | 0.000003 | 0.00 | 1 | 0.0000030000 |
+----------------------+----------+-------+-------+--------------+Похоже, что в запросе использовались три временные таблицы — две из них на диске — и было много неиндексированных чтений (Handler_read_rnd_next). Если бы мы ничего не знали о представлении, к которому только что обращались, то могли бы предположить, что запрос сделал объединение без индекса, возможно, из-за подзапроса, который создал временные таблицы, а затем использовал их с правой стороны в соединении. Временные таблицы, созданные для хранения результатов подзапросов, не имеют индексов, поэтому эта версия кажется правдоподобной.
Используя эту методику, имейте в виду, что команда SHOW STATUS создает временную таблицу и обращается к ней с помощью обработчика операций, поэтому на полученные результаты в действительности влияет и SHOW STATUS. Это зависит от версий сервера. Используя информацию о выполнении запроса, полученную от команды SHOW PROFILES, мы можем предположить, что количество временных таблиц завышено на 2.
Стоит отметить, что большую часть той же информации, по-видимому, можно получить, просмотрев план EXPLAIN для этого запроса. Но EXPLAIN — это оценка того, что сервер планирует делать, а просмотр счетчиков статуса — это измерение того, что он на самом деле сделал. EXPLAIN не скажет вам, например, была ли временная таблица создана на диске, что медленнее, чем в памяти.
Использование журнала медленных запросов
Что расширенный в Percona Server журнал медленных запросов расскажет об этом запросе? Вот что было зафиксировано при выполнении запроса, продемонстрированного в разделе о SHOW PROFILE:
mysql> FLUSH STATUS;
mysql> SELECT * FROM sakila. nicer_but_slower_film_list;
[query results omitted]
mysql> SHOW STATUS WHERE Variable_name LIKE 'Handler%'
OR Variable_name LIKE 'Created%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Created_tmp_disk_tables | 2 |
| Created_tmp_files | 0 |
| Created_tmp_tables | 3 |
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 1 |
| Handler_read_key | 7483 |
| Handler_read_next | 6462 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 5462 |
| Handler_read_rnd_next | 6478 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 6459 |
+----------------------------+-------+ nicer_but_slower_film_list;
[query results omitted]
mysql> SHOW STATUS WHERE Variable_name LIKE 'Handler%'
OR Variable_name LIKE 'Created%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Created_tmp_disk_tables | 2 |
| Created_tmp_files | 0 |
| Created_tmp_tables | 3 |
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 1 |
| Handler_read_key | 7483 |
| Handler_read_next | 6462 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 5462 |
| Handler_read_rnd_next | 6478 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 6459 |
+----------------------------+-------+
nicer_but_slower_film_list;
[query results omitted]
mysql> SHOW STATUS WHERE Variable_name LIKE 'Handler%'
OR Variable_name LIKE 'Created%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Created_tmp_disk_tables | 2 |
| Created_tmp_files | 0 |
| Created_tmp_tables | 3 |
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 1 |
| Handler_read_key | 7483 |
| Handler_read_next | 6462 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 5462 |
| Handler_read_rnd_next | 6478 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 6459 |
+----------------------------+-------+Похоже, что запрос действительно создал три временные таблицы, которые были скрыты от представления в SHOW PROFILE (возможно, из-за особенностей способа выполнения запроса сервером). Две временные таблицы находились на диске. Здесь мы сократили выведенную информацию для улучшения удобочитаемости. В конце концов, данные, полученные при выполнении команды
Две временные таблицы находились на диске. Здесь мы сократили выведенную информацию для улучшения удобочитаемости. В конце концов, данные, полученные при выполнении команды SHOW PROFILE по этому запросу, записываются в журнал, поэтому вы можете журналировать в Percona Server даже такой уровень детализации.
Согласитесь, эта весьма подробная запись в журнале медленных запросов содержит практически все, что вы можете видеть в SHOW PROFILE и SHOW STATUS, и еще кое-что. Это делает журнал очень полезным для поиска более подробной информации при нахождении плохого запроса с помощью утилиты pt-query-digest. Когда вы просмотрите отчет от pt-query-digest, увидите такую строку заголовка:
# Query 1: 0 QPS, 0x concurrency, ID 0xEE758C5E0D7EADEE at byte 3214 _____Вы можете использовать байтовое смещение для фокусировки на нужном разделе журнала следующим образом:
tail -c +3214 /path/to/query. log | head -n100 log | head -n100
log | head -n100Вуаля! Можно рассмотреть все подробности. Кстати, pt-query-digest понимает все добавленные пары «имя — значение» формата медленного журнала запросов Percona Server и автоматически выводит намного более подробный отчет.
Использование Performance Schema
На момент написания этой статьи таблицы Performance Schema, представленные в MySQL 5.5, не поддерживают профилирование на уровне запросов. Performance Schema появилась не так давно. Однако она быстро развивается, приобретая дополнительную функциональность в каждом следующем релизе. Но даже первоначальная функциональность MySQL 5.5 позволяет получать любопытную информацию. Например, следующий запрос покажет основные причины ожидания в системе:
mysql> SELECT event_name, count_star, sum_timer_wait
-> FROM events_waits_summary_global_by_event_name
-> ORDER BY sum_timer_wait DESC LIMIT 5;
+----------------------------------------+------------+------------------+
| event_name | count_star | sum_timer_wait |
+----------------------------------------+------------+------------------+
| innodb_log_file | 205438 | 2552133070220355 |
| Query_cache::COND_cache_status_changed | 8405302 | 2259497326493034 |
| Query_cache::structure_guard_mutex | 55769435 | 361568224932147 |
| innodb_data_file | 62423 | 347302500600411 |
| dict_table_stats | 15330162 | 53005067680923 |
+----------------------------------------+------------+------------------+Сейчас существует несколько моментов, ограничивающих использование Performance Schema в качестве инструмента профилирования общего назначения. Во-первых, она не обеспечивает достаточный уровень детализации выполнения запросов и затрат времени, который можно получить благодаря существующим инструментам. Во-вторых, она довольно долго не использовалась и в данный момент ее применение приводит к большим издержкам, чем применение привычного для многих инструмента профилирования. (Есть основания полагать, что это будет исправлено в ближайшее время.)
Во-первых, она не обеспечивает достаточный уровень детализации выполнения запросов и затрат времени, который можно получить благодаря существующим инструментам. Во-вторых, она довольно долго не использовалась и в данный момент ее применение приводит к большим издержкам, чем применение привычного для многих инструмента профилирования. (Есть основания полагать, что это будет исправлено в ближайшее время.)
Наконец, иногда она слишком сложна и низкоуровнева для использования большинством пользователей. Функции, реализованные к настоящему моменту, в основном нацелены на то, что нужно измерить при изменении исходного кода MySQL для улучшения производительности сервера. Сюда относятся такие элементы, как ожидания и мьютексы. Некоторые из функций MySQL 5.5 полезны для опытных пользователей, а не для разработчиков серверов. Однако пользователи все еще нуждаются в разработке удобных инструментов интерфейса. В настоящее время для написания сложных запросов к разнообразным таблицам метаданных с большим количеством столбцов требуется настоящее мастерство. Это довольно сложный для использования и понимания набор инструментов.
Это довольно сложный для использования и понимания набор инструментов.
Будет здорово, когда Performance Schema в более поздних версиях MySQL получит больше функциональности. И очень приятно, что Oracle реализует ее как таблицы, доступные через SQL, тем самым пользователи могут получать данные любым удобным для них способом. Однако пока она еще не способна заменить журнал медленных запросов или другие инструменты, помогающие сразу увидеть варианты улучшения производительности сервера и выполнения запросов.
Использование профиля для оптимизации
Итак, у вас есть профиль сервера или запроса — что с ним делать? Хороший профиль обычно делает проблему очевидной, но решения может и не быть (хотя чаще всего есть). На этом этапе, особенно при оптимизации запросов, вам нужно полагаться на знания о сервере и о том, как он выполняет запросы. Профиль или те данные, которые вы можете собрать, указывают направление движения и дают основания для применения ваших знаний и нахождения результатов с помощью дополнительных инструментов, таких как EXPLAIN.
В общем, хотя нахождение источника проблемы с помощью профиля со всеми метриками не должно представлять труда, наделе невозможно выполнить измерения абсолютно точно, поскольку оцениваемые системы не поддерживают этой возможности. Ранее, рассматривая пример, мы подозревали, что на временные таблицы и неиндексированные чтения затрачивается большая часть времени отклика, однако не можем этого доказать. Иногда проблемы трудно решить, потому что, возможно, не измерено все, что нужно, либо измерения сделаны в неверном направлении. Например, вы можете определять активность всего сервера вместо изучения того фрагмента, который пытаетесь оптимизировать, или анализировать измерения, проведенные с момента времени до начала выполнения запроса, а не тогда, когда он был запущен.
Существует еще одна возможность. Предположим, вы анализируете журнал медленных запросов и находите простой запрос, на несколько запусков которого затрачено неоправданно много времени, хотя он быстро запускался в тысячах других случаев. Вы снова запускаете запрос, и он выполняется молниеносно, как и должно быть. Применяете
Вы снова запускаете запрос, и он выполняется молниеносно, как и должно быть. Применяете EXPLAIN и обнаруживаете, что он правильно использует индекс. Вы пытаетесь использовать похожие запросы с разными значениями в разделе WHERE, чтобы убедиться, что запрос не обращается к кэшу, и они тоже выполняются быстро. Кажется, что с этим запросом все нормально. Что дальше?
Если у вас есть только стандартный журнал медленных запросов MySQL без плана выполнения или подробной информации о времени, вы знаете только, что запрос плохо работал, когда был журналирован, и не можете понять, почему это произошло. Возможно, что-то еще потребляло ресурсы в системе, например резервное копирование или какая-то блокировка или параллелизм тормозили ход запроса. Периодически возникающие проблемы — это особый случай, который мы рассмотрим в следующей статье.
Вас заинтересует / Intresting for you:
Примеры сложных запросов для выборки данных в СУБД MySQL
Всего лишь пару лет назад, в проектах, которые предусматривали работу с базами данных и построением статистики, основным изобилием используемых SQL-запросов, преобладало в основном множество запросов, ориентированных на стандартную выборку данных и нечасто можно было увидеть другие, которые безо всяких сомнений можно было бы отнести к “эксклюзиву”. Хотя сложность запроса и зависит от количества используемых таблиц, но если мы всего лишь возьмем и выведем данные полей трех или более таблиц имеющих стандартное объединение, то явная сложность такого запроса не выйдет за пределы стандартной.
Хотя сложность запроса и зависит от количества используемых таблиц, но если мы всего лишь возьмем и выведем данные полей трех или более таблиц имеющих стандартное объединение, то явная сложность такого запроса не выйдет за пределы стандартной.
В данной статье по мере возможности будут рассматриваться те запросы, примеры которых мне найти не удалось и которые, по моему мнению, не относятся к классу простых.
Сравнение данных за две даты
Хотя данная статистика из рода задач довольно редко встречаемых, но все-таки необходимость в ее получении иногда существует. И получить такую статистику ничуть не сложнее других.
Работать мы будем с двумя таблицами, структура которых представлена ниже:
Структура таблицы products
CREATE TABLE IF NOT EXISTS `products` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ShopID` int(11) NOT NULL, `Name` varchar(150) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=10 ;
Структура таблицы statistics
CREATE TABLE IF NOT EXISTS `statistics` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ProductID` bigint(20) NOT NULL, `Orders` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `ProductID` (`ProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=20 ;
Дело в том, что стандарт языка SQL допускает использование вложенных запросов везде, где разрешается использование ссылок на таблицы.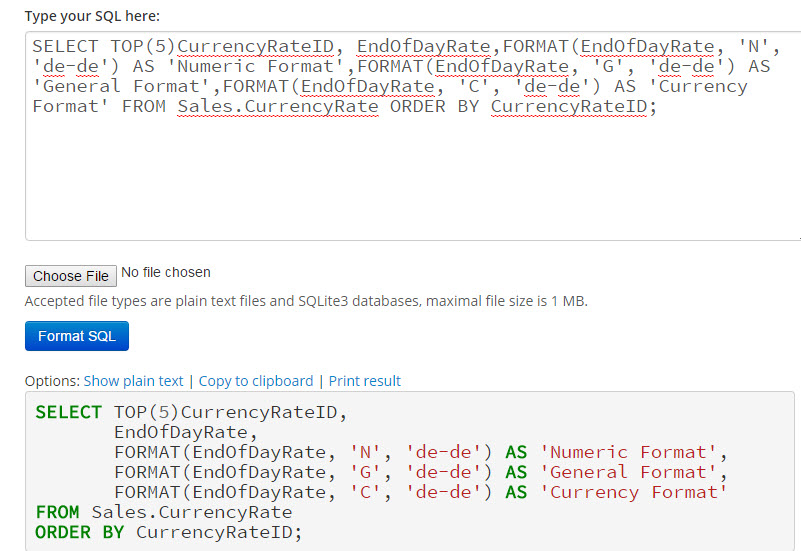 Здесь вместо явно указанных таблиц, благодаря использованию псевдонимов, будут применяться результирующие таблицы вложенных запросов с имеющейся связью один – к – одному. Результатом каждой результирующей таблицы будут данные о количестве произведенных заказов некоего товара за определенную дату, полученные путем выполнения запроса на выборку данных из таблицы statistics по требуемым критериям. Иными словами мы свяжем таблицу statistics саму с собой. Пример запроса:
Здесь вместо явно указанных таблиц, благодаря использованию псевдонимов, будут применяться результирующие таблицы вложенных запросов с имеющейся связью один – к – одному. Результатом каждой результирующей таблицы будут данные о количестве произведенных заказов некоего товара за определенную дату, полученные путем выполнения запроса на выборку данных из таблицы statistics по требуемым критериям. Иными словами мы свяжем таблицу statistics саму с собой. Пример запроса:
SELECT stat1.Name, stat1.Orders, stat1.Date, stat2.Orders, stat2.Date FROM (SELECT statistics.ProductID, products.Name, statistics.Orders, statistics.Date FROM products JOIN statistics ON products.id = statistics.ProductID WHERE DATE(statistics.date) = '2014-09-04') AS stat1 JOIN (SELECT statistics.ProductID, statistics.Orders, statistics.Date FROM statistics WHERE DATE(statistics.date) = '2014-09-12') AS stat2 ON stat1.ProductID = stat2.ProductID
В итоге имеем такой результат:
+------------------------+----------+------------+----------+------------+ | Name | Orders1 | Date1 | Orders2 | Date2 | +------------------------+----------+------------+----------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | 1 | 2014-09-12 | | Процессоры Pentium III | 1 | 2014-09-04 | 10 | 2014-09-12 | | Оптическая мышь Atech | 10 | 2014-09-04 | 3 | 2014-09-12 | | DVD-R | 2 | 2014-09-04 | 5 | 2014-09-12 | | DVD-RW | 22 | 2014-09-04 | 18 | 2014-09-12 | | Клавиатура MS 101 | 5 | 2014-09-04 | 1 | 2014-09-12 | | SDRAM II | 26 | 2014-09-04 | 12 | 2014-09-12 | | Flash RAM 8Gb | 8 | 2014-09-04 | 7 | 2014-09-12 | | Flash RAM 4Gb | 18 | 2014-09-04 | 30 | 2014-09-12 | +------------------------+----------+------------+----------+------------+
Подстановка нескольких значений из другой таблицы
Необходимость в данном запросе не является повседневной, но возникает не совсем уж и редко. Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Демонстрация данного запроса будет происходить на другом примере, а не на примере сетевой игры. Это чтобы не создавать заново все необходимые таблицы. В качестве данных возьмем таблицу products из примера “сравнение данных за две даты” и создадим еще одну недостающую таблицу replace_com, структура которой представлена ниже:
CREATE TABLE IF NOT EXISTS `replace_com` ( `id` int(11) NOT NULL AUTO_INCREMENT, `sProductID` int(11) NOT NULL, `rProductID` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `sProductID` (`sProductID`,`rProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=4 ;
Предположим, что у нас есть некий компьютерный салон и мы проводим модификации некоторых компьютерных составляющих, а все операции по замене комплектующих заносим в базу данных. В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
SELECT sProducts.Name AS sProduct, rProducts.Name AS rProduct, replace_com.Date FROM replace_com JOIN products AS sProducts ON sProducts.id = replace_com.sProductID JOIN products AS rProducts ON rProducts.id = replace_com.rProductID
Результирующая таблица данных:
+-----------------------+------------------------+------------+ | sProduct | rProduct | Date | +-----------------------+------------------------+------------+ | Процессоры Pentium II | Процессоры Pentium III | 2014-09-15 | | Flash RAM 4Gb | Flash RAM 8Gb | 2014-09-17 | | DVD-R | DVD-RW | 2014-09-18 | +-----------------------+------------------------+------------+
Вывод статистики с накоплением по дате
Предположим, что у нас имеется склад с некими товарами. Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
На первом этапе требуется установить переменную и присвоить ей нулевое значение:
SET @cvalue = 0
В следующем запросе, мы созданную ранее переменную и применим:
SELECT products.Name AS Name, (@cvalue := @cvalue + Orders) as Orders, Date FROM (SELECT ProductID AS ProductID, SUM(Orders) AS Orders, DATE(date) AS Date FROM statistics WHERE ProductID = '1' GROUP BY date) AS statistics JOIN products ON statistics.
 ProductID = products.id
ProductID = products.id
Итоговый отчет:
+-----------------------+--------+------------+ | Name | Orders | Date | +-----------------------+--------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | | Процессоры Pentium II | 2 | 2014-09-12 | | Процессоры Pentium II | 4 | 2014-09-14 | | Процессоры Pentium II | 6 | 2014-09-15 | +-----------------------+--------+------------+
Получить используемую в примерах базу данных можно здесь.
Формирование запроса в SQL
SQL символизирует структурированный язык запросов (Structured Query Language). Запросы являются наиболее часто используемым аспектом SQL. Есть категория пользователей SQL, которые используют язык только для формулировки запросов. Поэтому изучение SQL начинается с обсуждения запроса и того, как он выполняется в этом языке. Что такое запрос? Это команда, которая формулируется для СУБД и требует предоставить определенную указанную информацию. Эта информация обычно выводится непосредственно на экран дисплея компьютера или используемый терминал, хотя в ряде случаев ее можно направить на принтер, сохранить в файле или использовать в качестве исходных данных для другой команды или процесса.
Как осуществляется связь запросов?
Запросы являются частью DML. Но так как они совершенно не изменяют информации в таблицах, а лишь показывают ее пользователю, предположим, что запросы являются самостоятельной категорией и определяют команды DML, воздействующие на содержимое базы данных, а не просто показывающие его. Все запросы в SQL конструируются на базе одной команды. Структура этой команды проста, потому что ее можно расширять для того, чтобы выполнить очень сложные вычисления и обработку данных. Эта команда называется SELECT.
Команда SELECT
В простейшей форме команда SELECT дает инструкцию базе данных для поиска информации в таблице. Например, можно получить таблицу Salespeople, введя с клавиатуры следующее:
SELECT snum, sname, city, comm FROM Salespeople;
Выходные данные для этого запроса представлены на рисунке ниже.
Команда просто выводит все данные из таблицы. Большинство программ, как показано выше, также выводит заголовки столбцов. Некоторые программы допускают тщательное форматирование выходных данных, но это лежит за пределами спецификаций стандарта. Далее приводится объяснение каждой части этой команды:
| SELECT | Ключевое слово, которое сообщает базе данных, что команда является запросом. Все запросы начинаются с этого ключевогослова, за которым следует пробел. |
| snum, sname … | Список столбцов таблицы, которые должны быть представлены в результате выполнения запроса. Столбцы, имена которых не представлены в списке, не включаются в состав выходных данных команды. Это, однако, не приводит к удалению из таблиц таких столбцов или содержащейся в них информации, потому что запрос не воздействует на информацию, представленную в таблицах: он только извлекает данные. |
| FROM Salespeople | FROM, так же как и SELECT, является ключевым словом, которое должно быть представлено в каждом запросе. Заним следует пробел, а затем — имя таблицы, которая используется как источник информации для запроса. В приведенном примере это таблица Salespeople. Символ «точка с запятой»(;) используется во всех интерактивных командах SQL для сообщения базе данных, что команда сформулирована и готова к выполнению. В некоторых системах этот символ заменен на символ «слэш обратный» («\») в строке, которая непосредственно следует за концом команды. |
Стоит заметить, что запрос по своей природе не обязательно упорядочивает выходные данные каким-либо определенным образом. Одна и та же команда, выполненная над одними и теми же данными в различные моменты времени, в результате выдает данные, упорядоченные по-разному. Обычно строки выдаются в том порядке, в котором они представлены в таблице, но этот порядок может быть совершенно произвольным. Необязательно, что данные в результате выполнения запроса будут представлены в том порядке, в котором они вводятся или хранятся. Можно упорядочить выходные данные непосредственно с помощью SQL-команд, указав специальное предложение. Позже будет объяснено, как это сделать. Сейчас же просто констатируем факт отсутствия какого-либо порядка в представлении выходных данных.
Использование клавиши возврата каретки (клавиши Eпter) является произвольным. Можно ввести запрос в одной строке следующим образом:
SELECT snum, sname, city, comm FROM Salespeople;
Поскольку в SQL точка с запятой применяется для того, чтобы пометить конец команды, большинство SQL-пporpaмм использует клавишу «Возврат каретки» (выполняется нажатием клавиши Return или Enter) как пробел.
Выбор чего-либо простейшим способом
Если необходимо увидеть каждую колонку таблицы, существует упрощенный вариант сделать это. Можно использовать символ «*» («звездочка»), который заменяет полный список столбцов.
SELECT * FROM Salespeople;
Результат выполнения этой команды тот же, что и для рассмотренной ранее.
SELECT в общем виде
Обобщая предыдущие рассуждения, следует отметить, что команда SELECT начинается с ключевого слова SELECT, за которым следует пробел. После него следует список разделенных запятыми имен столбцов, которые необходимо увидеть. Если нужно увидеть все столбцы таблицы, то можно заменить список имен столбцов символом (*) (звездочка). За звездочкой следует ключевое слово FROM, за ним — пробел и имя таблицы, к которой направляется запрос. Символ точка с запятой(;) нужно использовать для того, чтобы закончить запрос и показать, что команда готова для выполнения.
Просмотр только определенных столбцов таблицы
Мощность команды SELECT заключается в ее свойстве извлекать из таблицы лишь определенную информацию. Надо отметить возможность просмотра только указанных столбцов таблицы. Для этого достаточно пропустить столбцы, которые нет необходимости просматривать, в части команды SELECT. Например, по запросу
SELECT sname, comm FROM Salespeople;
получаются выходные данные, представленные на рисунке ниже.
Существуют таблицы, включающие большое количество столбцов, содержащих данные, не все из которых требуются в определенный момент. Следовательно, возможность выбора и указания интересующих колонок весьма полезна.
Перестановка столбцов
Колонки таблицы упорядочены по определению, но это не значит, что их нужно извлекать в том же порядке. Звездочка (*) извлечет столбцы в соответствии с их порядком, но если указать столбцы раздельно, они выстраиваются их в любом желаемом порядке. В таблице Orders зададим такой порядок столбцов: сначала разместим столбец «дата заказа (odate), за ним — столбец «номер продавца» (snum), затем — «номер заказа» (onum) и «количество» (amt):
SELECT odate, snum, onum, amt FROM Orders;
Выходные данные, полученные по этому запросу, представлены на рисунке ниже.
Очевидно, что структура информации таблицах является просто основой для ее реструктуризации средствами SQL.
Устранение избыточных данных
DISТINCT — аргумент, дающий возможность исключить дублирующиеся значения из результата выполнения предложения SELECT. Предположим, необходимо узнать, какие продавцы имеют в настоящее время заказы в таблице Orders. Не имеет значения количество заказов каждого из продавцов, нужен лишь список номеров продавцов (snum). Необходимо ввести:
SELECT snum FROM Orders;
чтобы получить результат, представленный на рисунке ниже.
Для того чтобы получить список без повторений, который легче прочесть, нужно ввести следующую команду:
SELECT DISTINCT snum FROM Orders;
Выходные данные для этого запроса представлены на рисунке ниже.
DISTINCT отслеживает, какие значения появились в списке выходных данных, и исключает из него дублирующиеся значения. Это полезный способ исключить избыточные данные. Если таковых нет, не следует использовать DISТINCT, поскольку он может скрыть проблемы. Предположим, все имена покупателей различны. Если кто-то введет второго покупателя с фамилией Clemens в таблицу Customers при использовании SELECT DISТINCT cname, можно не заметить, что имеются дублирующиеся данные. Будут получены ошибочные сведения о Clemens, поскольку в этом случае нет информации об избыточности данных.
Параметры DISТINCT. DISТINCT можно задать только один раз для данного предложения SELECT. Если SELECT извлекает множество полей, то он исключает строки, в которых все выбранные поля идентичны. Строки, в которых некоторые значения одинаковы, а другие — различны, включаются в результат. DISТINCT, фактически, действует на всю выходную строку, а не на отдельное поле (исключение составляет его применение внутри агрегатных функций, см. главу 6), исключая возможность их повторения.
DISТINCT в сравнении с ALL. Альтернативой DISTINCT является ALL. Это ключевое слово имеет противоположное действие: повторяющиеся строки включаются в состав выходных данных. Поскольку часто бывает так, что не заданы ни DISТINCT, ни ALL, предполагается ALL; это ключевое слово имеет преимущество перед функциональным аргументом.
Источник: SQL для простых смертных / Мартинн Грабер
С уважением, Артём Санников
Сайт: ArtemSannikov.ru
Метки: MySQL, База данных.
| Раздел 1. Современные базы данных: принципы организации и проектирования | Раздел 2. Применение языка SQL в управлении базами данных MySQL | Раздел 3. Применение языка SQL в управлении базами данных MICROSOFT SQL SERVER | |||||||
| Обзор современных СУБД | Введение в СУБД MySQL и язык запросов SQL | Введение в СУБД MICROSOFT SQL SERVER и Transact-SQL | |||||||
| Принципы организации реляционных баз данных | Создание и модификация структуры данных. Базовые типы данных MySQL | Создание и модификация структуры данных. Базовые типы данных MICROSOFT SQL SERVER | |||||||
| Проектирование реляционных баз данных с использованием ER-диаграмм | Модификация данных | Модификация данных | |||||||
| Выборка данных | Выборка данных | ||||||||
| | Соединение нескольких таблиц в запросе | Соединение нескольких таблиц в запросе | |||||||
| | Операции над множествами | Операции над множествами | |||||||
| | Группировка и агрегация данных | Группировка и агрегация данных | |||||||
| | Использование подзапросов | Использование подзапросов | |||||||
| | Использование встроенных функций | Использование встроенных функций | |||||||
| | Хранимые процедуры | Использование табличных выражений | |||||||
| | Триггеры | Оконные, ранжирующие и агрегирующие функции | |||||||
| | Управление транзакциями и блокировками в MySQL | Транспонирование и вычисление подытогов | |||||||
| | | Хранимые процедуры и триггеры | |||||||
| | | Программирование | |||||||
| | | Транзакции | |||||||
| | | Оптимизация запросов | |||||||
| | | Чтение метаданных | |||||||
Basic MySQL Tutorial
Это базовое руководство MySQL объясняет некоторые из основных операторов SQL. Если вы впервые используете систему управления реляционными базами данных, в этом руководстве вы найдете все, что вам нужно знать для работы с MySQL, например, запросы данных, обновление данных, управление базами данных и создание таблиц.
Если вы уже знакомы с другими системами управления реляционными базами данных, такими как PostgreSQL, Oracle и Microsoft SQL Server, вы можете использовать это руководство, чтобы освежить свои знания и понять, чем диалект SQL MySQL отличается от других систем.
Раздел 1. Начало работы с MySQL
Этот раздел поможет вам начать работу с MySQL. Мы начнем установку MySQL, загрузку образца базы данных и загрузку данных на сервер MySQL для практики.
Раздел 2. Запрос данных
Этот раздел поможет вам узнать, как запрашивать данные с сервера базы данных MySQL. Мы начнем с простого оператора SELECT , который позволяет запрашивать данные из одной таблицы.
- SELECT — покажет вам, как использовать простой оператор
SELECTдля запроса данных из одной таблицы.
Раздел 3. Сортировка данных
- ORDER BY — покажет вам, как отсортировать набор результатов с помощью предложения
ORDER BY. Также будет рассмотрен пользовательский порядок сортировки с функциейFIELD.
Раздел 4. Фильтрация данных
- WHERE — узнайте, как использовать предложение
WHEREдля фильтрации строк на основе заданных условий. - SELECT DISTINCT — покажет, как использовать оператор
DISTINCTв оператореSELECTдля удаления повторяющихся строк в наборе результатов. - AND — познакомит вас с оператором
ANDдля объединения логических выражений для формирования сложного условия для фильтрации данных. - OR– познакомит вас с оператором
ORи покажет, как комбинировать операторORс операторомANDдля фильтрации данных. - IN — покажет вам, как использовать оператор
INв предложенииWHERE, чтобы определить, соответствует ли значение какому-либо значению в списке или подзапросе. - BETWEEN — покажет, как запрашивать данные на основе диапазона с помощью оператора
BETWEEN. - LIKE — предоставить вам методику запроса данных на основе определенного шаблона.
- LIMIT — используйте
LIMIT, чтобы ограничить количество строк, возвращаемых операторомSELECT - IS NULL — проверьте, является ли значение
NULLили нет, с помощью оператораIS NULL.
Раздел 5. Объединение таблиц
- Псевдонимы таблиц и столбцов — знакомство с псевдонимами таблиц и столбцов.
- Объединения — обзор объединений, поддерживаемых в MySQL, включая внутреннее соединение, левое соединение и правое соединение.
- INNER JOIN — запросить строки из таблицы, которая имеет совпадающие строки в другой таблице.
- LEFT JOIN — вернуть все строки из левой таблицы и совпадающие строки из правой таблицы или null, если в правой таблице не найдено совпадающих строк.
- RIGHT JOIN — вернуть все строки из правой таблицы и совпадающие строки из левой таблицы или null, если в левой таблице не найдено совпадающих строк.
- CROSS JOIN — создать декартово произведение строк из нескольких таблиц.
- Самосоединение — присоединить таблицу к самой себе, используя псевдоним таблицы, и соединить строки в одной таблице, используя внутреннее соединение и левое соединение.
Раздел 6. Группировка данных
- GROUP BY — покажет вам, как группировать строки в группы на основе столбцов или выражений.
- HAVING — фильтровать группы по определенному условию.
- ROLLUP — создание нескольких наборов группировок с учетом иерархии между столбцами, указанной в предложении
GROUP BY.
Раздел 7. Подзапросы
- Подзапрос — покажет, как вложить запрос (внутренний запрос) в другой запрос (внешний запрос) и использовать результат внутреннего запроса для внешнего запроса.
- Производная таблица — познакомит вас с концепцией производной таблицы и покажет, как ее использовать для упрощения сложных запросов.
- EXISTS — проверка на наличие строк.
Раздел 8. Общие табличные выражения
- Общее табличное выражение или CTE — объяснят вам концепцию общего табличного выражения и покажут, как использовать CTE для запроса данных из таблиц.
- Рекурсивный CTE — используйте рекурсивный CTE для просмотра иерархических данных.
Раздел 9.Операторы множества
- UNION и UNION ALL — объединяют два или более наборов результатов нескольких запросов в один набор результатов.
- INTERSECT — покажет вам несколько способов имитации оператора
INTERSECT. - MINUS — объясните вам оператор SQL MINUS и покажите, как его моделировать.
Раздел 10. Изменение данных в MySQL
В этом разделе вы узнаете, как вставлять, обновлять и удалять данные из таблиц с помощью различных операторов MySQL.
- INSERT — используйте различные формы оператора
INSERTдля вставки данных в таблицу. - INSERT Multiple Rows — вставить несколько строк в таблицу.
- INSERT INTO SELECT — вставить данные в таблицу из набора результатов запроса.
- INSERT IGNORE — объясните вам оператор
INSERT IGNORE, который вставляет строки в таблицу и игнорирует строки, вызывающие ошибки. - UPDATE — узнайте, как использовать оператор
UPDATEи его параметры для обновления данных в таблицах базы данных. - UPDATE JOIN — покажет вам, как выполнить обновление кросс-таблицы с помощью оператора
UPDATE JOINсINNER JOINиLEFT JOIN. - DELETE — покажет, как использовать оператор
DELETEдля удаления строк из одной или нескольких таблиц. - ON DELETE CASCADE — узнайте, как использовать действие
ON DELETE CASCADEдля внешнего ключа для автоматического удаления данных из дочерней таблицы при удалении данных из родительской таблицы. - УДАЛИТЬ СОЕДИНЕНИЕ — покажет, как удалить данные из нескольких таблиц.
- REPLACE — узнать, как вставлять или обновлять данные, зависит от того, существуют ли данные в таблице или нет.
- Подготовленный оператор — покажет, как использовать подготовленный оператор для выполнения запроса.
Раздел 11. Транзакция MySQL
- Транзакция — узнайте о транзакциях MySQL и о том, как использовать
COMMITиROLLBACKдля управления транзакциями в MySQL. - Блокировка таблицы — узнайте, как использовать блокировку MySQL для совместного доступа к таблицам между сеансами.
Раздел 12. Управление базами данных и таблицами MySQL
В этом разделе показано, как управлять наиболее важными объектами базы данных в MySQL, включая базы данных и таблицы.
- Выбор базы данных MySQL — покажите, как использовать оператор
USEдля выбора базы данных MySQL с помощью программыmysqlи MySQL Workbench. - Управление базами данных — изучите различные инструкции для управления базами данных MySQL, включая создание новой базы данных, удаление существующей базы данных, выбор базы данных и перечисление всех баз данных.
- CREATE DATABASE — покажет, как создать новую базу данных на сервере MySQL.
- DROP DATABASE — узнайте, как удалить существующую базу данных.
- Механизмы хранения MySQL — важно понимать особенности каждого механизма хранения, чтобы вы могли эффективно использовать их для максимальной производительности ваших баз данных.
- CREATE TABLE — покажет вам, как создавать новые таблицы в базе данных с помощью оператора
CREATE TABLE. - Последовательность MySQL — покажите, как использовать последовательность для автоматического создания уникальных чисел для столбца первичного ключа таблицы.
- ALTER TABLE — узнайте, как использовать оператор
ALTER TABLEдля изменения структуры таблицы. - Переименование таблицы — покажет, как переименовать таблицу с помощью оператора
RENAME TABLE. - Удаление столбца из таблицы — покажет, как использовать оператор
ALTER TABLE DROP COLUMNдля удаления одного или нескольких столбцов из таблицы. - Добавление нового столбца в таблицу — покажет, как добавить один или несколько столбцов в существующую таблицу с помощью оператора
ALTER TABLE ADD COLUMN. - DROP TABLE — показать вам, как удалить существующие таблицы с помощью оператора
DROP TABLE. - Временные таблицы — обсудите временную таблицу MySQL и покажите, как управлять временными таблицами.
- TRUNCATE TABLE — покажет вам, как использовать оператор
TRUNCATE TABLEдля быстрого удаления всех данных в таблице. - Сгенерированные столбцы — узнайте, как использовать сгенерированные MySQL столбцы для хранения данных, вычисленных из выражения или других столбцов.
Раздел 13.Типы данных MySQL
- Типы данных MySQL — покажут вам различные типы данных в MySQL, чтобы вы могли эффективно применять их при разработке таблиц базы данных.
- INT — покажем, как использовать целочисленный тип данных.
- DECIMAL — покажет вам, как использовать тип данных
DECIMALдля хранения точных значений в десятичном формате. - BIT — познакомим вас с типом данных
BITи тем, как хранить битовые значения в MySQL. - BOOLEAN — объясните вам, как MySQL обрабатывает логические значения с помощью внутреннего использования
TINYINT (1). - CHAR — справочник по типу данных
CHARдля хранения строки фиксированной длины. - VARCHAR — даст вам необходимое руководство по типу данных
VARCHAR. - ТЕКСТ — покажет, как хранить текстовые данные с использованием типа данных
ТЕКСТ. - DATE — познакомит вас с типом данных
DATEи покажет вам некоторые функции даты для эффективной обработки данных даты. - ВРЕМЯ — познакомит вас с функциями типа данных
TIMEи покажет, как использовать некоторые полезные временные функции для обработки данных времени. - DATETIME — познакомит вас с типом данных
DATETIMEи некоторыми полезными функциями для управления значениямиDATETIME. - TIMESTAMP — познакомит вас с
TIMESTAMPи его функциями, называемыми автоматической инициализацией и автоматическим обновлением, которые позволяют вам определять автоматически инициализированные и автоматически обновляемые столбцы для таблицы. - JSON — покажите, как использовать тип данных JSON для хранения документов JSON.
- ENUM — узнайте, как правильно использовать тип данных
ENUMдля хранения значений перечисления.
Раздел 14. Ограничения MySQL
- Ограничение NOT NULL — познакомит вас с ограничением
NOT NULLи покажет, как объявить столбецNOT NULLили добавить ограничениеNOT NULLк существующему столбцу. - Ограничение первичного ключа — руководство по использованию ограничения первичного ключа для создания первичного ключа для таблицы.
- Ограничение внешнего ключа — познакомит вас с внешним ключом и покажет шаг за шагом, как создавать и удалять внешние ключи.
- Отключить проверку внешнего ключа — узнайте, как отключить проверку внешнего ключа.
- Ограничение UNIQUE — покажет вам, как использовать ограничение
UNIQUEдля обеспечения уникальности значений в столбце или группе столбцов в таблице. - Ограничение CHECK — узнайте, как создать ограничения
CHECKдля обеспечения целостности данных. Эмуляция ограничения - CHECK — если вы используете MySQL 8.0.15 или более раннюю версию, вы можете эмулировать ограничения
CHECKс помощью представлений или триггеров.
Раздел 15. Глобализация MySQL
- Набор символов — обсудите набор символов и покажите шаг за шагом, как выполнять различные операции с наборами символов.
- Сопоставление — обсудите сопоставление и покажите, как установить наборы символов и сопоставления для сервера MySQL, базы данных, таблиц и столбцов.
Раздел 16. Импорт и экспорт MySQL CSV
Раздел 17. Расширенные методы
- Естественная сортировка — познакомит вас с различными методами естественной сортировки в MySQL с помощью предложения
ORDER BY.
Понимание запросов MySQL с объяснением
Вы находитесь на новой работе в качестве администратора базы данных или инженера по данным и просто заблудились, пытаясь понять, что эти безумно выглядящие запросы должны означать и делать. Почему 5 объединений и почему ORDER BY используется в подзапросе еще до того, как произойдет одно из соединений? Помните, что вас наняли по какой-то причине — скорее всего, эта причина также связана со многими запутанными запросами, которые были созданы и отредактированы за последнее десятилетие.
Ключевое слово EXPLAIN используется в различных базах данных SQL и предоставляет информацию о том, как ваша база данных SQL выполняет запрос. В MySQL EXPLAIN может использоваться перед запросом, начинающимся с SELECT , INSERT , DELETE , REPLACE и UPDATE . Для простого запроса это будет выглядеть так:
EXPLAIN SELECT * FROM foo WHERE foo.bar = 'инфраструктура как услуга' ИЛИ foo.бар = 'iaas';
Вместо обычного вывода результатов MySQL будет затем показывать свой план выполнения оператора, объясняя, какие процессы происходят в каком порядке при выполнении оператора.
Примечание: Если EXPLAIN не работает для вас, возможно, у пользователя вашей базы данных нет привилегии SELECT для таблиц или представлений, которые вы используете в своем операторе.
EXPLAIN — отличный инструмент для быстрого исправления медленных запросов. Хотя это, безусловно, может вам помочь, это не избавит вас от необходимости структурного мышления и хорошего обзора имеющихся моделей данных.Часто самым простым решением и самым быстрым советом является добавление индекса к конкретным столбцам таблицы, о которых идет речь, если они используются во многих запросах с проблемами производительности. Однако будьте осторожны, не используйте слишком много индексов, так как это может быть контрпродуктивным. Чтение индексов и таблицы имеет смысл только в том случае, если таблица имеет значительное количество строк и вам нужно всего несколько точек данных. Если вы получаете огромный набор результатов из таблицы и часто запрашиваете разные столбцы, индекс для каждого столбца не имеет смысла и больше снижает производительность, чем помогает.Чтобы узнать больше о фактических расчетах индекса по сравнению с отсутствием индекса, прочтите «Оценка производительности» в официальной документации MySQL.
Вещи, которые вы хотите избежать везде, где это возможно и применимо, — это сортировка и вычислений внутри запросов. Если вы думаете, что не можете избежать вычислений в своих запросах: да, вы можете. Напишите набор результатов в другом месте и вычислите точку данных вне запроса, это снизит нагрузку на базу данных и, следовательно, в целом будет лучше для вашего приложения.Просто убедитесь, что вы задокументировали, почему вы выполняете вычисления в своем приложении, а не сразу получаете результат в SQL. В противном случае придет следующий администратор или разработчик базы данных, и у него возникнет великолепная идея использовать вычисление в запросе типа: «О, смотрите, мой предшественник даже не знал, что вы можете сделать это в SQL!» Некоторые команды разработчиков, у которых еще не было неизбежной проблемы с умирающими базами данных, могут использовать вычисления в запросе для определения разницы между датами или аналогичными точками данных.
Общее практическое правило для SQL-запросов выглядит следующим образом:
Будьте точны и получайте только те результаты, которые вам нужны.
Давайте проверим более сложный запрос…
ВЫБЕРИТЕ site_options.domain, sites_users.user, site_taxes.monthly_statement_fee, site.name, AVG (цена) AS average_product_price FROM sites_orders_products, site_taxes, site, sites_users, site_options WHERE site_options.user_id И site_taxes.site_id = site.id И sites_orders_products.site_id = site.id ГРУППА ПО site.id ORDER BY site.date_modified desc LIMIT 5;
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| домен | пользователь | month_statement_fee | имя | average_product_price |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| www.xxxxxxxxxxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxx | 3.254781 |
| www.xxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | 9.471022 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxx | 8.646297 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxx | 9.042460 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxxx | 6.679182 |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
5 рядов в наборе (0,00 сек)
… и его выход EXPLAIN .
+ ------ + ------------- + -------------------------- ------- + -------- + ----------------- + --------------- + --------- + --------------------------------- + ----- - + ----------- +
| id | select_type | стол | тип | possible_keys | ключ | key_len | ref | строки | Экстра |
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
| 1 | ПРОСТО | сайты | индекс | ПЕРВИЧНЫЙ, user_id | ПЕРВИЧНЫЙ | 4 | NULL | 858 | Использование временных; Использование файловой сортировки |
| 1 | ПРОСТО | sites_options | ref | site_id | site_id | 4 | услуга.sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек)
Столбцы в выходных данных EXPLAIN с теми, которые требуют особого внимания для выявления проблем, выделены жирным шрифтом:
- id (идентификатор запроса)
- select_type (тип выписки)
- таблица (ссылка на таблицу) Тип
- (соединительный тип)
- possible_keys (какие ключи могли быть использованы)
- ключ (ключ, который был использован)
- key_len (длина используемого ключа)
- ref (столбцы по сравнению с индексом)
- строк (количество найденных строк)
- Extra (доп. Информация)
Чем выше количество искомых строк, тем лучше должен быть уровень оптимизации индексов и точности запроса, чтобы максимизировать производительность.Столбец Extra показывает возможные действия, на которых вы могли бы сосредоточиться, чтобы улучшить свой запрос, если это применимо.
Показать предупреждения;
Если запрос, который вы использовали с EXPLAIN , не разбирается правильно, вы можете ввести SHOW WARNINGS; в ваш редактор запросов MySQL, чтобы показать информацию о последнем операторе, который был запущен и не был диагностическим, т.е. он не будет отображать информацию для таких операторов, как SHOW FULL PROCESSLIST; . Хотя он не может дать правильный план выполнения запроса, как EXPLAIN , он может дать вам подсказки о тех фрагментах запроса, которые он может обработать.Допустим, мы используем запрос EXPLAIN SELECT * FROM foo, ГДЕ foo.bar = 'инфраструктура как услуга' ИЛИ foo.bar = 'iaas'; в любой базе данных, в которой фактически нет таблицы foo . Результат MySQL будет:
ОШИБКА 1146 (42S02): Таблица db.foo не существует
Если набрать ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; вывод выглядит следующим образом:
+ ------- + ------ + -------------------------------- ----- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- --- +
| Ошибка | 1146 | Таблица 'db.foo 'не существует |
+ ------- + ------ + ---------------------------------- --- +
1 ряд в комплекте (0,00 сек)
Давайте попробуем это с намеренной синтаксической ошибкой.
EXPLAIN SELECT * FROM foo WHERE name = ///;
Это генерирует следующие предупреждения:
> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ;
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Ошибка | 1064 | У вас есть ошибка в синтаксисе SQL; (...) рядом с '///' в строке 1 |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
Этот вывод предупреждений довольно прост и сразу отображается MySQL как вывод результата, но для более сложных запросов, которые не анализируются, все еще можно посмотреть, что происходит в тех фрагментах запроса, которые могут быть проанализированы. ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; включает специальные маркеры, которые могут предоставлять полезную информацию, например:
-
(фрагмент запроса) -
(условие, выражение1, выражение2) -
(фрагмент запроса) -
<временная таблица>: здесь будет создана внутренняя таблица для сохранения временных результатов, например, в подзапросах перед объединениями
Чтобы узнать больше об этих специальных маркерах, прочтите Extended Explain Output Format в официальной документации MySQL.
Есть несколько способов устранить основную причину плохой работы базы данных. Первое, на что следует обратить внимание, — это модель данных, то есть как структурированы данные и правильно ли вы используете базу данных? Для многих продуктов вполне подойдет база данных SQL. Следует помнить одну важную вещь — всегда отделять журналы доступа от обычной производственной базы данных, что, к сожалению, не происходит во многих компаниях. Чаще всего в этих случаях компания начинала с малого, росла и по сути все еще использовала одну и ту же базу данных, что означает, что они обращаются к одной и той же базе данных как для функций ведения журнала, так и для других транзакций.Это значительно снижает общую производительность, особенно по мере роста компании. Следовательно, очень важно создать подходящую и устойчивую модель данных.
Модель данных
Выбор модели данных, скорее всего, также откроет правильную форму базы данных (ов). Если ваш продукт не является очень простым, у вас, вероятно, будет несколько баз данных для нескольких вариантов использования — если вам нужно отображать числа, близкие к реальному времени, для журналов доступа, вам, скорее всего, понадобится высокопроизводительное хранилище данных, тогда как обычные транзакции могут происходить через SQL база данных, и у вас может быть база данных графов, в которой также накапливаются соответствующие точки данных обеих баз данных в механизм рекомендаций.
Программная архитектура всего продукта так же важна, как и сама база данных, так как плохой дизайн здесь приведет к возникновению узких мест, которые идут к базе данных и замедляют все как со стороны программного обеспечения, так и то, что база данных может выводить. Вам нужно будет выбрать, подходят ли контейнеры для вашего продукта, является ли монолит лучшим способом справиться с вещами, может ли вы иметь основной монолит с несколькими микросервисами, нацеленными на другие функции, распространенные в другом месте, и как вы получаете доступ, собираете, обрабатываете , и хранить данные.
Оборудование
Так же важно, как и ваша общая структура, ваше оборудование является ключевым компонентом производительности вашей базы данных. Exoscale предлагает вам различные варианты инстансов, которые вы можете использовать в зависимости от вашей транзакции и объема хранилища, а также желаемого времени отклика.
Крайне важно определить пиковые периоды вашего приложения и, следовательно, знать, когда по возможности пропускать более медленные административные запросы. Дисковый ввод-вывод и сетевая статистика также должны быть приняты во внимание при проектировании сроков транзакций и аналитики базы данных.
Сводка
В заключение, резюмированы основные моменты для долгосрочной работы:
- создать устойчивую модель данных, которая соответствует потребностям вашей компании
- выберите правильную форму базы данных
- используйте программную архитектуру, которая соответствует вашему продукту
- выполняет регулярные итерации, просматривая структуру ваших запросов и использует
EXPLAINдля более сложных запросов, оптимизирует использование для выбранных вами баз данных, а также в отношении обновлений баз данных и того, как они могут повлиять на вас - выберите экземпляры, которые лучше всего соответствуют потребностям вашего приложения и базы данных в соответствии с производительностью и пропускной способностью
Оператор MySQL SELECT с примерами
Что такое запрос SELECT в MySQL?
SELECT QUERY используется для выборки данных из базы данных MySQL.Базы данных хранят данные для последующего поиска. Цель MySQL Select — вернуть из таблиц базы данных одну или несколько строк, соответствующих заданному критерию. Запрос на выбор можно использовать на языке сценариев, таком как PHP, Ruby, или выполнить его через командную строку.
Синтаксис оператора SQL SELECT
Это наиболее часто используемая команда SQL, имеющая следующий общий синтаксис
SELECT [DISTINCT | ALL] {* | [fieldExpression [AS newName]} FROM tableName [псевдоним] [WHERE condition] [GROUP BY fieldName (s)] [HAVING condition] ORDER BY fieldName (s) HERE - SELECT — это ключевое слово SQL, которое позволяет база данных знает, что вы хотите получить данные.
- [ОТЛИЧИТЕЛЬНЫЙ | ALL] — это необязательные ключевые слова, которые можно использовать для точной настройки результатов, возвращаемых оператором SQL SELECT. Если ничего не указано, по умолчанию принимается ВСЕ.
- {* | [fieldExpression [AS newName]} должна быть указана по крайней мере одна часть, «*» выбирает все поля из указанного имени таблицы, fieldExpression выполняет некоторые вычисления с указанными полями, такие как добавление чисел или объединение двух строковых полей в одно.
- FROM tableName является обязательным и должно содержать хотя бы одну таблицу, несколько таблиц должны быть разделены запятыми или объединены с помощью ключевого слова JOIN.
- WHERE условие является необязательным, его можно использовать для указания критериев в наборе результатов, возвращаемом из запроса.
- GROUP BY используется для объединения записей с одинаковыми значениями полей.
- Условие HAVING используется для указания критериев при работе с ключевым словом GROUP BY.
- ORDER BY используется для указания порядка сортировки набора результатов.
*
Звездочка используется для выбора всех столбцов в таблице. Пример простой инструкции SELECT выглядит так, как показано ниже.
ВЫБРАТЬ * ИЗ `members`;
Приведенный выше оператор выбирает все поля из таблицы элементов. Точка с запятой означает конец оператора. Это не обязательно, но считается хорошей практикой заканчивать подобные заявления.
Практические примеры
Щелкните, чтобы загрузить базу данных myflix, используемую для практических примеров.
Вы можете научиться импортировать файл .sql в MySQL WorkBench
Примеры выполняются для следующих двух таблиц
Таблица 1: участников таблица
| членский_ номер | полные имена | пол | дата рождение | физический_адрес | почтовый_адрес | контактный_ номер | эл.почта |
|---|---|---|---|---|---|---|---|
| 1 | Джанет Джонс | Женский | 21-07-1980 | Участок № 4 | 906 253 542Этот адрес электронной почты защищен от спам-ботов.У вас должен быть включен JavaScript для просмотра. | ||
| 2 | Джанет Смит Джонс | Женский | 23-06-1980 | Melrose 123 | NULL | NULL | Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра. |
| 3 | Роберт Фил | Мужской | 12-07-1989 | 3rd Street 34 | NULL | 12345 | Этот адрес электронной почты защищен от спам-ботов.У вас должен быть включен JavaScript для просмотра. |
| 4 | Глория Уильямс | Женщина | 14-02-1984 | 2-я улица 23 | NULL | NULL | NULL |
Таблица 2:
Таблица 2:
кино
Получение списка участников
Давайте предположим, что мы хотим получить список всех зарегистрированных библиотек database, для этого мы воспользуемся сценарием, показанным ниже.
ВЫБРАТЬ * ИЗ `members`;
Выполнение вышеуказанного сценария в рабочей среде MySQL дает следующие результаты.
| членский_ номер | полные_имя | пол | дата_ рождения | физический_ адрес | почтовый_ адрес | контактный номер | эл. -1980 | Первая улица Участок № 4 | Личная сумка | 0759 253 542 | Этот адрес электронной почты защищен от спам-ботов.У вас должен быть включен JavaScript для просмотра. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | Джанет Смит Джонс | Женский | 23-06-1980 | Melrose 123 | NULL | NULL | Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра. | ||||
| 3 | Роберт Фил | Мужской | 12-07-1989 | 3rd Street 34 | NULL | 12345 | Этот адрес электронной почты защищен от спам-ботов.У вас должен быть включен JavaScript для просмотра. | ||||
| 4 | Gloria Williams | Female | 14-02-1984 | 2nd Street 23 | NULL | NULL | NULL |
все вышеперечисленные столбцы вернулись из нашего запроса таблица участников.
Допустим, нас интересуют только поля full_names, пол, physical_address и email. Следующий сценарий поможет нам добиться этого.
ВЫБЕРИТЕ `полные_имя`,` пол`, `физический_адрес`,` электронная почта` ОТ `members`;
Выполнение вышеуказанного сценария в рабочей среде MySQL дает следующие результаты.
| full_names | пол | физический_адрес | эл. Почта |
|---|---|---|---|
| Джанет Джонс | Женский | Участок № 4 | Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра. |
| Джанет Смит Джонс | Женский | Мелроуз 123 | Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра. |
| Роберт Фил | Мужской | 3rd Street 34 | Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра. |
| Gloria Williams | Female | 2nd Street 23 | NULL |
Получение списка фильмов
Помните, что в нашем обсуждении выше мы упоминали выражения, использованные в операторах SELECT.Допустим, мы хотим получить список фильмов из нашей базы данных. Мы хотим, чтобы название фильма и имя режиссера были в одном поле. Имя режиссера следует указывать в скобках. Мы также хотим узнать год, когда был выпущен фильм. Следующий сценарий помогает нам в этом.
ВЫБРАТЬ Concat (`title`, '(',` Director`, ')'), `year_released` FROM` movies`; ЗДЕСЬ
- Функция MySQL Concat () используется для объединения значений столбцов вместе.
- Строка Concat (`title`, ‘(‘,` director`, ‘)’) получает заголовок, добавляет открывающую скобку, за которой следует имя директора, а затем добавляет закрывающую скобку.
Строковые части разделены запятыми в функции Concat ().
Выполнение вышеуказанного сценария в рабочей среде MySQL дает следующий набор результатов.
| Concat (`title`, ‘(‘,` Director`, ‘)’) | year_released | ||||
|---|---|---|---|---|---|
| Пираты Карибского моря 4 (Роб Маршалл) | 2011 | ||||
| Забыть Сару Маршал (Николас Столлер) | 2008 | ||||
| NULL | Джим | NULL | NULL | ) | 2010 |
| NULL | 2007 | ||||
| NULL | 2007 | ||||
| NULL | 2007 | ||||
| Honey Mooners (Джон Шульц) | 906|||||
| NULL | 2012 |
Имена полей псевдонимов
В приведенном выше примере в качестве имени поля для наших результатов возвращен код конкатенации.Предположим, мы хотим использовать более информативное имя поля в нашем наборе результатов. Для этого мы будем использовать псевдоним столбца. Ниже приводится базовый синтаксис для псевдонима столбца
SELECT `имя_столбца | значение | выражение` [AS]` alias_name`;
ЗДЕСЬ
- «SELECT` имя_столбца | значение | выражение `» — это обычный оператор SELECT, который может быть именем столбца, значением или выражением.
- «[AS]» — необязательное ключевое слово перед псевдонимом, который обозначает выражение, значение или имя поля, которое будет возвращено как.
- «` alias_name` « — это псевдоним, который мы хотим вернуть в нашем наборе результатов в качестве имени поля.
Вышеупомянутый запрос с более значимым именем столбца
SELECT Concat (`title`, '(',` Director`, ')') AS 'Concat', `year_released` FROM` movies`; Получаем следующий результат
| Concat | year_released | ||
|---|---|---|---|
| Пираты Карибского моря 4 (Роб Маршалл) | 2011 | ||
| 5 Столлер6 (Никита) | NULL | 2008 | |
| Кодовое имя Черный (Эдгар Джимз) | 2010 | ||
| NULL | 2007 | ||
| NULL | 2007 | ||
| 9030 Honey John Schultz) | 2005 | ||
| NULL | 2012 |
Получение списка участников с указанием года рождения
Предположим, мы хотим получить список всех участников с указанием номера участника, полных имен и года рождения, мы можем использовать строковую функцию LEFT, чтобы извлечь год рождения из даты рождения fie ld.Показанный ниже сценарий помогает нам в этом.
ВЫБЕРИТЕ `member_number`,` full_names`, LEFT (`date_of_birth`, 4) AS` year_of_birth` ОТ участников;
ЗДЕСЬ
- «LEFT (` date_of_birth`, 4) « строковая функция LEFT принимает дату рождения в качестве параметра и возвращает только 4 символа слева.
- «AS` year_of_birth` « — это псевдоним столбца , имя , которое будет возвращено в наших результатах.Обратите внимание, что ключевое слово AS является необязательным. . Его можно не указывать, и запрос все равно будет работать.
Выполнение вышеуказанного запроса в рабочей среде MySQL для myflixdb дает нам результаты, показанные ниже.
| членский_номер | полные_имя | год_ рождения |
|---|---|---|
| 1 | Джанет Джонс | 1980 |
| 2 | Джанет 9050 9065 9065 Филлипс 9050 6 | |
| 4 | Глория Уильямс | 1984 |
SQL с использованием MySQL Workbench
Теперь мы собираемся использовать MySQL Workbench для создания сценария, который будет отображать все имена полей из нашей таблицы категорий.
1. Щелкните правой кнопкой мыши таблицу категорий. Щелкните на «Select Rows — Limit 1000»
2. Рабочая среда MySQL автоматически создаст SQL-запрос и вставит его в редактор.
3. Будут показаны результаты запроса
Обратите внимание, что мы не писали оператор SELECT сами. Инструментальные средства MySQL сгенерировали его для нас.
Зачем использовать команду SELECT SQL, когда у нас есть MySQL Workbench?
Теперь вы можете подумать, зачем изучать команду SQL SELECT для запроса данных из базы данных, если вы можете просто использовать такой инструмент, как рабочая среда MySQL, чтобы получить те же результаты, не зная языка SQL.Конечно, это возможно, но , изучая, как использовать команду SELECT , дает вам больше гибкости и управляют над вашими операторами SQL SELECT .
Workbench MySQL попадает в категорию инструментов QBE « Query by Example ». Он предназначен для ускорения генерации операторов SQL и повышения производительности труда пользователей.
Изучение команды SQL SELECT может позволить вам создавать сложных запросов , которые нельзя легко сгенерировать с помощью утилит Query by Example, таких как рабочая среда MySQL.
Для повышения производительности вы можете сгенерировать код с помощью MySQL workbench , затем настроить на , чтобы удовлетворить ваши требования . Это может произойти только в том случае, если вы понимаете, как работают операторы SQL!
Сводка
- Ключевое слово SQL SELECT используется для запроса данных из базы данных и является наиболее часто используемой командой.
- Самая простая форма имеет синтаксис «SELECT * FROM tableName;»
- Выражения также можно использовать в операторе выбора.Пример «ВЫБРАТЬ количество + цена из продаж»
- Команда SQL SELECT также может иметь другие необязательные параметры, такие как WHERE, GROUP BY, HAVING, ORDER BY. О них мы поговорим позже.
- Инструментальные средства MySQL могут помочь разрабатывать операторы SQL, выполнять их и выдавать выходной результат в том же окне.
Отображение запущенных запросов в MySQL
В MySQL есть оператор под названием «показать список процессов», чтобы показать вам выполняющиеся запросы на вашем сервере MySQL. Это может быть полезно, чтобы узнать, что происходит, если есть несколько больших, длинных запросов, потребляющих много циклов ЦП, или если вы получаете такие ошибки, как «слишком много соединений».
Синтаксис прост:
показать список процессов;
, который выведет что-то вроде этих строк:
+ -------- + -------- + ----------- + ------- - + --------- + ------ + ---------------------- + -------- -------------------------------------------------- -------------------------------------------- + | Id | Пользователь | Хост | db | Команда | Время | Государство | Информация | + -------- + -------- + ----------- + -------- + --------- + ------ + ---------------------- + -------------------- -------------------------------------------------- -------------------------------- + | 708163 | корень | localhost | NULL | Запрос | 0 | NULL | показать список процессов | | 708174 | тест | localhost | тест | Запрос | 2 | Копирование в таблицу tmp | выберите расст.имя, dist.filename, count (*) from orders_header h внутреннее соединение orders_detail d на h.ord | + -------- + -------- + ----------- + -------- + --------- + ------ + ---------------------- + -------------------- -------------------------------------------------- -------------------------------- + 2 ряда в наборе (0,00 сек)
Столбец «информация» показывает выполняемый запрос m или NULL, если в данный момент ничего не происходит. При запуске «show processlist» будут показаны только первые 100 символов запроса. Чтобы показать полный запрос, вместо этого запустите «показать полный список процессов».
Выполнение указанной выше команды из интерфейса командной строки MySQL с; разделитель может затруднить чтение вывода, особенно если запросы длинные и занимают несколько строк. Вместо этого при использовании разделителя G данные будут отображаться в более удобочитаемом формате, хотя в вашем терминале требуется больше строк. Это особенно полезно при запуске «показать полный список процессов», потому что некоторые из отображаемых запросов могут быть довольно длинными.
mysql> показать список процессовG *************************** 6.строка *************************** Id: 708163 Пользователь: root Хост: localhost db: NULL Команда: Запрос Время: 0 Состояние: NULL Информация: показать список процессов ************************** 7. ряд ******************** ******* Id: 708174 Пользователь: test Хост: localhost db: test Команда: Запрос Время: 3 Состояние: копирование в таблицу tmp Информация: выберите dist.name, dist.filename, count (*) from orders_header h внутреннее соединение orders_detail d на h.ord 2 строки в наборе (0,00 сек)
Если вы работаете как обычный пользователь, у которого нет привилегии «процесс», то «показать список процессов» покажет только те процессы, которые вы выполняете в данный момент.Если у пользователя есть привилегия процесса, он может видеть все.
Идентификация и завершение запросов с помощью инструмента командной строки MySQL
Длительные запросы MySQL не позволяют другим транзакциям обращаться к таблицам, необходимым для выполнения запроса, оставляя ваших пользователей на удержании. Чтобы уничтожить эти запросы, вам потребуется доступ к базе данных MySQL среды.
Повышение производительности веб-сайта
Сделайте ваш сайт быстрее. Посетите наш бесплатный еженедельный семинар, на котором вы узнаете о кэшировании страниц с помощью нашего Advanced CDN, нашего внутреннего кеша Redis и узнаете, как использовать New Relic® Performance Monitoring для мониторинга производительности.
После успешного создания локального MySQL-соединения с базой данных сайта выполните следующую команду, чтобы отобразить список активных потоков:
Просмотрите поле Время , чтобы определить самый длинный выполняющийся запрос, и выполните следующую команду, чтобы завершить его. В приведенном ниже примере замените на идентификатор запроса, который вы хотите завершить:
Если большое количество неверных запросов блокирует допустимые запросы, вы можете очистить их, не выполняя kill каждый раз. индивидуальная резьба.
Выполните следующее, чтобы сгенерировать команды kill из таблицы PROCESSLIST :
mysql> SELECT GROUP_CONCAT (CONCAT ('KILL', id, ';') SEPARATOR '') 'Вставьте следующий запрос, чтобы убить всех процессы 'FROM information_schema.processlist WHERE user <>' system user '\ G Скопируйте предоставленный запрос в выходные данные и выполните его в соответствии с инструкциями.
Устранение неполадок с помощью New Relic® Performance Monitoring
Чтобы лучше понять, что происходит с вашими запросами, ознакомьтесь с разделом «Устранение неполадок MySQL с помощью New Relic® Performance Monitoring».Используя наши интегрированные службы отчетности с New Relic® Performance Monitoring, вы можете изолировать проблемы с производительностью MySQL на своих сайтах Drupal или WordPress.
Просмотр журналов медленных запросов
Используйте журнал медленных запросов MySQL вашего сайта для устранения неполадок MySQL и выявления серьезных проблем с производительностью.
Включить Redis
Большинство фреймворков веб-сайтов, таких как Drupal и WordPress, используют базу данных для кэширования внутренних «объектов» приложения, создание которых может быть дорогостоящим (деревья меню, результаты фильтрации и т. Д.)) и сохранить кешированное содержимое страницы. Поскольку база данных также обрабатывает множество запросов для обычных запросов страниц, это наиболее частое узкое место, вызывающее увеличение времени загрузки.
Redis предоставляет альтернативный механизм кэширования, снимающий эту работу с базы данных, что имеет жизненно важное значение для масштабирования до большего числа вошедших в систему пользователей. Он также предоставляет ряд других полезных функций для разработчиков, которые хотят использовать его для управления очередями или для собственного кэширования.
Рассмотрим репликацию MySQL (WordPress)
Типичные сайты WordPress ограничены возможностями одной базы данных для обслуживания запросов на чтение и запись.В результате на сайтах с высоким трафиком могут возникать задержки при выполнении запросов. Репликация MySQL быстро копирует контент из «главной» базы данных в одну или несколько «реплик» баз данных. Это позволяет распределять запросы по нескольким базам данных, чтобы улучшить производительность сайта и время загрузки.
Как писать сложные запросы MySQL?
Расширенные запросы, предназначенные для решения сложных задач или нескольких задач, составляют важную часть работы любого администратора или разработчика базы данных.Сложные запросы MySQL должны обрабатываться со всей серьезностью, поскольку неточный код MySQL или плохо работающие сценарии могут вызвать серьезные ошибки и сбои приложений.
Что такое сложный запрос MySQL?
Сложные запросы MySQL к поисковым данным с использованием более чем одного параметра могут содержать комбинацию нескольких объединений в нескольких таблицах и довольно большого количества вложенных подзапросов (запросов, вложенных в другой запрос). Сложные запросы также часто связаны с частым использованием предложений AND и OR.
Сложные запросы обычно используются для извлечения сложных данных из нескольких таблиц. Расширенные запросы также могут использоваться для составления отчетов, объединения нескольких таблиц, вложенных запросов и блокировки транзакций.
Сложный запрос MySQL с несколькими операторами SELECT
В аналитических целях часто бывает необходимо получить данные из нескольких разных таблиц, чтобы сформировать единую таблицу результатов. Таким образом, сложные запросы MySQL с несколькими операторами SELECT являются наиболее распространенными сложными запросами, используемыми администраторами баз данных и разработчиками.Когда вы объединяете результаты нескольких операторов SELECT, вы можете выбрать, что включить в таблицу результатов. Именно это и делает их такими популярными.
Пример построения сложных MySQL-запросов в dbForge Studio для MySQL
Написание сложных запросов может пугать и несколько сбивать с толку новичка в MySQL. Здесь на помощь приходит dbForge Studio for MySQL. Его передовая функциональность Query Builder включает в себя простой в освоении и использовании визуальный конструктор запросов, который позволяет создавать запросы MySQL без ручного кодирования.
Шаг 1. Включение построителя запросов
Чтобы начать работу с Query Builder, выберите его в списке инструментов разработки SQL на начальной странице Studio.
Шаг 2. Добавление таблиц в запрос
Чтобы добавить в запрос таблицы и представления, просто перетащите их из дерева обозревателя баз данных на диаграмму запроса. Кроме того, вы можете щелкнуть правой кнопкой мыши необходимые таблицы в проводнике баз данных, выбрать команду «Отправить» в контекстном меню и затем выбрать «Построитель запросов».
Шаг 3. Создание подзапросов
dbForge Studio предлагает полную поддержку подзапросов во всех предложениях операторов SELECT . У каждого подзапроса могут быть свои собственные подзапросы. Когда вы создаете подзапрос или открываете его для визуального редактирования, появляется вкладка подзапроса документа запроса. Используя эти вкладки, вы можете легко перемещаться между подзапросами.
Чтобы создать подзапрос, щелкните правой кнопкой мыши тело диаграммы и выберите команду Создать подзапрос из контекстного меню.
Шаг 4. Создание СОЕДИНЕНИЙ между таблицами
dbForge Studio for MySQL позволяет визуально создавать следующие СОЕДИНЕНИЯ: INNER, LEFT OUTER, RIGHT OUTER, NATURAL и CROSS JOIN. Вы также можете легко установить довольно сложные условия для соединения любого типа.
Объединения создаются автоматически, когда на диаграмме помещается таблица с внешним ключом и связанная с ней таблица. Чтобы добавить соединение, перейдите на вкладку Joins редактора с вкладками и нажмите кнопку Add в верхней части узла дерева.Появится новое пустое соединение с пустым условием. Щелкните поле Введите имя таблицы и укажите объединяемые таблицы. Затем установите тип соединения, щелкнув текстовую ссылку красного цвета и выбрав необходимый элемент в контекстном меню. Вы также можете удалить соединение, нажав эту кнопку.
Ste p 5. Построение пунктов WHERE или HAVING, если необходимо
При извлечении данных может потребоваться отфильтровать или исключить записи. И лучший способ добиться этого — использовать предложения WHERE и HAVING.
Чтобы создать предложения WHERE и \ или HAVING, перейдите на соответствующие вкладки и внесите необходимые настройки с помощью интуитивно понятного интерфейса.
Шаг 6. Создание предложений GROUP BY или ORDER BY
Предложения GROUP BY и ORDER BY используются для организации выходных данных. Чтобы создать эти предложения, перейдите на соответствующую вкладку и выберите столбцы для сортировки.
Шаг 7. Просмотр и выполнение запроса
После того, как вы внесете все необходимые настройки, переключитесь в текстовое представление, чтобы проверить автоматически сгенерированный запрос.Если результат вас устраивает, нажмите кнопку «Выполнить» на главной панели инструментов, чтобы запустить скрипт.
Шаг 8. Анализ результата
Результат запроса будет немедленно отображен для анализа. Функциональность редактора данных, встроенная в dbForge Studio for MySQL, позволяет управлять данными наиболее удобным способом.
Заключение
Когда дело доходит до построения сложных запросов MySQL, работа с подзапросами, предложениями и условиями может показаться утомительной, особенно для новичков.Функциональность Query Builder, поставляемая с dbForge Studio for MySQL, обязательно устранит эту боль. Интуитивно понятный и хорошо продуманный графический интерфейс значительно упрощает создание сложных запросов и управление условиями JOIN.
Последние сообщения от команды dbForge (посмотреть все)
сложные запросы mysql, инструменты mysql, построитель запросов
Оптимизация запросовс помощью Mysql — MySql умнее, чем вы думаете.
Оптимизация запросов — это совместные усилия вас и mysql.
Чтобы получить представление об архитектуре mysql, быстро прочтите — Логическая архитектура MySQL
MySQL анализирует запросы для создания внутренней структуры (дерева синтаксического анализа), а затем применяет различные оптимизации. Они могут включать в себя переписывание запроса, определение порядка, в котором он будет читать таблицы, выбор используемых индексов и т. Д. Вы можете передавать подсказки оптимизатору с помощью специальных ключевых слов в запросе, влияя на процесс принятия решения.Вы также можете попросить сервер объяснить различные аспекты оптимизации.
Это позволяет узнать, какие решения принимает сервер, и дает вам ориентир для доработки запросов, схем и настроек, чтобы все работало максимально эффективно.
Переупорядочивание объединений
Таблицы не всегда нужно объединять в том порядке, который вы указываете в запросе. Определение наилучшего порядка соединения — важная оптимизация.
Преобразование ВНЕШНИХ СОЕДИНЕНИЙ во ВНУТРЕННИЕ СОЕДИНЕНИЯ
ВНЕШНЕЕ СОЕДИНЕНИЕ не обязательно должно выполняться как ВНЕШНЕЕ СОЕДИНЕНИЕ. Некоторые факторы, такие как предложение WHERE и схема таблицы, могут фактически привести к тому, что OUTER JOIN будет эквивалентным INNER JOIN. MySQL может распознать это и переписать соединение, что делает его пригодным для переупорядочения.
Применение правил алгебраической эквивалентности
MySQL применяет алгебраические преобразования для упрощения и упорядочивания выражений. Он также может сворачивать и сокращать константы, устраняя невозможные ограничения и постоянные условия.Например, член (5 = 5 И a> 5) уменьшится до просто a> 5. Точно так же (a 5 AND b = c AND a = 5. Эти правила очень полезны при написании условных запросов.
Оптимизация COUNT (), MIN () и MAX ()
Индексы и допустимость пустых значений столбцов часто помогают MySQL оптимизировать эти выражения. Например, чтобы найти минимальное значение крайнего левого столбца в индексе B-дерева, MySQL может просто запросить первую строку в индексе. Он может даже сделать это на этапе оптимизации запроса и обработать значение как константу для остальной части запроса.Точно так же, чтобы найти максимальное значение в индексе B-дерева, сервер считывает последнюю строку. Точно так же запросы COUNT (*) без предложения WHERE часто можно оптимизировать на некоторых механизмах хранения (таких как MyISAM, который постоянно ведет точное количество строк в таблице).
Покрывающие индексы
MySQL иногда может использовать индекс, чтобы избежать чтения данных строки, когда индекс содержит все столбцы, необходимые запросу, он возвращает данные из самого индекса.
Оптимизация подзапросов
MySQL может преобразовывать некоторые типы подзапросов в более эффективные альтернативные формы, сокращая их до поиска индекса вместо отдельных запросов.
Раннее завершение
MySQL может прекратить обработку запроса (или шага в запросе), как только он выполнит запрос или шаг. Очевидный случай — это предложение LIMIT, но есть несколько других видов досрочного завершения. Например, если MySQL обнаруживает невозможное условие, он может прервать весь запрос. Вы можете увидеть это в следующем примере:
его запрос остановлен на этапе оптимизации, но MySQL также может преждевременно завершить выполнение в некоторых других случаях. Сервер может использовать эту оптимизацию, когда механизм выполнения запросов распознает необходимость получения отдельных значений или для остановки, когда значение не существует.
Сравнение списков IN ()
На многих серверах баз данных IN () является просто синонимом нескольких предложений OR, поскольку они логически эквивалентны. Не так в MySQL, который сортирует значения в списке IN () и использует быстрый двоичный поиск, чтобы узнать, есть ли значение в списке. Это O (log n) по размеру списка, тогда как эквивалентная серия предложений OR — O (n) по размеру списка (т.е. намного медленнее для больших списков).
Спасибо MySQLMySQL выполняет больше оптимизаций, чем мы могли бы уместить во всем этом блоге, но это дает общее представление об имеющихся у него интеллектуальных способностях.
Уровень сервера, содержащий оптимизатор запросов, не хранит статистику
по данным и индексам. Это задача механизмов хранения, потому что каждый механизм хранения может хранить разные виды статистики (или вести их по-разному). Некоторые движки, такие как Archive Engine, вообще не ведут статистику!
Поскольку сервер не хранит статистику, оптимизатор запросов MySQL должен запрашивать у движков статистику по таблицам в запросе. Механизмы предоставляют оптимизатору статистику, такую как количество страниц в таблице или индексе, количество таблиц и индексов, длину строк и ключей, а также информацию о распределении ключей.Оптимизатор может использовать эту информацию, чтобы выбрать лучший план выполнения.
Оптимизатор запросов MySQL использует два вызова API, чтобы спросить механизмы хранения, как распределяются значения индексов, при принятии решения о том, как использовать индексы.
- Первый — это вызов records_in_range (), который принимает конечные точки диапазона и возвращает количество записей в этом диапазоне. Это может быть точным для некоторых механизмов хранения, таких как MyISAM, но это только оценка для InnoDB.
- Второй вызов API — это info (), который может возвращать различные типы данных, включая количество элементов индекса (приблизительное количество записей для каждого значения ключа).
Когда механизм хранения предоставляет оптимизатору неточную информацию о количестве строк, которые может исследовать запрос, или когда план запроса слишком сложен, чтобы точно знать, сколько строк будет сопоставлено на различных этапах, оптимизатор использует статистику индекса чтобы оценить количество строк. Оптимизатор MySQL основан на затратах, и основной показатель затрат — это объем данных, к которым будет обращаться запрос. Если статистика никогда не генерировалась или устарела, оптимизатор может принять неверные решения.Решение состоит в том, чтобы запустить ANALYZE TABLE, который восстанавливает статистику.
В InnoDb Статистика генерируется путем выборки нескольких случайных страниц в индексе и предположения, что остальная часть индекса выглядит аналогично.
Число выбранных страниц составляет восемь в более старых версиях InnoDB, но в более поздних версиях им можно управлять с помощью переменной innodb_stats_sample_pages. Установка этого значения больше восьми может теоретически помочь генерировать более репрезентативную статистику индекса, особенно для очень больших таблиц, но ваш опыт может отличаться.
Прежде чем писать быстрые запросы, помните, что все дело в времени ответа. Запросы — это задачи, но они состоят из подзадач, и эти подзадачи требуют времени. Чтобы оптимизировать запрос, вы должны оптимизировать его подзадачи, устраняя их, заставляя их выполняться реже или заставляя их выполняться быстрее.
Убедившись, что запросы извлекают только те данные, которые вам нужны, вы можете искать запросы, которые исследуют слишком много данных при генерировании результатов. В MySQL простейшими метриками стоимости запроса являются:
• Время ответа
• Количество проверенных строк
• Количество возвращаемых строк
Ни одна из этих метрик не является идеальным способом измерения стоимости запроса, но они примерно отражают объем данных MySQL должен иметь внутренний доступ для выполнения запроса и примерно отражать скорость выполнения запроса.Все три показателя регистрируются в журнале медленных запросов, поэтому просмотр журнала медленных запросов — один из лучших способов найти запросы, которые исследуют слишком много данных.
Когда вы думаете о стоимости запроса, подумайте о стоимости поиска одной строки в таблице. MySQL может использовать несколько методов доступа для поиска и возврата строки. Некоторые требуют проверки множества строк, но другие могут сгенерировать результат, не проверяя ни одной.