Установка и первичная настройка PostgreSQL на Ubuntu 16.04 – Vscale Community
Введение
PostgreSQL (произносится как «Пост-Грес-Кью-Эл») — свободная современная СУБД с широкими возможностями. Её используют такие компании, как Alibaba, Instagram, Skype, Yahoo и многие другие. Это говорит о надёжности системы, и при этом она является простой в установке, использовании и обслуживании. Поверхностно ознакомиться с ней можно по статье в Википедии: https://ru.wikipedia.org/wiki/PostgreSQL
PostgreSQL является кроссплатформенной СУБД с открытым исходным кодом, поэтому её можно установить практически на любой сервер. Все конфигурации серверов и все операционные системы, предоставляемые vscale, позволяют использование PostgreSQL.
Рассмотрим установку и настройку на примере Ubuntu 16.04 64bit.
Технические требования
• Пользователь с sudo-правами
• Ubuntu 16.04
Шаг 1. Выбор источника для установки
PostgreSQL является очень популярным сервером баз данных, поэтому присутствует в официальных репозиториях Ubuntu. Однако в PPA разработчиков PostgreSQL можно найти самую свежую версию. Например, на момент написания данной инструкции в репозитории Ubuntu имеется PostgreSQL 9.5, а из PPA можно установить 9.6. Если у вас нет потребности в самых последних возможностях данной СУБД, то текущий шаг можно пропустить. Иначе добавьте репозиторий PostgreSQL в системный список источников:
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
и добавьте для него ключ
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O - | sudo apt-key add -
Это позволит при обновлении пакетов получать наиболее свежие версии.
Шаг 2. Установка PostgreSQL
Если система установлена недавно и вы пропустили предыдущий шаг, то данный шаг можно пропустить, так как в процессе установки системы производится обновление индекса пакетов. В противном случае выполните команду:
sudo apt-get update
Эта команда произведёт обновление индекса, что позволит устанавливать свежие и актуальные пакеты.
Установка PostgreSQL из официальных репозиториев и из PPA производится одинаково. Загрузим и установим пакеты PostgreSQL и contrib (contrib предоставляет некоторый дополнительный функционал и утилиты):
sudo apt-get install postgresql postgresql-contrib
Шаг 3. Подключение к серверу баз данных
Во время установки программы в системе автоматически была создана учётная запись администратора баз данных — postgres. На данном этапе доступ к системе баз данных можно получить только через неё.
sudo su - postgres
psql
либо запустить оболочку от имени postgres без переключения сессии:
sudo -u postgres psql
Попав тем или иным способом в командную строку psql, вам необходимо знать, как из неё выйти. Это можно сделать с помощью ввода команды выхода:
\q
(сокращение от quit).
Шаг 4. Создание новой роли
Если вы производили установку по инструкции, то к этому моменту в вашей СУБД есть только одна роль — postgres. Рекомендуется не использовать данную роль для работы со своими базами данных, а создавать для каждой базы новую роль (или несколько при необходимости). Для создания новой роли предусмотрены два стандартных способа:
- интерактивный режим, в котором достаточно ответить на несколько простых вопросов;
- команда для создания роли через командную строку СУБД.
Мы не будем подробно останавливаться на интерактивном режиме, так как создать роль, которая полностью удовлетворяет требованиям в большинстве случаев, мы можем всего одной простой командой (перед этим нужно находиться в режиме командной строки как было описано на Шаге 3). Не забудьте заменить username на желаемое имя пользователя, а password — на пароль для этого пользователя:
create user username with password 'password';
Имя указывается без кавычек, а пароль — в одинарных кавычках.
Шаг 5. Создание базы данных
Находясь в режиме командной строки psql, создать базу данных мы можем командой create database и указав название базы данных. Например, чтобы воздать БД с именем vscale_db, выполните команду:
create database vscale_db;
Шаг 6. Назначение прав
Созданной ранее нами роли нужно назначить права на базу данных. В большинстве проектов, где у вас будет использоваться всего один пользователь базы данных, ему будут требоваться полные права. Выдать их можно следующим образом:
grant all privileges on database vscale_db to username;
где vscale_db — название базы данных, выбранное на шаге 5, а username — имя пользователя, заданное на шаге 4.
Вся минимально требующаяся предв
community.vscale.io
Установка и настройка PostgreSQL 10 на Linux Ubuntu Server | Info-Comp.ru
Привет! Материал сегодня будет посвящен рассмотрению процесса установки СУБД PostgreSQL 10 на серверную операционную систему Linux Ubuntu Server, а также первоначальной настройки PostgreSQL 10, для того чтобы можно было ее использовать, например, в сети своей организации.

Так как PostgreSQL 10 – это новая версия данной системы управления базами данных, то начать предлагаю с краткого рассмотрения новых возможностей 10 версии.
Примечание! 10 версия PostgreSQL была актуальна на момент написания статьи, на текущий момент доступны новые версии.
Что нового в PostgreSQL 10?
Начиная с PostgreSQL 10, меняется схема нумерации версий, это вызвано тем, что раньше выходило множество минорных версий (например, 9.x), многие из которых на самом деле вносили значительные изменения не соответствующие минорным, теперь мажорные версии будут нумероваться 10, 11, 12, а минорные 10.1, 10.2, 11.1 и так далее.
Основные нововведения:
- Логическая репликация с использованием публикации и подписки — теперь возможно осуществлять репликацию отдельных таблиц на другие базы, это реализовывается с помощью команд CREATE PUBLICATION и CREATE SUBSCRIPTION;
- Декларативное партиционирование таблиц – в PostgreSQL 10 добавился специальный синтаксис для партиционирования, который позволяет легко создавать и поддерживать таблицы с интервальной или списочной схемой партиционирования;
- Улучшенный параллелизм запросов – другими словами, появилась дополнительная оптимизация запроса, для того чтобы пользователь получал данные быстрей;
- Аутентификация пароля на основе SCRAM-SHA-256 – добавился новый метод аутентификации, который является более безопасным, чем метод с использованием MD5;
- Quorum Commit для синхронной репликации – теперь администратор может указать что, если какое-либо количество реплик подтвердило, что внесено изменение в базу данных, данное изменение можно считать надёжно зафиксированным;
- Значительные общие улучшения производительности;
- Улучшенный мониторинг и контроль.
Более детально обо всех нововведениях можете почитать на официальном сайте – PostgreSQL 10.
Установка PostgreSQL 10 на Linux Ubuntu Server 16.04
Как Вы уже, наверное, поняли рассматривать процесс установки и соответственно настройки PostgreSQL 10 мы будем на примере версии Ubuntu Server 16.04, так как эта версия имеет долгосрочную поддержку и на текущий момент является актуальной среди LTS версий.
Шаг 1
Установку и настройку PostgreSQL необходимо осуществлять с правами суперпользователя, поэтому давайте сразу переключимся на пользователя root. Для этого вводим sudo -i (или sudo su) и жмем Enter.
Шаг 2
Затем первое, что нам нужно сделать, это проверить есть ли в репозиториях версия PostgreSQL 10. Это можно сделать путем ввода следующей команды.
apt-cache search postgresql-10
Как видим, в Ubuntu Server 16.04 10 версии PostgreSQL нет, поэтому нам нужно подключить необходимый репозиторий, в котором присутствует PostgreSQL 10. Если у Вас более новая версия Ubuntu Server и в стандартных репозиториях есть 10 версия PostgreSQL, то дополнительный репозиторий Вам подключать не нужно, т.е. данный шаг Вы пропускаете.
Для подключения репозитория нам необходимо создать специальный файл с адресом нужного репозитория. Адреса для каждой версии Ubuntu разные, поэтому если у Вас версия Ubuntu не 16.04, то уточнить адрес Вы можете на официальном сайте PostgreSQL на странице загрузке – вот она.
После перехода на страницу выбираете версию Ubuntu, после чего у Вас отобразится адрес нужного репозитория.
Для упрощения процедуры создания файла давайте напишем скрипт с выводом адреса репозитория, а вывод перенаправим в файл. Для Ubuntu Server 16.04 подключение нужного репозитория будет выглядеть следующим образом.
sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ xenial-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
Также нам необходимо импортировать ключ подписи репозитория, для этого вводим команду.
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | \apt-key add -
Далее обновляем список пакетов.
apt-get update
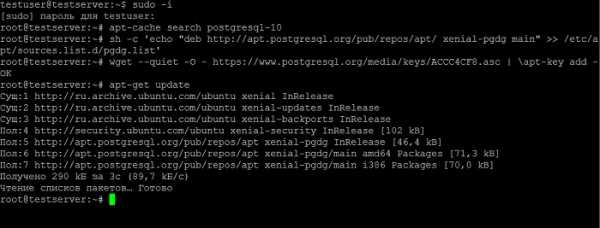
И еще раз проверяем наличие пакета с PostgreSQL 10.
apt-cache search postgresql-10
Теперь нужный пакет у нас есть, и мы можем переходить к установке PostgreSQL 10.
Шаг 3
Для установки PostgreSQL 10 пишем следующую команду.
apt-get -y install postgresql-10
По окончанию процесса установки проверяем, запущен ли сервер PostgreSQL.
systemctl status postgresql
Как видим, PostgreSQL 10 установился и работает.
Базовая настройка PostgreSQL 10 в Linux Ubuntu Server
После установки нам необходимо выполнить базовую настройку PostgreSQL 10, например: создать пользователя, указать какие сетевые интерфейсы будет прослушивать сервер, а также разрешить подключение по сети. Начнем мы с создания пользователя и базы данных.
Создание пользователя и базы данных в PostgreSQL
После установки, к серверу PostgreSQL мы можем подключиться только с помощью системного пользователя postgres, причем без пароля. Для этого переключаемся на пользователя postgres (учетная запись в Ubuntu создана автоматически во время установки PostgreSQL).
su - postgres
Запускаем psql — это консоль управления PostgreSQL.
psql
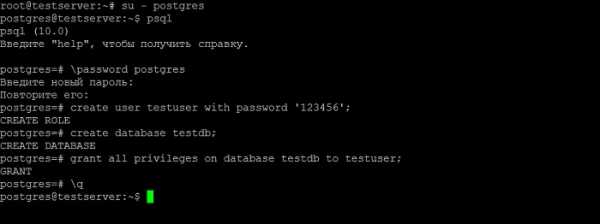
Сначала зададим пароль для пользователя postgres.
\password postgres
Затем создаем нового пользователя на сервере PostgreSQL, так как работать от имени postgres крайне не рекомендуется.
create user testuser with password '123456';
где, testuser – это имя пользователя, ‘123456’ – это его пароль.
Далее давайте создадим базу данных.
create database testdb;
где, testdb – это имя новой базы данных.
Теперь давайте дадим права на управление БД нашему новому пользователю.
grant all privileges on database testdb to testuser;
Все готово, выходим из консоли.
\q
Для проверки, давайте подключимся к PostgreSQL от имени нового пользователя, на предложение о вводе пароля вводим пароль от новой учетной записи.
psql -h localhost testdb testuser
Работает. Для выхода снова набираем \q.
\q
Для переключения обратно на root вводим exit.
exit
Разрешаем подключение к PostgreSQL по сети
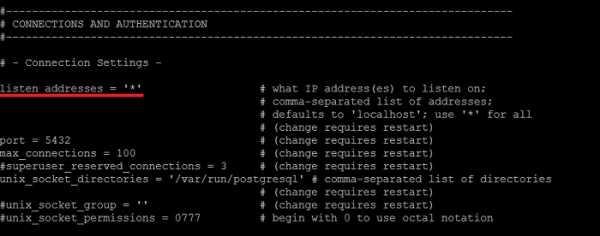
По умолчанию PostgreSQL прослушивает только адрес localhost, поэтому для того чтобы мы могли подключаться по сети, нам нужно указать какие сетевые интерфейсы будет просушивать PostgreSQL. Я для примера укажу, что прослушивать нужно все доступные интерфейсы. Если у Вас несколько сетевых интерфейсов, и Вы хотите, чтобы PostgreSQL использовал только один конкретный, то Вы его можете указать именно здесь.
Для этого открываем файл postgresql.conf, например редактором nano.
nano /etc/postgresql/10/main/postgresql.conf
Находим следующую строку.
#listen_addresses = 'localhost'
и заменяем на (вместо звездочки Вы в случае необходимости указываете IP адрес нужного интерфейса).
listen_addresses = '*'
Сохраняем изменения сочетанием клавиш CTRL+O и подтверждаем нажатием Enter, затем просто закрываем редактор nano сочетанием клавиш CTRL+X.
Теперь давайте разрешим подключение из сети 10.0.2.0/24 с методом аутентификации md5. Для этого открываем файл pg_hba.conf
nano /etc/postgresql/10/main/pg_hba.conf
Ищем вот такие строки.
И вносим следующие изменения (если IPv6 Вы не будете использовать, то можете закомментировать соответствующие строки знаком #).
Где, 10.0.2.0/24 адрес сети, из которой будет происходить подключение к текущему серверу PostgreSQL. Сохраняем изменения сочетанием клавиш CTRL+O, подтверждаем нажатием Enter и закрываем редактор nano сочетанием клавиш CTRL+X.
Перезапускаем PostgreSQL
systemctl restart postgresql
Все, установка и настройка PostgreSQL закончена, можете подключаться к серверу из сети клиентским приложением. Пока, надеюсь, материал был Вам полезен!
info-comp.ru
PostgreSQL 9.2 Начало! / Habr
Мне хотелось создатьPostgreSQL является объектно-реляционной системой управления базами данных (ОРСУБД) на основе POSTGRES, версия 4.2, разработанной в Университете Калифорнии в Беркли департаменте компьютерных наук.
PostgreSQL является open source потомком оригинального кода Berkeley. Он поддерживает большую часть стандарта SQL и предлагает множество современных функций:
Кроме того, PostgreSQL может быть расширен пользователем во многих отношениях, например, путем добавления новых
- типов данных
- функций
- операторов
- агрегатных функций
- индекс методов
- процедурных языков
Сборка и установка
Как и все любители мейнстрима PostgreSQL мы будем конечно же собирать, а не скачивать готовые пакеты (в репозитариях Debian, например, нет последней версии). Вот здесь лежит множество версий, скачивать конечно же лучше всего последнюю. На момент написания поста это версия 9.2.2
wget http://ftp.postgresql.org/pub/source/v9.2.2/postgresql-9.2.2.tar.gz
tar xzf postgresql-9.2.2.tar.gzТеперь у нас есть директория с исходниками сей прекрасной базы данных.
По умолчанию файлы базы будут установлены в директорию /usr/local/pgsql, но эту директорию можно изменить задав
--prefix=/path/to/pgsqlперед командой ./configure
Перед сборкой можно указать компилятор С++
export CC=gccPostgeSQL может использовать readline библиотеку, если у вас её нет и нет желания её ставить просто укажите опцию
--without-readlineНадеюсь у всех есть Autotools? Тогда вперед к сборке:
cd postgresql-9.2.2
./configure --without-readline
sudo make install cleanВсе господа! Поздравляю!
Настройка
Нам необходимо указать хранилище данных наших баз данных (кластер) и запустить её.
Есть один нюанс — владельцем директории данных и пользователь, который может запускать базу должен быть не root. Это сделано в целях безопасности системы. Поэтому создадим специального пользователя
sudo useradd postgres -p postgres -U -mИ далее все понятно
sudo chown -R postgres:postgres /usr/local/pgsqlВажный процесс. Мы должны инициализировать кластер баз дынных. Сделать мы должны это от имени пользователя postgres
initdb -D /usr/local/pgsql/dataТеперь нужно добавить запуск PostgreSQL в автостарт. Для этого существует уже готовый скрипт и лежит он в postgresql-9.2.2/contrib/start-scripts/linux
Этот файл можно открыть и обратить внимание на следующие переменные:
- prefix — это место куда мы ставили PostgreSQL и задавали в ./configure
- PGDATA — это то, где хранится кластер баз данных и куда должен иметь доступ наш пользователь postgres
- PGUSER — это тот самый пользователь, от лица которого будет все работать
Если все стоит верно, то добвляем наш скрипт в init.d
sudo cp ./postgresql-9.2.2/contrib/start-scripts/linux /etc/init.d/postgres
sudo update-rc.d postgres defaults
Перезапускам систему, чтобы проверить что наш скрипт работает.
Вводим
/usr/local/pgsql/bin/psql -U postgresИ если появится окно работы с базой, то настройка прошла успешно! Поздравляю!
По умолчанию создается база данных с именем postgres
Теперь важно поговорить о методах авторизации.
В /usr/local/pgsql/data/pg_hba.conf как раз есть необходимые для этого настройка
# TYPE DATABASE USER ADDRESS METHOD
local all all trust
host all all 127.0.0.1/32 trust
host all all ::1/128 trust
Первая строка отвечает за локальное соединение, вторая — за соединение про протоколу IPv4, а третья по протоколу IPv6.
Самый последний параметр — это как раз таки метод авторизации. Его и рассмотрим (только основные)
- trust — доступ к базе может получить кто угодно под любым именем, имеющий с ней соединение.
- reject — отклонить безоговорочно! Это подходит для фильтрации определенных IP адресов
- password — требует обязательного ввода пароля. Не подходит для локальных пользователей, только пользователи созданные командой CREATE USER
- ident — позволяет только пользователем зарегистрированным в файле /usr/local/pgsql/data/pg_ident.conf устанавливать соединение с базой.
Вкратце расскажу об основных утилитах, которые пригодятся в работе.
Утилиты для работы с базой
pg_config
Возвращает информацию о текущей установленной версии PostgreSQL.initdb
Инициализирует новое хранилище данных (кластер баз данных). Кластер представляет собой совокупность баз данных управляемых одним экземпляром севера. initdb должен быть запущен от имени будущего владельца сервера (как указано выше от имени postgres).pg_ctl
Управляет процессом работы сервера PostgreSQL. Позволяет запускать, выполнять перезапуск, останавливать работу сервера, указать лог файл и другое.psql
Клиент для работы с базой дынных. Позволяет выполнять SQL операции.createdb
Создает новую базу данных. По умолчанию, база данных создается от имени пользователя, который запускает команду. Однако, чтобы задать другого — необходимо использовать опцию -O (если у пользователя есть необходимые привилегии для этого). По сути — это обертка SQL команды CREATE DATABASE.dropdb
Удаляет базу данных. Является оберткой SQL команды DROP DATABASE.createuser
Добавляет нового пользователя базы дынных. Является оберткой SQL команды CREATE ROLE.dropuser
Удаляет пользователя базы данных. Является оберткой SQL команды DROP ROLE.createlang
Добавляет новый язык программирования в базу PostgreSQL. Является оберткой SQL команды CREATE LANGUAGE.droplang
Удаляет язык программирования. Является оберткой SQL команды DROP LANGUAGE.pg_dump
Создает бэкап (дамп) базы данных в файл.pg_restore
Восстанавливает бэкап (дамп) базы данных из файла.pg_dumpall
Создает бэкап (дамп) всего кластера в файл.reindexdb
Производит переиндексацию базы данных. Является оберткой SQL команды REINDEX.clusterdb
Производит перекластеризацию таблиц в базе данных. Является оберткой SQL команды CLUSTER.vacuumdb
Сборщик мусора и оптимизатор базы данных. Является оберткой SQL команды VACUUM.Менеджеры по работе с базой
Что касается менеджера по работа с базой, то есть php менеджер — это phpPgAdmin и GUI менеджер pgAdmin. Должен заметить, что они оба плохо поддерживают последнюю версию PostgreSQL.
P.S Если что-то забыл, скажите — добавлю.
habr.com
Установка и первоначальная настройка PostgreSQL
1. Установка
1.1. Установка из официального репозитория
Если для Вас важна последняя доступная версия PostgreSQL (если нет, я советую Вам хорошенько подумать), то Вам необходимо установить ее из официального репозитория PostgreSQL. Сделать это можно, следуя официальной инструкции. Затем, следует обновить пакеты:
$ sudo apt-get updateИ установить PostgreSQL командой:
$ sudo apt-get install postgresql-x.x- x.x — необходимая версия
Список всех доступных версий можно посмотреть командой:
$ sudo apt-cache search postgresql1.2. Установка из репозитория ОС
Установка PostgreSQL из репозитория ОС производится путем добавления двух основных пакетов:
$ sudo apt-get install postgresql postgresql-contrib2. Консоль PostgreSQL
Все доступные операции над базами данных и пользователями производится из консоли psql.
2.1. Вход в консоль
Для начала необходимо войти в систему от пользователя postgres, это возможно только с правами root:
# su - postgresПользователь postgres — это своеобразный суперпользователь для базы данных PostgreSQL. Затем, из-под пользователя postgres можно войти в консоль:
$ psqlИли проще, сразу входим в консоль psql под пользователем postgres:
$ sudo -u postgres psql2.2. Выход из консоли
Когда выполнены все операции над пользователями и базами данных PostgreSQL в консоли psql, не сразу можно сообразить, как из нее выйти. Тут все очень просто:
postgres=# \qИ, если это необходимо, уходим от пользователя postgres:
$ exit3. Пользователи PostgreSQL
Рекомендуется для каждой базы данных создать независимую прослойку, создав нового пользователя, и только ему дать права к управлению ей. Манипуляции с пользователями производятся с консоли psql.
3.1. Создание пользователя
Тут все достаточно просто:
# CREATE USER username WITH PASSWORD '12345';- username — логин нового пользователя
- ‘12345’ — Пароль пользователя. Вводится в кавычках
3.2. Удаление пользователя
Тут еще проще:
# DROP USER username;- username — логин пользователя, которого необходимо удалить.
4. Базы данных
Все манипуляции с базой данных также производятся в консоли psql.
4.1. Создание базы данных
Тут все также, как при создании пользователя:
# CREATE DATABASE dbname;- dbname — имя создаваемой базы данных
4.2. Удаление базы данных
# DROP DATABASE dbname;- dbname — имя удаляемой базы данных
Прошу заметить, что база данных откажется удаляться в определенных случаях:
- Если имеются пользователи с правами на эту базу. Перед удалением базы данных их права необходимо отозвать. Об этом далее.
- Если имеется хотя бы одна незакрытая сессия соединения с базой данных. В этом случае сессии необходимо будет закрыть. В крайнем случае, можно просто остановить сервера, взаимодействующие с этой базой данных на момент ее удаления (хотя, смысла их запускать после удаления базы данных мало)
4.3. Назначение прав пользователям
Наличие базы данных и пользователей в системе PostgreSQL само по себе не дает результатов. Для корректной работы определенного пользователя с определенной базой данных, ему необходимо назначить права на работу с ней. Для этого выполняем комманду:
# GRANT ALL PRIVILEGES ON DATABASE dbname TO username;- dbname — имя базы данных, права над работой которой необходимо дать доступ
- username — имя пользователя, которому будут предоставлены права над указанной базой данных
4.4. Удаление прав пользователей
Иногда, возникает необходимость сменить пользователя, управляющего базой данных, или просто отозвать права для ее последующего удаления. Рекомендую не пренебрегать этой командой и действовать по принципу “Один пользователь управляет одной базой данных”.
# REVOKE ALL PRIVILEGES ON DATABASE dbname FROM username;- dbname — имя базы данных, права над работой которой необходимо отозвать
- username — имя польователя, права которого необходимо отозвать
karimov.info
Оптимизация настроек PostgreSQL (postgresql.conf) | материализация идей
Здесь будут настройки для PostgreSQL, работающей в виртуальной машине ESXi 6.5.
Ресурсы выделенные для ВМ:
процессор — 8 vCPU;
память — 48 GB;
диск для ОС — 50 GB на LUN аппаратном RAID1 из SAS HDD;
диск для БД — 170 GB на программном RAID1 из SSD
диск для логов — 100 GB на программном RAID1 из SSD
Для редактирования настроек выполним команду:
mcedit /var/lib/pgsql/9.6/data/postgresql.conf
Закомментированные параметры, которые будем изменять необходимо активировать.
Процессор
autovacuum_max_workers = 4
autovacuum_max_workers = NCores/4..2 но не меньше 4
Количество процессов автовакуума. Общее правило — чем больше write-запросов, тем больше процессов. На read-only базе данных достаточно одного процесса.
ssl = off
Выключение шифрования. Для защищенных ЦОД’ов шифрование бессмысленно, но приводит к увеличению загрузки CPU
Память
shared_buffers = 12GB
shared_buffers = RAM/4
Количество памяти, выделенной PgSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PgSQL. Операционная система сама кеширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память.
temp_buffers = 256MB
Максимальное количество страниц для временных таблиц. Т.е. это верхний лимит размера временных таблиц в каждой сессии.
work_mem = 64MB
work_mem = RAM/32..64 или 32MB..128MB
Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребная память равна max_connections * work_mem, на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании. Это рекомендательное значение используется оптимайзером: он пытается предугадать размер необходимой памяти для запроса, и, если это значение больше work_mem, то указывает экзекьютору сразу создать временную таблицу. work_mem не является в полном смысле лимитом: оптимайзер может и промахнуться, и запрос займёт больше памяти, возможно в разы. Это значение можно уменьшать, следя за количеством создаваемых временных файлов:
maintenance_work_mem = 2GB
maintenance_work_mem = RAM/16..32 или work_mem * 4 или 256MB..4GB
Лимит памяти для обслуживающих задач, например по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и добавления внешних ключей. Размер выделяемой под эти операции памяти должен быть сравним с физическим размером самого большого индекса на диске.
effective_cache_size = 36GB
effective_cache_size = RAM — shared_buffers
Оценка размера кеша файловой системы. Увеличение параметра увеличивает склонность системы выбирать IndexScan планы. И это хорошо.
Диски
effective_io_concurrency = 5
Оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Для одиночного диска = 1, для RAID — 2 или больше.
random_page_cost = 1.3
random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для SSD
Стоимость чтения рандомной страницы (по-умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PgSQL к выбору планов с сканированием всей таблицы (PgSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). И это плохо.
autovacuum = on
Включение автовакуума.
autovacuum_naptime = 20s
Время сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать вакуумиться и, как следствие, вырастет bloat и размер таблиц и индексов. Малая величина приведет к бесполезному нагреванию.
bgwriter_delay = 20ms
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0
bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чем bgwriter_lru_maxpages.
synchronous_commit = off
Выключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. Но значительно увеличивает производительность.
wal_keep_segments = 256
wal_keep_segments = 32..256
Максимальное количество сегментов WAL между
checkpoint. Слишком частые checkpoint приводят к значительной нагрузке на дисковую подсистему по записи. Каждый сегмент имеет размер 16MB
wal_buffers = 16MB
Объём разделяемой памяти, который будет использоваться для буферизации данных WAL, ещё не записанных на диск. Значение по умолчанию, равное -1, задаёт размер, равный 1/32 (около 3%) от shared_buffers, но не меньше, чем 64 КБ и не больше, чем размер одного сегмента WAL (обычно 16 МБ). Это значение можно задать вручную, если выбираемое автоматически слишком мало или велико, но при этом любое положительное число меньше 32 КБ будет восприниматься как 32 КБ. Этот параметр можно задать только при запуске сервера.
Содержимое буферов WAL записывается на диск при фиксировании каждой транзакции, так что очень большие значения вряд ли принесут значительную пользу. Однако значение как минимум в несколько мегабайт может увеличить быстродействие при записи на нагруженном сервере, когда сразу множество клиентов фиксируют транзакции. Автонастройка, действующая при значении по умолчанию (-1), в большинстве случаев выбирает разумные значения.
default_statistics_target = 1000
Устанавливает целевое ограничение статистики по умолчанию, распространяющееся на столбцы, для которых командой ALTER TABLE SET STATISTICS не заданы отдельные ограничения. Чем больше установленное значение, тем больше времени требуется для выполнения ANALYZE, но тем выше может быть качество оценок планировщика. Значение этого параметра по умолчанию — 100.
checkpoint_completion_target = 0.9
Степень «размазывания» checkpoint’a. Скорость записи во время checkpoint’а регулируется так, что бы время checkpoint’а было равно времени, прошедшему с прошлого, умноженному на checkpoint_completion_
target.
min_wal_size = 4G
max_wal_size = 8G
min_wal_size = 512MB .. 4G
max_wal_size = 2 * min_wal_sizeМинимальное и максимальный объем WAL файлов. Аналогично checkpoint_segments
fsync = on
Выключение параметра приводит к росту производительности, но появляется значительный риск потери всех данных при внезапном выключении питания. Внимание: если RAID имеет кеш и находиться в режиме write-back, проверьте наличие и функциональность батарейки кеша RAID контроллера! Иначе данные записанные в кеш RAID могут быть потеряны при выключении питания, и, как следствие, PgSQL не гарантирует целостность данных.
row_security = off
Отключение контроля разрешения уровня записи
enable_nestloop = off
Включает или отключает использование планировщиком планов соединения с вложенными циклами. Полностью исключить вложенные циклы невозможно, но при выключении этого параметра планировщик не будет использовать данный метод, если можно применить другие. По умолчанию этот параметр имеет значение on.
Блокировки
max_locks_per_transaction = 256
Максимальное число блокировок индексов/таблиц в одной транзакции
Настройки под платформу 1С
standard_conforming_strings = off
Разрешить использовать символ \ для экранирования
escape_string_warning = off
Не выдавать предупреждение о использовании символа \ для экранирования
Настройка безопасности
Сделаем так, чтобы сервер PostgreSQL был виден только для сервера 1С: Предприятие, установленного на этой же машине.
listen_addresses = ‘localhost’
Если сервер 1С: Предприятие установлен на другой машине или существует необходимость подключиться подключиться к серверу СУБД с помощью оснастки PGAdmin, то вместо localhost нужно указать адрес этой машины.
Хранение базы данных
PostgreSQL как и почти любая СУБД критична к дисковой подсистеме, поэтому для повышения быстродействия СУБД разместим систему PostgreSQL, логи и сами базы на разные диски.
Останавливаем сервер
systemctl stop postgresql-9.6
Переносим логи на созданный RAID1 из 120GB SSD:
mv /var/lib/pgsql/9.6/data/pg_xlog /raid120 mv /var/lib/pgsql/9.6/data/pg_clog /raid120 mv /var/lib/pgsql/9.6/data/pg_log /raid120
Создаем символьные ссылки:
ln -s /raid120/pg_xlog /var/lib/pgsql/9.6/data/pg_xlog ln -s /raid120/pg_clog /var/lib/pgsql/9.6/data/pg_clog ln -s /raid120/pg_log /var/lib/pgsql/9.6/data/pg_log
Так же перенесем каталог с базами:
mv /var/lib/pgsql/9.6/data/base /raid200
и создадим символьную ссылку:
ln -s /raid200/base /var/lib/pgsql/9.6/data/base
запустим сервер и проверим его статус
i-fast.ru
Установка и настройка PostgreSQL для 1С:Предприятие
Установка PostgreSQL 9.6
Устанавливать будем сборку от компании Postgres Professional. На странице с версией для 1С:Предприятие найдем информацию об установке на CentOS 7 свежей версии PostgreSQL.
Подключим репозитории и установим PostgreSQL 9.6:
sudo rpm -ivh http://1c.postgrespro.ru/keys/postgrespro-1c-centos96.noarch.rpm sudo yum makecache sudo yum install postgresql-pro-1c-9.6
Базовая настройка PostgreSQL
Инициализируем служебные базы данных с русской локализацией:
su postgres /usr/pgsql-9.6/bin/initdb -D /var/lib/pgsql/9.6/data --locale=ru_RU.UTF-8 exit service postgresql-9.6 initdb
Запускаем службу PostgreSQL и добавляем его в автозагрузку:
systemctl enable postgresql-9.6 systemctl start postgresql-9.6 systemctl status postgresql-9.6
Задаем пароль пользователю postgres, для того чтобы была возможность подключаться к серверу удаленно:
su - postgres psql ALTER USER postgres WITH ENCRYPTED PASSWORD 'yourpassword'; \q exit
Для возможности пользователю postgres авторизовываться по паролю отредактируем файл pg_hba.conf:
mcedit /var/lib/pgsql/9.6/data/pg_hba.conf
в открывшемся файле раскомментируем и изменим строки:
host all all 127.0.0.1/32 ident на host all all 127.0.0.1/32 md5
host all all 0.0.0.0/0 ident на host all all 0.0.0.0/0 md5
Оптимизация настроек PostgreSQL (postgresql.conf) для 1С:Предприятие
Здесь будут настройки для PostgreSQL, работающей в виртуальной машине ESXi 6.5.
Ресурсы выделенные для ВМ:
процессор — 8 vCPU;
память — 48 GB;
диск для ОС — 50 GB на LUN аппаратном RAID1 из SAS HDD;
диск для БД — 170 GB на программном RAID1 из SSD
диск для логов — 100 GB на программном RAID1 из SSD
Для редактирования настроек выполним команду:
mcedit /var/lib/pgsql/9.6/data/postgresql.conf
Закомментированные параметры, которые будем изменять необходимо активировать.
Процессор
autovacuum_max_workers = 4
autovacuum_max_workers = NCores/4..2 но не меньше 4
Количество процессов автовакуума. Общее правило — чем больше write-запросов, тем больше процессов. На read-only базе данных достаточно одного процесса.
ssl = off
Выключение шифрования. Для защищенных ЦОД’ов шифрование бессмысленно, но приводит к увеличению загрузки CPU
Память
shared_buffers = 12GB
shared_buffers = RAM/4
Количество памяти, выделенной PgSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PgSQL. Операционная система сама кеширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память.
temp_buffers = 256MB
Максимальное количество страниц для временных таблиц. Т.е. это верхний лимит размера временных таблиц в каждой сессии.
work_mem = 64MB
work_mem = RAM/32..64 или 32MB..128MB
Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребная память равна max_connections * work_mem, на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании. Это рекомендательное значение используется оптимайзером: он пытается предугадать размер необходимой памяти для запроса, и, если это значение больше work_mem, то указывает экзекьютору сразу создать временную таблицу. work_mem не является в полном смысле лимитом: оптимайзер может и промахнуться, и запрос займёт больше памяти, возможно в разы. Это значение можно уменьшать, следя за количеством создаваемых временных файлов:
maintenance_work_mem = 2GB
maintenance_work_mem = RAM/16..32 или work_mem * 4 или 256MB..4GB
Лимит памяти для обслуживающих задач, например по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и добавления внешних ключей. Размер выделяемой под эти операции памяти должен быть сравним с физическим размером самого большого индекса на диске.
effective_cache_size = 36GB
effective_cache_size = RAM — shared_buffers
Оценка размера кеша файловой системы. Увеличение параметра увеличивает склонность системы выбирать IndexScan планы. И это хорошо.
Диски
effective_io_concurrency = 5
Оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Для одиночного диска = 1, для RAID — 2 или больше.
random_page_cost = 1.3
random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для SSD
Стоимость чтения рандомной страницы (по-умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PgSQL к выбору планов с сканированием всей таблицы (PgSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). И это плохо.
autovacuum = on
Включение автовакуума.
autovacuum_naptime = 20s
Время сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать вакуумиться и, как следствие, вырастет bloat и размер таблиц и индексов. Малая величина приведет к бесполезному нагреванию.
bgwriter_delay = 20ms
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0
bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чем bgwriter_lru_maxpages.
synchronous_commit = off
Выключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. Но значительно увеличивает производительность.
wal_keep_segments = 256
wal_keep_segments = 32..256
Максимальное количество сегментов WAL между
checkpoint. Слишком частые checkpoint приводят к значительной нагрузке на дисковую подсистему по записи. Каждый сегмент имеет размер 16MB
wal_buffers = 16MB
Объём разделяемой памяти, который будет использоваться для буферизации данных WAL, ещё не записанных на диск. Значение по умолчанию, равное -1, задаёт размер, равный 1/32 (около 3%) от shared_buffers, но не меньше, чем 64 КБ и не больше, чем размер одного сегмента WAL (обычно 16 МБ). Это значение можно задать вручную, если выбираемое автоматически слишком мало или велико, но при этом любое положительное число меньше 32 КБ будет восприниматься как 32 КБ. Этот параметр можно задать только при запуске сервера.
Содержимое буферов WAL записывается на диск при фиксировании каждой транзакции, так что очень большие значения вряд ли принесут значительную пользу. Однако значение как минимум в несколько мегабайт может увеличить быстродействие при записи на нагруженном сервере, когда сразу множество клиентов фиксируют транзакции. Автонастройка, действующая при значении по умолчанию (-1), в большинстве случаев выбирает разумные значения.
default_statistics_target = 1000
Устанавливает целевое ограничение статистики по умолчанию, распространяющееся на столбцы, для которых командой ALTER TABLE SET STATISTICS не заданы отдельные ограничения. Чем больше установленное значение, тем больше времени требуется для выполнения ANALYZE, но тем выше может быть качество оценок планировщика. Значение этого параметра по умолчанию — 100.
checkpoint_completion_target = 0.9
Степень «размазывания» checkpoint’a. Скорость записи во время checkpoint’а регулируется так, что бы время checkpoint’а было равно времени, прошедшему с прошлого, умноженному на checkpoint_completion_
target.
min_wal_size = 4G
max_wal_size = 8G
min_wal_size = 512MB .. 4G
max_wal_size = 2 * min_wal_sizeМинимальное и максимальный объем WAL файлов. Аналогично checkpoint_segments
fsync = on
Выключение параметра приводит к росту производительности, но появляется значительный риск потери всех данных при внезапном выключении питания. Внимание: если RAID имеет кеш и находиться в режиме write-back, проверьте наличие и функциональность батарейки кеша RAID контроллера! Иначе данные записанные в кеш RAID могут быть потеряны при выключении питания, и, как следствие, PgSQL не гарантирует целостность данных.
row_security = off
Отключение контроля разрешения уровня записи
enable_nestloop = off
Включает или отключает использование планировщиком планов соединения с вложенными циклами. Полностью исключить вложенные циклы невозможно, но при выключении этого параметра планировщик не будет использовать данный метод, если можно применить другие. По умолчанию этот параметр имеет значение on.
Блокировки
max_locks_per_transaction = 256
Максимальное число блокировок индексов/таблиц в одной транзакции
Настройки под платформу 1С
standard_conforming_strings = off
Разрешить использовать символ \ для экранирования
escape_string_warning = off
Не выдавать предупреждение о использовании символа \ для экранирования
Настройка безопасности
Сделаем так, чтобы сервер PostgreSQL был виден только для сервера 1С: Предприятие, установленного на этой же машине.
listen_addresses = ‘localhost’
Если сервер 1С: Предприятие установлен на другой машине или существует необходимость подключиться подключиться к серверу СУБД с помощью оснастки PGAdmin, то вместо localhost нужно указать адрес этой машины.
Хранение базы данных
PostgreSQL как и почти любая СУБД критична к дисковой подсистеме, поэтому для повышения быстродействия СУБД разместим систему PostgreSQL, логи и сами базы на разные диски.
Останавливаем сервер
systemctl stop postgresql-9.6
Переносим логи на созданный RAID1 из 120GB SSD:
mv /var/lib/pgsql/9.6/data/pg_xlog /raid120 mv /var/lib/pgsql/9.6/data/pg_clog /raid120 mv /var/lib/pgsql/9.6/data/pg_log /raid120
Создаем символьные ссылки:
ln -s /raid120/pg_xlog /var/lib/pgsql/9.6/data/pg_xlog ln -s /raid120/pg_clog /var/lib/pgsql/9.6/data/pg_clog ln -s /raid120/pg_log /var/lib/pgsql/9.6/data/pg_log
Так же перенесем каталог с базами:
mv /var/lib/pgsql/9.6/data/base /raid200
и создадим символьную ссылку:
ln -s /raid200/base /var/lib/pgsql/9.6/data/base
запустим сервер и проверим его статус
systemctl start postgresql-9.6 systemctl status postgresql-9.6
Поделиться ссылкой:
Похожее
kazhaev.ru
Установка и настройка PostgreSQL | www.info-x.org
# -----------------------------
# Конфигурационный файл PostgreSQL
# -----------------------------
#
# Формат файла такой:
#
# name = value
#
# Знак "=" не обязателен, можно просто использовать пробел. Комментарии
# начинается со знака "#" и может находиться в любой части строки. Полный
# список возможных параметров можно найти в документации PostgreSQL.
#
# Прокомментированные настройки в этом файле инициализированы значениями
# по умолчанию. Не забывайте перезагружать сервер после изменения параметров.
#
# Этот файл читается при запуске сервера и при получении им сигнала
# SIGHUP. После редактирования конфигурационного файла вы должны
# послать сигнал SIGHUP серверу, чтобы он перечитал его и изменения
# вступили в силу (так же, вы можете использовать команду pg_ctl reload).
# Некоторые параметры, представленные ниже, требуют перезапуска сервера.
#
# Любой параметр также можно задать с помощью аргументов командной строки,
# например "postgres -c log_connections=on". Некоторые параметры можно
# задать во время сессии с помощью SQL команды "SET".
#
# Memory units: kB = kilobytes MB = megabytes GB = gigabytes
# Time units: ms = milliseconds s = seconds min = minutes h = hours d = days
#------------------------------------------------------------------------------
# Директории и файлы
#------------------------------------------------------------------------------
# Значения по умолчанию для этих опций передаются с помощью
# параметра командной строки -D или переменной окружения PGDATA,
# которая представлена здесь как ConfigDir.
#data_directory = 'ConfigDir' # путь до кластера БД
# (требуется перезагрузка)
#hba_file = 'ConfigDir/pg_hba.conf' # host-based authentication file
# (требуется перезагрузка)
#ident_file = 'ConfigDir/pg_ident.conf' # ident configuration file
# (требуется перезагрузка)
# Если этот параметр не задан, то PID файл создаваться не будет.
#external_pid_file = '(none)' # Записывать PID файл
# (требуется перезагрузка)
#------------------------------------------------------------------------------
# Подключения и аутентификация
#------------------------------------------------------------------------------
# - Параметры подключения -
listen_addresses = '*' # на каком IP адресе(ах) принимать подключения;
# список разделенный запятыми;
# по умолчанию 'localhost', '*' = all
# (требуется перезагрузка)
port = 5432 # (требуется перезагрузка)
max_connections = 30 # (требуется перезагрузка)
# Внимание: Увеличение значения параметра max_connections потребует
# приблизительно 400 байт в разделяемой памяти на подключение, плюс
# блокировка пространства (смотрите max_locks_per_transaction). Так же
# вы должны увеличить параметр shared_buffers, чтобы принимать больше
# подключений.
superuser_reserved_connections = 1 # (требуется перезагрузка)
#unix_socket_directory = '' # (требуется перезагрузка)
#unix_socket_group = '' # (требуется перезагрузка)
#unix_socket_permissions = 0777 # 0 вначале означает 8-ую систему счисления
# (требуется перезагрузка)
#bonjour_name = '' # По умолчанию - имя компьютера
# (требуется перезагрузка)
# - Безопасность и аутентификация -
authentication_timeout = 1min # 1s-600s
ssl = on # (требуется перезагрузка)
#ssl_ciphers = 'ALL:!ADH:!LOW:!EXP:!MD5:@STRENGTH' # allowed SSL ciphers
# (требуется перезагрузка)
#ssl_renegotiation_limit = 512MB # amount of data between renegotiations
password_encryption = on
#db_user_namespace = off
# Kerberos and GSSAPI
#krb_server_keyfile = '' # (требуется перезагрузка)
#krb_srvname = 'postgres' # (требуется перезагрузка, только Kerberos)
#krb_server_hostname = '' # пустая строка, значит любая запись keytab
# (требуется перезагрузка, только Kerberos)
#krb_caseins_users = off # (требуется перезагрузка)
#krb_realm = '' # (требуется перезагрузка)
# - TCP Keepalives -
# смотрите "man 7 tcp"
#tcp_keepalives_idle = 0 # TCP_KEEPIDLE, in seconds;
# 0 - использовать системное значение
#tcp_keepalives_interval = 0 # TCP_KEEPINTVL, in seconds;
# 0 - использовать системное значение
#tcp_keepalives_count = 0 # TCP_KEEPCNT;
# 0 - использовать системное значение
#------------------------------------------------------------------------------
# Использование ресурсов (кроме WAL)
#------------------------------------------------------------------------------
# - Память -
shared_buffers = 128MB # минимум 128kB или max_connections*16kB
# (требуется перезагрузка)
temp_buffers = 8MB # минимум 800kB
max_prepared_transactions = 0 # может быть 0 или больше
# (требуется перезагрузка)
# Внимание: Увеличение значения параметра max_prepared_transactions потребует
# приблизительно 600 байт в разделяемой памяти на подключение, плюс
# блокировка пространства (смотрите max_locks_per_transaction).
work_mem = 2MB # минимум 64kB
maintenance_work_mem = 16MB # минимум 1MB
max_stack_depth = 32MB # минимум 100kB
# - Карта свободного пространства -
max_fsm_pages = 179200 # минимум max_fsm_relations*16, 6 байт на каждую
# (требуется перезагрузка)
#max_fsm_relations = 1000 # минимум 100, ~70 байт на каждый
# (требуется перезагрузка)
# - Использование ядерных ресурсов -
#max_files_per_process = 1000 # минимум 25
# (требуется перезагрузка)
#shared_preload_libraries = '' # (требуется перезагрузка)
# - Cost-Based Vacuum Delay -
#vacuum_cost_delay = 0 # 0-1000 milliseconds
#vacuum_cost_page_hit = 1 # 0-10000 credits
#vacuum_cost_page_miss = 10 # 0-10000 credits
#vacuum_cost_page_dirty = 20 # 0-10000 credits
#vacuum_cost_limit = 200 # 1-10000 credits
# - Background Writer -
#bgwriter_delay = 200ms # 10-10000ms between rounds
#bgwriter_lru_maxpages = 100 # 0-1000 max buffers written/round
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multipler on buffers scanned/round
#------------------------------------------------------------------------------
# Ведение лога
#------------------------------------------------------------------------------
# - Установки -
fsync = on # Вкл/выкл синхронизацию
synchronous_commit = on # Вызов fsync при коммите
wal_sync_method = fsync # the default is the first option
# supported by the operating system:
# open_datasync
# fdatasync
# fsync
# fsync_writethrough
# open_sync
full_page_writes = on # recover from partial page writes
wal_buffers = 128kB # минимум 32kB
# (требуется перезагрузка)
#wal_writer_delay = 200ms # 1-10000 milliseconds
#commit_delay = 0 # диапазон 0-100000, в микросекундах
#commit_siblings = 5 # диапазон 1-1000
# - Контрольные точки -
#checkpoint_segments = 3 # сегменты в лог файле, минимум 1, каждый 16MB
#checkpoint_timeout = 5min # диапазон 30s-1h
#checkpoint_completion_target = 0.5 # checkpoint target duration, 0.0 - 1.0
#checkpoint_warning = 30s # 0 is off
# - Архивирование -
archive_mode = off # разрешить архивирование
# (требуется перезагрузка)
#archive_command = '' # команда, используемая для архивирования сегментов
#archive_timeout = 0 # принудительно переключать сегмент в лог файле
# по истечению времени; 0 - выключено
#------------------------------------------------------------------------------
# Тюнинг планировщика запросов
#------------------------------------------------------------------------------
# - Конфигурация методов планирования -
enable_bitmapscan = on
enable_hashagg = on
enable_hashjoin = on
enable_indexscan = on
enable_mergejoin = on
enable_nestloop = on
enable_seqscan = on
enable_sort = on
enable_tidscan = on
# - Planner Cost Constants -
#seq_page_cost = 1.0 # measured on an arbitrary scale
#random_page_cost = 4.0 # same scale as above
#cpu_tuple_cost = 0.01 # same scale as above
#cpu_index_tuple_cost = 0.005 # same scale as above
#cpu_operator_cost = 0.0025 # same scale as above
#effective_cache_size = 128MB
# - Оптимизатор запросов -
geqo = on
#geqo_threshold = 12
#geqo_effort = 5 # диапазон 1-10
#geqo_pool_size = 0 # selects default based on effort
#geqo_generations = 0 # selects default based on effort
#geqo_selection_bias = 2.0 # диапазон 1.5-2.0
# - Другие параметры планировщика -
#default_statistics_target = 10 # диапазон 1-1000
#constraint_exclusion = off
#from_collapse_limit = 8
#join_collapse_limit = 8 # 1 disables collapsing of explicit
# JOIN clauses
#------------------------------------------------------------------------------
# Лог ошибок
#------------------------------------------------------------------------------
# - Куда слать логи -
#log_destination = 'syslog'
log_destination = 'stderr' # Возможные значение:
# stderr, csvlog, syslog and eventlog,
# зависят от платформы. csvlog
# требует, чтобы logging_collector был включен.
# This is used when logging to stderr:
logging_collector = on # Разрешить сбор сообщений с stderr или csvlog
# в лог файлы. Требуется для
# csvlogs.
# (требуется перезагрузка)
# Эти параметры используются только, если параметр logging_collector включен:
log_directory = 'pg_log' # директория - куда писать логи,
# может будь абсолютной или релятивной относительно PGDATA
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' # шаблон имени лог файла,
# можно использовать последовательности strftime()
#log_truncate_on_rotation = off # Если включено, то существующий файл будет
# очищен, а запись будет начата сначала файла.
# Файл будет очищаться только по срабатыванию
# таймера, то есть при перезапуске сервера или
# при достижении определенного размера,
# файл очищаться не будет. По умолчанию
# выключено, что означает дописывание
# в конец существующих файлов во всех случаях.
#log_rotation_age = 1d # Автоматическая ротация логов будет производиться
# по истечению заданного времени. 0 - выключено.
#log_rotation_size = 10MB # Автоматическая ротация логов будет производиться
# при достижении размера файла заданных размеров.
# 0 - выключено.
# Эти параметры имеют значение, если логи шлются в syslog:
#syslog_facility = 'LOCAL0'
#syslog_ident = 'postgres'
# - Уровень информативности -
#client_min_messages = notice # значения представлены в порядке
# понижения информативности:
# debug5
# debug4
# debug3
# debug2
# debug1
# log
# notice
# warning
# error
#log_min_messages = notice # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic
#log_error_verbosity = default # terse, default, or verbose messages
www.info-x.org