MS SQL Server и T-SQL
Создание таблиц
Последнее обновление: 26.06.2017
Ключевым объектом в базе данных являются таблицы. Таблицы состоят из строк и столбцов. Столбцы определяют тип информации, которая хранится, а строки содержат значения для этих столбцов.
В прошлой теме была создана база данных university. Теперь определим в ней первую таблицу. Опять же для создания таблицы в SQL Server Management Studio можно применить скрипт на языке SQL, либо воспользоваться графическим дизайнером. В данном случае выберем второе.
Для этого раскроем узел базы данных university в SQL Server Management Studio, нажмем на его подузел Tables правой кнопкой мыши и далее в контексто меню выберем New -> Table…:
После этого нам откроется дизайнер таблицы. В центральной части в таблице необходимо ввести данные о столбцах таблицы. Дизайнер содержит три поля:
Column Name: имя столбца
Data Type: тип данных столбца. Тип данных определяет, какие данные могут храниться в этом столбце. Например, если столбец представляет числовой тип, то он может хранить только числа.
Allow Nulls: может ли отсутствовать значение у столбца, то есть может ли он быть пустым
Допустим, нам надо создать таблицу с данными учащихся в учебном заведении. Для этого в дизайнере таблицы четыре столбца: Id, FirstName, LastName и Year, которые будут представлять соответственно уникальный идентификатор пользователя, его имя, фамилию и год рождения. У первого и четвертого столбца надо указать тип int (то есть целочисленный), а у столбцов FirstName и LastName — тип nvarchar(50) (строковый).
Затем в окне Properties, которая содержит свойства таблицы, в поле Name надо ввести имя таблицы — Students, а в поле Identity ввести Id, то есть тем самым указывая, что столбец Id будет идентификатором.
Имя таблицы должно быть уникальным в рамках базы данных. Как правило, название таблицы отражает название сущности, которая в ней хранится. Например, мы хотим сохранить студентов, поэтому таблица называется Students (слово студент во множественном числе на английском языке). Существуют разные мнения по поводу того, стоит использовать название сущности в единственном или множественном числе (Student или Students). В данном случае вопрос наименования таблицы всецело ложится на разработчика базы данных.
И в конце нам надо отметить, что столбец Id будет выполнять роль первичного ключа (primary key). Первичный ключ уникально идентифицирует каждую строку. В роли первичного ключа может выступать один столбец, а может и несколько.
Для установки первичного ключа нажмем на столбец Id правой кнопкой мыши и в появившемся меню выберем пункт Set Primary Key.
После этого напротив поля Id должен появиться золотой ключик. Этот ключик будет указывать, что столбец Id будет выполнять роль первичного ключа.
И после сохранения в базе данных university появится таблица Students:
Мы можем заметить, что название таблицы на самом деле начинается с префикса dbo. Этот префикс представляет схему. Схема определяет контейнер, который хранит объекты. То есть схема логически разграничивает базы данных. Если схема явным образом не указывается при создании объекта, то объект принадлежит схеме по умолчанию — схеме dbo.
Нажмем правой кнопкой мыши на название таблицы, и нам отобразится контекстное меню с опциями:
С помощью этих опций можно управлять таблицей. Так, опция Delete позволяет удалить таблицу. Опция Design откроет окно дизайнера таблицы, где мы можем при необходимости внести изменения в ее структуру.
Для добавления начальных данных можно выбрать опцию Edit Top 200 Rows. Она открывает в виде таблицы 200 первых строк и позволяет их изменить. Но так как у нас таблица только создана, то естественно в ней будет никаких данных. Введем пару строк — пару студентов, указав необходимые данные для столбцов:
В данном случае я добавил две строки.
Затем опять же по клику на таблицу правой кнопкой мыши мы можем выбрать в контекстном меню пункт Select To 1000 Rows, и будет запущен скрипт, который отобразит первые 1000 строк из таблицы:
metanit.com
Функция создания таблицы в SQL
Работа с базами данных непосредственно связана с изменением таблиц и содержащихся в них данных. Но перед началом проведения действий таблицы необходимо создать. Для автоматизации этого процесса существует специальная функция SQL — «CREATE TABLE».
Первым делом!
Перед тем как разбираться с процессом создания таблиц с помощью команды MS SQL «CREATE TABLE», стоит остановиться на том, что надо знать перед началом использования функции.
Прежде всего, необходимо придумать имя таблице — оно должно быть уникальным, в сравнении с другими, находящимися в базе данных, и следовать нескольким правилам. Имя должно начинаться с буквы (a-z), после чего могут следовать любые буквы, цифры и знак подчеркивания, при этом полученная фраза не должна быть зарезервированным словом. Длина названия таблицы не должна превышать 18 символов.
Определившись с именем, следует разработать структуру: придумать названия столбцам, продумать используемый в них тип данных и какие поля должны быть обязательно заполнены. Здесь же стоит сразу определить поля внешних и первичных ключей, а также возможные ограничения для значений данных.
Остальные нюансы таблицы можно достаточно легко подкорректировать, поэтому на этапе создания таблицы они могут быть продуманы не до конца.
Синтаксис
Разработав структуру таблицы, можно переходить к её созданию. Сделать это достаточно просто, воспользовавшись функцией SQL «CREATE TABLE». В ней пользователю требуется указать придуманные ранее имя таблицы и список столбцов, указав для каждого из них тип и имя. Синтаксис функции выглядит следующим образом:
CREATE TABLE table_name
({column_name datatype [DEFAULT expression] [column_constraint] …| table_constraint}
[,{column_name datatype [DEFAULT expression] [column_constraint]…| table_constraint}]…)
Аргументы, используемые в конструкции функции, означают следующее:
- table_name — имя таблицы
- column_name — имя столбца
- datatype — тип данных, используемый в данном поле
- DEFAULT — выражение, используемое в столбце по умолчанию.
Также возможно использование ещё двух аргументов функции:
- colum_constraint — параметры столбца
- table_constraint — параметры таблицы
В них пользователь может указать требуемые для работы ограничения или условия заполнения таблицы.
Особенности создания таблиц
При написании запроса с функцией SQL «CREATE TABLE», иногда необходимо установить правила заполнения полей. Для этого необходимо добавить специальные атрибуты функции, определяющие тот или иной набор условий.
Для того чтобы определить, может ли в ячейке находиться пустое значение, после указания имени и типа столбца следует прописать одно из ключевых слов: NULL (могут быть пустые значения) или NOT NULL (поле должно быть заполнено).
При создании таблицы в большинстве случаев требуется унифицировать каждую запись, чтобы избежать наличия двух одинаковых. Для этого чаще всего используют нумерацию строк. И, чтобы не требовать от пользователя знания последнего номера, имеющегося в таблице, в функции «CREATE TABLE» достаточно указать столбец первичного ключа, написав ключевое слово «Primary key» после соответствующего поля. Чаще всего именно по первичному ключу и происходит соединение таблиц между собой.
Для обеспечения сцепки с Primary key используется свойство внешнего ключа «FOREIGN KEY». Указав для столбца данное свойство, можно обеспечить, что в данном поле будет содержаться значение, совпадающее с одним из тех, что находятся в столбце первичного ключа этой же или другой таблицы. Таким образом можно обеспечить соответствие данных.
Чтобы обеспечить проверку на соответствие некоторому заданному набору или определению, следует воспользоваться атрибутом CHECK. Он прописывается последним в списке аргументов функции и в качестве личного параметра имеет некоторое логическое выражение. С его помощью можно ограничить список возможных значений, например, использование в поле таблицы «Пол» только буквы «М» и «Ж».
Помимо представленных, функция SQL «CREATE TABLE» имеет ещё множество специфических атрибутов, однако они используются на практике гораздо реже.
Примеры
Чтобы полноценно понять принцип работы функции, стоит рассмотреть на практике, как работает CREATE TABLE (SQL). Пример, приведенный ниже, создает таблицу, представленную на рисунке:
CREATE TABLE Custom
(ID CHAR(10) NOT NULL Primary key,
Custom_name CHAR(20),
Custom_address CHAR(30),
Custom_city CHAR(20),
Custom_Country CHAR(20),
ArcDate CHAR(20))
Как можно заметить, параметр возможного отсутствия значения в ячейке (NULL) можно опускать, так как он используется по умолчанию.
fb.ru
Пошаговое создание таблицы SQL
Прежде чем приступать к созданию таблицы SQL, необходимо определить модель базы данных. Спроектировать ER-диаграмму, в которой определить сущности, атрибуты и связи.
Основные понятия
Сущности – предметы или факты, информацию о которых необходимо хранить. Например, сотрудник фирмы или проекты, реализуемые предприятием. Атрибуты – составляющая, которая описывает или квалифицирует сущность. Например, атрибут сущности «работник» — заработная плата, а атрибут сущности «проект» — сметная стоимость. Связи – ассоциации между двумя элементами. Она может быть двунаправленная. Также существует рекурсивная связь, то есть связь сущности с самой собой.
Также необходимо определить ключи и условия, при которых сохранится целостность базы данных. Что это значит? Другими словами — ограничения, которые помогут сохранить базы данных в правильном и согласованном виде.
Переход от ER-диаграммы к табличной модели
Правила перехода к табличной модели:
- Преобразовать все сущности в таблицы.
- Преобразовать все атрибуты в столбцы, то есть каждый атрибут сущности должен быть отображен в имени столбца таблицы.
- Уникальные идентификаторы преобразовать в первичные ключи.
- Все связи преобразовать во внешние ключи.
- Осуществить создание таблицы SQL.
Создание базы
Сначала неоходимо запустить сервер MySQL. Для его запуска следует зайти в меню «Пуск», затем в «Программы», далее в MySQL и MySQL Server, выбрать MySQL-Command-Line-Client.
Для создания базы данных применяется команда Create Database. Данная функция имеет следующий формат:
CREATE DATABASE название_базы_данных.
Ограничения на название базы следующие:
- длина составляет до 64 знаков и может включать буквы, цифры, символы «» и «»;
- имя может начинаться с цифры, но в нем должны присутствовать буквы.
Нужно помнить и общее правило: любой запрос или команда заканчиваются разделителем (delimiter). В SQL принято в качестве разделителя использовать точку с запятой.
Серверу необходимо указать, с какой базой данных нужно будет работать. Для этого существует оператор USE. Этот оператор имеет простой синтаксис: USE название_базы_данных.
Создание таблицы SQL
Итак, модель спроектирована, база данных создана, и серверу указано, как именно с ней нужно работать. Теперь можно начинать создавать таблицы SQL. Существует язык определения данных (DDL). Он используется для создания таблицы MS SQL, а также для определения объектов и работы с их структурой. DDL включает в себя набор команд.
SQL Server создания таблицы
Используя всего лишь одну команду DDL, можно создавать различные объекты базы, варьируя ее параметры. Для создания таблицы SQL применяется команда Create Table. Формат tt выглядит следующим образом:
CREATE TADLE название_таблицы, (название_столбца1 тип данных [DEFAULT выражение] [ограничение_столбца], название_столбца2 тип данных [DEFAULT выражение] [ограничение_столбца],[ограничения_таблицы]).

Следует подробнее описать синтаксис указанной команды:
- Название таблицы должно иметь длину до 30 символов и начинаться с буквы. Допустимы только символы алфавита, буквы, а также символы «_», «$» и «#». Разрешено использование кириллицы. Важно отметить, что имена таблиц не должны совпадать с именами других объектов и с зарезервированными словами сервера базы данных, таких как Column, Table, Index и т. д.
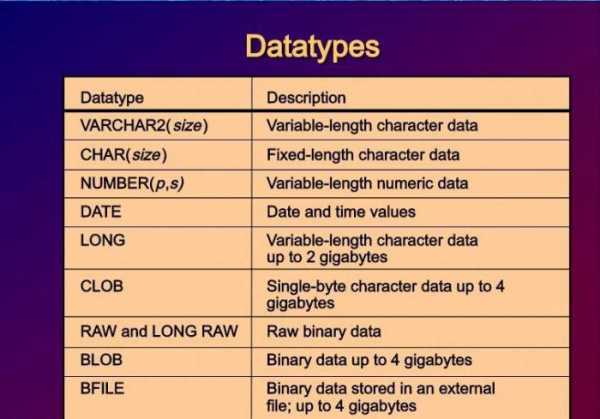
- Для каждого столбца следует обязательно указать тип данных. Существует стандартный набор, используемый большинством. Например, Char, Varchar, Number, Date, тип Null и т. д.
- С помощью параметра Default можно задать значение по умолчанию. Это гарантирует, что в таблице не будет неопределенных значений. Как это понимать? Значением по умолчанию может быть символ, выражение, функция. Важно помнить, что тип этих данных, заданных по умолчанию, должен совпадать с типом вводимых данных столбца.
- Ограничения на каждый столбец используют для реализации обеспечения условий целостности для данных на уровне таблицы. Есть и еще нюансы. Запрещено удалять таблицу, если есть зависимые от нее другие таблицы.
Как работать с базой
Для реализации крупных проектов чаще всего требуется создание нескольких баз данных, и каждая требует множество таблиц. Конечно, удержать всю информацию в голове пользователям невозможно. Для этого предусмотрена возможность посмотреть структуру баз данных и таблиц в них. Существует несколько команд, а именно:
- SHOW DATABASES – показывает на экране все созданные базы данных SQL;
- SHOW TABLES – выводит список всех таблиц для текущей базы данных, которые выбираются командой USE;
- DESCRIBE название_таблицы – показывает описание всех столбцов таблицы.
- ALTER TABLE – позволяет изменять структуру таблицы.
Последняя команда позволяет:
- добавить в таблицу столбец или ограничение;
- изменить существующий столбец;
- удалить столбец или столбцы;
- удалить ограничения целостности.
Синтаксис этой команды выглядит так: ALTER TABLE название_таблицы { [ADD название_столбца или ограничения] | [MODIFY название_изменяемого_столбца] | [DROP название_удалаяемого_столбца(ов)] | [DROP удаляемое_ограничение] | [{ENABLE | DISABLE} CONSTANT имя_ограничения ] | }.
Существуют и другие команды:
- RENAME – переименование таблицы.
- TRUNCATE TABLE -удаляет все строки из таблицы. Эта функция может быть нужна, когда необходимо заполнить таблицу заново, а хранить предыдущие данные нет необходимости.
Также бывают ситуации, когда структура базы поменялась и таблицу следует удалить. Для этого существует команда DROP. Конечно, предварительно нужно выбрать базу данных, из которой нужно удалить таблицу, если она отличается от текущей.
Синтаксис команды довольно простой: DROP TABLE название_таблицы.
В SQL Access создание таблиц и их изменение осуществляется теми же командами, перечисленными выше.
С помощью CREATE TABLE можно создать пустую таблицу и в дальнейшем заполнить ее данными. Но это еще не все. Также можно сразу создавать таблицу из другой таблицы. Как это? То есть существует возможность определить таблицу и заполнить ее данными другой таблицы. Для этого существует специальное ключевое слово AS.
Синтаксис очень простой:
- CREATE TABLE название_таблицы [(определение_столбцов)] AS подзапрос;
- определение_столбцов – имена столбцов, правила целостности для столбцов вновь создаваемой таблицы и значения по умолчанию;
- подзапрос – возвращает такие строки, которые нужно добавить в новую таблицу.
Таким образом, такая команда создает таблицу с определенными столбцами, вставляет в нее строки, которые возвращаются в запросе.
Временные таблицы
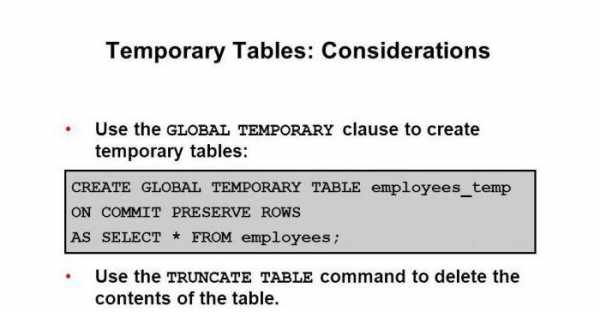
Временные таблицы — это таблицы, данные в которых стираются в конце каждого сеанса или раньше. Они используются для записи промежуточных значений или результатов. Их можно применять в качестве рабочих таблиц. Определять временные можно в любом сеансе, а пользоваться их данными можно только в текущем сеансе. Создание временных таблиц SQL происходит аналогично обычным, с использованием команды CREATE TABLE. Для того чтобы показать системе, что таблица временная, нужно использовать параметр GLOBAL TEMPORARY.

Предложение ON COMMIT устанавливает время жизни данных в такой таблице и может выполнять следующие действия:
- DELETE ROWS –очистить временную таблицу (удалить все данные сеанса) после каждого завершения транзакции. Обычно это значение используется по умолчанию.
- PRESERVE ROWS –оставить данные для использования их в следующей транзакции. Помимо этого, можно очистить таблицу только после завершения сеанса. Но есть особенности. Если произошел откат транзакции (ROLLBACK), таблица будет возвращена к состоянию на конец предыдущей транзакции.
Синтаксис создания временной таблицы может быть представлен таким образом: CREATE [GLOBAL TEMPORARY] TABLE название_таблицы, (название_столбца1 тип данных [DEFAULT выражение] [ограничение_столбца], название_столбца2 тип данных [DEFAULT выражение] [ограничение_столбца], [ограничения_таблицы]).
fb.ru
Создание и удаление таблиц в MS SQL Server
22.3KСоздание и удаление таблиц в ms sql server
Все данные в БД sql server хранятся в таблицах.
Таблицы состоят из колонок, объединяющих значения одного типа, и строк — записей в таблице. В одной БД может быть до 2 миллиардов таблиц, в таблице — 1024 колонки, в одной строке (записи) — 8060 байтов.
sql server поддерживает следующие типы данных:
Тип данных Обозначение Размер, байт
Бинарные данные binary
varbinary[(n)] 1-8000
Символы char[(n)]
varchar[(n)] 1-8000
( до 8000 символов)
Символы unicode nchar[(n)]
nvarchar[(n)] 1-8000
(до 4000 символов)
Дата и время datetime 8
smalldatetime 4
Точные числа decimal[(p[,s])]
numeric[(p[,s])] 5-17
Приблизительные числа float[(n)] real 4-8 4
Глобальный идентификатор uniqueidentifier 16
Целые числа int smallint, tinyint 4 2, 1
Денежки money, smallmoney 8, 4
Специальные bit, cursor,
Текст и изображение text, image 0-2 Гб
Текст unicode ntext 0-2 Гб
Таблицы можно создавать с помощью оператора create table языка transact-sql, а также с помощью enterprise manager. Рассмотрим сначала как это делается с помощью transact-sql.
Содание таблиц с помощью create table
Для создания таблиц применяется оператор create table.
Вот как выглядит упрощенный синтаксис этого оператора:
create table table_name
(column_name data_type [null | not null]
[,…n])
Например:
create table member ( member_no int not null, lastname char(50) not null, firstname char(50) not null, photo image null )
Этим оператором создается таблица member, состоящая из четырех колонок:
member_no — имеет тип int, значения null не допускаются
lastname — имеет тип char(50) — 50 символов, значения null не допускаются
firstname — аналогично lastname
photo — имеет тип image (изображение), допускается значение null
Примечание
null — специальное обозначение того, что элемент данных не имеет значения. В описании типа колонки указывается, что элементы данных могут быть неинициализированы. При указании not null — «пустые» значения не допускаются. Если при вставке записи пропустить значение для такой колонки, вставка не произойдет, и sql server сгенерирует ошибку.
Попробуйте выполнить эту команду. Запустите query analyzer. Соединитесь с Вашим сервером. Из списка БД выберите sqlstep. Скопируйте в окно команд команду создания таблицы и выполните ее. (Если не забыли, надо нажать f5 или ctrl-e).
Чтобы точно удостовериться, в том, что таблица была создана, наберите команду:
sp_help member
Выделите ее (как в обычном редакторе) и снова нажмите f5. В окно результатов будет выведена информация о таблице member.
На заметку!
sp_help — системная процедура, которая возвращает информацию об объектах БД (таблицах, хранимых процедурах и пр.).
Формат вызова таков:
sp_help <имя таблицы>
Удалить таблицу проще простого. Там же, в запросчике (так у нас называют query analyzer), наберите:
Выделите эту строку и нажмите f5. Таблица будет удалена, о чем Вас и уведомят. В нашем случае эта процедура проста. На самом деле в большой БД просто так удалить таблицу не получится, поскольку она будет связана с другими таблицами, и для удаления потребуется эти связи оборвать. Как это сделать см. следующие шаги.
Как создать таблицу с помощью sql server enterprise manager
Раскройте последовательно: sql server group, <Ваш sql server>, databases. Выберите БД (sqlstepbystep, я думаю :), нажмите правую кнопку мыши и выберите в контекстном меню пункт «new», а затем пункт «table…». Первым делом Вас спросят имя таблицы. Введите его и нажмите enter. На экране появится окно, в котором можно вводить:
Введите названия колонок, их тип и длину также как в примере выше. Нажмите на иконку с дискетой для сохранения таблицы и можете закрыть окно. Раскройте вашу БД, щелкните на категории «tables» и в списке таблиц увидите только что введенную таблицу. Для ее удаления выделите ее в списке, нажмите правую кнопку мыши и в контекстном меню выберите «delete». Таблица будет удалена.
Мы изучили как создаются и удалются таблицы. Следующий наш шаг — создание полноценной БД, на примере которой мы будем изучать:
что такое реляционная целостность БД и как она обеспечивается в sql server
как модифицировать данные в таблицах (операторы insert, update, delete, select)
как использовать хранимые процедуры и триггеры
www.internet-technologies.ru
Инструкция SELECT INTO в T-SQL или как создать таблицу на основе SQL запроса? | Info-Comp.ru
Если у Вас возникала необходимость сохранить результирующий набор данных, который вернул SQL запрос, то данная статья будет Вам интересна, так как в ней мы рассмотрим инструкцию SELECT INTO, с помощью которой в Microsoft SQL Server можно создать новую таблицу и заполнить ее результатом SQL запроса.
Начнем мы, конечно же, с описания самой инструкции SELECT INTO, а затем перейдем к примерам.
Инструкция SELECT INTO в Transact-SQL
SELECT INTO – инструкция в языке в T-SQL, которая создает новую таблицу и вставляет в нее результирующие строки из SQL запроса. Структура таблицы, т.е. количество и имена столбцов, а также типы данных и свойства допустимости значений NULL, будут на основе столбцов (выражений), указанных в списке выбора из источника в инструкции SELECT. Обычно инструкция SELECT INTO используется для объединения в одной таблице данных из нескольких таблиц, представлений, включая какие-то расчетные данные.
Для того чтобы использовать инструкцию SELECT INTO требуется разрешение CREATE TABLE в базе данных, в которой будет создана новая таблица.
Инструкция SELECT INTO имеет два аргумента:
- new_table — имя новой таблицы;
- filegroup – файловая группа. Если аргумент не указан, то используется файловая группа по умолчанию. Данная возможность доступна начиная с Microsoft SQL Server 2017.
Важные моменты про инструкцию SELECT INTO
- Инструкцию можно использовать для создания таблицы на текущем сервере, на удаленном сервере создание таблицы не поддерживается;
- Заполнить данными новую таблицу можно как с текущей базы данных и текущего сервера, так и с другой базы данных или с удаленного сервера. Например, указывать полное имя базы данных в виде база_данных.схема.имя_таблицы или в случае с удаленным сервером, связанный_сервер.база_данных.схема.имя_таблицы;
- Столбец идентификаторов в новой таблице не наследует свойство IDENTITY, если: инструкция содержит объединение (JOIN, UNION), предложение GROUP BY, агрегатную функцию, также, если столбец идентификаторов является частью выражения, получен из удаленного источника данных или встречается более чем один раз в списке выбора. Во всех подобных случаях столбец идентификаторов не наследует свойство IDENTITY и создается как NOT NULL;
- С помощью инструкции SELECT INTO нельзя создать секционированную таблицу, даже если исходная таблица является секционированной;
- В качестве новой таблицы можно указать обычную таблицу, а также временную таблицу, однако нельзя указать табличную переменную или возвращающий табличное значение параметр;
- Вычисляемый столбец, если такой есть в списке выбора инструкции SELECT INTO, в новой таблице он становится обычным, т.е. не вычисляемым;
- SELECT INTO нельзя использовать вместе с предложением COMPUTE;
- С помощью SELECT INTO в новую таблицу не переносятся индексы, ограничения и триггеры, их нужно создавать дополнительно, после выполнения инструкции, если они нужны;
- Предложение ORDER BY не гарантирует, что строки в новой таблице будут вставлены в указанном порядке.
- В новую таблицу не переносится атрибут FILESTREAM. Объекты BLOB FILESTREAM в новой таблице будут как объекты BLOB типа varbinary(max) и имеют ограничение в 2 ГБ;
- Объем данных, записываемый в журнал транзакций во время выполнения операций SELECT INTO, зависит от модели восстановления. В базах данных, в которых используется модель восстановления с неполным протоколированием, и простая модель, массовые операции, к которым относится SELECT INTO, минимально протоколируются. За счет этого инструкция SELECT INTO может оказаться более эффективней, чем отдельные инструкции по созданию таблицы и инструкции INSERT по заполнение ее данными.
Примеры использования SELECT INTO
Все примеры я буду выполнять в СУБД Microsoft SQL Server 2016 Express.
Исходные данные
Для начала давайте создадим две таблицы и заполним их данными, эти таблицы мы и будем объединять в примерах.
CREATE TABLE TestTable(
[ProductId] [INT] IDENTITY(1,1) NOT NULL,
[CategoryId] [INT] NOT NULL,
[ProductName] [VARCHAR](100) NOT NULL,
[Price] [money] NULL
) ON [PRIMARY]
GO
CREATE TABLE TestTable2(
[CategoryId] [INT] IDENTITY(1,1) NOT NULL,
[CategoryName] [VARCHAR](100) NOT NULL
) ON [PRIMARY]
GO
INSERT INTO TestTable
VALUES (1,'Клавиатура', 100),
(1, 'Мышь', 50),
(2, 'Телефон', 300)
GO
INSERT INTO TestTable2
VALUES ('Комплектующие компьютера'),
('Мобильные устройства')
GO
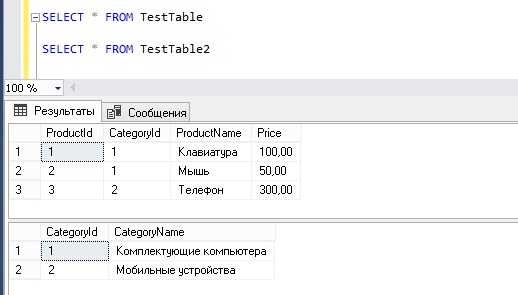
SELECT * FROM TestTable
SELECT * FROM TestTable2
Пример 1 – Создание таблицы с помощью инструкции SELECT INTO с объединением данных
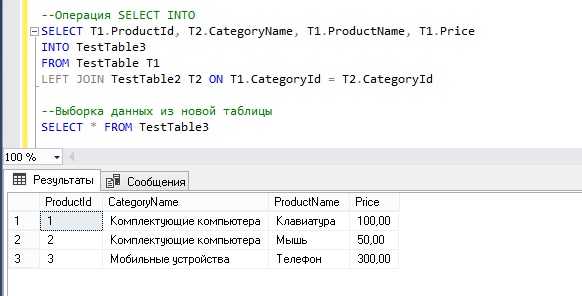
Давайте представим, что нам необходимо объединить две таблицы и сохранить полученный результат в новую таблицу (например, нам нужно получить товары с названием категории, к которой они относятся).
--Операция SELECT INTO SELECT T1.ProductId, T2.CategoryName, T1.ProductName, T1.Price INTO TestTable3 FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId --Выборка данных из новой таблицы SELECT * FROM TestTable3

В итоге мы создали таблицу с названием TestTable3 и заполнили ее объединёнными данными.
Пример 2 – Создание временной таблицы с помощью инструкции SELECT INTO с группировкой данных
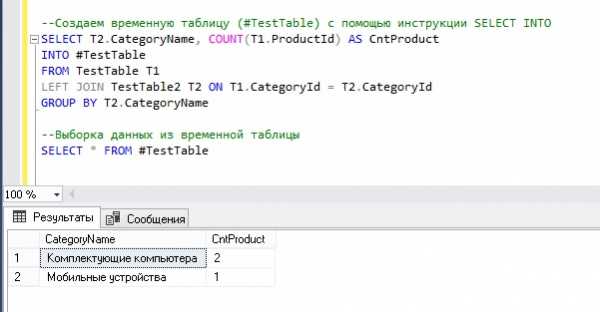
Сейчас давайте, допустим, что нам нужны сгруппированные данные, например, информация о количестве товаров в определенной категории, при этом эти данные нам нужно сохранить во временную таблицу, например, эту информацию мы будем использовать только в SQL инструкции, поэтому нам нет необходимости создавать полноценную таблицу.
--Создаем временную таблицу (#TestTable) с помощью инструкции SELECT INTO SELECT T2.CategoryName, COUNT(T1.ProductId) AS CntProduct INTO #TestTable FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId GROUP BY T2.CategoryName --Выборка данных из временной таблицы SELECT * FROM #TestTable
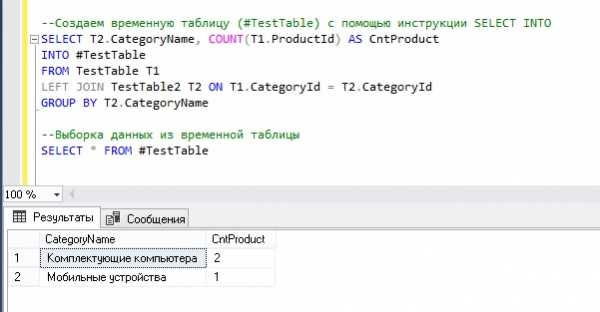
Как видим, у нас получилось создать временную таблицу #TestTable и заполнить ее сгруппированными данными.
Вот мы с Вами и рассмотрели инструкцию SELECT INTO в языке T-SQL, в своей книге «Путь программиста T-SQL» я подробно рассказываю про все конструкции языка T-SQL (рекомендую почитать), а у меня на этом все, пока!
info-comp.ru
Создание таблиц в Transact-SQL — Transact-SQL В подлиннике : Персональный сайт Михаила Флёнова
В последствии мы будем рассматривать различные возможности базы данных последовательно – создание, удаление и редактирование. Но иногда мы будем отходить от этой последовательности, как сейчас. Мы пока научились только создавать и удалять базу данных, но тут же переходим к рассмотрению создания таблиц, а редактирование баз увидим чуть позже (разд. 1.3).
Когда мы создали базу данных, можно переходить к созданию таблиц, которые будут содержать непосредственно данные. Если сравнить базу данных с файловой системой, то ее можно рассматривать как папку, а таблицы можно рассматривать как файлы в этой папке. Только базы данных не поддерживают вложенности, т.е. в одной базе не может быть другой базы данных.
База данных сама по себе не несет никакой пользы, как и папка без файлов, потому что и то и другое не могут хранить данные. Данные хранятся в таблицах (файлах файловой системы) и именно их мы научимся создавать в этом разделе.
Что такое таблица в базе данных MS SQL Server? Данный сервер работает с реляционными таблицами, которые представляют собой двухмерный массив данных, в котором колонка определяет значение, а строки – это данные. Например, таблица базы данных схожа с классическими таблицами (списками), которые мы строим в программе Excel или на бумаге в рефератах/курсовых.
Рассмотрим таблицу на примере. Допустим, что нам надо хранить в таблице список жителей дома. Не задумываясь о базах данных, а просто на бумаге для решения поставленной задачи мы нарисуем таблицу 1.1.
Таблица 1.1. Список жителей дома
| Фамилия | Имя | Отчество | Дата рождения | Адрес |
|---|---|---|---|---|
| Иванов | Иван | Иванович | 1.1.1950 | Шаболовка 37 |
| Петров | Петр | Петрович | 4.7.1967 | Королева 12 |
| … | … | … | … | … |
В ведении мы уже кратко говорили об уникальности, а сейчас нам предстоит поговорить об этом более подробно. Исходя из реляционной модели, все строки в базе данных должны быть уникальными. Это значит, что не может быть в списке жителей дома две записи для одного и того же жителя. Некоторые могут сказать, что это не проблема, потому что вероятность того, что в одном доме будет жить два человека с одними и теми же данными в полях ФИО и даты рождения. Вероятность маленькая, но она же есть! А ведь есть еще вероятность ошибки пользователя программы, который может ввести дважды одного и того же человека. Вот это уже станет действительно проблемой.
Чтобы понять, какие проблемы могут возникнуть при появлении в таблице одинаковых записей, представим, что у нас в списке 10 человек с одинаковыми ФИО и дата рождения (адрес опустим и не учитываем, чтобы пример был более реальным). Такой пример вполне реален. Если взять всех жителей России, то количество людей с фамилией Иванов будет не просто большим, а огромным, а совпадение остальных параметров также возможно.
Теперь представим, что у одной из записей, фамилия введена неверно и запись случайно двоит с 10 другими записями. Какую из 10 одинаковых строк должен изменить сервер? Любую, потому что записи одинаковые? Это не очень корректный выход, поэтому в стандарте SQL-92 сказано, что в реляционной таблице не может быть двух абсолютно одинаковых записей, хотя многие базы данных позволяют нарушить это ограничение и MS SQL Server не является исключением.
Чтобы обеспечить уникальность, было введено понятие ключевое поле. Это одно или несколько полей, которые обеспечивают уникальность строк в таблице. В нашем случае, ключевыми можно сделать ФИО и дату рождения. В этом случае, при попытке добавить новую строку, в которой значения в этих полях будут одинаковы с любой из уже существующих строк таблицы, база данных возвратит ошибку и не сможет добавить такую строку. Получается, что с помощью ключевых полей базы данных обеспечивают уникальность и по ним гарантировано можно найти одну и только одну запись. То есть, запросив из базы данных строку с определенными ФИО и датой рождения, мы получим только одну запись.
Некоторые базы данных позволяют создавать таблицы без ключевых полей, но я не рекомендую этого делать без особой надобности. Всегда создавайте ключевое поле. В MS SQL Server для этого можно использовать автоматически увеличиваемое поле, которое не требует дополнительных расходов на сопровождение.
В настоящее время Microsoft не рекомендует использовать в качестве ключа автоматически увеличиваемые поля. Да, эти поля достаточно просты в сопровождении, но не всегда эффективны, потому что автоматически увеличиваемое поле нельзя редактировать. Сейчас рекомендуется для ключа создавать поле типа GUID (Global Unique Identifier, Глобально Уникальный Идентификатор). Значения полей этого типа можно редактировать и достаточно просто сгенерировать самостоятельно.
Пессимисты считают, что GUID не могут быть идеальным решением проблемы ключевого поля, потому что значение генерируется и может возникнуть ситуация, когда будут сгенерированы два одинаковых значения. Оптимисты утверждают, что даже если все компьютеры в мире будут одновременно генерировать GUID, вероятность получения двух одинаковых значений стремиться к нулю.
В оптимистическое утверждение мне вериться с трудом, ведь количество возможных GUID ограничено и после генерации хотя бы 1/3 из этих значений вероятность получения повтора увеличивается в два раза. Но к пессимистам меня тоже отнести нельзя, потому что возможных вариантов GUID настолько много, что хватит даже для очень большой базы данных, с которой вы скорей всего никогда не встретитесь в своей практике. Поэтому, я использую GUID поля (и пока не разу не встречался с конфликтами GUID), о которых мы еще поговорим в разделе 2.24. А в этом разделе мы будем в основном создавать таблицы с ключевым полем в виде автоматически увеличиваемого поля, что намного удобнее при изучении языка запросов SQL.
Теперь посмотрим, как сервер хранит данные в строке. Иногда возникает необходимость хотя бы приблизительно рассчитать размер строки, а лучше всегда знать это значение. Это позволит вам более эффективно управлять размером базы данных.
Строка данных состоит из строки заголовка и порции данных. Заголовок содержит 4 байта информации о поле строки данных, таких как указатель, на расположение конца фиксированной порции данных строки, и какой размер переменной используется в строке.
Поле может содержать следующие элементы:
- Данные фиксированной длины (char, int и.т.д.) – помещаются в страницу перед данными, переменной длинны.
- Нулевые блоки (NULL) — это набор байтов переменной длинны.
- Переменные блоки (varchar) – содержат два байта, описывающие, какой длинны колонка. Дополнительные два байта на колонку указывают на конец каждой колонки, переменной длинны.
- Данные переменной длины (text, image) – Данные переменной длины хранятся в странице после переменных блоков.
По возможности, делайте размер строки (общий размер всех полей) компактным, что позволяет поместить больше строк в страницу. Это позволит уменьшить операции ввода вывода и улучшить работу буфера. Для того, чтобы размер строки был компактным, необходимо выделять каждому полю только необходимый размер. Например, для хранения данных о фамилии вполне достаточно 20 символов строки переменной длинны varchar, и не имеет смысла выделять поле типа char, фиксированной длинны в 50 символов.
Тип char имеет фиксированную длину, и в странице данных будет всегда съедать определенный размер данных (в данном случае 50 символов). Тип varchar будет отнимать только столько, сколько необходимо. Например, вы объявили поле типа varchar размером 50 символов, но записали в него только 10. В странице данных на диске будет выделено (помимо заголовка) только 10 символов и не каплей больше.
Типы данных переменной длины (text, ntext и image) могут храниться как одна коллекция страниц или данные в строке. Посмотрим, как они хранятся:
- text – может хранить 2 147 483 647 символов. Не Unicode текстовые данные не могут использоваться в качестве переменных или параметров в хранимых на сервере процедурах.
- ntext – может хранить 1 073 741 823 символа или 2 147 483 647 Unicode данных переменной длины.
- image – может хранить от 0 до 2 147 483 647 бинарных данных.
Так как text, ntext и image типы данных обычно большие, SQL Server хранит их вне строк. В строке на хранящиеся данные указывает только шестнадцати битный указатель. Если эти типы данных хранят небольшое количество данных, то вы можете включить опцию text in row. Вы можете также указать предел от 24 до 7000 байтов. Эту опцию для таблицы можно включить, используя системную процедуру sp_tableoption.
В следующем примере с помощью функции sp_tableoption устанавливается опция text in row и указывается, что до 1000 символов будет храниться в строке:
EXEC sp_tableoption N'TestDatabase', 'text in row', '1000'
Для вас пока может быть не очень понятна эта команда, потому что хранимые процедуры мы еще не изучали. Но в третьей главе мы рассмотрим эту тему более подробно.
Когда вы создаете таблицу, вы должны указать имя таблицы, имена колонок и типы данных колонок. Имена колонок должны быть уникальными для определенной таблицы, но вы можете использовать одно и то же имя в разных таблицах одной базы данных.
MS SQL Server позволяет создавать до 2 биллионов таблиц в базе данных, каждая таблица может содержать до 1024 колонки и общий размер полей в таблице может достигать 8060 байтов на строку (без учета text, ntext и image). Это действительно очень много. Превысить этот предел очень сложно, и я пока не слышал, чтобы кому-то его не хватило. Если вам все же не хватит количества полей, то можно создать две таблицы и связать их один к одному. Для этого используются внешние ключи, о которых мы будем говорить в разделе 1.2.6.
1.2.1. Оператор CREATE TABLE
С теорией таблиц закончено, теперь попробуем эту таблицу рассмотреть с точки зрения базы данных. Имена колонок в списке баз данных называются именами полей. Нам необходимо только создать таблицу в базе данных с такими полями и все готово для хранения списка.
Общий вид команды CREATE TABLE показан в листинге 1.5.
Листинг 1.5. Общий вид команды CREATE TABLE
CREATE TABLE
[ database_name.[ owner ] . | owner. ] table_name
( { < column_definition >
| column_name AS computed_column_expression
| < table_constraint > ::= [ CONSTRAINT constraint_name ]}
| [ { PRIMARY KEY | UNIQUE } [ ,...n ]
)
[ ON { filegroup | DEFAULT } ]
[ TEXTIMAGE_ON { filegroup | DEFAULT } ]
< column_definition > ::= { column_name data_type }
[ COLLATE < collation_name > ]
[ [ DEFAULT constant_expression ]
| [ IDENTITY [ ( seed , increment ) [ NOT FOR REPLICATION ] ] ]
]
[ ROWGUIDCOL]
[ < column_constraint > ] [ ...n ]
< column_constraint > ::= [ CONSTRAINT constraint_name ]
{ [ NULL | NOT NULL ]
| [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
[ WITH FILLFACTOR = fillfactor ]
[ON {filegroup | DEFAULT} ] ]
]
| [ [ FOREIGN KEY ]
REFERENCES ref_table [ ( ref_column ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
[ NOT FOR REPLICATION ]
]
| CHECK [ NOT FOR REPLICATION ]
( logical_expression )
}
< table_constraint > ::= [ CONSTRAINT constraint_name ]
{ [ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
{ ( column [ ASC | DESC ] [ ,...n ] ) }
[ WITH FILLFACTOR = fillfactor ]
[ ON { filegroup | DEFAULT } ]
]
| FOREIGN KEY
[ ( column [ ,...n ] ) ]
REFERENCES ref_table [ ( ref_column [ ,...n ] ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ]
( search_conditions )
}
Команда CREATE TABLE достаточно большая и сложная, потому что включает в себя не только создание самой таблицы, но и описание полей, ограничений, первичных и вторичных ключей. Поэтому, описание команды отнимет достаточно много времени, потому что без рассмотрения оператора CREATE TABLE по частям нам не обойтись, чем мы и будем заниматься ближайшие пару десятков страниц.
Прежде чем создавать какую-либо тестовую таблицу, давайте создадим базу данных, в которой будут проходить все следующие тестирования SQL запросов. Все предыдущие тестовые базы данных можно удалить и создать новую, чистую базу данных. Я для этого создал базу данных с именем TestDatabase с параметрами по умолчанию.
Теперь посмотрим, как создать таблицу и удалить ее. Подключитесь к своей тестовой базе данных (TestDatabase) и выполните следующий запрос:
CREATE TABLE TestTable ( id int )
Невозможно создавать пустую таблицу, без описания полей. Хотя бы одно поле должно быть создано. В данном примере создается таблица с именем TestTable. После имени в скобках указываются имена и типы полей в формате:
имя тип параметры
Обязательными являются только имя и тип, как в примере выше, а параметры могут отсутствовать. В этом случае, поле не будет обладать никакими дополнительными параметрами.
Если полей несколько, то все они перечисляются в скобках через запятую. В данном случае, описано только одно поле с именем id, тип int, и без параметров. Какие могут быть типы данных? Стандарт SQL описывает только основные типы: строка, число и т.д., но в MS SQL Server их намного больше. Все типы, которые поддерживает SQL Server 2000 можно увидеть в приложении 1.
Для удаления таблицы используется команда:
DROP TABLE имя
Где имя – это имя удаляемой таблицы. При этом вы должны быть подключены к серверу, таблицу которого вы удаляете, т.е. удаление происходит в текущей базе данных.
Следующий запрос показывает, как удалить таблицу TestTable, созданную нами ранее:
DROP TABLE TestTable
Если полей в таблице несколько, то их необходимо указывать в круглых скобках через запятую. Например:
CREATE TABLE TestTable ( id int, vcName varchar(30), vcLastName varchar(30), vcSurName varchar(30), cPol char(1), dBirthDay datetime )
В качестве дополнительных параметров можно указывать, например, явную кодировку (Collation) для поля. В следующем примере создается таблица с двумя текстовыми полями. В первом поле для хранения фамилии не указывается кодировка, поэтому для него будет взято значение из базы данных, а у второго поля явно указываем латинскую кодировку:
CREATE TABLE TestTable ( Famil varchar(10), Name varchar(10) collate latin1_general_cs_as )
При создании таблицы можно указать файловую группу, в которой должны храниться данные этой таблицы. Имя группы указывается после ключевого слова ON, за объявлением всех полей. В следующем примере создается таблица, данные которой будут помещены в группу с именем group1:
CREATE TABLE TestTable ( Famil varchar(10), Name varchar(10) collate latin1_general_cs_as ) ON group1
Если файловая группа не указана, то таблица создается в группе по умолчанию. Если вы создали пользовательскую группу, но она не является группой по умолчанию, то обязательно указывайте ее явно.
1.2.2. Автоинкрементные поля
Очень часто необходим какое-либо поле-счетчик, значение которого будет автоматически увеличиваться без вмешательства пользователя. Например, таким образом часто создаются ключевые поля и об этом методе мы говорили в разделе 1.2. Опытные программисты, которые работают с базами данных уже не первый день, с помощью таких полей добиваются уникальности данных. Например, очень часто можно видеть таблицы, в которых первое поле называется «id» (я люблю именовать их как Key1 или префикс id+имя таблицы), которое автоматически увеличивается при добавлении новых строк. Таким образом, можно сказать, что это поле всегда уникально.
Вы можете использовать свойство Identity (тождество) для создания колонки, которая содержит сгенерированное системой следующее значение, определяющее каждую строку, вставленную в таблицу. Тождественная колонка может использоваться не только для хранения значения первичного ключа, но и для определения строки, которая была вставлена в таблицу последней, ведь каждая новая строка будет получать число, которое больше любого существующего.
Когда SQL Server автоматически предоставляет значение ключа, можно уменьшить затраты, потому что облегчается программирование, первичный ключ будет коротким и уменьшаются пользовательские транзакции.
Автоматически увеличиваемое поле имеет следующие ограничения:
- В таблице может быть только одна Identity колонка, да я и не вижу смысла от создания двух автоматически увеличиваемых полей;
- Она должна использоваться с целочисленными типами данных, дробные типы запрещены;
- Значение в этом поле не может обновляться. В MS SQL Server есть способ обойти это ограничение (мы его увидим далее в этом разделе), но так можно нарушить целостность данных, поэтому этот метод обхода ограничения на редактирование поля необходимо использовать аккуратно и только в крайних случаях;
- Не разрешаются нулевые значения. Колонка всегда должна быть заполнена, и при этом, значение заноситься только сервером, вы не можете на него повлиять.
При разработке запросов вы можете использовать ключевое слово IDENTITYCOL в месте с именем колонки в запросе. Это позволяет вам ссылаться на колонку в таблице со свойством Identity, не зная имени колонки. Так как в таблице может быть только одна колонка со свойством Identity, сервер сам сможет найти нужное поле.
Вы можете управлять свойством Identity несколькими путями:
- Тождественное свойство не обеспечивает уникальности. Для уникальности автоматически увеличиваемого поля создавайте уникальный индекс. Да, он создается по умолчанию, но удалять его не стоит, иначе сервер не сможет гарантировать уникальности;
- Автоматическое увеличение можно устанавливать на поля следующих типов: tinyint, smallint, int, bigint, decimal(n,0) или numeric(n,0). Обратите внимание, что у типов decimal и numeric в качестве значения точности (количество знаков после запятой) должно быть 0, то есть дробной части не должно быть. Вы должны также учитывать, что количество возможных записей в таблице зависит от выбранного типа. Это значит, если выбрать тип tinyint (может принимать значения от 0 до 255), то в таблице может быть только 256 записей (если расчет начать с нуля). Дальше увеличение будет невозможно, а значит, новая запись не сможет быть добавлена. Выбирайте тот тип, которого будет достаточно.
В современных базах данных для обеспечения уникальности рекомендуют использовать глобально уникальные идентификаторы GUID (Globally Unique Identifier). Это действительно более мощный способ обеспечения целостности, но не очень удобный с точки зрения использования, поэтому программисты старой закалки продолжают использовать автоматическое увеличение.
Некоторые базы данных создают GUID идентификаторы для каждой строки, даже если пользователь не затребовал этого. При этом, идентификатор прячется и для его отображения необходимо включать специальную опцию или использовать специальную команду в SQL запросе. В MS SQL Server идентификаторы GUID создаются автоматически, если таблица участвует в репликации.
В таблице может быть только одна колонка с автоматически увеличиваемым значением. Чтобы задать данный тип поля, необходимо среди параметров указать ключевое слово IDENTITY в следующем виде:
IDENTITY [ ( seed , increment ) [ NOT FOR REPLICATION ] ]
После слова IDENTITY необходимо в круглых скобках указать два параметра – начальное значение (будет присвоено первой строке в таблице) и приращение. По умолчанию обоим параметрам присваивается значение 1. Следующий пример, показывает создание таблицы, с автоматически увеличиваемым полем ID:
CREATE TABLE TestTable ( id int IDENTITY(100, 2) )
В качестве начального значения выбрано число 100. При добавлении каждой последующей строки в поле будет записываться число на 2 больше, т.е. 102, 104, 106, 108 и т.д.
Для чего нужен ключ NOT FOR REPLICATION (не для репликации)? Допустим, что у вас есть два сервера баз данных, которые расположены в разных офисах и не объединены каналом связи. Необходимо иметь какую-то возможность объединения баз данных в одно целое. В MS SQL Server есть удобный инструмент решения данной проблемы – репликация. Репликация — это процесс слияния двух баз данных.
Но тут есть одна проблема. Допустим, у вас есть две базы данных DB1 и DB2. В базе данных DB1 может быть добавлена новая строка с определенным идентификатором, который был назначен автоматически. Во время репликации эта строка должна попасть в базу данных DB2, но при вставке средствами репликации в поле id будет сгенерировано другое значение. Строки получаться не одинаковыми и нарушается целостность данных.
Чтобы решить проблему, для поля с автоматически увеличиваемым значением можно указать ключ NOT FOR REPLICATION. В этом случае, при вставке новой строки из DB1 в DB2 во время репликации новый id не будет генерироваться, а будет использоваться тот, который был указан в DB1.
Но это не решает проблемы полностью, потому что идентификатор строки из DB1 может конфликтовать с уже существующей строкой в DB2, а это недопустимо. Эта проблема решается намного проще. В DB1 для поля ID задаем начальное значение 1, а для DB2 задаем начальное значение 100 000 000. Теперь новые строки в DB1 будут иметь номера 1, 2, 3, а в DB2 на 100 000 000 больше и пересечение в идентификаторах произойдет не скоро, а точнее, когда в DB1 будет добавлено 100 000 000 строк.
В общей базе данных у вас будут строки с идентификаторами из обеих таблиц, и по номеру вы можете легко определить, из какой базы данных он попал к вам в руки. Если поле id более 100 000 000, то это явно DB2.
Необходимо сделать одно замечание (хотя оно и выходит за рамки книги) – когда будете настраивать репликацию, обе базы данных должны иметь одинаковую структуру, а в мастере необходимо указать, что структуру базы данных реплицировать не надо. Если вы этого не сделаете, то сразу после выполнения мастера структура базы данных DB1 будет скопирована в DB2, и все настройки идентификаторов и начальных значений уничтожаться.
Итак, посмотрим на пример создания таблицы с автоматически увеличиваемым идентификатором и не участвующем в репликации:
CREATE TABLE TestTable1 ( id int IDENTITY(100, 2) NOT FOR REPLICATION )
Если вы используете автоматически увеличиваемое поле только для того, чтобы создать первичный ключ, то это не совсем корректное решение для базы данных, с которой работает множество человек. Дело в том, что в языках программирования строка добавляется на стороне клиента. В этот момент в этой строке значение автоматически увеличиваемого поля будет нулевым, и заполниться только после завершения ввода данных и выполнения оператора INSERT (мы его рассмотрим во 2-й главе). Очень часто это неудобно и в этом случае лучшим вариантом будет использование глобально уникальные идентификаторы GUID.
Если после ключевого слова IDENTITY ничего не указано, то подразумевается, что начальное значение и увеличение равно 1. Посмотрим на следующий запрос:
CREATE TABLE TestTable2 ( id int IDENTITY )
Он идентичен следующему:
CREATE TABLE TestTable2 ( id int IDENTITY(1,1) )
Начальное значение и приращение в виде единицы встречаются наверно в 90% случаев, и именно поэтому эти значения используется по умолчанию для IDENTITY полей.
www.flenov.info
Как создать таблицу в базе данных MS SQL Server 2008
В предыдущей статье показано как создавать новую базу данных в MS SQL Server. Информация в базе данных храниться в таблицах, которые являются отображением некоторых логических общностей. В нашей учебной базе, которая будет моделировать работу некой коммерческой фирмы по продаже товаров, как минимум, будут необходимы пять таблиц:
Sotrudniki — в этой таблице будет храниться информация о сотрудниках — Справочник сотрудников фирмы;
Tovary — будет содержать информацию о товарах — Справочник товаров;
Zakazy — сюда будем заносить информацию о сделанных заказах — оперативная таблица о сделанных заказах;
Zakazchiki — будет хранить информацию о заказчиках — Справочник заказчиков;
Postavschiki — хранит информацию о поставщиках товаров — Справочник поставщиков
Приблизительная номенклатура таблиц ясна. Конкретную структуру таблиц с необходимыми полями будем задавать во время их создания. Сейчас аккурат и займёмся этим моментом. Опять запускаем SQL Server Management Studio, выбираем БД, отмечаем ветку Таблицы и по правой кнопке нажимаем по пункту меню «Создать таблицу»: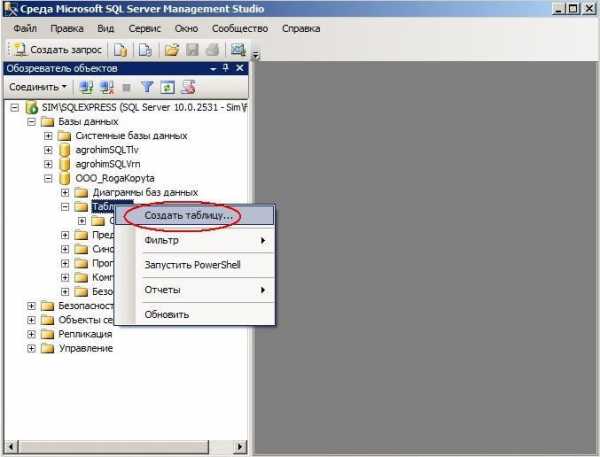
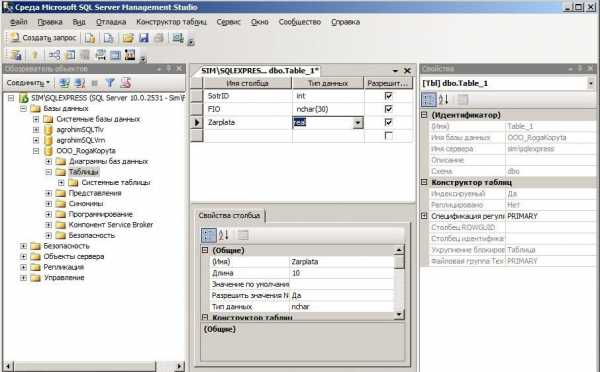
Для сохранения введённой информации о структуре таблицы щелкаем правой кнопкой по ярлыку с именем таблицы по умолчанию:
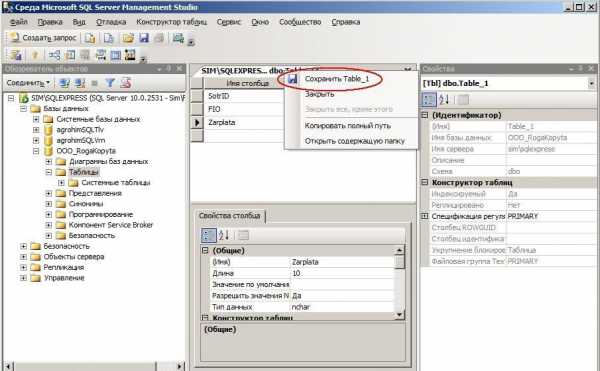
В следующей форме задаём имя таблицы:
После обновления, в «Обозревателе объектов» можно увидеть в списке таблиц только что созданную таблицу:
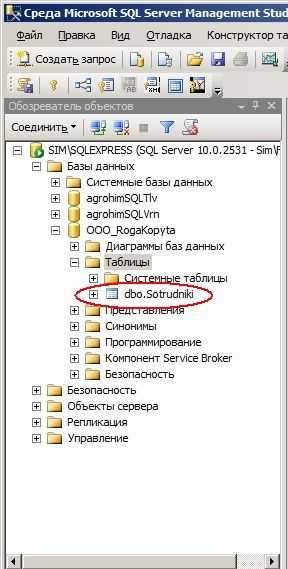
Первую таблицу в MS SQL Server успешно создали. (пока не обращайте внимание на префикс dbo в имени таблицы. Он означает владельца таблицы — database owner).
Естественно, если мы что-то забыли, всегда можно вставить в структуру таблицы новый столбец. Для этого становимся на нужную таблицу, жмём на правую кнопку мыши и выбираем в контекстном меню «Создать столбец«:
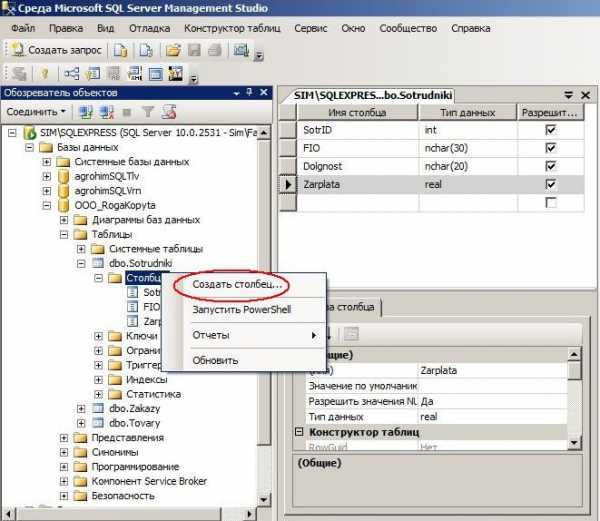
Далее становимся на строке столбца, перед которым желаем вставить новый и по правой кнопке нажимаем по «Вставить столбец«:
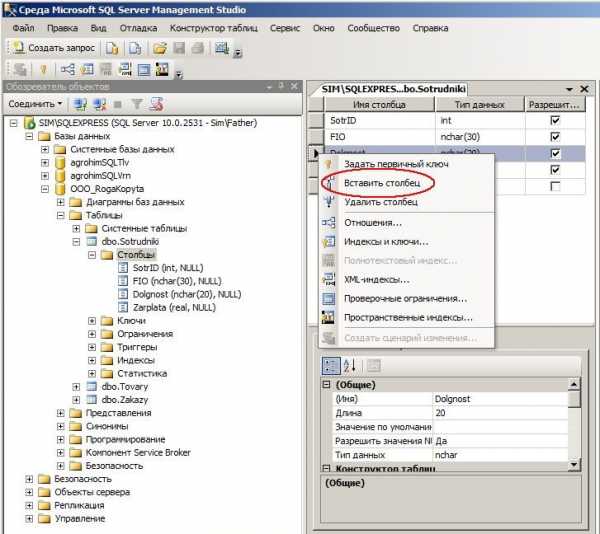
Вконтакте
Одноклассники
Мой мир
www.itworkroom.com