Как узнать всю информацию о сайте
Главная » Разное » Как узнать всю информацию о сайте
Информация о сайте
Здесь вы сможете провести полный анализ сайта, начиная с наличия его в каталогах и заканчивая подсчетом скорости загрузки. Наберитесь немного терпения, анализ требует некоторого времени. Введите в форму ниже адрес сайта, который хотите проанализировать и нажмите «Анализ».
Идёт обработка запроса, подождите секундочку
Используете браузер Mozilla Firefox или Internet Explorer? Тогда вы можете установить наш поисковый плагин для этого браузера. После его установки, вам ненужно будет заходить на сайт, чтобы провести проверку, все становится гораздо проще. Вы вводите адрес проверяемого сайта в строку нашего плагина, который встраивается в панель вашего браузера, и жмете поиск. Это все, вы уже на странице с результатами поиска.
Для того чтобы установить плагин просто нажмите на ссылку ниже.
Чаще всего проверяют:
| Сайт | Проверок |
|---|---|
vk. com com | 85719 |
| vkontakte.ru | 43342 |
| odnoklassniki.ru | 34432 |
| mail.ru | 16279 |
| 2ip.ru | 15687 |
| yandex.ru | 13347 |
| pornolab.net | 9737 |
| rutracker.org | 8830 |
| youtube.com | 8721 |
| vstatuse.in | 7064 |
Как я могу узнать, какая информация обо мне существует в Интернете?
Всемирная паутина — очень большое место. Некоторая информация о вас может относиться к тому, что некоторые называют поверхностной сетью, состоящей из веб-страниц, на которые ссылаются другие сайты, и поэтому ее могут найти поисковые системы, такие как Google. Но в отличие от обычных поисковых систем, брокеры данных собирают большую часть информации, которую они собирают, из того, что некоторые люди называют глубокой сетью. Глубокая сеть состоит из веб-страниц и доступных для поиска баз данных под поверхностью, на многие из которых никто не ссылается и которые не индексируются поисковыми системами, но на самом деле они составляют подавляющее большинство недвижимости в Интернете. Некоторые даже вручную пытаются получить официальные записи о людях. Затем они могут объединить ваши личные данные в подробный профиль и отобразить его в Интернете в одном удобном месте.
Некоторые даже вручную пытаются получить официальные записи о людях. Затем они могут объединить ваши личные данные в подробный профиль и отобразить его в Интернете в одном удобном месте.
Сайты поиска людей часто делятся на две категории: первичные и вторичные. Первичные сайты собирают вашу информацию из первичных источников, таких как открытые архивы государственных учреждений, коммунальных предприятий и т. Д. Некоторые сайты, которые с 2013 года считаются основными, включают Intelius, LexisNexis, PeopleFinders, Spoke, WhitePages, BeenVerified и DOBSearch.Вторичные сайты, как правило, получают информацию с первичных сайтов и из других источников в Интернете, включая другие вторичные сайты и социальные сети. Некоторые из них включают Spokeo, Pipl, Radaris, Mylife, Wink, LookUp, PeekYou, Waatp, yasni.com, Yatedo и 123People. Конечно, эти категории частично пересекаются.
Объявление
Пара популярных, удобных и иногда очень точных сайтов поиска людей — это Spokeo и Pipl. Spokeo позволяет выполнять поиск по имени, электронной почте, телефону, имени пользователя или почтовому адресу. Результаты будут отображаться в виде меток на карте, и вы можете перейти к выбранному вами человеку и перейти к профилю, который отображает массу личной информации, а также широкий спектр социальных сетей, блогов, покупок, фотографий, музыки и других сайтов на который у человека есть аккаунт. Несмотря на то, что он не может получить доступ к тому, что вы пометили как частный, он сообщит поисковику, что у вас есть личные учетные записи. И очевидно, что как только кто-то выполнит поиск, он продолжит поиск и агрегирование любой новой информации, связанной с этой информацией.Поиск бесплатный, но доступ к более подробной информации предоставляется за абонентскую плату.
Spokeo позволяет выполнять поиск по имени, электронной почте, телефону, имени пользователя или почтовому адресу. Результаты будут отображаться в виде меток на карте, и вы можете перейти к выбранному вами человеку и перейти к профилю, который отображает массу личной информации, а также широкий спектр социальных сетей, блогов, покупок, фотографий, музыки и других сайтов на который у человека есть аккаунт. Несмотря на то, что он не может получить доступ к тому, что вы пометили как частный, он сообщит поисковику, что у вас есть личные учетные записи. И очевидно, что как только кто-то выполнит поиск, он продолжит поиск и агрегирование любой новой информации, связанной с этой информацией.Поиск бесплатный, но доступ к более подробной информации предоставляется за абонентскую плату.
Pipl позволяет искать по имени, электронной почте, имени пользователя, номеру телефона и местоположению и, как сообщается, является одним из наиболее точных сайтов поиска людей. Вы можете выбрать человека, которого ищете, из списка возвращенных результатов. Он возвращает некоторые личные данные вместе со ссылками на другие сайты, которые могут содержать связанную информацию, в том числе поисковые сайты других людей, профили в социальных сетях и фотографии.Как и Spokeo, им очень легко пользоваться. Поиск бесплатный, так как он приносит доход с помощью рекламы и рекламных ссылок.
Он возвращает некоторые личные данные вместе со ссылками на другие сайты, которые могут содержать связанную информацию, в том числе поисковые сайты других людей, профили в социальных сетях и фотографии.Как и Spokeo, им очень легко пользоваться. Поиск бесплатный, так как он приносит доход с помощью рекламы и рекламных ссылок.
Это только верхушка айсберга, поскольку существуют сотни подобных сайтов с разной степенью удобства и точности, некоторые из которых связаны друг с другом, а некоторые — с бесплатными агентами.
Тот факт, что сущности накапливают этот тип данных и делают их доступными, очевидно, вызывает серьезную озабоченность по поводу конфиденциальности. Это упрощает такие вещи, как преследование и кража личных данных.Кроме того, существует проблема неточных данных. Есть много людей с одинаковыми или похожими именами или которые жили по одним и тем же адресам в разное время. Это и многое другое может привести к тому, что неверная информация будет связана с вашим профилем на этих сайтах. Это может стать проблемой, если вы проходите собеседование при приеме на работу или иным образом пытаетесь произвести хорошее впечатление в Интернете. Многие рекрутеры и менеджеры по найму ищут в Интернете людей, которых они ищут для работы.
Это может стать проблемой, если вы проходите собеседование при приеме на работу или иным образом пытаетесь произвести хорошее впечатление в Интернете. Многие рекрутеры и менеджеры по найму ищут в Интернете людей, которых они ищут для работы.
Большая часть неточной информации, вероятно, безвредна, но не исключено, что сайт делает что-то вроде связи судимости с неправильным человеком.Не говоря уже о том, что эти сайты могут помочь вашим профессиональным сотрудникам найти нелестную фотографию пьяного отпуска, которую опубликовал ваш друг. Из соображений конфиденциальности, безопасности и репутации в Интернете вы можете быть в курсе того, какая личная информация находится там, и постараться навести порядок.
.
Как найти информацию о ком-то в Интернете: 7 простых шагов
Если вы хотите найти человека, Интернет наводнен потенциальными ресурсами. Вы можете найти кого угодно в Интернете с помощью поисковых систем, социальных сетей и публичных записей среди других инструментов.
Будь то потерянный друг, мошенник-домовладелец или старый учитель, вы сможете найти их, немного покопавшись.Вот шаги, чтобы найти информацию о ком-либо в Интернете.
Шаг 1. Проверьте поиск Google
Google всегда должен быть вашим первым портом захода.Простой поиск может выявить всевозможную информацию о человеке, включая его работу, семью и город, в котором он живет.
Если у человека, о котором идет речь, есть обычное имя, попробуйте использовать некоторые логические операторы поиска Google, чтобы сузить фокус.
Научитесь лучше находить информацию с помощью поисковых систем: объяснение логики логического поиска
Для запроса примерно 50 миллиардов проиндексированных страниц тысячам серверов Google требуется всего полсекунды, а сканирование только первой страницы результатов поиска занимает значительно больше времени.Вдобавок к этому вы, скорее всего, отклонитесь и откроете нерелевантные сайты. Почему бы вам не оказать огромную услугу своему постоянно отвлекающемуся и легко перегружаемому мозгу и не научиться правильно строить поиск?
Также стоит заглянуть в Новости Google. Он раскроет все недавние заметные достижения или печально известные скандалы.
Он раскроет все недавние заметные достижения или печально известные скандалы.
Шаг 2. Настройте оповещение Google
Если вы не можете найти информацию с помощью Google, попробуйте настроить некоторые оповещения Google.Если что-то о человеке, которого вы ищете, появится в Интернете в будущем, вы получите уведомление на свой электронный почтовый ящик.
Чтобы настроить оповещение Google, зайдите в Google.ru / alerts и введите имя человека в поле поиска. Щелкните Показать параметры , чтобы настроить такие параметры, как язык, регион и частота уведомлений.
Шаг 3. Проверьте другие поисковые системы
Google — не единственное шоу в городе.Есть много поисковых систем. Все они имеют разные алгоритмы поиска, а это означает, что вы сможете найти альтернативные крупицы информации, используя их.
Ознакомьтесь с нашим обзором альтернатив Google, чтобы узнать больше.
Шаг 4. Проверьте основные социальные сети
По оценкам, в 2018 году 77 процентов людей в США имели хотя бы один профиль в социальных сетях.![]()
Хотя это меньше исторического максимума в 80 процентов в 2017 году (благодаря движению #DeleteFacebook), все же есть большая вероятность, что человек, которого вы хотите отследить, где-то поблизости.
Вам следует просканировать все обычные сайты, такие как Facebook, Twitter и Instagram.Но убедитесь, что вы не упускаете из виду LinkedIn. Некоторые профессионалы могут поддерживать свой профиль в LinkedIn как единственное место в социальных сетях.
Шаг 5. Проверьте общедоступные записи
«Государственные записи» — широкий термин.То, какие записи доступны в Интернете, является случайным. Если вам повезет, вы сможете найти свидетельство о рождении человека, свидетельство о браке, указ о разводе и многое другое.
Вы также можете проверить документы, такие как сертификаты землепользования и регистры компаний, чтобы узнать, есть ли у человека какие-либо записи, связанные с его именем.
Сайтов, на которые стоит обратить внимание:
Zabasearch — хорошая отправная точка, но он вернет огромное количество информации. Он извлекает информацию из общедоступных записей, таких как протоколы судебных заседаний, информация о регистрации избирателей, «Желтые страницы» и т. Д. Чтобы управлять потоком информации, вы можете сузить его до состояния для начала.
Он извлекает информацию из общедоступных записей, таких как протоколы судебных заседаний, информация о регистрации избирателей, «Желтые страницы» и т. Д. Чтобы управлять потоком информации, вы можете сузить его до состояния для начала.
Большая часть информации доступна бесплатно, и вам следует исчерпать все возможные варианты поиска, прежде чем выбирать платный маршрут.
VitalRec поможет вам найти свидетельства о рождении, записи о смерти, свидетельства о браке и указы о разводе для каждого штата, округа и городского архивного управления США.
Сайт также имеет несколько международных рекордов. Охватываемые страны включают Австралию, Австрию, Канаду, Чехию, Великобританию, Финляндию, Францию, Германию, Венгрию, Ирландию, Италию, Новую Зеландию, Нидерланды, Польшу, Португалию, Словакию и Швецию.
Национальный публичный веб-сайт для лиц, совершающих сексуальные преступления, или NSOPW для краткости — это список зарегистрированных в США лиц, совершивших сексуальные преступления.
Он содержит базы данных для всех 50 штатов, а также округа Колумбия, территорий США и Индии.
Служебные записи
ветеранов доступны в Национальном архиве США.Он включает фотографии, документы и доступные для поиска базы данных.
Обратите внимание, что данные не являются исчерпывающими. Кураторы Национального архива признают, что большая часть информации недоступна в Интернете.Это особенно верно для пластинок до Первой мировой войны.
Если человек, которого вы пытаетесь найти, является писателем, музыкантом или иным образом связан с творчеством, вы можете найти ссылку на него в Бюро регистрации авторских прав США.Все записи отдела доступны для поиска в Интернете.
Вы можете искать как личные, так и корпоративные имена.
В других странах есть собственные эквивалентные базы данных с возможностью поиска.
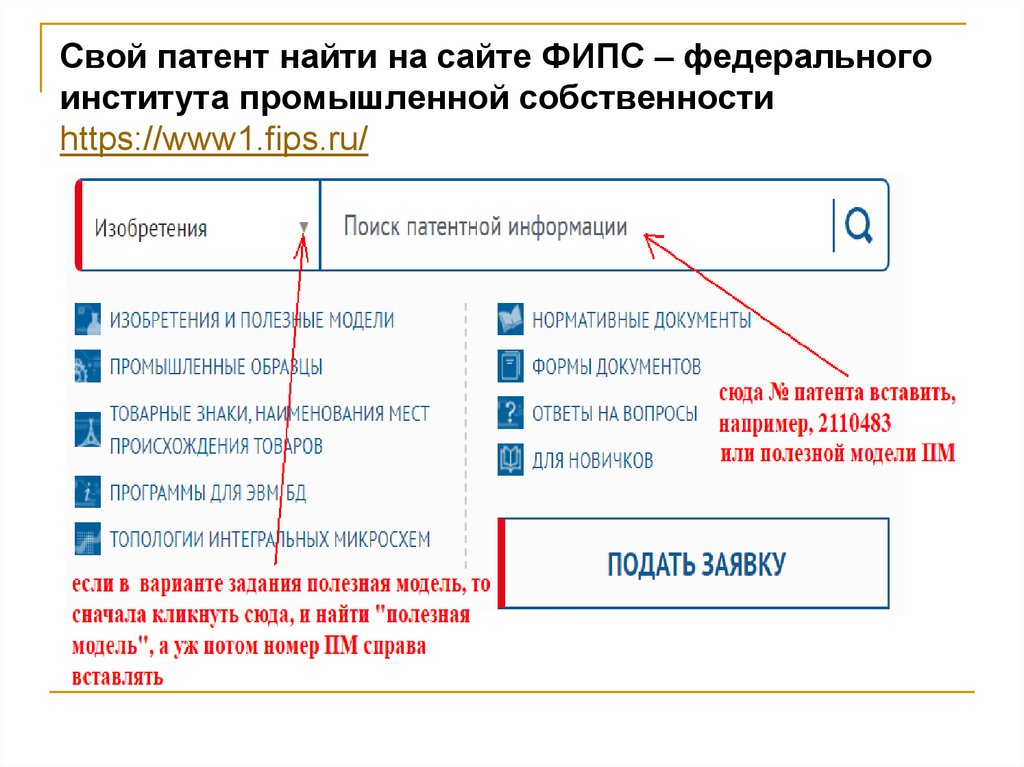
Патентные записи
Точно так же, если человек, которого вы хотите отследить, является ученым или изобретателем, вы можете найти его в публичных записях Управления США по патентам и товарным знакам.
Вы можете искать по имени, значку дизайна, ключевым словам и т. Д.
Опять же, другие страны имеют сопоставимые базы данных.
Есть вероятность, что человек находится в заключении. В конце концов, почти каждый 100 взрослый американец находится за решеткой.
Если они осуждены, они могут не отображаться в социальных сетях или на некоторых других сайтах, которые мы обсуждали.
Вы можете проверить общенациональный список заключенных на официальном сайте Федерального бюро тюрем.
Шаг 6. Проверьте нишевые поисковые системы
Все еще не повезло? Не волнуйтесь; у вас еще нет вариантов. Затем проверьте несколько нишевых поисковых систем.Они специализируются на конкретных отраслях, регионах и социальных сетях.
Некоторые нишевые поисковые системы, которые помогут вам найти кого-то в Интернете:
PeekYou сканирует учетные записи людей в социальных сетях вместе со ссылками на имя пользователя на других сайтах и блогах.
Для начала вам потребуется имя и (необязательно) номер телефона.
Pipl отлично справляется с обнаружением телефонных номеров, адресов и ссылок на публичные записи.Вы можете уточнить поиск по городу, штату и почтовому индексу, чтобы получить более узкий выбор результатов.
Если человек, которого вы ищете, умер, вы можете перейти на веб-сайт Find a Grave.Это самая обширная в мире база данных информации о могилах и надгробиях. Это коллекция фотографий и контента, отправленных пользователями.
На момент написания вы можете найти 170 миллионов памятников.Это смесь обычных умерших людей и ушедших известных людей.
В том же духе Interment.net имеет миллионы официальных записей о кладбищах с тысяч кладбищ по всему миру.
Данные доступны для США, Бельгии, Бразилии, Кубы, Кипра, Чешской Республики, Финляндии, Франции, Германии, Ирландии, Италии, Японии, Мексики, Новой Зеландии и Польши.
Шаг 7. Проверьте нишевые социальные сети
Наконец, стоит порыться в нескольких нишевых социальных сетях.Вы будете удивлены разнообразием существующих небольших сайтов. Есть сети для инвесторов, любителей пива, местных сообществ и многого другого.
Есть сети для инвесторов, любителей пива, местных сообществ и многого другого.
Мы писали о некоторых из лучших нишевых социальных сетей.Прочтите список, чтобы узнать, какие из них мы рекомендуем.
Еще больше сайтов для поиска людей в Интернете
Разнообразный набор инструментов, который мы рассмотрели, должен помочь вам начать поиск информации о ком-либо в Интернете.Чтобы узнать больше о новых возможностях, ознакомьтесь с нашим списком веб-сайтов, чтобы найти людей в Интернете.
И, говоря о поиске информации в Интернете, знаете ли вы, что вы можете получить в свои руки рассекреченные правительственные документы и секреты?
7 классных комиссионных онлайн-магазинов, чтобы спасти себя
Ищете выгодные предложения по покупкам в Интернете? Попробуйте онлайн-магазины комиссионных! Вы можете найти скрытые жемчужины и удивительные сделки в нужных местах.
Об авторе Дэн Прайс (Опубликовано 1376 статей)
Дэн присоединился к MakeUseOf в 2014 году и был директором по партнерским отношениям с июля 2020 года. Обратитесь к нему с вопросами о спонсируемом контенте, партнерских соглашениях, рекламных акциях и любых других формах партнерства. Вы также можете найти его каждый год бродящим по выставочной площадке CES в Лас-Вегасе, поздоровайтесь, если собираетесь. До своей писательской карьеры он был финансовым консультантом.
Обратитесь к нему с вопросами о спонсируемом контенте, партнерских соглашениях, рекламных акциях и любых других формах партнерства. Вы также можете найти его каждый год бродящим по выставочной площадке CES в Лас-Вегасе, поздоровайтесь, если собираетесь. До своей писательской карьеры он был финансовым консультантом.
Ещё от Dan Price
Подпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Подтвердите свой адрес электронной почты в только что отправленном вам электронном письме.
.
Как узнать личную информацию о ком-то в сети |
Есть множество причин, по которым вы можете захотеть узнать личную информацию о ком-то. Может быть, вы встречаетесь с новым человеком и хотите разузнать его, чтобы убедиться, что он ничего от вас не скрывает. Или, возможно, вы снимаете комнату в своем доме и хотите убедиться, что у этого человека нет судимости.
Существует несколько способов найти сведения о человеке по имени. Вы можете сделать это, посетив офисы государственного архива в вашем районе, и вы можете найти информацию о человеке в Интернете.Вот лучшие методы, которые вы можете использовать, чтобы узнать больше о человеке.
Социальные сети
Социальные сети — отличное место для начала поиска, потому что они бесплатны и просты в использовании. Посмотрите, сможете ли вы найти этого человека в самых популярных социальных сетях, среди которых:
- Твиттер
- Snapchat
Проще всего найти кого-то по имени в Facebook и Twitter, тогда как в Instagram и Twitter иногда бывает сложнее, поскольку в этих сетях есть имена пользователей.Тем не менее, вы часто можете найти людей в этих сетях только по их именам, выполнив поиск в самих сетях или используя поисковую систему и введя имя человека в сочетании с социальной сетью.
Социальные сети хорошо подходят для получения подробностей о чьей-либо личной жизни, и люди также иногда делают свою контактную информацию легко доступной на этих сайтах. Вы можете увидеть их историю работы и города, в которых они жили. Все зависит от того, сколько информации они решили опубликовать.
Вы можете увидеть их историю работы и города, в которых они жили. Все зависит от того, сколько информации они решили опубликовать.
Сайты для поиска людей и проверки биографических данных
Чтобы сразу получить любую личную информацию о человеке за символическую плату, существует FreeBackgroundCheck.org. Информация, доступная на этом сайте, включает:
Это делает FreeBackgroundCheck.org эффективным способом получить исчерпывающую информацию о человеке и даже найти скрытую информацию, которую вы не смогли бы получить с помощью многих других методов. Вот как вы можете использовать сайт для поиска людей по их имени:
- Перейдите на домашнюю страницу Free Background Check и убедитесь, что рядом с заголовком «Быстрый поиск записей» выбрана вкладка «Имя».
- Введите имя и фамилию человека в соответствующие поля. Если у вас есть город и штат, вы также можете указать его, чтобы было легче найти нужного человека.
- Щелкните Поиск.
- Найдите нужного человека в списке результатов и нажмите «Доступ к отчету».

- Выберите желаемый уровень доступа и пройдите процесс создания учетной записи.
Человек, которого вы ищете, никогда не узнает, что вы проверили его. Есть также несколько других методов поиска, если у вас есть больше, чем просто имя человека, так как вы также можете искать по номеру телефона, физическому адресу, адресу электронной почты или номерному знаку.
Государственные записи
В государственных архивах по каждому городу и округу хранится довольно много информации. Суды будут вести записи по уголовным делам, а окружные архивы будут вести записи о собственности.
Если вам нужна информация, которая, вероятно, является общедоступной, выясните, в каком офисе она должна быть, а затем посетите офис лично или зайдите на его веб-сайт. Рекомендуется сначала проверить в Интернете, чтобы сэкономить время, но имейте в виду, что не каждый офис будет публиковать свои записи в Интернете.
Настройте свой поиск на нужную информацию
Если ваша цель — узнать как можно больше о человеке, лучше всего объединить все перечисленные выше методы для проведения тщательного поиска. Однако, если вы ищете что-то конкретное, лучше выбрать метод поиска, который с наибольшей вероятностью позволит найти эту информацию.
Однако, если вы ищете что-то конкретное, лучше выбрать метод поиска, который с наибольшей вероятностью позволит найти эту информацию.
Для получения конфиденциальной информации или подробного изучения биографии человека лучше всего использовать бесплатную проверку биографических данных. Это может сработать для выяснения уголовного прошлого человека, но вы также можете получить более подробную информацию об уголовных делах через суды и их веб-сайты.
Если вы ищете больше о том, кто такой человек, чем он занимался в жизни, а также об их нынешних и предыдущих отношениях, вы, вероятно, добьетесь наибольшего успеха в социальных сетях, особенно если вы ищете кого-то, кто любит публиковать в сети все самое последнее из своей жизни.
Наконец, помните, что вы часто можете получить лучшие результаты, используя несколько методов поиска и используя информацию, которую вы найдете с одним, чтобы улучшить свой поиск с помощью другого. Возможно, вы не сможете найти какие-либо профили в социальных сетях по имени, но вы можете найти номер телефона с помощью бесплатной фоновой проверки, а затем использовать его для открытия учетной записи Facebook.
.
13 Веб-сайты для поиска людей в Интернете
В эпоху бума социальных сетей найти потерянных друзей и коллег легче, чем когда-либо прежде.
Вчерашний частный мир превратился в онлайн-мир.Каждый, у кого есть поисковая система, имеет открытый доступ к социальным сетям, правительственным базам данных и публичным записям.
Если вы ищете давно потерянного друга или, возможно, хотите проверить кого-нибудь, рассмотрите следующие бесплатные ресурсы, чтобы найти людей в Интернете.
Как бесплатно искать людей в Интернете
Интернет — это, по сути, гигантская база данных, переполненная точками данных о людях.Сегодня трудно найти кого-либо, кто не прокомментировал запись в блоге, не разместил сообщение на онлайн-форуме или не зарегистрировался на Facebook или Flickr.
Различные сайты используют эту информацию по-разному.Следующие 13 сайтов можно использовать для поиска людей в Интернете, но они могут получать данные из разных источников. В результате результаты могут немного отличаться.
В результате результаты могут немного отличаться.
Прежде чем начать, узнайте несколько подробностей о человеке.Начните с их дня рождения или штата, в котором они живут. Если у вас есть эти подробности, объем информации, которую вы можете найти в Интернете о человеке, просто поразителен. На самом деле, иногда это может оказаться непосильным.
При поиске людей в Интернете обязательно используйте несколько поисковых систем для достижения наилучших результатов.
Существует множество веб-сайтов, которые выполняют поиск в стандартных социальных сетях, таких как Facebook или Twitter.Но Pipl — это один из ресурсов, который проводит глубокий поиск имени на «нетипичных сайтах». Результаты поиска Pipl впечатляют.
Я использовал Pipl для глубокого поиска самого себя. Поиск извлек мои собственные данные из профилей на Soundcloud, Last.fm и другие, такие как сайты поиска работы и Google.
Я был впечатлен усилиями Pipl по обнаружению уличных адресов, номеров телефонов и даже членов семьи, собранных с разных веб-сайтов.
Однако, чтобы использовать Pipl, вам необходимо зарегистрироваться. Это немного расстраивает, но оно того стоит, поскольку результаты хорошие. Я даже искал свою жену, которая работает советником местного самоуправления, и Пипл обнаружила документ, в котором она упоминалась.Впечатляет!
Наверное, самый мощный инструмент для поиска тех, кто давно пользовался Интернетом, — это группы Google.Группы Google включили в свою базу данных более 800 миллионов сообщений Usenet, впечатляющий архив интернет-разговоров, начиная с 1981 года.
Например, если человек, которого вы ищете, учился в университете в это время, вы можете найти его след.Каналы Usenet были популярным способом выхода в Интернет до его бурного роста в конце 1990-х годов. Университеты, исследовательские центры, технологические компании и другие организации полагались на Usenet для сотрудничества и многого другого.
Вы можете не только найти того, кого ищете, но и получить представление об их мыслях, идеях и мотивах того времени.
Служба «100% бесплатный поиск людей», TruePeopleSearch.com дает хорошие результаты.
Но это зависит от того, где вы находитесь.
Для читателей из США это отличный инструмент, и, просто выполнив поиск по имени и стране проживания, вы найдете удивительно подробные результаты.
Вы должны получить хорошие результаты и для жителей Канады. TruePeopleSearch обычно возвращает список предыдущих адресов вместе с номерами телефонов.
Также обратите внимание на раздел «Возможные партнеры».Полезно для правоохранительных органов и частных лиц, здесь отображаются имена бывших соседей по комнате в колледже, коллег и т. Д. Без сомнения, это полезная информация, взятая из общедоступной информации Facebook.
Нравится TruePeopleSearch, FindPeopleSearch.com генерирует базовую «тизерную» информацию для проверки биографических данных. Тем не менее, эта информация может быть чрезвычайно полезной, когда вы пытаетесь узнать о ком-то больше. Что этот веб-сайт привносит в игру, так это то, что он предлагает более обширную информацию, чем другие.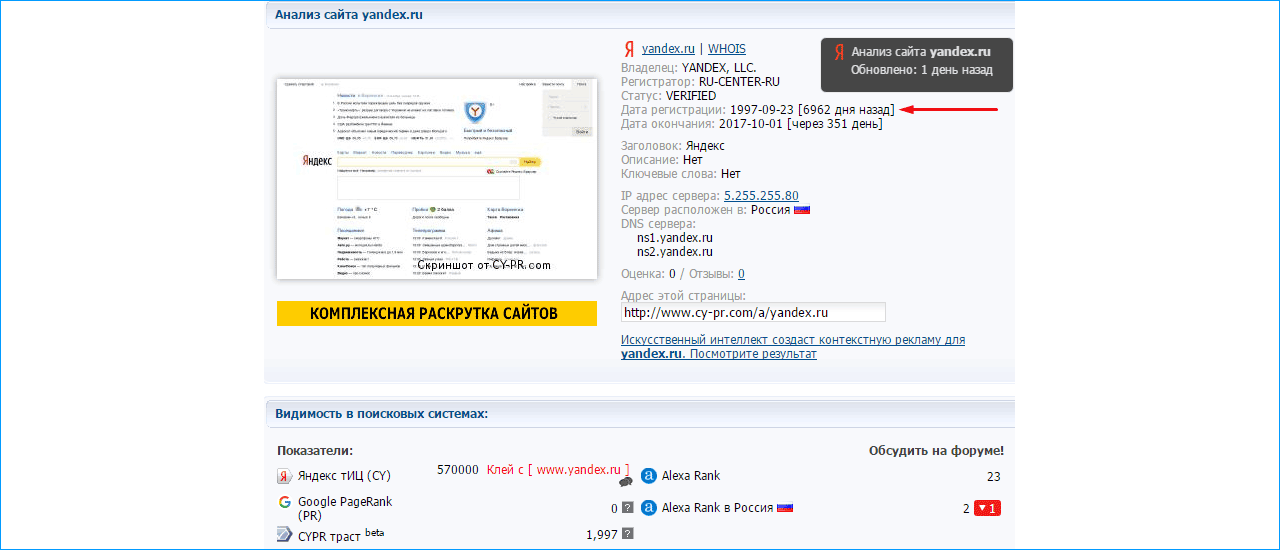
Однако, как и TruePeopleSearch, этот сайт не предлагает результатов за пределами Северной Америки.Но то, что он делает, делает хорошо. Например, после выбора вероятного кандидата FindPeopleSearch предоставляет карту с вероятным местоположением вашего карьера.
Информация о семье также может быть указана здесь, в зависимости от того, какие данные были сопоставлены для человека.Вы можете найти здесь важную семейную связь, например брата, сестру или даже тетю, дядю или двоюродного брата.
В то время как большинство людей ищут информацию в открытом доступе, PeekYou.com делает все возможное, чтобы изучить популярные социальные сети, такие как Pinterest, LinkedIn, Instagram и другие.
Результаты всегда впечатляют, хотя они могут быть несколько искажены.Например, поиск моих собственных записей смешал данные обо мне с записями других людей с похожими именами.
Кроме того, PeekYou дал мне новый инициал в середине, что, безусловно, удивило!
Как и все эти сайты, помните, что собранные данные могут быть неточными. Это может быть связано с ошибками в исходных данных или ошибками при совпадении имен.
Это может быть связано с ошибками в исходных данных или ошибками при совпадении имен.
Иногда для того, чтобы выследить кого-то, требуется немного больше творчества, чем просто ввести имя в поисковую систему.Другой подход — порыться на популярном веб-сайте, посвященном воссоединению средней школы Classmates.com.
Очевидно, вам необходимо иметь некоторое представление о средней школе (ах), которую посещал человек. В случае успеха вы найдете список людей, которые зарегистрировались на сайте в той же средней школе.
Начните с выбора школы по штату и городу, затем введите имя ученика для поиска. Многие люди зарегистрированы на сайте, поэтому у вас должны быть хорошие шансы найти того, кого вы ищете.
Обратите внимание, что это веб-сайт только для США.
Для поиска людей можно использовать различные генеалогические сайты, хотя процесс немного отличается.
Когда дело доходит до генеалогических записей, информация может быть ограничена для людей, которые еще живы. Это будет зависеть от законов о конфиденциальности данных и политики генеалогического сайта. Таким образом, хотя может быть полезно установить семейные связи с тем, кого вы ищете, информация будет скудной.
Это будет зависеть от законов о конфиденциальности данных и политики генеалогического сайта. Таким образом, хотя может быть полезно установить семейные связи с тем, кого вы ищете, информация будет скудной.
На странице результатов будет отображаться адресная информация и возможные родственники, а платная справочная информация также может быть получена с помощью PeopleFinders.
FamilyTreeNow — хороший вариант для генеалогических исследований.Интересует семейная история? Ознакомьтесь с нашим загружаемым руководством о том, как исследовать свое генеалогическое древо в Интернете.
Хотите разыскать кого-то, и у вас есть только его фотография? Используйте инструмент обратного поиска изображений, например TinEye.com. Этот сайт перевернет весь Интернет наизнанку для той же фотографии, и он покажет вам, была ли она загружена где-нибудь еще.
Сайт использует инновационную технологию распознавания изображений, которая может сопоставлять изображения на основе того, которое вы загружаете на сайт. Это впечатляющая технология, и она сработала, когда я ее впервые попробовал, сразу определив, что я загрузил ту же картинку в MakeUseOf. И он даже распознал изображение, когда только часть изображения соответствовала оригиналу. Очень впечатляющий материал.
Это впечатляющая технология, и она сработала, когда я ее впервые попробовал, сразу определив, что я загрузил ту же картинку в MakeUseOf. И он даже распознал изображение, когда только часть изображения соответствовала оригиналу. Очень впечатляющий материал.
Другой вариант обратного поиска изображений — это поиск картинок Google.
Google также является эффективным инструментом для поиска людей в Интернете. Перед тем, как попробовать, помните следующие советы.
- Заключите полное имя человека в кавычки (например, «Дэвид Ли Рот»).Google будет возвращать только результаты поиска с полным именем человека.
- Включите дополнительную информацию, которую вы уже знаете об этом человеке (например, экс-вокалист Van Halen «Сэмми Хагар»). Ваши результаты поиска будут еще точнее.
- Если человек связан с определенной организацией, попробуйте выполнить поиск только на этом сайте (например, «site: extreme-band.com» Gary Cherone «). Если это лицо указано на сайте как сотрудник или контактное лицо, вы узнайте их подробности
Эти советы работают хорошо — попробуйте!
На самом деле поиск людей с помощью Google работает настолько хорошо, что люди, которые ищут сайты, существовавшие много лет назад, закрылись. Кому они нужны, когда Google уже делает это лучше всего?
Кому они нужны, когда Google уже делает это лучше всего?
10. Найдите общедоступные записи с помощью поиска Zaba
Если вы проводите полную проверку биографических данных кого-то, то, вероятно, вас интересует не только его действия в Интернете. Вероятно, вы ищете любую из следующих сведений:
- Местожительство за последние несколько лет
- Проверка судимости
- Водительская запись
- Дата рождения и место рождения (для подтверждения гражданства)
- Проверка детского хищника
A у человека с судимостью или судебным решением есть удивительное количество информации о себе в Интернете.Все, что вам нужно, это имя и дата рождения человека, которого вы исследуете; расположение поможет сузить круг вопросов.
Один из лучших сайтов для проведения бесплатных запросов в публичные записи. Используя ZabaSearch, вы можете определить точные прошлые и текущие адреса и номера телефонов человека.
Однако для просмотра полного профиля вам потребуется заплатить 50 долларов через Intelius. Это включает в себя прошлые адреса, родственников, криминальное прошлое, банкротства и многое другое.
Это включает в себя прошлые адреса, родственников, криминальное прошлое, банкротства и многое другое.
Это предоставляет огромную базу данных для всех государственных и федеральных агентств.Большинство услуг, в которых вам необходимо заплатить за справочную информацию, поступают из этих бесплатных баз данных государственных и федеральных агентств. Вы можете найти данные бесплатно, выполнив поиск на этом веб-сайте, чтобы найти эти агентства и провести поиск самостоятельно.
Например, если копаться в агентствах штата Мэн, можно найти, где можно искать сведения о судимости штата Мэн.
Один из самых простых способов найти людей — это просто поискать в Facebook. Удивительно, кто появляется, когда вы ищете имя в Facebook.
Другие социальные сети также могут оказаться полезными для поиска людей. Например, многие люди избегают Facebook и активны в Twitter или даже в Instagram.
Между тем LinkedIn — отличный ресурс для поиска людей.Альтернатива Facebook, ориентированная на карьеру, есть большая вероятность, что вы найдете людей, которых не найдете больше нигде.
Если вы знаете, где работал или учился человек, которого вы ищете, LinkedIn — отличный вариант.Хотя без подписки LinkedIn вы не найдете слишком много деталей, их должно быть достаточно, чтобы продолжить.
Вы сможете узнать, чем они в последнее время занимались в профессиональном плане, а также с кем они связаны.
13 отличных поисковых систем для поиска людей в Интернете
К настоящему времени у вас должны быть все инструменты, необходимые для поиска людей в сети, мертвых или живых.Мы показали вам, как использовать следующие сайты поиска людей для бесплатных общедоступных записей:
- Pipl
- Группы Google
- TruePeopleSearch
- FindPeopleSearch
- PeekYou
- Одноклассники
- FamilyTreeNow
- TinEye
- Zaba
- USA.gov
Используйте эти инструменты, чтобы найти человека или людей, которых вы ищете, и вы сразу добьетесь успеха. Но что, если кто-то пытается вас выследить? Вот как узнать, кто вас ищет в Интернете.
Но что, если кто-то пытается вас выследить? Вот как узнать, кто вас ищет в Интернете.
8 самых крутых новых функций Android 11
Android 11 уже здесь; Давайте узнаем, что это дает, проверив самые крутые функции.
Об авторе Кристиан Коули (Опубликовано 1392 статей)
Заместитель редактора по безопасности, Linux, DIY, программированию и техническим вопросам.Он также выпускает The Really Useful Podcast и имеет большой опыт в поддержке настольных компьютеров и программного обеспечения. Автор статьи в журнале Linux Format, Кристиан — мастер Raspberry Pi, любитель Lego и фанат ретро-игр.
Ещё от Christian Cawley
Подпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Подтвердите свой адрес электронной почты в только что отправленном вам электронном письме.
.
Проверка сайта на мошенничество — инструкция и сервисы для анализа
За 2020 год Google обнаружил более 2 миллионов мошеннических сайтов. Люди не проверяют ресурсы, на которые заходят, а также с легкостью ведутся на манипуляции в сети. В этой статье мы рассмотрим способы, как определить сайт мошенника не только с помощью самостоятельного анализа, но и со специализированными сервисами.
- Проверка сайта на подлинность
- Доменное имя
- SSL-сертификат
- Пользовательские соглашения
- Возраст сайта
- Отзывы
- Проверка через «Яндекс» и Google
- WOT
- WebMoney Advisor
- WhoIS
- VirusTotal
- Dr.Web online
- Kaspersky VirusDesk
 org/ListItem»>
org/ListItem»>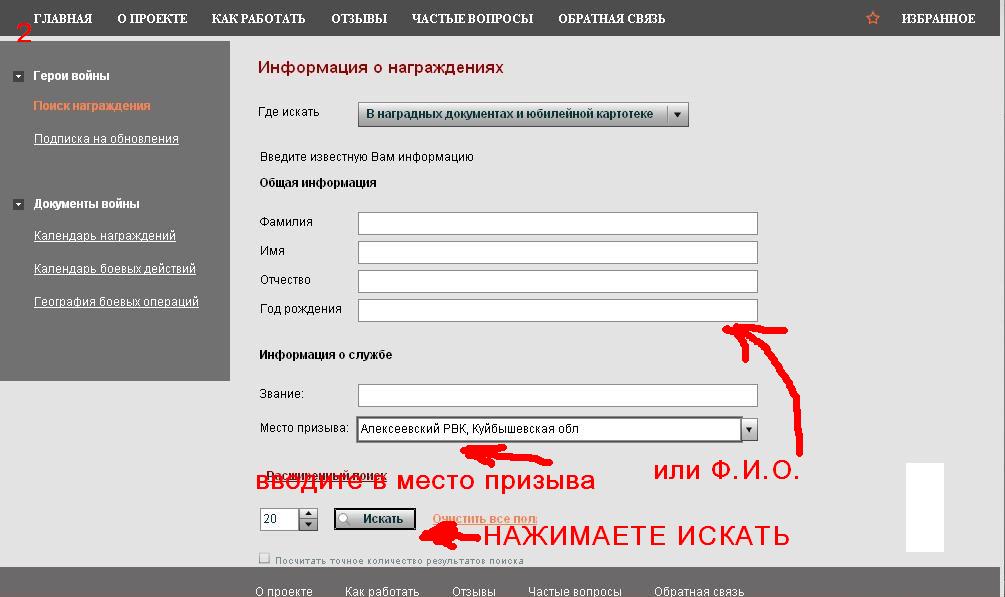 org/ListItem»>
Заключение
org/ListItem»>
ЗаключениеЧем могут быть опасны сайты мошенников
Популярный способ мошенничества — это телефонные звонки, когда мошенник представляется сотрудником банка и просит жертву продиктовать пароль или код из SMS.
Но существуют и другие методы перехватить данные пользователя:
- Обещание крупного заработка.
- Убеждение, что деньги срочно нужно перевести на другой счет, чтобы защитить данные.
- Просьба установить ПО для защиты данных либо, чтобы открыть сторонний файл.
- В периоды обострения ситуации с пандемией коронавируса мошенники активно предлагали пользователям пройти медицинское обследование или получить компенсацию за ущерб от COVID-19.
- Сообщение пожилым людям о том, что им полагаются выплаты и для их получения те должны сообщить банковские реквизиты.
- Рассылка друзьям со взломанного аккаунта с просьбой занять денег или помочь в трудной ситуации.
- Перенаправление пользователей на сторонний ресурс — якобы в связи с тем, что на официальном сайте ведутся технические работы.
- Закрытые форумы, на которых человек может найти ответ — но только после прохождения процедуры регистрации.
- Переход на поддельные сайты, которые полностью копируют популярные интернет-магазины или лендинги брендов, на которых компания якобы проводит розыгрыш.

Главная опасность заключается в том, что мошенники пытаются получить ваши личные данные и использовать их в корыстных целях. Этот процесс называется фишинг, что в переводе с английского языка означает «рыбалка» или «рыбная ловля».
Сайты мошенников ловят невнимательных пользователей, которые добровольно делятся конфиденциальной информацией: телефон, электронная почта, данные банковской карты, логины и пароли от личных кабинетов на других ресурсах.
Вы можете попасть на фишинговый сайт через ссылку в объявлении, рассылке или на поиске, где есть форма для заполнения данных или вирус, который сразу же активируется на вашем ПК или смартфоне.
Проверка сайта на подлинность
В этом разделе обсудим детали, на которые нужно обратить внимание, чтобы распознать мошеннический сайт.
Доменное имя
Часто мошенники регистрируют домены, URL которых похож на адреса сайтов официальных брендов — но содержит не слишком заметные опечатки или ошибки:
- Буквы заменены символами — «sendpu1se.com»
- Лишняя буква в названии— «sendpullse.com»
- Подмена алфавита, который выглядит, как латинские буквы.
SSL-сертификат
Проверьте безопасность ресурса. В адресной строке браузера рядом с URL сайта вы найдете символ в виде «замочка». Если он закрыт — сайт безопасен, если нет — проверяйте другие детали, потому что даже проверенные ресурсы иногда забывают купить или продлить SSL-сертификат.
Пример, как выглядит «Безопасное подключение»Вы можете нажать на раздел «Сертификат», который указан на скриншоте выше, и проверить срок его действия, а также увидеть, кому и кем было выдано разрешение.
В сертификате вы можете обратить внимание на его тип:
- Domain Validation — базовый уровень сертификата, который подтверждает только доменное имя.
- Domain Validation — базовый уровень сертификата, который подтверждает только доменное имя.

- Organization Validation — сертификат, который подтверждает существование домена и организации. Его могут получить только компании. Символ «замочка» в адресной строке имеет серый или белый цвет.
- Extended Validation — эффективное и дорогое решение, которое сложно получить, так как центр сертификации проверяет всю деятельность организации и запрашивает официальные документы. Символ «замочка» имеет зеленый цвет.
Внешний вид сайта
Посмотрите на сайт и ответьте на эти вопросы:
- Текст на сайте отвечает всем стандартам русского языка и нет ошибок?
- Все страницы сайта заполнены?
- Правильно заполнены карточки товаров?
- Кликабельна шапка сайта — логотип, номер телефона?
- Правильно указано официальное название компании?
- Есть реквизиты организации в подвале сайта или на его страницах: телефон, фирменное название, ИНН, юридический адрес и так далее?
Если вы ответили на эти вопросы «Нет» — скорее всего, попали на фишинговый сайт.
Пользовательские соглашения
Проверьте на сайте наличие пользовательского соглашения, условий доставки, гарантии и указана ли «Политика конфиденциальности данных». Найдите не только упоминание этих документов, но и сам текст.
Пример расположения документовВ пользовательском соглашении не должны быть упомянуты сторонние компании и другие реквизиты, отличающиеся от тех, что указаны на сайте.
Не нашли корректных документов пользовательского соглашения — закрывайте сайт.
Возраст сайта
Посмотрите футер сайта и найдите дату создания — возраст ресурса. Если портал создан недавно, закройте страницу.
Пример, как компания указывает возраст сайтаОтзывы
Изучите отзывы о домене. Если компания официальная, отзывы должны быть в карточках организаций на «Яндекс» и в Google, а также в специализированных сервисах — например, «Отзовик». В другом случае вы найдете сайты, на которых пользователи жалуются, что попали на фишинговый ресурс.
И самое важное, если вы заподозрили сайт в мошенничестве — ни в коем случае не заполняйте формы обратной связи и не переходите по ссылкам, с которыми вам предлагают ознакомиться. Форма может перекинуть вас, например, на QIWI Кошелек, в котором не будет возможности отследить передачу денег. На официальных ресурсах при этом всегда предусмотрено несколько способов для оплаты товара.
Форма может перекинуть вас, например, на QIWI Кошелек, в котором не будет возможности отследить передачу денег. На официальных ресурсах при этом всегда предусмотрено несколько способов для оплаты товара.
Бесплатная CRM для маркетинга и продаж
Принимайте заказы, контролируйте ход сделок с покупателями, собирайте базу контактов и запускайте маркетинговые кампании с помощью одного инструмента.
Попробовать бесплатно
Сервисы для проверки сайта на мошенничество
Сайт на мошенничество можно проверить через специализированные сервисы — о них и пойдет речь ниже.
Проверка через «Яндекс» и Google
Используйте бесплатные онлайн-инструменты от «Яндекс» и Google для проверки статуса сайта. Достаточно ввести URL ресурса, начать проверку и изучить результат поиска.
Ниже показан скриншот инструмента от Google:
Проверка сайта инструментом от GoogleА это вариант проверки от «Яндекс»:
Проверка сайта инструментом от «Яндекса»Плюсы:
- Быстрая проверка.
- Бесплатный сервис.

Минусы:
- Если сайт создан буквально на днях — скорее всего, эти инструменты еще не успели его проанализировать и оценить статус безопасности.
WOT
Web of Trust — бесплатный сервис для быстрой проверки сайтов. Чтобы он смог проанализировать сайт, вводите URL без знака «слэш» и «https://».
Страница проверки сайтаПлюсы:
- Позволяет проверить IP-адрес.
- Есть расширение для Google Chrome. Предоставляет отчет по каждому порталу. А если на сайте есть следы фишинга или запрещенного контента – доступ к ресурсу будет моментально заблокирован.
- Регулярно обновляются алгоритмы для поиска вредоносных сайтов.
Минусы:
- Не обнаружено.
WebMoney Advisor
WebMoney Advisor — сервис, который показывает рейтинг сайта и отзывы. Изначально создавался для проверки транзакций.
Инструмент Advisor на сайте WebMoneyПлюсы:
- Есть расширение для Google Chrome, которое показывает отзывы пользователей и рейтинг сайта.
- Можно посмотреть топ-500 сайтов по репутации.
- Показывает, есть ли на сайте возможность транзакций в системе WebMoney.

Минусы:
- Сайты, которые не проводят финансовые операции, находятся вне оценочного рейтинга.
- На репутацию можно влиять — присылать свои отзывы и ставить оценки с разных IP.
WhoIS
WhoIS — бесплатный сервис, который проверяет информацию о домене. Если вы хотите получать более точные и расширенные данные о сайтах — можете оформить подписку за 99 долларов в месяц.
Главная страница сервиса WhoISЭто результат проверки сайта: кто зарегистрировал, когда и с помощью какого провайдера. А ниже — оценка качества сайта и информация по IP.
Результат проверки в WhoIS
Плюсы:
- Быстрый и удобный сервис.
- Широкая база доменных имен.
- Позволяет отследить регистрационные данные мошенников.
Минусы:
- Может показывать устаревшую информацию.
- Нет данных по безопасности сайта.

VirusTotal
VirusTotal — бесплатный сервис, который проверяет не только ссылки, но и файлы на наличие вирусов.
Главная страница VirusTotalРезультат анализа сайта:
Пример проверки сайта в сервисе VirusTotalПлюсы:
- Сканирует ссылки и файлы.
- Быстрая проверка.
- Большая база антивирусных движков.
- Показывает детали сайта — IP-адрес, качество ресурса, метатеги, трекеры и ссылки на странице.
Минусы:
- Отсутствует мультиплатформенность.
Dr.Web online
Dr.Web online — сервис от антивируса для проверки вредоносных ссылок и мошеннических сайтов.
Инструмент для проверки вредоносного или мошеннического сайтаПлюсы:
- Можно установить расширение для браузера или смартфона.
- Простой интерфейс.
Минусы:
- Пользователь получает небольшой объем информации — сайт либо опасен, либо нет. Другие данные посмотреть нельзя.
 Другие данные посмотреть нельзя.
Другие данные посмотреть нельзя.Kaspersky VirusDesk
Kaspersky VirusDesk — инструмент, который собрал в себе возможности WhoIS. Может проверять сайты, ссылки, файлы и IP — способен предоставить информацию о регистрационных данных, но нет возможности проверить сайт на безопасность.
Чтобы получить полный доступ к информации — нужно заполнить анкету и запросить исследование. Стоимость вам озвучит специалист после проверки ваших данных.
Пример работы инструмента от KasperskyПлюсы:
- Проверяет сайты по репутационной базе.
- Показывает информацию о доменном имени.
- Есть возможность узнать регистрационные данные.
Минусы:
- Нет опции проверить сайт на безопасность.
Заключение
В этой статье мы рассмотрели понятие «фишинговые сайты» и определили ключевые детали, по которым можно распознать вредоносный портал. А также разобрали варианты специализированных сервисов, которые помогают понять, принадлежит ли он злоумышленникам.
Рекомендации, которые защитят вас от мошенников:
- Установите антивирус — подобных программах сейчас есть встроенный инструмент для проверки фишинга.
- Оформите виртуальную карту для онлайн-покупок, чтобы нигде не показывать свои личные данные.
- Подключите двухфакторную аутентификацию, чтобы в случае взлома можно было быстро вернуть доступ к данным.
- Используйте безопасные браузеры, которые поддерживают антифишинговую защиту, например, Google Chrome или Safari.
- Если вы не уверены в безопасности сайта, проверьте его через онлайн-сервисы — до того, как выполнять какие-либо действия на его страницах.
Чтобы самому создать качественный одностраничный сайт, воспользуйтесь нашим конструктором для создания лендингов. К нему вы сможете подключить CRM, email, Viber и SMS рассылки, а также чат-боты в таких мессенджерах, как ВКонтакте, Facebook Messenger, Telegram и WhatsApp!
Полная информация о сайте.
Не стесняясь скажу, это пожалуй самая полезная из статей, по крайней мере на момент написания и по крайней мере для меня, которую я писал на своем блоге.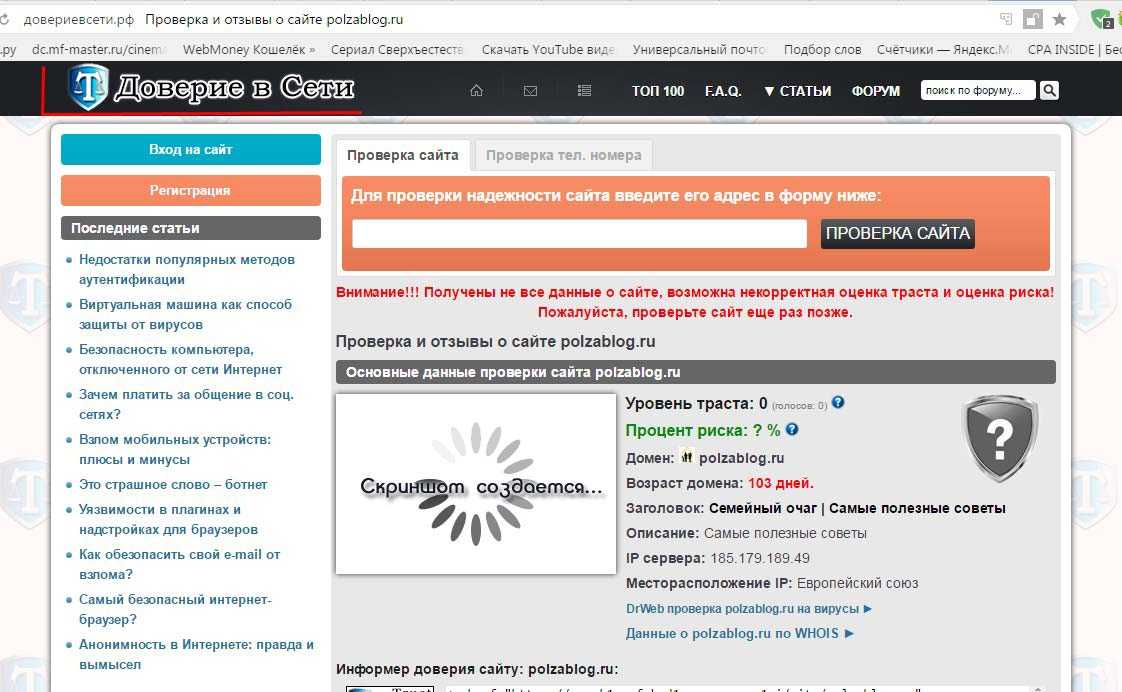 Вся информация, выложенная здесь является абсолютно открытой, но разбросана по всему интернету. Я уверен, что еще не раз буду обращаться к сервисам, описанным здесь, и конечно к этой статье с дополнениями.
Вся информация, выложенная здесь является абсолютно открытой, но разбросана по всему интернету. Я уверен, что еще не раз буду обращаться к сервисам, описанным здесь, и конечно к этой статье с дополнениями.
Надеюсь вся эта информация будет использована только в мирных целях, а не для сбора данных «об очередной жертве».
Экскурс.
Для того, чтобы понять откуда берется информация, нужно знать некоторые особенности работы интернета.
Все сайты лежат на серверах. Так как сейчас интернет окутывает весь мир, пользователю практически все равно, как далеко от него расположен сервер. Для того, чтобы добраться до сайта используются сложные алгоритмы маршрутизации по протоколу TCP/IP, но это совсем другая история.
Каждому серверу присвоен свой IP — числовой код. Тоже самое и с клиентом, но в этом случае он может часто меняться и это выглядит немного сложней. Между двумя точками (компьютерами) образуется соединение (канал), с помощью которого они могут общаться. Так как на одном сервере (как в общем-то и на клиенте) могут одновременно работать несколько сервисов (например HTTP — для передачи сайтов, FTP — протокол передачи файлов, MailServer — для почты и т.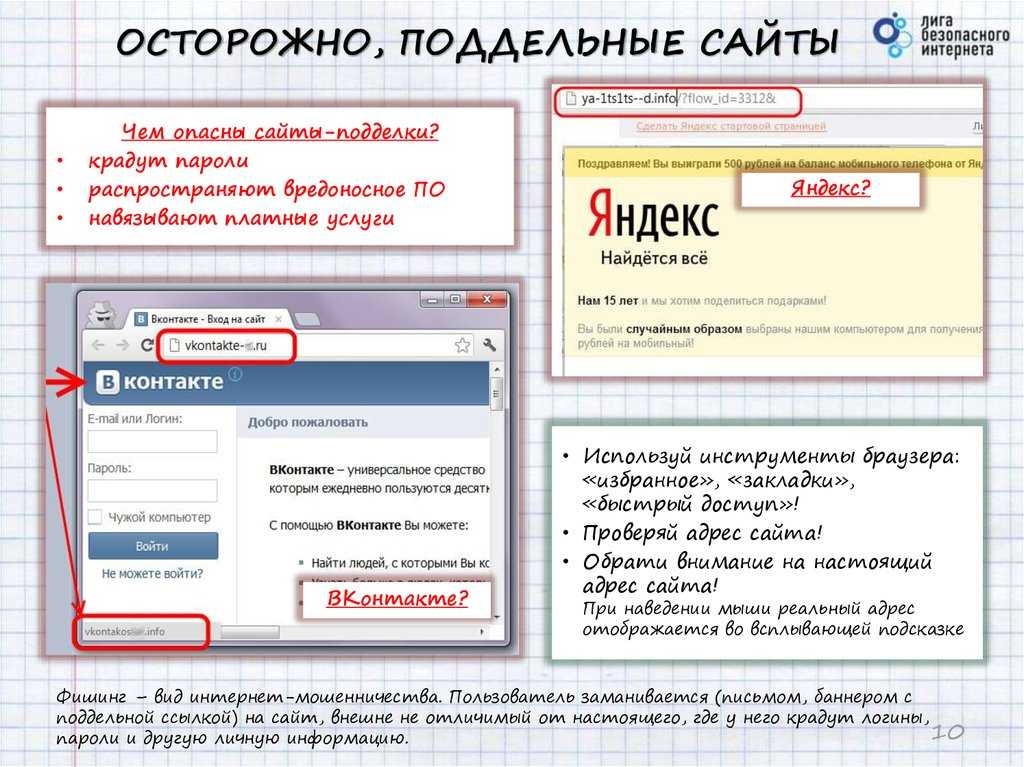 д.), для их определения используются порты. Например для HTTP — тот что отвечает за передачу HTML (страниц) и другого контента (картинок и музыки) всемирно принято использовать порт номер 80. Этот стандарт настолько вошел в наш мир, что нам даже не надо его писать в браузерной строке запроса. Например — http://domain.com равнозначно http://domain.com:80.
д.), для их определения используются порты. Например для HTTP — тот что отвечает за передачу HTML (страниц) и другого контента (картинок и музыки) всемирно принято использовать порт номер 80. Этот стандарт настолько вошел в наш мир, что нам даже не надо его писать в браузерной строке запроса. Например — http://domain.com равнозначно http://domain.com:80.
Последний вопрос, это имена. С начала рождения интернета каждому IP может соответствовать свое имя, этим занимаются DNS сервера, которые хранят таблицы имен и соответствующих им IP адресов. Сейчас, когда адресов начинает не хватать, одному IP может соответствовать несколько разных имен и сайтов. Этот подход называется — «Виртуальный сервер». Например на одном сервере с одним и тем-же IP может быть несколько разных сайтов http://domain2.com и http://domain3.com.
Определение владельца сайта.
Думаю теперь понятно, что имя сайта (домен) и его содержимое могут находится на разных серверах и волне комфортно могут существовать друг без друга. Но, чтобы сайт принял привычную форму, его автору нужно зарегистрировать имя и создать соглашение о хостинге. Это могут быть разные фирмы или фирма — предлагающая все в одном. И так, имя. Для регистрации имени нужно ввести определенные данные о пользователе, сейчас эта на большинстве доменов не контролируется, но каждая уважающая себя компания, никогда не будет скрывать от пользователей эти данные.
Но, чтобы сайт принял привычную форму, его автору нужно зарегистрировать имя и создать соглашение о хостинге. Это могут быть разные фирмы или фирма — предлагающая все в одном. И так, имя. Для регистрации имени нужно ввести определенные данные о пользователе, сейчас эта на большинстве доменов не контролируется, но каждая уважающая себя компания, никогда не будет скрывать от пользователей эти данные.
Для получения информации о владельце пользователя, используются сервис whois. Для разных доменов первого уровня он может быть свой. По этому, чтобы найти подходящий, придется воспользоваться поиском. whois.net например стоит первым в гугле. Это действительно не плохой сервис с поддержкой большого количества доменов.
Кроме пользовательской информации есть ещё даты — первая регистрация и дата истечения оплаты. Перед последней датой владелец должен оплатить домен на следующий год, иначе он его лишится.
Определение физического положения сайта.
По IP адресу сайта, можно узнать где находится сайт. Практически весь инструментарий есть на сайтах IPTools.com, tools.WebMax и DomainTools.com.
Практически весь инструментарий есть на сайтах IPTools.com, tools.WebMax и DomainTools.com.
Основной из них — это traceroute. Эта утилита показывает все точки сети (сервера, маршрутизаторы и т.д.), которые прошел сетевой пакет от одной точки до другой. Последней записью будет соответственно сервер сайта. Стоит также иметь в виду, что используя traceroute с сайтов, начальной точкой является не ваш компьютер, а сервер сайта предоставляющего этот сервис.
Есть также сервисы, которые определяют местоположение IP адреса на карте. Естественно, эта информация приблизительна до города, а иногда и страны. Для определения положения сервера можно использовать программу VisualRoute. В общем, она делает тоже самое, что и traceroute, плюс добавляет точки на карту. Недостаток в том, что эту программу нужно устанавливать на компьютер. К счастью есть альтернативы, например geoBytes IP Locator, который способен определить положение и показать его на карте.
Часто, но не всегда DNS сервер предоставляется той же компанией что и хостинг. Это можно проверить утилитой DIG (или nslookup, dnslookup). Она возвращает записи с сервера, которые разделены по секциям. Подробнее о секциях можно узнать из Википедии.
Это можно проверить утилитой DIG (или nslookup, dnslookup). Она возвращает записи с сервера, которые разделены по секциям. Подробнее о секциях можно узнать из Википедии.
Кто соседи сайта?
Если хостинг виртуальный (несколько сайтов на одном IP адресе) есть способ узнать о его «соседях».
Для этого можно использовать например сайт myipneighbors.com.
Проверка сервера на открытые порты.
Для этого используют широко известную в мире Linux утилиту NMAP. На нее есть и утилиты online. Не думаю, что эта информация может каким — либо образом быть полезна в мирных целях. Так что, больше информации на эту тему не понадобится.
Ознакомление с эволюцией сайта.
В сети есть так называемый архив сайтов. Сервис хранит изменения главной страницы по времени. Больше информации можно из моей предыдущей записи.
Посещаемость и рейтинг сайта.
Самые популярные сайты, такие как Yandex, Google, Yahoo, Live создают так называемый рейтинг сайта. Такой рейтинг в разных поисковых системах рассчитывается по своему. Дополнительную информацию о расчётах рейтинга можно узнать на соответствующих сайтах. Самый простой способ получить эту информацию в одном месте, это установить дополнение для FireFox — Alexa. Правда всю информацию, которую предоставляет сервис, можно получить только по первым, 100 тысячам по популярности сайтам. Тем не менее, кое-что можно узнать.
Дополнительную информацию о расчётах рейтинга можно узнать на соответствующих сайтах. Самый простой способ получить эту информацию в одном месте, это установить дополнение для FireFox — Alexa. Правда всю информацию, которую предоставляет сервис, можно получить только по первым, 100 тысячам по популярности сайтам. Тем не менее, кое-что можно узнать.
Еще одна интересная возможность мониторинга популярности сайтов по странам и категориям.
В дополнение стоит сказать расчете рейтинга в предположительной цене ресурса, такой расчет например использует logi.ru.
Подобный иностранный сайт, WebSiteOutlook, позволяет также определить примерное количество посещений. В моем случае цифры оказались несколько завышенными.
Добросовестность на предмет спама.
Первым шагом в борьбе со спамом стало создание баз данных о недобросовестных сайтах. Эти базы используют различные провайдеры или программы электронной почты. Эту информацию можно получить и с соответствующих сайтов. Среди таких, например, уже описанный WebMax.
Определение сервера, под которым работает сайт.
Сервер обычно можно определить если подключится к серверу с помощью telnet через 80-ый порт. Но DomainTools.com готов сделать все это за вас. Эта информация находится на его Whois, в панели Server Data.
Если нужна дополнительная информация или название подменено. Можно по пробовать HttpPrint.
Хостинг виртуальный или выделенный?
Думаю теперь тут все просто:
- Проверяем наличие «соседей» сайта.
- Получаем IP адрес сайта с помощью утилиты PING или любой подобной, и подставляем ее в браузер следующим образом — http://xxx.xxx.xxx.xxx, где xxx.xxx.xxx.xxx соответственно IP адрес. Если получаем ошибку или другой сайт, значит хостинг виртуальный.
Совместимость с браузерами.
Первое, что можно сделать, это провести проверку сайта на соответствие стандартов w3c в HTML, CSS и т.д. Скорее всего это не совсем то что вам надо. Несомненно, соответствие стандартам добавляет некоторую ценность сайту и подчёркивает профессионализм его разработчиков. Но к сожалению далеко не всегда это обозначает совместимость с разными браузерами. Для того чтобы определить совместимость сайта с разными версиями браузеров, совсем не обязательно их всех устанавливать. В сети есть незаменимый сервис, который создает изображения с разных браузеров в различных операционных системах. За несколько кликов можно получить вид из более 50 браузеров, включая их версии. Сервис называется BrowserShots.
Но к сожалению далеко не всегда это обозначает совместимость с разными браузерами. Для того чтобы определить совместимость сайта с разными версиями браузеров, совсем не обязательно их всех устанавливать. В сети есть незаменимый сервис, который создает изображения с разных браузеров в различных операционных системах. За несколько кликов можно получить вид из более 50 браузеров, включая их версии. Сервис называется BrowserShots.
Конкурентоспособность.
Гугл предаставляет не плохой сервис для сравнения популярности слов между собой. Его можно использовать и для сравнительного анализа сайта и его конкурентов. Cервис называется Trends. Для достаточно популярных сатов сравнительный анализ также делает Alexa.
Например следующий анализ стал для меня открытием: webmoney и e-gold.
Кто ссылается на сайт?
Мне сейчас сложно сказать как именно это сделать с помощью WEB. Но для FireFox есть отличный плагин — SeoQuake. Этот плагин собирает рейтинги разных ресурсов относительно текущего сайта, в том числе и показывает количество внешних ссылок, зарегистрированных различными поисковыми системами.
Какие ссылки проиндексировал Гугл?
Гугл предусматривает поиск по домену. Для этого нужно использовать ключевое слово ‘site’. Например: site:. Подобные ключевые слова управления поиском есть в любом популярном поисковике.
Добросовестность на предмет авторского права.
Для этого особых сервисов нет. Все что надо, это набрать часть проверяемого текста в кавычках. Проблема в том, что даже гугл часто ошибается выдавая копию гораздо выше оригинала. Печально.
Самые посещаемые суб-домены сайта.
Это довольно ценная информация даже с точки зрения безопасности.
До написания этой статьи у меня было предположение, что эту информацию должен дать DIG. Но нет, решение неожиданно — alexa. Если субдомен проиндексирован, он скорее всего будет в списке.
Другие сетевые инструменты
Вот еще несколько сайтов, которые предоставляют сервисы схожей тематики.
- abouthisite
- Очередной сайт собирающий различную информацию в одном месте.
- sitetruth
- Этот ресурс проверяет содержание сайта и пытается определить проблемные места. Такие как отсутствие адреса или сомнительное авторство.
- DomainCrawler
- Еще один сайт про домены и популярность сайта
 Такие как отсутствие адреса или сомнительное авторство.
Такие как отсутствие адреса или сомнительное авторство.Итоги.
Очень вероятно, что эта статья не освещает и половины информации, которую можно вытащить о сайте. Тем не менее, надеюсь, что она была полезной, и вы узнали что-то новое 🙂
UPD: sitehistory.ru
Метки:справочник, интернет, обзор, программы
Поиск информации в Интернете
Поиск информации в Интернете доктор П.М.Э. De BraСекция информационных систем
Департамент компьютерных наук
Эйндховенский технологический университет
PO Box 513, 5600 МБ Эйндховен
Нидерланды
Электронная почта [email protected] Аннотация
Всемирная паутина содержит огромное количество информации
на все мыслимые темы. Большая часть этой информации очень стабильна,
но некоторые из них генерируются динамически и поэтому недолговечны.
Отсутствие полного и полезного
каталог или указатель, однако затрудняет пользователям поиск
информацию, которую они хотят.
В этом документе дается обзор методов, используемых для поиска информацию в Интернете и основанные на ней средства поиска. Более полное представление о возможностях и ограничениях различные инструменты поиска могут помочь пользователям выбрать подходящий инструмент для каждой задачи.
1. Введение
С момента своего создания примерно в 1990 году Всемирная паутина росла с экспоненциальной скоростью (названный Тимом Бернерсом Ли медленным взрывом ), стать крупнейшим информационным пространством в Интернете, а возможно и в Мире. Рыхлая структура сети, облегчающая отдельные организации, чтобы стать частью Интернета и предоставлять информация на их собственном сервере также является источником крупнейших информационный кошмар мира: для многих пользователей он стал очень сложно, если не невозможно, найти информацию в Интернете, даже если известно, что она существует.
Информационный поиск — область исследований с долгой историей.
(Обзор см. в [MB85] и [GS89]. )
Процесс поиска информации можно разделить на три этапа:
)
Процесс поиска информации можно разделить на три этапа:
- поиск документов: Интернет состоит из миллионов документов, распределено по десяткам тысяч серверов; доступ ко всем потенциально интересным документам может быть затруднен.
- формулирование запросов: пользователь должен выразить, какой именно информацию, которую она ищет.
- определение релевантности: система должна определить, Документ содержит информацию, которую ищет пользователь.
Чтобы своевременно отвечать на запросы пользователей, большинство
инструменты поиска используют специально подготовленную базу данных вместо поиска
документы на лету. В зависимости от технологии, используемой для создания
этой базе данных на определенные типы вопросов можно или нельзя ответить.
Средства поиска, находящиеся в открытом доступе в Интернете, используют
различные типы баз данных и различные методы доступа к
документы в Сети. В результате они могут отвечать на разные вопросы,
и даже на один и тот же вопрос они могут давать разные ответы.
В этой статье дается обзор свободно доступных инструментов поиска,
методы, используемые для доступа в Интернет и для индексации информации.
Цель этой статьи — дать читателю лучшее представление
в проблеме поиска информации в Интернете, а также в достоинствах и
ограничения доступных инструментов поиска.
В результате они могут отвечать на разные вопросы,
и даже на один и тот же вопрос они могут давать разные ответы.
В этой статье дается обзор свободно доступных инструментов поиска,
методы, используемые для доступа в Интернет и для индексации информации.
Цель этой статьи — дать читателю лучшее представление
в проблеме поиска информации в Интернете, а также в достоинствах и
ограничения доступных инструментов поиска.
В этой статье мы будем использовать следующий пример поиска:
в Эйндховенском технологическом университете мы разработали курс
о гипертексте и гипермедиа. Полный текст этого курса
доступен в Интернете с начала 1994 года. Он состоит из 163 небольших
документов, между которыми имеется множество связей. Адрес
http://wwwis.win.tue.nl/2L670/.
Мы описываем наш опыт поиска первой страницы этого
Конечно, используя различные инструменты поиска в Интернете.
Мы также описываем наш опыт в поиске домашней страницы автора
(курса и этой статьи), Поль Де Бра,
и другого исследователя, Ad Aerts.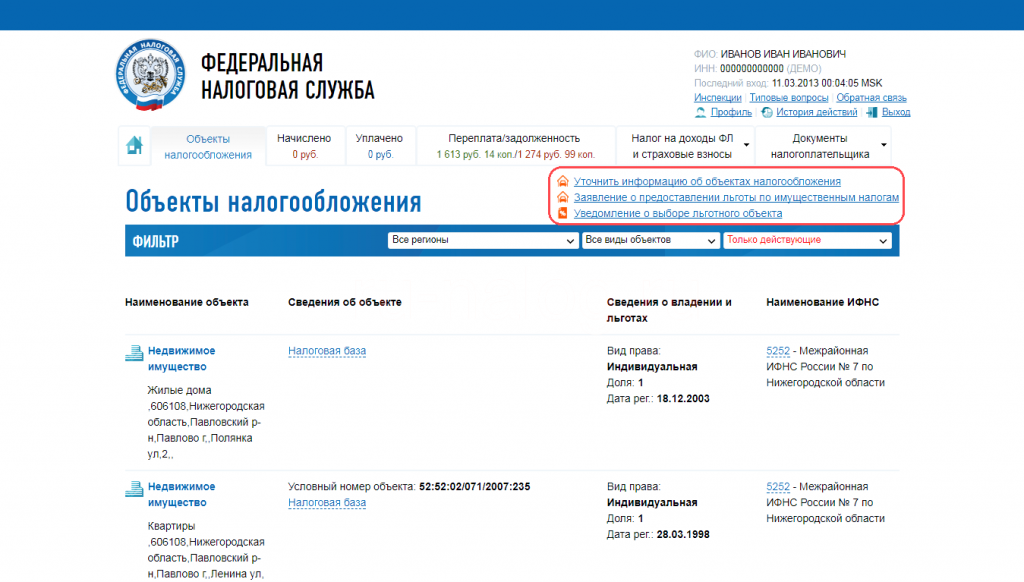
Структура этой статьи такова: в разделе 2 мы кратко набросать общую гипертекстовую структуру Всемирной паутины. Раздел 3 описывает, как «роботы» используются для поиска некоторых, большинства или всех документы в Сети. Раздел 4 описывает, как индексные базы данных хранят (описания) документы. и как поисковые системы позволяют пользователям находить информацию. Этот раздел также включает в себя наш опыт в поиске гипермедиа Конечно, и домашние страницы двух людей с использованием самых популярных инструментов поиска. Раздел 5 описывает Harvest, пример романа и распространяемого подход к решению основных проблем с поиском информации в Сети. В Разделе 6 мы даем несколько заключительных советов о том, какой инструмент использовать для какой поисковый запрос.
2. Гипертекстовая структура Интернета
Гипертекст определен Шнейдерманом и Кирсли.
[SK89] как база данных, которая имеет активные перекрестные ссылки и позволяет читателю
для «перехода» к другим частям базы данных по желанию. Это определение хорошо подходит для World Wide Web: документы имеют активные
ссылки друг на друга, что означает, что пользователь может переходить из одного документа
на другой, перейдя по этим ссылкам.
Пользователи также могут напрямую переходить к документам с помощью имени и
расположение документа.
Интернет использует Универсальные локаторы ресурсов (URL) для адреса
документы.
URL-адреса наиболее полезны, когда пользователь знает местоположение желаемого
документ.
При поиске информации обычно хотят узнать местоположение
документов, содержащих эту информацию, поэтому URL-адреса являются ответами
к запросам.
Это определение хорошо подходит для World Wide Web: документы имеют активные
ссылки друг на друга, что означает, что пользователь может переходить из одного документа
на другой, перейдя по этим ссылкам.
Пользователи также могут напрямую переходить к документам с помощью имени и
расположение документа.
Интернет использует Универсальные локаторы ресурсов (URL) для адреса
документы.
URL-адреса наиболее полезны, когда пользователь знает местоположение желаемого
документ.
При поиске информации обычно хотят узнать местоположение
документов, содержащих эту информацию, поэтому URL-адреса являются ответами
к запросам.
Инструменты поиска должны переходить по ссылкам, чтобы найти документы, путешествуя по Сети. На рис. 1 показана структура графа, подобная структуре Web. Показаны несколько серверов, имеющих много соединений между документами на тот же сервер и несколько подключений друг к другу.
Рисунок 1: графовая структура Интернета.
Помимо общего представления о графовой структуре Интернета, на рис. 1 также показывает, что хотя изображенный граф полностью связан невозможно достичь всех узлов графа из одного отправной точкой и перейдя по ссылкам вперед. Даже когда можно вернуться к ранее посещенным узлам, функция, предлагаемая большинством веб-браузеров, некоторые узлы по-прежнему остаются недоступными. Та же проблема существует и в «настоящей» Сети: весь Интернет не может быть доступен только по ссылкам. Нужны разные «хитрости», чтобы найти набор стартовых точек, из которых можно получить доступ ко всей сети.
Много информации в Интернете доступно с ftp-серверов
(ftp означает протокол передачи файлов), а примерно в 1991 и 1992 гг.
Серверы Gopher также стали популярными. FTP-серверы строго иерархичны.
потому что они обращаются к файлам непосредственно из файловой системы (Unix).
Серверы Gopher также являются иерархическими, использующими систему меню, но они могут
также содержат пункты меню, указывающие на информацию о других серверах. Найти все документы или файлы на таких иерархических серверах очень сложно.
проще (если вы знаете, где находятся серверы), чем найти документы
на сервере всемирной паутины.
Найти все документы или файлы на таких иерархических серверах очень сложно.
проще (если вы знаете, где находятся серверы), чем найти документы
на сервере всемирной паутины.
Проект паука RBSE [E94, E94a] из Хьюстонского университета исследовал структуру всемирной паутины, подсчитав количество ссылки из и на каждый документ. Чем больше ссылок на документ, тем легче его найти. документ по следующим ссылкам. Даже при посещении лишь небольшой части Интернета есть вероятность, что указатель найти такой документ. Когда есть много документов, на которые есть только несколько ссылок, большая часть Интернета должна быть посещена до указателя на такие документы найден. Паук RBSE обнаружил, что для 59% документов в Интернете на них указывает только одна ссылка, а на 96% их не более пять ссылок. Это означает, что большинство документов в Интернете трудно найти с помощью навигации.
3. Роботы или пауки World Wide Web
Просмотр или «серфинг» в Интернете состоит из запуска с известного
(URL-адрес) документа и следующие ссылки на другие документы по желанию. Программа браузера (графическая) показывает, где находятся привязки к ссылкам в
документ, например, подчеркивая их и/или отображая их в
другого цвета, чем остальная часть документа.
Документы в Интернете пишутся с использованием HTML, языка гипертекстовой разметки.
Ссылки встраиваются в документы с помощью тегов привязки HTML, содержащих
URL назначения ссылки.
Пользователи, которые помнят URL-адреса (или помещают их в горячий список), могут указать браузеру
чтобы перейти непосредственно к документу с заданным URL-адресом.
Программа браузера (графическая) показывает, где находятся привязки к ссылкам в
документ, например, подчеркивая их и/или отображая их в
другого цвета, чем остальная часть документа.
Документы в Интернете пишутся с использованием HTML, языка гипертекстовой разметки.
Ссылки встраиваются в документы с помощью тегов привязки HTML, содержащих
URL назначения ссылки.
Пользователи, которые помнят URL-адреса (или помещают их в горячий список), могут указать браузеру
чтобы перейти непосредственно к документу с заданным URL-адресом.
Для поиска информации в Интернете или просто сбора
документов для создания индексной базы данных необходимо запустить программу, которая
извлекает документы из Интернета почти так же, как пользователь, занимающийся серфингом
извлекает документы с помощью браузера.
Эти специальные программы называются роботов или пауков. Мартин Костер
(ранее в Nexor, теперь в WebCrawler) поддерживает
список
известных роботов и список рассылки для создателей и пользователей роботов.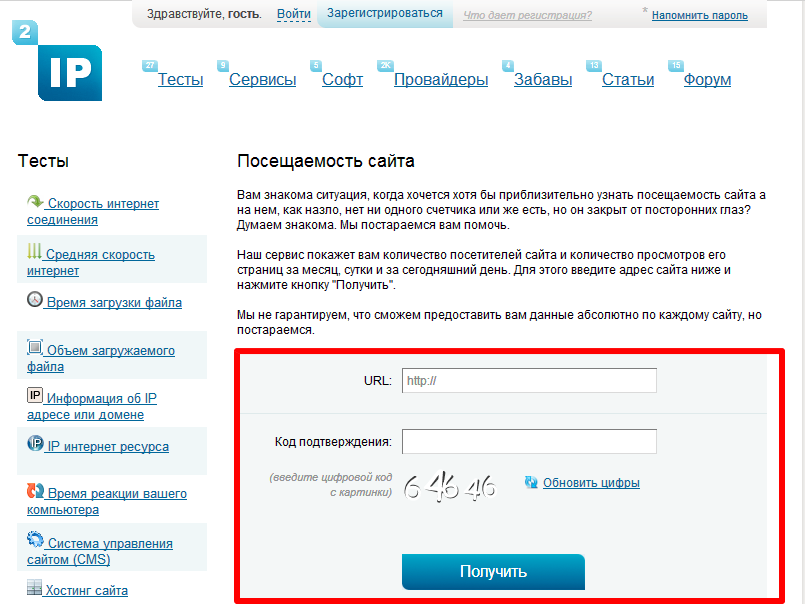
Хотя концептуально роботы или пауки бродят вокруг паутине, они лишь бродят виртуально, потому что на самом деле остаются на том же компьютере. Такие имена, как «WebWanderer» и «червь всемирной паутины». может предлагать программы, которые вторгаются в компьютеры по всему Интернету для извлечения информацию и отправить ее обратно на свою базу, но все, что они на самом деле делают извлекает документы из разных мест в Интернете на компьютер они проживают. Следовательно, они не представляют никакой опасности, как печально известные Интернет-червь [D89] еще в 1988 году.
3.1 Алгоритм робота
Все роботы используют следующий алгоритм для получения документов из Интернета:
- Алгоритм использует список известных URL-адресов. Этот список содержит не менее один URL для начала.
- URL-адрес берется из списка (с использованием эвристик, отличающихся для каждого робота), и соответствующий документ извлекается из Интернета.
- Документ анализируется для получения информации для индексной базы данных
и извлекать встроенные ссылки на другие документы.
- URL-адреса ссылок, найденных в документе, добавлены в список известных URL-адресов. (Порядок и позиция, в которой URL-адреса добавляются в список различается между роботами.)
- Если список пуст или превышен какой-то лимит (количество документов извлечено, размер индексной базы данных, время, прошедшее с момента запуска, и т. д.) алгоритм останавливается. В противном случае алгоритм продолжается с шага 2.

3.2 Начало работы с роботом
Как показано на рис. 1, одной отправной точки недостаточно для нахождения вся всемирная паутина. Таким образом, состав исходного списка известных URL-адресов представляет собой важный шаг к тому, чтобы найти как можно больше в Интернете. Также при использовании робота для поиска информации по определенной теме, первоначальный список документов, относящихся к этой теме, является большим шагом вперед.
Организация World Wide Web поддерживает
официальный
список веб-серверов
(на http://www.w3.org/hypertext/DataSources/WWW/Servers. html).
Этот список содержит указатели на подсписки для каждой страны.
Ни один из этих списков не является полным.
официальный список Нидерландов
(на http://www.nic.surfnet.nl/nlmenu.eng/w3all.html) и неофициальный графический обзор,
называется «Голландская домашняя страница»
(на http://www.eeb.ele.tue.nl/map/netherlands.html/) обычно содержат другой сервер
адреса. Более того, в большинстве организаций указывается только один сервер,
в то время как у них есть несколько других, до которых можно добраться через указанный
сервер.
В качестве отправной точки для поиска большей части Интернета используются такие списки.
чрезвычайно ценный.
Хотя они не предоставляют адрес для каждого сервера,
они приносят робота почти к каждому серверу в Интернете.
html).
Этот список содержит указатели на подсписки для каждой страны.
Ни один из этих списков не является полным.
официальный список Нидерландов
(на http://www.nic.surfnet.nl/nlmenu.eng/w3all.html) и неофициальный графический обзор,
называется «Голландская домашняя страница»
(на http://www.eeb.ele.tue.nl/map/netherlands.html/) обычно содержат другой сервер
адреса. Более того, в большинстве организаций указывается только один сервер,
в то время как у них есть несколько других, до которых можно добраться через указанный
сервер.
В качестве отправной точки для поиска большей части Интернета используются такие списки.
чрезвычайно ценный.
Хотя они не предоставляют адрес для каждого сервера,
они приносят робота почти к каждому серверу в Интернете.
Новая интересная информация часто появляется на серверах, которые еще не
зарегистрированы в официальных или неофициальных списках. Чтобы найти это
информация, которую некоторые сайты-роботы отслеживают по ряду списков рассылки и
Группы Usenet Netnews. Объявления о новых услугах или отчеты от
заинтересованные пользователи часто появляются в сетевых новостях задолго до появления каких-либо
ссылки на документы на известных веб-серверах.
Объявления о новых услугах или отчеты от
заинтересованные пользователи часто появляются в сетевых новостях задолго до появления каких-либо
ссылки на документы на известных веб-серверах.
3.3 Стратегии навигации
Процессы извлечения URL-адресов из списка и добавления в него новых URL-адресов определить стратегию навигации робота. Если вновь найденные URL-адреса всегда добавляются в ту же часть списка, что и где URL-адреса выбираются для получения следующего документа роботом перемещается в глубину. Если новые URL-адреса добавляются к одному концу список и URL-адреса выбираются с другого конца, который выполняет робот навигация в ширину.
Поведение большинства роботов находится где-то посередине между этими двумя крайностями. чтобы воспользоваться преимуществами обеих стратегий, не страдая от их недостатков.
- Стратегия поиска в глубину , исследованная в
[DV94], дает наилучшее общее распределение
URL-адреса в Интернете, что важно, когда относительно небольшой
часть Интернета может быть восстановлена. Навигация в глубину также создает опасность вести робота.
в бесконечно рекурсивные деревья документов на серверах, которые генерируют документы
на лету. Многие документы содержат ссылки на себя или на другие
документы, созданные с использованием одного и того же URL-адреса. Робот, который использует
навигация в глубину должна принимать особые меры предосторожности, чтобы избежать входа
такие бесконечные циклы.
- Стратегия в ширину при использовании с
первоначальный список, подобный официальному реестру серверов, дает отличные
результаты сначала, потому что он достигает многих разных серверов.
Однако в целом эта стратегия менее эффективна для проникновения в
Паутина глубоко, заходящая далеко за пределы исходных точек.
Кроме того, поскольку ссылки берутся из списка в том же порядке, что и
вставлены, пройдены все ссылки, встроенные в единый документ
последовательно. Во многих случаях эти ссылки указывают на документы на том же
сервер. Таким образом, навигация в ширину может привести к периодам
большая нагрузка на один сервер, который является наиболее важным
Причина, по которой менеджеры серверов (веб-мастера) не любят роботов, бродящих по их сайту.
 Навигация в глубину также создает опасность вести робота.
в бесконечно рекурсивные деревья документов на серверах, которые генерируют документы
на лету. Многие документы содержат ссылки на себя или на другие
документы, созданные с использованием одного и того же URL-адреса. Робот, который использует
навигация в глубину должна принимать особые меры предосторожности, чтобы избежать входа
такие бесконечные циклы.
Навигация в глубину также создает опасность вести робота.
в бесконечно рекурсивные деревья документов на серверах, которые генерируют документы
на лету. Многие документы содержат ссылки на себя или на другие
документы, созданные с использованием одного и того же URL-адреса. Робот, который использует
навигация в глубину должна принимать особые меры предосторожности, чтобы избежать входа
такие бесконечные циклы.
Некоторые базы данных поиска на основе роботов используют несколько роботов (иногда вызывал агентов ) параллельно, для достижения лучшей общей производительности поиска. Хотя такие действия получить большую долю общей пропускной способности сети, как правило, считается грубым и неприемлемым поведением, большинство роботов стараются не получить более одного документа с одного сервера одновременно или даже последовательно. (Netscape Navigator ведет себя еще более грубо. путем параллельной загрузки встроенных изображений с одного и того же сервера.) Параллельное использование нескольких агентов не только ускоряет общий процесс, он также позволяет избежать блокировки, когда робот сталкивается с очень медленным ссылка или сервер.
Специалисты по обслуживанию веб-серверов могут помочь сборщикам роботов избежать таких ловушек, как
бесконечные циклы или бесполезные документы, такие как содержимое кеша
или зеркало другого сервера. Большинство роботов соответствуют схеме исключения роботов.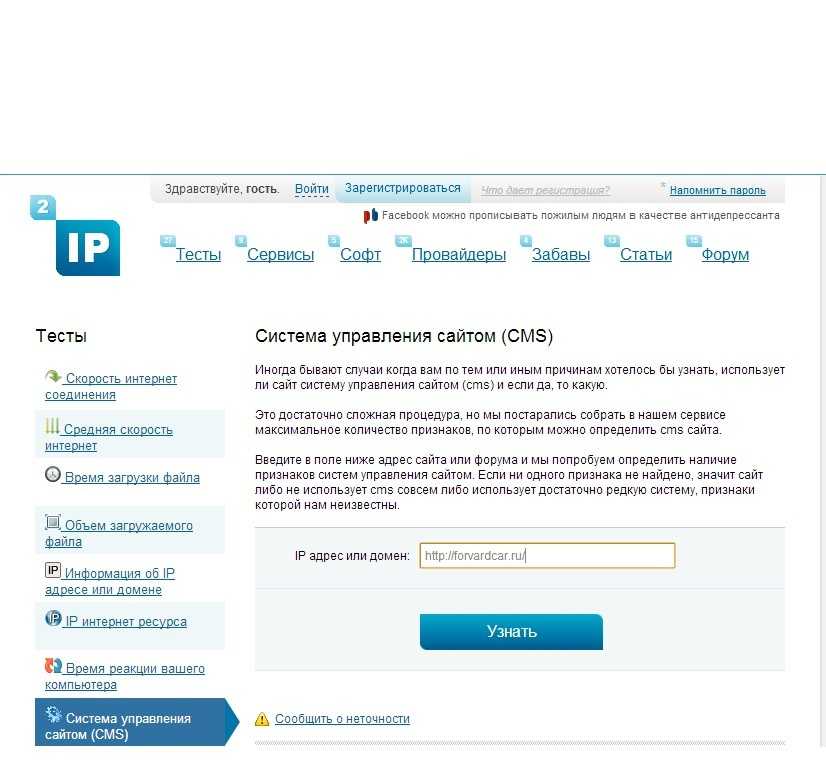 (см. http://info.webcrawler.com/mak/projects/robots/norobots.html)
которым все документы и/или каталоги, перечисленные в файле исключения роботов
(robots.txt) на веб-сервере игнорируются (т. е. не извлекаются)
посещение робота.
(см. http://info.webcrawler.com/mak/projects/robots/norobots.html)
которым все документы и/или каталоги, перечисленные в файле исключения роботов
(robots.txt) на веб-сервере игнорируются (т. е. не извлекаются)
посещение робота.
3.4 Ограничения производительности робота
В идеале робот должен загрузить всю сеть за относительно короткий период времени. времени, чтобы убедиться, что найденные документы актуальны, и что последние добавления не пропущены. Учитывая, что интернет-сеть всегда будет ограничена и очень загружена в течение недели, перезагрузка всей всемирной паутины в выходные дни кажется разумной целью. К сожалению, ни один робот не в состоянии добиться этого, независимо от приложенных усилий. в его создателях, с точки зрения компьютерного и сетевого оборудования.
Команда Lycos (бывшая CMU,
Университет Карнеги-Меллона, но теперь работает как независимая компания)
восстанавливал
Веб-документы более года, тем самым постепенно создавая и перестраивая
индексная база данных. За это время их роботы нашли
увеличение количества документов, достигающее сейчас около 20 миллионов,
в общей сложности более ста гигабайт (текстовой) информации.
Для того, чтобы получить столько информации
за одни выходные (около 50 часов) роботы должны были бы иметь возможность
загружать не менее 100 документов в секунду с постоянной скоростью более
5,5 Мбит/с (миллион бит в секунду). В настоящее время эта скорость передачи
невозможно, как из-за накладных расходов, связанных с протоколом TCP/IP,
используемый в Интернете, скорость света, которая ограничивает передачу пакета туда и обратно
раз на межконтинентальных соединениях, а многочисленные веб-серверы
подключен через медленные линии передачи данных. Предположим, что средняя передача
скорость, полученная через Интернет, составляет около 1 Кбит/с на одно соединение, всего
Для передачи 5,5 Мбит/с требуется 5500 одновременных подключений.
скорость, но в настоящее время большинство сетевых коммутаторов не могут обрабатывать 5500 одновременных
TCP/IP-соединения.
За это время их роботы нашли
увеличение количества документов, достигающее сейчас около 20 миллионов,
в общей сложности более ста гигабайт (текстовой) информации.
Для того, чтобы получить столько информации
за одни выходные (около 50 часов) роботы должны были бы иметь возможность
загружать не менее 100 документов в секунду с постоянной скоростью более
5,5 Мбит/с (миллион бит в секунду). В настоящее время эта скорость передачи
невозможно, как из-за накладных расходов, связанных с протоколом TCP/IP,
используемый в Интернете, скорость света, которая ограничивает передачу пакета туда и обратно
раз на межконтинентальных соединениях, а многочисленные веб-серверы
подключен через медленные линии передачи данных. Предположим, что средняя передача
скорость, полученная через Интернет, составляет около 1 Кбит/с на одно соединение, всего
Для передачи 5,5 Мбит/с требуется 5500 одновременных подключений.
скорость, но в настоящее время большинство сетевых коммутаторов не могут обрабатывать 5500 одновременных
TCP/IP-соединения.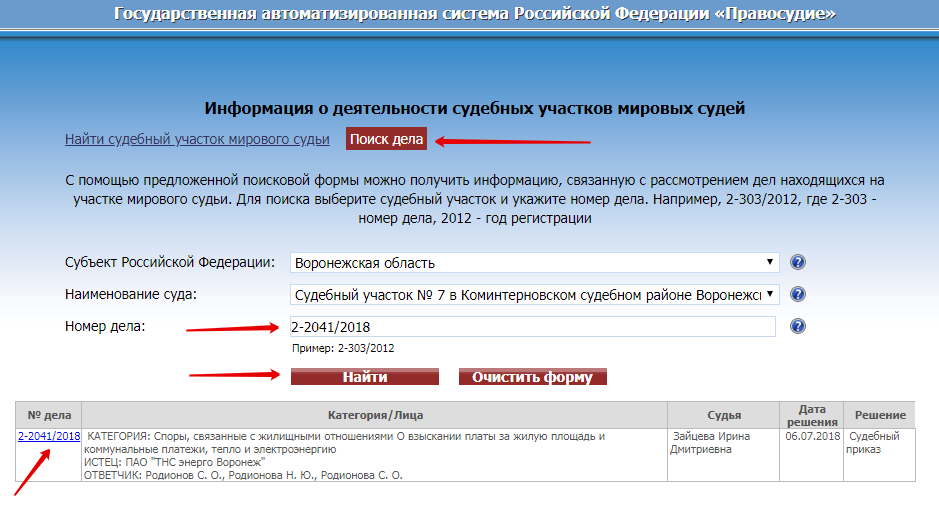
Из-за этих ограничений специалисты по обслуживанию роботов приняли различные подходы: Lycos пытается загрузить и перезагружать всю сеть как можно чаще, то есть каждый раз в несколько месяцев примерно до года. WebCrawler, с другой стороны, пытается загружать как можно больше с как можно большего количества разных серверов, в выходные дни, тем самым достигая более ограниченного охвата, но с более актуальная информация.
4. Индексные базы данных и поисковые системы
Интернет содержит более ста гигабайт текстовой информации. Предполагая, что у вас есть столько свободного места на диске, это все равно будет нецелесообразно последовательно искать через такое количество гигабайт для документов по определенной теме. Таким образом, индексные базы данных построены, которые связывают темы или слова непосредственно с соответствующими документами.
База данных индексов работает как инвертированный файл.
Обычный текстовый файл содержит строки текста. Учитывая строку номер один
легкий и прямой доступ к словам в этой строке. В инвертированном файле
заданное слово имеет прямой доступ к номерам строк, содержащих
Это слово. Интернет представляет собой текстовую базу данных, обеспечивающую легкий доступ к
содержание документа по его имени. Индексная база данных пытается предоставить
доступ к (именам или URL-адресам) документов,
дано описание их содержимого, например. несколько слов, которые должны произойти
в документах.
В инвертированном файле
заданное слово имеет прямой доступ к номерам строк, содержащих
Это слово. Интернет представляет собой текстовую базу данных, обеспечивающую легкий доступ к
содержание документа по его имени. Индексная база данных пытается предоставить
доступ к (именам или URL-адресам) документов,
дано описание их содержимого, например. несколько слов, которые должны произойти
в документах.
Создание индексных баз данных, как в целом, так и для Интернета, затруднен по ряду причин:
- Описание содержания документов должно быть таким, чтобы
пользователю легко давать эти описания, а
система для сопоставления документов и описаний.
В большинстве систем используются логические комбинации слов, которые должны или не должны
встречаются в документах.
Часто предмет нельзя описать одним словом или комбинацией
слов. Когда нужна фраза (состоящая из нескольких слов), система
должен быть в состоянии решить, встречаются ли отдельные слова фразы
в правильном порядке и рядом друг с другом. Иногда предмет лучше всего описать с помощью примера статьи или
Аннотация.
Некоторые программы поиска информации могут сопоставлять документы на предмет сходства.
Infoseek является общедоступным
служба, которая предлагает эту возможность для Интернета.
- При использовании слов для описания предметов или тем система должна
учитывать синонимы, слова, которые почти всегда связаны между собой, и
с выделением и удалением суффиксов. Это сложно сделать правильно
в целом. Такие слова, как «факт» и «фактический», описывают одну и ту же тему.
но это не значит, что суффикс «уал» всегда можно удалить.
При удалении «ual» из «equal» не остается ни одного английского слова.
Стемминг еще сложнее: система должна знать, что «поглощает» и
«поглощать» имеют ту же основу («поглощать»), хотя основа не обязательно должна быть
часть слова. С синонимами труднее всего работать, потому что
контекст может быть необходим для того, чтобы определить, являются ли они синонимами в
данный документ или нет. Слова «кошка» и «киска» не являются синонимами. все контексты, например.
- Из-за гигантских размеров Интернета количество слов или терминов которые используются для описания документа, должны быть ограничены. Слова, которые встречаются в очень многих документах бесполезны, равно как и слова, встречающиеся слишком редко (например, только один раз). В системе Lycos используется всего около 20 слов. на документ для идентификации каждого из 20 миллионов веб-документов. Это уже привело к созданию базы данных размером около 10 гигабайт.
 Иногда предмет лучше всего описать с помощью примера статьи или
Аннотация.
Некоторые программы поиска информации могут сопоставлять документы на предмет сходства.
Infoseek является общедоступным
служба, которая предлагает эту возможность для Интернета.
Иногда предмет лучше всего описать с помощью примера статьи или
Аннотация.
Некоторые программы поиска информации могут сопоставлять документы на предмет сходства.
Infoseek является общедоступным
служба, которая предлагает эту возможность для Интернета. все контексты, например.
все контексты, например.Четыре самых популярных поисковых инструмента в Интернете используют очень разные индексировать базы данных, которые в сочетании с различными методами их заполнения Использование роботов приводит к различным сильным и слабым сторонам:
- АЛИВЕБ
[К94]
использует подход, аналогичный инструменту поиска Archie для FTP-серверов.
Каждый веб-мастер должен создать файл, содержащий описание того, что
информацию можно найти на веб-сервере. Робот извлекает их
файлы время от времени (ежедневно) и перестраивает свою базу данных. Эта схема основана на созданных человеком сводных файлах и поэтому получила широкое распространение.
только ограниченное принятие.
Однако, поскольку он создает небольшую базу данных, его легко зеркально отразить.
на разные сайты, таким образом распределяя нагрузку поисковых операций.
Сайтов-зеркал ALIWEB около десятка.
- Yahoo начиналась как университет проект (в Стэнфорде) по созданию тематического каталога Интернета. Доступ к базе данных осуществляется через иерархическую систему меню темы и подтемы. Поиск в базе данных также можно осуществлять с помощью (тематических) ключевых слов. Большая часть базы данных создается вручную. Веб-мастера, желающие иметь некоторые из их URL-адресов, перечисленных Yahoo, могут отправлять запрос с описанием документов и предметной категории, к которой они относятся.
- Веб-краулер
[P94]
начинался как небольшой университетский проект аспиранта
(Брайан Пинкертон) в Вашингтонском университете.
WebCrawler извлекает как можно больше документов из как можно большего числа различных источников. сервера, насколько это возможно, в выходные дни.
Документы полностью индексируются с помощью комплекта индексирования NextStep.
WebCrawler хорошо работает для поиска тем, типичных для
много документов на одном сервере. Поскольку база данных WebCrawler может
содержать только несколько документов с одного сервера, он, скорее всего, будет содержать
информация, которая очень типична для этого сервера, но вряд ли будет содержать
информация, которая встречается только в одном или нескольких документах на этом сервере.
Например, WebCrawler может плохо работать для поиска личных домашних страниц,
но очень полезен для поиска серверов отдела по имени
факультета и института.
WebCrawler использует стратегию навигации в ширину для поиска документов.
Таким образом, документы, которые находятся на расстоянии многих ссылок от популярных или начальных
страницы веб-сервера вряд ли будут найдены WebCrawler.
Курс гипермедиа, 2Л670, упоминается на нескольких страницах нашего
веб-сервер отдела.
Поэтому мы ожидаем, что WebCrawler сможет найти этот документ,
в то время как мы ожидаем, что WebCrawler не сможет найти
домашняя страница некоторых наших сотрудников.
- Lycos начинался как проект в CMU.
Lycos пытается проиндексировать все документы во всей всемирной паутине,
а также документы, доступные через серверы Gopher и ftp.
Удерживать общий размер индексной базы данных в разумных пределах.
База данных Lycos index содержит всего несколько (около 20) слов на документ.
Следовательно, тот факт, что Lycos проиндексировал почти все документы в Интернете, не имеет значения.
означает, что с помощью Lycos легко найти конкретный документ.
Lycos найдет только те документы, для которых заданные слова являются типичными.
Слова, которые встречаются в документе только один раз и могут характеризовать
именно этот документ, возможно, не был выбран Lycos для включения
в своей базе данных.
Учитывая несколько хороших ключевых слов, Lycos сможет найти множество документов.
об этих темах.
Мы ожидаем, что Lycos сможет найти как курс гипермедиа 2L670, так и
домашние страницы наших сотрудников.
Поскольку Lycos уже давно индексирует документы, многие
URL-адреса, возвращаемые Lycos, могут указывать на документы, которые больше не существуют или
переехали. Кроме того, поскольку многие веб-сайты включают в себя шлюзы к общим
таких баз данных, как справочные страницы Unix, Lycos проиндексировала тысячи копий
эти популярные документы.
 Эта схема основана на созданных человеком сводных файлах и поэтому получила широкое распространение.
только ограниченное принятие.
Однако, поскольку он создает небольшую базу данных, его легко зеркально отразить.
на разные сайты, таким образом распределяя нагрузку поисковых операций.
Сайтов-зеркал ALIWEB около десятка.
Эта схема основана на созданных человеком сводных файлах и поэтому получила широкое распространение.
только ограниченное принятие.
Однако, поскольку он создает небольшую базу данных, его легко зеркально отразить.
на разные сайты, таким образом распределяя нагрузку поисковых операций.
Сайтов-зеркал ALIWEB около десятка. сервера, насколько это возможно, в выходные дни.
Документы полностью индексируются с помощью комплекта индексирования NextStep.
WebCrawler хорошо работает для поиска тем, типичных для
много документов на одном сервере. Поскольку база данных WebCrawler может
содержать только несколько документов с одного сервера, он, скорее всего, будет содержать
информация, которая очень типична для этого сервера, но вряд ли будет содержать
информация, которая встречается только в одном или нескольких документах на этом сервере.
Например, WebCrawler может плохо работать для поиска личных домашних страниц,
но очень полезен для поиска серверов отдела по имени
факультета и института.
WebCrawler использует стратегию навигации в ширину для поиска документов.
Таким образом, документы, которые находятся на расстоянии многих ссылок от популярных или начальных
страницы веб-сервера вряд ли будут найдены WebCrawler.
Курс гипермедиа, 2Л670, упоминается на нескольких страницах нашего
веб-сервер отдела.
Поэтому мы ожидаем, что WebCrawler сможет найти этот документ,
в то время как мы ожидаем, что WebCrawler не сможет найти
домашняя страница некоторых наших сотрудников.
сервера, насколько это возможно, в выходные дни.
Документы полностью индексируются с помощью комплекта индексирования NextStep.
WebCrawler хорошо работает для поиска тем, типичных для
много документов на одном сервере. Поскольку база данных WebCrawler может
содержать только несколько документов с одного сервера, он, скорее всего, будет содержать
информация, которая очень типична для этого сервера, но вряд ли будет содержать
информация, которая встречается только в одном или нескольких документах на этом сервере.
Например, WebCrawler может плохо работать для поиска личных домашних страниц,
но очень полезен для поиска серверов отдела по имени
факультета и института.
WebCrawler использует стратегию навигации в ширину для поиска документов.
Таким образом, документы, которые находятся на расстоянии многих ссылок от популярных или начальных
страницы веб-сервера вряд ли будут найдены WebCrawler.
Курс гипермедиа, 2Л670, упоминается на нескольких страницах нашего
веб-сервер отдела.
Поэтому мы ожидаем, что WebCrawler сможет найти этот документ,
в то время как мы ожидаем, что WebCrawler не сможет найти
домашняя страница некоторых наших сотрудников.
 Кроме того, поскольку многие веб-сайты включают в себя шлюзы к общим
таких баз данных, как справочные страницы Unix, Lycos проиндексировала тысячи копий
эти популярные документы.
Кроме того, поскольку многие веб-сайты включают в себя шлюзы к общим
таких баз данных, как справочные страницы Unix, Lycos проиндексировала тысячи копий
эти популярные документы.Существует множество других инструментов поиска, таких как четыре упомянутых выше.
- JumpStation поддерживает базу данных индексов, состоящую только из заголовков и названий документов. [B94] поддерживает базу данных индексов (3 миллиона) заголовков, URL-адресов и текста, используемых для ссылок. Как и ALIWEB, эти инструменты не индексируют содержимое веб-документов.
- Галактика TradeWave
(ранее EINet Galaxy),
и Глобальный сетевой навигатор
представляют собой каталоги на основе меню, очень похожие на Yahoo. (Навигатор глобальной сети
однако не предлагает поиск по ключевым словам, в то время как The TradeWave Galaxy
и Yahoo делают.)
Городская сеть
и виртуальный турист
предоставить указатель на основе географического положения, а не предмета.
Они отлично подходят для поиска сервера, если вы знаете, где он находится, но не знаете, как он. называется.
- База данных URL-адресов RBSE [Е94] обеспечивает поиск в 36 000 документов, проиндексированных с помощью WAIS. Это делает его сопоставимым с WebCrawler, но WebCrawler лучше поддерживается. Infoseek предлагает поиск в более чем один миллион документов. Он также предлагает услуги коммерческого поиска. Он стремится к полноте, как и Lycos, но должен содержать больше информации. для каждого документа, чтобы выполнить его поиск по сходству. Альта Виста является самым последней крупной поисковой базы данных и предлагается компанией Digital в качестве бесплатной услуги. Он утверждает, что содержит полнотекстовый индекс более 16 миллионов документов.
4.1 Логические операторы
Иногда документ можно идеально описать, указав несколько слов
что должно происходить в них. Иногда для описания используется несколько слов.
тема, и соответствующий документ может содержать некоторые, но, возможно, не все из них.
Иногда также известны слова, которые не должны встречаться в соответствующих документах. Инструменты поиска предлагают логические комбинации слов, чтобы пользователь мог
опишите документы, которые она ищет.
Средства поиска в Интернете весьма примитивны: они запрашивают ряд
ключевые слова, и пусть пользователь выбирает, должны ли встречаться некоторые или все,
то есть они предлагают выбор логического значения и и или .
Lycos, галактика TradeWave, WebCrawler и червь всемирной паутины
все предлагают этот выбор.
С Infoseek можно добавить знак + или - перед
слова, чтобы указать, что они должны или не должны встречаться в документах, чтобы
считать их актуальными.
Lycos предлагает больше возможностей, чем просто , , или .
Параметр может быть выбран, чтобы сообщить Lycos, чтобы он соответствовал по крайней мере определенному
количество (от 2 до 7) терминов.
С помощью других инструментов поиска можно искать документы, содержащие какие-либо или все
кодов курса гипермедиа 2L670, INF725 и INF706, но с
Lycos можно искать документы, содержащие как минимум два из этих трех
коды.
Обратите внимание, что ни одна из вышеперечисленных систем не предлагает полный набор логических формулы. Только Alta Vista позволяет комбинировать и , или и , а не , и используйте круглые скобки для создания любой логической комбинации, которую вы хотите, например, «(A или B), а не (C или D)».
4.2 Близость
При задании нескольких условий поиска (слов) ни один из доступных инструментов поиска предложить пользователю полный контроль над важностью слова, встречающиеся в определенном порядке, или рядом друг с другом, или в одном и том же структурный элемент документа (кроме поиска по заголовкам или URL). Однако это не означает, что близость слов не влияет по найденным документам или по их ранжированию. Не так много подробностей об этом обнародовано.
Чтобы учесть близость слов, база данных индекса
необходимо знать расположение слов в каждом документе.
Это делает базу данных намного больше, чем без близости.
Вместо того, чтобы действительно использовать близость, система Lycos просто отдает предпочтение
различать слова, которые встречаются близко к началу документа. Это не только обеспечивает ограниченную форму близости, но и увеличивает
важность, придаваемая названию документа, без необходимости
анализируя структуру документа, чтобы выяснить, что такое заголовок.
Некоторые инструменты поиска обеспечивают поиск по смежности с помощью заданные слова как один большой поисковый запрос. Это полезно при поиске названия курса гипермедиа, но это не полная замена близости в целом.
Infoseek предлагает лучшие возможности для контроля близости и слова
заказ. Поисковый термин "пользовательский интерфейс" (с кавычками) означает
что два слова должны стоять рядом друг с другом в заданном порядке.
Термин пользовательский интерфейс означает, что должны появиться два слова
в заданном порядке и рядом друг с другом. [пользовательский интерфейс] означает, что два слова должны стоять рядом друг с другом, но в любом порядке.
Alta Vista использует ключевое слово рядом с , чтобы указать, что два
термины не должны быть разделены более чем на десять слов в документе. (Alta Vista — единственный инструмент, который на самом деле объясняет, что именно означает
оператора близости.)
4.3 Взвешивание терминов
Не все слова одинаково важны в документе. Даже когда пользователь предоставляет несколько (четыре и более) значимых слов, поисковая система может найти много документов, содержащих эти слова. Для ранжирования документов (от наиболее релевантных к наименее релевантным) механизм нужно угадать, какие слова важнее других, как в документах и в поисковом запросе пользователя.
На рис. 2 ниже показано, как следует взвешивать слова (или термины). Слова, которые встречаются очень часто, бесполезны для поиска релевантных слов. документов, а слова, встречающиеся очень редко, могут быть нетипичными для документ же.
Рис. 2: разрешающая способность слов.
Важно учитывать как частоту появления слова в
отдельного документа и во всей базе документов.
Для курса гипермедиа используются коды 2L670, INF725 и INF706. не более или менее распространены, чем многие другие, но во всей сети эти
слова идеально подходят для различения курса и других документов.
При выборе нескольких слов для характеристики этого документа в Сети
эти термины идеальны, тогда как для характеристики этого документа в целом
(не зная, какие слова типичны в Сети) эти слова могут попасть
ниже нижнего предела, потому что они слишком редко встречаются в документе.
Lycos, например, отклонил коды 2L670 и INF725, которые встречаются
только один раз на первой странице курса, но сохранил INF706, который
происходит дважды.
В идеале пользователю будет предоставлена возможность изменить настройки системы.
вес по умолчанию для каждого из условий поиска. При поиске
«Команда Unix cat», слово «кошка» очень важно, потому что пользователь
не хочет получать информацию о других командах Unix. Система однако
может решить, что «кошка» — неважное слово, потому что их много
документы о кошках. Ни один из инструментов поиска в Интернете не предлагает
выбор изменения весов поисковых терминов. Но в некоторых системах
включая WebCrawler, пользователь может использовать недокументированную функцию, которая
придает больший вес словам, которые повторяются в запросе.
Таким образом, запрос «команды Unix cat» можно изменить на
«Команда Unix cat cat cat», чтобы указать, что поиск «кошки» является наиболее важным.
4.4 Поиск частей или выражений
Большинство поисковых систем в Интернете не слишком умны в отношении удаления и
основы слов, или об анализе структуры документов.
Они предлагают возможность найти точные совпадения слов или просто подстроки,
перекладывая большую часть этого бремени на пользователя.
ALIWEB — это поисковая система, которая позволяет использовать регулярные выражения.
помимо просто слов.
Это означает, что ALIWEB должен содержать полный текст резюме, который он
содержит.
Урожай
[SBDHM94] также имеет возможность выполнять
поиск по регулярному выражению и даже приблизительный поиск,
потому что формат индексной базы данных Glimpse поддерживает их. Он-лайн Fish-Search
[DBP94,DBP94a,DBP94b] предлагает одинаковый поиск по регулярным и приближенным выражениям,
а также ряд других.
Для поиска структурных частей документов индексная база данных потребуется проанализировать синтаксис HTML. Несколько поисковых систем, таких как World Wide Web Worm и TradeWave. Galaxy, предложите возможность поиска только по названиям документов, или только текст ссылки. Заголовок легко обнаружить (по тегу