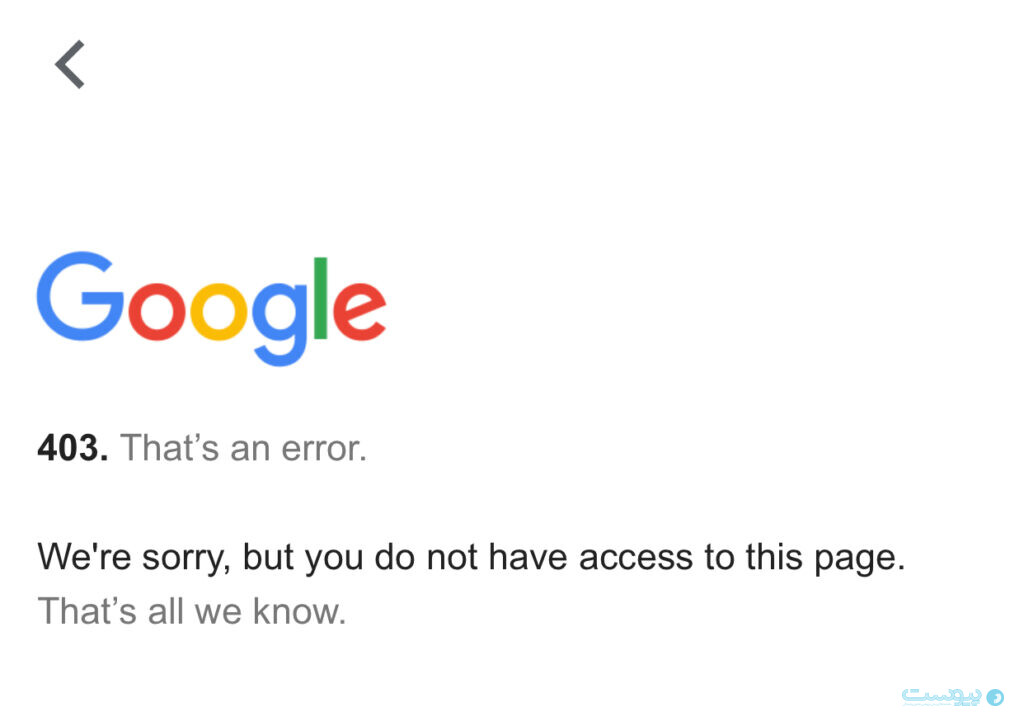
Ошибка 403 forbidden (доступ запрещён)
Информация обновлена:
9 октября 2022
Время на чтение:
5 минут
416
Содержание
- Что значит ошибка 403 на сайте
- Причины появления ошибки 403 forbidden access is denied
- 403 forbidden — как устранить владельцу сайта
- Ошибка 403 доступ запрещен — как исправить пользователю
Что значит ошибка 403 на сайте
Ошибка сервера 403 Forbidden означает ограниченный доступ либо отсутствие материала, который посетитель пытается найти на запрашиваемой странице. То есть сервер понял запрос, но отказывается авторизоваться. Это ошибка похожа на 401, однако в этом случае повторная аутентификация не будет иметь никакого значения.
Доступ запрещен (к примеру, у пользователя не хватает прав к запрашиваемому ресурсу). Чаще всего пользователь не может с этим ничего сделать и работать над ошибкой должен владелец сайта. Владелец мог случайно либо преднамеренно установить ограничение на требуемую страницу. Также запрет может быть установлен администратором сервера, разработчиком веб-приложения, интернет-провайдером, администратором сети, через которую производится доступ в интернет.
Код 403 также могут возвращать антивирусные программы.
Причины появления ошибки 403 forbidden access is denied
При попытке доступа к сайту ошибка 403 Forbidden может возникать по следующим причинам:
- Владельцем установлено ограничение на доступ к запрашиваемой странице (к примеру, по IP-адресу, браузеру или другим критериям).
- Посетитель сайта пытается зайти на страницу, которая доступна только зарегистрированным пользователем.
- На сайте либо данной странице проводятся технические работы, и она временно недоступна.

- Конкретного пользователя заблокировали за неправомерные действия: спам, флуд, попытки взлома и т.д.
При попытке доступа к собственному сайту ошибка 403 может говорить о следующем:
- Установлены неправильные права доступа к файлам каталогам сайта на хостинге.
- Корневая директория не содержит файлы сайта.
- Есть определенные ограничения в файле .htaccess.
- Хостинг-провайдер установил определенные ограничения.
- Скрипты работают некорректно.
403 forbidden — как устранить владельцу сайта
Если вы владелец сайта, есть большая вероятность, что у вас получится решить данную проблему. Вот что можно сделать при возникновении ошибки 403
- Проверить разрешения для файлов (права доступа). Они определяют к каким страницам или будет иметь доступ посетитель. каталогам
- Проверить владельца папок. Иногда 403 ошибка возникает из-за неверного владельца файлов или папок. Иногда права могут быть правильными, но владельцем файлов может быть человек, который не входит в группу доверенных пользователей. Решение — обладателем файлов и папок должен стать веб-сервер. Для этого нужно подключиться к серверу по SSH и ввести следующую строку: chown пользователь:группа//путь к файлу.
- Отключить файл .htaccess. Это файл, который находится в корне каталога. Если в файле .htaccess настройки выполнены неправильно, может появляться ошибка 403. Отключение файла настроек поможет понять, является ли он причиной проблемы. Чтобы найти данный файл, необходимо зайти на свой хостинг, зайти в диспетчер файлов, найти одноименный файл, щелкнуть на него и переименовать.
- Проверить свое подключение к серверу. Так, временные неполадки в работе сервера могут вызывать ошибку 403. Решение — владелец сайта должен выяснить связана ли данная ошибка с данными, которые хранятся на определенном сервере и временно недоступны.
- Проверить настройки MobSecurity или другой программы безопасности. Это ПО может блокировать страницы для тех пользователей, чьи действия считает подозрительными или. В результате посетитель сайта видит ошибку 403. Решение — добавить в настройки MobSecurity исключения (это получится сделать на VPS). На виртуальном хостинге так не получится, поэтому лучше связаться с провайдером для помощи и объяснить ему ситуацию. небезопасными
- Отключить плагины. Вспомните какие плагины были установлены последними. Отключите все расширения, установленные за последние несколько недель и посмотреть решится ли ситуация после этого.
- Почистить файлы Cookies. 403 ошибка может возникать из-за старых Cookies, поэтому не лишним будет их почистить.
- Включить доступ к каталогам. По умолчанию, их могут просматривать только определенная группа лиц.
 Иногда права могут быть правильными, но владельцем файлов может быть человек, который не входит в группу доверенных пользователей. Решение — обладателем файлов и папок должен стать веб-сервер. Для этого нужно подключиться к серверу по SSH и ввести следующую строку: chown пользователь:группа//путь к файлу.
Иногда права могут быть правильными, но владельцем файлов может быть человек, который не входит в группу доверенных пользователей. Решение — обладателем файлов и папок должен стать веб-сервер. Для этого нужно подключиться к серверу по SSH и ввести следующую строку: chown пользователь:группа//путь к файлу.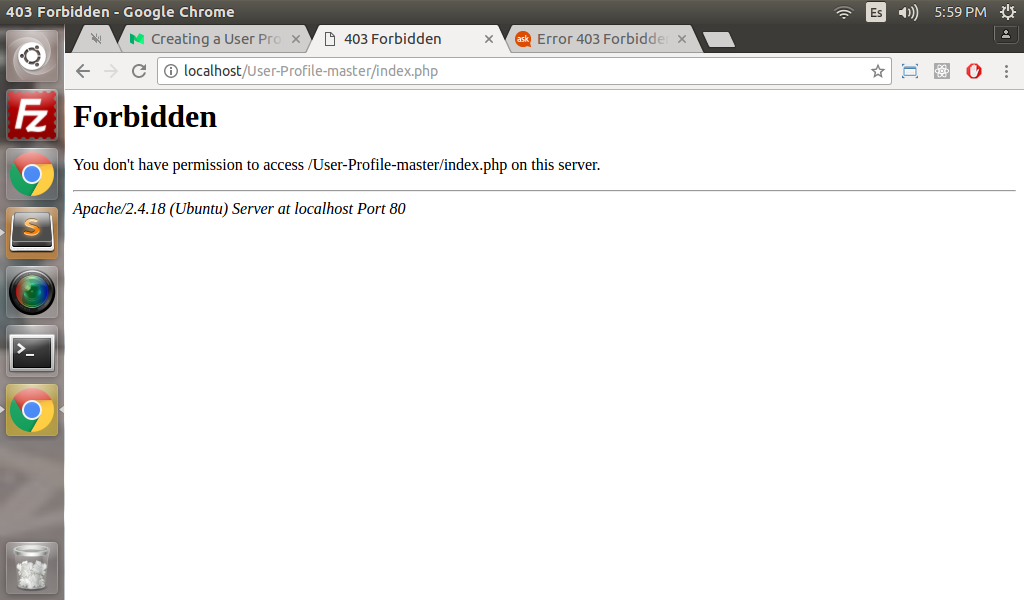 Это ПО может блокировать страницы для тех пользователей, чьи действия считает подозрительными или. В результате посетитель сайта видит ошибку 403. Решение — добавить в настройки MobSecurity исключения (это получится сделать на VPS). На виртуальном хостинге так не получится, поэтому лучше связаться с провайдером для помощи и объяснить ему ситуацию. небезопасными
Это ПО может блокировать страницы для тех пользователей, чьи действия считает подозрительными или. В результате посетитель сайта видит ошибку 403. Решение — добавить в настройки MobSecurity исключения (это получится сделать на VPS). На виртуальном хостинге так не получится, поэтому лучше связаться с провайдером для помощи и объяснить ему ситуацию. небезопаснымиОшибка 403 доступ запрещен — как исправить пользователю
Пользователь ничего не может сделать со своей стороны, так как ему запрещён доступ к той или иной странице.
Но все-равно есть действия, которые пользователь ресурса может сделать со своей стороны:
- Обновить страницу
- Перепроверьте лишний раз адрес, ведь иногда ошибка вызвана неверным URL. Посетитель должен убедиться, что он вводит в строку адрес страницы, а не адрес каталога. Дело в том, что большинство сайтов не предоставляет пользователям доступ к каталогам. В таком случае, на экране можно увидеть ошибку 403.
- Стоит очистить кэш и Cookies в браузере пользователя. Ведь ошибочная страница могла быть кэширована в браузере, в то время как владелец ресурса уже сменил адрес страницы, и для остальных пользователей она доступна. Минусом данного метода в том, что снова нужно будет войти во все учетные записи, в которые выходили раньше с этого браузера.
- Проверить имеется ли доступ к URL адресу. На некоторых сайтах, чтобы увидеть содержимое страницы, нужно сперва войти в систему. В таком случае, тоже может появляться ошибка 403. Вам нужно войти в систему, если вы уже были ранее зарегистрированы либо зарегистрироваться впервые, введя необходимы данные.
- Попробовать зайти позже. Всегда не лишним будет немного подождать и попробовать снова запросить доступ к странице. Это может сработать, потому что часто ошибка 403 вызвана неполадками на самом сайте, которые впоследствии могут быть исправлены владельцем ресурса.
- Выход из системы и вход. Если посетитель достаточно давно зарегистрирован на сайте и не выходил из него (не выключал компьютер) также может появиться ошибка 403. Веб-сервер не может распознать идентификатор сеанса. Решение — выйти из системы и снова в нее войти.
- Свяжитесь с владельцем. Можно найти контактную информацию на сайте, связаться с владельцем и описать возникшую проблему.
- Связаться с провайдером. Это может сработать в том случае, если вы убеждены в том, что сайт работает и только у вас нет доступа к нему.
 В таком случае, тоже может появляться ошибка 403. Вам нужно войти в систему, если вы уже были ранее зарегистрированы либо зарегистрироваться впервые, введя необходимы данные.
В таком случае, тоже может появляться ошибка 403. Вам нужно войти в систему, если вы уже были ранее зарегистрированы либо зарегистрироваться впервые, введя необходимы данные.
Помогла статья? Поставьте оценку
0 / 5. 0
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
-
- Применяется к:
- SharePoint Online
Симптомы
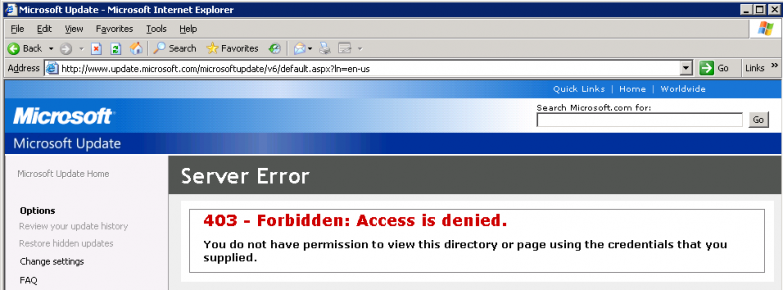
При попытке получить доступ к файлу с веб-сайта OneDrive или SharePoint, который вам предоставляет другой пользователь, вы получите следующее сообщение об ошибке:
Ошибка: 403 Запрещено
Причина
Ошибка «403 Запрещено» может возникнуть из-за одного из следующих условий:
Кэш браузера необходимо очистить.
Ваши разрешения на файл не реплицированы правильно на сервере.
Сайт OneDrive заблокирован.
Проблема влияет на службы SharePoint Online вашей организации.
Решение
Используйте доступный режим конфиденциальности веб-браузера при входе в Microsoft 365. Например, используйте режим InPrivate в Microsoft Edge или режим инкогнито в Google Chrome. Затем попробуйте получить доступ к файлу. Чтобы узнать, как просматривать окно InPrivate, ознакомьтесь с Microsoft Edge. Сведения о том, как просматривать окно инкогнито, см. в google Chrome.
Если вы можете получить доступ к файлу во время просмотра в режиме конфиденциальности, очистите кэш браузера. Сведения о том, как очистить кэш браузера, см. в разделе «Edge » или «Chrome».
Если это не решает проблему, обратитесь к администратору SharePoint или OneDrive в вашей организации. Если вы не можете узнать, кто это, Разделы справки найти администратора Microsoft 365?.
Заявление об отказе от ответственности за сведения о продуктах сторонних производителей
Сторонние продукты, которые обсуждаются в этой статье, производятся компаниями, независимыми от Microsoft. Корпорация Майкрософт не дает никаких явных, подразумеваемых и прочих гарантий относительно производительности или надежности этих продуктов.
Корпорация Майкрософт предоставляет контактные данные сторонних разработчиков, которые помогут вам найти дополнительные сведения по этой теме. Эти данные могут быть изменены без предварительного уведомления. Корпорация Майкрософт не гарантирует точность контактных данных сторонних разработчиков.
Действия для администраторов
Если очистка кэша не решает проблему, попробуйте использовать следующие методы.
Повторное предоставление общего доступа к файлуВозможно, разрешения для файла не реплицированы правильно или полностью. Попросите пользователя подождать 30 минут, прежде чем пытаться снова получить доступ к файлу. Если ошибка по-прежнему возникает через 30 минут, попробуйте выполнить действия, перечисленные в разделе «При доступе к сайту SharePoint» или «При доступе к сайту OneDrive» в разделе «Отказано в доступе», «Требуется разрешение на доступ к этому сайту» или «Пользователь не найден в каталоге» в SharePoint Online и OneDrive для бизнеса.
Если ошибка по-прежнему возникает через 30 минут, попробуйте выполнить действия, перечисленные в разделе «При доступе к сайту SharePoint» или «При доступе к сайту OneDrive» в разделе «Отказано в доступе», «Требуется разрешение на доступ к этому сайту» или «Пользователь не найден в каталоге» в SharePoint Online и OneDrive для бизнеса.
Возможно, сайт OneDrive пользователя находится в заблокированном состоянии NoAccess. Глобальный администратор или администратор SharePoint в Microsoft 365 может разблокировать сайт с помощью PowerShell или системы диагностики Microsoft 365. Дополнительные сведения см. в сообщениях об ошибках SharePoint или OneDrive только для чтения.
Проверка работоспособности службыКак администратор перейдите на страницу работоспособности службы(>Работоспособность служб) в Microsoft 365 Admin Центре. Проверьте наличие каких-либо рекомендаций или инцидентов, которые могут возникнуть. Если для SharePoint Online нет рекомендаций или инцидентов, можно выбрать «Сообщить о проблеме», если она вам доступна, или открыть новый запрос на обслуживание в службе технической поддержки Microsoft 365.
Если для SharePoint Online нет рекомендаций или инцидентов, можно выбрать «Сообщить о проблеме», если она вам доступна, или открыть новый запрос на обслуживание в службе технической поддержки Microsoft 365.
Ошибка 403 может возникнуть, если пользователь пытается получить доступ к сайту OneDrive, который не подготовлен. Попробуйте пользователю перейти к плитке OneDrive на портале Microsoft 365.
Если это не работает, подготовьте сайт с помощью командлета Request-SPOPersonalSite .
Доступ к данным OneDrive другого пользователяЕсли пользователь пытается получить доступ к данным OneDrive другого пользователя, например бывшего сотрудника, вы можете предоставить ему разрешения, выполнив действия, описанные в шаге 4 . Предоставление другому сотруднику доступа к данным OneDrive и Outlook.
Как устранить ошибку 403 на моем сайте —
Ошибка 403 возникает, когда возникает проблема с разрешениями на веб-сайте. В этой статье объясняется, что вызывает ошибку 403 и как устранить эту ошибку на вашем веб-сайте.
В этой статье объясняется, что вызывает ошибку 403 и как устранить эту ошибку на вашем веб-сайте.
Что такое ошибка 403?
Ошибка 403 означает, что пользователь не может получить доступ к определенным веб-страницам. Это общая ошибка, которая гласит: «У вас нет разрешения на просмотр этой страницы». Как правило, ошибка вызвана проблемой с URL-адресом или кэшированными файлами в браузере.
Решение 1. Исправьте любые ошибки URL-адреса
Безусловно, большинство ошибок 403 вызваны ошибками в URL-адресе. Убедитесь, что вы правильно написали каждую часть веб-сайта в адресной строке и что вы указываете фактическую страницу на веб-сайте.
Решение 2. Очистите историю браузера и кэш
На вашем компьютере хранятся временные файлы, которые помогают вам быстро подключаться к веб-сайтам и перемещаться по ним. Эти файлы иногда мешают каталогу веб-сайта и могут вызывать ошибку 403. Если вы все еще сталкиваетесь с ошибкой 403, очистите файлы cookie и кеш на странице истории вашего браузера и повторите попытку.
Решение 3. Измените файл index.html в файловом менеджере
Посетители могут столкнуться с ошибкой 403, если вы запретили пользователям просматривать каталог файлов вашего сайта. Вы можете изменить эту функцию в cPanel, выполнив следующие действия:
Перейдите в cPanel, перейдя на [yourdomain.com]/cpanel.
Нажмите кнопку «Диспетчер файлов» в разделе «Файлы».
3. «Создайте файл с именем index.html, который будет служить вашей домашней страницей для вашей папки, которая выдает ошибку 403. Любое из приведенных ниже имен файлов может быть загружено в вашу папку public_html и находится в порядке того, что будет отображаться первым и последним, если эти файлы существуют:
index.html.var
index.htm
index.html
index.shtml
index.xhtml
index.wml
index.perl
5 index.plx0
0 index.pl
индекс .ppl
index.cgi
index.jsp
index. js
js
index.jp
index.php4
index.php3
index.php 0
2html 90 default .htmпо умолчанию .html
home.htm
index.php5
default.html
default.htm
home.html
Решение 4. Убедитесь, что вы не заблокировали свой собственный IP-адрес
Иногда распространенной причиной ошибки 403 является то, что пользователь заблокировал свой собственный IP с помощью функции блокировки IP в cPanel. Убедитесь, что вы не заблокировали свой собственный IP-адрес, выполнив следующие действия:
В cPanel щелкните приложение IP Blocker на вкладке «Безопасность».
Проверьте в разделе «Текущие заблокированные IP-адреса», чтобы убедиться, что ваш собственный IP-адрес отсутствует в списке.
Решение 5. Отправьте заявку в службу поддержки
Если посетители вашего веб-сайта сообщают, что столкнулись с ошибкой 403, а вы безуспешно пытались решить проблему с помощью приведенных выше рекомендаций, мы рекомендуем вам заполнить заявку в службу поддержки. для наших техников. Это можно сделать на главной странице панели управления CHI.
для наших техников. Это можно сделать на главной странице панели управления CHI.
При отправке заявки убедитесь, что вы включили в нее конкретные сведения об ошибке, в том числе: точный URL-адрес ошибки, когда возникла ошибка и как ее можно воспроизвести.
Если у вас возникли проблемы с какой-либо из тем в этой статье, не стесняйтесь открыть чат с кем-нибудь из нашей службы технической поддержки на Weshost.com/support/.
Как устранить ошибки 403 Forbidden при очистке веб-страниц
Получение HTTP 403 Forbidden Error при очистке или сканировании веб-страниц является одной из наиболее распространенных ошибок HTTP, которые вы получаете.
Часто бывает только две возможные причины :
- URL-адрес, который вы пытаетесь очистить, запрещен, и вам необходимо авторизоваться для доступа к нему.
- Веб-сайт обнаруживает, что вы являетесь парсером, и возвращает код состояния HTTP
403 Forbiddenв виде страницы блокировки.
В большинстве случаев это вторая причина, т.е. веб-сайт блокирует ваши запросы, потому что считает вас парсером.
403 Запрещенные ошибки часто встречаются, когда вы пытаетесь очистить веб-сайты, защищенные Cloudflare, поскольку Cloudflare возвращает код состояния 403 .
В этом руководстве мы расскажем, как отлаживать 403 Forbidden Error и предоставьте решения, которые вы можете реализовать.
- Простой способ решить 403 Запрещенные ошибки при парсинге веб-страниц
- Использовать поддельные пользовательские агенты
- Оптимизировать заголовки запросов bidden Ошибки при парсинге веб-страниц
Если URL-адрес, который вы пытаетесь очистить, обычно доступен, но вы получаете 403 Forbidden Errors , вероятно, веб-сайт помечает ваш поисковый робот как парсер и блокирует ваши запросы.
Чтобы избежать обнаружения, нам нужно оптимизировать наших пауков, чтобы обойти меры противодействия ботам:
- Использование поддельных пользовательских агентов
- Оптимизация заголовков запросов
- Использование прокси
способ решить эту проблему — использовать интеллектуальное прокси-решение, такое как ScrapeOps Proxy Aggregator.
С агрегатором прокси-серверов ScrapeOps вам просто нужно отправить свои запросы на конечную точку прокси-сервера ScrapeOps, и наш агрегатор прокси-серверов оптимизирует ваш запрос с помощью лучшего пользовательского агента, заголовка и конфигурации прокси, чтобы гарантировать, что вы не получите
403ошибок с вашего целевого сайта.Просто получите бесплатный ключ API , зарегистрировав бесплатную учетную запись здесь, и отредактируйте парсер следующим образом:
запросы на импорт ': API_KEY, 'url': url}
proxy_url = 'https://proxy.scrapeops.io/v1/?' + urlencode(payload)
return proxy_urlr = request.get(get_scrapeops_url('http://quotes.toscrape.com/page/1/'))
print(r.text)Если вас блокирует Cloudflare , вы можете просто активировать обход Cloudflare ScrapeOps, добавив
bypass=cloudflareк запросу: ‘def get_scrapeops_url(url):
payload = {‘api_key’: API_KEY, ‘url’: url, ‘bypass’: ‘cloudflare’}
proxy_url = ‘https://proxy. scrapeops.io/v1/? ‘ + urlencode(полезная нагрузка)
return proxy_urlr = request.get(get_scrapeops_url(‘http://example.com/’))
print(r.text)Вы можете ознакомиться с полной документацией здесь.
Или, если вы предпочитаете попробовать оптимизировать свой пользовательский агент, заголовки и конфигурацию прокси-сервера самостоятельно, тогда читайте дальше, и мы объясним, как это сделать.
Используйте фальшивые пользовательские агенты веб-сайте при отправке запросов.
По умолчанию большинство HTTP-библиотек (Python Requests, Scrapy, NodeJs Axios и т. д.) либо не присоединяют к вашим запросам настоящие заголовки браузера, либо включают заголовки, идентифицирующие используемую библиотеку. Оба из них сразу сообщают веб-сайту, который вы пытаетесь очистить, что вы парсер, а не настоящий пользователь.
Например, давайте отправим запрос на
http://httpbin.org/headersс библиотекой запросов Python, используя настройку по умолчанию:
запросы на импортr = request.
get('http://httpbin.org/headers')
print(r.text)Вы получите такой ответ, который показывает, какие заголовки мы отправили на веб-сайт:
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python -requests/2.26.0",
}
}Здесь мы видим, что наш запрос с использованием библиотеки запросов Python добавляет к запросу очень мало заголовков и даже идентифицирует себя как библиотеку запросов python в
Заголовок User-Agent.
«User-Agent»: «python-requests/2.26.0»,Это сообщает веб-сайту, что ваши запросы исходят от парсера, поэтому им очень легко заблокировать ваши запросы и вернуть
403 Код состояния.Решение
Решение этой проблемы состоит в том, чтобы настроить парсер так, чтобы отправлял фальшивый пользовательский агент с каждым запросом . Таким образом, веб-сайту будет сложнее определить, исходят ли ваши запросы от парсера или от реального пользователя.
Вот как можно отправить поддельный пользовательский агент при выполнении запроса с помощью Python Requests.
импортные запросыHEADERS = {'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 12_2, как Mac OS X) AppleWebKit/605.1.15 (KHTML, как Gecko) Mobile/15E148'}
r = request.get('http://quotes.toscrape.com/page/1/', headers=HEADERS)
print(r.text)Здесь мы делаем наш запрос таким, как будто он исходит от iPad, что повысит шансы на прохождение запроса.
Это будет работать только с относительно небольшими парсерами, так как если вы используете один и тот же пользовательский агент для каждого отдельного запроса, веб-сайт с более сложным решением для защиты от ботов может легко обнаружить ваш парсер.
Чтобы решить проблему парсинга в масштабе, нам нужно вести большой список пользовательских агентов и выбирать разные для каждого запроса.
запросы на импорт
import randomuser_agents_list = [
'Mozilla/5. 0 (iPad; CPU OS 12_2, например Mac OS X) AppleWebKit/605.1.15 (KHTML, например Gecko) Mobile/15E148',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/99.0.4844.83 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например, Gecko) Chrome/99.0.4844.51 Safari/537.36'
]r = request.get('http://quotes.toscrape.com/page/1/', headers={'User-Agent' : random.choice(user_agents_list)})
print(r.text)Теперь, когда мы делаем запрос. Мы выберем случайный пользовательский агент для каждого запроса.
Во многих случаях простое добавление поддельных пользовательских агентов к вашим запросам решит 403 Forbidden Error , однако, если на веб-сайте установлена более сложная система обнаружения ботов, вам также потребуется оптимизировать заголовки запроса.
По умолчанию большинство HTTP-клиентов будут отправлять вместе с вашими запросами только базовые заголовки запросов, такие как
Accept,Accept-LanguageиUser-Agent.
Принять: 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
Accept-Language: 'en'
User-Agent: 'python-requests/2.26.0'Напротив, вот заголовки запроса браузера Chrome, работающего на компьютере MacOS отправит:
Connection: 'keep-alive'
Cache-Control: 'max-age=0'
sec-ch-ua: '" Not A;Brand";v="99", "Chromium" ;v="99", "Google Chrome";v="99"'
sec-ch-ua-mobile: '?0'
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/99.0.4844.83 Safari/537.36'
Принять: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application /signed-exchange;v=b3;q=0.9'
Sec-Fetch-Site: «нет»
Sec-Fetch-Mode: «навигация»
Sec-Fetch-User: «?1»
Sec-Fetch-Dest : 'document'
Accept-Encoding: 'gzip, deflate, br'
Accept-Language: 'en-GB,en-US;q=0. 9,en;q=0.8' Если веб-сайт действительно пытается предотвратить веб-скрейперы не смогут получить доступ к своему контенту, тогда они будут анализировать заголовки запроса, чтобы убедиться, что другие заголовки соответствуют установленному вами пользовательскому агенту, и что запрос включает в себя другие общие заголовки.0113 реальный браузер отправил бы .
Решение
Чтобы решить эту проблему, нам нужно убедиться, что мы оптимизировали заголовки запроса, в том числе убедиться, что поддельный пользовательский агент совместим с другими заголовками .
Это большая тема, поэтому, если вы хотите узнать больше об оптимизации заголовков, ознакомьтесь с нашим руководством по оптимизации заголовков.
Однако, подводя итог, мы хотим не просто отправить поддельный пользовательский агент при выполнении запроса, а полный набор заголовков, которые веб-браузеры обычно отправляют при посещении веб-сайтов.
Вот краткий пример добавления оптимизированных заголовков к нашим запросам:
запросы на импортHEADERS = {
"User-Agent": "Mozilla/5. 0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/ 20100101 Firefox/98.0",
"Принять": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Принять -Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": " 1",
"Sec-Fetch-Dest": "документ",
"Sec-Fetch-Mode": "навигация",
"Sec-Fetch-Site": "нет",
"Sec-Fetch-User": "? 1",
"Cache-Control": "max-age=0",
}r = request.get('http://quotes.toscrape.com/page/1/', headers=HEADERS)
print(r.text)Здесь мы добавляем один и тот же оптимизированный заголовок с поддельным пользовательским агентом к каждому запросу. Однако при очистке в масштабе вам понадобится список этих оптимизированных заголовков и чередование их.
Использовать чередующиеся прокси
Если приведенные выше решения не работают, весьма вероятно, что сервер пометил ваш IP-адрес как используемый парсером и либо ограничивает ваши запросы, либо полностью блокирует их.
Это особенно вероятно при парсинге больших объемов, так как веб-сайтам легко обнаружить парсеры, если они получают неестественно большое количество запросов с одного и того же IP-адреса.
Решение
Вам нужно будет отправлять запросы через меняющийся пул прокси.
Вот как это можно сделать Запросы Python:
запросы на импорт
из цикла импорта itertoolslist_proxy = [
'http://Имя пользователя:Пароль@IP1:20000',
'http://Имя пользователя:Пароль @IP2:20000',
'http://Имя пользователя:Пароль@IP3:20000',
'http://Имя пользователя:Пароль@IP4:20000',
]proxy_cycle = cycle(list_proxy)
proxy = следующий (proxy_cycle)для i в диапазоне (1, 10):
proxy = next(proxy_cycle)
print(proxy)
proxy = {
"http": прокси,
"https": прокси
}
r = request.get(url='http://quotes.toscrape.com/page/1/', прокси=прокси)
print(r. текст)Теперь ваш запрос будет направляться через другой прокси-сервер с каждым запросом.
 scrapeops.io/v1/? ‘ + urlencode(полезная нагрузка)
scrapeops.io/v1/? ‘ + urlencode(полезная нагрузка)  get('http://httpbin.org/headers')
get('http://httpbin.org/headers') 
 0 (iPad; CPU OS 12_2, например Mac OS X) AppleWebKit/605.1.15 (KHTML, например Gecko) Mobile/15E148',
0 (iPad; CPU OS 12_2, например Mac OS X) AppleWebKit/605.1.15 (KHTML, например Gecko) Mobile/15E148', 
 9,en;q=0.8'
9,en;q=0.8'  0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/ 20100101 Firefox/98.0",
0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/ 20100101 Firefox/98.0",