css3 — Как элементы списка расположить в одну строку без переноса?
Задать вопрос
Вопрос задан
Изменён 2 года 3 месяца назад
Просмотрен 831 раз
Необходимо чтобы все элементы списка всегда были на одной строке и при необходимости добавлялся скрол
html:
<ul>
<li>hello world</li>
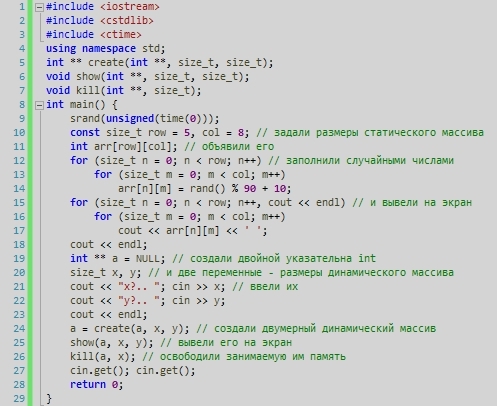
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
</ul>
</div>
css:
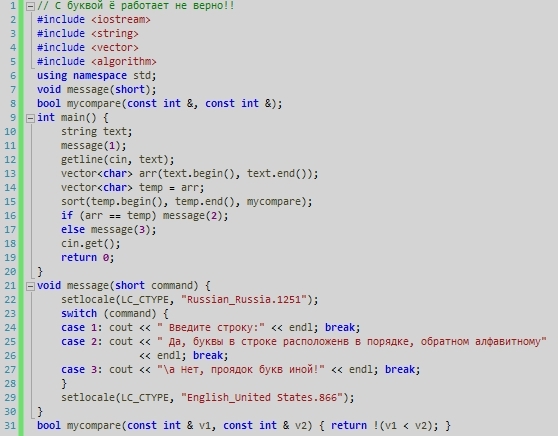
.box { width: 300px; height: 150px; border: 2px solid black; overflow: auto; } .list-item { display: inline; }
 box {
width: 300px;
height: 150px;
border: 2px solid black;
overflow: auto;
}
.list-item {
display: inline;
}
box {
width: 300px;
height: 150px;
border: 2px solid black;
overflow: auto;
}
.list-item {
display: inline;
}
- css3
- html5
- ul
- overflow
- li
Используйте white-space: nowrap — это свойство запрещает перенос inline и inline-block элементов
.box {
width: 300px;
height: 150px;
border: 2px solid black;
overflow: auto;
}
.list{
list-style: none;
padding: 0;
margin: 0;
white-space: nowrap;
}
.list-item {
display: inline;
}<div>
<ul>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
<li>hello world</li>
</ul>
</div>Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Модуль BeautifulSoup4 в Python, разбор HTML.
Извлечение данных из документов HTML и XML.
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер html.parser. BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml, html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
Содержание:# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль beautifulsoup4 (VirtualEnv):~$ python3 -m pip install -U beautifulsoup4
- Выбор парсера для использования в BeautifulSoup4.
- Парсер
lxml. - Парсер
html5lib. - Встроенный в Python парсер
html.parser.
- Парсер
- Основные приемы работы с BeautifulSoup4.
- Навигация по структуре HTML-документа.
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу.
- Поиск тегов при помощи CSS селекторов.
- Дочерние элементы.
- Родительские элементы.
- Изменение имен тегов HTML-документа.
- Добавление новых тегов в HTML-документ.
- Удаление и замена тегов в HTML-документе.
- Изменение атрибутов тегов HTML-документа.

Выбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке: <a></p>.
Парсер
lxml.Характеристики:
- Для запуска примера, необходимо установить модуль
lxml. - Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", "lxml")
# <html><body><a></a></body></html>
Обратите внимание, что тег <a> заключен в теги <body> и <html>, а висячий тег </p> просто игнорируется.
Парсер
html5lib.Характеристики:
- Для запуска примера, необходимо установить модуль
html5lib. - Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", "html5lib")
# <html><head></head><body><a><p></p></a></body></html>
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег </p>, и к тому же добавляет открывающий тег <p>. Также html5lib добавляет пустой тег <head> (lxml этого не сделал).
Встроенный в Python парсер
html.parser.Характеристики:
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как
lxml. - Более строгий, чем
html5lib.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", 'html.parser')
# <a></a>
Как и lxml, встроенный в Python парсер игнорирует закрывающий тег  В отличие от
В отличие от html5lib, этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги <html> или <body>.
Вывод: Парсер html5lib использует способы, которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход самый «правильный«.
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup(). Можно передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup
# передаем объект открытого файла
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
# передаем строку
soup = BeautifulSoup("<html>a web page</html>", 'html.parser')
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
>>> from bs4 import BeautifulSoup >>> html = "<html><head></head><body>Sacré bleu!</body></html>" >>> parse = BeautifulSoup(html, 'html.
 parser')
>>> print(parse)
# <html><head></head><body>Sacré bleu!</body></html>
parser')
>>> print(parse)
# <html><head></head><body>Sacré bleu!</body></html>
Дальнейшие примеры будут разбираться на следующей HTML-разметке.
html_doc = """<html><head><title>The Dormouse's story</title></head> <body> <p><b>The Dormouse's story</b></p> <p>Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie">Elsie</a>, <a href="http://example.com/lacie">Lacie</a> and <a href="http://example.com/tillie">Tillie</a>; and they lived at the bottom of a well.</p> <p>...</p>"""
Передача этого HTML-документа в конструктор класса
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(html_doc, 'html.parser') >>> print(soup.
 prettify())
# <html>
# <head>
# <title>
# The Dormouse's story
# </title>
# </head>
# <body>
# <p>
# <b>
# The Dormouse's story
# </b>
# </p>
# <p>
# Once upon a time there were three little sisters; and their names were
# <a href="http://example.com/elsie">
# Elsie
# </a>
# ,
# <a href="http://example.com/lacie">
# Lacie
# </a>
# and
# <a href="http://example.com/tillie">
# Tillie
# </a>
# ; and they lived at the bottom of a well.
# </p>
# <p>
# ...
# </p>
# </body>
# </html>
prettify())
# <html>
# <head>
# <title>
# The Dormouse's story
# </title>
# </head>
# <body>
# <p>
# <b>
# The Dormouse's story
# </b>
# </p>
# <p>
# Once upon a time there were three little sisters; and their names were
# <a href="http://example.com/elsie">
# Elsie
# </a>
# ,
# <a href="http://example.com/lacie">
# Lacie
# </a>
# and
# <a href="http://example.com/tillie">
# Tillie
# </a>
# ; and they lived at the bottom of a well.
# </p>
# <p>
# ...
# </p>
# </body>
# </html>
Навигация по структуре HTML-документа:
# извлечение тега `title` >>> soup.title # <title>The Dormouse's story</title> # извлечение имя тега >>> soup.title.name # 'title' # извлечение текста тега >>> soup.title.string # 'The Dormouse's story' # извлечение первого тега `<p>` >>> soup.p # <p><b>The Dormouse's story</b></p> # извлечение второго тега `<p>` и # представление его содержимого списком >>> soup.find_all('p')[1].contents # ['Once upon a time there were three little sisters; and their names were\n', # <a href="http://example.com/elsie">Elsie</a>, # ',\n', # <a href="http://example.com/lacie">Lacie</a>, # ' and\n', # <a href="http://example.com/tillie">Tillie</a>, # ';\nand they lived at the bottom of a well.'] # выдаст то же самое, только в виде генератора >>> soup.find_all('p')[1].strings # <generator object Tag._all_strings at 0x7ffa2eb43ac0>
Перемещаться по одному уровню можно при помощи атрибутов .previous_sibling и .next_sibling. Например, в представленном выше HTML, теги <a> обернуты в тег <p> — следовательно они находятся на одном уровне.
>>> first_a = soup.a >>> first_a # <a href="http://example.
 com/elsie">Elsie</a>
>>> first_a.previous_sibling
# 'Once upon a time there were three little sisters; and their names were\n'
>>> next = first_a.next_sibling
>>> next
# ',\n'
>>> next.next_sibling
# <a href="http://example.com/lacie">Lacie</a>
com/elsie">Elsie</a>
>>> first_a.previous_sibling
# 'Once upon a time there were three little sisters; and their names were\n'
>>> next = first_a.next_sibling
>>> next
# ',\n'
>>> next.next_sibling
# <a href="http://example.com/lacie">Lacie</a>
Так же можно перебрать одноуровневые элементы данного тега с помощью .next_siblings или .previous_siblings.
for sibling in soup.a.next_siblings:
print(repr(sibling))
# ',\n'
# <a href="http://example.com/lacie">Lacie</a>
# ' and\n'
# <a href="http://example.com/tillie">Tillie</a>
# '; and they lived at the bottom of a well.'
for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
# ' and\n'
# <a href="http://example.com/lacie">Lacie</a>
# ',\n'
# <a href="http://example.com/elsie">Elsie</a>
# 'Once upon a time there were three little sisters; and their names were\n'
Атрибут . строки или HTML-тега указывает на то, что было разобрано непосредственно после него. Это могло бы быть тем же, что и  next_element
next_element.next_sibling, но обычно результат резко отличается.
Возьмем последний тег <a>, его .next_sibling является строкой: конец предложения, которое было прервано началом тега <a>:
last_a = soup.find("a",)
last_a
# <a href="http://example.com/tillie">Tillie</a>
last_a.next_sibling
# ';\nand they lived at the bottom of a well.'
Однако .next_element этого тега <a> — это то, что было разобрано сразу после тега <a> — это слово Tillie, а не остальная часть предложения.
last_a_tag.next_element # 'Tillie'
Это потому, что в оригинальной разметке слово Tillie появилось перед точкой с запятой. Парсер обнаружил тег <a>, затем слово Tillie, затем закрывающий тег </a>, затем точку с запятой и оставшуюся часть предложения. Точка с запятой находится на том же уровне, что и тег
Точка с запятой находится на том же уровне, что и тег <a>, но слово Tillie встретилось первым.
Атрибут .previous_element является полной противоположностью .next_element. Он указывает на элемент, который был обнаружен при разборе непосредственно перед текущим:
last_a_tag.previous_element # ' and\n' last_a_tag.previous_element.next_element # <a href="http://example.com/tillie">Tillie</a>
При помощи атрибутов .next_elements и .previous_elements можно получить список элементов, в том порядке, в каком он был разобран парсером.
for element in last_a_tag.next_elements:
print(repr(element))
# 'Tillie'
# ';\nand they lived at the bottom of a well.'
# '\n'
# <p>...</p>
# '...'
# '\n'
Извлечение URL-адресов.
Одна из распространенных задач, это извлечение URL-адресов, найденных на странице в HTML-тегах <a>:
>>> for a in soup.
 find_all('a'):
... print(a.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
find_all('a'):
... print(a.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
Извлечение текста HTML-страницы.
Другая распространенная задача — извлечь весь текст со HTML-страницы:
# Весь текст HTML-страницы с разделителями `\n`
>>> soup.get_text('\n', strip='True')
# "The Dormouse's story\nThe Dormouse's story\n
# Once upon a time there were three little sisters; and their names were\n
# Elsie\n,\nLacie\nand\nTillie\n;\nand they lived at the bottom of a well.\n..."
# а можно создать список строк, а потом форматировать как надо
>>> [text for text in soup.stripped_strings]
# ["The Dormouse's story",
# "The Dormouse's story",
# 'Once upon a time there were three little sisters; and their names were',
# 'Elsie',
# ',',
# 'Lacie',
# 'and',
# 'Tillie',
# ';\nand they lived at the bottom of a well.',
# '...']
Поиск тегов по HTML-документу:
Найти первый совпавший HTML-тег можно методом BeautifulSoup., а всех совпавших элементов —  find()
find()BeautifulSoup.find_all().
# ищет все теги `<title>`
>>> soup.find_all("title")
# [<title>The Dormouse's story</title>]
# ищет все теги `<a>` и все теги `<b>`
>>> soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
# ищет все теги `<p>` с CSS классом "title"
>>> soup.find_all("p", "title")
# [<p><b>The Dormouse's story</b></p>]
# ищет все теги с CSS классом, в именах которых встречается "itl"
soup.find_all(class_=re.compile("itl"))
# [<p><b>The Dormouse's story</b></p>]
# ищет все теги с
>>> soup.find_all(id="link2")
# [<a href="http://example.com/lacie">Lacie</a>]
# ищет все теги `<a>`, содержащие указанные атрибуты
>>> soup. b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
 b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
Поиск тегов при помощи CSS селекторов:
>>> soup.select("title")
# [<title>The Dormouse's story</title>]
>>> soup.select("p:nth-of-type(3)")
# [<p>...</p>]
Поиск тега под другими тегами:
>>> soup.select("body a")
# [<a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie" >Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
>>> soup.select("html head title")
# [<title>The Dormouse's story</title>]
Поиск тега непосредственно под другими тегами:
>>> soup.select("head > title")
# [<title>The Dormouse's story</title>]
>>> soup.select("p > a:nth-of-type(2)")
# [<a href="http://example. com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
 com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
Поиск одноуровневых элементов:
# поиск всех `.sister` в которых нет `#link1`
>>> soup.select("#link1 ~ .sister")
# [<a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie" >Tillie</a>]
# поиск всех `.sister` в которых есть `#link1`
>>> soup.select("#link1 + .sister")
# [<a href="http://example.com/lacie">Lacie</a>]
# поиск всех `<a>` у которых есть сосед `<p>`
Поиск тега по классу CSS:
>>> soup.select(".sister")
# [<a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
Поиск тега по ID:
>>> soup.select("#link1")
# [<a href="http://example.com/elsie">Elsie</a>]
>>> soup. select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
 select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
Дочерние элементы.
Извлечение НЕПОСРЕДСТВЕННЫХ дочерних элементов тега. Если посмотреть на HTML-разметку в коде ниже, то, непосредственными дочерними элементами первого <ul> будут являться три тега <li> и тег <ul> со всеми вложенными тегами.
Обратите внимание, что все переводы строк \n и пробелы между тегами, так же будут считаться дочерними элементами. Так что имеет смысл заранее привести исходный HTML к «нормальному виду«, например так: re.sub(r'>\s+<', '><', html.replace('\n', ''))
html = """
<div>
<ul>
<li>текст 1</li>
<li>текст 2</li>
<ul>
<li>текст 2-1</li>
<li>текст 2-2</li>
</ul>
<li>текст 3</li>
</ul>
</div>
"""
>>> from bs4 import BeautifulSoup
>>> root = BeautifulSoup(html, 'html. parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
 parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
Извлечение ВСЕХ дочерних элементов. Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
>>> import re
# сразу уберем переводы строк из исходного HTML
>>> html = re.sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список ВСЕХ дочерних элементов
>>> list(first_ul.descendants)
# [<li>текст 1</li>,
# 'текст 1',
# <li>текст 2</li>,
# 'текст 2',
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
# <li>текст 2-1</li>,
# 'текст 2-1',
# <li>текст 2-2</li>,
# 'текст 2-2',
# <li>текст 3</li>,
# 'текст 3']
Обратите внимание, что простой текст, который находится внутри тега, так же считается дочерним элементом этого тега.
Если внутри тега есть более одного дочернего элемента (как в примерен выше) и необходимо извлечь только текст, то можно использовать атрибут . или генератор 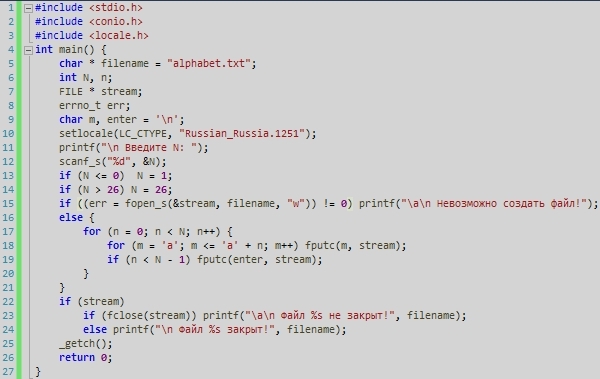 strings
strings.stripped_strings.
Генератор .stripped_strings дополнительно удаляет все переводы строк \n и пробелы между тегами в исходном HTML-документе.
>>> list(first_ul.strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3'] >>> first_ul.stripped_strings # <generator object Tag.stripped_strings at 0x7ffa2eb43ac0> >>> list(first_ul.stripped_strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3']
Родительские элементы.
Что бы получить доступ к родительскому элементу, необходимо использовать атрибут .parent.
html = """
<div>
<ul>
<li>текст 1</li>
<li>текст 2</li>
<ul>
<li>текст 2-1</li>
<li>текст 2-2</li>
</ul>
<li>текст 3</li>
</ul>
</div>
"""
>>> from bs4 import BeautifulSoup
>>> import re
# сразу уберем переводы строк и пробелы
# между тегами из исходного HTML
>>> html = re. sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
 sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
Taк же можно перебрать всех родителей элемента с помощью атрибута .parents.
>>> child_li[0] # <li>текст 2-1</li> >>> [parent.name for parent in child_li[0].parents] # ['ul', 'ul', 'div', '[document]']
Изменение имен тегов HTML-документа:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html. parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
 parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
Изменение HTML-тега <p> на тег <div>:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html.parser')
>>> soup.p.name = 'div'
>>> soup
# <div><b>Extremely bold</b></div>
Добавление новых тегов в HTML-документ.
Добавление нового тега в дерево HTML:
>>> soup = BeautifulSoup("<p><b></b></p>", 'html.parser')
>>> original_tag = soup.b
# создание нового тега `<a>`
>>> new_tag = soup.new_tag("a", href="http://example.com")
# строка нового тега `<a>`
>>> new_tag.string = "Link text"
# добавление тега `<a>` внутрь `<b>`
>>> original_tag. append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
 append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
Добавление новых тегов до/после определенного тега или внутрь тега.
>>> soup = BeautifulSoup("<p><b>leave</b></p>", 'html.parser')
>>> tag = soup.new_tag("i",)
>>> tag.string = "Don't"
# добавление нового тега <i> до тега <b>
>>> soup.b.insert_before(tag)
>>> soup.b
# <p><i>Don't</i><b>leave</b></p>
# добавление нового тега <i> после тега <b>
>>> soup.b.insert_after(tag)
>>> soup
# <p><b>leave</b><i>Don't</i></p>
# добавление нового тега <i> внутрь тега <b>
>>> soup.b.string.insert_before(tag)
>>> soup.b
# <p><b><i>Don't</i>leave</b></p>
Удаление и замена тегов в HTML-документе.

Удаляем тег или строку из дерева HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example.com</i></a>' >>> soup = BeautifulSoup(html, 'html.parser') >>> a_tag = soup.a # удаляем HTML-тег `<i>` с сохранением # в переменной `i_tag` >>> i_tag = soup.i.extract() # смотрим что получилось >>> a_tag # <a href="http://example.com/">I linked to</a> >>> i_tag # <i>example.com</i>
Заменяем тег и/или строку в дереве HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example</i></a>'
>>> soup = BeautifulSoup(html, 'html.parser')
>>> a_tag = soup.a
# создаем новый HTML тег
>>> new_tag = soup.new_tag("b")
>>> new_tag.string = "sample"
# производим замену тега `<i>` внутри тега `<a>`
>>> a_tag.i.replace_with(new_tag)
>>> a_tag
# <a href="http://example. com/">I linked to <b>sample</b></a>
 com/">I linked to <b>sample</b></a>
com/">I linked to <b>sample</b></a>
Изменение атрибутов тегов HTML-документа.
У тега может быть любое количество атрибутов. Тег <b id = "boldest"> имеет атрибут id, значение которого равно boldest. Доступ к атрибутам тега можно получить, обращаясь с тегом как со словарем:
>>> soup = BeautifulSoup('<p><b>bolder</b></p>', 'html.parser')
>>> tag = soup.b
>>> tag['id']
# 'boldest'
# доступ к словарю с атрибутами
>>> tag.attrs
# {'id': 'boldest'}
Можно добавлять и изменять атрибуты тега.
# изменяем `id` >>> tag['id'] = 'bold' # добавляем несколько значений в `class` >>> tag['class'] = ['new', 'bold'] # или >>> tag['class'] = 'new bold' >>> tag # <b>bolder</b>
А так же производить их удаление.
>>> del tag['id'] >>> del tag['class'] >>> tag # <b>bolder</b> >>> tag.
 get('id')
# None
get('id')
# None
html — как выровнять все мои li в одну строку?
Задавать вопрос
спросил
Изменено 1 год, 2 месяца назад
Просмотрено 156 тысяч раз
мой CSS
ул {
переполнение: скрыто;
}
ли {
дисплей: встроенный блок;
}
мой HTML
- а
- б
- с
- д
- е
- ж
- г
я хочу выровнять все мои элементы li в одну строку, если я это сделал, все работает нормально, за исключением того, что когда 3 или 4 li заполняют первую строку на моем теле, они переходят на вторую строку, я хочу, чтобы они были на 1 строке и все после заполнения 1 строки будет «скрыто»
НАПРИМЕР::
// ПРИМЕЧАНИЕ li содержит предложения не только из 1 буквы
ВЫВОД СЕЙЧАС ::
a b c d
е ж г
DESIRED OUTPUT ::
a b c d e f //все они в 1 строке, а остальные скрыты 'overflow:hidden'
- html
- css
Попробуйте ввести white-space:nowrap; в вашем
изменить: и использовать «встроенный», а не «встроенный блок», как указывали другие (и я забыл)
0
Это работает как вам угодно:
<голова>
<тип стиля="текст/CSS">
ул
{
переполнение-х: скрыто;
белое пространство: nowrap;
высота: 1см;
ширина: 100%;
}
ли
{
дисплей: встроенный;
}
<тело>
<ул>
1
Использование Display: table
HTML:
- 1
- 2
- 3
CSS:
ul.
 my-row {
дисплей: таблица;
ширина: 100%;
выравнивание текста: по центру;
}
ul.my-row > li {
отображение: таблица-ячейка;
}
my-row {
дисплей: таблица;
ширина: 100%;
выравнивание текста: по центру;
}
ul.my-row > li {
отображение: таблица-ячейка;
}
СЦСС:
ул {
&.моя-строка {
дисплей: таблица;
ширина: 100%;
выравнивание текста: по центру;
> ли {
отображение: таблица-ячейка;
}
}
}
У меня отлично работает
Вот что вам нужно. В этом случае вы не хотите, чтобы элементы списка рассматривались как блоки, которые можно обернуть.
ли {дисплей: встроенный}
уль {переполнение: скрыто}
1
Я бы порекомендовал: