Начало работы с HTML — Изучение веб-разработки
В этой статье мы охватим азы HTML, необходимые для начала работы. Дадим определение «элементам», «атрибутам», «тегам» и прочим важным понятиям, о которых вы, возможно, слышали, а также об их роли в языке. Мы также покажем, как устроены HTML-элементы, типичная HTML-страница, и объясним другие важные аспекты языка. По ходу дела, чтобы вы не заскучали, мы поиграем с настоящей HTML-страницей!
HTML (HyperText Markup Language — язык гипертекстовой разметки) не является языком программирования; это язык разметки, используемый для определения структуры веб-страниц, посещаемых пользователями. Они могут иметь сложную или простую структуру, всё зависит от замысла и желания веб-разработчика. HTML состоит из ряда элементов, которые вы используете для того, чтобы охватить, обернуть или разметить различные части содержимого, чтобы оно имело определенный вид или срабатывало определенным способом. Встроенные тэги могут преобразовать часть содержимого в гиперссылку, по которой можно перейти на другую веб-страницу, выделить курсивом слова и так далее.
Мой кот очень сердитый
Если мы хотим, чтобы строка отобразилась в таком же виде, мы можем определить её, как «параграф», заключив её в теги элемента «параграф» (<p>), например:
<p>Мой кот очень сердитый</p>Примечание: Метки в HTML нечувствительны к регистру, то есть они могут быть записаны в верхнем или нижнем регистре. Например, тег <title> может быть записан как <TITLE>, <Title>, <TiTlE>, и т.д., и он будет работать нормально. Лучшей практикой, однако, является запись всех тегов в нижнем регистре для обеспечения согласованности, удобочитаемости и других причин.
Давайте рассмотрим элемент «параграф» чуть подробнее:
Основными частями элемента являются:
- Открывающий тег: Он состоит из названия (обозначения) элемента (в нашем случае, p), помещённого внутри угловых скобок.
 Данный тег служит признаком начала элемента, с этого момента тег начинает влиять на следующее после него содержимое.
Данный тег служит признаком начала элемента, с этого момента тег начинает влиять на следующее после него содержимое. - Закрывающий тег: выглядит как и открывающий, но содержит слэш перед названием тега. Он служит признаком конца элемента. Пропуски закрывающих тегов — типичная ошибка новичков, которая может приводить к неопределённым результатам — в лучшем случае всё сработает правильно, в других страница может вовсе не прорисоваться или прорисоваться не как ожидалось.
- Содержимое: Как видно, в нашем случае содержимым является простой текст.
- Элемент: открывающий тег + закрывающий тег + содержимое = элемент.
 Данный тег служит признаком начала элемента, с этого момента тег начинает влиять на следующее после него содержимое.
Данный тег служит признаком начала элемента, с этого момента тег начинает влиять на следующее после него содержимое.Активное изучение: создание вашего первого HTML элемента
Отредактируйте строку текста ниже в поле <em> и </em> (вставьте <em> перед строкой, чтобы указать начало элемента, и </em> после нее, чтобы указать конец элемента) — эти действия должны выделить строку текста курсивом! Вы можете видеть изменения в реальном времени в поле Вывод.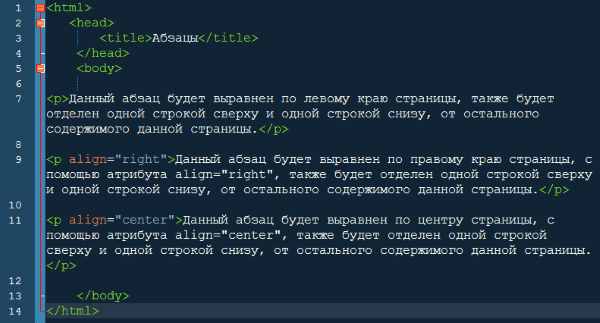
Если Вы ошиблись, то всегда можете начать снова, воспользовавшись кнопкой Сбросить. Если упражнение вызывает у Вас затруднения, то нажмите кнопку Показать решение, чтобы увидеть правильный ответ.
Вложенные элементы
Nesting_elements
Вы также можете вкладывать элементы внутрь других элементов — это называется вложенностью. Если мы хотим подчеркнуть, что наш кот очень сердитый, мы можем заключить слово «очень» в элемент <strong> , который означает, что это слово крайне важно в данном контексте:
<p>Мой кот <strong>очень</strong> сердитый.</p>Вы должны удостовериться, что элементы вложены должным образом: в следующем примере мы открываем p элемент первым, затем элемент strong, затем мы закрываем элемент strong первым, затем p. Следующее писать неправильно:
<p>Мой кот <strong>очень сердитый. </p></strong>
Элементы должны открываться и закрываться правильно таким образом, чтобы явно находиться внутри или снаружи друг друга. Если они перекрываются так, как в примере выше, то ваш браузер попытается «додумать» за вас, что вы имели в виду, и вы получите непредсказуемый результат. Так что не делайте так!
Блочные и строчные элементы
Block versus inline elements
Существует две важных категории элементов в HTML, которые вам стоит знать — элементы блочного уровня и строчные элементы.
- Элементы блочного уровня формируют видимый блок на странице — они окажутся на новой строке после любого контента, который шёл до них, и любой контент после них также окажется на новой строке. Чаще всего элементами блочного уровня бывают структурные элементы страницы, представляющие собой, например, параграфы (абзацы), списки, меню навигации, футеры, или подвалы, и т. п. Элементы блочного уровня не вкладываются в строчные элементы, но иногда могут вкладываться в другие элементы блочного уровня.
- Строчные элементы — это те, которые содержатся в элементах блочного уровня и окружают только малые части содержимого документа, не целые абзацы и группировки контента. Строчные элементы не приводят к появлению новой строки в документе: они обычно встречаются внутри абзаца текста, например, элемент
<em>или<strong>.
Посмотрите на следующий пример:
<em>Первый</em><em>второй</em><em>третий</em>
<p>четвертый</p><p>пятый</p><p>шестой</p>
<em> — это строчный элемент, так что, как вы здесь видите, первые три элемента находятся на одной строке друг с другом без пробелов между ними. С другой стороны, <p> — это элемент блочного уровня, так что каждый элемент находится на новой строке, с пространством выше и ниже каждого (этот интервал определяется CSS-оформлением по умолчанию, которое браузеры применяют к абзацам).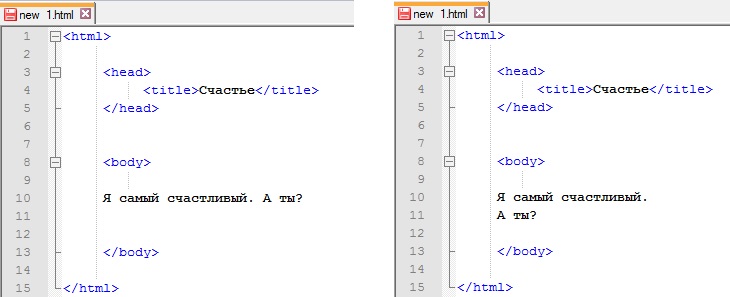
Примечание: HTML5 переопределил категории элементов в HTML: смотрите Категории типов содержимого элементов. Хотя эти определения точнее и однозначнее, чем те, которые были раньше, их гораздо сложнее понять, чем «блочный» и «строчный», поэтому мы будем придерживаться их в этом разделе.
Примечание: Не путайте термины «блочный» и «строчный», используемые в этом разделе, с одноименными типами отображения в CSS. Хотя по умолчанию они коррелируют, смена типа отображения в CSS не меняет категорию элемента и не влияет на то, во что его можно вкладывать и что можно вкладывать в него. Эта довольно частая путаница — одна из причин, почему HTML5 отказался от этих терминов.
Пустые элементы
Empty elements
Не все элементы соответствуют вышеупомянутому шаблону: открывающий тег, контент, закрывающий тег. Некоторые элементы состоят из одного тега и обычно используются для вставки чего-либо в то место документа, где размещены. Например, элемент
Например, элемент <img> вставляет картинку на страницу в том самом месте, где он расположен:
<img src="https://raw.githubusercontent.com/mdn/beginner-html-site/gh-pages/images/firefox-icon.png">Это выведет на вашу страницу следующее:
Примечание: Пустые элементы иногда называют void-элементами.
У элементов также могут быть атрибуты, которые выглядят так:
Атрибуты содержат дополнительную информацию об элементе, которая, по вашему мнению, не должна отображаться в содержимом элемента. В данном случае атрибут class позволяет вам дать элементу идентификационное имя, которое в дальнейшем может быть использовано для обращения к элементу с информацией о стиле и прочими вещами.
Атрибут должен иметь:
- Пробел между атрибутом и именем элемента (или предыдущим атрибутом, если у элемента уже есть один или несколько атрибутов).
- Имя атрибута и следующий за ним знак равенства.
- Значение атрибута, заключенное в кавычки.
Активное изучение: Добавление атрибутов в элемент
Active learning: Adding attributes to an element
Возьмём для примера элемент <a> — означает anchor (якорь) и делает текст внутри него гиперссылкой. Может иметь несколько атрибутов, вот несколько из них:
href: В значении этого атрибута прописывается веб-адрес, на который, по вашей задумке, должна указывать ссылка, куда браузер переходит, когда вы по ней кликаете. Например,title: Атрибутtitleописывает дополнительную информацию о ссылке, такую как: на какую страницу она ведет. Например,title="The Mozilla homepage". Она появится в виде всплывающей подсказки, когда вы наведете курсор на ссылку.target: Атрибутtargetопределяет контекст просмотра, который будет использоваться для отображения ссылки. Например, target="_blank"отобразит ссылку на новой вкладке. Если вы хотите отобразить ссылку на текущей вкладке, просто опустите этот атрибут.
 Например,
Например, Измените строку текста ниже в поле Ввод так, чтобы она вела на ваш любимый вебсайт. Сначала добавьте элемент <a>затем атрибут href и атрибут title. Наконец, укажите атрибут target чтобы открыть ссылку на новой вкладке. Вы можете наблюдать сделанные изменения в реальном времени в поле Вывод. Вы должны увидеть гиперссылку, при наведении курсора на которую появляется содержимое атрибута title, а при щелчке переходит по адресу в атрибуте href. Помните, что между именем элемента и каждым из атрибутов должен быть пробел.
Если Вы ошиблись, то всегда можете начать снова, воспользовавшись кнопкой Сбросить. Если упражнение вызывает у Вас затруднения, то нажмите кнопку Показать решение, чтобы увидеть правильный ответ.
Булевые атрибуты
Boolean attributes
Иногда вы будете видеть атрибуты, написанные без значения — это совершенно допустимо. Такие атрибуты называются булевые, и они могут иметь только одно значение, которое в основном совпадает с его именем. В качестве примера возьмем атрибут disabled, который можно назначить для формирования элементов ввода, если вы хотите, чтобы они были отключены (неактивны), так что пользователь не может вводить какие-либо данные в них.
<input type="text" disabled="disabled">
Для краткости совершенно допустимо записывать их следующим образом (мы также для справки разместили не деактивированный элемент input, чтобы дать вам большее понимание происходящего):
<input type="text" disabled>
<input type="text">
На выходе оба варианта будут выглядеть следующим образом:
Опускание кавычек вокруг значений атрибутов
Omitting quotes around attribute values
Осматриваясь во всемирной сети, вы будете встречать различные незнакомые способы написания разметки, включая написание значений атрибутов без кавычек. Это допустимо при определенных условиях, но разрушит вашу разметку при других. Например, возвращаясь к нашему упражнению с гиперссылкой, мы можем написать основной вариант только с атрибутом
Это допустимо при определенных условиях, но разрушит вашу разметку при других. Например, возвращаясь к нашему упражнению с гиперссылкой, мы можем написать основной вариант только с атрибутом href так:
<a href=https://www.mozilla.org/>любимый веб-сайт</a>Однако, как только мы добавим атрибут title в таком же стиле, мы поступим неверно:
<a href=https://www.mozilla.org/ title=The Mozilla homepage>favorite website</a>В этом месте браузер неверно истолкует вашу разметку, думая, что атрибут title — это на самом деле три разных атрибута — атрибут title со значением «The» и два булевых атрибута: Mozilla и homepage. Это, очевидно, не то, что имелось в виду, и приведёт к ошибке или неожиданному поведению кода, как это показано в живом примере ниже. Попробуйте навести курсор на ссылку, чтобы увидеть, на что похож текст title!
Наш совет: всегда используйте кавычки в атрибутах — это позволит избежать подобных проблем, и, следовательно, код будет более читабельным.
Одинарные или двойные кавычки?
Single or double quotes?
В этой статье вы заметите, что все атрибуты заключены в двойные кавычки. Однако, вы можете видеть одинарные кавычки в HTML документах других людей. Это исключительно дело вкуса, и вы можете свободно выбирать, какие из них предпочитаете. Обе следующие строки эквивалентны:
<a href="http://www.example.com">Ссылка к моему примеру.</a>
<a href='http://www.example.com'>Ссылка к моему примеру.</a>Однако вы должны убедиться, что не смешиваете их вместе. Следующее будет неверным!
<a href="http://www.example.com'>Ссылка к моему примеру.</a>Если вы используете один тип кавычек в своем HTML, то вы можете поместить внутрь их кавычки другого типа, не вызывая никаких проблем:
<a href="http://www.example.com" title="Isn't this fun?">A link to my example.</a>Если вы хотите вставить кавычки того же типа, то вы должны использовать объекты HTML. Например, это работать не будет:
Например, это работать не будет:
<a href='http://www.example.com' title='Isn't this fun?'>A link to my example.</a>Поэтому вам нужно сделать так:
<a href='http://www.example.com' title='Isn't this fun?'>A link to my example.</a>Ниже дан пример оборачивания основных, самостоятельных HTML элементов, которые сами по себе не очень полезны. Давайте посмотрим, как самостоятельные элементы объединяются для формирования всей HTML страницы:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Тестовая страница</title>
</head>
<body>
<p>Это — моя страница</p>
</body>
</html>Вот что мы имеем:
<!DOCTYPE html>: Объявление типа документа. Очень давно, ещё когда HTML был молод (1991/2), типы документов использовались в качестве ссылок на набор правил, которым HTML-страница должна была следовать, чтобы она считалась хорошей, что может означать автоматическую проверку ошибок и другие полезные вещи. Объявление типа документа выглядело примерно вот так:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
Однако в наши дни никто особо не думает о них, и типы документа стали историческим артефактом, которые должны быть включены везде, чтобы всё работало правильно.<!DOCTYPE html>— это самый короткий вид типа документа, который считается действующим. На самом деле это всё, что нужно вам знать о типах документов .<html></html>: Элемент<html>содержит в себе всё содержимое на всей странице, и иногда его называют «корневой элемент».<head></head>: Элемент<head>. Данный элемент выступает в качестве контейнера для всего содержимого, которое вы хотите включить в HTML документ, но не хотите показывать посетителям вашей страницы. Он включает такие вещи, как ключевые слова и описание страницы, которые вы хотели бы показывать в поисковых запросах, CSS для стилизирования вашего контента, объявление поддерживаемого набора символов и многое другое. Вы узнаете больше об этом из следующей статьи данного руководства.<meta charset="utf-8">: Этот элемент устанавливает в качестве символьной кодировки для вашего документа utf-8 , который включает большинство символов из всех известных человечеству языков. По существу, теперь страница сможет отобразить любой текстовый контент, который вы сможете в неё вложить. Нет причин не устанавливать эту кодировку, это также позволит избежать некоторых проблем позднее.<title></title>: Элемент<title>. Этот элемент устанавливает заголовок вашей страницы, который появляется во вкладке браузера, загружающей эту страницу, также это заглавие используется при описании страницы, когда вы сохраняете её в закладках или избранном.<body></body>: Элемент<body>. Он содержит весь контент, который вы хотите показывать посетителям вашей страницы, — текст, изображения, видео, игры, проигрываемые аудио дорожки или что-то ещё.
 Объявление типа документа выглядело примерно вот так:
Объявление типа документа выглядело примерно вот так: Вы узнаете больше об этом из следующей статьи данного руководства.
Вы узнаете больше об этом из следующей статьи данного руководства.
Активное изучение: Добавление элементов в ваш HTML-документ
Active learning: Adding some features to an HTML document
Если вы хотите поэкспериментировать с написанием HTML на своём компьютере, то можете:
- Скопировать пример HTML-страницы, расположенный выше.
- Создать новый файл в текстовом редакторе.
- Вставить код в ваш новый текстовый файл.
- Сохранить файл как
index.html.
Теперь можете открыть браузер и посмотреть, во что отрисовался код, а потом изменить его, обновить страницу и посмотреть, что получилось. Сначала страница выглядит так:
Для этого упражнения вы можете редактировать код локально на своём компьютере, как предлагается выше, а можете работать в редакторе, расположенном ниже. В редакторе показано только содержимое элемента <body>. Попробуйте сделать следующее:
- Добавьте заголовок страницы сразу за открывающим тегом
<body>. Текст должен находиться между открывающим тегом <h2>и закрывающим</h2>. - Напишите в параграфе о чём-нибудь, что кажется вам интересным.
- Выделите важные слова, обернув их в открывающий тег
<strong>и закрывающий</strong> - Добавьте ссылку на свой абзац так, как объяснено ранее в статье.
- Добавьте изображение в свой документ под абзацем, как объяснено ранее в статье. Если сможете использовать другую картинку (со своего компьютера или из интернета). Вы большой молодец!
 Текст должен находиться между открывающим тегом
Текст должен находиться между открывающим тегом Если вы запутались, всегда можно запустить пример сначала кнопкой Сбросить. Сдаётесь — посмотрите ответ, нажав на Показать решение.
Пробелы в HTML
Whitespace in HTML
Вы могли заметить, что в примерах кода из этой статьи много пробелов. Это вовсе не обязательно — следующие два примера эквивалентны:
<p>Собаки глупы.</p>
<p>Собаки
глупы. </p> </p>
</p>Не важно, сколько пустого места вы используете в разметке (что может включать пробелы и сдвиги строк): браузер при анализе кода сократит всё пустое место до одного пробела. Зачем использовать много пробелов? Ответ: это доступность для понимания — гораздо легче разобраться, что происходит в вашем коде, если он удобно отформатирован, а не просто собран вместе в одном большом беспорядке. В нашем коде каждый вложенный элемент сдвинут на два пробела относительно элемента, в котором он находится. Вы можете использовать любое форматирование (в частности, количество пробелов для отступа), но лучше придерживаться одного стиля.
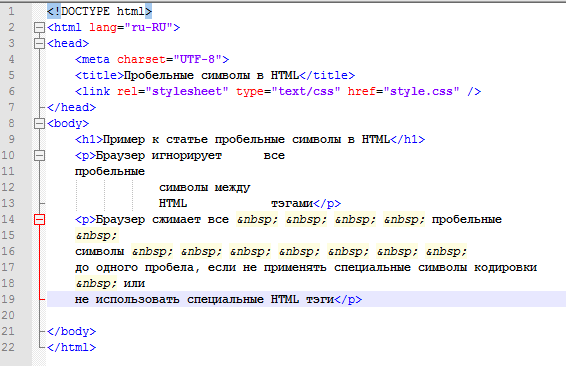
В HTML символы <, >, ", ' и & являются специальными. Они являются частью самого синтаксиса HTML. Так как же включить в текст один из этих специальных символов? Например, если вы хотите использовать амперсанд или знак «меньше» и не интерпретировать его как код.
Мы должны использовать ссылки-мнемоники — специальные коды, которые отображают спецсимволы, и могут быть использованы в необходимых позициях. Каждая ссылка-мнемоник начинается с ампресанда (&) и завершается точкой с запятой (;).
Каждая ссылка-мнемоник начинается с ампресанда (&) и завершается точкой с запятой (;).
| Буквенный символ | Символьный эквивалент |
|---|---|
| < | < |
| > | > |
| « | " |
| ‘ | ' |
| & | & |
В следующем примере вы видите два абзаца, которые рассказывают о веб-технологиях:
<p>В HTML вы определяете параграф элементом <p>.</p>
<p>В HTML вы определяете параграф элементом <p>.</p>В живом выводе ниже вы можете заметить, что первый абзац выводится неправильно, так как браузер считает, что второй элемент <p> является началом нового абзаца! Второй абзац нашего кода выводится правильно, потому что мы заменили угловые скобки на ссылки-мнемоники.
В HTML, как и в большинстве языков программирования, есть возможность писать комментарии в коде. Комментарии игнорируются обозревателем и не видны пользователю, их добавляют для того, чтобы пояснить, как работает написанный код, что делают отдельные его части и т. д. Такая практика полезна, если вы возвращаетесь к коду, который давно не видели или когда хотите передать его кому-то другому.
Чтобы превратить часть содержимого HTML-файла в комментарий, нужно поместить её в специальные маркеры <!-- и -->, например:
<p> Меня нет в комментариях( </p>
Как вы увидете ниже, первый параграф будет отображён на экране, а второй нет.
Вы дошли до конца статьи — надемся, вам понравилось путешествие по основам HTML. На этом этапе вы уже должны немного разобраться, как выглядит язык, как он работает на базовом уровне и уметь описать несколько элементов и атрибутов. Сейчас идеальное время и место, чтобы продолжить изучать HTML. В последующих статьях мы рассмотрим некоторые из вещей, которые вы уже рассмотрели, но намного подробнее, а также представим некоторые новые функции языка. Оставайтесь с нами!
В последующих статьях мы рассмотрим некоторые из вещей, которые вы уже рассмотрели, но намного подробнее, а также представим некоторые новые функции языка. Оставайтесь с нами!
Примечание: Сейчас, когда вы начинаете больше узнавать о HTML, вы также можете начать изучать основы каскадных таблиц стилей Cascading Style Sheets, или CSS. CSS — это язык, который используется для стилизации веб-страниц (например, изменение шрифта или цветов или изменение макета страницы). Как вы скоро поймете, HTML и CSS созданы друг для друга.
Перенос строки и разделительная линия в HTML — Разметка текста — codebra
Перенос строки при помощи HTML или CSS
Перевод строки, перенос строки, перенос на новую строку – это все об одном. В языке HTML перенос на новую строку применяется часто. Есть несколько путей: использовать тег <br> для перевода на новую строку, а можно использовать свойства CSS для переноса строки. Рассмотрим пример использования тега переноса строки:
Рассмотрим пример использования тега переноса строки:
Код HTML
Здесь текст
<br>
Этот текст на новой строкеВ CSS перенос строки можно осуществить по-разному, например вот так:
Код CSS
.br {
float: left;
width: 100%;
margin: 0 0 20px 0; /* отступ после строки 20 пикселей */
}Код HTML
Здесь текст
<div class = "br"></div>
Этот текст на новой строкеРазделительная линия при помощи HTML или CSS
В HTML создать разделительную линию очень просто. Используется тоже непарный тег <hr> — это и есть разделительная линия. Разделительная линия начинается с новой строки и после нее есть отступ. Вы можете управлять стилем горизонтальной линии, а так же можно сделать альтернативу ей. Далее пример разделительной линии при помощи тега:
Код HTML
Здесь текст
<hr>
И здесь текстА теперь давайте стилизуем (изменим стили, изменим внешний вид) нашу разделительную линию:
Код CSS
hr {
width: 80%; /* ширина линии */
height: 4px; /* высота / толщина линии */
background: #333; /* фон / цвет линии */
border: 0; /* рамка вокруг разделительной линии (уберем ее) */
margin: 5px 0 5px 0; /* отступ над и под линией 5 пикселей */
}И создадим альтернативу нашей разделительной линии при помощи тега <div> и CSS:
Код CSS
. line {
width: 80%; /* ширина линии */
height: 4px; /* высота / толщина линии */
background: #333; /* фон / цвет линии */
border: 0; /* рамка вокруг разделительной линии (уберем ее) */
margin: 5px 0 5px 0; /* отступ над и под линией 5 пикселей */
} line {
line {Код HTML
Здесь текст
<div class = "line"></div>
Здесь текстСпецсимволы. Горизонтальная линия. Бегущая строка. Комментарии. Учебник html
Глава 6
Прежде чем перейти к изучению очередной большой главы, расскажу немного о некоторых мелочах, которые как-то выпали из общего строя, но порой без них никак не обойтись. Эти, фигурально выражаясь, элементы html языка помогут решить ряд задач с которыми частенько приходится сталкиваться при создании той или иной странички, так что не стоит относится к ним с пренебрежением.
Иногда, а порой даже часто, как например в этом сайте, в тексте не обойтись без знаков «меньше чем»-< и «больше чем»- > , но как быть если браузеры определяют <слово> или фразу заключенные в эти знаки как тег и следовательно не будут его отображать на мониторе? Или допустим Вам и вправду в тексте надо написать некий <тег>, но не для того чтобы дать очередную команду браузеру, а чтобы привести пример его написания посетителям страницы?
Для этих целей были придуманы так называемые спецсимволы.
Так например спецсимвол < — будет значить что в этом месте текста нужно поставить знак < а спецсимвол > обозначит символ >.
Все спецсимволы начинают писаться со знака &— амперсант этот знак указывает браузеру, что далее будет идти имя спецсимвола и воспринимать его следует не как текст, а как команду. Тут встаёт очередной вопрос, а как собственно в тексте предназначенного для вывода на экран поставить сам знак &— амперсант?
Для знака & тоже есть свой спецсимвол — &
Такая вот путаница получается..
Ещё, пожалуй, отдельного внимания заслуживает спецсимвол — это неразрывный пробел мы с ним уже сталкивались. Дело в том, что когда Вы пишите текст в блокноте или html редакторе «простых» пробелов между словами можно поставить сколь угодно много, но вот при чтении страницы браузером все они «удаляются» и между словами на странице будет не более одного пробела. Отсюда часто возникают проблемы с оформлением текста, красную строку, например, никак не сделать… вот и придумали люди спецсимвол он воспринимается браузером не как пробел, а как знак, только невидимый человеческому глазу.
Отсюда часто возникают проблемы с оформлением текста, красную строку, например, никак не сделать… вот и придумали люди спецсимвол он воспринимается браузером не как пробел, а как знак, только невидимый человеческому глазу.
А неразрывным он называется по тому, что группа таких пробелов воспринимается как цельное слово, следовательно, не переносится на следующую строку, если предложение подходит к установленным рамкам или же к краю окна. Так что в окне может появиться горизонтальная полоса прокрутки, если Вам это ненужно, ставьте между ними обыкновенные пробелы
Пример использования спецсимволов:
<html><head>
<title>пример в примере</title>
</head>
<body bgcolor=»#dddddd» text=»#222222″>
<table bgcolor=»#ffffff» cellspacing=»0″ cellpadding=»5″ border=»0″>
<tr>
<td bgcolor=»#808080″> </td>
<td>
<html> <br>
<head> <br>
<title>Моя первая страничка</title><br>
</head><br>
<body><br>
<center><h3>Привет мир!!!</h3></center><br>
<br><br>
Это моя первая страничка!<br>
</body><br>
</html><br>
</td>
</tr>
</table>
</body>
</html>
Пример в примере… навивает на философские мысли о бесконечности…
Ну вот теперь Вы знаете, как примерно выглядят все эти примерчики по «ту сторону экрана».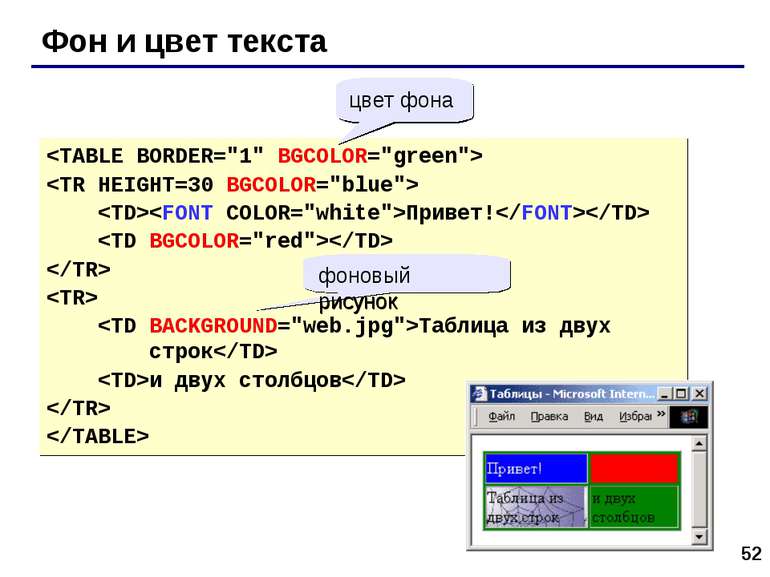 Кстати, раз уж начал открывать военные тайны, данный пример является таблицей из двух ячеек, одна тоненькая слева выполняет сугубо декоративную функцию.. так вот если перед Вами встанет задача нарисовать ячейку таблицы без какого либо содержания вставляйте в неё знак пробела . Помните правило <тег>здесь что то обязательно должно быть</тег>? Спецсимвол пробела один из выходов в данном случае.
Кстати, раз уж начал открывать военные тайны, данный пример является таблицей из двух ячеек, одна тоненькая слева выполняет сугубо декоративную функцию.. так вот если перед Вами встанет задача нарисовать ячейку таблицы без какого либо содержания вставляйте в неё знак пробела . Помните правило <тег>здесь что то обязательно должно быть</тег>? Спецсимвол пробела один из выходов в данном случае.
Кроме выше указанных есть еще целый ряд спецсимволов, чего там только нет: знаки зодиака, карточные масти, палочки, точечки, ёлочки, кругляшки, дроби.. Предназначены они уже не для каких-то «особых» задач, а просто выполняют свою роль ввиду отсутствия данных знаков на клавиатуре. Мою «коллекцию» спецсимволов можете посмотреть здесь.
Простой новый тег <hr> рисует в окне горизонтальную линию, не требует закрывающего тега. Часто применяется при верстке страницы в качестве декоративного элемента.
Имеет ряд атрибутов, align -выравнивание с одним из трёх значений (center, left, right) может быть применен, если задана длина линии атрибут width в пикселях или процентах. Так же можно задать толщину линии атрибут — size, цвет атрибут — color, и при необходимости отключить тень линии noshade.
Так же можно задать толщину линии атрибут — size, цвет атрибут — color, и при необходимости отключить тень линии noshade.
Пример:
<html><head>
<title>Горизонтальная линия</title>
</head>
<body>
Это просто линия по умолчанию: <hr>
<hr>
Это линия без тени: <hr noshade >
<hr noshade>
Это линия окрашенная в кранный цвет: <hr color=»#ff0000″>
<hr color=»#ff0000″>
Линия длиной 250 пикселей: <hr>
<hr >
Линия длиной 250 и толщиной 5 пикселей: <hr size=»5″>
<hr size=»5″>
Линия длиной 500, толщиной 50, синяя: <hr size=»50″ color=»#0000ff»>
<hr size=»50″ color=»#0000ff»>
Примеры выравнивания:
<hr align=»left» size=»5″>
<hr align=»center» size=»5″>
<hr align=»right» size=»5″>
<hr>
</body>
</html>
По моему достаточно просто и эффективно.
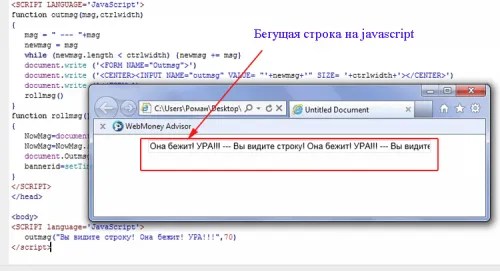
Тег <marquee> заставляет текст помещённый в него двигаться в том или ином направлении, проще говоря делает его бегущей строкой. Бегущая строка имеет ряд настроек скроллинга, которые задаются следующими атрибутами:
behavior — определяет тип скроллинга, может иметь следующие значения:- alternate — колебательные движения от края к краю
- scroll — прокручивание текста. текст будет выходить за рамки экрана и снова появляться с противоположной его стороны
- slide — прокручивание текста c остановкой.
loop задает количество прокруток бегущей строки.
direction — направление движения текста. значения:
- up — вверх,
- down — вниз,
- left — влево,
- right — вправо.

height — высота строки,
width — ширина строки.
Пример:
<html><head>
<title>Бегущая строка</title>
</head>
<body>
<div align=»center»><h3>Бегающие строки</h3></div>
<marquee>Бегущая строка по умолчанию</marquee>
<marquee direction=»right»>Бегущая строка слева направо</marquee>
<marquee behavior=»alternate»>Бегущая строка бегает от края к краю</marquee>
<marquee scrollamount=»10″>Бегущая строка со скоростью 10</marquee>
<marquee scrollamount=»1″>Бегущая строка со скоростью 1</marquee>
<marquee direction=»right» loop=»2″>Эта строка будет прокручиваться только два раза</marquee>
<marquee behavior=»slide»>Бегущая строка с остановкой</marquee>
<marquee bgcolor=»#b40000″>Бегущая строка с фоном</marquee>
<marquee width=400>Бегущая строка с ограничением ширены прокрутки</marquee>
<marquee direction=»up»>Бегущая строка снизу вверх</marquee>
<marquee hspace=»300″>Бегущая строка с отступами от границ</marquee>
</body>
</html>
Ну думаю, сами разберётесь, что к чему. Попробуйте использовать различные сочетания атрибутов для достижения нужного Вам эффекта. Добавлю лишь то, что с текстом бегущей строки можно делать то же самое, что и с обыкновенным текстом: менять размер, цвет, стиль, шрифт, сделать фразу из строки ссылкой.. прописывая нужные теги внутри тега <marquee>
Попробуйте использовать различные сочетания атрибутов для достижения нужного Вам эффекта. Добавлю лишь то, что с текстом бегущей строки можно делать то же самое, что и с обыкновенным текстом: менять размер, цвет, стиль, шрифт, сделать фразу из строки ссылкой.. прописывая нужные теги внутри тега <marquee>
Комментарии используются для того, чтобы облегчить свой собственный труд, а так же упростить понимание другим человеком кода Вашей странички. Пишутся они непосредственно в коде html документа, однако браузер не выводит эти «пометки» на экран. Для того чтобы заставить браузер игнорировать какой либо текст его необходимо заключить вот в такой набор символов:
<!— —>По принципу:
<!— здесь может быть любой текст —>Использовать комментарии очень полезно, разрабатывая большие и сложные по своей структуре документы, для того, чтобы потом самому с легкостью в нём ориентироваться..
Пример:
<html><head>
<title>Мой первый сайт</title>
</head>
<body text=»#484800″ bgcolor=»#ffffff» background=»graphics/fon.
 jpg»>
jpg»><center>
<!— Начало таблицы —>
<table cellpadding=»5″ cellspacing=»2″ border=»1″>
<tr>
<td colspan=»3″ bgcolor=»#b2ff80″>
<center><img src=»graphics/privet.jpg» alt=»Привет мир!!!»></center>
</td>
</tr>
<!— Строка с меню —>
<tr>
<td bgcolor=»#ffa0cf»>
<center><b><a href=» index.html»>Обо мне!!!</a></b></center>
</td>
<td bgcolor=»#c0e4ff»>
<center><b><a href=» myfoto.html»>Здесь мои фотки!!</a></b></center>
</td>
<td bgcolor=»#c0e4ff»>
<center><b><a href=»mailto:karlson@kruha.
 ru»>Напишите мне письмо..</a></b></center>
ru»>Напишите мне письмо..</a></b></center></td>
</tr>
<!— Конец меню —>
<!— Основное содержание —>
<tr>
<td colspan=»3″ valign=»top» bgcolor=»#b2ff80″>
<img src=»graphics/foto.jpg» align=»left» hspace=»10″ alt=»Это моя фотка!!!»>
<p align=»justify»> Разрешите представиться Карлсон! … … …</p>
</td>
</tr>
<!— Конец оновному содержанию —>
</table>
<!— Конец таблицы —>
</center>
</body>
</html>
Как видите старый пример ничем не изменился зато ориентироваться в его коде стало значительно легче.
Писать сайты на своём компьютере конечно дело хорошее, но пора задумываться о том, как Ваше творчество разместить в сети Интернет.
О том как это сделать читайте в статье «Публикация сайта». А совет собственно заключается в том, что на данном этапе обучения Вам пора обзавестись своим собственным местом (хостом) «тренировочным плацдармом» на каком либо сервере.. а также собственным именем сайта (доменом)… для начала, это место и имя могут быть бесплатными, даже я бы сказал должны быть бесплатными.. Там, в этом месте на сервере, Вы будите тренироваться выкладывать свои страницы., смотреть как и с какой скоростью они загружаются, так же Вы сможете показать своё творение миру (а можете и не показывать) и друзьям. Почему этим стоит заняться именно на данной стадии обучения? Да потому что с помощью того, что мы изучили, Вы уже можете делать вполне пристойные сайты!! нет конечно до конца обучения ещё рано, да и предела совершенствования мастерства как известно нет.., но это послужит хорошей тренировкой и так сказать поднимет Ваш морально боевой дух!!)) Знаете как это приятно, увидеть свою работу в действии!? Но, ещё раз повторюсь, о том как это дело провернуть читайте в статье «Публикация сайта».
 О том как это сделать читайте в статье «Публикация сайта». А совет собственно заключается в том, что на данном этапе обучения Вам пора обзавестись своим собственным местом (хостом) «тренировочным плацдармом» на каком либо сервере.. а также собственным именем сайта (доменом)… для начала, это место и имя могут быть бесплатными, даже я бы сказал должны быть бесплатными.. Там, в этом месте на сервере, Вы будите тренироваться выкладывать свои страницы., смотреть как и с какой скоростью они загружаются, так же Вы сможете показать своё творение миру (а можете и не показывать) и друзьям. Почему этим стоит заняться именно на данной стадии обучения? Да потому что с помощью того, что мы изучили, Вы уже можете делать вполне пристойные сайты!! нет конечно до конца обучения ещё рано, да и предела совершенствования мастерства как известно нет.., но это послужит хорошей тренировкой и так сказать поднимет Ваш морально боевой дух!!)) Знаете как это приятно, увидеть свою работу в действии!? Но, ещё раз повторюсь, о том как это дело провернуть читайте в статье «Публикация сайта».
О том как это сделать читайте в статье «Публикация сайта». А совет собственно заключается в том, что на данном этапе обучения Вам пора обзавестись своим собственным местом (хостом) «тренировочным плацдармом» на каком либо сервере.. а также собственным именем сайта (доменом)… для начала, это место и имя могут быть бесплатными, даже я бы сказал должны быть бесплатными.. Там, в этом месте на сервере, Вы будите тренироваться выкладывать свои страницы., смотреть как и с какой скоростью они загружаются, так же Вы сможете показать своё творение миру (а можете и не показывать) и друзьям. Почему этим стоит заняться именно на данной стадии обучения? Да потому что с помощью того, что мы изучили, Вы уже можете делать вполне пристойные сайты!! нет конечно до конца обучения ещё рано, да и предела совершенствования мастерства как известно нет.., но это послужит хорошей тренировкой и так сказать поднимет Ваш морально боевой дух!!)) Знаете как это приятно, увидеть свою работу в действии!? Но, ещё раз повторюсь, о том как это дело провернуть читайте в статье «Публикация сайта».
Создание бегущей строки в html
бегущая строка
Бегущая строка создается с помощью тегов
<marquee> и </marquee>
Между этими тегами вставляется текст или рисунок,или все вместе,которые должны прокручиваться.В тег <marquee> вставляются атрибуты строки,примерно так:
<marquee атрибуты>Контент бегущей строки </marquee>
Атрибуты бегущей строки:
behavior- тип движения со следующими значениями:
scroll— циклическая,
alternate— перемещение текста от одного края к другому
slide— остановка текста у одного края
| бегущая строка | бегущая строка | бегущая строка Вставка фото в бегущую строку |
direction- направление текста
up— весь текст идет снизу вверх
down— весь текст идет сверху вниз
left— текст идет налево
right— текст идет направо
Также используются следующие атрибуты:
scrollmount— шаг перемещения текста за заданный интервал времени со значениями в пикселях:
scrollmount— «1» «2» «3» ваш выбор
scrolldelay— интервал между шагами бегущей строки в миллисекундах к примеру:
scrolldelay— «100» «150» «200» ваш выбор
loop— число проходов текста
loop— «infinite»-постоянное прокручивание
loop=-«5» ваш выбор
hspace-«0»-ваш выбор-отступ поля справа и слева от бегущей строки в пикселях
vspace— «0»-ваш выбор-отступ поля сверху и снизу от бегущей строки в пикселях
width-«?» задает ширину бегущей строки в пикселях или процентах от ширины экрана
height-«?» задает высоту бегущей строки в пикселях или процентах
<font color=»#?»>бегущая строка</font> -определяет цвет текста в бегущей строке
Пример и код бегущей строки.
Без денег хорошо
но с деньгами лучше
Вот код этой строки.
<marquee behavior=»scroll» bgcolor=»#D8FFD0″ scrollAmount=»3″ scrolldelay=»10″
>
<font size=»5″ color=»#0804FB»>Без денег хорошо</font>
<img src=»dollar.jpg»>
<font size=»5″ color=»#0804FB»>но с деньгами лучше
</font></marquee>
HTML Таблицы
Таблица — это сетка из ячеек, формирующих строки и столбцы. Примерами таблиц могут служить различные финансовые отчеты, результаты спортивных соревнований, календари, расписания и т.д. Отдельный блок сетки называется ячейкой таблицы. Ячейки таблицы могут содержать самую разнообразную информацию, включая числа, текст, и даже видео и аудио объекты. С помощью языка HTML таблицы пишутся построчно.
Элемент <table> служит контейнером для элементов, определяющих содержимое таблицы. Чтобы создать строку таблицы, нужно добавить внутрь элемента <table> парный блочный тег <tr> (сокр. от англ. «tаЫе row» – строка таблицы). Сколько тегов <tr> вы добавите, столько строк в таблице и будет. Открывающий тег <tr> обозначает начало новой строки таблицы. После него помещаются элементы <td> (сокр. от англ. «tаЫе data» – данные таблицы), каждый из которых задает отдельную ячейку в этой строке. Внутрь элемента <td> вы помещаете свой контент (текст, числа, изображения и т.д.), отображаемый в этой ячейке. Конец строки обозначается закрывающим тегом </tr>.
от англ. «tаЫе row» – строка таблицы). Сколько тегов <tr> вы добавите, столько строк в таблице и будет. Открывающий тег <tr> обозначает начало новой строки таблицы. После него помещаются элементы <td> (сокр. от англ. «tаЫе data» – данные таблицы), каждый из которых задает отдельную ячейку в этой строке. Внутрь элемента <td> вы помещаете свой контент (текст, числа, изображения и т.д.), отображаемый в этой ячейке. Конец строки обозначается закрывающим тегом </tr>.
Элемент <th> (сокр. от англ. «tаЫе heading» – заголовок таблицы) — необязательный табличный элемент, который используется точно так же, как и элемент <td>, однако его назначение — создание заголовка строки или столбца. Как правило, элемент <th> размещают в первой строке таблицы. Браузеры отображают текст в элементе <th> жирным шрифтом и центрируют его относительно ячейки. Применение в коде элемента <th> помогает людям, которые пользуются программами экранного доступа, а также улучшает результативность индексирования таблиц поисковыми машинами.
Применение в коде элемента <th> помогает людям, которые пользуются программами экранного доступа, а также улучшает результативность индексирования таблиц поисковыми машинами.
Рассмотрим простую таблицу, которая состоит из трех строк и трех столбцов, причем ячейки первой строки будут заголовками соответствующих столбцов. По умолчанию таблицы обычно отображаются без рамки:
Пример: Простая HTML-таблица
| Заголовок 1 | Заголовок 2 | Заголовок 3 |
|---|---|---|
| Ячейка 2×1 | Ячейка 2×2 | Ячейка 2×3 |
| Ячейка 3×1 | Ячейка 3×2 | Ячейка 3×3 |
<table>
<tr><th>Заголовок 1</th><th>Заголовок 2</th><th>Заголовок 3</th></tr>
<tr><td>Ячейка 2x1 </td><td>Ячейка 2x2 </td><td>Ячейка 2x3 </td></tr>
<tr><td>Ячейка 3x1 </td><td>Ячейка 3x2 </td><td>Ячейка 3x3 </td></tr>
</table>
Граница таблицы
Мы уже знаем, что по умолчанию таблицы отображаются без рамки. Для добавления рамки вокруг таблицы нужно указать в документе
несколько простых правил таблиц стилей. Свойство border управляет отображением линий сетки таблицы, а также задает толщину рамки вокруг таблицы в пикселах. Рамка отображается вокруг таблицы и между ячейками. Добавим к уже созданной таблице рамку толщиной один пиксель, установив свойство border для всех элементов таблицы, например, вот так:
Для добавления рамки вокруг таблицы нужно указать в документе
несколько простых правил таблиц стилей. Свойство border управляет отображением линий сетки таблицы, а также задает толщину рамки вокруг таблицы в пикселах. Рамка отображается вокруг таблицы и между ячейками. Добавим к уже созданной таблице рамку толщиной один пиксель, установив свойство border для всех элементов таблицы, например, вот так:
<style>
table, th, td {
border: 1px solid black;
}
</style>Пример: Применение свойства
border| Заголовок 1 | Заголовок 2 | Заголовок 3 |
|---|---|---|
| Ячейка 2×1 | Ячейка 2×2 | Ячейка 2×3 |
| Ячейка 3×1 | Ячейка 3×2 | Ячейка 3×3 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Рамка вокруг таблицы</title>
<style>
table, th, td {
border: 1px solid black;
}
</style>
</head>
<body>
<table>
<tr><th>Заголовок 1</th><th>Заголовок 2</th><th>Заголовок 3</th></tr>
<tr><td>Ячейка 2x1 </td><td>Ячейка 2x2 </td><td>Ячейка 2x3 </td></tr>
<tr><td>Ячейка 3x1 </td><td>Ячейка 3x2 </td><td>Ячейка 3x3 </td></tr>
</table>
</body>
</html>Свойство border следует устанавливать как для самой таблицы <table> так и для её ячеек <th> и <td>. |
Одинарная рамка для таблицы
По умолчанию у смежных ячеек таблицы будет своя собственная граница. Это приводит к своего рода «двойной рамке», как видно из примера выше. Чтобы избавиться от «двойной рамки», добавьте свойство CSS border-collapse к своей таблице стилей:
<style>
table {
border-collapse: collapse;
}
</style>Пример: Применение свойства
border-collapse| Заголовок 1 | Заголовок 2 | Заголовок 3 |
|---|---|---|
| Ячейка 2×1 | Ячейка 2×2 | Ячейка 2×3 |
| Ячейка 3×1 | Ячейка 3×2 | Ячейка 3×3 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Рамка вокруг таблицы</title>
<style>
table {
border-collapse: collapse;
}
th, td {
border: 1px solid black;
}
</style>
</head>
<body>
<table>
<tr><th>Заголовок 1</th><th>Заголовок 2</th><th>Заголовок 3</th></tr>
<tr><td>Ячейка 2x1 </td><td>Ячейка 2x2 </td><td>Ячейка 2x3 </td></tr>
<tr><td>Ячейка 3x1 </td><td>Ячейка 3x2 </td><td>Ячейка 3x3 </td></tr>
</table>
</body>
</html>Поля и интервалы таблицы
По умолчанию размер ячеек таблицы подстраивается под их содержимое, но иногда бывает необходимо оставить вокруг табличных данных немного пространства (padding). Поскольку интервалы и поля относятся к элементам представления данных, это пространство настраивается с помощью стилевых таблиц CSS.
Поле ячейки (padding) — это расстояние между содержимым ячейки и ее границей (border). Для его добавления примените свойство padding к элементу <td> или <th>.
Интервал ячеек (border-spacing) — это расстояние между ними (<td> или <th>). Сначала присвойте значение separate свойству border-collapse элемента <table>, а затем установите расстояние между ячейками, изменив значение параметра border-spacing. Раньше за поля и интервал ячеек отвечали атрибуты cellpadding и cellspacing элемента <table>, но в спецификации HTML5 они были признаны устаревшими.
Поскольку интервалы и поля относятся к элементам представления данных, это пространство настраивается с помощью стилевых таблиц CSS.
Поле ячейки (padding) — это расстояние между содержимым ячейки и ее границей (border). Для его добавления примените свойство padding к элементу <td> или <th>.
Интервал ячеек (border-spacing) — это расстояние между ними (<td> или <th>). Сначала присвойте значение separate свойству border-collapse элемента <table>, а затем установите расстояние между ячейками, изменив значение параметра border-spacing. Раньше за поля и интервал ячеек отвечали атрибуты cellpadding и cellspacing элемента <table>, но в спецификации HTML5 они были признаны устаревшими.
Пример использования padding и border-spacing:
Пример: Применение свойств
padding и border-spacing| Ячейка 1 | Ячейка 2 |
| Ячейка 3 | Ячейка 4 |
| Ячейка 1 | Ячейка 2 |
| Ячейка 3 | Ячейка 4 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>padding и border-spacing</title>
<style>
table, td {
border: 1px solid black;
}
table {
border-spacing: 15px;
background-color:green;
}
td {
background-color:yellow;
padding: 15px;
}
</style>
</head>
<body>
<table>
<tr><td>Ячейка 1</td><td>Ячейка 2</td></tr>
<tr><td>Ячейка 3</td><td>Ячейка 4</td></tr>
</table>
</body>
</html>Примечание: Если к таблице применено свойство border-collapse: collapse, то интервал ячеек (border-spacing) не сработает. |
Ширина таблицы
Ширину, занимаемую таблицей в окне браузера, можно указать с помощью свойства width CSS, в пикселях или процентах. Указание ширины таблицы в пикселях позволяет определить её точную ширину. Процентное соотношение позволяет сделать таблицу гибкой, т.е. она будет «растягиваться» или «сжиматься» в зависимости от того, какие еще элементы находятся на странице и какие размеры окна браузера.
Вот пример использования свойства width:
table {width: 100%;}
Пример: Применение свойства
width| Ячейка 1 | Ячейка 2 |
| Ячейка 3 | Ячейка 4 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>width: 100%</title>
<style>
table {
border-collapse: collapse;
width: 100%;
}
th, td {
border: 1px solid black;
padding: 15px;
}
</style>
</head>
<body>
<table>
<tr><td>Ячейка 1</td><td>Ячейка 2</td></tr>
<tr><td>Ячейка 3</td><td>Ячейка 4</td></tr>
</table>
</body>
</html>Объединение ячеек (colspan и rowspan)
Одной из основных особенностей структуры таблицы является объединение ячеек, которое подразумевает растяжение ячейки и охват ею нескольких строк или столбцов. Это позволяет создавать сложные табличные структуры: заголовки <th> или ячейки <td> объединяются посредством добавления атрибутов colspan или rowspan. Атрибут colspan определяет количество ячеек, на которые простирается данная ячейка по горизонтали, а rowspan — по вертикали.
Это позволяет создавать сложные табличные структуры: заголовки <th> или ячейки <td> объединяются посредством добавления атрибутов colspan или rowspan. Атрибут colspan определяет количество ячеек, на которые простирается данная ячейка по горизонтали, а rowspan — по вертикали.
Объединение столбцов
Объединение столбцов достигается с помощью атрибута colspan в элементах <td> или <th> — ячейка растягивается вправо, охватывая последующие столбцы. В следующем примере значение атрибута colspan равно 2, а это значит, что ячейка должна занимать два столбца.
Пример: Применение атрибута
colspan| Ячейка на два столбца | |
|---|---|
| Ячейка 1 | Ячейка 2 |
| Ячейка 3 | Ячейка 4 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Атрибут colspan</title>
<style>
table {
border-collapse: collapse;
width: 100%;
}
th, td {
border: 1px solid black;
padding: 5px;
}
</style>
</head>
<body>
<table>
<tr><th colspan="2">Ячейка на два столбца</th></tr>
<tr><td>Ячейка 1</td><td>Ячейка 2</td></tr>
<tr><td>Ячейка 3</td><td>Ячейка 4</td></tr>
</table>
</body>
</html>Объединение строк
Строки, объединенные при помощи атрибута rowspan, ведут себя точно так же, как объединенные столбцы, с той лишь разницей, что диапазон ячеек задается сверху вниз и охватывает несколько строк.
В этом примере первая ячейка таблицы растягивается на две строки вниз:
Пример: Применение атрибута
rowspan| Ячейка на две строки | Ячейка 1 | Ячейка 2 |
|---|---|---|
| Ячейка 3 | Ячейка 4 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Атрибут rowspan</title>
<style>
table {
border-collapse: collapse;
width: 100%;
}
th, td {
border: 1px solid black;
padding: 5px;
}
</style>
</head>
<body>
<table>
<tr><th rowspan="2">Ячейка на две строки</th>
<td>Ячейка 1</td><td>Ячейка 2</td></tr>
<tr><td>Ячейка 3</td><td>Ячейка 4</td></tr>
</table>
</body>
</html>Заголовок таблицы
Для создания заголовка или подписи таблицы используется парный тег <caption> (от англ. caption – подпись). Элемент <caption> предназначен для организации заголовка таблицы. Располагается сразу после тега <table>, но вне описания строки или ячейки.
caption – подпись). Элемент <caption> предназначен для организации заголовка таблицы. Располагается сразу после тега <table>, но вне описания строки или ячейки.
Пример: Применение тега
<caption>| Ячейка на две строки | Ячейка 1 | Ячейка 2 |
|---|---|---|
| Ячейка 3 | Ячейка 4 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Элемент caption</title>
<style>
table {
border-collapse: collapse;
width: 100%;
}
th, td {
border: 1px solid black;
padding: 5px;
}
</style>
</head>
<body>
<table>
<caption>Это заголовок таблицы</caption>
<tr><th rowspan="2">Ячейка на две строки</th>
<td>Ячейка 1</td><td>Ячейка 2</td></tr>
<tr><td>Ячейка 3</td><td>Ячейка 4</td></tr>
</table>
</body>
</html>Теги группирования элементов таблиц
Для группирования элементов таблиц служат теги <thead>, <tbody> и <tfoot>. Так же, как веб-страница может содержать «шапку», «тело» и «подвал», таблица может содержать головную, основную и нижнюю части. Для логического группирования строк в верхней части таблицы (то есть для соз
дания верхней шапки таблицы) используется тег <thead>. Заголовки таблицы
должны быть помещены в элемент <thead>, например:
Так же, как веб-страница может содержать «шапку», «тело» и «подвал», таблица может содержать головную, основную и нижнюю части. Для логического группирования строк в верхней части таблицы (то есть для соз
дания верхней шапки таблицы) используется тег <thead>. Заголовки таблицы
должны быть помещены в элемент <thead>, например:
<thead>
<tr><th>Заголовок 1</th><th>Заголовок 2< /th></tr>
</thead>Основное содержимое (тело) таблицы должно находиться внутри элемента <tbody> (таких блоков в таблице может быть несколько). Для логического группирования строк в нижней части таблицы (то есть для создания «подвала» таблицы) используется тег <tfoot> (в одной таблице допускается не более одного тега <tfoot>). В исходном коде тег <tfoot> ставится до тега <tbody>.
Кроме логического группирования одной из причин использования элементов <thead> и <tfoot> является то, что если ваша таблица слишком длинная для единовременного отображения на экране (или для печати), то браузер будет отображать и заголовок (<thead>) и последнюю строку (<tfoot>), когда пользователь станет прокручивать вашу таблицу.
Пример: Теги
<thead>, <tbody> и <tfoot>| Это шапка таблицы | |||
|---|---|---|---|
| Это подвал таблицы | |||
| Ячейка 1 | Ячейка 2 | Ячейка 3 | Ячейка 4 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Теги thead, tbody и tfoot</title>
<style>
table {
border-collapse: collapse;
width: 100%;
}
th, td {
border: 1px solid black;
padding: 5px;
}
</style>
</head>
<body>
<table>
<thead>
<tr><th colspan="4">Это шапка таблицы</th></tr>
</thead>
<tfoot>
<tr><td colspan="4">Это подвал таблицы</td></tr>
</tfoot>
<tbody>
<tr><td>Ячейка 1</td><td>Ячейка 2</td><td>Ячейка 3</td><td>Ячейка 4</td></tr>
</tbody>
</table>
</body>
</html>Несмотря на то, что мы перед <tbody> добавили <tfoot>, он, тем не менее, появляется в конце таблицы.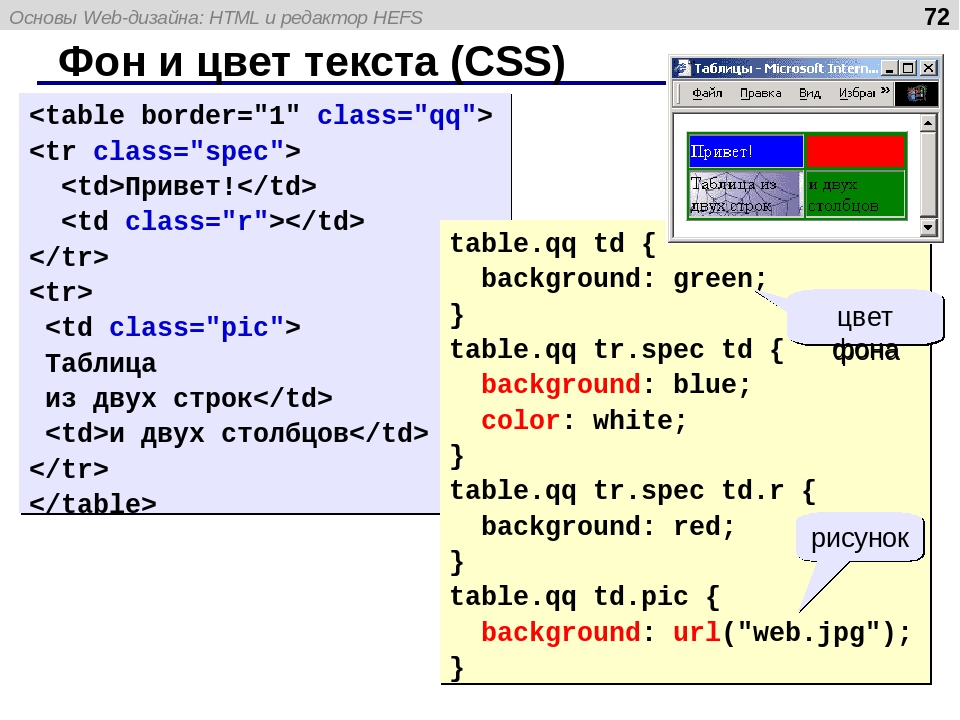 Это исходит из того, что <tbody> может содержать много строк. Но браузеру нужно отобразить нижнюю часть таблицы до получения всех (потенциально многочисленных) строк данных. Вот почему <tfoot> в коде прописывается перед элементом <tbody>.
Это исходит из того, что <tbody> может содержать много строк. Но браузеру нужно отобразить нижнюю часть таблицы до получения всех (потенциально многочисленных) строк данных. Вот почему <tfoot> в коде прописывается перед элементом <tbody>.
Задачи
Объединение столбцов
Напиште разметку для таблицы, изображенной на рис.1.
Задача HTML: Реши сам »Ячейка на два столбца Ячейка 1 Ячейка 2 Рис.1
Объединение строк
Напиште разметку для таблицы, изображенной на рис.1.
Задача HTML: Реши сам »Ячейка на три строки Ячейка 1 Ячейка 2 Ячейка 3 Рис.1
Убрать двойную рамку таблицы
По умолчанию граница таблицы имеет эффект двойной рамки, измените код так, чтобы все линии этой рамки стали одинарными.
Задача HTML: Реши сам »
<!DOCTYPE html> <html>Заголовок 1 Заголовок 2 Заголовок 3 Ячейка 1x1 Ячейка 1x2 Ячейка 1x3 Ячейка 2x1 Ячейка 2x2 Ячейка 2x3
<head>
<meta charset="UTF-8">
<title>Рамка вокруг таблицы</title> <style> table, th, td {border: 1px solid black;} </style> </head>
<body> <table> <tr><th>Заголовок 1</th><th>Заголовок 2</th><th>Заголовок 3</th></tr> <tr><td>Ячейка 1x1 </td><td>Ячейка 1x2 </td><td>Ячейка 1x3 </td></tr> <tr><td>Ячейка 2x1 </td><td>Ячейка 2x2 </td><td>Ячейка 2x3 </td></tr> </table> </body>
</html>

Широкая таблица
Сделайте чтобы эта таблица отображалось полностью на всю ширину окна браузера вне зависимости от ее ширины.
Задача HTML: Реши сам »
<!DOCTYPE html> <html>Заголовок 1 Заголовок 2 Заголовок 3 Ячейка 1x1 Ячейка 1x2 Ячейка 1x3 Ячейка 2x1 Ячейка 2x2 Ячейка 2x3
<head>
<meta charset="UTF-8">
<title>Ширина таблицы</title> <style> table {border-collapse: collapse;} th, td {border: 1px solid black;} </style> </head>
<body> <table> <tr><th>Заголовок 1</th><th>Заголовок 2</th><th>Заголовок 3</th></tr> <tr><td>Ячейка 1x1 </td><td>Ячейка 1x2 </td><td>Ячейка 1x3 </td></tr> <tr><td>Ячейка 2x1 </td><td>Ячейка 2x2 </td><td>Ячейка 2x3 </td></tr> </table> </body>
</html>
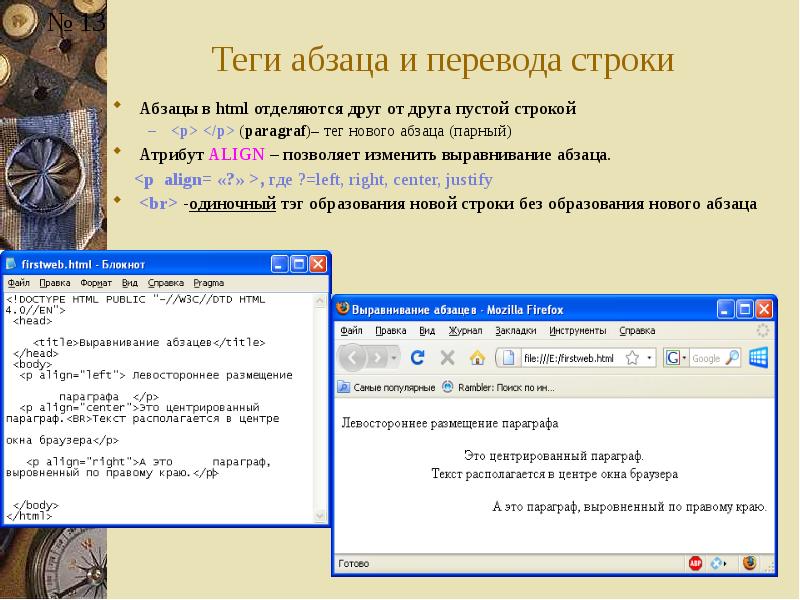
Заголовок таблицы
Измените приведенный код так, чтобы над таблицей появился основной заголовок (подпись), как показано на рис.
Задача HTML: Реши сам » 1.Основной заголовок таблицы Заголовок 1 Заголовок 2 Заголовок 3 Ячейка 1x1 Ячейка 1x2 Ячейка 1x3 Ячейка 2x1 Ячейка 2x2 Ячейка 2x3 Рис.1
<!DOCTYPE html> <html>
<head>
<meta charset="UTF-8">
<title>Ширина таблицы</title> <style> table {border-collapse: collapse;width:100%} th, td {border: 1px solid black;} </style> </head>
<body> <table> <tr><th>Заголовок 1</th><th>Заголовок 2</th><th>Заголовок 3</th></tr> <tr><td>Ячейка 1x1 </td><td>Ячейка 1x2 </td><td>Ячейка 1x3 </td></tr> <tr><td>Ячейка 2x1 </td><td>Ячейка 2x2 </td><td>Ячейка 2x3 </td></tr> </table> </body>
</html>
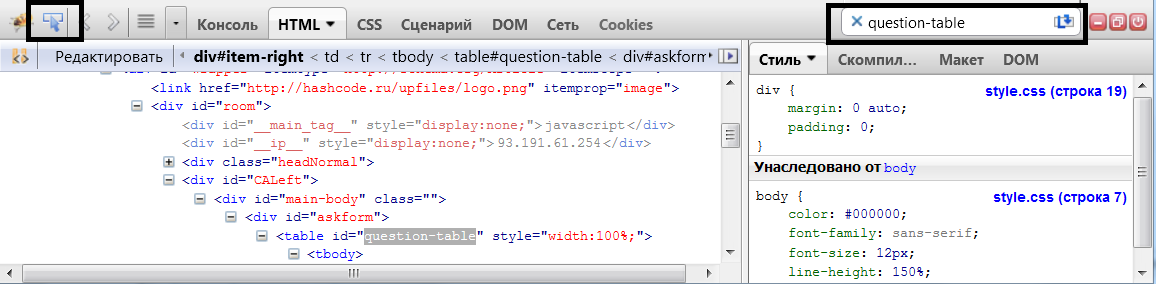 1.
1.Поле внутри ячеек
Измените приведенный код так, чтобы между текстом внутри ячеек и их границей появился зазор (поле) шириной 25px, как показано на рис.
Задача HTML: Реши сам » 1.Ячейка 1 Ячейка 2 Ячейка 3 Ячейка 4 Рис.1
<!DOCTYPE html> <html>
<head>
<meta charset="UTF-8">
<title>Интервал между ячейками</title> <style> table, td { border: 1px solid black; } </style> </head>
<body> <table> <tr><td>Ячейка 1</td><td>Ячейка 2</td></tr> <tr><td>Ячейка 3</td><td>Ячейка 4</td></tr> </table> </body>
</html>
 1.
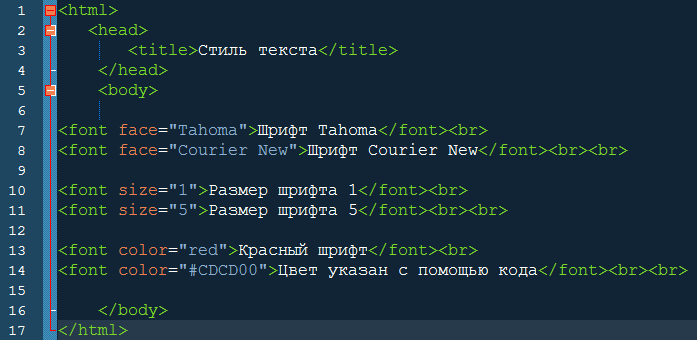
1.Объединение строк
Попробуйте написать разметку для таблицы, изображенной на рис.1. Совет: Строки всегда объединяются сверху вниз, поэтому ячейка с «ананасами» является частью первой строки.
фурма ананасы персики бананы груши авокадо Рис.
1<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Объединение строк</title> <style> table { border-collapse: collapse; width: 100%; } th, td { border: 1px solid black; padding: 5px; } </style> </head> <body> <table> <tr> <td>фурма</td> <td rowspan="3">ананасы</td> <td>персики</td> </tr> <tr> <td>бананы</td> <td rowspan="2">груши</td> </tr> <tr> <td>авокадо</td> </tr> </table> </body> </html>
 1
1Модуль ngx_http_sub_module
Модуль ngx_http_sub_module
Модуль ngx_http_sub_module — это фильтр,
изменяющий в ответе одну заданную строку на другую.
По умолчанию этот модуль не собирается, его сборку необходимо
разрешить с помощью конфигурационного параметра --with-http_sub_module.
Пример конфигурации
location / {
sub_filter '<a href="http://127.0.0.1:8080/' '<a href="https://$host/';
sub_filter '<img src="http://127.0.0.1:8080/' '<img src="https://$host/';
sub_filter_once on;
}
Директивы
| Синтаксис: | sub_filter |
|---|---|
| Умолчание: | — |
| Контекст: | http, server, location |
Задаёт строку, которую нужно заменить, и строку замены.
Заменяемая строка проверяется без учёта регистра.
В заменяемой строке (1. 9.4) и в строке замены можно использовать переменные.
На одном уровне конфигурации может
быть указано несколько директив
9.4) и в строке замены можно использовать переменные.
На одном уровне конфигурации может
быть указано несколько директив sub_filter (1.9.4).
Директивы наследуются с предыдущего уровня конфигурации при условии, что
на данном уровне не описаны свои директивы sub_filter.
| Синтаксис: | sub_filter_last_modified |
|---|---|
| Умолчание: | sub_filter_last_modified off; |
| Контекст: | http, server, location |
Эта директива появилась в версии 1.5.1.
Позволяет сохранить поле заголовка “Last-Modified”
исходного ответа во время замены
для лучшего кэширования ответов.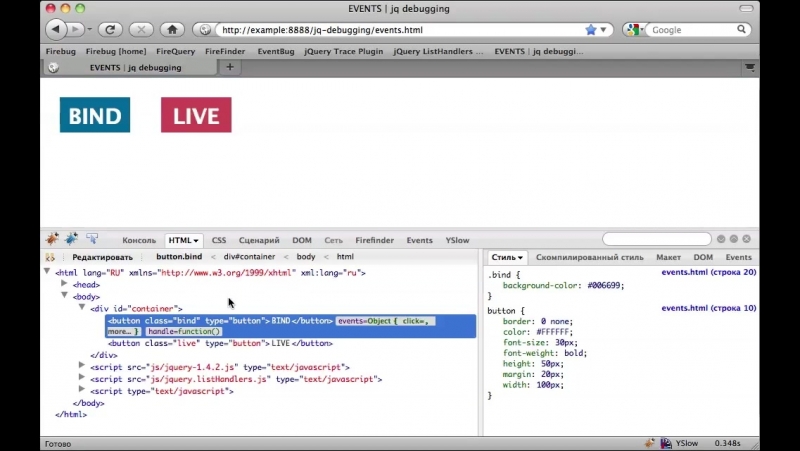
По умолчанию поле заголовка удаляется, так как содержимое ответа изменяется во время обработки.
| Синтаксис: | sub_filter_once |
|---|---|
| Умолчание: | sub_filter_once on; |
| Контекст: | http, server, location |
Определяет, сколько раз нужно искать каждую из заменяемых строк: один раз или многократно.
| Синтаксис: | sub_filter_types |
|---|---|
| Умолчание: | sub_filter_types text/html; |
| Контекст: | http, server, location |
Разрешает замену строк в ответах с указанными MIME-типами
в дополнение к “text/html”. Специальное значение “
Специальное значение “*” соответствует любому MIME-типу
(0.8.29).
Блочные и строчные элементы HTML. Свойство display CSS — учебник CSS
В HTML существует два типа элементов — блочные (block elements) и строчные (inline elements). Ниже вы узнаете особенности этих элементов и разницу между ними, а также способы управлять ими через правила CSS.
Блочные элементы
Блочные элементы являются основой, которая используется для верстки веб-страниц. Такой элемент представляет собой прямоугольник, который по умолчанию занимает всю доступную ширину страницы (если иное значение не указано в CSS), а длина элемента зависит от его содержимого. Такой элемент всегда начинается с новой строки, то есть, располагается под предыдущим элементом. Блочный элемент может содержать в себе другие блочные и строчные элементы.
Примеры блочных элементов: <div>, <p>, <ul>, <ol>, <h2> и т. д.
д.
Строчные элементы
В отличие от блочного, строчный элемент не переносится на новую строку, а располагается на той же строке, что и предыдущий элемент. Такие элементы, как правило, находятся внутри блочных элементов и их ширина зависит лишь от содержимого и настроек CSS. Еще одно отличие строчного элемента от блочного заключается к том, что в нем может находиться только контент и другие строчные элементы. Блочные элементы в строчные вкладывать нельзя.
Примеры строчных элементов: <a>, <span>, <strong>, <em>, <img> и т. д.
Блочные и строчные элементы HTML
Примечание: в HTML5 порядок вложения тегов такой роли не играет. Элементы уже не просто делятся на блочные и строчные, а группируются по смыслу и назначению, представляя собой категории контента.
CSS-свойство display: меняем тип элемента
При помощи крайне полезного свойства display в CSS можно заставить блочный элемент выглядеть как строчный и наоборот. Чтобы блочный элемент вел себя как inline-элемент (т. е. не переводился на новую строку), для него необходимо записать правило:
Чтобы блочный элемент вел себя как inline-элемент (т. е. не переводился на новую строку), для него необходимо записать правило:
display: inline;
Если же необходимо отобразить строчный элемент как block-элемент (чтобы до и после элемента происходил перенос строки), запишите следующее:
display: block;
Действие {display:inline} и {display:block}
Также можно сделать «гибрид» — блочный элемент с поведением, как у строчного. В этом случае всё содержимое таких блочных элементов будет отображаться, как обычно, но при этом блоки будут вести себя как строчные элементы, выстраиваясь в одной строке друг за другом и переносясь на новую строку лишь при необходимости. Схлопывание margin в таких случаях перестает действовать. Для превращения элемента в блочно-строчный запишите:
display: inline-block;
Действие {display:inline-block}
Далее в учебнике: свойство CSS border. Вы узнаете, как добавлять границы для элементов веб-страницы и какие настройки к ним можно применить, используя каскадные таблицы стилей.
Вы узнаете, как добавлять границы для элементов веб-страницы и какие настройки к ним можно применить, используя каскадные таблицы стилей.
Ссылка на строку JavaScript
Строки JavaScript
Строка JavaScript хранит серию символов, например «Джон Доу».
Строка может быть любым текстом внутри двойных или одинарных кавычек:
Строковые индексы отсчитываются от нуля: первый символ находится в позиции 0, второй в 1 и т. д.
Учебник по строкам см. В нашем учебном пособии по строкам JavaScript.
Свойства и методы строки
Примитивные значения, такие как John Doe, не могут иметь свойств. или методы (потому что они не являются объектами).
Но с помощью JavaScript методы и свойства также доступны для примитивные значения, потому что JavaScript обрабатывает примитивные значения как объекты при выполнении методов и свойств.
Свойства строки
| Имущество | Описание |
|---|---|
| конструктор | Возвращает функцию конструктора строки |
| длина | Возвращает длину строки |
| прототип | Позволяет добавлять свойства и методы к объекту |
Строковые методы
| Метод | Описание |
|---|---|
| диаграмма () | Возвращает символ по указанному индексу (позиции) |
| charCodeAt () | Возвращает Unicode символа по указанному индексу |
| concat () | Объединяет две или более строк и возвращает новую объединенную строку |
| заканчивается с () | Проверяет, заканчивается ли строка указанной строкой / символами |
| fromCharCode () | Преобразует значения Unicode в символы |
| включает () | Проверяет, содержит ли строка указанную строку / символы |
| indexOf () | Возвращает позицию первого найденного вхождения указанного значения в строке. |
| lastIndexOf () | Возвращает позицию последнего найденного вхождения указанного значения в строке. |
| локаль Сравнить () | Сравнивает две строки в текущей локали |
| совпадение () | Ищет в строке совпадение с регулярным выражением и возвращает совпадения. |
| повторить () | Возвращает новую строку с указанным количеством копий существующей строки |
| заменить () | Выполняет поиск указанного значения или регулярного выражения в строке и возвращает новую строку, в которой указанные значения заменяются. |
| поиск () | Ищет в строке указанное значение или регулярное выражение и возвращает позицию совпадения. |
| ломтик () | Извлекает часть строки и возвращает новую строку |
| сплит () | Разбивает строку на массив подстрок |
| начинается с () | Проверяет, начинается ли строка с указанных символов |
| substr () | Извлекает символы из строки, начиная с указанной начальной позиции и заканчивая указанным количеством символов |
| подстрока () | Извлекает символы из строки между двумя указанными индексами |
| toLocaleLowerCase () | Преобразует строку в строчные буквы в соответствии с локалью хоста |
| toLocaleUpperCase () | Преобразует строку в прописные буквы в соответствии с локалью хоста. |
| в нижний корпус () | Преобразует строку в строчные буквы |
| toString () | Возвращает значение объекта String |
| в верхний корпус () | Преобразует строку в прописные буквы |
| накладка () | Удаляет пробелы с обоих концов строки |
| valueOf () | Возвращает примитивное значение объекта String |
Все строковые методы возвращают новое значение.Они не меняют оригинал переменная.
Строковые методы оболочки HTML
Методы оболочки HTML возвращают строку, заключенную в соответствующий HTML-тег.
Это нестандартные методы и могут не работать как ожидается во всех браузерах.
| Метод | Описание |
|---|---|
| якорь () | Создает якорь |
| большой () | Показывает строку крупным шрифтом |
| мигает () | Отображает мигающую строку |
| полужирный () | Отображает строку полужирным шрифтом |
| фиксированная () | Отображает строку с использованием шрифта с фиксированным шагом |
| цвет шрифта () | Отображает строку с использованием указанного цвета |
| размер шрифта () | Отображает строку указанного размера. |
| курсив () | Отображает строку курсивом |
| ссылка () | Отображает строку как гиперссылку |
| малый () | Отображает строку с использованием мелкого шрифта |
| забастовка () | Показывает зачеркнутую строку |
| суб () | Отображает строку в виде нижнего индекса |
| суп () | Отображает строку в виде надстрочного текста |
Обработка текста — строки в JavaScript — Изучите веб-разработку
Далее мы обратим внимание на строки — так в программировании называются фрагменты текста.В этой статье мы рассмотрим все общие вещи, которые вам действительно следует знать о строках при изучении JavaScript, такие как создание строк, экранирование кавычек в строках и объединение строк.
| Предварительные требования: | Базовая компьютерная грамотность, базовое понимание HTML и CSS, понимание того, что такое JavaScript. |
|---|---|
| Цель: | Ознакомиться с основами работы со строками в JavaScript. |
Слова очень важны для людей — они составляют большую часть того, как мы общаемся.Поскольку Интернет — это в основном текстовая среда, предназначенная для того, чтобы люди могли общаться и обмениваться информацией, для нас полезно иметь контроль над словами, которые появляются в ней. HTML обеспечивает структуру и смысл нашего текста, CSS позволяет нам точно стилизовать его, а JavaScript содержит ряд функций для управления строками, создания пользовательских приветственных сообщений и подсказок, отображения правильных текстовых меток при необходимости, сортировки терминов в желаемом порядке, и многое другое.
Практически все программы, которые мы показывали вам до сих пор в курсе, включают некоторые манипуляции со строками.
На первый взгляд со строками работают так же, как с числами, но если копнуть глубже, можно заметить некоторые заметные различия. Начнем с ввода некоторых основных строк в консоль разработчика браузера, чтобы ознакомиться.
Начнем с ввода некоторых основных строк в консоль разработчика браузера, чтобы ознакомиться.
Создание строки
- Для начала введите следующие строки:
Как и в случае с числами, мы объявляем переменную, инициализируем ее строковым значением, а затем возвращаем значение.Единственное отличие здесь в том, что при написании строки вам нужно заключить значение в кавычки.let string = 'Революция не будет транслироваться по телевидению.'; нить; - Если вы этого не сделаете или пропустите одну из кавычек, вы получите сообщение об ошибке. Попробуйте ввести следующие строки:
Эти строки не работают, потому что любой текст без кавычек считается именем переменной, именем свойства, зарезервированным словом или подобным. Если браузер не может его найти, возникает ошибка (например,грамм. «отсутствует; до утверждения»). Если браузер видит, где начинается строка, но не может найти конец строки, как указано во второй кавычке, он выдает сообщение об ошибке (с «незавершенным строковым литералом»).let badString1 = Это тест; let badString2 = 'Это тест; let badString3 = Это тест '; Если ваша программа выдает такие ошибки, вернитесь и проверьте все свои строки, чтобы убедиться, что у вас нет пропущенных кавычек. - Следующее будет работать, если вы ранее определили переменную
string— попробуйте сейчас:пусть badString = строка; badString;badStringтеперь имеет то же значение, что и строка
 Если ваша программа выдает такие ошибки, вернитесь и проверьте все свои строки, чтобы убедиться, что у вас нет пропущенных кавычек.
Если ваша программа выдает такие ошибки, вернитесь и проверьте все свои строки, чтобы убедиться, что у вас нет пропущенных кавычек.Одиночные кавычки и двойные кавычки
- В JavaScript вы можете выбрать одинарные или двойные кавычки для обертывания строк. Оба следующих варианта будут работать нормально:
let sgl = 'Одиночные кавычки.'; let dbl = "Двойные кавычки"; sgl; dbl; - Между ними очень небольшая разница, и то, что вы используете, зависит от личных предпочтений. Однако вам следует выбрать одно и придерживаться его; код с разными кавычками может сбивать с толку, особенно если вы используете две разные кавычки в одной строке! Следующее вернет ошибку:
let badQuotes = 'Что, черт возьми? "; - Браузер будет думать, что строка не была закрыта, потому что в строке может появиться другой тип цитаты, который вы не используете для хранения ваших строк. Например, оба варианта подходят:
let sglDbl = 'Вы бы съели «рыбный ужин»?'; let dblSgl = "Мне грустно."; sglDbl; dblSgl; - Однако вы не можете включить одну и ту же кавычку в строку, если она используется для их содержания. Следующее приведет к ошибке, так как это сбивает браузер с толку относительно того, где заканчивается строка:
Это очень хорошо подводит нас к нашей следующей теме.let bigmouth = 'Я не имею права занимать свое место ...';
 Например, оба варианта подходят:
Например, оба варианта подходят:Экранирующие символы в строке
Чтобы исправить нашу предыдущую строку кода проблемы, нам нужно экранировать проблемную кавычку. Экранирование символов означает, что мы что-то делаем с ними, чтобы убедиться, что они распознаются как текст, а не как часть кода. В JavaScript мы делаем это, помещая обратную косую черту непосредственно перед символом. Попробуйте это:
let bigmouth = 'У меня нет права занять свое место ...';
большой рот; Это прекрасно работает. Таким же образом можно экранировать других персонажей, e.грамм.
Таким же образом можно экранировать других персонажей, e.грамм. \ ", и, кроме того, есть несколько специальных кодов. Подробнее см. Обозначение Escape.
- Concatenate — это причудливое программное слово, означающее« объединение ». Для объединения строк в JavaScript используется оператор« плюс »(+), тот же, который мы используем для сложения чисел, но в этом контексте он делает что-то другое. Давайте попробуем пример в нашей консоли.
Результатом этого является переменная с именемlet one = 'Привет,'; let two = 'как дела?'; пусть соединились = один + два; присоединился;, соединенная с, которая содержит значение «Привет, как дела?». - В последнем случае мы соединили только две строки, но вы можете присоединиться к любому количеству строк, если вы добавите
+между каждой парой. Попробуй это:пусть кратное = один + один + один + один + два; несколько; - Вы также можете использовать сочетание переменных и фактических строк. Попробуй это:
let response = one + 'Я в порядке -' + два; отклик;
 Попробуй это:
Попробуй это:Примечание : Когда вы вводите в код фактическую строку, заключенную в одинарные или двойные кавычки, она называется строковым литералом .
Конкатенация в контексте
Давайте посмотрим, как конкатенация используется в действии — вот пример из предыдущего курса:
const button = document.querySelector ('кнопка');
button.onclick = function () {
let name = prompt ('Как тебя зовут?');
alert ('Привет' + имя + ', приятно тебя видеть!');
} Здесь мы используем функцию window.prompt () в строке 4, которая просит пользователя ответить на вопрос через всплывающее диалоговое окно, а затем сохраняет введенный текст внутри заданной переменной — в данном случае name .Затем мы используем функцию window. в строке 5, чтобы отобразить другое всплывающее окно, содержащее строку, которую мы собрали из двух строковых литералов и переменной  alert ()
alert () name , путем объединения.
Числа и строки
- Итак, что происходит, когда мы пытаемся сложить (или объединить) строку и число? Попробуем в нашей консоли:
Вы можете ожидать, что это вернет ошибку, но все работает нормально. Попытка представить строку в виде числа на самом деле не имеет смысла, но представление числа в виде строки имеет смысл, поэтому браузер довольно ловко преобразует число в строку и объединяет две строки.«Передний» + 242; - Вы можете сделать это даже с двумя числами — вы можете заставить число превратиться в строку, заключив его в кавычки. Попробуйте следующее (мы используем оператор
typeof, чтобы проверить, является ли переменная числом или строкой):пусть myDate = '19' + '67'; typeof myDate; - Если у вас есть числовая переменная, которую вы хотите преобразовать в строку, но не изменять иначе, или строковую переменную, которую вы хотите преобразовать в число, но не изменять иначе, вы можете использовать следующие две конструкции:
- Объект
Numberпреобразует все, что ему передано, в число, если это возможно. Попробуйте следующее:пусть myString = '123'; пусть myNum = Число (myString); typeof myNum; - И наоборот, у каждого числа есть метод
toString (), который преобразует его в эквивалентную строку. Попробуй это:пусть myNum2 = 123; пусть myString2 = myNum2.toString (); typeof myString;
Number (), чтобы справиться с этим. Мы сделали именно это в нашей игре по угадыванию чисел, в строке 54. - Объект
 Попробуйте следующее:
Попробуйте следующее: Другой тип строкового синтаксиса, с которым вы можете столкнуться, — это литералов шаблона (иногда называемых строками шаблона). Это новый синтаксис, обеспечивающий более гибкие и удобные для чтения строки.
Примечание : Попробуйте ввести приведенные ниже примеры в консоль JavaScript вашего браузера, чтобы увидеть, какие результаты вы получите.
Чтобы превратить стандартный строковый литерал в шаблонный литерал, необходимо заменить кавычки ( '' или "" ) на символы обратной кавычки ( `). Итак, на простом примере:
let song = «Сражайся с молодежью»; Превратится в шаблонный литерал, например:
песня = `Fight the Youth`; Если мы хотим объединить строки или включить в них результаты выражений, писать традиционные строки будет неудобно:
пусть оценка = 9;
пусть highScore = 10;
let output = 'Мне нравится песня "' + song + '".Я дал ему оценку «+ (оценка / высшая оценка * 100) +»; Литералы шаблона значительно упрощают это:
output = `Мне нравится песня" $ {song} ". Я дал ему оценку $ {score / highScore * 100}%. `;  `;
`; Больше нет необходимости открывать и закрывать несколько струнных частей — всю партию можно просто обернуть одной парой обратных кавычек. Если вы хотите включить переменную или выражение в строку, вы включаете его в конструкцию $ {} , которая называется заполнителем .
Внутри шаблонных литералов можно включать сложные выражения, например:
пусть excScore = 45;
пусть excHighestScore = 70;
excReport = `Вы набрали $ {excScore} / $ {excHighestScore} ($ {Math.round ((excScore / excHighestScore * 100))}%). $ {examScore> = 49? "Молодец, вы прошли!" : «Не повезло, на этот раз ты не прошел». } `; - Первые два заполнителя здесь довольно просты, включают только простое значение в строке.
- Третий вычисляет результат в процентах и округляет его до ближайшего целого числа.
- Четвертый включает в себя использование тернарного оператора для проверки того, превышает ли балл определенную отметку, и распечатывает сообщение о прохождении или отказе в зависимости от результата.

Также следует отметить, что если вы хотите разделить традиционную строку на несколько строк, вам необходимо включить символ новой строки, \ n :
output = 'Мне нравится песня "' + song + '". \ NЯ поставил ей оценку' + (score / highScore * 100) + '%.'; Литералы шаблона учитывают разрывы строк в исходном коде, поэтому символы новой строки больше не нужны.Это даст тот же результат:
output = `Мне нравится песня" $ {song} ".
Я дал ему оценку $ {score / highScore * 100}%. `; Мы рекомендуем вам как можно скорее привыкнуть к использованию шаблонных литералов. Они хорошо поддерживаются современными браузерами, и единственное место, где вы обнаружите отсутствие поддержки, — это Internet Explorer. Во многих наших примерах по-прежнему используются стандартные строковые литералы, но в будущем мы включим и другие шаблонные литералы.
Дополнительные примеры и подробные сведения о расширенных функциях см. На странице справки по литералам шаблонов.
На странице справки по литералам шаблонов.
Вы дошли до конца этой статьи, но можете ли вы вспомнить самую важную информацию? Вы можете найти дополнительные тесты, чтобы убедиться, что вы сохранили эту информацию, прежде чем двигаться дальше — см. Проверка своих навыков: строки. Обратите внимание, что это также требует знаний из следующей статьи, так что вы можете сначала прочитать ее.
Это самые основы работы со строками в JavaScript. В следующей статье мы будем опираться на это, рассмотрев некоторые встроенные методы, доступные для строк в JavaScript, и то, как мы можем использовать их для преобразования наших строк в нужную нам форму.
14 струн | R для науки о данных
Введение
Эта глава знакомит вас с манипуляциями со строками в R. Вы узнаете основы того, как работают строки и как создавать их вручную, но основное внимание в этой главе будет уделено регулярным выражениям или, для краткости, регулярным выражениям. Регулярные выражения полезны, потому что строки обычно содержат неструктурированные или частично структурированные данные, а регулярные выражения — это краткий язык для описания шаблонов в строках. Когда вы впервые посмотрите на регулярное выражение, вы подумаете, что кошка шла по клавиатуре, но по мере того, как ваше понимание улучшится, они скоро начнут обретать смысл.
Когда вы впервые посмотрите на регулярное выражение, вы подумаете, что кошка шла по клавиатуре, но по мере того, как ваше понимание улучшится, они скоро начнут обретать смысл.
Предпосылки
В этой главе основное внимание будет уделено пакету stringr для манипуляций со строками, который является частью основного тидиверса.
Основы работы со струнами
Вы можете создавать строки как в одинарных, так и в двойных кавычках. В отличие от других языков, в поведении нет никакой разницы. Я рекомендую всегда использовать ", если вы не хотите создать строку, содержащую несколько " .
string1 <- "Это строка"
string2 <- 'Если я хочу включить «кавычки» внутри строки, я использую одинарные кавычки » Если вы забудете закрыть цитату, вы увидите + , символ продолжения:
> "Это строка без закрывающей кавычки
+
+
+ ПОМОГИТЕ Я застрял Если это случилось с вами, нажмите Escape и попробуйте еще раз!
Чтобы включить буквальную одинарную или двойную кавычку в строку, вы можете использовать \ , чтобы «экранировать» ее:
double_quote <- "\" "# или '"'
single_quote <- '\' '# или "'" Это означает, что если вы хотите включить буквальную обратную косую черту, вам нужно будет удвоить ее: "\\" .
Помните, что напечатанное представление строки не совпадает с самой строкой, потому что напечатанное представление показывает escape-символы. Чтобы увидеть необработанное содержимое строки, используйте writeLines () :
x <- c ("\" "," \\ ")
Икс
#> [1] "\" "" \\ "
writeLines (x)
#> "
#> \ Есть несколько других специальных символов. Наиболее распространенными являются "\ n" , новая строка и "\ t" , вкладка, но вы можете увидеть полный список, запросив помощь по телефону ": ? '"' или ? "' «.Иногда встречаются строки типа "\ u00b5" , это способ написания неанглийских символов, который работает на всех платформах:
x <- "\ u00b5"
Икс
#> [1] "µ" Несколько строк часто хранятся в векторе символов, который можно создать с помощью c () :
c («один», «два», «три»)
#> [1] "один" "два" "три" Длина струны
Base R содержит множество функций для работы со строками, но мы будем избегать их, потому что они могут быть непоследовательными, что затрудняет их запоминание. Вместо этого мы будем использовать функции из stringr. У них более интуитивно понятные названия, и все они начинаются с
Вместо этого мы будем использовать функции из stringr. У них более интуитивно понятные названия, и все они начинаются с str_ . Например, str_length () сообщает количество символов в строке:
str_length (c ("a", "R для науки о данных", NA))
#> [1] 1 18 NA Общий префикс str_ особенно полезен, если вы используете RStudio, потому что ввод str_ запустит автозаполнение, что позволит вам увидеть все функции Stringr:
Объединение струн
Чтобы объединить две или более строк, используйте str_c () :
str_c ("x", "y")
#> [1] "ху"
str_c ("x", "y", "z")
#> [1] "xyz" Используйте аргумент sep , чтобы указать, как они разделяются:
str_c ("x", "y", sep = ",")
#> [1] "x, y" Как и в большинстве других функций в R, пропущенные значения заразительны.Если вы хотите, чтобы они печатались как «NA» , используйте str_replace_na () :
x <- c ("abc", нет данных)
str_c ("| -", x, "- |")
#> [1] "| -abc- |" NA
str_c ("| -", str_replace_na (x), "- |")
#> [1] "| -abc- |" "| -NA- |" Как показано выше, str_c () векторизован и автоматически перерабатывает более короткие векторы до той же длины, что и самый длинный:
str_c ("префикс-", c ("a", "b", "c"), "-suffix")
#> [1] «префикс-а-суффикс» «префикс-b-суффикс» «префикс-с-суффикс» Объекты длины 0 отбрасываются без уведомления. Это особенно полезно в сочетании с
Это особенно полезно в сочетании с , если :
имя <- "Хэдли"
time_of_day <- "утро"
день рождения <- ЛОЖЬ
str_c (
"Хорошо", время_дня, "", имя,
if (день рождения) "и С ДНЕМ РОЖДЕНИЯ",
"."
)
#> [1] "Доброе утро, Хэдли". Чтобы свернуть вектор строк в одну строку, используйте collapse :
str_c (c ("x", "y", "z"), collapse = ",")
#> [1] "x, y, z" Подмножество строк
Вы можете извлечь части строки с помощью str_sub () .Помимо строки, str_sub () принимает аргументы start и end , которые задают (включительно) позицию подстроки:
x <- c («Яблоко», «Банан», «Груша»)
str_sub (х, 1, 3)
#> [1] "App" "Ban" "Pea"
# отрицательные числа считают в обратном порядке от конца
str_sub (х, -3, -1)
#> [1] "ple" "ana" "ear" Обратите внимание, что str_sub () не завершится ошибкой, если строка слишком короткая: она просто вернет как можно больше:
str_sub ("а", 1, 5)
#> [1] "a" Вы также можете использовать форму назначения str_sub () для изменения строк:
str_sub (x, 1, 1) <- str_to_lower (str_sub (x, 1, 1))
Икс
#> [1] «яблоко» «банан» «груша» Регион
Выше я использовал str_to_lower () , чтобы изменить текст на нижний регистр. Вы также можете использовать
Вы также можете использовать str_to_upper () или str_to_title () . Однако изменить регистр сложнее, чем может показаться на первый взгляд, потому что разные языки имеют разные правила изменения регистра. Вы можете выбрать, какой набор правил использовать, указав локаль:
# Турецкий имеет два "i": с точкой и без нее, и это
# имеет другое правило использования заглавных букв:
str_to_upper (c ("я", "ı"))
#> [1] «Я» «Я»
str_to_upper (c ("i", "ı"), locale = "tr")
#> [1] «İ» «I» Локаль указывается в виде кода языка ISO 639, который представляет собой двух- или трехбуквенное сокращение.Если вы еще не знаете код своего языка, в Википедии есть хороший список. Если вы оставите языковой стандарт пустым, он будет использовать текущий языковой стандарт, предоставленный вашей операционной системой.
Еще одна важная операция, на которую влияет локаль, - это сортировка. Базовые функции R order () и sort () сортируют строки, используя текущую локаль. Если вам нужна надежная работа на разных компьютерах, вы можете использовать
Если вам нужна надежная работа на разных компьютерах, вы можете использовать str_sort () и str_order () , которые принимают дополнительный аргумент locale :
x <- c («яблоко», «баклажан», «банан»)
str_sort (x, locale = "en") # английский
#> [1] "яблоко" "банан" "баклажан"
str_sort (x, locale = "haw") # гавайский
#> [1] "яблоко" "баклажан" "банан" Упражнения
В коде, который не использует stringr, вы часто будете видеть
paste ()иpaste0 ().В чем разница между двумя функциями? Какие функции Stringr они эквивалентны? Чем отличаются функции по обработкеNA?Опишите своими словами разницу между
sepиcollapseаргументы дляstr_c ().Используйте
str_length ()иstr_sub ()для извлечения среднего символа из строка. Что вы будете делать, если в строке будет четное количество символов?Что делает
str_wrap ()? Когда вы можете захотеть его использовать?Что делает
str_trim ()? Что противоположноstr_trim ()?Напишите функцию, которая поворачивает (например,g.
) вектор c («a», «b», «c»)в строкаa, b и c. Тщательно подумайте, что ему делать, если задан вектор длиной 0, 1 или 2.
 ) вектор
) вектор Сопоставление шаблонов с регулярными выражениями
Регулярные выражения - очень краткий язык, который позволяет описывать шаблоны в строках. На их понимание уходит время, но как только вы их поймете, вы найдете их чрезвычайно полезными.
Для изучения регулярных выражений мы будем использовать str_view () и str_view_all () .Эти функции принимают вектор символов и регулярное выражение и показывают, как они совпадают. Мы начнем с очень простых регулярных выражений, а затем постепенно будем усложнять их. Освоив сопоставление с образцом, вы научитесь применять эти идеи с различными строковыми функциями.
Основные матчи
Самые простые шаблоны соответствуют точным строкам:
x <- c («яблоко», «банан», «груша»)
str_view (x, "an") Следующая ступень сложности - ., что соответствует любому символу (кроме новой строки):
Но если «. »соответствует любому символу, как сопоставить символ« . ”? Вам нужно использовать «escape», чтобы сообщить регулярному выражению, которое вы хотите точно сопоставить, а не использовать его особое поведение. Подобно строкам, регулярные выражения используют обратную косую черту, \ , чтобы избежать особого поведения. Итак, чтобы соответствовать . , вам нужно регулярное выражение \. . К сожалению, это создает проблему. Мы используем строки для представления регулярных выражений, а \ также используется как escape-символ в строках.Итак, чтобы создать регулярное выражение \. нам нужна строка "\\." .
# Для создания регулярного выражения нам понадобится \\
точка <- "\\."
# Но само выражение содержит только один:
writeLines (точка)
#> \.
# И это говорит R искать явное.
str_view (c ("abc", "a. c", "bef"), "a \\. c") 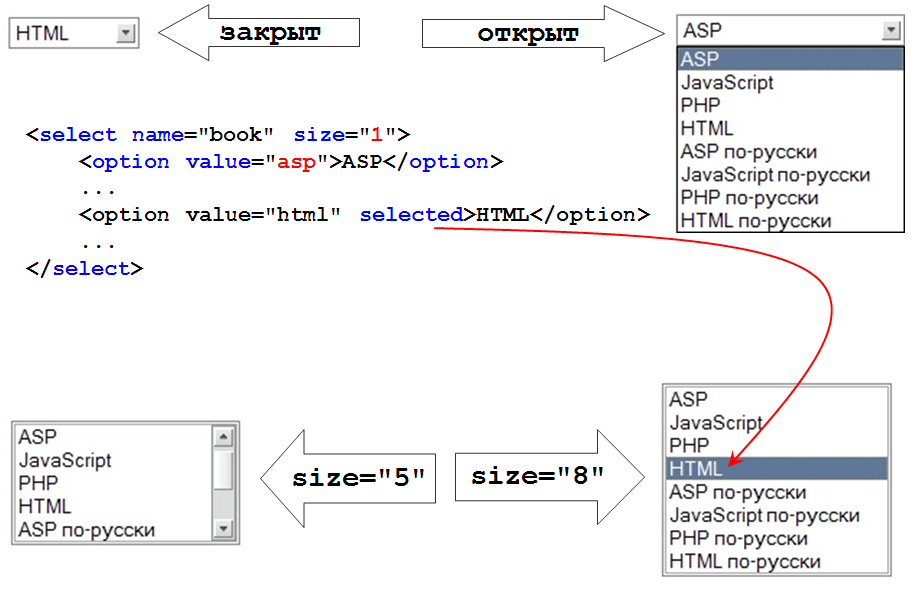 c", "bef"), "a \\. c")
c", "bef"), "a \\. c") Если \ используется как escape-символ в регулярных выражениях, как вы сопоставите литерал \ ? Что ж, вам нужно избежать этого, создав регулярное выражение \ .Чтобы создать это регулярное выражение, вам нужно использовать строку, которая также должна экранировать \ . Это означает, что для сопоставления букв \ вам нужно написать "\\\\" - вам нужно четыре обратных косых черты, чтобы соответствовать одному!
х <- "а \\ б"
writeLines (x)
#> a \ b
str_view (x, "\\\\") В этой книге я буду писать регулярное выражение как \. и строки, представляющие регулярное выражение как "\\." .
Упражнения
Объясните, почему каждая из этих строк не соответствует
\:"\","\\","\\\".Как бы вы сопоставили последовательность
"'\?Каким шаблонам будет соответствовать регулярное выражение
\ ., чтобы соответствовать началу строки. и $:x <- c («яблочный пирог», «яблоко», «яблочный пирог») str_view (x, "яблоко")Вы также можете сопоставить границу между словами с
\ b. Я не часто использую это в R, но иногда я использую его, когда выполняю поиск в RStudio, когда я хочу найти имя функции, которая является компонентом других функций. Например, я буду искать\ bsum \ b, чтобы не совпадать, сводка, сводкастрок, суммаи т. Д.$ "?Учитывая совокупность общих слов в строке
stringr :: words, создайте регулярный выражения, которые находят все слова которые:- Начните с буквы «y».
- Окончание на «x»
- Ровно три буквы. (Не обманывайте, используя
str_length ()!) - Имейте семь или более букв.
Поскольку этот список длинный, вы можете использовать аргумент
matchдляstr_view (), чтобы показать только совпадающие или несовпадающие слова. abc] : соответствует чему угодно, кроме a, b или c.Создавайте регулярные выражения, чтобы найти все слова, которые:
Начинайте с гласной.
Это только согласные. (Подсказка: подумайте о сопоставлении «Не» - гласные.)
Заканчивается на
ed, но не наeed.Заканчивается на
ingилиise.
Эмпирически проверьте правило «i до e, кроме c».
Всегда ли за «q» следует «u»?
Напишите регулярное выражение, которое соответствует слову, если оно, вероятно, написано на британском, а не на американском английском.
Создайте регулярное выражение, которое будет соответствовать номерам телефонов, как обычно написано в вашей стране.
-
?: 0 или 1 -
+: 1 или более -
*: 0 или больше -
{n}: ровно n -
{n,}: n или более -
{, m}: не более m -
{n, m}: между n и m -
"\\ {. + \\}" -
\ d {4} - \ d {2} - \ d {2} -
"\\\\ {4}"

 abc] : соответствует чему угодно, кроме a, b или c.
abc] : соответствует чему угодно, кроме a, b или c. Помните, что для создания регулярного выражения, содержащего \ d или \ s , вам нужно экранировать \ для строки, поэтому вы наберете "\\ d" или "\ \ s ".
Символьный класс, содержащий один символ, является хорошей альтернативой экранированию обратной косой черты, когда вы хотите включить один метасимвол в регулярное выражение. Многие люди считают это более читаемым.
# Ищите буквальный символ, который обычно имеет особое значение в регулярном выражении
str_view (c ("abc", "a.c »,« a * c »,« a c »),« a [.] c »)
str_view (c («abc», «a.c», «a * c», «a c»), «. [*] C»)
str_view (c («abc», «a.c», «a * c», «a c»), «a []») Это работает для большинства (но не для всех) метасимволов регулярных выражений: $ . | ? * + ( ) [ {. и
и - .
Вы можете использовать чередование для выбора одного или нескольких альтернативных шаблонов. Например, abc | d..f будет соответствовать либо «abc», либо «глухой» . Обратите внимание, что приоритет для | является низким, поэтому abc | xyz соответствует abc или xyz , а не abcyz или abxyz . Как и в случае с математическими выражениями, если приоритеты когда-либо сбиваются с толку, используйте круглые скобки, чтобы прояснить, что вы хотите:
str_view (c ("серый", "серый"), "gr (e | a) y") Упражнения
Повторение
Следующий шаг в развитии - это контроль количества совпадений шаблона:
x <- "1888 год - самый длинный год в римских цифрах: MDCCCLXXXVIII"
str_view (x, "CC?") Обратите внимание, что приоритет этих операторов высок, поэтому вы можете написать: colou? R для соответствия американскому или британскому написанию.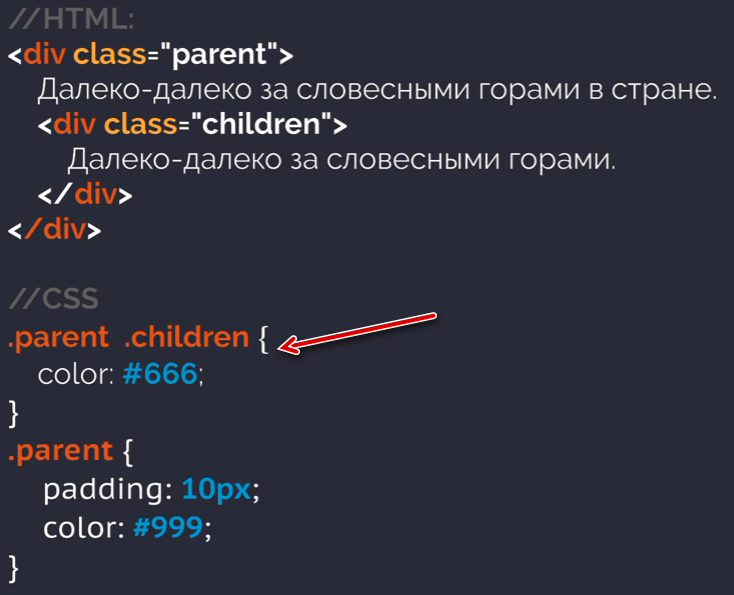 Это означает, что в большинстве случаев требуются круглые скобки, например,
Это означает, что в большинстве случаев требуются круглые скобки, например, bana (na) + .
Также можно точно указать количество совпадений:
По умолчанию эти совпадения являются «жадными»: они будут соответствовать самой длинной возможной строке. Вы можете сделать их «ленивыми», сопоставив самую короткую строку, указав ? после них.* $
Создавайте регулярные выражения, чтобы найти все слова, которые:
- Начните с трех согласных.
- Имеет три или более гласных подряд.
- Имеются две или более пары гласный-согласный подряд.
Решите кроссворды с регулярными выражениями для начинающих на
https://regexcrossword. com/challenges/beginner.
com/challenges/beginner.
Группировка и обратные ссылки
Ранее вы узнали о скобках как о способе устранения неоднозначности сложных выражений. Круглые скобки также создают группу захвата с номером (номер 1, 2 и т. Д.). Группа захвата хранит часть строки , совпадающую с частью регулярного выражения в круглых скобках. Вы можете ссылаться на тот же текст, который ранее соответствовал группе захвата с обратными ссылками , например, \ 1 , \ 2 и т. Д.Например, следующее регулярное выражение находит все фрукты с повторяющейся парой букв.
str_view (fruit, "(..) \\ 1", match = TRUE) (Вскоре вы также увидите, насколько они полезны в сочетании с str_match () .)
Упражнения
Опишите словами, чему будут соответствовать эти выражения:
-
(.) \ 1 \ 1 -
"(.) (.) \\ 2 \\ 1" -
(. .) \ 1 -
"(.). \\ 1. \\ 1" -
"(.) (.) (.). * \\ 3 \\ 2 \\ 1"
-
Создавать регулярные выражения для поиска слов, которые:
Начало и конец одного и того же символа.
Содержит повторяющуюся пару букв (например, «церковь» содержит дважды повторяемую букву «ч».)
Содержит одну букву, повторяющуюся как минимум в трех местах (например, «одиннадцать» содержит три «е».)
 .) \ 1
.) \ 1 Инструменты
Теперь, когда вы изучили основы регулярных выражений, пора научиться применять их к реальным задачам.В этом разделе вы познакомитесь с широким спектром строковых функций, которые позволят вам:
- Определите, какие строки соответствуют шаблону.
- Найдите позиции совпадений.
- Извлечь содержимое совпадений.
- Заменить совпадения новыми значениями.
- Разделить строку на основе совпадения.

Перед тем, как продолжить, сделаем небольшое предостережение: поскольку регулярные выражения настолько эффективны, легко попытаться решить любую проблему с помощью одного регулярного выражения.\ [\] \ r \\] | \\.) * \] (?: (?: \ r \ n)? [\ t]) *)) * \> (? 🙁 ?: \ r \ n)? [\ t]) *)) *)?; \ s *)
Это несколько патологический пример (потому что адреса электронной почты на самом деле удивительно сложны), но он используется в реальном коде. Подробнее см. Обсуждение stackoverflow на http://stackoverflow.com/a/201378.
Не забывайте, что вы изучаете язык программирования и в вашем распоряжении есть другие инструменты. Вместо создания одного сложного регулярного выражения часто проще написать серию более простых регулярных выражений.Если вы застряли, пытаясь создать одно регулярное выражение, которое решает вашу проблему, сделайте шаг назад и подумайте, можно ли разбить проблему на более мелкие части, решая каждую задачу, прежде чем переходить к следующей.
Обнаружить совпадения
Чтобы определить, соответствует ли вектор символов шаблону, используйте str_detect () . Он возвращает логический вектор той же длины, что и вход:
x <- c («яблоко», «банан», «груша»)
str_detect (x, "e")
#> [1] ИСТИНА ЛОЖЬ ИСТИНА Помните, что когда вы используете логический вектор в числовом контексте, FALSE становится 0, а TRUE становится 1.т "))
#> [1] 65
# Какая доля общих слов оканчивается на гласную?
означает (str_detect (слова, "[aeiou] $"))
#> [1] 0,2765306
Когда у вас есть сложные логические условия (например, соответствие a или b, но не c, кроме d), часто легче объединить несколько вызовов str_detect () с логическими операторами, чем пытаться создать одно регулярное выражение. Например, вот два способа найти все слова, не содержащие гласных:
# Найти все слова, содержащие хотя бы одну гласную, и исключить
no_vowels_1 <-! str_detect (слова, «[aeiou]»)
# Найти все слова, состоящие только из согласных (не гласных)
no_vowels_2 <- str_detect (слова, "^ [^ aeiou] + $")
идентичные (no_vowels_1, no_vowels_2)
#> [1] ИСТИНА Результаты идентичны, но я думаю, что первый подход значительно легче понять. Если ваше регулярное выражение становится чрезмерно сложным, попробуйте разбить его на более мелкие части, дать каждой части имя, а затем объединить части с помощью логических операций.
Если ваше регулярное выражение становится чрезмерно сложным, попробуйте разбить его на более мелкие части, дать каждой части имя, а затем объединить части с помощью логических операций.
Обычно str_detect () используется для выбора элементов, соответствующих шаблону. Вы можете сделать это с помощью логического подмножества или удобной оболочки str_subset () :
слов [str_detect (words, "x $")]
#> [1] "коробка" "секс" "шестерка" "налог"
str_subset (слова, "x $")
#> [1] «коробка» «пол» «шестерка» «налог» Однако, как правило, ваши строки представляют собой один столбец фрейма данных, и вместо этого вы хотите использовать фильтр:
df <- tibble (
слово = слова,
я = seq_along (слово)
)
df%>%
фильтр (str_detect (слово, "x $"))
#> # Стол: 4 x 2
#> слово i
#>
#> 1 коробка 108
#> 2 пол 747
#> 3 шесть 772
#> 4 налог 841 Вариант str_detect () : str_count () : вместо простого да или нет он сообщает вам, сколько совпадений в строке:
x <- c («яблоко», «банан», «груша»)
str_count (x, "а")
#> [1] 1 3 1
# Сколько в среднем гласных в слове?
означает (str_count (слова, "[aeiou]"))
#> [1] 1. aeiou] ")
)
#> # Стол: 980 x 4
#> слово i гласные согласные
#>
#> 1 а 1 1 0
#> 2 в состоянии 2 2 2
#> 3 примерно 3 3 2
#> 4 абсолютное 4 4 4
#> 5 принять 5 2 4
#> 6 счет 6 3 4
#> #… С еще 974 строками  aeiou] ")
)
#> # Стол: 980 x 4
#> слово i гласные согласные
#>
aeiou] ")
)
#> # Стол: 980 x 4
#> слово i гласные согласные
#> Обратите внимание, что совпадения никогда не перекрываются. Например, в «abababa» , сколько раз будет совпадать шаблон «aba» ? Регулярные выражения говорят два, а не три:
str_count ("abababa", "aba")
#> [1] 2
str_view_all ("abababa", "aba") Обратите внимание на использование str_view_all () .Как вы вскоре узнаете, многие строковые функции работают парами: одна функция работает с одним совпадением, а другая - со всеми совпадениями. Вторая функция будет иметь суффикс _all .
Упражнения
Для каждой из следующих задач попробуйте решить ее, используя как одну регулярное выражение и комбинация нескольких вызовов
str_detect ().Найдите все слова, которые начинаются или заканчиваются на
x.Найдите все слова, которые начинаются с гласной и заканчиваются согласной.
Существуют ли слова, содержащие хотя бы одно из разных гласный?
В каком слове больше всего гласных? Какое слово имеет высшее пропорция гласных? (Подсказка: какой знаменатель?)

Групповые матчи
Ранее в этой главе мы говорили об использовании круглых скобок для уточнения приоритета и для обратных ссылок при сопоставлении.] +) " has_noun <- предложения%>% str_subset (имя существительное)%>% голова (10) has_noun%>% str_extract (имя существительное) #> [1] "гладкая" "простыня" "глубина" "курица" "припаркованная" #> [6] "солнышко" "огромный" "мяч" "женщина" "помогает"
str_extract () дает нам полное совпадение; str_match () дает каждый отдельный компонент. Вместо вектора символов он возвращает матрицу с одним столбцом для полного соответствия, за которым следует один столбец для каждой группы:
Вместо вектора символов он возвращает матрицу с одним столбцом для полного соответствия, за которым следует один столбец для каждой группы:
has_noun%>%
str_match (имя существительное)
#> [, 1] [, 2] [, 3]
#> [1,] "гладкий" "" "гладкий"
#> [2,] "лист" "" "лист"
#> [3,] "глубина" "" "глубина"
#> [4,] "курица" "a" "курица"
#> [5,] "припаркованный" "" "припаркованный"
#> [6,] "солнце" "" "солнце"
#> [7,] "огромный" "" огромный "
#> [8,] "мяч" "" "мяч"
#> [9,] "женщина" "" женщина "
#> [10,] «а помогает» «а» «помогает» (Неудивительно, что наша эвристика для определения существительных неубедительна, и мы также подбираем такие прилагательные, как гладкий и припаркованный.] +) ",
remove = FALSE
)
#> # Таблица: 720 x 3
#> предложение статья существительное
#> Как и Найдите все слова, которые идут после «числа», например «один», «два», «три» и т. Д.
Вытяните и число, и слово. Найдите все схватки.Разделите части до и после
апостроф. С помощью Вместо замены на фиксированную строку вы можете использовать обратные ссылки для вставки компонентов соответствия. Заменить все косые черты в строке обратной косой чертой. Реализуйте простую версию Переключение первых и последних букв в Используйте Поскольку каждый компонент может содержать разное количество частей, возвращается список. Если вы работаете с вектором длины 1, проще всего просто извлечь первый элемент списка: В противном случае, как и другие строковые функции, возвращающие список, вы можете использовать Вы также можете запросить максимальное количество штук: Вместо того, чтобы разделять строки по шаблонам, вы также можете разделить их по символам, строкам, предложениям и словам Разделите строку, например Почему лучше разбить на Что делает разделение с пустой строкой ( В любом месте Highcharts, где встречаются текстовые строки, они допускают изменение с помощью форматеров форматов или форматов . Все параметры строки формата имеют соответствующие обратные вызовы средства форматирования. Тексты и метки в Highcharts представлены в HTML, но поскольку HTML анализируется и отображается в SVG, поддерживается только подмножество. Поддерживаются следующие теги: В большинстве мест, где текст обрабатывается в Highcharts, за ним также следует опция Использование HTML также позволяет устранить некоторые старые ошибки браузера с двунаправленным текстом. Подробнее читайте в разделе «Интернационализация». Обратите внимание, что это может стать угрозой безопасности из-за запуска неавторизованного кода в браузере, если содержимое метки поступает из ненадежного источника. Строки формата - это шаблоны для меток, в которые вставляются переменные. Строки формата были введены в Highcharts 2.3 и улучшены в 3.0, чтобы разрешить форматирование числа и даты. Примерами строк формата являются xAxis.labels.format, tooltip.pointFormat и legend.labelFormat. Переменные вставляются в скобках, например Числа отформатированы с использованием подмножества соглашений о форматировании с плавающей запятой из библиотеки C функции sprintf. Форматирование добавляется в скобки переменных и разделяется двоеточием. Обратите внимание, что хотя точка и запятая символизируют десятичную точку и разделитель тысяч соответственно, то, как они отображаются на самом деле, зависит от языковых настроек.Например: Даты позволяют, как и числа, добавлять формат после двоеточия. Допустимые соглашения о формате такие же, как и для Highcharts.dateFormat (). Например: Для полного контроля над обработкой строк и дополнительных возможностей сценариев вокруг меток вы можете необходимо использовать обратные вызовы средства форматирования. Начиная с версии 6.0.6, модуль специальных возможностей поддерживает строки расширенного формата, а также обрабатывает массивы и множественные условные выражения. Параметры, к которым это относится, можно найти в lang.accessibility. Массивы можно индексировать следующим образом: Формат: 'Это первый индекс: {myArray [0]}.Последний: {myArray [-1]}. ' Контекст: {myArray: [0, 1, 2, 3, 4, 5]} Результат: 'Это первый индекс: 0. Последний: 5.' Их также можно повторить с помощью функции Формат: 'Список содержит: {#each (myArray) cm}' Контекст: {myArray: [0, 1, 2]} Результат: 'Список содержит: 0см 1см 2см' Функция Формат: 'Список содержит: {#each (myArray, -1),} и {myArray [-1]}.' Контекст: {myArray: [0, 1, 2, 3]} Результат: «Список содержит: 0, 1, 2 и 3.» Используйте функцию Формат: 'Имеет {numPoints} {#plural (numPoints, points, point}.' Контекст: {numPoints: 5} Результат: 'Имеет 5 точек.' Необязательно есть дополнительные параметры для двойного и нулевого числа: Формат: 'Имеет {#plural (numPoints, many points, one point, two points, none}. ' Контекст: {numPoints: 2} Результат:' Имеет две точки.' Параметры dual или none будут иметь приоритет, если они указаны. Синтаксически это строки, в которых используются обратные кавычки (например, `) вместо одинарных (') или двойных (") кавычек. Шаблонные литералы имеют три мотивации: Другой распространенный вариант использования - это когда вы хотите сгенерировать некоторую строку из некоторых статических строк + некоторых переменных.Для этого вам понадобится некоторая шаблонная логика , и именно здесь строк шаблона первоначально получили свое название. var lyrics = 'Никогда не откажусь от тебя'; var html = ' курица
#> 5 Рис часто подают в круглых мисках.
курица
#> 5 Рис часто подают в круглых мисках. str_extract () , если вы хотите, чтобы для каждой строки были все совпадения, вам понадобится str_match_all () . Упражнения
Замена спичек
str_replace () и str_replace_all () позволяют заменять совпадения новыми строками. Самый простой способ - заменить шаблон фиксированной строкой:
x <- c («яблоко», «груша», «банан»)
str_replace (x, «[aeiou]», «-»)
#> [1] "-pple" "p-ar" "b-nana"
str_replace_all (x, «[aeiou]», «-»)
#> [1] "-ppl-" "p - r" "b-n-n-" str_replace_all () вы можете выполнить несколько замен, указав именованный вектор:
x <- c («1 дом», «2 машины», «3 человека»)
str_replace_all (x, c ("1" = "один", "2" = "два", "3" = "три"))
#> [1] "один дом" "две машины" "три человека"  ] +) "," \\ 1 \\ 3 \\ 2 ")%>%
голова (5)
#> [1] «Каноэ-береза скользила по гладким доскам».
#> [2] "Приклейте лист к темно-синему фону".
#> [3] «Глубину колодца легко определить».
#> [4] «В наши дни куриная ножка - редкое блюдо».
#> [5] «Рис часто подают в круглых мисках».
] +) "," \\ 1 \\ 3 \\ 2 ")%>%
голова (5)
#> [1] «Каноэ-береза скользила по гладким доскам».
#> [2] "Приклейте лист к темно-синему фону".
#> [3] «Глубину колодца легко определить».
#> [4] «В наши дни куриная ножка - редкое блюдо».
#> [5] «Рис часто подают в круглых мисках». Упражнения
str_to_lower () с помощью replace_all () . словах . Какая из этих струн
еще слова? Колка
str_split () , чтобы разделить строку на части. Например, мы можем разбить предложения на слова:
предложений%>%
голова (5)%>%
str_split ("")
#> [[1]]
#> [1] "Байдарка" "береза" "скользнула" "по" "" гладью "
#> [8] "доски".
#>
#> [[2]]
#> [1] "Приклейте" "" лист "" к "" "
#> [6] "темный" "синий" "фон.  "
#>
#> [[3]]
#> [1] «Легко» «сказать» «о« глубине »» «колодца».
#>
#> [[4]]
#> [1] "В эти" "дни" "" "курица" "ножка" "" "" а "
#> [8] «редкое» «блюдо».
#>
#> [[5]]
#> [1] "Рис" "часто" подается "в" круглых "мисках."
"
#>
#> [[3]]
#> [1] «Легко» «сказать» «о« глубине »» «колодца».
#>
#> [[4]]
#> [1] "В эти" "дни" "" "курица" "ножка" "" "" а "
#> [8] «редкое» «блюдо».
#>
#> [[5]]
#> [1] "Рис" "часто" подается "в" круглых "мисках."
"a | b | c | d"%>%
str_split ("\\ |")%>%
.[[1]]
#> [1] "a" "b" "c" "d" simpleify = TRUE для возврата матрицы:
предложений%>%
голова (5)%>%
str_split ("", simpleify = ИСТИНА)
#> [, 1] [, 2] [, 3] [, 4] [, 5] [, 6] [, 7] [, 8]
#> [1,] "" березовое "каноэ" скользило "" по "" гладким "доскам".
#> [2,] "Приклейте" "" лист "" к "" "" темному "" синему "" фону."
#> [3,] "" легко "" "сказать" "" глубину "" "" а "
#> [4,] "В эти" "дни" "" курица "" ножка "" "" а "" редко "
#> [5,] "Рис" "часто" подается "в" круглых "мисках. 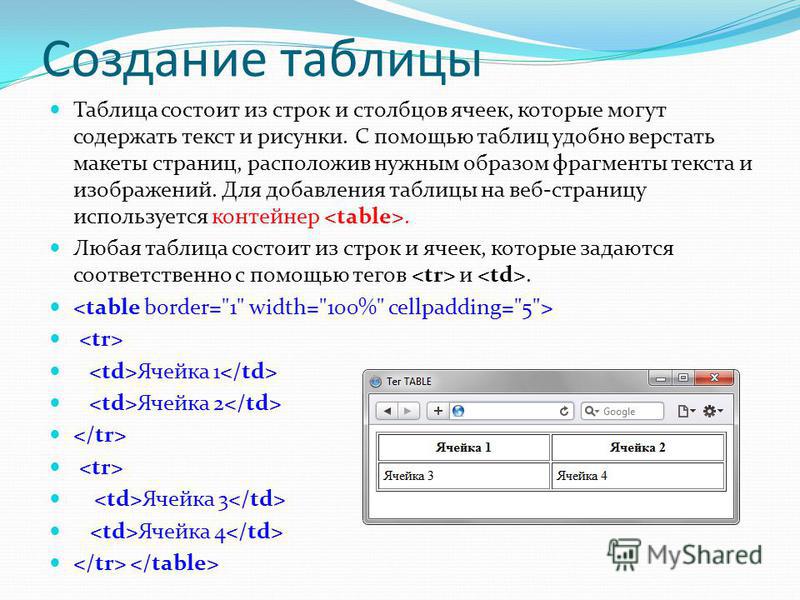 " ""
#> [, 9]
#> [1,] ""
#> [2,] ""
#> [3,] "хорошо".
#> [4,] "блюдо".
#> [5,] ""
" ""
#> [, 9]
#> [1,] ""
#> [2,] ""
#> [3,] "хорошо".
#> [4,] "блюдо".
#> [5,] ""
полей <- c ("Имя: Хэдли", "Страна: Новая Зеландия", "Возраст: 35")
поля%>% str_split (":", n = 2, simpleify = TRUE)
#> [, 1] [, 2]
#> [1,] "Имя" "Хэдли"
#> [2,] "Country" "NZ"
#> [3,] "Возраст" "35" border () s:
x <- "Это приговор.Это еще одно предложение ".
str_view_all (x, граница ("слово"))
str_split (x, "") [[1]]
#> [1] «Это» «есть» «предложение». "" "Этот"
#> [7] "это" еще одно "предложение".
str_split (x, граница ("слово")) [[1]]
#> [1] "This" "is" "" предложение "" This "" is "" другое "
#> [8] "предложение" Упражнения
"яблоки, груши и бананы" на отдельные
составные части.
границу ("слово") , чем на "" ? "" )? Экспериментируйте и
затем прочтите документацию. Найти совпадения
str_locate () и str_locate_all () дают вам начальную и конечную позиции каждого совпадения. Это особенно полезно, когда ни одна из других функций не делает именно то, что вы хотите.Вы можете использовать str_locate (), , чтобы найти соответствующий шаблон, str_sub () , чтобы извлечь и / или изменить их. Ярлыки и форматирование строк | Highcharts
Ярлыки и форматирование строк #
 Хотя обратные вызовы средства форматирования обладают большей гибкостью, строки формата обычно более компактны и совместимы с JSON.
Хотя обратные вызовы средства форматирования обладают большей гибкостью, строки формата обычно более компактны и совместимы с JSON. HTML в Highcharts #
, , , , ,
. Для промежутков можно использовать атрибут стиля, но обрабатывается только связанный с текстом CSS, который используется совместно с SVG. useHTML .Если это так, текст размещается в виде HTML поверх диаграммы. Это обеспечивает полную поддержку HTML и может быть хорошей идеей, если вы хотите добавить изображения в свои ярлыки, таблицы в свою всплывающую подсказку и т. Д. Недостатки: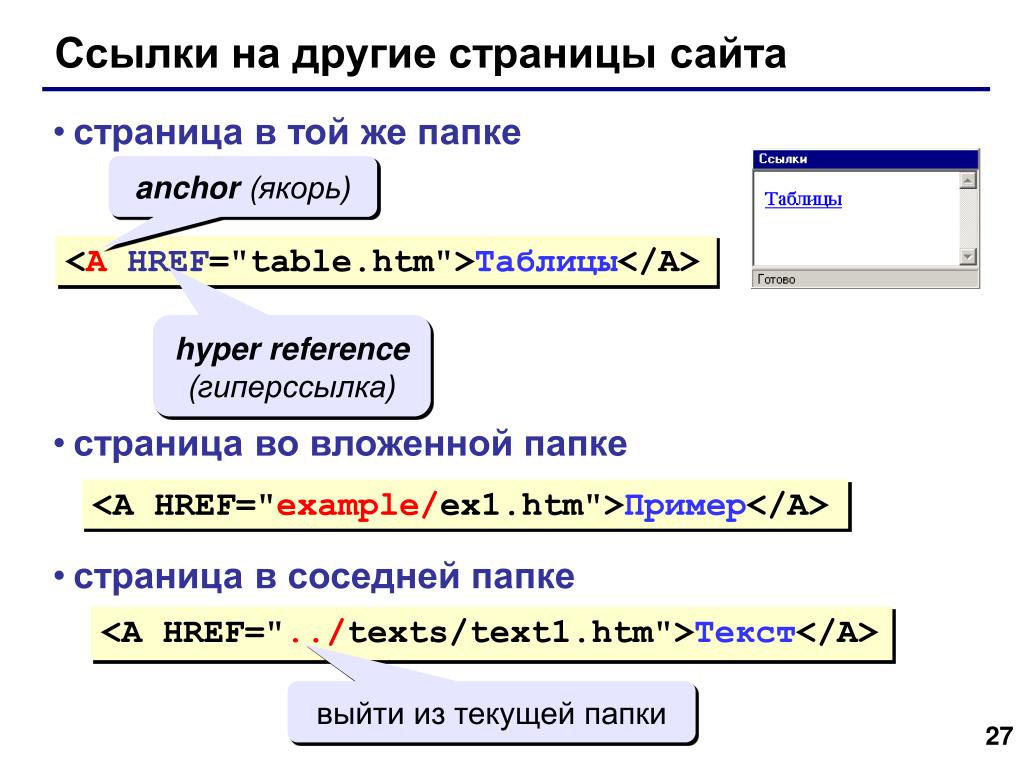 В частности, всплывающая подсказка может отображаться под меткой useHTML . Начиная с Highcharts v6.1.1 этого можно избежать, установив для tooltip.outside значение true.
В частности, всплывающая подсказка может отображаться под меткой useHTML . Начиная с Highcharts v6.1.1 этого можно избежать, установив для tooltip.outside значение true. Строки формата #
«Значение точки в {point.. x} равно {point.y}»
x} равно {point.y}» "{point.y: .2f}" [Демо] {point.y:,. 0f} [Демо] {point.y:,. 1f} [Демо, интернационализировано] {значение:% Y-% m-% d} [Демо] Обратные вызовы форматирования #
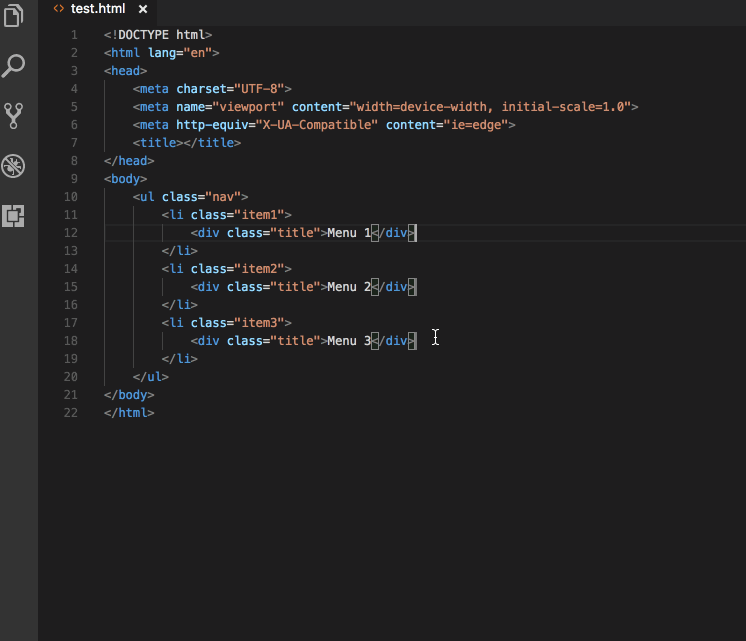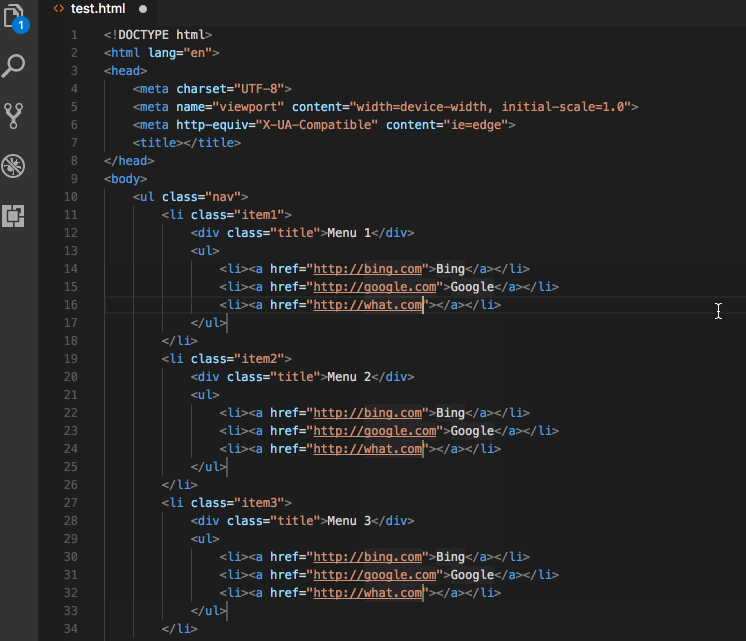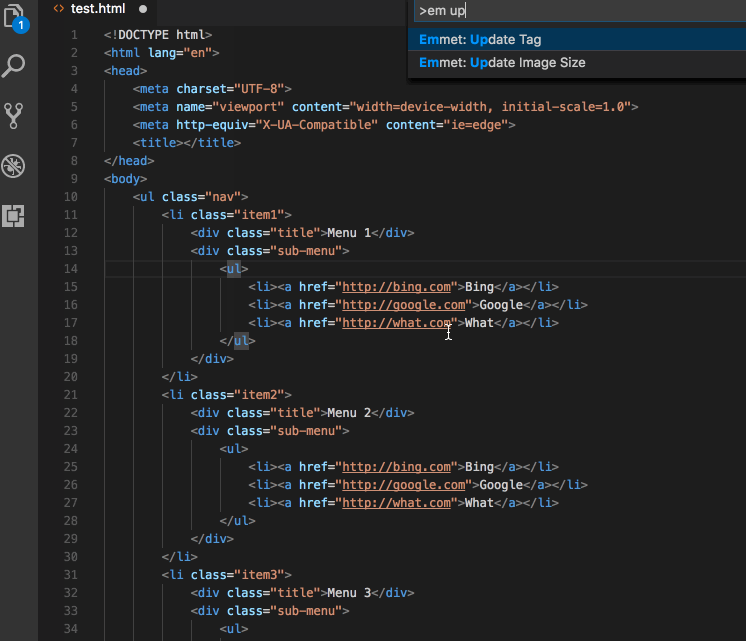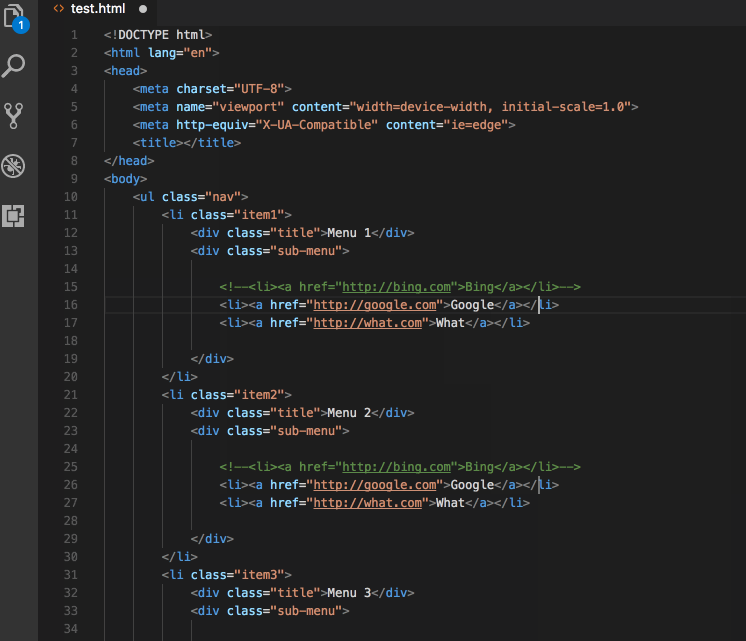 Эти средства форматирования возвращают HTML (подмножество). Примерами таких файлов являются xAxis.labels.formatter, tooltip.formatter и legend.labelFormatter. Часто вам нужно вызывать Highcharts.dateFormat () и Highcharts.numberFormat () из форматеров.
Эти средства форматирования возвращают HTML (подмножество). Примерами таких файлов являются xAxis.labels.formatter, tooltip.formatter и legend.labelFormatter. Часто вам нужно вызывать Highcharts.dateFormat () и Highcharts.numberFormat () из форматеров. Строки расширенного формата #
Копировать #each () . Это повторит содержимое выражения в скобках для каждого элемента. Пример:
Копировать #each () необязательно принимает параметр длины. Если положительный, этот параметр указывает максимальное количество элементов для итерации. Если отрицательный, функция вычтет число из длины массива. Используйте это, чтобы остановить итерацию до завершения массива. Пример:
Если положительный, этот параметр указывает максимальное количество элементов для итерации. Если отрицательный, функция вычтет число из длины массива. Используйте это, чтобы остановить итерацию до завершения массива. Пример:
Копировать #plural () , чтобы выбрать строку в зависимости от того, равен ли объект контекста 1.Основные аргументы: #plural (obj, множественное число, единственное число) . Пример:
Копировать #plural (obj, множественное число, единственное число, двойное число, нет) . Пример:
Пример:
Копировать Шаблонные строки - TypeScript Deep Dive
 С тех пор они были официально переименованы в шаблонные литералы . Вот как вы потенциально могли бы сгенерировать строку html ранее:
С тех пор они были официально переименованы в шаблонные литералы . Вот как вы потенциально могли бы сгенерировать строку html ранее:
Теперь с шаблонными литералами вы можете просто сделать:
var lyrics = 'Никогда не откажусь от тебя';
var html = `
$ {lyrics}`;
Обратите внимание, что любой заполнитель внутри интерполяции ( $ { и } ) обрабатывается как выражение JavaScript и оценивается как таковое. E.грамм. ты можешь заниматься причудливой математикой.
console.
 log (`1 и 1 составляют $ {1 + 1}`);
log (`1 и 1 составляют $ {1 + 1}`); f7d392ec589cb"> Вы когда-нибудь хотели вставить новую строку в строку JavaScript? Возможно, вы хотели вставить текст? Вам нужно было бы экранировать буквальную новую строку , используя наш любимый escape-символ \ , а затем вручную ввести новую строку в строку \ n на следующей строке. Это показано ниже:
var lyrics = "Никогда не сдам тебя \
\ nНикогда не подведу";
С TypeScript вы можете просто использовать строку шаблона:
var lyrics = `Никогда не дам тебя
Никогда не подведу`;
Вы можете поместить функцию (называемую тегом ) перед строкой шаблона, и она получит возможность предварительно обработать строковые литералы шаблона плюс значения всех выражений-заполнителей и вернуть результат. Несколько примечаний:
Несколько примечаний:
Все статические литералы передаются как массив для первого аргумента.
Все значения выражений заполнителей передаются в качестве оставшихся аргументов. Чаще всего вы просто используете остальные параметры, чтобы преобразовать их в массив.
Вот пример, в котором у нас есть функция тега (с именем htmlEscape ), которая экранирует html из всех заполнителей:
var say = "птица в руке> два в кустах";
var html = htmlEscape `
Я просто хочу сказать: $ {say}`;
function htmlEscape (литералы: TemplateStringsArray,...placeholder: строка []) {
let result = "";
для (let i = 0; i
length; i ++) {
result + = literals [i];
результат + = заполнители [i]
.replace (/ & / g, '& amp;')
.replace (/ "/ g, '& quot;')
.replace (/ '/ g,' & # 39; ')
.replace (/
.replace (/> / g,' & gt; ');
}
результат + = литералы [ литералы.длина - 1];
вернуть результат;
}
Примечание. Вы можете аннотировать
заполнителикак любые[]. Что бы вы ни аннотировали, TypeScript выполнит проверку типа, чтобы убедиться, что заполнители, используемые для вызова тега, соответствуют аннотации. Например, если вы ожидаете иметь дело со строкойиличислом, вы можете аннотировать.
 .. заполнители: (строка | число) []
.. заполнители: (строка | число) [] Для целей компиляции до ES6 код довольно прост.Многострочные строки становятся экранированными строками. Интерполяция строк становится конкатенацией строк . Шаблоны с тегами становятся вызовами функций.
Многострочные строки и интерполяция строк - отличные возможности для любого языка. Замечательно, что теперь вы можете использовать их в своем JavaScript (спасибо TypeScript!). Шаблоны с тегами позволяют создавать мощные строковые утилиты.
URL Encode Decode - процентное кодирование и декодирование URL.
Используйте онлайн-инструмент, указанный выше, для кодирования или декодирования строки текста.Для всемирной совместимости URI должны кодироваться единообразно. Чтобы сопоставить широкий диапазон символов, используемых во всем мире, с 60 или около того разрешенными символами в URI, используется двухэтапный процесс:
- Преобразование строки символов в последовательность байтов с использованием кодировки UTF-8
- Преобразует каждый байт, не являющийся буквой или цифрой ASCII, в% HH, где HH - шестнадцатеричное значение байта.
Например, строка: François, будет закодирована как: Fran% C3% A7ois
(«ç» кодируется в UTF-8 как два байта C3 (шестнадцатеричный) и A7 (шестнадцатеричный), которые затем записываются как три символа «% c3» и «% a7» соответственно.) Это может сделать URI довольно длинным (до 9 символов ASCII для одного символа Unicode), но намерение состоит в том, что браузерам нужно только для отображения декодированной формы, и многие протоколы могут отправлять UTF-8 без экранирования% HH.
Что такое кодировка URL?
Кодировка URL-адреса означает кодирование определенных символов в URL-адресе путем их замены одним или несколькими тройками символов, которые состоят из символ процента "% ", за которым следуют две шестнадцатеричные цифры.Две шестнадцатеричные цифры тройки (ей) представляют числовое значение заменяемого символа.
Термин URL-кодирование немного неточен, поскольку процедура кодирования не ограничивается URL-адреса (унифицированные указатели ресурсов), но также могут применяться к любым другие URI (унифицированные идентификаторы ресурсов) такие как URN (унифицированные имена ресурсов). Следовательно, следует предпочесть термин процентное кодирование.
Следовательно, следует предпочесть термин процентное кодирование.
Допустимые символы в URI: зарезервированных или незарезервированных (или символ процента как часть процентного кодирования). зарезервированных символов - это те символы, которые иногда имеют особое значение, в то время как незарезервированных символов не имеют такого смысл. Используя процентное кодирование, символы, которые в противном случае не были бы разрешены, представлены с использованием разрешенных символов. Наборы зарезервированных и незарезервированных символов и обстоятельства, при которых определенные зарезервированные символы имеют особое значение незначительно менялись с каждым пересмотром спецификаций, управляющих URI и схемами URI.
Согласно RFC 3986, символы в URL должны быть взяты из определенного набора незарезервированных и зарезервированных символов ASCII. В URL нельзя использовать любые другие символы.
Незарезервированные символы могут кодироваться, но не должны кодироваться. Незарезервированные символы:
Незарезервированные символы:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЫЭЮЯ
0 1 2 3 4 5 6 7 8 9 - _. ~
Зарезервированные символы должны кодироваться только при определенных обстоятельствах.Зарезервированные символы:
! * '(); : @ & = + $, /? % # []
RFC 3986 не определяет, в соответствии с каким символом таблица кодирования не-ASCII символов (например, умляуты ä, ö, ü) должны быть закодированным. Поскольку кодирование URL-адреса включает пару шестнадцатеричных цифр, а поскольку пара шестнадцатеричных цифр эквивалентна 8 битам, это будет теоретически можно использовать одну из 8-битных кодовых страниц для символов, отличных от ASCII (например,грамм. ISO-8859-1 для умляутов).
С другой стороны, поскольку многие языки имеют свою собственную 8-битную кодовую страницу, обработка всех этих различных 8-битных кодовых страниц была бы довольно сложной задачей. громоздкое дело. Некоторые языки даже не помещаются в 8-битную кодовую страницу (например, китайский). Следовательно, RFC 3629 предлагает использовать Таблица кодировки символов UTF-8 для символов, отличных от ASCII. Следующий инструмент учитывает это и предлагает выбрать между таблицей кодировки символов ASCII и символом UTF-8. таблица кодирования.Если вы выберете таблицу кодировки символов ASCII, появится предупреждающее сообщение, если URL-адрес закодирован / декодирован текст содержит символы, отличные от ASCII.
громоздкое дело. Некоторые языки даже не помещаются в 8-битную кодовую страницу (например, китайский). Следовательно, RFC 3629 предлагает использовать Таблица кодировки символов UTF-8 для символов, отличных от ASCII. Следующий инструмент учитывает это и предлагает выбрать между таблицей кодировки символов ASCII и символом UTF-8. таблица кодирования.Если вы выберете таблицу кодировки символов ASCII, появится предупреждающее сообщение, если URL-адрес закодирован / декодирован текст содержит символы, отличные от ASCII.
При отправке данных, которые были введены в формы HTML, имена и значения полей формы кодируются и отправляются на сервер в Сообщение HTTP-запроса с использованием метода GET или POST, или, исторически, по электронной почте. Кодировка, используемая по умолчанию, основана на очень ранней версии общих правил процентного кодирования URI с рядом модификаций, таких как нормализация новой строки и замена пробелов с « + » вместо «% 20 ». Тип данных MIME, закодированных таким образом, -
Тип данных MIME, закодированных таким образом, - application / x-www-form-urlencoded , и в настоящее время он определен (все еще очень устаревшим) в спецификациях HTML и XForms. В дополнение Спецификация CGI содержит правила того, как веб-серверы декодируют данные этого типа и делают их доступными для приложений.
При отправке в запросе HTTP GET данные application / x-www-form-urlencoded включаются в компонент запроса URI запроса. При отправке в запросе HTTP POST или по электронной почте данные помещаются в тело сообщения, а имя типа мультимедиа включается в заголовок Content-Type сообщения.
Запрос строки запроса | Ссылка на Elasticsearch [7.11]
Строка запроса «мини-язык» используется
Строка запроса и q Параметр строки запроса в API поиска .
Строка запроса разбивается на серию из терминов и операторов . А
термин может быть одним словом - quick или brown - или фразой, окруженной
двойные кавычки - "quick brown" - поиск всех слов в
фразу в том же порядке.
позволяют настраивать поиск - доступные параметры объяснено ниже.
Вы можете указать поля для поиска в синтаксисе запроса:
, где поле статуса
активныхстатус: активный
, где
заголовокполе содержитquickиликоричневыйназвание: (быстрое ИЛИ коричневое)
, где
авторполе содержит точную фразу"john smith"автор: "Джон Смит"
, где поле имени
Алиса(обратите внимание, как нам нужно избежать пробел с обратной косой чертой)имя \ имя: Алиса
где любое из полей
книга.название,book.contentилиbook.dateсодержитquickиликоричневый(обратите внимание, как нам нужно избежать*с помощью обратной косой черты):книга.
\ * :( быстро ИЛИ коричневый) , где поле
titleимеет любое ненулевое значение:_exists_: title
 \ * :( быстро ИЛИ коричневый)
\ * :( быстро ИЛИ коричневый) Поиск с подстановочными знаками может выполняться на отдельных условиях, используя ? заменить
один символ и * для замены нуля или более символов:
qu? Ck братан *
Имейте в виду, что запросы с подстановочными знаками могут использовать огромный объем памяти и
работают очень плохо - просто подумайте, сколько терминов нужно запросить
соответствует строке запроса "a * b * c *" .
Чистые подстановочные знаки \ * переписываются на существует запросов для повышения эффективности.
Как следствие, подстановочный знак "поле: *" будет соответствовать документам с пустым значением.
например:
{
"поле": ""
} ... и не совпадет с , если поле отсутствует или установлено с явным нулем значение как следующее:
{
"поле": ноль
} Разрешение подстановочного знака в начале слова (например, "* ing" ) особенно важно
тяжелый, потому что все термины в указателе нужно проверить, на всякий случай
они совпадают. Ведущие подстановочные знаки можно отключить, установив
Ведущие подстановочные знаки можно отключить, установив allow_leading_wildcard до ложь .
Только части цепочки анализа, которые работают на уровне персонажа, применяется. Так, например, если анализатор выполняет и нижний регистр, и стемминг будет применяться только в нижнем регистре: было бы неправильно выполнять происходит от слова, в котором отсутствуют некоторые буквы.
Если для параметра analysis_wildcard установлено значение true, запросы, заканчивающиеся на * , будут
проанализированы, и логический запрос будет построен из разных токенов,
обеспечение точных совпадений на первых токенах N-1 и совпадения префиксов на последних
токен.
Шаблоны регулярных выражений могут быть встроены в строку запроса с помощью
заключая их в косую черту ( "/ ):
имя: / joh? N (ath [oa] n) /
Поддерживаемый синтаксис регулярного выражения объясняется в Синтаксис регулярного выражения .
Параметр allow_leading_wildcard не контролирует
обычные выражения. Строка запроса, подобная следующей, заставит
Elasticsearch для посещения каждого термина в индексе:
/.* п /
Используйте с осторожностью!
Мы можем искать термины, которые похожи, но не совсем на наши поисковые запросы, с использованием «нечеткого» оператор:
quikc ~ brwn ~ foks ~
Здесь используется Расстояние Дамерау-Левенштейна найти все термины с максимальным количеством два изменения, где изменение - это вставка, удаление или замена одного символа, или перестановка двух соседних символы.
Расстояние редактирования по умолчанию равно 2 , но расстояние редактирования 1 должно быть
достаточно, чтобы поймать 80% всех человеческих орфографических ошибок.Его можно указать как:
quikc ~ 1
Избегайте смешивания нечеткости с подстановочными знаками
Смешивание операторов нечетких и подстановочных знаков не поддерживается . При смешивании один из операторов не применяется. Например,
вы можете искать приложение
При смешивании один из операторов не применяется. Например,
вы можете искать приложение ~ 1 (нечеткое) или приложение * (подстановочный знак), но поиск приложение * ~ 1 не применять нечеткий оператор ( ~ 1 ).
В то время как фразовый запрос (например, "john smith" ) ожидает, что все термины будут точно
в том же порядке, запрос близости позволяет указанным словам быть дальше
отдельно или в другом порядке.Точно так же, как нечеткие запросы могут
указать максимальное расстояние редактирования для символов в слове, поиск по близости
позволяет указать максимальное расстояние редактирования слов во фразе:
«лисица скорая» ~ 5
Чем ближе текст в поле к исходному порядку, указанному в
строка запроса, тем более релевантным считается этот документ. Когда
по сравнению с приведенным выше примером запроса фраза "quick fox" будет
более актуальным считается "бурый лисенок" .
Можно указать диапазоны для полей даты, числовых или строковых полей. Инклюзивные диапазоны
указаны в квадратных скобках [min TO max] , а исключительные диапазоны - с
фигурные скобки {min TO max} .
Всего дней в 2012 году:
дата: [2012-01-01 TO 2012-12-31]
Числа 1..5
количество: [от 1 до 5]
Теги между
alphaиomega, за исключениемalphaиomega:тег: {alpha TO omega}Числа от 10 до
количество: [10 TO *]
До 2012 г.
дата: {* TO 2012-01-01}
Фигурные и квадратные скобки можно комбинировать:
Диапазоны с одной неограниченной стороной могут использовать следующий синтаксис:
Возраст:> 10 возраст:> = 10 возраст: <10 возраст: <= 10
Чтобы объединить верхнюю и нижнюю границы с упрощенным синтаксисом, вы
нужно будет объединить два предложения с помощью оператора И :
возраст: (> = 10 И <20) возраст: (+> = 10 + <20)
Анализ диапазонов в строках запроса может быть сложным и подверженным ошибкам.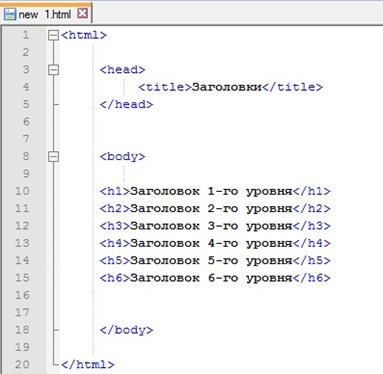 4
4
По умолчанию все термины являются необязательными, если соответствует один термин. Поиск
для foo bar baz найдет любой документ, содержащий один или несколько из foo или bar или baz . Мы уже обсуждали default_operator выше, что позволяет принудительно указать все условия, но есть
также логические операторы , которые могут использоваться в самой строке запроса
чтобы обеспечить больший контроль.
Предпочтительные операторы: + (должен присутствовать термин , ) и - (этот термин не должен присутствовать ).Все остальные условия необязательны.
Например, этот запрос:
quick brown + fox -news
заявляет, что:
-
лисадолжен присутствовать -
новостине должно быть -
quickикоричневыйнеобязательны - их наличие увеличивает актуальность
Знакомые логические операторы AND , OR и NOT (также записываются && , || и ! ) также поддерживаются, но имейте в виду, что они не соблюдают обычные
правила приоритета, поэтому круглые скобки следует использовать, когда несколько операторов
используется вместе. "~ *?: \ /
"~ *?: \ /
Неспособность правильно экранировать эти специальные символы может привести к синтаксической ошибке, которая препятствует выполнению вашего запроса.
< и > не может быть экранирован вообще. Единственный способ предотвратить их
попытка создать запрос диапазона - удалить их из строки запроса
полностью.
Пробелы и пустые запросыправить
Пробел не считается оператором.
Если строка запроса пуста или содержит только пробелы, запрос будет дает пустой набор результатов.
Избегайте использования запроса
query_string для вложенных документовправить query_string поиски не возвращают вложенные документы.Искать
вложенные документы используйте вложенный запрос .
Искать по нескольким полямправить
Вы можете использовать параметр fields для выполнения поиска query_string по
несколько полей.
Идея выполнения запроса query_string для нескольких полей состоит в том, чтобы
замените каждый термин запроса оператором ИЛИ следующим образом:
поле1: запрос_терм ИЛИ поле2: запрос_терм | ...
Например, следующий запрос
GET / _search
{
"запрос": {
"Строка запроса": {
"поля": ["содержание", "имя"],
"query": "это И то"
}
}
} соответствует тем же словам, что и
GET / _search
{
"запрос": {
"Строка запроса": {
"запрос": "(содержание: это ИЛИ имя: это) И (содержание: это ИЛИ имя: это)"
}
}
} Поскольку несколько запросов генерируются из отдельных условий поиска,
их объединение выполняется автоматически с помощью запроса dis_max с параметром tie_breaker .5 "],
"query": "это И то ИЛИ, таким образом",
"tie_breaker": 0
}
}
}
Простой подстановочный знак также можно использовать для поиска "внутри" определенных внутренних
элементы документа. Например, если у нас есть объект
Например, если у нас есть объект city с
несколько полей (или внутренний объект с полями) в нем, мы можем автоматически
поиск по всем полям "город":
GET / _search
{
"запрос": {
"Строка запроса" : {
"поля": ["город. *"],
"запрос": "это И то ИЛИ так"
}
}
} Другой вариант - обеспечить поиск полей с подстановочными знаками в запросе
сама строка (правильно экранирующая знак * ), например: г.\ *: что-то :
GET / _search
{
"запрос": {
"Строка запроса" : {
"запрос": "город. \\ * :( это И то ИЛИ таким образом)"
}
}
} Поскольку \ (обратная косая черта) является специальным символом в строках json, его необходимо
быть экранированным, следовательно, две обратные косые черты в приведенном выше запросе query_string .
Параметр fields может также включать имена полей на основе шаблонов,
позволяя автоматически расширяться до соответствующих полей (динамически
введенные поля включены). 5 "],
"запрос": "это И то ИЛИ так"
}
}
}
5 "],
"запрос": "это И то ИЛИ так"
}
}
}
Дополнительные параметры для поиска по нескольким полямправить
При выполнении запроса query_string для нескольких полей
Поддерживаются следующие дополнительные параметры.
-
тип (Необязательно, строка) Определяет, как запрос соответствует и оценивает документы. Действительный значения:
-
best_fields(по умолчанию) - Находит документы, соответствующие любому полю, и использует самые высокие
_scoreиз любого подходящего поля.Видетьbest_fields. -
bool_prefix - Создает запрос
match_bool_prefixдля каждого поля и объединяет_scoreиз каждое поле. См.bool_prefix. -
cross_fields - Обрабатывает поля с помощью того же анализатора
cross_fields. -
most_fields - Находит документы, соответствующие любому полю, и объединяет
_scoreиз каждого поля.См.most_fields. -
фраза - Выполняет запрос
match_phraseдля каждого поля и использует_scoreиз лучших поле. См. Фразу -
фраза_префикс - Выполняет запрос
match_phrase_prefixдля каждого поля и использует_scoreиз лучшее поле. См. Фразу
ПРИМЕЧАНИЕ: Дополнительные параметры верхнего уровня
multi_matchмогут быть доступны на основетипзначение.-
 Выглядит
для каждого слова в любом поле . См.
Выглядит
для каждого слова в любом поле . См. Синонимы и
query_string queryedit Запрос query_string поддерживает расширение синонимов с несколькими терминами с помощью фильтра токенов synonym_graph. При использовании этого фильтра парсер создает запрос фразы для каждого синонима, состоящего из нескольких терминов.
Например, следующий синоним:
При использовании этого фильтра парсер создает запрос фразы для каждого синонима, состоящего из нескольких терминов.
Например, следующий синоним: ny, new york произведет:
(ny OR ("Нью-Йорк"))
Также возможно сопоставление синонимов, состоящих из нескольких терминов, вместо союзов:
GET / _search
{
"запрос": {
"Строка запроса" : {
"default_field": "название",
"query": "ny city",
"auto_generate_synonyms_phrase_query": ложь
}
}
} В приведенном выше примере создается логический запрос:
(н-й OR (нью-энд-йорк)) город
, который соответствует документам с термином ny или соединением new AND york .По умолчанию для параметра auto_generate_synonyms_phrase_query установлено значение true .
Как
minimum_should_match работает для нескольких полейправить GET / _search
{
"запрос": {
"Строка запроса": {
"поля": [
"заглавие",
"содержание"
],
"query": "this that so",
"minimum_should_match": 2
}
}
} В приведенном выше примере создается логический запрос:
((content: this content: that content: so) | (title: this title: that title: so))
, который сопоставляет документы с дизъюнкцией max по полям title и содержание . Здесь нельзя применить параметр
Здесь нельзя применить параметр minimum_should_match .
GET / _search
{
"запрос": {
"Строка запроса": {
"поля": [
"заглавие",
"содержание"
],
"запрос": "это ИЛИ то ИЛИ таким образом",
"minimum_should_match": 2
}
}
} При добавлении явных операторов каждый термин следует рассматривать как отдельное предложение.
В приведенном выше примере создается логический запрос:
((content: this | title: this) (content: that | title: that) (content: Таким образом | заголовок: таким образом)) ~ 2
, который сопоставляет документы как минимум с двумя из трех пунктов "следует", каждое из они составлены из дизъюнкции max по полям для каждого члена.
Как
minimum_should_match работает для поиска по нескольким полямправить Значение cross_fields в поле типа указывает поля с одинаковыми
анализаторы группируются вместе при анализе входа.
GET / _search
{
"запрос": {
"Строка запроса": {
"поля": [
"заглавие",
"содержание"
],
"запрос": "это ИЛИ то ИЛИ таким образом",
"тип": "кросс-поля",
"minimum_should_match": 2
}
}
} В приведенном выше примере создается логический запрос:
(смешанный (условия: [поле2: это, поле1: это]) смешанный (условия: [поле2: то, поле1: то]) смешанный (условия: [поле2: таким образом, поле1: таким образом])) ~ 2
, который сопоставляет документы по крайней мере с двумя из трех смешанных запросов на термин.
.