Кодировка HTML уроки для начинающих академия
❮ Назад Дальше ❯
Для правильного отображения HTML-страницы веб-обозреватель должен знать, какой набор символов (кодировка) следует использовать.
Что такое кодировка символов?
ASCII был первым стандартом кодировки символов (также называемым набором символов). ASCII определены 128 различных буквенно-цифровых символов, которые могут быть использованы в Интернете: цифры (0-9), английские буквы (a-Z), и некоторые специальные символы, как! $ +-() @ < >.
ANSI (Windows-1252) был оригинальный набор символов Windows, с поддержкой 256 различных кодов символов.
ISO-8859-1 был стандартным набором символов для HTML 4. Этот набор символов также поддерживает 256 различные коды символов.
Так как ANSI и ISO-8859-1 были настолько ограничены, HTML 4 также поддерживал UTF-8.
UTF-8 (Юникод) охватывает почти все символы и символы в мире.
Кодировка символов по умолчанию для HTML5 — UTF-8.
Атрибут HTML-кодировки
Для правильного отображения HTML-страницы веб-обозреватель должен знать кодировку, используемую на странице.
Это указано в теге <meta> :
Для HTML4:
<meta http-equiv=»Content-Type» content=»text/html;charset=ISO-8859-1″>
Для HTML5:
<meta charset=»UTF-8″>
Если браузер обнаруживает ISO-8859-1 на веб-странице, по умолчанию используется ANSI, так как ANSI идентичен ISO-8859-1 за исключением того, что ANSI имеет 32 дополнительных символов.
Различия между наборами символов
В следующей таблице показаны различия между наборами символов, описанными выше:
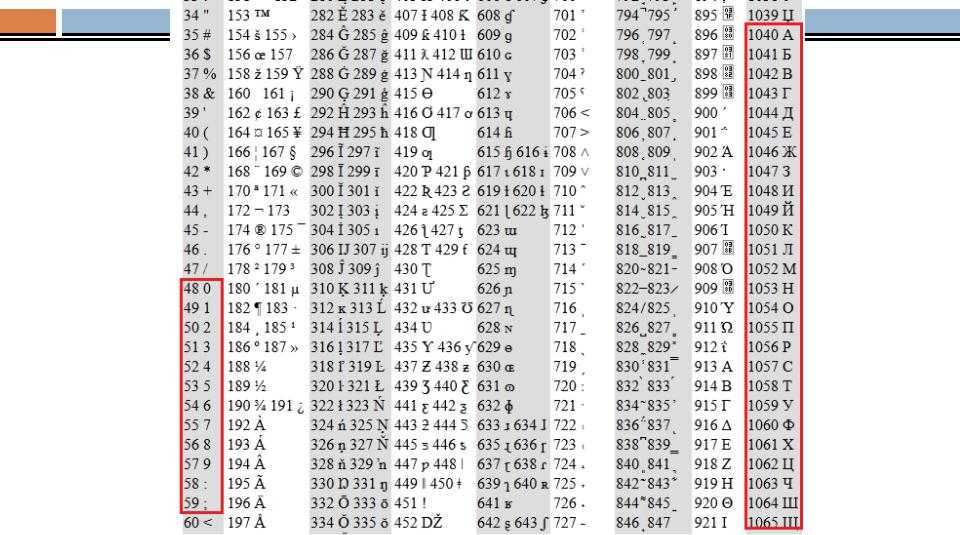
| Numb | ASCII | ANSI | 8859 | UTF-8 | Описание |
|---|---|---|---|---|---|
| 32 | space | ||||
| 33 | ! | ! | ! | ! | exclamation mark |
| 34 | « | « | « | « | quotation mark |
| 35 | # | # | # | # | number sign |
| 36 | $ | $ | $ | $ | dollar sign |
| 37 | % | % | % | % | percent sign |
| 38 | & | & | & | & | ampersand |
| 39 | ‘ | ‘ | ‘ | ‘ | apostrophe |
| 40 | ( | ( | ( | ( | left parenthesis |
| 41 | ) | ) | ) | ) | right parenthesis |
| 42 | * | * | * | * | asterisk |
| 43 | + | + | + | + | plus sign |
| 44 | , | , | , | , | comma |
| 45 | — | — | — | — | hyphen-minus |
| 46 | . | . | . | . | full stop |
| 47 | / | / | / | / | solidus |
| 48 | 0 | 0 | 0 | 0 | digit zero |
| 49 | 1 | 1 | 1 | 1 | digit one |
| 50 | 2 | 2 | 2 | 2 | digit two |
| 51 | 3 | 3 | 3 | 3 | digit three |
| 52 | 4 | 4 | 4 | 4 | digit four |
| 53 | 5 | 5 | 5 | 5 | digit five |
| 54 | 6 | 6 | 6 | 6 | digit six |
| 55 | 7 | 7 | 7 | 7 | digit seven |
| 56 | 8 | 8 | 8 | 8 | digit eight |
| 57 | 9 | 9 | 9 | 9 | digit nine |
| 58 | : | : | : | : | colon |
| 59 | ; | ; | ; | ; | semicolon |
| 60 | < | < | < | < | less-than sign |
| 61 | = | = | = | = | equals sign |
| 62 | > | > | > | > | greater-than sign |
| 63 | ? | ? | ? | ? | question mark |
| 64 | @ | @ | @ | @ | commercial at |
| 65 | A | A | A | A | Latin capital letter A |
| 66 | B | B | B | B | Latin capital letter B |
| 67 | C | C | C | C | Latin capital letter C |
| 68 | D | D | D | D | Latin capital letter D |
| 69 | E | E | E | E | Latin capital letter E |
| 70 | F | F | F | F | Latin capital letter F |
| 71 | G | G | G | G | Latin capital letter G |
| 72 | H | H | H | H | Latin capital letter H |
| 73 | I | I | I | I | Latin capital letter I |
| 74 | J | J | J | J | Latin capital letter J |
| 75 | K | K | K | K | Latin capital letter K |
| 76 | L | L | L | L | Latin capital letter L |
| 77 | M | M | M | M | Latin capital letter M |
| 78 | N | N | N | N | Latin capital letter N |
| 79 | O | O | O | O | Latin capital letter O |
| 80 | P | P | P | P | Latin capital letter P |
| 81 | Q | Q | Q | Q | Latin capital letter Q |
| 82 | R | R | R | R | Latin capital letter R |
| 83 | S | S | S | S | Latin capital letter S |
| 84 | T | T | T | T | Latin capital letter T |
| 85 | U | U | U | U | Latin capital letter U |
| 86 | V | V | V | Latin capital letter V | |
| 87 | W | W | W | W | Latin capital letter W |
| 88 | X | X | X | X | Latin capital letter X |
| 89 | Y | Y | Y | Y | Latin capital letter Y |
| 90 | Z | Z | Z | Z | Latin capital letter Z |
| 91 | [ | [ | [ | [ | left square bracket |
| 92 | \ | \ | \ | \ | reverse solidus |
| 93 | ] | ] | ] | ] | right square bracket |
| 94 | ^ | ^ | ^ | ^ | circumflex accent |
| 95 | _ | _ | _ | _ | low line |
| 96 | ` | ` | ` | ` | grave accent |
| 97 | a | a | a | a | Latin small letter a |
| 98 | b | b | b | b | Latin small letter b |
| 99 | c | c | c | c | Latin small letter c |
| 100 | d | d | d | d | Latin small letter d |
| 101 | e | e | e | e | Latin small letter e |
| 102 | f | f | f | f | Latin small letter f |
| 103 | g | g | g | g | Latin small letter g |
| 104 | h | h | h | h | Latin small letter h |
| 105 | i | i | i | i | Latin small letter i |
| 106 | j | j | j | j | Latin small letter j |
| 107 | k | k | k | k | Latin small letter k |
| 108 | l | l | l | l | Latin small letter l |
| 109 | m | m | m | m | Latin small letter m |
| 110 | n | n | n | n | Latin small letter n |
| 111 | o | o | o | o | Latin small letter o |
| 112 | p | p | p | p | Latin small letter p |
| 113 | q | q | q | q | Latin small letter q |
| 114 | r | r | r | r | Latin small letter r |
| 115 | s | s | s | s | Latin small letter s |
| 116 | t | t | t | t | Latin small letter t |
| 117 | u | u | u | u | Latin small letter u |
| 118 | v | v | v | v | Latin small letter v |
| 119 | w | w | w | w | Latin small letter w |
| 120 | x | x | x | x | Latin small letter x |
| 121 | y | y | y | y | Latin small letter y |
| 122 | z | z | z | z | Latin small letter z |
| 123 | { | { | { | { | left curly bracket |
| 124 | | | | | | | | | vertical line |
| 125 | } | } | } | } | right curly bracket |
| 126 | ~ | ~ | ~ | ~ | tilde |
| 127 | DEL | ||||
| 128 | | euro sign | |||
| 129 | | | | NOT USED | |
| 130 | | single low-9 quotation mark | |||
| 131 | | Latin small letter f with hook | |||
| 132 | | double low-9 quotation mark | |||
| 133 | horizontal ellipsis | ||||
| 134 | | dagger | |||
| 135 | | double dagger | |||
| 136 | | modifier letter circumflex accent | |||
| 137 | | per mille sign | |||
| 138 | | Latin capital letter S with caron | |||
| 139 | | single left-pointing angle quotation mark | |||
| 140 | | Latin capital ligature OE | |||
| 141 | | | | NOT USED | |
| 142 | | Latin capital letter Z with caron | |||
| 143 | | | | NOT USED | |
| 144 | | | | NOT USED | |
| 145 | | left single quotation mark | |||
| 146 | | right single quotation mark | |||
| 147 | | left double quotation mark | |||
| 148 | | right double quotation mark | |||
| 149 | | bullet | |||
| 150 | | en dash | |||
| 151 | | em dash | |||
| 152 | | small tilde | |||
| 153 | | trade mark sign | |||
| 154 | | Latin small letter s with caron | |||
| 155 | | single right-pointing angle quotation mark | |||
| 156 | | Latin small ligature oe | |||
| 157 | | | | NOT USED | |
| 158 | | Latin small letter z with caron | |||
| 159 | | Latin capital letter Y with diaeresis | |||
| 160 | no-break space | ||||
| 161 | ¡ | ¡ | ¡ | inverted exclamation mark | |
| 162 | ¢ | ¢ | ¢ | cent sign | |
| 163 | £ | £ | £ | pound sign | |
| 164 | ¤ | ¤ | ¤ | currency sign | |
| 165 | ¥ | ¥ | ¥ | yen sign | |
| 166 | ¦ | ¦ | ¦ | broken bar | |
| 167 | § | § | § | section sign | |
| 168 | ¨ | ¨ | ¨ | diaeresis | |
| 169 | © | © | © | copyright sign | |
| 170 | ª | ª | ª | feminine ordinal indicator | |
| 171 | « | « | « | left-pointing double angle quotation mark | |
| 172 | ¬ | ¬ | ¬ | not sign | |
| 173 | | | | soft hyphen | |
| 174 | ® | ® | ® | registered sign | |
| 175 | ¯ | ¯ | ¯ | macron | |
| 176 | ° | ° | ° | degree sign | |
| 177 | ± | ± | ± | plus-minus sign | |
| 178 | ² | ² | ² | superscript two | |
| 179 | ³ | ³ | ³ | superscript three | |
| 180 | ´ | ´ | ´ | acute accent | |
| 181 | µ | µ | µ | micro sign | |
| 182 | ¶ | ¶ | ¶ | pilcrow sign | |
| 183 | · | · | · | middle dot | |
| 184 | ¸ | ¸ | ¸ | cedilla | |
| 185 | ¹ | ¹ | ¹ | superscript one | |
| 186 | º | º | º | masculine ordinal indicator | |
| 187 | » | » | » | right-pointing double angle quotation mark | |
| 188 | ¼ | ¼ | ¼ | vulgar fraction one quarter | |
| 189 | ½ | ½ | ½ | vulgar fraction one half | |
| 190 | ¾ | ¾ | ¾ | vulgar fraction three quarters | |
| 191 | ¿ | ¿ | ¿ | inverted question mark | |
| 192 | À | À | À | Latin capital letter A with grave | |
| 193 | Á | Á | Á | Latin capital letter A with acute | |
| 194 | Â | Â | Â | Latin capital letter A with circumflex | |
| 195 | Ã | Ã | Ã | Latin capital letter A with tilde | |
| 196 | Ä | Ä | Ä | Latin capital letter A with diaeresis | |
| 197 | Å | Å | Å | Latin capital letter A with ring above | |
| 198 | Æ | Æ | Æ | Latin capital letter AE | |
| 199 | Ç | Ç | Ç | Latin capital letter C with cedilla | |
| 200 | È | È | È | Latin capital letter E with grave | |
| 201 | É | É | É | Latin capital letter E with acute | |
| 202 | Ê | Ê | Ê | Latin capital letter E with circumflex | |
| 203 | Ë | Ë | Ë | Latin capital letter E with diaeresis | |
| 204 | Ì | Ì | Ì | Latin capital letter I with grave | |
| 205 | Í | Í | Í | Latin capital letter I with acute | |
| 206 | Î | Î | Î | Latin capital letter I with circumflex | |
| 207 | Ï | Ï | Ï | Latin capital letter I with diaeresis | |
| 208 | Ð | Ð | Ð | Latin capital letter Eth | |
| 209 | Ñ | Ñ | Ñ | Latin capital letter N with tilde | |
| 210 | Ò | Ò | Ò | Latin capital letter O with grave | |
| 211 | Ó | Ó | Ó | Latin capital letter O with acute | |
| 212 | Ô | Ô | Ô | Latin capital letter O with circumflex | |
| 213 | Õ | Õ | Õ | Latin capital letter O with tilde | |
| 214 | Ö | Ö | Ö | Latin capital letter O with diaeresis | |
| 215 | × | × | × | multiplication sign | |
| 216 | Ø | Ø | Ø | Latin capital letter O with stroke | |
| 217 | Ù | Ù | Ù | Latin capital letter U with grave | |
| 218 | Ú | Ú | Ú | Latin capital letter U with acute | |
| 219 | Û | Û | Û | Latin capital letter U with circumflex | |
| 220 | Ü | Ü | Ü | Latin capital letter U with diaeresis | |
| 221 | Ý | Ý | Ý | Latin capital letter Y with acute | |
| 222 | Þ | Þ | Þ | Latin capital letter Thorn | |
| 223 | ß | ß | ß | Latin small letter sharp s | |
| 224 | à | à | à | Latin small letter a with grave | |
| 225 | á | á | á | Latin small letter a with acute | |
| 226 | â | â | â | Latin small letter a with circumflex | |
| 227 | ã | ã | ã | Latin small letter a with tilde | |
| 228 | ä | ä | ä | Latin small letter a with diaeresis | |
| 229 | å | å | å | Latin small letter a with ring above | |
| 230 | æ | æ | æ | Latin small letter ae | |
| 231 | ç | ç | ç | Latin small letter c with cedilla | |
| 232 | è | è | è | Latin small letter e with grave | |
| 233 | é | é | é | Latin small letter e with acute | |
| 234 | ê | ê | ê | Latin small letter e with circumflex | |
| 235 | ë | ë | ë | Latin small letter e with diaeresis | |
| 236 | ì | ì | ì | Latin small letter i with grave | |
| 237 | í | í | í | Latin small letter i with acute | |
| 238 | î | î | î | Latin small letter i with circumflex | |
| 239 | ï | ï | ï | Latin small letter i with diaeresis | |
| 240 | ð | ð | ð | Latin small letter eth | |
| 241 | ñ | ñ | ñ | Latin small letter n with tilde | |
| 242 | ò | ò | ò | Latin small letter o with grave | |
| 243 | ó | ó | ó | Latin small letter o with acute | |
| 244 | ô | ô | ô | Latin small letter o with circumflex | |
| 245 | õ | õ | õ | Latin small letter o with tilde | |
| 246 | ö | ö | ö | Latin small letter o with diaeresis | |
| 247 | ÷ | ÷ | ÷ | division sign | |
| 248 | ø | ø | ø | Latin small letter o with stroke | |
| 249 | ù | ù | ù | Latin small letter u with grave | |
| 250 | ú | ú | ú | Latin small letter u with acute | |
| 251 | û | û | û | Latin small letter with circumflex | |
| 252 | ü | ü | ü | Latin small letter u with diaeresis | |
| 253 | ý | ý | ý | Latin small letter y with acute | |
| 254 | þ | þ | þ | Latin small letter thorn | |
| 255 | ÿ | ÿ | ÿ | Latin small letter y with diaeresis |
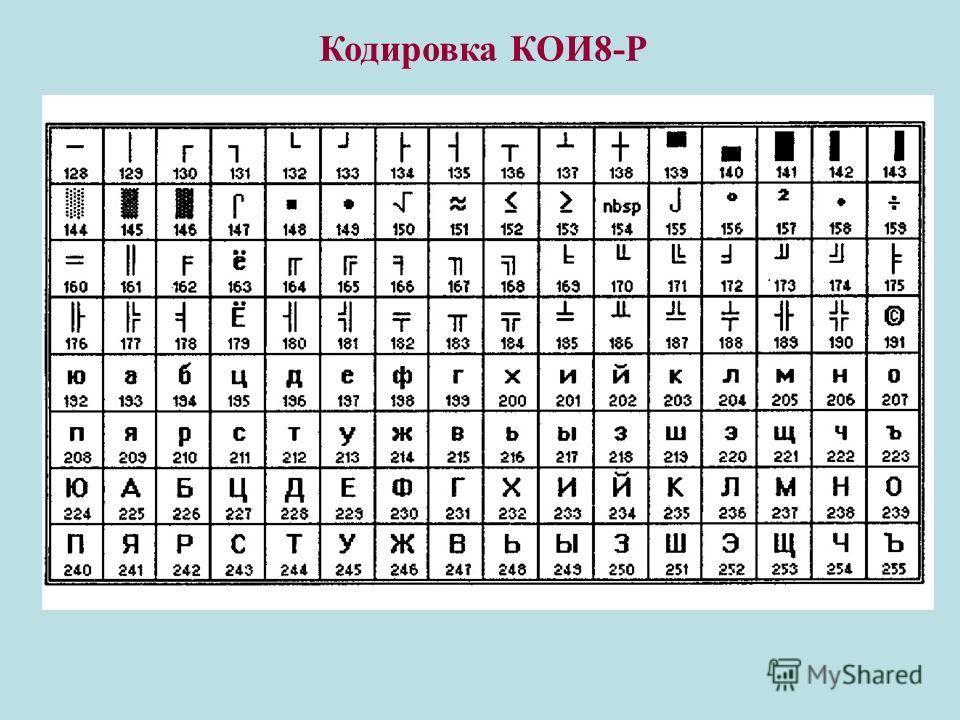
Набор символов ASCII
ASCII использует значения от 0 до 31 (и 127) для управляющих символов.
ASCII использует значения от 32 до 126 для букв, цифр и символов.
ASCII не использует значения от 128 до 255.
Набор символов ANSI (Windows-1252)
ANSI идентичен ASCII для значений от 0 до 127.
ANSI имеет собственный набор символов для значений от 128 до 159.
ANSI идентичен UTF-8 для значений от 160 до 255.
Кодировка ISO-8859-1
8859-1 идентичен ASCII для значений от 0 до 127.
8859-1 не использует значения от 128 до 159.
8859-1 идентичен UTF-8 для значений от 160 до 255.
Кодировка UTF-8
UTF-8 идентичен ASCII для значений от 0 до 127.
UTF-8 не использует значения от 128 до 159.
UTF-8 идентичен ANSI и 8859-1 для значений от 160 до 255.
UTF-8 продолжается от значения 256 с более чем 10 000 различных символов.
Для более пристального взгляда, изучите наш полный набор символов HTML.
❮ Назад Дальше ❯
Учебник HTML — Кодировка
❮ Назад Далее ❯
Чтобы правильно отобразить HTML страницу, веб браузер должен знать, какой набор символов использовать.
Что такое кодировка символов?
ASCII была первая стандартная кодировка символов (также называется набор символов). ASCII определенны 128 различных буквенно-цифровых символов, которые могут быть использованы в интернете: числа от (0-9), английские буквы (A-Z), и некоторые специальные символы, такие как ! $ + — ( ) @ < > .
ANSI (Windows-1252) был оригинальным Windows набор символов, с поддержкой 256 различных кодов символов.
ISO-8859-1 была кодировка по умолчанию для HTML 4. Этот набор символов тоже поддерживается 256 различных кодов символов.
Потому что ANSI и ISO-8859-1 были настолько ограничены, что HTML 4 также поддерживает UTF-8.
UTF-8 (Юникод) охватывает практически все знаки и символы в мире.
Кодировка по умолчанию для HTML5 является UTF-8.
HTML Атрибут charset
Для корректного отображения HTML страницы веб браузер должен знать набор символов, используемый на этой странице.
Это указано в теге <meta>:
<meta charset=»UTF-8″>
Если браузер обнаруживает ISO-8859-1 на веб странице, он по умолчанию использует ANSI.
Различия между наборами символов
В следующей таблице показаны различия между наборами символов, описанными выше:
| Число | ASCII | ANSI | 8859 | UTF-8 | Описание |
|---|---|---|---|---|---|
| 32 | Пространство | ||||
| 33 | ! | ! | ! | ! | Восклицательный знак |
| 34 | « | « | « | « | Кавычки двойные |
| 35 | # | # | # | # | Знак числа |
| 36 | $ | $ | $ | $ | Знак доллара |
| 37 | % | % | % | % | Знак процента |
| 38 | & | & | & | & | Амперсанд |
| 39 | ‘ | ‘ | ‘ | ‘ | Кавычки одинарные |
| 40 | ( | ( | ( | ( | Левая собка |
| 41 | ) | ) | ) | ) | Правая скобка |
| 42 | * | * | * | * | Звездочка |
| 43 | + | + | + | + | Плюс |
| 44 | , | , | , | , | Запятая |
| 45 | — | — | — | — | Дефис-минус |
| 46 | . | . | . | . | Точка |
| 47 | / | / | / | / | Косая черта |
| 48 | 0 | 0 | 0 | 0 | Число нуль |
| 49 | 1 | 1 | 1 | 1 | Число один |
| 50 | 2 | 2 | 2 | 2 | Число два |
| 51 | 3 | 3 | 3 | 3 | Число три |
| 52 | 4 | 4 | 4 | 4 | Число четыре |
| 53 | 5 | 5 | 5 | 5 | Число пять |
| 54 | 6 | 6 | 6 | 6 | Число шесть |
| 55 | 7 | 7 | 7 | 7 | Число семь |
| 56 | 8 | 8 | 8 | 8 | Число восемь |
| 57 | 9 | 9 | 9 | 9 | Число девять |
| 58 | : | : | : | : | Двоеточие |
| 59 | ; | ; | ; | ; | Точка с запятой |
| 60 | < | < | < | < | Знак меньше чем |
| 61 | = | = | = | = | Знак равенства |
| 62 | > | > | > | > | Знак больше чем |
| 63 | ? | ? | ? | ? | Знак вопроса |
| 64 | @ | @ | @ | @ | Коммерческая в |
| 65 | A | A | A | A | Латинская буква A |
| 66 | B | B | B | B | Латинская буква B |
| 67 | C | C | C | C | Латинская буква C |
| 68 | D | D | D | D | Латинская буква D |
| 69 | E | E | E | E | Латинская буква E |
| 70 | F | F | F | F | Латинская буква F |
| 71 | G | G | G | G | Латинская буква G |
| 72 | H | H | H | H | Латинская буква H |
| 73 | I | I | I | I | Латинская буква I |
| 74 | J | J | J | J | Латинская буква J |
| 75 | K | K | K | K | Латинская буква K |
| 76 | L | L | L | L | Латинская буква L |
| 77 | M | M | M | M | Латинская буква M |
| 78 | N | N | N | N | Латинская буква N |
| 79 | O | O | O | O | Латинская буква O |
| 80 | P | P | P | P | Латинская буква P |
| 81 | Q | Q | Q | Q | Латинская буква Q |
| 82 | R | R | R | R | Латинская буква R |
| 83 | S | S | S | S | Латинская буква S |
| 84 | T | T | T | T | Латинская буква T |
| 85 | U | U | U | U | Латинская буква U |
| 86 | V | V | V | V | Латинская буква V |
| 87 | W | W | W | W | Латинская буква W |
| 88 | X | X | X | X | Латинская буква X |
| 89 | Y | Y | Y | Y | Латинская буква Y |
| 90 | Z | Z | Z | Z | Латинская буква Z |
| 91 | [ | [ | [ | [ | Левая квадратная скобка |
| 92 | \ | \ | \ | \ | Обратный солидус |
| 93 | ] | ] | ] | ] | Правая квадратная скобка |
| 94 | ^ | ^ | ^ | ^ | Циркумфлекс ударение |
| 95 | _ | _ | _ | _ | Низкая линия |
| 96 | ` | ` | ` | ` | Знак ударения |
| 97 | a | a | a | a | Латинская строчная буква a |
| 98 | b | b | b | b | Латинская строчная буква b |
| 99 | c | c | c | c | Латинская строчная буква c |
| 100 | d | d | d | d | Латинская строчная буква d |
| 101 | e | e | e | e | Латинская строчная буква e |
| 102 | f | f | f | f | Латинская строчная буква f |
| 103 | g | g | g | g | Латинская строчная буква g |
| 104 | h | h | h | h | Латинская строчная буква h |
| 105 | i | i | i | i | Латинская строчная буква i |
| 106 | j | j | j | j | Латинская строчная буква j |
| 107 | k | k | k | k | Латинская строчная буква k |
| 108 | l | l | l | l | Латинская строчная буква l |
| 109 | m | m | m | m | Латинская строчная буква m |
| 110 | n | n | n | n | Латинская строчная буква n |
| 111 | o | o | o | o | Латинская строчная буква o |
| 112 | p | p | p | p | Латинская строчная буква p |
| 113 | q | q | q | q | Латинская строчная буква q |
| 114 | r | r | r | r | Латинская строчная буква r |
| 115 | s | s | s | s | Латинская строчная буква s |
| 116 | t | t | t | t | Латинская строчная буква t |
| 117 | u | u | u | u | Латинская строчная буква u |
| 118 | v | v | v | v | Латинская строчная буква v |
| 119 | w | w | w | w | Латинская строчная буква w |
| 120 | x | x | x | x | Латинская строчная буква x |
| 121 | y | y | y | y | Латинская строчная буква y |
| 122 | z | z | z | z | Латинская строчная буква z |
| 123 | { | { | { | { | Левая фигурная скобка |
| 124 | | | | | | | | | Вертикальная линия |
| 125 | } | } | } | } | Правая фигурная скобка |
| 126 | ~ | ~ | ~ | ~ | Тильда |
| 127 | DEL | ||||
| 128 | | Знак евро | |||
| 129 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 130 | | Одинарная 9 низкая кавычка | |||
| 131 | | Латинская строчная буква f с крючком | |||
| 132 | | Двойная 9 низкая кавычка | |||
| 133 | Горизонтальное многоточие | ||||
| 134 | | Кинжал | |||
| 135 | | Двойной кинжал | |||
| 136 | | Письмо модификатор облеченным ударением | |||
| 137 | | Знак промилле | |||
| 138 | | Латинская буква S с caron | |||
| 139 | | Одинарный угол влево низкая кавычка | |||
| 140 | | Латинская заглавная лигатура OE | |||
| 141 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 142 | | Латинская буква Z с caron | |||
| 143 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 144 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 145 | | Левая одинарная низкая кавычка | |||
| 146 | | Правая одинарная низкая кавычка | |||
| 147 | | Левая двойная низкая кавычка | |||
| 148 | | Правая двойная низкая кавычка | |||
| 149 | | Маркер | |||
| 150 | | Тире | |||
| 151 | | Длинное тире | |||
| 152 | | Маленькая тильда | |||
| 153 | | Знак торговой марки | |||
| 154 | | Латинская строчная буква s с caron | |||
| 155 | | Одинарный угол вправо низкая кавычка | |||
| 156 | | Латинская строчная лигатура oe | |||
| 157 | | | | НЕ ИСПОЛЬЗУЕТСЯ | |
| 158 | | Латинская строчная буква z с caron | |||
| 159 | | Латинская буква Y с diaeresis | |||
| 160 | Неразрывный пробел | ||||
| 161 | ¡ | ¡ | ¡ | Перевернутый восклицательный знак | |
| 162 | ¢ | ¢ | ¢ | Знак цента | |
| 163 | £ | £ | £ | Знак фунта | |
| 164 | ¤ | ¤ | ¤ | Знак валюты | |
| 165 | ¥ | ¥ | ¥ | Знак иены | |
| 166 | ¦ | ¦ | ¦ | Прерывистая полоса | |
| 167 | § | § | § | Знак раздела | |
| 168 | ¨ | ¨ | ¨ | Трема | |
| 169 | © | © | © | Знак авторского права | |
| 170 | ª | ª | ª | Женский порядковый индикатор | |
| 171 | « | « | « | Двойной угол влево | |
| 172 | ¬ | ¬ | ¬ | Знак нет | |
| 173 | | | | Мягкий дефис | |
| 174 | ® | ® | ® | Зарегистрированный знак | |
| 175 | ¯ | ¯ | ¯ | Макрон | |
| 176 | ° | ° | ° | Знак степени | |
| 177 | ± | ± | ± | Плюс-минус | |
| 178 | ² | ² | ² | Верхний индекс два | |
| 179 | ³ | ³ | ³ | Верхний индекс три | |
| 180 | ´ | ´ | ´ | Острый знак ударения | |
| 181 | µ | µ | µ | Микро знак | |
| 182 | ¶ | ¶ | ¶ | Знак абзаца | |
| 183 | · | · | · | Точка посередине | |
| 184 | ¸ | ¸ | ¸ | Седиль | |
| 185 | ¹ | ¹ | ¹ | Верхний индекс один | |
| 186 | º | º | º | Мужской порядковый индикатор | |
| 187 | » | » | » | Двойной угол вправо | |
| 188 | ¼ | ¼ | ¼ | Грубая дробь одна четвертая | |
| 189 | ½ | ½ | ½ | Грубая дробь одна вторая | |
| 190 | ¾ | ¾ | ¾ | Грубая дробь три четвертых | |
| 191 | ¿ | ¿ | ¿ | Перевернутый вопросительный знак | |
| 192 | À | À | À | Латинская буква A с grave | |
| 193 | Á | Á | Á | Латинская буква A с acute | |
| 194 | Â | Â | Â | Латинская буква A с circumflex | |
| 195 | Ã | Ã | Ã | Латинская буква A с tilde | |
| 196 | Ä | Ä | Ä | Латинская буква A с diaeresis | |
| 197 | Å | Å | Å | Латинская буква A с ring above | |
| 198 | Æ | Æ | Æ | Латинская буква AE | |
| 199 | Ç | Ç | Ç | Латинская буква C с cedilla | |
| 200 | È | È | È | Латинская буква E с grave | |
| 201 | É | É | É | Латинская буква E с acute | |
| 202 | Ê | Ê | Ê | Латинская буква E с circumflex | |
| 203 | Ë | Ë | Ë | Латинская буква E с diaeresis | |
| 204 | Ì | Ì | Ì | Латинская буква I с grave | |
| 205 | Í | Í | Í | Латинская буква I с acute | |
| 206 | Î | Î | Î | Латинская буква I с circumflex | |
| 207 | Ï | Ï | Ï | Латинская буква I с diaeresis | |
| 208 | Ð | Ð | Ð | Латинская буква Eth | |
| 209 | Ñ | Ñ | Ñ | Латинская буква N с tilde | |
| 210 | Ò | Ò | Ò | Латинская буква O с grave | |
| 211 | Ó | Ó | Ó | Латинская буква O с acute | |
| 212 | Ô | Ô | Ô | Латинская буква O с circumflex | |
| 213 | Õ | Õ | Õ | Латинская буква O с tilde | |
| 214 | Ö | Ö | Ö | Латинская буква O с diaeresis | |
| 215 | × | × | × | Знак умножения | |
| 216 | Ø | Ø | Ø | Латинская буква O с stroke | |
| 217 | Ù | Ù | Ù | Латинская буква U с grave | |
| 218 | Ú | Ú | Ú | Латинская буква U с acute | |
| 219 | Û | Û | Û | Латинская буква U с circumflex | |
| 220 | Ü | Ü | Ü | Латинская буква U с diaeresis | |
| 221 | Ý | Ý | Ý | Латинская буква Y с acute | |
| 222 | Þ | Þ | Þ | Латинская буква thorn | |
| 223 | ß | ß | ß | Латинская строчная буква sharp s | |
| 224 | à | à | à | Латинская строчная буква a с grave | |
| 225 | á | á | á | Латинская строчная буква a с acute | |
| 226 | â | â | â | Латинская строчная буква a с circumflex | |
| 227 | ã | ã | ã | Латинская строчная буква a с tilde | |
| 228 | ä | ä | ä | Латинская строчная буква a с diaeresis | |
| 229 | å | å | å | Латинская строчная буква a с ring above | |
| 230 | æ | æ | æ | Латинская строчная буква ae | |
| 231 | ç | ç | ç | Латинская строчная буква c с cedilla | |
| 232 | è | è | è | Латинская строчная буква e с grave | |
| 233 | é | é | é | Латинская строчная буква e с acute | |
| 234 | ê | ê | ê | Латинская строчная буква e с circumflex | |
| 235 | ë | ë | ë | Латинская строчная буква e с diaeresis | |
| 236 | ì | ì | ì | Латинская строчная буква i с grave | |
| 237 | í | í | í | Латинская строчная буква i с acute | |
| 238 | î | î | î | Латинская строчная буква i с circumflex | |
| 239 | ï | ï | ï | Латинская строчная буква i с diaeresis | |
| 240 | ð | ð | ð | Латинская строчная буква eth | |
| 241 | ñ | ñ | ñ | Латинская строчная буква n с tilde | |
| 242 | ò | ò | ò | Латинская строчная буква o с grave | |
| 243 | ó | ó | ó | Латинская строчная буква o с acute | |
| 244 | ô | ô | ô | Латинская строчная буква o с circumflex | |
| 245 | õ | õ | õ | Латинская строчная буква o с tilde | |
| 246 | ö | ö | ö | Латинская строчная буква o с diaeresis | |
| 247 | ÷ | ÷ | ÷ | division sign | |
| 248 | ø | ø | ø | Латинская строчная буква o с stroke | |
| 249 | ù | ù | ù | Латинская строчная буква u с grave | |
| 250 | ú | ú | ú | Латинская строчная буква u с acute | |
| 251 | û | û | û | Латинская строчная буква с circumflex | |
| 252 | ü | ü | ü | Латинская строчная буква u с diaeresis | |
| 253 | ý | ý | ý | Латинская строчная буква y с acute | |
| 254 | þ | þ | þ | Латинская строчная буква thorn | |
| 255 | ÿ | ÿ | ÿ | Латинская строчная буква y с тремой |
ASCII Набор символов
ASCII используются значения от 0 до 31 (и 127) для управляющих символов.
ASCII используются значения от 32 до 126 для букв, цифр и символов.
ASCII не используйте значения от 128 до 255.
ANSI Набор символов (Windows-1252)
ANSI идентичен ASCII для значений от 0 до 127.
ANSI имеет собственный набор символов для значений от 128 до 159.
ANSI идентична кодировке utf-8 для значений от 160 до 255.
ISO-8859-1 Набор символов
8859-1 идентичен ASCII для значений от 0 до 127.
8859-1 не используйте значения от 128 до 159.
8859-1 идентична кодировке utf-8 для значений от 160 до 255.
UTF-8 Набор символов
UTF-8 идентичен ASCII для значений от 0 до 127.
UTF-8 не используйте значения от 128 до 159.
UTF-8 идентичен ANSI и 8859-1 для значений от 160 до 255.
UTF-8 продолжается от значение 256 с более чем 10 000 различных символов.
Для более близкого взгляда, изучите наш Полный набор символов HTML справочник.
Правило CSS @charset
Вы можете использовать CSS правило @charset для указания кодировки символов, используемой в таблице стилей:
Пример
Установите кодировку таблицы стилей в Юникод UTF-8:
@charset «UTF-8»;
Подробнее о компании читайте здесь CSS Правило @charset.
❮ Назад Далее ❯
HTML — кодировки символов — CoderLessons.com
Кодировка символов – это метод преобразования байтов в символы. Чтобы правильно проверить или отобразить документ HTML, программа должна выбрать правильную кодировку символов.
Наиболее распространенным набором символов или кодировкой символов, используемой на компьютерах, является ASCII – американский стандартный код для обмена информацией , и это, вероятно, наиболее широко используемый набор символов для электронного кодирования текста.
Кодировка ASCII поддерживает только прописные и строчные буквы латинского алфавита, цифры 0-9 и некоторые дополнительные символы, которые в сумме составляют 128 символов. Вы можете взглянуть на полный набор печатных символов ASCII
Тем не менее, во многих языках используются либо латинские символы с акцентом, либо совершенно разные алфавиты. ASCII не обращается к этим символам; поэтому вам нужно узнать о кодировках символов, если вы хотите использовать любые символы, не входящие в ASCII.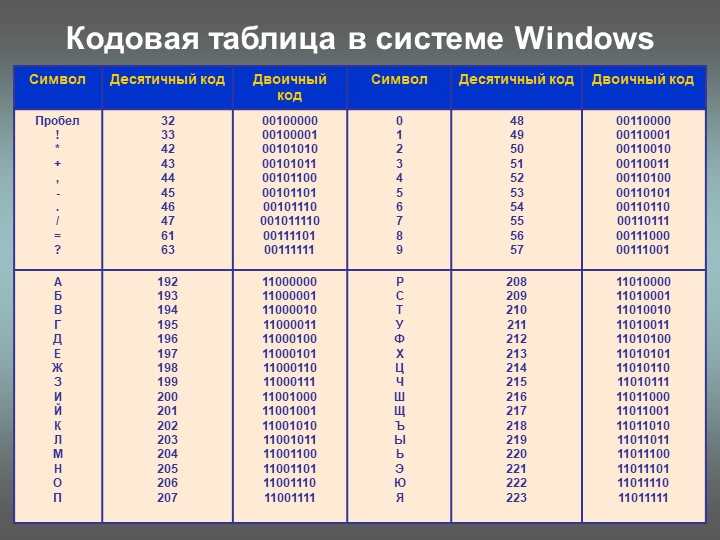
Международная организация стандартов создала ряд наборов символов для работы с различными национальными символами. Для документов на английском и большинстве других западноевропейских языков используется широко поддерживаемая кодировка ISO-8859-1.
Вот список Наборов символов, используемых во всем мире вместе с их описанием.
| Sr.No | Набор символов и описание |
|---|---|
| 1 | ISO-8859-1 Латинский алфавит часть 1 Покрытие Северной Америки, Западной Европы, Латинской Америки, Карибского бассейна, Канады, Африки |
| 2 | ISO-8859-2 Латинский алфавит часть 2 Покрытие Восточной Европы |
| 3 | ISO-8859-3 Латинский алфавит часть 3 Покрытие SE Europe, эсперанто, разные другие |
| 4 | ISO-8859-4 Латинский алфавит часть 4 Покрытие Скандинавия / Прибалтика (и другие, не входящие в ISO-8859-1) |
| 5 | ISO-8859-5 Латиница / кириллица часть 5 |
| 6 | ISO-8859-6 Латиница / арабский алфавит часть 6 |
| 7 | ISO-8859-7 Латинский / греческий алфавит часть 7 |
| 8 | ISO-8859-8 Латиница / иврит алфавит часть 8 |
| 9 | ISO-8859-9 Латинский 5 алфавит часть 9 То же, что ISO-8859-1 за исключением того, что турецкие символы заменяют исландские |
| 10 | ISO-8859-10 Латинская 6 Латинская 6 Лапландская, скандинавская и эскимосская |
| 11 | ISO-8859-15 То же, что ISO-8859-1, но с добавлением большего количества символов |
| 12 | ISO-2022-JP Латиница / японский алфавит часть 1 |
| 13 | ISO-2022-JP-2 Латинский / японский алфавит часть 2 |
| 14 | ISO-2022-KR Латинский / корейский алфавит часть 1 |
ISO-8859-1
Латинский алфавит часть 1
Покрытие Северной Америки, Западной Европы, Латинской Америки, Карибского бассейна, Канады, Африки
ISO-8859-2
Латинский алфавит часть 2
Покрытие Восточной Европы
ISO-8859-3
Латинский алфавит часть 3
Покрытие SE Europe, эсперанто, разные другие
ISO-8859-4
Латинский алфавит часть 4
Покрытие Скандинавия / Прибалтика (и другие, не входящие в ISO-8859-1)
ISO-8859-5
Латиница / кириллица часть 5
ISO-8859-6
Латиница / арабский алфавит часть 6
ISO-8859-7
Латинский / греческий алфавит часть 7
ISO-8859-8
Латиница / иврит алфавит часть 8
ISO-8859-9
Латинский 5 алфавит часть 9
То же, что ISO-8859-1 за исключением того, что турецкие символы заменяют исландские
ISO-8859-10
Латинская 6 Латинская 6 Лапландская, скандинавская и эскимосская
ISO-8859-15
То же, что ISO-8859-1, но с добавлением большего количества символов
ISO-2022-JP
Латиница / японский алфавит часть 1
ISO-2022-JP-2
Латинский / японский алфавит часть 2
ISO-2022-KR
Латинский / корейский алфавит часть 1
Консорциум Unicode был тогда создан, чтобы разработать способ показа всех символов разных языков вместо того, чтобы иметь эти разные несовместимые коды символов для разных языков.
Поэтому, если вы хотите создавать документы, которые используют символы из нескольких наборов символов, вы сможете сделать это, используя одиночные кодировки символов Unicode.
Поэтому Юникод определяет кодировки, которые могут обрабатывать строку особым образом, чтобы освободить место для огромного набора символов, который он охватывает. Они известны как UTF8, UTF-16 и UTF-32.
| Sr.No | Набор символов и описание |
|---|---|
| 1 | UTF-8 , Формат перевода Unicode, который поставляется в 8-битных единицах, то есть в байтах. Символ в UTF8 может иметь длину от 1 до 4 байтов, что делает UTF8 переменной ширины. |
| 2 | UTF-16 Формат перевода Unicode, который поставляется в 16-битных единицах, то есть в шортах. Это может быть 1 или 2 шорты длиной, что делает UTF16 переменной ширины. |
| 3 | UTF-32 Формат перевода Unicode, который поставляется в 32-битных единицах, то есть в длинных. |
 Это формат с фиксированной шириной и всегда 1 “длинный” в длину.
Это формат с фиксированной шириной и всегда 1 “длинный” в длину.UTF-8 ,
Формат перевода Unicode, который поставляется в 8-битных единицах, то есть в байтах. Символ в UTF8 может иметь длину от 1 до 4 байтов, что делает UTF8 переменной ширины.
UTF-16
Формат перевода Unicode, который поставляется в 16-битных единицах, то есть в шортах. Это может быть 1 или 2 шорты длиной, что делает UTF16 переменной ширины.
UTF-32
Формат перевода Unicode, который поставляется в 32-битных единицах, то есть в длинных. Это формат с фиксированной шириной и всегда 1 “длинный” в длину.
Первые 256 символов наборов символов Unicode соответствуют 256 символам ISO-8859-1.
По умолчанию процессоры HTML 4 должны поддерживать UTF-8, а процессоры XML должны поддерживать UTF-8 и UTF-16; поэтому все XHTML-совместимые процессоры также должны поддерживать UTF-16.
Проверка кодировки символов используя валидатор
Проверка кодировки символов используя валидаторВопрос
Как я могу проверить правильно ли кодирование символов моего документа используя W3C HTML Валидатор?
Ответ
Чтобы убедиться, что все получатели документа могут его правильно отобразить и интерпретировать, очень важно правильно указать
кодировку символов (‘charset’). Один из способов это проверить — использовать W3C Сервис Проверки Разметки. Валидатор обычно
определяет кодировку символов с HTTP заголовков и информации в документе. Если валидатор не в состоянии обнаружить кодировку, то её можно будет выбрать
на странице результатов валидатора с помощью раскрывающегося меню ‘Кодировка’ (пример).
Один из способов это проверить — использовать W3C Сервис Проверки Разметки. Валидатор обычно
определяет кодировку символов с HTTP заголовков и информации в документе. Если валидатор не в состоянии обнаружить кодировку, то её можно будет выбрать
на странице результатов валидатора с помощью раскрывающегося меню ‘Кодировка’ (пример).
Но часто, валидатор не жалуется, даже если обнаруженное или избранное неправильное кодирование. Причина этого в том, что много кодировок очень похожи, а валидатор проверяет только синтаксис разметки и не может решить имеет ли смысл декодированный текст или нет. Чтобы убедиться, что вы имеете правильное кодирование, которое означает, что документ будет корректно отображаться для читателей, используйте следующие пункты:
Если выбранные или обнаруженые кодирования:
US-ASCII,UTF-8,UTF-16, илиiso-2022-jp(Japanese JIS), и валидатор не жалуется на проблемы с кодировкой, то есть очень высокая вероятность того, что кодирование избранное правильно. Обратите внимание, что
Обратите внимание, что US-ASCIIявляется строгим подмножеством кодировкиUTF-8, и поэтому, еслиUS-ASCIIработает, тоUTF-8также будет работать.Для любого другого кодирования необходим визуальный контроль. Выберите опцию Show Source (показать источник) с Extended Interface (Расширенного интерфейса) валидатора, и проверьте правильно ли отображаются в тексте non-ASCII символы. Для страниц на иностранных языках, это, как правило, можно сделать достаточно быстро. Для страниц на Английском языке со всего несколькими non-ASCII символамы, это может быть более сложной задачей.
Например, если вы пытались интерпретировать главную страницу W3C как iso-8859-1, вам, возможно, придется пересмотреть источник почти до конца для того, чтобы найти такой текст, как ‘©’ и ‘®’ и увидеть, что это неправильный выбор. (Конечно, та страница, с самого начала указывает валидатору, что она закодирована в UTF-8, и поэтому на самом деле вам не нужно что-то еще проверять.
)В некоторых случаях более чем одна кодировка будет адекватно представлять символы в документе. Например, есть некоторое перекрытие между
iso-8859-1(Latin-1, Западная Европа) иiso-8859-2(Latin-2, Восточная Европа), и другие кодировки в этой серии. Если после тщательной проверки, вы не можете найти разницу, то любой выбор будет подходящим. Близкое сходство этих кодировок с точки зрения моделей байтов и с точки зрения фактически закодированных символов объясняет почему только визуальный осмотр может помочь убедиться правильное ли кодирование.Если ни одна из предложенных валидатором кодировок не работает, то вы либо имеете страницу в кодировке, которую валидатор (пока) не поддерживает, или как-то, текст в нескольких различных кодировках смешался на странице. В первом случае, напишите на validator mailing list (список рассылки валидатора) (public archive (общественный архив)), чтобы вашу кодировку символов добавили.
В последнем случае, вы должны исправить свою страницу, так как каждая Веб-страница может использовать только одну кодировку символов.
 Обратите внимание, что
Обратите внимание, что  )
) В последнем случае, вы должны исправить свою страницу, так как каждая Веб-страница может использовать только одну кодировку символов.
В последнем случае, вы должны исправить свою страницу, так как каждая Веб-страница может использовать только одну кодировку символов.Кстати говоря
Валидатор не может работать без информации о кодировке потому что SGML или XML проверка основана на проверке последовательностей символов в документе, но то, что валидатор принимает в качестве входных данных — просто последовательность байтов. Знание кодирования символов позволяет валидатору превращать байты в символы. В общем, все то же самое действительно для всех других видов приемников, включая браузеры. Если символы определены не правильно, то Веб браузер будет отображать некорректную информацию.
Валидатор делает это путем преобразования из указанного кодирования в UTF-8, и использует UTF-8 внутренне. Если преобразование в UTF-8 не удается
потому, что отдельная последовательность байтов не может появиться во входной кодировоке, то валидатор выдает сообщение об ошибке. В UTF-8 для информации на входе, валидатор
проверяет действительно ли только UTF-8 последовательности байтов используются.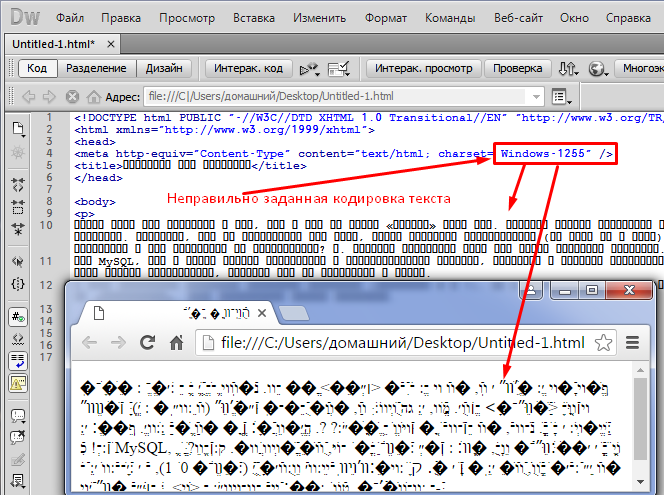
Обратите внимание, что визуальная проверка веб-страницы с помощью браузера без использования валидатор может провалиться, поскольку:
- Некоторые браузеры используют нестандартные способы выявления кодирования символов.
- Каждый браузер имеет настройки, которые используются для неотмеченных страниц, а если те настройки случайно будут правильной кодировкой страницы, то вы не увидите, что страница с должной информацией о кодировке не доходит.
- Кроме текста на странице, есть еще текст в атрибутах (например текст атрибута alt в
<img>), который нужно проверить.
Дополнительные материалы
Проверка HTTP Заголовков
Проверка Интернационализации (i18n)
Пособие, Обработка кодирования символов в HTML и CSS
Зареєстровані кодування символів (charsets) в IANA (валідатор підтримує тільки підмножину, яка широко застосовується, і, переважно, підтримує тільки імена, а не псевдоніми)
Ссылки по теме, Настройка сервера
- Проверка HTTP заголовка
- Настройка параметра HTTP charset
Ссылки по теме, Разработка HTML и CSS
- Символы
Ссылки по теме, Разработка SVG
- Символы
Кодировки символов в HTML
Список ссылок на символьные сущности см.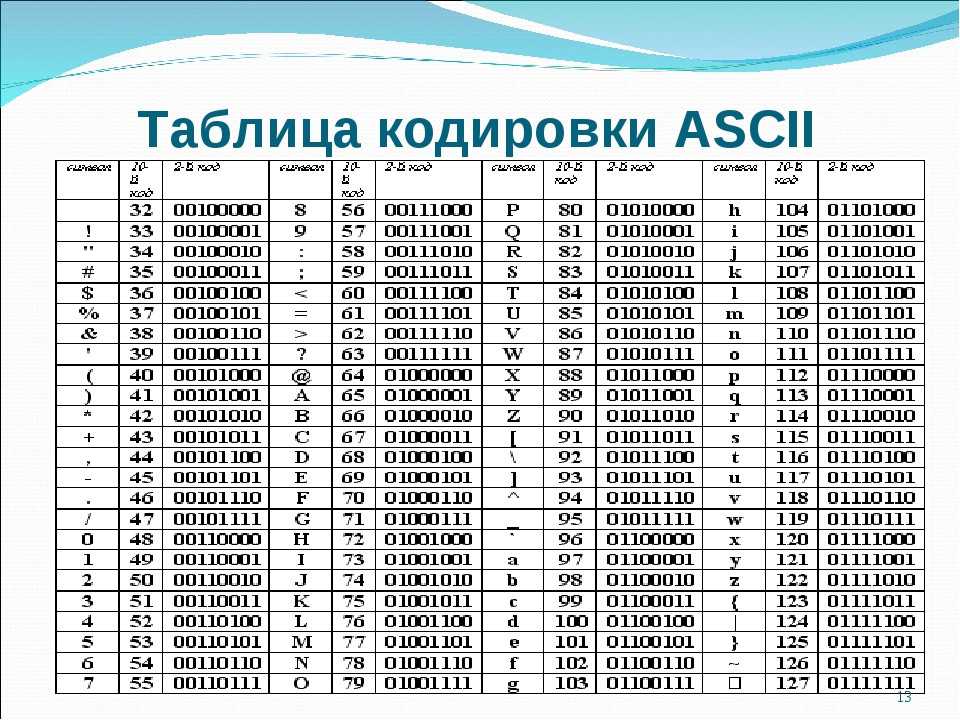 Список ссылок на символьные сущности XML и HTML.
Список ссылок на символьные сущности XML и HTML.
Для исправления ссылок в Википедии см. Справка: процентное кодирование § Исправление ссылок с неподдерживаемыми символами.
HTML (Язык гипертекстовой разметки) используется с 1991 года, но HTML 4.0 (декабрь 1997 года) был первой стандартизированной версией, в которой символы получили достаточно полное лечение. Когда HTML-документ включает специальные символы вне семибитного диапазона ASCII, стоит рассмотреть две цели: информационная честность, и универсальный браузер отображать.
Содержание
- 1 Указание кодировки символов документа
- 2 Разрешенные кодировки
- 3 Ссылки на символы
- 3.1 Ссылки на символы HTML
- 3.2 Ссылки на символы XML
- 4 Смотрите также
- 5 Рекомендации
- 6 внешняя ссылка
Указание кодировки символов документа
Есть несколько способов указать, какая кодировка символов используется в документе. Во-первых, веб сервер может включать кодировку символов или «кодировка» в Протокол передачи гипертекста (HTTP) Тип содержимого заголовок, который обычно выглядит так:[1]
Content-Type: текст / html; charset = ISO-8859-4
Этот метод дает HTTP-серверу удобный способ изменить кодировку документа в соответствии с согласование содержания; определенное программное обеспечение HTTP-сервера может это сделать, например Apache с модуль mod_charset_lite.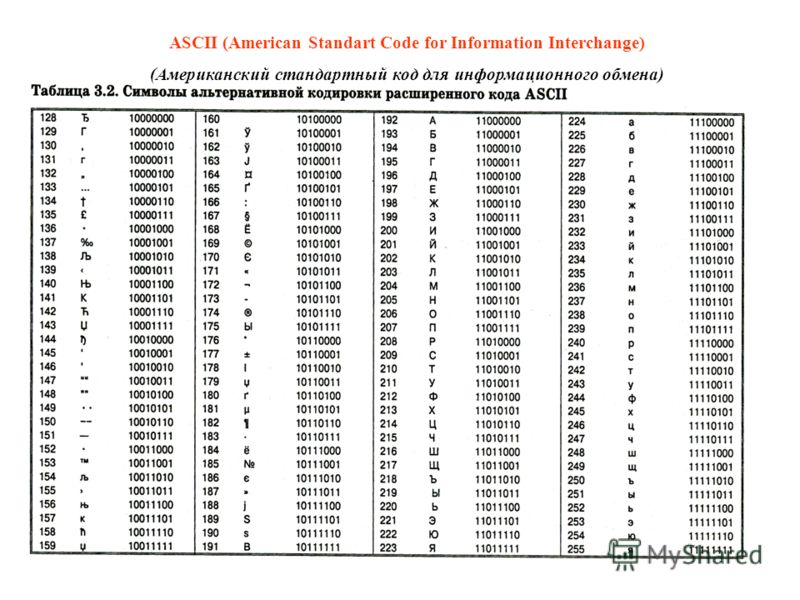 [2]
[2]
Для HTML эту информацию можно включить в голова элемент в верхней части документа:[3]
<мета http-Equiv="Тип содержимого" содержание="текст / html; charset = utf-8">
HTML5 также позволяет следующий синтаксис означать то же самое:[3]
<мета кодировка=«УТФ-8»>
XHTML у документов есть третий вариант: выразить кодировку символов через XML декларация следующего содержания:[4]
<?xml version="1.0" encoding="ISO-8859-1"?>
Поскольку кодировка символов не может быть известна до этого[требуется разъяснение ] объявление анализируется, может возникнуть проблема, зная, какая кодировка используется для самого объявления. Главный принцип заключается в том, что объявление должно быть закодировано в чистом ASCII, и поэтому (если объявление находится внутри файла) кодировка должна быть Расширение ASCII. Для того чтобы кодировки не были обратно совместимы с ASCII, браузеры должны иметь возможность анализировать объявления в таких кодировках. Примеры таких кодировок: UTF-16BE и UTF-16LE.
Примеры таких кодировок: UTF-16BE и UTF-16LE.
Начиная с HTML5 рекомендуемая кодировка UTF-8.[3] В спецификации определен «алгоритм сниффинга кодирования» для определения кодировки символов документа на основе нескольких источников ввода, включая:
- Явная инструкция пользователя
- Явный метатег в первых 1024 байтах документа.
- А Отметка порядка байтов в пределах первых трех байтов документа
- Тип содержимого HTTP или другая информация транспортного уровня
- Анализ байтов документа на предмет определенных последовательностей или диапазонов значений байтов,[5] и другие механизмы предварительного обнаружения.
Для ASCII-совместимых кодировок символов следствием неправильного выбора является то, что символы за пределами печатаемого диапазона ASCII (от 32 до 126) обычно отображаются неправильно. Это создает несколько проблем для английский — говорящие пользователи, но для других языков обычно — в некоторых случаях всегда — требуются символы вне этого диапазона. В CJK В средах, где используется несколько различных многобайтовых кодировок, также часто применяется автоматическое обнаружение. Наконец, браузеры обычно позволяют пользователю переопределить неверный метку кодировки вручную.
В CJK В средах, где используется несколько различных многобайтовых кодировок, также часто применяется автоматическое обнаружение. Наконец, браузеры обычно позволяют пользователю переопределить неверный метку кодировки вручную.
Многоязычные веб-сайты и веб-сайты на незападных языках все чаще используют UTF-8, что позволяет использовать одну и ту же кодировку для всех языков. UTF-16 или же UTF-32, которые также могут использоваться для всех языков, менее широко используются, поскольку их сложнее обрабатывать в языках программирования, которые предполагают байтовый Кодирование расширенного набора ASCII, и они менее эффективны для текста с высокой частотой символов ASCII, что обычно имеет место для документов HTML.
Успешный просмотр страницы не обязательно означает, что ее кодировка указана правильно. Если создатель страницы и читатель оба предполагают кодировку символов, зависящую от платформы, и сервер не отправляет никакой идентифицирующей информации, то читатель, тем не менее, будет видеть страницу так, как задумал создатель, но другие читатели на других платформах или с разными родными языками не увидит страницу должным образом.
Разрешенные кодировки
В WHATWG Стандарт кодирования, на который ссылаются последние стандарты HTML (текущий WHATWG HTML Living Standard, а также ранее конкурирующий W3C HTML 5.0 и 5.1) определяет список кодировок, которые браузеры должны поддерживать. Стандарты HTML запрещают поддержку других кодировок.[6][7][8] Стандарт кодирования также предусматривает, что новые форматы, новые протоколы (даже когда используются существующие форматы) и авторы новых документов должны использовать UTF-8 исключительно.[9]
Помимо UTF-8, следующие кодировки явно перечислены в самом стандарте HTML со ссылкой на стандарт кодирования:[8]
- ISO-8859-2
- ISO-8859-7
- ISO-8859-8
- Окна-874[а]
- Окна-1250
- Окна-1251
- Окна-1252[b]
- Окна-1254[c]
- Окна-1255
- Окна-1256
- Окна-1257
- Окна-1258
- GB18030[d]
- Big5[e]
- Shift JIS[f]
- ISO-2022-JP[грамм]
- EUC-KR[час]
- UTF-16BE[я]
- UTF-16LE[j]
- x-определяемый пользователем[k]
- ^ Также указано для
ТИС-620,ISO-8859-11и связанные ярлыки. В спецификации используется тот же индекс, что и для Shift JIS (поскольку он находится в пределах досягаемости набора кодов EUC 1), то есть включает расширения NEC. JIS X 0212 включен только для декодирования.[25]
 В спецификации используется тот же индекс, что и для Shift JIS (поскольку он находится в пределах досягаемости набора кодов EUC 1), то есть включает расширения NEC. JIS X 0212 включен только для декодирования.[25]
В спецификации используется тот же индекс, что и для Shift JIS (поскольку он находится в пределах досягаемости набора кодов EUC 1), то есть включает расширения NEC. JIS X 0212 включен только для декодирования.[25]Следующие кодировки указаны как явные примеры запрещенных кодировок:[8]
- ЦЭСУ-8
- UTF-7
- BOCU-1
- ГКГУ
- EBCDIC
- UTF-32
Стандарт также определяет «замещающий» декодер, который отображает весь контент, помеченный как определенные кодировки, в замещающий символ ( ), вообще отказываясь его обрабатывать. Это предназначено для предотвращения атак (например, межсайтовый скриптинг ), которые могут использовать разницу между клиентом и сервером в поддерживаемых кодировках для маскировки вредоносного содержимого.[26] Хотя та же проблема безопасности относится к ISO-2022-JP и UTF-16, которые также позволяют по-разному интерпретировать последовательности байтов ASCII, этот подход не рассматривался как выполнимый для них, поскольку они сравнительно чаще используются в развернутом контенте.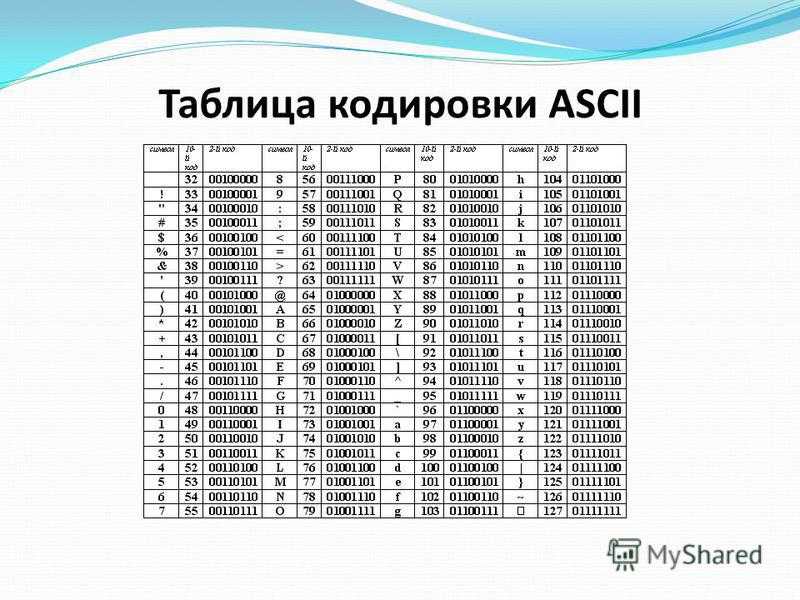 [27] Следующие кодировки обрабатываются так:[28]
[27] Следующие кодировки обрабатываются так:[28]
- ISO-2022-KR
- ISO-2022-CN
- ISO-2022-CN-EXT
- HZ-GB-2312
Ссылки на символы
Основные статьи: Ссылка на сущность символа и Ссылка на числовые символы
Помимо собственной кодировки символов, символы также могут быть закодированы как ссылки на символы, который может быть ссылки на числовые символы (десятичный или же шестнадцатеричный ) или же ссылки на символьные сущности. Ссылки на символьные сущности также иногда называют названные объекты, или же HTML-объекты для HTML. Использование символьных ссылок в HTML происходит от SGML.
Ссылки на символы HTML
А ссылка на числовой символ в HTML относится к символу по его Универсальный набор символов /Unicode кодовая точка, и использует формат
&#nnnn;
или же
Иксхххх;
куда nnnn это кодовая точка в десятичный форма, и хххх это кодовая точка в шестнадцатеричный форма. В Икс в XML-документах должен быть строчным. В nnnn или же хххх может быть любым количеством цифр и может включать в себя ведущие нули. В хххх может смешивать прописные и строчные буквы, хотя прописные буквы являются обычным стилем.
В Икс в XML-документах должен быть строчным. В nnnn или же хххх может быть любым количеством цифр и может включать в себя ведущие нули. В хххх может смешивать прописные и строчные буквы, хотя прописные буквы являются обычным стилем.
Не все веб-браузеры или же почтовые клиенты используется получателями HTML-документов, или текстовые редакторы используется авторами документов HTML, сможет отображать все символы HTML. Большинство современных программ способно отображать большинство или все символы языка пользователя, а также рисовать прямоугольник или другой четкий индикатор для символов, которые они не могут отобразить.
Для кодов от 0 до 127 исходный 7-битный ASCII стандартный набор, большинство этих символов можно использовать без ссылки на символ. Все коды от 160 до 255 могут быть созданы с помощью имена персонажей. Только несколько кодов с более высокими номерами могут быть созданы с использованием имен сущностей, но все они могут быть созданы с помощью ссылки на символ десятичного числа.
Ссылки на символьные сущности также могут иметь формат &имя; куда имя представляет собой буквенно-цифровую строку с учетом регистра. Например, «λ» также может быть закодировано как & лямбда; в HTML-документе. Ссылки на сущность персонажа & lt;, & gt;, & quot; и & amp; предопределены в HTML и SGML, потому что <, >, " и & уже используются для разграничения разметки. В частности, это не включало XML & апос; (‘) сущность до HTML5. Для получения списка всех названных ссылок на сущности символов HTML вместе с версиями, в которых они были представлены, см. Список ссылок на символьные сущности XML и HTML.
Излишнее использование ссылок на символы HTML может значительно снизить удобочитаемость HTML. Если кодировка символов для веб-страницы выбрана надлежащим образом, то ссылки на символы HTML обычно требуются только для символов-разделителей разметки, как указано выше, и для нескольких специальных символов (или вообще без них, если Unicode кодирование как UTF-8 используется). Неправильное экранирование HTML-объекта также может открыть уязвимости безопасности для атак с использованием инъекций, таких как межсайтовый скриптинг. Если атрибуты HTML не заключены в кавычки, некоторые символы, что наиболее важно пробел, такие как пробел и табуляция, должны быть экранированы с помощью сущностей. В других языках, связанных с HTML, есть свои методы экранирования символов.
Неправильное экранирование HTML-объекта также может открыть уязвимости безопасности для атак с использованием инъекций, таких как межсайтовый скриптинг. Если атрибуты HTML не заключены в кавычки, некоторые символы, что наиболее важно пробел, такие как пробел и табуляция, должны быть экранированы с помощью сущностей. В других языках, связанных с HTML, есть свои методы экранирования символов.
Ссылки на символы XML
В отличие от традиционного HTML с его большим диапазоном ссылок на символьные сущности, в XML имеется только пять предопределенных ссылок на символьные сущности. Они используются для экранирования символов, чувствительных к разметке в определенных контекстах:[29]
& amp;→ & (амперсанд, U + 0026)& lt;→& gt;→> (знак больше, U + 003E)& quot;→ «(кавычка, U + 0022)& апос;→ ‘(апостроф, U + 0027)
Все остальные ссылки на символьные сущности должны быть определены до того, как их можно будет использовать. Брей, Т.; Paoli, J .; Сперберг-Маккуин, К.; Maler, E .; Йерго, Ф. (26 ноября 2008 г.), «Ссылки на персонажей и сущностей», XML, W3C, получено 8 марта 2010
Брей, Т.; Paoli, J .; Сперберг-Маккуин, К.; Maler, E .; Йерго, Ф. (26 ноября 2008 г.), «Ссылки на персонажей и сущностей», XML, W3C, получено 8 марта 2010
внешняя ссылка
- Инструмент кодирования и декодирования HTML-сущностей онлайн
- Ссылки на символьные сущности в HTML4
- Полное руководство по кодированию веб-символов
- Глава HTML Entity Encoding в Руководстве по безопасности браузера — дополнительная информация о текущих браузерах и работе с ними
- Вики-статья проекта Open Web Application Security Project о межсайтовых сценариях (XSS)
Кодирование символов — HTML, CSS, JavaScript, Perl, PHP, MySQL: Weblibrary.biz
Главная » HTML
Рубрика: HTMLАвтор: w-admin
Я думаю, нет нужды доказывать, что основным языком Интернета является анг
лийский. В то же время для гипертекстовых документов предусмотрено исполь
В то же время для гипертекстовых документов предусмотрено исполь
зование национальных алфавитов. Стандартным режимом отображения являет
ся кодировка ISO Latin I (ISO 88591). Она подходит как для MSDOS (набор
символов ASCCII), так и для Windows, поэтому набор программ для просмотра и
редактирования кода HTML, достаточно широк. В то же время броузеры поддер
живают набор символов Unicode 2.0 (ISO10646), что позволяет использовать на
циональные алфавиты. С практической точки зрения это означает, что символы
могут кодироваться однобайтовым числом (коды в пределах 0255) или двубай
товым (065 535). В первом случае для использования национального алфавита
необходим атрибут charset (см. листинг 1.1), так как одни и те же коды символов
могут быть интерпретированы поразному для различных кодовых страниц,
А как быть, если атрибут charset не указан? Раскройте в MSIE подменю Вид коди
ровки меню Вид и проверьте, какие кодовые страницы доступны на вашем ком
пьютере.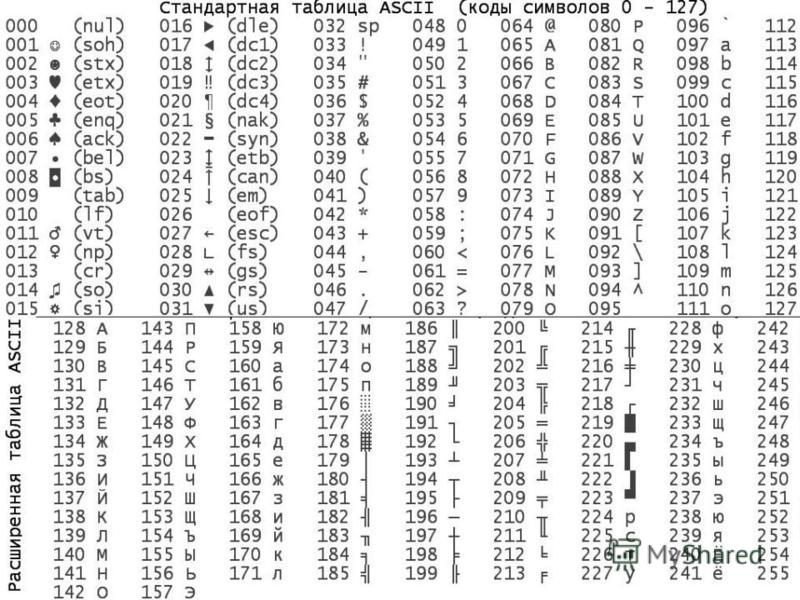 Наверняка вы найдете команды, отвечающие за отображение русских
Наверняка вы найдете команды, отвечающие за отображение русских
букв: Кириллица (Windows) и/или Кириллица (КОИ8Р). Это две наиболее популяр
ные в нашей стране кодировки. Самый простой вариант, когда для Webстраницы
не указана ни кодовая страница, ни конкретные шрифты. Тогда броузер будет
использовать шрифты, выбранные по умолчанию. Поскольку каждый пользова
тель настраивает программу для себя и применяет шрифты с национальными ал
фавитами, то с отображением отечественных ресурсов проблем обычно не возни
кает. Русский будет читать русские, а немец — немецкие тексты. Если страница
загружается из Интернета, то проблема тоже может быть решена: броузер анали
зирует текст страницы и пытается подобрать необходимую кодировку. Если он
делает это неправильно, пользователь всегда может применить упомянутую выше
команду и исправить положение.
Если в документе есть указание на определенную кодовую страницу, выбор
шрифта (в данном случае — некоторого подмножества символов, которые будут
служить для отображения кодов 128255) будет предопределен. Коды 32127, то
Коды 32127, то
есть знаки препинания, цифры и буквы латинского алфавита, отображаются в по
давляющем большинстве случаев правильно, а коды 128255 могут отображаться
поразному. Обычно программы поддерживают большое число национальных
алфавитов. Во время инсталляции программного обеспечения автоматически
устанавливаются и необходимые для этого шрифты.
Проблема чаще всего возникает, если кодовая страница указана неправильно. Напри
мер, при создании гипертекстовых документов в MS Word или MS FrontPage Express
в текст страницы автоматически добавляется конструкция типа charset=xxxxx,
которая не позволяет использовать кириллицу. В этом случае необходимо правиль
но указать значение атрибута: charset=windows1251 (или другое, если вам нужна
другая кодовая страница). Если вы посмотрите «фирменные» русские сайты в
Интернете, то обнаружите, что большинство переключателей кодировки предла
гают два варианта использования кириллицы: Windows и КОИ8.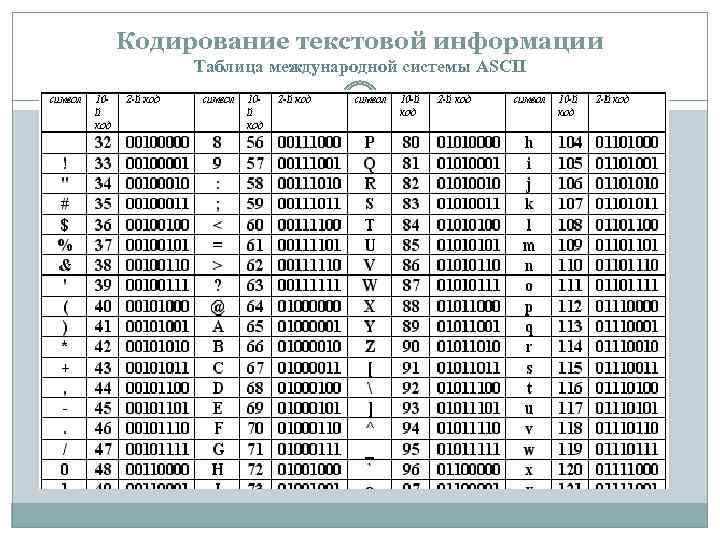
Почему же возникают такие сложности, когда существует система Unicode? От
вет прост: изза стремления разработчиков обеспечить себе комфортные услови;
работы. Действительно, все стандартные программы рассчитаны на однобайтно’
представление символов. А редактировать код HTML удобнее всего, просто ввод;
символы с клавиатуры. Если же документ использует кодировку Unicode, то дл;
работы с ним не подойдут такие средства, как Блокнот, Norton Commander шп
WordPad, и придется остановиться на гипертекстовом редакторе. В этом случа!
русская буква А будет выглядеть в режиме «источника» так: А (в десятично!
кодировке). Такую страницу будет сложно читать и редактировать. Вы может<
столкнуться с подобной кодировкой, если будете набирать кириллицу в неруси
фицированном гипертекстовом редакторе. Он может выполнить автоматическое
преобразование символов. Поэтому каждый новый редактор надо тестировать ш
возможность использования русских букв: набрать небольшой текст, сохранит!
документ, а затем просмотреть его в режиме источника.
0 458 просмотров
Понравилась статья? Поделиться с друзьями:
Кодирование и декодирование фрагмента текста в его HTML-эквивалент — HTML Entities Encoder/Decoder
Зарезервированные объекты, символы и символы в HTML
В этой таблице показан список зарезервированных объектов HTML со связанными с ними символами и описанием.
| Символ | Имя объекта | Описание |
|---|---|---|
| « | " | кавычки |
| ‘ | апостроф | |
| и | &ампер; | амперсанд |
| < | < | меньше |
| > | > | больше |
| неразрывный пробел | ||
| ¡ | !искл. | перевернутый восклицательный знак |
| ¢ | % | центов |
| £ | фунтов стерлингов; | фунтов |
| ¤ | &текущий; | валюта |
| ¥ | иен; | иен |
| ¦ | ¦ | сломанная вертикальная планка |
| § | &сек; | секция |
| ¨ | ¨ | интервал диэрезис |
| © | &копия; | авторское право |
| ª | ª | женский порядковый номер |
| « | « | угловая кавычка (слева) |
| ¬ | &нет; | отрицание |
| | мягкий дефис | |
| ® | ® | зарегистрированный товарный знак |
| ¯ | ¯ | интервал макрон |
| ° | &град; | градусов |
| ± | +плюс; | плюс-минус |
| ² | &up2; | верхний индекс 2 |
| ³ | &up3; | верхний индекс 3 |
| ´ | ´ | расстояние острое |
| µ | &микро; | микро |
| ¶ | &пара; | пункт |
| · | · | средняя точка |
| ¸ | &ced; | проставка седилья |
| № | &up1; | верхний индекс 1 |
| º | º | мужской порядковый номер |
| » | » | угловая кавычка (справа) |
| = | ¼ | дробь 1/4 |
| ½ | ½ | дробь 1/2 |
| ¾ | ¾ | дробь 3/4 |
| À | ¿ | перевернутый вопросительный знак |
| × | &раз; | умножение |
| ÷ | &разделить; | подразделение |
| À | À | заглавная буква а, серьезное ударение |
| Á | &Острый; | заглавная а, ударение |
| Â | &Цирк.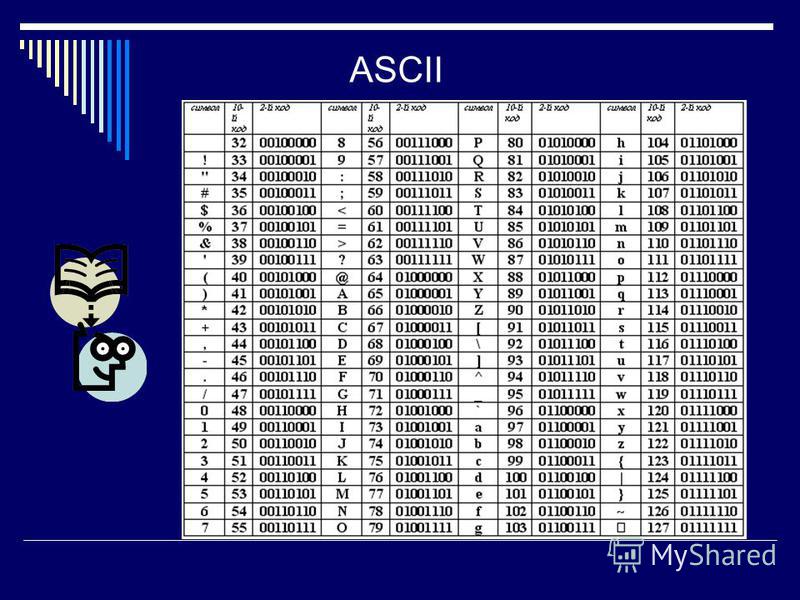 | заглавная а, ударение по циркумфлексу |
| Ã | &Атильда; | заглавная а, тильда |
| Ä | Ä | заглавная буква а, знак умляут |
| Å | &Кольцо; | заглавная буква а, кольцо |
| Æ | Æ | заглавная ае |
| Ç | Ç | заглавная с, седилья |
| Э | &Выгравировать; | заглавная е, серьезное ударение |
| É | É | заглавная е, акут |
| К | Ê | заглавная е, ударение по циркумфлексу |
| Ë | Ë | заглавная буква е, знак умлаут |
| М | &Изображение; | заглавная буква i, серьезное ударение |
| Н | Í | заглавная буква I, ударение |
| О | Î | заглавная буква i, ударение по циркумфлексу |
| О | Ï | заглавная буква i, знак умляут |
| Р | Ð | столица eth, исландский |
| С | &Nтильда; | заглавная н, тильда |
| Т | &Огрейв; | заглавная буква o, серьезное ударение |
| О | Ó | заглавная о, акут |
| Ô | Ô | заглавная о, циркумфлекс ударение |
| Х | &Отильда; | заглавная буква О, тильда |
| О | &Омл; | заглавная буква О, знак умляут |
| Ø | &Ослэш; | заглавная о, косая черта |
| Ù | &Угр. ; ; | заглавная буква «у», серьезный ударение |
| У | Ú | заглавная буква «у», ударение |
| О | Û | заглавная буква u, циркумфлекс ударение |
| О | Ü | заглавная буква «у», знак умлаут |
| О | Ý | заглавная буква y, акут |
| Þ | &ШИП; | заглавная ТОРН, исландский |
| ß | ß | маленькие острые s, немецкий |
| и | &грав; | маленькая а, серьезное ударение |
| á | á | малая а, острое ударение |
| — | &acir; | маленький а, циркумфлекс акцент |
| ã | &далее; | маленькая а, тильда |
| ä | ä | маленькая а, знак умляут |
| å | å | маленький, кольцо |
| æ | &elig; | малый ae |
| и | ç | малый c, седилья |
| и | &грав; | маленькая е, серьезное ударение |
| и | é | маленькая е, акут |
| ê | ê | маленькая буква e, циркумфлекс акцент |
| — | ë | маленькая е, знак умляут |
| х | ` | маленькая буква i, серьезное ударение |
| и | í | маленький я, острое ударение |
| î | î | маленький i, циркумфлекс акцент |
| ï | ï | маленький i, знак умляут |
| ð | &эт; | small eth, исландский |
| – | ñ | маленькая н, тильда |
| ò | ò | маленькое o, серьезное ударение |
| — | ó | маленькое о, острое ударение |
| х | ô | маленькое o, ударение по огибающей |
| х | õ | маленькая о, тильда |
| или | % | маленький о, знак умлаут |
| ø | &ослеш; | маленький о, косая черта |
| х | &уграв; | маленькая буква u, серьезное ударение |
| ú | ú | маленькая у, акут |
| х | û | маленькая буква u, циркумфлекс акцент |
| ü | ü | маленькая у, знак умляут |
| х | ý | маленький у, акут |
| + | &шип; | маленький шип, исландский |
| О | ÿ | маленький у, знак умлаут |
Образцы кода
Большинство языков программирования предоставляют способ преобразования объектов HTML в связанные с ними символы и наоборот.
- PHP
- .NET Framework
htmlentities
(PHP 4, PHP 5)Преобразование всех применимых символов в объекты HTML.
строка htmlentities (строка $string [ int $flags = ENT_COMPAT | ENT_HTML401 [ string $encoding = ini_get("default_charset") [ bool $double_encode = true ]]] ) Эта функция идентична htmlspecialchars() во всех отношениях, за исключением того, что с htmlentities() все символы, имеющие эквиваленты символов HTML, преобразуются в эти объекты.
Если вы хотите вместо этого декодировать (обратное), вы можете использовать html_entity_decode().
Метод HttpUtility.HtmlEncode (строка)
.NET Framework 4.6, 4.5, 4, 3.5, 3.0, 2.0, 1.1Преобразует строку в строку в кодировке HTML.
общедоступная статическая строка HtmlEncode (строка s)
Кодирование HTML преобразует символы, которые не разрешены в HTML, в эквиваленты символов; Декодирование HTML меняет кодировку на обратную. Например, при внедрении в блок текста символы < и > кодируются как < и > для HTTP-передачи.
Например, при внедрении в блок текста символы < и > кодируются как < и > для HTTP-передачи.
HTML | Charsets - GeeksforGeeks
Просмотреть обсуждение
Улучшить статью
Сохранить статью
- Уровень сложности: Easy
- Последнее обновление: 23 дек, 2021
Посмотреть обсуждение
Улучшить статью
Сохранить статью
Веб-браузер правильно отображает буквы, цифры и некоторые другие символы. Все это возможно из-за обязательного набора символов, который использует веб-браузер. Набор символов или кодировка символов имеют разные стандарты кодирования символов, которые присваивают этим наборам символов некоторые номера, которые можно использовать в Интернете.
ASCII: Американский стандартный код для обмена информацией (ANSII) создал эту кодировку символов. Эта кодировка символов используется в программировании на C/C++. Он состоит из 128 буквенно-цифровых символов, состоящих из букв (A-Z) и (a-z) и некоторых специальных символов, таких как + – * / ( ) @ и т. д.
Эта кодировка символов используется в программировании на C/C++. Он состоит из 128 буквенно-цифровых символов, состоящих из букв (A-Z) и (a-z) и некоторых специальных символов, таких как + – * / ( ) @ и т. д.
ANSI (Windows-1252): Американский национальный институт стандартов (ANSI) создал кодировку символов, поддерживающую 256 символов. Он используется как набор символов по умолчанию в Microsoft Windows.
ISO-8859-1: Используется в качестве набора символов по умолчанию в HTML4, а также поддерживает 256 символов. Международная организация по стандартизации (ISO) определяет стандартные наборы символов для различных алфавитов/языков. Он содержит цифры, прописные и строчные буквы английского алфавита и некоторые специальные символы.
UTF-8: Стандарты UTF-8 и UTF-16 были разработаны Консорциумом Unicode, поскольку наборы символов ISO-8859 ограничены и несовместимы с многоязычной средой. Он состоит из всех символов и знаков препинания.
Атрибут: Веб-браузер должен знать стандарт кодировки символов, используемый на странице html, и мы делаем это, как указано ниже.
Примеры:
HTML4
|
HTML5
|
Character set for different character encoding standard: В следующем списке показаны различные стандарты кодирования символов с их символами и присвоенными им числовыми кодами.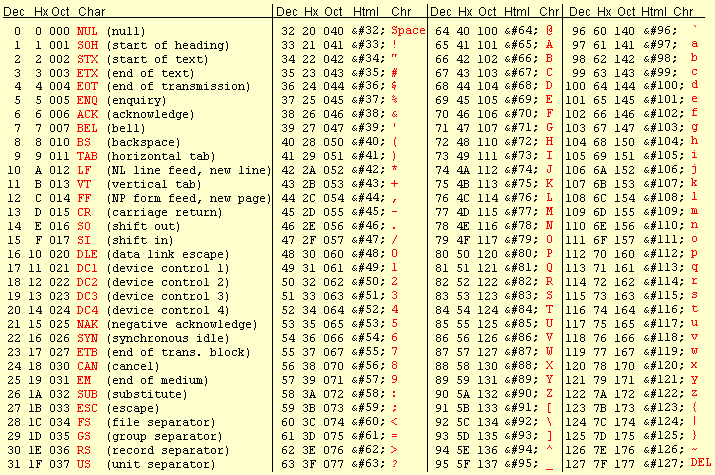
Таблица 1: Эта таблица содержит символы с одинаковыми номерами, присвоенными в разных кодировках.
| Номер | ASCII ANSI ISO-8859-1 UTF-8 | Описание | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32 | Пространство | ||||||||||||||||||||||
| 2020! | Восклицательный знак | ||||||||||||||||||||||
| 34 | " | Quotation Mark | |||||||||||||||||||||
| 35 | # | Hash Sign | |||||||||||||||||||||
| 36 | $ | Dollar Sign | |||||||||||||||||||||
| 37 | % | Percent Sign | |||||||||||||||||||||
| 38 | и | Амперс и знак | |||||||||||||||||||||
| 39 | ' | Апострофа.0021 | |||||||||||||||||||||
| 41 | ) | Closing Parenthesis | |||||||||||||||||||||
| 42 | * | Asterisk Sign | |||||||||||||||||||||
| 43 | + | Plus Sign | |||||||||||||||||||||
| 44 | , | Comma | |||||||||||||||||||||
| 45 | - | Дефис/знак минус | |||||||||||||||||||||
| 46 | . | Точка | |||||||||||||||||||||
| 47 | / | Знак косой черты/разделения | |||||||||||||||||||||
| 48 | 0 | Number Zero | |||||||||||||||||||||
| 49 | 1 | Number One | |||||||||||||||||||||
| 50 | 2 | Number Two | |||||||||||||||||||||
| 51 | 3 | Number Three | |||||||||||||||||||||
| 52 | 4 | Номер четыре | |||||||||||||||||||||
| 53 | 5 | Номер пять | |||||||||||||||||||||
| 54 | 6 | Номер шесть | 6 | Номер шесть | 6 | Число0009 | 55 | 7 | Number Seven | ||||||||||||||
| 56 | 8 | Number Eight | |||||||||||||||||||||
| 57 | 9 | Number Nine | |||||||||||||||||||||
| 58 | : | Colon | |||||||||||||||||||||
| 59 | ; | Semicolon | |||||||||||||||||||||
| 60 | < | Знак меньшего размера | |||||||||||||||||||||
| 61 | = | Равный знак | |||||||||||||||||||||
| 62 900 | > | Знак больше | |||||||||||||||||||||
| 63 | ? | Question Mark | |||||||||||||||||||||
| 64 | @ | at Sign | |||||||||||||||||||||
| 65 | A | Letter A | |||||||||||||||||||||
| 66 | B | Letter B | |||||||||||||||||||||
| 67 | C | Буква C | |||||||||||||||||||||
| 68 | D | Буква D | |||||||||||||||||||||
| 69 | E | Letter E | |||||||||||||||||||||
| 70 | F | Letter F | |||||||||||||||||||||
| 71 | G | Letter G | |||||||||||||||||||||
| 72 | H | Letter H | |||||||||||||||||||||
| 73 | I | Letter I | |||||||||||||||||||||
| 74 | J | ПИСЬМА J | |||||||||||||||||||||
| 75 | K | ПИСЬМА K | |||||||||||||||||||||
| L | .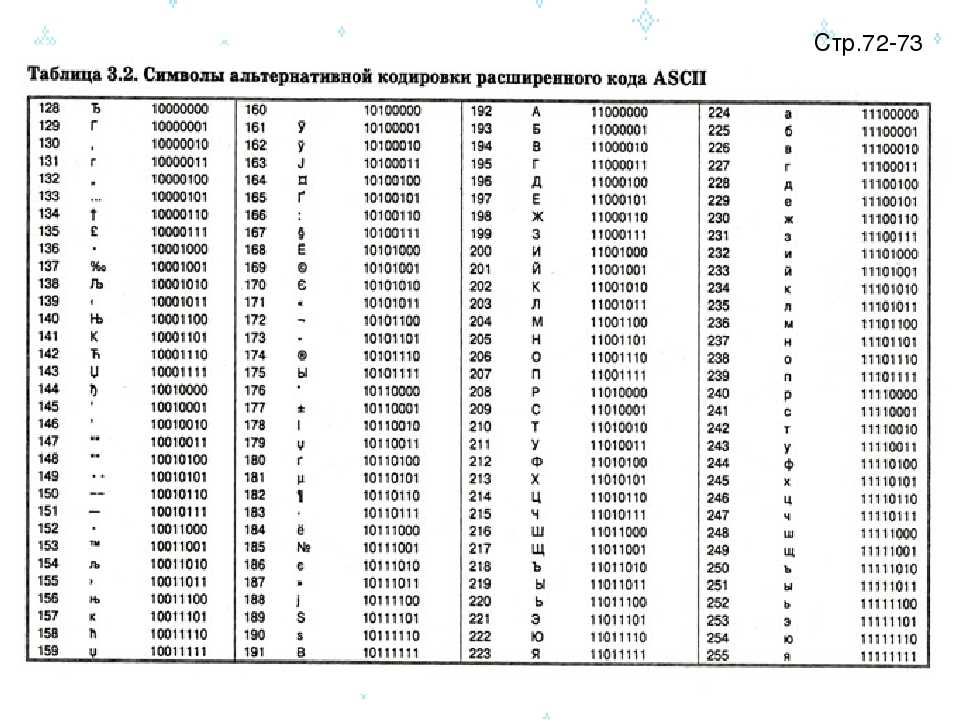 | 77 | M | Letter M | |||||||||||||||||||
| 78 | N | Letter N | |||||||||||||||||||||
| 79 | O | Letter O | |||||||||||||||||||||
| 80 | P | Letter P | |||||||||||||||||||||
| 81 | Q | За буква Q | |||||||||||||||||||||
| 82 | R | Буква R | |||||||||||||||||||||
| 83 | S | СПАСА | |||||||||||||||||||||
| .0020 Letter T | |||||||||||||||||||||||
| 85 | U | Letter U | |||||||||||||||||||||
| 86 | V | Letter V | |||||||||||||||||||||
| 87 | W | Letter W | |||||||||||||||||||||
| 88 | X | Letter X | |||||||||||||||||||||
| 89 | Y | буква Y | |||||||||||||||||||||
| 90 | Z | буква Z | |||||||||||||||||||||
| 91 | [ | . Возможный квадрат | 900 2 | [ | . | Circumflex Accent | |||||||||||||||||
| 95 | _ | Low Line | |||||||||||||||||||||
| 96 | ` | Grave Accent | |||||||||||||||||||||
| 97 | a | Letter a | |||||||||||||||||||||
| 98 | b | Письмо B | |||||||||||||||||||||
| 99 | C | Буква C | |||||||||||||||||||||
| 100 | D | Буква D | |||||||||||||||||||||
| 101 | E | буква E | 101 | E | . 0021 0021 | ||||||||||||||||||
| 102 | f | Letter f | |||||||||||||||||||||
| 103 | g | Letter g | |||||||||||||||||||||
| 104 | h | Letter h | |||||||||||||||||||||
| 105 | i | Letter i | |||||||||||||||||||||
| 106 | J | буква J | |||||||||||||||||||||
| 107 | K | ПИСЬМА K | |||||||||||||||||||||
| 108 | L | Буква L | 0 10920 10920 10920 L | . | m | Letter m | |||||||||||||||||
| 110 | n | Letter n | |||||||||||||||||||||
| 111 | o | Letter o | |||||||||||||||||||||
| 112 | p | Letter p | |||||||||||||||||||||
| 113 | q | Letter q | |||||||||||||||||||||
| 114 | r | Letter r | |||||||||||||||||||||
| 115 | s | Letter s | |||||||||||||||||||||
| 116 | t | Letter t | |||||||||||||||||||||
| 117 | u | Letter u | |||||||||||||||||||||
| 118 | v | Letter v | |||||||||||||||||||||
| 119 | w | Letter w | |||||||||||||||||||||
| 120 | x | Letter x | |||||||||||||||||||||
| 121 | Y | буква Y | |||||||||||||||||||||
| 122 | Z | Буква Z | |||||||||||||||||||||
| 123 | { | Открытие Ведпора.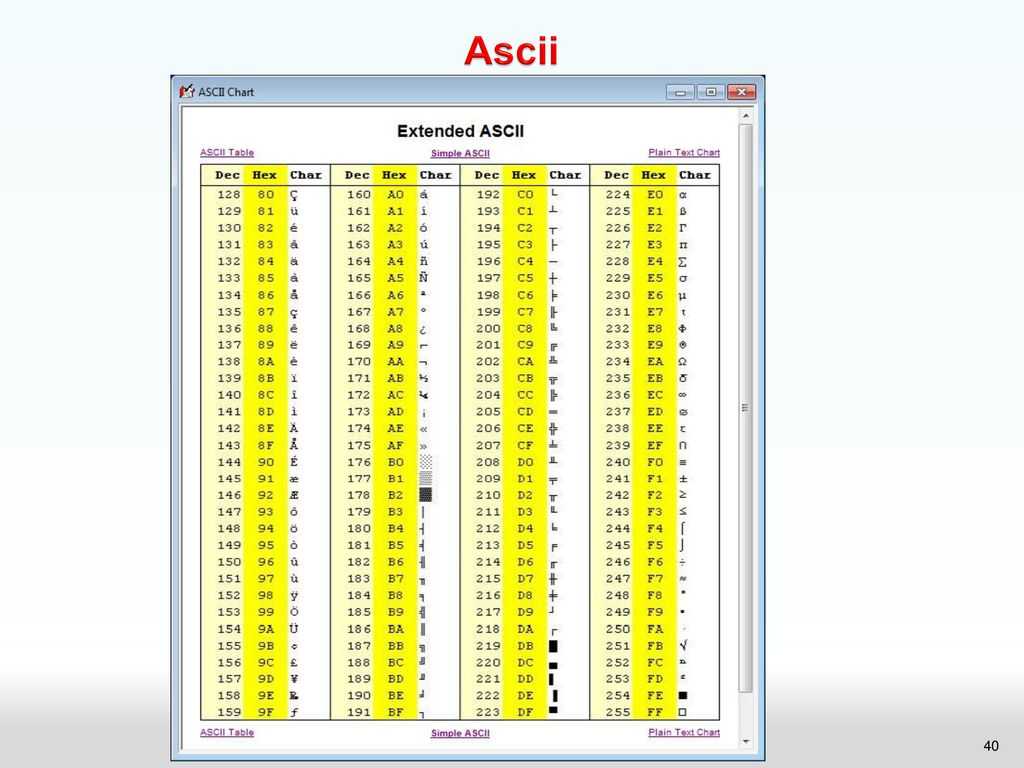 0009 0009 | 124 | | | Вертикальная линия | ||||||||||||||||||
| 125 | } | Закрытие Curly Crackket | |||||||||||||||||||||
| 126 | ~ | Tilde | 9008 989899 гг.
HTML Encoder / Decoder Используйте этот бесплатный онлайн-инструмент для кодирования HTML, чтобы преобразовать все применимые символы в соответствующие объекты HTML. HTML (язык гипертекстовой разметки) — это стандартный язык разметки для документов, предназначенных для отображения в веб-браузере. В этом могут помочь такие технологии, как каскадные таблицы стилей (CSS) и языки сценариев, такие как JavaScript. Веб-браузеры получают HTML-документы с веб-сервера или из локального хранилища и преобразуют документы в мультимедийные веб-страницы. HTML семантически описывает структуру веб-страницы и изначально включает подсказки для внешнего вида документа. HTML используется с 1991 года, но HTML 4.0 был первой стандартизированной версией, в которой интернациональные символы были достаточно полно обработаны. Когда документ HTML включает специальные символы за пределами диапазона семибитного ASCII, необходимо учитывать два аспекта: целостность информации и универсальное отображение в браузере. (Википедия) ASCII означает Американский стандартный код для обмена информацией, это стандарт кодирования символов для электронной связи. HTML-кодирование означает преобразование документа, содержащего специальные символы за пределами диапазона обычного семибитного ASCII, в стандартную форму. Используемый тип кодирования отправляется на сервер в виде информации заголовка, чтобы его можно было легко и правильно проанализировать браузерами. Веб-кодирование правильно отображает текст или строку в браузерах. Всякий раз, когда текст копируется с веб-страницы, наши браузеры напрямую копируют декодированные символы, которые не могут отображаться в браузерах. Ссылка на сущность символа HTML — это специальный набор символов (код), который браузер отображает как специальный символ или символ, соответствующий коду ссылки на сущность. Общий формат ссылки на символьный объект HTML: &, за которым следует некоторый код, а затем следует; без пробелов между ними. Инструмент HTML Encoder позволяет сразу кодировать и декодировать. Код HTMLКодировщик символов HTMLпреобразует все символы ASCII в их объекты HTML. Каждый символ имеет определенное значение, и каждый преобразованный код объекта передает исходное сообщение этого символа. Объект HTML — это фрагмент текста («строка»), начинающийся с амперсанда (&) и заканчивающийся точкой с запятой (;). Сущности часто используются для отображения зарезервированных символов (которые в противном случае интерпретировались бы как HTML-код) и невидимых символов (например, неразрывных пробелов). HTML имеет набор специальных символов, которые браузеры распознают как часть самого языка HTML. Например, меньше, чем Декодирование HTMLДекодирование символов HTML — это процесс, противоположный кодированию. Закодированные символы преобразуются обратно в исходную форму в процессе декодирования. Он декодирует строку, содержащую числовые ссылки на символы HTML, и возвращает декодированную строку. Вы также можете преобразовать код HTML в строку JavaScript. HTML Encoder также преобразует HTML-код в строку JavaScript Unicode, что означает, что текст выглядит зашифрованным при просмотре исходного кода, но при выполнении в качестве веб-страницы он выглядит нормально. Какие зарезервированные символы HTML? HTML имеет набор специальных символов, которые браузеры распознают как часть самого языка HTML. Но как заставить браузеры интерпретировать эти зарезервированные символы как часть содержимого, а не как часть HTML-кода? Здесь на помощь приходят ссылки на сущности символов HTML. Есть 3 зарезервированных символа, которые всегда следует заменять соответствующими ссылками на символы объектов.
Еще одна причина использовать кодировщик HTML для быстрого вывода специальных символов, которые недоступны на наших клавиатурах. Одним из таких символов, который используется довольно часто, является символ авторского права или ©. Ссылочный код символьного объекта для © — «©». Таким образом, наш кодировщик HTML может помочь вам быстро преобразовать символы и получить эквивалентные объекты HTML. Извините за это Как мы можем это улучшить? Спасибо за отзыв!Спасибо за отзыв! Считаете ли вы это полезным? Блог WHATWG — Дорога к HTML 5: кодировка символовпо Марк Пилигрим, Google в учебниках Добро пожаловать в мою полурегулярную колонку «Дорога к HTML 5», где я попытаюсь объяснить некоторые новые элементы, атрибуты и другие функции в предстоящей спецификации HTML 5. Особенностью дня является кодировка символов, в частности, как определить кодировку символов HTML-документа. Я никогда не был счастливее, чем когда пишу о кодировке символов. Но сначала, вот мое стандартное описание того, что такое кодировка символов:
И еще раз повторю свой стандартный набор справочных ссылок для тех из вас, кто ничего не знает о кодировке символов. Вы должны прочитать книгу Джоэла Спольски «Абсолютный минимум, который должен знать каждый разработчик программного обеспечения о Unicode и наборах символов (без оправданий!)» и «Символы против байтов» и все, что написано Мартином Дюрстом. Я также должен отметить, что вы всегда должны указывать кодировку символов на каждой HTML-странице, которую вы обслуживаете . Отсутствие указания кодировки может привести к уязвимостям в системе безопасности. Итак, как ваш браузер фактически определяет кодировку символов потока байтов, который отправляет веб-сервер? Если вы знакомы с заголовками HTTP, возможно, вы видели такой заголовок: .
Вкратце, это говорит о том, что веб-сервер думает, что отправляет вам HTML-документ, и что он считает, что документ использует кодировку символов Вкратце, это говорит о том, что веб-автор считает, что создал документ HTML с использованием кодировки символов Вот что говорит HTML 4.01 о порядке приоритета для определения кодировки символов:
И вот что говорит об этом HTML 5. Я не буду цитировать все это здесь, достаточно сказать, что это 7-шаговый алгоритм; шаг 4 имеет 2 подэтапа, первый из которых имеет 7 ветвей, один из которых имеет 8 подэтапов, один из которых фактически связан с отдельным алгоритмом, который сам состоит из 7 шагов... Так продолжается некоторое время . Суть в том, что
...а потом...
Две вещи должны бросаться в глаза здесь. Во-первых, WTF — это атрибут
Мне удалось найти лишь разрозненные обсуждения этого атрибута в списке рассылки WHATWG.
Лучшее объяснение нового атрибута
(Есть даже несколько Во-вторых, кто, черт возьми, думает, что WHATWG указывает на «умышленное нарушение спецификации модели персонажей W3C»‽ Это справедливый вопрос. Как и в случае со многими подобными вопросами, ответ заключается в том, что HTML 5 лишь кодифицирует то, что уже делают браузеры. Подводя итог: кодировка символов сложна, и несколько десятилетий плохо написанного программного обеспечения, используемого авторами, обученными копировать и вставлять, не упростило ее. Вы должны всегда указывать кодировку символов для каждого HTML-документа, иначе произойдут плохие вещи. Вы можете сделать это сложным путем (заголовок HTTP This Week in HTML 5 — Episode 21 ↔ This Все, что вам нужно знать о кодировании символовНа этой странице… Первое, что вам нужно знать о создании веб-страниц, — это важность и использование кодировки символов 9.6567 . НазначениеУстановка кодировки символов сообщает веб-браузерам, какой язык и, следовательно, какую систему письма и символы вы используете на веб-странице. Некоторые кодировки символовСуществует лотов различных кодировок символов, которые вы потенциально можете использовать на своих веб-страницах. В этом разделе я рассмотрю важные вещи, которые вы должны знать. US-ASCIIПриблизительно с 1960 года Американский стандартный код для обмена информацией (ASCII, произносится как аски ) основан на английском алфавите вместе с некоторыми другими символами, что дает в сумме 128:
На следующем рисунке показаны 128 символов в ASCII: ASCII не предусматривает каких-либо специальных символов, таких как евро (€), ничего, кроме английского, или любого форматирования (ни жирного, ни курсивного), поэтому его часто называют 9. Излишне говорить, что не используйте ASCII в качестве кодировки символов — она слишком ограничена! ИСО-8859-1ISO-8859-1 — стандартизированная кодировка символов. Часть ISO означает Международная организация по стандартизации , та же группа, которая определила стандарты для .
8859-1 — номер стандарта ISO (в данном случае для конкретной кодировки символов) ISO-8859-1 также известен как
ISO-8859-1 — это общепринятая кодировка символов в Интернете. Он содержит:
Вы можете увидеть эти дополнительные символы на рисунке ниже: ISO-8859-1 раньше был рекомендуемым объектом символов для веб-страниц, но это время давно прошло. Вместо этого используйте кодировку UTF-8, обсуждаемую далее. Кроме ISO-8859-1, кстати, существует множество других кодировок ISO-8859, в том числе и эти:
UTF-8 UTF-8 ( 8-битный формат преобразования Unicode ) — более новый стандарт, который датируется 1992-1993 годами. UTF-8 теперь широко рекомендуется и постепенно становится стандартным способом представления текста в файлах, электронной почте, веб-страницах и программном обеспечении. Как указать кодировку символовСуществует несколько способов сообщить веб-браузерам, какую кодировку символов используют ваши веб-страницы. Веб-серверЕсли ваш веб-сервер настроен на включение кодировки символов в заголовок HTTP Content-Type (скрытая информация, которая передается туда и обратно между веб-браузером и веб-сервером), вам не нужно ничего добавлять в свой интернет страницы. Вместо этого в заголовке HTTP Content-Type, который веб-сервер отправляет браузерам, содержится следующая информация: .Content-Type: text/html; кодировка = UTF-8 Имейте в виду, что это сработает, только если:
Как узнать, правда ли это?
Поскольку веб-страницы, которые мы создаем в классе, находятся на вашем локальном компьютере, а не на сервере, вам нужно будет использовать следующий метод: элемент HTML META. HTML-элемент METAНа вашей веб-странице вы вставляете такой элемент META внутри элемента HEAD: Этот элемент META появляется в вашем коде очень рано, еще до элемента TITLE, поэтому браузер знает, как отображать текст, который видят ваши пользователи. Что следует использовать В этом классе вы должны использовать META-элемент кодировки символов (опять же, поскольку ваши веб-страницы находятся на вашем локальном компьютере, а не размещены на веб-сервере). HTML 4.01Для HTML 4.01 используйте этот элемент META: Ваш код будет выглядеть так:
<голова>
HTML5Для HTML5 используйте этот элемент META: <метакодировка="utf-8"> Ваш код будет выглядеть так:
<голова>
<мета-кодировка="UTF-8">
Примечание по DTD и кодировке символовДо HTML 4.0 (1998) поддерживались только символы, использующие ISO-8859-1. Если вы хотите использовать символы китайского, кириллического, греческого, иврита, арабского или других нелатинских символов, вам необходимо использовать HTML 4. Дополнительная информацияИАНА. «Наборы персонажей». Управление по присвоению номеров в Интернете (2007 г.). http://www.iana.org/assignments/character-sets. Корпела, Юкка «Юкка». «Учебник по вопросам кода символов». ИТ и связь (2009). http://www.cs.tut.fi/~jkorpela/chars.html. Спольски, Джоэл. «Абсолютный минимум, который каждый разработчик программного обеспечения обязательно должен знать о Unicode и наборах символов (без оправданий!)». Джоэл о программном обеспечении (2003). http://www.joelonsoftware.com/articles/Unicode.html. Википедия. «АСКИИ». Википедия (2010). http://en.wikipedia.org/wiki/Ascii. Википедия. «Кодировки символов в HTML». Википедия (2010). http://en.wikipedia.org/wiki/Character_encodings_in_HTML. Википедия. «ИСО/МЭК 8859-1». Википедия (2010). http://en.wikipedia.org/wiki/Iso-8859-1. Википедия. «Юникод». Википедия (2010). http://en. |
 0021
0021 0021
0021 0020 245
0020 245 0009
0009

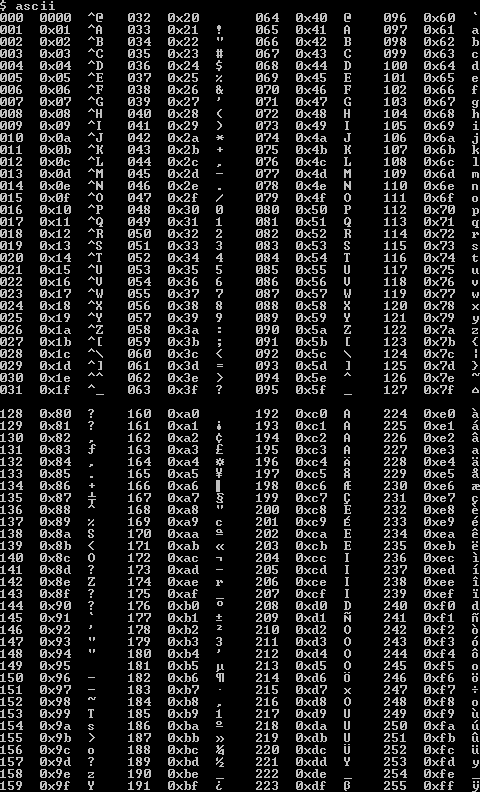 0020 Latin small letter f with hook
0020 Latin small letter f with hook 0021
0021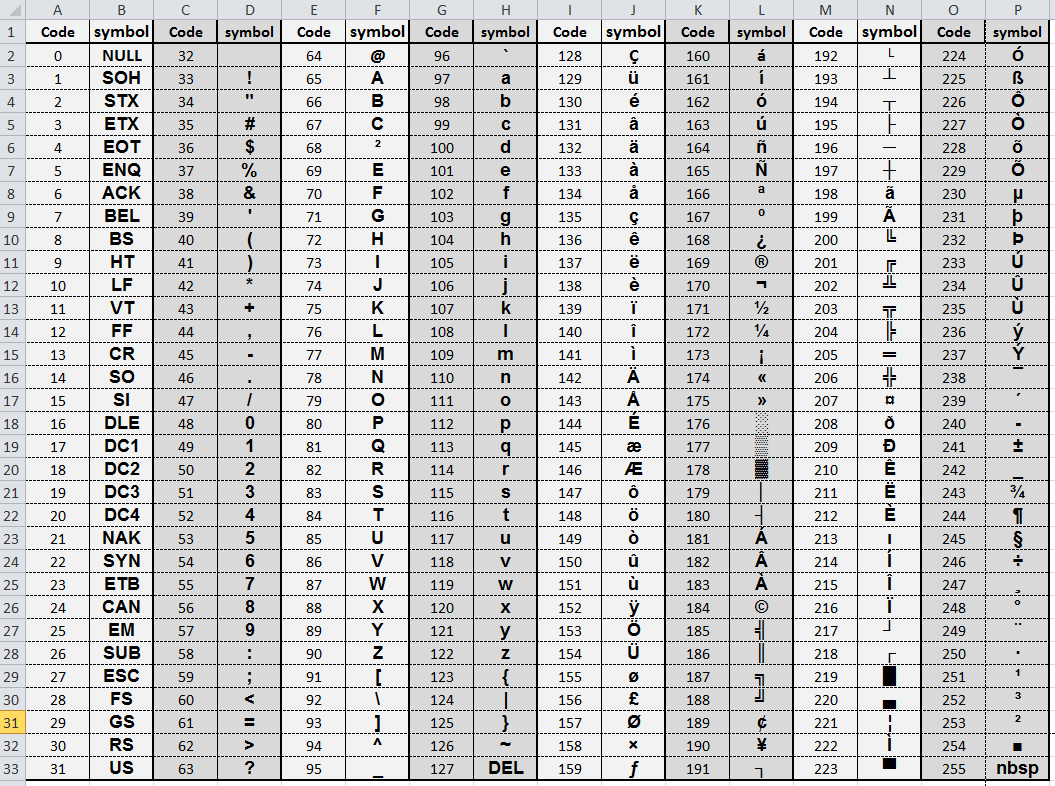 0021
0021 0021
0021 0021
0021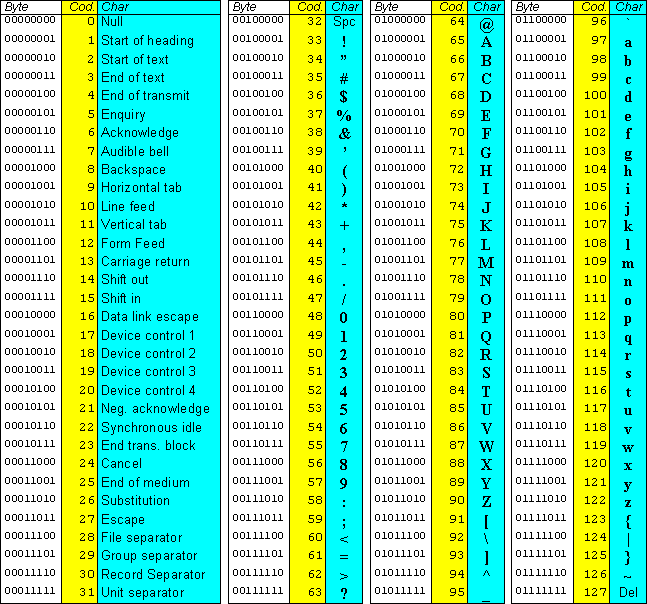 Ù
Ù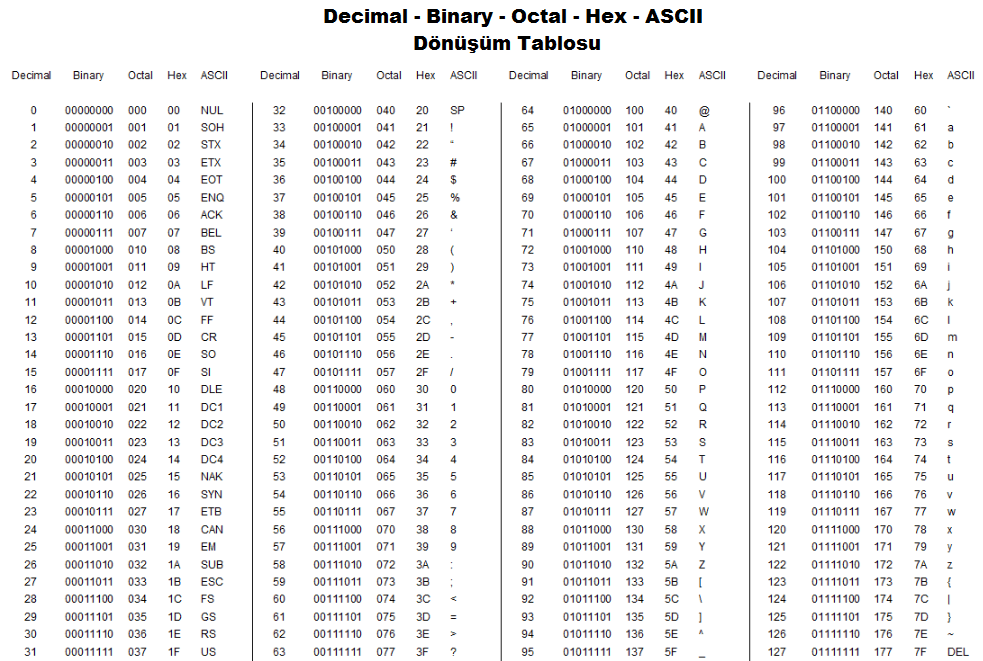 Инструмент также позволяет декодировать закодированные символы и преобразовывать HTML-код в строку JavaScript Unicode.
Инструмент также позволяет декодировать закодированные символы и преобразовывать HTML-код в строку JavaScript Unicode. ASCII является наиболее распространенным набором символов или кодировкой символов, используемых на компьютерах, и наиболее широко используемым набором символов для электронного кодирования текста. Это был первый стандарт кодирования символов. В нем определено 128 различных символов, включая английские буквы, цифры и наиболее распространенные специальные символы. Кодировка ASCII поддерживает только прописные и строчные буквы латинского алфавита, цифры 0-9., и некоторые дополнительные символы, всего 128 символов.
ASCII является наиболее распространенным набором символов или кодировкой символов, используемых на компьютерах, и наиболее широко используемым набором символов для электронного кодирования текста. Это был первый стандарт кодирования символов. В нем определено 128 различных символов, включая английские буквы, цифры и наиболее распространенные специальные символы. Кодировка ASCII поддерживает только прописные и строчные буквы латинского алфавита, цифры 0-9., и некоторые дополнительные символы, всего 128 символов.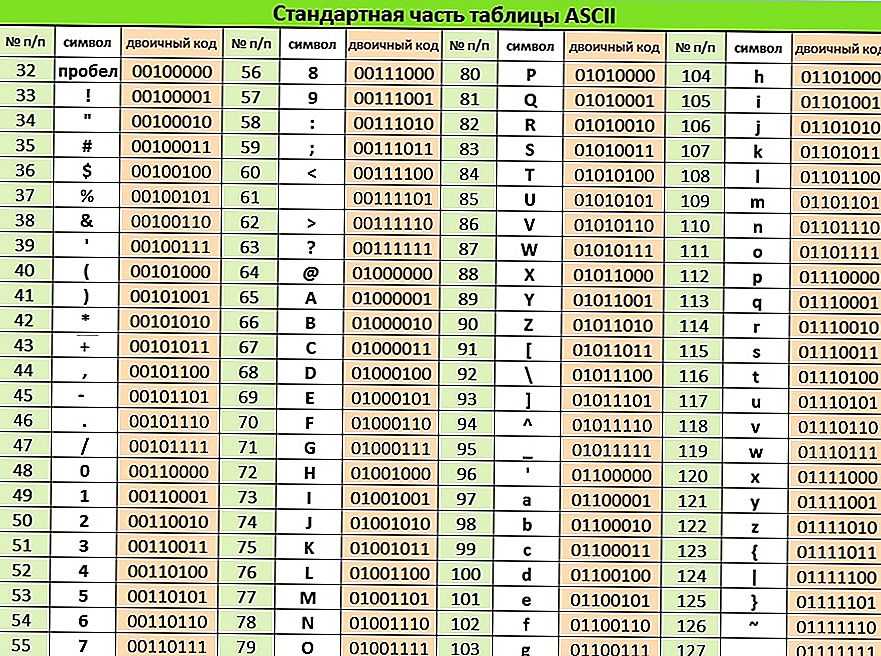 Эти символы ASCII должны быть закодированы для правильного отображения вывода.
Эти символы ASCII должны быть закодированы для правильного отображения вывода. Вы также можете использовать их вместо других символов, которые трудно набирать на стандартной клавиатуре.
Вы также можете использовать их вместо других символов, которые трудно набирать на стандартной клавиатуре. Например, браузеры интерпретируют
Например, браузеры интерпретируют Грубо говоря, кодировка символов обеспечивает соответствие между тем, что вы видите на экране, и тем, что ваш компьютер фактически хранит в памяти и на диске.
Грубо говоря, кодировка символов обеспечивает соответствие между тем, что вы видите на экране, и тем, что ваш компьютер фактически хранит в памяти и на диске.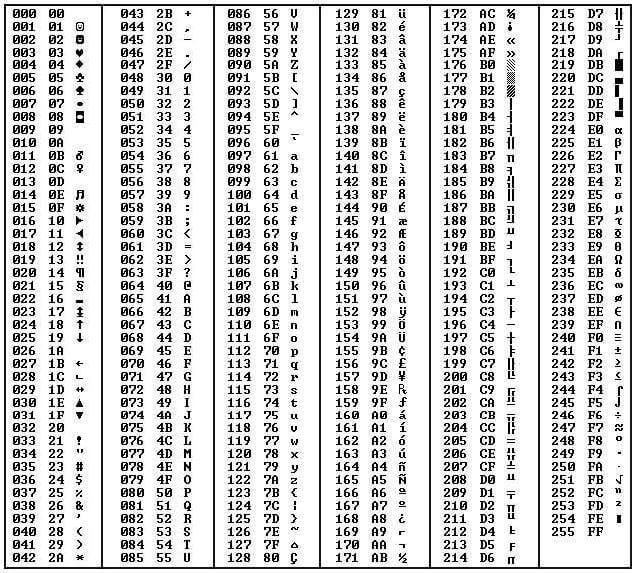
 Вы, наверное, тоже это видели:
Вы, наверное, тоже это видели:
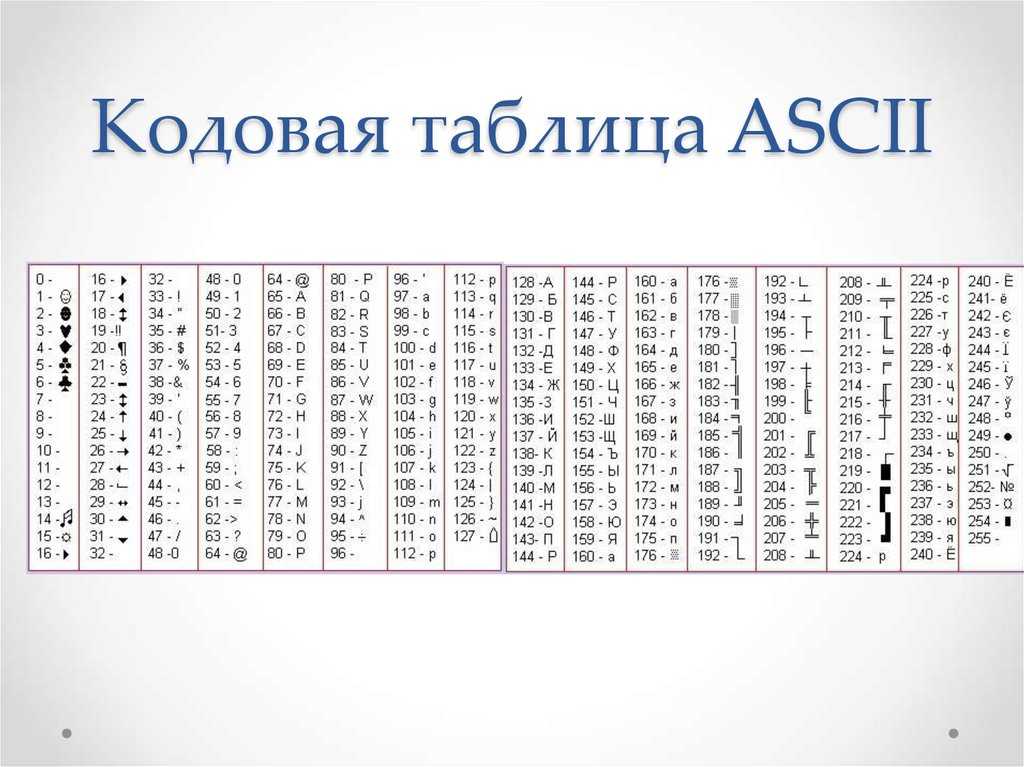

 ИСО-8859-1 и Windows-1252 очень похожие кодировки. Единственное, чем они отличаются, — это так называемые «умные кавычки» и «фигурные апострофы» — довольно маленькие типографские завитки, которые любят авторы и которые Microsoft Word (и многие другие редакторы) выводят по умолчанию. Многие авторы указывают кодировку ISO-8559-1 или US-ASCII (потому что они скопировали эту часть своего шаблона откуда-то еще), но затем используют фигурные кавычки из кодировки Windows-1252. Эта ошибка настолько распространена, что браузеры уже обрабатывают ISO-8859.-1 как Windows-1252. HTML 5 просто «прокладывает коровьи тропы».
ИСО-8859-1 и Windows-1252 очень похожие кодировки. Единственное, чем они отличаются, — это так называемые «умные кавычки» и «фигурные апострофы» — довольно маленькие типографские завитки, которые любят авторы и которые Microsoft Word (и многие другие редакторы) выводят по умолчанию. Многие авторы указывают кодировку ISO-8559-1 или US-ASCII (потому что они скопировали эту часть своего шаблона откуда-то еще), но затем используют фигурные кавычки из кодировки Windows-1252. Эта ошибка настолько распространена, что браузеры уже обрабатывают ISO-8859.-1 как Windows-1252. HTML 5 просто «прокладывает коровьи тропы». Сеть благодарит вас.
Сеть благодарит вас.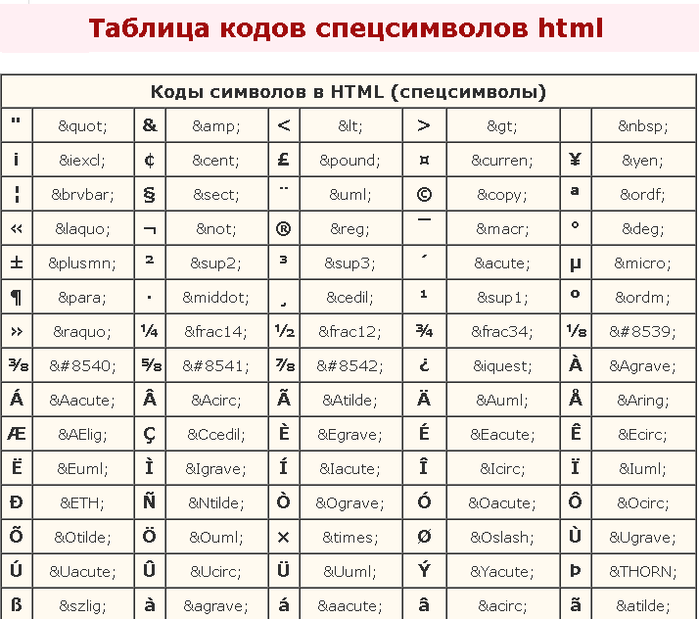 6566 обычный текст .
6566 обычный текст .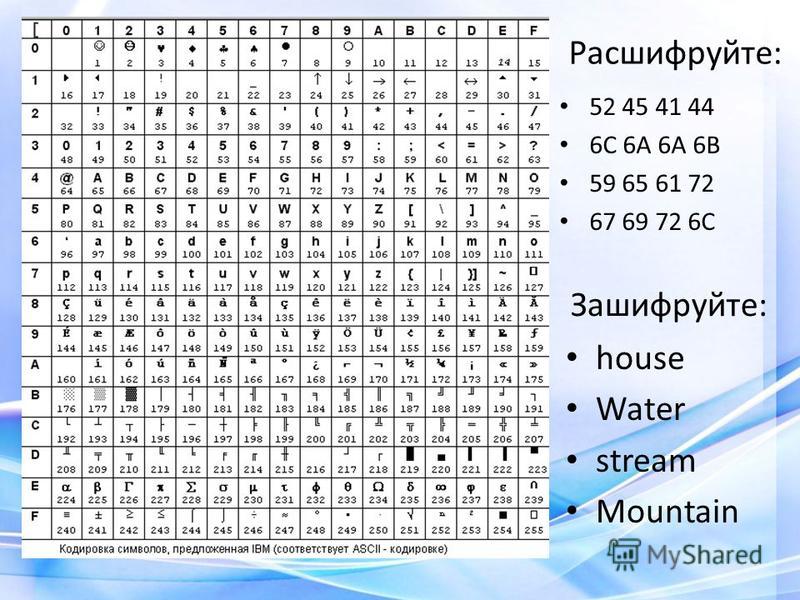
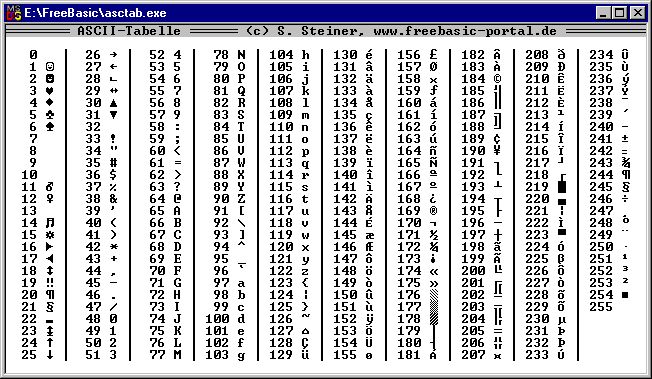 По сути, он может охватывать каждый символ любого языка мира: более 107 000 символов в 90 системах письма.
По сути, он может охватывать каждый символ любого языка мира: более 107 000 символов в 90 системах письма.
 Однако какой из них вы используете, зависит от вашего DTD.
Однако какой из них вы используете, зависит от вашего DTD. 0 или более позднюю версию (но вы все равно должны это делать!).
0 или более позднюю версию (но вы все равно должны это делать!).