Обзор протокола HTTP — HTTP
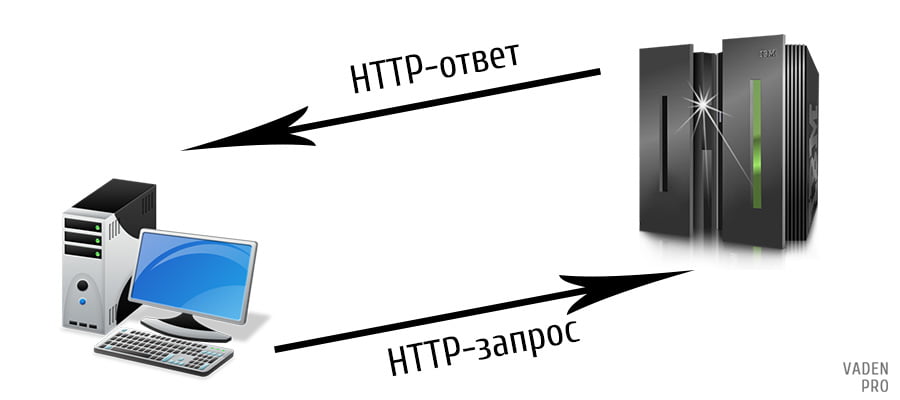
HTTP — это протокол, позволяющий получать различные ресурсы, например HTML-документы. Протокол HTTP лежит в основе обмена данными в Интернете. HTTP является протоколом клиент-серверного взаимодействия, что означает инициирование запросов к серверу самим получателем, обычно веб-браузером (web-browser). Полученный итоговый документ будет (может) состоять из различных поддокументов являющихся частью итогового документа: например, из отдельно полученного текста, описания структуры документа, изображений, видео-файлов, скриптов и многого другого.
Клиенты и серверы взаимодействуют, обмениваясь одиночными сообщениями (а не потоком данных). Сообщения, отправленные клиентом, обычно веб-браузером, называются запросами, а сообщения, отправленные сервером, называются ответами.
Хотя HTTP был разработан еще в начале 1990-х годов, за счет своей расширяемости в дальнейшем он все время совершенствовался.
HTTP — это клиент-серверный протокол, то есть запросы отправляются какой-то одной стороной — участником обмена (user-agent) (либо прокси вместо него). Чаще всего в качестве участника выступает веб-браузер, но им может быть кто угодно, например, робот, путешествующий по Сети для пополнения и обновления данных индексации веб-страниц для поисковых систем.
Каждый запрос (англ. request) отправляется серверу, который обрабатывает его и возвращает ответ (англ. response). Между этими запросами и ответами как правило существуют многочисленные посредники, называемые прокси, которые выполняют различные операции и работают как шлюзы или кэш, например.
Обычно между браузером и сервером гораздо больше различных устройств-посредников, которые играют какую-либо роль в обработке запроса: маршрутизаторы, модемы и так далее. Благодаря тому, что Сеть построена на основе системы уровней (слоёв) взаимодействия, эти посредники «спрятаны» на сетевом и транспортном уровнях. В этой системе уровней HTTP занимает самый верхний уровень, который называется «прикладным» (или «уровнем приложений»). Знания об уровнях сети, таких как представительский, сеансовый, транспортный, сетевой, канальный и физический, имеют важное значение для понимания работы сети и диагностики возможных проблем, но не требуются для описания и понимания HTTP.
Клиент: участник обмена
Участник обмена (user agent) — это любой инструмент или устройство, действующие от лица пользователя. Эту задачу преимущественно выполняет веб-браузер; в некоторых случаях участниками выступают программы, которые используются инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда является той сущностью, которая создаёт запрос. Сервер обычно этого не делает, хотя за многие годы существования сети были придуманы способы, которые могут позволить выполнить запросы со стороны сервера.
Чтобы отобразить веб страницу, браузер отправляет начальный запрос для получения HTML-документа этой страницы. После этого браузер изучает этот документ, и запрашивает дополнительные файлы, необходимые для отбражения содержания веб-страницы (исполняемые скрипты, информацию о макете страницы — CSS таблицы стилей, дополнительные ресурсы в виде изображений и видео-файлов), которые непосредственно являются частью исходного документа, но расположены в других местах сети.
Веб-страница является гипертекстовым документом. Это означает, что некоторые части отображаемого текста являются ссылками, которые могут быть активированы (обычно нажатием кнопки мыши) с целью получения и соответственно отображения новой веб-страницы (переход по ссылке). Это позволяет пользователю «перемещаться» по страницам сети (Internet). Браузер преобразует эти гиперссылки в HTTP-запросы и в дальнейшем полученные HTTP-ответы отображает в понятном для пользователя виде.
Веб-сервер
На другой стороне коммуникационного канала расположен сервер, который обслуживает (англ. serve) пользователя, предоставляя ему документы по запросу. С точки зрения конечного пользователя, сервер всегда является некой одной виртуальной машиной, полностью или частично генерирующей документ, хотя фактически он может быть группой серверов, между которыми балансируется нагрузка, то есть перераспределяются запросы различных пользователей, либо сложным программным обеспечением, опрашивающим другие компьютеры (такие как кэширующие серверы, серверы баз данных, серверы приложений электронной коммерции и другие).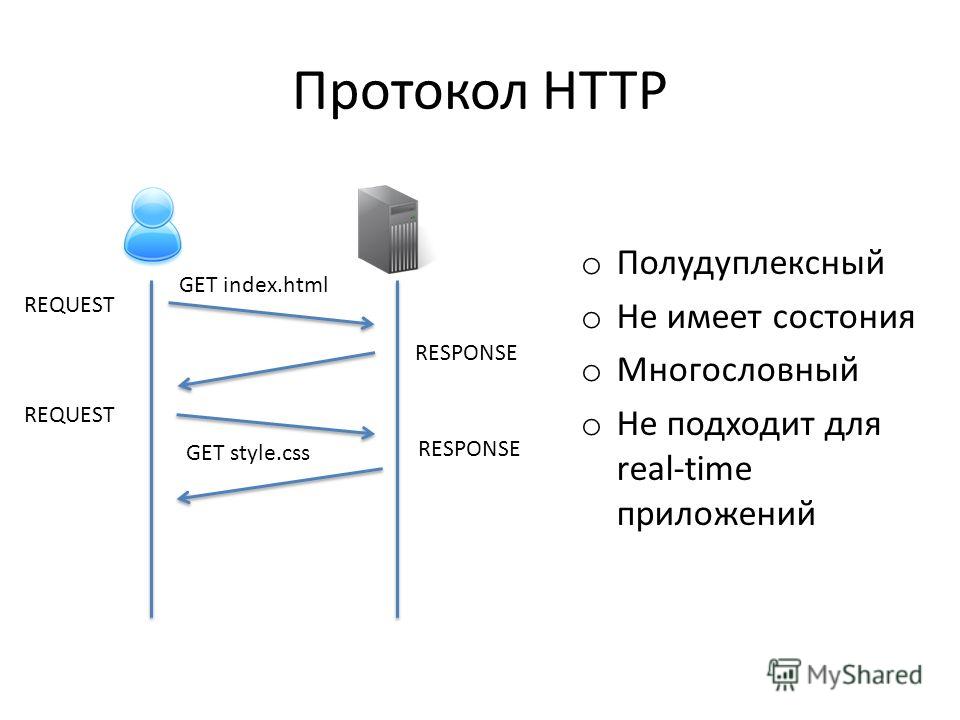
Сервер не обязательно расположен на одной машине, и наоборот — несколько серверов могут быть расположены (хоститься) на одной и той же машине. В соответствии с версией HTTP/1.1 и имея
Прокси
Между веб-браузером и сервером находятся большое количество сетевых узлов передающих HTTP сообщения. Из за слоистой структуры, большинство из них оперируют также на транспортном сетевом или физическом уровнях, становясь прозрачным на HTTP слое и потенциально снижая производительность. Эти операции на уровне приложений называются прокси. Они могут быть прозрачными, или нет, (изменяющие запросы не пройдут через них), и способны исполнять множество функций:
- caching (кеш может быть публичным или приватными, как кеш браузера)
- фильтрация (как сканирование антивируса, родительский контроль, …)
- выравнивание нагрузки (позволить нескольким серверам обслуживать разные запросы)
- аутентификация (контролировать доступом к разным ресурсам)
- протоколирование (разрешение на хранение истории операций)
HTTP — прост
Даже с большей сложностью, введенной в HTTP/2 путем инкапсуляции HTTP-сообщений в фреймы, HTTP, как правило, прост и удобен для восприятия человеком. HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более легкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более легкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP — расширяемый
Введенные в HTTP/1.0 HTTP-заголовки сделали этот протокол легким для расширения и экспериментирования. Новая функциональность может быть даже введена простым соглашением между клиентом и сервером о семантике нового заголовка.
HTTP не имеет состояния, но имеет сессию
HTTP не имеет состояния: не существует связи между двумя запросами, которые последовательно выполняются по одному соединению. Из этого немедленно следует возможность проблем для пользователя, пытающегося взаимодействовать с определенной страницей последовательно, например, при использовании корзины в электронном магазине. Но хотя ядро HTTP не имеет состояния, куки позволяют использовать сессии с сохранением состояния. Используя расширяемость заголовков, куки добавляются к рабочему потоку, позволяя сессии на каждом HTTP-запросе делиться некоторым контекстом, или состоянием.
HTTP и соединения
Соединение управляется на транспортном уровне, и потому принципиально выходит за границы HTTP. Хотя HTTP не требует, чтобы базовый транспортного протокол был основан на соединениях, требуя только надёжность, или отсутствие потерянных сообщений (т.е. как минимум представление ошибки). Среди двух наиболее распространенных транспортных протоколов Интернета, TCP надёжен, а UDP — нет. HTTP впоследствии полагается на стандарт TCP, являющийся основанным на соединениях, несмотря на то, что соединение не всегда требуется.
HTTP/1.0 открывал TCP-соединение для каждого обмена запросом/ответом, имея два важных недостатка: открытие соединения требует нескольких обменов сообщениями, и потому медленно, хотя становится более эффективным при отправке нескольких сообщений, или при регулярной отправке сообщений: теплые соединения более эффективны, чем холодные.
Для смягчения этих недостатков, HTTP/1.1 предоставил конвеерную обработку (которую оказалось трудно реализовать) и устойчивые соединения: лежащее в основе TCP соединение можно частично контролировать через заголовок  HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение теплым и более эффективным.
HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение теплым и более эффективным.
Проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP. Например, Google эксперементирует с QUIC, которая основана на UDP, для предоставления более надёжного и эффективного транспортного протокола.
Естественная расширяемость HTTP со временем позволила большее управление и функциональность Сети. Кэш и методы аутентификации были ранними функциями в истории HTTP. Способность ослабить первоначальные ограничения, напротив, была добавлена в 2010-е.
Ниже перечислены общие функции, управляемые с HTTP.
- Кэш
Сервер может инструктировать прокси и клиенты: что и как долго кэшировать. Клиент может инструктировать прокси промежуточных кэшей игнорировать хранимые документы. - Ослабление ограничений источника
Для предотвращения шпионских и других, нарушающих приватность, вторжений, веб-браузер обчеспечивает строгое разделение между веб-сайтами. Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности).
Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности). - Аутентификация
Некоторые страницы доступны только специальным пользователям. Базовая аутентификация может предоставляться через HTTP, либо через использование заголовкаWWW-Authenticateи подобных ему, либо с помощью настройки спецсессии, используя куки. - Прокси и тунелирование
Серверы и/или клиенты часто располагаются в интернете, и скрывают свои истинные IP-адреса от других. HTTP запросы идут через прокси для пересечения этого сетевого барьера. Не все прокси — HTTP прокси. SOCKS-протокол, например, оперирует на более низком уровне. Другие, как, например, ftp, могут быть обработаны этими прокси. - Сессии
Использование HTTP кук позволяет связать запрос с состоянием на сервере. Это создает сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.
 Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности).
Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности). Это создает сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.
Это создает сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.Когда клиент хочет взаимодействовать с сервером, являясь конечным сервером или промежуточным прокси, он выполняет следующие шаги:
- Открытие TCP соединения: TCP-соедиенение будет использоваться для отправки запроса или запросов, и получения ответа. Клиент может открыть новое соединение, переиспользовать существующее, или открыть несколько TCP-соединений к серверу.
- Отправка HTTP-сообщения: HTTP-собщения (до HTTP/2) — человеко-читаемо. Начиная с HTTP/2, простые сообщения инкапсилуруются во фреймы, делая невозможным их чтения напрямую, но принципиально остаются такими же.
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr - Читает ответ от сервера:
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html. .. (here comes the 29769 bytes of the requested web page) - Закрывает или переиспользует соединение для дальнейших запросов.
 .. (here comes the 29769 bytes of the requested web page)
.. (here comes the 29769 bytes of the requested web page)Если активирован HTTP-конвеер, несколько запросов могут быть отправлены без ожидания получения первого ответа целиком. HTTP-конвеер тяжело внедряется в существующие сети, где старые куски ПО сосуществуют с современными версиями. HTTP-конвеер был заменен в HTTP/2 на более надежные мультиплексивные запросы во фрейме.
HTTP/1.1 и более ранние HTTP сообщения человеко-читаемы. В версии HTTP/2 эти сообщения встроены в новую бинарную структуру, фрейм, позволяющий оптимизации, такие как компрессия заголовков и мультиплексирование. Даже если часть оригинального HTTP сообщения отправлена в этой версии HTTP, семантика каждого сообщения не изменяется и клиент воссоздаёт (виртуально) оригинальный HTTP-запрос. Это также полезно для понимания HTTP/2 сообщений в формате HTTP/1.1.
Существует два типа HTTP сообщений, запросы и ответы, каждый в своем формате.
Запросы
Примеры HTTP запросов:
Запросы содержат следующие элементы:
- HTTP-метод, обычно глагол подобно
GET,POSTили существительное, какOPTIONSилиHEAD, определяющее операцию, которую клиент хочет выполнить. Обычно, клиент хочет получить ресурс (используяGET) или передать значения HTML-формы (используяPOST), хотя другие операция могут быть необходимы в других случаях. - Путь к ресурсу: URL ресурсы лишены элементов, которые очевидны из контекста, например без protocol (
http://), domain (здесьdeveloper.mozilla.org), или TCP port (здесь80). - Версию HTTP-протокола.
- Заголовки (опционально), предоставляюшие дополнительную информацию для сервера.
- Или тело, для некоторых методов, таких как
POST, которое содержит отправленный ресурс.
Ответы
Примеры ответов:
Ответы содержат следующие элементы:
- Версию HTTP-протокола.
- HTTP код состояния, сообщающий об успешности запроса или причине неудачи.
- Сообщение состояния — краткое описание кода состояния.
- HTTP заголовки, подобно заголовкам в запросах.
- Опционально: тело, содержащее пересылаемый ресурс.

HTTP — легкий в использовании расширяемый протокол. Структура клиент-сервера, вместе со способностью к простому добавлению заголовков, позволяет HTTP продвигаться вместе с расширяющимися возможностями Сети.
Хотя HTTP/2 добавляет некоторую сложность, встраивая HTTP сообщения во фреймы для улучшения производительности, базовая структура сообщений осталась с HTTP/1.0. Сессионый поток остается простым, позволяя исследовать и отлаживать с простым монитором HTTP-сообщений.
Протокол HTTP — Документация по Веб-программированию 0.0.0
HTTP (HyperText Transfer Protocol — протокол передачи гипертекста) — символьно-ориентированный клиент-серверный протокол прикладного уровня без сохранения состояния, используемый сервисом World Wide Web.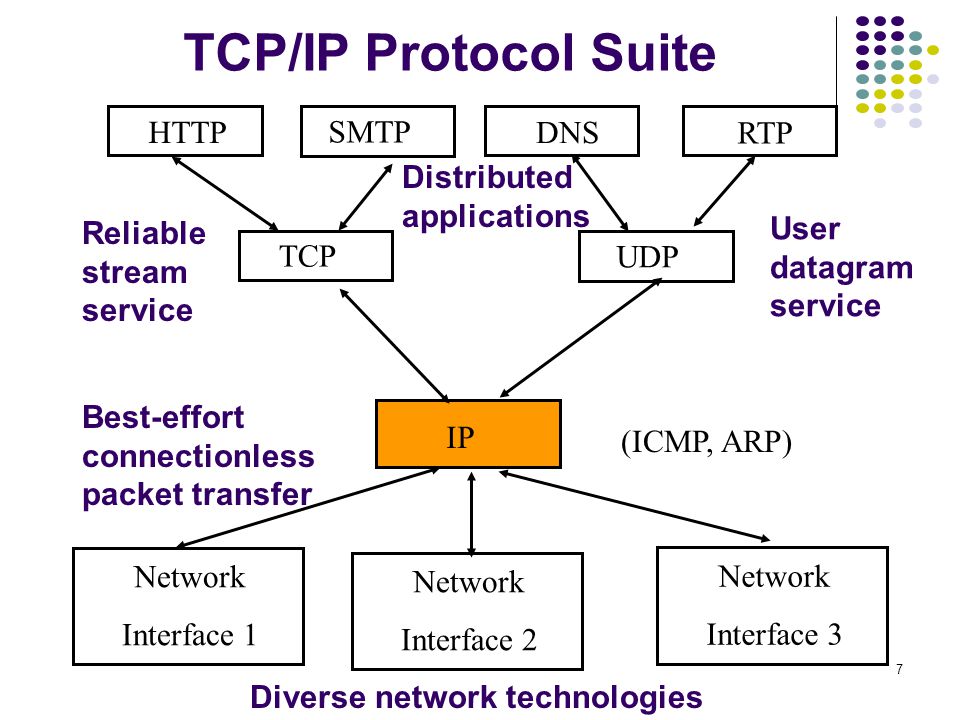
Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier – уникальный идентификатор ресурса) в запросе клиента. Основными ресурсами являются хранящиеся на сервере файлы, но ими могут быть и другие логические (напр. каталог на сервере) или абстрактные объекты (напр. ISBN). Протокол HTTP позволяет указать способ представления (кодирования) одного и того же ресурса по различным параметрам: mime-типу, языку и т. д. Благодаря этой возможности клиент и веб-сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
Структура протокола
Структура протокола определяет, что каждое HTTP-сообщение состоит из трёх частей (рис. 1), которые передаются в следующем порядке:
- Стартовая строка (англ. Starting line) — определяет тип сообщения;
- Заголовки (англ. Headers) — характеризуют тело сообщения, параметры передачи и прочие сведения;
- Тело сообщения (англ. Message Body) — непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.
 Обязательно должно отделяться от заголовков пустой строкой.
Обязательно должно отделяться от заголовков пустой строкой.Рис. 1. Структура протокола HTTP (дамп пакета, полученный сниффером Wireshark)
Стартовая строка HTTP
Cтартовая строка является обязательным элементом, так как указывает на тип запроса/ответа, заголовки и тело сообщения могут отсутствовать.
Стартовые строки различаются для запроса и ответа. Строка запроса выглядит так:
Метод URI HTTP/Версия протокола
Пример запроса:
GET /web-programming/index.html HTTP/1.1
Стартовая строка ответа сервера имеет следующий формат:
HTTP/Версия КодСостояния [Пояснение]
Например, на предыдущий наш запрос клиентом данной страницы сервер ответил строкой:
HTTP/1.1 200 Ok
Методы протокола
Метод HTTP (англ. HTTP Method) — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами (Табл. 1). Названия метода чувствительны к регистру.
Обычно метод представляет собой короткое английское слово, записанное заглавными буквами (Табл. 1). Названия метода чувствительны к регистру.
Таблица 1. Методы протокола HTTP
| Метод | Краткое описание |
|---|---|
| OPTIONS | Используется для определения возможностей веб-сервера или параметров соединения для конкретного ресурса. Предполагается, что запрос клиента может содержать тело сообщения для указания интересующих его сведений. Формат тела и порядок работы с ним в настоящий момент не определён. Сервер пока должен его игнорировать. Аналогичная ситуация и с телом в ответе сервера. Для того чтобы узнать возможности всего сервера, клиент должен указать в URI звёздочку — «*». Запросы «OPTIONS * HTTP/1.1» могут также применяться для проверки работоспособности сервера (аналогично «пингованию») и тестирования на предмет поддержки сервером протокола HTTP версии 1.1. Результат выполнения этого метода не кэшируется. |
| GET | Используется для запроса содержимого указанного ресурса. С помощью метода GET можно также начать какой-либо процесс. В этом случае в тело ответного сообщения следует включить информацию о ходе выполнения процесса. Клиент может передавать параметры выполнения запроса в URI целевого ресурса после символа «?»: GET /path/resource?param1=value1¶m2=value2 HTTP/1.1 Согласно стандарту HTTP, запросы типа GET считаются идемпотентными[4] — многократное повторение одного и того же запроса GET должно приводить к одинаковым результатам (при условии, что сам ресурс не изменился за время между запросами). Это позволяет кэшировать ответы на запросы GET. Кроме обычного метода GET, различают ещё условный GET и частичный GET. Условные запросы GET содержат заголовки If-Modified-Since, If-Match, If-Range и подобные. Частичные GET содержат в запросе Range. Порядок выполнения подобных запросов определён стандартами отдельно. |
| HEAD | Аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше копия ресурса помечается как устаревшая. |
| POST | Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом POST и он помещает их на страницу. При этом передаваемые данные (в примере с блогами — текст комментария) включаются в тело запроса. Аналогично с помощью метода POST обычно загружаются файлы. В отличие от метода GET, метод POST не считается идемпотентным[4], то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться одна копия этого комментария). При результатах выполнения 200 (Ok) и 204 (No Content) в тело ответа следует включить сообщение об итоге выполнения запроса. Если был создан ресурс, то серверу следует вернуть ответ 201 (Created) с указанием URI нового ресурса в заголовке Location. Сообщение ответа сервера на выполнение метода POST не кэшируется. |
| PUT | Применяется для загрузки содержимого запроса на указанный в запросе URI. Если по заданному URI не существовало ресурса, то сервер создаёт его и возвращает статус 201 (Created). Если же был изменён ресурс, то сервер возвращает 200 (Ok) или 204 (No Content). Сервер не должен игнорировать некорректные заголовки Content-* передаваемые клиентом вместе с сообщением. Если какой-то из этих заголовков не может быть распознан или не допустим при текущих условиях, то необходимо вернуть код ошибки 501 (Not Implemented). Фундаментальное различие методов POST и PUT заключается в понимании предназначений URI ресурсов. Сообщения ответов сервера на метод PUT не кэшируются. |
| PATCH | Аналогично PUT, но применяется только к фрагменту ресурса. |
| DELETE | Удаляет указанный ресурс. |
| TRACE | Возвращает полученный запрос так, что клиент может увидеть, что промежуточные сервера добавляют или изменяют в запросе. |
| LINK | Устанавливает связь указанного ресурса с другими. |
| UNLINK | Убирает связь указанного ресурса с другими. |

 Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения.
Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения.
 Метод POST предполагает, что по указанному URI будет производиться обработка передаваемого клиентом содержимого. Используя PUT, клиент предполагает, что загружаемое содержимое соответствуют находящемуся по данному URI ресурсу.
Метод POST предполагает, что по указанному URI будет производиться обработка передаваемого клиентом содержимого. Используя PUT, клиент предполагает, что загружаемое содержимое соответствуют находящемуся по данному URI ресурсу.Каждый сервер обязан поддерживать как минимум методы GET и HEAD. Если сервер не распознал указанный клиентом метод, то он должен вернуть статус 501 (Not Implemented). Если серверу метод известен, но он не применим к конкретному ресурсу, то возвращается сообщение с кодом 405 (Method Not Allowed). В обоих случаях серверу следует включить в сообщение ответа заголовок Allow со списком поддерживаемых методов.
Если серверу метод известен, но он не применим к конкретному ресурсу, то возвращается сообщение с кодом 405 (Method Not Allowed). В обоих случаях серверу следует включить в сообщение ответа заголовок Allow со списком поддерживаемых методов.
Наиболее востребованными являются методы GET и POST — на человеко-ориентированных ресурсах, POST — роботами поисковых машин и оффлайн-браузерами.
Примечание
Прокси-сервер
Прокси — это транзитный сервер, перенаправляющий HTTP-трафик. Прокси-серверы используются для ускорения выполнения запросов путем кэширования веб-страниц. В локальной сети применяется как межсетевой экран и средство управления HTTP-трафиком (например, для блокирования доступа к некоторым ресурсам). В Интернете прокси часто используют для анонимизации запросов — в этом случае веб-сервер получает ip-адрес прокси-сервера, а не реального клиента. В современных браузерах можно задать целый список прокси и переключаться между серверами из этого списка по мере необходимости (обычно такая возможность доступна через расширения или плагины браузера).
Коды состояния
Код состояния информирует клиента о результатах выполнения запроса и определяет его дальнейшее поведение. Набор кодов состояния является стандартом, и все они описаны в соответствующих документах RFC.
Каждый код представляется целым трехзначным числом. Первая цифра указывает на класс состояния, последующие — порядковый номер состояния (рис 1.). За кодом ответа обычно следует краткое описание на английском языке.
Рис. 1. Структура кода состояния HTTP
Введение новых кодов должно производиться только после согласования с IETF. Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода.
Применяемые в настоящее время классы кодов состояния и некоторые примеры ответов сервера приведены в табл. 2.
Таблица 2. Коды состояния протокола HTTP
| Класс кодов | Краткое описание |
|---|---|
| 1xx Informational (Информационный) | В этот класс выделены коды, информирующие о процессе передачи. Примеры ответов сервера: 100 Continue (Продолжать) 101 Switching Protocols (Переключение протоколов) 102 Processing (Идёт обработка) |
| 2xx Success (Успешно) | Сообщения данного класса информируют о случаях успешного принятия и обработки запроса клиента. В зависимости от статуса сервер может ещё передать заголовки и тело сообщения. Примеры ответов сервера: 200 OK (Успешно). 201 Created (Создано) 202 Accepted (Принято) 204 No Content (Нет содержимого) 206 Partial Content (Частичное содержимое) |
| 3xx Redirection (Перенаправление) | Коды статуса класса 3xx сообщают клиенту, что для успешного выполнения операции нужно произвести следующий запрос к другому URI. Обратите внимание, что при обращении к следующему ресурсу можно получить ответ из этого же класса кодов. Может получиться даже длинная цепочка из перенаправлений, которые, если будут производиться автоматически, создадут чрезмерную нагрузку на оборудование. Поэтому разработчики протокола HTTP настоятельно рекомендуют после второго подряд подобного ответа обязательно запрашивать подтверждение на перенаправление у пользователя (раньше рекомендовалось после 5-го). За этим следить обязан клиент, так как текущий сервер может перенаправить клиента на ресурс другого сервера. Клиент также должен предотвратить попадание в круговые перенаправления. Примеры ответов сервера: 300 Multiple Choices (Множественный выбор) 301 Moved Permanently (Перемещено навсегда) 304 Not Modified (Не изменялось) |
| 4xx Client Error (Ошибка клиента) | Класс кодов 4xx предназначен для указания ошибок со стороны клиента. Примеры ответов сервера: 401 Unauthorized (Неавторизован) 402 Payment Required (Требуется оплата) 403 Forbidden (Запрещено) 404 Not Found (Не найдено) 405 Method Not Allowed (Метод не поддерживается) 406 Not Acceptable (Не приемлемо) 407 Proxy Authentication Required (Требуется аутентификация прокси) |
| 5xx Server Error (Ошибка сервера) | Коды 5xx выделены под случаи неудачного выполнения операции по вине сервера. Для всех ситуаций, кроме использования метода HEAD, сервер должен включать в тело сообщения объяснение, которое клиент отобразит пользователю. Примеры ответов сервера: 500 Internal Server Error (Внутренняя ошибка сервера) 502 Bad Gateway (Плохой шлюз) 503 Service Unavailable (Сервис недоступен) 504 Gateway Timeout (Шлюз не отвечает) |
 В HTTP/1.0 сообщения с такими кодами должны игнорироваться. В HTTP/1.1 клиент должен быть готов принять этот класс сообщений как обычный ответ, но ничего отправлять серверу не нужно. Сами сообщения от сервера содержат только стартовую строку ответа и, если требуется, несколько специфичных для ответа полей заголовка. Прокси-сервера подобные сообщения должны отправлять дальше от сервера к клиенту.
В HTTP/1.0 сообщения с такими кодами должны игнорироваться. В HTTP/1.1 клиент должен быть готов принять этот класс сообщений как обычный ответ, но ничего отправлять серверу не нужно. Сами сообщения от сервера содержат только стартовую строку ответа и, если требуется, несколько специфичных для ответа полей заголовка. Прокси-сервера подобные сообщения должны отправлять дальше от сервера к клиенту. В большинстве случаев новый адрес указывается в поле Location заголовка. Клиент в этом случае должен, как правило, произвести автоматический переход (жарг. «редирект»).
В большинстве случаев новый адрес указывается в поле Location заголовка. Клиент в этом случае должен, как правило, произвести автоматический переход (жарг. «редирект»). При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя.
При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя.Заголовки HTTP
Заголовок HTTP (HTTP Header) — это строка в HTTP-сообщении, содержащая разделённую двоеточием пару вида «параметр-значение». Формат заголовка соответствует общему формату заголовков текстовых сетевых сообщений ARPA (RFC 822). Как правило, браузер и веб-сервер включают в сообщения более чем по одному заголовку. Заголовки должны отправляться раньше тела сообщения и отделяться от него хотя бы одной пустой строкой (CRLF).
Формат заголовка соответствует общему формату заголовков текстовых сетевых сообщений ARPA (RFC 822). Как правило, браузер и веб-сервер включают в сообщения более чем по одному заголовку. Заголовки должны отправляться раньше тела сообщения и отделяться от него хотя бы одной пустой строкой (CRLF).
Название параметра должно состоять минимум из одного печатного символа (ASCII-коды от 33 до 126). После названия сразу должен следовать символ двоеточия. Значение может содержать любые символы ASCII, кроме перевода строки (CR, код 10) и возврата каретки (LF, код 13).
Пробельные символы в начале и конце значения обрезаются. Последовательность нескольких пробельных символов внутри значения может восприниматься как один пробел. Регистр символов в названии и значении не имеет значения (если иное не предусмотрено форматом поля).
Пример заголовков ответа сервера:
Server: Apache/2.2.3 (CentOS) Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT Content-Type: text/html; charset=UTF-8 Accept-Ranges: bytes Date: Thu, 03 Mar 2011 04:04:36 GMT Content-Length: 2945 Age: 51 X-Cache: HIT from proxy.
 omgtu
Via: 1.0 proxy.omgtu (squid/3.1.8)
Connection: keep-alive
200 OK
omgtu
Via: 1.0 proxy.omgtu (squid/3.1.8)
Connection: keep-alive
200 OK
Все HTTP-заголовки разделяются на четыре основных группы:
- General Headers (Основные заголовки) — должны включаться в любое сообщение клиента и сервера.
- Request Headers (Заголовки запроса) — используются только в запросах клиента.
- Response Headers (Заголовки ответа) — присутствуют только в ответах сервера.
- Entity Headers (Заголовки сущности) — сопровождают каждую сущность сообщения.
Сущности (entity, в переводах также встречается название “объект”) — это полезная информация, передаваемая в запросе или ответе. Сущность состоит из метаинформации (заголовки) и непосредственно содержания (тело сообщения).
В отдельный класс заголовки сущности выделены, чтобы не путать их с заголовками запроса или заголовками ответа при передаче множественного содержимого (multipart/*). Заголовки запроса и ответа, как и основные заголовки, описывают всё сообщение в целом и размещаются только в начальном блоке заголовков, в то время как заголовки сущности характеризуют содержимое каждой части в отдельности, располагаясь непосредственно перед её телом.
В таблице 3 приведено краткое описание некоторых HTTP-заголовков.
Таблица 3. Заголовки HTTP
| Заголовок | Группа | Краткое описание |
|---|---|---|
| Allow | Entity | Список методов, применимых к запрашиваемому ресурсу. |
| Content-Encoding | Entity | Применяется при необходимости перекодировки содержимого (например, gzip/deflated). |
| Content-Language | Entity | Локализация содержимого (язык(и)) |
| Content-Length | Entity | Размер тела сообщения (в октетах) |
| Content-Range | Entity | Диапазон (используется для поддержания многопоточной загрузки или дозагрузки) |
| Content-Type | Entity | Указывает тип содержимого (mime-type, например text/html). Часто включает указание на таблицу символов локали (charset) Часто включает указание на таблицу символов локали (charset) |
| Expires | Entity | Дата/время, после которой ресурс считается устаревшим. Используется прокси-серверами |
| Last-Modified | Entity | Дата/время последней модификации сущности |
| Cache-Control | General | Определяет директивы управления механизмами кэширования. Для прокси-серверов. |
| Connection | General | Задает параметры, требуемые для конкретного соединения. |
| Date | General | Дата и время формирования сообщения |
| Pragma | General | Используется для специальных указаний, которые могут (опционально) применяется к любому получателю по всей цепочке запросов/ответов (например, pragma: no-cache). |
| Transfer-Encoding | General | Задает тип преобразования, применимого к телу сообщения. В отличие от Content-Encoding этот заголовок распространяется на все сообщение, а не только на сущность. |
| Via | General | Используется шлюзами и прокси для отображения промежуточных протоколов и узлов между клиентом и веб-сервером. |
| Warning | General | Дополнительная информация о текущем статусе, которая не может быть представлена в сообщении. |
| Accept | Request | Определяет применимые типы данных, ожидаемых в ответе. |
| Accept-Charset | Request | Определяет кодировку символов (charset) для данных, ожидаемых в ответе. |
| Accept-Encoding | Request | Определяет применимые форматы кодирования/декодирования содержимого (напр, gzip) |
| Accept-Language | Request | Применимые языки. Используется для согласования передачи. Используется для согласования передачи. |
| Authorization | Request | Учетные данные клиента, запрашивающего ресурс. |
| From | Request | Электронный адрес отправителя |
| Host | Request | Имя/сетевой адрес [и порт] сервера. Если порт не указан, используется 80. |
| If-Modified-Since | Request | Используется для выполнения условных методов (Если-Изменился…). Если запрашиваемый ресурс изменился, то он передается с сервера, иначе — из кэша. |
| Max-Forwards | Request | Представляет механиз ограничения количества шлюзов и прокси при использовании методов TRACE и OPTIONS. |
| Proxy-Authorization | Request | Используется при запросах, проходящих через прокси, требующие авторизации |
| Referer | Request | Адрес, с которого выполняется запрос. Этот заголовок отсутствует, если переход выполняется из адресной строки или, например, по ссылке из js-скрипта. Этот заголовок отсутствует, если переход выполняется из адресной строки или, например, по ссылке из js-скрипта. |
| User-Agent | Request | Информация о пользовательском агенте (клиенте) |
| Location | Response | Адрес перенаправления |
| Proxy-Authenticate | Response | Сообщение о статусе с кодом 407. |
| Server | Response | Информация о программном обеспечении сервера, отвечающего на запрос (это может быть как веб- так и прокси-сервер). |
В листинге 1 приведен фрагмент дампа заголовков при подключении к серверу http://example.org
Листинг 1. Заголовки HTTP
http://www.example.org/ GET http://www.example.org/ HTTP/1.1 Host: www.example.org User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9.2.13) Gecko/20101203 SUSE/3.
 6.13-0.2.1 Firefox/3.6.13
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7
Keep-Alive: 115
Proxy-Connection: keep-alive
HTTP/1.0 302 Moved Temporarily
Date: Thu, 03 Mar 2011 06:48:28 GMT
Location: http://www.iana.org/domains/example/
Server: BigIP
Content-Length: 0
X-Cache: MISS from proxy.omgtu
Via: 1.0 proxy.omgtu (squid/3.1.8)
Connection: keep-alive
----------------------------------------------------------
http://www.iana.org/domains/example/
GET http://www.iana.org/domains/example/ HTTP/1.1
Host: www.iana.org
User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9.2.13) Gecko/20101203 SUSE/3.6.13-0.2.1 Firefox/3.6.13
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7
Keep-Alive: 115
Proxy-Connection: keep-alive
HTTP/1.
6.13-0.2.1 Firefox/3.6.13
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7
Keep-Alive: 115
Proxy-Connection: keep-alive
HTTP/1.0 302 Moved Temporarily
Date: Thu, 03 Mar 2011 06:48:28 GMT
Location: http://www.iana.org/domains/example/
Server: BigIP
Content-Length: 0
X-Cache: MISS from proxy.omgtu
Via: 1.0 proxy.omgtu (squid/3.1.8)
Connection: keep-alive
----------------------------------------------------------
http://www.iana.org/domains/example/
GET http://www.iana.org/domains/example/ HTTP/1.1
Host: www.iana.org
User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9.2.13) Gecko/20101203 SUSE/3.6.13-0.2.1 Firefox/3.6.13
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7
Keep-Alive: 115
Proxy-Connection: keep-alive
HTTP/1.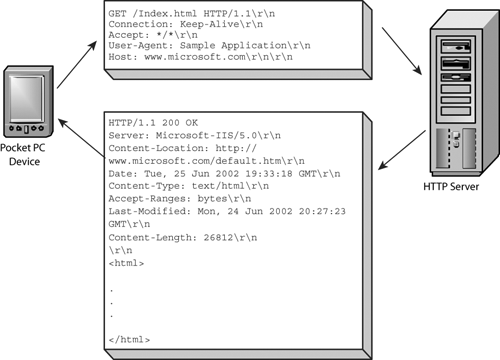 0 200 OK
Server: Apache/2.2.3 (CentOS)
Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT
Content-Type: text/html; charset=UTF-8
Accept-Ranges: bytes
Date: Thu, 03 Mar 2011 04:04:36 GMT
Content-Length: 2945
Age: 9858
X-Cache: HIT from proxy.omgtu
Via: 1.0 proxy.omgtu (squid/3.1.8)
Connection: keep-alive
....
0 200 OK
Server: Apache/2.2.3 (CentOS)
Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT
Content-Type: text/html; charset=UTF-8
Accept-Ranges: bytes
Date: Thu, 03 Mar 2011 04:04:36 GMT
Content-Length: 2945
Age: 9858
X-Cache: HIT from proxy.omgtu
Via: 1.0 proxy.omgtu (squid/3.1.8)
Connection: keep-alive
....
Несколько полезных примеров php-скриптов, обрабатывающих HTTP-заголовки, приведены в статье «Использование файла .htaccess» (редирект, отправка кода ошибки, установка last-modified и т.п.).
Тело сообщения
Тело HTTP сообщения (message-body), если оно присутствует, используется для передачи сущности, связанной с запросом или ответом. Тело сообщения (message-body) отличается от тела сущности (entity-body) только в том случае, когда при передаче применяется кодирование, указанное в заголовке Transfer-Encoding. В остальных случаях тело сообщения идентично телу сущности.
Заголовок Transfer-Encoding должен отправляться для указания любого кодирования передачи, примененного приложением в целях гарантирования безопасной и правильной передачи сообщения.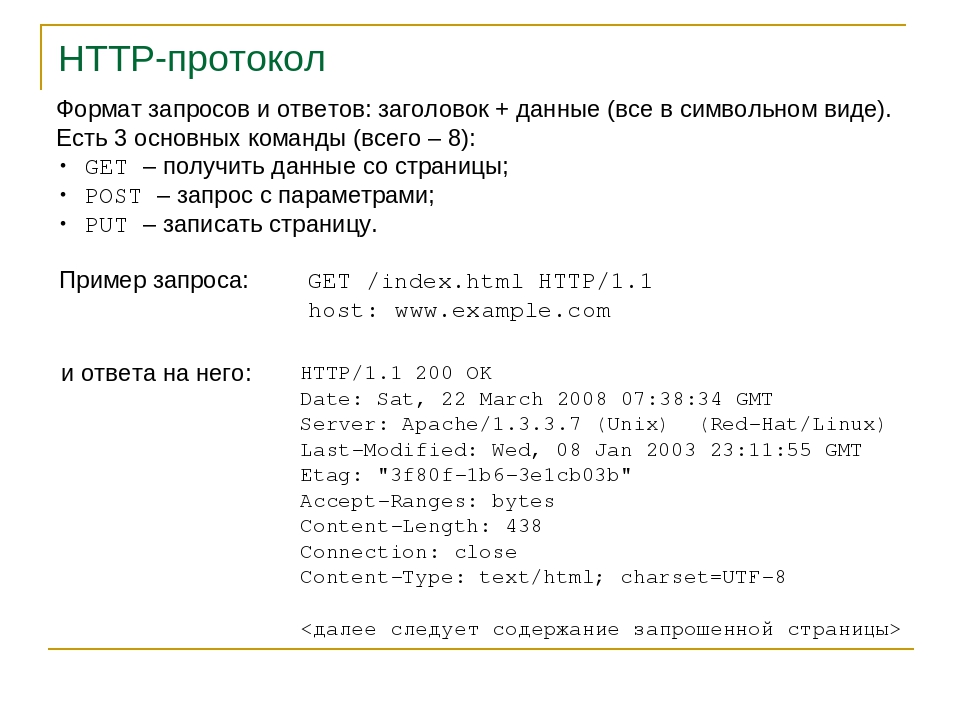 Transfer-Encoding — это свойство сообщения, а не сущности, и оно может быть добавлено или удалено любым приложением в цепочке запросов/ответов.
Transfer-Encoding — это свойство сообщения, а не сущности, и оно может быть добавлено или удалено любым приложением в цепочке запросов/ответов.
Присутствие тела сообщения в запросе отмечается добавлением к заголовкам запроса поля заголовка Content-Length или Transfer-Encoding. Тело сообщения (message-body) может быть добавлено в запрос только когда метод запроса допускает тело объекта (entity-body).
Все ответы содержат тело сообщения, возможно нулевой длины, кроме ответов на запрос методом HEAD и ответов с кодами статуса 1xx (Информационные), 204 (Нет содержимого, No Content), и 304 (Не модифицирован, Not Modified).
Контрольные вопросы
- В каком случае клиент получит от сервера ответ с кодом 418?
Протокол HTTP — HTML, CSS, JavaScript, Perl, PHP, MySQL: Weblibrary.biz
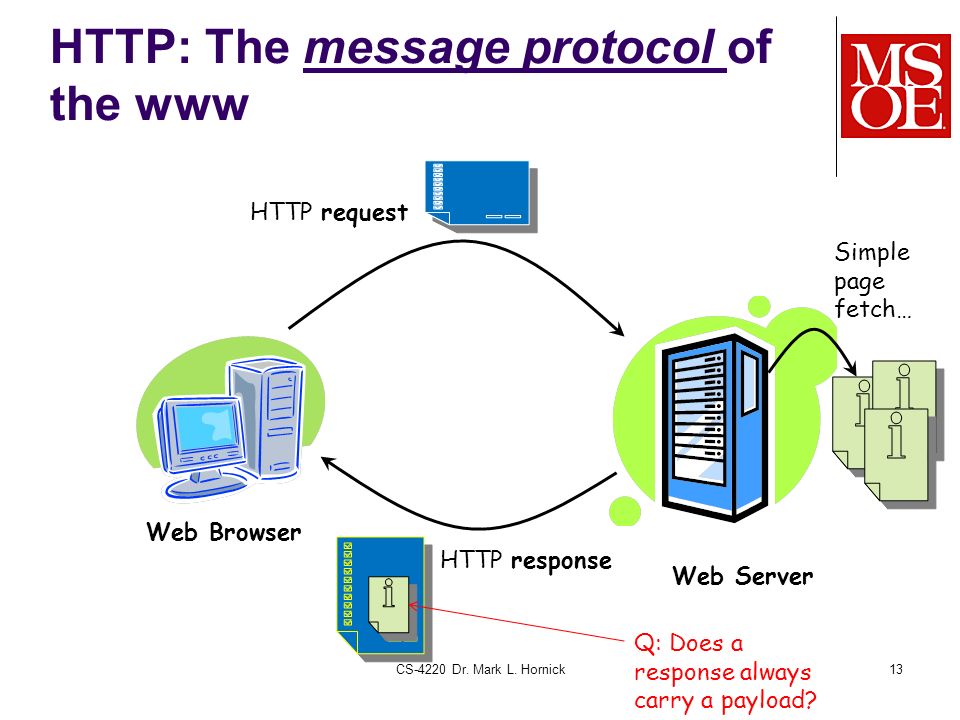
На 17-м занятии, “Введение в CGI”, мы уже говорили о том, как осуществляется взаимодействие между Web-броузером (таким как Netscape или Internet Explorer) и Web-сервером (например, Apache или IIS) с помощью протокола CGI. Рассматриваемый нами процесс был несколько упрощен. Теперь, после того как вы узнали, что такое CGI, пришло время разобраться с протоколами взаимодействия броузера и сервера более подробно. Чуть позже на этом же занятии вы познакомитесь с некоторыми методами управления этим взаимодействием, позволяющими решать ряд интересных задач.
Рассматриваемый нами процесс был несколько упрощен. Теперь, после того как вы узнали, что такое CGI, пришло время разобраться с протоколами взаимодействия броузера и сервера более подробно. Чуть позже на этом же занятии вы познакомитесь с некоторыми методами управления этим взаимодействием, позволяющими решать ряд интересных задач.
Упомянутое выше взаимодействие сервера и броузера описывается специальным протоколом, который называется протокол передачи гипертекста (Hypertext Transfer Protocol— HTTP). В настоящее время применяются две версии этого стандарта: HTTP 1.0 и HTTP 1.1 (для обсуждаемых ниже вопросов подходит любая из них).
Документы стандартов, в которых описаны протоколы, используемые в internet, называются Request For Comments, или RFC. Эти документы, поддерживаемые организацией Internet Engineering Task Force (IETF), можно просмотреть в Web no адресу http://vww. ietf.org. Протокол HTTP описан в документах RFC 1945 и RFC 2616. Однако имейте в виду, что эти документы рассчитаны на подготовленных пользователей.
Когда ваш Web-броузер устанавливает соединения с Web-сервером, броузер посылает серверу начальное сообщение, которое выглядит следующим образом:
По строке GET можно судить о том, с какого адреса URL вы пытаетесь получить документ и какую версию протокола используете. В данном случае вы используете версию 1.0 протокола HTTP.
Строка Connection означает, что вы хотели бы оставить это соединение открытым для получения нескольких страниц сразу. По умолчанию броузер создает отдельное соединение для каждого фрейма, страницы и изображения на Web-странице. Директива Keep-Alive просит сервер поддерживать соединение открытым, чтобы можно было принимать несколько элементов, используя одно и то же соединение.
Строки Accept определяют, какие виды данных вы хотели бы принимать с помощью этого соединения. Символы */* в конце первой строки Accept означают, что вы не прочь принимать любые виды данных. Следующая строка (iso-8859-l и остальные) определяет, какое кодирование символов может быть использовано для документа. Строка Accept-Encoding: gzip в данном случае означает, что для сжатия данных, получаемых от сервера, с целью их быстрой передачи может быть использована утилита gzip (GNU Zip). Наконец, строка Accept-Language говорит о том, какие языки приемлемы для этого броузера: английский (США), английский (Великобритания), немецкий, французский и т.д.
Строка Accept-Encoding: gzip в данном случае означает, что для сжатия данных, получаемых от сервера, с целью их быстрой передачи может быть использована утилита gzip (GNU Zip). Наконец, строка Accept-Language говорит о том, какие языки приемлемы для этого броузера: английский (США), английский (Великобритания), немецкий, французский и т.д.
В строке Host указывается имя сервера, обслуживающего Web-узел. Благодаря виртуальности обслуживания (пояснения ниже) это имя может отличаться от имени компьютера в URL.
Наконец, броузер идентифицирует себя для Web-сервера как Mozilla/4.51 [en]C-c32f404p (WinNT; U). В Web-терминологии броузер называется пользовательским агентом (user agent).
Затем сервер посылает броузеру ответ, который выглядит примерно так:
За ответом следует содержимое, запрашиваемой вами страницы.
Строка GET в данном случае означает, что сервер собирается передать броузеру Web-страницу. Код возврата 200 свидетельствует о том, что “все” прошло прекрасно. При этом сервер не забывает сказать “несколько слов о себе”, идентифицируя себя с помощью строки Server: в данном случае у нас “работает” Web-сервер Netscape-Enterprise/3.5.1G.
При этом сервер не забывает сказать “несколько слов о себе”, идентифицируя себя с помощью строки Server: в данном случае у нас “работает” Web-сервер Netscape-Enterprise/3.5.1G.
Строка Content-Length означает, что броузеру было передано 2222 байта. На основе этих данных ваш броузер теперь сможет вычислить процент завершения загрузки страницы. Строка Content-Type определяет тип посланной обратно страницы. Для HTML-страниц указывается тип text/html, а для изображений может быть установлен тип image/jpeg.
По дате Last-Modified броузер может “судить” о том, была ли изменена страница с момента ее последней загрузки. Большинство Web-броузеров помещает загруженные ранее страницы в локальную кэш-память, чтобы при повторном обращении к этой странице не нужно было ее снова и снова загружать из Internet. При этом полученная от сервера дата сравнивается с датой сохраненной копии, находящейся в кэш-памяти. Если страница на сервере не была изменена, броузер использует локальную копию.
Пример: получение страницы вручную
При желании можно получить Web-страницу вручную. К этой возможности программисты часто прибегают при тестировании CGI-программ, чтобы убедиться в том, что Web-сервер посылает корректные ответы.
Для выполнения этого примера вам потребуется специальная программа, называемая Telnet-клиентом. Telnet-клиент — это программа доступа к удаленному компьютеру с помощью программы эмуляции терминала, исходное назначение которой — обеспечить удаленное подключение к рабочим станциям UNIX. Однако она часто используется для задач отладки протокола HTTP.
Если у вас установлена система UNIX, то в ее поставку обязательно должна входить утилита telnet. Если вы используете Microsoft Windows, то программа telnet автоматически инсталлируется при установке протокола TCP/IP. Чтобы запустить Telnet-клиент, просто используйте команду Выполнить из системного меню Пуск. Если же у вас не установлена программа telnet или вы работаете в системе Macintosh, попробуйте поискать Telnet-клиент в Internet и загрузить его на свой компьютер.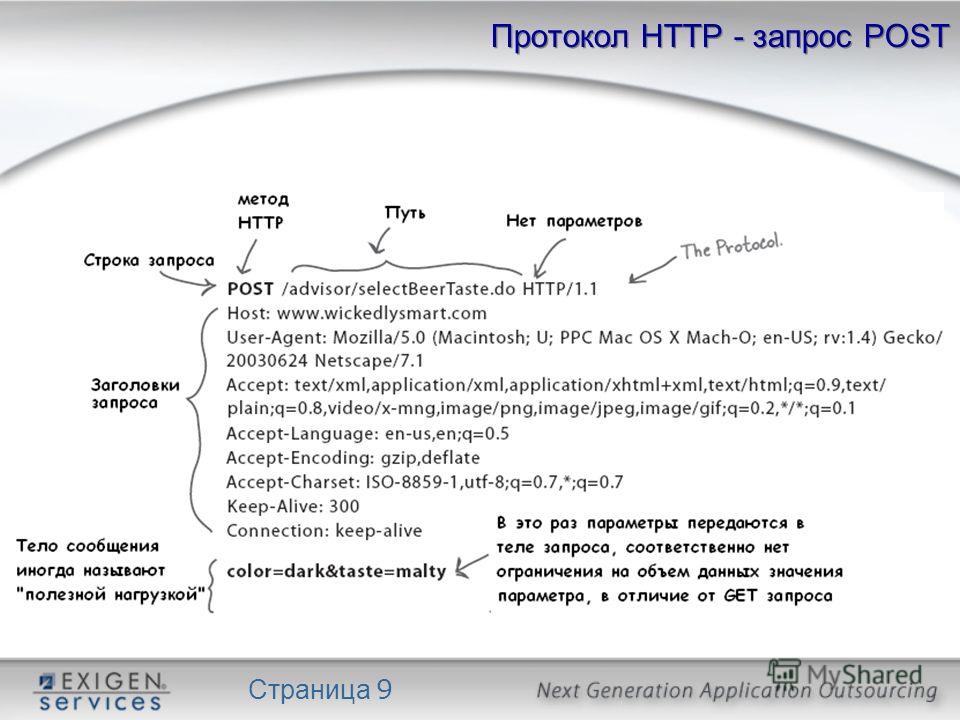
Подключение к Web-серверу с помощью telnet осуществляется следующим образом:
где www.webserver.com — имя Web-сервера, а 80 — номер порта, к которому вы хотите подключиться (именно этот порт обычно используется Web-серверами для установки соединения по протоколу HTTP). Если ваша программа telnet имеет графический интерфейс, то, возможно, придется установить эти значения в специальном диалоговом окне.
После подключения Telnet-клиента вы можете не получить никакого символа приглашения на ввод или сообщения о факте подключения. Не беспокойтесь: это нормальная ситуация. Сервер HTTP ожидает, что клиент “заговорит” первым, поэтому от сервера и не ожидается никакого приглашения. В системе UNIX вы получите сообщение, которое может иметь следующий вид:
Работая в других операционных системах (Windows или Macintosh), вы не увидите подобного сообщения.
Теперь нужно аккуратно и побыстрее ввести следующее:
После ввода этой строки нажмите клавишу <Enter> дважды. Web-сервер должен ответить обычным HTTP-заголовком и страницей верхнего уровня для данного Web-узла, а затем закрыть сеанс связи.
Web-сервер должен ответить обычным HTTP-заголовком и страницей верхнего уровня для данного Web-узла, а затем закрыть сеанс связи.
Пример: получение нетекстовой информации
Ваша CGI-программа не обязательно должна возвращать броузеру HTML-код. В действительности CGI-программа может отсылать броузеру все, что тот сможет принять и обработать.
Функция header в CGl-модуле информирует броузер о том, данные какого типа он будет получать. Для этого используется заголовок MIME Content-Type, который описывает содержимое данных, следующих за ним. В результате броузер сразу “узнает”, что ему нужно делать с полученными данными.
По умолчанию функния header посылает броузеру заголовок Content-Type типа text/html. И броузер “понимает”, что за заголовком следует содержимое, представляющее собой текст в формате HTML.
Предупредив броузер о типе получаемых данных, вы можете таким образом управлять способом обработки этих данных броузером. Данные могут выводиться в виде изображений, звука, передаваться дополнительному модулю броузера (browser plug-in) или внешней программе, запускаемой броузером.
Чтобы заставить функцию header послать нечто, отличное от обычного заголовка типа text/html, используйте ключ -type:
Среди тех типов MIME, указываемых в заголовке Content-Type, которые обычно посылаются броузеру, чаще других встречаются text/plain (для текстов, не подлежащих интерпретации броузером), image/gif и image/jpeg (для GIF- и JPEG-изображений), а также application/аррname (для данных, относящихся к конкретному приложению с именем аppnameе). Есть еще специальный тип MIME заголовка Content-Type application/octet-steam, означающий передачу необработанных двоичных данных, которые броузер должен просто сохранить в файле.
Описанные выше типы данных пригодятся вам на случай, если вы захотите создать Web-узел, показывающий “изображение дня” или рекламу Web-страниц. Ежедневное изменение Web-странии для отражения нового образа может превратиться в проблему. А если при этом вас не будет на месте, кто обновит “изображение дня”? Чтобы существенно облегчить себе жизнь, можно создать статическую HTML-страницу и написать CGI-программу на языке Perl, которая бы автоматически каждый день выводила новое изображение.
Для решения проблемы поместите следующий HTML-код в тело Web-страницы:
В приведенном фрагменте HTML-кода обратите внимание, что в дескрипторе <IMG> указана CG1-программа, а не GIF- или JPEG-изображение. Затем вам потребуется папка с изображениями, которых должно хватить хотя бы на месяц. Вы можете использовать любые изображения, главное, чтобы их файлы имели расширение .jpeg. К тому же заметьте, что эту программу можно легко адаптировать для изображений в формате GIF.
CGI-программа daily_image.cgi может иметь вид, представленный в листинге 20.1.
Проведем анализ программы.
- Строка 7. В этой строке задается каталог, в котором располагаются файлы изображений. Этот каталог можно заменить другим, соответствующим физическому расположению ваших файлов изображений.
- Строка 8. Как ни странно, но, поскольку эта CGI-программа не выдает никакого текста и поскольку HTML-страница, в которую она встроена, не отображает результат в виде текста, вы не можете просто выводить сообщения об ошибках. Если каталог $imagedir невозможно будет открыть, то будет отображен .jpg-файл, имя которого содержится в переменной $error.
- Строки 10—16. Эта процедура выводит изображения в стандартный выходной поток, который будет направлен броузеру. На Windows-платформах поток STDOUT рассматривается как текстовый файл, значит, при выводе .jpg-файла в поток STDOUT изображение будет искажено. Поэтому, чтобы сделать дескрипторы STDOUT и IMAGE бинарными, используется функция binmode. Под управлением системы UNIX нет необходимости в использовании функции binmode, но ее присутствие не повредит. Обратите внимание на строку 12: если изображение не удается открыть, нет смысла в выводе сообщения об ошибке, поэтому просто выполняется выход из программы.
- Строка 19. Эта строка выводит стандартный HTML-заголовок, за исключением того, что в строке Content-Type вместо обычного типа text/html используется image/jpeg.
- Строка 25. Открывается каталог с изображениями для чтения. Если каталог с изображениями не открывается, то вызывается функция display_image(), которой через переменную $error передается имя файла с изображением ошибки.
- Строка 26. Эта строка посложнее других, поэтому на ней стоит остановиться. Сначала содержимое каталога читается с помощью функции readdir. Затем из списка извлекаются имена файлов с расширением .jpg. Наконец, полученный список сортируется и присваивается переменной в @jpegs.
 Если каталог $imagedir невозможно будет открыть, то будет отображен .jpg-файл, имя которого содержится в переменной $error.
Если каталог $imagedir невозможно будет открыть, то будет отображен .jpg-файл, имя которого содержится в переменной $error.HTML и HTTP. Эти два популярные на сегодняшний день слова
Эта статья адресована для всех тех, кто хочет освежить в своей памяти или узнать, что означают эти два очень популярные на сегодняшний день в Интернете слова — HTML и HTTP. По возможности все написано максимально понятным языком. Также совсем чуть-чуть поговорим о связи между HTML и Мультимедиа.
Для начала HTTP и HTML — это разные вещи и желательно их не путать.
Что такое HTTP? HTTP – это протокол по которому вы получаете web страницы с Интернета.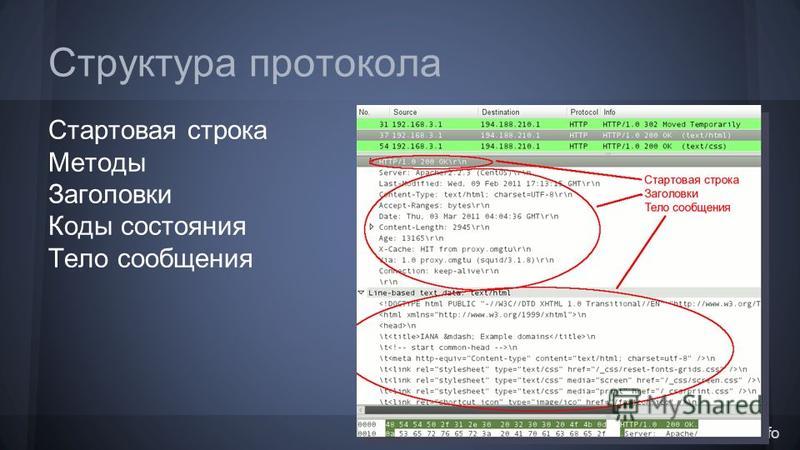 На сегодняшний день этот протокол используется повсеместно. Например, когда вы хотите зайти на какой-то web-сайт, вы набираете в своем Интернет браузере адрес страницы. Также перед адресом вы можете указать протокол, по которому будет передана web-страница, например, http://. Это как раз и есть тот самый HTTP протокол. Также бывает https://, что означает безопасное соединение. Т.е. вся информация будет передаваться в зашифрованном виде. ОК, теперь разберем, что означает слово протокол. Предлагаю простой вариант определения, постарался убрать все лишнее.
На сегодняшний день этот протокол используется повсеместно. Например, когда вы хотите зайти на какой-то web-сайт, вы набираете в своем Интернет браузере адрес страницы. Также перед адресом вы можете указать протокол, по которому будет передана web-страница, например, http://. Это как раз и есть тот самый HTTP протокол. Также бывает https://, что означает безопасное соединение. Т.е. вся информация будет передаваться в зашифрованном виде. ОК, теперь разберем, что означает слово протокол. Предлагаю простой вариант определения, постарался убрать все лишнее.
Протокол передачи данных – набор соглашений и правил, обеспечивающий передачу информации между программным обеспечением и разнесённой в пространстве аппаратурой. Протоколов существует огромное множество. Например, электронную почту вы получаете по протоколу SMTP, когда используете почтовый клиент (Outlook, The Bat и др.).
Теперь, что такое HTML? HTML – это язык разметки, с помощью которого создается большинство веб-страниц в Интернете. Язык HTML обрабатывается вашим браузером и отображается в виде web-страницы, т.е. в удобном для восприятия формате.
Язык HTML обрабатывается вашим браузером и отображается в виде web-страницы, т.е. в удобном для восприятия формате.
Давайте создадим что-нибудь простенькое с использованием языка HTML.
- Сначала создадим файл, например hello.html . Расширение html, как раз означает, что данный файл будет содержать язык разметки HTML.
- Поместим в этот файл следующие строчки языка HTML:
<html>
<head>
</head>
<body>
Привет! 🙂
</body>
</html>
Теперь я помещаю этот файл на свой web-сервер. Web-сервер – это программа, установленная на сервере, которая обрабатывает ваши запросы и выдает запрашиваемые web-страницы и не только.
Далее вы можете запросить эту HTML страничку, в вашем браузере, по адресу http://itmultimedia.ru/hello.html . Вы должны увидеть сообщение – “Привет! :)”.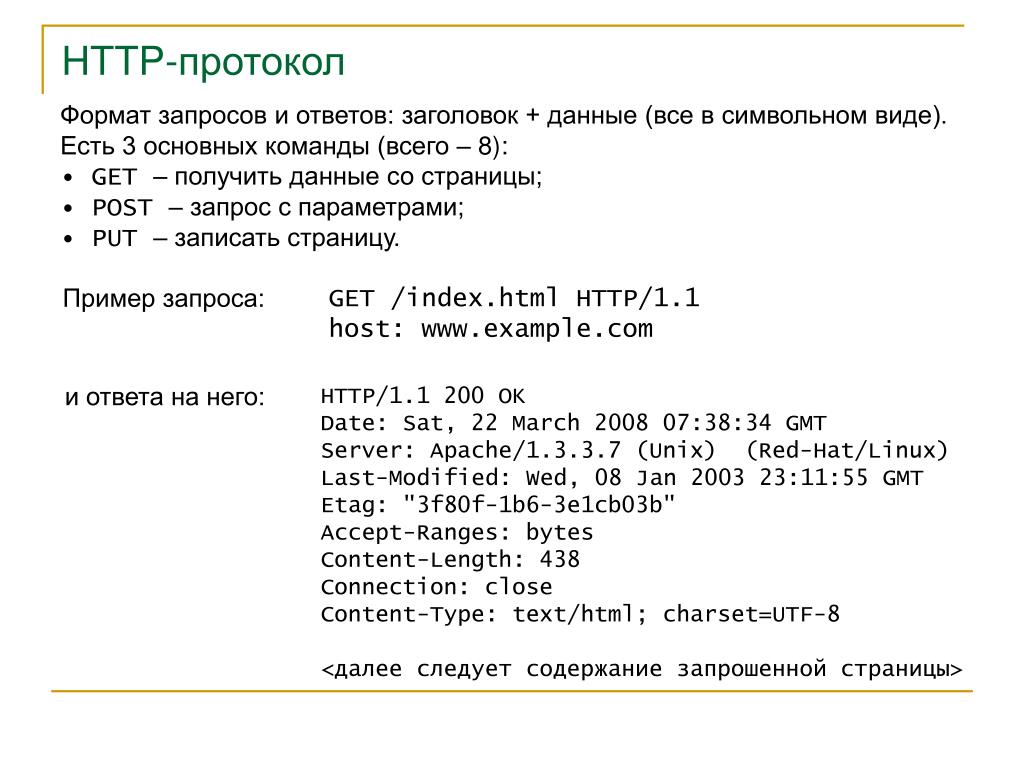 Получается, вы получили HTML страницу по протоколу HTTP.
Получается, вы получили HTML страницу по протоколу HTTP.
HTML и Мультимедиа.
Вначале я обещал рассказать немного о связи HTML и мультимедиа. Связь действительно есть и она заключается в том, что вы можете помещать различные мультимедийные приложения, например видео плеер на вашу web-страничку. Для встраивания мультимедийных элементов, как раз можно использовать HTML. В дальнейшем я расскажу более подробно, какие мультимедийные элементы существуют и каким образом их лучше встраивать.
Также на сегодняшний день, сайты и блоги вы можете создавать без каких либо знаний о HTML разметке и др. Так как, существуют специальные Интернет сервисы, на которых вы можете быстро создать свои страницы с использованием дружественного и понятного взаимодействия с Интернет сервисом (например в социальной сети vkontakte или facebook). Но в любом случае, понимание того, что означает HTML и HTTP всегда может вам пригодиться. Если у вас появилось желание создать свою простенькую страницу на HTML, в Интернете вы сможете найти огромное количество информации об этом.
Приглашаю всех подписаться на новости моей публичной страницы ВКонтакте, ее адрес http://vk.com/itmultimedia . Буду рад видеть Вас в своих подписчиках!
Всего хорошего!
Похожие статьи
Протокол Передачи ГИПЕРтекста HTTP для Чайников ты должен знать
HTTP расшифровывается, как Hypertext Transfer Protocol — протокол передачи гипертекста. Этот протокол являются основой системы world wide web, именно его мы используем, когда просматриваем странички в браузере.
Web придумал Тим Бернерс-Ли, когда работал в ЦЕРН в 1989 году. Кроме протокола HTTP, веб включал язык разметки HTML, Web-сервер и Web-браузер. Веб-браузер ЦЕРН работал в текстовом виде. Вскоре после этого, появились графические веб браузеры, которыми оказалось очень легко пользоваться. Именно благодаря графическим браузерам и вебу интернет стал очень популярен. Сейчас Тим Бернерс-Ли является директором консорциума W3C, которая издает стандарты для World Wide Web.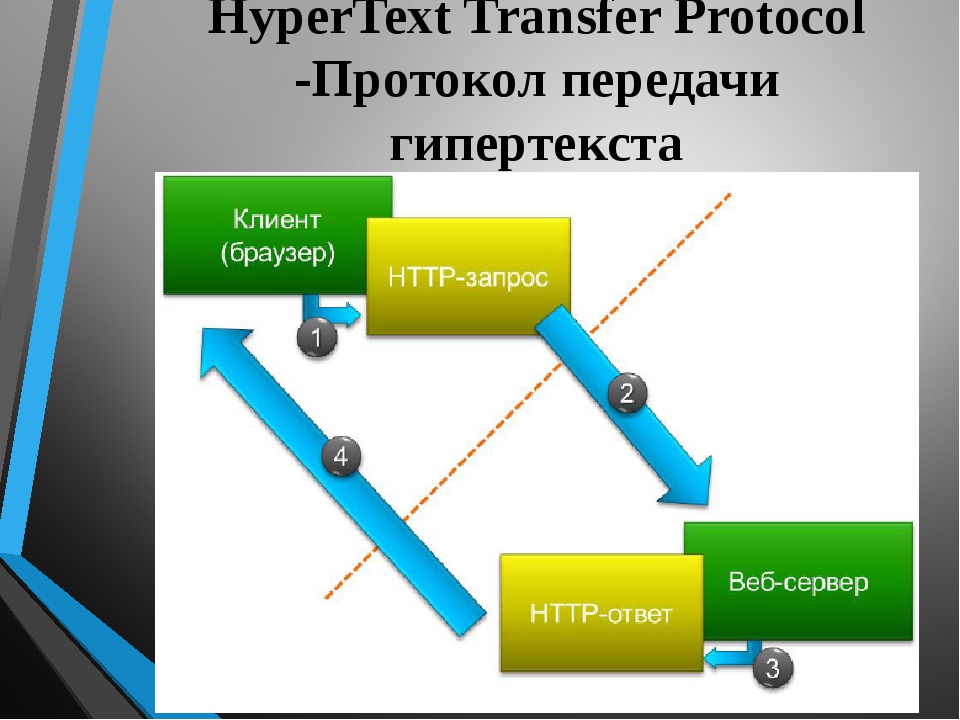
Гипертекст это специальный тип разметки, которую вы добавляйте в текстовые документы, для того чтобы определить, как показывает ту или иную часть текста. В языке HTML для этих целей используются теги.
Например, тег ˂h2˃ говорит, что дальше идет заголовок Протокол HTTP и закрывающийся тег ˂h2˃ заголовок закончился. Тег ˂u1˃ означает список, а ˂li˃ элемент списка.
Вот как этот гипертекстовый HTML документ показывает браузер.
Заголовок Протокол HTTP. Обычный текст, который был указан без разметки “Тим Бернер-Ли в ЦЕРН предложил концепцию Web в 1989 году”. И список.
URL — уникальное положение ресурсаБольшую роль в работе web и http играет URL (Uniform Resource Locator) — уникальное положение ресурса, по-русски его часто называют ссылка. Это уникальный адрес веб-страницы в интернете.
Рассмотрим, как устроены ссылки. Например, https://www.zvondozvon. ru/tehnologii/protokoli. Сначала идет название протокола, в нашем случае https. Затем :// и доменное имя сервера www.zvondozvon.ru на котором размещена страница, либо здесь может находиться IP-адрес сервера. После этого через слеш указывается имя конкретной страницы, которую мы хотим загрузить /tehnologii/protokoli.
ru/tehnologii/protokoli. Сначала идет название протокола, в нашем случае https. Затем :// и доменное имя сервера www.zvondozvon.ru на котором размещена страница, либо здесь может находиться IP-адрес сервера. После этого через слеш указывается имя конкретной страницы, которую мы хотим загрузить /tehnologii/protokoli.
URL рассчитаны не только на работу с http и html, но и например с другими протоколами, можно указать защищенный протокол https или протокол ftp. Также не обязательно использовать гипертекст, на веб-серверах могут размещаться обычные текстовые страницы.
Место протокола HTTP в стеке протоколов TCP/IPПротокол http находятся на прикладном уровне в стеке протоколов TCP/IP.
Он использует протокол транспортного уровня TCP, веб-сервер работает на 80 порту для клиента номер порта генерируются автоматически операционной системой. HTTP работает в режиме запрос-ответ. Клиент пересылают серверу запрос на передачу веб-страницы и сервер в ответ эту веб-страницу пересылает.
В отличии от некоторых других протоколов, которые были рассмотрены ранее на сайте в разделе протоколы в HTTP, нет какого-то жестко заданного формата пакетов, используется обычный текстовый режим.
Версии протокола HTTPЕсть несколько версий протокола HTTP. Первая, экспериментальная версия HTTP 0.9 была разработана в ЦЕРН в 1991 году. Первая официальная версия HTTP 1.0 была принята в качестве стандарта в 1996 году и почти сразу же после этого в 1997 году была принята расширенная версия протокола HTTP 1.1. Именно эта версия используется до сих пор. В 2015 году появилась новая версия протокола HTTP 2 сейчас эта версия только вводится в эксплуатацию она поддерживается еще не всеми браузерами и не всеми веб-серверами.
Структура пакета HTTPПакет HTTP состоит из 3 частей. Первая часть это запрос, либо со стороны клиента, либо от статус ответа со стороны сервера. Например, запрос GET означает, что клиент просит передать ему web-страницу, которая находится на сервере вот по такому пути GET/tehnologii/protokoli в ответ сервер пересылает статус выполнения операции код и символьное сообщение, например 200 OK.![]() Это означает, что страница нашлась на сервере и сервер передает ее в теле сообщения.
Это означает, что страница нашлась на сервере и сервер передает ее в теле сообщения.
Затем могут идти и заголовки, которых может быть несколько. В версии HTTP 1.0 заголовки были не обязательны, но в версии HTTP 1.1 в запросе обязательно использовать заголовок Host:www.zvondozvon.ru, где указываются доменное имя сервера, у которого вы хотите запросить веб-страницу. Это сделано из-за того, что на одном и том же IP-адресе, может работать несколько веб-сайтов и в web серверу необходимо знать с какого сайта вы хотите загрузить страницу.
Также могут быть другие заголовки, например тип передаваемого сообщения в примере Content-Type: text/html; charset=UTF-8, размер передаваемого сообщения Content-Length: 5161 байт.
И затем может идти тело сообщения в котором передается запрашиваемая веб-страница или передаются какие-то параметры на сервер. Тело сообщения является необязательным например, в запросе клиента на передачу веб-страницы с сервера тело не нужно.
Методы HTMLКлиент при обращении к серверу в запросе указывает метод, который он хочет использовать.
- Самые популярные методы это GET запрос на передачу веб-страницы, именно этот запрос используются чаще всего.
- POST передача данных на веб-сервер для обработки. Метод post используется например, когда вы пишите комментарии к роликам youtube, остальные методы, кроме get и post используются значительно реже.
- Метод HEAD запрашивает заголовок страницы, то же самое, что и GET только без тела сообщения, хотя HTTP разрабатывался для передачи веб-страниц, создатели HTTP предусмотрели возможность его использования для работы с ресурсами других типов.
- Метод PUT помещение ресурса на веб-сервер.
- Метод DELETE удаление страницы или ресурса с веб-сервера для выполнения этих методов необходимо иметь соответствующие права доступа.
- Метод TRACE позволяет отслеживать, что происходит со страницей, кто вносит в нее какие изменения.
- Метод OPTIONS позволяет узнать, какие именно методы поддерживаются для конкретного ресурса на веб-сервере.
- Метод CONNECT позволяет подключиться к веб-серверу через прокси.

В ответе сервера первое поле это статус обработки запроса, статусы сгруппированы в пять групп и для каждой группы используется код статуса состоящий из трехзначного числа.
- Статусы, которые начинаются на единицу (1ХХ), используются для передачи информационных сообщений.
- Статусы, которые начинаются на двойку (2ХХ), говорят о том, что запрос выполнен успешно, например наиболее популярный статус (200 OK), означает что страница найдена и она передается клиенту.
- Статусы, которые начинаются на тройку (3ХХ), говорят о перенаправлении, например статус 301 — постоянное перенаправление, говорит о том что страница была перемещена на другой адрес и все последующие запросы должны передаваться на этот новый адрес. Статус 307 тоже говорит о перенаправлении, но временном, сейчас доступ к странице можно получить по другому адресу, но через некоторое время необходимо снова обращаться к исходному адресу.
- Статусы, которые начинаются с четверки (4ХХ), говоря о том, что произошла какая-то ошибка на стороне клиента. Чаще всего встречается ошибка 404 — страница, которую запросил клиент не найдена на сервере. Также возможна ошибка 403 доступ к ресурсу, который запросил клиент запрещен и другие ошибки.
- Статусы начинающиеся на пять (5ХХ) говорят об ошибке на стороне сервера, например 500 — внутренняя ошибка сервера.
 Чаще всего встречается ошибка 404 — страница, которую запросил клиент не найдена на сервере. Также возможна ошибка 403 доступ к ресурсу, который запросил клиент запрещен и другие ошибки.
Чаще всего встречается ошибка 404 — страница, которую запросил клиент не найдена на сервере. Также возможна ошибка 403 доступ к ресурсу, который запросил клиент запрещен и другие ошибки. Рассмотрим примеры запроса и ответа HTTP.
Подключение по TCP к серверу www.zvondozvon.ru, порт 80.
————————————————
GET /tehnologii/protokoli HTTP 1.1
Host: www.zvondozvon.ru
HTTP работают в текстовом режиме, нам необходимо подключиться к веб-серверу, например www.zvondozvon.ru к порту 80 по протоколу TCP. Дальше мы пишем запрос, используем метод GET хотим получить ресурс /tehnologii/protokoli и указываем версию протокола по которой мы хотим работать HTTP 1.1. Так как мы используем версию 1. 1 нам необходимо указать заголовок host, доменное имя сервера с которым мы работаем www.zvondozvon.ru, этого вполне достаточно для того чтобы веб-сервер нам ответил.
1 нам необходимо указать заголовок host, доменное имя сервера с которым мы работаем www.zvondozvon.ru, этого вполне достаточно для того чтобы веб-сервер нам ответил.
HTTP/1.1 200 OK
Server: nginx
Content-Type: text/html; charset=UTF-8
Content-Length: 5161
˂html lang=”ru-RU”˃
˂head˃
…
˂/html˃
Ответ веб-сервера начинается со статуса 200 ok, обработка запроса произошла успешно, также вначале указываются версия протокола, которая используется HTTP 1.1. Затем идут несколько заголовков реализации веб-сервера nginx, тип передаваемой страницы текста html кодировка utf-8, длина страницы 5161 байт, также здесь могут идти другие заголовки, которые вам передал сервер.
Затем идет пустая строка и код веб-страницы. После передачи web страницы, соединение tcp разрывается, можно оставить соединение открытым для последующей работы, но для этого необходимо использовать дополнительный заголовок. )= и(•ㅅ•)
)= и(•ㅅ•)
Чтобы не ходить вокруг да около, давайте я вам приведу пример общения по HTTP протоколу.
Вот пример запроса, каким его отправляет ваш браузер, когда вы запрашиваете страницу http://example.com:
GET / HTTP/1.1
Host: example.com
Accept: text/html
А вот пример ответа:
HTTP/1.1 200 OK
Content-Length: 1983
Content-Type: text/html; charset=utf-8
<html>
<head>...</head>
<body>...</body>
</html>
Это очень упрощенные примеры, но и тут можно увидеть из чего состоят HTTP запрос и ответ:
- стартовая строка — для запроса содержит метод и путь запрашиваемой страницы, для ответа — версию протокола и код ответа
- заголовки — имеют формат ключ-значение разделенные двоеточием, каждый новый заголовок пишется с новой строки
- тело сообщения — непосредственно HTML либо данные отделяют от заголовков двумя переносами строки, могут отсутствовать, как в приведенном запросе
Так, вроде с протоколом разобрались — он простой, ведёт свою историю аж с 1992-го года, так что идеальным его не назовешь, но какой есть — отправили запрос — получите ответ, и всё, сервер и клиент никоим образом более не связаны.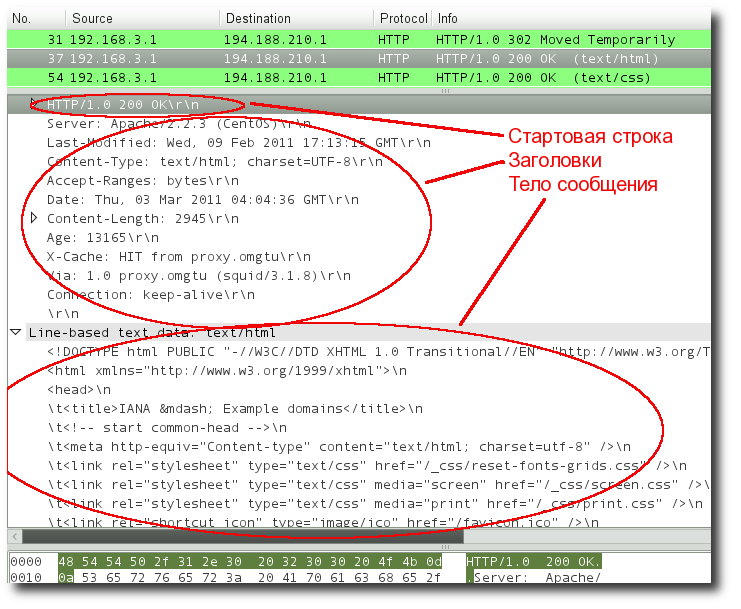 Но подобный сценарий отнюдь не единственный возможный, у нас же может быть авторизация, сервер должен каким-то образом понимать, что вот этот запрос пришёл от определенного пользователя, т.е. клиент и сервер должны общаться в рамках некой сессии. И да, для этого придумали следующий механизм:
Но подобный сценарий отнюдь не единственный возможный, у нас же может быть авторизация, сервер должен каким-то образом понимать, что вот этот запрос пришёл от определенного пользователя, т.е. клиент и сервер должны общаться в рамках некой сессии. И да, для этого придумали следующий механизм:
- При авторизации пользователя, сервер генерирует и запоминает уникальный ключ — идентификатор сессии, и сообщает его браузеру
- Браузер сохраняет этот ключ, и при каждом последующем запросе, его отправляет
Для реализации этого механизма и были созданы cookie (куки, печеньки) — простые текстовые файлы на вашем компьютере, по файлу для каждого домена (хотя некоторые браузеры более продвинутые, и используют для хранения SQLite базу данных), при этом браузер накладывает ограничение на количество записей и размер хранимых данных (для большинства браузеров это 4096 байт, см. RFC 2109 от 1997-го года)
Т.е. если украсть cookie из вашего браузера, то можно будет зайти на вашу страничку в facebook от вашего имени? Не пугайтесь, так сделать нельзя, по крайней мере с facebook, и дальше я вам покажу один из возможных способов защиты от данного вида атаки на ваших пользователей.
Давайте теперь посмотрим как изменятся наши запрос-ответ, будь там авторизация:
Request
POST /login/ HTTP/1.1
Host: example.com
Accept: text/html
login=Username&password=Userpass
Метод у нас изменился на POST, и в теле запроса у нас передаются логин и пароль. Если использовать метод GET, то строка
запроса будет содержать логин и пароль, что не очень правильно с идеологической точки зрения, и имеет ряд побочных явлений
в виде логирования (например, в том же access.log) и кеширования паролей в открытом виде.
Response
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Set-Cookie: KEY=VerySecretUniqueKey
<html>
<head>...</head>
<body>...</body>
</html>
Ответ сервер будет содержать заголовок Set-Cookie: KEY=VerySecretUniqueKey, что заставит браузер сохранить
эти данные в файлы cookie, и при следующем обращении к серверу — они будут отправлены и опознаны сервером:
Request
GET / HTTP/1. 1
Host: example.com
Accept: text/html
Cookie: KEY=VerySecretUniqueKey
 1
Host: example.com
Accept: text/html
Cookie: KEY=VerySecretUniqueKey
1
Host: example.com
Accept: text/html
Cookie: KEY=VerySecretUniqueKey
Как можно заметить, заголовки отправляемые браузером (Request Headers) и сервером (Response Headers) отличаются, хотя есть и общие и для запросов и для ответов (General Headers)
Сервер узнал нашего пользователя по присланным cookie, и дальше предоставит ему доступ к личной информации. Так что, с сессиями в HTTP разобрались? Идём дальше.
Эка я RFC в сотни страниц влепил в одну страничку, так же многое можно пропустить… Это да, если есть желание посмотрите на RFC2616, но пока можете не забивать этим голову.
что такое протокол HTTP · Блог PromoPult
Мы пишем много статей про оптимизацию сайта, но редко затрагиваем технические вопросы. Тем временем они важны: базовое понимание того, как все устроено «внутри» сайта, как «общаются» поисковики и веб-ресурсы, проясняет необходимость проведения тех или иных работ.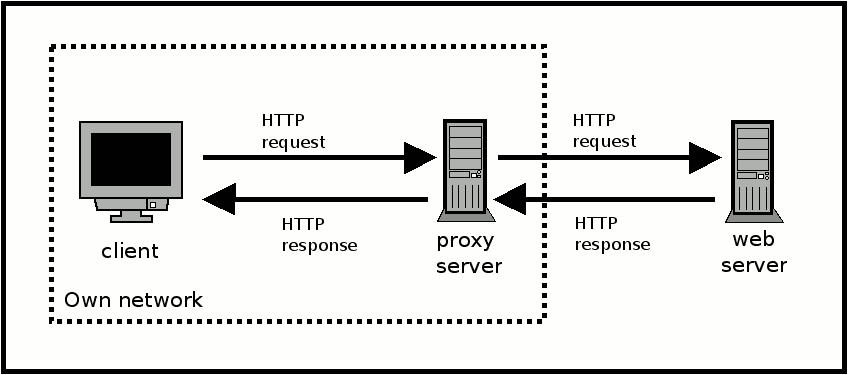 Начнем цикл технических статей с описания процесса взаимодействия в вебе. Постараемся рассказать просто о сложном.
Начнем цикл технических статей с описания процесса взаимодействия в вебе. Постараемся рассказать просто о сложном.
Как все взаимодействует в вебе?
Мы, пользователи, садимся за компьютер или берем в руки смартфон, чтобы что-то найти в интернете. Если нам нужно открыть сайт, мы используем браузер и указываем адрес в браузерной строке. Получив от нас сигнал, браузер отправляет запрос на DNS-сервер, где получает IP-адрес запрашиваемого нам ресурса. Получив IP-адрес, браузер обращается по нему повторно, и запрос уходит уже на сервер, где лежит нужный нам сайт. Этот повторный запрос содержит параметр Get и осуществляется посредством протокола http.
На том сервере, куда ушел повторный запрос браузера, установлена специальная программа, и в 90% случаев это Apache. Она обрабатывает запрос, обращается в файловую систему сервера, находит соответствующий файл и отправляет его браузеру в формате HTML. Что делает браузер? Он преобразует данный файл и отображает его на экране в понятном нам виде — в формате текста, картинок, видео и так далее. Произошло сложное взаимодействие пользователя и ряда программ — и все это за доли секунды!
Произошло сложное взаимодействие пользователя и ряда программ — и все это за доли секунды!
Когда вместо пользователя — поисковый робот
По аналогичной схеме, эмулируя функции браузера, к серверу обращается поисковый робот в процессе индексации сайтов. И точно также получает ответ в виде HTML-файла. Если в прошлом роботы анализировали просто HTML-код, то сейчас они стремятся смотреть на страницу как человек. Причем не только для десктопных устройств но и для мобильных — проверяют адаптивность HTML-страниц под всевозможные виды устройств пользователей. Обратите внимание на современные инструменты для вебмастеров, тот же Google PageSpeed Insights. Он показывает нам, как должен выглядеть сайт, который понравится и пользователям, и поисковым роботам. И это нужно учитывать при создании страниц.
Теперь давайте подробнее рассмотрим протокол http, а также https. Как с их помощью машина взаимодействует с сервером и получает запрашиваемый HTML-документ.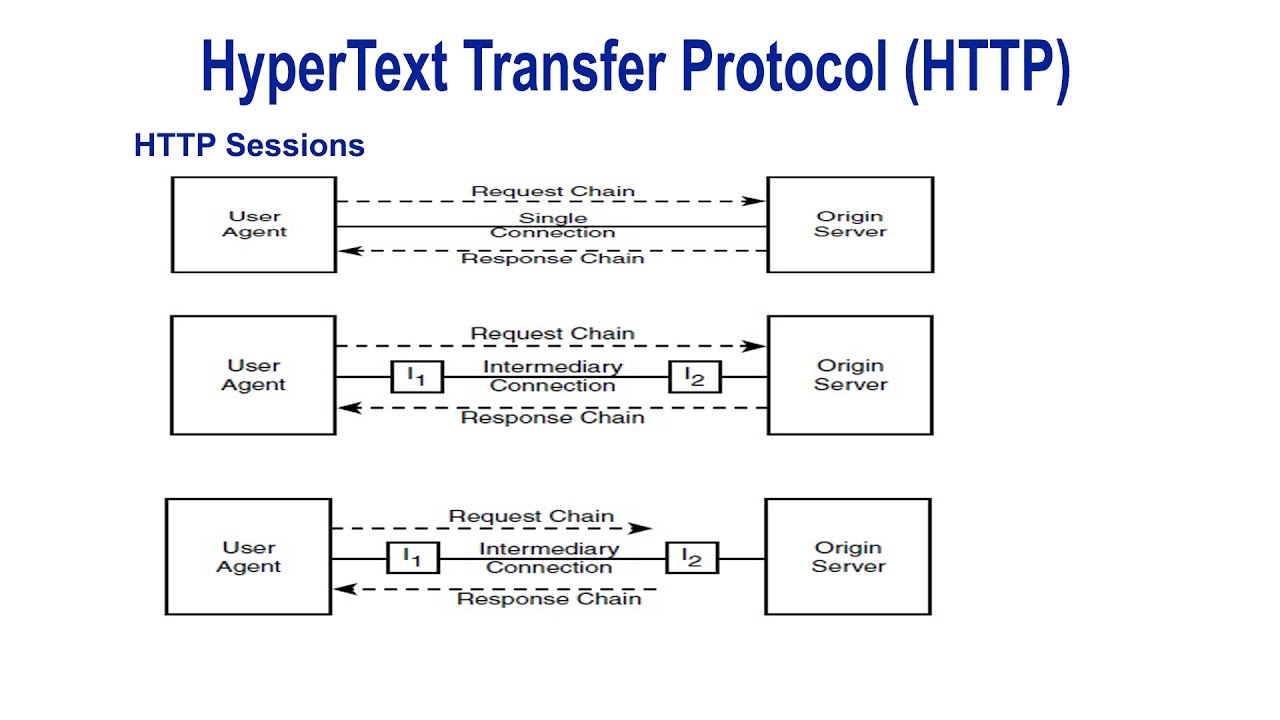 Чем они отличаются.
Чем они отличаются.
Протокол HTTP
HTTP (или «протокол передачи гипертекста») — это система передачи и получения информации в интернете. Его задача — просто передать информацию пользователю. И не важно, как данные попадают из пункта А в пункт Б. HTTP является протоколом «без сохранения состояния». Это значит, что он не хранит информацию о предыдущей сессии пользователя. То есть серверу нужно посылать меньше данных, что увеличивает скорость его работы.
Протокол HTTP обычно применяется для доступа к HTML-страницам, для которых не требуется дополнительных средств защиты. Они не связаны с конфиденциальной информацией, например данными о банковских картах пользователей.
Протокол HTTPS
Протокол HTTPS, то есть «безопасный протокол передачи гипертекста» был разработан для защищенных транзакций. Благодаря ему происходит обмен конфиденциальной информацией, исключая возможность украсть ценные данные. Чисто технически протоколы HTTP и HTTPS очень похожи. В обоих протоколах браузер устанавливает соединение с сервером через стандартный порт. Отличие в том, что они используют разные порты, а также HTTPS обеспечивает дополнительный уровень защиты за счет криптографического протокола SSL.
В обоих протоколах браузер устанавливает соединение с сервером через стандартный порт. Отличие в том, что они используют разные порты, а также HTTPS обеспечивает дополнительный уровень защиты за счет криптографического протокола SSL.
Очень грубо процесс передачи данных через HTTPS можно представить так: одна его часть смотрит на содержание данных — ЧТО ИМЕННО передается, а вторая часть на процесс — НАСКОЛЬКО БЕЗОПАСНО передаются данные. Обратите внимание: часто HTTPS и SSL используют как взаимозаменяемые термины, но это неправильно. SSL — это лишь дополнительный протокол.
Также вы можете услышать, что протокол HTTPS является предпочтительным для поисковых машин, когда они оценивают сайты. В первую очередь об этом говорит Google. Это действительно так, но применяется требование исключительно к тем сайтам, которым данный протокол действительно необходим. Они принимают оплату онлайн или содержат кабинет с персональными данными клиента. Например, это может быть интернет-магазин.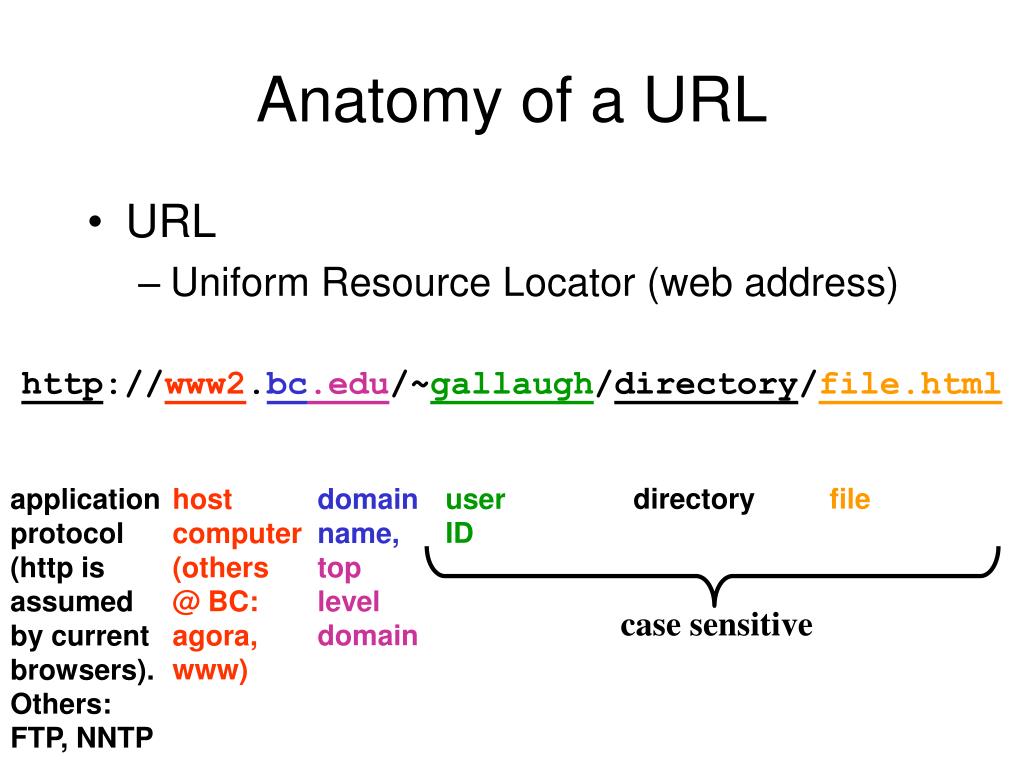 Для всех обычных сайтов, где нет конфиденциальных данных, вполне достаточно протокола HTTP.
Для всех обычных сайтов, где нет конфиденциальных данных, вполне достаточно протокола HTTP.
Заключение
Итак, сегодня мы разобрались, что пользователи и сайты взаимодействуют между собой посредством браузеров, серверов и специальных протоколов (HTTP или HTTPS). Точно таким же путем получают доступ к содержимому сайтов поисковые машины. В протоколе запроса «зашит» вопрос к серверу (GET), а значит программа — браузер или робот — получает на него какой-то ответ. От этого ответа зависит судьба индексации сайта. И крайне важно, чтобы статусы ответов были корректными. О том, что это такое, и какие статусы может получить поисковый робот от сервера, мы расскажем в следующей статье. А также рассмотрим, за счет чего можно управлять «встречами» с роботом и не отдавать для очередного сканирования страницы, если на них не было обновления контента.
Если вы занимаетесь оптимизацией сайта и вам требуется помощь или рекомендации по любому из технических вопросов, вы можете заказать эту услугу в новом SEO-модуле SeoPult. В рамках небольшого месячного бюджета наши специалисты будут аудировать ваш сайт и выполнять работы согласно чек-листу. Вы можете проводить работы самостоятельно по списку инструкций, разработанных нами. Вместе мы сделаем ваш сайт лучше, быстрее, удобнее — а значит успешнее!
В рамках небольшого месячного бюджета наши специалисты будут аудировать ваш сайт и выполнять работы согласно чек-листу. Вы можете проводить работы самостоятельно по списку инструкций, разработанных нами. Вместе мы сделаем ваш сайт лучше, быстрее, удобнее — а значит успешнее!
Что такое HTTP
HTTP означает H yper T ext T ransfer P rotocol
WWW предназначен для связи между веб-клиентами и серверами
Обмен данными между клиентскими компьютерами и веб-серверами осуществляется путем отправки HTTP-запросов и получение HTTP-ответов
Интернет-связь
Всемирная паутина — это связь между веб-клиентами и web сервера .
Клиенты часто являются браузерами (Chrome, Edge, Safari), но они может быть любой тип программы или устройства.
Серверы — это чаще всего компьютеры в облаке.
Веб-клиент
Облако
веб-сервер
HTTP-запрос / ответ
Связь между клиентами и серверами осуществляется посредством запросов и ответов :
- Клиент (браузер) отправляет HTTP-запрос в Интернет
- Веб-сервер получает запрос
- Сервер запускает приложение для обработки запроса
- Сервер возвращает HTTP-ответ (вывод) браузеру
- Клиент (браузер) получает ответ
Круг HTTP-запроса
Типичный круг HTTP-запроса / ответа:
- Браузер запрашивает HTML-страницу.Сервер возвращает HTML-файл.
- Браузер запрашивает таблицу стилей. Сервер возвращает файл CSS.
- Браузер запрашивает изображение в формате JPG. Сервер возвращает файл JPG.
- Браузер запрашивает код JavaScript. Сервер возвращает файл JS
- Браузер запрашивает данные. Сервер возвращает данные (в формате XML или JSON).
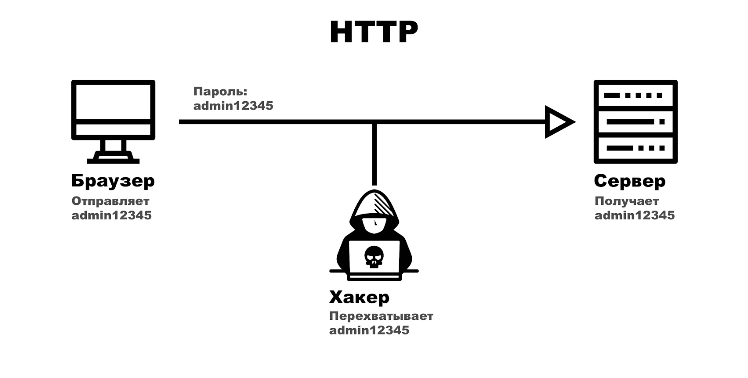 Сервер возвращает данные (в формате XML или JSON).
Сервер возвращает данные (в формате XML или JSON).XHR — запрос XML Http
Все браузеры имеют встроенный объект XMLHttpRequest (XHR) .
XHR — это объект JavaScript, который используется для передачи данных между веб-браузером и веб-сервером.
XHR часто используется для запроса и получения данных с целью изменения веб-страницы.
Несмотря на XML и Http в названии, XHR используется с другими протоколами, кроме HTTP, и данные могут быть разных типов, например HTML, CSS, XML, JSON и простой текст.
Объект XHR — это мечта веб-разработчиков , потому что вы можете:
- Обновить веб-страницу без перезагрузки страницы
- Запросить данные с сервера — после загрузки страницы
- Получить данные с сервера — после загрузки страницы
- Отправить данные на сервер — в фоновом режиме
Объект XHR является базовой концепцией AJAX и JSON :
Разница между HTML и HTTP
Разница между HTML и HTTP
Многие путают эти два термина, связанных с Интернетом. Они действительно такие же? Первое первым. HTML — это язык, а HTTP — это протокол. В этом нет особого смысла ..? все в порядке! Обсудим это подробнее.
Они действительно такие же? Первое первым. HTML — это язык, а HTTP — это протокол. В этом нет особого смысла ..? все в порядке! Обсудим это подробнее.
HTML ( H yper t ext M arkup L anguage) — это язык для маркировки обычного текста, чтобы он был преобразован в гипертекст. Опять же, не все так однозначно. Как правило, теги HTML (например, «
», «» и т. Д.) Используются для тега тега или , помечающего обычный текст , так что он становится гипертекстом, и несколько гипертекстовых страниц могут быть связаны друг с другом, в результате Интернет.Обратите внимание, что теги HTML используются также для отображения веб-страниц в браузере. Напротив, HTTP ( H yper t ext T ransfer P rotocol) — это протокол для передачи гипертекстовых страниц с веб-сервера в веб-браузер. Для обмена веб-страницами между сервером и браузером сеанс HTTP настраивается с использованием методов протокола (например, GET, POST и т.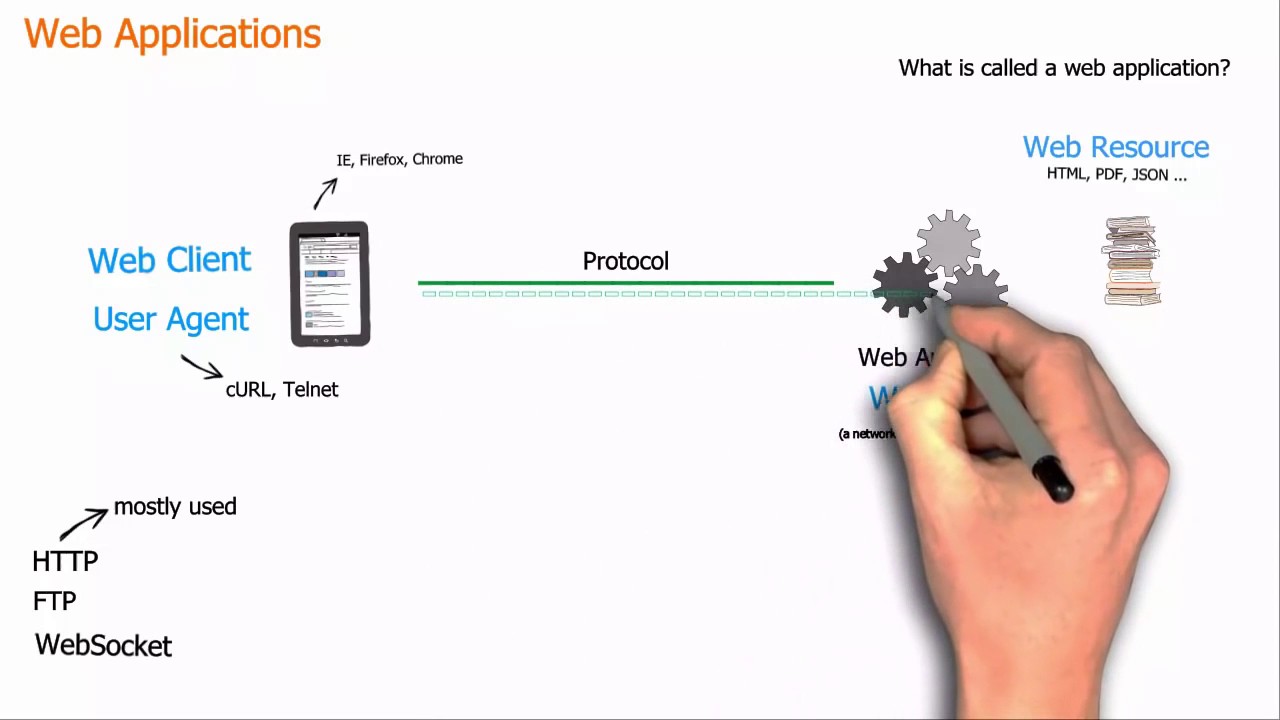 Д.). Это будет объяснено в другом посте.
Д.). Это будет объяснено в другом посте.Чтобы понять разницу между HTML и HTTP, можно провести аналогию.Подумайте о HTML как о языке C и о HTTP как о FTP . Теперь можно писать программы C на языке C, а затем можно передавать эти программы C с сервера клиентам, используя FTP (то есть протокол передачи файлов). Таким же образом веб-страницы (которые в основном являются HTML-страницами) написаны в HTML, и обмен этими веб-страницами между Сервером и Клиентами осуществляется с помощью HTTP. Поскольку HTML — это язык, а HTTP — это протокол, это две разные вещи, хотя и взаимосвязанные. Фактически, можно обмениваться веб-страницами HTML без HTTP (например,грамм. использование FTP для передачи HTML-страниц). Даже можно передавать не HTML-страницы, используя HTTP (например, используя HTTP для передачи XML-страниц). Подробнее о XML в другом посте. Мы надеемся, что вышесказанное проясняет разницу между HTML и HTTP.
Пожалуйста, сделайте Like / Tweet / G + 1, если вы сочтете это полезным. Также, пожалуйста, оставьте нам комментарий для дальнейших разъяснений или информации. Мы хотели бы помочь и поучиться 🙂
Также, пожалуйста, оставьте нам комментарий для дальнейших разъяснений или информации. Мы хотели бы помочь и поучиться 🙂
Вниманию читателя! Не прекращайте учиться сейчас. Ознакомьтесь со всеми важными концепциями теории CS для собеседований SDE с помощью курса CS Theory Course по доступной для студентов цене и будьте готовы к отрасли.
Протокол передачи гипертекста, версия 3 (HTTP / 3)
4.4. Сервер Push
Server push — это режим взаимодействия, который позволяет серверу отправлять обмен запрос-ответ клиенту в ожидании того, что клиент сделает указанный запрос. Это снижает использование сети потенциальной задержкой. прирост. Проталкивание сервера HTTP / 3 аналогично тому, что описано в Раздел 8.2 [HTTP2], но использует другие механизмы.¶
Каждой принудительной отправке сервером назначается уникальный идентификатор push-уведомления. Идентификатор push-уведомления
используется для обозначения толчка в различных контекстах на протяжении всего жизненного цикла
HTTP / 3 соединение. ¶
¶
Пространство Push ID начинается с нуля и заканчивается максимальным значением, установленным Кадр MAX_PUSH_ID; см. раздел 7.2.7. В частности, сервер не может нажимать до тех пор, пока клиент не отправит кадр MAX_PUSH_ID. Клиент отправляет MAX_PUSH_ID для управления количеством нажатий, которые может обещать сервер.А серверу СЛЕДУЕТ использовать идентификаторы push последовательно, начиная с нуля. Клиент ДОЛЖЕН рассматривать получение push-потока как ошибку соединения типа h4_ID_ERROR (Раздел 8), когда кадр MAX_PUSH_ID не был отправлен или когда поток ссылается на идентификатор push-уведомлений, который больше максимального идентификатора push-уведомлений.
Push ID используется в одном или нескольких кадрах PUSH_PROMISE (раздел 7.2.5)
которые несут раздел заголовка сообщения запроса. Эти кадры отправляются
поток запросов, сгенерировавший push. Это позволяет серверу
связанный с запросом клиента.Когда один и тот же идентификатор Push ID обещан на нескольких
потоков запросов, разделы поля распакованного запроса ДОЛЖНЫ содержать одинаковые
поля в том же порядке, и имя и значение в каждом поле ДОЛЖНЫ быть
идентичный.
Затем Push ID включается в push-поток, который в конечном итоге выполняет эти обещания; см. Раздел 6.2.2. Push-поток идентифицирует Push-ID обещание, которое он выполняет, затем содержит ответ на обещанный запрос как описано в разделе 4.1.¶
Наконец, Push ID можно использовать в кадрах CANCEL_PUSH; видеть Раздел 7.2.3. Клиенты используют эту рамку, чтобы указать, что они не хотят получите обещанный ресурс. Серверы используют этот фрейм, чтобы указать, что они не будут выполнить предыдущее обещание. ¶
Не все запросы можно отправить. Сервер МОЖЕТ отправлять запросы, которые имеют следующие объекты: ¶
Сервер ДОЛЖЕН включать значение в поле псевдозаголовка «: Authority» для
который является авторитетным сервером. Если клиент еще не подтвердил
соединение для источника, указанного в подталкиваемом запросе, оно ДОЛЖНО выполнить
тот же процесс проверки, что и перед отправкой запроса на это происхождение
о подключении; см. раздел 3.3. Если эта проверка не удалась,
клиент НЕ ДОЛЖЕН считать сервер авторитетным для этого источника.
Клиенты ДОЛЖНЫ отправлять кадр CANCEL_PUSH после получения кадра PUSH_PROMISE несет запрос, который не кэшируется, небезопасен, указывает на наличие тела запроса или для которого не учитывается авторитетный сервер. Любые соответствующие ответы НЕ ДОЛЖНЫ использоваться или кэшироваться.
Каждый отправленный ответ связан с одним или несколькими клиентскими запросами.Толчок связан с потоком запроса, в котором был кадр PUSH_PROMISE получила. Тот же серверный push может быть связан с дополнительным клиентом запросы с использованием кадра PUSH_PROMISE с тем же идентификатором Push ID по нескольким запросам потоки. Эти ассоциации не влияют на работу протокола, но МОГУТ учитываться пользовательскими агентами при принятии решения о том, как использовать переданные ресурсы. ¶
Порядок кадра PUSH_PROMISE по отношению к определенным частям ответа
важный. Серверу СЛЕДУЕТ отправлять кадры PUSH_PROMISE до отправки HEADERS.
или кадры ДАННЫХ, которые ссылаются на обещанные ответы.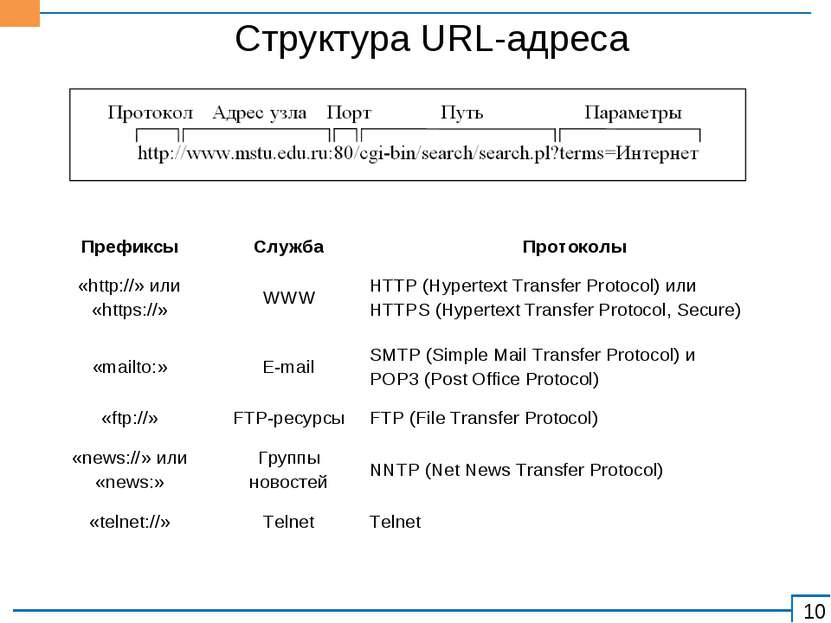 Это снижает шанс
что клиент запрашивает ресурс, который будет передан сервером ».
Это снижает шанс
что клиент запрашивает ресурс, который будет передан сервером ».
Из-за переупорядочения данные push-потока могут прибыть до соответствующего Фрейм PUSH_PROMISE. Когда клиент получает новый push-поток с пока неизвестный идентификатор push-уведомлений, как связанный клиентский запрос, так и отправленный поля заголовка запроса неизвестны. Клиент может буферизовать данные потока в ожидание соответствия PUSH_PROMISE. Клиент может использовать управление потоком (см. Раздел 4.1 [QUIC-TRANSPORT]), чтобы ограничить объем данных, которые сервер может зафиксировать в толкаемом потоке.¶
Данные push-потока также могут поступать после того, как клиент отменил push. В этом В этом случае клиент может прервать чтение потока с кодом ошибки h4_REQUEST_CANCELLED. Это просит сервер не передавать дополнительные данные и указывает, что он будет отклонен при получении.
Отправленные ответы, которые можно кэшировать (см. Раздел 3 [CACHING]), могут быть
хранится клиентом, если он реализует HTTP-кеш. Отправленные ответы
считается успешно проверенным на исходном сервере (например,g., если «no-cache»
присутствует директива ответа кеша; см. Раздел 5.2.2.3 [CACHING]) на
время получения отправленного ответа. ¶
Отправленные ответы
считается успешно проверенным на исходном сервере (например,g., если «no-cache»
присутствует директива ответа кеша; см. Раздел 5.2.2.3 [CACHING]) на
время получения отправленного ответа. ¶
Отправленные ответы, которые не кэшируются, НЕ ДОЛЖНЫ храниться ни в каком кэше HTTP. Они МОГУТ быть доступны приложению отдельно.
Страница не найдена | MIT
Перейти к содержанию ↓- Образование
- Исследование
- Инновации
- Прием + помощь
- Студенческая жизнь
- Новости
- Выпускников
- О MIT
- Подробнее ↓
- Прием + помощь
- Студенческая жизнь
- Новости
- Выпускников
- О MIT
Попробуйте поискать что-нибудь еще! Что вы ищете? Увидеть больше результатов
Предложения или отзывы?
http.
 client — клиент протокола HTTP — документация Python 3.9.2
client — клиент протокола HTTP — документация Python 3.9.2Это отправит запрос на сервер, используя HTTP-запрос метод метод и селектор url .
Если указано тело , указанные данные отправляются после того, как заголовки
законченный. Это может быть str , байтовый объект,
объект открытого файла или итеративный объект размером байта . Если кузов является строкой, она кодируется как ISO-8859-1, значение по умолчанию для HTTP.Если оно
является байтовым объектом, байты отправляются как есть. Если это файл
объект, содержимое файла отправляется; этот файловый объект должен
поддерживать как минимум метод read () . Если файловый объект является
экземпляр io.TextIOBase , данные, возвращаемые функцией чтения будет закодирован как ISO-8859-1, в противном случае данные, возвращаемые read () отправляется как есть. Если тело является повторяемым, элементы
iterable отправляются как есть, пока итерабельность не исчерпана.
Аргумент заголовков должен быть отображением дополнительных заголовков HTTP для отправки с просьбой.
Если заголовки не содержат ни Content-Length, ни Transfer-Encoding,
но есть тело запроса, одно из таких
поля заголовка будут добавлены автоматически. Если body is None , заголовок Content-Length установлен на 0 для
методы, ожидающие тела ( PUT , POST и PATCH ). Если тело — это строка или байтовый объект, который также не является
файл, заголовок Content-Length будет
установить его длину.Любой другой тип кузов (файлы
и итерации в целом) будут закодированы по фрагментам, а
Заголовок Transfer-Encoding будет автоматически установлен вместо
Content-Length.
Аргумент encode_chunked имеет значение, только если Transfer-Encoding
указано в заголовках . Если encode_chunked — False ,
Объект HTTPConnection предполагает, что все кодирование обрабатывается
код вызова. Если это
Если это Истина , тело будет закодировано по фрагментам.
Примечание
В протокол HTTP добавлено кодирование передачи фрагментов.
версия 1.1. Если известно, что HTTP-сервер не поддерживает HTTP 1.1,
вызывающий должен либо указать Content-Length, либо передать str или байтовый объект, который также не является файлом, как
представление тела.
Новое в версии 3.2: тело теперь может быть повторяемым.
Изменено в версии 3.6: Если ни Content-Length, ни Transfer-Encoding не установлены в Заголовки , , файл и итерируемые объекты body теперь кодируются по фрагментам.Был добавлен аргумент encode_chunked . Попытки определить Content-Length для файла не предпринимаются. объекты.
Whitehouse.gov HTML включает пасхальное яйцо для программистов
Последние 18 месяцев были диким временем для работы в сфере технологий. Мы увидели, как периферийные вычисления оживают, чтобы помочь предприятиям адаптироваться во время пандемии.![]() В то же время мы также видим, как 5G будет вызывать интерес, особенно с точки зрения сети, а не с точки зрения варианта использования.Мы также видим многих людей, которые сосредоточены на своих данных, но алгоритмы , которые компании тренируют с этими данными, станут их критически важными активами. Неважно, в какой компании или в какой отрасли; это действительно станет отличительным признаком для многих компаний.
В то же время мы также видим, как 5G будет вызывать интерес, особенно с точки зрения сети, а не с точки зрения варианта использования.Мы также видим многих людей, которые сосредоточены на своих данных, но алгоритмы , которые компании тренируют с этими данными, станут их критически важными активами. Неважно, в какой компании или в какой отрасли; это действительно станет отличительным признаком для многих компаний.
И особенно на фоне пандемии мы увидели, как компании используют технологии, чтобы либо безопасно возвращать работников, либо обслуживать своих клиентов по-новому , обучать детей по-новому — все, что ускорило происходящую цифровую трансформацию. Недавно я прочитал опрос McKinsey , в котором сообщается об» ускорении создания цифровых или улучшенных цифровых продуктов «.По регионам результаты показывают, что в среднем за семь лет темпы разработки этих продуктов и услуг компании увеличатся ».
Недавно я прочитал опрос McKinsey , в котором сообщается об» ускорении создания цифровых или улучшенных цифровых продуктов «.По регионам результаты показывают, что в среднем за семь лет темпы разработки этих продуктов и услуг компании увеличатся ».
Судя по тому, что мы наблюдаем в Intel, это спасает жизнь. и инвестиции, сберегающие отрасль, происходящие сегодня — полностью изменяя способ, которым пациенты проходят лечение , а предприятия работают.
Чего вы особенно ожидаете увидеть в этом году?
Что я считаю наиболее интересным, так это работа, сочетающая IoT с сетевыми возможностями — и я думаю, что это будет год обширные исследования и работа с нашими клиентами, чтобы объединить эти две вещи для решения реальных бизнес-задач.
Когда мы впервые начали интеграцию сетевых технологий и возможностей операционных технологий и распределили их по отраслевым вертикалям, мы могли рассчитывать количество заинтересованных клиентов и возможности с одной стороны.В прошлом году их было в пять раз больше, а в этом году мы уже видим, что это число значительно увеличилось. Итак, мы рады видеть, что отрасль продолжает расти с энтузиазмом в отношении масштабирования таких типов развертываний.
Какую роль играет ИИ на периферии и в чем вовлечена Intel?
Случай использования искусственного интеллекта недавно привлек мое внимание: сотрудников в ресторане проверяет устройство, которое проверяет температуру, пока сотрудники моют руки, и определяет, правильно ли они это сделали, прежде чем отправиться на работу.Я видел другие приложения, использующие аналогичную технологию в строительная промышленность , где алгоритм искусственного интеллекта сканирует, чтобы увидеть, правильно ли надеты шлем, очки, жилет и другое защитное оборудование сотрудников, чтобы определить, готовы ли они к работе. И самое приятное то, что работодатель может видеть совокупные данные об этих взаимодействиях, чтобы определить, требуется ли дополнительное обучение мытью рук или ношению шлемов.
И самое приятное то, что работодатель может видеть совокупные данные об этих взаимодействиях, чтобы определить, требуется ли дополнительное обучение мытью рук или ношению шлемов.
В Intel, помимо предоставления фундаментальной базовой технологии для реализации этих приложений, мы работаем с множеством сторонних разработчиков над созданием этих приложений. И мы помогаем разработчикам масштабировать их в разных отраслях с помощью наших специалистов по продажам. Таким образом, мы можем не создавать технологию сканирования, которая определяет, правильно ли вы используете оборудование, но мы организуем эту координацию в рамках нашей экосистемы со всеми нашими партнерами, чтобы эффективно разместить его на catalog , чтобы, если клиенты заинтересованы в таком приложении, мы могли предоставить им разные стороны, чтобы сделать это
Есть ли проблема с фрагментацией рынка и как ее решить?
Она очень фрагментирована. Я привел всего два примера, когда совершенно разные работники приходили на работу в разные компании. индустрии, и я могу дать вам еще пять, которые снова отличаются друг от друга.Хотя базовая технология, которую Intel создает для реализации этого типа инноваций, носит горизонтальный характер, реальность такова, что их реализация должна быть очень «вертикально ориентированной» и очень «ориентированной на варианты использования» — и при этом необходимо учитывать: география. Два приведенных мной примера использования сотрудников выглядят совершенно по-разному, если вы говорите о сотрудниках в Северной Америке, Индии или Германии. В общем, это проблема целостной экосистемы — и решение экосистемы.
Я привел всего два примера, когда совершенно разные работники приходили на работу в разные компании. индустрии, и я могу дать вам еще пять, которые снова отличаются друг от друга.Хотя базовая технология, которую Intel создает для реализации этого типа инноваций, носит горизонтальный характер, реальность такова, что их реализация должна быть очень «вертикально ориентированной» и очень «ориентированной на варианты использования» — и при этом необходимо учитывать: география. Два приведенных мной примера использования сотрудников выглядят совершенно по-разному, если вы говорите о сотрудниках в Северной Америке, Индии или Германии. В общем, это проблема целостной экосистемы — и решение экосистемы.
В Intel мы находимся в уникальной ситуации, чтобы организовать эти решения.
Люди склонны думать, что Intel предоставляет технические возможности, обеспечивающие периферийные вычисления — но у нас также есть возможности для разработчиков — и мы можем использовать нашу экосистему и масштабирование, чтобы помочь нашим конечным клиентам получить доступ к лучшие решения.
С какими проблемами сталкиваются клиенты, пытаясь внедрить периферийные вычисления?
Есть две общие проблемы. Один из них — технический вопрос: «С кем я могу работать?» У клиента может быть фокус на чипе, но на самом деле это более сложный вопрос, чем чип.Нам нравится эта сложность, потому что мы можем быть для них советником и предложите своим партнерам , с которыми они смогут решить эту сложную задачу, используя наши технические знания и экосистемную сеть.
Второе, с чем сталкиваются компании, — это проблема того, как получить финансирование, чтобы попасть в эту сферу, даже если бизнес-модель оправдывает инвестиции.Мир изменился. Компании не хотят выписывать крупный чек для этих типов инвестиций — им нужна модель с оплатой по мере использования, как вы видите в облаке. Мы работаем с клиентами, чтобы найти способ сделать это — и я думаю, что это будет важная часть дальнейшего разговора.
Вы можете увидеть это практически во всех аспектах технологий. сейчас же. Мы арендуем компьютеры больше, чем покупаем. Успех AWS свидетельствует о том, что компании могут арендовать вычислительные ресурсы у Amazon вместо того, чтобы строить собственный центр обработки данных — и этот подход дает множество преимуществ.В старом мире даже для этой видеоконференции, которую мы проводим сегодня, мы вложили бы капитал, чтобы сделать это. Теперь это просто услуга. И я думаю, что это преимущество как услуга уже не за горами.
У вас есть пример?
Клиент из Мексики хотел развернуть наружный Wi-Fi и добавить функции безопасности в Это. Таким образом, это была проблема периферийных вычислений, отчасти связанная с подключением. Но на самом деле это было нечто большее, чем просто установка. Мы не только творчески помогли решить технологическую задачу, но и координировали работу торговой площадки экосистема поставщиков для решения этой проблемы, но мы также нашли способ, чтобы клиент мог выйти на этот рынок с помощью модели, основанной на услугах, без необходимости затрат большого капитала.
Другим компаниям, производящим полупроводники, будет сложно найти партнерство по обе стороны этой проблемы, но Intel может это сделать, потому что у нас масштаб.
Как предприятия определяют, какие функции они хотят выполнять на периферии, а не в облаке?
На самом деле все сводится к вопросу о том, что вы пытаетесь выполнить do и как вы это делаете при минимальных затратах, высочайшем качестве и стандартах вычислимости.
Если у вас есть приложение, которое может выполнять то, что вам нужно, в облаке, вы, вероятно, запустите его там. Облако — отличная вещь: есть бесконечные вычисления и большой выбор в хорошо понятной среде разработчика.
Но есть много вещей, которые вы не можете или не должны делать в облаке по определенным причинам. Возьмем предыдущий пример с камерой. Допустим, у вас есть восемь камер с высокой плотностью съемки, и вы хотите, чтобы на них немедленно воздействовали. Возможно, вы не сможете позволить себе задержку, связанную с переходом в облако. Или это может быть финансовая проблема, потому что на самом деле гораздо дороже отправлять эти данные в облако снова и снова, и имеет смысл инвестировать в вычисления на границе. Есть нюансы в принятии решения. На самом деле все сводится к тому, что вы хотите от приложения, как быстро и сколько оно должно стоить.
Или это может быть финансовая проблема, потому что на самом деле гораздо дороже отправлять эти данные в облако снова и снова, и имеет смысл инвестировать в вычисления на границе. Есть нюансы в принятии решения. На самом деле все сводится к тому, что вы хотите от приложения, как быстро и сколько оно должно стоить.
Как Intel помогает разработчикам учиться, создавать и затем тестировать свои решения на периферии?
Чтобы реализовать на периферии то, что, как мы знаем, было интересным и сложным, потребовало от нас изменить наше внимание к тому, кто эти разработчики и что им небезразлично.Мы узнали, что им действительно все равно, на каком оборудовании они работают. Современные разработчики довольно хорошо разбираются в оборудовании — они просто предполагают, что вычислительные ресурсы будут доступны им для выполнения своей работы.
Чтобы убедиться, что мы можем это сделать, мы обычно ориентируемся на разработчиков по конкретным возможности. Самый сложный случай, который мы недавно изучали на периферии, — это сфокусированное видео, в частности, видео-логический и AI-логический вывод. Мы создали инструмент под названием OpenVINO , разработанный таким образом, что разработчикам не нужно было заботиться об оборудовании, на котором он работает. Это технология оптимизации моделей, которая позволяет им легко масштабироваться до различных аппаратных платформ. Это оказалось интересным предложением для этих разработчиков.
Мы создали инструмент под названием OpenVINO , разработанный таким образом, что разработчикам не нужно было заботиться об оборудовании, на котором он работает. Это технология оптимизации моделей, которая позволяет им легко масштабироваться до различных аппаратных платформ. Это оказалось интересным предложением для этих разработчиков.
Наша цель с OpenVINO демократизирует деятельность ИИ и логические выводы на периферии. Мы хотят упростить — передать эти инструменты в руки специалистов, не занимающихся данными, и заставить их работать. В рамках этого процесса мы также создаем среду, в которой они могут разрабатывать в любом месте, в любое время и в любом месте, где захотят. быть. Мы так гордимся нашим  intel.com/content/www/us/en/develop/tools/openvino-toolkit.html «rel =» noopener noreferrer «target =» _ blank «> OpenVINO и постоянно работаем над расширением сообщества и выпуском новых функций и возможностей для периферийных разработчиков.
intel.com/content/www/us/en/develop/tools/openvino-toolkit.html «rel =» noopener noreferrer «target =» _ blank «> OpenVINO и постоянно работаем над расширением сообщества и выпуском новых функций и возможностей для периферийных разработчиков.
Что нас ждет в будущем прорыве. что вы видите для Intel в области периферийных вычислений и Интернета вещей?
Я с нетерпением жду большого прорыва, когда мы покажем интегрированные 5G, виртуальную частную сеть и периферийные рабочие нагрузки в одном устройстве. .
Продолжай читать Показывай меньше
Настройте поддержку протокола прокси для вашего Classic Load Balancer
Прокси-протокол — это интернет-протокол, используемый для передачи информации о подключении от
источник, запрашивающий соединение с местом назначения, для которого соединение было
просил. Elastic Load Balancing использует протокол прокси версии 1, в котором используется удобочитаемый
формат заголовка.
Elastic Load Balancing использует протокол прокси версии 1, в котором используется удобочитаемый
формат заголовка.
По умолчанию, когда вы используете протокол управления передачей (TCP) как для внешнего интерфейса, так и для бэкэнд подключений, ваш Classic Load Balancer перенаправляет запросы экземплярам без изменение запроса заголовки.Если вы включите протокол прокси, в запрос заголовок с информацией о соединении, такой как IP-адрес источника, IP-адрес назначения адрес и номера портов. Затем заголовок отправляется экземпляру как часть запрос.
Консоль управления AWS не поддерживает включение протокола прокси.
Заголовок протокола прокси
Заголовок протокола прокси помогает определить IP-адрес клиента, когда вы есть балансировщик нагрузки, который использует TCP для внутренних соединений.Потому что балансировщики нагрузки перехватить трафик между клиентами и вашими экземплярами, журналы доступа с вашего Экземпляр содержит IP-адрес балансировщика нагрузки вместо исходного клиент. Вы можете проанализировать первую строку запроса, чтобы получить клиентский IP адрес и номер порта.
Адрес прокси в заголовке для IPv6 — это общедоступный IPv6-адрес вашего
балансировщик нагрузки. Этот IPv6-адрес совпадает с IP-адресом, полученным из вашего балансировщика нагрузки.
DNS-имя,
который начинается с
Этот IPv6-адрес совпадает с IP-адресом, полученным из вашего балансировщика нагрузки.
DNS-имя,
который начинается с ipv6 или dualstack . Если клиент подключается по IPv4,
адрес прокси в заголовке — это частный IPv4-адрес нагрузки
балансир
который невозможно разрешить с помощью поиска DNS за пределами сети EC2-Classic.
Строка протокола прокси — это одна строка, которая заканчивается символом возврата каретки и строкой.
подача
( "\ r \ n" ) и имеет следующий вид:
PROXY_STRING + одиночный пробел + INET_PROTOCOL + одиночный пробел + CLIENT_IP + одиночный пробел + PROXY_IP + одиночный пробел + CLIENT_PORT + одиночный пробел + PROXY_PORT + "\ r \ n" Пример: IPv4
Ниже приведен пример строки протокола прокси для IPv4.
ПРОКСИ TCP4 198.51.100.22 203.0.113.7 35646 80 \ r \ n Пример: IPv6 (только EC2-Classic)
Ниже приведен пример строки протокола прокси для IPv6.
ПРОКСИ TCP6 2001: DB8 :: 21f: 5bff: febf: ce22: 8a2e 2001: DB8 :: 12f: 8baa: eafc: ce29: 6b2e 35646 80 \ r \ n Предварительные требования для включения протокола прокси
Перед тем, как начать, сделайте следующее:
Убедитесь, что ваш балансировщик нагрузки не находится за прокси-сервером с включенным протоколом прокси.
Если протокол прокси включен и на прокси-сервере, и на балансировщике нагрузки,
балансировщик нагрузки добавляет к запросу еще один заголовок, в котором уже есть
заголовок с прокси-сервера. В зависимости от того, как ваш экземпляр
настроен, это дублирование может привести к ошибкам.Убедитесь, что ваши экземпляры могут обрабатывать информацию протокола прокси.
Убедитесь, что настройки вашего слушателя поддерживают протокол прокси.
Для дополнительной информации,
видеть
Конфигурации прослушивателя для классических балансировщиков нагрузки.
 Если протокол прокси включен и на прокси-сервере, и на балансировщике нагрузки,
балансировщик нагрузки добавляет к запросу еще один заголовок, в котором уже есть
заголовок с прокси-сервера. В зависимости от того, как ваш экземпляр
настроен, это дублирование может привести к ошибкам.
Если протокол прокси включен и на прокси-сервере, и на балансировщике нагрузки,
балансировщик нагрузки добавляет к запросу еще один заголовок, в котором уже есть
заголовок с прокси-сервера. В зависимости от того, как ваш экземпляр
настроен, это дублирование может привести к ошибкам. Для дополнительной информации,
видеть
Конфигурации прослушивателя для классических балансировщиков нагрузки.
Для дополнительной информации,
видеть
Конфигурации прослушивателя для классических балансировщиков нагрузки.Включить протокол прокси с помощью AWS CLI
Чтобы включить протокол прокси, необходимо создать политику типа ProxyProtocolPolicyType а затем включите политику для порта экземпляра.
Используйте следующую процедуру для создания новой политики для балансировщика нагрузки типа ProxyProtocolPolicyType , установите для вновь созданной политики значение
экземпляр на порту 80 и убедитесь, что политика включена.
Включение протокола прокси для балансировщика нагрузки
(Необязательно) Используйте следующую команду describe-load-balancer-policy-types для вывода списка политики, поддерживаемые эластичной балансировкой нагрузки:
aws elb describe-load-balancer-policy-typesОтвет включает имена и описания поддерживаемых типов политик.В следующий показывает вывод для типа
ProxyProtocolPolicyType:{ "PolicyTypeDescriptions": [ . ..
{
"PolicyAttributeTypeDescriptions": [
{
"Мощность": "ОДИН",
"AttributeName": "ProxyProtocol",
"AttributeType": "Boolean"
}
],
"PolicyTypeName": "ProxyProtocolPolicyType",
«Описание»: «Политика, определяющая, следует ли включать IP-адрес и порт отправителя.
запрос сообщений TCP.Эта политика действует только для прослушивателей TCP / SSL "
},
...
]
} Используйте следующую политику create-load-balancer-policy команда для создания политики, которая включает протокол прокси:
aws elb create-load-balancer-policy --load-balancer-namemy-loadbalancer--policy-namemy-ProxyProtocol-policy--policy-type-name ProxyProtocolPolicyType --policy-attributes AttributeName = ProxyProtocol, AttributeValue = trueИспользуйте следующие политики set-load-balancer-for-backend-server команда для включения вновь созданной политики на указанном порту.
Обратите внимание, что
эта команда заменяет текущий набор включенных политик.
Следовательно, параметр --policy-namesдолжен указывать как политику, которую вы добавляете в список (например,my-ProxyProtocol-policy) и любые политики, которые в настоящее время включены (например,my-existing-policy).aws elb set-load-balancer-policies-for-backend-server --load-balancer-namemy-loadbalancer--instance-port80--policy-namesmy-ProxyProtocol-policy my -существующая-политика(необязательно) Используйте следующие балансировщики описаний нагрузки.
команда, чтобы убедиться, что протокол прокси включен:aws elb describe-load-balancers --load-balancer-namemy-loadbalancerОтвет включает следующую информацию, которая показывает, что политика
my-ProxyProtocol-policypolicy связан с портом80.{ "LoadBalancerDescriptions": [ { ... "BackendServerDescriptions": [ { «InstancePort»: 80, "PolicyNames": [ "my-ProxyProtocol-policy" ] } ], ... } ] }
 ..
{
"PolicyAttributeTypeDescriptions": [
{
"Мощность": "ОДИН",
"AttributeName": "ProxyProtocol",
"AttributeType": "Boolean"
}
],
"PolicyTypeName": "ProxyProtocolPolicyType",
«Описание»: «Политика, определяющая, следует ли включать IP-адрес и порт отправителя.
запрос сообщений TCP.Эта политика действует только для прослушивателей TCP / SSL "
},
...
]
}
..
{
"PolicyAttributeTypeDescriptions": [
{
"Мощность": "ОДИН",
"AttributeName": "ProxyProtocol",
"AttributeType": "Boolean"
}
],
"PolicyTypeName": "ProxyProtocolPolicyType",
«Описание»: «Политика, определяющая, следует ли включать IP-адрес и порт отправителя.
запрос сообщений TCP.Эта политика действует только для прослушивателей TCP / SSL "
},
...
]
}  Обратите внимание, что
эта команда заменяет текущий набор включенных политик.
Следовательно, параметр
Обратите внимание, что
эта команда заменяет текущий набор включенных политик.
Следовательно, параметр 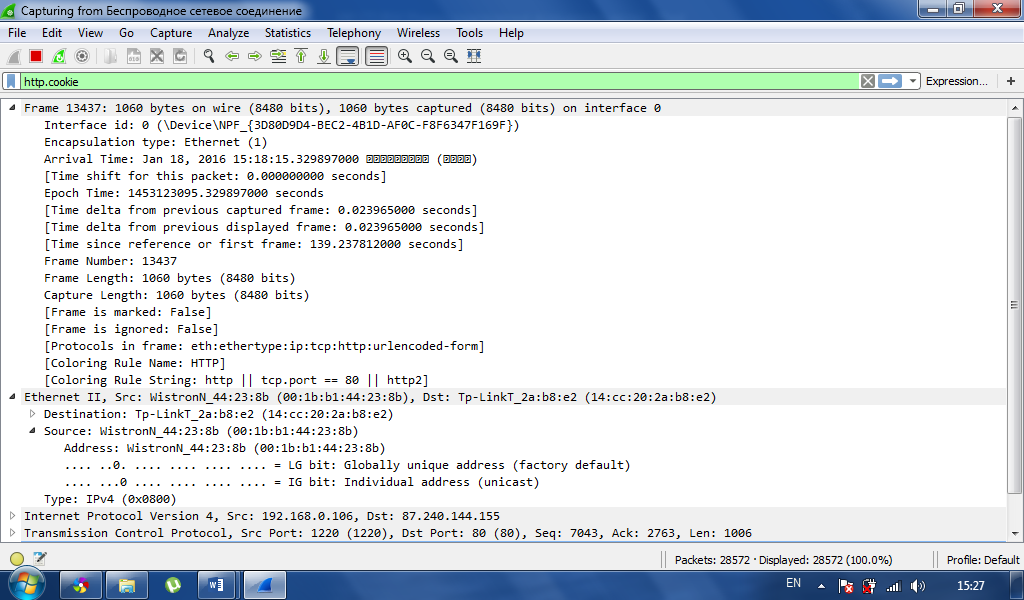 команда, чтобы убедиться, что протокол прокси включен:
команда, чтобы убедиться, что протокол прокси включен:Отключить протокол прокси с помощью AWS CLI
Вы можете отключить политики, связанные с вашим экземпляром, а затем включить их. позже.
позже.
Для отключения политики протокола прокси
Используйте следующую команду set-load-balancer-policies-for-backend-server. чтобы отключить политику протокола прокси, исключив ее из параметра
--policy-names, но включив параметр другие политики, которые должны оставаться включенными (например,my-existing-policy).aws elb set-load-balancer-policies-for-backend-server --load-balancer-namemy-loadbalancer--instance-port80--policy-namesmy-existing-policyЕсли нет других политик для включения, укажите пустую строку с опцией
--policy-namesследующим образом:aws elb set-load-balancer-policies-for-backend-server --load-balancer-namemy-loadbalancer--instance-port80--policy-names "[]"(Необязательно) Используйте следующую команду describe-load-balancers чтобы убедиться, что политика отключена:
aws elb describe-load-balancers --load-balancer-namemy-loadbalancerОтвет включает следующую информацию, которая показывает, что порты не связаны с политикой.
