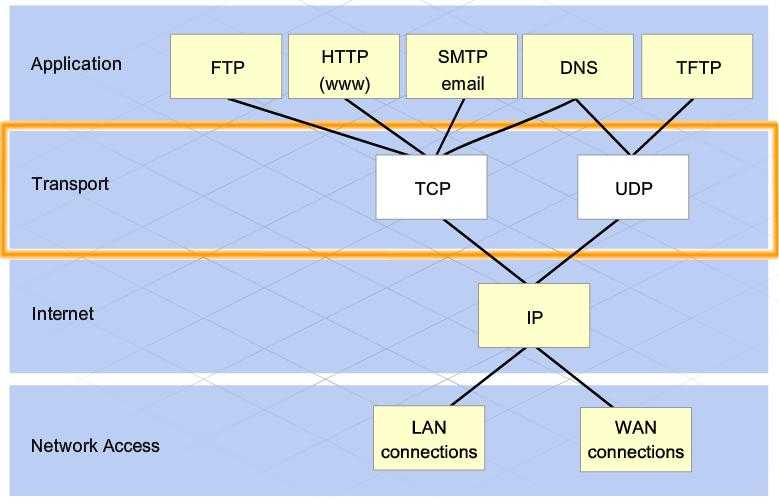
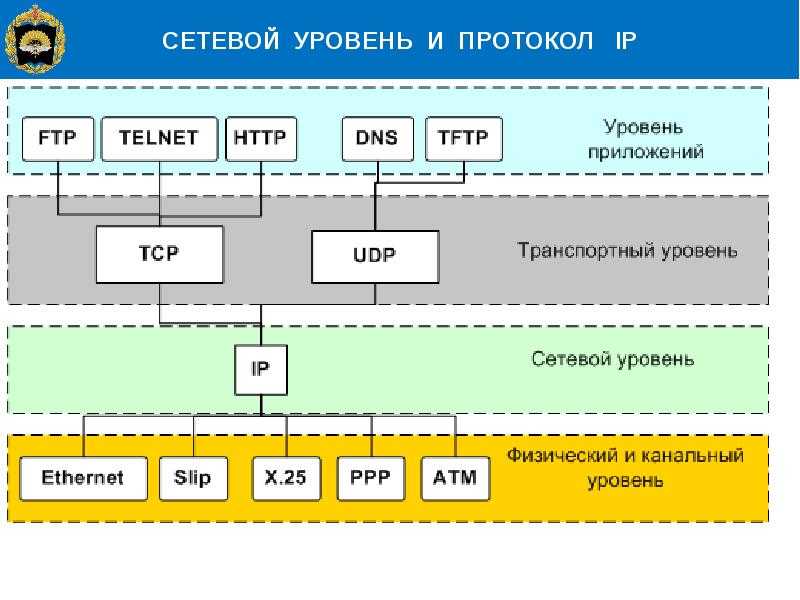
Connection management in HTTP/1.x — HTTP
Управление соединением является ключевой темой HTTP: открытие и поддержка соединения оказывает значительное влияние на производительность веб-сайтов и веб-приложений. В HTTP/1.x имеются следующие модели: краткосрочные соединения, постоянные соединения и конвейерная обработка HTTP (HTTP pipelining).
В качестве транспортного протокола, обеспечивающего связь между клиентом и сервером, HTTP по большей части использует TCP. Это краткосрочные (short-lived) соединения: при каждой отправке запроса открывается новое соединение, которое закрывается после того, как ответ получен.
Такой модели присущи проблемы в отношении производительности: ресурсы приходится затрачивать на открытие каждого соединения TCP. Клиенту и сервером необходимо обмениваться несколькими сообщениями. При отправке каждого запроса приходится считаться с запаздыванием и пропускной способностью сети. Современным веб-страницам требуется выполнять множество (десятки) запросов для передачи необходимой информации, что делает данную модель неэффективной.
В HTTP/1.1 были созданы две новые модели. Модель постоянного соединения оставляет соединение открытым между последовательными запросами, экономя время, требуемое для открытия новых соединений. Модель конвейерной обработки HTTP делает следующий шаг — она позволяет отсылать несколько запросов подряд, не дожидаясь ответа, что существенно сокращает время ожидания в сети.
В HTTP/2 внесены дополнительные модели управления соединением.
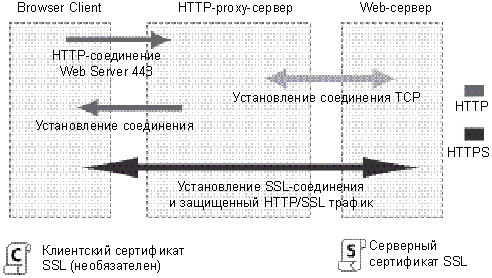
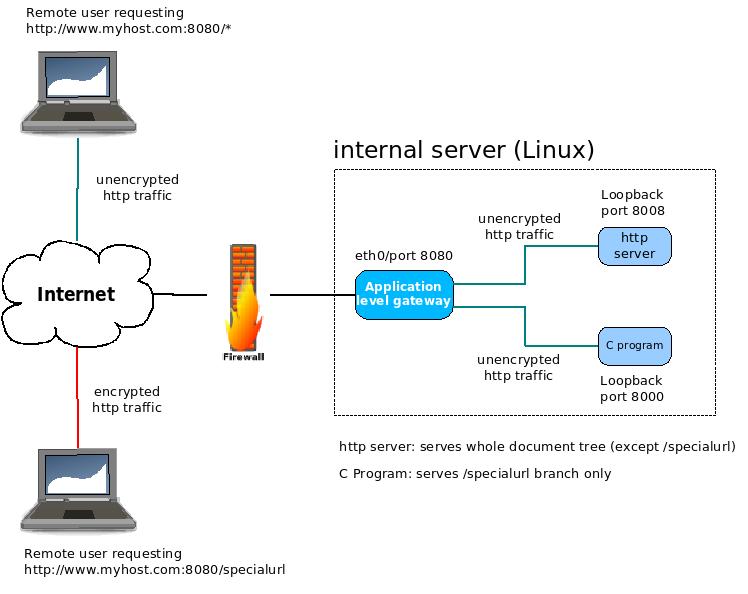
Важно отметить, что управление соединением в HTTP применяется к соединению между двумя последовательными узлами, и является пошаговым (hop-by-hop) а не «конец-к-концу» (end-to-end). Модель, используемая для соединения клиента с его первым прокси, может отличаться от модели соединения между прокси и конечным сервером (или любым из промежуточных серверов). Заголовки HTTP, вовлечённые в определение модели соединения, типа HTTPHeader(«Connection»)}} и Keep-Alive (en-US), являются пошаговыми заголовками, значения которых могут изменяться промежуточными узлами.
Исходной моделью в HTTP, в HTTP/1.0 она же является моделью по умолчанию, являются краткосрочные соединения (short-lived connections). Для каждого HTTP запроса используется отдельное соединение; это означает, что «рукопожатие» TCP происходит перед каждым из запросов HTTP, идущих один за другим.
TCP-рукопожатие само по себе затратно по времени, но TCP-соединения приспособились справляются с этой нагрузкой, превращаясь в устойчивые (или тёплые) соединения. Краткосрочные соединения не используют это полезное свойство TCP, так что эффективность оказывается ниже оптимальной из-за того что передача осуществляется по новому, холодному соединению.
Данная модель является моделью по умолчанию в HTTP/1.0 (при отсутствии заголовка Connection, или когда его значением является close). В HTTP/1.1 такая модель используется только если заголовок Connection
close.Если речь не идёт об очень старой, не поддерживающей постоянные соединения, системе, данную модель использовать нет смысла.
Краткосрочные соединения имеют два больших недостатка: требуется значительное время на установку нового соединения, и то, что эффективность TCP-соединения улучшается только по прошествии некоторого времени от начала его использования (тёплое соединение). Для решения этих проблем была разработана концепция постоянного соединения (persistent connection), ещё до появления HTTP/1.1. Его также называют соединением keep-alive
Постоянным называют соединение, которое остаётся открытым некоторый период времени и может быть использовано для нескольких запросов, благодаря чему отпадает необходимость в новых рукопожатиях TCP и используются средства повышения производительности TCP. Это соединение остаётся открытым не навсегда: праздные соединения закрываются по истечению некоторого времени (для задания минимального времени, на протяжении которого соединение должно оставаться открытым, сервер может использовать заголовок Keep-Alive (en-US)).
У постоянных соединений есть свои недочёты; даже работая вхолостую, они потребляют ресурсы сервера, а при высокой нагрузке могут проводиться DoS-атаки.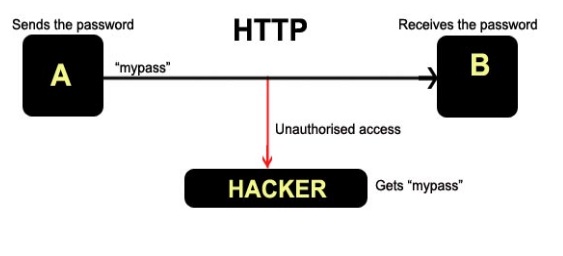
Соединения HTTP/1.0 по умолчанию не являются постоянными. Для превращения их в постоянные надо присвоить заголовку Connection значение, отличное от close — обычно retry-after.
В HTTP/1.1 соединения являются постоянными по умолчанию, так что этот заголовок больше не требуется (но часто добавляется в качестве защитной меры на случай, если потребуется откат к HTTP/1.0).
Конвейерная обработка HTTP в современных браузерах не активирована по умолчанию:
- Прокси с багами все ещё встречаются, что приводит к странным и непредсказуемым явлениям, которые веб-разработчикам трудно предсказать и диагностировать.
- Конвейерную обработку сложно правильно реализовать: объем передаваемых ресурсов, используемая RTT и эффективная пропускная способность имеют непосредственное влияние на те улучшения, что обеспечиваются конвейерной обработкой.
 Конвейерная обработка HTTP, таким образом, даёт существенное улучшение не во всех случаях.
Конвейерная обработка HTTP, таким образом, даёт существенное улучшение не во всех случаях. - Конвейерная обработка подвержена проблеме HOL.
 Конвейерная обработка HTTP, таким образом, даёт существенное улучшение не во всех случаях.
Конвейерная обработка HTTP, таким образом, даёт существенное улучшение не во всех случаях.По этим причинам в HTTP/2 на смену конвейерной обработке пришёл новый алгоритм, мультиплексность (multiplexing
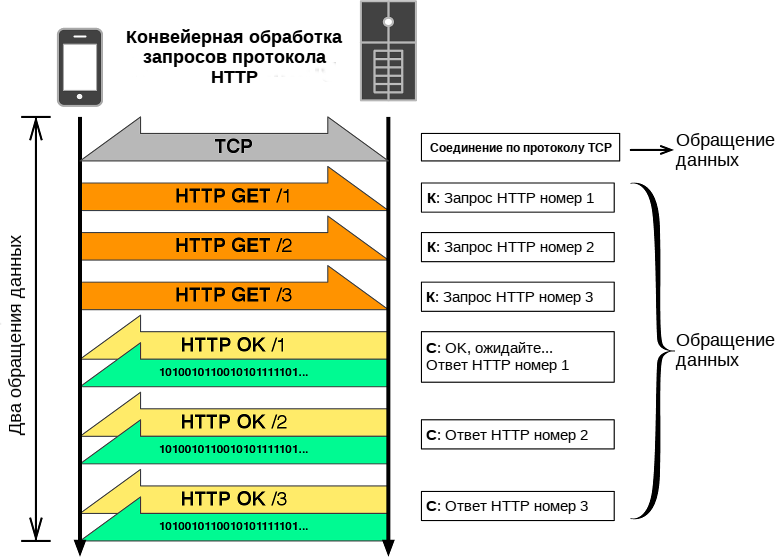
По умолчанию запросы HTTP идут последовательно. Новый запрос выдаётся только после того, как получен ответ на предыдущий. Из-за запаздываний в сети и ограничений на пропускную способность это может приводить к тому, что сервер увидит следующий запрос с существенной задержкой.
Конвейерная обработка это процесс отсылки последовательных запросов по одному постоянному соединению не дожидаясь ответа. Таким образом избегают задержки соединения. Теоретически, производительность можно было бы повысить также за счёт упаковки двух запросов HTTP в одно и то же сообщение TCP. Типичный MSS (Maximum Segment Size — Максимальный размер сегмента) достаточно велик, чтобы вместить несколько простых запросов, хотя требования на объем запросов HTTP продолжают расти.
Не все типы запросов HTTP позволяют конвейерную обработку: только идемпотентные методы, а именно GET, HEAD, PUT и DELETE, можно перезапускать безопасно: в случае сбоя содержимое конвейерной передачи можно просто повторить.
В наши дни любой удовлетворяющий требованиям HTTP/1.1 прокси или сервер должен поддерживать конвейерную обработку, хотя на практике возникает множество ограничений, поэтому ни один из современных браузеров не активирует этот режим по умолчанию.
Не используйте этот устаревший метод без крайней необходимости; вместо этого переходите на HTTP/2. В HTTP/2 доменное разделение больше не требуется: соединение HTTP/2 соединение прекрасно работает с параллельными неприоритезированными запросами. Доменное разделение даже вредит производительности. Большинство реализаций HTTP/2 использует метод, называемый слиянием соединений (connection coalescing) для возврата конечного доменного разделения.
Поскольку соединение HTTP/1.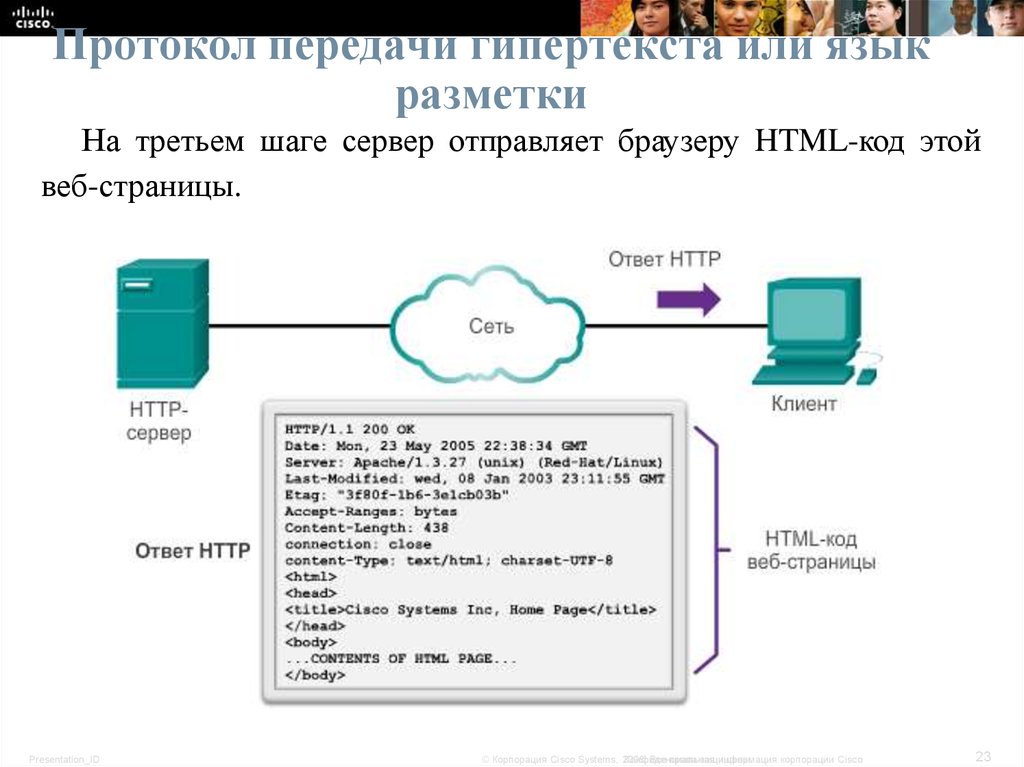 x является последовательными запросами, даже без упорядочивания, оно не может быть оптимальным без наличия достаточно большой пропускной способности. Браузеры находят решение в открытии нескольких соединений к каждому домену с отсылкой параллельных запросов. По умолчанию это когда-то было 2-3 соединения, но сейчас их число возросло примерно до 6 параллельных соединений. При попытке использовать большее количество есть риск спровоцировать защиту от DoS со стороны сервера.
x является последовательными запросами, даже без упорядочивания, оно не может быть оптимальным без наличия достаточно большой пропускной способности. Браузеры находят решение в открытии нескольких соединений к каждому домену с отсылкой параллельных запросов. По умолчанию это когда-то было 2-3 соединения, но сейчас их число возросло примерно до 6 параллельных соединений. При попытке использовать большее количество есть риск спровоцировать защиту от DoS со стороны сервера.
Если сервер хочет иметь более быстрый ответ от веб-сайта или приложения, он может открыть больше соединений. Например, вместо того, чтобы иметь все ресурсы на одном домене, скажем, www.example.com, он может распределить их по нескольким доменам, www1.example.com, www2.example.com, www3.example.com. Каждый из этих доменов разрешается на том же сервере, и веб-браузер откроет 6 соединений к каждому (в нашем примере число соединений возрастёт до 18). Этот метод называют доменным разделением (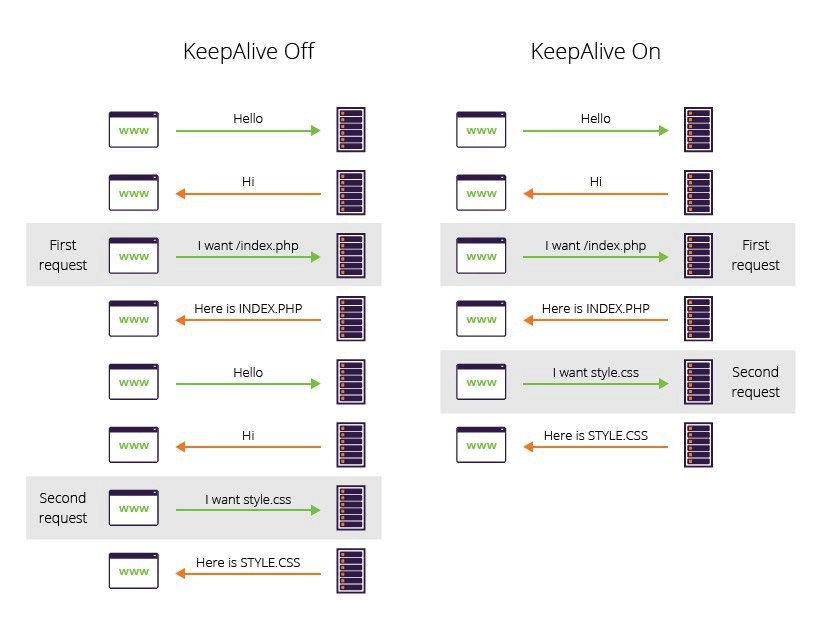
Улучшение управлением соединениями даёт существенное увеличение производительности в HTTP. В HTTP/1.1 и HTTP/1.0 использование постоянного соединения – по крайней мере пока оно не начинает работать вхолостую – приводит к лучшей производительности. Однако, проблемы с конвейерной обработкой привели к созданию более совершенных способов управления соединением, реализованными в HTTP/2.
Last modified: , by MDN contributors
HTTP соединение (HTTP Connections) | IT-блог о веб-технологиях, серверах, протоколах, базах данных, СУБД, SQL, компьютерных сетях, языках программирования и создание сайтов.
- 05.06.2016
- HTTP протокол, Сервера и протоколы
Привет, читатель блога ZametkiNaPolyah.ru! Продолжим знакомиться с протоколом HTTP в рубрике серверы и протоколы и ее разделе HTTP протокол. В данной записи мы с тобой поговорим про HTTP соединения и, в основном, о том, как они реализованы в HTTP протоколе версии 1.![]() 1. Для начала скажу, что на данный момент действуют постоянные HTTP соединения, это означает одну простую вещь: за одну TCP сессию можно отправить несколько HTTP запросов и получить столько же HTTP ответов, раньше это было далеко не так. Так же в этой записи мы затронем требования к передаче HTTP сообщений.
1. Для начала скажу, что на данный момент действуют постоянные HTTP соединения, это означает одну простую вещь: за одну TCP сессию можно отправить несколько HTTP запросов и получить столько же HTTP ответов, раньше это было далеко не так. Так же в этой записи мы затронем требования к передаче HTTP сообщений.
HTTP соединение (HTTP Connections)
Постоянные HTTP соединения (Persistent Connections HTTP)
Содержание статьи:
- Постоянные HTTP соединения (Persistent Connections HTTP)
- Требования к передаче сообщений и выбор HTTP соединений (HTTP Connections)
Если вы хотите узнать всё про протокол HTTP, обратитесь к навигации по рубрике HTTP протокол. HTTP соединение или HTTP Connections на данный момент является постоянным для каждого URL (читай про URI в HTTP), когда-то давно для каждого запроса клиента использовалось отдельное TCP соединение (даже если страница просто обновлялась), что создавало большую нагрузку на машины с HTTP серверами, потому что каждый элемент страницы, например изображение – это один или несколько запросов от клиента к серверу.
Давайте посмотрим, что дают постоянные HTTP соединения (HTTP Connections):
- Сейчас не требуется постоянно поднимать новое TCP соединение для запроса, поэтому существенно экономятся ресурсы серверов.
- HTTP запросы клиента и ответы сервера можно представить как непрерывно работающий конвейер, причем параллельный, в рамках одного TCP соединения.
- Для установки TCP соединения машине клиента и машине сервера обязательно нужно посылать пакеты, следовательно, третий уровень модели OSI был очень загружен, так было до появления постоянного HTTP соединения (HTTP Connections).
Поэтому на данный момент все HTTP клиенты и HTTP серверы разрабатываются с учетом того, чтобы работать, используя постоянные HTTP соединения между клиентом и сервером. В версии протокола HTTP 1.1 любой клиент по умолчанию считает, что ему нужно работать с сервером по постоянному HTTP соединению (Persistent Connection HTTP). Как только клиент и сервер прекратили общаться, им необходимо разорвать TCP соединение, делается это специальным полем в заголовке Connection (если не знаете, что такое заголовки и поля, то почитайте статью параметры HTTP). После того, как клиент получил сообщение о разрыве TCP соединения, он не должен (читай про требования HTTP) посылать серверу заголовки.
После того, как клиент получил сообщение о разрыве TCP соединения, он не должен (читай про требования HTTP) посылать серверу заголовки.
С учетом того, что HTTP соединение постоянное, клиент может посылать несколько HTTP запросов подряд, не ожидаю HTTP сообщений от сервера, но сервер должен посылать HTTP ответы на сообщения клиента в том порядке, в котором он получил запросы. С учетом того, что на данный момент используется постоянное HTTP соединение (HTTP Connections), сервера имеют определенные значения времени ожидания (конкретные цифры зависят непосредственно от настроек сервера), после которого они перестают поддерживать неактивные соединения.
Хочу заметить, что при закрытии TCP соединения клиент и сервер могут работать асинхронно (хотя HTTP протокол по всем определениям синхронный). Например, мы имеем неактивное HTTP соединение, у сервера закончилось время ожидания, и он отправляет клиенту сообщение о том, что он рвет TCP соединение, но в это же самое время клиент отправляет какой-то HTTP запрос, в этом случае программа клиента должна «справиться» без участия человека, а именно: отправить запрос на установку нового HTTP соединения и повторить предыдущий запрос.
В общем, суть данного поста в том, что на данный момент в HTTP поддерживается конвейерное постоянное HTTP соединение с возможностью асинхронной обработки события закрытия соединения.
Требования к передаче сообщений и выбор HTTP соединений (HTTP Connections)
Общие требования к передаче сообщений в стандарте HTTP:
- В HTTP 1.1 серверам следует поддерживать постоянные HTTP соединения.
- В HTTP1 клиентам следует во время отправки сообщения контролировать соединение на предмет ошибок. При обнаружении ошибки клиенту следует немедленно прекратить передачу. Если тело HTTP сообщения посылается с использованием кодирования по кускам, то кусок нулевой длины могут использоваться для индикации преждевременного конца сообщения.
- Протокол HTTP версии 1.1 предусматривает то, что клиент должен уметь работать с кодом состояния 100.
Сервера версии HTTP 1.1 должны уметь работать с клиентами 1.0 и ниже, при этом сервера не должны использовать сообщения с кодом состояния 100. Если клиент HTTP 1.1 взаимодействует с сервером 1.0 , то для корректной отправки повторного запроса он должен использовать следующий алгоритм:
Если клиент HTTP 1.1 взаимодействует с сервером 1.0 , то для корректной отправки повторного запроса он должен использовать следующий алгоритм:
- Инициализировать новое соединение с сервером.
- Передать заголовки запроса (request-headers).
- Инициализировать переменную R примерным временем передачи информации на сервер и обратно (например на основании времени установления соединения), или постоянным значение в 5 секунд, если время передачи не доступно.
- Вычислить T = R * (2**N), где N — число предыдущих повторов этого запроса.
- Либо дождаться от сервера ответа с кодом ошибки, либо просто выждать T секунд (смотря что произойдет раньше).
- Если ответа с кодом ошибки не получено, после T секунд передать тело запроса.
- Если клиент обнаруживает, что HTTP соединение было закрыто преждевременно, то ему нужно повторять начиная с шага 1, пока запрос не будет принят, либо пока не будет получен ошибочный ответ, либо пока у пользователя не кончится терпение и он не завершит процесс повторения.
Вот такие требования к передаче HTTP сообщений предъявляются стандартом HTTP. На этом мы закончим рассмотрение HTTP соединений, более полную информацию вы сможете узнать из стандарта HTTP 1.1.
Возможно, эти записи вам покажутся интересными
Постоянное соединение HTTP
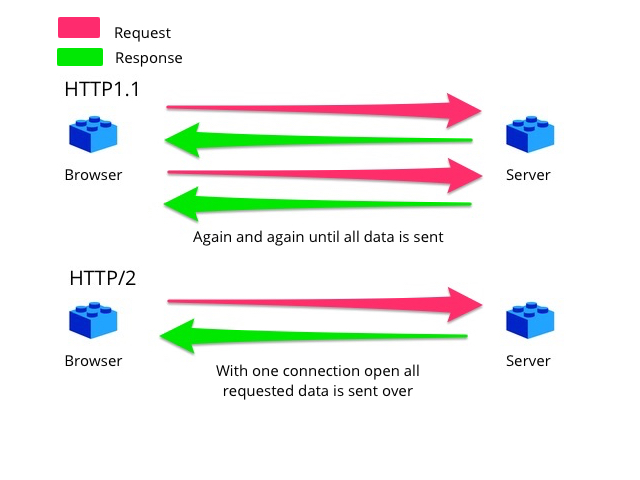
HTTP постоянное соединение, также называемый HTTP keep-alive, или же Повторное использование HTTP-соединения, идея использования одного TCP соединение для отправки и получения нескольких HTTP-запросы / response, в отличие от открытия нового соединения для каждой пары запрос / ответ. Новее HTTP / 2 Протокол использует ту же идею и развивает ее, позволяя мультиплексировать несколько одновременных запросов / ответов через одно соединение.
Содержание
- 1 Операция
- 1.1 HTTP 1.0
- 1.2 HTTP 1.1
- 1.2.1 Keepalive с фрагментированным кодированием передачи
- 2 Преимущества
- 3 Недостатки
- 4 Использование в веб-браузерах
- 5 Смотрите также
- 6 Рекомендации
- 7 внешняя ссылка
Операция
HTTP 1.
 0
0В HTTP 1.0 соединения не считаются постоянными, если не включен заголовок keep-alive,[1] хотя нет официальной спецификации того, как работает keepalive. По сути, это было добавлено к существующему протоколу. Если клиент поддерживает keep-alive, он добавляет к запросу дополнительный заголовок:
Подключение: keep-alive
Затем, когда сервер получает этот запрос и генерирует ответ, он также добавляет заголовок к ответу:
Подключение: keep-alive
После этого соединение не разрывается, а остается открытым. Когда клиент отправляет другой запрос, он использует то же соединение. Это будет продолжаться до тех пор, пока клиент или сервер не решат, что диалог завершен, и один из них не разорвет соединение.
HTTP 1.1
В HTTP 1.1 все соединения считаются постоянными, если не указано иное.[2] Постоянные соединения HTTP не используют отдельные сообщения поддержки активности, они просто позволяют нескольким запросам использовать одно соединение. Однако время ожидания соединения по умолчанию для Apache httpd 1.3 и 2.0 составляет всего 15 секунд.[3][4] и всего 5 секунд для Apache httpd 2.2 и выше.[5][6] Преимущество короткого тайм-аута заключается в возможности быстро доставить несколько компонентов веб-страницы, не потребляя при этом ресурсов для запуска нескольких серверных процессов или потоков слишком долго.[7]
Однако время ожидания соединения по умолчанию для Apache httpd 1.3 и 2.0 составляет всего 15 секунд.[3][4] и всего 5 секунд для Apache httpd 2.2 и выше.[5][6] Преимущество короткого тайм-аута заключается в возможности быстро доставить несколько компонентов веб-страницы, не потребляя при этом ресурсов для запуска нескольких серверных процессов или потоков слишком долго.[7]
Keepalive с кодирование передачи по частям
Keepalive затрудняет для клиента определение того, где заканчивается один ответ и начинается следующий, особенно во время конвейерной операции HTTP.[8] Это серьезная проблема, когда Content-Length нельзя использовать из-за потоковой передачи.[9] Чтобы решить эту проблему, HTTP 1.1 представил кодирование передачи по частям что определяет последний кусок кусочек.[10] В последний кусок бит устанавливается в конце каждого ответа, чтобы клиент знал, где начинается следующий ответ.
Преимущества
- Уменьшенный задержка в последующих запросах (нет подтверждение связи ).
- Уменьшенный ЦПУ использования и обратных поездок из-за меньшего количества новых подключений и Рукопожатия TLS.
- Позволяет Конвейерная обработка HTTP запросов и ответов.
- Уменьшенный перегрузка сети (меньше TCP-соединения ).
- Об ошибках можно сообщать без штрафа за закрытие TCP-соединения.
В соответствии с RFC 7230, раздел 6.4, «клиент должен ограничить количество одновременных открытых подключений, которые он поддерживает с данным сервером». Предыдущая версия спецификации HTTP / 1.1 заявленные конкретные максимальные значения но по словам RFC 7230 «это оказалось непрактичным для многих приложений … вместо этого … быть консервативным при открытии нескольких соединений». Эти рекомендации предназначены для уменьшения времени ответа HTTP и предотвращения перегрузки. Если конвейерная обработка HTTP реализована правильно, дополнительные соединения не принесут выигрыша в производительности, а дополнительные соединения могут вызвать проблемы с перегрузкой.![]() [11]
[11]
Недостатки
Если клиент не закроет соединение после получения всех необходимых ему данных, ресурсы, необходимые для поддержания соединения на сервере, будут недоступны для других клиентов. Насколько это влияет на доступность сервера и как долго ресурсы недоступны, зависит от архитектуры и конфигурации сервера.
Также состояние гонки может произойти, когда клиент отправляет запрос на сервер в то же время, когда сервер закрывает TCP-соединение.[12] Сервер должен отправить клиенту код состояния 408 Request Timeout непосредственно перед закрытием соединения. Когда клиент получает код состояния 408, после отправки запроса он может открыть новое соединение с сервером и повторно отправить запрос.[13] Не все клиенты будут повторно отправлять запрос, и многие из них сделают это только в том случае, если запрос имеет идемпотентный метод HTTP.
Использование в веб-браузерах
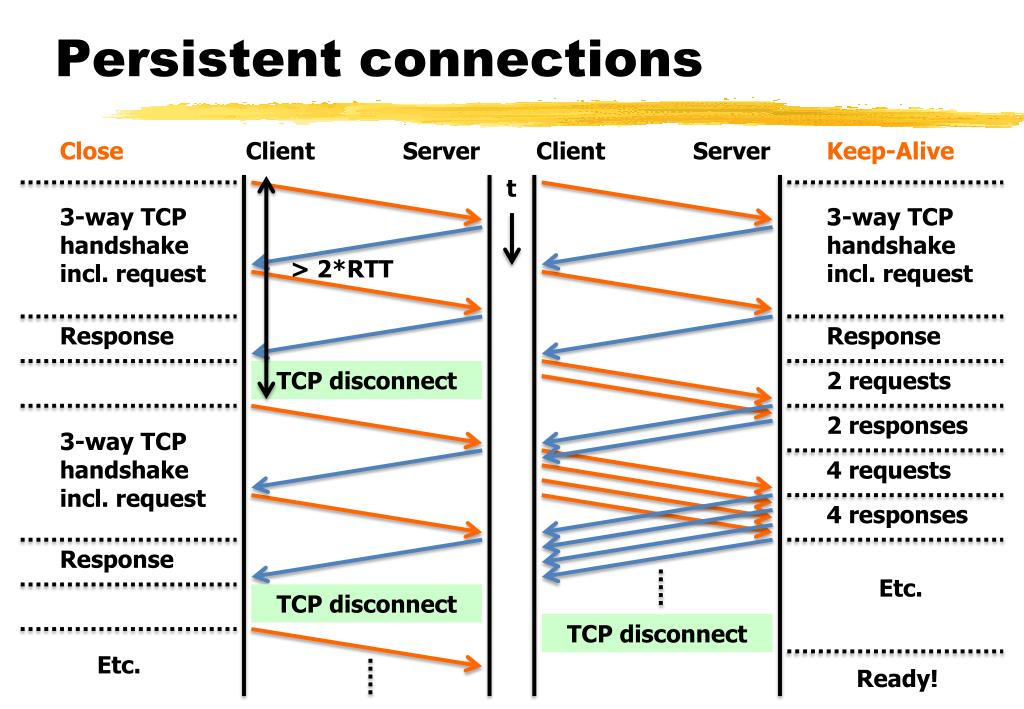
Схема множественного и постоянного подключения.
Все современные веб-браузеры, включая Гугл Хром, Fire Fox, Internet Explorer (с 4. «Network.http.keep-alive.timeout». Mozillazine.org. Получено 2009-07-17.
«Network.http.keep-alive.timeout». Mozillazine.org. Получено 2009-07-17.
внешняя ссылка
- Протокол передачи гипертекста (HTTP / 1.1): синтаксис и маршрутизация сообщений, управление подключениями, постоянство
- Постоянное соединение популярных браузеров (датировано)
- Поддержка Apache HTTPD Keep-Alive
- Влияние HTTP / 1.1, CSS1 и PNG на производительность сети
Управление соединениями в HTTP/1.x — HTTP
Управление соединениями является ключевой темой в HTTP: открытие и поддержание соединений в значительной степени влияет на производительность веб-сайтов и веб-приложений. В HTTP/1.x существует несколько моделей: кратковременных соединения , постоянных соединения и HTTP-конвейерная обработка.
HTTP в основном полагается на TCP для своего транспортного протокола, обеспечивая соединение между клиентом и сервером. В зачаточном состоянии HTTP использовал единую модель для обработки таких соединений. Эти соединения были недолговечными: новое создавалось каждый раз, когда требовалось отправить запрос, и закрывалось после получения ответа.
В зачаточном состоянии HTTP использовал единую модель для обработки таких соединений. Эти соединения были недолговечными: новое создавалось каждый раз, когда требовалось отправить запрос, и закрывалось после получения ответа.
Эта простая модель содержала врожденное ограничение производительности: открытие каждого TCP-соединения является ресурсоемкой операцией. Клиент и сервер должны обмениваться несколькими сообщениями. Задержка сети и пропускная способность влияют на производительность, когда требуется отправить запрос. Современные веб-страницы требуют большого количества запросов (дюжины и более) для обслуживания необходимого объема информации, что доказывает неэффективность этой более ранней модели.
В HTTP/1.1 созданы две новые модели. Модель постоянного соединения сохраняет соединения открытыми между последовательными запросами, сокращая время, необходимое для открытия новых соединений. Конвейерная модель HTTP делает еще один шаг вперед, отправляя несколько последовательных запросов, даже не дожидаясь ответа, что значительно снижает задержку в сети.
Примечание. HTTP/2 добавляет дополнительные модели для управления соединениями.
Важно отметить, что управление соединением в HTTP применяется к соединению между двумя последовательными узлами, которое является пошаговым, а не сквозным. Модель, используемая в соединениях между клиентом и его первым прокси, может отличаться от модели между прокси и целевым сервером (или любыми промежуточными прокси). Заголовки HTTP, участвующие в определении модели подключения, например Connection и Keep-Alive — это заголовки переходов, значения которых могут быть изменены промежуточными узлами.
Связанной темой является концепция обновлений соединения HTTP, когда соединение HTTP/1.1 обновляется до другого протокола, такого как TLS/1.0, WebSocket или даже HTTP/2 в открытом тексте. Этот механизм обновления протокола более подробно описан в другом месте.
Исходная модель HTTP и модель по умолчанию в HTTP/1.0 — кратковременных соединения . Каждый HTTP-запрос выполняется по отдельному соединению; это означает, что рукопожатие TCP происходит перед каждым HTTP-запросом, и они сериализуются.
Каждый HTTP-запрос выполняется по отдельному соединению; это означает, что рукопожатие TCP происходит перед каждым HTTP-запросом, и они сериализуются.
Установление связи TCP само по себе занимает много времени, но соединение TCP адаптируется к своей нагрузке, становясь более эффективным при более устойчивых (или теплых) соединениях. Краткосрочные соединения не используют эту эффективную функцию TCP, и производительность снижается по сравнению с оптимальной из-за продолжения передачи по новому холодному соединению.
Эта модель используется по умолчанию в HTTP/1.0 (если нет Заголовок соединения или, если его значение установлено на , закрыть ). В HTTP/1.1 эта модель используется только тогда, когда заголовок Connection отправляется со значением close .
Примечание: Если вы не имеете дело с очень старой системой, которая не поддерживает постоянное соединение, нет веских причин использовать эту модель.
Краткосрочные соединения имеют два основных недостатка: время, необходимое для установления нового соединения, является значительным, а производительность базового соединения TCP улучшается только тогда, когда это соединение использовалось в течение некоторого времени (горячее соединение). Чтобы облегчить эти проблемы, концепция 9Постоянное соединение 0003 было разработано еще до HTTP/1.1. В качестве альтернативы это можно назвать соединением проверки активности .
Постоянное соединение — это соединение, которое остается открытым в течение определенного периода времени и может повторно использоваться для нескольких запросов, избавляя от необходимости в новом квитировании TCP и используя возможности повышения производительности TCP. Это соединение не будет оставаться открытым вечно: бездействующие соединения закрываются через некоторое время (сервер может использовать заголовок Keep-Alive , чтобы указать минимальное время, в течение которого соединение должно оставаться открытым).
Постоянные соединения также имеют недостатки; даже в простое они потребляют ресурсы сервера, а при большой нагрузке могут проводиться DoS-атаки. В таких случаях использование непостоянных соединений, которые закрываются, как только они простаивают, может обеспечить лучшую производительность.
Соединения HTTP/1.0 по умолчанию не являются постоянными. Установка Connection на что-либо, кроме close , обычно retry-after , сделает их постоянными.
В HTTP/1.1 сохраняемость используется по умолчанию, и заголовок больше не нужен (но он часто добавляется в качестве защитной меры против случаев, когда требуется откат к HTTP/1.0).
Примечание: Конвейерная обработка HTTP по умолчанию не активирована в современных браузерах:
- Ошибочные прокси-серверы все еще распространены, что приводит к странному и неустойчивому поведению, которое веб-разработчики не могут легко предвидеть и диагностировать.
- Конвейерную обработку сложно реализовать правильно: размер передаваемого ресурса, фактическое значение RTT, которое будет использоваться, а также эффективная пропускная способность напрямую влияют на улучшение, обеспечиваемое конвейером. Не зная этого, важные сообщения могут быть задержаны за неважными. Понятие важного меняется даже во время макета страницы! Таким образом, конвейерная обработка HTTP в большинстве случаев приносит лишь незначительное улучшение.
- Конвейерная обработка подвержена проблеме HOL.
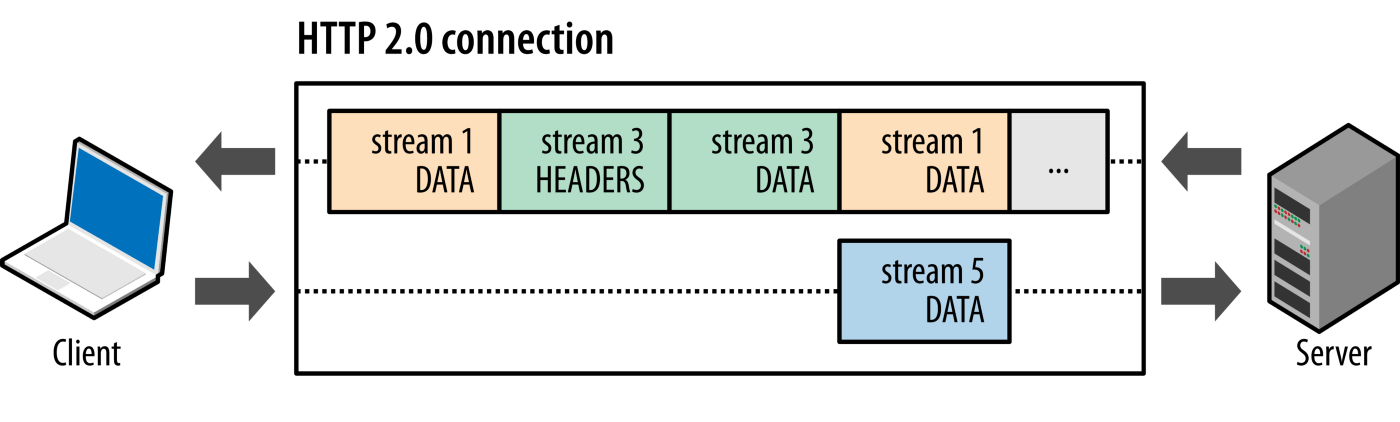
По этим причинам конвейерная обработка была заменена лучшим алгоритмом, мультиплексированием , который используется HTTP/2.
По умолчанию HTTP-запросы выполняются последовательно. Следующий запрос выдается только после получения ответа на текущий запрос. Поскольку на них влияют сетевые задержки и ограничения пропускной способности, это может привести к значительной задержке перед тем, как будет виден следующий запрос сервером.
Конвейерная обработка — это процесс отправки последовательных запросов по одному и тому же постоянному соединению без ожидания ответа. Это позволяет избежать задержки соединения. Теоретически производительность также можно было бы повысить, если бы два HTTP-запроса были упакованы в одно и то же TCP-сообщение. Типичный MSS (максимальный размер сегмента) достаточно велик, чтобы содержать несколько простых запросов, хотя спрос на размер HTTP-запросов продолжает расти.
Не все типы HTTP-запросов могут быть конвейеризированы: только идемпотентные методы, то есть GET , HEAD , PUT и DELETE , можно безопасно воспроизводить. В случае сбоя содержимое конвейера может быть повторено.
Сегодня каждый прокси-сервер и сервер, совместимые с HTTP/1.1, должны поддерживать конвейерную обработку, хотя на практике многие из них имеют ограничения: важная причина, по которой ни один современный браузер не активирует эту функцию по умолчанию.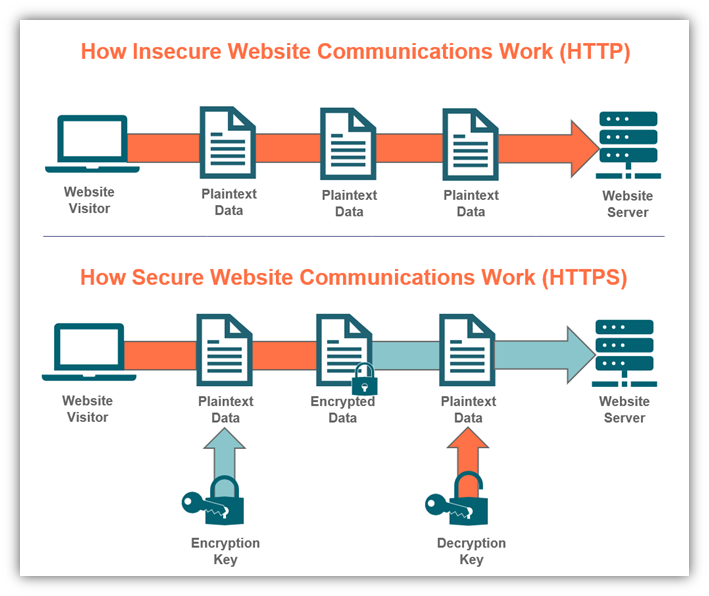
Примечание: Если у вас нет особой срочной необходимости, не используйте этот устаревший метод; вместо этого переключитесь на HTTP/2. В HTTP/2 сегментация домена больше не нужна: соединение HTTP/2 может очень хорошо обрабатывать параллельные неприоритетные запросы. Шардинг домена даже вредит производительности. В большинстве реализаций HTTP/2 используется метод, называемый объединением соединений, чтобы отменить возможное сегментирование домена.
Поскольку соединение HTTP/1.x сериализует запросы, даже без какого-либо порядка, оно не может быть оптимальным без достаточно большой доступной полосы пропускания. В качестве решения браузеры открывают несколько подключений к каждому домену, отправляя параллельные запросы. Когда-то по умолчанию было от 2 до 3 соединений, но теперь это увеличилось до более распространенного использования 6 параллельных соединений. Существует риск срабатывания защиты от DoS-атак на стороне сервера при попытках сделать больше, чем это число.
Если серверу требуется более быстрый ответ веб-сайта или приложения, сервер может принудительно открыть больше соединений. Например, вместо того, чтобы иметь все ресурсы в одном домене, скажем, www.example.com , он может быть разделен на несколько доменов, www1.example.com , www2.example.com , www3.example.com . Каждый из этих доменов разрешается в один и тот же сервер , и веб-браузер открывает 6 подключений к каждому (в нашем примере количество подключений увеличивается до 18). Этот метод называется шардингом домена .
Улучшенное управление соединениями позволяет значительно повысить производительность HTTP. С HTTP/1.1 или HTTP/1.0 использование постоянного соединения — по крайней мере, до тех пор, пока оно не станет бездействующим — обеспечивает наилучшую производительность. Однако неудача конвейерной обработки привела к разработке превосходных моделей управления соединениями, которые были включены в HTTP/2.
Последнее изменение: , участниками MDN
HTTP/1.1: Connections
HTTP/1.1: Connections часть протокола передачи гипертекста — HTTP/1.1RFC 2616 Филдинг и др.
8.1 Постоянные соединения
8.1.1 Назначение
До постоянных подключений использовалось отдельное TCP-соединение.
установлен для получения каждого URL-адреса, увеличивая нагрузку на HTTP-серверы
и вызывает перегрузку в Интернете. Использование встроенных изображений и
другие связанные данные часто требуют, чтобы клиент сделал несколько
запросов одного и того же сервера за короткий промежуток времени. Анализ
эти проблемы с производительностью и результаты прототипа
реализации доступны [26] [30]. Опыт внедрения и
измерения реальных реализаций HTTP/1.1 (RFC 2068) показывают хорошие
результаты [39]. Также были изучены альтернативы, например,
Т/ТКФ [27].
Постоянные HTTP-соединения имеют ряд преимуществ:
- за счет открытия и закрытия меньшего количества TCP-соединений экономится процессорное время.
в маршрутизаторах и хостах (клиенты, серверы, прокси, шлюзы,
туннели или кэши) и память, используемая для управления протоколом TCP.
блоки могут быть сохранены в hosts.
— HTTP-запросы и ответы могут передаваться по конвейеру при соединении.
Конвейерная обработка позволяет клиенту делать несколько запросов без
ожидание каждого ответа, позволяя одному TCP-соединению
использоваться гораздо более эффективно, с гораздо меньшим истекшим временем.
- Уменьшена перегрузка сети за счет уменьшения количества пакетов
вызванное открытием TCP, и предоставление TCP достаточного времени для
определить состояние перегрузки сети.
- Уменьшена задержка на последующие запросы, так как нет времени
потрачено на рукопожатие открытия TCP-соединения.
— HTTP может развиваться более изящно, поскольку можно сообщать об ошибках
без штрафа за закрытие TCP-соединения. Клиенты, использующие
будущие версии HTTP могут оптимистично попробовать новую функцию,
но если вы общаетесь со старым сервером, повторите попытку со старым
семантика после сообщения об ошибке.
Реализации HTTP ДОЛЖНЫ реализовывать постоянные соединения.
8.1.2 Общие операции
Существенная разница между HTTP/1.1 и более ранними версиями HTTP заключается в том, что постоянные соединения являются поведением по умолчанию любого HTTP-соединение. То есть, если не указано иное, клиент СЛЕДУЕТ предполагать, что сервер будет поддерживать постоянное соединение, даже после ответов об ошибках с сервера.
Постоянные соединения обеспечивают механизм, с помощью которого клиент и
сервер может сигнализировать о закрытии TCP-соединения. Эта сигнализация принимает
место с помощью поля заголовка Connection (раздел 14. 10). После закрытия
был сигнализирован, клиент НЕ ДОЛЖЕН отправлять запросы на этом
связь.
10). После закрытия
был сигнализирован, клиент НЕ ДОЛЖЕН отправлять запросы на этом
связь.
8.1.2.1 Согласование
Сервер HTTP/1.1 МОЖЕТ предполагать, что клиент HTTP/1.1 намерен поддерживать постоянное соединение, если заголовок Connection, включающий токен подключения «закрыть» был отправлен в запросе. Если сервер решает закрыть соединение сразу после отправки ответ, он ДОЛЖЕН отправить заголовок Connection, включая токен подключения близко.
Клиент HTTP/1.1 МОЖЕТ ожидать, что соединение останется открытым, но решить оставить его открытым в зависимости от того, будет ли ответ от сервера содержит заголовок Connection с токеном соединения close. В случае клиент не хочет поддерживать соединение дольше, чем это запрос, он ДОЛЖЕН отправить заголовок Connection, включая токен подключения близко.
Если клиент или сервер отправляет токен закрытия в
Заголовок подключения, этот запрос становится последним для
связь.
Клиенты и серверы НЕ ДОЛЖНЫ предполагать, что постоянное соединение поддерживается для версий HTTP ниже 1.1, если это явно не указано сигнализировал. См. раздел 19.6.2 для получения дополнительной информации о обратном совместимость с клиентами HTTP/1.0.
Чтобы оставаться постоянными, все сообщения в соединении ДОЛЖНЫ иметь самоопределяемую длину сообщения (т. е. не определяемую закрытием соединения), как описано в разделе 4.4.
8.1.2.2 Конвейерная обработка
Клиент, который поддерживает постоянные соединения, МОЖЕТ «конвейерно» запросы (т. е. отправлять несколько запросов, не дожидаясь каждого отклик). Сервер ДОЛЖЕН отправлять свои ответы на эти запросы в в том же порядке, в котором были получены запросы.
Клиенты, которые предполагают постоянные соединения и конвейер немедленно
после установления соединения СЛЕДУЕТ быть готовым повторить
соединение, если первая попытка конвейера не удалась. Если клиент делает
такая повторная попытка, она НЕ ДОЛЖНА выполнять конвейер, пока не узнает, что соединение установлено.
настойчивый. Клиенты ДОЛЖНЫ также быть готовы повторно отправить свои запросы, если
сервер закрывает соединение перед отправкой всех
соответствующие ответы.
Если клиент делает
такая повторная попытка, она НЕ ДОЛЖНА выполнять конвейер, пока не узнает, что соединение установлено.
настойчивый. Клиенты ДОЛЖНЫ также быть готовы повторно отправить свои запросы, если
сервер закрывает соединение перед отправкой всех
соответствующие ответы.
Клиенты НЕ ДОЛЖНЫ передавать запросы с использованием неидемпотентных методов или неидемпотентные последовательности методов (см. раздел 9.1.2). В противном случае преждевременное прекращение транспортного соединения может привести к неопределенные результаты. Клиент, желающий отправить неидемпотентный request ДОЛЖЕН ждать отправки этого запроса, пока он не получит статус ответа на предыдущий запрос.
8.1.3 Прокси-серверы
Особенно важно, чтобы прокси корректно реализовывали свойства поля заголовка Connection, как указано в разделе 14.10.
Прокси-сервер ДОЛЖЕН сигнализировать о постоянных соединениях отдельно с помощью
его клиенты и исходные серверы (или другие прокси-серверы), которые он
подключается к. Каждое постоянное соединение применяется только к одному транспорту
ссылка на сайт.
Каждое постоянное соединение применяется только к одному транспорту
ссылка на сайт.
Прокси-сервер НЕ ДОЛЖЕН устанавливать постоянное соединение HTTP/1.1. с клиентом HTTP/1.0 (но см. RFC 2068 [33] для информации и обсуждение проблем с заголовком Keep-Alive, реализованным много клиентов HTTP/1.0).
8.1.4 Практические соображения
Серверы обычно имеют некоторое время ожидания, после которого они больше не поддерживать неактивное соединение. Прокси-серверы могут сделать это более высокое значение, так как вполне вероятно, что клиент будет делать больше подключений через тот же сервер. Использование стойких соединений не предъявляет никаких требований к длине (или наличию) этот тайм-аут для клиента или сервера.
Когда клиент или сервер желает установить тайм-аут, он ДОЛЖЕН выдать изящный
близко к транспортному сообщению. Клиенты и серверы ДОЛЖНЫ
постоянно следите за другой стороной транспорта близко, и
реагировать на него соответствующим образом.![]() Если клиент или сервер не обнаруживает
другая сторона закроется быстро, это может привести к ненужному ресурсу
слив в сеть.
Если клиент или сервер не обнаруживает
другая сторона закроется быстро, это может привести к ненужному ресурсу
слив в сеть.
Клиент, сервер или прокси-сервер МОГУТ закрыть транспортное соединение в любой момент. время. Например, клиент мог начать отправлять новый запрос в то же время, что сервер решил закрыть «простой» связь. С точки зрения сервера соединение закрыт во время простоя, но с точки зрения клиента выполняется запрос.
Это означает, что клиенты, серверы и прокси-серверы ДОЛЖНЫ иметь возможность восстанавливать
от асинхронных событий закрытия. Программное обеспечение клиента СЛЕДУЕТ повторно открыть
транспортное соединение и повторная передача прерванной последовательности запросов
без взаимодействия с пользователем, пока последовательность запросов
идемпотент (см. раздел 9.1.2). Неидемпотентные методы или последовательности
НЕ ДОЛЖЕН автоматически повторяться, хотя пользовательские агенты МОГУТ предлагать
оператор-человек выбор повторной попытки запроса(ов).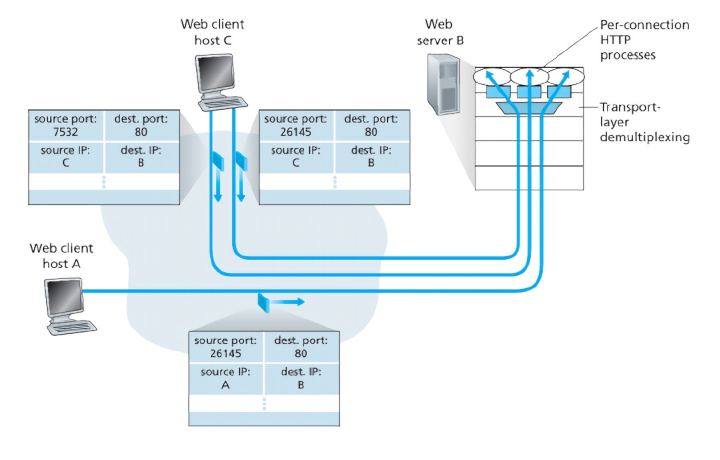 Подтверждение
программное обеспечение пользовательского агента с семантическим пониманием приложения
МОЖЕТ заменить подтверждение пользователя. Автоматический повтор НЕ ДОЛЖЕН
повторяться, если вторая последовательность запросов не удалась.
Подтверждение
программное обеспечение пользовательского агента с семантическим пониманием приложения
МОЖЕТ заменить подтверждение пользователя. Автоматический повтор НЕ ДОЛЖЕН
повторяться, если вторая последовательность запросов не удалась.
Серверы ДОЛЖНЫ всегда отвечать хотя бы на один запрос на соединение, если вообще возможно. Серверы НЕ ДОЛЖНЫ закрывать соединение в середина передачи ответа, если не произошел сбой сети или клиента подозревается.
Клиентам, использующим постоянные соединения, СЛЕДУЕТ ограничивать количество одновременные соединения, которые они поддерживают с данным сервером. А однопользовательский клиент НЕ ДОЛЖЕН поддерживать более 2 соединений с любой сервер или прокси. Прокси ДОЛЖЕН использовать до 2*N подключений к другой сервер или прокси, где N — количество одновременно активные пользователи. Эти рекомендации предназначены для улучшения ответа HTTP раз и избежать заторов.
8.
 2 Требования к передаче сообщений
2 Требования к передаче сообщений8.2.1 Постоянные соединения и управление потоком
Серверы HTTP/1.1 ДОЛЖНЫ поддерживать постоянные соединения и использовать TCP механизмы управления потоком для разрешения временных перегрузок, а не завершение соединений с ожиданием того, что клиенты попытаются повторить попытку. Последний метод может усугубить перегрузку сети.
8.2.2 Мониторинг соединений для сообщений об ошибках
Клиент HTTP/1.1 (или более поздней версии), отправляющий тело сообщения, ДОЛЖЕН отслеживать
сетевое соединение для состояния ошибки во время передачи
запрос. Если клиент видит статус ошибки, он ДОЛЖЕН
немедленно прекратить передачу тела. Если тело отправлено
с использованием «фрагментированного» кодирования (раздел 3.6), фрагмента нулевой длины и
пустой трейлер МОЖЕТ использоваться для преждевременной отметки конца сообщения.
Если телу предшествовал заголовок Content-Length, клиент ДОЛЖЕН
закрыть соединение.
8.2.3 Использование статуса 100 (продолжить)
Целью статуса 100 (Продолжить) (см. раздел 10.1.1) является разрешить клиенту, который отправляет сообщение запроса с телом запроса чтобы определить, готов ли исходный сервер принять запрос (на основе заголовков запроса) до того, как клиент отправит запрос тело. В некоторых случаях это может быть либо неуместным, либо крайне неэффективно для клиента отправлять тело, если сервер отклонит сообщение, не глядя на тело.
Требования к клиентам HTTP/1.1:
- Если клиент будет ждать ответа 100 (Продолжить) до
отправляя тело запроса, он ДОЛЖЕН отправить заголовок запроса Expect
поле (раздел 14.20) с ожиданием «100-продолжить».
- Клиент НЕ ДОЛЖЕН отправлять поле заголовка запроса Expect (раздел
14.20) с ожиданием «100-продолжить», если он не намерен
отправить тело запроса.
Из-за наличия более старых реализаций протокол позволяет
неоднозначные ситуации, в которых клиент может отправить «Ожидать: 100-
продолжить» без получения статуса 417 (ошибка ожидания)
или статус 100 (Продолжить). Поэтому, когда клиент отправляет это
поле заголовка на исходный сервер (возможно, через прокси), с которого он
никогда не видел статус 100 (Продолжить), клиент НЕ ДОЛЖЕН ждать
на неопределенный срок до отправки тела запроса.
Поэтому, когда клиент отправляет это
поле заголовка на исходный сервер (возможно, через прокси), с которого он
никогда не видел статус 100 (Продолжить), клиент НЕ ДОЛЖЕН ждать
на неопределенный срок до отправки тела запроса.
Требования к исходным серверам HTTP/1.1:
— при получении запроса, который включает заголовок запроса Expect.
поле с ожиданием «100-continue», исходный сервер ДОЛЖЕН
либо ответьте статусом 100 (Продолжить) и продолжайте читать
из входного потока или ответьте окончательным кодом состояния.
исходный сервер НЕ ДОЛЖЕН ждать тела запроса перед отправкой
ответ 100 (Продолжить). Если он отвечает с окончательным статусом
код, он МОЖЕТ закрыть транспортное соединение или МОЖЕТ продолжить
, чтобы прочитать и отбросить остальную часть запроса. НЕ ДОЛЖНО
выполнить запрошенный метод, если он возвращает окончательный код состояния.
- исходный сервер НЕ ДОЛЖЕН отправлять ответ 100 (продолжить), если
сообщение запроса не включает заголовок запроса Expect
поле с ожиданием «100-continue» и НЕ ДОЛЖНЫ отправлять
100 (Продолжить) ответ, если такой запрос исходит от HTTP/1. 0
(или более ранний) клиент. Из этого правила есть исключение: для
совместимости с RFC 2068, сервер МОЖЕТ отправить 100 (Продолжить)
статус в ответ на запрос HTTP/1.1 PUT или POST, который делает
не включать поле заголовка запроса Expect со значением «100-
продолжить" ожидание. Это исключение, целью которого является
чтобы свести к минимуму любые задержки обработки клиентов, связанные с
необъявленный статус ожидания 100 (Продолжить), применяется только к
Запросы HTTP/1.1, а не к запросам с любым другим HTTP-
значение версии.
 0
(или более ранний) клиент. Из этого правила есть исключение: для
совместимости с RFC 2068, сервер МОЖЕТ отправить 100 (Продолжить)
статус в ответ на запрос HTTP/1.1 PUT или POST, который делает
не включать поле заголовка запроса Expect со значением «100-
продолжить" ожидание. Это исключение, целью которого является
чтобы свести к минимуму любые задержки обработки клиентов, связанные с
необъявленный статус ожидания 100 (Продолжить), применяется только к
Запросы HTTP/1.1, а не к запросам с любым другим HTTP-
значение версии.
0
(или более ранний) клиент. Из этого правила есть исключение: для
совместимости с RFC 2068, сервер МОЖЕТ отправить 100 (Продолжить)
статус в ответ на запрос HTTP/1.1 PUT или POST, который делает
не включать поле заголовка запроса Expect со значением «100-
продолжить" ожидание. Это исключение, целью которого является
чтобы свести к минимуму любые задержки обработки клиентов, связанные с
необъявленный статус ожидания 100 (Продолжить), применяется только к
Запросы HTTP/1.1, а не к запросам с любым другим HTTP-
значение версии.
- Исходный сервер МОЖЕТ пропустить ответ 100 (Продолжить), если он
уже получил часть или все тело запроса для
соответствующий запрос.
- Исходный сервер, отправляющий ответ 100 (Продолжить), ДОЛЖЕН
в конечном итоге отправить окончательный код состояния, как только тело запроса
получено и обработано, если это не прерывает транспортировку
соединение преждевременно.

- Если исходный сервер получает запрос, который не включает
Ожидайте поле заголовка запроса с ожиданием «100-продолжить»,
запрос включает тело запроса, и сервер отвечает
с окончательным кодом состояния перед чтением всего тела запроса
с транспортного соединения, то сервер НЕ ДОЛЖЕН закрываться
транспортное соединение, пока оно не прочитает весь запрос,
или пока клиент не закроет соединение. В противном случае клиент
не может надежно получить ответное сообщение. Однако это
требование не должно толковаться как препятствующее серверу
защиты от атак типа «отказ в обслуживании» или от
сильно сломанные клиентские реализации.
Требования к прокси HTTP/1.1:
- Если прокси-сервер получает запрос, который включает запрос Expect-
поле заголовка с ожиданием «100-continue» и прокси
либо знает, что сервер следующего перехода соответствует HTTP/1. 1, либо
выше или не знает HTTP-версию следующего перехода
сервер, он ДОЛЖЕН переслать запрос, включая заголовок Expect
поле.
 1, либо
выше или не знает HTTP-версию следующего перехода
сервер, он ДОЛЖЕН переслать запрос, включая заголовок Expect
поле.
1, либо
выше или не знает HTTP-версию следующего перехода
сервер, он ДОЛЖЕН переслать запрос, включая заголовок Expect
поле.
- Если прокси знает, что версия сервера следующего перехода
HTTP/1.0 или ниже, он НЕ ДОЛЖЕН пересылать запрос, и он ДОЛЖЕН
ответить со статусом 417 (Ожидание не выполнено).
- Прокси-серверы ДОЛЖНЫ поддерживать кеш, записывающий версию HTTP
числа, полученные от серверов следующего перехода, на которые недавно ссылались.
- Прокси-сервер НЕ ДОЛЖЕН пересылать ответ 100 (Продолжить), если
сообщение запроса было получено от HTTP/1.0 (или более ранней версии)
client и не включал поле заголовка запроса Expect с
ожидание «100-продолжить». Это требование имеет приоритет перед
общее правило пересылки ответов 1xx (см. раздел 10.1).
8.2.4 Поведение клиента, если сервер преждевременно закрывает соединение
Если клиент HTTP/1. 1 отправляет запрос, содержащий тело запроса,
но который не включает поле заголовка запроса Expect с
Ожидание «100-продолжить», и если клиент не напрямую
подключен к исходному серверу HTTP/1.1, и если клиент видит
соединение закрывается до получения какого-либо статуса от сервера,
клиент ДОЛЖЕН повторить запрос. Если клиент повторит попытку
запроса, он МОЖЕТ использовать следующую «бинарную экспоненциальную отсрочку»
алгоритм, чтобы быть уверенным в получении надежного ответа:
1 отправляет запрос, содержащий тело запроса,
но который не включает поле заголовка запроса Expect с
Ожидание «100-продолжить», и если клиент не напрямую
подключен к исходному серверу HTTP/1.1, и если клиент видит
соединение закрывается до получения какого-либо статуса от сервера,
клиент ДОЛЖЕН повторить запрос. Если клиент повторит попытку
запроса, он МОЖЕТ использовать следующую «бинарную экспоненциальную отсрочку»
алгоритм, чтобы быть уверенным в получении надежного ответа:
1. Инициировать новое подключение к серверу
2. Передайте заголовки запроса
3. Инициализируйте переменную R оценкой времени приема-передачи до
сервера (например, исходя из времени, которое потребовалось для установки
соединение), или на постоянное значение 5 секунд, если округление
время поездки недоступно.
4. Вычислить T = R * (2**N), где N — количество предыдущих
повторы этого запроса.
5. Дождитесь либо ответа об ошибке от сервера, либо T
секунд (в зависимости от того, что наступит раньше)
6. Если ответ об ошибке не получен, через T секунд передать
тело запроса.
7. Если клиент видит, что соединение закрыто преждевременно,
повторять с шага 1, пока запрос не будет принят, ошибка
получен ответ, или пользователь становится нетерпеливым и
завершает процесс повторной попытки.
Если в какой-то момент получен статус ошибки, клиент
- НЕ СЛЕДУЕТ продолжать и
- СЛЕДУЕТ закрыть соединение, если оно не завершило отправку
сообщение запроса.
http.client — клиент протокола HTTP — документация Python 3.10.8
Исходный код: Lib/http/client.py
Этот модуль определяет классы, которые реализуют клиентскую сторону HTTP и
протоколы HTTPS. Обычно не используется напрямую — модуль urllib. использует его для обработки URL-адресов, использующих HTTP и HTTPS. request
request
См. также
Пакет запросов рекомендуется для клиентского интерфейса HTTP более высокого уровня.
Примечание
Поддержка HTTPS доступна только в том случае, если Python был скомпилирован с поддержкой SSL
(через модуль ssl ).
Модуль предоставляет следующие классы:
- класс
http.клиент.HTTPConnection( хост , порт=Нет , [ тайм-аут ,] source_address=Нет , размер блока=8192 ) Экземпляр
HTTPConnectionпредставляет одну транзакцию с сервер. Его следует создать, передав ему хост и необязательный порт. количество. Если номер порта не передан, порт извлекается из хоста. строка, если она имеет видhost:port, иначе порт HTTP по умолчанию (80) использовал. Если задан необязательный параметр timeout , блокировка операции (например, попытки подключения) прекратятся по истечении этого количества секунд (если он не указан, используется глобальная настройка времени ожидания по умолчанию). Факультативный параметр source_address может быть кортежем (хост, порт)
для использования в качестве исходного адреса, с которого выполняется HTTP-соединение.
Необязательный параметр blocksize устанавливает размер буфера в байтах для
отправка тела сообщения в виде файла.Например, следующие вызовы создают все экземпляры, которые подключаются к серверу. на том же хосте и порту:
>>> h2 = http.client.HTTPConnection('www.python.org') >>> h3 = http.client.HTTPConnection('www.python.org:80') >>> h4 = http.client.HTTPConnection('www.python.org', 80) >>> h5 = http.client.HTTPConnection('www.python.org', 80, timeout=10)Изменено в версии 3.2: добавлен source_address .
Изменено в версии 3.4: Параметр strict удален. «Простые ответы» в стиле HTTP 0.9 больше не поддерживается.
Изменено в версии 3.7: Добавлен параметр blocksize .
 Факультативный параметр source_address может быть кортежем (хост, порт)
для использования в качестве исходного адреса, с которого выполняется HTTP-соединение.
Необязательный параметр blocksize устанавливает размер буфера в байтах для
отправка тела сообщения в виде файла.
Факультативный параметр source_address может быть кортежем (хост, порт)
для использования в качестве исходного адреса, с которого выполняется HTTP-соединение.
Необязательный параметр blocksize устанавливает размер буфера в байтах для
отправка тела сообщения в виде файла.- класс
http.клиент. HTTPSConnection( host , port=None , key_file=None , cert_file=None , [ timeout ,] source_address=Нет , * , context=Нет , check_hostname=Нет , blocksize=8192 ) Подкласс
HTTPConnection, который использует SSL для связи с защищенные серверы. Порт по умолчанию —443. Если указан контекст , он должен быть экземпляромssl.SSLContext, описывающим различные SSL опции.Дополнительные сведения о передовом опыте см. в разделе Вопросы безопасности.
Изменено в версии 3.2: source_address , context и check_hostname добавлены.
Изменено в версии 3.2: этот класс теперь по возможности поддерживает виртуальные хосты HTTPS (т. е. если
ssl.HAS_SNIверно).Изменено в версии 3.4: Параметр strict удален. «Простые ответы» в стиле HTTP 0.
9
больше не поддерживается.Изменено в версии 3.4.3: теперь этот класс выполняет все необходимые проверки сертификатов и имен хостов. по умолчанию. Чтобы вернуться к предыдущему, непроверенному поведению
ssl._create_unverified_context()может быть передан в контекст параметр.Изменено в версии 3.8: этот класс теперь включает TLS 1.3.
ssl.SSLContext.post_handshake_authдля контекста по умолчанию или когда cert_file передается с пользовательским контекстом .Изменено в версии 3.10: этот класс теперь отправляет расширение ALPN с индикатором протокола.
http/1.1, если не указан контекст . Пользовательский контекст должен установить Протоколы ALPN сset_alpn_protocol().Устарело, начиная с версии 3.6: key_file и cert_file устарели в пользу context . Вместо этого используйте
ssl.SSLContext.или позвольте load_cert_chain() ssl.create_default_context()выберите доверенный ЦС системы сертификаты для вас.Параметр check_hostname также устарел; в
ssl.SSLContext.check_hostnameатрибут контекста должен использоваться вместо этого.

 9
больше не поддерживается.
9
больше не поддерживается.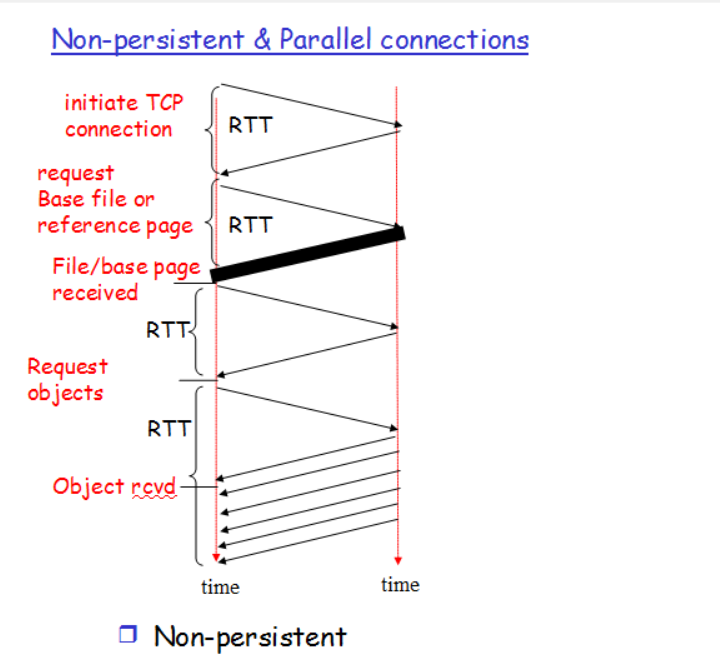 load_cert_chain()
load_cert_chain() - класс
http.клиент.HTTPResponse( sock , уровень отладки = 0 , метод = нет , url = нет ) Класс, экземпляры которого возвращаются при успешном соединении. Нет создается непосредственно пользователем.
Изменено в версии 3.4: Параметр strict удален. «Простые ответы» в стиле HTTP 0.9 больше не поддерживается.
Этот модуль выполняет следующие функции:
Разобрать заголовки из указателя файла fp , представляющего HTTP ответ на запрос. Файл должен быть считывателем
BufferedIOBase. (т. е. не текст) и должен содержать допустимый заголовок в стиле RFC 2822 .Эта функция возвращает экземпляр
http.client.HTTPMessageкоторый содержит поля заголовка, но не содержит полезной нагрузки (аналогичноHTTPResponse.msgиhttp.server.BaseHTTPRequestHandler.headers). После возврата указатель файла fp готов к чтению тела HTTP.Примечание
parse_headers()не анализирует начальную строку HTTP-сообщения; он анализирует только строкиName: value. Файл должен быть готов к прочитайте эти строки поля, поэтому первая строка уже должна быть использована перед вызовом функции.
 (т. е. не текст) и должен содержать допустимый заголовок в стиле RFC 2822 .
(т. е. не текст) и должен содержать допустимый заголовок в стиле RFC 2822 .При необходимости возникают следующие исключения:
- исключение
http.client.Исключение HTTP Базовый класс других исключений в этом модуле. Это подкласс
Исключение.
- исключение
http. client. Не подключен Подкласс
HTTPException.
 client.
client. - исключение
http.client.Неверный URL-адрес Подкласс
HTTPException, возникает, если указан порт и либо нечисловое или пустое.
- исключение
http.client.Неизвестный протокол Подкласс
HTTPException.
- исключение
http.client.UnknownTransferEncoding Подкласс
HTTPException.
- исключение
http.client.Нереализованный режим файла Подкласс
HTTPException.
- исключение
http.client.Неполное чтение Подкласс
HTTPException.

- исключение
http.client.Непроперконнектионстате Подкласс
HTTPException.
- исключение
http.client.Не удается отправить запрос Подкласс
ImproperConnectionState.
Подкласс
ImproperConnectionState.
- исключение
http.client.Ответ не готов Подкласс
ImproperConnectionState.
- исключение
http.client.BadStatusLine Подкласс
HTTPException. Возникает, если сервер отвечает HTTP код состояния, который мы не понимаем.
- исключение
http.client.LineTooLong Подкласс
HTTPException. Поднимается, если линия слишком длинная
принимается по протоколу HTTP от сервера.
 Поднимается, если линия слишком длинная
принимается по протоколу HTTP от сервера.
Поднимается, если линия слишком длинная
принимается по протоколу HTTP от сервера.- исключение
http.client.Удаленное отключение Подкласс
ConnectionResetErrorиBadStatusLine. Поднятый поHTTPConnection.getresponse()при попытке прочитать ответ приводит к тому, что данные не считываются из соединения, что указывает на то, что удаленный конец закрыл соединение.Новое в версии 3.5: ранее
BadStatusLine('')был поднят.
Константы, определенные в этом модуле:
-
http.клиент.HTTP_ПОРТ Порт по умолчанию для протокола HTTP (всегда
80).
-
http.клиент.HTTPS_ПОРТ Порт по умолчанию для протокола HTTPS (всегда
443).
-
http. клиент. ответов Этот словарь сопоставляет коды состояния HTTP 1.1 с именами W3C.
Пример:
http.client.responses[http.client.NOT_FOUND]равно'Не найдено'.
 клиент.
клиент. См. коды состояния HTTP для получения списка кодов состояния HTTP, которые доступны в этом модуле как константы.
Объекты HTTPConnection
Экземпляры HTTPConnection имеют следующие методы:
-
HTTP-соединение.запрос( метод , url , body = None , headers = {} , * , encode_chunked = False ) Это отправит запрос на сервер с использованием HTTP-запроса. метод метод и селектор URL .
Если указано тело , указанные данные отправляются после того, как заголовки законченный. Это может быть
str, байтовый объект, объект открытого файла или итерациябайта. Если тело это строка, она закодирована как ISO-8859-1, по умолчанию для HTTP. Если это
является байтоподобным объектом, байты отправляются как есть. Если это файл
объект, содержимое файла отправляется; этот файловый объект должен
поддерживать как минимум метод read(). Если файловый объект является экземплярio.TextIOBase, данные, возвращенныеread()метод будет закодирован как ISO-8859-1, в противном случае данные, возвращаемыеread()отправляется как есть. Если тело является итерируемым, элементы iterable отправляются как есть, пока iterable не будет исчерпан.Аргумент заголовков должен быть сопоставлением дополнительных заголовков HTTP для отправки с запросом.
Если заголовки не содержат ни Content-Length, ни Transfer-Encoding, но есть тело запроса, одно из тех поля заголовка будут добавлены автоматически. Если body равно
None, заголовок Content-Length имеет значение0для методы, ожидающие тело (PUT,POSTиPATCH). Если body — это строка или байтовый объект, который также не является
файл, заголовок Content-Length
установить на его длину. Любой другой тип тела (файлы
и итерации в целом) будут закодированы фрагментами, а
Заголовок Transfer-Encoding будет автоматически установлен вместо
Содержание-длина.Аргумент encode_chunked имеет значение только в том случае, если Transfer-Encoding указано в заголовках . Если encode_chunked равно
False, Объект HTTPConnection предполагает, что все кодирование обрабатывается код вызова. Если этоTrue, тело будет кодировано фрагментами.Примечание
В протокол HTTP добавлено кодирование передачи по частям. версия 1.1. Если HTTP-сервер не поддерживает HTTP 1.1, вызывающий должен либо указать Content-Length, либо передать
strили байтоподобный объект, который также не является файлом, поскольку представление тела.Новое в версии 3.
2: тело теперь может быть итерируемым.Изменено в версии 3.6: Если ни Content-Length, ни Transfer-Encoding не установлены в заголовки , файлы и итерируемые тела объекты теперь кодируются фрагментами. Добавлен аргумент encode_chunked . Не предпринимается никаких попыток определить Content-Length для файла объекты.
 Если тело это строка, она закодирована как ISO-8859-1, по умолчанию для HTTP. Если это
является байтоподобным объектом, байты отправляются как есть. Если это файл
объект, содержимое файла отправляется; этот файловый объект должен
поддерживать как минимум метод
Если тело это строка, она закодирована как ISO-8859-1, по умолчанию для HTTP. Если это
является байтоподобным объектом, байты отправляются как есть. Если это файл
объект, содержимое файла отправляется; этот файловый объект должен
поддерживать как минимум метод  Если body — это строка или байтовый объект, который также не является
файл, заголовок Content-Length
установить на его длину. Любой другой тип тела (файлы
и итерации в целом) будут закодированы фрагментами, а
Заголовок Transfer-Encoding будет автоматически установлен вместо
Содержание-длина.
Если body — это строка или байтовый объект, который также не является
файл, заголовок Content-Length
установить на его длину. Любой другой тип тела (файлы
и итерации в целом) будут закодированы фрагментами, а
Заголовок Transfer-Encoding будет автоматически установлен вместо
Содержание-длина. 2: тело теперь может быть итерируемым.
2: тело теперь может быть итерируемым.-
HTTP-соединение.получить ответ() Должен вызываться после отправки запроса на получение ответа от сервера. Возвращает
Экземпляр HTTPResponse.Примечание
Обратите внимание, что вы должны прочитать весь ответ, прежде чем отправлять новый запрос к серверу.
Изменено в версии 3.5: если возникает ошибка
ConnectionErrorили подкласс,Объект HTTPConnectionбудет готов к повторному подключению, когда отправляется новый запрос.
-
HTTP-соединение.set_debuglevel( уровень ) Установить уровень отладки.
Уровень отладки по умолчанию — 9.0023 0 , что означает нет
вывод отладки распечатывается. Любое значение больше 0вызовет все определенный текущий отладочный вывод для вывода на стандартный вывод. Уровень отладкиHTTPResponse.Новое в версии 3.1.
 Уровень отладки по умолчанию — 9.0023 0 , что означает нет
вывод отладки распечатывается. Любое значение больше
Уровень отладки по умолчанию — 9.0023 0 , что означает нет
вывод отладки распечатывается. Любое значение больше -
HTTP-соединение.set_tunnel( хост , порт=нет , заголовки=нет ) Установите хост и порт для туннелирования HTTP Connect. Это позволяет запускать соединение через прокси-сервер.
Аргументы узла и порта указывают конечную точку туннелируемого соединения. (т. е. адрес, включенный в запрос CONNECT, , а не адрес Прокси сервер).
Аргумент заголовков должен быть отображением дополнительных заголовков HTTP для отправки с запрос СОЕДИНЕНИЕ.
Например, для туннелирования через прокси-сервер HTTPS, работающий локально на порту 8080, мы бы передали адрес прокси на
HTTPSConnectionконструктор, и адрес хоста, до которого мы в конечном итоге хотим добратьсяset_tunnel()метод:>>> импортировать http.
client
>>> conn = http.client.HTTPSConnection("localhost", 8080)
>>> conn.set_tunnel("www.python.org")
>>> conn.request("HEAD","/index.html")
Новое в версии 3.2.
 client
>>> conn = http.client.HTTPSConnection("localhost", 8080)
>>> conn.set_tunnel("www.python.org")
>>> conn.request("HEAD","/index.html")
client
>>> conn = http.client.HTTPSConnection("localhost", 8080)
>>> conn.set_tunnel("www.python.org")
>>> conn.request("HEAD","/index.html")
-
HTTP-соединение.подключить() Подключиться к серверу, указанному при создании объекта. По умолчанию, это вызывается автоматически при выполнении запроса, если клиент не уже есть связь.
Вызывает событие аудита
http.client.connectс аргументамисам,хост,порт.
-
HTTP-соединение.закрыть() Закройте соединение с сервером.
-
HTTP-соединение.блочный Размер буфера в байтах для отправки тела сообщения в виде файла.
Новое в версии 3.7.
В качестве альтернативы описанному выше методу request() вы можете
также отправьте свой запрос шаг за шагом, используя четыре функции ниже.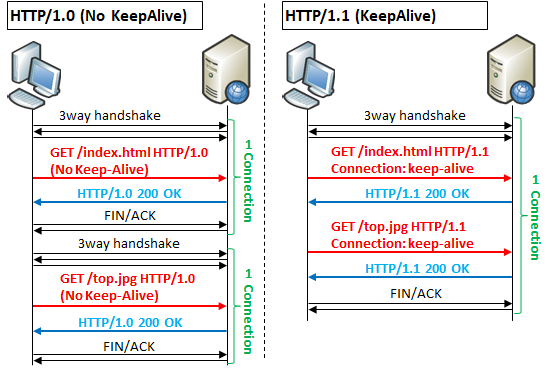
-
HTTP-соединение.putrequest(метод , URL , skip_host=False , skip_accept_encoding=False ) Это должен быть первый вызов после установления соединения с сервером. сделанный. Он отправляет на сервер строку, состоящую из метод строка, строка url и версия HTTP (
HTTP/1.1). Чтобы отключить автоматический отправка заголовковHost:илиAccept-Encoding:(например, чтобы принять дополнительные кодировки контента), укажите skip_host или skip_accept_encoding с неложными значениями.
Отправьте на сервер заголовок в стиле RFC 822 . Он отправляет строку на сервер состоящий из заголовка, двоеточия и пробела, а также первого аргумента. Если больше задаются аргументы, отправляются строки продолжения, каждая из которых состоит из табуляции и Аргумент.
Отправить на сервер пустую строку, сигнализирующую об окончании заголовков.
необязательный аргумент message_body может использоваться для передачи тела сообщения
связанные с запросом.Если encode_chunked равно
True, результат каждой итерации message_body будет кодироваться фрагментами, как указано в RFC 7230 , Раздел 3.3.1. Способ кодирования данных зависит от типа тело_сообщения . Если message_body реализует интерфейс буфера, кодирование приведет к созданию одного фрагмента. Если message_body являетсяcollections.abc.Iterable, каждая итерация из message_body приведет к фрагменту. Если message_body является файловый объект, каждый вызов.read()приведет к фрагменту. Метод автоматически сигнализирует об окончании закодированных данных. сразу после message_body .Примечание
Из-за спецификации фрагментированного кодирования пустые фрагменты полученный телом итератора, будет игнорироваться кодировщиком фрагментов.
Это делается для того, чтобы избежать преждевременного прекращения чтения запроса
целевой сервер из-за неправильной кодировки.Новое в версии 3.6: поддержка фрагментированного кодирования. Параметр encode_chunked был добавлен.
 необязательный аргумент message_body может использоваться для передачи тела сообщения
связанные с запросом.
необязательный аргумент message_body может использоваться для передачи тела сообщения
связанные с запросом.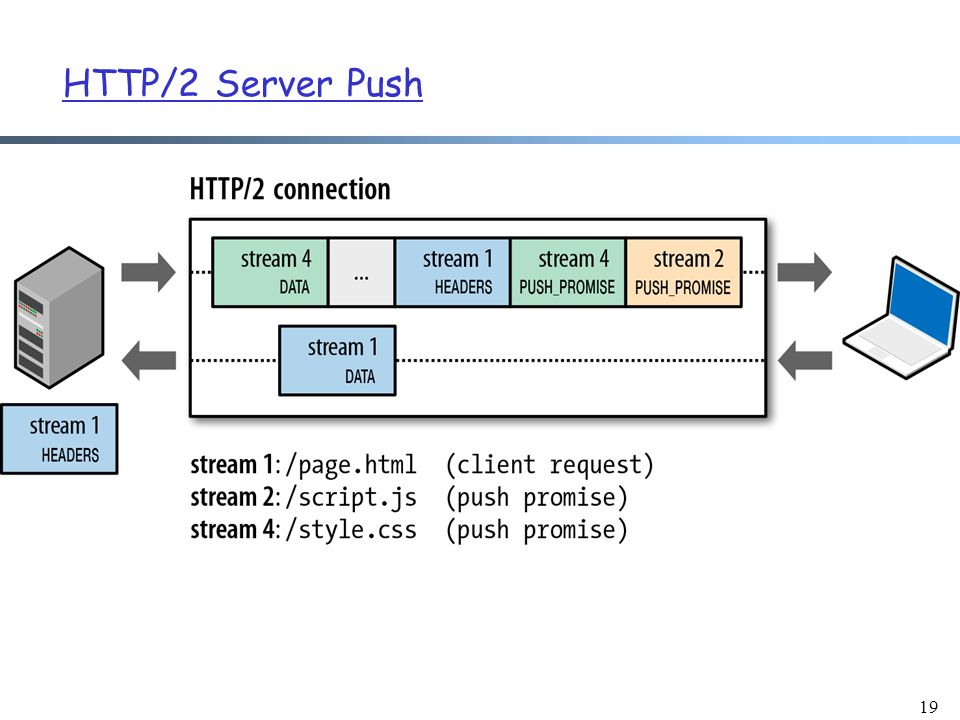 Это делается для того, чтобы избежать преждевременного прекращения чтения запроса
целевой сервер из-за неправильной кодировки.
Это делается для того, чтобы избежать преждевременного прекращения чтения запроса
целевой сервер из-за неправильной кодировки.-
HTTP-соединение.отправить( данные ) Отправить данные на сервер. Это следует использовать непосредственно только после
метод endheaders()был вызван и доgetresponse()называется.Инициирует событие аудита
http.client.sendс аргументамиself,data.
Объекты ответа HTTP
Экземпляр HTTPResponse упаковывает ответ HTTP от
сервер. Он обеспечивает доступ к заголовкам запроса и сущности
тело. Ответ представляет собой итерируемый объект и может использоваться в with
утверждение.
Изменено в версии 3.5: Интерфейс io.BufferedIOBase теперь реализован и
поддерживаются все его операции чтения.
-
HTTP-ответ.читать([ от ]) Читает и возвращает тело ответа или до следующих или байт.
-
HTTP-ответ.преобразование в( б ) Считывает до следующих len(b) байт тела ответа в буфер б . Возвращает количество прочитанных байтов.
Новое в версии 3.3.
Вернуть значение заголовка имя или по умолчанию если заголовка нет соответствие имени . Если имеется более одного заголовка с именем name , вернуть все значения, соединенные ‘, ‘. Если по умолчанию является любым итерируемым другим чем одна строка, ее элементы также возвращаются, соединяясь запятыми.
Возвращает список кортежей (заголовок, значение).
-
HTTP-ответ.файл №() Возврат
файла №базового сокета.
-
HTTP-ответ.сообщение Экземпляр
http.client.HTTPMessage, содержащий ответ заголовки.http.client.HTTPMessageявляется подклассомэлектронная почта.сообщение.Сообщение.
-
HTTP-ответ.версия Версия протокола HTTP, используемая сервером. 10 для HTTP/1.0, 11 для HTTP/1.1.
-
HTTP-ответ.адрес URL-адрес извлеченного ресурса, обычно используемый для определения того, было ли выполнено перенаправление.
Заголовки ответа в виде экземпляра
email.message.EmailMessage.
-
HTTP-ответ.статус Код состояния, возвращенный сервером.
-
HTTP-ответ.причина Фраза причины, возвращенная сервером.

-
HTTP-ответ.уровень отладки Отладочный крючок. Если
уровень отладкибольше нуля, сообщения будет выведен на стандартный вывод по мере чтения и анализа ответа.
-
HTTP-ответ.закрытый Является
True, если поток закрыт.
-
HTTP-ответ.получить номер() Устарело, начиная с версии 3.9: Устарело в пользу
url.
-
HTTP-ответ.информация() Устарело, начиная с версии 3.9: Устарело в пользу заголовков
-
HTTP-ответ.получить статус() Устарело, начиная с версии 3.9: Устарело в пользу
статуса.
Примеры
Вот пример сеанса, в котором используется метод GET :
>>> импортировать http.
 client
>>> соединение = http.client.HTTPSConnection("www.python.org")
>>> conn.request("GET", "/")
>>> r1 = conn.getresponse()
>>> print(r1.статус, r1.причина)
200 ОК
>>> data1 = r1.read() # Это вернет все содержимое.
>>> # Следующий пример демонстрирует чтение данных порциями.
>>> conn.request("GET", "/")
>>> r1 = conn.getresponse()
>>> в то время как чанк := r1.read(200):
... печать (репр (фрагмент))
b'\n
client
>>> соединение = http.client.HTTPSConnection("www.python.org")
>>> conn.request("GET", "/")
>>> r1 = conn.getresponse()
>>> print(r1.статус, r1.причина)
200 ОК
>>> data1 = r1.read() # Это вернет все содержимое.
>>> # Следующий пример демонстрирует чтение данных порциями.
>>> conn.request("GET", "/")
>>> r1 = conn.getresponse()
>>> в то время как чанк := r1.read(200):
... печать (репр (фрагмент))
b'\n