String.prototype.indexOf() — JavaScript | MDN
Метод indexOf() возвращает индекс первого вхождения указанного значения в строковый объект String, на котором он был вызван, начиная с индекса fromIndex. Возвращает -1, если значение не найдено.
str.indexOf(searchValue, [fromIndex])Параметры
searchValue- Строка, представляющая искомое значение.
fromIndex- Необязательный параметр. Местоположение внутри строки, откуда начинать поиск. Может быть любым целым числом. Значение по умолчанию установлено в 0. Если
fromIndex < 0, поиск ведётся по всей строке (так же, как если бы был передан 0). ЕслиfromIndex >= str.length, метод вернёт -1, но только в том случае, еслиsearchValueне равен пустой строке, в этом случае он вернётstr.length.
Символы в строке идут слева направо.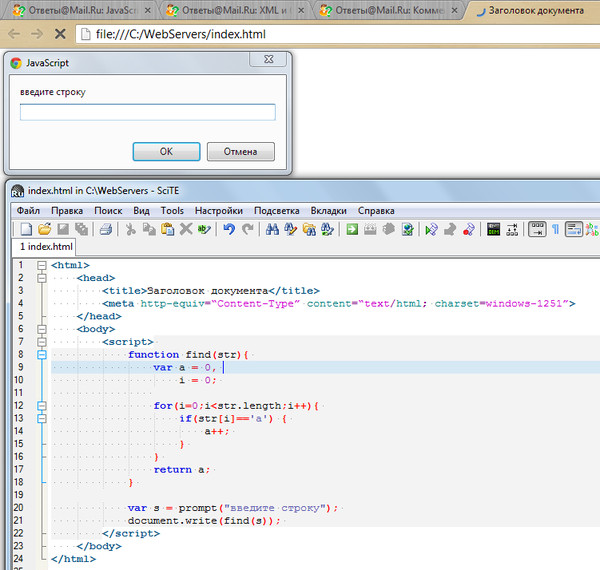 Индекс первого символа равен 0, а последнего символа в строке
Индекс первого символа равен 0, а последнего символа в строке stringName равен stringName.length - 1.
'Синий кит'.indexOf('Синий'); 'Синий кит'.indexOf('Голубой'); 'Синий кит'.indexOf('кит', 0); 'Синий кит'.indexOf('кит', 5); 'Синий кит'.indexOf('', 8); 'Синий кит'.indexOf('', 9); 'Синий кит'.indexOf('', 10);
Регистрозависимость
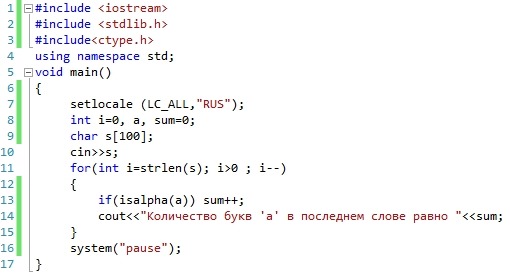
Метод indexOf() является регистрозависимым. Например, следующее выражение вернёт -1:
'Синий кит'.indexOf('синий');
Проверка на вхождение
Обратите внимание, что значение 0 не вычисляется в true, а значение -1 не вычисляется в false. Поэтому, для проверки того, что конкретная строка содержится в другой строке, правильно делать так:
'Синий кит'.indexOf('Синий') !== -1;
'Синий кит'.indexOf('Голубой') !== -1;
Пример: использование методов
indexOf() и lastIndexOf()В следующем примере используются методы indexOf() и "Дивный новый мир".
var anyString = 'Дивный новый мир';
console.log('Индекс первого вхождения «й» с начала строки равен ' + anyString.indexOf('й'));
console.log('Индекс первого вхождения «й» с конца строки равен ' + anyString.lastIndexOf('й'));
console.log('Индекс вхождения «новый» с начала строки равен ' + anyString.indexOf('новый'));
console.log('Индекс вхождения «новый» с конца строки равен ' + anyString.lastIndexOf('новый'));
Пример: метод
indexOf() и регистрозависимостьВ следующем примере определяются две строковых переменных. Переменные содержат одинаковые строки, за исключение того, что слова во второй строке начинаются с заглавных букв. Первый вызов метода indexOf() является регистрозависимым, строка "чеддер" в переменной myCapString не будет найдена, так что второй вызов метода console.log() отобразит -1.
var myString = 'бри, пеппер джек, чеддер'; var myCapString = 'Бри, Пеппер Джек, Чеддер'; console.log('Вызов myString.indexOf("чеддер") вернул ' + myString.indexOf('чеддер')); console.log('Вызов myCapString.indexOf("чеддер") вернул ' + myCapString.indexOf('чеддер'));
 log('Вызов myString.indexOf("чеддер") вернул ' + myString.indexOf('чеддер'));
console.log('Вызов myCapString.indexOf("чеддер") вернул ' + myCapString.indexOf('чеддер'));
log('Вызов myString.indexOf("чеддер") вернул ' + myString.indexOf('чеддер'));
console.log('Вызов myCapString.indexOf("чеддер") вернул ' + myCapString.indexOf('чеддер'));
Пример: использование метода
indexOf() для подсчёта вхождений буквы в строкуСледующий пример устанавливает значение переменной count в количество вхождений буквы в в строку str:
var str = 'Быть или не быть, вот в чём вопрос.';
var count = 0;
var pos = str.indexOf('в');
while (pos !== -1) {
count++;
pos = str.indexOf('в', pos + 1);
}
console.log(count);
| Возможность | Chrome | Firefox (Gecko) | Internet Explorer | Opera | Safari |
|---|---|---|---|---|---|
| Базовая поддержка | (Да) | (Да) | (Да) | (Да) |
| Возможность | Android | Chrome для Android | Firefox Mobile (Gecko) | IE Mobile | Opera Mobile | Safari Mobile |
|---|---|---|---|---|---|---|
| Базовая поддержка | (Да) | (Да) | (Да) | (Да) | (Да) | (Да) |
Введение в регулярные выражения в JavaScript | by Victoria Likhanova | NOP::Nuances of Programming
Первым делом необходимо выяснить, что такое регулярные выражения. Регулярные выражения — это способ описания шаблона или правила. Их можно использовать, чтобы проверить, есть ли в строке совпадения с шаблоном. Плюс регулярных выражений в том, что их можно использовать во многих языках программирования.
Регулярные выражения — это способ описания шаблона или правила. Их можно использовать, чтобы проверить, есть ли в строке совпадения с шаблоном. Плюс регулярных выражений в том, что их можно использовать во многих языках программирования.
Регулярные выражения — это не просто ещё одна часть языка JavaScript, вроде свойства или чего-то подобного. По сути, это небольшой самостоятельный язык, независимый от других. Ещё одно достоинство регулярных выражений: они крайне удобны, так как позволяют выполнять сложные манипуляции со строками и при этом экономить код.
Недостаток регулярных выражений в том, что часто они выглядят странно и даже пугающе. Особенно это касается более сложных шаблонов. По этой причине многие программисты не горят желанием их изучать. И это неправильно. Регулярные выражения могут быть мощным инструментом, позволяющим писать меньше кода. Надеюсь, это руководство поможет вам преодолеть страх перед их изучением.
Если с помощью JavaScript вы хотите создать регулярное выражение (описать шаблон), есть два способа это сделать.
Первый способ — использование конструктора. Это громкое слово на самом деле означает функцию-конструктор объекта RegExp. Конструктор принимает два параметра. Первый — шаблон, который вы хотите описать. Это обязательный параметр. В конце концов, зачем вообще создавать регулярное выражение, если нет шаблона?
Второй параметр — строка с флагами (flags). Не волнуйтесь, скоро мы с ними познакомимся. Этот параметр необязательный. Стоит запомнить одно: после создания регулярного выражения флаги уже нельзя будет добавить или убрать. Поэтому, если хотите использовать флаг, добавьте его на этапе создания выражения.
// Синтаксис конструктора регулярных выраженийЛитерал регулярных выражений
new RegExp(pattern[, flags])// Создание регулярного выражения
// с помощью конструктора
// без флагов
const myPattern = new RegExp('[a-z]')// Создание регулярного выражения
// с помощью конструктора
// с одним флагом
const myPattern = new RegExp('[a-z]', 'g')
Второй способ — использование литерала. Как и конструктор, литерал регулярных выражений состоит из двух частей. Первая часть — это описываемый шаблон. Он заключается в слэши (
Как и конструктор, литерал регулярных выражений состоит из двух частей. Первая часть — это описываемый шаблон. Он заключается в слэши (//). После закрывающего слэша идёт вторая часть — флаги. Они необязательны.
// Синтаксис литерала регулярных выражений
/pattern/flags// Создание регулярного выражения
// с помощью литерала
// без флагов
const myPattern = /[a-z]/// Создание регулярного выражения
// с помощью литерала
// с одним флагом
const myPattern = /[a-z]/g
Примечание: два слэша в литерале регулярных выражений используются для того, чтобы заключить в них шаблон. Если ваш шаблон предполагает использование ещё одного или нескольких прямых слэшей, их необходимо экранировать обратным слэшем (\), то есть \ /.
Конструктор и литерал выполняют одну функцию, но есть одно важное различие. Регулярное выражение, созданное при помощи конструктора, компилируется при выполнении программы, литерал — на этапе загрузки скрипта. Это значит, что литерал нельзя изменить динамически, в то время как конструктор — можно.
Регулярное выражение, созданное при помощи конструктора, компилируется при выполнении программы, литерал — на этапе загрузки скрипта. Это значит, что литерал нельзя изменить динамически, в то время как конструктор — можно.
Таким образом, если вам нужно (или может понадобиться) изменить шаблон на лету, создавайте регулярное выражение с помощью конструктора. Также конструктор будет лучшим решением, если шаблон нужно создавать динамически. С другой стороны, если вам не понадобится менять или создавать шаблон, вы можете воспользоваться литералом.
Прежде чем приступить к созданию шаблонов, давайте кратко рассмотрим, как они используются. С помощью описанных ниже методов мы сможем в дальнейшем применять разные способы создания шаблонов.
test()Для работы с регулярными выражениями есть несколько методов. Простейший из них — test(). При использовании этого метода необходимо передать функции проверяемую строку в качестве аргумента. В результате метод возвращает булево значение: true — если в строке есть совпадения с шаблоном, false — если совпадений нет.
// Синтаксис метода test()
// /шаблон/.test('проверяемый текст')
// Проверка строки,
// когда test() не находит совпадений
myPattern.test('There was a cat and dog in the house.')
// false
// Создание переменной,
// которой присваивается текст для проверки
const myString = 'The world of code.'
// Создание шаблона
const myPattern = /code/
// Проверка текста с помощью шаблона,
// когда test() находит совпадение
myPattern.test(myString)
// true
exec()
Ещё один метод, который можно использовать — exec(). Если есть совпадение, метод exec() возвращает массив. Массив содержит в себе информацию об используемом шаблоне, позиции, на которой было найдено совпадение, проверяемом тексте и наборах. Если совпадений нет, метод exec() возвращает null.
Необходимо запомнить одну вещь: метод exec() возвращает информацию только о первом найденном в тексте совпадении. Он прекращает работу после нахождения первого совпадения. Не используйте этот метод, если хотите получить множественные совпадения.
Он прекращает работу после нахождения первого совпадения. Не используйте этот метод, если хотите получить множественные совпадения.
// Синтаксис метода exec()
// /шаблон/.exec('проверяемый текст')
// Создание строки для проверки
const myString = 'The world of code is not full of code.'// Описание шаблона
const myPattern = /code/// Использование exec() для проверки текста,
// когда exec() находит совпадение
myPattern.exec(myString)
// [
// 'code',
// index: 13,
// input: 'The world of code is not full of code.',
// groups: undefined
// ]
// Описание другого шаблона
const myPatternTwo = /JavaScript/// Использование exec() с новым шаблоном для новой проверки текста,
// когда exec() не находит совпадений
myPatternTwo.exec(myString)
// null
test() и exec() — не единственные методы, которые можно использовать для поиска совпадений строки с шаблоном. Есть ещё
Есть ещё search(), match() и matchAll(). Эти методы принадлежат не объекту RegExp, а строкам. Несмотря на это, они позволяют применять регулярные выражения.
Чтобы использовать эти методы, нужно инвертировать синтаксис. Поскольку методы вызываются на строках, а не на шаблонах, в качестве аргумента надо передать не строку, а шаблон.
search()
Первый метод, search(), ищет в строке заданный шаблон. Если он находит совпадение, то возвращает позицию в строке, где это совпадение начинается. Если совпадения нет, возвращается -1. Нужно запомнить, что метод search() возвращает позицию только первого совпадения. После нахождения первого совпадения он прекращает работу.
// Синтаксис метода search()
// 'проверяемый текст'.search(/шаблон/)
// Создание текста для проверки
const myString = 'The world of code is not full of code.'// Описание шаблона
const myPattern = /code/// Использование search() для поиска
//совпадения строки с шаблоном,
//когда search() находит совпадение
myString.
// -13
// Вызов search() прямо на строке,
// когда search() не находит совпадений
'Another day in the life.'.search(myPattern)
// -1
 search(myPattern)
search(myPattern)match()
match() — второй метод объекта String, который позволяет использовать регулярные выражения. Он работает аналогично exec(): при нахождении совпадения метод match() возвращает массив с информацией об использованном шаблоне, позиции в строке, на которой было найдено совпадение, проверяемом тексте и наборах.
Так же как и exec(), match() возвращает null при отсутствии совпадений. При использовании метода match() с флагом g для поиска всех совпадений с шаблоном возвращается массив из всех совпадений.
// Синтаксис метода match()
// 'проверяемый текст'.match(/шаблон/)
// Создание текста для проверки
const myString = 'The world of code is not full of code.
const myPattern = /code/// Использование match() для поиска совпадения в тексте
myString.match(myPattern)
// [
// 'code',
// index: 13,
// input: 'The world of code is not full of code.',
// groups: undefined
// ]'Another day in the life.'.match(myPattern)
// null
// Использование match() для поиска всех совпадений
// Создание текста для проверки
const myString = 'The world of code is not full of code.'// Описание шаблона
const myPattern = /code/g // добавление флага 'g'// Использование match() для поиска совпадения в тексте
myString.match(myPattern)
// [ 'code', 'code' ]
 '// Описание шаблона
'// Описание шаблонаmatchAll()
Подобно методу match(), matchAll() возвращает все совпадения при использовании флага g в шаблоне. Однако работает он по-другому. Метод matchAll() возвращает объект RegExp String Iterator. Есть несколько способов извлечь из него все совпадения.
Есть несколько способов извлечь из него все совпадения.
Во-первых, можно пройтись по объекту циклом for…of и вернуть или записать все совпадения. Также можно использовать Array.from(), чтобы создать массив из содержимого объекта, или оператор spread, который даст точно такой же результат, как и Array.from().
// Синтаксис метода match()
// 'проверяемый текст'.match(/шаблон/)// Создание текста для проверки
const myString = 'The world of code is not full of code.'// Описание шаблона
const myPattern = /code/g
// Обратите внимание, что используется флаг 'g'// Использование matchAll() для поиска совпадений в тексте
const matches = myString.matchAll(myPattern)// Использование цикла for...of для получения всех совпадений
for (const match of matches) {
console.log(match)
}
// [
// [
// 'code',
// index: 13,
// input: 'The world of code is not full of code.
// groups: undefined
// ],
// [
// 'code',
// index: 33,
// input: 'The world of code is not full of code.',
// groups: undefined
// ]
// ]
// Использование Array.from() для получения всех совпадений
const matches = Array.from(myString.matchAll(myPattern))
// [
// [
// 'code',
// index: 13,
// input: 'The world of code is not full of code.',
// groups: undefined
// ],
// [
// 'code',
// index: 33,
// input: 'The world of code is not full of code.',
// groups: undefined
// ]
// ]// Использование оператора spread для получения всех совпадений
const matches = [...myString.matchAll(myPattern)]
// [
// [
// 'code',
// index: 13,
// input: 'The world of code is not full of code.
// groups: undefined
// ],
// [
// 'code',
// index: 33,
// input: 'The world of code is not full of code.',
// groups: undefined
// ]
// ]
 ',
', ',
',Вы узнали, как создавать и использовать регулярные выражения. Теперь давайте рассмотрим процесс создания шаблонов. Простейший способ составлять регулярные выражения —применение простых шаблонов. Это значит, что необходимо создать строку с особым текстом, а затем проверить, имеет ли какая-то другая строка совпадения с этим текстом.
// Создание простого шаблона
// с использованием литерала регулярного выражения
const myPattern = /JavaScript/// Проверка строки на совпадения с шаблоном
myPattern.test('One of the most popular languages is also JavaScript.')
// true// Проверка строки на совпадения с шаблоном
myPattern.test('What happens if you combine Java with scripting?')
// false
До сих пор мы использовали регулярные выражения из простых шаблонов. \t\r\n\v\f]).
\t\r\n\v\f]).
Примеры:
// . - любой символ, кроме первой строкиОператоры контроля
const myPattern = /./console.log(myPattern.test(''))
// falseconsole.log(myPattern.test('word'))
// trueconsole.log(myPattern.test('9'))
// true
// \d - одноразрядное число
const myPattern = /\d/console.log(myPattern.test('3'))
// trueconsole.log(myPattern.test('word'))
// false
// \w - отдельный буквенно-числовой словообразующий символ
const myPattern = /\w/console.log(myPattern.test(''))
// falseconsole.log(myPattern.test('word'))
// trueconsole.log(myPattern.test('9'))
// true
// \s - отдельный символ разделителя
const myPattern = /\s/console.log(myPattern.test(''))
// falseconsole.log(myPattern.test(' '))
// trueconsole.log(myPattern.test('foo'))
// false
// \D - отдельный нечисловой символ
const myPattern = /\D/console.
// trueconsole.log(myPattern.test('1'))
// false
// \W - отдельный несловообразующий символ
const myPattern = /\W/console.log(myPattern.test('Worm'))
// falseconsole.log(myPattern.test('1'))
// falseconsole.log(myPattern.test('*'))
// trueconsole.log(myPattern.test(' '))
// true
// \S - отдельный символ, который не является разделителем
const myPattern = /\S/console.log(myPattern.test('clap'))
// trueconsole.log(myPattern.test(''))
// falseconsole.log(myPattern.test('-'))
// true
 log(myPattern.test('Worm'))
log(myPattern.test('Worm'))Ещё один вид специальных символов — это операторы контроля. Такие символы позволяют описывать шаблоны с границами, то есть указывать, где начинается или заканчивается слово или строка. С помощью операторов контроля также можно создавать более сложные шаблоны, такие как опережающие проверки, ретроспективные проверки и условные выражения. re/console.log(myPattern.test(‘write’))
re/console.log(myPattern.test(‘write’))
// falseconsole.log(myPattern.test(‘read’))
// trueconsole.log(myPattern.test(‘real’))
// trueconsole.log(myPattern.test(‘free’))
// false
// $ — Конец строки
const myPattern = /ne$/console.log(myPattern.test(‘all is done’))
// trueconsole.log(myPattern.test(‘on the phone’))
// trueconsole.log(myPattern.test(‘in Rome’))
// falseconsole.log(myPattern.test(‘Buy toner’))
// false
// \b — Граница слова
const myPattern = /\bro/console.log(myPattern.test(‘road’))
// trueconsole.log(myPattern.test(‘steep’))
// falseconsole.log(myPattern.test(‘umbro’))
// false// Или
const myPattern = /\btea\b/console.log(myPattern.test(‘tea’))
// trueconsole.log(myPattern.test(‘steap’))
// falseconsole.log(myPattern.test(‘tear’))
// false
// \B — Несловообразующая граница
const myPattern = /\Btea\B/console. log(myPattern.test(‘tea’))
log(myPattern.test(‘tea’))
// falseconsole.log(myPattern.test(‘steap’))
// trueconsole.log(myPattern.test(‘tear’))
// false
// x(?=y) — Опережающая проверка
const myPattern = /doo(?=dle)/console.log(myPattern.test(‘poodle’))
// falseconsole.log(myPattern.test(‘doodle’))
// trueconsole.log(myPattern.test(‘moodle’))
// false
// x(?!y) — Негативная опережающая проверка
const myPattern = /gl(?!u)/console.log(myPattern.test(‘glue’))
// falseconsole.log(myPattern.test(‘gleam’))
// true
// (?<=y)x — Ретроспективная проверка
const myPattern = /(?<=re)a/console.log(myPattern.test(‘realm’))
// trueconsole.log(myPattern.test(‘read’))
// trueconsole.log(myPattern.test(‘rest’))
// false
// (?<!y)x — Негативная ретроспективная проверка
const myPattern = /(?<!re)a/console.log(myPattern. test(‘break’))
test(‘break’))
// falseconsole.log(myPattern.test(‘treat’))
// falseconsole.log(myPattern.test(‘take’))
// true
Квантификаторы используются, когда необходимо указать количество символов или выражений, по которым производится сопоставление.
/* Квантификатор - Значение */
* - 0 или более совпадений с предшествующим выражением.
+ - 1 или более совпадений с предшествующим выражением.
? - Предшествующее выражение необязательно (то есть совпадений 0 или 1).
x{n} - "n" должно быть целым положительным числом. Количество вхождений предшествующего выражения "x" равно "n".
x{n, } - "n" должно быть целым положительным числом. Количество вхождений предшествующего выражения "x" равно, как минимум, "n".
x{n, m} - "n" может быть равно 0 или целому положительному числу. "m" - целое положительное число. Если "m" > "n", количество вхождений предшествующего выражения "x" равно минимум "n" и максимум "m".

Примеры:
// * - 0 или более совпадений с предшествующим выражениемАльтернация
const myPattern = /bo*k/console.log(myPattern.test('b'))
// falseconsole.log(myPattern.test('bk'))
// trueconsole.log(myPattern.test('bok'))
// true
// + - 1 или более совпадений с предшествующим выражением
const myPattern = /\d+/console.log(myPattern.test('word'))
// falseconsole.log(myPattern.test(13))
// true
// ? - Предшествующее выражение необязательно, совпадений 0 или 1
const myPattern = /foo?bar/console.log(myPattern.test('foobar'))
// trueconsole.log(myPattern.test('fooobar'))
// false
// x{n} - Количество вхождений предшествующего выражения "x" равно "n"
const myPattern = /bo{2}m/console.log(myPattern.test('bom'))
// falseconsole.log(myPattern.test('boom'))
// trueconsole.log(myPattern.test('booom'))
// false
// x{n, } - Количество вхождений предшествующего выражения "x" равно, как минимум, "n"
const myPattern = /do{2,}r/console.
// false (нет других символов, кроме входящих в диапазон от 'b' до 'g')console.log(myPattern.test('jklm'))
// true (есть другие символы, кроме входящих в диапазон от 'b' до 'g')
// (x) - "x", значение запоминается для дальнейшего использования.
const myPattern = /(na)da\1/console.log(myPattern.test('nadana'))
// true - \1 запоминает и использует совпадение 'na' из первого выражения в скобках.console.log(myPattern.test('nada'))
// false
// (?<name>x) - Создание именованной скобочной группы, к которой можно обратиться по указанному имени.
const myPattern = /(?<foo>is)/console.log(myPattern.test('Work is created.'))
// trueconsole.log(myPattern.test('Just a text'))
// false
// (?:x) - "x", значение не запоминается.
const myPattern = /(?:war)/console.log(myPattern.test('warsawwar'))
// trueconsole.
// false
 b-g]/console.log(myPattern.test('bcd'))
b-g]/console.log(myPattern.test('bcd')) log(myPattern.test('arsaw'))
log(myPattern.test('arsaw'))Альтернация позволяет находить соответствие, по крайней мере, одному из нескольких выражений.
/* Альтернация - Значение */
| - выражение до или после символа |, как в булевом ИЛИ (||).
Примеры:
// | - Выражение до или после символа |Флаги
const myPattern = /(black|white)swan/console.log(myPattern.test('black swan'))
// trueconsole.log(myPattern.test('white swan'))
// trueconsole.log(myPattern.test('gray swan'))
// false
Флаги — последний тип символов, которые используются в регулярных выражениях. С помощью флагов можно легко расширить функционал шаблонов. К примеру, флаги позволяют игнорировать регистр букв, чтобы шаблон находил совпадения и в верхнем, и в нижнем регистрах, находить множественные совпадения и совпадения в многострочном тексте и т. д.
/* Флаг - Значение */
g – Глобальный поиск, не останавливается после нахождения первого совпадения.
 " и заканчивается "$" (начало и конец каждой строки).
" и заканчивается "$" (начало и конец каждой строки).Примеры:
// флаг g - Глобальный поиск
const myPattern = /xyz/gconsole.log(myPattern.test('One xyz and one more xyz'))
// true// флаг i - Игнорирование регистра
const myPattern = /xyz/iconsole.log(myPattern.test('XyZ'))
// true - регистр символов не имеет значения при нечувствительном к регистру поиске.
// флаг s - Точка (.) соответствует переводу на новую строку
const myPattern = /foo.bar/sconsole.log(myPattern.test('foo\nbar'))
// trueconsole.log(myPattern.test('foo bar'))
// trueconsole.log(myPattern.test('foobar'))
// false
Понимать и изучать регулярные выражения может быть непросто. Однако с помощью их короткого кода можно решать очень сложные задачи. И это определённо стоит стараний. Надеюсь, это руководство помогло вам разобраться в работе и способах применения регулярных выражений.
Читайте также:
Читайте нас в телеграмме, vk и Яндекс. Дзен
Дзен
Самые необходимые строковые и числовые методы в JavaScript
В этой статье, а скорее памятке, вы найдете все самые необходимые методы для работы со строками и числами (за исключением Math)в JavaScript, которые нужно просто знать, чтобы не городить огородов, а воспользоваться методами, доступными “из коробки”.
JavaScript Reference: String
+ числовые методы оттуда жеString
У объекта String есть один статический метод, String.fromCharCode(), который обычно используют для создания строкового представления последовательности Unicode символов. В этом примере мы делаем простую строку с использованием ASCII кодов:
String.fromCodePoint(70, 108, 97, 118, 105, 111) //'Flavio'Вы также можете использовать восьмеричные и шестнадцатеричные числа:
String.fromCodePoint(0x46, 0154, parseInt(141, 8), 118, 105, 111) //'Flavio'Все другие, описанные ниже методы, это методы “из коробки”

charAt()
Отдаёт символ под заданным индексом i.
Примеры:
'Flavio'.charAt(0) //'F'
'Flavio'.charAt(1) //'l'
'Flavio'.charAt(2) //'a'Если вы зададите индекс, который не подходит по строке, то на выходе вы получите уже пустую строку.
В JavaScript нет типа char, так что char это строка с длиной 1.
charCodeAt()
Отдаёт код символа под индексом i. Как и с charAt(), отдаёт Unicode 16-битное целое число, представляющее символ:
'Flavio'.charCodeAt(0) //70 'Flavio'.charCodeAt(1) //108 'Flavio'.charCodeAt(2) //97
Вызов toString() после него, отдаст шестнадцатеричное число, которое вы можете найти в любой Unicode таблице, такой как эта.
codePointAt()
Этот метод был представлен уже в ES2015, чтобы работать с Unicode символами, которые не могут быть представлены как единичная 16-ти битная Unicode единица и которым вместо этого нужно их две.
Используя charCodeAt(), вам надо получить первый и второй, и затем совместить их. Используя
К примеру, этот китайский символ “𠮷” состоит из двух UTF-16 частей:
"𠮷".charCodeAt(0).toString(16) //d842
"𠮷".charCodeAt(1).toString(16) //dfb7Комбинируем эти два unicode символа:
"\ud842\udfb7" //"𠮷"Вы можете получить тот же результат, но только используя codePointAt():
"𠮷".codePointAt(0) //20bb7Если вы создаете новый символ, комбинируя эти unicode символы:
"\u{20bb7}" //"𠮷"concat()
Объединяет актуальную строку со строкой str.
Пример:
'Flavio'.concat(' ').concat('Copes') //'Flavio Copes'Вы можете указывать сколько угодно аргументов и в таком случае, все эти аргументы будут объединены в строку.
'Flavio'.concat(' ', 'Copes') //'Flavio Copes'endsWith()
Проверяет заканчивается ли строка со значением другой строки str.
'JavaScript'.endsWith('Script') //true
'JavaScript'.endsWith('script') //falseВы можете передать второй параметр с целым числом и endWith() будет рассматривать оригинальную строку, как если бы она этой заданной длины:
'JavaScript'.endsWith('Script', 5) //false
'JavaScript'.endsWith('aS', 5) //trueincludes()
Проверяет есть ли в строке значение строки str.
'JavaScript'.includes('Script') //true
'JavaScript'.includes('script') //false
'JavaScript'.includes('JavaScript') //true
'JavaScript'.includes('aSc') //true
'JavaScript'.includes('C++') //falseincludes() также принимает второй опциональный параметр, целое число, которое указывает на позицию с которой начинать поиск.
'a nice string'.includes('nice') //true 'a nice string'.includes('nice', 3) //false 'a nice string'.includes('nice', 2) //true
indexOf()
Даёт позицию начала заданной строки str в строке, на которой применяется метод.
'JavaScript'.indexOf('Script') //4
'JavaScript'.indexOf('JavaScript') //0
'JavaScript'.indexOf('aSc') //3
'JavaScript'.indexOf('C++') //-1Вы можете передать второй параметр, чтобы указать точку старта:
'a nice string'.indexOf('nice') !== -1 //true
'a nice string'.indexOf('nice', 3) !== -1 //false
'a nice string'.indexOf('nice', 2) !== -1 //truelastIndexOf()
Даёт позицию последнего появления строки str в актуальной строке.
Отдаёт -1, если поисковая строка не найдена.
'JavaScript is a great language. Yes I mean JavaScript'.lastIndexOf('Script') //47
'JavaScript'.lastIndexOf('C++') //-1localeCompare()
Этот метод сравнивает строки и возвращает число (отрицательное или положительное), которое говорит, является ли данная строка меньше, равной или больше, чем строка переданная как аргумент, но в зависимости от языка.
Язык определяется настоящим местоположением или вы можете указать его, как второй аргумент:
'a'.localeCompare('à') //-1
'a'.localeCompare('à', 'it-IT') //-1Очень часто его используют для сортировки массивов:
['a', 'b', 'c', 'd'].sort((a, b) => a.localeCompare(b))Где бы вы обычно использовали:
['a', 'b', 'c', 'd'].sort((a, b) => (a > b) ? 1 : -1)Только тут мы можем это сделать с помощью localeCompare(), который позволит нам работать с алфавитами по всему миру.
Объект переданный как третий аргумент, может быть использован для передачи дополнительных условий. Посмотрите все возможные значения для этих условий на MDN.
match()
А вот работа с регулярными выражениями RegEx.
'Hi Flavio'.match(/avio/)
// Array [ 'avio' ]
'Test 123123329'.match(/\d+/)
// Array [ "123123329" ]
'hey'.match(/(hey|ho)/)
//Array [ "hey", "hey" ]
'123s'. (\d{3})(?:\s)(\w+)$/)
//Array [ "123 s", "123", "s" ]
'I saw a bear'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear\b/) //null
'cool_bear'.match(/\bbear\b/) //null (\d{3})(?:\s)(\w+)$/)
//Array [ "123 s", "123", "s" ]
'I saw a bear'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear\b/) //null
'cool_bear'.match(/\bbear\b/) //null
(\d{3})(?:\s)(\w+)$/)
//Array [ "123 s", "123", "s" ]
'I saw a bear'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear\b/) //null
'cool_bear'.match(/\bbear\b/) //nullnormalize()
В Unicode есть четыре главные формы нормализации. Их коды это NFC, NFD, NFKC и NFKD. На Википедии есть хорошая статья про это.
Метод normalize() возвращает строку, нормализованную в соответствии с указанной формой, которую вы передаёте как параметр. (NFC используется как стандарт, если она не указана в ручную).
Вот пример с MDN:
'\u1E9B\u0323'.normalize() //ẛ̣
'\u1E9B\u0323'.normalize('NFD') //ẛ̣
'\u1E9B\u0323'.normalize('NFKD') //ṩ
'\u1E9B\u0323'.normalize('NFKC') //ṩpadEnd()
Смысл этого метода в том, чтобы добавлять в строку символы и пробелы, пока она не достигнет заданной длины.
padEnd() был представлен в ES2017, как метод добавляющий символы в конец строки.
padEnd(targetLength [, padString])Простое применение:
Смысл этого метода в том, чтобы добавлять строки или символы как в предыдущем методе, но уже с самого начала строки:
padStart(targetLength [, padString])repeat()
Этот метод был представлен в ES2015 и повторяет строки заданное количество раз:
'Ho'.repeat(3) //'HoHoHo'Отдает пустую строку, если параметр не указан или параметр равен нулю. А в случае с отрицательным числом вы получите RangeError.
replace()
Этот метод находит первое упоминание str1 в заданной строке и заменяет его на str2.
Отдаёт новую строку, не трогая оригинальную.
'JavaScript'.replace('Java', 'Type') //'TypeScript'Вы можете передать регулярное выражение как первый аргумент:
'JavaScript'. replace(/Java/, 'Type') //'TypeScript' replace(/Java/, 'Type') //'TypeScript'
replace(/Java/, 'Type') //'TypeScript'replace() заменяет только первое упоминание, но а если вы будете использовать regex как поиск строки, то вы можете использовать (/g):
'JavaScript JavaX'.replace(/Java/g, 'Type') //'TypeScript TypeX'Второй параметр может быть функцией. Эта функция будет вызвана с заданным количеством аргументов, когда найдётся совпадение (или каждое совпадение в случае с regex /g):
- Нужная строка
- Целое число, которое указывает позицию в строке, где произошло совпадение
- Строка
Отдающееся значение функции заменит совпадающую часть строки.
Пример:
'JavaScript'.replace(/Java/, (match, index, originalString) => {
console.log(match, index, originalString)
return 'Test'
}) //TestScriptЭто работает и для обычных строк, а не только для регулярок:
'JavaScript'.replace('Java', (match, index, originalString) => {
console. log(match, index, originalString)
return 'Test'
}) //TestScript log(match, index, originalString)
return 'Test'
}) //TestScript
log(match, index, originalString)
return 'Test'
}) //TestScriptВ случае c regex, когда выбираются группы, все эти значения будут переданы как аргументы прямо после параметра совпадения.
'2015-01-02'.replace(/(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/, (match, year, month, day, index, originalString) => {
console.log(match, year, month, day, index, originalString)
return 'Test'
}) //Testsearch()
Отдаёт расположение первого совпадения строки str в заданной строке.
Этот метод отдаёт индекс начала упоминания или -1, если такого не было найдено.
'JavaScript'.search('Script') //4
'JavaScript'.search('TypeScript') //-1Вы можете использовать регулярные выражения (и на самом деле, даже если вы передаёте строку, то внутренне оно тоже применяется как регулярное выражение).
'JavaScript'.search(/Script/) //4
'JavaScript'. search(/script/i) //4
'JavaScript'.search(/a+v/) //1 search(/script/i) //4
'JavaScript'.search(/a+v/) //1
search(/script/i) //4
'JavaScript'.search(/a+v/) //1В этой статье подробно рассказывается про метод slice() и его родственников.
Отдает новую строку, которая является частью строки на которой применялся метод, от позиций begin до end.
Оригинальная строка не изменяется.
end опциональна.
'This is my car'.slice(5) //is my car
'This is my car'.slice(5, 10) //is myЕсли вы выставите первым параметром отрицательное число, то начальный индекс будет считаться с конца и второй параметр тоже должен быть отрицательным, всегда ведя отсчет с конца:
'This is my car'.slice(-6) //my car
'This is my car'.slice(-6, -4) //mysplit()
Этот метод вырезает строку при её нахождении в строке на которой применяется метод (чувствительный к регистру) и отдаёт массив с токенами.
const phrase = 'I love my dog! Dogs are great'
const tokens = phrase. split('dog')
tokens //["I love my ", "! Dogs are great"] split('dog')
tokens //["I love my ", "! Dogs are great"]
split('dog')
tokens //["I love my ", "! Dogs are great"]startsWith()
Проверяет начинается ли строка со значения str.
Вы можете вызвать startWith() на любой строке, указать подстроку и проверить отдаёт результат true или false.
'testing'.startsWith('test') //true
'going on testing'.startsWith('test') //falseЭтот метод допускает второй параметр, который позволит вам указать с какого символа вам надо начать проверку:
'testing'.startsWith('test', 2) //false
'going on testing'.startsWith('test', 9) //truetoLocaleLowerCase()
Этот метод отдаёт новую строку, которая представляет собой изначальную строку в нижнем регистре, в соответствии с нормами разметки указанной локали.
Собственно, первый параметр представляет локаль, но он опционален. Если его пропустить, то будет использоваться актуальная локаль:
'Testing'. toLocaleLowerCase() //'testing'
'Testing'.toLocaleLowerCase('it') //'testing'
'Testing'.toLocaleLowerCase('tr') //'testing' toLocaleLowerCase() //'testing'
'Testing'.toLocaleLowerCase('it') //'testing'
'Testing'.toLocaleLowerCase('tr') //'testing'
toLocaleLowerCase() //'testing'
'Testing'.toLocaleLowerCase('it') //'testing'
'Testing'.toLocaleLowerCase('tr') //'testing'Как и всегда, мы можем не осознавать все преимущества интернационализации, но я читал на MDN, что правила разметки текста в турецком языке отличаются от других языков, чьё описание основано на латинице.
В общем, это как и toLowerCase(), но с учетом локали.
toLocaleUpperCase()
Этот метод отдаёт новую строку, которая представляет собой изначальную строку в верхнем регистре, в соответствии с нормами разметки указанной локали.
Первым параметром указывается локаль, но это опционально, как и в случае с методом выше:
'Testing'.toLocaleUpperCase() //'TESTING'
'Testing'.toLocaleUpperCase('it') //'TESTING'
'Testing'.toLocaleUpperCase('tr') //'TESTİNG'toLowerCase()
Этот метод отдаёт новую строку с текстом в нижнем регистре.
Не изменяет изначальную строку.
Не принимает параметры.
Использование:
'Testing'.toLowerCase() //'testing'Работает как и toLocaleLowerCase(), но не учитывает локали.
toString()
Отдает строку из заданного строчного объекта.
const str = new String('Test')
str.toString() //'Test'toUpperCase()
Отдаёт новую строку с текстом в верхнем регистре.
Не изменяет оригинальную строку.
Не принимает параметры.
Использование:
'Testing'.toUpperCase() //'TESTING'Если вы передадите пустую строку, то он возвратит пустую строку.
Метод похож на toLocaleUpperCase(), но не принимает параметры.
trim()
Отдает новую строку удаляя пробелы вначале и в конце оригинальной строки.
'Testing'.trim() //'Testing'
' Testing'.trim() //'Testing'
' Testing '.trim() //'Testing'
'Testing '. trim() //'Testing'trimEnd()
Отдаёт новую строку, удаляя пробелы только из конца оригинальной строки.
'Testing'.trimEnd() //'Testing'
' Testing'.trimEnd() //' Testing'
' Testing '.trimEnd() //' Testing'
'Testing '.trimEnd() //'Testing'trimStart()
Отдаёт новую строку, удаляя пробелы из начала оригинальной строки.
'Testing'.trimStart() //'Testing'
' Testing'.trimStart() //'Testing'
' Testing '.trimStart() //'Testing '
'Testing'.trimStart() //'Testing'valueOf()
Отдает строчное представление заданного строчного объекта:
const str = new String('Test')
str.valueOf() //'Test'Это тоже самое, что и toString()
Теперь пройдемся по числовым методам.
isInteger()
Отдаст true, если переданное значение является целым числом. Всё иное, такое как, логические значения, строки, объекты, массивы, отдают false.
Number.isInteger(1) //true
Number.isInteger(-237) //true
Number.isInteger(0) //true
Number.isInteger(0.2) //false
Number.isInteger('Flavio') //false
Number.isInteger(true) //false
Number.isInteger({}) //false
Number.isInteger([1, 2, 3]) //falseisNaN()
NaN это особый случай. Число является NaN, только если оно NaN или если это выражения деления ноль на ноль, что отдаёт NaN. Во всех других случаях мы можем передать ему что захотим, но получим false:
Number.isNaN(NaN) //true
Number.isNaN(0 / 0) //true
Number.isNaN(1) //false
Number.isNaN('Flavio') //false
Number.isNaN(true) //false
Number.isNaN({}) //false
Number.isNaN([1, 2, 3]) //falseisSafeInteger()
Число может удовлетворять Number.isInteger(), но не Number.isSafeInteger(), если оно заходит за пределы безопасных целых чисел.
Так что, всё что выше 2⁵³ и ниже -2⁵³ не является безопасным.
Number.isSafeInteger(Math.pow(2, 53)) // false
Number.isSafeInteger(Math.pow(2, 53) - 1) // true
Number.isSafeInteger(Math.pow(2, 53) + 1) // false
Number.isSafeInteger(-Math.pow(2, 53)) // false
Number.isSafeInteger(-Math.pow(2, 53) - 1) // false
Number.isSafeInteger(-Math.pow(2, 53) + 1) // trueparseFloat()
Парсит аргумент как дробное число и отдаёт его. Аргумент при этом является строкой:
Number.parseFloat('10') //10
Number.parseFloat('10.00') //10
Number.parseFloat('237,21') //237
Number.parseFloat('237.21') //237.21
Number.parseFloat('12 34 56') //12
Number.parseFloat(' 36 ') //36
Number.parseFloat('36 is my age') //36
Number.parseFloat('-10') //-10
Number.parseFloat('-10.2') //-10.2Как вы видите Number.parseFloat() довольно гибок. Он также может конвертировать строки со словами, выделяя только первое число, но в этом случае строка должна начинаться с числа:
Number. parseFloat('I am Flavio and I am 36') //NaN parseFloat('I am Flavio and I am 36') //NaN
parseFloat('I am Flavio and I am 36') //NaNparseInt()
Парсит аргумент как целое число и отдаёт его:
Number.parseInt('10') //10
Number.parseInt('10.00') //10
Number.parseInt('237,21') //237
Number.parseInt('237.21') //237
Number.parseInt('12 34 56') //12
Number.parseInt(' 36 ') //36
Number.parseInt('36 is my age') //36Как вы видите Number.parseInt() тоже гибок. Он также может конвертировать строки со словами, выделяя первое число, строка должна начинаться с числа.
Number.parseInt('I am Flavio and I am 36') //NaNВы можете передать второй параметр, чтобы указать систему счисления. Десятичная стоит по-дефолту, но вы можете применять восьмеричные и шестнадцатеричные числовые конверсии:
Number.parseInt('10', 10) //10
Number.parseInt('010') //10
Number.parseInt('010', 8) //8
Number.parseInt('10', 8) //8
Number.parseInt('10', 16) //16Функция InStr (Visual Basic для приложений)
-
 000Z» data-article-date-source=»ms.date»>08/14/2019
000Z» data-article-date-source=»ms.date»>08/14/2019 - Чтение занимает 2 мин
В этой статье
Возвращает значение типа Variant (Long), определяющее положение первого вхождения одной строки в другую.Returns a Variant (Long) specifying the position of the first occurrence of one string within another.
Примечание
Хотите создавать решения, которые расширяют возможности Office на разнообразных платформах?Interested in developing solutions that extend the Office experience across multiple platforms? Ознакомьтесь с новой моделью надстроек Office.Check out the new Office Add-ins model. Надстройки Office занимают меньше места по сравнению с надстройками и решениями VSTO, и вы можете создавать их, используя практически любую технологию веб-программирования, например HTML5, JavaScript, CSS3 и XML.Office Add-ins have a small footprint compared to VSTO Add-ins and solutions, and you can build them by using almost any web programming technology, such as HTML5, JavaScript, CSS3, and XML.
СинтаксисSyntax
InStr([ начало ], строка1, строка2, [ сравнение ])InStr([ start ], string1, string2, [ compare ])
В синтаксисе функции InStr используются следующие аргументы:The InStr function syntax has these arguments:
| ЧастьPart | ОписаниеDescription |
|---|---|
| началоstart | Необязательно.Optional. Числовое выражение, которое задает начальную точку для поиска.Numeric expression that sets the starting position for each search. Если этот аргумент опущен, поиск начинается с первого знака строки.If omitted, search begins at the first character position. Если аргумент начало содержит значение Null, возникает ошибка.If start contains Null, an error occurs. Аргумент начало является обязательным, если задан аргумент сравнение. The start argument is required if compare is specified. The start argument is required if compare is specified. |
| строка1string1 | Обязательно.Required. Строковое выражение, поиск в котором выполняется.String expression being searched. |
| строка2string2 | Обязательно.Required. Искомое строковое выражение.String expression sought. |
| сравнениеcompare | Необязательно.Optional. Определяет тип сравнения строк.Specifies the type of string comparison. Если аргумент сравнение содержит значение Null, возникает ошибка.If compare is Null, an error occurs. Если аргумент сравнение опущен, тип сравнения определяется параметром Option Compare.If compare is omitted, the Option Compare setting determines the type of comparison. Укажите допустимый LCID (код языка), чтобы использовать для сравнения правила, определяемые языковым стандартом. Specify a valid LCID (LocaleID) to use locale-specific rules in the comparison. Specify a valid LCID (LocaleID) to use locale-specific rules in the comparison. |
ПараметрыSettings
Аргумент сравнение может принимать следующие значения:The compare argument settings are as follows.
| КонстантаConstant | ЗначениеValue | ОписаниеDescription |
|---|---|---|
| vbUseCompareOptionvbUseCompareOption | –1-1 | Выполняется сравнение с помощью параметра оператора Option Compare.Performs a comparison by using the setting of the Option Compare statement. |
| vbBinaryComparevbBinaryCompare | 00 | Выполняется двоичное сравнение.Performs a binary comparison. |
| vbTextComparevbTextCompare | 11 | Выполняется текстовое сравнение.Performs a textual comparison. |
| vbDatabaseComparevbDatabaseCompare | 22 | Только Microsoft Access. Microsoft Access only. Выполняется сравнение на основе сведений из базы данных.Performs a comparison based on information in your database. Microsoft Access only. Выполняется сравнение на основе сведений из базы данных.Performs a comparison based on information in your database. |
Возвращаемые значенияReturn values
| ЕслиIf | Возвращаемое значениеInStr returns |
|---|---|
| строка1 является пустойstring1 is zero-length | 00 |
| строка1 равна Nullstring1 is Null | NullNull |
| строка2 является пустойstring2 is zero-length | началоstart |
| строка2 равна Nullstring2 is Null | NullNull |
| строка2 не найденаstring2 is not found | 00 |
| строка2 найдена в строке1string2 is found within string1 | Позиция найденного соответствияPosition at which match is found |
| начало > строка2start > string2 | 00 |
ПримечанияRemarks
Функция InStrB используется с байтовыми данными, содержащимися в строке. The InStrB function is used with byte data contained in a string. Функция InStrB возвращает позицию байта, а не позицию знака первого вхождения одной строки в другую.Instead of returning the character position of the first occurrence of one string within another, InStrB returns the byte position.
The InStrB function is used with byte data contained in a string. Функция InStrB возвращает позицию байта, а не позицию знака первого вхождения одной строки в другую.Instead of returning the character position of the first occurrence of one string within another, InStrB returns the byte position.
ПримерExample
В данном примере функция InStr используется для получения позиции первого вхождения одной строки в другую.This example uses the InStr function to return the position of the first occurrence of one string within another.
Dim SearchString, SearchChar, MyPos
SearchString ="XXpXXpXXPXXP" ' String to search in.
SearchChar = "P" ' Search for "P".
' A textual comparison starting at position 4. Returns 6.
MyPos = Instr(4, SearchString, SearchChar, 1)
' A binary comparison starting at position 1. Returns 9.
MyPos = Instr(1, SearchString, SearchChar, 0)
' Comparison is binary by default (last argument is omitted).
MyPos = Instr(SearchString, SearchChar) ' Returns 9.
MyPos = Instr(1, SearchString, "W") ' Returns 0.
 MyPos = Instr(SearchString, SearchChar) ' Returns 9.
MyPos = Instr(1, SearchString, "W") ' Returns 0.
MyPos = Instr(SearchString, SearchChar) ' Returns 9.
MyPos = Instr(1, SearchString, "W") ' Returns 0.
См. такжеSee also
Поддержка и обратная связьSupport and feedback
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи?Have questions or feedback about Office VBA or this documentation? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.Please see Office VBA support and feedback for guidance about the ways you can receive support and provide feedback.
Шпаргалка по регулярным выражениям
Квантификаторы
| Аналог | Пример | Описание | |
|---|---|---|---|
| ? | {0,1} | a? | одно или ноль вхождений «а» |
| + | {1,} | a+ | одно или более вхождений «а» |
| * | {0,} | a* | ноль или более вхождений «а» |
Модификаторы
Символ «минус» (-) меред модификатором (за исключением U) создаёт его отрицание.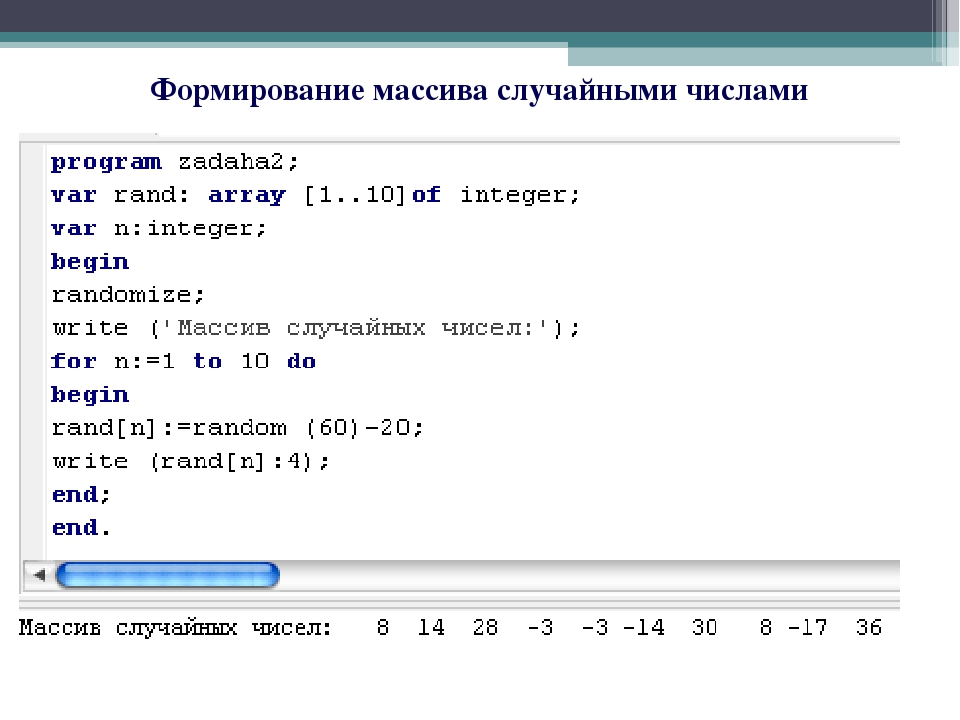 — начало строки в тексте,
— начало строки в тексте, $— конец строки в тексте.
Спецсимволы
| Аналог | Описание | |
|---|---|---|
| () | подмаска, вложенное выражение | |
| [] | групповой символ | |
| {a,b} | количество вхождений от «a» до «b» | |
| | | логическое «или», в случае с односимвольными альтернативами используйте [] | |
| \ | экранирование спец символа | |
| . | любой сивол, кроме перевода строки | |
| \d | [0-9] | десятичная цифра |
| \D | [^\d] | любой символ, кроме десятичной цифры |
| \f | конец (разрыв) страницы | |
| \n | перевод строки | |
| \pL | буква в кодировке UTF-8 при использовании модификатора u | |
| \r | возврат каретки | |
| \s | [ \t\v\r\n\f] | пробельный символ |
| \S | [^\s] | любой символ, кроме промельного |
| \t | табуляция | |
| \w | [0-9a-z_] | любая цифра, буква или знак подчеркивания |
| \W | [^\w] | любой символ, кроме цифры, буквы или знака подчеркивания |
| \v | вертикальная табуляция |
Спецсимволы внутри символьного класса
| Пример | Описание | |
|---|---|---|
| ^ | [^da] | отрицание, любой символ кроме «d» или «a» |
| — | [a-z] | интервал, любой симво от «a» до «z» |
Позиция внутри строки
| Пример | Соответствие | Описание | |
|---|---|---|---|
| ^ | ^a | aaa aaa | начало строки |
| $ | a$ | aaa aaa | конец строки |
| \A | \Aa | aaa aaa aaa aaa | начало текста |
| \z | a\z | aaa aaa aaa aaa | конец текста |
| \b | a\b \ba | aaa aaa aaa aaa | граница слова, утверждение: предыдущий символ словесный, а следующий — нет, либо наоборот |
| \B | \Ba\B | aaa aaa | отсутствие границы слова |
| \G | \Ga | aaa aaa | Предыдущий успешный поиск, поиск остановился на 4-й позиции — там, где не нашлось a |
 обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.Символьные классы
Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, \dсоответствует любой цифре от 0 до 9 включительно, \wсоответствует буквам и цифрам, а
\W— всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит
так:
\w\sPOSIX
POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов.
Утверждения
Поначалу практически у всех возникают трудности с пониманием утверждений, однако познакомившись с ними ближе, вы
будете использовать их довольно часто. Утверждения предоставляют способ сказать: «я хочу найти в этом документе
каждое слово, включающее букву “q”, за которой не следует “werty”». \s]*).
\s]*).
Кванторы
Кванторы позволяют определить часть шаблона, которая должна повторяться несколько раз подряд. Например, если вы хотите выяснить, содержит ли документ строку из от 10 до 20 (включительно) букв «a», то можно использовать этот шаблон:
a{10,20}По умолчанию кванторы — «жадные». Поэтому квантор +, означающий «один или больше раз», будет
соответствовать максимально возможному значению. Иногда это вызывает проблемы, и тогда вы можете сказать квантору
перестать быть жадным (стать «ленивым»), используя специальный модификатор. Посмотрите на этот код:
".*"Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой:
<a href="helloworld.htm" title="Привет, Мир">Привет, Мир</a>Приведенный выше шаблон найдет в этой строке вот такую подстроку:
"helloworld.htm" title="Привет, Мир"Он оказался слишком жадным, захватив наибольший кусок текста, который смог.
".*?"Этот шаблон также соответствует любым символам, заключенным в двойные кавычки. Но ленивая версия (обратите внимание
на модификатор ?) ищет наименьшее из возможных вхождений, и поэтому найдет каждую подстроку в двойных
кавычках по отдельности:
"helloworld.htm" "Привет, Мир"Экранирование в регулярных выражениях
Регулярные выражения используют некоторые символы для обозначения различных частей шаблона. Однако, возникает
проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном
выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто
использовать «.» в качестве шаблона — это приведет к нахождению практически всего. Итак, вам
необходимо сообщить парсеру, что эта точка должна считаться обычной точкой, а не «любым символом». Это делается с
помощью знака экранирования.
Знак экранирования, предшествующий символу вроде точки, заставляет парсер игнорировать его функцию и считать обычным символом. Есть несколько символов, требующих такого экранирования в большинстве шаблонов и языков. Вы можете найти их в правом нижнем углу шпаргалки («Мета-символы»).
Шаблон для нахождения точки таков:
\.Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования. Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Спецсимволы экранирования в регулярных выражениях
| Выражение | Соответствие |
|---|---|
| \ | не соответствует ничему, только экранирует следующий за ним символ. Это нужно, если вы хотите ввести метасимволы !$()*+.в качестве их буквальных значений. |
| \Q | не соответствует ничему, только экранирует все символы вплоть до \E |
| \E | не соответствует ничему, только прекращает экранирование, начатое \Q |
 {|}
{|}Подстановка строк
Подстановка строк подробно описана в следующем параграфе «Группы и диапазоны», однако здесь следует упомянуть о существовании «пассивных» групп. Это группы, игнорируемые при подстановке, что очень полезно, если вы хотите использовать в шаблоне условие «или», но не хотите, чтобы эта группа принимала участие в подстановке.
Группы и диапазоны
Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон:
[A-Fa-f0-9]Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F:
[^A-Fa-f0-9]Группы наиболее часто применяются, когда в шаблоне необходимо условие «или»; когда нужно сослаться на часть шаблона
из другой его части; а также при подстановке строк.
Использовать «или» очень просто: следующий шаблон ищет «ab» или «bc»:
(ab|bc)Если в регулярном выражении необходимо сослаться на какую-то из предшествующих групп, следует использовать
\n, где вместо nподставить номер нужной группы. Вам может понадобиться шаблон,
соответствующий буквам «aaa» или «bbb», за которыми следует число, а затем те же три буквы. Такой шаблон реализуется
с помощью групп:
(aaa|bbb)[0-9]+\1Первая часть шаблона ищет «aaa» или «bbb», объединяя найденные буквы в группу. За этим следует поиск одной или более
цифр ([0-9]+), и наконец \1. Последняя часть шаблона ссылается на первую группу и ищет то
же самое. Она ищет совпадение с текстом, уже найденным первой частью шаблона, а не соответствующее ему. Таким
образом, «aaa123bbb» не будет удовлетворять вышеприведенному шаблону, так как \1будет искать «aaa»
после числа. A-Za-z0-9])
A-Za-z0-9])
Он найдет любые вхождения слова «wish» вместе с предыдущим и следующим символами, если только это не буквы или цифры. Тогда ваша подстановка может быть такой:
$1<b>$2</b>$3Ею будет заменена вся найденная по шаблону строка. Мы начинаем замену с первого найденного символа (который не буква
и не цифра), отмечая его $1. Без этого мы бы просто удалили этот символ из текста. То же касается конца
подстановки ($3). В середину мы добавили HTML тег для жирного начертания (разумеется, вместо него вы
можете использовать CSS или <strong>), выделив им вторую группу, найденную по шаблону
($2).
Модификаторы шаблонов
Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Они позволяют изменить работу парсера.
Например, модификатор iзаставляет парсер игнорировать регистры.
Регулярные выражения в Perl обрамляются одним и тем же символом в начале и в конце. Это может быть любой символ (чаще
используется «/»), и выглядит все таким образом:
Это может быть любой символ (чаще
используется «/»), и выглядит все таким образом:
/pattern/Модификаторы добавляются в конец этой строки, вот так:
/pattern/iМета-символы
Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон:
\(Шпаргалка представляет собой общее руководство по шаблонам регулярных выражений без учета специфики какого-либо языка. Она представлена в виде таблицы, помещающейся на одном печатном листе формата A4. Создана под лицензией Creative Commons на базе шпаргалки, автором которой является Dave Child. Скачать в PDF, PNG.
- Регулярные выражения
Губкинские спортсмены стали бронзовыми призерами областной Спартакиады
21-22 февраля 2021 года в ОЗК «Лесная сказка» Губкинского района стартовала ежегодная областная Спартакиада среди муниципальных районов и городских округов Белгородской области под девизом «За физическое и нравственное здоровье нации».
В открытии приняли участие начальник управления физической культуры и спорта Белгородской области Наталья Жигалова, начальник отдела физической культуры и спорта администрации Губкинского городского округа Юрий Чуев, директор ОГБУ «Центр спортивной подготовки Белгородской области» Елена Шеенко, директор ОЗК «Лесная сказка» Сергей Спасенков, президент БРОСО «Федерация лыжных гонок Белгородской области» Евгений Ходячих.
Первый вид областной Спартакиады ― лыжные гонки среди сборных команд муниципальных образований и городских округов Белгородской области, в которых приняли участие более 200 спортсменов из 22 муниципалитетов. Мужскую команду Губкинского городского округа представляли именитые и опытные спортсмены ― Алексей Елманов, Рукавицын Николай, Ильин Александр, Безруков Иван, Чуев Александр, не раз защищавшие честь нашего округа. Женскую команду ― молодые перспективные спортсменки: Евгения Черникова, Екатерина Чуева, Кристина Хворостянова, Виктория Орлова, Алена Жилинкова.
В первый день соревнований проходила индивидуальная гонка: мужчины ― 10 км, женщины ― 5 км. Во второй день соревнований команды состязались в эстафетных гонках: мужчины 4 х 5 км, женщины 4 х 3 км. По итогам результатов двух дней команда губкинских спортсменов набрав 19425 очков в своей подгруппе завоевала бронзу, золото у Старооскольского городского округа (20239 очков), серебро у г. Белгород (19727 очков).
Отдел физической культуры и спорта
Появилась первая пьеса, написанная искусственным интеллектом
«Это своего рода футуристический «Маленький принц»» — объясняет драматург Дэвид Кошняк, который руководил процессом создания сценария. Как и в классической французской детской книге, 60-минутная постановка повествует о путешествии персонажа (на этот раз робота). Он выходит в мир, чтобы узнать об обществе, человеческих эмоциях и даже смерти. Сама пьеса называется «ИИ: когда робот пишет пьесу».
Он выходит в мир, чтобы узнать об обществе, человеческих эмоциях и даже смерти. Сама пьеса называется «ИИ: когда робот пишет пьесу».
Скрипт создан широко доступной системой искусственного интеллекта (ИИ) GPT-2. Этот «робот», созданный компанией OpenAI Илона Маска, представляет собой компьютерную модель, предназначенную для генерации текста путем фильтрации огромного хранилища информации, доступного в интернете.
До сих пор эта технология использовалась для написания фейковых новостей, рассказов и стихов. Спектакль — первая театральная постановка GPT-2, утверждает авторская группа.
Вот как это работает. Сначала человек вводит в программу подсказку, зацепку для начала пьесы. Исследователи из Карлова университета в Праге начали с двух предложений диалога, в которых один или два персонажа обсуждают человеческие чувства и переживания. Затем программа использует информацию подсказки и генерирует до 1 000 слов дополнительного текста.
Результат далек от Уильяма Шекспира. После нескольких предложений программа начинает писать вещи, которые иногда не соответствуют логической сюжетной линии, или утверждения, противоречащие другим отрывкам текста. Например, ИИ иногда забывал, что главным героем был робот, а не человек. «Иногда в процессе диалога мужчина превращался в женщину», — объясняет компьютерный лингвист Карлова университета Рудольф Роза, который начал работать над проектом два года назад.
Это происходит потому, что программа действительно не знает значения предложений, добавляет Чад ДеЧан, эксперт по искусственному интеллекту из Колумбийского университета. «Он просто соединяет слова, которые, вероятно, будут использоваться вместе, одно за другим».
По мере того, как это продолжается, появляется все больше места для ерунды.
Чтобы этого не произошло, команда не позволила GPT-2 сразу написать всю пьесу. Вместо этого исследователи разбили шоу на восемь сцен продолжительностью менее 5 минут каждая. Кроме того, ученые иногда меняли текст, например, изменяя отрывки, в которых ИИ менял пол персонажа от строки к строке, или повторяя исходную текстовую подсказку до тех пор, пока программа не выдаст разумную прозу. Однако 90% окончательного сценария осталось нетронутым, и лишь в 10% вмешивался человек.
Вместо этого исследователи разбили шоу на восемь сцен продолжительностью менее 5 минут каждая. Кроме того, ученые иногда меняли текст, например, изменяя отрывки, в которых ИИ менял пол персонажа от строки к строке, или повторяя исходную текстовую подсказку до тех пор, пока программа не выдаст разумную прозу. Однако 90% окончательного сценария осталось нетронутым, и лишь в 10% вмешивался человек.
Полностью самостоятельное написание пьесы станет возможным через 15 лет, объясняют эксперты. Тогда технология станет достаточно хорошей для создания сложного и связного текста, подобного театральной пьесе, от начала до конца. Тем не менее, эксперимент — по-прежнему хороший способ показать аудитории, на что способен искусственный интеллект, заключают ученые.
Читать далее
Физики создали аналог черной дыры и подтвердили теорию Хокинга. К чему это приведет?
Появилась первая панорама Марса. Она состоит из 142 фото!
От Антарктиды отделился гигантский айсберг. Его площадь — 1270 квадратных километров
3 способа замены всех вхождений строк в JavaScript
Нет простого способа заменить все вхождения строк в JavaScript. Java, которая в первые дни послужила источником вдохновения для JavaScript, с 1995 года использует метод replaceAll () для строк!
В этом посте вы узнаете, как заменить все вхождения строки в JavaScript путем разделения и соединения строки, а также string.replace () в сочетании с глобальным регулярным выражением.
Кроме того, вы узнаете о новой строке предложения.replaceAll () (на этапе 4), который переносит метод replace all в строки JavaScript. Это самый удобный подход.
Это самый удобный подход.
1. Разделение и объединение массива
Если вы погуглите, как «заменить все вхождения строк в JavaScript», скорее всего, первый подход, который вы найдете, — это использовать промежуточный массив.
Вот как это работает:
- Разделить строку
частейс помощью поиска
константные части = нить.разделить (поиск); - Затем соедините части, поместив строку
replaceмежду ними:
const resultString = piece.join (заменить); Например, давайте заменим все пробелы '' дефисами '-' в 'duck duck go' строка:
const search = '';
const replaceWith = '-';
const result = 'duck duck go'.split (поиск) .join (replaceWith);
результат; «утка, утка, вперед».split ('') разбивает строку на части: ['утка', 'утка', 'иди'] .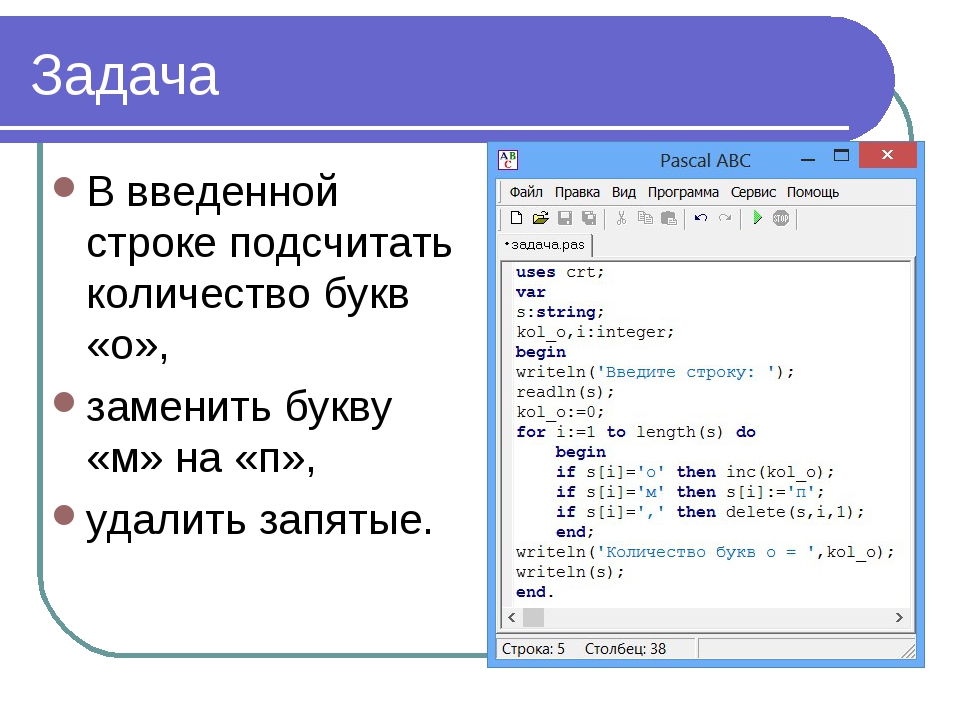
Затем части ['duck', 'duck', 'go']. Join ('-') соединяются путем вставки '-' между ними, в результате получается строка 'duck-duck- иди '.
Вот обобщенная вспомогательная функция, использующая подход разделения и объединения:
function replaceAll (строка, поиск, замена) {
return string.split (поиск) .join (заменить);
}
replaceAll ('abba', 'а', 'я');
replaceAll («давай, давай, давай!», «давай», «двигайся»);
replaceAll ('ой', 'z', 'y'); Этот подход требует преобразования строки в массив, а затем обратно в строку.Давайте продолжим поиски лучших альтернатив.
2.
replace () глобальным регулярным выражением Строковый метод string.replace (regExpSearch, replaceWith) выполняет поиск и заменяет вхождения регулярного выражения regExpSearch на replaceWith string.
Чтобы метод replace () заменял все вхождения шаблона, вы должны включить глобальный флаг в регулярном выражении:
- Добавить
gпосле в конце литерала регулярного выражения:/ search / g - Или при использовании конструктора регулярных выражений добавьте ко второму аргументу
'g':new RegExp ('search', 'g')
Заменим все вхождения ' на ' - ':
const searchRegExp = / \ s / g;
const replaceWith = '-';
const result = 'duck duck go'. replace (searchRegExp, replaceWith);
результат;  replace (searchRegExp, replaceWith);
результат;
replace (searchRegExp, replaceWith);
результат; Литерал регулярного выражения / \ s / g (обратите внимание на глобальный флаг g ) соответствует пространству '' .
'duck duck go'.replace (/ \ s / g,' - ') заменяет все совпадения / \ s / g на ' - ', что приводит к ' duck-duck-go ' .
Вы можете легко сделать нечувствительными к регистру заменами , добавив к регулярному выражению флаг i :
const searchRegExp = / duck / gi; const replaceWith = 'гусь';
const result = 'УТКА Утка, вперед'.replace (searchRegExp, replaceWith);
результат; Регулярное выражение / duck / gi выполняет глобальный поиск без учета регистра (обратите внимание на флаги i и g ). / duck / gi соответствует 'DUCK' , а также 'Duck' .
Вызов 'DUCK Duck go'. заменяет все совпадения подстрок  replace (/ duck / gi,' goose ')
replace (/ duck / gi,' goose ') / duck / gi на ' goose '.
2.1 Регулярное выражение из строки
Когда регулярное выражение создается из строки, необходимо экранировать символы - [] / {} () * +? .$ | , потому что они имеют особое значение в регулярном выражении.
Из-за этого специальные символы представляют собой проблему, когда вы хотите заменить все операции. Вот пример:
const search = '+';
const searchRegExp = новое регулярное выражение (поиск, 'g'); const replaceWith = '-';
const result = '5 + 2 + 1'. заменить (searchRegExp, replaceWith); Приведенный выше фрагмент пытается преобразовать строку поиска '+' в регулярное выражение.Но '+' является недопустимым регулярным выражением, поэтому выдается SyntaxError: Invalid regular expression: / + / .
Экранирование символа '\\ +' решает проблему.
Тем не менее, стоит ли экранировать строку поиска с помощью такой функции, как escapeRegExp (), которая будет использоваться в качестве регулярного выражения? Скорее всего, нет.
2.2
заменить () строкой Если первый аргумент , поиск из строки.replace (search, replaceWith) — это строка, тогда метод заменяет только первое вхождение из search :
const search = ''; const replace = '-';
const result = 'duck duck go'.replace (поиск, замена);
результат; 'duck duck go'.replace (' ',' - ') заменяет только первое появление пробела.
3.
replaceAll () метод Наконец, метод string.replaceAll (search, replaceWith) заменяет все появления search string на replaceWith .
Заменим все вхождения ' на ' - ':
const search = '';
const replaceWith = '-';
const result = 'duck duck go'. replaceAll (search, replaceWith);
результат;  replaceAll (search, replaceWith);
результат;
replaceAll (search, replaceWith);
результат; 'duck duck go'.replaceAll (' ',' - ') заменяет все вхождения строки ' ' на ' - '.
string.replaceAll (search, replaceWith) — лучший способ заменить все вхождения строки в строке
Обратите внимание, что в настоящее время поддержка методов в браузерах ограничена, и вам может потребоваться полифил.
3.1 Разница между
replaceAll () и replace () Строковые методы replaceAll (search, replaceWith) и replace (search, replaceWith) работают одинаково, кроме двух вещей:
- Если
searchаргумент является строкой,replaceAll ()заменяет все вхождения изsearchнаreplaceWith, аreplace ()только первое вхождение - Если аргумент
searchявляется неглобальным регулярным выражением, тогдаreplaceAll ()генерирует исключениеTypeError.

4. Ключ на вынос
Примитивный подход к замене всех вхождений состоит в том, чтобы разделить строку на фрагменты по строке поиска, объединить строку обратно, поместив строку замены между фрагментами: string.split (search) .join (replaceWith) . Этот подход работает, но он хакерский.
Другой подход — использовать string.replace (/ SEARCH / g, replaceWith) с регулярным выражением с включенным глобальным флагом.
К сожалению, вы не можете легко сгенерировать регулярные выражения из строки во время выполнения, потому что специальные символы регулярных выражений должны быть экранированы.А работа с регулярным выражением для простой замены строк — это непосильная задача.
Наконец, новый строковый метод string.replaceAll (search, replaceWith) заменяет все вхождения строки. Этот метод предлагается на этапе 4, и, надеюсь, вскоре он появится в новом стандарте JavaScript.
Я рекомендую использовать string. для замены строк. replaceAll ()
replaceAll ()
Какие еще способы заменить все вхождения строки вы знаете? Пожалуйста, поделитесь в комментариях ниже!
Найти все перестановки строки в Javascript | автор: noam sauer-utley
Хорошо, вернемся к нашему коду.
Теперь, если мы хотим использовать подход основной теоремы, мы можем обновить наш план до чего-то более ясного, чем // сделать что-нибудь .
Для простоты я хотел бы назначить текущий элемент, который мы повторяем, переменной char .
Итак, первое, что мы должны сделать, это разбить нашу строку на подзадачи.
Для начала у нас есть текущий символ, он же строка [i] , он же char . Чтобы начать разбиение остальной части строки , нам нужно собрать оставшиеся символы.
Так же, как мы присвоили текущий символ переменной char , давайте назначим оставшиеся символы переменной unknownChars .
Примечание : Существует много разных способов сбора оставшихся символов . Это всего лишь один из способов.
Чтобы собрать эти символы, мы можем использовать срез строкового метода. Подстрока — аналогичный метод, поэтому, если вы более знакомы с ним, вы можете использовать его.Slice является неразрушающим, поэтому нам не нужно беспокоиться об изменении нашей исходной строки — результат, который мы получим, разрезая нашу строку, будет отдельной новой строкой.
Итак, мы разрежем символы от индекса 0 (первый символ в строке) до индекса и (наш текущий символ, char ). Затем мы объединим символы из индекса i + 1 (следующий символ после char ) с индексом string.length (последний символ в строке ).
Итак, теперь у нас есть две строки меньшего размера — char и restChars .
Что теперь?
Что ж, давайте посмотрим на основную теорему:
Вызов процедуры p рекурсивно для каждой подзадачи
Итак, мы собираемся вызвать нашу функцию findPermutations для нашей строки savedChars .
Тогда что?
Объедините результаты подзадач
Я знал, что нам понадобится этот пустой массив.
Хорошо, а как это выглядит в JavaScript?
Итак, мы кое-что сделали.
Мы рекурсивно вызвали findPermutations на оставшихся символах . Для каждого результата этой функции, который я назначил переменной с именем перестановка , мы можем протолкнуть строку, которая представляет собой комбинацию char и перестановки в наш permutationsArray .
Итак, давайте посмотрим, что мы получим, когда вернем permutationsArray .
Ладно, отлично! При вводе «abc» наша функция findPermutations возвращает все шесть перестановок!
Но позвольте мне попробовать еще кое-что.
Ну, это нехорошо. Если символ в нашей строке повторяется, мы получаем каждую перестановку дважды. Многие строки содержат повторяющиеся символы.
Есть много разных способов удалить лишние элементы, но я решил использовать метод indexOf JavaScript, чтобы определить, был ли текущий символ уже запущен с помощью нашего метода findPermutations . indexOf возвращает первый индекс символа, поэтому, если мы уже выполнили findPermutations для «a», например, indexOf («a») будет отличаться от индекса char , текущий , позже «а».
Если это правда, мы можем продолжить , что по существу пропустит текущий итерационный цикл и перейдет к следующему.
Давайте запустим findPermutation с этим добавлением.
Отлично! 🌟 Подход, основанный на основной теореме, позволил нам быстро разбить эту проблему на небольшие части и начать возвращать правильные результаты, оставив лишь несколько настроек, необходимых здесь и там, чтобы предоставить наше решение в точно желаемом формате.
Обзор:
Итак, в чем же снова заключался наш подход, основанный на основной теореме?
1: Установите базовый вариант — если размер нашего ввода меньше определенной константы, решите его напрямую без рекурсии.
2: Если ввод больше указанной константы, разбейте его на более мелкие части.
3: Вызов функции рекурсивно для частей, пока они не станут достаточно маленькими для непосредственного решения.
4: Объедините результаты по частям и верните законченное решение.
Я обнаружил, что эта модель — действительно удобный инструмент, который надежно дает мне отправную точку при решении алгоритмических задач. Хотя это не совсем применимо к каждой проблеме алгоритма и не всегда является наиболее эффективным или элегантным решением, это надежная рабочая модель, которая может хорошо вам служить!
| Функция | Описание |
| по возрастанию | Находит значение ASCII символа. |
| Двоичный код | Преобразует строку в двоичный объект. |
| двоичный код | Преобразует двоичные данные в строку. |
| Канонизировать | Канонизация или декодирование входной строки. |
| Кодировка Декод | Преобразует строку в ее двоичное представление. |
| Кодировка | Использует указанную кодировку для преобразования двоичных данных в строку. |
| Chr | Преобразует числовое значение в символ UCS-2. |
| CОбосновать | Центрирует строку по длине поля. |
| Сравнить | Выполняет сравнение двух строк с учетом регистра. |
| СравнитьNoCase | Выполняет сравнение двух строк без учета регистра. |
| DayOfWeekAsString | Определяет день недели в виде строки от 1 до 7. |
| Расшифровать | Расшифровывает строку, зашифрованную с помощью функции шифрования. |
| EncodeForCSS | Кодирует входную строку для использования в CSS. |
| EncodeForDN | Кодирует заданную строку для безопасного вывода в отличительных именах LDAP. |
| EncodeForHTML | Кодирует входную строку для безопасного вывода в теле тега HTML. |
| EncodeForHTMLAttribute | Кодирует входную строку для безопасного вывода в значение атрибута тега HTML. |
| EncodeForJavaScript | Кодирует входную строку для использования в JavaScript. |
| EncodeForLDAP | Кодирует входную строку для безопасного вывода в запросах LDAP. |
| EncodeForURL | Кодирует входную строку для использования в URL-адресах. |
| EncodeForXML | Кодирует строку для XML. |
| EncodeForXMLAttribute | Кодирует строку, которая может использоваться как атрибут XML. |
| Зашифровать | Шифрует строку. |
| Найти | Находит первое вхождение подстроки в строке с указанной начальной позиции. |
| FindNoCase | Находит первое вхождение подстроки в строке с указанной начальной позиции. При поиске регистр не учитывается. |
| FindOneOf | Находит первое вхождение любого одного из набора символов в строке с указанной начальной позиции. |
| FormatBaseN | Преобразует число в строку с основанием, указанным в системе счисления. |
| GenerateSecretKey | Создает безопасное случайное значение ключа. |
| GetToken | Определяет, присутствует ли в строке токен из списка в параметре delimiters. |
| Хэш | Преобразует строку в шестнадцатеричную строку фиксированной длины. |
| Hmac | Создает код аутентификации сообщения на основе хэша для данной строки на основе алгоритма и кодировки. |
| HTMLCodeFormat | Заменяет специальные символы в строке их эквивалентами с экранированием HTML и вставляет тегиив начало и конец строки. |
| HTMLEditFormat | Устаревшая функция |
| Вставка | Вставляет подстроку в строку после указанной позиции символа. |
| JSStringFormat | Экранирует специальные символы JavaScript, такие как одинарные кавычки, двойные кавычки и перевод строки. |
| LCase | Преобразует буквенные символы в строке в нижний регистр. |
| Левый | Возвращает количество символов до крайнего левого значения в строке. |
| Лен | Определяет длину строкового или двоичного объекта. |
| ListValueCount | Подсчитывает экземпляры указанного значения в списке. При поиске учитывается регистр. |
| ListValueCountNoCase | Подсчитывает экземпляры указанного значения в списке. При поиске регистр не учитывается. При поиске регистр не учитывается. |
| LОбосновать | Выравнивание символов в строке указанной длины по левому краю. |
| LSIs Валюта | Определяет, является ли строка допустимым представлением денежной суммы в текущем языковом стандарте. |
| БИС Дата | Определяет, является ли строка допустимым представлением значения даты / времени в текущем языковом стандарте. |
| БИС Числовые | Определяет, является ли строка допустимым представлением числа в текущей локали. |
| LSParseCurrency | Преобразует строку валюты, зависящую от языкового стандарта, в форматированное число. |
| LSParseDateTime | Преобразует строку, которая является допустимым представлением даты / времени в текущем языковом стандарте, в объект даты / времени. |
| LSParseEuroCurrency | Форматирует строку валюты, зависящую от языкового стандарта, как число. |
| LSParseNumber | Преобразует строку, которая является допустимым числовым представлением в текущем языковом стандарте, в форматированное число. |
| LTrim | Удаляет начальные пробелы из строки. |
| Средний | Извлекает подстроку из строки. |
| MonthAsString | Определяет название месяца, соответствующего month_number. |
| ParagraphFormat | Заменяет одинарные и двойные символы новой строки пробелами и тегами абзаца HTML соответственно. |
| ParseDateTime | Анализирует строку даты / времени в соответствии с английским (U.S.) соглашения о локали. |
| REFind | Использует регулярное выражение (RE) для поиска в строке шаблона. При поиске учитывается регистр. |
| REFindNoCase | Использует регулярное выражение (RE) для поиска шаблона в строке, начиная с указанной позиции. При поиске регистр не учитывается. При поиске регистр не учитывается. |
| REM Матч | Использует регулярное выражение (RE) для поиска шаблона в строке, начиная с указанной позиции.При поиске учитывается регистр. |
| REMatchNoCase | Использует регулярное выражение (RE) для поиска шаблона в строке, начиная с указанной позиции. При поиске учитывается регистр. |
| RemoveChars | Удаляет символы из строки. |
| RepeatString | Создает строку, содержащую указанное количество повторений указанной строки. |
| Заменить | Заменяет вхождения substring1 в строке на объект в указанной области.При поиске учитывается регистр. |
| Список замен | Заменяет вхождения элементов из списка с разделителями в строке соответствующими элементами из другого списка с разделителями. При поиске учитывается регистр. |
| ReplaceNoCase | Заменяет вхождения substring1 на substring2 в указанной области.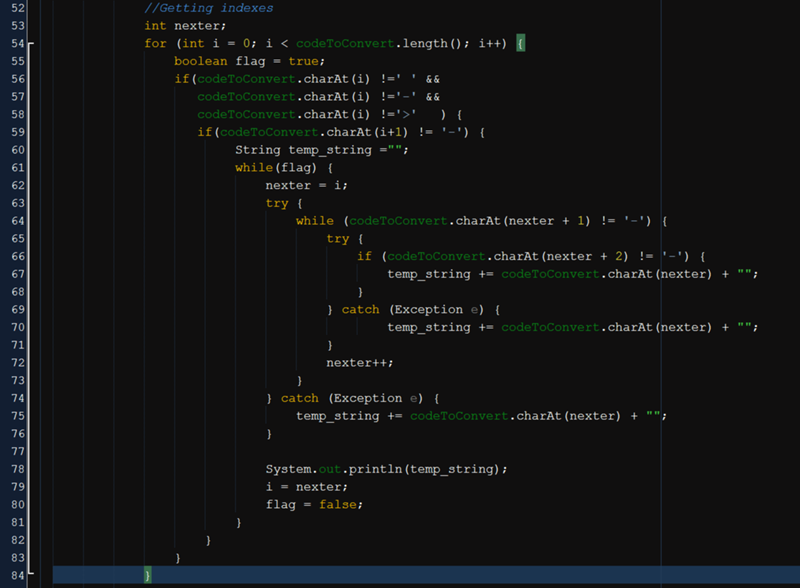 При поиске регистр не учитывается. При поиске регистр не учитывается. |
| RER Заменить | Использует регулярное выражение (RE) для поиска в строке шаблона строки и замены его другим.При поиске учитывается регистр. |
| REReplaceNoCase | Использует регулярное выражение для поиска в строке шаблона строки и замены ее другим. При поиске регистр не учитывается. |
| Задний ход | Изменяет порядок элементов, например символов в строке или цифр в числе. |
| Правый | Получает указанное количество символов из строки, начиная справа. |
| RОбосновать | Выравнивание символов строки по правому краю. |
| RTrim | Удаляет пробелы в конце строки. |
| Диапазон без | Получает символы из строки от начала до символа в указанном наборе символов. |
| Диапазон, включая | Получает символы из строки от начала до символа, не входящего в указанный набор символов. |
| StripCR | Удаляет возвращаемые символы из строки. |
| ToBase64 | Вычисляет представление строки или двоичного объекта в формате Base64. |
| ToBinary | Вычисляет двоичное представление данных в кодировке Base64, документа PDF или электронной таблицы. |
| ToString | Преобразует значение в строку. |
| Накладка | Удаляет начальные и конечные пробелы и управляющие символы из строки. |
| UCase | Преобразует буквенные символы в строке в верхний регистр. |
| URL Декод | Расшифровывает строку в кодировке URL. |
| URLEncodedFormat | Создает строку в кодировке URL. |
| Вал | Преобразует числовые символы, встречающиеся в начале строки, в число. |
| Обертка | Переносит текст так, чтобы каждая строка содержала указанное максимальное количество символов.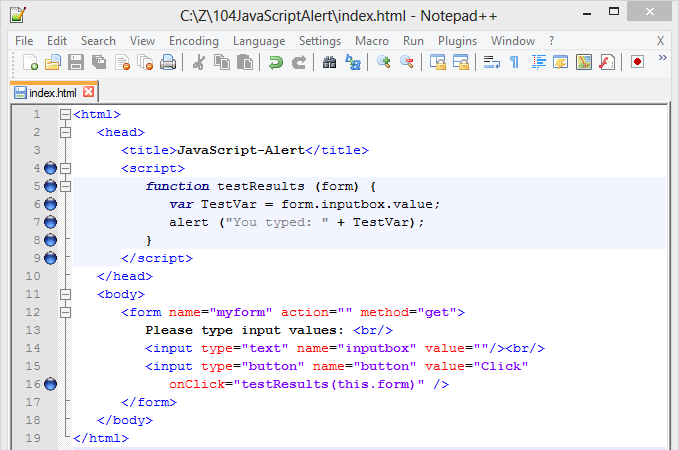 |
| XmlFormat | Экранирует специальные символы XML в строке, чтобы строку можно было использовать как текст в XML. |
nextapps-de / flexsearch: библиотека полнотекстового поиска нового поколения для браузера и Node.js
Предварительная версия v0.7.0-rev2
Предварительный просмотр новой версии доступен в ветви «0.7.0» в течение одного месяца (или более, если необходимо), прежде чем она попадет в главную ветку. Было бы действительно полезно, если бы вы могли протестировать интеграцию будущей версии в ваши существующие проекты в течение этого времени и дать мне несколько отзывов.
На самом деле существует большая проблема с переносом веток функций, поэтому я буду выпускать их одну за другой, сгруппированные по их зависимостям:
Release Group A (выпущено)
Группа выпуска B (выпущена)
Группа выпуска A / B (rev2)
Группа выпуска C (неизданная)
Группа выпуска D (неизданная)
Прочтите документацию обо всех новых функциях
Установить новую версию:
npm установить nextapps-de / flexsearch # 0.
 7,0
7,0 Web — самая быстрая и наиболее гибкая для памяти библиотека полнотекстового поиска с нулевыми зависимостями.
Когда дело доходит до скорости прямого поиска, FlexSearch превосходит любую отдельную поисковую библиотеку, а также предоставляет гибкие возможности поиска, такие как поиск по нескольким полям, фонетические преобразования или частичное сопоставление. В зависимости от используемых параметров он также обеспечивает наиболее эффективный с точки зрения памяти индекс. FlexSearch представляет новый алгоритм оценки, называемый «контекстным индексом», основанный на архитектуре лексического словаря с предварительной оценкой, который фактически выполняет запросы до 1000000 раз быстрее по сравнению с другими библиотеками.FlexSearch также предоставляет вам неблокирующую модель асинхронной обработки, а также веб-работников для выполнения любых обновлений или запросов к индексу параллельно через выделенные сбалансированные потоки.
FlexSearch Server доступен здесь: https://github. com/nextapps-de/flexsearch-server.
com/nextapps-de/flexsearch-server.
• Справочник по API • Пользовательские сборки • Сервер Flexsearch • Журнал изменений
Поддерживаемые платформы:
Демоверсии:
Сравнение библиотек:
Плагины (внешние):
Получить последнюю версию (стабильный выпуск):
Все функции:
Также довольно просто сделать кастомные сборки
Benchmark Рейтинг
Сравнение: эталон «Путешествие Гулливера»
Тест-запрос: «Путешествие Гулливера»
| Рейтинг | Имя библиотеки | Версия библиотеки | Одиночная фраза (оп / с) | Несколько фраз (оп / с) | Not Found (op / s) |
| 1 | FlexSearch * | 0.3,6 | 363757 | 182603 | 1627219 |
| 2 | Уэйд | 0,3,3 | 899 | 6098 | 214286 |
| 3 | Поиск JS | 1. 4.2 4.2 | 735 | 8889 | 800000 |
| 4 | JSii | 1.0 | 551 | 9970 | 75000 |
| 5 | Lunr.js | 2.3.5 | 355 | 1051 | 25000 |
| 6 | Elasticlunr.js | 0,9,6 | 327 | 781 | 6667 |
| 7 | BulkSearch | 0.1,3 | 265 | 535 | 2778 |
| 8 | bm25 | 0,2 | 71 | 116 | 2065 |
| 9 | Предохранитель | 3. 3.0 3.0 | 0,5 | 0.4 | 0,7 |
* Для этого теста использовалась предустановка «быстро»
Сравнение результатов: эталонный тест «Путешествие Гулливера»
Контекстный поиск
Примечание: Эта функция фактически не включена по умолчанию. Читайте здесь, как включить.
FlexSearch представляет новый механизм оценки под названием Contextual Search , который был изобретен Томасом Вилкерлингом, автором этой библиотеки.Контекстный поиск невероятно повышает количество запросов до совершенно нового уровня, но также требует некоторой дополнительной памяти (в зависимости от глубины ).
Основная идея этой концепции — ограничить релевантность контекстом вместо того, чтобы рассчитывать релевантность на всем (неограниченном) расстоянии.
Таким образом, контекстный поиск также улучшает результаты запросов на основе релевантности для большого количества текстовых данных.
Лексический словарь с предварительной оценкой / контекстная карта
Индекс состоит из находящегося в памяти предварительно оцененного словаря в качестве основы.Наибольшая сложность этих алгоритмов возникает при расчете перекрестков. Как следствие, каждый дополнительный термин в запросе может значительно усложнить задачу. Контекстная карта вступает в игру, когда запрос содержит более 1 члена , и увеличивает эффект для каждого дополнительного члена за счет уменьшения сложности вычислений пересечений. Вместо увеличения сложность снижается на каждый дополнительный член. Сам контекстный индекс также основан на предварительно оцененном словаре и следует стратегии, ориентированной на память.
| Тип | Сложность |
| Каждый запрос с одним термином: | 1 |
| Лексический словарь с предварительной оценкой (соло): | TERM_COUNT * TERM_MATCHES |
| Лексический словарь с предварительной оценкой + контекстная карта: | TERM_MATCHES / TERM_COUNT |
Сложность для одного термина всегда равна 1.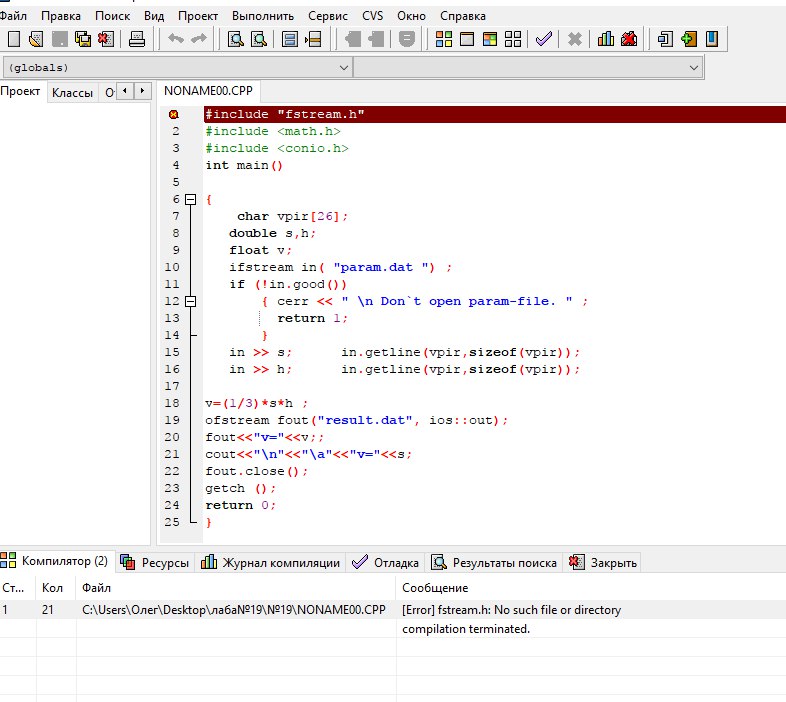
Сравните BulkSearch с FlexSearch
| BulkSearch | FlexSearch | |
| Доступ | Индекс, оптимизированный для чтения и записи | Оптимизированный индекс для чтения-памяти |
| Память | Большой: ~ 1 Мб на 100 000 слов | Tiny: ~ 100 Кб на 100 000 слов |
| Тип индекса | Группа закодированных строковых данных, разделенных на фрагменты |
|
| Прочность |
|
|
| Слабые |
|
|
| Разбиение на страницы | Есть | № |
| Подстановочные знаки | Есть | № |
Имейте в виду, что обновление существующих элементов или удаление элементов из индекса требует значительных затрат.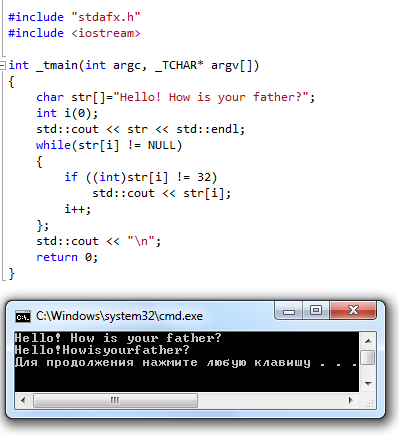 Если существующие элементы вашего индекса необходимо постоянно обновлять / удалять, то BulkSearch может быть лучшим выбором.
Если существующие элементы вашего индекса необходимо постоянно обновлять / удалять, то BulkSearch может быть лучшим выбором.
Установка
HTML / Javascript
Используйте flexsearch.min.js для производства и flexsearch.js для разработки.
... Использовать последнее из CDN:
Или конкретная версия:
Драм:
var FlexSearch = require ("./ flexsearch.js"); Node.js
npm установить flexsearch
В ваш код укажите следующее:
var FlexSearch = require ("flexsearch"); Или укажите варианты, если требуются:
var index = require ("flexsearch"). создать ({/ * параметры * /}); 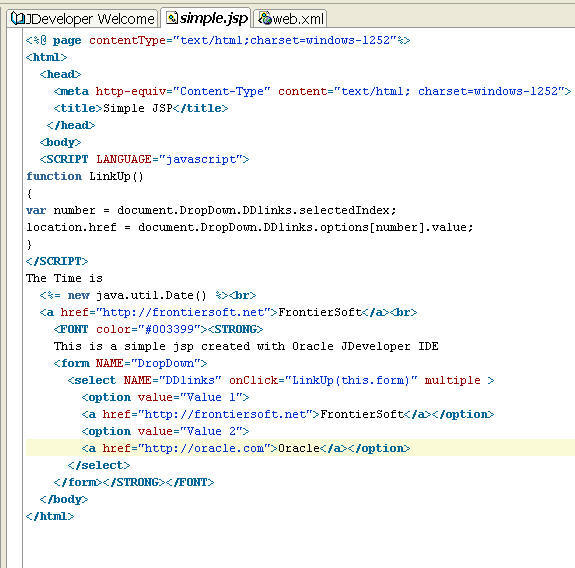 создать ({/ * параметры * /});
создать ({/ * параметры * /}); Обзор API
Глобальные методы:
Методы индекса:
Свойства индекса:
Использование
Создать новый индекс
FlexSearch. создать (<параметры>)
var index = новый FlexSearch ();
в качестве альтернативы вы также можете использовать:
var index = FlexSearch.create ();
Создайте новый индекс и выберите одну из предустановок:
var index = new FlexSearch ("скорость"); Создать новый индекс с настраиваемыми параметрами:
var index = new FlexSearch ({
// значения по умолчанию:
кодировать: "баланс",
tokenize: "вперед",
порог: 0,
асинхронный: ложь,
рабочий: ложь,
кеш: ложь
}); Создание нового индекса и расширение предустановки с помощью пользовательских параметров:
var index = new FlexSearch ("memory", {
кодировать: "баланс",
tokenize: "вперед",
порог: 0
}); Просмотреть все доступные индивидуальные параметры.
Добавить текстовый элемент в индекс
Индекс. добавить (идентификатор, строка)
index.add (10025, «Джон Доу»);
Искать товары
Индекс. поиск (строка | параметры, <предел>, <обратный вызов>)
Ограничить результат:
index.search («Джон», 10);
Асинхронный поиск
Выполнять запросы асинхронно:
index.search ("Джон", функция (результат) {
// массив результатов
}); Передача обратного вызова всегда будет выполняться как асинхронная, даже если параметр «async» не был установлен.
Выполнять запросы асинхронно (на основе обещаний):
Убедитесь, что на этом экземпляре включена опция «async», чтобы получать обещания.
index.search ("Джон"). Then (function (result) {
// массив результатов
}); Альтернативно ES6:
поиск асинхронной функции (запрос) {
const результат = ожидание index. search (запрос);
// ...
}  search (запрос);
// ...
}
search (запрос);
// ...
} Пользовательский поиск
Передавать настраиваемые параметры для каждого запроса:
Индекс.поиск({
запрос: "Джон",
предел: 1000,
порог: 5, //> = порог
глубина: 3, // <= глубина
callback: function (results) {
// ...
}
}); То же, что и выше, также можно записать как:
index.search ("Джон", {
предел: 1000,
порог: 5,
глубина: 3
}, функция (результаты) {
// ....
}); Просмотреть все доступные параметры пользовательского поиска.
Пагинация
FlexSearch обеспечивает разбиение на страницы на основе курсора, которое может внедряться в самый внутренний процесс.Это дает возможность для многих улучшений производительности.
Реализация курсора может часто меняться. Просто возьмите курсор как есть и не ожидайте какого-либо конкретного значения или формата.
Чтобы включить разбиение на страницы, вы должны передать поле page в настраиваемом объекте поиска (необязательно также ограничение как максимальное количество элементов на странице).
Получить первую страницу результатов:
var response = index.search ("Джон Доу", {
предел: 5,
page: true
}); Всегда при прохождении страницы в рамках пользовательского поиска ответ имеет следующий формат:
{
"page": "xxx: xxx",
"следующий": "ххх: ххх",
"результат": []
} - страница - указатель на текущую страницу
- следующая - это указатель на следующую страницу или null , если страниц не осталось
- результат дает результаты поиска
Получить вторую (следующую) страницу результатов:
Индекс.search ("Джон Доу", {
предел: 10,
страница: response.next
}); Предел можно изменить для каждого запроса.
Предложения
Получите также предложения по запросу:
index.
 search ({
запрос: "Джон Доу",
предложить: правда
});
search ({
запрос: "Джон Доу",
предложить: правда
}); Когда предложение включено, все результаты будут заполнены (до предела, по умолчанию 1000) с похожими совпадениями, упорядоченными по релевантности.
На самом деле фонетические подсказки не поддерживаются, для этого используйте кодировщик и токенизатор, которые предоставляют аналогичные функции.Предложения вступают в игру, когда в запросе содержится несколько слов / фраз. Предположим, что запрос содержит 3 слова. Когда индекс соответствует только 2 из 3 слов, обычно вы не получите результатов, но с включенным предложением вы также получите результаты, когда было сопоставлено 2 из 3 слов, а также было сопоставлено 1 из 3 слов (зависит от лимита), также отсортировано по актуальности.
Примечание: Планируется улучшить эту функцию и обеспечить большую гибкость.
Обновить элемент из индекса
Индекс. обновление (идентификатор, строка)
index.
 update (10025, «Дорожный бегун»);
update (10025, «Дорожный бегун»); Удалить элемент из индекса
Индекс. удалить (id)
Обнулить индекс
Уничтожить индекс
Повторно инициализировать индекс
Индекс. init (<параметры>)
Инициализация (с такими же параметрами):
Инициализировать с новыми параметрами:
index.init ({
/* опции */
}); Повторная инициализация также уничтожит старый индекс.
Получить длину
Получить длину индекса:
var length = index.length;
Получить регистр
Получить индекс (регистр) экземпляра:
Регистр имеет формат «@» + id .
Важно: Не изменяйте вручную, просто используйте его только для чтения.
Добавить пользовательское сопоставление
FlexSearch.
 registerMatcher ({ REGEX: REPLACE })
registerMatcher ({ REGEX: REPLACE }) Добавить глобальные сопоставители для всех экземпляров:
FlexSearch.registerMatcher ({
'ä': 'a', // заменяет все 'ä' на 'a'
'ó': 'о',
'[ûúù]': 'u' // заменяет несколько
}); Добавить частные сопоставители для конкретного экземпляра:
index.addMatcher ({
'ä': 'a', // заменяет все 'ä' на 'a'
'ó': 'о',
'[ûúù]': 'u' // заменяет несколько
}); Добавить пользовательский кодировщик
Назначьте пользовательский кодировщик, передав функцию во время создания / инициализации индекса:
var index = new FlexSearch ({
encode: function (str) {
// что-то делаем с str...
return str;
}
}); Функция кодировщика получает строку в качестве параметра и должна возвращать измененную строку.
Вызов пользовательского кодировщика напрямую:
var encoded = index.
 encode ("образец текста");
encode ("образец текста"); Зарегистрировать глобальный кодировщик
FlexSearch. registerEncoder (имя, кодировщик)
Глобальные энкодеры могут использоваться всеми экземплярами.
FlexSearch.registerEncoder ("пробел", function (str) {
возврат ул.заменить (/ \ s / g, "");
}); Инициализировать индекс и назначить глобальный кодировщик:
var index = new FlexSearch ({кодировать: "пробел"}); Позвоните напрямую в глобальный кодировщик:
var encoded = FlexSearch.encode («пробел», «образец текста»);
Смешивание / расширение нескольких энкодеров
FlexSearch.registerEncoder ('смешанный', function (str) {
str = this.encode ("icase", str); // встроенный
str = this.encode ("пробел", str); // обычай
// делаем что-то еще с str...
return str;
}); Добавить собственный токенизатор
Токенизатор разделяет слова на компоненты или части.

Определите частный пользовательский токенизатор во время создания / инициализации:
var index = new FlexSearch ({
tokenize: function (str) {
return str.split (/ \ s - \ // g);
}
}); Функция токенизатора получает строку в качестве параметра и должна возвращать массив строк (частей).
Добавить языковой стеммер и / или фильтр
Stemmer: несколько лингвистических мутаций одного и того же слова (e.грамм. "бег" и "бег")
Фильтр: черный список слов, которые нужно отфильтровать из индексации (например, «и», «на» или «быть»)
Назначьте частный настраиваемый стеммер или фильтр во время создания / инициализации:
var index = new FlexSearch ({
STEMMER: {
// объект {ключ: замена}
"ational": "съел",
"тионал": "тион",
"enci": "ence",
"ing": ""
},
фильтр: [
// черный список массива
"в",
"в",
"является",
"не",
"Это",
"это"
]
}); Использование специального стеммера, например. г .:
г .:
var index = new FlexSearch ({
stemmer: function (значение) {
// применяем некоторые замены
// ...
возвращаемое значение;
}
}); Использование настраиваемого фильтра, например:
var index = new FlexSearch ({
filter: function (значение) {
// просто добавляем в индекс значения длиной> 1
возвращаемое значение. длина> 1;
}
}); Или глобально назначьте стеммер / фильтры языку:
Stemmer передаются как объект (пара ключ-значение), фильтруются как массив.
FlexSearch.registerLanguage ("нас", {
стеммер: {/ * ... * /},
фильтр: [/ * ... * /]
}); Или используйте предустановленный стеммер или фильтр ваших предпочтительных языков:
. ..  ..
.. Теперь вы можете назначить встроенный стеммер при создании / инициализации:
var index_en = новый FlexSearch ({
стеммер: "en",
filter: "en"
});
var index_de = новый FlexSearch ({
стеммер: "де",
фильтр: [/ * пользовательский * /]
}); В узле.js, вам просто нужно потребовать файлы языкового пакета, чтобы сделать их доступными:
требуется ("flexsearch.js");
требуется ("lang / en.js");
требуется ("lang / de.js"); Также можно скомпилировать языковые пакеты в сборку следующим образом:
Компиляция узлаSUPPORT_LANG_EN = true SUPPORT_LANG_DE = true
Опора справа налево
Установите токенизатор как минимум в «реверсивный» или «полный» при использовании RTL.
Просто установите для поля "rtl" значение true и используйте совместимый токенизатор:
var index = FlexSearch.Создайте({
кодировать: "icase",
tokenize: "обратный",
rtl: true
}); CJK Word Break (китайский, японский, корейский)
Установите собственный токенизатор, который соответствует вашим потребностям, например:
var index = FlexSearch.
 create ({
кодировать: ложь,
tokenize: function (str) {
return str.replace (/ [\ x00- \ x7F] / g, "") .split ("");
}
});
create ({
кодировать: ложь,
tokenize: function (str) {
return str.replace (/ [\ x00- \ x7F] / g, "") .split ("");
}
}); Вы также можете передать пользовательскую функцию кодировщика для применения некоторых лингвистических преобразований.
index.add (0, «单词»);
var results = index.поиск ("单词"); Получить информацию об индексе
Эта функция доступна в режиме DEBUG .
Возвращает информацию, например:
{
"id": 0,
«память»: 10000,
«штук»: 500,
«последовательностей»: 3000,
"совпадения": 0,
«символов»: 3500,
"cache": ложь,
"совпадение": 0,
«рабочий»: ложь,
«порог»: 7,
«глубина»: 3,
"contextual": правда
} Индекс документов (полевой поиск)
Дескриптор документа
Предположим, что документ представляет собой массив данных вроде:
var docs = [{
id: 0,
title: "Заголовок",
cat: "Категория",
content: «Тело»
}, {
id: 1,
title: "Заголовок",
cat: "Категория",
content: «Тело»
}]; Укажите дескриптор документа doc при инициализации нового индекса, например. грамм. относится к приведенному выше примеру:
грамм. относится к приведенному выше примеру:
var index = new FlexSearch ({
tokenize: "строгий",
глубина: 3,
doc: {
я сделал",
поле: "содержание"
}
}); В приведенном выше примере будет просто проиндексировано поле «контент», чтобы проиндексировать несколько полей, передайте массив:
var index = new FlexSearch ({
doc: {
я сделал",
поле: [
"заглавие",
"Кот",
"содержание"
]
}
}); Вы также можете предоставить пользовательские предустановки для каждого поля отдельно:
var index = new FlexSearch ({
doc: {
я сделал",
поле: {
заглавие: {
кодировать: "экстра",
tokenize: "обратный",
порог: 7
},
Кот: {
кодировать: ложь,
tokenize: function (val) {
return [val];
}
},
content: "память"
}
}
}); Сложные объекты
Предположим, что массив документов выглядит более сложным (имеет вложенные ветви и т. Д.), например:
Д.), например:
var docs = [{
данные:{
id: 0,
title: "Фу",
тело: {
content: "Foobar"
}
}
}, {
данные:{
id: 1,
заголовка",
тело: {
content: "Foobar"
}
}
}]; Затем используйте обозначение, разделенное двоеточиями «root🧒child» , чтобы определить иерархию в дескрипторе документа:
var index = new FlexSearch ({
doc: {
id: "данные: id",
поле: [
"данные: заголовок",
"данные: тело: содержание"
]
}
}); Подсказка: Это альтернатива индексированию документов, содержащих вложенные массивы: https: // github.com / nextapps-de / flexsearch / issues / 36
Добавить / обновить / удалить документы из / в указателе
Просто передайте массив документа (или отдельный объект) в индекс:
Обновить индекс с одним объектом или массивом объектов:
index.
 update ({
данные:{
id: 0,
title: "Фу",
тело: {
содержание: «Бар»
}
}
});
update ({
данные:{
id: 0,
title: "Фу",
тело: {
содержание: «Бар»
}
}
}); Удалить отдельный объект или массив объектов из индекса:
Когда идентификатор известен, вы также можете просто удалить его (быстрее):
Field-Search
Поиск дает вам несколько вариантов при использовании документов.
Двоеточие также должно применяться для поиска соответственно.
Будет произведен поиск по всем проиндексированным полям:
var results = index.search ("тело"); Это будет искать в определенном поле):
var results = index.search ({
поле: "название",
запрос: "foobar"
}); var results = index.search ({
поле: "данные: тело: содержание",
запрос: "foobar"
}); Это также можно было бы записать как:
var results = index.search ("foobar", {
поле: "данные: тело: содержание",
}); Искать один и тот же запрос в нескольких полях:
Использование bool в качестве логического оператора при поиске по нескольким полям.
 Оператор по умолчанию, если он не задан, - "или" .
Оператор по умолчанию, если он не задан, - "или" . var results = index.search ({
запрос: "foobar",
поле: ["заголовок", "тело"],
bool: "или"
}); Можно также записать как:
var results = index.search ("foobar", {
поле: ["заголовок", "тело"],
bool: "или"
}); Искать разные запросы по нескольким полям:
var results = index.поиск([{
поле: "название",
запрос: "foo"
}, {
поле: "тело",
запрос: "бар"
}]); Просмотреть все доступные параметры поиска по полю.
Настроить магазин
Вы можете независимо определить, какие поля должны быть проиндексированы, а какие должны быть сохранены. Таким образом вы можете индексировать поля, которые не должны быть включены в результат поиска.
Когда был установлен атрибут
store, вы должны включить все поля, которые должны быть сохранены явно (действует как белый список).

Если атрибут
storeне был установлен, исходный документ сохраняется как резервный.
var index = new FlexSearch ({
doc: {
я сделал",
field: "body: content", // индекс
store: "title" // магазин
}
}); Также несколько полей:
var index = new FlexSearch ({
doc: {
я сделал",
field: ["title", "body: content"],
store: ["title", "body: content"]
}
}); Логические операторы
Есть 3 разных оператора (и, или, не).Просто пройдите в пользовательский поиск в поле bool :
var results = index.search ([{
поле: "название",
запрос: "foobar",
bool: "и"
}, {
поле: "тело",
запрос: "контент",
bool: "или"
}, {
поле: "черный список",
запрос: "xxx",
bool: "не"
}]); - "и" означает, что требуется в результате
- "или" означает необязательный в результате
- «не» указывает на то, что запрещено в результате
Найти / Где
При индексировании документов вы также можете получать результаты по определенным атрибутам.
Двоеточие также должно применяться для использования «где» и «найти» соответственно.
Найти документ по атрибуту
index.find («кот», «комедия»);
То же, что:
index.find ({"кот": "комедия"}); Для получения ID вы также можете использовать короткую форму:
Получение документа по идентификатору - фактически самый быстрый способ получить результат из документов.
Найти с помощью пользовательской функции:
index.find (функция (элемент) {
вернуть изделие.кот === "комедия";
}); Поиск документов по нескольким атрибутам
Получите только первый результат:
index.find ({
кот: "комедия",
год: "2018"
}); Получить все подходящие результаты:
index.where ({
кот: "комедия",
год: "2018"
}); Получите все результаты и установите лимит:
index.where ({
кот: "комедия",
год: "2018"
}, 100); Получить все с помощью настраиваемой функции:
index.
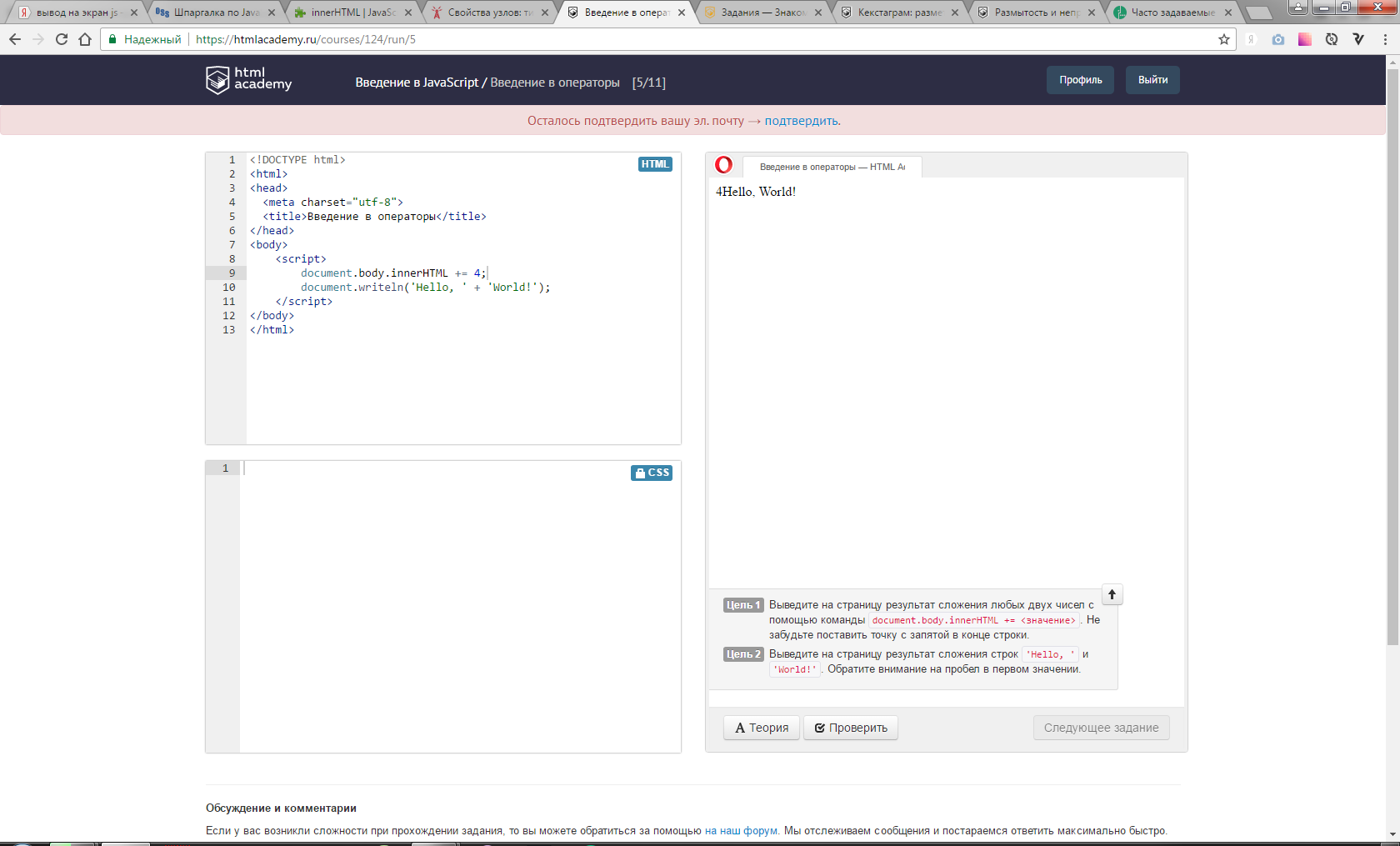 where (функция (элемент) {
вернуть изделие.кот === "комедия";
});
where (функция (элемент) {
вернуть изделие.кот === "комедия";
}); Объедините нечеткий поиск с предложением where
Добавьте контент, например:
index.add ([{
id: 0,
title: "Foobar",
кот: "приключение",
content: «Тело»
}, {
id: 1,
title: "Заголовок",
кот: "комедия",
content: "Foobar"
}]); Используя поиск, а также примените предложение where:
index.search ("foo", {
поле: [
"заглавие",
"тело"
],
куда: {
"кот": "комедия"
},
предел: 10
}); Теги
ВАЖНОЕ ПРИМЕЧАНИЕ: Эта функция будет удалена из-за отсутствия масштабирования и избыточности.
Тегирование во многом похоже на добавление дополнительного индекса в столбец базы данных. Всякий раз, когда вы используете index.where () для индексированного / помеченного атрибута, действительно улучшается производительность, но также за счет некоторой дополнительной памяти.
Двоеточие также должно применяться к тегам соответственно.
Добавьте один тег в индекс:
var index = new FlexSearch ({
doc: {
я сделал",
поле: ["название", "содержание"],
тег: "кот"
}
}); Или добавьте несколько тегов в индекс:
var index = new FlexSearch ({
doc: {
я сделал",
поле: ["название", "содержание"],
тег: ["кот", "год"]
}
}); Добавить содержание:
Индекс.Добавить([{
id: 0,
title: "Foobar",
кот: "приключение",
год: "2018",
content: «Тело»
}, {
id: 1,
title: "Заголовок",
кот: "комедия",
год: "2018",
content: "Foobar"
}]); Найти все документы по признаку:
index.where ({"кот": "комедия"}, 10); Поскольку атрибут «кошка» был помечен (имеет собственный индекс), это выражение выполняется очень быстро. На самом деле это самый быстрый способ получить несколько результатов из документов.
Найдите документы, а также примените пункт where:
Индекс.search ("foo", {
поле: [
"заглавие",
"содержание"
],
куда: {
"кот": "комедия"
},
предел: 10
}); Дополнительное предложение where имеет значительную стоимость. Использование того же выражения без , где работает значительно лучше (в зависимости от количества совпадений).
Пользовательская сортировка
Двоеточие также должно применяться для пользовательской сортировки соответственно.
Сортировать по признаку:
var results = index.search ("Джон", {
предел: 100,
sort: "данные: заголовок"
}); Порядок сортировки по умолчанию - от наименьшего к наибольшему.
Сортировать по пользовательской функции:
var results = index.search ("Джон", {
предел: 100,
sort: function (a, b) {
возвращаться (
a. id b.id? 1: 0
));
}
}); .png) id
id Цепочка
Методы простой цепочки, например:
var index = FlexSearch.create ()
.addMatcher ({'â': 'a'})
.add (0, 'фу')
.add (1, 'бар'); index.remove (0) .update (1, 'foo'). Add (2, 'foobar');
Включить контекстную оценку
Создайте индекс и просто установите предел релевантности как «глубину»:
var index = new FlexSearch ({
кодировать: "icase",
tokenize: "строгий",
порог: 7,
глубина: 3
}); Фактически контекстным индексом поддерживается только токенизатор "strict".
Контекстный индекс требует дополнительного объема памяти в зависимости от глубины.
Попробуйте использовать минимальную глубину и наивысший порог , который соответствует вашим потребностям.

Во время поиска можно изменить значения для порога и глубины (см. Пользовательский поиск). Ограничение состоит в том, что порог можно только поднять, с другой стороны, глубину можно только понизить.
Включить автоматическую балансировку кэша
Создайте индекс и просто установите лимит записей кеша:
var index = new FlexSearch ({
профиль: "оценка",
кэш: 1000
}); При передаче числа в качестве лимита кэш автоматически балансирует сохраненные записи в зависимости от их популярности.
При использовании только «true» кэш не ограничен и работает в 2–3 раза быстрее (потому что балансировщик запускать не нужно).
Web-Worker (только браузер)
Worker получает свою собственную выделенную память, а также работает в собственном выделенном потоке, не блокируя пользовательский интерфейс во время обработки. Веб-воркер значительно увеличивает скорость и объем доступной памяти, особенно для больших индексов. Индекс FlexSearch был протестирован с текстовым файлом размером 250 Мб, содержащим 10 миллионов слов.
Веб-воркер значительно увеличивает скорость и объем доступной памяти, особенно для больших индексов. Индекс FlexSearch был протестирован с текстовым файлом размером 250 Мб, содержащим 10 миллионов слов.
Когда индекс недостаточно велик, быстрее не использовать веб-воркера.
Создайте индекс и просто установите количество параллельных потоков:
var index = new FlexSearch ({
кодировать: "icase",
tokenize: "полный",
асинхронный: правда,
рабочий: 4
}); Обычное добавление элементов в рабочий индекс (асинхронный режим):
Индекс.добавить (10025, «Джон Доу»);
Выполните поиск и просто передайте обратный вызов, например:
index.search ("Джон Доу", функция (результаты) {
// что-то делаем с массивом результатов
}); Или используйте обещания соответственно:
index.search ("Джон Доу"). Then (function (results) {
// что-то делаем с массивом результатов
}); Опции
FlexSearch обладает широкими возможностями настройки.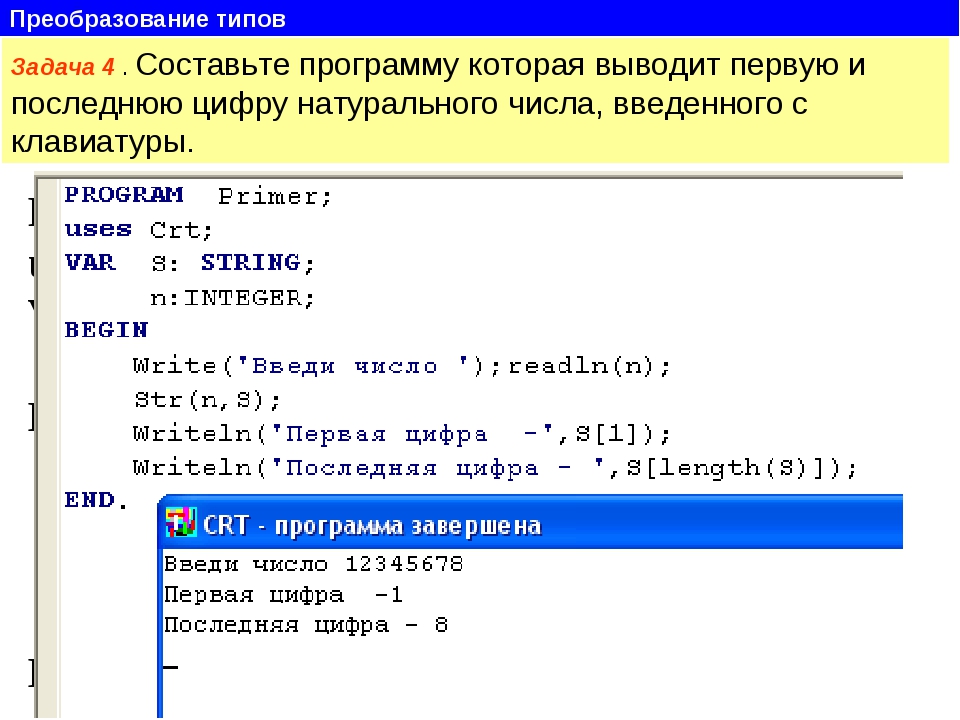 Использование правильных параметров может действительно улучшить ваши результаты, а также сэкономить память и время запроса.
Использование правильных параметров может действительно улучшить ваши результаты, а также сэкономить память и время запроса.
Индекс инициализации
| Опция | Значения | Описание |
| профиль | "память" "скорость" "совпадение" "оценка" "баланс" "быстро" | Профиль конфигурации. Выберите свое предпочтение. |
| токенизировать | "строгий" "вперед" "назад" "полный" функция () | Режим индексации (токенизатор). Выберите один из встроенных модулей или передайте настраиваемую функцию токенизатора. |
| раздельный | RegExp строка | Правило разделения слов при использовании нестандартного токенизатора (встроенного, например, «вперед»). Используйте строку / символ или регулярное выражение (по умолчанию: Используйте строку / символ или регулярное выражение (по умолчанию: / \ W + / ). |
| кодировать | false "icase" "простой" "расширенный" "дополнительный" "баланс" функция () | Тип кодировки. Выберите одну из встроенных функций или передайте пользовательскую функцию кодирования. |
| кэш | ложь правда {число} | Включение / отключение и / или установка емкости кэшированных записей. При передаче числа в качестве лимита кэш автоматически балансирует сохраненные записи в зависимости от их популярности . Примечание: при использовании только «true» кеш не имеет ограничений и фактически в 2–3 раза быстрее (потому что балансировщик запускать не нужно). |
| асинхронный | правда ложь | Включение / отключение асинхронной обработки. Каждое задание будет поставлено в очередь для неблокирующей обработки. Рекомендуется при использовании WebWorkers. |
| рабочий | ложный {номер} | Включение / отключение и установка количества запущенных рабочих потоков. |
| глубина | ложный {номер} | Включить / отключить контекстное индексирование, а также установить контекстное расстояние релевантности.Глубина - это максимальное количество слов / токенов от термина, которое считается релевантным. |
| порог | ложный {номер} | Включить / выключить порог минимальной релевантности, который должны иметь все результаты. Примечание. Также можно установить более низкий порог для индексации и передать более высокое значение при вызове index.search (options) . |
| разрешение | {номер} | Устанавливает разрешение оценки (по умолчанию: 9). |
| стеммер | ложь {строка} {функция} | Отключить или передать флаг сокращения языка (ISO-3166) или настраиваемый объект. |
| фильтр | ложь {строка} {функция} | Отключить или передать флаг сокращения языка (ISO-3166) или настраиваемый массив. |
| RTL | правда ложь | Включает кодирование справа налево. |

Пользовательский поиск
| Опция | Значения | Описание |
| предел | номер | Устанавливает предел результатов. |
| предложить | правда, ложь | Включает предложения в результатах. |
| где | объект | Используйте предложение where для неиндексированных полей. |
| поле | строка, массив <строка> | Задает поля документа, в которых следует выполнять поиск. Если поле не задано, поиск будет выполняться по всем полям. Также поддерживаются настраиваемые параметры для каждого поля. |
| булев | "и", или " | "Задает используемый логический оператор при поиске по нескольким полям. |
| стр. | истина, ложь, курсор | Разрешает разбивать результаты на страницы. |
Вы также можете переопределить следующие настройки индекса с помощью пользовательского поиска (v0.7.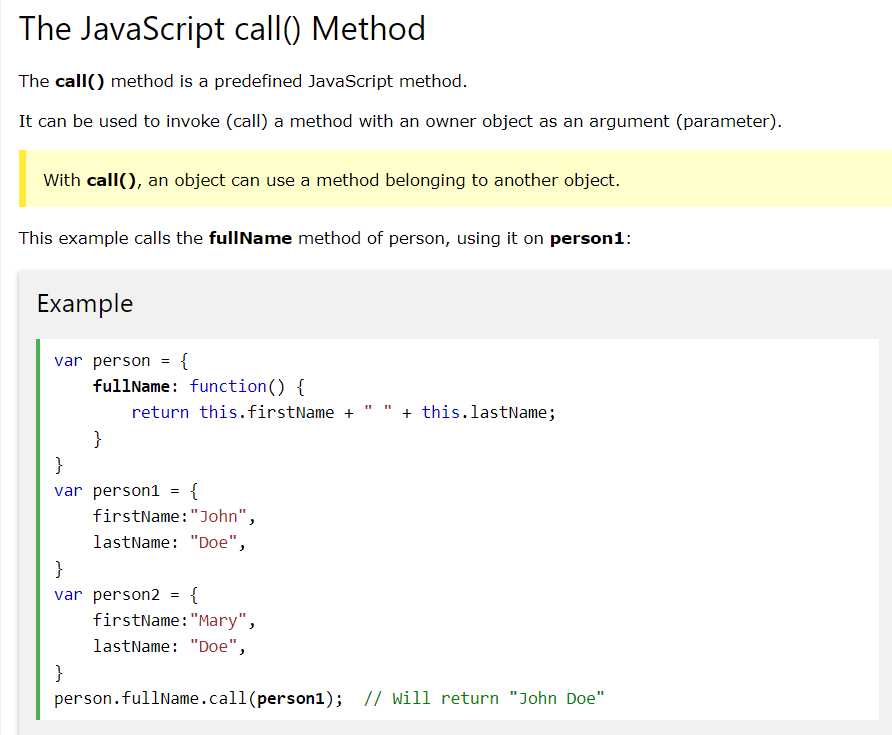 0):
0):
- кодировать
- сплит
- токенизировать
- порог
- кэш
- асинхронный
Параметры пользовательского поиска имеют приоритет над параметрами индекса.
Поиск по полю (v0.7.0)
| Опция | Значения | Описание |
| предел | номер | Устанавливает предел результатов для каждого поля. |
| предложить | правда, ложь | Включает предложения в результатах для каждого поля. |
| булев | "и", "или", "не" | Задает используемый логический оператор при поиске по нескольким полям. |
| наддув | номер | Включает усиление полей. |
Вы также можете переопределить следующие настройки индекса для каждого поля с помощью настраиваемого поиска по полю:
- кодировать
- сплит
- токенизировать
- порог
Параметры поиска по полю переопределяют параметры пользовательского поиска и параметры индекса.
Глубина, порог, разрешение?
В то время как глубина является минимальной релевантностью для контекстного индекса , порог является минимальной релевантностью для лексического индекса . Пороговая оценка - это усовершенствованный вариант обычного подсчета баллов, который использует расстояние до документа и частичное расстояние вместо TF-IDF. Окончательная оценка основана на трех видах дистанции.
Разрешение, с другой стороны, указывает максимальное значение оценки.Окончательное значение оценки является целым числом, поэтому разрешение влияет на количество сегментов, которые может иметь оценка. Когда разрешение равно 1, существует только один уровень оценки для всех совпадающих терминов. Чтобы получить более дифференцированные результаты, вам нужно поднять разрешение.
Разница обоих влияет на производительность при более высоких значениях (сложность = , разрешение - порог ).

Комбинация разрешения и порога дает вам хороший контроль над вашими совпадениями, а также производительность, например.грамм. когда разрешение равно 25, а порог равен 22, тогда результат содержит только супер-релевантные совпадения. Цель всегда должна заключаться в том, чтобы получить в результате то, что действительно необходимо. Кроме того, это также значительно улучшает производительность.
Токенизатор
Tokenizer влияет на требуемую память, а также на время запроса и гибкость частичных совпадений. Попробуйте выбрать самый верхний из этих токенизаторов, который соответствует вашим потребностям:
| Опция | Описание | Пример | Коэффициент памяти (n = длина слова) |
| «строгий» | индекс целых слов | foobar | * 1 |
| "вперед" | инкрементно индексирует слова в прямом направлении | fo obar foob ar | * п |
| "реверс" | инкрементно индексируют слова в обоих направлениях | фооб ар фо обар | * 2n - 1 |
| "полный" | индекс всевозможных комбинаций | fo oba r f oob ar | * n * (n - 1) |
Энкодеры
Encoding влияет на требуемую память, а также на время запроса и фонетические совпадения.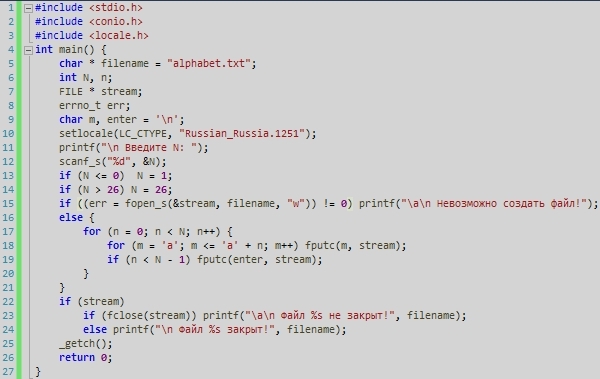 Попробуйте выбрать самый верхний из этих кодировщиков, который соответствует вашим потребностям, или передайте собственный кодировщик:
Попробуйте выбрать самый верхний из этих кодировщиков, который соответствует вашим потребностям, или передайте собственный кодировщик:
| Опция | Описание | Ложноположительные результаты | Сжатие |
| ложный | Отключить кодировку | № | № |
| icase (по умолчанию) | Кодировка без учета регистра | № | № |
| "простой" | Фонетические нормализации | № | ~ 7% |
| «продвинутый» | Фонетические нормализации + буквальные преобразования | № | ~ 35% |
| "экстра" | Фонетические нормализации + преобразования Soundex | да | ~ 60% |
| функция () | Передача пользовательской кодировки через функцию (строка): строка |
Сравнение соответствия кодировщика
Ссылочная строка: "Björn-Phillipp Mayer"
| Запрос | icase | простой | продвинутый | экстра |
| Бьорн | да | да | да | да |
| björ | да | да | да | да |
| Бьорн | № | да | да | да |
| Бьорн | № | № | да | да |
| Филипп | № | № | да | да |
| филипп | № | № | да | да |
| Бьёрнфиллип | № | да | да | да |
| Майер | № | № | да | да |
| Бьорн Майер | № | № | да | да |
| Майер Филипп | № | № | да | да |
| byorn mair | № | № | № | да |
| (ложные срабатывания) | нет | нет | нет | да |
Использование памяти
Требуемый объем памяти для индекса зависит от нескольких параметров:
| Кодировка | Использование памяти каждыми ~ 100000 проиндексированных слов |
| ложный | 260 кб |
| icase (по умолчанию) | 210 кб |
| "простой" | 190 кб |
| "расширенный" | 150 кб |
| "экстра" | 90 кб |
| Режим | Умножается на: (n = средняя длина проиндексированных слов) |
| "строгий" | * 1 |
| "вперед" | * п |
| "реверс" | * 2n - 1 |
| "полный" | * n * (n - 1) |
| Контекстный указатель | Умножьте полученную выше сумму на: |
| * (глубина * 2 + 1) |
Добавление, удаление или обновление существующих элементов имеет аналогичную сложность. Контекстный индекс растет экспоненциально, поэтому на самом деле он поддерживается как раз для токенизатора "strict" .
Контекстный индекс растет экспоненциально, поэтому на самом деле он поддерживается как раз для токенизатора "strict" .
Сравните потребление памяти
Для этого теста использовалась книга «Путешествия Гулливера» (Swift Jonathan 1726).
пресетов
Вы можете передать предустановку во время создания / инициализации. Они представляют следующие настройки:
"по умолчанию" : Стандартный профиль
{
кодировать: "icase",
tokenize: "вперед",
разрешение: 9
} «память» : профиль, оптимизированный для памяти
{
кодировать: "экстра",
tokenize: "строгий",
порог: 0,
разрешение: 1
} "скорость" : профиль, оптимизированный по скорости
{
кодировать: "icase",
tokenize: "строгий",
порог: 1,
разрешение: 3,
глубина: 2
} "совпадение" : Соответствующий-толерантный профиль
{
кодировать: "экстра",
tokenize: "полный",
порог: 1,
разрешение: 3
} «оценка» : профиль, оптимизированный по релевантности
{
кодировать: "экстра",
tokenize: "строгий",
порог: 1,
разрешение: 9,
глубина: 4
} «баланс» : Самый сбалансированный профиль
{
кодировать: "баланс",
tokenize: "строгий",
порог: 0,
разрешение: 3,
глубина: 3
} «быстрый» : Абсолютно самый быстрый профиль
{
кодировать: "icase",
порог: 8,
разрешение: 9,
глубина: 1
} Сравните эти пресеты:
Руководство по производительности
Методы получения результатов, отсортированные от самого быстрого к самому медленному:
-
индекс. найти (id) -> doc -
index.where ({field: string}) -> Произвольныйс тегом в том же поле -
index.search (запрос) -> Arraryпри добавлении id и содержимого в индекс (без документов) -
index.search (запрос) -> Arraryпри использовании документов -
index.search (query, {where}) -> Arraryпри использовании документов и предложение where -
индекс.где ({field: [string, string]}) -> Arrary, когда тег был установлен в одно из двух полей -
index.where ({field: string}) -> Arrary, если для этого поля не был установлен тег
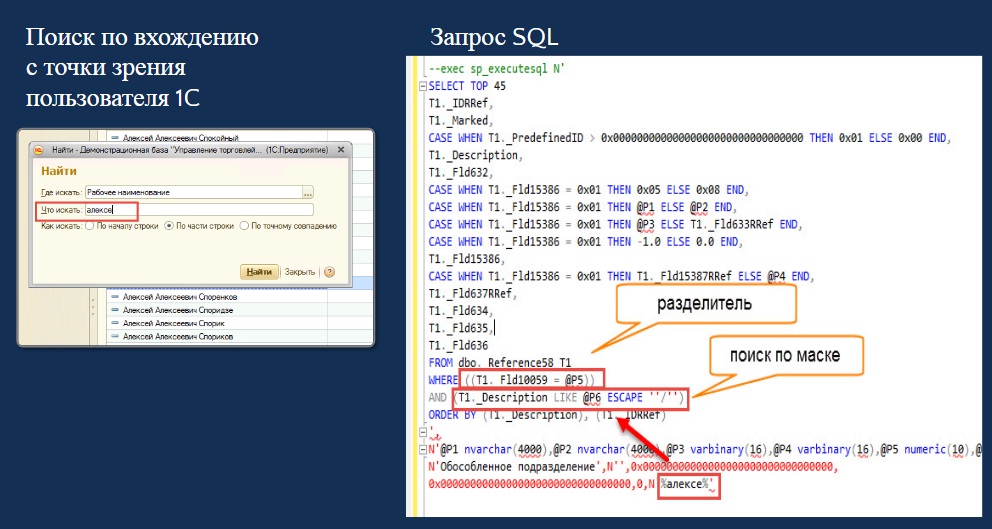 найти (id) -> doc
найти (id) -> doc Методы изменения индекса с самого быстрого на самый медленный:
-
index.add (идентификатор, строка) -
index.add (docs) -
index.delete (идентификатор, строка) -
index. delete (документы) -
индекс.обновление (идентификатор, строка) -
index.update (документы)
 delete (документы)
delete (документы) Контрольный список производительности:
- Использование только пар id-content для индекса работает почти быстрее, чем использование docs
- Дополнительное предложение where в
index.search ()имеет значительную стоимость - При добавлении нескольких полей документов в индекс попробуйте установить минимально возможную предустановку для каждого поля отдельно
- Убедитесь, что кэш-память с автоматической балансировкой включена и имеет значимое значение
- Используя индекс
.где ()для поиска документов очень медленно, если не используется поле с тегами - Получение документа по ID через
index.find (id)очень быстро - Не включайте async , а также worker , если индекс не требует его
- Использовать числовые идентификаторы (длина типа данных идентификаторов существенно влияет на потребление памяти)
- Попробуйте включить контекстный индекс , установив для глубины минимальное значимое значение, а для токенизатора - «строгий»
- Пройти предел при поиске (меньшие значения работают лучше)
- Пройдите минимальный порог при поиске (более высокие значения работают лучше)
- Попытайтесь уменьшить размер содержимого проиндексированных документов, просто добавив атрибуты, которые вам действительно нужны для возврата из результатов
Лучшие Лрактики
Разделить сложность
По возможности старайтесь разделить контент по категориям и добавить их в собственный индекс, например. г .:
г .:
var action = new FlexSearch (); var adventure = new FlexSearch (); var comedy = new FlexSearch ();
Таким образом, вы также можете указать разные настройки для каждой категории. На самом деле это самый быстрый способ выполнить нечеткий поиск.
Чтобы сделать этот обходной путь более расширяемым, вы можете использовать короткий помощник:
var index = {};
function add (id, cat, content) {
(индекс [кошка] || (
index [cat] = новый FlexSearch
)). add (id, content);
}
функция search (cat, query) {
индекс возврата [кот]?
index [cat].поисковый запрос) : [];
} Добавить в индекс:
add (1, «действие», «Название фильма»); add (2, «приключение», «название фильма»); add (3, «комедия», «название фильма»);
Выполнить запросы:
var results = search ("действие", "название фильма"); // -> [1] Разделение индексов по категориям значительно повышает производительность.
Использовать числовые идентификаторы
Рекомендуется использовать числовые значения идентификатора в качестве ссылки при добавлении содержимого в индекс. Длина передаваемых идентификаторов в байтах существенно влияет на потребление памяти.Если это невозможно, вам следует подумать об использовании таблицы индексов и сопоставить идентификаторы с индексами, это становится важным, особенно при использовании контекстных индексов для большого количества контента.
Длина передаваемых идентификаторов в байтах существенно влияет на потребление памяти.Если это невозможно, вам следует подумать об использовании таблицы индексов и сопоставить идентификаторы с индексами, это становится важным, особенно при использовании контекстных индексов для большого количества контента.
Индекс экспорта / импорта
index.export () возвращает сериализованный дамп в виде строки.
index.import (string) принимает сериализованный дамп как строку и загружает его в индекс.
Предположим, у вас есть один или несколько индексов:
var feeds_2017 = новый FlexSearch (); var feeds_2018 = новый FlexSearch (); var feeds_2019 = новый FlexSearch ();
Экспортные индексы, e.грамм. в локальное хранилище:
localStorage.setItem ("feeds_2017", feeds_2017.export ());
localStorage.setItem ("feeds_2018", feeds_2018.export ());
localStorage.setItem ("feeds_2019", feeds_2019. export ());  export ());
export ()); Импортировать индексы, например из локального хранилища:
feeds_2017.import (localStorage.getItem ("feeds_2017"));
feeds_2018.import (localStorage.getItem ("feeds_2018"));
feeds_2019.import (localStorage.getItem ("feeds_2019")); Отключить сериализацию
Передайте флаг конфигурации для управления сериализацией:
var data = index.экспорт ({сериализовать: ложь}); Используйте ту же конфигурацию соответственно при импорте данных:
index.import (данные, {сериализовать: ложь}); Отдельный экспорт (документы)
Передайте флаг конфигурации, чтобы отделить индекс и документы от экспорта:
var idx = index.export ({index: true, doc: false}); var docs = index.export ({index: false, doc: true}); Используйте ту же конфигурацию соответственно при импорте данных:
index.import (idx, {index: true, doc: false}); Индекс.импорт (документы, {индекс: ложь, документ: истина}); Вы также можете передавать документы как внешние данные, предположим, что данных - это массив документов:
index.
 import (idx, {index: true, doc: data});
import (idx, {index: true, doc: data}); Отладка
Не используйте DEBUG в производственных сборках.
При возникновении проблем можно временно установить флаг DEBUG на true поверх flexsearch.js :
Это включает консольное ведение журнала нескольких процессов.Просто откройте консоль браузера, чтобы эта информация стала видимой.
Статистика профилировщика
Не используйте PROFILER в производственных сборках.
Для сбора статистики производительности ваших индексов вам необходимо временно установить флаг PROFILER на true поверх flexsearch.js :
Это позволяет профилировать несколько процессов.
Массив всех профилей доступен на:
Вы также можете просто открыть консоль браузера и ввести эту строку, чтобы получить статистику.
Индекс массива соответствует index.
 id .
id .Получить статистику по определенному индексу:
Полезная нагрузка возвращаемой статистики разделена на несколько категорий. Каждая из этих категорий предоставляет свои собственные статистические значения.
Свойства статистики профилировщика
| Имущество | Описание |
| время | Сумма времени (мс), которое занимает процесс (чем меньше, тем лучше) |
| количество | Как часто вызывали процесс |
| опс | Среднее количество операций в секунду (чем больше, тем лучше) |
| нано | Средняя стоимость (нс) на операцию / звонок (чем меньше, тем лучше) |
Пользовательские сборки
Полная сборка:
Компактная сборка:
Легкая сборка:
Сборка языковых пакетов:
Пользовательская сборка:
npm запустить пользовательскую сборку SUPPORT_WORKER = true SUPPORT_ASYNC = true
В пользовательских сборках для каждого флага сборки по умолчанию будет установлено значение false .
В качестве альтернативы вы также можете использовать:
Компиляция узлаSUPPORT_WORKER = true
Пользовательская сборка будет сохранена в flexsearch.custom.xxxxx.js («xxxxx» - это хэш, основанный на используемых флагах сборки).
Поддерживаемые флаги сборки
| Флаг | Значения |
| ОТЛАДКА | правда, ложь |
| ПРОФИЛЕР | правда, ложь |
| SUPPORT_ENCODER | правда, ложь |
| ПОДДЕРЖКА ДОКУМЕНТА | правда, ложь |
| ГДЕ ОПОРА | правда, ложь |
| ПОДДЕРЖКА | правда, ложь |
| SUPPORT_CACHE | правда, ложь |
| ПОДДЕРЖКА_ASYNC | правда, ложь |
| SUPPORT_PRESET | правда, ложь |
| SUPPORT_INFO | правда, ложь |
| ПОДДЕРЖКА_СЕРИАЛИЗАЦИЯ | правда, ложь |
| ПОДДЕРЖКА_ПОДАВКА | правда, ложь |
| ПОДДЕРЖКА | правда, ложь |
| ОПЕРАТОР_ОПЕРАТОРА | правда, ложь |
| SUPPORT_CALLBACK | правда, ложь |
| Языковые пакеты | |
| SUPPORT_LANG_EN | правда, ложь |
| SUPPORT_LANG_DE | правда, ложь |
| Флаги компилятора | |
| LANGUAGE_OUT | ECMASCRIPT3 ECMASCRIPT5 ECMASCRIPT5_STRICT ECMASCRIPT6 ECMASCRIPT6_STRICT ECMASCRIPT_2015 ECMASCRIPT_2017 STABLE |
Вклад
Не стесняйтесь вносить свой вклад в этот проект, а также не стесняйтесь обращаться ко мне (https: // github.com / ts-thomas), если у вас возникнут вопросы.
История изменений
Copyright 2019 Nextapps GmbH
Выпущено по лицензии Apache 2.0
JavaScript: проверьте, содержит ли строка подстроку
В этом руководстве вы увидите несколько способов проверить, содержит ли строка подстроку, с помощью JavaScript.
Другие руководства из серии JavaScript Array.
Использование indexOf
Вы можете использовать String.indexOf для поиска подстроки в строке. indexOf Метод возвращает индекс больше 0, если в строке присутствует подстрока. Если подстрока не найдена, возвращается -1.
Вот код, который демонстрирует то же самое:
var position = 'codehandbook'.indexOf (' рука ')
console.log ('подстрока начинается с индекса', позиция) Приведенный выше код отобразит следующий результат:
// вывод
"подстрока начинается с индекса" 4 Итак, если метод indexOf возвращает -1, подстрока не найдена, а если он возвращает значение больше -1, подстрока найдена.
Использование RegExp
Вы можете использовать регулярные выражения, чтобы проверить, содержит ли строка подстроку. Чтобы это сработало, вам нужно создать регулярное выражение, используя строку поиска, и протестировать его с основной строкой. Вот код JavaScript, который показывает то же самое:
var mainString = 'codehandbook'
var substr = / рука /
var found = substr.test (mainString)
if (found) {
console.log ('Подстрока найдена !!')
} еще {
console.log ('Подстрока не найдена !!')
} Как видно из приведенного выше кода, вы преобразовали поисковый запрос в регулярное выражение и использовали метод test , чтобы проверить, найдена ли подстрока.
Использование включает
Вы можете проверить, содержит ли строка подстроку, используя метод includes . Он возвращает true, если подстрока найдена, и false, если подстрока не найдена. Вот пример кода JavaScript:
var found = 'codehandbook'.includes (' рука ')
if (found) {
console.log ('Подстрока найдена !!')
} еще {
console.log ('Подстрока не найдена !!')
} Приведенный выше код будет иметь следующий вывод:
// вывод
"Подстрока найдена !!" Завершение
В этом руководстве вы узнали о различных методах проверки наличия в строке подстроки.Вы использовали какой-либо другой подход для поиска подстроки? Сообщите нам свои мысли в комментариях ниже.
16 способов поиска, поиска и редактирования с помощью Chrome DevTools
Я постоянно возился с поиском, поиском и редактированием параметров пользовательского интерфейса в инструментах разработчика Chrome (также известных как Chrome DevTools). Проблема в том, что я не нашел времени, чтобы достаточно хорошо изучить основы, чтобы запомнить базовые процедуры поиска-поиска-редактирования в промежутках между использованием DevTools. Мне нужно исправить этот недостаток.
В этой статье я собираюсь помочь себе и, надеюсь, вы, читатель, получите четкое представление о том, как находить и делать что-то с помощью Chrome DevTools. Ниже вы найдете 16 коротких видеороликов, в которых подробно описаны решения наиболее распространенных процедур поиска-поиска-редактирования с использованием Chrome DevTools.
1. Поиск текущего HTML
Вы хотите выполнить поиск текстовой строки на текущей HTML-странице.
Процедура : На панели элементов используйте сочетание клавиш (win: Ctrl + f, mac: Cmd + f), чтобы открыть пользовательский интерфейс ввода поиска.Введите любой текст, который вы хотите найти на текущей HTML-странице.
Поиск по всем источникам
Вы хотите выполнить поиск по текстовой строке по всему тексту, содержащемуся во всех исходных файлах, используемых текущей HTML-страницей.
Процедура : на любой панели используйте сочетание клавиш (win: Ctrl + Shift + f, mac: Cmd + Opt + f), чтобы открыть панель поиска. Введите любой текст, который вы хотите найти на текущей HTML-странице. Обратите внимание, что щелчок по одному из результатов (номер строки из источника) откроет источник на панели источников.
3. Поиск источника
Вы хотите выполнить поиск текстовой строки в отдельном исходном файле.
Процедура : на панели источника выберите и откройте исходный файл, затем используйте сочетание клавиш (win: Ctrl + f, mac: Cmd + f), чтобы открыть пользовательский интерфейс ввода поиска. Введите любой текст, который вы хотите найти в текущем исходном файле (Примечание: для отмены минимизации исходного файла щелкните значок {} ).
4.Поиск по именам и путям исходных файлов
Вы хотите выполнить поиск текстовой строки по всем именам и путям исходных файлов.
Подпрограмма : на панели источника используйте сочетание клавиш (win: Ctrl + p, mac: Cmd + p), чтобы открыть пользовательский интерфейс открытого файла. Введите любой текст, который вы хотите найти в текущем исходном файле.
5. Поиск ввода / вывода консоли
Вы хотите выполнить поиск текстовой строки на входе и выходе из консоли.
Процедура : на панели консоли используйте сочетание клавиш (win: Ctrl + f, mac: Cmd + f), чтобы открыть пользовательский интерфейс ввода поиска. Введите любой текст, который хотите видеть в консоли.
6. Поиск имен файлов и значений поиска URL (например,
? Foo = bar )Вы хотите выполнить поиск текстовой строки по всем именам файлов и значениям поиска URL, отправленным по сети.
Процедура : На сетевой панели используйте сочетание клавиш (win: Ctrl + f, mac: Cmd + f), чтобы открыть пользовательский интерфейс ввода поиска.Введите любой текст, который вы хотите найти в сетевом пути / имени.
7. Поиск файла
.css для определенного селектора Вы хотите найти в исходном файле .css определенный селектор CSS.
Процедура : на панели источника выберите и откройте исходный файл .css, затем используйте сочетание клавиш (win: Shift + Ctrl + o, mac: Shift + Cmd + o), чтобы открыть список пользовательского интерфейса с возможностью фильтрации текста. Селекторы CSS, содержащиеся в исходном файле (Примечание: чтобы восстановить исходный код, щелкните значок {} ).
8. Поиск в файле
.js определенной функции Вы хотите найти в исходном файле .js определенную функцию JavaScript.
Процедура : на панели источника выберите и откройте исходный файл .js, затем используйте сочетание клавиш (win: Shift + Ctrl + o, mac: Shift + Cmd + o), чтобы открыть список пользовательского интерфейса с возможностью фильтрации текста. Функции JavaScript, содержащиеся в исходном файле (Примечание: чтобы восстановить исходный код, щелкните значок {} ).
9. Визуальный поиск узла DOM
Вы хотите выбрать узел DOM на панели элементов визуально с помощью указателя мыши.
Процедура : На панели элементов щелкните значок увеличения. Затем используйте мышь, чтобы навести курсор на элементы на странице. Щелкните элемент, который хотите просмотреть, и он станет выбранным на панели элементов для дальнейшего изучения.
10. Поиск узла DOM с помощью селектора
Вы хотите найти элемент (ы) узла в DOM с помощью селектора CSS.
Процедура 1 : На панели элементов используйте сочетание клавиш (win: Ctrl + f, mac: Cmd + f), чтобы открыть пользовательский интерфейс ввода поиска. Введите селектор CSS в пользовательский интерфейс ввода поиска.
Процедура 2 : На панели консоли используйте консольные команды $ ('selector') или $$ ('selector') для выбора элемента (ов) из DOM. $ использует метод DOM querySelector , который возвращает единственный соответствующий элемент DOM, а $$ использует querySelectorAll , который возвращает массив всех совпадающих элементов.Однако, если ваш сайт использует jQuery, $ по умолчанию будет использовать jQuery, а не querySelector (подробности см. В документации).
11. Редактировать HTML
Вы хотите внести изменения в текущую HTML-страницу и просматривать изменения "на лету".
Процедура 1 : На панели элементов щелкните правой кнопкой мыши узел элемента или текстовый узел (который также будет включать все дочерние узлы) и выберите «Редактировать как HTML». Внесите изменения, затем щелкните выбранный узел, чтобы изменения вступили в силу.(Примечание: вы также можете перетаскивать узлы DOM на панели элементов, чтобы изменить положение узла в дереве DOM. Узел также можно удалить, выбрав узел, нажав клавишу удаления на клавиатуре).
12. Редактировать атрибуты элемента
Вы хотите изменить определенный атрибут в узле элемента на странице HTML и просматривать изменения на лету.
Процедура 1 : На панели элементов щелкните правой кнопкой мыши узел элемента и выберите «Добавить атрибут».Если вы щелкните правой кнопкой мыши фактический атрибут в DOM, вы можете выбрать «Редактировать атрибут», чтобы отредактировать конкретный. Внесите изменения, используя встроенное поле ввода, затем нажмите Enter.
13. Редактировать файлы CSS
Вы хотите внести изменения в файл .css и просматривать изменения на лету.
Routine 1 : на панели источников выберите и откройте исходный файл .css и начните редактирование. Изменения немедленно вступают в силу, если CSS действителен.
14. Редактировать CSS и унаследованные CSS элемента
Вы хотите внести изменения в указанный или унаследованный CSS узла элемента и просматривать изменения «на лету».
Процедура : На панели элементов выберите узел элемента. Справа от панели элементов находится панель «стили», которую можно использовать для добавления и редактирования всего CSS, применяемого и унаследованного выбранным узлом элемента.
15.Редактировать будущее с использованием JavaScript
Вы хотите внести изменения в JavaScript после загрузки страницы, чтобы изменения сразу же вступили в силу на странице для будущего запуска JavaScript.
Routine : Единственный JavaScript, который вы можете обновить на лету, - это JavaScript, который продолжит работу после начальной загрузки страницы (то есть функция обратного вызова обработчика кликов). На панели «Исходный код» выберите и откройте исходный файл .js и начните редактировать любой код JavaScript, который может быть вызван после загрузки исходной страницы.Сохраните (выигрыш: Ctrl + s, mac: Cmd + s) после редактирования.
Заключение
Изучив эти 16 подпрограмм, вы получите четкое представление об основных сценариях использования Chrome Devtools. Фактически, эти процедуры могут быть наиболее распространенным способом привлечения Devtools, и, зная их, вы наверняка станете более эффективным разработчиком, если не станете лучшим разработчиком интерфейсов.
Кроме того, знаете ли вы, что Telerik предлагает плагин Kendo UI Inspector для Chrome DevTools? Это значительно упрощает поиск, поиск и редактирование виджетов и инструментов Kendo UI.Посмотрите видео ниже, демонстрирующее его использование.
| Query | Пример | Описание |
|---|---|---|
| любые условия | | Соответствует одному или нескольким терминам, например cts: and-query .Смежные термины и фразы неявно объединяются с И . Например, собака кошка совпадает с собака И кошка . |
| " | " | Термины в двойных кавычках рассматриваются как фраза. Смежные термины и фразы неявно объединяются с И . Например, собака "усы кошки" соответствует документам, содержащим как термин собака , так и фразу усы кошки . |
| () | (кошка ИЛИ собака) зебра | Круглые скобки указывают на группировку. Пример соответствует документам, содержащим хотя бы один из терминов cat или dog , а также содержит термин zebra . |
| - запрос | | Операция НЕ, например cts: not-query .Например, cat -dog соответствует документам, которые содержат термин cat , но не содержат термин dog . |
запрос1 И запрос2 | (кошка ИЛИ собака) И зебра | Сопоставьте два выражения запроса, например cts: and-query . Например, собака И кошка соответствует документам, содержащим термин собака и термин кошка . И - это способ объединения терминов и фраз по умолчанию, поэтому предыдущий пример эквивалентен dog cat . |
запрос1 ИЛИ запрос2 | собака ИЛИ кошка | Соответствует любому из двух запросов, например cts: or-query . Пример соответствует документам, содержащим хотя бы один из терминов cat или dog . |
query1 NOT_IN query2 | собака НЕ_ИН "собачья будка" | Соответствует одному запросу, если совпадение не перекрывается с другим, например cts: not-in-query .Пример соответствует вхождению dog , если его нет во фразе dog house . |
query1 NEAR query2 | (корм для кошек) NEAR мышь | Найдите документы, содержащие совпадения с запросами по обе стороны от оператора NEAR , когда совпадения происходят в пределах 10 терминов друг от друга, как в случае cts: near-query .Например, собака NEAR cat соответствует документам, содержащим dog в пределах 10 терминов cat . |
query1 NEAR / N query2 | собака РЯДОМ / 2 кошки | Найти документы, содержащие совпадения с запросами по обе стороны от оператора NEAR, когда совпадения встречаются в пределах N терминов друг друга, как с cts: near-query . Пример соответствует документам, в которых термин dog встречается в пределах 2 членов термина cat . |
ограничение : значение | | Найдите документы, которые соответствуют именованному ограничению с заданным значением, например, cts: element-range-query или другим запросом диапазона. Дополнительные сведения см. В разделе «Использование операторов отношения к ограничениям». |
оператор : состояние | | Примените оператор конфигурации среды выполнения, например порядок сортировки, определенный XML-элементом operator или свойством JSON в параметрах поиска.Для получения дополнительной информации см. Параметры оператора. |
ограничение LT значение | цвет LT красный
день рождения LT 1999-12-31 | Найдите документы, которые соответствуют ограничению именованного диапазона со значением меньше значение . Дополнительные сведения см. В разделе «Использование операторов отношения к ограничениям». |
ограничение LE значение | цвет LE красный
день рождения ЛЭ 1999-12-31 | Найдите документы, которые соответствуют ограничению именованного диапазона со значением, меньшим или равным , значением .Дополнительные сведения см. В разделе «Использование операторов отношения к ограничениям». |
ограничение GT значение | цвет GT красный
день рождения GT 1999-12-31 | Найдите документы, которые соответствуют ограничению именованного диапазона со значением, превышающим , значение . Дополнительные сведения см. В разделе «Использование операторов отношения к ограничениям». |
ограничение GE значение | цвет GE красный
день рождения GE 1999-12-31 | Найдите документы, которые соответствуют ограничению именованного диапазона со значением, большим или равным , значение .Дополнительные сведения см. В разделе «Использование операторов отношения к ограничениям». |
ограничение NE значение | цвет NE красный
день рождения NE 1999-12-31 | Найдите документы, которые соответствуют ограничению именованного диапазона со значением, не равным , значение . |