Шаблоны баз данных
При первом запуске программы MS Access открывается окно, в котором отображается новый компонент интерфейса пользователя Access 2010 – представление Backstage.
Представлением Backstage является место, в котором можно выполнять управление файлами.
При открытии программы Access вместе с командами Создать базу данных, Открыть, выполнить установку Параметров и списком последних баз данных, которые были использованы, предоставляется возможность выбора многочисленных шаблонов для создания разнообразных типовых баз данных (рисунок 1).
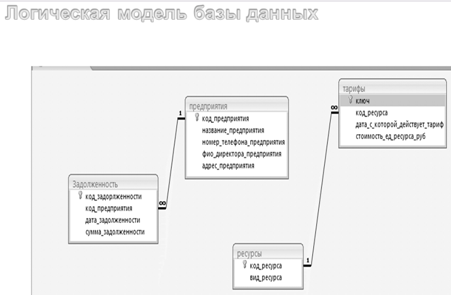
Шаблоны БД
Определение 1
Шаблоном MS Access является файл, который при открытии представляет полнофункциональное приложение базы данных.
При открытии базы данных на вкладке Файл отображается представление Backstage, которое содержит команды, применимые ко всей базе данных, но при этом естественно шаблоны баз данных не отображаются.
После выполнения закрытия базы данных в окне представления Backstage библиотека готовых шаблонов для приложений баз данных восстанавливается. Шаблоны типовых баз данных содержат все необходимые отчеты, запросы, формы и таблицы для предметных областей разнообразных сфер личной и деловой жизни. Подобные стандартные приложения могут быть использованы без выполнения настройки и модификации, или же взяты в виде основы и адаптированы соответственно характеру информации, которую необходимо сохранить и обработать.
После выбора необходимого шаблона достаточно определить место, в котором нужно сохранить базу данных, которая создается, и нажать кнопку
Особенности шаблонов БД
Типовые базы данных позволяют начинающему пользователю изучить основные принципы построения базы данных и пользовательского приложения и развить практические навыки по работе в среде MS Access.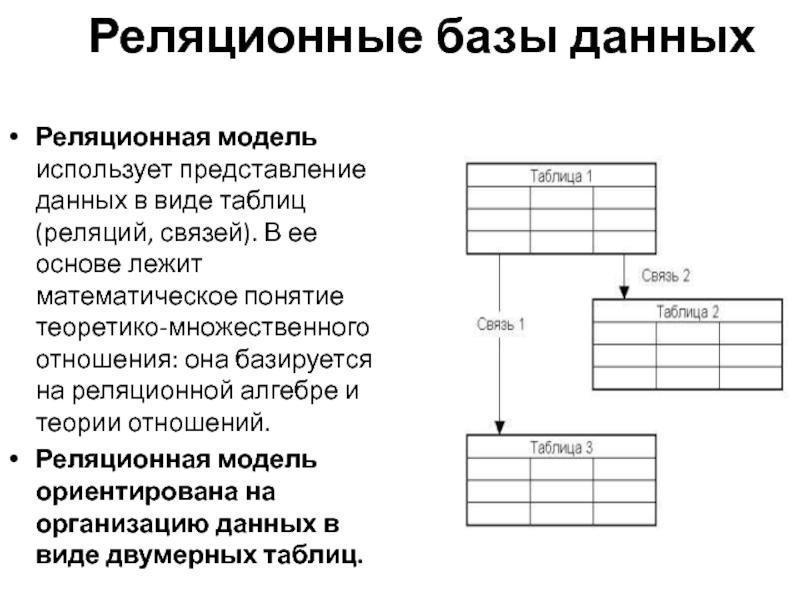 При использовании типовой базой пользователю предоставляется возможность научится выполнять просмотр и изменение данных с помощью форм, выполнять запросы для получения информации из связанных таблиц, подготавливать отчеты.
При использовании типовой базой пользователю предоставляется возможность научится выполнять просмотр и изменение данных с помощью форм, выполнять запросы для получения информации из связанных таблиц, подготавливать отчеты.
Возможна загрузка новых шаблонов приложений с сайта Microsoft Office.com. В разделе шаблонов Office на выбор предлагается множество самых различных шаблонов для сложных и простых задач, использование которых возможно для собственного применения или использования в коммерческих целях.
Просмотр шаблонов из Интернета выполняется так же легко, как в случае размещения их на локальном компьютере. Шаблоны, которые имеются, для удобства обзора расположены по логическим категориям. Если выбрать шаблон для просмотра, отобразится приблизительная длительность его загрузки, размер, и, при необходимости, дополнительные системные требования. Достаточно одного щелчка, чтобы загрузить и открыть шаблон.
Шаблоны приложений MS Access 2010 предоставляют возможность ускорить создание приложений и приступить к работе с ними, особенно это важно в том случае, когда у пользователя нет навыков проектирования баз данных и знания языков программирования.
Замечание 1
Обратим внимание, что при использовании типовой базы данных не стоит рассчитывать на то, что она полностью сможет удовлетворить желания пользователя. База данных, которая создана по шаблону, может быть изменена и расширена, но такая работа потребует от пользователя практически тех же усилий и знаний, что и при создании новой базы данных.
Среди шаблонов баз данных MS Access наиболее часто используемым для обучения работы с базами данных является Борей.
Создание форм для ввода данных в таблицы базы данных Access 2007
2.4. Microsoft Access 2007
2.4.6. Создание и использование форм для ввода данных в таблицы базы данных Access 2007
В Access 2007 можно вводить данные непосредственно в таблицу в режиме таблица. Но обычно для ввода данных в БД Access 2007 используют формы (forms). Form ускоряет работу с базой данных. Form в БД — это структурированное интерактивное окно с элементами управления, в котором отображаются поля одной или нескольких таблиц или запросов.
Но обычно для ввода данных в БД Access 2007 используют формы (forms). Form ускоряет работу с базой данных. Form в БД — это структурированное интерактивное окно с элементами управления, в котором отображаются поля одной или нескольких таблиц или запросов.
Форму можно использовать для ввода, изменения или отображения данных из таблицы или запроса. В Microsoft Office Access 2007 предусмотрены новые средства, помогающие быстро создавать forms, а также новые типы форм и функциональные возможности.
Формы в БД Access можно создавать с помощью различных средств:
- инструмента Form;
- инструмента Разделенная form;
- инструмента Несколько элементов;
- инструмента Пустая form;
- Мастера form;
- Конструктора form.
Все средства создания форм помещены в группу forms на вкладке Создание (рис. 1).
Рис. 1.
Режим макета — это более наглядный режим редактирования (изменения) форм, чем режим конструктора. В режиме макета изменения выполняются фактически в реальной форме, поэтому в этом режиме целесообразно выполнять более простые изменения, связанные с ее внешним видом.
В тех случаях, когда в режиме макета невозможно выполнить изменения в форме, целесообразно применять режим конструктора. Режим конструктора предоставляет пользователю более широкие возможности для редактирования (изменения) форм, в этом режиме можно добавлять поля, настраиваемые элементы и составлять программы.
Режим конструктора предоставляет пользователю более широкие возможности для редактирования (изменения) форм, в этом режиме можно добавлять поля, настраиваемые элементы и составлять программы.
Инструмент «Форма». Для быстрого создания формы, т.е. создания одним щелчком мыши можно воспользоваться инструментом Form. В этом случае надо выделить таблицу в области объектов. Затем перейти на вкладку Создание и щелкнуть на пиктограмме Form. На экране будет отображена form (рис 2).
Рис. 2.
Если Access обнаруживает одну таблицу, связанную отношением «один-ко-многим» с таблицей или запросом, который использовался для создания формы, Access добавляет таблицу данных в форму, основанную на связанной таблице или запросе. Если таблица данных в форме не нужна, ее можно удалить.
Средство «Разделенная форма». Разделенная form — новая возможность в Microsoft Access 2007, которая позволяет одновременно отображать данные в режиме формы и в режиме таблицы. В области объектов (переходов) выделить таблицу, например Успеваемость. Далее щелкнуть на пиктограмме «Разделенная forms» на вкладке Создать. На экране будет отображена form (3).
Рис. 3.
Инструмент «Несколько элементов». Форму, в которой отображается не одна, а одновременно несколько записей, можно создать инструментом «Несколько элементов» (рис. 4). Чтобы создать данную форму выделим в области объектов (переходов) одну из таблиц (например, Успеваемость). Затем перейдем на вкладку Создание и щелкнем на пиктограмме «Несколько элементов». На экране будет отображена form (рис. 4) в режиме макета.
Рис. 4.
Form похожа на таблицу, в ней одновременно отображаются несколько записей. Но эта form предоставляет возможности для настройки, так как она отображается в режиме макета. В режиме макета можно легко осуществлять доработку формы (например, добавлять элементы управления и т.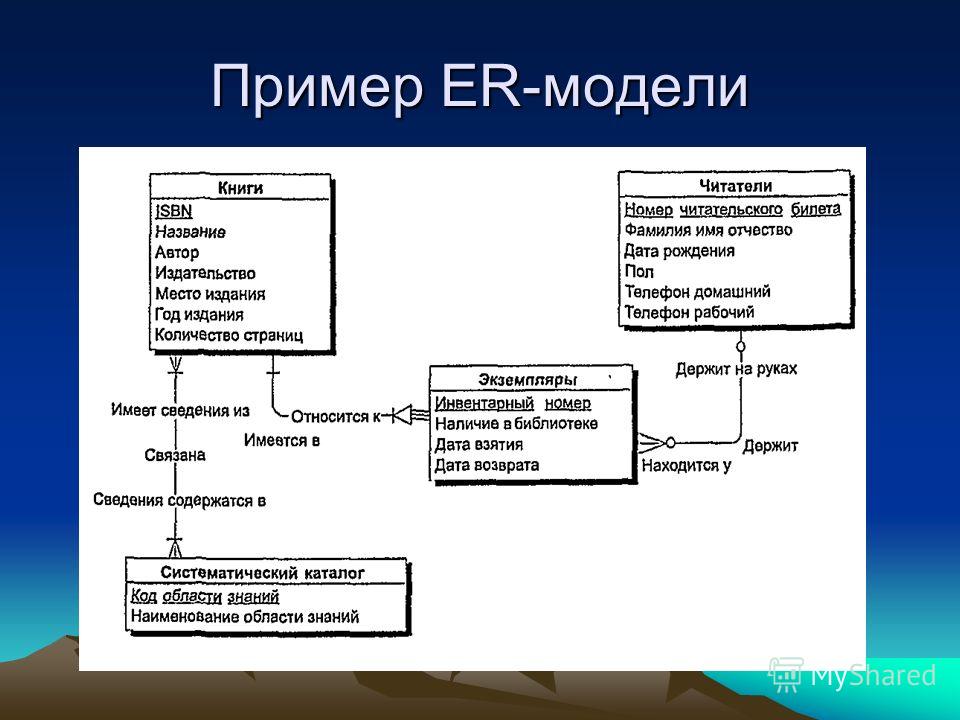
Средство Пустая форма. Этот инструмент можно использовать в том случае, если необходимо быстро создать форму с несколькими полями. Form открывается в режиме «Работа с макетами форм» и при этом отображается область Список полей (рис. 5).
Рис. 5.
Мастер форм. Создание форм при помощи мастера форм осуществляется быстро, и это средство позволяет включить в форму поля из нескольких связанных таблиц или запросов. На вкладке Создание в группе Формы надо нажать кнопку Другие формы, а затем выбрать команду Мастер форм. Откроется окно диалога Создание форм, в котором необходимо отвечать на вопросы каждого текущего экрана Мастера и щелкать на кнопке Далее.
В первом окне необходимо выбрать поля из источника данных (таблиц или запросов). Для этого надо открыть список Таблицы и запросы, щелкнув на кнопку, справа. Например, выберем из списка таблицу Студенты.
Рис. 6.
Затем все «Доступные поля» переведем в «Выбранные поля», выделив их и щелкнув на кнопку >>. Необходимо отметить, что, если form создается на основе нескольких таблиц, необходимо повторить действия для каждой таблицы – источника. Затем необходимо щелкнуть на кнопке Далее. В следующем окне надо выбрать внешний вид, например в один столбец и щелкнуть Далее. В следующем окне выберем требуемый стиль — официальный
После выбора стиля, требуется перейти в последнее окно, щелкнув на кнопке Далее. В последнем окне Мастера требуется ввести имя (например, Студенты мастер_форм) и указать дальнейшие действия: Открыть форму для просмотра и ввода данных; Изменить макет формы.
После ввода имени формы (например, Студенты), выбора режима: «Открыть форму для просмотра и ввода данных» и щелчка на кнопке Готово, получим следующую форму для ввода и просмотра записей в таблицу Студенты.
Рис. 7.
Конструктор форм. Для создания новой пустой формы Студенты необходимо выполнить следующее:
Для создания новой пустой формы Студенты необходимо выполнить следующее:
- В окне приложения Access 2007 выбрать вкладку Создание. Выполнить щелчок на пиктограмме «Конструктор форм». В окне редактирования появится окно Form1 с пустой областью данных.
- Для отображения списка полей требуемой таблицы выполнить щелчок на пиктограмме «Добавить существующие поля», появится список таблиц. Щелкнув на знак «+» таблицы (например, Студенты), откроется список необходимых полей (рис.7).
Рис. 8.
3. Поля из списка переместить на форму. Добавление полей осуществляется при нажатой левой кнопки мыши.
4. Поместить поля на форму (рис. 9).
Рис. 9.
5. Перемещение полей и их имен по форме производиться следующим образом:
- Выделить поле с именем щелчком мыши. Вокруг него появятся маркеры перемещения и изменения размеров. Перемещать поле можно вместе с привязанным к нему именем или отдельно от него.
- Для перемещения поместить указатель мыши на квадратик, находящийся в левом верхнем углу элемента. Указатель мыши в виде четырех направленной стрелки позволяет перемещать объект.
- Нажать кнопку мыши и, удерживая ее, буксировать поле или его имя в нужное место в форме. Затем отпустить кнопку мыши.
- Для изменения надписи, связанной с полем необходимо выполнить на ней двойной щелчок мышью и выполнить необходимые изменения. Затем закрыть окно.
- Для изменения размеров поместить курсор на размерные маркеры, при этом курсор примет вид двунаправленной стрелки. Нажать кнопку мыши, буксировать в нужном направлении, затем отпустить кнопку мыши.
- Для удаления поля выделить его, нажать клавишу Delete или другим способом.
6. Сохранить форму.
7. Просмотреть форму Студенты_конструктор, выполнив на ней двойной щелчок в области переходов.
Просмотреть форму Студенты_конструктор, выполнив на ней двойной щелчок в области переходов.
Рис. 10.
Если вид формы не удовлетворяет, ее можно открыть в режиме Конструктор и внести необходимые изменения, затем сохранить.
Далее >>> Раздел: 2.4.7. Создание отчетов в Access 2007
| Access |
Базы данных Access. |
|
База данных — это набор сведений, относящихся к определенной теме или задаче,
такой как отслеживание заказов клиентов или хранение коллекции звукозаписей.
Если база данных хранится не на компьютере или на компьютере хранятся только ее
части, приходится отслеживать сведения из целого ряда других источников, которые
пользователь должен скоординировать и организовать самостоятельно. Файлы баз данных Microsoft Access Microsoft Access позволяет управлять всеми сведениями из одного файла базы данных. В рамках этого файла используются следующие объекты:
|
|
|
1. Данные сохраняются один раз в одной таблице, но просматриваются из различных
расположений. При изменении данных они автоматически обновляются везде, где
появляются. |
|
|
Таблицы и связи Для хранения данных создайте по одной таблице на каждый тип отслеживаемых сведений. Для объединения данных из нескольких таблиц в запросе, форме, отчете или на странице доступа к данным определите связи между таблицами.
1. Сведения о клиентах, которые когда-то хранились в списке почтовой рассылки,
теперь находятся в таблице «Клиенты». |
|
|
Запросы Для поиска и вывода данных, удовлетворяющих заданным условиям, включая данные из нескольких таблиц, создайте запрос. Запрос также может обновлять или удалять несколько записей одновременно и выполнять стандартные или пользовательские вычисления с данными.
1. В этом запросе выполняется доступ к разным таблицам для отображения кода
заказа, названия компании, города и даты исполнения для заказчиков из
определенного города, сделавших заказы, которые следует выполнить в одном
месяце. |
|
|
Формы Для простоты просмотра, ввода и изменения данных непосредственно в таблице создайте форму. При открытии формы Microsoft Access отбирает данные из одной или более таблиц и выводит их на экран с использованием макета, выбранного в мастере форм или созданного пользователем самостоятельно в режиме конструктора (Режим конструктора. Окно, в котором отображается макет следующих объектов базы данных: таблицы, запросы, формы, отчеты, макросы и страницы доступа к данным. В режиме конструктора пользователь создает новые объекты базы данных или изменяет макеты существующих.).
1. В таблице одновременно отображается несколько записей, но для просмотра всех
данных в одной записи может потребоваться прокрутка. Кроме того, при просмотре
таблицы невозможно одновременно обновить данные в нескольких таблицах. |
|
|
Отчеты Для анализа данных или представления их определенным образом в печатном виде создайте отчет. Например, можно напечатать один отчет, группирующий данные и вычисляющий итоговые значения, и еще один отчет с другими данными, отформатированными для печати почтовых наклеек.
1. Создание почтовых наклеек с помощью отчета. |
|
|
Страницы доступа к данным Чтобы сделать данные доступными через Интернет или интрасеть для создания
отчетов в интерактивном режиме, ввода данных или их анализа используйте
страницы доступа к данным.
1. Щелкните индикатор развертывания… |
|


 Microsoft Access извлекает данные из одной или
нескольких таблиц и отображает их на экране с использованием макета,
разработанного пользователем в режиме конструктора или созданного с помощью
мастера страниц.
Microsoft Access извлекает данные из одной или
нескольких таблиц и отображает их на экране с использованием макета,
разработанного пользователем в режиме конструктора или созданного с помощью
мастера страниц.Рекомендация: Модель данных
Обзор
Модели данных служат для проектирования структуры постоянных хранилищ данных, используемых системой. Профайл на языке UML для проектирования базы данных предоставляет разработчикам базы данных набор элементов моделирования, позволяющих разрабатывать подробный макет таблиц в базе данных и моделировать макет физической памяти базы данных. Профайл базы данных на языке UML также предоставляет конструкции для моделирования целостности по ссылкам (ограничений и триггеров), а также хранимых процедур, предназначенных для управления доступом к базе данных.
Модели данных могут создаваться на уровне предприятия, отдела или отдельного приложения. Модели данных на уровне предприятия или отдела могут использоваться для предоставления стандартных определений для ключевых бизнес-сущностей (таких как клиент и сотрудник), которые будут применяться всеми приложениями всего бизнес-процесса или его части. С помощью этих типов Моделей данных можно также определить, какая система предприятия будет «владельцем» данных для конкретной бизнес-сущности и какие другие системы будут пользователями (подписчиками) данных.
Настоящая рекомендация описывает модельные элементы профайла UML, предназначенные для конструирования Модели данных для
реляционной базы данных. Поскольку по общей теории баз данных существует бесчисленное множество публикаций, здесь
она не рассматривается. Начальная информация по реляционным Моделям данных и Моделям объектов приведена в разделе
Концепция: реляционные базы данных и объектная ориентация.
Начальная информация по реляционным Моделям данных и Моделям объектов приведена в разделе
Концепция: реляционные базы данных и объектная ориентация.
Примечание: приведенные в настоящей рекомендации примеры моделирования данных основаны на языке UML 1.3. На момент написания настоящей рекомендации профайл моделирования данных на языке UML 1.4 был недоступен.
Этапы Моделирования данных
Как описано в [NBG01], разработка Модели данных подразделяется на три основных этапа: концептуальный, логический и физический. Эти этапы моделирования данных отражают разные уровни подробности в проектировании механизмов постоянного хранения и извлечения данных приложения. Концептуальное моделирование данных обсуждается в разделе КонцепцииКонцептуальное моделирование данных. Логическое и физическое моделирование данных рассматриваются в следующих двух разделах настоящей рекомендации.
Логическое моделирование данных
В логическом моделировании данных Проектировщик базы данных занимается выявлением ключевых сущностей и взаимосвязей, отвечающих за захват важнейшей информации, которую приложению необходимо хранить в базе данных. Во время выполнения задач Анализа варианта использования, Проектирования варианта использования и Проектирования классов Проектировщик базы данных и Проектировщик должны работать совместно, чтобы создаваемые макеты анализа и классов проектирования для приложения адекватно поддерживали разработку базы данных. Во время выполнения задачи Проектирования классов проектировщик базы данных и проектировщик должны выявить набор классов в Модели проектирования, которым потребуется хранить данные в базе данных.
Этот набор постоянных классов в Модели проектирования предоставляет Панель модели проектирования, которая хотя и
отличается от традиционной Логической модели данных, но отвечает многим тем же потребностям. Постоянные классы,
используемые в Модели проектирования, действуют так же, как и традиционные сущности в Логической модели данных. Эти
классы проектирования в точности отражают данные, которые необходимо хранить постоянно, в том числе все столбцы данных
(атрибуты), которые необходимо хранить, и ключевые взаимосвязи. Все это делает классы проектирования удобной отправной
точкой в физическом проектировании базы данных.
Эти
классы проектирования в точности отражают данные, которые необходимо хранить постоянно, в том числе все столбцы данных
(атрибуты), которые необходимо хранить, и ключевые взаимосвязи. Все это делает классы проектирования удобной отправной
точкой в физическом проектировании базы данных.
Создавать отдельную Логическую модель данных необязательно. В лучшем случае, итоговая модель будет захватывать ту же информацию, но в другой форме. В худшем случае, итоговая модель не будет захватывать информацию и поэтому не будет удовлетворять бизнес-потребностям приложения. Если база данных должна будет обслуживать отдельное приложение, то наилучшей отправной точкой будет представление данных с точки зрения приложения. Проектировщик базы данных создает таблицы из этого набора постоянных классов проектирования, чтобы сформировать первоначальную Физическую модель данных.
Вместе с тем, возможны случаи, когда проектировщику базы данных потребуется создать идеализированный макет базы данных, не зависящую от макета приложения. В этом случае, логический макет базы данных представляется в виде отдельной Логической модели данных, входящей в состав общей модели (см. раздел Рабочий продукт: модель данных). Эта Логическая модель данных отражает ключевые логические сущности и их взаимосвязи, необходимые для соблюдения требований системы к постоянному хранению данных в соответствии с общей архитектурой приложения. Логическая модель данных может быть сконструирована с помощью элементов моделирования из профайла UML, предназначенного для проектирования базы данных; эти элементы описаны в последующих разделах настоящей рекомендации. Для проектов, использующих этот подход, тесное сотрудничество между проектировщиками приложений и проектировщиками баз данных абсолютно необходимо для успешной разработки базы данных.
Логическая модель данных может быть уточнена путем применения стандартных правил нормализации, как описано в разделе Концепция: нормализация, прежде чем ее элементы будут использованы для создания
физического макета базы данных.
На приведенном ниже рисунке изображен основной подход, основанный на использовании классов Модели проектирования в качестве источника информации для логического проектирования баз данных, позволяющего создать первоначальную Физическую модель данных. На нем также изображен альтернативный подход, основанный на использовании отдельной Логической модели данных.
Подходы к логическому моделированию данных
Физическое моделирование данных
Физическое моделирование данных — это заключительная стадия разработки при проектировании базы данных. Физическая модель данных состоит из подробных макетов таблиц базы данных и их взаимосвязей, созданных первоначально из постоянных классов проектирования и их взаимосвязей. Механика преобразования классов Модели проектирования в таблицы обсуждается в разделе Рекомендация: прямая разработка баз данных. Физическая модель данных является частью Модели данных, а не самостоятельным артефактом.
Таблицы в Физической модели данных содержат определенные столбцы, а также необходимые ключи и индексы. В таблицах также могут быть триггеры, определенные для поддержки тех или иных функций базы данных и целостности системы по ссылкам. В дополнение к таблицам, созданы хранимые процедуры; они задокументированы и связаны с базой данных, в которой они будут находиться.
На приведенной ниже диаграмме показан пример некоторых элементов Физической модели данных. Этот пример модели входит в состав Физической модели данных вымышленного приложения электронного аукциона. На нем изображены четыре таблицы (Auction, Bid, Item и AuctionCategory), а также одна хранимая процедура (sp_Auction) и ее класс контейнера (AuctionManagement). На рисунке также изображены столбцы каждой таблицы, ограничения по первичному и внешнему ключам и определенные для таблиц индексы.
Пример элементов (физической) модели данных
Физическая модель данных содержит также отображения таблиц в физические единицы хранения (табличные пространства) в
базе данных. Пример такого отображения приведен на следующем рисунке. В этом примере таблицы Auction и
OrderStatus отображаются в табличное пространство PRIMARY. Диаграмма также иллюстрирует моделирование реализации таблиц
в базе данных (в данном примере — PearlCircle).
Пример такого отображения приведен на следующем рисунке. В этом примере таблицы Auction и
OrderStatus отображаются в табличное пространство PRIMARY. Диаграмма также иллюстрирует моделирование реализации таблиц
в базе данных (в данном примере — PearlCircle).
Пример элементов модели хранения данных
В проектах, в которых база данных уже существует, проектировщик базы данных может выполнить обратную разработку существующей базы данных для заполнения Физической модели данных. Дополнительная информация приведена в разделе Рекомендация: обратная разработка реляционных баз данных.
Элементы модели данных
В этом разделе даны общие рекомендации по моделированию каждого основного элемента Модели данных на основе профайла UML, предназначенного для моделирования баз данных. После краткого описания каждого элемента модели UML приводится иллюстрирующий его пример. Раздел Взаимосвязи настоящей рекомендации включает описание использования элементов модели.
Пакет
Стандартные пакеты UML служат для группировки и организации элементов Модели данных. Например, пакеты могут применяться для организации Модели данных в виде отдельных Логических и Физических моделей данных. Пакеты также могут применяться для определения логически связанных групп таблиц в Модели данных, образующих важнейшие «тематические области» данных для бизнес-домена разрабатываемого приложения. На следующем рисунке приведен пример двух пакетов тематических областей ((Auction Management и UserAccount Management), используемых для организации панелей и таблиц в Модели данных.
Пример пакетов тематических областей
Таблица
В профайле UML, предназначенном для моделирования баз данных, таблица моделируется как класс со стереотипом
<<Table>>. Столбцы в таблице моделируются как атрибуты со стереотипом <<column>>. Один
или несколько столбцов могут быть обозначены как первичный ключ, чтобы обеспечить уникальность записей строк в таблице.
Столбцы могут быть также обозначены как внешние ключи. С первичными и внешними ключами связаны ограничения,
моделируемые как операции со стереотипами <<Primary Key>> и <<Foreign Key>> соответственно.
На следующем рисунке изображена структура примера таблицы, используемой для управления информацией о предметах,
проданных на аукционе в вымышленной системе электронного аукциона.
Один
или несколько столбцов могут быть обозначены как первичный ключ, чтобы обеспечить уникальность записей строк в таблице.
Столбцы могут быть также обозначены как внешние ключи. С первичными и внешними ключами связаны ограничения,
моделируемые как операции со стереотипами <<Primary Key>> и <<Foreign Key>> соответственно.
На следующем рисунке изображена структура примера таблицы, используемой для управления информацией о предметах,
проданных на аукционе в вымышленной системе электронного аукциона.
Пример таблицы
Таблицы могут быть связаны с другими таблицами посредством взаимосвязей следующих типов:
- определяющие (составное агрегирование)
- неопределяющие (ассоциация)
Раздел Взаимосвязи настоящей рекомендации содержит примеры применения этих взаимосвязей. Информация о том, как эти типы взаимосвязей можно отобразить в элементы Модели данных, приведена в разделе Рекомендация: обратное проектирование реляционных баз данных.
Триггер
Триггер — это процедурная функция, запускаемая в результате выполнения некоторого действия в таблице, в которой она находится. Триггер запускается при вставке, обновлении или удалении строки таблицы. Кроме того, триггер может запускаться до или после выполнения табличной команды. Триггеры определены как операции в таблице. Соответствующие операции относятся к стереотипу <<Trigger>>.
Пример триггера
Предметный указатель
Предметные указатели, или индексы, используются в качестве механизмов, ускоряющих доступ к информации, когда поиск в
таблице выполняется по конкретным столбцам. Предметный указатель моделируется в таблице как операция со
стереотипом <<index>>. Предметные указатели могут быть уникальными, а также кластерными или
некластерными.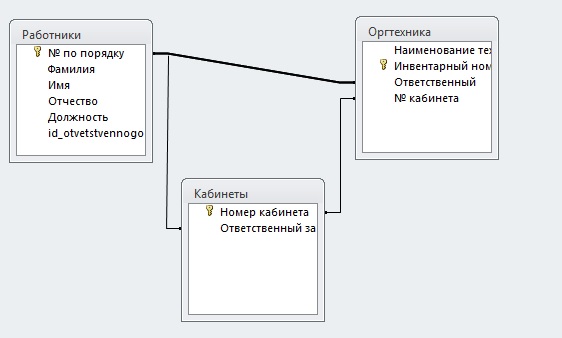 Кластерные предметные указатели устанавливают обязательное соответствие между порядком строк данных в
таблице и порядком значений указателя. Пример операции предметного указателя (IX_auctioncategory) приведен на следующем
рисунке.
Кластерные предметные указатели устанавливают обязательное соответствие между порядком строк данных в
таблице и порядком значений указателя. Пример операции предметного указателя (IX_auctioncategory) приведен на следующем
рисунке.
Пример предметного указателя
Панель
Панель — это виртуальная таблица без независимого постоянного хранилища. Панель обладает характеристиками и поведениями таблицы и обращается к данным в столбцах из таблицы или таблиц, с которыми у нее определены взаимосвязи. Панели применяются для предоставления более эффективного доступа к информации в одной или нескольких таблицах; они также могут использоваться для установления бизнес-правил для ограничения доступа к данным в таблицах. В приведенном ниже примере объект AuctionView определен как «панель» информации в таблице Auction, показанной в разделе физического моделирования данных настоящей рекомендации.
Панели моделируются как классы со стереотипом <<view>>. Атрибуты класса панели — это столбцы из таблиц, на которые ссылается панель. Типы данных столбцов в панели наследуются из таблиц, от которых зависит панель.
Пример панели
Домен
Домен — это механизм, который служит для создания пользовательских типов данных, применимых к столбцам различных таблиц. Домен моделируется как класс со стереотипом <<Domain>>. В приведенном ниже примере домен определен для zip-кода «zip + 4».
Пример домена
Контейнер хранимых процедур
Контейнер хранимых процедур — это совокупность хранимых процедур в Модели данных. Контейнер хранимых процедур создается
как класс UML со стереотипом <<SP Container>>. В макете базы данных могут быть созданы несколько
контейнеров хранимых процедур. Пустые контейнеры хранимых процедур недопустимы.
Пустые контейнеры хранимых процедур недопустимы.
Хранимая процедура
Хранимая процедура — это независимая процедура, обычно находящаяся на сервере баз данных. Хранимые процедуры документируются как операции, сгруппированные в классы со стереотипом <<SP Container>>. Операции относятся к стереотипу <<SP>>. В приведенном ниже примере показана операция одной хранимой процедуры (SP_Auction) в классе контейнера с именем AuctionManagement. При проектировании хранимых процедур проектировщику базы данных должны быть известны все соглашения об именах, применяемые конкретной RDBMS.
Пример контейнера хранимых процедур и хранимой процедуры
Табличное пространство
Табличное пространство представляет пространство памяти, выделяемое таким объектам, как таблицы, хранимые процедуры и предметные указатели. Табличные пространства связаны с конкретной базой данных через взаимосвязь зависимости. Число табличных пространств и способ отображения в них отдельных таблиц зависят от сложности Модели данных. Часто используемые таблицы может потребоваться разбить на несколько табличных пространств. Наоборот, таблицы, не содержащие больших объемов часто используемых данных, можно объединить в одно табличное пространство.
Для каждого табличного пространства определен контейнер. Контейнер табличного пространства — это физическое запоминающее устройство для табличного пространства. Хотя для одного табличного пространства могут существовать несколько контейнеров, рекомендуется, чтобы контейнер табличного пространства был связан только с одним табличным пространством. Контейнеры табличных пространств определены как атрибуты табличного пространства; они не моделируются явно.
Пример табличного пространства
Схема
Схема документирует организацию или структуру базы данных. Схема представлена как пакет со стереотипом <<Schema>>. Когда схема определена как пакет, таблицы, образующие этот пакет, должны входить в состав этой схемы. Для того чтобы задокументировать взаимосвязь между базой данных и схемой, создается зависимость между базой данных и схемой.
Пример схемы
База данных
База данных — это совокупность данных, которая доступна и управляема. Управление и доступ к информации в базе данных осуществляется с помощью коммерческой системы управления базой данных (DBMS). База данных представлена в Модели данных как компонент со стереотипом <<Database>>.
Пример базы данных
Взаимосвязь
Профайл UML, предназначенный для моделирования базы данных, определяет допустимые взаимосвязи между основными элементами Модели данных. В следующих разделах приведены примеры различных типов взаимосвязей.
Неопределяющая
Неопределяющей называется взаимосвязь между двумя таблицами, существующими в базе данных независимо друг от друга. Неопределяющая взаимосвязь документируется посредством ассоциации между таблицами. Стереотип ассоциации — <<Non-Identifying>>. В следующем примере иллюстрируется неопределяющая взаимосвязь между таблицами Item и AuctionCategory.
Пример неопределяющей взаимосвязи
Определяющая
Определяющей называется взаимосвязь между двумя таблицами, в которой дочерняя таблица должна сосуществовать с родительской таблицей. Определяющая взаимосвязь документируется посредством составного агрегирования между двумя таблицами. Стереотип составного агрегирования — <<Identifying>>. Ниже изображен пример определяющей взаимосвязи. В нем показано, что у экземпляров дочерней таблицы (CreditCard) должна быть связанная запись в родительской таблице (UserAccount).
Пример определяющей взаимосвязи
И для ассоциации, и для составного агрегирования должна быть определена множественность, чтобы можно было задокументировать число строк во взаимосвязи. В приведенном выше примере, для каждой строки в таблице UserAccount может существовать 0 или более строк CreditCard в таблице CreditCard. Для каждой строки в таблице CreditCard существует ровно одна строка в таблице UserAccount. Множественность иногда называют также кардинальным числом.
Панели базы данных
При определении взаимосвязи панели базы данных в таблице используется взаимосвязь зависимости, ведущая от панели к таблице. Стереотип зависимости — <<Derive>>. Как правило, зависимости панели присвоено имя, причем оно совпадает с именем таблицы, определенным во взаимосвязи зависимости в панели базы данных.
Пример взаимосвязи зависимости между панелью и таблицей
Табличное пространство
Взаимосвязь зависимости служит для связывания табличного пространства с конкретной базой данных. Как показано на следующем рисунке, взаимосвязь обозначает зависимость базы данных от табличного пространства. Несколько табличных пространств могут быть связаны с одной базой данных в модели.
Пример взаимосвязи зависимости между табличным пространством и базой данных
Взаимосвязь зависимости служит для документирования взаимосвязей между табличными пространствами и таблицами в табличном пространстве. Одна или несколько таблиц могут быть связаны с одним табличным пространством, и одна таблица может быть связана с несколькими табличными пространствами. В приведенном ниже примере показано, что таблица Auction связана с одним табличным пространством, которое называется PRIMARY.
Пример взаимосвязи зависимости между таблицей и табличным пространством
РеализацииРеализации служат для установления взаимосвязи между базой данных и существующими в ней таблицами. Таблица может быть реализована посредством нескольких баз данных в Модели данных.
Пример взаимосвязи реализации между таблицей и базой данных
Хранимые процедуры
Взаимосвязь зависимости служит для документирования взаимосвязи между контейнером хранимых процедур и таблицами, с которыми работают хранимые процедуры из контейнеров хранимых процедур. В следующем примере изображен этот тип взаимосвязи: хранимая процедура SP_Auction служит для доступа к информации в таблице Auction.
Пример взаимосвязи зависимости между контейнером хранимых процедур и таблицей
Эволюция Модели данных
Начальный этап
На начальном этапе первоначальные задачи моделирования данных могут выполняться совместно с разработкой опытных прототипов как часть задач «Выполнить архитектурный синтез». В проектах, в которых база данных уже существует, проектировщик базы данных может выполнить обратную разработку существующей базы данных, чтобы разработать начальную Физическую модель данных на основе структуры существующей базы данных. Дополнительная информация приведена в разделе Рекомендация: обратная разработка реляционных баз данных. Элементы Физической модели данных при необходимости можно преобразовать в элементы Модели проектирования, чтобы поддержать задачи по разработке опытных прототипов.
Этап уточнения
Этап уточнения предназначен для исключения технического риска и создания устойчивой (контрольной версии) архитектуры системы. В крупномасштабных системах низкая производительность, обусловленная неудачно спроектированной Моделью данных, является основной архитектурной проблемой. По этой причине, и моделирование данных, и разработка архитектурного прототипа, позволяющие оценить будущую производительность базы данных, существенны при разработке устойчивой архитектуры. Поскольку архитектурно значимые варианты использования подробно разбираются и анализируются на каждой итерации, элементы Модели данных определяются на основе разработки макетов постоянных классов из вариантов использования. Кода макеты классов стабилизируются, проектировщик базы данных может время от времени преобразовывать их в таблицы Модели данных и определять соответствующие элементы модели хранения данных.
К моменту окончания этапа уточнения основные структуры базы данных (таблицы, предметные указатели и столбцы первичного и внешнего ключей) должны уже находиться на месте, чтобы поддерживать выполнение определенных архитектурно значимых сценариев для приложения. Кроме того, в базу данных должен быть загружен репрезентативный объем данных для поддержки тестирования архитектурной производительности. В зависимости от результатов тестирования производительности, может потребоваться скорректировать Модель данных с помощью приемов оптимизации, включая, но не ограничиваясь этим, денормализацию, оптимизацию атрибутов физической памяти или распределения, а также индексацию.
Этап построения
Основная реструктуризация Модели данных не должна происходить на этапе построения. Однако во время итераций этапа построения могут быть определены дополнительные таблицы и элементы хранения данных — на основе подробного проектирования набора вариантов использования и утвержденных запросов на изменение, предназначенных для данной итерации. При проектировании базы данных, на этапе построения основное внимание должно уделяться непрерывному отслеживанию производительности базы данных и оптимизации ее макета с помощью денормализации, индексации, создания панелей базы данных и применения других приемов.
Физическая модель данных — это артефакт проектирования, обслуживаемый проектировщиком базы данных на этапе построения. Обслуживание может выполняться путем внесения непосредственных обновлений в модель или путем считывания обновлений, внесенных непосредственно в базу данных, с помощью соответствующих инструментов.
Этап внедрения
Модель данных, как и Модель проектирования, обслуживается на этапе внедрения в ответ на утвержденные запросы на изменение. Проектировщик базы данных должен поддерживать синхронизацию Модели данных с базой данных по мере того, как приложение проходит через окончательный тест на приемлемость и развертывается в рабочую версию.
Общие рекомендации по разработке
Если коллектив разработчиков применяет современные средства визуального моделирования, которые могут преобразовывать классы в таблицы (и наоборот), или может выполнять прямую и обратную разработку баз данных, или и то, и другое, то он должен выработать рекомендации по управлению процессами преобразования и создания. Эти рекомендации необходимы прежде всего для больших проектов, когда коллектив работает параллельно над базой данных и над макетом приложения. Коллектив разработчиков должен определить моменты в процессе разработки приложения (цикл компоновки/выпуска), когда будет уместно выполнить преобразования классов в таблицы и прямую разработку базы данных. После создания первоначальной базы данных коллектив разработчиков должен создать для своих членов рекомендации по управлению синхронизацией Модели данных и базы данных, которым нужно будет следовать по мере эволюции макета и кода системы в процессе создания проекта.
Универсальная печатная форма | НПП ПРО-М Абонентское обслуживание компьютеров
Универсальная печать в word из любого объекта конфигурации поддерживающего технологию подключаемых печатных форм. Позволяет создавать пользовательские шаблоны в word, c возможностью заполнения данными из базы данных. Поддерживается возможность вывода таблиц в word.
Это не просто очередная обработка печати в Word, это механизм, который позволит Вам самостоятельно создавать свои формы и размещать их в требуемых объектах. Вы сможете создавать шаблоны для договоров с контрагентами и они будут доступны при печати из справочника договоры, или формы для заказа клиента и т.д. И для этого не придется вносить изменения в конфигурацию или привлекать программиста.
Универсальная печатная форма поможет автоматизировать подготовку договоров, коммерческих предложений и других бланков используемых на предприятии. Теперь пользователь может самостоятельно создать любой шаблон в Word, определить заполняемые параметры и получить готовый бланк. Это позволит освободить сотрудников от рутинной работы, избавит от ненужных ошибок, описок в оформляемых бланках.
Возможности продукта:
- Создание макетов печатных форм любой сложности, без привлечения программиста.
- Использование любых данных базы для заполнения шаблонов.
- Заполнение не только реквизитов, но и табличных частей.
- Работает на любой конфигурации на основе БСП (УТ11, КА 2.х, ERP, БП 3.0 , ЗУП 3.х, Розница 2.0.)
Как это работает:
- Создаем макет в word, объявляем параметры и таблицы по правилам описанным в инструкции.
- Добавляем печатную форму из поставки к необходимым объектам конфигурации.
- Переходим в нужный объект, который необходимо вывести в макет, например, элемент справочника договоры, и вызываем печатную форму.
- Добавляем наш макет и настраиваем соответствие параметров макета с данными базы, а также таблиц с табличными частями объекта базы.
- При необходимости используются функции форматирования, склонения или прочие функции в редакторе формул.
- Выводим данные объекта печати в макет.
- Имеется возможность использования произвольных источников данных при помощи схем СКД.
Дальнейшая разработка:
- Планируется организовать возможность отправки полученного бланка на электронную почту
контакта. - Подключить использование OpenOffice.
- Организовать возможность работы на вебклиенте.
Технические требования:
- Операционная система Windows на клиенте 1с.
- Установленный Word
- Конфигурация на основе БСП, управляемые формы
- Не работает под веб клиентом.
Причины купить
- Возможность создания макетов печатных форм без привлечения программиста.
- Создание макетов с любым пользовательским оформлением.
- Сокращение трудозатрат на оформление различных бланков на предприятии.
Достоинства
- Не требует изменения конфигурации.
- Возможность печати таблиц.
- Интуитивно понятный интерфейс.
Разработка баз данных (MS Access)
Длительность курса: 40 ак.ч.
График обучения: 5 дней по 8 ак.ч. или 10 дней по 4 ак.ч.
Система управления базами данных СУБД Microsoft Access, появившаяся в 1992 году, быстро завоевала популярность среди пользователей программ офисного направления в силу того, что она позволяет повысить производительность труда при работе с большим объемом табличных данных и помогает принимать более удачные деловые решения в бизнесе. Большой набор новых, удобных инструментов для работы с данными и интуитивно понятный интерфейс позволяют быстро создавать довольно сложные базы данных даже непрофессионалам.
MS Access можно использовать для создания простых или очень сложных приложений баз данных. В этой СУБД представлены новые эффективные способы организации, отслеживания, управления, обновления и распространения данных.
Тесная интеграция с другими приложениями MS Office позволяет легко обмениваться данными, в частности с MS Word, MS Excel, MS PowerPoint, а также с данными других типов.
MS Access можно применять для создания удобного пользовательского интерфейса с помощью форм, а также для подготовки печатных документов – отчетов, наклеек, диаграмм.
Хотя курс не затрагивает вопросы программирования на Visual Basic for Applications, рассматривается более простое средство автоматизации работы, доступное подавляющему большинству пользователей, – макросы.
Курс построен на конкретных примерах и решениях, многие из которых Вы сможете непосредственно использовать в своей дальнейшей практической работе.
Кроме всего прочего, данный курс может рассматриваться как подготовка к сдаче сертифицированного теста Microsoft Office Specialist.
Знания и умения, полученные в результате обучения
После окончания данного курса Вы научитесь:
- проектировать базы данных;
- создавать таблицы, устанавливать связи между ними, определять свойства полей и полей подстановок, сортировать и фильтровать данные в таблицах;
- импортировать (экспортировать) и связывать данные из внешних источников, в частности MS Excel, текстовых файлов или других баз MS Access;
- создавать запросы на выборку данных из таблицы и/или запросов по заданным критериям, производить модификацию данных с помощью запросов на обновление, добавление и удаление данных, создавать новые таблицы;
- разрабатывать и настраивать формы – мощный инструмент для работы в удобном пользовательском интерфейсе с информацией, хранящейся в базе данных;
- разрабатывать отчеты: от простейших, содержащих исходные данные, до сложных многоуровневых с получением итоговых данных и нужных вычислений;
- создавать макросы для автоматизации некоторых действий с объектами базы данных и самими данными;
- создавать собственные панели инструментов и меню;
- настраивать сервисные возможности базы данных и внешний вид приложения;
- использовать механизм защиты информации Microsoft Access 2007.
Очистка базы данных от документов и задач | Статья
Опубликовано:
7 ноября 2011 в 15:50
37 26
Часто возникает необходимость почистить базу данных от документов и задач. Например, когда ее надо кому-нибудь передать или сделать небольшую базу разработки. Но во-первых, не у всех под рукой список таблиц, которые нужно очищать. Во-вторых, многие забывают, что удалять шаблоны и макеты из базы данных не стоит. В третьих, чистить таблицы при помощи delete не всегда оптимально, а не полная чистка таблиц при помощи truncate может вызвать затруднения, т.к. требует использования динамического SQL. Поэтому представляю вашему вниманию SQL-скрипт удаления документов, задач и заданий.
Скрипт работает на SQL 2005, на 2000 потребуются некоторые изменения в части обращения к системным таблицам сервера. Версии DIRECTUM 4.5 — 4.8.
Разумеется, если требуется уменьшить физический размер базы данных, то получившееся в результате выполнения скрипта свободное место в БД нужно освободить командой Shrink.
-- Удалить временные таблицы, если они есть
if exists (select * from sys.objects
where object_id = object_id(N'tmpSBEDoc') and type in (N'U'))
drop table tmpSBEDoc
if exists (select * from sys.objects
where object_id = object_id(N'tmpSBEDocVer') and type in (N'U'))
drop table tmpSBEDocVer
if exists (select * from sys.objects
where object_id = object_id(N'tmpSBEDocAcc') and type in (N'U'))
drop table tmpSBEDocAcc
-- Удалить карточки документов кроме шаблонов и макетов
declare @DocumentModelsCardTypeID int
declare @TemplatesCardTypeID int
select @DocumentModelsCardTypeID = TypeID from SBEDocTypes where Code = 'DocumentModels'
select @TemplatesCardTypeID = TypeID from SBEDocTypes where Code = 'ШАД'
select * into tmpSBEDoc from SBEDoc
where (TypeID = @DocumentModelsCardTypeID) or (TypeID = @TemplatesCardTypeID)
alter table tmpSBEDoc drop column timestamp
declare @ColumnList varchar(2000)
select @ColumnList = COALESCE(@ColumnList + ', ', '') + column_name
from information_schema.columns
where table_name = 'SBEDoc'
and column_name 'timestamp'
order by ordinal_position
alter table SBEDoc disable trigger all
set identity_insert SBEDoc on
truncate table SBEDoc
exec('insert into SBEDoc (' + @ColumnList +') select * from tmpSBEDoc')
set identity_insert SBEDoc off
alter table SBEDoc enable trigger all
-- Удалить версии документов кроме шаблонов и макетов
select * into tmpSBEDocVer from SBEDocVer where
(TypeID = @DocumentModelsCardTypeID) or (TypeID = @TemplatesCardTypeID)
alter table tmpSBEDocVer drop column timestamp
select @ColumnList = NULL
select @ColumnList = COALESCE(@ColumnList + ', ', '') + column_name
from information_schema.columns
where table_name = 'SBEDocVer'
and column_name 'timestamp'
order by ordinal_position
alter table SBEDocVer disable trigger all
set identity_insert SBEDocVer on
truncate table SBEDocVer
exec('insert into SBEDocVer (' + @ColumnList +') select * from tmpSBEDocVer')
set identity_insert SBEDocVer off
alter table SBEDocVer enable trigger all
-- Удалить права доступа на документы кроме шаблонов и макетов
select * into tmpSBEDocAcc from SBEDocAcc where
(TypeID = @DocumentModelsCardTypeID) or (TypeID = @TemplatesCardTypeID)
alter table tmpSBEDocAcc drop column timestamp
select @ColumnList = NULL
select @ColumnList = COALESCE(@ColumnList + ', ', '') + column_name
from information_schema.columns
where table_name = 'SBEDocAcc'
and column_name 'timestamp'
order by ordinal_position
alter table SBEDocAcc disable trigger all
set identity_insert SBEDocAcc on
truncate table SBEDocAcc
exec('insert into SBEDocAcc (' + @ColumnList +') select * from tmpSBEDocAcc')
set identity_insert SBEDocAcc off
alter table SBEDocAcc enable trigger all
-- Удалить связи документов, задач и заданий
delete from SBLinks where DestType = 'E' or SourceType = 'E'
or DestType = 'T' or DestType = 'J'
-- Удалить подписи документов
truncate table SBEDocSignature
-- Удалить историю
truncate table SBEDocProtocol
truncate table SBTaskProtocol
truncate table XProtokol
-- Удалить все задачи и задания
truncate table SBTask
truncate table SBTaskJob
truncate table SBTaskAcc
truncate table SBTaskAttach
truncate table SBTaskText
truncate table SBTaskRoute
truncate table SBTaskObserv
truncate table SBTaskSignature
truncate table SBWorkflowProcessing
-- Удалить временные таблицы
if exists (select * from sys.objects where object_id = object_id(N'tmpSBEDoc') and type in (N'U'))
drop table tmpSBEDoc
if exists (select * from sys.objects where object_id = object_id(N'tmpSBEDocVer') and type in (N'U'))
drop table tmpSBEDocVer
if exists (select * from sys.objects where object_id = object_id(N'tmpSBEDocAcc') and type in (N'U'))
drop table tmpSBEDocAccРуководство по: Макет базы данных — MediaWiki
- Схема перенаправляет сюда; для получения информации о пространстве имен Schema: см. Extension: EventLogging, а о структуре extension.json см. Manual: Extension.json / Schema.
До MediaWiki 1.35 код SQL, который создает базовые таблицы MySQL / MariaDB для любой версии MediaWiki — с подробными комментариями — находится в исходном файле maintenance / tables.sql.
По состоянию на 1.35 (и продолжается в 1.36) соответствующий файл находится в исходном файле maintenance / tables.json, который затем преобразуется в maintenance / tables-generated.sql. В этих версиях обслуживание / tables.sql менее актуально, хотя некоторые таблицы все еще находятся там, которые еще не были перенесены.
Наиболее важными таблицами, вероятно, являются страница, редакция, текст и пользователь.
История версий
В следующей таблице показан диапазон версий MediaWiki, в которых каждая таблица существовала в схеме.Красные строки указывают на таблицы, которые больше не используются ядром и не добавляются установщиком в конкретной версии. Однако они могут по-прежнему использоваться расширениями. Обратите внимание: заголовки таблиц повторяются через каждые 10 строк для ясности.
Системы управления базами данных
В мастере MediaWiki table.sql в настоящее время переносится в maintenance / tables.json, и там должны находиться документирующие комментарии вместо результирующих файлов sql.
См. Последние версии, совместимые с MariaDB / MySQL, в Git: maintenance / tables.sql, обслуживание / таблицы-сгенерированные.sql.
При использовании SQLite вместо этого следует просматривать файл maintenance / sqlite / tables-generated.sql и немигрированные таблицы MySQL в файле maintenance / tables.sql.
При использовании PostgreSQL вместо них следует просматривать файлы maintenance / postgres / tables.sql и maintenance / postgres / tables-generated.sql.
Если вы используете Microsoft SQL Server, см. Maintenance / mssql / tables.sql. (удалено в 1.34)
Если вы используете Oracle, см. Maintenance / oracle / tables.sql. (удалено в 1.34)
См. Также
Руководство по созданию схемы базы данных: примеры и передовые методы
Разработка схемы базы данных — это стратегия построения основы для управления данными. Как и в архитектуре, надежная база данных должна иметь план, чтобы поддерживать проект в нужном русле.
Схема базы данных похожа на проект для огромных объемов данных. Схема — это каркасная структура, представляющая логическое представление базы данных в целом.За счет определения категорий данных и создания отношений между этими категориями дизайн схемы базы данных значительно упрощает использование и интерпретацию данных. В этой статье будет представлен обзор того, как работает разработка схемы базы данных, а также примеры и передовые методы, которые помогут вам оптимизировать свои базы данных.
Содержание
- Важность проектирования схемы базы данных
- Как компании используют схемы схем баз данных?
- Что включают в себя проекты схемы базы данных?
- Лучшие практики и сценарии использования для проектирования схем
- Заключение
Базы данных хранят все важные данные, необходимые для работы программных приложений и систем.Всегда есть по крайней мере одна база данных, которая постоянно работает, чтобы поддерживать работу приложений.
Но количество информации, содержащейся в базе данных без возможности ее разбить и проанализировать. Неэффективно организованные базы данных отнимают уйму энергии, сбивают с толку, их сложно поддерживать и администрировать. Вот где в игру вступает дизайн схемы базы данных.
Структура схемы базы данных организует данные в отдельные объекты, определяет, как создавать отношения между организованными объектами и как применять ограничения к данным.
Разработчики баз данных создают схему, чтобы дать программистам и аналитикам логическое понимание данных, облегчая извлечение, обработку и создание информации.
Кейт подключил несколько источников данных к Amazon Redshift для преобразования, организации и анализа данных о клиентах. MongoDB Амазонка Redshift
Дэйв Шуман
Технический директор и соучредитель Raise.мне
Они действительно предоставили интерфейс в этот мир преобразования данных, который работает. Это интуитивно понятно, с ним легко справиться […], и когда это становится для нас слишком запутанным, [группа поддержки клиентов Xplenty] иногда работает целый день, просто пытаясь помочь нам решить нашу проблему, и никогда не сдавайся, пока он не будет решен.
УЗНАЙТЕ, МОЖЕМ ЛИ МЫ ИНТЕГРИРОВАТЬ ВАШИ ДАННЫЕКОМПАНИИ ПО ВСЕМУ МИРУ ДОВЕРЯЮТ
Вам нравится эта статья?
Получайте отличный контент еженедельно с новостной рассылкой Xplenty!
Как компании используют схемы схем баз данных?Проект схемы базы данных может существовать как в визуальном представлении, так и в виде набора формул или использовать ограничения, которые управляют базой данных.Затем разработчики выражают эти формулы на разных языках определения данных в зависимости от используемой вами системы баз данных. Несмотря на то, что ведущие системы баз данных имеют несколько разные определения схем, MySQL, Oracle Database и SQL Server поддерживают оператор CREATE SCHEMA.
Схемы базы данныхописывают архитектуру базы данных и помогают обеспечить следующее:
- Записи данных имеют единообразное форматирование
- Все записи имеют уникальный первичный ключ
- Важные данные отсутствуют
Например, вы создаете схемы для разных отделов.Аналитики в каждом отделе будут иметь доступ к учетной записи схемы отдела. Аналитик по бухгалтерскому учету будет создавать таблицы и представления внутри схемы учета. Затем аналитик может предложить другим членам команды доступ для чтения таблицы, в которой перечислены расходы сотрудников за период, идентификационные номера сотрудников и т. Д. В другой таблице могут быть указаны зарплаты сотрудников. Аналитики могут определить, какие роли и пользователи могут читать, записывать или редактировать данные в конкретных наборах данных в базе данных.
Что включают в себя проекты схемы базы данных?Мы можем в общих чертах разделить схемы баз данных на две категории:
- Физическая схема базы данных: Физическая схема базы данных относится к физическому хранению данных в системе хранения и форме используемого хранилища (файлы, индексы и т. Д.)). Он определяет, как вы в дальнейшем будете хранить данные. Физическая схема помогает упорядочить данные в ясной и логической форме, определяя все ее атрибуты.
- Схема логической базы данных: Логическая схема описывает все логические ограничения, применяемые к данным, и определяет поля, таблицы, отношения, представления, ограничения целостности и т. Д. Эти требования предоставляют полезную информацию, которую программисты могут применить к физическому проекту базы данных. Правила или ограничения, определенные в этой логической модели, помогают определить, как данные в разных таблицах соотносятся друг с другом.
Определение физических таблиц в схеме происходит из логической модели данных. Сущности становятся таблицами, атрибуты сущности становятся полями таблиц и т. Д.
Возвращаясь к нашему примеру бухгалтерского учета, определенная схема может содержать структуру из двух таблиц:
Таблица1:
Заголовок: Пользователи
Поля: ID, ФИО, электронная почта, дата рождения, отдел
Таблица 2:
Название: Сверхурочная работа
Поля: ID, полное имя, период времени, количество часов
В этой единой схеме есть несколько частей информации, включая заголовки имен таблиц, поля, которые содержит каждая таблица, отношения между таблицами (т.e Ссылки «Оплата сверхурочных» на пользователя), а также любую дополнительную информацию, которая имеет отношение к делу. Затем разработчики или администраторы преобразуют эти таблицы схем в код SQL.
Лучшие практики и сценарии использования для проектирования схем
Чтобы максимально использовать возможности проектирования схемы базы данных, важно следовать этим передовым методам, чтобы у разработчиков была четкая точка отсчета о том, какие таблицы и поля содержит проект и т. Д.
- Определите и используйте соответствующие соглашения об именах, чтобы сделать схемы проектирования базы данных наиболее эффективными.
- Хотя вы можете выбрать конкретный стиль или придерживаться стандарта ISO, самое важное — это согласованность в полях вашего имени. Следующие советы также помогут вам эффективно структурировать схему.
- Старайтесь не использовать зарезервированные слова SQL Server в именах таблиц, столбцах, полях и т. Д., Поскольку это может привести к синтаксической ошибке.
- Не используйте дефисы, кавычки, пробелы, специальные символы и т. Д., Потому что они недействительны или потребуют дополнительного шага.
- Используйте Singular для имен таблиц (т.е. используйте StudentName вместо StudentNames). Таблица представляет собой коллекцию, поэтому нет необходимости использовать название во множественном числе.
- Опустите ненужные префиксы или суффиксы для имен таблиц (например, используйте Department вместо DepartmentList, TableDepartments и т. Д.)
- Хранить пароли в зашифрованном виде.
- Не давайте каждому пользователю роли администратора — запрашивайте аутентификацию для доступа к базе данных.
- Дизайн базы данных документов со схемами и инструкциями.Напишите строки комментариев для скриптов, триггеров и т. Д.
- Используйте нормализацию по мере необходимости для оптимизации производительности. И чрезмерная нормализация, и недостаточная нормализация приведут к снижению производительности.
Понимание ваших данных и атрибутов каждого элемента поможет вам построить наиболее эффективный дизайн схемы базы данных. Хорошо спроектированная схема может позволить вашим данным расти экспоненциально. По мере того, как вы продолжаете расширять свои данные, вы можете анализировать каждое поле по отношению к другим, которые вы собираете в своей схеме.
Как только вы получите четкое представление об этом процессе, вы можете продолжать добавлять данные из разных источников. Цель состоит в том, чтобы ввести как можно больше элементов вашей базы данных и организовать их в логические группы, которые ваша команда сможет усвоить и интерпретировать.
Кейт подключил несколько источников данных к Amazon Redshift для преобразования, организации и анализа данных о клиентах. Амазонка Redshift
Кейт Слейтер
Старший разработчик Creative Anvil
До того, как мы начали с Xplenty, мы пытались перенести данные из множества разных источников в Redshift.Xplenty помог нам сделать это быстро и легко. Лучшая особенность платформы — это возможность манипулировать данными по мере необходимости, не усложняя процесс. Кроме того, поддержка отличная — они всегда отзывчивы и готовы помочь.
УЗНАЙТЕ, МОЖЕМ ЛИ МЫ ИНТЕГРИРОВАТЬ ВАШИ ДАННЫЕКОМПАНИИ ПО ВСЕМУ МИРУ ДОВЕРЯЮТ
Вам нравится эта статья?
Получайте отличный контент еженедельно с новостной рассылкой Xplenty!
Нужна помощь в разработке схемы базы данных?
Схемы базы данныхпомогают администраторам и разработчикам понять сложную структуру вашей базы данных, чтобы они могли продолжать ее наращивать и эффективно управлять.Надеюсь, эти рекомендации и передовой опыт помогут вам начать правильную работу при проектировании схемы базы данных. Если вам нужна помощь в разработке или обновлении системы управления базами данных, запланируйте демонстрацию с Xplenty или свяжитесь с нашей службой поддержки сегодня, чтобы узнать больше.
6 примеров схем базы данных и способы их использования
В этой статье рассматриваются шесть схем баз данных:
- Плоская модель для небольших простых приложений
- Иерархическая модель предназначена для вложенных данных, таких как XML или JSON.
- Сетевая модель полезна для картографирования и пространственных данных, а также для изображения рабочих процессов.
- Реляционная модель наилучшим образом отражает приложения объектно-ориентированного программирования
- Схема «звезда» и схема «снежинка» предназначены для анализа больших наборов данных
Выбор правильной схемы базы данных может облегчить множество страданий и страданий на протяжении всего жизненного цикла программного проекта.Неправильный дизайн схемы может привести к изнурительным узким местам в приложении и может быть дорогостоящим для рефакторинга. Например, если вы на раннем этапе не осознавали, что ваше приложение будет полагаться на несколько таблиц JOIN, ваша служба в конечном итоге остановится, когда вы достигнете определенного количества пользователей и данных. Чтобы решить эту проблему, данные, вероятно, придется переместить в новые таблицы, код должен будет указывать на эти новые таблицы, а затем эти таблицы должны будут иметь правильные JOIN. Это означает, что вам понадобится очень сильная тестовая среда (исходный код базы данных и ) для тестирования ваших изменений, вам понадобится план управления целостностью данных и план обновления исходного кода базы данных и одновременно. время.Самое главное, что как только вы начнете переносить свою базу данных на новую схему, пути назад почти не будет.
Содержание:
- Плоская модель
- Иерархическая модель
- Сетевая модель
- Реляционная модель
- Схема звезды
- Схема снежинки
Кейт подключил несколько источников данных к Amazon Redshift для преобразования, организации и анализа данных о клиентах. Амазонка Redshift
Кейт Слейтер
Старший разработчик Creative Anvil
До того, как мы начали с Xplenty, мы пытались перенести данные из множества разных источников в Redshift.Xplenty помог нам сделать это быстро и легко. Лучшая особенность платформы — это возможность манипулировать данными по мере необходимости, не усложняя процесс. Кроме того, поддержка отличная — они всегда отзывчивы и готовы помочь.
УЗНАЙТЕ, МОЖЕМ ЛИ МЫ ИНТЕГРИРОВАТЬ ВАШИ ДАННЫЕКОМПАНИИ ПО ВСЕМУ МИРУ ДОВЕРЯЮТ
Вам нравится эта статья?
Получайте отличный контент еженедельно с новостной рассылкой Xplenty!
Плоская модель
Схема плоской модели — это единый двумерный массив, в котором элементы в каждом столбце относятся к одному типу данных, а элементы в одной строке связаны друг с другом.Думайте об этом как об одной электронной таблице Excel или единой таблице базы данных без каких-либо связей. Они лучше всего подходят для простых небольших приложений, в которых нет слишком большого количества данных или сложных отношений. Например, если вы ведете малый бизнес с небольшим количеством сотрудников и хотите хранить информацию об их зарплате, достаточно будет единой плоской модели данных. Эта модель соответствует принципу KISS.
Иерархическая модель
Иерархические модели имеют древовидную структуру с «корневым» узлом данных и дочерними узлами, которые отходят от этого корня.Между родительскими и дочерними узлами существует связь «один ко многим». Этот тип схемы данных лучше всего отражается в файлах XML или JSON, где сущность может иметь под-сущности, которые не используются совместно с другими сущностями.
Иерархические модели отлично подходят для хранения вложенных данных. Например, изучение таксономии опирается на иерархический набор данных: Царство, Тип, Класс, Порядок, Семейство, Род и Виды. Если вы читаете это, вы, вероятно, являетесь представителем рода Homo Sapiens. Есть и другие представители рода Homo — например, Homo neanderthalensis, — но наш вид не существует ни в одном другом роде.
С точки зрения базы данных, нужно искать «тройные хранилища». Тройное хранилище — это тип базы данных, в которой данные хранятся в форме «троек». «Тройка» — это запись данных, состоящая из субъекта, предиката и объекта (в указанном порядке).
Сетевая модель
Сетевая модель похожа на иерархическую модель в том смысле, что она представляет собой последовательность узлов и вершин, однако допускает отношения «многие ко многим». С теоретической точки зрения это означает, что на графике могут быть циклы.Цикл на графике указывает, что существует путь вершин, в котором вы можете начинать и заканчивать в одном и том же узле. Это очень важное различие, так как оно покажет вам границы, в которых может работать ваше приложение. Если ваше программное обеспечение не ожидает каких-либо циклов, но он существует в ваших данных, вы можете неожиданно запустить свое программное обеспечение через этот цикл навсегда.
В компьютерных науках и теории графов есть классическая задача под названием «Коммивояжер». В этой статье не будут подробно рассказываться о том, что делает эту проблему классической (Google «делает ли p = NP?», Если вы хотите узнать об этом больше), но проблема заключается в следующем:
Учитывая список городов и расстояния между каждой парой городов, каков самый короткий маршрут, который проходит через каждый город ровно один раз и возвращается в исходный город?
Этот тип вопросов задают тысячи компаний каждый день, поскольку правильный ответ — залог успеха любой логистической компании.Миллиарды долларов заключаются в способности компании эффективно перемещать свои товары из точки А в точку Б, и поэтому глубокое понимание того, как применять сетевую модель, имеет жизненно важное значение. Большинство приложений, которым требуются пространственные вычисления, вероятно, выиграют от хранения данных в базе данных, смоделированной сетью. ГИС, географические информационные системы, — это программное обеспечение, которое позволяет пользователям эффективно хранить и анализировать картографические данные.
Сетевая модель также полезна при изображении рабочих процессов, особенно когда есть несколько путей к одному и тому же результату.Возьмем, к примеру, сеть ресторанов. Типичный рабочий процесс — сервер говорит повару, что ему приготовить, скажем, «бургер с картофелем фри». Повар приготовит восхитительный гамбургер со всеми готовыми блюдами, поджарит соленую порцию картофеля фри, выложит все на тарелку, шлепнет на прилавок и объявит «заказ готов!» Сервер возьмет тарелку и проведет заключительный тест на обеспечение качества, чтобы убедиться, что это то, о чем просил посетитель. Может быть, они не просили помидоров, поэтому официант вынимает ломтик помидора из бургера и передает тарелку счастливому и голодному покупателю.В этом сценарии существует связь «многие ко многим» между едой и различными типами сотрудников, и поэтому этот рабочий процесс лучше всего структурировать с помощью сетевой модели.
Реляционная модель
Введение модели реляционной базы данных открыло новую эру обработки данных. Интересно, что изобретатель реляционной базы данных Эдгар Кодд из IBM в 1970-х годах дал другое определение того, что означает «реляционная». Но за десятилетия использования сообщество программистов пришло к более универсальному пониманию того, что такое реляционная база данных.То есть мы храним данные в виде отношений (то есть таблиц), и есть операторы отношения, которые мы выполняем с данными, чтобы управлять ими и вычислять на их основе. Люди используют системы управления реляционными базами данных для управления своими реляционными базами данных. Ознакомьтесь с нашим подробным описанием СУБД здесь.
Реляционные базы данных лучше всего рассматривать как серию объектов, некоторые из которых связаны друг с другом определенным образом. Важно думать о них как о своих конкретных существах. Если вы создаете программное обеспечение, которое следует подходу объектно-ориентированного программирования, было бы лучше хранить данные каждого объекта в виде отдельной таблицы с базой данных.Например, если вы программируете автомобиль, у вас может быть объект для шин, осей, двигателя, сидений, краски и т. Д. Шины прикрепляются к осям, которые вращаются из-за двигателя и т. Д. Представляя каждый из этих объектов в виде собственной таблицы со связью между соответствующими объектами (шина к оси, ось к двигателю и т. д.) будет оптимальным способом аккуратно хранить данные и понимать, как работает автомобиль.
Распространенная ошибка, которую делают люди при использовании реляционных моделей данных, — это применять ее к наборам данных, которые могут иметь отношения, но не зависят от этих отношений.Например, ось зависит от двигателя автомобиля. Но если вы работали в отделе продаж, есть первичный набор данных («мы продавали 300 автомобилей по 10 000 долларов каждый последний квартал»), а затем вторичный набор данных («20% из них были синими»). Ключевой информацией для отдела продаж являются номера продаж, и эта информация не зависит от знания цвета проданных автомобилей. Этот тип данных о продажах лучше подходит для звездообразной схемы, которую мы вскоре обсудим.
Схема звезды
Схема «звезда» — это другой способ организации данных.Это отличный подход к дизайну для хранения и анализа огромных объемов данных, основанный на использовании «фактов» и «измерений». «Факт» — это числовая точка данных, которая управляет бизнес-процессами, а «измерение» — это описание этого факта. Вернемся к нашему примеру с цифрами продаж автомобилей: таблица «фактов» будет содержать информацию о количестве продаж, а соответствующая «размерная» таблица будет иметь цвет этих автомобилей.
Дополнительная литература: Snowflake Schemas vs.Звездные схемы
Кейт подключил несколько источников данных к Amazon Redshift для преобразования, организации и анализа данных о клиентах. MongoDB Амазонка Redshift
Дэйв Шуман
Технический директор и соучредитель Raise.me
Они действительно предоставили интерфейс в этот мир преобразования данных, который работает.Это интуитивно понятно, с ним легко справиться […], и когда это становится для нас слишком запутанным, [группа поддержки клиентов Xplenty] иногда работает целый день, просто пытаясь помочь нам решить нашу проблему, и никогда не сдавайся, пока он не будет решен.
УЗНАЙТЕ, МОЖЕМ ЛИ МЫ ИНТЕГРИРОВАТЬ ВАШИ ДАННЫЕКОМПАНИИ ПО ВСЕМУ МИРУ ДОВЕРЯЮТ
Вам нравится эта статья?
Получайте отличный контент еженедельно с новостной рассылкой Xplenty!
Классная особенность звездообразных схем заключается в том, что они просто абстракции поверх традиционных реляционных баз данных.То есть, если у вас есть СУБД, вы можете использовать ее для структурирования данных в звездообразную схему.
Схема снежинки
Поскольку звездная схема является адаптацией модели реляционной базы данных, схема «снежинка» является адаптацией звездной схемы. Его название происходит от того, как можно было бы изобразить ERD (диаграмму сущности-отношения) схемы снежинки: как вы уже догадались, она начинает выглядеть как снежинка. Как и в случае со звездообразной схемой, существует центральная таблица «фактов», в которой хранятся основные точки данных и ссылки на ее таблицы измерений.В отличие от звездообразной схемы, размерные таблицы могут иметь свои собственные размерные таблицы, что расширяет возможности описания измерения.
Следуя нашему дизайну базы данных автомобилей, предположим, что операционный отдел должен иметь возможность прогнозировать, какие ресурсы им потребуются для создания своих автомобилей. Как и отдел продаж, они хотят знать, какие автомобили и сколько продаются. В приведенном выше примере звездной схемы у нас была размерная таблица, показывающая цвет проданных автомобилей.Операционный отдел может захотеть узнать больше о краске, кроме цвета: марка краски, стоимость, количество слоев и т. Д. В этом сценарии будет полезна схема «снежинка», потому что таблица размеров «цвет» требует наличия собственных таблиц размеров ( марка краски, стоимость, количество слоев и т. д.).
Дизайн схемыс Xplenty
Мы в Xplenty гордимся тем, что являемся ведущими распорядителями данных. От сложных приложений до обработки массивных наборов данных — у нас есть все необходимое.Позвольте нам помочь вам избежать стрессовых и дорогостоящих миграций баз данных. Запланируйте звонок с нашей командой поддержки высшего уровня и испытайте платформу Xplenty без всякого риска!
DbSchema Layouts
Индекс
Что такое макет?
Макет — это диаграмма базы данных со связанными данными и инструментами запросов. Думайте об этом как о доске, на которой вы можете создать собственное представление схемы базы данных. Внутри макета вы можете редактировать таблицы и внешние ключи, просто дважды щелкнув по ним.Добавляйте таблицы, внешние ключи, группы, выноски и получайте доступ к инструментам обработки данных, таким как обозреватель реляционных данных или редактор SQL. Вы можете создать столько макетов, сколько вам нужно, каждый из которых ориентирован на определенную часть схемы. Таблица может присутствовать в нескольких макетах .
Почему мы используем макеты?
- Макеты позволяют разделять сложные базы данных на более конкретные разделы. Поэтому вы можете лучше понять базы данных;
- Макет предлагает визуальное представление базы данных;
- Вы можете редактировать таблицы, столбцы, внешние ключи и многое другое, просто щелкая по ним;
- Каждый макет сохраняется в файле модели, чтобы его можно было открыть позже.
- Другие инструменты DbSchema открыты в макете и будут сохранены в файл проекта вместе с макетом.
Обозначения в схемах
Внутри макета все представлено графически. Это поможет вам лучше понять базу данных. и легко просматривать данные.
1. Таблица
2. Внешние ключи
Внешние ключи также могут иметь различное визуальное представление в зависимости от их числа и порядкового числа .Это последствия характера столбцов и индексов.
- Количество элементов представляет максимальное количество раз, когда запись из таблицы может соотноситься с записями из другой таблицы.
- Порядок представляет минимальное количество раз, когда запись из таблицы может соотноситься с записями из другой таблицы.
На основе ссылочного столбца существует 4 состояния, в которых может находиться внешний ключ. Мы постараемся их лучше понять посмотрев несколько примеров:
Имейте в виду, что ТАБЛИЦА 1 будет родительской таблицей , а ТАБЛИЦА 2 будет дочерней таблицей .
- Один к нулю или много
В дочерней таблице ссылочный столбец не является обязательным или уникальным. В этом случае родительская таблица (1) может ссылаться на ноль или много записей в дочерней таблице (2).
- Один к одному или многим
В дочерней таблице ссылочный столбец является обязательным, но не уникальным.В этом случае столбец из родительской таблицы может относиться к одному (обязательному) или многим.
- Один к одному
В дочерней таблице ссылочный столбец является обязательным и уникальным. В этом случае столбец из родительской таблицы может относятся только к одной записи из дочерней таблицы.
- Один к нулю или один
В дочерней таблице ссылочный столбец уникален, но не обязателен.В этом случае столбец из родительской таблицы может ссылаться на одну или ноль записей из дочерней таблицы.
Схема проектирования онлайн или офлайн
Используя DbSchema, вы можете создать схему при подключении к базе данных ( онлайн, ) или без базы данных.
соединение ( офлайн ).
В оперативном режиме все изменения таблиц и столбцов будут применены к базе данных.Выполненные операторы отображаются слева на панели История SQL .
В автономном режиме изменения будут применены только к модели DbSchema, которая будет сохранена в файл. Вам необходимо подключиться к базе данных и выбрать один из вариантов схемы (Обновить / сравнить с базой данных).
Добавить таблицы в макет
1. Добавьте таблицы из древовидной панели, перетащив на .
2. Добавьте таблицы, используя значок внешнего ключа .
Авто место
Если вы откроете новую модель схемы, которая изначально не была разработана в DbSchema, диаграмма может появиться
грязный и неорганизованный.
DbSchema включает опцию, которая мгновенно организует схему за вас.
Чтобы получить к нему доступ, щелкните правой кнопкой мыши макет и выберите опцию Автоматическое размещение .
Видимость и положение столбца
DbSchema не позволяет изменять размер таблиц.Вместо этого вы можете выбрать видимые столбцы. Причина этого в том, что мы фокусируемся на больших и очень больших диаграммах, где эта функция будет конфликтовать с нашими алгоритмами для диаграммы оптимального обращения.- Измените видимость столбца, дважды щелкнув заголовок таблицы. Затем выберите, хотите ли вы его увидеть или нет, из виден столбец .
- Измените положение столбца, нажав кнопки Вверх или Вниз .
Виртуальные внешние ключи
Есть базы данных, которые не содержат внешних ключей. В этих ситуациях вы можете создать виртуальных внешних ключей . Виртуальные внешние ключи будут созданы только в DbSchema и сохранятся в файле модели.
Маршрутизация по внешнему ключу
Линия внешнего ключа маршрутизируется автоматически.
DbSchema оптимизирован для управления большими диаграммами, где эта функция может создать проблемы.
Вы можете выбрать один из двух режимов маршрутизации строк внешнего ключа: от таблицы к таблице или от столбца к столбцу.
Во втором случае линия будет указывать на задействованные столбцы. Два внешних ключа могут объединиться в одну строку, если они указывают на один и тот же столбец.
Показать тип данных
Выберите этот параметр в меню, чтобы отобразить тип данных столбца непосредственно на диаграмме. Этот параметр устанавливается для каждого макета.
Добавить уточнения
Добавьте выноски, щелкнув правой кнопкой мыши пустую часть макета. Выберите вариант Создать выноску .
Быстрый просмотр данных таблицы
Просматривайте данные из таблиц прямо в макете. Удерживайте SHIFT + CTRL и щелкните в заголовке таблицы, чтобы увидеть ее содержимое.
Инструменты для обработки данных
Вы можете открыть меню инструмента данных, просто щелкнув заголовок таблицы.◉ Схема базы данных
Этот документ описывает ключевые компоненты схемы базы данных и должен отвечать вопросы вроде того, как хранить новые типы данных.
Система баз данных
Phabricator использует MySQL или другую MySQL-совместимую базу данных (например, MariaDB или Amazon RDS).
Phabricator использует движок таблиц InnoDB. Единственное исключение — таблица search_documentfield, в которой используется MyISAM, поскольку MySQL не поддерживает полнотекстовый поиск в InnoDB (в последних версиях есть, но мы не добавили поддержку пока что).
Мы вряд ли когда-нибудь будем поддерживать другие несовместимые базы данных, такие как PostgreSQL или SQLite.
Драйверы PHP
Phabricator поддерживает MySQL и Расширения MySQLi PHP.
Базы данных
Каждое приложение Phabricator имеет свою собственную базу данных. Имена начинаются с префикса phabricator_ (это настраивается).
Phabricator использует отдельную базу данных для каждого приложения. Чтобы понять почему, см. Зачем Phabricator нужно так много баз данных ?.
Подключения
Phabricator указывает, будет ли он использовать открытое соединение только для чтения или также для письма.Это позволяет открывать подключения для записи к первичному и читать подключения к реплике в настройках первичной / реплики (которые на самом деле не поддерживается пока).
Столы
Большинство имен таблиц имеют префиксы с именами их приложений. Например, Дифференциальные ревизии хранятся в базе данных phabricator_differential и таблица diff_revision. Обычно это упрощает распознавание запросов. и пойми.
Исключение составляют несколько таблиц, которые используют одну и ту же схему в разных базы данных, такие как edge.
Мы используем имена таблиц в нижнем регистре со словами, разделенными подчеркиванием.
Имена столбцов
Phabricator использует имена CamelCase для столбцов. Главное преимущество в том, что они напрямую сопоставляются со свойствами в PHP-классах.
Не используйте зарезервированные слова MySQL (например, порядок) для имен столбцов.
Типы данных
Phabricator определяет набор абстрактных типов данных (таких как uint32, epoch и phid), которые сопоставляются с типами столбцов MySQL. Отображение зависит от MySQL версия.
Phabricator использует наборы символов utf8mb4, если они доступны (MySQL 5.5 или новее), и двоичные наборы символов в большинстве других случаев. Основная мотивация — разрешить сохранение 4-байтовых символов Юникода (набор символов utf8, который более широко доступны, не поддерживает их). В более новой версии MySQL мы используем utf8mb4, чтобы воспользоваться улучшенными правилами сортировки.
Phabricator хранит даты с абстрактным типом данных эпохи, который отображается на int без знака. Хотя это делает даты менее читаемыми при просмотре базы данных, это делает управление датой и временем более согласованным и просто в приложении.
Мы не используем тип данных enum, потому что каждое изменение списка возможных values требует изменения таблицы (что медленно для больших таблиц). Мы используем числа (или короткие строки в некоторых случаях) вместо этого отображаются на константы PHP.
JSON и другие сериализованные данные
Некоторые данные не требуют структурированного доступа — нам не нужно фильтровать или сортировать по их. Мы храним эти данные в виде текстовых полей в формате JSON. Этот подход имеет несколько преимуществ:
- Если мы решим добавить еще одно неструктурированное поле, нам не нужно изменять таблицу (что медленно для больших таблиц в MySQL).
- Структура таблицы не загромождена полями, которые могли не использоваться большую часть времени.
Пример такого использования можно найти в столбце дифференциал_диффропертидата.
Первичные ключи
В большинстве таблиц есть столбец с автоматическим приращением с именем id. Добавление столбца идентификатора подходит для большинства таблиц (даже для таблиц с другим естественным уникальным ключом), поскольку это улучшает согласованность и упрощает выполнение общих операций на объектах.
Например, LiskMigrationIterator позволяет очень легко применять переход к таблице с использованием постоянного объема памяти при условии, что таблица имеет столбец идентификатора.
Индексы
Создайте все индексы, необходимые для быстрого выполнения запроса в большинстве случаев. Не надо создавать индексы, которые не используются. Вы можете анализировать запросы с помощью DarkConsole.
Более старые версии MySQL не могут использовать индексы для поиска кортежей: (a, b) IN ((% s,% d), (% s,% d)). Вместо этого используйте И и ИЛИ: ((a =% s AND b =% d) OR (a =% s AND b =% d)).
Внешние ключи
Мы не используем внешние ключи, потому что они сложны, и у нас нет опыта значительные проблемы с несогласованностью данных, которые могут помочь предотвратить внешние ключи.Эмпирически мы были свидетелями из первых рук, как отношения ON DELETE CASCADE случайно уничтожить огромные объемы данных. Мы можем использовать внешние ключи в конце концов, но в настоящее время для них нет веских доводов.
PHID
Каждый глобально упоминаемый объект в Phabricator имеет связанный PHID («Phabricator ID»), который служит глобальным идентификатором, подобным GUID. Мы используем PHID для ссылки на данные в разных базах данных.
Мы используем как автоматически увеличивающиеся идентификаторы, так и глобальные идентификаторы PHID, потому что каждый из них полезен в разные контексты.Автоинкрементные идентификаторы упорядочены и позволяют нам для создания коротких, удобочитаемых имен объектов (например, D2258) и URI. Глобальные PHID позволяют нам отображать отношения между различными типами объекты однородным образом.
Например, такую инфраструктуру, как «подписчики», можно легко реализовать с помощью Отношения PHID: разные типы объектов (пользователи, проекты, списки рассылки) разрешено подписываться на разные типы объектов (ревизии, задачи, так далее). Без PHID нам нужно было бы добавить столбец «тип», чтобы избежать конфликта идентификаторов; использование PHID упрощает реализацию подобных функций.
транзакции
Транзакционный код должен быть написан с использованием транзакций. Пример такого кода: вставка нескольких записей, одна из которых не имеет смысла без другой, или выбор данных, которые позже будут использоваться для обновления. См. Главу в LiskDAO.
Расширенные функции
Мы не используем расширенные функции MySQL, такие как триггеры, хранимые процедуры или события, потому что нам больше нравится выражать логику приложения в PHP, чем в SQL. Некоторые из этих функций (особенно триггеры) также могут вызывать множество путаница и, как правило, труднее отлаживать, профилировать, управлять версиями, обновите, и поймите, чем код приложения.
Денормализация схемы
Phabricator экономно использует денормализацию схемы. Избегайте денормализации, если есть веская причина (обычно производительность) для денормализации.
Изменения и миграции схемы
Чтобы создать новое изменение схемы или миграцию:
Создать патч базы данных . Патчи базы данных входят в ресурсы / sql / autopatches /. Чтобы изменить схему, используйте файл .sql и напишите в SQL. Чтобы выполнить миграцию, используйте файл .php и напишите на PHP.Назови свое файл ГГГГММДД.patchname.ext. Например, 20141225.christmas.sql.
Держите заплатки маленькими . Большинство операторов изменения схемы не являются транзакционными. Если патч содержит несколько операторов SQL и дает сбой на полпути, обычно откатиться нельзя. Когда пользователь позже пытается снова применить патч, первый оператор (который, например, добавляет столбец) может завершиться ошибкой (поскольку столбец уже существует). Этого можно избежать, сохраняя небольшие патчи (обычно один заявление на патч).
Использовать переменные пространства имен и набора символов . При определении патча .sql, вы должны использовать эти переменные вместо жестко заданных пространств имен или символов имена наборов:
| Переменная | Значение | Примечания |
|---|---|---|
| {$ NAMESPACE} | Пространство имен хранилища | По умолчанию используется фабрикатор |
| {$ CHARSET} | {$ COLLATE_TEXT} | Сортировка текста | Для большей части текста (с учетом регистра) |
| {$ COLLATE_SORT} | Сортировка сортировки | Для сортируемого текста (без учета регистра) | Полнотекстовый набор символов | Определить явно для полнотекстового поиска |
| {$ COLLATE_FULLTEXT} | Полнотекстовый подбор по копиям | Определить явно для полнотекстового поиска |
Проверьте свой патч .Запустите обновление bin / storage, чтобы протестировать исправление.
См. Также
| Содержит столбцы из таблицы назначений, которые будут сохранены в случае будущего изменения схемы. |
| Содержит имена и описания кодов, используемых в столбце |
| Одна строка для каждого пути файла отчета о проверке, проверенных строк кода и количества дефектов. |
| Это настраиваемые поля, которые вы определили для дефектов, по одной строке для каждого дефекта. Если вы измените определение настраиваемого поля, макет этой таблицы также изменится (автоматически и немедленно).Предупреждение: поскольку для имен столбцов используются точные заголовки настраиваемых полей, если вы измените заголовок настраиваемого поля, это изменит определение этого представления. В рабочих процессах рецензирования у каждого рецензирования может быть свое собственное подмножество настраиваемых полей. В этом случае поля |
| То же, что и |
| Эта таблица содержит список возможных значений, определенных в раскрывающемся списке и в настраиваемых полях для дефектов с множественным выбором. |
| Содержит коды и названия «состояния неисправности».Присоединитесь к этой таблице, если вы хотите отобразить более удобные для пользователя имена состояний дефекта. |
| Содержит столбцы из таблицы дефектов, которые будут сохранены в случае будущего изменения схемы. |
| Показывает значения настраиваемого поля участника, которые пользователи выбрали в обзорах.В этой таблице показаны значения только для настраиваемых полей типа «Однострочный текст». Значение NULL означает, что для шаблона обзора было определено настраиваемое поле, но пользователь не указал значение. |
| Показывает значения настраиваемого поля участника, которые пользователи выбрали в обзорах. В этой таблице показаны значения только для настраиваемых полей типа «Многострочный текст». Значение NULL означает, что для шаблона обзора было определено настраиваемое поле, но пользователь не указал значение. |
| Показывает значения настраиваемого поля участника, которые пользователи выбрали в обзорах. В этой таблице показаны значения для настраиваемых полей типа «Раскрывающийся» и «Множественный выбор». Значение NULL означает, что для шаблона обзора было определено настраиваемое поле, но пользователь не указал значение. В случае полей с множественным выбором, если пользователь выбрал несколько значений, в результатах появится несколько строк, по одной для каждого выбора. |
| Отражает различные фазы, на которых может находиться обзор. |
| Отчеты о затраченных человеко-часах для каждой уникальной комбинации обзора, пользователя и роли. Включает данные только для текущих участников проверки. Если пользователь был участником, но не сейчас, этот человек не будет включен в этот результат.Однако это время будет включено в представление |
| Одна строка для каждого автора отчета об обзоре, рецензента, часов переделки и общего количества человеко-часов, потраченных на проверку.
|
| Одна строка на автора отчета об обзоре, рецензента и общее количество комментариев, сделанных в рецензии. |
| Одна строка на проверку, в которой указывается количество дефектов, созданных в ходе проверки. |
| Одна строка для каждого обзора, содержащая множество стандартных показателей, таких как количество проверок, количество дефектов, плотность дефектов и отдельные числа, использованные для формирования этих соотношений.Некоторые значения будут содержать |
| Перечисляет все версии, фактически связанные с рецензией, хотя и с связанной рецензией. |
| Одна строка на обзор, в которой указывается количество файлов и показатели строк (общее, добавленное, измененное, удаленное) для всех файлов в обзоре. |
| Это настраиваемые поля, которые вы определили для обзоров, по одной строке для каждого обзора. Если вы измените определение настраиваемого поля, макет этой таблицы также изменится (автоматически и немедленно). В рабочих процессах рецензирования у каждого рецензирования может быть свое собственное подмножество настраиваемых полей. В этом случае поля |
| То же, что и |
| Эта таблица содержит список возможных значений, определенных в раскрывающемся списке и с множественным выбором пользовательских полей обзора. |
| Содержит столбцы из обзорной таблицы, которые будут сохранены в случае будущего изменения схемы. |
| Содержит столбцы из таблицы ролей, которые будут сохранены в случае будущего изменения схемы. |
| Дополнительные пользовательские настройки, одна строка для каждого пользователя.Большая часть пользовательской информации и предпочтений хранится в таблице |
| То же, что |
| Содержит столбцы из пользовательской таблицы, которые будут сохранены в случае будущего изменения схемы. |
apache spark - Создание схемы схемы базы данных для Databricks
Возможны 2 варианта:
- с использованием Spark SQL с
показать базы данных,показать таблицы в,описать таблицу... - с использованием
spark.catalog.list Базы данных,spark.catalog.listTables,spark.catagog.listColumns.
2-й вариант не очень эффективен, когда у вас много таблиц в базе данных / пространстве имен, хотя его немного проще использовать программно. Но в обоих случаях реализация представляет собой всего 3 вложенных цикла, повторяющих список баз данных, затем список таблиц внутри базы данных, а затем список столбцов внутри таблицы. Эти данные можно использовать для создания диаграммы с помощью вашего любимого инструмента для построения диаграмм.
Вот код для создания исходного кода для PlantUML (полный код здесь):
# Этот сценарий генерирует диаграмму PlantUML для таблиц, видимых Spark.
# Схема хранится в файле db_schema.puml, поэтому просто запустите
# 'java -jar plantuml.jar db_schema.puml', чтобы получить файл PNG из pyspark.sql импортировать SparkSession
из pyspark.sql.utils import AnalysisException # Переменные # список баз данных / пространств имен для анализа. Может быть пустым, тогда все существующие
Будет обработано # базы данных / пространства имен
database = ["a", "airbnb"] # передать базы данных / пространство имен для обработки
# измените это, если вы хотите также включить временные таблицы
include_temp = Ложь # выполнение
искра = SparkSession.builder.appName («Генератор схемы базы данных»). getOrCreate () # если базы данных не указаны, то получить список из Spark
если len (базы данных) == 0:
базы данных = [db ["пространство имен"] для базы данных в spark.