Базы данных и СУБД – База знаний Timeweb Community
Для правильной работы сайта нужны не только файлы с кодом страниц, но и базы данных. Для взаимодействия с БД используются системы управления базами данных (СУБД). В этой статье я расскажу о базах данных и СУБД, их разновидностях и основных отличиях.
Как работают базы данных
В базе данных может содержаться различная информация: личные данные пользователей, записи, даты, заказы, список клиентов и так далее. К примеру, если у вас интернет-магазин, то база данных вашего сайта может содержать прайс-листы, каталог товаров или услуг, отчеты, статистику и информацию о покупателях.
Любую информацию можно быстро заносить в базу данных и так же быстро извлекать ее при необходимости.
Важную роль играет взаимосвязь информации в базе данных: изменение одной строчки может привести к значительным изменениям других строк. Работать с данными таким образом гораздо проще и быстрее, чем если бы изменения касались только одного места.
Однако это не значит, что база данных обязательно должна быть у каждого сайта – к примеру, если у вас сайт-визитка, и никакой новой информации вы на сайте не размещаете, то база данных вам будет попросту не нужна.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Система управления базами данных (СУБД)
Система управления базами данных (сокращенно СУБД) – это программное обеспечение для создания и работы с базами данных.
Главная функция СУБД – это управление данными (которые могут быть как во внешней, так и в оперативной памяти). СУБД обязательно поддерживает языки баз данных, а также отвечает за копирование и восстановление информации после каких-либо сбоев.
Реляционные СУБД и язык SQL
Реляционные и объектно-реляционные СУБД являются одними из самых распространенных систем. Они представляют собой таблицы, в которых каждый столбец (он называется «field» или «поле») упорядочен и имеет определенное уникальное название. Последовательность строк (их называют «records» или «записи») определяется последовательностью ввода информации в таблицу. При этом обрабатывание столбцов и строк может происходить в любом порядке. Таблицы с данными связаны между собой специальными отношениями, благодаря чему с данными из разных таблиц можно работать – к примеру, объединять их при помощи одного запроса.
Последовательность строк (их называют «records» или «записи») определяется последовательностью ввода информации в таблицу. При этом обрабатывание столбцов и строк может происходить в любом порядке. Таблицы с данными связаны между собой специальными отношениями, благодаря чему с данными из разных таблиц можно работать – к примеру, объединять их при помощи одного запроса.
Для управления реляционными базами данных применяется особый язык программирования – SQL. Сокращение расшифровывается как «Structured query language», в переводе на русский – «язык структурированных запросов».
Команды, которые используются в SQL, делятся на:
- манипулирующие данными,
- определяющие данные,
- управляющие данными.
Схема работы с базой данных выглядит следующим образом:
5 лучших СУБД
Далее я кратко расскажу о лучших СУБД, которые чаще всего используются при создании веб-проектов.
MySQL
MySQL является одной из самых популярных и распространенных СУБД, которая используется во многих компаниях (например, Facebook, Wikipedia, Twitter, LinkedIn, Alibaba и других). MySQL представляет собой реляционную СУБД, которая относится к свободному программному обеспечению: она распространяется на условиях GNU Public License. Как правило, эту систему управления базами данных определяют как хорошую, быструю и гибкую, рекомендованную к применению в небольших или средних проектах.
MySQL представляет собой реляционную СУБД, которая относится к свободному программному обеспечению: она распространяется на условиях GNU Public License. Как правило, эту систему управления базами данных определяют как хорошую, быструю и гибкую, рекомендованную к применению в небольших или средних проектах.
У MySQL есть множество различных преимуществ. Например, она поддерживает различные типы таблиц – как известные MyISAM и InnoDB, так и более экзотичные HEAP и MERGE. Кроме того, количество поддерживаемых типов постоянно растет. MySQL выполняет все команды быстро – возможно, сейчас это самая быстрая СУБД из всех существующих. С этой системой управления базами данных может одновременно работать неограниченное количество пользователей, а число строк в таблицах может достигать 50 миллионов.
Так как в сравнении с некоторыми другими системами MySQL поддерживает меньшее количество возможностей, то и работать с ней значительно проще, чем, к примеру, с PostgreSQL, о которой будет рассказано ниже.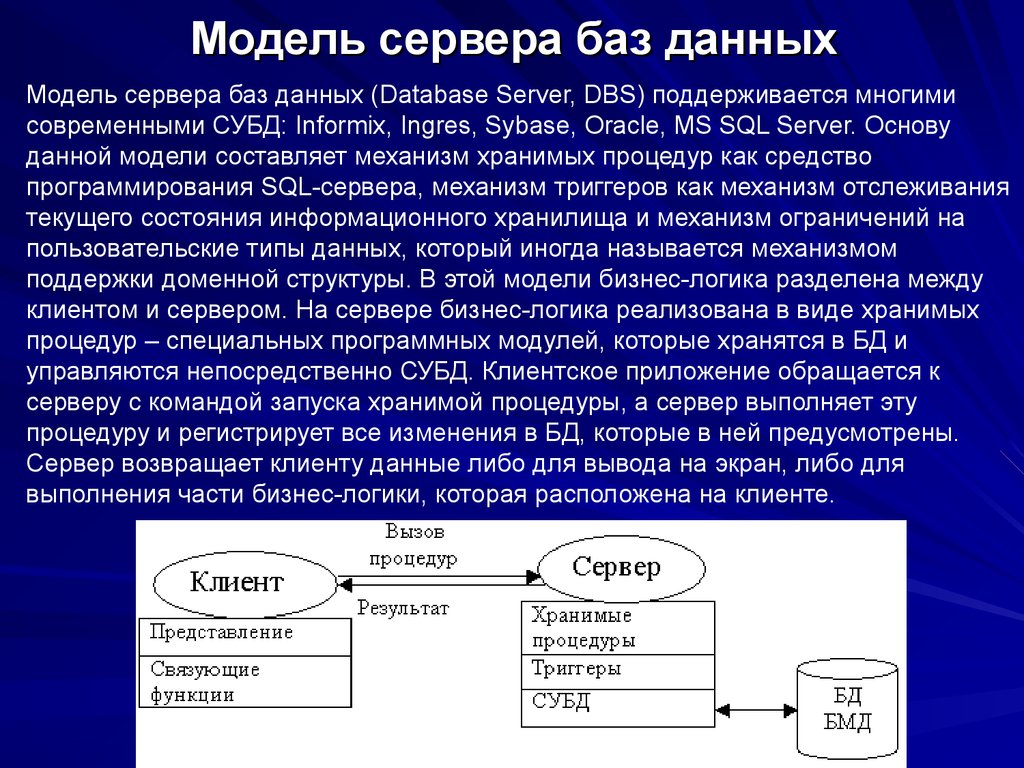
Для работы с MySQL используется не только текстовый, но и графический режим. Это становится реальным благодаря приложению phpMyAdmin: для работы в приложении вам даже не нужно знать SQL-команды, а администрировать свою базу данных можно прямо через браузер.
MySQL – это выбор тех, кому необходима СУБД для проекта небольшого или среднего размера, быстрая и удобная в работе и без сложностей с администрированием.
PostgreSQL
Эта свободно распространяемая система управления базами данных относится к объектно-реляционному типу СУБД. Как и в случае с MySQL, работа с PostgreSQL основывается на языке SQL, однако, в отличие от MySQL, PostgreSQL поддерживает стандарт SQL-2011. Эта СУБД не имеет ограничений ни по максимальному размеру базы данных, ни по максимуму записей или индексов в таблице.
Если говорить о преимуществах PostgreSQL, то в первую очередь это надежность транзакций и репликаций, возможность наследования и легкая расширяемость. PostgreSQL поддерживает различные расширения и варианты языков программирования, такие как PL/Perl, PL/Python и PL/Java. Также есть возможность загружать C-совместимые модули.
Также есть возможность загружать C-совместимые модули.
Многие отмечают, что в отличие от MySQL данная СУБД имеет хорошую и подробную документацию, которая дает ответы практически на все вопросы.
О том, что это более масштабная, чем MySQL, СУБД, говорит и тот факт, что PostgreSQL периодически сравнивают с такой мощной системой управления данных, как Oracle. Все это позволяет говорить о PostgreSQL как об одной из самых продвинутых СУБД на данный момент.
SQLite
На данный момент это одна из самых компактных СУБД. Также она является встраиваемой и реляционной.
SQLite позволяет хранить все данные в одном файле и, благодаря своему небольшому объему, отличается завидным быстродействием. SQLite значительно отличается от MySQL и PostgreSQL своей структурой: движок и интерфейс этой СУБД находятся в одной библиотеке – и именно это позволяет выполнять все запросы очень быстро. Другие СУБД (MySQL, PostgreSQL, Oracle и т.д.) используют парадигму «клиент-сервер», когда взаимодействие происходит через сетевой протокол.
Из недостатков можно отметить отсутствие системы пользователей и возможности увеличения производительности.
Oracle
Эта СУБД относится к объектно-реляционному типу. Название произошло от названия разработавшей эту систему фирмы Oracle. Наравне с SQL СУБД использует процедурное расширение под названием PL/SQL, а также язык Java.
Oracle – это система, отличающаяся стабильностью уже не один десяток лет, поэтому ее выбирают корпорации, для которых важна надежность восстановления после сбоев, отлаженная процедура бэкапа, возможность масштабирования и другие ценные возможности. К тому же эта СУБД обеспечивает отличную безопасность и эффектную защиту данных.
В отличие от других СУБД, стоимость покупки и использования Oracle достаточно высока, и именно это зачастую является значимым препятствием к ее использованию в небольших фирмах. Вероятно, именно это также является причиной того, что в рейтинге лучших СУБД на 2016 год в России Oracle находится лишь на 6-м месте.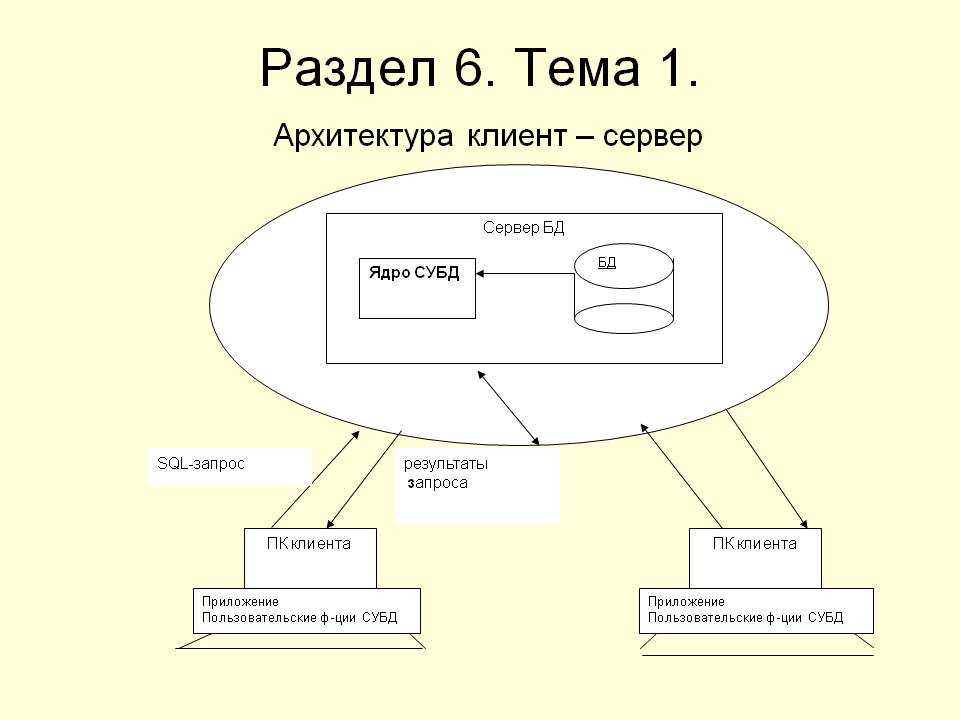
MongoDB
Эта СУБД отличается тем, что она предназначена для хранения иерархических структур данных, и поэтому ее называют документоориентированной (она представляет собой документное хранилище без использования таблиц или схем). MongoDB имеет открытый исходный код.
Используя идентификатор, вы можете производить быстрые операции над объектом. Также эта СУБД хорошо показывает себя и при сложных взаимодействиях. В первую очередь речь идет о быстродействии – в некоторых случаях приложение, написанное на MongoDB, будет работать быстрее, чем такое же приложение, использующее SQL, т.к. MongoDB относится к классу СУБД NoSQL и пользуется объектным языком запросов, который значительно легче SQL.
Однако этот язык имеет и свои ограничения, и потому MongoDB следует использовать в случаях, когда нет необходимости в сложных и нетривиальных выборках.
Заключение
Выбор СУБД – это важный момент при создании своего ресурса. Отталкивайтесь от своих задач и возможностей, пробуйте и экспериментируйте, чтобы найти именно тот вариант, который будет наиболее подходящим.
Обзор систем управления базами данных (СУБД) для систем контроля и управления доступом (СКУД)
Любая современная сетевая СКУД нуждается в базе данных, так как является по своей сути информационной системой, предназначенной для хранения, обработки и анализа информации о происходящих на защищаемом объекте событиях. Также в СКУД должны храниться настройки оборудования, коды карт и личные данные пользователей, уровни доступа и другая нужная информация.
Источник:
статья была опубликована в журнале «Технологии Защиты» № 1, 2014
Терминология
Частая ошибка многих специалистов по безопасности — некорректное использование термина «база данных» (БД) вместо термина «система управления базами данных» (СУБД). Давайте разберёмся, что к чему.
База данных — представленная в объективной форме совокупность самостоятельных материалов, систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины.
Система управления базами данных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
То есть, упрощённо, «база данных» — это сами данные, представленные в виде совокупности файлов на дисках, с которыми как раз работает «система управления базами данных» (СУБД) — программный продукт, имеющий средства для создания, наполнения, модификации и поиска по базам данных.
Разработчики различных приложений, в том числе и разработчики СКУД, работают именно с СУБД и выбирают СУБД под свои нужды.
Требования к СУБД, применяемым в СКУД
Какие же особенные требования следует предъявить к СУБД, используемой в СКУД с точки зрения пользователя?
- Во-первых — надёжность: никакие данные не должны пропасть! Сбои должны быть минимизированы и не должны приводить к потерям данных, базы должны быть надёжно защищены от несанкционированного доступа, на режимных объектах могут потребоваться функции шифрования данных, необходимо также обеспечивать регулярное резервное копирование баз данных и возможность восстановления из архива при необходимости.

- Во-вторых — производительность: СУБД должна обеспечивать приемлемый уровень производительности для решения возложенных на неё задач.
- В-третьих, на мой взгляд, это уверенность в том, что СУБД будет поддерживаться производителем, и вы не останетесь один на один с проблемой в случае какого-то серьёзного сбоя или сложной ситуации.
Виды СУБД
СУБД на данный момент существует великое множество и классифицируются они по разным признакам. Но мы не будем останавливаться в данной статье на всём многообразии этих типов, опустим перспективные и экзотические технологии типа объектно-ориентированных и иерархических СУБД. Стандартом де-факто в современных информационных системах являются реляционные СУБД, в которых данные хранятся в табличном виде, о них мы и будем говорить. Так чем же различаются все эти системы? Перечислю ключевые параметры важные как для разработчиков, так и для пользователей системы.
Способы доступа к БД
- Клиент-серверные СУБД
- Файл-серверные СУБД
- Встраиваемые СУБД
В клиент-серверных СУБД (Microsoft SQL Server, Oracle, Firebird, PostgreSQL, InterBase, MySQL и др.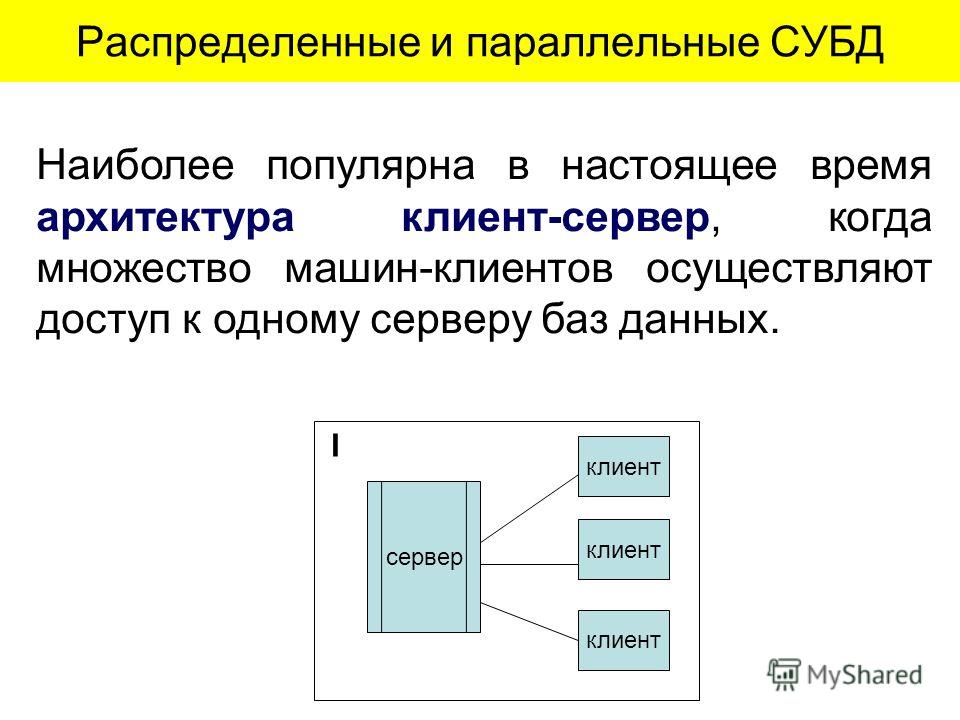 )
)
- Вся обработка данных ведётся в одном месте, на сервере, в том же месте, где хранятся (обычно) данные.
- К файлам данных имеет доступ только один сервер, одна система — это сама СУБД.
- Приложения-клиенты посылают запросы на обработку и получение данных из СУБД и получают ответы.
- Приложения-клиенты не имеют непосредственного доступа к файлам данных.
Все промышленные СУБД на данный момент являются именно клиент-серверными.
В файл-серверных СУБД (Paradox, Microsoft Access, FoxPro, dBase и др.), наоборот,
- Приложения имеют общий доступ ко всем файлам базы данных (хранящимся обычно в каком-то разделяемом файловом хранилище) и совместно обрабатывают эти данные.
- Каждое приложение самостоятельно обрабатывает данные.
На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком.
Встраиваемые СУБД (SQLite, Firebird Embedded, Microsoft SQL Server Compact и др.)
- Поставляются в составе готового программного продукта, не требуя процедуры самостоятельной установки.
- Предназначены для локального хранения данных приложения и не рассчитаны на коллективное использование в сети.
Встраиваемая бесплатная СУБД SQLite широко используется в известной мобильной ОС Android, разработанной в компании Google, и во многих мобильных приложениях.
Схема лицензирования
- Бесплатные СУБД
- Коммерческие промышленные СУБД (большинство производителей предлагают также бесплатную ограниченную версию)
Файл-серверные и встраиваемые СУБД практически все являются бесплатными, из бесплатных клиент-серверных СУБД наиболее известные: Firebird, PostgreSQL и MySQL.
Чисто коммерческий продукт, разработанный компанией Borland: СУБД InterBase. Ранее у этой СУБД была бесплатная версия с открытым исходным кодом: InterBase 6.0, но проект InterBase 6.0 Open Source Edition перестал поддерживаться компанией Borland. В 2001 году группа энтузиастов создала отдельный Open source проект СУБД Firebird, упомянутой выше, который получил широкую известность и множество поклонников среди разработчиков.
Большинство производителей промышленных СУБД дают возможность пользоваться бесплатными редакциями своих продуктов, которые являются урезанными по функционалу и по производительности вариантами полнофункциональной версии СУБД.
Сравнение свободных и коммерческих СУБД
Свободные СУБД
+
- Бесплатно.
- Менее требовательны к железу.
- Богатый функционал.
- Хорошая производительность.
- Надежность.
−
- Проект в любой момент может закрыться, т.к. поддерживается энтузиастами.
- Сложнее найти грамотного специалиста для обслуживания.
Коммерческие СУБД
+
- Высокая производительность.
- Масштабируемость.
- Надёжность.
- Поддерживаемость.
- Задокументированность.
- Встроенные инструменты для разработки и администрирования.
−
- Требовательность к ресурсам.
- Высокая цена.
В приведённой ниже таблице приведены ограничения наиболее часто используемых бесплатных редакций промышленных СУБД.
| Компания-производитель | Бесплатные версии | Ограничения |
| Microsoft | SQL Server 2005/2008 Express Edition | Размер базы данных — до 4 Гб, количество баз не ограничено, использует не более 1 Гб оперативной памяти и только 1 процессор (ядро) на многопроцессорных и многоядерных машинах. Поддерживаемые платформы: только Windows 2005 — только x86, 2008 — x86 и x64. |
| SQL Server 2008 R2/2012/2014/2016/2017/2019 Express Edition | Размер базы данных — до 10 Гб, количество баз не ограничено, использует не более 1 Гб оперативной памяти и только 1 процессор (ядро) на многопроцессорных и многоядерных машинах. Поддерживаемые платформы: только Windows x86 и x64. | |
| Oracle | Oracle Database 11g Express Edition, (Oracle Database XE) |
Суммарно до 11Гб пользовательских данных, использует не более 1Гб оперативной памяти и только 1 процессор (ядро) на многопроцессорных и многоядерных машинах. Поддерживаемые платформы: Windows x86, Linux x64. Поддерживаемые платформы: Windows x86, Linux x64.
|
| IBM | IBM DB2 Express-C | Размер базы не ограничен, используется до 4Гб оперативной памяти и до 2-х процессоров. Поддерживаемые платформы: Windows x86 и x64, Linux x86 и x64, Unix x86 и x64, Solaris x86 и x64, Mac OS X |
При превышении максимального размера базы запись в БД прекратится, но эту проблему легко предотвратить. В основном, объём требуется для хранения постоянно накапливающихся в системе событий, остальные данные (настройки контроллеров, данные субъектов доступа, уровни доступа и т.п.) относительно статичны и только на сверхкрупных системах могут превысить ограничения бесплатных Express-версий. Необходимо настроить средствами вашей СУБД процедуру периодического удаления старых событий из БД. Во многих СКУД эти процедуры предусмотрены разработчиками и их надо просто настроить.
Что касается ограничений по производительности: если система небольшая, не подразумевает больших нагрузок на СУБД, спокойно можно ограничиться бесплатной редакцией, её будет более чем достаточно. Если же задача накладывает повышенные требования на подсистему СУБД: большое количество пользователей в системе, большой трафик событий и поток обновлений данных в системе (объекты с большим количеством временных посетителей) и высокие требования к глубине архива событий, то всегда можно перейти с бесплатной редакции на коммерческий вариант, оплатив необходимую лицензию.
СУБД в СКУД
В таблице ниже приведены данные из открытых источников относительно типа применяемой СУБД в популярных в России системах контроля и управления доступом.
| Производитель | СКУД | СУБД |
| Parsec | ParsecNET 3 |
Microsoft SQL Server (в поставке 2012 Express, заявлена поддержка версий 2008 R2 и выше) — центральная БД; SQLite — локальные базы рабочих станций.
|
| Elsys | Бастион 2 | Oracle (в поставке 11g Express), заявлена поддержка версий Oracle 12с, Oracle SE2, также может использоваться СУБД PostgreSQL 10 или Postgres Pro |
| Perco | S20 | Firebird 2.0 |
| НВП Болид | Орион ПРО |
Microsoft SQL Server (в поставке 2012 Express), заявлена поддержка версий 2008/2012/2014 |
| РусГард | RusGuard | Microsoft SQL Server (в поставке 2014 Express), заявлена поддержка версий 2014/2016 |
| Равелин ЛТД | Gate | Microsoft Access |
| ПромАвтоматика Сервис | Сфинкс | MySQL |
| Кодос | ИКБ Кодос | Firebird |
| TSS | Семь Печатей | Firebird |
| Bosсh |
Access PE |
Microsoft SQL Server (рекомендуется версия 2014 Express Edition) |
| Honeywell | Pro-Watch | Microsoft SQL Server 2012/2014/2016 |
| Siemens | SiPass | Microsoft SQL Server 2000 |
| ААМ Системз | Apacs 3000 |
Firebird 2. 5 (входит в комплект поставки), поддерживается также Microsoft SQL Server 2017 5 (входит в комплект поставки), поддерживается также Microsoft SQL Server 2017 |
| Lyrix |
Borland Interbase 2007 (в комплекте поставки), поддержка Oracle 10g и Microsoft SQL Server 2005 |
Как видно, большинство производителей СКУД поставляют бесплатную версию промышленной клиент-серверной СУБД Microsoft SQL Server Express Edition и свободную (бесплатную) кроссплатформенную СУБД Firefird (примерно 50 на 50).
Конкретный выбор той или иной СУБД — дело вкуса и предпочтений каждого производителя, благо — выбор есть. При выборе разработчики учитывают также вопросы удобства и простоты администрирования, наличие встроенных бесплатных инструментов для администрирования и разработки.
СУБД для СКУД помимо высокой надёжности и производительности должна быть удобной и недорогой в поддержке. Разработчики СКУД прекрасно понимают, что даже на крупных объектах зачастую нет выделенных специалистов для обслуживания СКУД, обладающих навыками администрирования СУБД, поэтому стараются включать в свои продукты функции, облегчающие и автоматизирующие процессы обслуживания базы данных.
Прежде всего — резервное копирование БД, основа основ, которая позволяет администратору системы спокойно спать. Все СУБД имеют собственные средства для создания резервных копий, но хорошим тоном считается, когда функция резервного копирования интегрирована в продукт и администратору необходимо лишь включить/настроить её и периодически проверять функционирование.
Вторая частая проблема — восстановление данных после сбоя. Здесь опять же на выручку приходит свежая резервная копия, но если её нет, или критично восстановление всех возможных данных, то потребуются дополнительные усилия. К счастью, в промышленных СУБД (чего не скажешь о старых файловых СУБД типа Paradox) такие явления происходят нечасто, их может вызвать разве что «умирающий» жёсткий диск или сбой электропитания. В этом случае потребуются услуги специалиста-администратора СУБД, который сможет с помощью встроенных в любую серьёзную СУБД инструментов восстановить максимум из возможного. Также следует учесть, что некоторые производители СКУД в рамках технической поддержки оказывают услуги по восстановлению баз.
Также следует учесть, что некоторые производители СКУД в рамках технической поддержки оказывают услуги по восстановлению баз.
Рекомендации
- При выборе СКУД обратите внимание на то, какая СУБД поставляется совместно с системой.
- Если вы эксплуатируете СКУД, то выясните, какая СУБД в ней используется.
- Оцените трафик данных и нагрузку в вашей системе, чтобы определиться с требуемыми аппаратными ресурсами сервера СУБД и нужной редакцией СУБД (проконсультируйтесь у производителя вашей СКУД при необходимости).
- Если в вашей СКУД используется Express-версия Microsoft SQL Server или Oracle, то необходимо задаться вопросом: «Насколько нам хватит бесплатного объёма базы?». Настройте периодическое удаление из базы старых событий средствами СКУД (если таковые имеются) либо же рассмотрите вопрос о миграции на платную неограниченную версию СУБД.
- Настройте резервное копирование баз данных средствами СКУД или же средствами СУБД и регулярно проверяйте его выполнение.
- Найдите специалиста по СУБД (администратора), к которому можно будет обратиться в случае повреждения базы данных, узнайте в технической поддержке производителя СКУД возможность предоставления такого рода услуг.
Хотите узнать больше?
Пройдите бесплатный курс «Основы систем контроля и управления доступом» в Академии Parsec. На курсе будут рассмотрены основные компоненты СКУД, их назначение и принципы работы, основные термины, необходимые для понимая устройства и специфики работы систем контроля доступа. По окончании курса вы получите сертификат.
Конфигуратор СКУД
Автоматический подбор оборудования и программного обеспечения профессиональной системы контроля доступа
Перейти к подбору
Определение СУБД. Что такое система управления базами данных?
Содержание:
- Определение СУБД
- Состав СУБД
- Основные функции СУБД
- СУБД по модели данных
- СУБД по степени распределённости
- По способу доступа к БД
- Список литературы по теме
Представим, что в ваше распоряжение попала какая-либо база данных. Она содержит очень полезные, для вас или кого-то ещё, сведения. Однако вы ничего не сможете с ней сделать!
Она содержит очень полезные, для вас или кого-то ещё, сведения. Однако вы ничего не сможете с ней сделать!
Можно попытаться открыть её текстовым редактором и извлечь часть данных. Но это будет лишь набор данных в непонятном для вас порядке. Ещё меньше пользы вы получите из БД, если она будет зашифрована. Отсюда возникает вопрос — с помощью чего была создана структура базы данных, и как потом с ней работать?
Оказывается, с одной стороны всё значительно проще, а с другой стороны — гораздо сложнее, чем вы себе представляете. Поясню, что для работы с определенным типом и моделью базы данных используется та или иная программа. В информатике их называют системой управления базами данных.
Cистема управления базами данных
Cистема управления базами данных
Дадим определение системы управления базами данных.
Система управления базами данных (СУБД) представляет собой комплекс языковых и программных средств, которые обеспечивают управление созданием и использованием баз данных.
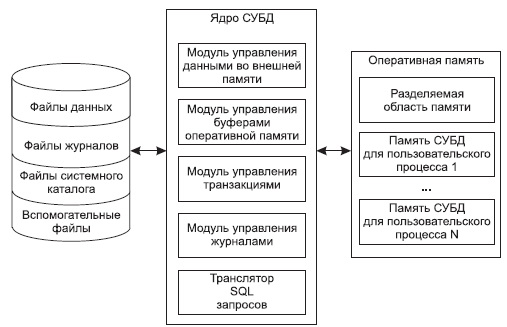
Современная СУБД состоит из:
- ядра — части программ СУБД, отвечающих за управление данными в памяти и журнализацию
- Процессора языка базы данных, обеспечивающего оптимизацию запросов на извлечение и изменение данных, и создание БД
- Подсистемы поддержки времени исполнения, интерпретирующую программы манипуляции данными, которые создают интерфейс пользователя СУБД
- Сервисных программ (внешних утилит), которые обеспечивают прочие возможности по обслуживанию информационных систем.
Так как через СУБД осуществляют все процессы, применимые к базам данных, следовательно, лучше будет выделить только её основные возможности.
Основными функциями СУБД являются
- Управление данными, хранящимися во внешней памяти
- Управление данными, загруженными в оперативную память с использованием дискового кэша
- Журнализация событий и изменений, резервное копирование и восстановление БД после сбоев
- поддержка языков обращения с БД (язык определения данных, язык манипулирования данными).
Кстати, по этой теме вы можете скачать презентацию в PowerPoint.
Классификации СУБД
Существует несколько признаков, по которым можно классифицировать СУБД.
СУБД по модели данных бывают:
- Иерархические СУБД
- Сетевые СУБД
- Реляционные СУБД
- Объектно-ориентированные СУБД
- Объектно-реляционные СУБД
В настоящее время в серьезных проекта используются 2 последних типа.
СУБД по степени распределённости
- Локальные (СУБД размещается только на одном компьютере)
- Распределённые (части СУБД могут размещаться на 2-х и более компьютерах).
Наверняка, вам будет полезным тест по СУБД, который есть на нашем проекте.
По способу доступа к БД
Файл-серверные СУБД
В них файлы с данными расположены централизованно на специальном файл-сервере. СУБД же должны быть расположены на каждом клиенте (рабочей станции). Доступ СУБД к данным производится посредством локальной сети. Поддержка синхронизации чтений и обновлений осуществляется за счет временных блокировок затребованных файлов.
СУБД же должны быть расположены на каждом клиенте (рабочей станции). Доступ СУБД к данным производится посредством локальной сети. Поддержка синхронизации чтений и обновлений осуществляется за счет временных блокировок затребованных файлов.
Плюсом этой архитектуры можно назвать низкую нагрузку на файловый сервер.
К минусам же: высокая загрузка трафиком локальной сети; сложность или невозможность централизованного управления; нельзя обеспечить такие важные характеристики как надёжность, доступность и безопасность. Файл-серверные СУБД используют в локальных приложениях; в системах с малой интенсивностью обработки данных и небольшими пиковыми нагрузками на базу данных.
Сейчас её при создании крупной информационной системы не используют.
Примеры файл-серверных СУБД:
- dBase,
- FoxPro,
- Microsoft Access,
- Paradox,
- Visual FoxPro.
Клиент-серверные СУБД
Клиент-серверная СУБД расположена на сервере вместе с базой данных и осуществляет доступ к БД исключительно в монопольном режиме. Все запросы на обработку данных клиентских приложений и станций обрабатываются централизованно.
Все запросы на обработку данных клиентских приложений и станций обрабатываются централизованно.
Недостатком такого типа СУБД можно назвать повышенные требования к серверу.
Достоинствами: более низкую загрузку локальной сети; преимущества централизованного управления; поддержку высокой надёжности, доступности и безопасности.
Примеры клиент-серверных СУБД:
- Caché,
- Firebird,
- IBM DB2,
- Informix,
- Interbase,
- MS SQL Server,
- MySQL, Oracle,
- PostgreSQL,
- Sybase Adaptive Server Enterprise,
- ЛИНТЕР.
Встраиваемые СУБД
Это вид СУБД, который может выступать лишь в качестве составной части определенного программного комплекса, без необходимости процедуры отдельной установки. Такой вид СУБД может быть использован для локального хранения данных своего приложения и не рассчитан на коллективное использование в компьютерной сети. Физически же это зачастую реализуется в виде подключаемой библиотеки. Со стороны приложения доступ к данным происходит посредством SQL-запросов либо через специальный программный интерфейс.
Физически же это зачастую реализуется в виде подключаемой библиотеки. Со стороны приложения доступ к данным происходит посредством SQL-запросов либо через специальный программный интерфейс.
Примеры встраиваемых СУБД:
- Firebird Embedded,
- BerkeleyDB,
- Microsoft SQL Server Compact,
- OpenEdge,
- SQLite,
- ЛИНТЕР.
Для рассмотрения лишь части основных возможностей и внутреннего устройства любой СУБД требуется один или несколько отдельных учебных курсов.
Список литературы по теме:
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. C. J. Date Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с.
 Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с.
Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с.Файловая система NTFS Что такое информация?
Базы данных (СУБД) — курсы в Санкт-Петербурге
- О курсах
- Правила приёма
- Учебный процесс
- Документы
- Расписание
Расписание
- Каталог курсов
- Онлайн курсы
- Продукты и технологии
- Производители
- Поиск курса
Используйте символы русского и английского языка и цифры Используйте символы русского и английского языка и цифры
Разработка веб-приложений
Базы данных
Программирование
Microsoft
Python
Тестирование ПО
Oracle
MySQL
PostgreSQL
Базы данных (СУБД)
Тестирование ПО
Программирование
PostgreSQL.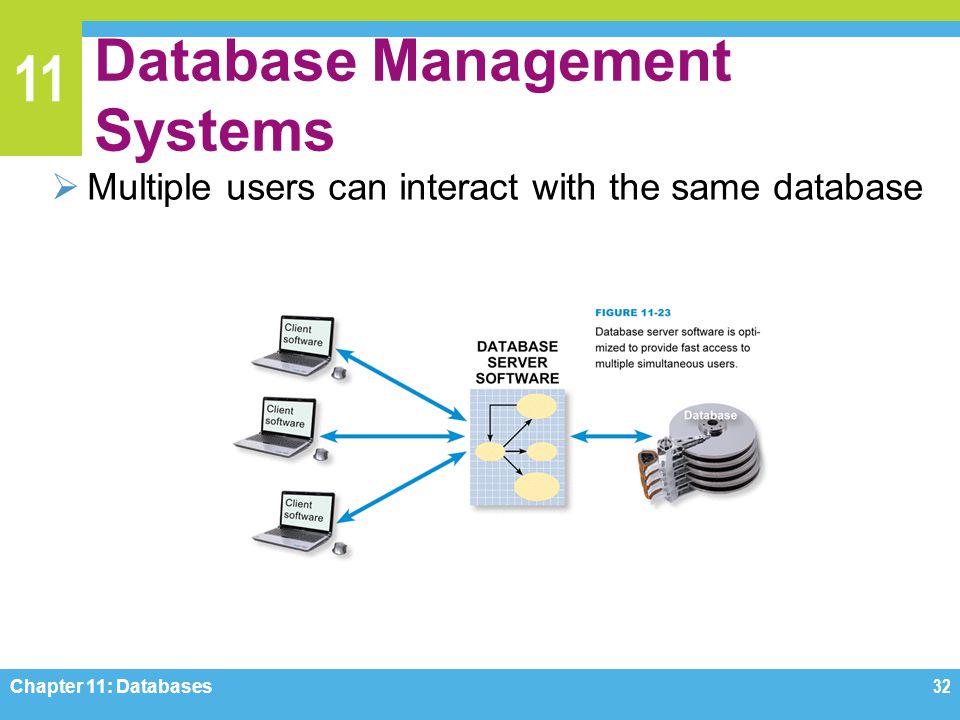 org
Системный анализ
Системный анализ
Анализ данных
Анализ данных
org
Системный анализ
Системный анализ
Анализ данных
Анализ данных
DEV-DB. Основы баз данных для программистов
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 40 ак. часов, 10 занятий по 4 ак. часа либо 5 занятий по 8 ак. часов
10.10.2022
18:00
Записаться
10.10.2022
18:00
Записаться
10.10.2022
18:00
Записаться
20.03.2023
18:00
Записаться
20.03.2023
18:00
Записаться
DB-DSA. Технологии обработки и анализа данных в PowerBI
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 40 ак. часов, 10 занятий по 4 ак. часа или 5 занятий по 4 ак. часа
часов, 10 занятий по 4 ак. часа или 5 занятий по 4 ак. часа
Оставить заявку
ORA-01. Основы Oracle SQL
Курс фокусируется на изучении синтаксиса языка программирования для решения следующих задач: извлечения информации из баз данных, манипулирования данными, создания объектов, управления доступом к информации, просмотра метаданных.
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 5 дней по 8 ак.ч. или 10 дней по 4 ак. часа
Оставить заявку
ORA-02. Расширенный Oracle SQL
Курс предназначен для специалистов, которым необходимо получение расширенных навыков программирования на структурированном языке реляционных баз данных SQL.
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 5 занятий по 8 ак.ч. или 10 занятий по 4 ак. часа
Оставить заявку
ORA-03. Основы PL/SQL
Курс фокусируется на изучении языковых конструкций процедурного языка программирования Oracle PL/SQL, а также основных приемов работы с ними.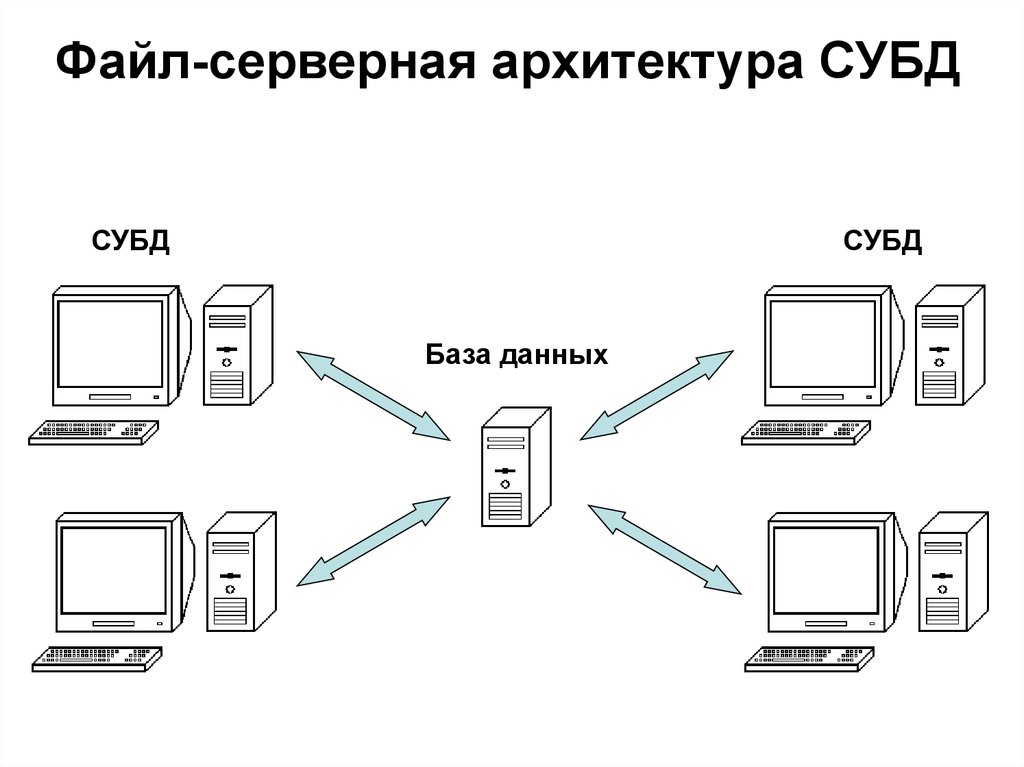
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 5 дней по 8 ак.ч. или 10 дней по 4 ак. часа
Оставить заявку
PSQL-Base. Основы языка SQL PostgreSQL
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 5 дней по 8 .ак.ч.
Оставить заявку
PSQL-Dev. Разработка баз данных PostgreSQL
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 5 дней по 8 .ак.ч.
Оставить заявку
QA-DB. Основы баз данных для тестировщиков
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 40 ак. часов, 10 занятий по 4 ак. часа либо 5 занятий по 8 ак. часов
Оставить заявку
DB-BASE. Основы проектирования реляционных баз данных
В курсе изучаются основы проектирования и реализации реляционных баз данных.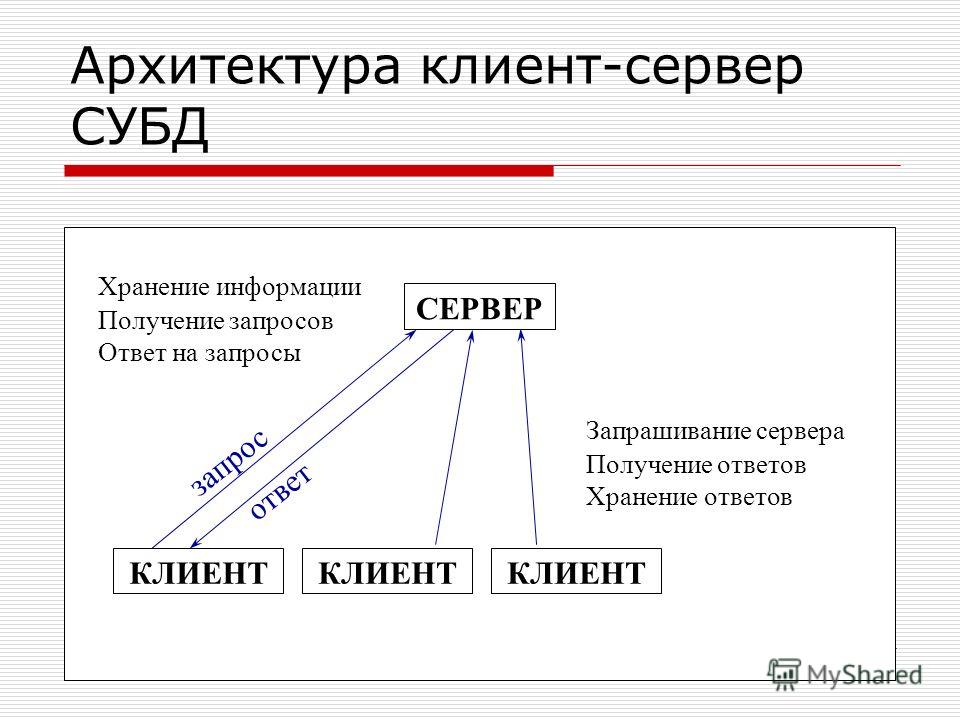
Уровень сложности:
Длительность курса: 32 ак.ч. очно
График обучения: 32 ак. часа, 8 занятий по 4 ак. часа или 4 занятия по 8 ак. часов
Оставить заявку
BEND-DB. Администрирование и разработка баз данных (MYSQL)
Курс предназначен для изучения языка запросов SQL и реляционной системы управления базами данных MySQL.
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 5 дней по 8 .ак.ч. или 10 дней по 4 ак.ч
Оставить заявку
DB-INTRO. Основы баз данных
Целью данного курса является совершенствование концептуальных представлений о системах управления базами данных, базовых знаний по теории баз данных, а также приобретение практических навыков работы с базами данных SQL для широкого круга специалистов, работающих с данным,
Уровень сложности:
Длительность курса: 24 ак. ч. очно
ч. очно
График обучения: 24 ак. часа, 6 занятий по 4 ак. часа или 3 занятия по 8 ак. часов
Оставить заявку
DB-INTRO. Основы баз данных
Целью данного курса является совершенствование концептуальных представлений о системах управления базами данных, базовых знаний по теории баз данных, а также приобретение практических навыков работы с базами данных SQL для широкого круга специалистов, работающих с данным,
Уровень сложности:
Длительность курса: 28 ак.ч. очно
График обучения: 28 ак. часа, 7 занятий по 4 ак. часа или 3 занятия по 8 ак. часов
Оставить заявку
PDA-DB. Основы баз данных
Обучаясь на курсе вы познакомитесь с основами технологий баз данных, научитесь работать с объектами баз данных выполнять запросы к базам данных и узнаете что такое транзакции.
Уровень сложности:
Длительность курса: 32 ак.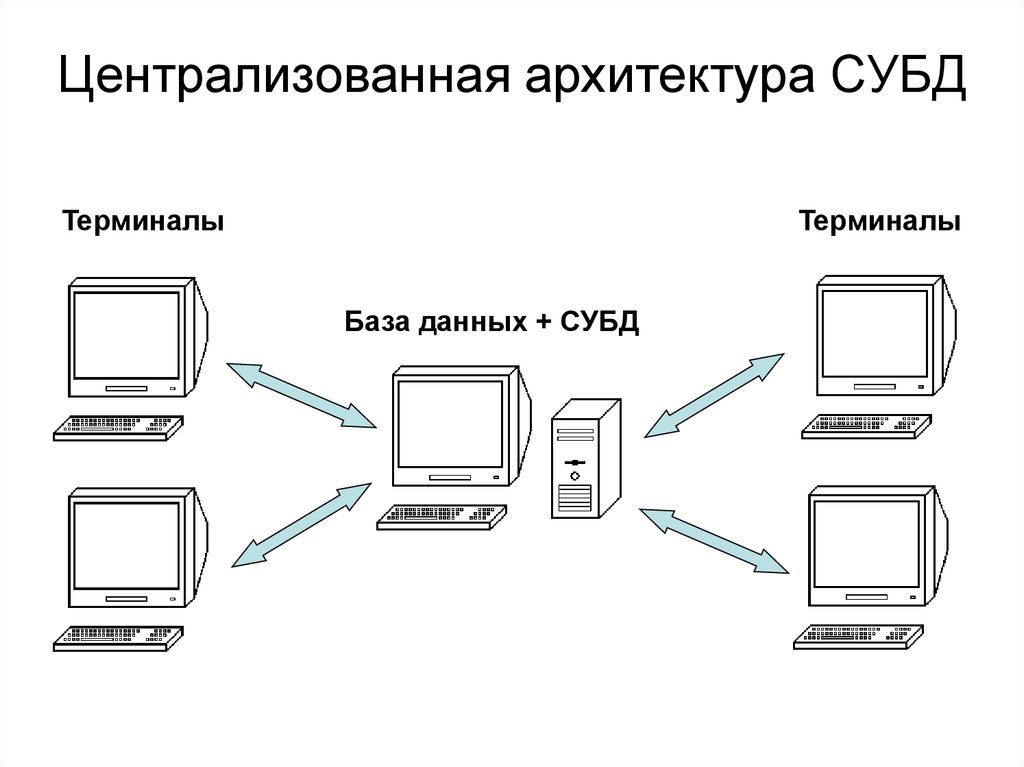 ч. очно
ч. очно
График обучения: 32 ак. часа, 8 занятий по 4 ак. часа
Оставить заявку
SA-DS. Введение в Data Science и анализ данных
Целью реализации программы повышения квалификации является формирование теоретического представления об основных современных методах анализа данных, а также приобретение практических навыков в области анализа данных.
Уровень сложности:
Длительность курса: 16 ак.ч. очно
График обучения: 16 ак. часов, 4 занятия по 4 ак. часа
Оставить заявку
ORA-05. Администрирование СУБД Oracle 11g, часть 1
Курс фокусируется на формировании у слушателей основных знаний и навыков по администрированию СУБД Oracle.
Уровень сложности:
Длительность курса: 40 ак. ч. очно
ч. очно
График обучения: 5 дней по 8 ак.ч.
Оставить заявку
ORA-06. Администрирование СУБД Oracle 11g, часть 2
В данном курсе основной упор делается на изучение концепции резервного копирования и восстановления баз данных, на различных способах их выполнения в разнообразных ситуациях.
Уровень сложности:
Длительность курса: 40 ак.ч. очно
График обучения: 5 дней по 8 ак.ч.
Оставить заявку
Что такое СУБД. Подробное описание для начинающих | Info-Comp.ru
Приветствую Вас нас сайте Info-Comp.ru! Сегодня я максимально просто, специально для начинающих, попытаюсь рассказать Вам о том, что такое СУБД, и для чего это нужно.
Содержание
- Что такое СУБД
- Что такое база данных
- Какие бывают СУБД
- Что такое SQL
- Microsoft SQL Server
- Oracle Database
- MySQL
- PostgreSQL
- Выводы
Что такое СУБД
Итак, давайте сразу начнем с расшифровки, что же такое СУБД.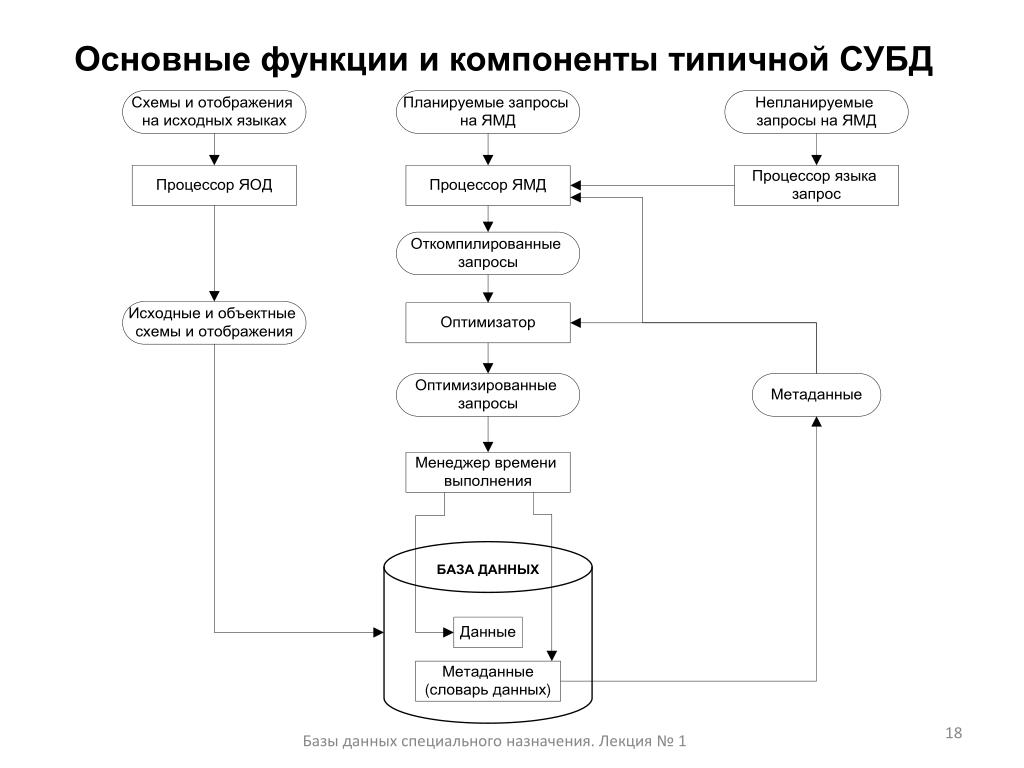
СУБД – это система управления базами данных.
Иными словами, СУБД относится к сфере компьютерных баз данных.
Однако, чтобы понять, чем по своей сути является СУБД и для чего нужна эта система, необходимо начать с рассмотрения понятия базы данных.
Что такое база данных
Обычно под базой данных принято понимать любой набор информации, который хранится определенным образом, и этой информацией можно воспользоваться.
Однако если говорить о компьютерных базах данных, то здесь, конечно же, речь идет о так называемых реляционных базах данных.
Реляционная база данных – это упорядоченная информация, связанная между собой определёнными отношениями.
Логически такая база данных представлена в виде таблиц, в которых и хранится вся эта информация.
Физически база данных представляет собой, конечно же, обычные файлы, созданные в специальном формате.
И здесь возникает вопрос, если база данных — это файлы, созданные в специальном формате, то как создать такие файлы и редактировать их?
Для этого, как Вы понимаете, нужен специальный инструмент, т. е. программа, которая могла бы создавать базы данных и управлять ими, иными словами, работать с файлами базы данных.
е. программа, которая могла бы создавать базы данных и управлять ими, иными словами, работать с файлами базы данных.
Такой программой как раз и выступает СУБД, т.е. система управления базами данных.
Какие бывают СУБД
На самом деле СУБД — это некая разновидность программ, иными словами, существует достаточно много различных СУБД, как платных, так и бесплатных.
Заметка! Рейтинг популярности систем управления базами данных (СУБД).
Что такое SQL
Каждая СУБД хранит файлы базы данных по-своему, т.е. в своем собственном формате, однако для того чтобы нам с Вами было легче управлять данными в базе данных был разработан специальный язык, который является стандартом и он позволяет нам, независимо от того в какой СУБД создана база данных, манипулировать данными в этой базе данных. Этот язык назвали SQL.
SQL (Structured Query Language) — язык структурированных запросов, с помощью него пишутся специальные запросы к базе данных с целью получения данных из базы данных или для манипулирования этими данными.
Язык SQL – как было уже отмечено, это стандарт, он реализован во всех реляционных базах данных, таким образом, если Вы знаете язык SQL, то Вы можете работать с данными в любой системе управления базами данных.
Однако у каждой СУБД, конечно же, есть расширение этого стандарта, для того чтобы, например, полноценно программировать, получать системную информацию, упрощать SQL запросы и инструкции.
Поэтому, если Вам нужно будет разрабатывать какую-нибудь бизнес логику в базе данных, писать сложные аналитические запросы на выборку, или обычные запросы, но в более упрощенном варианте, то Вам обязательно стоит учитывать, в какой СУБД Вы будете работать, для того чтобы изучить расширение языка SQL конкретно этой СУБД, так как и синтаксис, и возможности этих расширений, конечно же, отличаются.
Среди всех СУБД по функциональности и популярности можно выделить следующие системы.
Microsoft SQL Server
Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях.
Она очень популярна в корпоративном секторе, особенно в крупных компаниях.
Microsoft SQL Server – это очень функциональная СУБД, и она, конечно же, распространяется платно. Однако у SQL Server есть редакция Express, которую можно использовать абсолютно бесплатно, например, для обучения или для разработки приложений, которые будут обрабатывать данные на небольших серверах (размером до 10 ГБ).
В Microsoft SQL Server для программирования в базах данных используется расширение языка SQL – Тransact-SQL, сокращенно T-SQL.
Заметка! Что такое T-SQL. Подробное описание для начинающих.
Oracle Database
Oracle Database – это система управления базами данных от компании Oracle. Это еще одна очень функциональная СУБД, которая также популярна среди крупных компаний. Возможности Oracle Database и Microsoft SQL Server сопоставимы, поэтому они являются серьезными конкурентами друг другу, и стоимость их полнофункциональных версий очень высокая.
В Oracle Database используется язык PL/SQL (Procedural Language / Structured Query Language) — это процедурное расширение языка SQL, разработанное компанией Oracle.
Заметка! Знакомство с Oracle Database Express Edition (XE) – что это такое?.
MySQL
MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила очень широкую популярность в интернете, так как именно на MySQL работают чуть ли не все web-сайты, иными словами, большинство сайтов в интернете используют эту СУБД как средство хранения данных.
Заметка! Установка MySQL 8 на Windows 10.
PostgreSQL
PostgreSQL – эта система управления базами данных также является бесплатной, и она очень популярна и функциональна.
В PostgreSQL используется язык PL/pgSQL – это процедурное расширение языка SQL.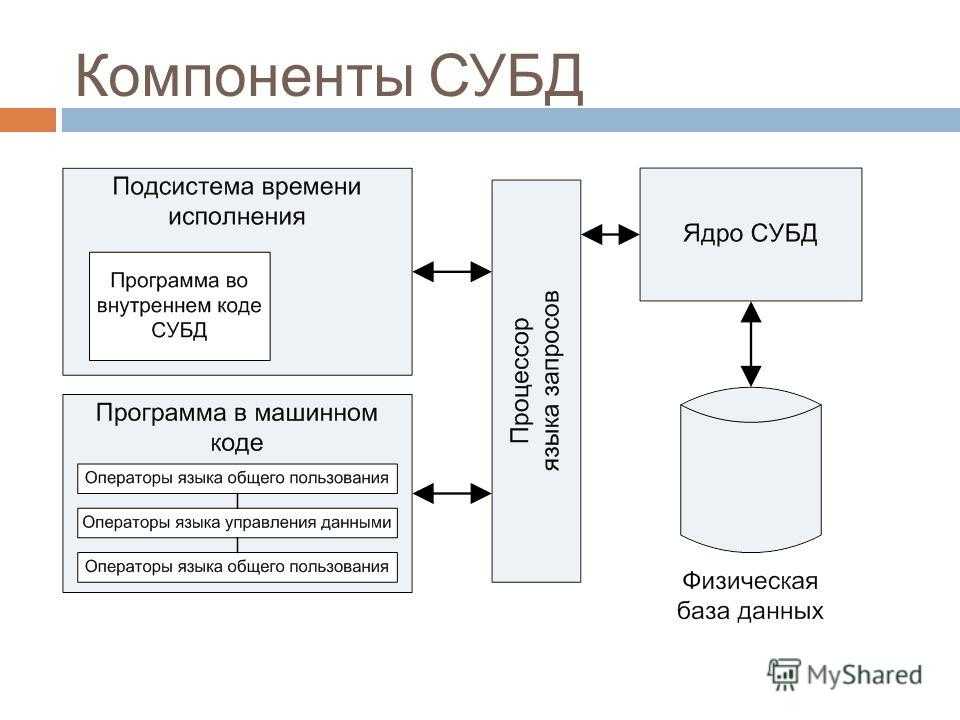
Заметка! Как создать базу данных в PostgreSQL с помощью pgAdmin 4.
Выводы
В заключение давайте подведем итог.
СУБД (система управления базами данных) – это разновидность программ, с помощью которых создаются и управляются базы данных.
Надеюсь, я понятно ответил на вопрос «что такое СУБД» и для чего это нужно. А также надеюсь, что материал был Вам интересен и полезен.
На сегодня это все, удачи Вам, пока!
Заметка! Если Вас интересует язык SQL, то рекомендую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней язык SQL рассматривается как стандарт, чтобы после прочтения данной книги можно было работать с языком SQL в любой системе управления базами данных.
Система управления обучением ›
Название курса — Базы данных
Описание курса (о чем курс),
Понятия База данных (БД), Система управления базами данных (СУБД), архитектура СУБД, модели данных, реляционные языки, нормализация, основы языка Transact-SQL
Правообладатель Федеральное государственное бюджетное образовательное учреждение высшего образования «Ростовский государственный университет путей сообщения»
(ФГБОУ ВО РГУПС), имеет лицензию на образовательную деятельность.
Автор-составитель к.т.н., доц. кафедры «Вычислительная техника и автоматизированные системы управления» ФГБОУ ВО РГУПС Игнатьева Олеся Владимировна
Программа (содержание) курса:
Лекция 1. Введение в базы данных и СУБД
1.1. Введение
1.2. Краткая история создания СУБД
1.3. Основные определения и термины
1.4. Языки баз данных
1.5. Компоненты среды СУБД
1.6. Функции СУБД
1.7. Преимущества и недостатки СУБД
Лекция 2. Архитектура СУБД
2.1. Трехуровневая архитектура ANSI-SPARC
2.2. Архитектура многопользовательских СУБД
Лекция 3. Архитектура СУБД (продолжение)
3.1. Трехуровневая архитектура «клиент-сервер»
3.2. Архитектура распределенных СУБД
3.3. Архитектура параллельных СУБД
Лекция 4. Модели данных
4.1. Определение и классификация моделей данных
4.2. Реляционная модель данных
Лекция 5. Модели данных (продолжение)
5. 1 – Иерархические модели данных
1 – Иерархические модели данных
5.2 – Сетевые модели данных
5.3 – Физические модели данных
Лекция 6 – Модель «сущность-связь»
6.1. Определение ER-модели данных
6.2. Определение ER-модели данных (продолжение)
6.3. Структурные ограничения
6.4. Проблемы ER-моделирования
Лекция 7 — Реляционная модель данных
7.1. Краткая история, определение и терминология реляционной модели данных
7.2. Структурная часть реляционной модели данных
7.3. Целостная часть реляционной модели данных
Лекция 8 — Реляционные языки (часть 1)
8.1. Основные определения
8.2. Реляционная алгебра
Лекция 9 — Реляционные языки (часть 2)
9.1. Реляционная алгебра (продолжение)
9.2. Реляционное исчисление
9.3. Задачи реляционной алгебры
Лекция 10 – Нормализация (часть 1)
10.1. Определение и цели нормализации
10.2. Первая нормальная форма
10.3. Вторая нормальная форма
Лекция 11 – Нормализация (часть 2)
11. 1. Третья нормальная форма
1. Третья нормальная форма
11.2. Нормальная форма Бойса-Кодда
11.3. Четвертая нормальная форма
11.4. Пятая нормальная форма
Лекция 12 — Введение в SQL. Основы языка Transact-SQL.
12.1. Введение в язык SQL
12.2. История создания и стандарты языка SQL
Лекция 13 – SQL. Определение баз данных
13.1. Команда Create Database (Transact-SQL)
13.2. Команда Alter Database (Transact-SQL)
13.3. Команда Drop Database (Transact-SQL)
Лекция 14 — SQL. Определение таблиц.
14.1. Создание таблиц Create Table (Transact-SQL)
14.2. Создание таблиц Create Table. Определение ограничений
14.3. Создание таблиц Create Table. Определение ограничений (продолжение)
Лекция 15 — SQL. Выборка данных. Однотабличные запросы
15.1. Выборка данных. Синтаксис оператора SELECT. Запросы с использованием операторов сравнения
15.2. Запросы SELECT с использованием специальных операторов
15.3. Запросы SELECT с использованием специальных операторов (продолжение)
Лекция 16 — SQL. Выборка данных. Многотабличные запросы
Выборка данных. Многотабличные запросы
16.1. Запросы на соединение таблиц
16.2. Запросы на соединение таблиц (продолжение)
16.3. Запросы внешнего соединения таблиц
Формируемые компетенции и результаты обучения:
Знает: основы систем управления базами данных; механизмы мониторинга системы управления базами данных; основные методы разработки программного обеспечения для баз данных; основные модели данных и их организацию, структуры данных;
программные средства для баз данных и возможности их применения для решения практических задач ; теорию баз данных и основные структуры данных; принципы построения языков запросов и манипулирования данными; основы современных систем управления базами данных; системы хранения и анализа баз данных;
основы современных систем управления базами данных, основные модели данных и их организацию; системное программное обеспечение и прикладное программное обеспечение баз данных; технические спецификации на программные компоненты баз данных и их взаимодействие;
методы и средства проектирования баз данных.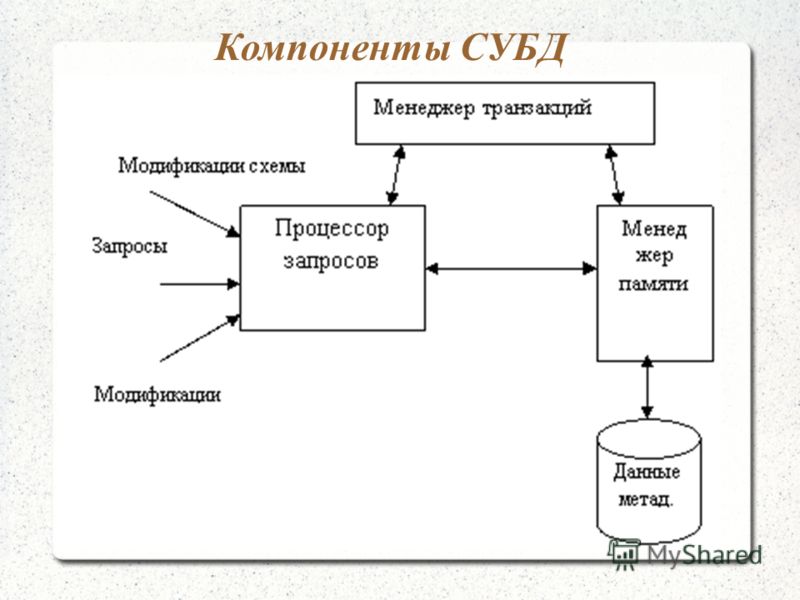 — теоретические основы, методы проектирования баз данных и создания приложений на их основе;
— теоретические основы, методы проектирования баз данных и создания приложений на их основе;
основные принципы проектирования, логическую и физическую структуру баз данных. — методы организации данных на уровне проектирования и методы разработки приложений с базами данных;
современные инструментальные средства и технологии объектно-ориентированного программирования для разработки программных комплексов для баз данных.
Умеет: применять языки программирования на разработку программ управления базами данных;
применять языки программирования на разработку приложений для база данных; находить и анализировать техническую документацию по использованию программного средства, выбирать и использовать необходимые функции программных средств для разработки баз данных;
применять способы и механизмы управления данными, методы и средства проектирования баз данных и программных интерфейсов;
разрабатывать базы данных и прикладных программ для управления данными; осуществлять концептуальное, функциональное и логическое проектирование систем на основе баз данных;
выбирать современные информационные технологии и программные средства для разработки баз данных ; применять языки программирования на разработку приложений для база данных
Имеет навыки: разработки алгоритмов функционирования разрабатываемых компонентов системы управления базами данных;
работы с современными системами программирования, включая объектно-ориентированные для разработки приложений баз данных
работы с современными системами управления базами данных;
проектирования баз данных и программных интерфейсов;
разработки приложений для управления базами данных на основе объектно-ориентированного программирования;
проектировать базы данных и программные приложения для управления данными; разработки приложений на основе систем управления базами данных.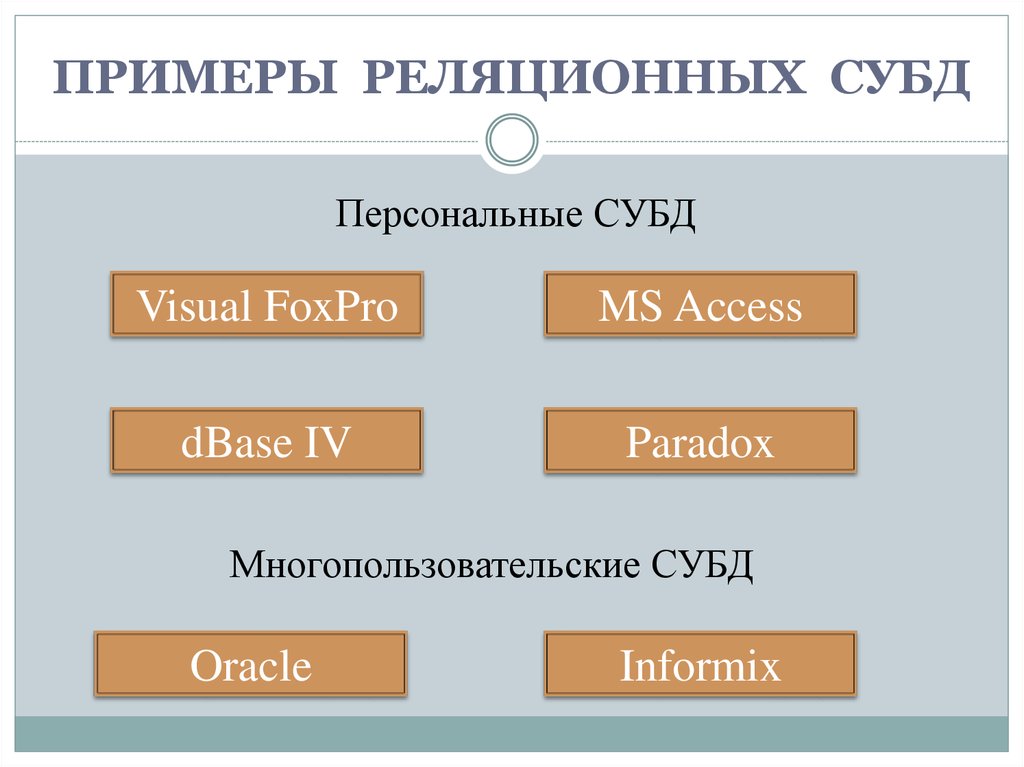
Рекомендуемые направления подготовки: 09.03.01 Информатика и вычислительная техника
Входные требования (пререквизиты). Требования к входным знаниям, умениям и компетенциям обучающегося, необходимым для изучения данной дисциплины, соответствуют требованиям по результатам освоения предшествующих дисциплин : «Информатика и программирование», «Объектно-ориентированное программирование», «Теоретические основы информационных и компьютерных технологий».
Общая трудоемкость 8 зачетных единиц (288 часов)
Длительность курса 40 недель.
Что такое SubD?
Я написал небольшую серию статей о различных типах данных САПР, отличных от NURBS, на сайтах Engineering.com и EngineersRule.com. Как пользователи САПР, мы привыкли в ужасе отшатываться всякий раз, когда сталкиваемся с входящими данными, такими как STL, OBJ, XYZ или рядом других типов. Я помню, как в конце 90-х первый толчок для VRML был огромным разочарованием. Тот факт, что он был таким медленным, и вы действительно ничего не могли с ним сделать, вероятно, отбросил дополненную реальность на годы назад. Они предприняли еще одну попытку до 2010 года с большим успехом, но она все еще не была готова к прайм-тайму.
Тот факт, что он был таким медленным, и вы действительно ничего не могли с ним сделать, вероятно, отбросил дополненную реальность на годы назад. Они предприняли еще одну попытку до 2010 года с большим успехом, но она все еще не была готова к прайм-тайму.
Насколько инженеры будут вовлечены, будет сетка в FEA или экспорт файла STL — набор точек, соединенных линиями для создания многоугольных форм, тетраэдров или четырехгранников.
Недавний взрыв 3D-сканирования и 3D-печати действительно бросает вызов этому типу данных. Вы не можете больше игнорировать это. Это как 3D CAD бросает вызов 2D CAD в середине 1990-х.
SubD, или моделирование подразделов, представляет собой набор поверхностей, основанный на клетке точек. Вы можете тянуть и дергать клетку, чтобы изменить форму поверхности. Это что-то вроде 3D-эквивалента сплайна, где вы перемещаете контрольные точки.
Движок Pixar поддерживает большинство разработчиков моделей SubD.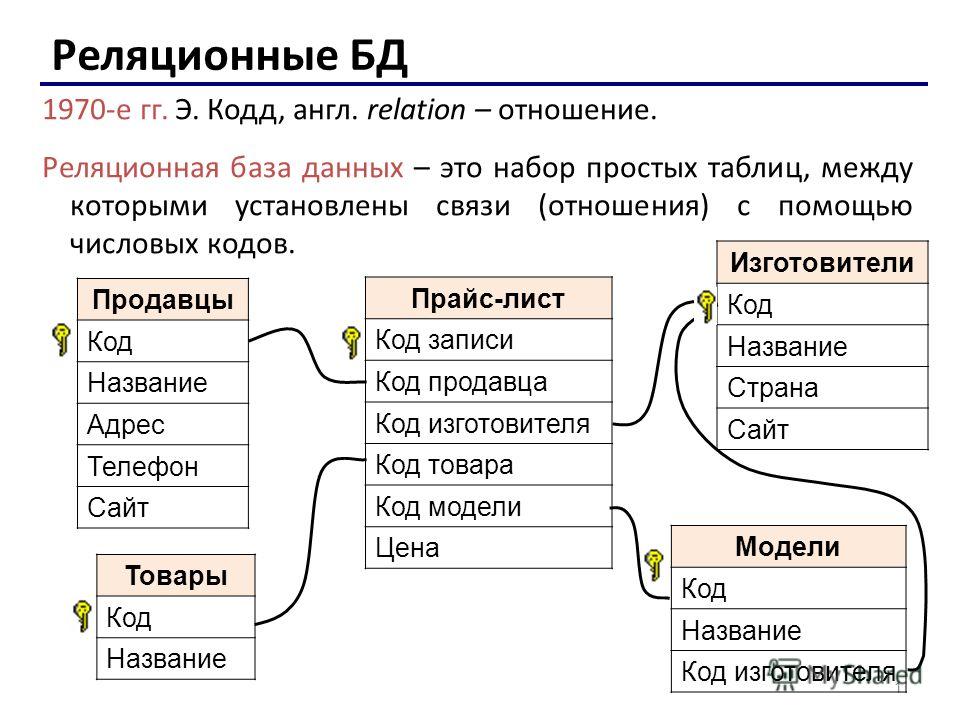
SubD традиционно был областью применения таких приложений, как 3dsMax, Maya, Blender, Cinema4D, Zbrush, Mudbox, modo и т. д. Вспомните Pixar. Все эти анимированные персонажи имеют похожий округло-выпуклый вид, потому что они сделаны с использованием одних и тех же инструментов и методов. Персонажи появляются в играх и фильмах, а также в воображении художников компьютерной графики выходного дня.
Пользователи CAD насмехаются над данными такого типа, потому что они дешевы, быстры, органичны и, что хуже всего, неточны. Полная противоположность большей части того, что мы делаем. Я думаю, в основном мы издевались, потому что не могли использовать такие данные в своей работе и потому что у нас не было инструментов для работы с ними. Geomagic — это единственный инструмент, который серьезные инженеры могут использовать для манипулирования точечными данными, и это дорого — как подержанный автомобиль. Вам почти нужно специализироваться, чтобы иметь возможность позволить себе такие вещи.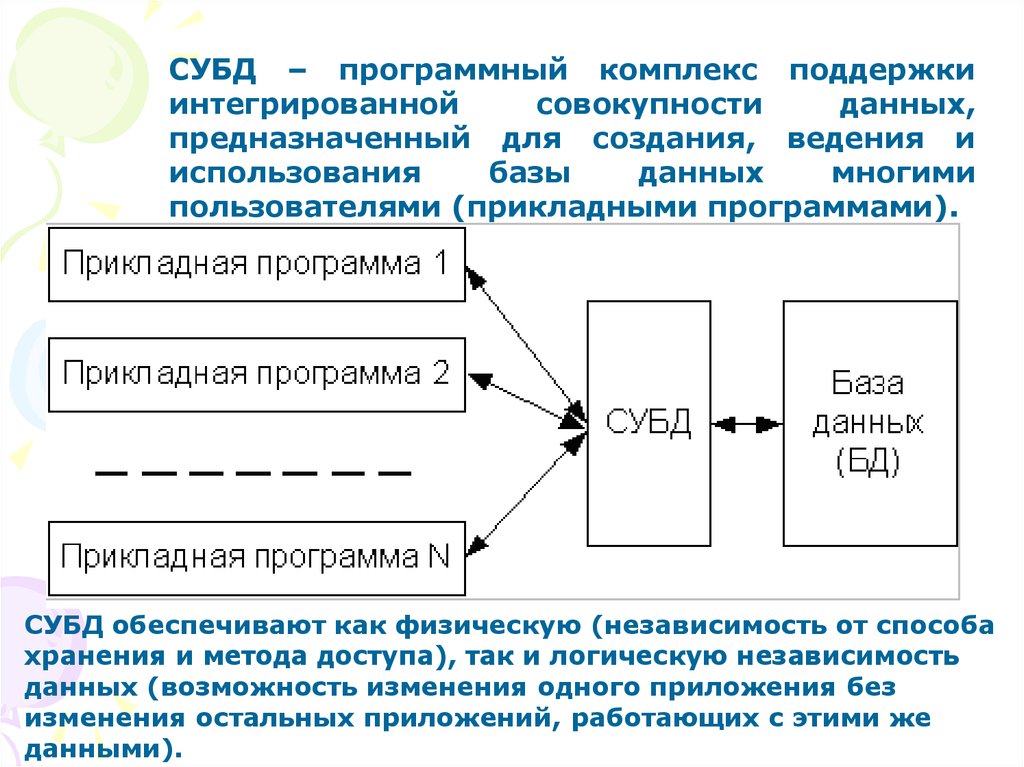
Что ж, пора перестать издеваться. Многие типы данных, которые были несовместимы и недоступны для нас, пользователей инженерных САПР, быстро становятся обязательными для чтения. Инструменты моделирования сабдивов были в Siemens NX в течение некоторого времени, а теперь есть в Autodesk Fusion 360 и появятся в Rhino 7. Я даже слышал слух, что участвует еще один игрок среднего уровня (и это не SW, хотя DS делает есть предложение в этом пространстве, оно не является частью текущего ПО).
Предоставлено DezignstuffПочему важно моделирование субд? Что ж, это важно для таких парней, как я, которые разрабатывают много крутых или органических вещей. Скажем, вы моделируете Corvette в своем любимом историческом САПР на основе NURBS. Скажем, на это уходит неделя со всеми частями и, может быть, 80% деталей, плюс наброски, лофты, границы, заливки и все эти особенности.
Теперь предположим, что вы должны были сделать ту же машину в 3dsMax. Это займет гораздо меньше времени, особенно такие сложные вещи, как тело. Тело может занять пару часов, если вы знаете, что делаете, вместо пары дней.
Тело может занять пару часов, если вы знаете, что делаете, вместо пары дней.
Можно перейти к более сложным вещам, например, к куколке. Куколка была единственным проектом, который я когда-либо начинал в SW, от которого мне действительно пришлось отказаться. В САПР NURBS сделать действительно хорошую куклу или любую человеческую фигурку не очень реалистично. Но с помощью Subd Modeler это делается постоянно.
Технологии окружают нас повсюдуДизайнерам продуктов приходится очень часто делать подобные вещи. Этот блог, и, если быть до конца честным, большую часть последних 15 лет моей жизни, я посвятил обучению людей, написанию статей и обсуждению того, как сложно выполнять расширенное моделирование поверхностей в программном обеспечении для проектирования механических систем, которое никогда не было на самом деле. намеревался это сделать.
Здесь на помощь приходит subd. Это просто. Нет истории. Там нет дерева признаков. Есть просто куча фигур, которые вы перемещаете по экрану, пока они не станут правильными.
Недостатки? Ну, может быть, это не на 100% точно по размерам. Это точность, как прищур одного глаза. Или уровень точности эскиз за эскизом. В любом случае, органические формы в основном связаны не с точностью, а с формой. Subd материал естественно смешанный. Можете ли вы представить, каково это — больше не беспокоиться о том, как смешивать отдельные функции?
Rhino 7 в настоящее время находится в стадии бета-тестирования.Что, если бы существовала система, использующая разные инструменты для того, для чего они хороши? Subd для форм, NURBS для инженерных функций? Это будущее САПР. И не только будущее, это происходит сейчас. Это настоящая инновация, а не возврат платформы в облако, похожее на мейнфрейм. Для меня это очевидное расширение синхронной технологии (Siemens), которая уже есть в NX. Это также часть их конвергентной технологии, которая объединяет эти различные типы данных с традиционными NURBS.
Но, Мэтт, разве принятие субд не отбрасывает все, что ты делал в эпизодах Dezignstuff? Ну, это один из способов взглянуть на это. Другим может быть то, что вы можете увидеть параллельные эпизоды с использованием разных методов.
Другим может быть то, что вы можете увидеть параллельные эпизоды с использованием разных методов.
На Youtube есть тысячи видеороликов, показывающих, как строить вещи в моделировании субд. Есть много разных инструментов, которые вы можете использовать по цене от десятков тысяч долларов до бесплатных. Это совершенно другой мир, чем NURBS CAD, в котором живет большинство из нас, хотя и есть некоторые параллели. Концепция рисования сплайнов и контроля кривизны сплайнов имеет некоторые параллели в subd. Это просто гораздо более интуитивная техника. Что хорошо и что плохо. Если я услышу, как еще один ютубер скажет «vertisee» (единственное число от множественного числа единственного числа «vertex»), я начну добавлять Геритол в чей-нибудь тост с авокадо. Снижение планки входа в мир дизайна для изделий сложной формы обязательно создаст некоторые шероховатости, но эта планка должна быть снижена.
Большинство инструментов subd, которые вы видите сегодня, управляются API-интерфейсом библиотеки Pixar OpenSubdiv, который уходит своими корнями в игру, созданную в 1996 году. Но каждый реализует инструменты по-разному и создает новые способы управления геометрией. Это совершенно другой способ работы по сравнению со стандартным методом эскизов и элементов в САПР на основе истории. Вместо того, чтобы думать о продукте как о серии процессов, нас больше будет интересовать фактическая форма, потому что мы можем контролировать ее напрямую.
Но каждый реализует инструменты по-разному и создает новые способы управления геометрией. Это совершенно другой способ работы по сравнению со стандартным методом эскизов и элементов в САПР на основе истории. Вместо того, чтобы думать о продукте как о серии процессов, нас больше будет интересовать фактическая форма, потому что мы можем контролировать ее напрямую.
Если вы читали мои предыдущие разглагольствования о недостатках программного обеспечения, основанного на истории, вы, возможно, предвидели это. Есть некоторые параллели между subd и прямым редактированием. Я полагаю, что некоторые люди, возможно, будут сопротивляться этому или, возможно, не поймут инструменты редактирования. Я был удивлен, когда люди в массовом порядке держались подальше от синхронных технологий, и то же самое может произойти и здесь. Но я, например, собираюсь вмешаться. Я готов к этим переменам.
Границы микрорайонов и жилых массивов
Разграничение. Сообщество. Гиперлокальный.
Гиперлокальный.
Районы и жилые районы ATTOM для гиперлокального поиска
Данные о границах микрорайонов и жилых районов ATTOM предоставляют общенациональный иерархический набор границ и названий, которые лучше всего отражают консенсусное мнение местных жителей.
Районные и жилые районы — это небольшие географические районы, состоящие из социальных сообществ со своей собственной идентичностью, а также названия и границы, знакомые местным жителям. Это делает их вершиной гиперлокального поиска и превосходит почтовые индексы или города в большинстве случаев использования. Исследования показали, что потребители предпочитают возможности гиперлокального поиска. Опытные операторы поисковых порталов включают эти наборы данных о границах в свои платформы.
Тщательно исследовано и оцифровано
Наше исследование, созданное специально для поиска недвижимости, включает официальные карты городов и округов, местные туристические и медиа-сайты, генеральные планы сообществ, веб-сайты MLS и риэлторов, веб-сайты ТСЖ, планы участков застройщика, данные юридических подразделений оценщиков. и спутниковые снимки. Наши ГИС-аналитики также виртуально объезжают целые города в Google Street View, чтобы просмотреть вывески и вывески квартир. Отзывы также предоставляются местными экспертами из нашей общенациональной сети профессионалов в сфере недвижимости.
и спутниковые снимки. Наши ГИС-аналитики также виртуально объезжают целые города в Google Street View, чтобы просмотреть вывески и вывески квартир. Отзывы также предоставляются местными экспертами из нашей общенациональной сети профессионалов в сфере недвижимости.
Наши аналитики ГИС вручную оцифровывают эти границы районов и жилых кварталов, отслеживая опорные слои, такие как улицы, границы участков и гидрографию.
Общенациональное покрытие доступно в США и Канаде и включает сотни тысяч границ в более чем 600 городских районах и 10 000 больших и малых городов.
Иерархия соседства поддерживает множество вариантов использования
Вместе наборы данных Neighborhood (уровни 1–3) и Residential Subdivision (уровень 4) образуют иерархию однозначных непересекающихся границ.
- Уровень 1: Макрорайоны
- Уровень 2: Районы
- Уровень 3: Подрайоны
- Уровень 4: Жилые кварталы
Уровень 1: Макрорайоны
Макрорайоны представляют собой крупнейший тип микрорайона по размеру и отображают регионы, основные районы города или большие спланированные сообщества.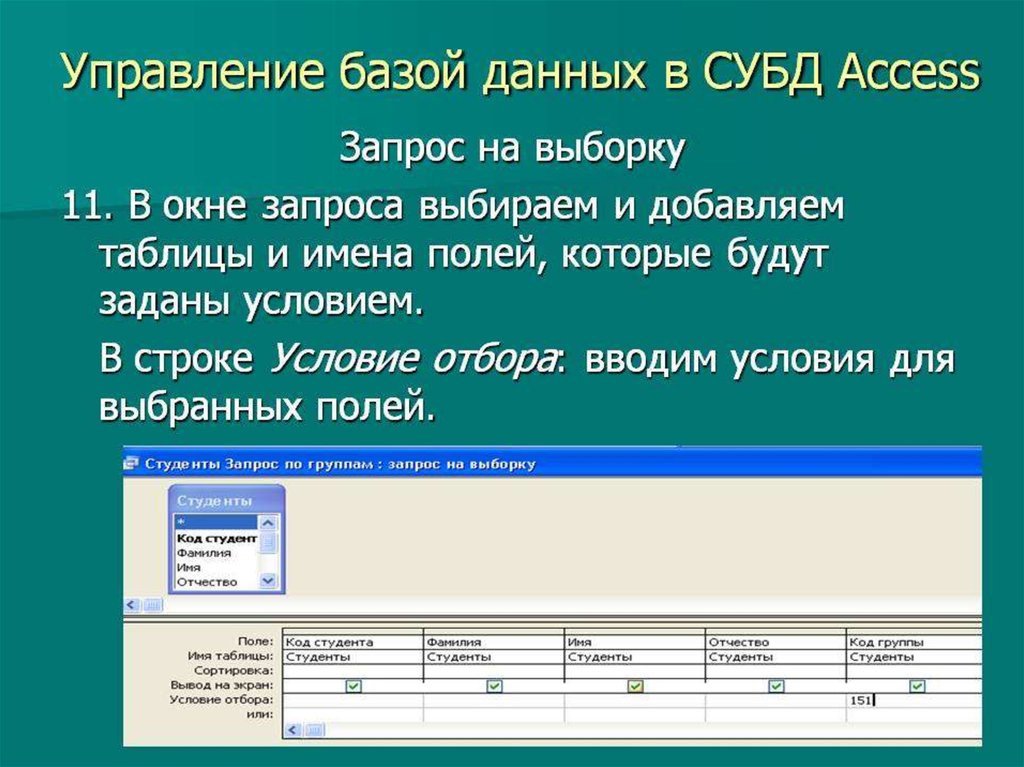
Уровень 2: Районы
Этот уровень представляет собой общее определение района на уровне города, обычно состоящего из разговорной группы улиц и часто упоминаемого местными жителями. Окрестности уровня 2 обычно образуют целостную ткань, покрывающую всю территорию объединенного города.
Уровень 3: Подрайоны
Подрайоны — это меньшие по размеру названные районы, которые обычно находятся в центре города внутри более крупного Района 2-го уровня. Часто это деловые, развлекательные, художественные или исторические районы.
Уровень 4: Жилые районы
Жилые районы Продукт состоит из границ подразделений, кондоминиумов, таунхаусов, многоквартирных комплексов, пенсионных комплексов и других жилых массивов.
Как можно использовать данные ATTOM о границах районов и населенных пунктов?
Порталы недвижимости позволяют пользователям находить недвижимость в определенном районе или районе в режиме реального времени с помощью геопространственной фильтрации.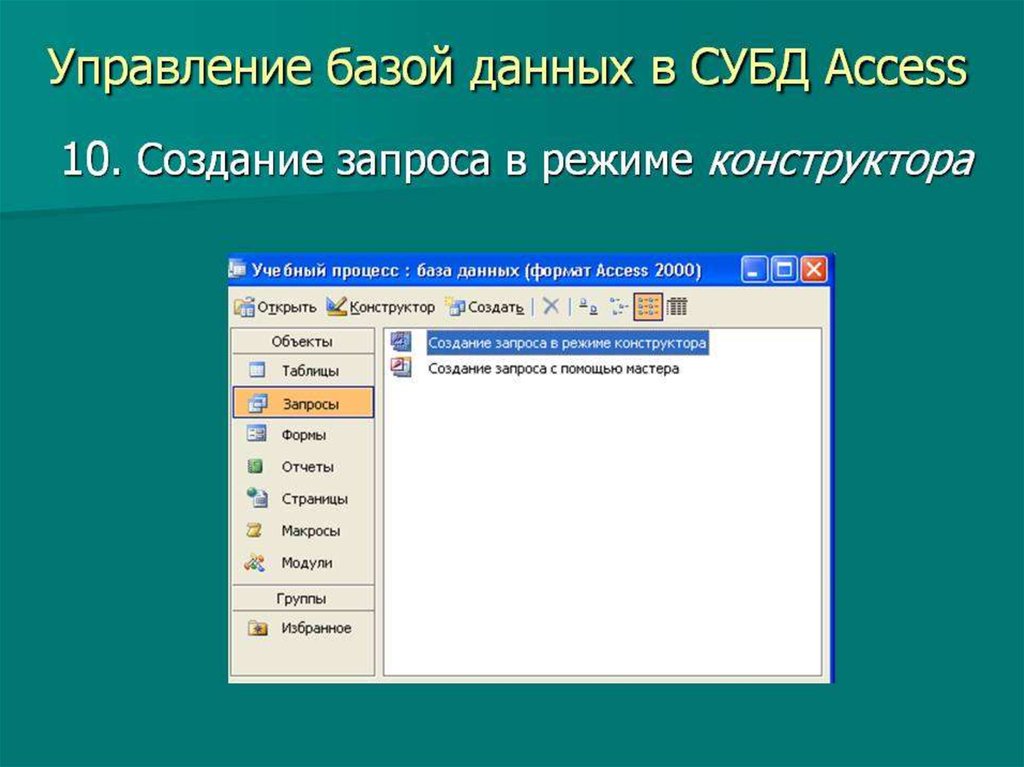 Каталог названий районов и подразделений также можно добавить в омнибокс с автоматическим предложением для более удобного поиска.
Каталог названий районов и подразделений также можно добавить в омнибокс с автоматическим предложением для более удобного поиска.
Узнать больше
Специалисты по недвижимости могут создавать целевые страницы по районам и районам для поддержки поиска и поисковой оптимизации. Привлекательные целевые страницы включают границы района и района, а также отдельно доступные демографические данные, местные школы и рейтинги, последние тенденции в сфере недвижимости, рекомендуемые списки и достопримечательности.
Узнать больше
Платформы технологий и данных могут использовать гиперлокальные данные о границах районов и жилых районов, включая демографические данные, данные о стоимости жизни, климате, преступности и тенденциях в сфере недвижимости, чтобы предлагать привлекательные визуализации и сравнения районов.
Узнать больше
Платформы данных о недвижимости также могут использовать эти границы массово или через API для пометки записей о собственности с соответствующими названиями районов и подразделений, а также другими деталями как часть.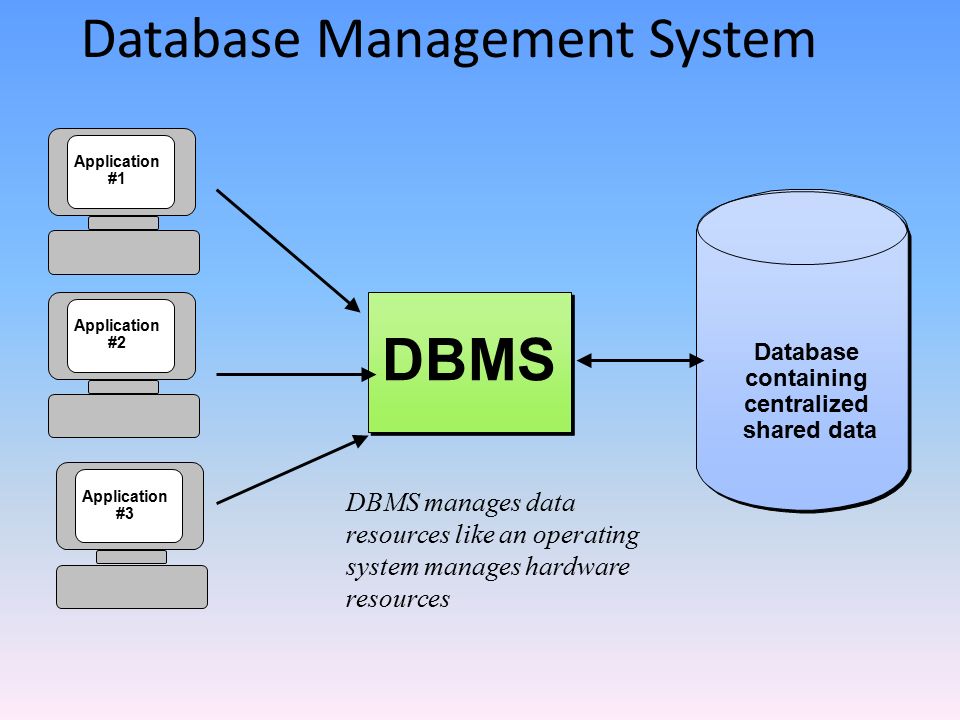 их пакетные процессы.
их пакетные процессы.
Узнать больше
Институциональные инвесторы могут лучше оценивать риски, анализируя тенденции рынка районов и районов. Выявление сопоставимых домов в одном и том же районе или районе также приводит к более точной оценке.
Подробнее
Маркетологи могут использовать эти границы района и отдельно доступные демографические и социально-экономические данные для разработки эффективных гиперлокальных кампаний, повышающих коэффициент конверсии.
Подробнее
Веб-семинар «Преимущества данных о границах для вашего бизнеса»
Подробно изучите различные продукты данных о границах, которые может предложить ATTOM, включая кварталы, жилые и школьные зоны посещаемости, а также ценность представления контента в этих значимых, гиперлокальные уровни.
Выводы высокого уровня включают:
- Экономическое обоснование – Узнайте, почему границы районов, жилых и школьных зон важны для пользователей и как они могут стимулировать трафик и увеличивать доход.
- Примеры использования – Узнайте о различных способах использования этих граничных продуктов и связанной с ними контекстной информации для обеспечения более надежных возможностей поиска и релевантного гиперлокального контента
- Преимущества – Узнайте, почему точность, актуальность и охват этих унифицированных геопространственных граничных продуктов делают их лучшим выбором для ваших приложений.
- И многое другое…

При участии: Пит Юнкер, старший вице-президент по продуктам данных, ATTOM Data Solutions
Разнообразие решений для ваших потребностей в данных
, чтобы связаться с экспертом по данным сегодня и узнать, как ваш бизнес может получить доступ к исчерпывающим данным о недвижимости ATTOM в различных гибких форматах, таких как:
- ATTOM Cloud
- API данных свойств
- Лицензирование массовых данных
- Отчеты о свойствах
- Маркетинговые списки
- Тенденции рынка недвижимости
- Соответствие и добавление
Откройте для себя ATTOM и посмотрите наши Таблица элементов данных .
Немедленно получите образцы данных – это быстро и просто!
Связанные данные
Поверхности разделения
- Обзор
- Кусочно-параметрические поверхности
- Параметрические патчи
- Кусочные поверхности
- Произвольная топология
- Регулярные и неправильные элементы
- Топология без коллектора
- Подразделение против тесселяции
- Подразделение
- Мозаика
- Что использовать?
- Данные сетки и топология
- Отделение данных от топологии
- Вершина и переменные данные
- Данные и топология с изменением лица
- Схемы и опции
- Схемы разделения
- Граничные правила интерполяции
- Правила интерполяции с изменяющимся лицом
- Полуострые складки
- Другие варианты
- Правило Чайкина
- Правило «Подразделение треугольника»
Обзор
Поверхности подразделения — это распространенный примитив моделирования, получивший популярность в
анимации и визуальных эффектов за последние десятилетия.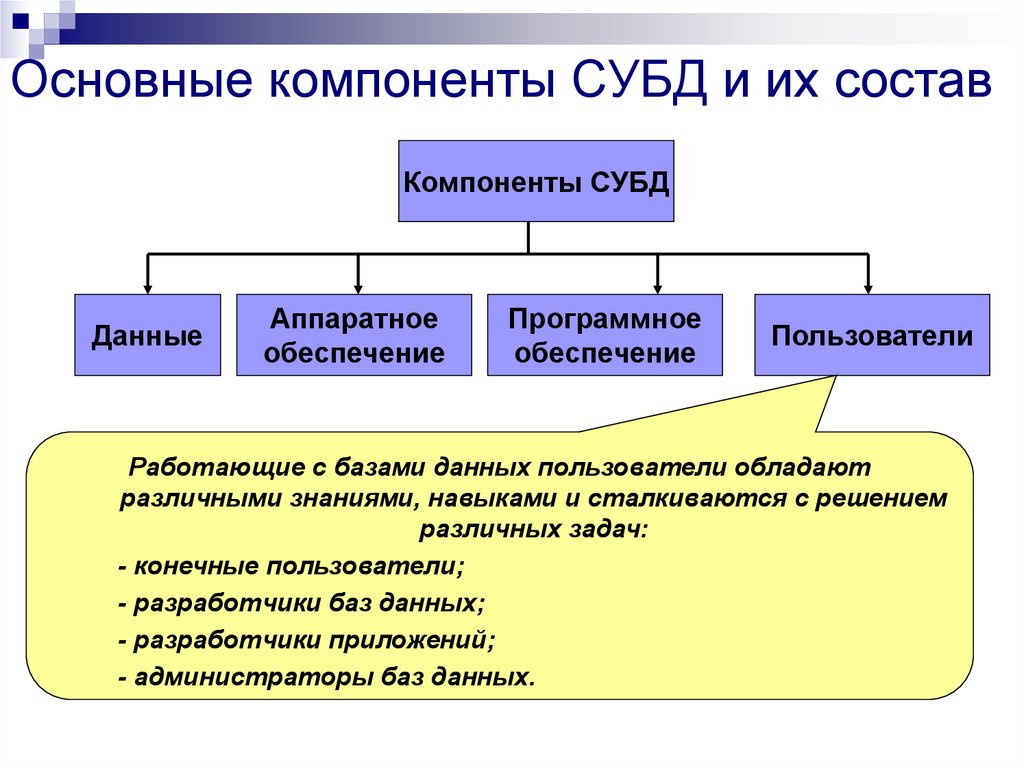
Как следует из названия, поверхности подразделения в основном представляют собой поверхностей .
В частности, поверхности подразделения представляют собой кусочно-параметрические поверхности , определенные на сетки произвольная топология — оба понятия, которые будут описаны в разделах которые следуют.
Подразделение — это операция, которая может быть применена к полигональной сетке для ее уточнения.
математический аппарат, определяющий лежащую в основе гладкую поверхность, к которой повторяются повторные подразделения
сетки сходится. Явное подразделение просто применить некоторое количество
раз, чтобы обеспечить более гладкую сетку, и эта простота исторически привела ко многим инструментам
представляя форму таким образом. Напротив, получение гладкой поверхности, которая в конечном итоге
определяет форму — ее «предельная поверхность» — значительно сложнее, но обеспечивает большую
точность и гибкость. Эти различия привели к путанице в том, как некоторые инструменты
подвергать поверхности подразделения.
Эти различия привели к путанице в том, как некоторые инструменты
подвергать поверхности подразделения.
Конечная цель состоит в том, чтобы все инструменты использовали поверхности подразделения как настоящие поверхностные примитивы. Поэтому основное внимание здесь уделяется не столько подразделению, сколько природе. поверхности, которая получается в результате. Помимо последовательного выполнения подразделение, которое включает в себя ряд широко используемых расширений функций. Ценность OpenSubdiv в том, что он делает предельную поверхность более доступной.
С момента своего появления OpenSubdiv вызвал интерес у пользователей и разработчиков.
с широким спектром навыков, интересов и опыта. Этот документ
предназначен для представления поверхностей подразделения с точки зрения, полезной для использования
из OpenSubdiv. Одной из целей, которым он служит, является предоставление обзора высокого уровня для тех,
с меньшим опытом работы с алгоритмами или математикой подразделения.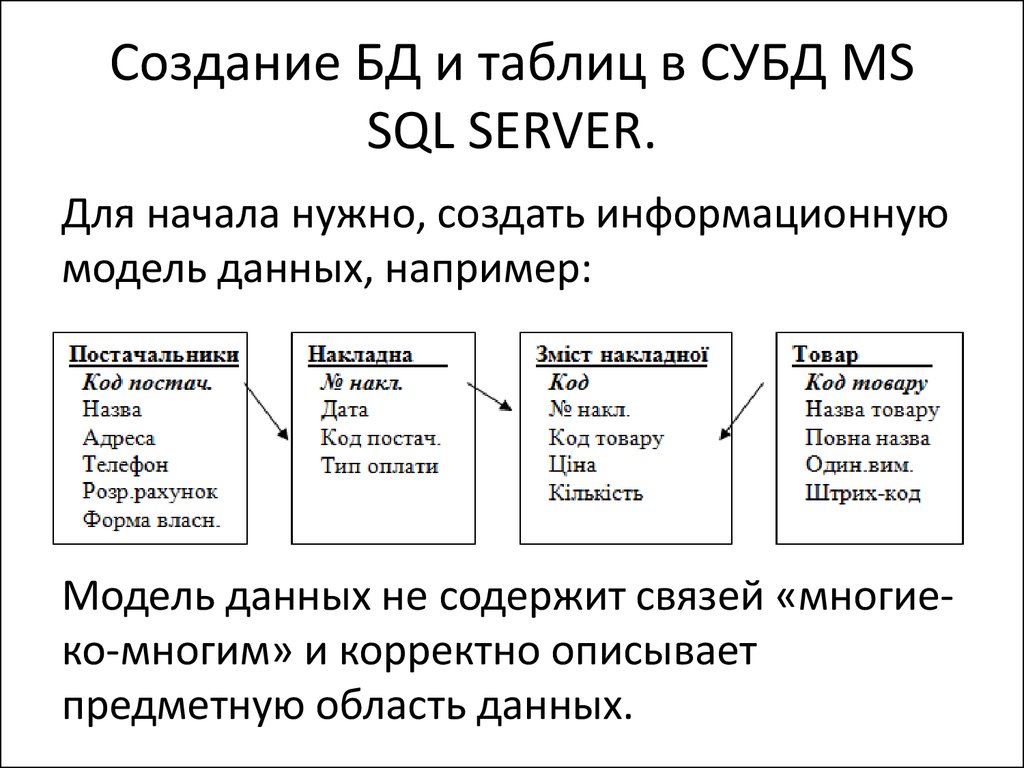 Другой
состоит в том, чтобы предоставить обзор набора функций, доступных в OpenSubdiv, и
представить эти возможности с помощью терминологии, используемой OpenSubdiv (поскольку большая часть
перегружен).
Другой
состоит в том, чтобы предоставить обзор набора функций, доступных в OpenSubdiv, и
представить эти возможности с помощью терминологии, используемой OpenSubdiv (поскольку большая часть
перегружен).
Кусочно-параметрические поверхности
Кусочно-параметрические поверхности, возможно, являются наиболее широко используемым геометрическим представлением в промышленном дизайне, развлечениях и многих других областях. Многие объекты, которыми мы занимаемся с повседневными делами — автомобили, мобильные телефоны, ноутбуки — были спроектированы и визуализированы в первую очередь как кусочно-параметрические поверхности до того, как эти проекты были утверждены и реализованы.
Кусочно-параметрические поверхности в конечном итоге представляют собой просто наборы более простых примитивов моделирования
называются патчами. Патчи представляют собой «кусочки» большей поверхности в большинстве случаев.
точно так же, как грань или полигон составляют часть полигональной сетки.
Параметрические заплатки
Заплатки являются строительными блоками кусочно-гладких поверхностей и множества различных видов Патчи эволюционировали, чтобы удовлетворить потребности геометрического моделирования. Два наиболее эффективных и общие исправления показаны ниже:
Одиночный бикубический патч B-Spline | Одинарная бикубическая накладка Безье |
Патчи состоят из набора точек или вершин, влияющих на прямоугольный кусок гладкой поверхность (существуют также треугольные участки). Этот прямоугольник «параметризован» в двух своих направлений, превращая простой 2D-прямоугольник в 3D-поверхность:
(u,v) 2D домен патча | Преобразование от (u, v) до (x, y, z) |
Точки, контролирующие форму поверхности, обычно называют контрольными.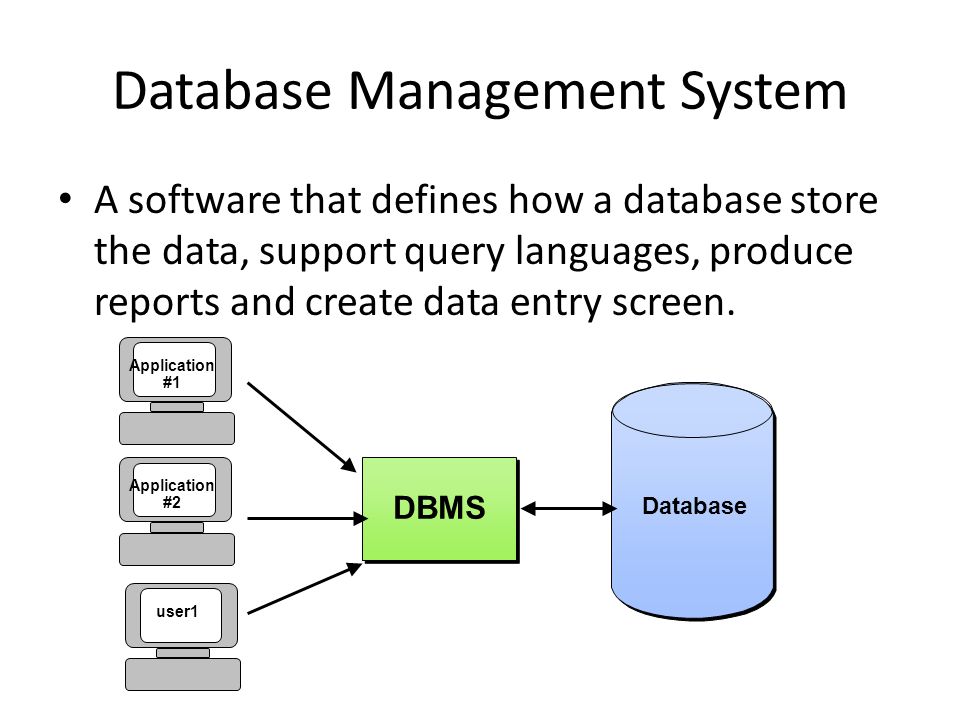 точки или контрольные вершины, а также совокупность всего множества, определяющая заплату как
контрольная сетка, контрольный корпус, контрольная клетка или просто корпус, клетка,
и т. д. Для краткости мы будем часто использовать термин «клетка», который служит нам
в общем позже.
точки или контрольные вершины, а также совокупность всего множества, определяющая заплату как
контрольная сетка, контрольный корпус, контрольная клетка или просто корпус, клетка,
и т. д. Для краткости мы будем часто использовать термин «клетка», который служит нам
в общем позже.
Таким образом, патч состоит из двух объектов: контрольных точек и поверхности. затронуты ими.
То, как контрольные точки влияют на поверхность, определяет различные типы патчи уникальные. Даже патчи, определяемые одним и тем же количеством точек, могут иметь разные значения. поведение. Обратите внимание, что все 16 точек патча B-Spline выше относительно далеки от поверхность, которую они определяют, по сравнению с аналогичной заплатой Безье. Два патча в этот пример на самом деле представляет один и тот же кусок поверхности — каждый с набором контрольных точек, оказывающих на него различное влияние. С точки зрения математики, каждый элемент управления точка имеет связанную с ней «базисную функцию», которая воздействует на поверхность в конкретном способ, когда перемещается только эта точка:
Базовая функция бикубического B-сплайна | Бикубическая базисная функция Безье |
Именно эти базовые функции часто дают начало названиям различных патчей.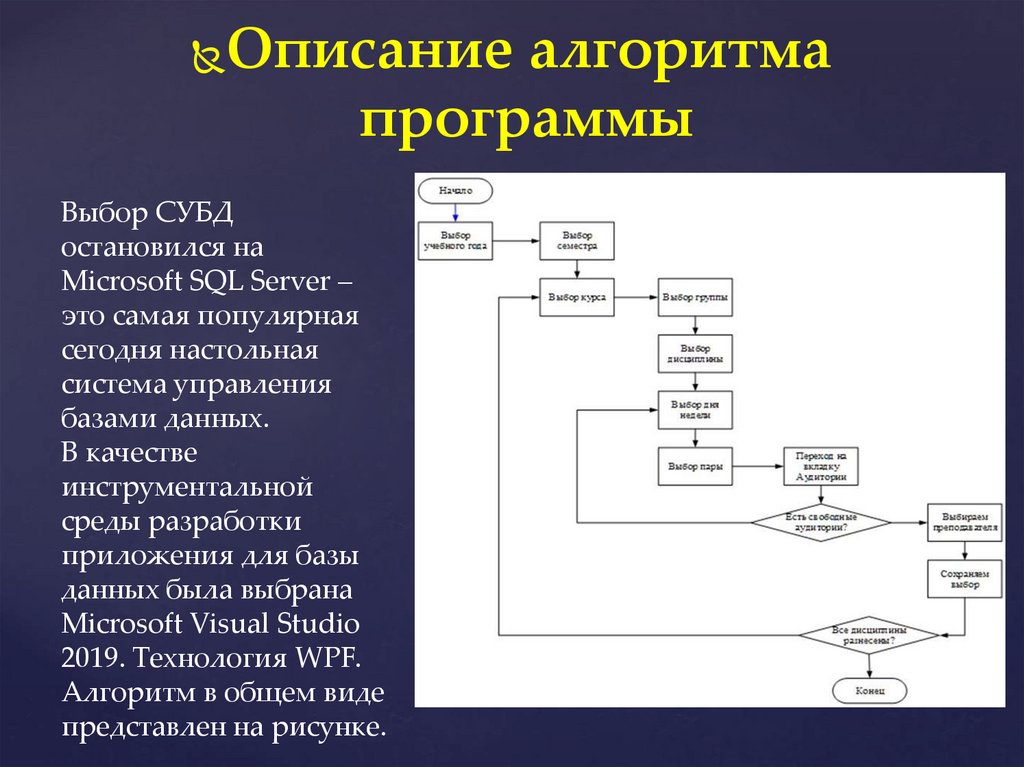
У этих различных свойств контрольных точек патчей есть свои плюсы и минусы. которые становятся более очевидными, когда мы собираем заплатки в кусочные поверхности.
Кусочные поверхности
Кусочно-параметрические поверхности представляют собой наборы заплат.
Для прямоугольных патчей одним из самых простых способов создания коллекции является определение набор патчей с использованием прямоугольной сетки контрольных точек:
Кусочная поверхность B-сплайна | Кусочная поверхность Безье |
Обратите внимание, что мы можем перекрывать точки соседних участков B-сплайна. Это перекрытие
означает, что перемещение одной контрольной точки влияет на несколько патчей, но также обеспечивает
что эти патчи всегда плавно соединяются (это было замыслом дизайна и не соответствовало действительности
для других типов патчей). Смежные пятна Безье имеют общие точки только на их границах.
и координировать точки на этих границах, чтобы поверхность оставалась гладкой.
можно, но неудобно. Это делает B-сплайны более подходящим представлением поверхности.
для интерактивного моделирования, но патчи Безье служат многим другим полезным целям.
Смежные пятна Безье имеют общие точки только на их границах.
и координировать точки на этих границах, чтобы поверхность оставалась гладкой.
можно, но неудобно. Это делает B-сплайны более подходящим представлением поверхности.
для интерактивного моделирования, но патчи Безье служат многим другим полезным целям.
Более сложная B-шлицевая поверхность:
Часть более сложной поверхности B-Spline |
Точно так же, как заплата состояла из клетки и поверхности, то же самое теперь верно и для коллекция. Клеткой управления управляет дизайнер, и поверхность каждой патчей отображается, чтобы они могли оценить его эффект.
Произвольная топология
Обсуждаемые до сих пор кусочные поверхности были ограничены наборами патчей
по регулярным сеткам контрольных точек. Существует определенная простота с прямоугольным
параметрические поверхности, которые привлекательны, но представление поверхности, которое поддерживает
произвольная топология имеет много других преимуществ.
Прямоугольные параметрические поверхности получили широкое распространение, несмотря на их топологическую ограничений, и их популярность сохраняется и сегодня в некоторых областях. Сложные объекты часто нужно много таких поверхностей, чтобы представить их, и множество методов эволюционировали, чтобы эффективно собирать их, в том числе «сшивать» несколько поверхностей вместе или резать отверстия в них («обрезки»). Это сложные методы, и, хотя они эффективны в одни контексты (например, промышленный дизайн) они становятся громоздкими в других (например, анимация и визуальные эффекты).
Одна полигональная сетка может представлять формы гораздо более сложные, чем одна прямоугольная кусочно-поверхность, но ее граненый характер со временем становится проблемой.
Поверхности подразделения сочетают в себе топологическую гибкость полигональных сеток с
базовая гладкость кусочно-параметрических поверхностей. Так же, как прямоугольный кусочно
параметрические поверхности имеют набор контрольных точек (его клетка хранится в виде сетки)
и базовая поверхность, поверхности подразделения также имеют набор контрольных точек
(его клетка хранится как сетка) и нижележащая поверхность (часто называемая его «пределом»).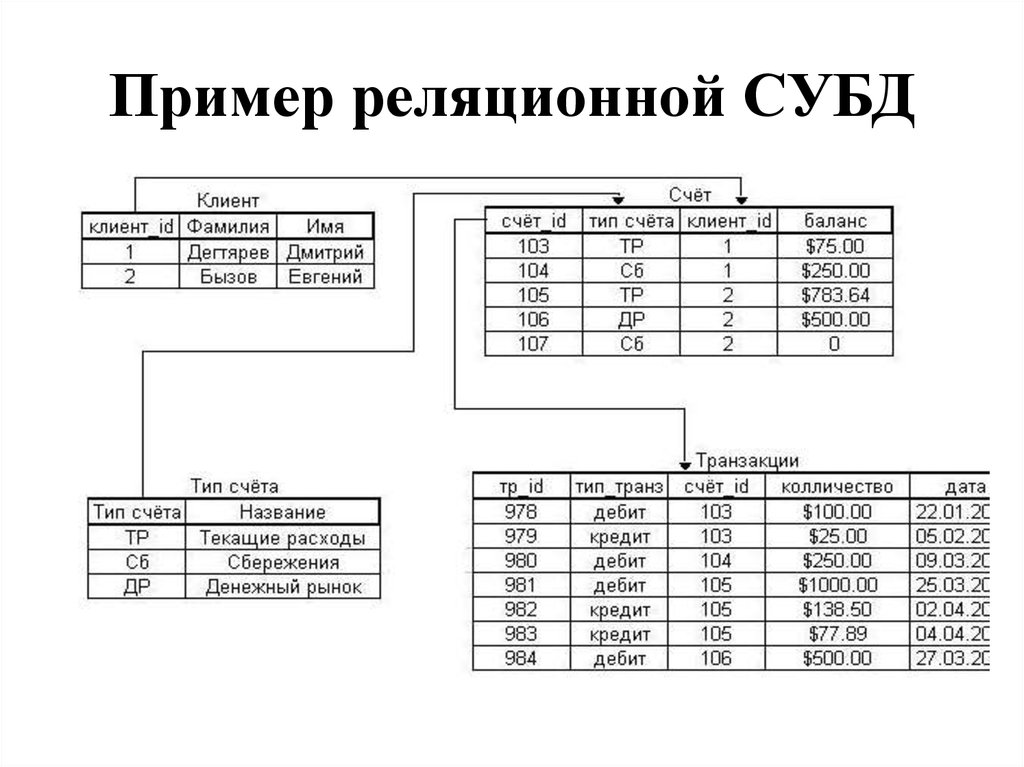 поверхность»).
поверхность»).
Правильные и неправильные элементы
Сетка содержит вершины и грани, образующие клетку для нижележащей поверхность, и топология этой сетки может быть произвольно сложной.
В областях, где грани и вершины сетки соединяются в прямоугольную форму сетки предельная поверхность становится одной из прямоугольных кусочно-параметрических ранее упомянутые поверхности. Эти области сетки называются «регулярными»: они обеспечивают поведение, знакомое по использованию подобных прямоугольных поверхностей и с их предельной поверхностью относительно просто иметь дело. Все остальные области являются считаются «неправильными»: они обеспечивают желаемую топологическую гибкость и поэтому менее знакомы (и в некоторых случаях менее предсказуемы), а их предельная поверхность может быть намного сложнее.
Неправильные элементы бывают разных форм. Наиболее широко упоминается
экстраординарная вершина, т. е. вершина, которая в случае четверного подразделения
схема, подобная Кэтмуллу-Кларку, не имеет четырех инцидентных граней.
Неправильная вершина и инцидент лица | Правильные и неправильные участки поверхность |
Присутствие этих неправильных элементов делает предельную поверхность вокруг них также нерегулярно, т. е. не может быть представлено так же просто, как для регулярного регионы.
Стоит отметить, что области неправильной формы уменьшаются в размерах и становятся более «изолированными». как применяется подразделение. Лицо с множеством необычных вершин вокруг него создает очень сложную поверхность, и выделение этих элементов является способом помогите разобраться с этой сложностью:
Две вершины валентности-5 рядом | Изоляция подразделяется один раз | Изоляция разделена дважды |
В этих областях вообще необходимо выполнить какое-то локальное подразделение
разбить эти куски поверхности на более мелкие, более управляемые части, и
термин «адаптивное подразделение признаков» стал популярным в последние годы для описания
этот процесс.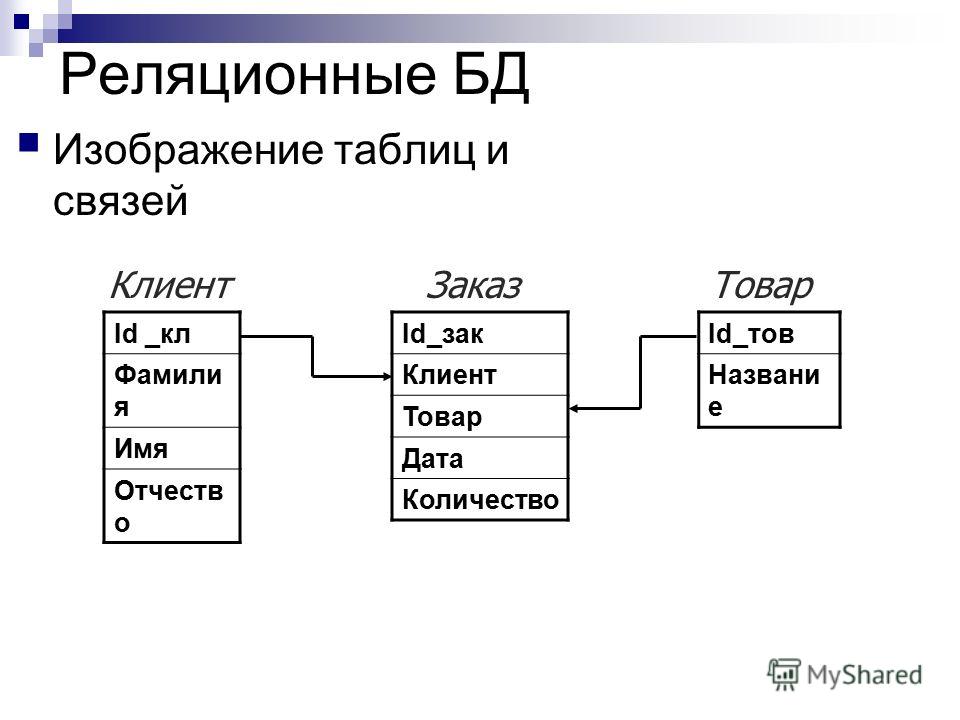 Независимо от того, делается ли это явно или неявно, глобально или локально,
важнее всего то, что для каждого из них существует базовая часть предельной поверхности.
лицо — хотя и потенциально сложное с неправильными чертами — которое может
оцениваются почти так же, как прямоугольные кусочные поверхности.
Независимо от того, делается ли это явно или неявно, глобально или локально,
важнее всего то, что для каждого из них существует базовая часть предельной поверхности.
лицо — хотя и потенциально сложное с неправильными чертами — которое может
оцениваются почти так же, как прямоугольные кусочные поверхности.
Патчи обычных регионов | Патчи неправильной области |
В то время как поддержка гладкой поверхности в этих неровных областях является основным преимуществом
поверхностей подразделения, как сложность результирующих поверхностей, так и их
качества являются причинами, чтобы использовать их с осторожностью. Когда топология в значительной степени нерегулярна,
его поверхность связана с более высокими затратами, поэтому сведение к минимуму неровностей
выгодно. А в некоторых случаях качество поверхности, т.е. воспринимаемое
гладкость неровных поверхностей может привести к нежелательным артефактам.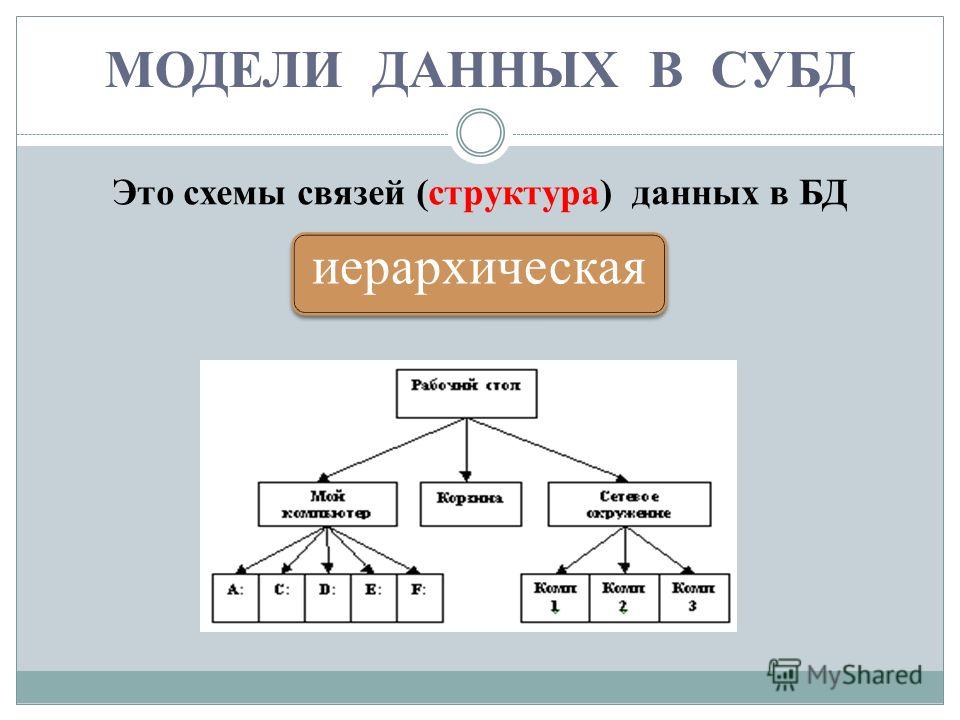
Произвольная полигональная сетка часто не будет хорошей клеткой подразделения, независимо от того, того, насколько хороша эта полигональная сетка.
Как и в случае с прямоугольными кусочно-параметрическими поверхностями, сепаратор должен иметь форму воздействовать на нижележащую поверхность, которую он должен представлять. Видеть Советы по моделированию для соответствующих рекомендаций.
Немногообразная топология
Поскольку клетка поверхности подразделения хранится в сетке, и часто манипулируются в том же контексте, что и полигональные сетки, тема многообразия требует некоторого внимания.
Существует множество определений или описаний того, что отличает коллектор
сетка от той, которой нет.
Они варьируются от кратких, но абстрактных математических определений до наборов
примеры, показывающие многообразные и неоднородные сетки — все они имеют свою ценность
и адекватная аудитория.
Следующее не является строгим определением, но служит
хорошо иллюстрирует большинство локальных топологических конфигураций, которые создают сетку. быть не многообразным.
быть не многообразным.
Рассмотрим «стояние» на гранях меша и «обход» каждой вершины в очереди. Предполагая правый порядок намотки граней, встаньте сбоку от лицо в положительном нормальном направлении. И при ходьбе переступай через каждую инцидентное ребро в направлении против часовой стрелки к следующей инцидентной грани.
Для внутренней вершины:
- начало в углу любой инцидентной грани
- обход вершины по каждому инцидентному ребру до следующей непосещенной грани; повторить
- , если вы вернетесь туда, откуда начали, и ни одна грань или ребро инцидента не были посещены, сетка неразборная
Аналогично, для граничной вершины:
- начало в углу грани, содержащей переднее граничное ребро
- обход вершины по каждому инцидентному ребру до следующей непосещенной грани; повторить
- , если вы достигли другого граничного ребра, и ни одна из инцидентных граней или ребер не была посещена, сетка неразборная
Если таким образом можно обойти все вершины и не встретить
особенности, сетка, вероятно, многообразна.
Очевидно, что если вершина не имеет граней, нечего ходить, и этот тест не может быть успешным, так что это снова не многообразный. Все грани вокруг вершины также должны находиться в одном и том же ориентация, в противном случае две смежные грани имеют нормали в противоположных направлениях и сетка будет считаться не многообразной, поэтому мы действительно должны включить это ограничение при переходе на следующую грань, чтобы быть более строгим.
Рассмотрим обход указанных вершин следующих многообразных сеток:
Ребра с > 2 смежными гранями | Грани имеют общую вершину, но не имеют ребер |
Как упоминалось ранее, многие инструменты не поддерживают многообразные сетки, и в
некоторые контексты, т.е. 3D-печати, их следует строго избегать. Иногда
сетка коллектора может быть желательной и обязательной в качестве конечного результата, но сетка
может временно стать неоднородным из-за определенной последовательности моделирования
операции.
Вместо того, чтобы поддерживать или защищать использование многообразных сеток, OpenSubdiv стремится быть надежным при наличии неоднородных функций, чтобы упростить использование своих клиентов, избавляя их от необходимости топологического анализа для определить, когда можно или нельзя использовать OpenSubdiv. Хотя правила подразделения не так хорошо стандартизированы в областях, где сетка не является многообразной, OpenSubdiv обеспечивает простые правила и разумную предельную поверхность в большинстве случаев.
Поверхность вокруг ребер с > 2 инцидентами лица | Поверхность для граней, имеющих общую вершину, но не края |
Как и в случае с правильными и неправильными чертами, поскольку каждое лицо имеет
соответствующий кусок поверхности, связанный с ним — будь то локально многообразный или
нет — можно сказать, что термин «произвольная топология» включает топологию без многообразия.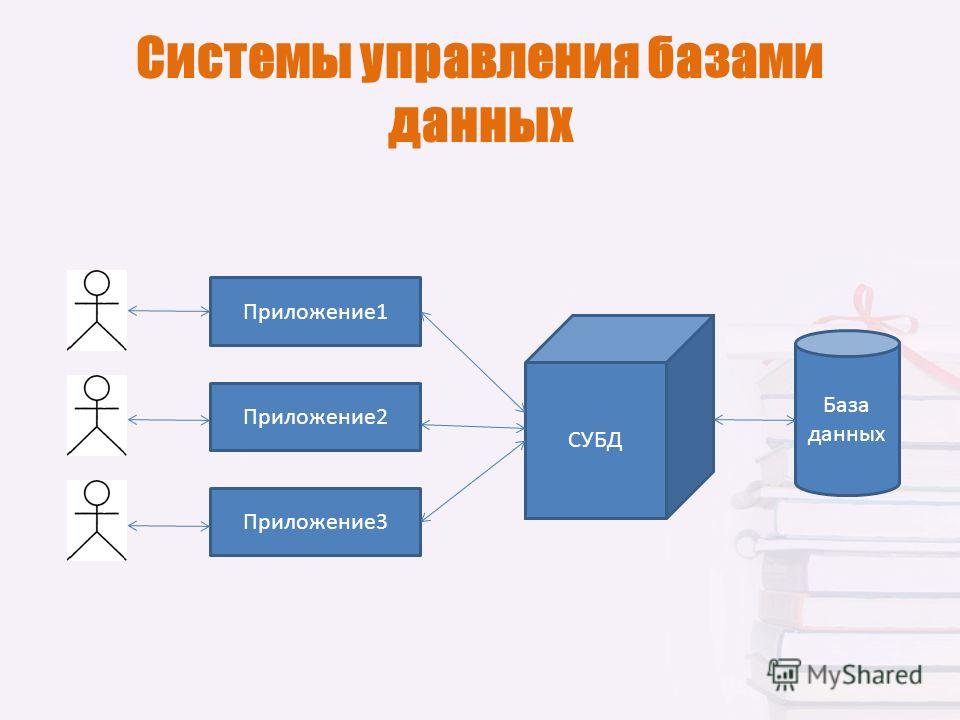
Подразделение против тесселяции
В предыдущих разделах поверхности подразделения показаны как кусочно-параметрические поверхности произвольная топология. Как кусочно-параметрические поверхности, они состоят из клетки и нижележащая поверхность, определяемая этой клеткой.
Для отображения поверхностей подразделения используются два метода: разделение и тесселяция. Оба имеют правомерное использование, но между ними есть важное различие:
.
- подразделение работает на клети и производит очищенную клетка
- тесселяция работает на поверхности и производит дискретизацию этой поверхности
Наличие и относительная простота алгоритма подразделения позволяет легко
наносить повторно, чтобы приблизить форму поверхности, но в результате
усовершенствованная клетка, это приближение не всегда очень точное. По сравнению с
клетка, уточненная до другого уровня, или тесселяция, использующая точки, оцененные напрямую
на предельной поверхности расхождения могут сбивать с толку.
По сравнению с
клетка, уточненная до другого уровня, или тесселяция, использующая точки, оцененные напрямую
на предельной поверхности расхождения могут сбивать с толку.
Subdivision
Subdivision — это процесс, который дает «поверхностям подразделения» их имя, но это не так. уникальный для них. Будучи кусочно-параметрическими поверхностями, давайте сначала рассмотрим подразделение в контекст более простых параметрических патчей, из которых они состоят.
Подразделение — это частный случай уточнения , который является ключом к успеху некоторых
наиболее широко используемые типы параметрических площадок и их агрегатных поверхностей. Поверхность может
быть «уточненным», когда существует алгоритм, позволяющий ввести больше контрольных точек , сохраняя при этом форму поверхности точно такой же, как . Для интерактива и дизайна
целях, это позволяет разработчику ввести большее разрешение для более точного управления без
введение нежелательных побочных эффектов в форму. Для более аналитических целей это позволяет
поверхность, которую нужно разбить на части, часто адаптивно, сохраняя при этом верность
оригинальная форма.
Для более аналитических целей это позволяет
поверхность, которую нужно разбить на части, часто адаптивно, сохраняя при этом верность
оригинальная форма.
Одна из причин, почему заплаты B-spline и Bezier настолько широко используются, заключается в том, что они оба можно доработать. Единое подразделение — процесс разделения каждого из патчей. в одном или обоих своих направлениях — это частный случай утончения, что оба из поддерживаются эти типы патчей:
Поверхность B-Spline и ее каркас | Разделенная клетка 1x | Клетка, разделенная на 2 части |
В случаях, показанных выше для B-шлицев, однородно очищенные сепараторы производят одинаковые
предельная поверхность как оригинал (предоставляется в большем количестве штук). Поэтому справедливо сказать, что оба
однородные B-сплайны и поверхности Безье являются поверхностями подразделения.
Предельная поверхность остается неизменной со многими другими контрольными точками (примерно 4x с каждой итерация подразделения), и эти точки находятся ближе к поверхности (но не на ней). Это может показаться заманчивым использовать эти новые контрольные точки для представления поверхности, но используя те же количество точек, оцененных в соответствующих равномерно расположенных параметрических точках на Поверхность обычно проще и эффективнее.
Обратите внимание, что точки клетки обычно не имеют векторов нормалей, связанных с их, хотя мы можем явно вычислить нормали для произвольных мест на поверхности, просто как мы делаем для положения. Таким образом, при отображении клетки в виде заштрихованной поверхности векторы нормалей на каждой контрольные точки должны быть продуманы. Как положения, так и нормали точек на Таким образом, более тонкая клетка является обеими аппроксимациями.
То же верно и для более общих поверхностей подразделения. Subdivision уточнит сетку
произвольной топологии, но полученные точки не будут лежать на предельной поверхности и любой нормали
векторы, выдуманные из этих точек и связанные с ними, будут лишь приближениями к тем,
предельной поверхности.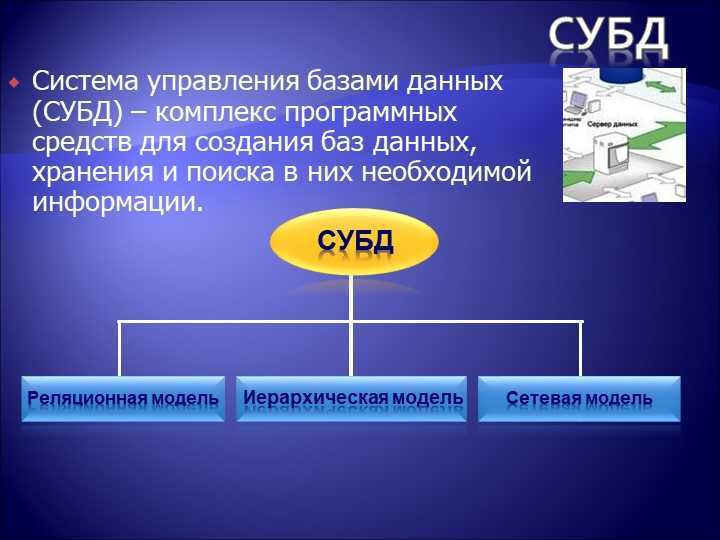
Мозаика
Нет необходимости использовать подразделение для аппроксимации параметрической поверхности, когда ее можно вычисляется напрямую, т. е. может быть тесселяции. Мы можем оценить в произвольных местах на поверхность и соедините полученные точки, чтобы сформировать мозаику — дискретизацию предельная поверхность — гораздо более гибкая, чем результаты, полученные при однородном подразделении:
Равномерная (3×3) тесселяция B-сплайна поверхность | Мозаика с адаптацией к кривизне B-сплайна поверхность |
Для простой параметрической поверхности прямая оценка предельной поверхности также проста,
но для более сложных поверхностей подразделения произвольной топологии это не так.
Отсутствие четкого понимания взаимосвязи между предельной поверхностью и
Cage исторически приводил к тому, что многие приложения избегали тесселяции.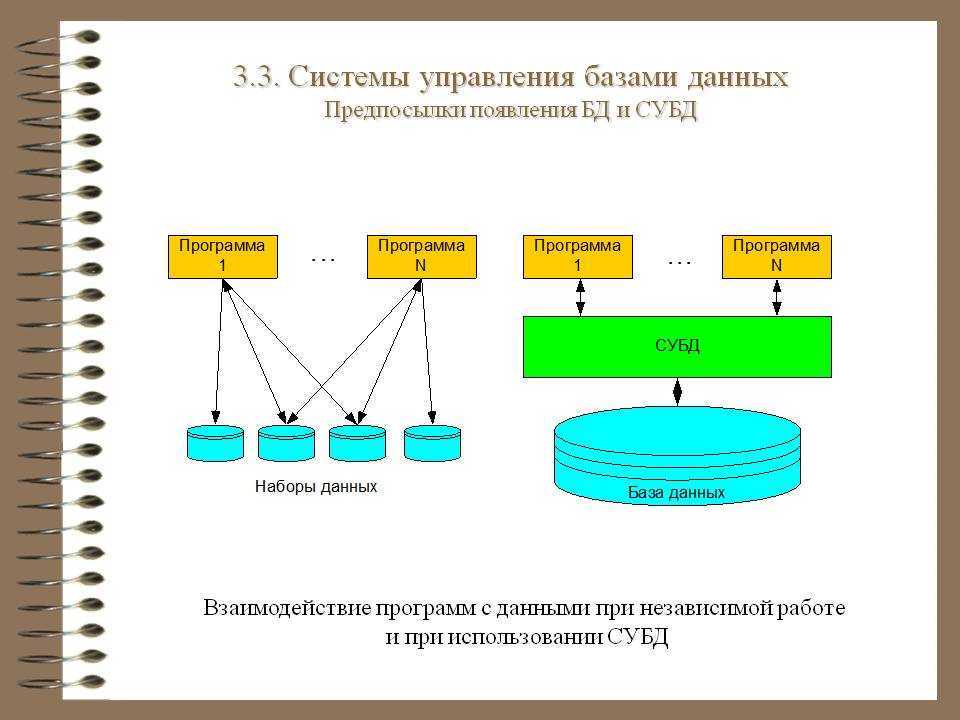
Стоит отметить, что подразделение можно использовать для создания тесселяции, даже если предельная поверхность недоступна для прямой оценки. Рекурсивный характер подразделения приводит к формулам, позволяющим вычислить точку на предельной поверхности, которая соответствует каждой точке клетки. Этот процесс часто называют «защелкиванием». или «выталкивание» точек клетки на предельную поверхность.
Подразделен 1x и привязан к предельной поверхности | 2-кратное разделение и привязка к предельной поверхности |
Поскольку конечным результатом является
связанный набор точек на предельной поверхности, это образует мозаику предела
поверхность, и мы считаем это отдельным процессом для подразделения (хотя он действительно использует
из него). Тот факт, что такая тесселяция могла быть достигнута с помощью подразделения, является
неотличимы от конечного результата — та же самая тесселяция могла бы так же легко
был сгенерирован путем оценки предельных участков клетки равномерно 2x, 4x, 8x и т.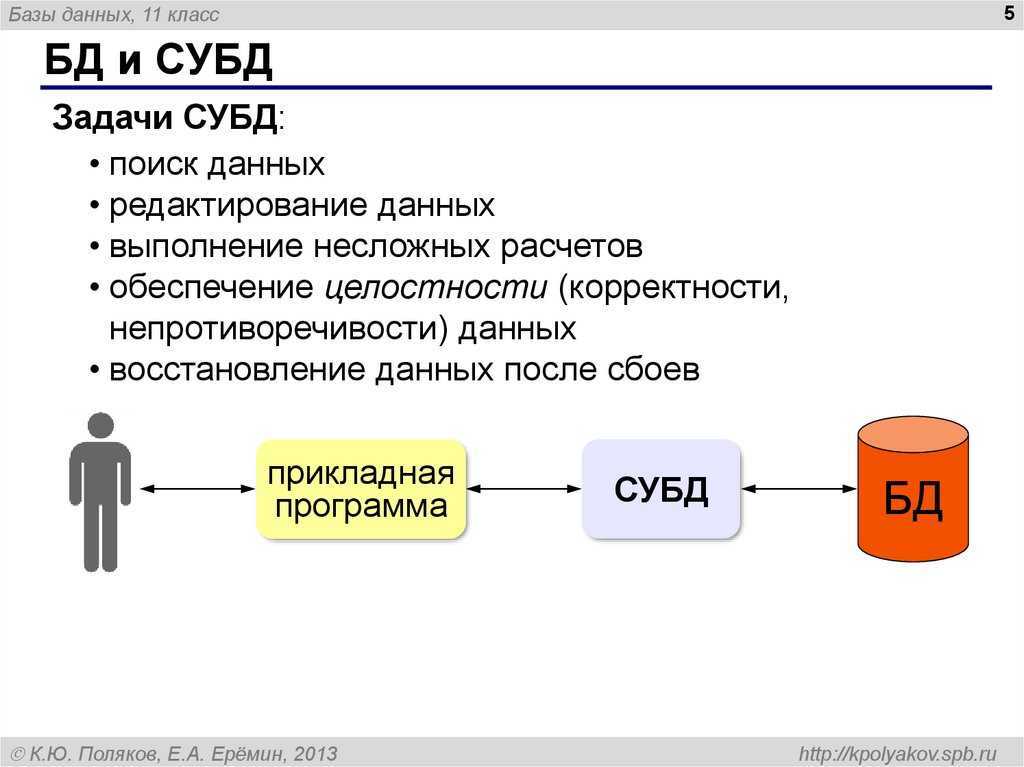 д. вдоль
каждое ребро.
д. вдоль
каждое ребро.
Что использовать?
Subdivision, несомненно, полезен при создании более тонких клеток для манипулирования поверхностью, но тесселяция предпочтительнее для отображения поверхности, когда патчи доступны для прямой оценки. Было время, когда глобальная утонченность преследовалась в ограниченных масштабах. круги как способ быстрой оценки параметрических поверхностей вдоль изопараметрических линий, но обычно преобладает оценка патчей, то есть тесселяция.
Значительная путаница возникла из-за того, как эти два метода использовались и
представленный при отображении формы в приложениях конечного пользователя. Можно утверждать, что если
приложение отображает представление поверхности, которое является удовлетворительным для его
целях, то не нужно обременять пользователя дополнительной терминологией и
выбор. Но когда два представления одной и той же поверхности значительно различаются между собой.
два приложения, отсутствие какого-либо объяснения или контроля приводит к путанице.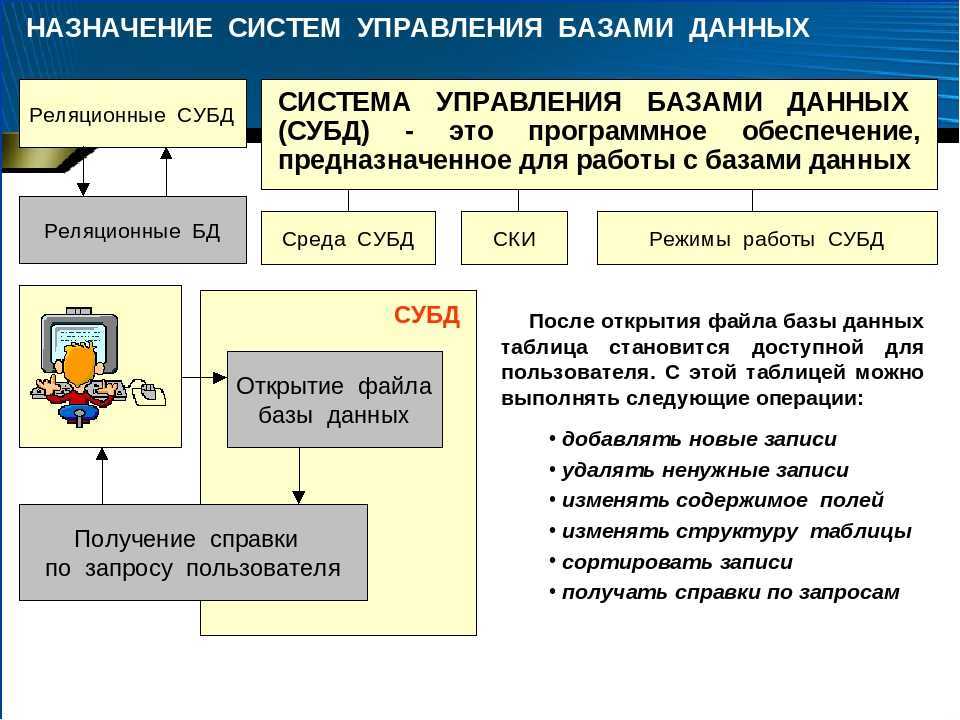
Пока приложения выбирают способ отображения поверхности по-разному, мы ищем баланс между простотой и контролем. Так как подразделяемые точки не лежат на пределе поверхности, важно, чтобы пользователи понимали, когда вместо этого используется subdivision тесселяции. Это особенно верно в тех случаях, когда клетка и поверхности отображаются в одном стиле, так как у пользователей нет визуальной подсказки, чтобы сделать это различие.
Данные сетки и топология
Способность поверхностей подразделения поддерживать произвольную топологию приводит к использованию сетки для хранения как топологии клетки, так и значений данных, связанных с ее контрольные точки, т. е. его вершины. Форма сетки или поверхность подразделения которая получается в результате, представляет собой комбинацию топологии сетки и положения данные, связанные с его вершинами.
При работе с сетками есть преимущества в отделении топологии от данных,
и это еще более важно при работе с поверхностями подразделения.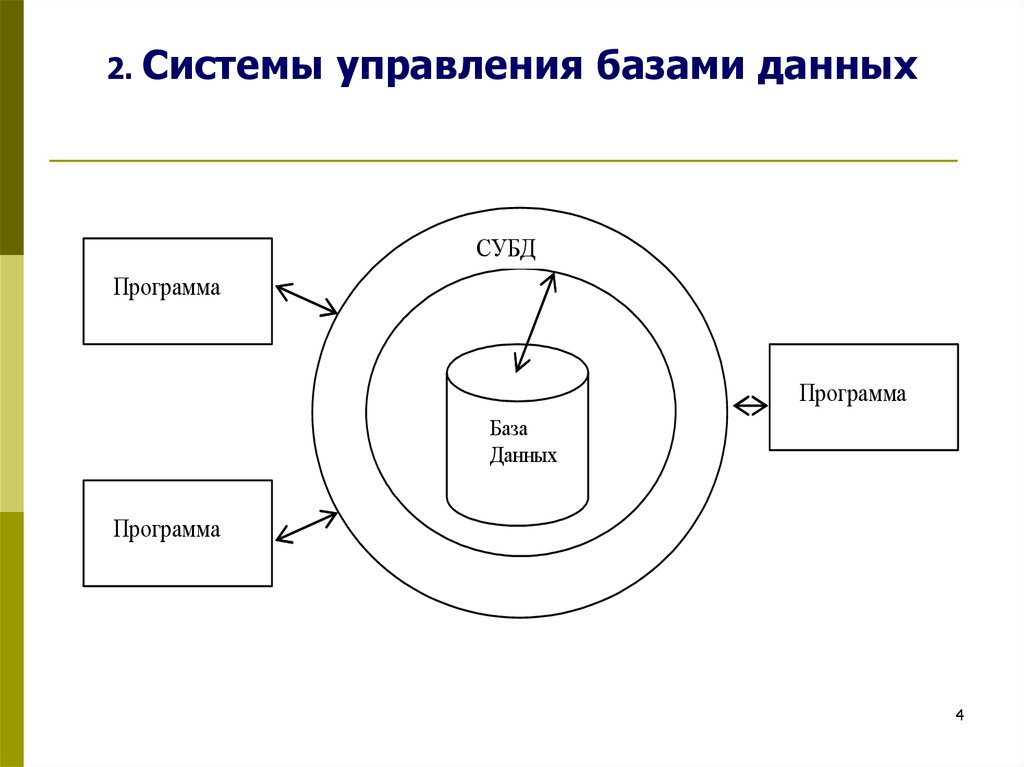 Форма»
Упомянутое выше, это не только форма сетки (в данном случае клетка), но может
быть формой уточненной клетки или предельной поверхности. Наблюдая за ролями, которые оба
данные и топология играют важную роль в таких операциях, как подразделение и оценка.
преимущества могут быть получены за счет управления данными, топологией и связанными с ними вычислениями
соответственно.
Форма»
Упомянутое выше, это не только форма сетки (в данном случае клетка), но может
быть формой уточненной клетки или предельной поверхности. Наблюдая за ролями, которые оба
данные и топология играют важную роль в таких операциях, как подразделение и оценка.
преимущества могут быть получены за счет управления данными, топологией и связанными с ними вычислениями
соответственно.
В то время как основной целью поверхностей подразделения является использование данных о положении, связанных с вершины для определения гладкой непрерывной предельной поверхности, во многих случаях непозиционные данные связаны с сеткой. Эти данные часто могут быть интерполированы плавно, как позиция, но часто предпочтительнее интерполировать ее линейно или даже сделать его прерывистым по краям сетки. Координаты текстуры и цвет являются общими примеры здесь.
Кроме положения, которое назначается вершинам и ассоциируется с ними, нет
ограничения на то, как произвольные данные могут или должны быть связаны или интерполированы. Текстура
координаты, например, могут быть назначены для создания полностью гладкой предельной поверхности
как положение, линейно интерполированное по граням или даже сделанное прерывистым между
их. Однако необходимо учитывать последствия — как с точки зрения управления данными,
и производительность, которые описаны ниже как терминология и методы, используемые для
достижения каждого определены.
Текстура
координаты, например, могут быть назначены для создания полностью гладкой предельной поверхности
как положение, линейно интерполированное по граням или даже сделанное прерывистым между
их. Однако необходимо учитывать последствия — как с точки зрения управления данными,
и производительность, которые описаны ниже как терминология и методы, используемые для
достижения каждого определены.
Отделение данных от топологии
В то время как топология сеток, используемых для хранения поверхностей подразделения, произвольно сложна и переменной, топология параметрических участков, составляющих его предельную поверхность, имеет вид простой и фиксированный. Патчи Bicubic B-Spline и Bezier задаются простыми 4×4. сетка контрольных точек и набор базисных функций для каждой точки, которые в совокупности сформировать полученную поверхность.
Для такого патча положение в данном параметрическом месте является результатом
комбинация данных о местоположении, связанных с его контрольными точками и весами
соответствующие базисные функции ( веса , являющиеся значениями вычисляемых базисных функций
в параметрическом месте). Топология и базисные функции остаются прежними, поэтому мы
может использовать веса, независимые от данных. Если позиции управления
изменения точек, мы можем просто рекомбинировать новые данные о положении с весами, которые мы
только что использовал и применил ту же комбинацию.
Топология и базисные функции остаются прежними, поэтому мы
может использовать веса, независимые от данных. Если позиции управления
изменения точек, мы можем просто рекомбинировать новые данные о положении с весами, которые мы
только что использовал и применил ту же комбинацию.
| Фиксированная топология параметрического патча и двух форм, полученных из двух наборов позиций. | ||
Аналогично, для кусочной поверхности положение в данном параметрическом месте равно
результат одного патча, содержащего это параметрическое местоположение, оцененное в заданном
должность. Используемые контрольные точки представляют собой подмножество контрольных точек, связанных с
именно этот патч. Если топология поверхности фиксирована, то и топология фиксирована.
коллекции патчей, составляющих эту поверхность. Если позиции тех.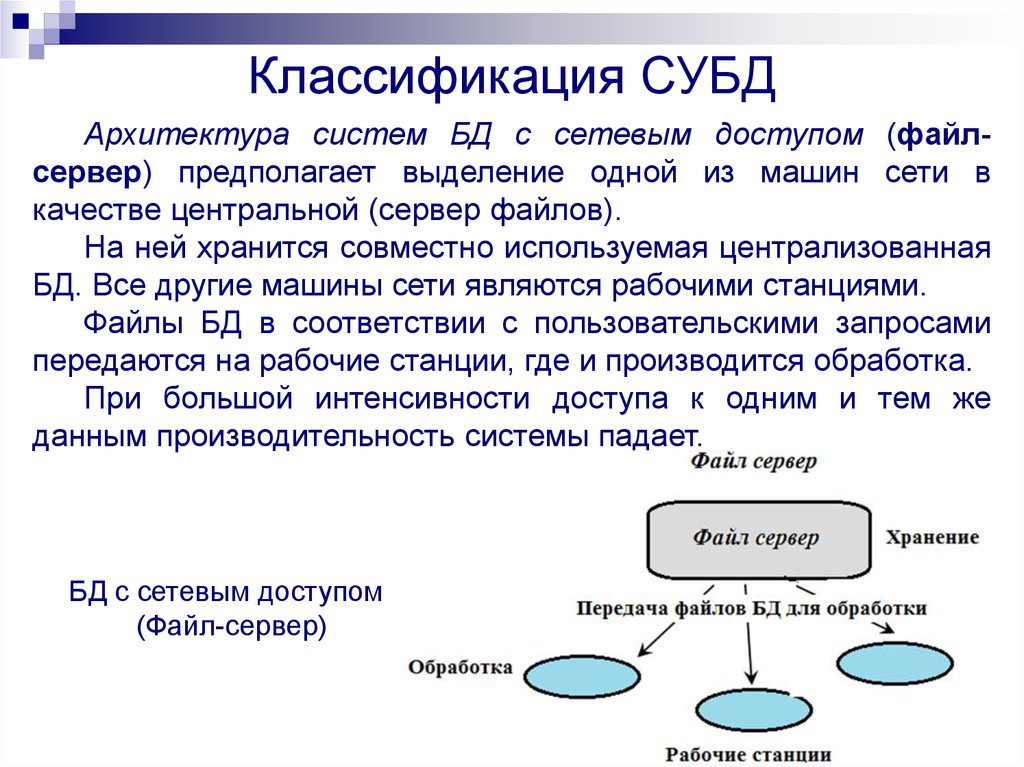 контрольные точки меняются, мы можем рекомбинировать новые данные о положении с теми же весами для
подмножество точек, связанных с патчем.
контрольные точки меняются, мы можем рекомбинировать новые данные о положении с теми же весами для
подмножество точек, связанных с патчем.
| Более сложная, но фиксированная топология поверхности и две формы, возникающие из двух наборов позиций. | ||
Это верно для кусочной поверхности произвольной топологии. Независимо от того, насколько сложным топология, пока она остается фиксированной (т. е. отношения между вершинами, ребрами и лица не меняются (или любые другие настройки, влияющие на правила подразделения)), применяются те же техники.
Это всего лишь один пример ценности отделения вычислений, связанных с топологией, от те, которые связаны с данными. И подразделение, и оценка могут быть разбиты на этапы. включая топологию (вычисление весов) и объединение данных по отдельности.
Три формы, полученные из трех наборов позиций сетки с фиксированной топологией. | ||
При фиксированной топологии возможна огромная экономия за счет предварительного расчета информации связанных с топологией и организации данных, связанных с контрольными точками в путь, который может быть эффективно объединен с ним. Это ключ к пониманию некоторых методы, используемые для обработки поверхностей подразделения.
Для сетки произвольной топологии контрольными точками подстилающей поверхности являются вершины и данные о положении, связанные с ними, наиболее знакомы. Но нет ничего это требует, чтобы контрольные точки патча представляли положение — то же самое методы применяются независимо от типа используемых данных.
Вершины и переменные данные
Наиболее типичная и фундаментальная операция — оценка положения на поверхности, т.е.
оценить основные участки предельной поверхности, используя позиции (x, y, z) в
вершины сетки. При заданном параметрическом (u, v) местоположении на одном таком участке независимая от данных
метод оценки сначала вычисляет веса, а затем объединяет (x, y, z) позиции вершин
что приводит к положению (x, y, z) в этом месте.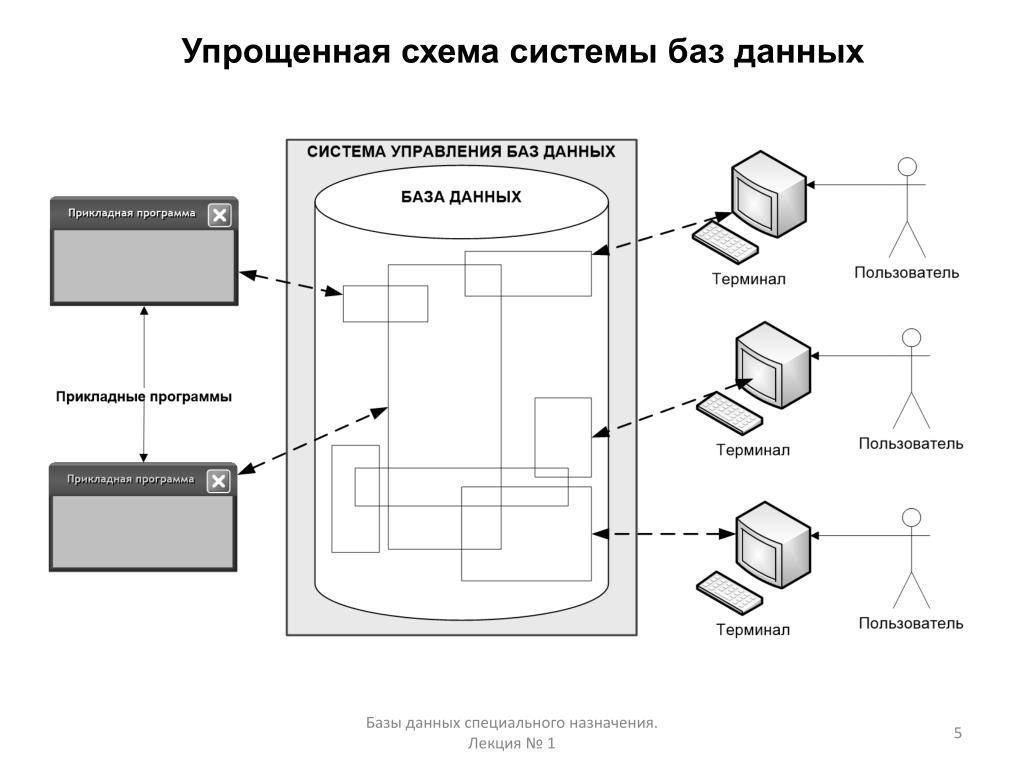 Но веса и их комбинация
может применяться к любым данным в вершинах, например. цвет, координаты текстуры или что-то еще
еще.
Но веса и их комбинация
может применяться к любым данным в вершинах, например. цвет, координаты текстуры или что-то еще
еще.
Данные, связанные с вершинами, которые интерполируются таким образом, включая положение, называются быть «вершинными» данными или иметь «вершинную» интерполяцию. Указание других данных как «вершины» данные приведут к тому, что они будут плавно интерполированы точно таким же образом (с использованием именно одинаковые веса) как положение. Таким образом, чтобы получить простую 2D-проекцию поверхности для координаты текстуры, будут использоваться 2D-значения, соответствующие (x, y) позиций.
Если вместо этого требуется линейная интерполяция данных, связанных с вершинами, данные называются
быть «изменяющимися» данными или иметь «изменяющуюся» интерполяцию. Здесь нелинейная оценка
патчи, определяющие гладкую предельную поверхность, игнорируются, а веса для простых линейных
используются интерполяции. Это обычный выбор координат текстуры для оценки
текстуры без необходимости бикубических патчей в вычислительном отношении дешевле. Линейный
интерполяция не будет отражать гладкость, требуемую для истинной проекции между
вершины, но и вершинная, и переменная интерполяция имеют свое применение.
Линейный
интерполяция не будет отражать гладкость, требуемую для истинной проекции между
вершины, но и вершинная, и переменная интерполяция имеют свое применение.
Спроецированная текстура плавно интерполирована из данных вершины | Спроецированная текстура с линейной интерполяцией по разным данным |
Поскольку и вершины, и переменные данные связаны с вершинами (уникальное значение, присвоенное каждому), результирующая поверхность будет сплошной — кусочно-гладкой в случае вершинных данных и кусочно-линейным в случае варьирования.
Данные с изменяющимися гранями и топология должно быть несколько значений, связанных с вершинами, ребрами и/или гранями, чтобы прерывность существования.
Разрывы становятся возможными за счет присвоения значений углам граней, подобных
тому, как вершины назначаются углам граней при определении
топология сетки. Вспоминая назначение вершин граням:
Индексы вершин назначаются всем углам каждой грани как часть построения сетки и часто называют гранями-вершинами отдельной грани или сетки. Все грани-вершины, которые имеют один и тот же индекс вершины, будут соединены этой вершиной и те же данные вершины, связанные с ним.
Путем присвоения другого набора индексов граням-вершинам — индексы, не относящиеся к вершины, но некоторый набор данных, который будет связан с углами каждой грани — углы которые имеют одну и ту же вершину, больше не нужно использовать одно и то же значение данных, и данные могут быть сделано прерывистым между гранями:
Этот метод связывания значений данных с гранями-вершинами меша называется
назначение «изменяющихся лиц» данных для интерполяции «изменяющихся лиц». Интерполированное значение
будет постоянно меняться в пределах грани (т. е. участок предельной поверхности, связанный с
с гранью), но не обязательно через ребра или вершины, общие с соседними
лица.
Непересекающиеся УФ-области с изменяющимися гранями, нанесенные на предельную поверхность |
Комбинация связывания значений данных не с вершинами (контрольными точками) но углы лица и возникающие в результате разрывы, зависящие от данных, сделать этот подход значительно более сложным, чем вершинный или варьирующий. Добавленный сложность данных сама по себе является причиной использовать их только в случае необходимости, т.е. когда разрывы желательны и присутствуют.
Частично сложность работы с изменяющимися данными лица и интерполяцией заключается в том, как
которым может быть определено поведение интерполяции. Если данные непрерывны,
интерполяция может быть задана такой же гладкой, как базовая предельная поверхность вершины
данных или просто линейно, как это достигается с переменными данными.
Там, где данные прерывисты — по внутренним краям и вокруг вершин —
разрывы создают границы для данных и разбивают нижележащую поверхность на
непересекающиеся области. Интерполяцию вдоль этих границ также можно задать как
гладкой или линейной по ряду причин (многие из которых имеют историческую основу).
Более полное описание различных вариантов линейной интерполяции с изменением лица. данные и интерполяция приведены позже. Эти опции позволяют обрабатывать данные как либо вершинные, либо переменные, но с дополнительным наличием разрывов.
Важный момент, который следует помнить при интерполяции с изменением лица, заключается в том, что каждый набор данных может иметь свои собственные разрывы — это приводит к тому, что каждый набор данных имеет как уникальные топология и размер.
Топология, указанная для набора данных с изменяющимися лицами, называется канал и уникален для интерполяции с изменением лица. В отличие от вершинных и переменных
интерполяции, которые связывают значение данных с вершиной, количество значений в
гранепеременный канал не фиксируется количеством вершин или граней. Количество
индексы, присвоенные углам граней, будут одинаковыми для всех каналов, но количество
уникальных значений, на которые ссылаются эти индексы, может и не быть. Мы можем воспользоваться
общая топология сетки в областях, где данные непрерывны, но мы теряем некоторые из этих
преимущества вокруг разрывов. Это приводит к более высокой сложности и стоимости
канала с изменяющимся лицом по сравнению с вершиной или изменяющимися данными. Если топология для
канал фиксирован, однако аналогичные методы могут применяться для вычисления коэффициента
связанных с топологией, чтобы изменения в данных могли быть эффективно обработаны.
Схемы и опции
В то время как в предыдущих разделах поверхности разделения описывались в более общих чертах, в этом В разделе описывается ряд общих вариантов (часто называемых расширениями от до алгоритмы подразделения) и способы их представления в OpenSubdiv.
Количество и характер расширений здесь значительно усложняют то, что в противном случае
довольно простые алгоритмы подразделения. Исторически приложения поддерживали либо
подмножество или имели разные реализации одной и той же функции. OpenSubdiv стремится
обеспечить последовательную и эффективную реализацию этого набора функций.
Учитывая различное представление некоторых из этих функций в других местах, выбранное название здесь подчеркивается OpenSubdiv.
Схемы подразделения
OpenSubdiv предоставляет два хорошо известных типа поверхности подразделения — Catmull-Clark (часто упоминается более кратко как «Catmark») и подразделение Loop. Кэтмулл-Кларк используется более широко и подходит для четырехъядерных сеток, в то время как Loop предпочтительнее (и требует) для чисто триангулированных сетки.
Многие примеры из предыдущих разделов иллюстрируют более популярную модель Catmull-Clark. схема. Для примера цикла:
Правила интерполяции границ
Правила интерполяции границ управляют тем, как подразделение и предельная поверхность ведут себя для граней смежные с граничными ребрами и вершинами.
Следующие варианты доступны через перечисление Sdc::Options::VtxBoundaryInterpolation :
| Mode | Поведение |
|---|---|
| VTX_BOUNDARY_NONE | По умолчанию интерполяция граничных краев не применяется; граничные грани помечаются как отверстия, чтобы граница вершины продолжают поддерживать соседние внутренние грани, но нет поверхности, соответствующей границе лица генерируются; граничные грани могут быть выборочно интерполируется путем повышения резкости всех инцидентных граничных ребер вершины лица |
| VTX_BOUNDARY_EDGE_ONLY | Последовательность граничных вершин определяет гладкую кривую до которого простирается предельная поверхность вдоль граничных граней |
| VTX_BOUNDARY_EDGE_AND_CORNER | Аналогичен только кромке, но плавная кривая получается на граница сделана для интерполяции угловых вершин (вершины ровно с одной инцидентной гранью) |
На примере сетки:
На практике интерполяция границ вообще редко используется — эта функция
его использование позволяет плавно соединять отдельные сетки путем репликации
вершины вдоль границ, но это использование ограничено. Учитывая глобальный характер
настройки, обычно предпочтительнее явно делать граничные грани отверстиями
в местах соединения поверхностей из отдельных сеток, а не резкость
края для интерполяции желаемых границ повсюду.
Оставшиеся варианты «только край» и «край и угол» затем различаются только в зависимости от того, является ли поверхность в вершинах углов гладкой или острой.
Правила интерполяции с изменением лица
Правила интерполяции с изменением лица управляют интерполяцией данных с изменением лица как в внутри гранепеременных областей (гладких или линейных) и на границах, где она прерывистый (ограниченный линейностью или «закреплением» несколькими способами). Где топология непрерывна, а интерполяция выбрана гладкой, поведение интерполяция с изменением граней будет соответствовать интерполяции вершин.
Варианты интерполяции с изменением лица чаще всего доступны в контексте UV.
для текстурных координат и ряд названий для таких вариантов развились в разных
приложений с годами. Выбор, предлагаемый OpenSubdiv, охватывает широкий спектр популярных
Приложения. Эта функция называется линейной интерполяцией с изменением лица 90 269, а не Граница интерполяция обычно используется — чтобы подчеркнуть, что она может быть применена
ко всей поверхности (не только к границам) и что эффекты должны сделать поверхность
вести себя более линейно различными способами.
Следующие варианты доступны для перечисления Sdc::Options::FVarLinearInterpolation — порядок здесь с применением все более линейных ограничений:
| Режим | Поведение |
|---|---|
| FVAR_LINEAR_NONE | гладкая везде, где сетка гладкая |
| FVAR_LINEAR_CORNERS_ONLY | линейная интерполяция (заострение или закрепление) только углов |
| FVAR_LINEAR_CORNERS_PLUS1 | CORNERS_ONLY + повышение резкости стыков 3-х и более областей |
| FVAR_LINEAR_CORNERS_PLUS2 | CORNERS_PLUS1 + заточка вытачек и вогнутых углов |
| FVAR_LINEAR_BOUNDARIES | линейная интерполяция по всем граничным кромкам и углам |
| FVAR_LINEAR_ALL | линейная интерполяция везде (границы и интерьер) |
Эти правила не могут сделать интерполяцию данных с изменяющимся лицом более гладкой, чем
что из вершин. Наличие острых элементов сетки, созданной
значения резкости, правила граничной интерполяции или сама схема подразделения
(например, билинейный) имеют приоритет.
Все режимы интерполяции с изменением лица показаны в UV-пространстве с использованием простого изображения 4×4. сетка четырехугольников, разделенных на три UV-области (расположение их контрольных точек подразумевало интерполяцией в случае FVAR_LINEAR_ALL):
(Для тех, кто знаком, эта форма и назначенные ей наборы UV доступны для проверки в форме «catmark_fvar_bound1» примера OpenSubdiv и фигур регрессии.)
Полуострые складки
Так же, как некоторые типы параметрических поверхностей поддерживают дополнительные элементы управления формой для влияет на сгиб вдоль границ между поверхностными элементами, OpenSubdiv обеспечивает дополнительные значения резкости или «веса», связанные с ребрами и вершинами, чтобы добиться аналогичных результатов в произвольной топологии.
Установка значений резкости на максимальное значение (в данном случае 10 — число, выбранное для
исторические причины) эффективно изменяет правила подразделения, так что границы
между кусочно-гладкими поверхностями бесконечно острые или разрывные.
Но поскольку поверхности реального мира никогда не имеют бесконечно острых краев, особенно при достаточно близком рассмотрении часто предпочтительнее установить резкость ниже этого значения, что делает складку «полурезкой». Постоянное значение веса назначается последовательности ребер, соединенных ребер, поэтому позволяет создавать функции, похожие на скругления и переходы, без добавления дополнительных рядов вершин (хотя эта техника все еще имеет свои достоинства):
Значения резкости находятся в диапазоне от 0 до 10, при этом значение 0 (или меньше) не влияет на поверхность и значение 10 (или больше), что делает элемент полностью резким.
Следует отметить, что бесконечно острые складки действительно касаются
разрывы на поверхности, подразумевая, что геометрические нормали также
прерывистый там. Следовательно, смещение по нормали, скорее всего, приведет к разрыву
отделить поверхность вдоль сгиба. Если вы действительно хотите сместить поверхность в
складку, может быть лучше сделать складку полуострой.
Другие опции
В то время как предыдущие опции представляют функции, доступные в широком спектре инструментов и форматы моделирования, существует несколько других, признание и принятие которых является более ограниченным. В некоторых случаях они предлагают улучшения нежелательного поведения подразделения. алгоритмы, но их эффекты далеко не идеальны.
Учитывая их ограниченную эффективность и отсутствие признания, эти варианты следует используется с осторожностью.
Правило Чайкина
«Правило Чайкина» представляет собой разновидность метода полуострой биговки, улучшить внешний вид складок вдоль последовательности соединенных краев, когда резкость значения различаются. Этот выбор изменяет подразделение значений резкости с использованием шкалы Чайкина. алгоритм подразделения кривой для рассмотрения всех значений резкости краев вокруг общего вершина при определении резкости дочерних ребер.
Метод биговки может быть установлен с использованием значений, определенных в перечислении Sdc::Options::CreasingMethod :
| Режим | Поведение |
|---|---|
| СКЛАД_УНИФОРМ | Применение обычных полуострых правил сгиба |
| CREASE_CHAIKIN | Нанесение полуострых правил сгиба «Чайкин» |
Пример интерполяции смежных полуострых складок:
«Разделение треугольником» Правило
Правило подразделения треугольника — это правило, добавленное к схеме Кэтмулла-Кларка, которое
изменяет поведение на треугольных гранях, чтобы улучшить нежелательную поверхность
артефакты, которые часто приводят к таким областям.
| Режим | Поведение |
|---|---|
| TRI_SUB_CATMARK | Вес схемы Catmark по умолчанию |
| TRI_SUB_SMOOTH | Гири «Гладкий треугольник» |
Пример цилиндра:
Это правило было установлено эмпирическим путем, чтобы сделать треугольники более плавными. Однако это правило нарушает прекрасное свойство двух отдельных мешей. соединены плавно, перекрывая их границы; то есть когда есть треугольники ни на одной из границ невозможно бесшовное объединение сеток
Закон штата Миннесота о практике работы с данными — Справочник администратора CHS
Предыдущая глава Оглавление Следующая глава
Что такое Закон штата Миннесота о практике работы с данными?
Что такое государственные данные?
Определения и классификации данных
Сбор и хранение данных
Теннессен предупреждения
Освобождение данных
Правительственные предмет Data Data
3. Информированные. к Закону штата Миннесота о практике работы с данными
Эта глава предназначена только как очень общий и поверхностный обзор некоторых наиболее важных положений Закона штата Миннесота о практике работы с данными правительства и не должна рассматриваться как юридическая консультация. MGDPA налагает юридические обязательства и требования на правительственные организации и других лиц, к которым применяется MGDPA. Несоблюдение какого-либо конкретного положения MGDPA, например, раскрытие информации, которая не должна была быть раскрыта, или непредоставление данных лицу, имеющему на это право, может привести к денежным штрафам и санкциям для агентства, уголовному преследованию и потере работы. для отдельных государственных служащих, ответственных за несоблюдение MGDPA. Поскольку многие положения MGDPA можно охарактеризовать как неясные, сложные и запутанные, настоятельно рекомендуется, чтобы все вопросы, касающиеся получения, классификации, хранения, использования и распространения информации, передавались на рассмотрение Ответственному органу и юридическим лицам. совет.
Что такое Закон штата Миннесота о практике работы с данными?
Закон Миннесоты о практике работы с данными правительства (MGDPA), Minn. Stat. § 13 — это закон штата, который регулирует сбор, создание, хранение (поддержание), использование и выпуск (распространение) государственных данных. MGDPA устанавливает определенные требования, касающиеся права общественности на доступ к государственным данным и прав лиц, являющихся субъектами государственных данных.
Вкратце, MGDPA регулирует:
- Какую информацию можно собирать
- Кто может видеть или иметь информацию
- Классификация конкретных типов государственных данных
- Обязанности государственных служащих по выполнению положений MGDPA
- Процедуры доступа к информации
- Процедуры классификации информации
- Гражданские санкции за нарушение MGDPA
- Взимание платы за копии государственных данных
Актуальный текст Minn. Stat. § 13 и Minn. R. 1205, Правила, регулирующие работу с данными, обнародованные Административным департаментом штата Миннесота, можно найти в Интернете.
Что такое государственные данные?
Правительственные данные определяются как «все данные, собираемые, создаваемые, получаемые, поддерживаемые или распространяемые любым государственным органом, независимо от их физической формы, носителя или условий использования». Таким образом, до тех пор, пока информация каким-либо образом записывается или хранится государственным органом, она является государственными данными, независимо от того, в какой физической форме они находятся, как они хранятся или используются. Правительственные данные могут храниться на бумаге, в электронной форме, на аудио- или видеопленке, на диаграммах, картах и т. д. Правительственные данные не включают мысленные впечатления.
Важно помнить, что государственные данные регулируются на уровне отдельных позиций или элементов данных. Документ, запись или файл содержат множество элементов данных.
Кто должен соблюдать MGDPA?
MGDPA применяется ко всем данным, собираемым, создаваемым, получаемым, поддерживаемым или распространяемым любым государственным органом. MGDPA определяет «государственное учреждение» как «государственное агентство, общегосударственную систему или политическое подразделение». Термин «политическое подразделение» для целей MGDPA включает округа, города, школьные округа, специальные округа, советы, комиссии и округ; а также органы, созданные законом, местным постановлением или положением устава. Субъекты уровня штата включают Миннесотский университет и офисы, департаменты, комиссии, должностные лица, бюро, отделы, советы, органы власти, округа и агентства на уровне штата.
Системы штата также подпадают под действие MGDPA. Общегосударственная система — это любая система ведения учета или управления данными, установленная федеральным законом, законом штата, административным решением или соглашением или соглашением о совместных полномочиях и являющаяся общей для любой комбинации государственных органов и/или политических подразделений.
Кроме того, если государственное учреждение заключает договор с частной стороной для выполнения какой-либо государственной функции, эта частная сторона подпадает под действие MGDPA в отношении любых данных, созданных, собранных, полученных, сохраненных, используемых, поддерживаемых или распространяемых. при выполнении соглашения и должен соблюдать MGDPA, как если бы он был государственным органом.
Каковы последствия несоблюдения MGDPA?
Государственному учреждению может быть предъявлен иск за нарушение любых положений MGDPA. Иск о принуждении государственного органа к соблюдению MGDPA может быть подан либо в Окружной суд Миннесоты, либо в Управление административных слушаний Миннесоты. Правительственному органу, уличенному в нарушении, может быть приказано соблюдать MGDPA, выплатить гражданский штраф в размере до 1000 долларов и оплатить расходы и расходы потерпевшего лица, включая гонорары адвокатов. Кроме того, MGDPA предусматривает уголовные наказания и дисциплинарные меры, включая увольнение с государственной службы, для всех, кто умышленно (сознательно) нарушает положение MGDPA.
Где можно найти дополнительную информацию о MGDPA?
Следующие источники могут предоставить полезную информацию о MGDPA и других законах об использовании данных.
Можно проконсультироваться с ассоциациями местных органов власти для получения информации, относящейся к вопросам использования данных в рамках их юрисдикции.
- Ассоциация округов Миннесоты
- Межправительственный фонд округа Миннесота
- Лига городов Миннесоты
- Ассоциация школьных советов Миннесоты
- Миннесотская ассоциация должностных лиц округа
- Ассоциация полиции и блюстителей порядка штата Миннесота
Дополнительную информацию, образовательные ресурсы и помощь по вопросам работы с данными можно получить по адресу: Административный департамент Миннесоты: Data Practices Office.
Заключения, выданные Уполномоченным по административным вопросам в соответствии с Минстатом. §13.072, доступны на веб-сайте IPAD. Копии индивидуальных мнений, сводка мнений и индекс мнений Комиссара можно получить в IPAD по запросу.
Определения и классификации данных
MGDPA устанавливает систему классификации данных, которая в общих чертах определяет, кто имеет законное право доступа к правительственным данным. Эта система классификации построена на основе определений, представленных в Minn. Stat. §13.02. См. также: Minn. R. 1205.0200.
Почти все правительственные данные являются либо данными о физических лицах, либо данными, не касающимися физических лиц. MGDPA определяет «физическое лицо» как физическое лицо, а в случае несовершеннолетнего или недееспособного лица — родителя или опекуна. Таким образом, другие юридические лица, такие как корпорации, не считаются «физическими лицами» для целей MGDPA. «Данные о физических лицах» — это все правительственные данные, в которых любое физическое лицо является или может быть идентифицировано как субъект этих данных. Данные о физических лицах классифицируются как общедоступные, частные или конфиденциальные. Напротив, «данные не о физических лицах» — это все государственные данные, которые не являются данными о физических лицах и классифицируются как общедоступные, непубличные или защищенные непубличные. Эта система классификации определяет, как обрабатываются государственные данные.
- Общедоступные данные : Общедоступные данные доступны всем. MGDPA предусматривает, что, если это специально не разрешено законом, государственное учреждение не может требовать от лиц идентифицировать себя, указывать причину или обосновывать запрос на получение доступа к общедоступным правительственным данным.
- Частные данные : Частные данные о физических лицах — это данные, классифицируемые законом или федеральным законом как непубличные, но доступные для отдельного субъекта этих данных.
- Конфиденциальные данные : Конфиденциальными данными о физических лицах являются данные, не обнародованные законом или федеральным законодательством и недоступные субъекту этих данных.
- Непубличные данные : Непубличные данные — это данные не о физических лицах, которые законом или федеральным законом закрыты для общественности, но доступны любому субъекту этих данных.
- Защищенные непубличные данные : Защищенные непубличные данные — это данные не о физических лицах, которые не являются общедоступными и недоступными для субъекта этих данных.
MGDPA указывает, что все правительственные данные являются общедоступными, за исключением случаев, когда законом, временной классификацией, изданной Уполномоченным по административным вопросам, или федеральным законом данные классифицируются как частные или конфиденциальные в отношении данных о физических лицах; или, в случае данных не о физических лицах, как непубличные или защищенные непубличные. В связи с этим:
| Сведения о физических лицах | Данные об умерших | Данные не о физических лицах | ||||||
|
|
| ||||||
|
|
| ||||||
|
|
|
* Частные и конфиденциальные данные об умерших становятся общедоступными через десять лет после смерти субъекта данных и через 30 лет после создания данных.
Сбор и хранение данных
Связанная глава : Правительственные записи и хранение
Какие средства контроля применяются для сбора и хранения данных о физических лицах?
Государственные органы могут собирать и хранить общедоступные, частные и/или конфиденциальные данные о физических лицах только в том случае, если это необходимо для администрирования или управления программой, разрешенной законом штата или местным постановлением, или предписанной федеральным правительством. Организация не может собирать или хранить какие-либо данные о физических лицах без надлежащих юридических полномочий, явных или подразумеваемых.
Перед тем, как законодательный орган Миннесоты завершил свою сессию 2012–2013 годов, он принял законопроект, который пересматривает Закон штата Миннесота о методах работы с данными, чтобы классифицировать «индивидуальные личные адреса электронной почты и номера телефонов, собранные государственными органами для целей уведомления, как частные данные о физических лицах и разрешить обмен данными между государственными органами».
Какие действия должен предпринять государственный орган перед сбором и хранением данных о физических лицах?
- Укажите конкретные юридические полномочия по сбору, использованию, распространению и хранению общедоступных, частных или конфиденциальных данных о физических лицах.
- Определите, какие типы данных о лицах он собирает или хранит, и как эти данные классифицируются.
- Назначьте «Ответственный орган», который несет полную ответственность за сбор, использование и распространение государственных данных.
- В соответствии с Минстатом. §13.05, подд. 1, подготовить общедоступный документ, содержащий, среди прочего, описание каждой категории записей, файлов или процессов, связанных с частными или конфиденциальными данными о физических лицах, хранящихся у этой организации. Этот публичный документ должен содержать имя, должность и адрес ответственного органа организации. В документ должны быть включены формы, которые организация использует для сбора личных и конфиденциальных данных о физических лицах. Документ необходимо обновлять ежегодно. Субъекты не обязаны готовить публичный документ для данных не о физических лицах.
Предупреждения Tennessen
Всякий раз, когда государственное учреждение просит физическое лицо предоставить личные или конфиденциальные данные о себе, оно должно направить этому лицу уведомление, иногда называемое предупреждением Tennessen.
Что должно быть включено в уведомление?
В соответствии со Стат. Миннесоты. §13.04, подд. 1, физическое лицо, которого просят предоставить личные или конфиденциальные данные о физическом лице, должно быть проинформировано:
- Цель и предполагаемое использование данных в государственном органе, собирающем данные . Вот почему данные запрашиваются и как они будут использоваться внутри собирающей организации;
- Может ли физическое лицо отказаться от предоставления данных или обязано ли оно по закону предоставить данные . Субъект имеет право знать, требуется ли от него/нее по закону предоставление запрошенных данных;
- Любые известные последствия предоставления или отказа предоставления данных для лица . Организация обязана указать последствия, известные ей на момент направления уведомления; и
- Идентификационные данные других лиц или организаций, уполномоченных по закону на получение данных . В уведомлении должны быть конкретно указаны получатели, которые известны организации на момент направления уведомления.
Когда должно быть сделано предупреждение Теннессена?
Предупреждение Теннессена выдается в момент сбора данных. Уведомление должно быть направлено всякий раз, когда:
- Государственный орган запрашивает данные;
- Данные запрашиваются у физического лица;
- Запрошенные данные являются частными или конфиденциальными; и
- Данные относятся к лицу, у которого они запрашиваются.
Все четыре из этих условий должны присутствовать, прежде чем будет вынесено предупреждение Tennessen.
Когда предупреждение Tennessen не требуется?
Уведомление не обязательно должно быть сделано сотрудниками правоохранительных органов, расследующими преступление. Уведомление не должно направляться субъекту данных, когда:
- субъект данных не является физическим лицом;
- субъект предлагает информацию, которая не была запрошена государственным органом;
- запрашиваемая у субъекта информация касается кого-то другого;
- объект запрашивает или получает информацию о субъекте от кого-то другого; или
- информация, запрошенная у субъекта, является общедоступной информацией об этом субъекте.
Как государственный орган решает, что включить в предупреждение штата Теннессен?
Подготовка предупреждения Теннессена должна осуществляться только юрисконсультом организации или в тесном сотрудничестве с ним. Каждое уведомление должно быть «адаптировано» к требованиям конкретной организации, программы или мероприятия по сбору данных, для которого оно готовится. В рамках любой конкретной организации, вероятно, потребуется более одного уведомления.
При выборе слов и выражений для предупреждения Теннессена важно использовать язык, понятный большинству людей. Цель состоит в том, чтобы позволить субъекту данных принять осмысленное решение предоставить или не предоставить запрошенную информацию. Предполагая, что уведомление является полным и точным, этот выбор может иметь смысл только в том случае, если субъект ясно понимает уведомление. Также испытуемому должна быть предоставлена возможность задать вопросы о предупреждении Теннессена и получить четкое объяснение.
Чтобы защитить государственное учреждение от возможных претензий в будущем, предупреждение штата Теннессен должно быть сделано в письменной форме или в другом записанном формате, хотя закон специально этого не требует. В связи с этим физическое лицо должно подписать подтверждение того, что оно получило уведомление, и копия письменного уведомления должна быть передана субъекту данных, а оригинал хранится у государственного органа с соответствующими данными. Когда информация собирается по телефону, уведомление должно быть предоставлено в устной форме. Предприятие должно регистрировать такие сведения, как было ли направлено уведомление, дата подачи и личность лица, направившего уведомление. Если уведомление дается устно, государственное учреждение может также пожелать направить уведомление в письменной форме как можно скорее.
Означает ли это, что данные никогда не могут быть сохранены, если не было выдано предупреждение Tennessen?
Частные или конфиденциальные данные, собранные до 1 августа 1975 г. (дата вступления в силу требования предупреждения штата Теннессен), могут храниться по причинам, по которым данные были собраны. Эти данные также могут храниться по соображениям общественного здравоохранения, безопасности или благополучия, если организация получает одобрение Уполномоченного по административным вопросам.
Разглашение данных
MGDPA предоставляет каждому представителю общественности право просматривать и иметь копии всех общедоступных данных, хранящихся в государственных органах. MGDPA также возлагает на государственные органы различные обязательства, связанные с этим правом.
Каково основное требование для правильного ответа на запрос данных?
Чтобы должным образом отвечать на запросы государственных данных, каждый государственный орган должен определить типы данных, которые он поддерживает, и определить, как классифицируется каждый тип данных.
Кто может сделать запрос данных?
Любой может воспользоваться правом на доступ к общедоступным правительственным данным, сделав запрос данных.
Какие данные может запрашивать человек?
Лицо, запрашивающее правительственные данные, может запросить доступ к определенным типам данных или элементам данных, к определенным документам или частям документов, ко всем записям, файлам или базам данных или ко всем общедоступным данным, хранящимся в организации.
Лицо может запросить либо проверку (или просмотр) данных, либо попросить правительство воспроизвести и предоставить копию этих данных. Как правило, государственный орган не может взимать плату только за проверку данных, но от запрашивающей стороны может потребоваться оплата копий или электронной передачи данных. Вопросы относительно того, может ли запрашивающее лицо взимать сборы, и если да, то какие виды деятельности могут подлежать возмещению, а также размер сборов, должны быть переданы Ответственному органу организации или юрисконсульту.
Должен ли государственный орган отвечать на запрос данных?
После того, как объект получил запрос, он должен ответить на него должным образом и быстро. То, что считается уместным и быстрым, зависит от объема запроса и может варьироваться в зависимости от таких факторов, как размер и сложность объекта, тип и/или количество запрашиваемых данных, ясность запроса данных и количество сотрудников, готовых ответить на запрос. Все запросы данных должны быть немедленно переданы Ответственному органу или юрисконсульту.
Каков правильный ответ, если запрошенные данные не являются общедоступными?
Организация не может распространять какие-либо частные или конфиденциальные данные о физических лицах без надлежащих юридических полномочий. Как уже отмечалось, субъект данных имеет право видеть данные о себе, должным образом классифицированные как частные, но может не иметь права на данные, классифицированные как конфиденциальные.
Если организация определяет, что запрошенные данные не являются общедоступными, она должна сообщить об этом запрашивающей стороне. Это может быть сделано устно во время запроса или может быть сделано в письменной форме как можно скорее после того, как запрос сделан. При информировании запрашивающей стороны организация должна указать конкретную статью закона, временную классификацию или конкретное положение федерального закона, в соответствии с которым данные классифицируются как частные, конфиденциальные, непубличные или охраняемые непубличные. Заявление общего характера, например: «Мы не можем предоставить вам данные из-за закона о конфиденциальности данных», — неуместный ответ. Организация должна указать конкретный раздел закона, который классифицирует данные как закрытые.
Если запрашивающая сторона запрашивает письменное подтверждение того, что запрос был отклонен, организация должна предоставить подтверждение со ссылкой на конкретную статью закона, временную классификацию или конкретное положение федерального закона, на котором основан отказ.
Государственный орган может раскрывать частные, конфиденциальные, непубличные или охраняемые непубличные данные (1), если такое раскрытие специально разрешено законом штата, местным или федеральным законодательством; или (2) по распоряжению судьи окружного суда или административного слушателя.
Права субъектов государственных данных
MGDPA устанавливает особые права для лиц, являющихся субъектами государственных данных, и устанавливает контроль над тем, как государственные органы собирают, хранят, используют и раскрывают данные о физических лицах. Законодательный орган установил эти права и средства контроля, потому что решения, принимаемые государственными органами при использовании информации об этих лицах, могут иметь большое влияние на их жизнь.
Эти права позволяют субъекту данных решать, предоставлять ли запрашиваемые данные; чтобы увидеть, какую информацию объект хранит об этом субъекте; определить, является ли эта информация точной, полной и актуальной, и какое влияние данные могут оказать (или оказали) на решения, принятые организацией; и чтобы неточные и/или неполные данные не создавали проблем для человека.
Индивидуальные права на доступ к данным о себе
MGDPA предоставляет определенные права лицам, которые являются субъектами государственных данных. Одним из этих прав является право субъекта данных на доступ к данным о себе:
- Субъект данных имеет право спросить и получить информацию о том, хранит ли организация данные о себе, и классифицируются ли эти данные как публичный, частный или конфиденциальный.
- Субъект данных имеет право просматривать все общедоступные и частные данные о себе.
- При определенных обстоятельствах данные о несовершеннолетнем субъекте данных могут быть скрыты от родителя или опекуна.
- Субъект не может взимать плату за предоставление субъекту возможности просматривать данные о себе.
- Субъект имеет право на получение информации о содержании и значении общедоступных и частных данных о себе по запросу.
- Субъект имеет право иметь копии всех общедоступных и личных данных о себе.
- Организация может взимать плату за предоставление субъекту данных копий общедоступных и/или личных данных о себе.
Индивидуальные права оспаривать точность и/или полноту общедоступных и личных данных о себе
- Субъект данных имеет право оспаривать точность и/или полноту общедоступных и личных данных о себе.
- Субъект данных имеет право включить заявление о несогласии со спорными данными.
- Если субъект определяет, что оспариваемые данные являются точными и/или полными, а субъект данных не согласен с этим определением, субъект имеет право обжаловать решение субъекта у Уполномоченного по административным вопросам.
Информированное согласие на раскрытие государственных данных для государственных организаций, подпадающих под действие Закона Миннесоты о практике работы с государственными данными
Minn. Stat. § 13.05, подп. 4, ограничивает последующее использование и распространение частных или конфиденциальных данных, полученных от отдельных лиц, тем, что описано в предупреждении Теннессена. Если организация желает использовать или разглашать данные способом, не указанным в предупреждении Теннессена, в этом законодательном разделе требуется, чтобы организация получила информированное согласие физического лица.
Стандарты получения информированного согласия изложены в Minn. Stat. § 13.05, подп. 4(d) и Миннесота 1205.1400. Форма согласия должна быть заполнена для распространения личных данных о физических лицах, когда а) раскрытие данных необходимо для администрирования или управления юридически разрешенной программой и б) применяется одно из следующих условий:
- Субъект данных не был получил предупреждение Теннессена, когда данные были собраны от этого субъекта.
- Выпуск данных предназначен для цели или для получателя, который не был включен в предупреждение Теннессена.
- Предупреждение Tennessen не было выдано, поскольку данные не были получены от субъекта данных.
- В других ситуациях, когда требуется согласие субъекта данных для раскрытия данных об этом субъекте.
Next : Защита данных и безопасность
Система управления базами данных Subd. Система управления базами данных Microsoft Servers SQL
В 70-х гг. прошлого века IBM разработала язык программирования, предназначенный для создания запросов (вопросов к базе данных). Он назывался SEQUEL (Структурированный английский язык запросов). Со временем в SEQUEL были добавлены новые функции. Вскоре он перестал быть языком только для запросов. С его помощью стали создавать целые базы данных и управлять защитой движка базы данных. Популярность нового языка настолько возросла, что его пришлось сделать доступным для широкой публики и назвать SQL. Так как обе аббревиатуры читаются практически одинаково, их легко перепутать в разговоре.
Современные процессоры баз данных используют разные версии SQL. SQL Server использует особый вариант SQL, называемый Transact-SQL (T-SQL). Первоначально SQL Server (программа создания базы данных, понимающая SQL) была разработана Microsoft совместно с Sybase Corporation для использования на платформах IBM OS/2 и создала собственную операционную систему Windows NT Advanced Server. С этого момента было принято решение разрабатывать SQL Server только для сред Windows NT. Результатом стал SQL Server 4.2, который вскоре был обновлен до версии 4.21. Вскоре между Microsoft и Sybase пробежала черная кошка; в результате Sybase приступила к созданию собственного ядра базы данных для Windows NT. Им стала программа Sybase Adaptive Server Enterprise. Чтобы не отставать от конкурентов, Microsoft представила SQL Server 6.0, а вскоре и SQL Server 6.5. Обе программы работали на Windows NT. Но SQL Server 7.0 работал не только под Windows NT, но и под Windows 9.5/98.
SQL Server 7.0 стал крупной победой разработчиков ядра СУБД. Он превзошел возможности всех конкурирующих программ. Но в SQL Server 7.0 ядро процессора сильно изменилось. В SQL Server 7.0 полностью изменена не только архитектура ядра; к нему были добавлены оптимизатор запросов и улучшенная система сохранения данных. В SQL Server 2000 добавлен ряд дополнительных функций, увеличена масштабируемость, надежность и доступность данных. Программа делает работу администратора проще и приятнее. SQL Server 2000 реализован как служба в Windows NT Workstation, Windows NT Server и любой Windows 2000. В Windows ME он работает как отдельное приложение в текущем пользовательском сеансе. Все встроенные утилиты, такие как SQL Server Enterprise Manager, работают как клиент-серверные вспомогательные приложения, что позволяет вам управлять базой данных из любой точки сети.
Основными задачами системы SQL Server являются организация одновременного доступа к данным большого количества пользователей, а также манипулирование информацией, хранящейся в базе данных. SQL Server поддерживает реляционную модель данных.
В системах, организованных по архитектуре клиент/сервер, поддерживается совместное использование данных. Здесь каждый компьютер выполняет операции с хранением, доступом и обработкой данных. В этом случае выполняемые задачи распределяются между сервером и рабочими станциями; это разделение необходимо учитывать в создаваемых системах.
SQL Server — это серверная часть приложения, к которому подключаются различные клиенты, включая утилиты, поставляемые с SQL Server (например, SQL Query Analyzer). К преимуществам SQL Server относятся:
Обработка данных в среде клиент/сервер осуществляется при запуске запроса. Сервер выбирает необходимые данные и отправляет клиенту только запрошенные строки таблицы. Это не только сокращает время передачи данных, но и ускоряет обработку запроса рабочей станцией.
Основные операции, связанные с управлением работой SQL-сервера, выполняются с помощью ряда утилит, входящих в состав системы.
Электронная документация по SQL Server — это основной источник информации о SQL Server для пользователя. В электронной документации вы можете найти ответы на любые вопросы о SQL Server. Books Online состоит из набора отдельных руководств, хранящихся в электронном виде. При необходимости вы можете заказать бумажную копию в Microsoft. Само руководство организовано в виде HTML-документов и просматривается в Microsoft Internet Explorer версии 5. 0 и выше.
Books Online дает вам все, что вы ожидаете от обычного учебника, а также дополнительные возможности поиска, отображения и печати необходимой информации.
Левая панель диалогового окна электронной документации по SQL Server содержит несколько вкладок:
- Содержание. Вся информация о SQL Server представлена в виде разделов, организованных по темам (как в обычном справочнике).
- Индекс (указатель индекса). Содержит алфавитный список ключевых слов электронной книги. После ввода искомого слова в верхнее поле список автоматически прокрутится до того места, где в нем встречается это слово.
- Поиск (Поиск). Эта вкладка используется чаще всего. После ввода слова, имени, команды или параметра в поле поиска и нажатия кнопки «Список тем» результат поиска отображается в виде списка.
- Избранное. Как и Internet Explorer, Books Online позволяет сохранять список избранных тем, к которым обращались чаще всего.
Утилита SQL Server Service Manager отвечает за управление службами SQL Server на компьютере в локальной сети, на котором установлен SQL Server. При запуске этой утилиты на экране появляется диалоговое окно. Поле Сервер содержит имя используемого сервера. Поле Сервис указывает сервис, статус которого проверяется на данном сервере. Графически статус службы представлен следующим образом: зеленая стрелка указывает на то, что служба работает в данный момент; остальные значки символизируют приостановку или полную остановку услуги. Утилита Service Manager — это основная утилита, используемая для управления SQL Server.
Раскрывающийся список Служб содержит все службы, которыми управляет эта утилита. Среди них SQL Server, агент SQL Server, координатор распределенных транзакций и Microsoft Search. Раскрывающийся список Сервер используется для указания сервера, на котором работают службы. Именованные экземпляры также представлены в этом списке. Оба поля в диалоговом окне достаточно интеллектуальны, чтобы принимать значения с ключом (например, имя_сервера_имя_экземпляра). После ввода имени сервера и указания нужной службы в поле Служба утилита Service Manager подключается к удаленному серверу и берет на себя управление службами.
Все функции этого приложения встроены в утилиту SQL Server Enterprise Manager. Он запускается с панели задач Windows и поэтому более удобен в использовании.
Утилита Client Network, которая играет важную роль в подключении клиентских компьютеров SQL Server, проста в использовании. При запуске клиентской сети на экране появляется диалоговое окно, в котором указывается, какие протоколы используются по умолчанию клиентским приложением для подключения к SQL Server. По умолчанию SQL Server 2000 использует сетевую библиотеку TCP/IP независимо от операционной системы, управляющей компьютером. В нижней части диалогового окна есть еще две опции: Force Protocol Encryption (шифрование) и Enable Shared Memory Protocol (локальное подключение к SQL Server). Второй вариант позволяет автоматически подключаться к SQL Server, установленному на локальном компьютере. Вы можете отключить его при необходимости. Первый вариант необходим для установки зашифрованного соединения между клиентским приложением и сервером, на котором установлен SQL Server 2000.
Утилита Server Network во многом похожа на Client Network. Но в отличие от утилиты Client Configuration, которая управляет тем, как клиентское программное обеспечение подключается к SQL Server, Server Network управляет работой сетевых библиотек. Именно эта утилита определяет протоколы, которые серверы под управлением SQL Server 2000 используют для связи с клиентскими приложениями.
SQL Server Query Analyzer — это утилита, позволяющая выполнять команды языка запросов Transact-SQL. Эта утилита работает в среде Windows, что упрощает ее использование. При запуске система запрашивает имя SQL-сервера, имя пользователя и пароль в диалоговом окне. Используя введенную информацию, система подключает утилиту к этому SQL-серверу. Главное окно утилиты разделено на две части. Вверху пользователь вводит команды, требующие выполнения. По завершении ввода воспользуйтесь кнопкой запуска SQL-запроса, после чего результаты выполнения запроса отобразятся внизу этого окна. Здесь же можно проверить правильность выполнения запроса, не запуская его, и сохранить для дальнейшего использования.
SQL Server Enterprise Manager — утилита, позволяющая пользователю выполнять все операции администрирования SQL-сервера, получать доступ ко всем его объектам, а также запускать различные утилиты и приложения. Наличие утилиты на компьютере позволяет настраивать удаленные серверы, т.е. утилиту можно запускать не только на самом сервере, но и на компьютере рабочей станции. Главное системное окно очень похоже на проводник Windows. С левой стороны расположены основные объекты SQL-сервера. Использование символов + и — слева от названия объекта позволяет выявить его составляющие, что, в свою очередь, дает возможность их редактирования. При выборе нужного объекта в правой части окна утилиты отображаются возможности настройки его параметров.
Утилита Profiler используется для мониторинга всех процессов, запущенных в SQL Server. Он также используется для настройки среды для достижения максимальной производительности; для этого анализируется план выполнения запроса и на основании полученных результатов принимается правильное решение. Profiler позволяет отслеживать не только активность отдельных приложений, выполнение команд, но и каждого пользователя SQL Server. SQL Server 2000 позволяет одновременно отслеживать до 100 событий.
Утилита OSQL добавляет интерфейс ODBC к SQL Server. Эта программа позволяет использовать команды ODBC для подключения к SQL Server. Как правило, он используется для выполнения пакетных запросов, предназначенных для производственных задач.
ISQL — это программа командной строки, появившаяся в предыдущих версиях SQL Server. Он использует DB-Library для подключения к SQL Server. Поскольку ISQL полностью зависит от DB-Library, новые команды в ней остаются недоступными. Среди них поддержка Unicode.
SQL Server 2000 оснащен лучшими инструментами, когда-либо созданными Microsoft. С помощью всего одной консоли управления, оснащенной графическим интерфейсом, легко управлять большой базой данных всей организации. В SQL Server интегрированы все необходимые программы: утилиты для запуска запросов, мониторинга состояния системы и используемых сервисов.
Инструменты SQL Server позволяют даже настраивать сетевые подключения и устранять некоторые проблемы с сетью. Некоторые инструменты SQL Server запускаются из главного меню Windows, другие — из командной строки или из папки mssqlinn.
Введение
1. СУБД SQL-Server: основные возможности и применение в СЭД
Заключение
Библиография
Введение
Документ является основным способом представления информации на любом современном предприятии. Важность сохранности и умелого использования информационных ресурсов предприятия для успешного ведения бизнеса неоспорима. Способность принять правильное решение и вовремя отреагировать на ситуацию, гибко реагировать на все изменения рынка зависит не только от таланта и опыта менеджеров. Эффективность управления предприятием зависит и от того, насколько разумно оно организует документооборот. На самом деле неэффективное использование накопленной информации (или, что еще хуже, ее потеря) может привести к потере всего бизнеса. Ведь не полученная вовремя информация или документ – это, прежде всего, потерянные деньги, время и упущенные возможности. В результате на любом предприятии, где ведется активная работа с различными документами, рано или поздно возникает проблема систематизации, обработки и безопасного хранения значительных объемов информации. Важную роль в оптимизации деятельности предприятия любого размера и профиля деятельности играют современные системы электронного документооборота.
Для того, чтобы выбрать СЭД, устраивающую организацию по всем параметрам, необходимо многому научиться. В частности, не только сами СЭД, но и СУБД.
Целью данной работы является ознакомление с СУБД SQL Server и отдельными элементами СЭД «Директум» и «Евфрат-рабочий процесс».
1. Знакомство с СУБД SQL Server, ее основными возможностями и применением;
2. Определение маршрута движения документов в СЭД «Директум» и «Евфрат-документооборот»
1. СУБД SQL-Server: основные возможности и применение в СЭД
СУБД SQL-Server появилась в 1989 году и с тех пор существенно изменилась. Огромные изменения коснулись масштабируемости, целостности, простоты администрирования, производительности и функциональности продукта.
Microsoft SQL Server — это система управления реляционными базами данных (СУБД). Реляционные базы данных хранят данные в таблицах. Связанные данные могут быть сгруппированы в таблицы, а также могут быть установлены отношения между таблицами. Отсюда и пошло название реляционный — от английского слова реляционный (связанный, связанный, взаимозависимый). Пользователи получают доступ к данным на сервере через приложения, а администраторы выполняют задачи по настройке, администрированию и обслуживанию базы данных, напрямую обращаясь к серверу. SQL Server — это масштабируемая база данных, что означает, что она может хранить значительные объемы данных и поддерживать одновременный доступ к базе данных многих пользователей.
Microsoft SQL Server 6.5 — одна из самых мощных клиент-серверных СУБД. Данная СУБД позволяет удовлетворить такие требования к распределенным системам обработки данных, как репликация данных, параллельная обработка, поддержка больших баз данных на относительно недорогих аппаратных платформах при сохранении простоты управления и использования.
MS SQL Server не предназначен непосредственно для разработки пользовательских приложений, а выполняет функции управления базой данных. Сервер имеет средства удаленного администрирования и управления операциями, организованные на основе объектно-ориентированной распределенной среды управления.
Microsoft SQL Server 6.5 предназначен исключительно для поддержки систем, работающих в среде клиент-сервер. Он поддерживает широкий спектр инструментов разработки и очень легко интегрируется с приложениями, работающими на ПК.
SQL Server может реплицировать информацию в базы данных других форматов, включая Oracle, IBM DB2, Sybase, Microsoft Access и другие СУБД (при наличии ODBC-драйвера, соответствующего определенным требованиям).
Microsoft SQL Server 6.5 содержит помощника администратора. Этот инструмент позволяет назначать основные процедуры обслуживания базы данных и планировать их выполнение. Операции обслуживания базы данных включают в себя проверку размещения страниц, проверку целостности указателей в таблицах (в том числе системных) и индексов, обновление информации, необходимой оптимизатору, реорганизацию страниц в таблицах и индексах, создание безопасных копий таблиц и журналов транзакций. Все эти операции можно настроить на автоматический запуск по расписанию, заданному администратором.
Требования к программному и аппаратному обеспечению
Одним из главных событий, определивших судьбу Microsoft SQL Server, стало решение Microsoft сосредоточиться исключительно на поддержке только платформы Windows NT. Можно найти множество аргументов, подтверждающих как правильность, так и ошибочность такого решения. В результате его принятия популярность SQL Server определяется прежде всего популярностью платформы, которую он поддерживает, в настоящее время Windows 2000 и ее будущих потомков. Эта СУБД настолько связана с операционной системой, что ее надежность, масштабируемость и производительность определяются надежностью, масштабируемостью и производительностью самой платформы, а положение SQL Server на рынке будет зависеть от выхода новых версий Windows 9.0003
Чем шире используются распределенные вычисления, тем важнее становится возможность хранить данные в любом месте, в частности на рабочей станции или ноутбуке. Несмотря на утверждения некоторых аналитиков о том, что в эпоху интернет-приложений настольные системы управления базами данных больше не нужны, они по-прежнему широко используются во всех сферах бизнеса. SQL Server можно использовать на любых Intel-совместимых компьютерах под управлением Windows 9x, Windows NT, Windows 2000. Существует также версия SQL Server 2000 для Windows CE, предназначенная для использования на мобильных устройствах.
Одним из преимуществ SQL Server является простота использования, в частности администрирования. SQL Server Enterprise Manager, входящий во все редакции Microsoft SQL Server (кроме MSDE), представляет собой полнофункциональный и достаточно простой инструмент для администрирования данной СУБД.
По данным Совета по производительности обработки транзакций (TPC), SQL Server теперь является лидером по производительности.
Таким образом, основными преимуществами SQL Server являются:
Высокая степень защиты данных.
Мощные инструменты для работы с данными.
Высокая производительность.
Хранение больших массивов данных.
Хранение данных, требующих соблюдения конфиденциальности или недопустимости их утраты.
Постепенно этот продукт, начав с небольшого, но амбициозного проекта, превратился в то, с чем сегодня имеют дело пользователи. Основные возможности последних версий еще раз подтверждают тот факт, что Microsoft продолжает развивать свои продукты, стараясь удовлетворить возрастающие запросы потребителей.
2. Определение маршрута движения документов в СЭД «Директум» и «Евфрат-документооборот»
Модули, отвечающие за документооборот, называются модулями маршрутизации документов. В общем случае используется свободная и жесткая маршрутизация документов. При свободной маршрутизации любой пользователь, участвующий в рабочем процессе, может по своему усмотрению изменить существующий (или задать новый) маршрут прохождения документов. При жесткой маршрутизации маршруты прохождения документов строго регламентированы, и пользователи не имеют права их менять. Однако при жесткой маршрутизации обработка логических операций может производиться при изменении маршрута при выполнении некоторых заранее заданных условий (например, отправка документа руководству при превышении конкретным пользователем своих служебных полномочий, скажем, финансовых). В большинстве СЭД модуль маршрутизации входит в комплект, в некоторых его необходимо приобретать отдельно. В частности, полнофункциональные модули маршрутизации разрабатываются и поставляются третьими сторонами.
Евфрат
Cognitive Technologies предлагает программу Euphrates. Он работает под управлением MS Windows 95/98/NT/2000 и обеспечивает комплексную автоматизацию делопроизводства, включая регистрацию, контроль исполнения, организацию и ведение электронных архивов документов, полученных из различных источников. К основным возможностям системы относятся:
Создание корпоративных электронных архивов;
Внесение бумажных документов в базу данных системы с использованием сканера и системы распознавания CuneiForm;
Поиск текста по содержанию документов и реквизитов;
Морфологический анализ документов для повышения эффективности поиска.
Кроме того, система поддерживает графические форматы (TIF, PCX, JPG, BMP, GIF), формат электронных таблиц Excel, а также обеспечивает режим быстрого просмотра с сохранением исходного форматирования.
Варианты рабочего стола Секретариат, Бухгалтерия, Управление персоналом, Страховая компания, Euphrates Home Base позволяют организовать рабочее место каждого отдельного сотрудника. Вы можете гибко управлять подачей информации, подбирать шрифты и т. д. Печать информации любого типа осуществляется как через соответствующее приложение, так и напрямую из Евфрата. Имеется набор служебных утилит для тестирования базы данных, ее сжатия и архивирования. Открытый интерфейс позволяет создавать и подключать фильтры для работы с информацией любого типа и формата.
Последнее обновление: 24.06.2017
SQL Server — одна из самых популярных систем управления базами данных (СУБД) в мире. Эта СУБД подходит для самых разных проектов: от небольших приложений до крупных высоконагруженных проектов.
SQL Server был создан Microsoft. Первая версия вышла в 1987 году. А текущая версия — это версия 16, которая была выпущена в 2016 году и будет использоваться в текущем руководстве.
SQL Server долгое время был исключительно системой управления базами данных для Windows, но начиная с версии 16 эта система доступна и для Linux.
SQL Server характеризуется такими особенностями, как:
Производительность. SQL Server работает очень быстро.
Надежность и безопасность. SQL Server обеспечивает шифрование данных.
Простота. С этой СУБД относительно легко работать и администрировать.
Центральным аспектом MS SQL Server, как и любой СУБД, является база данных. База данных – это хранилище данных, организованное определенным образом. Нередко база данных физически представляет файл на жестком диске, хотя такое сопоставление не требуется. Системы управления базами данных или СУБД используются для хранения и администрирования баз данных. И как раз MS SQL Server является одной из таких СУБД.
MS SQL Server использует реляционную модель для организации баз данных. Эта модель базы данных была разработана еще в 1970 году Эдгаром Коддом. И сегодня это фактически стандарт организации баз данных.
Реляционная модель предполагает хранение данных в виде таблиц, каждая из которых состоит из строк и столбцов. Каждая строка хранит отдельный объект, а столбцы содержат атрибуты этого объекта.
Первичный ключ используется для идентификации каждой строки в таблице. Первичный ключ может быть одним или несколькими столбцами. Используя первичный ключ, мы можем ссылаться на определенную строку в таблице. Соответственно, две строки не могут иметь один и тот же первичный ключ.
Через ключи одна таблица может быть связана с другой, то есть могут быть организованы связи между двумя таблицами. А саму таблицу можно представить как отношение («relation»).
SQL (язык структурированных запросов) используется для взаимодействия с базой данных. Клиент (например, внешняя программа) отправляет запрос на языке SQL с помощью специального API. СУБД правильно интерпретирует и выполняет запрос, а затем отправляет результат клиенту.
SQL изначально был разработан IBM для системы баз данных под названием System/R. При этом сам язык назывался SEQUEL (Structured English Query Language). Хотя ни база данных, ни сам язык впоследствии официально не публиковались, традиционно сам термин SQL часто произносится как «продолжение».
В 1979 году Relational Software Inc. разработала первую систему управления базами данных, которая называлась Oracle и использовала язык SQL. Благодаря успеху этого продукта компания была переименована в Oracle.
Впоследствии стали появляться и другие СУБД, использующие SQL. В результате в 1989 году Американский национальный институт стандартов (ANSI) кодифицировал язык и опубликовал свой первый стандарт. После этого стандарт периодически обновлялся и дополнялся. Последнее обновление произошло в 2011 году. Но, несмотря на наличие стандарта, производители СУБД часто используют собственные реализации языка SQL, которые немного отличаются друг от друга.
Существует две разновидности языка SQL: PL-SQL и T-SQL. PL-SQL используется в таких системах баз данных, как Oracle и MySQL. T-SQL (Transact-SQL) используется в SQL Server. Именно поэтому T-SQL будет рассмотрен в рамках текущего руководства.
В зависимости от задачи, которую выполняет команда T-SQL, она может быть одного из следующих типов:
CREATE : создает объекты базы данных (сама база данных, таблицы, индексы и т. д.)
ALTER : Изменяет объекты базы данных
DROP: удаляет объекты базы данных
TRUNCATE: удаляет все данные из таблиц
SELECT : выборка данных из базы данных
ОБНОВЛЕНИЕ: обновляет данные
INSERT: добавляет новые данные
УДАЛИТЬ: удаляет данные
DDL (язык определения данных). К этому типу относятся различные команды, создающие базу данных, таблицы, индексы, хранимые процедуры и так далее. В общем, данные определены.
В частности, к этому типу можно отнести следующие команды:
DML (язык манипулирования данными/язык манипулирования данными). К этому типу относятся команды выбора данных, их обновления, добавления, удаления — в общем, все те команды, с помощью которых мы можем управлять данными.
Этот тип включает следующие команды:
DCL (язык управления данными/язык управления доступом к данным). К этому типу относятся команды, управляющие правами доступа к данным. В частности, это следующие команды:
Microsoft SQL Server 2008.
10.1 Общая структура СУБД
Для лучшего понимания принципов работы современных СУБД рассмотрим устройство одной из самых распространенных клиент-серверных СУБД — Microsoft SQL Server 2008. Хотя все коммерческие СУБД разные, обычно достаточно знать, как работает одна СУБД чтобы быстро начать работу с другой СУБД. Краткий обзор возможностей Microsoft SQL Server — 2008 был дан в разделе, посвященном краткому обзору современных СУБД. В этом разделе мы рассмотрим основные моменты, связанные со структурой соответствующей СУБД (архитектура базы данных и структура программного обеспечения).
Под архитектурой (структурой) базы данных конкретной СУБД понимаются основные модели представления данных, используемые в соответствующей СУБД, а также взаимосвязь между этими моделями. .
В соответствии с различными уровнями описания данных, рассмотренными в «Различные архитектурные решения, используемые при реализации многопользовательской СУБД. Краткий обзор СУБД», выделяют разные уровни абстракции архитектуры базы данных.
логический уровень (уровень модели данных СУБД) — средство представления концептуальной модели . Здесь у каждой СУБД есть некоторые отличия, но они не очень существенны. Обратите внимание, что разные СУБД имеют существенно разные механизмы перехода с логического на уровень физического представления.
Физический уровень (внутреннее представление данных в памяти компьютера — физическая структура базы данных) . Этот уровень рассмотрения включает в себя проверку базы данных на уровне файлов, хранящихся на жестком диске. Структура этих файлов является особенностью каждой конкретной СУБД, в т.ч. и Microsoft SQL Server.
Рис. 10.1.
10.2. Архитектура базы данных. логический уровень
Рассмотрим представления базы данных логического уровня (http://msdn.microsoft.com). Microsoft SQL Server 2008 — реляционная СУБД (данные представлены в виде таблиц). Таким образом, таблицы являются основной структурой модели данных данной СУБД.
Таблицы и типы данных
Таблицы содержат данные обо всех сущностях в концептуальной модели базы данных. При описании каждого столбца (поля) пользователь должен определить тип соответствующих данных. Microsoft SQL Server 2008 поддерживает традиционные типы данных (строка символов с различным представлением, число с плавающей запятой длиной 8 или 4 байта, целое число длиной 2 или 4 байта, дата и время, поле примечания, логическое значение и т. д.). ) и новые типы данных. Кроме того, Microsoft SQL Server 2008 предоставляет специальный инструмент для создания пользовательских типов данных.
Рассмотрим краткое описание некоторых новых типов данных, значительно расширяющих возможности пользователя (http://www.oszone.net).
Тип данных иерархии
Тип данных иерархии позволяет создавать отношения между элементами данных в таблице, чтобы указать положение в иерархии отношений между строками таблицы. В результате использования этого типа данных в таблице строки таблицы могут отображать определенную иерархическую структуру, соответствующую отношениям между данными в этой таблице.
Типы пространственных данных
Пространственные данные — это данные, определяющие географические местоположения и формы, в основном на Земле. Это могут быть достопримечательности, дороги и даже расположение компании. SQL Server 2008 предоставляет типы данных geography и геометрии для работы с этой информацией. Тип данных geography работает с информацией о сферической Земле. Сферическая модель Земли использует кривизну земной поверхности в своих расчетах. Информация о местоположении представлена широтой и долготой. Эта модель хорошо подходит для морского, военного планирования и краткосрочного наземного применения. Эту модель следует использовать, если данные хранятся в виде широт и долгот.
Тип данных геометрия работает с плоской или плоской моделью Земли. В этой модели земля считается плоской проекцией с определенной точки. Модель плоской земли не учитывает кривизну земной поверхности, поэтому она в основном используется для описания коротких расстояний, например, в приложении базы данных, описывающем внутреннюю часть здания.
Типы geography и геометрия создаются из векторных объектов, указанных в форматах Well-Known Text (WKT) или Well-Known Binary (WKB). Это форматы передачи пространственных данных, описанные в Open Geospatial Consortium (OGC) Simple Features for SQL Specifications.
Ключи
В каждой таблице должен быть определен первичный ключ — минимальный набор атрибутов, однозначно идентифицирующих каждую запись в таблице . Для реализации связи между таблицами в одну из связанных таблиц включается дополнительное поле (несколько полей) — первичный ключ другой таблицы. Дополнительно включенное поле или поля в этом случае называются внешним ключом соответствующей таблицы.
Помимо таблиц, модель данных Microsoft SQL Server 2008 включает ряд других компонентов. Приведем краткую характеристику основных из них.
Индексы
В статье «Использование формального аппарата для оптимизации схем взаимоотношений» была рассмотрена концепция индекса. Здесь концепция индекса отнесена к логическому уровню для удобства пользователя. Индексы созданы для ускорения поиска необходимой информации и содержат информацию об упорядочении данных по различным критериям. . Индексация может выполняться по одному или нескольким столбцам. Индексация может быть выполнена в любое время. Индекс содержит ключи, построенные из одного или нескольких столбцов в таблице или представлении. Эти ключи хранятся в виде дерева со сбалансированной структурой, которое поддерживает быстрый поиск строк по значениям их ключей в SQL Server.
Представление
Представление — это виртуальная таблица, содержимое которой определяется запросом . Представление формируется на основе SQL-запроса SELECT, сформированного по обычным правилам. Таким образом, представление представляет собой именованный запрос SELECT.
Как и настоящая таблица, представление состоит из набора именованных столбцов и строк данных. Пока представление не проиндексировано, оно не существует в базе данных как хранимая коллекция значений. Строки и столбцы данных извлекаются из таблиц, указанных в запросе, определяющем представление, и динамически создаются при доступе к представлению. Представление выполняет функцию фильтрации базовых таблиц, на которые оно ссылается. Запрос, определяющий представление, может быть вызван для одной или нескольких таблиц или других представлений в текущей или других базах данных. Вы также можете использовать распределенные запросы для определения представлений с данными из нескольких разнородных источников. Это полезно, например, если вы хотите объединить структурированные таким образом данные, принадлежащие разным серверам, на каждом из которых хранятся данные определенного отдела организации.
Сборки
Сборки — это файлы динамических библиотек, которые используются в экземпляре SQL Server для развертывания функций, хранимых процедур, триггеров, определяемых пользователем агрегатов и определяемых пользователем типов .
Ограничения
Ограничения позволяют указать метод, с помощью которого компонент Database Engine автоматически обеспечивает целостность базы данных . Ограничения определяют правила разрешения определенных значений в столбцах и являются стандартным механизмом обеспечения целостности. Рекомендуется использовать лимиты, а не триггеры, правила и значения по умолчанию. Оптимизатор запросов также использует определения ограничений для создания высокопроизводительных запросов планов выполнения.
Правила
Правила — еще один специальный механизм, предназначенный для обеспечения целостности базы данных, аналогичный по функциональности некоторым типам ограничений. . Microsoft отмечает, что, когда это возможно, использование ограничений предпочтительнее по ряду причин и может быть удалено в будущем выпуске.
Значения по умолчанию
Значения по умолчанию определяют, какими значениями заполнить столбец, если для этого столбца не указано значение при вставке строки . Значением по умолчанию может быть любое выражение, результатом которого является константа, например сама константа, встроенная функция или математическое выражение.
Первая версия Microsoft Servers SQL была представлена компанией еще в 1988 году. СУБД сразу позиционировалась как реляционная, имеющая, по заявлению производителя, три преимущества:
- хранимые процедуры, благодаря которым выборка данных было ускорено и сохранена их целостность в многопользовательском режиме;
- постоянный доступ к администрированию без отключения пользователей;
- открытая серверная платформа, позволяющая создавать сторонние приложения, использующие SQL Server.
2005 под кодовым названием Yukon с улучшенной масштабируемостью стал первым выпуском, полностью поддерживающим технологию .NET. Улучшилась поддержка распределенных данных, появились первые инструменты отчетности и анализа информации.
Интернет-интеграция позволила использовать SQL Server 2005 в качестве основы для создания систем электронной коммерции с простым и безопасным доступом к данным через популярные браузеры с использованием встроенного Брандмауэра. Версия Enterprise поддерживала параллельные вычисления на неограниченном количестве процессоров.
Версия 2005 была заменена на Microsoft SQL Server 2008, который до сих пор является одним из самых популярных серверов баз данных, а чуть позже появилась следующая версия — SQL Servers 2012, с поддержкой совместимости с .NET Framework и другой дополнительной информацией технологии обработки и среда разработки Visual Studio. Для доступа к SQL был создан специальный модуль Azure.
Transact SQL
С 1992 года SQL является стандартом для доступа к базе данных. Почти все языки программирования используют его для доступа к базе данных, даже если пользователю кажется, что он работает с информацией напрямую. Базовый синтаксис языка остается прежним для обеспечения совместимости, но каждый поставщик баз данных пытается добавить в SQL дополнительные возможности. Компромисс найти не удалось, и после «войны стандартов» осталось два лидера: PL/SQL от Oracle и Transact-SQL от Microsoft Servers SQL.
T-SQL процедурно расширяет SQL для доступа к Microsoft Servers SQL. Но это не исключает разработки приложений на «стандартных» операторах.
Автоматизируйте свой бизнес с помощью SQL Server 2008 R2
Надежная работа бизнес-приложений чрезвычайно важна для современного бизнеса. Малейшая простая база данных может привести к огромным потерям. Сервер базы данных Microsoft SQL Server 2008 R2 позволяет надежно и безопасно хранить практически неограниченную информацию с помощью привычных всем администраторам средств управления. Поддерживается вертикальное масштабирование до 256 процессоров.
Технология Hyper-V максимально использует возможности современных многоядерных систем. Поддержка нескольких виртуальных систем на одном процессоре снижает нагрузку и улучшает масштабируемость.
Анализ данных
Для быстрого анализа потоков данных в режиме реального времени используется компонент SQL Server StreamInsight, оптимизированный для данного типа задач. Вы можете разрабатывать собственные приложения на основе .NET.
Непрерывность бизнеса и безопасность данных
Поддержка оптимальной производительности в любое время обеспечивается регулятором ресурсов, встроенным в сервер. Администратор может управлять нагрузкой и системными ресурсами, устанавливать ограничения для приложений на использование ресурсов процессора и памяти. Функции шифрования обеспечивают гибкую и прозрачную защиту информации и ведут журнал доступа к ней.
Неограниченный размер базы данных
Хранилище данных можно масштабировать быстро и безопасно. Пользователи могут использовать готовые шаблоны Fast Track Date Warehouse для поддержки дисковых массивов емкостью до 48 ТБ. Базовая конфигурация поддерживает оборудование ведущих производителей, таких как HP, EMC и IBM. Функции сжатия данных UCS 2 позволяют более экономно экономить место на диске.
Повышение эффективности работы разработчиков и администраторов
Новые программные мастера позволяют быстро устранять недогруженные серверы, улучшать контроль и оптимизировать производительность без необходимости привлечения внешних сторонних специалистов. Управляйте работой своих приложений и баз данных, находите улучшения в своих информационных панелях и ускоряйте обновления и установки.
Инструменты для личного бизнес-анализа В компаниях никогда не было единого мнения о том, кто должен заниматься аналитикой — ИТ-отделы или непосредственно пользователи. Система создания персональных отчетов решает эту задачу за счет современных инструментов безопасного и эффективного построения, анализа и моделирования бизнес-процессов. Поддерживает прямой доступ к базам данных в Microsoft Office и SharePoint Server. Корпоративная информация может быть интегрирована с другими типами контента, такими как карты, графика и видео.
Удобная среда для совместной работы
Предоставьте своим сотрудникам доступ к информации, совместной разработке и анализу данных с помощью приложения PowerPivot для электронных таблиц Excel. Программа позволяет анализировать информацию и моделировать бизнес-процессы, а также публиковать отчеты для общего доступа в Интернете или системе SharePoint.
Для визуального создания внутренних отчетов предлагается система Report Builder 3.0, поддерживающая множество форматов и широкий набор предустановленных шаблонов.
Работа с базами данных бесплатно
Компания предоставляет небольшим проектам и начинающим разработчикам специальную бесплатную версию Microsoft SQL Server Express. Сюда входят те же технологии баз данных, что и в «полных» версиях SQL Server.
Поддерживаются среды разработки Visual Studio и Web Developer. Создавайте сложные таблицы и запросы, разрабатывайте веб-приложения с поддержкой баз данных, получайте доступ к информации непосредственно из PHP.
Получите всю мощь Transact-SQL и самых передовых технологий доступа к данным ADO.NET и LINQ. Поддерживаются хранимые процедуры, триггеры и функции.
Сконцентрируйтесь на элементах бизнес-логики, и система самостоятельно оптимизирует структуру базы данных.
Создавайте насыщенные отчеты любой сложности. Используйте подсистему поиска, интегрируйте отчеты с приложениями Microsoft Office и добавляйте в документы географическую информацию.
Разработанные приложения могут работать при отсутствии подключения к серверу базы данных. Синхронизация выполняется автоматически с использованием проприетарной технологии репликации транзакций Sync Framework.
Администрируйте свою инфраструктуру с помощью политик управления для всех баз данных и приложений. Общие операционные сценарии сокращают время на оптимизацию запросов, создание и восстановление резервных копий в масштабе предприятия.
SQL Server 2008 R2 Express Edition идеально подходит для быстрого развертывания веб-сайтов и интернет-магазинов, программ для личного пользования, малого бизнеса. Это отличный вариант для начала и обучения.
Управление базами данных с помощью SQL Server Management Studio
Microsoft SQL Server Management — это специализированная среда для создания, доступа и управления базами данных и всеми элементами SQL Server, включая службы отчетов.
Система объединяет в одном интерфейсе все возможности программ администрирования более ранних версий, таких как Query Analyzer и Enterprise Manager. Администраторы получают программное обеспечение с большим набором графических объектов разработки и управления, а также расширенный скриптовый язык для работы с базой данных.
Отдельного внимания заслуживает редактор кода Microsoft Server Management Studio. Он позволяет создавать сценарии на языке Transact-SQL, программировать многомерные запросы доступа к данным и анализировать данные с поддержкой сохранения результатов в формате XML. Создание запросов и скриптов возможно без подключения к сети или серверу с последующим выполнением и синхронизацией. Имеется широкий набор предустановленных шаблонов и система контроля версий.
Модуль Object Explorer позволяет просматривать и управлять любыми встроенными объектами SQL Microsoft Server на всех серверах и экземплярах баз данных. Легкий доступ к нужной информации необходим для быстрой разработки приложений и контроля версий.
Система основана на системе изолированной оболочки Visual Studio, которая поддерживает расширяемые настройки и сторонние расширения. В Интернете существует множество сообществ, в которых можно найти всю необходимую информацию и примеры кода для разработки собственных средств управления и обработки данных.
По данным исследовательской компании Forrester Research, сервер баз данных Microsoft SQL Server 2012 вошел в тройку лидеров на рынке корпоративных хранилищ информации в 2013 году. Эксперты отмечают, что стремительный рост доли рынка Microsoft обусловлен комплексным подходом корпорации к автоматизации бизнеса процессы. Microsoft SQL Server — это современная платформа для управления и хранения всех типов данных, дополненная средствами аналитики и разработки. Отдельно стоит отметить простоту интеграции с другими продуктами компании, такими как Office и SharePoint.
Поиск информации о вашей недвижимости в Интернете
Эти инструкции помогут вам найти информацию о вашей собственности в нашей системе данных о недвижимости. Вы можете осуществлять поиск в онлайн-базе данных по адресу, названию улицы, идентификатору учетной записи или ссылке на карту. Вы не можете искать по имени владельца, городу, району, району или почтовому индексу.
Воспользуйтесь нашим поиском данных о недвижимости по адресу http://sdat.dat.maryland.gov/RealProperty/Pages/default.aspx
Выберите соответствующий округ из выпадающего меню.
Поиск по адресу
- Не используйте указатели улиц (например, «Север», «Юго-Восток», «Запад» и т. д.) или какие-либо сокращения улиц.
- Не используйте суффиксы названий улиц (например, «Авеню», «Улица», «Путь» и т. д.) или любые сокращения суффиксов названий улиц.
- Чтобы выполнить конкретный поиск по названию улицы, введите полное название. Например, поиск по слову «Престон» будет возвращать только те записи, в имени которых есть «Престон». Если вы не можете найти подходящую недвижимость, выполните общий поиск, усекая название улицы и добавляя звездочку (*). Это вернет названия улиц, соответствующие усеченному поиску. Например, поиск по «301 Pr*» вернет 301 Preston Street, 301 President Street, 301 Pratt Street и т. д.
- Если вы все еще не можете найти дом, попробуйте не указывать номер дома. Хотя это может привести к нескольким совпадениям, это даст вам представление о том, правильно ли вы назвали улицу. Кроме того, официальный номер улицы, присвоенный собственности местным правительством, может не совпадать с номером, который использует владелец.
Использование уведомления об оценке для поиска по номеру счета
Идентификационный номер счета вашего имущества указан над вашим именем и адресом в уведомлении об оценке. Ищите информацию в следующем формате:
АККТ № 01 02 1234564 40500 0391 302000 С
ДОЭ, ДЖОН
123 ГЛАВНАЯ СТ
ANYTOWNIN, MD 21200-0000
В приведенном выше примере идентификационный номер счета собственности (ACCT #) состоит из кода округа 01, оценочного округа 02 и номера счета 123456. Код округа определяет юрисдикцию, в которой находится имущество.
| Аллегани — 01 | Чарльз — 09 | Принц Джордж — 17 |
| Энн Арундел — 02 | Дорчестер -10 | Королевы Анны — 18 |
| Балтимор Сити — 03 | Фредерик — 11 | Сент-Мэрис — 19 |
| Округ Балтимор — 04 | Гаррет — 12 | Сомерсет — 20 |
| Калверт — 05 | Харфорд — 13 | Талбот — 21 |
| Кэролайн — 06 | Ховард — 14 | Вашингтон — 22 |
| Кэрролл — 07 | Кент — 15 | Викомико — 23 |
| Сесил — 08 | Монтгомери — 16 | Вустер — 24 |
Примечание. Если код вашего округа 02 (округ Энн Арундел) или 03 (город Балтимор), структура вашего номера счета отличается. См. приведенные ниже инструкции для округа Энн Арундел и города Балтимор.
Выберите округ, в котором находится недвижимость, сопоставив код округа с соответствующим названием из приведенной выше таблицы кодов округов. Название округа также можно определить, взглянув на обратный адрес SDAT в уведомлении об оценке. Обратным адресом будет офис SDAT округа, в котором расположено имущество, например, имущество, расположенное в округе Гарретт, будет иметь следующий обратный адрес:
, штат Мэриленд,
.
Департамент оценки и налогообложения
ОКРУГ ГАРРЕТ
Почтовый ящик 388
Окленд, Мэриленд 21550-0388
Округ Энн Арундел:
После ACCT # 02 следуют двухзначный район оценки, трехзначный код подразделения и 8-значный номер счета. Вам понадобится район, подразделение и номера счетов для поиска вашего имущества
Пример: ACCT# 02 01 333 44444444
Код округа: 02 Код района: 01 Номер подразделения: 333 Номер счета: 44444444
Город Балтимор:
После ACCT # 03 следуют двухзначный блок, двухзначный раздел, блок (состоит из четырех цифр, за которым в некоторых случаях следует буква) и лот (состоит из трех цифр, за которым в некоторых случаях следует буква).