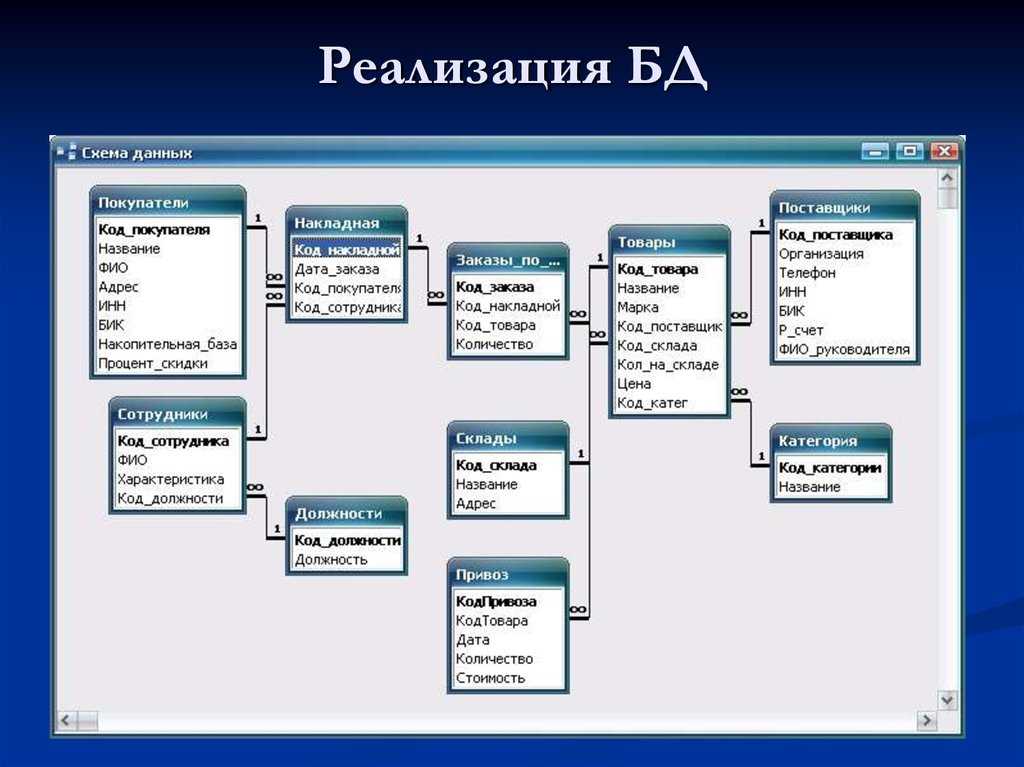
начало работы с базами данных
Проверьте, как это работает!
Базы данных и веб-приложения могут принести большую пользу вашему бизнесу. Проектирование базы данных играет важнейшую роль в достижении ваших целей независимо от того, что вам нужно: управлять сведениями о сотрудниках, предоставлять еженедельные отчеты по данным или отслеживать заказы клиентов. Уделив время изучению всех нюансов проектирования баз данных, вы сможете создавать базы, которые будут не только отвечать вашим текущим требованиям, но и адаптироваться к изменениям.
Важно: Веб-приложения Access отличаются от классических баз данных. В этой статье не рассматривается проектирование веб-приложений.
Понятия и термины
Для начала рассмотрим основные термины и понятия. Чтобы спроектировать полезную базу данных, необходимо создать таблицы с данными по одному объекту. В таблицах можно собрать все данные по этому объекту и отобразить их полях, которые содержат наименьшую единицу данных.
В таблицах можно собрать все данные по этому объекту и отобразить их полях, которые содержат наименьшую единицу данных.
|
Реляционные базы данных |
База данных, в которой данные разделены на таблицы по типу электронных. Каждая таблица включает данные по одному объекту, например по клиентам (одна таблица) или товарам (другая таблица). |
|
Записи и поля |
Области хранения отдельных данных в таблице. В каждой строке (или записи) хранится уникальный элемент данных, например имя клиента. Столбцы (или поля) содержат сведения по каждой точке данных в виде наименьшей единицы: имя может находиться в одном столбце, а фамилия — в другом. |
|
Первичный ключ |
Значение, которое обеспечивает уникальность каждой записи. Допустим, есть два клиента с одинаковыми именами, например Юрий Богданов. Но у одного из них первичный ключ записей — 12, а у другого — 58. |
|
Иерархические отношения |
Общие связи между таблицами. Например, у одного клиента может быть несколько заказов. Родительские таблицы имеют первичные ключи. Детские таблицы имеют внешниеключи , которые являются значениями из первичного ключа, которые показывают, как записи детской таблицы связаны с родительской таблицей. |
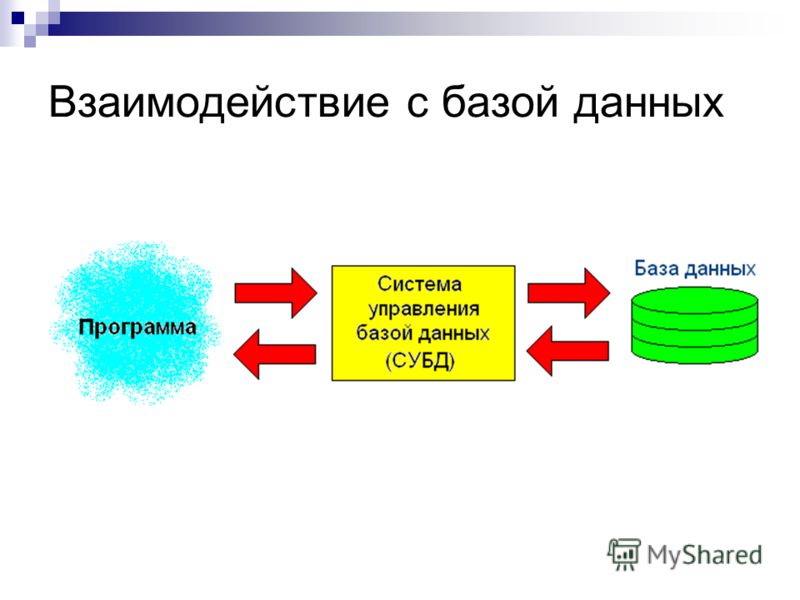

Что понимать под хорошим проектированием базы данных?
В основе проектирования хорошей базы данных лежат два принципа:
-
Избегайте повторяющихся сведений (избыточных данных). Они занимают много места на диске и повышают вероятность ошибок.
-
Следите за правильностью и полнотой данных. Неполные или неправильные сведения отображаются в запросах и отчетах, что в конечном итоге может привести к принятию ошибочных решений.
Чтобы избежать этих проблем:
-
Объединяйте таблицы с помощью ключей, а не путем дублирования данных.
-
Используйте процессы, которые обеспечивают точность и целостность информации в базе данных.
Проектируйте базу данных с учетом своих требований к обработке данных и созданию отчетов по ним.
 org/ListItem»>
org/ListItem»>
Разделяйте информацию в базе данных по таблицам для отдельных объектов. Избегайте повторения информации в нескольких таблицах. (Например, имена клиентов должны находиться только в одной таблице.)
Чтобы повысить пользу баз данных в долгосрочной перспективе, выполните следующие пять шагов по проектированию:
Шаг 1.
 Определение назначения базы данных
Определение назначения базы данных
Прежде чем начать, сформулируйте цель базы данных.
Чтобы спроектировать специализированную базу данных, определите ее назначение и часто обращайтесь к этому определению. Если вам нужна небольшая база данных для домашнего бизнеса, можно дать простое определение, например: «Эта база данных содержит список сведений о клиентах для рассылки и создания отчетов». Для корпоративной базы данных можно дать определение из нескольких абзацев, в котором будет описано, когда и как люди с различными ролями используют базу данных и содержащуюся в ней информацию. Создайте специальное и подробное определение цели и периодически обращайтесь к нему в процессе проектирования.
Шаг 2. Поиск и упорядочение необходимых сведений
Соберите все типы данных, которые необходимо записывать, например названия товаров и номера заказов.
Начните с существующих сведений и методов отслеживания. Предположим, вы записываете заказы на покупку в книге учета или ведете записи о клиентах в бумажных формах. Используйте эти источники, чтобы создать список собираемых сведений (например, всех полей в формах). Если в настоящее время вы не собираете важные сведения, подумайте, какие дискретные данные вам необходимы. Каждый отдельный тип данных становится полем в вашей базе данных.
Не беспокойтесь, если ваш первый список несовершенен — вы сможете доработать его со временем. Однако всегда помните о людях, которые будут пользоваться этой информацией, и учитывайте их мнение.
Затем подумайте, что вы ждете от своей базы данных и какие отчеты или рассылки вы хотите создавать. Убедитесь, что вы собираете данные, которые отвечают этим целям. Например, если вам нужен отчет о продажах по регионам, вам необходимо собирать данные о продажах на региональном уровне. Попробуйте сделать набросок желаемого отчета, используя фактические данные. Затем составьте список данных, необходимых для создания отчета. Сделайте то же самое для рассылок или других выходных данных, которые нужно получить из базы данных.
Попробуйте сделать набросок желаемого отчета, используя фактические данные. Затем составьте список данных, необходимых для создания отчета. Сделайте то же самое для рассылок или других выходных данных, которые нужно получить из базы данных.
Пример
Предположим, вы даете клиентам возможность подписаться на периодическую рассылку (или отказаться от нее) и хотите распечатать список подписавшихся пользователей. Вам нужно создать столбец «Отправка почты» в таблице «Клиенты» с допустимыми значениями «Да» и «Нет».
Для тех, кто хочет получать рассылку, вам нужно добавить электронный адрес, что также требует отдельного поля. Если вы хотите использовать соответствующее обращение к получателю (например, «Уважаемый» или «Уважаемая»), добавьте поле «Обращение». Если в письмах вы хотите обращаться к клиентам по имени, добавьте поле «Имя».
Совет: Не забывайте разбивать данные на наименьшие единицы, например имя и фамилию в таблице «Клиенты».
Шаг 3. Разделение данных по таблицам
Разделите элементы данных на основные объекты, например товары, клиенты или заказы. Каждый объект выносится в таблицу.
После создания списка необходимых сведений определите основные объекты, необходимые для организации данных. Избегайте повторения данных между объектами. Например, предварительный список для базы данных по продажам товаров может выглядеть так:
К основным объектам относятся клиенты, поставщики, товары и заказы. Поэтому начните с соответствующих четырех таблиц: по клиентам, поставщикам и т. д. Возможно, ваша конечная цель состоит не в этом, но это будет хорошим началом.
Примечание: Лучшие базы данных содержат несколько таблиц. Избегайте искушения поместить все данные в одну таблицу. Это приведет к повторению информации, увеличению размера базы данных и повышению вероятности ошибок. Каждый элемент данных должен записываться только один раз. Если вы обнаружите повторяющиеся сведения, например адрес поставщика, измените структуру базы данных так, чтобы эта информация находилась в отдельной таблице.
Избегайте искушения поместить все данные в одну таблицу. Это приведет к повторению информации, увеличению размера базы данных и повышению вероятности ошибок. Каждый элемент данных должен записываться только один раз. Если вы обнаружите повторяющиеся сведения, например адрес поставщика, измените структуру базы данных так, чтобы эта информация находилась в отдельной таблице.
Чтобы понять, почему чем больше таблиц, тем лучше, рассмотрим следующую таблицу:
Каждая строка содержит сведения о товаре и его поставщике. Так как у вас может быть несколько продуктов от одного поставщика, имена и адреса поставщиков должны повторяться многократно. Это пустая трата места на диске. Вместо этого зафиксировать сведения о поставщике только один раз в отдельной таблице «Поставщики» и связать ее с таблицей «Товары».
Вторая проблема проектирования возникает тогда, когда нужно изменить сведения о поставщике. Предположим, вам нужно изменить адрес поставщика. А так как адрес указан во многих полях, можно случайно изменить его в одном поле и забыть изменить в других. Эту проблему можно решить, записав адрес поставщика только в одном поле.
Эту проблему можно решить, записав адрес поставщика только в одном поле.
Наконец, предположим, у вас есть только один товар, поставляемый компанией Coho Winery, и вы хотите удалить этот товар, но сохранить имя и адрес поставщика. Как удалить запись о товаре, не потеряв сведений о поставщике, с такой структурой базы данных? Это невозможно. Так как каждая запись содержит информацию о товаре вместе с данными о поставщике, их невозможно удалить по отдельности. Чтобы разделить эти сведения, необходимо сделать из одной таблицы две: одну — для сведений о товаре, другую —для сведений о поставщике. И только после этого удаление записи о товаре не будет приводить к удалению сведений о поставщике.
Шаг 4. Превращение элементов данных в столбцы
Определите, какие данные необходимо хранить в каждой таблице. Эти отдельные элементы данных становятся полями в таблице. Например, таблица «Сотрудники» может содержать такие поля, как «Фамилия», «Имя» и «Дата приема на работу».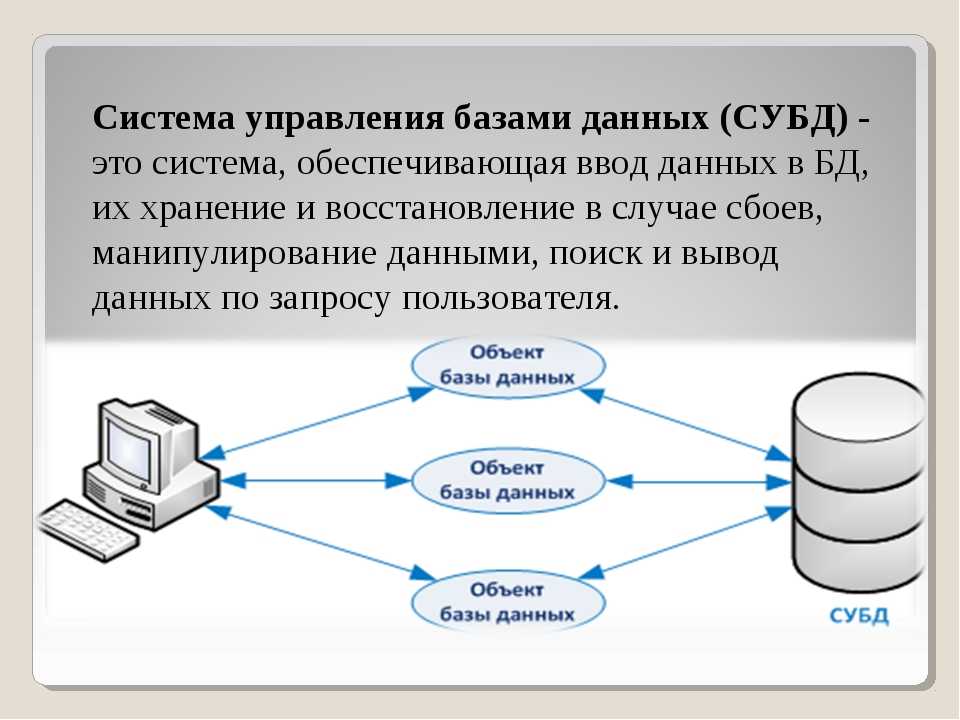
После выбора объекта для таблицы базы данных столбцы в ней должны содержать сведения только об этом объекте. Например, таблица по товарам должна содержать сведения только о товарах, а не о поставщиках.
Чтобы определить, какие данные нужно отследить в таблице, используйте ранее созданный список. Например, таблица «Клиенты» может содержать такие поля: «Имя», «Фамилия», «Адрес», «Отправка почты», «Обращение» и «Электронный адрес.» Каждая запись (клиент) в таблице содержит один и тот же набор столбцов, поэтому по каждому клиенту можно хранить одинаковую информацию.
Создайте первый список, а затем просмотрите и уточните его. Не забудьте разбить данные на наименьшие возможные поля. Например, если исходный список имеет адрес в качестве поля, разобьйте его на Адрес, Город, Область и Почтовый индекс или, если ваши клиенты являются глобальными, на еще большее поле. Это, например, позволяет выполнять рассылки в правильном формате или отчет по заказам по штатам.
Доработав столбцы с данными во всех таблицах, вы готовы выбрать первичный ключ для каждой из них.
Шаг 5. Задание первичных ключей
Выберите первичный ключ для каждой таблицы. Первичный ключ, например код товара или код заказа, является уникальным идентификатором каждой записи. Если у вас нет явного уникального идентификатора, его можно создать с помощью Access.
Вам нужно однозначно определить каждую строку в каждой таблице. Вернемся к примеру с двумя клиентами с одинаковым именем. Так как у них одно и то же имя, им нужно дать уникальный идентификатор.
Поэтому каждая таблица должна содержать столбец (или набор столбцов), который однозначно определяет каждую строку. Это и есть первичный ключ. Он часто является уникальным числом, например кодом сотрудника или порядковым номером Используя первичные ключи, Access быстро связывает данные из нескольких таблиц и сводит их для вас воедино.
Иногда первичный ключ состоит из нескольких полей. Например, в таблице «Сведения о заказе», которая содержит позиции по заказам, первичный ключ может включать два столбца: «Код заказа» и «Код товара». Если в первичном ключе используется несколько столбцов, он также называется составным ключом.
Если у вас уже есть уникальный идентификатор для данных в таблице, например номера товаров, однозначно определяющие каждый продукт в каталоге, используйте его, но только если эти значения соответствуют следующим правилам первичных ключей:
-
Идентификатор для каждой записи всегда уникален. Повторяющиеся значения в первичном ключе не допускаются.
-
Для каждого элемента всегда существует значение. Каждая запись в таблице должна иметь первичный ключ.
 Если вы создаете ключ с помощью нескольких столбцов, например «Группа позиций» и «Код позиции», всегда должны присутствовать оба значения.
Если вы создаете ключ с помощью нескольких столбцов, например «Группа позиций» и «Код позиции», всегда должны присутствовать оба значения. -
Первичный ключ представляет собой неизменное значение. Так как на ключи ссылаются другие таблицы, при любом изменении первичного ключа в одной таблице необходимо изменить его во всех других. Частые изменения повышают риск возникновения ошибок.
 Если вы создаете ключ с помощью нескольких столбцов, например «Группа позиций» и «Код позиции», всегда должны присутствовать оба значения.
Если вы создаете ключ с помощью нескольких столбцов, например «Группа позиций» и «Код позиции», всегда должны присутствовать оба значения.Если у вас нет явного идентификатора, то в качестве первичного ключа используйте произвольный уникальный номер. Например, вы можете присвоить каждому заказу уникальный номер, только чтобы идентифицировать его.
Совет: Чтобы создать уникальный номер в качестве первичного ключа, добавьте столбец, используя тип данных «Счетчик». Этот тип данных автоматически присваивает каждой записи уникальное числовое значение. Такой идентификатор не содержит фактических сведений о строке, которую он представляет. Он идеален в качестве первичного ключа, так как в отличие от ключей, содержащих фактические данные о строке (например, номер телефона или имя клиента), числа не изменяются.
Такой идентификатор не содержит фактических сведений о строке, которую он представляет. Он идеален в качестве первичного ключа, так как в отличие от ключей, содержащих фактические данные о строке (например, номер телефона или имя клиента), числа не изменяются.
Вам нужны дополнительные возможности?
Руководство по именованию полей, элементов управления и объектов
Общие сведения о таблицах
Обучение работе с Excel
Обучение работе с Outlook
Что такое NoSQL? | Нереляционные базы данных, модели данных с гибкой схемой | AWS
Высокопроизводительные нереляционные базы данных с гибкими моделями данных
Базы данных NoSQL специально созданы для определенных моделей данных и обладают гибкими схемами, что позволяет разрабатывать современные приложения. Базы данных NoSQL получили широкое распространение в связи с простотой разработки, функциональностью и производительностью при любых масштабах. Ресурсы, представленные на этой странице, помогут разобраться с базами данных NoSQL и начать работу с ними.
Базы данных NoSQL получили широкое распространение в связи с простотой разработки, функциональностью и производительностью при любых масштабах. Ресурсы, представленные на этой странице, помогут разобраться с базами данных NoSQL и начать работу с ними.
Базы данных в AWS: подходящий инструмент для подходящей работы
Базы данных NoSQL используют разнообразные модели данных для доступа к данным и управления ими. Базы данных таких типов оптимизированы для приложений, которые работают с большим объемом данных, нуждаются в низкой задержке и гибких моделях данных. Все это достигается путем смягчения жестких требований к непротиворечивости данных, характерных для других типов БД.
Рассмотрим пример моделирования схемы для простой базы данных книг.
- В реляционной базе данных запись о книге часто разделяется на несколько частей (или «нормализуется») и хранится в отдельных таблицах, отношения между которыми определяются ограничениями первичных и внешних ключей. В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
 В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.- В базе данных NoSQL запись о книге обычно хранится как документ JSON. Для каждой книги, или элемента, значения «ISBN», «Название книги», «Номер издания», «Имя автора и «ИД автора» хранятся в качестве атрибутов в едином документе. В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
Базы данных NoSQL хорошо подходят для многих современных приложений, например мобильных, игровых, интернет‑приложений, когда требуются гибкие масштабируемые базы данных с высокой производительностью и широкими функциональными возможностями, способные обеспечивать максимальное удобство использования.
- Гибкость. Как правило, базы данных NoSQL предлагают гибкие схемы, что позволяет осуществлять разработку быстрее и обеспечивает возможность поэтапной реализации. Благодаря использованию гибких моделей данных БД NoSQL хорошо подходят для частично структурированных и неструктурированных данных.
- Масштабируемость. Базы данных NoSQL рассчитаны на масштабирование с использованием распределенных кластеров аппаратного обеспечения, а не путем добавления дорогих надежных серверов. Некоторые поставщики облачных услуг проводят эти операции в фоновом режиме, обеспечивая полностью управляемый сервис.
- Высокая производительность. Базы данных NoSQL оптимизированы для конкретных моделей данных и шаблонов доступа, что позволяет достичь более высокой производительности по сравнению с реляционными базами данных.
- Широкие функциональные возможности. Базы данных NoSQL предоставляют API и типы данных с широкой функциональностью, которые специально разработаны для соответствующих моделей данных.

БД на основе пар «ключ‑значение». Базы данных с использованием пар «ключ‑значение» поддерживают высокую разделяемость и обеспечивают беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД. Хорошими примерами использования для баз данных типа «ключ‑значение» являются игровые, рекламные приложения и приложения IoT. Amazon DynamoDB обеспечивает стабильную работу БД с задержкой не более нескольких миллисекунд при любом масштабе. Такая устойчивая производительность послужила основной причиной переноса Snapchat Stories в сервис DynamoDB, поскольку эта возможность Snapchat связана с самой большой нагрузкой на запись в хранилище.
Документ В коде приложения данные часто представлены как объект или документ в формате, подобном JSON, поскольку для разработчиков это эффективная и интуитивная модель данных. Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения. Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем. Amazon DocumentDB (совместимая с MongoDB) и MongoDB — распространенные документные базы данных, которые предоставляют функциональные и интуитивно понятные API для гибкой разработки.
Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем. Amazon DocumentDB (совместимая с MongoDB) и MongoDB — распространенные документные базы данных, которые предоставляют функциональные и интуитивно понятные API для гибкой разработки.
Графовые БД. Графовые базы данных упрощают разработку и запуск приложений, работающих с наборами сложносвязанных данных. Типичные примеры использования графовых баз данных – социальные сети, сервисы рекомендаций, системы выявления мошенничества и графы знаний. Amazon Neptune – это полностью управляемый сервис графовых баз данных. Neptune поддерживает модель Property Graph и Resource Description Framework (RDF), предоставляя на выбор два графовых API: TinkerPop и RDF / SPARQL. К числу распространенных графовых БД относятся Neo4j и Giraph.
К числу распространенных графовых БД относятся Neo4j и Giraph.
БД в памяти. Часто в игровых и рекламных приложениях используются таблицы лидеров, хранение сессий и аналитика в реальном времени. Такие возможности требуют отклика в пределах нескольких микросекунд, при этом резкое возрастание трафика возможно в любой момент. Amazon MemoryDB для Redis – это совместимый с Redis надежный сервис базы данных в памяти, который уменьшает задержку чтения до миллисекунд и обеспечивает надежность в нескольких зонах доступности. MemoryDB специально создана для обеспечения сверхвысокой производительности и надежности, поэтому ее можно использовать как основную базу данных для современных приложений на базе микросервисов. Amazon ElastiCache – это полностью управляемый сервис кэширования в памяти, совместимый с Redis и Memcached для обслуживания рабочих нагрузок с низкой задержкой и высокой пропускной способностью. Такие клиенты, как Tinder, которым требуется, чтобы их приложения давали отклик в режиме реального времени, пользуются системами хранения данных в памяти, а не на диске. Еще одним примером специально разработанного хранилища данных является Amazon DynamoDB Accelerator (DAX). DAX позволяет DynamoDB считывать данные в несколько раз быстрее.
Еще одним примером специально разработанного хранилища данных является Amazon DynamoDB Accelerator (DAX). DAX позволяет DynamoDB считывать данные в несколько раз быстрее.
Поисковые БД. Многие приложения формируют журналы, чтобы разработчикам было проще выявлять и устранять неполадки. Сервис Amazon OpenSearch – специально разработанный сервис для визуализации и аналитики автоматически генерируемых потоков данных в режиме, близком к реальному времени, путем индексирования, агрегации частично структурированных журналов и метрик и поиска по ним. Кроме того, сервис Amazon OpenSearch – это мощный, высокопроизводительный сервис для полнотекстового поиска. Компания Expedia задействует более 150 доменов сервиса Amazon OpenSearch, 30 ТБ данных и 30 миллиардов документов для разнообразных особо важных примеров использования – от операционного мониторинга и устранения неисправностей до отслеживания стека распределенных приложений и оптимизации затрат.
В течение десятилетий центральное место в разработке приложений занимала реляционная модель данных, которая использовалась в реляционных базах данных, таких как Oracle, DB2, SQL Server, MySQL и PostgreSQL. Но в середине – конце 2000‑х годов заметное распространение стали получать и другие модели данных. Для обозначения появившихся классов БД и моделей данных был введен термин «NoSQL». Часто «NoSQL» используется в качестве синонима к термину «нереляционный».
Но в середине – конце 2000‑х годов заметное распространение стали получать и другие модели данных. Для обозначения появившихся классов БД и моделей данных был введен термин «NoSQL». Часто «NoSQL» используется в качестве синонима к термину «нереляционный».
Существует множество типов БД NoSQL с различными особенностями, но в таблице ниже приведены основные отличия баз данных NoSQL от SQL.
Начало работы с NoSQL
В следующей таблице приведено сравнение терминологии некоторых баз данных NoSQL с терминологией баз данных SQL.
| SQL | MongoDB | DynamoDB | Cassandra | Couchbase |
|---|---|---|---|---|
| Таблица | Коллекция | Таблица | Таблица | Корзина данных |
| Ряд | Документ | Элемент | Ряд | Документ |
| Столбец | Поле | Атрибут | Столбец | Поле |
| Первичный ключ | ObjectId | Первичный ключ | Первичный ключ | ИД документа |
| Индекс | Индекс | Вторичный индекс | Индекс | Индекс |
| Представление | Представление | Глобальный вторичный индекс | Материализованное представление | Представление |
| Вложенная таблица или объект | Встроенный документ | Карта | Карта | Карта |
| Массив | Массив | Список | Список | Список |
| Список |
| Список |
| Первичный ключ |
Начать работу с DynamoDB очень просто. Страница по началу работы с DynamoDB поможет создать первую таблицу за несколько щелчков мышью. Можно загрузить техническое описание AWS, чтобы изучить рекомендации по миграции рабочих нагрузок из реляционной системы управления базой данных (РСУБД) в DynamoDB.
Страница по началу работы с DynamoDB поможет создать первую таблицу за несколько щелчков мышью. Можно загрузить техническое описание AWS, чтобы изучить рекомендации по миграции рабочих нагрузок из реляционной системы управления базой данных (РСУБД) в DynamoDB.
Начать работу с Amazon DynamoDB
What is Amazon DynamoDB?
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- Инклюзивность, многообразие и равенство AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Портфолио решений AWS
- Центр архитектурных решений
- Вопросы и ответы по продуктам и техническим темам
- Отчеты аналитиков
- Партнерская сеть AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- . NET на AWS
- Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
 NET на AWS
NET на AWSПоддержка
- Связаться с нами
- Работа в AWS
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
Amazon.com – работодатель равных возможностей. Мы предоставляем равные права представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
Несколько баз данных | Документация Django 4.0
Это тематическое руководство описывает поддержку Django для взаимодействия с несколькими базами данных. Большая часть остальной документации Django предполагает, что вы взаимодействуете с одной базой данных. Если вы хотите взаимодействовать с несколькими базами данных, вам придется предпринять некоторые дополнительные шаги.
Большая часть остальной документации Django предполагает, что вы взаимодействуете с одной базой данных. Если вы хотите взаимодействовать с несколькими базами данных, вам придется предпринять некоторые дополнительные шаги.
См.также
Информацию о тестировании с несколькими базами данных см. в Поддержка нескольких баз данных.
Определение ваших баз данных
Первый шаг к использованию более чем одной базы данных с Django — сообщить Django о серверах баз данных, которые вы будете использовать. Это делается с помощью параметра DATABASES. Эта настройка сопоставляет псевдонимы баз данных, которые являются способом обращения к конкретной базе данных в Django, со словарем настроек для этого конкретного соединения. Настройки во внутренних словарях полностью описаны в документации DATABASES.
Базы данных могут иметь любой выбранный вами псевдоним. Однако, псевдоним default имеет особое значение. Django использует базу данных с псевдонимом default, если не выбрана другая база данных.
Ниже приведен пример settings.py фрагмента, определяющего две базы данных — базу данных PostgreSQL по умолчанию и базу данных MySQL под названием users:
DATABASES = {
'default': {
'NAME': 'app_data',
'ENGINE': 'django.db.backends.postgresql',
'USER': 'postgres_user',
'PASSWORD': 's3krit'
},
'users': {
'NAME': 'user_data',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'priv4te'
}
}
Если концепция базы данных default не имеет смысла в контексте вашего проекта, вам нужно быть внимательным, чтобы всегда указывать базу данных, которую вы хотите использовать. Django требует, чтобы была определена запись default базы данных, но словарь параметров можно оставить пустым, если она не будет использоваться. Для этого вы должны настроить DATABASE_ROUTERS для всех моделей вашего приложения, включая модели любых используемых вами приложений и приложений сторонних разработчиков, чтобы никакие запросы не направлялись к базе данных по умолчанию. Ниже приведен пример
Ниже приведен пример settings.py фрагмента, определяющего две базы данных не по умолчанию, при этом default запись намеренно оставлена пустой:
DATABASES = {
'default': {},
'users': {
'NAME': 'user_data',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'superS3cret'
},
'customers': {
'NAME': 'customer_data',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_cust',
'PASSWORD': 'veryPriv@ate'
}
}
Если вы попытаетесь получить доступ к базе данных, которую вы не определили в настройках DATABASES, Django вызовет исключение django.utils.connection.ConnectionDoesNotExist.
Синхронизация баз данных
Команда управления migrate работает с одной базой данных за один раз. По умолчанию она работает с базой данных default, но, указав опцию --database, вы можете указать ей синхронизировать другую базу данных. Так, для синхронизации всех моделей на всех базах данных в первом примере выше, вам нужно вызвать:
Так, для синхронизации всех моделей на всех базах данных в первом примере выше, вам нужно вызвать:
$ ./manage.py migrate $ ./manage.py migrate --database=users
Если вы не хотите, чтобы каждое приложение было синхронизировано с определенной базой данных, вы можете определить database router, который реализует политику, ограничивающую доступность определенных моделей.
Если, как во втором примере выше, вы оставили базу данных default пустой, вы должны указывать имя базы данных каждый раз, когда запускаете migrate. Отсутствие имени базы данных приведет к ошибке. Для второго примера:
$ ./manage.py migrate --database=users $ ./manage.py migrate --database=customers
Использование других команд управления
Большинство других команд django-admin, взаимодействующих с базой данных, работают так же, как и migrate — они работают только с одной базой данных одновременно, используя --database для управления используемой базой данных.
Исключением из этого правила является команда makemigrations. Она проверяет историю миграций в базах данных, чтобы отловить проблемы с существующими файлами миграций (которые могут быть вызваны их редактированием) перед созданием новых миграций. По умолчанию она проверяет только базу данных default, но обращается к методу allow_migrate() и routers, если таковые установлены.
Автоматическая маршрутизация баз данных
Самый простой способ использовать несколько баз данных — настроить схему маршрутизации баз данных. Схема маршрутизации по умолчанию гарантирует, что объекты остаются «прилипшими» к своей исходной базе данных (т.е. объект, извлеченный из базы данных foo, будет сохранен в той же базе данных). Схема маршрутизации по умолчанию гарантирует, что если база данных не указана, все запросы возвращаются к базе данных default.
Вам не нужно ничего делать, чтобы активировать схему маршрутизации по умолчанию — она предоставляется «из коробки» в каждом проекте Django. Однако, если вы хотите реализовать более интересное поведение распределения баз данных, вы можете определить и установить свои собственные маршрутизаторы баз данных.
Однако, если вы хотите реализовать более интересное поведение распределения баз данных, вы можете определить и установить свои собственные маршрутизаторы баз данных.
Маршрутизаторы баз данных
Маршрутизатор базы данных — это класс, который предоставляет до четырех методов:
-
db_for_read(model, **hints) Предложите базу данных, которая должна использоваться для операций чтения объектов типа
model.Если операция с базой данных способна предоставить какую-либо дополнительную информацию, которая может помочь в выборе базы данных, она будет предоставлена в словаре
hints. Подробности о допустимых подсказках приведены в below.Возвращает
None, если предложение отсутствует.
-
db_for_write(model, **hints) Предложите базу данных, которая должна использоваться для записи объектов типа Model.
Если операция с базой данных способна предоставить какую-либо дополнительную информацию, которая может помочь в выборе базы данных, она будет предоставлена в словаре
hints. Подробности о допустимых подсказках приведены в below.Возвращает
None, если предложение отсутствует.

-
allow_relation(obj1, obj2, **hints) Возвращает
True, если связь междуobj1иobj2должна быть разрешена,False, если связь должна быть запрещена, илиNone, если маршрутизатор не имеет мнения. Это чисто проверочная операция, используемая внешним ключом и операциями «многие ко многим» для определения того, должна ли быть разрешена связь между двумя объектами.Если ни один маршрутизатор не имеет мнения (т.е. все маршрутизаторы возвращают
None), допускаются только отношения в пределах одной базы данных.
-
allow_migrate(db, app_label, model_name=None, **hints) Определите, разрешена ли операция миграции для базы данных с псевдонимом
db. ВозвращаетTrue, если операция должна быть запущена,False, если она не должна быть запущена, илиNone, если маршрутизатор не имеет мнения.Позиционный аргумент
app_label— это метка переносимого приложения.model_nameустанавливается большинством операций миграции в значениеmodel._meta.model_name(строчная версия модели__name__) мигрируемой модели. Для операцийNoneиRunPythonего значение равноRunSQL, если только они не предоставляют его с помощью подсказок.hintsиспользуются некоторыми операциями для передачи дополнительной информации маршрутизатору.Когда установлено
model_name,hintsобычно содержит класс модели под ключом'model'. Обратите внимание, что он может быть historical model, и, следовательно, не иметь никаких пользовательских атрибутов, методов или менеджеров. Вы должны полагаться только на _meta.Этот метод также может быть использован для определения доступности модели на данной базе данных.
makemigrationsвсегда создает миграции для изменений модели, но еслиallow_migrate()возвращаетFalse, любые операции миграции дляmodel_nameбудут молча пропущены при выполненииmigrateнаdb. Изменение поведенияallow_migrate()для моделей, которые уже имеют миграции, может привести к неработающим внешним ключам, лишним таблицам или отсутствующим таблицам. Когдаmakemigrationsпроверяет историю миграций, он пропускает базы данных, в которые не разрешено мигрировать ни одному приложению.
 Обратите внимание, что он может быть historical model, и, следовательно, не иметь никаких пользовательских атрибутов, методов или менеджеров. Вы должны полагаться только на
Обратите внимание, что он может быть historical model, и, следовательно, не иметь никаких пользовательских атрибутов, методов или менеджеров. Вы должны полагаться только на Маршрутизатор не обязан предоставлять все эти методы — он может опустить один или несколько из них.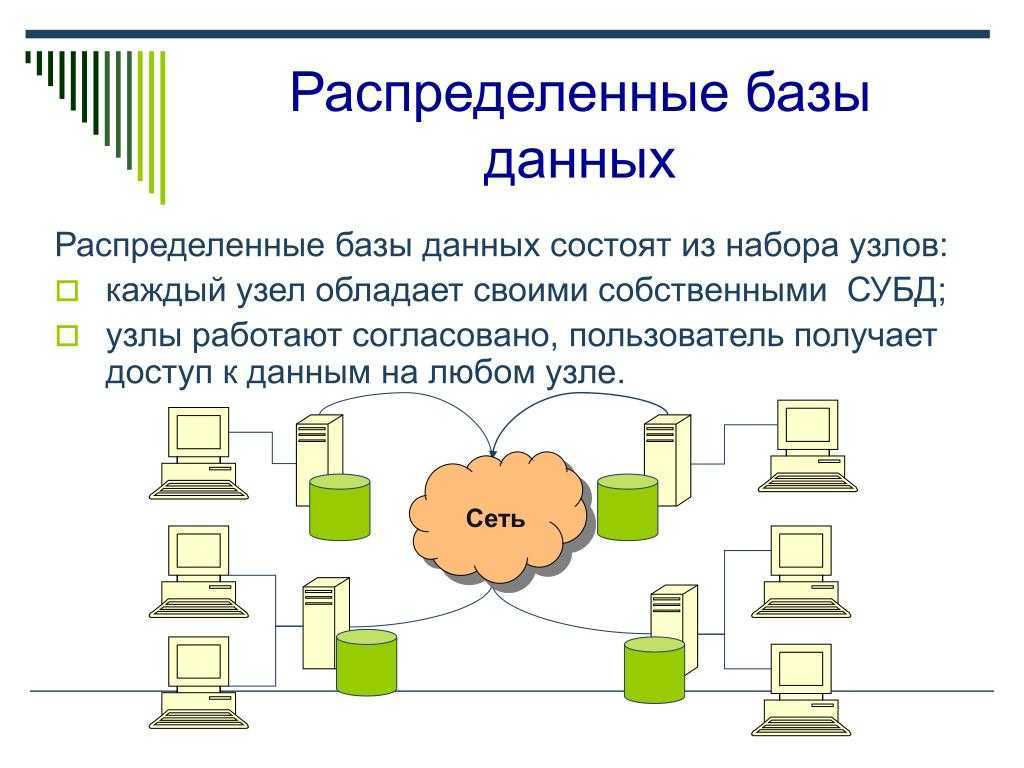 Если один из методов опущен, Django пропустит этот маршрутизатор при выполнении соответствующей проверки.
Если один из методов опущен, Django пропустит этот маршрутизатор при выполнении соответствующей проверки.
Подсказки
Подсказки, полученные маршрутизатором баз данных, могут быть использованы для принятия решения о том, какая база данных должна получить данный запрос.
В настоящее время единственной подсказкой, которая будет предоставлена, является instance, экземпляр объекта, связанный с выполняемой операцией чтения или записи. Это может быть экземпляр, который сохраняется, или экземпляр, который добавляется в отношение «многие-ко-многим». В некоторых случаях подсказка экземпляра вообще не предоставляется. Маршрутизатор проверяет существование подсказки экземпляра и определяет, следует ли использовать эту подсказку для изменения поведения маршрутизации.
Использование маршрутизаторов
Маршрутизаторы базы данных устанавливаются с помощью настройки DATABASE_ROUTERS. Эта настройка определяет список имен классов, каждый из которых указывает маршрутизатор, который должен использоваться главным маршрутизатором (django.). db.router
db.router
Главный маршрутизатор используется операциями с базами данных Django для распределения использования баз данных. Всякий раз, когда запросу нужно узнать, какую базу данных использовать, он обращается к главному маршрутизатору, предоставляя модель и подсказку (если она доступна). Затем Django пробует каждый маршрутизатор по очереди, пока не будет найдено предложение базы данных. Если предложение не найдено, он пробует текущий instance._state.db экземпляр подсказки. Если экземпляр подсказки не был предоставлен, или instance._state.db является None, главный маршрутизатор выделит базу данных default.
Пример
Только для примера!
Этот пример предназначен для демонстрации того, как инфраструктура маршрутизаторов может быть использована для изменения использования базы данных. В нем намеренно игнорируются некоторые сложные вопросы, чтобы продемонстрировать, как используются маршрутизаторы.
Этот пример не будет работать, если какая-либо из моделей в myapp содержит связи с моделями вне базы данных other. В Cross-database relationships возникают проблемы ссылочной целостности, с которыми Django в настоящее время не может справиться.
В Cross-database relationships возникают проблемы ссылочной целостности, с которыми Django в настоящее время не может справиться.
Описанная конфигурация основной/реплика (в некоторых базах данных называемая ведущей/ведомой) также несовершенна — она не предоставляет никакого решения для обработки задержки репликации (т.е. несоответствий запросов, возникающих из-за времени, необходимого для распространения записи на реплики). В нем также не рассматривается взаимодействие транзакций со стратегией использования базы данных.
Итак, что это означает на практике? Рассмотрим еще один пример конфигурации. В этой конфигурации будет несколько баз данных: одна для приложения auth, а все остальные приложения используют первичную/реплику с двумя копиями для чтения. Вот настройки, определяющие эти базы данных:
DATABASES = {
'default': {},
'auth_db': {
'NAME': 'auth_db_name',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'swordfish',
},
'primary': {
'NAME': 'primary_name',
'ENGINE': 'django. db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'spam',
},
'replica1': {
'NAME': 'replica1_name',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'eggs',
},
'replica2': {
'NAME': 'replica2_name',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'bacon',
},
}
 db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'spam',
},
'replica1': {
'NAME': 'replica1_name',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'eggs',
},
'replica2': {
'NAME': 'replica2_name',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'bacon',
},
}
db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'spam',
},
'replica1': {
'NAME': 'replica1_name',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'eggs',
},
'replica2': {
'NAME': 'replica2_name',
'ENGINE': 'django.db.backends.mysql',
'USER': 'mysql_user',
'PASSWORD': 'bacon',
},
}
Теперь нам нужно разобраться с маршрутизацией. Сначала нам нужен маршрутизатор, который знает, что нужно посылать запросы для приложений auth и contenttypes в auth_db (модели auth связаны с ContentType, поэтому они должны храниться в одной базе данных):
class AuthRouter:
"""
A router to control all database operations on models in the
auth and contenttypes applications.
"""
route_app_labels = {'auth', 'contenttypes'}
def db_for_read(self, model, **hints):
"""
Attempts to read auth and contenttypes models go to auth_db.
"""
if model._meta.app_label in self.route_app_labels:
return 'auth_db'
return None
def db_for_write(self, model, **hints):
"""
Attempts to write auth and contenttypes models go to auth_db.
"""
if model._meta.app_label in self.route_app_labels:
return 'auth_db'
return None
def allow_relation(self, obj1, obj2, **hints):
"""
Allow relations if a model in the auth or contenttypes apps is
involved.
"""
if (
obj1._meta.app_label in self.route_app_labels or
obj2._meta.app_label in self.route_app_labels
):
return True
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
Make sure the auth and contenttypes apps only appear in the
'auth_db' database.
"""
if app_label in self.route_app_labels:
return db == 'auth_db'
return None
 """
if model._meta.app_label in self.route_app_labels:
return 'auth_db'
return None
def db_for_write(self, model, **hints):
"""
Attempts to write auth and contenttypes models go to auth_db.
"""
if model._meta.app_label in self.route_app_labels:
return 'auth_db'
return None
def allow_relation(self, obj1, obj2, **hints):
"""
Allow relations if a model in the auth or contenttypes apps is
involved.
"""
if (
obj1._meta.app_label in self.route_app_labels or
obj2._meta.app_label in self.route_app_labels
):
return True
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
Make sure the auth and contenttypes apps only appear in the
'auth_db' database.
"""
if model._meta.app_label in self.route_app_labels:
return 'auth_db'
return None
def db_for_write(self, model, **hints):
"""
Attempts to write auth and contenttypes models go to auth_db.
"""
if model._meta.app_label in self.route_app_labels:
return 'auth_db'
return None
def allow_relation(self, obj1, obj2, **hints):
"""
Allow relations if a model in the auth or contenttypes apps is
involved.
"""
if (
obj1._meta.app_label in self.route_app_labels or
obj2._meta.app_label in self.route_app_labels
):
return True
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
Make sure the auth and contenttypes apps only appear in the
'auth_db' database. """
if app_label in self.route_app_labels:
return db == 'auth_db'
return None
"""
if app_label in self.route_app_labels:
return db == 'auth_db'
return None
И нам также нужен маршрутизатор, который отправляет все другие приложения к конфигурации основной/реплики, и случайным образом выбирает реплику для чтения из:
import random
class PrimaryReplicaRouter:
def db_for_read(self, model, **hints):
"""
Reads go to a randomly-chosen replica.
"""
return random.choice(['replica1', 'replica2'])
def db_for_write(self, model, **hints):
"""
Writes always go to primary.
"""
return 'primary'
def allow_relation(self, obj1, obj2, **hints):
"""
Relations between objects are allowed if both objects are
in the primary/replica pool.
"""
db_set = {'primary', 'replica1', 'replica2'}
if obj1. _state.db in db_set and obj2._state.db in db_set:
return True
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
All non-auth models end up in this pool.
"""
return True
 _state.db in db_set and obj2._state.db in db_set:
return True
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
All non-auth models end up in this pool.
"""
return True
_state.db in db_set and obj2._state.db in db_set:
return True
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
All non-auth models end up in this pool.
"""
return True
Наконец, в файл настроек мы добавляем следующее (заменяя path.to. реальным Python-путем к модулю (модулям), где определены маршрутизаторы):
DATABASE_ROUTERS = ['path.to.AuthRouter', 'path.to.PrimaryReplicaRouter']
Порядок, в котором обрабатываются маршрутизаторы, имеет значение. Маршрутизаторы будут запрашиваться в том порядке, в котором они перечислены в настройке DATABASE_ROUTERS. В данном примере параметр AuthRouter обрабатывается раньше, чем PrimaryReplicaRouter, и в результате решения, касающиеся моделей в параметре auth, обрабатываются до принятия любого другого решения. Если бы параметр DATABASE_ROUTERS перечислял два маршрутизатора в другом порядке, то первым обрабатывался бы параметр PrimaryReplicaRouter.. Всеобъемлющий характер реализации PrimaryReplicaRouter означает, что все модели будут доступны во всех базах данных. allow_migrate()
allow_migrate()
После установки этой установки и переноса всех баз данных в соответствии с Синхронизация баз данных, давайте запустим некоторый код Django:
>>> # This retrieval will be performed on the 'auth_db' database >>> fred = User.objects.get(username='fred') >>> fred.first_name = 'Frederick' >>> # This save will also be directed to 'auth_db' >>> fred.save() >>> # These retrieval will be randomly allocated to a replica database >>> dna = Person.objects.get(name='Douglas Adams') >>> # A new object has no database allocation when created >>> mh = Book(title='Mostly Harmless') >>> # This assignment will consult the router, and set mh onto >>> # the same database as the author object >>> mh.
 author = dna
>>> # This save will force the 'mh' instance onto the primary database...
>>> mh.save()
>>> # ... but if we re-retrieve the object, it will come back on a replica
>>> mh = Book.objects.get(title='Mostly Harmless')
author = dna
>>> # This save will force the 'mh' instance onto the primary database...
>>> mh.save()
>>> # ... but if we re-retrieve the object, it will come back on a replica
>>> mh = Book.objects.get(title='Mostly Harmless')
В этом примере определен маршрутизатор для обработки взаимодействия с моделями из приложения auth, и другие маршрутизаторы для обработки взаимодействия со всеми остальными приложениями. Если вы оставили свою базу данных default пустой и не хотите определять маршрутизатор для обработки всех приложений, не указанных иначе, ваши маршрутизаторы должны обрабатывать имена всех приложений в INSTALLED_APPS перед миграцией. Смотрите Поведение приложений вклада для получения информации о приложениях, которые должны находиться в одной базе данных.
Ручной выбор базы данных
Django также предоставляет API, который позволяет вам полностью контролировать использование базы данных в вашем коде. Выделенная вручную база данных будет иметь приоритет над базой данных, выделенной маршрутизатором.
Выделенная вручную база данных будет иметь приоритет над базой данных, выделенной маршрутизатором.
Ручной выбор базы данных для
QuerySetВы можете выбрать базу данных для QuerySet в любой точке «цепочки» QuerySet. Вызовите using() на QuerySet, чтобы получить другой QuerySet, который использует указанную базу данных.
using() принимает единственный аргумент: псевдоним базы данных, на которой вы хотите выполнить запрос. Например:
>>> # This will run on the 'default' database.
>>> Author.objects.all()
>>> # So will this.
>>> Author.objects.using('default').all()
>>> # This will run on the 'other' database.
>>> Author.objects.using('other').all()
Выбор базы данных для
save()Используйте ключевые слова using и Model.save(), чтобы указать, в какую базу данных должны быть сохранены данные.
Например, чтобы сохранить объект в базе данных legacy_users, вы используете следующее:
>>> my_object.save(using='legacy_users')
Если вы не укажете using, метод save() будет сохранять в базу данных по умолчанию, выделенную маршрутизаторами.
Перемещение объекта из одной базы данных в другую
Если вы сохранили экземпляр в одной базе данных, может возникнуть соблазн использовать save(using=...) как способ переноса экземпляра в новую базу данных. Однако если не предпринять соответствующих шагов, это может привести к неожиданным последствиям.
Рассмотрим следующий пример:
>>> p = Person(name='Fred') >>> p.save(using='first') # (statement 1) >>> p.save(using='second') # (statement 2)
В операторе 1 новый объект Person сохраняется в базе данных first. На данный момент у p нет первичного ключа, поэтому Django выдает SQL-оператор INSERT.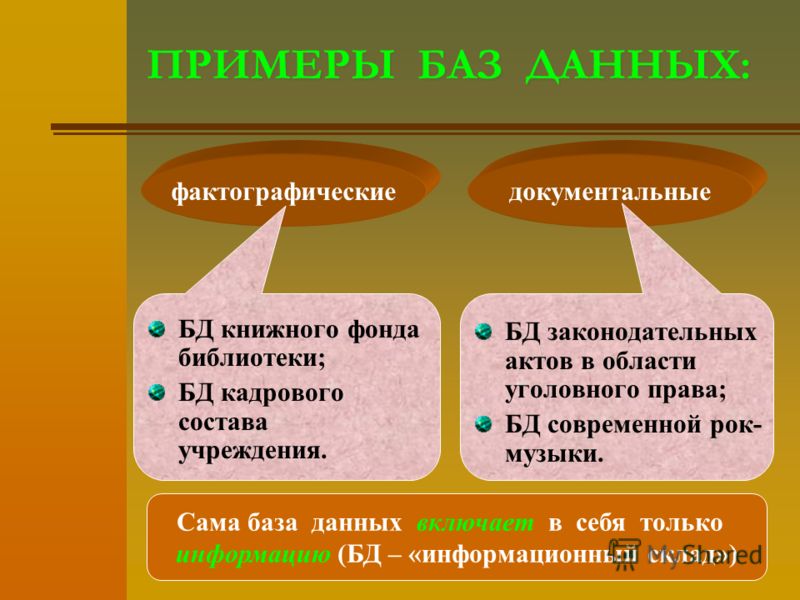 Это создает первичный ключ, и Django присваивает этот первичный ключ объекту
Это создает первичный ключ, и Django присваивает этот первичный ключ объекту p.
Когда происходит сохранение в операторе 2, p уже имеет значение первичного ключа, и Django попытается использовать этот первичный ключ в новой базе данных. Если значение первичного ключа не используется в базе данных second, то у вас не будет никаких проблем — объект будет скопирован в новую базу данных.
Однако, если первичный ключ p уже используется в базе данных second, существующий объект в базе данных second будет переопределен при сохранении p.
Этого можно избежать двумя способами. Во-первых, вы можете очистить первичный ключ экземпляра. Если у объекта нет первичного ключа, Django будет рассматривать его как новый объект, избегая потери данных в базе данных second:
>>> p = Person(name='Fred') >>> p.save(using='first') >>> p.pk = None # Clear the primary key.
 >>> p.save(using='second') # Write a completely new object.
>>> p.save(using='second') # Write a completely new object.
Второй вариант — использовать опцию force_insert для save(), чтобы Django выполнил SQL INSERT:
>>> p = Person(name='Fred') >>> p.save(using='first') >>> p.save(using='second', force_insert=True)
Это гарантирует, что человек с именем Fred будет иметь один и тот же первичный ключ в обеих базах данных. Если этот первичный ключ уже используется при попытке сохранения в базе данных second, будет выдана ошибка.
Выбор базы данных для удаления
По умолчанию вызов для удаления существующего объекта будет выполнен на той же базе данных, которая была использована для получения объекта в первую очередь:
>>> u = User.objects.using('legacy_users').get(username='fred')
>>> u.delete() # will delete from the `legacy_users` database
Чтобы указать базу данных, из которой будет удалена модель, передайте аргумент с ключевым словом using в метод Model.. Этот аргумент работает так же, как и аргумент  delete()
delete()using с ключевым словом в методе save().
Например, если вы переносите пользователя из базы данных legacy_users в базу данных new_users, вы можете использовать следующие команды:
>>> user_obj.save(using='new_users') >>> user_obj.delete(using='legacy_users')
Использование менеджеров с несколькими базами данных
Используйте метод db_manager() для менеджеров, чтобы предоставить менеджерам доступ к базе данных не по умолчанию.
Например, допустим, у вас есть пользовательский метод менеджера, который обращается к базе данных — User.objects.create_user(). Поскольку create_user() является методом менеджера, а не методом QuerySet, вы не можете сделать User.objects.using('new_users').create_user(). (Метод create_user() доступен только для User., менеджера, а не для  objects
objectsQuerySet объектов, производных от менеджера). Решением является использование метода db_manager(), например, так:
User.objects.db_manager('new_users').create_user(...)
db_manager() возвращает копию менеджера, привязанную к указанной вами базе данных.
Использование
get_queryset() с несколькими базами данныхЕсли вы переопределяете get_queryset() на вашем менеджере, убедитесь, что вы либо вызываете метод на родителе (используя super()), либо выполняете соответствующую обработку атрибута _db на менеджере (строка, содержащая имя используемой базы данных).
Например, если вы хотите вернуть пользовательский класс QuerySet из метода get_queryset, вы можете сделать следующее:
class MyManager(models.Manager):
def get_queryset(self):
qs = CustomQuerySet(self.model)
if self. _db is not None:
qs = qs.using(self._db)
return qs
 _db is not None:
qs = qs.using(self._db)
return qs
_db is not None:
qs = qs.using(self._db)
return qs
Использование нескольких баз данных в интерфейсе администратора Django
В админке Django нет явной поддержки нескольких баз данных. Если вы хотите предоставить интерфейс администратора для модели на базе данных, отличной от той, которая указана в вашей цепочке маршрутизации, вам нужно будет написать пользовательские ModelAdmin классы, которые будут направлять администратора на использование конкретной базы данных для контента.
ModelAdmin объекты имеют пять методов, которые требуют настройки для поддержки нескольких баз данных:
class MultiDBModelAdmin(admin.ModelAdmin):
# A handy constant for the name of the alternate database.
using = 'other'
def save_model(self, request, obj, form, change):
# Tell Django to save objects to the 'other' database.
obj.save(using=self.using)
def delete_model(self, request, obj):
# Tell Django to delete objects from the 'other' database
obj. delete(using=self.using)
def get_queryset(self, request):
# Tell Django to look for objects on the 'other' database.
return super().get_queryset(request).using(self.using)
def formfield_for_foreignkey(self, db_field, request, **kwargs):
# Tell Django to populate ForeignKey widgets using a query
# on the 'other' database.
return super().formfield_for_foreignkey(db_field, request, using=self.using, **kwargs)
def formfield_for_manytomany(self, db_field, request, **kwargs):
# Tell Django to populate ManyToMany widgets using a query
# on the 'other' database.
return super().formfield_for_manytomany(db_field, request, using=self.using, **kwargs)
 delete(using=self.using)
def get_queryset(self, request):
# Tell Django to look for objects on the 'other' database.
return super().get_queryset(request).using(self.using)
def formfield_for_foreignkey(self, db_field, request, **kwargs):
# Tell Django to populate ForeignKey widgets using a query
# on the 'other' database.
return super().formfield_for_foreignkey(db_field, request, using=self.using, **kwargs)
def formfield_for_manytomany(self, db_field, request, **kwargs):
# Tell Django to populate ManyToMany widgets using a query
# on the 'other' database.
return super().formfield_for_manytomany(db_field, request, using=self.using, **kwargs)
delete(using=self.using)
def get_queryset(self, request):
# Tell Django to look for objects on the 'other' database.
return super().get_queryset(request).using(self.using)
def formfield_for_foreignkey(self, db_field, request, **kwargs):
# Tell Django to populate ForeignKey widgets using a query
# on the 'other' database.
return super().formfield_for_foreignkey(db_field, request, using=self.using, **kwargs)
def formfield_for_manytomany(self, db_field, request, **kwargs):
# Tell Django to populate ManyToMany widgets using a query
# on the 'other' database.
return super().formfield_for_manytomany(db_field, request, using=self.using, **kwargs)
Представленная здесь реализация реализует стратегию использования нескольких баз данных, при которой все объекты данного типа хранятся в определенной базе данных (например, все объекты User находятся в базе данных other). Если ваше использование нескольких баз данных более сложное, ваша
Если ваше использование нескольких баз данных более сложное, ваша ModelAdmin должна отражать эту стратегию.
С объектами InlineModelAdmin можно работать аналогичным образом. Для них требуется три специализированных метода:
class MultiDBTabularInline(admin.TabularInline):
using = 'other'
def get_queryset(self, request):
# Tell Django to look for inline objects on the 'other' database.
return super().get_queryset(request).using(self.using)
def formfield_for_foreignkey(self, db_field, request, **kwargs):
# Tell Django to populate ForeignKey widgets using a query
# on the 'other' database.
return super().formfield_for_foreignkey(db_field, request, using=self.using, **kwargs)
def formfield_for_manytomany(self, db_field, request, **kwargs):
# Tell Django to populate ManyToMany widgets using a query
# on the 'other' database.
return super().formfield_for_manytomany(db_field, request, using=self.using, **kwargs)
 return super().formfield_for_manytomany(db_field, request, using=self.using, **kwargs)
return super().formfield_for_manytomany(db_field, request, using=self.using, **kwargs)
Как только вы написали определения администраторов модели, их можно зарегистрировать в любом экземпляре Admin:
from django.contrib import admin
# Specialize the multi-db admin objects for use with specific models.
class BookInline(MultiDBTabularInline):
model = Book
class PublisherAdmin(MultiDBModelAdmin):
inlines = [BookInline]
admin.site.register(Author, MultiDBModelAdmin)
admin.site.register(Publisher, PublisherAdmin)
othersite = admin.AdminSite('othersite')
othersite.register(Publisher, MultiDBModelAdmin)
Этот пример устанавливает два сайта администратора. На первом сайте открыты объекты Author и Publisher; объекты Publisher имеют табличную вставку, показывающую книги, опубликованные данным издателем. Второй сайт раскрывает только издателей, без встроенных элементов.
Использование необработанных курсоров с несколькими базами данных
Если вы используете более одной базы данных, вы можете использовать django.db.connections для получения соединения (и курсора) для конкретной базы данных. django.db.connections — это объект типа словаря, который позволяет вам получить конкретное соединение, используя его псевдоним:
from django.db import connections
with connections['my_db_alias'].cursor() as cursor:
...
Ограничения, связанные с использованием нескольких баз данных
Межбазовые отношения
В настоящее время Django не поддерживает отношения типа «внешний ключ» или «многие ко многим», охватывающие несколько баз данных. Если вы использовали маршрутизатор для разделения моделей по разным базам данных, все отношения типа «внешний ключ» и «многие-ко-многим», определенные этими моделями, должны быть внутренними для одной базы данных.
Это происходит из-за ссылочной целостности. Для того чтобы поддерживать связь между двумя объектами, Django необходимо знать, что первичный ключ связанного объекта действителен. Если первичный ключ хранится в отдельной базе данных, то невозможно легко оценить действительность первичного ключа.
Для того чтобы поддерживать связь между двумя объектами, Django необходимо знать, что первичный ключ связанного объекта действителен. Если первичный ключ хранится в отдельной базе данных, то невозможно легко оценить действительность первичного ключа.
Если вы используете Postgres, Oracle или MySQL с InnoDB, это обеспечивается на уровне целостности базы данных — ключевые ограничения на уровне базы данных предотвращают создание отношений, которые не могут быть проверены.
Однако, если вы используете SQLite или MySQL с таблицами MyISAM, то принудительная ссылочная целостность отсутствует; в результате вы можете «подделать» перекрестные внешние ключи базы данных. Однако такая конфигурация официально не поддерживается Django.
Поведение приложений вклада
Несколько приложений contrib включают модели, и некоторые приложения зависят от других. Поскольку межбазовые связи невозможны, это создает некоторые ограничения на то, как вы можете разделить эти модели по базам данных:
- каждый из
contenttypes., ContentTypesessions.Sessionиsites.Siteможет быть сохранен в любой базе данных, при наличии подходящего маршрутизатора. - Модели
auth—User,GroupиPermission— связаны между собой и связаны сContentType, поэтому они должны храниться в той же базе данных, что иContentType. adminзависит отauth, поэтому его модели должны находиться в той же базе данных, что иauth.flatpagesиredirectsзависят отsites, поэтому их модели должны находиться в той же базе данных, что иsites.
 ContentType
ContentTypeКроме того, некоторые объекты автоматически создаются сразу после того, как migrate создает таблицу для их хранения в базе данных:
- по умолчанию
Site, - a
ContentTypeдля каждой модели (включая те, которые не хранятся в этой базе данных), Permissions для каждой модели (включая те, которые не хранятся в этой базе данных).

Для распространенных настроек с несколькими базами данных не имеет смысла иметь эти объекты в нескольких базах данных. К распространенным настройкам относятся первичная/репликативная база данных и подключение к внешним базам данных. Поэтому рекомендуется написать database router, который позволяет синхронизировать эти три модели только с одной базой данных. Используйте тот же подход для приложений contrib и сторонних приложений, которым не нужны их таблицы в нескольких базах данных.
Предупреждение
Если вы синхронизируете типы содержимого с несколькими базами данных, имейте в виду, что их первичные ключи могут не совпадать в разных базах данных. Это может привести к повреждению или потере данных.
Бизнес-ассоциация студентов-предпринимателей Стэнфорда
Наши программы
, созданные по образцу того, как стартапы совершенствуют идеи, разделены на три основные группы: Inspire, Create, Launch
цель довести студентов от идеи до реализации до запуска стартапа. Благодаря мероприятиям с лидерами мнений и отраслевыми партнерами мы надеемся вдохновить любого студента, с опытом или без него, на получение навыков, чтобы стать предпринимателем.
Благодаря мероприятиям с лидерами мнений и отраслевыми партнерами мы надеемся вдохновить любого студента, с опытом или без него, на получение навыков, чтобы стать предпринимателем.
Чтобы быть в курсе текущих событий BASES, следите за нами в Facebook и Twitter.
Класс лидеров предпринимательской мысли
ETL представляет собой серию еженедельных выступлений, в которой успешные предприниматели читают лекции на тему по своему выбору. Лидерская группа, стоящая за классом, стремится делиться полезными советами и жизненными уроками с большим сообществом. Больше информации на etl.stanford.edu
Саммит «Женщины в предпринимательстве»
Саммит «Женщины в предпринимательстве» — это дневная презентация и семинар, во время которого приходят спикеры и рассказывают об опыте женщин в предпринимательстве, трудности, с которыми женщины сталкиваются на работе и в обществе, и многие другие темы, дающие пищу для размышлений. Мероприятие открыто для студентов всех полов. Саммит направлен на то, чтобы привить студентам знания и уверенность, чтобы они могли влиять на общество. За дополнительной информацией обращайтесь к вице-президентам Global Entrepreneurship Анухи Паркер ([email protected]) и Лукасу Босману ([email protected]).
Мероприятие открыто для студентов всех полов. Саммит направлен на то, чтобы привить студентам знания и уверенность, чтобы они могли влиять на общество. За дополнительной информацией обращайтесь к вице-президентам Global Entrepreneurship Анухи Паркер ([email protected]) и Лукасу Босману ([email protected]).
Саммит по социальному воздействию
Саммит по социальному воздействию собирает ключевых арендаторов, стоящих за предпринимательской деятельностью, и использует их как метод достижения социального воздействия. На саммите представлены программные выступления руководителей некоммерческих организаций и других социальных предпринимателей. Для получения дополнительной информации, пожалуйста, свяжитесь с вице-президентом по социальному воздействию Оливией Вайнер ([email protected]).
Ярмарка вакансий стартапов
Ярмарка вакансий стартапов, в которой принимают участие более 1000 студентов Стэнфордского университета, представляет собой невероятную возможность для студентов пообщаться, а компаниям найти технические таланты. В BASES Startup Career Fair принимают участие как крупные, так и малые предприятия, начинающие и устоявшиеся. Их единственное сходство заключается в том, что они ищут преданных и способных студентов как для летних программ, так и для работы на полный рабочий день. За дополнительной информацией обращайтесь к вице-президентам по развитию стартапов Джессике Франк ([email protected]) и Эбигейл Прайс ([email protected]).
В BASES Startup Career Fair принимают участие как крупные, так и малые предприятия, начинающие и устоявшиеся. Их единственное сходство заключается в том, что они ищут преданных и способных студентов как для летних программ, так и для работы на полный рабочий день. За дополнительной информацией обращайтесь к вице-президентам по развитию стартапов Джессике Франк ([email protected]) и Эбигейл Прайс ([email protected]).
Походы: автобусы/походы выходного дня
Походы облегчают однодневные поездки в компании/мероприятия в районе залива. Прошлые поездки включают Oculus, Dropbox и Disrupt SF. BASES Bus дает представление о том, как конкретная отрасль подходит к инновациям, приглашая студентов на места, чтобы они могли увидеть, как их рабочие места способствуют реализации трансформационных идей.
Startup Collab
Startup Collab работает в партнерстве с известными стартапами в районе залива Сан-Франциско, чтобы найти некоторые из наиболее интересных технических проблем, с которыми они сталкиваются, и позволить студентам Стэнфорда попробовать их решение.
Конкурсы по консалтинговым кейсам
В ходе конкурсов по консалтинговым кейсам студенты будут работать над кейсом вместе с наставником из одной из наших компаний-партнеров. После представления дела проводится церемония награждения и нетворкинг, где участники могут пообщаться с профессионалами, которые фактически подготовили исходный бриф.
BASES Challenge
Challenge — это соревнование стартапов на всех этапах, в ходе которого пытаются найти наиболее жизнеспособный стартап, предлагая призовой фонд в размере 100 000 долларов США. Призовой фонд распределяется по категориям, а стартап-победитель получает 45 000 долларов. В конкурсе ежегодно принимают участие более 200 компаний, которых оценивает талантливая команда отраслевых экспертов. Среди прошлых победителей Ravel, Boosted и Biomimedica. Для получения дополнительной информации, пожалуйста, свяжитесь с вице-президентами Challenge Бетани Чен ([email protected]) и Спенсер Чемтоб (chemtob@stanford. edu).
edu).
Frosh Battalion
Программа Frosh Battalion отбирает выдающихся первокурсников Стэнфорда для участия в программе погружения в предпринимательство. BASES гордится тем, что помогает своим членам Frosh Battalion начать свой профессиональный опыт с первых кварталов в Стэнфорде. Для получения дополнительной информации, пожалуйста, свяжитесь с вице-президентами по развитию Эндрю Янгом ([email protected]) и Оливией Теста ([email protected]).
Профессиональное развитие
Программа профессионального развития BASES представляет собой творческий подход к повышению квалификации участников на рабочем месте. На серии интимных семинаров им даются подробные инструкции о том, как написать отличное резюме, советы по установлению контактов и многое другое. И отраслевые партнеры, и преподаватели помогают участникам давать значимые профессиональные советы и мудрость.
Наставничество + отношения с выпускниками
Мы связываем более широкое сообщество BASES с наставниками и выпускниками по всей стране, которые могут помочь участникам усовершенствовать свои идеи о продуктах и бизнес-планы, создавая при этом ценную личную сеть.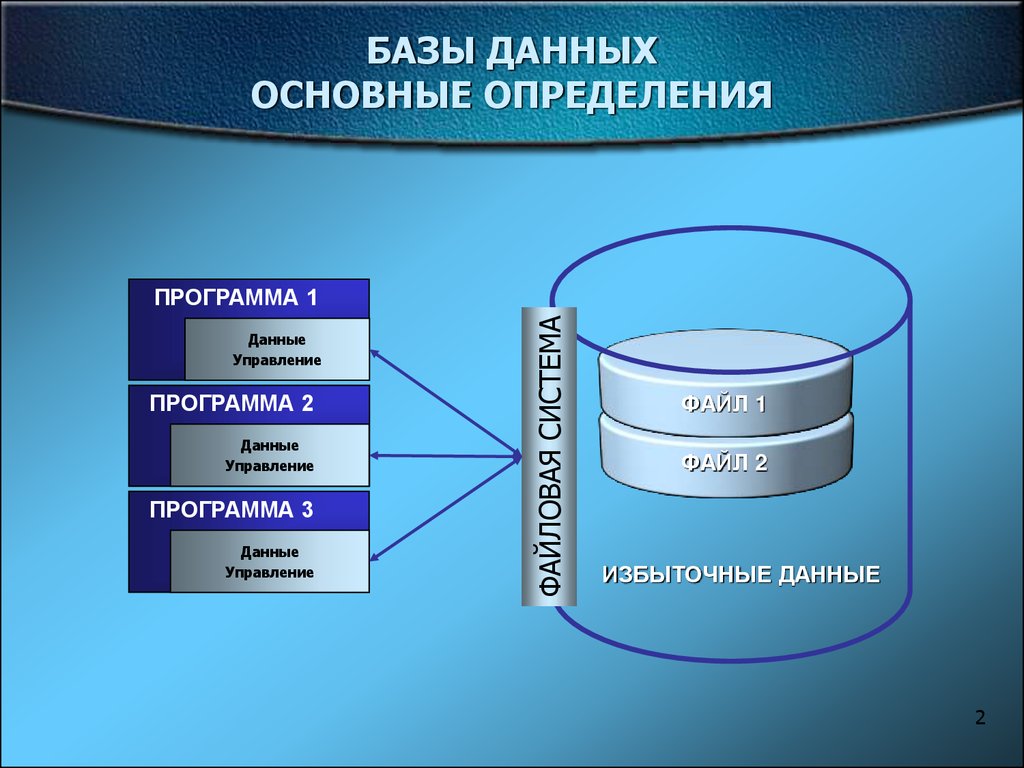
Бизнес-ассоциация студентов-предпринимателей Стэнфорда
4.23.21 | Глобальный виртуальный саммит
регистр
Совместно с Стэнфордские ангелы и предприниматели , Стэнфордская бизнес-школа CSI , Стэнфордские права и международные правосудие , WINGS HUMPRANCE и Международный центр юстиции , WINGS . , ETH Zurich Innovation & Entrepreneurship Lab , ICTS Bangalore , Environmental Clinic at University of São Paulo , UN University Lab at Macau
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
На этом саммите соберутся студенты, бизнес-профессионалы, ученые и государственные служащие из самых разных слоев общества со всего мира, чтобы обсудить важные вопросы, касающиеся устойчивого развития. Устойчивость будет рассматриваться через Цели ООН в области устойчивого развития (ЦУР), которые сосредоточены на продвижении инклюзивного развития, связанного с экологией, социальным равенством, экономическим равенством и правами человека. Спикеры расскажут о роли технологий, инноваций и сотрудничества. Мы коллективно переосмыслим, как спроектировать постпандемический мир, чтобы значительно увеличить внедрение устойчивых методов ведения бизнеса и образа жизни, подчеркнув при этом необходимость разнообразия точек зрения. Этот саммит служит призывом к действию для всех, кто стремится к позитивным и долгосрочным глобальным изменениям.
Устойчивость будет рассматриваться через Цели ООН в области устойчивого развития (ЦУР), которые сосредоточены на продвижении инклюзивного развития, связанного с экологией, социальным равенством, экономическим равенством и правами человека. Спикеры расскажут о роли технологий, инноваций и сотрудничества. Мы коллективно переосмыслим, как спроектировать постпандемический мир, чтобы значительно увеличить внедрение устойчивых методов ведения бизнеса и образа жизни, подчеркнув при этом необходимость разнообразия точек зрения. Этот саммит служит призывом к действию для всех, кто стремится к позитивным и долгосрочным глобальным изменениям.
Программирование
Summit ShowersTom Steyer
Sanda Ojiambo
Renatta Dessalien
Yanis varoufakis
Янис Варуфейс 9000
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Основатель, Nextgen America/Tomkat Center по устойчивой энергии
Исполнительный директор UN Global Compact
Координатор резидента, ООН Индия
Основатель Mera25 и бывший министр финансов Греции
Siddharth Chatterge
Miriam
Сэм Гамильтон
Тоомас Ильвес
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Постоянный координатор, ООН в Китае
Соучредитель и управляющий директор, Ulu Ventures
SVP, Technology at Visa
Ex-President, Estonia
Magdalena Aninat
Steve boyle
Rajesh gopakumar
mehran Sahami
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Директор CEFIS — Филантропия и социальные инвестиции
SVP, Cisco
Директор, Международный центр теоретических наук
Профессор компьютерных наук, Стэнфордский университет
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9
9.
Дэвид Коэн
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Исполнительный директор WINGS
Основатель/генеральный директор Caspar.AI
Директор Американо-азиатского центра управления технологиями
Директор, Центр по правам человека и международному юстиции в Стэнфордском университете
Рави Маривала
MAMELLO THINYANE
ANN EDMINSTER
Сара Генри
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Управляющий директор, Scientific Precision
Главный научный сотрудник Исследовательского института Университета ООН в Макао
Консультант по зеленой архитектуре, дизайн AVEnues
Исполнительный директор, Глобальный центр гендерного равенства в Стэнфорде
Matthias De Bievre 60000
73
3 Сёрен Йоргенсен ДЖЕЙН САН
Temina Madon
Генеральный директор, Visions
Бывший генеральный консул Дании для Калифорнии
, Trip. com Group
Глава сообщества, South Park Commons
Matt Boshoshian
Meng Liu
Динша Мистре
Оливия Сваак-Голдман
Исполнительный директор, AMCC
Руководитель Азиатско-Тихоокеанских сетей, Глобальный договор ООН
Лектор, научный сотрудник Стэнфордской школы права
Исполнительный директор, Комиссия по правосудию дикой природы
Ditte Jorgensen
Jingbo Huang
Gayathri Divecha
Tabata Amaral
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Генеральный директор по энергетике, Европейская комиссия
Директор Научно-исследовательского института Университета Организации Объединенных Наций в Макао
Глава CSR, Godrej Industries and Associate Companies
Федеральный депутат, Демократическая рабочая партия (PDT)
Сопредседатели саммита Анухи Паркер
Лукас Босман
Радхика Шах
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Вице-президент по глобальному предпринимательству, BASES
Вице-президент по глобальному предпринимательству, BASES
Сопрезидент, Stanford Angels & Entrepreneurs
КОМИТЕТ ПО ПЛАНИРОВАНИЮ КОНФЕРЕНЦИИ ПО УСТОЙЧИВОМУ РАЗВИТИЮ
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Посмотреть в полном размере
Учить больше
Разрешенные бесплатные базы и их влияние
Тренеры по бейсболу во всем мире стремятся научить своих игроков навыкам и навыкам, необходимым для игры в бейсбол. Будучи игроком, я помню, как тренеры на всех уровнях, от Малой лиги до колледжа, проповедовали важность ограничения количества свободных баз — таких вещей, как прогулки, удары по полям и ошибки — которые наша команда давала нашему противнику.
На более высоких уровнях любительского бейсбола, где победы и поражения становятся более важными факторами, наши тренеры должны иметь в виду количество свободных баз, разрешенных за игру. Если бы мы сохранили бесплатные базы, от которых отказались, также называемые «халявой», «90s», «мешки» или другие жаргонные термины, которые вы, возможно, помните — ниже этого порога наши шансы на победу в игре значительно возрастут, по крайней мере, так нам сказали. В межсезонье у наших тренеров даже были футболки с надписью «Свободных 90-х нет» на спине.
Это своего рода общепринятая мудрость, которая передается из поколения в поколение, и на ней логично зацикливаться. Предоставление вашему противнику дополнительных шансов попасть на базу или перейти на следующую базу, не заработав их по-настоящему, только снижает ваши шансы на победу.
Это также своего рода общепринятое мнение, которое мы можем анализировать с помощью объективных данных. Эпоха аналитики поставила под сомнение такие эмпирические правила и традиционные жемчужины мудрости во всех аспектах игры. Добавим этот в список. Имеет ли значение эта давняя поговорка об ограничении бесплатных баз на уровне Высшей лиги? Влияет ли это на победу и поражение?
Методология
Чтобы изучить вопросы, связанные с влиянием разрешенных бесплатных баз, я взял сезонные данные о питчах и защите на уровне команд из FanGraphs с 2012 по 2022 год. По некоторым вопросам данные включают сокращенный 2020 год. сезона, а по некоторым вопросам — нет, надеюсь, по понятным причинам. Я буду обозначать, какие есть какие, по мере того, как мы проходим.
Статистические данные, которые считались «свободными базами» в этом анализе:
- Прогулки разрешены
- Удар по полям
- Балки
- Разрешены украденные базы
- Дикие поля
- Пропущенные мячи
- Ошибки
Я не пытался выяснить ни одну из этих категорий, которые могли бы привести к получению противником нескольких баз, например, ошибка броска с несколькими базами. Я придерживался простоты и предполагал, что каждый случай одной из перечисленных выше вещей — это всего лишь одна база.
На протяжении всего этого анализа я буду полагаться на корреляцию и обсуждать ее, то есть взаимосвязь и закономерности, которые показывают данные между разрешенными свободными основаниями и другими переменными. Важно отметить, что это отличается от причинно-следственной связи или утверждения, что одна переменная вызывает другую. Я хочу отметить, что я не буду претендовать на причинно-следственную связь ни с одной из этих работ.
Сводная статистика
За десять полных сезонов в наборе данных (исключая 2020 год) средняя команда Высшей лиги предоставила своим противникам 814,7 бесплатных баз в течение сезона. Наименьшее количество, разрешенное за сезон, составило 608 на чемпионате Вашингтона 2014 года. Самым большим было 1112 игроков в Чикаго Уайт Сокс в 2018 году.
В расчете на каждую игру (включая 2020 год) команды имеют в среднем около 5,06 разрешенных бесплатных баз за игру. На приведенном ниже графике показано среднее, максимальное и минимальное значение на уровне команды для каждого сезона:
Данные FanGraphs
Вы можете видеть, что среднее значение варьируется в пределах 5,0 за игру в каждом сезоне, а сезонные диапазоны варьируются от чуть ниже 4,0 в 2014, 2014 и 2017 годах до уровня чуть ниже 7,0 в 2018 году.
На гистограмме ниже показано распределение средних оценок сезонных команд:0007
Данные FanGraphs
Большинство оценок за один сезон сосредоточено вокруг общего среднего значения 5,06 и находится в диапазоне от 4,0 до 6,0. Межквартильный размах — разброс середины распределения — находится между 4,7 и 5,4.
Давайте закончим этот раздел описательной статистики разбивкой по командам. На приведенном ниже графике показано среднее количество бесплатных баз, разрешенных для каждой команды за игру с 2012 по 2022 год, по сравнению с их максимальными и минимальными оценками за один сезон за тот же период времени:
Данные FanGraphs
Данные за последние одиннадцать сезонов показывают, что в среднем Доджерс допустили наименьшее количество свободных баз, а Уайт Сокс и Пайретс — больше всего. При этом мы также можем видеть, что у Доджерс самая низкая максимальная оценка в наборе, за которой следуют оценки от Янки и Рэев. Эти клубы, даже в свои худшие по этому показателю сезоны, держались примерно на уровне 5,06 в среднем по лиге. С другой стороны, лучшие сезоны Питтсбурга и Колорадо с точки зрения допустимого количества свободных баз были близки к общему среднему показателю лиги.
Бесплатные и разрешенные прогоны
Охарактеризовав данные, давайте перейдем к самому интересному. Этот раздел будет посвящен взаимосвязи между свободными базами и разрешенными пробегами. Как вы можете сделать вывод из того, где разные команды появились на последнем графике в разделе выше, данные показывают довольно сильную положительную связь.
Чтобы исследовать эту взаимосвязь, я сопоставил тридцати разрешенных оценок на уровне команд с их разрешенными пробегами в каждом сезоне в наборе данных. Например, в 2014 году соотношение между разрешенными свободными базами команды и разрешенными пробегами (оба значения для каждой игры) составляло 0,41. Это оказались самые слабые отношения за одиннадцать сезонов. На приведенной ниже диаграмме показаны результаты коэффициента корреляции для каждого сезона:
Данные FanGraphs
По всему набору данных – по 330 точек данных для разрешенных бесплатных баз и разрешенных запусков на игру – корреляция оказалась равной 0,65. Это довольно сильный сигнал о том, что команды, которые допускают меньше пробежек, как правило, отдают меньше бесплатных баз.
Давайте еще раз посмотрим на диаграмму по командам, показанную в предыдущем разделе, с учетом следующего вывода:
Данные FanGraphs самый. «Доджерс» были №1 по наименьшему количеству разрешенных свободных баз, а также №1 по предотвращению забегов с 2012 года. Восемь из десяти лучших команд по предотвращению забегов также входят в первую десятку по наименьшему количеству потерянных свободных баз. Общий тренд черных точек данных отслеживается вверх и вправо, как и синих точек. Это согласуется с тем, что мы видели за последнее десятилетие. Такие команды, как Dodgers, Guardians, Cardinals, Yankees и Rays, неизменно были одними из лучших в предотвращении убеганий, а также среди лучших в ограничении бесплатных баз, которые они раздают.
Бесплатные и выигрыш
Далее я хотел понять взаимосвязь между разрешенными бесплатными базами и выигрышем. Я повторил то же упражнение, что и выше, на этот раз сравнив количество бесплатных баз на уровне команды, разрешенных за игру, с процентом побед команды в каждом сезоне. Вот коэффициенты корреляции для каждого сезона:
Данные FanGraphs
На этот раз связь отрицательная. Команды, которые предоставили больше бесплатных баз, как правило, выигрывали меньше, а команды, которые разрешали меньше бесплатных баз, как правило, выигрывали больше. Как и раньше, связь довольно сильная, от -0,38 до -0,79.на протяжении одиннадцати сезонов. По общему набору данных за одиннадцать сезонов коэффициент корреляции оказался равным -0,52.
Вот график по командам, который довольно четко показывает эту отрицательную связь:
Данные FanGraphs баз за полные сезоны или около 4,80 за игру в целом. Команды, у которых были рекорды проигрышей, допускали в среднем 857 свободных баз за полные сезоны или около 5,34 за игру. Семь из десяти лучших команд по проценту побед с 2012 года также входят в первую десятку по наименьшему количеству потерянных бесплатных баз. Начиная с сезона 2012 года, команды, у которых количество свободных баз было лучше, чем в среднем по сезонной лиге, позволяли выигрывать с коэффициентом 0,532 по сравнению с процентом побед 0,468 у команд с худшим, чем в среднем по сезонной лиге.
Я вытащил подмножество только тех команд, которые вышли в плей-офф за последние одиннадцать сезонов, и проанализировал разрешенные им свободные базы. Неудивительно, учитывая приведенные выше данные, что команды плей-офф допускали меньше бесплатных баз за игру (4,80), чем команды, не входящие в плей-офф (5,20). Из команд, вышедших в плей-офф, 73,7% были лучше, чем в среднем по сезонной лиге, включая все двенадцать команд, прошедших квалификацию плей-офф 2022 года. Из команд, которые вышли в Мировую серию, 80% из них были лучше, чем в среднем по лиге.
Является ли ограничение халявы навыком?
Поскольку приведенные выше данные, по-видимому, указывают на то, что возможность ограничить раздачу бесплатных баз желательна, следующий вопрос заключается в том, является ли этот навык повторяемым. Показывают ли данные, могут ли организации надежно ограничить бесплатные базы, которые они раздают с течением времени?
Чтобы проверить это, я обратился к методу анализа, который сравнивает бесплатные базы команд, разрешенные в одном году, и в следующем году, ища взаимосвязь. Если команды смогут надежно ограничивать бесплатные базы, мы ожидаем, что из года в год будут сохраняться положительные отношения, которые сохранятся с течением времени. Если это настоящий навык, то команды, которые хороши в этом в одном сезоне, должны быть хороши и в следующем, отчасти потому, что из года в год у них будет большая часть одних и тех же игроков.
 com Group
com Group Будучи игроком, я помню, как тренеры на всех уровнях, от Малой лиги до колледжа, проповедовали важность ограничения количества свободных баз — таких вещей, как прогулки, удары по полям и ошибки — которые наша команда давала нашему противнику.
Будучи игроком, я помню, как тренеры на всех уровнях, от Малой лиги до колледжа, проповедовали важность ограничения количества свободных баз — таких вещей, как прогулки, удары по полям и ошибки — которые наша команда давала нашему противнику.
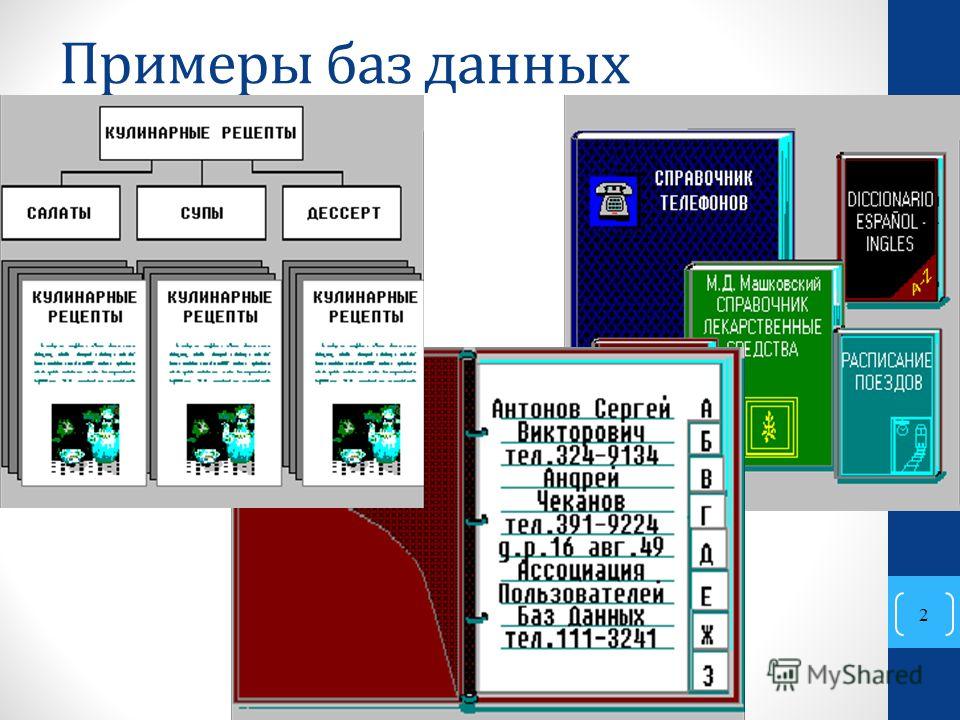 Я придерживался простоты и предполагал, что каждый случай одной из перечисленных выше вещей — это всего лишь одна база.
Я придерживался простоты и предполагал, что каждый случай одной из перечисленных выше вещей — это всего лишь одна база. На приведенном ниже графике показано среднее, максимальное и минимальное значение на уровне команды для каждого сезона:
На приведенном ниже графике показано среднее, максимальное и минимальное значение на уровне команды для каждого сезона: При этом мы также можем видеть, что у Доджерс самая низкая максимальная оценка в наборе, за которой следуют оценки от Янки и Рэев. Эти клубы, даже в свои худшие по этому показателю сезоны, держались примерно на уровне 5,06 в среднем по лиге. С другой стороны, лучшие сезоны Питтсбурга и Колорадо с точки зрения допустимого количества свободных баз были близки к общему среднему показателю лиги.
При этом мы также можем видеть, что у Доджерс самая низкая максимальная оценка в наборе, за которой следуют оценки от Янки и Рэев. Эти клубы, даже в свои худшие по этому показателю сезоны, держались примерно на уровне 5,06 в среднем по лиге. С другой стороны, лучшие сезоны Питтсбурга и Колорадо с точки зрения допустимого количества свободных баз были близки к общему среднему показателю лиги. Это оказались самые слабые отношения за одиннадцать сезонов. На приведенной ниже диаграмме показаны результаты коэффициента корреляции для каждого сезона:
Это оказались самые слабые отношения за одиннадцать сезонов. На приведенной ниже диаграмме показаны результаты коэффициента корреляции для каждого сезона: Такие команды, как Dodgers, Guardians, Cardinals, Yankees и Rays, неизменно были одними из лучших в предотвращении убеганий, а также среди лучших в ограничении бесплатных баз, которые они раздают.
Такие команды, как Dodgers, Guardians, Cardinals, Yankees и Rays, неизменно были одними из лучших в предотвращении убеганий, а также среди лучших в ограничении бесплатных баз, которые они раздают.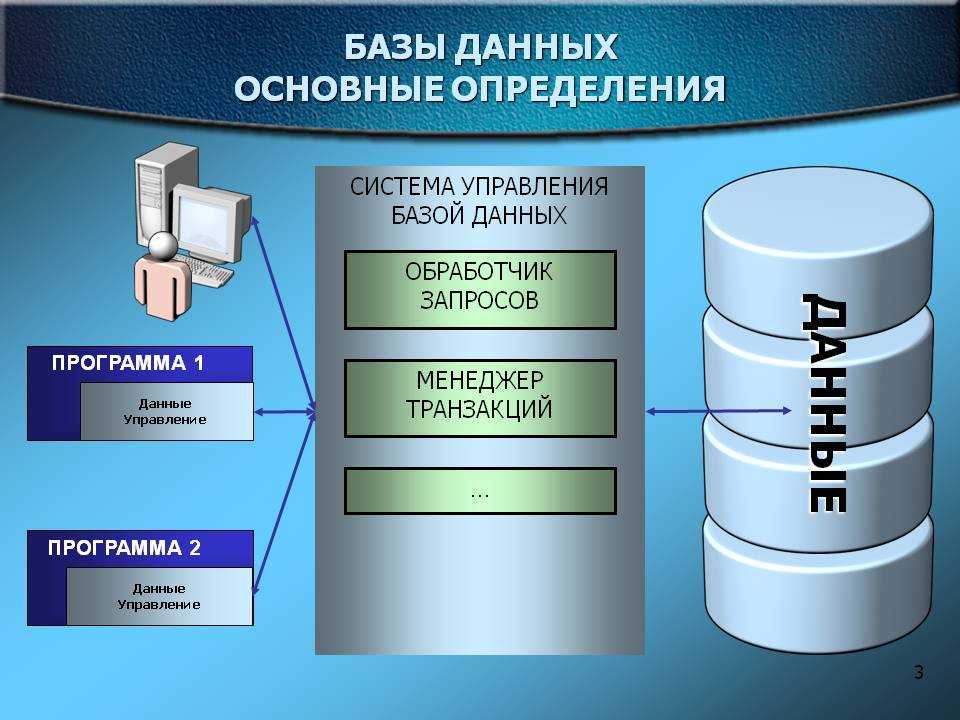
 Из команд, вышедших в плей-офф, 73,7% были лучше, чем в среднем по сезонной лиге, включая все двенадцать команд, прошедших квалификацию плей-офф 2022 года. Из команд, которые вышли в Мировую серию, 80% из них были лучше, чем в среднем по лиге.
Из команд, вышедших в плей-офф, 73,7% были лучше, чем в среднем по сезонной лиге, включая все двенадцать команд, прошедших квалификацию плей-офф 2022 года. Из команд, которые вышли в Мировую серию, 80% из них были лучше, чем в среднем по лиге.