Что такое База Данных (БД) / Хабр
База данных — это место для хранения данных. Используется в том числе в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов… Вы делаете заказ, а система сохраняет ваши данные в базе.
В этот статье я на простых примерах расскажу, что такое база данных и как она выглядит. А потом поясню некоторые термины из конкретной (реляционной) базы. Те, с которыми вы почти наверняка столкнетесь на работе.
Статья рассчитана на начинающих тестировщиков или аналитиков, то есть тех, кто будет работать с базой, но не на супер-глубоком уровне. Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Содержание
Что такое база данных
Как она выглядит
Как получить информацию из базы
Как связать данные между собой
Зачем в базе индексы
Что делать, если запрос к БД тормозит
Преимущества базы данных
Что знать для собеседования
Статьи и книги по теме
Резюме
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.
Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!
Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.

Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги…
Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
То же самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.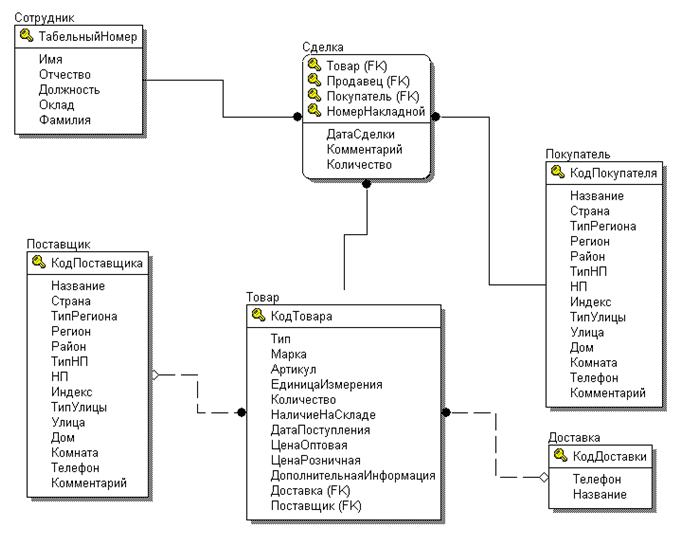
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
Пример базы OracleЦель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Да, базы бывают разные. Классификацию можно изучить, можно выучить. Но по факту от начинающего тестировщика обычно нужно уметь достать информацию из реляционной БД («обычно» != «всегда», если что).
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
select — выбери мне такие-то колонки…
from — из такой-то таблицы базы…
where — такую-то информацию…
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
Дай мне информацию по клиенту, у которого ФИО = «Назина Ольга»
Переделываю в SQL:
select * from clients where name = 'Назина Ольга';
В дословном переводе:
select -- выбери мне * -- все колонки (можно выбирать конкретные, а можно сразу все) from clients -- из таблицы clients where name = 'Назина Ольга'; -- где поле name имеет значение 'Назина Ольга'
См также:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
Открыть файл с нужными данными (clients)
Поставить фильтр на колонку «ФИО» — «Назина Ольга».

То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. То же самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order | order (таблица order) | fio (таблица client) | phone (таблица contacts) |
1 | Пицца «Маргарита» | Иванова Мария | +7 (926) 555-33-44 |
2 | Комбо набор 1 | Петров Павел | +7 (926) 555-22-33 |
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
last_name | first_name | birthdate | VIP |
Иванов | Иван | 01.02.1977 | true |
Петрова | Мария | 02.04.1989 | false |
Сидоров | Павел | 03. | false |
Иванов | Вася | 04.04.1987 | false |
Ромашкина | Алина | 16.11.2000 | true |
 02.1991
02.1991В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order | addr | date | time |
Пицца «Маргарита» | ул Ленина, д5 | 05.05.2020 | 06:00 |
Роллы «Филадельфия» и «Канада» | Студеный пр-д, д 10 | 15.08.2020 | 10:15 |
Пицца 35 см, роллы комбо 1 | Заревый, д10 | 08.09.2020 | 07:13 |
Пицца с сосиками по краям | Турчанинов, 6 | 08. | 08:00 |
Комбо набор 3, обед №4 | Яблочная ул, 20 | 08.09.2020 | 08:30 |
 09.2020
09.2020Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам… В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
Но есть минусы:
Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
Чтобы избежать дублей, таблицы принято разделять:
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ.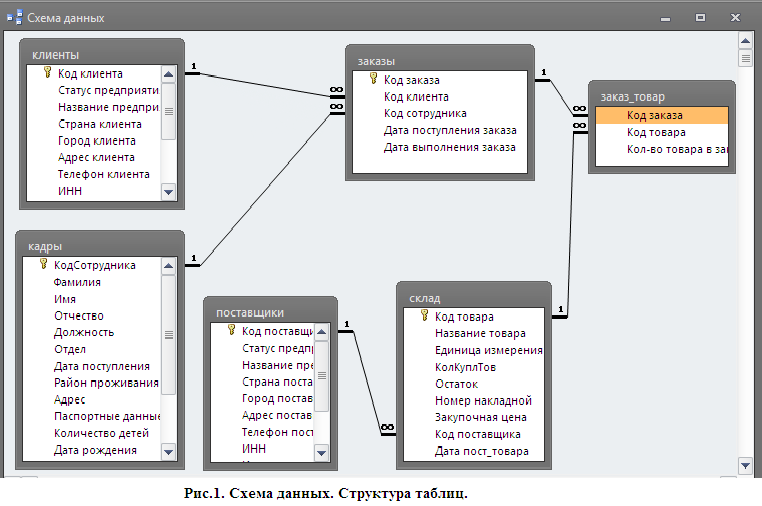 Для связи таблиц используется foreign key, внешний ключ.
Для связи таблиц используется foreign key, внешний ключ.
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку… А если у нас два клиента Ивана? Или три Маши? Десять Саш… Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.
А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Есть таблица постояльцев:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
Тут привозят еще одного Барсика. Добавляем его в таблицу:
— Имя Барсик, 5 лет! (мы не указываем ID)
Система добавляет:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
3 | Барсик | 5 |
ID сгенерился автоматически.
Теперь, если в другой таблице надо будет сослаться на котика, мы будем делать это именно через уникальный идентификатор. Например, у нас есть таблица комнат для постояльцев, куда мы заносим информацию о том, кто там живет:
 Последнее значение было 2, значит, новый Барсик получил номер 3. Обратите внимание — Барсиков уже два, но их легко различить, ведь у них разные идентификаторы!
Последнее значение было 2, значит, новый Барсик получил номер 3. Обратите внимание — Барсиков уже два, но их легко различить, ведь у них разные идентификаторы!id_room | square | id_cat (ссылка на id в таблице котиков) |
1 | 5 | 1 |
2 | 10 | 2 |
3 | 10 |
|
Мы видим, что в первой комнате живет котик с id = 1, а во второй — с id = 2. В третьей комнате пока никто не живет. Так, благодаря связке таблиц, мы всегда можем понять, что именно за котофей там проживает.
Итак, теперь мы знаем, что идентификатор лучше делать первичным ключом, дабы обеспечить его уникальность. Можно сделать поле автоинкрементальным, чтобы оно заполнялось само. Так и поступим в таблице клиентов:
Можно сделать поле автоинкрементальным, чтобы оно заполнялось само. Так и поступим в таблице клиентов:
И в таблице заказов! «id_order» пусть генерится сам и всегда будет уникален. А еще в таблицу заказов мы добавим колонку «id_client» и повесим на нее foreign key, ссылку на «id_client» в таблице клиентов.
Ключей может быть несколько. Одна таблица может ссылаться на несколько других. Скажем, в заказе мы ссылаемся на клиента и поставщика.
И наоборот, несколько таблиц могут ссылаться на одну и ту же колонку текущей таблицы. ID клиента мы можем указывать в таблице адресов, телефонов, email адресов, документов, заказов… Ограничений на это нет.
Зачем в базе индексы
Давайте представим, что у нас есть табличка excel. Если она небольшая (пара строк, пара колонок), то найти нужную ячейку не составит труда:
Открыли файлик — открывается моментально (если нет проблем с жестким диском)
Нажали «Ctrl + F», ввели запрос — тут же нашли результат.
Но что, если у нас сотни колонок и миллионы строк в файлике? Тогда начинаются тормоза. Файл открывается долго, в поиск значение ввели и система подвисла, обрабатывая результат…
Всё то же самое и в базе данных. Если табличка маленькая, любой запрос к ней отработает моментально. Если же таблица будет большая и с кучей данных, то результата запроса можно ждать минут по 15. А иногда и пару часов!
Если вы заранее знаете, что данных в базе будет много, нужно продумать основные сценарии поиска. И на колонки, по которым будете искать, нужно повесить индексы.
Индекс — это как алфавитный указатель в библиотеке. Вот представьте, заходите вы в библиотеку и хотите найти «Преступление и наказание» Достоевского. А все книги стоят «от балды», никакого порядка. Чтобы найти нужную, надо обойти все стелажи и просмотреть все полки!
Совсем другое дело, если книги отсортированы по авторам. А внутри автора — по названию. Тогда найти нужную книгу будет легко!
Индекс играет ту же роль для базы данных.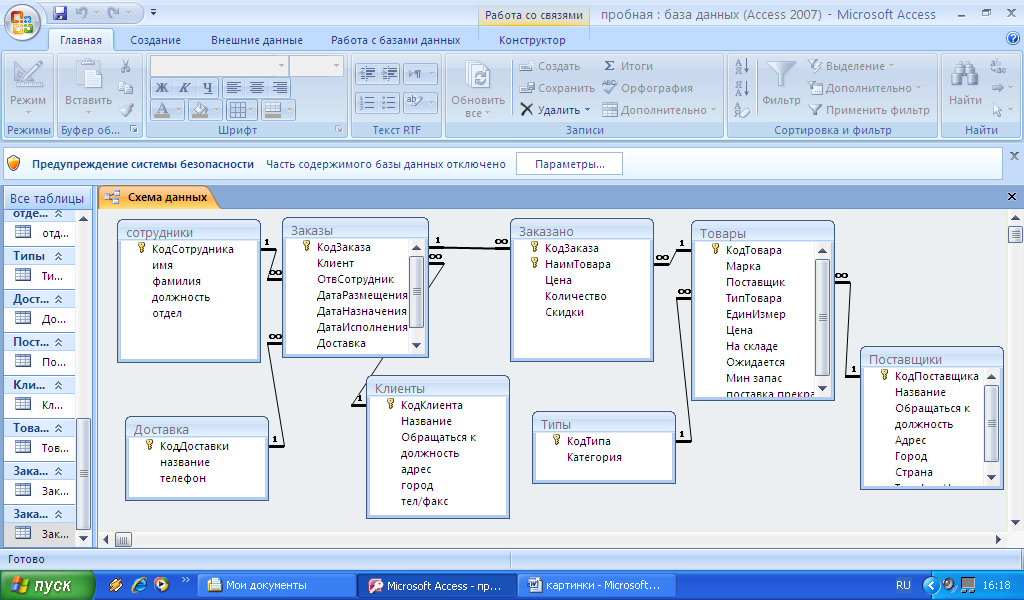 Если повесить его на колонку таблицы, поиск по ней пойдет быстрее!
Если повесить его на колонку таблицы, поиск по ней пойдет быстрее!
А можно повесить индекс на несколько нужных колонок (автор + название). Тут главное — не забывать порядок поиска в индексе. Если у нас индекс сначала по автору, а потом по названию, он будет бесполезен для поиска по названию, придется все равно пересматривать все книги. Поэтому, если нам часто нужно искать по названию и почти никогда — только по автору, имеет смысл поменять порядок в индексе — сначала название, потом автор.
Что делать, если запрос к БД тормозит
Если мы говорим о тестировщиках (а статья написана в первую очередь для них), то тут есть 2 варианта:
Вы работаете с базой напрямую, составляете запросы к ней. И эти запросы работают медленно.
Медленно работает система, но уже поняли, что тормозит выборка из БД (например, увидели в логах).
Первый вариант мы разбирать не будем. Потому что это не про базу, а про SQL. И, если вы работаете с базой, то должны уметь писать сложные запросы, применять хинты там, где нужно, и так далее.
А вот что делать во втором случае? Это не задача тестировщика — разбираться в том, почему запрос работает медленно. Этим занимаются DBA (администраторы баз данных) или разработчики.
Зато задача тестировщика — предоставить разработчику всю нужную информацию. Иногда её можно запросить у заказчика и его админов, а иногда нужно достать самому. Обычно для этого нужно:
Получить план запроса
Пересобрать статистику и проверить, продолжает ли тормозить
План запроса
Смотрите, когда вы выполняете любой запрос, что делает система:
Строит план выполнения запроса (как ей кажется, оптимальный)
Выполняет его
Посмотреть план можно через ключевые слова. В Oracle это EXPLAIN PLAN:
EXPLAIN PLAN FOR -- построй мне план для... SELECT last_name FROM employees; -- вот такого запроса!
А если вы работаете через графический интерфейс, то там обычно можно просто выделить запрос и нажать горячую клавишу. Выглядит ответ примерно так:
Выглядит ответ примерно так:
А теперь изменим запрос, сделав выборку по одному конкретному человеку по колонке с индексом:
Оп, цена запроса уже 5 ms. Это, на минуточку, в 170 раз быстрее!
И это простейший запрос на тестовой базе. В реальной базе данных будет сильно больше, поэтому проход таблицы по индексированной колонке существенно сократит время выполнения запроса.
Вот пример плана чуть более сложного запроса, когда мы делаем выборку из двух таблиц:
Вы не обязаны понимать, «что тут вообще происходит», но вам нужно уметь получать этот план. Пригодится.
Допустим, поступает жалоба от заказчика — клиент открывает карточку в вебе, а она открывается минуту. Что-то где-то тормозит! Но что и где? Начинаем разбираться. Причины бывают разные:
Что-то где-то тормозит! Но что и где? Начинаем разбираться. Причины бывают разные:
Тормозит на уровне БД — тут или сам запрос долго отрабатывает, или статистику давно не пересобирали, или диски подыхают.
Тормозит на уровне приложения — тогда надо копаться внутри кода функции «открыть карточку», что она там делает, получив ответ от Базы (и снова есть вариант «подыхают диски, на которых установлено ПО»).
Тормозит на уровне сети — сервер приложения и сервер БД обычно размещают на разных машинах. Значит, есть общение между ними по интернету. А интернет может тупить.
Если есть подозрение, что тормозит сам select, разработчик попросит прислать план его выполнения на реальной базе. Конечно, если «с той стороны» грамотные админы, они это сделают сами. Но иногда это нужно уметь вам. Например, если вас отправили в банк разбираться на месте, что пошло не так. Вы проверяете разные гипотезы и собираете информацию для разработчика.
Собираете план, сохраняете в файлик и прикладываете в задачу в джире. Или отправляете по почте.
У меня бывало, что именно так находился баг — на тестовой базе запрос идет по правильному пути, а на боевой — нет. И на боевой идет не по индексам, что сильно его тормозит. Тут уже дальше разработчик думает, почему так получилось и как именно это исправить.
Статистика в БД
Именно статистика позволяет базе данных выбрать оптимальный план выполнения запроса. Почему вообще возникают проблемы вида «на тестовой базе один план, на боевой другой»?
Да потому, что один и тот же запрос можно выполнить несколькими способами. Например, у нас есть таблица клиентов и таблица телефонов, и мы пишем такой запрос:
Найди мне всех клиентов, созданных в этом году,
У которых оператор связи в телефоне — Мегафон
Как можно выполнить запрос? Можно сначала обойти таблицу клиентов и поискать тех, кто создан в этом году.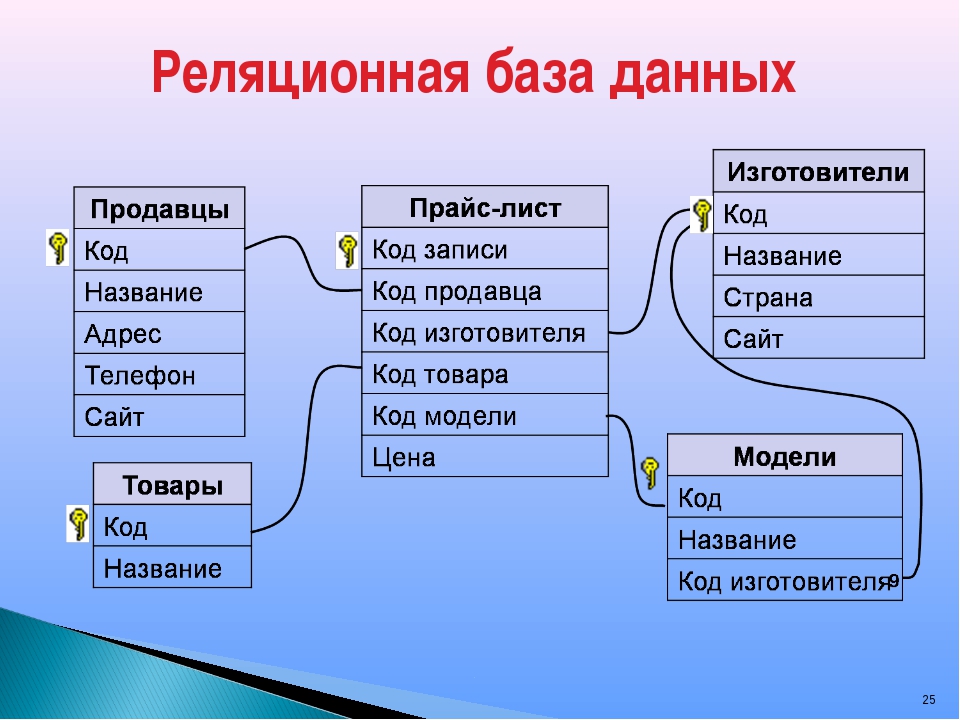 А потом уже для них проверять телефоны. Можно наоборот, проверить все телефоны на оператора и потом уже для связанных клиентов проверять дату создания.
А потом уже для них проверять телефоны. Можно наоборот, проверить все телефоны на оператора и потом уже для связанных клиентов проверять дату создания.
Какой вариант будет лучше? Никто не скажет без данных по таблицам. Может, у нас мало клиентов, но кучи телефонов (база перекупщиков), тогда быстрее будет начать с клиентов. А может, у нас миллионы клиентов, но всего пара сотен телефонов, тогда мы начнем с них.
Так вот, в статистике по БД хранится в том числе информация о распределении данных и характеристики хранения таблиц и индексов. И когда вы запускаете запрос, база (а точнее, оптимизатор внутри нее) строит возможные планы выполнения. Для каждого плана рассчитывает примерное время выполнения, а потом выбирает лучшее.
Время же он рассчитывает, ориентируясь на статистику:
Именно поэтому просто пересбор статистики иногда убирает проблему «у нас тут тормозит». Прилетело в таблицу много данных, а статистика об этом не знает, и чешет по таблице через фуллскан, считая, что информации там мало.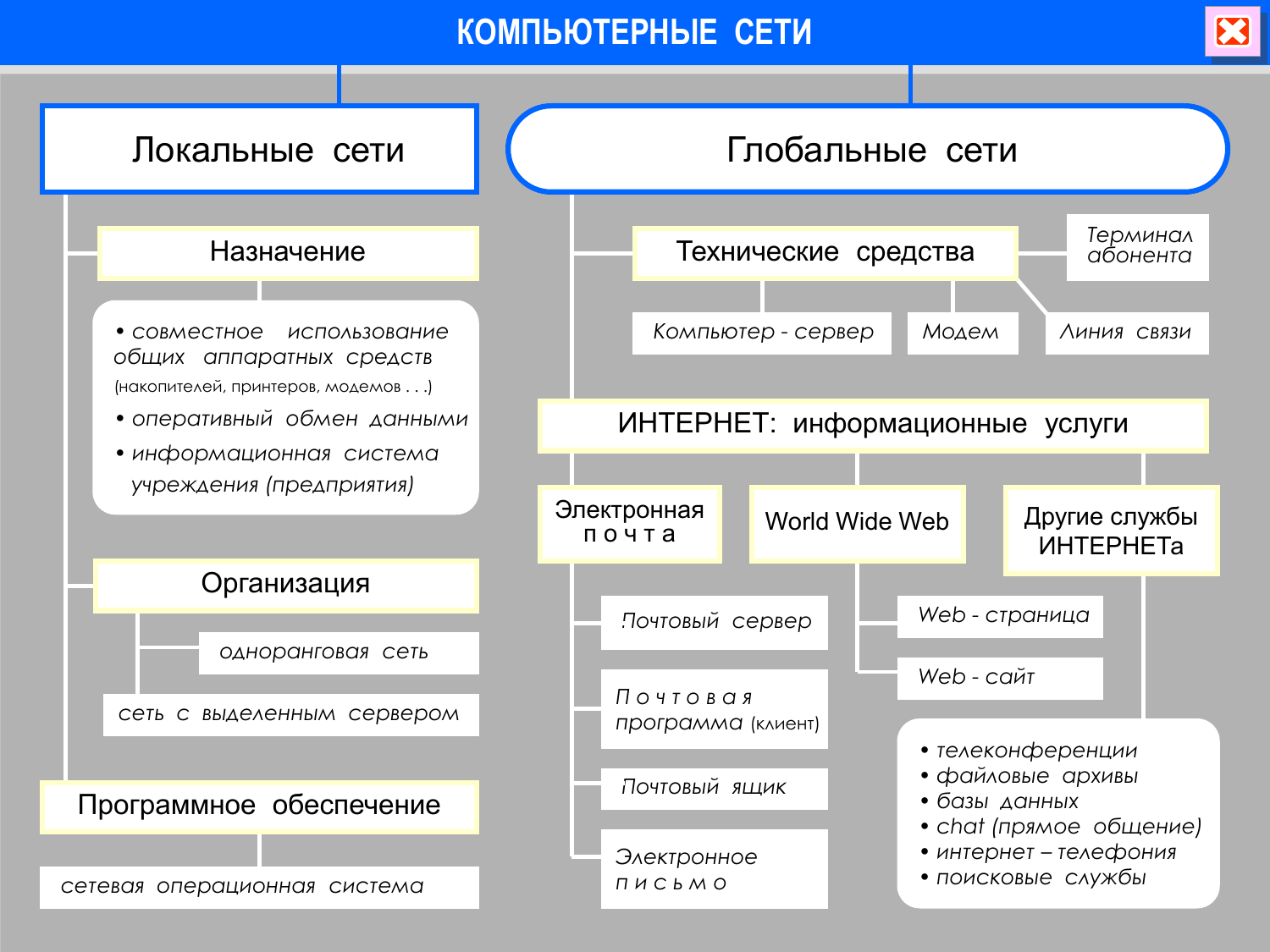
См также:
Ручной и автоматический сбор статистики оптимизатора в базе данных Oracle
Практические методы оптимизации запросов в Apache Spark — подробнее об оптимизации запросов, в том числе и про индексы
Преимущества реляционных баз данных
Почему используют реляционную базу данных:
Она поддерживают требования ACID (по крайней мере транзакционная БД)
Это единый синтаксис SQL, который используется повсеместно
Требования ACID
ACID — это аббревиатура из требований, которые обеспечивают сохранность ваших данных:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надёжность
Если база данных не поддерживает их, то могут быть печальные последствия из серии «Деньги с одного счета ушли, на другой не пришли? Ну сорян, бывает».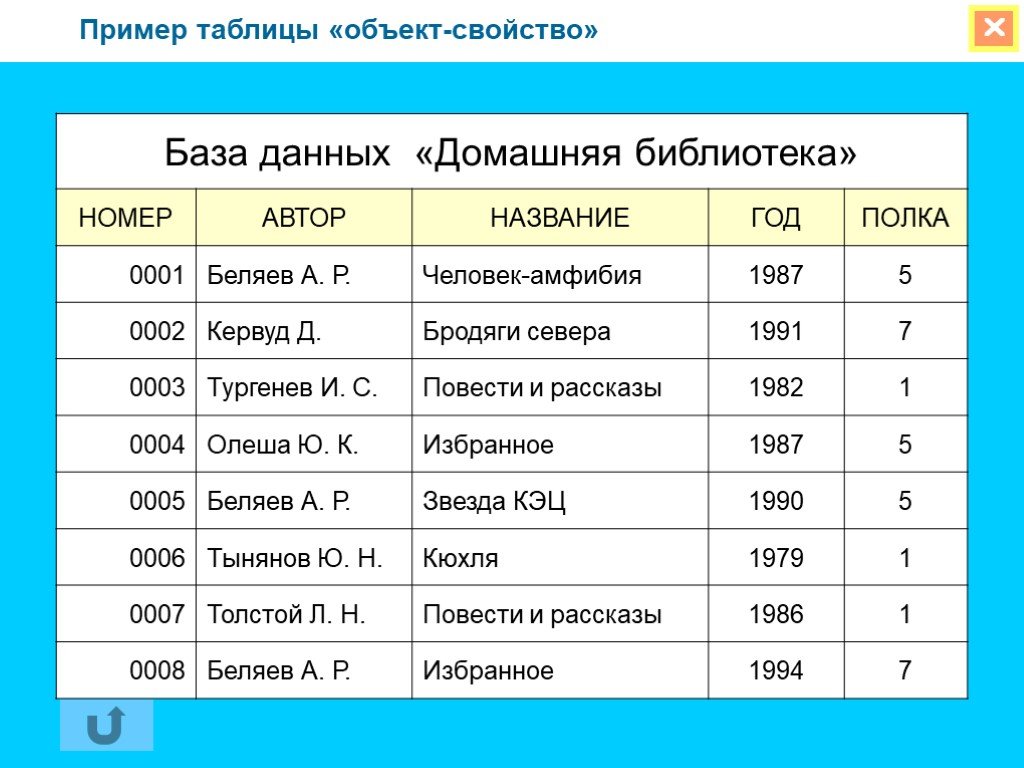
См также:
Требования ACID на простом языке — подробнее об этих требованиях
Единый синтаксис SQL
Я спросила знакомого разработчика:
— Ну и что, что единый синтаксис? В чем его плюшка то?
Ответ прекрасен, так что делюсь с вами:
— Почему в школе все преподают на русском? Почему не каждый свой язык? Одна школа — один, другая — другой. А ещё лучше не школа, а для каждого человека. Почему вавилонскую башню недостроили?
Как разработчик пишет код? Написал, проверил на коленке. Если не работает — думает, почему. Если непонятно, идет гуглить похожие ошибки. А что проще нагуглить? Ошибку распространенной БД, или сделанный на коленке костыль для работы с файлами? Вот то-то и оно…
Что знать для собеседования
Для начала я хочу уточнить, что я сама тестировщик. И мои статьи в первую очередь для тестировщиков ))
Зато тестировщика спрашивают про SQL. Вот вам обсуждение из чатика выпускников, пригодится для повторения материала:
— В вакансии написано: уметь составлять простые SQL запросы.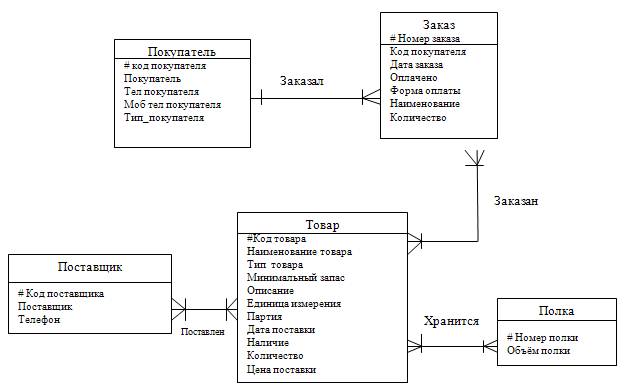 А простые это какие в народном понимании?
А простые это какие в народном понимании?
— (inner, outer) join, select, insert, update, create, последнее время популярны индексы, group by, having, distinct.
SQL выходит за рамки данной статьи, здесь я лишь пояснила, что это вообще такое. А дальше читайте статьи / книги из следующего раздела, или гуглите каждое слово из цитаты выше.
Статьи и книги по теме
База данных
Википедия
Какие бывают базы данных
Базы данных. Виды и типы баз данных. Структура реляционных баз данных. Проектирование баз данных. Сетевые и иерархические базы данных.
SQL
Книги:
Изучаем SQL. Линн Бейли — Обожаю эту линейку книг, серию Head First O`Reilly. И всем рекомендую)) Просто и доступно даже о сложном пишут.
Статьи:
Как изучить основы SQL за 2 дня
Полезные запросы
Тренажеры:
http://www.sql-ex.ru/ — Бесплатный тренажер для практики
Ресурсы и инструменты для практики с базами данных | SQL
Задачка по SQL. Найти объединенные данные
Найти объединенные данные
Резюме
База данных — это место для хранения данных. Они бывают самых разных видов, даже файловые! Но самые распространенные — реляционные базы данных, где данные хранятся в виде таблиц.
Если посмотреть на информацию о таблице в БД, мы можем увидеть ее ключи и индексы. Что это такое:
1. PK — primary key, первичный ключ. Гарантирует уникальность данных, часто используется для колонки с ID. Если ключ наложен на одну колонку — каждое значение в ячейках этой колонки уникальное. Если на несколько — комбинации строк по колонкам уникальны.
2. FK — foreign key, внешний ключ. Нужен для связки двух таблиц в разных соотношениях (1:1, 1:N, N:N). Этот ключ указываем в «дочерней» таблице, то есть в той, которая ссылается на родительскую (в таблице с данными по лицевому счету отсылка на client_id из таблицы клиентов).
3. Индекс. Нужен для ускорения выборки из таблицы.
Транзакционные базы данных выполняют требования ACID:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надежность
См также:
Что такое транзакция
И за это их выбирают разработчики. Мы получаем не просто хранилище данных. Наши данные защищены от неприятностей типа отключения электричества на середине бизнес-операции (с одного счета деньги списать, на другой записать). А еще по ним можно быстро искать, ведь разработчики баз данных оптимизируют свои приложения для этого.
Поэтому логика приложения — отдельно, база — отдельно. Так и получается клиент-серверная архитектура =)
См также:
Клиент-серверная архитектура в картинках
Чтобы достать данные из базы, надо написать запрос к ней на языке SQL (Structured Query Language). Разработчики пишут SQL-запросы внутри кода приложения. А тестировщики используют SQL для:
Разработчики пишут SQL-запросы внутри кода приложения. А тестировщики используют SQL для:
Поиска по базе — правильно ли данные сохранились? В нужные таблицы легли? Это select-запросы.
Подготовки тестовых данных — а что, если это значение будет пустое? А что, если у меня будет 2 лицевых счета на одной карточке? Можно готовить данные через графический интерфейс, но намного быстрее отправить несколько запросов в базу. Когда есть к ней доступ и вы знаете SQL =)
План-минимум для изучения: select, join, insert, update, create, delete, group by, having, distinct.
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Так вот, тестировщика на собеседовании не будут спрашивать про базы данных. Разработчика ещё могут спросить, а вас то зачем? Вполне достаточно понимания, что это вообще такое. И про ключи могут спросить — что такое primary или foreign key, зачем они вообще нужны.
База данных
TransTrade NET 3.0НАЧАЛО РАБОТЫЗапуск программы
Структура интерфейса
С чего начать?
Реквизиты организации
Базовые возможности
УЧЕТ ЗАКАЗОВЖурнал заказов
Создание заказа
Редактирование заказа
Дублирование заказа
Нумерация заказов
Номер заказа клиента
Состояние заказа
Статус заказа
Блокировка заказа
Скрытие заказа в архив
Удаление заказа
Свойства заказа
Быстрый фильтр
Выборка заказов
Фильтр заказов
Найти в журнале
Поиск документа
Контрагент
Журнал предзаказов
ОПЕРАЦИИДокументы по заказам
Итого по журналу
Установка признаков
Присвоить статус
Частичная оплата
Проведение оплаты по контрагенту
Поиск контрагента
СПРАВОЧНИКИКлиенты
Исполнители
Транспорт
Прицепы
Водители
Типы транспорта и тарифы
Фиксированные ставки
Виды расходов
Виды документов
Информационные позиции
Категории контрагентов
Источники заказов
Статусы заказов
БУХГАЛТЕРИЯПлатежные документы
Журнал платежных документов
Счет-реестр
Платежные документы от исполнителя
Платежный календарь
Акт сверки взаиморасчетов
Обмен данных с 1С
Загрузка банковской выписки
Электронный документооборот
Настройки платежных документов
ДОКУМЕНТЫПечатная форма заявки
Договор на оказание услуг
Путевой лист
Журнал путевых листов
Транспортная накладная
Товарно-транспортная накладная
Доверенность
Поручение экспедитору
Экспедиторская расписка
Командировочные документы
Почтовые конверты
ИНФОРМИРОВАНИЕОтправка заявки по электронной почте
Отправка произвольного письма
Рассылка писем
Журнал отправленных писем
SMS-уведомление по заказу
Рассылка SMS
Журнал отправленных SMS
ПОЛЕЗНЫЕ ВОЗМОЖНОСТИАдаптация под специфику деятельности
Специальные тарифы
Расходы по заказу
Хозрасходы по месяцам
Транспортные расходы
Документооборот по заказу
Занятость водителей
Мульти Фирма
Поручения
АТИ Сервис
CRM — управление взаимоотношениями с клиентами
Телефония
Мультимодальные перевозки и субподрядчики
Мобильное приложение
Планирование маршрута
Страхование груза
ОТЧЕТЫРасчет за период
Детализация оказания услуг
Дебет-кредит
Оплата за период
Частичная оплата
Моя статистика
Сведения по заказу
Финансы по заказу
Конструктор отчетов
Сводный отчет
Финансовый отчет
Надежность контрагентов
Наличие документов
Реестр сдачи документов
Контроль движения документов
Реестр документов для клиента
Прикрепленные документы
Общий отчет с примечаниями
Отчет по субподрядичкам
Порожний пробег
Отчет по персоналу
Сводная книга по месяцам
Суммарный трудовой отчет по водителям
Журнал учета доходов и расходов по неделям
Зарплата менеджерам
Расчетный лист по менеджеру
Обороты по дням
Активность клиентов
Динамика активности клиентов
Статистика по водителям
Реестр плановых оплат
Платежи за период
Ведомость по счетам
История заказов
Отчет по расходам
Сводка по транспорту
Расходы и рентабельность
Контроль движения документов за период
Реестр документов для клиента за период
АДМИНИСТРИРОВАНИЕУчетные записи пользователей
Статусы полномочий
Журнал действий
Параметры системы
Документы
Дополнительные настройки
База данных
Сервисная утилита
Резервное копирование
Системные операции с базой данных
Импорт данных
Офис-обмен
Формулы расчета
Почтовые настройки
SMS-настройки
Редактирование бланков документов
Индивидуальный бланк заявки для контрагента
Добавление печати и подписи в бланк заявки
Добавление печати и подписи в бланк счета
Разные бланки фирм
Переменные для бланка заявки
Переменные для бланка договора
Разные типы печатных заявок
Разные типы договоров услуг
ЧАСТО ЗАДАВАЕМЫЕ ВОПРОСЫДанный пользователь уже находится в системе
Система Office обнаружила проблему с файлом
Мелкий текст в Windows 10
Изменение пароля облачной базы данных
Не открывается журнал заказов с облачной базой
Неправильно заданы даты периода заказа
Несколько точек загрузки и выгрузки в заявке
Загруженные документы не проводятся в 1С
Вывести на принтер или в PDF две страницы
Не удалось получить файл с FTP-сервера
Способ расчета НДС 0%
В зависимости от конфигурации вашей программы, база данных может быть локальной или облачной.
Локальная база данных — хранится на вашем рабочем компьютере или в папке общего доступа на офисном сервере, и предназначается для многопользовательского локального использования в офисном помещении, где компьютеры объединены в единую локальную сеть (проводную или беспроводную).
Облачная база данных — хранится на виртуальном сервере, доступна через Интернет, и предназначается для возможности мобильного многопользовательского использования и удаленной работы, вне зависимости от места нахождения сотрудников.
| Локальная база |
Стандартное имя файла базы данных — DataBASE.TT
По умолчанию программа использует файл базы данных из папки с программными файлами TransTrade. Для того чтобы изменить расположение файла базы данных, воспользуйтесь следующей командой главного меню:
УПРАВЛЕНИЕ → Настройки БД
Путь к базе данных — локальный или сетевой путь расположения файла базы данных.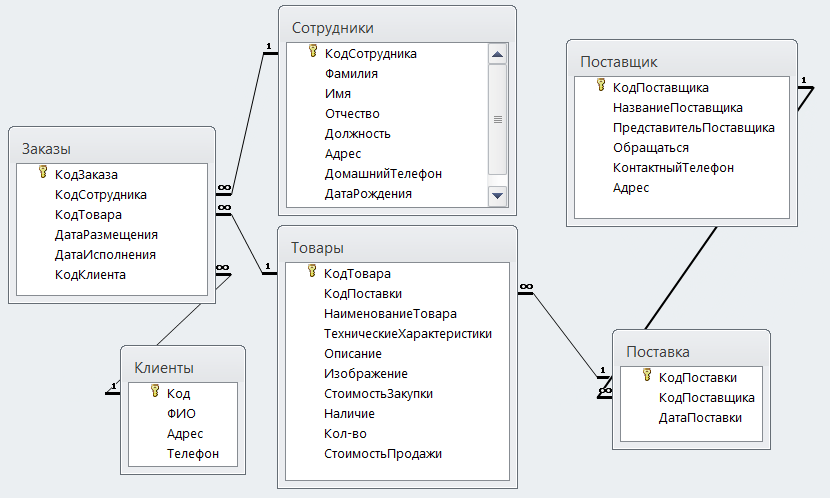
Примеры указания пути к базе данных
D:\TransTrade\DataBASE.TT
\\SERVER\TransTrade\DataBASE.TT
\\SERVER\TransTrade\
Щелкните Указать, чтобы выбрать местонахождение файла база данных. Также можно указать путь вручную.
По умолчанию — возвращает системный путь к базе данных из папки с программой.
Для подтверждения внесения изменений нажмите кнопку Применить.
Также изменить путь к базе данных можно при помощи сервисной утилиты TransTrade Service, инструкция по использованию которой представлена в отдельном разделе данного руководства пользователя:
АДМИНИСТРИРОВАНИЕ → Сервисная утилита
Управление резервным копированием базы данных:
АДМИНИСТРИРОВАНИЕ → Резервное копирование
| Общий доступ |
Для организации многопользовательской работы в локальной сети необходимо чтобы все пользователи были подключены к единой базе данных. С этой целью программа устанавливается на одном компьютере в сетевой папке общего доступа, а на другие рабочие места выносятся ярлыки для запуска программы. Таким образом, каждый сотрудник запускает программу со своего рабочего места и работает под своей учетной записью, используя персональный логин и пароль, подключаясь к единой базе данных.
С этой целью программа устанавливается на одном компьютере в сетевой папке общего доступа, а на другие рабочие места выносятся ярлыки для запуска программы. Таким образом, каждый сотрудник запускает программу со своего рабочего места и работает под своей учетной записью, используя персональный логин и пароль, подключаясь к единой базе данных.
В качестве компьютера, на котором будут размещены программные файлы TransTrade, может выступать как офисный сервер, так и обычный главный компьютер. Важно то, что данный компьютер должен быть постоянно включенным, когда используется программа.
Выберите компьютер, подходящий для установки программы, и создайте на нем папку общего доступа с правами на чтение и изменение. Например, на диске D создайте папку TransTrade.
Чтобы открыть общий доступ для созданной папки TransTrade, выполните следующие действия:
1. Откройте свойства папки — щелкните правой кнопкой мыши на папке и в контекстном меню выберите команду Свойства.
2. В окне свойств папки на вкладке Доступ нажмите кнопку Расширенная настройка.
3. Затем включите опцию Открыть общий доступ к этой папке и нажмите кнопку Разрешения:
4. В разрешениях включите отметки Чтение и Изменение:
5. Нажмите OK. Потом в предыдущем окне — тоже OK.
Теперь папка TransTrade доступна по сети. Если на другом компьютере в этой локальной сети открыть сетевое окружение, в общем доступе появится папка TransTrade. Следовательно, с любого компьютера в офисе есть доступ к этой сетевой папке.
Следовательно, с любого компьютера в офисе есть доступ к этой сетевой папке.
Поместите в эту сетевую папку весь комплект программных файлов TransTrade.
Комплект файлов включает в себя папку Бланки, приложение TransTrade.exe, базу данных DataBASE.TT и прочие системные файлы:
Если комплект файлов упакован в zip-архив, обязательно извлеките все файлы из архива в папку:
После распаковки комплекта файлов из архива, рекомендуется удалить zip-архив.
Теперь, запустив из папки общего доступа приложение TransTrade.exe, программу можно использовать на любом компьютере.
Для удобства запуска программы на других рабочих местах вынесите ярлык на рабочий стол. Для этого вызовите контекстное меню щелчком правой кнопкой мыши на файле TransTrade. exe и выберите команду Отправить → Рабочий стол (создать ярлык):
exe и выберите команду Отправить → Рабочий стол (создать ярлык):
Переименуйте ярлык на TransTrade.
Описанный способ организации многопользовательской работы по сети является рекомендованным. Также при желании можно установить программу на каждом компьютере в офисе, а файл базы данных поместить в папку общего доступа, после чего на каждом рабочем месте изменить путь к файлу базы данных.
| Облачная база |
Примечание: «Интернет-сервер» — это дополнительный модуль, который приобретается отдельно. Инструкции в данном разделе актуальны, если конфигурация программы включает модуль «Интернет-сервер».
Интернет сервер — это полностью готовое решение для использования программы в режиме онлайн в любом месте, где есть подключение к Интернету. Актуально, если ваша рабочая деятельность предполагает необходимость использования программы в разных территориально удаленных друг от друга местах.
Актуально, если ваша рабочая деятельность предполагает необходимость использования программы в разных территориально удаленных друг от друга местах.
В данном случе программа использует облачное хранение базы данных — ваши данные хранятся на специальном виртуальном сервере, к которому подключена программа во время ее использования. Все заказы и документы сохраняются в единой базе данных и доступны всем пользователям системы в режиме реального времени.
Вместе с программой передается PDF-документ с описанием сервиса облачного хранения данных и вашими доступами.
Программа поставляется с уже предустановленными настройками подключения к базе данных и не требует дополнительных действий.
Программа готова к использованию.
Комплект файлов включает в себя папку Бланки, приложение TransTrade. exe, файл с настройками подключения config.set и прочие системные файлы:
exe, файл с настройками подключения config.set и прочие системные файлы:
Если комплект файлов упакован в zip-архив, обязательно извлеките все файлы из архива в папку:
После распаковки комплекта файлов из архива, рекомендуется удалить zip-архив.
Данный комплект программных файлов требуется на каждом компьютере, где планируется использовать программу.
Предоставьте ссылку для загрузки вашего комплекта файлов всем сотрудникам, кому необходимо установить программу.
Имея данный комплект программных файлов, программу можно использовать на любом рабочем месте, используя свой логин и пароль доступа.
Для удобства запуска программы вынесите ярлык на рабочий стол. Для этого вызовите контекстное меню щелчком правой кнопкой мыши на файле TransTrade.exe и выберите команду Отправить → Рабочий стол (создать ярлык):
Переименуйте ярлык на TransTrade.
Изменить настройки подключения к базе данных можно при помощи сервисной утилиты TransTrade Service, инструкция по использованию которой представлена в отдельном разделе данного руководства пользователя:
АДМИНИСТРИРОВАНИЕ → Сервисная утилита
Не то же самое • UDLib/SEARCH
Перейти к содержимомуФинансируемое государством сотрудничество между Департаментом образования штата Делавэр и библиотекой Университета штата Делавэр, предоставляющее онлайн-журналы, журналы, энциклопедии и обучение для всех государственных школ штата Делавэр K-12
Базы данных
База данных представляет собой набор информации, организованной таким образом, чтобы к ее содержимому можно было легко получить доступ, управлять им и обновлять его.
Базы данных в большинстве библиотек обычно представляют собой электронные форматы периодических указателей, которые традиционно создавались в печатном виде.
Периодические указатели
Периодический указатель содержит список статей, опубликованных по заданной теме за определенный период времени. Некоторые периодические указатели носят очень общий характер и охватывают множество тем; другие специализированы и очень подробно охватывают одну тему. Многие индексы доступны для поиска с помощью компьютера. Периодические индексы, поиск по которым может осуществлять компьютер, называются электронными индексами или базами данных. Эти базы данных содержат цитаты и/или рефераты статей. Некоторые базы данных даже сами содержат целые статьи; они называются полнотекстовыми статьями.
Базы данных в Интернете
Во многих случаях Интернет используется как инструмент для подключения информации из удаленных электронных периодических указателей к компьютерам по всему миру. Базы данных, предоставляющие доступ к своей информации через Интернет, называются онлайновыми базами данных. Статьи, доступ к которым осуществляется через онлайновые базы данных, отличаются от обычных документов, найденных в Интернете. Библиотеки подписываются, уплачивая ежегодную плату, чтобы иметь возможность предоставлять доступ к базам данных с использованием Интернета для передачи информации. Содержимое этих указателей, или баз данных, столь же надежно, как и содержимое указателей периодических печатных изданий, и во многих случаях они более актуальны, чем указатели печатных изданий, поскольку их легче обновлять.
Библиотеки подписываются, уплачивая ежегодную плату, чтобы иметь возможность предоставлять доступ к базам данных с использованием Интернета для передачи информации. Содержимое этих указателей, или баз данных, столь же надежно, как и содержимое указателей периодических печатных изданий, и во многих случаях они более актуальны, чем указатели печатных изданий, поскольку их легче обновлять.
UDLib/SEARCH
UDLib/SEARCH — это программа, которая управляет подпиской штата на электронные периодические издания и энциклопедии для всех государственных школ штата Делавэр. Каждый компьютер, подключенный к Интернету в этих школах, может получить доступ к этим базам данных.
Базы данных UDLib/SEARCH содержат полные тексты или цитаты тысяч опубликованных статей в широком спектре предметных областей. В базах данных очень легко искать, а статьи, которые они извлекают, производятся из надежных источников. Эти статьи написаны на уровне чтения младших школьников и включают бесчисленное количество фотографий, иллюстраций, таблиц и видеоклипов для дальнейшего расширения исследовательской деятельности учащихся.
Интернет
Интернет — это глобальная ассоциация миллионов компьютеров, передающая данные и позволяющая обмениваться информацией с одного компьютера на другой.
Интернет представляет собой сеть сетей, соединяющих компьютеры с компьютерами, использующими протоколы TCP/IP. Каждый запускает программное обеспечение для предоставления или «обслуживания» информации и/или для доступа и просмотра информации. Интернет — это транспортное средство для информации, хранящейся в файлах или документах на другом компьютере.
Адрес или URL-адрес (унифицированный указатель ресурсов): Сайты, URL-адреса которых заканчиваются на edu, gov, org или mil, публикуются образовательными учреждениями, правительством или организациями и обычно более надежны, чем те, которые заканчиваются на com или net, которые производятся коммерческими или сетевыми организациями.
Авторство: На многих страницах указано имя человека или организации, ответственных за их создание. Если эта информация предоставляется вместе с полномочиями автора или областью знаний, это может быть полезно для определения того, хорошо ли человек осведомлен о теме, о которой он / она говорит.
Если эта информация предоставляется вместе с полномочиями автора или областью знаний, это может быть полезно для определения того, хорошо ли человек осведомлен о теме, о которой он / она говорит.
Валюта: В нижней части многих веб-страниц указана дата последнего обновления страницы. Валюта страницы часто влияет на надежность содержащейся на ней информации.
Финансируемое государством сотрудничество между Департаментом образования штата Делавэр и библиотекой Университета штата Делавэр, предоставляющее онлайн-журналы, журналы, энциклопедии и обучение для всех государственных школ штата Делавэр K-12
© 2023 UDLib/ПОИСК
Интернет против баз данных | Публичная библиотека Лос-Анджелеса
Существует разница между Интернетом и базами данных, доступными через Интернет.
Интернет:
Интернет — это всемирная система компьютерных сетей. Когда вы ищете в Интернете с помощью поисковых систем, таких как Google и Yahoo, вы ищете в «бесплатных» областях Интернета. Результатом будет список веб-сайтов. Любой может разместить веб-сайт, поэтому вам необходимо оценить веб-сайт, чтобы определить, является ли информация точной и надежной. Публичная библиотека Лос-Анджелеса предлагает ссылки на несколько отличных веб-сайтов по темам в разделе веб-ресурсов, а также через Kids’ Path и Teen Web.
Результатом будет список веб-сайтов. Любой может разместить веб-сайт, поэтому вам необходимо оценить веб-сайт, чтобы определить, является ли информация точной и надежной. Публичная библиотека Лос-Анджелеса предлагает ссылки на несколько отличных веб-сайтов по темам в разделе веб-ресурсов, а также через Kids’ Path и Teen Web.
Базы данных библиотек:
Публичная библиотека Лос-Анджелеса также предоставляет доступ к нескольким базам данных, доступным через Интернет. Эти базы данных не бесплатны. Библиотека подписывается на эти базы данных за плату, а затем предоставляет доступ к ним нашим посетителям. Эти базы данных содержат такую информацию, как газетные, журнальные и энциклопедические статьи. Материалы поступают от издательств, поэтому они проверены на точность и достоверность. Некоторые издатели больше не предоставляют информацию в печатном формате. Теперь единственный способ получить информацию, которая ранее предоставлялась в печатном виде, — через онлайн-базу данных. Несколько баз данных взяты из печатных источников, которые издатели теперь также продают в онлайн-формате. Например, статья, которую вы прочитали в Los Angeles Times через базу данных ProQuest, будет той же самой статьей, которая была напечатана в газете Los Angeles Times. В базах данных не всегда есть все статьи из журналов или газет, которые они освещают, и они не включают рекламу. Некоторые из них предоставляют только аннотацию или короткий абзац из статьи вместо полного текста. В этом случае вам придется перейти к источнику печати, чтобы получить копию полной статьи.
Несколько баз данных взяты из печатных источников, которые издатели теперь также продают в онлайн-формате. Например, статья, которую вы прочитали в Los Angeles Times через базу данных ProQuest, будет той же самой статьей, которая была напечатана в газете Los Angeles Times. В базах данных не всегда есть все статьи из журналов или газет, которые они освещают, и они не включают рекламу. Некоторые из них предоставляют только аннотацию или короткий абзац из статьи вместо полного текста. В этом случае вам придется перейти к источнику печати, чтобы получить копию полной статьи.
Когда я использую Интернет и когда я использую базу данных?
Используйте Интернет, когда вы:
- Желаете оценить содержание веб-сайта
- Хотите перейти на определенный веб-сайт
- Хотите получить информацию по уникальной теме
- Хотите правительственную информацию, такую как налоговые формы
- Нужны другие сайты по всему миру
В Интернете действительно есть отличная информация, в том числе информация, которая больше нигде недоступна.