Хеширование – что это и зачем
Криптографические хеш-функции — незаменимый и повсеместно распространенный инструмент, используемый для выполнения целого ряда задач, включая аутентификацию, проверку целостности данных, защиту файлов и даже обнаружение зловредного ПО. Существует масса алгоритмов хеширования, отличающихся криптостойкостью, сложностью, разрядностью и другими свойствами. Считается, что идея хеширования принадлежит сотруднику IBM, появилась около 50 лет назад и с тех пор не претерпела принципиальных изменений. Зато в наши дни хеширование обрело массу новых свойств и используется в очень многих областях информационных технологий.
Что такое хеш?
Если коротко, то криптографическая хеш-функция, чаще называемая просто хешем, — это математический алгоритм, преобразовывающий произвольный массив данных в состоящую из букв и цифр строку фиксированной длины. Причем при условии использования того же типа хеша длина эта будет оставаться неизменной, вне зависимости от объема вводных данных. Криптостойкой хеш-функция может быть только в том случае, если выполняются главные требования: стойкость к восстановлению хешируемых данных и стойкость к коллизиям, то есть образованию из двух разных массивов данных двух одинаковых значений хеша. Интересно, что под данные требования формально не подпадает ни один из существующих алгоритмов, поскольку нахождение обратного хешу значения — вопрос лишь вычислительных мощностей. По факту же в случае с некоторыми особо продвинутыми алгоритмами этот процесс может занимать чудовищно много времени.
Криптостойкой хеш-функция может быть только в том случае, если выполняются главные требования: стойкость к восстановлению хешируемых данных и стойкость к коллизиям, то есть образованию из двух разных массивов данных двух одинаковых значений хеша. Интересно, что под данные требования формально не подпадает ни один из существующих алгоритмов, поскольку нахождение обратного хешу значения — вопрос лишь вычислительных мощностей. По факту же в случае с некоторыми особо продвинутыми алгоритмами этот процесс может занимать чудовищно много времени.
Как работает хеш?
Например, мое имя — Brian — после преобразования хеш-функцией SHA-1 (одной из самых распространенных наряду с MD5 и SHA-2) при помощи онлайн-генератора будет выглядеть так: 75c450c3f963befb912ee79f0b63e563652780f0. Как вам скажет, наверное, любой другой Брайан, данное имя нередко пишут с ошибкой, что в итоге превращает его в слово brain (мозг). Это настолько частая опечатка, что однажды я даже получил настоящие водительские права, на которых вместо моего имени красовалось Brain Donohue. Впрочем, это уже другая история. Так вот, если снова воспользоваться алгоритмом SHA-1, то слово Brain трансформируется в строку 97fb724268c2de1e6432d3816239463a6aaf8450. Как видите, результаты значительно отличаются друг от друга, даже несмотря на то, что разница между моим именем и названием органа центральной нервной системы заключается лишь в последовательности написания двух гласных. Более того, если я преобразую тем же алгоритмом собственное имя, но написанное уже со строчной буквы, то результат все равно не будет иметь ничего общего с двумя предыдущими: 760e7dab2836853c63805033e514668301fa9c47.
Впрочем, это уже другая история. Так вот, если снова воспользоваться алгоритмом SHA-1, то слово Brain трансформируется в строку 97fb724268c2de1e6432d3816239463a6aaf8450. Как видите, результаты значительно отличаются друг от друга, даже несмотря на то, что разница между моим именем и названием органа центральной нервной системы заключается лишь в последовательности написания двух гласных. Более того, если я преобразую тем же алгоритмом собственное имя, но написанное уже со строчной буквы, то результат все равно не будет иметь ничего общего с двумя предыдущими: 760e7dab2836853c63805033e514668301fa9c47.
Впрочем, кое-что общее у них все же есть: каждая строка имеет длину ровно 40 символов. Казалось бы, ничего удивительного, ведь все введенные мною слова также имели одинаковую длину — 5 букв. Однако если вы захешируете весь предыдущий абзац целиком, то все равно получите последовательность, состоящую ровно из 40 символов: c5e7346089419bb4ab47aaa61ef3755d122826e2. То есть 1128 символов, включая пробелы, были ужаты до строки той же длины, что и пятибуквенное слово. То же самое произойдет даже с полным собранием сочинений Уильяма Шекспира: на выходе вы получите строку из 40 букв и цифр. При всем этом не может существовать двух разных массивов данных, которые преобразовывались бы в одинаковый хеш.
То же самое произойдет даже с полным собранием сочинений Уильяма Шекспира: на выходе вы получите строку из 40 букв и цифр. При всем этом не может существовать двух разных массивов данных, которые преобразовывались бы в одинаковый хеш.
Вот как это выглядит, если изобразить все вышесказанное в виде схемы:
Для чего используется хеш?
Отличный вопрос. Однако ответ не так прост, поскольку криптохеши используются для огромного количества вещей.
Для нас с вами, простых пользователей, наиболее распространенная область применения хеширования — хранение паролей. К примеру, если вы забыли пароль к какому-либо онлайн-сервису, скорее всего, придется воспользоваться функцией восстановления пароля. В этом случае вы, впрочем, не получите свой старый пароль, поскольку онлайн-сервис на самом деле не хранит пользовательские пароли в виде обычного текста. Вместо этого он хранит их в виде хеш-значений. То есть даже сам сервис не может знать, как в действительности выглядит ваш пароль. Исключение составляют только те случаи, когда пароль очень прост и его хеш-значение широко известно в кругах взломщиков. Таким образом, если вы, воспользовавшись функцией восстановления, вдруг получили старый пароль в открытом виде, то можете быть уверены: используемый вами сервис не хеширует пользовательские пароли, что очень плохо.
Исключение составляют только те случаи, когда пароль очень прост и его хеш-значение широко известно в кругах взломщиков. Таким образом, если вы, воспользовавшись функцией восстановления, вдруг получили старый пароль в открытом виде, то можете быть уверены: используемый вами сервис не хеширует пользовательские пароли, что очень плохо.
Вы даже можете провести простой эксперимент: попробуйте при помощи специального сайта произвести преобразование какого-нибудь простого пароля вроде «123456» или «password» из их хеш-значений (созданных алгоритмом MD5) обратно в текст. Вероятность того, что в базе хешей найдутся данные о введенных вами простых паролях, очень высока. В моем случае хеши слов «brain» (8b373710bcf876edd91f281e50ed58ab) и «Brian» (4d236810821e8e83a025f2a83ea31820) успешно распознались, а вот хеш предыдущего абзаца — нет. Отличный пример, как раз для тех, кто все еще использует простые пароли.
Еще один пример, покруче. Не так давно по тематическим сайтам прокатилась новость о том, что популярный облачный сервис Dropbox заблокировал одного из своих пользователей за распространение контента, защищенного авторскими правами.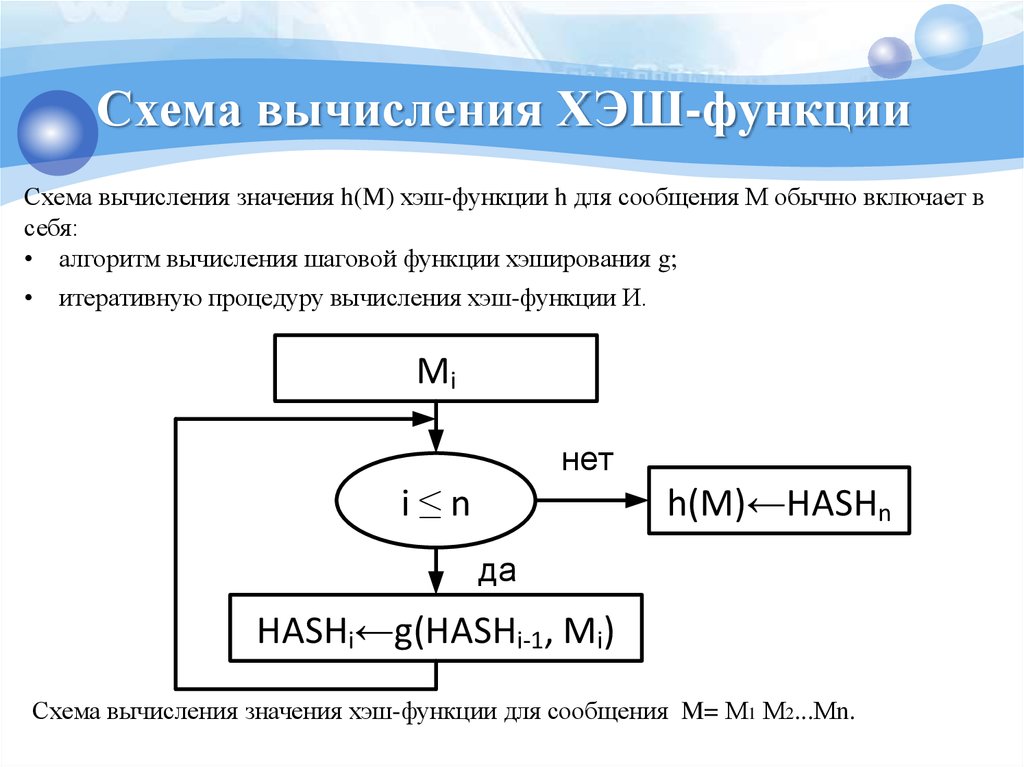 Герой истории тут же написал об этом в твиттере, запустив волну негодования среди пользователей сервиса, ринувшихся обвинять Dropbox в том, что он якобы позволяет себе просматривать содержимое клиентских аккаунтов, хотя не имеет права этого делать.
Герой истории тут же написал об этом в твиттере, запустив волну негодования среди пользователей сервиса, ринувшихся обвинять Dropbox в том, что он якобы позволяет себе просматривать содержимое клиентских аккаунтов, хотя не имеет права этого делать.
Впрочем, необходимости в этом все равно не было. Дело в том, что владелец защищенного копирайтом контента имел на руках хеш-коды определенных аудио- и видеофайлов, запрещенных к распространению, и занес их в список блокируемых хешей. Когда пользователь предпринял попытку незаконно распространить некий контент, автоматические сканеры Dropbox засекли файлы, чьи хеши оказались в пресловутом списке, и заблокировали возможность их распространения.
Где еще можно использовать хеш-функции помимо систем хранения паролей и защиты медиафайлов? На самом деле задач, где используется хеширование, гораздо больше, чем я знаю и тем более могу описать в одной статье. Однако есть одна особенная область применения хешей, особо близкая нам как сотрудникам «Лаборатории Касперского»: хеширование широко используется для детектирования зловредных программ защитным ПО, в том числе и тем, что выпускается нашей компанией.
Как при помощи хеша ловить вирусы?
Примерно так же, как звукозаписывающие лейблы и кинопрокатные компании защищают свой контент, сообщество создает списки зловредов (многие из них доступны публично), а точнее, списки их хешей. Причем это может быть хеш не всего зловреда целиком, а лишь какого-либо его специфического и хорошо узнаваемого компонента. С одной стороны, это позволяет пользователю, обнаружившему подозрительный файл, тут же внести его хеш-код в одну из подобных открытых баз данных и проверить, не является ли файл вредоносным. С другой — то же самое может сделать и антивирусная программа, чей «движок» использует данный метод детектирования наряду с другими, более сложными.
Криптографические хеш-функции также могут использоваться для защиты от фальсификации передаваемой информации. Иными словами, вы можете удостовериться в том, что файл по пути куда-либо не претерпел никаких изменений, сравнив его хеши, снятые непосредственно до отправки и сразу после получения. Если данные были изменены даже всего на 1 байт, хеш-коды будут отличаться, как мы уже убедились в самом начале статьи. Недостаток такого подхода лишь в том, что криптографическое хеширование требует больше вычислительных мощностей или времени на вычисление, чем алгоритмы с отсутствием криптостойкости. Зато они в разы надежнее.
Если данные были изменены даже всего на 1 байт, хеш-коды будут отличаться, как мы уже убедились в самом начале статьи. Недостаток такого подхода лишь в том, что криптографическое хеширование требует больше вычислительных мощностей или времени на вычисление, чем алгоритмы с отсутствием криптостойкости. Зато они в разы надежнее.
Кстати, в повседневной жизни мы, сами того не подозревая, иногда пользуемся простейшими хешами. Например, представьте, что вы совершаете переезд и упаковали все вещи по коробкам и ящикам. Погрузив их в грузовик, вы фиксируете количество багажных мест (то есть, по сути, количество коробок) и запоминаете это значение. По окончании выгрузки на новом месте, вместо того чтобы проверять наличие каждой коробки по списку, достаточно будет просто пересчитать их и сравнить получившееся значение с тем, что вы запомнили раньше. Если значения совпали, значит, ни одна коробка не потерялась.
Советы
Продавцы воздуха в онлайн-магазинах
Рассказываем, как мошенники обманывают пользователей известного маркетплейса с помощью поддельной страницы оплаты товара.
Подпишитесь на нашу еженедельную рассылку
- Email*
- *
- Я согласен(а) предоставить мой адрес электронной почты АО “Лаборатория Касперского“, чтобы получать уведомления о новых публикациях на сайте. Я могу отозвать свое согласие в любое время, нажав на кнопку “отписаться” в конце любого из писем, отправленных мне по вышеуказанным причинам.
Что такое Хэширование? Под капотом блокчейна / Хабр
Очень многие из вас, наверное, уже слышали о технологии блокчейн, однако важно знать о принципе работы хэширования в этой системе. Технология Блокчейн является одним из самых инновационных открытий прошлого века. Мы можем так заявить без преувеличения, так как наблюдаем за влиянием, которое оно оказало на протяжении последних нескольких лет, и влиянием, которое оно будет иметь в будущем. Для того чтобы понять устройство и предназначение самой технологии блокчейн, сначала мы должны понять один из основных принципов создания блокчейна.
Так что же такое хэширование?
Простыми словами, хэширование означает ввод информации любой длины и размера в исходной строке и выдачу результата фиксированной длины заданной алгоритмом функции хэширования. В контексте криптовалют, таких как Биткоин, транзакции после хэширования на выходе выглядят как набор символов определённой алгоритмом длины (Биткоин использует SHA-256).
Input- вводимые данные, hash- хэш
Посмотрим, как работает процесс хэширования. Мы собираемся внести определенные данные. Для этого, мы будем использовать SHA-256 (безопасный алгоритм хэширования из семейства SHA-2, размером 256 бит).
Как видите, в случае SHA-256, независимо от того, насколько объёмные ваши вводимые данные (input), вывод всегда будет иметь фиксированную 256-битную длину. Это крайне необходимо, когда вы имеете дело с огромным количеством данных и транзакций. Таким образом, вместо того, чтобы помнить вводимые данные, которые могут быть огромными, вы можете просто запомнить хэш и отслеживать его.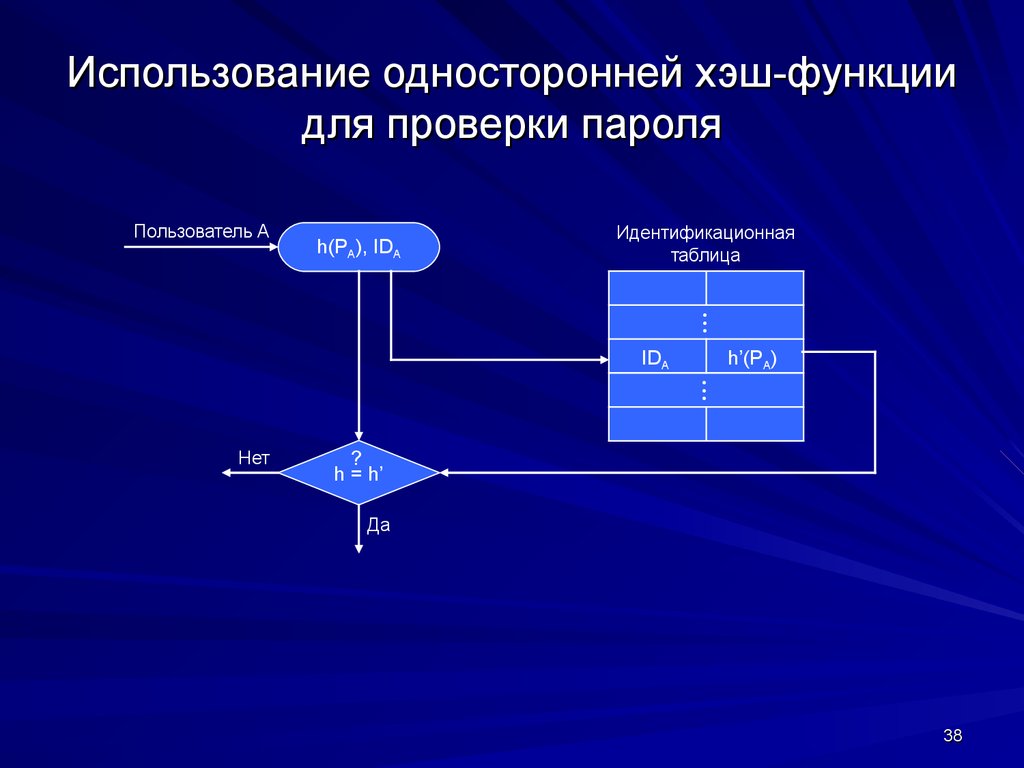 Прежде чем продолжать, необходимо познакомиться с различными свойствами функций хэширования и тем, как они реализуются в блокчейн.
Прежде чем продолжать, необходимо познакомиться с различными свойствами функций хэширования и тем, как они реализуются в блокчейн.
Криптографические хэш-функции
Криптографическая хэш-функция — это специальный класс хэш-функций, который имеет различные свойства, необходимые для криптографии. Существуют определенные свойства, которые должна иметь криптографическая хэш-функция, чтобы считаться безопасной. Давайте разберемся с ними по очереди.
Свойство 1: Детерминированние
Это означает, что независимо от того, сколько раз вы анализируете определенный вход через хэш-функцию, вы всегда получите тот же результат. Это важно, потому что если вы будете получать разные хэши каждый раз, будет невозможно отслеживать ввод.
Свойство 2: Быстрое вычисление
Хэш-функция должна быть способна быстро возвращать хэш-вход. Если процесс не достаточно быстрый, система просто не будет эффективна.
Свойство 3: Сложность обратного вычисления
Сложность обратного вычисления означает, что с учетом H (A) невозможно определить A, где A – вводимые данные и H(А) – хэш.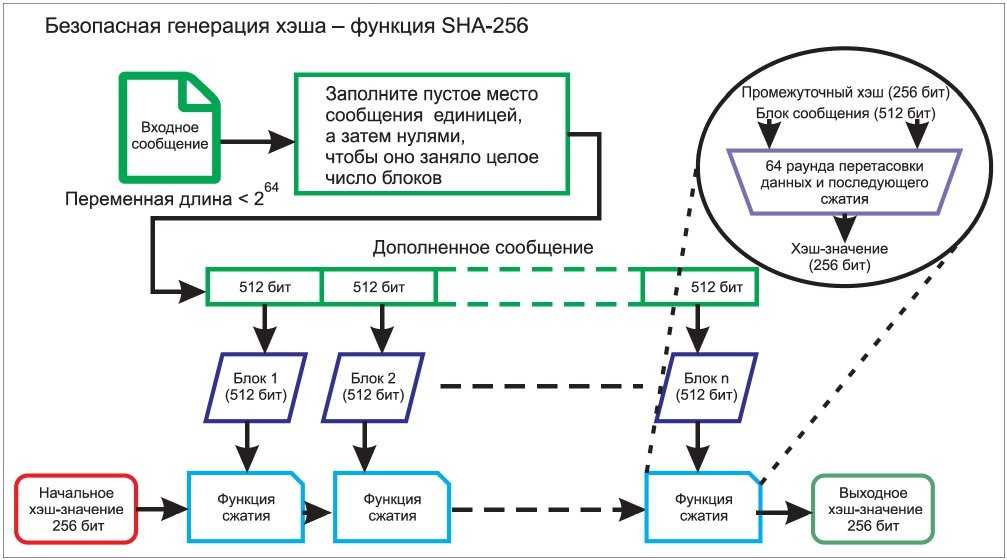 Обратите внимание на использование слова “невозможно” вместо слова “неосуществимо”. Мы уже знаем, что определить исходные данные по их хэш-значению можно. Возьмем пример.
Обратите внимание на использование слова “невозможно” вместо слова “неосуществимо”. Мы уже знаем, что определить исходные данные по их хэш-значению можно. Возьмем пример.
Предположим, вы играете в кости, а итоговое число — это хэш числа, которое появляется из кости. Как вы сможете определить, что такое исходный номер? Просто все, что вам нужно сделать, — это найти хэши всех чисел от 1 до 6 и сравнить. Поскольку хэш-функции детерминированы, хэш конкретного номера всегда будет одним и тем же, поэтому вы можете просто сравнить хэши и узнать исходный номер.
Но это работает только тогда, когда данный объем данных очень мал. Что происходит, когда у вас есть огромный объем данных? Предположим, вы имеете дело с 128-битным хэшем. Единственный метод, с помощью которого вы должны найти исходные данные, — это метод «грубой силы». Метод «грубой силы» означает, что вам нужно выбрать случайный ввод, хэшировать его, а затем сравнить результат с исследуемым хэшем и повторить, пока не найдете совпадение.
Таким образом, можно пробить функцию обратного вычисления с помощью метода «грубой силы», но потребуется очень много времени и вычислительных ресурсов, поэтому это бесполезно.
Свойство 4: Небольшие изменения в вводимых данных изменяют хэш
Даже если вы внесете небольшие изменения в исходные данные, изменения, которые будут отражены в хэше, будут огромными. Давайте проверим с помощью SHA-256:
Видите? Даже если вы только что изменили регистр первой буквы, обратите внимание, насколько это повлияло на выходной хэш. Это необходимая функция, так как свойство хэширования приводит к одному из основных качеств блокчейна – его неизменности (подробнее об этом позже).
Свойство 5: Коллизионная устойчивость
Учитывая два разных типа исходных данных A и B, где H (A) и H (B) являются их соответствующими хэшами, для H (A) не может быть равен H (B). 64.
64.
Как вы заметили, намного легче разрушить коллизионную устойчивость, нежели найти обратное вычисление хэша. Для этого обычно требуется много времени. Итак, если вы используете такую функцию, как SHA-256, можно с уверенностью предположить, что если H (A) = H (B), то A = B.
Свойство 6: Головоломка
Свойства Головоломки имеет сильнейшее воздействие на темы касающиеся криптовалют (об этом позже, когда мы углубимся в крипто схемы). Сначала давайте определим свойство, после чего мы подробно рассмотрим каждый термин.
Для каждого выхода «Y», если k выбран из распределения с высокой мин-энтропией, невозможно найти вводные данные x такие, что H (k | x) = Y.
Вероятно, это, выше вашего понимания! Но все в порядке, давайте теперь разберемся с этим определением.
В чем смысл «высокой мин-энтропии»?
Это означает, что распределение, из которого выбрано значение, рассредоточено так, что мы выбираем случайное значение, имеющее незначительную вероятность.
 61 хэша.
61 хэша.
Хэширование и структуры данных.
Структура данных — это специализированный способ хранения данных. Если вы хотите понять, как работает система «блокчейн», то есть два основных свойства структуры данных, которые могут помочь вам в этом:
1. Указатели
2. Связанные списки
Указатели
В программировании указатели — это переменные, в которых хранится адрес другой переменной, независимо от используемого языка программирования.
Например, запись int a = 10 означает, что существует некая переменная «a», хранящая в себе целочисленное значение равное 10. Так выглядит стандартная переменная.
Однако, вместо сохранения значений, указатели хранят в себе адреса других переменных. Именно поэтому они и получили свое название, потому как буквально указывают на расположение других переменных.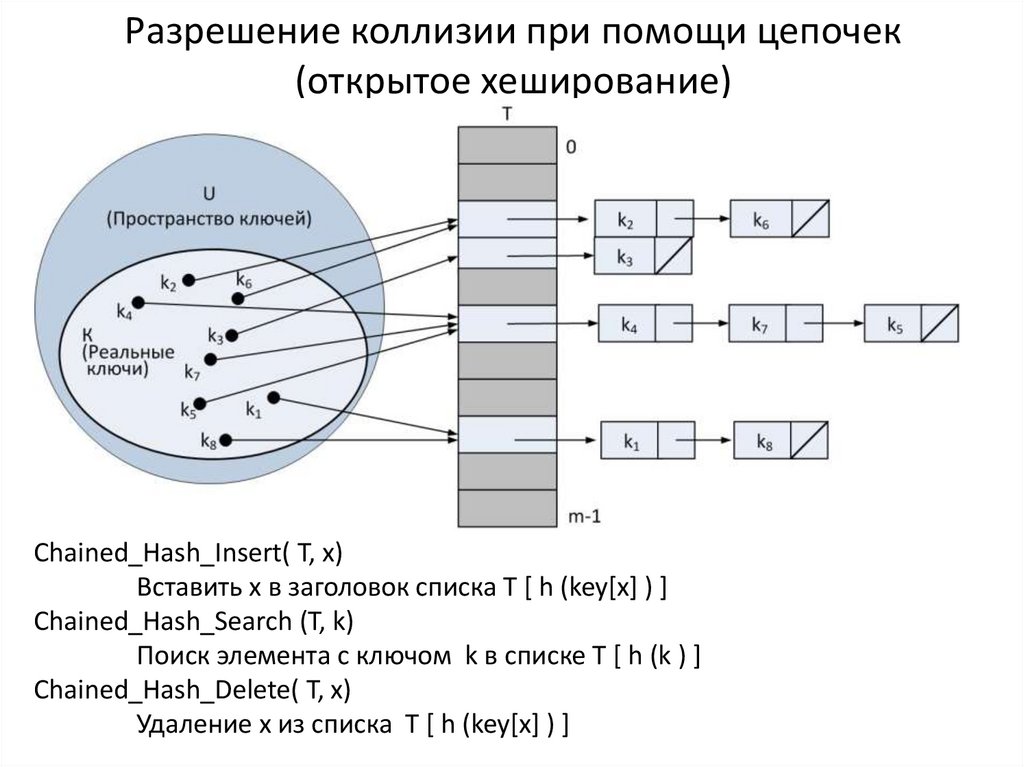
Связанные списки
Связанный список является одним из наиболее важных элементов в структурах данных. Структура связанного списка выглядит следующим образом:
*Head – заголовок; Data – данные; Pointer – указатель; Record – запись; Null – ноль
Это последовательность блоков, каждый из которых содержит данные, связанные со следующим с помощью указателя. Переменная указателя в данном случае содержит адрес следующего узла, благодаря чему выполняется соединение. Как показано на схеме, последний узел отмечен нулевым указателем, что означает, что он не имеет значения.
Важно отметить, что указатель внутри каждого блока содержит адрес предыдущего. Так формируется цепочка. Возникает вопрос, что это значит для первого блока в списке и где находится его указатель?
Первый блок называется «блоком генезиса», а его указатель находится в самой системе. Выглядит это следующим образом:
*H ( ) – Хэшированные указатели изображаются таким образом
Если вам интересно, что означает «хэш-указатель», то мы с радостью поясним.
Как вы уже поняли, именно на этом основана структура блокчейна. Цепочка блоков представляет собой связанный список. Рассмотрим, как устроена структура блокчейна:
* Hash of previous block header – хэш предыдущего заголовка блока; Merkle Root – Корень Меркла; Transactions – транзакции; Simplified Bitcoin Blockchain – Упрощенный блокчейн Биткоина.
Блокчейн представляет собой связанный список, содержащий данные, а так же указатель хэширования, указывающий на предыдущий блок, создавая таким образов связную цепочку. Что такое хэш-указатель? Он похож на обычный указатель, но вместо того, чтобы просто содержать адрес предыдущего блока, он также содержит хэш данных, находящихся внутри предыдущего блока. Именно эта небольшая настройка делает блокчейн настолько надежным. Представим на секунду, что хакер атакует блок 3 и пытается изменить данные. Из-за свойств хэш-функций даже небольшое изменение в данных сильно изменит хэш. Это означает, что любые незначительные изменения, произведенные в блоке 3, изменят хэш, хранящийся в блоке 2, что, в свою очередь, изменит данные и хэш блока 2, а это приведет к изменениям в блоке 1 и так далее. Цепочка будет полностью изменена, а это невозможно. Но как же выглядит заголовок блока?
Цепочка будет полностью изменена, а это невозможно. Но как же выглядит заголовок блока?
* Prev_Hash – предыдущий хэш; Tx – транзакция; Tx_Root – корень транзакции; Timestamp – временная отметка; Nonce – уникальный символ.
Заголовок блока состоит из следующих компонентов:
· Версия: номер версии блока
· Время: текущая временная метка
· Текущая сложная цель (См. ниже)
· Хэш предыдущего блока
· Уникальный символ (См. ниже)
· Хэш корня Меркла
Прямо сейчас, давайте сосредоточимся на том, что из себя представляет хэш корня Меркла. Но до этого нам необходимо разобраться с понятием Дерева Меркла.
Что такое Дерево Меркла?
Источник: Wikipedia
На приведенной выше диаграмме показано, как выглядит дерево Меркла. В дереве Меркла каждый нелистовой узел является хэшем значений их дочерних узлов.
Листовой узел: Листовые узлы являются узлами в самом нижнем ярусе дерева. Поэтому, следуя приведенной выше схеме, листовыми будут считаться узлы L1, L2, L3 и L4.
Поэтому, следуя приведенной выше схеме, листовыми будут считаться узлы L1, L2, L3 и L4.
Дочерние узлы: Для узла все узлы, находящиеся ниже его уровня и которые входят в него, являются его дочерними узлами. На диаграмме узлы с надписью «Hash 0-0» и «Hash 0-1» являются дочерними узлами узла с надписью «Hash 0».
Корневой узел: единственный узел, находящийся на самом высоком уровне, с надписью «Top Hash» является корневым.
Так какое же отношение Дерево Меркла имеет к блокчейну?
Каждый блок содержит большое количество транзакций. Будет очень неэффективно хранить все данные внутри каждого блока в виде серии. Это сделает поиск какой-либо конкретной операции крайне громоздким и займет много времени. Но время, необходимое для выяснения, на принадлежность конкретной транзакции к этому блоку или нет, значительно сокращается, если Вы используете дерево Меркла.
Давайте посмотрим на пример на следующем Хэш-дереве:
Изображение предоставлено проектом: Coursera
Теперь предположим, я хочу узнать, принадлежат ли эти данные блоку или нет:
Вместо того, чтобы проходить через сложный процесс просматривания каждого отдельного процесса хэша, а также видеть принадлежит ли он данным или нет, я просто могу отследить след хэша, ведущий к данным:
Это значительно сокращает время.
Хэширование в майнинге: крипто-головоломки.
Когда мы говорим «майнинг», в основном, это означает поиск нового блока, который будет добавлен в блокчейн. Майнеры всего мира постоянно работают над тем, чтобы убедиться, что цепочка продолжает расти. Раньше людям было проще работать, используя для майнинга лишь свои ноутбуки, но со временем они начали формировать «пулы», объединяя при этом мощность компьютеров и майнеров, что может стать проблемой. Существуют ограничения для каждой криптовалюты, например, для биткоина они составляют 21 миллион. Между созданием каждого блока должен быть определенный временной интервал заданный протоколом. Для биткоина время между созданием блока занимает всего 10 минут. Если бы блокам было разрешено создаваться быстрее, это привело бы к:
- Большому количеству коллизий: будет создано больше хэш-функций, которые неизбежно вызовут больше коллизий.
- Большому количеству брошенных блоков: Если много майнеров пойдут впереди протокола, они будут одновременно хаотично создавать новые блоки без сохранения целостности основной цепочки, что приведет к «осиротевшим» блокам.


Таким образом, чтобы ограничить создание блоков, устанавливается определенный уровень сложности. Майнинг чем-то напоминает игру: решаешь задачу – получаешь награду. Усиление сложности делает решение задачи намного сложнее и, следовательно, на нее затрачивается большее количество времени.WRT, которая начинается с множества нулей. При увеличении уровня сложности, увеличивается количество нулей. Уровень сложности изменяется после каждого 2016-го блока.
Процесс Майнинга
Примечание: в этом разделе мы будем говорить о выработке биткоинов.
Когда протокол Биткоина хочет добавить новый блок в цепочку, майнинг – это процедура, которой он следует. Всякий раз, когда появляется новый блок, все их содержимое сначала хэшируется. Если подобранный хэш больше или равен, установленному протоколом уровню сложности, он добавляется в блокчейн, а все в сообществе признают новый блок.
Однако, это не так просто. Вам должно очень повезти, чтобы получить новый блок таким образом. Так как, именно здесь присваивается уникальный символ. Уникальный символ (nonce) — это одноразовый код, который объединен с хэшем блока. Затем эта строка вновь меняется и сравнивается с уровнем сложности. Если она соответствует уровню сложности, то случайный код изменяется. Это повторяется миллион раз до тех пор, пока требования не будут наконец выполнены. Когда же это происходит, то блок добавляется в цепочку блоков.
Вам должно очень повезти, чтобы получить новый блок таким образом. Так как, именно здесь присваивается уникальный символ. Уникальный символ (nonce) — это одноразовый код, который объединен с хэшем блока. Затем эта строка вновь меняется и сравнивается с уровнем сложности. Если она соответствует уровню сложности, то случайный код изменяется. Это повторяется миллион раз до тех пор, пока требования не будут наконец выполнены. Когда же это происходит, то блок добавляется в цепочку блоков.
Подводя итоги:
• Выполняется хэш содержимого нового блока.
• К хэшу добавляется nonce (специальный символ).
• Новая строка снова хэшируется.
• Конечный хэш сравнивается с уровнем сложности, чтобы проверить меньше он его или нет
• Если нет, то nonce изменяется, и процесс повторяется снова.
• Если да, то блок добавляется в цепочку, а общедоступная книга (блокчейн) обновляется и сообщает нодам о присоединении нового блока.
• Майнеры, ответственные за данный процесс, награждаются биткоинами.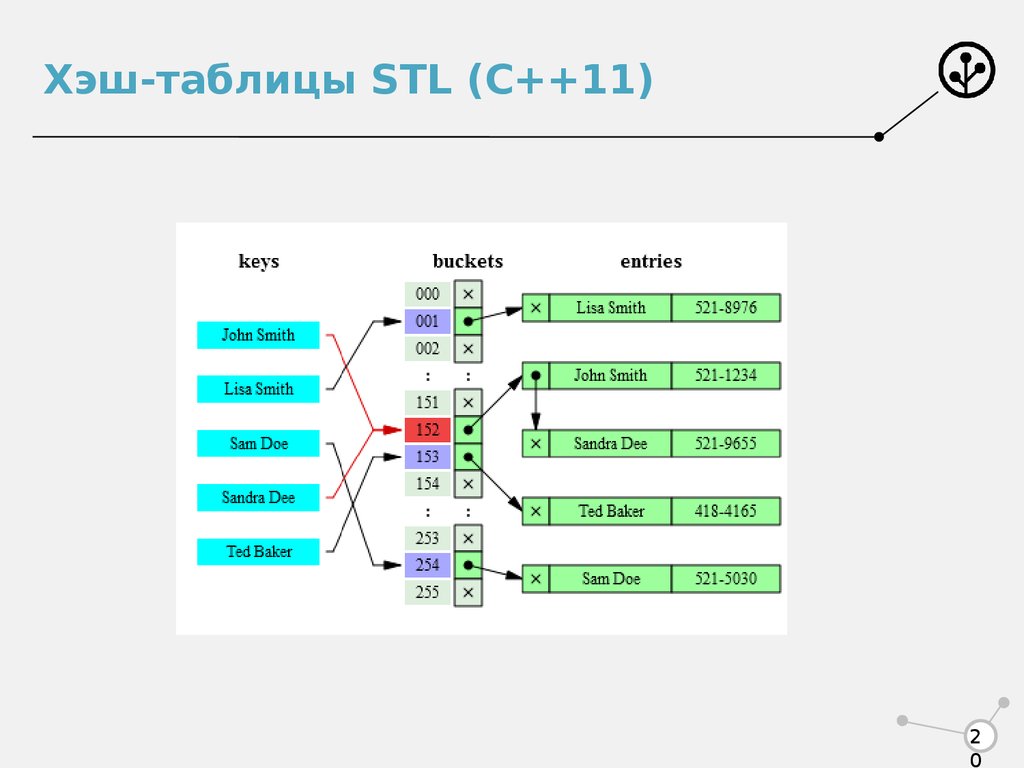
Помните номер свойства 6 хэш-функций? Удобство использования задачи?
Для каждого выхода «Y», если k выбран из распределения с высокой мин-энтропией, невозможно найти вход x таким образом, H (k | x) = Y.
Так что, когда дело доходит до майнинга биткоинов:
• К = Уникальный символ
• x = хэш блока
• Y = цель проблемы
Весь процесс абсолютно случайный, основанный на генерации случайных чисел, следующий протоколу Proof Of Work и означающий:
- Решение задач должно быть сложным.
- Однако проверка ответа должна быть простой для всех. Это делается для того, чтобы убедиться, что для решения проблемы не использовались недозволенные методы.
Что такое скорость хэширования?
Скорость хэширования в основном означает, насколько быстро эти операции хэширования происходят во время майнинга. Высокий уровень хэширования означает, что в процессе майнинга участвуют всё большее количество людей и майнеров, и в результате система функционирует нормально.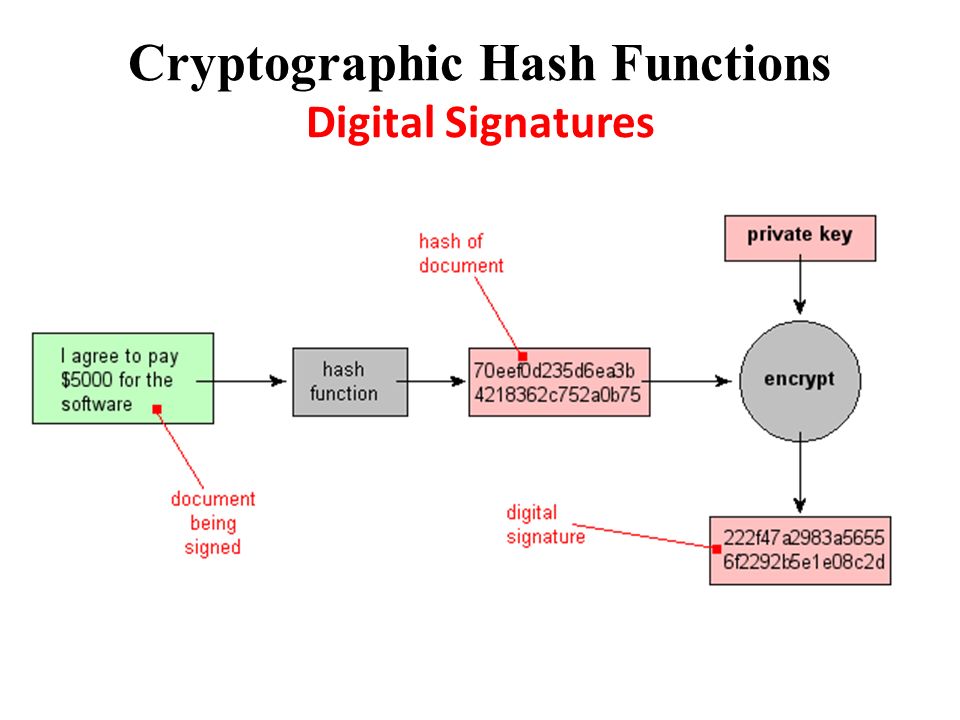 Если скорость хэширования слишком высокая, уровень сложности пропорционально увеличивается. Если скорость хэша слишком медленная, то соответственно, уровень сложности уменьшается.
Если скорость хэширования слишком высокая, уровень сложности пропорционально увеличивается. Если скорость хэша слишком медленная, то соответственно, уровень сложности уменьшается.
Вывод
Хэширование действительно является основополагающим в создании технологии блокчейн. Если кто-то хочет понять, что такое блокчейн, он должен начать с того, чтобы понять, что означает хэширование.
Что такое хеширование, шифрование и кодировка
Эти три термина часто путают — они означают три абсолютно разных вещи. Для того, чтобы понять разницу, давайте сначала проясним некоторые моменты.
С точки зрения безопасности, когда вы отправляете данные/сообщение в интернете:
- Вы хотите, чтобы другой человек знал, что это письмо отправили вы, а не кто-либо другой.
- Вы хотите, чтобы сообщение получили в том же формате, в каком вы отправили — без изменений.
- Вы хотите, чтобы ваше сообщение не могли прочитать злоумышленники.

Эти три пункта можно назвать по-другому:
- Проверка личности
- Целостность сообщения
- Конфиденциальность
Чтобы это было возможным, используются хеширование и шифрование. Начнем с хеширования.
Хеширование
Давайте представим жизнь без хеширования. Например, сегодня день рождения друга, и вы хотите отправить ему поздравление. Ваш веселый товарищ-ботан решает над вами посмеяться, перехватывает сообщение и превращает «С Днем рождения» в «Покойся с миром». Это вполне вероятно, и вы, возможно, даже об этом не узнаете.
Чтобы такого не случалось, на помощь приходит хеширование — оно защищает целостность данных.
Хеш — это число, которое генерируется из текста с помощью хеш-алгоритма. Это число меньше оригинального текста.
Алгоритм хеширования
Алгоритм работает так, что для каждого текста генерируется уникальный хеш. И восстановить текст из хеша, перехватив сообщение, практически невозможно.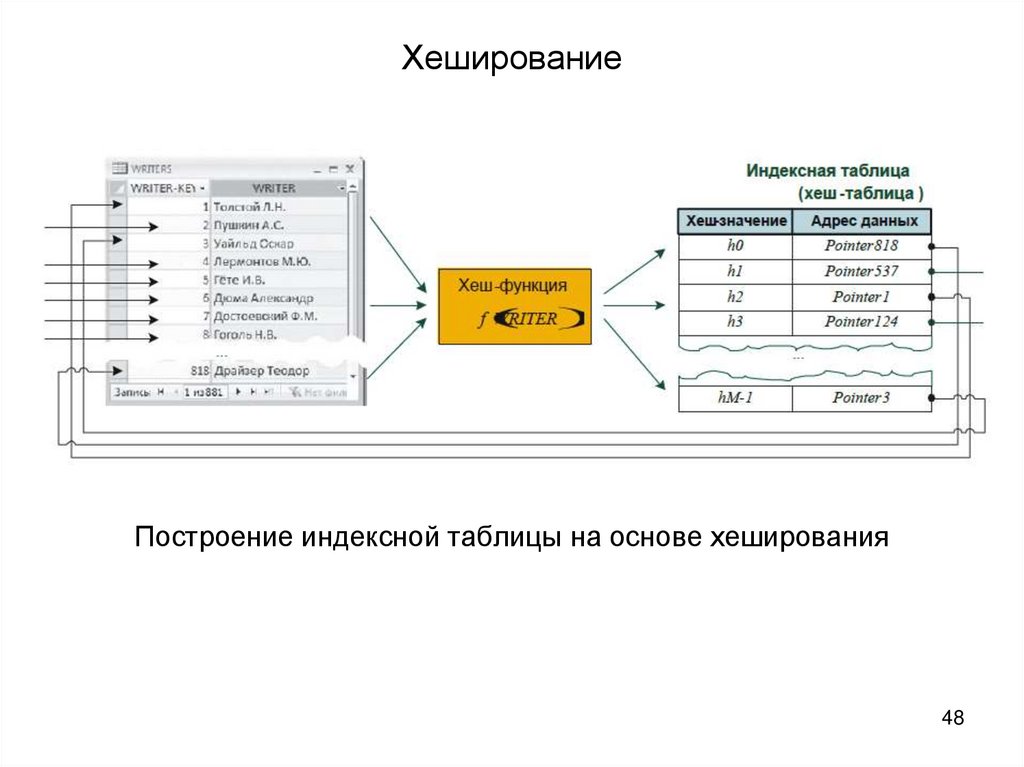
Одно из незаменимых свойств хеширования — его уникальность. Одно и то же значение хеша не может использоваться для разного текста. Малейшее изменение в тексте полностью изменит значение хеша. Это называется эффектом лавины.
В примере ниже мы использовали алгоритм SHA-1.
Текст: Все любят пончики.
Значение SHA-1 текста: daebbfdea9a516477d489f32c982a1ba1855bcd
Давайте не будем оспаривать фразу про пончики и сосредоточимся пока на хешировании. Теперь если мы немного поменяем текст, хеш полностью изменится.
Текст: Все любят пончик.
Значение SHA-1 текста: 8f2bd584a1854d37f9e98f9ec4da6d757940f388
Как вы видите, поменялась одна буква, а хеш изменился до неузнаваемости.
Хеширование нужно:
- Чтобы информация в базах данных не дублировалась;
- Для цифровых подписей и SSL-сертификатов;
- Чтобы найти конкретную информацию в больших базах данных;
- В компьютерной графике.

Шифрование
Почти невозможно представить интернет без шифрования. Шифрование — это то, что делает интернет безопасным. При шифровании конфиденциальная информация превращается в нечитаемый формат, чтобы хакер не смог ее перехватить.
Шифрование и дешифровка
Данные шифруются с помощью криптографических ключей. Информация шифруется до отправления и расшифровывается получателем. Таким образом, при передаче данные находятся в безопасности.
В зависимости от природы ключей шифрование может делиться на 2 категории: симметричное и асимметричное.
Симметричное шифрование: Данные шифруются и расшифровываются при помощи одного криптографического ключа. Это значит, что ключ, используемый для шифрования, используется и для расшифровки.
Асимметричное шифрование: Это довольно новый метод. В нем используются два разных ключа — один для шифрования, второй для расшифровки. Один ключ называется публичным, второй секретным.
Публичные ключи везде — у вас он тоже есть, даже если вы об этом не знаете. Один из них сохраняется в вашем браузере каждый раз, когда вы заходите на сайт с SSL-сертификатом.
Когда вы отправляете данные на зашифрованный сайт, этот сайт закодирован публичным ключом. Приватный ключ есть только у получателя, и он должен хранить его в недоступном месте. Секретный ключ расшифровывает зашифрованные данные. Когда используются два разных ключа, шифрование проходит безопаснее и чуть медленнее.
Оба эти метода используются в SSL/TLS-сертификатах. Асимметричное шифрование сначала применяется к процессу рукопожатия SSL — валидации сервера. Как только между клиентом и сервером устанавливается соединение, данные шифруются с помощью симметричного шифрования.
Кодировка
В отличие от шифрования и хеширования кодировка используется не в целях безопасности. При кодировке данные превращаются в другие форматы, чтобы множество систем могли их использовать.
В кодировке не используются ключи. Алгоритм, который берется для кодировки данных, также используется, чтобы раскодировать их. ASCII и UNICODE — примеры таких алгоритмов кодировки.
Алгоритм, который берется для кодировки данных, также используется, чтобы раскодировать их. ASCII и UNICODE — примеры таких алгоритмов кодировки.
Резюмируем
Хеширование: ряд цифр, который генерируется, чтобы подтвердить целостность данных с помощью алгоритмов хэширования.
Шифрование: Метод, который используется, чтобы зашифровать данные, превратив их в формат, не поддающийся расшифровке.
Кодировка: Превращение данных из одного формата в другой.
Источник: статья в блоге Cheap SSL Security
Что такое хеширование? | Binance Academy
Хеширование относится к процессу создания определенного вывода из входных данных разного размера. Это делается с помощью математических формул, также известных как хэш-функции (реализованные в виде алгоритмов хеширования).
Не все хэш-функции предполагают использование криптографии, а только те, которые специально предназначенные для этого, так называемые криптографические хэш-функции, которые лежат в основе криптовалюты.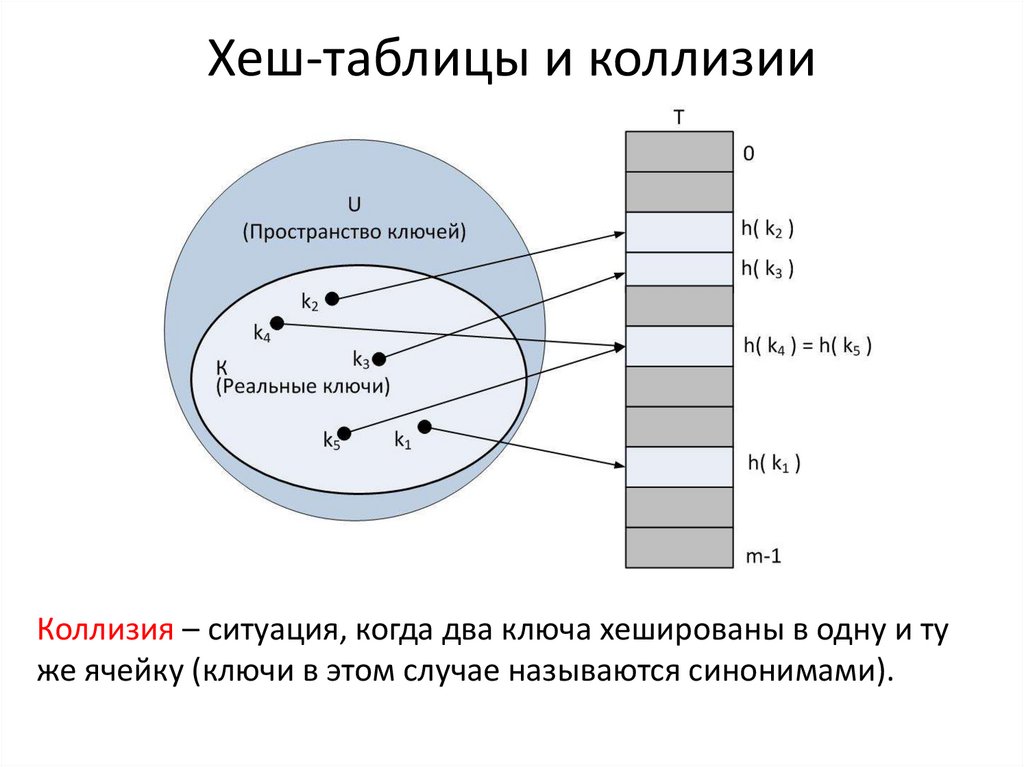 Благодаря их работе, блокчейны и другие распределенные системы способны достичь высокого уровня целостности данных и безопасности.
Благодаря их работе, блокчейны и другие распределенные системы способны достичь высокого уровня целостности данных и безопасности.
Как обычные, так и криптографические хэш-функции являются детерминированными. Быть детерминированным означает, что до тех пор, пока входные данные не изменяются, алгоритм хеширования всегда будет выдавать один и тот же результат (также известный как дайджест или хэш).
Алгоритмы хеширования в криптовалютах разработаны таким образом, что их функция работает в одностороннем порядке, это означает, что данные не могут быть возвращены в обратном порядке без вложения большого количества времени и ресурсов для осуществления вычислений. Другими словами, довольно легко создать выход из входных данных, но относительно трудно осуществить процесс в обратном направлении (сгенерировать вывод на основе входных данных). Чем сложнее найти входное значение, тем более безопасным считается алгоритм хеширования.
Как работает хэш-функция?
Различные виды хэш-функций производят вывод разной величины, но возможный размер данных на выходе для каждого из алгоритмов хеширования всегда является постоянным. Например, алгоритм SHA-256 может производить вывод исключительно в формате 256-бит, в то время как SHA-1 всегда генерирует 160-битный дайджест.
Например, алгоритм SHA-256 может производить вывод исключительно в формате 256-бит, в то время как SHA-1 всегда генерирует 160-битный дайджест.
Чтобы проиллюстрировать это, давайте пропустим слова “Binance“ и “binance” через алгоритм хеширования SHA-256 (тот, который используется в биткоин).
SHA-256 | |
Входные данные | Результат (256 бит) |
Binance | f1624fcc63b615ac0e95daf9ab78434ec2e8ffe402144dc631b055f711225191 |
binance | 59bba357145ca539dcd1ac957abc1ec5833319ddcae7f5e8b5da0c36624784b2 |
Обратите внимание, что незначительное изменение (регистр первой буквы) привело к совершенно другому значению хэша. Поскольку мы используем SHA-256, данные на выходе всегда будут иметь фиксированный размер в 256 бит (или 64 символа), независимо от величины ввода. Помимо этого, не имеет значения какое количество раз мы пропустим эти два слова через алгоритм, два выхода не будут видоизменяться, поскольку они являются постоянными.
Таким же образом, если мы пропустим одни и те же входные данные с помощью алгоритма хеширования SHA-1, мы получим следующие результаты:
SHA-1 | |
Входные данные | Результат (160 бит) |
Binance | 7f0dc9146570c608ac9d6e0d11f8d409a1ee6ed1 |
binance | e58605c14a76ff98679322cca0eae7b3c4e08936 |
Стоит отметить, что акроним SHA расшифровывается как Secure Hash Algorithms (безопасный алгоритм хеширования). Он относится к набору криптографических хэш-функций, который включает такие алгоритмы как SHA-0 и SHA-1 вместе с группами SHA-2 и SHA-3. SHA-256 является частью группы SHA-2, наряду с SHA-512 и другими аналогами. В настоящее время, только группы SHA-2 и SHA-3 считаются безопасными.
Почему это имеет значение?
Обычные хэш-функции обладают широким спектром вариантов использования, включая поиск по базе данных, анализ больших файлов и управление данными. В свою очередь, криптографические хэш-функции обширно используются в приложениях связанных с информационной безопасностью для аутентификации сообщений и цифровой дактилоскопии. Когда речь заходит о биткоине, криптографические хэш-функции являются неотъемлемой частью в процессе майнинга, а также занимают основную роль в генерации новых ключей и адресов.
В свою очередь, криптографические хэш-функции обширно используются в приложениях связанных с информационной безопасностью для аутентификации сообщений и цифровой дактилоскопии. Когда речь заходит о биткоине, криптографические хэш-функции являются неотъемлемой частью в процессе майнинга, а также занимают основную роль в генерации новых ключей и адресов.
Хеширование демонстрирует весь свой потенциал при работе с огромным количеством информации. Например, можно пропустить большой файл или набор данных через хэш-функцию, а затем использовать вывод для быстрой проверки точности и целостности данных. Это возможно благодаря детерминированной природе хэш-функций: вход всегда будет приводить к упрощенному сжатому выходу (хэшу). Такой метод устраняет необходимость хранить и запоминать большие объемы данных.
Хеширование является в особенности полезным в отношении технологии блокчейн. В блокчейне биткоина осуществляется несколько операций, которые включают себя хеширование, большая часть которого заключается в майнинге. По факту, практически все криптовалютные протоколы полагаются на хеширование для связывания и сжатия групп транзакций в блоки, а также для создания криптографической взаимосвязи и эффективного построения цепочки из блоков.
По факту, практически все криптовалютные протоколы полагаются на хеширование для связывания и сжатия групп транзакций в блоки, а также для создания криптографической взаимосвязи и эффективного построения цепочки из блоков.
Криптографические хэш-функции
Опять же обращаем ваше внимание на то, что хэш-функция, которая использует криптографические методы, может быть определена как криптографическая хэш-функция. Для того, чтобы ее взломать потребуется бесчисленное множество попыток грубого подбора чисел. Чтобы реверсировать криптографическую хэш-функцию, потребуется подбирать входные данные методом проб и ошибок, пока не будет получен соответствующий вывод. Тем не менее, существует возможность того, что разные входы будут производить одинаковый вывод, в таком случае возникает коллизия.
С технической точки зрения, криптографическая хэш-функция должна соответствовать трем свойствам, чтобы считаться безопасной. Мы можем описать их как: устойчивость к коллизии, и устойчивость к поиску первого и второго прообраза.
Прежде чем начать разбирать каждое свойство, обобщим их логику в трех коротких предложениях.
Устойчивость к коллизии: невозможно найти два разных входа, которые производят хэш, аналогичный выводу.
Устойчивость к поиску первого прообраза: отсутствие способа или алгоритма обратного восстановления хэш-функцию (нахождение входа по заданному выходу).
Устойчивость к поиску второго прообраза: невозможно найти любой второй вход, который бы пересекался с первым.
Устойчивость к коллизии
Как упоминалось ранее, коллизия происходит, когда разные входные данные производят одинаковый хэш. Таким образом, хэш-функция считается устойчивой к коллизиям до тех пор, пока кто-либо не обнаружит коллизию. Обратите внимание, что коллизии всегда будут существовать для любой из хэш-функций, в связи с бесконечным количеством входных данных и ограниченным количеством выводов.
Таким образом, хэш-функция устойчива к коллизии, когда вероятность ее обнаружения настолько мала, что для этого потребуются миллионы лет вычислений. По этой причине, несмотря на то, что не существует хэш-функций без коллизий, некоторые из них на столько сильные, что могут считаться устойчивыми (например, SHA-256).
По этой причине, несмотря на то, что не существует хэш-функций без коллизий, некоторые из них на столько сильные, что могут считаться устойчивыми (например, SHA-256).
Среди различных алгоритмов SHA группы SHA-0 и SHA-1 больше не являются безопасными, поскольку в них были обнаружены коллизии. В настоящее время только группы SHA-2 и SHA-3 считаются самыми безопасными и устойчивыми к коллизиям.
Устойчивость к поиску первого прообраза
Данное свойство тесно взаимосвязано с концепцией односторонних функций. Хэш-функция считается устойчивой к поиску первого прообраза, до тех пор, пока существует очень низкая вероятность того, что кто-то сможет найти вход, с помощью которого можно будет сгенерировать определенный вывод.
Обратите внимание, что это свойство отличается от предыдущего, поскольку злоумышленнику потребуется угадывать входные данные, опираясь на определенный вывод. Такой вид коллизии происходит, когда кто-то находит два разных входа, которые производят один и тот же код на выходе, не придавая значения входным данным, которые для этого использовались.
Свойство устойчивости к поиску первого прообраза является ценным для защиты данных, поскольку простой хэш сообщения может доказать его подлинность без необходимости разглашения дополнительной информации. На практике многие поставщики услуг и веб-приложения хранят и используют хэши, сгенерированные из паролей вместо того, чтобы пользоваться ими в текстовом формате.
Устойчивость к поиску второго прообраза
Для упрощения вашего понимания, можно сказать, что данный вид устойчивости находится где-то между двумя другими свойствами. Атака нахождения второго прообраза заключается в нахождении определенного входа, с помощью которого можно сгенерировать вывод, который изначально образовывался посредством других входных данных, которые были заведомо известны.
Другими словами, атака нахождения второго прообраза включает в себя обнаружение коллизии, но вместо поиска двух случайных входов, которые генерируют один и тот же хэш, атака нацелена на поиск входных данных, с помощью которых можно воссоздать хэш, который изначально был сгенерирован с помощью другого входа.
Следовательно, любая хэш-функция, устойчивая к коллизиям, также устойчива и к подобным атакам, поскольку последняя всегда подразумевает коллизию. Тем не менее, все еще остается возможность для осуществления атаки нахождения первого прообраза на функцию устойчивую к коллизиям, поскольку это предполагает поиск одних входных данных посредством одного вывода.
Майнинг
В майнинге присутствует множество этапов, которые осуществляются с помощью хэш-функций, они включают в себя проверку баланса, связывание входов и выходов транзакций и хеширование всех операций в блоке для формирования дерева Меркла. Но одна из основных причин, по которой блокчейн биткоина является безопасным, заключается в том, что майнеры должны выполнить как можно большее количество операций связанных с хешированием, чтобы в конечном итоге найти правильное решение для следующего блока.
Майнер должен пытаться подобрать несколько разных входных данных при создании хэша для своего блока-кандидата. Проверить блок можно будет только в том случае, если правильно сгенерирован вывод в виде хэша начинается с определенного количества нулей.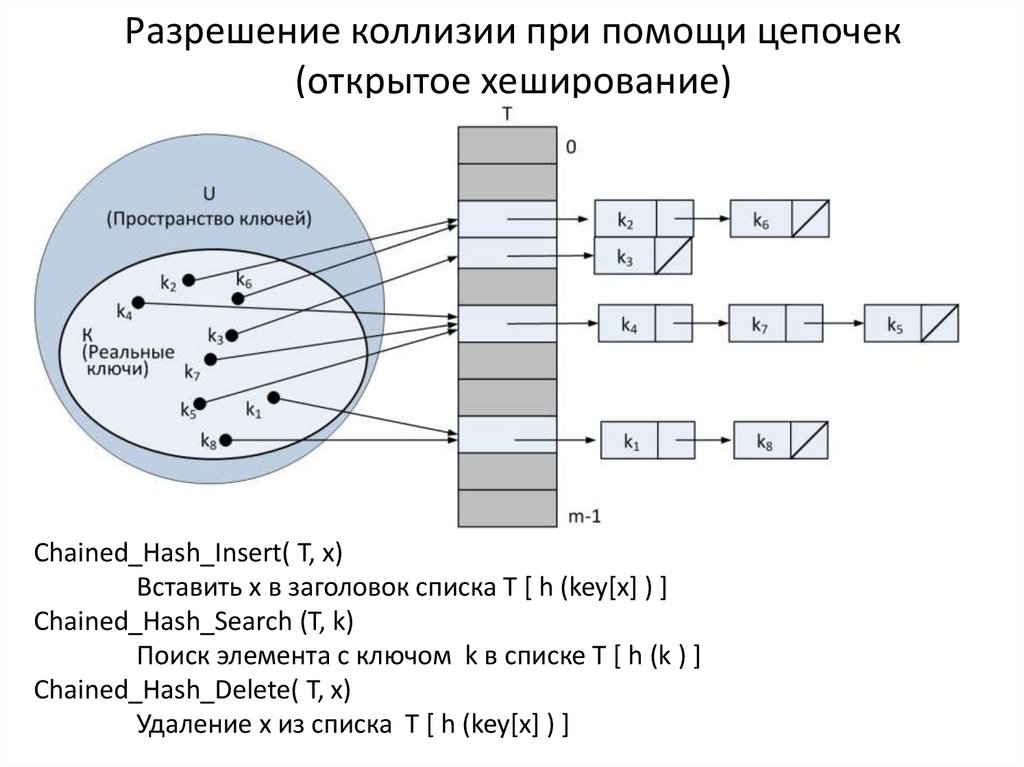 Количество нулей определяет сложность майнинга и она меняется в зависимости от хешрейта сети.
Количество нулей определяет сложность майнинга и она меняется в зависимости от хешрейта сети.
В этом случае, хешрейт представляет собой количество мощности вашего компьютера, которое вы инвестируете в майнинг биткоинов. Если хешрейт начинает увеличиваться, протокол биткоина автоматически отрегулирует сложность майнинга так, чтобы среднее время необходимое для добычи блока составляло не более 10 минут. Если несколько майнеров примут решение прекратить майнинг, что приведет к значительному снижению хешрейта, сложность добычи будет скорректирована таким образом, чтобы временно облегчить вычислительную работу (до тех пор, пока среднее время формирования блока не вернется к 10 минутам).
Обратите внимание, что майнерам не нужно искать коллизии, в связи с некоторым количеством хэшей, которые они могут генерировать в качестве валидного выхода (начинающегося с определенного количества нулей). Таким образом, существует несколько возможных решений для определенного блока и майнеры должны найти только одно из них, в соответствии с порогом, который определяется сложностью майнинга.
Поскольку майнинг биткоина является столь затратной задачей, у майнеров нет причин обманывать систему, так как это приведет к значительным финансовым убыткам. Соответственно, чем больше майнеров присоединяется к блокчейну, тем больше и сильнее он становится.
Заключение
Нет сомнений в том, что хэш-функции являются одним из основных инструментов информатики, особенно при работе с огромными объемами данных. В сочетании с криптографией, алгоритмы хеширования могут быть весьма универсальными, предлагая безопасность и множество способов аутентификации. Таким образом, криптографические хеш-функции жизненно важны практически для всех криптовалютных сетей, поэтому понимание их свойств и механизмов работы, безусловно полезно для всех, кто интересуется технологией блокчейн.
Хэширование | это… Что такое Хэширование?
Хеширование (иногда хэширование, англ. hashing) — преобразование входного массива данных произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования также называются хеш-функциями или функциями свёртки, а их результаты называют хешем, хеш-кодом или дайджестом сообщения (англ. message digest).
Такие преобразования также называются хеш-функциями или функциями свёртки, а их результаты называют хешем, хеш-кодом или дайджестом сообщения (англ. message digest).
Существует множество алгоритмов хеширования с различными характеристиками (разрядность, вычислительная сложность, криптостойкость и т. п.). Выбор той или иной хеш-функции определяется спецификой решаемой задачи. Простейшими примерами хеш-функций могут служить контрольная сумма или CRC.
В общем случае однозначного соответствия между исходными данными и хеш-кодом нет. Поэтому существует множество массивов данных, дающих одинаковые хеш-коды — так называемые коллизии. Вероятность возникновения коллизий играет немаловажную роль в оценке «качества» хеш-функций.
Содержание
|
 1.2 Проверка парольной фразы
1.2 Проверка парольной фразыКонтрольные суммы
Основная статья: Контрольная сумма
Несложные, крайне быстрые и легко реализуемые аппаратно алгоритмы, используемые для защиты от непреднамеренных искажений, в том числе ошибок аппаратуры.
По скорости вычисления в десятки и сотни раз быстрее, чем криптографические хеш-функции, и значительно проще в аппаратной реализации.
Платой за столь высокую скорость является отсутствие криптостойкости — легкая возможность подогнать сообщение под заранее известную сумму. Также обычно разрядность контрольных сумм (типичное число: 32 бита) ниже, чем криптографических хешей (типичные числа: 128, 160 и 256 бит), что означает возможность возникновения непреднамеренных коллизий.
Простейшим случаем такого алгоритма является деление сообщения на 32- или 16- битные слова и их суммирование, что применяется, например, в TCP/IP.
Как правило, к такому алгоритму предъявляются требования отслеживания типичных аппаратных ошибок, таких, как несколько подряд идущих ошибочных бит до заданной длины. Семейство алгоритмов т. н. «циклический избыточных кодов» удовлетворяет этим требованиям. К ним относится, например, CRC32, применяемый в аппаратуре ZIP.
Криптографические хеш-функции
Среди множества существующих хеш-функций принято выделять криптографически стойкие, применяемые в криптографии. Криптостойкая хеш-функция прежде всего должна обладать стойкостью к коллизиям двух типов:
- Стойкость к коллизиям первого рода: для заданного сообщения должно быть практически невозможно подобрать другое сообщение , имеющее такой же хеш. Это свойство также называется необратимостью хеш-функции.
- Стойкость к коллизиям второго рода: должно быть практически невозможно подобрать пару сообщений , имеющих одинаковый хеш.
Согласно парадоксу о днях рождения, нахождение коллизии для хеш-функции с длиной значений n бит требует в среднем перебора около 2n / 2 операций.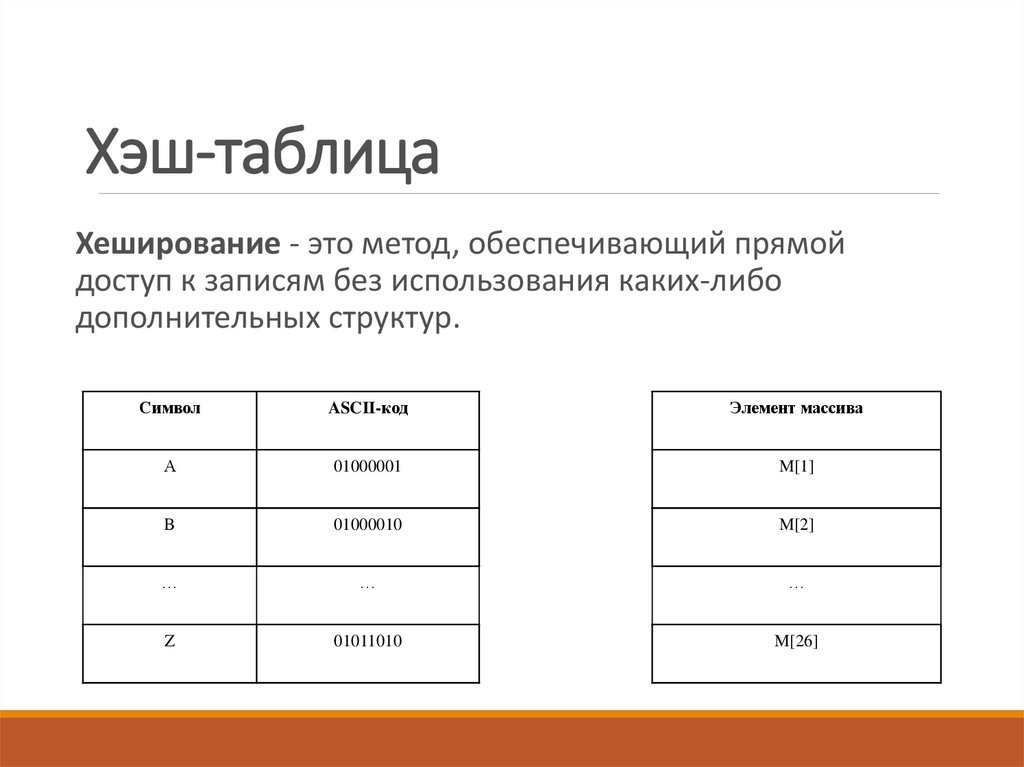 Поэтому n-битная хеш-функция считается криптостойкой, если вычислительная сложность нахождения коллизий для нее близка к 2n / 2.
Поэтому n-битная хеш-функция считается криптостойкой, если вычислительная сложность нахождения коллизий для нее близка к 2n / 2.
Простейшим (хотя и не всегда приемлемым) способом усложнения поиска коллизий является увеличение разрядности хеша, например, путем параллельного использования двух или более различных хеш-функций.
Для криптографических хеш-функций также важно, чтобы при малейшем изменении аргумента значение функции сильно изменялось. В частности, значение хеша не должно давать утечки информации даже об отдельных битах аргумента. Это требование является залогом криптостойкости алгоритмов шифрования, хеширующих пользовательский пароль для получения ключа.
Применение хеширования
Хеш-функции также используются в некоторых структурах данных — хеш-таблицаx и декартовых деревьях. Требования к хеш-функции в этом случае другие:
- хорошая перемешиваемость данных
- быстрый алгоритм вычисления
Сверка данных
В общем случае это применение можно описать, как проверка некоторой информации на идентичность оригиналу, без использования оригинала.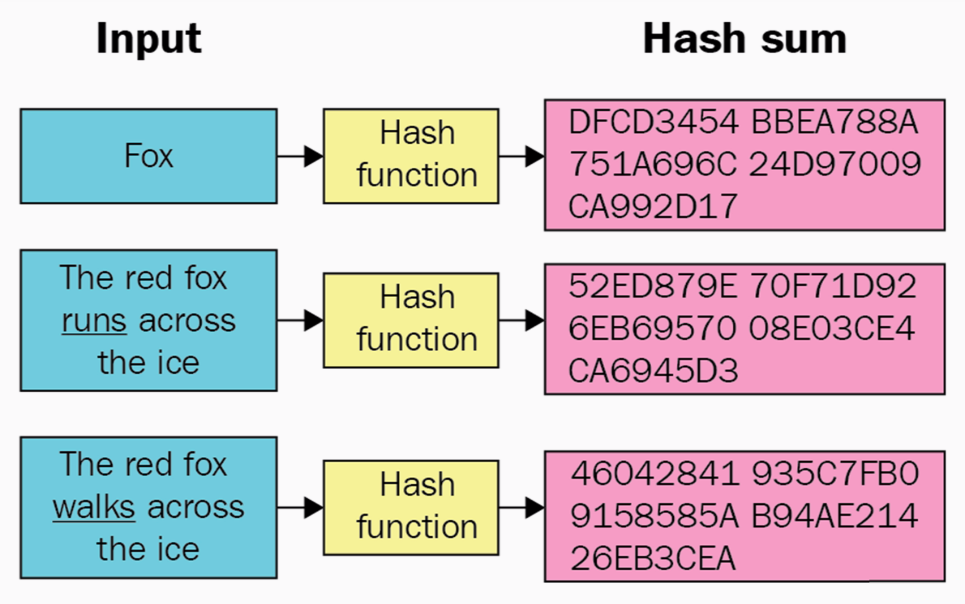 Для сверки используется хеш-значение проверяемой информации. Различают два основных направления этого применения:
Для сверки используется хеш-значение проверяемой информации. Различают два основных направления этого применения:
Проверка на наличие ошибок
Например, контрольная сумма может быть передана по каналу связи вместе с основным текстом. На приёмном конце, контрольная сумма может быть рассчитана заново и её можно сравнить с переданным значением. Если будет обнаружено расхождение, то это значит, что при передаче возникли искажения и можно запросить повтор.
Бытовым аналогом хеширования в данном случае может служить приём, когда при переездах в памяти держат количество мест багажа. Тогда для проверки не нужно вспоминать про каждый чемодан, а достаточно их посчитать. Совпадение будет означать, что ни один чемодан не потерян. То есть, количество мест багажа является его хеш-кодом.
Проверка парольной фразы
В большинстве случаев парольные фразы не хранятся на целевых объектах, хранятся лишь их хеш-значения. Хранить парольные фразы нецелесообразно, так как в случае несанкционированного доступа к файлу с фразами злоумышленник узнает все парольные фразы и сразу сможет ими воспользоваться, а при хранении хеш-значений он узнает лишь хеш-значения, которые не обратимы в исходные данные, в данном случае в парольную фразу.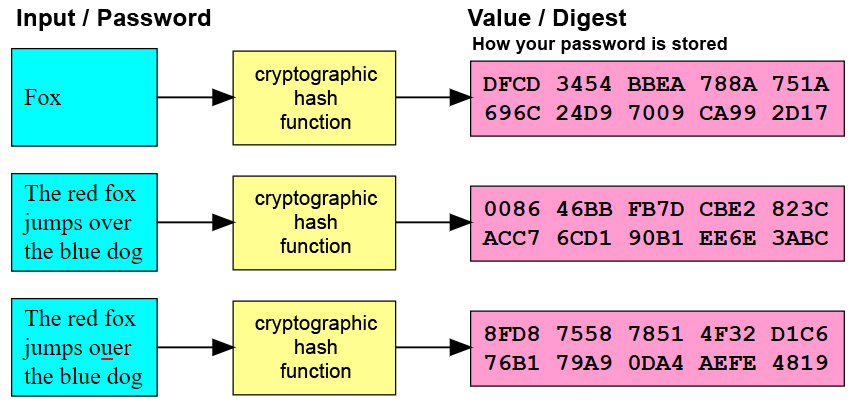 В ходе процедуры аутентификации вычисляется хеш-значение введённой парольной фразы, и сравнивается с сохранённым.
В ходе процедуры аутентификации вычисляется хеш-значение введённой парольной фразы, и сравнивается с сохранённым.
Примером в данном случае могут служить ОС GNU/Linux и Microsoft Windows XP. В них хранятся лишь хеш-значения парольных фраз из учётных записей пользователей.
Ускорение поиска данных
Основная статья: Хеш-таблица
Например, при записи текстовых полей в базе данных может рассчитываться их хеш код и данные могут помещаться в раздел, соответствующий этому хеш-коду. Тогда при поиске данных надо будет сначала вычислить хеш-код текста и сразу станет известно, в каком разделе их надо искать, то есть, искать надо будет не по всей базе, а только по одному её разделу (это сильно ускоряет поиск).
Бытовым аналогом хеширования в данном случае может служить помещение слов в словаре по алфавиту. Первая буква слова является его хеш-кодом, и при поиске мы просматриваем не весь словарь, а только нужную букву.
Список алгоритмов
- CRC
- SHA-2 (SHA-224, SHA-256, SHA-384, SHA-512)
- MD2
- MD5
- RIPEMD-160
- RIPEMD-320
- Snefru
- Tiger (Whirlpool
- ГОСТ Р34. 11-94 (ГОСТ 34.311-95)
- IP Internet Checksum (RFC 1071)
 11-94 (ГОСТ 34.311-95)
11-94 (ГОСТ 34.311-95)Ссылки
- Информация по алгоритмам хеширования
Хэш и хеширование — что это такое простыми словами? — Тюлягин
Здравствуйте, уважаемые читатели проекта Тюлягин! В сегодняшней статье про криптовалюты мы поговорим о хэше и хешировании. В статье вы узнаете что такое хэш и хэш-функция, узнаете как устроены хэши в целом и как работает хеширование в криптовалютах. Кроме этого приведены примеры хэша и даны ответы на наиболее популярные ответы о хэше и хешировании. Обо всем этом далее в статье.
Содержание статьи:
- Что такое хэш?
- Как работают хэши
- Хеширование и криптовалюты
- Особенности хэша
- Пример хэша
- Популярные вопросы о хэше
- Резюме
Что такое хэш?
Хэш — это математическая функция, которая преобразует ввод произвольной длины в зашифрованный вывод фиксированной длины. Таким образом, независимо от исходного количества данных или размера файла, его уникальный хэш всегда будет одного и того же размера. Более того, хэши нельзя использовать для «обратного проектирования» входных данных из хешированных выходных данных, поскольку хэш-функции являются «односторонними» (как в мясорубке: вы не можете вернуть говяжий фарш обратно в стейк). Тем не менее, если вы используете такую функцию для одних и тех же данных, ее хэш будет идентичным, поэтому вы можете проверить, что данные такие же (т. е. без изменений), если вы уже знаете его хэш.
Таким образом, независимо от исходного количества данных или размера файла, его уникальный хэш всегда будет одного и того же размера. Более того, хэши нельзя использовать для «обратного проектирования» входных данных из хешированных выходных данных, поскольку хэш-функции являются «односторонними» (как в мясорубке: вы не можете вернуть говяжий фарш обратно в стейк). Тем не менее, если вы используете такую функцию для одних и тех же данных, ее хэш будет идентичным, поэтому вы можете проверить, что данные такие же (т. е. без изменений), если вы уже знаете его хэш.
Хеширование также важно для управления блокчейном в криптовалюте.
Как работают хэш-функции
Типичные хэш-функции принимают входные данные переменной длины для возврата выходных данных фиксированной длины. Криптографическая хэш-функция сочетает в себе возможности хэш-функций по передаче сообщений со свойствами безопасности.
Хэш-функции — это обычно используемые структуры данных в вычислительных системах для таких задач, как проверка целостности сообщений и аутентификация информации.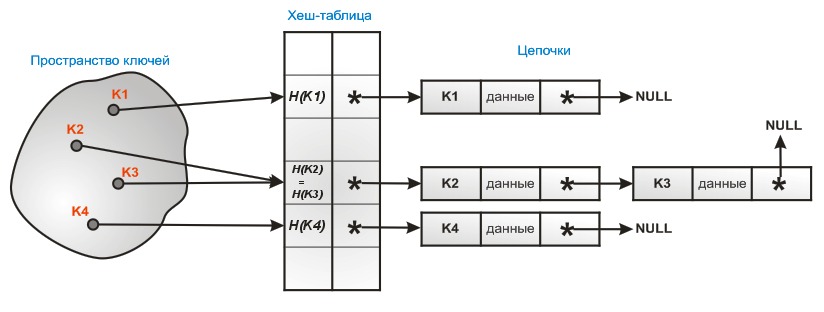 Хотя они считаются криптографически «слабыми», поскольку могут быть решены за полиномиальное время, их нелегко расшифровать.
Хотя они считаются криптографически «слабыми», поскольку могут быть решены за полиномиальное время, их нелегко расшифровать.
Криптографические хэш-функции добавляют функции безопасности к типичным хэш-функциям, что затрудняет обнаружение содержимого сообщения или информации о получателях и отправителях.
В частности, криптографические хэш-функции обладают этими тремя свойствами:
- Они «без коллизий». Это означает, что никакие два входных хэша не должны отображаться в один и тот же выходной хэш.
- Их можно скрыть. Должно быть трудно угадать входное значение для хэш-функции по ее выходным данным.
- Они должны быть паззл-ориентированными (быть головоломкой). Должно быть сложно подобрать вход, который обеспечивает предопределенный выход. Таким образом, входные данные следует выбирать из максимально широкого распределения.
Благодаря особенностям хэша они широко используются в онлайн-безопасности — от защиты паролей до обнаружения утечек данных и проверки целостности загруженного файла.

Хеширование и криптовалюты
Основой криптовалюты является блокчейн, который представляет собой глобальный распределенный реестр, образованный путем связывания отдельных блоков данных транзакции. Блокчейн содержит только подтвержденные транзакции, что предотвращает мошеннические транзакции и двойное расходование валюты. Полученное зашифрованное значение представляет собой серию цифр и букв, не похожих на исходные данные, и называется хэшем. Майнинг криптовалюты предполагает работу с этим хэшем.
Хеширование требует обработки данных из блока с помощью математической функции, что приводит к выходу фиксированной длины. Использование вывода фиксированной длины повышает безопасность, поскольку любой, кто пытается расшифровать хэш, не сможет определить, насколько длинным или коротким является ввод, просто посмотрев на длину вывода.
Решение хэша начинается с данных, имеющихся в заголовке блока, и, по сути, решает сложную математическую задачу. Заголовок каждого блока содержит номер версии, метку времени, хэш, использованный в предыдущем блоке, хэш корня Меркла, одноразовый номер (nonce) и целевой хэш.
Майнер сосредотачивается на nonce, строке чисел. Этот номер добавляется к хешированному содержимому предыдущего блока, которое затем хешируется. Если этот новый хэш меньше или равен целевому хэшу, то он принимается в качестве решения, майнеру дается вознаграждение, и блок добавляется в цепочку блоков.
Процесс проверки транзакций блокчейна основан на шифровании данных с использованием алгоритмического хеширования.
Особенности хэша
Решение хэша требует, чтобы майнер определил, какую строку использовать в качестве одноразового номера, что само по себе требует значительного количества проб и ошибок. Это потому, что одноразовый номер — это случайная строка. Маловероятно, что майнер успешно найдет правильный одноразовый номер с первой попытки, а это означает, что майнер потенциально может протестировать большое количество вариантов одноразового номера, прежде чем сделать его правильным. Чем выше сложность — мера того, насколько сложно создать хэш, который удовлетворяет требованиям целевого хэша — тем больше времени, вероятно, потребуется для генерации решения.
Пример хэша и хеширования
Хеширование слова «привет» даст результат той же длины, что и хэш для «Я иду в магазин». Функция, используемая для генерации хэша, является детерминированной, что означает, что она будет давать один и тот же результат каждый раз, когда используется один и тот же ввод. Он может эффективно генерировать хешированный ввод, это также затрудняет определение ввода (что приводит к майнингу), а также вносит небольшие изменения в результат ввода в неузнаваемый, совершенно другой хэш.
Обработка хэш-функций, необходимых для шифрования новых блоков, требует значительной вычислительной мощности компьютера, что может быть дорогостоящим. Чтобы побудить людей и компании, называемые майнерами, инвестировать в необходимую технологию, сети криптовалюты вознаграждают их как новыми токенами криптовалюты, так и комиссией за транзакцию. Майнеры получают вознаграждение только в том случае, если они первыми создают хэш, который соответствует требованиям, изложенным в целевом хэш-коде.
Популярные вопросы о хэше
Что такое хэш и хэш-функция?
Хэш-функции — это математические функции, которые преобразуют или «отображают» заданный набор данных в битовую строку фиксированного размера, также известную как «хэш» (хэш кодом, хэш суммой, значением хэша и т.д.).
Как рассчитывается хэш?
Хэш-функция использует сложные математические алгоритмы, которые преобразуют данные произвольной длины в данные фиксированной длины (например, 256 символов). Если вы измените один бит в любом месте исходных данных, изменится все значение хэш-функции, что сделает его полезным для проверки точности цифровых файлов и других данных.
Для чего используются хэши в блокчейнах?
Хэши используются в нескольких частях блокчейн-системы. Во-первых, каждый блок содержит хэш заголовка блока предыдущего блока, гарантируя, что ничего не было изменено при добавлении новых блоков. Майнинг криптовалюты с использованием доказательства выполнения работы (PoW), кроме того, использует хеширование случайно сгенерированных чисел для достижения определенного хешированного значения, содержащего серию нулей в начале. Эта произвольная функция требует больших ресурсов, что затрудняет перехват сети злоумышленником.
Эта произвольная функция требует больших ресурсов, что затрудняет перехват сети злоумышленником.
Резюме
- Хэш — это функция, которая удовлетворяет требования к шифрованию, необходимые для решения вычислений в цепочке блоков.
- Хэши имеют фиксированную длину, так как практически невозможно угадать длину хэша, если кто-то пытался взломать блокчейн.
- Одни и те же данные всегда будут давать одно и то же хешированное значение.
- Хэш, как одноразовый номер или решение, является основой сети блокчейн.
- Хэш создается на основе информации, содержащейся в заголовке блока.
А на этом сегодня все про хэш и хеширование. Надеюсь статья оказалась для вас полезной. Делитесь статьей в социальных сетях и мессенджерах и добавляйте сайт в закладки. Успехов и до новых встреч на страницах проекта Тюлягин!
Что такое хэширование и как оно работает?
По
- Эндрю Золя
Хэширование — это процесс преобразования любого заданного ключа или строки символов в другое значение. Обычно это представляется более коротким значением фиксированной длины или ключом, который представляет и упрощает поиск или использование исходной строки.
Обычно это представляется более коротким значением фиксированной длины или ключом, который представляет и упрощает поиск или использование исходной строки.
Наиболее популярным применением хеширования является реализация хеш-таблиц. Хэш-таблица хранит пары ключ-значение в списке, доступном через ее индекс. Поскольку количество пар «ключ-значение» не ограничено, хеш-функция сопоставляет ключи с размером таблицы. Затем хеш-значение становится индексом для определенного элемента.
Хэш-функция генерирует новые значения в соответствии с математическим алгоритмом хеширования, известным как хэш-значение или просто хэш. Чтобы предотвратить преобразование хэша обратно в исходный ключ, хороший хэш всегда использует алгоритм одностороннего хеширования.
Хеширование относится, помимо прочего, к индексации и поиску данных, цифровым подписям, кибербезопасности и криптографии.
Для чего используется хеширование?Поиск данных
Хэширование использует функции или алгоритмы для сопоставления данных объекта с репрезентативным целочисленным значением. Затем хэш можно использовать для сужения поиска при обнаружении этих элементов на карте данных объекта.
Затем хэш можно использовать для сужения поиска при обнаружении этих элементов на карте данных объекта.
Например, в хеш-таблицах разработчики хранят данные — возможно, запись о клиенте — в виде пар ключ-значение. Ключ помогает идентифицировать данные и выступает в качестве входных данных для функции хеширования, в то время как хеш-код или целое число затем сопоставляются с фиксированным размером.
Хэш-таблицы поддерживают следующие функции:
- вставка (ключ, значение)
- получить (ключ)
- удалить (ключ)
Цифровые подписи
Помимо возможности быстрого извлечения данных, хеширование помогает шифровать и расшифровывать цифровые подписи, используемые для аутентификации отправителей и получателей сообщений. В этом сценарии хэш-функция преобразует цифровую подпись до того, как хешированное значение (известное как дайджест сообщения) и подпись будут отправлены получателю отдельными передачами.
После получения та же хеш-функция извлекает дайджест сообщения из подписи, которая затем сравнивается с дайджестом переданного сообщения, чтобы убедиться, что они совпадают. В односторонней операции хеширования хэш-функция индексирует исходное значение или ключ и обеспечивает доступ к данным, связанным с определенным извлеченным значением или ключом.
Когда кто-то создает и шифрует цифровую подпись с помощью закрытого ключа, хэш-данные также создаются и шифруются. Затем открытый ключ подписывающей стороны позволяет получателю расшифровать подпись. Что такое хеширование в структуре данных?Десятичная классификация Дьюи уже много лет хорошо работает в библиотеках, и лежащая в ее основе концепция так же хорошо работает в компьютерных науках. Инженеры-программисты могут сэкономить место в файле и время, сократив исходные активы данных и входные строки до коротких буквенно-цифровых хэш-ключей.
Когда кто-то ищет элемент на карте данных, хеширование помогает сузить поиск. В этом сценарии хэш-коды создают индекс для хранения значений. Итак, здесь хеширование используется для индексации и извлечения информации из базы данных, поскольку это помогает ускорить процесс; гораздо проще найти элемент, используя его более короткий хэш-ключ, чем его исходное значение.
В этом сценарии хэш-коды создают индекс для хранения значений. Итак, здесь хеширование используется для индексации и извлечения информации из базы данных, поскольку это помогает ускорить процесс; гораздо проще найти элемент, используя его более короткий хэш-ключ, чем его исходное значение.
Многие алгоритмы шифрования используют хеширование для повышения кибербезопасности. Хэшированные строки и входные данные бессмысленны для хакеров без ключа дешифрования.
Например, если хакеры взламывают базу данных и находят такие данные, как «Джон Доу, номер социального страхования 273-76-1989», они могут немедленно использовать эту информацию для своих гнусных действий. Однако хэшированное значение, такое как «a87b3», бесполезно для злоумышленников, если у них нет ключа для его расшифровки.
Таким образом, хеширование помогает защитить пароли, хранящиеся в базе данных.
Что такое хеширование в криптографии? Криптография использует несколько хеш-функций для защиты данных.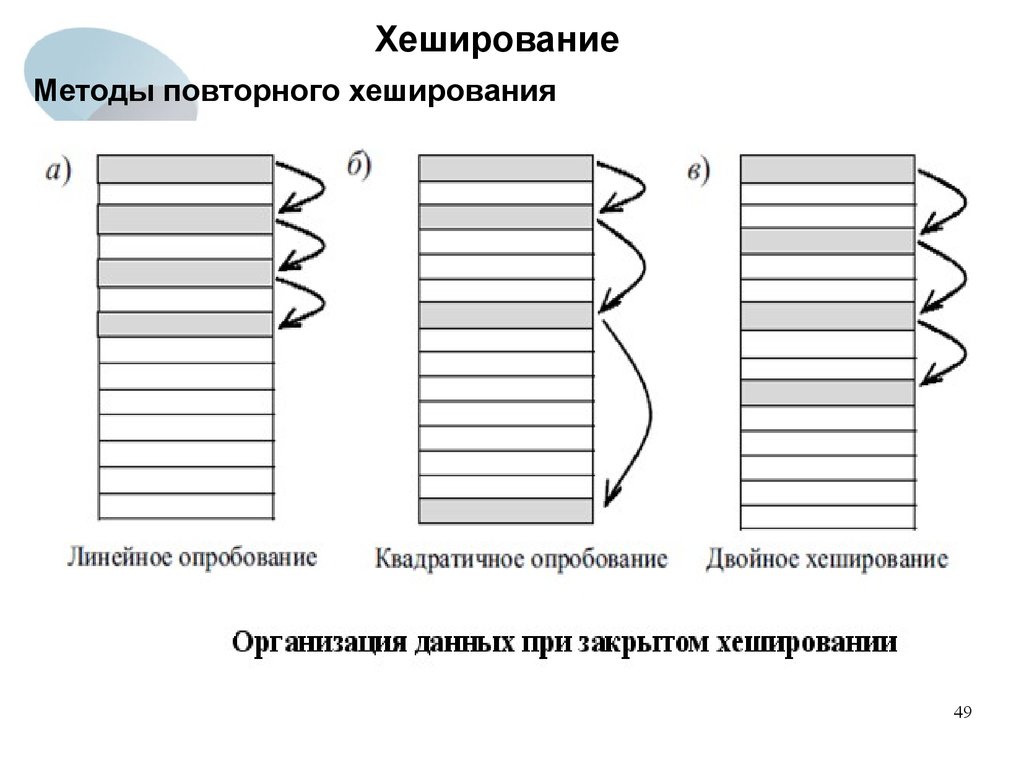 Вот некоторые из самых популярных криптографических хэшей:
Вот некоторые из самых популярных криптографических хэшей:
- Алгоритм безопасного хеширования 1 (SHA-1)
- Алгоритм безопасного хеширования 2 (SHA-2)
- Алгоритм безопасного хеширования 3 (SHA-3)
- МД2
- МД4
- MD5
Хэш-функции дайджеста сообщений, такие как MD2, MD4 и MD5, помогают хэшировать цифровые подписи. После хеширования подпись преобразуется в более короткое значение, называемое дайджестом сообщения.
Secure Hash Algorithm (SHA) — это стандартный алгоритм, используемый для создания более крупного (160-битного) дайджеста сообщения. Хотя это похоже на хэш-функцию MD4 для дайджеста сообщений и хорошо подходит для хранения и извлечения базы данных, это не лучший подход для криптографических целей или проверки ошибок. SHA-2 используется для создания большего (224-битного) дайджеста сообщения. SHA-3 является преемником SHA-2.
Что такое столкновение? Хеширование в кибербезопасности требует однонаправленных процессов, использующих алгоритм одностороннего хеширования. Это важный шаг, чтобы помешать злоумышленникам восстановить исходное состояние хэша. В то же время два ключа также могут генерировать идентичный хэш. Это явление называется столкновением.
Это важный шаг, чтобы помешать злоумышленникам восстановить исходное состояние хэша. В то же время два ключа также могут генерировать идентичный хэш. Это явление называется столкновением.
Хорошая хеш-функция никогда не выдает одно и то же значение хеш-функции из двух разных входных данных. Таким образом, хеш-функция с чрезвычайно низким риском коллизий считается приемлемой.
Открытая адресация и раздельное связывание — два способа устранения коллизий при их возникновении. Открытая адресация обрабатывает коллизии, сохраняя все данные в самой хеш-таблице, а затем ища доступность в следующем месте, созданном алгоритмом.
Методы открытой адресации включают:
- двойное хеширование
- линейное зондирование
- квадратичное зондирование
Раздельное связывание, напротив, позволяет избежать коллизий, заставляя каждую ячейку хэш-таблицы указывать на связанные списки записей с идентичными значениями хэш-функции.
 youtube.com/embed/uw4aTvRDHB4?rel=0″ title=»YouTube video player» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»>
youtube.com/embed/uw4aTvRDHB4?rel=0″ title=»YouTube video player» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»> Чтобы дополнительно обеспечить уникальность зашифрованных выходных данных, специалисты по кибербезопасности могут также добавлять случайные данные в хеш-функцию. Этот подход, известный как «посол», гарантирует уникальный результат, даже если входные данные идентичны.
Использование соли препятствует доступу злоумышленников к неуникальным паролям. Это связано с тем, что каждое хэш-значение уникально, даже если пользователи повторно используют свои пароли. Соление добавляет еще один уровень безопасности для предотвращения атак на радужные таблицы.
Хеширование также можно использовать при анализе или предотвращении подделки файлов. Это связано с тем, что каждый исходный файл генерирует хэш и сохраняет его в данных файла. Когда получатель получает файл и хэш вместе, он может проверить хэш, чтобы определить, был ли файл скомпрометирован. Если кто-то манипулировал файлом в пути, хеш отразил бы это изменение.
Если кто-то манипулировал файлом в пути, хеш отразил бы это изменение.
Последнее обновление: июнь 2021 г.
Продолжить чтение О хешировании- Как использовать открытый ключ и закрытый ключ в цифровых подписях
- Как кибербезопасность ИИ предотвращает атаки и как хакеры дают отпор
- 8 передовых методов электронной подписи, которые можно внедрить в рабочий процесс
- Взвешивание проблем шифрования с двойным ключом, выплаты
- Основы шифрования: как работает асимметричное и симметричное шифрование
Симметричное и асимметричное шифрование: в чем разница?
Автор: Майкл Кобб
криптографическая контрольная сумма
Автор: Рахул Авати
GUID (глобальный уникальный идентификатор)
Автор: Александр Гиллис
UUID (универсальный уникальный идентификатор)
Автор: Александр Гиллис
ПоискБизнесАналитика
- Google запускает три новых инструмента для своего облака данных
Инструменты управления данными и аналитики, включая новые платформы обмена данными и озера данных, предназначены для предоставления пользователям доступа .
.. - Sisense добавляет три новых встроенных аналитических возможности
Новая интеграция с GitLab, многопользовательская среда и усовершенствования Extense Framework предназначены для дальнейшего …
- Дополнительная автоматизация, встроенная аналитика в планах Tableau
Новые возможности, запланированные к выпуску в рамках двух последних обновлений платформы поставщика в 2022 году, предназначены для ускорения …
 ..
..ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Сервис автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных. Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу.
.. - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи AWS сталкиваются с выбором при развертывании Kubernetes: запускать его самостоятельно на EC2 или позволить Amazon выполнять тяжелую работу с помощью EKS. См…
 ..
..SearchContentManagement
- 7 распространенных угроз безопасности обмена файлами
ИТ-администраторы должны понимать основные риски безопасности при обмене файлами и что делать, чтобы они не создавали уязвимостей …
- Как создать контент-стратегию электронной коммерции для увеличения продаж
Стратегия контента, включающая автоматизированную CMS, полезную информацию о продукте и визуальные эффекты, может привлечь внимание клиентов к вашему …
- 5 безбумажных офисных программных инструментов, на которые следует обратить внимание
Выбор подходящего безбумажного программного обеспечения для офиса, казалось бы, бесконечный, начинается с понимания того, что .
..
 ..
..ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь в …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, в связи с чем …
ПоискSAP
- Сантандер присоединяется к SAP MBC, чтобы внедрить финансы в процессы
SAP Multi-Bank Connectivity добавил Santander Bank в свой список партнеров, чтобы помочь компаниям упростить внедрение .
.. - В 50 лет SAP оказалась на очередном распутье
За свою 50-летнюю историю компания SAP вывела бизнес и технологические тренды на вершину индустрии ERP, но сейчас она находится на перепутье …
- Сторонняя поддержка SAP обеспечивает гибкость миграции
Сторонние поставщики услуг поддержки заявляют, что они могут обеспечить большую гибкость при меньших затратах, но клиенты должны подумать…
 ..
..Что такое хеширование? Преимущества, типы и многое другое
Автор: Конрад Чанг, 2BrightSparks Pte. Ltd.
Если вы переносите файл с одного компьютера на другой, как убедиться, что скопированный файл совпадает с исходным? Один из методов, который вы могли бы использовать, называется хэшированием. По сути, это процесс, который переводит информацию о файле в код. Два хеш-значения (исходного файла и его копии) можно сравнить, чтобы убедиться, что файлы равны.
Что такое хеширование?
Хеширование — это алгоритм, который вычисляет значение битовой строки фиксированного размера из файла.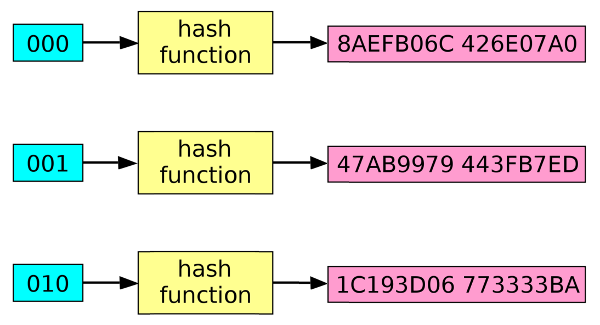 Файл в основном содержит блоки данных. Хэширование преобразует эти данные в гораздо более короткое значение фиксированной длины или ключ, представляющий исходную строку. Хэш-значение можно считать дистиллированной сводкой всего, что находится в этом файле.
Файл в основном содержит блоки данных. Хэширование преобразует эти данные в гораздо более короткое значение фиксированной длины или ключ, представляющий исходную строку. Хэш-значение можно считать дистиллированной сводкой всего, что находится в этом файле.
Хороший алгоритм хеширования должен обладать свойством, называемым лавинным эффектом, при котором результирующий хэш-выход может значительно или полностью измениться даже при изменении одного бита или байта данных в файле. Хеш-функция, которая этого не делает, считается плохой рандомизацией, которую хакерам будет легко взломать.
Хэш обычно представляет собой шестнадцатеричную строку из нескольких символов. Хэширование также является однонаправленным процессом, поэтому вы никогда не сможете работать в обратном направлении, чтобы получить исходные данные.
Хороший алгоритм хеширования должен быть достаточно сложным, чтобы он не давал одно и то же значение хеш-функции из двух разных входных данных. Если это так, это известно как хеш-коллизия. Алгоритм хеширования можно считать хорошим и приемлемым только в том случае, если он предлагает очень низкую вероятность коллизии.
Алгоритм хеширования можно считать хорошим и приемлемым только в том случае, если он предлагает очень низкую вероятность коллизии.
Каковы преимущества хеширования?
Одним из основных применений хеширования является сравнение двух файлов на предмет равенства. Не открывая два файла документа для их дословного сравнения, рассчитанные хэш-значения этих файлов позволят владельцу сразу узнать, отличаются ли они.
Хеширование также используется для проверки целостности файла после его передачи из одного места в другое, как правило, в программе резервного копирования файлов, такой как SyncBack. Чтобы убедиться, что передаваемый файл не поврежден, пользователь может сравнить хэш-значение обоих файлов. Если они совпадают, то переданный файл является идентичной копией.
В некоторых случаях зашифрованный файл может быть спроектирован так, чтобы никогда не изменять размер файла, а также дату и время последней модификации (например, файлы-контейнеры виртуального диска). В таких случаях было бы невозможно с первого взгляда определить, отличаются ли два похожих файла или нет, но значения хеш-функции легко отличили бы эти файлы друг от друга, если они разные.
В таких случаях было бы невозможно с первого взгляда определить, отличаются ли два похожих файла или нет, но значения хеш-функции легко отличили бы эти файлы друг от друга, если они разные.
Типы хэширования
Существует множество различных типов хеш-алгоритмов, таких как RipeMD, Tiger, xxhash и другие, но наиболее распространенными типами хеширования, используемыми для проверки целостности файлов, являются MD5, SHA-2 и CRC32.
MD5 — хэш-функция MD5 кодирует строку информации и кодирует ее в 128-битный отпечаток пальца. MD5 часто используется в качестве контрольной суммы для проверки целостности данных. Однако известно, что из-за своего возраста MD5 также страдает от обширных уязвимостей, связанных с коллизиями хэшей, но он по-прежнему остается одним из наиболее широко используемых алгоритмов в мире.
SHA-2 — SHA-2, разработанный Агентством национальной безопасности (АНБ), представляет собой криптографическую хеш-функцию. SHA-2 включает в себя существенные отличия от своего предшественника SHA-1. Семейство SHA-2 состоит из шести хэш-функций с дайджестами (хеш-значениями) размером 224, 256, 384 или 512 бит: SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224, SHA. -512/256.
SHA-2 включает в себя существенные отличия от своего предшественника SHA-1. Семейство SHA-2 состоит из шести хэш-функций с дайджестами (хеш-значениями) размером 224, 256, 384 или 512 бит: SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224, SHA. -512/256.
CRC32 — проверка циклическим избыточным кодом (CRC) — это код обнаружения ошибок, часто используемый для обнаружения случайных изменений данных. Кодирование одной и той же строки данных с использованием CRC32 всегда приводит к одному и тому же выводу хэша, поэтому CRC32 иногда используется в качестве алгоритма хеширования для проверки целостности файлов. В наши дни CRC32 редко используется за пределами Zip-файлов и FTP-серверов.
Использование хеширования в программе 2BrightSparks
В программе резервного копирования и синхронизации SyncBackPro/SE/Free хеширование в основном используется для проверки целостности файлов во время или после сеанса передачи данных. Например, пользователь SyncBack может включить проверку файлов ( Изменить профиль > Копировать/удалить ) или использовать более медленный, но более надежный метод ( Изменить профиль > Параметры сравнения ), который позволит хэшировать для проверки различий файлов. В зависимости от того, какой параметр используется и где находятся файлы резервных копий, будут использоваться разные хэш-функции.
В зависимости от того, какой параметр используется и где находятся файлы резервных копий, будут использоваться разные хэш-функции.
Другими областями, где используется хеширование, являются возобновление на FTP, проверка целостности данных, сценарии и иногда для аутентификации в облачных профилях (скрипты и облачное резервное копирование поддерживаются только SyncBackPro).
2BrightSparks также имеет вспомогательную программу под названием HashOnClick, которую можно использовать для обеспечения идентичности файлов. HashOnClick является частью утилиты OnClick, которая совершенно бесплатна. В HashOnClick доступно несколько типов алгоритмов хеширования.
Вы можете посетить нашу страницу загрузок, если хотите проверить какое-либо программное обеспечение 2BrightSparks.
Сводка
В заключение хочу сказать, что хеширование — полезный инструмент для проверки правильности копирования файлов между двумя ресурсами. Его также можно использовать для проверки идентичности файлов без их открытия и сравнения. Чтобы узнать больше о хешировании, посетите страницу Википедии.
Чтобы узнать больше о хешировании, посетите страницу Википедии.
Что такое хеширование и как оно работает?
Технологии защиты данных приветствуются. Они повышают точность данных и удобство использования. Следовательно, хеширование является популярной темой в дискурсе кибербезопасности.
Увеличение спроса на данные вызвало повышенный интерес к процессам анонимизации, и лучшим подходом к этому является хеширование.
В этой статье вы узнаете о преимуществах хеширования и о том, как оно работает.
Что такое хеширование?
Если вы купили новый телефон, а его термоусадочная пленка порвалась, это свидетельствует о том, что его открывали, использовали, заменяли или даже повреждали. Хеширование почти такое же, но для данных, а не для физических объектов.
Точно так же хеширование похоже на виртуальную термоусадочную пленку, наложенную на программное обеспечение или данные, чтобы информировать пользователей о том, были ли они заменены или использованы каким-либо образом.
Хеширование — это алгоритм, вычисляющий строковое значение из файла фиксированного размера. Он содержит массу данных, преобразованных в короткий фиксированный ключ или значение. Обычно сводка информации или данных находится в исходном отправленном файле.
Хеширование — один из лучших и наиболее безопасных способов идентификации и сравнения баз данных и файлов. Он преобразует данные в фиксированный размер без учета начального ввода данных. Полученный результат называется хеш-значением или кодом. Более того, термин «хэш» может использоваться для описания как значения, так и хэш-функции.
Каковы преимущества хеширования?
Есть много преимуществ хеширования, включая хеш-функции современной криптографии. Некоторые из этих преимуществ перечислены ниже.
1. Поиск данных
Одним из преимуществ хеширования является то, что оно использует алгоритмы для сопоставления данных объекта с целочисленным значением. Хэш удобен, потому что его можно использовать для сужения поиска при поиске элементов на карте данных объекта.
Например, хеш-таблицы в виде пар ключ-значение помогают идентифицировать данные и работать как входная хэш-функция. Затем хэш-код сопоставляется с фиксированным размером.
Хэш-таблицыподдерживают такие функции, как вставка (ключ, значение), получение (ключ) и удаление (ключ).
2. Цифровые подписи
Подписание документов в цифровом виде сегодня является обычной практикой. Помимо извлечения данных, хеширование также помогает шифровать и расшифровывать цифровые подписи, используемые для аутентификации отправителей и получателей сообщений. Хэш помогает преобразовать цифровую подпись, которая является одновременно и значением хеш-функции, и подписью, и отправляется получателю отдельной передачей.
После отправки хэш будет сравниваться с переданным сообщением, чтобы убедиться, что они совпадают. В односторонней операции хеширования хэш-функция индексирует исходное значение или ключ и обеспечивает доступ к данным, связанным с определенным извлеченным значением или ключом.
Простейший метод цифровой подписи — создать хэш отправляемой информации и зашифровать его с помощью вашего закрытого ключа (пары ключей асимметричного шифрования), чтобы любой, у кого есть ваш открытый ключ, мог увидеть настоящий хэш и убедиться, что содержимое действительно.
3. Защита паролем
Создание надежных паролей — эффективный способ держать злоумышленников в страхе.
Одним из преимуществ хеширования является то, что его пароль нельзя изменить, украсть или изменить. Это похвально, тем более, что кибер-злоумышленники могут маневрировать паролями, используя атаки грубой силы. Это эффективная схема шифрования ключей, которую невозможно использовать не по назначению. Если хэш-код будет украден, он будет бесполезен, потому что его нельзя применить где-либо еще. Владельцы веб-сайтов используют этот метод для защиты паролей своих пользователей.
Как работает хеширование?
Хеширование — это односторонняя криптографическая функция, поскольку хэши необратимы. Результат хеширования не позволяет воссоздать содержимое файла. Однако он позволяет узнать, похожи ли два файла, не зная их содержимого.
Результат хеширования не позволяет воссоздать содержимое файла. Однако он позволяет узнать, похожи ли два файла, не зная их содержимого.
Давайте посмотрим, как работает хеширование.
1. Алгоритм дайджеста сообщения
Одним из способов хеширования является использование алгоритма дайджеста сообщения. Часть хэш-функций использует хэш для генерации уникального значения и уникального симметричного ключа. Этот алгоритм также известен как алгоритм только для шифрования, поскольку он может генерировать исключительное значение, которое невозможно расшифровать.
Алгоритм дайджеста сообщения работает, помогая вам обрабатывать сообщение переменной длины в выходные данные фиксированной длины около 128 бит. Затем это входное сообщение будет разбито на фрагменты по 512 бит.
2. Вирпул
Хеширование работает через алгоритм Whirlpool, поскольку это одна из хеш-функций. Первоначально Whirlpool назывался Whirlpool-0, но после нескольких подразделений он стал известен как Whirlpool-T, позже известный как Whirlpool.
Это криптографически безопасная хэш-функция, не имеющая недостатков, связанных с хешированием секретов. Однако использование Whirlpool напрямую для хеширования паролей — это плохо, потому что это быстро и позволяет хакерам угадывать множество паролей за секунду.
Whirlpool работает, беря сообщение размером менее 2256 бит и возвращая его в 512-битный дайджест сообщения. Он также используется бесплатно для любых целей.
3. Ривест-Шамир-Адлеман (ЮАР)
Rivest-Shamir-Adleman (RSA) — один из алгоритмов, используемых для хеширования. Современные компьютеры в основном используют его для шифрования и дешифрования сообщения. Это криптографический алгоритм, который использует как открытый ключ, так и закрытый ключ, где шифрование выполняется с помощью открытого ключа, а дешифрование — с помощью закрытого ключа.
Хеширование работает с использованием RSA, поскольку RSA создает и публикует закрытые и открытые ключи на основе больших простых чисел и дополнительного значения. Простые числа держатся в секрете. Сообщения могут быть зашифрованы и расшифрованы вами, но могут быть расшифрованы, только если вы знаете простые числа.
Простые числа держатся в секрете. Сообщения могут быть зашифрованы и расшифрованы вами, но могут быть расшифрованы, только если вы знаете простые числа.
4. Алгоритм безопасного хеширования (SHA)
Алгоритм безопасного хэширования(SHA) — это семейство криптографических функций, предназначенных для хранения и хранения данных. Он работает путем преобразования данных с помощью хэш-функции, но не может быть преобразован в исходные данные. Это связано с тем, что этот алгоритм включает в себя побитовые операции, функции сжатия и модульные дополнения и используется для шифрования паролей.
Использование хеширования для защиты данных
Хэширование — это инструмент компьютерной безопасности, который может сообщить вам, когда два файла идентичны и защищены, чтобы избежать конфликта.
Иногда файлы могут выглядеть одинаково, имея одинаковую функциональность и поведение, но разные хэши. Таким образом, полагаться на хэш для обнаружения — хороший подход, который гарантирует, что ваши данные не будут скомпрометированы.
Что такое хеширование? — Определение из Techopedia
Что означает хеширование?
Хэширование — это процесс преобразования заданного ключа в код. Хеш-функция используется для замены информации вновь сгенерированным хеш-кодом. В частности, хеширование — это практика взятия строки или входного ключа, переменной, созданной для хранения описательных данных, и представления ее с помощью хеш-значения, которое обычно определяется алгоритмом и представляет собой гораздо более короткую строку, чем исходная.
Хэш-таблица создаст список, в котором все пары значений будут храниться и легко доступны через ее индекс. Результатом является метод очень эффективного доступа к значениям ключей в таблице базы данных, а также метод повышения безопасности базы данных посредством шифрования.
Хеширование использует алгоритмы, которые преобразуют блоки данных из файла в гораздо более короткое значение или ключ фиксированной длины, которые представляют эти строки.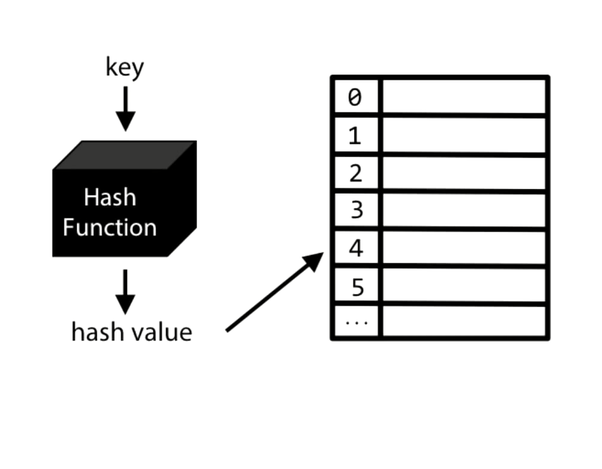 Результирующее хэш-значение является своего рода концентрированной сводкой каждой строки в заданном файле и должно иметь возможность изменяться даже при изменении одного байта данных в этом файле (эффект лавины). Это обеспечивает огромные преимущества хеширования с точки зрения сжатия данных. Хотя хеширование не является сжатием, оно может работать очень похоже на сжатие файлов, поскольку берет больший набор данных и сжимает его до более удобной формы.
Результирующее хэш-значение является своего рода концентрированной сводкой каждой строки в заданном файле и должно иметь возможность изменяться даже при изменении одного байта данных в этом файле (эффект лавины). Это обеспечивает огромные преимущества хеширования с точки зрения сжатия данных. Хотя хеширование не является сжатием, оно может работать очень похоже на сжатие файлов, поскольку берет больший набор данных и сжимает его до более удобной формы.
Предположим, что в базе данных 4000 раз записано «ID кошелька Джона». Взяв все эти повторяющиеся строки и хешировав их в более короткую строку, вы сэкономите массу памяти.
Techopedia объясняет хеширование
Подумайте о фразе из трех слов, закодированной в базе данных или другом месте памяти, которую можно хэшировать в короткое буквенно-цифровое значение, состоящее всего из нескольких букв и цифр. Это может быть невероятно эффективным в масштабе, и это только одна из причин, по которой используется хеширование.
Хеширование в информатике и шифровании
Хеширование имеет несколько ключевых применений в информатике. Возможно, сегодня в мире, где кибербезопасность играет ключевую роль, наибольшее внимание уделяется использованию хеширования в шифровании.
Поскольку хешированные строки и входные данные не имеют своей первоначальной формы, их нельзя украсть так, как если бы они не были хешированы. Если хакер проникнет в базу данных и найдет исходную строку, например «Идентификатор кошелька Джона 34567», он может просто подобрать, получить или украсть эту информацию и использовать ее в своих интересах, но если вместо этого он найдет хэш-значение, например «a67b2,» эта информация для них совершенно бесполезна, если у них нет ключа для ее расшифровки. SHA-1, SHA-2 и MD5 — популярные криптографические хэши.
Хорошая хеш-функция в целях безопасности должна быть однонаправленным процессом, использующим алгоритм одностороннего хеширования. В противном случае хакеры могут легко перепроектировать хэш, чтобы преобразовать его обратно в исходные данные, что, в первую очередь, нанесет ущерб цели шифрования.
В противном случае хакеры могут легко перепроектировать хэш, чтобы преобразовать его обратно в исходные данные, что, в первую очередь, нанесет ущерб цели шифрования.
Чтобы еще больше повысить уникальность зашифрованных выходных данных, к входным данным хеш-функции можно добавить случайные данные. Этот метод известен как «соление» и гарантирует уникальный результат даже в случае идентичных входных данных. Например, хакеры могут угадывать пароли пользователей в базе данных с помощью радужной таблицы или получать к ним доступ с помощью атаки по словарю. Некоторые пользователи могут использовать один и тот же пароль, который, если хакер угадает, будет украден для всех из них. Добавление соли не позволяет хакеру получить доступ к этим неуникальным паролям, поскольку каждое хеш-значение теперь будет уникальным и остановит любую атаку на радужную таблицу.
Использование хеширования при извлечении из базы данных
Хеширование можно использовать при извлечении из базы данных. Здесь пригодится еще один пример — многие эксперты сравнивают хеширование с ключевой библиотечной инновацией 20-го века — десятичной системой Дьюи.
Здесь пригодится еще один пример — многие эксперты сравнивают хеширование с ключевой библиотечной инновацией 20-го века — десятичной системой Дьюи.
В некотором смысле то, что вы получаете, когда получаете хэш-значение, похоже на получение десятичного числа по системе Дьюи для книги. Вместо поиска названия книги вы ищете адрес или идентификатор в десятичной системе Дьюи, а также несколько ключевых буквенно-цифровых символов названия книги или автора.
Мы видели, насколько хорошо десятичная система Дьюи работает в библиотеках, и точно так же она работает в информатике. Короче говоря, сжимая эти исходные входные строки и активы данных в короткие буквенно-цифровые хэш-ключи, инженеры могут сделать несколько ключевых улучшений кибербезопасности и одновременно сэкономить место в файле.
Роль хеширования в подделке файлов
Хеширование также полезно для предотвращения или анализа подделки файлов. Исходный файл будет генерировать хэш, который хранится вместе с данными файла. Файл и хэш отправляются вместе, и принимающая сторона проверяет этот хеш, чтобы убедиться, что файл не был скомпрометирован. Если в файле были какие-либо изменения, хэш покажет это.
Исходный файл будет генерировать хэш, который хранится вместе с данными файла. Файл и хэш отправляются вместе, и принимающая сторона проверяет этот хеш, чтобы убедиться, что файл не был скомпрометирован. Если в файле были какие-либо изменения, хэш покажет это.
Все это показывает, почему хеширование является такой популярной частью обработки БД.
Что такое хеширование? — Определение из Techopedia
Что означает хеширование?
Хэширование — это процесс преобразования заданного ключа в код. Хеш-функция используется для замены информации вновь сгенерированным хеш-кодом. В частности, хеширование — это практика взятия строки или входного ключа, переменной, созданной для хранения описательных данных, и представления ее с помощью хеш-значения, которое обычно определяется алгоритмом и представляет собой гораздо более короткую строку, чем исходная.
Хэш-таблица создаст список, в котором все пары значений будут храниться и легко доступны через ее индекс. Результатом является метод очень эффективного доступа к значениям ключей в таблице базы данных, а также метод повышения безопасности базы данных посредством шифрования.
Результатом является метод очень эффективного доступа к значениям ключей в таблице базы данных, а также метод повышения безопасности базы данных посредством шифрования.
Хеширование использует алгоритмы, которые преобразуют блоки данных из файла в гораздо более короткое значение или ключ фиксированной длины, которые представляют эти строки. Результирующее хэш-значение является своего рода концентрированной сводкой каждой строки в заданном файле и должно иметь возможность изменяться даже при изменении одного байта данных в этом файле (эффект лавины). Это обеспечивает огромные преимущества хеширования с точки зрения сжатия данных. Хотя хеширование не является сжатием, оно может работать очень похоже на сжатие файлов, поскольку берет больший набор данных и сжимает его до более удобной формы.
Предположим, что в базе данных 4000 раз записано «ID кошелька Джона». Взяв все эти повторяющиеся строки и хешировав их в более короткую строку, вы сэкономите массу памяти.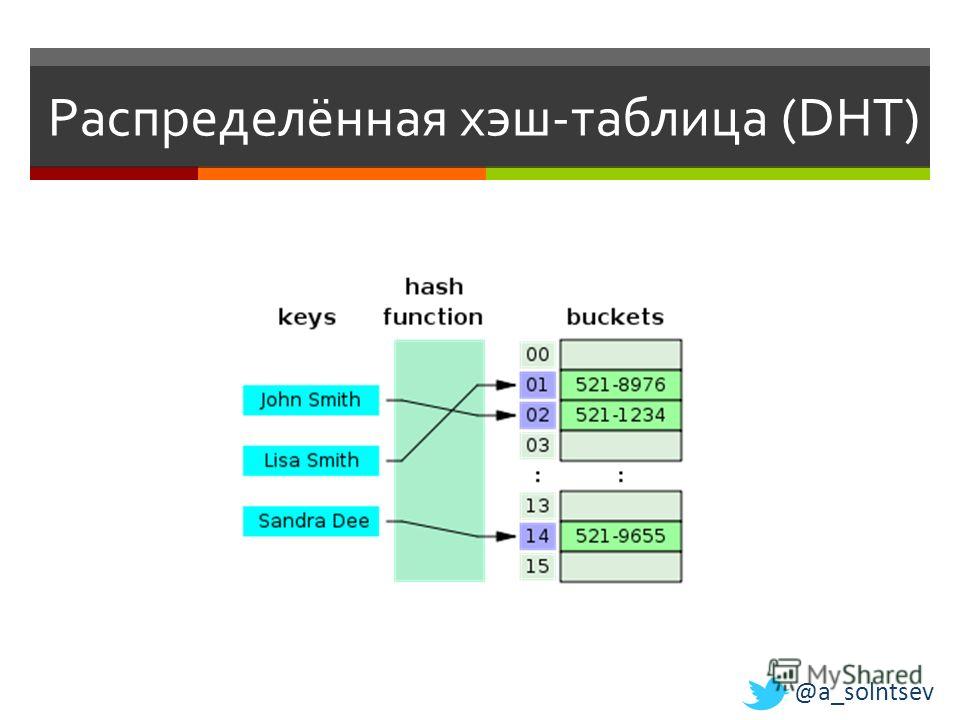
Techopedia объясняет хеширование
Подумайте о фразе из трех слов, закодированной в базе данных или другом месте памяти, которую можно хэшировать в короткое буквенно-цифровое значение, состоящее всего из нескольких букв и цифр. Это может быть невероятно эффективным в масштабе, и это только одна из причин, по которой используется хеширование.
Хеширование в информатике и шифровании
Хеширование имеет несколько ключевых применений в информатике. Возможно, сегодня в мире, где кибербезопасность играет ключевую роль, наибольшее внимание уделяется использованию хеширования в шифровании.
Поскольку хешированные строки и входные данные не имеют своей первоначальной формы, их нельзя украсть так, как если бы они не были хешированы. Если хакер проникнет в базу данных и найдет исходную строку, например «Идентификатор кошелька Джона 34567», он может просто подобрать, получить или украсть эту информацию и использовать ее в своих интересах, но если вместо этого он найдет хэш-значение, например «a67b2,» эта информация для них совершенно бесполезна, если у них нет ключа для ее расшифровки. SHA-1, SHA-2 и MD5 — популярные криптографические хэши.
SHA-1, SHA-2 и MD5 — популярные криптографические хэши.
Хорошая хеш-функция в целях безопасности должна быть однонаправленным процессом, использующим алгоритм одностороннего хеширования. В противном случае хакеры могут легко перепроектировать хэш, чтобы преобразовать его обратно в исходные данные, что, в первую очередь, нанесет ущерб цели шифрования.
Чтобы еще больше повысить уникальность зашифрованных выходных данных, к входным данным хеш-функции можно добавить случайные данные. Этот метод известен как «соление» и гарантирует уникальный результат даже в случае идентичных входных данных. Например, хакеры могут угадывать пароли пользователей в базе данных с помощью радужной таблицы или получать к ним доступ с помощью атаки по словарю. Некоторые пользователи могут использовать один и тот же пароль, который, если хакер угадает, будет украден для всех из них. Добавление соли не позволяет хакеру получить доступ к этим неуникальным паролям, поскольку каждое хеш-значение теперь будет уникальным и остановит любую атаку на радужную таблицу.
Использование хеширования при извлечении из базы данных
Хеширование можно использовать при извлечении из базы данных. Здесь пригодится еще один пример — многие эксперты сравнивают хеширование с ключевой библиотечной инновацией 20-го века — десятичной системой Дьюи.
В некотором смысле то, что вы получаете, когда получаете хэш-значение, похоже на получение десятичного числа по системе Дьюи для книги. Вместо поиска названия книги вы ищете адрес или идентификатор в десятичной системе Дьюи, а также несколько ключевых буквенно-цифровых символов названия книги или автора.
Мы видели, насколько хорошо десятичная система Дьюи работает в библиотеках, и точно так же она работает в информатике. Короче говоря, сжимая эти исходные входные строки и активы данных в короткие буквенно-цифровые хэш-ключи, инженеры могут сделать несколько ключевых улучшений кибербезопасности и одновременно сэкономить место в файле.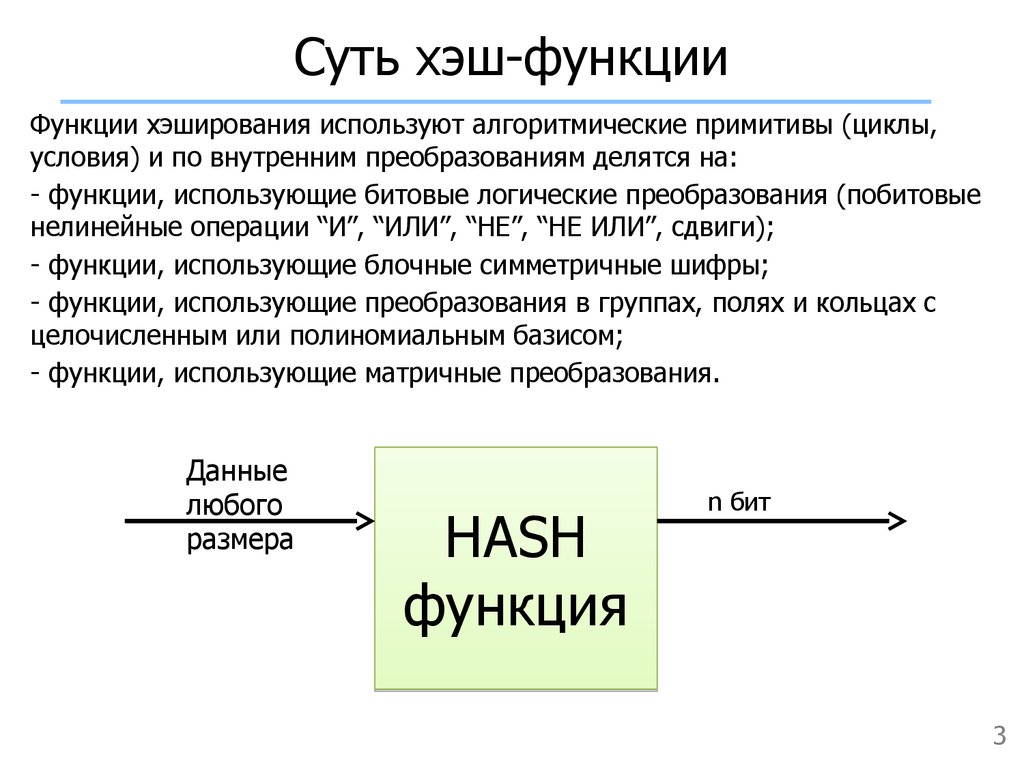
Роль хеширования в подделке файлов
Хеширование также полезно для предотвращения или анализа подделки файлов. Исходный файл будет генерировать хэш, который хранится вместе с данными файла. Файл и хэш отправляются вместе, и принимающая сторона проверяет этот хеш, чтобы убедиться, что файл не был скомпрометирован. Если в файле были какие-либо изменения, хэш покажет это.
Все это показывает, почему хеширование является такой популярной частью обработки БД.
Что такое хеширование? — Определение из Techopedia
Что означает хеширование?
Хэширование — это процесс преобразования заданного ключа в код. Хеш-функция используется для замены информации вновь сгенерированным хеш-кодом. В частности, хеширование — это практика взятия строки или входного ключа, переменной, созданной для хранения описательных данных, и представления ее с помощью хеш-значения, которое обычно определяется алгоритмом и представляет собой гораздо более короткую строку, чем исходная.
Хэш-таблица создаст список, в котором все пары значений будут храниться и легко доступны через ее индекс. Результатом является метод очень эффективного доступа к значениям ключей в таблице базы данных, а также метод повышения безопасности базы данных посредством шифрования.
Хеширование использует алгоритмы, которые преобразуют блоки данных из файла в гораздо более короткое значение или ключ фиксированной длины, которые представляют эти строки. Результирующее хэш-значение является своего рода концентрированной сводкой каждой строки в заданном файле и должно иметь возможность изменяться даже при изменении одного байта данных в этом файле (эффект лавины). Это обеспечивает огромные преимущества хеширования с точки зрения сжатия данных. Хотя хеширование не является сжатием, оно может работать очень похоже на сжатие файлов, поскольку берет больший набор данных и сжимает его до более удобной формы.
Предположим, что в базе данных 4000 раз записано «ID кошелька Джона». Взяв все эти повторяющиеся строки и хешировав их в более короткую строку, вы сэкономите массу памяти.
Взяв все эти повторяющиеся строки и хешировав их в более короткую строку, вы сэкономите массу памяти.
Techopedia объясняет хеширование
Подумайте о фразе из трех слов, закодированной в базе данных или другом месте памяти, которую можно хэшировать в короткое буквенно-цифровое значение, состоящее всего из нескольких букв и цифр. Это может быть невероятно эффективным в масштабе, и это только одна из причин, по которой используется хеширование.
Хеширование в информатике и шифровании
Хеширование имеет несколько ключевых применений в информатике. Возможно, сегодня в мире, где кибербезопасность играет ключевую роль, наибольшее внимание уделяется использованию хеширования в шифровании.
Поскольку хешированные строки и входные данные не имеют своей первоначальной формы, их нельзя украсть так, как если бы они не были хешированы. Если хакер проникнет в базу данных и найдет исходную строку, например «Идентификатор кошелька Джона 34567», он может просто подобрать, получить или украсть эту информацию и использовать ее в своих интересах, но если вместо этого он найдет хэш-значение, например «a67b2,» эта информация для них совершенно бесполезна, если у них нет ключа для ее расшифровки. SHA-1, SHA-2 и MD5 — популярные криптографические хэши.
SHA-1, SHA-2 и MD5 — популярные криптографические хэши.
Хорошая хеш-функция в целях безопасности должна быть однонаправленным процессом, использующим алгоритм одностороннего хеширования. В противном случае хакеры могут легко перепроектировать хэш, чтобы преобразовать его обратно в исходные данные, что, в первую очередь, нанесет ущерб цели шифрования.
Чтобы еще больше повысить уникальность зашифрованных выходных данных, к входным данным хеш-функции можно добавить случайные данные. Этот метод известен как «соление» и гарантирует уникальный результат даже в случае идентичных входных данных. Например, хакеры могут угадывать пароли пользователей в базе данных с помощью радужной таблицы или получать к ним доступ с помощью атаки по словарю. Некоторые пользователи могут использовать один и тот же пароль, который, если хакер угадает, будет украден для всех из них. Добавление соли не позволяет хакеру получить доступ к этим неуникальным паролям, поскольку каждое хеш-значение теперь будет уникальным и остановит любую атаку на радужную таблицу.
Использование хеширования при извлечении из базы данных
Хеширование можно использовать при извлечении из базы данных. Здесь пригодится еще один пример — многие эксперты сравнивают хеширование с ключевой библиотечной инновацией 20-го века — десятичной системой Дьюи.
В некотором смысле то, что вы получаете, когда получаете хэш-значение, похоже на получение десятичного числа по системе Дьюи для книги. Вместо поиска названия книги вы ищете адрес или идентификатор в десятичной системе Дьюи, а также несколько ключевых буквенно-цифровых символов названия книги или автора.
Мы видели, насколько хорошо десятичная система Дьюи работает в библиотеках, и точно так же она работает в информатике. Короче говоря, сжимая эти исходные входные строки и активы данных в короткие буквенно-цифровые хэш-ключи, инженеры могут сделать несколько ключевых улучшений кибербезопасности и одновременно сэкономить место в файле.