UTF8 | это… Что такое UTF8?
ТолкованиеПеревод
- UTF8
UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста.
Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байтов (реально только до 4 байт, поскольку использование кодов больше 221 не планируется), в которых первый байт всегда имеет вид
11xxxxxx, а остальные —10xxxxxx.Проще говоря, в формате UTF-8 символы латинского алфавита, знаки препинания и управляющие символы ASCII записываются кодами US-ASCII, a все остальные символы кодируются при помощи нескольких октетов со старшим битом 1.

- Даже если программа не распознаёт Юникод, то латинские буквы, арабские цифры и знаки препинания будут отображаться правильно.
- В случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму по сравнению с [1][2]
- На первый взгляд может показаться, что UTF-16 удобнее, так как в ней большинство символов кодируется ровно двумя байтами. Однако это сводится на нет необходимостью поддержки суррогатных пар, о которых часто забывают при использовании UTF-16, реализовывая лишь поддержку символов UCS-2.
Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9[3]. Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Символы UTF-8 получаются из Unicode следующим образом:
Unicode UTF-8 0x00000000—0x0000007F0xxxxxxx0x00000080—0x000007FF110xxxxx 10xxxxxx0x00000800—0x0000FFFF1110xxxx 10xxxxxx 10xxxxxx0x001FFFFF11110xxx 10xxxxxx 10xxxxxx 10xxxxxxТакже теоретически возможны, но не включены в стандарты:
Unicode UTF-8 0x00200000—0x03FFFFFF111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx0x04000000—0x7FFFFFFF1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxxЗамечание: Символы, закодированные в UTF-8, могут быть длиной до шести байтов, однако стандарт Unicode не определяет символов выше
0x10ffff, поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.Содержание
- 1 Неиспользуемые значения байтов
- 2 Примечания
- 3 Ссылки
- 4 См. также
Неиспользуемые значения байтов
В тексте UTF-8 принципиально не может быть байтов со значениями 254 (0xFE) и 255 (0xFF). Поскольку в Юникоде не определены символы с кодами выше 221, то в UTF-8 оказываются неиспользуемыми также значения байтов от 248 до 253 (0xF8—0xFE). Если запрещены искусственно удлинённые (за счёт добавления ведущих нулей) последовательности UTF-8, то не используются также байтовые значения 192 и 193 (0xC0 и 0xC1).
Примечания
- ↑ 1 2 Well, I’m Back String Theory (англ.). Robert O’Callahan (2008-03-01). Проверено 1 марта 2008.
- ↑ Ростислав Чебыкин Всем кодировкам кодировка. UTF‑8: современно, грамотно, удобно.. HTML и CSS. Проверено 22 марта 2009.
- ↑ http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt (англ.)
Ссылки
См. также
- Юникод в GNU/Linux
- Юникод в FreeBSD
- Plan 9


Wikimedia Foundation. 2010.
Игры ⚽ Нужно сделать НИР?
- UTF-16 Big Endian
- UTF-32
Полезное
UTF — универсальная кодировка для всего
В прошлый раз мы рассказали про Юникод — универсальную таблицу символов, в которой есть знаки почти всех языков. Вот краткое содержание:
- Когда компьютеры только появились, у них была кодировка только для букв латинского алфавита и некоторых знаков — всего 7 бит и 128 символов.
- С развитием технологий многие страны сделали себе альтернативные восьмибитные кодировки — в них можно было хранить уже 256 символов.
- Кроме латиницы, в таких кодировках записывали буквы национальных алфавитов и другие нужные символы.
- Это сработало в тех странах, где алфавит состоит из небольшого числа букв (20—40), но не решило проблему с иероглифами. Тогда страны Азии сделали свои кодировки.
- В итоге всё это привело к тому, что файл с одного компьютера мог не прочитаться на другом компьютере, если там не было нужной кодировки.
- Для решения этих проблем сделали Юникод — универсальную таблицу, в которую можно поместить 1 112 064 символа.
- Сейчас в Юникоде записаны символы почти всех языков мира, но свободных позиций там осталось ещё около 80%.

Получается, что Юникод — универсальное решение проблемы совместимости текста. Текстовый файл, записанный в таком формате, можно прочитать на любом современном компьютере. Поддержка Юникода есть во всех новых операционных системах последних лет.
Кодирование и шифрование — в чём разница?
Чтобы пользоваться Юникодом, нужна была новая кодировка, которая бы определяла правила хранения информации о каждом символе. Такой кодировкой стала UTF — про неё и поговорим.
UTF — универсальная кодировка для хранения символов
Юникод как таковой отвечает на вопрос «Как мы храним символы?». Он объясняет, каким символам мы присваиваем какие коды; по какому принципу выделяем эти коды; какие символы используем, а какие нет.
Но также нам нужно знать, как хранить и передавать данные о символах Юникода. Вот это и есть UTF.
UTF (Unicode Transformation Format) — это стандарт кодирования символов Unicode. Разберём на куски:
- Стандарт — то есть всеобщая договорённость. Разработчик в России и Мексике открывают одну и ту же документацию и одинаково понимают, как им работать с данными. Договорились такие.
- Кодирование — то есть как мы представляем эти данные на компьютере. Это одно большое число? Несколько чисел поменьше? Сколько байтов выделять на эти символы? Нужно ли специально говорить компьютеру, что сейчас будут символы Юникода?
Что такое UTF-8?
Сейчас самая популярная разновидность UTF-кодировки — это UTF-8.
Чаще всего упоминание UTF-8 можно встретить в самом начале HTML-кода, когда мы объявляем кодировку в заголовке страницы. Строчка <meta charset=»utf-8″> как раз говорит браузеру, что всё текстовое содержимое страницы нужно отображать по формату UTF-8.
Число 8 означает, что для хранения данных используются 8 бит информации. Ещё есть 16- и 32-битные кодировки: UTF-16 и UTF-32.
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title></title> </head> <body> </body> </html>
Проблема нулевых байтов
Сейчас немного информатики, потерпите.
Компьютер кодирует числа с помощью единиц и нулей в двоичной системе счисления. Она позволяет закодировать любое число, если дать ей достаточно места в памяти. Эти места измеряются в битах. Одним битом можно закодировать 0 или 1; двумя битами — числа от 0 до 3; восемью битами — от 0 до 255 и так далее. Биты слишком мелкие, поэтому для удобства хранения и обработки компьютеры группируют их по 8 бит, это называется байтом. В памяти можно выделять только байты, а не отдельные биты.
Биты слишком мелкие, поэтому для удобства хранения и обработки компьютеры группируют их по 8 бит, это называется байтом. В памяти можно выделять только байты, а не отдельные биты.
Максимальное количество символов в Юникоде — 1 112 064. Для хранения числа такого размера нам нужен 21 бит. Получается, что кодировка должна уметь работать с 21-битными числами.
Самое простое решение — выделить на каждый символ по 3 байта, то есть 24 бита. Например, символ с номером 998 536 в двоичной системе счисления выглядит так:
Двоичное счисление на пальцах
11110011110010001000
Если мы разобьём это на три байта и добавим впереди нужное количество нулей до трёх байтов, то получится такое:
00001111 00111100 10001000
Кажется, что мы сразу нашли способ кодирования: просто выделяй на все символы по три байта и кайфуй.
Но что, если нам нужен, например, символ под номером 150?
150₁₀ = 10010110₂
Разобьем снова на три байта:
00000000 00000000 10010110
У нас получилось в самом начале два нулевых байта. Проблема в том, что многие системы передачи данных воспринимают нулевые байты как конец передачи. Если они встретят такую последовательность, то решат, что передача окончена, а всё, что идёт дальше, — лишний шум, который обрабатывать не нужно. Если в нашем Юникод-тексте много символов из начала таблицы (например, всё на английском), то с чтением такого файла возникнут проблемы.
Проблема в том, что многие системы передачи данных воспринимают нулевые байты как конец передачи. Если они встретят такую последовательность, то решат, что передача окончена, а всё, что идёт дальше, — лишний шум, который обрабатывать не нужно. Если в нашем Юникод-тексте много символов из начала таблицы (например, всё на английском), то с чтением такого файла возникнут проблемы.
Чтобы выйти из этой ситуации, придумали UTF-8 — кодировку с плавающим количеством символов.
Как устроена кодировка UTF-8
В UTF-8 каждый символ кодируется разным количеством байтов — всё зависит от того, какой длины исходное число. Сначала расскажем теорию, потом нарисуем, как это работает.
До 7 бит — выделяется один байт, первый бит всегда ноль: 0xxxxxxxx. Иксы — это биты нашего числа. Например, буква A стоит на 65-м месте в таблице, а если перевести 65 в двоичный код, получится 1000001. Ставим эти 7 бит в наш шаблон и получаем нужный юникод-байт: 01000001.
Ноль здесь — признак того, что перед нами символ из первых 128 символов таблицы. Они совпадают с таблицей ASCII, поэтому одним байтом можно закодировать все стандартные математические символы, знаки препинания и буквы латинского алфавита.
Если первым в символе идёт ноль, кодировка понимает, что перед нами — один восьмибитный символ. Двух-, трёх- и четырёхбайтные символы всегда начинаются с единицы.
8—11 бит: выделяется два байта — 110xxxxx 10xxxxxx. Две единицы в начале говорят, что перед нами символ из двух байтов. Последовательность 10 в начале второго байта — признак того, что это продолжение предыдущего байта.
12—16 бит: тут уже три байта — 1110xxxx 10xxxxxx 10xxxxxx. Три единицы в начале — признак трёхбайтного символа. Каждый байт продолжения начинается с 10.
17—21 бит: для кодирования нужно четыре байта: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx.
Короче: в кодировке UTF договорились, что много байтов выделяют только на те символы, которые стоят где-то в глубине таблицы, то есть всякие сложные национальные кодировки, эмодзи и иконки. Чем ближе к началу таблицы символ, тем меньше байтов на него выделяют. А чтобы компьютер понимал, сколько байтов выделено на каждый конкретный символ, сначала ставят специальные маркеры-подсказки.
Чем ближе к началу таблицы символ, тем меньше байтов на него выделяют. А чтобы компьютер понимал, сколько байтов выделено на каждый конкретный символ, сначала ставят специальные маркеры-подсказки.
Практика: кодируем символы в UTF-8
Закодируем в UTF-8 такой Юникод-символ — 𐍈 с порядковым номером 66376.
Для этого сначала переведём число 66376 в двоичный формат:
66376 = 10000001101001000
Здесь 17 бит, поэтому для кодирования в UTF-8 нам понадобится 4 байта. Вот шаблон, который нам нужно будет заполнить:
Подготовим наше двоичное число к заполнению по этому шаблону. Для этого разобьем его справа налево на те же группы: 3—6—6—6 символов:
Теперь подставим эти значения в наш четырёхбитный шаблон:
И переведём в шестнадцатеричную систему счисления:
Получается, что символ 𐍈 закодируется в четырёх байтах как F0 90 8D 88.
Почему нельзя просто всё кодировать одинаковым количеством бит
Можно, причём так часто делают в некоторых системах. Для этого там используют кодировки UTF-16 и UTF-32 — в них на каждый символ отводится сразу 2 или 4 байта.
Для этого там используют кодировки UTF-16 и UTF-32 — в них на каждый символ отводится сразу 2 или 4 байта.
Проблема такого подхода в том, что это увеличивает объём памяти, нужный для хранения данных. Проще говоря, те символы, на которых в UTF-8 хватило бы одного байта, здесь занимают в 2–4 раза больше.
С другой стороны, такие кодировки иногда проще в обработке, поэтому их, например, используют как штатные кодировки операционных систем. Так, UTF-16 — стандартная кодировка файловой системы NTFS в Windows.
У меня большая флешка, но на неё не влезают большие файлы. Почему?
Проблемы с безопасностью
Так как Юникод с помощью UTF-8 сам преобразует символы в последовательность байтов и наоборот, есть ситуации, когда это может навредить системе и привести к взлому.
Например, пользователю могут прислать файл, который называется otchetexe. txt — кажется, что это обычный текстовый файл, который можно смело открывать. Но на самом деле файл называется otchet[U+202E]txt.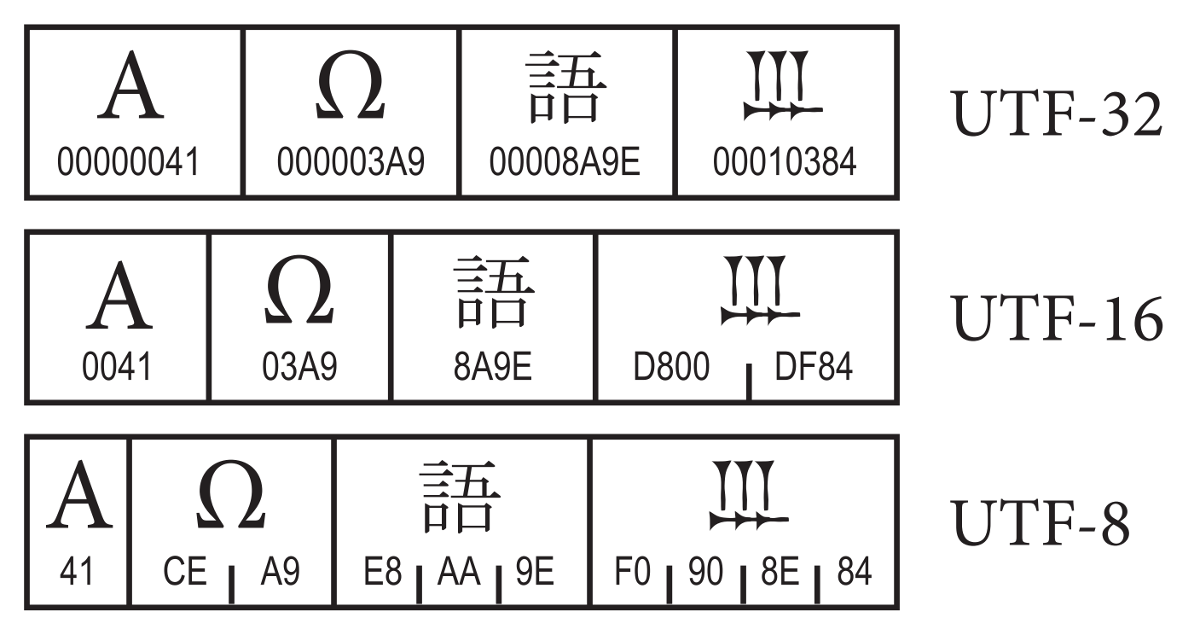 exe, а U+202E — это специальный юникод-символ, который включает написание справа налево. После того как Юникод встречает этот символ, он выводит всё написанное после него в обратном порядке. Так простой текстовый файл превращается в исполняемый .exe-файл для Windows. Если его запустить с правами администратора, он может натворить много всякого.
exe, а U+202E — это специальный юникод-символ, который включает написание справа налево. После того как Юникод встречает этот символ, он выводит всё написанное после него в обратном порядке. Так простой текстовый файл превращается в исполняемый .exe-файл для Windows. Если его запустить с правами администратора, он может натворить много всякого.
Как устроены файлы
Ещё пример — использование Юникода в разных SQL- и PHP-запросах. Из-за сложных преобразований может произойти переполнение стека — а этим уже могут воспользоваться злоумышленники, чтобы внедрить нужный код для выполнения.
На самом деле Юникод с этой точки зрения — большая дыра в безопасности любой системы, поэтому при работе с ним в критичных ситуациях используют белые списки, то есть те символы, которые использовать безопасно.
Текст:
Михаил Полянин
Редактор:
Максим Ильяхов
Художник:
Алексей Сухов
Корректор:
Ирина Михеева
Вёрстка:
Кирилл Климентьев
Соцсети:
Виталий Вебер
Что такое UTF-8?
UTF-8 — это формат преобразования Unicode, в котором для представления символа используются 8-битные блоки.

Символы здесь относятся к буквам алфавита, числам и числовым значениям, знакам препинания, специальным символам (валюты, математические символы, эмодзи…).
С 2009 года UTF-8 является доминирующей кодировкой (любой, а не только кодировки Unicode) для Интернета, и по состоянию на март 2020 года на ее долю приходится 95,0% всех веб-страниц. UTF-8 превзошла все остальные кодировки в 2008 г. и более 60% Интернета в 2012 г.
Кодировка символов
Кодировка символов является обязательной информацией для всех, кто планирует создавать контент за пределами языков, использующих основные символы латинского алфавита. Кодировка символов относится к правильной читаемости символов в тексте пользователями, машинами и поисковыми системами.
Компьютеры хранят символы как одиночные или сгруппированные байты. Кодировка символов — это способ правильного отображения этих байтов (символов).
Важно различать шрифты и кодировка символов — хотя у вас может быть правильная кодировка символов, выбранный шрифт может не отображать правильный символ, а вместо этого предлагать нечитаемые значки, такие как пустые квадраты, вопросительные знаки и т. д.
д.
ASCII основы
В начале был ASCII — американский стандартный код для обмена информацией. ASCII — это стандарт кодирования символов для цифровой связи. ASCII включает в себя основные символы, знаки препинания, цифры и буквы, которые присутствуют в английском алфавите.
Однако по мере того, как Интернет расширялся от основ английского языка, миллиарды пользователей почти не использовали латинские символы для доступа к соответствующему контенту, и на смену ASCII пришла новая кодировка символов.
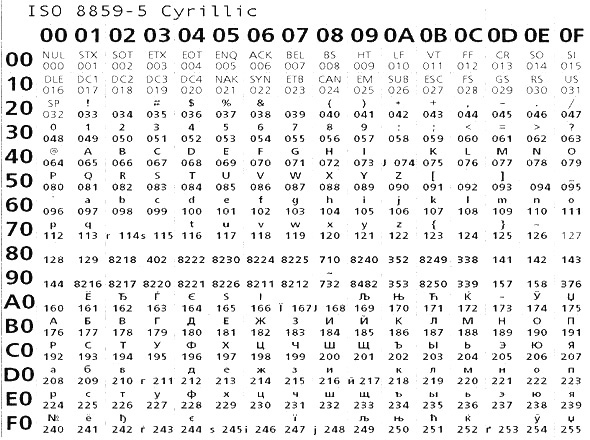
Полезно знать, что первые 256 кодовых точек (уникальные числа для каждого символа) ASCII, ISO-8859 и UTF-8 идентичны. Хотя ISO-8859 охватывает большинство языков, использующих арабскую письменность, UTF-8 еще больше расширяется и охватывает большинство живых языков и письменностей в мире.
Если вы еще не думали о своей целевой аудитории (текущей и будущей), самое время это сделать.
Что такое UTF-8?
Формат преобразования UTF-8 или Unicode является расширением ASCII. UTF-8 кодирует кодовые точки от одного до четырех байтов.
UTF-8 кодирует кодовые точки от одного до четырех байтов.
Структура UTF-8:
Один байт : первые 128 символов (соответствующих символам ASCII).
Три байта : Включает другие символы для таких языков, как китайский, японский, корейский
Четыре байта : Включает исторические сценарии, математические символы и эмодзи.
Совместима ли UTF-8 с ASCII?
Коды UTF-8 для стандартных символов ASCII соответствуют. Это делает UTF-8 идеальной для обратной совместимости с существующим текстом ASCII. Однако имейте в виду, что UTF-8 и UTF-16 не так совместимы.
В целом, UTF-8 доминирует в Интернете и является рекомендуемой кодировкой, начиная с HTML5.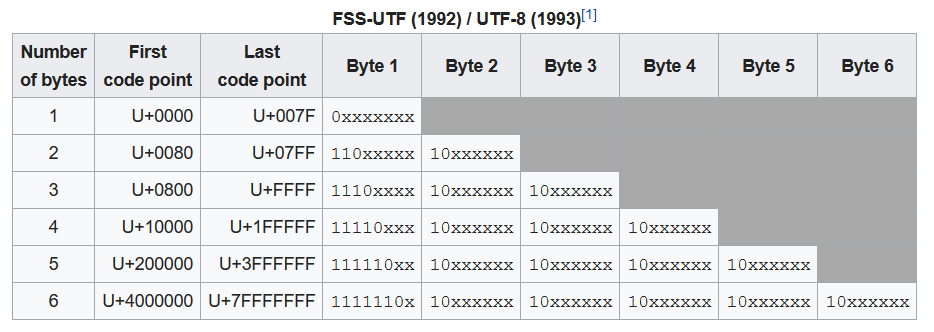
Почему это важно для вас?
Поскольку HTML-страница может быть только в одной кодировке, предпочтительнее использовать UTF-8. Он поддерживает множество языков и позволяет использовать разные языки на странице.
Поскольку все символы ASCII в UTF-8 имеют одинаковые байты, это также упрощает обратную совместимость. Кодировка
. В чем разница между UTF-8 и Unicode?
Мое объяснение после прочтения многочисленных постов и статей на эту тему:
«Юникод» — это гигантская таблица шириной 21 бит, эти 21 бит обеспечивают место для 1 114 112 кодовых точек / значений / полей / мест для хранения символов.
Из этих 1 114 112 кодовых точек 1 111 998 могут хранить символы Unicode, потому что 2048 кодовых точек зарезервированы как суррогаты, а 66 кодовых точек зарезервированы как несимволы. Итак, существует 1 111 998 кодовых точек, в которых можно хранить уникальный символ, символ, эмодзи и т. д.
Однако на данный момент было использовано только 144 697 из этих 1 114 112 кодовых точек. Эти 144 697 кодовых точек содержат символы, охватывающие все языки, а также символы, смайлики и т. д.
Эти 144 697 кодовых точек содержат символы, охватывающие все языки, а также символы, смайлики и т. д.
Каждому символу в «Юникоде» назначается определенная кодовая точка, также имеющая определенное значение / номер Юникода. Например, символ «❤» имеет следующее значение, также известное как номер Unicode «U+2764». Значение «U+2764» занимает ровно одну кодовую точку из 1 114 112 кодовых точек. Значение «U+2764» выглядит в двоичном виде так: «11100010 10011101 10100100», что составляет ровно 3 байта или 24 бита (без двух пробелов, каждый из которых занимает 1 бит, но я добавил их только для наглядности). , чтобы сделать 24-битные более читабельными, поэтому, пожалуйста, игнорируйте их).
Теперь, как наш компьютер должен знать, следует ли читать эти 3 байта «11100010 10011101 10100100» по отдельности или вместе? Если эти 3 байта прочитать отдельно, а затем преобразовать в символы, результатом будет «Ô, Ø, ñ», что довольно сильно отличается от нашего сердечного смайлика «❤».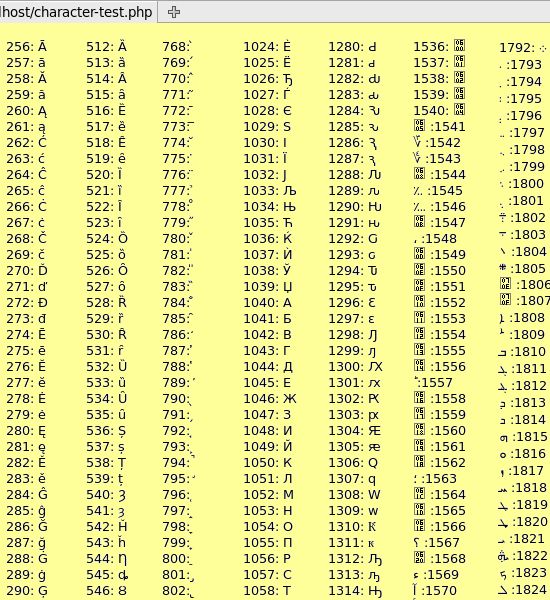
Чтобы решить эту проблему, люди изобрели стандарты кодирования. Наиболее популярным является UTF-8 с 2008 года. UTF-8 составляет в среднем 97,6% всех веб-страниц, поэтому мы будем использовать UTF-8 для примера ниже.
2.1 — Что такое кодирование?
Кодирование, просто говоря, означает преобразование чего-то из одного в другое. В нашем случае мы конвертируем данные, точнее байты в формат UTF-8, Я также хотел бы перефразировать это предложение как «преобразование байтов в байты UTF-8», хотя это может быть технически неправильно.
2.2 Немного информации о формате UTF-8 и почему он так важен
UTF-8 использует минимум 1 байт для хранения символа и максимум 4 байта. Благодаря формату UTF-8 у нас могут быть символы, занимающие более 1 байта информации.
Это очень важно, потому что если бы не формат UTF-8, у нас не было бы такого огромного разнообразия алфавитов, так как буквы некоторых алфавитов не помещаются в 1 байт, Мы бы тоже вообще не иметь смайликов, так как каждый требует не менее 3 байтов. Я почти уверен, что вы уже поняли суть, так что давайте продолжим.
Я почти уверен, что вы уже поняли суть, так что давайте продолжим.
2.3 Пример кодирования китайского символа в UTF-8
Теперь предположим, что у нас есть китайский символ «汉».
Этот символ занимает ровно 16 двоичных битов «01101100 01001001», таким образом, как мы обсуждали выше, мы не можем прочитать этот символ, если мы не закодируем его в UTF-8, потому что компьютер не сможет узнать, если эти 2 байта следует читать по отдельности или вместе.
Преобразование 2 байтов этого символа «汉» в байты, как мне нравится называть это UTF-8, приведет к следующему: 10110001 10001001″
Итак, как мы получили 3 байта вместо 2? Как это должно быть кодировкой UTF-8, превращающей 2 байта в 3?
Чтобы объяснить, как работает кодировка UTF-8, я буквально скопирую ответ @MatthiasBraun, большое спасибо ему за его потрясающее объяснение.
2.4 Как на самом деле работает кодировка UTF-8?
Здесь у нас есть шаблон для кодирования байтов в UTF-8.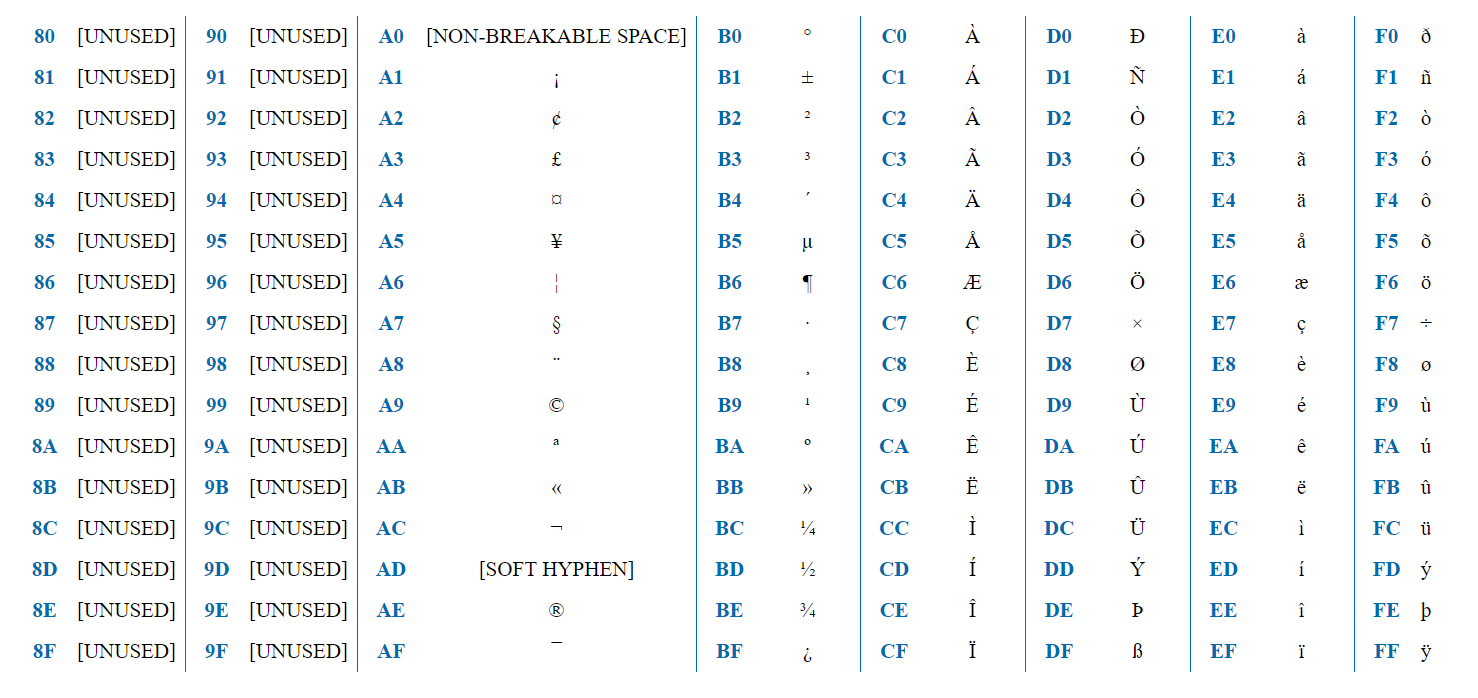 Вот как происходит кодирование, довольно увлекательно, если вы спросите меня!
Вот как происходит кодирование, довольно увлекательно, если вы спросите меня!
Теперь внимательно посмотрите на таблицу ниже, и мы пройдемся по ней вместе.
Двоичный формат байтов в последовательности:
1-й байт 2-й байт 3-й байт 4-й байт Количество свободных битов Максимальное выражаемое значение Unicode
0xxxxxxx 7 007F шестнадцатеричный (127)
110xxxxx 10xxxxxx (5+6)=11 07FF hex (2047)
1110xxxx 10xxxxxx 10xxxxxx (4+6+6)=16 FFFF hex (65535)
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (3+6+6+6)=21 10FFFF hex (1 114 111)
Символы «x» в приведенной выше таблице обозначают количество «Свободных Bits», эти биты пусты, и мы можем в них писать.
Остальные биты зарезервированы для формата UTF-8, они используются как заголовки/маркеры. Благодаря этим заголовкам, когда байты читать с использованием кодировки UTF-8, компьютер знает, какие байты читать вместе, а какие по отдельности.
Размер вашего символа в байтах после кодирования в формате UTF-8, зависит от того, сколько бит вам нужно записать.
В нашем случае символ «汉» занимает ровно 2 байта или 16 бит:
«01101100 01001001»
таким образом, размер нашего символа после кодирования в UTF-8 будет 3 байта или 24 бита
«11100110 10110001 10001001»
, потому что «3 байта UTF-8» имеют 16 свободных битов, которые мы можем записать в
- Решение, шаг за шагом ниже:
2.5 Решение:
Заполнитель заголовка Заполните наш двоичный результат
1110 хххх 0110 11100110
10 хххххх 110001 10110001
10 хххххх 001001 10001001
2.6 Сводка:
Китайский иероглиф: 汉
его значение Юникода: U+6C49
преобразовать 6C49 в двоичный код: 01101100 01001001
кодировать 6C49 как UTF-8: 11100110 10110001 10001001
Оригинальное объяснение разницы между кодировками UTF-8, UTF-16 и UTF-32:
https://javarevisited.