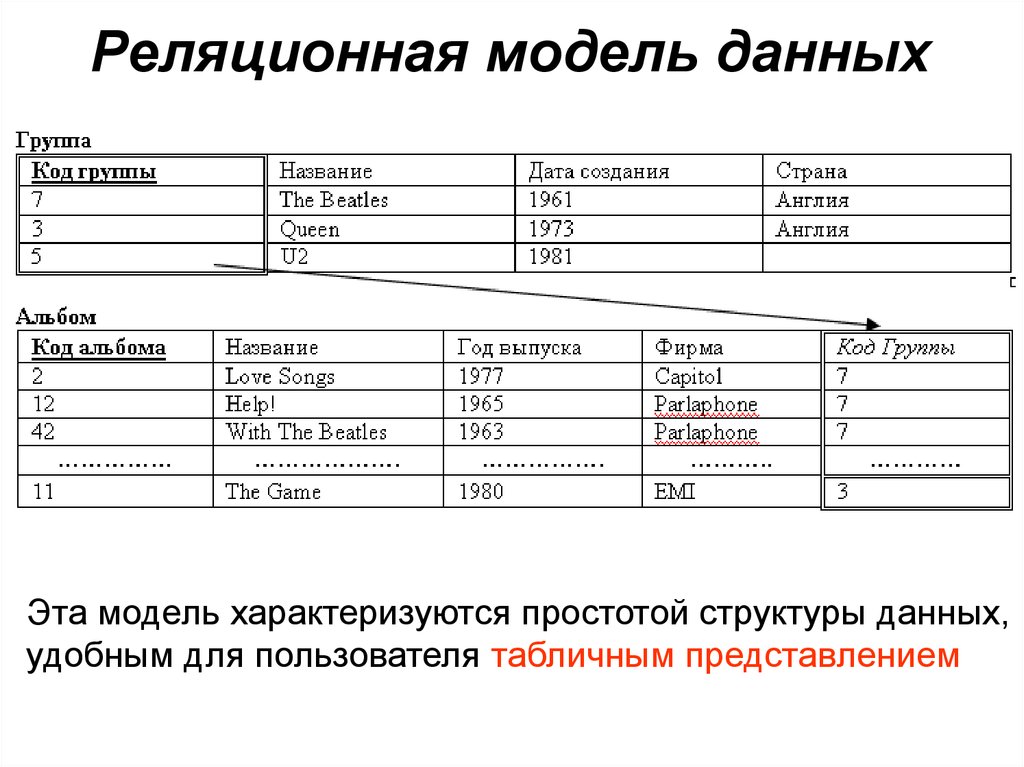
Что такое реляционная база данных? – Amazon Web Services (AWS)
Реляционная база данных – это набор данных с предопределенными связями между ними. Эти данные организованны в виде набора таблиц, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных. В каждом столбце таблицы хранится определенный тип данных, в каждой ячейке – значение атрибута. Каждая стока таблицы представляет собой набор связанных значений, относящихся к одному объекту или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки из нескольких таблиц могут быть связаны с помощью внешних ключей. К этим данным можно получить доступ многими способами, и при этом реорганизовывать таблицы БД не требуется.
6:44
Understanding Amazon Relational Database Service (RDS)SQL (Structured Query Language) – основной интерфейс работы с реляционными базами данных.
Целостность данных
Целостность данных – это полнота, точность и единообразие данных. Для поддержания целостности данных в реляционных БД используется ряд инструментов. В их число входят первичные ключи, внешние ключи, ограничения «Not NULL», «Unique», «Default» и «Check». Эти ограничения целостности позволяют применять практические правила к данным в таблицах и гарантировать точность и надежность данных. Большинство ядер БД также поддерживает интеграцию пользовательского кода, который выполняется в ответ на определенные операции в БД.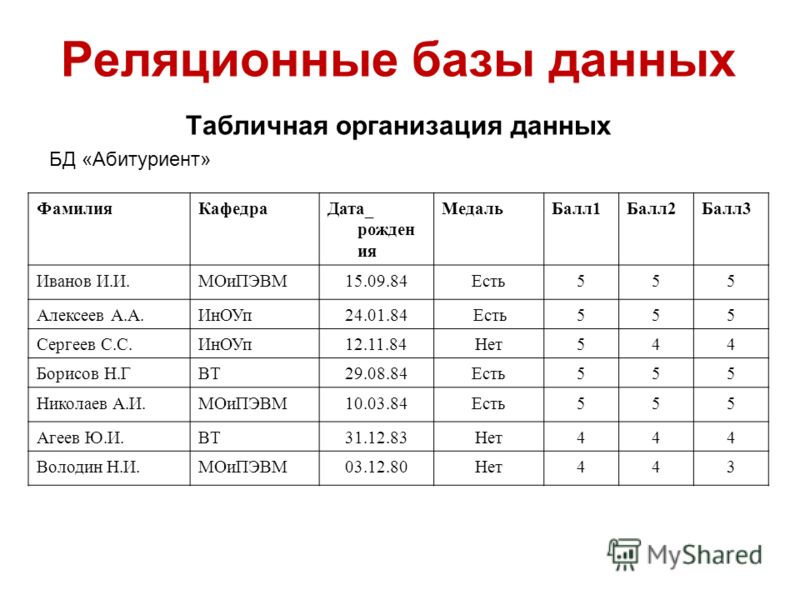
Транзакции
Транзакция в базе данных – это один или несколько операторов SQL, выполненных в виде последовательности операций, представляющих собой единую логическую задачу. Транзакция представляет собой неделимое действие, то есть она должна быть выполнена как единое целое и либо должна быть записана в базу данных целиком, либо не должен быть записан ни один из ее компонентов. В терминологии реляционных баз данных транзакция завершается либо действием COMMIT, либо ROLLBACK. Каждая транзакция рассматривается как внутренне связный, надежный и независимый от других транзакций элемент.
Соответствие требованиям ACID
Для соблюдения целостности данных все транзакции в БД должны соответствовать требованиям ACID, то есть быть атомарными, единообразными, изолированными и надежными.
Атомарность – это условие, при котором либо транзакция успешно выполняется целиком, либо, если какая-либо из ее частей не выполняется, вся транзакция отменяется.
Amazon Aurora
Amazon Aurora – это совместимое с MySQL и PostgreSQL ядро реляционной БД, совмещающее в себе скорость и доступность сложных коммерческих БД с простотой и экономичностью баз данных с открытым исходным кодом. Производительность Amazon Aurora в пять раз выше, чем производительность MySQL. Сервис обеспечивает безопасность, доступность и надежность на уровне коммерческой базы данных, а стоит в десять раз меньше. Подробнее »
Oracle
С помощью Amazon RDS можно за считаные минуты выполнить экономичное развертывание различных версий баз данных Oracle с настраиваемой мощностью аппаратных ресурсов.
Microsoft SQL Server
Amazon RDS for SQL Server упрощает настройку, эксплуатацию и масштабирование SQL Server в облаке. Поддерживается развертывание разных версий SQL Server, включая Express, Web, Standard и Enterprise. Amazon RDS for SQL Server обеспечивает непосредственный доступ к встроенным возможностям SQL Server, поэтому существующие приложения и инструменты будут работать без изменений. Подробнее »
MySQL – это СУБД с открытым исходным кодом, используемая для многих интернет-приложений. Amazon RDS для MySQL предоставляет доступ к возможностям уже знакомого движка БД MySQL. Это означает, что код, приложения и инструменты, которые применяются с существующими базами данных, можно использовать с сервисом Amazon RDS без каких-либо изменений.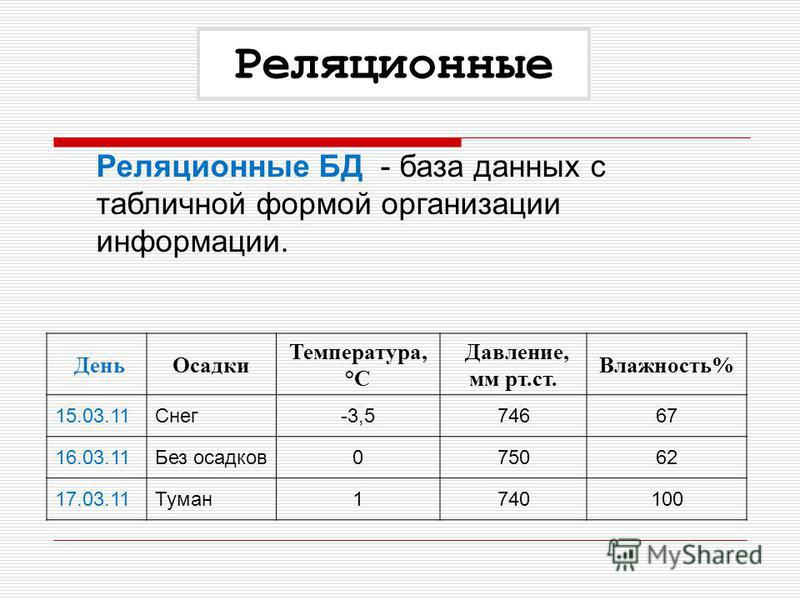 Подробнее »
Подробнее »
PostgreSQL
PostgreSQL – это мощная объектно-реляционная СУБД корпоративного класса с отрытым исходным кодом, ориентированная на соответствие стандартам и возможность расширения. PostgreSQL отличается широким набором мощных функций и выполняет сохраненные процедуры более чем на 12 языках, включая Java, Perl, Python, Ruby, Tcl, C/C++ и собственный язык PL/pgSQL, аналог PL/SQL от Oracle. Подробнее »
MariaDB
MariaDB – это совместимое с MySQL ядро БД, ответвление MySQL, разработанное под руководством разработчиков оригинальной версии MySQL. Amazon RDS упрощает настройку, эксплуатацию и масштабирование развертываний MariaDB в облаке. С помощью Amazon RDS можно всего за несколько минут выполнить экономичное развертывание масштабируемых баз данных MariaDB с возможностью настройки объема аппаратных ресурсов. Подробнее »
Начать работу с Amazon RDS очень просто. Воспользуйтесь нашим Руководством по началу работы для создания первого инстанса Amazon RDS с помощью нескольких щелчков мышью.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
Что такое реляционная база данных
Реляционные базы данных представляют собой базы данных, которые используются для хранения и предоставления доступа к взаимосвязанным элементам информации. Реляционные базы данных основаны на реляционной модели — интуитивно понятном, наглядном табличном способе представления данных. Каждая строка, содержащая в таблице такой базы данных, представляет собой запись с уникальным идентификатором, который называют ключом. Столбцы таблицы имеют атрибуты данных, а каждая запись обычно содержит значение для каждого атрибута, что дает возможность легко устанавливать взаимосвязь между элементами данных.
Лучшая РСУБД в отрасли
Пример реляционной базы данных
В качестве примера рассмотрим две таблицы, которые небольшое предприятие использует для обработки заказов продукции.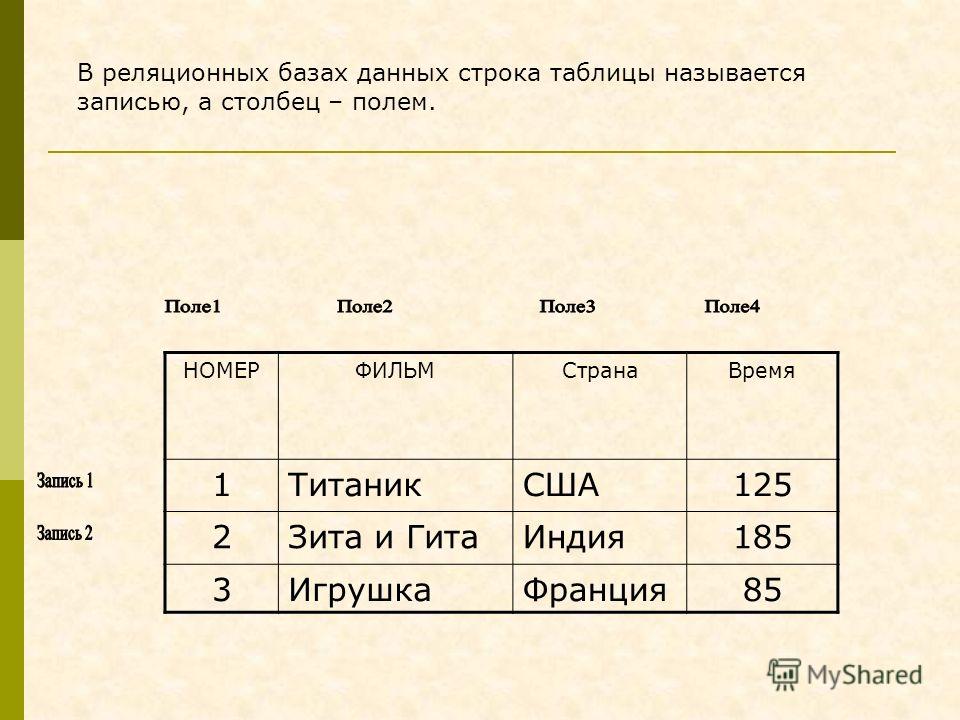 Первая таблица содержит информацию о заказчиках: каждая запись в ней включает в себя имя и адрес заказчика, платежные данные и информацию о доставке, номер телефона и т. д. Каждый элемент информации (атрибут) помещен в отдельный столбец базы данных, которому назначен уникальный идентификатор (ключ) для каждой строки. Во второй таблице (с информацией о заказе) каждая запись содержит идентификатор заказчика, совершившего заказ, название заказанного продукта, его количество, размер или цвет и т. д. Записи в этой таблице не содержат таких данных, как имя заказчика или его контактные данные.
Первая таблица содержит информацию о заказчиках: каждая запись в ней включает в себя имя и адрес заказчика, платежные данные и информацию о доставке, номер телефона и т. д. Каждый элемент информации (атрибут) помещен в отдельный столбец базы данных, которому назначен уникальный идентификатор (ключ) для каждой строки. Во второй таблице (с информацией о заказе) каждая запись содержит идентификатор заказчика, совершившего заказ, название заказанного продукта, его количество, размер или цвет и т. д. Записи в этой таблице не содержат таких данных, как имя заказчика или его контактные данные.
У обеих таблиц есть только один общий элемент — идентификатор столбца (ключ). Благодаря наличию этого общего столбца реляционные базы данных могут устанавливать взаимосвязи между двумя таблицами. Когда приложение для обработки заказов передает заказ в базу данных, база данных обращается к таблице со сведениями о заказах, извлекает сведения о продукции и использует идентификатор заказчика из этой таблицы чтобы найти сведения об оплате и доставке в таблице с информацией о нем.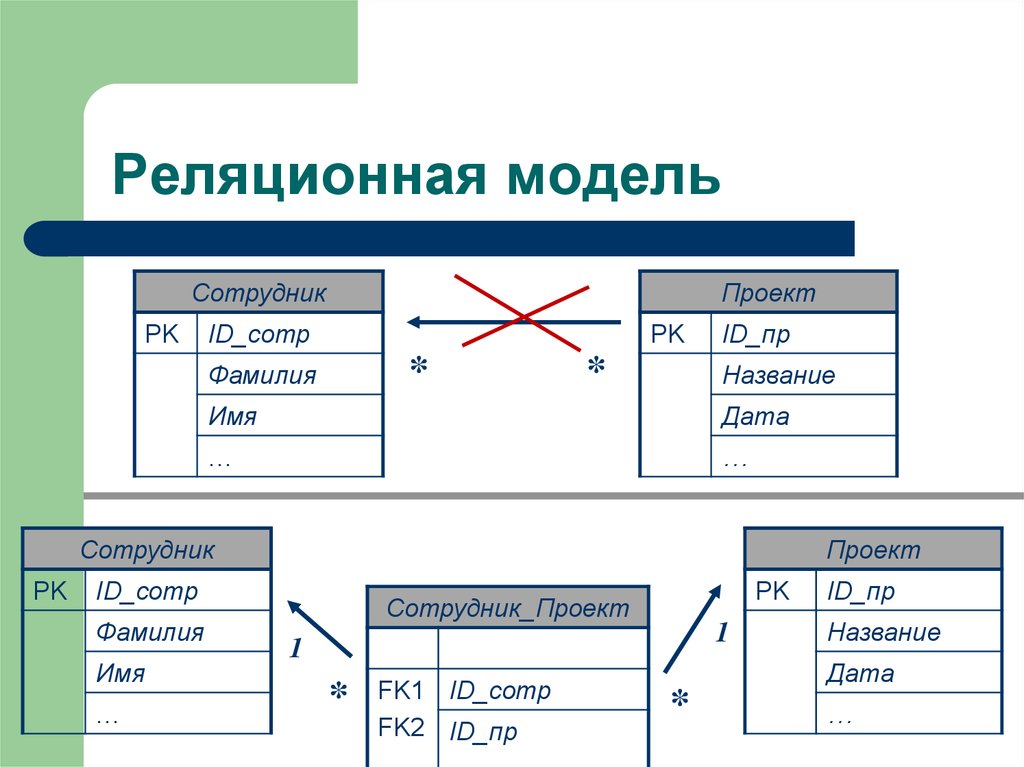
Структура реляционных баз данных
Реляционная модель подразумевает логическую структуру данных: таблицы, представления и индексы. Логическая структура отличается от физической структуры хранения. Такое разделение дает возможность администраторам управлять физической системой хранения, не меняя данных, содержащихся в логической структуре. Например, изменение имени файла базы данных не повлияет на хранящиеся в нем таблицы.
Разделение между физическим и логическим уровнем распространяется в том числе на операции, которые представляют собой четко определенные действия с данными и структурами базы данных. Логические операции дают возможность приложениям определять требования к необходимому содержанию, в то время как физические операции определяют способ доступа к данным и выполнения задачи.
Чтобы обеспечить точность и доступность данных, в реляционных базах должны соблюдаться определенные правила целостности.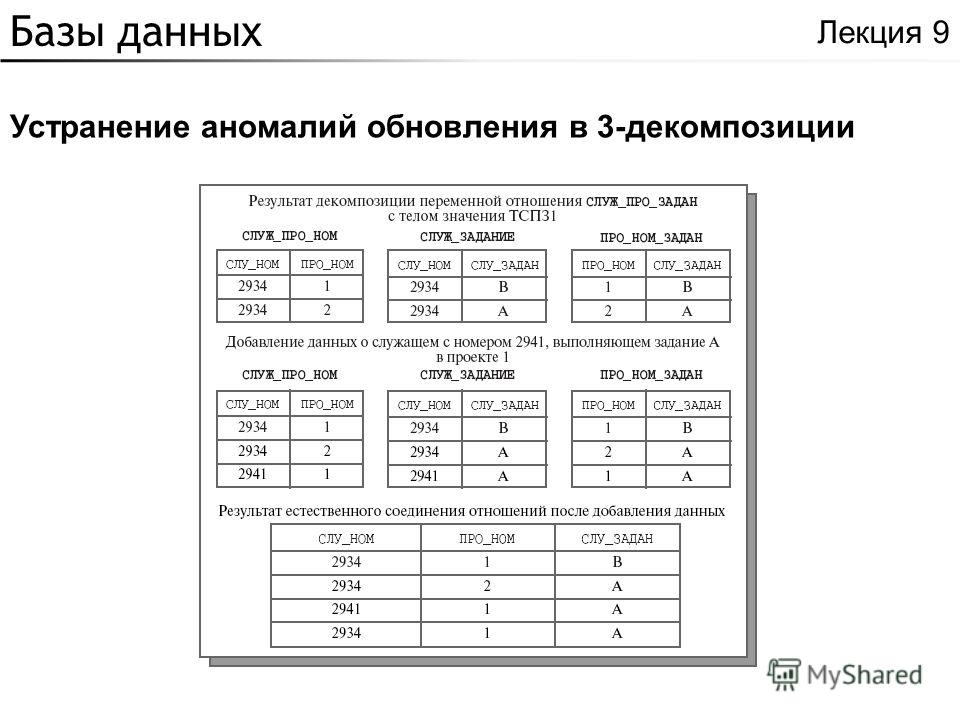 Например, в правилах целостности можно запретить использование дубликатов строк в таблицах, чтобы устранить вероятность попадания неправильной информации в базу данных.
Например, в правилах целостности можно запретить использование дубликатов строк в таблицах, чтобы устранить вероятность попадания неправильной информации в базу данных.
Реляционная модель
В первых базах данных данные каждого приложения хранились в отдельной уникальной структуре. Если разработчик хотел создать приложение для использования таких данных, он должен был хорошо знать конкретную структуру, чтобы найти необходимые данные. Такой метод организации был неэффективен, сложен в обслуживании и затруднял оптимизацию эффективности приложений. Реляционная модель была разработана, чтобы устранить потребность в использовании разнообразных структур данных.
Она обеспечила стандартный способ представления данных и отправки запросов, которые могли быть использованы в любых приложениях. Разработчики уяснили, что таблицы являются ключевым преимуществом реляционных баз данных, так как обеспечивают интуитивно понятный, эффективный и гибкий способ хранения структурированной информации и получения к ней доступа.
Со временем, когда разработчики стали использовать язык структурированных запросов (SQL) для записи данных в базу и отправки запросов, стало очевидным и другое преимущество реляционной модели. Вот уже на протяжении многих лет SQL широко используется в качестве языка запросов в базах данных. Он основан на алгоритмах реляционной алгебры и четкой математической структуре, что обеспечивает простоту и эффективность при оптимизации любых запросов к базе данных. Для сравнения: при использовании других подходов приходится создавать отдельные, уникальные запросы.
Преимущества системы управления реляционными базами данных
Компании всех типов и размеров используют простую, но функциональную реляционную модель для обслуживания разнообразных информационных потребностей. Реляционные базы данных применяются для отслеживания товарных запасов, обработки торговых транзакций через Интернет, управления большими объемами критически важных данных заказчиков и т. д. Реляционные базы данных можно рекомендовать для обслуживания любых информационных потребностей, где элементы данных связаны между собой и необходимо обеспечивать безопасное и надежное управление ими на основе правил целостности.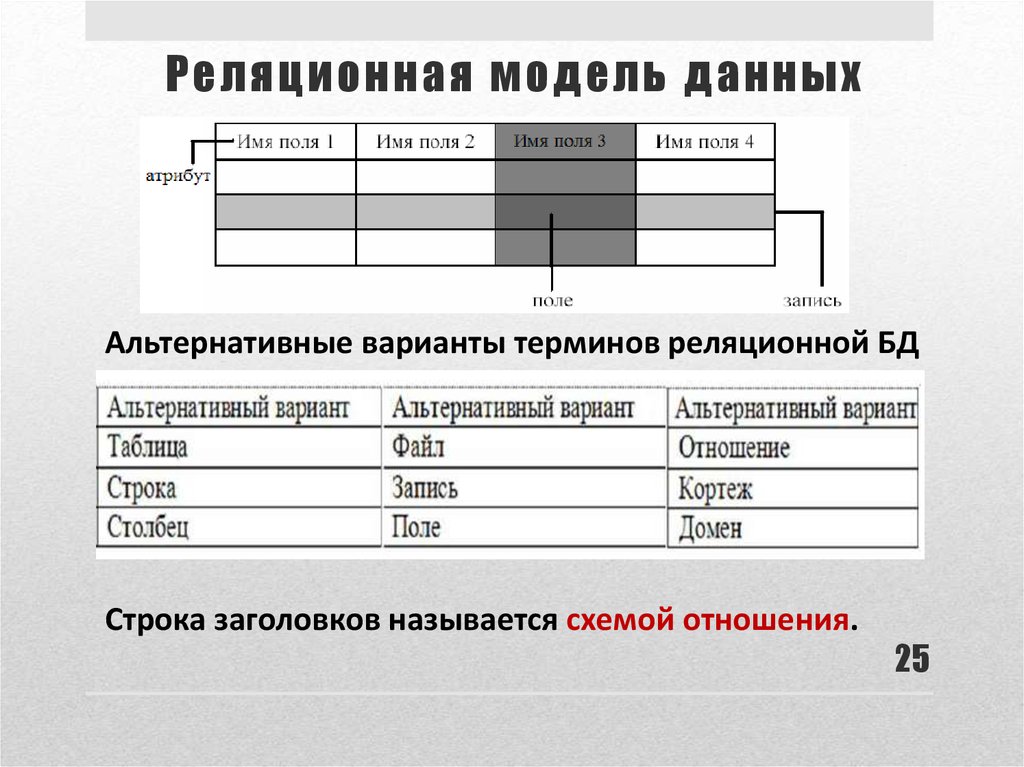
Реляционные базы данных появились в 1970-х годах. На сегодняшний день преимущества реляционного подхода сделали его самой распространенной моделью для баз данных в мире.
Реляционная модель и согласованность данных
Реляционная модель наиболее эффективно поддерживает целостность данных во всех приложениях и копиях (экземплярах) базы данных. Например, когда заказчик кладет деньги на счет с помощью банкомата, а затем проверяет баланс на мобильном телефоне, он ожидает, что поступившие средства сразу же отобразятся на счете. Реляционные базы данных отлично подходят для обеспечения целостности данных в различных экземплярах базы в одно и то же время.
Другие типы баз данных не могут одновременно поддерживать целостность больших объемов данных. Некоторые современные типы баз данных, такие как NoSQL, обеспечивают только так называемую окончательную целостность. Это значит, что, когда выполняется масштабирование данных или несколько пользователей одновременно используют одни и те же данные, необходимо некоторое время на внесение изменений. В некоторых случаях окончательная целостность вполне приемлема (например, для обновления позиций в товарном каталоге), однако для критически важной операционной деятельности бизнеса (например, транзакций с использованием корзины) реляционные базы представляют собой фундаментальный стандарт.
В некоторых случаях окончательная целостность вполне приемлема (например, для обновления позиций в товарном каталоге), однако для критически важной операционной деятельности бизнеса (например, транзакций с использованием корзины) реляционные базы представляют собой фундаментальный стандарт.
Фиксация изменений и атомарность
В реляционных базах данных используются очень детальные и строгие бизнес-правила и политики в отношении фиксации изменений в базе данных (то есть сохранения изменений в данных на постоянной основе). Рассмотрим для примера складскую базу данных, в которой отслеживаются три запчасти, всегда использующиеся в комплекте. Когда одну из них извлекают из товарных запасов, две другие также должны извлекаться. Если одна из трех запчастей недоступна, две другие также не могут быть проданы отдельно, то есть, чтобы в базу данных можно было внести изменения, должны быть доступны все три запчасти. Реляционная база данных не разрешит сохранять изменения, если они не касаются всех трех запчастей. Эту особенность реляционных баз данных называют атомарностью или неразрывностью. Неразрывность необходима для сохранения точности данных в базе и обеспечения соответствия с правилами, нормативными положениями и бизнес-политиками.
Эту особенность реляционных баз данных называют атомарностью или неразрывностью. Неразрывность необходима для сохранения точности данных в базе и обеспечения соответствия с правилами, нормативными положениями и бизнес-политиками.
Свойства ACID и РСУБД
Транзакции реляционных баз данных определяются четырьмя основными свойствами: атомарность, согласованность, изоляция и долговечность, которые обычно обозначаются аббревиатурой ACID.
- Неразрывность определяет все элементы, которые необходимы для совершения транзакции в базе данных.
- Согласованность или целостность определяет правила сохранения состояния данных после выполнения транзакции.
- Изолированность гарантирует, что во избежание путаницы транзакция не повлияет на другие элементы до окончательного сохранения изменений.
- Неизменность обеспечивает неизменность данных после сохранения изменений в результате транзакции.
Хранимые процедуры и реляционные базы данных
Доступ к данным включает в себя множество повторяющихся действий.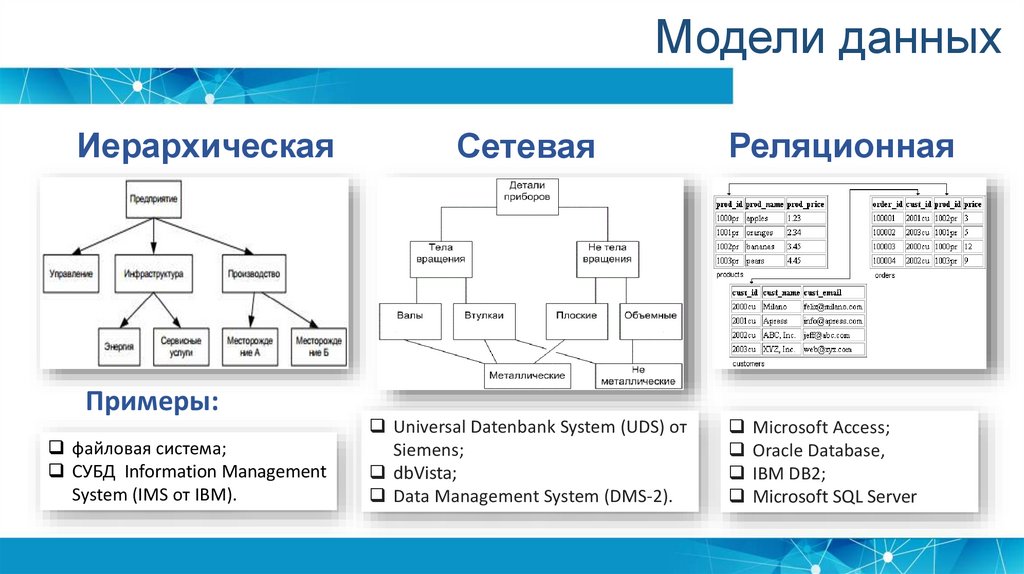 Например, иногда для получения нужного результата простой запрос для получения информации из таблицы необходимо повторить сотню или тысячу раз. Для таких сценариев доступа к базе данных необходимо что-то вроде программного кода. Разработчикам каждый раз писать стандартный код доступа к данным для нового приложения было бы утомительно. К счастью, реляционные базы данных поддерживают хранимые процедуры, представляющие собой блоки кода, к которым можно получить доступ с помощью обычного вызова со стороны кода приложения. Например, одну и ту же хранимую процедуру можно использовать для последовательной маркировки записей в целях удобства пользователей для различных приложений. Хранимые процедуры также помогают разработчикам убедиться в правильной реализации определенных функций данных в приложении.
Например, иногда для получения нужного результата простой запрос для получения информации из таблицы необходимо повторить сотню или тысячу раз. Для таких сценариев доступа к базе данных необходимо что-то вроде программного кода. Разработчикам каждый раз писать стандартный код доступа к данным для нового приложения было бы утомительно. К счастью, реляционные базы данных поддерживают хранимые процедуры, представляющие собой блоки кода, к которым можно получить доступ с помощью обычного вызова со стороны кода приложения. Например, одну и ту же хранимую процедуру можно использовать для последовательной маркировки записей в целях удобства пользователей для различных приложений. Хранимые процедуры также помогают разработчикам убедиться в правильной реализации определенных функций данных в приложении.
Блокировки базы данных и параллельный доступ
Когда несколько пользователей или приложений пытаются одновременно изменить одни и те же данные, это может вести к возникновению конфликта в базе. Блокировки и параллельный доступ снижают вероятность конфликтов и способствуют сохранению целостности данных.
Блокировки и параллельный доступ снижают вероятность конфликтов и способствуют сохранению целостности данных.
Блокировка не разрешает другим пользователям и приложениям получать доступ к данным во время их обновления. В некоторых базах данных блокировка может применяться к целой таблице, что негативно отражается на эффективности приложения. В других типах баз данных, например реляционных базах Oracle, блокировка выполняется на уровне одной записи, оставляя другие записи в таблице доступными. Такой подход помогает сохранить эффективность приложения.
Инструмент параллельного доступа используется, когда несколько пользователей или приложений пытаются одновременно выполнить запросы к одной базе данных. Он обеспечивает доступ пользователей и приложений к базе данных в соответствии с политиками контроля.
Характеристики, на которые следует обратить внимание при выборе реляционной базы данных
Программное обеспечение, которое используется для сохранения, контроля и извлечения данных в базе, а также выполнения к ней запросов, называют системой управления реляционной базой данных (РСУБД). РСУБД обеспечивает интерфейс между пользователями и приложениями и базой данных, а также административные функции для управления хранением данных, их эффективностью и доступом к ним.
При выборе типа базы данных и продуктов на основе реляционных баз данных необходимо учитывать несколько факторов. Выбор РСУБД зависит от потребностей Вашей компании. Задайте себе следующие вопросы.
- Каковы наши требования к точности данных? Будем ли мы использовать бизнес-логику для хранения и обеспечения точности данных? Предъявляются ли к нашим данным более строгие требования в отношении точности (например, если Вы работаете с финансовыми данными и отчетностью)?
- Нужна ли нам масштабируемость? Какими объемами данных требуется управлять и каков прогнозируемый рост этих объемов? Должна ли модель базы данных поддерживать зеркальные копии (как отдельные экземпляры) в целях масштабирования? Если да, сможем ли мы обеспечивать целостность данных в этих экземплярах?
- Насколько важно наличие параллельного доступа? Потребуется ли пользователям и приложениям одновременный доступ к данным? Поддерживает ли ПО базы данных параллельный доступ без ущерба для безопасности?
- Каковы наши потребности в эффективности и надежности баз данных? Требуется ли нам высокоэффективная и надежная система? Каковы требования к скорости выполнения запросов? Какие гарантии дает поставщик услуг в соответствии с соглашением об уровне обслуживания (SLA) или на случай незапланированного простоя?
Реляционная база данных будущего: автономная база данных
На протяжении лет реляционные базы данных улучшали производительность, надежность и безопасность и становились проще в обслуживании.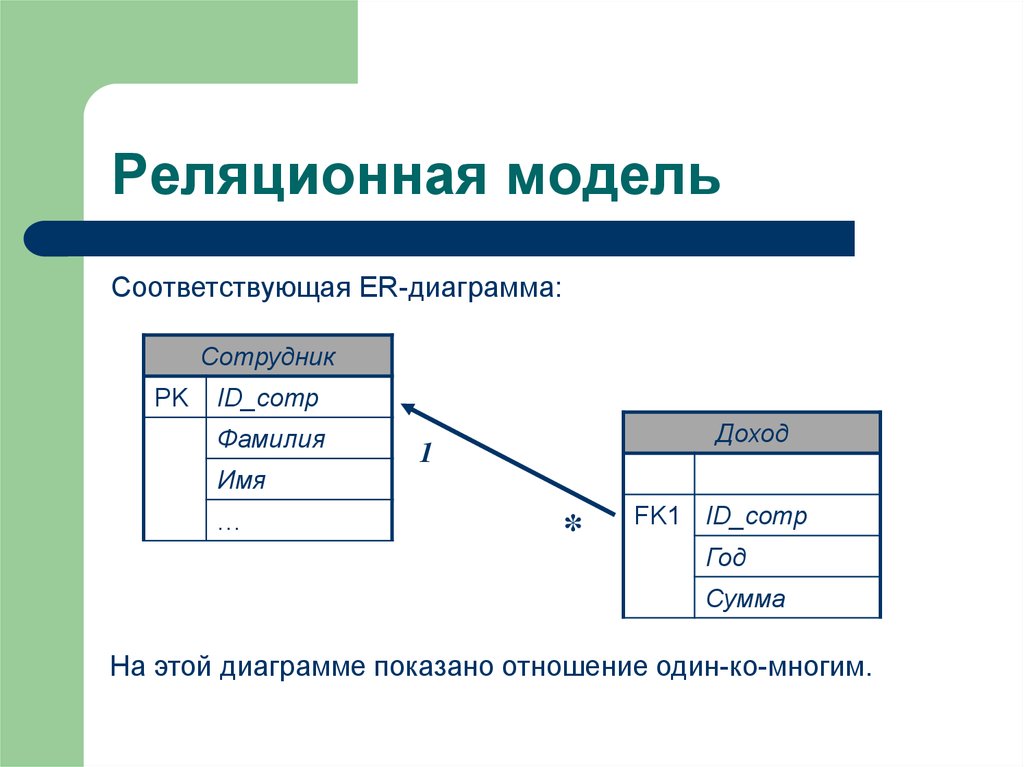 Однако их структура становилась все более сложной, и, как следствие, администрирование такой базы данных начало требовать немалых усилий. Вместо того чтобы использовать свои навыки для разработки инновационных приложений, которые будут приносить прибыль организации, разработчики вынуждены посвящать львиную долю времени на управление базой данных для оптимизации ее эффективности.
Однако их структура становилась все более сложной, и, как следствие, администрирование такой базы данных начало требовать немалых усилий. Вместо того чтобы использовать свои навыки для разработки инновационных приложений, которые будут приносить прибыль организации, разработчики вынуждены посвящать львиную долю времени на управление базой данных для оптимизации ее эффективности.
Сегодня автономные технологии используются, чтобы расширить возможности реляционной модели, технологии облачных баз данных и машинного обучения и создать реляционную базу данных нового типа. Самоуправляемая база данных (которую также называют автономной) сохраняет все преимущества и возможности реляционной модели и добавляет к ним средства на основе искусственного интеллекта, машинного обучения и автоматизации для мониторинга и оптимизации скорости выполнения запросов и управления. Например, чтобы улучшить скорость выполнения запросов, самоуправляемая база данных строит прогнозы и проверяет индексы, а затем применяет лучшие результаты на практике — и все это без участия администратора. Самоуправляемые базы данных постоянно вносят такие улучшения в собственную работу без человеческого вмешательства.
Автономные технологии дают возможность разработчикам больше не тратить время на рутинные задачи обслуживания. Например, больше не нужно заблаговременно определять требования к инфраструктуре. При использовании самоуправляемой базы данных можно расширять системы хранения и добавлять вычислительные ресурсы по мере возникновения необходимости в них. Разработчики могут создавать автономные реляционные базы данных всего за несколько шагов, ускоряя процесс разработки приложений.
Подробнее о СУБД Oracle Database
Что такое реляционная база данных?
Как работают реляционные базы данных, как осуществляется управление ими с помощью систем управления реляционными базами данных
Что такое реляционная база данных?
Реляционные базы данных — это базы данных, предназначенные для хранения и организации точек данных с заданными отношениями для быстрого доступа.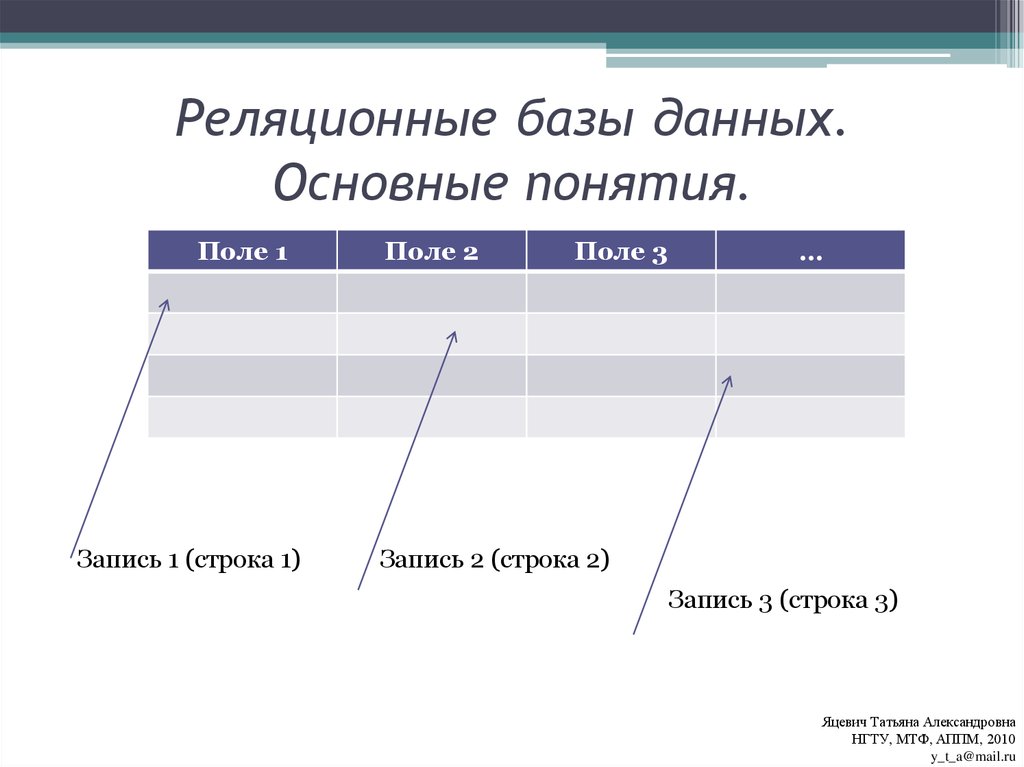 Данные в реляционных базах данных упорядочиваются в виде таблиц, которые содержат информацию о каждой сущности и представляют заданные заранее категории с помощью строк и столбцов. Такое структурирование данных повышает эффективность и гибкость доступа, поэтому реляционные базы данных — наиболее распространенный тип баз данных. Реляционные базы данных поддерживают язык SQL. Это стандартизированный язык программирования, применяемый для хранения, обработки и получения данных. В рамках SQL существует встроенный язык для создания таблиц (DDL — язык описания данных) и язык для обработки данных (DML — язык обработки данных).
Данные в реляционных базах данных упорядочиваются в виде таблиц, которые содержат информацию о каждой сущности и представляют заданные заранее категории с помощью строк и столбцов. Такое структурирование данных повышает эффективность и гибкость доступа, поэтому реляционные базы данных — наиболее распространенный тип баз данных. Реляционные базы данных поддерживают язык SQL. Это стандартизированный язык программирования, применяемый для хранения, обработки и получения данных. В рамках SQL существует встроенный язык для создания таблиц (DDL — язык описания данных) и язык для обработки данных (DML — язык обработки данных).
Что означает понятие «реляционный»? Это слово означает указание на отношение или наличие отношения. В контексте баз данных понятие «реляционный» относится главным образом к самим данным. Реляционные наборы данных обладают заранее заданными отношениями между собой. Например, база данных, содержащая сведения о клиентах компании, также может содержать данные об отдельных транзакциях, связанных с каждым счетом. Основное внимание в реляционных базах данных уделяется отношениям между хранящимися элементами данных.
Основное внимание в реляционных базах данных уделяется отношениям между хранящимися элементами данных.
Характеристики реляционных баз данных:
- Базы данных состоят из множества сущностей
- Стандартным интерфейсом является язык SQL
- Высокая структурированность, представление с помощью схемы (логической и физической)
- Снижение избыточности данных
Как работают реляционные базы данных
Реляционные базы данных обычно используют таблицы с данными, упорядоченными в виде строк (с сущностями) и столбцов (с атрибутами сущностей). Процесс упорядочения данных в таблицах называется нормализацией. Каждая строка содержит уникальный идентификатор или ключ, связывающий таблицы для установления отношения между ними. При отправке запроса к реляционной базе данных ключ используется для поиска связанных данных в разных наборах данных. Например, службе технической поддержки может потребоваться отслеживать взаимодействие клиентов по следующим характеристикам: тип проблемы, время решения проблемы, уровень удовлетворенности клиента. Все три характеристики объединяет идентификатор клиента: он позволяет создавать отношения и обеспечивает эффективную работу табличной структуры.
Например, службе технической поддержки может потребоваться отслеживать взаимодействие клиентов по следующим характеристикам: тип проблемы, время решения проблемы, уровень удовлетворенности клиента. Все три характеристики объединяет идентификатор клиента: он позволяет создавать отношения и обеспечивает эффективную работу табличной структуры.
Подробнее о базах данных
Примеры реляционных баз данных
Реляционные базы данных эффективны для любой информации, в которых точки данных связаны друг с другом и нуждаются в согласованном и безопасном управлении на основе правил. Именно поэтому такие базы данных чаще всего применяются коммерческими компаниями и предприятиями. Когда компании анализируют собственные данные, они применяют реляционные базы данных для получения аналитических данных. Отчеты, создаваемые коммерческими компаниями для отслеживания складских запасов, финансов, продаж или для подготовки прогнозов на будущее, во многих случаях создаются с помощью реляционных баз данных.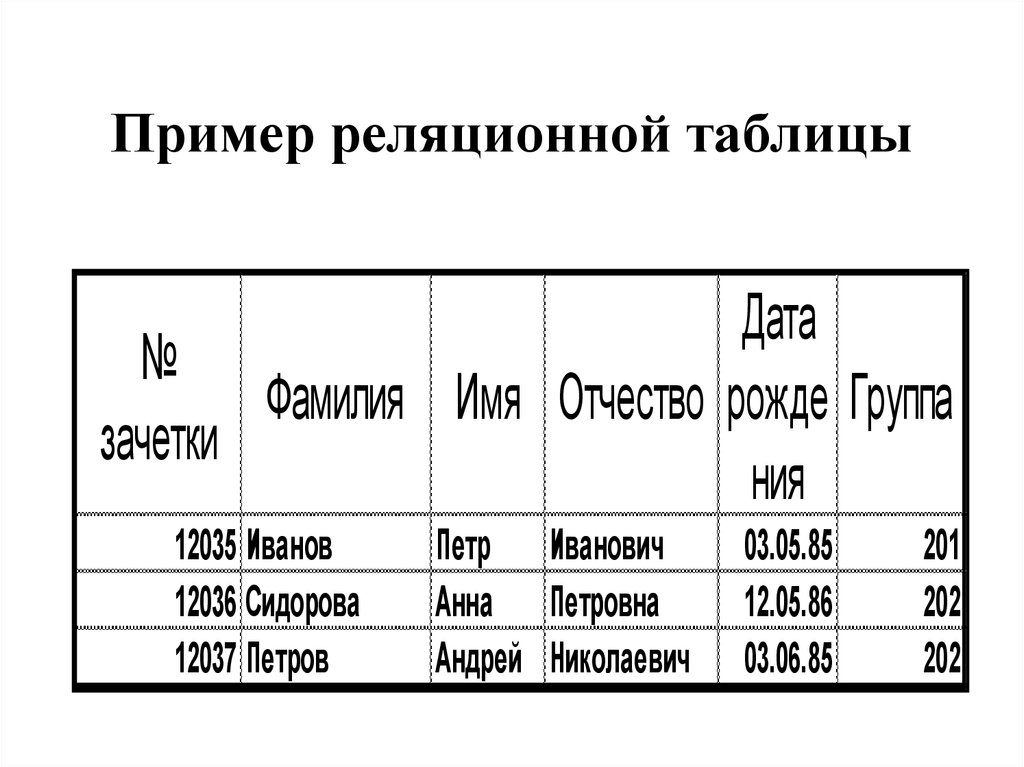
Как упорядочены данные в реляционных базах данных? Для хранения, поиска и получения данных в реляционных базах данных используются таблицы с отношениями между ними. В реляционных базах данных схема базы данных определяет как логическую, так и физическую организацию данных.
Реляционные базы данных обладают так называемым режимом согласованности или целостности, который опирается на четыре свойства: атомарность, согласованность, изоляция и устойчивость. Ниже описывается значение всех этих четырех свойств.
- Атомарность определяет элементы, образующие полную транзакцию.
- Согласованность определяет правила поддержания целостности данных после транзакций.
- Благодаря изоляции эффекты транзакций являются невидимыми для других транзакций, чтобы не возникало конфликтов между ними.
- Устойчивость означает постоянство изменений данных после каждой зафиксированной транзакции.
Благодаря этим свойствам реляционные базы данных эффективно работают в решениях, где требуется высокая точность, например в транзакциях в финансовой сфере и в розничной торговле. Эта сфера называется оперативной обработкой транзакций (OLTP). Финансовые организации применяют базы данных для отслеживания огромного количества транзакций клиентов: от запросов выписки по счету до перевода средств между счетами. Реляционные базы данных идеально подходят для применения в банковской сфере, поскольку такие базы данных поддерживают значительное количество клиентов, поддерживают частые изменения данных в транзакциях и обладают малым временем отклика.
Эта сфера называется оперативной обработкой транзакций (OLTP). Финансовые организации применяют базы данных для отслеживания огромного количества транзакций клиентов: от запросов выписки по счету до перевода средств между счетами. Реляционные базы данных идеально подходят для применения в банковской сфере, поскольку такие базы данных поддерживают значительное количество клиентов, поддерживают частые изменения данных в транзакциях и обладают малым временем отклика.
К реляционным базам данных относятся: SQL Server, Управляемый экземпляр SQL Azure, База данных SQL Azure, MySQL, PostgreSQL и MariaDB.
Что такое реляционная база данных MySQL?
MySQL — это распространенная реляционная база данных SQL с открытым кодом, выполняющая все основные команды SQL, такие как запись и запрос данных. MySQL — это надежная, стабильная и безопасная система управления базами данных (СУБД), она получила широкое распространение благодаря поддержке наиболее популярных языков программирования и протоколов. Благодаря высокой устойчивости MySQL используется в качестве основного хранилища данных во многих крупных организациях. MySQL также можно использовать в качестве встроенной базы данных для программного обеспечения, оборудования и устройств.
Благодаря высокой устойчивости MySQL используется в качестве основного хранилища данных во многих крупных организациях. MySQL также можно использовать в качестве встроенной базы данных для программного обеспечения, оборудования и устройств.
В MySQL обычно применяются надежные и гибкие средства безопасности, такие как проверка на основе узлов и шифрование трафика с использованием паролей. Веб-разработчики часто используют MySQL, поскольку базы данных MySQL отличаются простотой использования и содержат ряд функций для эффективной работы: обновляемые представления, хранимые процедуры и триггеры (особые процедуры, которые запускаются при выполнении определенных действий на сервере базы данных). MySQL является популярной платформой транзакций для электронной коммерции, поскольку MySQL прекрасно подходит для управления транзакциями, профилями пользователей и данными о складских запасах товаров. Среди преимуществ MySQL — высокий уровень совместимости с другими системами, а также поддержка развертывания в средах с виртуализацией, например на облачных платформах.
Что такое реляционная система управления базами данных?
Реляционные базы данных предназначены для управления значительными объемами критически важных для бизнеса данных клиентов. Тем не менее, по мере увеличения объема данных повышается сложность баз данных, становится труднее хранить данные в упорядоченном, доступном и безопасном состоянии. Для решения этой проблемы применяются системы управления базами данных (СУБД): они добавляют к реляционным таблицам уровень средств управления. Существуют разные структуры баз данных и разные системы управления, в которых доступны разные уровни организации, масштабируемости и применения. Когда администраторы работают с крупными объемами структурированных и неструктурированных данных (большие данные) в реальном времени, системы управления реляционными базами данных помогают анализировать и обобщать данные, чтобы обнаруживать заранее заданные отношения. Управление данных с помощью реляционных СУБД наиболее выгодно для бизнеса, поскольку дает возможность сделать более управляемыми данные, использующиеся несколькими приложениями или расположенные в разных местах.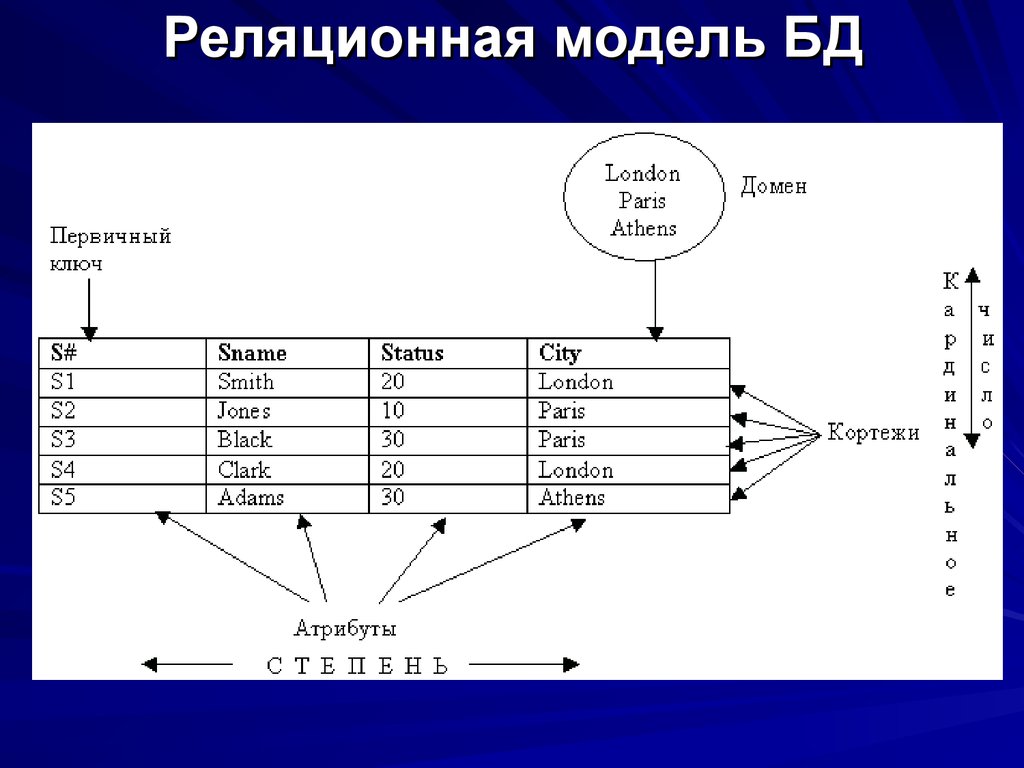
Реляционные СУБД используют программное обеспечение, образующее постоянный интерфейс между пользователями, приложениями и базой данных, поэтому для пользователей данных упрощается навигация. Такой подход наиболее эффективен при работе с большими данными, поскольку объем данных определяет необходимость согласованности для пользователей, выполняющих запросы. Выбор СУБД зависит от расположения данных, от типа используемой архитектуры и от планируемого масштабирования.
Что такое реляционная модель базы данных?
Реляционная модель базы данных обычно обладает следующими характеристиками: высокая структурированность и поддержка языка программирования SQL. Многие базы данных используют реляционную модель, поскольку они предназначены для упорядочения данных и выявления отношений между основными точками данных, чтобы упрощать сортировку и поиск информации. В большинстве реляционных моделей используется традиционная табличная структура со столбцами и строками: это эффективный, интуитивный и гибкий способ хранения структурированных данных. Реляционная модель также решает проблему наличия множества произвольных структур данных в базах данных.
Реляционная модель также решает проблему наличия множества произвольных структур данных в базах данных.
Масштаб моделей реляционных баз данных может различаться в самых широких пределах: от небольших решений на настольных компьютерах до крупных облачных систем. Такие модели используют базы данных SQL или способны обрабатывать инструкции SQL для работы запросов и обновлений. Реляционные модели определяются логической структурой данных (таблицы, индексы и представления) и отдельны от структур физических хранилищ (физических файлов). Согласованность данных является важнейшим признаком реляционных моделей баз данных, поскольку в таких базах данных поддерживается целостность данных между приложениями и копиями баз данных, которые также называются экземплярами. В реляционной модели базы данных экземпляры одной базы данных всегда содержат одинаковые данные.
В реляционных базах данных, разработанных в облаке, автоматически настраивается высокая доступность, то есть производится репликация или копирование данных в несколько участников, при этом участники находятся в разных зонах доступности.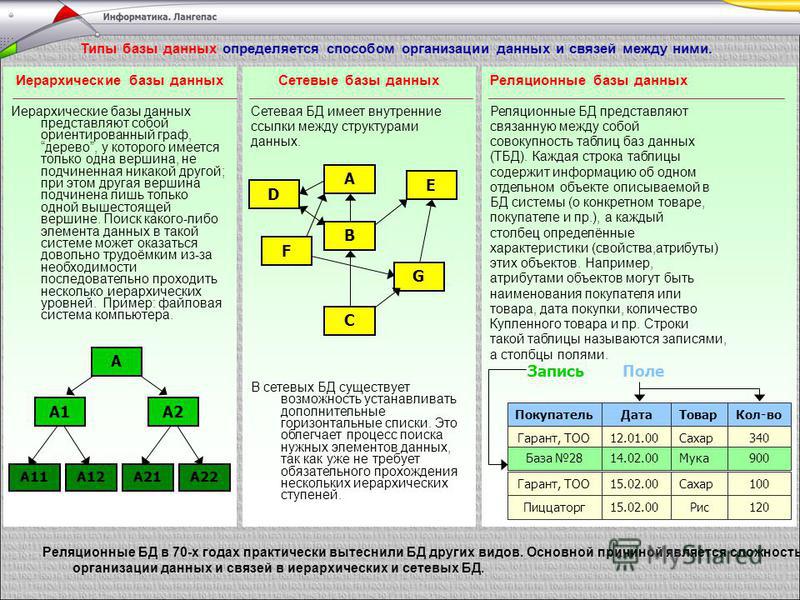 Поэтому данные остаются доступными даже при отключении какого-либо центра обработки данных.
Поэтому данные остаются доступными даже при отключении какого-либо центра обработки данных.
Большие данные и реляционные базы данных
Традиционные реляционные базы данных предназначены для обработки больших объемов структурированных данных. Именно поэтому реляционные базы данных прекрасно подходят для структурированных больших данных: они опираются на SQL и могут использовать СУБД для управления данными. Тем не менее, в более крупных и более сложных наборах больших данных повышается разнообразие, то есть данные, поступающие из новых источников, становятся менее структурированными. В силу этого зачастую приходится применять нереляционные базы данных (NoSQL), которые поддерживают работу с неструктурированными и с полуструктурированными данными.
Вопросы и ответы
Виды баз данных — реляционные и другие подходы к организации БД в программировании
В этой статье мы рассмотрим основные виды баз данных. На конкретных примерах выявим преимущества и недостатки каждой модели, изучим сценарии их применения.
Что такое база данных
База данных — это набор сведений об объектах, структурированный определенным образом. Обычно базы данных управляются специальным ПО, или системами управления базами данных (СУБД).
В зависимости от вида логическая структура базы данных может иметь различное описание. Это различие влияет на то, какая именно БД используется в разработке конкретного продукта или технологии.
Простейшие типы баз данных
К таким базам данных относятся БД, где хранятся данные с простой структурой: например, список разрешенных IP-адресов для доступа к сети, настройки окружения проекта, список подписчиков на рассылку компании и прочее. Они все еще широко распространены.
Текстовые файлы
Информация об объектах собирается в простых по структуре файлах различных форматов – txt, csv и др. Для разделения полей применяются пробелы, табуляция, запятые, точка с запятой и двоеточие.
Примеры: etc/passwd и etc/fstab в Unix-подобных системах, csv-файлы, ini-файлы и др.
Особенности:
- Просто использовать. Для работы с файлами достаточно примитивного текстового редактора.
- Удобно работать с конфигурационными данными приложений (учетные данные, настройки подключения к удаленным серверам и устройствам, порты и пр.).
Ограничения:
- Сложно установить связи между компонентами данных.
- Не для всех типов информации.
Иерархические базы данных
В отличие от текстовых файлов здесь между хранимыми объектами устанавливаются связи. Объекты делятся на родителей (основные классы или категории объектов) и потомков (экземпляры этих классов или категорий). При этом у каждого потомка может быть не более одного родителя.
Пример иерархической базы данных.Графическим представлением такой базы данных является древовидная структура.
Примеры: Организация файловых систем; DNS и LDAP-соединения.
Особенности:
- Отношения между объектами реализованы в виде физических указателей.
 Например, в файловой системе путь к папке или файлу строится из имен корневых и вложенных каталогов;
Например, в файловой системе путь к папке или файлу строится из имен корневых и вложенных каталогов; - Моделирование отношений вложенности и подчиненности.
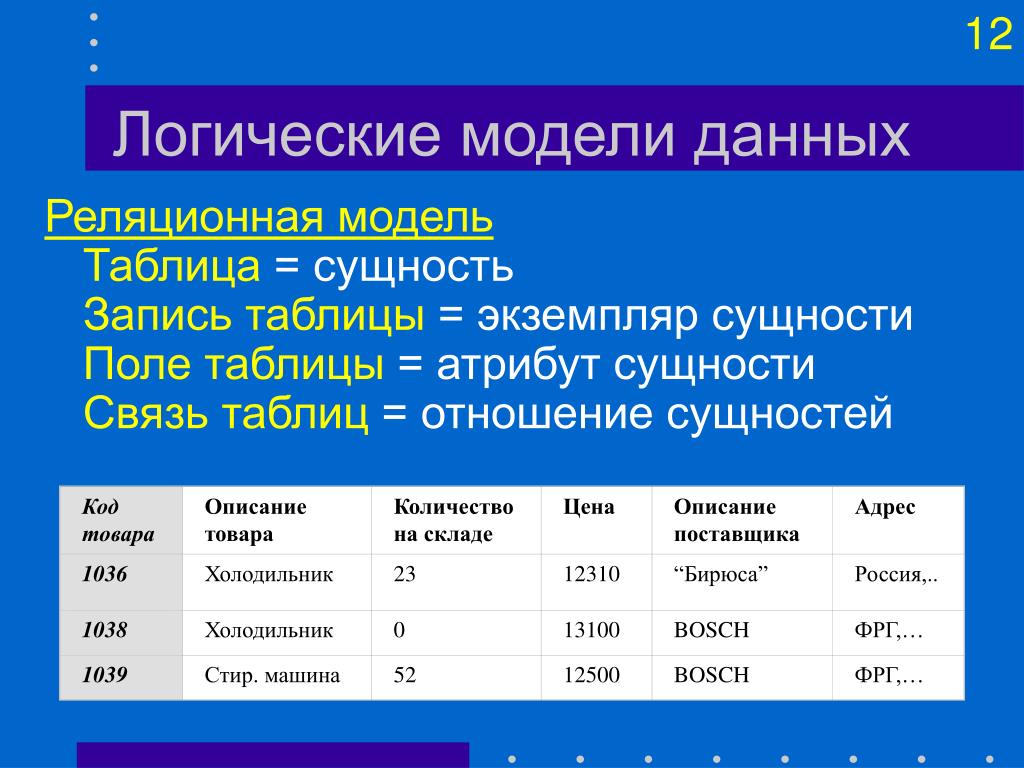 Например, в файловой системе путь к папке или файлу строится из имен корневых и вложенных каталогов;
Например, в файловой системе путь к папке или файлу строится из имен корневых и вложенных каталогов;Ограничения: Технология иерархической организации не предполагает связи «многие-ко-многим», а значит, система хранения данных довольно ограничена.
Сетевые базы данных
Эта технология развивает иерархический подход за счет моделирования сложных отношений между объектами. Здесь потомки могут иметь более одного родителя, однако ограничения иерархического подхода сохраняются.
Пример сетевой базы данных.Пример: IDMS — специализированная СУБД для мейнфреймов.
Реляционные базы данных
Данный тип БД является старейшим: теоретические основы подхода заложены британским ученым Эдгаром Коддом в 1970 году. Здесь данные формируются в таблицы из строк и столбцов. В строках приводятся сведения об объектах (значения свойств), а в столбцах — сами свойства объектов (поля).
Нормализация
Сложные взаимоотношения объектов в реляционных БД моделируются с помощью внешних ключей – ссылок на другие таблицы. Это позволяет подходить к вопросу проектирования базы данных с позиций нормализации – минимизации избыточности при описании свойств объектов.
Например, если речь идет о меню ресторана, то у каждого блюда есть вес, цена, наименование, калорийность и категория, к которой оно относится — горячие закуски, холодные закуски, первые блюда, десерты, салаты и так далее. Связь между блюдами и категорией выполняется посредством ссылочного поля индекса категории в таблице блюд.
Такой подход позволяет:
- Минимизировать объем базы данных: не нужно каждому блюду прописывать название категории.
- Повысить целостность системы: в указанном примере все блюда привязаны к категориям меню. Добавление блюда без категории невозможно, равно как и указание в качестве ссылки индекса несуществующей категории.
- Упростить масштабирование: новые блюда могут быть добавлены в существующие категории. Также не исключается добавление новых категорий, привязка новых блюд к ним и перераспределение блюд по категориям.
- Повысить отказоустойчивость: за счет оптимальной организации схемы таблиц запросы на выборку и агрегацию будут работать с меньшим объемом данных, а значит, быстрее, чем без нормализации. При увеличении числа записей в таблицах со временем это позволит поддерживать положительный пользовательский опыт.
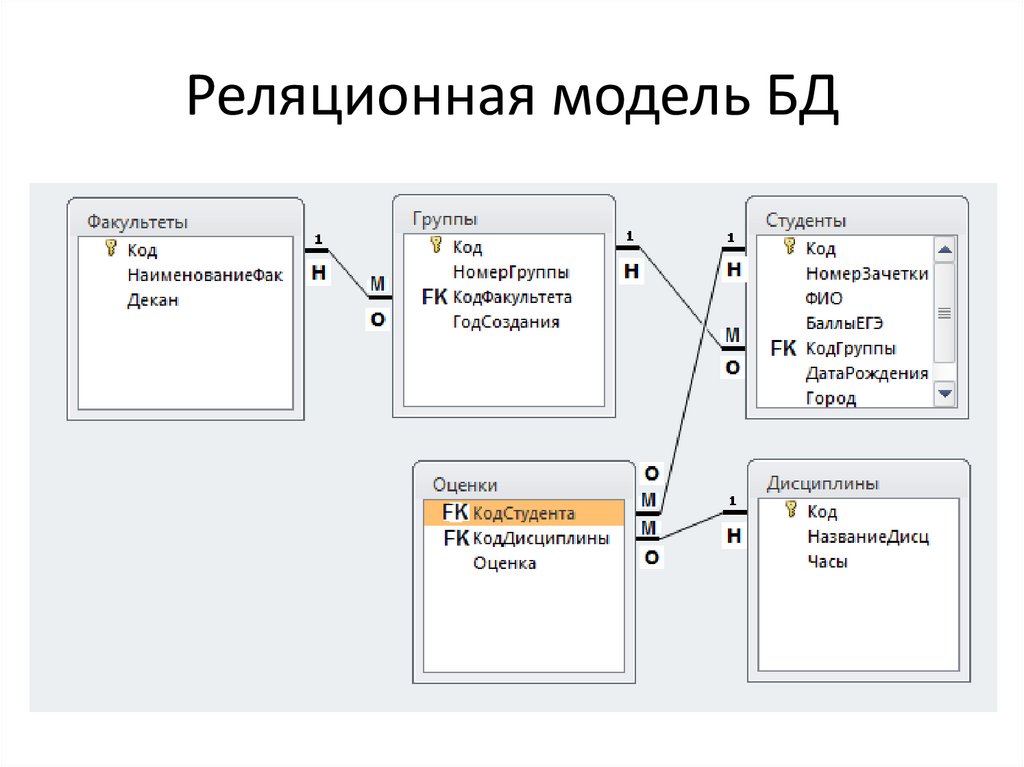
 Также не исключается добавление новых категорий, привязка новых блюд к ним и перераспределение блюд по категориям.
Также не исключается добавление новых категорий, привязка новых блюд к ним и перераспределение блюд по категориям.Наглядный пример моделирования сложных взаимоотношений в реляционных БД приведен на рисунке выше. Здесь мы видим модель базы данных учебного заведения, где есть следующие объекты: ученик, курс, преподаватель, отдел, направление обучения.
Связь преподавателя с отделом организована через секцию и курс (внешние ключи id курса и id преподавателя в таблице Секция, а также Отдел в таблице Курс). Связь ученика с направлением обучения реализована через таблицу Направление обучения студента (внешние ключи id студента и id направления обучения).
Таким образом, чтобы посчитать, например, количество студентов на курсе и детализировать статистику по преподавателям, необходимо написать запрос с присоединением учеников к направлению, курсу и преподавателям, сделав соответствующую группировку по преподавателям.
Язык запросов SQL
Запросы в реляционных базах данных формируют с помощью структурированного языка SQL. Его предложения позволяют:
- делать выборки,
- проводить агрегации и группировки,
- изменять и удалять данные,
- модифицировать структуру БД (создавать таблицы, поля),
- управлять доступом пользователей к тем или иным операциям и пр.
Денормализация
Помимо нормализации, в реляционных БД существует и обратный процесс — денормализация. Он направлен на перенос наиболее часто используемых полей из внешних таблиц во внутренние. Рассмотрим это на примере мессенджера.
Пользователь (user) оставляет сообщения (messages) в чатах (chat). Структура данных такова, что сообщения связаны с пользователем и чатом через внешние ключи (user_from и user_to, а также chat_id в таблице сообщений; user_id и chat_id в таблице user_chat_link). Поскольку схема нормализована, то различные запросы на выборку, подсчет и агрегацию статистики по чатам, пользователям и сообщениям необходимо выполнять с помощью присоединения внешних таблиц.
На относительно небольших объемах данных эти запросы будут отрабатывать быстро, а с увеличением размера базы – замедляться. Причина кроется в механизме присоединения. Он основан на построчном сравнении двух и более таблиц по условию соединения — например, равенство chat_id в messages и id в chat. А это дает нагрузку на сервер базы данных, которая с ростом ее размера только увеличивается. Для оптимизации такого рода запросов и существует механизм денормализации.
В таблицу связи пользователя и чата user_chat_link добавлены дублирующие поля имени чата (chat_name) и аватара (chat_logo). Также туда выводятся последнее сообщение (last_msg) и количество непрочитанных сообщений (unread_msg_count).
Теперь для получения указанных выше полей и проведения аналитики по ним можно использовать таблицу user_chat_link без необходимости соединения с таблицей сообщений. Тем не менее, такой подход имеет ограничения.
За счет дополнительных полей оптимизируются запросы на чтение и агрегацию данных, однако ценой этого является вынужденная избыточность и усложнение бизнес-логики приложения. В частности, усложняется написание запросов изменения данных (update и delete), а также модификации структуры базы (create).
В частности, усложняется написание запросов изменения данных (update и delete), а также модификации структуры базы (create).
Использование денормализации должно быть тщательно осмыслено. Нужно быть уверенным в том, что нормализованная структура, оптимизированные запросы и правильно настроенные индексы более не способны удовлетворять критерию быстродействия.
Преимущества реляционного подхода:
- определение сложных отношений между объектами,
- нормализация и денормализация данных,
- структурированный язык запросов,
- богатая история развития и широкое распространение (основной инструмент при разработке различных приложений и сервисов).
Недостатки подхода: жесткая структура сведений об объектах.
Примеры: MySQL, MariaDB, PostgreSQL, SQLite и др.
NoSQL и нереляционные базы данных
Все преимущества и недостатки реляционных БД основаны на жесткой структуризации и типизации сведений об объектах.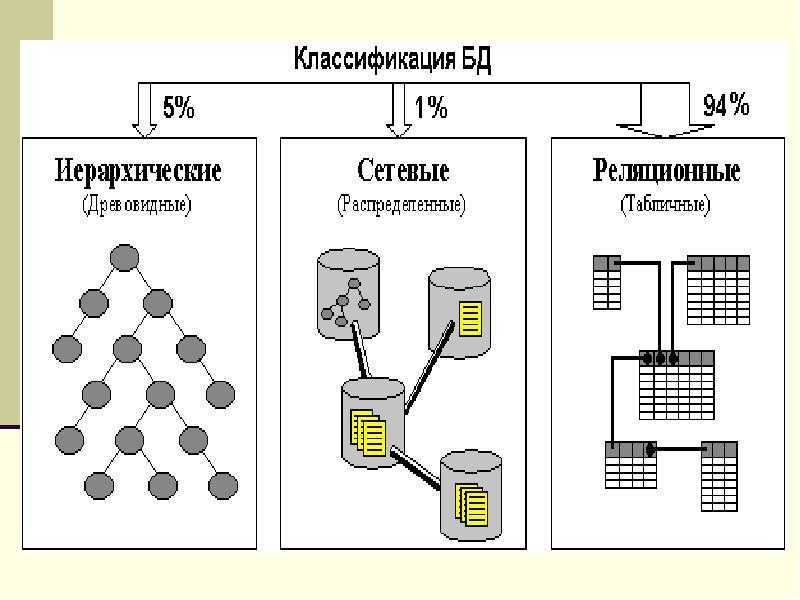 С одной стороны, можно оптимизировать хранение и индексирование данных за счет нормализации или же денормализации. С другой — сложно организовать хранение и обработку плохо структурированных (например, объекты кэша) или вовсе не структурированных данных (например, данные из нескольких источников).
С одной стороны, можно оптимизировать хранение и индексирование данных за счет нормализации или же денормализации. С другой — сложно организовать хранение и обработку плохо структурированных (например, объекты кэша) или вовсе не структурированных данных (например, данные из нескольких источников).
Для борьбы с этими ограничениями было разработано семейство нереляционных БД. Рассмотрим их подробнее.
Базы данных «Ключ-значение»
Это простейшая разновидность нереляционных БД. Данные хранятся в виде словаря, где указателем выступает ключ.
Особенности:
- Хранение и обработка разных по типу и содержанию данных: в одном хранилище под разными ключами могут находиться файлы, строки, текст, числа, JSON-объекты и другие типы данных.
- Высокая скорость доступа к данным за счет адресного хранения.
- Легкое масштабирование. Можно создать правила шардирования по определенным ключам – например, сессии пользователей разных сайтов хранятся в различных сегментах БД.
Ограничения: Поскольку подход не предполагает жесткой типизации и структуризации данных, то контроль их валидности, а также нейминг ключей отдаются на откуп разработчику.
Примеры: Amazon, DynamoDB, Redis, Riak, LevelDB, различные хранилища кэша – например, Memcached и пр.
Документоориентированные БД
В отличие от баз типа «Ключ-значение» данные здесь хранятся в структурированных форматах – XML, JSON, BSON. Тем не менее, сохраняется адресный доступ к данным по ключу. При этом содержимое документа может иметь различный набор свойств.
Например, каталог профилей пользователей: один в качестве предпочтений указал любимое блюдо, а другой – видеоигру. Поскольку эти сведения нельзя хранить в одном поле ввиду логической и структурной разобщенности, они записываются в отдельные свойства отдельных документов. При необходимости можно добавить в документы новые свойства, не нарушив при этом общей целостности данных.
Особенности:
- хорошо подходят для быстрой разработки систем и сервисов, работающих с по-разному структурированными данными,
- легко масштабируются и меняют структуру при необходимости.

Примеры: MongoDB, RethinkDB, CouchDB, DocumentDB.
Графовые базы данных
Это семейство баз предназначено для моделирования сложных отношений с помощью теории графов, где связями выступают ребра графа, а сами объекты – это узлы или вершины.
Пример структуры графовой базы данных.Такой подход может пригодиться при анализе профилей пользователей социальных сетей. Один пользователь подписан на обновления второго, другой пользователь подписан на определенное сообщество и так далее. Также технология может использоваться при анализе экономической активности контрагентов для выявления различных схем мошенничества. Например, можно отследить использование определенных счетов, карт или реквизитов контрагентов в различных операциях.
Особенности: высокая производительность, поскольку обход ребер и вершин значительно быстрее анализа множества внешних и внутренних таблиц и их соединения по условию отбора в реляционных БД.
Примеры: Neo4J, JanusGraph, Dgraph, OrientDB.
Колоночные базы данных
Как можно понять из названия, записи в таких базах хранятся не по строкам, а по столбцам (колонкам). Вместо таблиц здесь используются колоночные семейства. Они содержат ключи, указывающие на формат строки записи информации об объекте. Каждая строка имеет свой набор свойств, что позволяет хранить в рамках одного семейства разно структурированные данные.
Технология активно используется при построении аналитических систем и сервисов, работающих с большими объемами данных.
На рисунке приведен пример колоночного хранения информации о фруктах. Известно три типа фруктов: яблоки, виноград, бананы. Все они объединены в семейство фруктов.
У каждого фрукта индивидуальный набор свойств. Для яблок это цвет, цена и наличие. У винограда это цвет, цена, число ягод в связке и происхождение (импортный или нет). У бананов же это цвет, цена, число в связке и зрелость.
Чтобы получить детальную сводку по одному типу фруктов, достаточно в запросе указать его идентификатор. При этом можно построить аналитический запрос по общим для всего семейства признакам – например, посчитать число фруктов с группировкой по цвету, вычислить среднюю цену на все фрукты в магазине и т.д.
При этом можно построить аналитический запрос по общим для всего семейства признакам – например, посчитать число фруктов с группировкой по цвету, вычислить среднюю цену на все фрукты в магазине и т.д.
Особенности:
- С группировкой свойств по колонкам при запросе индексируется меньший объем данных, что обеспечивает высокую скорость его выполнения.
- Широкие возможности масштабирования и модификации структуры — так, при добавлении новых колонок не придется их жестко формализовывать, как в случае с реляционными базами.
Примеры: Cassandra, HBase, ClickHouse.
Базы данных временных рядов
Данный тип БД можно использовать при необходимости отслеживания исторической динамики по ряду показателей. Здесь данные группируются по временным меткам. Базы временных рядом чаще ориентированы на запись, чем на построение сложных аналитических запросов.
На рисунке выше приведен пример использования такой БД для отслеживания состояния ПК во времени по ряду показателей – температуре процессора, загрузке системы и потреблению оперативной памяти.
Особенности: Можно обрабатывать постоянный поток входных данных.
Ограничения: Производительность зависит от объема поступающей информации, количества отслеживаемых метрик, а также временного лага между записью новых данных и запросами на чтение
Примеры БД: OpenTSDB, Prometheus, InfluxDB, TimescaleDB
Комбинированные базы
Эта разновидность баз совмещает в себе SQL- и NoSQL-подходы к организации хранения и обработки данных. Этот класс баз включает в себя NewSQL и многомодельные решения. Рассмотрим их подробнее.
Базы данных NewSQL
Данный тип решений для хранения информации стремится обеспечить компромисс между масштабируемостью и согласованностью при сохранении реляционного подхода.
Термин предложил в 2011 году аналитик компании 451 Group Мэтью Аслет. Он отмечал высокую потребность в таких системах для сфер, работающих с критическими данными, — здравоохранение, FinTech и пр. Характерными признаками этих решений являются: использование алгоритмов обеспечения консенсуса (алгоритм Paxos, Raft и др.), шардирование и заточка под горизонтальное масштабирование.
Характерными признаками этих решений являются: использование алгоритмов обеспечения консенсуса (алгоритм Paxos, Raft и др.), шардирование и заточка под горизонтальное масштабирование.
Особенности:
- широкие возможности масштабирования,
- высокая производительность и доступность данных.
Ограничения: Высокие требования к аппаратным ресурсам разработчиков. Но если разрабатываемый продукт является высоконагруженной системой, то применение такой БД имеет смысл.
Примеры баз такого типа: MemSQL, VoltDB, Spanner и др.
Многомодельные базы
Такие БД сочетают в себе несколько подходов к организации данных одновременно. Это обеспечивает функциональное разнообразие при разработке систем с их использованием.
Особенности:
- возможность в одном запросе работать с данными, хранящимися в разных типах баз, не нарушая при этом согласованности;
- обширные возможности масштабирования за счет легкой интеграции новых моделей баз данных в существующую инфраструктуру проекта.

Пример решения данного типа: ArangoDB.
Базы данных в Selectel
В Selectel вы можете запустить готовые облачные базы данных — поддерживаем такие СУБД, как PostgreSQL (в том числе для 1С:Предприятие), MySQL, Redis, TimescaleDB.
Облачные базы данных позволяют исключить работу с инфраструктурой: поднять нужное количество нод можно за несколько минут в панели управления компании. Решение отказоустойчивое и легко масштабируется. На экстренный случай создаются резервные копии для отката состояния базы на срок до семи дней.
Большинство рутинных операций по системному администрированию (настройка, конфигурация, обслуживание и обеспечение безопасности) выполняются специалистами Selectel.
→ Как начать работу с облачными базами данных
Запустите свою базу данных в облаке
Быстрое развертывание самых популярных реляционных и NoSQl-баз данных.
Подробнее
Заключение
В данной статье мы рассмотрели 11 видов баз данных. Каждый имеет свои особенности и ограничения. Решение о выборе того или иного вида необходимо принимать с учетом:
Каждый имеет свои особенности и ограничения. Решение о выборе того или иного вида необходимо принимать с учетом:
- сложности хранимых данных и взаимосвязей между ними,
- производительности операций чтения/записи и модификации структуры БД на планируемом объеме данных,
- опыта команды разработки,
- стадии жизненного цикла разрабатываемого продукта (производите ли вы доработку действующего решения либо создаете что-то принципиально новое, каковы ваши текущие и перспективные ресурсные возможности).
Автор: Роман Андреев.
Реляционные базы данных для не кодеров — Как закодировать реляционную базу данных?
Понимание концепции баз данных и их различных типов, таких как реляционные и нереляционные базы данных, может быть сложным для людей, не имеющих опыта в кодировании и разработке приложений. Однако это не означает, что это невыполнимая задача. Эта статья поможет вам получить полные знания о реляционных базах данных, их плюсах и минусах, примерах, а также о том, как можно создать реляционную базу данных, даже не имея опыта кодирования. Давайте начнем с основ реляционных баз данных.
Давайте начнем с основ реляционных баз данных.
Обзор реляционной базы данных
Реляционная база данных — это коллекция правильно организованной информации с четко определенными взаимосвязями, чтобы к ней можно было легко получить доступ и извлечь ее. Согласно традиционной модели реляционной базы данных, структуры данных, включающие таблицы данных, представления и индексы, хранятся отдельно от физических структур хранения. В результате администраторы баз данных могут редактировать физическое хранилище данных, не затрагивая логическую структуру данных.
Различные типы организаций, особенно крупные предприятия, используют реляционные базы данных для организации данных и формирования четких взаимосвязей между ключевыми точками данных. Таким образом, становится легко искать и находить нужную информацию, необходимую для принятия ключевых бизнес-решений. Структурированные данные, как правило, являются основой эффективной реляционной базы данных.
Работа с реляционной базой данных
Реляционная база данных использует таблицы данных для хранения информации о связанных объектах.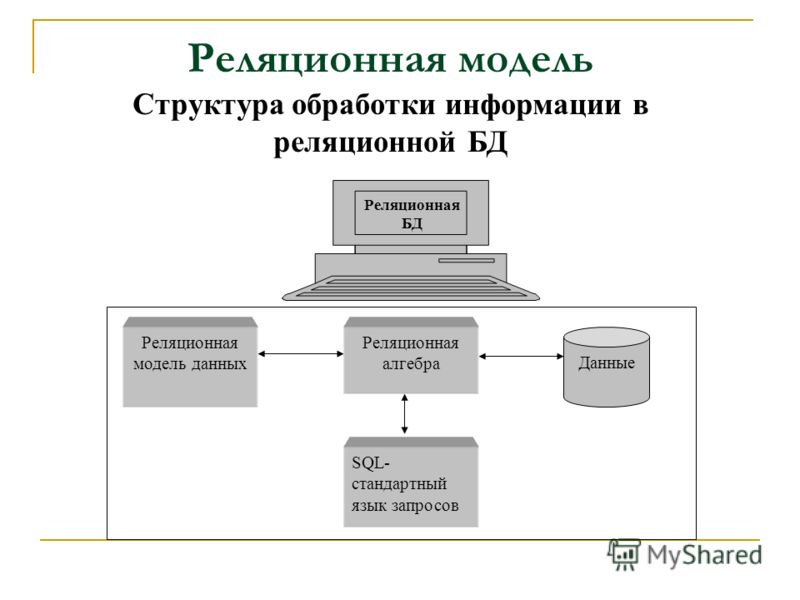 Каждая строка имеет уникальный идентификатор, называемый ключом, а каждый столбец — атрибуты данных. В реляционной базе данных легко определить взаимосвязи между точками данных, поскольку каждая запись присваивает значение каждому признаку базы данных.
Каждая строка имеет уникальный идентификатор, называемый ключом, а каждый столбец — атрибуты данных. В реляционной базе данных легко определить взаимосвязи между точками данных, поскольку каждая запись присваивает значение каждому признаку базы данных.
Язык структурированных запросов (SQL) — это стандартный пользовательский и прикладной программный интерфейс (API) реляционной базы данных. Целью кодовых операторов SQL является создание интерактивных запросов к информации, содержащейся в реляционной базе данных, и сбор данных для принятия решений и составления отчетов. Также важно иметь четко определенные правила целостности данных, чтобы сделать реляционную базу данных точной и доступной.
Структура реляционной базы данных
Вы можете лучше понять принцип работы и создания реляционной базы данных, ознакомившись с ее структурой. Таблицы в реляционной базе данных имеют ключевой столбец, который содержит уникальное значение для каждой строки. Этот столбец известен как первичный ключ.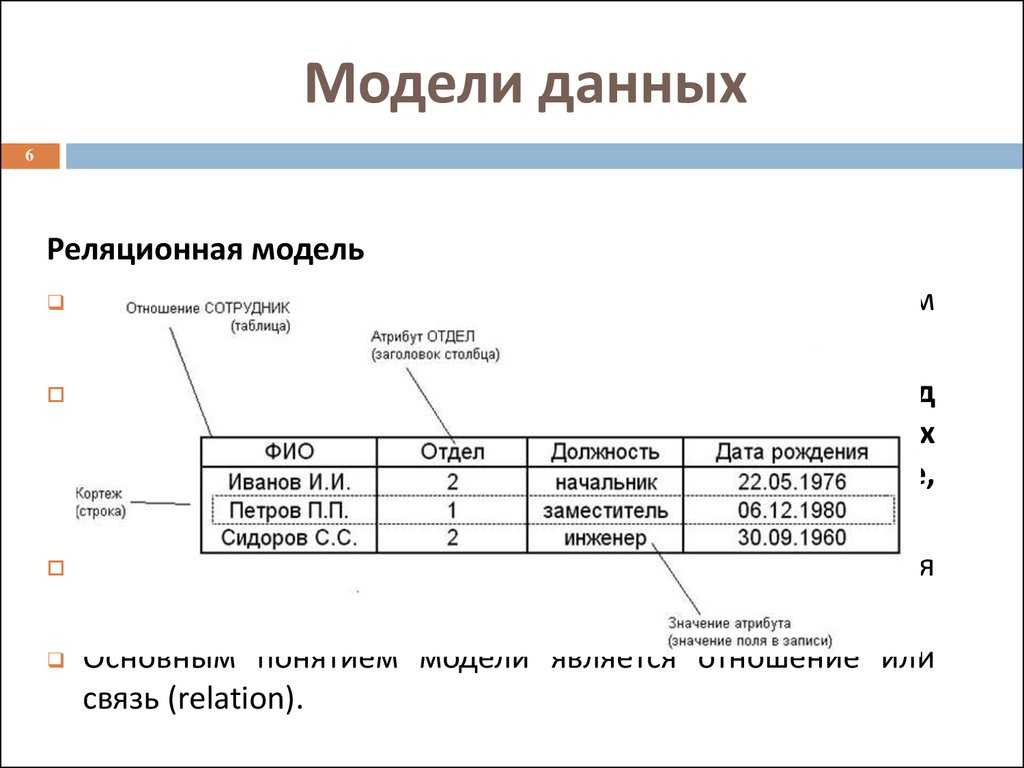
В то время как столбцы в одной таблице ссылаются на первичные ключи в других таблицах, они называются внешними ключами. Наличие этих столбцов крайне важно, поскольку данные в различных таблицах связаны друг с другом через совпадающие значения в ключевых столбцах. Столбцы также называют полями или атрибутами, а строки — записями.
В идеальной реляционной базе данных каждая таблица должна представлять определенный тип сущности, например, клиента, продукт или доход. Каждая строка относится к конкретному экземпляру этого типа сущности, а столбец относится к конкретному значению этого экземпляра, такому как имя клиента, цена продукта или точная сумма.
Пример
База данных продаж организации имеет две таблицы, называемые «Доходы» и «Услуги».
- Таблица услуг будет иметь столбцы для названия, продолжительности и стоимости.
- Таблица доходов будет иметь столбцы для даты продажи, точной оплаты, скидки и адреса.
Каждая запись в доходах будет иметь внешний ключ, который ссылается на первичный ключ таблицы услуг. Для каждого продукта может быть несколько продаж, поэтому такой тип связи между таблицами услуг и доходов называется связью «один ко многим». Мы подробно рассмотрим типы отношений в реляционных базах данных далее в статье.
Для каждого продукта может быть несколько продаж, поэтому такой тип связи между таблицами услуг и доходов называется связью «один ко многим». Мы подробно рассмотрим типы отношений в реляционных базах данных далее в статье.
Важность реляционных баз данных
Теперь, когда вы знакомы с основами реляционных баз данных, вы можете задаться вопросом, почему они важны и в чем их преимущества. Давайте подробно рассмотрим плюсы и минусы реляционных баз данных, чтобы вы могли овладеть искусством создания реляционных баз данных для разработки приложений.
Плюсы
Ниже перечислены основные преимущества использования реляционных баз данных:
- Максимальная точность данных
Минимальный риск дублирования данных, поскольку реляционные базы данных строятся с использованием ключей. При наличии нескольких записей одних и тех же данных может быть сложно определить, какой источник информации является надежным. Удаление дубликатов в реляционных базах данных гарантирует точность ваших данных.
- Гибкость
При создании реляционной базы данных вы не будете ограничены в будущем при добавлении дополнительных данных. База данных обеспечивает гибкость, позволяя расширяться и изменяться по мере необходимости в соответствии с требованиями к информации, которая будет храниться.
- Простой и быстрый доступ к данным
В других видах баз данных, которые зависят от информационной иерархии или предопределенных путей доступа к информации, трудно искать, фильтровать и упорядочивать данные так, как вам нужно. Вместо этого извлечь нужные вам точные данные из реляционной базы данных значительно проще.
Минусы
Есть и несколько недостатков использования реляционных баз данных при разработке приложений.
- Сложная структура
Поскольку необходимо создавать столбцы, а данные должны соответствовать довольно строгим категориям, реляционные базы данных требуют большой структуры и планирования.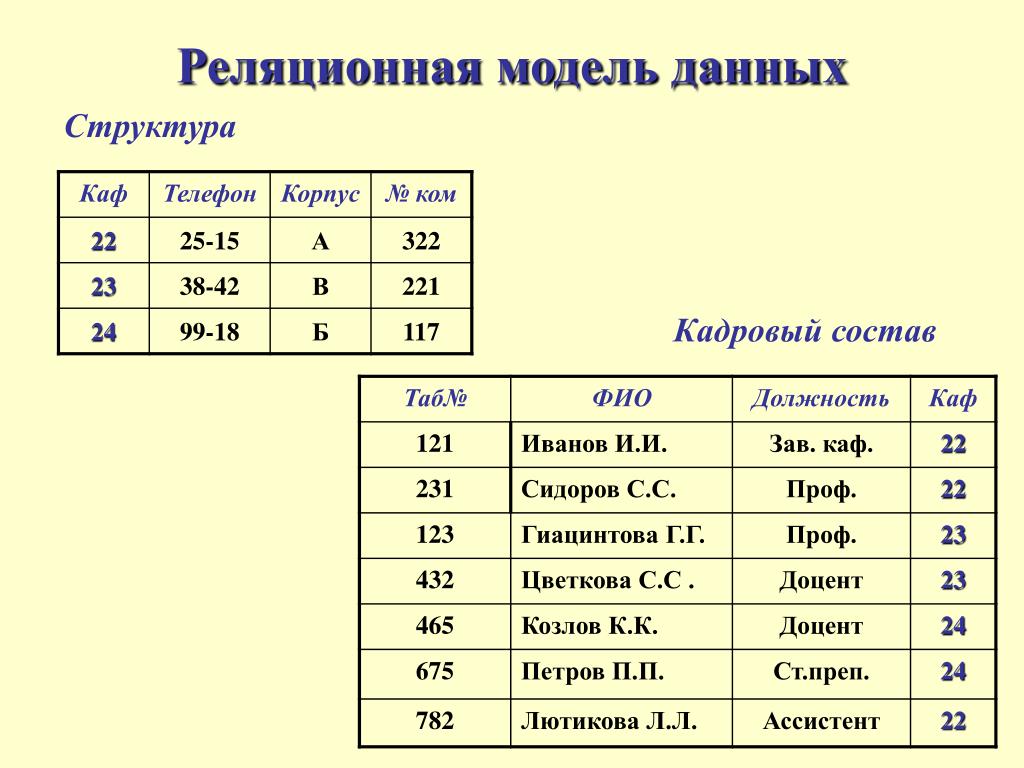 Хотя такая структура имеет ряд преимуществ, у нее есть и существенные недостатки, включая проблемы с обслуживанием и отсутствие адаптивности и масштабируемости без надлежащего опыта.
Хотя такая структура имеет ряд преимуществ, у нее есть и существенные недостатки, включая проблемы с обслуживанием и отсутствие адаптивности и масштабируемости без надлежащего опыта.
- Сложность обслуживания
Для поддержания реляционной базы данных на высоком уровне требуется значительное количество времени, усилий и знаний. Администраторы баз данных обычно нанимают экспертов по базам данных и разработчиков для управления и оптимизации базы данных.
- Негибкость для неструктурированных данных
Большие объемы неструктурированных данных плохо подходят для управления реляционными базами данных. Реляционные базы данных — не лучший выбор для данных, которые в основном являются качественными, трудноописуемыми или динамичными, поскольку схема должна меняться со временем по мере изменения или развития данных, что требует времени. Нереляционная база данных больше подходит для работы с неструктурированными данными.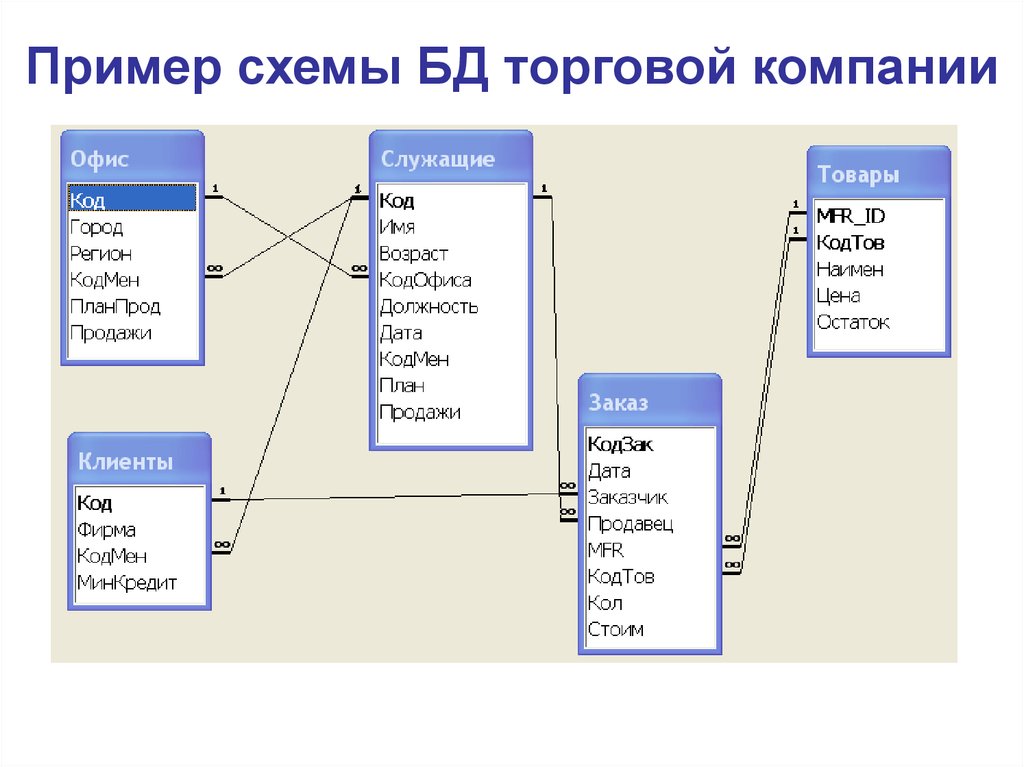
Реляционные базы данных не могут эффективно масштабироваться горизонтально по многочисленным серверам и физическим архитектурам хранения данных. Когда набор данных растет и становится более разрозненным, структура нарушается, а использование многочисленных серверов влияет на производительность (например, время отклика приложений) и доступность. Управление реляционными базами данных на нескольких серверах является сложной задачей.
Как закодировать реляционную базу данных?
При кодировании реляционной базы данных пользователям приходится определять область потенциальных значений в столбце данных и ограничения. Например, область потенциальных клиентов может допускать до 100 имен клиентов, но вы можете ограничить ее одной таблицей, чтобы допустить только десять имен клиентов.
При создании реляционной базы данных также важно учитывать ограничения. Целостность сущности полезна для того, чтобы сделать первичный ключ таблицы уникальным и гарантировать, что его значение не будет установлено на null.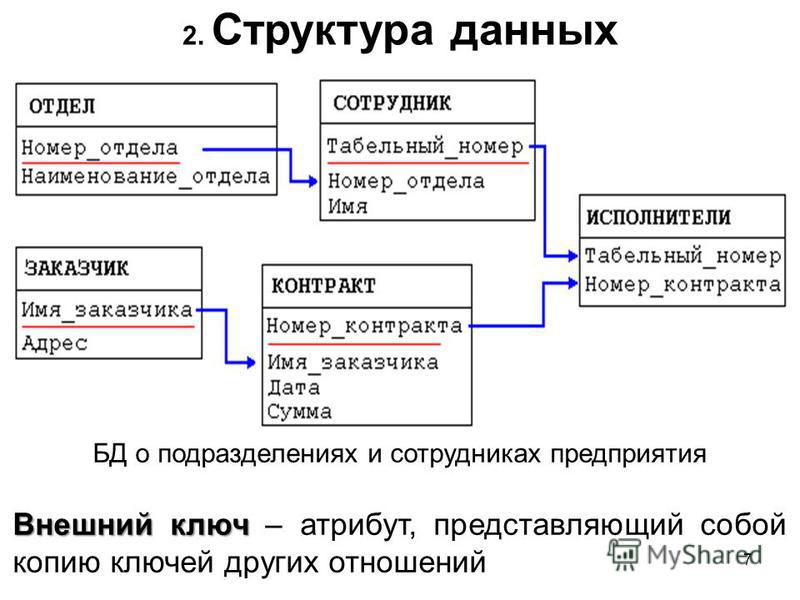 Ссылочная целостность необходима для того, чтобы каждое значение в столбце внешнего ключа находилось в первичном ключе исходной таблицы.
Ссылочная целостность необходима для того, чтобы каждое значение в столбце внешнего ключа находилось в первичном ключе исходной таблицы.
Вы также должны знать, что, в отличие от нереляционных баз данных, реляционные базы данных обладают физической независимостью данных. Система может вносить изменения во внутреннюю схему, не затрагивая внешние схемы или приложения. Владея этими понятиями, вы можете полагаться на реляционные системы управления базами данных, такие как Microsoft Access, Oracle и MySQL, для создания сложных баз данных с минимальным опытом кодирования или вообще без него.
Что является примером реляционной базы данных?
Цель стандартных реляционных баз данных — позволить пользователям управлять и организовывать предопределенные отношения данных в нескольких базах данных. В настоящее время облачные реляционные базы данных становятся очень популярными, поскольку организации могут передать на аутсорсинг такие важные процессы, как обслуживание базы данных и поддержка инфраструктуры.
К наиболее популярным примерам реляционных баз данных относятся:
- MySQL используется в таких веб-приложениях, как Joomla и WordPress.
- SQLite — популярная библиотека на языке Си, используемая для встраивания функций реляционных баз данных в программные пакеты.
- Microsoft Access — популярная часть пакета Microsoft Office и Microsoft 365. Он имеет удобный интерфейс, облегчающий новичкам управление и разработку реляционных баз данных.
- PostgreSQL — это система управления реляционными базами данных (РСУБД) с открытым исходным кодом, которая ориентирована на соответствие стандартам ANSI SQL и предоставляет множество полезных функций, таких как расширяемость.
- Microsoft Azure SQL, Google Cloud SQL, Amazon Relational Database Service и IBM DB2 on Cloud — вот некоторые из современных популярных облачных СУБД.
Каковы типы отношений в базе данных?
В реляционной базе данных существует четыре различных типа определенных отношений.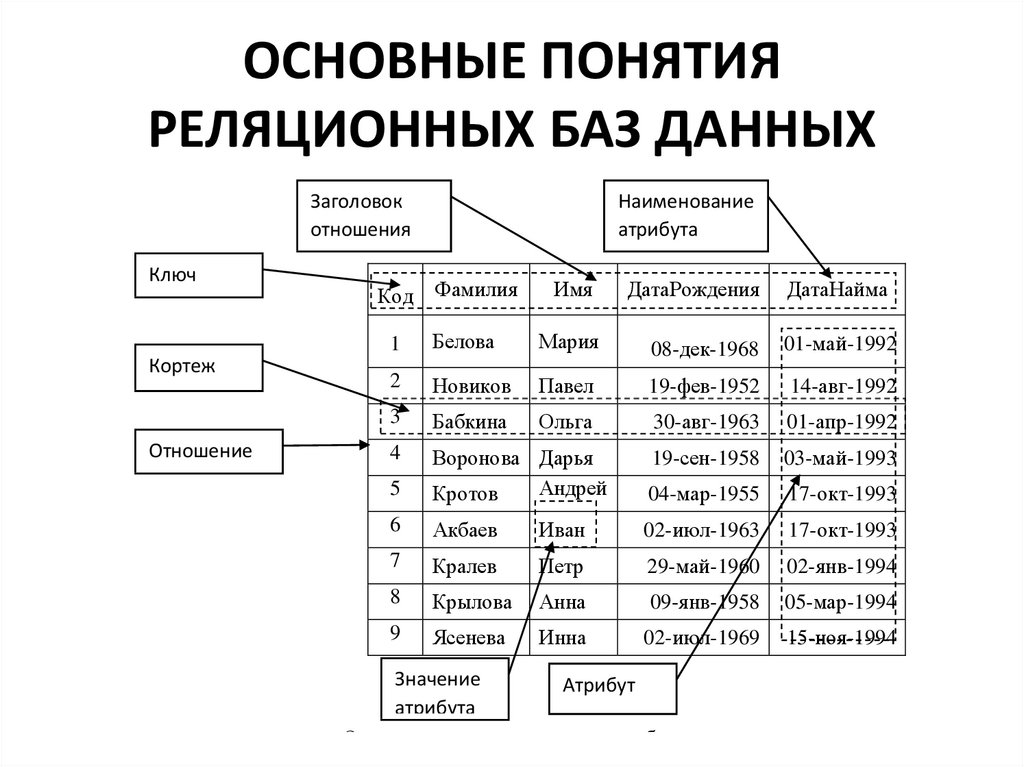 Вы должны быть знакомы с этими отношениями, чтобы иметь возможность выбрать правильное отношение и добиться максимальной точности.
Вы должны быть знакомы с этими отношениями, чтобы иметь возможность выбрать правильное отношение и добиться максимальной точности.
- Один-к-одному
Как следует из названия, в отношениях «один к одному» одна строка в одной таблице связана только с одной строкой в другой таблице. - Один-ко-многим
В отношениях «один-ко-многим» одна строка информации связана со многими записями в различной коллекции. - Многие-к-одному
Это противоположность отношениям «один-ко-многим». Проще говоря, многие строки информации связаны с одной записью в отношениях «многие-к-одному». - Многие-ко-многим
В отношениях «многие-ко-многим» одна строка в таблице может быть связана со многими строками во второй таблице. Аналогично, одна строка во второй таблице может быть связана со многими строками в первой таблице.
Каковы три основных вида отношений в реляционной базе данных?
Существует определенный тип данных, который вы выбираете при создании соединения, чтобы указать, что вы хотите, чтобы этот атрибут был задан существующей коллекцией. Это не типичное свойство, где вы можете выбрать тип данных, например, текст, целое число, дату или картинку. То, сможете ли вы отображать, организовывать и фильтровать данные таким образом, который имеет смысл для вашего приложения, зависит от того, насколько правильно вы настроите связи. Один-к-одному, один-ко-многим и многие-ко-многим — это три основные связи в реляционной базе данных.
Это не типичное свойство, где вы можете выбрать тип данных, например, текст, целое число, дату или картинку. То, сможете ли вы отображать, организовывать и фильтровать данные таким образом, который имеет смысл для вашего приложения, зависит от того, насколько правильно вы настроите связи. Один-к-одному, один-ко-многим и многие-ко-многим — это три основные связи в реляционной базе данных.
Реляционные базы данных полезны для организации структурированных данных в табличные форматы с установленными отношениями. Однако выбор оптимальной архитектуры базы данных включает в себя гораздо больше, чем просто выбор между реляционной и нереляционной моделями. Ключевыми факторами являются тип используемых или создаваемых данных и приложений. Узнайте о некоторых дополнительных аспектах, которые необходимо учитывать при выборе модели базы данных для корпоративного приложения.
Заключение
Общее создание, внедрение, развертывание и обслуживание реляционной базы данных может быть сложным процессом, особенно если вы не знакомы с кодированием. Хорошо то, что существуют платформы без кода, такие как AppMaster, которые позволяют создавать мощные бэкенды и базы данных как для мобильных приложений, так и для веб-приложений. Это полезно для создания надежных, эффективных и безопасных баз данных, не беспокоясь о своих навыках кодирования и при этом получая наилучшие результаты.
Хорошо то, что существуют платформы без кода, такие как AppMaster, которые позволяют создавать мощные бэкенды и базы данных как для мобильных приложений, так и для веб-приложений. Это полезно для создания надежных, эффективных и безопасных баз данных, не беспокоясь о своих навыках кодирования и при этом получая наилучшие результаты.
Платформы No-code позволяют создавать сложные приложения, не тратя лишних денег на наем разработчиков и администраторов баз данных. Поэтому вам следует ознакомиться с такими платформами, как AppMaster, чтобы воспользоваться преимуществами современных инструментов и технологий на основе искусственного интеллекта в разработке мобильных приложений и создании реляционных баз данных без кодирования.
Введение в реляционные базы данных
2 октября, 2021 11:26 дп 152 views | Комментариев нетmySQL | Amber | Комментировать запись
Системы управления базами данных (СУБД) – это программы, которые позволяют пользователям взаимодействовать с БД.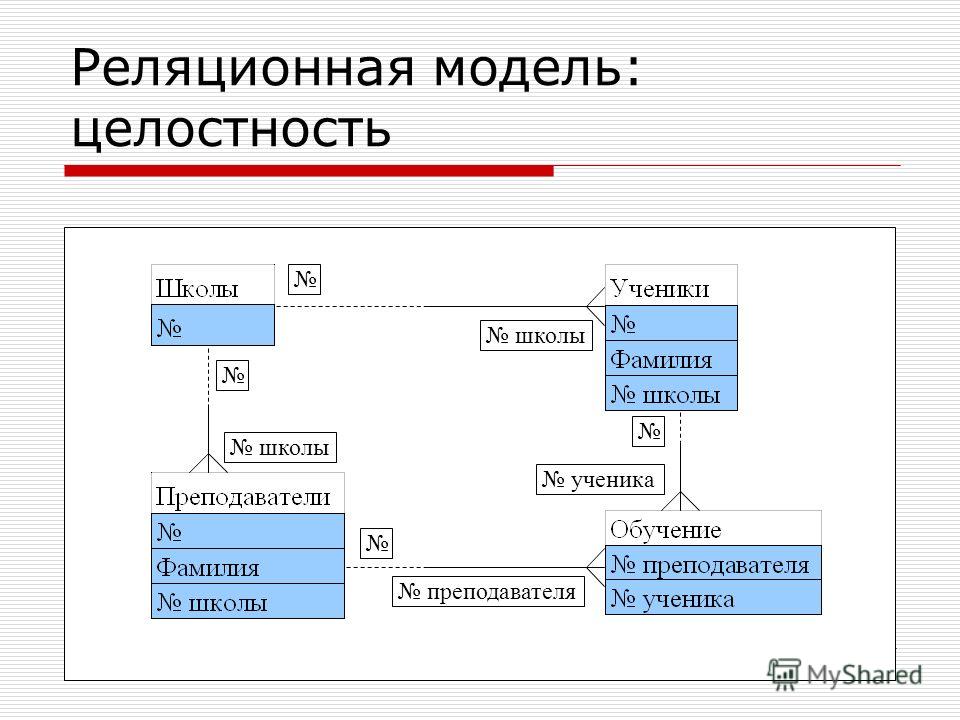 СУБД позволяет управлять доступом к базе данных, записывать данные, отправлять запросы и выполнять любые другие задачи, связанные с управлением БД.
СУБД позволяет управлять доступом к базе данных, записывать данные, отправлять запросы и выполнять любые другие задачи, связанные с управлением БД.
Однако для решения любой из этих задач СУБД должна иметь какую-то базовую модель, которая определяет, как организованы данные. Реляционная модель – это один из подходов к организации данных, который появился в конце 1960-х и нашел настолько широкое применение в программном обеспечении СУБД, что на момент написания этой статьи четыре из пяти самых популярных СУБД – реляционные.
В этой статье мы поговорим об истории реляционной модели, о том, как реляционные БД организуют данные и как они используются сегодня.
История реляционной модели
Базы данных – это логически смоделированные кластеры информации. Любая коллекция данных является базой данных, независимо от того, как и где она хранится. Даже физическая папка, содержащая информацию о заработной плате, является базой данных, как и стопка больничных бланков пациентов. До того, как хранение и управление данными с помощью компьютеров стало обычной практикой, физические базы данных, подобные этим, были очень широко распространены.
До того, как хранение и управление данными с помощью компьютеров стало обычной практикой, физические базы данных, подобные этим, были очень широко распространены.
Примерно в середине ХХ века развитие информатики привело к увеличению вычислительной мощности, а также к увеличению емкости локальной и внешней памяти машин. И тогда ученые начали осознавать потенциал этих машин и стали использовать их для хранения и управления все большими объемами данных.
Однако тогда не было никаких теорий о том, каким образом компьютеры могут логически организовать данные. Одно дело хранить несортированные данные на машине, но разработать систему, которая бы позволили добавлять, извлекать, сортировать и иным образом управлять данными единообразным и практичным способом гораздо сложнее. Потребность в логической структуре для хранения и организации данных привела к возникновению ряда предложений о том, как использовать компьютеры для управления данными.
Одной из первых моделей БД была иерархическая модель, данные в которой организованы в древовидную структуру, аналогичную современным файловым системам.
Иерархическая модель широко применялась в ранних СУБД, однако оказалась недостаточно гибкой. Отдельные записи в ней могут иметь несколько дочерних записей, однако по иерархии каждая запись может иметь только одного «родителя». Поэтому ранние иерархические базы данных были ограничены только отношениями «один к одному» и «один ко многим». Отсутствие поддержки отношения «многие ко многим» становилось проблемой при работе с точками данных, которые нужно связать с несколькими родителями.
В конце 1960-х ученый-компьютерщик Эдгар Ф. Кодд, работавший в IBM, разработал реляционную модель управления базами данных. Реляционная модель Кодда позволяет связывать отдельные записи более чем с одной таблицей, тем самым создавая между точками данных отношения «многие ко многим» (в дополнение к отношениям «один ко многим»). Когда дело касалось проектирования структур БД, эта модель обеспечила большую гибкость, чем другие существующие на тот момент модели. Это означало, что реляционные системы управления базами данных (РСУБД) могли удовлетворить гораздо более широкий спектр потребностей.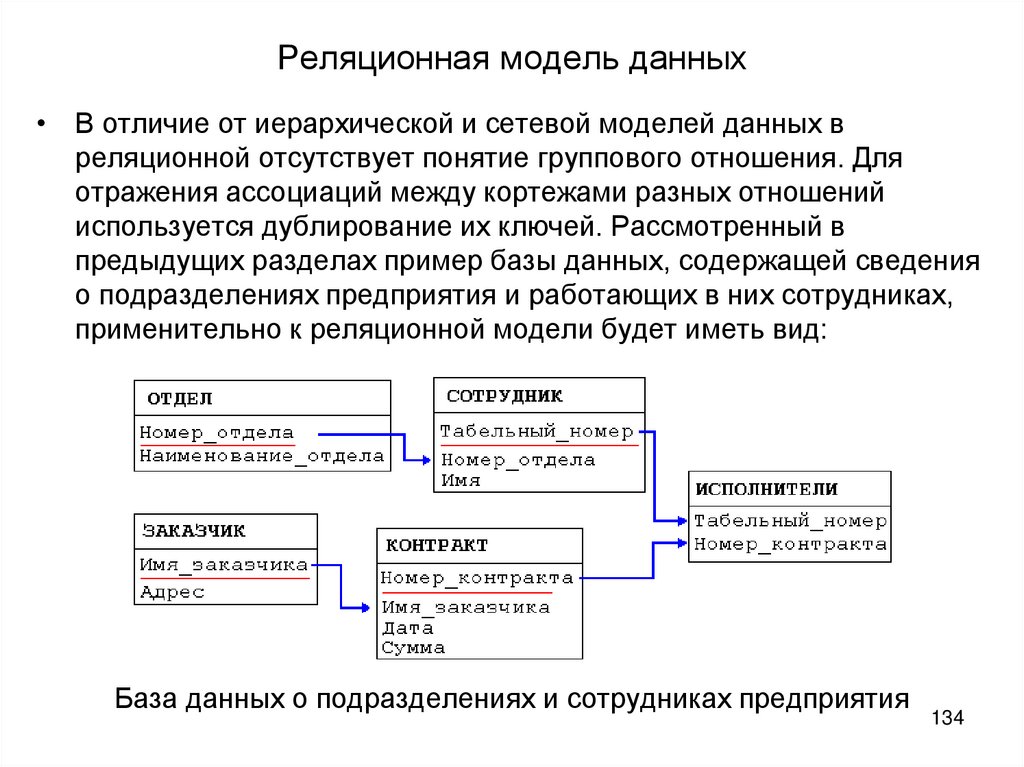
Кодд предложил язык для управления реляционными данными по имени Alpha, который повлиял на развитие более поздних языков БД. Двое коллег Кодда из IBM, Дональд Чемберлин и Рэймонд Бойс, создали свой язык, вдохновленный Alpha. Они назвали его SEQUEL (Structured English Query Language), но такая торговая марка уже существовала, и тогда они сократили название языка до SQL (Structured Query Language).
Из-за аппаратных ограничений ранние реляционные базы данных были очень медленными. Чтобы технология получила широкое распространение, потребовалось некоторое время. Но к середине 1980-х годов реляционная модель Кодда была реализована в ряде коммерческих продуктов для управления базами данных как от IBM, так и от ее конкурентов. Эти вендоры последовали примеру IBM, разработав и внедрив свои собственные диалекты SQL. К 1987 году и Американский национальный институт стандартов, и Международная организация по стандартизации ратифицировали и опубликовали стандарты для SQL, укрепив его статус как принятого языка для управления СУБД.
Благодаря такому широкому использованию реляционной модели во многих отраслях она стала стандартной моделью для управления данными. Даже с появлением баз данных NoSQL реляционные БД остаются доминирующими инструментами для хранения и организации данных.
Как реляционные БД организуют данные
Теперь у вас есть общее представление об истории развития реляционной модели. Давайте же подробнее рассмотрим, как модель организует данные.
Основными элементами реляционной модели являются отношения (relations), которые пользователи и современные РСУБД распознают как таблицы. Отношение – это набор кортежей или строк в таблице, где каждый кортеж имеет набор атрибутов или столбцов.
Столбец – это наименьшая организационная структура реляционной базы данных. Он представляет различные аспекты, определяющие записи в таблице. Отсюда их более формальное название – атрибуты. Вы можете рассматривать каждый кортеж как уникальный экземпляр любого типа ассоциаций, содержащихся в таблице. В качестве примера можно привести сотрудников компании, продажи в онлайн-бизнесе или результаты лабораторных тестов. Допустим, в таблице, содержащей записи о школьных учителях, кортежи могут иметь такие атрибуты, как name, subjects, start_date и т.п.
В качестве примера можно привести сотрудников компании, продажи в онлайн-бизнесе или результаты лабораторных тестов. Допустим, в таблице, содержащей записи о школьных учителях, кортежи могут иметь такие атрибуты, как name, subjects, start_date и т.п.
При создании столбцов нужно указать тип данных, который определяет, какие записи разрешено хранить в этом столбце. РСУБД часто поддерживают уникальные типы данных, которые не могут быть напрямую взаимозаменяемы с аналогичными типами данных в других системах. Но есть и общие типы данных, к которым относятся даты, строки, целые числа и логические значения.
В реляционной модели каждая таблица содержит по крайней мере один столбец, который можно использовать для однозначной идентификации каждой строки, он называется первичным ключом. Такой ключ важен, потому что позволяет пользователям не думать о том, где их данные хранятся физически; вместо этого СУБД будет отслеживать каждую запись и возвращать ее на разовой основе. В свою очередь, это значит, что записи не имеют определенного логического порядка, и пользователи имеют возможность возвращать свои данные в любом порядке или через любые доступные фильтры.
Если у вас есть две таблицы, которые вы хотите связать друг с другом, вы можете сделать это с помощью внешнего ключа. Внешний ключ – это, по сути, копия первичного ключа одной таблицы (родительской), вставленная в столбец другой таблицы (дочерней).
Если вы попытаетесь добавить запись в дочернюю таблицу, а значение, введенное в столбец внешнего ключа, не существует в первичном ключе родительской таблицы, оператор вставки будет недействительным. Это помогает поддерживать целостность на уровне отношений, поскольку строки в обеих таблицах всегда будут связаны правильно.
Структурные элементы реляционной модели помогают хранить данные в организованном порядке, но хранение данных как таковое полезно только в том случае, если вы можете их извлечь. Чтобы получить информацию из СУБД, вы можете отправить запрос. Как упоминалось ранее, для управления данными и запросов к ним большинство реляционных БД используют SQL. SQL позволяет фильтровать и управлять результатами запроса с помощью различных операторов, предикатов и выражений, давая нам точный контроль над тем, какие данные будут отображаться в наборе результатов.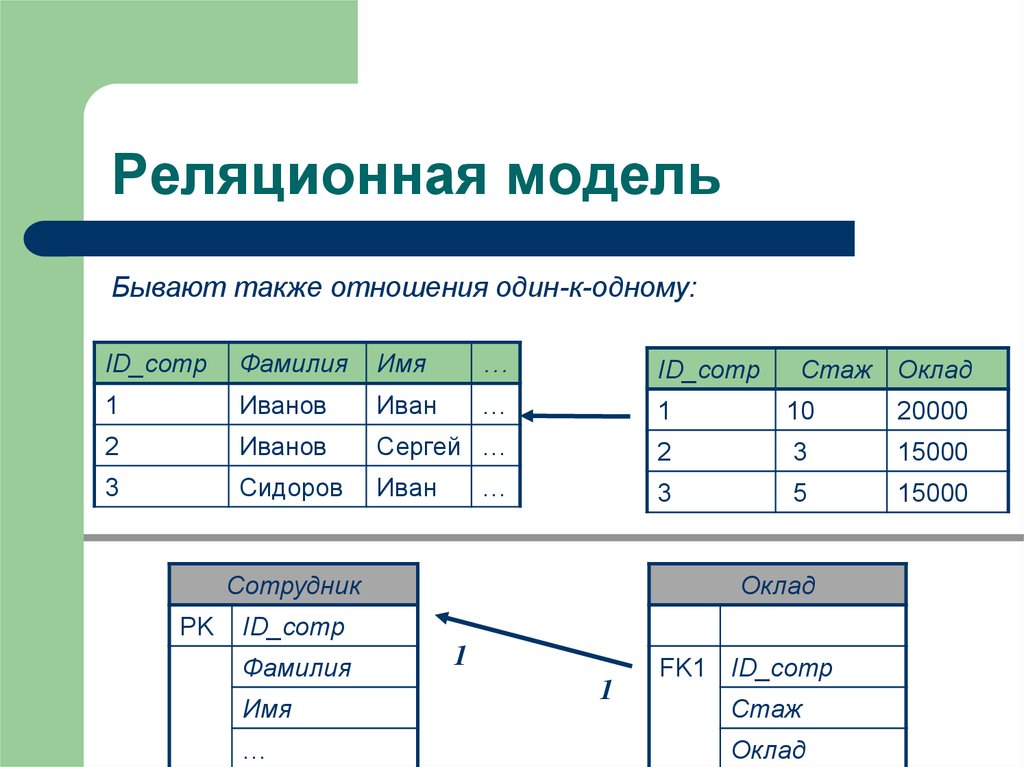
Преимущества и недостатки реляционных баз данных
Ознакомившись с организационной структурой реляционных баз данных, давайте теперь рассмотрим некоторые из их преимуществ и недостатков.
Современный SQL и базы данных, реализующие его, несколько отличаются от реляционной модели Кодда. Например, модель Кодда диктует, что каждая строка в таблице должна быть уникальной, в то время как из соображений практичности большинство современных РБД допускают дублирование строк. Некоторые пользователи не считают базу данных SQL «настоящей» реляционной базой, если она не соответствует каждой из спецификаций реляционной модели, описанной Коддом. Однако на практике любая СУБД, использующая SQL и хотя бы в некоторой степени придерживающаяся реляционной модели, скорее всего, будет относиться к РСУБД.
Популярность реляционных баз данных быстро росла, а вместе с этим росла и ценность данных. В связи с этим начали проявляться некоторые недостатки реляционной модели. Во-первых, реляционную базу данных сложно масштабировать по горизонтали.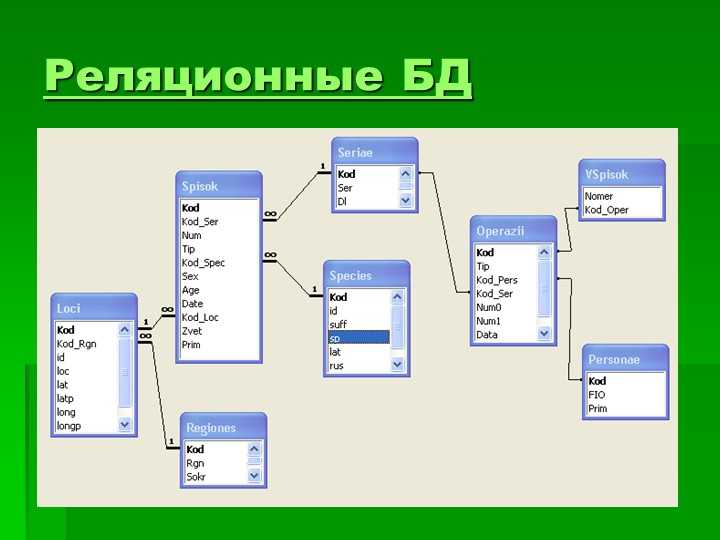 Горизонтальное масштабирование – это практика добавления новых машин к существующему стеку, чтобы распределить нагрузку и обеспечить более быструю обработку трафик.
Горизонтальное масштабирование – это практика добавления новых машин к существующему стеку, чтобы распределить нагрузку и обеспечить более быструю обработку трафик.
Примечание: Горизонтальное масштабирование часто противопоставляется вертикальному, которое подразумевает обновление оборудования существующего сервера (обычно путем добавления дополнительной оперативной памяти или процессора).
Причина, по которой реляционную базу данных сложно масштабировать по горизонтали, связана с тем фактом, что реляционная модель предназначена для обеспечения согласованности. Следовательно, клиенты, запрашивающие одну и ту же базу данных, всегда будут получать одни и те же данные. Но если реляционную базу данных масштабировать по горизонтали и разместить на нескольких машинах, ей становится сложно обеспечить согласованность, поскольку клиенты могут записывать данные на одну ноду, но не на другие. Вероятно, между внесением записи и ее отражением на других нодах пройдет некоторое время, а подобная задержка приведет к несогласованности данных.
Еще одно ограничение, представленное РСУБД, заключается в том, что реляционная модель была разработана для управления структурированными данными (то есть данными, которые соответствуют предопределенному типу или, по крайней мере, организованы некоторым заранее определенным образом, благодаря чему их легко сортировать и искать). Однако с распространением персональных компьютеров и появлением Интернета в начале 1990-х годов широкое распространение получили неструктурированные данные (сообщения электронной почты, фотографии, видео и т.п.).
Конечно, ничто из вышеописанного не означает, что реляционные базы данных бесполезны. Напротив, даже по прошествии более 50 лет реляционная модель по-прежнему остается доминирующей структурой для управления данными. Ее распространенность и долговечность означают, что реляционные базы данных – зрелая технология, что само по себе является одним из их основных преимуществ. Существует множество приложений, предназначенных для работы с реляционной моделью, а также множество профессионалов и экспертов в области реляционных баз данных.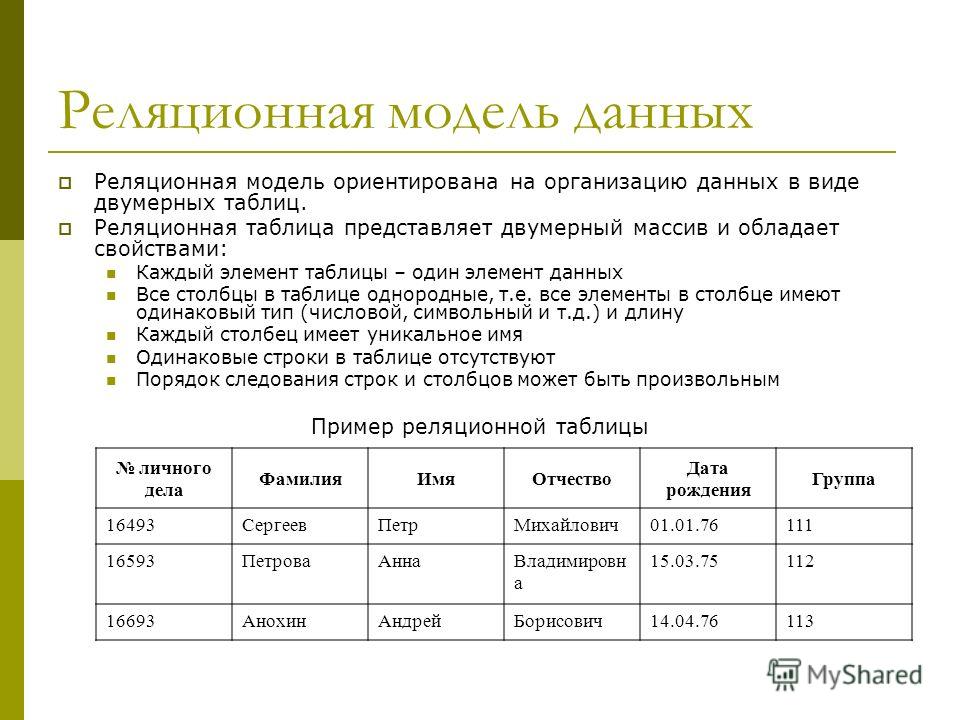 Для тех же, кто хочет начать работу с РДБ, доступен широкий спектр самых разных обучающих и справочных ресурсов.
Для тех же, кто хочет начать работу с РДБ, доступен широкий спектр самых разных обучающих и справочных ресурсов.
Еще одно преимущество реляционных баз данных состоит в том, что почти каждая СУБД поддерживает транзакции. Транзакция состоит из одного или нескольких отдельных SQL-операторов, выполняемых последовательно как единая задача. Транзакции представляют собой подход «все или ничего»: каждый SQL-оператор в транзакции должен быть действительным; в противном случае вся транзакция не будет выполнена. Это обеспечивает целостность данных при внесении изменений в несколько строк или таблиц.
В конце концов, реляционные базы данных чрезвычайно гибки. Они использовались для создания множества приложений и по сей день эффективно справляются даже с очень большими объемами данных. SQL также является чрезвычайно мощным инструментом, он позволяет добавлять и изменять данные на ходу, а также менять структуру схем и таблиц БД, не влияя на существующие данные.
Заключение
Благодаря своей гибкости и дизайну, обеспечивающему целостность данных, даже спустя более 50 лет после выхода реляционные БД остаются основным способом управления и хранения данных. Сегодня существуют более современные базы данных NoSQL, но несмотря на это умение работать с реляционной моделью является ключевым моментом для любого, кто хочет создавать приложения.
Сегодня существуют более современные базы данных NoSQL, но несмотря на это умение работать с реляционной моделью является ключевым моментом для любого, кто хочет создавать приложения.
Читайте также: Краткий обзор реляционных систем управления базами данных
Tags: SQLЧто такое реляционная база данных
Реляционная база данных — это тип базы данных, в которой хранятся точки данных, связанные друг с другом, и предоставляется доступ к ним. Реляционные базы данных основаны на реляционной модели — интуитивно понятном и простом способе представления данных в таблицах. В реляционной базе данных каждая строка таблицы представляет собой запись с уникальным идентификатором, называемым ключом. Столбцы таблицы содержат атрибуты данных, и каждая запись обычно имеет значение для каждого атрибута, что упрощает установление отношений между точками данных.
Лучшая в отрасли RBDMS
Пример реляционной базы данных
Вот простой пример двух таблиц, которые малый бизнес может использовать для обработки заказов на свою продукцию. Первая таблица — это таблица информации о клиенте, поэтому каждая запись включает имя клиента, адрес, информацию о доставке и выставлении счетов, номер телефона и другую контактную информацию. Каждый бит информации (каждый атрибут) находится в своем собственном столбце, и база данных присваивает каждой строке уникальный идентификатор (ключ). Во второй таблице — таблице заказов клиентов — каждая запись включает идентификатор клиента, разместившего заказ, заказанный продукт, количество, выбранный размер и цвет и т. д., но не имя клиента или контактную информацию.
Первая таблица — это таблица информации о клиенте, поэтому каждая запись включает имя клиента, адрес, информацию о доставке и выставлении счетов, номер телефона и другую контактную информацию. Каждый бит информации (каждый атрибут) находится в своем собственном столбце, и база данных присваивает каждой строке уникальный идентификатор (ключ). Во второй таблице — таблице заказов клиентов — каждая запись включает идентификатор клиента, разместившего заказ, заказанный продукт, количество, выбранный размер и цвет и т. д., но не имя клиента или контактную информацию.
Эти две таблицы имеют только одну общую черту: столбец ID (ключ). Но благодаря этому общему столбцу реляционная база данных может создать связь между двумя таблицами. Затем, когда приложение обработки заказов компании отправляет заказ в базу данных, база данных может перейти к таблице заказов клиентов, получить правильную информацию о заказе продукта и использовать идентификатор клиента из этой таблицы для поиска счетов и доставки клиента. информация в информационной таблице клиента. Затем склад может получить правильный продукт, клиент может получить своевременную доставку заказа, а компания может получить оплату.
информация в информационной таблице клиента. Затем склад может получить правильный продукт, клиент может получить своевременную доставку заказа, а компания может получить оплату.
Структура реляционных баз данных
Реляционная модель означает, что логические структуры данных — таблицы данных, представления и индексы — отделены от физических структур хранения. Это разделение означает, что администраторы баз данных могут управлять физическим хранилищем данных, не затрагивая доступ к этим данным как к логической структуре. Например, переименование файла базы данных не приводит к переименованию хранящихся в нем таблиц.
Различие между логическими и физическими также применяется к операциям базы данных, которые представляют собой четко определенные действия, позволяющие приложениям манипулировать данными и структурами базы данных. Логические операции позволяют приложению указывать необходимое ему содержимое, а физические операции определяют, как следует обращаться к этим данным, а затем выполняют задачу.
Чтобы данные всегда были точными и доступными, реляционные базы данных следуют определенным правилам целостности. Например, правило целостности может указать, что повторяющиеся строки не разрешены в таблице, чтобы исключить возможность ввода ошибочной информации в базу данных.
Реляционная модель
В первые годы существования баз данных каждое приложение хранило данные в собственной уникальной структуре. Когда разработчики хотели создавать приложения для использования этих данных, им нужно было много знать о конкретной структуре данных, чтобы найти нужные данные. Эти структуры данных были неэффективны, их было сложно поддерживать и трудно оптимизировать для обеспечения хорошей производительности приложений. Модель реляционной базы данных была разработана для решения проблемы множества произвольных структур данных.
Реляционная модель данных обеспечивает стандартный способ представления и запроса данных, который может использоваться любым приложением. С самого начала разработчики осознавали, что главная сила модели реляционной базы данных заключалась в использовании таблиц, которые представляли собой интуитивно понятный, эффективный и гибкий способ хранения структурированной информации и доступа к ней.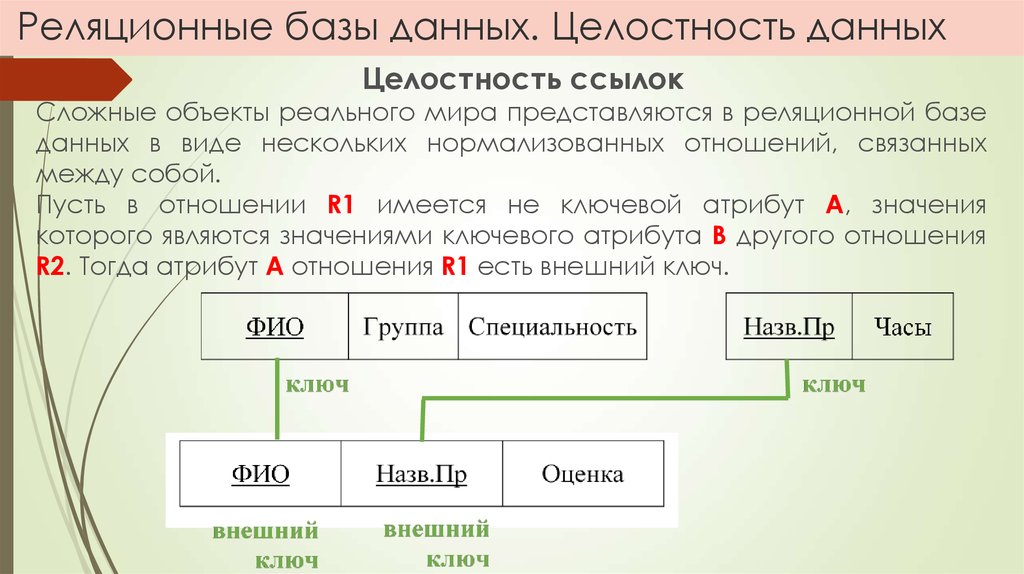
Со временем появилась еще одна сильная сторона реляционной модели, поскольку разработчики начали использовать язык структурированных запросов (SQL) для записи и запроса данных в базе данных. В течение многих лет SQL широко использовался в качестве языка запросов к базе данных. Основанный на реляционной алгебре, SQL предоставляет внутренне согласованный математический язык, который упрощает повышение производительности всех запросов к базе данных. Для сравнения, другие подходы должны определять отдельные запросы.
Преимущества системы управления реляционными базами данных
Простая, но мощная реляционная модель используется организациями всех типов и размеров для самых разнообразных информационных потребностей. Реляционные базы данных используются для отслеживания запасов, обработки транзакций электронной торговли, управления огромными объемами критически важной информации о клиентах и многого другого. Реляционная база данных может рассматриваться для любой потребности в информации, в которой точки данных связаны друг с другом и должны управляться безопасным, основанным на правилах и согласованным способом.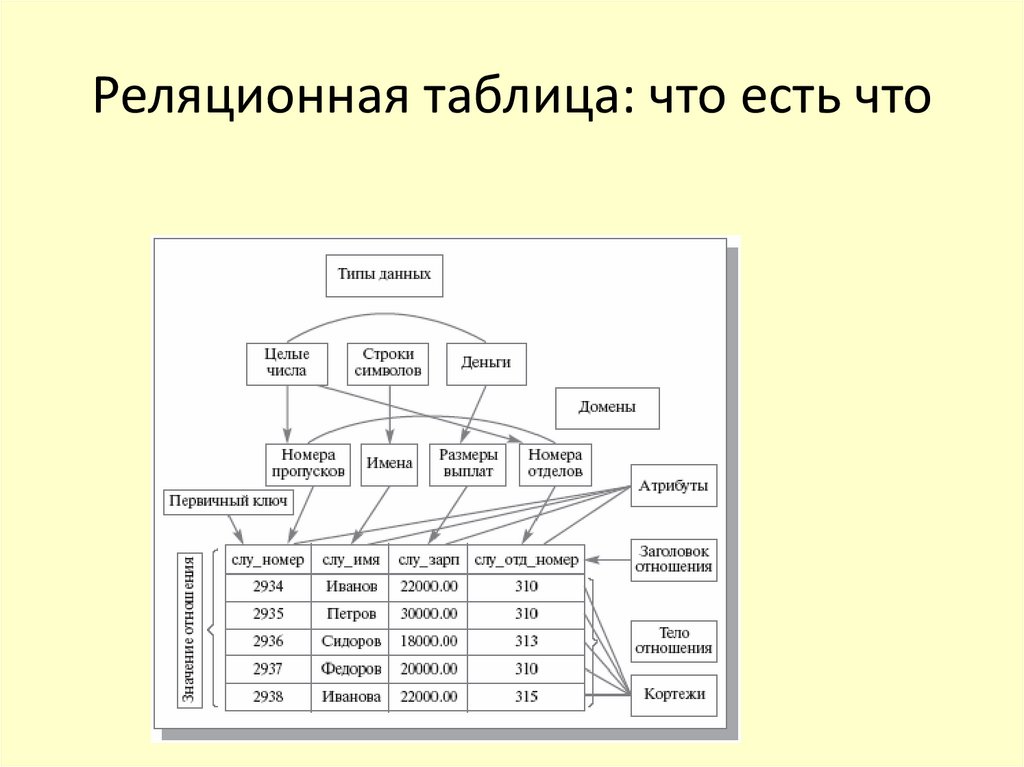
Реляционные базы данных существуют с 1970-х годов. Сегодня преимущества реляционной модели продолжают делать ее наиболее широко используемой моделью для баз данных.
Реляционная модель и согласованность данных
Реляционная модель лучше всего обеспечивает согласованность данных в приложениях и копиях баз данных (называемых экземплярами). Например, когда клиент вносит деньги в банкомат, а затем просматривает баланс счета на мобильном телефоне, клиент ожидает, что этот депозит будет немедленно отражен в обновленном балансе счета. Реляционные базы данных превосходны в такой согласованности данных, гарантируя, что несколько экземпляров базы данных всегда будут иметь одни и те же данные.
Для других типов баз данных сложно поддерживать такой уровень своевременной согласованности с большими объемами данных. Некоторые современные базы данных, такие как NoSQL, могут обеспечивать только «согласованность в конечном итоге». В соответствии с этим принципом, когда база данных масштабируется или когда несколько пользователей одновременно обращаются к одним и тем же данным, данным требуется некоторое время, чтобы «наверстать упущенное». Возможная непротиворечивость приемлема для некоторых целей, например для ведения списков в каталоге продуктов, но для важных бизнес-операций, таких как операции с корзиной покупок, реляционная база данных по-прежнему остается золотым стандартом.
Возможная непротиворечивость приемлема для некоторых целей, например для ведения списков в каталоге продуктов, но для важных бизнес-операций, таких как операции с корзиной покупок, реляционная база данных по-прежнему остается золотым стандартом.
Приверженность и атомарность
Реляционные базы данных обрабатывают бизнес-правила и политики на очень детальном уровне, со строгими политиками в отношении обязательности (то есть, делая изменения в базе данных постоянными). Например, рассмотрим базу данных инвентаризации, которая отслеживает три детали, которые всегда используются вместе. Когда одна часть вытягивается из инвентаря, две другие тоже должны вытягиваться. Если одна из трех частей недоступна, ни одна из частей не должна быть извлечена — все три части должны быть доступны до того, как база данных примет какое-либо обязательство. Реляционная база данных не будет фиксировать одну часть, пока не узнает, что может фиксировать все три. Эта многогранная возможность обязательства называется атомарностью. Атомарность — это ключ к поддержанию точности данных в базе данных и обеспечению их соответствия правилам, положениям и политикам бизнеса.
Атомарность — это ключ к поддержанию точности данных в базе данных и обеспечению их соответствия правилам, положениям и политикам бизнеса.
Свойства ACID и РСУБД
Четыре важнейших свойства определяют транзакции реляционной базы данных: атомарность, непротиворечивость, изоляция и устойчивость — обычно называемые ACID.
- Атомарность определяет все элементы, составляющие полную транзакцию базы данных.
- Согласованность определяет правила поддержания точек данных в правильном состоянии после транзакции.
- Изоляция сохраняет эффект транзакции невидимым для других, пока она не будет зафиксирована, чтобы избежать путаницы.
- Долговечность гарантирует, что изменения данных станут постоянными после фиксации транзакции.
Хранимые процедуры и реляционные базы данных
Доступ к данным включает множество повторяющихся действий. Например, простой запрос на получение информации из таблицы данных может потребоваться повторить сотни или тысячи раз, чтобы получить желаемый результат. Эти функции доступа к данным требуют некоторого типа кода для доступа к базе данных. Разработчики приложений не хотят писать новый код для этих функций в каждом новом приложении. К счастью, реляционные базы данных допускают хранимые процедуры, представляющие собой блоки кода, доступ к которым можно получить с помощью простого вызова приложения. Например, одна хранимая процедура может обеспечить согласованную маркировку записей для пользователей нескольких приложений. Хранимые процедуры также могут помочь разработчикам убедиться, что определенные функции данных в приложении реализованы определенным образом.
Эти функции доступа к данным требуют некоторого типа кода для доступа к базе данных. Разработчики приложений не хотят писать новый код для этих функций в каждом новом приложении. К счастью, реляционные базы данных допускают хранимые процедуры, представляющие собой блоки кода, доступ к которым можно получить с помощью простого вызова приложения. Например, одна хранимая процедура может обеспечить согласованную маркировку записей для пользователей нескольких приложений. Хранимые процедуры также могут помочь разработчикам убедиться, что определенные функции данных в приложении реализованы определенным образом.
Блокировка базы данных и параллелизм
Конфликты могут возникать в базе данных, когда несколько пользователей или приложений пытаются изменить одни и те же данные одновременно. Методы блокировки и параллелизма снижают вероятность конфликтов, сохраняя при этом целостность данных.
Блокировка предотвращает доступ других пользователей и приложений к данным во время их обновления. В некоторых базах данных блокировка применяется ко всей таблице, что отрицательно сказывается на производительности приложения. Другие базы данных, такие как реляционные базы данных Oracle, применяют блокировки на уровне записей, оставляя другие записи в таблице доступными, что помогает повысить производительность приложений.
В некоторых базах данных блокировка применяется ко всей таблице, что отрицательно сказывается на производительности приложения. Другие базы данных, такие как реляционные базы данных Oracle, применяют блокировки на уровне записей, оставляя другие записи в таблице доступными, что помогает повысить производительность приложений.
Параллелизм управляет активностью, когда несколько пользователей или приложений одновременно вызывают запросы к одной и той же базе данных. Эта возможность обеспечивает правильный доступ для пользователей и приложений в соответствии с политиками, определенными для управления данными.
На что обратить внимание при выборе реляционной базы данных
Программное обеспечение, используемое для хранения, управления, запроса и извлечения данных, хранящихся в реляционной базе данных, называется системой управления реляционной базой данных (RDBMS). РСУБД обеспечивает интерфейс между пользователями, приложениями и базой данных, а также административные функции для управления хранением данных, доступом и производительностью.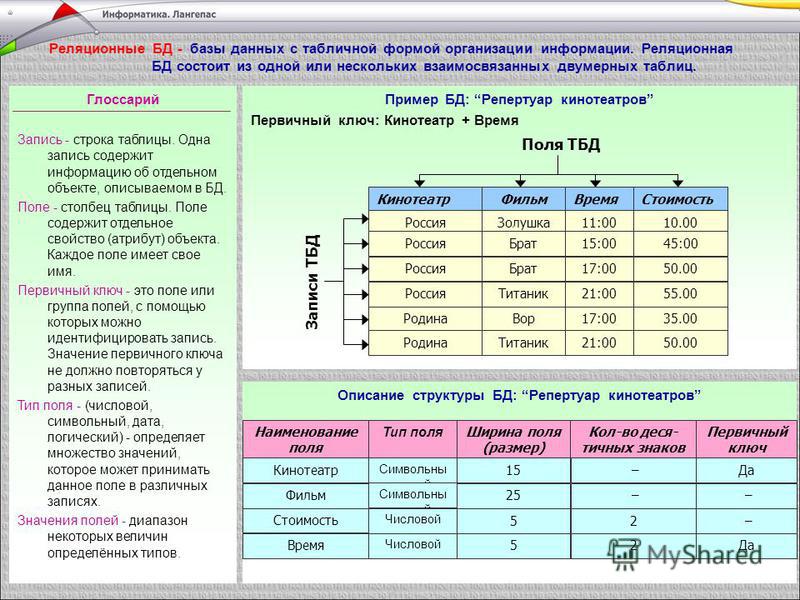
Несколько факторов могут повлиять на ваше решение при выборе между типами баз данных и продуктами реляционных баз данных. Выбранная вами СУБД будет зависеть от потребностей вашего бизнеса. Задайте себе следующие вопросы:
- Каковы наши требования к точности данных? Будут ли хранение и точность данных зависеть от бизнес-логики? Есть ли у наших данных строгие требования к точности (например, финансовые данные и правительственные отчеты)?
- Нужна ли нам масштабируемость? Каков масштаб данных, которыми нужно управлять, и каков их ожидаемый рост? Должна ли модель базы данных поддерживать зеркальные копии базы данных (как отдельные экземпляры) для масштабируемости? Если да, то может ли он поддерживать согласованность данных в этих экземплярах?
- Насколько важен параллелизм? Потребуется ли нескольким пользователям и приложениям одновременный доступ к данным? Поддерживает ли программное обеспечение базы данных параллелизм при защите данных?
- Каковы наши потребности в производительности и надежности? Нужен ли нам высокопроизводительный и надежный продукт? Каковы требования к производительности запроса-ответа? Каковы обязательства поставщика по соглашениям об уровне обслуживания (SLA) или незапланированным простоям?
Реляционная база данных будущего: самоуправляемая база данных
За прошедшие годы реляционные базы данных стали лучше, быстрее, надежнее и с ними стало проще работать. Но они также стали более сложными, и администрирование базы данных уже давно стало работой на полный рабочий день. Вместо того чтобы использовать свой опыт для разработки инновационных приложений, приносящих пользу бизнесу, разработчикам приходилось тратить большую часть своего времени на действия по управлению, необходимые для оптимизации производительности базы данных.
Но они также стали более сложными, и администрирование базы данных уже давно стало работой на полный рабочий день. Вместо того чтобы использовать свой опыт для разработки инновационных приложений, приносящих пользу бизнесу, разработчикам приходилось тратить большую часть своего времени на действия по управлению, необходимые для оптимизации производительности базы данных.
Сегодня автономная технология опирается на сильные стороны реляционной модели, технологии облачных баз данных и машинного обучения, чтобы создать реляционную базу данных нового типа. Автономная база данных (также известная как автономная база данных) поддерживает мощь и преимущества реляционной модели, но использует искусственный интеллект (ИИ), машинное обучение и автоматизацию для мониторинга и повышения производительности запросов и задач управления. Например, чтобы повысить производительность запросов, автономная база данных может выдвигать гипотезы и тестировать индексы, чтобы выполнять запросы быстрее, а затем запускать лучшие из них в рабочую среду — и все это самостоятельно.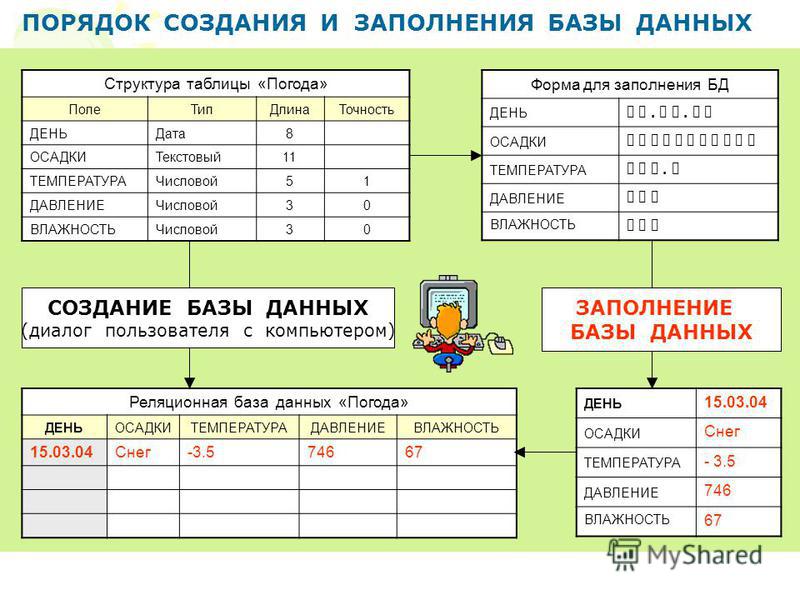 База данных с самостоятельным вождением непрерывно вносит эти улучшения без участия человека.
База данных с самостоятельным вождением непрерывно вносит эти улучшения без участия человека.
Автономная технология освобождает разработчиков от рутинных задач по управлению базой данных. Например, им больше не нужно заранее определять требования к инфраструктуре. Вместо этого с автономной базой данных они могут добавлять ресурсы хранения и вычислений по мере необходимости для поддержки роста базы данных. Всего за несколько шагов разработчики могут легко создать автономную реляционную базу данных, что сокращает время разработки приложений.
Узнайте больше о Oracle RDBMS Database
Что такое реляционная база данных? – Amazon Web Services (AWS)
Реляционная база данных представляет собой набор элементов данных с предопределенными отношениями между ними. Эти элементы организованы в виде набора таблиц со столбцами и строками. Таблицы используются для хранения информации об объектах, которые должны быть представлены в базе данных.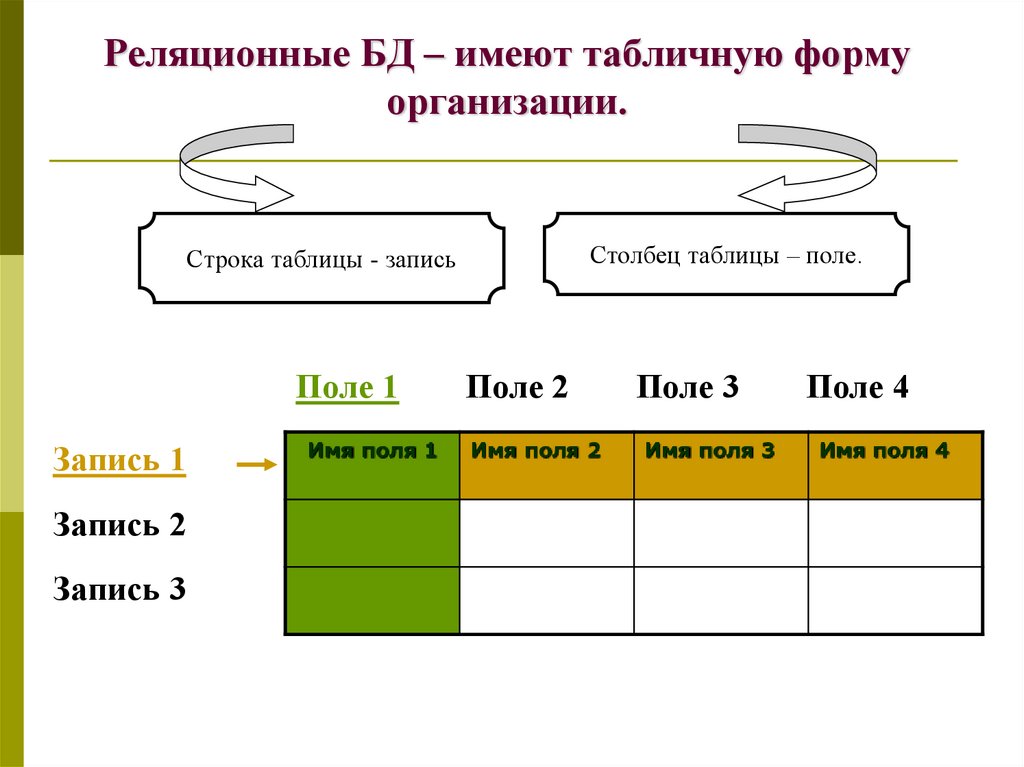 Каждый столбец в таблице содержит определенный тип данных, а поле хранит фактическое значение атрибута. Строки в таблице представляют набор связанных значений одного объекта или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки в нескольких таблицах могут быть связаны с помощью внешних ключей. Доступ к этим данным можно получить различными способами без реорганизации самих таблиц базы данных.
Каждый столбец в таблице содержит определенный тип данных, а поле хранит фактическое значение атрибута. Строки в таблице представляют набор связанных значений одного объекта или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки в нескольких таблицах могут быть связаны с помощью внешних ключей. Доступ к этим данным можно получить различными способами без реорганизации самих таблиц базы данных.
6:44
Понимание Amazon Relational Database Service (RDS) SQL или язык структурированных запросов — это основной интерфейс, используемый для связи с реляционными базами данных. SQL стал стандартом Американского национального института стандартов (ANSI) в 1986 году. Стандарт ANSI SQL поддерживается всеми популярными механизмами реляционных баз данных, и некоторые из этих механизмов также имеют расширение ANSI SQL для поддержки функций, специфичных для этого механизма.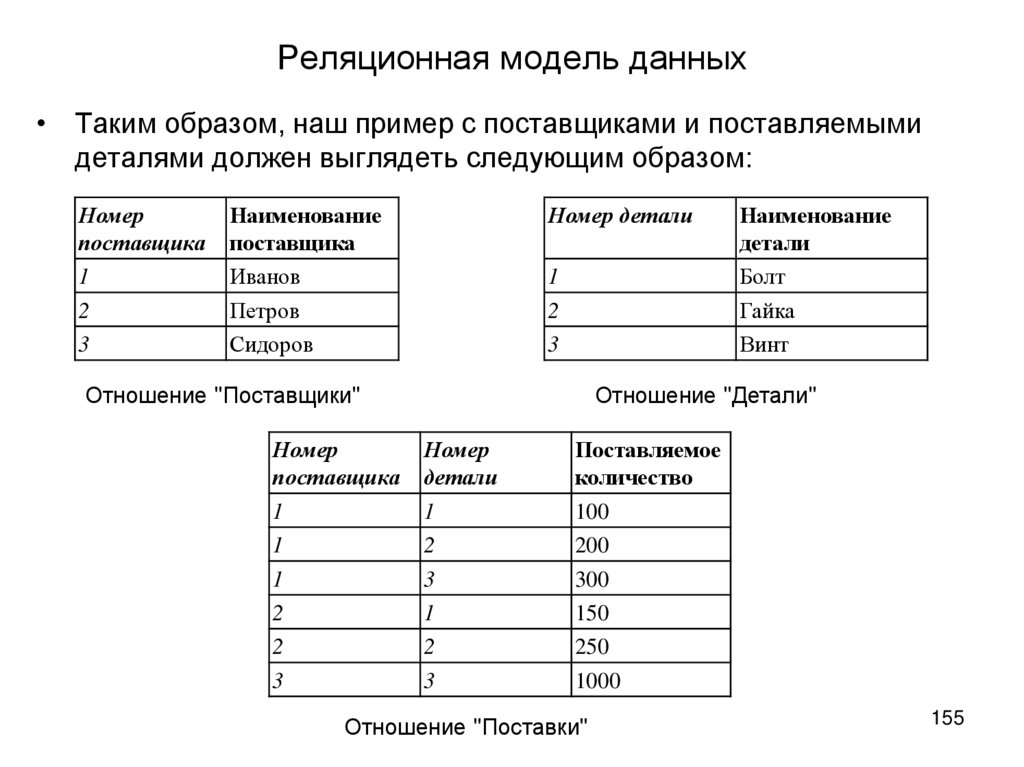 SQL используется для добавления, обновления или удаления строк данных, извлечения подмножеств данных для приложений обработки транзакций и аналитики, а также для управления всеми аспектами базы данных.
SQL используется для добавления, обновления или удаления строк данных, извлечения подмножеств данных для приложений обработки транзакций и аналитики, а также для управления всеми аспектами базы данных.
Целостность данных
Целостность данных — это полная полнота, точность и согласованность данных. Реляционные базы данных используют набор ограничений для обеспечения целостности данных в базе данных. К ним относятся первичные ключи, внешние ключи, ограничение «Not NULL», ограничение «Unique», ограничение «Default» и ограничение «Check». Эти ограничения целостности помогают применять бизнес-правила к данным в таблицах для обеспечения точности и надежности данных. В дополнение к этому, большинство реляционных баз данных также позволяют встраивать пользовательский код в триггеры, которые выполняются на основе действия в базе данных.
Транзакции
Транзакция базы данных — это один или несколько операторов SQL, которые выполняются как последовательность операций, формирующих единую логическую единицу работы. Транзакции обеспечивают предложение «все или ничего», что означает, что вся транзакция должна завершиться как единое целое и быть записана в базу данных, иначе ни один из отдельных компонентов транзакции не должен пройти. В терминологии реляционной базы данных результатом транзакции является COMMIT или ROLLBACK. Каждая транзакция обрабатывается последовательно и надежно независимо от других транзакций.
Транзакции обеспечивают предложение «все или ничего», что означает, что вся транзакция должна завершиться как единое целое и быть записана в базу данных, иначе ни один из отдельных компонентов транзакции не должен пройти. В терминологии реляционной базы данных результатом транзакции является COMMIT или ROLLBACK. Каждая транзакция обрабатывается последовательно и надежно независимо от других транзакций.
Соответствие ACID
Все транзакции базы данных должны быть совместимы с ACID или быть атомарными, непротиворечивыми, изолированными и устойчивыми для обеспечения целостности данных.
Атомарность требует, чтобы либо транзакция в целом была успешно выполнена, либо в случае сбоя части транзакции вся транзакция была признана недействительной. Согласованность требует, чтобы данные, записываемые в базу данных как часть транзакции, соответствовали всем определенным правилам и ограничениям, включая ограничения, каскады и триггеры. Изоляция имеет решающее значение для достижения контроля параллелизма и гарантирует, что каждая транзакция независима сама от себя. Долговечность требует, чтобы все изменения, внесенные в базу данных, были постоянными после успешного завершения транзакции.
Долговечность требует, чтобы все изменения, внесенные в базу данных, были постоянными после успешного завершения транзакции.
Amazon Aurora
Amazon Aurora — это движок реляционной базы данных, совместимый с MySQL и PostgreSQL, который сочетает в себе скорость и доступность высококачественных коммерческих баз данных с простотой и экономичностью баз данных с открытым исходным кодом. Amazon Aurora обеспечивает до пяти раз более высокую производительность, чем MySQL, а также безопасность, доступность и надежность коммерческой базы данных при стоимости в десять раз меньше. Узнать больше »
Oracle
Amazon RDS позволяет развертывать несколько выпусков базы данных Oracle за считанные минуты с помощью экономически эффективных и масштабируемых аппаратных ресурсов. Вы можете использовать существующие лицензии Oracle или платить за использование лицензий по часам. RDS позволяет вам сосредоточиться на разработке приложений, управляя сложными задачами администрирования базы данных, включая выделение ресурсов, резервное копирование, установку исправлений, мониторинг и масштабирование оборудования.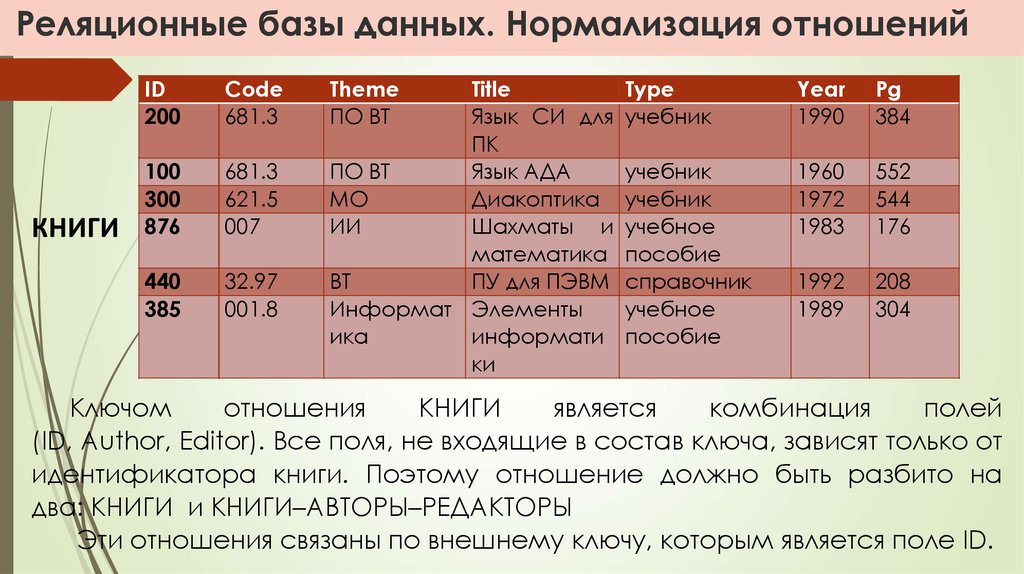 Узнать больше »
Узнать больше »
Microsoft SQL Server
Amazon RDS для SQL Server упрощает настройку, эксплуатацию и масштабирование SQL Server в облаке. Вы можете развернуть несколько выпусков SQL Server, включая Express, Web, Standard и Enterprise. Поскольку Amazon RDS для SQL Server предоставляет вам прямой доступ к собственным возможностям SQL Server, ваши приложения и инструменты должны работать без каких-либо изменений. Узнать больше »
MySQL — это система управления реляционными базами данных (RDBMS) с открытым исходным кодом, используемая очень большим количеством веб-приложений. Amazon RDS для MySQL предоставляет вам доступ к возможностям знакомого ядра базы данных MySQL. Это означает, что код, приложения и инструменты, которые вы уже используете сегодня с существующими базами данных, можно использовать с Amazon RDS без каких-либо изменений. Узнать больше »
PostgreSQL
PostgreSQL — это мощная система объектно-реляционных баз данных корпоративного класса с открытым исходным кодом, ориентированная на расширяемость и соответствие стандартам. PostgreSQL может похвастаться множеством сложных функций и запускает хранимые процедуры более чем на дюжине языков программирования, включая Java, Perl, Python, Ruby, Tcl, C/C++ и собственный PL/pgSQL, аналогичный PL/SQL Oracle. Узнать больше »
PostgreSQL может похвастаться множеством сложных функций и запускает хранимые процедуры более чем на дюжине языков программирования, включая Java, Perl, Python, Ruby, Tcl, C/C++ и собственный PL/pgSQL, аналогичный PL/SQL Oracle. Узнать больше »
MariaDB
MariaDB — это MySQL-совместимая база данных, которая является ответвлением MySQL и разрабатывается первоначальными разработчиками MySQL. Amazon RDS упрощает настройку, эксплуатацию и масштабирование развертываний MariaDB в облаке. С помощью Amazon RDS вы можете за считанные минуты развернуть масштабируемые базы данных MariaDB, используя экономичную аппаратную емкость с изменяемым размером. Узнать больше »
Начать работу с Amazon RDS просто. Следуйте нашему Руководству по началу работы, чтобы создать свой первый инстанс Amazon RDS за несколько кликов.
Поддержка AWS для Internet Explorer заканчивается 31.07.2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
Подробнее »
Что такое реляционная база данных?
По
- Бен Луткевич, Технический писатель
- Жаклин Бискобинг, Старший управляющий редактор, Новости
Реляционная база данных — это набор информации, который организует точки данных с определенными отношениями для легкого доступа. В модели реляционной базы данных структуры данных, включая таблицы данных, индексы и представления, остаются отдельными от структур физического хранилища, что позволяет администраторам баз данных редактировать физическое хранилище данных, не затрагивая логическую структуру данных.
На предприятии реляционные базы данных используются для организации данных и определения взаимосвязей между ключевыми точками данных. Они упрощают сортировку и поиск информации, что помогает организациям более эффективно принимать бизнес-решения и минимизировать затраты. Они хорошо работают со структурированными данными.
Они хорошо работают со структурированными данными.
Таблицы данных, используемые в реляционной базе данных, хранят информацию о связанных объектах. Каждая строка содержит запись с уникальным идентификатором, известным как ключ, а каждый столбец содержит атрибуты данных. Каждая запись присваивает значение каждой функции, что упрощает определение отношений между точками данных.
Стандартным интерфейсом пользователя и прикладной программы (API) реляционной базы данных является язык структурированных запросов. Операторы кода SQL используются как для интерактивных запросов информации из реляционной базы данных, так и для сбора данных для отчетов. Для обеспечения точности и доступности реляционной базы данных необходимо соблюдать определенные правила целостности данных.
 techtarget.com/searchdatamanagement/definition/relational-database&enablejsapi=1&origin=https://www.techtarget.com» type=»text/html» frameborder=»0″> Какова структура модели реляционной базы данных?
techtarget.com/searchdatamanagement/definition/relational-database&enablejsapi=1&origin=https://www.techtarget.com» type=»text/html» frameborder=»0″> Какова структура модели реляционной базы данных?Э. Ф. Кодд, в то время молодой программист в IBM, изобрел реляционную базу данных в 1970 году. В своей статье «Реляционная модель данных для больших общих банков данных» Кодд предложил перейти от хранения данных в иерархических или навигационных структурах к организации данных в таблицы, содержащие строки и столбцы.
Каждая таблица, иногда называемая отношением , в реляционной базе данных содержит одну или несколько категорий данных в столбцах или атрибуты . Каждая строка, также называемая записью или кортежем , содержит уникальный экземпляр данных — или ключ — для категорий, определенных столбцами. Каждая таблица имеет уникальный первичный ключ, который идентифицирует информацию в таблице. Отношения между таблицами можно установить с помощью внешних ключей — поля в таблице, которое ссылается на первичный ключ другой таблицы.
Отношения между таблицами можно установить с помощью внешних ключей — поля в таблице, которое ссылается на первичный ключ другой таблицы.
Например, типичная база данных записей бизнес-заказов будет включать таблицу, описывающую клиента, со столбцами для имени, адреса, номера телефона и т. д. Другая таблица будет описывать заказ, включая такую информацию, как продукт, клиент, дата и цена продажи.
Пользователь может получить отчет базы данных, содержащий необходимые ему данные. Например, менеджеру филиала может потребоваться отчет обо всех клиентах, купивших товары после определенной даты. Менеджер по финансовым услугам в той же компании может из тех же таблиц получить отчет о счетах, которые необходимо оплатить.
При создании реляционной базы данных пользователи определяют область возможных значений в столбце данных и ограничения, которые могут применяться к этому значению данных.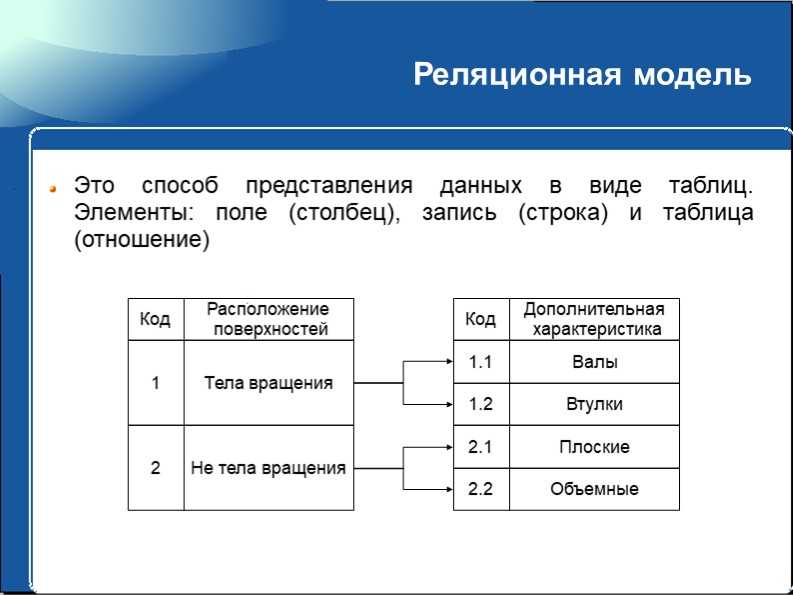 Например, домен возможных клиентов может допускать до 10 возможных имен клиентов, но в одной таблице он ограничен возможностью указания только трех из этих имен клиентов.
Например, домен возможных клиентов может допускать до 10 возможных имен клиентов, но в одной таблице он ограничен возможностью указания только трех из этих имен клиентов.
Два ограничения относятся к целостности данных и первичным и внешним ключам:
- Целостность объекта гарантирует, что первичный ключ в таблице уникален и его значение не равно нулю.
- Ссылочная целостность требует, чтобы каждое значение в столбце внешнего ключа находилось в первичном ключе таблицы, из которой оно произошло.
Кроме того, реляционные базы данных обладают физической независимостью от данных. Это относится к способности системы вносить изменения во внутреннюю схему без изменения внешних схем или прикладных программ. Изменения внутренней схемы могут включать следующее:
- использование новых запоминающих устройств;
- изменение индексов;
- переход с определенного метода доступа на другой;
- с использованием разных структур данных; и
- с использованием различных структур хранения или организации файлов.

Независимость от логических данных — это способность системы управлять концептуальной схемой без изменения внешней схемы или прикладных программ. Концептуальные изменения схемы могут включать добавление или удаление новых отношений, сущностей или атрибутов без изменения существующих внешних схем или переписывания прикладных программ.
Какие существуют типы баз данных?Существует несколько категорий баз данных, от простых плоских файлов, которые не являются реляционными, до NoSQL и более новых графовых баз данных, которые считаются еще более реляционными, чем стандартные реляционные базы данных. Некоторые типы баз данных включают следующие:
База данных плоских файлов. Эти базы данных состоят из одной таблицы данных, между которыми нет взаимосвязи — обычно это текстовые файлы. Этот тип файла позволяет пользователям указывать атрибуты данных, такие как столбцы и типы данных.
Узнайте о преимуществах и недостатках плоских файлов и реляционных баз данных.
База данных NoSQL. Этот тип базы данных является альтернативой, которая особенно полезна для больших распределенных наборов данных. Базы данных NoSQL поддерживают различные модели данных, включая форматы «ключ-значение», «документ», «столбец» и «график».
Графическая база данных. Выход за рамки традиционных моделей реляционных данных на основе столбцов и строк; эта база данных NoSQL использует узлы и ребра, которые представляют связи между отношениями данных и могут обнаруживать новые отношения между данными. Графовые базы данных более сложны, чем реляционные базы данных. Они используются для обнаружения мошенничества или механизмов веб-рекомендаций.
Сравните графовые и реляционные базы данных. Объектно-реляционная база данных (ORD). ORD состоит как из системы управления реляционной базой данных (RDBMS), так и из системы управления объектно-ориентированной базой данных (OODBMS).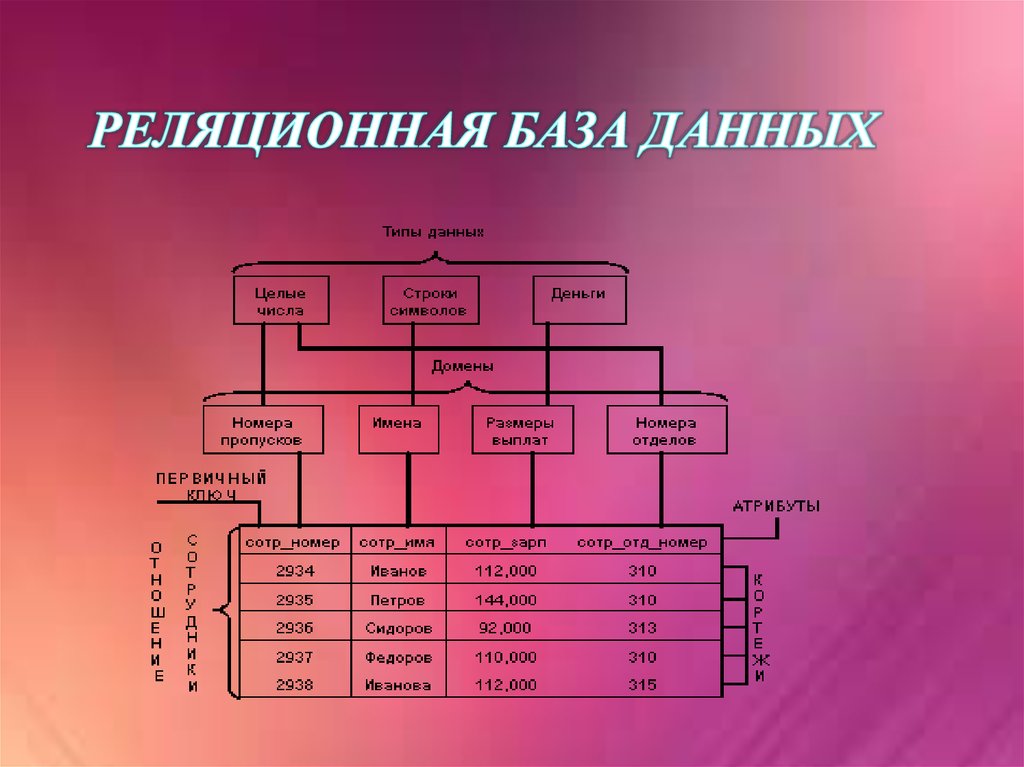 Он содержит характеристики моделей РСУБД и ООСУБД. Для хранения данных используется традиционная база данных. Затем к нему обращаются и манипулируют с помощью запросов, написанных на языке запросов, таком как SQL. Поэтому базовый подход ORD основан на реляционной базе данных.
Он содержит характеристики моделей РСУБД и ООСУБД. Для хранения данных используется традиционная база данных. Затем к нему обращаются и манипулируют с помощью запросов, написанных на языке запросов, таком как SQL. Поэтому базовый подход ORD основан на реляционной базе данных.
Однако ORD также можно рассматривать как объектное хранилище, особенно для программного обеспечения, написанного на объектно-ориентированном языке программирования, что, таким образом, опирается на объектно-ориентированные характеристики. В этой ситуации для хранения и извлечения данных используются API.
См. характеристики РСУБД по сравнению с СУБД и где они пересекаются. Каковы преимущества реляционных баз данных?Ключевые преимущества реляционных баз данных включают следующее:
- Классификация данных . Администраторы баз данных могут легко классифицировать и хранить данные в реляционной базе данных, которые затем можно запрашивать и фильтровать для извлечения информации для отчетов. Реляционные базы данных также легко расширяются и не зависят от физической организации. После создания исходной базы данных можно добавить новую категорию данных без изменения существующих приложений.
- Точность . Данные сохраняются только один раз, исключая дедупликацию данных в процедурах хранения.
- Простота использования. Пользователи могут легко выполнять сложные запросы с помощью SQL, основного языка запросов, используемого в реляционных базах данных.
- Сотрудничество. Несколько пользователей могут получить доступ к одной и той же базе данных.
- Безопасность. Прямой доступ к данным в таблицах в СУБД может быть ограничен определенными пользователями.
 Реляционные базы данных также легко расширяются и не зависят от физической организации. После создания исходной базы данных можно добавить новую категорию данных без изменения существующих приложений.
Реляционные базы данных также легко расширяются и не зависят от физической организации. После создания исходной базы данных можно добавить новую категорию данных без изменения существующих приложений.К недостаткам реляционных баз данных относятся следующие:
- Структура. Реляционные базы данных требуют большой структуры и определенного уровня планирования, поскольку столбцы должны быть определены, а данные должны правильно вписываться в несколько жестких категорий. Структура хороша в некоторых ситуациях, но создает проблемы, связанные с другими недостатками, такими как обслуживание и отсутствие гибкости и масштабируемости.
- Проблемы с обслуживанием. Разработчики и другой персонал, отвечающий за базу данных, должны тратить время на управление и оптимизацию базы данных по мере добавления в нее данных.
- Негибкость. Реляционные базы данных не идеальны для обработки больших объемов неструктурированных данных. Данные, которые в значительной степени являются качественными, трудно определяемыми или динамическими, не являются оптимальными для реляционных баз данных, потому что по мере изменения или развития данных схема должна развиваться вместе с ними, что требует времени.
- Отсутствие масштабируемости . Реляционные базы данных плохо масштабируются по горизонтали в физических структурах хранения с несколькими серверами. Трудно управлять реляционными базами данных на нескольких серверах, потому что по мере того, как набор данных становится больше и более распределенным, структура нарушается, а использование нескольких серверов влияет на производительность (например, время отклика приложений) и доступность.
 Структура хороша в некоторых ситуациях, но создает проблемы, связанные с другими недостатками, такими как обслуживание и отсутствие гибкости и масштабируемости.
Структура хороша в некоторых ситуациях, но создает проблемы, связанные с другими недостатками, такими как обслуживание и отсутствие гибкости и масштабируемости.
Стандартные реляционные базы данных позволяют пользователям управлять предопределенными отношениями данных между несколькими базами данных. Популярные примеры стандартных реляционных баз данных включают Microsoft SQL Server, Oracle Database, MySQL и IBM DB2.
Облачные реляционные базы данных или база данных как услуга также широко используются, поскольку они позволяют компаниям передавать на аутсорсинг обслуживание базы данных, установку исправлений и поддержку инфраструктуры. Облачные реляционные базы данных включают Amazon Relational Database Service, Google Cloud SQL, IBM DB2 on Cloud, SQL Azure и Oracle Cloud.
В чем разница между реляционными базами данных, нереляционными базами данных и NoSQL? Наиболее важное различие между системами реляционных баз данных и системами нереляционных баз данных заключается в том, что реляционные базы данных нормализованы.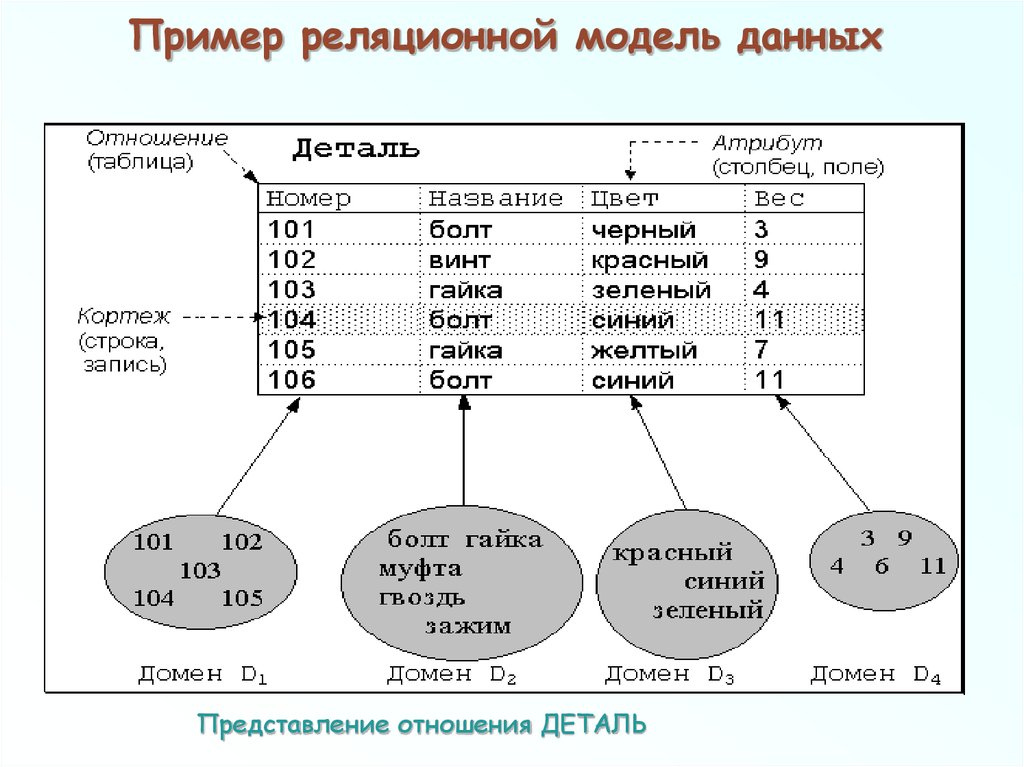 То есть они хранят данные в табличной форме, организованной в виде таблицы со строками и столбцами. Нереляционная база данных хранит данные в виде файлов.
То есть они хранят данные в табличной форме, организованной в виде таблицы со строками и столбцами. Нереляционная база данных хранит данные в виде файлов.
Другие отличия включают следующее:
- Использование первичных ключей. Каждая таблица реляционной базы данных имеет идентификатор первичного ключа. В нереляционной базе данных данные обычно хранятся в иерархической или навигационной форме без использования первичных ключей.
- Отношения значений данных. Поскольку данные в реляционной базе данных хранятся в таблицах, связь между этими значениями данных также сохраняется. Поскольку нереляционная база данных хранит данные в виде файлов, между значениями данных нет никакой связи.
- Ограничения целостности. В реляционной базе данных ограничениями целостности являются любые ограничения, обеспечивающие целостность базы данных. Они определены с целью атомарности, согласованности, изоляции и долговечности или ACID. Нереляционные базы данных не используют ограничения целостности.
- Структурированные и неструктурированные данные. Реляционные базы данных хорошо работают со структурированными данными, которые соответствуют предопределенной модели данных и мало изменяются. Нереляционные базы данных лучше подходят для неструктурированных данных, которые не соответствуют предопределенной модели данных и не могут храниться в СУБД. Примеры неструктурированных данных включают текст, электронные письма, фотографии, видео и веб-страницы.
 Нереляционные базы данных не используют ограничения целостности.
Нереляционные базы данных не используют ограничения целостности.Нереляционные базы данных также называются базами данных NoSQL. Термины используются взаимозаменяемо, но есть различия.
SQL — это язык запросов, который используется с реляционными базами данных. Реляционные базы данных и их системы управления почти всегда используют SQL в качестве основного языка запросов. Базы данных NoSQL или не только SQL используют SQL и другие языки запросов.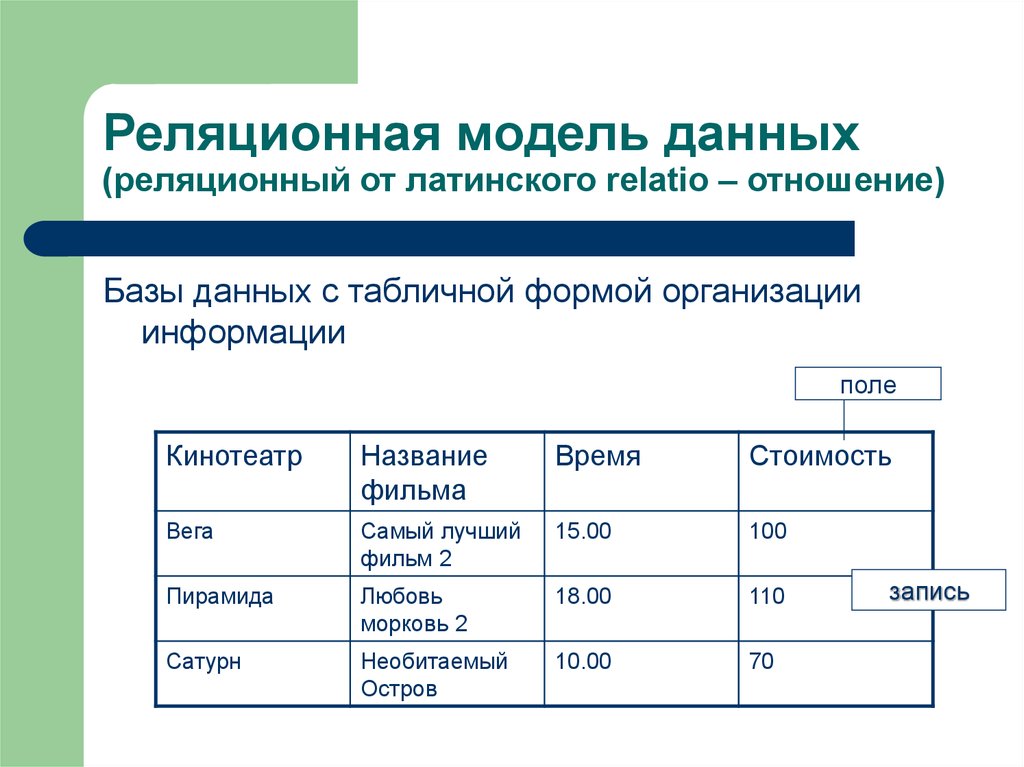 Например, программа управления базой данных NoSQL MongoDB использует документы, подобные JSON, для хранения и организации данных. (Технически он использует вариант вызова JSON BSON или двоичный JSON.)
Например, программа управления базой данных NoSQL MongoDB использует документы, подобные JSON, для хранения и организации данных. (Технически он использует вариант вызова JSON BSON или двоичный JSON.)
Обозначение баз данных как нереляционных и реляционных приводит к их категоризации на основе их архитектуры, а обращение к ним как к базам данных SQL и NoSQL приводит к их классификации на основе языка запросов, будь то исключительно SQL или не только SQL. Часто реляционную базу данных можно назвать базой данных SQL, поскольку многие из них используют SQL, а нереляционные базы данных можно назвать базами данных NoSQL. NoSQL и нереляционные базы данных хорошо работают с более изменчивыми моделями данных, такими как инженерные детали и молекулярное моделирование, где данные постоянно меняются.
Как реляционные, так и нереляционные платформы баз данных имеют свои недостатки. Базы данных NewSQL стремятся обеспечить преимущества обоих типов, предлагая целостность данных и управление доступом к приложениям, которые предлагают реляционные базы данных, и горизонтальную масштабируемость, которую обеспечивают нереляционные платформы или платформы NoSQL.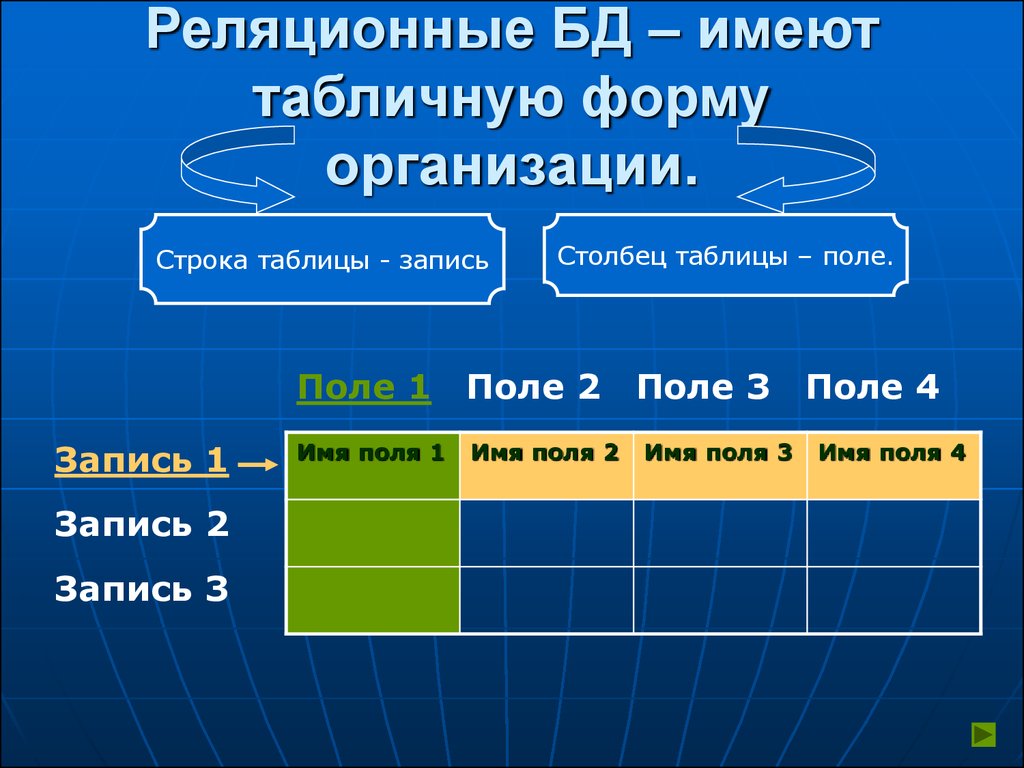
Реляционные базы данных работают со структурированными данными с определенными отношениями, которые можно организовать в табличном формате. Однако выбор правильной архитектуры базы данных — это гораздо больше, чем просто выбор между реляционной и нереляционной базой данных. Тип используемых или разрабатываемых данных и приложений являются ключевыми факторами, которые следует учитывать. Узнайте о некоторых других факторах, которые следует учитывать при выборе модели базы данных для корпоративного приложения.
Некоторые инициативы требуют особого внимания при выборе программного обеспечения базы данных. Например, в инициативах IoT возникает проблема между SQL и NoSQL, а также между статическими и потоковыми данными.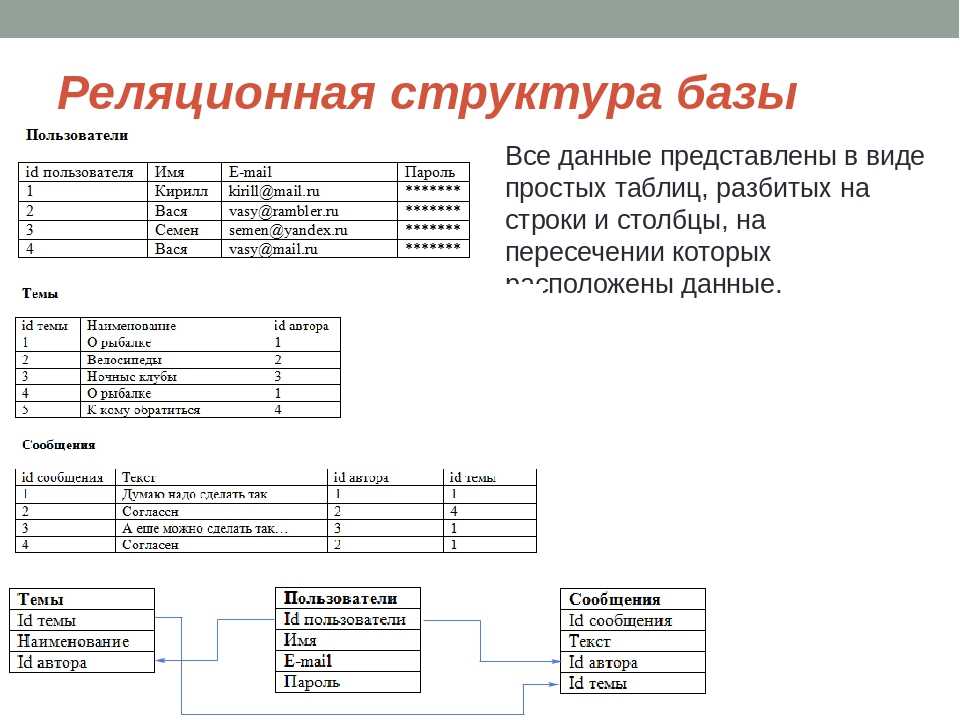 Узнайте, на что следует обращать внимание при выборе базы данных для проекта Интернета вещей.
Узнайте, на что следует обращать внимание при выборе базы данных для проекта Интернета вещей.
Последнее обновление: июнь 2021 г.
Продолжить чтение О реляционной базе данных- Сравнение баз данных NoSQL, чтобы помочь вам выбрать правильный магазин
- Графовая база данных и реляционная база данных: ключевые отличия
- Машина времени DBA и будущее данных
- Хранилище данных и озеро данных: основные отличия
- Разработчики программного обеспечения борются с наследием реляционных баз данных
Сравнение типов баз данных NoSQL в облаке
Автор: Курт Марко
Объяснение типов баз данных NoSQL: График
Автор: Алекс Уильямс
Объяснение типов баз данных NoSQL: базы данных на основе документов
Автор: Алекс Уильямс
Google Cloud Spanner
Автор: Джек Вон
ПоискБизнесАналитика
- Дополнительная автоматизация, встроенная аналитика в планах Tableau
Новые возможности, запланированные к выпуску в составе двух последних обновлений платформы поставщика в 2022 году, призваны ускорить .
.. - Tableau представляет интеграцию с Salesforce Genie
Комбинация предназначена для того, чтобы совместные клиенты поставщика аналитических услуг и гиганта CRM могли более легко подключаться к своим …
- Ricoh модернизирует свою аналитику с помощью Qlik
Компания, занимающаяся управлением информацией и цифровыми услугами, начинает развивать культуру данных, и платформа поставщика BI имеет …
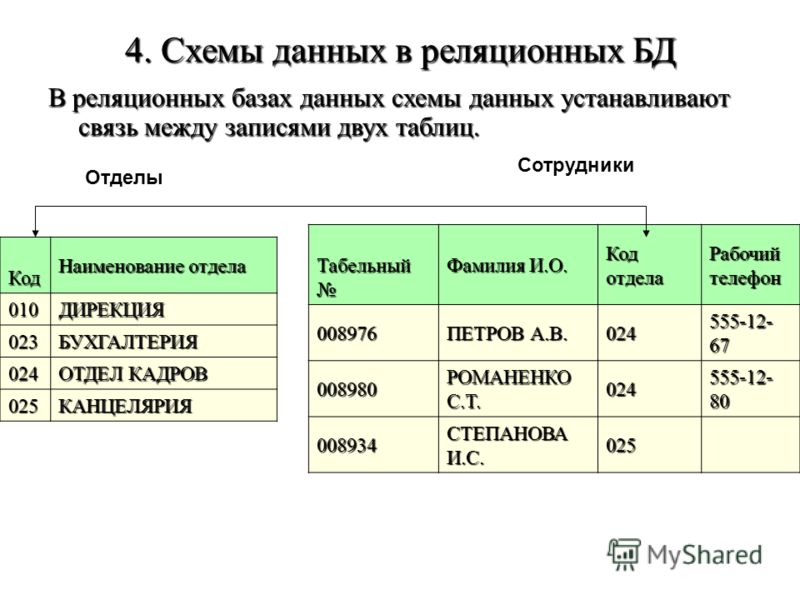 ..
..ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Сервис автоматизирует …
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных. Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу.
.. - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи
AWS сталкиваются с выбором при развертывании Kubernetes: запустить его самостоятельно на EC2 или позволить Amazon выполнить тяжелую работу с помощью EKS. См…
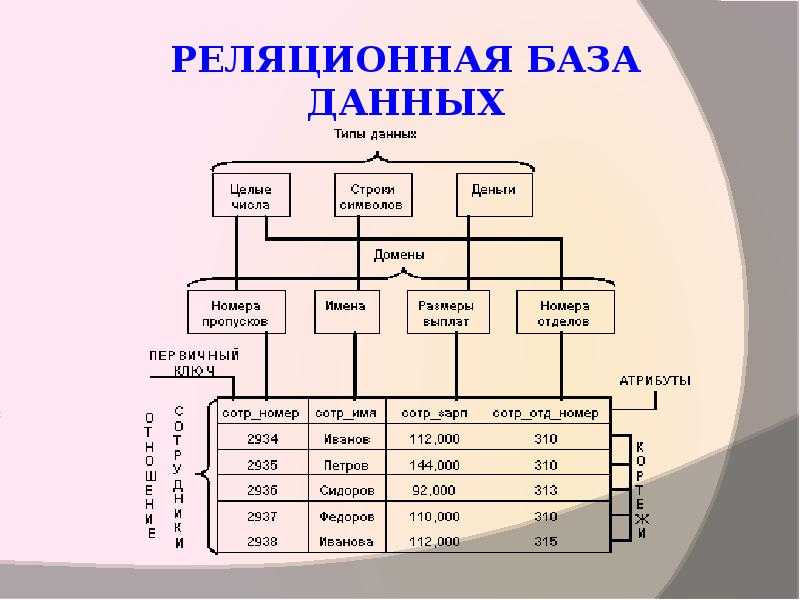 ..
..SearchContentManagement
- Как создать контент-стратегию электронной коммерции для увеличения продаж
Стратегия контента, включающая автоматизированную CMS, полезную информацию о продукте и визуальные эффекты, может привлечь внимание клиентов к вашему …
- 5 безбумажных офисных программных инструментов, на которые следует обратить внимание
Выбор подходящего безбумажного офисного программного обеспечения начинается с, казалось бы, бесконечного количества вариантов выбора.
- Викторина: проверьте свои знания в области управления цифровыми активами
Системы
DAM помогают отделам маркетинга управлять мультимедийным контентом, с которым они работают каждый день.
С помощью этого теста проверьте свои знания о …
 С помощью этого теста проверьте свои знания о …
С помощью этого теста проверьте свои знания о …ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, в связи с чем …
ПоискSAP
- Сантандер присоединяется к SAP MBC, чтобы внедрить финансы в процессы
SAP Multi-Bank Connectivity добавил Santander Bank в свой список партнеров, чтобы помочь компаниям упростить внедрение .
.. - В 50 лет SAP оказалась на очередном распутье
За свою 50-летнюю историю SAP вывел бизнес и технологические тренды на вершину индустрии ERP, но сейчас находится на перепутье …
- Сторонняя поддержка SAP обеспечивает гибкость миграции
Сторонние поставщики услуг поддержки заявляют, что они могут обеспечить большую гибкость при меньших затратах, но клиенты должны подумать …
 ..
..Что такое система управления реляционными базами данных?
Что такое база данных?
База данных представляет собой набор данных, хранящихся в компьютере. Эти данные обычно структурированы таким образом, чтобы сделать данные легко доступными.
Что такое реляционная база данных?
Реляционная база данных — это тип базы данных. Он использует структуру, которая позволяет нам идентифицировать и получать доступ к данным по отношению к другой части данных в базе данных.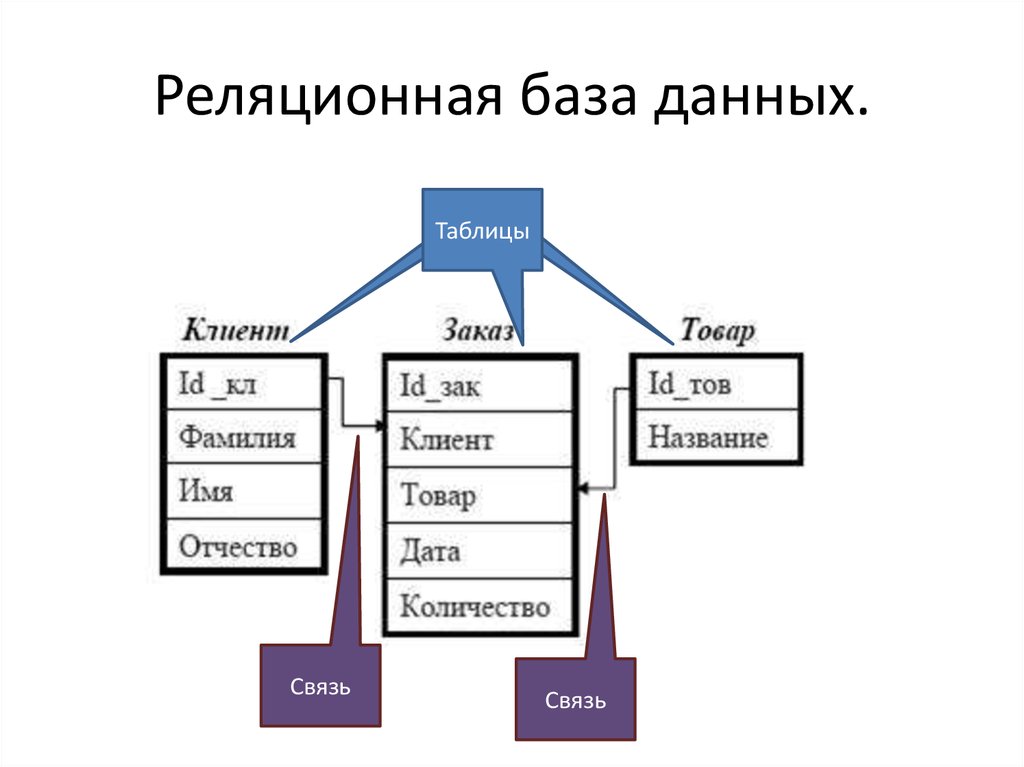 Часто данные в реляционной базе данных организованы в виде таблиц.
Часто данные в реляционной базе данных организованы в виде таблиц.
Таблицы: строки и столбцы
Таблицы могут содержать сотни, тысячи, иногда даже миллионы строк данных. Эти строки часто называют записей .
Таблицы также могут иметь много столбцов данных. Столбцы помечены описательным именем (например, age ) и имеют определенный тип данных .
Например, столбец с именем age может иметь тип INTEGER (обозначающий тип данных, которые он предназначен для хранения).
В приведенной выше таблице есть три столбца ( имя , возраст и страна ).
Столбцы имя и страна хранят строковые типы данных, тогда как age хранит целочисленные типы данных. Набор столбцов и типов данных составляют схему этой таблицы.
В таблице также есть четыре строки или записи (по одной для Натальи, Неда, Зенаса и Лауры).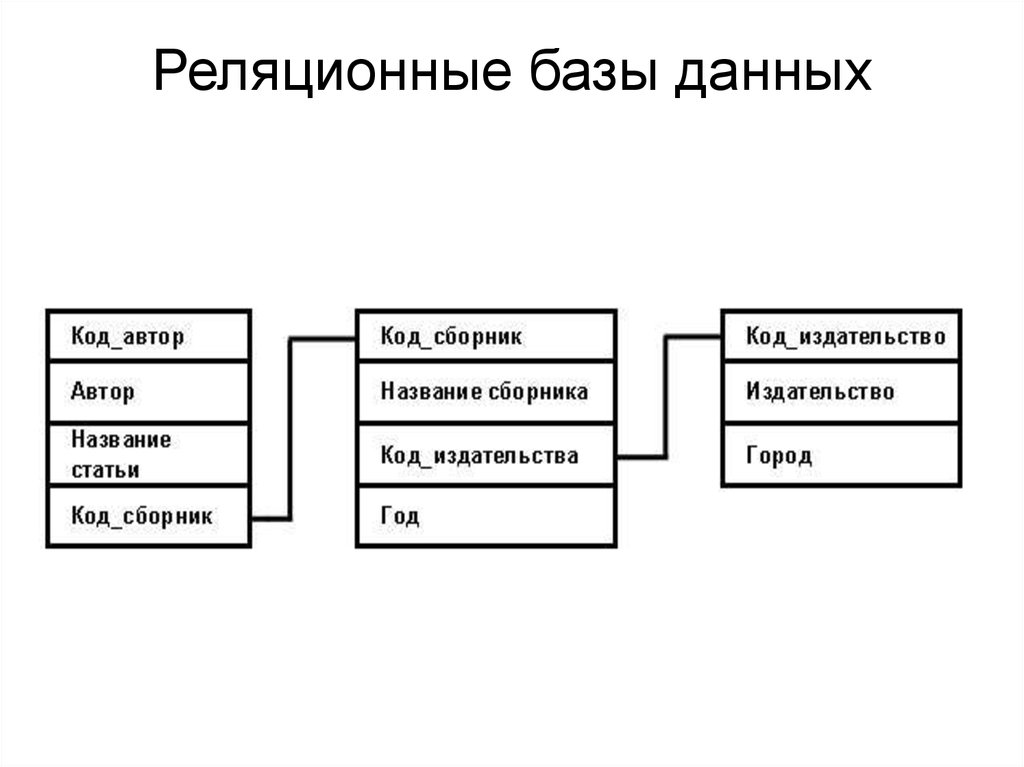
Что такое система управления реляционными базами данных (RDBMS)?
Система управления реляционной базой данных (RDBMS) — это программа, позволяющая создавать, обновлять и администрировать реляционную базу данных. Большинство систем управления реляционными базами данных используют язык SQL для доступа к базе данных.
Что такое SQL?
SQL ( S структурированный Q uery L язык) — это язык программирования, используемый для связи с данными, хранящимися в системе управления реляционными базами данных. Синтаксис SQL подобен английскому языку, что делает его относительно простым для написания, чтения и интерпретации.
Многие СУБД используют SQL (и варианты SQL) для доступа к данным в таблицах. Например, SQLite — это система управления реляционными базами данных. SQLite содержит минимальный набор команд SQL (одинаковых для всех СУБД). Другие СУБД могут использовать другие варианты.
(SQL часто произносится одним из двух способов. Вы можете произнести его, произнося каждую букву отдельно, например, «S-Q-L», или произнести его, используя слово «sequel».)
Вы можете произнести его, произнося каждую букву отдельно, например, «S-Q-L», или произнести его, используя слово «sequel».)
Популярные системы управления реляционными базами данных
Синтаксис SQL может немного отличаться в зависимости от используемой СУБД. Вот краткое описание популярных СУБД:
MySQL
MySQL — самая популярная база данных SQL с открытым исходным кодом. Обычно он используется для разработки веб-приложений, и доступ к нему часто осуществляется с помощью PHP.
Основные преимущества MySQL заключаются в том, что она проста в использовании, недорога, надежна (существует с 1995 г.) и имеет большое сообщество разработчиков, которые могут помочь ответить на вопросы.
Некоторые из недостатков заключаются в том, что известно, что он страдает от низкой производительности при масштабировании, разработка открытого исходного кода отстает с тех пор, как Oracle взяла под свой контроль MySQL, и он не включает в себя некоторые расширенные функции, к которым разработчики могли привыкнуть.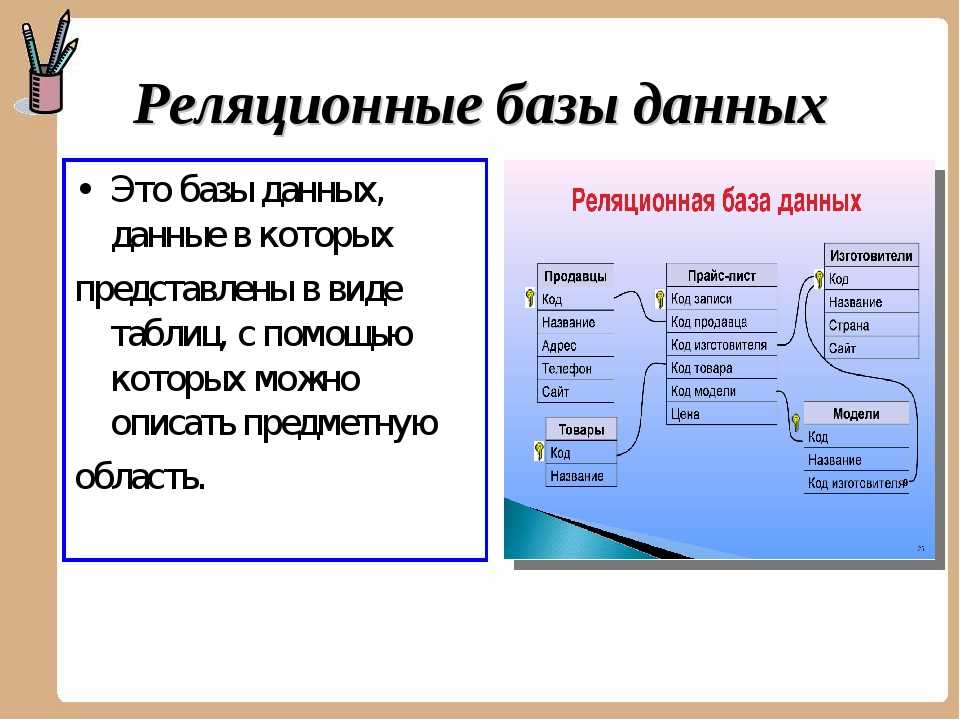
PostgreSQL
PostgreSQL — это база данных SQL с открытым исходным кодом, которая не контролируется какой-либо корпорацией. Обычно он используется для разработки веб-приложений.
PostgreSQL обладает многими преимуществами MySQL. Он прост в использовании, недорог, надежен и имеет большое сообщество разработчиков. Он также предоставляет некоторые дополнительные функции, такие как поддержка внешнего ключа, не требуя сложной настройки.
Основным недостатком PostgreSQL является то, что его производительность может быть ниже, чем у других баз данных, таких как MySQL. Он также немного менее популярен, чем MySQL.
Для получения дополнительной информации о PostgreSQL, включая инструкции по установке, прочитайте эту статью.
Oracle DB
Корпорация Oracle владеет базой данных Oracle, и исходный код не является открытым.
Oracle DB предназначена для крупных приложений, особенно в банковской сфере. Большинство ведущих мировых банков используют приложения Oracle, потому что Oracle предлагает мощную комбинацию технологий и комплексных, предварительно интегрированных бизнес-приложений, включая основные функции, созданные специально для банков.
Большинство ведущих мировых банков используют приложения Oracle, потому что Oracle предлагает мощную комбинацию технологий и комплексных, предварительно интегрированных бизнес-приложений, включая основные функции, созданные специально для банков.
Основным недостатком использования Oracle является то, что он не является бесплатным, как его конкуренты с открытым исходным кодом, и может быть довольно дорогим.
SQL Server
Microsoft владеет SQL Server. Как и в Oracle DB, исходный код закрыт.
Крупные корпоративные приложения в основном используют SQL Server.
Microsoft предлагает бесплатную версию начального уровня под названием Express , но она может стать очень дорогой при масштабировании приложения.
SQLite
SQLite — популярная база данных SQL с открытым исходным кодом. Он может хранить всю базу данных в одном файле. Одним из наиболее значительных преимуществ этого является то, что все данные могут храниться локально без необходимости подключения вашей базы данных к серверу.
SQLite — популярный выбор для баз данных в мобильных телефонах, КПК, MP3-плеерах, телевизионных приставках и других электронных устройствах. Курсы SQL на Codecademy используют SQLite.
Для получения дополнительной информации о SQLite, включая инструкции по установке, прочитайте эту статью.
Использование РСУБД в Codecademy
В Codecademy мы используем как SQLite, так и PostgreSQL. Хотя это может показаться запутанным, не волнуйтесь! Мы хотим подчеркнуть, что базовый синтаксис, который вы изучите, может использоваться в обеих системах. Например, синтаксис для создания таблиц, вставки данных в эти таблицы и извлечения данных из этих таблиц идентичен. Это одна из приятных сторон изучения SQL — изучив основы одной СУБД, вы легко сможете начать работу в другой.
При этом давайте взглянем на некоторые из более тонких деталей:
Расширения файлов — при работе с базами данных в Codecademy обратите внимание на имя файла, в который вы пишете.
Если ваш файл заканчивается на .sqlite, вы используете базу данных SQLite. Если ваш файл заканчивается на.sql, вы работаете с PostgreSQL.Типы данных — Вы узнаете о типах данных очень рано, изучая СУБД. Следует отметить, что SQLite и PostgreSQL имеют несколько разные типы данных. Например, если вы хотите сохранить текст в базе данных SQLite, вы будете использовать
ТЕКСТтип данных. Если вы работаете с PostgreSQL, у вас есть гораздо больше возможностей. Вы можете использоватьvarchar(n),char(n)илиtext. Каждый тип имеет свои тонкие различия. Это хороший пример того, что PostgreSQL немного более надежен, чем SQLite, но основные концепции остаются прежними.Встроенные таблицы — По мере прохождения более сложных уроков по базам данных вы начнете узнавать, как получить доступ к встроенным таблицам. Например, если вы пройдете наш урок по индексам, вы узнаете, как просматривать таблицу, которую система автоматически создает для отслеживания существующих индексов.
В зависимости от того, какую СУБД вы используете (в этом уроке мы используем PostgreSQL), синтаксис для этого будет разным. Каждый раз, когда вы пишете SQL о самой базе данных, а не о данных, этот синтаксис, скорее всего, будет уникальным для используемой вами СУБД.
 Если ваш файл заканчивается на
Если ваш файл заканчивается на  В зависимости от того, какую СУБД вы используете (в этом уроке мы используем PostgreSQL), синтаксис для этого будет разным. Каждый раз, когда вы пишете SQL о самой базе данных, а не о данных, этот синтаксис, скорее всего, будет уникальным для используемой вами СУБД.
В зависимости от того, какую СУБД вы используете (в этом уроке мы используем PostgreSQL), синтаксис для этого будет разным. Каждый раз, когда вы пишете SQL о самой базе данных, а не о данных, этот синтаксис, скорее всего, будет уникальным для используемой вами СУБД.Заключение
Реляционные базы данных хранят данные в таблицах. Таблицы могут увеличиваться в размерах и содержать множество столбцов и записей. Системы управления реляционными базами данных (RDBMS) используют SQL (и варианты SQL) для управления данными в этих больших таблицах. Выбор СУБД зависит от сложности вашего приложения.
Только Proкарьерный путь
Data Scientist: Специалист по аналитике
Подходит для начинающих,
69 Уроки
курс
Начало работы вне платформы для науки о данных
Подходит для начинающих,
1 Урок
Что такое реляционная база данных? {Примеры, преимущества и недостатки}
Введение
С таким количеством доступных вариантов может быть сложно выбрать решение для базы данных, которое идеально соответствует вашим потребностям.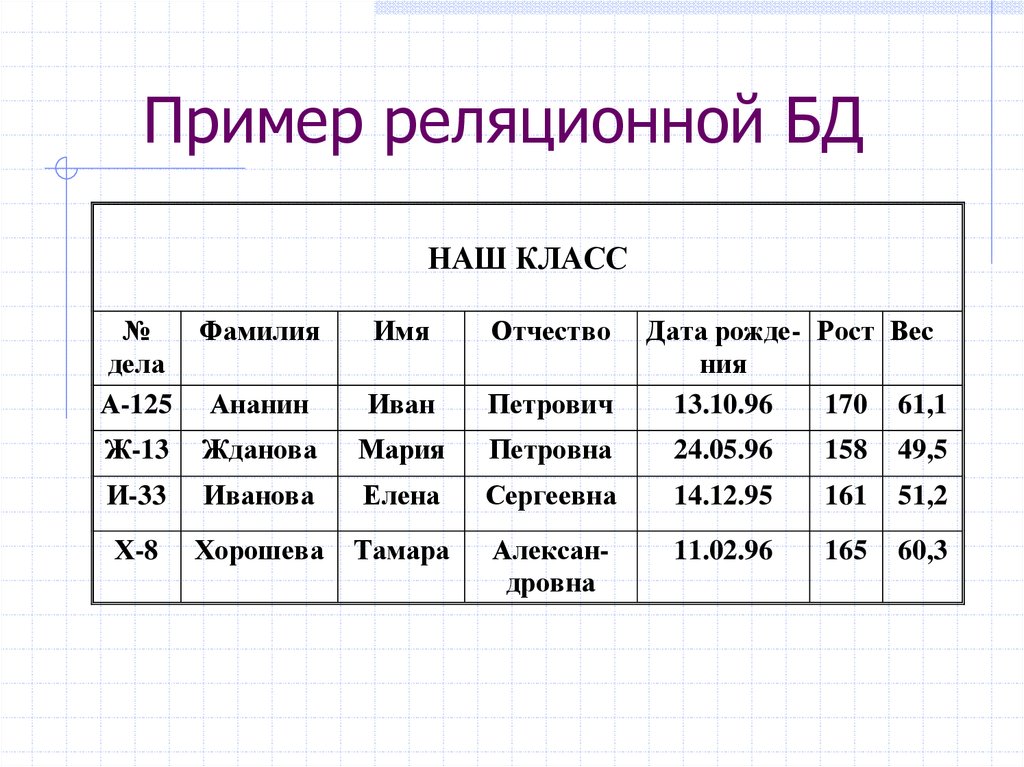 Когда дело доходит до типов баз данных, одним из популярных вариантов является реляционная база данных.
Когда дело доходит до типов баз данных, одним из популярных вариантов является реляционная база данных.
В этой статье мы расскажем о структуре реляционных баз данных, о том, как они работают, а также о преимуществах и недостатках их использования. Мы также будем использовать примеры, чтобы проиллюстрировать, как реляционные базы данных организуют данные.
Определение реляционной базы данных
Реляционная база данных — это тип базы данных, который фокусируется на отношениях между сохраненными элементами данных. Это позволяет пользователям устанавливать связи между различными наборами данных в базе данных и использовать эти связи для управления и ссылки на связанные данные.
Многие реляционные базы данных используют SQL (язык структурированных запросов) для выполнения запросов и обслуживания данных.
Реляционные и нереляционные базы данных
Реляционные базы данных сосредоточены на отношениях между данными. Следовательно, база данных отношений должна хранить данные строго структурированным образом. Это обеспечивает более быстрое индексирование и время ответа на запросы, а также делает данные более безопасными и согласованными.
Следовательно, база данных отношений должна хранить данные строго структурированным образом. Это обеспечивает более быстрое индексирование и время ответа на запросы, а также делает данные более безопасными и согласованными.
С другой стороны, базам данных NoSQL не нужно так сильно полагаться на структуру, что позволяет им хранить большие объемы данных, оставаться гибкими и легко масштабировать хранилище и производительность.
Примечание: Для более подробного изучения различий между реляционными и нереляционными базами данных ознакомьтесь с нашей статьей, посвященной сравнению SQL и NoSQL.
Как организованы данные в реляционной базе данных?
Системы реляционных баз данных Используйте модель, которая организует данные в таблиц из строк (также называется записи или КУТА ) и колонны (также называемые 15050505050505050505050505053695050536 505050536 150505050536 15050505050536 150505050536 150505050536. полей ). Как правило, столбцы представляют категории данных, а строки представляют отдельные экземпляры.
полей ). Как правило, столбцы представляют категории данных, а строки представляют отдельные экземпляры.
В качестве примера возьмем цифровую витрину. В нашей базе данных может быть таблица, содержащая информацию о клиентах, со столбцами, представляющими имена или адреса клиентов, а каждая строка содержит данные для одного отдельного клиента.
Эти таблицы могут быть связаны или связаны с использованием ключей . Каждая строка в таблице идентифицируется с помощью уникального ключа, называемого первичным ключом . Этот первичный ключ можно добавить в другую таблицу, став внешним ключом . Отношения первичный/внешний ключ составляют основу работы реляционных баз данных.
Возвращаясь к нашему примеру, если у нас есть таблица, представляющая заказы на продукты, один из столбцов может содержать информацию о клиентах. Здесь мы можем импортировать первичный ключ, который ссылается на строку с информацией для конкретного клиента.
Таким образом, мы можем ссылаться на данные или дублировать данные из таблицы информации о клиентах. Это также означает, что эти две таблицы теперь связаны.
Примечание: Если вы новичок в базах данных, наша статья Что такое база данных является хорошей отправной точкой для изучения всего, что вам нужно знать.
Примеры реляционных баз данных
Теперь, когда мы рассмотрели, как они работают, вот некоторые из наиболее популярных примеров реляционных баз данных:
MySQL
приобретена Sun Microsystems (теперь Oracle Corporation). Он по-прежнему доступен под лицензией с открытым исходным кодом с добавлением различных проприетарных лицензий.
MySQL имеет встроенную поддержку репликации с соответствием ACID, кластеризацию без совместного использования и поддерживает несколько механизмов хранения. Однако использование некоторых механизмов хранения может привести к некорректной работе SQL.
MySQL отличается быстрым вводом данных и масштабируемостью, сохраняя при этом высокую доступность и производительность. Это делает его чрезвычайно полезным для веб-разработки и разработки приложений.
Это делает его чрезвычайно полезным для веб-разработки и разработки приложений.
PostgreSQL
PostgreSQL — это бесплатный менеджер реляционных баз данных, доступный по лицензии с открытым исходным кодом. Он разделяет некоторые функции с MySQL, с заметным добавлением MVCC (контроль параллелизма нескольких версий), что делает его совместимым с ACID.
PostgreSQL сохраняет высокий уровень производительности и гибкости даже при работе с большими базами данных. Это правильный выбор для пользователей, которым требуется высокая скорость чтения/записи и обширный анализ данных.
Некоторые известные пользователи PostgreSQL включают Reddit, Skype и Instagram.
MariaDB
MariaDB начиналась как форк MySQL, управляемый сообществом, после того, как последний был куплен Oracle. Он по-прежнему с открытым исходным кодом и доступен по лицензии GNU General Public License.
MariaDB основывается на базе MySQL, добавляя поддержку еще большего количества механизмов хранения и устраняя ограничения механизмов хранения. Это позволяет ему работать даже быстрее, чем MySQL, и запускать как SQL, так и NoSQL в одной базе данных.
Известные пользователи MariaDB включают Google, Mozilla и Фонд Викимедиа.
SQLite
В отличие от других записей в этом списке, SQLite не является менеджером базы данных клиент-сервер, а скорее встроен в конечное приложение. Это делает его легким и способным работать с широким спектром систем и платформ.
Это также вызывает некоторые ограничения, так как SQLite лишь частично предоставляет триггеры, имеет ограниченную функцию ALTER TABLE и не может записывать в представления. Он также ограничивает максимальный размер базы данных до 32 000 столбцов и 140 ТБ.
Поэтому SQLite лучше всего использовать в качестве компонента базы данных для других приложений. Известное использование включает популярные браузеры, такие как Google Chrome, Mozilla Firefox, Opera и Safari.
Что такое система управления реляционными базами данных?
Система управления базами данных (СУБД) — это программное решение, которое помогает пользователям просматривать, запрашивать и управлять базами данных.
Системы управления реляционными базами данных (RDBMS) являются более продвинутым подмножеством СУБД, обрабатывающим реляционные базы данных.
дБм против RDBMS
Вот некоторые из различий между более общими растворами DBMS и RDBMS:
| СТМС | RDBMS 0906 9999989898989898989898989898989898989898998 998 98 998 98 98| 989898998 998989898989898998 гг. | Хранит большие объемы данных в виде связанных друг с другом таблиц. | |
| Одновременно возможен доступ только к одному элементу данных. | Может обращаться к нескольким элементам данных одновременно. | ||
| Работа с большими объемами данных замедляет выборку. | Реляционный подход позволяет быстро получать данные даже для больших баз данных. | ||
| Нет нормализации базы данных. | Позволяет нормализовать базу данных. | ||
| Не поддерживает распределенные базы данных. | Поддерживает распределенные базы данных. | ||
| Поддерживает одного пользователя. | Поддерживает несколько пользователей. | ||
| Низкий уровень безопасности. | Несколько уровней безопасности. | ||
| Низкие требования к программному и аппаратному обеспечению. | Высокие требования к программному и аппаратному обеспечению. |
Преимущества и недостатки реляционных баз данных
Как и любая другая модель базы данных, использование реляционных баз данных имеет свои преимущества и недостатки: другие типы баз данных, что упрощает их использование.
Эта табличная структура смещает акцент на обработку данных, что позволяет повысить производительность и использовать сложные высокоуровневые запросы.
Наконец, реляционные базы данных позволяют легко масштабировать данные, просто добавляя строки, столбцы или целые таблицы без изменения общей структуры базы данных.
Недостатки
Существуют пределы масштабируемости реляционных баз данных. Что касается размера, некоторые базы данных имеют фиксированные ограничения на длину столбцов. Если ваша база данных построена на одном выделенном сервере, масштабирование требует покупки дополнительного места на сервере, что в долгосрочной перспективе обходится дорого.
Кроме того, постоянное добавление новых элементов в базу данных может сделать ее настолько сложной, что становится трудно установить отношения между новыми фрагментами данных. Сложные отношения данных также замедляют выполнение запросов и отрицательно сказываются на производительности.
Заключение
Прочитав эту статью, вы должны иметь четкое представление о том, как работают реляционные базы данных. Вы также должны быть знакомы с некоторыми наиболее известными примерами систем управления реляционными базами данных.
Объяснение реляционных баз данных | IBM
Автор: IBM Cloud Education
Узнайте, как работают реляционные базы данных и чем они отличаются от других вариантов хранения данных.
Что такое реляционная база данных?
Реляционная база данных организует данные в строки и столбцы, которые вместе образуют таблицу. Данные обычно структурированы по нескольким таблицам, которые могут быть объединены с помощью первичного или внешнего ключа. Эти уникальные идентификаторы демонстрируют различные отношения, существующие между таблицами, и эти отношения обычно иллюстрируются с помощью различных типов моделей данных. Аналитики используют SQL-запросы для объединения различных точек данных и обобщения эффективности бизнеса, что позволяет организациям получать ценную информацию, оптимизировать рабочие процессы и выявлять новые возможности.
Например, представьте, что ваша компания ведет таблицу базы данных с информацией о клиентах, которая содержит данные компании на уровне учетной записи. Также может быть другая таблица, в которой описаны все отдельные транзакции, связанные с этой учетной записью. Вместе эти таблицы могут предоставить информацию о различных отраслях, приобретающих конкретный программный продукт.
Столбцы (или поля) для таблицы клиентов могут быть Идентификатор клиента , Название компании , Адрес компании , Промышленность и т.д.; столбцами для таблицы транзакций могут быть Дата транзакции , Идентификатор клиента , Сумма транзакции , Способ оплаты и т. д. Таблицы могут быть объединены вместе с общим полем Идентификатор клиента . Таким образом, вы можете запросить таблицу для получения ценных отчетов, таких как отчеты о продажах по отраслям или компаниям, которые могут информировать потенциальных клиентов.
Реляционные базы данных также обычно связаны с транзакционными базами данных, которые коллективно выполняют команды или транзакции. Популярным примером, который используется для иллюстрации этого, является банковский перевод. Определенная сумма снимается с одного счета, а затем зачисляется на другой. Вся сумма денег снимается и депонируется, и эта транзакция не может происходить ни в каком частичном смысле. Транзакции имеют определенные свойства. Представленные аббревиатурой ACID, свойства ACID определяются как:
- Атомарность: Все изменения данных выполняются так, как если бы они были одной операцией. То есть выполняются все изменения или ни одно из них.
- Непротиворечивость: Данные остаются в согласованном состоянии от состояния до завершения, усиливая целостность данных.
- Изоляция: Промежуточное состояние транзакции не видно другим транзакциям, и в результате одновременно выполняемые транзакции кажутся сериализованными.
- Долговечность: После успешного завершения транзакции изменения данных сохраняются и не отменяются даже в случае сбоя системы.
Эти свойства обеспечивают надежную обработку транзакций.
Сравнение реляционной базы данных с системой управления реляционной базой данных В то время как реляционная база данных организует данные на основе реляционной модели данных, система управления реляционной базой данных (RDBMS) представляет собой более конкретную ссылку на базовое программное обеспечение базы данных, которое позволяет пользователям поддерживать Это. Эти программы позволяют пользователям создавать, обновлять, вставлять или удалять данные в системе и обеспечивают:
- Структура данных
- Многопользовательский доступ
- Контроль привилегий
- Доступ к сети
Примеры популярных систем СУБД включают MySQL, PostgreSQL и IBM DB2. Кроме того, система реляционных баз данных отличается от базовой системы управления базами данных (СУБД) тем, что она хранит данные в таблицах, а СУБД хранит информацию в виде файлов.
Что такое SQL?
Изобретенный Доном Чемберлином и Рэем Бойсом в IBM, язык структурированных запросов (SQL) является стандартным языком программирования для взаимодействия с системами управления реляционными базами данных, позволяя администратору базы данных легко добавлять, обновлять или удалять строки данных. Первоначально известный как SEQUEL, он был упрощен до SQL из-за проблемы с торговой маркой. Запросы SQL также позволяют пользователям извлекать данные из баз данных, используя всего несколько строк кода. Учитывая эту взаимосвязь, легко понять, почему реляционные базы данных иногда также называют «базами данных SQL».
Используя приведенный выше пример, вы можете создать запрос для поиска первых 10 транзакций по компаниям за определенный год со следующим кодом:
SELECT COMPANY_NAME, SUM(TRANSACTION_AMOUNT)
FROM TRANSACTION_TABLE A
3
3
слева соединение Customer_Table Bна A.Customer_ID = B.Customer_ID
, где год (дата) = 2022
Группа на 1
по заказу на
.0051 2 DESCLIMIT 10
Способность объединять данные таким образом помогает нам уменьшить избыточность в наших системах данных, позволяя группам обработки данных вести одну главную таблицу для клиентов вместо дублирования этой информации, если в системе была другая транзакция. будущее. Чтобы узнать больше, Дон подробно описывает историю SQL в своей статье здесь (ссылка находится за пределами IBM).
Краткая история реляционных баз данных
До появления реляционных баз данных компании использовали иерархическую систему баз данных с древовидной структурой для таблиц данных. Эти ранние системы управления базами данных (СУБД) позволяли пользователям организовывать большие объемы данных. Однако они были сложными, часто являлись собственностью конкретного приложения и ограничивали способы обнаружения в данных. Эти ограничения в конечном итоге побудили исследователя IBM Эдгара Ф. Кодда опубликовать статью (ссылка находится за пределами IBM) (PDF, 1429).KB) в 1970 году под названием «Реляционная модель данных для больших общих банков данных», в которой теоретизировалась модель реляционной базы данных. В этой предложенной модели информацию можно было извлекать без специальных компьютерных знаний. Он предложил упорядочивать данные на основе значимых отношений в виде кортежей. , или пары атрибут-значение. Наборы кортежей назывались отношениями, что в конечном итоге позволяло объединять данные между таблицами. R (R для реляционных), чтобы доказать эту реляционную теорию с помощью того, что она назвала «реализацией промышленного уровня». В конечном итоге он также стал испытательным полигоном для SQL, что позволило ему получить более широкое распространение за короткий период времени.Однако внедрение SQL в Oracle также не повредило его популярности среди администраторов баз данных9.0003
К 1983 году IBM представила семейство реляционных баз данных DB2, названное так потому, что это было второе семейство программ IBM для управления базами данных. Сегодня это один из самых успешных продуктов IBM, который продолжает ежедневно обрабатывать миллиарды транзакций в облачной инфраструктуре и устанавливает базовый уровень для приложений машинного обучения.
Чтобы узнать больше об истории IBM, нажмите здесь.
Реляционные и нереляционные базы данных
В то время как реляционные базы данных структурируют данные в табличном формате, нереляционные базы данных не имеют такой жесткой схемы базы данных. Фактически нереляционные базы данных организуют данные по-разному в зависимости от типа базы данных. Независимо от типа нереляционной базы данных, все они направлены на решение проблем гибкости и масштабируемости, присущих реляционным моделям, которые не идеальны для неструктурированных форматов данных, таких как текст, видео и изображения. К этим типам баз данных относятся:
- Хранилище «ключ-значение»: Эта модель данных без схемы организована в словарь пар «ключ-значение», где каждый элемент имеет ключ и значение. Ключ может быть чем-то похожим, найденным в базе данных SQL, например идентификатором корзины покупок, а значением может быть массив данных, например, каждый отдельный элемент в корзине покупок этого пользователя. Он обычно используется для кэширования и хранения информации о сеансе пользователя, например о корзинах. Однако это не идеально, когда вам нужно получить несколько записей одновременно. Redis и Memcached являются примерами баз данных с открытым исходным кодом с этой моделью данных.
- Хранилище документов: Как следует из названия, базы данных документов хранят данные в виде документов. Они могут быть полезны при управлении полуструктурированными данными, а данные обычно хранятся в форматах JSON, XML или BSON. Это сохраняет данные вместе, когда они используются в приложениях, уменьшая объем перевода, необходимый для использования данных. Разработчики также получают больше гибкости, поскольку схемы данных не должны совпадать в документах (например, имя или имя). Однако это может быть проблематично для сложных транзакций, что приводит к повреждению данных. Популярные варианты использования баз данных документов включают системы управления контентом и профили пользователей. Примером документно-ориентированной базы данных является MongoDB, компонент базы данных стека MEAN.
- Хранилище с широкими столбцами: Эти базы данных хранят информацию в столбцах, что позволяет пользователям получать доступ только к определенным столбцам, которые им нужны, без выделения дополнительной памяти для ненужных данных. Эта база данных пытается устранить недостатки хранилищ пар «ключ-значение» и документов, но поскольку это может быть более сложная система для управления, ее не рекомендуется использовать для новых групп и проектов. Apache HBase и Apache Cassandra являются примерами баз данных с широкими столбцами с открытым исходным кодом. ApacheHBase построен на основе распределенной файловой системы Hadoop, которая обеспечивает способ хранения наборов разреженных данных, который обычно используется во многих приложениях для работы с большими данными. ApacheCassandra, с другой стороны, был разработан для управления большими объемами данных на нескольких серверах и кластеризации, охватывающей несколько центров обработки данных. Он использовался для различных вариантов использования, таких как веб-сайты социальных сетей и анализ данных в реальном времени.
- Хранилище графа: База данных этого типа обычно содержит данные из графа знаний. Элементы данных хранятся в виде узлов, ребер и свойств. Любой объект, место или человек может быть узлом. Ребро определяет отношения между узлами. Базы данных графов используются для хранения и управления сетью соединений между элементами внутри графа. Neo4j (ссылка находится за пределами IBM), служба базы данных на основе графов, основанная на Java, с выпуском сообщества с открытым исходным кодом, где пользователи могут приобретать лицензии на онлайн-резервное копирование и расширения для обеспечения высокой доступности или предварительно упакованную лицензионную версию с включенным резервным копированием и расширениями.
Базы данных NoSQL также отдают предпочтение доступности, а не согласованности.
Когда компьютеры работают в сети, им неизменно необходимо решить, отдавать ли предпочтение стабильным результатам (где все ответы всегда одинаковы) или длительному времени безотказной работы, называемому «доступностью». Это называется «теорией CAP», что означает согласованность, доступность или устойчивость к разделам. Реляционные базы данных обеспечивают постоянную синхронизацию и согласованность информации. Некоторые базы данных NoSQL, такие как Redis, предпочитают всегда предоставлять ответ. Это означает, что информация, которую вы получаете из запроса, может быть неверной на несколько секунд — возможно, на полминуты. На сайтах социальных сетей это означает видеть старую фотографию профиля, когда самой новой всего несколько минут. Альтернативой может быть тайм-аут или ошибка. С другой стороны, в банковских и финансовых операциях ошибка и повторная отправка могут быть лучше, чем старая, неверная информация.
Полный список различий между SQL и NoSQL см. в статье «Базы данных SQL и NoSQL: в чем разница?»
Преимущества реляционных баз данных
Основным преимуществом подхода к реляционным базам данных является возможность создания значимой информации путем объединения таблиц. Объединение таблиц позволяет понять отношения между данными или то, как таблицы соединяются. SQL включает в себя возможность подсчитывать, добавлять, группировать, а также комбинировать запросы. SQL может выполнять основные математические функции и промежуточные итоги, а также логические преобразования. Аналитики могут упорядочить результаты по дате, имени или любому столбцу. Эти функции делают реляционный подход самым популярным инструментом запросов в бизнесе сегодня.
Реляционные базы данных имеют несколько преимуществ по сравнению с другими форматами баз данных:
Простота использования
В силу продолжительности жизни продукта, вокруг реляционных баз данных существует больше сообщества, что частично увековечивает их дальнейшее использование. SQL также упрощает извлечение наборов данных из нескольких таблиц и выполнение простых преобразований, таких как фильтрация и агрегирование. Использование индексов в реляционных базах данных также позволяет им быстро находить эту информацию без поиска каждой строки в выбранной таблице.
Хотя реляционные базы данных исторически рассматривались как более жесткий и негибкий вариант хранения данных, достижения в области технологий и возможностей DBaaS меняют это представление. Несмотря на то, что по сравнению с предложениями баз данных NoSQL накладные расходы на разработку схем по-прежнему выше, реляционные базы данных становятся более гибкими по мере их миграции в облачные среды.
Снижение избыточности
Реляционные базы данных могут устранить избыточность двумя способами. Сама реляционная модель уменьшает избыточность данных с помощью процесса, известного как нормализация. Как отмечалось ранее, таблица клиентов должна регистрировать только уникальные записи информации о клиентах, а не дублировать эту информацию для нескольких транзакций.
Сохраненные процедуры также помогают уменьшить повторяющуюся работу. Например, если доступ к базе данных ограничен определенными ролями, функциями или командами, хранимая процедура может помочь управлять контролем доступа. Эти многоразовые функции высвобождают желанное время разработчиков приложений для выполнения важной работы.
Простота резервного копирования и аварийного восстановления
Реляционные базы данных являются транзакционными — они гарантируют согласованность состояния всей системы в любой момент. Большинство реляционных баз данных предлагают простые варианты экспорта и импорта, что упрощает резервное копирование и восстановление. Этот экспорт может происходить даже во время работы базы данных, что упрощает восстановление в случае сбоя. Современные облачные реляционные базы данных могут выполнять непрерывное зеркальное отображение, благодаря чему потеря данных при восстановлении измеряется секундами или даже меньше. Большинство облачных сервисов позволяют создавать реплики чтения, например, в IBM Cloud® Databases for PostgreSQL. Эти реплики чтения позволяют хранить копию ваших данных только для чтения в облачном центре обработки данных. Реплики также можно повысить до экземпляров с возможностью чтения и записи для аварийного восстановления.
Реляционные базы данных и IBM Cloud®
IBM поддерживает размещенные в облаке версии ряда реляционных баз данных.
- IBM Db2 on Cloud — это первоклассная коммерческая реляционная база данных, созданная для обеспечения высокой производительности и обеспечивающая доступность с SLA на уровне 99,99 %.