Что такое таблица кодировки? — ТолВИКИ
Автор-составитель: Русачкова Елена
Таблица кодировки — Это таблица, где каждой букве алфавита (а также цифрам и специальным знакам) присвоен уникальный номер — код символа.
Первой широко используемой кодировкой, в которую вошли символы кириллицы, была KOI8. Ее возникновение связывают с периодом адаптации ОС Unix к русским символам. До сих пор KOI8 является основной кодировкой Unix.
Шло время, на арену вышла Microsoft со своей операционной системой DOS. Вместо того чтобы воспользоваться готовыми стандартами, она решила пойти своим путем.
Так появилась codepage 866. Обладатели Win9x вспомнят строки, появлявшиеся на экране при запуске:
mode con codepage prepare=((866) C:\WINDOWS\COMMAND\ega3.cpi) mode con codepage select=866
Это и есть поддержка кодировки DOS. Эта кодировка была удобна тем, что предусматривала символы для создания рамок, так называемую псевдографику.
От семейства компьютеров Macintosh нам досталась кодировка MAC. Семейство ОС Windows 9.x преподнесло нам Win-1251. Наконец, от международной организации по стандартам ISO нам досталась кодировка ISO-8859-5. Жаль, но единого стандарта кодировки для кириллических символов до сих пор не существует. Однако определенные сдвиги есть — сейчас идет активная работа над перспективной кодировкой UNICODE, которая, по идее, должна решить проблемы с распознаванием кириллицы.
Чаще всего проблемы с распознаванием кодировки возникают при чтении электронной почты и просмотре веб- страниц. Пока вы ведете переписку на английском, никакие кодировки вам не страшны. Но стоит отправить на компьютер сообщение с поддерживающего кириллицу мобильного телефона (а это стандарт
Но мир не без добрых людей. Специально для таких ситуаций существуют программы- перекодировщики.
wiki.tgl.net.ru
Таблицы кодировки — SysadminWiki.ru
Исторически так сложилось, что кириллическая кодировка существует в нескольких видах.
Windows-1251
Кодировка Windows-1251 (cp1251) является стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. У неё существуют разновидности: казахская, чувашская и т.д. Первая часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Вторая часть (под символами указаны шестнадцатеричные коды Unicode) приводится ниже:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | Ђ 0402 | Ѓ 0403 | ‚ 201A | ѓ 0453 | „ 201E | … 2026 | † 2020 | ‡ 2021 | € 20AC | ‰ 2030 | Љ 0409 | ‹ 2039 | Њ 040A | Ќ 040C | Ћ 040B | Џ 040F |
| 9 | ђ 0452 | ‘ 2018 | ’ 2019 | “ 201C | ” 201D | • 2022 | – 2013 | — 2014 | ™ 2122 | љ 0459 | › 203A | њ 045A | ќ 045C | ћ 045B | џ 045F | |
| A | 00A0 | Ў 040E | ў 045E | Ј 0408 | ¤ 00A4 | Ґ 0490 | ¦ 00A6 | § 00A7 | Ё 0401 | © 00A9 | Є 0404 | « 00AB | ¬ 00AC | 00AD | ® 00AE | Ї 0407 |
| B | ° 00B0 | ± 00B1 | І 0406 | і 0456 | ґ 0491 | µ 00B5 | ¶ 00B6 | · 00B7 | ё 0451 | № 2116 | є 0454 | » 00BB | ј 0458 | Ѕ 0405 | ѕ 0455 | ї 0457 |
| C | А 0410 | Б 0411 | В 0412 | Г 0413 | Д 0414 | Е 0415 | Ж 0416 | З 0417 | И 0418 | Й 0419 | К 041A | Л 041B | М 041C | Н 041D | О 041E | П 041F |
| D | Р 0420 | С 0421 | Т 0422 | У 0423 | Ф 0424 | Х 0425 | Ц 0426 | Ч 0427 | Ш 0428 | Щ 0429 | Ъ 042A | Ы 042B | Ь 042C | Э 042D | Ю 042E | Я 042F |
| E | а 0430 | б 0431 | в 0432 | г 0433 | д 0434 | е 0435 | ж 0436 | з 0437 | и 0438 | й 0439 | к 043A | л 043B | м 043C | н 043D | о 043E | п 043F |
| F | р 0440 | с 0441 | т 0442 | у 0443 | ф 0444 | х 0445 | ц 0446 | ч 0447 | ш 0448 | щ 0449 | ъ 044A | ы 044B | ь 044C | э 044D | ю 044E | я 044F |
cp866
В консоли русифицированных систем семейства Windows NT используется кодировка cp866. Первая часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Вторая часть (под символами указаны шестнадцатеричные коды Unicode):
Для кодировки cp866 существуют разновидности (чувашская, ГОСТ 19768-87 и т.д.).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | А 0410 | Б 0411 | В | Г 0413 | Д 0414 | Е 0415 | Ж 0416 | З 0417 | И 0418 | Й 0419 | К 041A | Л 041B | М 041C | Н 041D | О 041E | П 041F |
| 9 | Р 0420 | С 0421 | Т 0422 | У 0423 | Ф 0424 | Х 0425 | Ц 0426 | Ч 0427 | Ш 0428 | Щ 0429 | Ъ 042A | Ы 042B | Ь 042C | Э 042D | Ю 042E | Я 042F |
| A | а 0430 | б 0431 | в 0432 | г 0433 | д 0434 | е 0435 | ж 0436 | з 0437 | и 0438 | й 0439 | к 043A | л 043B | м 043C | н 043D | о 043E | п 043F |
| B | ░ 2591 | ▒ 2592 | ▓ 2593 | │ 2502 | ┤ 2524 | ╡ 2561 | ╢ 2562 | ╖ 2556 | ╕ 2555 | ╣ 2563 | ║ 2551 | ╗ 2557 | ╝ 255D | ╜ 255C | ╛ 255B | ┐ 2510 |
| C | └ | ┴ 2534 | ┬ 252C | ├ 251C | ─ 2500 | ┼ 253C | ╞ 255E | ╟ 255F | ╚ 255A | ╔ 2554 | ╩ 2569 | ╦ 2566 | ╠ 2560 | ═ 2550 | ╬ 256C | ╧ 2567 |
| D | ╨ 2568 | ╤ 2564 | ╥ 2565 | ╙ 2559 | ╘ 2558 | ╒ 2552 | ╓ 2553 | ╫ 256B | ╪ 256A | ┘ 2518 | ┌ 250C | █ 2588 | ▄ 2584 | ▌ 258C | ▐ 2590 | ▀ 2580 |
| E | р | с 0441 | т 0442 | у 0443 | ф 0444 | х 0445 | ц 0446 | ч 0447 | ш 0448 | щ 0449 | ъ 044A | ы 044B | ь 044C | э 044D | ю 044E | я 044F |
| F | Ё 0401 | ё 0451 | Є 0404 | є 0454 | Ї 0407 | ї 0457 | Ў 040E | ў 045E | ° 00B0 | ∙ 2219 | · 00B7 | √ 221A | № 2116 | ¤ 00A4 | ■ 25A0 | 00A0 |
KOI8
Стандартом для русской кириллицы в юникс-подобных операционных системах является кодировка КОИ-8 (код обмена информацией, 8 битов), или KOI8. Существует несколько вариантов кодировки КОИ-8 для различных кириллических алфавитов. Русский алфавит описывается в кодировке KOI8-R, украинский — в KOI8-U, существуют также кодировки KOI8-RU (русско-белорусско-украинская), KOI8-T (таджикская) и т.д.
Разработчики КОИ-8 разместили символы русского алфавита таким образом, что если в тексте, написанном в КОИ-8, убирать восьмой бит каждого символа, то получается «читабельный» текст, хотя он и написан латинскими символами.
Вторая часть кодировки KOI8-R (русская), под символами указаны шестнадцатеричные коды Unicode:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | ─ 2500 | │ 2502 | ┌ 250C | ┐ 2510 | └ 2514 | ┘ 2518 | ├ 251C | ┤ 2524 | ┬ 252C | ┴ 2534 | ┼ 253C | ▀ 2580 | ▄ 2584 | █ 2588 | ▌ 258C | ▐ 2590 |
| 9 | ░ 2591 | ▒ 2592 | ▓ 2593 | ⌠23 20 | ■ 25A0 | ∙ 2219 | √ 221A | ≈ 2248 | ≤ 2264 | ≥ 2265 | 00A0 | ⌡ 2321 | ° 00B0 | ² 00B2 | · 00B7 | ÷ 00F7 |
| A | ═ 2550 | ║ 2551 | ╒ 2552 | ё 0451 | ╓ 2553 | ╔ 2554 | ╕ 2555 | ╖ 2556 | ╗ 2557 | ╘ 2558 | ╙ 2559 | ╚ 255A | ╛ 255B | ╜ 255C | ╝ 255D | ╞ 255E |
| B | ╟ 255F | ╠ 2560 | ╡ 2561 | Ё 0401 | ╢ 2562 | ╣ 2563 | ╤ 2564 | ╥ 2565 | ╦ 2566 | ╧ 2567 | ╨ 2568 | ╩ 2569 | ╪ 256A | ╫ 256B | ╬ 256C | © 00A9 |
| C | ю 044E | а 0430 | б 0431 | ц 0446 | д 0434 | е 0435 | ф 0444 | г 0433 | х 0445 | и 0438 | й 0439 | к 043A | л 043B | м 043C | н 043D | о 043E |
| D | п 043F | я 044F | р 0440 | с 0441 | т 0442 | у 0443 | ж 0436 | в 0432 | ь 044C | ы 044B | з 0437 | ш 0448 | э 044D | щ 0449 | ч 0447 | ъ 044A |
| C | Ю 042E | А 0410 | Б 0411 | Ц 0426 | Д 0414 | Е 0415 | Ф 0424 | Г 0413 | Х 0425 | И 0418 | Й 0419 | К 041A | Л 041B | М 041C | Н 041D | О 041E |
| D | П 041F | Я 042F | Р 0420 | С 0421 | Т 0422 | У 0423 | Ж 0416 | В 0412 | Ь 042C | Ы 042B | З 0417 | Ш 0428 | Э 042D | Щ 0429 | Ч 0427 | Ъ 042A |
Юникод (Unicode)
В Юникоде нет русских букв с ударением, поэтому приходится их делать составными, добавляя символ U+0301 («combining acute accent») после ударной гласной (например, ы́ э́ ю́ я́).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 400 | Ѐ | Ё | Ђ | Ѓ | Є | Ѕ | І | Ї | Ј | Љ | Њ | Ћ | Ќ | Ѝ | Ў | Џ |
| 410 | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| 420 | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| 430 | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| 440 | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
| 450 | ѐ | ё | ђ | ѓ | є | ѕ | і | ї | ј | љ | њ | ћ | ќ | ѝ | ў | џ |
| 460 | Ѡ | ѡ | Ѣ | ѣ | Ѥ | ѥ | Ѧ | ѧ | Ѩ | ѩ | Ѫ | ѫ | Ѭ | ѭ | Ѯ | ѯ |
| 470 | Ѱ | ѱ | Ѳ | ѳ | Ѵ | ѵ | Ѷ | ѷ | Ѹ | ѹ | Ѻ | ѻ | Ѽ | ѽ | Ѿ | ѿ |
| 480 | Ҁ | ҁ | ҂ | ҃ | ҄ | ҅ | ҆ | ҇ | ҈ | ҉ | Ҋ | ҋ | Ҍ | ҍ | Ҏ | ҏ |
| 490 | Ґ | ґ | Ғ | ғ | Ҕ | ҕ | Җ | җ | Ҙ | ҙ | Қ | қ | Ҝ | ҝ | Ҟ | ҟ |
| 4A0 | Ҡ | ҡ | Ң | ң | Ҥ | ҥ | Ҧ | ҧ | Ҩ | ҩ | Ҫ | ҫ | Ҭ | ҭ | Ү | ү |
| 4B0 | Ұ | ұ | Ҳ | ҳ | Ҵ | ҵ | Ҷ | ҷ | Ҹ | ҹ | Һ | һ | Ҽ | ҽ | Ҿ | ҿ |
| 4C0 | Ӏ | Ӂ | ӂ | Ӄ | ӄ | Ӆ | ӆ | Ӈ | ӈ | Ӊ | ӊ | Ӌ | ӌ | Ӎ | ӎ | ӏ |
| 4D0 | Ӑ | ӑ | Ӓ | ӓ | Ӕ | ӕ | Ӗ | ӗ | Ә | ә | Ӛ | ӛ | Ӝ | ӝ | Ӟ | ӟ |
| 4E0 | Ӡ | ӡ | Ӣ | ӣ | Ӥ | ӥ | Ӧ | ӧ | Ө | ө | Ӫ | ӫ | Ӭ | ӭ | Ӯ | ӯ |
| 4F0 | Ӱ | ӱ | Ӳ | ӳ | Ӵ | ӵ | Ӷ | ӷ | Ӹ | ӹ | Ӻ | ӻ | Ӽ | ӽ | Ӿ | ӿ |
| 500 | Ԁ | ԁ | Ԃ | ԃ | Ԅ | ԅ | Ԇ | ԇ | Ԉ | ԉ | Ԋ | ԋ | Ԍ | ԍ | Ԏ | ԏ |
| 510 | Ԑ | ԑ | Ԓ | ԓ | Ԕ | ԕ | Ԗ | ԗ | Ԙ | ԙ | Ԛ | ԛ | Ԝ | ԝ | Ԟ | ԟ |
| 520 | Ԡ | ԡ | Ԣ | ԣ | Ԥ | ԥ | Ԧ | ԧ | ||||||||
| 2DE0 | ⷠ | ⷡ | ⷢ | ⷣ | ⷤ | ⷥ | ⷦ | ⷧ | ⷨ | ⷩ | ⷪ | ⷫ | ⷬ | ⷭ | ⷮ | ⷯ |
| 2DF0 | ⷰ | ⷱ | ⷲ | ⷳ | ⷴ | ⷵ | ⷶ | ⷷ | ⷸ | ⷹ | ⷺ | ⷻ | ⷼ | ⷽ | ⷾ | ⷿ |
| A640 | Ꙁ | ꙁ | Ꙃ | ꙃ | Ꙅ | ꙅ | Ꙇ | ꙇ | Ꙉ | ꙉ | Ꙋ | ꙋ | Ꙍ | ꙍ | Ꙏ | ꙏ |
| A650 | Ꙑ | ꙑ | Ꙓ | ꙓ | Ꙕ | ꙕ | Ꙗ | ꙗ | Ꙙ | ꙙ | Ꙛ | ꙛ | Ꙝ | ꙝ | Ꙟ | ꙟ |
| A660 | Ꙡ | ꙡ | Ꙣ | ꙣ | Ꙥ | ꙥ | Ꙧ | ꙧ | Ꙩ | ꙩ | Ꙫ | ꙫ | Ꙭ | ꙭ | ꙮ | ꙯ |
| A670 | ꙰ | ꙱ | ꙲ | ꙳ | ꙼ | ꙽ | ꙾ | ꙿ | ||||||||
| A680 | Ꚁ | ꚁ | Ꚃ | ꚃ | Ꚅ | ꚅ | Ꚇ | ꚇ | Ꚉ | ꚉ | Ꚋ | ꚋ | Ꚍ | ꚍ | Ꚏ | ꚏ |
| A690 | Ꚑ | ꚑ | Ꚓ | ꚓ | Ꚕ | ꚕ | Ꚗ | ꚗ |
www.sysadminwiki.ru
Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With TextЕсли вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
Чтобы с помощью битов представлять нечно полезное, нам нужны правила. Надо сконвертировать последовательность бит в что-то похожее на буквы, числа и изображения, используя схему кодирования, или, коротко, кодировку. Вот так, например:
01100010 01101001 01110100 01110011
b i t s
В этой кодировке, 01100010 представляет из себя ‘b’, 01101001 — ‘i’, 01110100 — ‘t’, 01110011 — ‘s’. Конкретная последовательность бит соответствует букве, а буква – конкретной последовательности битов. Если вы можете запомнить последовательности для 26 букв или умеете действительно быстро находить нужное соответствие, то вы сможете читать биты, как книги.
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
bits character01000001 A
01000010 B
01000011 C
01000100 D
01000101 E
01000110 F
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие. В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100«Hello World»
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded form
code |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.
Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский. И, прежде чем вы спросите, да, есть кодировки только для упрощенного китайского. А разве одной недостаточно?
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
GB18030 покрывает довольно большой диапазон символов, включая большую часть латинских символов, но в конце концов, это всего лишь еще одна кодировка среди многих других.
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер. Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Итак, и сколько же байт использует Unicode для кодирования? Нисколько. Потому что Unicode – это не кодировка.
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все. Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
bits encoding characters11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Какого черта мой текст нечитаем?
ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 01011011
10000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант. Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
Большинство браузеров предоставляют возможность указать кодировку страницы с помощью специального пункта меню. Иные программы тоже имеют аналогичные пункты.
У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.
habr.com
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему —
01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.
В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
habr.com
таблица кодировки символов — это… Что такое таблица кодировки символов?
- таблица кодировки символов
- symbol table
Большой англо-русский и русско-английский словарь. 2001.
- таблица кодирования векторов
- таблица кодировки цвета
Смотреть что такое «таблица кодировки символов» в других словарях:
Таблица Головина — Таблица Головина Сивцева Таблица Головина Сивцева таблица, используемая для определения остроты зрения человека … Википедия
Набор символов Юникод — Юникод, или Уникод (англ. Unicode) стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium,… … Википедия
Набор символов — (англ. character set) таблица, задающая кодировку конечного множества символов алфавита (обычно элементов текста: букв, цифр, знаков препинания). Такая таблица сопоставляет каждому символу последовательность длиной в один или несколько… … Википедия
Кодировка символов — Набор символов (англ. character set) определённая таблица кодировки конечного множества знаков. Такая таблица сопоставляет каждому символу последовательность длиной в один или несколько байтов. Хотя термин «набор символов» (англ. character set,… … Википедия
Кодовая таблица — таблица соответствий символов и их компьютерных кодов. В РФ распространены следующие кодировки: WIN1251 (Windows), KOI 8 (Unix), СP866 (DOS), Macintosh, ISO 8859 5 (Unix). По английски: Code table См. также: Компьютерные программы Финансовый… … Финансовый словарь
Каскадная таблица стилей — Запрос «CSS» перенаправляется сюда. Но у этой аббревиатуры могут быть и другие значения см. CSS (значения). CSS (англ. Cascading Style Sheets каскадные таблицы стилей) технология описания внешнего вида документа, написанного языком разметки.… … Википедия
Работа с GMT под Windows — Связать? … Википедия
UCS-4 — Юникод, или Уникод (англ. Unicode) стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium,… … Википедия
UNICODE — Юникод, или Уникод (англ. Unicode) стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium,… … Википедия
UTF-32LE — Юникод, или Уникод (англ. Unicode) стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium,… … Википедия
UTF-32 Little Endian — Юникод, или Уникод (англ. Unicode) стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium,… … Википедия
dic.academic.ru
Кодирование информации. Двоичное кодирование. Единицы измерения информации
Тема: Информация вокруг нас
Урок: Кодирование информации. Двоичное кодирование. Единицы измерения информации
На данном уроке будут рассмотрены следующие вопросы:
1. Кодирование как изменение формы представления информации.
2. Как компьютер распознает информацию?
3. Как измерить информацию?
4. Единицы измерения информации.
В мире кодов
Зачем люди кодируют информацию?
1. Скрыть ее от других (зеркальная тайнопись Леонардо да Винчи, военные шифровки).
2. Записать информацию короче (стенография, аббревиатура, дорожные знаки).
3. Для более легкой обработки и передачи (азбука Морзе, перевод в электрические сигналы — машинные коды).
Кодирование — это представление информации с помощью некоторого кода.
Код — это система условных знаков для представления информации.
Способы кодирования информации
1. Графический (см. Рис. 1) (с помощью рисунков и знаков).

Рис. 1. Система сигнальных флагов (Источник)
2. Числовой (с помощью чисел).
Например: 11001111 11100101.
3. Символьный (с помощью символов алфавита).
Например: НКМБМ ЧГЁУ.
Декодирование — это действие по восстановлению первоначальной формы представления информации. Для декодирования необходимо знать код и правила кодирования.
Средством кодирования и декодирования служит кодовая таблица соответствия. Например, соответствие в различных системах счисления — 24 — XXIV, соответствие алфавита каким-либо символам (Рис. 2).

Рис. 2. Пример шифра (Источник)
Примеры кодирования информации
Примером кодирования информации является азбука Морзе (см. Рис. 3).

Рис. 3. Азбука Морзе (Источник)
В азбуке Морзе используется всего 2 символа — точка и тире (короткий и длинный звук).
Еще одним примером кодирования информации является флажковая азбука (см. Рис. 4).

Рис. 4. Флажковая азбука (Источник)
Также примером является азбука флагов (см. Рис. 5).

Рис. 5. Азбука флагов (Источник)
Всем известный пример кодирования — нотная азбука (см. Рис. 6).

Рис. 6. Нотная азбука (Источник)
Рассмотрим следующую задачу:
Используя таблицу флажковой азбуки (см. Рис. 7), необходимо решить следующую задачу:

Рис. 7
Старший помощник Лом сдает экзамен капитану Врунгелю. Помогите ему прочитать следующий текст (см. Рис. 8):
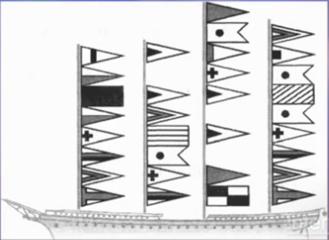
Рис. 8
Представление информации происходит в различных формах в процессе восприятия окружающей среды живыми организмами и человеком, в процессах обмена информацией между человеком и человеком, человеком и компьютером, компьютером и компьютером.
Кодирование — это операция преобразования знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы.
Примером может служить язык жестов (см. Рис. 9).
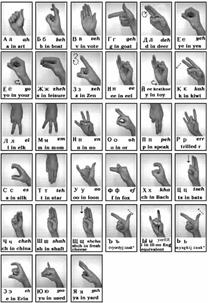
Рис. 9. Азбука жестов (Источник)
Вокруг нас существуют преимущественно два сигнала, например:
— Светофор: красный — зеленый;
— Вопрос: да — нет;
— Лампа: горит — не горит;
— Можно — нельзя;
— Хорошо — плохо;
— Истина — ложь;
— Вперед — назад;
— Есть — нет;
— 1 — 0.
Всё это сигналы, обозначающие количество информации в 1 бит.
1 бит — это такое количество информации, которое позволяет нам выбрать один вариант из двух возможных.
Компьютер — это электрическая машина, работающая на электронных схемах. Чтобы компьютер распознал и понял вводимую информацию, ее надо перевести на компьютерный (машинный) язык.
Алгоритм, предназначенный для исполнителя, должен быть записан, то есть закодирован, на языке, понятном компьютеру.
Это электрические сигналы: проходит ток или не проходит ток.
Машинный двоичный язык — последовательность «0» и «1». Каждое двоичное число может принимать значение 0 или 1.
Каждая цифра машинного двоичного кода несет количество информации, равное 1 бит.
|
Устройства |
1 |
0 |
|
Электронные схемы |
Проводят электрический ток |
Не проводят электрический ток |
|
Участок поверхности магнитного носителя (жесткий диск, дискета) |
Намагничен |
Размагничен |
|
Участок поверхности лазерного диска |
Отражает луч |
Не отражает луч |
Двоичное число, которое представляет наименьшую единицу информации, называется бит. Бит может принимать значение либо 0, либо 1. Наличие магнитного или электронного сигнала в компьютере означает 1, отсутствие 0.
Строка из 8 битов называется байт. Эту строку компьютер обрабатывает как отдельный символ (число, букву).
Рассмотрим пример. Слово ALICE состоит из 5 букв, каждая из которых на языке компьютера представлена одним байтом (см. Рис. 10). Стало быть, Alice можно измерить как 5 байт.
Рис. 10. Двоичный код (Источник)
Кроме бита и байта, существуют и другие единицы измерения информации.
|
Название |
Сокращенное обозначение |
Размер в байтах |
Степень |
|
Килобайт |
Кбайт, Kb |
1 024 |
210 |
|
Мегабайт |
Мбайт, Mb |
1 048 576 |
220 |
|
Гигабайт |
Гбайт, Gb |
1 079 741 824 |
230 |
|
Терабайт |
Тбайт, Tb |
1 099 511 627 776 |
240 |
Список литературы
1. Босова Л.Л. Информатика и ИКТ: Учебник для 5 класса. – М.: БИНОМ. Лаборатория знаний, 2012.
2. Босова Л.Л. Информатика: Рабочая тетрадь для 5 класса. – М.: БИНОМ. Лаборатория знаний, 2010.
3. Босова Л.Л., Босова А.Ю. Уроки информатики в 5-6 классах: Методическое пособие. – М.: БИНОМ. Лаборатория знаний, 2010.
Рекомендованные ссылки на ресурсы интернет
1. Учительский портал (Источник).
2. Фестиваль «Открытый урок» (Источник).
3. Информатика в школе (Источник).
Домашнее задание
1. §1.6, 1.7 (Босова Л.Л. Информатика и ИКТ: Учебник для 5 класса).
2. Стр. 28, задания 1, 4; стр. 30, задания 1, 4, 5, 6 (Босова Л.Л. Информатика и ИКТ: Учебник для 5 класса).
interneturok.ru
Что такое таблица кодировок символов??
компьютер не понимет ничего кроме 0 и 1 0- нет сигнала 1- есть каждая буква представлена как набор 0 и 1 (в основном представление идет в шеснадцатиричном коде- для языков верхнего уровня, а уж потом переводится в двоичный)
каждому символу (на клавиатуре) — соответствует свой код если запустите WORD в меню выберите вставка-символ то увидите эту самую табличку кодировки символов а внизу таблички будет указан код выбранного символа (правда — десятичный) <a rel=»nofollow» href=»http://www.internet-school.ru/Enc.ashx?item=3689″ target=»_blank»>http://www.internet-school.ru/Enc.ashx?item=3689</a>
Это всё равно что называть одно и тоже действие человека на разных языках. Для компа все действия сводиться к 1\0, а как эти 1 и 0 будут отображаться на экране (какими символоми) зависит от таблицы.
Каждый символ (не важно, имеет он графическое представление или нет — к примеру символ клавиши Esc не имеет такого представления) имеет свой код. Причем, существуют разные способы кодирования. Основным способом является представление символов в виде одного байта. Это позволяет закодировать все символы английской раскладки, цифры, знаки препинания и т. п. Кроме того, в такую таблицу символов так же входит и национальные символы (для России — кириллица) . Но если есть необходимость кодировать одновременно и кириллицу, и греческий, и арабский алфавит, 1 байта на символ становится мало. В этом случае могут использоваться кодировки из 2-3-4 байт (как Unicode), а так же кодировки переменной длинны (к примеру, UTF-8).
touch.otvet.mail.ru