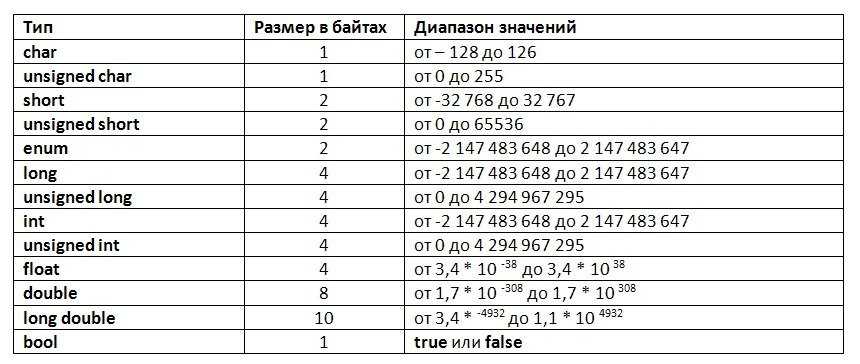
Out double c что означает
Double – 64-разрядная переменная с плавающей запятой
Тип double — это основной тип данных, который используется для переменных, содержащих числа с дробной частью. Double используется в C , C++ , C# и других языках программирования. Он может представлять как дробные, так и целые значения длинной до 15 знаков.
Применение DOUBLE
Тип float раньше использовался из-за того, что он был меньше double и позволял быстрее работать с тысячами и миллионами чисел с плавающей запятой. Но вычислительная мощность новых процессоров выросла настолько, что преимуществами float перед double можно пренебречь. Многие программисты считают double типом по умолчанию для чисел с плавающей запятой.
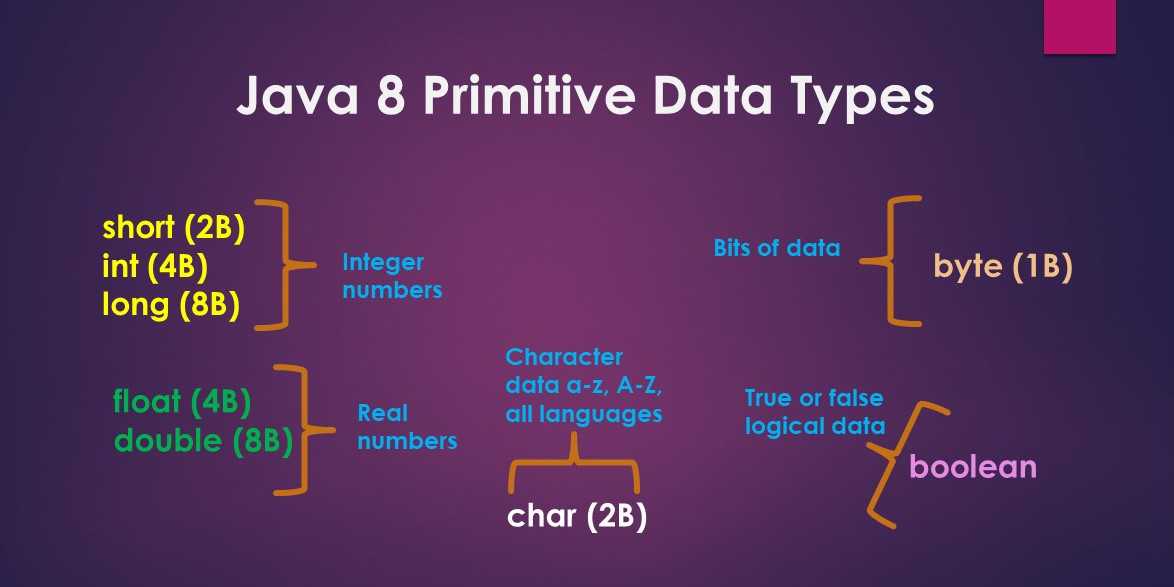
DOUBLE, FLOAT И INT
Другие числовые типы данных — это float и int . Типы данных double и float похожи, но отличаются точностью и диапазоном:
- Float — 32-битный тип, вмещающий семь цифр. Его диапазон — примерно от 1.5 х 215; 10 -45 до 3.4 х 10 38 ;
- Double — 64-битный тип, вмещающий 15 или 16 цифр с диапазоном от 5.
 0 х 10 345 to 1.7 х 10 308 .
0 х 10 345 to 1.7 х 10 308 .
 0 х 10 345 to 1.7 х 10 308 .
0 х 10 345 to 1.7 х 10 308 .Int также относится к числовым типам данных, но с ним можно использовать только целые числа, которым не нужна запятая. Таким образом, int содержит только целые числа, но при этом занимает меньше места. Он позволяет быстрее совершать математические операции, а также эффективнее других типов данных использует кэш-память и пропускную способность соединения.
Данная публикация представляет собой перевод статьи « Definition of Double in C, C++ and C# » , подготовленной дружной командой проекта Интернет-технологии.ру
Mетоды могут как принимать, так и не принимать параметров, а также возвращать или не возвращать значения вызывающей стороне. Хотя определение метода в C# выглядит довольно понятно, существует несколько ключевых слов, с помощью которых можно управлять способом передачи аргументов интересующему методу:
| Модификатор параметра | Описание |
|---|---|
| (отсутствует) | Если параметр не сопровождается модификатором, предполагается, что он должен передаваться по значению, т. е. вызываемый метод должен получать копию исходных данных е. вызываемый метод должен получать копию исходных данных |
| out | Выходные параметры должны присваиваться вызываемым методом (и, следовательно, передаваться по ссылке). Если параметрам out в вызываемом методе значения не присвоены, компилятор сообщит об ошибке |
| ref | Это значение первоначально присваивается вызывающим кодом и при желании может повторно присваиваться в вызываемом методе (поскольку данные также передаются по ссылке). Если параметрам ref в вызываемом методе значения не присвоены, компилятор никакой ошибки генерировать не будет |
| params | Этот модификатор позволяет передавать в виде одного логического параметра переменное количество аргументов. В каждом методе может присутствовать только один модификатор params и он должен обязательно указываться последним в списке параметров. В реальности необходимость в использовании модификатора params возникает не особо часто, однако он применяется во многих методах внутри библиотек базовых классов |
Нередко требуется, чтобы метод оперировал теми аргументами, которые ему передаются. Характерным тому примером служит метод Swap(), осуществляющий перестановку значений своих аргументов. Но поскольку аргументы простых типов передаются по значению, то, используя выбираемый в C# по умолчанию механизм вызова по значению для передачи аргумента параметру, невозможно написать метод, меняющий местами значения двух его аргументов, например типа int. Это затруднение разрешает
Характерным тому примером служит метод Swap(), осуществляющий перестановку значений своих аргументов. Но поскольку аргументы простых типов передаются по значению, то, используя выбираемый в C# по умолчанию механизм вызова по значению для передачи аргумента параметру, невозможно написать метод, меняющий местами значения двух его аргументов, например типа int. Это затруднение разрешает
Как вам должно быть уже известно, значение возвращается из метода вызывающей части программы с помощью оператора return. Но метод может одновременно возвратить лишь одно значение. А что, если из метода требуется возвратить два или более фрагментов информации, например, целую и дробную части числового значения с плавающей точкой? Такой метод можно написать, используя модификатор out.
Давайте отдельно рассмотрим роль каждого из вышеуказанных ключевых слов.
Модификатор ref
Модификатор параметра ref принудительно организует вызов по ссылке, а не по значению. Этот модификатор указывается как при объявлении, так и при вызове метода.
Этот модификатор указывается как при объявлении, так и при вызове метода.
Параметры, сопровождаемые таким модификатором, называются ссылочными и применяются, когда нужно позволить методу выполнять операции и обычно также изменять значения различных элементов данных, объявляемых в вызывающем коде (например, в процедуре сортировки или обмена). Обратите внимание на следующие отличия между ссылочными и выходными параметрами:
Выходные параметры
Это параметры, которые не нужно инициализировать перед передачей методу. Причина в том, что метод сам должен присваивать значения выходным параметрам перед выходом.
Ссылочные параметры
Эти параметры нужно обязательно инициализировать перед передачей методу. Причина в том, что они подразумевают передачу ссылки на уже существующую переменную. Если первоначальное значение ей не присвоено, это будет равнозначно выполнению операции над неинициализированной локальной переменной.
Давайте рассмотрим пример использования модификатора ref:
В отношении модификатора ref необходимо иметь в виду следующее. Аргументу, передаваемому по ссылке с помощью этого модификатора, должно быть присвоено значение до вызова метода. Дело в том, что в методе, получающем такой аргумент в качестве параметра, предполагается, что параметр ссылается на действительное значение. Следовательно, при использовании модификатора ref в методе нельзя задать первоначальное значение аргумента.
Аргументу, передаваемому по ссылке с помощью этого модификатора, должно быть присвоено значение до вызова метода. Дело в том, что в методе, получающем такой аргумент в качестве параметра, предполагается, что параметр ссылается на действительное значение. Следовательно, при использовании модификатора ref в методе нельзя задать первоначальное значение аргумента.
Модификатор out
Модификатор параметра out подобен модификатору ref, за одним исключением: он служит только для передачи значения за пределы метода. Поэтому переменной, используемой в качестве параметра out, не нужно (да и бесполезно) присваивать какое-то значение. Более того, в методе параметр out считается неинициализированным, т.е. предполагается, что у него отсутствует первоначальное значение. Это означает, что значение должно быть присвоено данному параметру в методе до его завершения. Следовательно, после вызова метода параметр out будет содержать некоторое значение.
Обратите внимание, что использование модификатора out в данном примере позволяет возвращать из метода сразу четыре значения.
Модификатор params
В C# поддерживается использование массивов параметров за счет применения ключевого слова params. Ключевое слово params позволяет передавать методу переменное количество аргументов одного типа в виде единственного логического параметра. Аргументы, помеченные ключевым словом params, могут обрабатываться, если вызывающий код на их месте передает строго типизированный массив или разделенный запятыми список элементов.
Число элементов массива параметров будет равно числу аргументов, передаваемых методу. А для получения аргументов в программе организуется доступ к данному массиву:
В тех случаях, когда у метода имеются обычные параметры, а также параметр переменной длины типа params, он должен быть указан последним в списке параметров данного метода. Но в любом случае параметр типа params должен быть единственным.
Ключевое out инициирует передачу аргументов по ссылке. The out keyword causes arguments to be passed by reference. В результате этот формальный параметр становится псевдонимом для аргумента, который должен представлять собой переменную. It makes the formal parameter an alias for the argument, which must be a variable. Другими словами, любая операция в параметре осуществляется с аргументом. In other words, any operation on the parameter is made on the argument. Оно схоже с ключевым словом ref за исключением того, что при использовании ref перед передачей переменную необходимо инициализировать. It is like the ref keyword, except that ref requires that the variable be initialized before it is passed. Оно также похоже на ключевое слово in за исключением того, что in не позволяет вызываемому методу изменять значение аргумента. It is also like the in keyword, except that in does not allow the called method to modify the argument value. Для применения параметра out определение метода и метод вызова должны явно использовать ключевое слово out . To use an out parameter, both the method definition and the calling method must explicitly use the out keyword.
В результате этот формальный параметр становится псевдонимом для аргумента, который должен представлять собой переменную. It makes the formal parameter an alias for the argument, which must be a variable. Другими словами, любая операция в параметре осуществляется с аргументом. In other words, any operation on the parameter is made on the argument. Оно схоже с ключевым словом ref за исключением того, что при использовании ref перед передачей переменную необходимо инициализировать. It is like the ref keyword, except that ref requires that the variable be initialized before it is passed. Оно также похоже на ключевое слово in за исключением того, что in не позволяет вызываемому методу изменять значение аргумента. It is also like the in keyword, except that in does not allow the called method to modify the argument value. Для применения параметра out определение метода и метод вызова должны явно использовать ключевое слово out . To use an out parameter, both the method definition and the calling method must explicitly use the out keyword. Пример: For example:
Пример: For example:
Ключевое слово out также можно использовать с параметром универсального типа для указания на то, что тип параметра является ковариантным. The out keyword can also be used with a generic type parameter to specify that the type parameter is covariant. Дополнительные сведения об использовании ключевого слова out в этом контексте см. в разделе out (универсальный модификатор). For more information on the use of the out keyword in this context, see out (Generic Modifier).
Переменные, передаваемые в качестве аргументов out , не требуется инициализировать перед передачей в вызове метода. Variables passed as out arguments do not have to be initialized before being passed in a method call. Но перед передачей управления из вызванного метода он должен присвоить значение. However, the called method is required to assign a value before the method returns.
Ключевые слова in , ref и out не считаются частью сигнатуры метода для разрешения перегрузки. The in , ref , and out keywords are not considered part of the method signature for the purpose of overload resolution. Таким образом, методы не могут быть перегружены, если единственное различие состоит в том, что один метод принимает аргумент ref или in , а другой — out . Therefore, methods cannot be overloaded if the only difference is that one method takes a ref or in argument and the other takes an out argument. Следующий код, например, компилироваться не будет. The following code, for example, will not compile:
Таким образом, методы не могут быть перегружены, если единственное различие состоит в том, что один метод принимает аргумент ref или in , а другой — out . Therefore, methods cannot be overloaded if the only difference is that one method takes a ref or in argument and the other takes an out argument. Следующий код, например, компилироваться не будет. The following code, for example, will not compile:
Перегрузка допустима, если один метод принимает аргумент ref , in или out , а другой не использует ни один из этих модификаторов, как показано ниже. Overloading is legal, however, if one method takes a ref , in , or out argument and the other has none of those modifiers, like this:
Компилятор выбирает наиболее подходящую перегрузку, сравнивая модификаторы параметров в месте вызова с модификаторами параметров в вызове метода. The compiler chooses the best overload by matching the parameter modifiers at the call site to the parameter modifiers used in the method call.
Свойства не являются переменными и поэтому не могут быть переданы как параметры out . Properties are not variables and therefore cannot be passed as out parameters.
Properties are not variables and therefore cannot be passed as out parameters.
Ключевые слова in , ref и out запрещено использовать для следующих типов методов. You can’t use the in , ref , and out keywords for the following kinds of methods:
Асинхронные методы, которые определяются с помощью модификатора async. Async methods, which you define by using the async modifier.
Методы итератора, которые включают оператор yield return или yield break . Iterator methods, which include a yield return or yield break statement.
Объявление параметров out Declaring out parameters
Объявление метода с аргументами out — стандартное решение для возвращения нескольких значений. Declaring a method with out arguments is a classic workaround to return multiple values. Начиная с версии C# 7.0, вы можете использовать кортежи для таких сценариев. Beginning with C# 7.0, consider tuples for similar scenarios. В следующем примере используется out для возвращения трех переменных с помощью вызова одного метода. The following example uses out to return three variables with a single method call. Обратите внимание, что третьему аргумент присвоено значение null. Note that the third argument is assigned to null. Это позволяет методам возвращать значения по желанию. This enables methods to return values optionally.
The following example uses out to return three variables with a single method call. Обратите внимание, что третьему аргумент присвоено значение null. Note that the third argument is assigned to null. Это позволяет методам возвращать значения по желанию. This enables methods to return values optionally.
Вызов метода с аргументом out Calling a method with an out argument
В C# 6 и более ранних версиях необходимо было объявлять переменную в отдельном операторе, прежде чем передавать ее как аргумент out . In C# 6 and earlier, you must declare a variable in a separate statement before you pass it as an out argument. В следующем примере переменная number объявляется перед передачей в метод Int32.TryParse, который пытается преобразовать строку в число. The following example declares a variable named number before it is passed to the Int32.TryParse method, which attempts to convert a string to a number.
Начиная с C# версии 7.0 переменную out можно объявлять в списке аргументов вызова метода, а не отдельно. Starting with C# 7.0, you can declare the out variable in the argument list of the method call, rather than in a separate variable declaration. Это делает код более кратким и удобным для восприятия, а также предотвращает непреднамеренное присвоение значения переменной перед вызовом метода. This produces more compact, readable code, and also prevents you from inadvertently assigning a value to the variable before the method call. Следующий пример аналогичен предыдущему за тем исключением, что переменная number объявляется в вызове метода Int32.TryParse. The following example is like the previous example, except that it defines the number variable in the call to the Int32.TryParse method.
Starting with C# 7.0, you can declare the out variable in the argument list of the method call, rather than in a separate variable declaration. Это делает код более кратким и удобным для восприятия, а также предотвращает непреднамеренное присвоение значения переменной перед вызовом метода. This produces more compact, readable code, and also prevents you from inadvertently assigning a value to the variable before the method call. Следующий пример аналогичен предыдущему за тем исключением, что переменная number объявляется в вызове метода Int32.TryParse. The following example is like the previous example, except that it defines the number variable in the call to the Int32.TryParse method.
В предыдущем примере переменная number строго типизирована как int . In the previous example, the number variable is strongly typed as an int . Вы также можете объявить неявно типизированную локальную переменную, как в приведенном ниже примере. You can also declare an implicitly typed local variable, as the following example does.
Спецификация языка C# C# Language Specification
Дополнительные сведения см. в спецификации языка C#. For more information, see the C# Language Specification. Спецификация языка является предписывающим источником информации о синтаксисе и использовании языка C#. The language specification is the definitive source for C# syntax and usage.
Double, Float — не вещественные числа / Хабр
Во многих источниках тип double и float, числа с плавающей запятой/точкой зачем-то называют вещественными. Такое чувство что кто-то когда-то совершил ошибку или не внимательно написал эту глупость и все как один начали её повторять, совершенно не задумываясь о чём они говорят.
Ладно это были бы просто троечники студенты и любители, так эту ошибку говорят и те, кто обучают специалистов. И эта проблема терминологии не одного ЯП, их правда много (Java, C++, C#, Python, JS и т.д.) везде, где бы я не искал, всегда находятся статьи, ответы, лекции, где дробные числа называют вещественными!
Вот ОЧЕНЬ МАЛЕНЬКАЯ выборка:
https://javarush.
ru/quests/lectures/questsyntaxpro.level04.lecture06 — JavaRushhttps://docs-python.ru/tutorial/osnovnye-vstroennye-tipy-python/tip-dannyh-float-veschestvennye-chisla/ — Docs Python3
http://cppstudio.com/post/310/ — CppStudio
https://ejudge.ru/study/3sem/sem07.pdf — Ejudge
https://ru.wikipedia.org/wiki/Система_типов_Си — даже всеми любимая Wikipedia!
Ещё раз повторюсь это очень маленькая выборка, можете набрать в гугл поиске, по ключевым словам, и удостовериться что их полно.
 ru/quests/lectures/questsyntaxpro.level04.lecture06 — JavaRush
ru/quests/lectures/questsyntaxpro.level04.lecture06 — JavaRushНачнём с простого, что такое вещественное число коим называют double и float. Будет немного формул, но не пугайтесь, прочитайте пожалуйста до конца, они очень простые, к каждой я даю интуитивное объяснение.
Вещественное число
Определение можете прочитать в Википедии или дочитать до конца мою статью, где я простым языком скажу или вы сами поймёте, но нужно проследить за мыслью, которую я хочу донести до вас. Я напишу формулой из теории множеств:
R = Q ∪ I
Где, R — множество вещественных чисел;
Q — множество рациональных чисел;
I — множество иррациональных чисел.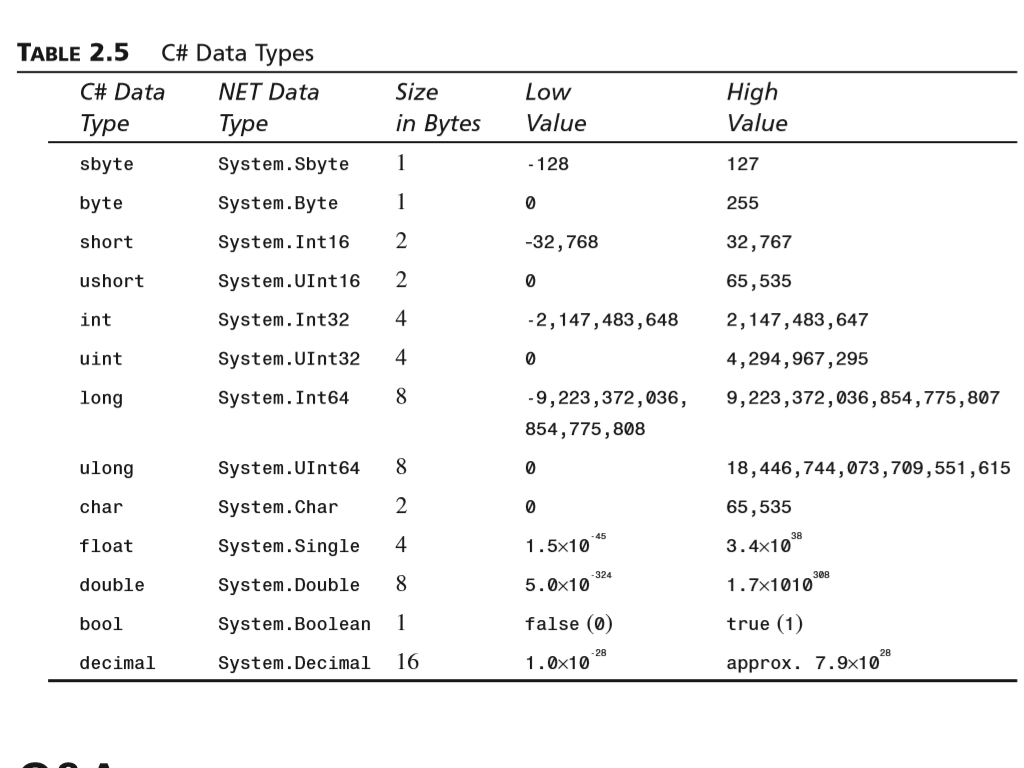
Так же Q ⊂ R и I ⊂ R.
Расшифровка тем, кто не очень с теорией множеств. Вещественные числа эта числа которые включают в себя Рациональные и Иррациональные числа (R = Q ∪ I), т.к. Вещественные числа включают их в себя, то Рациональные числа и Иррациональные числа являются подмножеством множества Вещественных (Q ⊂ R и I ⊂ R), причём строго, то есть Q != R и I != R, это очевидная мысль, но её требуется подчеркнуть.
Теперь к самому интересному, какие числа называются Рациональными и Иррациональными (представляю себя преподавателем начальных курсов технических вузов).
Рациональные
Начнём с Рациональных, возьмём определение из википедии.
Рациональное число (от лат. ratio «отношение, деление, дробь») — число, которое можно представить в виде обыкновенной дроби m/n, где m — целое число, а n — натуральное.
Так же стоит отметить, что Рациональные включают в себя Целые и Натуральные числа (-1, 0, 1, 2 …) их можно выразить в виде дроби, 1 = 1/1, 2 = 2/1, -1 = -1/1, 0 = 0/1 и т. д.
д.
Почему это важно? Потому что Иррациональные числа не включают в себя Целые и Натуральные числа, это отдельный класс чисел.
Иррациональные
Берём определение из Википедии.
Иррациональное число — это вещественное число, которое не является рациональным, то есть не может быть представлено в виде обыкновенной дроби m/n, где m,n — целые числа, n != 0. Иррациональное число может быть представлено в виде бесконечной непериодической десятичной дроби.
Так же приведу примеры иррациональных чисел, чтобы стало понятно: π (число пи), e (число Эйлера), √2.
Вы начали что-то подозревать? Если нет я помогу вам.
Первое предложение определения — это то, о чём я вам говорил, то, что Иррациональные числа — это отдельный класс чисел и он не включает в себя Целые и Натуральные.
Но самое важное здесь это второе предложение «Иррациональное число может быть представлено в виде бесконечной непериодической десятичной дроби.».
Что это значит? Заметили, что в примерах я дал вам буквенное обозначение? Это не просто так, это представление иррационального числа, ВАЖНО — сама запись π это не само иррациональное число, это всего лишь его представление, и оно является чем угодно, но не иррациональным числом. Само Иррациональное число оно бесконечно. Понимаете?
Само Иррациональное число оно бесконечно. Понимаете?
То есть его невозможно записать по определению. Никакой памяти в компьютере не хватит чтобы его записать. Это невозможно!
И мало того что в большинстве (я не проверял прям на всех, но очень сомневаюсь, что хотя бы в одном это есть) языков в которых используется термин Вещественный тип нельзя чисто синтаксически сделать запись по типу: «double a = π», попросту будет ошибка компиляции, так ещё если и возможно с помощью латинских букв подключая библиотеки, то в конечном-то итоге эта переменная будет ссылаться на конечное представление, а то есть рациональное этого иррационального числа!
Всё с чем мы можем работать это ТОЛЬКО РАЦИОНАЛЬНЫЕ ЧИСЛА, представления иррациональных чисел они ТОЖЕ рациональные и ТОЛЬКО рациональные. Они большие, они могут быть ооооочень большими, но они всё равно рациональные!
R = Q ∪ I, если мы исключаем I из-за невозможности работы с ними в прямом смысле без представлений получается R’ = R\I, R’ = Q, а Q у нас рациональные числа.
Так почему же так много людей и весьма неглупых всё ещё допускают эту простую ошибку? Эту ошибку можно было описать в пару предложений, но я хотел донести до вас последовательно как к этому прийти, используя общепринятую терминологию.
Спасибо.
P.S. Это моя оригинальная статья AfterWing, не является переводом, доработкой другой какой-либо статьи на русском/английском и др. языках.
Double or Nothing / Хабр
Если вы выбрали C++ в качестве языка программирования, то учить его придётся всю жизнь. Смиритесь. Или выбирайте другой язык.
Чего только стоят новые стандарты, появляющиеся каждые 3 года. И каждый раз с какими-то полезными нововведениями в синтаксисе! Как им только это удаётся?
Есть разные способы совершенствоваться в С++. Кто-то читает Страуструпа от корки до корки, а потом почитывает стандарты. Кто-то ничего не читает и программирует по наитию — тупиковый путь, на мой взгляд.
Мне же нравится читать крупицы мудрости, бережно сформулированные для понимания простых смертных каким-нибудь гуру программирования.
Одна из моих любимых таких вещей — Guru of the Week (GotW) Херба Саттера.
Написано остроумно. И сколько пользы для программистки! Некоторые статьи уже морально устарели: кому нужен auto_ptr в наши дни? Но большинство ценно и сегодня.
Приведу здесь перевод выпуска №67 «Double or Nothing» от 29 февраля 2000 года. Моё любимое место — про тепловую смерть конечно
«Сложность 4/10
Нет. Этот выпуск не об азартных играх. Он, впрочем, о разных видах «float» так сказать, и даёт вам возможность проверить навыки касающиеся базовых операций над числами с плавающей точкой в C и C++.
Проблема
Вопрос Йуного Гуру (JG)
1) В чём разница между «float» и «double»?
Вопрос Гуру
2) Допустим следующая программа выполняется за 1 секунду, что неудивительно для современного настольного компьютера:
int main() {
double x = 1e8;
while (x > 0) { --x; }
return 0;
}
Как долго по-вашему она будет выполняться, если заменить «double» на «float»? Почему?
Решение
1) В чём разница между «float» и «double»?
Цитата из секции 3. 9.1/8 стандарта C++:
9.1/8 стандарта C++:
Существует три типа чисел с плавающей точкой: float, double и long double. Тип double предоставляет по меньшей мере такую же точность как float, а тип long double — по меньшей мере такую же точность как double. Множество значений типа float является подмножеством множества значений типа double; множество значений типа double является подмножеством множества значений типа long double.
Колесо Времени
2) Как долго по вашему программа из вопроса 2 будет выполняться, если заменить «double» на «float»? Почему?
Она будет выполняться или примерно 1 секунду (в конкретных реализациях float’ы могут быть быстрее, такими же быстрыми или медленнее, чем double’ы) или бесконечно, в зависимости от того может или нет тип float представлять все целые числа от 0 до 1e8 включительно.
Цитата из стандарта выше означает, что могут существовать такие значения, которые могут быть представлены типом double, но не могут быть представлены типом float. В частности, на многих популярных платформах и во многих компиляторах double может точно представить все целые числа в диапазоне [0, 1e8], а float — не может.
Что если float не может точно представить все целые числа в диапазоне от 0 до 1e8? Тогда изменённая программа начнёт обратный отсчёт, но в конце концов достигнет значения N, которое не может быть представлено и для которого N-1==N (из-за недостаточной точности чисел с плавающей точкой) … и тогда цикл застрянет на этом значении пока машина, на которой запущена программа не разрядится (из-за проблем в локальной энергосети или ограничений батареи), её операционная система не сломается (некоторые платформы более подвержены этому, чем другие), Солнце не превратится в переменную звезду и спалит внутренние планеты или вселенная не погибнет тепловой смертью — любое, что произойдёт раньше*.
Слово о Сужающих Преобразованиях
Некоторые люди могут интересоваться: «Хорошо, кроме всеобщей тепловой смерти нет ли здесь другой проблемы? Константа 1e8 имеет тип double. Тогда если мы просто заменим «double» на «float», программа не скомпилируется по причине сужающего преобразования, верно?»
Хорошо, давайте процитируем стандарт ещё раз, на этот раз секцию 4. 8/1:
8/1:
rvalue [выражение справа от знака «=» — прим. переводчицы] типа с плавающей точкой может быть преобразовано к rvalue другого типа с плавающей точкой. Если исходное значение может быть точно представлено целевым типом данных, результатом преобразования будет являться то точное представление. Если исходное значение лежит между двух последовательных значений целевого типа данных, результат преобразования определяется реализацией в качестве одного из этих двух значений. Иначе поведение не определено.
Это означает, что константа типа double может быть неявно (то есть молчаливо) преобразована в константу типа float, даже если это действие приводит к потере точности (то есть данных). Этому было позволено остаться как есть по причине совместимости с C и удобства использования. Но стоит держать это в уме, когда делаете работу с типами с плавающей точкой.
Качественный компилятор предупредит вас, если вы попытаетесь сделать что-то, поведение чего не определено. Например, присвоить значение типа double, которое меньше минимального или больше максимального значения, представимого типом float, к сущности типа float. По-настоящему хороший компилятор выдаст опциональное предупреждение, если вы попытаетесь сделать что-то, поведение чего может быть определено, но что влечёт потерю информации. Например, присвоить значение типа double, которое лежит между минимальным и максимальным значением типа float, но не может быть в точности представлено типом float, к сущности типа float.
По-настоящему хороший компилятор выдаст опциональное предупреждение, если вы попытаетесь сделать что-то, поведение чего может быть определено, но что влечёт потерю информации. Например, присвоить значение типа double, которое лежит между минимальным и максимальным значением типа float, но не может быть в точности представлено типом float, к сущности типа float.
Примечания
*Действительно, раз программа оставляет компьютер работать впустую, она также впустую увеличивает энтропию вселенной, таким образом приближая упомянутую тепловую смерть. Вкратце, такая программа довольно недружественна к окружающей среде и должна считаться угрозой для нашего биологического вида. Не пишите так код**.
** Конечно, выполнение любой дополнительной работы, людьми ли или машинами, также увеличивает энтропию вселенной, приближая тепловую смерть. Это хороший аргумент, который нужно иметь ввиду, когда работодатель требует переработок.»
(c) Херб Саттер, GotW
Что такое C++
Назад
C++ — компилируемый, статически типизированный язык программирования общего назначения.
Поддерживает такие парадигмы программирования как процедурное программирование, объектно-ориентированное программирование, обобщённое программирование, обеспечивает модульность, раздельную компиляцию, обработку исключений, абстракцию данных, объявление типов (классов) объектов, виртуальные функции. Стандартная библиотека включает, в том числе, общеупотребительные контейнеры и алгоритмы. C++ сочетает свойства как высокоуровневых, так и низкоуровневых языков. В сравнении с его предшественником — языком C, — наибольшее внимание уделено поддержке объектно-ориентированного и обобщённого программирования.
C++ широко используется для разработки программного обеспечения, являясь одним из самых популярных языков программирования. Область его применения включает создание операционных систем, разнообразных прикладных программ, драйверов устройств, приложений для встраиваемых систем, высокопроизводительных серверов, а также развлекательных приложений. Существует множество реализаций языка C++, как бесплатных, так и коммерческих и для различных платформ.
Обзор языка
Необъектно-ориентированные особенности
Типы:
- Символьные: char, wchar_t(char16_t и char32_t, в стандарте C++11).
- Целочисленные знаковые: signed char, short int, int, long int(и long long int, в стандарте C++11).
- Целочисленные беззнаковые: unsigned char, unsigned short int, unsigned int, unsigned long int(иunsigned long long int, в стандарте C++11).
- С плавающей точкой: float, double, long double.
- Логический: bool.
Операции сравнения возвращают тип bool. Выражения в скобках после if, while приводятся к типу bool.
Функции могут принимать аргументы по ссылке. Функции могут возвращать результат по ссылке. Cсылки сходны с указателями, со следующими особенностями: перед использованием ссылка должна быть инициализирована; ссылка всегда указывает на один и тот же адрес; в выражении ссылка обозначает непосредственно тот объект или ту функцию, на которую она указывает, обращение же к объекту или функции через указатель требует разыменование указателя.
Нововведения:
- inlineфункции.
- Описатель volatile
- Пространства имён(namespace)
- Шаблоны template
- Операторыnew, new[], delete и delete[]
Объектно-ориентированные особенности
C++ добавляет к C объектно-ориентированные возможности. Он вводит классы, которые обеспечивают три самых важных свойства ООП: инкапсуляцию, наследование и полиморфизм.
Методы класса — это функции, которые смогут применяться к экземплярам класса. Грубо говоря, метод — это функция объявленная внутри класса и предназначенная для работы с его объектами. Методы объявляются в теле класса. Описываться могут там же, но могут и за пределами класса (внутри класса в таком случае достаточно представить прототип метода, а за пределами класса определять метод поставив перед его именем — имя класса и оператор ::). Методы и поля входящие в состав класса называются членами класса. При этом методы часто называют функциями-членами класса.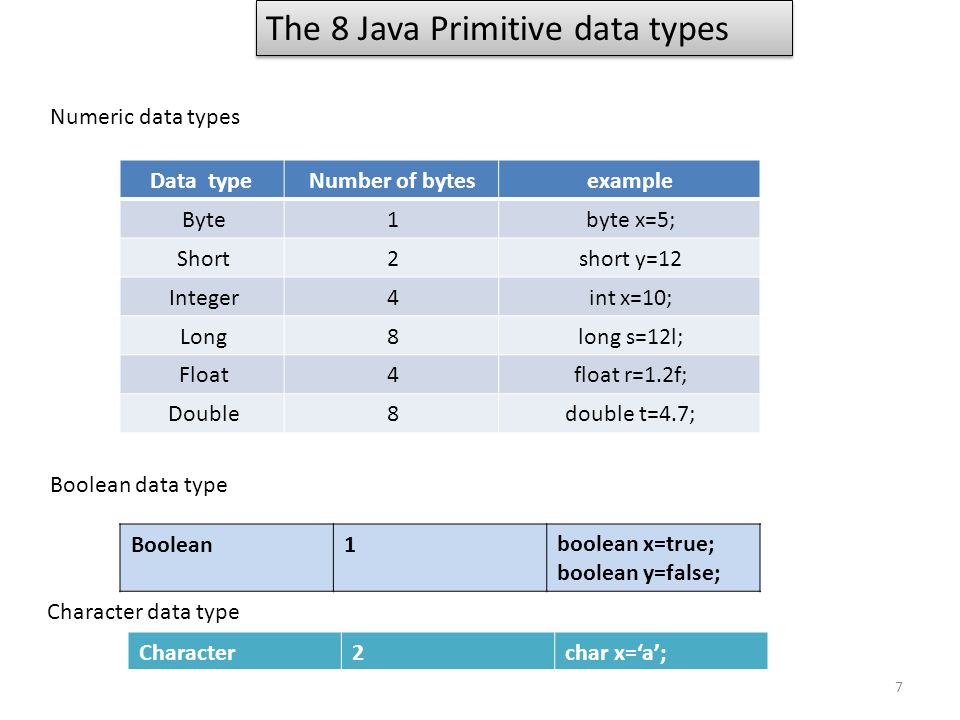
Наследование
В C++ при наследовании одного класса от другого наследуется реализация класса, плюс класс-наследник может добавлять свои поля и функции или переопределять функции базового класса. Множественное наследование разрешено.
Конструктор наследника вызывает конструкторы базовых классов, а затем конструкторы нестатических членов-данных, являющихся экземплярами классов. Деструктор работает в обратном порядке.
Наследование бывает публичным, защищённым и закрытым.
Полиморфизм
Целью полиморфизма, применительно к объектно-ориентированному программированию, является использование одного имени для задания общих для класса действий. Выполнение каждого конкретного действия будет определяться типом данных.
Преимуществом полиморфизма является то, что он помогает снижать сложность программ, разрешая использование того же интерфейса для задания единого класса действий. Выбор же конкретного действия, в зависимости от ситуации, возлагается на компилятор. Полиморфизм может применяться также и к операторам.
Полиморфизм может применяться также и к операторам.
Инкапсуляция
Основным способом организации информации в C++ являются классы. В отличие от структуры (struct) языка C, которая может состоять только из полей и вложенных типов, класс (class) C++ может состоять из полей, вложенных типов и функций-членов. Инкапсуляция в С++ реализуется через указание уровня доступа к членам класса: они бывают публичными (public), защищёнными (protected) и закрытыми (private). В C++ структуры отличаются от классов тем, что по умолчанию члены и базовые классы у структуры публичные, а у класса — собственные.
Стандартная библиотека
В языке программирования C++ термин Стандартная Библиотека означает коллекцию классов и функций, написанных на базовом языке. Стандартная Библиотека поддерживает несколько основных контейнеров, функций для работы с этими контейнерами, объектов-функции, основных типов строк и потоков (включая интерактивный и файловый ввод-вывод), поддержку некоторых языковых особенностей, и часто используемые функции для выполнения таких задач, как, например, нахождение квадратного корня числа.
Стандартная библиотека шаблонов (STL) — подмножество стандартной библиотеки C++ и содержит контейнеры, алгоритмы, итераторы, объекты-функции и т. д.
Заголовочные файлы стандартной библиотеки C++ не имеют расширения «.h».
Стандартная библиотека C++ содержит последние расширения C++ стандарта ANSI (включая библиотеку стандартных шаблонов и новую библиотеку iostream). Она представляет собой набор файлов заголовков.
Отличия от Си
Новые возможности:
- поддержка объектно-ориентированного программирования;
- поддержка обобщённого программирования через шаблоны;
- дополнительные типы данных;
- исключения;
- пространства имён;
- встраиваемые (inline) функции;
- перегрузка операторов;
- перегрузка функций;
- ссылки и операторы управления свободно распределяемой памятью;
- дополнения к стандартной библиотеке.
В С++ не разрешается:
- вызывать функцию main() внутри программы, в то время как в C это действие правомерно.
- неявное приведение типов между несвязанными типами указателей.
- использовать функции, которые ещё не объявлены.
Достоинства и недостатки
С++ — язык, складывающийся эволюционно. Каждый элемент С++ заимствовался из других языков отдельно и независимо от остальных элементов (ничто из предложенного С++ за всю историю его развития не было новшеством в Computer Science), что сделало язык чрезвычайно сложным, со множеством дублирующихся и взаимно противоречивых элементов, блоки которых основаны на разных формальных базах.
Критики С++ не противопоставляют ему какой-либо конкретный язык, а наоборот, утверждают, что для всякого случая применения С++ всегда существует альтернативный инструментарий, позволяющий решить ту же задачу более эффективно и качественно. В свою очередь, сторонники С++ считают некорректным сравнивать различные аспекты С++ с совершенно различными языками, так как общий набор средств и возможностей С++ существенно шире, чем в большинстве языков, с которыми проводится сравнение, и сама по себе широта возможностей, на их взгляд, является веским оправданием несовершенства каждой отдельно взятой возможности. Более того, по их мнению, высокая совместимость с Си является одной из принципиальных черт языка, и потому все недостатки С++ оправданы преимуществами, предоставляемыми этой совместимостью.
В свою очередь, сторонники С++ считают некорректным сравнивать различные аспекты С++ с совершенно различными языками, так как общий набор средств и возможностей С++ существенно шире, чем в большинстве языков, с которыми проводится сравнение, и сама по себе широта возможностей, на их взгляд, является веским оправданием несовершенства каждой отдельно взятой возможности. Более того, по их мнению, высокая совместимость с Си является одной из принципиальных черт языка, и потому все недостатки С++ оправданы преимуществами, предоставляемыми этой совместимостью.
Достоинства:
- Высокая совместимость с языком Си
- Вычислительная производительность
- Поддержка различных стилей программирования: структурное, объектно-ориентированное, обобщённое программирование, функциональное программирование, порождающее метапрограммирование.
- Автоматический вызов деструкторов объектов (в порядке обратном вызову конструкторов) упрощает и повышает надёжность управления памятью и другими ресурсами (открытыми файлами, сетевыми соединениями, т. п.).
- Перегрузка операторов
- Шаблоны (дают возможность построения обобщённых контейнеров и алгоритмов для разных типов данных)
- Возможность расширения языка для поддержки парадигм, которые не поддерживаются компиляторами напрямую
- Доступность. Для С++ существует огромное количество учебной литературы, переведённой на всевозможные языки
 п.).
п.).Недостатки:
- Плохо продуманный синтаксис сужает спектр применимости языка
- Язык не содержит многих важных возможностей
- Язык содержит опасные возможности
- Производительность труда программистов на языке оказывается неоправданно низка
- Громоздкость синтаксиса
- Тяжелое наследие
- Необходимость следить за памятью
У вас нет прав для комментирования.
Основы — SwiftBook
Swift — новый язык программирования для разработки приложений под iOS, macOS, watchOS и tvOS. Несмотря на это, многие части Swift могут быть вам знакомы из вашего опыта разработки на C и Objective-C.
Swift предоставляет свои собственные версии фундаментальных типов C и Objective-C, включая Int для целых чисел, Double и Float для значений с плавающей точкой, Bool для булевых значений, String для текста. Swift также предоставляет мощные версии трех основных типов коллекций, Array, Set и Dictionary, как описано в разделе Типы коллекций.
Подобно C, Swift использует переменные для хранения и обращения к значениям по уникальному имени. Swift также широко использует переменные, значения которых не могут быть изменены. Они известны как константы, и являются гораздо более мощными, чем константы в C. Константы используются в Swift повсеместно, чтобы сделать код безопаснее и чище в случаях, когда вы работаете со значениями, которые не должны меняться.
В дополнение к знакомым типам, Swift включает расширенные типы, которых нет в Objective-C. К ним относятся кортежи, которые позволяют создавать и передавать группы значений. Кортежи могут возвращать несколько значений из функции как одно целое значение.
Swift также включает опциональные типы, которые позволяют работать с отсутствующими значениями. Опциональные значения говорят либо «здесь есть значение, и оно равно х», либо «здесь нет значения вообще». Опциональные типы подобны использованию nil с указателями в Objective-C, но они работают со всеми типами, не только с классами. Опциональные значения безопаснее и выразительнее чем nil указатели в Objective-C, и находятся в сердце многих наиболее мощных особенностей Swift.
Swift — язык типобезопасный, что означает, что Swift помогает вам понять, с какими типами значений ваш код может работать. Если кусок вашего кода ожидает String, безопасность типов не даст вам передать ему Int по ошибке. Кроме того, безопасность типов не позволит вам случайно передать опциональный String куску кода, который ожидает неопциональный String. Безопасность типов позволяет вам улавливать и исправлять ошибки как можно раньше в процессе разработки.
Безопасность типов позволяет вам улавливать и исправлять ошибки как можно раньше в процессе разработки.
Константы и переменные связывают имя (например, maximumNumberOfLoginAttempts или welcomeMessage) со значением определенного типа (например, число 10 или строка «Hello»). Значение константы не может быть изменено после его установки, тогда как переменной может быть установлено другое значение в будущем.
Объявление констант и переменных
Константы и переменные должны быть объявлены, перед тем как их использовать. Константы объявляются с помощью ключевого слова let, а переменные с помощью var. Вот пример того, как константы и переменные могут быть использованы для отслеживания количества попыток входа, которые совершил пользователь:
let maximumNumberOfLoginAttempts = 10 var currentLoginAttempt = 0
Этот код можно прочесть как:
«Объяви новую константу с именем maximumNumberOfLoginAttempts, и задай ей значение 10. Потом, объяви новую переменную с именем currentLoginAttempt, и задай ей начальное значение 0. »
»
В этом примере максимальное количество доступных попыток входа объявлено как константа, потому что максимальное значение никогда не меняется. Счетчик текущего количества попыток входа объявлен как переменная, потому что это значение должно увеличиваться после каждой неудачной попытки входа.
Вы можете объявить несколько констант или несколько переменных на одной строке, разделяя их запятыми:
var x = 0.0, y = 0.0, z = 0.0
Заметка
Если хранимое значение в вашем коде не будет меняться, всегда объявляйте его как константу, используя ключевое слово let. Используйте переменные только для хранения значений, которые должны будут меняться.
Аннотация типов
Вы можете добавить обозначение типа, когда объявляете константу или переменную, чтобы иметь четкое представление о типах значений, которые могут хранить константы или переменные. Написать обозначение типа, можно поместив двоеточие после имени константы или переменной, затем пробел, за которым следует название используемого типа.
Этот пример добавляет обозначение типа для переменной с именем welcomeMessage, чтобы обозначить, что переменная может хранить String:
var welcomeMessage: String
Двоеточие в объявлении значит «…типа…», поэтому код выше может быть прочитан как:
«Объяви переменную с именем welcomeMessage, тип которой будет String»
Фраза «тип которой будет String» означает «может хранить любое String значение». Представьте, что словосочетание «тип которой будет такой-то» означает — значение, которое будет храниться.
Теперь переменной welcomeMessage можно присвоить любое текстовое значение, без каких либо ошибок:
welcomeMessage = "Hello"
Вы можете создать несколько переменных одного типа в одной строке, разделенной запятыми, с одной аннотацией типа после последнего имени переменной:
var red, green, blue: Double
Заметка
Редко когда вам понадобится обозначать тип на практике. Когда вы даете начальное значение константе или переменной на момент объявления, Swift всегда может вывести тип, который будет использовать в константе или переменной. Это описано в Строгая типизация и Вывод типов. В примере welcomeMessage выше, не было присвоения начального значения, так что тип переменной welcomeMessage указывается с помощью обозначения типа вместо того, чтобы вывести из начального значения.
Это описано в Строгая типизация и Вывод типов. В примере welcomeMessage выше, не было присвоения начального значения, так что тип переменной welcomeMessage указывается с помощью обозначения типа вместо того, чтобы вывести из начального значения.
Название констант и переменных
Вы можете использовать почти любые символы для названий констант и переменных, включая Unicode-символы:
let π = 3.14159 let 你好 = "你好世界" let ?? = "dogcow"
Имена констант и переменных не могут содержать пробелы, математические символы, стрелки, приватные (или невалидные) кодовые точки Unicode, а так же символы отрисовки линий или прямоугольников. Так же имена не могут начинаться с цифр, хотя цифры могут быть включены в имя в любом другом месте. Если вы объявили константу или переменную определенного типа, то вы не можете объявить ее заново с тем же именем или заставить хранить внутри себя значение другого типа. Также вы не можете изменить константу на переменную, а переменную на константу.
Заметка
Если вам нужно объявить константу или переменную тем же именем, что и зарезервированное слово Swift, то вы можете воспользоваться обратными кавычками (`) написанными вокруг этого слова. Однако старайтесь избегать имен совпадающих с ключевыми словами Swift и используйте такие имена только в тех случаях, когда у вас абсолютно нет выбора.
Вы можете изменить значение переменной на другое значение совместимого типа. В примере ниже значение friendlyWelcome изменено с “Hello!” на “Bonjour!”:
var friendlyWelcome = “Hello!” friendlyWelcome = “Bonjour!” // теперь friendlyWelcome имеет значение “Bonjour!”
В отличие от переменных, значение константы не может быть изменено, после того, как было установлено. Если вы попытаетесь его изменить, то будет выведена ошибка компиляции:
let languageName = "Swift" languageName = "Swift++" // Это ошибка компилляции: languageName cannot be changed (значение languageName не может быть изменено).
Печать констант и переменных
Вы можете напечатать текущее значение константы или переменной при помощи функции print(_:separator:terminator:):
print(friendlyWelcome) // Выведет "Bonjour!"
Функция print(_:separator:terminator:) является глобальной, которая выводит одно или более значений в подходящем виде. В Xcode, например, функция print(_:separator:terminator:) выводит значения в консоль. Параметры separator и terminator имеют дефолтные значения, так что при использовании функции их можно просто пропустить. По умолчанию функция заканчивает вывод символом переноса строки. Чтобы вывести в консоль значения без переноса на новую строку, вам нужно указать пустую строку в параметре terminator, например, print(someValue, terminator: «»). Для получения дополнительной информации по дефолтным значениям параметров обратитесь в раздел «Значения по умолчанию для параметров».
Swift использует интерполяцию строки для включения имени константы или переменной в качестве плейсхолдера внутри строки, что подсказывает Swift подменить это имя на текущее значение, которое хранится в этой константе или переменной. Поместите имя константы или переменной в круглые скобки, а затем добавьте обратный слеш (\) перед открывающей скобкой:
Поместите имя константы или переменной в круглые скобки, а затем добавьте обратный слеш (\) перед открывающей скобкой:
print("Текущее значение friendlyWelcome равно \(friendlyWelcome)")
// Выведет "Текущее значение friendlyWelcome равно Bonjour!"Заметка
Все опции, которые вы можете использовать в интерполяции строки вы сможете найти в разделе «Интерполяция строк».
Используйте комментарии, чтобы добавить неисполняемый текст в коде, как примечание или напоминание самому себе. Комментарии игнорируются компилятором Swift во время компиляции кода.
Комментарии в Swift очень похожи на комментарии в C. Однострочные комментарии начинаются с двух слешей (//):
// это комментарий
Вы также можете написать многострочные комментарии, которые начинаются со слеша и звездочки (/*) и заканчиваются звездочкой, за которой следует слеш (*/):
/* это тоже комментарий, но написанный на двух строках */
В отличие от многострочных комментариев в C, многострочные комментарии в Swift могут быть вложены в другие многострочные комментарии. Вы можете написать вложенные комментарии, начав многострочный блок комментариев, а затем, начать второй многострочный комментарий внутри первого блока. Затем второй блок закрывается, а за ним закрывается первый блок:
Вы можете написать вложенные комментарии, начав многострочный блок комментариев, а затем, начать второй многострочный комментарий внутри первого блока. Затем второй блок закрывается, а за ним закрывается первый блок:
/* это начало первого многострочного комментария /* это второго, вложенного многострочного комментария */ это конец первого многострочного комментария */
Вложенные многострочные комментарии позволяют закомментировать большие блоки кода быстро и легко, даже если код уже содержит многострочные комментарии.
В отличие от многих других языков, Swift не требует писать точку с запятой (;) после каждого выражения в коде, хотя вы можете делать это, если хотите. Однако точки с запятой требуются, если вы хотите написать несколько отдельных выражений на одной строке:
let cat = "?"; print(cat) // Выведет "?"
Integer (целое число) — это число, не содержащее дробной части, например, как 42 и -23. Целые числа могут быть либо знаковыми (положительными, ноль или отрицательными) либо беззнаковыми (положительными или ноль).
Swift предусматривает знаковые и беззнаковые целые числа в 8, 16, 32 и 64 битном форматах. Эти целые числа придерживаются соглашения об именах, аналогичных именам в C, в том, что 8-разрядное беззнаковое целое число имеет тип Uint8, а 32-разрядное целое число имеет тип Int32. Как и все типы в Swift, эти типы целых чисел пишутся с заглавной буквы.
Границы целых чисел
Вы можете получить доступ к минимальному и максимальному значению каждого типа целого числа с помощью его свойств min и max:
let minValue = UInt8.min // minValue равен 0, а его тип UInt8 let maxValue = UInt8.max // maxValue равен 255, а его тип UInt8
Тип значения этих свойств соответствует размеру числа (в примере выше этот тип UInt8) и поэтому может быть использован в выражениях наряду с другими значениями того же типа.
Int
В большинстве случаев вам не нужно будет указывать конкретный размер целого числа для использования в коде. В Swift есть дополнительный тип целого числа — Int, который имеет тот же размер что и разрядность системы:
- На 32-битной платформе, Int того же размера что и Int32
- На 64-битной платформе, Int того же размера что и Int64
Если вам не нужно работать с конкретным размером целого числа, всегда используйте в своем коде Int для целых чисел.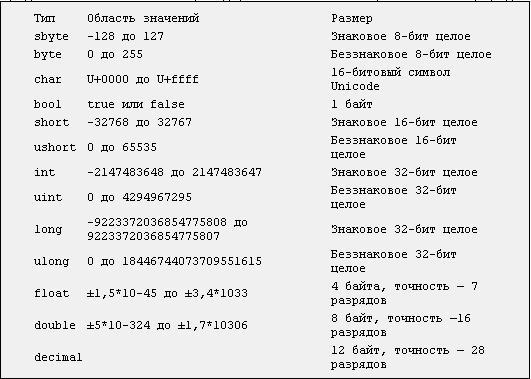 Это придает коду логичность и совместимость. Даже на 32-битных платформах, Int может хранить любое значение в пределах -2 147 483 648 и 2 147 483 647, а этого достаточно для многих диапазонов целых чисел.
Это придает коду логичность и совместимость. Даже на 32-битных платформах, Int может хранить любое значение в пределах -2 147 483 648 и 2 147 483 647, а этого достаточно для многих диапазонов целых чисел.
UInt
Swift также предусматривает беззнаковый тип целого числа — UInt, который имеет тот же размер что и разрядность системы:
- На 32-битной платформе, UInt того же размера что и UInt32
- На 64-битной платформе, UInt того же размера что и UInt64
Заметка
Используйте UInt, только когда вам действительно нужен тип беззнакового целого с размером таким же, как разрядность системы. Если это не так, использовать Int предпочтительнее, даже когда известно, что значения будут неотрицательными. Постоянное использование Int для целых чисел способствует совместимости кода, позволяет избежать преобразования между разными типами чисел, и соответствует выводу типа целого числа, как описано в Строгая типизация и Вывод Типов.
Число с плавающей точкой — это число с дробной частью, например как 3. 14159, 0.1, и -273.15.
14159, 0.1, и -273.15.
Типы с плавающей точкой могут представлять гораздо более широкий спектр значений, чем типы целых значений, и могут хранить числа намного больше (или меньше) чем может хранить Int. Swift предоставляет два знаковых типа с плавающей точкой:
- Double — представляет собой 64-битное число с плавающей точкой. Используйте его когда число с плавающей точкой должно быть очень большим или чрезвычайно точным
- Float — представляет собой 32-битное число с плавающей точкой. Используйте его, когда значение не нуждается в 64-битной точности.
Заметка
Double имеет точность минимум 15 десятичных цифр, в то время как точность Float может быть всего лишь 6 десятичных цифр. Соответствующий тип числа с плавающей точкой используется в зависимости от характера и диапазона значений, c которыми вы должны работать в коде. В случаях, где возможно использование обоих типов, предпочтительным считается Double.
Swift — язык со строгой типизацией. Язык со строгой типизацией призывает вас иметь четкое представление о типах значений, с которыми может работать ваш код. Если часть вашего кода ожидает String, вы не сможете передать ему Int по ошибке.
Язык со строгой типизацией призывает вас иметь четкое представление о типах значений, с которыми может работать ваш код. Если часть вашего кода ожидает String, вы не сможете передать ему Int по ошибке.
Поскольку Swift имеет строгую типизацию, он выполняет проверку типов при компиляции кода и отмечает любые несоответствующие типы как ошибки. Это позволяет в процессе разработки ловить и как можно раньше исправлять ошибки.
Проверка типов поможет вам избежать ошибок при работе с различными типами значений. Тем не менее, это не означает, что при объявлении вы должны указывать тип каждой константы или переменной. Если вы не укажете нужный вам тип значения, Swift будет использовать вывод типов, чтобы вычислить соответствующий тип. Вывод типов позволяет компилятору вывести тип конкретного выражения автоматически во время компиляции, просто путем изучения значения, которого вы ему передаете.
Благодаря выводу типов, Swift требует гораздо меньше объявления типов, чем языки, такие как C или Objective-C. Константам и переменным все же нужно присваивать тип, но большая часть работы с указанием типов будет сделана за вас.
Константам и переменным все же нужно присваивать тип, но большая часть работы с указанием типов будет сделана за вас.
Вывод типов особенно полезен, когда вы объявляете константу или переменную с начальным значением. Часто это делается путем присвоения литерального значения (или литерала) к константам или переменным в момент объявления. (Литеральное значение — значение, которое появляется непосредственно в исходном коде, например как 42 и 3,14159 в примерах ниже.)
Например, если вы присваиваете литеральное значение 42 к новой константе не сказав какого она типа, Swift делает вывод, что вы хотите чтобы константа была Int, потому что вы присвоили ей значение, которое похоже на целое число:
let meaningOfLife = 42 // meaningOfLife выводится как тип Int
Точно так же, если вы не указали тип для литерала с плавающей точкой, Swift делает вывод, что вы хотите создать Double:
let pi = 3.14159 // pi выводится как тип Double
Swift всегда выбирает Double (вместо Float), когда выводит тип чисел с плавающей точкой.
Если объединить целые литералы и литералы с плавающей точкой в одном выражении, в этом случае тип будет выводиться как Double:
let anotherPi = 3 + 0.14159 // anotherPi тоже выводится как тип Double
Литеральное значение 3 не имеет явного типа само по себе, так что соответствующий тип Double выводится из наличия литерала с плавающей точкой как часть сложения.
Числовые литералы могут быть написаны как:
- Десятичное число, без префикса
- Двоичное число, с префиксом 0b
- Восьмеричное число, с префиксом 0o
- Шестнадцатеричное число, с префиксом 0x
Все эти литералы целого числа имеют десятичное значение 17:
let decimalInteger = 17 let binaryInteger = 0b10001 // 17 в двоичной нотации let octalInteger = 0o21 // 17 в восмеричной нотации let hexadecimalInteger = 0x11 // 17 в шестнадцатеричной нотации
Литералы с плавающей точкой могут быть десятичными (без префикса) или шестнадцатеричными (с префиксом 0x). Они всегда должны иметь число (десятичное или шестнадцатеричное) по обе стороны от дробной точки. Они также могут иметь экспоненту, с указанием в верхнем или нижнем регистре е для десятичных чисел с плавающей точкой, или в верхнем или нижнем регистре р для шестнадцатеричных чисел с плавающей точкой.
Они всегда должны иметь число (десятичное или шестнадцатеричное) по обе стороны от дробной точки. Они также могут иметь экспоненту, с указанием в верхнем или нижнем регистре е для десятичных чисел с плавающей точкой, или в верхнем или нижнем регистре р для шестнадцатеричных чисел с плавающей точкой.
Для десятичных чисел с показателем степени ехр, базовое число умножается на 10exp:
- 1.25e2 означает 1.25 × 102, или 125.0.
- 1.25e-2 означает 1.25 × 10-2, или 0.0125.
Для шестнадцатеричных чисел с показателем степени ехр, базовое число умножается на 2exp:
- 0xFp2 означает 15 × 22, или 60.0.
- 0xFp-2 означает 15 × 2-2, или 3.75.
Все эти числа с плавающей точкой имеют десятичное значение 12.1875:
let decimalDouble = 12.1875 let exponentDouble = 1.21875e1 let hexadecimalDouble = 0xC.3p0
Числовые литералы могут содержать дополнительное форматирование, чтобы их было удобнее читать. Целые числа и числа с плавающей точкой могут быть дополнены нулями и могут содержать символы подчеркивания для увеличения читабельности. Ни один тип форматирования не влияет на базовое значение литерала:
Целые числа и числа с плавающей точкой могут быть дополнены нулями и могут содержать символы подчеркивания для увеличения читабельности. Ни один тип форматирования не влияет на базовое значение литерала:
let paddedDouble = 000123.456 let oneMillion = 1_000_000 let justOverOneMillion = 1_000_000.000_000_1
Используйте Int для всех целочисленных констант и переменных в коде, даже когда они неотрицательны. Использование стандартного типа целых чисел в большинстве случаев означает, что ваши целочисленные константы и переменные будут совместимы в коде и будут соответствовать типу, выведенному из целочисленного литерала.
Используйте другие типы целых чисел, только если вам это действительно нужно, например, когда используются данные с заданным размером из внешнего источника, или для производительности, использования памяти или других важных оптимизаций. Использование типов с определенным размером в таких ситуациях помогает уловить случайное переполнение значения и неявно задокументированные данные, используемые в коде.
Преобразования целых чисел
Диапазон значений, который может храниться в целочисленных константах и переменных, различен для каждого числового типа. Int8 константы и переменные могут хранить значения между -128 и 127, тогда как UInt8 константы и переменные могут хранить числа между 0 и 255. Если число не подходит для переменной или константы с определенным размером, выводится ошибка во время компиляции:
let cannotBeNegative: UInt8 = -1 // UInt8 не может хранить отрицательные значения, поэтому эта строка выведет ошибку let tooBig: Int8 = Int8.max + 1 // Int8 не может хранить число больше своего максимального значения, // так что это тоже выведет ошибку
Поскольку каждый числовой тип может хранить разный диапазон значений, в зависимости от конкретного случая вам придется обращаться к преобразованию числовых типов. Этот подход предотвращает скрытые ошибки преобразования и помогает сделать причину преобразования понятной.
Чтобы преобразовать один числовой тип в другой, необходимо создать новое число желаемого типа из существующего значения.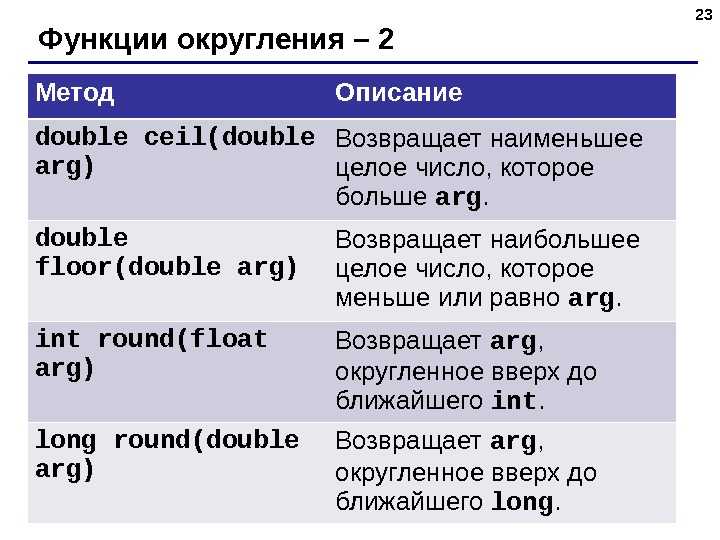 Ниже, в примере, константа twoThousand имеет тип UInt16, тогда как константа one — UInt8. Сложить их напрямую не получится, потому что они разного типа. Вместо этого, в примере вызывается функция UInt16(one) для создания нового числа UInt16 из значения константы one:
Ниже, в примере, константа twoThousand имеет тип UInt16, тогда как константа one — UInt8. Сложить их напрямую не получится, потому что они разного типа. Вместо этого, в примере вызывается функция UInt16(one) для создания нового числа UInt16 из значения константы one:
let twoThousand: UInt16 = 2_000 let one: UInt8 = 1 let twoThousandAndOne = twoThousand + UInt16(one)
Теперь, из-за того, что обе части сложения имеют тип UInt16 — операция сложения допустима. Для конечной константы (twoThousandAndOne) выведен тип UInt16, потому что это сложение двух UInt16 значений.
НазваниеТипа(начальноеЗначение) — стандартный способ вызвать инициализатор типов Swift и передать начальное значение. Честно говоря, у UInt16 есть инициализатор, который принимает UInt8 значение, и, таким образом, этот инициализатор используется, чтобы создать новый UInt16 из существующего UInt8. Здесь вы не можете передать любой тип, однако это должен быть тип, для которого у UInt16 есть инициализатор. Расширение существующих типов с помощью создания инициализаторов, которые принимают новые типы (включая объявление вашего типа) рассматривается в главе Расширения.
Расширение существующих типов с помощью создания инициализаторов, которые принимают новые типы (включая объявление вашего типа) рассматривается в главе Расширения.
Преобразования целых чисел и чисел с плавающей точкой
Преобразование между целыми числами и числами с плавающей точкой должно происходить явно:
let three = 3 let pointOneFourOneFiveNine = 0.14159 let pi = Double(three) + pointOneFourOneFiveNine // pi равно 3.14159, и для него выведен тип Double
Здесь, значение константы three используется для создания нового значения типа Double, так что обе части сложения имеют один тип. Без этого преобразования сложение не будет проходить. Обратное преобразование числа с плавающей точкой в целое число тоже должно происходить явно. Так что тип целого числа может быть инициализирован с помощью Double и Float значений:
let integerPi = Int(pi) // integerPi равен 3, и для него выведен тип Int
Числа с плавающей точкой всегда урезаются, когда вы используете инициализацию целого числа через этот способ. Это означает, что 4.75 будет 4, а -3.9 будет -3.
Это означает, что 4.75 будет 4, а -3.9 будет -3.
Заметка
Правила объединения числовых констант и переменных отличается от правил числовых литералов. Литеральное значение 3 может напрямую сложиться с литеральным значением 0.14159, потому что числовые литералы сами по себе не имеют явного типа. Их тип выводится только в момент оценки значения компилятором.
Псевдонимы типов задают альтернативное имя для существующего типа. Можно задать псевдоним типа с помощью ключевого слова typealias.
Псевдонимы типов полезны, когда вы хотите обратиться к существующему типу по имени, которое больше подходит по контексту, например, когда вы работаете с данными определенного размера из внешнего источника:
typealias AudioSample = UInt16
После того как вы один раз задали псевдоним типа, вы можете использовать псевдоним везде, где вы хотели бы его использовать
var maxAmplitudeFound = AudioSample.min // maxAmplitudeFound теперь 0
Здесь AudioSample определен как псевдоним для UInt16. Поскольку это псевдоним, вызов AudioSample.min фактически вызовет UInt16.min, что показывает начальное значение 0 для переменной maxAmplitudeFound.
Поскольку это псевдоним, вызов AudioSample.min фактически вызовет UInt16.min, что показывает начальное значение 0 для переменной maxAmplitudeFound.
В Swift есть простой логический тип Bool. Этот тип называют логическим, потому что он может быть только true или false. Swift предусматривает две логические константы, true и false соответственно:
let orangesAreOrange = true let turnipsAreDelicious = false
Типы для orangesAreOrange и turnipsAreDelicious были выведены как Bool, исходя из того факта, что мы им присвоили логические литералы. Так же как с Int и Double в предыдущих главах, вам не нужно указывать константы или переменные как Bool, если при создании вы присвоили им значения true или false. Вывод типов помогает сделать код Swift кратким и читабельным тогда, когда вы создаете константы или переменные со значениями которые точно известны.
Логические значения очень полезны когда вы работаете с условными операторами, такими как оператор if:
if turnipsAreDelicious {
print("Mmm, tasty turnips!")
} else {
print("Eww, turnips are horrible. ")
}
// Выведет "Eww, turnips are horrible." ")
}
// Выведет "Eww, turnips are horrible."
")
}
// Выведет "Eww, turnips are horrible."Условные операторы, такие как оператор if детально рассматриваются в главе Управление потоком.
Строгая типизация Swift препятствует замене значения Bool на не логическое значение. Следующий пример выведет ошибку компиляции:
let i = 1
if i {
// этот пример не скомпилируется, и выдаст ошибку компиляции
}Тем не менее, альтернативный пример ниже правильный:
let i = 1
if i == 1 {
// этот пример выполнится успешно
}Результат сравнения i == 1 имеет тип Bool, и поэтому этот второй пример совершает проверку типов. Такие сравнения как i == 1 обсуждаются в главе Базовые операторы.
Как в других примерах строгой типизации в Swift, этот подход предотвращает случайные ошибки и гарантирует, что замысел определенной части кода понятен.
Кортежи группируют несколько значений в одно составное значение. Значения внутри кортежа могут быть любого типа, то есть, нет необходимости, чтобы они были одного и того же типа.
В данном примере (404, «Not Found») это кортеж, который описывает код HTTP статуса. Код HTTP статуса — особое значение, возвращаемое веб-сервером каждый раз, когда вы запрашиваете веб-страницу. Код статуса 404 Not Found возвращается, когда вы запрашиваете страницу, которая не существует.
let http404Error = (404, "Not Found") // http404Error имеет тип (Int, String), и равен (404, "Not Found")
Чтобы передать код статуса, кортеж (404, «Not Found») группирует вместе два отдельных значения Int и String: число и понятное человеку описание. Это может быть описано как «кортеж типа (Int, String)».
Вы можете создать кортеж с любой расстановкой типов, и они могут содержать сколько угодно нужных вам типов. Ничто вам не мешает иметь кортеж типа (Int, Int, Int), или типа (String, Bool), или же с любой другой расстановкой типов по вашему желанию.
Вы можете разложить содержимое кортежа на отдельные константы и переменные, к которым можно получить доступ привычным способом:
let (statusCode, statusMessage) = http404Error
print("The status code is \(statusCode)")
// Выведет "The status code is 404"
print("The status message is \(statusMessage)")
// Выведет "The status message is Not Found"Если вам нужны только некоторые из значений кортежа, вы можете игнорировать части кортежа во время разложения с помощью символа подчеркивания (_):
let (justTheStatusCode, _) = http404Error
print("The status code is \(justTheStatusCode)")
// Выведет "The status code is 404"В качестве альтернативы можно получать доступ к отдельным частям кортежа, используя числовые индексы, начинающиеся с нуля:
print("The status code is \(http404Error. 0)")
// Выведет "The status code is 404"
print("The status message is \(http404Error.1)")
// Выведет "The status message is Not Found" 0)")
// Выведет "The status code is 404"
print("The status message is \(http404Error.1)")
// Выведет "The status message is Not Found"
0)")
// Выведет "The status code is 404"
print("The status message is \(http404Error.1)")
// Выведет "The status message is Not Found"Вы можете давать имена отдельным элементам кортежа во время объявления:
let http200Status = (statusCode: 200, description: "OK")
Когда вы присвоили имя элементу кортежа, вы можете обратиться к нему по имени:
print("The status code is \(http200Status.statusCode)")
// Выведет "The status code is 200"
print("The status message is \(http200Status.description)")
// Выведет "The status message is OK"Кортежи особенно полезны в качестве возвращаемых значений функций. Функция, которая пытается получить веб-страницу, может вернуть кортеж типа (Int, String), чтобы описать успех или неудачу в поиске страницы. Возвращая кортеж с двумя отдельными значениями разного типа, функция дает более полезную информацию о ее результате, чем, если бы, возвращала единственное значение одного типа, возвращаемое функцией. Для более подробной информации смотрите главу Функции, возвращающие несколько значений.
Для более подробной информации смотрите главу Функции, возвращающие несколько значений.
Заметка
Кортежи полезны для временной группировки связанных значений. Они не подходят для создания сложных структур данных. Если ваша структура данных, вероятно, будет выходить за рамки временной структуры, то такие вещи лучше проектируйте с помощью классов или структур, вместо кортежей. Для получения дополнительной информации смотрите главу Классы и структуры.
Опциональные типы используются в тех случаях, когда значение может отсутствовать. Опциональный тип подразумевает, что возможны два варианта: или значение есть, и его можно извлечь из опционала, либо его вообще нет.
Заметка
В C или Objective-C нет понятия опционалов. Ближайшее понятие в Objective-C это возможность вернуть nil из метода, который в противном случае вернул бы объект. В этом случае nil обозначает «отсутствие допустимого объекта». Тем не менее, это работает только для объектов, и не работает для структур, простых типов C, или значений перечисления. Для этих типов, методы Objective-C, как правило, возвращают специальное значение (например, NSNotFound), чтобы указать отсутствие значения. Этот подход предполагает, что разработчик, который вызвал метод, знает, что есть это специальное значение и что его нужно учитывать. Опционалы Swift позволяют указать отсутствие значения для абсолютно любого типа, без необходимости использования специальных констант.
Для этих типов, методы Objective-C, как правило, возвращают специальное значение (например, NSNotFound), чтобы указать отсутствие значения. Этот подход предполагает, что разработчик, который вызвал метод, знает, что есть это специальное значение и что его нужно учитывать. Опционалы Swift позволяют указать отсутствие значения для абсолютно любого типа, без необходимости использования специальных констант.
Приведем пример, который покажет, как опционалы могут справиться с отсутствием значения. У типа Int в Swift есть инициализатор, который пытается преобразовать значение String в значение типа Int. Тем не менее, не каждая строка может быть преобразована в целое число. Строка «123» может быть преобразована в числовое значение 123, но строка «hello, world» не имеет очевидного числового значения для преобразования.
В приведенном ниже примере используется метод Int() для попытки преобразовать String в Int:
let possibleNumber = "123" let convertedNumber = Int(possibleNumber) // для convertedNumber выведен тип "Int?", или "опциональный Int"
Поскольку метод Int() может иметь недопустимый аргумент, он возвращает опциональный Int, вместо Int. Опциональный Int записывается как Int?, а не Int. Знак вопроса означает, что содержащееся в ней значение является опциональным, что означает, что он может содержать некое Int значение, или он может вообще не содержать никакого значения. (Он не может содержать ничего другого, например, Bool значение или значение String. Он либо Int, либо вообще ничто)
Опциональный Int записывается как Int?, а не Int. Знак вопроса означает, что содержащееся в ней значение является опциональным, что означает, что он может содержать некое Int значение, или он может вообще не содержать никакого значения. (Он не может содержать ничего другого, например, Bool значение или значение String. Он либо Int, либо вообще ничто)
nil
Мы можем установить опциональную переменную в состояние отсутствия значения, путем присвоения ему специального значения nil
var serverResponseCode: Int? = 404 // serverResponseCode содержит реальное Int значение 404 serverResponseCode = nil // serverResponseCode теперь не содержит значения
Заметка
nil не может быть использован с не опциональными константами и переменными. Если значение константы или переменной при определенных условиях в коде должно когда-нибудь отсутствовать, всегда объявляйте их как опциональное значение соответствующего типа.
Если объявить опциональную переменную без присвоения значения по умолчанию, то переменная автоматически установится в nil для вас:
var surveyAnswer: String? // surveyAnswer автоматически установится в nil
Заметка
nil в Swift не то же самое что nil в Objective-C. В Objective-C nil является указателем на несуществующий объект. В Swift nil не является указателем, а является отсутствием значения определенного типа. Устанавливаться в nil могут опционалы любого типа, а не только типы объектов.
В Objective-C nil является указателем на несуществующий объект. В Swift nil не является указателем, а является отсутствием значения определенного типа. Устанавливаться в nil могут опционалы любого типа, а не только типы объектов.
Инструкция If и Принудительное извлечение
Вы можете использовать инструкцию if, сравнивая опционал с nil, чтобы проверить, содержит ли опционал значение. Это сравнение можно сделать с помощью оператора «равенства» (==) или оператора «неравенства» (!=).
Если опционал имеет значение, он будет рассматриваться как «неравным» nil:
if convertedNumber != nil {
print("convertedNumber contains some integer value.")
}
// Выведет "convertedNumber contains some integer value."Если вы уверены, что опционал содержит значение, вы можете получить доступ к его значению, добавив восклицательный знак (!) в конце имени опционала. Восклицательный знак фактически говорит: «Я знаю точно, что этот опционал содержит значение, пожалуйста, используй его».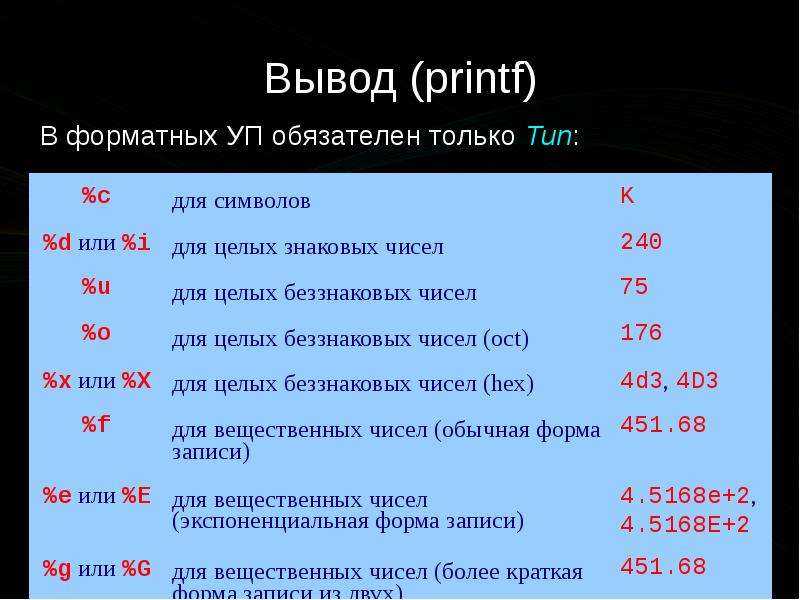 Это выражение известно как Принудительное извлечение значения опционала:
Это выражение известно как Принудительное извлечение значения опционала:
if convertedNumber != nil {
print("convertedNumber has an integer value of \(convertedNumber!).")
}
// Выведет "convertedNumber has an integer value of 123."Более подробную информацию об инструкции if можно получить в главе Управление потоком.
Заметка
Попытка использовать ! к несуществующему опциональному значению вызовет runtime ошибку. Всегда будьте уверены в том, что опционал содержит не-nil значение, перед тем как использовать ! чтобы принудительно извлечь это значение.
Привязка опционалов
Можно использовать Привязку опционалов, чтобы выяснить содержит ли опционал значение, и если да, то сделать это значение доступным в качестве временной константы или переменной. Привязка опционалов может использоваться с инструкциями if и while, для проверки значения внутри опционала, и извлечения этого значения в константу или переменную, в рамках одного действия. Инструкции if и while более подробно представлены в главе Управление потоком.
Инструкции if и while более подробно представлены в главе Управление потоком.
Привязку опционалов для инструкции if можно писать как показано ниже:
- if let constantName = someOptional {
- statements
- }
Мы можем переписать пример possibleNumber сверху, используя привязку опционалов, а не принудительное извлечение:
if let actualNumber = Int(possibleNumber) {
print("\(possibleNumber) has an integer value of \(actualNumber)")
} else {
print("\(possibleNumber) could not be converted to an integer")
}
// Выведет "123" has an integer value of 123Это может быть прочитано как:
«Если опциональный Int возвращаемый Int(possibleNumber) содержит значение, установи в новую константу с названием actualNumber значение, содержащееся в опционале.»
Если преобразование прошло успешно, константа actualNumber становится доступной для использования внутри первого ветвления инструкции if. Он уже инициализируется значением, содержащимся внутри опционала, и поэтому нет необходимости в использовании ! для доступа к его значению. В этом примере, actualNumber просто используется, чтобы напечатать результат преобразования.
В этом примере, actualNumber просто используется, чтобы напечатать результат преобразования.
Вы можете использовать и константы и переменные для привязки опционалов. Если вы хотели использовать значение actualNumber внутри первого ветвления инструкции if, вы могли бы написать if var actualNumber вместо этого, и значение, содержащееся в опционале, будет использоваться как переменная, а не константа.
Вы можете включать столько опциональных привязок и логических условий в единственную инструкцию if, сколько вам требуется, разделяя их запятыми. Если какое-то значение в опциональной привязке равно nil, или любое логическое условие вычисляется как false, то все условия выражения будет считаться false. Следующие инструкции if эквиваленты:
if let firstNumber = Int("4"), let secondNumber = Int("42"), firstNumber < secondNumber && secondNumber < 100 {
print("\(firstNumber) < \(secondNumber) < 100")
}
// Выведет "4 < 42 < 100"
if let firstNumber = Int("4") {
if let secondNumber = Int("42") {
if firstNumber < secondNumber && secondNumber < 100 {
print("\(firstNumber) < \(secondNumber) < 100")
}
}
}
// Выведет "4 < 42 < 100"Заметка
Константы и переменные, созданные через опциональную привязку в инструкции if, будут доступны только в теле инструкции if. В противоположность этому, константы и переменные, созданные через инструкцию guard, доступны в строках кода, следующих за инструкцией guard, что отражено в разделе Ранний Выход.
В противоположность этому, константы и переменные, созданные через инструкцию guard, доступны в строках кода, следующих за инструкцией guard, что отражено в разделе Ранний Выход.
Неявно извлеченные опционалы
Как описано выше, опционалы показывают, что константам или переменным разрешено не иметь «никакого значения». Опционалы можно проверить с помощью инструкции if, чтобы увидеть существует ли значение, и при условии, если оно существует, можно извлечь его с помощью привязки опционалов для доступа к опциональному значению.
Иногда, сразу понятно из структуры программы, что опционал всегда будет иметь значение, после того как это значение впервые было установлено. В этих случаях, очень полезно избавиться от проверки и извлечения значения опционала каждый раз при обращении к нему, потому что можно с уверенностью утверждать, что он постоянно имеет значение.
Эти виды опционалов называются неявно извлеченные опционалы. Их можно писать, используя восклицательный знак (String!), вместо вопросительного знака (String?), после типа, который вы хотите сделать опциональным.
Вместо того, чтобы ставить восклицательный знак (!) после опционала, когда вы его используете, поместите восклицательный знак (!) после опционала, когда вы его объявляете.
Неявно извлеченные опционалы полезны, когда известно, что значение опционала существует непосредственно после первого объявления опционала, и точно будет существовать после этого. Неявно извлечённые опционалы в основном используются во время инициализации класса, как описано в разделе «Бесхозные ссылки и неявно извлеченные опциональные свойства».
Честно говоря, неявно извлеченные опционалы — это нормальные опционалы, но они могут быть использованы как не опциональные значения, без необходимости в извлечении опционального значения каждый раз при доступе. Следующий пример показывает разницу в поведении между опциональной строкой и неявно извлеченной опциональной строкой при доступе к их внутреннему значению как к явному String:
let possibleString: String? = "An optional string." let forcedString: String = possibleString! // необходим восклицательный знак let assumedString: String! = "An implicitly unwrapped optional string.
 "
let implicitString: String = assumedString // восклицательный знак не нужен
"
let implicitString: String = assumedString // восклицательный знак не нуженВы можете считать неявно извлеченные опционалы обычными опционалами дающими разрешение на принудительное извлечение, если это требуется. Когда вы используете неявно извлеченный опционал, то Swift сначала пробует использовать его в качестве обычного опционального значения, если так его использовать не получается, то уже пробует принудительно извлечь значение. В коде выше опциональное значение assumedString является принудительно извлеченным прежде, чем будет записано в implicitString, так как implicitString имеет явный неопциональный тип String. В коде ниже optionalString не имеет явного типа, так что является обычным опционалом.
let optionalString = assumedString // Тип optionalString является "String?" и assumedString не является принудительно извлеченным значением.
Если вы попытаетесь получить доступ к неявно извлеченному опционалу когда он не содержит значения — вы получите runtime ошибку.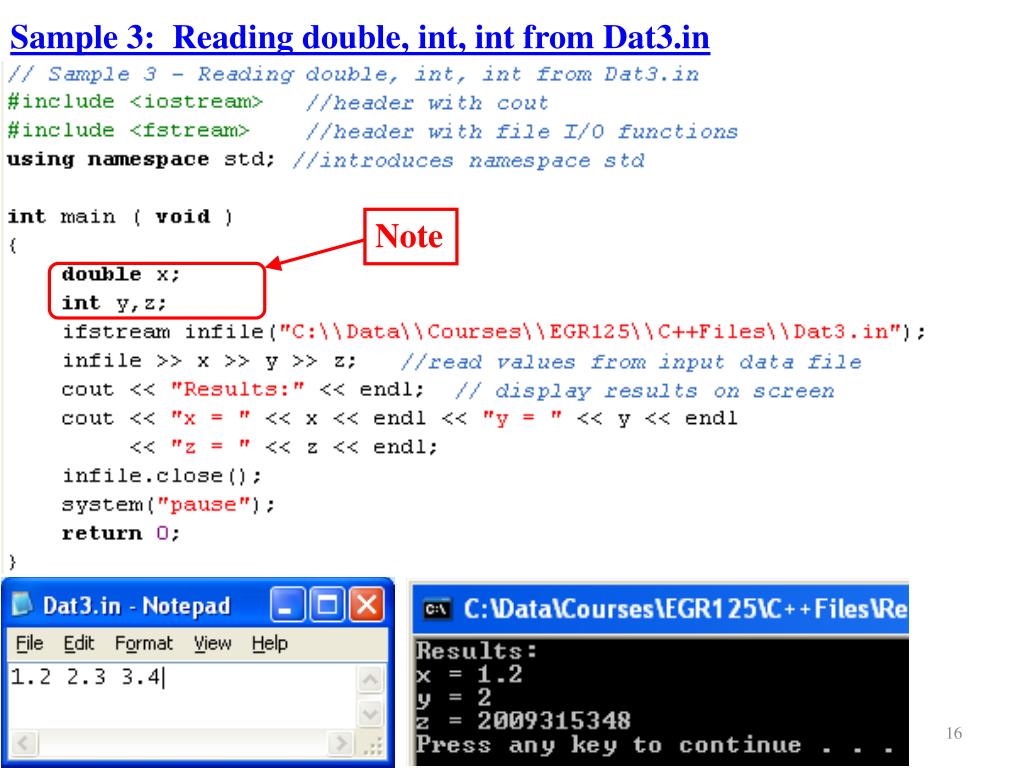 Результат будет абсолютно тот же, если бы вы разместили восклицательный знак после нормального опционала, который не содержит значения.
Результат будет абсолютно тот же, если бы вы разместили восклицательный знак после нормального опционала, который не содержит значения.
Вы можете проверить не является ли неявно извлеченный опционал nil точно так же как вы проверяете обычный опционал:
if assumedString != nil {
print(assumedString!)
}
// Выведет "An implicitly unwrapped optional string."Вы также можете использовать неявно извлеченный опционал с привязкой опционалов, чтобы проверить и извлечь его значение в одном выражении:
if let definiteString = assumedString {
print(definiteString)
}
// Выведет "An implicitly unwrapped optional string."Заметка
Не используйте неявно извлечённый опционал, если существует вероятность, что в будущем переменная может стать nil. Всегда используйте нормальный тип опционала, если вам нужно проверять на nil значение в течение срока службы переменной.
Вы используете обработку ошибок в ответ на появление условий возникновения ошибок во время выполнения программы.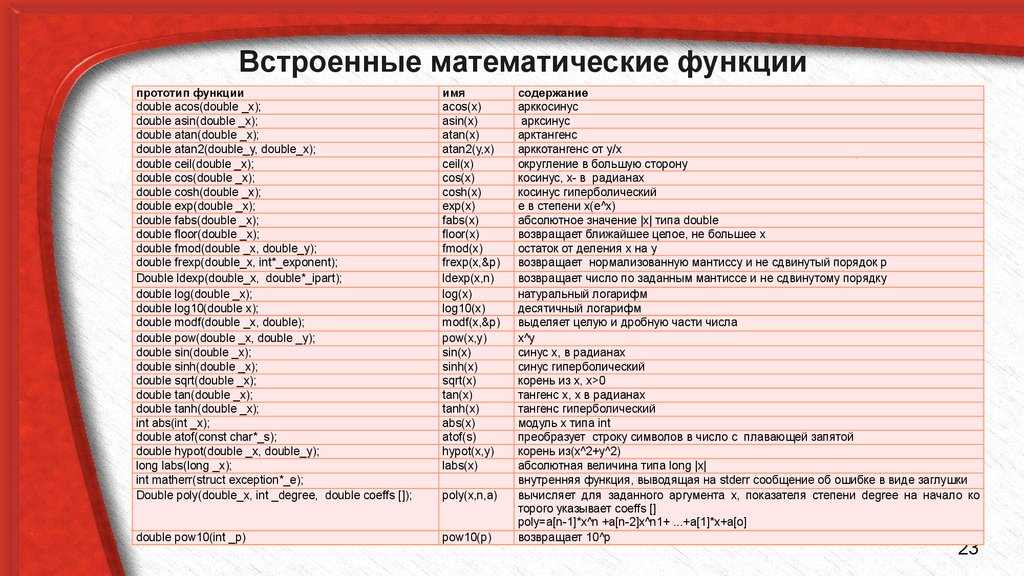
В отличие от опционалов, которые могут использовать наличие или отсутствие значения для сообщения об успехе или неудаче функции, обработка ошибок позволяет определить причину сбоя, и, при необходимости, передать ошибку в другую часть вашей программы.
Когда функция обнаруживает условие ошибки, она выдает сообщение об ошибке. Тот, кто вызывает функцию, может затем поймать ошибку и среагировать соответствующим образом.
func canThrowAnError() throws {
// эта функция может сгенерировать ошибку
}Функция сообщает о возможности генерации ошибки, включив ключевое слово throws в объявление. Когда вы вызываете функцию, которая может выбросить ошибку, вы добавляете ключевое слово try в выражение. Swift автоматически передает ошибки из их текущей области, пока они не будут обработаны условием catch.
do {
try canThrowAnError()
// ошибка не была сгенерирована
} catch {
// ошибка сгенерирована
}Выражение do создает область, содержащую объект, которая позволяет ошибкам быть переданными в одно или несколько условий catch.
Вот пример того, как обработка ошибок может быть использована в ответ на различные условия возникновения ошибок:
func makeASandwich() throws {
// ...
}
do {
try makeASandwich()
eatASandwich()
} catch SandwichError.outOfCleanDishes {
washDishes()
} catch SandwichError.missingIngredients(let ingredients) {
buyGroceries(ingredients)
}В этом примере, функция makeASandwich() генерирует ошибку, если нет чистых тарелок или если отсутствуют какие-либо ингредиенты. Так как makeASandwich() может выдавать ошибку, то вызов функции заворачивают в выражении try. При заворачивании вызова функции в выражение do, генерация каких-либо ошибок, будет передаваться на предусмотренные условия catch.
Если ошибка не генерируется, то вызывается функция eatASandwich(). Если ошибка все таки генерируется, и она соответствует SandwichError.outOfCleanDishes, то вызывается функция washDishes(). Если генерируется ошибка, и она соответствует SandwichError. missingIngredients , то функция buyGroceries(_:) вызывается с соответствующим значением [String], захваченным шаблоном catch.
missingIngredients , то функция buyGroceries(_:) вызывается с соответствующим значением [String], захваченным шаблоном catch.
Генерация, вылавливание и передача ошибок рассмотрены более подробно в главе Обработка ошибок.
Утверждения и предусловия являются проверками во время исполнения. Вы используете их для того, чтобы убедиться, что какое-либо условие уже выполнено, прежде чем начнется исполнение последующего кода. Если булево значение в утверждении или в предусловии равно true, то выполнение кода просто продолжается далее, но если значение равно false, то текущее состояние исполнения программы некорректно и выполнение кода останавливается и ваше приложение завершает работу.
Используйте утверждения и предусловия для выражения допущений, которые вы делаете, пока пишете код, таким образом вы будете использовать их в качестве части вашего кода. Утверждения помогают находить вам ошибки и некорректные допущения, а предусловия помогают обнаружить проблемы в рабочем приложении.
В дополнение к сравниванию ваших ожиданий и действительности во время исполнения, и утверждения, и предусловия становятся полезными при использовании, так как они по сути становятся документацией к вашему коду. В отличии от Обработки ошибок, о которых мы с вами говорили чуть ранее, утверждения и предусловия не используются для ожидаемых ошибок, получив которые ваше приложение может восстановить свою работу. Так как ошибка, полученная через утверждение или предусловие является индикатором некорректной работы программы, то нет возможности отловить эту ошибку в утверждении, которое ее вызвало.
Использование утверждений и предусловий не являются заменой проектированию вашего кода таким образом, где вероятность того, что появятся некорректные условия будет маловероятна. Однако их использование для обеспечения правильности данных и состояния заставляет ваше приложение прекращать работу по причине ошибки более предсказуемо, если наступает некорректное состояние, которое помогает быстрее найти эту самую ошибку.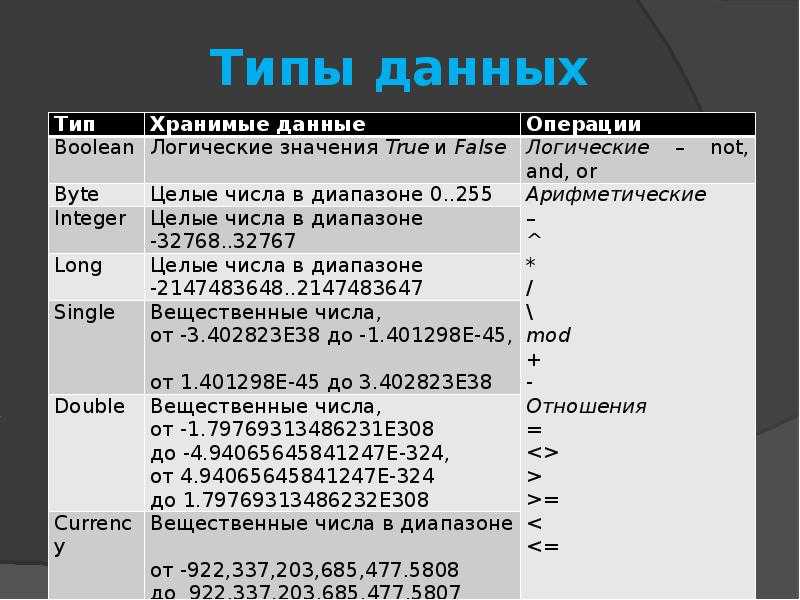 Прекращение работы как только наступает некорректное состояние позволяет ограничить ущерб, который вызывается этим самым некорректным состоянием.
Прекращение работы как только наступает некорректное состояние позволяет ограничить ущерб, который вызывается этим самым некорректным состоянием.
Различие между утверждениями и предусловиями в том, когда они проверяются: утверждения проверяются только в сборках дебаггера, а предусловия проверяются и в сборках дебаггера и продакшн сборках. В продакшн сборках условие внутри утверждения не вычисляется. Это означает, что вы можете использовать сколько угодно утверждений в процессе разработки без влияния на производительность продакшена.
Отладка с помощью утверждений
Утверждения записываются как функция стандартной библиотеки Swift assert(_:_:file:line:). Вы передаете в эту функцию выражение, которые оценивается как true или false и сообщение, которое должно отображаться, если результат условия будет false. Например:
let age = -3 assert(age >= 0, "Возраст человека не может быть меньше нуля") // это приведет к вызову утверждения, потому что age >= 0, а указанное значение < 0.
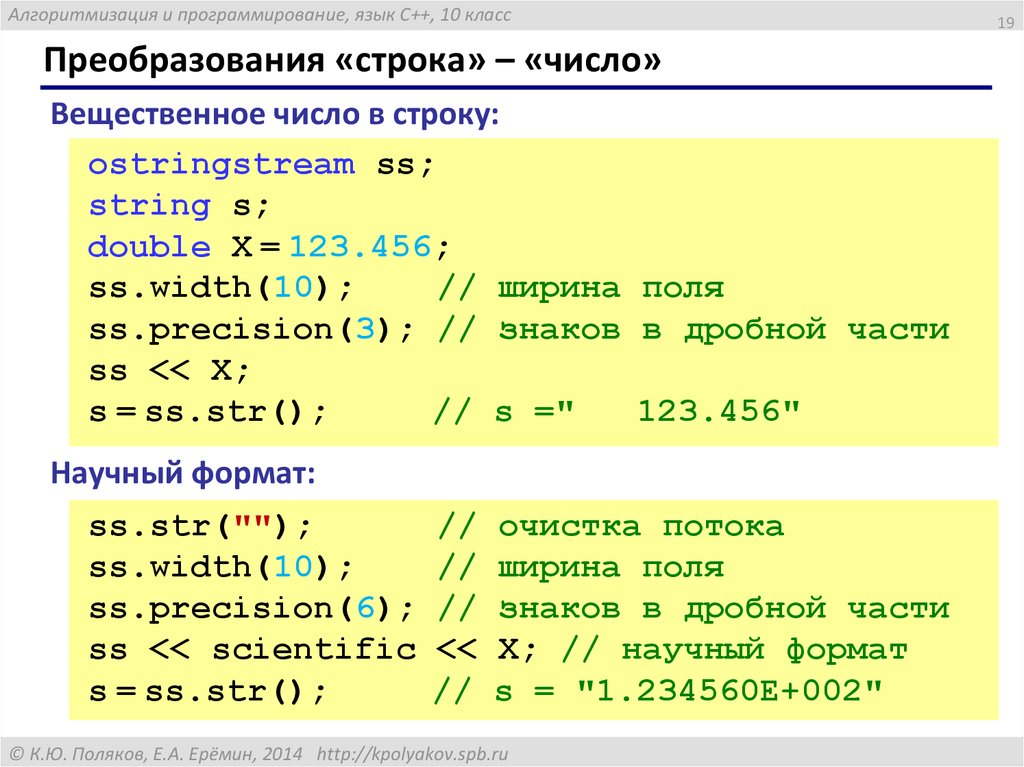
В этом примере, выполнение кода продолжится, только если age >= 0 вычислится в true, что может случиться, если значение age не отрицательное. Если значение age отрицательное, как в коде выше, тогда age >= 0 вычислится как false, и запустится утверждение, завершив за собой приложение.
Сообщение утверждения можно пропускать по желанию, как в следующем примере:
assert(age >= 0)
Если код уже проверяет условие, то вы используете функцию assertionFailure(_:file:line:) для индикации того, что утверждение не выполнилось. Например:
if age > 10 {
print("Ты можешь покататься на американских горках и чертовом колесе.")
} else if age > 0 {
print("Ты можешь покататься на чертовом колесе.")
} else {
assertionFailure("Возраст человека не может быть отрицательным.")
}
Обеспечение предусловиями
Используйте предусловие везде, где условие потенциально может получить значение false, но для дальнейшего исполнения кода оно определенно должно равняться true.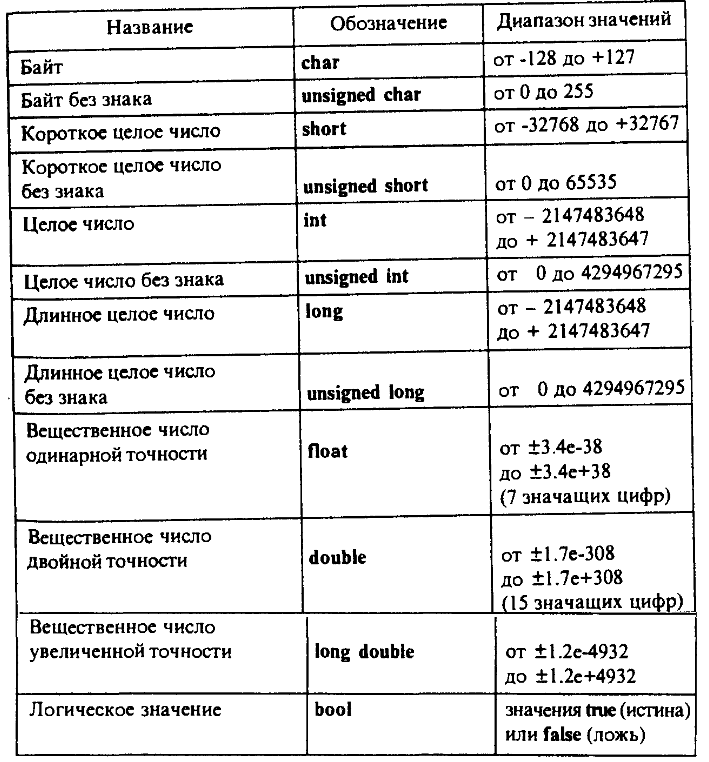 Например, используйте предусловие для проверки того, что значение сабскрипта не вышло за границы диапазона или для проверки того, что в функцию было передано корректное значение.
Например, используйте предусловие для проверки того, что значение сабскрипта не вышло за границы диапазона или для проверки того, что в функцию было передано корректное значение.
Для использования предусловий вызовите функцию precondition(_:_:file:line:). Вы передаете этой функции выражение, которое вычисляется как true или false и сообщение, которое должно отобразиться, если условие будет иметь значение как false. Например:
// В реализации сабскрипта... precondition(index > 0, "Индекс должен быть больше нуля.")
Вы так же можете вызвать функцию preconditionFailure(_:_:file:line:) для индикации, что отказ работы уже произошел, например, если сработал дефолтный кейс инструкции switch, когда известно, что все валидные значения должны быть обработаны любым кейсом, кроме дефолтного.
Заметка
Если вы компилируете в режиме -0unchecked, то предусловия не проверяются. Компилятор предполагает, что предусловия всегда получают значения true, и он оптимизирует ваш код соответствующим образом. Однако, функция fatalError(_:file:line:) всегда останавливает исполнение, несмотря на настройки оптимизации.
Однако, функция fatalError(_:file:line:) всегда останавливает исполнение, несмотря на настройки оптимизации.
Вы можете использовать функцию fatalError (_:file:line:) во время прототипирования или ранней разработки для создания заглушек для функциональности, которая еще не реализована, написав fatalError («Unimplemented») в качестве реализации заглушки. Поскольку фатальные ошибки никогда не оптимизируются, в отличие от утверждений или предусловий, вы можете быть уверены, что выполнение кода всегда прекратится, если оно встречает реализацию заглушки.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
НОУ ИНТУИТ | Лекция | Основы языка Си: структура Си-программы, базовые типы и конструирование новых типов, операции и выражения
< Лекция 12 || Лекция 8: 1234567
Аннотация: Лекция посвящена введению в язык Си. Объясняются общие принципы построения Си-программы: разбиение проекта на h- и c-файлы, т.е. разделение интерфейса и реализации, использование препроцессора. Приводятся базовые типы языка Си, конструкции массива и указателя, позволяющие строить новые типы, а также модификаторы типов. Рассматриваются всевозможные операции и выражения языка Си.
Приводятся базовые типы языка Си, конструкции массива и указателя, позволяющие строить новые типы, а также модификаторы типов. Рассматриваются всевозможные операции и выражения языка Си.
Ключевые слова: Си, Java, указатель, адрес, массив, программа, контроль, операционная система, API, application program, interface, компилятор, слово, оператор DEFINE, файл, прототип функции, имя функции, константы, переменная, представление, standard input, препроцессор, директива, символическое имя, понимание текста, функция, алгоритм, значение, аргумент, вещественное число, вычисленное значение, вызов функции, стандартный поток вывода, логический тип, класс, тело оператора, специальный тип данных, volatility, Intel 80286, операции, сложение, умножение, оператор присваивания, префиксные операции, сумма элементов массива, аргумент операции, эквивалентное выражение, type cast, неявное преобразование
Основы языка Си
В настоящее время язык Си и объектно-ориентированные языки
его группы (прежде всего C++, а также Java и C#) являются основными
в практическом программировании. Достоинство языка Си — это,
прежде всего, его простота и лаконичность. Язык Си легко учится.
Главные понятия языка Си, такие, как статические и локальные
переменные, массивы, указатели, функции и т.д., максимально приближены
к архитектуре реальных компьютеров. Так, указатель — это просто адрес
памяти, массив — непрерывная область памяти, локальные переменные — это
переменные, расположенные в аппаратном стеке,
статические — в статической памяти. Программист,
пишущий на Си, всегда достаточно точно представляет себе, как
созданная им программа будет работать на любой конкретной архитектуре.
Другими словами, язык Си предоставляет программисту
полный контроль над компьютером.
Достоинство языка Си — это,
прежде всего, его простота и лаконичность. Язык Си легко учится.
Главные понятия языка Си, такие, как статические и локальные
переменные, массивы, указатели, функции и т.д., максимально приближены
к архитектуре реальных компьютеров. Так, указатель — это просто адрес
памяти, массив — непрерывная область памяти, локальные переменные — это
переменные, расположенные в аппаратном стеке,
статические — в статической памяти. Программист,
пишущий на Си, всегда достаточно точно представляет себе, как
созданная им программа будет работать на любой конкретной архитектуре.
Другими словами, язык Си предоставляет программисту
полный контроль над компьютером.
Первоначально язык Си задумывался как заменитель Ассемблера
для написания операционных систем. Поскольку Си — это язык
высокого уровня, не зависящий от конкретной архитектуры, текст
операционной системы оказывался легко переносимым с одной платформы на
другую. Первой операционной системой, написанной практически целиком на
Си, была система Unix. В настоящее время почти все используемые операционные системы написаны на Си. Кроме того, средства программирования, которые операционная система
предоставляет разработчикам прикладных программ (так называемый API —
Application Program Interface), — это наборы системных функций на языке Си.
В настоящее время почти все используемые операционные системы написаны на Си. Кроме того, средства программирования, которые операционная система
предоставляет разработчикам прикладных программ (так называемый API —
Application Program Interface), — это наборы системных функций на языке Си.
Тем не менее, область применения языка Си не ограничилась разработкой операционных систем. Язык Си оказался очень удобен в программах обработки текстов и изображений, в научных и инженерных расчетах. Объектно-ориентированные языки на основе Си отлично подходят для программирования в оконных средах.
В данном разделе будут приведены лишь основные понятия языка Си (и частично C++). Это не заменяет чтения полного учебника по Си или C++, например, книг [6] и [8].
Мы будем использовать компилятор C++ вместо Cи. Дело в том,
что язык Си почти целиком входит в C++, т. е. нормальная программа,
написанная на Си, является корректной C++ программой. Слово
«нормальная» означает, что она не содержит неудачных конструкций,
оставшихся от ранних версий Си и не используемых в настоящее
время. Компилятор C++ предпочтительнее, чем компилятор Си, т.к.
он имеет более строгий контроль ошибок. Кроме того, некоторые
конструкции C++, не связанные с объектно-ориентированным программированием,
очень удобны и фактически являются улучшением
языка Си. Это, прежде всего, комментарии //, возможность описывать
локальные переменные в любой точке программы, а не только в начале блока,
и также задание констант без использования оператора #define препроцесора.
Мы будем использовать эти возможности
C++, оставаясь по существу в рамках языка Си.
е. нормальная программа,
написанная на Си, является корректной C++ программой. Слово
«нормальная» означает, что она не содержит неудачных конструкций,
оставшихся от ранних версий Си и не используемых в настоящее
время. Компилятор C++ предпочтительнее, чем компилятор Си, т.к.
он имеет более строгий контроль ошибок. Кроме того, некоторые
конструкции C++, не связанные с объектно-ориентированным программированием,
очень удобны и фактически являются улучшением
языка Си. Это, прежде всего, комментарии //, возможность описывать
локальные переменные в любой точке программы, а не только в начале блока,
и также задание констант без использования оператора #define препроцесора.
Мы будем использовать эти возможности
C++, оставаясь по существу в рамках языка Си.
Структура Си-программы
Любая достаточно большая программа на Си (программисты используют термин проект ) состоит из файлов. Файлы транслируются Си-компилятором независимо друг от друга и затем объединяются программой-построителем задач, в результате чего создается файл с программой, готовой к выполнению.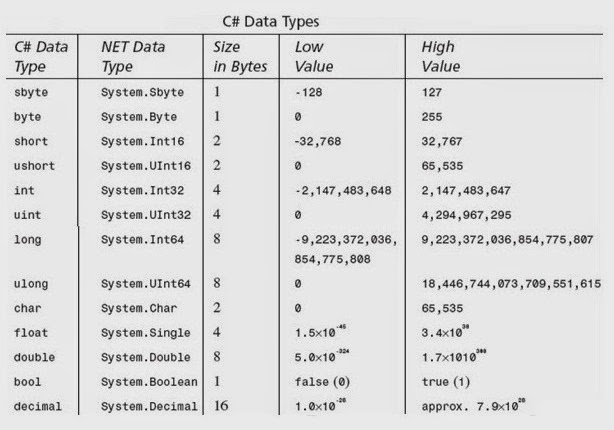 Файлы, содержащие тексты Си-программы, называются исходными.
Файлы, содержащие тексты Си-программы, называются исходными.
В языке Си исходные файлы бывают двух типов:
- заголовочные, или h-файлы;
- файлы реализации, или Cи-файлы.
Имена заголовочных файлов имеют расширение » .h «. Имена файлов реализации имеют расширения » .c » для языка Си и » .cpp «, » .cxx » или » .cc » для языка C++.
К сожалению, в отличие от языка Си, программисты не сумели договориться о едином расширении имен для файлов, содержащих программы на C++. Мы будем использовать расширение » .h » для заголовочных файлов и расширение » .cpp » для файлов реализации.
Заголовочные файлы содержат только описания. Прежде всего, это прототипы функций. Прототип функции описывает имя функции, тип возвращаемого значения, число и типы ее аргументов.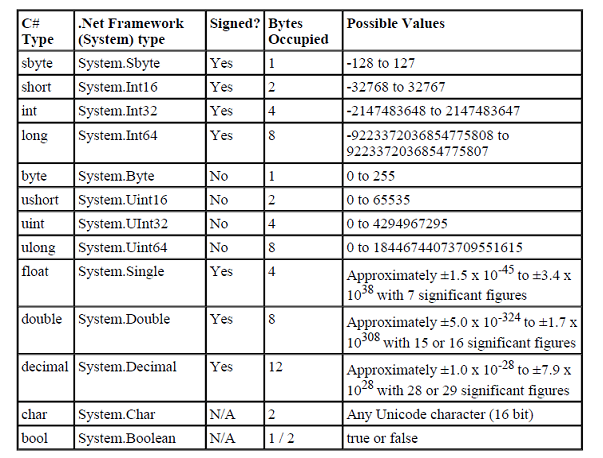 Сам текст функции в h-файле не содержится. Также в h-файлах описываются имена и типы внешних переменных, константы, новые типы, структуры и т.п. В общем, h-файлы содержат лишь интерфейсы, т.е. информацию, необходимую для использования программ, уже написанных другими программистами (или тем же программистом раньше). Заголовочные файлы лишь сообщают информацию о других программах. При трансляции заголовочных файлов, как правило, никакие объекты не создаются. Например, в заголовочном файле нельзя определить глобальную переменную. Строка описания
Сам текст функции в h-файле не содержится. Также в h-файлах описываются имена и типы внешних переменных, константы, новые типы, структуры и т.п. В общем, h-файлы содержат лишь интерфейсы, т.е. информацию, необходимую для использования программ, уже написанных другими программистами (или тем же программистом раньше). Заголовочные файлы лишь сообщают информацию о других программах. При трансляции заголовочных файлов, как правило, никакие объекты не создаются. Например, в заголовочном файле нельзя определить глобальную переменную. Строка описания
int x;
определяющая целочисленную переменную x, является ошибкой. Вместо этого следует использовать описание
extern int x;
означающее, что переменная x определена где-то в файле реализации (в каком — неизвестно). Слово extern (внешняя) лишь сообщает информацию о внешней переменной, но не определяет эту переменную.
Файлы реализации, или Cи-файлы, содержат тексты функций и определения глобальных переменных. Говоря упрощенно, Си-файлы содержат сами программы, а h-файлы — лишь информацию о программах.
Представление исходных текстов в виде заголовочных файлов и файлов реализации необходимо для создания больших проектов, имеющих модульную структуру. Заголовочные файлы служат для передачи информации между модулями. Файлы реализации — это отдельные модули, которые разрабатываются и транслируются независимо друг от друга и объединяются при создании выполняемой программы.
Файлы реализации могут подключать описания, содержащиеся в заголовочных файлах. Сами заголовочные файлы также могут использовать другие заголовочные файлы. Заголовочный файл подключается с помощью директивы препроцессора #include. Например, описания стандартных функций ввода-вывода включаются с помощью строки
#include <stdio.
 h>
h>(stdio — от слов standard input/output). Имя h-файла записывается в угловых скобках, если этот h-файл является частью стандартной Си-библиотеки и расположен в одном из системных каталогов. Имена h-файлов, созданных самим программистом в рамках разрабатываемого проекта и расположенных в текущем каталоге, указываются в двойных кавычках, например,
#include "abcd.h"
Препроцессор — это программа предварительной обработки текста непосредственно перед трансляцией. Команды препроцессора называются директивами. Директивы препроцессора содержат символ диез # в начале строки. Препроцессор используется в основном для подключения h-файлов. В Си также очень часто используется директива #define для задания символических имен констант. Так, строка
#define PI 3.14159265
задает символическое имя PI для константы 3. 14159265. После этого
имя PI можно использовать вместо числового значения. Препроцессор
находит все вхождения слова PI в текст и заменяет их на константу.
Таким образом, препроцессор осуществляет подмену одного текста другим.
Необходимость использования препроцессора всегда свидетельствует о
недостаточной выразительности языка. Так, в любом Ассемблере средства
препроцессирования используются довольно интенсивно. В Си по возможности
следует избегать чрезмерного увлечения командами препроцессора — это
затрудняет понимание текста программы и зачастую ведет к трудно
исправляемым ошибкам. В C++ можно обойтись без использования директив #define для задания констант. Например, в C++ константу PI можно задать
с помощью нормального описания
14159265. После этого
имя PI можно использовать вместо числового значения. Препроцессор
находит все вхождения слова PI в текст и заменяет их на константу.
Таким образом, препроцессор осуществляет подмену одного текста другим.
Необходимость использования препроцессора всегда свидетельствует о
недостаточной выразительности языка. Так, в любом Ассемблере средства
препроцессирования используются довольно интенсивно. В Си по возможности
следует избегать чрезмерного увлечения командами препроцессора — это
затрудняет понимание текста программы и зачастую ведет к трудно
исправляемым ошибкам. В C++ можно обойтись без использования директив #define для задания констант. Например, в C++ константу PI можно задать
с помощью нормального описания
const double PI = 3.14159265;
Это является одним из аргументов в пользу применения компилятора C++ вместо Си даже при трансляции программ, не содержащих конструкции класса.
Дальше >>
< Лекция 12 || Лекция 8: 1234567
Что такое двойник в C?
Соммарио:
- Что такое двойник в C?
- Есть ли в C двойник?
- Сколько стоит двойное число в C?
- Что такое long double в C?
- Что означает %d в C?
- Что такое printf() в C?
- Double лучше, чем float?
- Какова дальность действия двойника?
- Почему %d используется в C?
- Что такое #include в C?
- Как называется %d в C?
- Почему он называется printf?
- Двойное число — это то же самое, что и число с плавающей запятой?
- Что такое диапазон с плавающей запятой в C?
- Что такое диапазон коротких?
- Что означает %d в C?
- Что такое Getch C?
- Что такое scanf() в C?
- Должен ли я использовать float или double Swift?
- Что плавает в C?
Что такое двойник в C?
Двойной тип данных в языке C, который хранит высокоточные данные с плавающей запятой или числа в памяти компьютера .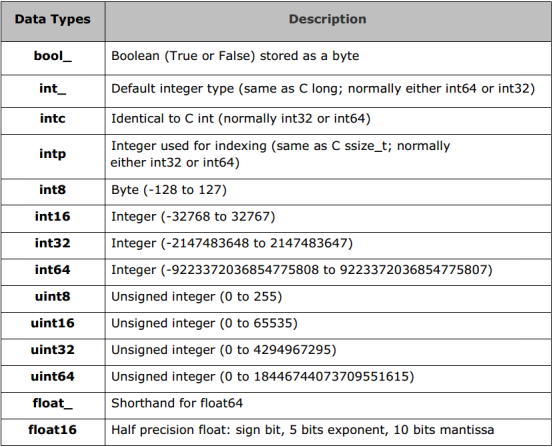 Он называется двойным типом данных, потому что он может содержать двойной размер данных по сравнению с типом данных с плавающей запятой. Двойник имеет 8 байтов, что равно 64 битам.
Он называется двойным типом данных, потому что он может содержать двойной размер данных по сравнению с типом данных с плавающей запятой. Двойник имеет 8 байтов, что равно 64 битам.
Есть ли двойник в C?
C, C++, C# и многие другие языки программирования распознают тип double. Тип double может представлять как дробные, так и целые значения. Он может содержать до 15 цифр всего , включая до и после запятой.
Сколько стоит двойное число в C?
Floating-Point Types
| Type | Storage size | Value range |
|---|---|---|
| float | 4 byte | 1.2E-38 to 3.4E+38 |
| double | 8 byte | от 2.3E-308 до 1.7E+308 |
| long double | 10 байт | от 3.4E-4932 до 1.1E+4932 | 9 Что такое long double? Он указывает только имя числового типа данных, например, int или float. Что означает %d в C?В языке программирования C %d и %i являются спецификаторами формата, например, где %d указывает десятичный тип переменной , а %i указывает целочисленный тип. Что такое printf() в C?1. Функция printf() на языке C: на языке программирования C функция printf() равна 9.0051 используется для вывода («знаков, строк, чисел с плавающей запятой, целых, восьмеричных и шестнадцатеричных значений») на экран вывода. Мы используем функцию printf() со спецификатором формата %d для отображения значения целочисленной переменной. Double лучше, чем float? Double более точен, чем float , и может хранить 64 бита, что вдвое превышает количество битов, которое может хранить float. Каков радиус действия двойника?В этой статье
Почему %d используется в C?%d сообщает printf, что соответствующий аргумент следует рассматривать как целочисленное значение ; тип соответствующего аргумента должен быть int . Что такое #include в C? Директива препроцессора #include используется для вставки кода данного файла в текущий файл . Как называется %d в C?Нотация % называется , а спецификатор формата . Например, %d сообщает printf(), что нужно напечатать целое число. Почему он называется printf?«printf» — это имя одной из основных функций вывода C, а означает «отформатировано для печати» . Строки формата printf дополняют строки формата scanf, которые обеспечивают форматированный ввод (анализ). … Сама строка формата очень часто является строковым литералом, что позволяет проводить статический анализ вызова функции. Двойное значение — это то же самое, что и число с плавающей запятой? И Double, и Float используются для представления десятичных чисел, но они делают это немного по-разному. Что такое диапазон с плавающей запятой в C?Значения одинарной точности с типом float имеют 4 байта, состоящие из знакового бита, 8-битной двоичной экспоненты с избыточным значением 127 и 23-битной мантиссы. Мантисса представляет собой число от 1,0 до 2,0. … Это представление дает диапазон приблизительно от 3.4E-38 до 3.4E+38 для плавающего типа. Что такое диапазон коротких?short: тип данных short представляет собой 16-разрядное целое число в дополнении до двух со знаком. Он имеет минимальное значение -32 768 и максимальное значение 32 767 (включительно) . Что означает %d в C?%s для строки %d для десятичного (или целого) %c для символа . Что такое Getch C? Метод getch() приостанавливает работу консоли вывода до тех пор, пока не будет нажата клавиша . Что такое scanf() в C?В языке программирования C scanf — это функция, которая считывает отформатированные данные из стандартного ввода (т. е. стандартный поток ввода, который обычно является клавиатурой, если только он не перенаправлен), а затем записывает результаты в заданные аргументы. Должен ли я использовать float или double Swift?Swift всегда выбирает Double (а не Float ) при выводе типа чисел с плавающей запятой. Если вы комбинируете в выражении целочисленные литералы и литералы с плавающей запятой, тип Double будет выводиться из контекста: пусть otherPi = 3 + 0,14159. Что плавает в C? «Константа с плавающей запятой» — это десятичное число, которое представляет вещественное число со знаком . Типы данных — Руководство NumPy v1.23См. также Объекты типа данных Типы массивов и преобразования между типамиNumPy поддерживает гораздо большее разнообразие числовых типов, чем Python. В этом разделе показано, какие из них доступны, и как изменить тип данных массива. Поддерживаемые типы примитивов тесно связаны с типами в C:
Поскольку многие из них имеют определения, зависящие от платформы, набор фиксированных размеров
предоставляются псевдонимы (см. NumPy являются экземплярами объектов Расширенные типы, не перечисленные выше, рассматриваются в раздел Структурированные массивы. Существует 5 основных числовых типов, представляющих логические значения (bool), целые числа (int),
целые числа без знака (uint), числа с плавающей запятой (float) и комплексные числа. Те, что с цифрами
в их названии указывают разрядность типа (т.е. сколько бит необходимо
для представления одного значения в памяти). Некоторые типы, такие как Типы данных можно использовать в качестве функций для преобразования чисел Python в скаляры массивов. (объяснение см. в разделе скалярных массивов), последовательности чисел Python для массивов этого типа или в качестве аргументов для ключевого слова dtype, что многие numpy функции или методы принимают. Некоторые примеры: >>> х = np.float32 (1.0) >>> х 1,0 >>> у = np.int_([1,2,4]) >>> г массив([1, 2, 4]) >>> z = np.arange(3, dtype=np.uint8) >>> г массив ([0, 1, 2], dtype = uint8) Типы массивов также могут обозначаться кодами символов, в основном для сохранения обратная совместимость со старыми пакетами, такими как Numeric. Немного документация может по-прежнему ссылаться на них, например: >>> np.array([1, 2, 3], dtype='f') массив([1., 2., 3.], dtype=float32) 906:30
Обратите внимание, что для целочисленного типа
Тип
float — это число двойной точности с плавающей запятой в Python В Python числа с плавающей запятой обычно реализуются с использованием языка C
Если вы не используете специальную реализацию, отличную от CPython, вы можете предположить, что используется Число двойной точности с плавающей запятой
Во многих других языках программирования, таких как C, числа с плавающей запятой одинарной точности используются как Обратите внимание, что в NumPy вы можете явно указать тип с количеством битов, например,
Используйте
Модуль sys включен в стандартную библиотеку, поэтому дополнительная установка не требуется. система импорта печать (sys.float_info) # sys.float_info(max=1.7976931348623157e+308, max_exp=1024, max_10_exp=308, min=2.2250738585072014e-308, min_exp=-1021, min_10_exp=-307, dig=15, mant_dig-503, epsilon4=2.2039e 16, основание=2, раунды=1) печать (тип (sys.float_info)) # <класс 'sys.float_info'> источник: sys_float_info.py Вы можете получить значение каждого элемента в виде атрибута, например печать (sys.float_info.max) # 1.7976931348623157e+308 источник: sys_float_info.py Список элементов и пояснения к ним см. в официальной документации. Каждый элемент соответствует константе с плавающей запятой, определенной в стандартном заголовочном файле
Максимальное значение, которое может представлять печать (sys.float_info.max) # 1.7976931348623157e+308 источник: sys_float_info.py Значения, превышающие это, обрабатываются как
печать(1.8e+308) # информация печать (тип (1.8e + 308)) # <класс 'плавающий'> источник: sys_float_info.py В шестнадцатеричном формате это выглядит следующим образом. печать (sys.float_info.max.hex()) # 0x1.ffffffffffffffp+1023 источник: sys_float_info.py Минимальное значение, которое может представлять с плавающей запятой Минимальное отрицательное значение Минимальное отрицательное значение, которое может представлять печать (-sys.float_info.max) # -1.7976931348623157e+308 печать(-1.8e+308) # -инф печать (тип (-1.8e + 308)) # <класс 'плавающий'> источник: sys_float_info.py Минимальное положительное нормализованное значение: sys.float_info.min Вы можете получить минимальное положительное нормализованное значение с помощью печать (sys.float_info.min) №2.2250738585072014э-308 источник: sys_float_info.py Нормализованное число — это значение, показатель степени которого не равен печать (sys.float_info.min.hex()) # 0x1.0000000000000p-1022 источник: sys_float_info.py Минимальное положительное денормализованное значение Значения, экспонента которых равна
Минимальное положительное денормализованное значение можно преобразовать из шестнадцатеричной строки следующим образом: print(float.fromhex('0x0.0000000000001p-1022'))
№5е-324
print(format(float.fromhex('0x0.00000000000001p-1022'), '.17'))
# 4.9406564584124654e-324
источник: sys_float_info.py Значение меньше этого считается равным печать(1e-323) № 1э-323 печать (1e-324) # 0.0 источник: sys_float_info.py В Python 3.9 или более поздней версии вы можете получить минимальное положительное денормализованное значение, передав
импорт математики печать (математика. ulp (0,0)) №5е-324 печать (формат (math.ulp (0,0), '.17')) # 4.9406564584124654e-324 источник: math_ulp.py Что означает двойной знак процента1 ответ на этот вопрос.0 голосов Согласно справочной странице «Арифметические операторы» (доступной через «проценты процента»), 'x mod y' обозначается как «процент процента». , что полезно только в том случае, если вы достаточно программировали, чтобы знать, что это относится к модульному делению, т. Е. Целочисленное деление x на y и возврат остатка. Это применимо в широком диапазоне ситуаций. Например (от @GavinSimpson в комментариях), %% полезен, если вы выполняете цикл и хотите вывести на экран какой-то индикатор выполнения на каждой n-й итерации (например, используйте if (i %% 10 == 0) { # сделать что-то}, чтобы сделать что-то каждую 10-ю итерацию). Так как %% также работает для чисел с плавающей запятой в R, я только что откопал пример, где if (any(wts %% 1 != 0)) используется для проверки того, где любое из значений wts не является целое число. ответил 14 июня по Сохаил • 2960 балловСвязанные вопросы в области анализа данныхinf означает бесконечность и применяется только ... ПОДРОБНЕЕ ответил 14 ноября 2018 г. в аналитике данных по Маверик • 10 840 баллов • 903 просмотра
Ошибка означает, что R не смог ... ПОДРОБНЕЕ ответил 29 октября 2018 г. в аналитике данных по Али • 11 340 баллов • 1153 просмотра
Позвольте мне объяснить это на примере. ... ПОДРОБНЕЕ ответил 31 октября 2018 г.
Эта ошибка возникает при попытке ... ПОДРОБНЕЕ ответил 31 октября 2018 г. в аналитике данных по Калги • 52 350 баллов • 256 просмотров
Уважаемый Косик, Надеюсь, у тебя все отлично. Вы можете ... ПОДРОБНЕЕ ответил 18 декабря 2017 г. в аналитике данных по Судхир • 1610 баллов • 452 просмотра
Мы бы начали с загрузки ... ПОДРОБНЕЕ ответил 26 марта 2018 г. в аналитике данных по Бхарани • 4 660 баллов • 493 просмотра
Вы можете использовать пакет "dplyr" для ... ПОДРОБНЕЕ ответил 26 марта 2018 г.
Ниже приведен код для выполнения ... ПОДРОБНЕЕ ответил 27 марта 2018 г. в аналитике данных по Бхарани • 4 660 баллов • 513 просмотров
Так как строка требует обработки ... ПОДРОБНЕЕ ответил 24 июня в аналитике данных по Сохаил • 2960 баллов • 31 просмотр Сюжетный персонаж или пч является стандартным ... ПОДРОБНЕЕ ответил 23 июня в аналитике данных по Сохаил • 2960 баллов • 71 просмотр
Подпишитесь на нашу рассылку новостей и получайте персональные рекомендации.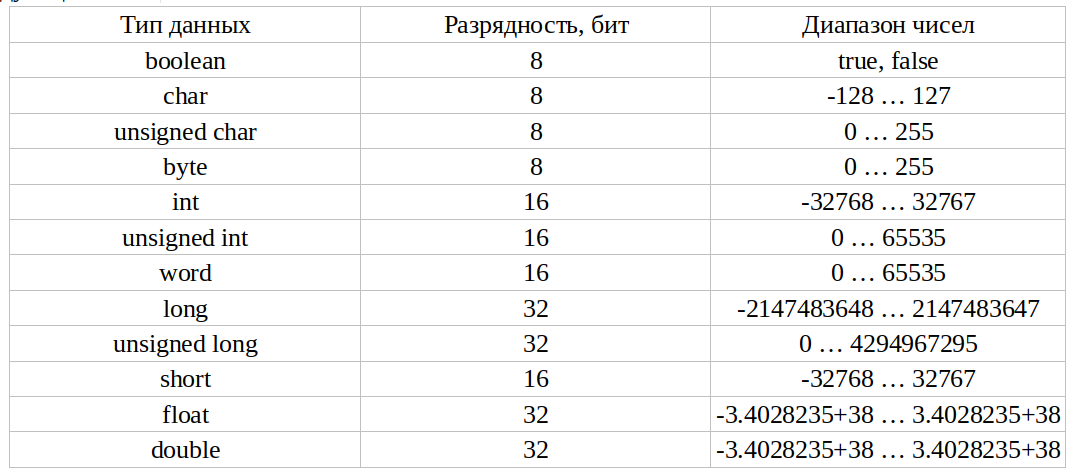 Уже есть учетная запись? . летучих в C | Руководство по работе ключевого слова Volatile в C с примерами Ключевое слово volatile в C — это не что иное, как квалификатор, который используется программистом при объявлении переменной в исходном коде. Он используется для информирования компилятора о том, что значение переменной может быть изменено в любое время без какой-либо задачи, заданной исходным кодом. Volatile обычно применяется к переменной, когда мы ее объявляем. Основная причина использования ключевого слова volatile заключается в том, что оно используется для предотвращения оптимизации объектов в нашем исходном коде. Следовательно, объект, объявленный как volatile, не может быть оптимизирован, поскольку его значение может быть легко изменено кодом. Как мы видели, что такое Volatile в C. Точно так же мы увидим синтаксис, используемый для представления volatile объекта в коде. Но имейте в виду, что значение ключевого слова volatile не может быть изменено программой явно. Синтаксис Объяснение: В приведенном выше объявлении ключевое слово volatile обязательно для использования, тогда data_type означает любой тип данных, который может быть целочисленным, плавающим или двойным. Наконец, имя переменной по нашему выбору. Поскольку оба объявления верны, мы можем использовать любое из вышеперечисленных для объявления изменчивой переменной. Например: Как работает ключевое слово Volatile в C? Теперь давайте посмотрим, как ключевое слово volatile работает в коде программирования на C, на некоторых примерах кода с кратким объяснением. В приведенных ниже двух кодах мы увидим, как программа меняется, когда мы используем ключевое слово volatile при объявлении переменной по сравнению с ключевым словом volatile. Мы увидим, как изменится эффективность кода при использовании volatile и как быстро мы сможем применить этот функционал в нашем коде. Примеры реализации Volatile в CВот пример кода, демонстрирующий работу ключевого слова volatile: Пример #1Без использования ключевого слова Volatile: Код: Вывод: Объяснение: В приведенном выше коде мы объявили целочисленную переменную с присвоенным ей значением 0. Пример #2С использованием ключевого слова Volatile: Код: Вывод: Объяснение: В приведенном выше коде мы объявили изменяемую целочисленную переменную a. Пример #3Вот еще один программный код на C, демонстрирующий работу ключевого слова volatile в C: Код: Вывод: Объяснение: В приведенном выше коде вы можете видеть, что мы объявили константную изменчивую переменную целочисленного типа данных с именем local_value и присвоили ей значение 25. Заключениеvolatile играет важную роль в программировании на C, поскольку компилятор не может угадать значение. Основная причина использования volatile заключается в том, что он может изменить значение в любое время, когда пользователь захочет, чтобы оно было изменено, или когда другой поток работает, но использует ту же переменную. Рекомендуемые статьиЭто руководство по Volatile на C. Здесь мы обсуждаем введение в Volatile на C, а также синтаксис, работу и соответствующие примеры для лучшего понимания. Вы также можете ознакомиться с другими нашими статьями по теме, чтобы узнать больше –
Что это означает в бухгалтерском учете и как оно используетсяЧто такое двойная запись? Двойная запись, фундаментальная концепция, лежащая в основе современной бухгалтерии и бухгалтерского учета, утверждает, что каждая финансовая операция имеет одинаковые и противоположные последствия по крайней мере в двух разных счетах. Ресурсы знак равно Обязательства + Беспристрастность \begin{align} &\text{Активы} = \text{Обязательства} + \text{Капитал} \\ \end{align} Активы=Обязательства+Собственный капитал В системе двойной записи кредиты компенсируются дебетами в главной бухгалтерской книге или Т-счете. Двойная записьОсновы двойной записиВ системе двойной записи транзакции записываются по дебету и кредиту. Поскольку дебет на одном счете компенсирует кредит на другом, сумма всех дебетов должна равняться сумме всех кредитов. Система двойной записи стандартизирует учетный процесс и повышает точность подготовленных финансовых отчетов, позволяя лучше выявлять ошибки. Типы счетов Бухгалтерский учет и бухгалтерский учет - это способы измерения, записи и передачи финансовой информации фирмы. Хозяйственная операция — это экономическое событие, которое регистрируется для целей бухгалтерского учета. В рамках систематического процесса учета эти взаимодействия обычно классифицируются как счета. Существует семь различных типов счетов, по которым можно классифицировать все бизнес-операции:
Бухгалтерия и учет отслеживают изменения в каждой учетной записи по мере того, как компания продолжает свою деятельность. Дебет и кредит Дебеты и кредиты необходимы для системы двойной записи. В бухгалтерском учете под дебетом понимается запись в левой части бухгалтерской книги, а под кредитом — запись в правой части бухгалтерской книги. Чтобы быть в балансе, общая сумма дебетов и кредитов для транзакции должна быть равна. Дебет не всегда соответствует увеличению, а кредит не всегда соответствует уменьшению. Дебет может увеличивать один счет и уменьшать другой. Например, дебет увеличивает счета активов, но уменьшает счета обязательств и собственного капитала, что поддерживает общее уравнение бухгалтерского учета Активы = Обязательства + Капитал. В отчете о прибылях и убытках дебеты увеличивают остатки на счетах расходов и убытков, а кредиты уменьшают их остатки. Дебеты уменьшают доходы и балансы счетов, а кредиты увеличивают их балансы. Система двойной записиДвойная бухгалтерия была разработана в торговый период Европы, чтобы помочь рационализировать коммерческие операции и сделать торговлю более эффективной. Это также помогло торговцам и банкирам понять свои затраты и прибыль. Некоторые мыслители утверждали, что двойная бухгалтерия была ключевой вычислительной технологией, ответственной за рождение капитализма. Уравнение бухгалтерского учета составляет основу бухгалтерского учета с двойной записью и является кратким представлением концепции, которая расширяется до сложного, расширенного и многоэлементного отображения балансового отчета. По сути, репрезентация приравнивает все виды использования капитала (активов) ко всем источникам капитала (где заемный капитал ведет к обязательствам, а собственный капитал ведет к акционерному капиталу). Для компании, ведущей точные счета, каждая отдельная бизнес-транзакция будет представлена как минимум в двух ее счетах. Например, если бизнес берет кредит у финансового учреждения, такого как банк, заемные деньги увеличат активы компании, и обязательства по кредиту также увеличатся на эквивалентную сумму. Если бизнес покупает сырье, заплатив наличными, это приведет к увеличению запасов (актива) при уменьшении денежного капитала (другого актива). Поскольку каждая транзакция, осуществляемая компанией, затрагивает два или более счетов, система бухгалтерского учета называется бухгалтерским учетом с двойной записью. Эта практика гарантирует, что уравнение бухгалтерского учета всегда остается сбалансированным, то есть значение левой части уравнения всегда будет соответствовать значению правой части. Ключевые выводы
Реальный пример двойной записиПекарня покупает парк рефрижераторов в кредит; общая покупка в кредит составила 250 000 долларов. Новый набор грузовиков будет использоваться в бизнес-операциях и не будет продаваться в течение как минимум 10 лет — их предполагаемого срока полезного использования. Чтобы учесть покупку в кредит, записи должны быть сделаны в соответствующих бухгалтерских книгах. Поскольку бизнес накопил больше активов, будет произведен дебет счета активов на сумму стоимости покупки (250 000 долларов США). |
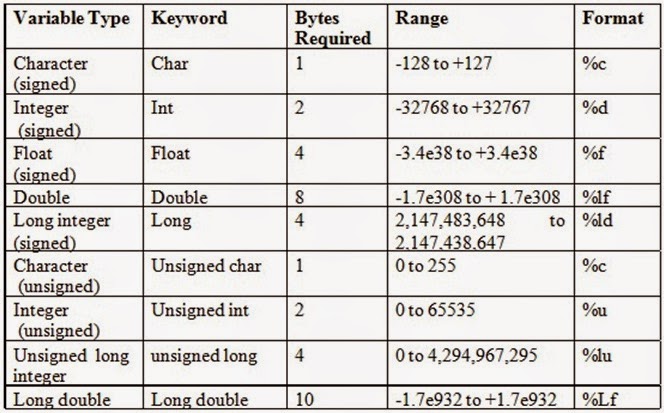 … Длинные двойные карты либо в IEEE четырехкратная точность формат с плавающей запятой или 80-битный формат IEEE с плавающей запятой. Диапазоны вещественных типов C при использовании формата с плавающей запятой IEEE следующие.
… Длинные двойные карты либо в IEEE четырехкратная точность формат с плавающей запятой или 80-битный формат IEEE с плавающей запятой. Диапазоны вещественных типов C при использовании формата с плавающей запятой IEEE следующие. Double более точен, и для хранения больших чисел мы предпочитаем double, а не float. Например, для хранения годовой зарплаты генерального директора компании более точным выбором будет значение double.
Double более точен, и для хранения больших чисел мы предпочитаем double, а не float. Например, для хранения годовой зарплаты генерального директора компании более точным выбором будет значение double. Он используется для включения системных и пользовательских заголовочных файлов. Используя директиву #include, мы предоставляем информацию препроцессору, где искать заголовочные файлы. …
Он используется для включения системных и пользовательских заголовочных файлов. Используя директиву #include, мы предоставляем информацию препроцессору, где искать заголовочные файлы. … … Для Float это означает, что у него всего четыре десятичных знака, а у Double по-прежнему двенадцать.
… Для Float это означает, что у него всего четыре десятичных знака, а у Double по-прежнему двенадцать.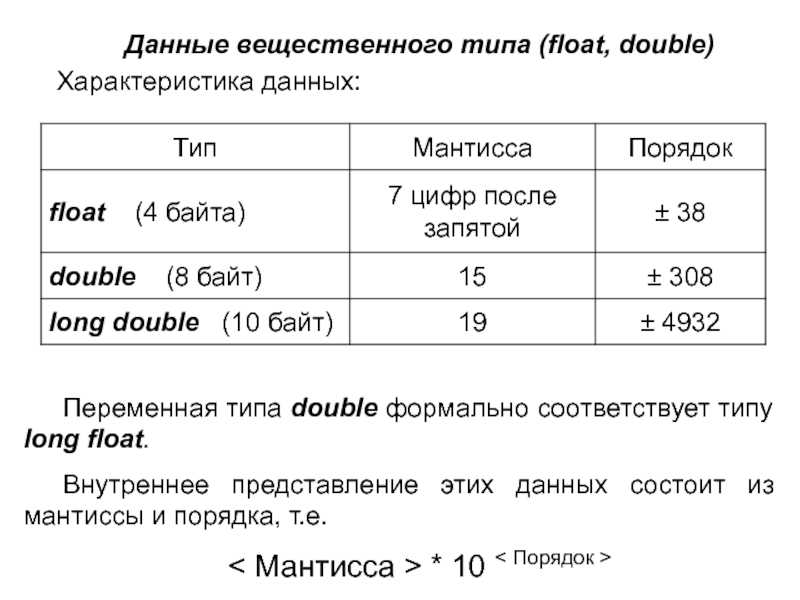 Он не использует буфер для хранения вводимого символа. Введенный символ сразу же возвращается, не дожидаясь нажатия клавиши ввода. … Метод getch() можно использовать для приема скрытых входных данных, таких как пароль, номера контактов банкомата и т. д.
Он не использует буфер для хранения вводимого символа. Введенный символ сразу же возвращается, не дожидаясь нажатия клавиши ввода. … Метод getch() можно использовать для приема скрытых входных данных, таких как пароль, номера контактов банкомата и т. д. Представление вещественного числа со знаком включает целую часть, дробную часть и показатель степени.
Представление вещественного числа со знаком включает целую часть, дробную часть и показатель степени. ubyte
ubyte 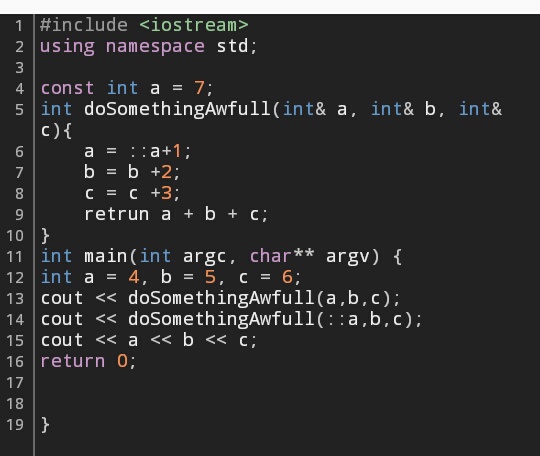 longlong
longlong  longdouble
longdouble  Размерные псевдонимы).
Размерные псевдонимы).
 astype(с плавающей запятой)
массив([0., 1., 2.])
>>> np.int8(z)
массив ([0, 1, 2], dtype = int8)
astype(с плавающей запятой)
массив([0., 1., 2.])
>>> np.int8(z)
массив ([0, 1, 2], dtype = int8)
 Скаляры массива отличаются от скаляров Python, но
по большей части они могут использоваться взаимозаменяемо (основной
исключение составляют версии Python старше v2.x, где целочисленный массив
скаляры не могут выступать в качестве индексов для списков и кортежей). Есть некоторые
исключения, например, когда код требует очень специфических атрибутов скаляра
или когда он специально проверяет, является ли значение скаляром Python. В общем,
проблемы легко устраняются явным преобразованием скаляров массивов
в скаляры Python, используя соответствующую функцию типа Python
(например,
Скаляры массива отличаются от скаляров Python, но
по большей части они могут использоваться взаимозаменяемо (основной
исключение составляют версии Python старше v2.x, где целочисленный массив
скаляры не могут выступать в качестве индексов для списков и кортежей). Есть некоторые
исключения, например, когда код требует очень специфических атрибутов скаляра
или когда он специально проверяет, является ли значение скаляром Python. В общем,
проблемы легко устраняются явным преобразованием скаляров массивов
в скаляры Python, используя соответствующую функцию типа Python
(например,  Скаляры NumPy также имеют много одинаковых
массивы методов.
Скаляры NumPy также имеют много одинаковых
массивы методов. finfo
finfo 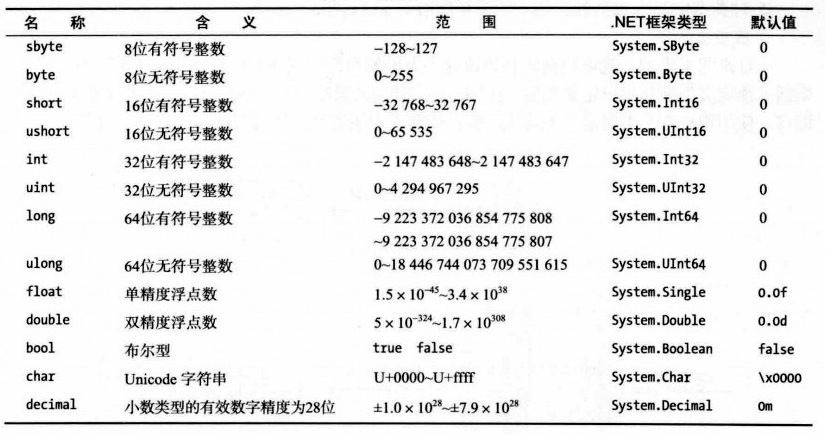 почти эквивалентно
почти эквивалентно  longdouble
longdouble  Может
быть полезным для проверки вашего кода со значением
Может
быть полезным для проверки вашего кода со значением  float_info.max
float_info.max  9.7
9.7 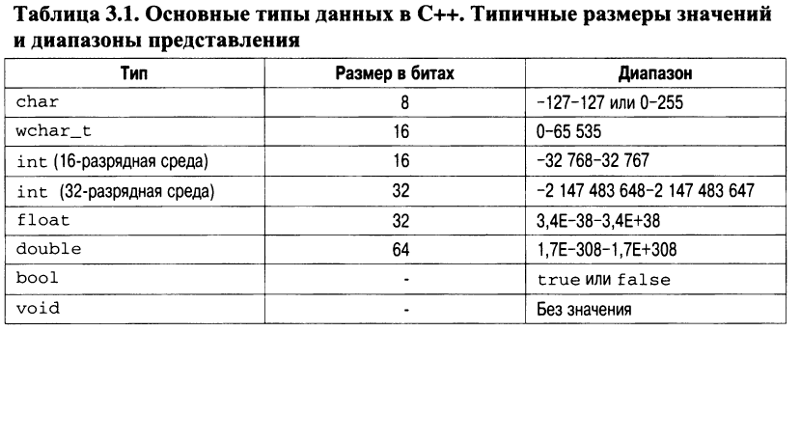 float_info
float_info 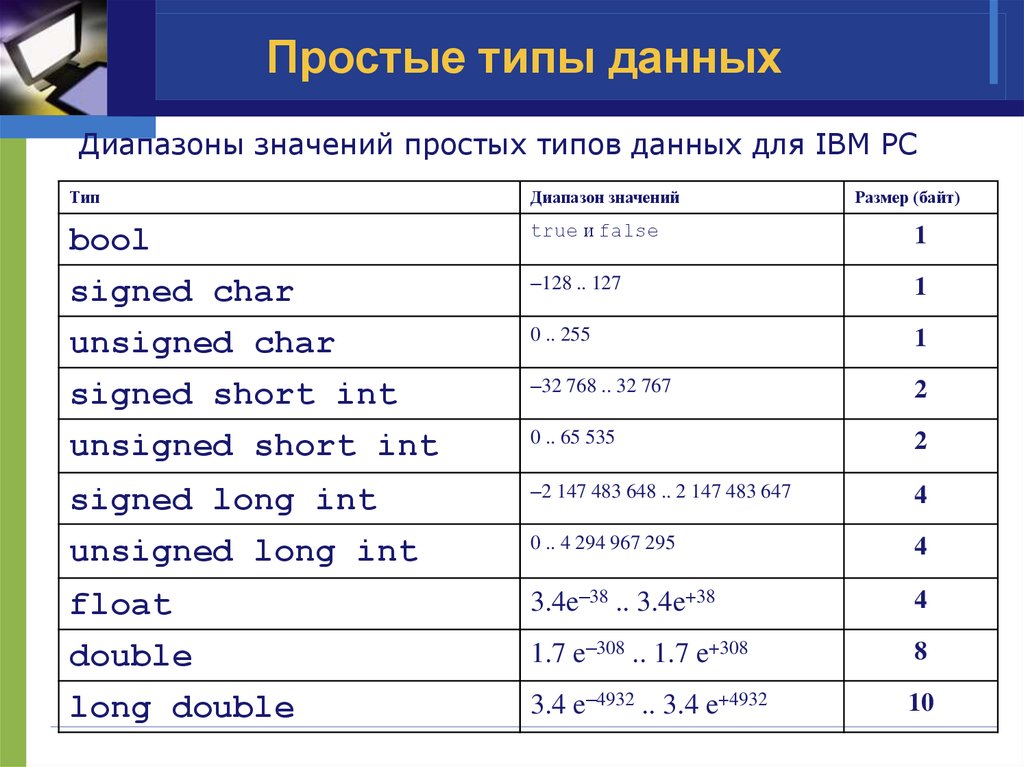 h
h  Это отражает значение системного макроса FLT_ROUNDS во время запуска интерпретатора
Это отражает значение системного макроса FLT_ROUNDS во время запуска интерпретатора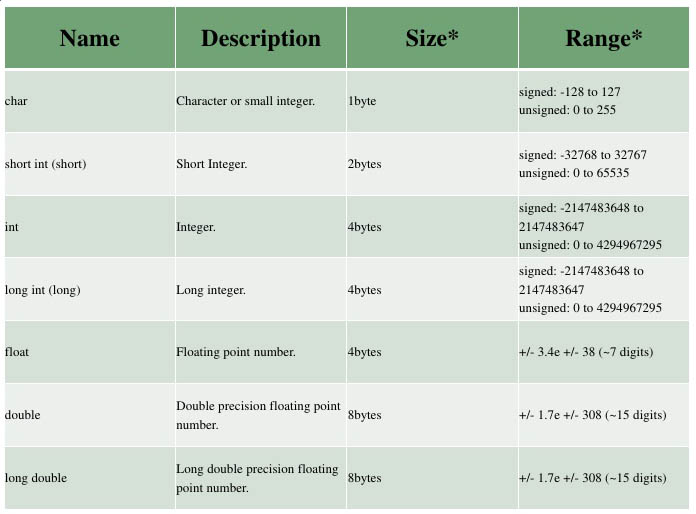 float_info.max
float_info.max  float_info.min
float_info.min 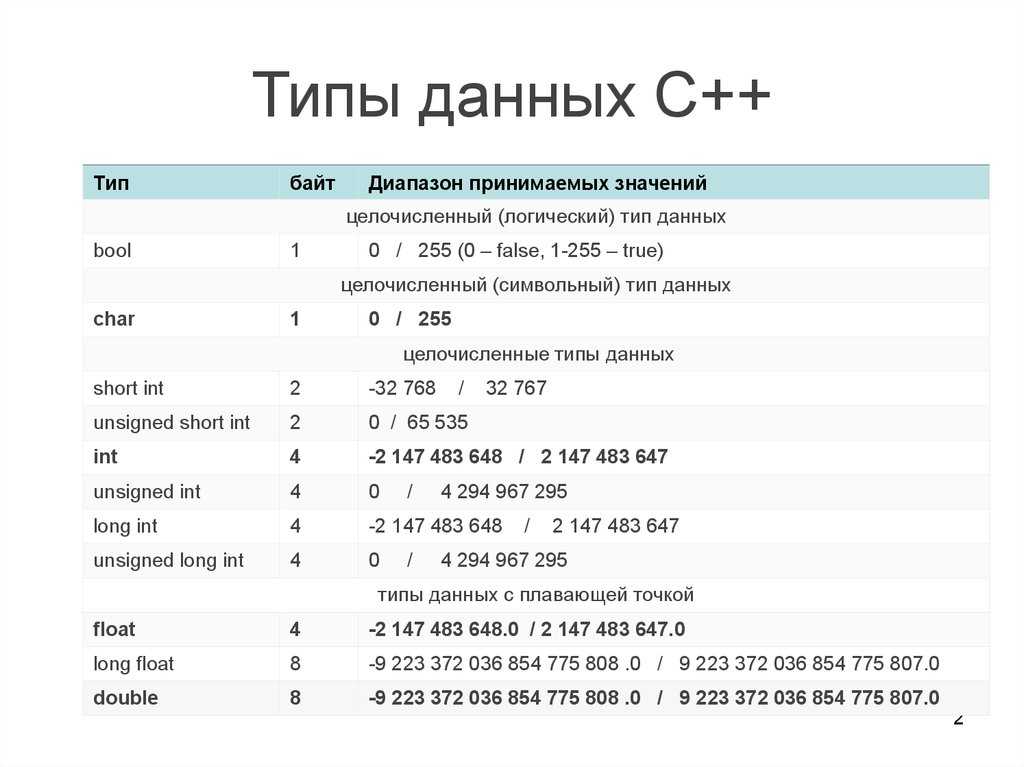 0
0 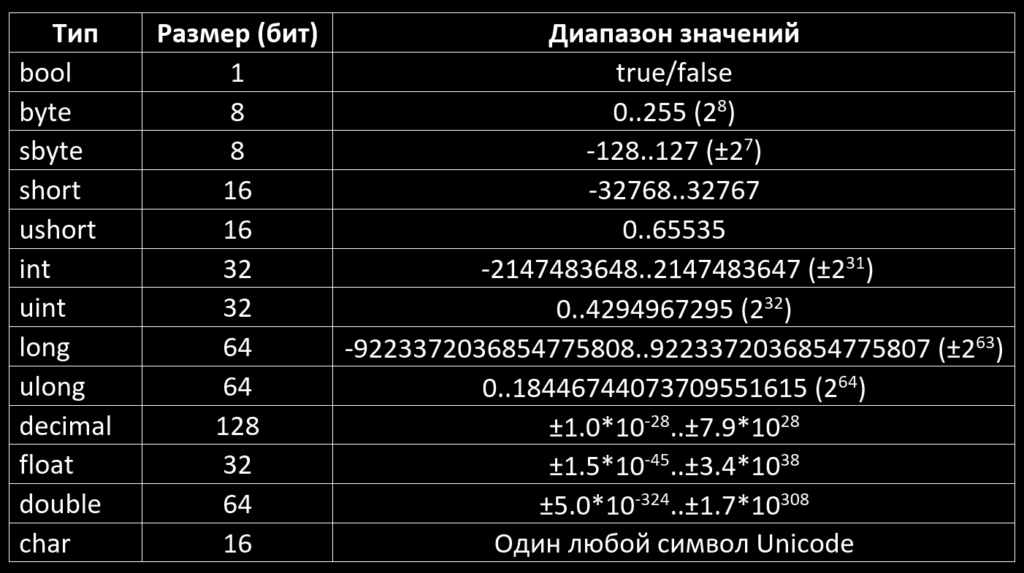
 в аналитике данных по
Калги • 52 350 баллов • 669Просмотры
в аналитике данных по
Калги • 52 350 баллов • 669Просмотры в аналитике данных по
Бхарани • 4 660 баллов • 4448 просмотров
в аналитике данных по
Бхарани • 4 660 баллов • 4448 просмотров
 Volatile используется в программировании на C, когда нам нужно пойти и прочитать значение, сохраненное указателем, по адресу, указанному указателем. Если вам нужно изменить в своем коде что-то, что находится вне досягаемости компилятора, вы можете использовать это ключевое слово volatile перед переменной, для которой вы хотите изменить значение.
Volatile используется в программировании на C, когда нам нужно пойти и прочитать значение, сохраненное указателем, по адресу, указанному указателем. Если вам нужно изменить в своем коде что-то, что находится вне досягаемости компилятора, вы можете использовать это ключевое слово volatile перед переменной, для которой вы хотите изменить значение. Затем в основном классе мы установили условие if, которое будет оставаться истинным до тех пор, пока значение переменной a не станет равным 0. Как вы можете видеть, вывод всегда будет равен 0, поскольку условие всегда будет оставаться истинным, поэтому этот код выиграл. t перейти к части else, так как она будет игнорировать часть else. Но все изменится, когда мы добавим ключевое слово volatile в объявление целочисленной переменной a. Давайте посмотрим на другой код.
Затем в основном классе мы установили условие if, которое будет оставаться истинным до тех пор, пока значение переменной a не станет равным 0. Как вы можете видеть, вывод всегда будет равен 0, поскольку условие всегда будет оставаться истинным, поэтому этот код выиграл. t перейти к части else, так как она будет игнорировать часть else. Но все изменится, когда мы добавим ключевое слово volatile в объявление целочисленной переменной a. Давайте посмотрим на другой код.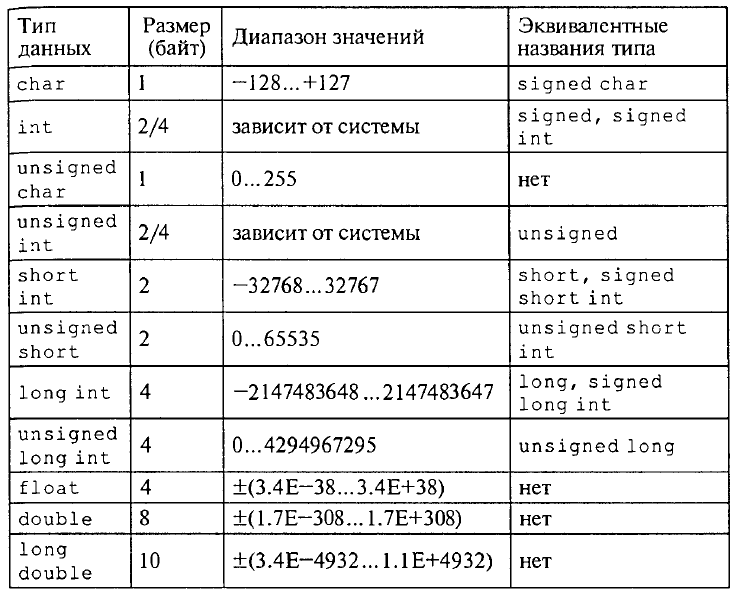 Затем в основном классе мы установили две вещи: одна — значение целочисленной переменной равно 0, а вторая — условие if, которое будет выполняться до тех пор, пока значение переменной a не будет равно 0. Как вы можете видеть, вывод всегда будет 0, так как условие всегда будет оставаться истинным, потому что переменная объявлена как volatile. Следовательно, компилятор не будет оптимизировать часть кода else из-за ключевого слова volatile, используемого перед целым числом. Таким образом, компилятор будет знать, что переменная может измениться в любое время. Следовательно, он прочитает часть else как окончательный исполняемый код и отобразит результат.
Затем в основном классе мы установили две вещи: одна — значение целочисленной переменной равно 0, а вторая — условие if, которое будет выполняться до тех пор, пока значение переменной a не будет равно 0. Как вы можете видеть, вывод всегда будет 0, так как условие всегда будет оставаться истинным, потому что переменная объявлена как volatile. Следовательно, компилятор не будет оптимизировать часть кода else из-за ключевого слова volatile, используемого перед целым числом. Таким образом, компилятор будет знать, что переменная может измениться в любое время. Следовательно, он прочитает часть else как окончательный исполняемый код и отобразит результат.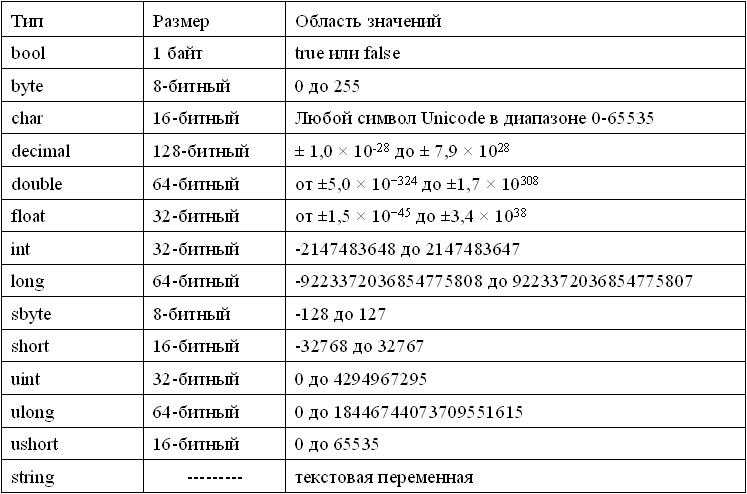 Затем мы объявили указатель целочисленного типа данных, в котором мы храним адресное значение «local_value». Кроме того, мы печатаем старое значение, а затем печатаем измененное значение на экране. Эта модификация возможна только благодаря ключевому слову volatile, которое мы использовали при объявлении переменной.
Затем мы объявили указатель целочисленного типа данных, в котором мы храним адресное значение «local_value». Кроме того, мы печатаем старое значение, а затем печатаем измененное значение на экране. Эта модификация возможна только благодаря ключевому слову volatile, которое мы использовали при объявлении переменной.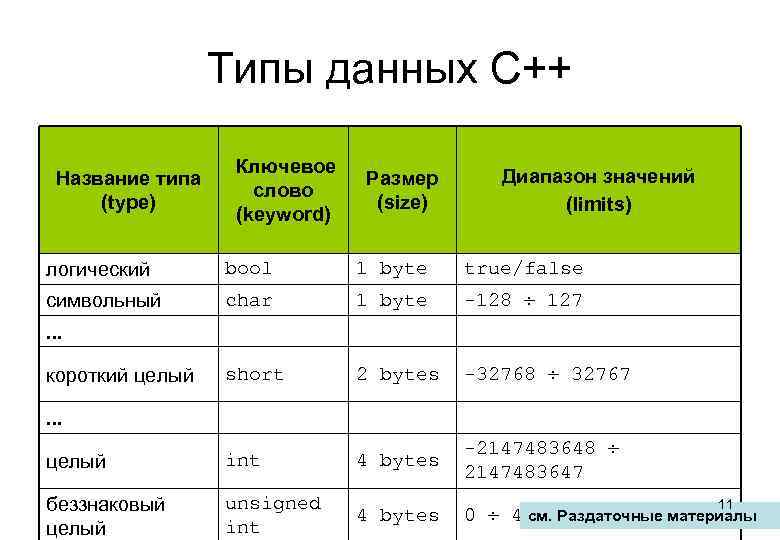 Он используется для удовлетворения уравнения бухгалтерского учета:
Он используется для удовлетворения уравнения бухгалтерского учета: В общих чертах это деловое взаимодействие между экономическими субъектами, такими как клиенты и предприятия или поставщики и предприятия.
В общих чертах это деловое взаимодействие между экономическими субъектами, такими как клиенты и предприятия или поставщики и предприятия.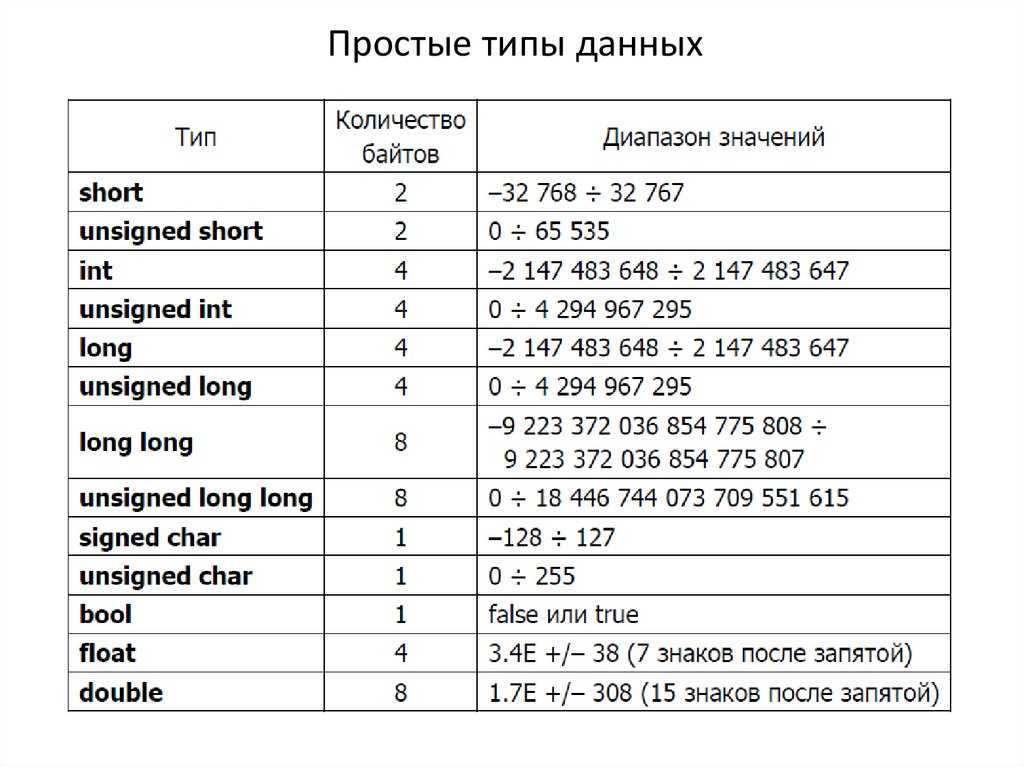
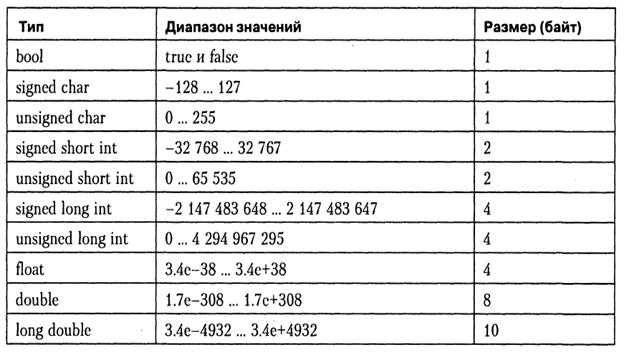 Бухгалтерский баланс основан на системе двойной записи, где общие активы компании равны сумме обязательств и акционерного капитала.
Бухгалтерский баланс основан на системе двойной записи, где общие активы компании равны сумме обязательств и акционерного капитала.