Как массивы и списки работают на Python
Массивы и списки являются одними из наиболее полезных структур данных в программировании. Сегодня я расскажу вам основы, а также покажу несколько простых примеров Python массивов.
Чтобы изучить рассматриваемые в этой статье концепции, вам не требуется заранее много знать. Базовые знания парадигмы программирования и Python желательны, но это не обязательно.
Рассматриваемые в этой статье принципы могут быть применены в любом языке программирования. Я буду демонстрировать примеры на Python. Это простой для изучения язык предоставляет превосходную платформу для понимания того, что происходит. В дополнение к этому существует отличный онлайн-интерпретатор Python.
Структура данных — это способ эффективного хранения данных. Легко запутаться, потому что структуры данных не являются типом данных, которые сообщают компилятору (или в случае Python интерпретатору), как их использовать. Структуры данных определяют операции, которые могут выполняться и реализуют конкретные правила и положения.
Возможно, вы слышали о линейных типах данных (элементы последовательны):
- Массив;
- Матрица;
- Таблица поиска.
Аналогичным образом, списки часто содержат правила и методы для регулирования того, как они работают. Типы списков:
- Связный список;
- Двойной связный список;
- Список массивов или динамический массив.
Существует множество различных структур данных. Возможно, вы слышали о бинарных деревьях, графах или хэшах.
Python массивы и списки представляют собой простой набор связанных значений, которые называются элементами. Обычно это любой тип данных, включая объекты или другие списки! При работе с массивами все данные должны быть одинаковыми — нельзя хранить вместе строки и целые числа. Вам почти всегда придется указывать, сколько элементов нужно хранить. Динамические массивы существуют, но проще начать с массивов фиксированной длиной.
Python несколько усложняет ситуацию. Он не всегда придерживается строгих определений структур данных. Большинство объектов в Python обычно являются списками, поэтому создавая массив, вы проделываете больше работы. Вот начальный код:
from array import array
numbers = array('i', [2, 4, 6, 8])
print numbers[0]Первая строка импортирует модуль array, необходимый для работы с массивами. Вторая строка создает новый массив numbers и инициализирует его значениями 2, 4, 6 и 8. Каждому элементу присваивается целочисленное значение, называемое ключом или индексом. Ключи начинаются с нуля, поэтому [0] будет обращаться к первому элементу (2):
Вам наверно интересно, для чего используется «i». Это typecode, который сообщает Python, что массив будет хранить целые числа. Обычно подобные вещи в Python не нужны. Причина этого проста. Массивы в Python основаны на базовых C-массивах операционной системы. Это означает, что они быстрые и стабильные, но не всегда могут придерживаться синтаксиса Python.
Нельзя хранить элементы разных типов в этих массивах. Допустим, вы захотели сохранить строку «makeuseof.com»:
numbers = array('i', [2, 4, 6, "makeuseof.com"])Это вызовет исключение при работе с Python массивом строк:
Вот как можно вывести все элементы:
Этот метод доступа к элементам массива работает хорошо, и идеально подходит для решения задачи. Плохо то, что это — доступ ко всему массиву.
Каждый язык программирования реализует цикл, который идеально подходит для итерации (циклизации) над элементами списка.
Наиболее распространенные циклы while и for. Python делает это еще проще, предоставляя цикл for in:
for number in numbers:
print numberОбратите внимание на то, что вам не нужно обращаться к элементам по их ключу. Это лучший способ работы с массивом. Альтернативный способ перебора списка — это цикл for:
for i in range(len(numbers)):
print numbers[i]Этот пример делает то же самое, что и предыдущий. Но в нем нужно указать количество элементов в массиве (len (cars)), а также передать i в качестве ключа. Это почти тот же код, который выполняется в цикле for in. Этот способ обеспечивает большую гибкость и выполняется немного быстрее (хотя цикла for in в большинстве случаев более чем достаточно).
Теперь, когда вы знаете, как работают Python двумерные массивы, давайте посмотрим на список. Иногда он может сбивать с толку, поскольку люди используют различные взаимозаменяемые термины, но списки — это массивы … отчасти.
Список — это особый тип массива. Различие состоит в том, что списки могут содержать смешанные типы данных. Помните, массивы должны содержать элементы одного типа. Списки в Python просты:
cars = ['Ford', 'Austin', 'Lancia']
Этот синтаксис объявляет список под названием cars. В квадратных скобках объявляется каждый элемент списка. Каждый элемент является строкой, поэтому их объявляют внутри кавычек. Python знает, что это объект, поэтому оператор print выводит содержимое списка:
Как и в случае с массивом, можно осуществлять Python сортировку массива с помощью циклов:
for car in cars:
print car
Настоящий фокус со списками — их смешанный тип. Добавьте дополнительные данные:
cars = ['Ford', 'Austin', 'Lancia', 1, 0.56]
Это даже не вызвало исключения:
Также просто добавить новые элементы в список (что невозможно с массивами):
cars = ['Ford', 'Austin']
print cars
cars.append('Lancia')
print cars
Можно объединить два списка в один:
cars = ['Ford', 'Austin'] print cars other_cars = ['Lotus', 'Lancia'] cars.extend(other_cars) print cars
Также легко удалить элементы Python ассоциативного массива, используя синтаксис remove:
cars = ['Ford', 'Austin', 'Lotus', 'Lancia']
print cars
cars.remove('Ford')
print cars
Вы узнали что-нибудь новое? Поделитесь с нами своими мыслями в комментариях!
Данная публикация представляет собой перевод статьи «How Arrays and Lists Work in Python» , подготовленной дружной командой проекта Интернет-технологии.ру
www.internet-technologies.ru
Динамический массив в Python
Я пытаюсь удалить конкретную строку и столбец из квадратного списка «m» итеративно. Вначале я использовал квадратный список, как квадратную матрицу «m», и попытался использовать команду «delete» из numpy следующим образом:
from numpy import* import numpy as np m=array([[1,2,3],[4,5,6],[7,8,9]]) #deleting row and column "0" #x is the new matrix without the row and column "0" x=np.delete((np.delete(m,0,0)),0,1) print x x=[[5,6],[8,9]]
Проблема с командой «удалить», так как я не уверен, что эту команду можно использовать в итеративном цикле. В частности, я хочу знать, как я могу удалить и конкретные строки и столбцы из списка «y»:
m=([[1,2,3],[4,5,6],[7,8,9]]) y=[[1],[0],[1],[0]]
Примечание. Если в списке «y» появляется число «1», в списке «m» удалите соответствующую строку и столбец.
Если в списке «y» появится число «1», удалите соответствующую строку и столбец в списке «m». Например, в этом случае число «1» появляется в списке «y» в позиции «0», нам нужно удалить первую строку и первый столбец в списке «m». Это желаемый список «m» для первого появления числа «1» в списке «y»: m = [[5,6], [8,9]]
Примечание: размер списка «m» изменился, теперь 2×2. Это мой первый вопрос, как я могу использовать список динамических слов в Python? Как можно указать новое измерение?
Поскольку число «1» снова появляется в списке «y», нам нужно удалить соответствующую строку и столбец в новом списке «m», в этом случае желаемый список «m» будет иметь вид: m = [[5]]
Я пытался разными способами, я получил этот совет с этого форума (другой способ, используя список понимания):
#row to delete roww=0 #column to delete column=0 m=([[1,2,3],[4,5,6],[7,8,9]]) a=[j[:column]+j[column+1:] for i,j in enumerate(m) if i!=roww] print a
Примечание: я не знаю, как использовать динамические массивы в Python, потому что мне нужна помощь. Некоторые люди думают, что это домашнее задание, но это ложь, я стараюсь изучать Python, потому что он более дружелюбный. Раньше я использовал Fortran, но с Python я ненавижу это. Благодарю.
Я пытаюсь включить массив, который определяет, какие строки и столбцы должны быть удалены. Это моя оригинальная идея:
from numpy import*
import numpy as np
mat=array([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]]
x=[[1],[0],[1],[0]]
for i in x:
if i==1:
row=0
col=0
mat=np.delete(np.delete(mat,row,0),col,1)
print matКогда один появляется в первой строке (строка 0) в «х», это желаемая матрица:
mat=array([[6,7,8],[10,11,12],[14,15,16]]
Когда один появляется в третьей строке (строка 2) в «х», это желаемая матрица:
mat=array([[6,8], [14,16]])
Примечание: x дает индекс для удаления в исходной матрице «mat».
Еще раз спасибо.
qa-help.ru
Как создать динамический массив — python
Как я понимаю, тип list в Python — это динамический массив указателей, который увеличивает его емкость при добавлении элементов к нему. И массив в NumPy использует область непрерывной памяти для хранения всех данных массива.
Существуют ли типы, которые динамически увеличивают его емкость как список и сохраняют значение в виде массива NumPy? Что-то вроде List in С#. И это здорово, если тип имеет тот же интерфейс, что и массив NumPy.
Я могу создать класс, который обертывает массив NumPy внутри и изменяет размер массива при его заполнении, например:
class DynamicArray(object):
def __init__(self):
self._data = np.zeros(100)
self._size = 0
def get_data(self):
return self._data[:self._size]
def append(self, value):
if len(self._data) == self._size:
self._data = np.resize(self._data, int(len(self._data)*1.25))
self._data[self._size] = value
self._size += 1
но DynamicArray не может использоваться как массив NumPy, и я думаю, что все представления, возвращаемые get_data(), прежде чем np.resize() будет содержать старый массив.
Изменить: тип массива в массиве — это динамический массив. Следующая программа проверяет коэффициент увеличения списка и массива:
from array import array
import time
import numpy as np
import pylab as pl
def test_time(func):
arrs = [func() for i in xrange(2000)]
t = []
for i in xrange(2000):
start = time.clock()
for a in arrs:
a.append(i)
t.append(time.clock()-start)
return np.array(t)
t_list = test_time(lambda:[])
t_array = test_time(lambda:array("d"))
pl.subplot(211)
pl.plot(t_list, label="list")
pl.plot(t_array, label="array")
pl.legend()
pl.subplot(212)
pl.plot(np.where(t_list>2*np.median(t_list))[0])
pl.plot(np.where(t_array>2*np.median(t_array))[0])
pl.show()
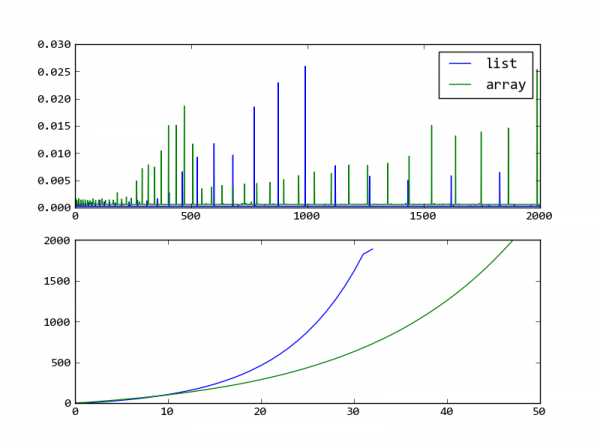
из графика: коэффициент увеличения списка больше, чем массив.
qaru.site
В Python Как объявить динамический массив Ru Python
В Python list представляет собой динамический массив. Вы можете создать такой способ:
lst = [] # Declares an empty list named lst Или вы можете заполнить его предметами:
lst = [1,2,3] Вы можете добавлять элементы, используя «append»:
lst.append('a') Вы можете перебирать элементы списка с помощью цикла for :
for item in lst: # Do something with item Или, если вы хотите отслеживать текущий индекс:
for idx, item in enumerate(lst): # idx is the current idx, while item is lst[idx] Чтобы удалить элементы, вы можете использовать команду del или функцию удаления, как в:
del lst[0] # Deletes the first item lst.remove(x) # Removes the first occurence of x in the list Обратите внимание, однако, что нельзя перебирать список и изменять его одновременно; для этого вам следует вместо этого перебирать фрагмент списка (который в основном является копией списка). Как в:
for item in lst[:]: # Notice the [:] which makes a slice # Now we can modify lst, since we are iterating over a copy of it В python динамический массив является «массивом» из модуля массива. Например
from array import array x = array('d') #'d' denotes an array of type double x.append(1.1) x.append(2.2) x.pop() # returns 2.2 Этот тип данных по существу является перекрестком между встроенным типом «список» и типом «ndarray» numpy. Как и ndarray, элементы в массивах являются типами C, указанными при инициализации. Они не являются указателями на объекты python; это может помочь избежать некоторых злоупотреблений и семантических ошибок и скромно повысить производительность.
Однако этот тип данных имеет, по существу, те же методы, что и список python, за исключением нескольких методов преобразования строк и файлов. Ему не хватает всех дополнительных числовых функций ndarray.
Подробнее см. https://docs.python.org/2/library/array.html .
www.rupython.com
как создавать, формат и базовые операции с матрицами на Питоне

Python — популярный и динамический язык программирования. Он позволяет решать разные задачи по разработке ПО, при выполнении которых часто используются массивы. С их помощью вы сможете добавить однотипные данные и избежать дублирования кода.
Одномерные массивы в Python представляют собой список элементов. Значения указываются внутри квадратных скобок, где перечисляются через запятую. Как правило, любой элемент можно вызвать по индексу и присвоить ему новое значение.
Пустой список:
Массив строк в Python:
Prime = ['string1', 'string2', 'string3'] Prime[1] = 'string2'; //true
Чтобы возвратить число элементов внутри списка, используют функцию len():
Когда нужно перечислить элементы массива, применяют цикл for. В «Питоне» этот цикл перебирает элементы, а не индексы, как в Pascal:
Идём дальше. Создать и добавить цикл в Python можно с помощью генератора заполнения списков. Записывается он в следующем виде: [значение массива for имя переменной in число элементов];
Если говорить про создание не одномерного, а двумерного массива, то он в Python создаётся путём использования вложенных генераторов, и выглядит это так:
[[0 for j in range(m)] for i in range(n)]

Как создаются матрицы в Python?
Добавление и модификация массивов или матриц (matrix) в Python осуществляется с помощью библиотеки NumPy. Вы можете создать таким образом и одномерный, и двумерный, и многомерный массив. Библиотека обладает широким набором пакетов, которые необходимы, чтобы успешно решать различные математические задачи. Она не только поддерживает создание двумерных и многомерных массивов, но обеспечивает работу однородных многомерных матриц.
Чтобы получить доступ и начать использовать функции данного пакета, его импортируют:
Функция array() — один из самых простых способов, позволяющих динамически задать одно- и двумерный массив в Python. Она создаёт объект типа ndarray:
array = np.array(/* множество элементов */)
Для проверки используется функция array.type() — принимает в качестве аргумента имя массива, который был создан.
Если хотите сделать переопределение типа массива, используйте на стадии создания dtype=np.complex:
array2 = np.array([ /*элементы*/, dtype=np.complex)
Когда стоит задача задать одномерный или двумерный массив определённой длины в Python, и его значения на данном этапе неизвестны, происходит его заполнение нулями функцией zeros(). Кроме того, можно получить матрицу из единиц через функцию ones(). При этом в качестве аргументов принимают число элементов и число вложенных массивов внутри:
К примеру, так в Python происходит задание двух массивов внутри, которые по длине имеют два элемента:
array([ [[0, 0]] [[0, 0]]] )
Если хотите вывести одно- либо двумерный массив на экран, вам поможет функция print(). Учтите, что если матрица слишком велика для печати, NumPy скроет центральную часть и выведет лишь крайние значения. Дабы увидеть массив полностью, используется функция set_printoptions(). При этом по умолчанию выводятся не все элементы, а происходит вывод только первой тысячи. И это значение массива указывается в качестве аргумента с ключевым словом threshold.
Базовые операции в NumPy
Все действия, производимые над компонентами массива, оборачиваются созданием нового массива. При этом массивы и матрицы взаимодействуют в том случае, если имеют один и тот же размер:
array1 = np.array([[1, 2, 3], [1, 2, 3]]) array2 = np.array([[1, 2, 3], [1, 2, 3], [1, 2, 3]])
Если выполнить array1 + array2, компилятор скажет об ошибке, а всё потому, что размер первого matrix равен двум, а второго трём.
array1 = np.array([1, 2, 5, 7]) array2 = arange([1, 5, 1])
В данном случае array1 + array2 вернёт нам массив со следующими элементами: 2, 4, 8, 11. Здесь не возникнет ошибки, т. к. матрицы имеют одинаковые размеры. Причём вместо ручного сложения часто применяют функцию, входящую в класс ndarray sum():
np.array(array1 + array1) == array1 + array2
В ndarray входит большая библиотека методов, необходимых для выполнения математических операций.
Форма матрицы в Python
Lenght matrix (длина матрицы) в Python определяет форму. Длину матрицы проверяют методом shape().
Массив с 2-мя либо 3-мя элементами будет иметь форму (2, 2, 3). И это состояние изменится, когда в shape() будут указаны аргументы: первый — число подмассивов, второй — размерность каждого подмассива.
Те же задачи и ту же операцию выполнит reshape(). Здесь lenght
otus.ru
Основы Python — кратко. Часть 3. Списки, кортежи, файлы. / Habr
В общем-то последняя из готовых глав. Остальные будут выходить чуть реже, поскольку еще не написаны (но я уверен что будут, хотя это зависит только от ваших пожеланий, уважаемые читатели 🙂Также следует заметить что это это, видимо, последний «простой урок», дальше я постараюсь углубиться во все аспекты программирования, которые мы прошли «по верхам» и продолжить более детально.
В общем, те кому не интересно — читают следующую новость, а остальных — прошу пройти .
Python для начинающих. Глава третья. «List, tuple, etc.»
Кортежи.
Кортежи (англ. tuple) используется для представления неизменяемой последовательности разнородных объектов. Они обычно записываются в круглых скобках, но если неоднозначности не возникает, то скобки можно опустить.
>>> t = (2, 2.05, "Hello") >>> t (2, 2.0499999999999998, 'Hello') >>> (a, b, c) = t >>> print a, b, c 2 2.05 Hello >>> z, y, x = t >>> print z, y, x 2 2.05 Hello >>> a=1 >>> b=2 >>> a,b=b,a >>> print a,b 2 1 >>> x = 12, >>> x (12,)
Как видно из примера, кортеж может быть использован и в левой части оператора присваивания. Значения из кортежа в левой части оператора присваивания связываются с аналогичными элементами правой части. Этот факт как раз и дает нам такие замечательные возможности как массовая инициализация переменных и возврат множества значений из функции одновременно. Последний пример демонстрирует создание кортежа из одного элмента (его часто называют синглтоном).
Списки
В Пайтоне отсутствуют массивы в традиционном понимании этого термина. Вместо них для хранения однородных (и не только) объектов используются списки. Они задаются тремя способами.
Простое перечисление:
>>> a = [2, 2.25, "Python"] >>> a [2, 2.25, 'Python']
Преобразуем строку в список
>>> b = list("help")
>>> b
['h', 'e', 'l', 'p']Создание с помощью списковых включений. В данном случае мы берем кубы всех нечетных чисел от 0 до 19. Этому синтаксису я планирую посвятить отдельное занятие.
>>> c = [x ** 3 for x in range(20) if x%2==1] >>> c [1, 27, 125, 343, 729, 1331, 2197, 3375, 4913, 6859]
Для работы со списками определен ряд операторов и функций:
len(s) Длина последовательности s
x in s Проверка принадлежности элемента последовательности. В новых версиях Python можно проверять принадлежность подстроки строке. Возвращает True или False
x not in s = not x in s
s + s1 Конкатенация последовательностей
s*n или n*s Последовательность из n раз повторенной s. Если n
s[i] Возвращает i-й элемент s или len(s)+i-й, если i
s[i:j:d] Срез из последовательности s от i до j с шагом d будет рассматриваться ниже
min(s) Наименьший элемент s
max(s) Наибольший элемент s
s[i] = x i-й элемент списка s заменяется на x
s[i:j:d] = t Срез от i до j (с шагом d) заменяется на (список) t
del s[i:j:d] Удаление элементов среза из последовательности
Кроме того, для списков определен ряд методов.
append(x) Добавляет элемент в конец последовательности
count(x) Считает количество элементов, равных x
extend(s) Добавляет к концу последовательности последовательность s
index(x) Возвращает наименьшее i, такое, что s[i] == x. Возбуждает исключение ValueError, если x не найден в s
insert(i, x) Вставляет элемент x в i-й промежуток
pop(i) Возвращает i-й элемент, удаляя его из последовательности
reverse() Меняет порядок элементов s на обратный
sort([cmpfunc]) Сортирует элементы s. Может быть указана своя функция сравнения cmpfunc
Для преобразования кортежа в список есть функция list, для обратной операции — tuple.
Об индексировании списков и выделении подпоследовательностей следует еще раз упомянуть отдельно (этот механизм работает аналогично и для строк). Для получения элемента используются квадратные скобки, в которых находится индекс элемента. Элементы нумеруются с нуля. Отрицательное значение индекса указывает на элементы с конца. Первый с конца списка (строки) элемент имеет индекс -1.
>>> s = [0, 1, 2, 3, 4] >>> print s[0], s[-1], s[3] 0 4 3 >>> s[2] = -2 >>> print s [0, 1, -2, 3, 4] >>> del s[2] >>> print s [0, 1, 3, 4]
Сложнее обстоят дела со срезами. Для получения срезов последовательности в Пайтоне принято указывать не номера элементов, а номера «промежутков» между ними. Перед первым элементом последовательности промежуток имеет индекс 0, перед вторым – 1 и так далее. Отрицательные значения отсчитывают элементы с конца строки.
В общем виде срез записывается в следующем виде:
список[начало: конец: шаг]
По умолчанию начало среза равно 0, конец среза равен len(список), шаг равен 1. Если шаг не указывается, второй символ «:» можно опустить.
С помощью среза можно указать подмножество для вставки списка в другой список, даже при нулевой длине. Это удобно для вставки списка в строго определенной позиции.
>>> l = range(12) >>> l [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] >>> l[1:3] [1, 2] >>> l[-1:] [11] >>> l[::2] [0, 2, 4, 6, 8, 10] >>> l[0:1]=[-1,-1,-1] >>> l [-1, -1, -1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] >>> del l[:3] >>> l [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Словари
Словарь (хэш, предопределенный массив) – изменяемая структура данных, предназначенная для хранения элементов вида ключ: значение. Все легко показывается на примере.
Создаем хеши.
>>> h2 = {1:"one", 2:"two", 3:"three"}
>>> h3 = {0:"zero", 5:"five"}
>>> h4 = {"z":1, "y":2, "x":3}
#Цикл по паре ключ-значение
>>> for key, value in h2.items():
... print key, " ", value
...
1 one
2 two
3 three
#Цикл по ключам
>>> for key in h3.keys():
... print key, " ", h3[key]
...
0 zero
5 five
#Цикл по значениям
>>> for v in h4.values():
... print v
...
2
3
1
#Добавление элементов из другого хеша
>>> h2.update(h4)
#Количество пар в хеше
>>> len(h2)
6Тип file
Объекты этого типа предназначены для работы с внешними данными. Чаще всего данному объекту соответствует файл на диске, но это далеко не всегда так. Файловые объекты должны поддерживать основные методы: read(), write(), readline(), readlines(), seek(), tell(), close() и т.п.
Следующий пример показывает копирование файла:
f1 = open("file1.txt", "r")
f2 = open("file2.txt", "w")
for line in f1.readlines():
f2.write(line)
f2.close()
f1.close()(этот пример можно записать массой других способов, многие из которых сильно отличаются по оптимальности, но это тоже тема отдельного разговора)
В принципе, большинству функций абсолютно безразлично, передан им объект типа файл, или любой другой объект с такими же методами. Так, приведенный выше пример можно очень легко модифицировать для скачивания файла из Интерне, заменив в нем первую строку на следующий код.
import urllib
f1 = urllib.urlopen("http://python.onego.ru") Задачи:
— Разработать программу «массовой закачки» URL-ов из файла urls.txt
— Разработать программу, скачивающую страницу по указанному URL со всем ее содержимым.
— Написать программу, которая получив на входе произвольный список удалит из него все повторяющиеся элементы.
habr.com
python — Динамический массив в Python
Я пытаюсь удалить конкретную строку и столбец из квадратного списка «m» итеративно. Вначале я использовал квадратный список, как квадратную матрицу «m», и попытался использовать команду «delete» из numpy следующим образом:
from numpy import*
import numpy as np
m=array([[1,2,3],[4,5,6],[7,8,9]])
#deleting row and column "0"
#x is the new matrix without the row and column "0"
x=np.delete((np.delete(m,0,0)),0,1)
print x
x=[[5,6],[8,9]]
Проблема с командой «удалить», так как я не уверен, что эту команду можно использовать в итеративном цикле. В частности, я хочу знать, как я могу удалить и конкретные строки и столбцы из списка «y»:
m=([[1,2,3],[4,5,6],[7,8,9]])
y=[[1],[0],[1],[0]]
Примечание. Если в списке «y» появляется число «1», в списке «m» удалите соответствующую строку и столбец.
Если в списке «y» появится число «1», удалите соответствующую строку и столбец в списке «m». Например, в этом случае число «1» появляется в списке «y» в позиции «0», нам нужно удалить первую строку и первый столбец в списке «m». Это желаемый список «m» для первого появления числа «1» в списке «y»: m = [[5,6], [8,9]]
Примечание: размер списка «m» изменился, теперь 2×2. Это мой первый вопрос, как я могу использовать список динамических слов в Python? Как можно указать новое измерение?
Поскольку число «1» снова появляется в списке «y», нам нужно удалить соответствующую строку и столбец в новом списке «m», в этом случае желаемый список «m» будет иметь вид: m = [[5]]
Я пытался разными способами, я получил этот совет с этого форума (другой способ, используя список понимания):
#row to delete
roww=0
#column to delete
column=0
m=([[1,2,3],[4,5,6],[7,8,9]])
a=[j[:column]+j[column+1:] for i,j in enumerate(m) if i!=roww]
print a
Примечание: я не знаю, как использовать динамические массивы в Python, потому что мне нужна помощь. Некоторые люди думают, что это домашнее задание, но это ложь, я стараюсь изучать Python, потому что он более дружелюбный. Раньше я использовал Fortran, но с Python я ненавижу это. Благодарю.
Я пытаюсь включить массив, который определяет, какие строки и столбцы должны быть удалены. Это моя оригинальная идея:
from numpy import*
import numpy as np
mat=array([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]]
x=[[1],[0],[1],[0]]
for i in x:
if i==1:
row=0
col=0
mat=np.delete(np.delete(mat,row,0),col,1)
print mat
Когда один появляется в первой строке (строка 0) в «х», это желаемая матрица:
mat=array([[6,7,8],[10,11,12],[14,15,16]]
Когда один появляется в третьей строке (строка 2) в «х», это желаемая матрица:
mat=array([[6,8], [14,16]])
Примечание: x дает индекс для удаления в исходной матрице «mat».
Еще раз спасибо.
geekquestion.com