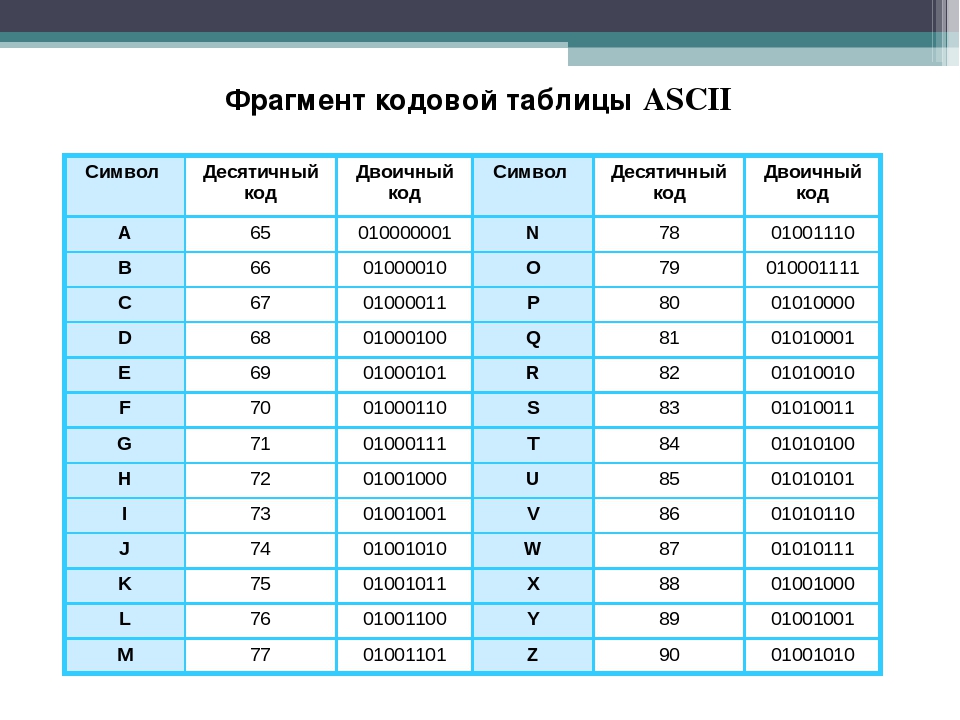
Сколько символов в таблице кодов ascii. Кодирование текстовой информации
Множество символов, с помощью которых записывается текст, называется алфавитом .
Число символов в алфавите – это его мощность .
Формула определения количества информации: N = 2 b ,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
1 байт = 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.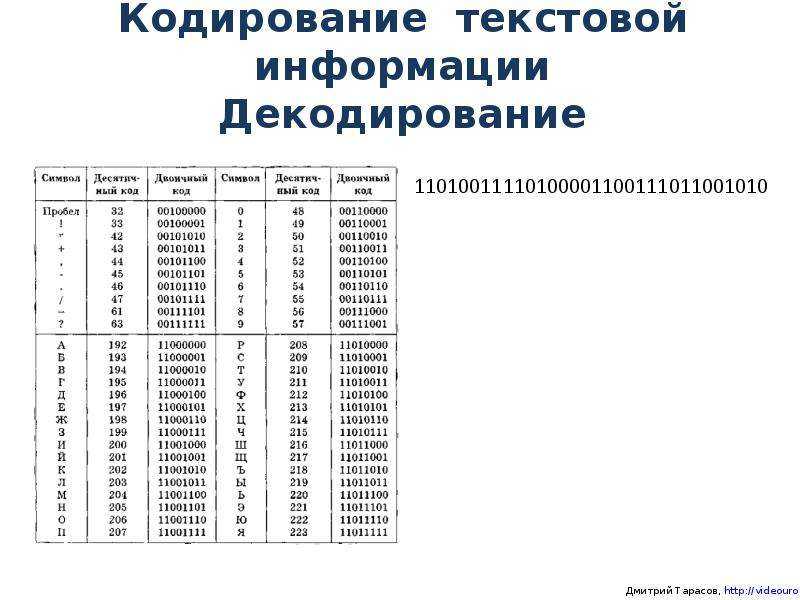
Структура таблицы кодировки ASCII
Порядковый номер | Код | Символ |
0 — 31 | 00000000 — 00011111 | Символы с номерами от 0 до 31 принято называть управляющими. |
32 — 127 | 00100000 — 01111111 | Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. |
128 — 255 | 10000000 — 11111111 | Альтернативная часть таблицы (русская). |
Первая половина таблицы кодов ASCII
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
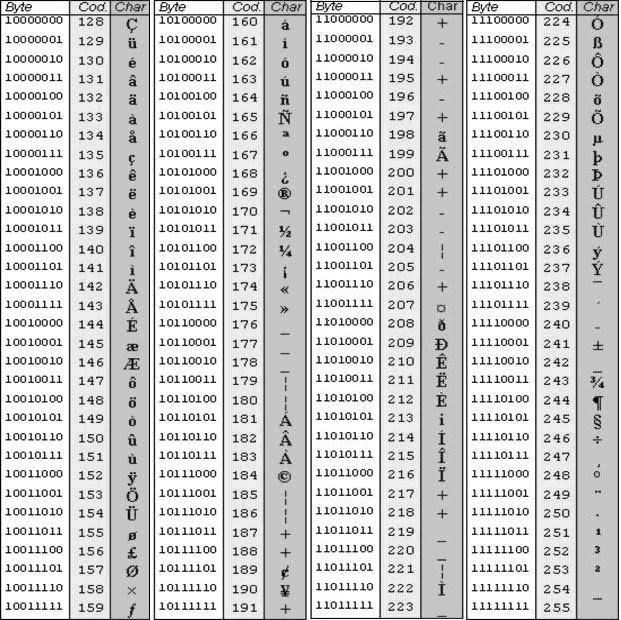
Вторая половина таблицы кодов ASCII
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode . Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.
Внутреннее представление слов в памяти компьютера
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать — на экране монитора видна какая-то «абракадабра». Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.
Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.
Как известно, компьютер хранит информацию в двоичном виде, представляя её в качестве последовательности единиц и нулей. Чтобы перевести информацию в форму, удобную для человеческого восприятия, каждая уникальная последовательность цифр при отображении заменяется на соответствующий ей символ.
Одной из систем соотнесения бинарных кодов с печатными и управляющими символами является
При сегодняшнем уровне развития компьютерных технологий от пользователя не требуется знание кода каждого конкретного символа. Однако общее понимание того, как осуществляется кодирование, является крайне полезным, а для некоторых категорий специалистов и вовсе необходимым.
Создание ASCII
В первоначальном виде кодировка была разработана в 1963 году и затем в течение 25 лет дважды обновлялась.
В исходном варианте таблица символов ASCII включала 128 символов, позже появилась расширенная версия, где первые 128 знаков были сохранены, а кодам с задействованным восьмым битом поставлены в соответствие отсутствовавшие ранее символы.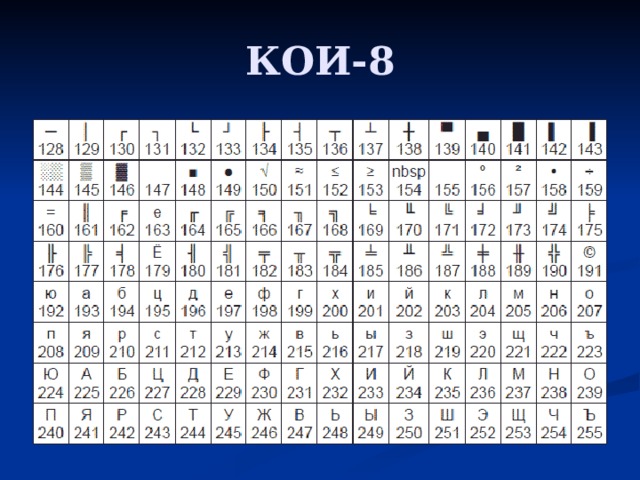
На протяжении многих лет данная кодировка являлась самой популярной в мире. В 2006 году ведущее место заняла Latin 1252, а с конца 2007 года по настоящее время лидирующую позицию прочно держит Юникод.
Компьютерное представление ASCII
Каждый ASCII-символ имеет собственный код, состоящий из 8 знаков, представляющих собой нуль или единицу. Минимальным числом в таком представлении является нуль (восемь нулей в двоичной системе), который и является кодом первого элемента в таблице.
Два кода в таблице были отведены под переключение между стандартной US-ASCII и её национальным вариантом.
После того как ASCII стала включать не 128, а 256 знаков, распространение получил вариант кодировки, при котором исходная версия таблицы была сохранена в первых 128 кодах с нулевым 8-м битом. Знаки национальной письменности хранились в верхней половине таблицы (128-255-я позиции).
Знать непосредственно коды символов ASCII пользователю не требуется. Разработчику программного обеспечения обычно достаточно знать номер элемента в таблице, чтобы при необходимости рассчитать его код, используя бинарную систему.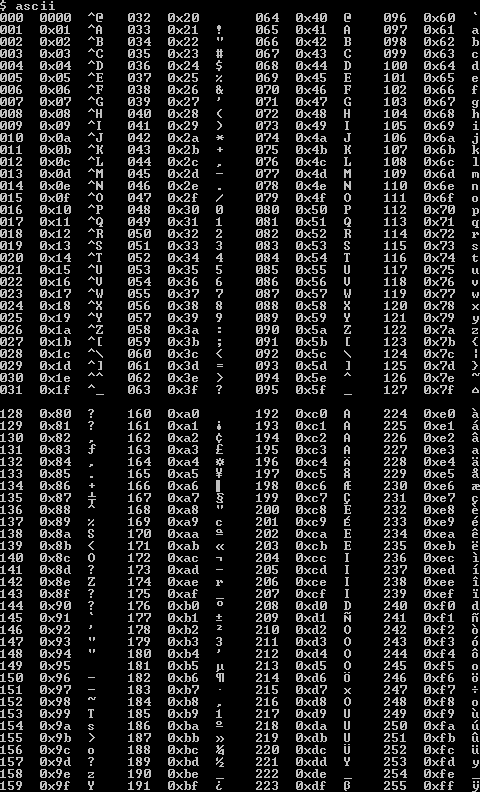
Русский язык
После разработки в начале 70-х годов кодировок для скандинавских языков, китайского, корейского, греческого и др., созданием собственного варианта занялся и Советский Союз. Вскоре был разработан вариант 8-битной кодировки под названием КОИ8, сохраняющей первые 128 кодов символов ASCII и выделяющей столько же позиций под буквы национального алфавита и дополнительные знаки.
До внедрения Юникода КОИ8 доминировала в российском сегменте интернета. Существовали варианты кодировки как для русского, так и для украинского алфавита.
Проблемы ASCII
Поскольку количество элементов даже в расширенной таблице не превышало 256, возможность вмещения в одну кодировку нескольких различных письменностей отсутствовала. В 90-е годы в Рунете появилась проблема «крокозябр», когда тексты, набранные русскими символами ASCII, отображались некорректно.
Проблема заключалась в несоответствии кодов различных вариантов ASCII друг другу. Вспомним, что на позициях 128-255 могли располагаться различные знаки, и при смене одной кириллической кодировки на другую все буквы текста заменялись на другие, имеющие идентичный номер в другой версии кодировки.
Текущее состояние
С появлением Юникода популярность ASCII резко пошла на убыль.
Причина этого кроется в том факте, что новая кодировка позволила вместить знаки почти всех письменных языков. При этом первые 128 символов ASCII соответствуют тем же символам в Юникоде.
В 2000-м ASCII была самой популярной кодировкой в интернете и использовалась на 60 % проиндексированных «Гуглом» веб-страниц. Уже к 2012 году доля таких страниц упала до 17 %, а место самой популярной кодировки занял Юникод (UTF-8).
Таким образом, ASCII является важной частью истории информационных технологий, однако её использование в дальнейшем видится малоперспективным.
19.12.13 23.8K
Для того, чтобы грамотно использовать ASCII , необходимо расширить знания в данной сфере и о возможностях кодирования.
Что это такое?
ASCII
представляет собой кодировочную таблицу печатных символов (см. скриншот №1), набираемых на компьютерной клавиатуре, для передачи информации и некоторых кодов.
Кодировка ASCII была разработана в Америке, поэтому стандартная кодировочная таблица обычно включает в себя английский алфавит с цифрами, что в общей сложности составляет около 128 символов. Но тогда возникает справедливый вопрос: что делать, если необходима кодировка национального алфавита?
Для решения подобных вопросов были разработаны другие версии таблицы ASCII . Например, для языков с иноязычной структурой были или убраны буквы английского алфавита, или к ним добавлялись дополнительные символы в виде национального алфавита. Так, в кодировке ASCII могут присутствовать русские буквы для национального использования (см. скриншот №2).
Где применяется система кодировки ASCII?
Данная кодировочная система необходима не только для набора текстовой информации на клавиатуре. Она также используется в графике. Например, в программе ASCII Art Maker
графические изображения различных расширений состоят из спектра символов кодировки ASCII
(см. скриншот №3).
Например, в программе ASCII Art Maker
графические изображения различных расширений состоят из спектра символов кодировки ASCII
(см. скриншот №3).
Как правило, подобные программы можно разделить на те, что выполняют функцию графических редакторов, инвертируя изображение в текст, и на те, что конвертируют изображение в ASCII -графику. Всем известный смайлик (или как его еще называют «улыбающееся человеческое лицо ») тоже является примером кодировочного символа.
Данный метод кодировки также может быть востребован во время написания или создания документа HTML. Например, вы вводите определённый и необходимый вам набор знаков, а при просмотре самой страницы на экран будет выведен символ, соответствующий данному коду.
Кроме всего прочего данный вид кодировки необходим при создании многоязычного сайта, потому что знаки, которые не входят в ту или иную национальную таблицу, нужно будет заменить ASCII кодами. Если читатель непосредственно связан с информационно-коммуникативными технологиями (ИКТ), то ему будет полезно ознакомиться и с такими системами как:
- Переносимый набор символов;
- Управляющие символы;
- EBCDIC;
- VISCII;
- YUSCII;
- Юникод;
- ASCII art;
- КОИ-8.


Свойства таблицы ASCII
Как и любая систематизированная программа, ASCII обладает своими характерными свойствами. Так, например, десятеричная система исчисления (цифры от 0 до 9) преобразуется в двоичную систему исчисления (т.е. каждая десятеричная цифра преобразуется в двоичную 288=1001000 соответственно).
Буквы, располагающиеся в верхних и нижних колонках, отличаются друг от друга лишь битом, что существенно снижает уровень сложности проверки и редактирование регистра.
При всех этих свойствах кодировка ASCII работает как восьми битная, хотя изначально предусматривалась как семи битная.
Применение ASCII в программах Microsoft Office:
В случае необходимости данный вариант кодирования информации может быть использован в Microsoft Notepad и Microsoft Office Word. В рамках этих приложений документ может быть сохранен в формате ASCII , но в этом случае при наборе текста невозможно будет использование некоторых функций.
В частности, будет недоступно выделение жирным и полужирным шрифтом, потому что кодирование сохраняет лишь смысл набранной информации, а не общий вид и форму. Добавить такие коды в документ вы можете с помощью следующих программных приложений.
Добавить такие коды в документ вы можете с помощью следующих программных приложений.
В компьютере понимается процесс ее преобразования в форму, позволяющую организовать более удобную передачу, хранение или автоматическую переработку этих данных. С этой целью используются различные таблицы. Кодировка ASCII — это первая система, разработанная в Соединенных Штатах для работы с англоязычным текстом, которая получила впоследствии распространение во всем мире. Ее описанию, особенностям, свойствам и дальнейшему использованию посвящена статья, представленная ниже.
Отображение и хранение информации в ЭВМ
Символы на мониторе компьютера или того или иного мобильного цифрового гаджета формируются на основе наборов векторных форм всевозможных знаков и кода, позволяющего найти среди них тот символ, который необходимо вставить в нужное место. Он представляет собой последовательностей бит. Таким образом, каждому символу должен однозначно соответствовать набор нулей и единиц, которые стоят в определенном, уникальном порядке.
Как все начиналось
Исторически сложилось так, что первые ЭВМ были англоязычными. Для кодирования символьной информации в них было достаточно использовать всего лишь 7 бит памяти, тогда как для этой цели выделялся 1 байт, состоящий из 8 битов. Количество знаков, понимаемых компьютером в таком случае, было равно 128. В число таких символов входили английский алфавит с его знаками препинания, числа и некоторые специальные символы. Англоязычная семибитная кодировка с соответствующей таблицей (кодовой страницей), разработанная в 1963 году, была названа American Standard Code for Information Interchange. Обычно для ее обозначения использовалась и используется и по сей день аббревиатура «Кодировка ASCII».
Переход к мультиязычности
Со временем компьютеры стали широко использоваться и в неанглоговорящих странах. В связи с этим появилась нужда в кодировках, позволяющих использовать национальные языки. Было решено не изобретать велосипед, и взять за основу ASCII. Таблица кодировки в новой редакции значительно расширилась.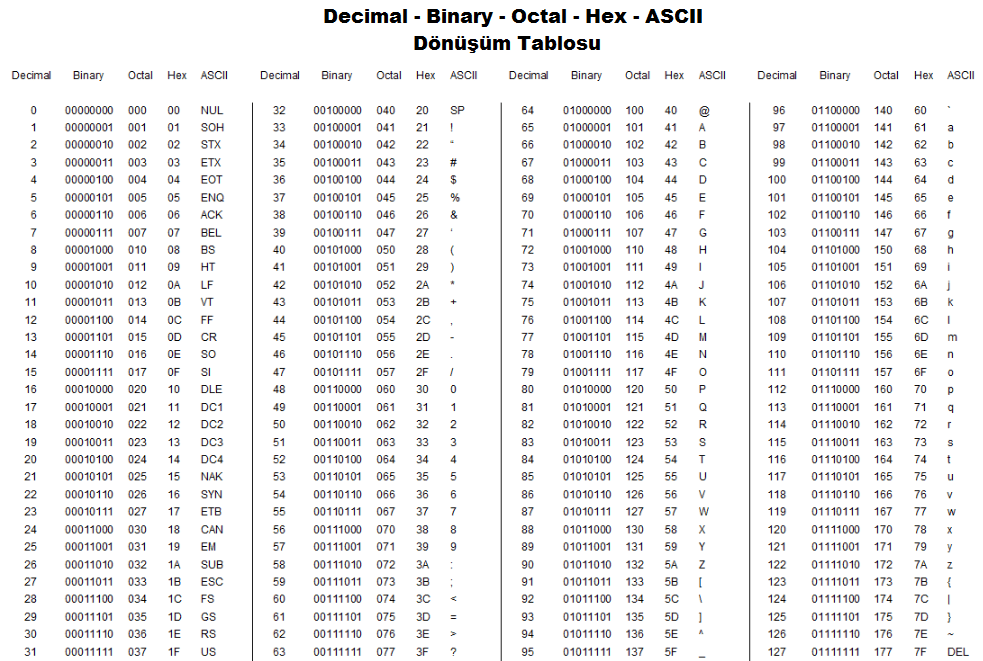 Использование 8-го бита позволило переводить на компьютерный язык уже 256 символов.
Использование 8-го бита позволило переводить на компьютерный язык уже 256 символов.
Описание
Кодировка ASCII имеет таблицу, которая делится на 2 части. Общепринятым международным стандартом принято считать лишь ее первую половину. В нее входят:
- Символы с порядковыми номерами от 0 до 31, кодируемые последовательностями от 00000000 до 00011111. Они отведены для управляющих символов, которые руководят процессом вывода текста на экран или принтер, подачей звукового сигнала и т. п.
- Символы с NN в таблице от 32 до 127, кодируемые последовательностями от 00100000 до 01111111 составляют стандартную часть таблицы. В их число входят пробел (N 32), буквы латинского алфавита (строчные и прописные), десятизначные цифры от 0 до 9, знаки препинания, скобки разного начертания и другие символы.
- Символы с порядковыми номерами от 128 до 255, кодируемые последовательностями от 10000000 до 11111111. В их число включены буквы национальных алфавитов, отличные от латинского. Именно эта альтернативная часть таблицы кодировка ASCII используется для преобразования в компьютерную форму русских символов.
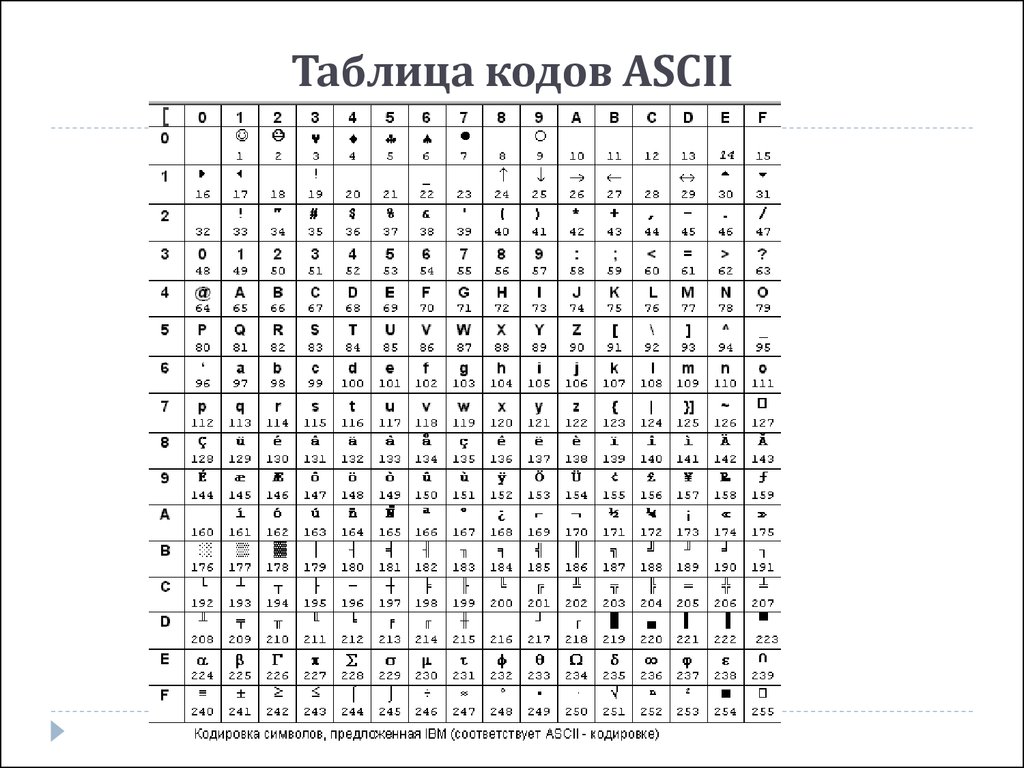 Именно эта альтернативная часть таблицы кодировка ASCII используется для преобразования в компьютерную форму русских символов.
Именно эта альтернативная часть таблицы кодировка ASCII используется для преобразования в компьютерную форму русских символов.Некоторые свойства
К особенностям кодировки ASCII относится отличие букв «A» — «Z» нижнего и верхнего регистров только одним битом. Это обстоятельство значительно упрощает преобразование регистра, а также его проверку на принадлежность к заданному диапазону значений. Кроме того, все буквы в системае кодировки ASCII представляются собственными порядковыми номерами в алфавите, которые записаны 5 цифрами в двоичной системе счисления, перед которыми для букв нижнего регистра стоит 011 2 , а верхнего — 010 2 .
К числу особенностей кодировки ASCII можно причислить и представление 10 цифр — «0»-«9». Во второй системе счисления они начинаются с 00112, а заканчиваются 2-ми значениями чисел. Так, 0101 2 эквивалентно десятичному числу пять, поэтому символ «5» записывается как 0011 01012. Опираясь на сказанное, можно легко преобразовать двоично-десятичные числа в строку в кодировке ASCII посредством добавления слева битовой последовательности 00112 к каждому полубайту.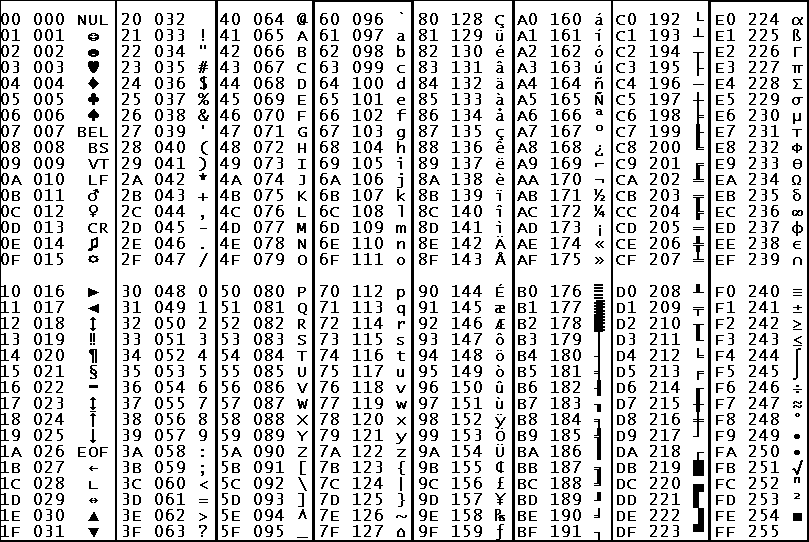
«Юникод»
Как известно, для отображения текстов на языках группы юго-восточной Азии требуются тысячи знаков. Такое их количество никак не описывается в одном байте информации, поэтому даже расширенные версии ASCII уже не могли удовлетворять возросшие потребности пользователей из разных стран.
Так, возникла необходимость создания универсальной кодировки текста, разработкой которой при сотрудничестве со многими лидерами мировой IT-индустрии занялся консорциум «Юникод». Его специалистами была создана система UTF 32. В ней для кодирования 1 символа выделялось 32 бита, составляющих 4 байта информации. Главным недостатком было резкое увеличение объема необходимой памяти в целых 4 раза, что влекло за собой множество проблем.
В то же время для большинства стран с официальными языками, относящимися к индоевропейской группе, количество знаков, равное 2 32 , является более чем избыточным.
В результате дальнейшей работы специалистов из консорциума «Юникод» появилась кодировка UTF-16.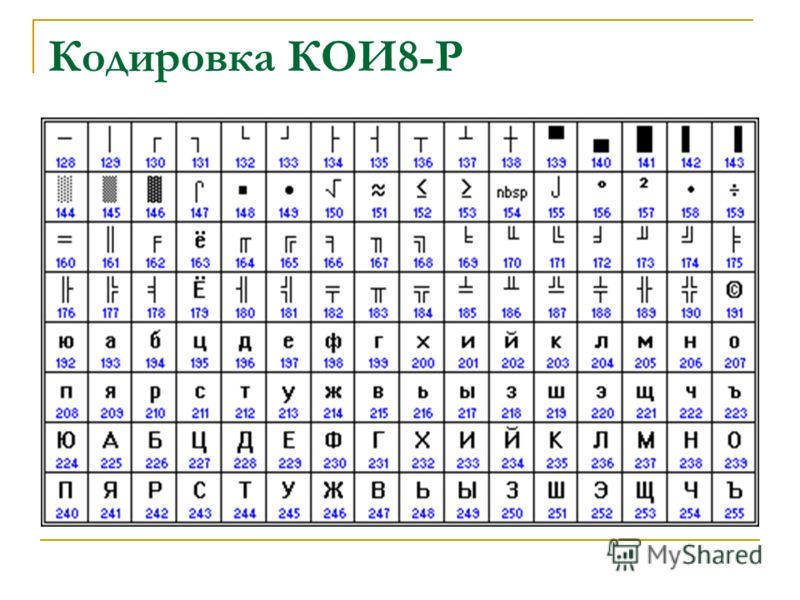 Она стала тем вариантом преобразования символьной информации, которая устроила всех как по объему требуемой памяти, так и по числу кодируемых символов. Именно поэтому UTF-16 была принята по умолчанию и в ней для одного знака требуется зарезервировать 2 байта.
Она стала тем вариантом преобразования символьной информации, которая устроила всех как по объему требуемой памяти, так и по числу кодируемых символов. Именно поэтому UTF-16 была принята по умолчанию и в ней для одного знака требуется зарезервировать 2 байта.
Даже эта достаточно продвинутая и удачная версия «Юникода» имела некоторые недостатки, и после перехода от расширенной версии ASCII к UTF-16 увеличивала вес документа в два раза.
В связи с этим было решено использовать кодировку переменной длины UTF-8. В таком случае каждый символ исходного текста кодируется последовательностью длиной от 1 до 6 байт.
Связь с American standard code for information interchange
Все знаки латинского алфавита в UTF-8 переменной длины кодируются в 1 байт, как в системе кодировки ASCII.
Особенностью ЮТФ-8 является то, что в случае текста на латинице без использования других символов, даже программы, не понимающие «Юникод», все равно позволят его прочитать. Иными словами, базовая часть кодировки текста ASCII просто переходит в состав новой UTF переменной длины. Кириллические знаки в ЮТФ-8 занимают 2 байта, а, например, грузинские — 3 байта. Созданием UTF-16 и 8 была решена основная проблема создания единого кодового пространства в шрифтах. С тех пор производителям шрифтов остается только заполнять таблицу векторными формами символов текста исходя из своих потребностей.
Кириллические знаки в ЮТФ-8 занимают 2 байта, а, например, грузинские — 3 байта. Созданием UTF-16 и 8 была решена основная проблема создания единого кодового пространства в шрифтах. С тех пор производителям шрифтов остается только заполнять таблицу векторными формами символов текста исходя из своих потребностей.
В различных операционных системах предпочтение отдается различным кодировкам. Чтобы иметь возможность читать и редактировать тексты, набранные в другой кодировке, применяются программы перекодировки русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики и позволяют читать текст вне зависимости от кодировки.
Теперь вы знаете, сколько символов в кодировке ASCII и, как и почему она была разработана. Конечно, сегодня наибольшее распространение в мире получил стандарт «Юникод». Однако нельзя забывать, что он создан на базе ASCII, поэтому следует по достоинству оценивать вклад его разработчиков в сферу IT.
Каждый компьютер имеет свой набор символов, который он реализует.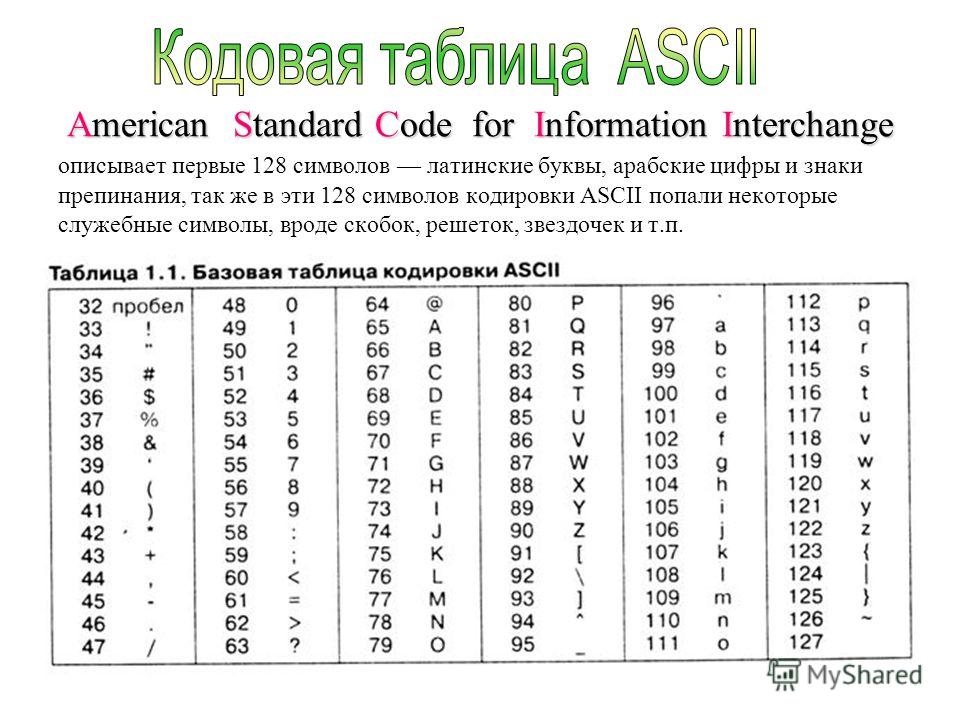 Такой набор содержит 26 заглавных и строчных букв, цифры и специальные символы (точка, пробел и тд). Символы при переводе в целые числа имеют название кодами. Были разработаны стандарты, что бы компьютеры имели одинаковые наборы кодов.
Такой набор содержит 26 заглавных и строчных букв, цифры и специальные символы (точка, пробел и тд). Символы при переводе в целые числа имеют название кодами. Были разработаны стандарты, что бы компьютеры имели одинаковые наборы кодов.
Стандарт ASCII
ASCII (American Standart Code for Inmormation Interchange) — американский стандартный код для обмена информацией. Каждый символ ASCII имеет 7 битов, поэтому максимальное число символов — 128 (таблица 1). Коды от 0 до 1F являются управляющими символами, которые не печатаются. Множество непечатных символов ASCII нужны для передачи данных. К примеру послание может состоять из символа начала заголовка SOH, самого заголовка и символа начала текста STX, самого текста и символа конца текста ETX, и символ конца передачи EOT. Однако данные по сети передаются в пакетах, которые сами отвечают за начало передачи и конец. Так что непечатные символы почти не используются.
Таблица 1 — таблица кодов ASCII
| Число | Команда | Значение | Число | Команда | Значение |
|---|---|---|---|---|---|
| 0 | NUL | Пустой указатель | 10 | DLE | Выход из системы передачи |
| 1 | SOH | начало заголовка | 11 | DC1 | Управление устройством |
| 2 | STX | Начало текста | 12 | DC2 | Управление устройством |
| 3 | ETX | Конец текста | 13 | DC3 | Управление устройством |
| 4 | EOT | Конец передачи | 14 | DC4 | Управление устройством |
| 5 | ACK | Запрос | 15 | NAK | Неподтверждение приема |
| 6 | BEL | Подтверждение приема | 16 | SYN | Простой |
| 7 | BS | Символ звонка | 17 | ETB | Конец блока передачи |
| 8 | HT | Отступ назад | 18 | CAN | Отмета |
| 9 | LF | Горизонтальная табуляция | 19 | EM | Конец носителя |
| A | VT | Перевод строки | 1A | SUB | Подстрочный индекс |
| B | FF | Вертикальная табуляция | 1B | ESC | Выход |
| C | CR | Перевод страницы | 1C | FS | Разделитель файлов |
| D | SO | Возврат каретки | 1D | GS | Разделитель группы |
| E | SI | Переключение на дополнительный регистр | 1E | RS | Разделитель записи |
| SI | Переключение на стандартный регистр | 1F | US | Разделитель модуля |
| Число | Символ | Число | Символ | Число | Символ | Число | Символ | Число | Символ | Число | Символ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 20 | пробел | 30 | 0 | 40 | @ | 50 | P | 60 | .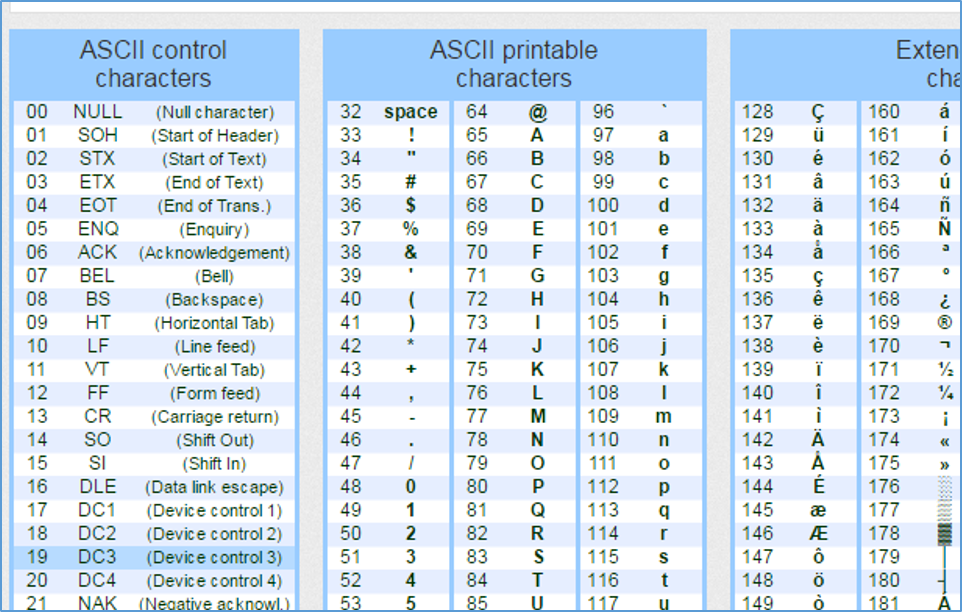 | 70 | p |
| 21 | ! | 31 | 1 | 41 | A | 51 | Q | 61 | a | 71 | q |
| 22 | ‘ | 32 | 2 | 42 | B | 52 | R | 62 | b | 72 | r |
| 23 | # | 33 | 3 | 43 | C | 53 | S | 63 | c | 73 | s |
| 24 | φ | 34 | 4 | 44 | D | 54 | T | 64 | d | 74 | t |
| 25 | % | 35 | 5 | 45 | E | 55 | И | 65 | e | 75 | и |
| 26 | & | 36 | 6 | 46 | F | 56 | V | 66 | f | 76 | v |
| 27 | ‘ | 37 | 7 | 47 | G | 57 | W | 67 | g | 77 | w |
| 28 | ( | 38 | 8 | 48 | H | 58 | X | 68 | h | 78 | x |
| 29 | ) | 39 | 9 | 49 | I | 59 | Y | 69 | i | 70 | y |
| 2A | ‘ | 3A | ; | 4A | J | 5A | Z | 6A | j | 7A | z |
| 2B | + | 3B | ; | 4B | K | 5B | [ | 6B | k | 7B | { |
| 2C | ‘ | 3C | 4C | L | 5C | \ | 6C | l | 7C | | | |
| 2D | — | 3D | = | 4D | M | 5D | ] | 6D | m | 7D | } |
| 2E | 3E | > | 4E | N | 5E | — | 6E | n | 7E | ~ | |
| 2F | / | 3F | g | 4F | O | 5F | _ | 6F | o | 7F | DEL |
Стандарт Unicode
Предыдущая кодировка отлично подходит для английского языка, однако для других языков она не удобная.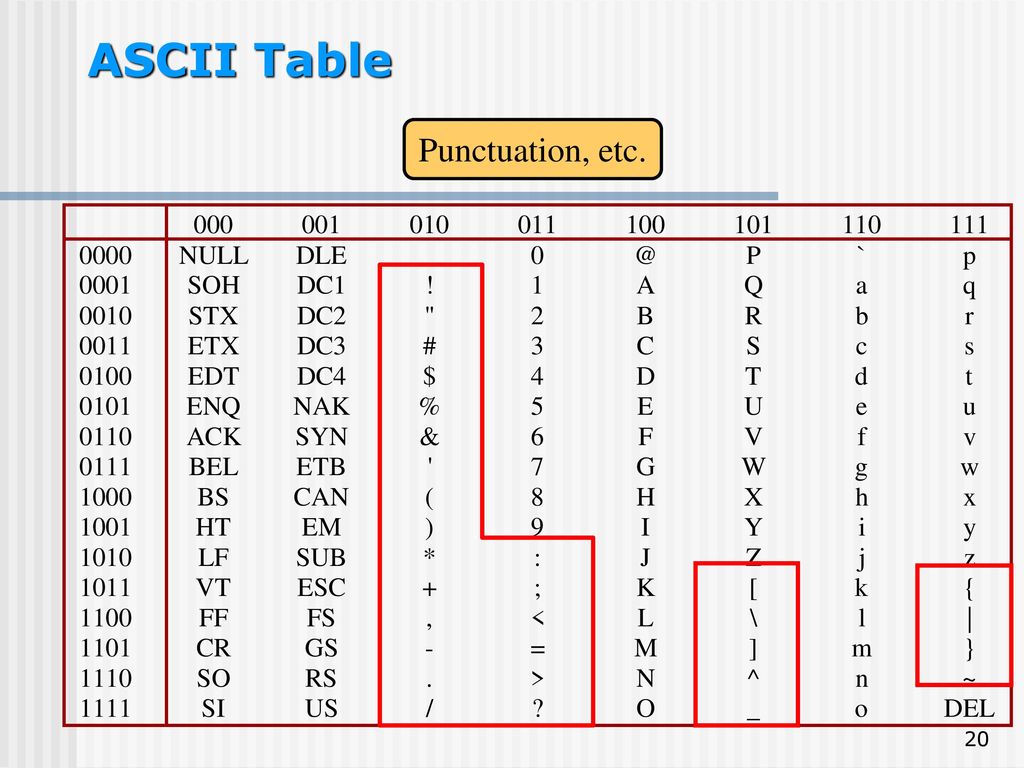 К примеру в немецком языке есть умляуты, а в французском надстрочные знаки. Некоторые языки имеют совершенно разные алфавиты. Первой попыткой расширения ASCII был IS646, который расширял предыдущую кодировку еще на 128 символов. Добавлены были латинские буквы со штрихами и диакритическими знаками, и получил название — Latin 1. Следующая попытка была IS 8859 — которые содержал кодовую страницу. Были еще попытки расширений, но это все было не универсальным. Была создана кодировка UNICODE (is 10646). Идея кодировка в том, что бы приписать каждому символу единое постоянное 16-битное значение, которое называется — указателем кода . Всего получается 65536 указателей. Для экономии места использовали Latin-1 для кодов 0 -255, легко изменяя ASII в UNICODE. Такой стандарт решил много проблем, однако не все. В связи с поступлением новых слов, к примеру для японского языка нужно увеличивать количество терминов где-то на 20 тыс. Также нужно включить шрифт брайля.
К примеру в немецком языке есть умляуты, а в французском надстрочные знаки. Некоторые языки имеют совершенно разные алфавиты. Первой попыткой расширения ASCII был IS646, который расширял предыдущую кодировку еще на 128 символов. Добавлены были латинские буквы со штрихами и диакритическими знаками, и получил название — Latin 1. Следующая попытка была IS 8859 — которые содержал кодовую страницу. Были еще попытки расширений, но это все было не универсальным. Была создана кодировка UNICODE (is 10646). Идея кодировка в том, что бы приписать каждому символу единое постоянное 16-битное значение, которое называется — указателем кода . Всего получается 65536 указателей. Для экономии места использовали Latin-1 для кодов 0 -255, легко изменяя ASII в UNICODE. Такой стандарт решил много проблем, однако не все. В связи с поступлением новых слов, к примеру для японского языка нужно увеличивать количество терминов где-то на 20 тыс. Также нужно включить шрифт брайля.
§ 2. Представление текстовой информации в компьютере — ЗФТШ, МФТИ
Всякий текст состоит из символов — букв, цифр, знаков препинания и т. д., — которые человек различает по начертанию. Однако для компьютерного представления текстовой информации такой метод неудобен, а для компьютерной обработки текстов — и вовсе неприемлем. Используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов, его составляющих. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются кодовые таблицы символов, в которых для каждого символа устанавливается соответствие между его кодом и изображением. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
д., — которые человек различает по начертанию. Однако для компьютерного представления текстовой информации такой метод неудобен, а для компьютерной обработки текстов — и вовсе неприемлем. Используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов, его составляющих. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются кодовые таблицы символов, в которых для каждого символа устанавливается соответствие между его кодом и изображением. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Основой для компьютерных стандартов кодирования символов послужил ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах и применяемый в США для любых видов передачи информации. 7=128`, из них первые `32` символа — «управляющие», а остальные — «изображаемые», т. е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например:
|
Cимвол |
Действие |
Английское название |
|
№7 |
Подача стандартного звукового сигнала |
Beep |
|
№8 |
Затереть предыдущий символ |
Back Space (BS) |
|
№13 |
Перевод строки |
Line Feed (LF) |
|
№26 |
Конец текстового файла |
End Of File (EOF) |
|
№27 |
Отмена предыдущего ввода |
Escape (ESC) |
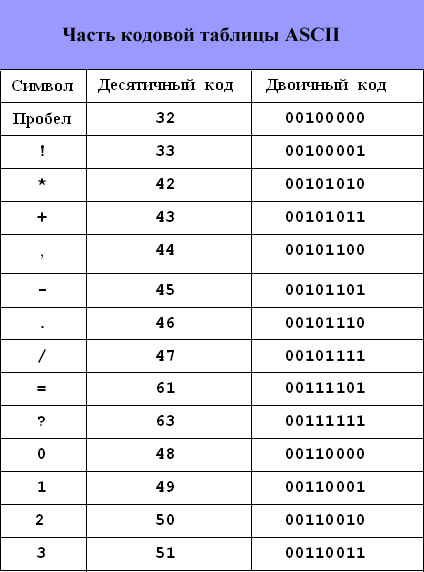
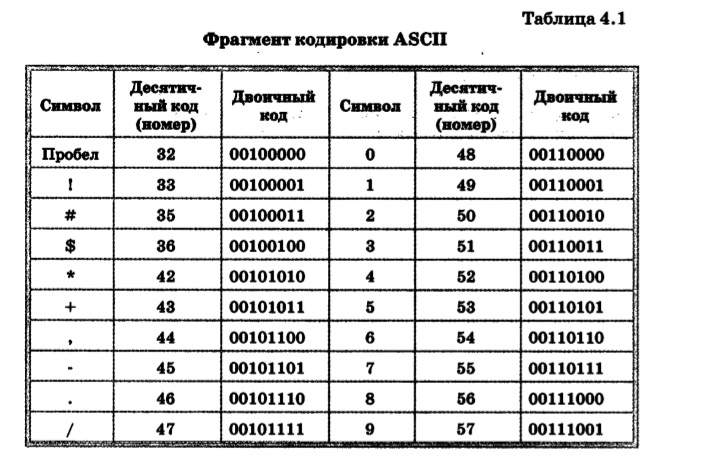
К изображаемым символам в ASCII относятся буквы английского (латинского) алфавита (заглавные и прописные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Фрагмент кодировки ASCII приведён в таблице.
Фрагмент кодировки ASCII приведён в таблице.
|
Символ |
Десятичный код |
Двоичный код |
Символ |
Десятичный код |
Двоичный код |
|
Пробел |
`32` |
`00100000` |
`0` |
`48` |
`00110000` |
|
`!` |
`33` |
`00100001` |
`1` |
`49` |
`00110001` |
|
# |
`35` |
`00100011` |
`2` |
`50` |
`00110010` |
|
$ |
`36` |
`00100100` |
`3` |
`51` |
`00110011` |
|
`**` |
`42` |
`00101010` |
`4` |
`52` |
`00110100` |
|
`+` |
`43` |
00101011 |
5 |
53 |
`00110101` |
|
, |
`44` |
`00101100` |
`6` |
`54` |
`00110110` |
|
`–` |
`45` |
`00101101` |
`7` |
`55` |
`00110111` |
|
. |
`46` |
`00101110` |
`8` |
`56` |
`00111000` |
|
/ |
`47` |
`00101111` |
`9` |
`57` |
`00111001` |
|
`A` |
`65` |
`01000001` |
`N` |
`78` |
`01001110` |
|
`B` |
`66` |
`01000010` |
`O` |
`79` |
`01001111` |
|
`C` |
`67` |
`01000011` |
`P` |
`80` |
`01010000` |
|
`D` |
`68` |
`01000100` |
`Q` |
`81` |
`01010001` |
|
`E` |
`69` |
`01000101` |
`R` |
`82` |
`01010010` |
|
`F` |
`70` |
`01000110` |
`S` |
`83` |
`01010011` |
|
`G` |
`71` |
`01000111` |
`T` |
`84` |
`01010100` |
|
`H` |
`72` |
`01001000` |
`U` |
`85` |
`01010101` |
|
`I` |
`73` |
`01001001` |
`V` |
`86` |
`01010110` |
|
`J` |
`74` |
`01001010` |
`W` |
`87` |
`01010111` |
|
`K` |
`75` |
`01001011` |
`X` |
`88` |
`01011000` |
|
`L` |
`76` |
`01001100` |
`Y` |
`89` |
`01011001` |
|
`M` |
`77` |
`01001101` |
`Z` |
`90` |
`01011010` |
Хотя в ASCII символы кодируются `7`-ю битами, в памяти компьютера под каждый символ отводится ровно `1` байт (`8` бит).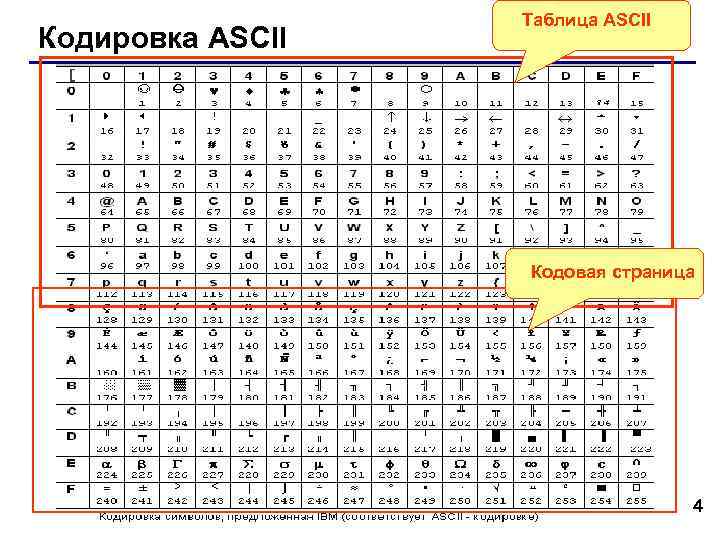 И получается, что один бит из каждого байта не используется.
И получается, что один бит из каждого байта не используется.
Главный недостаток стандарта ASCII заключается в том, что он рассчитан на передачу только текста, состоящего из английских букв. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII-кодировки, в которых применялись однобайтные коды символов; при этом первые `128` символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со `128`-го по `255`-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано по нескольку вариантов кодовых таблиц (например, для русского языка их около десятка).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Указав кодовую таблицу, автоматически выбирают и язык, которым можно пользоваться в дополнение к английскому; точнее, выбирается то, как будут интерпретироваться символы с кодами более `127`.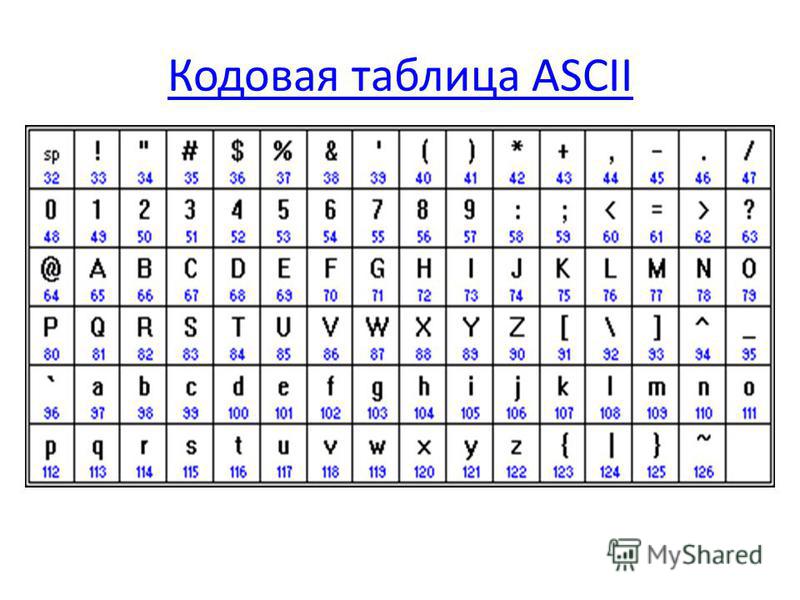
Для русского языка наиболее распространёнными являются однобайтовые кодовые таблицы СР-`866`, Windows-`1251`, ISO `8859-5` и КОИ-`8`. В них первые `128` символов совпадают с ASCII-кодировкой, а русские буквы помещены во второй части таблицы (с номерами `128-255`), однако коды русских букв в этих кодировках различны! Сравните, например, кодировки КОИ-`8` (Код Обмена Информацией `8`-битный, международное название «koi-`8`r») и Windows-`1251`, фрагменты которых приведены в таблицах на странице `13`.
Несовпадение кодовых таблиц приводит к ряду неприятных эффектов: один и тот же текст (неанглийский) имеет различное компьютерное представление в разных кодировках, соответственно, текст, набранный в одной кодировке, будет нечитабельным в другой!
Однобайтовые кодировки обладают одним серьёзным ограничением: количество различных кодов символов в отдельно взятой кодировке недостаточно велико, чтобы можно было пользоваться одновременно несколькими языками. Для устранения этого ограничения в 1993-м году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы всех языков мира. 16`), а в целом стандарт Unicode описывает все алфавиты современных и мёртвых языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; внесены все математические и иные научные символьные обозначения, и даже — некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений Дж.Р.Р. Толкиена). Потенциальная информационная ёмкость Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
16`), а в целом стандарт Unicode описывает все алфавиты современных и мёртвых языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; внесены все математические и иные научные символьные обозначения, и даже — некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений Дж.Р.Р. Толкиена). Потенциальная информационная ёмкость Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
В современных компьютерах и операционных системах используется укороченная, `16`-битная версия Unicode, в которую входят все современные алфавиты; эта часть Unicode называется базовой многоязыковой страницей (Base Multilingual Plane, BMP).
Сколькими битами кодируется 1 символ в unicode. Кодирование текста
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время)
занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту , то есть I = 1 байт = 8 битов.
Для кодирования одного символа требуется 1 байт информации. Если рассматривать символы как возможные события, то можно вычислить, какое количество различных символов можно закодировать: N = 2I = 28 = 256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр. Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111.
Таким образом, человек различает символы по их начертаниям, а компьютер — по их кодам. При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение символа
преобразуется в его двоичный код.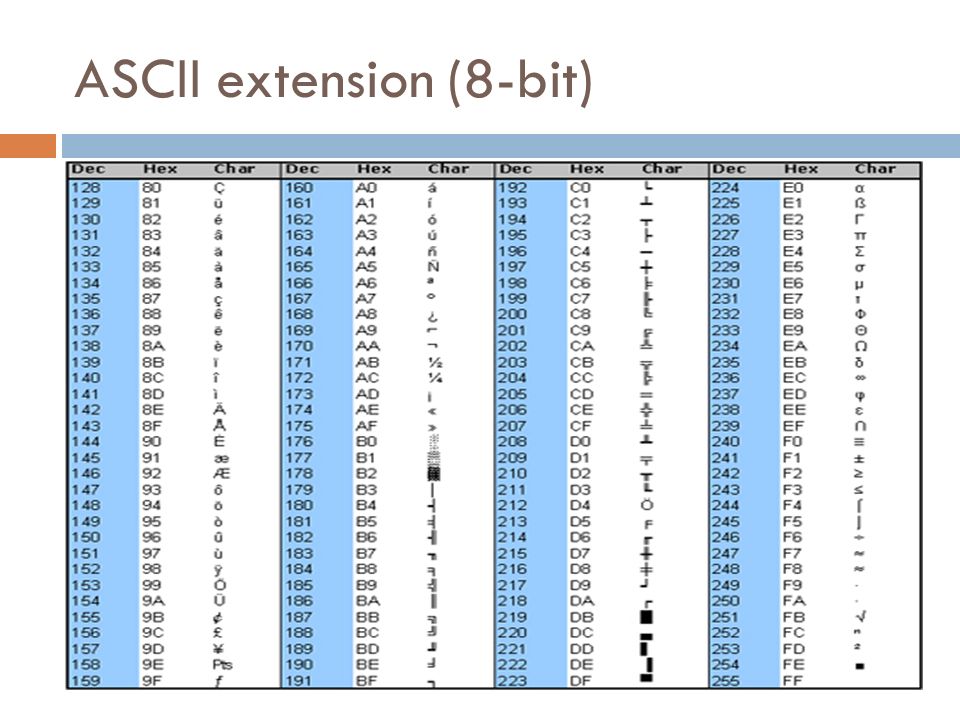
Пользователь нажимает на клавиатуре клавишу с символом, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в
оперативной памяти компьютера, где занимает один байт. В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его
изображение. В качестве международного стандарта принята кодовая таблица ASCII (American Standart Code for Information Interchange) Таблица стандартной части ASCII Важно, что присвоение символу
конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и так далее). Коды
с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания. Коды с 128 по 255 являются национальными, то есть
в национальных кодировках одному и тому же коду соответствуют различные символы.
К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов, а N = 216 = 65536 различных
Юникод — появление универсальной кодировки текста (UTF 32, UTF 16 и UTF 8)Эти тысячи символов языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных кодировках ASCII. В
результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при
сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.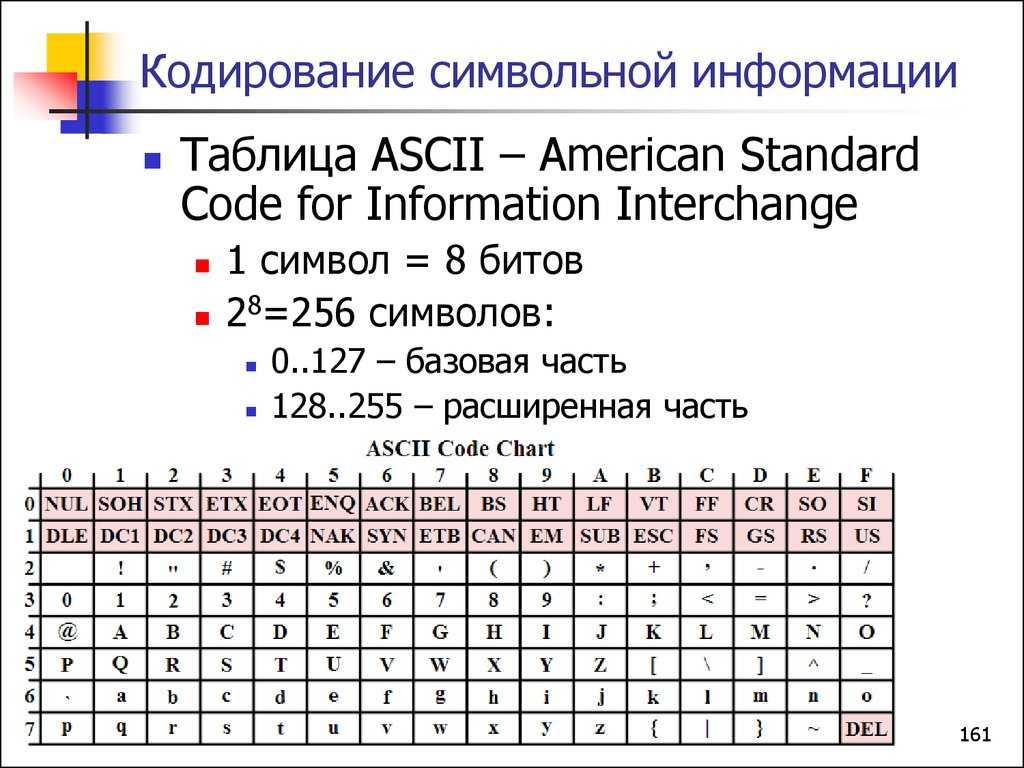
Первой кодировкой текста, вышедшей под эгидой консорциума Юникод, была кодировка UTF 32 . Цифра в названии кодировки UTF 32 означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного символа в новой универсальной кодировке UTF 32.
В результате чего один и то же файл с текстом, закодированный в расширенной кодировке ASCII и в кодировке UTF 32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью UTF 32 число символов равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество символов использовать в кодировке вовсе и не было необходимости, однако при использовании UTF 32 они ни за что ни про что
получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных.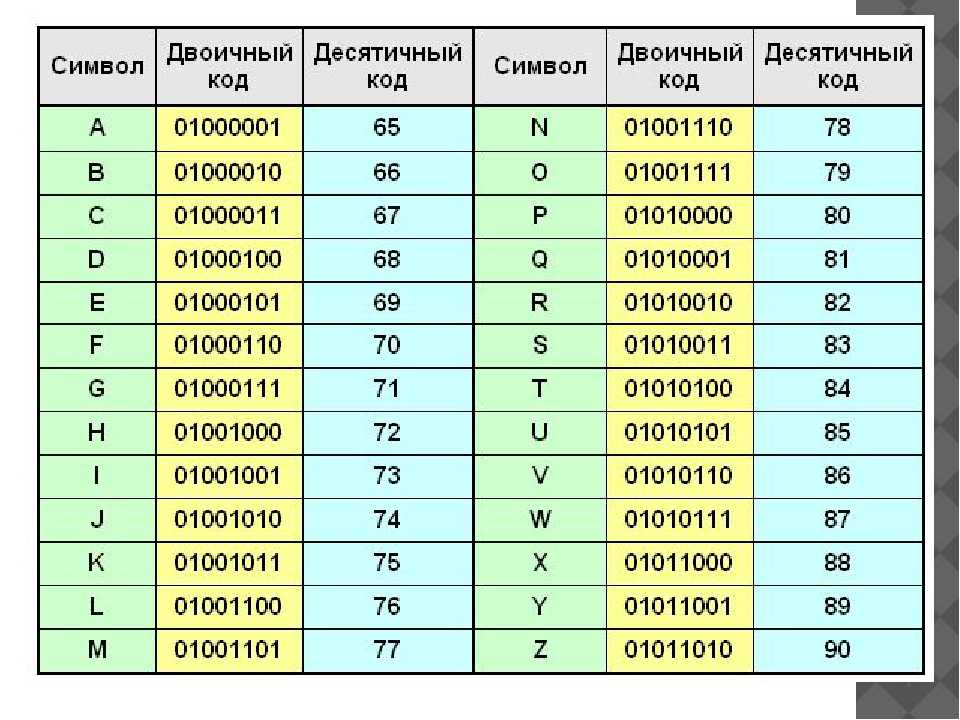 Это много и такое расточительство себе никто не мог
позволить.
Это много и такое расточительство себе никто не мог
позволить.
В результате развития универсальной кодировки Юникод появилась UTF 16 , которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. UTF 16 использует два байта для кодирования одного символа. Например, в операционной системе Windows вы можете пройти по пути Пуск — Программы — Стандартные — Служебные — Таблица символов.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберите в Дополнительных параметрах набор символов Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из этих символов вы сможете увидеть его двухбайтовый код в кодировке UTF 16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF 16 с помощью 16 бит? 65 536 символов (два в степени шестнадцать) было принято за базовое пространство в Юникод. Помимо этого существуют способы
закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
Помимо этого существуют способы
закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
Но даже удачная версия кодировки Юникод под названием UTF 16 не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии кодировки ASCII к UTF 16 вес документов увеличивался в два раза (один байт на один символ в ASCII и два байта на тот же самый символ в кодировке UTF 16). Вот именно для удовлетворения всех и вся в консорциуме Юникод было решено придумать кодировку текста переменной длины .
Такую кодировку в Юникод назвали UTF 8 . Несмотря на восьмерку в названии UTF 8 является полноценной кодировкой переменной длины, т.е. каждый символ текста может быть
закодирован в последовательность длинной от одного до шести байт. На практике же в UTF 8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже
даже теоретически не возможно представить.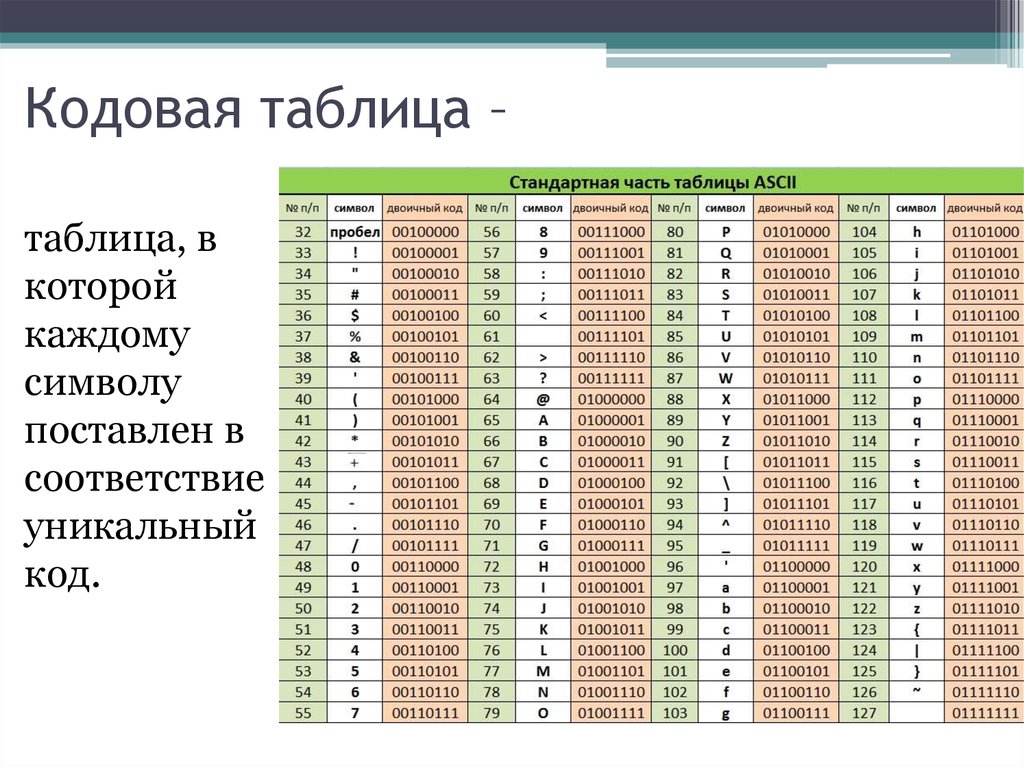
В UTF 8 все латинские символы кодируются в один байт, так же как и в старой кодировке ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в UTF 8. Т.е. базовая часть кодировки ASCII перешла в UTF 8.
Кириллические же символы в UTF 8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания кодировок UTF 16 и UTF 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. Производителям шрифтов остается только исходя из своих сил и возможностей заполнять это кодовое пространство векторными формами символов текста.
Теоретически
давно существует решение этих проблем.
Оно называетсяUnicode (Юникод). Unicode –
это кодировочная таблица, в которой
для кодирования каждого символа
используется 2 байта, т.е. 16 бит. На
основании такой таблицы может быть
закодированоN=2 16 =65 536
символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по
той причине, что если код одного символа
будет занимать не один байт, а два байта,
что для хранения текста понадобится
вдвое больше дискового пространства,
а для его передачи по каналам связи –
вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита — в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж
романа «Двенадцать стульев») составляет
30 слов. Сколько бит достаточно, чтобы
закодировать весь словарный запас
Эллочки? Варианты: 8, 5, 3, 1.
Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения).
Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации.
Память носителей в свою очередь имеет ограниченную ёмкость , т.е. способность вместить в себе определенный объем. Ёмкость памяти электронных носителей информации, естественно, также измеряется в байтах.
Однако байт – мелкая единица измерения объема данных, более крупными являются килобайт, мегабайт, гигабайт, терабайт…
Следует запомнить,
что приставки “кило”, “мега”, “гига”…
не являются в данном случае десятичными.
Так “кило” в слове “килобайт” не
означает “тысяча”, т. е. не означает
“10 3 ”. Бит – двоичная единица, и
по этой причине в информатике удобно
пользоваться единицами измерения
кратными числу “2”, а не числу “10”.
е. не означает
“10 3 ”. Бит – двоичная единица, и
по этой причине в информатике удобно
пользоваться единицами измерения
кратными числу “2”, а не числу “10”.
1 байт = 2 3 =8 бит, 1 килобайт = 2 10 = 1024 байта. В двоичном виде 1 килобайт = &10000000000 байт.
Т.е. “кило” здесь обозначает ближайшее к тысяче число, являющееся при этом степенью числа 2, т.е. являющееся “круглым” числом в двоичной системе счисления.
Таблица 10.
Именование | Обозначение | Значение в байтах | |
килобайт | |||
мегабайт | 2 10 Kb = 2 20 b | ||
гигабайт | 2 10 Mb = 2 30 b | ||
терабайт | 2 10 Gb = 2 40 b | 1 099 511 627 776 b | |
В связи, с тем, что
единицы измерения объема и ёмкости
носителей информации кратны 2 и не
кратны 10, большинство задач по этой
теме проще решается тогда, когда
фигурирующие в них значения представляются
степенями числа 2. Рассмотрим пример
подобной задачи и ее решение:
Рассмотрим пример
подобной задачи и ее решение:
В текстовом файле хранится текст объемом в 400 страниц. Каждая страница содержит 3200 символов. Если используется кодировка KOI-8 (8 бит на один символ), то размер файла составит:
Решение
Определяем общее количество символов в текстовом файле. При этом мы представляем числа, кратные степени числа 2 в виде степени числа 2, т.е. вместо 4, записываем 2 2 и т.п. Для определения степени можно использовать Таблицу 7.
символов.
2) По условию задачи 1 символ занимает 8 бит, т.е. 1 байт => файл занимает 2 7 *10000 байт.
3) 1 килобайт = 2 10 байт => объем файла в килобайтах равен:
.
Сколько бит в одном килобайте?
&10000000000000.
Чему равен 1 Мбайт?
1000000 байт.
1024 байта;
1024 килобайта;
Сколько бит в сообщении объемом четверть
килобайта? Варианты: 250, 512, 2000, 2048.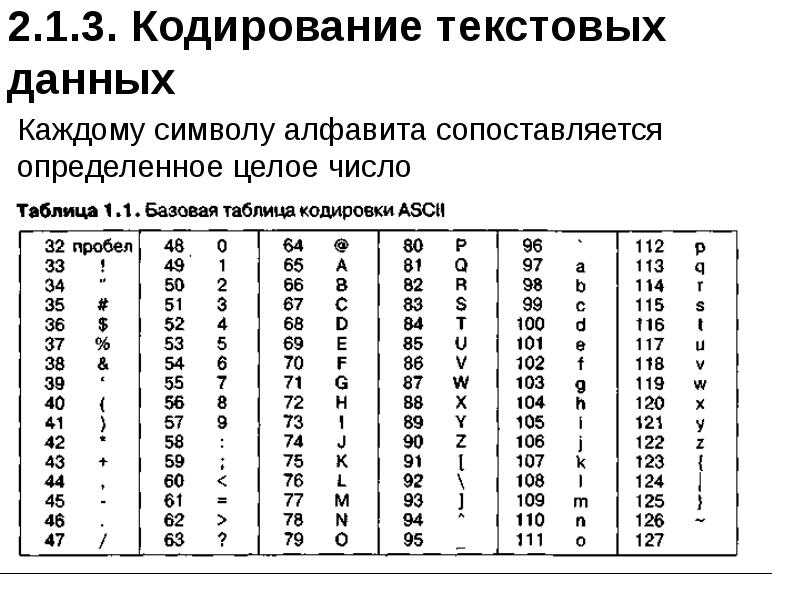
Объем текстового файла 640 Kb . Файл содержит книгу, которая набрана в среднем по32 строки на странице и по64 символа в строке. Сколько страниц в книге: 160, 320, 540, 640, 1280?
Досье на сотрудников занимают 8 Mb . Каждое из них содержит16 страниц (32 строки по64 символа в строке). Сколько сотрудников в организации: 256; 512; 1024; 2048?
Этот пост для тех, кто не понимает, что такое UTF-8, но хочет это понять, а доступная документация часто очень обширно освещает этот вопрос. Я попробую здесь описать это так, как сам бы хотел, чтобы раньше мне кто-то так рассказал. Так как часто у меня по поводу UTF-8 была в голове каша.
Несколько простых правил
- Итак, UTF-8 — это «обертка» для Unicode. Это не отдельная кодировка символов, это «обертнутый» Unicode. Вы, наверное, знаете Base64 кодировку, или слышали о ней — она может обернуть бинарные данные в печатаемые символы. Дак вот, UTF-8 это такой же Base64 для Unicode, как Base64 для бинарных данных. Это раз. Если вы это поймете, то уже многое станет ясно. И она также, как Base64, признана решить проблему совместимости в символах (Base64 была придумана для email, чтобы передавать файлы почтой, в которой все символы — печатаемые)
- Далее, если код работает с UTF-8, то внутри он все равно работает с Unicode кодировками, то есть, где-то глубоко внутри есть таблицы символов именно Unicode символов. Правда, можно не иметь таблиц символов Unicode, если надо просто посчитать, сколько символов в строке, например (см. ниже)
- UTF-8 сделан с той целью, чтобы старые программы и сегодняшние компьютеры могли работать нормально с Unicode символами, как со старыми кодировками, типа KOI8, Windows-1251 и т.п.. В UTF-8 нет байтов с нулями, все байты — они либо от 0x01 — 0x7F, как обычный ASCII, либо 0x80 — 0xFF, что также работает под программами, написанными на Си, как и работало бы не с ASCII символами. Правда, для корректной работы с символами программа должна знать Unicode таблицы.
- Все, что имеет старший 7-ой бит в байте (если считать биты с нулевого) UTF-8 — часть кодированного потока Unicode.
 Это раз. Если вы это поймете, то уже многое станет ясно. И она также, как Base64, признана решить проблему совместимости в символах (Base64 была придумана для email, чтобы передавать файлы почтой, в которой все символы — печатаемые)
Это раз. Если вы это поймете, то уже многое станет ясно. И она также, как Base64, признана решить проблему совместимости в символах (Base64 была придумана для email, чтобы передавать файлы почтой, в которой все символы — печатаемые)
UTF-8 изнутри
Если вы знаете битовую систему, то вот вам краткая памятка , как кодируется UTF-8:
Первый байт Unicode символа в UTF-8 начинается с байта, где 7-ой бит всегда единица, и 6-ой бит всегда также единица. При этом в первом байте, если смотреть на биты слева направо (7-ой, 6-ой и так до нулевого), идет столько единиц, сколько байтов, включая первый, идет на кодирование одного Unicode символа. Заканчивается последовательность единиц нулем. А после этого идут биты самого Unicode символа. Остальные биты Unicode символа попадают во второй, или даже в третий байты (максимум три, почему — смотрите чуть ниже). Остальные байты, кроме первого, всегда идут с началом ’10’ и потом 6 битов следующей части Unicode символа.
Пример
Например: есть байты 110
10000 и второй 10
011110 . Первый — начинается с ‘110’ — это значит, что раз две единицы — будет два байта UTF-8 потока, и второй байт, как и все остальные, начинается с ’10’. А кодируют эти два байта символ Unicode, который состоит из 10100 битов от первого куска + 101101 от второго, получается -> 10000011110 -> 41E в 16-ричной системе, или U+041E в написании Unicode обозначений. Это символ большая русская О .
А кодируют эти два байта символ Unicode, который состоит из 10100 битов от первого куска + 101101 от второго, получается -> 10000011110 -> 41E в 16-ричной системе, или U+041E в написании Unicode обозначений. Это символ большая русская О .
Сколько максимум байт на символ?
Также, давайте посмотрим, сколько максимум байт уходит в UTF-8, чтобы закодировать 16 бит кодировки Unicode. Вторые и далее байты всегда максимум могут вместить 6 бит. Значит, если начать с конечных байтов, то два байта уйдут точно (2-ой и третий), а первый должен начинаться с ‘1110’, чтобы закодировать три. Значит первый байт максимум в таком варианте может закодировать первые 4 бита символа Unicode. Получается 4 + 6 + 6 = 16 байт. Выходит, что UTF-8 может иметь либо 2, либо 3 байта на символ Unicode (один не может, так как нет надобности кодировать 6 бит (8 — 2 бита ’10’) — они будут ASCII символом. Именно поэтому первый байт UTF-8 никогда не может начинаться с ’10’).
Заключение
Кстати, благодаря такой кодировке, можно взять любой байт в потоке, и определить: является ли байт Unicode символом (если 7-ой бит — значит не ASCII), если да, то первый ли он в потоке UTF-8 или не первый (если ’10’, значит не первый), если не первый, то мы можем переместиться назад побайтово, чтобы найти первый код UTF-8 (у которого 6-ой бит будет 1), либо переместится вправо и пропустить все ’10’ байты, чтобы найти следующий символ. Благодаря такой кодировке, программы также могут, не зная Unicode, считать, сколько символов в строке (на основании первого байта UTF-8 вычислить длину символа в байтах). Вообщем, если подумать, кодировка UTF-8 придумана очень грамотно, и в то же время очень эффективно.
Благодаря такой кодировке, программы также могут, не зная Unicode, считать, сколько символов в строке (на основании первого байта UTF-8 вычислить длину символа в байтах). Вообщем, если подумать, кодировка UTF-8 придумана очень грамотно, и в то же время очень эффективно.
Кодирование информации
Любые числа (в определенных пределах) в памяти компьютера кодируются числами двоичной системы счисления. Для этого существуют простые и понятные правила перевода. Однако на сегодняшний день компьютер используется куда шире, чем в роли исполнителя трудоемких вычислений. Например, в памяти ЭВМ хранятся текстовая и мультимедийная информация. Поэтому возникает первый вопрос:
Как в памяти компьютера хранятся символы (буквы)?
Каждая буква принадлежит определенному алфавиту, в котором символы следуют друг за другом и, следовательно, могут быть пронумерованы последовательными целыми числами. Каждой букве можно сопоставить целое положительное число и назвать его кодом символа . Именно этот код будет храниться в памяти компьютера, а при выводе на экран или бумагу «преобразовываться» в соответствующий ему символ. Чтобы отличить представление чисел от представления символов в памяти компьютера, приходится также хранить информацию о том, какие именно данные закодированы в конкретной области памяти.
Именно этот код будет храниться в памяти компьютера, а при выводе на экран или бумагу «преобразовываться» в соответствующий ему символ. Чтобы отличить представление чисел от представления символов в памяти компьютера, приходится также хранить информацию о том, какие именно данные закодированы в конкретной области памяти.
Соответствие букв определенного алфавита с числами-кодами формирует так называемую таблицу кодирования . Другими словами, каждый символ конкретного алфавита имеет свой числовой код в соответствии с определенной таблицей кодирования.
Однако алфавитов в мире очень много (английский, русский, китайский и др.). Поэтому следующий вопрос:
Как закодировать все используемые на компьютере алфавиты?
Для ответа на этот вопрос пойдем историческим путем.
В 60-х годах XX века в американском национальном институте стандартизации (ANSI) была разработана таблица кодирования символов, которая впоследствии была использована во всех операционных системах.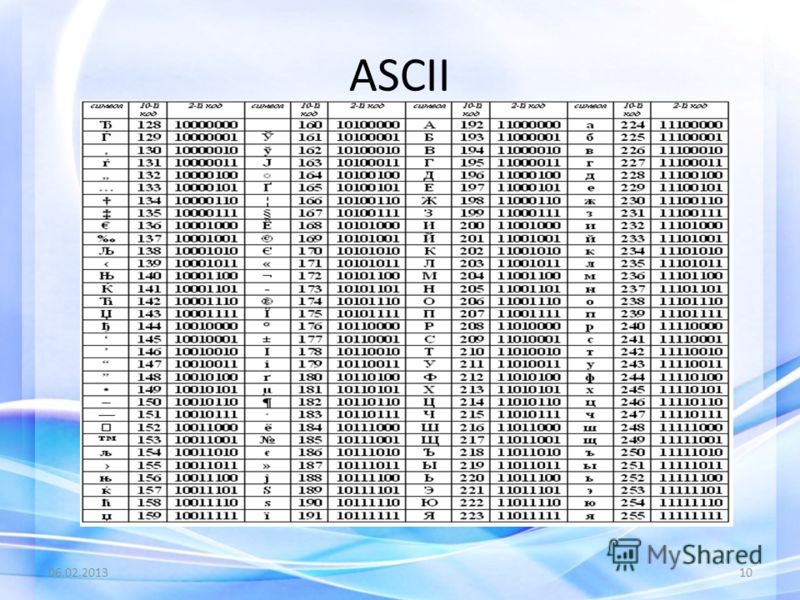 Эта таблица называется ASCII (American Standard Code for Information Interchange – американский стандартный код для обмена информацией) . Чуть позже появилась расширенная версия ASCII .
Эта таблица называется ASCII (American Standard Code for Information Interchange – американский стандартный код для обмена информацией) . Чуть позже появилась расширенная версия ASCII .
В соответствие с таблицей кодирования ASCII для представления одного символа выделяется 1 байт (8 бит). Набор из 8 ячеек может принять 2 8 = 256 различных значений. Первые 128 значений (от 0 до 127) постоянны и формируют так называемую основную часть таблицы, куда входят десятичные цифры, буквы латинского алфавита (заглавные и строчные), знаки препинания (точка, запятая, скобки и др.), а также пробел и различные служебные символы (табуляция, перевод строки и др.). Значения от 128 до 255 формируют дополнительную часть таблицы, где принято кодировать символы национальных алфавитов.
Поскольку национальных алфавитов огромное множество, то расширенные ASCII-таблицы существуют во множестве вариантов. Даже для русского языка существуют несколько таблиц кодирования (распространены Windows-1251 и Koi8-r). Все это создает дополнительные трудности. Например, мы отправляем письмо, написанное в одной кодировке, а получатель пытается прочитать ее в другой. В результате видит кракозябры. Поэтому читающему требуется применить для текста другую таблицу кодирования.
Все это создает дополнительные трудности. Например, мы отправляем письмо, написанное в одной кодировке, а получатель пытается прочитать ее в другой. В результате видит кракозябры. Поэтому читающему требуется применить для текста другую таблицу кодирования.
Есть и другая проблема. В алфавитах некоторых языков слишком много символов и они не помещаются в отведенные им позиции с 128 до 255 однобайтовой кодировки.
Третья проблема — что делать, если в тексте используется несколько языков (например, русский, английский и французский)? Нельзя же использовать две таблицы сразу …
Чтобы решить эти проблемы одним разом была разработана кодировка Unicode.
Стандарт кодирования символов Unicode
Для решения вышеизложенных проблем в начале 90-х был разработан стандарт кодирования символов, получивший название Unicode . Данный стандарт позволяет использовать в тексте почти любые языки и символы.
В Unicode для кодирования символов предоставляется 31 бит (4 байта за вычетом одного бита).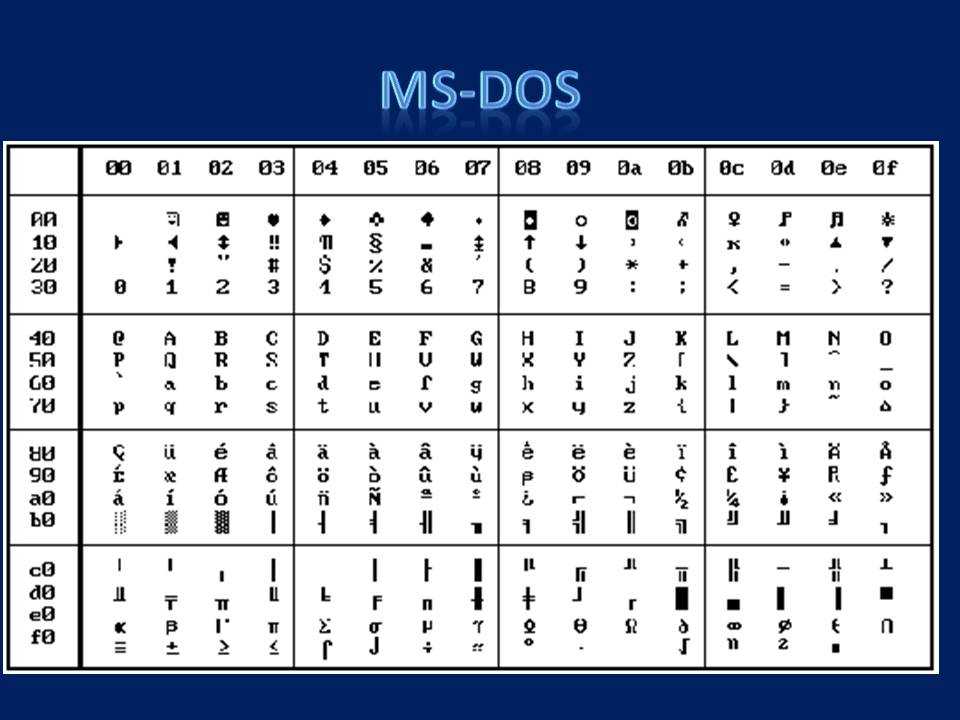 Количество возможных комбинаций дает запредельное число: 2 31 = 2 147 483 684 (т.е. более двух миллиардов). Поэтому Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и иные специальные символы. Однако информационная емкость 31-битового Unicode все равно остается слишком большой. Поэтому чаще используется сокращенная 16-битовая версия (2 16 = 65 536 значений), где кодируются все современные алфавиты.
Количество возможных комбинаций дает запредельное число: 2 31 = 2 147 483 684 (т.е. более двух миллиардов). Поэтому Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и иные специальные символы. Однако информационная емкость 31-битового Unicode все равно остается слишком большой. Поэтому чаще используется сокращенная 16-битовая версия (2 16 = 65 536 значений), где кодируются все современные алфавиты.
В Unicode первые 128 кодов совпадают с таблицей ASCII.
В настоящее время большая часть пользователей при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др.
На основании одной ячейки информационной ёмкостью 1 бит можно закодировать только 2 различных состояния. Для того чтобы каждый символ, который можно ввести с клавиатуры в латинском регистре, получил свой уникальный двоичный код, требуется 7 бит. На основании последовательности из 7 бит, в соответствии с формулой Хартли, может быть получено N=2 7 =128 различных комбинаций из нулей и единиц, т. е. двоичных кодов. Поставив в соответствие каждому символу его двоичный код, мы получим кодировочную таблицу. Человек оперирует символами, компьютер – их двоичными кодами.
е. двоичных кодов. Поставив в соответствие каждому символу его двоичный код, мы получим кодировочную таблицу. Человек оперирует символами, компьютер – их двоичными кодами.
Для латинской раскладки клавиатуры такая кодировочная таблица одна на весь мир, поэтому текст, набранный с использованием латинской раскладки, будет адекватно отображен на любом компьютере. Эта таблица носит название ASCII (American Standard Code of Information Interchange) по-английски произносится [э́ски], по-русски произносится [а́ски]. Ниже приводится вся таблица ASCII, коды в которой указаны в десятичном виде. По ней можно определить, что когда вы вводите с клавиатуры, скажем, символ “*”, компьютер его воспринимает как код 42(10), в свою очередь 42(10)=101010(2) – это и есть двоичный код символа “*”. Коды с 0 по 31 в этой таблице не задействованы.
Таблица символов ASCII
| код | символ | код | символ | код | символ | код | символ | код | символ | код | символ |
| Пробел | . | @ | P | » | p | ||||||
| ! | A | Q | a | q | |||||||
| » | B | R | b | r | |||||||
| # | C | S | c | s | |||||||
| $ | D | T | d | t | |||||||
| % | E | U | e | u | |||||||
| & | F | V | f | v | |||||||
| » | G | W | g | w | |||||||
| ( | H | X | h | x | |||||||
| ) | I | Y | i | y | |||||||
| * | J | Z | j | z | |||||||
| + | : | K | [ | k | { | ||||||
| , | ; | L | \ | l | | | ||||||
| — | M | ] | m | } | |||||||
. | n | ~ | |||||||||
| / | ? | O | _ | o | DEL |
Для того чтобы закодировать один символ используют количество информации равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы — это возможные события):
К = 2 I = 2 8 = 256,
т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ — 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы, не будут правильно отображаться в другой кодировке. Наглядно это можно представить в виде фрагмента объединенной таблицы кодировки символов.
Наглядно это можно представить в виде фрагмента объединенной таблицы кодировки символов.
Одному и тому же двоичному коду ставится в соответствие различные символы.
| Двоичный код | Десятичный код | КОИ8 | СР1251 | СР866 | Мас | ISO |
| б | В | — | — | Т |
Впрочем, в большинстве случаев о перекодировке текстовых документов заботится на пользователь, а специальные программы — конверторы, которые встроены в приложения.
Начиная с 1997 г. последние версии Microsoft Office поддерживают новую кодировку. Она называется Unicode (Юникод) . Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII.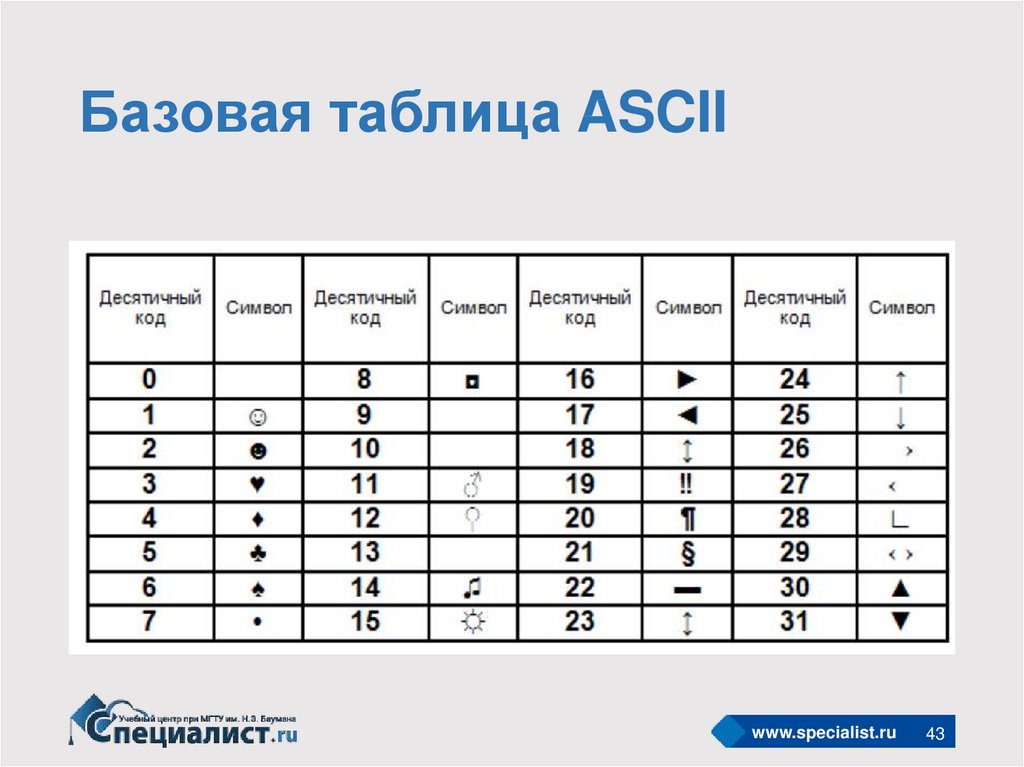 Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита — в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита — в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
Чтобы определить числовой код символа можно или воспользоваться кодовой таблицей. Для этого в меню нужно выбрать пункт «Вставка» — «Символ», после чего на экране появляется диалоговая панель Символ. В диалоговом окне появляется таблица символов для выбранного шрифта. Символы в этой таблице располагаются построчно, последовательно слева направо, начиная с символа Пробел.
Понимание таблицы ASCII
Компьютеры обычно работают, занижая числа, и для перевода чисел в символы создается стандарт. В этом стандарте каждому символу присвоена определенная цифра, будь то алфавит или любой символ, и этот стандарт называется стандартом ASCII. Использование ASCII для каждого символа упростило общение между машинами и людьми.
ASCII — это аббревиатура «Американского стандартного кода для обмена информацией», и из названия можно предположить, что это код, используемый для обмена информацией от машины к человеку или от машины к машине.
Что такое
— кодировка символовЧтобы понять ASCII, вы должны знать кодировку символов. Кодирование символов — это процесс присвоения чисел/цифр символам, и эти символы могут быть разных типов, например, графические символы или символы человеческого языка. Он используется для хранения, передачи или управления данными с помощью компьютеров.
Кодировка символов выполняется для того, чтобы компьютеры могли интерпретировать и обрабатывать символы. Например, мы можем предположить некоторые числа и присвоить их алфавитам. Существует 26 алфавитов, и давайте присвоим число от 1 до 26 всем заглавным алфавитам, это означает, что мы закодировали символы/алфавиты, присвоив им число.
В приведенной выше таблице буквам L, I, N, U и X присвоены номера 12, 9, 14, 21 и 24 соответственно.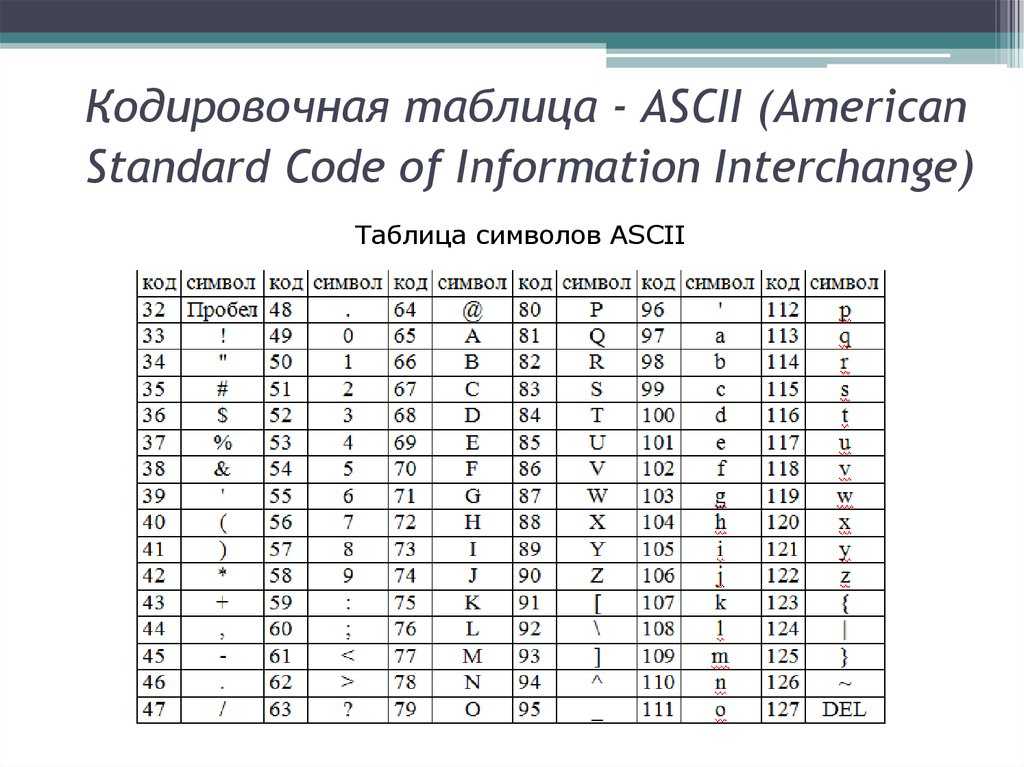 Теперь компьютерам будет проще расшифровывать и печатать символы. Но чтобы охватить все символы английского языка, Американская ассоциация стандартов (NSA) выпустила первую версию ASCII в 1963 году. ASCII был одним из первых стандартов, созданных для компьютерного обмена информацией.
Теперь компьютерам будет проще расшифровывать и печатать символы. Но чтобы охватить все символы английского языка, Американская ассоциация стандартов (NSA) выпустила первую версию ASCII в 1963 году. ASCII был одним из первых стандартов, созданных для компьютерного обмена информацией.
Почему ASCII важен
Ну, это важно, потому что это связь между нашим компьютером и памятью, и теперь это стандарт для каждого компьютера. Информация, хранящаяся в памяти, представлена в виде нулей и единиц, а ASCII помогает преобразовать эту информацию в символы или в удобочитаемый формат.
Коды ASCII используются в телекоммуникационных устройствах, компьютерах и другом сопутствующем оборудовании.
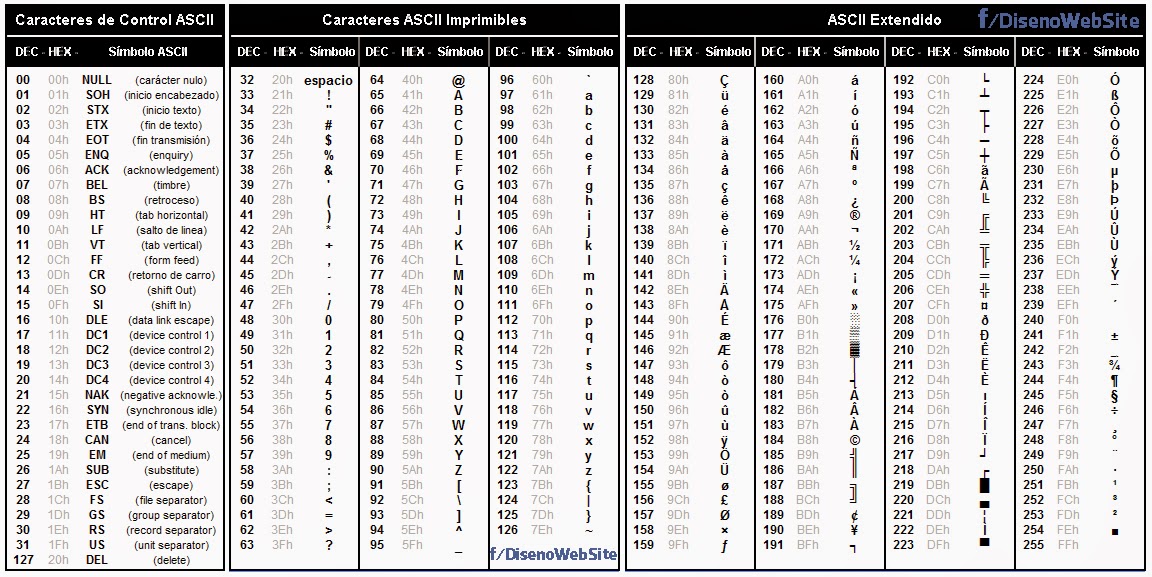
Стандартная таблица ASCII
Стандартная таблица ASCII является 7-битной и содержит символы с кодами ASCII в диапазоне от 0 до 127. Стандарт ASCII используется, поскольку компьютер не может напрямую хранить какие-либо символы или преобразовывать их в двоичные данные. количество. Используя ASCII, компьютер узнает о символах, поэтому эти ASCII затем преобразуются компьютером в двоичные цифры.
количество. Используя ASCII, компьютер узнает о символах, поэтому эти ASCII затем преобразуются компьютером в двоичные цифры.
Понимание таблицы ASCII
Чтобы найти значение ASCII любого символа, вам необходимо обратиться к стандартной таблице ASCII, как показано ниже:
Значение ASCII «A» будет равно 65, а «&» — 38. Аналогично , для фигурных скобок «{}» будут использоваться 123 и 125 ASCII.
Давайте рассмотрим пример слова «Linux», как оно хранится в памяти:
Поскольку компьютер не распознает символы, поэтому ASCII присваивает номер всем символам, и соответствующее двоичное значение сохраняется в жесткий диск. Слово «Linux» будет сохранено в памяти в двоичном формате, как показано на изображении выше. ASCII помогает в записи и чтении соответствующих данных символов из памяти.
Имеется 128 символов, и каждому символу присвоен номер ASCII. Давайте разделим таблицу на две категории, чтобы лучше понять ее:
- Управляющие символы
- печатных символов
Управляющие символы в таблице ASCII
Символы ASCII от 0 до 32 и 127 являются управляющими символами; их также называют непечатными персонажами или NPC.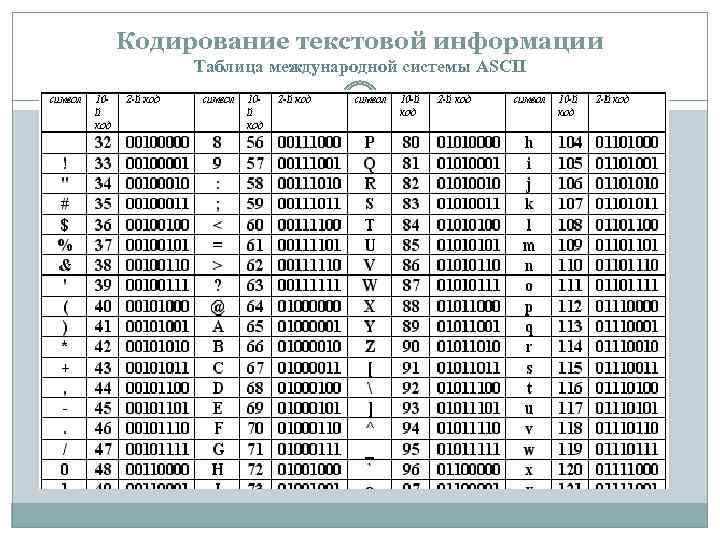 Как следует из названия, управляющие символы управляют размещением печатных символов или используются для управления устройствами, подключенными к компьютеру.
Как следует из названия, управляющие символы управляют размещением печатных символов или используются для управления устройствами, подключенными к компьютеру.
Некоторые управляющие символы связаны с клавишами клавиатуры. Например, клавиша возврата; когда вы нажимаете клавишу, эффект может отображаться на экране, но он не печатает никаких символов.
Аналогично, для связи с компьютером для окончания любого текста или начала текста используются ASCII для соответствующих символов. Эти управляющие символы сообщают компьютеру, как запускать код и печатать вывод.
Таблица всех управляющих символов:
Печатные символы в таблице ASCII
Печатные символы — это те символы, которые визуально отображаются на экране, такие как все алфавиты, цифры, символы и операторы. Печатный символ можно дополнительно классифицировать как:
- Числа и символы
- Алфавиты
Цифры и символы включают все числовые значения от 0 до 9 и такие символы, как операторы сложения и вычитания, а категория Алфавиты включает все буквы английского алфавита с прописными и строчными буквами.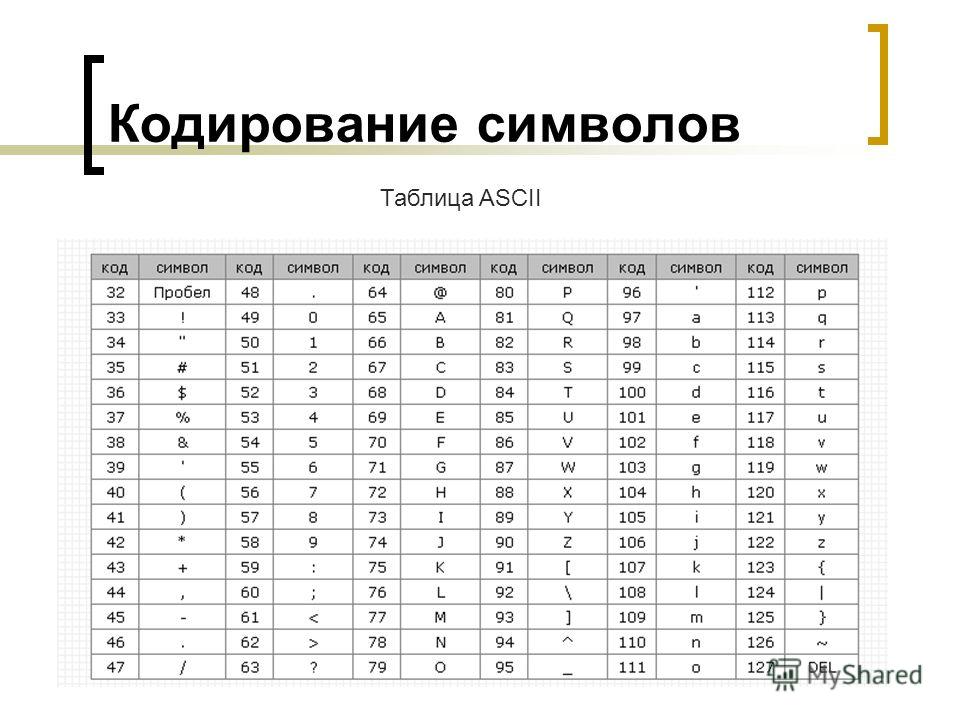
Эта часть содержит символы и имеет коды ASCII от 32 до 64, от 91 до 96 и от 123 до 126. Эти символы включают математические операторы (+, -, * ,/) и знаки препинания.
Например, ASCII для косой черты «/» будет 47, а для добавления «+» будет 43.
Алфавиты
ASCII для прописных и строчных букв. ASCII от 65 до 90 включает все прописные буквы, а от 97 до 122 включает все строчные буквы.
Например, ASCII заглавной «О» и маленькой «о» будет 79 и 111 соответственно.
Заключение
Компьютеры могут сохранять данные только в числах, потому что они понимают только язык чисел. Итак, чтобы компьютеры понимали символы, каждый символ должен быть определенным числом. Символы включают не только алфавиты, но и различные символы, которые можно использовать в программировании. В этой статье обсуждается стандартная таблица ASCII, чтобы дать лучшее представление о том, как ее можно понять и как она полезна для связи между различными устройствами и компьютерами.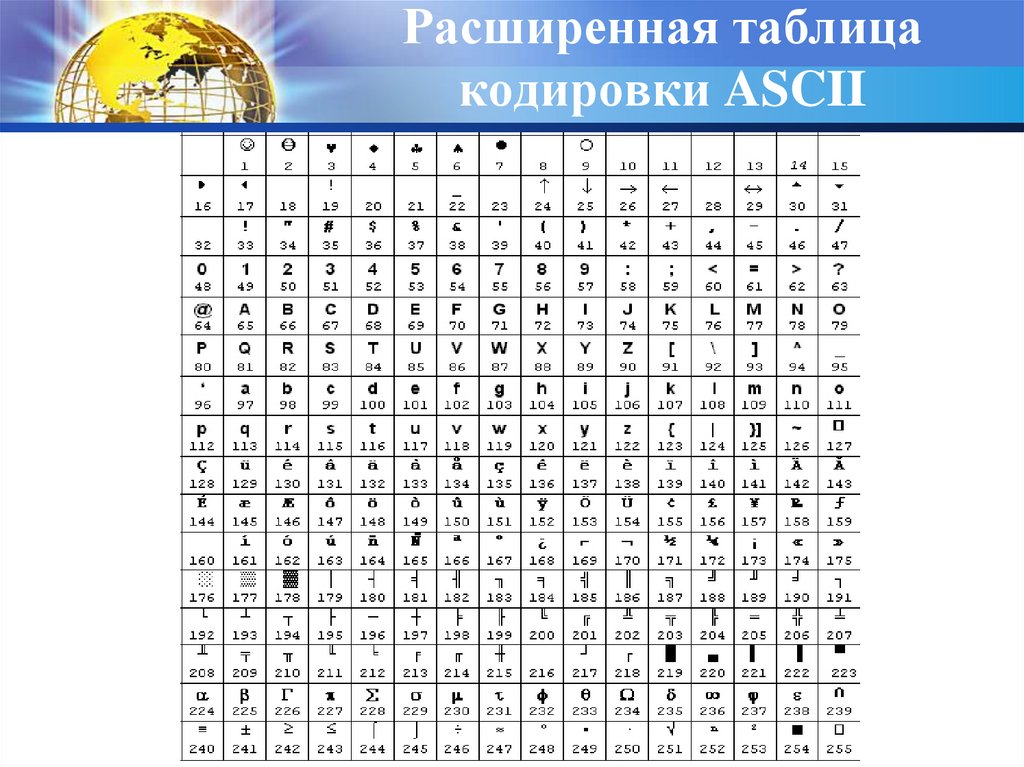
Диаграмма ASCII и набор символов ISO 1252 Latin-1
Следующая таблица представляет собой сопоставление символов, используемых в стандарте набора символов ASCII и ISO Latin-1 1252. Десятичный столбец «Dec» может использоваться для определения номера функций ApplyTilde и ProcessTilde в шрифтах штрих-кода IDAutomation, компонентах и программном обеспечении для печати этикеток.
Первые 128 символов обозначаются как US-ASCII и одинаковы во всех странах и регионах. Символы выше 128 в этой таблице являются уникальными для набора символов ISO Latin-1 1252 и различаются в зависимости от настроек страны и региона. Юникод относится к общему набору символов, который одинаков для всех систем, стран и регионов. Для правильного кодирования символов Unicode выше 0x7f в штрих-коде, таком как матрица данных или QR-код, необходимо преобразование в UTF-8. 9_
 0124
0124Что такое ASCII и для чего используется ASCII? (Файл PDF)
Вот что такое ASCII и как он используется:
Компьютеры используют ASCII, таблицу символов. Английский алфавит, числа и другие распространенные символы закодированы в таблице ASCII в виде двоичного кода.
Английский алфавит, числа и другие распространенные символы закодированы в таблице ASCII в виде двоичного кода.
Символы в компьютерах хранятся не как символы, а как последовательности двоичных битов: 1 и 0.
Например, 01000001 означает «A», потому что так говорит ASCII.
Если вы хотите узнать все об ASCII, то вы находитесь в правильном месте.
Начнем!
Вы когда-нибудь слышали ASCII?
Американский стандартный код для обмена информацией — это метод кодирования символов, используемый в электронной связи.
Это краткое определение ASCII, но есть еще способ сказать по теме, как покажет вам это руководство.
Поскольку полное название довольно сложное, этот термин обычно сокращается до ASCII.
Вы также можете увидеть его как US-ASCII. Это термин, который предпочитает Управление по присвоению номеров в Интернете, IANA.
Стандартный код ASCII обслуживает телекоммуникационные устройства, компьютеры и другую технику.
Большинство современных схем кодирования символов, используемых сегодня, основаны на ASCII, таких как UTF-8 и ISO-8859-1.
В этом руководстве объясняется, что такое код ASCII, как он используется, почему он важен, рассказывается об истории ASCII и его целях сегодня.
Что такое ASCII?
Так что же такое код ASCII?
Во-первых, напомним, что означает ASCII: американский стандартный код для обмена информацией.
Кстати, ASCII произносится как «ключ» (на всякий случай, если вам когда-нибудь придется произнести это вслух).
Теперь, когда вы разобрались с терминологией, переходим к вашему вопросу.
ASCII — это стандартная система кодирования, которая назначает числа, буквы и символы 256 слотам в 8-битном коде — ниже вы узнаете, что такое 8-бит.
Десятичный код ASCII состоит из двоичного кода, языка, используемого компьютерами.
ASCII соответствует английскому алфавиту.
Базовая таблица ASCII включает 128 символов, представленных в виде 7-битных целых чисел.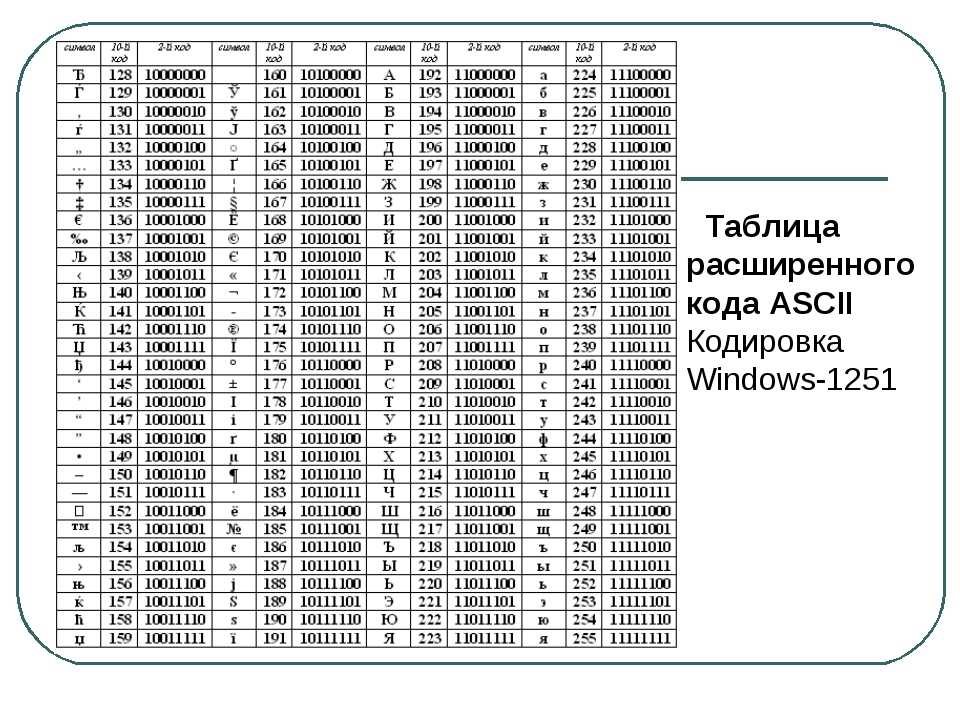
Можно напечатать 95 закодированных символов. К ним относятся цифры от 0 до 9 и буквы от a до z, как в нижнем, так и в верхнем регистре, а также знаки препинания.
Код ASCII также включает 33 контрольных кода, которые нельзя распечатать. Эти коды возникли с помощью телетайпов, и большинство из них сейчас устарели.
Существует также расширение базовой таблицы ASCII, добавляющее еще 128 символов.
Таким образом, базовая и расширенная таблицы ASCII в сумме составляют 256 символов. Вы найдете полную таблицу ASCII ниже.
Для чего используется ASCII?
Компьютеры сами не хранят символы как символы. Не существует изображения каждой буквы где-то на жестком диске вашего компьютера.
Вместо этого каждый символ кодируется как последовательность двоичных битов: 1 и 0.
Например, код заглавной буквы «А» — 01000001.
Но как ваш компьютер узнает, что 01000001 означает букву «А»?
Здесь вступает в игру ASCII: 01000001 означает «A», потому что ASCII так говорит.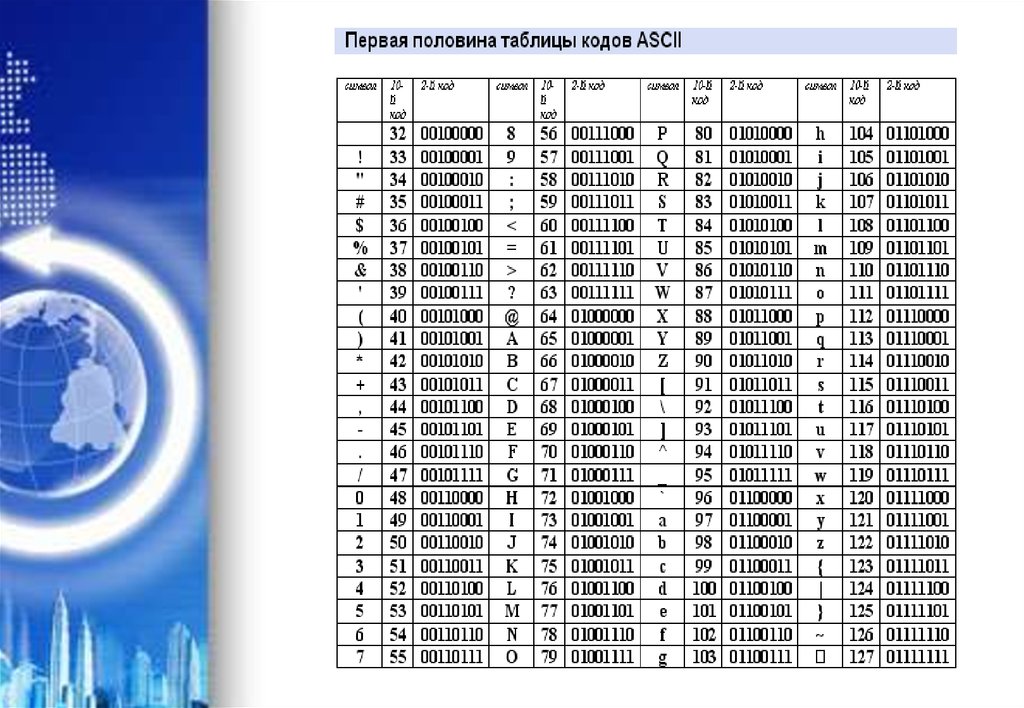
Что касается того, что говорит ASCII, компьютерная индустрия коллективно согласилась:
Они разработали стандарт кодирования символов — ASCII.
Что делает стандарт кодирования символов, так это определяет все возможные символы и присваивает каждому символу строку битов.
Что такое 8-бит?
Как уже упоминалось, ASCII — это стандартная система кодирования, в которой числа, буквы, знаки препинания и символы назначаются 256 слотам 8-битного кода.
Теперь вам, наверное, интересно, что такое 8-бит?
8-bit — ранняя программа или компьютерное аппаратное устройство. Он характеризуется способностью передавать восемь бит данных одновременно.
Кстати, 8 бит это 1 байт как следующая стандартная единица выше бита.
Бит — это основная единица информации в вычислениях. Бит имеет одно из двух возможных значений. Например:
- 1 или 0
- + или –
- истина или ложь
Таким образом, бит представляет 2 значения: 1 или 0.
2 бита вместе могут представлять 4 значения: 0 и 0, 0 и 1, 1 и 1, 0 и 1.
3 бита вместе могут представлять 8 значений. 3 бита означают 2 в степени 3: 2 * 2 * 2 = 8.
И так далее.
Следовательно, 8 бит могут хранить 256 различных значений: 2 * 2 * 2 * 2 * 2 * 2 * 2 * 2 = 256.
Возьмем, к примеру, процессор Intel 8080. Это был один из первых широко используемых компьютерных процессоров. Он работал на 8-битной архитектуре. Это означает, что он может обрабатывать 8 бит за один шаг.
Для сравнения: современные компьютерные процессоры работают на 64-битной архитектуре.
Что такое таблица ASCII и что она содержит?
Таблица кодов ASCII состоит из всеобъемлющей структуры, состоящей из трех разделов:
- Непечатаемые: Непечатаемые коды состоят из системных кодов от 0 до 31.
- Нижний ASCII: Нижний ASCII состоит из системного коды от 32 до 127. Эта часть таблицы ASCII восходит к 7-битным таблицам символов, использовавшимся в старых американских системах.
- Высший ASCII: Высший ASCII состоит из кодов от 128 до 255. Это программируемая часть таблицы ASCII.
Символы происходят из языка операционной системы современных компьютерных технологий.
Вы можете просмотреть полные значения и коды ASCII в обзорных таблицах, которые показывают символы наряду с их десятичным, шестнадцатеричным, восьмеричным, HTML и двоичным значением.
Существует также расширенная таблица ASCII. Он включает расширенный ASCII, который использует восемь битов вместо семи.
Это добавляет еще 128 символов, давая ASCII возможность содержать дополнительные символы, включая буквы иностранных языков, нарисованные символы и специальные символы.
Итак, сколько там символов ASCII? Это зависит.
Если вы посмотрите на элементарную кодовую таблицу ASCII, там 128 символов (7 бит).
Если вы смотрите на расширенную таблицу ASCII, вы должны учитывать добавленные 128 символов, в результате чего общее количество символов достигает 256 (8 бит).
Вот полная таблица ASCII с 256 записями — посмотрите, как двоичные файлы записей до записи № 128 имеют семь или меньше мест, а двоичные файлы записей после записи № 128 имеют восемь мест:
Полная мастер-таблица ASCII
В конце этой статьи находится загружаемая PDF-версия этой полной мастер-таблицы ASCII.
ASCII 7-бит и ASCII 8-бит: в чем разница?
Итак, прежде чем продолжить, важно различать два типа ASCII:
7-битный ASCII и 8-битный ASCII. Это две разные версии ASCII.
Вы можете услышать ссылку на любой из них, поэтому очень важно понимать, что означает каждый термин.
7-битная версия представляет собой оригинальный ASCII и содержит 128 символов. Он включает в себя как печатные, так и непечатаемые символы от 0 до 127, а также десятичное число.
Существует также 8-битный ASCII, состоящий из 255 символов плюс десятичное число.
8-битный ASCII также называется расширенным ASCII.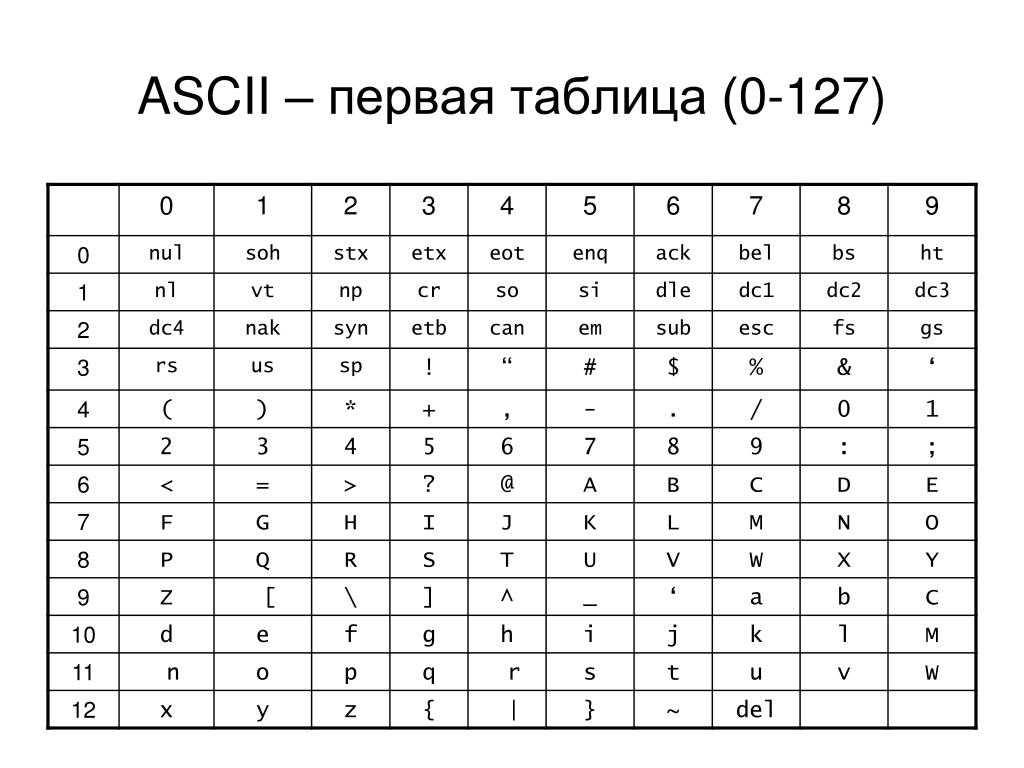 Это современный принятый стандарт.
Это современный принятый стандарт.
Сколько символов ASCII можно распечатать?
Выше вы видели ссылку на печатный и непечатаемый ASCII.
Какие символы ASCII можно распечатать?
«Печать» просто означает, что можно напечатать все указанные символы.
Можно распечатать любой широко используемый код ASCII. Однако не все символы ASCII могут быть напечатаны.
Итак, сколько символов ASCII вы можете напечатать?
Вы можете напечатать 95 символов 7-битного ASCII. 33 символа ASCII непечатаемые.
«Непечатаемый» символ представляет собой непечатаемый или непишущийся символ. Их также называют управляющими символами.
Примеры непечатаемых символов ASCII включают перевод строки, перевод страницы, возврат каретки, экранирование, удаление и возврат — вы можете проверить их в приведенной выше таблице ASCII.
Кто присваивает значения ASCII?
ASCII имеет множество значений, соответствующих различным символам. Это даже имеет значение для пространства.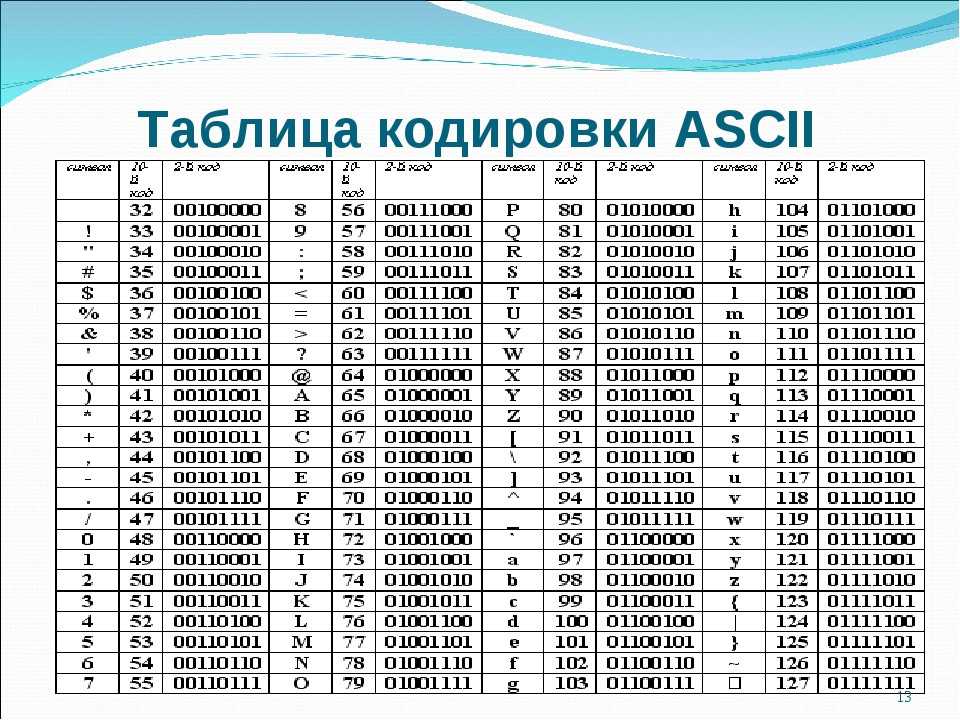
Значение пробела в десятичном формате ASCII равно 32, а в двоичном — 10000. Но кто присваивает эти значения и как присваиваются значения ASCII?
Значения ASCII присваиваются INCITS (Международным комитетом по стандартам информационных технологий). Это организация по разработке стандартов, аккредитованная ANSI (Американским национальным институтом стандартов).
INCITS состоит из разработчиков информационных технологий.
INCITS изначально был известен как X3 и NCITS.
Вы можете узнать больше об этой группе, которая также стоит за стандартизацией ASCII, в разделе об истории стандартизации ASCII ниже.
Почему ASCII так важен?
Теперь вы знаете основы ASCII, в том числе, что это такое и кто определяет значения ASCII.
Однако вы все еще можете не понимать, почему ASCII так важен. В этом разделе объясняется, почему это так важно.
ASCII необходим в современном мире, потому что он служит связующим звеном между тем, что человек видит на экране компьютера, и тем, что находится на жестком диске его компьютера.
Без ASCII современные вычисления были бы гораздо более сложными и гораздо менее оптимизированными.
ASCII обеспечивает общий язык для всех компьютеров для установления этой связи между экраном и жестким диском.
Важность ASCII в деталях: общий язык для компьютеров
Вы все еще запутались?
ASCII переводит человеческий текст в компьютерный текст и наоборот.
Компьютеры общаются с помощью двоичного кода, сложного языка, состоящего из последовательности нулей и единиц (0, 1). Это алфавит для ноутбука.
Тем временем у людей есть свой алфавит.
Например, английский алфавит состоит из азбуки. Другие языки используют другие алфавиты. Например, русский использует кириллицу.
В прошлом у компьютеров были свои версии этих различных алфавитов и языков.
Рассмотрим это так:
В то время как некоторые компьютеры использовали компьютерный эквивалент кириллицы, другие использовали компьютерный эквивалент латинского алфавита (тот, который используется для английского языка).
Из-за этого было чрезвычайно сложно установить связь и согласованность между компьютерами.
ASCII дал всем компьютерам один язык с одним алфавитом.
В этом отношении ASCII был революционной разработкой, позволившей компьютерам обмениваться файлами и документами и проложившей путь для современного компьютерного программирования.
Примеры ASCII в действии в повседневной жизни
Файлы ASCII могут служить общим знаменателем для всех видов преобразования данных.
Например, программа не может преобразовать свои данные в другой формат программы.
Однако обе программы могут вводить и выводить файлы ASCII.
Это означает, что преобразование возможно, даже если эти два программного обеспечения несовместимы.
Символы ASCII также используются при отправке или получении электронной почты.
В следующем разделе рассматривается, почему используется код ASCII.
Почему используется код ASCII?
Вы получили ответ на вопрос «что такое код ASCII?»
Вы, наверное, все еще задаетесь вопросом, что такое вместо .
Таблицы ASCII широко используются в компьютерных кругах. По сути, они служат «переводчиком Google» между людьми и жесткими дисками компьютеров.
Жесткий диск — это, по сути, память компьютера. В нем хранится информация о транзисторах или магнитах, которые можно включать и выключать.
Жесткие диски полагаются на байты.
Байт — единица цифровой информации. Обычно он состоит из восьми битов. 8-битный байт обычно называют октетом.
Таблица ASCII используется для перевода байта данных (двоичного кода, состоящего из восьми нулей и единиц) в букву, которую может прочитать человек, например «a» или «A» или цифру «2».
На практике, какова цель ASCII?
Таблицы ASCII используются во всех компьютерных системах.
Таким образом, вы можете читать текстовый документ, написанный на вашем ПК, даже если вы используете Mac, потому что код ASCII каждая система знает, какой двоичный код обозначает какой символ.
Это лишь один из многих примеров того, как ASCII делает современную жизнь более управляемой.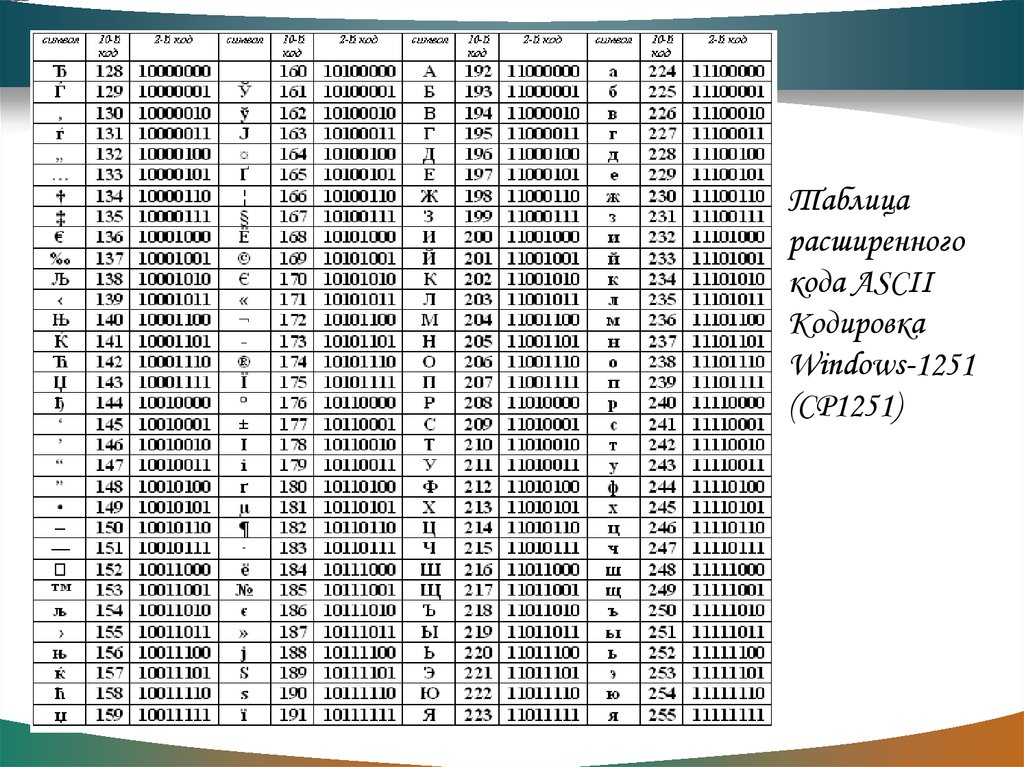
Где хранится ASCII?
Понятно, что для использования ASCII компьютерное оборудование должно где-то хранить эту удобную таблицу ASCII, верно?
Не совсем.
Компьютеры не могут работать с символами, как в ASCII.
Все, о чем заботятся компьютеры, это их язык, двоичный — компьютеры хранят только числа.
Связь 8-битного числа с печатным символом, понятным человеку, совершенно произвольна для ноутбука.
Хотите понять, как работает ASCII и где он хранится?
Тогда важно понимать роль компилятора.
Что такое компилятор?
В компьютерном программировании компилятор — это тип программы, отвечающей за перевод компьютерного кода, написанного на одном языке программирования, называемом исходным языком, на другой тип языка, известный как целевой язык.
Существуют разные виды компиляторов.
Например, кросс-компилятор может работать на компьютере с операционной системой, отличной от операционной системы другого компьютера.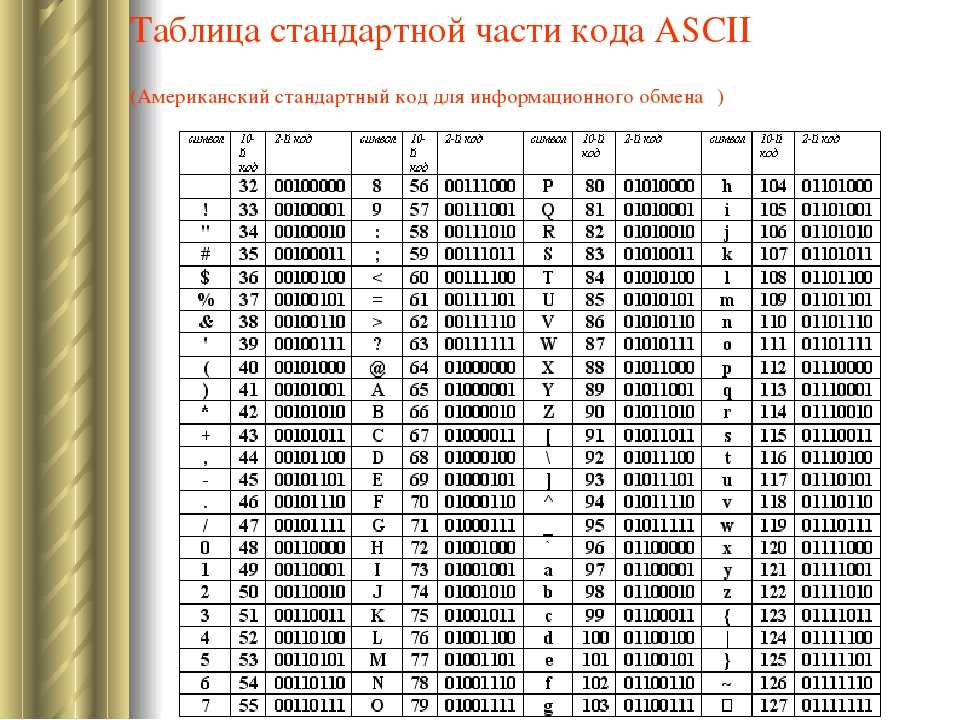
В отличие от этого, компилятор исходного кода может выполнять перевод между языками программирования высокого уровня.
Почему компиляторы важны для ASCII?
Компьютерные программы должны регулярно выполнять операции с текстовыми строками.
Текстовая строка состоит из символов, которые переводятся в машинный код.
Компилятор должен сначала сохранить каждый символ в ячейке основной памяти, куда ЦП (центральный процессор) может получить доступ, чтобы завершить это преобразование.
Затем компилятор должен сгенерировать машинные инструкции для вывода реальных символов на экран.
Программирование с использованием символов возможно, поскольку компилятор принимает исходный код, а аппаратное обеспечение, выполняющее этот исходный код, соглашается с тем, как отображать символы в числа.
Кодировка используется для определения того, что, например, «А» равно 65. Это 9Компилятор 3815 , хранящий символы.
Короче говоря, таблица ASCII управляется операционной системой, такой как Windows, macOS или Linux.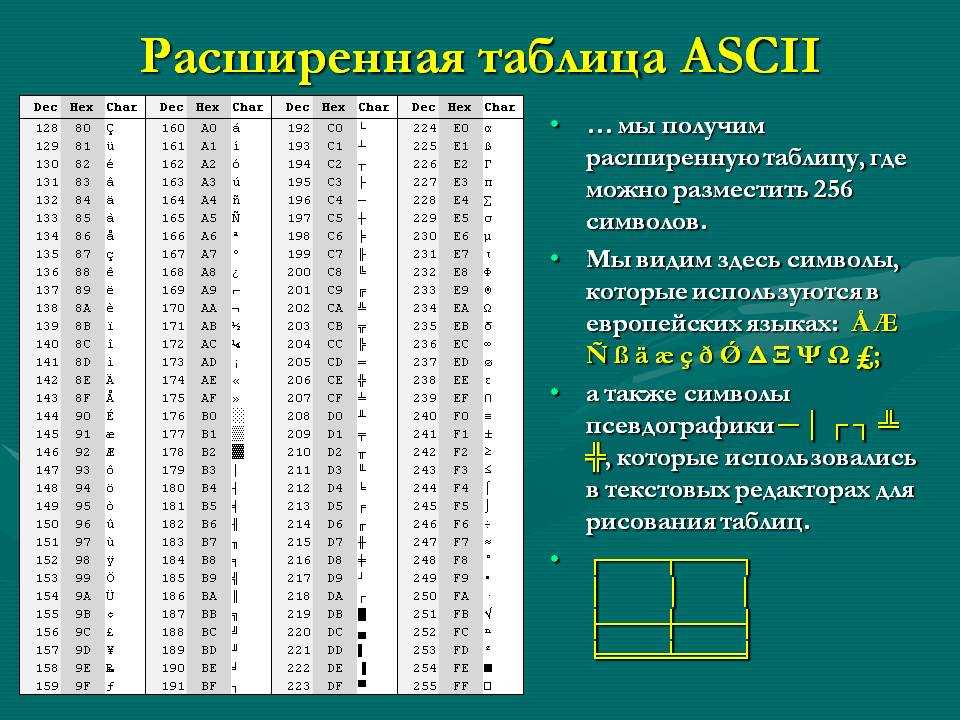 У него нет определенного физического местоположения, такого как PDF-файл или ваша любимая фотография, сделанная прошлым летом.
У него нет определенного физического местоположения, такого как PDF-файл или ваша любимая фотография, сделанная прошлым летом.
Как символы ASCII размещаются в оперативной памяти — это, вероятно, ваш следующий вопрос, верно?
Программа считывает символы ASCII, когда они вводятся с клавиатуры. Затем он сохраняет их в последовательных местах байта. Сделанный.
Что такое примеры ASCII?
Часто проще объяснить ASCII на примерах.
Понимание того, как символы ASCII соответствуют значениям, понятным людям, помогает объяснить концепцию.
Что такое пример ASCII?
Вот некоторые примеры ASCII:
- Строчная буква «i» представлена в коде ASCII двоичным 1101001 и десятичным 105.
- Строчный символ «h» равен 01101000 в двоичном коде и имеет десятичное значение 104,
- Строчная буква «а» представлена цифрой 97 в десятичном формате и 01100001 в двоичном формате.
- Заглавная буква «А» представлена в десятичном виде цифрой 65 и 01000001 в двоичном формате.

Какова история ASCII?
Понимание исторического значения кода ASCII помогает понять его актуальность сегодня.
Во-первых, важно признать, что ASCII берет свое начало в телеграфном коде.
По сравнению с более ранними телеграфными кодами, ASCII был разработан, чтобы быть более удобным для целей алфавитного алфавита и сортировки списков.
В нем также размещались устройства, отличные от телепринтеров.
ASCII и телеграф
До того, как появились телефоны и интернет, телеграф позволял осуществлять междугороднюю связь в режиме реального времени. Он передавал печатные коды по радиоволнам или по проводам.
Код ASCII был впервые коммерчески использован компанией Bell как часть семибитного кода телетайпа для телеграфных услуг.
Имя «Белл» вам ничего не говорит?
Вы можете связать его с Александром Грэмом Беллом, которому приписывают изобретение первого практичного телефона. Он также является основателем телефонной компании Bell, основанной в 1877 году.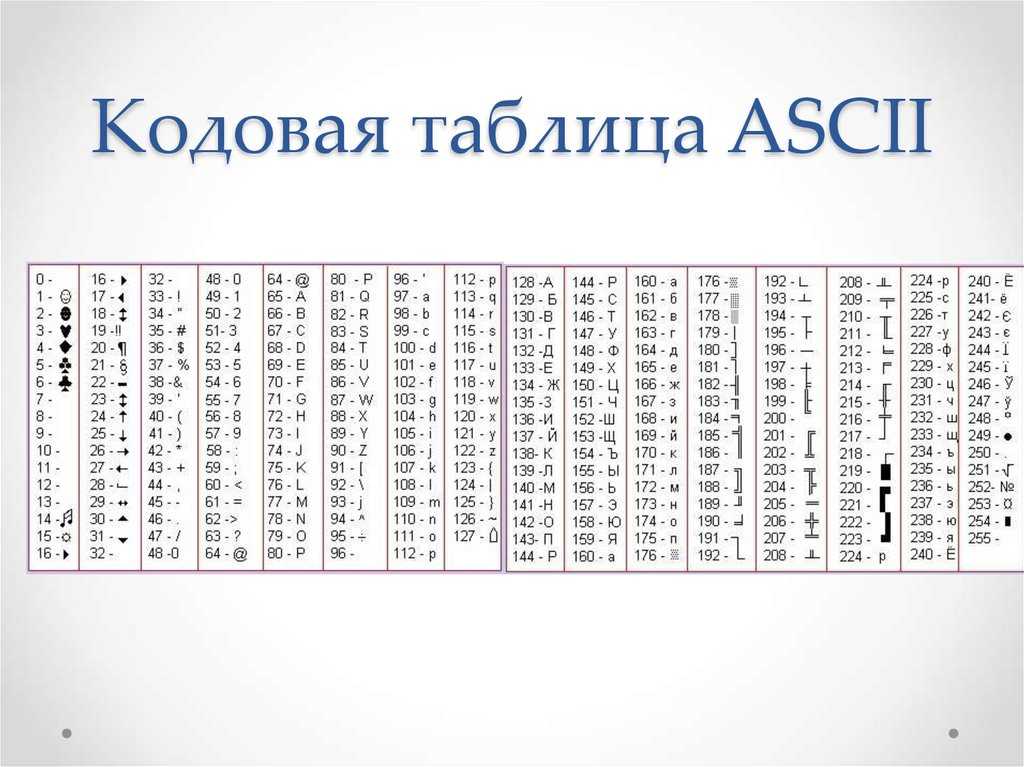 0003
0003
Дочерняя компания Bell American Telephone and Telegraph Company (название, которое вы все еще можете узнать как AT&T) была основным поставщиком телеграфных услуг.
Стандартизация ASCII
Так когда же был изобретен ASCII?
На заре развития компьютерных технологий существовали десятки различных способов представления цифр и букв в памяти компьютера.
Частично это было связано с тем, что размер одной части компьютерной памяти не был стандартизирован до середины 19 века.00с.
Итак, до 1960-х годов для вычислений использовались разные коды.
IBM использовала один код, в то время как AT&T использовала другой код (расширенный двоично-десятичный код обмена (EBCDIC), а военные США использовали еще один другой код.
Это было, мягко говоря, не очень удобно.
В В 1960-х годах инженеры IBM возглавили усилия по созданию единого кода для связи, и началась работа по стандартизации кода ASCII для повседневного использования.
Это привело к созданию подкомитета X3.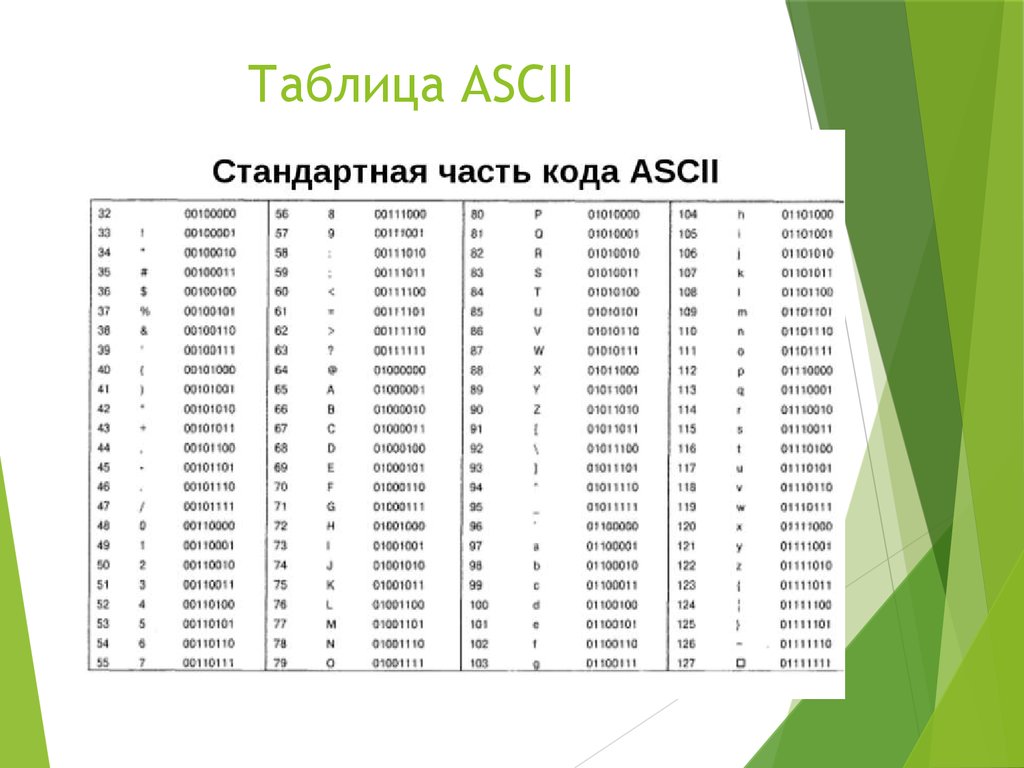 2 Американской ассоциации стандартов (ASA)9.0003
2 Американской ассоциации стандартов (ASA)9.0003
6 октября 1960 года подкомитет ASA X3.2 собрался для стандартизации ASCII. Если вам интересно, «кто изобрел код ASCII?» там твой ответ.
Первая редакция кода ASCII была опубликована в 1963 году. После этой первой встречи 28 кодовых позиций остались с открытыми значениями, зарезервированными для будущего назначения.
ASCII был впервые коммерчески использован AT&T в 1963 году. Он служил семибитным кодом телепринтера для сети AT&T TeletypeWriter eXchange, TWX.
Коммерческое использование ASCII
Код ASCII был пересмотрен в 1967 году. К этому моменту комитет X3.2 внес ряд изменений.
Например, они добавили новые символы, в том числе вертикальную черту и фигурную скобку, и удалили другие.
Последнее обновление было сделано в 1986 году.
В 1968 году президент США Линдон Б. Джонсон издал указ, согласно которому любой компьютер, приобретаемый федеральным правительством, должен поддерживать кодировку ASCII.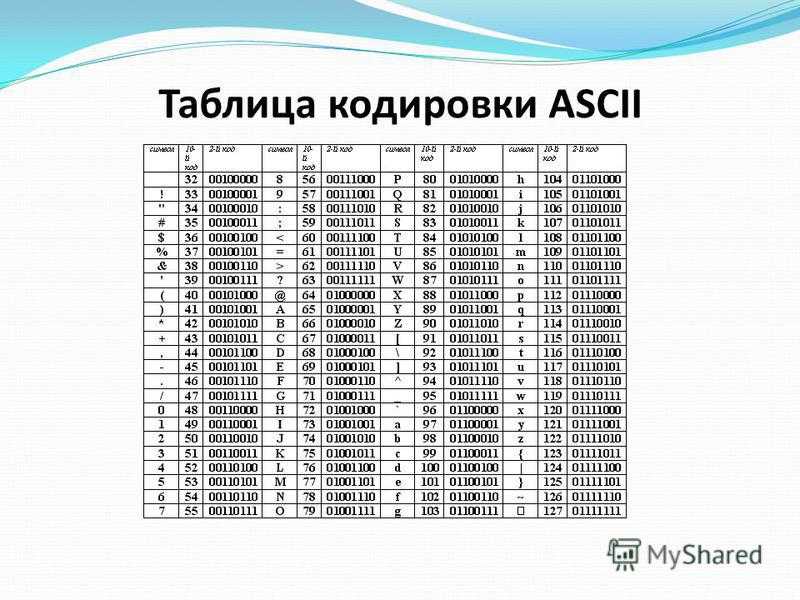 Это была важная веха, указывающая на переход сверху вниз к коду ASCII.
Это была важная веха, указывающая на переход сверху вниз к коду ASCII.
Позже, в 1970-х, ASCII стал широко использоваться, когда Intel разработала восьмибитные микропроцессоры.
Наконец, основной конкурент ASCII, EBCDIC, в 1980-х был фактически упразднен.
К этому моменту был разработан персональный компьютер, позволивший ASCII стать более актуальным для широкой публики.
Разработка расширенного ASCII
Как бы то ни было, набор символов ASCII едва ли может покрыть все потребности английского языка. В нем не хватает многих глифов, и он слишком мал для универсального использования.
Итак, когда был разработан расширенный ASCII?
В 1970-х разработчики компьютеров уже заметили эту проблему.
Пытаясь разработать технологию для глобальных рынков, они обнаружили, что ASCII не может охватывать все.
Например, в некоторых европейских языках используются буквы с диакритическими знаками (например, ä, ï, ö, ë, ÿ).
Существуют также другие символы и коды, используемые во всем мире, такие как «£» для британского фунта (который затем был перепутан с американской интерпретацией фунта, #).
В 1970-х годах компьютеры были стандартизированы для восьмибитных байтов. К этому времени стало очевидно, что компьютерные технологии и программное обеспечение не будут обрабатывать текст, использующий наборы из 256 символов. В результате был расширен ASCII.
Это позволило добавить 128 дополнительных символов или расширенный код ASCII.
Разработанные восьмибитные кодировки охватывали в основном западноевропейские языки, такие как немецкий, французский, испанский и голландский.
С тех пор было разработано множество проприетарных наборов 8-битных символов ASCII.
Транскодирование относится к процессу перевода между этими уникальными, специально разработанными наборами и стандартом ASCII.
Несмотря на попытки координации на международном уровне, проприетарные наборы остаются оптимальным решением в тех случаях, когда традиционный расширенный ASCII оказывается недостаточным.
ASCII в новейшей истории
Обратите внимание, что ASA теперь называется Американским национальным институтом стандартов или ANSI.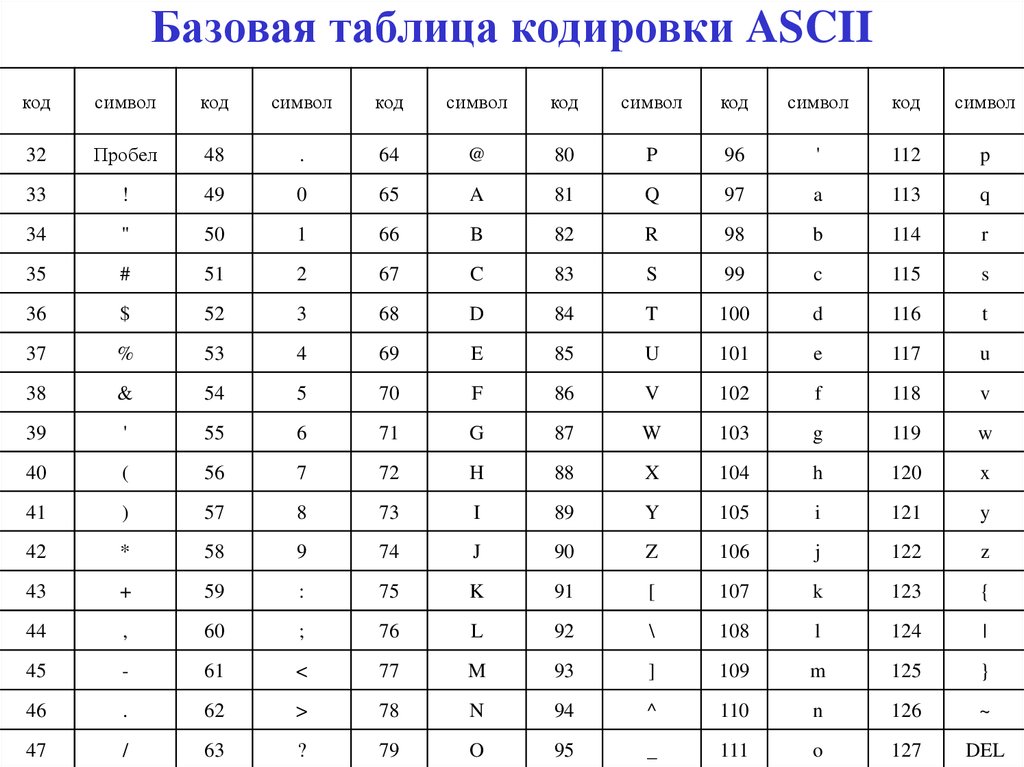
Напротив, подкомитет X3.2 теперь называется рабочей группой X3.2.4 или Международным комитетом по стандартам информационных технологий, или INCITS.
ASCII был наиболее распространенным типом кодировки символов, используемым во всемирной паутине до 2007 года, после чего преобладала UTF-8.
В отличие от ASCII, UTF-8 обратно совместим.
Как ASCII используется в современном мире?
Вышеприведенная информация охватывает много материала, от значения ASCII до таблиц и истории развития ASCII.
Итак, кто сегодня использует ASCII?
Это все еще актуально?
Абсолютно.
Однако, как уже упоминалось, ASCII имеет ограничения.
Трудно распространить на неанглийские алфавиты, такие как кириллица.
Юникод — это ответ.
Это попытка создать таблицу символов, которая может охватывать все, от африканских до азиатских сценариев.
Поддерживаются символы, отличные от ASCII.
Для чего сегодня используется ASCII?
По сей день ASCII служит стандартным компьютерным языком.
Основной принцип остается прежним:
ASCII использует коды из таблицы ASCII для преобразования компьютерной информации в информацию, которую люди могут прочитать.
Этот набор символов помогает компьютерам и людям «общаться», поскольку компьютеры понимают только двоичные данные, а люди понимают только язык.
Сегодня ASCII является стандартом практически для любой операционной системы.
Когда сегодня используется ASCII?
Что касается того, где используется код ASCII, ответ почти везде.
Современные расширенные версии ASCII сохраняют актуальность и могут даже включать языки, отличные от английского, а также научные, логические и математические описания.
Когда компьютер извлекает данные, он проверяет номер символа, например, десятичное число 65.
Затем он переводит эту информацию в соответствующий символ десятичного числа 65 (в американском английском ASCII, что означает заглавную букву «А»). ).
Например, вот ваша азбука, как ее видит компьютер: «0110001 0110010 0110011».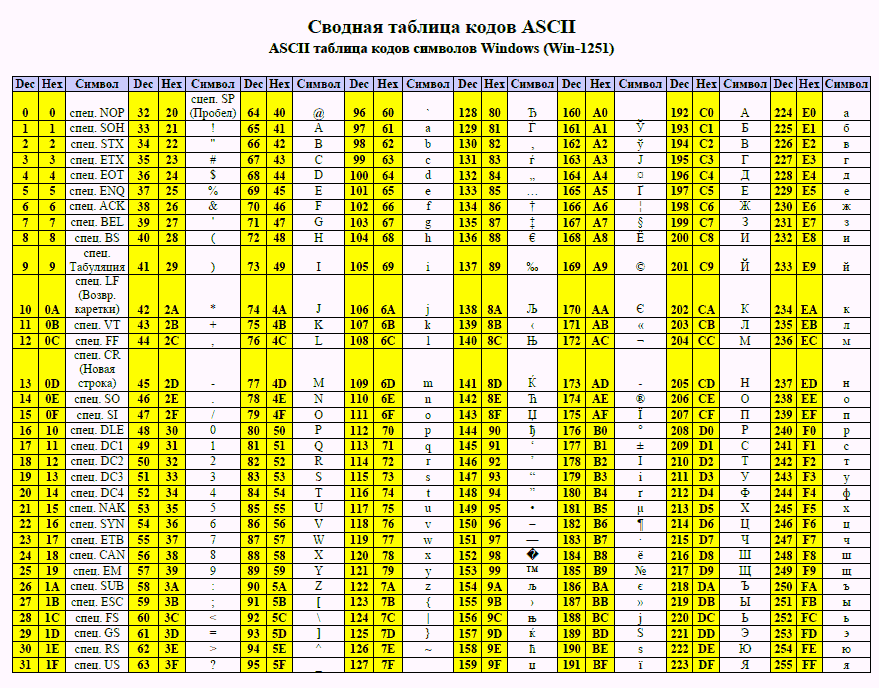 Вам это может показаться бредом, но для компьютера это очевидно. На экране он читается как «ABC».
Вам это может показаться бредом, но для компьютера это очевидно. На экране он читается как «ABC».
Кто использует ASCII?
Хотя вы, несомненно, уже понимаете ценность ASCII, вам все еще может быть интересно, кто на земле использует этот материал?
Ответ: программисты.
Программисты перехватывают нажатия клавиш по коду символа, а затем решают, что делать при нажатии отдельных клавиш.
Очевидно, для информационных систем для бизнеса, таких как ERP или CRM.
ASCII остается базовым стандартом для таких задач.
Что такое нетрадиционное использование ASCII?
ASCII по-прежнему в конечном счете предназначен для улучшения функциональности компьютеров и улучшения совместимости между различными системами.
Впрочем, ASCII можно использовать и для более, скажем так, несерьезных целей.
Читайте дальше, чтобы узнать о двух забавных способах использования ASCII.
ASCII Emojis
Английский язык сильно изменился с момента разработки ASCII в 1960-х годах.
Способы общения людей изменились, появилось больше текстовых сообщений.
Одним из наиболее значительных результатов стало использование эмодзи.
Что делает ASCII со смайликами?
Может ли ASCII представлять эмодзи?
Не так, как вы себе представляете.
Традиционная таблица ASCII не была расширена, чтобы включить, например, целый раздел для эмодзи.
Однако существуют так называемые смайлики ASCII, которые вы можете проверить.
Существует даже расширение ASCIImoji для Chrome. Он позволяет ввести слово и получить смайлик.
Например, если вы наберете (медведь), вы увидите это на экране: ʕ·͡ᴥ·ʔ
Вы можете просмотреть полный список здесь, но будьте осторожны, не все они подходят для работы (NSFW)!
Итак, может ли ASCII представлять эмодзи?
Вид.
Однако это не традиционный подход к ASCII. Принцип работы аналогичен тому, как работает код ASCII.
В этом случае, однако, то, как ASCII используется для представления текста, вместо этого используется для описания изображений.
ASCII, статья
Другое современное использование ASCII — искусство ASCII.
Это просто изображения, созданные компьютерами посредством стратегического позиционирования строк кода.
Строки кода расположены таким образом, что издалека они выглядят как рисунки и рисунки.
С технической точки зрения ASCII-арт — это тип графического дизайна. Он использует компьютеры для представления изображений, собранных вместе с использованием символов ASCII.
Используются только 95 печатных символов ASCII.
Подобно ASCII в целом, искусство ASCII восходит к гораздо более старой технологии.
В то время как ASCII берет свое начало в телеграмме, ASCII находит свое вдохновение в искусстве пишущей машинки, которое использует пишущую машинку для рисования изображения с использованием точно расположенных букв.
Самые старые известные образцы ASCII-графики были созданы Кеннетом Ноултоном, пионером компьютерного искусства, работавшим в Bell Labs в 1960-х годах.
С тех пор у ASCII-графики появилось множество поклонников.
Искусство ASCII — это не только эстетика. Как и ASCII, он был разработан из-за практической необходимости.
ASCII был изобретен отчасти потому, что первые принтеры не имели графических технологий, которые есть сегодня. Таким образом, символы иногда использовались вместо графических знаков.
Кроме того, массовые принтеры часто также используют символы ASCII для простого обозначения разделения между различными заданиями на печать.
Вставка «графического изображения» облегчила обнаружение оператором компьютера. Искусство ASCII также использовалось в электронных письмах до того, как можно было встроить изображения.
Примеры ASCII Art
Некоторые изображения кода ASCII стали очень популярными.
Вы можете своими глазами увидеть известные картины, воссозданные в формате ASCII онлайн.
От «Рождения Венеры» Сандро Боттичелли до «Постоянства памяти» Сальвадора Дали — вы, вероятно, узнаете немало таких творений, даже если они «нарисованы» с использованием ASCII.