системный вызов write(), на самом деле, не такой уж и атомарный / Хабр
Недавно я читал материал Эвана Джонса «Устойчивое хранение данных и файловые API Linux». Я полагаю, что автор этой довольно хорошей статьи ошибается, говоря о том, чего можно ожидать от команды write() (и в том виде, в каком она описана в стандарте POSIX, и на практике). Начну с цитаты из статьи:
Системный вызов write() определён в стандарте IEEE POSIX как попытка записи данных в файловый дескриптор. После успешного завершения работы write() операции чтения данных должны возвращать именно те байты, которые были до этого записаны, делая это даже в том случае, если к данным обращаются из других процессов или потоков (вот соответствующий раздел стандарта POSIX). Здесь, в разделе, посвящённом взаимодействию потоков с обычными файловыми операциями, имеется примечание, в котором говорится, что если каждый из двух потоков вызывает эти функции, то каждый вызов должен видеть либо все обозначенные последствия, к которым приводит выполнение другого вызова, либо не видеть вообще никаких последствий.
Означает ли это, что операция write() является атомарной? С технической точки зрения — да. Операции чтения данных должны возвращать либо всё, либо ничего из того, что было записано с помощью write(). […].
К сожалению, то, что операции записи, в целом, атомарны — это не то, что говорится в стандарте POSIX, и даже если именно это и попытались выразить авторы стандарта — весьма вероятно то, что ни одна версия Unix этому стандарту не соответствует, и то, что ни одна из них не даёт нам полностью атомарных команд записи данных. Прежде всего, то, что в стандарте POSIX чётко сказано об атомарности, применяется лишь в двух ситуациях: когда что-то пишется в конвейер или в FIFO, или когда речь идёт о нескольких потоках одного и того же процесса, выполняющих некие действия. А то, что стандарт POSIX говорит об операциях записи, смешанных с операциями чтения, имеет гораздо более ограниченную область применения.
После того как произошёл успешный возврат из операции записи (write()) в обычный файл:
- Любая успешная операция чтения (read()) данных из каждой байтовой позиции файла, которая была модифицирована этой операцией записи, должна возвращать данные, установленные для этой позиции командой write() до тех пор, пока данные в таких позициях не будут снова модифицированы.
Это не требует какого-то особого поведения от команд чтения данных из файла, запущенных другим процессом до возврата из команды записи (включая те, которые начались до начала работы write()). Если выполнить подобную команду read(), POSIX позволяет этой команде вовсе не прочитать данные, записываемые write(), прочитать лишь некоторую часть этих данных, или прочитать их все. Подобная команда  При таком подходе, определённо, не реализуется обычная, привычная всем, атомарная схема работы, когда либо видны все результаты работы некоей команды, либо результаты её работы не видны вовсе. Так как разрешено кросс-процессное выполнение команды
При таком подходе, определённо, не реализуется обычная, привычная всем, атомарная схема работы, когда либо видны все результаты работы некоей команды, либо результаты её работы не видны вовсе. Так как разрешено кросс-процессное выполнение команды read() во время выполнения команды write(), выполнение команды чтения может привести к возврату частичного результата работы команды записи. Мы не назвали бы «атомарной» SQL-базу данных, которая позволяет прочитать результаты незавершённой транзакции. Но именно это стандарт POSIX позволяет команде
(Это, кроме того, именно то, что, почти гарантированно, дают нам реальные Unix-системы, хотя тут возможно много ситуаций, и Unix-системы я на предмет этого не тестировал. Например, меня бы не удивило, если бы оказалось, что выровненные операции записи фрагментов данных, размеры которых соответствуют размерам страниц (или блоков файловой системы), на практике, оказались бы атомарными во множестве Unix-систем. )
)
Если подумать о том, что потребуется для реализации атомарных операций записи в файлы в многопроцессной среде, то сложившаяся ситуация не должна выглядеть удивительной. Так как Unix-программы не ожидают коротких сеансов записи в файлы, мы не можем упростить проблему, установив лимит размера данных, запись которых необходимо выполнять атомарно, а потом ограничив write() этим размером. Пользователь может запросить у системы запись мегабайтов или даже гигабайтов данных в одном вызове write() и эта операция должна быть атомарной. Во внутренний буфер ядра придётся собирать слишком много данных, а затем придётся менять видимое состояние соответствующего раздела файла, укладывая всё это в одно действие. Вместо этого подобное, вероятно, потребует блокировки некоего диапазона байтов, где read() блокируют друг друга при перекрытии захваченных ими диапазонов. А это означает, что придётся выполнять очень много блокировок, так как в этом процессе придётся принимать участие каждой операции write() и каждой операции read().
(Операцию чтения данных из файлов, которые никто не открывал для записи, можно оптимизировать, но при таком подходе, всё равно, придётся блокировать файл, делая так, чтобы его нельзя было бы открыть для записи до тех пор, пока не будет завершена операция
Но блокировать файлы лишь при выполнении команды read() в современных Unix-системах недостаточно, так как многие программы, на самом деле, читают данные, используя отображение файлов на память с помощью системного вызова mmap(). Если действительно требуется, чтобы операция write() была бы атомарной, нужно блокировать и операции чтения данных из памяти при выполнении команды записи. А это требует довольно-таки ресурсозатратных манипуляций с таблицей страниц. Если заботиться ещё и о mmap(), то возникнет одна проблема, которая заключается в том, что когда чтение осуществляется через отображение файла на память, команда  Тот, кто читает данные из памяти, на которую отображается файл, может столкнуться со страницей, находящейся в процессе копирования в неё байтов, записанных с помощью
Тот, кто читает данные из памяти, на которую отображается файл, может столкнуться со страницей, находящейся в процессе копирования в неё байтов, записанных с помощью write().
(Это может произойти даже с read() и write(), так как и та и другая команды могут получить доступ к одной и той же странице данных из файла в буферном кеше ядра. Но тут, вероятно, легче применить механизм блокировки.)
Помимо проблем с производительностью тут наблюдаются и проблемы со справедливостью распределения системных ресурсов. Если команда write() является, по отношению к команде read(), атомарной, это значит, что длительная операция write() может остановить другую команду на значительное время. Пользователям не нравятся медленные и откладываемые на какое-то время операции read() и write(). Подобное, кроме того, даст удобный инструмент для DoS-атак путём записи данных в файлы, открываемые для чтения. Для этого достаточно снова и снова запрашивать у системы выполнение операции над всем файлом за один заход (или над таким его фрагментом, над которым можно выполнить нужную операцию).
Для этого достаточно снова и снова запрашивать у системы выполнение операции над всем файлом за один заход (или над таким его фрагментом, над которым можно выполнить нужную операцию).
Правда, большая часть затрат системных ресурсов происходит из-за того, что мы рассуждаем о кросс-процессных атомарных операциях записи, так как это значит, что действия по выполнению блокировок должно выполнять ядро. Кросс-поточная атомарная операция write() может быть реализована полностью на уровне пользователя, в пределах отдельного процесса (при условии, что библиотека C перехватывает операции read() и write() при работе в многопоточном режиме). В большинстве случаев можно обойтись какой-нибудь простой системой блокировки всего файла, хотя тем, кто работает с базами данных, это, вероятно, не понравится. Вопросы справедливости распределения системных ресурсов и задержки операций из-за блокировок при работе в пределах одного процесса теряют остроту, так как единственным, кому это повредит, будет тот, кто запустил соответствующий процесс.![]()
(Большинство программ не выполняют операции read() и write() над одним и тем же файлом в одно и то же время из двух потоков.)
P.S. Обратите внимание на то, что даже операции записи в конвейеры и в FIFO являются атомарными только если объём записываемых данных достаточно мал. Запись больших объёмов данных, очевидно, не должна быть атомарной (и в реальных Unix-системах она таковой обычно и не является). Если бы стандарт POSIX требовал бы атомарности при записи ограниченных объёмов данных в конвейеры, и при этом указывал бы на то, что запись любых объёмов данных в файлы так же должна быть атомарной, это выглядело бы довольно-таки необычно.
P.P.S. Я с осторожностью относился бы к принятию как данности того, что в некоем варианте Unix, в многопоточной среде, полностью реализованы атомарные операции read() и write(). Возможно, я настроен скептически, но я бы сначала это как следует проверил. Всё это похоже на излишне прихотливые требования POSIX, на которые разработчики систем закрывают глаза во имя простоты и высокой производительности своих решений.
Приходилось ли вам сталкиваться с проблемами, вызванными одновременным выполнением записи в файл и чтения из него?
VBA Excel. Операторы чтения и записи в файл
Чтение и запись в файл, открытый с помощью оператора Open. Операторы Input, Line Input, Write и функция EOF. Примеры использования в VBA Excel.
Операторы чтения и записи в файл
Оператор Input #
Оператор Input # считывает данные из открытого файла с последовательным доступом и присваивает эти данные переменным.
Оператор Input # используется только с файлами, открытыми в режиме Input или Binary. При прочтении стандартные строковые или числовые значения присваиваются переменным без изменения.
Синтаксис оператора Input #:
Input #Номер_файла, Переменные |
Компоненты оператора Input #:
- Номер_файла – обязательный параметр, представляющий из себя номер, присвоенный файлу при открытии с помощью оператора Open.

- Переменные – обязательный параметр, представляющий из себя список переменных, разделенных запятой, которым присваиваются значения, считанные из файла.
Особенности применения оператора Input #:
- Элементы данных в файле должны быть указаны в том же порядке, что и переменные в списке Переменные, и соответствовать им по типу данных. Если переменная числовая, а данные текстовые, этой переменной будет присвоено нулевое значение.
- Если при чтении данных достигнут конец файла, чтение прерывается и возникает ошибка. Для ее предупреждения в коде VBA Excel используется функция EOF.
- Чтобы данные из файла могли быть правильно прочитаны и записаны в переменные с помощью оператора Input #, они должны быть записаны в файл с помощью оператора Write #. Он обеспечивает правильное разделение каждого из полей (элементов) данных.
Оператор Line Input #
Оператор Line Input # считывает одну строку из открытого файла с последовательным доступом и присваивает ее значение строковой переменной.
Оператор Line Input # считывает из файла по одному символу до тех пор, пока не встретится символ возврата каретки (Chr(13)) или последовательность символа возврата каретки и перевода строки (Chr (13) + Chr(10)).
Синтаксис оператора Line Input #:
Line Input #Номер_файла, Переменная |
Компоненты оператора Line Input #:
- Номер_файла – обязательный параметр, представляющий из себя номер, присвоенный файлу при открытии с помощью оператора Open.
- Переменная – обязательный параметр, представляющий из себя имя переменной, объявленной как String или Variant, которой присваивается строка, считанная из файла.
Оператор Write #
Оператор Write # записывает данные в файл с последовательным доступом.
Синтаксис оператора Write #:
Write #Номер_файла, [Данные] |
Компоненты оператора Write #:
- Номер_файла – обязательный параметр, представляющий из себя номер, присвоенный файлу при открытии с помощью оператора Open.
- Данные – необязательный параметр, представляющий из себя одно или несколько числовых или строковых выражений, разделенных запятой, которые нужно записать в файл.

Особенности применения оператора Write #:
- Данные, записанные с помощью оператора Write #, считываются из файла с помощью оператора Input #.
- Если опустить параметр Данные и добавить запятую после Номер_файла, в файл будет добавлена пустая строка.
- Несколько выражений в списке Данные могут быть разделены точкой с запятой или запятой.
- Числовые данные всегда записываются с точкой в качестве разделителя целой и дробной части.
- Оператор Write # вставляет запятые между элементами и прямые парные кавычки вокруг строк при их записи в файл.
- После записи в файл последнего символа из параметра Данные оператор Write # вставляет символы возврата каретки и перевода строки (Chr (13) + Chr(10)).
Функция EOF
Функция EOF возвращает логическое значение True, когда достигнут конец файла, открытого для последовательного (Input) или произвольного (Random) доступа.
Синтаксис функции EOF:
EOF (Номер_файла) |
Номер_файла – это номер, присвоенный файлу при открытии с помощью оператора Open.
Функция EOF используется для предупреждения ошибок, вызываемых попытками выполнить чтение после конца файла. Она возвращает значение False, пока не будет достигнут конец файла.
Примеры чтения и записи в файл
Пример 1
Открытие (или создание, если он не существует) текстового файла для чтения и записи и запись в него одной строки, состоящей из двух текстовых и одного числового значений. Файл с именем myFile1.txt будет создан в той же папке, где расположен файл Excel с кодом VBA.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Sub Test1() Dim ff As Integer, ws As Object ‘Получаем свободный номер для открываемого файла ff = FreeFile ‘Открываем (или создаем) файл для чтения и записи Open ThisWorkbook.Path & «\myFile1.txt» For Output As ff ‘Записываем в файл одну строку Write #ff, «Дает корова молоко!», _ «Куда идет король?», 25.35847 ‘Закрываем файл Close ff ‘Открываем файл для просмотра Set ws = CreateObject(«WScript.Shell») ws.Run ThisWorkbook.Path & «\myFile1.txt» Set ws = Nothing End Sub |
Строки и число можно предварительно присвоить переменным, объявленным с соответствующими типами данных, и использовать их для записи данных в файл (в строках кода с оператором Write #, как в этом и следующем примерах).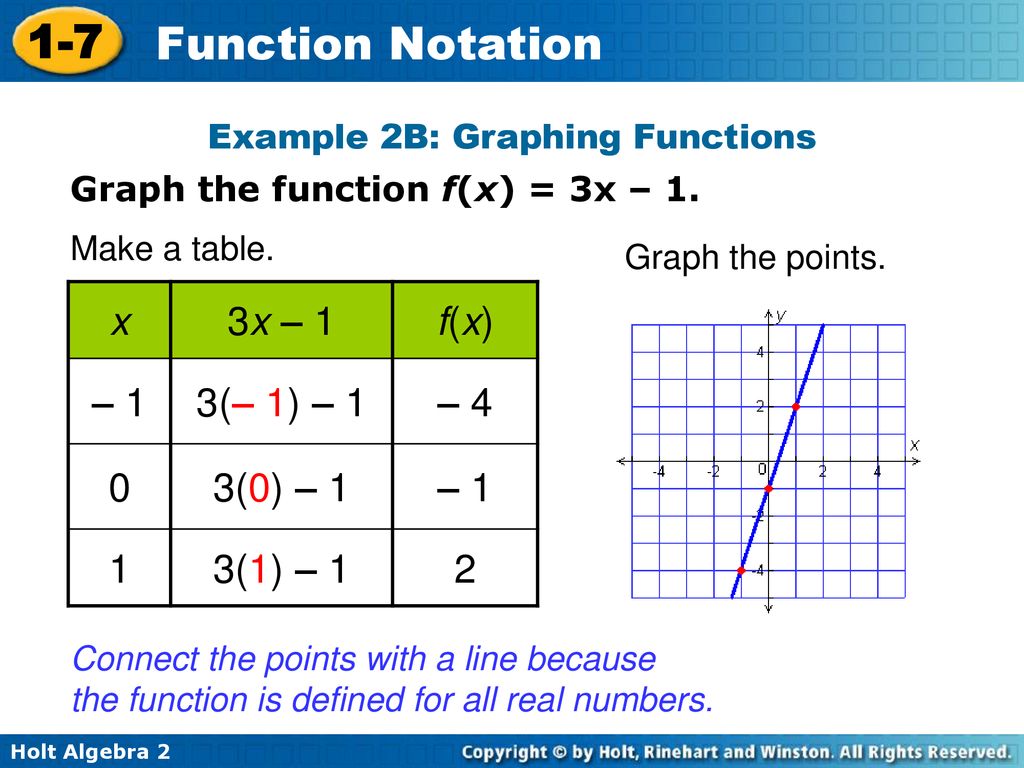
Пример 2
Открытие (или создание, если он не существует) файла без расширения для чтения и записи и запись в него трех строк: двух текстовых и одной в числовом формате. Файл с именем myFile2 будет создан в той же папке, где расположен файл Excel с кодом VBA.
Так как у файла нет расширения, Windows выведет диалоговое окно для выбора открывающей его программы. Выберите любой текстовый редактор или интернет-браузер.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | Sub Test2() Dim ff As Integer, ws As Object ‘Получаем свободный номер для открываемого файла ff = FreeFile ‘Открываем (или создаем) файл для чтения и записи Open ThisWorkbook.Path & «\myFile2» For Output As ff ‘Записываем в файл три строки Write #ff, «Дает корова молоко!» Write #ff, «Куда идет король?» Write #ff, 25. ‘Закрываем файл Close ff ‘Открываем файл для просмотра Set ws = CreateObject(«WScript.Shell») ws.Run ThisWorkbook.Path & «\myFile2» Set ws = Nothing End Sub |
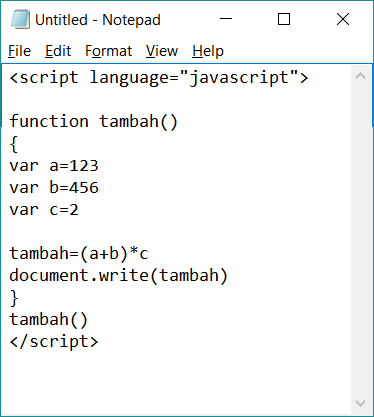 35847
35847Пример 3
Считываем строку, разделенную на отдельные элементы, из файла myFile1.txt и записываем в три переменные, по типу данных соответствующие элементам.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Sub Test3() Dim ff As Integer, str1 As String, _ str2 As String, num1 As Single ‘Получаем свободный номер для открываемого файла ff = FreeFile ‘Открываем файл myFile1.txt для чтения Open ThisWorkbook.Path & «\myFile1.txt» For Input As ff ‘Считываем строку из файла и записываем в переменные Input #ff, str1, str2, num1 Close ff ‘Смотрим, что записалось в переменные MsgBox «str1 = » & str1 & vbNewLine _ & «str2 = » & str2 & vbNewLine _ & «num1 = » & num1 End Sub |
Попробуйте заменить в этом примере строку Input #ff, str1, str2, num1 сначала на строку Input #ff, str1, затем на строку Line Input #ff, str1, чтобы наглядно увидеть разницу между операторами Input # и Line Input #.
В следующих примерах (4 и 5) замена оператора Input # на Line Input # не приведет ни к каким изменениям, так как данные в строках файла myFile2 не разделены на элементы (поля).
Пример 4
Считываем поочередно три строки из файла myFile2 и записываем в три элемента массива, объявленного как Variant, так как в этот файл ранее были записаны две строки с текстом и одна с числом.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Sub Test4() Dim ff As Integer, a(2) As Variant, i As Byte ‘Получаем свободный номер для открываемого файла ff = FreeFile ‘Открываем файл myFile2 для чтения Open ThisWorkbook.Path & «\myFile2» For Input As ff ‘Считываем строки из файла и записываем в элементы массива For i = 0 To 2 Input #ff, a(i) Next Close ff ‘Смотрим, что записалось в элементы массива MsgBox «a(0) = » & a(0) & vbNewLine _ & «a(1) = » & a(1) & vbNewLine _ & «a(2) = » & a(2) End Sub |
Пример 5
Считываем с помощью цикла Do While… Loop все строки из файла myFile2 и записываем построчно в переменную, объявленную как String (число из третьей строки запишется как текст). Для остановки цикла при достижении конца файла используем функцию EOF.
Для остановки цикла при достижении конца файла используем функцию EOF.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Sub Test5() Dim ff As Integer, a As Variant, b As String ‘Получаем свободный номер для открываемого файла ff = FreeFile ‘Открываем файл myFile2 для чтения Open ThisWorkbook.Path & «\myFile2» For Input As ff ‘Считываем строки из файла и записываем в элементы массива Do While Not EOF(ff) Input #ff, a b = b & a & vbNewLine Loop Close ff ‘Смотрим, что записалось в переменную MsgBox b End Sub |
Предыдущая часть темы об открытии файла для ввода и вывода информации опубликована в статье: Оператор Open (синтаксис, параметры). Смотрите также связанную статью: Функция FreeFile.
Смотрите, как создавать и открывать текстовые файлы с помощью методов CreateTextFile и OpenTextFile. Чтение файла, запись и добавление информации с помощью объекта TextStream.
Чтение файла, запись и добавление информации с помощью объекта TextStream.
Содержание рубрики VBA Excel по тематическим разделам со ссылками на все статьи.
Функции ModBus | LAZY SMART
06.12.2016 Один комментарий Рубрика: Промышленная автоматизация, Протоколы связи
В предыдущих статьях мы рассмотрели общую структуру протокола ModBus и его разновидности ModBus RTU и ModBus TCP. В этой статье мы подробно рассмотрим наиболее употребимые функции протокола. Структура функций не зависит от конкретной версии протокола (RTU или TCP).
Вспомним, как выглядит общая структура пакета ModBus:
Блоки «Адрес подчинённого устройства» и «Блок контроля подлинности» различаются в зависимости от версии протокола (RTU или TCP), а вот «Номер функции» и «Данные» в любой реализации одинаковы. Эти два блока образуют часть пакета, которую называют PDU (Protocol Data Unit), — именно она и важна при рассмотрении функций ModBus.
Функция для чтения состояния дискретных выходов устройства.
Запрос:
Ответ:
N* — количество запрошенных дискретных выходов/8. Состояния дискретных выходов (coils) передаются в виде 8-битных слов, поэтому параметр N равен ближайшему целому количеству слов, в которые умещается заданное количество coils.
n = N, если N делится на 8 без остатка, в противном случае n=N+1. Параметр n
Например, нужно прочитать 5 выходов. Тогда в ответе N=5/8=n=1. То есть в ответе после кода функции будет идти 1, а потом ещё один байт, в котором младшие 5 бит будут обозначать состояние запрошенных выходов.
Если устройство обнаружило ошибку при выполнении функции, оно отвечает исключением.
Ответ-исключение:
Коды ошибок стандартные. Их описание можно посмотреть в этой статье.
Пример:
Запрос 19 дискретных выходов, начиная с адреса 19:
В ответе 3 полезных байта:
Состояния входов:
1 полезный байт — состояние выходов с адресами 19 -26: 11001101
2 полезный байт — состояние выходов с адресами 27 -34: 01101011
2 полезный байт — состояние выходов с адресами 35 -37: 00000101 (значащие только 3 младших бита, остальные нули)
Read Discrete Inputs -02 (0х02)Функция для чтения состояния дискретных входов устройства.
Запрос:
Ответ:
N* — количество запрошенных дискретных входов/8. Состояния дискретных входов (inputs) передаются в виде 8-битных слов, поэтому параметр N равен ближайшему целому количеству слов, в которые умещается заданное количество входов.
n = N, если N делится на 8 без остатка, в противном случае n=N+1. Параметр n
Например, нужно прочитать 5 входов. Тогда в ответе N=5/8=n=1. То есть в ответе после кода функции будет идти 1, а потом ещё один байт, в котором младшие 5 бит будут обозначать состояние запрошенных входов.
Если устройство обнаружило ошибку при выполнении функции, оно отвечает исключением.
Ответ-исключение:
Коды ошибок стандартные. Их описание можно посмотреть в этой статье.
Пример:
Запрос 22 дискретных входа, начиная с адреса 196:
В ответе 3 полезных байта:
Состояния входов:
1 полезный байт — состояние выходов с адресами 196 -203: 10101100
2 полезный байт — состояние выходов с адресами 204 -211: 11011011
2 полезный байт — состояние выходов с адресами 212 -217: 00110101 (значащие только 6 младших бита, остальные нули)
Read Holding Registers — 03 (0х03)Функция для чтения регистров общего назначения устройства.
Запрос:
Ответ:
N — количество запрошенных регистров. Каждый регистр состоит из двух байт, поэтому количество полезных байт в ответе равно 2*N.
Если устройство обнаружило ошибку при выполнении функции, оно отвечает исключением.
Ответ-исключение:
Коды ошибок стандартные. Их описание можно посмотреть в этой статье.
Пример:
Запрос на чтение трёх регистров начиная с адреса 107:
В ответе значение 3-х регистров = 6 полезных байта:
Значения регистров (в десятичном виде):
регистр с адресом 107: 555
регистр с адресом 108: 0
регистр с адресом 109: 100
Read Input Registers — 04 (0х04)Функция для чтения входных регистров устройства. По своей структуре полностью идентична предыдущей функции, поэтому разбирать её подробно не имеет смысла.
Единственное отличие этой функции от функции 0х03 Read Holding Registers в том, что она обращается к другой области внутри устройства.
Производитель устройства с поддержкой ModBus сам определяет область памяти, в которой будут хранится «Input Registers».
Input Registers — также 16-битные регистры. В классическом представлении ModBus эти регистры предназначены для хранения значений сигнала на аналоговых входах устройства.
Пример:
Запрос двух входных регистров, начиная с адреса 1:
В ответе содержится значения двух регистров = 4 байта данных:
Значения регистров (в десятичном виде):
регистр с адресом 1: 320
регистр с адресом 2: 17
Write Single Coil — 05 (0х05)Функция для изменения состояния одного из дискретных выходов (coil) устройства.
Состояние выхода («вкл»/ «выкл») определяется константой, записываемой в регистр, соответствующий данному выходу. Значение константы 0хFF00 — определяет состояние «ВКЛ», а значение 0х0000 — состояние «ВЫКЛ».
Запрос:
Ответ:
При успешном выполнении команды ответ совпадает с запросом.
Ответ-исключение:
Коды ошибок стандартные. Их описание можно посмотреть в этой статье.
Пример:
Запрос на «включение» выхода с адресом 172:
Если команда выполнена без ошибок, то ответ совпадает с запросом:
Write Single Register — 06 (0х06)Функция для записи значения в один из регистров общего назначения (holding registers) устройства.
Состояние выхода («вкл»/ «выкл») определяется константой, записываемой в регистр, соответствующий данному выходу. Значение константы 0хFF00 — определяет состояние «ВКЛ», а значение 0х0000 — состояние «ВЫКЛ».
Запрос:
Ответ:
При успешном выполнении команды ответ совпадает с запросом.
Ответ-исключение:
Коды ошибок стандартные. Их описание можно посмотреть в этой статье.
Пример:
Запись значения «3» в регистр с адресом 1:
Если команда выполнена без ошибок, то ответ совпадает с запросом:
Write Multiple Coils — 15 (0х0F)Функция для изменения состояния сразу нескольких дискретных выходов устройства.
Запрос:
Значения выходов которые нужно записать передаются в виде 8-ми битных слов, т.е. каждый байт данных содержит состояние 8-ми выходов. Поэтому количество байт передаваемых данных равно ближайшему целому от деления количества выходов на 8:
N = количество выходов / 8. Если остаток от деления не равен 0, то N = N+1.
Ответ:
Ответ-исключение:
Коды ошибок стандартные. Их описание можно посмотреть в этой статье.
Пример:
Запрос на запись состояния 10 выходов, начиная с выхода с адресом 19 (13 HEX):
Запрос содержит два байта данных, содержащих состояния выходов, которые нужно записать:
(CD 01 hex) (1100 1101 0000 0001 binary). Соответствие битов состояния и выходов устройства определяется следующим образом:
Бит: 1 1 0 0 1 1 0 1 0 0 0 0 0 0 0 1
Выход: 26 25 24 23 22 21 20 19 — — — — — — 28 27
Первый байт данных (CD hex) соответствует выходам 26-19. Младший бит соответствует выходу 19.
Младший бит соответствует выходу 19.
Второй байт (01 hex) соответствует выходам 28-27. Младший бит соответствует выходу 27.
Неиспользуемые биты в последнем байте — нули.
В ответе содержится подтверждение успешной записи:
Write Multiple Registers — 16 (0х10)Функция для записи значений в несколько (от 1 до 123) последовательно расположенных регистров общего назначения (holding registers).
Запрос:
N — количество регистров, в которые нужно записать новые значения. Регистры ModBus 16-битные, поэтому на каждый регистр приходится два байта данных.
Ответ:
В ответе содержится подтверждение успешной записи:
Ответ-исключение:
Коды ошибок стандартные. Их описание можно посмотреть в этой статье.
Пример:
Запрос на запись состояния двух регистров, начиная с регистра с адресом 1:
В ответе содержится подтверждение успешной записи:
Tags: ModBus
Запись облачных функций | Документация Cloud Functions
Cloud Functions поддерживает запись исходного кода в
ряд языков программирования. Выбранный вами язык выполнения и тип функции, которую вы хотите написать
определить, как структурировать код и реализовать функцию. Эта страница
предоставляет обзор типов облачных функций и ожиданий от них.
исходный код.
Выбранный вами язык выполнения и тип функции, которую вы хотите написать
определить, как структурировать код и реализовать функцию. Эта страница
предоставляет обзор типов облачных функций и ожиданий от них.
исходный код.
Типы облачных функций
Существует два типа облачных функций:
HTTP-функции , которые обрабатывают HTTP-запросы и используют HTTP-триггеры. Видеть Написать HTTP-функции для получения информации о реализации функций HTTP.
Функции, управляемые событиями , которые обрабатывают события из вашей облачной среды. и используйте триггеры событий, как описано в Триггеры облачных функций. Видеть Пишите функции, управляемые событиями для получения информации о реализации функций, управляемых событиями.
Используйте функцию HTTP, когда вам нужно, чтобы ваша функция имела конечную точку URL и
отвечать на HTTP-запросы, например, на веб-перехватчики. Используйте функцию, управляемую событиями
когда ваша функция должна запускаться непосредственно в ответ на события внутри
ваш проект Google Cloud, например сообщения в теме Pub/Sub или изменения
в корзине облачного хранилища.
Используйте функцию, управляемую событиями
когда ваша функция должна запускаться непосредственно в ответ на события внутри
ваш проект Google Cloud, например сообщения в теме Pub/Sub или изменения
в корзине облачного хранилища.
Структура исходного каталога
Чтобы облачные функции могли найти определение вашей функции, каждый Языковая среда выполнения имеет требования к структурированию исходного кода. Основа Структура каталогов для функции в каждой среде выполнения показана ниже.
Node.js
Базовая структура каталогов для функций Node.js выглядит следующим образом:
. ├── index.js └── package.json
По умолчанию Cloud Functions пытается загрузить исходный код из файла.
по имени 93.0.0″
}
} Примечание: Вы можете добавить зависимость Functions Framework с помощью
npm, запустив npm install @google-cloud/functions-framework .
Код в вашем основном файле должен определять точку входа вашей функции и может импортировать другой код и модули Node.js как обычно. Основной файл также может определить несколько точек входа в функцию, которые можно развернуть по отдельности.
питон
Базовая структура каталогов для функций Python выглядит следующим образом:
. ├── main.py └── требования.txt
Cloud Functions загружает исходный код из файла с именем main.py в
корень вашего каталога функций. Ваш основной файл должен называться main.py .
Ваш файл requirements.txt должен содержать
Фреймворк функций для Python
как зависимость:
функций-фреймворк==3.*
Код в файле main. должен определять ваш
точка входа функции и может импортировать другой код и внешний
зависимости как обычно.  py
py файл main.py также может определять несколько функций
точки входа, которые можно развернуть отдельно.
Идти
Базовая структура каталогов для функций Go выглядит следующим образом:
. ├── myfunction.go └── go.mod
Ваша функция должна находиться в пакете Go в корне вашего проекта. Посылка
и его исходные файлы могут иметь любое имя, за исключением того, что ваша функция не может быть в пакет основной . Если вам нужен основной пакет , например, для локального тестирования,
вы можете создать его в подкаталоге:
.
├── myfunction.go
├── go.mod
└── cmd/
└── main. go
 go
go
Ваш файл go.mod должен содержать
Фреймворк функций для Go
как зависимость:
example.com/my-module требовать ( github.com/GoogleCloudPlatform/functions-framework-go v1.5.2 )Примечание: Вы можете добавить зависимость Functions Framework, запустив
перейдите на github.com/GoogleCloudPlatform/functions-framework-go .Код в вашем корневом пакете должен определять ваш точка входа в функцию и может импортировать другой код из подпакетов и зависимости как обычно. Ваш пакет также может определять несколько функций точки входа, которые можно развернуть отдельно.
Примечание: Пример настройки базового проекта Cloud Functions в Go: см. Платформа функций для Go Quickstart на GitHub.Ява
Базовая структура каталогов для функций Java выглядит следующим образом:
.
 ├── pom.xml
└── источник/
└── главная/
└── java/
└── MyFunction.java
├── pom.xml
└── источник/
└── главная/
└── java/
└── MyFunction.java
Исходные файлы Java должны находиться в каталоге src/main/java/ и могут иметь
любое имя. Если ваши исходные файлы объявляют пакет, добавьте дополнительный каталог в src/main/java с именем пакета:
.
├── pom.xml
└── источник/
└── главная/
└── java/
└── мой пакет/
└── MyFunction.java
Мы рекомендуем размещать связанные тесты в подкаталоге src/test/java/.
java в соответствующие языку имена (например, заводной , kotlin или scala ).
Ваш файл pom.xml должен включать
Фреймворк функций для Java
как зависимость:
...
<зависимость>
com.google.cloud.functions
функции-фреймворк-api
<версия>1.0.4
...
Код в ваших исходных файлах должен определять ваш точка входа функции и может импортировать другой код и внешний зависимости как обычно. Ваши исходные файлы также могут определять несколько функций точки входа, которые можно развернуть отдельно.
С#
Базовая структура каталогов для функций .NET выглядит следующим образом:
. ├── MyFunction.cs └── MyProject.csproj
Вы можете структурировать свои проекты так же, как любой другой исходный код .NET.
Ваши исходные файлы могут иметь любое имя.
.fs и .fsproj для F#, .vb и .vbproj для Visual Basic).Ваш файл проекта должен включать Платформа функций для .NET как зависимость:
...
Код в ваших исходных файлах должен определять ваш точка входа функции и может импортировать другой код и внешний зависимости как обычно. Ваши исходные файлы также могут определять несколько функций точки входа, которые можно развернуть отдельно.
Вы также можете использовать пакет шаблонов Cloud Functions для .NET для создания необходимых файлов.
Примечание: Для получения информации о файловой структуре в отношении функций, использующих несколько локальных проектов . NET, см.
Развертывание функции с локальной зависимостью проекта.
NET, см.
Развертывание функции с локальной зависимостью проекта.Рубин
Базовая структура каталогов для функций Ruby выглядит следующим образом:
. ├── приложение.rb ├── Gemfile └── Gemfile.lock
Cloud Functions загружает исходный код из файла с именем app.rb в
корень вашего каталога функций. Ваш основной файл должен называться заяв.рб .
Ваш файл Gemfile должен включать
Фреймворк функций для Ruby
как зависимость:
источник "https://rubygems.org" гем "функции_фреймворк", "~> 1.0"Примечание: Вы можете добавить зависимость Functions Framework с помощью Упаковщик при запуске Пакет
добавляет functions_framework .
Код в вашем файле app.rb должен определять ваш
точка входа функции и может импортировать другой код и внешний
зависимости как обычно. 9Файл 0035 app.rb также может определять несколько функций
точки входа, которые можно развернуть отдельно.
PHP
Базовая структура каталогов для функций PHP выглядит следующим образом:
. ├── index.php └── composer.json
Cloud Functions загружает исходный код из файла с именем index.php в
корень вашего каталога функций. Ваш основной файл должен называться index.php .
Ваш файл composer.json должен содержать
Фреймворк функций для PHP
как зависимость: 91,1 дюйма
}
} Примечание: Вы можете добавить зависимость Functions Framework с помощью
Композитор, запустив композитор требует google/cloud-functions-framework .
Код в файле index.php должен определять ваш
точка входа функции и может импортировать другой код и внешний
зависимости как обычно. Файл index.php также может определять несколько функций.
точки входа, которые можно развернуть отдельно.
Если вы планируете сгруппировать несколько функций в один проект, зная, что каждая функция может в конечном итоге использовать один и тот же набор зависимостей. Однако некоторым функциям могут не потребоваться все зависимости.
Где возможно, мы рекомендуем разделить большие многофункциональные кодовые базы и помещая каждую функцию в свой собственный каталог верхнего уровня, как показано выше, со своим собственный исходный код и файлы конфигурации проекта. Такой подход минимизирует количество зависимостей, необходимых для конкретной функции, что, в свою очередь, снижает объем памяти, необходимый вашей функции.
Точка входа в функцию
В вашем исходном коде должна быть определена точка входа для вашей функции, которая является
определенный код, который выполняется при вызове облачной функции. Вы указываете эту точку входа при развертывании своей функции.
Вы указываете эту точку входа при развертывании своей функции.
То, как вы определяете точку входа, зависит от используемой среды выполнения языка. Для некоторых языков точкой входа является функция, тогда как для других класс. Чтобы узнать больше об определении точек входа и реализации Облачные функции на разных языках, см. Написать HTTP-функции а также Пишите функции, управляемые событиями.
Зависимости
Вы можете управлять зависимостями, используя стандартные инструменты для каждой среды выполнения. Для большего информацию см. на соответствующей странице:
- Указание зависимостей в Node.js
- Указание зависимостей в Python
- Указание зависимостей в Go
- Указание зависимостей в Java
- Указание зависимостей в .NET
- Указание зависимостей в Ruby
- Указание зависимостей в PHP
Следующие шаги
- Узнайте, как писать функции HTTP.
- Узнайте, как писать функции, управляемые событиями.
- Узнайте о триггерах Cloud Functions.
Обзор функций Azure | Microsoft Узнайте
Обратная связь Редактировать
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 2 минуты на чтение
Функции Azure — это бессерверное решение, позволяющее писать меньше кода, поддерживать меньше инфраструктуры и экономить на расходах. Вместо того, чтобы беспокоиться о развертывании и обслуживании серверов, облачная инфраструктура предоставляет все современные ресурсы, необходимые для обеспечения работы ваших приложений.
Вы сосредотачиваетесь на фрагментах кода, которые наиболее важны для вас, а функции Azure берут на себя все остальное.
Мы часто создаем системы, способные реагировать на серию критических событий. Независимо от того, создаете ли вы веб-API, реагируете на изменения в базе данных, обрабатываете потоки данных IoT или даже управляете очередями сообщений, — каждому приложению нужен способ запуска некоторого кода при возникновении этих событий.
Чтобы удовлетворить эту потребность, Функции Azure обеспечивают «вычисления по требованию» двумя важными способами.
Во-первых, Функции Azure позволяют реализовать логику вашей системы в готовых блоках кода. Эти блоки кода называются «функциями». Различные функции могут запускаться в любое время, когда вам нужно отреагировать на критические события.
Во-вторых, по мере увеличения количества запросов Функции Azure удовлетворяют потребности, используя столько ресурсов и экземпляров функций, сколько необходимо, но только тогда, когда это необходимо.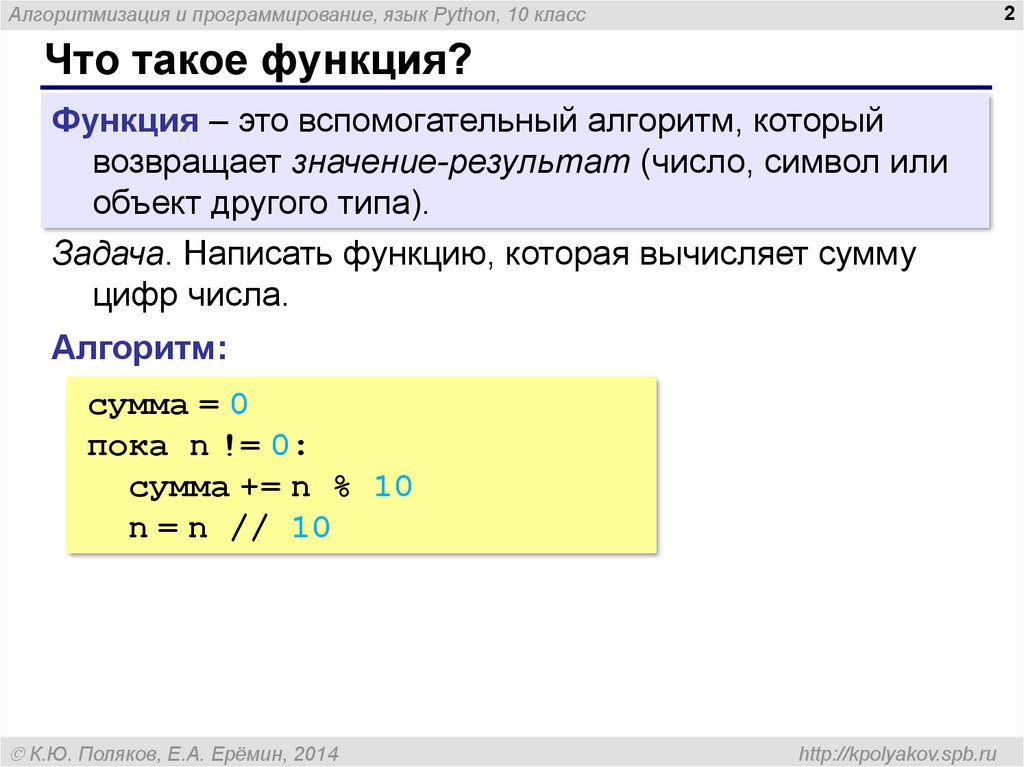 По мере падения запросов любые дополнительные ресурсы и экземпляры приложений автоматически отключаются.
По мере падения запросов любые дополнительные ресурсы и экземпляры приложений автоматически отключаются.
Откуда берутся все вычислительные ресурсы? Функции Azure предоставляют столько вычислительных ресурсов, сколько необходимо для удовлетворения потребностей вашего приложения.
Предоставление вычислительных ресурсов по запросу — суть бессерверных вычислений в Функциях Azure.
Сценарии
Во многих случаях функция интегрируется с массивом облачных сервисов для обеспечения многофункциональных реализаций.
Ниже приведен общий , но ни в коем случае не исчерпывающий набор сценариев для Функций Azure.
| Если вы хотите… | затем… |
|---|---|
| Создание веб-API | Реализуйте конечную точку для своих веб-приложений с помощью триггера HTTP |
| Обработка загрузки файлов | Код выполнения при загрузке или изменении файла в хранилище BLOB-объектов |
| Создание бессерверного рабочего процесса | Объединение ряда функций вместе с использованием надежных функций |
| Реагировать на изменения базы данных | Запуск пользовательской логики при создании или обновлении документа в Azure Cosmos DB |
| Запуск запланированных задач | Выполнять код через заданные интервалы времени |
| Создание надежных систем очереди сообщений | Обработка очередей сообщений с помощью хранилища очередей, служебной шины или концентраторов событий |
| Анализ потоков данных IoT | Сбор и обработка данных с устройств Интернета вещей |
| Данные процесса в режиме реального времени | Используйте функции и SignalR для ответа на данные в данный момент |
При создании функций вам доступны следующие параметры и ресурсы:
Используйте предпочитаемый язык : Напишите функции на C#, Java, JavaScript, PowerShell или Python или используйте пользовательский обработчик для виртуального использования любой другой язык.
Автоматизация развертывания : От подхода на основе инструментов до использования внешних конвейеров доступно множество вариантов развертывания.
Устранение неполадок функции : Используйте инструменты мониторинга и стратегии тестирования, чтобы получить представление о своих приложениях.
Гибкие варианты ценообразования : С планом потребления вы платите только за то, что ваши функции работают, в то время как планы Premium и App Service предлагают функции для особых потребностей.

Следующие шаги
Начало работы с помощью уроков, примеров и интерактивных руководств
Обратная связь
Отправить и просмотреть отзыв для
Этот продукт Эта страница
Просмотреть все отзывы о странице
Как написать и активировать функцию в WordPress
Если вы начинаете разработку собственных плагинов WordPress или создаете свои собственные темы, навык, который вам необходимо освоить, — это написание функций.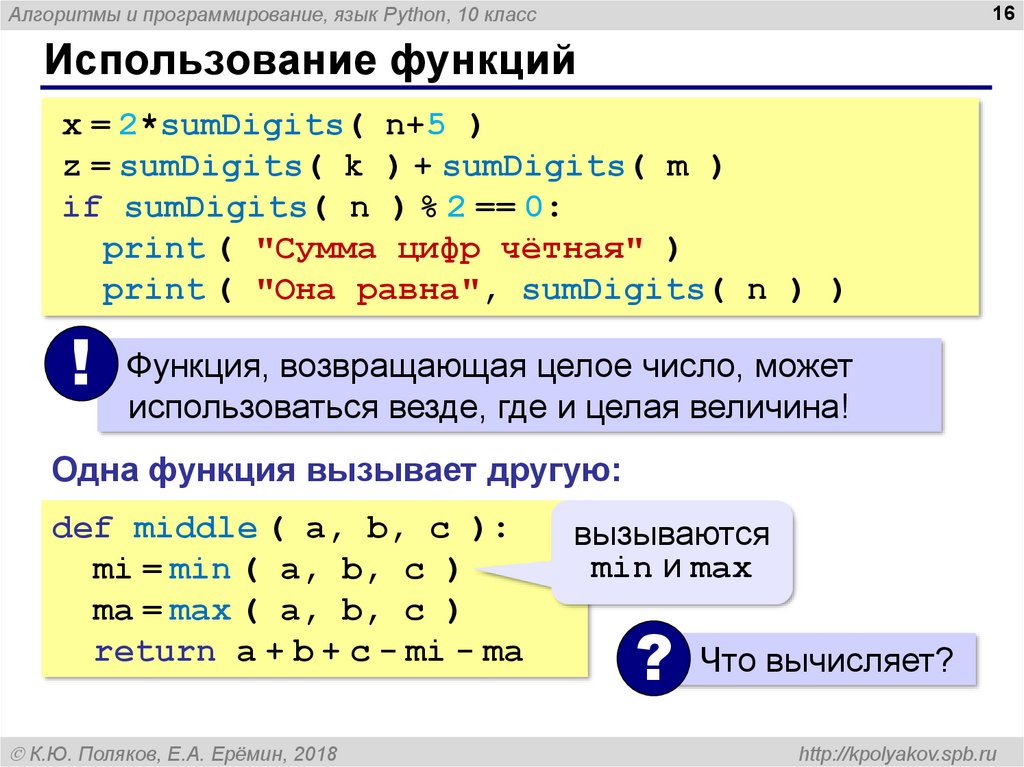
Возможно, вы написали функцию, которая не работала, и в отчаянии сдались. Или, может быть, вас смущают хуки действий и фильтров, и вы не знаете, как заставить свою функцию работать.
В этом посте я помогу вам преодолеть любые проблемы с прорезыванием зубов при написании функций. Я покажу вам, как структурировать вашу функцию, дам советы по передовому опыту и разъясню методы, которые вы можете использовать для активации вашей функции.
Итак, приступим!
- Что вам понадобится
- Где вы должны разместить свою функцию?
- Написание вашей функции
- Добавление комментариев
- Открытие функции
- Заполнение функции
- Активация функции
- Кодирование функции в файл шаблона темы
- Запуск вашей функции с помощью хука действия
- Запуск вашей функции с помощью хука фильтра
- Использование условных тегов
Что вам понадобится
Чтобы следовать этому руководству, полезно, если у вас есть функция, над которой вы уже работаете. Таким образом, вы сможете применить полученные знания на практике и получить от этого больше. В этом случае вам понадобятся некоторые инструменты:
Таким образом, вы сможете применить полученные знания на практике и получить от этого больше. В этом случае вам понадобятся некоторые инструменты:
- Редактор кода
- Разрабатываемая установка WordPress
- Файл для вашей функции — который может быть в файле functions.php вашей темы или может быть в плагине.
Если у вас его нет, потому что вы еще не приступили к своей функции, не беспокойтесь — читайте дальше, и вы узнаете, как начать работу.
Где разместить свою функцию?
Прежде чем начать, вам нужно подумать, куда вы собираетесь поместить код своей функции. У вас есть два варианта: файл функций вашей темы или плагин.
То, что вы используете, будет зависеть от цели вашей функции:
- Если это связано с дизайном и отображением вашего контента, поместите его в свою тему. Он напрямую связан с темой и будет работать только вместе с остальным кодом темы.
- Если он функционален (а большинство функций таковы, подсказка в названии), то поместите его в плагин.
Многие из нас начинают с нашего файла функций, так как это проще, а затем мы переходим к созданию плагинов, когда обретаем уверенность. Создать плагин на самом деле очень просто — ознакомьтесь с нашим руководством по созданию плагинов.
Если вы уверены, что ваш плагин должен находиться в файле функций темы, а в вашей теме его еще нет, то ознакомьтесь с нашим исчерпывающим руководством по файлу функций.
Написание функции
Итак, теперь у вас открыт файл (либо functions.php или файл вашего плагина), и вы готовы написать эту функцию. Разобьем на части.
Я знаю, о чем вы думаете: комментарии, не могли бы мы уже начать писать код? Но я всегда добавляю комментарии перед кодированием своего плагина. Таким образом, я могу видеть, для чего предназначена моя функция, когда я возвращаюсь к ней. Иногда мне не нужно возвращаться к фрагменту кода в течение многих лет, и поверьте мне, я забуду, как этот код работал, когда я это сделаю! И если кому-то еще когда-нибудь понадобится поработать над вашей функцией, комментарии помогут им понять, что она делает.
Моя функция будет простой, чтобы зарегистрировать пару шрифтов Google в моей теме. Он находится в файле функций темы, потому что он связан с отображением, а не с макетом. Но сначала я добавлю несколько комментариев:
Loading gist a7f108077e4daa3528082038402d367d
Я форматирую свои комментарии таким образом, чтобы они были понятными и их было легко найти, когда я быстро пролистываю файл позже.
Открытие функции
Теперь пришло время написать функцию. Вы открываете его со словом функция и название функции. Вы всегда должны использовать префикс к имени вашей функции, чтобы обеспечить уникальность ее имени. Таким образом, он не будет конфликтовать ни с какими функциями вашей темы или сторонних плагинов. Используйте свое имя, свои инициалы или название или инициалы сайта или плагина, для которого вы пишете код.
За этим следует фигурные скобки, внутри которых находится код вашей темы:
Загрузка gist 0b7d5b094da3ebd23761e1c9cc5b6e53
Заполнение функции
Весь код, который вы хотите, чтобы функция запускала, заключен в фигурные скобки. Это включает в себя любые условные теги, которые я объясню более подробно позже. Вот мой код для моей функции шрифтов Google:
Это включает в себя любые условные теги, которые я объясню более подробно позже. Вот мой код для моей функции шрифтов Google:
Loading gist 21b6fd4ca38cbad3984ae98c6d686f73
Я не собираюсь учить вас, как кодировать конкретную функцию здесь, так как это будет зависеть от того, чего вы пытаетесь достичь. У нас есть много других постов, которые помогут вам с различными функциями — не говоря уже о наших курсах Академии по разработке WordPress!
Вот полная функция:
Загрузка сути d0a301f3673c015db5c4d1ceb9a89efc
Но как только вы это сделаете, вы можете открыть страницу на своем сайте и удивиться, почему ничего не происходит. Это потому, что вы еще не активировали свою функцию.
Активация функции
Функция бесполезна, если вы не активируете ее каким-либо образом, сообщая WordPress, когда запускать функцию. Для этого у вас есть три варианта:
- Закодируйте функцию непосредственно в файл шаблона вашей темы (или в другой файл плагина).
- Прикрепите его к крючку.
- Прикрепите его к крючку фильтра.

Давайте рассмотрим каждый из них.
Кодирование функции в файле шаблона темы
Этот параметр доступен только в том случае, если вы работаете со своей собственной темой.
Если вы хотите сделать это со сторонней темой, вам придется создать дочернюю тему, продублировать соответствующий файл шаблона темы из родительской темы в вашей дочерней теме и добавить к нему свою функцию. Если файл шаблона будет изменен будущим обновлением родительской темы, файл вашей дочерней темы (который будет использовать WordPress) не будет отражать это.
Я предполагаю, что вы работаете с темой, которую разработали сами, и у вас есть фрагмент кода, который вы хотите повторить в нескольких файлах шаблонов. Вместо того, чтобы создавать включаемый файл и вызывать его в этих файлах, вы решили использовать свой файл функций и создать функцию, что более эффективно для фрагмента кода.
WPMU DEV AccountFREE
Управление неограниченным количеством сайтов WP бесплатно
Неограниченное количество сайтов
Кредитная карта не требуется
Давайте представим, что ваша функция выводит дату. Вот:
Вот:
Загрузка GIST F993BA9DF32F662DBD0E514D6BF18638
СЕЙЧАС, чтобы добавить этот код в свою тему, вы добавите это в свой шаблон. как! Вы просто добавляете этот код в соответствующий файл шаблона в своей теме.
Запуск вашей функции с помощью хука действия
Альтернативой является использование хука действия. Это код, который позволяет запускать прикрепленный к нему код каждый раз, когда WordPress сталкивается с хуком.
Вы можете либо использовать хуки, уже предоставленные WordPress, либо создать свои собственные.
В случае функции шрифтов, которую я описал выше, вы должны использовать хук, предоставленный WordPress: хук wp_enqueue_scripts . Итак, чтобы выпустить мою функцию, я бы добавил это за пределы брекетов:
Загрузка GIST B022BF0FF1271C71A88F856800A38858
, так что моя полная функция будет выглядеть как:
gist 87cf84a40ffaabed514d8821bde8095c
c.c.c.c.c.c.c.c. c.c.c.c.c.C. . Вместо того, чтобы кодировать мою функцию для вывода даты непосредственно в файл шаблона моей темы (в данном случае цикл), я использую
c.c.c.c.c.C. . Вместо того, чтобы кодировать мою функцию для вывода даты непосредственно в файл шаблона моей темы (в данном случае цикл), я использую do_action() , чтобы добавить хук действия, а затем подключить к нему мою функцию.Таким образом, в моем шаблонном файле я добавляю это:
Загрузка GIST 7AF44A9A0ACF03FDBF6451DAEDBEF936
Затем я прикрепляю свою функцию, так что все, что считывает:
. вид крючка — фильтрующий крючок. Это уже будет обернуто вокруг некоторого кода или содержимого, когда оно будет создано, и ваша функция переопределит это. Это полезно, если вы хотите что-то закодировать в файле шаблона темы, но дать себе возможность переопределить это позже. WordPress также предоставляет вам ряд перехватчиков фильтров для использования с различными функциями.
Если вы не уверены в разнице между двумя типами хуков, наше руководство по действиям и фильтрам хуков прояснит для вас ситуацию.
Вот пример: фрагмент текста в файле шаблона.
Примечание. Я знаю, что запись текста непосредственно в файлы шаблонов — не лучшая практика. Я также знаю, что делать это таким образом без интернализации — тоже плохая практика. Но это простой пример, поэтому, пожалуйста, не бейте меня в комментариях.
Чтобы добавить ловушку фильтра в файл шаблона, используйте кнопку Apply_filters () Функция с именем фильтра в качестве первого параметра и содержимого по умолчанию в качестве второго:
Загрузка GIST 1B476072BEB36934C4DB325467E8CF9F
И вот как вы подключили функцию. что функция add_filter() после функции очень похожа на функцию add_action() . Первый параметр — это имя хука, а второй — имя функции. Также обратите внимание, что apply_filters() часто предшествует функция echo , потому что она повторяет некоторый текст (в данном случае заголовок).
Использование условных тегов
Когда вы используете хуки для запуска своих функций, вы можете комбинировать это с условными тегами, чтобы определить обстоятельства, при которых функция будет запускаться.
Я часто вижу, что люди ошибаются в расположении условных тегов. Логика может подсказать вам, что вы хотите, чтобы функция срабатывала только при определенных обстоятельствах, поэтому вы помещаете условный тег вне функции, верно?
Неправильно.
Вот два способа, которыми я это видел, оба НЕПРАВИЛЬНО . Во -первых, обертывание тега вокруг крючка Action:
Загрузка GIST 3A63EC5DA0269136B051368C2B4F5D35
и второй, обертывая его вокруг функции, а также 7899924278278282828282828828288.saled wordEd. внутри вашей функции. Таким образом, функция будет срабатывать во всех случаях, но если условие не выполняется, на самом деле ничего не произойдет.
Вот правильный способ использования условного тега для проверки отдельного поста:
Загрузка сущности 19dca9a6fb7559b2846403ac1f93c31f
Использование условного тега, подобного этому, упрощает и делает более точным, а также является мощным инструментом для функций.