Что такое хеширование, шифрование и кодировка
Эти три термина часто путают — они означают три абсолютно разных вещи. Для того, чтобы понять разницу, давайте сначала проясним некоторые моменты.
С точки зрения безопасности, когда вы отправляете данные/сообщение в интернете:
- Вы хотите, чтобы другой человек знал, что это письмо отправили вы, а не кто-либо другой.
- Вы хотите, чтобы сообщение получили в том же формате, в каком вы отправили — без изменений.
- Вы хотите, чтобы ваше сообщение не могли прочитать злоумышленники.
Эти три пункта можно назвать по-другому:
- Проверка личности
- Целостность сообщения
- Конфиденциальность
Чтобы это было возможным, используются хеширование и шифрование. Начнем с хеширования.
Хеширование
Давайте представим жизнь без хеширования. Например, сегодня день рождения друга, и вы хотите отправить ему поздравление. Ваш веселый товарищ-ботан решает над вами посмеяться, перехватывает сообщение и превращает «С Днем рождения» в «Покойся с миром».
Чтобы такого не случалось, на помощь приходит хеширование — оно защищает целостность данных.
Хеш — это число, которое генерируется из текста с помощью хеш-алгоритма. Это число меньше оригинального текста.
Алгоритм хеширования
Алгоритм работает так, что для каждого текста генерируется уникальный хеш. И восстановить текст из хеша, перехватив сообщение, практически невозможно.
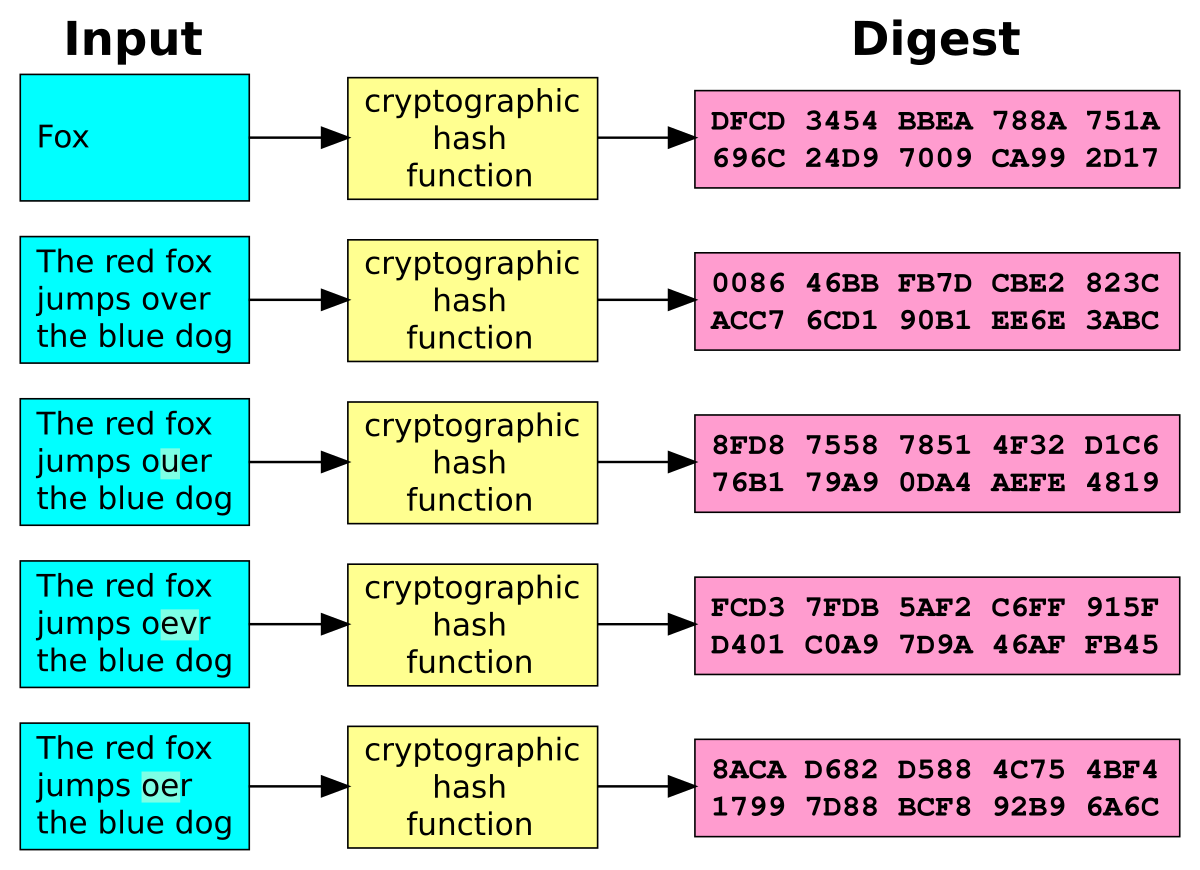
Одно из незаменимых свойств хеширования — его уникальность. Одно и то же значение хеша не может использоваться для разного текста. Малейшее изменение в тексте полностью изменит значение хеша. Это называется эффектом лавины.
В примере ниже мы использовали алгоритм SHA-1.
Текст: Все любят пончики.
Значение SHA-1 текста: daebbfdea9a516477d489f32c982a1ba1855bcd
Давайте не будем оспаривать фразу про пончики и сосредоточимся пока на хешировании. Теперь если мы немного поменяем текст, хеш полностью изменится.
Текст: Все любят пончик.
Значение SHA-1 текста: 8f2bd584a1854d37f9e98f9ec4da6d757940f388
Как вы видите, поменялась одна буква, а хеш изменился до неузнаваемости.
Хеширование нужно:
- Чтобы информация в базах данных не дублировалась;
- Для цифровых подписей и SSL-сертификатов;
- Чтобы найти конкретную информацию в больших базах данных;
- В компьютерной графике.
Шифрование
Почти невозможно представить интернет без шифрования. Шифрование — это то, что делает интернет безопасным. При шифровании конфиденциальная информация превращается в нечитаемый формат, чтобы хакер не смог ее перехватить.
Шифрование и дешифровка
Данные шифруются с помощью криптографических ключей. Информация шифруется до отправления и расшифровывается получателем. Таким образом, при передаче данные находятся в безопасности.
В зависимости от природы ключей шифрование может делиться на 2 категории: симметричное и асимметричное.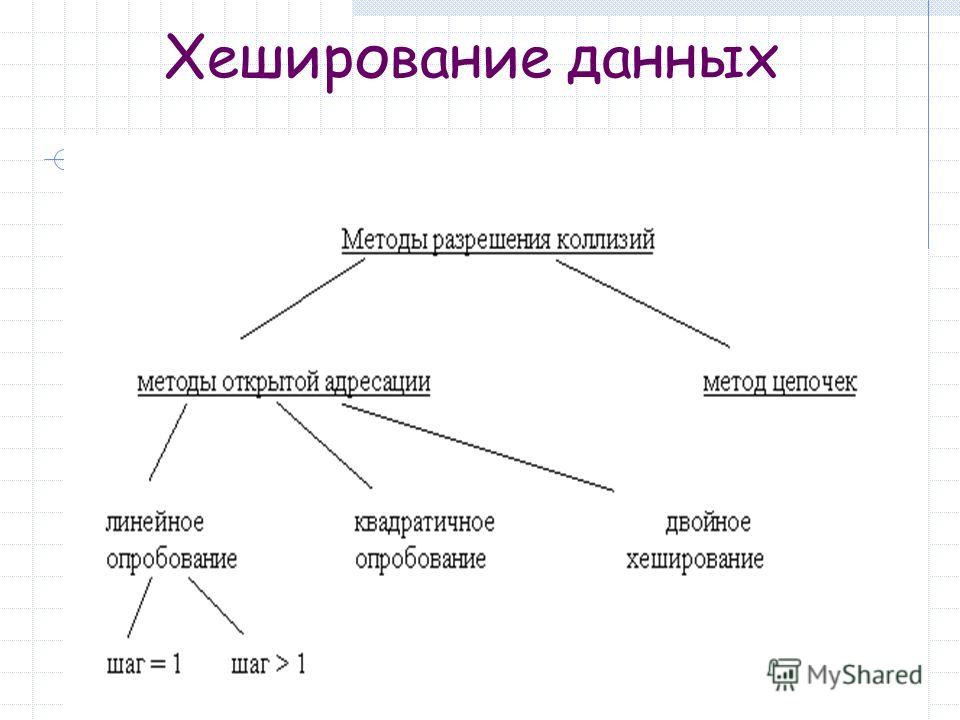
Симметричное шифрование: Данные шифруются и расшифровываются при помощи одного криптографического ключа. Это значит, что ключ, используемый для шифрования, используется и для расшифровки.
Асимметричное шифрование: Это довольно новый метод. В нем используются два разных ключа — один для шифрования, второй для расшифровки. Один ключ называется публичным, второй секретным.
Публичные ключи везде — у вас он тоже есть, даже если вы об этом не знаете. Один из них сохраняется в вашем браузере каждый раз, когда вы заходите на сайт с SSL-сертификатом.
Когда вы отправляете данные на зашифрованный сайт, этот сайт закодирован публичным ключом. Приватный ключ есть только у получателя, и он должен хранить его в недоступном месте. Секретный ключ расшифровывает зашифрованные данные. Когда используются два разных ключа, шифрование проходит безопаснее и чуть медленнее.
Оба эти метода используются в SSL/TLS-сертификатах. Асимметричное шифрование сначала применяется к процессу рукопожатия SSL — валидации сервера.
Кодировка
В отличие от шифрования и хеширования кодировка используется не в целях безопасности. При кодировке данные превращаются в другие форматы, чтобы множество систем могли их использовать.
В кодировке не используются ключи. Алгоритм, который берется для кодировки данных, также используется, чтобы раскодировать их. ASCII и UNICODE — примеры таких алгоритмов кодировки.
Резюмируем
Хеширование: ряд цифр, который генерируется, чтобы подтвердить целостность данных с помощью алгоритмов хэширования.
Шифрование: Метод, который используется, чтобы зашифровать данные, превратив их в формат, не поддающийся расшифровке.
Кодировка: Превращение данных из одного формата в другой.
Источник: статья в блоге Cheap SSL Security
Что такое хеширование? | Binance Academy
Хеширование относится к процессу создания определенного вывода из входных данных разного размера. Это делается с помощью математических формул, также известных как хэш-функции (реализованные в виде алгоритмов хеширования).
Это делается с помощью математических формул, также известных как хэш-функции (реализованные в виде алгоритмов хеширования).
Не все хэш-функции предполагают использование криптографии, а только те, которые специально предназначенные для этого, так называемые криптографические хэш-функции, которые лежат в основе криптовалюты. Благодаря их работе, блокчейны и другие распределенные системы способны достичь высокого уровня целостности данных и безопасности.
Как обычные, так и криптографические хэш-функции являются детерминированными. Быть детерминированным означает, что до тех пор, пока входные данные не изменяются, алгоритм хеширования всегда будет выдавать один и тот же результат (также известный как дайджест или хэш).
Алгоритмы хеширования в криптовалютах разработаны таким образом, что их функция работает в одностороннем порядке, это означает, что данные не могут быть возвращены в обратном порядке без вложения большого количества времени и ресурсов для осуществления вычислений.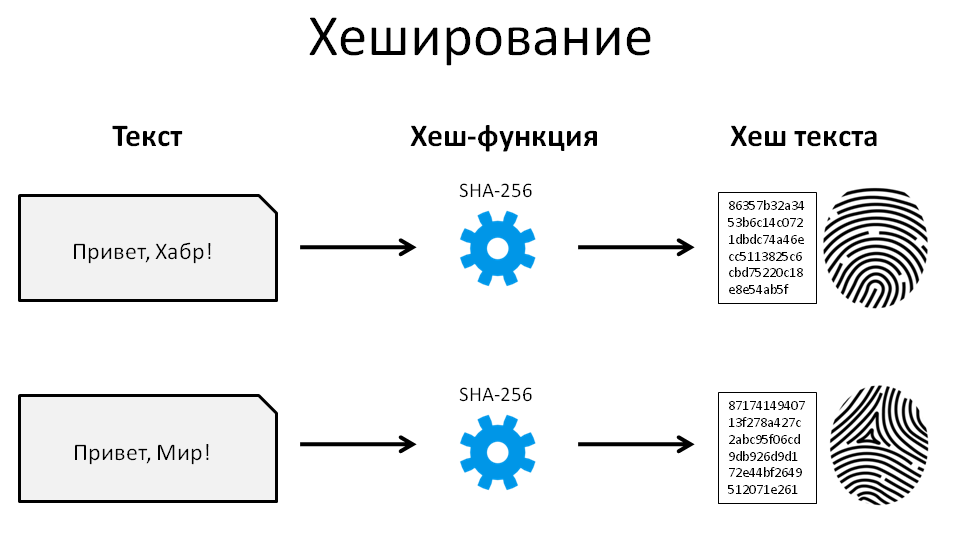 Другими словами, довольно легко создать выход из входных данных, но относительно трудно осуществить процесс в обратном направлении (сгенерировать вывод на основе входных данных). Чем сложнее найти входное значение, тем более безопасным считается алгоритм хеширования.
Другими словами, довольно легко создать выход из входных данных, но относительно трудно осуществить процесс в обратном направлении (сгенерировать вывод на основе входных данных). Чем сложнее найти входное значение, тем более безопасным считается алгоритм хеширования.
Как работает хэш-функция?
Различные виды хэш-функций производят вывод разной величины, но возможный размер данных на выходе для каждого из алгоритмов хеширования всегда является постоянным. Например, алгоритм SHA-256 может производить вывод исключительно в формате 256-бит, в то время как SHA-1 всегда генерирует 160-битный дайджест.
Чтобы проиллюстрировать это, давайте пропустим слова “Binance“ и “binance” через алгоритм хеширования SHA-256 (тот, который используется в биткоин).
SHA-256 | |
Входные данные | Результат (256 бит) |
Binance | f1624fcc63b615ac0e95daf9ab78434ec2e8ffe402144dc631b055f711225191 |
binance | 59bba357145ca539dcd1ac957abc1ec5833319ddcae7f5e8b5da0c36624784b2 |
Обратите внимание, что незначительное изменение (регистр первой буквы) привело к совершенно другому значению хэша. Поскольку мы используем SHA-256, данные на выходе всегда будут иметь фиксированный размер в 256 бит (или 64 символа), независимо от величины ввода. Помимо этого, не имеет значения какое количество раз мы пропустим эти два слова через алгоритм, два выхода не будут видоизменяться, поскольку они являются постоянными.
Поскольку мы используем SHA-256, данные на выходе всегда будут иметь фиксированный размер в 256 бит (или 64 символа), независимо от величины ввода. Помимо этого, не имеет значения какое количество раз мы пропустим эти два слова через алгоритм, два выхода не будут видоизменяться, поскольку они являются постоянными.
Таким же образом, если мы пропустим одни и те же входные данные с помощью алгоритма хеширования SHA-1, мы получим следующие результаты:
SHA-1 | |
Входные данные | Результат (160 бит) |
Binance | 7f0dc9146570c608ac9d6e0d11f8d409a1ee6ed1 |
binance | e58605c14a76ff98679322cca0eae7b3c4e08936 |
Стоит отметить, что акроним SHA расшифровывается как Secure Hash Algorithms (безопасный алгоритм хеширования). Он относится к набору криптографических хэш-функций, который включает такие алгоритмы как SHA-0 и SHA-1 вместе с группами SHA-2 и SHA-3. SHA-256 является частью группы SHA-2, наряду с SHA-512 и другими аналогами. В настоящее время, только группы SHA-2 и SHA-3 считаются безопасными.
SHA-256 является частью группы SHA-2, наряду с SHA-512 и другими аналогами. В настоящее время, только группы SHA-2 и SHA-3 считаются безопасными.
Почему это имеет значение?
Обычные хэш-функции обладают широким спектром вариантов использования, включая поиск по базе данных, анализ больших файлов и управление данными. В свою очередь, криптографические хэш-функции обширно используются в приложениях связанных с информационной безопасностью для аутентификации сообщений и цифровой дактилоскопии. Когда речь заходит о биткоине, криптографические хэш-функции являются неотъемлемой частью в процессе майнинга, а также занимают основную роль в генерации новых ключей и адресов.
Хеширование демонстрирует весь свой потенциал при работе с огромным количеством информации. Например, можно пропустить большой файл или набор данных через хэш-функцию, а затем использовать вывод для быстрой проверки точности и целостности данных. Это возможно благодаря детерминированной природе хэш-функций: вход всегда будет приводить к упрощенному сжатому выходу (хэшу). Такой метод устраняет необходимость хранить и запоминать большие объемы данных.
Такой метод устраняет необходимость хранить и запоминать большие объемы данных.
Хеширование является в особенности полезным в отношении технологии блокчейн. В блокчейне биткоина осуществляется несколько операций, которые включают себя хеширование, большая часть которого заключается в майнинге. По факту, практически все криптовалютные протоколы полагаются на хеширование для связывания и сжатия групп транзакций в блоки, а также для создания криптографической взаимосвязи и эффективного построения цепочки из блоков.
Криптографические хэш-функции
Опять же обращаем ваше внимание на то, что хэш-функция, которая использует криптографические методы, может быть определена как криптографическая хэш-функция. Для того, чтобы ее взломать потребуется бесчисленное множество попыток грубого подбора чисел. Чтобы реверсировать криптографическую хэш-функцию, потребуется подбирать входные данные методом проб и ошибок, пока не будет получен соответствующий вывод. Тем не менее, существует возможность того, что разные входы будут производить одинаковый вывод, в таком случае возникает коллизия.
С технической точки зрения, криптографическая хэш-функция должна соответствовать трем свойствам, чтобы считаться безопасной. Мы можем описать их как: устойчивость к коллизии, и устойчивость к поиску первого и второго прообраза.
Прежде чем начать разбирать каждое свойство, обобщим их логику в трех коротких предложениях.
Устойчивость к коллизии: невозможно найти два разных входа, которые производят хэш, аналогичный выводу.
Устойчивость к поиску первого прообраза: отсутствие способа или алгоритма обратного восстановления хэш-функцию (нахождение входа по заданному выходу).
Устойчивость к поиску второго прообраза: невозможно найти любой второй вход, который бы пересекался с первым.
Устойчивость к коллизии
Как упоминалось ранее, коллизия происходит, когда разные входные данные производят одинаковый хэш. Таким образом, хэш-функция считается устойчивой к коллизиям до тех пор, пока кто-либо не обнаружит коллизию. Обратите внимание, что коллизии всегда будут существовать для любой из хэш-функций, в связи с бесконечным количеством входных данных и ограниченным количеством выводов.
Таким образом, хэш-функция устойчива к коллизии, когда вероятность ее обнаружения настолько мала, что для этого потребуются миллионы лет вычислений. По этой причине, несмотря на то, что не существует хэш-функций без коллизий, некоторые из них на столько сильные, что могут считаться устойчивыми (например, SHA-256).
Среди различных алгоритмов SHA группы SHA-0 и SHA-1 больше не являются безопасными, поскольку в них были обнаружены коллизии. В настоящее время только группы SHA-2 и SHA-3 считаются самыми безопасными и устойчивыми к коллизиям.
Устойчивость к поиску первого прообраза
Данное свойство тесно взаимосвязано с концепцией односторонних функций. Хэш-функция считается устойчивой к поиску первого прообраза, до тех пор, пока существует очень низкая вероятность того, что кто-то сможет найти вход, с помощью которого можно будет сгенерировать определенный вывод.
Обратите внимание, что это свойство отличается от предыдущего, поскольку злоумышленнику потребуется угадывать входные данные, опираясь на определенный вывод.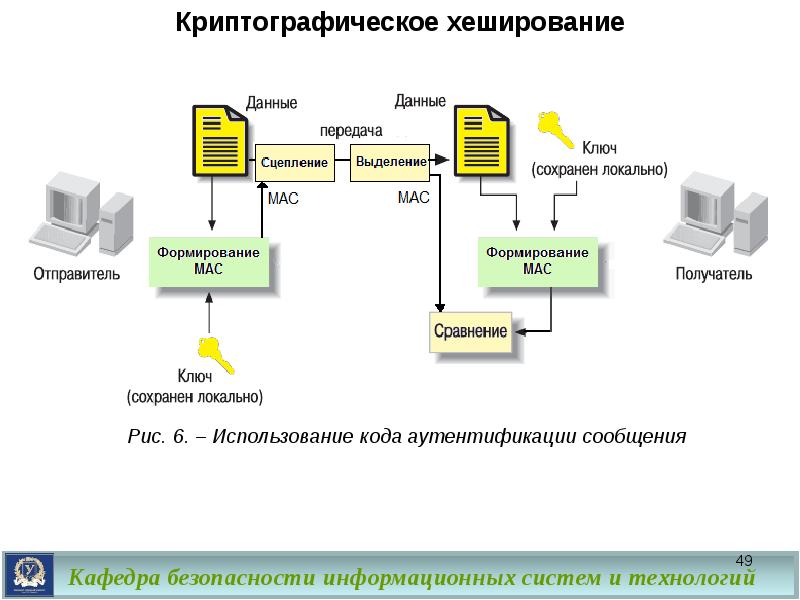 Такой вид коллизии происходит, когда кто-то находит два разных входа, которые производят один и тот же код на выходе, не придавая значения входным данным, которые для этого использовались.
Такой вид коллизии происходит, когда кто-то находит два разных входа, которые производят один и тот же код на выходе, не придавая значения входным данным, которые для этого использовались.
Свойство устойчивости к поиску первого прообраза является ценным для защиты данных, поскольку простой хэш сообщения может доказать его подлинность без необходимости разглашения дополнительной информации. На практике многие поставщики услуг и веб-приложения хранят и используют хэши, сгенерированные из паролей вместо того, чтобы пользоваться ими в текстовом формате.
Устойчивость к поиску второго прообраза
Для упрощения вашего понимания, можно сказать, что данный вид устойчивости находится где-то между двумя другими свойствами. Атака нахождения второго прообраза заключается в нахождении определенного входа, с помощью которого можно сгенерировать вывод, который изначально образовывался посредством других входных данных, которые были заведомо известны.
Другими словами, атака нахождения второго прообраза включает в себя обнаружение коллизии, но вместо поиска двух случайных входов, которые генерируют один и тот же хэш, атака нацелена на поиск входных данных, с помощью которых можно воссоздать хэш, который изначально был сгенерирован с помощью другого входа.
Следовательно, любая хэш-функция, устойчивая к коллизиям, также устойчива и к подобным атакам, поскольку последняя всегда подразумевает коллизию. Тем не менее, все еще остается возможность для осуществления атаки нахождения первого прообраза на функцию устойчивую к коллизиям, поскольку это предполагает поиск одних входных данных посредством одного вывода.
Майнинг
В майнинге присутствует множество этапов, которые осуществляются с помощью хэш-функций, они включают в себя проверку баланса, связывание входов и выходов транзакций и хеширование всех операций в блоке для формирования дерева Меркла. Но одна из основных причин, по которой блокчейн биткоина является безопасным, заключается в том, что майнеры должны выполнить как можно большее количество операций связанных с хешированием, чтобы в конечном итоге найти правильное решение для следующего блока.
Майнер должен пытаться подобрать несколько разных входных данных при создании хэша для своего блока-кандидата. Проверить блок можно будет только в том случае, если правильно сгенерирован вывод в виде хэша начинается с определенного количества нулей. Количество нулей определяет сложность майнинга и она меняется в зависимости от хешрейта сети.
Количество нулей определяет сложность майнинга и она меняется в зависимости от хешрейта сети.
В этом случае, хешрейт представляет собой количество мощности вашего компьютера, которое вы инвестируете в майнинг биткоинов. Если хешрейт начинает увеличиваться, протокол биткоина автоматически отрегулирует сложность майнинга так, чтобы среднее время необходимое для добычи блока составляло не более 10 минут. Если несколько майнеров примут решение прекратить майнинг, что приведет к значительному снижению хешрейта, сложность добычи будет скорректирована таким образом, чтобы временно облегчить вычислительную работу (до тех пор, пока среднее время формирования блока не вернется к 10 минутам).
Обратите внимание, что майнерам не нужно искать коллизии, в связи с некоторым количеством хэшей, которые они могут генерировать в качестве валидного выхода (начинающегося с определенного количества нулей). Таким образом, существует несколько возможных решений для определенного блока и майнеры должны найти только одно из них, в соответствии с порогом, который определяется сложностью майнинга.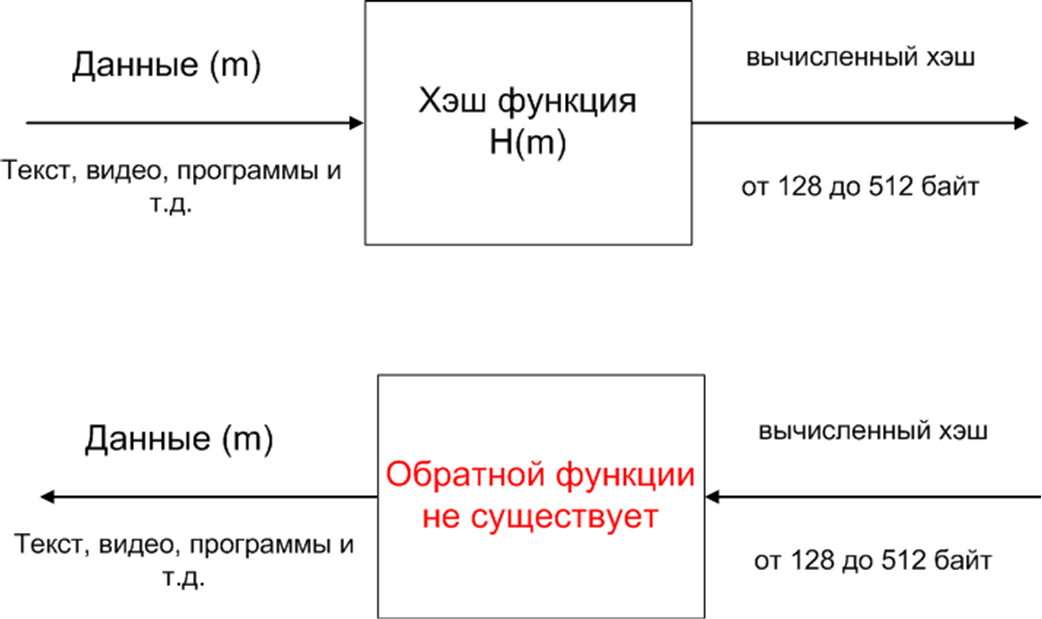
Поскольку майнинг биткоина является столь затратной задачей, у майнеров нет причин обманывать систему, так как это приведет к значительным финансовым убыткам. Соответственно, чем больше майнеров присоединяется к блокчейну, тем больше и сильнее он становится.
Заключение
Нет сомнений в том, что хэш-функции являются одним из основных инструментов информатики, особенно при работе с огромными объемами данных. В сочетании с криптографией, алгоритмы хеширования могут быть весьма универсальными, предлагая безопасность и множество способов аутентификации. Таким образом, криптографические хеш-функции жизненно важны практически для всех криптовалютных сетей, поэтому понимание их свойств и механизмов работы, безусловно полезно для всех, кто интересуется технологией блокчейн.
что это такое простыми словами
Хэш или хэш-функция – одна из основных составляющих современной криптографии и алгоритма блокчейна.
Хэширование представляет собой преобразование любого объема информации в уникальный набор символов, который присущ только этому массиву входящей информации.
У хэш-функции есть несколько обязательных свойств:
- Хэш всегда уникален для каждого массива информации. Однако иногда случаются так называемые коллизии, когда для разных входных блоков информации вычисляются одинаковые хэш-коды.
- При самом незначительном изменении входной информации ее хэш полностью меняется.
- Хэш-функция необратима и не позволяет восстанавливать исходный массив информации из символьной строки. Это можно сделать, только перебрав все возможные варианты, что при бесконечном количестве информации требует много времени и денег.
- Хэширование позволяет достаточно быстро вычислить нужный хэш для достаточно большого объема информации.
- Алгоритм работы хэш-функции, как правило, делается открытым, чтобы при необходимости можно было оценить ее стойкость к восстановлению начальных данных по выдаваемому хэшу.

- Хэш-функция должна уметь приводить любой объем данных к числу заданной длины.

Такой пример не часто встречается в реальной работе, но он наглядно показывает, насколько хэш-функция может облегчить работу с большими объемами информации.
Например, в массив из нескольких миллионов разных строк длиной 1 млн символов нужно добавить еще одну, при условии, что там ее еще нет. Чтобы не заниматься посимвольным сравнением каждой строки, можно предварительно вычислить хэш каждой из них, и уже сделать сравнение по нему. Вся работа упрощается и ускоряется в разы.
Проверка целостности данных при передачеДля таких проверок часто используются простые хэш-функции.
Например, один пользователь передает другому определенный массив данных, а затем хэш от него. Получатель информации, захэшировав информацию у себя и сравнив хэши, может удостовериться, что он получил именно те данные, которые были отправлены.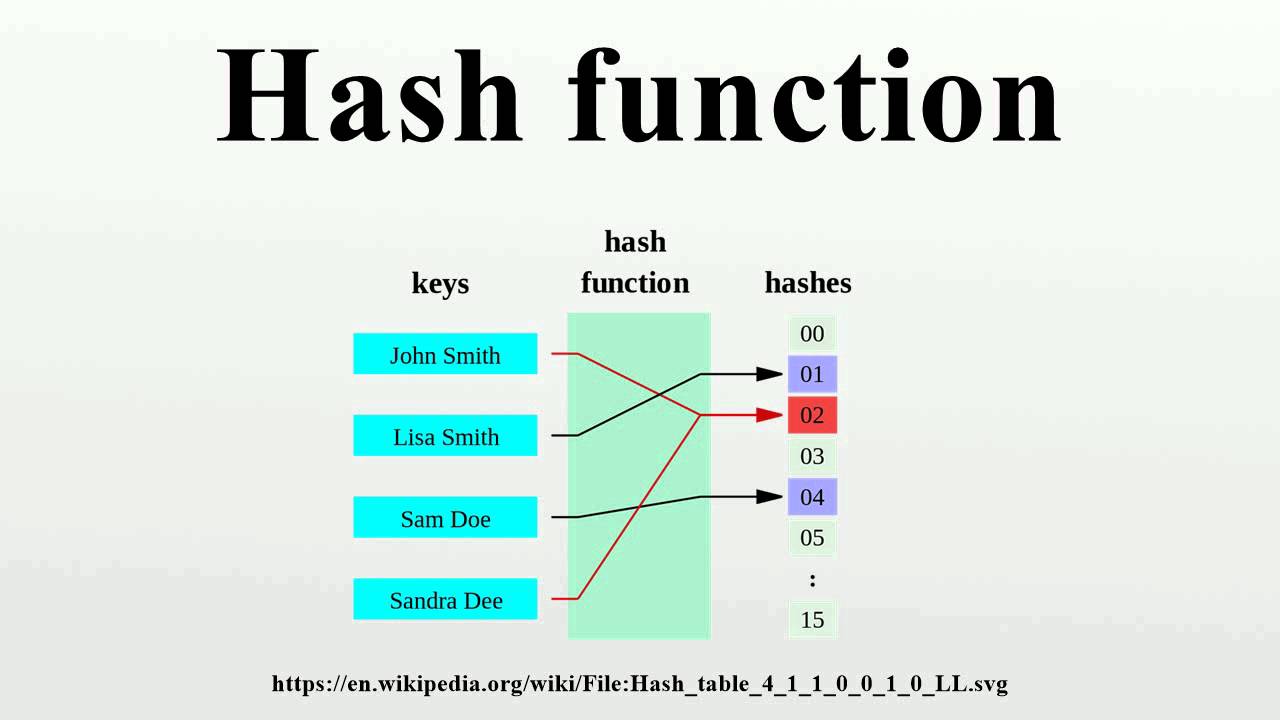
В технологии блокчейн хэш также используется для проверки целостности данных. Хэш выступает гарантией целостности цепочки транзакций (платежей) и защищает ее от несанкционированных изменений. Благодаря ему и распределенным вычислениям взломать блокчен очень сложно.
ШифрованиеНа практике некоторые хэш-функции также используются для шифрования. Благодаря практически полностью хаотичному соответствию хэшей исходным данным, практически невозможно вычислить начальный массив данных. Такие хэш-функции должны быть очень стойкими к коллизиям, т.е. должна обладать минимальной вероятностью получения двух одинаковых хэшей для двух разных массивов данных. Расчеты по таким алгоритмам более сложные и требует больше времени, но зато отличаются надежностью.
Использование хэша в данной технологии позволяет пользователю, который подписывает документ, быть уверенным, что он подписывает именно тот документ, который требуется. Также хэш используется при формировании электронной цифровой подписи и аутентификации пользователей.
Также хэш используется при формировании электронной цифровой подписи и аутентификации пользователей.
Для доступа к сайтам и серверам по логину и паролю тоже часто используют хэширование.
Пользователь регистрируется на сайте:
- Заполняет форму регистрации, включая поле Пароль,
- Пароль обрабатывается хэш-функцией и помещается в базу данных,
- Оригинальное значение пароля нигде не используется.
Пользователь входит на сайт:
- Вводит свой логин и пароль,
- Пароль хэшируется и сравнивается с данными базы,
- Если хэши совпадают, пользователя заходит на сайт.
Хэш — что это такое? Определение, значение, перевод
Хэш, он же хеш, это английское слово hash, которое в русском языке чаще всего употребляется в составных словах «хэш-функция», «хэш-сумма» или «хэш-алгоритм». Давайте попробуем разобраться, что это такое и для чего оно нужно.
Давайте попробуем разобраться, что это такое и для чего оно нужно.Понятие «хэширование» означает детерминистское (однозначное и точно известное) вычисление набора символов фиксированной длины на основе входных данных произвольной длины. При этом изменение хотя бы одного символа в исходных данных гарантирует (с вероятностью, близкой к 100%), что и полученная фиксированная строка будет иной. Можно сказать, что хеширование это «снятие отпечатка» с большого набора данных.
Для чего всё это нужно? Давайте рассмотрим пример: вы скачали большой файл (положим, zip-архив) и желаете убедиться, что в нём нет ошибок. Вы можете узнать «хэш-сумму» (тот самый отпечаток) этого файла и сверить его с опубликованным на сайте. Если строки хэш-сумм различаются, то файл однозначно «битый».
Другой пример: чтобы обезопасить данные пользователей, банк не должен хранить их пароли такими, какие они есть, в своей базе данных. Вместо этого банк хранит хэш-суммы этих паролей и каждый раз при вводе пароля вычисляет его хэш-сумму и сверяет её с хранимой в базе. И тут возникает резонный вопрос о возможных «коллизиях», то есть одинаковых результатах хэширования разных паролей. Хорошая хэш-функция должна сводить коллизии к абсолютному минимуму, а для этого её нужно сделать довольно сложной и запутанной.
И тут возникает резонный вопрос о возможных «коллизиях», то есть одинаковых результатах хэширования разных паролей. Хорошая хэш-функция должна сводить коллизии к абсолютному минимуму, а для этого её нужно сделать довольно сложной и запутанной.
Вы узнали, откуда произошло слово Хэш, его объяснение простыми словами, перевод, происхождение и смысл.
Пожалуйста, поделитесь ссылкой «Что такое Хэш?» с друзьями:
И не забудьте подписаться на самый интересный паблик ВКонтакте!
Хэш, он же хеш, это английское слово hash, которое в русском языке чаще всего употребляется в составных словах «хэш-функция», «хэш-сумма» или «хэш-алгоритм». Давайте попробуем разобраться, что это такое и для чего оно нужно.
Понятие «хэширование» означает детерминистское (однозначное и точно известное) вычисление набора символов фиксированной длины на основе входных данных произвольной длины. При этом изменение хотя бы одного символа в исходных данных гарантирует (с вероятностью, близкой к 100%), что и полученная фиксированная строка будет иной. Можно сказать, что хеширование это «снятие отпечатка» с большого набора данных.
Можно сказать, что хеширование это «снятие отпечатка» с большого набора данных.
Для чего всё это нужно? Давайте рассмотрим пример: вы скачали большой файл (положим, zip-архив) и желаете убедиться, что в нём нет ошибок. Вы можете узнать «хэш-сумму» (тот самый отпечаток) этого файла и сверить его с опубликованным на сайте. Если строки хэш-сумм различаются, то файл однозначно «битый».
Другой пример: чтобы обезопасить данные пользователей, банк не должен хранить их пароли такими, какие они есть, в своей базе данных. Вместо этого банк хранит хэш-суммы этих паролей и каждый раз при вводе пароля вычисляет его хэш-сумму и сверяет её с хранимой в базе. И тут возникает резонный вопрос о возможных «коллизиях», то есть одинаковых результатах хэширования разных паролей. Хорошая хэш-функция должна сводить коллизии к абсолютному минимуму, а для этого её нужно сделать довольно сложной и запутанной.
Что такое хеширование, шифрование в блокчейне? Алгоритмы, коды
Хеширование – это создание последовательности символов (хешей) с использованием математической функции. Эта последовательность характеризуется высоким уровнем защищенности и позволяет безопасно отправлять сообщения. Процесс, в том числе, применяют в криптографии.
Эта последовательность характеризуется высоким уровнем защищенности и позволяет безопасно отправлять сообщения. Процесс, в том числе, применяют в криптографии.
Редакция BeInCrypto собрала всю информацию по теме в одном материале, чтобы дать развернутый ответ на вопрос о том, что такое хеширование.
Криптографические хеш-функции
Это определенный вид хеша, который безопасен и идеально подходит для криптографии. Хеш-функции обладают следующими особенностями:
Детерминированность – при определенной входной величине каждый раз должен производиться фиксированный объем хешей.
Вычислительная эффективность – компьютерная мощность должна быть достаточной для быстрого возврата хешей. Большинство компьютеров могут обрабатывать хеш-функцию за долю секунды.
Устойчивость к нахождению прообраза – Хеш-функция не должна выдавать никакую информации о входном значении.
Устойчивость к коллизиям – Получение двух входов, которые могли бы дать два выхода. Должно быть очень сложным или невозможным. Поскольку длина входного значения может быть любой, его вариации бесконечны.
Должно быть очень сложным или невозможным. Поскольку длина входного значения может быть любой, его вариации бесконечны.
У выходов длина фиксированная и, соответственно, в этом случае количество вариантов ограничено. При этом несколько входов могут произвести одинаковый выход.
Если устойчивость к коллизиям недостаточно высока, могут происходить так называемые атаки «дней рождения». Это атака, в которой математика преобладает над теорией вероятности. Возможно, вы уже слышали о подобных случаях. Самый простой пример иллюстрации таких атак – если в комнате находится 27 человек, есть 50%-ная вероятность того, что у двух присутствующих совпадают дни рождения.
Почему так происходит? На одного человека вероятность составляет 1/365, исходя из количества дней в году. На второго человека приходится такая же вероятность. Для определения вероятности совпадения их дней рождения нужно умножить один показатель на другой.
Итак, получается, что есть 365 дат дней рождения и 365 вероятностей совпадения, и если извлечь корень из этого числа, выходит, что у 23 рандомно выбранных человек вероятность совпадения дат рождения составляет 50%.
Если применить эту теорию к хешированию, становится понятно, что с технической точки зрения ни одна хеш-функция не является полностью устойчивой к коллизии, но прежде чем это произойдет может пройти очень много времени.
Что такое хеширование в блокчейне
Биткоин функционирует на базе блокчейна и использует алгоритм хеширования SHA-256 (алгоритм криптографического хеширования 256). С его помощью любой объем информации можно преобразовать в строку из 64 символов.
Хеширование онлайн через алгоритм SHA-256В случае с биткоином хеш-функции выполняют три основные задачи:
- Майнинг – майнеры конкурируют за решение задач. Каждый майнер берет информацию из блоков, о которых они уже знают и выстраивают из них новый блок. Если на выходе алгоритм выдает значение, меньшее целевой цифры, оно считается действительным и может быть принято остальными участниками сети. Таким образом, майнер получает право на создание следующего блока.
- Соединение блоков – в целях дополнительной безопасности. Каждый блок в блокчейне связан с предыдущим, что достигается посредством хеш-указателя (переменные, хранящие адрес другой переменной). По сути, каждый блок содержит результат хеширования от предыдущего блока в блокчейне. Благодаря этой функции можно легко отслеживать историю в блокчейне и исключить вероятность добавления вредоносного блока в сеть.
- Создание ключей – чтобы отправить или получить криптовалюту необходимы частный и публичный ключи. Оба ключа связаны друг с другом через хеш-функцию. Это неотъемлемый компонент, который исключает получение вашего частного ключа третьими лицами.
 Каждый блок в блокчейне связан с предыдущим, что достигается посредством хеш-указателя (переменные, хранящие адрес другой переменной). По сути, каждый блок содержит результат хеширования от предыдущего блока в блокчейне. Благодаря этой функции можно легко отслеживать историю в блокчейне и исключить вероятность добавления вредоносного блока в сеть.
Каждый блок в блокчейне связан с предыдущим, что достигается посредством хеш-указателя (переменные, хранящие адрес другой переменной). По сути, каждый блок содержит результат хеширования от предыдущего блока в блокчейне. Благодаря этой функции можно легко отслеживать историю в блокчейне и исключить вероятность добавления вредоносного блока в сеть.Почему это важно
Хеш-функция обеспечивает криптовалюте высокий уровень безопасности. И хотя в теории ничто не защищено от взломов в полной мере, такой подход дает максимально высокий из доступных на сегодняшний день уровней сложности.
При хеш-функций можно достигать высокого уровня безопасности систем. В том числе, с ее помощью возможно хеширование паролей и шифрование других данных.
Предлагаем продолжить обсуждение этой темы в нашем Telegram-канале.
Дисклеймер
Вся информация, содержащаяся на нашем вебсайте, публикуется на принципах добросовестности и объективности, а также исключительно с ознакомительной целью. Читатель самостоятельно несет полную ответственность за любые действия, совершаемые им на основании информации, полученной на нашем вебсайте.Хэширование в строковых задачах — Алгоритмика
Хэширование в строковых задачах — АлгоритмикаХэш — это какая-то функция, сопоставляющая объектам какого-то множества числовые значения из ограниченного промежутка.
«Хорошая» хэш-функция:
- Быстро считается — за линейное от размера объекта время;
- Имеет не очень большие значения — влезающие в 64 бита;
- «Детерминированно-случайная» — если хэш может принимать \(n\) различных значений, то вероятность того, что хэши от двух случайных объектов совпадут, равна примерно \(\frac{1}{n}\).
Обычно хэш-функция не является взаимно однозначной: одному хэшу может соответствовать много объектов. Такие функции называют сюръективными.
Для некоторых задач удобнее работать с хэшами, чем с самими объектами. Пусть даны \(n\) строк длины \(m\), и нас просят \(q\) раз проверять произвольные две на равенство. Вместо наивной проверки за \(O(q \cdot n \cdot m)\), мы можем посчитать хэши всех строк, сохранить, и во время ответа на запрос сравнивать два числа, а не две строки.
Применения в реальной жизни
- Чек-суммы. Простой и быстрый способ проверить целостность большого передаваемого файла — посчитать хэш-функцию на стороне отправителя и на стороне получателя и сравнить.
- Хэш-таблица. Класс
unordered_setиз STL можно реализовать так: заведём \(n\) изначально пустых односвязных списков. Возьмем какую-нибудь хэш-функцию \(f\) с областью значений \([0, n)\). При обработке.insert(x)мы будем добавлять элемент \(x\) в \(f(x)\)-тый список. При ответе на .find(x)мы будем проверять, лежит ли \(x\)-тый элемент в \(f(x)\)-том списке. Благодаря «равномерности» хэш-функции, после \(k\) добавлений ожидаемое количество сравнений будет равно \(\frac{k}{n}\) = \(O(1)\) при правильном выборе \(n\). - Мемоизация. В динамическом программировании нам иногда надо работать с состояниями, которые непонятно как кодировать, чтобы «разгладить» в массив. Пример: шахматные позиции. В таком случае нужно писать динамику рекурсивно и хранить подсчитанные значения в хэш-таблице, а для идентификации состояния использовать его хэш.
- Проверка на изоморфизм. Если нам нужно проверить, что какие-нибудь сложные структуры (например, деревья) совпадают, то мы можем придумать для них хэш-функцию и сравнивать их хэши аналогично примеру со строками.
- Криптография. Правильнее и безопаснее хранить хэши паролей в базе данных вместо самих паролей — хэш-функцию нельзя однозначно восстановить.
- Поиск в многомерных пространствах. Детерминированный поиск ближайшей точки среди \(m\) точек в \(n\)-мерном пространстве быстро не решается. Однако можно придумать хэш-функцию, присваивающую лежащим рядом элементам одинаковые хэши, и делать поиск только среди элементов с тем же хэшом, что у запроса.
 При ответе на
При ответе на 
Хэшируемые объекты могут быть самыми разными: строки, изображения, графы, шахматные позиции, просто битовые файлы.
Сегодня же мы остановимся на строках.
Полиномиальное хэширование
Лайфхак: пока вы не выучили все детерминированные строковые алгоритмы, научитесь пользоваться хэшами.
Будем считать, что строка — это последовательность чисел от \(1\) до \(m\) (размер алфавита). В C++ char это на самом деле тоже число, поэтому можно вычитать из символов минимальный код и кастовать в число: int x = (int) (c - 'a' + 1).
Определим прямой полиномиальный хэш строки как значение следующего многочлена:
\[ h_f = (s_0 + s_1 k + s_2 k^2 + \ldots + s_n k^n) \mod p \]
Здесь \(k\) — произвольное число больше размера алфавита, а \(p\) — достаточно большой модуль, вообще говоря, не обязательно простой. 2)\) и добавим их все в
2)\) и добавим их все в std::set. Чтобы получить ответ, просто вызовем set.size().
Поиск подстроки в строке. Можно посчитать хэши от шаблона (строки, которую ищем) и пройтись «окном» размера шаблона по тексту, поддерживая хэш текущей подстроки. Если хэш какой-то из этих подстрок совпал с хэшом шаблона, то мы нашли нужную подстроку. Это называется алгоритмом Рабина-Карпа.
Сравнение строк (больше-меньше, а не только равенство). У любых двух строк есть какой-то общий префикс (возможно, пустой). Сделаем бинпоиск по его длине, а дальше сравним два символа, идущие за ним.
Палиндромность подстроки. Можно посчитать два массива — обратные хэши и прямые. Проверка на палиндром будет заключаться в сравнении значений hash_substring() на первом массиве и на втором.
Количество палиндромов. Можно перебрать центр палиндрома, а для каждого центра — бинпоиском его размер. Проверять подстроку на палиндромность мы уже умеем. Как и всегда в задачах на палиндромы, случаи четных и нечетных палиндромов нужно обрабатывать отдельно.
Как и всегда в задачах на палиндромы, случаи четных и нечетных палиндромов нужно обрабатывать отдельно.
Хранение строк в декартовом дереве
Если для вас всё вышеперечисленное тривиально: можно делать много клёвых вещей, если «оборачивать» строки в декартово дерево. В вершине дерева можно хранить символ, а также хэш подстроки, соответствующей её поддереву. Чтобы поддерживать хэш, нужно просто добавить в upd() пересчёт хэша от конкатенации трёх строк — левого сына, своего собственного символа и правого сына.
Имея такое дерево, мы можем обрабатывать запросы, связанные с изменением строки: удаление и вставка символа, перемещение и переворот подстрок, а если дерево персистентное — то и копирование подстрок. При запросе хэша подстроки нам, как обычно, нужно просто вырезать нужную подстроку и взять хэш, который будет лежать в вершине-корне.
Если нам не нужно обрабатывать запросы вставки и удаления символов, а, например, только изменения, то можно использовать и дерево отрезков вместо декартова.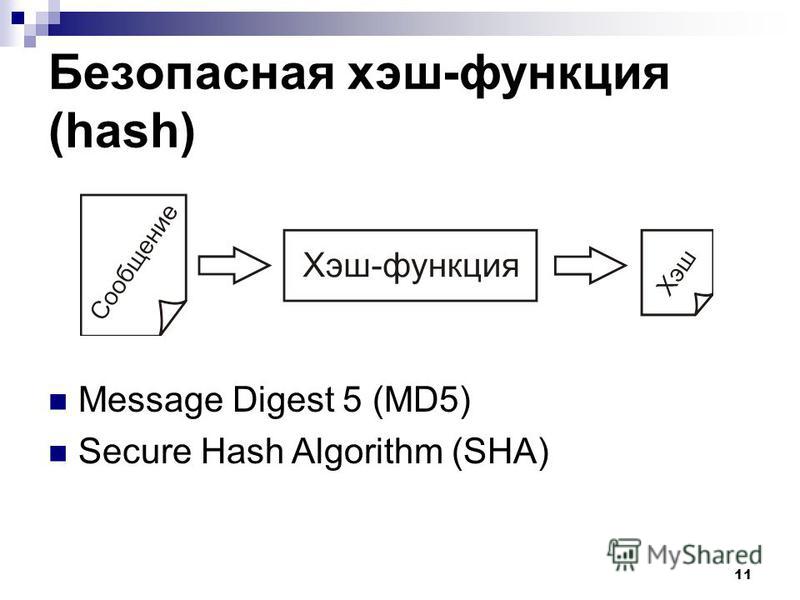 {64}\). У него есть несколько преимуществ:
{64}\). У него есть несколько преимуществ:
- Он большой — второй модуль точно не понадобится.
- С ним ни о каких переполнениях заботиться не нужно — если все хранить в
unsigned long long, процессор сам автоматически сделает эти взятия остатков при переполнении. - С ним хэширование будет быстрее — раз переполнение происходит на уровне процессора, можно не выполнять долгую операцию
%.
Всё с этим модулем было прекрасно, пока не придумали тест против него. Однако, его добавляют далеко не на все контесты — имейте это в виду.
В выборе же \(k\) ограничения не такие серьезные:
- Она должна быть чуть больше размера словаря — иначе можно изменить две соседние буквы и получить коллизию.
- Она должна быть взаимно проста с модулем — иначе в какой-то момент всё может занулиться.
Главное — чтобы значения \(k\) и модуля не знал человек, который генерирует тесты.
Парадокс дней рождений
В группе, состоящей из 23 или более человек, вероятность совпадения дней рождения хотя бы у двух людей превышает 50%.
Примечание: формально, из этого явно не следует, что вероятности тоже стремятся к 0 и 1.
Бонус: «мета-задача»
Дана произвольная строка, по которой известным только авторам задачи способом генерируется ответ yes/no. В задаче 100 тестов. У вас есть 20 попыток отослать решение. В качестве фидбэка вам доступны вердикты на каждом тесте. Вердиктов всего два: OK (ответ совпал) и WA. Попытки поделить на ноль, выделить терабайт памяти и подобное тоже считаются как WA.
«Решите» задачу.
PHP: Хеширование паролей — Manual
I feel like I should comment some of the clams being posted as replies here.For starters, speed IS an issue with MD5 in particular and also SHA1. I’ve written my own MD5 bruteforce application just for the fun of it, and using only my CPU I can easily check a hash against about 200mill. hash per second.
With 100 billion per second it would then take 7,21389578984e+15 / 3600 = ~20 hours to figure out what it actually says. Keep in mind that you’ll need to add the numbers for 1-7 characters as well. 20 hours is not a lot if you want to target a single user.So on essence:
There’s a reason why newer hash algorithms are specifically designed not to be easily implemented on GPUs.Oh, and I can see there’s someone mentioning MD5 and rainbow tables. If you read the numbers here, I hope you realize how incredibly stupid and useless rainbow tables have become in terms of MD5. Unless the input to MD5 is really huge, you’re just not going to be able to compete with GPUs here. By the time a storage media is able to produce far beyond 3TB/s, the CPUs and GPUs will have reached much higher speeds.
As for SHA1, my belief is that it’s about a third slower than MD5. I can’t verify this myself, but it seems to be the case judging the numbers presented for MD5 and SHA1.
The moral here:
Please do as told. Don’t every use MD5 and SHA1 for hasing passwords ever again. We all know passwords aren’t going to be that long for most people, and that’s a major disadvantage. Adding long salts will help for sure, but unless you want to add some hundred bytes of salt, there’s going to be fast bruteforce applications out there ready to reverse engineer your passwords or your users’ passwords.Разница между шифрованием, хешированием и засаливанием
Шифрование и хеширование выполняют разные функции, несмотря на их сходство.
Quick, знаете ли вы разницу между шифрованием и хешированием? Вы знаете, что такое соление? Вы думаете, что соление хеша — это всего лишь часть ирландского завтрака?
Если не считать шуток, если вы обратите внимание на мир кибербезопасности, вы, вероятно, услышите, как эти термины обсуждают. Часто без объяснения причин.
Итак, сегодня давайте поговорим о разнице между шифрованием и хешированием и ответим на любые вопросы, которые вы, возможно, боялись задать.
Давайте разберемся.
Что такое шифрование?
Шифрование — это практика шифрования информации таким образом, что только кто-то с соответствующим ключом может расшифровать и прочитать ее.Шифрование — это двусторонняя функция. Когда вы что-то шифруете, вы делаете это с намерением расшифровать это позже.
Это ключевое различие между шифрованием и хешированием (простите за каламбур).
Для шифрования данных вы используете так называемый шифр, который представляет собой алгоритм — серию четко определенных шагов, которые можно выполнять процедурно — для шифрования и дешифрования информации. Алгоритм также можно назвать ключом шифрования. Я понимаю, что слово «алгоритм» имеет пугающий оттенок из-за шрамов, которые у всех нас остались от математики в средней школе и колледже.Но, как вы увидите, алгоритм на самом деле не более чем набор правил, и на самом деле они могут быть довольно простыми.
Шифрование имеет долгую историю. Он восходит как минимум к 1900 году до нашей эры, когда была обнаружена стена гробницы с высеченными на ней нестандартными иероглифами. С тех пор было бесчисленное множество исторических примеров.
Древние египтяне использовали простую форму шифрования. Как и Цезарь, чей шифр является одним из самых важных примеров шифрования в истории.Цезарь использовал примитивный шифр сдвига, который менял буквы, отсчитывая заданное количество разрядов в алфавите. Однако это было чрезвычайно полезно, делая любую информацию, перехваченную противниками Цезаря, практически бесполезной.
Пару тысяч лет спустя номенклатурный шифр — тип шифра подстановки, который меняет символы на обычные слова в попытке избежать метода дешифрования, называемого частотным анализом, — обезглавил Марию Королеву Шотландии и убил группу заговорщиков, когда их сообщения были перехватывается и расшифровывается буквальным человеком (мужчинами) в середине.
Как работает шифрование?
Давайте посмотрим на шифрование с помощью простого шифра.
Очевидно, что с самого начала мы прошли долгий путь, но сосредоточимся только на концепциях. Предложение в необработанной форме имеет открытый текст — неформатированный, некодированный — состояние, в которое оно вернется после расшифровки.
Давайте продолжим фразу «не будь придурком», которая, кстати, также является единственным правилом для нашего раздела комментариев. Я собираюсь применить алгоритм / ключ шифрования и превратить его в зашифрованный текст.
Plaintext: Не будь придуркомСтановилось:
Зашифрованный текст: GrqwehdmhunЯ опустил знаки препинания для простоты, но шифрованный текст обычно передается без пробелов и знаков препинания, чтобы избежать ошибок и скрыть границы слов.
Исторические алгоритмы шифрования
Давайте начнем с рассмотрения некоторых различных типов шифров, а затем перейдем к современным алгоритмам, которые используются в сегодняшнем шифровании.
Shift Ciphers — Как и в примере, который мы обсуждали выше, две стороны определяют число от 1-25 и сдвигают буквы на это количество пробелов в алфавите. Номер смены служит ключом.
Шифры замещения — Эти шифры заменяют открытый текст зашифрованным текстом с использованием алгоритма, который является фиксированной системой. Ключ — это документ, который показывает фиксированную систему, которую можно использовать для обратного проектирования шифрования.
Transposition Ciphers — Этот алгоритм использует набор правил, которые служат ключом для изменения порядка текста в различных перестановках, которые затем могут быть зашифрованы.Распространенными примерами являются шифры Rail Fence и Route.
Полиалфавитные шифры — это тип шифра подстановки, в котором используется несколько алфавитов для дальнейшего усложнения несанкционированного дешифрования зашифрованного текста.
Шифры номенклатуры — Тип шифра подстановки, который заменяет обычные слова открытого текста символами, чтобы попытаться отбросить определенную форму криптоанализа.
Криптоанализ — это исследование криптосистем с целью поиска в них слабых мест.Одна из наиболее распространенных форм криптоанализа, восходящая к арабскому математику Аль-Кинди, жившему около 800 г. н.э., называется частотным анализом. Он проверяет зашифрованный текст на наличие повторяющихся символов или строк символов и перекрестно ссылается на них со словами, которые часто встречаются в расшифровываемом сообщении.
Так, например, если вы пишете сообщение Наполеону, вполне логично, что вы будете использовать его имя несколько раз. Сопоставив версию зашифрованного текста с его именем, вы сможете начать сопоставление ключа и расшифровку сообщения.
Полиалфавитные шифры и номенклатурные шифры лучше подходили для частотного анализа, чем их классические аналоги. Полиалфавитные шифры продолжали использоваться до Второй мировой войны, когда машина Enigma была взломана.
Современное шифрование
Прежде чем мы сможем говорить о современных шифровальных шифрах, нам нужно немного поговорить об открытых и закрытых ключах и о том, как цифровая революция изменила шифрование. Все примеры, которые мы только что рассмотрели, мы называем криптографией закрытого ключа.Шифрование полностью зависело от закрытого ключа, который нужно было физически обменять, чтобы дешифрование произошло. Если вы что-то знаете о частных ключах, так это то, что они неприкосновенны. Взлом вашего закрытого ключа может иметь катастрофические последствия.
Сегодня, благодаря компьютерным технологиям и Интернету, мы можем практиковать криптографию с открытым ключом.В криптографии с открытым ключом один открытый ключ используется для шифрования, а другой закрытый ключ — для дешифрования. Вы видите это во время рукопожатия SSL, когда они решили исторически опасные проблемы с обменом физическим ключом, используя общедоступный ключ для шифрования симметричного сеансового ключа и отправки его обратно на сервер для дешифрования с помощью его закрытого ключа. Ну, на самом деле вы этого не замечаете, но вы уловили мою мысль.
Сегодня наиболее распространенными формами шифрования являются:
- Асимметричное шифрование — это пример открытого ключа, который мы только что привели.Один ключ шифрует, другой — дешифрует. Шифрование идет только в одну сторону.
- Симметричное шифрование — это ближе к форме шифрования с закрытым ключом. У каждой стороны есть свой ключ, который можно как зашифровать, так и расшифровать. Как мы обсуждали в приведенном выше примере, после асимметричного шифрования, которое происходит при подтверждении связи SSL, браузер и сервер обмениваются данными, используя симметричный ключ сеанса, который передается вместе.
Между ними асимметричное шифрование имеет тенденцию быть более надежным из-за его одностороннего характера.
Когда вы покупаете сертификат SSL и видите, что «2048-битный» перебрасывается, это относится к длине закрытого ключа, в частности закрытого ключа RSA. Когда вы видите «256-битный», это обычно относится к размеру симметричных ключей сеанса, которые используются во время фактического взаимодействия. Это не означает, что симметричное шифрование менее безопасно.
Причина, по которой для обмена данными используется симметричное 256-битное шифрование, заключается в том, что оно быстрее, что означает лучшую производительность и меньшие накладные расходы для серверов.
Более пристальный взгляд на рукопожатие SSL / TLS
Во всем шифровании Патрик Ноэ
Когда вы подключаетесь к веб-сайту через HTTPS, под капотом происходит много всего. В первую очередь всем нужно… пожать руку ?!
Прочитайте больше
Современные алгоритмы шифрования
Теперь, когда мы обсудили симметричное и асимметричное шифрование, мы можем перейти к некоторым современным алгоритмам шифрования.
AES — AES означает Advanced Encryption Standard, первоначально называвшийся Rijndael, это спецификация шифрования, опубликованная Национальным институтом стандартов и технологий (NIST) еще в 2001 году.
RSA — RSA означает Rivest-Shamir-Adlemen, после его создателей, это алгоритм шифрования с открытым ключом (асимметричный), который существует с 1978 года и до сих пор широко используется. Он использует факторизацию простых чисел для шифрования открытого текста.
[Забавный факт: неудачно названный Клиффорд Кокс, математик, работающий в британской разведывательной службе GCHQ, изобрел эквивалентную систему пятью годами ранее, в 1973 году, но рассекречена она была только в 1997 году.]
ECC — ECC — это аббревиатура от Elliptic Curve Cryptography, которая основывается на алгебраической структуре эллиптических кривых над конечными полями.
PGP — PGP означает Pretty Good Privacy, он был создан в 1991 году Филом Циммерманом. На самом деле это скорее набор алгоритмов, чем один, все для хеширования, сжатия данных и криптографии с открытым и закрытым ключом.На каждом этапе используется свой алгоритм. PGP критиковали за плохое удобство использования, отсутствие повсеместности и длину его ключей.
Когда следует использовать шифрование?
Как мы обсуждали ранее, шифрование — это двусторонняя функция. Вы шифруете информацию, чтобы потом расшифровать ее. Таким образом, переписка с кем-то в Интернете, защита ваших облачных данных или передача финансовых данных — все это примеры случаев, когда уместно шифрование.
Ключ в том, что шифрование обратимо.Хеширования нет.
Что такое хеширование?
Хеширование — это практика использования алгоритма для сопоставления данных любого размера с фиксированной длиной.
Теперь, в то время как шифрование предназначено для защиты данных при передаче, хеширование предназначено для проверки того, что файл или фрагмент данных не были изменены — что они подлинные.Другими словами, это контрольная сумма.
Вот как это работает: каждый алгоритм хеширования имеет фиксированную длину. Так, например, вы можете слышать о SHA-256, что означает, что алгоритм будет выводить хэш-значение, которое составляет 256 бит, обычно представленное 64-символьной шестнадцатеричной строкой (h / t Matthew Haslett).
Каждое значение хеш-функции уникально. Если два разных файла создают одно и то же уникальное хеш-значение, это называется коллизией, и это делает алгоритм практически бесполезным.
В любом случае, вот пример хеширования. Допустим, вы хотите поставить цифровую подпись на программу и сделать ее доступной для загрузки на своем веб-сайте.Для этого вы собираетесь создать хэш скрипта или исполняемого файла, который вы подписываете, а затем, добавив свою цифровую подпись, вы тоже хешируете его. После этого все зашифровывается, чтобы его можно было загрузить.
Когда клиент загружает программное обеспечение, его браузер расшифровывает файл, а затем проверяет два уникальных значения хеш-функции. Затем браузер запустит ту же хеш-функцию, используя тот же алгоритм, и снова хеширует файл и подпись.
Если это не так, браузер выдает предупреждение.
Вот как работает подписывание кода. Просто помните, что никакие два файла не могут создавать одинаковое значение хеш-функции, поэтому любое изменение — даже самая маленькая настройка — приведет к разному значению.
Общие алгоритмы хеширования
Как и в случае с шифрованием, давайте рассмотрим некоторые из наиболее распространенных алгоритмов хеширования, используемых сегодня.
MD4 — MD4 — это ненавистный к себе хэш-алгоритм, созданный в 1990 году, даже его создатель Рональд Ривест признает, что у него есть проблемы с безопасностью.Однако 128-битный алгоритм хеширования оказал влияние, его влияние можно почувствовать в более поздних алгоритмах, таких как WMD5, WRIPEMD и семейство WHSA.
MD5 — MD5 — еще один алгоритм хеширования, разработанный Рэем Ривестом, который, как известно, подвержен уязвимостям.
SHA — SHA означает алгоритм хэширования безопасности и, вероятно, наиболее известен как алгоритм хеширования, используемый в большинстве комплектов шифров SSL / TLS.Набор шифров — это набор шифров и алгоритмов, которые используются для соединений SSL / TLS. SHA обрабатывает аспекты хеширования. SHA-1, как мы упоминали ранее, устарел. SHA-2 теперь является обязательным. SHA-2 иногда известен как SHA-256, хотя также доступны варианты с большей длиной в битах.
RIPEMD — Семейство алгоритмов криптографического хеширования с длиной 128, 160, 256 и 320 бит. Он был разработан в рамках проекта ЕС Ripe Гансом Доббертином и группой ученых в 1996 году.Его 256- и 320-битные варианты на самом деле не добавляют дополнительной безопасности, они просто уменьшают вероятность конфликта.
WHIRLPOOL — Разработан Виктором Рейменом (соавтором алгоритма AES, о котором мы говорили ранее) и Пауло Баррето в 2000 году. С тех пор он претерпел две модификации.Он производит 512-битные хэши, которые обычно представлены 128-значными шестнадцатеричными числами.
TIGER — довольно новый алгоритм, который начинает набирать обороты в сетях обмена файлами и торрент-сайтах. В настоящее время нет известных атак, эффективных против его полного 24-раундового варианта.
Что такое соление?
Salting — это концепция, которая обычно относится к хешированию паролей. По сути, это уникальное значение, которое можно добавить в конец пароля для создания другого значения хеш-функции.Это добавляет уровень безопасности к процессу хеширования, особенно против атак методом грубой силы.
В любом случае, при засолке добавочная стоимость называется «солью».
Идея состоит в том, что, добавляя соль в конец пароля и затем хешируя его, вы существенно усложняете процесс взлома пароля.
Давайте посмотрим на небольшой пример.
Скажите пароль, который я хочу солить, выглядит так:
7X57CKG72JVNSSS9Ваша соль — это просто слово СОЛЬ
Перед хешированием вы добавляете SALT в конец данных. Итак, это будет выглядеть так:
7X57CKG72JVNSSS9SALTХэш-значение отличается от хеш-значения простого несоленого пароля. Помните, что даже малейшее изменение хешируемых данных приведет к другому уникальному хеш-значению. Посолив свой пароль, вы, по сути, скрываете его реальное хеш-значение, добавляя дополнительный бит данных и изменяя его.
Так вот, если злоумышленник знает вашу соль, это бесполезно. Они могут просто добавить его в конец каждого варианта пароля, который они пытаются использовать, и в конечном итоге его найдут. Вот почему соль для каждого пароля должна быть разной — для защиты от атак с радужной таблицей [предложение Джона в комментариях].
Мы могли бы написать целую статью о безопасности паролей и о том, остается ли это еще полезной защитой — и мы когда-нибудь будем, — но пока это должно быть приемлемое определение соления.
И быстро в сторону, если вы еще не сложили два и два вместе, наше имя, Hashed Out, является игрой на популярной идиоме для обсуждения чего-либо и процесса хеширования, связанного с шифрованием SSL. Привет, Патрик, это действительно умно, . Спасибо, что заметили.
What we Hashed Out (для скиммеров)
Вот что мы обсудили сегодня:
- Шифрование — это двусторонняя функция, при которой информация шифруется таким образом, чтобы ее можно было расшифровать позже.
- Хеширование — это односторонняя функция, при которой данные отображаются в значение фиксированной длины. Хеширование в основном используется для аутентификации.
- Посоление — это дополнительный шаг во время хеширования, обычно связанный с хешированными паролями, который добавляет дополнительное значение в конец пароля, изменяющее полученное хеш-значение.
Хеширование — Глоссарий кибербезопасности
Хеширование — это алгоритм, выполняемый с данными, такими как файл или сообщение, для получения числа, называемого хешем (иногда называемого контрольной суммой).Хеш используется для проверки того, что данные не изменены, не подделаны или не повреждены. Другими словами, вы можете проверить целостность данных.
Ключевым моментом в хешировании является то, что независимо от того, сколько раз вы выполняете алгоритм хеширования для данных, хеш всегда будет одинаковым, если данные одинаковы.
Хеши создаются как минимум дважды, чтобы их можно было сравнивать.
- Patch file. Patch_v2_3.zip
- Контрольная сумма SHA-1. d4723ac6f72daea2c7793ac113863c5082644229
Контрольная сумма алгоритма безопасного хеширования 1 (SHA-1) — это вычисленный хэш, отображаемый в шестнадцатеричном формате. Клиенты могут загрузить файл, а затем вычислить хэш для загруженного файла. Если вычисленный хэш совпадает с хешем, опубликованным на веб-сайте, он проверяет, сохранил ли файл целостность.Другими словами, файл не изменился.
Алгоритмы хеширования:
MD5
Дайджест сообщения 5 (MD5) — это общий алгоритм хеширования, который создает 128-битный хэш. Хэши обычно отображаются в шестнадцатеричном формате вместо потока единиц и нулей. Например, хеш MD5 отображается как 32 шестнадцатеричных символа вместо 128 бит.
SHA
Secure Hash Algorithm (SHA) — еще один алгоритм хеширования.Существует несколько вариантов SHA, сгруппированных в четыре семейства — SHA-0, SHA-1, SHA-2 и SHA-3:
- SHA-0 не используется.
- SHA-1 — это обновленная версия, которая создает 160-битные хэши. Это похоже на хеш MD5, за исключением того, что он создает 160-битные хэши вместо 128-битных.
- SHA-2 улучшенный SHA-1 для устранения потенциальных недостатков. Он включает четыре версии. SHA-256 создает 256-битные хэши, а SHA-512 создает 512-битные хэши. SHA-224 (224-битные хэши) и SHA-384 (384-битные хэши) создают усеченные версии SHA-256 и SHA-512 соответственно.
- SHA-3 (ранее известный как Keccak) является альтернативой SHA-2. Агентство национальной безопасности США (АНБ) создало SHA-1 и SHA-2. SHA-3 был создан вне NSA и был выбран в открытом конкурсе, не принадлежащем NSA. Он может создавать хэши того же размера, что и SHA-2 (224 бит, 256 бит, 384 бит и 512 бит).
HMAC
Другой метод, используемый для обеспечения целостности, — это хэш-код аутентификации сообщения (HMAC). HMAC представляет собой строку битов фиксированной длины, аналогичную другим алгоритмам хеширования, таким как MD5 и SHA-1 (известные как HMAC-MD5 и HMAC-SHA1).Однако HMAC также использует общий секретный ключ, чтобы добавить некоторую случайность к результату, и только отправитель и получатель знают секретный ключ.
В качестве примера представьте, что один сервер отправляет сообщение другому серверу, используя HMAC-MD5. Он начинается с создания хэша сообщения с помощью MD5, а затем использует секретный ключ для выполнения другого вычисления хеша. Затем сервер отправляет сообщение и хэш HMAC-MD5 второму серверу. Второй сервер выполняет те же вычисления и сравнивает полученный хэш HMAC-MD5 со своим результатом.Как и при любом другом сравнении хешей, если два хеша одинаковы, сообщение сохраняет целостность, но если хеши разные, сообщение теряет целостность.
RIPEMD
Дайджест сообщения оценки примитивов целостности RACE (RIPEMD) — еще одна хеш-функция, используемая для проверки целостности. Он не так широко используется, как MD5, SHA и HMAC.
Хеш-файлы
Многие приложения вычисляют и сравнивают хеш-коды автоматически без какого-либо вмешательства пользователя. Например, цифровые подписи используют хеши в электронной почте, а почтовые приложения автоматически создают и сравнивают хеши.
Кроме того, есть несколько приложений, которые можно использовать для вычисления хэшей вручную. Например, sha1sum.exe — это бесплатная программа, которую каждый может использовать для создания хэшей файлов. Поиск в Google по запросу «скачать sha1sum» покажет несколько мест. Он запускает алгоритм хеширования SHA-1 для файла для создания хеша.
Стоит подчеркнуть, что хэши — это односторонние функции. Другими словами, вы можете вычислить хеш для файла или сообщения, но вы не можете использовать хеш для воспроизведения исходных данных.
В качестве примера хэш SHA-1 из сообщения «Я сдам экзамен на безопасность +»: 765591c4611be5e03bea41882ffdaa159352cf49. Однако вы не можете посмотреть на хэш и идентифицировать сообщение или даже узнать, что это хеш сообщения из шести слов.
Хеширование паролей
Пароли часто хранятся в виде хэшей.Когда пользователь создает новый пароль, система вычисляет хэш для пароля, а затем сохраняет хеш. Позже, когда пользователь аутентифицируется путем ввода имени пользователя и пароля, система вычисляет хэш введенного пароля, а затем сравнивает его с сохраненным хешем. Если хеши совпадают, это означает, что пользователь ввел правильный пароль.
Key Stretching
Key Stretching (иногда называемое усилением ключа) — это метод, используемый для увеличения надежности сохраненных паролей и может помочь предотвратить атаки методом грубой силы и радужной таблицы.
Bcrypt основан на блочном шифре Blowfish и используется во многих дистрибутивах Unix и Linux для защиты паролей, хранящихся в файле теневых паролей. Bcrypt солирует пароль, добавляя дополнительные случайные биты перед его шифрованием с помощью Blowfish. Bcrypt может проходить этот процесс несколько раз, чтобы защитить себя от попыток узнать пароль.В результате получается строка из 60 символов.
В качестве примера, если ваш пароль — IL0ve $ ecurity, приложение может зашифровать его с помощью bcrypt и случайной соли. Это может выглядеть так, которое приложение хранит в базе данных:
$ 2b $ 12 $ HXIKtJr93DH59BzzKQhehOI9pGjRA / 03ENcFRby1jH7nXwt1Tn0kGПозже, когда пользователь аутентифицируется с помощью имени пользователя и пароля, приложение запускает bcrypt с предоставленным паролем и сравнивает его.
В качестве дополнительной меры можно добавить немного перца к соли для дальнейшей рандомизации строки bcrypt. В этом контексте перец — это еще один набор случайных битов, хранящихся в другом месте.
PBKDF2 использует соли не менее 64 бит и использует псевдослучайные функции, такие как HMAC, для защиты паролей. Многие алгоритмы, такие как Wi-Fi Protected Access II (WPA2), мобильная операционная система Apple iOS и операционные системы Cisco, используют PBKDF2 для повышения безопасности паролей.Некоторые приложения отправляют пароль через процесс PBKDF2 до 1000000 раз для создания хэша. Размер результирующего хэша зависит от PBKDF2 в зависимости от того, как он реализован. Чаще всего используются размеры 128, 256 и 512 бит.
Некоторые эксперты по безопасности считают, что PBKDF2 более подвержен атакам методом грубой силы, чем bcrypt.
Хеширование сообщений
Хеширование обеспечивает целостность сообщений. Он дает уверенность тому, кто получает сообщение, что сообщение не было изменено. Представьте, что Лиза отправляет сообщение Барту. Сообщение: «Цена 75 долларов США». Это сообщение не является секретным, поэтому шифровать его не нужно. Однако мы хотим обеспечить целостность, поэтому это объяснение сосредоточено только на хешировании.
В этом примере что-то изменило сообщение до того, как оно достигнет Барта. Когда Барт получает сообщение и исходный хэш, теперь появляется сообщение «Цена составляет 75». Обратите внимание, что сообщение изменяется при передаче, но хэш не изменяется. Программа на компьютере Барта вычисляет хэш MD5 для полученного сообщения как 564294439E1617F5628A3E3EB75643FE.
- Хеш, созданный на компьютере Лизы и полученный компьютером Барта: D9B93C99B62646ABD06C887039053F56
- Хеш, созданный на компьютере Барта: 564294439E1617F5628A3E3EB75643FE, поэтому вы знаете, что 900FE — это разные 900 сообщение потеряло целостность.Программа на компьютере Барта сообщит о несоответствии. Барт не знает, в чем проблема. Это могло быть изменение сообщения злоумышленником или техническая проблема. Однако Барт знает, что полученное сообщение не совпадает с отправленным, и ему не следует доверять ему.
Использование HMAC
Возможно, вы заметили проблему в объяснении хешированного сообщения. Если злоумышленник может изменить сообщение, почему злоумышленник также не может изменить хеш? Другими словами, если Хакер Гарри изменил сообщение на «Цена.75 », он также мог вычислить хэш измененного сообщения и заменить исходный хеш измененным. Вот результат:
- Хэш, созданный на компьютере Лизы: D9B93C99B62646ABD06C887039053F56
- Измененный хеш, вставленный злоумышленником после изменения сообщения: 564294439E1617F5628A3E3EB75643FE
900FE Хэш, созданный для измененного сообщения63 на компьютере Bart9448, был рассчитан хеш-код484E9: 9484E быть таким же, как полученный хеш.С HMAC компьютеры Лизы и Барта будут знать один и тот же секретный ключ и использовать его для создания хеша HMAC-MD5, а не только хеша MD5.
См. Также Integrity .
Готовы ли вы получить сертификат Security +? Учебный пакетSY0-501 Вот что вы получитеЧто говорят люди
Пройдите первый раз, задав вопросы практического теста качества, вопросы на основе результатов, карточки и аудио.
Получите пакет онлайн-обучения, который поможет вам:
- Изучите с использованием нескольких онлайн-материалов
- Используйте их, чтобы дополнить книгу Дэррила Гибсона CompTIA Security + Get Certified Get Ahead: SY0-501 Study Guide или любое другое учебное пособие, которое вы используете
- Убедитесь, что вы готовы к экзамену, независимо от того, какое учебное пособие вы используете.
SY0-501 Полный учебный пакет доступен здесь.
Пакет включает в себя сотни вопросов практического теста с несколькими вариантами ответов, вопросы на основе результатов, аудио и карточки.
Более 300 реалистичных вопросов SY0-501 Security + Practice Test
Все вопросы содержат пояснения, чтобы вы знали, почему правильные ответы и почему неправильные ответы неверны. Эти вопросы основаны на главах CompTIA Security + Get Certified Get Ahead: SY0-501 Study Guide и организованы по ним. Смотрите демо здесь.
Дополнительный банк практик Контрольные вопросы
Как минимум 65 новых вопросов с несколькими вариантами ответов в дополнительном банке тестов.Время от времени добавляются вопросы. Здесь вы можете увидеть, что было добавлено за последнее время.
Четыре набора вопросов, основанных на производительности
Четыре набора вопросов, основанных на производительности, включая более 35 вопросов.
Набор онлайн-карточек
- 494 Онлайн-безопасность + Глоссарий Флэш-карты
- 222 Онлайн-безопасность + Флэш-карты сокращений
- 223 Онлайн-безопасность + Запомните этот слайд из популярного CompTIA Security + Получите сертификат Получить вперед: SY0-501 Учебное пособие
Проверить демо здесь.
Аудио — SY0-501 Безопасность + Аудиофайлы «Запомни это»
Учитесь, слушая.
Более одного часа 20 минут аудио повторения блоков «Помни это» из популярного CompTIA Security +: Get Certified Get Ahead: SY0-501 Study Guide. (Загрузка MP3.)
Аудио — SY0-501 Безопасность + аудиофайлы с вопросами и ответами
Учимся путем прослушивания.
Более двух часов и 53 минут аудио, повторяющих вопросы и ответы из 11 глав популярного CompTIA Security +: Get Certified Get Ahead: SY0-501 Study Guide.
Bonus # 1
Аудио из обзоров в конце каждой главы CompTIA Security +: Get Certified Get Ahead: SY0-501 Study Guide. Более часа 40 минут дополнительного звука.Bonus # 2
Доступ ко всему онлайн-контенту, который доступен бесплатно всем, кто приобретает CompTIA Security + Get Certified Get Ahead: SY0-501 Study Guide. Сюда входят лабораторные работы, вопросы дополнительных практических тестов и дополнительные материалы.
Бонус № 3
Расширенный доступ . Получите доступ к учебным материалам в общей сложности на 60 дней, потому что иногда жизнь случаетсяBonus # 4
Купон со скидкой 10% . Доступ к коду купона, который даст вам 10% скидку на экзамен. При текущей цене ваучера Security + в 330 долларов это может сэкономить вам 33 доллара.Получите полный учебный пакет SY0-501 здесь.
«Я готовлюсь к экзамену sec + и прохожу тест по главе в режиме обучения — мне очень полезно внимательно прочитать ответы, чтобы понять, почему ответ правильный, а почему другие — нет.
«Сдал сегодня свой экзамен по безопасности + впервые и сдал его с 831 баллом. Я считаю, что практические экзамены в режиме обучения были наиболее полезными — особенно хорошо написанные объяснения не только того, почему был правильный ответ. правильно, но почему неправильные ответы были неправильными.Спасибо, что сделали очень полезный продукт ».
«Лично это один из лучших банков для тестирования Security +, и я его настоятельно рекомендую».
«Я только что сдал мой Security + сегодня !!!!! Ваш материал действительно помог. Для людей, которые в настоящее время используют этот материал, используйте все доступные инструменты. Также используйте вопросы о производительности и любые вопросы, которые вы задали неправильно, чтобы понять, почему эти вопросы были неправильными.
«Большое спасибо за безопасность + материалы. Сегодня прошел тест на безопасность +. Я изучал только 4 дня, подробное объяснение каждого вопроса стало причиной, по которой я смогла пройти тест ».
«После исследования я нашел вашу программу и очень рад! Вы помогли мне понять, почему мои неправильные ответы были неправильными и почему правильные ответы верны. Это помогло мне на живом экзамене.Я сдал экзамен сегодня, и это было очень сложно, но я сдал его с 762 баллом. Я не думаю, что смог бы сдать без ваших онлайн-тестов и материалов ».
Что такое хеширование? — Определение с сайта WhatIs.com
Хеширование — это преобразование строки символов в обычно более короткое значение фиксированной длины или ключ, представляющий исходную строку. Хеширование используется для индексации и извлечения элементов в базе данных, потому что быстрее найти элемент с использованием более короткого хешированного ключа, чем с использованием исходного значения.
В качестве простого примера использования хеширования в базах данных группа людей может быть организована в базу данных следующим образом:
Абернати, Сара Эппердингл, Роско Мур, Уилфред Смит, Дэвид (и многие другие, отсортированные в алфавитном порядке)
Каждое из этих имен будет ключом в базе данных для данных этого человека. Механизм поиска в базе данных должен сначала начать поиск совпадений по имени по символам, пока он не найдет совпадение (или не исключит другие записи).Но если бы каждое из имен было хешировано, можно было бы (в зависимости от количества имен в базе данных) сгенерировать уникальный четырехзначный ключ для каждого имени. Например:
7864 Абернати, Сара 9802 Эппердингл, Роско 1990 Мур, Уилфред 8822 Смит, Дэвид (и т. Д.)
Поиск любого имени сначала будет состоять из вычисления хеш-значения (с использованием той же хеш-функции, которая используется для хранения элемента), а затем сравнения на совпадение с использованием этого значения.
Алгоритм хеширования называется хеш-функцией — вероятно, термин происходит от идеи, что полученное хеш-значение можно рассматривать как «смешанную» версию представленного значения.
В дополнение к более быстрому извлечению данных, хеширование также используется для шифрования и дешифрования цифровых подписей (используется для аутентификации отправителей и получателей сообщений). Цифровая подпись преобразуется с помощью хеш-функции, а затем хешированное значение (известное как дайджест сообщения) и подпись отправляются получателю отдельными передачами.Используя ту же хеш-функцию, что и отправитель, получатель извлекает дайджест сообщения из подписи и сравнивает его с дайджестом сообщения, который он также получил. (Они должны быть одинаковыми.)
Хеш-функция используется для индексации исходного значения или ключа, а затем используется позже каждый раз, когда необходимо получить данные, связанные со значением или ключом.
Вот несколько относительно простых хэш-функций, которые использовались:
- Метод деления-остатка: Размер количества элементов в таблице оценивается. Это число затем используется как делитель для каждого исходного значения или ключа для извлечения частного и остатка.Остальное — хеш-значение. (Поскольку этот метод может вызвать ряд коллизий, любой поисковый механизм должен уметь распознавать коллизию и предлагать альтернативный механизм поиска.)
- Метод складывания: Этот метод делит исходное значение (в данном случае цифры) на несколько частей, складывает части вместе, а затем использует последние четыре цифры (или какое-либо другое произвольное количество цифр, которое будет работать) в качестве хешированного значения.
- Метод преобразования системы счисления: Если значение или ключ являются цифровыми, основание числа (или основание системы счисления) может быть изменено, что приведет к другой последовательности цифр.(Например, ключ с десятичным номером может быть преобразован в ключ с шестнадцатеричным номером.) Цифры высокого порядка могут быть отброшены, чтобы соответствовать хеш-значению постоянной длины.
- Метод перестановки цифр: Это просто взятие части исходного значения или ключа, например цифр в позициях с 3 по 6, изменение их порядка в обратном порядке, а затем использование этой последовательности цифр в качестве хэш-значения или ключа.
В криптографии используется несколько хорошо известных хеш-функций. К ним относятся хэш-функции дайджеста сообщения MD2, MD4 и MD5, используемые для хеширования цифровых подписей в более короткое значение, называемое дайджестом сообщения, и алгоритм безопасного хеширования (SHA), стандартный алгоритм, который увеличивает (60- bit) дайджест сообщения и аналогичен MD4.
Определение хэша
Хэш — это функция, преобразующая одно значение в другое. Хеширование данных — обычная практика в информатике и используется для нескольких различных целей. Примеры включают криптографию, сжатие, создание контрольной суммы и индексирование данных.
Хеширование естественно подходит для криптографии, потому что оно маскирует исходные данные другим значением.Хеш-функцию можно использовать для генерации значения, которое можно декодировать только путем поиска значения в хеш-таблице. Таблица может быть массивом, базой данных или другой структурой данных. Хорошая криптографическая хеш-функция необратима, то есть ее нельзя реконструировать.
Поскольку хешированные значения обычно меньше исходных, хеш-функция может генерировать повторяющиеся хешированные значения. Они известны как «коллизии» и возникают, когда идентичные значения создаются из разных исходных данных.Коллизии можно разрешить, используя несколько хэш-функций или создав таблицу переполнения, когда встречаются повторяющиеся хешированные значения. Коллизий можно избежать, используя большие хеш-значения.
Различные типы сжатия, такие как сжатие изображений с потерями и сжатие мультимедиа, могут включать хэш-функции для уменьшения размера файла. Путем хеширования данных в более мелкие значения медиафайлы могут быть сжаты на более мелкие куски. Этот тип одностороннего хеширования нельзя отменить, но он может привести к приближению исходных данных, что требует меньше места на диске.
Хэши также используются для создания контрольных сумм, которые проверяют целостность файлов. Контрольная сумма — это небольшое значение, которое генерируется на основе битов файла или блока данных, например образа диска. Когда функция контрольной суммы запускается для копии файла (например, файла, загруженного из Интернета), она должна выдавать то же хешированное значение, что и исходный файл. Если файл не дает той же контрольной суммы, что-то в файле было изменено.
Наконец, для индексации данных используются хэши.Значения хеширования можно использовать для сопоставления данных с отдельными «сегментами» в хеш-таблице. Каждая корзина имеет уникальный идентификатор, который служит указателем на исходные данные. Это создает индекс, который значительно меньше исходных данных, что позволяет искать значения и получать к ним доступ более эффективно.
Обновлено: 21 апреля 2018 г.
TechTerms — Компьютерный словарь технических терминов
Эта страница содержит техническое определение хэша. Он объясняет в компьютерной терминологии, что означает хэш, и является одним из многих программных терминов в словаре TechTerms.
Все определения на веб-сайте TechTerms составлены так, чтобы быть технически точными, но также простыми для понимания. Если вы найдете это определение хэша полезным, вы можете сослаться на него, используя приведенные выше ссылки для цитирования. Если вы считаете, что термин следует обновить или добавить в словарь TechTerms, напишите в TechTerms!
Подпишитесь на информационный бюллетень TechTerms, чтобы получать избранные термины и тесты прямо в свой почтовый ящик. Вы можете получать электронную почту ежедневно или еженедельно.
Подписаться
Односторонний путь к усиленной безопасности
Суть аутентификации состоит в том, чтобы предоставить пользователям набор учетных данных, таких как имя пользователя и пароль, и убедиться, что они предоставляют правильные учетные данные всякий раз, когда им нужен доступ к приложению.Следовательно, нам нужен способ сохранить эти учетные данные в нашей базе данных для будущих сравнений. Однако хранение паролей на стороне сервера для аутентификации — сложная задача. Давайте рассмотрим один из механизмов, который делает хранение паролей безопасным и простым: хеширование.
Хранение паролей — рискованное и сложное дело
Простым подходом к хранению паролей является создание таблицы в нашей базе данных, которая сопоставляет имя пользователя с паролем. Когда пользователь входит в систему, сервер получает запрос на аутентификацию с полезной нагрузкой, содержащей имя пользователя и пароль.Мы ищем имя пользователя в таблице и сравниваем предоставленный пароль с сохраненным паролем. Соответствие дает пользователю доступ к приложению.
Уровень безопасности и отказоустойчивость этой модели зависит от того, как хранится пароль. Самый простой, но также и наименее безопасный формат хранения паролей — это открытый текст .
Как объяснил Дэн Корнелл из Denim Group, открытый текст относится к «читаемым данным, переданным или сохраненным в незашифрованном виде », например, в незашифрованном виде.Возможно, вы также видели термины plaintext и plain text . Какая разница? Согласно Корнеллу, открытый текст относится к данным, которые будут использоваться в качестве входных данных для криптографического алгоритма, в то время как простой текст относится к неформатированному тексту, например к содержимому обычного текстового файла или
.txt. По мере продвижения вперед важно понимать разницу между этими терминами.Хранение паролей в виде открытого текста эквивалентно их записи на листе цифровой бумаги.Если злоумышленник проникнет в базу данных и украдет таблицу паролей, он сможет получить доступ к каждой учетной записи пользователя. Эта проблема усугубляется тем фактом, что многие пользователи повторно используют или используют варианты одного пароля, что потенциально позволяет злоумышленнику получить доступ к другим службам, отличным от того, который подвергается взлому. Все это звучит как кошмар безопасности!
Атака может исходить изнутри организации. Инженер-мошенник, имеющий доступ к базе данных, может злоупотребить этим правом доступа, получить учетные данные в открытом виде и получить доступ к любой учетной записи.
Более безопасный способ сохранить пароль — преобразовать его в данные, которые нельзя преобразовать обратно в исходный пароль. Этот механизм известен как хеширование . Давайте узнаем больше о теории хеширования, его преимуществах и ограничениях.
«Мы должны защищать учетные записи пользователей как от внутреннего, так и от внешнего несанкционированного доступа. Хранение открытого текста никогда не должно быть вариантом для паролей. Хеширование и« соление »всегда должны быть частью стратегии управления паролями.«
Твитнуть
Что насчет хеширования?
По словарному определению, хеширование означает «измельчение чего-либо на мелкие кусочки», чтобы это выглядело как «беспорядок». Это определение тесно связано с тем, что представляет собой хеширование в вычислениях.
В криптографии хэш-функция — это математический алгоритм, который отображает данные любого размера в битовую строку фиксированного размера. Мы можем ссылаться на вход функции как на сообщение или просто как на вход.Вывод строковой функции фиксированного размера известен как хэш или дайджест сообщения . Как указано в OWASP, хэш-функции, используемые в криптографии, имеют следующие ключевые свойства:
- Вычислить хэш легко и практично, но «сложно или невозможно повторно сгенерировать исходный ввод, если известно только значение хеш-функции».
- Трудно создать начальный ввод, который соответствовал бы конкретному желаемому выводу.
Таким образом, в отличие от шифрования, хеширование является односторонним механизмом.Хешированные данные практически не могут быть «нехешированы».
Обычно используемые алгоритмы хеширования включают алгоритмы дайджеста сообщений (MDx), такие как MD5, и алгоритмы безопасного хеширования (SHA), такие как SHA-1 и семейство SHA-2, которое включает широко используемый алгоритм SHA-256. Позже мы узнаем о силе этих алгоритмов и о том, что некоторые из них устарели из-за быстрого развития вычислений или вышли из употребления из-за уязвимостей безопасности.
В биткойнах для обеспечения целостности и цепочки блоков используется алгоритм SHA-256 в качестве базовой криптографической хеш-функции. Давайте посмотрим на пример хеширования с использованием SHA-256 и Python.
Если вы хотите продолжить, вы можете использовать онлайн-среду Python repl.it для простого запуска скриптов Python.
IDE Python repl.it предоставляет вам редактор кода для ввода кода Python, кнопки для сохранения или запуска сценария и консоль для визуализации вывода сценария.
В редакторе кода введите следующую команду, чтобы импортировать метод конструктора хэш-алгоритма SHA-256 из модуля
hashlib:из hashlib import sha256В строке ниже создайте экземпляр класса
sha256:h = sha256 ()Затем используйте метод
update ()для обновления хеш-объекта:ч.обновление (b'python1990K00L ')Затем используйте метод
hexdigest (), чтобы получить дайджест строки, переданной методуupdate ():hash = h.hexdigest ()Дайджест — это результат хэш-функции.
Наконец, распечатайте хэш-переменную
, чтобы увидеть хеш-значение в консоли:печать (хеш)Полный сценарий выглядит так:
из hashlib import sha256 h = sha256 () часобновление (b'python1990K00L ') хэш = h.hexdigest () печать (хеш)Чтобы запустить сценарий, нажмите кнопку «запустить» вверху экрана. На консоли вы должны увидеть следующий вывод:
d1e8a70b5ccab1dc2f56bbf7e99f064a660c08e361a35751b9c483c88943d082Напомним, что вы предоставляете хэш-функции строку в качестве ввода и получаете другую строку в качестве вывода, которая представляет собой хешированный ввод:
Ввод:
питон1990K00LХэш (SHA-256):
d1e8a70b5ccab1dc2f56bbf7e99f064a660c08e361a35751b9c483c88943d082Попробуйте хешировать строку
python.Получили следующий хеш?11a4a60b518bf24989d481468076e5d5982884626aed9faeb35b8576fcd223e1«Понимание блокчейнов и криптовалют, таких как биткойн, становится проще, если вы понимаете, как работают криптографические хеш-функции».
Твитнуть
Используя SHA-256, мы преобразовали ввод произвольного размера в битовую строку фиксированного размера. Обратите внимание, как, несмотря на разницу в длине между
python1990K00Lиpython, каждый ввод создает хэш одинаковой длины.Почему это?Используя
hexdigest (), вы создали шестнадцатеричное представление хеш-значения. Для любого ввода каждый дайджест сообщения в шестнадцатеричном формате содержит 64 шестнадцатеричных цифры. Каждая пара цифр представляет собой байт. Таким образом, дайджест имеет 32 байта. Поскольку каждый байт содержит 8 бит информации, всего хеш-строка представляет 256 бит информации. По этой причине этот алгоритм называется SHA-256, и все его входные данные имеют выход равного размера.Некоторые хэш-функции широко используются, но их свойства и требования не обеспечивают безопасности.Например, проверка циклическим избыточным кодом (CRC) — это хеш-функция, используемая в сетевых приложениях для обнаружения ошибок, но она не устойчива к предварительному изображению, что делает ее непригодной для использования в приложениях безопасности, таких как цифровые подписи.
В этой статье мы собираемся изучить свойства, которые делают хеш-функцию подходящей для использования в приложениях безопасности. Для начала мы должны знать, что даже если бы мы нашли подробности того, как входные данные криптографической хеш-функции вычисляются в хеш-функции, для нас было бы непрактично возвращать хеш-код обратно во входные данные.Почему это?
Криптографические хеш-функции практически необратимы
Хеш-функции ведут себя как односторонние функции, используя математические операции, которые чрезвычайно сложно и громоздко возвращать, например, оператор по модулю.
Оператор по модулю дает нам остаток от деления. Например,
5 mod 3— это2, поскольку остаток от5/3равен2с использованием целочисленного деления. Эта операция является детерминированной, поскольку один и тот же ввод всегда дает один и тот же вывод: математически5/3всегда дает2.Однако важной характеристикой операции по модулю является то, что мы не можем найти исходные операнды с учетом результата. В этом смысле хеш-функции необратимы.Знание того, что результатом операции по модулю является
2, говорит нам только о том, чтоx, деленное наy, имеет напоминание2, но ничего не говорит нам оxиy. Существует бесконечное количество значений, которые можно заменить наxиyнаx mod y, чтобы вернуть2:7 мод 5 = 2 9 мод 7 = 2 2 мод 3 = 2 10 мод 8 = 2 ...При использовании криптографической хеш-функции мы не должны иметь возможность найти прообраз , глядя на хэш . Предварительное изображение — это то, что мы называем значением, которое создает определенный конкретный хэш при использовании в качестве входных данных для хеш-функции — значение открытого текста. Следовательно, криптографическая хеш-функция предназначена для защиты от атак с предварительным изображением; это должно быть , устойчивое к предварительному изображению . Таким образом, если злоумышленник знает хэш, с вычислительной точки зрения невозможно найти какой-либо вход, который хеширует этот заданный выход.Это свойство делает хеширование одной из основ биткойнов и блокчейнов.
Если вам интересно, как работает хеш-функция, эта статья в Википедии предоставляет все подробности о том, как работает Secure Hash Algorithm 2 (SHA-2).
Небольшое изменение имеет большое влияние
Еще одно достоинство безопасной хеш-функции состоит в том, что ее результат нелегко предсказать. Хэш для
dontpwnme4будет сильно отличаться от хеша дляdontpwnme5, даже если изменится только последний символ в строке, и обе строки будут смежными в алфавитно отсортированном списке:Ввод:
dontpwnme4Хэш (SHA-256):
4420d1918bbcf7686defdf9560bb5087d20076de5f77b7cb4c3b40bf46ec428bВвод:
dontpwnme5Хэш (SHA-256) :
3fc79ff6a81da0b5fc62499d6b6db7dbf1268328052d2da32badef7f82331dd6Вот сценарий Python, используемый для вычисления этих значений, если он вам понадобится:
из hashlib import sha256 h = sha256 () часобновить (b '') хэш = h.hexdigest () печать (хеш) Замените
на нужную строку для хеширования и запустите ее на repl.it.Это свойство известно как эффект лавины и имеет желаемый эффект, заключающийся в том, что при незначительном изменении входа значительно изменяется выход.
Следовательно, у нас нет реального способа определить, какой хэш
dontpwnme6будет основан на двух предыдущих хэшах; вывод не является последовательным.Использование криптографического хеширования для более безопасного хранения паролей
Необратимые математические свойства хеширования делают его феноменальным механизмом для сокрытия паролей в состоянии покоя и в движении. Еще одно важное свойство, делающее хэш-функции подходящими для хранения паролей, — это их детерминированность.
Детерминированная функция — это функция, которая при одном и том же вводе всегда производит одинаковый вывод. Это жизненно важно для аутентификации, так как нам нужна гарантия того, что данный пароль всегда будет давать один и тот же хэш; в противном случае было бы невозможно последовательно проверять учетные данные пользователя с помощью этого метода.
Чтобы интегрировать хеширование в рабочий процесс хранения паролей, при создании пользователя вместо хранения пароля в виде открытого текста мы хэшируем пароль и сохраняем имя пользователя и пару хешей в таблице базы данных. Когда пользователь входит в систему, мы хэшируем отправленный пароль и сравниваем его с хешем, связанным с предоставленным именем пользователя. Если хешированный пароль и сохраненный хеш совпадают, у нас есть действующий логин. Важно отметить, что мы никогда не сохраняем пароль в открытом виде в процессе, мы хэшируем его, а затем забываем.
В то время как передача пароля должна быть зашифрована, хэш пароля не нужно шифровать при хранении. При правильной реализации хеширование паролей является криптографически безопасным. Эта реализация будет включать использование соли для преодоления ограничений хэш-функций.
Уникальность — ключевое свойство солей; длина помогает уникальности.
Ограничения хеш-функций
Хеширование кажется довольно надежным.Но если злоумышленник взламывает сервер и крадет хеш-коды паролей, все, что он может увидеть, — это данные произвольного вида, которые невозможно преобразовать в открытый текст из-за архитектуры хеш-функций. Злоумышленнику потребуется предоставить входные данные для хеш-функции для создания хеш-кода, который затем может быть использован для аутентификации, что может быть выполнено в автономном режиме, не поднимая никаких красных флажков на сервере.
Затем злоумышленник может либо украсть пароль в открытом виде у пользователя с помощью современных методов фишинга и спуфинга, либо попробовать атаку грубой силой , при которой злоумышленник вводит случайные пароли в хэш-функцию до тех пор, пока не будет найден соответствующий хэш.
Атака полным перебором в значительной степени неэффективна, поскольку выполнение хэш-функций может быть настроено на довольно длительное время. Это повышение скорости хеширования будет объяснено более подробно позже. Есть ли у злоумышленника другие варианты?
Поскольку хеш-функции детерминированы (один и тот же ввод функции всегда приводит к одному и тому же хешу), если бы пара пользователей использовала один и тот же пароль, их хеш-код был бы идентичным. Если значительное количество людей сопоставлено с одним и тем же хешем, это может быть индикатором того, что хеш представляет собой часто используемый пароль, и позволяет злоумышленнику значительно сократить количество паролей, которые можно использовать для взлома с помощью грубой силы.
Кроме того, с помощью атаки по радужной таблице злоумышленник может использовать большую базу данных предварительно вычисленных цепочек хэшей, чтобы найти входные данные украденных хэшей паролей. Хеш-цепочка — это одна строка в радужной таблице, хранящаяся как начальное значение хеш-функции и конечное значение, полученное после множества повторных операций с этим начальным значением. Поскольку атака радужной таблицы должна повторно вычислять многие из этих операций, мы можем смягчить атаку радужной таблицы, усилив хеширование с помощью процедуры, которая добавляет уникальные случайные данные к каждому входу в момент их сохранения.Эта практика известна как добавление соли к хешу , и она дает солёных хэшей паролей .
С солью хеш основан не только на значении пароля. Вход состоит из пароля и соли. Радужная таблица строится для набора несоленых хешей. Если каждый предварительный образ включает уникальное значение, которое невозможно угадать, радужная таблица бесполезна. Когда злоумышленник овладевает «солью», радужная таблица должна быть пересчитана, что в идеале заняло бы очень много времени, что еще больше снижает этот вектор атаки.
«Уловка состоит в том, чтобы гарантировать, что усилия по« взлому »хеширования превышают ценность, которую злоумышленники получат от этого. Ничего из этого не о« невзламываемости »; усилие.» — Тройская охота
Скорость не нужна
По словам Джеффа Этвуда, «хэши, используемые для обеспечения безопасности, должны быть медленными». Криптографическая хеш-функция, используемая для хеширования паролей, должна быть медленной для вычисления, потому что быстро вычисляемый алгоритм может сделать атаки методом грубой силы более осуществимыми, особенно с быстро развивающейся мощностью современного оборудования.Мы можем добиться этого, сделав вычисление хэша медленным, используя множество внутренних итераций или увеличив объем памяти для вычислений.
Медленная криптографическая хеш-функция затрудняет этот процесс, но не останавливает его, поскольку скорость вычисления хеш-функции влияет как на пользователей, умышленно, так и на злонамеренных. Важно достичь хорошего баланса скорости и удобства использования для функций хеширования. Пользователь с благими намерениями не окажет заметного влияния на производительность при попытке единственного действительного входа в систему.
Атаки с коллизией исключают хэш-функции
Поскольку хеш-функции могут принимать входные данные любого размера, но создавать хеши, которые представляют собой строки фиксированного размера, набор всех возможных входных данных бесконечен, а набор всех возможных выходных данных конечен. Это позволяет отображать несколько входных данных в один и тот же хэш. Следовательно, даже если бы мы смогли отменить хэш, мы не знали бы наверняка, что результатом был выбранный вход. Это называется столкновением, и это нежелательный эффект.
Криптографическая коллизия возникает, когда два уникальных входа производят один и тот же хэш. Следовательно, атака коллизии — это попытка найти два предварительных изображения, которые производят один и тот же хэш. Злоумышленник может использовать эту коллизию, чтобы обмануть системы, которые полагаются на хешированные значения, путем подделки действительного хэша с использованием неверных или вредоносных данных. Следовательно, криптографические хеш-функции также должны быть устойчивы к атакам на основе коллизий, так как злоумышленникам будет очень сложно найти эти уникальные значения.
Источник: Объявление о первом конфликте SHA1 (Google)
«Так как входные данные могут иметь бесконечную длину, но хэши имеют фиксированную длину, коллизии возможны. Несмотря на то, что риск коллизий статистически очень низок, коллизии были обнаружены в часто используемых хеш-функциях».
Твитнуть
Для простых алгоритмов хеширования простой поиск в Google позволит нам найти инструменты, которые конвертируют хэш обратно в его ввод в виде открытого текста.Алгоритм MD5 сегодня считается вредоносным, и Google объявила о первом конфликте SHA1 в 2017 году. Оба алгоритма хеширования были сочтены небезопасными для использования и не рекомендованы Google из-за возникновения криптографических конфликтов.
Google рекомендует использовать более сильные алгоритмы хеширования, такие как SHA-256 и SHA-3. Другие варианты, обычно используемые на практике, — это
bcrypt,scryptи многие другие, которые вы можете найти в этом списке криптографических алгоритмов. Однако, как мы выяснили ранее, одного хеширования недостаточно, и его следует сочетать с солями.Узнайте больше о том, как добавление соли к хешированию — лучший способ хранения паролей.Резюме
Давайте резюмируем то, что мы узнали из этой статьи:
- Основная цель хеширования — создать отпечаток данных для оценки целостности данных.
- Функция хеширования принимает произвольные входные данные и преобразует их в выходные данные фиксированной длины.
- Чтобы считаться криптографической хэш-функцией, хеш-функция должна быть устойчивой к предварительному изображению и стойкой к конфликтам.
- Из-за радужных таблиц одного хеширования недостаточно для защиты паролей для массового использования. Чтобы смягчить этот вектор атаки, хеширование должно включать использование криптографических солей.
- Хеширование паролей используется для проверки целостности вашего пароля, отправленного во время входа в систему, по сохраненному хешу, чтобы ваш фактический пароль никогда не сохранялся.
- Не все криптографические алгоритмы подходят для современной промышленности. На момент написания этой статьи Google сообщил, что MD5 и SHA-1 уязвимы из-за коллизий.Семейство SHA-2 является лучшим вариантом.
Упрощение управления паролями с помощью Auth0
С помощью Auth0 можно минимизировать накладные расходы на хеширование, обработку паролей и управление паролями. Мы решаем самые сложные случаи использования идентификационных данных с помощью расширяемой и простой в интеграции платформы, которая обеспечивает безопасность миллиардов входов в систему каждый месяц.
Auth0 помогает предотвратить попадание важных идентификационных данных в чужие руки. Мы никогда не храним пароли в открытом виде. Пароли всегда хешируются и обрабатываются с помощью bcrypt.Кроме того, предлагается шифрование данных в состоянии покоя и при передаче с использованием TLS с как минимум 128-битным шифрованием AES. Мы встроили в наш продукт самые современные средства безопасности, чтобы защитить ваш бизнес и ваших пользователей.
Сделайте Интернет безопаснее, зарегистрируйте бесплатную учетную запись Auth0 сегодня.
Полное руководство по согласованному хешированию
В последние годы, с появлением таких понятий, как облачные вычисления и большие данные, распределенные системы приобрели популярность и актуальность.
Один из таких типов систем, распределенные кэши, которые обеспечивают работу многих динамических веб-сайтов и веб-приложений с высокой посещаемостью, обычно представляют собой частный случай распределенного хеширования. Они используют алгоритм, известный как последовательное хеширование.
Что такое согласованное хеширование? Какая мотивация стоит за этим и почему это должно вас волновать?
В этой статье я сначала рассмотрю общую концепцию хеширования и его цель, а затем дам описание распределенного хеширования и связанных с ним проблем.Это, в свою очередь, приведет нас к нашему заголовку.
Что такое хеширование?
Что такое «хеширование»? Merriam-Webster определяет существительное hash как «рубленое мясо, смешанное с картофелем и подрумяненное», а глагол — как «нарезать (как мясо и картофель) на мелкие кусочки». Итак, если отвлечься от кулинарных деталей, хеш примерно означает «нарезать и перемешать» — и именно отсюда происходит технический термин.
Хэш-функция — это функция, которая отображает один фрагмент данных, обычно описывающий какой-либо объект, часто произвольного размера, на другой фрагмент данных, обычно целое число, известное как хэш-код или просто хеш-код .
Например, некоторая хеш-функция, предназначенная для хеширования строк с диапазоном вывода
0 .. 100, может отображать строкуHello, скажем, на номер57,Hasta la vista, babyв число33и любую другую возможную строку до некоторого числа в этом диапазоне. Поскольку возможных входов намного больше, чем выходов, любому заданному числу будет сопоставлено много разных строк, явление, известное как коллизия . Хорошие хеш-функции должны каким-то образом «измельчать и смешивать» (отсюда и термин) входные данные таким образом, чтобы выходные данные для различных входных значений распределялись как можно более равномерно по выходному диапазону.Хеш-функции имеют много применений, и для каждого из них могут потребоваться разные свойства. Существует тип хэш-функции, известный как криптографические хэш-функции , которые должны соответствовать ограниченному набору свойств и использоваться в целях безопасности, включая такие приложения, как защита паролем, проверка целостности и снятие отпечатков пальцев с сообщений, а также обнаружение повреждения данных, среди прочего. другие, но они выходят за рамки данной статьи.
Некриптографические хэш-функции также имеют несколько применений, наиболее распространенным из которых является их использование в хэш-таблицах , которые нас беспокоят и которые мы рассмотрим более подробно.
Введение в хеш-таблицы (хэш-карты)
Представьте, что нам нужно было вести список всех членов какого-то клуба, имея при этом возможность искать любого конкретного члена. Мы могли бы справиться с этим, сохраняя список в массиве (или связанном списке), и для выполнения поиска перебирать элементы до тех пор, пока не найдем нужный (например, мы можем искать по их имени). В худшем случае это будет означать проверку всех участников (если тот, который мы ищем, последний или его нет вообще), или в среднем половину из них.С точки зрения теории сложности, тогда поиск будет иметь сложность
O (n), и он будет достаточно быстрым для небольшого списка, но он будет становиться все медленнее и медленнее прямо пропорционально количеству членов.Как это можно улучшить? Предположим, у всех этих членов клуба был член
с идентификатором, который оказался порядковым номером, отражающим порядок, в котором они вступили в клуб.Предполагая, что поиск по
IDбыл приемлемым, мы могли бы разместить все элементы в массиве с их индексами, соответствующими ихIDs (например, элемент сID = 10будет с индексом10в массив).Это позволит нам получить доступ к каждому участнику напрямую, без какого-либо поиска. Это было бы очень эффективно, на самом деле, настолько эффективно, насколько это возможно, соответствуя минимально возможной сложности,O (1), также известное как с постоянным временем .Но, надо признать, сценарий нашего члена клуба
IDнесколько надуманный. Что, если быIDбыли большими, непоследовательными или случайными числами? Или, если поиск поIDбыл неприемлем, и вместо этого нам нужно было искать по имени (или другому полю)? Безусловно, было бы полезно сохранить наш быстрый прямой доступ (или что-то близкое к нему), в то же время имея возможность обрабатывать произвольные наборы данных и менее строгие критерии поиска.Здесь на помощь приходят хэш-функции. Подходящую хеш-функцию можно использовать для сопоставления произвольного фрагмента данных с целым числом, которое будет играть ту же роль, что и член нашего клуба
ID, хотя и с некоторыми важными отличиями.Во-первых, хорошая хеш-функция обычно имеет широкий диапазон вывода (обычно весь диапазон 32- или 64-битных целых чисел), поэтому создание массива для всех возможных индексов было бы непрактичным или просто невозможным, а также колоссальной тратой объем памяти.Чтобы преодолеть это, мы можем иметь массив разумного размера (скажем, вдвое больше количества элементов, которые мы ожидаем сохранить) и выполнить операцию по модулю над хешем, чтобы получить индекс массива. Таким образом, индекс будет выглядеть так:
index = hash (object) mod N, гдеN— размер массива.Во-вторых, хэши объектов не будут уникальными (если мы не работаем с фиксированным набором данных и специально созданной идеальной хеш-функцией, но мы не будем обсуждать это здесь). Произойдет коллизий, (дополнительно увеличенных операцией по модулю), и поэтому простой прямой доступ к индексу не будет работать.Есть несколько способов справиться с этим, но типичный из них — прикрепить список, обычно известный как сегмент , к каждому индексу массива, чтобы содержать все объекты, совместно использующие данный индекс.
Итак, у нас есть массив размером
N, где каждая запись указывает на сегмент объекта. Чтобы добавить новый объект, нам нужно вычислить его хэшпо модулю Nи проверить сегмент по полученному индексу, добавив объект, если его еще нет. Чтобы найти объект, мы делаем то же самое, просто заглядывая в ведро, чтобы проверить, есть ли там объект.Такая структура называется хеш-таблицей , и, хотя поиск в сегментах является линейным, хеш-таблица правильного размера должна иметь достаточно небольшое количество объектов на сегмент, в результате чего почти постоянный доступ по времени (средняя сложностьO (N / k), гдеk— количество ковшей).В случае сложных объектов хеш-функция обычно применяется не ко всему объекту, а к ключу . В нашем примере с членом клуба каждый объект может содержать несколько полей (например, имя, возраст, адрес, адрес электронной почты, телефон), но мы могли бы выбрать, скажем, адрес электронной почты, который будет действовать в качестве ключа, чтобы к электронному письму применялась хеш-функция. Только.Фактически, ключ не обязательно должен быть частью объекта; обычно хранятся пары ключ / значение, где ключ обычно представляет собой относительно короткую строку, а значение может быть произвольной частью данных. В таких случаях хеш-таблица или хеш-карта используется в качестве словаря , и именно так некоторые языки высокого уровня реализуют объекты или ассоциативные массивы.
Горизонтальное масштабирование: распределенное хеширование
Теперь, когда мы обсудили хеширование, мы готовы рассмотреть распределенное хеширование .
В некоторых ситуациях может быть необходимо или желательно разделить хеш-таблицу на несколько частей, размещенных на разных серверах. Одна из основных причин этого — обойти ограничения памяти, связанные с использованием одного компьютера, что позволяет создавать произвольно большие хеш-таблицы (при наличии достаточного количества серверов).
В таком сценарии объекты (и их ключи) распределены между несколькими серверами, отсюда и название.
Типичным вариантом использования для этого является реализация кешей в памяти, таких как Memcached.
Такие установки состоят из пула кэширующих серверов, на которых размещается множество пар ключ / значение и которые используются для обеспечения быстрого доступа к данным, изначально сохраненным (или вычисленным) в другом месте. Например, чтобы снизить нагрузку на сервер базы данных и в то же время повысить производительность, приложение может быть спроектировано так, чтобы сначала получать данные с серверов кеширования, и только если их там нет — ситуация, известная как промах в кэше — обратиться к базе данных, выполнив соответствующий запрос и кэшировав результаты с соответствующим ключом, чтобы его можно было найти в следующий раз, когда это понадобится.
Итак, как происходит раздача? Какие критерии используются для определения, какие ключи размещать на каких серверах?
Самый простой способ — взять хэш по модулю количества серверов. То есть
server = hash (key) mod N, гдеN— размер пула. Чтобы сохранить или получить ключ, клиент сначала вычисляет хэш, применяет операциюпо модулю Nи использует полученный индекс для связи с соответствующим сервером (возможно, с помощью таблицы поиска IP-адресов).Обратите внимание, что хеш-функция, используемая для распределения ключей, должна быть одной и той же для всех клиентов, но не обязательно должна быть той же самой, которая используется внутри кэширующих серверов.Давайте посмотрим на пример. Скажем, у нас есть три сервера,
A,BиC, и у нас есть несколько строковых ключей с их хэшами:
КЛЮЧ ХЭШ HASH мод 3 «Джон» 1633428562 2 «счет» 7594634739 0 «Джейн» 5000799124 1 «Стив» 9787173343 0 «Катя» 3421657995 2 Клиент хочет получить значение ключа
john.Его хэшпо модулю 3равен2, поэтому он должен связаться с серверомC. Ключ там не найден, поэтому клиент извлекает данные из источника и добавляет их. Бассейн выглядит так:Затем другой клиент (или тот же самый) хочет получить значение ключа
банкноты. Его хэшпо модулю 3равен0, поэтому он должен связаться с серверомA. Ключ там не найден, поэтому клиент извлекает данные из источника и добавляет их.Бассейн сейчас выглядит так:После добавления остальных ключей пул будет выглядеть так:
A Б С «счет» «Джейн» «Джон» «Стив» «катя» Проблема повторного хеширования
Эта схема распределения проста, интуитивно понятна и отлично работает. То есть до тех пор, пока не изменится количество серверов.Что произойдет, если один из серверов выйдет из строя или станет недоступным? Разумеется, ключи необходимо перераспределить для учета пропавшего сервера. То же самое происходит, если в пул добавляются один или несколько новых серверов; ключи необходимо перераспределить, чтобы включить новые серверы. Это верно для любой схемы распределения, но проблема с нашим простым распределением по модулю состоит в том, что при изменении количества серверов большинство хэшей
по модулю Nизменится, поэтому большинство ключей необходимо будет переместить на другой сервер.Таким образом, даже если один сервер будет удален или добавлен, все ключи, скорее всего, придется перефразировать на другом сервере.В нашем предыдущем примере, если бы мы удалили сервер
C, нам пришлось бы повторно хешировать все ключи, используя хэшпо модулю 2вместо хешапо модулю 3, и новые места для ключей станут:
КЛЮЧ ХЭШ Мод HASH 2 «Джон» 1633428562 0 «счет» 7594634739 1 «Джейн» 5000799124 0 «Стив» 9787173343 1 «Катя» 3421657995 1
A Б «Джон» «счет» «Джейн» «Стив» «катя» Обратите внимание, что все ключевые местоположения изменились, а не только те, которые были на сервере
C.В типичном случае использования, о котором мы упоминали ранее (кэширование), это будет означать, что внезапно ключи не будут найдены, потому что они еще не будут присутствовать в своем новом местоположении.
Таким образом, большинство запросов приведет к пропускам, и исходные данные, вероятно, потребуется повторно получить из источника для повторного хеширования, что создает большую нагрузку на исходный сервер (ы) (обычно база данных). Это может сильно снизить производительность и, возможно, привести к сбою исходных серверов.
Решение: постоянное хеширование
Итак, как решить эту проблему? Нам нужна схема распределения, в которой , а не напрямую зависят от количества серверов, чтобы при добавлении или удалении серверов количество ключей, которые необходимо переместить, было минимальным.Одна такая схема — умная, но удивительно простая — называется согласованное хеширование и впервые была описана Karger et al. в MIT в академической статье 1997 года (согласно Википедии).
Согласованное хеширование — это схема распределенного хеширования, которая работает независимо от количества серверов или объектов в распределенной хэш-таблице , назначая им позицию в абстрактном круге или хэш-кольце . Это позволяет масштабировать серверы и объекты, не влияя на систему в целом.
Представьте, что мы сопоставили диапазон вывода хэша с краем круга. Это означает, что минимально возможное значение хеш-функции, ноль, будет соответствовать углу нуля, максимальное возможное значение (некоторое большое целое число, которое мы назовем
INT_MAX) будет соответствовать углу 2𝝅 радиан (или 360 градусов), и все остальные значения хэша линейно поместятся где-то посередине. Итак, мы могли бы взять ключ, вычислить его хэш и выяснить, где он находится на краю круга. ПредполагаяINT_MAXиз 10 10 (например, sake), ключи из нашего предыдущего примера будут выглядеть так:
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) «Джон» 1633428562 58.8 «счет» 7594634739 273,4 «Джейн» 5000799124 180 «Стив» 9787173343 352,3 «Катя» 3421657995 123,2 Теперь представьте, что мы также разместили серверы на краю круга, присвоив им также псевдослучайно углы.Это следует делать повторяющимся образом (или, по крайней мере, таким образом, чтобы все клиенты соглашались с углами зрения серверов). Удобный способ сделать это — хешировать имя сервера (или IP-адрес, или какой-либо идентификатор) — как мы поступаем с любым другим ключом — чтобы определить его угол.
В нашем примере это может выглядеть так:
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) «Джон» 1633428562 58.8 «счет» 7594634739 273,4 «Джейн» 5000799124 180 «Стив» 9787173343 352,3 «Катя» 3421657995 123,2 «А» 5572014558 200,6 «Б» 8077113362 290.8 «C» 2269549488 81,7 Поскольку у нас есть ключи и для объектов, и для серверов в одном круге, мы можем определить простое правило для связывания первого со вторым: каждый ключ объекта будет принадлежать серверу, чей ключ является ближайшим, в направлении против часовой стрелки ( или по часовой стрелке, в зависимости от используемых условных обозначений). Другими словами, чтобы выяснить, какой сервер запрашивать данный ключ, нам нужно найти ключ на круге и двигаться в направлении восходящего угла, пока не найдем сервер.
В нашем примере:
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) «Джон» 1633428562 58,7 «C» 2269549488 81,7 «Катя» 3421657995 123,1 «Джейн» 5000799124 180 «А» 5572014557 200.5 «счет» 7594634739 273,4 «Б» 8077113361 290,7 «Стив» 787173343 352,3
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) ТАБЛИЧКА СЕРВЕР «Джон» 1632929716 58.7 «C» С «Катя» 3421831276 123,1 «А» A «Джейн» 5000648311 180 «А» A «счет» 7594873884 273,4 «Б» B «Стив» 9786437450 352.3 «C» С С точки зрения программирования, мы будем вести отсортированный список значений сервера (которые могут быть углами или числами в любом реальном интервале) и просматривать этот список (или использовать двоичный поиск), чтобы найти первый сервер со значением больше или равно желаемой клавише. Если такого значения не найдено, нам нужно выполнить цикл, взяв первое значение из списка.
Чтобы ключи объектов равномерно распределялись между серверами, нам нужно применить простой трюк: присвоить каждому серверу не одну, а несколько меток (углов).Таким образом, вместо меток
A,BиC, мы могли бы иметь, скажем,A0 .. A9,B0 .. B9иC0 .. C9, разбросанные по кругу. Фактор увеличения количества меток (ключей сервера), известный как вес , зависит от ситуации (и может даже быть разным для каждого сервера), чтобы настроить вероятность того, что ключи окажутся на каждом из них. Например, если бы серверBбыл вдвое мощнее остальных, ему можно было бы назначить вдвое больше меток, и в результате он мог бы содержать вдвое больше объектов (в среднем).В нашем примере мы предположим, что все три сервера имеют одинаковый вес 10 (это хорошо работает для трех серверов, от 10 до 50 серверов, вес в диапазоне от 100 до 500 будет работать лучше, а для более крупных пулов может потребоваться еще больше. веса):
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) «C6» 408965526 14,7 «A1» 473 017 «A2» 548798874 19.7 «A3» 1466730567 52,8 «C4» 1493080938 53,7 «Джон» 1633428562 58,7 «B2» 1808009038 65 «C0» 1982701318 71,3 «B3» 2058758486 74.1 «A7» 2162578920 77,8 «B4» 2660265921 95,7 «C9» 3359725419 120,9 «Катя» 3421657995 123,1 «A5» 3434972143 123,6 «C1» 3672205973 132.1 «C8» 3750588567 135 «B0» 40475 145,7 «B8» 4755525684 171,1 «A9» 4769549830 171,7 «Джейн» 5000799124 180 «C7» 5014097839 180.5 «B1» 5444659173 196 «A6» 6210502707 223,5 «A0» 6511384141 234,4 «B9» 72 872
262,5 «C3» 7330467663 263,8 «C5» 7502566333 270 «счет» 7594634739 273.4 «A4» 8047401090 289,7 «C2» 8605012288 309,7 «A8» 8997397092 323,9 «B7» - 80553
325,3 «B5» 9368225254 337,2 «B6» 9379713761 337.6 «Стив» 9787173343 352,3
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) ТАБЛИЧКА СЕРВЕР «Джон» 1632929716 58,7 «B2» B «Катя» 3421831276 123,1 «А5» A «Джейн» 5000648311 180 «C7» С «счет» 7594873884 273.4 «A4» A «Стив» 9786437450 352,3 «C6» С Итак, в чем преимущество всего этого кругового подхода? Представьте себе сервер
Cудален. Чтобы учесть это, мы должны удалить меткиC0 .. C9из круга. Это приводит к тому, что ключи объектов, ранее соседствующие с удаленными метками, теперь случайным образом помечаютсяAxиBx, переназначая их серверамA,иB.Но что происходит с другими ключами объектов, которые изначально принадлежали
AиB? Ничего! В этом вся прелесть: отсутствие ярлыковCxникоим образом не влияет на эти клавиши. Таким образом, удаление сервера приводит к тому, что его объектные ключи случайным образом переназначаются остальным серверам, оставляет все остальные ключи нетронутыми :
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) «A1» 473 017 «A2» 548798874 19.7 «A3» 1466730567 52,8 «Джон» 1633428562 58,7 «B2» 1808009038 65 «B3» 2058758486 74,1 «A7» 2162578920 77,8 «B4» 2660265921 95.7 «Катя» 3421657995 123,1 «A5» 3434972143 123,6 «B0» 40475 145,7 «B8» 4755525684 171,1 «A9» 4769549830 171,7 «Джейн» 5000799124 180 «B1» 5444659173 196 «A6» 6210502707 223.5 «A0» 6511384141 234,4 «B9» 72 872
262,5 «счет» 7594634739 273,4 «A4» 8047401090 289,7 «A8» 8997397092 323,9 «B7» - 80553
325.3 «B5» 9368225254 337,2 «B6» 9379713761 337,6 «Стив» 9787173343 352,3
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) ТАБЛИЧКА СЕРВЕР «Джон» 1632929716 58.7 «B2» B «Катя» 3421831276 123,1 «А5» A «Джейн» 5000648311 180 «В1» B «счет» 7594873884 273,4 «A4» A «Стив» 9786437450 352.3 «А1» A Нечто подобное происходит, если вместо удаления сервера мы добавляем его. Если бы мы хотели добавить в наш пример сервер
D(скажем, в качестве замены дляC), нам нужно было бы добавить меткиD0 .. D9. В результате примерно одна треть существующих ключей (все принадлежащиеAилиB) будет переназначена наD, а остальные останутся прежними:
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) «D2» 4398 15.8 «A1» 473 017 «A2» 548798874 19,7 «D8» 796709216 28,6 «D1» 1008580939 36,3 «A3» 1466730567 52,8 «D5» 1587548309 57.1 «Джон» 1633428562 58,7 «B2» 1808009038 65 «B3» 2058758486 74,1 «A7» 2162578920 77,8 «B4» 2660265921 95,7 «D4» 25217 104.7 «Катя» 3421657995 123,1 «A5» 3434972143 123,6 «D7» 3567129743 128,4 «B0» 40475 145,7 «B8» 4755525684 171,1 «A9» 4769549830 171.7 «Джейн» 5000799124 180 «B1» 5444659173 196 «D6» 57030 205,3 "A6" 6210502707 223,5 "A0" 6511384141 234,4 "B9" 72 872
262.5 «счет» 7594634739 273,4 "A4" 8047401090 289,7 "D0" 8272587142 297,8 "A8" 8997397092 323,9 "B7" - 80553
325,3 "D3" 08874 325.7 "D9" 9314459653 335,3 "B5" 9368225254 337,2 "B6" 9379713761 337,6 «Стив» 9787173343 352,3
КЛЮЧ ХЭШ УГОЛ (ГРАДУС) ТАБЛИЧКА СЕРВЕР "Джон" 1632929716 58.7 "B2" B «Катя» 3421831276 123,1 "А5" A "Джейн" 5000648311 180 "В1" B «счет» 7594873884 273,4 "A4" A «Стив» 9786437450 352.3 "Д2" D Вот как согласованное хеширование решает проблему повторного хеширования.
Как правило, необходимо переназначить только
k / N ключей, когдаk- это количество ключей, аN- это количество серверов (точнее, максимальное из начального и конечного количества серверов).Что дальше?
Мы заметили, что при использовании распределенного кэширования для оптимизации производительности может случиться так, что количество серверов кэширования изменится (причиной этого может быть сбой сервера или необходимость добавить или удалить сервер для увеличения или уменьшения общей емкости).Используя согласованное хеширование для распределения ключей между серверами, мы можем быть уверены, что, если это произойдет, количество повторно хешируемых ключей - и, следовательно, влияние на исходные серверы - будет сведено к минимуму, что предотвратит возможные простои или проблемы с производительностью.
Существуют клиенты для нескольких систем, таких как Memcached и Redis, которые изначально включают поддержку согласованного хеширования.
В качестве альтернативы, вы можете реализовать алгоритм самостоятельно, на выбранном вами языке, и это должно быть относительно легко, когда концепция будет понятна.
Если вас интересует наука о данных, у Toptal есть одни из лучших статей по этой теме в блоге
.Хеширование: что нужно знать о паролях
В моей последней статье я упоминал, что лучший способ защитить себя в Интернете - это использовать хороший менеджер паролей и уникальные пароли для всех ваших сайтов. Однако я не стал подробно объяснять, почему именно так. Таким образом, на этот раз на Я обещаю, что придумаю имя для этой колонки. В конце концов, , я расскажу о хороших, плохих и уродливых аспектах входа на веб-сайты.
Существует множество способов защитить свои учетные записи в Интернете, но мы начнем с, пожалуй, самого распространенного: простого пароля. Концепция пароля проста: последовательность символов и слов, известных только вам, которую веб-сайт проверяет по своей базе данных. Однако на самом деле пароли обманчиво сложны по двум основным направлениям: как определить «надежный» пароль и как веб-сайт на самом деле проверяет, что у вас правильный.
1: Создание пароля
Короче говоря, «надежный» пароль сложно угадать.Но как определить «трудно угадать»? Вы можете определить его строго по длине: в конце концов, чем больше символов в пароле, тем сложнее выбрать правильную последовательность. Однако длина не говорит всей истории: «swarthmorecollege» и «y2oUcgM> $ c2Y, 8Z4p» содержат семнадцать символов, но первый пароль намного слабее (особенно если вы используете его для своей учетной записи Swarthmore!) Лучший способ определить «надежность пароля» - это шаблонов пароля ; например, «необычное словарное слово с тремя цифрами в конце», или «четыре случайных общих слова», или «восемь символов чистой случайной тарабарщины».Затем вы можете подсчитать, сколько паролей вы можете сгенерировать из этих шаблонов. Например, если у вас есть пароль, состоящий всего из четырех цифр (например, пароль вашего смартфона), у вас будет 10 x 10 x 10 x 10 = 10 000 возможных паролей. Действуя почти таким же образом, мы можем вычислить, что для этих трех шаблонов, упомянутых ранее, существует 171 миллион (необычное слово с тремя цифрами), 16 триллионов (четыре слова) и 6 квадриллионов (тарабарщина) возможных паролей.
Вы могли заметить в этом последнем абзаце, что пароль из случайных общих слов имеет на много возможных комбинаций на больше, чем словарное слово с числами и символами, что может показаться нелогичным, потому что «возьмите простое слово и добавьте к нему много дерьма. »- это рецепт, который заставляют вас использовать многие веб-сайты для удовлетворения требований к паролям.Это связано с тем, что эти требования к паролю основаны на правительственной публикации 2003 года (которая сама по себе в основном была основана на случайном отчете, написанном в 1980-х годах), что, как позже признал автор, было полностью неверным. Перефразируя статью по ссылке, эти странные требования к паролю не учитывают тот факт, что требования слишком обременительны и просто приводят к тому, что пользователи обходят меры безопасности (написание паролей на стикерах и т.п.). Таким образом, когда не использует веб-сайт с ужасными требованиями к паролям, вы должны следовать новой правительственной публикации , которая рекомендует длинные пароли, состоящие в основном из словарных слов.Это мой любимый генератор паролей, который создает пароли типа «Machinery-Sock-Party-Active-4» или «Deer-Long-Intention-Complication-0». Цифры на самом деле ничего не делают более безопасным, но они полезны для удовлетворения запросов веб-сайтов с глупыми запросами паролей. (Вот смотрите на вас, логин Swarthmore!) В качестве альтернативы вы можете использовать генератор паролей, встроенный в ваш менеджер паролей. Я уже упоминал, что вам следует использовать менеджер паролей? Потому что вам следует использовать менеджер паролей.
2: Сохранение пароля
Несмотря наМенеджер паролей, мы рассмотрели половину аутентификации на основе пароля: создание пароля. Теперь перейдем к другой половине: что именно происходит с этим паролем после того, как вы его введете? Ответ сложнее, чем вы думаете, и он может принимать различные формы в зависимости от того, насколько хороши дизайнеры веб-сайта в своей работе.
Существует несколько различных способов создания системы аутентификации по паролю.Самый простой и очевидный способ - вести большую базу данных всех имен пользователей и связанных с ними паролей. Всякий раз, когда кто-то пытается войти в систему, просто найдите его имя пользователя и сравните пароли. Это очень простой подход, поэтому его используют многие старые веб-сайты, которые ничего не знают. Основная проблема с хранением таких паролей - в виде обычного текста, доступного для всех, кто может читать базу данных - заключается в том, что если хакер взломает, им будет тривиально легко украсть каждое отдельное имя пользователя и связанный с ним пароль и опробовать их где угодно .В зависимости от того, насколько ужасна общая безопасность веб-сайта, хакер может даже обманом заставить веб-сайт случайно передать им кучу паролей, используя программный сбой. (Это произошло с «сайтом социальных приложений» RockYou в 2009 году, что привело к утечке 30 миллионов имен пользователей и паролей.) Веб-сайт, на самом деле знающий пароль пользователя, является довольно серьезным недостатком безопасности, поэтому, если вы когда-нибудь получите электронное письмо от веб-сайт, который содержит ваш фактический пароль, то вы не должны доверять этому сайту свои данные, если вам не нужно.
Но подождите: как веб-сайт должен проверять ваш пароль, если он не хранит ваш пароль? Ответ кроется в чудесном математическом волшебстве, известном как хеш-функция. Хеш-функция принимает произвольные данные и выводит полную чушь. Однако есть два важных момента в хэш-функциях, которые делают их очень полезными при хранении паролей: они всегда производят один и тот же вывод для данного ввода, и фактически невозможно восстановить ввод из вывода.Программисты могут использовать эти знания для создания более безопасной системы паролей. Каждый раз, когда кто-то устанавливает свой пароль, система запускает его через хеш-функцию, а затем сохраняет , что в своей базе данных, прежде чем удалить исходный пароль из памяти. Когда пользователь возвращается, веб-сайт хеширует все, что он вводит, и сравнивает его с записью в базе данных. Таким образом, сервер абсолютно не знает, какой у них пароль, и даже если вся его база данных будет украдена хакерами, они не смогут фактически использовать что-либо в ней.
За исключением того, что это не , а так просто, и мы упускаем один последний шаг. Самое замечательное в хэш-функции то, что она всегда обеспечивает одинаковый вывод для заданного ввода. Недостатком хеш-функции также является то, что она всегда обеспечивает один и тот же вывод для заданного ввода. Поскольку большинство паролей представляют собой довольно распространенные строки («ааааааа», «пароль» и т. Д.), Хакер может просто заранее хешировать несколько паролей (или использовать общедоступные таблицы) и искать в своей украденной базе данных любые совпадающие хеши. .Способ предотвратить это - использовать salt : кусок случайных данных, который добавляется в конец вашего пароля перед тем, как он будет введен в хэш-функцию. Иными словами, весьма вероятно, что кто-то заранее вычислил хэш для «пароля», но гораздо менее вероятно, что существует заранее созданный хеш для «password.NxnU7B@8kxR». Затем случайные данные сохраняются рядом с результатом хеширования, так что при необходимости проверки система добавляет случайные данные к предоставленному паролю и сравнивает их с существующим хешем.
3: помимо пароля
Хорошо защищенный пароль (что, к сожалению, довольно редкое явление, особенно в старых системах) очень и очень сложно взломать с помощью современных технологий. По крайней мере, довольно сложно выйти из базы данных компании, которая ее хранит (или как бы ее хэша). Но если злоумышленнику удастся получить пароль - будь то использование какой-то ошибки, допущенной компанией, взлома плохо защищенного веб-сайта, на котором вы использовали тот же пароль, или путем обмана вас передать его через схему фишинга - тогда вся эта безопасность напрасна .Итак, если мы даже не можем предположить, что пользователь, который представляет правильное имя пользователя и пароль, не является подлым актером, что нам делать дальше?
Ответ - через многофакторную аутентификацию (MFA). «Фактор» - это все, что вы можете использовать для подтверждения своей личности, и они делятся на три отдельные категории: «то, что у вас есть», например смартфон; «Что-то, что вы знаете», например, пароль; и «что-то вы есть», которое охватывает биометрические данные, такие как распознавание лиц или отпечатков пальцев. MFA - это одновременное использование методов в нескольких категориях.Это надмножество двухфакторной аутентификации (2FA), при которой пароль чаще всего обозначается как «что-то, что вы знаете» и смартфон, который получает текст, генерирует код или (в приложении Duo, которое мы все знаем и любим) отправляет вам уведомление как «что-то, что у вас есть». Но 2FA может быть более разнообразным, чем это: подумайте о том, чтобы провести свою кредитную карту (что-то, что у вас есть) и написать подпись (мышечная память, по сути, то, чем вы являетесь). Обратите внимание, что процесс, который сбрасывает ваш пароль, отправляя на ваш телефон код аутентификации, не является двухфакторной системой аутентификации, потому что вам на самом деле не нужно знать пароль, вам просто нужно иметь телефон.
Специальная разновидность 2FA, используемая множеством веб-сайтов, работает, потому что значительно менее вероятно, что хакер, находящийся за тысячи миль от вас, получит доступ к вашему телефону. Но как ваш телефон генерирует правильный код? Что ж, коды двухфакторной аутентификации, полученные через текстовое сообщение, довольно утомительны (сервер просто генерирует некоторые случайные числа и отправляет их вам), а также несколько уязвимы для атак. Более интересные виды генерируются таким приложением, как Google Authenticator.(Приложение Duo Mobile представляет собой аналогичную концепцию, но отличается от того, о чем я говорю здесь.) Они генерируются с использованием метода, известного как одноразовый пароль на основе времени. Хотя чаще всего он работает на вашем телефоне, он также может работать на ноутбуке или настольном компьютере или даже на специальном устройстве-связке ключей, которое ничего не делает, кроме генерирования паролей. Для этого даже не требуется подключение к Интернету. Все, что ему нужно, - это секретный ключ, предоставляемый веб-сайтом при первой настройке TOTP, который был передан на ваш телефон при сканировании QR-кода, предоставленного веб-сайтом, а также приблизительное представление о том, сколько сейчас времени.И сервер, и ваше устройство TOTP используют общий секретный ключ для шифрования небольшого фрагмента данных на основе текущего времени, а затем сервер проверяет то, что вы ввели, на соответствие тому, каким, по его мнению, должен быть результат. Код меняется каждые тридцать секунд, хотя сервер будет принимать код от минуты или двух в любом направлении, чтобы компенсировать рассинхронизацию часов устройств.
Вам следует использовать ту или иную форму 2FA на любом поддерживающем ее веб-сайте, а в настоящее время это большинство основных веб-сайтов (включая Google, Instagram, PayPal и т. Д.).Но помните, что, как и любой метод аутентификации, ничто не защитит вашу учетную запись от взлома. Фактически, нет абсолютно никакого способа создать защищенную от взлома учетную запись, не сделав невозможным вход в систему! Лучшее, что вы можете сделать, - это иметь достаточное количество уровней безопасности, чтобы максимально затруднить взлом ваших учетных записей, при этом сохраняя при этом простоту вашей повседневной жизни. И эта идея возвращает нас к тому, с чего якобы началась эта колонка: управление паролями.
4: Менеджеры паролей
Менеджер паролей - это в самом широком смысле то, что хранит ваши пароли вне вашего мозга.Все ваши пароли где-то в текстовом файле? Технически это менеджер паролей! (Хотя это ужасная идея.) Однако, когда я говорю «вам нужен менеджер паролей», я имею в виду именно онлайн-менеджер паролей. Они синхронизируют ваши пароли на всех ваших устройствах (включая смартфоны) и имеют множество других функций, таких как создание паролей или хранение документов. Любой компетентный менеджер паролей также будет включать в себя сквозное шифрование, что означает, что ваши пароли зашифровываются перед отправкой на сервер, а их онлайн-сервис, по сути, действует как разросшийся Google Диск для фрагментов данных паролей.Результатом этого является то, что даже если бы компания была взломана, злоумышленники просто получили бы много бесполезной тарабарщины, запечатанной в волшебных конвертах из предыдущей статьи. Единственный способ узнать ваши пароли - расшифровать их с помощью вашего мастер-пароля.
Самый лучший способ, которым менеджер паролей делает вас более защищенным, - это снижение радиуса взлома утечки данных. У меня более сотни различных учетных записей в Интернете - если какая-либо из них будет взломана и не будут приняты меры безопасности, о которых я говорил выше, то любая другая учетная запись, которую я использовал с тем же паролем, теперь окажется в опасности.Очевидно, я не могу вспомнить 200 разных паролей, но мой менеджер паролей может! И вместо того, чтобы использовать запоминающиеся пароли, я могу использовать пароли, которые настолько надежны, насколько желает мое сердце. Кроме того, в то время как Google Chrome и Apple имеют свои собственные функции для автоматического заполнения паролей, использование стороннего менеджера паролей позволяет легко синхронизировать данные во всех основных браузерах и операционных системах. Хотя на передачу всех паролей в диспетчер паролей в первый раз может уйти час или два, после этого процесс регистрации на веб-сайте увеличивается примерно на тридцать секунд в обмен на возможность мгновенного входа в систему каждый раз. последующий раз.
Я использую менеджер паролей, в частности 1Password, с 2018 года. Их индивидуальный план обойдется вам в 36 долларов в год, или он стоит моей семье около 60 долларов в год для семейного плана, который включает пять учетных записей и возможность делиться некоторыми пароли (например, ваш домашний Wi-Fi) между участниками. Существуют хорошие менеджеры паролей за меньшую плату или даже бесплатно (например, BitWarden), но я не использовал ни один из них, поэтому я не имею права давать рекомендации - для получения дополнительной информации о них просмотрите ссылки ниже .
Если вы ищете менеджер паролей, 1Password сослужит вам хорошую службу, но я не провел достаточно исследований, чтобы иметь возможность одобрить его среди других. Я рекомендую вам ознакомиться с обзорами (PCMag, CNET, New York Times) и принять обоснованное решение, исходя из вашего конкретного варианта использования и ценовой категории.
Если вам удалось остаться со мной так долго, то спасибо за чтение! Надеюсь, вы кое-что узнали об удивительно подробном мире паролей и безопасности учетных записей.Конечно, одна статья лишь поверхностно затрагивает тему; Я не рассказывал, как работают эти кнопки «войти с помощью Google / Apple / Facebook», или как вы можете войти в Moodle, введя свои учетные данные Swarthmore (при этом Moodle никогда не знает вашего пароля), или различия в алгоритмах хеширования, или миллион другие вещи. Однако я нахожу подобные вещи абсолютно захватывающими и надеюсь, что мне удалось заставить вас чувствовать то же самое. Теперь воспользуйтесь полученными знаниями, чтобы получить менеджер паролей.
Некоторые заключительные примечания:
- Обсуждение надежности пароля в основном основано на , комиксе xkcd и соответствующем вики-комментариях . Возможные комбинации паролей были рассчитаны следующим образом: «необычное слово» - это одно из 171 476 слов в текущем употреблении согласно Оксфордскому словарю английского языка, «общие слова» предполагают список из 2000 слов, а «случайная тарабарщина» - случайный набор из 94 печатаемых символов ASCII (не включая пробел).
- На самом деле есть еще кое-что о хранении паролей, о которых я не рассказывал (например, параметры настройки и рабочие факторы). Если вы хотите узнать о них больше, вот довольно доступное объяснение .
- Для получения дополнительной информации о безопасности диспетчера паролей 1Password выпустила технический документ , в котором подробно рассматриваются все механизмы криптографии и безопасности, присутствующие в их продукте. Он хорошо написан и предоставляет отличный обзор безопасного дизайна, который остается удобным для пользователя, но не совсем для слабонервных. LastPass и Dashlane также имеют похожие технические документы.
Если у вас есть дополнительные вопросы, вы хотите увидеть колонку по определенной теме или думаете, что я что-то не так, напишите мне по адресу [email protected] . Вы также можете написать мне в Instagram @ software.
 2)\), то ожидание равно константе, а если \(d\) асимптотически больше или меньше, то \(X\) стремится нулю или бесконечности соответственно.
2)\), то ожидание равно константе, а если \(d\) асимптотически больше или меньше, то \(X\) стремится нулю или бесконечности соответственно. 8 = 7,21389578984e+15 combinations.
8 = 7,21389578984e+15 combinations. The issue with speeds is basically very much the same here as well.
The issue with speeds is basically very much the same here as well. Попутно мы также поговорим о засолке, поскольку она появляется в новостях почти каждый раз, когда база данных паролей взламывается.
Попутно мы также поговорим о засолке, поскольку она появляется в новостях почти каждый раз, когда база данных паролей взламывается.
 Мы возьмем страницу из учебника Цезаря и воспользуемся шифром смены. Я собираюсь зашифровать предложение с помощью моноалфавитного шифра сдвига, который просто заменяет каждую букву буквой, которая последовательно идет на три места впереди нее.
Мы возьмем страницу из учебника Цезаря и воспользуемся шифром смены. Я собираюсь зашифровать предложение с помощью моноалфавитного шифра сдвига, который просто заменяет каждую букву буквой, которая последовательно идет на три места впереди нее. Итак, при условии, что я поделился им с ними, некоторые теперь могут использовать соответствующий ключ — в данном случае обратный алгоритму, который использовался для шифрования, — чтобы расшифровать это сообщение и прочитать его. Очевидно, что шифры, которые мы используем в цифровом шифровании, намного сложнее, но вы понимаете общую концепцию, лежащую в основе этого.
Итак, при условии, что я поделился им с ними, некоторые теперь могут использовать соответствующий ключ — в данном случае обратный алгоритму, который использовался для шифрования, — чтобы расшифровать это сообщение и прочитать его. Очевидно, что шифры, которые мы используем в цифровом шифровании, намного сложнее, но вы понимаете общую концепцию, лежащую в основе этого.

 Так что необходимость физически носить и передавать его только увеличивает риск. На протяжении всей истории люди фактически умирали из-за компрометации закрытых ключей.
Так что необходимость физически носить и передавать его только увеличивает риск. На протяжении всей истории люди фактически умирали из-за компрометации закрытых ключей. Это концепция, лежащая в основе PKI (инфраструктуры открытого ключа), модели доверия, лежащей в основе SSL / TLS.
Это концепция, лежащая в основе PKI (инфраструктуры открытого ключа), модели доверия, лежащей в основе SSL / TLS.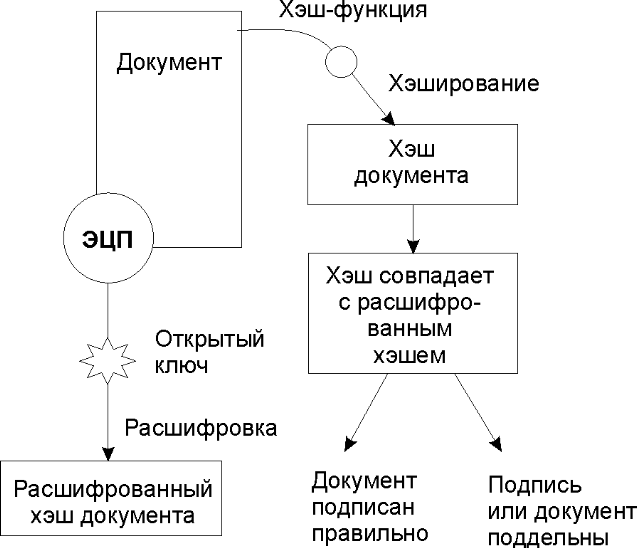 Суперкомпьютеру все равно потребовались бы тысячи лет, чтобы расшифровать 256-битное шифрование.
Суперкомпьютеру все равно потребовались бы тысячи лет, чтобы расшифровать 256-битное шифрование. Он пропускает открытый текст через ряд «этапов преобразования», определенных размер ключа, каждый раунд состоит из нескольких этапов обработки. Давайте не будем заходить слишком далеко в сорняки на этом. AES — это общий алгоритм с SSL / TLS. Он заменил стандарт шифрования данных (DES), созданный в 1977 году.
Он пропускает открытый текст через ряд «этапов преобразования», определенных размер ключа, каждый раунд состоит из нескольких этапов обработки. Давайте не будем заходить слишком далеко в сорняки на этом. AES — это общий алгоритм с SSL / TLS. Он заменил стандарт шифрования данных (DES), созданный в 1977 году. Хотя ECC существует с 1985 года, он используется только с 2004 года. ECC имеет явные преимущества перед RSA и, вероятно, будет играть более заметную роль в будущем SSL / TLS.
Хотя ECC существует с 1985 года, он используется только с 2004 года. ECC имеет явные преимущества перед RSA и, вероятно, будет играть более заметную роль в будущем SSL / TLS. Это называется хеш-значением (или иногда хеш-кодом, или хеш-суммой, или даже хеш-дайджестом, если вам нравится). В то время как шифрование — это двусторонняя функция, хеширование — односторонняя функция. Хотя технически возможно обратное хеширование чего-либо, необходимая вычислительная мощность делает это невозможным. Хеширование одностороннее.
Это называется хеш-значением (или иногда хеш-кодом, или хеш-суммой, или даже хеш-дайджестом, если вам нравится). В то время как шифрование — это двусторонняя функция, хеширование — односторонняя функция. Хотя технически возможно обратное хеширование чего-либо, необходимая вычислительная мощность делает это невозможным. Хеширование одностороннее. В прошлом году Google создал конфликт с алгоритмом хеширования SHA-1, чтобы продемонстрировать его уязвимость. SHA-1 был официально заменен SHA-2 в начале 2016 года. Но у Google был смысл, чтобы выделить два года средств, человеко-часы и таланты в партнерстве с лабораторией в Амстердаме, чтобы сделать что-то, что в тот момент было скорее абстракцией в реальность. Это долгий путь, чтобы доказать свою точку зрения. Но Google пошел туда.
В прошлом году Google создал конфликт с алгоритмом хеширования SHA-1, чтобы продемонстрировать его уязвимость. SHA-1 был официально заменен SHA-2 в начале 2016 года. Но у Google был смысл, чтобы выделить два года средств, человеко-часы и таланты в партнерстве с лабораторией в Амстердаме, чтобы сделать что-то, что в тот момент было скорее абстракцией в реальность. Это долгий путь, чтобы доказать свою точку зрения. Но Google пошел туда. Если браузер выдает одно и то же значение хеш-функции, значит, он знает, что и подпись, и файл являются подлинными — они не были изменены.
Если браузер выдает одно и то же значение хеш-функции, значит, он знает, что и подпись, и файл являются подлинными — они не были изменены.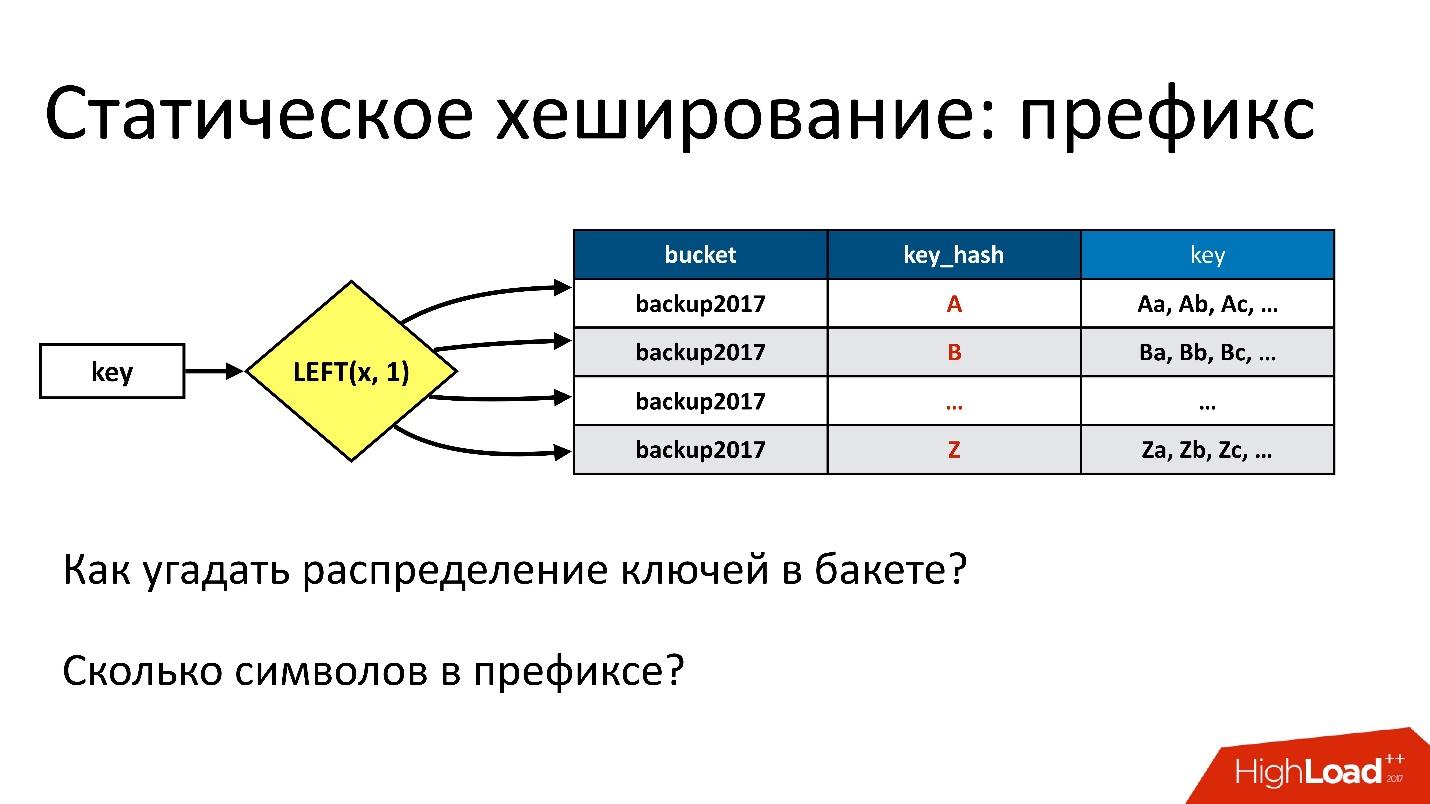 Он был создан в 1992 году как преемник MD4. В настоящее время MD6 находится в разработке, но с 2009 года Ривест удалил его из рассмотрения NIST для SHA-3.
Он был создан в 1992 году как преемник MD4. В настоящее время MD6 находится в разработке, но с 2009 года Ривест удалил его из рассмотрения NIST для SHA-3.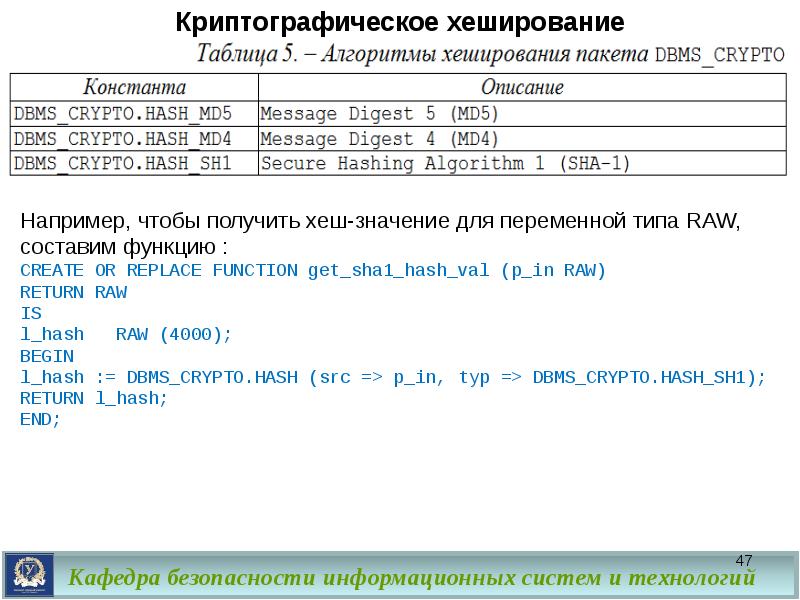 В 2004 году сообщалось о коллизии для RIPEMD-128, что означает, что RIPEMD-160 — единственный алгоритм из этого семейства, достойный своей соли (это будет потрясающий каламбур примерно в двух абзацах).
В 2004 году сообщалось о коллизии для RIPEMD-128, что означает, что RIPEMD-160 — единственный алгоритм из этого семейства, достойный своей соли (это будет потрясающий каламбур примерно в двух абзацах). Атака методом грубой силы — это попытка компьютера или ботнета использовать все возможные комбинации букв и цифр, пока не будет найден пароль.
Атака методом грубой силы — это попытка компьютера или ботнета использовать все возможные комбинации букв и цифр, пока не будет найден пароль.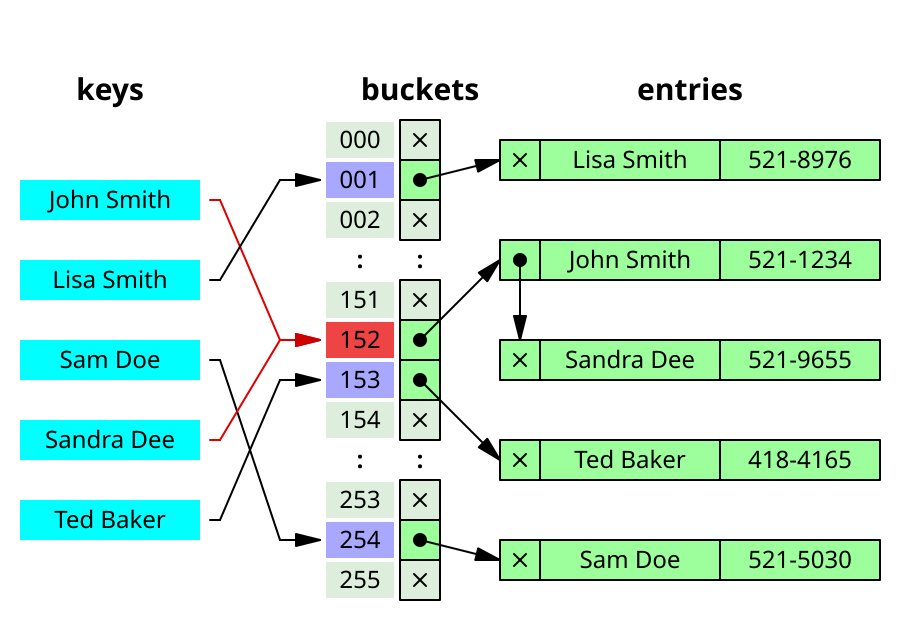

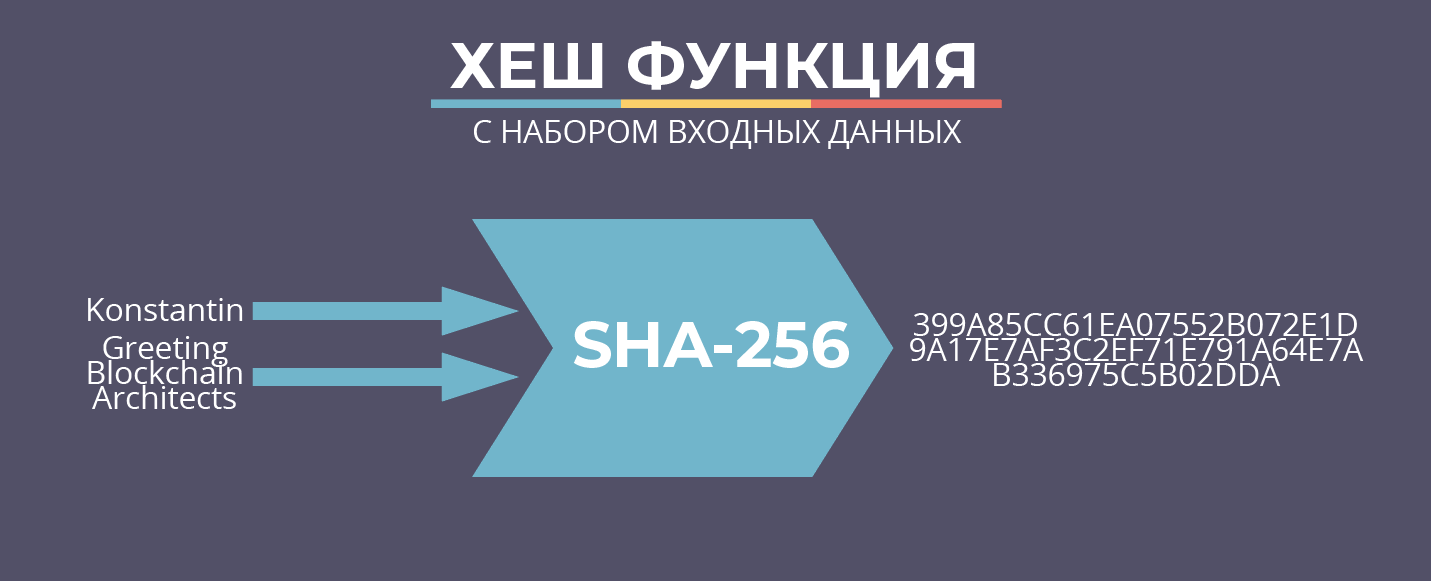 В качестве примера представьте, что компания-разработчик программного обеспечения выпускает патч для приложения, которое клиенты могут загрузить.Они могут вычислить хэш патча и разместить ссылку на файл патча и хеш на сайте компании. Они могут указать его как:
В качестве примера представьте, что компания-разработчик программного обеспечения выпускает патч для приложения, которое клиенты могут загрузить.Они могут вычислить хэш патча и разместить ссылку на файл патча и хеш на сайте компании. Они могут указать его как: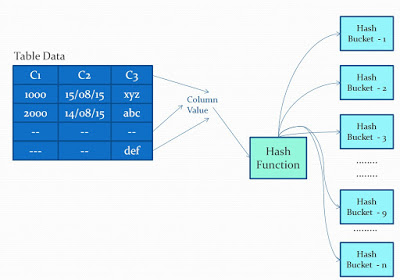 Шестнадцатеричные символы состоят из 4 бит и используют числа от 0 до 9 и символы от a до f.
Шестнадцатеричные символы состоят из 4 бит и используют числа от 0 до 9 и символы от a до f.

 Ключевые методы растягивания добавляют к паролям дополнительные случайные биты, чтобы сделать их еще более сложными. Двумя распространенными методами расширения ключей являются bcrypt и функция вывода ключей на основе пароля 2 (PBKDF2).
Ключевые методы растягивания добавляют к паролям дополнительные случайные биты, чтобы сделать их еще более сложными. Двумя распространенными методами расширения ключей являются bcrypt и функция вывода ключей на основе пароля 2 (PBKDF2). пароль, зашифрованный bcrypt. Если результат bcrypt предоставленного пароля совпадает с сохраненным результатом bcrypt, пользователь аутентифицируется.
пароль, зашифрованный bcrypt. Если результат bcrypt предоставленного пароля совпадает с сохраненным результатом bcrypt, пользователь аутентифицируется. Открытая группа создала Конкурс хеширования паролей (PHC). Они получили и оценили 24 различных алгоритма хеширования в качестве альтернативы.В июле 2015 года PHC выбрал Argon2 в качестве победителя конкурса и рекомендовал использовать его вместо устаревших алгоритмов, таких как PBKDF2.
Открытая группа создала Конкурс хеширования паролей (PHC). Они получили и оценили 24 различных алгоритма хеширования в качестве альтернативы.В июле 2015 года PHC выбрал Argon2 в качестве победителя конкурса и рекомендовал использовать его вместо устаревших алгоритмов, таких как PBKDF2.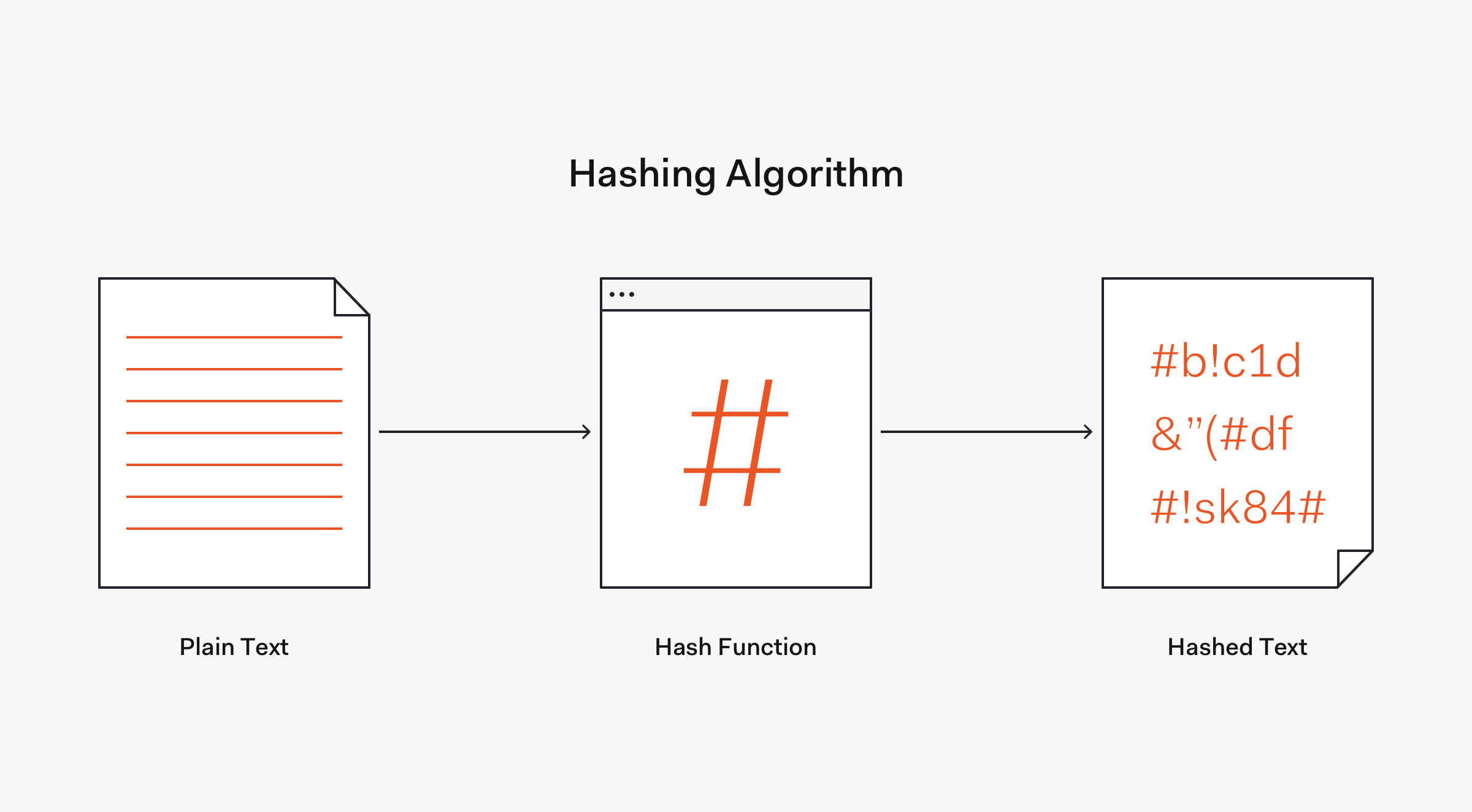 Затем он сравнивает полученный хэш с вычисленным:
Затем он сравнивает полученный хэш с вычисленным: Это ошибочно указывает на то, что сообщение сохранило целостность. HMAC помогает решить эту проблему.
Это ошибочно указывает на то, что сообщение сохранило целостность. HMAC помогает решить эту проблему.
 Эти вопросы показывают, чего вы можете ожидать от живого экзамена. Они включают перетаскивание, сопоставление, сортировку и заполнение пустых вопросов. Смотрите демо здесь.
Эти вопросы показывают, чего вы можете ожидать от живого экзамена. Они включают перетаскивание, сопоставление, сортировку и заполнение пустых вопросов. Смотрите демо здесь. (Загрузка MP3.)
(Загрузка MP3.) У меня появилась привычка, как и у некоторых из нас, запоминать вопросы и ответы, это путь к неудаче. Надеюсь, этот процесс в режиме обучения поможет получить все концепции и пройти тест sec +, который я сдам через месяц ».
У меня появилась привычка, как и у некоторых из нас, запоминать вопросы и ответы, это путь к неудаче. Надеюсь, этот процесс в режиме обучения поможет получить все концепции и пройти тест sec +, который я сдам через месяц ». Наконец, если у вас есть доступ к аудиообзорам, используйте их по дороге на экзамен.Это действительно помогает ».
Наконец, если у вас есть доступ к аудиообзорам, используйте их по дороге на экзамен.Это действительно помогает ». Он также используется во многих алгоритмах шифрования.
Он также используется во многих алгоритмах шифрования.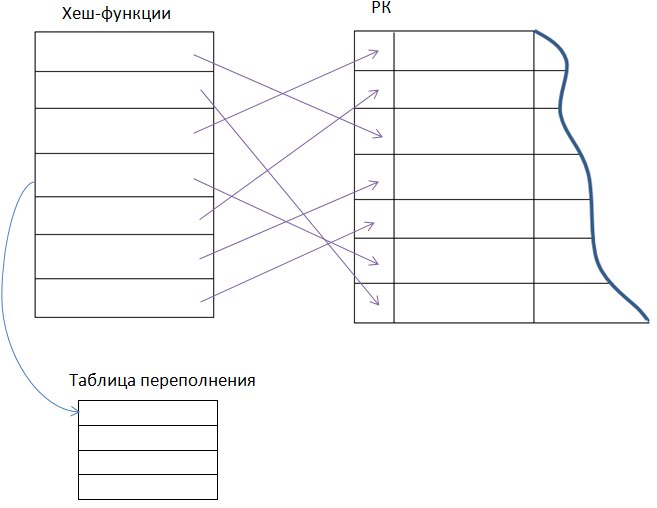 В общем, было бы намного быстрее найти совпадение по четырем цифрам, каждая из которых имеет только 10 возможностей, чем по непредсказуемой длине значения, где каждый символ имел 26 возможностей.
В общем, было бы намного быстрее найти совпадение по четырем цифрам, каждая из которых имеет только 10 возможностей, чем по непредсказуемой длине значения, где каждый символ имел 26 возможностей. Таким образом, хеширование всегда является односторонней операцией. Нет необходимости «реконструировать» хэш-функцию путем анализа хешированных значений. Фактически, идеальная хеш-функция не может быть получена с помощью такого анализа.Хорошая хеш-функция также не должна выдавать одно и то же хеш-значение из двух разных входных данных. Если это так, это называется коллизией . Хэш-функция, которая предлагает чрезвычайно низкий риск столкновения, может считаться приемлемой.
Таким образом, хеширование всегда является односторонней операцией. Нет необходимости «реконструировать» хэш-функцию путем анализа хешированных значений. Фактически, идеальная хеш-функция не может быть получена с помощью такого анализа.Хорошая хеш-функция также не должна выдавать одно и то же хеш-значение из двух разных входных данных. Если это так, это называется коллизией . Хэш-функция, которая предлагает чрезвычайно низкий риск столкновения, может считаться приемлемой. или ключ.
или ключ.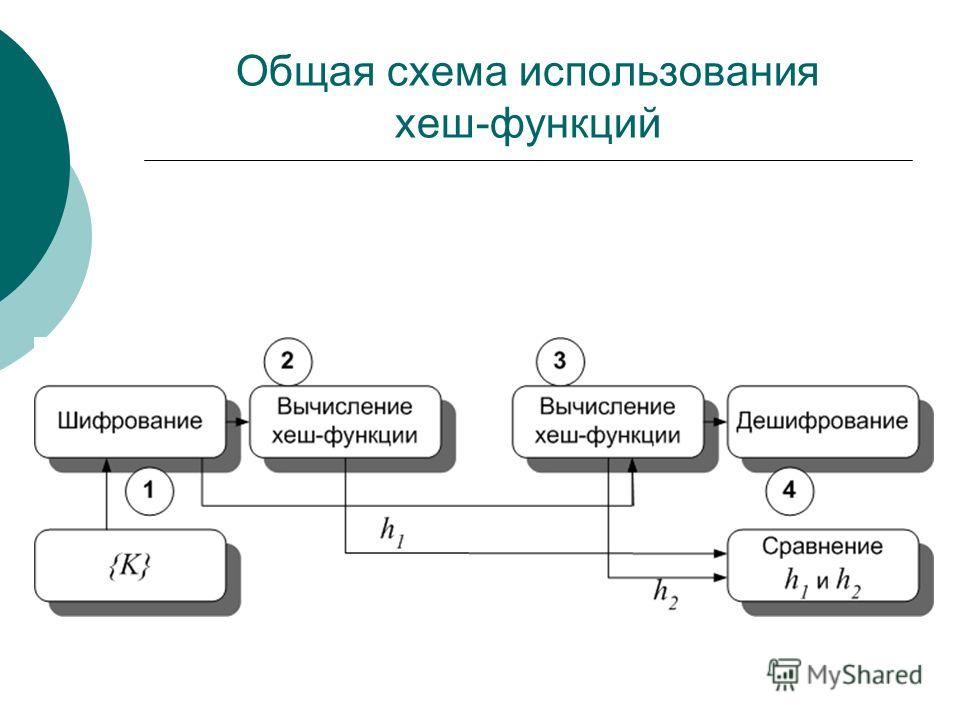 Однако хеш-функция, которая хорошо работает для хранения и извлечения базы данных, может не работать в целях шифрования или проверки ошибок.
Однако хеш-функция, которая хорошо работает для хранения и извлечения базы данных, может не работать в целях шифрования или проверки ошибок.