Хеширование (Скрытие) Строк В Python
Прежде всего, позвольте мне сказать, что вы не можете гарантировать уникальные результаты. Если вы хотите получить уникальные результаты для всех строк в юниверсе, вам лучше сохранить самую строку (или сжатую версию).
Подробнее об этом за секунду. Сначала сделаем хэши.
путь hashlib
Вы можете использовать любой из основных криптографических хэшей для хэша строки с несколькими шагами:
>>> import hashlib
>>> sha = hashlib.sha1("I am a cat")
>>> sha.hexdigest()
'576f38148ae68c924070538b45a8ef0f73ed8710'
У вас есть выбор между SHA1, SHA224, SHA256, SHA384, SHA512 и MD5 в отношении встроенных модулей.
Какая разница между этими хэш-алгоритмами?
Функция хеша работает, беря данные переменной длины и превращая их в данные фиксированной длины.
Фиксированная длина, в случае каждого из алгоритмов SHA, встроенных в hashlib, — это количество бит, указанное в имени (за исключением sha1, которое составляет 160 бит). Если вам нужна большая уверенность в том, что две строки не попадут в одно и то же ведро (то же значение хэша), выберите хеш с большим дайджестом (фиксированная длина).
В отсортированном порядке это размеры дайджеста, с которыми вы должны работать:
Algorithm Digest Size (in bits)
md5 128
sha1 160
sha224 224
sha256 256
sha384 384
sha512 512
Чем больше дайджест, тем меньше вероятность столкновения, если ваша хеш-функция стоит соли.
Подождите, как насчет
hash()?Встроенная функция hash() возвращает целые числа, которые также могут быть просты в использовании для цели. Однако есть проблемы.
>>> hash('moo')
6387157653034356308
Если ваша программа будет запущена в разных системах, вы не можете быть уверены, что hash вернет ту же самую вещь.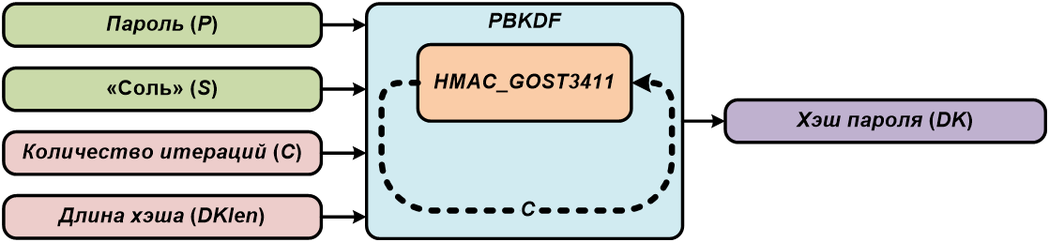 На самом деле, я работаю на 64-битном поле, используя 64-битный Python. Эти значения будут сильно отличаться от 32-битного Python.
На самом деле, я работаю на 64-битном поле, используя 64-битный Python. Эти значения будут сильно отличаться от 32-битного Python.
Для Python 3.3+, как указано @gnibbler, hash() рандомизируется между прогонами. Он будет работать в течение одного прогона, но почти наверняка не будет работать в разных версиях вашей программы (вытаскивая из упомянутого текстового файла).
Почему hash() будет построен таким образом? Ну, встроенный хэш существует по одной конкретной причине. Хэш-таблицы/словари/поиск таблиц в памяти. Не для криптографического использования, а для дешевых поисков во время выполнения.
Не используйте hash(), используйте hashlib.
hashlib — хеширование строк в Python на примерах — MD5, SHA1
В Python хеш-функция принимает вводную последовательность с переменной длиной в байтах и конвертирует ее в последовательность с фиксированной длиной. Данная функция односторонняя.
Содержание статьи
Это значит, что если f является функцией хеширования, f(x) вычисляется довольно быстро и без лишних сложностей, однако на повторное получение х потребуется очень много времени. Значение, что возвращается хеш-функцией, обычно называют хешем, дайджестом сообщения, значением хеша или контрольной суммой. В подобающем большинстве случаев для предоставленного ввода хеш-функция создает уникальный вывод. Однако, в зависимости от алгоритма, есть вероятность возникновения конфликта, вызванного особенностями математических теорий, что лежат в основе этих функций.
Что такое хеш-функция Python
Хеш-функции

Как Python-разработчику, вам могут понадобиться эти функции для проверки дубликатов данных и файлов, проверки целостности данных при передаче информации по сети, безопасного хранения паролей в базах данных или, возможно, для какой-либо работы, связанной с криптографией.
Мы собрали ТОП Книг для Python программиста которые помогут быстро изучить язык программирования Python. Список книг: Книги по PythonОбратите внимание, что хеш-функции не являются криптографическим протоколом, они не шифруют и не дешифруют информацию, но являются фундаментальной частью многих криптографических протоколов и инструментов.
Популярные хеш-функции Python
Некоторые часто используемые хеш-функции:
- MD5: Алгоритм производит хеш со значением в 128 битов. Широко используется для проверки целостности данных. Не подходит для использования в иных областях по причине уязвимости в безопасности MD5.
- SHA: Группа алгоритмов, что были разработаны NSA Соединенных Штатов. Они являются частью Федерального стандарта обработки информации США. Эти алгоритмы широко используются в нескольких криптографических приложениях. Длина сообщения варьируется от 160 до 512 бит.
Модуль hashlib, включенный в стандартную библиотеку Python, представляет собой модуль, содержащий интерфейс для самых популярных алгоритмов хеширования. hashlib реализует некоторые алгоритмы, однако, если у вас установлен OpenSSL, hashlib также может использовать эти алгоритмы.
Данный код предназначен для работы в Python 3.5 и выше. При желании запустить эти примеры в Python 2.x, просто удалите вызовы attributems_available и algorithms_guaranteed.
Сначала импортируется модуль
Теперь для списка доступных алгоритмов используются algorithms_available и algorithms_guaranteed.
print(hashlib.algorithms_available) print(hashlib.algorithms_guaranteed)
print(hashlib.algorithms_available) print(hashlib.algorithms_guaranteed) |
Метод algorithms_available создает список всех алгоритмов, доступных в системе, включая те, что доступны через OpenSSl. В данном случае в списке можно заметить дубликаты названий. md5, sha1, sha224, sha256, sha384, sha512.
Примеры кода с хеш-функциями в Python
Код ниже принимает строку "Hello World" и выводит дайджест HEX данной строки. hexdigest возвращает строку HEX, что представляет хеш, и в случае, если вам нужна последовательность байтов, нужно использовать дайджест.
MD5 — пример хеширования
import hashlib hash_object = hashlib.md5(b’Hello World’) print(hash_object.hexdigest())
import hashlib
hash_object = hashlib.md5(b’Hello World’) print(hash_object.hexdigest()) |
Обратите внимание, что "b" предшествует литералу строки, происходит конвертация строки в байты, оттого, что функция хеширования принимает только последовательность байтов в качестве параметра. В предыдущей версии библиотеки принимался литерал строки.
Итак, если вам нужно принять какой-то ввод с консоли и хешировать его, не забудьте закодировать строку в последовательности байтов:
import hashlib mystring = input(‘Enter String to hash: ‘) # Предположительно по умолчанию UTF-8 hash_object = hashlib.md5(mystring.encode()) print(hash_object.hexdigest())
import hashlib
mystring = input(‘Enter String to hash: ‘)
# Предположительно по умолчанию UTF-8 hash_object = hashlib. print(hash_object.hexdigest()) |
 md5(mystring.encode())
md5(mystring.encode())Предположим, нам нужно хешировать строку "Hello Word" с помощью функции MD5. Тогда результатом будет 0a4d55a8d778e5022fab701977c5d840bbc486d0.
SHA1 — пример хеширования
import hashlib hash_object = hashlib.sha1(b’Hello World’) hex_dig = hash_object.hexdigest() print(hex_dig)
import hashlib
hash_object = hashlib.sha1(b’Hello World’) hex_dig = hash_object.hexdigest()
print(hex_dig) |
Хеширование на SHA224
import hashlib hash_object = hashlib.sha224(b’Hello World’) hex_dig = hash_object.hexdigest() print(hex_dig)
import hashlib
hash_object = hashlib.sha224(b’Hello World’) hex_dig = hash_object.hexdigest()
print(hex_dig) |
Хеширование на SHA256
import hashlib hash_object = hashlib.sha256(b’Hello World’) hex_dig = hash_object.hexdigest() print(hex_dig)
import hashlib
hash_object = hashlib.sha256(b’Hello World’) hex_dig = hash_object.hexdigest()
print(hex_dig) |
Пример хеширования на SHA384
import hashlib hash_object = hashlib.sha384(b’Hello World’) hex_dig = hash_object.hexdigest() print(hex_dig)
import hashlib
hash_object = hashlib.sha384(b’Hello World’) hex_dig = hash_object.hexdigest()
print(hex_dig) |
Пример хеширования на SHA512
import hashlib hash_object = hashlib.sha512(b’Hello World’) hex_dig = hash_object.hexdigest() print(hex_dig)
import hashlib
hash_object = hashlib.sha512(b’Hello World’) hex_dig = hash_object.
print(hex_dig) |
 hexdigest()
hexdigest()Использование алгоритмов OpenSSL
Предположим, вам нужен алгоритм, предоставленный OpenSSL. Используя algorithms_available, можно найти название необходимого алгоритма.
В данном случае, на моем компьютере доступен «DSA». Вы можете использовать методы new и update:
import hashlib hash_object = hashlib.new(‘DSA’) hash_object.update(b’Hello World’) print(hash_object.hexdigest())
import hashlib
hash_object = hashlib.new(‘DSA’) hash_object.update(b’Hello World’)
print(hash_object.hexdigest()) |
Реальный пример хеширования паролей Python
В следующем примере пароли будут хешироваться для последующего сохранения в базе данных. Здесь мы будем использовать salt. salt является случайной последовательностью, добавленной к строке пароля перед использованием хеш-функции. salt используется для предотвращения перебора по словарю (dictionary attack) и атак радужной таблицы (rainbow tables attacks).
Тем не менее, если вы занимаетесь реально функционирующим приложением и работаете над паролями пользователей, следите за последними зафиксированными уязвимостями в данной области. Для более подробного ознакомления с темой защиты паролей можете просмотреть следующую статью.
Код для Python 3.x
import uuid import hashlib def hash_password(password): # uuid используется для генерации случайного числа salt = uuid.uuid4().hex return hashlib.sha256(salt.encode() + password.encode()).hexdigest() + ‘:’ + salt def check_password(hashed_password, user_password): password, salt = hashed_password.split(‘:’) return password == hashlib.sha256(salt.encode() + user_password.encode()).hexdigest() new_pass = input(‘Введите пароль: ‘) hashed_password = hash_password(new_pass) print(‘Строка для хранения в базе данных: ‘ + hashed_password) old_pass = input(‘Введите пароль еще раз для проверки: ‘) if check_password(hashed_password, old_pass): print(‘Вы ввели правильный пароль’) else: print(‘Извините, но пароли не совпадают’)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import uuid import hashlib def hash_password(password): # uuid используется для генерации случайного числа salt = uuid. return hashlib.sha256(salt.encode() + password.encode()).hexdigest() + ‘:’ + salt
def check_password(hashed_password, user_password): password, salt = hashed_password.split(‘:’) return password == hashlib.sha256(salt.encode() + user_password.encode()).hexdigest() new_pass = input(‘Введите пароль: ‘) hashed_password = hash_password(new_pass) print(‘Строка для хранения в базе данных: ‘ + hashed_password) old_pass = input(‘Введите пароль еще раз для проверки: ‘)
if check_password(hashed_password, old_pass): print(‘Вы ввели правильный пароль’) else: print(‘Извините, но пароли не совпадают’) |
 uuid4().hex
uuid4().hexКод для Python 2.x
import uuid import hashlib def hash_password(password): # uuid используется для генерации случайного числа salt = uuid.uuid4().hex return hashlib.sha256(salt.encode() + password.encode()).hexdigest() + ‘:’ + salt def check_password(hashed_password, user_password): password, salt = hashed_password.split(‘:’) return password == hashlib.sha256(salt.encode() + user_password.encode()).hexdigest() new_pass = raw_input(‘Введите пароль: ‘) hashed_password = hash_password(new_pass) print(‘Строка для сохранения в базе данных: ‘ + hashed_password) old_pass = raw_input(‘Введите пароль еще раз для проверки: ‘) if check_password(hashed_password, old_pass): print(‘Вы ввели правильный пароль’) else: print(‘Извините, но пароли не совпадают’)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import uuid import hashlib def hash_password(password): # uuid используется для генерации случайного числа salt = uuid.uuid4().hex return hashlib.sha256(salt.encode() + password.encode()).hexdigest() + ‘:’ + salt
def check_password(hashed_password, user_password): password, salt = hashed_password. return password == hashlib.sha256(salt.encode() + user_password.encode()).hexdigest() new_pass = raw_input(‘Введите пароль: ‘) hashed_password = hash_password(new_pass) print(‘Строка для сохранения в базе данных: ‘ + hashed_password) old_pass = raw_input(‘Введите пароль еще раз для проверки: ‘) if check_password(hashed_password, old_pass): print(‘Вы ввели правильный пароль’) else: print(‘Извините, но пароли не совпадают’) |
 split(‘:’)
split(‘:’)Хеширование — Криптография
Хеширование (иногда «хэширование», англ. hashing) — преобразование по детерминированному алгоритму входного массива данных произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования также называются хеш-функциями или функциями свёртки, а их результаты называют хешем, хеш-кодом или сводкой сообщения(англ. message digest).
Хеширование применяется для построения ассоциативных массивов, поиска дубликатов в сериях наборов данных, построения достаточно уникальных идентификаторов для наборов данных, контрольное суммирование с целью обнаружения случайных или намеренных ошибок при хранении или передаче, для хранения паролей в системах защиты (в этом случае доступ к области памяти, где находятся пароли, не позволяет восстановить сам пароль), при выработке электронной подписи (на практике часто подписывается не само сообщение, а его хеш-образ).
В общем случае однозначного соответствия между исходными данными и хеш-кодом нет в силу того, что количество значений хеш-функций меньше, чем вариантов входного массива; существует множество массивов с разным содержимым, но дающих одинаковые хеш-коды — так называемые коллизии. Вероятность возникновения коллизий играет немаловажную роль в оценке качества хеш-функций.
Существует множество алгоритмов хеширования с различными свойствами (разрядность, вычислительная сложность, криптостойкость и т. п.). Выбор той или иной хеш-функции определяется спецификой решаемой задачи. Простейшими примерами хеш-функций могут служить контрольная сумма или CRC.
п.). Выбор той или иной хеш-функции определяется спецификой решаемой задачи. Простейшими примерами хеш-функций могут служить контрольная сумма или CRC.
История
Дональд Кнут относит первую систематическую идею хеширования к сотруднику IBM Хансу Петеру Луну (нем. Hans Peter Luhn), предложившему хеш-кодирование в январе 1953 года.
В 1956 году Арнольд Думи (англ. Arnold Dumey) в своей работе «Computers and automation» первым представил концепцию хеширования таковой, какой её знает большинство программистов сейчас. Думи рассматривал хеширование, как решение «Проблемы словаря», а также предложил использовать в качестве хеш-адреса остаток деления на простое число.[1]
Первой серьёзной работой, связанной с поиском в больших файлах, была статья Уэсли Питерсона (англ. W. Wesley Peterson) в IBM Journal of Research and Development 1957 года, в которой он определил открытую адресацию, а также указал на ухудшение производительности при удалении. Спустя шесть лет была опубликована работа Вернера Бухгольца (нем. Werner Buchholz), в которой проведено обширное исследование хеш-функций. В течение нескольких последующих лет хеширование широко использовалось, однако не было опубликовано никаких значимых работ.
В 1967 году хеширование в современном значении упомянуто в книге Херберта Хеллермана «Принципы цифровых вычислительных систем». В 1968 году Роберт Моррис (англ. Robert Morris) опубликовал в Communications of the ACM большой обзор по хешированию, эта работа считается ключевой публикацией, вводящей понятие о хешировании в научный оборот и закрепившей ранее применявшийся только в жаргоне специалистов термин «хеш».
До начала 1990-х годов в русскоязычной литературе в качестве эквивалента термину «хеширование» благодаря работам Андрея Ершова использовалось слово «расстановка», а для коллизий использовался термин «конфликт» (Ершов использовал «расстановку» с 1956 года, в русскоязычном издании книги Вирта «Алгоритмы и структуры данных» 1989 года также используется термин «расстановка»). Предлагалось также назвать метод русским словом «окрошка». Однако ни один из этих вариантов не прижился, и в русскоязычной литературе используется преимущественно термин «хеширование».[3]
Предлагалось также назвать метод русским словом «окрошка». Однако ни один из этих вариантов не прижился, и в русскоязычной литературе используется преимущественно термин «хеширование».[3]
Виды хеш-функций
Хорошая хеш-функция должна удовлетворять двум свойствам:
- Быстро вычисляться;
- Минимизировать количество коллизий
Предположим, для определённости, что количество ключей , а хеш-функция имеет не более различных значений:
В качестве примера «плохой» хеш-функции можно привести функцию с , которая десятизначному натуральном числу сопоставляет три цифры выбранные из середины двадцатизначного квадрата числа . Казалось бы значения хеш-кодов должны равномерно распределиться между «000» и «999», но для реальных данных такой метод подходит лишь в том случае, если ключи не имеют большого количества нулей слева или справа.[3]
Однако существует несколько более простых и надежных методов, на которых базируются многие хеш-функции.
Хеш-функции, основанные на делении
Первый метод заключается в том, что мы используем в качестве хеша остаток от деления на , где — это количество всех возможных хешей:
При этом очевидно, что при чётном значение функции будет чётным, при чётном , и нечётным — при нечётном, что может привести к значительному смещению данных в файлах. Также не следует использовать в качестве степень основания счисления компьютера, так как хеш-код будет зависеть только от нескольких цифр числа , расположенных справа, что приведет к большому количеству коллизий. На практике обычно выбирают простое — в большинстве случаев этот выбор вполне удовлетворителен.
Ещё следует сказать о методе хеширования, основанном на делении на полином по модулю два. В данном методе также должна являться степенью двойки, а бинарные ключи () представляются в виде полиномов. В этом случае в качестве хеш-кода берутся значения коэффциентов полинома, полученного как остаток от деления на заранее выбранный полином степени :
При правильном выборе такой способ гарантирует отсутствие коллизий между почти одинаковыми ключами. [3]
[3]
Мультипликативная схема хеширования
Второй метод состоит в выборе некоторой целой константы , взаимно простой с , где — количество представимых машинным словом значений (в компьютерах IBM PC ). Тогда можем взять хеш-функцию вида:
В этом случае, на компьютере с двоичной системой счисления, является степенью двойки и будет состоять из старших битов правой половины произведения .
Среди преимуществ этих двух методов стоит отметь, что они выгодно используют то, что реальные ключи неслучайны, например в том случае если ключи представляют собой арифметическую прогрессию (допустим последовательность имён «ИМЯ1», «ИМЯ2», «ИМЯ3»). Мультипликативный метод отобразит арифметическую прогрессию в приближенно арифметическую прогрессию различных хеш-значений, что уменьшает количество коллизий по сравнению со случайной ситуацией.[3]
Одной из вариаций данного метода является хеширование Фибоначчи, основанное на свойствах золотого сечения. В качестве здесь выбирается ближайшее к целое число, взаимно простое с
Хеширование строк переменной длины
Вышеизложенные методы применимы и в том случае, если нам необходимо рассматривать ключи, состоящие из нескольких слов или ключи переменной длины. Например можно скомбинировать слова в одно при помощи сложения по модулю или операции «исключающее или». Одним из алгоритмов, работающих по такому принципу является хеш-функция Пирсона.
Хеширование Пирсона (англ. Pearson hashing) — алгоритм, предложенный Питером Пирсоном (англ. Peter Pearson) для процессоров с 8-битными регистрами, задачей которого является быстрое вычисление хеш-кода для строки произвольной длины. На вход функция получает слово , состоящее из символов, каждый размером 1 байт, и возвращает значение в диапазоне от 0 до 255. Причем значение хеш-кода зависит от каждого символа входного слова.
Алгоритм можно описать следующим псевдокодом, который получает на вход строку и использует таблицу перестановок
h := 0
for each c in W loop
index := h xor c
h := T[index]
end loop
return h
Среди преимуществ алгоритма следует отметить:
- Простоту вычисления;
- Не существует таких входных данных, для которых вероятность коллизии наибольшая;
- Возможность модификации в идеальную хеш-функцию.


В качестве альтернативного способа хеширования ключей, состоящих из символов (), можно предложить вычисление
Идеальное хеширование
Идеальной хеш-функцией (англ. Perfect hash function) называется такая функция, которая отображает каждый ключ из набора в множество целых чисел без коллизий. В математических терминах это инъективное отображение.
Описание
- Функция называется идеальной хеш-функцией для , если она инъективна на ;
- Функция называется минимальной идеальной хеш-функцией для , если она является ИХФ и ;
- Для целого , функция называется -идеальной хеш-функцией (k-PHF) для если для каждого имеем .
Идеальное хеширование применяется в тех случаях, когда мы хотим присвоить уникальный идентификатор ключу, без сохранения какой-либо информации о ключе. Одним из наиболее очевидных примеров использования идеального (или скорее k-идеального) хеширования является ситуация, когда мы располагаем небольшой быстрой памятью, где размещаем значения хешей, связанных с данными хранящимися в большой, но медленной памяти. Причем размер блока можно выбрать таким, что необходимые нам данные, хранящиеся в медленной памяти, будут получены за один запрос. Подобный подход используется, например, в аппаратных маршрутизаторах. Также идеальное хеширование используется для ускорения работы алгоритмов на графах, в тех случаях, когда представление графа не умещается в основной памяти.
Универсальное хеширование
Универсальным хешированием (англ. Universal hashing) называется хеширование, при котором используется не одна конкретная хеш-функция, а происходит выбор из заданного семейства по случайному алгоритму. Использование универсального хеширования обычно обеспечивает низкое число коллизий. Универсальное хеширование имеет множество применений, например, в реализации хеш-таблиц и криптографии.
Описание
Предположим, что мы хотим отобразить ключи из пространства в числа . На входе алгоритм получает некоторый набор данных и размерностью , причем неизвестный заранее. Как правило целью хеширования является получение наименьшего числа коллизий, чего трудно добиться используя какую-то определенную хеш-функцию.
На входе алгоритм получает некоторый набор данных и размерностью , причем неизвестный заранее. Как правило целью хеширования является получение наименьшего числа коллизий, чего трудно добиться используя какую-то определенную хеш-функцию.
В качестве решения такой проблемы можно выбирать функцию случайным образом из определенного набора, называемого универсальным семейством .
Хеширование и хеш-таблицы — PDF Free Download
Алгоритмы и структуры данных
Алгоритмы и структуры данных Косяков Михаил Сергеевич к.т.н., доцент кафедры ВТ Тараканов Денис Сергеевич ассистент кафедры ВТ Бабаянц Александр Амаякович https://vk.com/algoclass_2018 Содержание курса
ПодробнееРазрешение коллизий в хеш-функциях
Краевая научно-практическая конференция учебно-исследовательских работ учащихся 6-11 классов Прикладные и фундаментальные вопросы математики и физики Прикладные вопросы математики Разрешение коллизий в
ПодробнееСтроки. Евгений Капун. 16 ноября 2012 г.
Строки Евгений Капун 16 ноября 2012 г. Хеши Хеш строки число, вычисляемое на основе содержимого строки, такое что: Хеши равных строк совпадают. Хеши различных строк с большой вероятностью различаются.
Подробнее727A — Превращение: из A в B
Технокубок 2017 — Отборочный Раунд 1 Разбор задач первого отборочного раунда Технокубка 2016/2017 727A — Превращение: из A в B Будем решать задачу в обратную сторону попытаемся получить из числа B число
ПодробнееПрактика программирования 18
Практика программирования 18 Эффективность различных контейнеров B-деревья Префиксные деревья Хеш-таблица Кувшинов Д. Р. КМиММ УрФУ Екатеринбург 2012 Эффективность контейнеров: поиск по номеру N число элементов
Р. КМиММ УрФУ Екатеринбург 2012 Эффективность контейнеров: поиск по номеру N число элементов
Теория чисел. Евгений Капун. 14 ноября 2012 г.
Теория чисел Евгений Капун 14 ноября 2012 г. Простые числа В некоторых задачах требуется сгенерировать все простые числа, не большие заданного. Простейший метод сделать это: перебирать все числа, для каждого
ПодробнееЗадача 1 «Выбор зала»
Задача 1 «Выбор зала» Пусть длина меньшей стороны равна x, а большей y. Тогда заметим, что должны выполняться следующие ограничения: y x x y A, следовательно y A / x 2 (x + y) C, следовательно y C / 2
ПодробнееЛабораторная работа 7
2 Лабораторная работа 7 Обработка строк с использованием множественного типа данных Задание: составить программу заданной обработки массива слов. В процессе обработки использовать множественных тип данных.
ПодробнееЗадача A. Высота дерева (!) (1 балл)
Задача A. Высота дерева (!) (1 балл) height.in height.out 256 мегабайт Высотой дерева называется максимальное число вершин дерева в цепочке, начинающейся в корне дерева, заканчивающейся в одном из его
ПодробнееЗадача A. Хеши префиксов
Учебно-тренировочные сборы к РОИ-7, группы В и С Санкт-Петербург, Аничков дворец, 9 марта 7 года Задача A. Хеши префиксов hash.in hash.out seconds 56 мегабайта Полиномиальным хешом строки s длины n будем
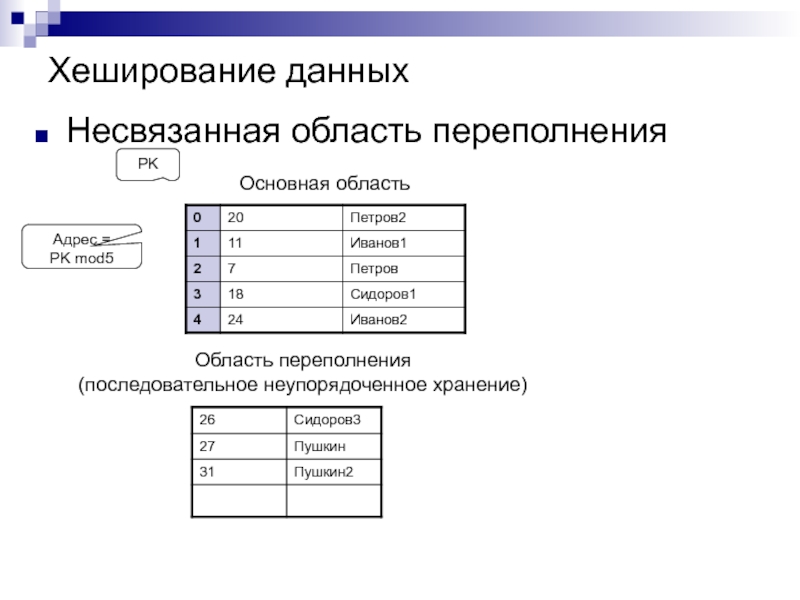
ПодробнееХеширование данных АиСД 1
Хеширование данных Хеширование — разбиение множества ключей (однозначно характеризующих элементы хранения и представленных, как правило, в виде текстовых строк или чисел) на непересекающиеся подмножества
Подробнее Лекция 6:Словари. Хеш-таблицы. КурносовМихаил Георгиевич к.т.н. доцент Кафедры вычислительных систем Сибирский государственный университет телекоммуникаций и информатики http://www.mkurnosov.net Контроль
Хеш-таблицы. КурносовМихаил Георгиевич к.т.н. доцент Кафедры вычислительных систем Сибирский государственный университет телекоммуникаций и информатики http://www.mkurnosov.net Контроль
Задача A. Взлом хеш-функции
Задача A. Взлом хеш-функции crack.in crack.out В некоторых задачах защиты информации используются так называемые хеш-функции. Одним из важнейших классов хеш-функций являются так называемые полиномиальные
ПодробнееСимвольный тип — char
Символьный тип — char Предназначен для работы с одиночными символами: буквами, цифрами, знаками. Пример: Var Alpha : char; Begin Alpha :=’p’; Alpha :=’+’; Alpha :=’3′; Alpha :=’ ‘; {пробел} Alpha :=»»;
ПодробнееЗадача A. Декартово дерево
Задача A. Декартово дерево tree.in tree.out 1 секунда Вам даны пары чисел (a i, b i ). Необходимо построить декартово дерево, такое что i-я вершина имеет ключи (a i, b i ), вершины с ключом a i образуют
ПодробнееСтруктуры и алгоритмы обработки данных
Кафедра математического обеспечения АСУ Г.А. ШЕЙНИНА Структуры и алгоритмы обработки данных Рекомендовано редакционно-издательским советом университета в качестве методических указаний для студентов специальности
ПодробнееЕГЭ Н. В. Потехин
ЕГЭ 2017 Н. В. Потехин 1. Сколько существует натуральных чисел x, для которых выполнено неравенство 11011100 2 < x < DF 16? В ответе укажите только количество чисел, сами числа писать не нужно. 2. Логическая
Подробнее2. s=»это тестовая строка»? len(s) Результат: 19
Строковые функции Упражнения и задания: Перед выполнением каждого задания обязательно откройте HELP и найдите описания команд, после чего выполняйте упражнения в командном окне: Определение длины строки.
Задача 6 «Гипершашки»
Задача 5 «Три сына» Заметим следующее: чтобы минимизировать сумму квадратов необходимо стараться выбрать числа a, b и c близкими к n/3. Формализуем это утверждение. Докажем сначала вспомогательный факт
ПодробнееНеасимптотическая оптимизация
Неасимптотическая оптимизация Евгений Капун 15 ноября 2012 г. Введение Бывает, что даже асимптотически оптимальные алгоритмы не укладываются в ограничение времени. Это связано с тем, что константный множитель
Подробнее4. Динамическое программирование
4. Динамическое программирование 4.1. Наибольшая возрастающая подпоследовательность (Longest increasing subsequence) Вам требуется написать программу, которая по заданной последовательности находит максимальную
ПодробнееЛекция 8 12 октября 2018 г.
Лекция 8 12 октября 2018 г. Регистрация piazza.com/tversu.ru/other/cs101 Основная сраница piazza.com/tversu.ru/other/cs101/home Опр. 1: Помехоустойчивые коды это такие коды, которые позволяют обнаружить
ПодробнееЗадача A. Декартово дерево
Задача A. Декартово дерево tree.in tree.out 1 секунда Вам даны пары чисел (a i, b i ). Необходимо построить декартово дерево, такое что i-я вершина имеет ключи (a i, b i ), вершины с ключом a i образуют
ПодробнееMIDTERM. 24.03.2019 ВАРИАНТ 1 1.1 1.2 1.3 1.4 1.5 1.6 2 3 4.1 4.2 5.1 5.2 5.3 6.1 6.2 6.3 Фамилия, имя студента Фамилия преподавателя, ведущего семинары Группа 1. Решение каждой задачи должно быть обосновано,
ПодробнееУрок 4.
 Циклы и массивы.
Циклы и массивы.Урок 4. Циклы и массивы. О чем урок: циклы while do-while for массивы функции для работы с массивами Смотреть урок: [marafon_4.mp4] Циклы Цикл управляющая конструкция, предназначенная для многократного
ПодробнееЗадача о счастливых билетах
Задача о счастливых билетах 1 Постановка задачи На лекции вы наверняка разбирали задачу о счастливых билетах. Здесь не будет повторения лекции, а будет разобрана аналогичная задача с другим определением
Подробнее0.1. Деревья отрезков 1
0.1. Деревья отрезков 1 0.1 Деревья отрезков 0.1.1 Определение В олимпиадном программировании одной из наиболее часто используемых структур данных является дерево отрезков. Дерево отрезков структура данных,
ПодробнееЗадача A. Экономическая грамотность
Задача A. Экономическая грамотность 1 секунда Многие банки при оплате покупок их банковскими картами предлагают систему возврата части потраченных средств, называемую cashback. Мама Алёны имеет три подобные
ПодробнееЦелые числа. Битовые операции
Целые числа. Битовые операции Шокуров Антон В. [email protected] 16 февраля 2017 г. Версия: 0.12 Аннотация Целые числа имеют свою специфику. Используются в целочисленной арифметике, а также для
ПодробнееЗадача A. Скобочный спор
Задача A. Скобочный спор ЗКШ 014. День Владимир и Владислав живут в общежитии одного из математических факультетов главного университета Байтландии. Владислав уже четверокурсник и поэтому считает, что
ПодробнееРешение задач в среде Delphi
Решение задач в среде Delphi Тема: Использование алгоритмической конструкции «Счетный цикл и цикл с предусловием» в задачах на целочисленную арифметику. Тюкавина Татьяна Михайловна Задача 1. Написать программу,
Тюкавина Татьяна Михайловна Задача 1. Написать программу,
Делимость и модульная арифметика
Лекция. Введение в теоретико-числовые алгоритмы Делимость и модульная арифметика, отношение сравнимости, бинарное возвещение в степень, простые числа, наименьшее общее кратное, наибольший общий делитель,
ПодробнееМОДУЛЬНАЯ АРИФМЕТИКА
МОДУЛЬНАЯ АРИФМЕТИКА В некоторых приложениях удобно выполнять арифметические операции над целыми числами, заданными в так называемом модульном представлении Это представление предполагает, что целое число
ПодробнееСим. Значение. A Q g w
Лабораторная работа 0 (Предварительная. В которой нужно вспомнить, как пользоваться языками программирования) В работах можно пользоваться любыми языками программирования, но скриптовые подойдут лучше.
ПодробнееСодержание. I Основы 23. Предисловие 14
Содержание Предисловие 14 I Основы 23 Введение 24 1 Роль алгоритмов в вычислениях 26 1.1 Что такое алгоритмы 26 1.2 Алгоритмы как технология 32 2 Приступаем к изучению 38 2.1 Сортировка вставкой 38 2.2
ПодробнееЗадачи по базовым алгоритмам
Задачи по базовым алгоритмам Алгоритмы с массивами 1. Нахождение максимума, минимума, второго максимума, второго минимума в массиве за один проход. Нахождение вторых максимумов/минимумов как с учётом повторяющихся
ПодробнееМультипликативная схема хеширования
Второй метод
состоит в выборе некоторой целой
константы ,
взаимно простой с ,
где —
количество представимых машинным словом
значений (в компьютерах IBM
PC ). Тогда можем взять хеш-функцию вида:
Тогда можем взять хеш-функцию вида:
В этом случае, на компьютере с двоичной системой счисления, является степенью двойки и будет состоять из старших битов правой половины произведения .
Среди преимуществ этих двух методов стоит отметь, что они выгодно используют то, что реальные ключи неслучайны, например в том случае если ключи представляют собойарифметическую прогрессию (допустим последовательность имён «ИМЯ1», «ИМЯ2», «ИМЯ3»). Мультипликативный метод отобразит арифметическую прогрессию в приближенно арифметическую прогрессию различных хеш-значений, что уменьшает количество коллизий по сравнению со случайной ситуацией.
Одной из вариаций данного метода является хеширование Фибоначчи, основанное на свойствах золотого сечения. В качестве здесь выбирается ближайшее к целое число, взаимно простое с
Хеширование строк переменной длины
Вышеизложенные методы применимы и в том случае, если нам необходимо рассматривать ключи, состоящие из нескольких слов или ключи переменной длины. Например можно скомбинировать слова в одно при помощи сложения по модулю или операции «исключающее или». Одним из алгоритмов, работающих по такому принципу, является хеш-функция Пирсона.
Хеширование Пирсона — алгоритм, предложенный Питером Пирсоном для процессоров с 8-битными регистрами, задачей которого является быстрое вычисление хеш-кода для строки произвольной длины. На вход функция получает слово , состоящее из символов, каждый размером 1 байт, и возвращает значение в диапазоне от 0 до 255. При этом значение хеш-кода зависит от каждого символа входного слова.
Алгоритм можно описать следующим псевдокодом, который получает на вход строку и использует таблицу перестановок :
h := 0
for each c in W loop
index := h xor c
h := T[index]
end loop
return h
Среди преимуществ алгоритма следует отметить:
простоту вычисления;
не существует таких входных данных, для которых вероятность коллизии наибольшая;
возможность модификации в идеальную хеш-функцию.
В качестве альтернативного способа хеширования ключей, состоящих из символов (), можно предложить вычисление
Идеальное хеширование
Идеальной хеш-функцией (англ. Perfect hash function) называется такая функция, которая отображает каждый ключ из набора в множество целых чисел без коллизий. В математических терминах это инъективное отображение.
Описание Функция называется идеальной хеш-функцией для , если она инъективна на ;
Функция называется минимальной идеальной хеш-функцией для , если она является ИХФ и ;
Для целого , функция называется -идеальной хеш-функцией (k-PHF) для если для каждого имеем .
Идеальное хеширование применяется в тех случаях, когда мы хотим присвоить уникальный идентификатор ключу, без сохранения какой-либо информации о ключе. Одним из наиболее очевидных примеров использования идеального (или скорее -идеального) хеширования является ситуация, когда мы располагаем небольшой быстрой памятью, где размещаем значения хешей, связанных с данными хранящимися в большой, но медленной памяти. Причем размер блока можно выбрать таким, что необходимые нам данные, хранящиеся в медленной памяти, будут получены за один запрос. Подобный подход используется, например, в аппаратных маршрутизаторах. Также идеальное хеширование используется для ускорения работы алгоритмов на графах, в тех случаях, когда представление графа не умещается в основной памяти.
Википедия — свободная энциклопедия
Избранная статья
Прохождение Венеры по диску Солнца — разновидность астрономического прохождения (транзита), — имеет место тогда, когда планета Венера находится точно между Солнцем и Землёй, закрывая собой крошечную часть солнечного диска. При этом планета выглядит с Земли как маленькое чёрное пятнышко, перемещающееся по Солнцу. Прохождения схожи с солнечными затмениями, когда наша звезда закрывается Луной, но хотя диаметр Венеры почти в 4 раза больше, чем у Луны, во время прохождения она выглядит примерно в 30 раз меньше Солнца, так как находится значительно дальше от Земли, чем Луна. Такой видимый размер Венеры делает её доступной для наблюдений даже невооружённым глазом (только с фильтрами от яркого солнечного света), в виде точки, на пределе разрешающей способности глаза. До наступления эпохи покорения космоса наблюдения этого явления позволили астрономам вычислить расстояние от Земли до Солнца методом параллакса, кроме того, при наблюдении прохождения 1761 года М. В. Ломоносов открыл атмосферу Венеры.
Продолжительность прохождения обычно составляет несколько часов (в 2004 году оно длилось 6 часов). В то же время, это одно из самых редких предсказуемых астрономических явлений. Каждые 243 года повторяются 4 прохождения: два в декабре (с разницей в 8 лет), затем промежуток в 121,5 года, ещё два в июне (опять с разницей 8 лет) и промежуток в 105,5 года. Последние декабрьские прохождения произошли 9 декабря 1874 года и 6 декабря 1882 года, а июньские — 8 июня 2004 года и 6 июня 2012 года. Последующие прохождения произойдут в 2117 и 2125 годах, опять в декабре. Во время прохождения наблюдается «явление Ломоносова», а также «эффект чёрной капли».
Хорошая статья
Резня в Благае (сербохорв. Масакр у Благају / Masakr u Blagaju) — массовое убийство от 400 до 530 сербов хорватскими усташами, произошедшее 9 мая 1941 года, во время Второй мировой войны. Эта резня стала вторым по счету массовым убийством после создания Независимого государства Хорватия и была частью геноцида сербов.
Жертвами были сербы из села Велюн и его окрестностей, обвинённые в причастности к убийству местного мельника-хорвата Йосо Мравунаца и его семьи. Усташи утверждали, что убийство было совершено на почве национальной ненависти и свидетельствовало о начале сербского восстания. Задержанных сербов (их число, по разным оценкам, составило от 400 до 530 человек) содержали в одной из школ Благая, где многие из них подверглись пыткам и избиениям. Усташи планировали провести «народный суд», но оставшаяся в живых дочь Мравунаца не смогла опознать убийц среди задержанных сербов, а прокуратура отказалась возбуждать дело против кого-либо без доказательства вины. Один из высокопоставленных усташей Векослав Лубурич, недовольный таким развитием событий, организовал новый «специальный суд». День спустя дочь Мравунаца указала на одного из задержанных сербов. После этого 36 человек были расстреляны. Затем усташи казнили остальных задержанных.
Изображение дня
Эхинопсисы, растущие на холме посреди солончака Уюни
Обзор некоторых алгоритмов нестрогого сопоставления записей применительно к задаче исключения дублирования персональных данных
Пусть задан непустой алфавит
и известны вероятности появления различных
символов алфавита. Пусть также на множестве символов задана функция ,
отображающая буквы в числа от 1 до m. Эта функция, как несложно видеть, задает разбиение
алфавита на m подмножеств.
Определение. Сигнатурой слова будем называть вектор размерности m,
k-ый элемент которого равняется единице, если в слове есть символ такой, что
, и нулю в противном случае. Номером сигнатуры слова будем называть число
.[2]
является хеш-функцией, отображающей множество слов в отрезок целых чисел
от 0 до , что позволяет организовать словарь в виде хеш-таблицы.
Пусть слово получено из в результате одной операции редактирования: замены,
добавления (удаления) буквы или перестановки символов. В силу определения сигнатуры,
битовые векторы и отличаются не более чем в одном разряде в случае
операции добавления (удаления), и не более чем двух разрядах – в случае замены. Несложно
также видеть, что, если при замене символов изменяются два элемента сигнатуры, то общее
количество единиц (модуль сигнатуры) остается неизменным, а произвольные перестановки,
вообще, не влияют на сигнатуру.
Метод хеширования по сигнатуре обладает следующими достоинствами:
позволяет осуществлять с высокой скоростью поиск на точное равенство и поиск,
допускающий одну-две «ошибки» в задании поискового запроса;
ХС эффективно, как в случае «прямых» чтений с диска, так и из кэша;
ХС использует компактный индекс. При правильном выборе параметров объем
индекса не более чем на 10-20% превышает размер файла, содержащего список
терминов словаря;
отличается простотой реализации.
ХС присущ и один довольно существенный недостаток: он медленно работает, если
индекс фрагментирован: то есть в том случае, если списки слов с одинаковыми сигнатурами
разбросаны по несмежным секторам на диске. В настоящее время это не является большой
проблемой, потому что, с одной стороны, размеры памяти компьютера часто позволяют
загрузить словарь целиком, а с другой стороны, дефрагментация словаря, как правило,
осуществляется в течении нескольких минут.
java — Хорошая хеш-функция для строк
Вот простая хеш-функция, которую я использую для построенной мной хеш-таблицы. Это в основном для того, чтобы взять текстовый файл и сохранить каждое слово в индексе, который представляет собой алфавитный порядок.
int generatehashkey (const char * имя)
{
int x = tolower (имя [0]) - 97;
если (x <0 || x> 25)
х = 26;
вернуть x;
}
По сути, это слова хешируются в соответствии с их первой буквой.Таким образом, слово, начинающееся с «a», получит хэш-ключ 0, «b» — 1 и так далее, а «z» будет 25. Числа и символы будут иметь хэш-ключ 26. Это дает преимущество. ; Вы можете легко и быстро вычислить, где данное слово будет проиндексировано в хеш-таблице, поскольку все это в алфавитном порядке, примерно так: Код можно найти здесь: https://github.com/abhijitcpatil/general
Предоставляя следующий текст в качестве ввода: Аттикус однажды сказал Джему: «Я бы предпочел, чтобы ты стрелял в консервные банки на заднем дворе, но я знаю, что ты пойдешь. после птиц.Стреляй во всех синих соек, если сможешь попасть в них, но помни, что убить пересмешника — грех ». Это был единственный раз, когда я когда-либо слышал, как Аттикус говорил, что делать что-то — грех, и я спросил мисс Моди об этом. «Твой отец прав, — сказала она. «Пересмешники не делать что-то одно, кроме создания музыки для нас. Они не доедают народные сады, не гнездятся в кукурузных колыбелях, они ничего не делают но поют для нас свои сердца. Вот почему грех убить пересмешник.
Это будет вывод:
0 -> а о спросили и Аттикус все после Аттикуса
1 -> но только синие птицы.но задний двор
2 -> кроватки кукурузные банки консервные банки
3 -> не делай не делай не делай день
4 -> ешьте наслаждайтесь. кроме когда-либо
5 -> для отца
6 -> сады идут
7 -> сердца услышали удар
8 -> это в нем. Я это я это если я в
9 -> Джей Джем
10 -> убить убить знать
11 ->
12 -> пересмешник. музыка делает Моди Мисс пересмешник ».
13 -> гнездо
14 -> один только один
15 -> народные
16 -> 17 -> правильно помню скорее
18 -> грех петь сказал. она что-то грешит, говорит грех, стрелять, стрелять
19 -> к Это их дело Они к тому, чтобы приурочить То к олову, чтобы
20 -> нас.до нас
21 ->
22 -> зачем было нужно
23 ->
24 -> ты ты будешь ты
25 ->
26 -> «Mockingbirds» «Your‘ em »I’d
c — алгоритмы хеширования для строк
Я читаю хеширование с помощью алгоритмов на C ++ Роберта Седвика
Эта реализация хеш-функции для строковых ключей включает одно умножение и одно сложение для каждого символа в ключе. Если бы мы заменили константу 127 на 128, программа просто вычислила бы остаток от деления числа, соответствующего 7-битному ASCII-представлению ключа, на размер таблицы, используя метод Хорнера.Основание 127 помогает нам избежать аномалий, если размер таблицы является степенью 2 или кратной 2.
int хэш (char * v, int M)
{int h = 0, a = 127;
для (; * v! = 0; v ++)
h = (a * h + * v)% M;
return h;
}
Теоретически идеальная универсальная хеш-функция — это функция, для которой вероятность столкновения двух различных ключей в таблице размера M составляет ровно 1 / M. Можно доказать, что, используя последовательность различных случайных значений вместо фиксированного произвольного значения для коэффициента a в программе 14.1 превращает модульное хеширование в универсальную хеш-функцию. Однако стоимость создания нового случайного числа для каждого символа в ключе, вероятно, будет непомерно высокой. Программа 14.2 демонстрирует практический компромисс: мы меняем коэффициенты, генерируя простую псевдослучайную последовательность.
Таким образом, чтобы использовать хеширование для реализации абстрактной таблицы символов, первым шагом является расширение интерфейса абстрактного типа для включения операции хеширования, которая преобразует ключи в неотрицательные целые числа, меньшие, чем размер таблицы M.Прямая реализация
встроенный хэш int (ключ v, int M) {return (int) M * (v-s) /; }
выполняет работу для ключей с плавающей запятой между значениями s и t; для целочисленных ключей мы можем просто вернуть v% M. Если M не является простым, хеш-функция может вернуть
(число) (0,616161 * (с плавающей запятой) v)% M
или результат аналогичного целочисленного вычисления, например
(16161 * (без знака) v)% M.
Мой вопрос, как автор подразумевает простое основание 127, помогает нам избежать аномалий, если размер таблицы является степенью 2 или кратной 2?
Что означает authorm, говоря «для целочисленных ключей, мы можем просто вернуть v% M.»?
Что автор имеет в виду, говоря «Если M не является простым, хеш-функция может вернуть
(int) (.616161 * (float) v)% M
или результат аналогичного целочисленного вычисления, например
(16161 * (без знака) v)% M.
Как автор придумал .616161 и 16161?
Просьба помочь разобраться на простом примере
Хеш-функции
Исчерпывающий набор хеш-функций, визуализатор хеширования и некоторые тесты результаты [см. Mckenzie et al. Выбор алгоритма хеширования , SP&E 20 (2): 209-224, февраль 1990] когда-нибудь будет доступен. Если ты просто хочешь иметь хорошую хеш-функцию и не могу ждать, djb2 — один из лучших строковые хэш-функции, которые я знаю. у него отличная раздача и скорость на многих разные наборы ключей и размеры столов. у тебя вряд ли получится лучше с одна из «хорошо известных» функций, таких как PJW, K&R [1] и т. д. См. Также tpop стр. 126 для получения информации. построение графиков хэш-функций.
djb2
об этом алгоритме (k = 33) впервые сообщил Дэн Бернштейн много лет назад. назад в комп.str [i]; магия числа 33 (почему оно работает лучше многих других постоянные, простые или непрямые) так и не получили адекватного объяснения.
беззнаковый длинный
хеш (беззнаковый символ * str)
{
беззнаковый длинный хеш = 5381;
int c;
в то время как (c = * str ++)
хэш = ((хеш
сдбм
этот алгоритм был создан для sdbm (публичная реализация ndbm)
библиотека базы данных. было обнаружено, что он хорошо справляется с битами скремблирования, что приводит к лучшему
распределение ключей и меньшее количество разделений.это тоже бывает хорошо
общая функция хеширования с хорошим распределением. фактическая функция
hash (i) = hash (i - 1) * 65599 + str [i]; то, что включено ниже, - это
более быстрая версия, используемая в gawk. [есть даже более быстрая версия для безымянных устройств]
магическая константа 65599 была выбрана буквально из воздуха во время экспериментов с
разные константы, и оказывается простым. это один из
алгоритмы, используемые в berkeley db (см.
sleepycat) и в других местах.
статический беззнаковый длинный
sdbm (str)
беззнаковый char * str;
{
беззнаковый длинный хеш = 0;
int c;
в то время как (c = * str ++)
хэш = c + (хеш
проиграть потерять
Эта хеш-функция появилась в K&R (1-е изд.), Но, по крайней мере, читатель был
предупредил: « Это не лучший алгоритм, но он имеет достоинство
крайняя простота ."Это преуменьшение; это ужасный
алгоритм хеширования, и он мог бы быть намного лучше, не жертвуя его
«крайняя простота». [см. вторую редакцию!] Многие программисты на C
используйте эту функцию без фактического тестирования или проверки чего-то вроде
Кнута Сортировка и поиск , так что он застрял. Сейчас он смешанный
с в противном случае респектабельным кодом, например. cnews. вздох. [смотрите также:
tpop]
беззнаковый длинный
хеш (беззнаковый символ * str)
{
unsigned int hash = 0;
int c;
в то время как (c = * str ++)
хэш + = c;
вернуть хеш;
}
Как работает хеш-функция Java String (2)
Сглаживание перекоса
Эта страница является продолжением первой страницы нашего обсуждения того, как работает хеш-функция Java String.До сих пор мы представили гипотетический набор случайных строк, в котором каждый символ имеет особое распространение. Мы обнаружили, что, что довольно типично для строки, символы смещены в сторону определенных битов. В нашем примере биты 4 и 5 имели вероятность установки чуть более 70% и 75%. соответственно для данного персонажа. Младшие биты показали лучшую случайность: то есть их шанс быть установленным был ближе к 50%.
Уловка строковой хеш-функции состоит в том, чтобы попытаться сгладить эту предвзятость. путем смешивания битов со смещенной вероятностью с другими битами, в частности те, где вероятность уже достаточно беспристрастна.
Первое: не очень хорошая хеш-функция
Напомним, что функция Java String объединяет последовательные символы путем умножения текущего хэша на 31 и последующего добавления нового символа. Чтобы показать, почему это работает достаточно хорошо для типичных строк, давайте начнем с изменив его так, чтобы вместо этого мы использовали значение 32 в качестве хэш-кода. В другом словами, давайте представим, что хеш-функция такова:
int hash = 0; для (int я = 0; я Обратите внимание, что это, возможно, плохая хеш-функция для строк 1 (и, возможно, для большинства вещей).Проблема в том, что мы умножаем на степень 2 , что на самом деле просто сдвигает текущий хэш. Затем происходит некоторое смешение: старшие биты символа и будет смешан с младшими битами предыдущего символа (теперь сдвинут влево на 5 размещает так, чтобы его нижние 3 бита совпадали с верхними 3 битами и -й символ). Однако этого недостаточно, чтобы полностью удалить образец смещения результирующего хэш-кода.Проблема может быть проиллюстрирована если мы возьмем случайный ряд из 5 символов (с распределением, которое мы обсуждаем). График справа показывает вероятность каждого последующего бита. устанавливаемого хэш-кода. На графике все еще есть характерные «горбы», где биты с высоким вероятность в исходных символах, составляющих хэш-код не получают достаточно шанса взаимодействовать с более случайным образом распределенные биты. (Хотя «горб» теперь охватывает ширину в 1 бит а не 2 в исходном дистрибутиве.) | Вероятность установки последовательных битов в хэш-коде случайным образом сгенерированной 5-символьной строки, когда выбрано 32 как множитель в хеш-функции. |
Улучшение множителяТеперь мы строим тот же график, используя 31 в качестве множителя, как в Java реализация функции хеш-кода String. Умножение на 31 фактически означает, что мы сдвигаем хеш на 5 позиций, но затем вычитая исходное несмещенное значение: int hash = 0; для (int я = 0; я Теперь между битами происходит дальнейшее взаимодействие.Во-первых, добавив i -й символ и вычитая хеш (с предыдущим символ в его младших битах) приносит битовые вероятности в символе ближе к 50%. (Например, если у нас есть два бита, каждый с вероятностью 70% от установленного значения, то вычитание одного из другого оставляет вероятность 42%, что результирующий бит будет установлен, с вероятностью 21%, что перенос от долота влево.) А теперь, вместо того, чтобы просто комбинировать старшие биты номера и с младшими битами предыдущего характер, обычно есть взаимодействия между младшими битами n th символ и старшие биты n-1 -го символа. | Вероятность установки последовательных битов в хэш-коде случайным образом сгенерированной 5-символьной строки, когда выбирается 31 как множитель в хеш-функции. |
Результат этих различных точек взаимодействия намного более плоский распределение битов в восстановленном хэш-коде. С 5-символьными клавишами профиль довольно плоский до 22 бита, что означает, что мы можем хранить несколько миллионов такие ключи довольно эффективно.
Далее …
В зависимости от ваших потребностей, вот несколько советов о том, что читать дальше:
1. Иногда используется как строковая хеш-функция, например в Гране В. (2004), Алгоритмика и программирование на Java , Данод, 2-е изд, с. 277, г. но если это возможно, это только тогда, когда хеш-таблица имеет простое число ведра (чего больше не делает реализация HashMap).
Если вам понравилась эта статья по программированию на Java, поделитесь ею с друзьями и коллегами.Следите за автором в Твиттере, чтобы следить за последними новостями и тирадами. Следуйте @BitterCoffey
Содержание редакционной страницы написано Нилом Коффи. Copyright © Javamex UK 2021. Все права защищены.
std :: hash — cppreference.com
шаблон <ключ класса> | (начиная с C ++ 11) | |
Каждая специализация этого шаблона либо включена, («нетронутая»), либо отключена, («отравлена»).Для каждого типа Key , для которого ни библиотека, ни пользователь не предоставляют включенную специализацию std :: hash , эта специализация существует и отключена. Отключенные специализации не удовлетворяют Hash, не удовлетворяют FunctionObject, и все следующие значения являются ложными:
Другими словами, они существуют, но не могут быть использованы.
Разрешенные специализации шаблона хеширования определяют функциональный объект, реализующий хеш-функцию.Экземпляры этого функционального объекта удовлетворяют Hash. В частности, они определяют оператор () const, который:
- Принимает один параметр типа
Ключ. - Возвращает значение типа std :: size_t, представляющее хеш-значение параметра.
- Не вызывает исключений при вызове.
- Для двух одинаковых параметров
k1иk2std :: hash() (k1) == std :: hash () (k2). - Для двух разных параметров
k1иk2, которые не равны, вероятность того, что std :: hash() (k1) == std :: hash () (k2) должна быть очень маленький, приближается к 1.0 / std :: numeric_limits :: max ().
Все явные и частичные специализации хэша , предоставляемые стандартной библиотекой, — это DefaultConstructible, CopyAssignable, Swappable и Destructible. Предоставляемые пользователем специализации hash также должны соответствовать этим требованиям.
Неупорядоченные ассоциативные контейнеры std :: unordered_set, std :: unordered_multiset, std :: unordered_map, std :: unordered_multimap используют специализации шаблона std :: hash в качестве хэш-функции по умолчанию.
[править] Примечания
Фактические хэш-функции зависят от реализации и не обязаны удовлетворять никаким другим критериям качества, кроме указанных выше. Примечательно, что в некоторых реализациях используются тривиальные (идентификационные) хэш-функции, которые отображают целое число самому себе. Другими словами, эти хеш-функции предназначены для работы с неупорядоченными ассоциативными контейнерами, но не как, например, криптографические хеши.
Хеш-функции необходимы только для получения одного и того же результата для одного и того же ввода в рамках одного выполнения программы; это позволяет использовать соленые хэши, предотвращающие коллизионные атаки типа «отказ в обслуживании».
Нет специализации для строк C. std :: hash
Типы элементов
| (до C ++ 20) |
[править] Функции-члены
| создает объект хэш-функции (общедоступная функция-член) | |
| вычисляет хэш аргумента (общедоступная функция-член) |
[править] Стандартные специализации для базовых типов
| шаблон <> struct hash шаблон <> struct hash | ||
В дополнение к вышесказанному стандартная библиотека предоставляет специализации для всех перечислимых типов (с ограниченными и незаданными областями).Они могут быть (но не обязательно) реализованы как std :: hash
Стандартная библиотека предоставляет включенные специализации std :: hash для std :: nullptr_t и всех cv-неквалифицированных арифметических типов (включая любые расширенные целочисленные типы), всех типов перечисления и всех типов указателей.
Каждый заголовок стандартной библиотеки, объявляющий шаблон std :: hash , предоставляет все включенные специализации, описанные выше.Эти заголовки включают
[править] Стандартные специализации для типов библиотек
Примечание: дополнительные специализации для std :: pair и стандартных типов контейнеров, а также служебные функции для составления хэшей доступны в ускоренном режиме.хэш
[править] Пример
#include#include #include <функциональный> #include <строка> #include <неупорядоченный_набор> struct S { std :: string first_name; std :: string last_name; }; bool operator == (const S & lhs, const S & rhs) { return lhs.first_name == rhs.first_name && lhs.last_name == rhs.last_name; } // пользовательский хеш может быть отдельным объектом функции: struct MyHash { std :: size_t operator () (S const & s) const noexcept { std :: size_t h2 = std :: hash {} (s.(h3 << 1); // или используйте boost :: hash_combine } }; } int main () { std :: string str = "Знакомьтесь, новый босс ..."; std :: size_t str_hash = std :: hash {} (str); std :: cout << "hash (" << std :: quoted (str) << ") =" << str_hash << '\ n'; S obj = {"Хьюберт", "Фарнсворт"}; // использование автономного объекта функции std :: cout << "hash (" << std :: quoted (obj.first_name) << "," << std :: quoted (obj.last_name) << ") =" << MyHash {} (obj) << "(с использованием MyHash) \ n" << std :: setw (31) << "или" << std :: hash {} (obj) << "(с использованием внедренной специализации std :: hash) \ n"; // пользовательский хеш позволяет использовать пользовательские типы в неупорядоченных контейнерах // В примере будет использоваться введенная выше специализация std :: hash, // чтобы вместо этого использовать MyHash, передайте его как второй аргумент шаблона std :: unordered_setnames = {obj, {"Бендер", "Родригес"}, {"Туранга", "Лила"}}; для (авто & s: имена) std :: cout << std :: quoted (s.first_name) << '' << std :: quoted (s.last_name) << '\ n'; }
Возможный выход:
hash («Знакомьтесь, новый босс ...») = 1861821886482076440
hash ("Hubert", "Farnsworth") = 17622465712001802105 (с использованием MyHash)
или 17622465712001802105 (с использованием внедренной специализации std :: hash )
"Туранга" "Лила"
«Бендер» «Родригес»
"Хьюберт" "Фарнсворт" [править] Отчеты о дефектах
Следующие ниже отчеты о дефектах, изменяющих поведение, были применены задним числом к ранее опубликованным стандартам C ++.
| DR | Применяется к | Поведение, как опубликовано | Правильное поведение |
|---|---|---|---|
| LWG 2148 | C ++ 11 | специализаций для перечислений отсутствовали | предоставлено |
| LWG 2543 | C ++ 11 | хэш может быть несовместим с SFINAE | сделал SFINAE дружественным из-за отключенных специализаций |
| LWG 2817 | C ++ 11 | специализация для nullptr_t отсутствовала | предоставлено |
хеш-функция | R Документация
Векторизованные хеш-функции
Все хэш-функции либо вычисляют хеш-дайджест для ключа == NULL , либо HMAC
(хешированный код аутентификации сообщения), когда ключ не равен NULL .Поддерживается
входные данные - двоичные (необработанный вектор), строки (вектор символов) или объект соединения.
Использование
sha1 (x, key = NULL) sha224 (x, key = NULL)
sha256 (x, key = NULL)
sha384 (x, key = NULL)
sha512 (x, key = NULL)
sha2 (x, size = 256, key = NULL)
md4 (x, key = NULL)
md5 (x, key = NULL)
blake2b (x, key = NULL)
blake2s (x, key = NULL)
ripemd160 (x, key = NULL)
multihash (x, algos = c ("md5", "sha1", "sha256", "sha384", "sha512"))
Аргументы
- x
вектор символов, необработанный вектор или объект связи.
- ключ
строка или необработанный вектор, используемый в качестве ключа для хеширования HMAC
- размер
должно быть равно 224 256 384 или 512
- алгоритмов
строковый вектор с названиями алгоритмов хеширования
Детали
Самый эффективный способ вычисления хэшей - использование входных соединений, например объект file () или url ().В этом случае хэш вычисляется в потоковом режиме, почти не используя память или дисковое пространство, независимо от размера данных. При использовании входа подключения в мультихеше функция, данные считываются только один раз при потоковой передаче в несколько хеш-функций одновременно. Поэтому несколько хешей вычисляются одновременно, без нужно хранить какие-либо данные или скачивать их несколько раз.
Функции векторизованы для случая символьных векторов: вектор с n strings возвращает n хэшей.При передаче объекта подключения содержимое будет
быть потоковым хешированием, что минимизирует объем требуемой памяти. Это рекомендуется
для хеширования файлов с диска или сети.
Семейство алгоритмов sha2 (sha224, sha256, sha384 и sha512) обычно рекомендуется для конфиденциальной информации. В то время как sha1 и md5 обычно достаточно для идентификаторы, устойчивые к коллизиям, они больше не считаются безопасными для криптографических целей.
В приложениях, в которых хэши должны быть необратимыми (например, имена или пароли), это часто рекомендуется использовать случайный ключ для хеширования HMAC.Это предотвращает атаки, когда мы можем искать хэши общих и / или коротких строк. См. Примеры. Общий частный случай добавляет случайную соль к большому количеству записей для проверки уникальности в пределах набор данных, одновременно отображая результаты, несравнимые с другими наборами данных.
Алгоритмы blake2b и blake2s доступны, только если в вашей системе
libssl 1.1 или новее.
Список литературы
Типы дайджеста: https: // www.openssl.org/docs/man1.1.1/man1/openssl-dgst.html
Псевдонимы
- хеширование
- sha1
- hmac
- Mac
- sha224
- sha256
- sha384
- sha512
- sha2
- мкр.
- мкр5
- blake2b
- blake2s
- ripemd160
- мультихэш
Примеры
# NOT RUN {
# Поддержка как строковых, так и бинарных
md5 (c ("foo", "bar"))
md5 ("foo", key = "secret")
хэш <- md5 (charToRaw ("foo"))
в качестве.символ (hash, sep = ":")
# Сравнить с дайджестом
digest :: digest ("foo", "md5", serialize = FALSE)
# Другой способ
дайджест :: дайджест (автомобили, пропуск = 0)
md5 (сериализовать (автомобили, NULL))
# Stream-verify из соединений (включая файлы)
myfile <- system.file ("ЦИТИРОВАНИЕ")
md5 (файл (myfile))
md5 (файл (myfile), ключ = "секрет")
#}
# НЕ РАБОТАТЬ {
проверьте md5 из: http://cran.r-project.org/bin/windows/base/old/3.1.1/md5sum.txt
md5 (url ("http://cran.r-project.org/bin/windows/base/old/3.1.1/R-3.1.1-win.exe"))
#}
# НЕ РАБОТАТЬ {
# Используйте соль, чтобы предотвратить атаки по словарю
sha1 ("admin") # googleable
sha1 ("admin", key = "random_salt_value") # не googleable
# Используйте случайную соль для идентификации дубликатов при анонимности значений
sha256 ("john") # googleable
sha256 (c ("Джон", "Мэри", "Джон"), ключ = "random_salt_value")
#}
Документация воспроизведена из пакета openssl, версия 1.4.3,
Лицензия: MIT + файловая ЛИЦЕНЗИЯ Примеры сообщества
Похоже, примеров пока нет.
Почему string.GetHashCode () отличается каждый раз, когда я запускаю свою программу в .NET Core?
Этот пост является частью второго ежегодного появления C #. Посетите домашнюю страницу, чтобы увидеть до 50 сообщений в блогах о C # в декабре 2018 года!
В этом посте я описываю характеристику GetHashCode () , которая была для меня новой до тех пор, пока меня недавно не укусила она - то, что вызов GetHashCode () в строке дает другое значение каждый раз, когда вы запускаете программу в .NET Core!
В этом посте я покажу проблему в действии и чем отличается реализация .NET Core GetHashCode () от .NET Framework. Затем я смотрю на , почему это так и почему это вообще хорошо. Наконец, если вам нужно убедиться, что GetHashCode () дает одно и то же значение каждый раз, когда вы запускаете свою программу (спойлер: обычно нет), я предлагаю альтернативную реализацию, которую вы можете использовать вместо встроенного GetHashCode. () .
тл; др; Я настоятельно рекомендую прочитать весь пост, но если вы здесь только ради детерминированного
GetHashCode (), то см. Ниже. Просто помните, что это небезопасно использовать в любых ситуациях, уязвимых для хеш-атак!
Поведение:
GetHashCode () генерирует разные случайные значения для каждого выполнения программы в .NET Core . Самый простой способ понять описываемое мной поведение - это увидеть его в действии.Возьмем эту очень простую программу, которая дважды подряд вызывает GetHashCode () в строке
с использованием системы;
статический класс Program
{
static void Main (строка [] аргументы)
{
Console.WriteLine («Привет, мир!». GetHashCode ());
Console.WriteLine («Привет, мир!». GetHashCode ());
}
}
Если вы запустите эту программу на .NET Framework, то каждый раз, когда вы запустите программу, вы будете получать одно и то же значение:
> dotnet run -c Выпуск -f net471
-19827
-19827
> dotnet run -c Release -f net471
-19827
-19827
> dotnet run -c Release -f net471
-19827
-19827
Напротив, если вы компилируете ту же программу для.NET Core, вы получаете одно и то же значение для каждого вызова GetHashCode () в рамках одного и того же выполнения программы , но другое значение для разных выполнений программы:
> dotnet run -c Выпуск -f netcoreapp2.1
-1105880285
-1105880285
> dotnet run -c Release -f netcoreapp2.1
1569543669
1569543669
> dotnet run -c Release -f netcoreapp2.1
-1477343390
-1477343390
Это застало меня врасплох и явилось источником ошибки, которую я не мог понять без этого знания (я вернусь к этому позже).
С каких это пор ?!
Я был потрясен, когда обнаружил такое поведение, поэтому стал рыться в документации и на GitHub. Конечно же, прямо в документации это поведение хорошо задокументировано: (выделено мной)
Стабильность самого хэш-кода не гарантируется. Хеш-коды для одинаковых строк могут различаться в разных реализациях .NET, в разных версиях .NET и на разных платформах .NET (например, 32-разрядных и 64-разрядных) для одной версии.СЕТЬ. В некоторых случаях они могут даже различаться в зависимости от домена приложения. Это означает, что два последующих запуска одной и той же программы могут возвращать разные хэш-коды.
Во многих отношениях такое поведение интересно тем, что я никогда раньше с ним не сталкивался. Моя первая мысль заключалась в том, что я, должно быть, зависел от этого поведения в .NET Framework, но после небольшого размышления я не мог придумать ни одного случая, когда это было бы так. Как оказалось, я всегда использовал GetHashCode () так, как он был разработан.Кто бы мог подумать!
Ключевым моментом является то, что хэш-коды являются детерминированными для данного выполнения программы , это означает, что только раз, когда это будет проблемой, если вы сохраняете хэш-код вне процесса и загружаете его в другой. Это объясняет следующий комментарий в документации:
В результате хэш-коды никогда не должны использоваться вне домена приложения, в котором они были созданы, они никогда не должны использоваться в качестве ключевых полей в коллекции, и они никогда не должны сохраняться.
Когда я обнаружил такое поведение, я пытался сохранить вывод строки string.GetHashCode () в файл и загрузить значения в другом процессе. Это явно недопустимо, учитывая предыдущее предупреждение!
В качестве небольшого отступления, на самом деле можно включить поведение рандомизированного хэш-кода и в .NET Framework. Для этого необходимо включить элемент в файле app.config приложения :
<конфигурация>
<время выполнения>
Это позволяет использовать тот же код рандомизации, который используется .NET Core, с .NET Framework. Фактически, если вы посмотрите на эталонный источник .NET Framework 4.7.2 для string.cs , вы увидите, что GetHashCode () выглядит следующим образом:
публичное переопределение int GetHashCode () {
#if FEATURE_RANDOMIZED_STRING_HASHING
если (HashHelpers.s_UseRandomizedStringHashing)
{
return InternalMarvin32HashString (this, this.Length, 0);
}
#endif
}
Вызов InternalMarvin32HashString вызывает собственный код для выполнения случайного хеширования. Алгоритм Марвина, который он использует, на самом деле запатентован, но если вам интересно, вы можете увидеть здесь версию C # (это часть реализации Core CLR). Я считаю, что функция рандомизированного хеширования была введена в .NET Framework 4.5 (но не цитируйте меня по этому поводу!).
Как только я понял, что меня беспокоит случайное хеширование, я, естественно, проверил, можно ли его отключить. Оказывается, в .NET Core всегда включен . Но почему?
Почему рандомизация
GetHashCode () - это хорошо?Ответ на этот вопрос был затронут Стивеном Тубом в комментарии к проблеме, которую я обнаружил во время чтения моей проблемы:
Вопрос: Почему .NET Core использует случайное хеширование строк?
A: Безопасность, предотвращение DoS-атак и т. Д.
Это вызвало у меня интерес - что это были за DoS-атаки и как они влияют на GetHashCode () ?
Насколько я понимаю, это восходит к докладу, сделанному в конце 2011 года на 28-м Конгрессе по коммуникации Хаоса (28C3), в котором было показано, что целый ряд языков подвержен так называемой методике, известной как "хэш-флуд". ". Если вас интересуют подробности, я настоятельно рекомендую посмотреть видео выступления, которое я был очень впечатлен, найдя его на You Tube.Местами это определенно перешло мне в голову, но я попытаюсь объяснить суть этого здесь.
Хеш-таблицы и хеш-флуд
Заявление об ограничении ответственности: у меня нет степени в области компьютерных наук, поэтому я вполне могу быть немного расторопным с правильной терминологией. Надеюсь, это описание уязвимости в любом случае имеет смысл.
Хеш-таблицы - это структура данных, которая позволяет хранить значение с помощью ключа . Сама хеш-таблица состоит из множества сегментов.Если вы хотите вставить значение в хеш-таблицу, вы используете хеш-функцию , чтобы вычислить, какому сегменту соответствует ключ , и сохранить там пару «ключ-значение».
В лучшем случае вставка значения в хеш-таблицу представляет собой операцию O (1) , то есть она занимает постоянное время. В идеале хеш-функция распределяет ключи по сегментам равномерно, так что в каждом сегменте хранится не более 1 значения. Если да, то неважно, сколько значений вы храните, для сохранения значения всегда требуется одинаковое количество времени.Более того, удаление и получение значения также составляют O (1) .
Что-то падает, если два разных ключа хешируются в одно и то же ведро. Это относительно обычное явление: типичные хеш-функции, используемые с хеш-таблицами, разработаны так, чтобы быть быстрыми и давать фиксированный результат. Они пытаются снизить вероятность коллизий, но они не являются криптографическими хэш-функциями (они обеспечивают более надежные гарантии. См. 7:28 в видео на YouTube для более подробного обсуждения этого).
Когда вы получаете хэш-конфликт в хеш-таблице, типичные реализации сохраняют пары ключ-значение в виде связанного списка внутри корзины.Когда вы вставляете новое значение и получаете коллизию, хеш-таблица проверяет каждый из элементов, чтобы увидеть, существует ли он уже в корзине. Если нет, то он добавляет элемент в конец списка.
Это нормально, когда вы получаете только случайную коллизию, но что, если каждый поиск приводит к коллизии. Представьте, что вашу хеш-таблицу просят вставить 10 000 элементов, каждый из которых имеет свой ключ, но из которых все хешируются в одну и ту же корзину.
Первый элемент, Foo , вставляется быстро, поскольку в сегменте нет предыдущих значений.Второй элемент, Bar , занимает немного больше времени, поскольку он является первым, по сравнению с существующим элементом Foo , хранящимся в связанном списке корзины, перед добавлением в конец списка. Третий элемент Baz занимает еще больше времени по сравнению с каждым из ранее хешированных значений перед добавлением в список.
Каждая отдельная вставка занимает O (n) раз, так как она должна сравниваться с каждым существующим значением в связанном списке. Если вы можете найти значения Foo , Bar , Baz и т. Д.что все хешируют с тем же значением, то время для вставки этих n элементов составляет полином O (n²) раз. Это очень далеко от предполагаемой производительности O (1) в лучшем случае и является сутью атаки хеш-лавинной рассылки.
Хеш-флуд и веб-приложения
Итак, это объясняет саму атаку, но почему это проблема? По двум основным причинам:
В своем выступлении Александр Клинк и Джулиан Вельде описывают атаки на несколько фреймворков веб-приложений, включая ASP.NET (не-Core - вспомните 2011 год!). Большинство фреймворков веб-приложений (включая ASP.NET) считывают параметры HTTP POST в хеш-таблицу. В ASP.NET параметры запроса доступны как NameValueCollection (хэш-таблица) в HttpContext.Request.Form .
Используя знания о реализации GetHashCode () , можно вычислить (или идентифицировать с помощью грубой силы) широкий спектр значений, которые будут конфликтовать. Оттуда вы можете создать вредоносный HTTP POST.Например, если Foo , Bar , Baz все дают одно и то же значение GetHashCode () , вы можете создать вредоносный пост, который использует все эти параметры в теле:
POST / HTTP / 1.1
example.com
приложение / x-www-form-urlencoded
9999999
Foo = 1 & Bar = 1 & Baz = 1 .... + еще много столкновений
Когда приложение ASP.NET пытается создать объект HttpContext , оно послушно раскладывает тело на NameValueCollection , инициируя атаку хеш-лавинной рассылки из-за хэш-коллизий.
Для некоторой перспективы здесь, когда Александр и Джулиан тестировали атаку с 4 МБ пост-данных (предел на тот момент), ЦП потребовалось ~ 11 часов , чтобы завершить хеширование. 😱 O (n²) сука…
Очевидно, что даже в то время существовали встроенные средства защиты от такого рода побегов; IIS ограничит вас 90 секундами процессорного времени. Но нетрудно увидеть потенциал атак типа «отказ в обслуживании».
Итак, вот оно.Похоже, Microsoft очень серьезно отнеслась к этому исследованию и уязвимости (в отличие от людей из PhP, судя по всему!). Изначально они ограничивали количество параметров, которые вы можете передать в запросе, чтобы уменьшить влияние проблемы. Впоследствии они представили рандомизированное поведение GetHashCode () , которое мы обсуждали.
Что делать, если вам нужно, чтобы GetHashCode () был детерминированным при выполнении программы?
Это подводит меня к рассмотрению проблемы. Мне нужен детерминированный GetHashCode () , который работал бы при выполнении программ.Если вы окажетесь в подобной ситуации, возможно, вам стоит перестать идти по этой линии.
А тебе реально надо?
Если результат GetHashCode () будет открыт для внешнего мира таким образом, что вы останетесь открытыми для хеш-флуда, вам, вероятно, следует переосмыслить свой подход. В частности, если пользовательский ввод добавляется в хеш-таблицу (как свойство Request.Form ), то вы уязвимы для атаки.
Помимо атаки, которую я здесь обсуждал, я настоятельно рекомендую прочитать некоторые сообщения Эрика Липперта о GetHashCode () .Они старые, но совершенно актуальные. Хотел бы я найти их раньше в своем расследовании!
Если вы действительно, на самом деле , конечно, вам нужен детерминированный GetHashCode () для строк, тогда вам придется делать свои собственные вещи.
Детерминированная реализация
GetHashCode () В моем случае я довольно уверен ™, что могу использовать детерминированный GetHashCode () . По сути, я вычисляю хэш-код для целой группы строк «в автономном режиме» и сохраняю эти значения на диске.В самом приложении я сравниваю строку, предоставленную пользователем, с существующими хэш-кодами. Я не вставляю этих значений в хеш-таблицу, а просто сравниваю их с уже «полной» хеш-таблицей. так что я думаю, что я в порядке.
Подскажите пожалуйста, если я ошибаюсь!
Создание детерминированной реализации GetHashCode () было интересным погружением во все виды кодовых баз:
В конце концов, я остановился на версии где-то между ними.стр [я + 1]; } вернуть hash2 + (hash3 * 1566083941); } }
Эта реализация очень похожа на по ссылкам, приведенным выше. Я не буду пытаться объяснять это здесь. Это делает некоторые математические вычисления. Интересным моментом для тех, кто не видел его раньше, является ключевое слово unchecked . Это отключает проверку переполнения для целочисленной арифметики, выполняемой внутри функции. Если функция была выполнена в контексте с проверкой и не использовала ключевое слово unchecked , вы можете получить исключение OverflowException во время выполнения:
проверил
{
var max = int.MaxValue;
var val = max + 1;
}
Теперь мы можем обновить нашу небольшую тестовую программу, чтобы использовать метод расширения GetDeterministicHashCode () :
с использованием системы;
статический класс Program
{
static void Main (строка [] аргументы)
{
Console.WriteLine («Привет, мир!». GetDeterministicHashCode ());
Console.WriteLine («Привет, мир!». GetDeterministicHashCode ());
}
}
И мы получаем одно и то же значение при каждом выполнении программы, даже когда она работает.NET Core:
> dotnet run -c Выпуск -f netcoreapp2.1
1726978645
1726978645
> dotnet run -c Release -f netcoreapp2.1
1726978645
1726978645
Одна вещь, в которой я не уверен на 100%, - это то, получите ли вы такое же значение на архитектурах, отличных от 64-битных. Если кто-то знает ответ наверняка, мне было бы очень интересно, иначе мне нужно пойти и протестировать!
Как я уже говорил ранее, вообще говоря, вам не нужно использовать этот код. Вы должны использовать его только в очень определенных обстоятельствах, когда вы знаете, что не уязвимы для атак на основе хешей.
Если вы хотите реализовать
GetHashCode ()для других типов , взгляните на сообщение Мухаммада Рехана Саида. Он описывает вспомогательную структуру для генерации хэш-кодов. Он также обсуждает встроенную структуруHashCodeв .NET Core 2.1.
Сводка
Этот пост был представителем моего пути к пониманию string.GetHashCode () и того, почему разные исполнения программы дают разный хэш-код для одной и той же строки.Рандомизированные хэш-коды - это функция безопасности, предназначенная для уменьшения хэш-флуда. Этот тип атаки использует знание базовой хеш-функции для генерации множества коллизий. Из-за типичной конструкции хеш-таблицы это приводит к падению производительности вставки с O (1) до O (n²) , что приводит к атаке типа «отказ в обслуживании».