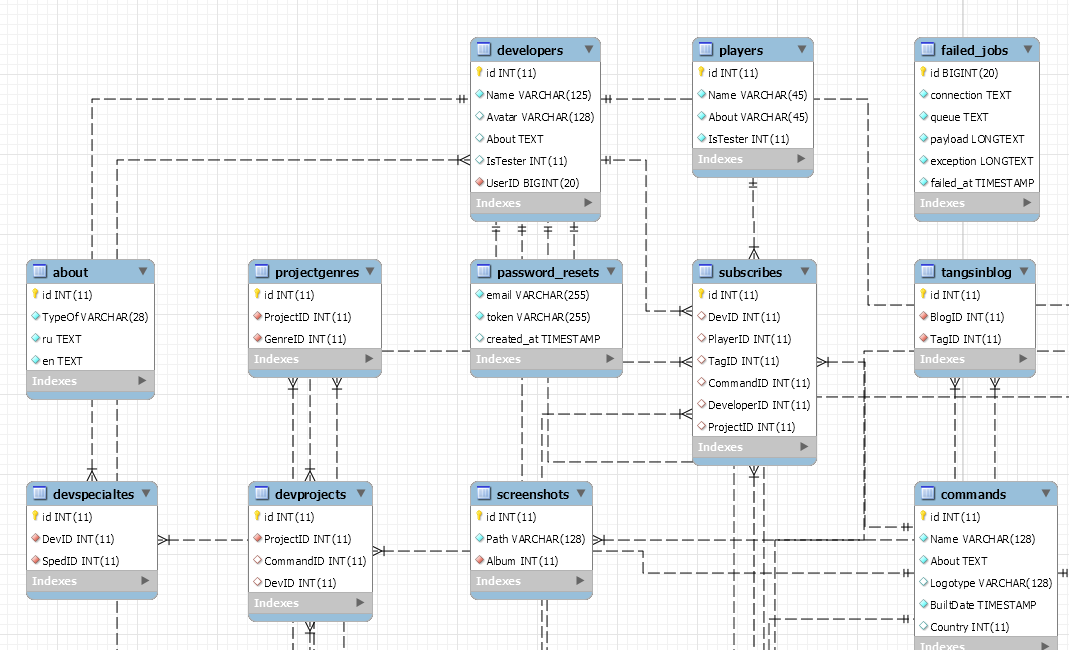
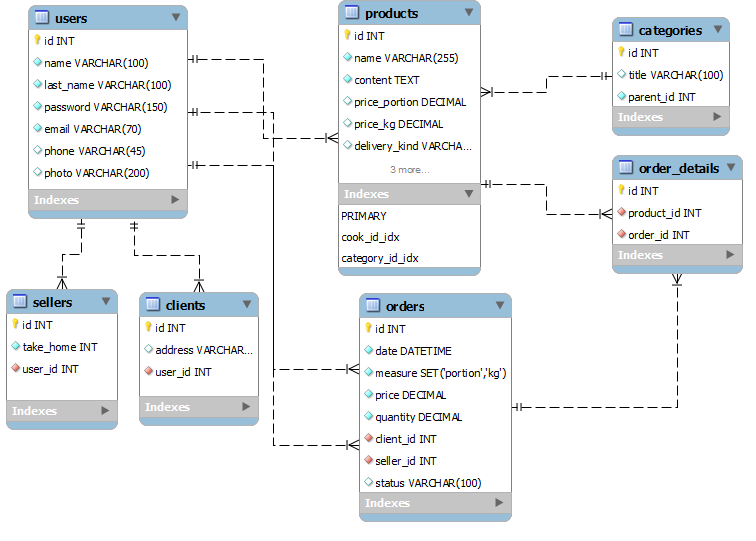
Топ-7 интересных идей и тем проекта SQL для начинающих в 2021 году
В модном деловом мире произошел всплеск разрешения на основе данных в предыдущие несколько лет. А извлечение и фильтрация важной информации из разрозненных хранилищ данных стало проще с помощью таких языков программирования, как SQL. Одна из множества причин изучать SQL. Кроме того, сегодня базы данных SQL используются практически на каждом веб-сайте или веб-приложении. Как студенты колледжа информатики или начинающие разработчики, вы всегда ищете простые в реализации идеи проектов SQL. Итак, ниже мы собрали для вас несколько привлекающих внимание.
После того, как вы построите и спроектируете базу данных с реальной применимостью, это не только улучшит ваше концептуальное понимание, но и дополнительно повысит ваши способности решать проблемы. Итак, оттачивайте свои способности и развивайте свою профессию, реализуя следующие концепции проекта базы данных SQL! в начале карьеры.
Лучшие идеи проектов SQL для начинающих1. Централизованная база данных колледжей
Централизованная база данных колледжейВ школе есть образовательные отделы, например, отделение английского языка, отделение математики, отделение истории и так далее. И каждое подразделение предлагает широкий выбор курсов. Теперь инструктор может обучить пару конечно. Скажем, профессор выбирает категорию по статистике, а также по математическому анализу.
Будучи студентом математического факультета, вы можете записаться на каждый из этих курсов. В связи с этим на каждом курсе колледжа могут обучаться самые разные студенты. Здесь необходимо отметить, что в конкретном курсе может быть только один преподаватель, чтобы избежать дублирования.
Читайте также: 30 лучших вопросов и ответов на собеседованиях по Git, которые вам нужно знать в 2021 году
2
. База данных железнодорожной системыВ этой системе базы данных рекомендуется моделировать совершенно разные железнодорожные станции, железнодорожные пути между стыковочными станциями, детали поезда (новое количество для каждого поезда), железнодорожные маршруты и расписание поездов, а также информацию о резервировании пассажиров. Чтобы упростить себе задачу, вы можете предположить, что каждый из поездов курсирует каждый день и имеет только однодневное путешествие до своих мест. Что касается записи, вы можете сосредоточиться на сохранении следующих данных для каждой станции на железнодорожном маршруте:
Чтобы упростить себе задачу, вы можете предположить, что каждый из поездов курсирует каждый день и имеет только однодневное путешествие до своих мест. Что касается записи, вы можете сосредоточиться на сохранении следующих данных для каждой станции на железнодорожном маршруте:
- По времени: когда поезд прибывает на станцию.
- Время выхода: когда поезд отправляется со станции (это может быть то же самое, что и вовремя, если поезд не останавливается на станции).
- Порядковый номер станции: Порядок станции в маршруте.
Точно так же вы можете вести учет студентов. База данных будет включать в себя общую информацию о студентах (сопоставимую с именем, адресом, контактной информацией, годом приема, курсами и многими другими), файл посещаемости, файл оценок или результатов, файл платы, файл стипендии и многие другие. Автоматическая база данных студентов упрощает процесс администрирования колледжа до получения солидного диплома.
Система управления онлайн-библиотекой предоставляет удобный метод выпуска книг и, кроме того, просмотра различных книг и названий, доступных в классе. Любая такая система управленческой информации (MIS) может быть просто разработана в Asp. Net с использованием C #. А SQL-запросы позволяют быстро получить необходимую информацию.
Возьмем, к примеру, библиотеку вашего колледжа, где каждый преподаватель и студент колледжа может выпускать книги. Обычно количество дней, в которые важно вернуть книгу, варьируется для каждой группы. Кроме того, у каждой книги есть идентификатор романа, даже если они являются копиями идентичной книги того же автора. Таким образом, система управления библиотекой имеет запись для каждой книги, фиксирующую, кто ее выпустил, период сложности и размер штрафа, если таковой имеется.
Читайте также: MySQL против MongoDB: разница между SQL и MongoDB
5. База данных розничных онлайн-приложенийПоскольку во всем мире наблюдается стремительный рост электронной коммерции, базы данных программного обеспечения для розничной онлайн-торговли входят в число самых популярных концепций SQL-проектов. Приложение позволяет клиенту регистрироваться и покупать товар через Интернет. Процесс регистрации иногда включает в себя эпоху уникального идентификатора покупателя и пароля и во многих случаях объединяет такую информацию, как имя, адрес, контактную информацию, банковские реквизиты и многие другие.
Приложение позволяет клиенту регистрироваться и покупать товар через Интернет. Процесс регистрации иногда включает в себя эпоху уникального идентификатора покупателя и пароля и во многих случаях объединяет такую информацию, как имя, адрес, контактную информацию, банковские реквизиты и многие другие.
Как только потребитель покупает продукт, создается счет, в первую очередь, на основе количества, цены и скидки, если таковая имеется. Клиент должен выбрать способ оплаты, чтобы оплатить транзакцию раньше, чем она будет доставлена в выбранное место.
6. Система управления больницейЭто веб-система или программное обеспечение, которое позволяет вам управлять работой больницы или любого другого медицинского учреждения. Он создает научный и стандартизированный документ о пациентах, документах и комнатах, которым может управлять только администратор. Все пациенты и документы будут иметь уникальные данные и будут связаны в базе данных, в зависимости от продолжающегося лечения. Кроме того, могут быть отдельные модули для госпитализации, выписки больного, обязанностей медсестер и мальчиков из палаты, медицинских магазинов и многого другого.
Кроме того, могут быть отдельные модули для госпитализации, выписки больного, обязанностей медсестер и мальчиков из палаты, медицинских магазинов и многого другого.
Читайте также: 9 простых интересных идей и тем для проектов СУБД для начинающих в 2021 году
7. Управление инвентарным контролемИнвентарный контроль — это метод обеспечения того, чтобы предприятие поддерживало достаточный запас материалов и продукции для безотлагательного удовлетворения запросов покупателей. Любые условия затоваривания и недостаточности запасов нежелательны, и цель состоит в том, чтобы максимизировать прибыльность за счет сохранения запасов на оптимальном уровне.
В связи с этим цели разработки базы данных управления запасами будут сосредоточены на хранении требуемых объектов, увеличении оборачиваемости запасов, сохранении диапазонов ценных бумаг, приобретении сырья по сниженным ценам, снижении цен на хранение, снижении цен на страховое покрытие и многого другого. другие.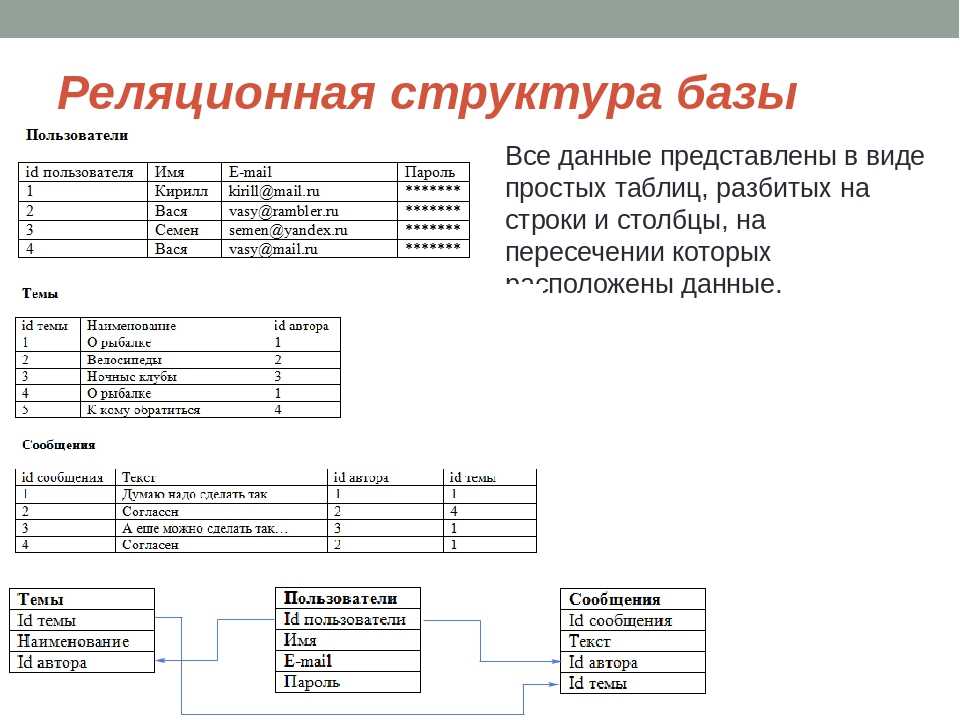
Инициативы создают атмосферу активного обучения, в которой мысли могут критически предполагать и использовать стратегии, основанные на запросах, для поиска вариантов. Принимая во внимание, что при выборе вашего предприятия SQL, вам иногда следует выбирать проект, в котором вы, по крайней мере, используете методы нормализации базы данных. Это подходы к проектированию, которые уменьшают зависимость и избыточность знаний. С приведенными выше концепциями выполнения SQL все готово.
Следите за нами в Instagram (@uniquenewsonline) и Facebook (@uniquenewswebsite) получать регулярные обновления новостей бесплатно
5 трендов баз данных. Идеи с конференции VLDB’21 / Хабр
В середине августа мы приняли участие в международной научной конференции VLDB (Very Large Data Bases), и хотим поделиться актуальными идеями о работе с базами данных.
Если вы специалист по базам данных, или так или иначе связаны с ними, то приглашаем к чтению.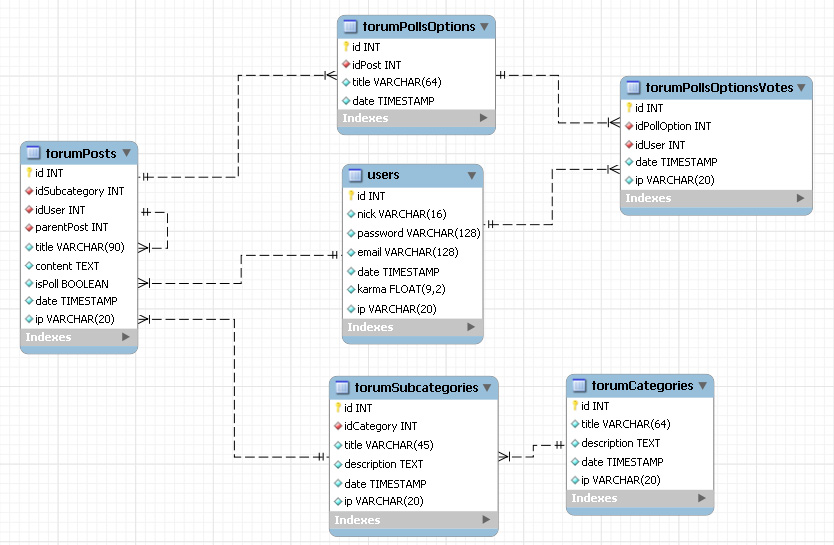
Немного контекста
Коротко о конференции. VLDB интересна тем, что не смотря на научный уклон, к ней проявляют интерес и со стороны бизнеса. Зачастую на VLDB читают доклады от Microsoft, Oracle, Google и т.д. Более академические доклады читают представители MIT, Stanford, CMU, TUM.
Как вы понимаете, отбор на конференцию довольно серьезный (только 10-15% докладчиков получают возможность выступить, а за всю историю современной России можно насчитать не более десяти докладов, которые туда прошли).
Автор: Чернышев Георгий, Руководитель Лаборатории Юнидата. Занимаюсь исследованиями в области работы с данными, помогаю связывать научную теорию с практикой.
Дальнейшее описание трендов будет представлено через призму опыта и интересов автора. В основном занимался реляционными read-only движками, недавно начал смотреть всё про управление данными – data profiling, data cleaning и data quality.
Графов, транзакций, differential privacy и других идей в данном обзоре не будет. На конференции 250+ работ, посмотреть все нереально (конференция шла неделю, ~12 часов в день). Но для интересующихся есть ссылка. Все работы есть в открытом доступе, причем у некоторых есть видео на Ютубе.
На конференции 250+ работ, посмотреть все нереально (конференция шла неделю, ~12 часов в день). Но для интересующихся есть ссылка. Все работы есть в открытом доступе, причем у некоторых есть видео на Ютубе.
Теперь перейдём к трендам.
Тренд №1
Машинное обучение и классические базы данных. К 2021 году можно сказать, что машинное обучение “пришло” в классические базы данных, и уже видны некоторые промежуточные итоги. Можно, потому что появились доклады вида «tutorial». То есть, в докладах дают обзор существующих исследований, с классификацией и какими-то размышлениями. К слову сказать, на данной конференции такой доклад был, и довольно интересный. По ссылке анонсы и слайды всех tutorial с данной конференции.
Внутри этого тренда можно выделить следующие направления:
1) Оценка размера результата (cardinality estimation). Кажется, что это самый большой успех применения машинного обучения. Предложенные подходы дают очень хорошую точность, ошибка предсказания иногда в десятки раз лучше альтернатив (гистограмм). При этом, на времени выполнения запроса статистика улучшенного качества не отражается настолько прямолинейно. Например, на воркшопе LADSIOS в докладе про Microsoft Cosmos говорилось, что на наборе запросов улучшение по времени работы в районе 7%.
При этом, на времени выполнения запроса статистика улучшенного качества не отражается настолько прямолинейно. Например, на воркшопе LADSIOS в докладе про Microsoft Cosmos говорилось, что на наборе запросов улучшение по времени работы в районе 7%.
2) Оптимизация (join order selection). На мой взгляд здесь результаты хуже. Исследовательские прототипы есть, но, в отличие от предыдущего направления, внедрить это в продакшн, и заставить стабильно работать, требует огромных инженерных усилий. Кроме того, подобную систему надо будет еще смочь администрировать, хотя в случае cloud-native баз все должно быть легче. Впрочем, время покажет.
3) Структуры данных, оптимизированные под данные (instance optimized data structures). Собственно, ради них я и пошел на эту конференцию, а точнее на воркшоп LADSIOS. Потенциально это революция, которая началась еще пару лет назад. На пальцах, идея этого подхода следующая: заменить классический индекс (пусть, на B-дереве), на иерархию “моделей”, которые будут предсказывать, где лежит ключ. Результаты очень многообещающие: рост производительности в разы, а размер индекса становится меньше в тысячу раз.
Результаты очень многообещающие: рост производительности в разы, а размер индекса становится меньше в тысячу раз.
В прошлом году прогремел индекс ALEX (статья ALEX: An Updatable Adaptive Learned Index). На рисунках ниже представлены результаты бенчмарка, где можно видеть, что классика серьезно проигрывает на всех запросах, кроме bulk loading. Темой активно занимается академия и компании. Например на том же воркшопе был рассказ от Microsoft про их усилия в этом направлении. Вцелом, сообщество не ограничиваются B-деревом, пробуют другие, а также пытаются встраивать такие подходы в сторейдж.
Конечно, сейчас там полно проблем – значения переменного размера, обновления, и прочее. Однако если все это действительно заработает, то под вопросом окажутся даже базовые программистские курсы. Я веду практику по программированию и структурам данных на матмехе СПбГУ, и, конечно, рассказываю про B-дерево и другие. Если действительно те структуры лучше – смысла давать “классические” деревья поиска станет совсем мало, и возможно надо будет как-то модернизировать программу. Причем учебников по новинкам даже на западе сейчас нет.
Причем учебников по новинкам даже на западе сейчас нет.
Тренд №2
Исследование датасетов (dataset exploration / data lake exploration / dataset discovery) – это родственные темы, которые решают задачи такого рода: необходимо найти определенный набор данных, или просто разобраться в скоплении таблиц. Это очень горячая тема в академическом сообществе, причем с практическим “выхлопом”: есть пилотные проекты во многих организациях, в том числе банках.
На конференции таких работ было много, ради экономии места я опишу три. Этот класс работ “стоит на плечах гигантов”: в нем используются как классические наработки из области баз данных 90х-00х, таких как schema matching и entity resolution, так и совсем новые, такие как определение семантического типа колонки по данным при помощи глубокого обучения, о котором мы писали ранее.
1) Auctus: A Dataset Search Engine for Data Discovery and Augmentation – эта статья меня поразила больше всего (здесь есть видео). Идея в том, чтобы создать своеобразный гугл для таблиц, который умеет гораздо больше, чем просто искать по ключевому слову. Есть простой профайлер и детектор семантического типа колонки, может делать привязку к google maps. Можно искать датасеты не только по ключевым словам, но и по времени, месту (региону). Далее, можно искать “подклеиваемые” датасеты: снизу (unionable) и справа (joinable). Один из экранов этой системы представлен на рисунке ниже (взято из оригинальной статьи, там есть больше).
Есть простой профайлер и детектор семантического типа колонки, может делать привязку к google maps. Можно искать датасеты не только по ключевым словам, но и по времени, месту (региону). Далее, можно искать “подклеиваемые” датасеты: снизу (unionable) и справа (joinable). Один из экранов этой системы представлен на рисунке ниже (взято из оригинальной статьи, там есть больше).
2) DICE: Data Discovery by Example – проект MIT у которого немного другая задача. Есть data lake, куча таблиц и нам надо найти какие-то данные. Вручную искать тяжело, автоматически – надо знать язык запросов, и тоже придется поработать. Идея: query-by-example – мы покажем, как должны выглядеть результаты, а система найдет. Система ищет не просто таблицы, а результат: он может лежать в нескольких исходных таблицах, которые надо соединять. Система интерактивна, с циклом общения с пользователем.
3) A data discovery platform empowered by knowledge graph technologies challenges and opportunities. Это статья с воркшопа SEA Data, проект Concordia University. Делают систему KGLac, пытаются использовать базу знаний для поиска таблиц. База строится на отношениях между колонками, которые вычисляются с помощью эмбеддингов, которые берутся из колонок (данных). Конечная цель – гонять SPARQL запросы на этом графе. Может интегрироваться с питоном.
Делают систему KGLac, пытаются использовать базу знаний для поиска таблиц. База строится на отношениях между колонками, которые вычисляются с помощью эмбеддингов, которые берутся из колонок (данных). Конечная цель – гонять SPARQL запросы на этом графе. Может интегрироваться с питоном.
Тренд №3
Визуальная аналитика. Тут идея такая: сделать коллаборативный dashboard, на который можно визуально накидывать данные, модели машобуча, и другие объекты. Их можно по-всякому соединять и строить пайплайны. Можно создавать различную визуализацию, считать метрики, использовать их для принятия решений.
Интегрируются базы данных, питон, spark, файлы. Причём, это всё обычно работает на СУБД с поддержкой частичных ответов на потоках данных (progressive computation), а также на истории данных (provenance). Одной из ключевых особенностей являются новые пользовательские интерфейсы, когда, например можно визуально выбирать подмножество данных из результата SQL, представленного в виде, допустим, графика.
Здесь мне запомнились две работы:
1) Davos: A System for Interactive Data-Driven Decision Making. Это industrial, то есть
продукт уже существует. Доклад от компании, которая является результатом коммерциализации MIT&Brown University. На рисунке ниже изображен скриншот предоставляемого dashboard, взятый из статьи.
2) Набор демонстраций от Eugene Wu. Это скорее рассказ про отдельные компоненты для построения системы, подобной Davos, про их устройство. Доклад (кейноут) был сделан на воркшопе SEA Data.
Тренд №4
Семантика данных, управление данными. Многие учёные, на которых я ориентировался, когда занимался движками, несколько лет назад отошли от своих обычных тем, и стали смотреть в это направление.
Причин на мой взгляд две:
1) Движковая тема исчерпала себя и стала “индустриальной”. То есть, стало требоваться очень много инжиниринга для того, чтобы сделать что-то интересное. Не секрет, что академические учёные зачастую не имеют достаточного количества ресурсов, которые можно на потратить реализацию.
2) Наработки в машинном обучении, а конкретно, в глубоком обучении, позволили “подвигать” старые темы, за которые брались еще с 80х, и где больших успехов, в общем, достигнуто тогда не было.
В целом, такое блуждание учёных – это нормальный процесс, надо просто подождать каких-то подвижек (в оборудовании, в задачах, в моделях данных, и т.д.) и движки опять вернутся 🙂
Возвращаясь, собственно, к вопросу, какими темами начали заниматься, то это в первую очередь качество данных. Далее я перечислю подтемы и запомнившиеся работы, причем иногда выходя за рамки конференции VLDB, но оставаясь в рамках сообщества.
1) Entity Matching, Entity Resolution, Record Linkage, Duplicate detection. Это очень старый набор тем, родом прямо из 80х, который испытал уже несколько всплесков интереса. Суть такова: есть набор записей в таблице (таблицах), в ней возможны дубликаты, которые надо как-то найти и убрать. Причем дубликаты могут быть семантическими, а не просто опечатками. Например, в случае двух таблиц с персональными данными человека, в одной из них может не быть отчества, или же имя и отчество могут совместно храниться в одной колонке.
Технологии глубокого машинного обучения могут позволить сделать еще один заход на эту проблему. Я отобрал три работы которые на мой взгляд интересны.
* Deep Entity Matching with Pre-Trained Language Models – Сериализуют обе записи в последовательности токенов, затем применяют языковую модель (из семейства BERT) для классификации пары предложений.
* Deep Learning for Blocking in Entity Matching A Design Space Exploration – Работа раскрывает проблему распределения записей-кандидатов по блокам. Дело в том, что сравнивать каждую запись с каждой очень дорого на больших датасетах, поэтому обычно делают двухфазные алгоритмы. На первой фазе распределяют по блокам, где вероятно совпадение, а потом делают попарное сравнение внутри блока. Авторы сравнивали различные методы машинного обучения с классическими, в ней проведена просто огромная работа.
Еще на SIGMOD’21 был кейноут от Wang-Chiew Tan “Deep Data Integration”, то есть уже сейчас сделано гораздо больше. От того же автора есть очень свежая статья Deep Entity Matching: Challenges and Opportunities, которая, как я подозреваю, перекликается с кейноутом.
2) Schema Matching и Schema Mapping. Это тоже две очень старые и очень сложные задачи. Идея первой: имея на входе две базы данных, описывающих какие-то схожие (или даже одни и те же) предметные области, сопоставить таблицы (схему базы) друг с другом. Вторая скорее про то, как имея уже некоторое сопоставление, перевести одну схему в другую.
На конференции мне запомнилась работа “Valentine in Action: Matching Tabular Data at Scale”. Тут авторы представили огромный фреймворк, в котором есть не только множество известных алгоритмов, но и генераторы данных, и оценщик метрик качества.
3) Data profiling и data cleaning. Data profiling посвящена извлечению различных свойств (закономерностей) из данных (таблиц) и тому, как представить их пользователю. Тут важно отметить, что эти закономерности обычно доступны для трактовки и понимания. Их примерами могут служить функциональные зависимости или уникальные наборы колонок (unique column combinations): проекции, в которых нет дубликатов. Data cleaning – это, собственно, очистка данных с помощью этих закономерностей. Как это можно сделать? Допустим, если функциональная зависимость почти выполняется, то есть, верна на всей таблице кроме одной записи, то скорее всего в этой записи опечатка.
Data cleaning – это, собственно, очистка данных с помощью этих закономерностей. Как это можно сделать? Допустим, если функциональная зависимость почти выполняется, то есть, верна на всей таблице кроме одной записи, то скорее всего в этой записи опечатка.
В последние лет пять направление data profiling также набрало значительную популярность в сообществе баз данных. Для этих целей очень хорошо подошли именно функциональные зависимости. Подготовительный шаг – автоматический поиск зависимостей в данных – был уже достаточно хорошо проработан в последние годы, а на самой конференции получила продолжение уже именно сама тема использования зависимостей для очистки.
Зависимости можно использовать двумя способами: в автоматическом режиме, и в ручном. В автоматическом режиме некоторый алгоритм получает набор зависимостей, сам выбирает схему исправлений и её придерживается. Обычно такие алгоритмы очень затратны по вычислительным ресурсам (так как основной ресурс уходит на выбор схемы), и в статье Horizon: Scalable Dependency-driven Data Cleaning был представлен очень быстрый алгоритм такого рода.
В ручном же режиме пользователь как-то работает с зависимостями и данными и сам выбирает, что и как исправлять для каждого случая. Тут система openclean (статья From Papers to Practice: The openclean Open-Source Data Cleaning Library) приходит на помощь. Её идея – собрать open-source библиотеку для очистки данных. Она позволяет использовать довольно большой арсенал средств по профайлингу и очистке данных в питоне. При этом она интегрирует в себе некоторые известные результаты сообщества баз данных, например для поиска зависимостей она использует алгоритмы из проекта Metanome.
4) Получение данных из таблиц, построение баз знаний. Тут такая идея: построить базу знаний на тройках субъект-действие-объект. Из троек получается граф, описывающий некоторую область. При этом, стараются не вводить данные вручную, а пытаются парсить из интернета. Например википедию. Такая база позволит отвечать на вопросы вида “кто получил нобелевскую премию по математике в 2021 году”. Баз знаний, построенных на подобных принципах, несколько, например Yago или Wikidata. Вроде как на подобных технологиях работают быстрые ответы у поисковых систем.
Вроде как на подобных технологиях работают быстрые ответы у поисковых систем.
Данные для баз знаний хорошо берутся из таблиц, поэтому, традиционно, сообщество баз данных любит извлекать знания из таблиц. Более десяти лет назад, еще аспирантом, я впервые послушал Герхарда Вейкума, одного из авторов Yago. Наверное, он один из лучших лекторов, кого я слушал в свой жизни. На этой конференции от него был кейноут, куда я конечно же пошел. Он назывался Knowledge Graphs 2021: a Data Odyssey, и там рассказывалось про применение глубокого обучения для вот таких задач.
Глубокое обучение позволяет извлекать более сложные факты из таблиц и, в общем-то, открывает новые горизонты и в этой области тоже. Однако все осложняется высоченными требованиями к точности, ведь факты в базе должны быть истинными. Обеспечить такую точность сложно. Было приведено несколько интересных примеров, когда система ошибалась.
Ещё о базах знаний на конференции был туториал On the Limits of Machine Knowledge Completeness Recall and Negation in Web scale Knowledge. Также недавно у авторов обоих докладов вышла книга – Machine Knowledge Creation and Curation of Comprehensive Knowledge Bases.
Также недавно у авторов обоих докладов вышла книга – Machine Knowledge Creation and Curation of Comprehensive Knowledge Bases.
Далее, на конференции была представлена работа TURL: Table Understanding through Representation Learning. В каком-то смысле это расширение подхода Sherlock, который мы разбирали ранее.
Наконец, я хочу отметить работу The Secret Life of Wikipedia Tables, с воркшопа SEA Data. Там занимаются сопоставлением разных версий одной и той же таблицы, и авторы провели анализ таблиц из википедии. Получился очень интересный рассказ. Ниже представлена некоторая статистика по таблицам из работы, довольно интересная на мой взгляд (в самой статье ее еще больше). А сам алгоритм, которым сопоставляли, был представлен еще в работе Structured Object Matching Across Web Page Revisions.
Тренд №5
Будущее курсов по базам данным. Отличительной чертой VLDB этого года было множество обсуждений, в том числе в формате круглого стола. Есть большой вопрос, волнующий всё сообщество баз данных: не устарел ли их материал в свете роста data science и интереса к нему.
Было выступление одного из авторов «книги с коровой» (знаменитого на западе учебника по базам данных), а сам круглый стол так и назывался: “The future of database education: is the cow book dead?”. Далее я накидаю разных интересных мыслей от выступавших.
С позиции студентов ситуация такова: “базы данных тебя, конечно, накормят, но захватывающие вещи лежат в другой стороне”. Дело в том, что хайп по data science и машинному обучению привел к тому, что теперь все IT-студенты хотят этих курсов, а среди идущих в западную IT-аспирантуру более 50% пытаются попасть именно на машинное обучение и ИИ. И надо сказать, что академическое сообщество прислушивается: в западных вузах уже на втором курсе достаточно массово преподают этот самый data science.
При этом, это не только хайп, это фундаментальная разница в изучаемых объектах. Есть такое противопоставление:
Реляционные базы | CSV, dataframes, NoSQL |
Таблицы | текст, NLP, изображения |
SQL | Python + Pandas + Pytorch |
Соответственно и методы работы с ними разные. Причем кажется, что справа – объекты сложнее и потенциально богаче смыслом.
Причем кажется, что справа – объекты сложнее и потенциально богаче смыслом.
Мысль об устаревании подогревается и появлением облачных технологий: все современные СУБД работают в облаке, серьезный data science – в облаке. Масса других систем там же. Вообще, облачность это просто способ предоставить ресурсы, и на мой взгляд, эта тематика универсально востребована.
При этом классический курс баз данных (книга с коровой, книги Ульмана, Дэйта) устарел на 20 лет. Он делался под те реалии, под то железо и технологии. Высказывалось мнение, что от старого (вводного) курса останется 25%, а остальное будет дополнено из data science и облака. Как вариант, предлагалось убрать из общего курса нелюбимые мной транзакции и восстановление, так как это стало слишком нишевым. Пора делить информацию: делать один вводный курс, за которым последует серия новых курсов.
Причем вводный курс должен покрывать три темы: cloud, ML-for-DB, DB-for-ML. Надо делать курсы под набор специальностей: DBAs; Business/Data Analysts; Data Scientists; Domain Scientists; Data Engineers; ML Engineers. Аналогичная эволюция за 50 лет прошла в software engineering, где появились: test engineer, software development engineer, security, network admin, system admin, DBA. Кроме того, надо избавляться от массового представления, что базы данных это реляционные СУБД (RDBMS supremacy 🙂 ) – это сильно мешает жить. Базы данных, это вообще про любые способы хранения, обработки и представления данных.
Аналогичная эволюция за 50 лет прошла в software engineering, где появились: test engineer, software development engineer, security, network admin, system admin, DBA. Кроме того, надо избавляться от массового представления, что базы данных это реляционные СУБД (RDBMS supremacy 🙂 ) – это сильно мешает жить. Базы данных, это вообще про любые способы хранения, обработки и представления данных.
Отмечалось, что то, что происходит сейчас с data science vs databases это ровно тоже самое, что происходило в 70х с computer science vs math, когда математики говорили что computer science это просто еще одна прикладная наука. Тогда computer science победила: финансирование, студенты, рабочие места и, самое главное, возможность определять направление развития человечества осталась за ними.
Были и позитивные мнения: отставить doom & gloom. Сообщество успешно, есть ядерный набор алгоритмов, методов, идей, который всегда останется за ним. Рынок баз данных растет и вырастет в разы, люди востребованы индустрией, сообщество рождает успешные компании (Snowflake, Databricks).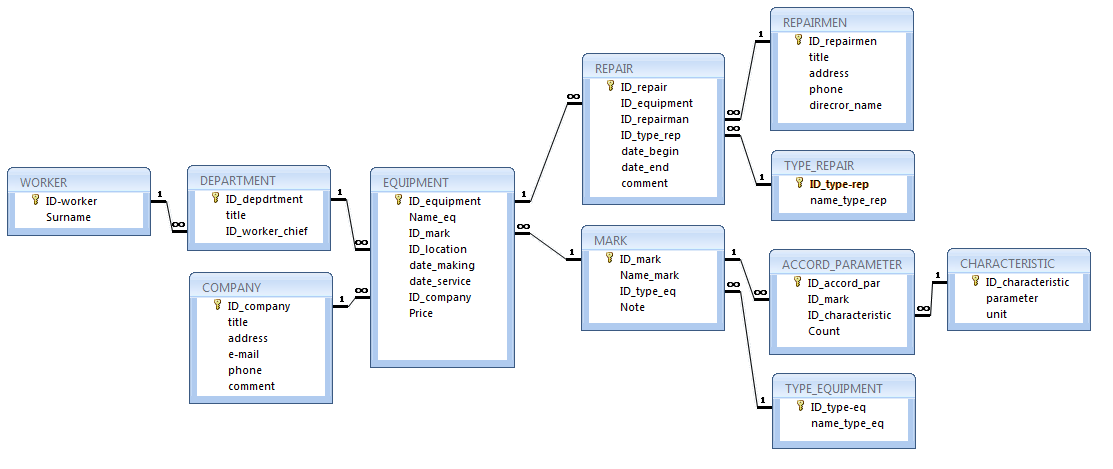
При этом надо начать говорить о “Data Infrastructure”: это покроет и облачные системы, и data science. Ведь эта пара и есть собственно то, что называется машинным обучением. Необходимо адаптироваться и расширять курсы обучения на data infrastructure и data science.
Теперь про, собственно, варианты что делать с курсами обучения (в университетах и не только). Высказывались профессоры из разных университетов.
Кто-то делился опытом про вводный курс без баз данных вообще, ибо data scientist’у это не нужно. Data scientist должен концентрироваться на том, как использовать данные, а не как их хранить. При этом, и о хранении неплохо было бы что-то знать.
В другом вузе data scientist’ов учат SQL, так как все их инструменты становятся неудобными, когда сложность схемы возрастает. Их инструменты достаточно примитивны, а оптимизаторов нет вообще – это ниша для привнесения опыта из классического БД.
Был рассказан и достаточно интересный вариант действий: “отпустить” курс по БД. В одном вузе был эксперимент, когда БД сделали необязательным курсом, но он все равно был самым популярным. Причем, такая модель достаточно известна: есть и другие вузы, которые так делают, в одном из них 500 человек ежегодно выбирают базы данных. И сейчас есть возможность также поступить с курсами по data science и БД. Пусть студенты сами разбираются, что они хотят.
В одном вузе был эксперимент, когда БД сделали необязательным курсом, но он все равно был самым популярным. Причем, такая модель достаточно известна: есть и другие вузы, которые так делают, в одном из них 500 человек ежегодно выбирают базы данных. И сейчас есть возможность также поступить с курсами по data science и БД. Пусть студенты сами разбираются, что они хотят.
Далее, если вернуться к варианту с деревом курсов, то еще стоит вопрос, кому это всё читать (и как это всё прослушать), так что подход с деревом курсов не факт что хорош. А про отмирание классического курса высказывалось мнение, что есть люди, которые строят системы, и без знаний всех этих приемов из области БД им будет плохо.
Отдельно высказывалось проблема, что нет учебника, объединяющего базы данных и data science, даже на западе. Его надо делать, и работа эта не простая.
Наконец, по поводу «книги с коровой» было сказано следующее: не книга с коровой мертва (она еще полезна и используется почти всеми выступающими), а в целом учебники мертвы. Люди теперь получают информацию по-другому, и тут тоже надо адаптироваться.
Люди теперь получают информацию по-другому, и тут тоже надо адаптироваться.
В итоге можно сказать, что множество университетов уже разделило учебные программы на БД и Data scientist. Но какой курс “главнее” ещё не ясно. Например, сейчас в Германии большинство университетов имеют классическое БД в качестве обязательного курса. Американские же университеты запустили целые направления по data science, где курс по базам данных не главный. Время покажет, устоит ли классика.
Подготовил Георгий Чернышев
11 лучших проектов баз данных, над которыми предстоит работать в 2023 году
Содержание
За последние несколько лет в современном деловом мире наблюдается всплеск принятия решений на основе данных. Благодаря революционному развитию программных технологий с помощью таких языков программирования, как SQL (язык структурированных запросов), извлечение и фильтрация ценной информации из хранилищ данных стало проще. Затем на основе этой жизненно важной, убедительной и ценной информации принимаются многие важные бизнес-решения. Одна из различных причин для изучения SQL заключается в том, что в настоящее время почти каждый веб-сайт или веб-страница использует базы данных SQL.
Одна из различных причин для изучения SQL заключается в том, что в настоящее время почти каждый веб-сайт или веб-страница использует базы данных SQL.
Каждый студент, изучающий информатику, или начинающий разработчик всегда ищет удобные, простые в реализации идеи проектов SQL. Помня об этом, мы предложили несколько интересных проектов баз данных, чтобы вы могли лучше понять базы данных. Вы также можете расширить свои знания о базах данных с помощью этого бесплатного курса по СУБД.
Создание и проектирование базы данных, применимой в реальной жизни, всегда является хорошей практикой и помогает улучшить концептуальное понимание и улучшить навыки решения проблем. Давайте рассмотрим следующие идеи проектов баз данных, которые помогут отточить навыки и начать карьеру.
Проект базы данных Идеи Система управления счета за электроэнергию ПререквизитA) Требования к оборудованию:
- Pentium 4 с минимальной скоростью:
- Pentium 4 с минимальной скоростью.

- ОЗУ не менее 512 МБ
- Жесткий диск не менее 100 МБ свободного места
b) Требования к программному обеспечению:
- Windows 7 и выше
- Wamp-сервер
- Веб-браузер (Firefox или Chrome)
- HTML
- CSS (каскадные таблицы стилей)
- Начальная загрузка
- JavaScript
- PHP
- MySQL
- Платформа Laravel.
Основной целью разработки системы управления счетами за электроэнергию является ведение учета счетов клиентов. Администратор может управлять всеми учетными записями клиентов, а зарегистрированные пользователи, такие как сотрудники и клиенты, могут управлять только своими учетными записями. Эта система помогает поддерживать счета и платежи.
В этом проекте различные модули, такие как «Вход», «Пользователь», «Администратор», «Запросы», «Отдел» и «Счетчики», разработаны с учетом основных потребностей, возникающих во время генерации, распределения, оплаты, оплаты и оплаты счетов за электроэнергию.
Вариант использования 1: Создание счета за электроэнергию для клиента.
Основное действующее лицо: Администратор
Предварительное условие:
- Администратор вошел в систему.
Основной сценарий успеха:
- Администратор проверяет запись пользователя
- Администратор проверяет предыдущую историю платежей
- Администратор вводит текущие показания для создания счета.
- Система подтверждает формирование счета.
- Сгенерированный счет сохраняется как запись для отправки клиенту в установленный срок.
a) Требования к оборудованию:
- Процессор P IV
- ОЗУ 250 МБ
- Минимальное необходимое пространство 100 МБ
- Дисплей 16-битный цвет
b) Требования к программному обеспечению:
- Платформа Win 2000/XP
- . NET Framework
- База данных IIS Visual Studio 2008 SQL Server 2005
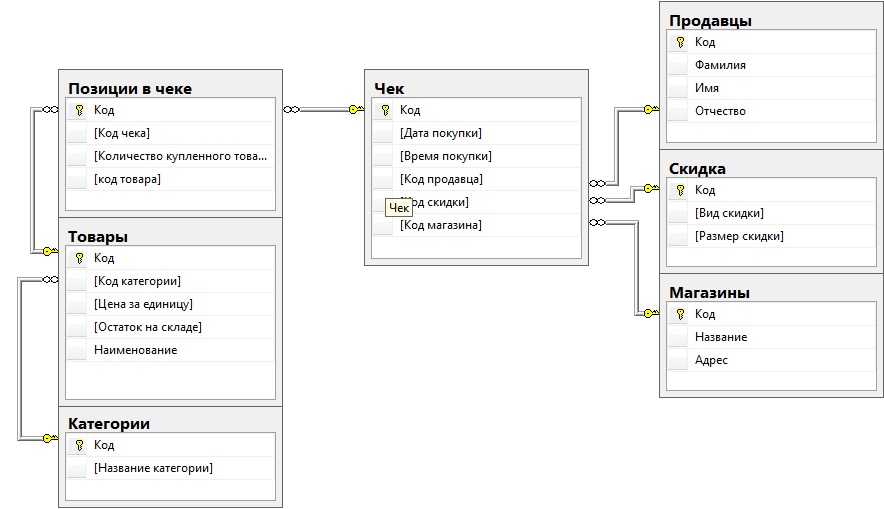
Многие люди воспринимают шоппинг как развлечение. Онлайн-шоппинг гудит, когда люди получают большой выбор на одной платформе по сравнению с традиционными покупками. По этой причине предпочтение отдается онлайн-покупкам в больших масштабах.
Основной целью этого проекта является разработка простого в использовании веб-интерфейса для онлайн-покупателей, который обеспечит им приятные впечатления от онлайн-покупок. Различные модули, такие как модуль продуктов магазина, модуль описания продукта и модуль корзины покупок, предназначены для разных функций.
Вариант использования 1: Клиент просматривает список продуктов.
Основное действующее лицо: Клиент
Предварительное условие: Клиент просматривает базу данных розничных онлайн-приложений
Основной сценарий успеха:
- Клиент вводит Поисковый термин в текстовое поле поиска, которое снабжено водяным знаком.
- Он фильтрует продукты, используя раскрывающиеся списки.
- Он перетащил товар в корзину.
Исключение Сценарий: В случае, если введенный в поле поиска товар отсутствует в номенклатуре, система выдаст сообщение «Товар не найден»
Управление запасами Предварительные условияa) Требования к оборудованию:
- Двухъядерный процессор 2-го поколения
- ОЗУ-4 ГБ
- Жесткий диск-80 ГБ
- Windows 7/8/8.1/10
b) Требования к программному обеспечению:
- Front End Java
- Серверная часть MySQL
- Облачная система SaaS
- Быстрое интернет-соединение
Управление запасами — это необходимый процесс, который помогает предприятиям поддерживать достаточный запас материалов и продуктов, чтобы требования клиентов могли быть удовлетворены без промедления.
Переизбыток и недостаток запасов — обе эти ситуации вредны для бизнеса. Таким образом, всегда лучше поддерживать запасы на оптимальном уровне, чтобы всегда получать прибыль в разумных масштабах.
Целью разработки базы данных управления запасами является предоставление предприятиям возможности сосредоточиться на следующем:
- Для стабилизации производства
- Чтобы воспользоваться ценовыми скидками.
- Возможность удовлетворить спрос в течение периода пополнения
- Во избежание потери заказов (продаж)
- Чтобы идти в ногу с меняющимися рыночными условиями.
Вариант использования 1: Просмотр текущего состояния элемента.
Основное действующее лицо: Администратор
Условие: Администратор вошел в систему
Основной сценарий успеха:
- Администратор вводит название элемента в поле поиска .
- Администратор проверяет статус доступности элемента.
Исключение Сценарий: Если элемент не существует в списке, система покажет сообщение «Элемент не найден». :
- Операционная система Windows
- Жесткий диск 40 ГБ
- ОЗУ 256 МБ
- Процессор Pentium(R) Двухъядерный ЦП
b) Требования к программному обеспечению:
- Язык Java
- Net beans IDE 7.0.1
- MS SQL сервер 2005
В настоящее время концепция онлайн-системы управления библиотекой набирает популярность. Он обеспечивает удобный способ выпуска книг, а также позволяет просматривать различные книги и названия, доступные в категории.
Например, в библиотеке колледжа преподавателям и студентам могут быть выданы книги. Однако количество дней для возврата книг у обоих разное. Каждой книге и даже их копиям одних и тех же авторов присваивается уникальный идентификатор, который помогает вести различные записи, например, кому выдана книга, дата выпуска, продолжительность, дата возврата, сборы, сумма штрафа и т.
д.Вариант использования 1: Просмотр доступности книги.
Основное действующее лицо: Пользователь
Условие: Пользователь вошел в систему
Основной сценарий успеха:
- Пользователь вводит название книги в поле поиска системы.
- Появился список книг, содержащих книги, соответствующие термину, введенному в поле поиска.
- Пользователь может выбрать нужную книгу из раскрывающегося списка и предпринять дальнейшие действия.
Исключение Сценарий: Если этой книги нет в списке, система покажет сообщение «Не найдено».
Управление базой данных учащихся Предварительные требования:a) Аппаратные требования:
- Система Intel I3core
- Жесткий диск 8 ГБ
- 14-дюймовый цветной монитор
- Оптическая мышь
b) Требования к программному обеспечению:
- ОС Windows7/8/10
- ASP. Net с C# (пакет обновления 1)
- SQL Server 2014
- Визуальная студия 2013
С помощью базы данных можно создать систему управления студенческим учётом. База данных содержит общую информацию о студентах, такую как имя, контактная информация, адрес, год поступления, курсы, файл посещаемости, файл оплаты, файл стипендии и т. д. Эта автоматизированная система полезна и в значительной степени упростит процесс управления университетом.
Основное действующее лицо: Администратор
Условие: Администратор вошел в систему
Основной сценарий успеха:
- Администратор открывает страницу регистрации.
- Он вводит данные учащегося в соответствующие поля.
- Он перепроверяет все детали.
- Наконец, он нажал кнопку отправки, чтобы завершить процесс.
- Система показывает сообщение «Завершено».
Исключение Сценарий:
a) Аппаратные требования:
- ПК с процессором с частотой не менее 2 ГГц
- Минимум 2 ГБ оперативной памяти
- Жесткий диск минимум 200 МБ
- Привод CD-ROM требуется только в том случае, если программное обеспечение приобретается на компакт-диске; в этом нет необходимости для программного обеспечения, приобретаемого для загрузки.
- Минимальное разрешение экрана 1024×768 или выше.
b) Требования к программному обеспечению:
- Microsoft Windows 8 и Windows 8.1 устанавливаются с правами администратора.
- Microsoft Windows 10 (установлена с правами администратора). Обратите внимание, что Программное обеспечение работает с 32-разрядными и 64-разрядными версиями ОС Microsoft Windows. В ОС должны быть установлены все последние обновления Microsoft.
- Платформа Microsoft .NET версии 2.0,
- Платформа Microsoft .NET версии 3.5,
- Платформа Microsoft .NET версии 4.0
- Microsoft .NET framework версии 4.5 (должен быть установлен).
- Безопасность транспортного уровня TLS 1.2.
- Internet Explorer версии 11 или выше
Эта база данных SQL пользуется большим спросом, поскольку она широко используется в промышленности. Это используется для управления системой заработной платы организации. Он выполняет множество действий, таких как расчет ежемесячной заработной платы, налогов и социального обеспечения сотрудников. Он использует данные о сотрудниках, такие как имя, должность, шкала заработной платы, льготы и т. д., для расчета заработной платы и ведения учета отпусков и посещаемости сотрудников.
Его программное обеспечение использует специальные формулы для создания выходных данных из банковских файлов и зарплатных ведомостей.
Он также создает налоговый файл для налоговой инспекции, и этот файл хранится в базе данных.
ВЫСОКИТЕЛЬНОСТЬ 1: Сохранение записей нового сотрудника
Основной актер: Admin
Предварительный условие: Админник вошел в систему
Основной сценарий успеха:
- В главной программе, главная программа, «Главная программа». администратор нажимает кнопку «Добавить».
- Введите данные во все поля, такие как имя, возраст, должность, адрес и т. д.
- Щелчки по кнопке Сохранить
- Щелчки по кнопке «Отправить»
Исключение Сценарий: Если данные в каком-либо поле не соответствуют требуемым критериям, система выдаст ошибку.
Голосовая справочная система транспорта Предварительные требования:a) Аппаратные требования:
- Процессор DIV/Dual/Core/Core/I3/I5/I7/Выше
- Жесткий диск, 500 ГБ/выше
- ОЗУ 1 ГБ/больше
- Клавиатура, 108 клавиш, улучшенная
- Оптическая мышь
b) Требования к программному обеспечению:
- Windows 7
- Asp. net
- SQL-сервер
- Visual Studio 2010
- Веб-сервер IIS (5.1 или выше)
- Internet Explorer/Google Chrome
Этот инновационный инструмент помогает сэкономить время в путешествии. Всем известно, что длинные очереди перед транспортным диспетчером на терминалах общественного транспорта — обычное дело, потому что только здесь пассажиры могут получить информацию о различных видах транспорта. В этом случае использование технологичных транспортных справочных систем может помочь сэкономить время и силы.
С помощью базы данных можно разработать автоматизированную систему для автобусных остановок, железнодорожных вокзалов и аэропортов, которая будет принимать голосовые команды на вход и отвечать в голосовом формате на выходе.
Использование варианта использования 1: Запрос о шине
Основной актер: Пользователь
Предварительный условие: Пользователь, вошел в систему
Основной сценарий успеха:
- . Пользователь дает голосовой вход. спросите конкретный автобус.
- Система формирует ответ в текстовом виде о данной шине, если она доступна.
a) Аппаратные требования:
- Жесткий диск, не менее 20 ГБ
- 1 ГБ ОЗУ или больше.
- Intel Pentium 4 или выше
b) Программное обеспечение:
- Windows XP или Windows Vista.
- MS-SQL Server 2005
- ASP .NET с C# .NET
- MS-Visual Studio .NET 2008
- IE 6 или Mozilla Firefox.
Эта система очень полезна, особенно в крупных корпоративных организациях с массивными центрами обработки данных и несколькими серверами. Поскольку на этих серверах размещается большое количество приложений, становится сложно управлять их функциями.
Когда сервер не работает или выходит из строя, организация получает информацию от клиентов. Имея это в виду, использование веб-решения для мониторинга сбоев этих серверов может помочь обеспечить быстрые корректирующие действия.Функция этого приложения заключается в том, чтобы периодически пинговать серверы на основе заранее определенных правил, а затем отправлять SMS заранее определенному списку специалистов, когда сервер оказывается неработоспособным. Это сообщение содержит подробные сведения о сервере, времени сбоя и т. д.
Вариант использования 1: Проверка рабочего состояния сервера
Основное действующее лицо: Администратор система
Основной сценарий успеха:
- Администратор пропинговал сервер
- Администратор получает текущее состояние сервера.
- Если Администратор обнаруживает проблемы с сервером, он отправляет SMS заранее определенному списку специалистов.
a) Требования к программному обеспечению:
- Операционная система Windows 7 или выше
- JRE 1. 8
- сервер MySQL
b) Аппаратные требования:
- Процессор Core i5
- 4 ГБ оперативной памяти
- Жесткий диск 20 ГБ (терминал)
- 1 ТБ места на жестком диске на сервере
Этот тип веб-системы или программного приложения предназначен для эффективного и бесперебойного управления работой больницы или любого другого медицинского учреждения. Систематическая и стандартизированная запись пациентов, врачей и кабинетов создается с помощью этого приложения таким образом, чтобы администратор мог контролировать ее. Уникальный идентификатор предоставляется всем пациентам и врачам, связанным с базой данных, на основе текущего лечения. Все детали, такие как госпитализация, выписка пациентов, обязанности медсестер и фельдшеров, медицинские запасы и т. д., будут поддерживаться отдельными модулями.
ВЫСОКИТЕЛЬНОСТЬ 1: Просмотреть историю встреч
Основной актер: Админ
Предварительное условие: Администратор вошел в систему
Основной сценарий успеха:
- Addion Addan Addan Opense.
- Администратор просмотреть всю историю встреч
a) Аппаратные требования:
- Процессор Intel Pentium 4 или выше с тактовой частотой 1,4 ГГц
- 512 МБ ОЗУ
b) Требования к программному обеспечению:
- Windows XP, Vista, 7/8/8.1
- .NT платформа
- Сервер базы данных SQL
- Visual Studio 2013
- АСП.NET
- С#
В колледже есть много академических факультетов, таких как факультет английского языка, факультет математики, факультет истории и многие другие. Каждое отделение предлагает различные курсы. И, возможно, инструктор может преподавать более одного курса. Например, профессор физики может также преподавать математику.
Студент, изучающий математику, может записаться на оба курса. Таким образом, на курсе в колледже может быть любое количество студентов, но важно то, что для обоих этих курсов может быть только один преподаватель, чтобы избежать дублирования.
ВЫСОКИТЕЛЬНОСТЬ 1: Новый вход
Основной актер: Админ
Предварительный условие: Админ вошел в систему
Основной сценарий успеха:
- Правильно Имя, возраст, адрес, название курса, продолжительность курса и т. д. в различных полях.
- Теперь администратор нажимает кнопку отправки для создания записей учащихся.
A) Требования к аппаратному обеспечению:
Серверный сайт:
- Процесс 3,6 GHZ .
- ОЗУ 2 ГБ
- Жесткий диск 80 ГБ
Сайт клиента:
- Процессор 2,4 ГГц
- ОЗУ 1 ГБ
- Жесткий диск 20 ГБ
b) Требования к программному обеспечению:
Сайт сервера:
- Windows Server 2008
- . NET Framework 4.0
- Веб-сервер IIS 7.0
- Внешний интерфейс — Microsoft ASP.Net 2010 с C#
- Серверная часть — SQL Server 2008
Сайт клиента:
- Windows XP
- Internet Explorer 6.0
Основной целью разработки системы управления онлайн-донорством крови является установление связи между донорами крови и организацией и создание электронной информации.
С помощью этого приложения любой или любая организация, которая хочет сдать кровь на благое дело, может зарегистрироваться. А также любой, кому требуется кровь, может зарегистрироваться через этот сайт.
Права администратора позволяют добавлять, удалять и изменять при необходимости. Целью создания проекта «Онлайн-система управления донорством крови» является разработка онлайн-информации о донорстве крови. Весь проект был разработан с учетом технологии распределенных вычислений клиент-сервер.
Использование варианта 1: Новая регистрация
Первичный актер: Admin
Предварительное условие: Администратор, вошел в систему
Основной сценарий успеха:
- Addion Addion Addense Adveless Adveles recistration.
- Администратор вводит все данные нового пользователя в систему
- Администратор, наконец, отправил запись в систему, нажав кнопку Отправить .
В заключение этой статьи мы можем заключить, что проект играет жизненно важную роль в строительстве бетонного фундамента. Это обеспечивает яркую учебную атмосферу, в которой разум критически функционирует для мышления и использования лучших методов и решений для выполнения задачи.
Важный совет — выбирать такие SQL-проекты, в которых можно удобно применять методы нормализации базы данных. Эти подходы к проектированию уменьшают зависимость и избыточность данных, и идеи проекта SQL, упомянутые в статье, являются хорошими, с которых вы можете начать.
Мы проводим обучение и курсы на основе баз данных; вы можете посетить наш веб-сайт «grearlearning.com». На этих курсах мы предоставляем проекты, практические занятия, тематические исследования и наставничество с отраслевыми экспертами, чтобы мы могли подготовить вас в соответствии с отраслевыми стандартами. Мы также предоставляем рекомендации и помощь, чтобы получить работу в ведущих компаниях.
Всегда рады любым вопросам. Продолжайте учиться и повышать квалификацию в Great Learning Academy.
Рекомендуемые статьи- Учебник по СУБД | Начало работы с системой управления базами данных
- Топ-17 СУБД (система управления базами данных) Вопросы для собеседования
- Руководство администратора базы данных
- Обзор базы данных AWS и ее типов
18 лучших проектов баз данных, идеи для учащихся выпускных курсов
18 лучших проектов баз данных, идеи для студентов1.
Проект базы данных управления запасамиЦели разработки: поддерживать надлежащий ассортимент необходимых товаров, увеличивать оборачиваемость запасов, сокращать и поддерживать оптимальные уровни запасов и страховых запасов, добиваться низких цен на сырье, снижать стоимость хранения, снижать стоимость страхования, снижать налоги.
Нужна помощь с домашним заданием по базе данных?
2. Проект базы данных системы ведения учета учащихся
Цели разработки: файл студента, содержащий информацию о студенте, файл потока, файл с оценками, файл с оплатой, концессия/стипендия и т. д.
3. Проект базы данных розничных онлайн-приложений
Покупатель может зарегистрироваться, чтобы приобрести товар. Клиент предоставит номер банковского счета и название банка (может иметь несколько номеров счетов). После регистрации у каждого клиента будет уникальный клиент, идентификатор пользователя и пароль. Покупатель может приобрести один или несколько товаров в разных количествах.
Предметы могут быть разных классов в зависимости от их цены.На основании количества, цены товара и скидки (если есть) на приобретенные товары будет сформирован счет. Для оплаты счета требуется банковский счет. Товары можно заказать у одного или нескольких поставщиков.
4. Проект базы данных колледжей
Колледж состоит из множества отделений. Каждое отделение может предложить любое количество курсов. В отделе может работать много инструкторов, но инструктор может работать только в одном отделе. Для каждого отдела есть опережение, и инструктор может быть заведующим только одним отделением. Каждый инструктор может пройти любое количество курсов, а курс может пройти только один инструктор.
Студент может записаться на любое количество курсов, и на каждом курсе может быть любое количество студентов.
5. Проект базы данных железнодорожной системы
Железнодорожная система, для которой необходимо смоделировать следующее:
- Станции.
- Пути, соединительные станции. Для простоты можно предположить, что между любыми двумя станциями существует только одна дорожка. Все треки вместе образуют график.
- Поезда с идентификатором и названием.
- Расписания поездов, в которых указано, сколько времени поезд проходит через каждую станцию на своем маршруте.
Для простоты можно предположить, что каждый поезд достигает пункта назначения в один и тот же день и каждый поезд ходит каждый день. Кроме того, для простоты предположим, что для каждого поезда, для каждой станции на его маршруте вы храните.
- Время истекло
- Тайм-аут (то же самое, что и время ожидания, если оно не останавливается).
- Порядковый номер, чтобы станции на маршруте поезда можно было упорядочить по порядковому номеру.
- Бронирование пассажиров, состоящее из поезда, даты, от станции до станции, вагона, места и имени пассажира.
6. Проект базы данных системы управления больницей
Пациент будет иметь уникальный идентификатор пациента.
Полное описание пациента с личными данными и номером телефона, а затем Болезнь и проводимое лечение. Врач будет лечить пациентов, один врач может лечить более 1 пациента. Кроме того, каждый врач будет иметь уникальный идентификатор. Врач и пациенты будут связаны между собой. Пациенты могут быть госпитализированы.Таким образом, там будут разные номера палат, а также палаты операционных и отделений интенсивной терапии. Есть несколько медсестер и фельдшеров для обслуживания больницы и ухода за больными. В зависимости от количества дней и лечения будет сформирован счет.
Проверить проект системы управления больницей
7. Проект базы данных системы управления библиотекой
Студент и преподаватель могут выпускать книги. Различные ограничения на количество книг, которые могут выдать ученик и учитель. Кроме того, количество дней будет разным для студентов и преподавателей для выпуска любой книги. У каждой книги будет свой идентификатор. Кроме того, каждая книга с одним и тем же названием и одним и тем же автором (но количество экземпляров) будет иметь разные идентификаторы.
Будет сделана запись всей книги, кто выдал эту книгу и когда, а также продолжительность. Деталь штрафа (когда книга не возвращается за один раз) тоже сохраняется.
Вы также можете проверить эти сообщения:
- Система управления Банком крови
- Система управления отелем
- Система управления заработной платой
- Система управления информацией о пациентах
8. Проект базы данных системы управления заработной платой
Здесь будет запись (уникальный идентификатор) всех сотрудников любой организации. В соответствии с датой вступления и датой, до которой создается заработная плата, будет введено количество дней. Базовая заработная плата будет определяться в зависимости от должности сотрудника и отдела. Затем будут добавлены такие компоненты, как DA, HRA, медицинское пособие, задолженность, и будут вычтены расходы на общежитие / автобус, безопасность, фонд социального обеспечения и другие. Количество отпусков, взятых работником.
9. Проект базы данных организаций здравоохранения
Эта организация предоставляет следующие функции:
- Неотложная помощь 24×7
- Группы поддержки
- Поддержка и помощь по телефону
Любой новый Пациент сначала регистрируется в своей базе данных перед встречей с врачом. Врач может обновить данные, относящиеся к пациенту, после постановки диагноза (включая диагностированное заболевание и рецепт). Эта организация также предоставляет помещения для приема пациентов, находящихся в критическом состоянии. Помимо врачей, в этой организации есть медсестры и фельдшеры.
За каждой медсестрой и фельдшером закреплен врач. Также их можно назначать пациентам (заботиться о них). Счет оплачивается пациентом наличными и с помощью электронного банкинга. Учет каждого произведенного платежа также ведется организацией. Также ведется запись каждого полученного звонка для оказания помощи и поддержки существующему лицу.
Проект системы управления клиникой Check
10.
Проект базы данных управления рестораном- Ресторан ведет каталог со списком продуктов питания и напитков, которые он предоставляет.
- Ресторан не только обеспечивает питание в собственном помещении, но и принимает заказы онлайн через свой сайт. Заказы по телефону также развлекают.
- Для доставки заказов у нас есть курьеры. Каждому курьеру присваивается определенный код города. Курьер не может доставлять за пределами области, которая не назначена курьеру (для каждого курьера может быть одна область, закрепленная за этим курьером).
- Ведется запись клиента, чтобы премиальные клиенты могли получать скидки.
Он удовлетворит информационные потребности своей учебной программы. Четко укажите сущности, отношения и ключевые ограничения.
Описание среды выглядит следующим образом:
- В компании работает 10 инструкторов, и на каждой тренировке может работать до 100 стажеров.
- Компания предлагает 4 курса передовых технологий, каждый из которых преподается группой из 4 и более инструкторов.
- Каждый инструктор назначается не более чем в две группы преподавателей или может быть назначен для проведения исследований. Каждый стажер проходит один курс передовых технологий за сеанс обучения.
12. База данных системы донорства крови Проект
Система, в которой данные пациента, данные донора, данные банка крови будут храниться и будут взаимосвязаны друг с другом.
Данные пациента — имя пациента, идентификатор пациента, группа крови пациента, выявленное заболевание.
Данные Донара — Имя Донара, Идентификатор Донара, Группа Донара Буд, Медицинское заключение Донара, Адрес Донара, Контактный номер Донара.
Данные банка крови – Название банка крови, Адрес банка крови, Имя донора банка крови, Контактный номер банка крови, Адрес банка крови.Попробуйте реализовать такой сценарий в базе данных, создайте для него схему, ER-диаграмму и попытайтесь его нормализовать.
13.
Проект базы данных управления художественной галереейРазработка схемы E-R для художественной галереи. Галерея хранит информацию о «Художнике», его имени, месте рождения, возрасте и стиле искусства о «Художественном произведении», художнике, годе его создания, уникальном названии, типе искусства и ценах. Произведения искусства подразделяются на различные виды, такие как «Поэтесса», «Работа 19-го века».натюрморты ХХ века и т.д.
Галерея хранит информацию о Клиентах, таких как их Уникальное имя, Адрес, Общая сумма долларов, которые они потратили на Галерею, и лайки Клиентов.
14. Проект базы данных системы управления гостиницей
Гостиница представляет собой улей множества операций, таких как фронт-офис, бронирование и резервирование, банкет, финансы, управление персоналом, инвентаризация, управление материальными потоками, управление качеством, безопасность, управление энергопотреблением, ведение домашнего хозяйства, CRM и многое другое. В гостинице есть несколько номеров, и это номера разных категорий.
По категории номера каждый номер имеет разную цену.В отеле есть несколько сотрудников, которые управляют услугами, предоставляемыми клиентам. Клиент может забронировать номер как онлайн, так и наличными в отеле. Запись о клиенте хранится в базе данных отеля, которая содержит личность клиента, его адрес, время регистрации, время выезда и т. д. Отель предоставляет своим клиентам еду и напитки и выставляет счет за это во время их выезда. .
15. Проект базы данных системы управления школой
Разработка базы данных для хранения информации о школьном персонале (система управления персоналом в Ms access) и учащихся, удовлетворяющая следующим свойствам:
- У сотрудников будет свой идентификатор, имя и классы, которые они преподают.
- У учащегося будет имя, номер списка, секция, класс.
- Еще одна таблица, содержащая информацию о разделе, предмете и учителе.
- Далее будет информация о плате для студентов.
- Один содержит информацию о заработной плате учителей.
- Комнаты распределяются по классам с учетом того, что время одной и той же комнаты или лаборатории не совпадает, студенты не могут быть введены более чем в одну секцию, там не должно быть студентов, которые не заплатили взносы до определенной даты.
16. Проект базы данных системы управления оптовыми продажами
- Сохраняйте информацию о запасах, такую как их идентификатор, имя, количество.
- Храните информацию о покупателях, у которых менеджер должен покупать акции, такие как идентификатор покупателя, имя, адрес, идентификатор акции, которую нужно купить.
- Подробная информация о клиентах, т. е. имя, адрес, идентификатор.
- Список неплательщиков, которые не выплатили причитающуюся сумму.
- Список оплаченных или ожидающих платежей.
- Запас, который нужно купить, если количество становится меньше определенного значения.
- Расчет прибыли за месяц.
- Количество не может быть продано покупателю, если требуемое количество отсутствует на складе, и необходимо сохранить дату поставки, до которой запас может быть предоставлен.
17. Проект базы данных системы управления заработной платой
- Ведется список сотрудников с идентификатором, именем, должностью, опытом.
- Сведения о зарплате с идентификатором сотрудника, текущей зарплатой.
- Информация о заработной плате с указанием идентификатора сотрудника, заработной платы CTC, вычета PF или любого другого вычета и чистой заработной платы, а также сведений об общих сбережениях сотрудника.
- Надбавки к зарплате должны быть предоставлены к следующему году, если таковые имеются, в зависимости от ограничений.
- Вычет из месячной заработной платы, если таковой имеется, в зависимости от каких-либо несоответствий в работе и суммы, подлежащей вычету.
18. База данных системы управления банкоматами Проект
Подумай о себе и напиши в комментарии. Я выберу лучший из комментариев и опубликую здесь.
Вам нужен мой опыт?
Вы беспокоитесь о своем проекте базы данных? Не волнуйтесь, я могу вам помочь.
- Pentium 4 с минимальной скоростью.


 NET Framework
NET Framework

 д.
д.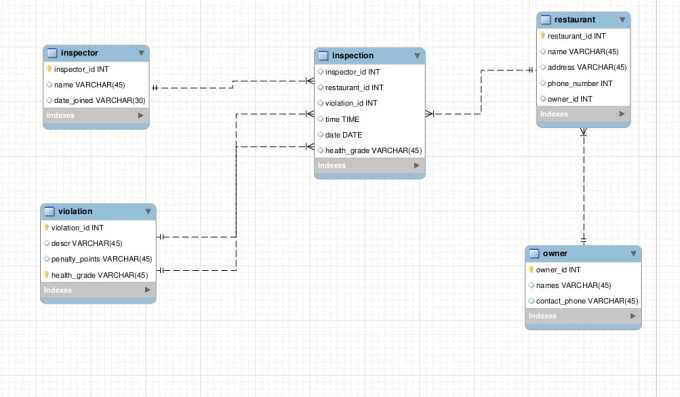 Net с C# (пакет обновления 1)
Net с C# (пакет обновления 1)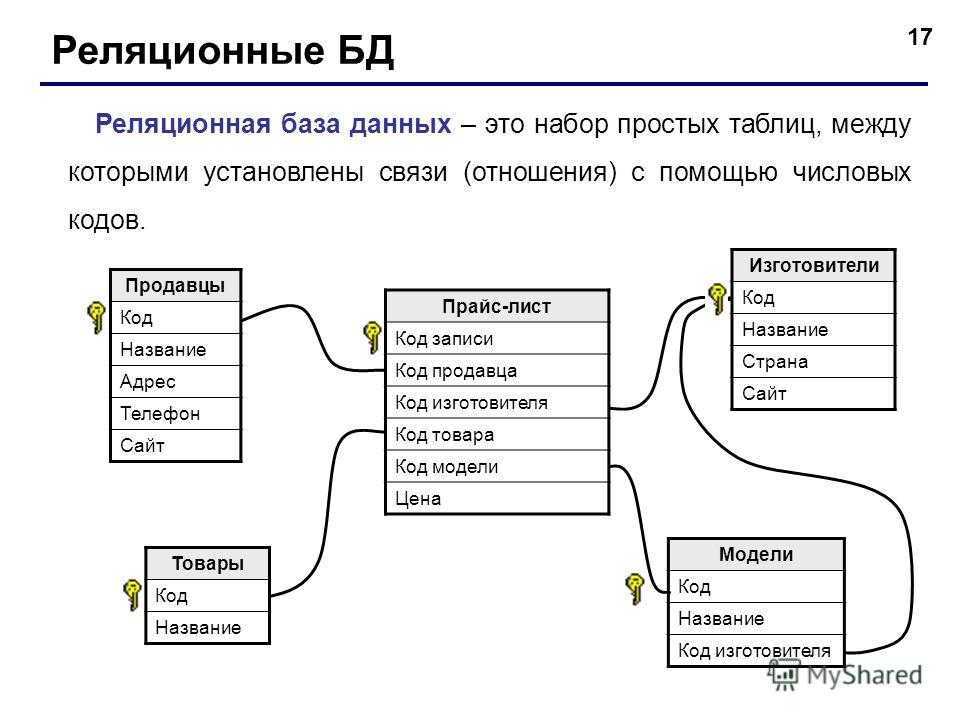
 Обратите внимание, что Программное обеспечение работает с 32-разрядными и 64-разрядными версиями ОС Microsoft Windows. В ОС должны быть установлены все последние обновления Microsoft.
Обратите внимание, что Программное обеспечение работает с 32-разрядными и 64-разрядными версиями ОС Microsoft Windows. В ОС должны быть установлены все последние обновления Microsoft.
 net
net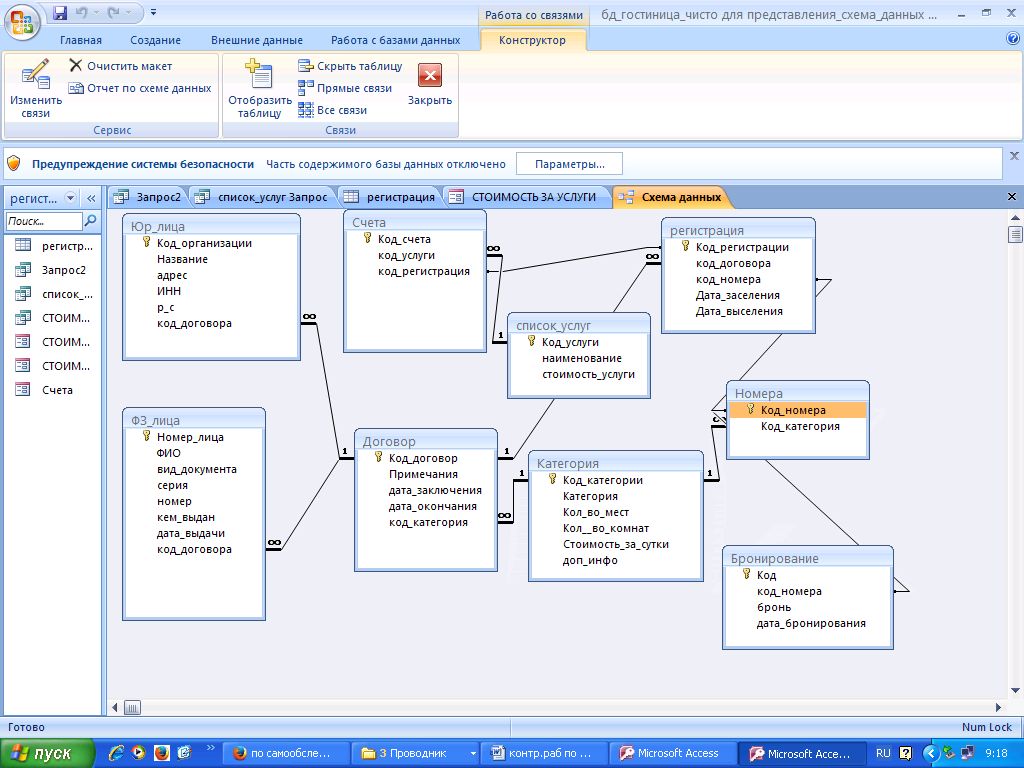 Пользователь дает голосовой вход. спросите конкретный автобус.
Пользователь дает голосовой вход. спросите конкретный автобус.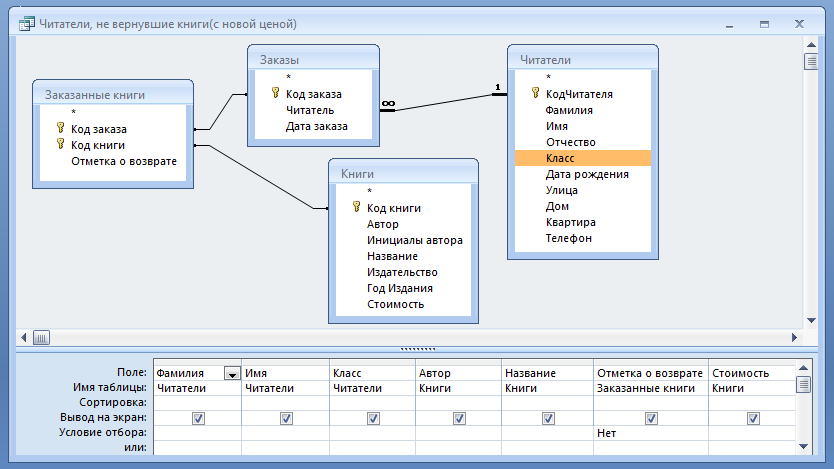 Когда сервер не работает или выходит из строя, организация получает информацию от клиентов. Имея это в виду, использование веб-решения для мониторинга сбоев этих серверов может помочь обеспечить быстрые корректирующие действия.
Когда сервер не работает или выходит из строя, организация получает информацию от клиентов. Имея это в виду, использование веб-решения для мониторинга сбоев этих серверов может помочь обеспечить быстрые корректирующие действия.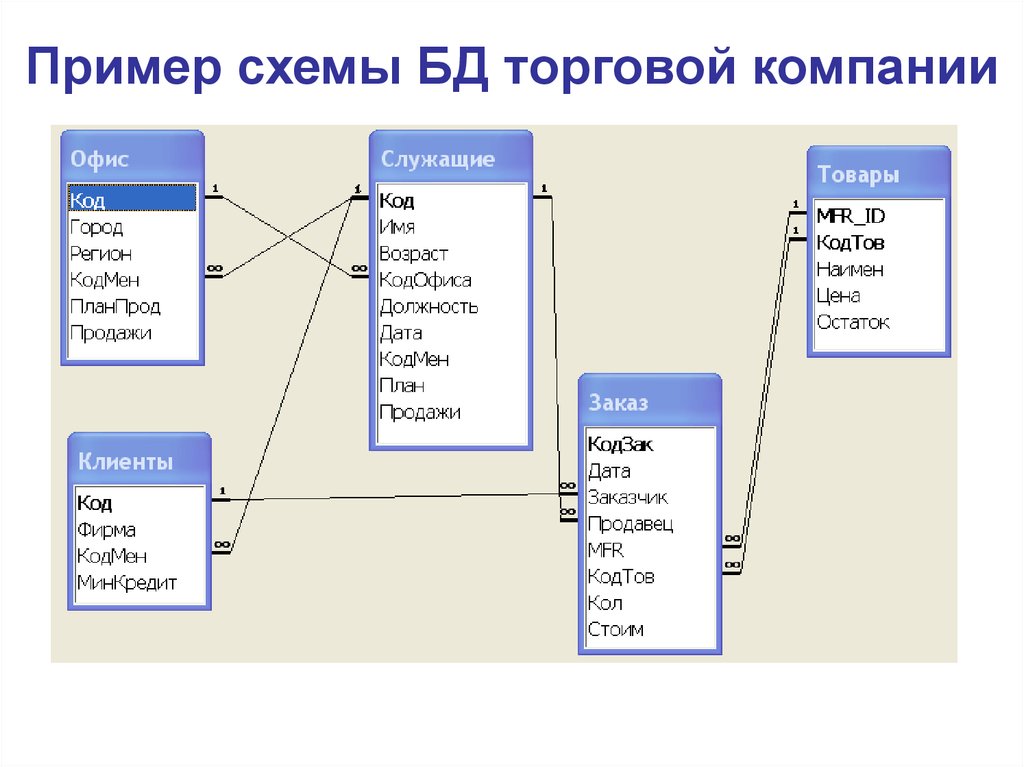 8
8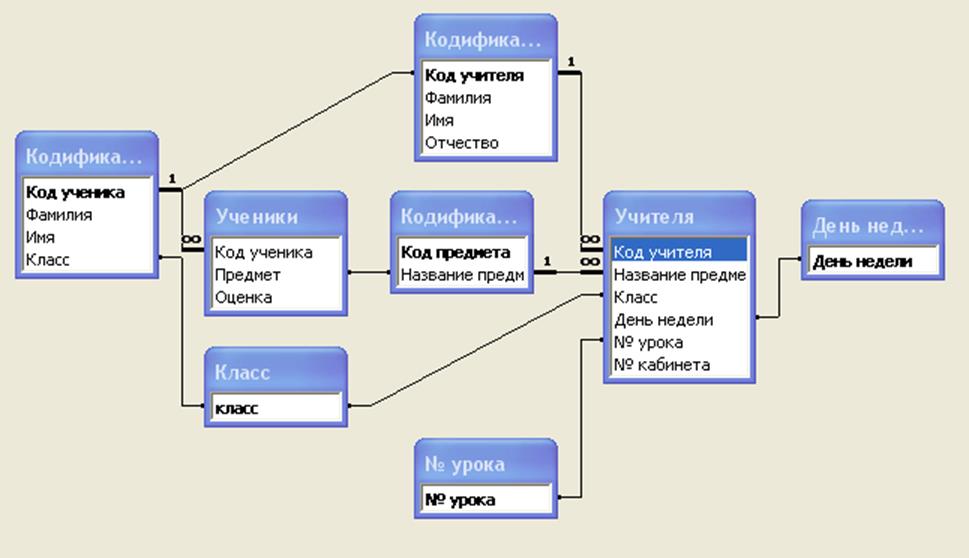
 NET Framework 4.0
NET Framework 4.0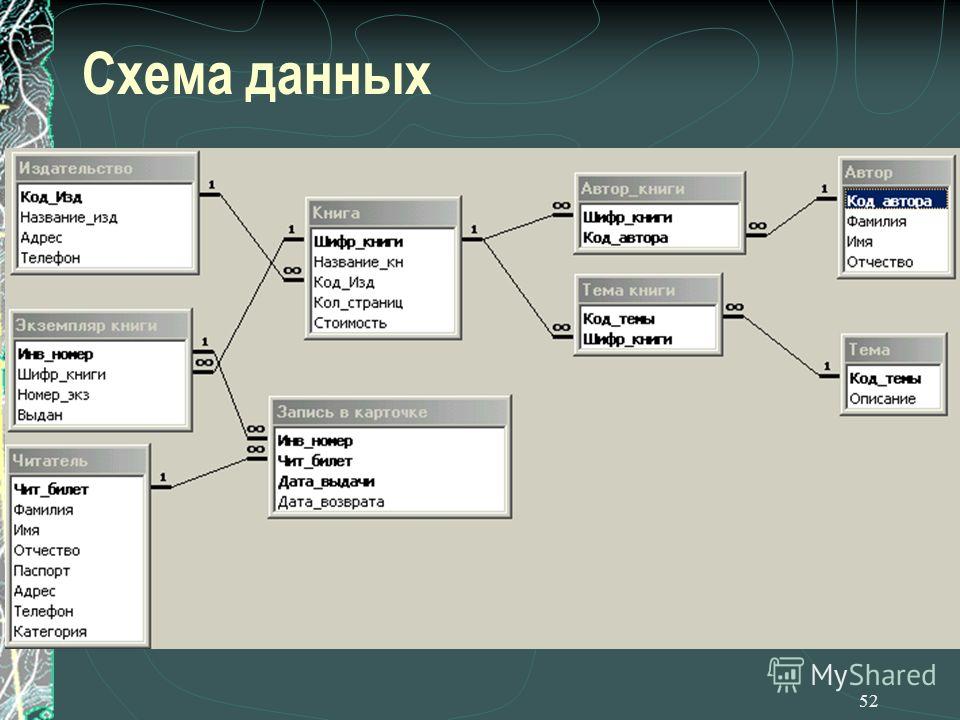

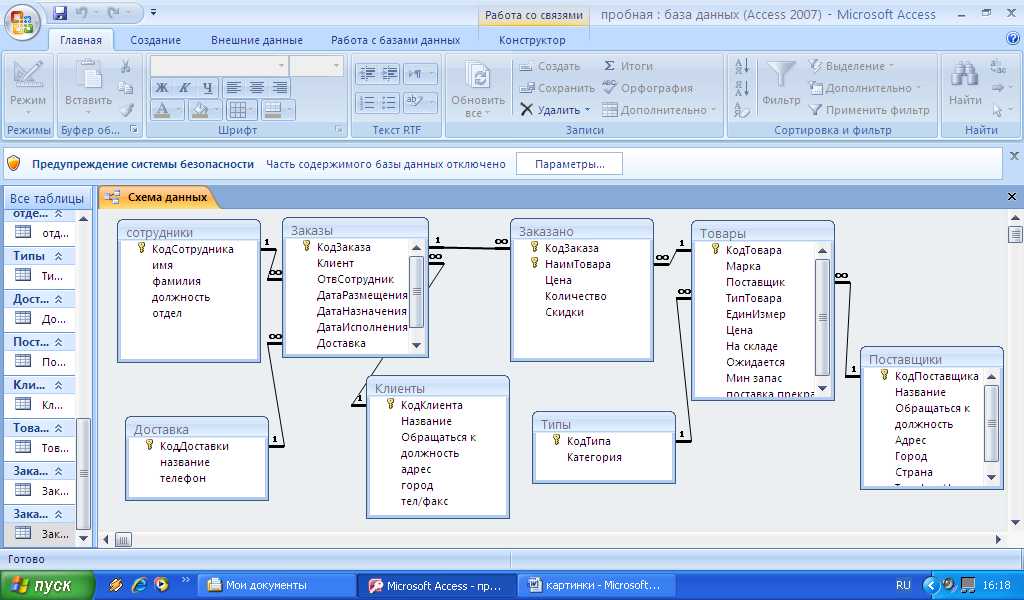 Проект базы данных управления запасами
Проект базы данных управления запасами Предметы могут быть разных классов в зависимости от их цены.
Предметы могут быть разных классов в зависимости от их цены.
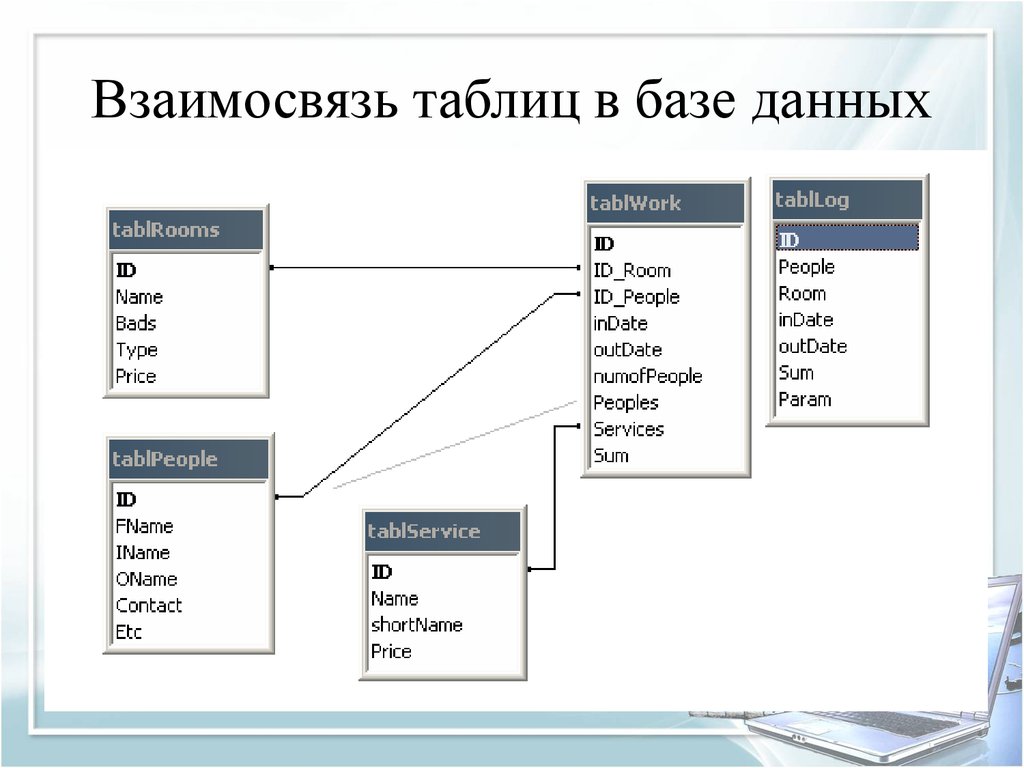 Полное описание пациента с личными данными и номером телефона, а затем Болезнь и проводимое лечение. Врач будет лечить пациентов, один врач может лечить более 1 пациента. Кроме того, каждый врач будет иметь уникальный идентификатор. Врач и пациенты будут связаны между собой. Пациенты могут быть госпитализированы.
Полное описание пациента с личными данными и номером телефона, а затем Болезнь и проводимое лечение. Врач будет лечить пациентов, один врач может лечить более 1 пациента. Кроме того, каждый врач будет иметь уникальный идентификатор. Врач и пациенты будут связаны между собой. Пациенты могут быть госпитализированы.
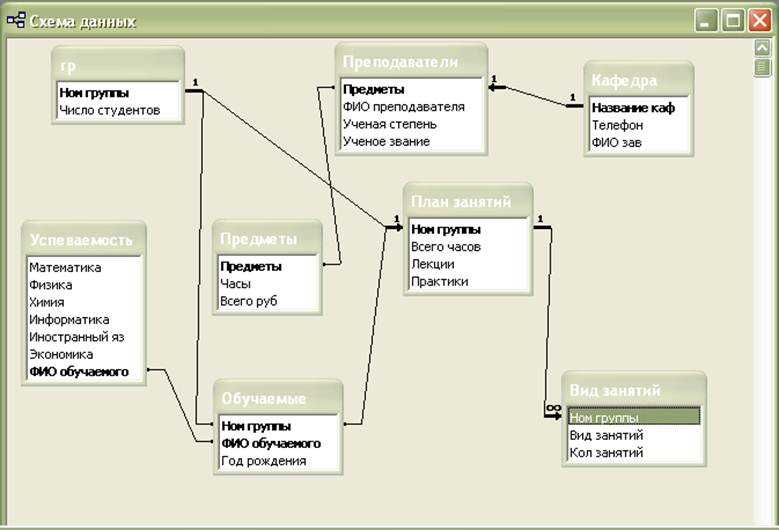
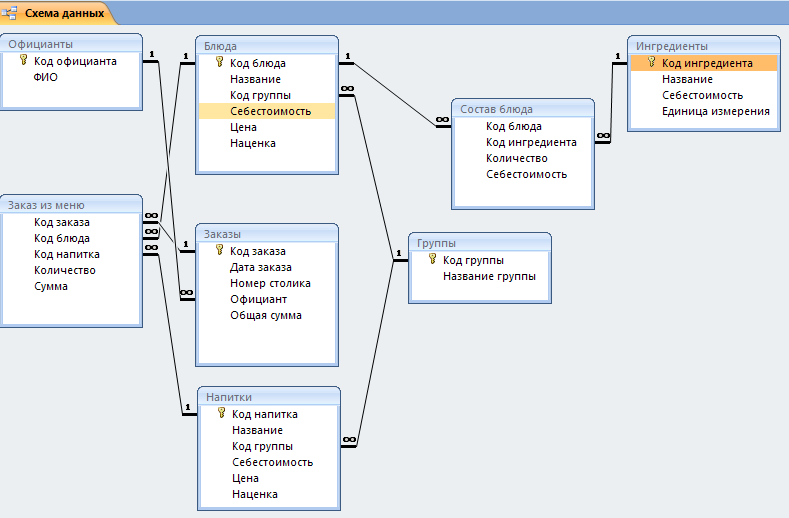 Проект базы данных управления рестораном
Проект базы данных управления рестораном
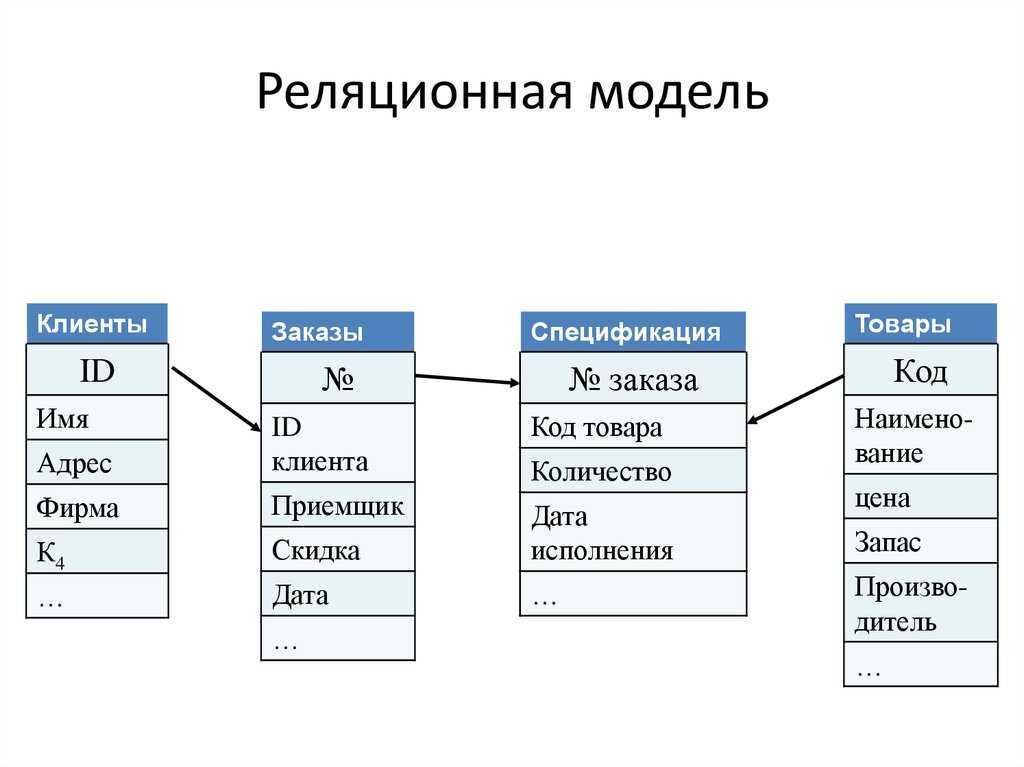 Проект базы данных управления художественной галереей
Проект базы данных управления художественной галереей По категории номера каждый номер имеет разную цену.
По категории номера каждый номер имеет разную цену.