что это такое, как узнать тематический индекс цитирования сайта, принцип расчета показателя
Если говорить про показатели сайта, то одним из первых, на который стоит обратить внимание, будет тИЦ сайта. Также как и PR, этот показатель является одним из основополагающих показателей, говорящих об успешности продвижения сайта.
В этой статье ответим на вопрос, что такое значение тИЦ, и рассмотрим методы, которыми можно его увеличить.
Аббревиатура тИЦ расшифровывается как тематический индекс цитирования сайта, который определяется количеством и качеством ресурсов, которые ссылаются на ваш сайт. Причем индекс цитирования сайта обеспечивается только ссылками с тематических ресурсов и значимость от ссылок с разных сайтов тоже является различной. Чем большим показателем тИЦ обладает ресурс, на котором находится ссылка на ваш проект, тем более он представляется полезным для тИЦ Яндекса вашего сайта.
Изначально показатель тИЦ появился в 1997 году благодаря поисковой системе Яндекс, которая разработала алгоритм расчета ссылок с внешних ресурсов. Этот алгоритм предполагал наличие специальной формулы, которая опирается не только на количество ресурсов, но и на их качество, которое определяется различными показателями.
При расчете тематического индекса цитирования учитывается только вес внешних сайтов, которые ссылаются на анализируемый сайт. Поэтому индекс цитирования нельзя увеличить про помощи внутренних ссылок либо при помощи размещения нескольких ссылок на одном и том же стороннем ресурсе. Причем оказывают влияние на тематический индекс цитирования Яндекса только ссылки на тех ресурсах, которые индексируются поисковой системой.
Некоторые начинающие вебмастера полагают, что индекс цитирования Яндекса влияет на ранжирование в поисковой выдаче. Это абсолютно ошибочное мнение, сегодня поисковые машины не обращают никакого внимания на величину этого показателя.
Это абсолютно ошибочное мнение, сегодня поисковые машины не обращают никакого внимания на величину этого показателя.
А вот на позицию ресурса в Яндекс.Каталоге этот показатель оказывает непосредственное влияние, поскольку именно по нему сортируются сайты в каталоге. А Яндекс.Каталог, в свою очередь, может дать сайту довольно большое количество трафика, соответственно увеличение показателя тИЦ может существенно увеличить посещаемость вашего ресурса.
Также тИЦ сайта имеет значение при определении цены ссылок с вашего ресурса. К примеру, при работе с такой популярной биржей ссылок, как sape.ru, с сайта, на котором находится около пятисот страниц и показатель тИЦ которого имеет значение от 0 до 10, можно зарабатывать примерно 0,5-2 доллара в сутки. Но если увеличить показатель тИЦ такого ресурса до 100, то можно получать прибыль размером от 10 долларов в сутки.
Как нетрудно догадаться, для того чтобы увеличить индекс цитирования, в первую очередь нужно размещать ссылки на свой сайт на других ресурсах.
Наращивать тИЦ можно самостоятельно, обмениваясь ссылками с владельцами сайтов, тематика которых совпадает с тематикой вашего сайта. Такой обмен выгоден обеим сторонам, поэтому многие владельцы сайтов охотно идут на такие меры. При этом, конечно, желательно, чтобы ваш сайт был выполнен на достаточно достойном уровне, иначе владельцы других сайтов вряд ли захотят меняться с вами ссылками. А если и захотят, то кликнувшие ссылку посетителя навсегда могут уйти к вашему конкуренту, который больше времени уделяет качеству своего ресурса. Также и вам не стоит выбирать для обмена некачественные сайты (с неуникальным контентом, поисковым спамом, обилием рекламы), поскольку это не окажет нужного эффекта на увеличение показателя тИЦ.
Можно повышать индекс цитирования яндекса при помощи специальных бирж. Этот способ, конечно, платный, но при этом он более эффективен и дает результаты существенно быстрее. В то же время у него есть существенный минус — используя биржи ссылок без должного опыта, можно навлечь на свой сайт санкции со стороны как Яндекса, так и Google.
В то же время у него есть существенный минус — используя биржи ссылок без должного опыта, можно навлечь на свой сайт санкции со стороны как Яндекса, так и Google.
Существуют различные биржи для размещения ссылок, вот наиболее известные из них:
- Sape;
- GoGetlinks;
- Блогун;
- MainLink;
- GetGoodLinks.
При работе с биржами ссылок специалисты утверждают, что лучше разместить ссылки на нескольких более авторитетных и дорогостоящих ресурсах, чем на большом количестве более дешевых ресурсов.
Синонимы:
нет
Все термины на букву «Т»
Все термины в глоссарии
(Голосов: 4, Рейтинг: 5) | ||||
Тематический индекс цитирования или как Яндекс у ученых учился » Статьи
Когда количество сайтов начало исчисляться десятками и сотнями тысяч, перед ведущей отечественной поисковой системой Яндекс возникла непростая задача – ввести для них какой-то показатель, по которому можно было бы дать оценку «авторитетности», весу ресурса с точки зрения поисковой системы.
Специалисты Яндекса решили не усложнять схему и позаимствовали индекс цитирования – принцип, по которому в научном мире оцениваются труды того или иного ученого. Чем больше на статью химика Иванова ссылались в других работах, тем выше индекс цитирования этого материала и самого ученого. Разумеется, все не настолько тривиально, ведь важно еще и качество ссылки. Одно дело, если работу Иванова упомянул главный редактор крупнейшего отраслевого издания для профессионалов, и совсем другое, если это произошло в региональной газете «Вечерний Урюпинск». Значимость ссылки в каком-либо источнике зависит и от его собственного индекса цитирования. Эта схема проста и очевидна, поэтому неудивительно, что Яндекс использовал именно ее.
Впрочем, Яндекс не был бы Яндексом, если бы не внес в уже существующий алгоритм определенные изменения. Так, индекс цитирования от Яндекса получил приставку «тематический». При вычислении веса ссылки с одного ресурса на другой учитывается их тематическая близость. Необходимость подобной меры очевидна: в научном мире и без того все просто, журнал «Сельская жизнь» едва ли будет ссылаться на научные изыскания в области квантовой физики. В Интернете же возможно все: ссылки сегодня продаются и покупаются «на каждом углу», поэтому тематичность ссылок – важный фактор в оценке индекса цитирования ресурса, или тИЦ.
тИЦ – полезный инструмент или игрушка Яндекса?
Любой специалист в сфере SEO с уверенностью скажет Вам, что прямой зависимости между величиной показателя тИЦ сайта и его ценностью для пользователя или же «любовью» со стороны поисковых систем нет. С другой стороны, индекс цитирования ресурса все-таки может служить определенной мерой оценки, ведь тИЦ учитывает тематическую близость доноров и реципиентов ссылок, соответственно демонстрируя авторитетность сайта в определенной области с точки зрения ресурсов схожей тематики.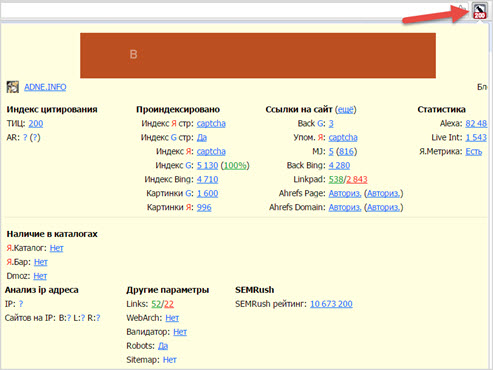
Яндекс позиционирует собственный индекс цитирования в первую очередь как способ корректного ранжирования сайтов в разделах Яндекс.Каталога. Специалисты компании неоднократно утверждали, что алгоритм тИЦ и алгоритм, по которому Яндекс определяет позиции сайта в поисковой выдаче, никак не связаны. Короче говоря, тИЦ на выдачу не влияет. Изучение первой десятки сайтов в выдаче по определенным запросам и сравнение их позиций с позициями в аналогичном ранге по тИЦ часто подтверждают это утверждение. Разумеется, случается и такое, что сайты располагаются в поисковой выдаче как будто с учетом тИЦ. Это имеет простое логическое объяснение: высокий показатель тИЦ является следствием активной работы над сайтом. Следствием таких действий является и соответствующее высокое место в выдаче по ключевым запросам.
Индекс цитирования, таким образом, несет прямую пользу лишь сайтам, которые включены в каталог Яндекса, – они занимают более высокие позиции в своих рубриках. Но многие до сих пор используют тИЦ от Яндекса в качестве основного фактора оценки качества сайта. Следовательно, в высоких показателях тИЦ заинтересованы продавцы ссылок: чем выше тИЦ сайта, тем дороже ссылки, с него продаваемые. Этим объясняется то, как активно сегодня ведется поиск свободных доменов с тИЦ. На них можно разместить сайт и продавать ссылки сразу, без предварительной работы по продвижению и увеличению показателя индекса цитирования. Свободные домены с тИЦ, вернее информация о таковых, предлагаются практически на всех ведущих ресурсах Рунета, посвященных поисковому продвижению и интернет-коммерции. Списки свободных доменов с тИЦ предоставляют также некоторые регистраторы доменов, которые таким способом привлекают новых клиентов. Компания Demis Group время от времени регистрирует свободные домены с тИЦ для новых сайтов клиентов, которые планируют активно продвигаться с помощью Яндекс.Каталога.
Но многие до сих пор используют тИЦ от Яндекса в качестве основного фактора оценки качества сайта. Следовательно, в высоких показателях тИЦ заинтересованы продавцы ссылок: чем выше тИЦ сайта, тем дороже ссылки, с него продаваемые. Этим объясняется то, как активно сегодня ведется поиск свободных доменов с тИЦ. На них можно разместить сайт и продавать ссылки сразу, без предварительной работы по продвижению и увеличению показателя индекса цитирования. Свободные домены с тИЦ, вернее информация о таковых, предлагаются практически на всех ведущих ресурсах Рунета, посвященных поисковому продвижению и интернет-коммерции. Списки свободных доменов с тИЦ предоставляют также некоторые регистраторы доменов, которые таким способом привлекают новых клиентов. Компания Demis Group время от времени регистрирует свободные домены с тИЦ для новых сайтов клиентов, которые планируют активно продвигаться с помощью Яндекс.Каталога.
Информационная врезка
Свободные домены с тИЦ – доменные имена, доступные для регистрации, имеющие показатель тИЦ Яндекса более 10 (определяется с помощью Яндекс. Бара или специальных сервисов). Свободные домены могут иметь ненулевой тИЦ даже в том случае, если они находятся под санкциями поисковой системы, поэтому потенциальным покупателям следует быть осторожными, особенно если речь идет о высоком показателе тИЦ, который зачастую имеют свободные домены, запрещенные к индексации Яндексом.
Бара или специальных сервисов). Свободные домены могут иметь ненулевой тИЦ даже в том случае, если они находятся под санкциями поисковой системы, поэтому потенциальным покупателям следует быть осторожными, особенно если речь идет о высоком показателе тИЦ, который зачастую имеют свободные домены, запрещенные к индексации Яндексом.
Ярослав ШАКУЛА, Demis Group
Полезно 0
Что такое взвешенный индекс цитирования? На что он влияет?
Ранжирование сайтов в поисковой выдаче происходит не случайным образом. Для их оценки поисковики используют различные рейтинги и параметры. Если алгоритм определяет, что страница соответствует определенным критериям, то помечает ее как качественную и интересную для пользователей. Такие ресурсы оказываются в выдаче на более высоких позициях, чем те, которые не соответствуют критериям алгоритма.
Один из параметров, важных для Яндекса, это вИЦ, взвешенный индекс цитирования. Он вычисляется по такому же алгоритму, как и тИЦ (тематический индекс цитирования), только рассчитывается не для ресурса в целом, а для каждой страницы по отдельности. Алгоритм учитывает количество ссылок, которые ведут на страницу с разных ресурсов.
Он вычисляется по такому же алгоритму, как и тИЦ (тематический индекс цитирования), только рассчитывается не для ресурса в целом, а для каждой страницы по отдельности. Алгоритм учитывает количество ссылок, которые ведут на страницу с разных ресурсов.
«Индекс цитирования» – это понятие, которое активно используется в академической науке. Оно используется для оценки значимости научного труда через количество упоминаний и ссылок на него в других научных работах. То есть, чем больше авторов ссылается на какой-то труд, тем он значимее и полезнее.
В Яндексе для расчета взвешенного индекса цитирования взяли те же самые параметры, с которыми работал Google при создании PageRank (PR) – показателя авторитетности страницы.
Стоит отметить, что Google перестал использовать PageRank в 2016 году, а в августе 2018 года Яндекс упразднил тИЦ – тематический индекс цитирования.
Но вернемся к истории.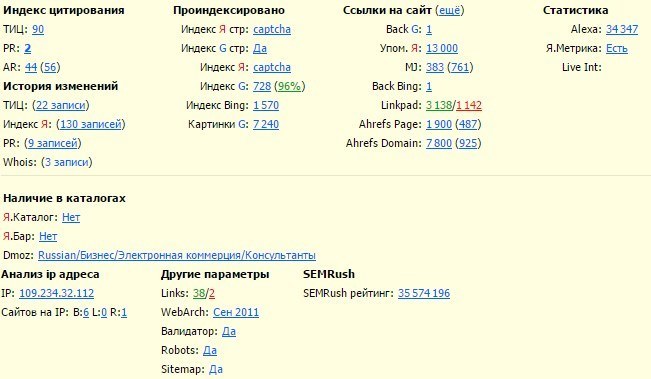 Google первым решил присваивать страницам определенный рейтинг, который влиял бы на их позиции в органической выдаче поиска. Этот показатель рассчитывался достаточно просто – чем больше ресурсов ссылалось на сайт, тем популярнее он был. Постепенно алгоритм расчета PR усложнялся, совершенствовался и начал учитывать не только количество, но и качество ссылающихся источников. Чем солиднее был ресурс, на котором размещалась ссылка, тем больше баллов это прибавляло к рейтингу сайта.
Google первым решил присваивать страницам определенный рейтинг, который влиял бы на их позиции в органической выдаче поиска. Этот показатель рассчитывался достаточно просто – чем больше ресурсов ссылалось на сайт, тем популярнее он был. Постепенно алгоритм расчета PR усложнялся, совершенствовался и начал учитывать не только количество, но и качество ссылающихся источников. Чем солиднее был ресурс, на котором размещалась ссылка, тем больше баллов это прибавляло к рейтингу сайта.
Яндекс перенял этот опыт и создал свой показатель – вИЦ. Сначала он был самым важным критерием, который определял релевантность страницы и ее положение в поиске. До 2004-2005 года на многих сайтах даже можно было увидеть кнопку с точной величиной вИЦ. Но постепенно SEO-специалисты стали создавать веб-кольца и практиковать массовую закупку ссылок. Эти способы признали черными методами продвижения, и они серьезно повлияли на судьбу вИЦ. Теперь это не главный, а лишь один из многих факторов, который влияет на ранжирование сайта.
*Знаете, как определить матёрого SEOшника? Спросите у него, видел ли он своими глазами на сайте кнопку с вИЦ. Если да, значит, он застал времена зарождения SEO.
Как рассчитывается показательКак и в случае с любыми другими инструментами поисковика, точный алгоритм оценки засекречен и не доступен обычным пользователям. Но в справке Яндекса и других открытых источниках есть информация о том, что он:
- учитывает количество ссылок на целевой сайт, размещенных на сторонних ресурсах;
- обращает внимание на авторитетность сайтов, которые разместили ссылки – вес ссылок с доверенных источников будет больше, чем с сомнительных;
- больше ориентируется на русскоязычные ресурсы, что логично – это же отечественный Яндекс.
Известно, что показатель обновляется примерно 1 раз в месяц.
Значимость ВИЦ для продвижения
Точное значение вИЦ известно только поисковой системе, и его никак нельзя узнать. Но это не мешает данному показателю быть одним из факторов, который влияет на ранжирование сайтов в выдаче.
Но это не мешает данному показателю быть одним из факторов, который влияет на ранжирование сайтов в выдаче.
Он помогает определять вес ссылочной массы сайта; рассчитывает статический вес ресурса, который напрямую влияет на позиции в выдаче; а также определяет надежность и безопасность ссылок, которые ведут на продвигаемый сайт.
Чтобы продвинуть сайт в выдаче, нужно повышать его вИЦ. Для этого нужно размещать на сайте только качественный и полезный контент, который интересен и важен пользователям. При этом важно помнить про ключевые слова – их не должно быть в избытке, иначе можно попасть под фильтры. Также можно наращивать ссылочную массу, размещая ссылки на авторитетных ресурсах с высоким вИЦ.
Цитирование сайта: определяющий элемент авторитетности ресурса
тИЦ (тематический индекс цитирования) — показатель авторитетности ресурса для поисковых систем, который определяется по значимости сайтов, ссылающихся на вас.
Тематический — потому что учитывает только ссылки ресурсов смежной и аналогичной тематики.
Индекс — потому что это всегда определённый цифровой показатель, который и демонстрирует суммарную значимость тематических ресурсов, которые вас процитировали. Этот цифровой показатель исчисляется не по количеству ссылок, а по тИЦ каждого ссылающегося сайта.
Цитирование — распространение информации о вас тематическими сайтами посредством размещения ссылок. При вычислении тематического индекса цитирования основное значение имеет качество ссылок, а не их количество.
Информация об авторитетности ресурса может в определённой мере помочь посетителям оценить его полезность
Например, ваш сайт процитировали 100 раз. Даже если 70 ссылок принадлежат «уважаемым» и тематическим ресурсам, это не значит, что ваш тИЦ сразу составит, например 100, а всё потому, что будет считаться не количество таких ссылок, а их вес, который зависит от тИЦ ссылающихся сайтов. Этот индекс постоянно меняется. Его изначальный показатель равен нулю. Минимальный тИЦ — 0. Шаг шкалы с увеличением показателей постоянно меняется.
Этот индекс постоянно меняется. Его изначальный показатель равен нулю. Минимальный тИЦ — 0. Шаг шкалы с увеличением показателей постоянно меняется.
Как узнать тИЦ и зачем его повышать?
Индекс цитирования относится к показателям эффективности поисковой оптимизации, именно он влияет на продвижение сайта в выдаче. Качественные и количественные показатели по ссылкам имеют взаимодополняющее воздействие. Аналогом тИЦ для Google является PR (pagerank).
тИЦ напрямую не влияет на ваши позиции в поисковой выдаче. Но, тем не менее, взаимосвязь данного показателя и рейтинга вашего сайта у поисковых ботов есть. Так что, в любом случае, те ресурсы, у которых высокий индекс цитирования, никогда не будут размещаться на последних страницах поисковой выдачи. Не стоит также забывать и о том, что на поисковую выдачу влияет качество ссылочной массы, размещённой на сайте. В этом ключе принцип «чем больше качественных и рабочих ссылок, тем лучше для продвижения» совпадает с принципом увеличения тИЦ.
Узнать тематический индекс цитирования чужого сайта можно с помощью «Яндекс.Вебмастера». Данный инструмент позволяет увидеть динамику роста и падения тИЦ, узнать точный индекс, а также проанализировать имеющиеся исходящие ссылки. Существует и множество других бесплатных сервисов, которые анализируют ссылочную массу сайта и следят за изменениями тИЦ. PR-CY — один из наиболее известных.
На что нужно обратить внимание при выборе ссылочных площадок?
Законы современной оптимизации просты и понятны — сделайте свой сайт полезным, и у него будет всё: высокий рейтинг в поисковой выдаче, большое количество уникальных посетителей и высокий тИЦ. Яркое доказательство работоспособности такого подхода — это Википедия. Её тИЦ исчисляется десятками тысяч, хотя сам сайт не особо заботится об увеличении этого показателя. Он просто предлагает полезный пользователям контент. Так и ваш сайт должен быть полезным, интересным и удобным в первую очередь, а уже потом можно обратить внимание на подбор сайтов для обмена ссылками.
- Сайты обязательно должны быть тематическими. Если не придерживаться этого правила, пользы от цитирования ваших материалов будет мало.
- Ресурсы, с которыми вы будете взаимодействовать, должны быть авторитетными (с достаточно высоким тИЦ). Иначе ваш собственный индекс просто не будет расти.
- Оптимальные показатели по тИЦ — от 30 и выше. Именно на сайты с таким индексом цитирования вы и должны ориентироваться.
Ваш ориентир — не тысячный тИЦ по ссылочной массе, а полезный во всех отношениях ресурс.Таким является, например, Википедия.
Искусственно повышать тИЦ нет необходимости: существенно ваши позиции в поисковой выдаче от этого не изменятся. Нужно регулярно наполнять сайт полезными и интересными статьями, взаимодействовать с небольшим количеством наиболее авторитетных ресурсов, и тогда ваш тИЦ будет расти.
понедельник — пятница с 10:00 до 18:00
О компанииNetPromoter — инновационная технологическая компания-разработчик программных решений в области кибермаркетинга. Компания основана в 1999 году и специализируется на разработке индивидуальных решений в области продвижения, мониторинга и анализа ресурса. За время существования компании был накоплен огромный опыт работы, результатом которого стало создание комплекса программного обеспечения и услуг Page Promoter. Высокий профессиональный уровень наших сотрудников в сочетании с самыми передовыми технологиями позволяет гарантировать нашим клиентам полную отдачу вложенных средств, а также неизменное качество и эффективность предложенных услуг. подробнее | Главная / О программе / Помощь / Часто задаваемые вопросы / Тематический Индекс ЦитированияЧто такое Тематический Индекс Цитирования?
Тематический индекс цитирования — это критерий, используемый Яндексом для оценки «важности» страниц.
Наш тематический индекс цитирования (тИЦ) определяет «авторитетность» интернет-ресурсов с учетом качественной характеристики ссылок на них с других сайтов. Эту качественную характеристику мы называем «весом» ссылки. Рассчитывается она по специально разработанному алгоритму. Большую роль играет тематическая близость ресурса и ссылающихся на него сайтов. Проверить тематический индекс цитирования можно несколькими способами. Во-первых, можно найти сайт в каталоге Яндекса, если он там зарегистрирован. Возле описания сайта всегда присутствует информация о его индексе цитирования, то есть тИЦ его главной страницы, при этом все сайты в каждой рубрике каталога размещены по мере убывания тИЦ. Второй способ — установить на своем браузере Яндекс.Бар, который показывает тИЦ текущего сайта, подобно Google Toolbar. Также, можно посмотреть тИЦ, открыв в вашем браузере адрес http://search.yaca.yandex.ru/yca/cy/ch/somesite.com
при этом, не забыв поменять Некоторые вебмастера устанавливают у себя на сайтах «Яндекс.Денежку», то есть счетчик, на котором отображается тИЦ ресурса:
Следует, однако, с предосторожностью относиться к Яндексовскому индексу цитирования, поскольку его повышение не является обязательным залогом успеха в результатах поиска Яндекса. |
 Москва
Москва Само по себе количество ссылок на ресурс также влияет на значение его тИЦ, но тИЦ определяется не количеством ссылок, а суммой их весов.
Само по себе количество ссылок на ресурс также влияет на значение его тИЦ, но тИЦ определяется не количеством ссылок, а суммой их весов.  Скорее, это дополнительный фактор, оказывающий положительное влияние на рейтинг, позиция же сайта на Яндексе определяется совокупностью тИЦ и состояния оптимизации самого ресурса.
Скорее, это дополнительный фактор, оказывающий положительное влияние на рейтинг, позиция же сайта на Яндексе определяется совокупностью тИЦ и состояния оптимизации самого ресурса.Индекс цитирования | ТИЦ сайта
Глоссарий
ТИЦ (тематический индекс цитирования) — это условная мера значимости интернет ресурса, применяемая поисковым сервисом Яндекс. В настоящее время ТИЦ сайта заменён новым параметром — ИКС (Индекс качества сайта), поэтому ТИЦ имеет в большей степени историческое значение.
Что такое ТИЦ сайтаИндекс цитирования сайта определяется прежде всего количеством других ссылок на этот интернет ресурс. Для определения ТИЦ сайта значение имеет не только количество ссылок, но и их условное качество. В расчёт принимаются следующие два основных параметра качества ссылок:
- Интернет ресурс, который ссылается на сайт, должен быть проиндексирован поисковой машиной Яндекс (то есть, Яндекс должен знать о существовании этого сайта).


Примечание. Поисковая машина ТИЦ Яндекса узнаёт о существовании сайта двумя способами: найдя сайт по ссылке с другого, уже проиндексированного интернет ресурса, или после регистрации сайта в Яндексе вручную.
- Также имеет значение ТИЦ сайта, с которого размещена ссылка. Так, Яндекс избегает включать в расчёт индекса цитирования сайта ссылки с тех ресурсов, на которых пользователи могут самостоятельно размещать информацию и ссылаться на другие сайты.
Примечание. Внутренние ссылки на самом сайте и ссылки с ресурсов на бесплатных хостингах не учитываются поисковой машиной Яндекс при расчёте ТИЦ сайта.
Таким образом, для увеличения индекса цитирования и продвижения сайта в поисковой машине Яндекс необходимо стремиться получить ссылки на сайтах с наибольшим собственным ТИЦ. Это ведёт к повышению ТИЦ сайта, на который ведут ссылки.
Индекс качества сайта (ИКС)Параметра ИКС сайта в настоящее время полностью заменил ТИЦ. Алгоритмы расчёта индекса сайта существенно изменились по сравнению с расчётом индекса цитирования сайта. В частности, при расчёте ИКС не имеет принципиального значения количество ссылок на сайт.
Алгоритмы расчёта индекса сайта существенно изменились по сравнению с расчётом индекса цитирования сайта. В частности, при расчёте ИКС не имеет принципиального значения количество ссылок на сайт.
Примечание. Посмотреть на параметры ИКС для своих сайтов веб-администратор может там же, где раньше располагалось значение ТИЦ.
Смотрите также: Pagerank
Перейти к: Поисковая оптимизация
Глоссарий
«Яндекс» заменит тематический индекс цитирования на индекс качества сайта Статьи редакции
Поисковик теперь не считает ссылки с других сайтов главным показателем качества.
«Яндекс» представил новую метрику для оценки качества сайтов — индекс качества сайтов (ИКС).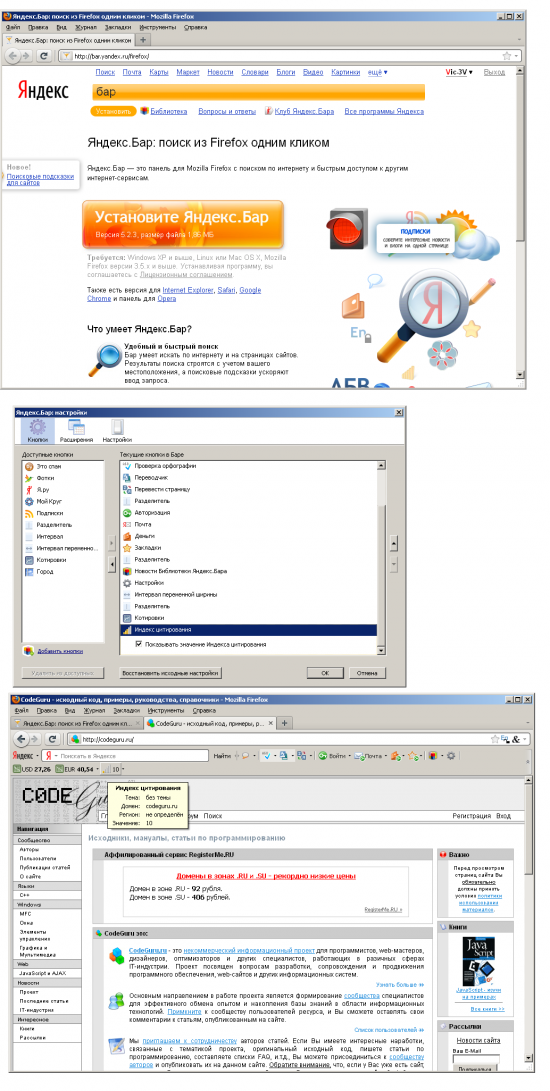 Об этом vc.ru рассказали в компании.
Об этом vc.ru рассказали в компании.
После 27 августа ИКС будет отображаться в «Яндекс.Вебмастере» вместо тематического индекса цитирования (тИЦ). Индекс цитирования отражал авторитетность сайта: он учитывал количество и значимость ссылок, которые ведут на сайт с других сайтов.
Новая метрика будет рассчитываться алгоритмом на основе данных из «Яндекс.Поиска» и других сервисов «Яндекса». В компании уточнили, что новый индекс будет точнее отображать ситуацию в выдаче поисковика «Яндекса».
Ссылки с других ресурсов давно перестали быть главным показателем качества сайта.
Елена Першина
менеджер по маркетингу сервисов «Яндекса» для вебмастеров
ИКС будет доступен в «Яндекс.Вебмастере» после 27 августа. Владельцы сайтов смогут измерить ИКС своей площадки и сравнить его с показателями других сайтов.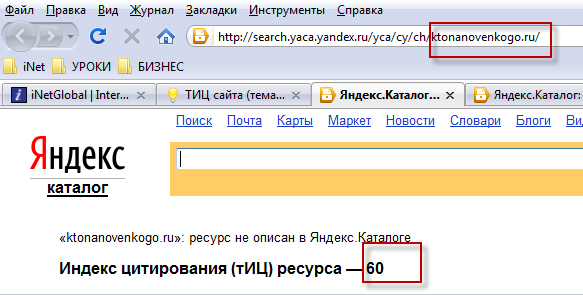
12 665 просмотров
{ «author_name»: «Лера Михайлова», «author_type»: «editor», «tags»: [«\u043d\u043e\u0432\u043e\u0441\u0442\u044c»,»\u043d\u043e\u0432\u043e\u0441\u0442\u0438″,»\u0438\u043d\u0441\u0442\u0440\u0443\u043c\u0435\u043d\u0442\u044b»,»seo»], «comments»: 112, «likes»: 57, «favorites»: 29, «is_advertisement»: false, «subsite_label»: «seo», «id»: 44128, «is_wide»: false, «is_ugc»: false, «date»: «Wed, 22 Aug 2018 10:02:19 +0300», «is_special»: false }
{«id»:78969,»url»:»https:\/\/vc.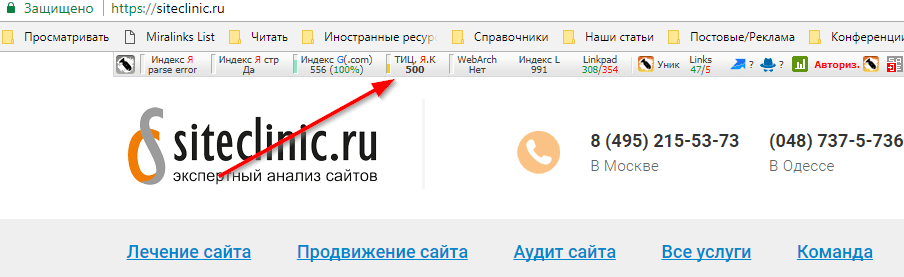 ru\/u\/78969-lera-mihaylova»,»name»:»\u041b\u0435\u0440\u0430 \u041c\u0438\u0445\u0430\u0439\u043b\u043e\u0432\u0430″,»avatar»:»84516d92-b701-d03f-a7c7-e52be4c7a9df»,»karma»:89401,»description»:»»,»isMe»:false,»isPlus»:true,»isVerified»:false,»isSubscribed»:false,»isNotificationsEnabled»:false,»isShowMessengerButton»:false}
ru\/u\/78969-lera-mihaylova»,»name»:»\u041b\u0435\u0440\u0430 \u041c\u0438\u0445\u0430\u0439\u043b\u043e\u0432\u0430″,»avatar»:»84516d92-b701-d03f-a7c7-e52be4c7a9df»,»karma»:89401,»description»:»»,»isMe»:false,»isPlus»:true,»isVerified»:false,»isSubscribed»:false,»isNotificationsEnabled»:false,»isShowMessengerButton»:false}
10 простых способов увеличить количество цитирований: контрольный список
Количество публикуемых вами статей важно для вашей карьеры. «Публикуйте раньше и чаще» снова и снова звучит в исследованиях. Тем не менее, количество цитирований вашей работы также важно, поскольку оно может указывать на влияние, которое ваше исследование оказывает на сферу деятельности.
Увеличение количества цитирований также может положительно повлиять на вашу карьеру, потому что финансирующие агентства часто обращают внимание на сочетание количества статей и количества цитирований при принятии решений о гранте.
Чтобы увеличить количество цитирований и добиться максимального эффекта, рассмотрите следующие 10 простых методов:
Процитируйте ваши прошлые работы, если они имеют отношение к новой рукописи.
Однако не ссылайтесь на каждую написанную вами статью только для того, чтобы увеличить количество цитирований.Тщательно подбирайте ключевые слова. Выберите ключевые слова, которые будут искать исследователи в вашей области, чтобы ваша статья появилась в поиске по базе данных.
Используйте ключевые слова и фразы в заголовке и несколько раз в резюме. Повторение ключевых слов и фраз увеличит вероятность того, что ваша статья окажется в верхней части списка поисковых систем, что повысит вероятность ее прочтения.
Используйте единообразную форму вашего имени на всех своих бумагах. Использование одного и того же имени на всех ваших статьях поможет другим найти все ваши опубликованные работы. Если ваше имя очень распространено, рассмотрите возможность получения идентификатора исследования, например ORCID. Вы можете указать свой ORCID в своей подписи электронной почты и связать этот идентификатор со своим списком публикаций, чтобы любой, кому вы отправляете электронную почту, имел доступ к вашим публикациям.
Убедитесь, что ваша информация верна. Убедитесь, что ваше имя и место работы указаны правильно на окончательных оттисках вашей рукописи, а также проверьте точность информации в статье при поиске в базе данных.
Сделайте вашу рукопись легко доступной. Если ваша статья не опубликована в журнале с открытым доступом, опубликуйте свои распечатки до или после публикации в репозиторий. Проверьте SHERPA RoMEO, чтобы узнать об авторских правах и политике самоархивирования вашего издателя в отношении публикации опубликованной рукописи.
Поделитесь своими данными. Есть некоторые свидетельства того, что обмен вашими данными может увеличить количество цитирований. Рассмотрите возможность публикации на веб-сайтах для обмена данными, таких как figshare или SlideShare, или внесите свой вклад в Википедию и предоставьте ссылки на ваши опубликованные рукописи.
Представляйте свои работы на конференциях.
Хотя презентации конференций не цитируются другими, это сделает ваше исследование более заметным для академического и исследовательского сообщества.Ознакомьтесь с этими советами, чтобы максимально использовать вашу следующую исследовательскую конференцию.Используйте социальные сети. Предоставьте ссылки на свои статьи в социальных сетях (например, Facebook, Twitter, Academia.edu, ResearchGate, Mendeley) и на странице вашего профиля в университете.
Активно продвигайте свою работу. Поговорите о вашей статье с другими исследователями, даже с теми, кто не в вашей области, и отправьте копии вашей статьи по электронной почте исследователям, которые могут быть заинтересованы. Создайте блог или веб-сайт, посвященный вашему исследованию, и поделитесь им.
 Однако не ссылайтесь на каждую написанную вами статью только для того, чтобы увеличить количество цитирований.
Однако не ссылайтесь на каждую написанную вами статью только для того, чтобы увеличить количество цитирований.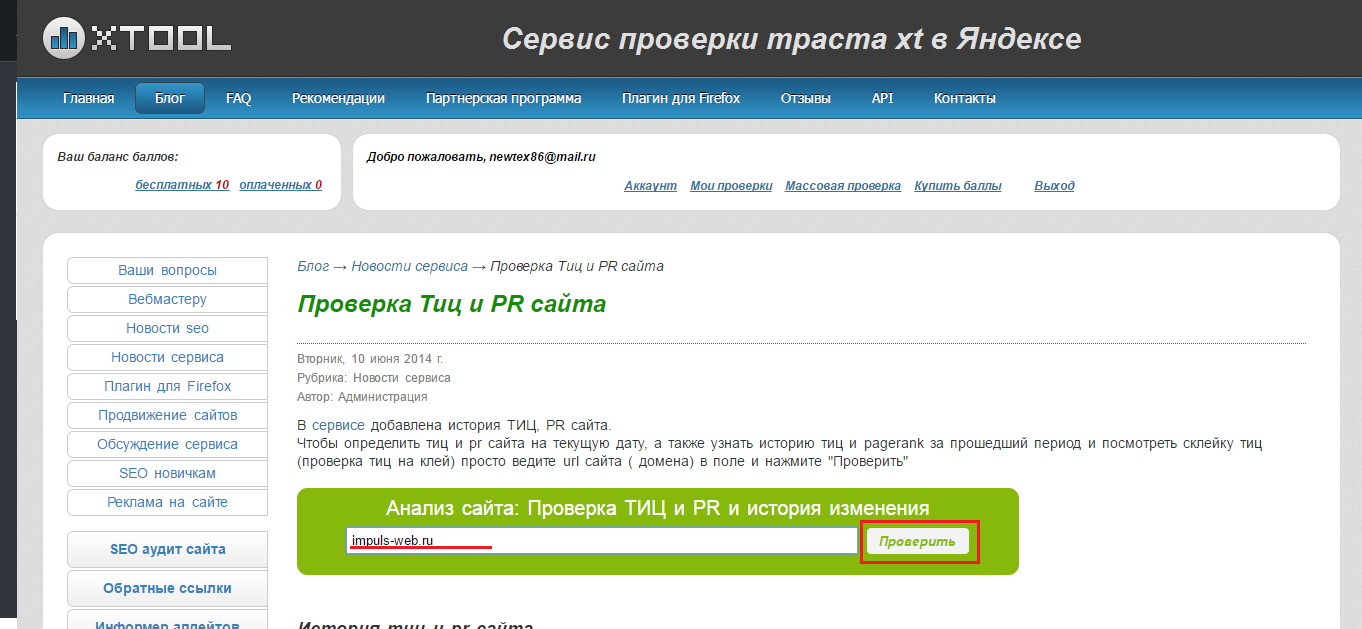
 Хотя презентации конференций не цитируются другими, это сделает ваше исследование более заметным для академического и исследовательского сообщества.Ознакомьтесь с этими советами, чтобы максимально использовать вашу следующую исследовательскую конференцию.
Хотя презентации конференций не цитируются другими, это сделает ваше исследование более заметным для академического и исследовательского сообщества.Ознакомьтесь с этими советами, чтобы максимально использовать вашу следующую исследовательскую конференцию.Дополнительное чтение:
Поделитесь с коллегами
Индексы цитирования открытий нового поколения — обзор ситуации в 2020 году (I) | Аарон Тэй | Академические библиотекари и открытый доступ
Прежде чем переходить к новому поколению индексов цитирования, возможно, важно понять позиции, которые занимают в этой области три больших индекса цитирования — Web of Science, Scopus и Google Scholar.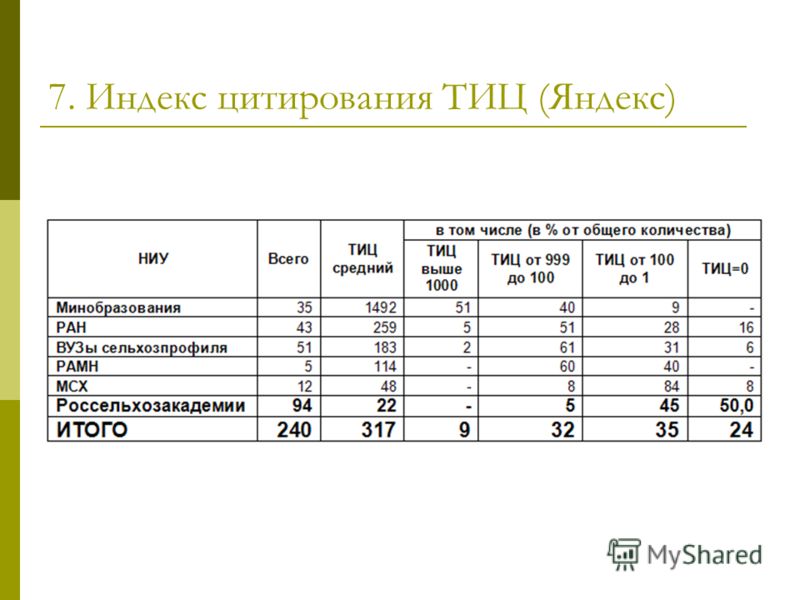
Web of Science , конечно же, индекс цитирования OG.Созданный Юджином Гарфилдом в 60-х годах, индекс цитирования Science, как он был известен, существовал в печатной форме до перехода на первые унаследованные компьютерные системы в 80-х годах. Принадлежащая серии компаний, в первую очередь Thompson Reuters в 2000-х годах, она была выделена в отдельную компанию — Clarivate в 2015 году.
Четкая временная шкалаЕсли вас смущает терминология, технически это название Web of Science. веб-платформы, на которой размещены различные базы данных и индексы цитирования.Наиболее важные из этих баз данных / индексов цитирования — это так называемая «Основная коллекция». Традиционно они состояли из расширенного индекса научного цитирования (SCIE), индекса цитирования в области социальных наук (SSCI), индекса цитирования в области искусства и гуманитарных наук (AHCI), и сейчас их гораздо больше, но это те, о которых вы все еще слышите больше всего.
Из-за наследия Web of Science в течение многих лет имел устаревший интерфейс с ограничениями для поиска, которые выглядят странно для современных глаз (например,грамм. из-за ограничений на хранение / обработку, существовавших в прошлые дни, был проиндексирован только первый автор и т. д.), однако многое из этого было постепенно исправлено за последние 5 лет.
из-за ограничений на хранение / обработку, существовавших в прошлые дни, был проиндексирован только первый автор и т. д.), однако многое из этого было постепенно исправлено за последние 5 лет.
Тем временем в 2004 году Elsevier запустила Scopus , нацеленную на устранение таких недостатков. Scopus можно было бы описать как Web of Science , но он был разработан с нуля с учетом возможностей 2000-х годов и, как следствие, имел относительно современный пользовательский интерфейс и лучшие возможности поиска.
Типичный интерфейс Scopus на 2020 год С точки зрения содержания, когда Scopus впервые был запущен, он позиционировался как индекс цитирования, охватывающий больше оснований с точки зрения названий журналов, чем Web of Science.С другой стороны, в то время новый Scopus не мог сравниться с ретроспективным индексированием источников Web of Science (многие из которых в то время были в печатном формате) и ограничивался индексированием контента с 1996 года и новее.
Сегодня различия между ними уменьшились, Scopus вернулся назад, чтобы заполнить свои резервные файлы до 70-х годов (хотя Web of Science все еще идет еще дальше), а Web of Science добавил дополнительные индексы, такие как Индекс цитирования Emerging Sources Citation Index (ESCI), чтобы опровергнуть аргументы, что Web of Science слишком избирательно.
И Scopus , и Web of Science также расширились, чтобы индексировать исходные материалы, которые представляют собой не только журнальные статьи, но также статьи и книги конференций. (например, Clarivate’s Book Citation Index (BKCI), Conference Proceedings Citation Index (CPCI))
Однако, несмотря на расширение индексов цитирования, Scopus и Web of Science подвергались критике со стороны различных библиометрических исследований и «Science of Science »за перекос в сторону STEM и предвзятость по отношению к журналам, не на английском языке (e. грамм. без учета региональных журналов).
грамм. без учета региональных журналов).
В частности, потому что использование Scopus и Web of Science в качестве библиометрических источников доминирует в рейтингах университетов (например, THE в предыдущих выпусках рейтингов и рейтингов QS обычно использовались только Scopus или Web of Science ). Считается, что использования только таких индексов цитирования может быть недостаточно для получения истинной картины качества и эффективности исследований.Рейтинг
Times Higher Education World University Rankings в прошлом использовал Web of Science в качестве источника, но с 2020 года использует Scopus. Последние исследования 2020 года, такие как — Сравнение источников библиографических данных: влияние на надежность рейтингов университетов и Оценка открытости вузов. производительность доступа: методология, проблемы и оценка предполагают, что показатели и порядок ранжирования с использованием разных показателей могут сильно отличаться, если вы используете разные и часто более крупные источники данных, чем те, что есть только в Web of Science или Scopus.
Давайте теперь перейдем к последнему из трех — Google Scholar , вероятно, крупнейшему источнику данных.
В тот момент, когда Scopus выходил на рынок и в конечном итоге закрепился рядом с Web of Science , чтобы сформировать дуополию, на рынок вышел еще один новый претендент — Google Scholar.
Анураг, соучредитель Google Scholar в 2015 году — размышляя об изменениях, связанных с запуском Google ScholarВ 10-летней ретроспективе, опубликованной в 2014 году, Анураг Ачарья написал о своем пути изобретения и разработки Google Scholar. (См. Также недавнее размышление Анурага в 2020 году)
Какую проблему пытался решить Google Scholar ? Анураг поделился своим опытом учебы в Индии, и, конечно же, доступ часто был проблемой. Но он обнаружил, что, когда он не мог получить доступ к чему-то, он мог, по крайней мере, писать письма, прося об этом людей, и удивительно (по крайней мере для меня), когда он это делал
«Примерно половина людей пришла бы вам что-то.
 , возможно перепечатка.
, возможно перепечатка.и все же он подумал, что
«… если вы не знали, что информация была там, вы ничего не могли с этим поделать.
Другими словами, мне показалось, что он считает, что проблема обнаружения почти так же важна, как и проблема доступа, и это отражено в работе Google Scholar .
Можно с уверенностью сказать, что сегодня, 16 лет спустя, он добился огромного успеха до такой степени, что многие читатели этой статьи, возможно, едва ли смогут сопереживать опыту Анурага, когда он был студентом (доступ сегодня рассматривается как большая проблема. ). Google Scholar , вероятно, самая популярная и широко используемая междисциплинарная академическая поисковая система в мире, и ничто не может сравниться с ней.
Первое, что приходит на ум, — это размер и скорость индексации по сравнению с обычными базами данных.
Ранее я обнаружил, что Google Scholar , как правило, очень быстро индексирует недавно опубликованные статьи (включая «статьи в прессе», статьи типа «Ранний просмотр») по сравнению с большинством традиционных АиИ и библиотечных баз данных.
И действительно В исследовании 2016 года было обнаружено, что
«средняя разница в задержке между GS и Scopus при индексировании документов в журналах, включенных в Scopus, составляет около 2 месяцев.Этот результат предполагает, что скорость индексации журналов, включенных в Scopus, в GS выше, чем у тех же журналов в Scopus. Задержка в значительной степени, но не исключительно, вызвана тем фактом, что списки литературы в статьях в прессе добавляются с задержкой в Scopus »
С точки зрения размера индекса в отличие от Web of Science и Scopus , которые, как известно, Выборочный по своей природе в индексируемых журналах, Google Scholar перевернул все с ног на голову и попытался проиндексировать все в Интернете, с которым сталкивались его сборщики, при условии, что это выглядело как научное.
В те дни идея хищных журналов еще не существовала, и сегодня некоторые, например Microsoft Academic, пытаются использовать различные статистические методы, чтобы отфильтровать их.
 Но даже сегодня некоторые индексы цитирования просто пытаются включить все, и можно сказать, что у них есть политика «индексировать их все и позволять Богу (или читателю) разобрать их».
Но даже сегодня некоторые индексы цитирования просто пытаются включить все, и можно сказать, что у них есть политика «индексировать их все и позволять Богу (или читателю) разобрать их».Хотя все это звучит легко сказать, трудно описать, насколько большим был технологический скачок и сдвиг парадигмы в 2004 году по сравнению с тем, что делали Web of Science и Scopus в то время, особенно когда это было сделано почти полностью автоматически (сегодня Google Scholar все еще имеет небольшую команду).
Это потребовало от Google решения ряда сложных технических проблем, таких как навигация и сбор контента в репозиториях, часто сопровождающиеся плохими метаданными в репозиториях (вплоть до того, что они изобрели теги Highwire, потому что Dublin Core не вырезал их), очищая академические статьи PDF-файлы для данных и определения, группировки и объединения различных вариантов документов для идентификации основного элемента вместе, чтобы ссылки могли творить чудеса для ранжирования релевантности.
Нельзя сказать, что в первые годы, когда Google Scholar был запущен в 2004 году, проблем не было, но я считаю, что к 2010-м и, конечно же, к 2015-м годам много ранней критики Google Scholar, которые, по сути, были пробелами в освещении. и метаданные крайне низкого качества, которые можно было легко найти из Google Scholar с помощью нескольких щелчков мышью, были в основном исправлены
В отличие от других индексов, как традиционных, так и новых и будущих, таких как Microsoft Academic (на основе Microsoft Academic graph — MAG) , Semantic Scholar и т. Д., Google Scholar скромно раскрывает размер своего индекса, будь то с точки зрения номеров статей или даже с точки зрения проиндексированных названий источников / журналов.
Отсутствие API для извлечения данных усложняет задачу.
Это привело к серии научных работ, в которых пытаются оценить размер индекса Google Scholar с использованием множества косвенных методов, например Методика захвата-повторного захвата Khabsa & Giles (2014) использует известный размер Microsoft Academic Search для сравнения, чтобы оценить размер Google Scholar, в то время как в Методах 2015 года для оценки размера Google Scholar (2015) использовалось целых 6 различных методов. многие из них включают «абсурдные запросы» и запросы диапазона, чтобы попытаться заставить Google Scholar вернуть все результаты.См. Также недавнюю статью 2019 года, в которой сравниваются размеры Google Scholar с другими крупными индексами.
многие из них включают «абсурдные запросы» и запросы диапазона, чтобы попытаться заставить Google Scholar вернуть все результаты.См. Также недавнюю статью 2019 года, в которой сравниваются размеры Google Scholar с другими крупными индексами.
Итак, к 2015 году, вероятно, надежной оценкой будет то, что Google Scholar будет иметь около 160 миллионов статей, а к настоящему времени может превысить 200 миллионов. Для сравнения Scopus в 2020 году сегодня показывает около 70 миллионов статей.
Когда я пишу об индексах с более чем 100 миллионами статей, я часто получаю комментарии, что это невозможно.В конце концов, Crossref является основным (но не единственным) регистрационным агентством DOI, которое присваивает DOI для научного контента — всего лишь 100 миллионов DOI, выпущенных в сентябре 2018 года, и даже не все DOI Crossref зарегистрированы для статей в журналах.
Во-вторых, как описано в 10-летней ретроспективе, Anurag не остановился просто на индексировании метаданных, которое в то время было стандартом для всех A&S. Вместо этого он постучал в дверь издателей от Elsevier до ACS, чтобы получить разрешение для сканеров Google Scholar сканировать за платный доступ для индексирования полного текста.
В то время как некоторые поначалу сопротивлялись, один за другим издатели уступали, поскольку игнорирование трафика Google Scholar было просто глупо, особенно если бы этого не делали их конкуренты (я видел оценки издателей, показывающие, что большая часть их рефералов приходит из Google и Scholar , а не библиотечные системы).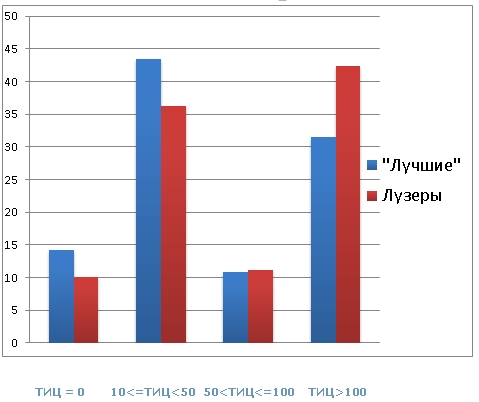
Тот факт, что Google Scholar индексирует полные тексты почти всех крупных издателей, является большим преимуществом, о котором я редко упоминаю . Возможность Google Scholar отображать фрагменты того, какие термины вашего запроса совпадают в документе, дает вам безумное количество контекста, которое невозможно, если вы не индексируете полный текст.
Вы можете легко сказать, даже не углубляясь в статью, чтобы увидеть, будет ли она актуальной.
Google Scholar соответствует полному тексту, а поисковые отрывки сообщают вам, какие статьи соответствуют вашему ключевому слову в conrexr. Действительно, популярность Google Scholar не является большой загадкой.
Он очень хорошо выполняет основы целенаправленно, с почти непревзойденным охватом, полнотекстовой индексацией и отличным релевантным рейтингом по многим дисциплинам (что, я думаю, само по себе является функцией большого количества глазных яблок и щелчков, которые помогают Google оптимизировать их рейтинг релевантности. Это то, что у новых сервисов возникнут проблемы с сопоставлением).
Это то, что у новых сервисов возникнут проблемы с сопоставлением).
Другая причина его популярности, о которой редко говорят, потому что большинство исследователей связаны с организациями с доступом к платному доступу, заключается в том, что до того, как открытый доступ стал большим событием, Google Scholar почти единолично несла эстафету, находя и надежно ссылаясь на бесплатные книги для чтения. копий везде, где он был доступен (страница журнала, репозиторий, сеть академических исследований, домашняя страница автора), задолго до того, как другие поисковые системы и базы данных начали серьезно относиться к предоставлению доступа к бесплатному чтению статей.
Даже сегодня большинство возможностей поиска в открытом доступе, которые вы видите в базах данных, осуществляется через Unpaywall, и Google Scholar по-прежнему остается одним из самых надежных источников ссылок на бесплатные копии для чтения.
В 2010-х библиотеки пытались создать свою собственную версию Google Scholar и возлагали надежды на «службы обнаружения Web Scale», такие как Summon, Primo, EDS и Worldcat Discovery.
Ни одному из них не удалось сильно повлиять на популярность Google Scholar , вероятно, потому, что это была нечестная борьба с самого начала.
В то время как Google Scholar был полностью сосредоточен на своей цели — обнаружении статей, таких как контент, библиотечные системы часто использовались для выполнения нескольких ролей, например используется в качестве известного стиля поиска для студентов, ищущих учебники, или для историков, ищущих архивы и т. д., что приводит к компромиссам.
Exlibris Primo — популярная служба поиска библиотек, в которой заявлено использование Хотя я бы не осмелился сказать, что Google Scholar — единственный и лучший инструмент для поиска во всех ситуациях (например, специализированный дисциплинарный инструмент, такой как Pubmed или Psycinfo часто может быть даже лучшим выбором), если бы вы знали только один инструмент для использования во всех случаях использования, вероятно, было бы не так уж и плохо выбрать по умолчанию Google Scholar .
Хотя индексы цитирования по своей природе обеспечивают подсчет цитирований, возможно, многие, такие как Google Scholar, больше ориентированы на использование в первую очередь в качестве инструмента открытия, а не инструмента, предназначенного для старших администраторов и библиометристов, для выполнения библиометрического анализа и оценки исследований.
К 2010-м годам Google Scholar почти с опозданием начала добавлять функции. Ничего особенного, в основном без проблем, например, сохраненные списки, простые функции цитирования, рекомендации, основанные на вашем профиле и связанные с ним работы по профилям, которые вы отслеживаете, предложения запросов, улучшенная мобильная поддержка, идентифицирует, когда вы сокращаете и прошлые цитаты и т. Д.
Google Scholar — функция My Library Они даже начали расширяться в сторону предоставления и отслеживания показателей, запустив профили Google Scholar в 2011 году и создав Scholar Metrics в 2012 году — ежегодный рейтинг журналов — который сравнивается с ранжированными списками журналов — Clarivate — Journal Citation Отчеты и показатели журнала Scopus от Elsevier.
Как Google Scholar преуспел в этой попытке войти в игру цитирования по сравнению с Scopus и Web of Science ?
Мне кажется, что с точки зрения поискового инструмента Google Scholar уже давно обнаружил Web of Science или Scopus ( см. Также различные опросы о поведении исследователей, такие как этот отчет JISC за 2015 год ) .Конечно, хотя будут некоторые стойкие исследователи (либо профессора старой школы, которые начали свою карьеру там, где Индекс научного цитирования был всемогущим, либо из определенных стран, где публикации в журналах «SSCIE» имеют большое значение, но даже это может скоро закончиться), кто будет настаивать на поиске в Web of Science или Scopus , потому что они могут цитировать только те журналы, которые включены в эти индексы, но в целом их будет меньше исследователей, чьим первым инстинктом будет поиск Google Scholar , особенно тех, кто в области менее хорошо охвачены Web of Science .
Но как насчет Google Scholar , использующего в качестве библиометрического источника для оценки?
Нет сомнений в том, что я думаю, что профили Google Scholar чрезвычайно популярны из-за простоты настройки и обслуживания, повышенной видимости (это даже дает вам возможность появиться на панели знаний Google для поиска Google!).
И есть исследователи, которым нравится метрик Google Scholar за более высокое количество цитируемых, которые они получают, обычно извлекаемые с помощью программного обеспечения Харцинга для публикации или уничтожения, единственного инструмента, официально разрешенного (или, по крайней мере, предполагаемого некоторыми) Google Scholar , чтобы получить результаты из Google Scholar для библиометрического анализа.
Один из наиболее часто задаваемых вопросов о Google Scholar — почему он не предлагает API или какой-либо способ массового извлечения данных. В настоящее время способы получения обширных данных Google Scholar по массе ограничиваются извлечением со страниц исследования GS с помощью скриптов, расширений браузера и других инструментов (наиболее известных из них — Hazing’s Publish или Perish). Эти методы, как известно, очень ограничены для крупномасштабного использования и будет постоянно использовать контрмеры, такие как Captchas. Я не знаю, есть ли официальный ответ на вопрос, почему Google Scholar не предоставляет API, но общее убеждение / подозрение заключается в том, что в обмен на получение Google Scholar разрешения на индексирование полного текста за платным доступом издателя им не разрешено предоставлять контент через API.(Сравните с тем, как у Microsoft Academic есть API, но он не предоставляет / не индексирует полный текст).
Однако в целом в гонке за приемлемость в качестве поставщика метрических данных Google Scholar занимает в лучшем случае третье место по сравнению с двумя другими. Отчасти в отличие от Web of Science или Scopus , здесь нет простого способа массового получения данных Google Scholar из-за отсутствия API или интерфейсов, предназначенных для глубокого библиометрического анализа (Clarivate предлагает надстройку incites и Elsevier предлагает Scival)
Кроме того, смысл по-прежнему заключается только в количестве цитирований и показателях из «надлежащих индексов цитирования», таких как подсчет Web of Science и Scopus.С этой идеей связана, но несколько менее решительно сейчас, идея публикации только в журнале, индексируемом по этим индексам цитирования
Отчасти это чистая инерция, немного укоренившаяся в возможно правильной идее, что данные Google Scholar все еще слишком нечисто и неточно для использования по сравнению с Scopus и Web of Science. Но я думаю, что тот факт, что все авторитетные рейтинги университетов используют Scopus или Web of Science, определенно имеет к этому отношение.
Я бы сказал, что до тех пор, пока Scopus и Web of Science сохранят свою власть в качестве де-факто инструментов для измерения и оценки исследований, их уменьшенная роль в открытии (позаимствованная в основном из Google Scholar ) не повредит им что плохо.
Затраты на качество. Представители Clarivate и Elsevier, несомненно, оправдают ценники на свои продукты этим аргументом. Когда они были единственной игрой в городе, этот аргумент был сильным, но теперь, когда появляются конкуренты, многие из которых бесплатные ( Microsoft Academic , COCI и т. Д.), Этот аргумент снова поднимает голову, особенно когда освещение некоторых открытых наборы данных сопоставимы или больше (например, из Micosoft Academic Graph). Хотя важно отметить, что охват и качество / точность могут не коррелировать.
Каков относительный охват различных новых источников цитирования по сравнению с Web of Science и Scopus? Исследования по этому вопросу еще не многочисленны, но в общих закономерностях начали появились — с точкой зрения охвата (измеряются цитатами) — Google Scholar неоспорим по величине в охвате следует Microsoft Academic (доступны открытые данные с помощью Microsoft Academic Graph) . Размеры , Scopus и Web of Science находятся на следующем уровне по размеру.
К сожалению, множество открытых цитат в Crossref, например OpenCitations ‘ COCI (, который получен из данных Crossref и ориентирован на ссылки doi to doi citation) занимает последнее место из-за сдерживания очень немногих крупных издателей, а именно Elsevier, ACS, IEEE, которые отказываются делать открытые ссылки. из своих журналов, которые хранятся в Crossref.
Обновление декабрь 2020! — Elsevier удивил академический мир, объявив, что подпишет Декларацию об оценке исследований (DORA), которая включает требование о том, чтобы списки ссылок на все статьи были открыты для доступа через Crossref.Это отличный шанс почувствовать недостающий пробел цитат в Crossref! Этот анализ, проведенный в 2017 году, например, показывает, что 65% ссылок из журнальных статей, размещенных в Crossref, которые хранятся близко, принадлежат одному издателю — Elsevier! Сейчас внимание сосредоточено на IEEE, Kluwer и ACS
Ранние исследования, сравнивающие индексы цитирования нового поколения (часто основанные на бесплатных источниках, таких как Microsoft Academic Graph, Crossref sources ) и золотых стандартных, таких как Scopus, действительно обнаружили, первые имеют тенденцию быть менее точными по разным причинам (много скопированных данных и т. д.).
Так же, как Google Scholar извлекает выгоду из эффекта Мэтью / сети, заключающегося в увеличении количества посетителей, ведущих к большему количеству данных для оптимизации релевантности, Scopus и Web of Science как * * исчерпывающие библиометрические / цитируемые источники выигрывают на протяжении десятилетий. исследователей и библиотекарей, которые заинтересованы просматривать данные и указывать на ошибки, которые нужно исправить (особенно в их собственных работах).
Также интересно, могут ли учреждения, использующие продукты Elsevier & Clarivate, такие как Scival, Incites, PURE, также подавать сигналы для повышения качества e.грамм. точность аффилированности и т.д. так далеко.
Интересно, как унаследованные системы, такие как Web of Science или Scopus , продолжают оправдывать свое существование как дорогостоящие A&S, когда вы получаете большую часть такого же охвата, а, возможно, даже больше, из свободно доступных источников.Вы можете выбирать из таких источников, как Lens.org , которые имеют приятный удобный интерфейс, или для тех, кто разбирается в технических вопросах, работая с открытыми данными, предоставленными Microsoft Academic Graph , для создания пользовательских панелей мониторинга
Будут ли такие открытые данные цитирования продолжать улучшаться в качестве, возможно, за счет усилий краудсорсинга? Дойдем ли мы до того момента, когда открытые источники цитирования станут достаточно хорошими, а достоинства открытости начнут преобладать над качеством?
Ответ на подобные вопросы, я думаю, повлияет на то, как будущее индексов цитирования будет развиваться в области библиометрии.
- Этический / моральный аргумент
Один из типов аргументов против Google Scholar имеет тенденцию нацеливаться на опасность чрезмерной зависимости от единственной монополитической стороны, которая сможет удовлетворить все потребности в научных открытиях. Обычно утверждают, что Google известен тем, что резко отказывается от проектов, и не помогает то, что Google Scholar не является особо важной службой. Было бы катастрофой, если бы мы сложили все яйца в одну корзину, а они сломались…
Академические библиотеки использовали этот аргумент, чтобы противостоять аргументам, чтобы отказаться от открытий и уступить их Google и Google Scholar и вместо этого сосредоточиться на доставке.
Еще один морально-этический аргумент против Google Scholar — это аргумент, что если каждый будет использовать Google Scholar , это может дать им слишком много власти, и даже если они не будут шпионить за нами в каких-либо злых целях, они легко смогут чтобы получить доступ к всемирной модели поисков в академическом мире и проанализировать ее, чтобы получить еще большее представление о мире, ведь Знание — сила.
Примечание. Анураг Ачарья много раз довольно жестко утверждал, что Google Scholar, в отличие от Google, мало отслеживает индивидуальные поисковые запросы и персонализацию.Послушайте его ответ на уточняющий вопрос Лизы Хинчлифф в 2015 году. Но, конечно, майнинг в совокупности все еще может быть очень ценным без отслеживания отдельных лиц.
Хотя все эти аргументы прекрасны, я подозреваю, что прагматизм имеет тенденцию преобладать, и ученые будут использовать то, что работает. Чтобы заставить меня отказаться от использования по умолчанию инструмента, который все чаще становится Google Scholar , вам нужно будет показать мне что-то такое же хорошее и, скорее всего, значительно лучше для меня.В конце концов, моральные и этические аргументы зашли так далеко.
Возможно, главный аргумент этического типа, который я могу придумать, который, возможно, может сработать, — это усилить толчок к открытой науке и аргументировать, что данные Google Scholar непрозрачны, поскольку нет API или данных для проверки, поэтому делаем литературу обзоры с его использованием не являются кошерными, поскольку результаты не воспроизводятся.
С другой стороны, некоторые из последних конкурентов Google Scholar фактически предоставляют и / или потребляют открытые данные — примеры включают Microsoft с их данными Microsoft Academic Graph, лицензированными по ODC-BY, и S2ORC Semantic Scholar, что делает результаты несколько более прозрачными.
Одна из проблем, связанных с желанием сделать такие данные открытыми, а поиск — прозрачным, я подозреваю, означает компромисс с желаемой функцией пользователя, заключающейся в возможности поиска по полному тексту, даже в тех полных текстах, которые скрыты за платным доступом. Из-за проблем с авторским правом S2ORC может публиковать только метаданные и документы в открытом доступе, в то время как данные Microsoft Academic Graph, которые используются в Microsoft Academic, могут быть выпущены как открытые данные именно потому, что они не содержат полного текста (хотя он может обрабатывать полный текст для трансформационного использования e.грамм. выделить направление исследований).
По какой-то причине крупномасштабное полнотекстовое индексирование для индексов цитирования открытий встречается редко. Помимо Google Scholar, возможно, Dimensions — единственное, что делает это в любом масштабе. Большинство других, таких как MAG, либо не соответствуют полному тексту, либо соответствуют только полному тексту из относительно небольшого корпуса документов открытого доступа (например, рисунок Lens.org из JISC CORE)
2. Конкуренция с Google Scholar в качестве инструмента поиска на Утилита
По-прежнему оставляя в стороне такие моральные аргументы, я вижу два способа, которыми новые конкуренты могут отличиться от Google Scholar в игре-открытии.
Но во-первых, чтобы у вас был шанс быть конкурентоспособным, мы предполагаем, что у вас есть ресурсы, аналогичные Google, вы можете решить проблему, чтобы сканировать Интернет и добывать необходимые данные (например, исследование Microsoft) или если это не удается, объединить существующие открытые данные (которых сейчас много) для создания собственного индекса, который по размеру не уступает Google Scholar.
Google Scholar, Microsoft Academic, Scopus, Dimensions, Web of Science и COCI OpenCitations: междисциплинарное сравнение охвата с помощью цитирования (рис. 1)На самом деле, вероятно, несмотря на всю конкуренцию со стороны таких конкурентов, как Microsoft, которые используют аналогичные методы, Google Scholar по-прежнему имеет самый большой индекс? Все исследования размера индексов, за которыми я следил, по-прежнему указывают в одном направлении.
Проще говоря, Google Scholar больше, чем все остальные, часто в значительных количествах, независимо от того, как вы его нарезаете. Честно говоря, некоторые, такие как Microsoft Academic, действительно приближаются к некоторым исследованиям, но бесспорным королем охвата по-прежнему остается Google Scholar, как я напишите это в 2020 году.
Например, см. здесь исследование 2020 года, в котором сравнивается Google Scholar с другими важными новыми источниками, включая Web of Science, Scopus, COCI (по сути, открытые ссылки Crossref) и Dimensions.
Как вы можете видеть, Google Scholar покрывает 88% всего агрегированного набора, в то время как ближайший конкурент Microsoft Academic покрывает только 60%.
Исследователи и библиотекари, специализирующиеся на систематических обзорах, уже давно знают, что Google Scholar не позволяет эффективно контролировать поиск.
Хотя Google Scholar действительно включает большинство статей, которые определены для систематического обзора в свой индекс (высокая степень отзыва), отсутствие функций контроля точности означает, что вы не можете эффективно выполнять поиск, чтобы получить эти статьи (низкая точность).
Среди некоторых функций, которые ему не хватает, включают
- Поддержка длинных сложных запросов — поиск ограничен 256 символами
- Поддержка вложенного логического поиска
- Нет поддержки подстановочных знаков и близости (поддерживается автостемпинг, не может быть легко отключен)
- Только ограниченная поддержка поиска по определенным полям
- Максимум 1000 результатов, без массового экспорта
Добавьте тот факт, что также считается, что результаты поиска Google Scholar не всегда воспроизводимы, и даже опасаются пузыря Google Scholar (который может или не может быть удачным), и, похоже, это области, в которых конкурент может улучшить.
Похоже, что это тот подход, который использует Lens.org с чрезвычайно мощными функциями структурированного поиска, такими как множество полевых поисков и фасетов, а также сложный синтаксис логического поиска. Я рассмотрю Lens.org во второй части этой серии, а пока, если вам интересно, взгляните на — 7 причин, почему вам следует попробовать Lens.org (обновлено до версии 5.16.0 — март 2019)
Структурированный поиск Lens.orgТем не менее, насколько велик рынок для пользователей, которым нужны такие функции? Большинство исследователей, похоже, удовлетворены ограниченным контролем, который у них есть в Google Scholar.
Во-вторых, можно использовать противоположный подход и продвигаться к полностью семантическому способу поиска.
Что я имею в виду?
Хотя Google Scholar не является на 100% строго логическим, как мы видели ранее, он все еще имеет атрибуты системы поиска по ключевым словам, вы можете использовать функции ИЛИ, использовать кавычки для поиска по фразе и т. Д., Что дает вам некоторый контроль над поиском (хотя часто вы можете не осознавать, что Google Scholar может иногда незаметно изменять часть вашего поиска, расширяя термины, отбрасывая термин или два и т. д.).
Но это ничто по сравнению с такими системами, как Microsoft Academic или Semantic Scholar , где логические операторы, даже такие простые, как OR, полностью выбрасываются из окна, и система пытается интерпретировать ваш поиск.
Microsoft Academic интерпретирует ваш поиск таким образом, что даже с одним словом в названии он может угадать правильное название статьи (пример из блога)И, конечно же, Google Scholar был довольно консервативным при добавлении функций в Google Scholar (at по крайней мере на первый взгляд) и за последние 25 лет, хотя Google далеко продвинулся за рамки «парадигмы 10 синих ссылок», добавив Графы знаний, Избранные фрагменты веб-страниц для обработки запросов вопросов и ответов и даже новейшие методы НЛП, такие как BERT, неясно, как много Google Scholar выиграл, помимо общих изменений.
Может быть, некоторые из новых инновационных «семантических» функций для добавления дополнительного контекста к поиску помогут продвинуться дальше Google Scholar?
Контекстуализация исследования
Один из основных подходов, которые я видел в некоторых из новых указателей цитирования, — это стремление к конекстуализации исследований путем отслеживания ссылок, выходящих за рамки простых ссылок между статьями или даже статьями конференций и книгами.
Например, Digital Science’s Dimensions отслеживает связи между бумажными публикациями, грантами, спонсорами, клиническими испытаниями, наборами данных, патентами, политическими документами и т. Д.
Semantic Scholar делает то же самое, связывая статьи с препринтами, слайдами, видео, презентациями, библиотеками кода и даже упоминаниями в Интернете (твиты, сообщения в блогах, новости).
Другой важной областью было автоматическое извлечение тем / сущностей для автоматического присвоения понятий, что лучше всего видно в Microsoft Academic, автоматически генерирующем теги «Область исследования» .
Используя передовые методы НЛП, такие как иерархическое моделирование тем, они могут автоматически генерировать и классифицировать документы по сотням тысяч контролируемых тем в 6-слойной иерархической системе, которая не только используется внутренним механизмом, но также подвергается воздействию человек-пользователь, который может использовать его для просмотра.
Страница области исследований Microsoft Academic — «Классификация библиотек»Они утверждают, что эта система является самообучающейся и способна быстро распознавать новые кластеры возникающих исследований, таких как тема COVID-19.
Еще одна интересная область — применение семантики в поведении цитирования.
Например, вместо простого подсчета цитирований, Semantic Scholar использует методы НЛП для типизации цитирований в зависимости от того, относится ли цитирование к методу, результатам или предыстории, а также от того, имеет ли ссылка в статье большое влияние на статью.
Это позволяет Semantic Scholar внести свой вклад в очень полезную функцию Google Scholar «поиск по цитируемой статье», которую я часто использую при просмотре основополагающих статей или обзорных статей с сотнями ссылок.
Типичный поиск по цитированию статьи в Google ScholarВ Semantic Scholar , помимо простого ключевого слова в цитируемых статьях, вы можете фильтровать его, используя различные критерии, такие как тип цитирования.
Учебник семантического ученого по обзору цитированияДругие возможные нововведения, такие как scites классификация цитат по «поддержке», «оспариванию» (опять же через НЛП), также представляют собой интересные попытки попробовать другой подход.
Визуализация scite по типам цитированияОдно из последних улучшений scite, даже позволяет вам выборочно детализировать и прослеживать график цитирования по типу цитирования, давая новый виток старой практике цитирования.
Конечно, на данный момент неясно, будет ли что-либо из этого не чем иным, как классными трюками, которые не сработают, и вполне может быть, что превосходство Google Scholar в качестве чистого инструмента для поиска может быть невыгодным, даже если оно было выполнимо.
В то время как конкуренты, такие как Microsoft Academic и Semantic Scholar , поддерживаемые богатыми ресурсами карманами, могут позволить себе участвовать в игре, нетрудно спорить, пытаясь заработать деньги на отрасли, где бесплатно предоставляется отличный Google Scholar существует, и там, где такие гиганты, как Microsoft, пытаются предоставлять столь же бесплатные услуги по обнаружению, кажется глупой затеей.
Добавьте к этому все большее количество индексов открытий, которые появляются благодаря использованию открытых метаданных (например, Lens.org , Scinapse ). Мне кажется, что игра на открытие быстро превращается в ситуацию «красного океана», если вы для прибыльной компании.
Возможно, признание этого Dimensions коммерческой компанией Digital Science дает услугу по обнаружению fremium, которая в значительной степени соответствует Google Scholar по большинству функций (например, как Google Scholar , Dimensions использует комплексный подход, включающий все журналы он может видеть) и даже выдает еще несколько дополнительных наборов фильтров.
Однако я подозреваю, что Dimensions на самом деле не предназначен для конкуренции с Google Scholar , но больше нацелен на Scopus и Web of Science и их позиции как арбитры качества исследований.
В отличие от Microsoft Academic , бесплатная версия Dimensions фактически скрывает институциональный фильтр в версии fremium, четко осознавая тот факт, что основным вариантом использования будет библиометрия на уровне института и блокируя ее, чтобы гарантировать, что библиотеки или исследовательские офисы тем, кто захочет использовать его таким образом, придется заплатить.
Вы видите, что аналогичное решение было принято для сервиса 1Science 1Findr , приобретенного Elsevier, где опять же в версии freemium отсутствуют институциональные фильтры
Думайте о Dimensons как о более инклюзивной Web of Science, охвате Scopus и в отличие от Google Scholar есть API и простые способы массового извлечения данных
Если посмотреть на дополнительные наборы функций Dimensions плюс и, в частности, Dimensions аналитики, я думаю, что функции , такие как настраиваемая аналитика и информационные панели, поддержка Google BigQuery и т. Д. очевидно, что продукт премиум-класса больше нацелен на людей, которым нужен более широкий охват, чем в Scopus или Web of Science (аналог Google Scholar ) и легкий массовый доступ к библиометрии для оценки (в отличие от Google Scholar ).
Конечно, попытаться свергнуть Scopus или Web of Science или, по крайней мере, усилить их бизнес, чтобы получить признание в качестве надежного поставщика показателей, не менее легко, чем вытеснить Google Scholar в сфере открытий.
Как уже упоминалось, Scopus и Web of Science уже создали торговую марку в этих областях и имеют встроенную базу, состоящую из тысяч библиотекарей и исследователей, которые неизбежно обнаруживают ошибки и помогают выявлять ошибки для исправления. , что приводит к относительно чистым данным.
Кроме того, чтобы индекс цитирования был признан заслуживающим доверия, он должен быть изучен как можно большим количеством сторонних исследователей, а Scopus и Web of Science , несмотря на все их недостатки, чрезвычайно хорошо изучены благодаря десятилетиям исследований. . Именно здесь цифровая наука поощряет библиометристов, заинтересованных в проведении исследования данных Dimensions , чтобы подать заявку на доступ. Работа с библиотеками и учреждениями, пытающаяся использовать данные Dimensions для измерения, — это то, что продолжается. курс.
По состоянию на 2020 год еще слишком рано говорить, сможет ли Dimensions закрепиться, чтобы бросить вызов лидерам, но это выглядит многообещающим. Еще один возможный претендент на библиометрический формат — это открытые данные Microsoft Academic , которые снова имеют всеобъемлющее покрытие, такое как Dimensions , а также простой массовый доступ к данным через API или облачное хранилище Azure (технически данные бесплатны, вы платите за хранение / доступ в Azure).
Есть причина, по которой Google Scholar и Web of Science / Scopus являются королями холмов в своих различных областях.
У них сильная узнаваемость бренда, хорошее начало в разработке и масса пользователей, которые приводят к почти опасному циклу улучшений. Соревноваться с такими устоявшимися конкурентами непросто, даже если у вас глубокие карманы (Microsoft) или убийственная идея (scite).
Будет интересно посмотреть, как будет выглядеть ландшафт в 2030 году.
Следите за обновлениями, мы перейдем ко второй части, где я рассматриваю каждый конкретный индекс.
Каково ваше влияние? Расчет вашего индекса Хирша
Индекс Хирша [1] , как и количество цитируемых ссылок, является мерой научной значимости.Он сочетает в себе оценку количества (количество публикаций) и качества (ссылки на эти публикации) путем подсчета наиболее цитируемых работ исследователя и количества цитирований, полученных этими работами в других публикациях.
Расчет h-индекса
Ваш индекс Хирша основан на списке ваших публикаций, ранжированных в порядке убывания по количеству цитирований. Значение h равно количеству статей (N) в списке, содержащих N или более ссылок.
В приведенном ниже примере исследователь будет иметь индекс Хирша, равный 8, поскольку 8 статей были процитированы не менее 8 раз, а каждая из остальных статей была процитирована 8 или менее раз.
Очевидно, что исследователь не может иметь высокий индекс Хирша без значительного количества публикаций — но плодотворной работы недостаточно. Работа должна быть процитирована другими исследователями, чтобы она учитывалась для индекса Хирша.Индекс Хирша считается репрезентативным измерением воздействия исследования, поскольку он не учитывает непропорционально высокий вес часто цитируемых публикаций и работ, которые еще не цитировались. Однако с индексом Хирша есть проблемы. Хотя основной расчет индекса Хирша одинаков для разных баз данных, результат может варьироваться в зависимости от содержания конкретной базы данных или включения более старых публикаций.На индекс Хирша также может влиять самоцитирование [2] .
Инструменты для расчета индекса Хирша
Следующие ресурсы можно использовать для расчета вашего индекса Хирша. Обратите внимание, что Web of Science и Scopus лицензированы Университетом Макгилла для преподавателей, сотрудников, исследователей и студентов МакГилла и требуют аутентификации с использованием адреса электронной почты и пароля McGill.
Поскольку охват базами данных цитирования различается, ни один ресурс не сможет обеспечить всестороннюю оценку воздействия.Для полного анализа влияния автора или публикации необходимо поискать в нескольких базах данных все возможные цитаты.
Чтобы узнать больше об отслеживании цитирования и измерении результатов вашего исследования, обратитесь к библиотекарю вашей больницы.
Версия для печати:
Первая база данных, включающая индекс Хирша, Web of Science индексирует более 10 000 журналов в области искусства, гуманитарных, естественных и социальных наук. Web of Science требует аутентификации с использованием имени пользователя и пароля McGill.
Чтобы найти свой h-индекс, начните с выбора опции поиска по автору. Выберите «Биомедицина и биологические науки» на вкладке «Область исследования». Вы можете дополнительно ограничить свой поиск, выбрав «Университет Макгилла» в качестве организации.
На странице результатов щелкните «Создать отчет о цитировании».
Отчет о цитировании будет включать ваш индекс Хирша в Web of Science, а также ряд других показателей, включая общее количество цитирований и среднее количество цитирований на элемент.Чтобы удалить элементы, которые не были созданы вами, из отчета о цитировании, установите их с помощью флажков и нажмите «Перейти».Междисциплинарная база данных рецензируемой литературы, Scopus индексирует более широкий круг журналов, чем Web of Science, что может привести к более высокому индексу Хирша. Однако ссылки на статьи до 1996 г., опубликованные после 1996 г., в настоящее время не включаются в расчет индекса Хирша, предоставляемый Scopus. Как и Web of Science, Scopus требует аутентификации с использованием имени пользователя и пароля McGill.
Чтобы найти свой h-индекс, начните с выбора опции поиска по автору. Ограничьте поиск, набрав «МакГилл» в поле аффилированности. Вы можете дополнительно ограничить свои результаты по предметным областям «Науки о жизни» и «Науки о здоровье».
Выберите подходящего автора среди результатов поиска и нажмите «Просмотреть обзор цитирования».
Обзор цитирования будет включать ваш индекс Хирша в Scopus, а также количество цитирований в год для каждой из ваших публикаций.Google Scholar предоставляет простой способ узнать, кто цитирует ваши публикации, и построить график цитирования с течением времени. Помимо журналов, Scholar индексирует выбор академических веб-сайтов, диссертаций и других публикаций, что также может привести к более высокому индексу Хирша.
Используя учетную запись Google (Gmail), создайте профиль в Google Scholar Citations. Этот профиль может быть публичным или приватным. После завершения в вашем профиле будет отображаться все время, когда ваши статьи цитировались в других документах Академии Google, а также будет предоставлен индекс Хирша.
Publish or Perish — бесплатная программа, которая находит и анализирует академические цитаты. Он использует Google Scholar и Microsoft Academic Search для получения ссылок и предоставляет различные статистические данные и показатели, включая h-индекс. Хотя программное обеспечение Publish или Perish можно установить без прав администратора, установка на общедоступных компьютерах не рекомендуется.
_________________________________________________________________________________
1 — Hirsch, J.Э. (2005). Индекс для количественной оценки результатов научных исследований человека. Труды Национальной академии наук Соединенных Штатов Америки , 102 (46), 16569-16572.
2 — Бартнек, К., и Коккельманс, С. (2011). Выявление манипуляций с индексом Хирша с помощью анализа самоцитирования. Наукометрия , 87 (1), 85-98.Каталог периодических изданий MLA | Modern Language Association
Справочник периодических изданий MLA предоставляет подробную информацию о более чем 6000 журналах и книжных сериях, которые охватывают литературу, теорию литературы, драматическое искусство, фольклор, язык, лингвистику, педагогику, риторику и композицию, а также историю печати и издательский.Статьи, опубликованные в работах, перечисленных в справочнике, проиндексированы в международной библиографии MLA .
Справочник является ценным ресурсом для ученых, ищущих выходы для публикации своих работ, а также для библиотекарей, работающих над поиском периодических изданий, которые наилучшим образом соответствуют потребностям их учреждений.
Справочник периодических изданий MLA доступен в виде онлайн-базы данных, включенной в подписку на Международную библиографию MLA через всех ее поставщиков.Члены MLA могут бесплатно искать в каталоге через веб-сайт MLA.
Кто использует Справочник
Ученые и студенты, желающие представить свои работы для публикации , используют Справочник периодических изданий , чтобы определить журналы и серии, которые, скорее всего, рассмотрят их работу. Каталог включает важную информацию, такую как освещаемые темы, редакционная политика, контактная информация и правила подачи заявок. По мере изучения новых областей интересов исследователи могут находить соответствующие публикации с помощью тематического поиска в каталоге.
Ученые и студенты также используют каталог, чтобы найти дополнительную информацию о незнакомых ресурсах, которые они обнаруживают в своих библиотеках или которые цитируют сокурсники или исследователи.
Библиотекари используют MLA Directory of Periodicals , чтобы найти материалы, которые лучше всего подходят их преподавателям, студентам и учебным программам.
Что находится в Справочнике
В каждой записи журнала или серии содержится подробная информация, в том числе:
Сведения о публикации, , например, издатель, спонсирующая организация, ISSN, частота и год первой публикации
Редакционные политики , такие как объем, включая тематические термины, назначенные редактором каталога; экспертная оценка; среднее количество читателей на рукопись; язык или языки публикации; прием рецензий на книги, кратких заметок, рефератов и рекламы; политика авторского права; и расходы, связанные с публикацией
Контактная информация редакторов, , включая адреса электронной почты, номера телефонов, номера факсов и почтовые адреса для рукописей
Требования к подаче, , включая рекомендуемый стиль и формат для подачи статей, длину статьи и требования к подаче вслепую
Доступность в электронном виде , включая URL-адреса для отправки статей и ссылки на открытый доступ к онлайн-контенту, если таковой имеется
Информация о подписке с полной контактной информацией о подписке, дистрибьюторами, ценами на подписку и номерами тиражей
Полезная статистика, , такая как среднее количество рукописей разных типов, представляемых в журнал каждый год, и количество опубликованных, время от подачи до решения и время от решения до публикации
Эта информация собрана сотрудниками MLA или предоставлена редакторами публикаций, представленных в списках.
Все версии Справочника периодических изданий доступны для поиска по ключевым словам и определенным полям и предоставляют надежные расширенные возможности поиска и фильтрации. Библиотеки, подписанные на WorldCat , могут напрямую ссылаться на свои библиотечные фонды из записей каталога.
Правила подачи заявок
Редакторам и издателям журналов или серий, не включенных в настоящее время в Справочник периодических изданий , предлагается отправить образец печатного издания или PDF-копии журнала или серии редактору справочника.Отправьте URL-адрес, если журнал доступен только в Интернете.
Образцы журналов могут быть отправлены по почте (предпочтительно) или по электронной почте.
Эл. Почта: [email protected]
Телефон: 646 576-5085
Почта: Справочник периодических изданий MLA , 85 Broad Street, suite 500, New York, NY 10004-2434Типы публикаций, включенных в
MLA Directory of Periodicals
Любые регулярно публикуемые печатные или онлайн-журналы, доступные университетам и библиотекам, которые регулярно включают статьи по языку, лингвистике, фольклору, педагогике или фильмам
Любая серия, в которой публикуются книги по языку, лингвистике, фольклору, педагогике или кино, независимо от периодичности выпуска серии
Требования к электронным журналам и другим серийным онлайн-публикациям
Проверяться индексатором
Относится к языку и литературе
Определить редакцию и редколлегию
Иметь установленную редакционную политику
Укажите издателя и / или спонсирующую организацию
Обеспечивает архивирование прошлых выпусков (т.д., обеспечить постоянный доступ)
Периодически публиковать новый контент
Укажите гонорары авторов на веб-сайте публикации
Электронные сериалы обычно имеют ISSN, CODEN или идентификатор цифрового объекта и спонсируются академической организацией или учреждением.
Для обеспечения полного охвата в международной библиографии MLA редакторы или издатели должны иметь систему информирования MLA о публикации нового выпуска.
MLA по своему усмотрению оставляет за собой право отказать во включении публикации в Справочник периодических изданий MLA по любой причине.
Индекс цитирования СПД «Примечания к Священным Писаниям
Поиск авторитетных цитат
Несколько лет назад профессор BYU по имени Ричард Гэлбрейт создал на бумаге индекс цитирования Священных Писаний, который позже был преобразован в веб-приложения и мобильные приложения Стивеном Лиддлом, также профессором BYU. С тех пор Индекс цитирования СПД был дополнительно запрограммирован другими студентами, чтобы превратить его в замечательный ресурс, который позволяет вам искать ссылки на стихи и находить все ссылки на них, сделанные в Генеральных конференциях, Журнале бесед и учений. Пророка Джозефа Смита.Это веб-сайт, который следует добавить в закладки.
https://scriptures.byu.edu
Павел дает нам кроличью нору
Я приведу вам пример, а затем рекомендую вам проверить его.
Допустим, вы читаете Новый Завет и встречаете 1 Коринфянам 2:10.
10 «Но Бог открыл их нам Духом Своим, ибо Дух исследует все, да, глубины Бога».
Мы можем остановиться и задуматься, как Дух все исследует.Что именно это означает? Я думал, мы, , были теми, кто исследовал и искал истину, и Дух подтвердил бы это, но этот стих указывал, что Дух проводил поиск.
Вы можете начать с поиска в Примечаниях к Священным Писаниям слова «searchcheth», чтобы увидеть, где еще используется это слово (и я настоятельно рекомендую такое поведение :)).
Вы также можете поискать «глубокий» и посмотреть, о чем еще говорят «глубокие вещи» в Священных Писаниях. Не забывайте записывать свои вопросы по ходу дела.Это забавные кроличьи норы, которые стоит исследовать.
Погружение в Индекс цитирования СПД
Вы можете задаться вопросом, что другие авторитеты сказали об этом стихе, и в этом случае вы захотите обратиться к этому ресурсу, «Указателю цитирования Священных Писаний СПД».
В левой части сайта вы можете читать Священные Писания, но сила этого сайта в том, что вы выберете правую (сторону) . ->
Щелкните «1 Кор» в области Нового Завета, а затем щелкните главу 2.Вы увидите список всех ссылок и различных способов, которыми эти ссылки были указаны во всех источниках, из которых они взяты. Иногда это делает его немного сложным, потому что стих, который вы исследуете, может быть найден во множестве разных цитат. Например, 1 Коринфянам 2:10 выглядит как это изображение справа.
При нажатии на каждую из этих ссылок вы увидите такие результаты:
Survey Says?
Вот несколько цитат, которые я нашел в этих результатах, которые помогают пролить немного больше света на этот стих, которые вы можете скопировать / вставить в заметку, привязанную к этому стиху, если хотите.
«У меня есть старое издание Нового Завета на латинском, иврите, немецком и греческом языках. … Слава Богу, что у меня есть эта старая книга; но я больше благодарю его за дар Святого Духа. У меня самая старая книга в мире; но в моем сердце самая старая книга, даже дар Святого Духа. … Святой Дух… пребывает во мне и постигает больше всего мира; и я присоединюсь к нему ». (Джозеф Смит, History of the Church, 6: 307–8)
«Я искренне благодарен за то, что мы живем в век мира, когда мы можем получать наставления силой и мудростью того Духа, который исследует все (1 Кор.2:10), тот Дух, Который все понимает и различает мысли и намерения сердца. (Евр. 4:12) Все остальные проповеди тщетны. Вместе с ним я могу сказать, что это одно из величайших удовольствий в моей жизни — говорить, когда у меня есть Дух Господа, чтобы помочь мне ». (Старейшина Орсон Пратт, JD 7: 308)
«Спаситель имеет слова вечной жизни. (Иоанна 6:68) Ничто другое не принесет нам пользы. Нет спасения в том, чтобы верить злому рассказу о ближнем. (У. и 3. 42:27) Я советую всем идти к совершенству (Евреям 6: 1) и искать глубже (1 Коринфянам 2:10) и глубже в тайнах благочестия.(1 Тимофею 3:16; У. и З. 19:10) Человек ничего не может сделать для себя (Иоанна 15: 5; Иоанна 5: 19,30), если Бог не направит его (1 Фес. 3:11) в правильном направлении; и Священство предназначено для этой цели ». (Джозеф Смит, TPJS, стр. 364)
Подведем итоги
Повторное прочтение этого стиха в свете этого знания помогает мне понять, что Дух обладает всезнающим разумом Бога. От этого ничего не скрыто. Он раскрывает все, включая мысли и намерения сердец всех людей.Наша привилегия — стремиться к более близким отношениям со Святым Духом, чтобы познавать глубокие вещи и открывать нам тайны Бога через Духа и получать руководство для нашей жизни. Это идеальный личный наставник.
Пожалуйста, поделитесь своими мыслями и мыслями ниже и помните о Индексе цитирования СПД , когда вы изучаете Священные Писания и находите отрывок, о котором хотите узнать больше.
Нравится:
Нравится Загрузка …
Web of Science Citation Connection
Описание проекта
Библиотеки UCF запрашивают 86 827 долларов (87 827 долларов за вычетом доли в 1000 долларов от библиотек UCF) для единовременной покупки Web of Science (WoS) Citation Connection .Ресурсы содержимого, добавленные с помощью Citation Connection , включают:
- Индекс цитирования данных (DCI) — с 1900 г. по настоящее время (5 709 768 записей)
- Derwent Innovations Index (DII) — База данных патентов — 1963 г. — по настоящее время (30 136 471 запись)
- Указатель цитирования книг: Scholarly Books, 2005 — настоящее время (1 013 836 записей)
- Указатель цитирования трудов конференции: 1990 — настоящее время (8 550 021 запись)
- Index Chemicus (IC) — 1989-настоящее время (400 735 записей)
- Current Chemical Reactions (CCR) — 1993-настоящее время (235 964 записи)
- Current Contents Connect (CCC) — с 1998 г. по настоящее время (22 484 694 записи)
При покупке Citation Connection пользователи UCF получат полный доступ ко всем ресурсам, предлагаемым в настоящее время на платформе Web of Science, на которой уже размещены существующие подписки UCF на Core Journal Citation Indexes (т.e.Science Citation Index, Social Science Citation Index и Humanites Citation Index), Incites (JCR) и BioSIS. Citation Connection расширит доступ UCF к индексации цитирования к исследованиям, которые исторически трудно было отслеживать, особенно по ссылкам на книги, материалы конференций, данным и патентам как в глубоких архивах, так и в текущих файлах. Приобретение Citation Connection позволит UCF иметь полную индексацию WoS и ссылки на:
- Журналы — для своевременного формального представления научных работ, представляющих здравые, четко определенные концепции, соответствующие критериям коллег
- Proceedings — Предложите форум для первоначального представления концепций, которые показывают многообещающие, но могут потребовать дополнительного обсуждения, объяснения, тестирования или
- Книги. Для исчерпывающего обзора темы книги обычно предоставляют более широкий, глубокий и всесторонний подход, чем журналы и другие формы научного общения.
- Research Data — Вся информация, в любой форме, собранная во время исследования Истинный исходный материал, связанный с любым престижным исследовательским проектом.
- Патенты — Обеспечивая полное раскрытие всех деталей изобретения, патенты являются фундаментальным компонентом всемирной публикуемой научной информации. Важным источником технологии, но также и огромным количеством чистой научной информации.
Web of Science (WoS) — уважаемое академическое издательство, наиболее известное благодаря предоставлению уникального источника индексов и показателей цитирования.После тщательных переговоров, основанных на текущей подписке UCF на Web of Science, Incites (JCR) и Endnote, WoS предлагает Citation Connection по льготной ставке в 87 827 долларов, чтобы быть конкурентоспособным в процессе технологического сбора UCF. Кроме того, WoS также будет включать текущие данные всех этих индексов цитирования без каких-либо дополнительных затрат в наши текущие подписки WoS, что сделает эту разовую покупку еще более исключительной.
Доступ студентов к ресурсам проекта
Эти дополнительные индексы цитирования, предоставленные Citation Connection в Web of Science, предлагают уникальные функции, которые позволяют легко связывать и объединять различные ресурсы, например.грамм. журнальные статьи, книги, данные, научные труды и патенты, которые часто распространяются в широком диапазоне источников по частям.
Доступ к контенту может получить неограниченное количество одновременных пользователей (24 × 7), и нет ограничений на количество одновременных пользователей. UCF будет владеть коллекциями и, следовательно, будет удовлетворять учебные и исследовательские потребности сообщества UCF в будущем.
Citation Connection в Web of Science будет доступен для всех студентов, преподавателей и сотрудников UCF в любом месте, в любое время, 24 часа в сутки, 7 дней в неделю.Это также принесет пользу региональным кампусам UCF, онлайн-курсам и программам дистанционного обучения.
Студенты и преподаватели смогут найти контент, напрямую выполнив поиск в интерфейсе Web of Science, который доступен на странице Базы данных на домашней странице библиотеки UCF. Контент также будет представлен в тематических базах данных и справочниках библиотек. Все материалы и функции будут доступны через удобный интерфейс Web of Science, который предоставляет возможности для просмотра по коллекции, институциональной принадлежности или автору.Результаты легко экспортируются в различные форматы файлов, удобные для пользователей.
Web of Science позволит добросовестно использовать контент в образовательных целях, включая встраивание ссылок в веб-курсы и холст. Доступ будет доступен для всех студентов и сотрудников UCF, при этом доступ за пределами кампуса будет разрешен аутентификацией Shibboleth.
На основе индексов, включенных в Citation Connection , мы определили программы и колледжи, которые, вероятно, получат наибольшую выгоду от покупки этих коллекций.Студенты старших курсов бакалавриата и магистратуры особенно выиграют от этой покупки. Общее количество учащихся 30 790 подробно указано в таблице ниже. Кроме того, 2256 преподавателей UCF сочтут Citation Connection бесценным для своих преподавательских и исследовательских нужд.
В таблице ниже показан студент UCF, который получит прямую выгоду от покупки Web of Science Citation Connection .
КОЛЛЕДЖ ИЛИ ПРОГРАММА ПРИЕМ НА СТУДЕНТ (Senior +) Колледж инженерии и информатики 5 021 Медицинский колледж 1,097 Колледж оптики и фотоники 208 Колледж наук 5,089 Педагогический и гуманитарный колледж 3,773 Колледж здравоохранения и общественных дел 5,538 Колледж медсестер 1,550 Искусство и гуманитарные науки 2,852 Розен Колледж гостиничного менеджмента 1,455 Колледж делового администрирования 4,207 ИТОГО 30,790 Окончательный подсчет осенью 2015 г. по колледжам и майорам https: // ikm.ucf.edu/files/2016/03/Enrollment-2015-16-II.-Fall-2015.pdf
Поддержание этой коллекции требует небольшой ежегодной платы за платформу, которая типична для цифровых коллекций такого качества. Библиотеки UCF будут финансировать этот ежегодный взнос из существующих фондов. Весь контент и функции, связанные с Web of Science, будут размещаться в Web of Science, поэтому никаких новых требований к персоналу или инфраструктуре UCF не возникнет.
Пособие для обучения студентов
Citation Connection в Web of Science добавит большую коллекцию цитат, раскрывая научный ландшафт, который трудно найти другим способом.В отличие от типичных библиотечных ресурсов, которые, как правило, включают в себя полный текст журнальных статей, книг и документов. Web of Science предоставляет ссылки на этот научный контент, связывает различные источники с помощью цитат в едином интерфейсе и производит аналитику, которая измеряет влияние на результаты исследований. WoS специализируется на индексировании цитирования, позволяя исследователям отслеживать эволюцию темы исследования с помощью «тематического» поиска и определять влияние одной публикации или автора на другие статьи, книги и предметы с помощью поиска «по цитированию работы».WoS включает инструменты анализа для отслеживания количества цитирований статей и авторов, в результате чего создается единый интерфейс для поиска аналитики, которая измеряет влияние на результаты исследований и подчеркивает достижения научного сообщества UCF.
Коллекции, отобранные для покупки, тесно связаны с курсами UCF, особенно с теми, которые относятся к выпускным или старшим курсам бакалавриата, где назначаются более интенсивные исследования. Это один из лучших единственных ресурсов, где можно найти результаты различных исследований по теме, чтобы сформировать всеобъемлющую исследовательскую идею, которая может иметь решающее значение для разработки любого предложения о гранте студентами и преподавателями.Студенты, изучающие общественные науки и дисциплины STEM, могут найти ссылки на данные, относящиеся к 1900 году, которые обычно трудно идентифицировать. Точно так же студенты STEM получат доступ к ссылкам на патенты из Derwent Innovation Index за 1963 год. Не менее интересным является то, что при покупке будут добавлены ссылки на книги и материалы конференций, что должно принести пользу студентам и преподавателям социальных и гуманитарных наук. Citation Connection также расширит аналитику, предоставляемую нашими текущими подписками на Web of Science, выделив студентов и ученых с высокой отдачей и высокой производительностью по сравнению с аналогичными университетами.
Преподаватели поддерживают предложенную покупку как для своего обучения, так и для исследований, например, при разработке заявки на грант:
Они принесут пользу студентам (AMPAC, NSTC и MSE), а также выпускникам, которые проходят несколько курсов по методам (например, EGN1111 и EMA6111) или работают над повышением своих компетенций в области методов (например, бакалавриат проводится ежегодно). В этом поможет нынешний факультет.
Др.Судипта Seal , доктор философии, университет Заслуженный Профессор и профессор Pegasus, директор Нанотехнологического центра UCF (NSTC), Центра перспективной обработки и анализа материалов (AMPAC) и материаловедения и инженерии (MSE)
Я считаю, что материалы Web of Science будут очень полезным дополнением к библиотечным ресурсам как часть
tec h f ee предложение t ha t is be ing d. Th e mater ials ac quir e d w ould bene fi 9018 9018 indian 9018 9018 9018 eng дюйм eer дюйм g un dergr adua te s и gr 9018 sdua 9018 9018 9018 9018 9018 9018 tedua 9018 a re tak ing ряд классов методов, таких как промышленная инженерия, например, обязательный курс для всех докторских степеней промышленной инженерии.Студенты D или студенты, которые работают над расширением своих исследовательских возможностей. Кроме того, он будет напрямую поддерживать исследования доктора философии в области промышленного машиностроения. студенты и преподаватели кафедры.
Dr.W ald emar Karw o w s k П ч.Д. , D.Sc. , P .E. , C. P .E., Pega sus Pr of e sso r и Стул
Одна новая функция WOS кажется особенно многообещающей: Citation Connection. В то время как многие из наших преподавателей и студентов знакомы с использованием Google Scholar, Citation Connection предлагает ссылки на документы конференций, книги и многое другое с помощью единого поиска.Если позволяет бюджет приобретения, я надеюсь, что вы подумаете о добавлении этого ресурса в нашу коллекцию.
Д-р Дэйв Л. Эдиберн , доктор философии, декан ассоциации по исследованиям и развитию факультета, Педагогический колледж и человеческая деятельность
Я рад написать это письмо поддержки предложений по оплате технических услуг, которые добавят важную базу данных в коллекцию баз данных Web of Science — Citation Connection.
Я считаю, что материалы Web of Science будут очень полезным дополнением к библиотечным ресурсам в рамках рассматриваемого предложения по оплате за технические услуги. Они принесут пользу студентам, изучающим гражданские, экологические и строительные инженеры, а также выпускникам, которые изучают несколько классов методов (например, CCE4404 и CWR5515) или работают над повышением своей компетенции в области методов (например, проекты бакалавриата для междисциплинарного дисплея для инженерного анализа Ежегодно в Департаменте CECE проводится мероприятие по статике (IDEAS).
Доктор Динбао Ван , Доктор философии, доцент кафедры гражданского, экологического и строительного проектирования
Это предложение направлено на удовлетворение потребности преподавателей и студентов в доступе к важной информации для разработки заявки на грант, подготовки и распространения рукописей и студенческих проектов. В частности, сеть научного цитирования Connection состоит из ряда специальных ресурсов от Derwent for Patents до Data Citation Index и BIOSIS.В Web of Science используется общая система классификации, которая позволяет пользователям любого уровня знаний пользоваться этими мощными ресурсами.
Citation Connection в Web of Science также предоставит учащимся полный спектр научных работ. Платформа предоставляет студентам возможность понять, как можно объединить несколько форм научного общения, чтобы получить полную картину исследовательской идеи. Связывая исследования с помощью ссылок, студенты увидят, как различные формы научных результатов играют определенную роль в мире исследований.Как исследователь и профессор UCF я полностью одобряю и поддерживаю UCF в приобретении этой столь необходимой платформы.
Д-р Элеазар Васкес III , доктор философии, BCBA-D, доцент кафедры детских, семейных и общественных наук, Педагогический колледж и гуманитарная деятельность, научный сотрудник iSTEM
Библиотеки UCF работают напрямую с преподавателями и студентами, например: Колледж последипломного образования, факультетский центр преподавания и обучения для публикации этих материалов.Библиотеки будут предлагать информационные материалы для распространения во время различных мероприятий, таких как конференции по развитию факультетов. Кроме того, библиотекари будут рассказывать студентам о Web of Science, включая Citation Connection, во время занятий по информационной грамотности. Citation Connection на Web of Science принесет пользу преподавателям, предоставив контент для исследований факультета и контент для заданий курса.
Метрики успеха проекта и план оценки
Библиотеки UCF будут измерять успех Citation Connection в Web of Science с помощью отчетов и опросов удовлетворенности.Отчеты COUNTER (отраслевой стандартный формат для онлайн-статистики использования) будут отслеживать количество поисков и кликов в стандартном формате.
Отобранным преподавателям и студентам будет предложено прокомментировать эти продукты. Ожидается, что благодаря уникальному содержанию и другому интерфейсу Web of Science будет расти на 3–10% в год в течение первых трех лет. Содержимое в Citation Connection является уникальным и не доступно иначе. Ожидается, что студенты и преподаватели сочтут этот контент очень полезным.
После внедрения Citation Connection библиотеки UCF будут проводить обучение по использованию контента посредством множества информационных возможностей как для студентов, так и для преподавателей. Библиотекари-предметники будут сотрудничать с академическими программами и подразделениями, указанными выше, для его продвижения. Сеансы библиографических инструкций, индивидуальные справочные занятия, индивидуальные исследовательские консультации и LibGuides будут использоваться для продвижения коллекции и предоставления необходимых инструкций.Кроме того, отобранные преподаватели и студенты могут попросить комментарии для качественной оценки.
Библиотеки будут ежегодно измерять успех Citation Connection с помощью данных об использовании COUNTER, предоставляемых административным сайтом Web of Science. Годовые отчеты об использовании включены в годовой отчет библиотек и будут служить важным ориентиром. Для достижения значимой количественной оценки будет проведено трехлетнее сравнение временных рядов через три года после полного использования этих ресурсов.
Устойчивость проекта
Запрошенные средства покроют всю стоимость покупки Web of Science Citation Connection . Кроме того, текущие ссылки на все индексы, включенные в Citation Connection, будут автоматически включены в общую подписку Web of Science. Библиотеки будут поддерживать ссылки и поддерживать доступ. Любые текущие расходы на поддержание коллекции будут оплачиваться из фондов библиотеки.Весь контент и функции, связанные с Web of Science, будут размещаться в Web of Science, поэтому никаких новых требований к персоналу или инфраструктуре UCF не возникнет.
Описание бюджета предложения по вознаграждению за технологии
Запрошенное финансирование платы за технологию в размере 86 827 долларов США в сочетании с долей в размере 1 000 долларов США на библиотеки UCF покроет всю покупку Citation Connection у Web of Science.
Стоимость на одного одновременно обслуживаемого студента оценивается в 2 доллара (87 827 долларов / 30 790 = 2 доллара), исходя из непосредственной выгоды для студентов.Однако эта цена на студента может вводить в заблуждение, потому что преподаватели и другие студенты могут получать доступ к продуктам неограниченное время. Со временем стоимость использования может быть намного ниже.
Web of Science стремится участвовать в процессе выплаты вознаграждения UCF Technology Fee и поэтому предложила единовременную плату в размере 87 827 долларов США за покупку Citation Connection. Кроме того, UCF получит доступ ко всему текущему контенту, охватываемому различными индексами, что делает это предложение исключительным.
Космическое управление
Место для проекта не требуется.
Влияние исследований | Библиотека Калифорнийского университета в Беркли
Почему мы говорим о воздействии?
Помимо прочего, вам может помочь осознание вашего научного вклада:
- Укрепите свою позицию при подаче заявления о повышении или повышении в должности
- Количественно оценить рентабельность инвестиций в исследования для продления грантов и отчетов о ходе работы
- Укрепляйте будущие запросы на финансирование, показывая ценность вашего исследования
- Понять свою аудиторию и научиться обращаться к ней
- Определите, кто использует вашу работу, и подтвердите, что она должным образом указана
- Определите соавторов в пределах или за пределами вашей предметной области
- Управляйте своей научной репутацией
Измерение вашего воздействия
Измерение воздействия — несовершенная наука, и многие вообще возражают против этого.Здесь мы просто хотим представить информацию о существующих статистических показателях, чтобы вы могли принимать обоснованные решения о том, как и стоит ли оценивать свое влияние.
Часто для измерения воздействия используются такие метрики, как: метрики уровня статьи , метрики уровня автора , метрики журнала или издателя и альтернативных метрик .
Показатели на уровне статьи
Метрики на уровне статей позволяют количественно оценить охват и влияние опубликованных исследований.Для этого мы можем использовать различные показатели, такие как количество цитирований, влияние цитирования, взвешенное по полю, или статистику читательской аудитории в социальных сетях.
например Количество цитирований : Сколько раз цитировалась ваша статья? Это может быть трудно оценить и придать смысл. Очевидно, что то, насколько свежа ваша статья, влияет на количество ее цитирований. Кроме того, база данных или источник статистики сильно влияет на подсчет, потому что база данных должна иметь возможность сканировать большое количество возможных мест, где можно было бы цитировать вашу статью, — и не все базы данных имеют доступ к одной и той же информации в этом отношении.
например Влияние на цитируемость с учетом поля : Поскольку публикациям требуется время для накопления цитирований, это нормально, что общее количество цитирований для последних статей меньше. Более того, ссылки на исследования в одной области могут накапливаться быстрее, чем в других, потому что в этой области просто публикуется больше публикаций. Поэтому вместо сравнения абсолютного количества цитирований вы можете рассмотреть другой показатель цитирования, называемый средневзвешенным влиянием цитирования (также известный как FWCI), который корректирует эти различия.Взвешенное значение цитирования делит количество цитирований, полученных публикацией, на среднее количество цитирований, полученных публикациями в той же области, того же типа и опубликованными в том же году. Среднее значение в мире индексируется до 1,00. Значения выше 1,00 указывают на влияние цитирования выше среднего, а значения ниже 1,00 также указывают на влияние цитирования ниже среднего. Однако это частная статистика, а это означает, что вам потребуется доступ к продукту SCOPUS от Elsevier, который предоставляет Калифорнийский университет в Беркли.
например Уровень читаемости сайта в социальных сетях : Другой показатель на уровне статьи — это что-то вроде читательской аудитории Mendeley, которая показывает количество пользователей Mendeley, которые добавили определенную статью в свою личную библиотеку. Это число считается ранним индикатором влияния работы, и обычно количество читателей Mendeley умеренно коррелирует с будущими цитированиями.
Показатели на уровне автора
Показатели на уровне автора отражают продуктивность автора и разнообразие охвата.Мы можем обратиться к показателям общей научной продукции, количества журналов, количества категорий журналов, а также H-индекса или H-графика.
например Количество журналов: Количество журналов указывает на разнообразие портфолио публикаций автора: в скольких различных журналах появились публикации этого автора? Это может быть полезно, чтобы показать превосходство авторов, которые работают в традиционных дисциплинах и имеют широкий спектр журналов, в которые можно подавать заявки.
эл.грамм. Количество категорий журналов : Количество категорий журналов адресов, в скольких категориях журналов кто-то опубликовал. Это может быть полезно для отслеживания широты / охвата стипендий и междисциплинарности.
- например H-index: H-index — это метрика на уровне автора, которая пытается измерить как продуктивность, так и влияние цитируемости публикаций ученого или ученого. Определение индекса таково, что ученый с индексом h опубликовал h статей, каждая из которых цитировалась в других статьях не менее h раз.Считается, что после 20 лет исследований индекс h 20 — хороший, 40 — выдающийся, 60 — действительно исключительный.
Показатели журнала или издателя
например Вывод ученых: Выводы ученых демонстрируют продуктивность автора: сколько публикаций у этого автора? Это хороший показатель для сравнения авторов, которые похожи и находятся на аналогичном этапе карьеры.
Показатели журнала или издателя указывают на вес или престиж, который, как считается, несут конкретные публикации.Некоторые меры включают:
например Рейтинг журнала SCImago и рейтинг страны : Рейтинг журнала SCImago и рейтинг страны можно считать «средним престижем статьи» и основан на том, что не все ссылки на вашу работу одинаковы. (Другими словами, ваши статьи могут цитироваться в публикациях разного престижа.) Здесь предметная область, качество и репутация журналов, в которых цитируются ваши публикации, имеют прямое влияние на «ценность» цитирования.
например Влияние на публикацию (IPP): IPP дает вам представление о среднем количестве цитирований, которое, вероятно, получит публикация, опубликованная в журнале. Он измеряет соотношение цитирований на статью, опубликованную в журнале. В отличие от стандартного импакт-фактора, метрика IPP использует трехлетнее окно цитирования, которое широко считается оптимальным периодом времени для точного измерения цитирований в большинстве предметных областей.
эл.грамм. Нормализованное по источнику влияние на статью: При нормализации для цитирования в предметной области необработанное влияние на публикацию (IPP) становится Нормализованным воздействием на источник на статью (SNIP). SNIP измеряет влияние контекстного цитирования путем взвешивания цитат на основе общего количества цитирований в предметной области. Воздействию одной цитаты придается большее значение в предметных областях, где цитирование менее вероятно, и наоборот.
Альтметрики
Альтметрики учитывают «нетрадиционные» цитирования ваших научных работ.Они обращаются к тому факту, что научные дискуссии вышли за рамки рецензируемой статьи. Люди теперь, например, пишут в Твиттере и блогах о ваших статьях, и альтметрики накапливают эти упоминания. Чтобы узнать, как ваша работа цитируется и используется таким образом, узнайте больше на Altmetric.com.
Мониторинг вашего воздействия
Существует множество существующих и новых инструментов, которые помогут вам отслеживать ваш научный вклад, позволяя вам создать виртуальный научный профиль, в котором вы вводите и отслеживаете всю свою профессиональную деятельность и публикации.
При выборе одного из этих инструментов полезно учитывать:
- Из каких источников информации выбранные вами инструменты «извлекают» или индексируют? Чем большее количество источников может «прочитать» инструмент, тем полнее будут ваши показатели.
- Какова бизнес-модель вашего инструмента? Является ли это коммерческим и доступным с премиум-функциями за определенную плату, или это бесплатная платформа, доступная для всех? Например, Symplectic’s Elements и Elsevier’s Pure — это лицензированные платформы, которые часто обходятся учреждению дорого, тогда как Impact Story, ORCID и Google Scholar предлагают бесплатные профильные услуги.
- Распространяли ли вы копии своих научных материалов также через репозиторий учреждения? Многие инструменты профилирования не ориентированы на фактическое сохранение копии вашей работы. Итак, чтобы копия вашей работы оставалась общедоступной, лучше всего убедиться, что вы также разместили копию в своем институциональном репозитории (в случае UC это eScholarship.org).
Имея это в виду, вот несколько инструментов профилирования, из которых вы можете выбрать:
ImpactStory:
С их сайта: «Impactstory — это веб-сайт с открытым исходным кодом, который помогает исследователям изучать и делиться воздействием своих исследований в Интернете.Помогая исследователям рассказывать истории о своей работе, основанные на данных, мы помогаем создать новую систему поощрения ученых, которая ценит и поощряет стипендии, присущие Интернету. Мы финансируемся Национальным научным фондом и Фондом Альфреда П. Слоана и зарегистрированы как некоммерческая корпорация 501 (c) (3) «.
ORCID:
С их сайта: ORCID предоставляет идентификатор для использования людьми со своим именем, когда они занимаются исследованиями, стипендиями и инновационной деятельностью.Мы предоставляем открытые инструменты, которые обеспечивают прозрачные и надежные связи между исследователями, их вкладом и членством. Мы предоставляем эту услугу, чтобы помочь людям найти информацию и упростить отчетность и анализ ».
Цитирование в Google Scholar
С их сайта: Google Scholar Citations предоставляет авторам простой способ отслеживать цитирование их статей. Вы можете проверить, кто цитирует ваши публикации, построить график цитирования с течением времени и вычислить несколько показателей цитирования.Вы также можете сделать свой профиль общедоступным, чтобы он мог отображаться в результатах Google Scholar, когда люди ищут ваше имя … Лучше всего, его быстро настроить и легко поддерживать, даже если вы написали сотни статей и даже если ваше имя разделяют несколько разных ученых. Вы можете добавлять группы связанных статей, а не только одну статью за раз; а ваши показатели цитирования вычисляются и обновляются автоматически по мере того, как Google Scholar находит новые ссылки на вашу работу в Интернете. Вы можете выбрать автоматическое обновление списка статей, просмотр обновлений самостоятельно или обновление статей вручную в любое время.
ResearchGate
С их сайта: делитесь своими публикациями, получайте доступ к миллионам других и публикуйте свои данные. Общайтесь и сотрудничайте с коллегами, коллегами, соавторами и специалистами в своей области. Получите статистику и узнайте, кто читал и цитировал ваши работы.
Academia.edu
С их сайта: Academia.edu — это платформа, где ученые могут делиться исследовательскими работами. Миссия компании — ускорить мировые исследования.Ученые используют Academia.edu для того, чтобы делиться своими исследованиями, отслеживать глубокую аналитику воздействия своих исследований и отслеживать исследования ученых, за которыми они следят.
Платные или проприетарные системы профилирования, такие как Elements или Pure.
Это программные системы, помогающие собирать, понимать и демонстрировать научную деятельность. В настоящее время они недоступны в Калифорнийском университете в Беркли.
Повышение вашего влияния
В целом мы рекомендуем три всеобъемлющие стратегии для повышения вашего научного влияния:
А.Расскажите о своей работе и процитируйте ее
B. Продвигайте свою работу и будьте социальными
C. Разработка и выполнение личного плана
Мы обсудим каждую из этих стратегий с подробностями ниже.
A. Расскажите о своей работе и процитируйте ее
Публикуйте препринты или пост-отпечатки в репозиториях с открытым доступом.
Институциональные или специализированные репозитории с открытым доступом (например, eScholarship.org для публикаций UC, BioArXiv, Humanities Commons и т. Д.)) позволяют вам самостоятельно архивировать копию своей работы, чтобы она была доступна бесплатно читателям по всему миру. Моревоер, эти репозитории проиндексированы в Google, чтобы можно было легко найти вашу стипендию. Это потрясающий способ привлечь внимание читателей и увеличить влияние, а также способствует прогрессу и знаниям, делая версию своей работы доступной для всех. Чтобы выбрать репозиторий, который подходит именно вам, вы можете проверить DOAR (Каталог репозиториев открытого доступа).
Как преподаватель, штатный сотрудник или студент UC, вы автоматически получаете право в соответствии с политиками открытого доступа UC размещать предпечатную копию ваших научных статей (в широком смысле) в репозиторий UC, eScholarship.Вы также можете проверить веб-инструмент Sherpa / ROMEO, чтобы определить, есть ли другие версии вашей стипендии, которые ваш издатель разрешил для депозита.
Опубликовать в открытом доступе.
Открытый доступ — это бесплатная, немедленная онлайн-доступность стипендии. Это означает, что когда люди публикуют научную статью в журнале с открытым доступом, она публикуется в сети для любого доступа — без необходимости для читателей (или читательских учреждений) платить за нее какие-либо сборы или абонентскую плату (также известную как «платный доступ»). .
Paywall ограничивает читателей. Огромная ценность публикации в открытом доступе означает, что барьеры между читателями и научными публикациями устранены, что упрощает для всех поиск, использование, цитирование и развитие знаний и идей. Таким образом, открытый доступ связывает вашу стипендию с миром и помогает повысить ваше влияние. Публикация в открытом доступе часто является условием финансирования исследований, поэтому вам следует проверять свои гранты.
Издатели с открытым доступом могут запросить плату за публикацию вашей стипендии в Интернете вместо сборов, которые они обычно получали бы от институционального членства в журнале или публикации.Библиотека Калифорнийского университета в Беркли имеет фонд для покрытия этих расходов. Вы можете узнать больше в нашем Руководстве BRII (Berkeley Research Impact Initiative) о подаче заявки на это финансирование.
Все результаты исследований доступны в открытом доступе.
Ваша «последняя» публикация — традиционно статья, глава или научная монография — не единственное, что читатели хотят получить и процитировать. Вы также можете публиковать свои исследовательские данные, код, программное обеспечение, презентации, рабочие документы и другие подтверждающие документы и документацию в открытом доступе.Фактически, в некоторых случаях это может потребоваться вашим спонсорам. Совместное использование этих других исследовательских инструментов не только способствует развитию знаний и науки, но также может помочь повысить ваше влияние и цитируемость.
Вы можете найти подходящее открытое место для всех ваших выходов. Например, можно:
- Опубликовать код на GitHub
- Публикация наборов данных на FigShare или Dryad
- Публикация презентаций на SlideShare
Опубликуйте несколько статей по той же теме.
Если вы написали журнальную статью, вы можете рассказать о ней, дополнив ее сообщением в блоге или журнальной статьей, тем самым привлекая большее внимание читателей, интересующихся вашей темой. Более того, публикация вашей статьи в открытом доступе с самого начала также помогает журналистам узнавать о вашей работе, облегчая им написание собственных дополнительных журнальных статей о ваших исследованиях.
Пишите для своей аудитории и публикуйте в источниках, которые они читают.
Конечно, многие из нас хотели бы иметь возможность публиковаться в журналах с большим влиянием или в журналах, ориентированных на нашу аудиторию. Чтобы найти наиболее подходящие журналы, может быть полезно просмотреть объем журнала и критерии подачи заявок, а также сравнить те, с которыми, по вашему мнению, является ваша предполагаемая аудитория.
Используйте постоянные идентификаторы, чтобы отличить вас и вашу работу от других авторов.
В мире более 7 миллиардов человек. Если кто-то ищет ваши статьи по вашему имени, как вы можете быть уверены, что они найдут ваши, а не чужие? Как вы можете быть уверены, что цитаты действительно отражают цитаты вашей работы, а не чужой? Постоянные идентификаторы — как для вас, так и для ваших публикаций — помогают устранить неоднозначность.
- ORCID: во многом так же, как номер социального страхования однозначно идентифицирует вас, ORCID «обеспечивает постоянный цифровой идентификатор, который отличает вас от любого другого исследователя, и, благодаря интеграции в ключевые рабочие процессы исследования, такие как отправка рукописей и грантов, поддерживает автоматическое связь между вами и вашей профессиональной деятельностью, гарантирующая признание вашей работы ». . Издатели и спонсоры все чаще запрашивают ваш ORCID при подаче статьи или заявки, чтобы они также могли отличить вас от других исследователей.ORCID можно создавать бесплатно, и это занимает считанные минуты. Они также позволяют вам создать страницу личного веб-профиля, на которой вы можете связать всю стипендию со своим уникальным идентификатором, создав профиль, который будет уникальным для вас.
- Идентификаторы цифровых объектов (DOI): DOI — это тип постоянного идентификатора, который используется для уникальной идентификации цифровых объектов, таких как научные статьи, главы или наборы данных. Метаданные о цифровом объекте хранятся в связи с DOI, который часто включает URL-адрес, по которому можно найти объект.Значение DOI состоит в том, что идентификатор остается фиксированным в течение всего срока существования цифрового объекта , даже если вы позже измените конкретный URL-адрес, на котором размещена ваша статья. Таким образом, обращение к онлайн-документу по его DOI обеспечивает более стабильную связь, чем простое использование его URL. По этой причине издатели и репозитории часто присваивают DOI каждой из ваших публикаций. Если вы являетесь исследователем Калифорнийского университета в Беркли и вносите депозит в систему электронных стипендий, вы можете получить DOI через службу EZID.
Б.Продвигайте свою работу и будьте социальными
Хотя для некоторых людей это может показаться слишком хвалебным, обсуждение вопросов, интересующих вас и вашу аудиторию, может помочь позиционировать вас как идейного лидера в вашей сфере. Поэтому может быть полезно участвовать и сотрудничать в продвижении и обсуждении вашей работы через социальные сети, блоги, рассылки, личные сети и многое другое.
И не упускайте из виду свои исследования, которые все еще продолжаются! Обсуждение того, что происходит, может вызвать интерес.
C. Разработайте и выполните личный план.
Возможно, лучший способ усилить свое влияние — разработать план, адаптированный к вашим потребностям, и периодически проверять себя, работает ли он. Ваш план должен быть сосредоточен на тактике, которая сделает вашу работу видимой, доступной и многоразовой .
Как мог бы выглядеть такой план? Вот пример, который вы можете адаптировать:
- Создать и поддерживать онлайн-профиль (GoogleScholar и т. Д.))
- Используйте постоянные идентификаторы (например, ORCID, DOI) для устранения неоднозначности / связывания
- Публикуйте в журналах открытого доступа или выберите варианты открытого доступа
- Creative Commons лицензирует вашу работу для повторного использования
- Публикация пре- или пост-распечаток в репозитариях (eScholarship, PubMed Central и т. Д.)
- Сделайте взаимодействие в социальных сетях привычкой
- Вовлекайте аудиторию в содержательное обсуждение
- Связаться с другими исследователями
- Обращение к разным аудиториям через несколько публикаций
- Проверьте свои цели
Вопросы?
Вы хотите больше поговорить о стратегиях адаптации, которые подходят именно вам? Пожалуйста, свяжитесь с нами по адресу schol-comm @ berkeley.