sql — MySQL индексы и ускорение выборки данных
Вопрос задан
Изменён 6 лет 5 месяцев назад
Просмотрен 3k раза
Создаётся простая таблица данных:
CREATE TABLE IF NOT EXISTS `table_1` (
id INT NOT NULL AUTO_INCREMENT,
user_id INT( 33 ),
user_name VARCHAR( 255 ),
PRIMARY KEY ( `id` )
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci
Как видно из этого примера, в колонке id создаются уникальные ключи (за счёт AUTO_INCREMENT). Поле user_id также содержит уникальные значения идентификаторов пользователей, генерируемые скриптом (использую mt_rand) во время регистрации в личном кабинете.
Для выборки делаю следующий запрос:
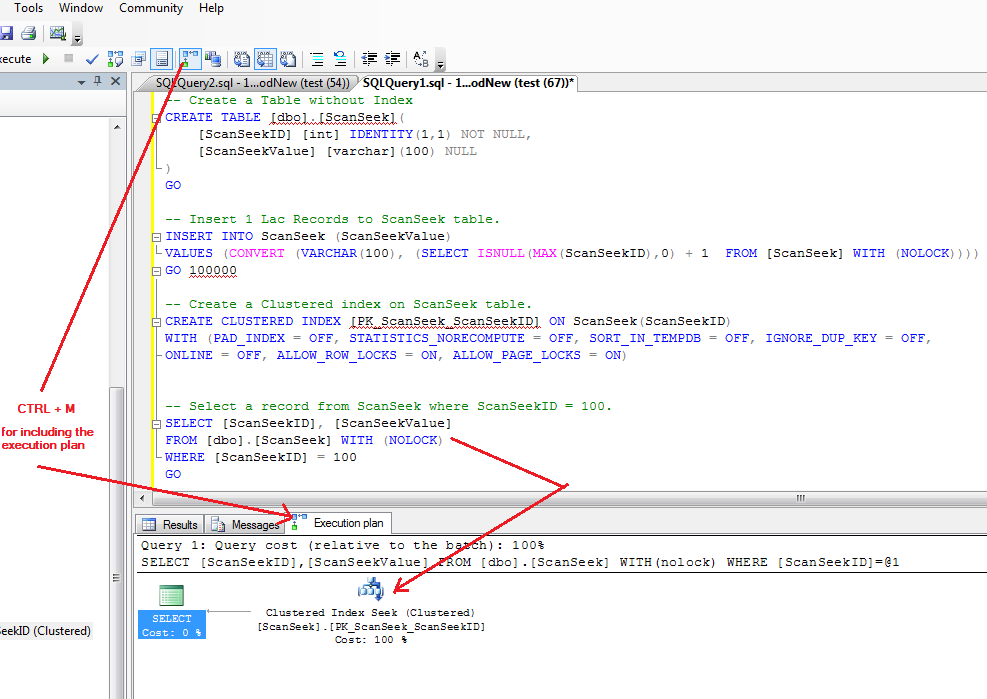
SELECT `user_name` FROM `table_1` WHERE `user_id`=28572
Задумался об использовании индексов в своей таблице данных, для ускорения выборки.
Наличие индекса может существенно повысить скорость выполнения некоторых запросов и сократить время поиска необходимых данных за счет физического или логического их упорядочивания.
Вопросы:
Нужно ли создавать индексы для поля
user_idдля ускорения выборки из миллионов записей, если все значения идентификаторов в этом поле и так уникальны?Если всё таки нужно, то какой индекс создать: кластерный или не кластерный (не совсем понимаю различия между ними)?
Условие
WHERE(в моём примере сверху) заставляет СУБД перебирать все записи в таблице? Или же СУБД сразу обращается конкретно только к тем записям, которые удовлетворяют условиям поиска (
- mysql
- sql
5
Нужно ли создавать индексы для поля user_id для ускорения выборки из миллионов записей, если все значения идентификаторов в этом поле и так уникальны?
Да, нужно — потому что собираетесь часто делать выборку из таблицы по признаку содержимого этого поля. Раз архитектурой обусловлена уникальность данных, попадающих в это поле, будет хорошей идеей использовать UNIQUE индекс. Если на поле назначен уникальный индекс — БД не даст вставить запись с дублирующимся его значением. Такой шаг в сторону нормализации.
Раз архитектурой обусловлена уникальность данных, попадающих в это поле, будет хорошей идеей использовать UNIQUE индекс. Если на поле назначен уникальный индекс — БД не даст вставить запись с дублирующимся его значением. Такой шаг в сторону нормализации.
Если всё таки нужно, то какой индекс создать: кластерный или не кластерный(не совсем понимаю различия между ними)?
Кластерный индекс не нужен, пока Вы явно не осознаете его необходимость. Сюрприз: в InnoDB первичный ключ всегда кластерный. И он у Вас уже есть. Не думайте пока об этом.
Условие WHERE заставляет СУБД перебирать все записи в таблице?
Да. Узнать это (и многое другое) можно, выполнив запрос с ключевым словом EXPLAIN перед ним ( Это дорогая с точки зрения ввода-вывода операция, поэтому грамотная расстановка индексов — суть половина успеха оптимизации БД для быстрой работы.
Это дорогая с точки зрения ввода-вывода операция, поэтому грамотная расстановка индексов — суть половина успеха оптимизации БД для быстрой работы.
Добавлю к ответу @Mirdin
Класерный индекс физически упорядочивает таблицу по индексу. Самый быстрый (для поиска). Очевидно что он может быть только один. PK всегда кластерный индекс по умолчанию.
Вы можете сократить время выполнения на 50% (в среднем) если добавите
LIMIT 0,1— т.к. база не знает о уникальности вашего столбца. Без лимита она будет перебирать все значения таблицы, даже если уже найдёт совпадение.
Но правильно да, сделать этот столбец:
ALTER TABLE `table_1` ADD UNIQUE INDEX `user_id`
Касательно вашего комментария. Это довольно сложный вопрос и он сильно зависит от того какие запросы вы делаете. Если у вас составной индекс по столбцам (А, Б, В) то индекс принесёт пользу когда вы ищете (WHERE) по одному или нескольким столбам слева, т.
А, (А и Б), (А и Б и В). А если вы ищете только по Б — работать не будет. С другой стороны если у вас есть отдельные индексы по, например A и Б, то при включении обоих полей скорее всего отработает только 1 индекс, а второй будет простой поиск (хотя тут я не уверен). Нужно понимать что наибольший урон приходится на первую фильтрацию — т.е. когда сканируется таблица на миллион записей, например. Если по одному индексу отсеялось 99%, то поиск по 10000 записей, даже без индекса, уже не так смертельно.В общем как вы наверное поняли однозначного ответа нет. Действуйте последовательно, добавьте один индекс и посмотрите на результат. Вполне возможно что одного индекса будет достаточно.
4
- Да, если часто фильтруете именно по этому полю.
- Не кластерный, у вас уже есть PK.
- Сервер не владеет магией, поэтому, если нет индекса, будет перебирать все записи в таблице, если есть то пройдется по структуре которую реализует индекс, но это тоже не «сразу обращается конкретно только к тем записям».
 ..
..
 ..
..P.S. Написал вообщем, конкретно в MySQL могут быть какие-то отличия.
Мои пять копеек, хоть и спустя год, но для будущих поколений: — если вы используете админку для редактирования/удаления табл пользователей, то поле id желательно, хотя можно обойтись и без него. В этом случае сделайте так:
CREATE TABLE IF NOT EXISTS `table_1` (
user_id INT( 33 ) NOT NULL,
user_name VARCHAR( 255 ),
PRIMARY KEY ( `user_id` )
) ENGINE=InnoDB
Если все-таки, поле id (PK) принципиально необходимо, то в вашем случае лучше использовать HASH индексы:
CREATE TABLE IF NOT EXISTS `table_1` (
id INT NOT NULL AUTO_INCREMENT,
user_id INT( 33 ),
user_name VARCHAR( 255 ),
PRIMARY KEY ( `id` ),
UNIQUE INDEX idx_user (user_id) USING HASH
) ENGINE=InnoDB
Время доступа по индексу типа HASH будет О(1) в отличие от O(lg2(N)) для BTREE, на больших объемах — это в принципе заметно.
Ваш ответ
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
| Разница между HASH и BTREE индесами в MySQL | |
| Hash: | |
| — представляет собой результат функции по ключу | |
| — не видит растояния до ближайших элементов | |
| — не может использоваться для операций диапазонов > и < | |
| — сравнивание ключа целиком | |
| — линейный при индексировании | |
| — О(1) при вытаскивании значения | |
| BTREE: | |
| — индекс индексов | |
| — сбалансированное дерево в листьях которого гаранируется одинаковое количество предков | |
| — поиск по диапазонам, =, >, >=, <, <=, or BETWEEN operators | |
| — для поиска можно использовать префикс ключа | |
| — может быть использован для сравнения LIKE, если аргумент LIKE является постоянной строкой, которая не начинается с шаблонного символа | |
| Например, следующие SELECT, операторы используют индексы: | |
| SELECT * FROM имя_таблицы WHERE key_col LIKE ‘Patrick%’; | |
| SELECT * FROM имя_таблицы WHERE key_col LIKE ‘Pat%_ck%’; | |
| — В первом заявлении, только строки с «Patrick» <= key_col < ‘Patricl’ считаются | |
— Во втором заявлении, только строки с «Pat» <= key_col < ‘Pau’ считаются. | |
| Следующие SELECT не используют индексы: | |
| SELECT * FROM имя_таблицы WHERE key_col LIKE ‘% Patrick%’; | |
| SELECT * FROM имя_таблицы WHERE key_col LIKE other_col; | |
| — В первом заявлении LIKE значение начинается с символа подстановки. | |
| — Во втором заявлении LIKE значение не является постоянной величиной. | |
| InnoDb и MyISAM: | |
| — первичный индекс (PRIMARY KEY) только BTREE | |
| MEMORY | |
| — первичный индекс (PRIMARY KEY) по умолчанию HASH, можно выбрать BTREE | |
| NDB | |
| — можно использовать как BTREE, так и HASH | |
MySQL 5. 7 7 | |
| CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name | |
| [index_type] | |
| ON tbl_name (index_col_name,…) | |
| [index_option] | |
| [algorithm_option | lock_option] … | |
| index_col_name: | |
| col_name [(length)] [ASC | DESC] | |
| index_type: | |
| USING {BTREE | HASH} | |
| index_option: | |
| KEY_BLOCK_SIZE [=] value | |
| | index_type | |
| | WITH PARSER parser_name | |
| | COMMENT ‘string’ | |
| algorithm_option: | |
| ALGORITHM [=] {DEFAULT|INPLACE|COPY} | |
| lock_option: | |
| LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE} |
Как индексировать столбцы JSON с помощью MySQL
Автор оригинала: Vlad Mihalcea.
Вступление
В этой статье я собираюсь объяснить, как мы можем индексировать столбцы JSON при использовании MySQL.
В то время как другие системы реляционных баз данных предоставляют индексы GIN (Обобщенный инвертированный индекс), MySQL позволяет вам индексировать виртуальный столбец, который отражает выражение пути JSON, которое вы хотите индексировать.
Таблица базы данных
Давайте предположим, что у нас есть следующая база данных книга таблица:
| id | isbn | properties |
|----|----------------|----------------------------------------------------------------|
| 1 | 978-9730228236 |{ |
| | | "price":44. 99, |
| | | "title":"High-Performance Java Persistence", |
| | | "author":"Vlad Mihalcea", |
| | | "reviews":[ |
| | | { |
| | | "date":"2017-11-14", |
| | | "rating":5, |
| | | "review":"Excellent book to understand Java Persistence", |
| | | "reviewer":"Cristiano" |
| | | }, |
| | | { |
| | | "date":"2019-01-27", |
| | | "rating":5, |
| | | "review":"The best JPA ORM book out there", |
| | | "reviewer":"T. W" |
| | | }, |
| | | { |
| | | "date":"2016-12-24", |
| | | "rating":4, |
| | | "review":"The most informative book", |
| | | "reviewer":"Shaikh" |
| | | } |
| | | ], |
| | | "publisher":"Amazon" |
| | |} |
|----|----------------|----------------------------------------------------------------|
 99, |
| | | "title":"High-Performance Java Persistence", |
| | | "author":"Vlad Mihalcea", |
| | | "reviews":[ |
| | | { |
| | | "date":"2017-11-14", |
| | | "rating":5, |
| | | "review":"Excellent book to understand Java Persistence", |
| | | "reviewer":"Cristiano" |
| | | }, |
| | | { |
| | | "date":"2019-01-27", |
| | | "rating":5, |
| | | "review":"The best JPA ORM book out there", |
| | | "reviewer":"T.
99, |
| | | "title":"High-Performance Java Persistence", |
| | | "author":"Vlad Mihalcea", |
| | | "reviews":[ |
| | | { |
| | | "date":"2017-11-14", |
| | | "rating":5, |
| | | "review":"Excellent book to understand Java Persistence", |
| | | "reviewer":"Cristiano" |
| | | }, |
| | | { |
| | | "date":"2019-01-27", |
| | | "rating":5, |
| | | "review":"The best JPA ORM book out there", |
| | | "reviewer":"T. W" |
| | | }, |
| | | { |
| | | "date":"2016-12-24", |
| | | "rating":4, |
| | | "review":"The most informative book", |
| | | "reviewer":"Shaikh" |
| | | } |
| | | ], |
| | | "publisher":"Amazon" |
| | |} |
|----|----------------|----------------------------------------------------------------|
W" |
| | | }, |
| | | { |
| | | "date":"2016-12-24", |
| | | "rating":4, |
| | | "review":"The most informative book", |
| | | "reviewer":"Shaikh" |
| | | } |
| | | ], |
| | | "publisher":"Amazon" |
| | |} |
|----|----------------|----------------------------------------------------------------|
Тип столбца свойства – json , поэтому мы можем хранить объекты JSON как свойства книги.
Запрос столбцов MySQL JSON без индекса
Если мы попытаемся отфильтровать одну запись по ее связанному заголовку атрибуту, расположенному внутри свойств JSONObject:
SELECT isbn FROM book WHERE properties ->> "$.title" = 'High-Performance Java Persistence'
Сканирование всей таблицы будет использоваться для фильтрации всех записей, найденных в таблице книга :
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "50. 25"
},
"table": {
"table_name": "book",
"access_type": "ALL",
"rows_examined_per_scan": 500,
"rows_produced_per_join": 500,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "50.00",
"prefix_cost": "50.25",
"data_read_per_join": "140K"
},
"used_columns": [
"isbn",
"properties"
],
"attached_condition": "(
json_unquote(
json_extract(
`high_performance_sql`.`book`.`properties`,'$.title'
)
) = 'High-Performance Java Persistence'
)"
}
}
}
 25"
},
"table": {
"table_name": "book",
"access_type": "ALL",
"rows_examined_per_scan": 500,
"rows_produced_per_join": 500,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "50.00",
"prefix_cost": "50.25",
"data_read_per_join": "140K"
},
"used_columns": [
"isbn",
"properties"
],
"attached_condition": "(
json_unquote(
json_extract(
`high_performance_sql`.`book`.`properties`,'$.title'
)
) = 'High-Performance Java Persistence'
)"
}
}
}
25"
},
"table": {
"table_name": "book",
"access_type": "ALL",
"rows_examined_per_scan": 500,
"rows_produced_per_join": 500,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "50.00",
"prefix_cost": "50.25",
"data_read_per_join": "140K"
},
"used_columns": [
"isbn",
"properties"
],
"attached_condition": "(
json_unquote(
json_extract(
`high_performance_sql`.`book`.`properties`,'$.title'
)
) = 'High-Performance Java Persistence'
)"
}
}
}
Тип доступа ВСЕ означает, что все страницы были отсканированы, что также подтверждается атрибутом rows_examined_per_scan , поскольку в таблице книга у нас всего 500 записей.
Добавьте виртуальный столбец MySQL для индексирования выражения пути JSON
В MySQL единственный способ индексировать выражение JSONPath-это добавить виртуальный столбец, который отражает рассматриваемое выражение пути, и создать индекс для виртуального столбца.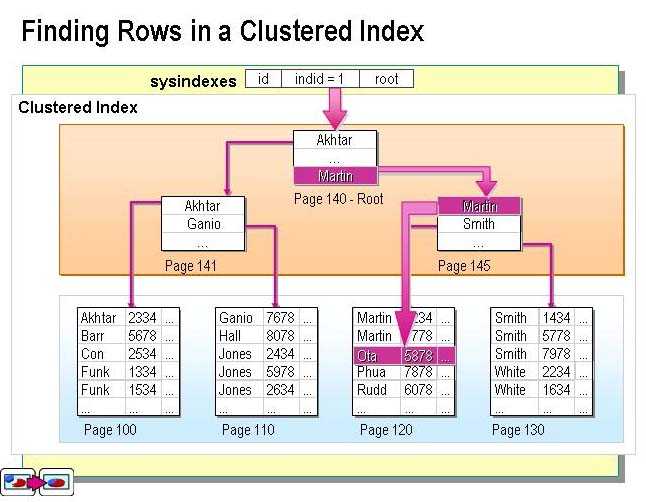
По этой причине мы собираемся добавить следующий заголовок виртуальный столбец в нашу книгу таблицу:
ALTER TABLE book ADD COLUMN title VARCHAR(50) GENERATED ALWAYS AS ( properties ->> \"$.title\" )
Как вы можете видеть, столбец title сопоставляется с выражением $.title пути в столбце свойства JSON.
Далее мы добавим индекс в столбец title , например:
CREATE INDEX book_title_idx ON book (title)
И при повторном выполнении предыдущего SQL-запроса мы теперь получаем следующий план выполнения:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "0. 35"
},
"table": {
"table_name": "book",
"access_type": "ref",
"possible_keys": [
"book_title_idx"
],
"key": "book_title_idx",
"used_key_parts": [
"title"
],
"key_length": "203",
"ref": [
"const"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 1,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "0.10",
"prefix_cost": "0.35",
"data_read_per_join": "288"
},
"used_columns": [
"isbn",
"properties",
"title"
]
}
}
}
 35"
},
"table": {
"table_name": "book",
"access_type": "ref",
"possible_keys": [
"book_title_idx"
],
"key": "book_title_idx",
"used_key_parts": [
"title"
],
"key_length": "203",
"ref": [
"const"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 1,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "0.10",
"prefix_cost": "0.35",
"data_read_per_join": "288"
},
"used_columns": [
"isbn",
"properties",
"title"
]
}
}
}
35"
},
"table": {
"table_name": "book",
"access_type": "ref",
"possible_keys": [
"book_title_idx"
],
"key": "book_title_idx",
"used_key_parts": [
"title"
],
"key_length": "203",
"ref": [
"const"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 1,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "0.10",
"prefix_cost": "0.35",
"data_read_per_join": "288"
},
"used_columns": [
"isbn",
"properties",
"title"
]
}
}
}
Не то, чтобы атрибут ключ ссылался на только что созданный индекс book_title_idx , что означает, что SQL-запрос не использует индекс для фильтрации записей book , что также подтверждается атрибутом rows_examined_per_scan , поскольку была отсканирована одна строка индекса.
Обновление индексированного атрибута JSON
Если вы обновите индексированный атрибут JSON:
UPDATE
book
SET
properties = JSON_SET(
properties,
'$. title',
'High-Performance Java Persistence, 2nd edition'
)
WHERE
isbn = '978-9730228236'
 title',
'High-Performance Java Persistence, 2nd edition'
)
WHERE
isbn = '978-9730228236'
title',
'High-Performance Java Persistence, 2nd edition'
)
WHERE
isbn = '978-9730228236'
Вы увидите, что виртуальный столбец title соответствующим образом обновлен:
| id | isbn | properties | title |
|----|----------------|----------------------------------------------------------------|------------------------------------------------|
| 1 | 978-9730228236 |{ | High-Performance Java Persistence, 2nd edition |
| | | "price":44.99, | |
| | | "title":"High-Performance Java Persistence, 2nd edition", | |
| | | "author":"Vlad Mihalcea", | |
| | | "reviews":[ | |
| | | { | |
| | | "date":"2017-11-14", | |
| | | "rating":5, | |
| | | "review":"Excellent book to understand Java Persistence", | |
| | | "reviewer":"Cristiano" | |
| | | }, | |
| | | { | |
| | | "date":"2019-01-27", | |
| | | "rating":5, | |
| | | "review":"The best JPA ORM book out there", | |
| | | "reviewer":"T. W" | |
| | | }, | |
| | | { | |
| | | "date":"2016-12-24", | |
| | | "rating":4, | |
| | | "review":"The most informative book", | |
| | | "reviewer":"Shaikh" | |
| | | } | |
| | | ], | |
| | | "publisher":"Amazon" | |
| | |} | |
|----|----------------|----------------------------------------------------------------|------------------------------------------------|
 W" | |
| | | }, | |
| | | { | |
| | | "date":"2016-12-24", | |
| | | "rating":4, | |
| | | "review":"The most informative book", | |
| | | "reviewer":"Shaikh" | |
| | | } | |
| | | ], | |
| | | "publisher":"Amazon" | |
| | |} | |
|----|----------------|----------------------------------------------------------------|------------------------------------------------|
W" | |
| | | }, | |
| | | { | |
| | | "date":"2016-12-24", | |
| | | "rating":4, | |
| | | "review":"The most informative book", | |
| | | "reviewer":"Shaikh" | |
| | | } | |
| | | ], | |
| | | "publisher":"Amazon" | |
| | |} | |
|----|----------------|----------------------------------------------------------------|------------------------------------------------|
Однако, хотя вы можете изменить индексированный атрибут JSON, вам не разрешается изменять виртуальный столбец напрямую. Если вы попытаетесь это сделать, MySQL выдаст исключение.
Если вы попытаетесь это сделать, MySQL выдаст исключение.
Вывод
Типы столбцов JSON могут быть очень полезны, особенно если вы внедряете журнал аудита .
Хотя добавление индекса GIN в столбцы JSON в MySQL запрещено, вы можете определить виртуальный столбец и добавить к нему индекс.
Однако вам необходимо убедиться, что атрибут JSON, который вы используете для индексирования, является высокоселективным, так как в противном случае компонент database engine может не использовать индекс при создании плана выполнения SQL.
Индексы и порядок MySQL [mysql, indexing, sql-order-by]
Это вопрос, который у меня был навсегда.
Насколько я знаю, порядок индексов имеет значение. Таким образом, такой индекс, как [first_name, last_name], – это не то же самое, что [last_name, first_name], верно?
Если я определяю только первый индекс, значит ли это, что он будет использоваться только для
SELECT * FROM table WHERE first_name="john" AND last_name="doe";
а не для
SELECT * FROM table WHERE last_name="doe" AND first_name="john";
Поскольку я использую ORM, я понятия не имею, в каком порядке будут вызываться эти столбцы. Означает ли это, что я должен добавлять индексы ко всем перестановкам? Это выполнимо, если у меня индекс из 2 столбцов, но что произойдет, если мой индекс будет состоять из 3 или 4 столбцов?
Означает ли это, что я должен добавлять индексы ко всем перестановкам? Это выполнимо, если у меня индекс из 2 столбцов, но что произойдет, если мой индекс будет состоять из 3 или 4 столбцов?
mysql indexing sql-order-by
person Julien Genestoux schedule 09.08.2009 source источник
Ответы (3)
arrow_upward
59
arrow_downward
Порядок индекса имеет значение, когда условия запроса применяются только к ЧАСТИ индекса. Рассмотреть возможность:
SELECT * FROM table WHERE first_name="john" AND last_name="doe"SELECT * FROM table WHERE first_name="john"SELECT * FROM table WHERE last_name="doe"
Если ваш индекс (first_name, last_name), запросы 1 и 2 будут использовать его, а запрос № 3 — нет. Если ваш индекс (
Если ваш индекс (last_name, first_name), запросы 1 и 3 будут использовать его, а запрос № 2 — нет. Изменение порядка условий в предложении WHERE ни в том, ни в другом случае не влияет.
Подробности здесь
Обновление:
Если вышеизложенное неясно, MySQL может использовать индекс только в том случае, если столбцы в условиях запроса образуют крайний левый префикс индекса. Запрос № 2 выше не может использовать индекс (last_name, first_name), поскольку он основан только на first_name, а first_name НЕ является крайним левым префиксом индекса (last_name, first_name).
Порядок условий ВНУТРИ запроса не имеет значения; запрос № 1 выше сможет использовать индекс (last_name, first_name) просто отлично, потому что его условия first_name и last_name и, взятые вместе, они ДЕЙСТВИТЕЛЬНО образуют крайний левый префикс индекса (last_name, first_name).
person ChssPly76 schedule 09.08.2009
arrow_upward
5
arrow_downward
ChssPly76 прав в том, что порядок логических выражений не обязательно должен совпадать с порядком столбцов в индексе. Логические операторы являются коммутативными, и оптимизатор MySQL достаточно умен, чтобы знать, как сопоставить выражение с показатель в большинстве случаев.
Я также хочу добавить, что вы должны научиться использовать EXPLAIN функция MySQL, чтобы вы могли сами увидеть, какие индексы оптимизатор выберет для данного запроса.
person Community schedule 09.08.2009
arrow_upward
3
arrow_downward
Почему бы не расширить ответ немного, чтобы сразу все было кристально ясно.
Если таблица имеет индекс с несколькими столбцами, оптимизатор может использовать любой крайний левый префикс индекса для поиска строк. Например, если у вас есть индекс с тремя столбцами для (col1, col2, col3), у вас есть возможности индексированного поиска для (col1), (col1, col2) и (col1, col2, col3).
MySQL не может использовать индекс, если столбцы не образуют крайний левый префикс индекса. Предположим, что у вас есть операторы SELECT, показанные здесь:
SELECT * FROM tbl_name WHERE col1=val1; SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2; SELECT * FROM tbl_name WHERE col2=val2; SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;
Если индекс существует для (col1, col2, col3), только первые два запроса используют этот индекс. Третий и четвертый запросы включают индексированные столбцы, но (col2) и (col2, col3) не являются крайними левыми префиксами (col1, col2, col3). — Разработчик MySQL
— Разработчик MySQL
person Berky schedule 06.04.2014
Понимание индексов в MySQL: часть первая
блог
Лукас Вилейкис
Индексы в MySQL — очень сложный зверь. Мы рассматривали индексы MySQL в прошлом, но мы никогда не погружались в них глубже — мы сделаем это в этой серии сообщений в блоге. Этот пост в блоге должен служить очень общим руководством по индексам, в то время как в других частях этой серии эти темы будут рассмотрены немного глубже.
Что такое индексы?
В общем, как уже отмечалось в предыдущей записи блога об индексах, индекс представляет собой алфавитный список записей со ссылками на страницы, на которых они упоминаются. В MySQL индекс — это структура данных, которая чаще всего используется для быстрого поиска строк. Вы также можете услышать термин «ключи» — он также относится к индексам.
Что делают индексы?
В MySQL индексы используются для быстрого поиска строк с определенными значениями столбцов и предотвращения чтения всей таблицы для поиска каких-либо строк, относящихся к запросу. Индексы в основном используются, когда данные, хранящиеся в системе баз данных (например, MySQL), становятся больше, потому что чем больше таблица, тем выше вероятность того, что вы могли бы извлечь выгоду из индексов.
Типы индексов MySQL
Что касается MySQL, вы, возможно, слышали о наличии нескольких типов индексов:
ИНДЕКС B-дерева — такой индекс часто используется для ускорения запросов SELECT, соответствующих предложению WHERE. Такой индекс можно использовать в полях, значения которых не обязательно должны быть уникальными, он также принимает значения NULL.
ПОЛНОТЕКСТНЫЙ ИНДЕКС — такой индекс используется для использования возможностей полнотекстового поиска.
Этот тип индекса находит ключевые слова в тексте вместо прямого сравнения значений со значениями в индексе.УНИКАЛЬНЫЙ ИНДЕКС часто используется для удаления повторяющихся значений из таблицы. Обеспечивает уникальность значений строки.
ПЕРВИЧНЫЙ КЛЮЧ также является индексом — он часто используется вместе с полями, имеющими атрибут AUTO_INCREMENT. Этот тип индекса не принимает значения NULL, и после установки значения в столбце, который имеет ПЕРВИЧНЫЙ КЛЮЧ, не могут быть изменены.
ИНДЕКС ПО УБЫВАНИЮ — это индекс, в котором строки хранятся в порядке убывания. Этот тип индекса был представлен в MySQL 8.0 — MySQL будет использовать этот тип индекса, когда запросом запрашивается убывающий порядок.
 Этот тип индекса находит ключевые слова в тексте вместо прямого сравнения значений со значениями в индексе.
Этот тип индекса находит ключевые слова в тексте вместо прямого сравнения значений со значениями в индексе.Выбор оптимальных типов данных для индексов в MySQL
Что касается индексов, также необходимо помнить, что MySQL поддерживает широкий спектр типов данных, и некоторые типы данных нельзя использовать вместе с определенными типами индексов ( например, индексы FULLTEXT можно использовать только для текстовых столбцов (CHAR, VARCHAR или TEXT) — они не могут использоваться для любых других типов данных), поэтому, прежде чем выбирать индексы для своей базы данных, определитесь с типом данных. будет использоваться в рассматриваемом столбце (решите, какой класс данных вы собираетесь хранить: вы собираетесь хранить числа? строковые значения? как числа, так и строковые значения? и т. д.), затем определите диапазон значений, которые вы собираетесь хранить. которые вы собираетесь хранить (выберите тот, который, по вашему мнению, вы не превысите, потому что увеличение диапазона типов данных может оказаться трудоемкой задачей позже — мы рекомендуем вам использовать простой тип данных), и если вы не намереваетесь использовать значения NULL в своих столбцах, укажите ваши поля как NOT NULL всякий раз, когда вы можете — когда столбец, допускающий значение NULL, индексируется, для каждой записи требуется дополнительный байт.
будет использоваться в рассматриваемом столбце (решите, какой класс данных вы собираетесь хранить: вы собираетесь хранить числа? строковые значения? как числа, так и строковые значения? и т. д.), затем определите диапазон значений, которые вы собираетесь хранить. которые вы собираетесь хранить (выберите тот, который, по вашему мнению, вы не превысите, потому что увеличение диапазона типов данных может оказаться трудоемкой задачей позже — мы рекомендуем вам использовать простой тип данных), и если вы не намереваетесь использовать значения NULL в своих столбцах, укажите ваши поля как NOT NULL всякий раз, когда вы можете — когда столбец, допускающий значение NULL, индексируется, для каждой записи требуется дополнительный байт.
Выбор оптимальных наборов символов и сопоставлений для индексов в MySQL
Помимо типов данных, также имейте в виду, что каждый символ в MySQL занимает место. Например, каждый символ UTF-8 может занимать от 1 до 4 байтов, поэтому вы можете не индексировать, например, 255 символов и использовать только, скажем, 50 или 100 символов для определенного столбца.
Преимущества и недостатки использования индексов в MySQL
Основным преимуществом использования индексов в MySQL является повышение производительности поисковых запросов, соответствующих предложению WHERE. Индексы ускоряют выполнение запросов SELECT, соответствующих предложению WHERE, поскольку MySQL не считывает всю таблицу, чтобы найти строки, относящиеся к запросу. Однако имейте в виду, что индексы имеют свои недостатки. Основные из них следующие:
Индексы занимают место на диске.
Индексы снижают производительность запросов INSERT, UPDATE и DELETE — при обновлении данных индекс необходимо обновлять вместе с ним.
MySQL не защищает вас от одновременного использования нескольких типов индексов. Другими словами, вы можете использовать PRIMARY KEY, INDEX и UNIQUE INDEX для одного и того же столбца — MySQL не защитит вас от такой ошибки.
Если вы подозреваете, что некоторые из ваших запросов становятся медленнее, рассмотрите возможность заглянуть на вкладку «Монитор запросов» в ClusterControl. помочь вам выбрать лучшие индексы для вашей таблицы.
Как выбрать лучший индекс для использования?
Чтобы выбрать лучший индекс для использования, вы можете использовать встроенные механизмы MySQL. Например, вы можете использовать объяснитель запросов — запрос EXPLAIN. Он объяснит, какая таблица используется, есть ли в ней разделы или нет, какие индексы можно использовать и какой ключ (индекс) используется. Он также вернет длину индекса и количество строк, которые возвращает ваш запрос:
mysql> EXPLAIN SELECT * FROM demo_table WHERE demo_field = ‘demo’G
*************************** 1-й ряд ********************** *******
идентификатор: 1
select_type: ПРОСТОЙ
таблица: demo_table
разделы: NULL
тип: ссылка
возможные_ключи: demo_field
ключ: demo_field
key_len: 1022
ссылка: константа
ряды: 1
отфильтровано: 100. 00
Дополнительно: НОЛЬ
1 строка в наборе, 1 предупреждение (0,00 с)  00
Дополнительно: НОЛЬ
1 строка в наборе, 1 предупреждение (0,00 с)
00
Дополнительно: НОЛЬ
1 строка в наборе, 1 предупреждение (0,00 с) В этом случае имейте в виду, что индексы часто используются, чтобы помочь MySQL эффективно извлекать данные, когда наборы данных больше, чем обычно. Если ваша таблица небольшая, вам может не понадобиться использовать индексы, но если вы видите, что ваши таблицы становятся все больше и больше, скорее всего, вы можете извлечь выгоду из индекса.
Тем не менее, чтобы выбрать лучший индекс для вашего конкретного сценария, имейте в виду, что индексы также могут быть основной причиной проблем с производительностью. Имейте в виду, что будет ли MySQL эффективно использовать индексы или нет, зависит от нескольких факторов, включая дизайн ваших запросов, используемые индексы, типы используемых индексов, а также загрузку вашей базы данных во время выполнения запроса и другие вещи. Вот несколько вещей, которые следует учитывать при использовании индексов в MySQL:
Сколько у вас данных? Возможно, что-то из этого лишнее?
Какие запросы вы используете? Будут ли в ваших запросах использоваться предложения LIKE? Что насчет заказа?
Какой тип индекса вам нужно использовать для повышения производительности ваших запросов?
Будут ли ваши индексы большими или маленькими? Вам нужно использовать индекс для префикса столбца, чтобы уменьшить его размер?
Стоит отметить, что вам, вероятно, следует избегать использования нескольких типов индексов (например, индекса B-Tree, UNIQUE INDEX и PRIMARY KEY) в одном и том же столбце.
Повышение производительности запросов с помощью индексов
Чтобы повысить производительность запросов с помощью индексов, вам нужно взглянуть на свои запросы — в этом может помочь инструкция EXPLAIN. В целом, если вы хотите, чтобы индексы повышали производительность ваших запросов, вам следует учитывать несколько вещей:
- .
Запрашивайте базу данных только о том, что вам нужно. В большинстве случаев использование столбца SELECT будет быстрее, чем использование SELECT * (то есть без использования индексов)
Индекс B-дерева может подойти, если вы ищете точные значения (например, SELECT * FROM demo_table WHERE some_field = ‘x’) или если вы хотите искать значения с использованием подстановочных знаков (например, SELECT * FROM demo_table WHERE some_field LIKE ‘demo %’ — в этом случае имейте в виду, что использование запросов LIKE с чем-либо в начале может принести больше вреда, чем пользы — избегайте использования запросов LIKE со знаком процента перед текстом, который вы ищете — таким образом MySQL может не использовать индекс, потому что он не знает, с чего начинается значение строки) — хотя имейте в виду, что индекс B-дерева также может использоваться для сравнения столбцов в выражениях, которые используют равенство (=), больше, чем (> ), больше или равно (>=), меньше (
Полнотекстовый индекс может подойти, если вы обнаружите, что используете полнотекстовые поисковые запросы (MATCH … AGAINST()) или если ваша база данных спроектирована таким образом, что использует только текстовые столбцы — индексы FULLTEXT могут использовать TEXT, CHAR или столбцы VARCHAR, их нельзя использовать для столбцов любых других типов.
Покрывающий индекс может быть полезен, если вы хотите выполнять запросы без дополнительного чтения операций ввода-вывода для больших таблиц. Чтобы создать покрывающий индекс, закройте предложения WHERE, GROUP BY и SELECT, используемые в запросе.

Мы подробнее рассмотрим типы индексов в следующих частях этой серии блогов, но в целом, если вы используете такие запросы, как SELECT * FROM demo_table WHERE some_field = ‘x’, B-tree INDEX может подойти, если вы используете запросы MATCH() AGAINST(), вам, вероятно, следует изучить индекс FULLTEXT, если в вашей таблице очень длинные значения строк, вам, вероятно, следует изучить индексацию части столбца.
Сколько индексов нужно иметь?
Если вы когда-либо использовали индексы для повышения производительности ваших запросов SELECT, вы, вероятно, задавались вопросом: сколько индексов у вас должно быть на самом деле? Чтобы это понять, нужно помнить следующее: 9. 0003
0003
Индексы обычно наиболее эффективны при работе с большими объемами данных.
MySQL использует только один индекс для каждого оператора SELECT в запросе (подзапросы рассматриваются как отдельные операторы) — используйте запрос EXPLAIN, чтобы узнать, какие индексы наиболее эффективны для используемых вами запросов.
Индексы должны сделать все ваши операторы SELECT достаточно быстрыми без слишком большого ущерба для дискового пространства — однако «достаточно быстро» является относительным, поэтому вам придется поэкспериментировать.
Индексы и механизмы хранения
При работе с индексами в MySQL также имейте в виду, что могут быть некоторые ограничения, если вы используете различные механизмы (например, если вы используете MyISAM, а не InnoDB). Подробнее мы расскажем в отдельном блоге, а вот несколько идей:
Подробнее мы расскажем в отдельном блоге, а вот несколько идей:
Максимальное количество индексов на таблицы MyISAM и InnoDB — 64, максимальное количество столбцов на индекс в обоих механизмах хранения — 16.
Максимальная длина ключа для InnoDB — 3500 байт, максимальная длина ключа для MyISAM — 1000 байт.
Полнотекстовые индексы имеют ограничения в некоторых механизмах хранения — например, полнотекстовые индексы InnoDB имеют 36 стоп-слов, список стоп-слов MyISAM немного больше и содержит 143 стоп-слова. InnoDB извлекает эти стоп-слова из переменной innodb_ft_server_stopword_table, а MyISAM извлекает эти стоп-слова из файла storage/myisam/ft_static.c — все слова, найденные в файле, будут рассматриваться как стоп-слова.
MyISAM был единственным механизмом хранения с поддержкой параметров полнотекстового поиска, пока не появился MySQL 5.
6 (точнее, MySQL 5.6.4), что означает, что InnoDB поддерживает полнотекстовые индексы, начиная с MySQL 5.6.4. Когда используется индекс FULLTEXT, он находит ключевые слова в тексте, а не сравнивает значения напрямую со значениями в индексе.Индексы играют очень важную роль для InnoDB — InnoDB блокирует строки при доступе к ним, поэтому уменьшение количества строк, к которым обращается InnoDB, может уменьшить количество блокировок.
MySQL позволяет использовать повторяющиеся индексы для одного и того же столбца.
Некоторые механизмы хранения имеют определенные типы индексов по умолчанию (например, для механизма хранения MEMORY тип индекса по умолчанию — хеш)
 6 (точнее, MySQL 5.6.4), что означает, что InnoDB поддерживает полнотекстовые индексы, начиная с MySQL 5.6.4. Когда используется индекс FULLTEXT, он находит ключевые слова в тексте, а не сравнивает значения напрямую со значениями в индексе.
6 (точнее, MySQL 5.6.4), что означает, что InnoDB поддерживает полнотекстовые индексы, начиная с MySQL 5.6.4. Когда используется индекс FULLTEXT, он находит ключевые слова в тексте, а не сравнивает значения напрямую со значениями в индексе.Резюме
В этой части об индексах в MySQL мы рассмотрели некоторые общие моменты, связанные с индексами в этой системе управления реляционными базами данных. В следующих сообщениях блога мы рассмотрим несколько более подробных сценариев использования индексов в MySQL, включая использование индексов в определенных механизмах хранения и т. д., а также объясним, как можно использовать ClusterControl для достижения ваших целей производительности в MySQL.
В следующих сообщениях блога мы рассмотрим несколько более подробных сценариев использования индексов в MySQL, включая использование индексов в определенных механизмах хранения и т. д., а также объясним, как можно использовать ClusterControl для достижения ваших целей производительности в MySQL.
21 сентября 2022 г. Алекс Ю
Внедрение Sovereign DBaaS с использованием ClusterControl и Conductor — часть I
2 августа 2022 г. Сара Моррис
ClusterControl добавляет масштабирование для Redis, SQL Server и Elasticsearch в последнем выпуске
.8 июня 2022 г. Кайл Баззелл
Архитектуры частного облака и локальной базы данных с ClusterControl
Подпишитесь, чтобы получать наш лучший и самый свежий контент
Подписка на рассылку новостей
Скрытый
Государственный
CAPTCHA
Индексация— mysql не использует index.
 помогите понять почему
помогите понять почемуЗадавать вопрос
Спросил
Изменено 1 год, 2 месяца назад
просмотрено 252 раза
есть тест таблицы:
показать создать тест таблицы; СОЗДАТЬ ТАБЛИЦУ `тест` ( `id` int(11) NOT NULL AUTO_INCREMENT, длинный текст `body` НЕ NULL, `timestamp` int(11) NOT NULL, `handle_after` datetime NOT NULL, `status` varchar(100) NOT NULL, `queue_id` varchar(255) НЕ NULL, ПЕРВИЧНЫЙ КЛЮЧ (`id`), KEY `idxTimestampStatus` (`отметка времени`,`статус`), KEY `idxTimestampStatus2` (`status`,`timestamp`) ) ДВИГАТЕЛЬ = InnoDB AUTO_INCREMENT = 80000 НАБОР ШИМОВ ПО УМОЛЧАНИЮ = utf8
есть два выбора
1) выберите * из теста, где статус = 'in_queue' и отметка времени > 1625721850; 2) выберите идентификатор из теста, где статус = 'in_queue' и отметка времени> 1625721850;
при первом выборе объясните, покажите мне, что индексы не используются
во втором выбранном индексе используется idxTimestampStatus.
MariaDB [db]> объяснить выбор * из теста, где статус = 'in_queue' и отметка времени > 1625721850; +------+-------------+-------+------+------------- ---------------------------+------+---------+----- -+----------+--------------+ | идентификатор | тип_выбора | стол | тип | возможные_ключи | ключ | key_len | ссылка | строки | Экстра | +------+-------------+-------+------+------------- ---------------------------+------+---------+----- -+----------+--------------+ | 1 | ПРОСТО | тест | ВСЕ | idxTimestampStatus, idxTimestampStatus2 | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | 80000 | Использование где | +------+-------------+-------+------+------------- ---------------------------+------+---------+----- -+----------+--------------+ MariaDB [db]> объяснить идентификатор выбора из теста, где статус = 'in_queue' и отметка времени > 1625721850; +------+-------------+-------+------+------------- ---------------------------+-------+ ---------+-------+-------+----------- -+ | идентификатор | тип_выбора | стол | тип | возможные_ключи | ключ | key_len | ссылка | строки | Экстра | +------+-------------+-------+------+------------- ---------------------------+-------+ ---------+-------+-------+----------- -+ | 1 | ПРОСТО | тест | ссылка | idxTimestampStatus, idxTimestampStatus2 | idxTimestampStatus2 | 302 | константа | 4 | Использование где; Использование индекса | +------+-------------+-------+------+------------- ---------------------------+-------+ ---------+-------+-------+----------- -+
Помогите мне понять, что я делаю не так? Как мне создать индекс для первого выбора? почему количество столбцов влияет на использование индекса?
- mysql
- индексирование
14
То, что вы видели, ожидаемо. («Количество столбцов» не вызвало того, что вы видели.) Прочитайте все пункты ниже; различные их комбинации должны охватывать все вопросы, затронутые как в Вопросе, так и в Комментарии.
(«Количество столбцов» не вызвало того, что вы видели.) Прочитайте все пункты ниже; различные их комбинации должны охватывать все вопросы, затронутые как в Вопросе, так и в Комментарии.
Выбор между сканированием индекса и таблицы:
- Оптимизатор использует статистику, чтобы выбрать между использованием индекса и выполнением полного сканирования таблицы.
- Если необходимо извлечь менее (около) 20 % строк, будет использоваться индекс. Это включает в себя скачки назад и вперед между BTree индекса и BTree данных.
- Если требуется больше таблицы, считается более эффективным просто просмотреть таблицу, игнорируя любые строки, которые не соответствуют
WHERE. - «20%» не является фиксированным числом.
SELECT id ... статус ... метка времени;
- В InnoDB вторичный индекс неявно включает столбцы
PRIMARY KEY. - Если все столбцы, упомянутые в запросе, находятся в индексе, то этот индекс является «покрывающим». Это означает, что всю работу можно выполнять в BTree индекса, не затрагивая BTree данных.
-
Использование индекса== «покрытие». (То естьEXPLAINдает эту подсказку.) - «Покрытие» имеет приоритет над обсуждением «20%».
 Это означает, что всю работу можно выполнять в BTree индекса, не затрагивая BTree данных.
Это означает, что всю работу можно выполнять в BTree индекса, не затрагивая BTree данных. SELECT * ... статус ... отметка времени;
-
SELECT *необходимо получить все столбцы, поэтому «покрытие» не применяется, и значение «20%» становится актуальным. - Если бы
1625721850было большим числом,EXPLAINпереключился бы сALLнаIndex.
idxTimestampStatus2 ( статус , метка времени )
- Порядок пунктов в
ГДЕимеет значение , а не . - Порядок столбцов в «составном» индексе важен. («Составной» == многоколоночный)
- Сначала поместите столбцы
=, затем один столбец «диапазон» (например,>).

Дополнительные обсуждения: http://mysql.rjweb.org/doc.php/index_cookbook_mysql
Твой ответ
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Индекс MySQL — ответы на все вопросы
Если вы работали с базами данных, термин индекс довольно распространен. Будь то реляционная база данных или база данных NoSql. Всякий раз, когда запрос занимает больше времени, первый вопрос, который мы слышим: используется ли столбец, в котором условие было проиндексировано?
Будь то реляционная база данных или база данных NoSql. Всякий раз, когда запрос занимает больше времени, первый вопрос, который мы слышим: используется ли столбец, в котором условие было проиндексировано?
Вот несколько часто задаваемых вопросов, которые помогут нам понять, как работает MySQL?
Как мои данные хранятся в MySQL?
MySQL хранит каждую таблицу в виде хэша (учтите, что пока сохраните это для другого поста), где у вас есть ключ индекса и значения строки, хранящиеся против него. Этот ключ индекса называется ключом индекса кластеризации.
Что такое индекс кластеризации?
Это специальный индекс, используемый MySQL для хранения фактических данных. Когда вы указываете первичный ключ, этот столбец будет использоваться в качестве ключа индекса кластеризации.
Учтите, что этот хеш представляет собой таблицу сообщения и ключ — это значение столбца первичного ключа, значение — это фактические данные строки.
{
«1» => {id: 1, title: «Индексирование Mysql», статус: «опубликовано»},
«2» => {id: 2, title: «Улучшение производительности запросов», статус: «черновик» «},
}
когда вы это сделаете, select * from posts where id=2
внутри он делает posts["2"] , что возвращает значения за время O(1).
Что произойдет, если я не укажу первичный ключ?
MySQL пытается найти столбец, который не равен нулю и имеет уникальный индекс. Если его нет, он автоматически создает скрытый кластеризованный индекс, используя идентификаторы строк.
сообщения = {
«rowid1» => {id: 1, title: «Индексирование Mysql», статус: «опубликовано»},
«rowid2» => {id: 2, title: «Улучшение производительности запросов», статус: «черновик»},
}
Теперь предположим, что id становится обычным столбцом без уникального/первичного индекса
Теперь MySQL должен просмотреть все значения, чтобы найти значение, для которого id=2. Не будет поля, которое можно запросить за время O(1). Вот почему всегда рекомендуется определять первичный ключ.
Не будет поля, которое можно запросить за время O(1). Вот почему всегда рекомендуется определять первичный ключ.
Как быстро выполняется поиск с primary_key независимо от размера таблицы?
Как вы теперь знаете, первичный ключ используется в качестве ключа индекса кластеризации, отсюда и высокая производительность.
Что происходит, когда я хочу проиндексировать другой столбец?
Чаще всего вы захотите выполнить запрос с некоторыми конкретными полями, и эти индексы, которые вы создаете для этих полей, называются некластеризованными индексами или вторичными индексами.
Чем он отличается от индекса кластеризации?
В индексе кластеризации хранятся фактические данные, тогда как в индексе без кластеризации хранится только ссылка на фактические данные.
Например, некластеризованный индекс статуса будет выглядеть как
(опять же, не вдаваясь в подробности)
index_on_status = {
«опубликовано» => [&ref1, &ref3, &ref4],
«черновик» => [&ref2, &eref5]
}
выберите * из сообщений, где статус = «опубликовано»
Этот запрос будет использовать индекс index_on_status по индексу первичного ключа, так как с использованием этого индекса можно искать только 3 строки, в то время как он должен искать во всех 5 строках с использованием индекса первичного ключа.
Как MySQL выбирает, какой индекс использовать?
При запуске запроса MySQL анализирует все возможные доступные индексы и идентифицирует индекс, который при использовании будет иметь наименьшее количество строк для поиска указанного условия.
Какой параметр здесь влияет на решение?
Количество элементов — это ключ к выбору индекса.
Проще говоря, кардинальность = уникальность столбца.
Чем выше кардинальность, тем лучше группировка записей и, следовательно, выше производительность поиска.
Вот почему первичный ключ имеет наилучшую возможную производительность, так как кардинальность максимальна. Каждый ключ будет иметь только одну запись для поиска.
Что делать, если кардинальность индексируемого столбца мала?
Это самая распространенная ошибка разработчиков. Рассмотрим столбец статус , который может иметь только 2 значения [‘опубликовано’, ‘черновик’]
По мере увеличения масштаба все записи будут группироваться только в пределах одного из этих двух ключей, и даже после использования этого индекса количество записей в который MySQL должен выполнять итеративный поиск, высок.
Какой столбец должен быть проиндексирован?
Опять же, это зависит от варианта использования приложения, но перед индексацией столбца разработчик должен проанализировать, как индекс поможет запросу. Во сколько раз мы уменьшаем количество поисков? Будет ли индекс работать в масштабе? Будет ли каждое ведро равномерно распределено во времени?
Поскольку индекс повышает производительность, почему бы не индексировать все столбцы по умолчанию?
Индексирование повышает производительность запросов, но требует дополнительного места для хранения, и каждый раз, когда выполняется операция вставки/удаления/обновления, все соответствующие индексы также должны обновляться. Это издержки использования индексов.
Что произойдет, если у меня есть два индекса и я выполняю запросы с обоими индексированными полями? Будут ли использоваться оба индекса?
MySQL выбирает только один индекс для поискового запроса из всех возможных индексов. Это распространенное заблуждение, что если мы проиндексируем два поля и используем их в запросе, запрос будет быстрым. НЕТ! Поймите, как MySQL выполняет внутренний поиск, и вам будет легко визуализировать поиск.
Это распространенное заблуждение, что если мы проиндексируем два поля и используем их в запросе, запрос будет быстрым. НЕТ! Поймите, как MySQL выполняет внутренний поиск, и вам будет легко визуализировать поиск.
Что, если я хочу выполнять поиск по двум полям и при этом получать более высокую производительность?
Композитный указатель на помощь.
Что такое составной индекс?
Это индексы для нескольких столбцов.
MySQL поддерживает до 16 столбцов для составного индекса.
Когда следует использовать составной индекс?
Если вы хотите выполнять поиск по нескольким полям, а индексация одного поля по-прежнему приводит к большому количеству строк, вы можете рассмотреть возможность создания составного индекса с нужными вам столбцами.
Могу ли я запросить все комбинации составного индекса?
№
Предположим, что составной индекс столбцов (created_at, status, likes)
Рассматривайте это как вложенный хэш слева направо. Этот индекс можно использовать при запросе с
Этот индекс можно использовать при запросе с
.а. created_at, статус, лайки
b. created_at, статус
c. created_at
Не при использовании любых других комбинаций.
Как я могу увидеть, какой индекс используется для запроса?
Использовать Объяснить . Объясните, наш отладчик в MySQL, который помогает нам посмотреть на
- Какие возможные ключи доступны для этого запроса?
- Какой индекс выбрал MySQL?
- Сколько строк будет найдено для этого запроса с использованием выбранного индекса?
Это все часто задаваемые вопросы, которые я имел в виду, не стесняйтесь оставлять вопросы, которые у вас есть, или обсуждать что-то конкретное.
Воспринимайте эту статью как фору, необходимую для более глубокого изучения особенностей.
Как индексы работают в Mysql
В этой серии статей мы углубимся в то, что такое индексы, как они работают, каковы преимущества и недостатки использования индексов, многостолбцовых индексов и какие есть подводные камни и ловушки. использования индекса.
использования индекса.
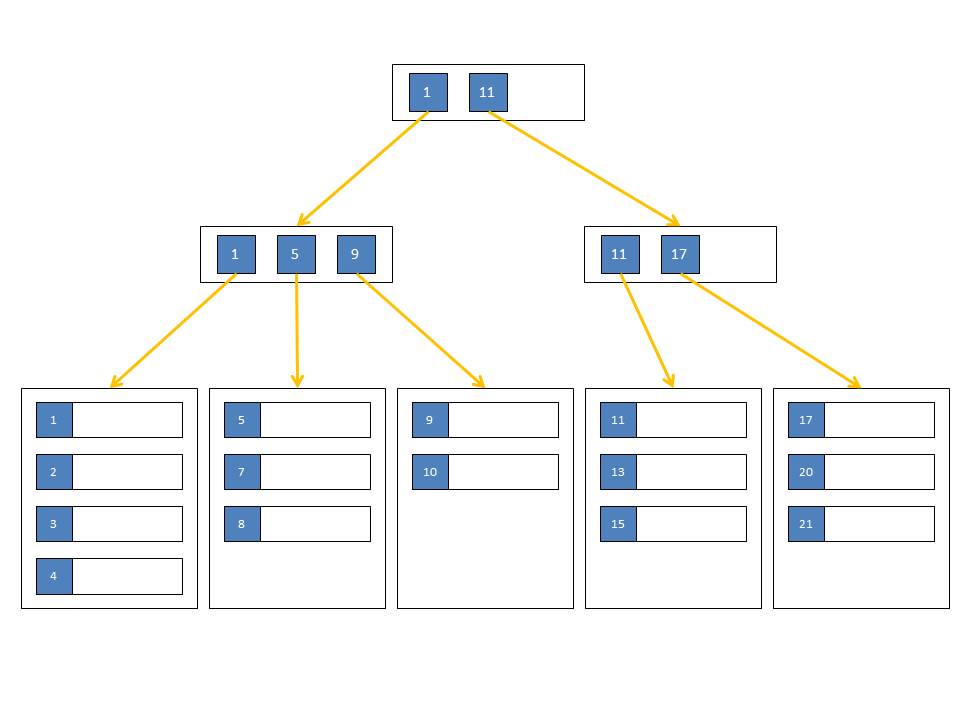
Мы часто сталкивались с примером индекса в книге как индекса базы данных. По сути, это хорошая отправная точка, которая поможет вам ответить на вопросы интервью, но давайте немного углубимся и посмотрим, что на самом деле происходит за кулисами. Индексы в основном представляют собой структуры данных, которые ускоряют чтение. Большинство индексов являются реализацией деревьев B+. Хотя это может быть и хэш-структура данных. Оба имеют свои плюсы и минусы. В этой статье мы увидим, как работают индексы B+ Tree.
Но зачем вообще нужен индекс? Давайте рассмотрим таблицу Employee всего с двумя столбцами, один для первичного ключа, а другой для имени. Теперь, если вы ищете сотрудника, он будет сканировать всю таблицу, и это проблема. Для таблицы, содержащей миллион записей, база данных должна будет сканировать все миллион строк, а это не масштабируется. Мало того, что запрос займет время, операции ввода-вывода и ЦП также будут потрачены впустую в этой операции сканирования.
Если мы посмотрим на столбец types для команды объяснения , мы увидим ALL , что означает полное сканирование таблицы. Следовательно, без индекса сложность поиска или запроса на чтение составляет O (n). Обратите внимание, что столбец rows представляет собой не общее количество строк, возвращенных из запроса, а общее количество строк, которые база данных должна будет просмотреть , чтобы выполнить запрос. Давайте создадим индекс для столбца name и снова посмотрим, как обстоят дела с запросом.
имя используется, как указано в поле ключа . Создав индекс, мы видим, что теперь тип изменился на ref с ВСЕ , также, если вы проверите столбец Extra , мы увидим Использование индекса , что означает, что все данные были обслужены. из индекса, и на таблицу не ссылались. Теперь, если вы помните, у нас есть индекс только по столбцу
из индекса, и на таблицу не ссылались. Теперь, если вы помните, у нас есть индекс только по столбцу name , а так как мы читаем только id в запросе, то почему только индекс может вернуть данные? Ну, это потому, что индекс также имеет соответствующий первичный ключ вместе со значением. Давайте посмотрим, как индекс выглядит на самом деле.
Все конечные узлы находятся на одном уровне, также конечные узлы связаны и действуют как двусвязный список, так что при необходимости обход может происходить в обоих направлениях. Кроме того, каждый узел, помимо сохранения значения и первичного ключа, также хранит указатель на фактическую строку в таблице для доступа к любому другому полю. С b-деревьями, поскольку листовые узлы сортируются, поиск занимает всего O(log n) раз. И с такой логарифмической сложностью даже для базы данных с миллионом строк пришлось бы выполнить около 20 операций поиска, чтобы найти данные.
Мы установили, что индексация столбца ускоряет чтение, тогда должны ли мы индексировать все столбцы? Точно нет !!! Как и все остальное, индексы также являются компромиссом между чтением и записью . Чем больше столбцов вы индексируете, тем больше индексов нужно обновлять при записи, что замедляет общую запись. Поэтому индексируйте только те столбцы, которые часто запрашиваются. Если вы считаете, что вам нужно проиндексировать каждый столбец, возможно, MySQL не является правильным выбором для начала.
Чем больше столбцов вы индексируете, тем больше индексов нужно обновлять при записи, что замедляет общую запись. Поэтому индексируйте только те столбцы, которые часто запрашиваются. Если вы считаете, что вам нужно проиндексировать каждый столбец, возможно, MySQL не является правильным выбором для начала.
Что еще мы должны иметь в виду, при индексировании другой точкой будет сколько различных строк присутствует с некоторым значением , если индексируется логический тип столбца, и если распределение значений также составляет около 50-50% , т.е. почти 50% true и остальные 50% false, индексирование мало чем поможет, так как в любом случае половина таблицы будет проиндексирована. Также называется кардинальностью столбца, 90 557, чем выше кардинальность, тем лучше будет работать индекс.
Резюме:
- Индексы представляют собой структуру данных, которая ускоряет чтение.
- MySQL использует только один индекс на таблицу для каждого запроса кроме UNION.
- Не индексируйте все столбцы, так как это приведет к дополнительным издержкам при записи. Мы должны индексировать только те столбцы, которые часто запрашиваются/читаются. Индексировать столбец, если для этого столбца выполняется порядок
по. - Столбцы с большим числом элементов лучше работают при индексации.
- Применение
объяснить, чтобы получить планировщик запросов, понять все поля в выводеобъяснить. Важно отметить, чтоtypeиrows.

В следующей части статьи мы поймем, какое значение имеет порядок в многостолбцовых индексах. Мы также увидим некоторые распространенные ловушки при использовании индекса.
MySQL :: Справочное руководство по MySQL 8.0 :: 8.3.1 Как MySQL использует индексы
Высокая производительность MySQL
Глава 4. Индексы Индексы позволяют MySQL быстро находить и извлекать набор записей из миллионов или даже миллиардов, которые может содержать таблица. Если вы использовали… — Подборка из High Performance MySQL [Книга]
Если вы использовали… — Подборка из High Performance MySQL [Книга]
Онлайн-обучение O’Reilly
MySQL :: Справочное руководство по MySQL 8.0 :: 8.8.2 EXPLAIN Формат вывода
Как индексы базы данных работают внутри
База данных Индексы — это структуры данных, которые ускоряют чтение. Мы увидим, как работает многостолбцовый индекс и почему порядок имеет значение, на примерах.
Создание в масштабе Рахул Мишра
Azure DB для MySQL (предварительная версия) — Azure Cognitive Search
- Статья
- 7 минут на чтение
Важно
Поддержка MySQL в настоящее время находится в общедоступной предварительной версии в соответствии с Дополнительными условиями использования. Используйте предварительную версию REST API (предварительная версия 2020-06-30 или более поздняя версия) для индексации вашего контента. На данный момент поддержка портала отсутствует.
Используйте предварительную версию REST API (предварительная версия 2020-06-30 или более поздняя версия) для индексации вашего контента. На данный момент поддержка портала отсутствует.
В этой статье вы узнаете, как настроить индексатор , который импортирует содержимое из базы данных Azure для MySQL и делает его доступным для поиска в Azure Cognitive Search.
Эта статья дополняет статью Создание индексаторов в Когнитивном поиске Azure информацией, относящейся к индексированию файлов в базе данных Azure для MySQL. Он использует REST API для демонстрации рабочего процесса, состоящего из трех частей, общего для всех индексаторов:
- Создание источника данных
- Создать индекс
- Создать индексатор
При настройке включения максимальной отметки и обратимого удаления индексатор принимает все изменения, загрузки и удаления для вашей базы данных MySQL. Он отражает эти изменения в вашем поисковом индексе. Извлечение данных происходит, когда вы отправляете запрос на создание индексатора.
Предварительные требования
Зарегистрируйтесь для получения предварительной версии, чтобы оставить отзыв и получить помощь по любым возникающим проблемам.
База данных Azure для одного сервера MySQL.
Таблица или представление, предоставляющее содержимое. Требуется первичный ключ. Если вы используете представление, оно должно иметь столбец верхнего уровня.
Разрешения на чтение. Строка подключения с полным доступом включает ключ, предоставляющий доступ к содержимому, но если вы используете роли Azure, убедитесь, что управляемое удостоверение службы поиска имеет разрешения Reader в MySQL.
Клиент REST, например Postman или Visual Studio Code, с расширением для Когнитивного поиска Azure для отправки вызовов REST, которые создают источник данных, индекс и индексатор.
Вы также можете использовать Azure SDK для .NET. Вы не можете использовать портал для создания индексаторов, но вы можете управлять индексаторами и источниками данных после их создания.
Дополнительные сведения см. в статье База данных Azure для MySQL.
Ограничения предварительного просмотра
В настоящее время отслеживание изменений и обнаружение удаления не работают, если дата или временная метка одинаковы для всех строк. Это ограничение является известной проблемой, которую необходимо устранить в обновлении предварительной версии. Пока эта проблема не будет решена, не добавляйте набор навыков в индексатор MySQL.
Предварительный просмотр не поддерживает типы геометрии и капли.
Как уже отмечалось, портал не поддерживает создание индексаторов, но на портале можно управлять индексатором MySQL и источником данных, если они существуют. Например, вы можете редактировать определения, а также сбрасывать, запускать или планировать индексатор.
Определение источника данных
Определение источника данных указывает данные для индексирования, учетные данные и политики для идентификации изменений в данных. Источник данных определяется как независимый ресурс, поэтому его могут использовать несколько индексаторов.
Создать или обновить источник данных определяет определение. Обязательно используйте предварительную версию REST API (2020-06-30-Preview или более позднюю) при создании источника данных.
POST https://[имя службы поиска].search.windows.net/datasources?api-version=2020-06-30-Preview Тип содержимого: приложение/json API-ключ: [ключ администратора] { "имя": "отель-mysql-ds" "description" : "[Описание источника данных MySQL]", "тип": "mysql", "реквизиты для входа" : { "строка соединения": "Server=[MySQLServerName].MySQL.database.azure.com; Port=3306; Database=[DatabaseName]; Uid=[UserName]; Pwd=[Password]; SslMode=Preferred;" }, "контейнер": { "имя": "[имя_таблицы]" }, "политика изменения данных" : { "@odata.type": "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy", "highWaterMarkColumnName": "[HighWaterMarkColumn]" } }Задайте для
типзначение"mysql"(обязательно).Установите учетные данные
Установите
контейнерна имя таблицы.Установите
dataChangeDetectionPolicy, если данные изменчивы и вы хотите, чтобы индексатор извлекал только новые и обновленные элементы при последующих запусках.Установите
dataDeletionDetectionPolicy, если вы хотите удалить поисковые документы из поискового индекса при удалении исходного элемента.
Добавление полей поиска в индекс
В индекс поиска добавьте поля индекса поиска, соответствующие полям в вашей таблице.
Создать или обновить индекс определяет поля:
{
"имя": "отели-mysql-ix",
"поля": [
{ "name": "ID", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "HotelName", "type": "Edm. String", "доступный для поиска": true, "filterable": false },
{ "имя": "Категория", "тип": "Edm.String", "доступный для поиска": ложь, "фильтруемый": истина, "сортируемый": истина },
{ «имя»: «Город», «тип»: «Edm.String», «доступный для поиска»: false, «фильтруемый»: true, «сортируемый»: true },
{ "name": "Описание", "type": "Edm.String", "доступный для поиска": false, "filterable": false, "sortable": false }
]
 String", "доступный для поиска": true, "filterable": false },
{ "имя": "Категория", "тип": "Edm.String", "доступный для поиска": ложь, "фильтруемый": истина, "сортируемый": истина },
{ «имя»: «Город», «тип»: «Edm.String», «доступный для поиска»: false, «фильтруемый»: true, «сортируемый»: true },
{ "name": "Описание", "type": "Edm.String", "доступный для поиска": false, "filterable": false, "sortable": false }
]
String", "доступный для поиска": true, "filterable": false },
{ "имя": "Категория", "тип": "Edm.String", "доступный для поиска": ложь, "фильтруемый": истина, "сортируемый": истина },
{ «имя»: «Город», «тип»: «Edm.String», «доступный для поиска»: false, «фильтруемый»: true, «сортируемый»: true },
{ "name": "Описание", "type": "Edm.String", "доступный для поиска": false, "filterable": false, "sortable": false }
]
Если первичный ключ в исходной таблице совпадает с ключом документа (в данном случае «ID»), индексатор импортирует первичный ключ в качестве ключа документа.
Сопоставление типов данных
В следующей таблице база данных MySQL сопоставляется с эквивалентами Cognitive Search. Дополнительные сведения см. в разделе Поддерживаемые типы данных (Azure Cognitive Search).
Примечание
Предварительный просмотр не поддерживает типы геометрии и капли.
| Типы данных MySQL | Типы полей когнитивного поиска |
|---|---|
логическое значение , логическое значение | Edm. Boolean, Edm.String Boolean, Edm.String |
tinyint , smallint , mediumint , int , integer , year | Edm.Int32, Edm.Int64, Edm.String |
большое число | Edm.Int64, Edm.String |
плавающая , двойная , вещественная | Edm.Double, Edm.String |
дата , дата и время , метка времени | Edm.DateTimeOffset, Edm.String |
char , varchar , tinytext , mediumtext , text , longtext , enum , set , time | Эдм.Струна |
| беззнаковые числовые данные, последовательные, десятичные, десятичные, битовые, блобовые, двоичные, геометрические | Н/Д |
Настройка и запуск индексатора MySQL
После создания индекса и источника данных можно приступить к созданию индексатора.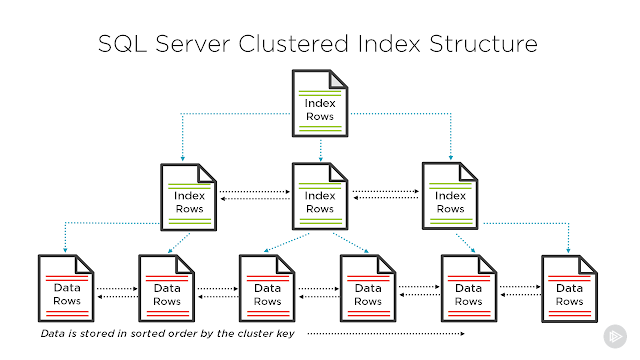 Конфигурация индексатора определяет входные данные, параметры и свойства, управляющие поведением во время выполнения.
Конфигурация индексатора определяет входные данные, параметры и свойства, управляющие поведением во время выполнения.
Создайте или обновите индексатор, дав ему имя и сославшись на источник данных и целевой индекс:
POST https://[имя службы поиска].search.windows.net/indexers?api-version=2020-06-30 { "имя": "отели-mysql-idxr", "dataSourceName": "отели-mysql-ds", "targetIndexName": "отели-mysql-ix", "отключено": ноль, "расписание": ноль, "параметры": { "Размер партии": ноль, "maxFailedItems": ноль, "maxFailedItemsPerBatch": ноль, "base64EncodeKeys": ноль, "конфигурация": { } }, "сопоставления полей" : [ ], "ключ шифрования": ноль }Укажите сопоставления полей, если есть различия в имени или типе поля или если вам нужно несколько версий исходного поля в индексе поиска.
Индексатор запускается автоматически при его создании. Вы можете предотвратить его запуск, установив disabled на true . Чтобы управлять выполнением индексатора, запускайте индексатор по запросу или по расписанию.
Чтобы управлять выполнением индексатора, запускайте индексатор по запросу или по расписанию.
Чтобы отслеживать состояние индексатора и историю выполнения, отправьте запрос на получение статуса индексатора:
ПОЛУЧИТЬ https://myservice.search.windows.net/indexers/myindexer/status?api-version=2020-06-30 Тип содержимого: приложение/json API-ключ: [ключ администратора]
Ответ включает состояние и количество обработанных элементов. Он должен выглядеть примерно так, как показано в следующем примере:
{
"статус": "работает",
"последний результат": {
"статус":"успех",
"Сообщение об ошибке": ноль,
"startTime":"2022-02-21T00:23:24.957Z",
"endTime":"2022-02-21T00:36:47.752Z",
"ошибки": [],
"элементы обработаны": 1599501,
"itemsFailed":0,
«initialTrackingState»: ноль,
"finalTrackingState": ноль
},
"История выполнения":
[
{
"статус":"успех",
"Сообщение об ошибке": ноль,
"startTime":"2022-02-21T00:23:24. 957Z",
"endTime":"2022-02-21T00:36:47.752Z",
"ошибки": [],
«Обработано предметов»: 1599501,
"itemsFailed":0,
«initialTrackingState»: ноль,
"finalTrackingState": ноль
},
... более ранние предметы истории
]
}
 957Z",
"endTime":"2022-02-21T00:36:47.752Z",
"ошибки": [],
«Обработано предметов»: 1599501,
"itemsFailed":0,
«initialTrackingState»: ноль,
"finalTrackingState": ноль
},
... более ранние предметы истории
]
}
957Z",
"endTime":"2022-02-21T00:36:47.752Z",
"ошибки": [],
«Обработано предметов»: 1599501,
"itemsFailed":0,
«initialTrackingState»: ноль,
"finalTrackingState": ноль
},
... более ранние предметы истории
]
}
История выполнения содержит до 50 последних завершенных выполнений, которые отсортированы в обратном хронологическом порядке, так что последнее выполнение идет первым.
Индексирование новых и измененных строк
После того, как индексатор полностью заполнил поисковый индекс, вы можете захотеть, чтобы последующие запуски индексатора постепенно индексировали только новые и измененные строки в вашей базе данных.
Чтобы включить добавочное индексирование, задайте свойство dataChangeDetectionPolicy в определении источника данных. Это свойство сообщает индексатору, какой механизм отслеживания изменений используется для ваших данных.
Для индексаторов Базы данных Azure для MySQL поддерживается только политика HighWaterMarkChangeDetectionPolicy .
Политика обнаружения изменений индексатора зависит от наличия столбца высшей отметки , который фиксирует версию строки или дату и время последнего обновления строки. Часто это столбец DATE , DATETIME или TIMESTAMP с детализацией, достаточной для удовлетворения требований столбца высокой отметки.
В вашей базе данных MySQL столбец высшей отметки должен соответствовать следующим требованиям:
- Все вставки данных должны указывать значение для столбца.
- Все обновления элемента также изменяют значение столбца.
- Значение этого столбца увеличивается с каждой вставкой или обновлением.
- Запросы со следующими предложениями
WHEREиORDER BYмогут выполняться эффективно:WHERE [Столбец максимального значения] > [Текущее значение максимального значения] ORDER BY [Столбец максимального значения]
В следующем примере показано определение источника данных с политикой обнаружения изменений:
POST https://[имя службы поиска].
 search.windows.net/datasources?api-version=2020-06-30-Preview
Тип содержимого: приложение/json
API-ключ: [ключ администратора]
{
"имя" : "[Имя источника данных]",
"тип": "mysql",
«учетные данные» : { «connectionString» : «[строка подключения]» },
«контейнер» : { «имя» : «[имя таблицы или представления]» },
"политика изменения данных" : {
"@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy",
"highWaterMarkColumnName" : "[имя столбца last_updated]"
}
}
search.windows.net/datasources?api-version=2020-06-30-Preview
Тип содержимого: приложение/json
API-ключ: [ключ администратора]
{
"имя" : "[Имя источника данных]",
"тип": "mysql",
«учетные данные» : { «connectionString» : «[строка подключения]» },
«контейнер» : { «имя» : «[имя таблицы или представления]» },
"политика изменения данных" : {
"@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy",
"highWaterMarkColumnName" : "[имя столбца last_updated]"
}
}
Важно
Если вы используете представление, вы должны установить политику верхнего предела в вашем источнике данных индексатора.
Если в исходной таблице нет индекса для столбца с наивысшей точкой, время ожидания запросов, используемых индексатором MySQL, может истечь. В частности, условие ORDER BY [High Water Mark Column] требует, чтобы индекс работал эффективно, когда таблица содержит много строк.
Индексирование удаленных строк
Когда строки удаляются из таблицы или представления, вы обычно также хотите удалить эти строки из поискового индекса. Однако если строки физически удаляются из таблицы, индексатор не может определить наличие записей, которых больше не существует. Решение состоит в том, чтобы использовать метод обратимого удаления для логического удаления строк, не удаляя их из таблицы. Добавьте столбец в таблицу или просмотрите и пометьте строки как удаленные, используя этот столбец.
Для столбца, в котором указано состояние удаления, можно настроить индексатор для удаления любых документов поиска, для которых состояние удаления установлено на true . Свойство конфигурации, которое поддерживает это поведение, — это политика обнаружения удаления данных, которая указана в определении источника данных следующим образом:
{
…,
«Политика удаления данных»: {
"@odata.type" : "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy",
"softDeleteColumnName" : "[имя столбца]",
"softDeleteMarkerValue": "[значение, указывающее, что строка удалена]"
}
}
softDeleteMarkerValue должно быть строкой. Например, если у вас есть целочисленный столбец, в котором удаленные строки отмечены значением 1, используйте
Например, если у вас есть целочисленный столбец, в котором удаленные строки отмечены значением 1, используйте "1" . Если у вас есть бит , где удаленные строки отмечены логическим значением true, используйте строковый литерал True или true (регистр не имеет значения).
Следующие шаги
Теперь вы можете запускать индексатор, отслеживать состояние или планировать выполнение индексатора. Следующие статьи относятся к индексаторам, извлекающим содержимое из Azure MySQL:
- Индексирование больших наборов данных
- Доступ индексатора к содержимому, защищенному функциями сетевой безопасности Azure
7 способов убедить MySQL использовать правильный индекс – code.openark.org
Иногда MySQL ошибается. Он не использует правильный индекс.
Бывает так, что MySQL генерирует действительно плохой план запроса (EXPLAIN говорит, что собирается исследовать около 10 000 000 строк), когда другой план (скоро показывающий, как он был сгенерирован) говорит: «Конечно, я могу сделать это со 100 строками, используя ключ».
Реальная история
У клиента возникли проблемы с базой данных. Выполнение запросов занимало 15 минут, и в целом БД не отвечала. Просматривая журнал медленных запросов, я нашел криминальный запрос. Позвольте мне ввести вас в курс дела:
Таблица определяется следующим образом:
СОЗДАТЬ ТАБЛИЦУ t ( идентификатор INT UNSIGNED AUTO_INCREMENT, введите INT UNSIGNED, уровень TINYINT без знака, ... ПЕРВИЧНЫЙ КЛЮЧ(идентификатор), KEY `тип` (тип) ) ДВИГАТЕЛЬ=InnoDB;
Оскорбительный запрос был следующим:
ВЫБЕРИТЕ идентификатор ИЗ данных ГДЕ тип = 12345 И уровень> 3 ЗАКАЗАТЬ ПО ID
Факты были следующими:
- `t` имеет около 10 000 000 строк.
- Индекс по `типу` является выборочным: в среднем около 100 строк на значение.
- Запрос занял много времени.
- EXPLAIN показал, что MySQL использует ПЕРВИЧНЫЙ КЛЮЧ, следовательно, ищет 10 000 000 строк, отфильтрованных «используя где».
- другое EXPLAIN показало, что при использовании ключа «тип» ожидается только 110 строк, которые будут отфильтрованы «используя где», а затем отсортированы «используя сортировку файлов»
Итак, MySQL признала, что создает неверный план. другой план был лучше по своим меркам.
Решение проблемы
Давайте рассмотрим 7 способов решения проблемы, начиная с более агрессивных решений и заканчивая усовершенствованием для достижения желаемого поведения посредством незначительных изменений.
Решение №1: ОПТИМИЗАЦИЯ
Если MySQL ошибся, это может быть связано с частыми изменениями таблицы. Это влияет на статистику. Если у нас есть время (таблица заблокирована в это время), мы могли бы помочь, перестроив таблицу.
Решение №2: ANALYZE
ANALYZE TABLE требует меньше времени, особенно в InnoDB, где его почти не замечают. ANALYZE обновит статистику индекса и поможет в создании лучших планов запросов.
Но подождите, два приведенных выше решения хороши, но в данном случае MySQL уже признает, что есть лучшие планы. Дело в том, что я пытался запустить ANALYZE несколько раз, но безрезультатно.
Дело в том, что я пытался запустить ANALYZE несколько раз, но безрезультатно.
Решение №3: ИСПОЛЬЗУЙТЕ ИНДЕКС
Так как вопрос был срочным, моя первая мысль была о совершенном оружии:
ВЫБРАТЬ идентификатор ИЗ данных ИСПОЛЬЗОВАТЬ ИНДЕКС (тип) ГДЕ тип = 12345 И уровень> 3 ЗАКАЗАТЬ ПО ID
Это указывает MySQL рассматривать только перечисленные индексы; в нашем примере я хочу, чтобы MySQL рассматривал возможность использования индекса `type`. Именно с помощью этого метода был получен других (хороших) результатов EXPLAIN. Я мог бы пойти еще более безжалостно и попросить FORCE INDEX.
Решение №4: ИГНОРИРОВАТЬ ИНДЕКС
Аналогичным подходом может быть явный отказ от использования ПЕРВИЧНОГО КЛЮЧА, например:
ВЫБРАТЬ ИД ИЗ данных ИГНОРИРОВАТЬ ИНДЕКС (ПЕРВИЧНЫЙ) ГДЕ тип = 12345 И уровень> 3 ЗАКАЗАТЬ ПО ID
Момент размышления
Приведенные выше решения «уродливы» в том смысле, что это не стандартный SQL. Это слишком специфично для MySQL.
Это слишком специфично для MySQL.
Я попросил программистов быстро переписать и задумался над несколькими моментами: почему MySQL настаивает на использовании ПЕРВИЧНОГО КЛЮЧА. Было ли это потому, что я запросил его только для столбца «id»? Я переписал так:
ВЫБЕРИТЕ идентификатор, тип, уровень ИЗ данных ГДЕ тип = 12345 И уровень> 3 ЗАКАЗАТЬ ПО ID
Нет. ОБЪЯСНЕНИЕ дало мне такой же плохой план. Тогда это должно быть предложение ORDER BY:
ВЫБЕРИТЕ идентификатор ИЗ данных ГДЕ тип = 12345 И уровень > 3
Конечно же, EXPLAIN теперь показывает использование индекса `type`, читая только 110 строк. Таким образом, MySQL предпочитал сканировать 10 000 000 строк только для того, чтобы строки генерировались в правильном ПОРЯДКЕ, и поэтому сортировка не требовалась, когда он мог прочитать 110 строк (где каждая строка представляет собой просто INT) и отсортировать их в кратчайшие сроки.
Вооружившись этим знанием, вы можете воспользоваться еще несколькими вариантами.
Решение №5. Переместите некоторую логику в приложение
Примерно в этот момент я получил сообщение о том, что программисты не смогли добавить часть USE INDEX. Почему? Они использовали структуру EJB, которая ограничивала ваши SQL-подобные запросы чем-то очень общим. Что ж, вы всегда можете отказаться от части ORDER BY и выполнить сортировку на стороне приложения. Это не весело, но это было сделано.
Решение № 6. Отказ от использования PRIMARY KEY
Можем ли мы заставить MySQL использовать индекс `type`, сохранить ORDER BY и делать все это со стандартным SQL? Конечно. Это делает следующий запрос:
ВЫБЕРИТЕ идентификатор, тип, уровень ИЗ данных ГДЕ тип = 12345 И уровень> 3 ЗАКАЗАТЬ ПО id+0
id+0 — это функция столбца `id`. Это делает MySQL неспособным использовать PRIMARY KEY (или любой другой индекс на `id`, если бы он был).
В своей книге «Настройка SQL» Дэн Тоу посвящает главу советам и советам, подобным приведенным выше. Он показывает, как контролировать использование или неиспользование индексов, порядок вычисления подзапросов и многое другое.
Он показывает, как контролировать использование или неиспользование индексов, порядок вычисления подзапросов и многое другое.
К сожалению, спецификация EJB запрещает это. Вы не можете ЗАКАЗАТЬ по функции. Только на обычной колонке.
Решение №7: Заставьте MySQL думать, что проблема сложнее, чем она есть на самом деле
Вариантов почти нет. За мгновение до того, как остановиться на сортировке на стороне приложения, можно рассмотреть еще один вопрос: раз MySQL однажды обманули, можно ли снова обмануть ее, чтобы все исправить? Можем ли мы обмануть его, поверив, что ПЕРВИЧНЫЙ КЛЮЧ не стоит использовать? Это делает следующий запрос:
ВЫБЕРИТЕ идентификатор, тип, уровень ИЗ данных ГДЕ тип = 12345 И уровень> 3 ORDER BY id, type, level
Давайте задумаемся над этим. В каком порядке сейчас возвращаются строки? Ответ: точно так же, как и раньше. Так как `id` является ПЕРВИЧНЫМ КЛЮЧОМ, он также УНИКАЛЬНЫЙ, поэтому нет двух одинаковых значений `id`.