Ирина — опенсорс русский голосовой помощник. Offline-ready / Хабр
— Ирина, таймер…
— Ставлю таймер на пять минут.
Вполне себе обыденная история из моего быта. Я таки сделал собственного автономного голосового помощника.
TL;DR> Ирина вполне неплохо работает дома 24×7.
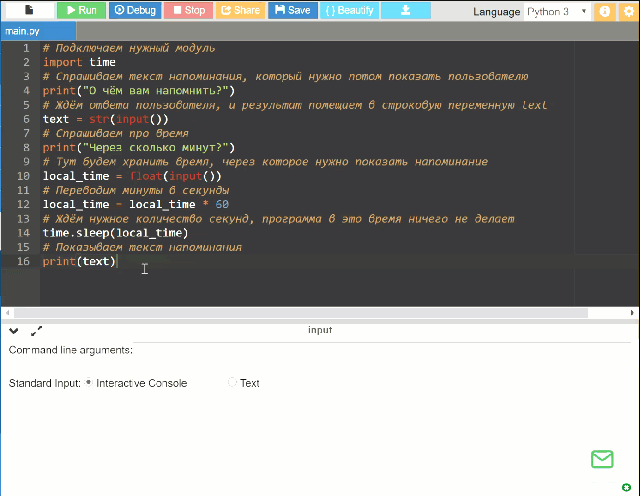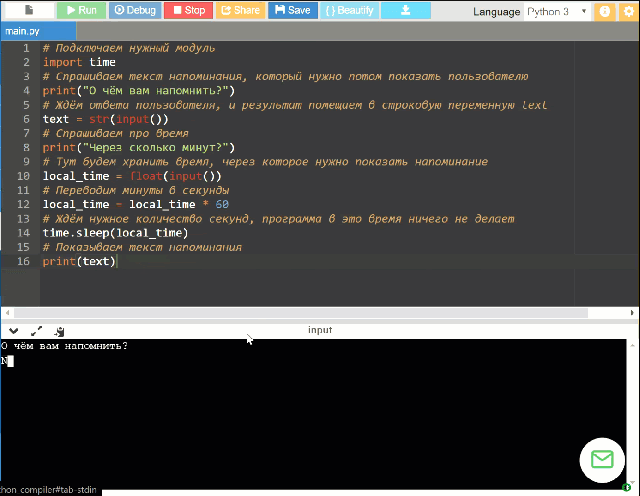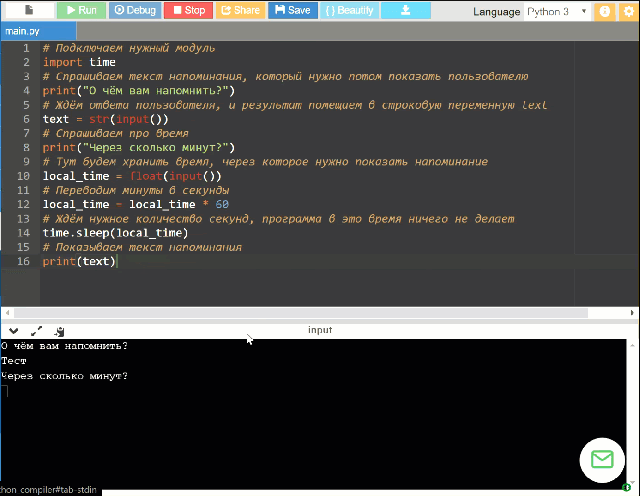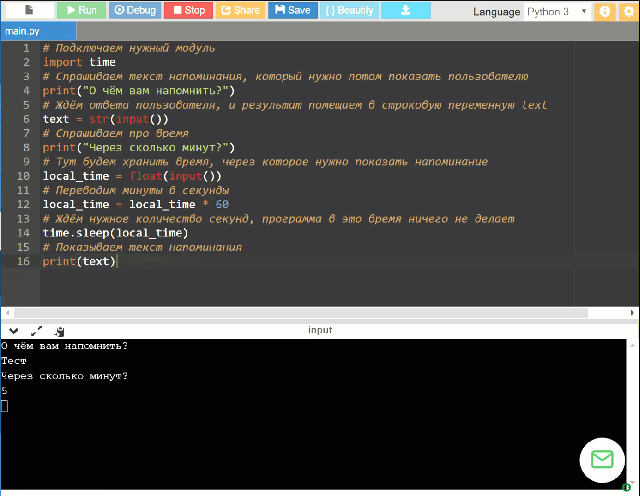
Потребуется установить Python 3.5+ и зависимости через pip (немного знаний Python).
Скиллы «из коробки»: таймер, погода, контроль медиа (громче/тише/дальше), контроль плеера MPC-HC, запуск медиа из папки, расписание ближайших электричек, «подбрось кубик/монетку».
Плагинами добавляются: другие скиллы, Text-to-Speech и Speech-to-Text движки.
Мотивация
За каждым проектом стоят причины, побудившие автора им заняться. Давайте сначала немного о них.
Во-первых, я не в восторге, что общедоступные голосовые помощники контролируются корпорациями. Я не могу точно сказать, что X порекомендует моему ребенку на запрос «мультики» и что покажет ему на Ютубе. Я бы предпочел контролировать это самостоятельно, пусть на это уйдёт и несколько больше времени.
Я бы предпочел контролировать это самостоятельно, пусть на это уйдёт и несколько больше времени.
Во-вторых, оффлайн. Почти везде голос распознаётся на серверах, и это а) потенциально небезопасно, б) есть кейсы (например, дача), где стабильный онлайн не очень-то доступен.
В-третьих, четкая работа помощника по командам. Мне хотелось бы точно знать, что происходит, когда я произношу то или иное слово. Идея «поболтать с Алисой» мне несколько чужда — в частности, потому, что я не могу до конца доверять мотивациям людей, её создающим. Если брать ребенка, то мне бы хотелось, чтобы он учился командовать компьютером, а не болтать с ним; в конце концов, именно однозначно понимаемый набор команд можно назвать алгоритмом.
В-четвертых, короткие команды. Наверное, их можно настроить и в других помощниках, но тут это сделать гораздо проще — можно их просто запрограммировать.
В-пятых, сложные сценарии. Если весь код у вас на руках, то сделать при необходимости сценарий в духе «реши десять арифметических задачек, а потом можешь посмотреть мультик» гораздо проще.
Если вы в первом приближении разделяете часть моих мотиваций — возможно, Ирина вам подойдет.
Архитектурные компромиссы
Нельзя объять необъятное
При создании этого проекта я заложил в него некоторые компромиссы. Они усложнят работу в одном случае, и упростят в другом. Давайте с ними ознакомимся, прежде чем переходить к технической части.
Основная цель проекта — дать программисту возможность быстро дополнять навыки голосового помощника и настраивать их под себя.
Установка помощника сделана больше для программиста на Python, нежели для конечного пользователя. Потребуется скачать проект с Github, установить зависимости через pip, и запустить Python-файл. Зато дописывать проще. (Я не против, если кто-то упакует это в EXE, но я сам не чувствую в этом необходимости)
Установка плагинов. Плагины надо кинуть в папку plugins, а после их запуска можно настроить их JSON-конфиг (для тех, у кого предусмотрены настройки) в папке options.
 Возможно, имело смысл сделать какой-нибудь онлайн-репозиторий, и механизм установки, но я делал быстро и максимально просто.
Возможно, имело смысл сделать какой-нибудь онлайн-репозиторий, и механизм установки, но я делал быстро и максимально просто.Мультиязычность. Мультиязычность бы потребовала умение обрабатывать разные языки (определенная сложность парсинга команд), а также каждый раз работать с локализованными строками. Я посчитал, что её поддержание обойдется слишком дорого программисту, пишущему «для себя». Поэтому многоязычность плагинов не поддерживается — всё только на русском, но просто. (Ядро поддерживает многоязычность, т.к. там не так много языкозависимых строк. При желании вы можете просто переписать нужные вам плагины на нужный вам язык. Также можно подключить другие Text-to-Speech и Speech-to-Text движки, и работать на другом языке)
Не Python-style кода (личное). С Python я начал работать не так давно, и до сих пор много работаю на других языках. Поэтому при написании кода я часто использую типовое ООП, хотя возможно, что-то можно было сделать компактнее.
 Возможно, имело смысл сделать какой-нибудь онлайн-репозиторий, и механизм установки, но я делал быстро и максимально просто.
Возможно, имело смысл сделать какой-нибудь онлайн-репозиторий, и механизм установки, но я делал быстро и максимально просто.
Если указанные компромиссы вас не отпугнули — думаю, имеет смысл познакомиться с Ириной.
Быстрый старт
Скачайте проект с Github
Для быстрой установки всех требуемых зависимостей можно воспользоваться командой:
pip install -r requirements.txtДля запуска запустите файл runva_vosk.py из корневой папки. По умолчанию он запустит оффлайн-распознаватель vosk для распознавания речи с микрофона, и pyttsx движок для озвучивания ассистента (стандартный движок Windows для синтеза речи).
После запуска проверить можно простой командой — скажите «Ирина, привет!» в микрофон
Общая логика
Запуск всех команд начинается с имени ассистента (настраивается в options/core.json, по умолчанию — Ирина). Так сделано, чтобы исключить неверные срабатывания при постоянном прослушивании микрофона. Далее будут описываться команды без префикса «Ирина».
Плагины
Поддержка плагинов сделана на собственном движке Jaa. py — минималистичный однофайловый движок поддержки плагинов и их настроек.
py — минималистичный однофайловый движок поддержки плагинов и их настроек.
Плагины располагаются в папке plugins и должны начинаться с префикса «plugins_». Плагины задают навыки/скиллы голосового помощника.
Настройки плагинов, если таковые есть, располагаются в папке «options» (создается после первого запуска).
Готовые плагины
С Ириной поставляются плагины, которые закрывают большую часть обыденных кейсов использования голосового помощника (если вы, конечно, не собираетесь с ним общаться). Для каждого плагина написано, требуется ли онлайн. Для отключения удалите его из папки.
plugin_greetings.py — приветствие (оффлайн). Пример команды: «ирина, привет»
plugin_timer.py — таймер (оффлайн). Примеры: «таймер, таймер шесть минут, таймер десять секунд, таймер десять» (без указания единиц ставит на минуты — «таймер десять» — на десять минут. Просто «таймер» ставит на пять минут)
plugin_mediacmds.py — команды управления медиа (оффлайн). Пример: «дальше, громче, тише, сильно громче, сильно тише, пауза». (Если установлено mpcIsUseHttpRemote, то сначала делается попытка вызвать команду плеера MPC-HC, если не удается — используется эмуляция мультимедийных клавиш)
Пример: «дальше, громче, тише, сильно громче, сильно тише, пауза». (Если установлено mpcIsUseHttpRemote, то сначала делается попытка вызвать команду плеера MPC-HC, если не удается — используется эмуляция мультимедийных клавиш)
plugin_mpchcmult.py — проигрывание мультиков через MPC-HC из определенной папки (оффлайн). Пример «мультик <название_мультика>». Папка задается в конфиге. При вызове команды в папке ищется файл с соответствующим названием <название_мультика> и любым расширением. Если найден — запускается на проигрывание. (Как можно догадаться, этот плагин предназначен для показа отобранных медиа без обращения к ютубу.)
plugin_random.py — рандом (оффлайн). Примеры: «подбрось|брось кубик|монетку». Содержит примеры парсинга дерева команд (команды можно задавать деревом). Больше демонстрационный плагин.
plugin_weatherowm.py — погода (онлайн). Примеры: «погода, погода завтра, погода послезавтра, прогноз погоды». Требует установки в конфиге бесплатного API-ключа отсюда, а также местоположения пользователя.
Требует установки в конфиге бесплатного API-ключа отсюда, а также местоположения пользователя.
plugin_yandex_rasp.py — расписание ближайших электричек через Яндекс.Расписания. Пример: «электричка, электрички». Требует установки в конфиге бесплатного API-ключа для личных нужд (до 500 запросов в сутки) отсюда, а также станций отправления и назначения. (Если вы ездите на электричке — фраза «ирина, электричка» очень удобна для проверки расписания)
plugin_tts_pyttsx.py — (оффлайн) позволяет делать TTS (Text-To-Speech, озвучку текста) через pyttsx движок. Используется по умолчанию.
plugin_tts_console.py — (оффлайн) заглушка для отладки. Вместо работы TTS просто выводит текст в консоль.
Свои Text-to-Speech и Speech-to-Text движки
По умолчанию для распознания речи используется движок VOSK, для синтеза — Windows (голос Irene).
Дописать свои варианты вполне можно, это стандартная операция. Детали — в Github.
Уже доступен STT через модуль SpeechReсognition (онлайн-распознавание от Гугла и пр.), а также TTS через Silero (нейросетевая генерация оффлайн). Мне не очень понравился результат Silero (хотя сам проект прекрасен) — генерируется дольше, задержка в несколько секунд, а также есть «металлические» шумы, но, возможно, он подойдет вам. (Кстати, в одном из комментариев @putnik поделился собственным анализом доступных движков TTS и STT.)
Кстати, имя помощника тоже настраивается в файле конфигурации — так что если нужно, можете сделать, чтобы он откликался на имя «Джарвис». И можно поставить мужской голос, конечно.
Аналоги
Честно говоря, я начал писать свой проект без анализа аналогов. Ну, точнее, беглый гуглеж позволил мне найти прекрасную хабрастатью @EnjiRouz Пишем голосового ассистента на Python, а также соответствующий репозиторий, который и послужил основой для проекта.
Правда, например, код для получения погоды c OpenWeatherMap пришлось полностью переписать, потому что они перестали поддерживать старое API.
Лишь позднее, в декабре на хабре появилась статья Программируем умный дом, а к ней довольно интересный коммент putnik, который попробовал самые разные системы. Процитирую:
Ну и более конкретно прокомментирую часть про голосовых ассистентов, так как я этим сейчас активно занимаюсь:
Один из самых больших проектов на github с открытым кодом голосового помощника называется Leon. Система сделана французом…
…и поэтому поддерживает только два языка: английский и французский. К тому же проект имеет довольно небольшое сообщество и в основном разрабатывается автором. Как следствие, набор модулей, которые обеспечивают интеграцию, довольно скуден.
После, у нас есть JARVIS из Железного Человека. <…> Это позволит вам создавать вашу собственную Сири в пределах отдельно взятой сети.
Интересно, получилось ли у автора создать собственную Сири, или всё же самостоятельная настройка споттера, распознавания голоса и озвучки текста на отдельно взятой малинке всё же сильно выходят за рамки «небольшой конфигурации». Ну, и если ничего не поменялось, то у него была проблема с поддержкой даже не русского, а вообще какой-либо локализации. Так что, вероятно, вам придётся делать форк и переводить все сообщения.
Ну, и если ничего не поменялось, то у него была проблема с поддержкой даже не русского, а вообще какой-либо локализации. Так что, вероятно, вам придётся делать форк и переводить все сообщения.
Чуть более популярная чем Jarvis, но уступающая Леону — система Mycroft.
Про эту знаю несколько больше, так как выбрал её и сейчас занимаюсь локализацией. И хорошо, если хотя бы к новому году смогу получить сколько-нибудь работающее решение.
Ядро небольшое, почти всё вынесено в плагины и навыки. Есть какое-никакое сообщество, которое эти навыки пишет и поддерживает. Хотя встречается довольно много говна и палок не самых лучших архитектурных решений. Ядро в интернет ломится за настройками навыков, которые хранятся на сервере, сами навыки за данными. По умному дому более-менее нормальная интеграция есть только с Home Assistant, остальное вам придётся писать с нуля. По музыке есть интеграция со Spotify (если вас не смущает необходимость хранить пароль в открытом виде на чужих серверах).
Лично я немного потыкал Jarvis, который мне показался похожим по архитектуре на мою собственную. Сделан достаточно удобно; но это, вообще говоря, проект, рассчитанный под консольные команды(!) на английском(!). Т.е. адекватная локализация на русский — дело крайне большое; не говоря уже о том, что ряд кейсов плохо укладывается в голосовое, а не консольное управление (например, игра «Быки и коровы»).
В общем, на мой взгляд, проект «Ирина» для русского пользователя — совсем неплохо. С другими проектами придется серьезно решать проблемы локализации. Хотя, конечно, интеграций в аналогах больше — но при желании их можно попытаться портировать под Ирину.
Заключение
Честно говоря, я сам не ожидал, но Ирина вполне себе прижилась у нас в семье.
Самый часто используемый навык — таймер, потому что рядом кухня. Иногда используется погода и электрички. Мультики пока ещё не востребованы, думаю заняться ими позже.
Крутится это все на ноутбуке, который в настоящее время является сервером. Встроенного микрофона хватает на эффективное распознавание с 2-3 метров; хотя, конечно, иногда не срабатывает и приходится либо повторять, либо подходить вплотную.
Встроенного микрофона хватает на эффективное распознавание с 2-3 метров; хотя, конечно, иногда не срабатывает и приходится либо повторять, либо подходить вплотную.
Загрузка процессора минимальна; думаю, пойдет и на Малинке, но, конечно, не пробовал.
Свои плагины
Честно говоря, у меня уже есть несколько собственных плагинов чисто «под себя».
Например, по «ирина, запусти музыку» открывается Яндекс.Музыка.
Еще у нас есть локальный, не сетевой доставщик неплохой пиццы (PushPizza, если кому интересно). Где-то за полчаса я написал плагин, который проверяет, в каком состоянии доставка — готовится, или едет. Написан алгоритм с использованием библиотеки pyautogui, позволяющей эмулировать ввод пользователя (мышь и клавиатуру):
Открыть страницу доставки
Подождать чуть-чуть
Найти на экране картинку (форму ввода телефона) (да, в pyautogui такое есть из коробки)
Перевести туда мышь и кликнуть
Сэмулировать ввод телефона
Вуаля! Страница со статусом доставки доступна
В общем, вроде писать плагины оказалось несложно. (Если вы вдруг что-то напишете и захотите поделиться, можете кидать ссылки сюда.
(Если вы вдруг что-то напишете и захотите поделиться, можете кидать ссылки сюда.
Благодарности
@EnjiRouz за проект голосового ассистента, который стал основой (правда, был очень сильно переработан), а также за отличную статью на Хабре: Пишем голосового ассистента на Python
AlphaCephei за прекрасную библиотеку распознавания Vosk.
@putnik за разбор других голосовых помощников и список TTS и STT решений
Github проекта
UPD: Некоторые добавления с момента публикации статьи
Добавлен TTS плагин для RHVoice
Вышла версия 3.x — с возможностью многомашинных инсталляций. На центральном сервере запускается REST/JSON сервер с Ириной (FastAPI). Сервер делает всю работу плюс даже TTS. От клиентов требуется отправлять только распознавать данные с микрофона и отсылать команды серверу. Так что Ирину можно запускать на нескольких машинах в разных комнатах.
Для клиента в базовом варианте (vosk) сделал готовый EXE-файл (auto-py-to-exe), который не привязан к установке Питона.
Его вроде можно запускать вообще где угодно.Учитывая, что у Ирины теперь есть REST API, при желании можно запилить какие-нибудь интеграции (например, написать клиент для Телеграм и удаленно вызывать команды)
В комментах к статье есть обсуждение с проблемами установки под Linux; возможно, кому-то пригодится
 Его вроде можно запускать вообще где угодно.
Его вроде можно запускать вообще где угодно.Ирина — опенсорс русский голосовой помощник. Offline-ready
— Ирина, таймер…
— Ставлю таймер на пять минут.
Вполне себе обыденная история из моего быта. Я таки сделал собственного автономного голосового помощника.
TL;DR> Ирина вполне неплохо работает дома 24×7.
Потребуется установить Python 3.5+ и зависимости через pip (немного знаний Python).
Скиллы «из коробки»: таймер, погода, контроль медиа (громче/тише/дальше), контроль плеера MPC-HC, запуск медиа из папки, расписание ближайших электричек, «подбрось кубик/монетку».
Плагинами добавляются: другие скиллы, Text-to-Speech и Speech-to-Text движки.

Мотивация
За каждым проектом стоят причины, побудившие автора им заняться. Давайте сначала немного о них.
Во-первых, я не в восторге, что общедоступные голосовые помощники контролируются корпорациями. Я не могу точно сказать, что X порекомендует моему ребенку на запрос «мультики» и что покажет ему на Ютубе. Я бы предпочел контролировать это самостоятельно, пусть на это уйдёт и несколько больше времени.
Во-вторых, оффлайн. Почти везде голос распознаётся на серверах, и это а) потенциально небезопасно, б) есть кейсы (например, дача), где стабильный онлайн не очень-то доступен.
В-третьих, четкая работа помощника по командам. Мне хотелось бы точно знать, что происходит, когда я произношу то или иное слово. Идея «поболтать с Алисой» мне несколько чужда — в частности, потому, что я не могу до конца доверять мотивациям людей, её создающим. Если брать ребенка, то мне бы хотелось, чтобы он учился командовать компьютером, а не болтать с ним; в конце концов, именно однозначно понимаемый набор команд можно назвать 
В-четвертых, короткие команды. Наверное, их можно настроить и в других помощниках, но тут это сделать гораздо проще — можно их просто запрограммировать.
В-пятых, сложные сценарии. Если весь код у вас на руках, то сделать при необходимости сценарий в духе «реши десять арифметических задачек, а потом можешь посмотреть мультик» гораздо проще.
Если вы в первом приближении разделяете часть моих мотиваций — возможно, Ирина вам подойдет.
Архитектурные компромиссы
Нельзя объять необъятное
При создании этого проекта я заложил в него некоторые компромиссы. Они усложнят работу в одном случае, и упростят в другом. Давайте с ними ознакомимся, прежде чем переходить к технической части.
Основная цель проекта — дать программисту возможность быстро дополнять навыки голосового помощника и настраивать их под себя.
Установка помощника сделана больше для программиста на Python, нежели для конечного пользователя.
Установка плагинов. Плагины надо кинуть в папку plugins, а после их запуска можно настроить их JSON-конфиг в папке config. Возможно, имело смысл сделать какой-нибудь онлайн-репозиторий, и механизм установки, но я делал быстро и максимально просто.
Мультиязычность. Мультиязычность бы потребовала умение обрабатывать разные языки (определенная сложность парсинга команд), а также каждый раз работать с локализованными строками. Я посчитал, что её поддержание обойдется слишком дорого программисту, пишущему «для себя». Поэтому многоязычность плагинов не поддерживается — всё только на русском, но просто. (
Не Python-style кода (личное). С Python я начал работать не так давно, и до сих пор много работаю на других языках. Поэтому при написании кода я часто использую типовое ООП, хотя возможно, что-то можно было сделать компактнее.

 Также можно подключить другие Text-to-Speech и Speech-to-Text движки, и работать на другом языке)
Также можно подключить другие Text-to-Speech и Speech-to-Text движки, и работать на другом языке)Если указанные компромиссы вас не отпугнули — думаю, имеет смысл познакомиться с Ириной.
Быстрый старт
Скачайте проект с Github: https://github.com/janvarev/Irene-Voice-Assistant
Для быстрой установки всех требуемых зависимостей можно воспользоваться командой:
pip install requirements.txtДля запуска запустите файл runva_vosk.py из корневой папки. По умолчанию он запустит оффлайн-распознаватель vosk для распознавания речи с микрофона, и pyttsx движок для озвучивания ассистента (стандартный движок Windows для синтеза речи).
После запуска проверить можно простой командой — скажите «Ирина, привет!» в микрофон

Общая логика
Запуск всех команд начинается с имени ассистента (настраивается в options/core.json, по умолчанию — Ирина). Так сделано, чтобы исключить неверные срабатывания при постоянном прослушивании микрофона. Далее будут описываться команды без префикса «Ирина».
Плагины
Поддержка плагинов сделана на собственном движке Jaa.py — минималистичный однофайловый движок поддержки плагинов и их настроек.
Плагины располагаются в папке plugins и должны начинаться с префикса «plugins_». Плагины задают навыки/скиллы голосового помощника.
Настройки плагинов, если таковые есть, располагаются в папке «options» (создается после первого запуска).
Готовые плагины
С Ириной поставляются плагины, которые закрывают большую часть обыденных кейсов использования голосового помощника (если вы, конечно, не собираетесь с ним общаться). Для каждого плагина написано, требуется ли онлайн. Для отключения удалите его из папки.
Для отключения удалите его из папки.
plugin_greetings.py — приветствие (оффлайн). Пример команды: «ирина, привет»
plugin_timer.py — таймер (оффлайн). Примеры: «таймер, таймер шесть минут, таймер десять секунд, таймер десять» (без указания единиц ставит на минуты — «таймер десять» — на десять минут. Просто «таймер» ставит на пять минут)
plugin_mediacmds.py — команды управления медиа (оффлайн). Пример: «дальше, громче, тише, сильно громче, сильно тише, пауза». (Если установлено mpcIsUseHttpRemote, то сначала делается попытка вызвать команду плеера MPC-HC, если не удается — используется эмуляция мультимедийных клавиш)
plugin_mpchcmult.py — проигрывание мультиков через MPC-HC из определенной папки (оффлайн). Пример «мультик <название_мультика>». Папка задается в конфиге. При вызове команды в папке ищется файл с соответствующим названием <название_мультика> и любым расширением. Если найден — запускается на проигрывание. (Как можно догадаться, этот плагин предназначен для показа отобранных медиа без обращения к ютубу.)
(Как можно догадаться, этот плагин предназначен для показа отобранных медиа без обращения к ютубу.)
plugin_random.py — рандом (оффлайн). Примеры: «подбрось|брось кубик|монетку». Содержит примеры парсинга дерева команд (команды можно задавать деревом). Больше демонстрационный плагин.
plugin_weatherowm.py — погода (онлайн). Примеры: «погода, погода завтра, погода послезавтра, прогноз погоды». Требует установки в конфиге бесплатного API-ключа с https://openweathermap.org/ , а также местоположения пользователя.
plugin_yandex_rasp.py — расписание ближайших электричек через Яндекс.Расписания. Пример: «электричка, электрички». Требует установки в конфиге бесплатного API-ключа для личных нужд (до 500 запросов в сутки) с https://yandex.ru/dev/rasp/raspapi/ , а также станций отправления и назначения. (Если вы ездите на электричке — фраза «ирина, электричка» очень удобна для проверки расписания)
plugin_tts_pyttsx.py — (оффлайн) позволяет делать TTS (Text-To-Speech, озвучку текста) через pyttsx движок. Используется по умолчанию.
Используется по умолчанию.
plugin_tts_console.py — (оффлайн) заглушка для отладки. Вместо работы TTS просто выводит текст в консоль.
Свои Text-to-Speech и Speech-to-Text движки
По умолчанию для распознания речи используется движок VOSK, для синтеза — Windows (голос Irene).
Дописать свои варианты вполне можно, это стандартная операция. Детали — в Github.
Уже доступен STT через модуль SpeechReсognition (онлайн-распознавание от Гугла и пр.), а также TTS через Silero (нейросетевая генерация оффлайн). Мне не очень понравился результат Silero (хотя сам проект прекрасен) — генерируется дольше, задержка в несколько секунд, а также есть «металлические» шумы, но, возможно, он подойдет вам. (Кстати, в одном из комментариев @putnik поделился собственным анализом доступных движков TTS и STT.)
Кстати, имя помощника тоже настраивается в файле конфигурации — так что если нужно, можете сделать, чтобы он откликался на имя «Джарвис». И можно поставить мужской голос, конечно.
Аналоги
Честно говоря, я начал писать свой проект без анализа аналогов. Ну, точнее, беглый гуглеж позволил мне найти прекрасную хабрастатью @EnjiRouz Пишем голосового ассистента на Python, а также соответствующий репозиторий, который и послужил основой для проекта.
Правда, например, код для получения погоды c OpenWeatherMap пришлось полностью переписать, потому что они перестали поддерживать старое API.
Лишь позднее, в декабре на хабре появилась статья Программируем умный дом, а к ней довольно интересный коммент putnik, который попробовал самые разные системы. Процитирую:
Ну и более конкретно прокомментирую часть про голосовых ассистентов, так как я этим сейчас активно занимаюсь:
Один из самых больших проектов на github с открытым кодом голосового помощника называется Leon. Система сделана французом…
…и поэтому поддерживает только два языка: английский и французский. К тому же проект имеет довольно небольшое сообщество и в основном разрабатывается автором.
После, у нас есть JARVIS из Железного Человека. <…> Это позволит вам создавать вашу собственную Сири в пределах отдельно взятой сети.
Интересно, получилось ли у автора создать собственную Сири, или всё же самостоятельная настройка споттера, распознавания голоса и озвучки текста на отдельно взятой малинке всё же сильно выходят за рамки «небольшой конфигурации». Ну, и если ничего не поменялось, то у него была проблема с поддержкой даже не русского, а вообще какой-либо локализации. Так что, вероятно, вам придётся делать форк и переводить все сообщения.
Чуть более популярная чем Jarvis, но уступающая Леону — система Mycroft.
Про эту знаю несколько больше, так как выбрал её и сейчас занимаюсь локализацией. И хорошо, если хотя бы к новому году смогу получить сколько-нибудь работающее решение.
Ядро небольшое, почти всё вынесено в плагины и навыки. Есть какое-никакое сообщество, которое эти навыки пишет и поддерживает. Хотя встречается довольно много
Есть какое-никакое сообщество, которое эти навыки пишет и поддерживает. Хотя встречается довольно много говна и палок не самых лучших архитектурных решений. Ядро в интернет ломится за настройками навыков, которые хранятся на сервере, сами навыки за данными. По умному дому более-менее нормальная интеграция есть только с Home Assistant, остальное вам придётся писать с нуля. По музыке есть интеграция со Spotify (если вас не смущает необходимость хранить пароль в открытом виде на чужих серверах).
Лично я немного потыкал Jarvis, который мне показался похожим по архитектуре на мою собственную. Сделан достаточно удобно; но это, вообще говоря, проект, рассчитанный под консольные команды(!) на английском(!). Т.е. адекватная локализация на русский — дело крайне большое; не говоря уже о том, что ряд кейсов плохо укладывается в голосовое, а не консольное управление (например, игра «Быки и коровы»).
В общем, на мой взгляд, проект «Ирина» для русского пользователя — совсем неплохо.
Заключение
Честно говоря, я сам не ожидал, но Ирина вполне себе прижилась у нас в семье.
Самый часто используемый навык — таймер, потому что рядом кухня. Иногда используется погода и электрички. Мультики пока ещё не востребованы, думаю заняться ими позже.
Крутится это все на ноутбуке, который в настоящее время является сервером. Встроенного микрофона хватает на эффективное распознавание с 2-3 метров; хотя, конечно, иногда не срабатывает и приходится либо повторять, либо подходить вплотную.
Загрузка процессора минимальна; думаю, пойдет и на Малинке, но, конечно, не пробовал.
Свои плагины
Честно говоря, у меня уже есть несколько собственных плагинов чисто «под себя».
Например, по «ирина, запусти музыку» открывается Яндекс.Музыка.
Еще у нас есть локальный, не сетевой доставщик неплохой пиццы (PushPizza, если кому интересно).
Открыть страницу доставки
Подождать чуть-чуть
Найти на экране картинку (форму ввода телефона) (да, в pyautogui такое есть из коробки)
Перевести туда мышь и кликнуть
Сэмулировать ввод телефона
Вуаля! Страница со статусом доставки доступна
В общем, вроде писать плагины оказалось несложно. (Если вы вдруг что-то напишете и захотите поделиться, можете кидать ссылки в https://github.com/janvarev/Irene-Voice-Assistant/issues/1
Благодарности
@EnjiRouz за проект голосового ассистента: https://github.com/EnjiRouz/Voice-Assistant-App, который стал основой (правда, был очень сильно переработан), а также за отличную статью на Хабре: Пишем голосового ассистента на Python
AlphaCephei за прекрасную библиотеку распозавания Vosk ( https://alphacephei. com/vosk/index.ru )
com/vosk/index.ru )
@putnik за разбор других голосовых помощников и список TTS и STT решений
Github проекта
Многопоточность— быстрый и точный таймер повторения Python
спросил
Изменено 10 лет назад
Просмотрено 14 тысяч раз
Мне нужно быстро и точно отправлять повторяющиеся сообщения из списка. Один список должен отправлять сообщения каждые 100 мс с окном +/- 10 мс. Я попытался использовать приведенный ниже код, но проблема в том, что таймер ждет 100 мс, а затем необходимо выполнить все вычисления, из-за чего таймер выпадает из допустимого окна.
Просто уменьшить время ожидания — грязный и ненадежный способ. В цикле сообщений есть блокировка на случай, если список редактируется во время цикла.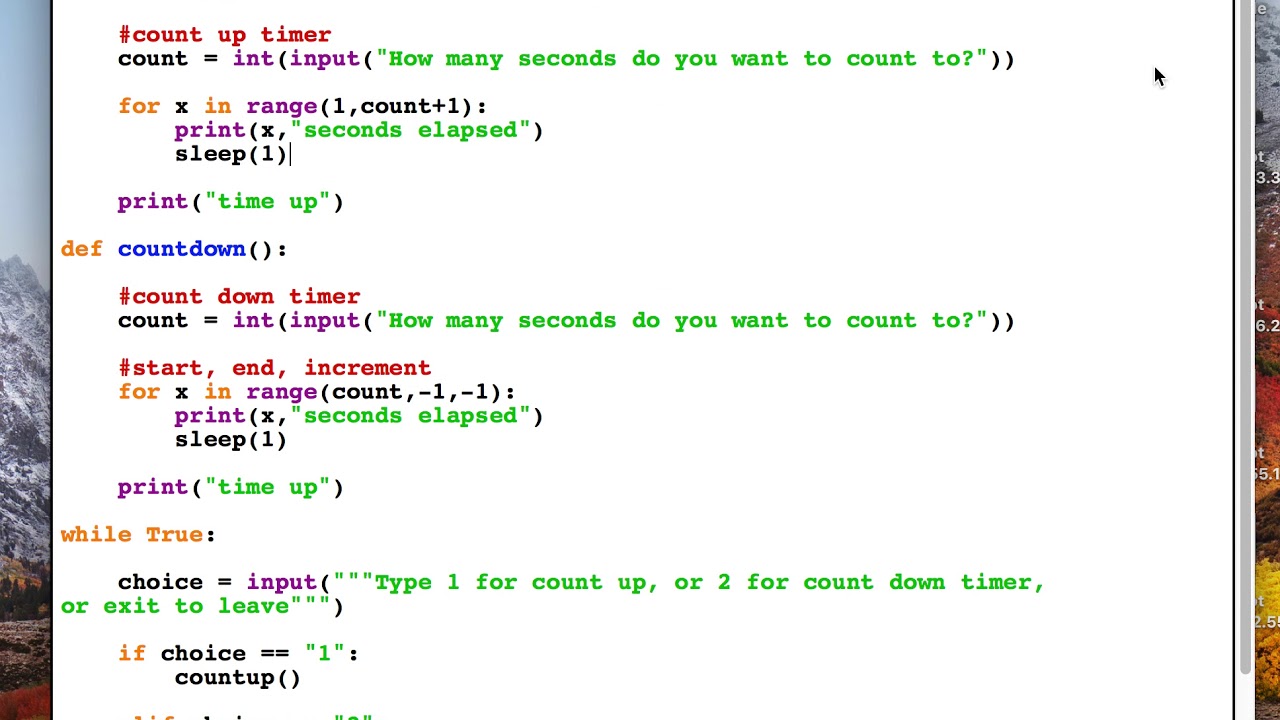
Мысли о том, как заставить python постоянно отправлять сообщения около 100 мс? Спасибо
от таймера потокового импорта
из блокировки импорта потоков
класс RepeatingTimer (объект):
def __init__(self,interval, function, *args, **kwargs):
super(RepeatingTimer, self).__init__()
self.args = аргументы
self.kwargs = кварги
self.function = функция
self.interval = интервал
самостоятельный запуск ()
деф старт(сам):
селф.обратный вызов()
деф стоп(сам):
self.interval = Ложь
Обратный вызов защиты (сам):
если собственный интервал:
self.function(*self.args, **self.kwargs)
Таймер (self.interval, self.callback, ).start()
цикл защиты (список сообщений):
listLock.acquire()
для m в messageList:
функция записи (м)
listLock.релиз()
MESSAGE_LIST = [] #Представьте, что это заполнено сообщениями
списокLock = Блокировка()
rt = RepeatingTimer (0,1, цикл, MESSAGE_LIST)
# Делайте другие вещи после этого
Я понимаю, что writeFunction вызовет некоторую задержку, но не более 10 мс.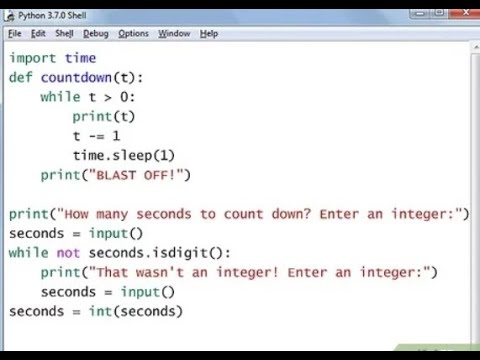 По сути, мне нужно вызывать функцию каждые 100 мс для каждого сообщения. Список сообщений небольшой, обычно меньше элементов.
По сути, мне нужно вызывать функцию каждые 100 мс для каждого сообщения. Список сообщений небольшой, обычно меньше элементов.
Следующая задача состоит в том, чтобы эта работа выполнялась каждые 10 мс, +/-1 мс: P
- python
- многопоточность
- таймер
- повтор
Да, простое ожидание утомительно, и есть альтернативы получше.
Во-первых, вам нужен высокоточный таймер в Python. Есть несколько альтернатив, и в зависимости от вашей ОС вы можете выбрать наиболее точную.
Во-вторых, вы должны знать основы вытесняющей многозадачности и понимать, что нет высокоточной функции сна , и что ее фактическое разрешение также будет отличаться от ОС к ОС. Например, если мы говорим о Windows, минимальный интервал сна может составлять около 10-13 мс.
И в-третьих, помните, что всегда можно дождаться очень точного интервала времени (при условии, что у вас есть таймер с высоким разрешением), но за счет высокой загрузки процессора.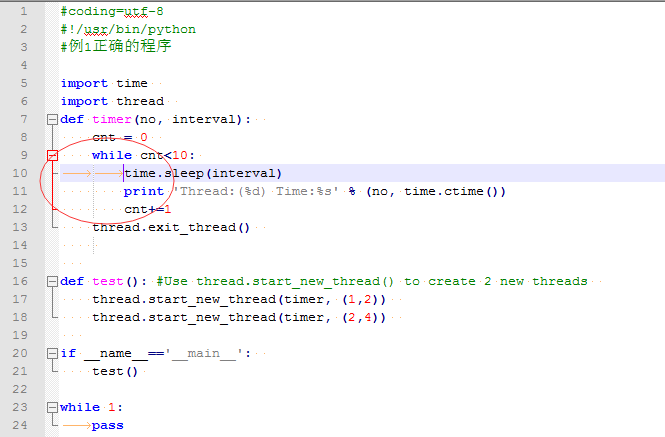 Техника называется занятым ожиданием:
Техника называется занятым ожиданием:
пока (правда):
если time.clock() == что-то:
перерыв
Таким образом, актуальным решением является создание гибридного таймера. Он будет использовать обычную функцию sleep для ожидания основной части интервала, а затем начнет проверять высокоточный таймер в цикле, выполняя трюк sleep(0) . Sleep(0) будет (в зависимости от платформы) ожидать минимально возможное количество времени, освобождая оставшуюся часть оставшегося временного интервала для других процессов и переключая контекст ЦП. Вот соответствующее обсуждение.
Эта идея подробно описана в статье Ryan Geiss Timing in Win32. Это на C и для Windows API, но основные принципы применимы и здесь.
2Сохранить время начала. Отправить сообщение. Получите время окончания. Рассчитать timeTaken=конец-начало. Преобразовать в секунды FP. Сон (0,1-timeTaken). Петля назад.
попробуйте это:
#!/usr/bin/python время импорта; # Это необходимо для включения модуля времени.
 из таймера потокового импорта
def hello (начало, интервал, количество):
тики = время.время()
t = Таймер (интервал - (тикает-начало-количество*интервал), привет, [начало, интервал, количество+1])
т.старт()
print "Количество тиков с 00:00 1 января 1970:", галочки, "#", количество
dt = 1,25 # интервал в сек.
t = Timer(dt, hello, [round(time.time()), dt, 0]) # начать сначала с полной секунды, раунд только для тестирования здесь
т.старт()
из таймера потокового импорта
def hello (начало, интервал, количество):
тики = время.время()
t = Таймер (интервал - (тикает-начало-количество*интервал), привет, [начало, интервал, количество+1])
т.старт()
print "Количество тиков с 00:00 1 января 1970:", галочки, "#", количество
dt = 1,25 # интервал в сек.
t = Timer(dt, hello, [round(time.time()), dt, 0]) # начать сначала с полной секунды, раунд только для тестирования здесь
т.старт()
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Таймер высокого разрешения в Python
спросил
Изменено 1 год, 8 месяцев назад
Просмотрено 470 раз
Можно ли использовать таймер с высоким разрешением в python, и если да, то какой API мне нужно использовать?
Я хочу создать миди-часы. Если я рассчитываю необходимую точность для худшего случая, я получаю 240 ударов в минуту и сетку 32T -> 10,4 мс. Это возможно?
- python
Возможный ответ на вопрос — но только для Windows — можно найти здесь:
Как реализовать высокоскоростную последовательную выборку?
Хитрость заключается в использовании мультимедийных таймеров с минимальным разрешением 1 мс:
https://learn. microsoft.com/en-us/windows/win32/multimedia/multimedia-timers
microsoft.com/en-us/windows/win32/multimedia/multimedia-timers
Редактировать:
Я использую класс mmtimer из ответа выше, но я изменяю тестовую функцию, чтобы записывать события в запись numpy для дальнейшего исследования:
мс = 25 # интервал в мс
продолжительность_записи = 1
x = np.zeros(100000, dtype=np.float) # достаточно памяти для записи событий
количество = 0
определить тик():
глобальный счет
глобальный х
т = время.perf_counter()
х [количество] = т * 1000
количество += 1
t1 = ммтаймер (мс, тик)
t1.start(Истина)
time.sleep (record_duration)
t1.стоп()
время_начала = х[0]
для я в диапазоне (количество):
х[i] -= время_начала
print("{0:.3f}".format(x[i]), "{0:.3f}".format(x[i] - i*ms))
Вывод:
0,000 0,000 24,622 -0,378 49,390 -0,610 75,090 0,090 99,207 -0,793 124,401 -0,599 149,167 -0,833 174,550 -0,450 200,112 0,112 225,008 0,008 249,212 -0,788 275,106 0,106 299,707 -0,293 324,156 -0,844 349,960 -0,040 374,333 -0,667 399,455 -0,545 424,175 -0,825 449,152 -0,848 474,053 -0,947 499,657 -0,343 524,595 -0,405 549,784 -0,216 574,261 -0,739 599,254 -0,746 624,142 -0,858 650,043 0,043 674,987 -0,013 699,720 -0,280 724,398 -0,602 749,914 -0,086 774,612 -0,388 799,372 -0,628 824,491 -0,509 849,886 -0,114 874,204 -0,796 900,226 0,226 924,123 -0,877 950,098 0,098 975,054 0,054 999,169 -0,831
На мой взгляд, таймер достаточно хорош, чтобы построить на нем миди-часы.