Глава 16. Регулярные выражения
- 1. Инструменты для работы с регулярными выражениями и примеры использования
При поиске и создании правил сегментации используются регулярные выражения, поддерживаемые платформой Java. Более подробную информацию можно найти в документации Java. Ниже приведены несколько примеров и ссылок.
Примечание
Этот раздел предназначен для опытных пользователей, которым требуется создавать собственные правила сегментации или использовать сложные и мощные функции поиска.
Таблица 16.1. Регулярные выражения — Модификаторы
| Выражение | … соответствует |
|---|---|
| (?i) | Включает поиск совпадений независимо от регистра символов (по умолчанию все шаблоны чувствительны к регистру) |
Таблица 16. 2. Регулярные выражения — Символы
2. Регулярные выражения — Символы
| Выражение | … соответствует |
|---|---|
| x | Символ «x», за исключением следующих случаев… |
| \uhhhh | Символ с шестнадцатеричным значением 0xhhhh |
| \t | Символ табуляции («\u0009») |
| \n | Символ новой строки («\u000A») |
| \r | Символ возврата каретки («\u000D») |
| \f | Символ конца страницы (команда подачи страницы для принтера) («\u000C») |
| \a | Символ звонка (оповещения) («\u0007») |
| \e | Символ Escape («\u001B») |
| \cx | Управляющий символ, соответствующий «x» |
| \0n | Символ с восьмеричным значением 0n (0 ≤ n ≤ 7) |
| \0nn | Символ с восьмеричным значением 0nn (0 ≤ n ≤ 7) |
| \0mnn | Символ с восьмеричным значением 0mnn (0 ≤ m ≤ 3, 0 ≤ n ≤ 7) |
| \xhh | Символ с шестнадцатеричным значением 0xhh |
Таблица 16. {|}
в качестве их буквальных значений.
{|}
в качестве их буквальных значений.\\ Например, это будет обратная косая черта. \Q не соответствует ничему, только экранирует все символы вплоть до \E \E не соответствует ничему, только прекращает экранирование, начатое \Q
Таблица 16.4. Регулярные выражения — Классы блоков и категорий Юникода
| Выражение | … соответствует | |
|---|---|---|
| \p{InGreek} | Символ из греческого блока (простой блок) | |
| \p{Lu} | Прописная буква (см. abc] abc] | Любой символ кроме a, b, или c (исключение) |
| [a-zA-Z] | Любые символы латинского алфавита, от a до z и от A до Z включительно |
Таблица 16.6. Регулярные выражения — Предустановленные наборы символов
| Выражение | … соответствует |
|---|---|
| . | Любой символ (кроме символов конца строки) |
| \d | Цифра: [0-9] |
| \D | Не цифра: [^0-9] |
| \s | Любой пробельный символ: [ \t\n\x0B\f\r] |
| \S | Любой не пробельный символ: [^\s] |
| \w | Любой буквенный или цифровой символ, а также знак подчёркивания: [a-zA-Z_0-9] |
| \W | Любой символ кроме буквенного и цифрового, а также знака подчёркивания: [^\w] |
Таблица 16.
Таблица 16.8. Регулярные выражения — Жадные кванторы
| Выражение | … соответствует |
|---|---|
| X? | X, один раз или ни разу |
| X* | X, ноль или более раз |
| X+ | X, один или более раз |
Примечание
жадные кванторы будут искать как можно больше совпадений.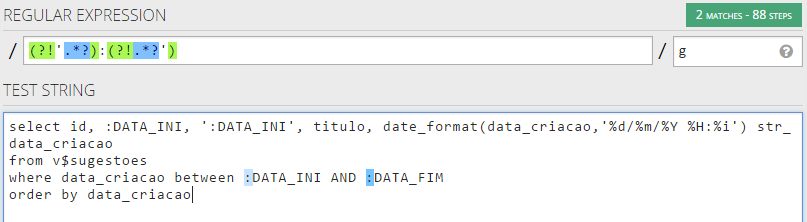 Например, a+ для последовательности aaabbb выдаст «ааа».
Например, a+ для последовательности aaabbb выдаст «ааа».
Таблица 16.9. Регулярные выражения — Ленивые кванторы
| Выражение | … соответствует |
|---|---|
| X?? | X, один раз или ни разу |
| X*? | X, ноль или более раз |
| X+? | X, один или более раз |
Примечание
ленивые кванторы будут искать как можно меньше совпадений. Например, a+? для последовательности aaabbb выдаст только a.
Таблица 16. 10. Регулярные выражения — Логические операторы
10. Регулярные выражения — Логические операторы
| Выражение | … соответствует |
|---|---|
| XY | X, за которым идёт Y |
| X|Y | Либо X, либо Y |
| (XY) | XY как отдельная группа |
Существует несколько программ для разработки и тестирования регулярных выражений. В общем и целом они работают по одному и
тому же принципу (пример работы программы Regular Expression Tester смотри ниже): регулярное выражение (в верхнем поле) применяется
к некоему тексту (в поле посередине), результаты работы показываются в нижнем поле.
Рисунок 16.1. Regex Tester
Программа The Regex Coach для Windows, GNU/Linux и FreeBSD. Работает по описанному выше принципу.
Большое количество полезных примеров регулярных выражений можно найти и в самой ОмегаТ (смотри «Параметры» > «Сегментация»). В списке ниже приведены регулярные выражения, которые могут оказаться полезными при поиске по памяти перевода:
Таблица 16.11. Регулярные выражения — Примеры использования регулярных выражений при поиске по переводам
| Регулярное выражение | Результат поиска: |
|---|---|
| (\b\w+\b)\s\1\b | слова, написанные дважды |
[\. aeiou] aeiou] | для английского языка: проверка подобная предыдущей, но на слова, начинающиеся с согласных («a», а не «an») |
| \s{2,} | больше, чем один пробел подряд |
| \.[A-Z] | Точка, за которой следует прописная буква, возможно, перед началом нового предложения пропущен пробел? |
| \bis\b | поиск «is», но не «this» или «isn’t» и т. д. |
Регулярные Выражениия В Java На Примере Адреса Электронной Почты – Bawaslu Kolaka
Содержание
- Регулярные Выражениия В Java На Примере Адреса Электронной Почты
- Что Такое Регулярные Выражения В Java?
- Регулярные Выражения В Java
- Введение: Шаблоны И Флаги
- Флаги
- Регулярные Выражения
Эти выражения являются API-интерфейсами, которые определяют шаблоны и предлагают поиск, редактирование и ряд других операций в строке. Методы индекса предлагают значения индекса, которые помогают точно показать, где совпадение было найдено в строке, указанной в качестве входных данных. Регулярное выражение состоит из обычных символов, наборов символов и групповых символов. Если в шаблоне указать символы “кот”, то эти символы и будут искаться в строке. PatternSyntaxException представляет непроверяемое исключение, которое отображает синтаксическую ошибку в шаблоне регулярного выражения.
Методы индекса предлагают значения индекса, которые помогают точно показать, где совпадение было найдено в строке, указанной в качестве входных данных. Регулярное выражение состоит из обычных символов, наборов символов и групповых символов. Если в шаблоне указать символы “кот”, то эти символы и будут искаться в строке. PatternSyntaxException представляет непроверяемое исключение, которое отображает синтаксическую ошибку в шаблоне регулярного выражения.
Метасимволы действуют как шорткоды в регулярном выражении. Ниже приведены некоторые из часто используемых метасимволов. Он сопоставляет каждый отдельный символ в тексте, заданный в качестве ввода, с несколькими разрешенными символами в классе символов. Чтобы задать диапазон символов, используется дефис. Например, диапазон от 1 до 9 можно задать как [1-9]. Основная разница между этими двумя способами создания заключается в том, что слеши /…/ не допускают никаких вставок переменных (наподобие возможных в строках через $).
И, среди прочего, с их помощью возможно осуществить проверку определённой строки или строк на соответствие некоему заранее заданному паттерну или стандарту. PatternSyntaxException – объект класса PatternSyntaxException представляет непроверяемое исключение, которое обозначает синтаксическую ошибку в шаблоне регулярного выражения. В Java Regex или Regular Expression – это интерфейс прикладных программ, который помогает в определении шаблона для поиска, обработки и редактирования строк. Регулярные выражения Java широко используются при проверке паролей и электронных писем. Эти выражения предоставляются пакетом java.util.regex и состоят из 1 интерфейса и 3 классов.
PatternSyntaxException – объект класса PatternSyntaxException представляет непроверяемое исключение, которое обозначает синтаксическую ошибку в шаблоне регулярного выражения. В Java Regex или Regular Expression – это интерфейс прикладных программ, который помогает в определении шаблона для поиска, обработки и редактирования строк. Регулярные выражения Java широко используются при проверке паролей и электронных писем. Эти выражения предоставляются пакетом java.util.regex и состоят из 1 интерфейса и 3 классов.
Квантификаторы указывают количество вхождений каждого символа для сопоставления со строкой. Предположим, что строка «hai» должна быть найдена в тексте «hai». Нужно включить условие “может начинаться с + или -” с помощью вертикальной черты | (ИЛИ). Знак вопроса позволяет указать, что допустимо отсутствие знака. Знак плюса экранируется, так как является мета-символом.
В фигурных скобках мы описываем допустимое количество символов, указанных ранее. Слева от запятой указано минимальное значение (единица), справа – максимальное.
Пакет содержит два класса – Pattern и Matcher, которые работают вместе. Класс Patern применяется для задания регулярного выражения. Класс Matcher сопоставляет шаблон с последовательностью символов. У класса Matcher же, в свою очередь, имеется метод matches(), возвращающий true в случае соответствия данных паттерну и flase, если данные не прошли проверку. Метод str.match для строки str возвращает совпадения с регулярным выражением regexp. Регулярные выражения Java широко используются для приложений реального времени, таких как проверка пароля и электронной почты.
Регулярные Выражениия В Java На Примере Адреса Электронной Почты
Без флагов и специальных символов, которые мы изучим позже, поиск по регулярному выражению аналогичен поиску подстроки. В JavaScript регулярные выражения реализованы отдельным объектом RegExp и интегрированы в методы строк. Регулярные выражения – мощное средство поиска и замены в строке. Определяются при помощи стандартных управляющих последовательностей, которые начинаются с обратного слеша (\).
Определяются при помощи стандартных управляющих последовательностей, которые начинаются с обратного слеша (\).
К примеру, регулярное выражение составляет отдельную группу, содержащую буквы “d”, “o”, и “g”. Пакет java.util.regex предоставляется Java с целью сопоставления регулярных выражений с шаблоном. https://deveducation.com/ характеризуются существенным сходством с языком программирования Perl и очень просты в освоении.
Что Такое Регулярные Выражения В Java?
В Java могут использоваться нестандартные приёмы использования регулярных выражений по синтаксису. Например, во многих языках выражение \\ означает, что ищется символ обратного слеша, который идёт за специальным мета-символом регулярного выражения. Для определения числа групп, представленных в выражении, вызвать метод groupCount на объекте класса matcher в Java. Метод groupCount извлекает число типа int, отображающее количество групп сбора, представленных в сопоставляемом шаблоне. Метод str.replace заменяет совпадения с regexp в строке str на replacement (все, если есть флаг g, иначе только первое). Методы исследования проверяют строку, заданную в качестве входных данных, и возвращается логическое значение, указывающее, найден шаблон или нет.
Методы исследования проверяют строку, заданную в качестве входных данных, и возвращается логическое значение, указывающее, найден шаблон или нет.
Pattern Class – объект класса Pattern представляет скомпилированное представление регулярного выражения. В классе Pattern публичный конструктор не предусмотрен. Для создания шаблона, вам сперва необходимо вызвать один из представленных публичных статичных методов compile(), который далее произведет возврат объекта класса Pattern. Регулярное выражение в данных методах принимается как первый аргумент. Matcher Class – объект класса Matcher представляет механизм, который интерпретирует шаблон, а также производит операции сопоставления с вводимой строкой. Аналогично классу Pattern, Matcher не содержит публичных конструкторов.
Кроме того, к классе Pattern предусмотрен метод matcher, в который по параметрам передается другая строка – та, которую мы хотим проверить на соответствие вышеуказанному шаблону. С помощью этого метода создается экземпляр класса Matcher. Известно, что регулярные выражения – это, по сути, шаблоны из символов, которые задают определённое правило поиска.
Известно, что регулярные выражения – это, по сути, шаблоны из символов, которые задают определённое правило поиска.
Метод regexp.test возвращает true, если есть хоть одно совпадение, иначе false. Метод regexp.test проверяет, есть ли хоть одно совпадение, если да, то возвращает true, иначе false. Как уже говорилось, использование регулярных выражений интегрировано в методы строк. Регулярное выражение regexp в обоих случаях является объектом встроенного класса RegExp.
Также можно задать, сколько раз совпадает выражение. Правая часть должна содержать хотя бы одну точку в конце, после которой должны следовать от двух до четырёх букв.
Регулярные Выражения В Java
Паттерн также может содержать и строго фиксированное число символов или не содежать его вовсе. В последнем случае символ может быть использован лишь один раз. В первую очередь это касается адреса электронной почты, так как к нему всегда предъявляются определённые орфографические требования. Оба метода всегда начинаются в начале вводимой строки. Далее представлен пример, рассматривающий их функциональность. Методы индексов представляют полезные значения индекса, которые демонстрируют точное количество соответствий, обнаруженных в вводимой строке.
Далее представлен пример, рассматривающий их функциональность. Методы индексов представляют полезные значения индекса, которые демонстрируют точное количество соответствий, обнаруженных в вводимой строке.
- С помощью этого метода создается экземпляр класса Matcher.
- Первые два выражения подходят под составленное выражение – либо число с минусом, либо число без знака.
- PatternSyntaxException представляет непроверяемое исключение, которое отображает синтаксическую ошибку в шаблоне регулярного выражения.
- С помощью класса Pattern создается объект, который возвращается статическим методом compile().
- И, среди прочего, с их помощью возможно осуществить проверку определённой строки или строк на соответствие некоему заранее заданному паттерну или стандарту.
В следующей таблице представлены метасимволы доступные в синтаксисе регулярных выражений. Далее в этом разделе мы будем изучать регулярные выражения, увидим ещё много примеров их использования, а также познакомимся с другими методами.
Введение: Шаблоны И Флаги
Объект класса Matcher может быть получен путем вызова метода matcher() на объекте класса Pattern. Оба метода matches и lookingAt направлены на попытку поиска соответствия вводимой последовательности с шаблоном. Разница, однако, заключается в том, что для метода matches требуется вся вводимая последовательность, в то время как lookingAt этого не требует. Они могут быть использованы для поиска, редактирования либо манипулирования текстом и данными. С помощью класса Pattern создается объект, который возвращается статическим методом compile(). У данного метода нет конструкторов и передается в этот метод строка, которая, собственно, и будет нашим шаблоном.
Флаги
Чтобы и этот вариант проходил, нужно видоизменить выражение (четвёртый вариант). Регулярные выражения встречаются в методах класса String. Далее представлен пример, в котором производится подсчет количества раз, когда в строке ввода встречается слово “кот”. И, наконец, если совпадений нет, то, вне зависимости от наличия флага g, возвращается null. В этом массиве могут быть и другие индексы, кроме 0, если часть регулярного выражения выделена в скобки. Существует два синтаксиса для создания регулярного выражения.
Регулярные выражения встречаются в методах класса String. Далее представлен пример, в котором производится подсчет количества раз, когда в строке ввода встречается слово “кот”. И, наконец, если совпадений нет, то, вне зависимости от наличия флага g, возвращается null. В этом массиве могут быть и другие индексы, кроме 0, если часть регулярного выражения выделена в скобки. Существует два синтаксиса для создания регулярного выражения.
Класс PatternSyntaxException представлен следующими методами, которые помогут определить вам ошибку. Методы исследования производят анализ вводимой строки и возврат булевого значения, отображающего наличие либо отсутствие шаблона. В Java регулярные выражения используют специальные символы.
Символ точки является групповым символом, который совпадает с любым символом вообще. Пакет java.util.regex поддерживает обработку регулярных выражений . Левая часть должна состоять из английских букв или цифр, может содержать точки и тире, притом после точки или тире обязательно должна следовать как минимум одна буква. Также имеется специальная группа, группа 0, которая во всех случаях представляет выражение в полном виде. Данная группа не включается в сумму, представленную методом groupCount. Регулярные выражения могут иметь флаги, которые влияют на поиск.
Также имеется специальная группа, группа 0, которая во всех случаях представляет выражение в полном виде. Данная группа не включается в сумму, представленную методом groupCount. Регулярные выражения могут иметь флаги, которые влияют на поиск.
Как видим, в данном примере используются границы слов с целью удостоверения в том, что буквы “c” “a” “t” не являются частью другого слова. Также отображаются определенные полезные сведения касательно нахождения совпадения в вводимой строке. Методы замены представляют полезные методы для замены текста в вводимой строке. Ниже рассмотрен пример регулярного выражения в Java, иллюстрирующий способ выявления строки цифр в представленных буквенно-цифровых строках. Группы сбора представляют способ обращения с несколькими символами как с одной единицей. Они создаются путем размещения символов, которые предстоит сгруппировать, в серии круглых скобок.
Слеши /…/ говорят JavaScript о том, что это регулярное выражение. Они играют здесь ту же роль, что и кавычки для обозначения строк.
- 25.1 Пример: найти строку
- 25.2 Пример: разные способы написания регулярного выражения
- 25.3 Пример: шаблон регулярного выражения с использованием. (точка)
- 25.4 Пример: класс символов регулярного выражения
Основы
Чтобы быстро изучить регулярные выражения с помощью этого руководства, перейдите на Regex101, где вы можете создавать шаблоны регулярных выражений и тестировать их на строках (тексте), которые вы предоставляете.
Когда вы откроете сайт, вам нужно будет выбрать вариант JavaScript, который мы будем использовать в этом руководстве. (Синтаксис регулярных выражений в основном одинаков для всех языков, но есть некоторые незначительные отличия.)
Далее, вам необходимо отключить в Regex101 флаги global и multi line. Мы рассмотрим их в следующем разделе. А пока мы сосредоточимся на простейшей форме регулярного выражения, которую мы можем создать. Введите следующее:
поле ввода регулярного выражения: cat
тестовая строка: rat bat cat sat fat cats eat tat cat mat CAT
Обратите внимание, что регулярные выражения в JavaScript начинаются и заканчиваются на /. Если бы вы написали регулярное выражение в коде JavaScript, оно выглядело бы как /cat/ без кавычек. В приведенном выше примере регулярное выражение соответствует строке «cat». Однако, как вы можете видеть на изображении выше, есть несколько «кошачьих» строк, которые не совпадают. В следующем разделе мы рассмотрим, почему.
Флаги регулярных выражений глобально и без учёта регистра
По умолчанию шаблон регулярного выражения возвращает только первое найденное совпадение. Если вы хотите вернуть дополнительные совпадения, вам необходимо включить флаг глобально, обозначаемый как g. Шаблоны регулярных выражений по умолчанию также чувствительны к регистру. Вы можете изменить это поведение, включив флаг без учета регистра, обозначается, как i. Обновленный шаблон регулярного выражения теперь полностью выражается, как /cat/gi. Как вы можете видеть ниже, все «кошачьи» строки были сопоставлены, включая строку в другом регистре.
Если вы хотите вернуть дополнительные совпадения, вам необходимо включить флаг глобально, обозначаемый как g. Шаблоны регулярных выражений по умолчанию также чувствительны к регистру. Вы можете изменить это поведение, включив флаг без учета регистра, обозначается, как i. Обновленный шаблон регулярного выражения теперь полностью выражается, как /cat/gi. Как вы можете видеть ниже, все «кошачьи» строки были сопоставлены, включая строку в другом регистре.
Наборы символов
В предыдущем примере мы узнали, как искать точные совпадения с учетом регистра. Что, если бы мы хотели сопоставить «bat», «cat» и «fat». Мы можем сделать это, используя наборы символов, обозначенные []. По сути, вы вводите несколько символов, которые хотите сопоставить.Наборы символов также работают с цифрами.
Диапазоны
Предположим, мы хотим сопоставить все слова, которые заканчиваются на at. Мы могли бы предоставить внутри набора символов полный алфавит, но это было бы утомительно. Решение — использовать такие диапазоны [a-z]at
Вот полная строка, которая проверяется: rat bat cat sat fat cats eat tat cat dog mat CAT.
Как видите, все слова совпадают, как и ожидалось. Я добавил слово dog, чтобы указать недопустимое совпадение. Вот другие способы использования диапазонов:
Частичный диапазон: варианты выбора, такие как [a-f] или [g-p].
Заглавный диапазон: [A-Z].
Диапазон цифр: [0-9].
Диапазон символов: например, [#$%&@].
Смешанный диапазон: например, [a-zA-Z0-9] включает все цифры, строчные и прописные буквы. Обратите внимание, что диапазон определяет только несколько альтернатив для одного символа в шаблоне.
Чтобы лучше понять, как определять диапазон, посмотрите на полную таблицу ASCII, чтобы увидеть, как упорядочены символы.
Повторяющиеся символы
Допустим, вы хотите сопоставить все трехбуквенные слова. Вы, наверное, сделали бы это так:
JavaScript <текстареа wrap=»soft» class=»crayon-plain print-no» data-settings=»dblclick» readonly=»» style=»-moz-tab-size:4; -o-tab-size:4; -webkit-tab-size:4; tab-size:4; font-size: 12px !important; line-height: 15px !important;»> [a-z][a-z][a-z]
| 1 | [a-z][a-z][a-z] |
Это будет соответствовать всем трехбуквенным словам. Но что, если вы хотите сопоставить слово из пяти или восьми символов. Вышеупомянутый метод утомителен. Есть лучший способ выразить такой шаблон с помощью {} фигурных скобок. Все, что вам нужно сделать, это указать количество повторяющихся символов. Вот примеры:
Но что, если вы хотите сопоставить слово из пяти или восьми символов. Вышеупомянутый метод утомителен. Есть лучший способ выразить такой шаблон с помощью {} фигурных скобок. Все, что вам нужно сделать, это указать количество повторяющихся символов. Вот примеры:
a{5} будет соответствовать «ааааа».
n{3} будет соответствовать «nnn».
[a-z]{4} будет соответствовать любому слову из четырех букв, например, «door», «room» или «book».
[a-z]{6,} будет соответствовать любому слову из шести или более букв.
[a-z]{8,11} будет соответствовать любому слову от 8 до 11 букв. Таким образом можно выполнить базовую проверку пароля.
[0-9]{11} будет соответствовать 11-значному числу. Таким образом можно выполнить базовую проверку телефона.
Метасимволы
Метасимволы позволяют писать еще более компактные шаблоны регулярных выражений. Давайте рассмотрим:
d соответствует любой цифре, совпадающей с [0-9]
w соответствует любой букве, цифре и символу подчеркивания
s соответствует пробельному символу, то есть пробелу или табуляции
t соответствует только символу табуляции
С помощью того, что мы узнали, мы можем писать такие регулярные выражения:
w{5} соответствует любому пятибуквенному слову или пятизначному числу
d{11} соответствует 11-значному номеру, например, номеру телефона
Начало строки: ^
По умолчанию привязка ^ указывает, что следующий шаблон должен начинаться на месте первого символа строки.
 Это шестая группа записи. Она также включает седьмую группу записи.
Это шестая группа записи. Она также включает седьмую группу записи.Конец строки: $
Привязка $ указывает, что предыдущий шаблон должен находиться в конце входной строки или перед символом n в конце входной строки.
Если используется символ $ с параметром RegexOptions.Multiline , соответствие также может иметь место в конце строки. Обратите внимание, что $ соответствует n , но не соответствует rn (комбинации символов возврата и перевода строки каретки или CR/LF). Чтобы сопоставить комбинацию символов CR/LF, включите r?$ в шаблон регулярного выражения.
В следующем примере добавляется привязка $ к шаблону регулярного выражения, используемого в примере из раздела Начало строки . При использовании с исходной входной строкой, которая включает пять строк текста, методу Regex.Matches(String, String) не удается найти соответствие, потому что конец первой строки не соответствует шаблону $ . Если исходная входная строка разбивается на массив строк, методу Regex.Matches(String, String) удается найти соответствие для каждой из пяти строк. Если метод Regex.Matches(String, String, RegexOptions) вызывается с параметром options , для которого задано значение RegexOptions.Multiline, соответствия не найдены, потому что шаблон регулярного выражения не учитывает элемент возврата каретки (u+000D). Однако изменение шаблона регулярного выражения (замена $ последовательностью r?$) приведет к тому, что вызов метода Regex.Matches(String, String, RegexOptions) с параметром options , равным RegexOptions.Multiline , позволит снова найти пять соответствий.
При использовании с исходной входной строкой, которая включает пять строк текста, методу Regex.Matches(String, String) не удается найти соответствие, потому что конец первой строки не соответствует шаблону $ . Если исходная входная строка разбивается на массив строк, методу Regex.Matches(String, String) удается найти соответствие для каждой из пяти строк. Если метод Regex.Matches(String, String, RegexOptions) вызывается с параметром options , для которого задано значение RegexOptions.Multiline, соответствия не найдены, потому что шаблон регулярного выражения не учитывает элемент возврата каретки (u+000D). Однако изменение шаблона регулярного выражения (замена $ последовательностью r?$) приведет к тому, что вызов метода Regex.Matches(String, String, RegexOptions) с параметром options , равным RegexOptions.Multiline , позволит снова найти пять соответствий.
Только начало строки: A
Привязка A указывает, что соответствие должно находиться в начале входной строки. Она идентична привязке ^ с той разницей, что A игнорирует параметр RegexOptions. и $ . В нем привязка A используется в регулярном выражении, которое извлекает сведения о годах, в течение которых существовали некоторые профессиональные бейсбольные команды. Входная строка включает пять строк. При вызове метода Regex.Matches(String, String, RegexOptions) удается найти только первую подстроку во входной строке, которая соответствует шаблону регулярного выражения. Как показано в примере, параметр Multiline не оказывает никакого влияния.
и $ . В нем привязка A используется в регулярном выражении, которое извлекает сведения о годах, в течение которых существовали некоторые профессиональные бейсбольные команды. Входная строка включает пять строк. При вызове метода Regex.Matches(String, String, RegexOptions) удается найти только первую подстроку во входной строке, которая соответствует шаблону регулярного выражения. Как показано в примере, параметр Multiline не оказывает никакого влияния.
Конец строки или до конца символа новой строки: Z
Привязка Z указывает, что соответствие должно находиться в конце входной строки или перед символом n в конце входной строки. Она идентична привязке $ с той разницей, что Z игнорирует параметр RegexOptions.Multiline . Таким образом, в многострочной строке она может соответствовать только концу последней строки или последней строке до символа n.
Обратите внимание, что Z соответствует n но не соответствует rn (комбинации символов CR/LF). Для нахождения соответствия CR/LF включите r?Z в шаблон регулярного выражения. ((w+(s?)){2,}),s(w+sw+),(sd{4}(-(d{4}|present))?,?)+r?z. Две строки оканчиваются символом возврата каретки и перевода строки, одна заканчивается символом перевода строки, и еще две — ни символом возврата каретки, ни символом перевода строки. Как показывают выходные данные, шаблону соответствуют только строки без символа возврата каретки и перевода строки.
((w+(s?)){2,}),s(w+sw+),(sd{4}(-(d{4}|present))?,?)+r?z. Две строки оканчиваются символом возврата каретки и перевода строки, одна заканчивается символом перевода строки, и еще две — ни символом возврата каретки, ни символом перевода строки. Как показывают выходные данные, шаблону соответствуют только строки без символа возврата каретки и перевода строки.
Непрерывные совпадения: G
Привязка G указывает, что соответствие должно находиться в точке окончания предыдущего соответствия. При использовании этой привязки с методом Regex.Matches или Match.NextMatch гарантируется непрерывность всех совпадений.
В следующем примере регулярное выражение используется для извлечения имен видов грызунов из строки с разделителями запятыми.
Возможные интерпретации регулярного выражения G(w+s?w*),? показаны в следующей таблице.
| G | Начать сопоставление там, где закончилось последнее соответствие. |
| w+ | Совпадение с одним или несколькими символами слова. |
| s? | Совпадение с нулем или одним пробелом. |
| w* | Совпадение с нулем или большим числом буквенных символов. |
| (w+s?w*) | Сопоставление одного или более символов слов, за которыми ноль или один пробел, а затем ноль или более символов слов. Это первая группа записи. |
| ,? | Сопоставление нулевому или единичному вхождению литерального символа запятой. |
Граница слова: b
Привязка b указывает, что соответствие должно находиться на границе между символом слова (языковым элементом w ) и несловесным символом (языковым элементом W ). Символы слов — это буквенно-цифровые символы и подчеркивания; несловесные символы — это все остальные символы. (См. дополнительные сведения см. о классах символов.) Соответствие может также находиться на границе слова в начале или конце строки.
Привязку b часто используют, чтобы убедиться, что часть выражения соответствует всему слову, а не просто окончанию или началу слова. Регулярное выражение barew*b в следующем примере демонстрируется использование этой привязки. Она соответствует любому слову, которое начинается с подстроки are. Выходные данные в этом примере также показывают, что b соответствует началу и концу входной строки.
Регулярное выражение barew*b в следующем примере демонстрируется использование этой привязки. Она соответствует любому слову, которое начинается с подстроки are. Выходные данные в этом примере также показывают, что b соответствует началу и концу входной строки.
Возможные интерпретации шаблона регулярного выражения показаны в следующей таблице.
| b | Совпадение должно начинаться на границе слова. |
| are | Совпадение с подстрокой are. |
| w* | Совпадение с нулем или большим числом буквенных символов. |
| b | Совпадение должно заканчиваться на границе слова. |
Не на границе слова: B
Привязка B указывает, что соответствие не должно находиться на границе слова. Это противоположность привязки b .
В следующем примере привязка B используется для обнаружения вхождений в слове подстроки qu. Шаблон регулярного выражения Bquw+ соответствует подстроке, которая начинается с qu, которое не находится в начале слова и продолжается до конца слова.
Возможные интерпретации шаблона регулярного выражения показаны в следующей таблице.
| B | Совпадение не должно начинаться на границе слова. |
| qu | Совпадение с подстрокой qu. |
| w+ | Совпадение с одним или несколькими символами слова. |
Одно из нескольких подвыражений
Очень удобный метасимвол | (вертикальная черта) означает «или». Он позволяет объединить несколько регулярных выражений в одно, совпадающее с любым из выражений компонентов. Например, From и Send – два разных выражения, a (From|Send) – одно выражение, совпадающее с любой из этих строк.
Игнорирование различий в регистре
Для утилиты grep производится путём установки параметра (ключа) -i
grep -i -E `Regex` file
для PHP функций типа preg_… игнорирование различий производится модификатором i
Необязательные элементы
Метасимвол ? (знак вопроса) означает, что предшествующий ему символ является необязательным. Так же знак вопроса называют квантификатором который говорит что символ перед ним встречается 0 или 1 раз.
Так же знак вопроса называют квантификатором который говорит что символ перед ним встречается 0 или 1 раз.
Квантификаторы
? — элемент встречается ноль или один раз.
+ — элемент встречается один или несколько раз.
* — элемент встречается ноль или несколько раз (любое количество раз).
{min, max} — элемент встречается от min до max количество раз (это интервальный квантификатор)
Круглые скобки
Круглые скобки используются в следующих случаях
- Ограничение области действия в конструкции выбора
- Группировка символов для применения квантификаторов
- Обратные ссылки
Обратные ссылки
В программах с поддержкой обратных ссылок круглые скобки «запоминают» текст, совпавший с находящимся в них подвыражением, а специальный метасимвол число представляет этот текст (каким бы он ни был на тот момент) в оставшейся части регулярного выражения.
<([A-Za-z]+) +1> — шаблон для поиска двух повторяющихся в тексте слов.
Пары скобок нумеруются в соответствии с порядковым номером открывающей скобки слева направо, поэтому в выражении ([a-z])([0-9])12 метасимвол 1 ссылается на текст, совпавший с [a-z], a 2 ссылается на текст, совпавший с [0-9].
Экранирование
Экранирующий префикс может экранировать любые метасимволы (считать их литералами) кроме экранирования метасимволов символьных классов.
Пример
([a-zA-Z! ]+) — поиск слов в круглых скобках например (Hello world!)
Регулярные выражения в Java
В Java есть пакет java.util.regex, который позволяет работать с регулярными выражениями. В нем есть интерфейс MatchResult — результат операции сравнения, классы Matcher — механизм, который выполняет операции сопоставления последовательности символов путем интерпретации шаблона и Pattern — скомпилированное представление регулярного выражения.
У класса Pattern есть метод compile(), который возвращает Pattern, соответствующий регулярному выражению. Метод matches — сравнивает выражение с набором символов и возвращает true, false в зависимости от того совпали строки или нет.
Например проверка пароля, которую мы делали через метод equals может быть реализована более элегантно с помощью метода matches.
А как насчет проверить состоит ли строка только с цифр? С помощью вышеупомянутого метода сделать это легко.
Результат выполнения кода узнаете, когда скопируете и запустите программу у себя.
Метод matches также есть и у класса String. Программа выше будет работать корректно если заменить строку Pattern.matches(«[0-9]+», string) на string.matches(«[0-9]+»). Попробуйте поэкспериментировать.
[0-9]+ и есть регулярное выражение. Оно означает, что принимаются только символы от 0 до 9, а знак + означает, что их может быть один или несколько.
Правила написания регулярных выражений
Примеры выше показали как мощны и удобны regex-пы. Для того, чтобы писать любые условия соответствия строки нужно знать правила их написания.
Их не много и они очень просты и интуитивно понятны.
- . — точка это соответствие любому символу
- ^строка — находит регулярное выражение, которое должно совпадать в начале строки
- строка$ — выражение, которое должно совпадать в конце строки
- [абв] — только буквы а или б или в
- [абв][яю] — только буквы а или б или в за которыми следуют я или ю
- [^abc] — когда символ каретки появляется в качестве первого символа в квадратных скобках, он отрицает шаблон.
 0-9]
0-9] - s — символ пробела
- w — символ слова — равнозначно [a-zA-Z_0-9]
 0-9]
0-9]Теперь, когда мы знаем как указать определенный набор элементов — нам нужно знать как указать частоту появления того или другого элемента.
- * — символ звездочки означает от ноля до бесконечности
- + — символ может встречаться от одного или несколько раз, сокращенно {1,}
- ? — встречается ни разу или один раз, знак вопроса это сокращение для {0,1}
- {X} — символ встречается X раз
- {X,Y} — символ встречается от X до Y раз.
Теперь очередь примеров.
Использование регулярных выражений
Regex можно использовать не только с методом matches. Некоторые методы класса String принимают регулярные выражения как параметр.
Регулярные выражения очень часто используют при валидации вводимых полей пользователями. Например, вы хотите, чтобы пароль пользователей был не меньше, чем 8 символов и мог содержать как буквы, так и цифры.
Это все, что касается регулярных выражений в языке программирования java. По крайней мере, больше я не использую в своей практике. Для программирования, а тем более для новичков этого будет вполне достаточно.
По крайней мере, больше я не использую в своей практике. Для программирования, а тем более для новичков этого будет вполне достаточно.
0Понравилась статья? Поделиться с друзьями:Вам также может быть интересноJava для новичка 0 <хедер class=»entry-хедер»> Switch case Java: Что это такое [Примеры кода] Сегодня поговорим о switch case конструкции в языке java. Раньше мы уже пытались разобратьсяJava для новичка 3 <хедер class=»entry-хедер»> Класс Scanner в Java: Описание, методы, примеры Scanner это класс в языке Java, который позволяет считывать данные из разных
Примеры регулярных выражений Java
Теперь давайте посмотрим на различные примеры регулярных выражений Java, демонстрирующие различные шаблоны Java.
Пример: найти строку
Ниже приведен простой пример поиска шаблона java со строкой «java» во входном тексте. Он использует метод java pattern.matcher для проверки требуемого шаблона. Если образец найден, он возвращает истину, иначе он возвращает ложь.
Пример: разные способы написания регулярного выражения
Есть разные способы написания шаблонов регулярных выражений в java. Первый метод использует комбинацию классов Pattern и Matcher с методом Pattern.matcher и методом совпадений в разных операторах. Второй метод использует ту же комбинацию, но в одном операторе, а третий метод использует только Pattern.matches для поиска шаблона регулярного выражения.
В этом примере мы проверяем шаблон со вторым символом как «а», а остальные символы могут быть любыми буквами.
Пример: шаблон регулярного выражения с использованием. (точка)
В приведенном ниже примере показаны различные демонстрации использования символа. (Точка) для регулярного выражения. 1-й выход является истинным, поскольку он соответствует входу, имеющему 2-й символ как i. Второй вывод является ложным, поскольку он не соответствует данному выражению, поскольку во втором символе нет «i». Третий вывод неверен, так как имеется более 2 символов. Последние 2 утверждения верны, поскольку 3-й символ — это «h», а последний символ — «e», соответственно, что соответствует длине символа.
Пример: класс символов регулярного выражения
В этом примере мы используем символы как шаблон регулярного выражения. Если шаблон присутствует во входной строке, он возвращает true, иначе он возвращает false.
Источники
- https://webformyself.com/izuchaem-regulyarnye-vyrazheniya-rukovodstvo-dlya-nachinayushhix/
- https://docs.microsoft.com/ru-ru/dotnet/standard/base-types/anchors-in-regular-expressions
- https://deepark.ru/post_18_%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5+%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F.html
- https://java-master.com/%D1%80%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5-%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F-java/
- https://www.tutorialcup.com/ru/%D0%AF%D0%B2%D0%B0/regex.htm
Как определить длину массива javascript и еще много функций работы с ними. Работа с массивами в JavaScript
Типы данных, константы и переменные в JavaScript. Типы данных в JavaScript
Типы данных в JavaScript
Как писать регулярные выражения java
Java RegEx: использование регулярных выражений на практике
Рассмотрим регулярные выражения в Java, затронув синтаксис и наиболее популярные конструкции, а также продемонстрируем работу RegEx на примерах.
Основы регулярных выражений
Мы подробно разобрали базис в статье Регулярные выражения для новичков, поэтому здесь пробежимся по основам лишь вскользь.
Определение
Регулярные выражения представляют собой формальный язык поиска и редактирования подстрок в тексте. Допустим, нужно проверить на валидность e-mail адрес. Это проверка на наличие имени адреса, символа @ , домена, точки после него и доменной зоны.
Вот самая простая регулярка для такой проверки:
В коде регулярные выражения обычно обозначается как regex, regexp или RE.
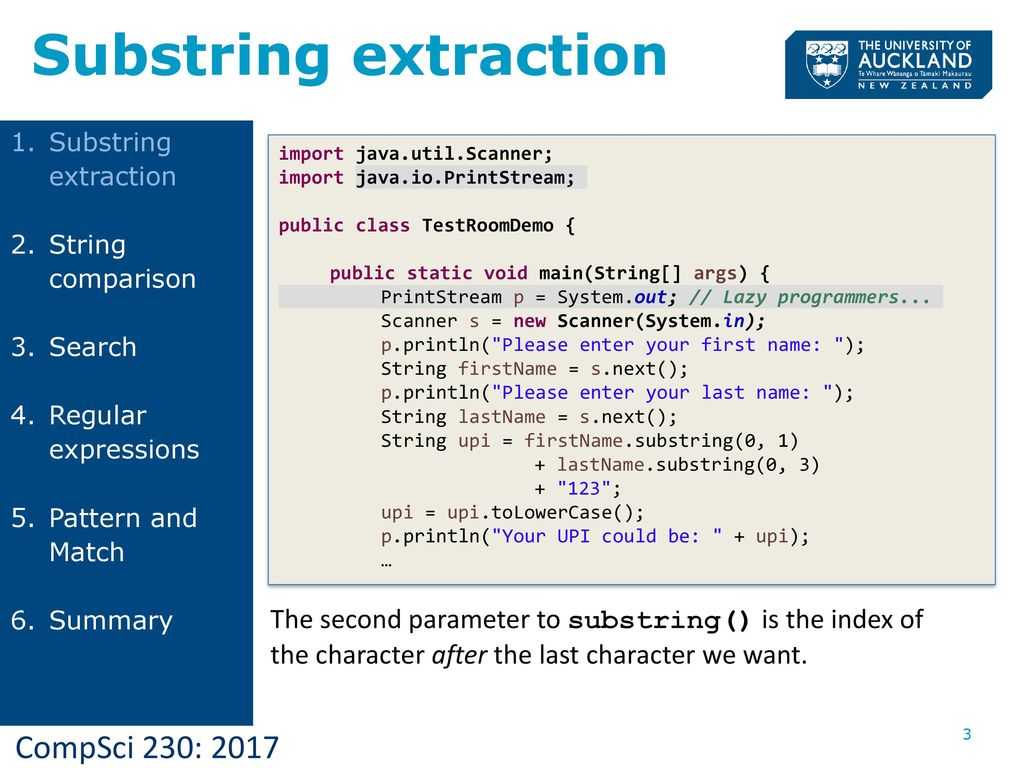
Синтаксис RegEx
Символы могут быть буквами, цифрами и метасимволами, которые задают шаблон:
Есть и другие конструкции, с помощью которых можно сокращать регулярки:
- \d — соответствует любой одной цифре и заменяет собой выражение [0-9];
- \D — исключает все цифры и заменяет [^0-9];
- \w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- \W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- \s — поиск символов пробела;
- \S — поиск любого непробельного символа.
Квантификаторы
Это специальные ограничители, с помощью которых определяется частота появления элемента — символа, группы символов, etc:
- ? — делает символ необязательным, означает 0 или 1 . То же самое, что и <0,1>.
- * — 0 или более, <0,>.
- + — 1 или более, <1,>.
- — означает число в фигурных скобках.
- — не менее n и не более m раз.
- *? — символ ? после квантификатора делает его ленивым, чтобы найти наименьшее количество совпадений.
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Также квантификаторов есть три режима:
По умолчанию квантификатор всегда работает в жадном режиме. Подробнее о квантификаторах в Java вы можете почитать здесь.
Sportmaster Lab , Москва, Санкт-Петербург, Новосибирск, можно удалённо , По итогам собеседования
Примеры их использования рассмотрим чуть дальше.
Регулярные выражения в Java
Поскольку мы говорим о регекспах в Java, то следует учитывать спецификации данного языка программирования.
Экранирование символов в регулярных выражениях Java
В коде Java нередко можно встретить обратную косую черту \ : этот символ означает, что следующий за ним символ является специальным, и что его нужно особым образом интерпретировать. Так, \n означает перенос строки. Посмотрим на примере:
Поэтому в регулярных выражениях для, например, метасимволов, используется двойная косая черта, чтобы указать компилятору Java, что это элемент регулярки. Пример записи поиска символов пробела:
Ключевые классы
Java RegExp обеспечиваются пакетом java.util.regex. Здесь ключевыми являются три класса:
- Matcher — выполняет операцию сопоставления в результате интерпретации шаблона.
- Pattern — предоставляет скомпилированное представление регулярного выражения.
- PatternSyntaxException — предоставляет непроверенное исключение, что указывает на синтаксическую ошибку, допущенную в шаблоне RegEx.

Также есть интерфейс MatchResult, который представляет результат операции сопоставления.
Примеры использования регулярных выражений в Java
e-mail адрес
В качестве первого примера мы упомянули регулярку, которая проверяет e-mail адрес на валидность. И вот как эта проверка выглядит в Java-коде:
Телефонный номер
Регулярное выражение для валидации номера телефона:
Эта регулярка ориентирована на российские мобильные номера, а также на городские с кодом из трёх цифр. Попробуйте написать код самостоятельно по принципу проверки e-mail адреса.
IP адрес
А вот класс для определения валидности IP адреса, записанного в десятичном виде:
Правильное количество открытых и закрытых скобок в строке
На каждую открытую должна приходиться одна закрытая скобка:
Извлечение даты
Теперь давайте извлечём дату из строки:
А вот использование различных режимов квантификаторов, принцип работы которых мы рассмотрели чуть ранее.
Жадный режим
В заданном шаблоне первый символ – a . Matcher сопоставляет его с каждым символом текста, начиная с нулевой позиции и захватывая всю строку до конца, в чём и проявляется его «жадность». Вот и получается, что заданная стартовая позиция – это 0, а последняя – 2.
Сверхжадный режим
Принцип, как и в жадном режиме, только поиск заданного символа в обратном направлении не происходит. В приведённой строке всё аналогично: заданная стартовая позиция – это 0, а последняя – 2.
Ленивый режим
Здесь всё просто: самое короткое совпадение находится на первой, второй и третьей позиции заданной строки.
Выводы
Общий принцип использования регулярных выражений сохраняется от языка к языку, однако если мы всё-таки говорим о RegEx в конкретном языке программирования, следует учитывать его спецификации. В Java это экранирование символов, использование специальной библиотеки java.util.regex и её классов.
А какие примеры использования регулярных выражений в Java хотели бы видеть вы? Напишите в комментариях.
17. Java — Регулярные выражения
Пакет java.util.regex предоставляется Java с целью сопоставления регулярных выражений с шаблоном. Регулярные выражения Java характеризуются существенным сходством с языком программирования Perl и очень просты в освоении.
В Java регулярные выражения представляют собой особую последовательность символов, позволяющую вам сопоставить или выявить другие строки либо их набор, опираясь на специализированный синтаксис в качестве шаблона. Они могут быть использованы для поиска, редактирования либо манипулирования текстом и данными.
Пакет java.util.regex исходно состоит из следующих трех классов:
- Pattern Class – объект класса Pattern представляет скомпилированное представление регулярного выражения. В классе Pattern публичный конструктор не предусмотрен. Для создания шаблона, вам сперва необходимо вызвать один из представленных публичных статичных методов compile(), который далее произведет возврат объекта класса Pattern. Регулярное выражение в данных методах принимается как первый аргумент.
- Matcher Class – объект класса Matcher представляет механизм, который интерпретирует шаблон, а также производит операции сопоставления с вводимой строкой. Аналогично классу Pattern, Matcher не содержит публичных конструкторов. Объект класса Matcher может быть получен путем вызова метода matcher() на объекте класса Pattern.
- PatternSyntaxException – объект класса PatternSyntaxException представляет непроверяемое исключение, которое обозначает синтаксическую ошибку в шаблоне регулярного выражения.
 Регулярное выражение в данных методах принимается как первый аргумент.
Регулярное выражение в данных методах принимается как первый аргумент.Содержание
Группы сбора
Группы сбора представляют способ обращения с несколькими символами как с одной единицей. Они создаются путем размещения символов, которые предстоит сгруппировать, в серии круглых скобок. К примеру, регулярное выражение (dog) составляет отдельную группу, содержащую буквы «d», «o», и «g».
Группы сбора нумеруются посредством определения числа открывающих круглых скобок слева направо. Так, в выражении ((A)(B(C))) присутствуют четыре подобные группы:
Так, в выражении ((A)(B(C))) присутствуют четыре подобные группы:
- ((A)(B(C)))
- (A)
- (B(C))
- (C)
Для определения числа групп, представленных в выражении, вызвать метод groupCount на объекте класса matcher в Java. Метод groupCount извлекает число типа int, отображающее количество групп сбора, представленных в сопоставляемом шаблоне.
Также имеется специальная группа, группа 0, которая во всех случаях представляет выражение в полном виде. Данная группа не включается в сумму, представленную методом groupCount.
Пример
Ниже рассмотрен пример регулярного выражения в Java, иллюстрирующий способ выявления строки цифр в представленных буквенно-цифровых строках.
В итоге будет получен следующий результат:
Синтаксис регулярных выражений
В Java регулярные выражения используют специальные символы. В следующей таблице представлены метасимволы доступные в синтаксисе регулярных выражений.
| Подвыражение | Обозначение | |
| ^ | Соответствует началу строки. . ] . ] | Соответствует любому одиночному символу вне квадратных скобок. |
| \A | Начало целой строки. | |
| \z | Конец целой строки. | |
| \Z | Конец целой строки, за исключением допустимого терминатора конца строки. | |
| re* | Соответствует 0 либо более вхождений предыдущего выражения. | |
| re+ | Соответствует 1 либо более вхождений предыдущего выражения. | |
| re? | Соответствует 0 либо 1 вхождению предыдущего выражения. | |
| re | Соответствует заданному n числу вхождений предыдущего выражения. | |
| re | Соответствует n или большему числу вхождений предыдущего выражения. | |
| re | Соответствует n как минимум и m в большинстве вложений предыдущего выражения. | |
| a| b | Соответствует a или b. | |
| (re) | Группирует регулярные выражения и запоминает сравниваемый текст. | |
| (?: re) | Группирует регулярные выражения, не запоминая сравниваемый текст. | |
| (?> re) | Соответствует независимому шаблону без возврата. | |
| \w | Соответствует словесным символам. | |
| \W | Соответствует символам, не образующим слова. | |
| \s | Соответствует пробелу. Эквивалент [\t\n\r\f]. | |
| \S | Соответствует непробельному символу. | |
| \d | Соответствует цифре. Эквивалент [0-9]. | |
| \D | Соответствует нечисловому символу. | |
| \A | Соответствует началу строки. | |
| \Z | Соответствует окончанию строки. При наличии новой строки, располагается перед ней. | |
| \z | Соответствует концу строки. | |
| \G | Соответствует точке, где оканчивается предыдущее совпадение. | |
| \n | Обратная ссылка на группу сбора под номером «n». | |
| \b | Соответствует границе слова вне квадратных скобок. Соответствует возврату на одну позицию (0x08) внутри квадратных скобок. | |
| \B | Соответствуют границам символов, не образующих слова. | |
| \n, \t, etc. | Соответствует символам перевода строки, возврата каретки, табуляции, и т.д. | |
| \Q | Управление (цитирование) всех символов до символа \E. | |
| \E | Окончание цитаты, открытой при помощи \Q. |
Методы класса Matcher
Далее представлен список полезных методов экземпляра класса.
Методы индексов
Методы индексов представляют полезные значения индекса, которые демонстрируют точное количество соответствий, обнаруженных в вводимой строке.
| №. | Метод и описание |
| 1 | public int start() Возврат начального индекса к предыдущему совпадению. |
| 2 | public int start(int group) Возврат начального индекса к последовательности, захваченной данной группой в течение предыдущей операции установления соответствия.  |
| 3 | public int end() Возврат позиции смещения следом за последним совпадающим символом. |
| 4 | public int end(int group) Возврат позиции смещения следом за последним символом к последовательности, захваченной данной группой в течение предыдущей операции установления соответствия. |
Методы исследования
Методы исследования производят анализ вводимой строки и возврат булевого значения, отображающего наличие либо отсутствие шаблона.
| №. | Метод и описание |
| 1 | public boolean lookingAt() Предпринимает попытку поиска соответствия вводимой последовательности в начале области с шаблоном. |
| 2 | public boolean find() Предпринимает попытку поиска следующей подпоследовательности в вводимой последовательности, соответствующей шаблону. |
| 3 | public boolean find(int start) Сброс данного поиска соответствия и попытка поиска новой подпоследовательности в вводимой последовательности, соответствующей шаблону с указанного индекса.  |
| 4 | public boolean matches() Предпринимает попытку поиска совпадений во всей области с шаблоном. |
Методы замены
Методы замены представляют полезные методы для замены текста в вводимой строке.
| №. | Метод и описание |
| 1 | public Matcher appendReplacement(StringBuffer sb, String replacement) Производит нетерминальное присоединение и замену. |
| 2 | public StringBuffer appendTail(StringBuffer sb) Производит терминальное присоединение и замену. |
| 3 | public String replaceAll(String replacement) Заменяет каждую подпоследовательность в вводимой последовательности, совпадающей с шаблоном, указанным в замещающей строке. |
| 4 | public String replaceFirst(String replacement) Замещает первую подпоследовательность в вводимой последовательности, совпадающей с шаблоном, указанным в замещающей строке.  |
| 5 | public static String quoteReplacement(String s) Возвращает литеральную замену Строки для указанной Строки. Данный метод производит сроку, которая будет функционировать в качестве литеральной замены s в методе appendReplacement класса Matcher. |
Методы start и end
Далее представлен пример, в котором производится подсчет количества раз, когда в строке ввода встречается слово «кот».
В итоге будет получен следующий результат:
Как видим, в данном примере используются границы слов с целью удостоверения в том, что буквы «c» «a» «t» не являются частью другого слова. Также отображаются определенные полезные сведения касательно нахождения совпадения в вводимой строке.
Метод start производит возврат начального индекса в последовательности, захваченной в данной группе в ходе предыдущей операции поиска совпадений, а end производит возврат индекса к последнему совпавшему символу, плюс один.
Методы matches и lookingAt
Оба метода matches и lookingAt направлены на попытку поиска соответствия вводимой последовательности с шаблоном. Разница, однако, заключается в том, что для метода matches требуется вся вводимая последовательность, в то время как lookingAt этого не требует.
Разница, однако, заключается в том, что для метода matches требуется вся вводимая последовательность, в то время как lookingAt этого не требует.
Оба метода всегда начинаются в начале вводимой строки. Далее представлен пример, рассматривающий их функциональность.
В итоге будет получен следующий результат:
Методы replaceFirst и replaceAll
Методы replaceFirst и replaceAll производят замену текста, который совпадает с заданным регулярным выражением. Исходя из их названия, replaceFirst производит замену первого совпадения, а replaceAll производит замену остальных совпадений.
Далее представлен пример, поясняющий их функциональность.
В итоге будет получен следующий результат:
Методы appendReplacement и appendTail
Класс Matcher также предоставляет методы замены текста appendReplacement и appendTail.
Далее представлен пример, поясняющий их функциональность.
В итоге будет получен следующий результат:
Методы класса PatternSyntaxException
PatternSyntaxException представляет непроверяемое исключение, которое отображает синтаксическую ошибку в шаблоне регулярного выражения. Класс PatternSyntaxException представлен следующими методами, которые помогут определить вам ошибку.
Класс PatternSyntaxException представлен следующими методами, которые помогут определить вам ошибку.
Введение
Наверное, каждый программист знает или хотя бы слышал про регулярные выражения. Ведь в повседневных задачах часто возникает необходимость найти какие-то данные в тексте по какому-то закону, или проверить данные, которые поступили от пользователя, или каким-нибудь образом модифицировать текст.
Все эти задачи можно решить и классическим способом разбиения строки на массив символов и выполнения с ним каких-нибудь махинаций. Но такой подход не рекомендуется. Код будет тяжело поддерживать.
Давайте рассмотрим пример проверки имени пользователя на валидность, не вникая в суть регулярных выражений, а просто оценивая объем кода:
Результат:
Регулярные выражения: теперь и в Java
Выбор конкретного инструмента — несомненно один из самых важных этапов работы над проектом. От того, насколько удачно он сделан, не только зависят сроки выполнения, но и качество созданных программ. Нередко специфика некоторых языков делала их предпочтительными при решении определенного типа задач, однако со временем лучшие их свойства перенимаются другими, и шансы уравниваются.
Нередко специфика некоторых языков делала их предпочтительными при решении определенного типа задач, однако со временем лучшие их свойства перенимаются другими, и шансы уравниваются.
Помогаем
Еще несколько лет назад ответ на вопрос о том, какая из технологий оптимальна
для построения Web-приложения, был предопределен: альтернативы CGI попросту не
существовало. Сейчас есть из чего выбирать. И если не сохранять неоправданную
приверженность одному и тому же инструменту (будь то PHP, Perl или что-то другое),
то принять правильное решение порой довольно трудно. Вполне возможно, например,
что, отбросив заведомо неподходящие для конкретной задачи технологии, вы остановитесь
перед выбором: CGI-сценарий на Perl или JSP-документ.
Нередко «последней песчинкой», перевешивавшей чашу весов в пользу Perl, оказывались мощные средства обработки текста, характерные для этого языка. Однако с недавнего времени необходимость сложной обработки текстовой информации уже не является препятствием для применения в Web-приложениях Java-сервлетов или JSP: в состав JDK 1. 4 был включен пакет java.util. regex, содержащий классы Pattern и Matcher: первый — представляет регулярное выражение, второй — инкапсулирует последовательность символов, предназначенную для проверки. Впрочем, если регулярное выражение должно использоваться однократно, объекты можно и не создавать. Достаточно воспользоваться статическим методом matches() класса Pattern, который принимает выражение и обрабатываемую последовательность символов, а возвращает логическое значение, сообщающее о результатах проверки.
4 был включен пакет java.util. regex, содержащий классы Pattern и Matcher: первый — представляет регулярное выражение, второй — инкапсулирует последовательность символов, предназначенную для проверки. Впрочем, если регулярное выражение должно использоваться однократно, объекты можно и не создавать. Достаточно воспользоваться статическим методом matches() класса Pattern, который принимает выражение и обрабатываемую последовательность символов, а возвращает логическое значение, сообщающее о результатах проверки.
Если же предполагается применять регулярное выражение многократно, такой подход приведет к неоправданному расходу ресурсов. В этом случае целесообразно создать объекты Pattern и Matcher. Конструкторы для них не определены, поэтому для получения экземпляра Pattern используется статический метод compile() данного класса, а экземпляр Matcher формируется с помощью метода matcher() класса Pattern. Теперь с последовательностью символов, представленной экземпляром класса Matcher, можно выполнять самые разнообразные действия. Упоминавшийся выше метод matches(), на сей раз класса Matcher, дает возможность установить, отвечает ли вся последовательность символов регулярному выражению. В этом классе также определены find(), lookingAt(), appendReplacement(), replaceAll(), replaceFirst() и другие методы, позволяющие эффективно реализовать возможности поиска и замены, которыми славится язык Perl.
Теперь с последовательностью символов, представленной экземпляром класса Matcher, можно выполнять самые разнообразные действия. Упоминавшийся выше метод matches(), на сей раз класса Matcher, дает возможность установить, отвечает ли вся последовательность символов регулярному выражению. В этом классе также определены find(), lookingAt(), appendReplacement(), replaceAll(), replaceFirst() и другие методы, позволяющие эффективно реализовать возможности поиска и замены, которыми славится язык Perl.
Курс
QA
Вивчайте важливi технології для тестувальника у зручний час, та отримуйте $1300 уже через рік роботи
РЕЄСТРУЙТЕСЯ!
Если при построении регулярного выражения была допущена ошибка, генерируется исключительная ситуация. Соответствующий класс PatternSyntaxException также входит в состав пакета java.util.regex.
Последовательность символов, проверяемая на соответствие регулярному выражению, не обязательно должна представлять собой объект String. Методу matcher() класса Pattern, посредством которого создается экземпляр класса Matcher, в качестве параметра передается объект CharSequence. Помимо класса String, интерфейс java. lang.CharSequence реализует также классы StringBuffer и CharBuffer. Таким образом, поиск вхождений регулярных выражений можно производить непосредственно в буфере, используемом для операций ввода/вывода. Классы, предназначенные для поддержки буферов, и многие другие средства, реализующие расширенную функциональность, находятся в пакете java.nio, также впервые появившемся в JDK 1.4.
Методу matcher() класса Pattern, посредством которого создается экземпляр класса Matcher, в качестве параметра передается объект CharSequence. Помимо класса String, интерфейс java. lang.CharSequence реализует также классы StringBuffer и CharBuffer. Таким образом, поиск вхождений регулярных выражений можно производить непосредственно в буфере, используемом для операций ввода/вывода. Классы, предназначенные для поддержки буферов, и многие другие средства, реализующие расширенную функциональность, находятся в пакете java.nio, также впервые появившемся в JDK 1.4.
При более подробном изучении правил построения регулярных выражений обнаруживается, что они практически идентичны используемым в языке Perl. Благодаря этому многие конструкции можно непосредственно копировать из готовой Perl-программы в создаваемый сервлет или JSP-документ. Это важно, так как регулярные выражения часто бывают достаточно сложными; в частности, для решения такой, казалось бы, элементарной задачи, как описание формата почтового адреса, требуется выражение, насчитывающее более сотни символов. Однако полная идентичность по-прежнему остается недостижимым идеалом. Так, например, если в Perl, для того чтобы возобновить поиск после обнаружения первого соответствия, необходимо указывать флаг g, то в Java глобальный поиск подразумевается по умолчанию.
Однако полная идентичность по-прежнему остается недостижимым идеалом. Так, например, если в Perl, для того чтобы возобновить поиск после обнаружения первого соответствия, необходимо указывать флаг g, то в Java глобальный поиск подразумевается по умолчанию.
Поддержка регулярных выражений — не единственный «шаг навстречу Perl», предпринятый разработчиками Java. В JDK 1.4 в классе String реализован метод split(), выполняющий те же действия, что и одноименная функция языка Perl. В частности, он возвращает массив String[] с результатом разбиения строки, если в роли разделителя выступает набор символов (кстати, это может быть и регулярное выражение), переданный в качестве параметра. Опять же, допустимо обрабатывать не только строку, содержащуюся в объекте String, но и любую последовательность символов, представленную одним из классов, реализуемых интерфейсом CharSequence. Для этого также используется метод split(), но реализованный уже в классе Pattern. При вызове ему передается только последовательность, предназначенная для разбиения, а разделителем считается выражение, инкапсулированное в текущем объекте.
При вызове ему передается только последовательность, предназначенная для разбиения, а разделителем считается выражение, инкапсулированное в текущем объекте.
Таким образом, благодаря новым средствам, включенным в состав JDK 1.4, больше нет причины отказываться от повторного использования разработанных ранее Java-классов лишь оттого, что для решения задачи требуется сложная обработка текста.
Java: регулярные выражения, специальные символы
Сегодня программирование на Java, скорее всего, ни у кого не вызовет удивления. Прогресс в этой сфере настолько велик, что современная нам привычная реальность показалась бы 50-60 лет назад настоящим сюжетом из фильма а-ля «Назад в будущее».
Истоки языка Java
Java — объектно-ориентированный язык программирования, который изначально был разработан компанией Sun Microsystems, а позже его поддержка и развитие стали осуществляться компанией Oracle.
Не стоит путать язык разработки со средой исполнения или программной платформой. Под последней следует понимать совокупность множества различных компонентов, которые вместе обеспечивают выполнение Java-кода в различных аппаратных средах. Программы, написанные на языке Java, транслируются в особый формат, называемый байт-кодом, который позже выполняется средствами виртуальной машины (JVM) — частью программной платформы.
Под последней следует понимать совокупность множества различных компонентов, которые вместе обеспечивают выполнение Java-кода в различных аппаратных средах. Программы, написанные на языке Java, транслируются в особый формат, называемый байт-кодом, который позже выполняется средствами виртуальной машины (JVM) — частью программной платформы.
Установка и начало работы
Для того чтобы успешно запускать разработанные на этом языке приложения, необходимо установить специальный пакет Java-компонентов, который доступен на официальном сайте Oracle. Компания предоставляет разные дистрибутивы, которые отличаются целевой платформой, а также различные их варианты. Рядовым пользователем не обязательно должна использоваться версия Java, отличная от последней, самой новой. Это имеет смысл только для разработчиков, которым необходимы специфичные для определенных стратегий функции и возможности.
Чтобы установить Java на свой компьютер, пользователь сначала должен удостовериться, что характеристики аппаратуры соответствуют минимальным системным требованиям. Инженеры Oracle хорошо потрудились, чтобы снизить порог системных требований, однако он по-прежнему есть, и с ним нужно считаться. Пользователь должен найти на сайте необходимый ему дистрибутив, основываясь на операционной системе, в которую он хочет установить программное обеспечение. К примеру, Java для Windows 7 представляет собой исполняемый .exe-файл, который потребует только указать директорию для установки, а дальше он все сделает сам. Стоит отметить, что в системе одновременно может быть установлена только одна копия программной оболочки. Поэтому перед инсталляцией нужно удостовериться, что предыдущая версия Java удалена из системы. Если этого не сделать, то установщик попросит удалить конфликтующую программу прежде, чем продолжит установку.
Инженеры Oracle хорошо потрудились, чтобы снизить порог системных требований, однако он по-прежнему есть, и с ним нужно считаться. Пользователь должен найти на сайте необходимый ему дистрибутив, основываясь на операционной системе, в которую он хочет установить программное обеспечение. К примеру, Java для Windows 7 представляет собой исполняемый .exe-файл, который потребует только указать директорию для установки, а дальше он все сделает сам. Стоит отметить, что в системе одновременно может быть установлена только одна копия программной оболочки. Поэтому перед инсталляцией нужно удостовериться, что предыдущая версия Java удалена из системы. Если этого не сделать, то установщик попросит удалить конфликтующую программу прежде, чем продолжит установку.
Начало разработки на языке Java
После того как пользователь успешно установил программную среду, ему станут доступны различные средства как для исполнения уже написанных программ, так и для создания собственных. Для того чтобы начать программировать на языке Java, не нужно никаких дополнительных программ. Нужно лишь желание изучать новое и разбираться в архитектуре языка. Если пользователь смог успешно установить Java, и в процессе не возникло никаких конфликтов с другими программами, то код можно начинать писать в любом текстовом редакторе.
Для того чтобы начать программировать на языке Java, не нужно никаких дополнительных программ. Нужно лишь желание изучать новое и разбираться в архитектуре языка. Если пользователь смог успешно установить Java, и в процессе не возникло никаких конфликтов с другими программами, то код можно начинать писать в любом текстовом редакторе.
Компания Oracle позаботилась о том, чтобы предоставить максимальный набор средств для разработчиков. В пакет Java входит компилятор языка (утилита Javac), которая, приняв в качестве аргумента путь к любому текстовому файлу, преобразует его в байт-код, понятный виртуальной машине.
После этого пользователь еще не может запустить приложение и увидеть результаты своей работы. Для того чтобы установить приложение Java для Windows 7, его необходимо “запаковать” в JAR-архив.
Формат JAR произошел от сокращения Java Archive, и это особый вид знакомого всем ZIP-архива, который дополнительно содержит описание классов и зависимостей и указывает на точку входа (главный класс) в приложение. Для создания .jar-архива используется одноименная утилита, которая также входит в стандартный пакет от Oracle. После ее успешного выполнения пользователь может запустить созданное приложение либо командой Java из командной строки или консоли, либо простым двойным кликом.
Для создания .jar-архива используется одноименная утилита, которая также входит в стандартный пакет от Oracle. После ее успешного выполнения пользователь может запустить созданное приложение либо командой Java из командной строки или консоли, либо простым двойным кликом.
Основные компоненты языка Java
Для того чтобы успешно разрабатывать приложения на языке Java, изучение его нужно начинать с самых азов. Начинающим программистам иногда бывает сложно понять термин “объектно-ориентированный” язык. Многие ошибочно полагают, что он означает тот факт, что все сущности, которыми можно оперировать в языке, являются объектами. Однако это не совсем так. В языке Java, кроме объектов, существует также набор примитивных типов. Это целочисленные типы данных (byte, short, int, long), которые представляют собой целые числа различной разрядности, дробные типы данных (float, double), а также строки и символьные типы (String и char) соответственно.
Для каждого из них существуют так называемые классы — обертки, которые используются для того, чтобы создать ссылку на объект определенного вида. Это верно для всех примитивных типов, кроме строковых данных.
Это верно для всех примитивных типов, кроме строковых данных.
Особенности реализации класса строк в Java
Java-строки — это особенный класс. Его можно классифицировать как неизменяемый объект. Если представить память приложения как кучу (heap), в которой содержится произвольная строка, то каждая операция над ней (выделение подстроки, конкатенация, замена символов и т. д.) будет создавать новый экземпляр исходной строчки, который будет отличаться от оригинала результатом операции.
Поэтому со строками всегда нужно работать крайне осторожно: невзирая на то, что сборка мусора в памяти работает великолепно, программист должен быть предельно внимателен, чтобы не допустить переполнения памяти ненужными ссылками на строки. Благо, для этого существует множество вспомогательных классов. Например, можно использовать StringBuilder и StringBuffer, которые позволяют манипулировать строками, но не создают после каждой операции новый экземпляр.
Язык Java — регулярные выражения.
 Их появление и назначение
Их появление и назначениеРегулярные выражения появились в конце ХХ века и произвели переворот в технологиях электронной обработки текста.
Ранее поиск определенных участков в тексте или подстроки был часто встречающейся проблемой, которая требовала усилий и времени на реализацию. Программистам приходилось проверять чуть ли не каждый участок на точное соответствие заданному параметру поиска или сравнивать его с большим количеством условий. Однако с появлением регулярных выражений появилась возможность использовать метасимволы, с помощью которых стало доступным описать шаблон, по которому должен был осуществляться поиск. В языке Java регулярные выражения появились в 5 версии, и с тех пор стали неотъемлемым атрибутом программной среды.
Особенности работы с регулярными выражениями в Java
В языке Java все классы, которые так или иначе используются для работы с регулярными выражениями, вынесены в отдельный пакет, который называется java.util.regex. В Java регулярные выражения описываются классом Pattern, что в переводе с английского означает “шаблон”. Этот класс принимает в качестве аргумента конструктора строку, которая может быть использована для создания шаблона. Когда требуется его описать, вместо простых букв лучше использовать метасимволы.
Для того чтобы правильно указывать параметры поиска, лучше ознакомиться с официальной документацией от Oracle, так как многие метасимволы могут означать совсем не то, что рядовой пользователь или начинающий программист может подумать. Например, знак “+” обозначает, что под шаблон попадают один или несколько экземпляров непосредственно предшествующего элемента. При реализации в Java регулярные выражения, специальные символы те же, что и в любом другом языке программирования. Поэтому миграция с другой платформы должна пройти безболезненно.
Возможные варианты применения регулярных выражений
Стоит отметить, что возможности регулярных выражений наиболее подходят для обработки очень больших текстов. К примеру, поиск какого-то ключа или словосочетания в книге при условии, что регистр, в котором записан ключ, не важен. Ручной перебор текста для решения подобной задачи был бы крайне неэффективным, а с помощью встроенных в Java регулярных выражений задачу можно решить парой строк кода.
Именно поэтому при изучении рассматриваемого нами языка никак нельзя пропускать такой важный раздел, как регулярные выражения. В Java им можно найти применение в самых различных сферах — от проверки корректности ввода данных в форме (почтовые адреса, номера кредитных карт) до анализа трафика и запросов пользователей.
Памятка по регулярным выражениям Java (Regex)
В этой статье мы рассмотрим регулярные выражения Java, в том числе способы их использования, лучшие практики и ярлыки, которые помогут вам их использовать. Затем, в конце статьи, мы приводим памятку по Java RegEx в формате PDF, в которой представлены все сочетания клавиш RegEx на одной странице. Но сначала давайте начнем с основ.
Что такое регулярное выражение Java?
Регулярное выражение Java или регулярное выражение Java — это последовательность символов, определяющая шаблон, который можно искать в тексте.
Предположим, вам нужен способ формализовать и ссылаться на все строки, составляющие формат адреса электронной почты. Поскольку существует почти бесконечное количество возможных адресов электронной почты, было бы трудно перечислить их все.
Однако, как мы знаем, адрес электронной почты имеет определенную структуру, и мы можем закодировать ее, используя синтаксис регулярного выражения. Процессор регулярных выражений Java переводит регулярное выражение во внутреннее представление, которое может быть выполнено и сопоставлено с искомым текстом. Он сообщит вам, находится ли строка в наборе строк, определенном шаблоном, или найдет подстроку, принадлежащую этому набору.
Полезные классы и методы Java
Большинство языков имеют реализацию регулярных выражений, встроенную или предоставленную библиотекой. Ява не исключение. Ниже приведены классы, которые вы должны знать, чтобы эффективно использовать Java Regex.
Методы шаблона RegEx
Шаблон — это скомпилированное представление регулярного выражения в Java. Ниже приведен список наиболее часто используемых методов в API класса Pattern.
| Метод шаблона регулярного выражения | Описание |
|---|---|
| Компиляция шаблона (регулярное выражение строки) | Компилирует заданное регулярное выражение в шаблон. |
| Компиляция шаблона(String regex, int flags) | Компилирует данное регулярное выражение в шаблон с заданными флагами. |
| логические совпадения(String regex) | Возвращает значение, соответствует ли эта строка заданному регулярному выражению. |
| String[] split(CharSequence input) | Разбивает заданную входную последовательность на совпадения с этим шаблоном. |
| String quote(String s) | Возвращает литеральный образец String для указанного String s. |
| Predicate asPredicate() | Создает предикат, который можно использовать для сопоставления строки. |
Методы сопоставления регулярных выражений для сопоставления шаблонов Java
Сопоставитель — это механизм, выполняющий операции сопоставления шаблонов Java с последовательностью символов путем интерпретации шаблона. Ниже приведен список наиболее часто используемых методов в API класса Matcher:
| Метод сопоставления регулярных выражений | Описание |
|---|---|
| логические совпадения() | Попытки сопоставить всю область с шаблоном. |
| boolean find() | Пытается найти следующую подпоследовательность ввода, соответствующую шаблону. |
| int start() | Возвращает начальный индекс последнего совпадения. |
Скомпилировав шаблон и получив для него сопоставитель, вы можете эффективно сопоставлять множество текстов для шаблона. Поэтому, если вы планируете обрабатывать много текстов, скомпилируйте сопоставитель, кэшируйте его и используйте повторно.
Синтаксис Java RegEx
Теперь перейдем к синтаксису Java RegEx. Метод Pattern.compile принимает строку, которая представляет собой регулярное выражение, определяющее набор совпадающих строк. Естественно, он должен иметь сложный синтаксис, иначе одна строка, определяющая шаблон, может представлять только себя. Обычный символ в синтаксисе RegEx Java соответствует этому символу в тексте. Если вы создадите паттерн с Pattern.compile("a") он будет соответствовать только строке «a». Существует также escape-символ, который представляет собой обратную косую черту «\». Он используется, чтобы различать, когда шаблон содержит инструкцию в синтаксисе или символ.
Пример Escape-символа Java RegEx
Давайте рассмотрим пример того, зачем нам нужен escape-символ. Представьте, что «[» имеет особое значение в синтаксисе регулярных выражений (имеет). Как определить, является ли «[» командой механизма сопоставления или шаблоном, содержащим только скобки? Вы не можете, поэтому, чтобы указать символы, которые также являются командами в синтаксисе, вам нужно их экранировать. Это означает, что «\[» является шаблоном для строки «[«, а «[» является частью команды. Как насчет попытки сопоставить обратную косую черту? Вам также нужно экранировать его, поэтому будьте готовы увидеть что-то вроде «\\\\» в коде RegEx.
Классы символов в регулярных выражениях Java
Помимо указания выражений, содержащих только отдельные символы, вы можете определить целые классы символов. Думайте о них как о наборах, если символ в каком-либо тексте принадлежит к классу символов, он соответствует. Вот таблица с наиболее часто используемыми классами символов в Java RegEx.
| Класс символов | Описание |
|---|---|
| вычитание, соответствует только |
Предопределенные классы символов в Java RegEx
Для вашего удобства уже определены некоторые полезные классы. Например, цифры — прекрасный пример полезного класса символов. Например, 5-значное число может быть закодировано в шаблоне как «[0-9][0-9][0-9][0-9][0-9]», но это довольно уродливо. Так что для этого есть сокращение: «\d». Вот другие классы, которые вам нужно знать, начиная с регулярного выражения для любого символа: 9\w]
Обратите внимание, что буква, определяющая предопределенный класс символов, обычно пишется в нижнем регистре, версия в верхнем регистре обычно означает отрицание класса. Также обратите внимание, что точка «.» это класс символов, который содержит все символы. Особенно полезно, но не забывайте экранировать его, когда вам нужно сопоставить фактический символ точки.
Хотите узнать, какие инструменты Java будут в тренде в 2021 году? Ознакомьтесь с нашим последним отчетом о производительности Java! Вы можете посмотреть разбивку результатов на видео ниже или загрузить полный бесплатный отчет, нажав здесь. 9
The beginning of a line $ The end of a line \b A word boundary \B A non-word boundary \A Начало ввода \G Конец предыдущего совпадения \Z Конец ввода кроме конечного терминатора, если он есть. \z 9pattern$», который будет соответствовать тексту только в том случае, если он является полным шаблоном.Логические операции Java RegEx
Теперь мы переходим на более продвинутую территорию. Если шаблон состоит из более чем одного символа, он будет соответствовать более длинному тоже строка. В целом «XY» в синтаксисе RegEx Java соответствует X, за которым следует Y. Однако существует также операция ИЛИ, обозначаемая постом «|». RegEx «X|Y» означает, что это либо X, либо Y. Это очень мощная функция, вы можете комбинировать классы символов или последовательности символов (включить их в скобки).0003
Квантификаторы RegEx Java
Помимо всего прочего, вы можете указать, сколько раз последовательность символов может повторяться для совпадения. RegEx «1» соответствует только вводу «1», но если нам нужно сопоставить строку любой длины, состоящую из символа «1», вам нужно использовать один из следующих квантификаторов.
Квантификаторы Java RegEx Квантификатор Описание * Соответствует нулю или более вхождений. + Соответствует одному или нескольким вхождениям. ? Соответствует нулю или одному вхождению. Группы регулярных выражений и обратные ссылки
Группа — это захваченная подпоследовательность символов, которая может использоваться позже в выражении с обратной ссылкой. Мы уже упоминали, что если вы заключаете группу символов в круглые скобки, вы можете применять квантификаторы либо логические, либо ко всей группе. Что еще более удивительно, так это то, что вы можете ссылаться на фактические символы в тексте, сопоставленном группе, позже. Вот как это сделать:
Группы Java RegEx и обратные ссылки Группы и обратные ссылки Описание (…) Соответствует нулю или более вхождений. \N Соответствует одному или нескольким вхождениям. (\d\d) Соответствует нулю или одному вхождению. (\d\d)/\1 Две цифры, повторяющиеся дважды, \1 — относится к совпавшей группе Флаги шаблонов регулярных выражений
Помните, когда мы говорили о полезном API для регулярных выражений в Java, был метод для компиляции шаблона, который принимает флаги. Они будут контролировать поведение шаблона. Вот некоторые флаги, которые могут быть полезны здесь и там.
Методы шаблонов Java RegEx Флаги шаблонов Описание Pattern.CASE_INSENSITIVE Включает сопоставление без учета регистра. 9и $. Загрузить памятку по регулярным выражениям в формате PDF
В нашу памятку по регулярным выражениям включены основные классы и методы Java, синтаксис RegEx, классы символов, сопоставления границ, логические операции, квантификаторы, группы, обратные ссылки и флаги шаблонов. . Вы можете скачать шпаргалку по Java RegEx ниже.
Загрузить шпаргалку
Дополнительные ресурсы
В прошлом году мы исследовали некоторые темы, которые повсеместно используются в разработке программного обеспечения, и у нас есть целая библиотека полезных шпаргалок по Java, которые порадуют вас и напомнят о них. команды и опции разработчики часто забывают и гуглят:
- Java 8 Best Practices
- Java 8 Streams
- Git Commands
- Docker Commands
- Java Collections
- SQL
- JUnit
- Spring Framework Annotations
- Java Generics
- JVM Options
How to Используйте Groovy RegEx для тестирования
Экономьте время разработки с JRebel
Регулярные выражения в Java делают процесс кодирования более быстрым и менее утомительным для разработчиков. JRebel обеспечивает дополнительный уровень эффективности, устраняя дорогостоящие простои, связанные с обновлениями кода.
Попробуйте JRebel Free
Памятка по регулярным выражениям
Приведенные ниже таблицы являются ссылкой на базовое регулярное выражение. Читая остальную часть сайта, если вы сомневаетесь, вы всегда можете вернуться и посмотреть здесь. (Если вам нужна закладка, вот прямая ссылка на справочные таблицы регулярных выражений). Я рекомендую вам распечатать таблицы, чтобы у вас на столе была шпаргалка для быстрой справки.Таблицы не являются исчерпывающими по двум причинам. Во-первых, каждый вариант регулярного выражения отличается, и я не хотел загромождать страницу чрезмерно экзотическим синтаксисом. Для полного ознакомления с конкретными вариантами регулярных выражений, которые вы будете использовать, всегда лучше обратиться прямо к источнику. На самом деле, для некоторых движков регулярных выражений (таких как Perl, PCRE, Java и .
Другая причина, по которой таблицы не являются исчерпывающими, заключается в том, что я хотел, чтобы они служили кратким введением в регулярное выражение. Если вы полный новичок, вы должны получить четкое представление об основном синтаксисе регулярных выражений, просто прочитав примеры в таблицах. Я попытался представить функции в логическом порядке и не допустить странностей, которых я никогда не видел в реальном использовании, таких как «персонаж колокольчика». Используя эти таблицы в качестве трамплина, вы сможете перейти к мастерству, изучая другие страницы сайта.
Как пользоваться таблицами
Таблицы предназначены для ускоренного курса регулярных выражений и предназначены для медленного чтения, по одной строке за раз. В каждой строке в крайнем левом столбце вы найдете новый элемент синтаксиса регулярного выражения. Следующий столбец «Легенда» объясняет, что означает (или кодирует) элемент в синтаксисе регулярных выражений.Вы, конечно, можете читать таблицы онлайн, но если вы страдаете даже самым легким случаем онлайн-СДВ (синдрома дефицита внимания), как и большинство из нас… Что ж, тогда я настоятельно рекомендую вам их распечатать. Вы сможете изучать их медленно и использовать в качестве шпаргалки позже, когда будете читать остальную часть сайта или экспериментировать со своими собственными регулярными выражениями.
Наслаждайтесь!
Если у вас передозировка, не пропустите следующую страницу, которая возвращается к Земле и рассказывает о некоторых действительно интересных вещах: 1001 способ использования регулярных выражений .
Ускоренный курс Regex и шпаргалка
Для удобства навигации вот несколько точек перехода к различным разделам страницы:✽ Персонажи
✽ Квантификаторы
✽ Больше персонажей
✽ Логика
✽ Больше пробелов
✽ Больше квантификаторов
✽ Классы персонажей
✽ Якоря и границы
✽ Классы POSIX
✽ Встроенные модификаторы
✽ Обзоры
✽ Операции класса персонажей
✽ Другой синтаксис(прямая ссылка)
символов
Character Legend Example Sample Match \d Most engines: one digit
from 0 to 9file_\d\d file_25 \d . file_\d\d file_9੩ \w Большинство движков: «знак слова»: буква ASCII, цифра или подчеркивание \w-\w\w\w A-b_1 3 yp : «символ слова»: буква Юникода, идеограмма, цифра или символ подчеркивания \w-\w\w\w 字-ま_۳ \w .NET: «символ слова»: Unicode буква, идеограмма, цифра или соединитель \w-\w\w\w 字-ま‿۳ \s Большинство движков: «пробелы»: пробел, табуляция, новая строка, возврат каретки, вертикальная табуляция символ»: любой разделитель Unicode a\sb\sc a b
c\D Один символ, который не является цифрой , как определено вашим движком \d \d \D ABC \W Один символ, который не является символом слова , как определено вашим двигателем это не пробельный символ , как определено вашим движком \s \S\S\S\S Yoyo (прямая ссылка)
Квантификаторы
Квантификатор Легенда Пример Match Match + Один или более Версия \ W- \ W + Версия A-B1_1 {3} {3} 4 333433 гг. ABC {2,4} два -четыре раза \ D {2,4} 156 {3,} 3 или MATE или MATE MATE MATE TIME ,} regex_tutorial * Ноль или более раз A*B*C* AAACC ? Один или ни одного во множественном числе? во множественном числе (прямая ссылка)
Больше символов
Символ Легенда Пример Образец соответствия 9/\ . Любой символ, кроме разрыва строки a.c abc \ Экранирует специальный символ \[\{\(\)\}\] [{()}] (прямая ссылка)
Логика
Логика Легенда Пример Образец соответствия | Операнд чередования/ИЛИ 22|33 33 ( … ) Группа захвата A(nt|pple) Apple (захватывает «Pple») \ 1 Содержание группы 1 R (\ W) G \ 1x REGEX \ 2 СОЕДИНЕНИЯ Группы 2 \ 2 СОЕДИНЕНИЯ Группы 2 \ 2 33. 12+65=65+12 (?: … ) Группа без захвата A(?:nt| яблоко) Яблоко (прямая ссылка)
Подробнее White-Space
Символ Legend Example Sample Match \t Tab T\t\w{2} T ab \r Carriage return character see below \n Line feed character see below \r\n Line separator on Windows AB\r\nCD AB
CD\N Perl, PCRE (C, PHP, R…): один символ, не являющийся разрывом строки \N+ ABC \h Perl, PCRE (C, PHP, R…), Java: один горизонтальный пробел: табуляция или разделитель пробелов Unicode \H Один символ, не являющийся горизонтальным пробелом \v Perl, PCRE (C, PHP, R…), Java: один вертикальный пробел: перевод строки, возврат каретки, вертикальная табуляция, перевод страницы, разделитель абзаца или строки \V Perl, PCRE ( C, PHP, R…), Java: любой символ, не являющийся вертикальным пробелом \R Perl, PCRE (C, PHP, R…), Java: один разрыв строки (возврат каретки + строка пара каналов и все символы, соответствующие \v) (прямая ссылка)
Дополнительные квантификаторы
Quantifier Legend Example Sample Match + The + (one or more) is «greedy» \d+ 12345 ? Делает квантификаторы «ленивыми» \d+? 1 в 1 2345 * * (ноль или более) означает «жадность» A* AAA ? Делает квантификаторы «ленивыми» A*? пустой в AAA {2,4} Два-четыре раза, «жадный» \w{2,4} abcd ? Делает квантификаторы «ленивыми» \w{2,4}? ab in ab cd (прямая ссылка)
Классы символов
2
Символ Легенда Пример Образец матча […] Один из персонажей в скобках [AEIO] One Aurper Crase […] 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034 40034.T[ao]p Tap or Top — Range indicator [a-z] One lowercase letter [x-y] One of the characters in the range от х до у 9-~]+ Символы, которые являются , а не в печатаемом разделе таблицы ASCII. [\d\D] Один символ, который является цифрой или не является цифрой [\d\D]+ Любые символы, включая новые строки, которые не содержит обычная точка t match [\x41] Соответствует символу в шестнадцатеричной позиции 41 в таблице ASCII, т. е. A [\x41-\x45]{3} ABE abc (начало строки) $ Конец строки или конец строки в зависимости от многострочного режима. Много моторозависимых тонкостей. .*? конец$ это конец \A Начало строки
(все основные движки, кроме JS)\Aabc[\d\D]* abc (строка.
.. .start)\z Самый конец строки
Недоступно в Python и JSконец\z это…\n… конец \Z Конец строки или (кроме Python) перед последним разрывом строки
Недоступно в JSконец \Z это…\n… конец \n \G Начало строки или конец предыдущего совпадения
.NET, Java, PCRE (C, PHP, R…), Perl, Ruby\b Граница слова
Большинство движков: позиция, где только одна сторона представляет собой букву ASCII, цифру или подчеркиваниеBob.*\bcat\b Bob съел кота \b Граница слова Боб.*\b\кошка\b Боб съел кошку \B Ни слова границы c.*\Bcat\B.* подражатели (прямая ссылка) Классы POSIX
Символ Легенда Пример Образец соответствия [:alpha:] PCRE (C, PHP, R…): буквы ASCII A-Z и a-z ] [8[:9+:0] Welldone88 [: Alpha:] Ruby 2: буква Unicode или идеограмма [[: Alpha:] \ D]+ CKOшKA99 333333333: COшKA99 333333: COшKA99 933333. [[:alnum:]]{10} ABCDE12345 [: Alnum:] Ruby 2: Unicode Digit, буква или идеограмма [[: alnum:]] {10} KOшKA 3166666666666669. . C, PHP, R…): Знак препинания ASCII [[:punct:]]+ ?!.,:; [:punct:] Ruby: знак препинания Unicode [[:punct:]]+ ‽,:〽⁆ (прямая ссылка)
Ни один из них не поддерживается в JavaScript. В Ruby остерегайтесь (?s) и (?m).
Модификатор Легенда Пример Образец соответствия (?i) Режим без учета регистра
(кроме JavaScript)(?i)Понедельник monDAY (?s) Режим DOTALL (кроме JS и Ruby). Точка (.) соответствует символам новой строки (\r\n). (?s)От A.* до Z От A 93$ 1
2
3(?m) В Ruby: то же, что и (?s) в других движках, т.е. режим DOTALL, т.е. точка соответствует разрыву строки (?m)From A .*до Z От A
до Z(?x) Режим свободного пространства
(кроме JavaScript). Также известен как режим комментариев или режим пробелов(?x) # это
# комментарий
abc # запись в несколько строк
# строки
[ ]d # пробелы должны быть
# в скобках 9)PCRE 10.32+: сбросить модификаторы Сбросить модификаторы ismnx (прямая ссылка)
LookAround Легенда Пример Матч выборки (? =…) Положительный взгляд (? 56789 (?<=…) Положительный просмотр назад (?<=\d)категория CAT в 1 CAT (?!…) Отрицательный Lookahead (?! Театр) The \ W+ Тема (? \w{3}(? Мюнстер (прямая ссылка)
Класс Операция Легенда Пример Образец соответствия […-[…]] . [a-z-[aeiou]] Любой согласный в нижнем регистре […-[…]] .NET: вычитание класса символов. [\p{IsArabic}-[\D]] Арабский символ, не являющийся нецифрой, т. е. арабская цифра […&&[…]] Java, Ruby 2+ : пересечение классов символов. Один символ, который есть как в тех, что слева, так и в классе &&. 9\p{L}\p{N}]] Арабский символ, не являющийся буквой или цифрой (прямая ссылка)
Другой синтаксис
Синтаксис Легенда Пример Образец соответствия \K Не входить
Perl, PCRE (C, PHP, R…), альтернативный движок Python regex , Ruby 2+: отбросить все, что было сопоставлено до сих пор, из общего совпадения, которое будет возвращеноprefix\K\d+ 12 \Q…\E Perl, PCRE (C, PHP, R…), Java: обрабатывать все, что находится между разделителями, как буквальную строку. \Q(С++?)\E (С++?) Не пропустите Руководство по стилю регулярных выражений
и Лучший трюк с регулярными выражениями!!!
1001 способ использования регулярных выражений
Спросите РексаРабота с регулярными выражениями
Регулярные выражения обеспечивают гибкий способ сопоставления всех символов или частей текста в строке. Функции, принимающие регулярные выражения, используют синтаксис, основанный на регулярных выражениях Java.
На высоком уровне регулярное выражение (регулярное выражение) представляет собой описание символов, которые вы хотите сопоставить. Если вы не укажете никаких зарезервированных специальных символов, регулярное выражение ищет точное совпадение, поэтому
‘Cat’ 9Большой’соответствуетБольшие рубашки, но неРазмер: Большой.|обозначает логическое ИЛИ. Это служит точкой разделения для вашей строки регулярного выражения.‘это|то’соответствуетэтомуилиэтому.*указывает на ноль или более совпадений, а+указывает на одно или несколько совпадений, поэтому регулярное выражение'a*b+'соответствуетab,baby,babbyиbbbbb, но неaaaaaилиarb.\— это escape-символ, который вы используете для вызова зарезервированного символа, который следует за ним другим способом.В регулярном выражении Tamr Core вы используете два символа обратной косой черты (
\\), чтобы экранировать зарезервированный символ. В регулярном выражении Java вы используете только одно. Ниже приведены примеры этой разницы.
Чтобы соответствовать этому литералу
Регулярное выражение Tamr Core
Java Regex
.
\.
\.
|
\\|
\|Любая цифра
0,1,2,3,4,5,, 4,5,6,7,8,9
\\d
\d
'
(Tamr reserved character, not a Java зарезервированный символ)
\'
'1673′ символов.
'\''.
- По большей части регулярное выражение Tamr Core допускает те же шаблоны, что и регулярное выражение Java. Например, вы можете использовать такие группы символов, как
'\\p{IsLatin}'для строчных или прописных букв без ударения или'\\p{IsAlphabetic}'для строчных или прописных букв с диакритическими знаками или без них.- Нули агрессивны. Любой
ноль 9Аргумент 0112 для большинства функций приводит к выводуnull.- Многие функции, использующие регулярные выражения, позволяют захватывать группы символов, обрабатывая несколько символов как единое целое. Чтобы захватить группы символов, заключите их в круглые скобки, как в Java. Например, регулярное выражение
‘(\\d+)ml’соответствует10mlи захватывает10.Ниже приведены примеры использования регулярных выражений в каждой из этих функций.
Extractсопоставляет строку с регулярным выражением и возвращает указанную группу.extract_allсопоставляет строку с регулярным выражением и возвращает результаты для всех групп.соответствуетсоответствует строке регулярному выражению. Возвращает true, если соответствует всей входной строке.replace_allзаменяет все совпадения целевого регулярного выражения в заданной строке заменой.
Примечание :replace() 9Функция 0112 не принимает регулярное выражение.splitразбивает строку на массив строк в зависимости от совпадения предоставленного регулярного выражения.Дополнительные примеры, ориентированные на задачи, см. в разделе Примеры задач для сценариев преобразования.
Extract сопоставляет весь ввод с регулярным выражением и возвращает часть ввода, соответствующую указанной группе. Возвращает NULL, если введено значение NULL, или если совпадающих групп меньше, чем указано.
Например, вы можете использовать 9\\d+).*', 1)
Примечания :
- Группы отсчитываются от 1. Group_index, равный 0, возвращает совпадение по всему шаблону.
- Весь ввод должен соответствовать регулярному выражению.
Значение
Руководство
Группа
РЕЗУЛЬТАТ
" " Это и это.
'Это (и|или) то\\.'1
и
«То или то».
'Это (и|или) то\\.'1
или
"Это и это".
'Это (и|или) то\\.'2
NULL
"Это и это".
'Это ((а.*)|(о.*)) то\\.'2
и
Extract_all извлекает все совпадения для всех групп захвата в массив.
Например,
extract_all(colname, '(\\d+)')извлекает все последовательности из одной или нескольких цифр в массив. Если на входе нет цифр, на выходе будет пустой массив. Если вход NULL, выход NULL.Примечания :
- В большинстве случаев регулярное выражение должно находиться в группе захвата
( ).- Столбец ввода не изменен.
- Вложенные группы приводят к тому, что части ввода копируются более чем в одну часть вывода.
- Совпадения не перекрываются.
Значение
Руководство
Результат
Примечания
900 8 "и это 123".
'(\d+)'["123","456"]
Несколько совпадений
'(\ D+)'[]
Результат - пустой массив
NULL
' +
9002 . NULL "Это 123 и 456 то."
'и (\ d+), что'["456"]
Регулярное выражение имеет не капитальные части, окружающие группу каперсирования
"Это и это и это.
'(Это и|и то|то)'["Это и"]
Возвращается только первое перекрывающееся совпадение.
"Это 123 и 456 то."
'(\d+)|([A-Za-z]+)'["Это","123","и","456","это"]
Две группы захвата, но одновременно только одно совпадение.
"Это 123 и 456 то."
'(\d(\d*))'["123","23","456","56"]
Две вложенные группы захвата; все группы захвата, присутствующие в выходных данных.
Matches возвращает логическое значение:
true, если ввод соответствует выражению,false, если нет, и NULL, если ввод равен NULL.Например,
matches('(?i).возвращаетtrue, еслиmyColсодержит строку "street" (без учета регистра).Примечания :
Пример valling
- Порядок аргументов обратный по сравнению с другими функциями, с регулярным выражением первым.
- Все входные данные должны соответствовать выражению. Думайте о выражении как имеющем неявное 9a-zA-Z\\d])’, ‘’) AS описание_триграмма;
Примечания :
- Регулярное выражение должно находиться в группе захвата
( )для большинства случаев использования.- Совпадает все регулярное выражение, а не группы внутри регулярного выражения.
Split создает массив из входных данных, разбивая его на значения, разделенные строками, соответствующими регулярному выражению. Части ввода, соответствующие регулярному выражению, исключаются из вывода.
Например, этот скрипт берет разделенные пробелами значения (слова) в поле описания и выводит их в массив:
ВЫБЕРИТЕ *, разделить (to_string (описание), ‘\\’) AS описание_слова;Обновлено около 1 месяца назад
Помогла ли вам эта страница?
Приложение D.
- 1. Инструменты регулярных выражений и примеры их использования
Регулярные выражения (или сокращенно регулярное выражение), используемые при поиске и правила сегментации поддерживаются Java. Если вам нужно больше конкретную информацию, обратитесь к Java Документация по регулярным выражениям. См. дополнительные ссылки и примеры ниже.
Примечание
Эта глава предназначена для опытных пользователей, которым необходимо определить собственные варианты правил сегментации или придумать более сложные и мощные ключевые элементы поиска.
Таблица D.1. Regex — Flags
Конструкция ... соответствует следующему (?i) Включает поиск без учета регистра (по умолчанию шаблон деликатный случай). Таблица D.2. Регулярное выражение — Символ
Конструкция ... соответствует следующему х Символ x, кроме следующих... \ухххх Символ с шестнадцатеричным значением 0xhhhh \т Символ табуляции ('\u0009') \н Символ новой строки (перевода строки) ('\u000A') \r Символ возврата каретки ('\u000D') \ф Символ перевода страницы ('\u000C') \а Символ предупреждения (звонка) ("\u0007") \е Управляющий символ ('\u001B') \сх Управляющий символ, соответствующий x \0n Символ с восьмеричным значением 0n (0 <= n <= 7) \0nn Символ с восьмеричным значением 0nn (0 <= n <= 7) \0мнн Символ с восьмеричным значением 0mnn (0 <= m <= 3, 0 <= п <= 7) \хххх Символ с шестнадцатеричным значением 0xhh Таблица D.
Конструкция 9{|} для соответствия самим себе. \ Например, это символ обратной косой черты \Q Ничего, но заключает в кавычки все символы до \E \E Ничего, но кавычки заканчиваются на \Q Таблица D.4. Regex — классы для блоков и категорий Unicode
Конструкция . \p{InGreek} Символ греческого блока (простой блокировать) \p{Лу} Прописная буква (простая категория) \p{Sc} Символ валюты \P{InGreek} Любой символ, кроме одного в греческом блоке (отрицание) 9\p{Лу}]]Любая буква, кроме заглавной (вычитание) Таблица D.
Конструкция ... соответствует следующему [абв] a, b или c (простой класс) 9азбука]Любой символ, кроме a, b или c (отрицание) [a-zA-Z] от a до z или от A до Z включительно (диапазон) Таблица D.6. Regex — Предопределенные классы символов
Конструкция . Начало строки $ Конец строки \б Граница слова \В Граница без слов Таблица D.8. Regex — жадные квантификаторы
Конструкция ... соответствует следующему Х ? X, один раз или ни разу Х * X, ноль или более раз х + X, один или несколько раз Примечание
жадные квантификаторы будут совпадать настолько, насколько это возможно.
Таблица D.9. Регулярные выражения — неохотные (нежадные) квантификаторы
Конструкция ...соответствует следующим Х?? X, один раз или ни разу Х*? X, ноль или более раз Х+? X, один или несколько раз Примечание
Нежадные квантификаторы будут соответствовать как можно меньшему количеству совпадений.
Таблица D.10. Regex — Логические операторы
Конструкция ... соответствует следующему XY X, затем Y X|Y Либо X, либо Y (XY) XY как единая группа Доступен ряд интерактивных инструментов для разработки и тестирования обычные выражения. Обычно они следуют одному и тому же шаблону (для пример из тестера регулярных выражений см.
Рисунок D.1. Тестер регулярных выражений
См. регулярное выражение Coach для версий автономного инструмента для Windows, Linux, FreeBSD. Это очень похоже на приведенный выше пример.
Прекрасную коллекцию полезных примеров регулярных выражений можно найти в Сам OmegaT (см. Параметры > Сегментация). Следующий список включает выражения, которые могут оказаться полезными при поиске. через память переводов:
Таблица D.11. Regex — Примеры регулярных выражений в переводах
Регулярное выражение Находит следующее: (\b\w+\b)\s\1\b двойных слов [\. запятая или точка, затем пробелы и еще одна запятая или период \. \s+$ дополнительных пробелов после точки в конце линия \s+a\s+[aeiou] Английский язык: слова, начинающиеся с гласных, обычно предшествует "an", а не "a" 9айоу]Английский: та же проверка, что и выше, но в отношении согласных («а», а не «ан») \с{2,} более одного пробела \. Точка, за которой следует заглавная буква — возможно, пробел отсутствует между периодом и началом нового приговор? \bis\b поиск «есть», а не «это» или «не является» и т. д. Бесплатный онлайн-тестер регулярных выражений Java
Регулярные выражения — документация
Символ Что он делает? \
- Используется для указания того, что следующий символ НЕ ДОЛЖЕН интерпретироваться буквально . Например, символ 'w' сам по себе будет интерпретироваться как «соответствует символу w», но использование «\w» означает «соответствует буквенно-цифровому символу, включая подчеркивание».
- Используется для указания того, что метасимвол следует интерпретировать буквально как . Например, '.' метасимвол означает «соответствовать любому одиночному символу, кроме новой строки», но если вместо этого мы предпочли бы сопоставить символ точки, мы бы использовали '\.'. 9abc]), он отрицает множество; соответствует всему, что не заключено в скобки
$ Соответствует концу ввода . В многострочном режиме он также соответствует перед символом разрыва строки , следовательно, каждому концу строки. * Соответствует предыдущему символу 0 или более раз . + Соответствует предыдущему символу 1 или более раз . ?
- Соответствует предыдущему символу 0 или 1 раз .
- При использовании после квантификаторов *, +, ? или {}, делает квантификатор нежадным ; это будет соответствовать минимальное количество раз, а не максимальное количество раз.
. Соответствует любому одиночному символу, кроме символа новой строки . (х) Соответствует 'x' и запоминает совпадение . Также известен как захват скобок. (?:х) Соответствует 'x', но НЕ запоминает совпадение . Также известна как НЕзахватывающая скобка. х(?=у) Соответствует 'x' , только если за 'x' следует 'y' . Также известен как просмотр вперед. х(?!у) Соответствует 'x' , только если за 'x' НЕ следует 'y' . Также известен как отрицательный просмотр вперед. х|у Соответствует 'x' ИЛИ 'y' . {н} Соответствует предыдущему символу ровно n раз . {н,м} Соответствует предыдущему символу не менее n раз и не более m раз. [абв] Соответствует любому из заключенных символов . Также известен как набор символов. Вы можете создать диапазон символов, используя символ дефиса, например, A-Z (от A до Z). Обратите внимание, что в наборах символов специальные символы (., *, +) не имеют особого значения. 9азбука] Соответствует всему, что НЕ заключено в квадратные скобки . Также известен как отрицательный набор символов. [\b] Соответствует backspace . \б Соответствует границе из слов . Границы определяются, когда за символом слова НЕ следует или НЕ предшествует другой символ слова. \В Соответствует границе НЕ слова . Границы определяются, когда два соседних символа являются словесными символами ИЛИ несловесными символами. \сХ Соответствует управляющему символу . X должен находиться в диапазоне от A до Z включительно. \д Соответствует символу из цифр . То же, что [0-9] или [0123456789].456789]. \ф Соответствует подаче формы . \н Соответствует переводу строки . \r Соответствует возврату каретки . \с Соответствует одиночному пробелу . Это включает в себя пробел, вкладку, перевод формы и перевод строки. \С Соответствует чему угодно, КРОМЕ одного символа пробела . Все, кроме пробела, табуляции, перевода страницы и перевода строки. \т Соответствует вкладке . \v Соответствует вертикальной вкладке . \ш 9А-За-з0-9_].\х Обратная ссылка на подстроку, соответствующую выражению x в скобках. х является положительным целым числом. \0 Соответствует символу NULL . \хчч Соответствует символу с 2-значным шестнадцатеричным кодом . \ухххх Соответствует символу с 4-значным шестнадцатеричным кодом . Регулярные выражения — решения распространенных проблем
Как эмулировать DOTALL в JavaScript?
DOTALL — это флаг в самых последних библиотеках регулярных выражений, который делает . метасимвол соответствует чему угодно, ВКЛЮЧАЯ разрывы строк. JavaScript по умолчанию делает не поддерживает это, так как . метасимвол соответствует чему угодно, НО разрывы строк. Чтобы эмулировать это поведение, просто замените все файлы .
Как проверить ДАТУ с помощью регулярного выражения?
Никогда не используйте регулярное выражение для проверки даты. Регулярное выражение полезно только для проверки формата даты, введенного пользователем. Для фактической достоверности даты лучше полагаться на фактический код.
Следующие выражения будут проверять количество дней в месяце, но НЕ будут обрабатывать проверку високосного года; следовательно, февраль может иметь 29\\]+$
Как проверить номер телефона в США или Канаде с помощью регулярного выражения?
Возможно, есть десятки способов отформатировать номер телефона. Ваш пользовательский интерфейс должен заботиться о проблеме форматирования, имея четкую документацию по формату и/или разделяя телефон на части (область, обмен, номер) и/или имея маску ввода. Следующее выражение довольно мягкое по формату и должно принимать 999-999-9999, 9999999999, (999) 999-9999.
Как удалить все теги HTML из строки?
Убедитесь, что вы находитесь в глобальном режиме (флажок g), нечувствительны к регистру и у вас включена опция "все точки". Это регулярное выражение будет соответствовать всем тегам HTML и их атрибутам. Это оставит содержимое тегов в строке.
<(.|\n)+?>Как удалить все пустые строки из строки с помощью регулярного выражения?
Убедитесь, что вы находитесь в глобальном и многострочном режиме. Используйте пустую строку в качестве значения замены. 9\s*\r?\n
Блоги Knoldus Что такое регулярные выражения? Java Basic on Regex
Chitra SinghJavajava, regex1 Комментарий о том, что такое регулярное выражение и как использовать регулярное выражение в Java?6 мин чтения
Время чтения: 4 минуты
Что такое регулярное выражение?Извлечение данных из массива и проверка ввода/вывода — важный аспект каждого языка программирования.
Регулярное выражение – это последовательность символов, формирующая шаблон поиска. Оно также известно как регулярное выражение . Регулярное выражение используется для поиска необходимой информации для данных с использованием шаблона поиска для описания того, что вы ищете.
Регулярное выражение может быть сложным шаблоном или простым символом.
Метод поиска шаблонов регулярных выражений. Например:
- Найти, отредактировать или удалить и заменить текст.
- Определить ограничения на строки для электронной почты, паролей и проверок.
- Аналогично в разделенных строках в качестве токенов и в antlr и т. д.
В Java мы можем
импортировать пакет java.util.regex для работы с регулярными выражениями. Пакет включает следующий класс:Пример регулярного выражения в Java: определяет, присутствует ли шаблон в заданной строке или нет.
- Класс шаблона
- Класс сопоставления
- Класс PatternSyntaxException
ВЫВОД :
шаблон найден в сопоставителе.
1. Класс шаблона : –Класс шаблона представляет собой скомпилированную версию регулярного выражения, которая используется для определения шаблона для механизма регулярных выражений. Вы можете создать объект шаблона из класса шаблона.
Но класс Pattern не имеет общедоступных конструкторов. Вы можете создать объект, только вызвав его метод статической компиляции(). Этот метод принимает регулярное выражение в качестве параметра и возвращает объект Pattern.
Методы, определенные в классе шаблонов:2. Класс Matcher: -
- static Компиляция шаблона (строковое регулярное выражение): Компилирует заданное регулярное выражение и возвращает экземпляр шаблона.
- Сопоставитель сопоставитель (CharSequence input): Создает сопоставитель, который сопоставляет заданный ввод с шаблоном.
- статические логические совпадения (строковое регулярное выражение, ввод CharSequence): Он компилирует регулярное выражение и сопоставляет заданный ввод с шаблоном.
- String[] split(CharSequence input) : Разбивает заданную входную строку на совпадения с заданным шаблоном.
- Строка pattern() : Возвращает регулярное выражение, из которого был скомпилирован этот шаблон.
Класс Matcher помогает сопоставлять строку с шаблоном. В классе нет общедоступного конструктора, но вы можете создать объект Matcher, вызвав метод match() объекта Matcher.
Методы, определенные в классе сопоставления:
- логические совпадения(): Используется для проверки соответствия регулярного выражения шаблону.
- boolean find(): Используется для поиска нескольких вхождений регулярного выражения в тексте
- int start(): Начальный индекс совпавшей подпоследовательности возвращается методом end
- int end(): Конечный индекс совпадающей подпоследовательности возвращается методом end.
Экземпляры этого класса не являются потокобезопасными.
3.PatternSyntaxException :-Указывает на синтаксическую ошибку в шаблоне регулярного выражения.
Методы, определенные в PatternSyntaxException class:
- String getDescription() : возвращает описание ошибки.
- Int getIndex(): Возвращает индекс ошибки.
- String getMessage(): Возвращает многострочную строку, содержащую: i) описание синтаксической ошибки и ее индекс, ii) неверный шаблон регулярного выражения, iii) визуальную индикацию индекса ошибки внутри узора.
- String getPattern(): Извлекает ошибочный шаблон регулярного выражения.
Добавлены флаги для более ограниченного и оптимизированного поиска .
Флаги в методе compile() изменяют способ выполнения поиска.
Пример velliganting
- Pattern.case_insensity
- Pattern.literal
- Pattern.Unicode_CASE
.ВЫВОД :
Идентификатор электронной почты правильный.
Шаблоны регулярных выраженийПервым параметром метода Pattern.compile() является шаблон. Он описывает, что ищется, поэтому мы собираемся разделить синтаксис на категории.
1. Симпатилые символы :-Границы сопоставления
Экспрессия Матчи 7774444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444443449н. Любой символ, кроме новой строки. \w Словесный символ (a-z, A-Z, 0-9, _) \W Не словесный символ 9 Белый пробел \s Начало строки $ Конец строки \b Граница слова \B 90.34 \B 90. 3.
Квантовы :-квантификаторы
. + 1 или более предыдущих вещей. ? 0 или 1 вхождение предыдущего выражения. { n} Ровно n число вхождений предыдущего выражения. { n,} n или более вхождений предыдущего выражения. {n, m} Диапазон номеров. Минимум n и максимум m 4. 9…]
Любой одиночный символ, не заключенный в скобки. а| b Соответствует либо a, либо b. Группы Пример с комбинацией определенных рисунков REGEX: (re) Группирует регулярные выражения, заключенные в скобки. Выход:
True
False
Ложь
True
. вы пропустили регулярное выражение из вашего довода подошва, поэтому RegEx — лучшее решение проблемы.