Access SQL. Основные понятия, лексика и синтаксис
Для извлечения данных из базы данных используется язык SQL. SQL — это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.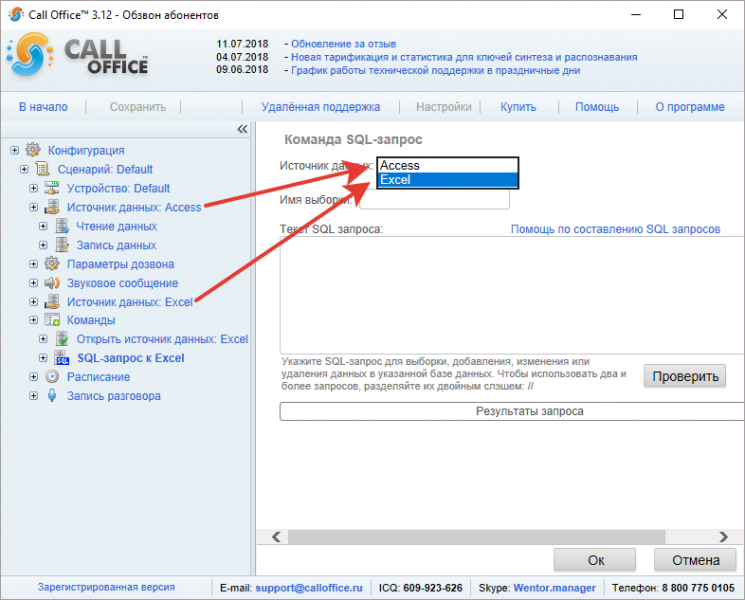
В этой статье
Что такое SQL?
SQL — это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI.
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = 'Mary';
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье.
Инструкции SELECT
-
таблицы, в которых содержатся данные;
-
связи между данными из разных источников;
-
поля или вычисления, на основе которых отбираются данные;
-
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
-
необходимость и способ сортировки.

Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
Предложение SQL | Описание | Обязательное |
|---|---|---|
|
SELECT |
Определяет поля, которые содержат нужные данные. |
Да |
|
|
Определяет таблицы, которые содержат поля, указанные в предложении SELECT. |
Да |
|
WHERE |
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты. |
Нет |
|
ORDER BY |
Определяет порядок сортировки результатов. |
Нет |
|
GROUP BY |
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение. |
Только при наличии таких полей |
HAVING |
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение. |
Нет |
Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
Термин SQL | Сопоставимая часть речи | Определение | Пример |
|---|---|---|---|
|
идентификатор |
существительное |
Имя, используемое для идентификации объекта базы данных, например имя поля. |
Клиенты.[НомерТелефона] |
|
оператор |
глагол или наречие |
Ключевое слово, которое представляет действие или изменяет его. |
AS |
|
константа |
|
Значение, которое не изменяется, например число или NULL. |
42 |
|
выражение |
прилагательное |
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения. |
>= Товары.[Цена] |


К началу страницы
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
-
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
-
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
1. Предложение SELECT
2. Предложение FROM
Предложение FROM
3. Предложение WHERE
Эту инструкцию SQL следует читать так: «Выбрать данные из полей «Адрес электронной почты» и «Компания» таблицы «Контакты», а именно те записи, в которых поле «Город» имеет значение «Ростов».
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT [E-mail Address], Company
Это предложение SELECT. Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Если идентификатор содержит пробелы или специальные знаки (например, «Адрес электронной почты»), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM.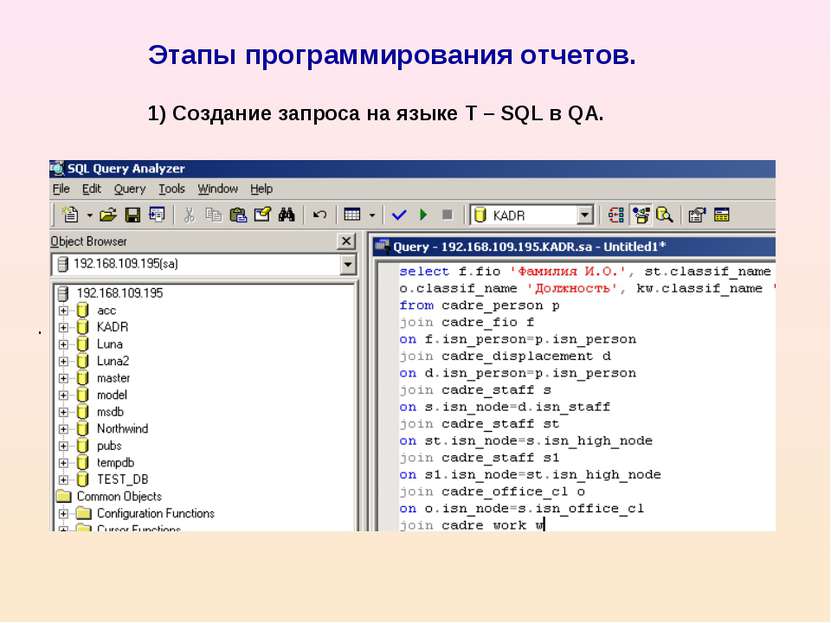 Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City=»Seattle»
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город=»Ростов»).
Примечание: В отличие от предложений SELECT и FROM, предложение WHERE является необязательным элементом инструкции SELECT.
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий.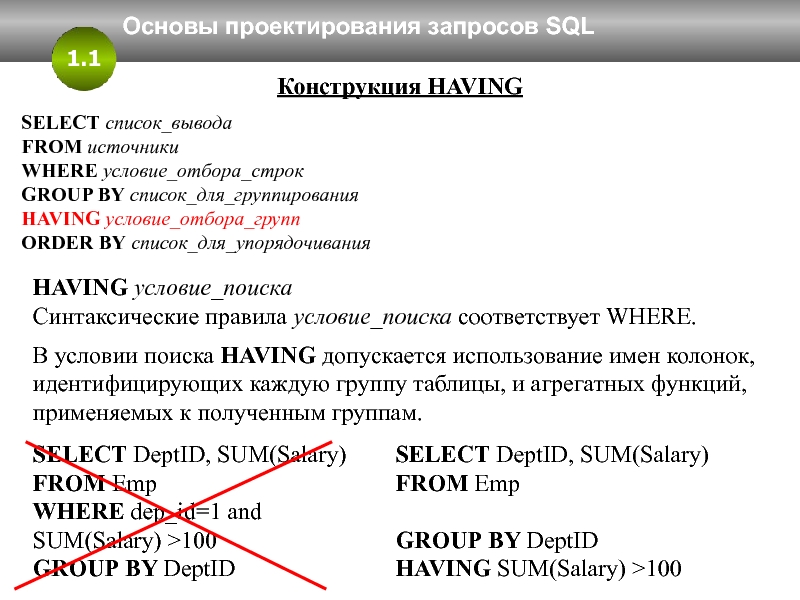 Дополнительные сведения об использовании этих предложений см. в следующих статьях:
Дополнительные сведения об использовании этих предложений см. в следующих статьях:
К началу страницы
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю «Компания» в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля «Компания», — отсортировать их по полю «Адрес электронной почты» в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC, [E-mail Address]
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY.
в статье Предложение ORDER BY.
К началу страницы
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
SELECT COUNT([E-mail Address]), Company
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример. Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY.
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT([E-mail Address]), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT([E-mail Address])>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING.
К началу страницы
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION [ALL]
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются «Товары» и «Услуги». Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
К началу страницы
Оператор SELECT. Простой SQL-запрос, синтаксис, примеры
За выборку данных из таблиц базы данных в SQL отвечает оператор SELECT. В этой статье будет рассмотрен его простейший синтаксис и примеры.
Чтобы выполнить простой запрос к базе данных достаточно указать всего 2 условия (предложения):
- Какие столбцы необходимо выгрузить;
- Из какой таблицы необходимо выгрузить столбцы.
На языке SQL это выглядит следующим образом:
SELECT <Перечень столбцов> FROM <Перечень таблиц>
Имена столбцов перечисляются через запятую сразу после ключевого слова SELECT. Затем следует ключевой слово FROM с наименованиями таблиц. Если таблиц несколько, то они так же указываются через запятую.
Запросы к нескольким таблицам не рассматриваются в данном материале, так как это тема относится к соединению таблиц либо требует знания предложения WHERE.
Столбцы и таблицы могут быть перечислены в любом порядке и повторяться несколько раз.
Подключение к базе данных
На сервере часто присутствует более одной базы данных. Поэтому, прежде чем выполнить запрос, потребуется подключиться к конкретной базе. Научимся это делать в SQL Server Management Studio:
Теперь любой запрос будет выполняться именно в ее контексте.
Создание SQL-запроса
Выполним первую задачу:
Необходимо получить Фамилии, Имена и Отчества всех сотрудников.
В поле запроса введите следующий SQL-код:
SELECT Фамилия, Имя, Отчество FROM Сотрудники
Первая строка запроса содержит выгружаемые столбцы, вторая строка указывает таблицу столбцов. На самом деле, код напоминает обычное предложение: «Выбрать столбцы Фамилия, Имя, Отчество из таблицы Сотрудники».
Нажмите на кнопку «Выполнить» на панели редактора SQL. Внизу окна запроса должен появиться результат его выполнения. Под результатом отображается статус и продолжительность запроса, а также количество выгруженных строк. Если Вы все сделаете правильно, то статус будет сообщать «Запрос успешно выполнен», а количество строк равняться 39.
Пояснения синтаксиса
Не имеет значения в каком регистре будут написаны ключевые слова и наименования. Такой вариант полностью идентичен предыдущему:
select ФаМиЛия, иМЯ, ОтчествО froM сотрудники
Также можно не начинать каждое условие с новой строки.
Рекомендуем писать запросы аккуратно, чтобы их было проще понимать и искать ошибки.
Иные варианты запроса
Перед написанием кода говорилось о необходимости подключения к БД. Но можно обойтись и без подключения в этом конкретном случае (в некоторых программах это обязательное требование). Достаточно в предложении FROM дополнительно указать имя базы данных и имя схемы (по умолчанию dbo):
SELECT Фамилия, Имя, Отчество FROM CallCenter.dbo.Сотрудники
Теперь опишем синтаксис простой инструкции SELECT (необязательные части запроса взяты в квадратные скобки):
SELECT [Имя_таблицы.]Имя_столбца[, [Имя_таблицы.]Имя_столбца2 …] FROM [[Имя_базы_данных.]Имя_Схемы.]Имя_таблицы
Дополнительные имена загромождают код запроса, поэтому можно использовать инструкцию USE. Она переключит контекст на указанную базу данных:
USE CallCenter SELECT Фамилия, Имя, Отчество FROM Сотрудники
Такой подход обеспечит подключение к нужной базе.
Многословные имена столбцов и таблиц могут содержать пробелы между словами. В таких случаях их имена заключаются в квадратные скобки, чтобы запрос сработал корректно. Например, [имя столбца].
- < Назад
- Вперёд >
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Добавить комментарий
Понятие и назначение SQL запроса: что такое SQL запрос
Содержание статьи:
Вступление
Для работы с различными реляционными базами данных, включая Oracle, MySQL, PostgreSQL, DBase, FoxPro, Clipper, Paradox был создан единый язык запросов к базам данных. Назвали его язык SQL, что означает Structured Query Language — структурированный язык запросов.
В данной статье используем СУБД MySql. Именно для пользователя, СУБД MySql имеет наибольшее практическое применение, как в управлении различными расширениями, так и в их создании. Как-никак, все локальные сервера, CMS, платформы интернет магазинов работают именно с СУБД MySql.
Понятие и назначение SQL запроса для администрирования БД
Реляционная база данных это таблица с информацией, разнесенной по столбцам (поля или атрибуты) и строкам (записи или кортежи) таблицы. Чтобы изменить или удалить данные в столбцах и строках, а также данные в определенных ячейках (пресечение столбца и строки) можно воспользоваться прикладными инструментами (например, phpmyadmin) или сделать SQL запрос к базе данных, по которому выполнится нужное действие.
Что можно делать с помощью SQL запросов
При помощи запросов SQL можно:
- Создавать таблицы БД;
- Изменять таблицы БД;
- Удалять таблицы БД;
- Вставлять записи (строки) в таблицы БД;
- Редактировать записи в таблицах БД;
- Извлекать выборочную информацию из таблиц БД;
- Удалять выборочную информацию из БД.
Это не полный перечень возможностей SQL запросов, но и он дает представление, что с помощью SQL запросов можно сделать с базой данных всё что необходимо.
Операторы SQL запроса
Язык SQL имеет большой список различных операторов, каждый из которых «задает» определенную команду. Справочник по операторам тут: (http://www.mysql.ru/docs/man/Database_Administration.html/CREATE_TABLE.html). В следующих статьях будем рассматривать, как работают основные операторы SQL и как с их помощью управлять базами данных.
В завершении перечислю, операторы sql запросов, которые будем рассматривать в ближайших статьях раздела:
- CREATE TABLE – оператор sql для создания таблицы базы данных;
- ALTER TABLE – оператор sql для изменения таблицы БД;
- INSERT INTRO – вставка информации (строк) в таблицы БД;
- UPDATE – оператор для редактирования информации в таблицах БД;
- SELECT – извлечение информации из таблиц БД;
- DELET – удаление информации из таблиц БД.
©WebOnTo.ru
Другие статьи раздела: СУБД
Похожие статьи:
Как сделать сложные запросы SQL проще для написания? [закрыто]
Я основываю большую часть этого на попытках получить «правильный» ответ, чтобы вы могли обнаружить, что есть некоторые проблемы с производительностью. Нет смысла ускорять неправильный запрос.
Поймите отношения таблицы — большинство будет один ко многим. Знать таблицу «многие». Определите поля, необходимые для ваших объединений.
Подумайте о сценариях ЛЕВОГО присоединения — выберите всех сотрудников и их зарплату с прошлого месяца. Что если они не получили зарплату в прошлом месяце?
Знайте набор результатов: 1) В электронной таблице вручную введите хотя бы одну правильную запись для вашего запроса. 2) Напишите запрос в достаточно простой форме, чтобы определить, сколько записей должно быть возвращено. Используйте оба из них, чтобы проверить ваш запрос, чтобы убедиться, что присоединение к новой таблице не изменит результат.
Разбейте ваш запрос на управляемые части — вам не нужно писать все сразу. Сложные запросы иногда могут быть просто набором простых запросов.
Остерегайтесь смешанных уровней агрегации : если вам нужно поместить ежемесячные, квартальные и текущие значения в один и тот же набор результатов, вам нужно будет рассчитать их отдельно в запросах, сгруппированных по разным значениям.
Знайте, когда объединяться Иногда легче разделить подгруппы на свои собственные операторы выбора. Если у вас есть таблица, смешанная с менеджерами и другими сотрудниками, и в каждом столбце вы должны делать операторы Case, основанные на членстве в одной из этих групп, может быть проще написать запрос Manager и объединить его с запросом Employee. Каждый из них будет содержать свою собственную логику. Необходимость включать элементы из разных таблиц в разные строки — очевидное применение.
Сложные / вложенные формулы — Старайтесь последовательно делать отступы и не бойтесь использовать несколько строк. «Дело, когда дело, когда дело, когда» сводит вас с ума. Потратьте время, чтобы обдумать это. Сохраните сложные кальки для последнего. Получите правильные записи, выбранные в первую очередь. Затем вы атакуете сложные формулы, зная, что работаете с правильными значениями. Просмотр значений, используемых в формулах, поможет вам определить области, в которых необходимо учитывать значения NULL, и где обрабатывать ошибку деления на ноль.
Тестируйте часто, когда вы добавляете новые таблицы, чтобы убедиться, что вы все еще получаете желаемый набор результатов и знаете, какое соединение или предложение является виновником.
SQL-запросов для настройки производительности | Advanced SQL
Начиная с этого места? Этот урок является частью полного руководства по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
Урок по подзапросам познакомил с идеей, что иногда можно создать тот же желаемый набор результатов с помощью более быстрого запроса. В этом уроке вы научитесь определять, когда ваши запросы можно улучшить, и как их улучшить.
Теория времени выполнения запросов
База данных — это часть программного обеспечения, которое запускается на компьютере, и на него распространяются те же ограничения, что и на все программное обеспечение: она может обрабатывать столько информации, сколько способно обработать ее оборудование.Способ ускорить выполнение запроса — уменьшить количество вычислений, которые должно выполнять программное обеспечение (и, следовательно, оборудование). Для этого вам понадобится некоторое понимание того, как SQL на самом деле производит вычисления. Во-первых, давайте рассмотрим некоторые высокоуровневые вещи, которые повлияют на количество вычислений, которые вам необходимо выполнить, и, следовательно, на время выполнения ваших запросов:
- Размер таблицы: Если ваш запрос попадет в одну или несколько таблиц с миллионами строк или более, это может повлиять на производительность.
- Объединений: Если ваш запрос объединяет две таблицы таким образом, что значительно увеличивает количество строк в наборе результатов, ваш запрос, вероятно, будет медленным. Пример этого есть в уроке по подзапросам.
- Агрегации: Объединение нескольких строк для получения результата требует больше вычислений, чем простое извлечение этих строк.
Время выполнения запроса также зависит от некоторых вещей, которые вы не можете контролировать, связанных с самой базой данных:
- Другие пользователи, выполняющие запросы: Чем больше запросов выполняется одновременно в базе данных, тем больше база данных должна обрабатывать в данный момент времени и тем медленнее все будет выполняться.Это может быть особенно плохо, если другие выполняют особо ресурсоемкие запросы, удовлетворяющие некоторым из вышеперечисленных критериев.
- Программное обеспечение баз данных и оптимизация: Это то, что вы, вероятно, не можете контролировать, но если вы знаете, какую систему используете, вы можете работать в ее рамках, чтобы сделать ваши запросы более эффективными.
А пока давайте проигнорируем то, что вы не можете контролировать, и поработаем над тем, что можете.
Размер уменьшающегося стола
Фильтрация данных для включения только необходимых наблюдений может значительно повысить скорость выполнения запросов.Как вы это сделаете, полностью зависит от проблемы, которую вы пытаетесь решить. Например, если у вас есть данные временного ряда, ограничение небольшим временным окном может значительно ускорить выполнение ваших запросов:
ВЫБРАТЬ *
ИЗ benn.sample_event_table
ГДЕ event_date> = '2014-03-01'
И event_date <'2014-04-01'
Имейте в виду, что вы всегда можете выполнить исследовательский анализ на подмножестве данных, уточнить свою работу до окончательного запроса, затем снять ограничение и выполнить свою работу по всему набору данных.Выполнение последнего запроса может занять много времени, но, по крайней мере, вы можете быстро выполнить промежуточные шаги.
Вот почему Mode по умолчанию применяет предложение LIMIT - 100 строк часто больше, чем нужно для определения следующего шага анализа, и это достаточно маленький набор данных, который быстро вернется.
Стоит отметить, что LIMIT не совсем так же работает с агрегациями - агрегация выполняется, затем результаты ограничиваются указанным количеством строк.Итак, если вы объединяете в одну строку, как показано ниже, LIMIT 100 ничего не сделает для ускорения вашего запроса:
ВЫБРАТЬ СЧЕТЧИК (*)
ИЗ benn.sample_event_table
ПРЕДЕЛ 100
Если вы хотите ограничить набор данных перед подсчетом (чтобы ускорить процесс), попробуйте сделать это в подзапросе:
ВЫБРАТЬ СЧЕТЧИК (*)
ИЗ (
ВЫБРАТЬ *
ИЗ benn.sample_event_table
ПРЕДЕЛ 100
) sub
Примечание. Использование LIMIT резко изменит ваши результаты, поэтому вы должны использовать его для проверки логики запроса, но не для получения фактических результатов.
В общем, при работе с подзапросами вы должны убедиться, что ограничили объем данных, с которыми вы работаете, в том месте, где они будут выполнены в первую очередь. Это означает установку LIMIT в подзапрос, а не во внешний запрос. Опять же, это сделано для ускорения выполнения запроса, чтобы вы могли протестировать - НЕ для получения хороших результатов.
Упрощение соединений
В некотором смысле это продолжение предыдущего совета. Точно так же, как лучше сокращать данные в той точке запроса, которая выполняется раньше, лучше уменьшить размеры таблиц перед их объединением.Возьмем этот пример, в котором информация о спортивных командах колледжей добавляется в список игроков в разных колледжах:
SELECT team.conference AS конференция,
player.school_name,
COUNT (1) AS игроков
ОТ игроков benn.college_football_players
ПРИСОЕДИНЯЙТЕСЬ к командам benn.college_football_teams
ON team.school_name = player.school_name
ГРУППА ПО 1,2
В 26 298 строк benn.college_football_players . Это означает, что 26 298 строк необходимо оценить на предмет совпадений в другой таблице.Но если таблица benn.college_football_players была предварительно агрегирована, вы можете уменьшить количество строк, которые необходимо оценить в соединении. Сначала посмотрим на агрегацию:
ВЫБЕРИТЕ игроков.school_name,
COUNT (*) как игроки
ОТ игроков benn.college_football_players
ГРУППА ПО 1
Приведенный выше запрос возвращает 252 результата. Таким образом, удаление этого параметра в подзапросе и последующее присоединение к нему во внешнем запросе существенно снизит стоимость соединения:
ВЫБРАТЬ команды.конференция,
sub. *
ИЗ (
ВЫБЕРИТЕ player.school_name,
COUNT (*) как игроки
ОТ игроков benn.college_football_players
ГРУППА ПО 1
) sub
ПРИСОЕДИНЯЙТЕСЬ к командам benn.college_football_teams
ON team.school_name = sub.school_name
В этом конкретном случае вы не заметите огромной разницы, потому что 30 000 строк не так уж сложно для обработки базы данных. Но если бы вы говорили о сотнях тысяч строк или более, вы бы заметили улучшение за счет агрегирования перед объединением.При этом убедитесь, что то, что вы делаете, логически согласовано - вам следует беспокоиться о точности своей работы, прежде чем беспокоиться о скорости бега.
ОБЪЯСНИТЬ
Вы можете добавить EXPLAIN в начало любого (рабочего) запроса, чтобы понять, сколько времени это займет. Это не совсем точно, но это полезный инструмент. Попробуйте запустить это:
ОБЪЯСНИТЬ
ВЫБРАТЬ *
ИЗ benn.sample_event_table
ГДЕ event_date> = '2014-03-01'
И event_date <'2014-04-01'
ПРЕДЕЛ 100
Вы получите этот вывод.Он называется планом запроса и показывает порядок, в котором будет выполняться ваш запрос:
Сначала выполняется запись внизу списка. Таким образом, это показывает, что предложение WHERE , ограничивающее диапазон дат, будет выполнено первым. Затем база данных просканирует 600 строк (это приблизительное количество). Вы можете увидеть стоимость, указанную рядом с количеством строк - более высокие числа означают более длительное время выполнения. Вы должны использовать это скорее как ссылку, чем как абсолютную меру.Чтобы уточнить, это наиболее полезно, если вы запускаете EXPLAIN в запросе, изменяете дорогостоящие шаги, а затем снова запускаете EXPLAIN , чтобы увидеть, уменьшились ли затраты. Наконец, предложение LIMIT выполняется последним, и его выполнение действительно дешево (24,65 против 147,87 для предложения WHERE ).
Подробнее см. В документации Postgres.
Создание запроса с использованием CREATE в режиме SQL
SQL - это комплексный способ запроса вашей базы данных.Используйте эти разделы, чтобы получить уверенность в использовании:
Шаблон SQL
Основные ключевые слова SQL в простом запросе
CA Dataquery
для решения бизнес-задачи
Если хотите, вы можете следовать следующим урокам, используя свои собственные данные и правильные имена для вашей собственной базы данных.
Перед первым чтением этих разделов рекомендуется ознакомиться с концепциями баз данных и терминологией, обсуждаемыми в разделе «Понимание терминологии».В следующих разделах представлены концепции построения базового запроса с использованиемCA Dataquery
EDITOR. В них входят:Краткий обзор панели РЕДАКТОР
Советы по планированию запроса
Пример типичной бизнес-ситуации и образец запроса, который удовлетворяет потребности
Учебное пособие по созданию образца запроса
Информация об определении формата отчета по умолчанию для использования при каждом выполнении запроса
В этих разделах содержится достаточно информации, чтобы вы могли начать создавать свои собственные запросы SQL в РЕДАКТОРЕ.Они также предоставляют введение в некоторые расширенные возможности запросов SQL и определение формата вывода запроса.
На этой странице обсуждаются следующие темы:
Вы можете выбрать один из нескольких методов для создания нового запроса. Вы можете использовать Guided илиCA Dataquery
EDITOR, доступный с функцией CREATE. И вы можете получить доступ к РЕДАКТОРУ любым из способов, описанных в разделе Доступ к РЕДАКТОРУ. Однако, прежде чем делать что-либо из этого, вы должны иметь общее представление о том, чего вы хотите достичь, прежде чем начать.Перед созданием запроса вы должны знать следующее:
Какие данные сообщать.
Идентификаторы авторизации для таблиц, в которых будет выполняться поиск, если таблицы не идентифицируются по вашему идентификатору авторизации.
Следует ли выбирать только определенные строки данных (например, только данные для определенных почтовых индексов).
Вам необходимо решить следующее:
Какие таблицы базы данных содержат нужные вам данные.
Следует ли искать более чем в одной таблице.
При планировании запроса вы должны быть знакомы с опциями определения формата, доступными на панелях выполнения. Получение отчета предоставляет подробную информацию о спецификациях формата отчета, включая контрольные разрывы, промежуточные и итоговые суммы.
CA Dataquery
может предоставить онлайн-информацию о таблицах и столбцах для идентификатора авторизации SQL, отображаемого на панели ПРОФИЛЬ ПОЛЬЗОВАТЕЛЯ.(Для получения дополнительной информации см. Управление профилем пользователя CA Dataquery.) АдминистраторCA Dataquery
может получить отчетCA Datacom® Datadictionary ™
, в котором перечислены имена таблиц и столбцов, а также другая соответствующая информация.При написании запроса или диалогового окна существуют определенные ограничения на то, что вы можете делать. Вам не следует:
- Используйте слова, значение которых может быть неправильно истолковано
CA Dataquery
. - Превышено ограничение строки для конкретного сайта панели РЕДАКТОР.(Пределы строк зависят от определенных параметров установки. Информацию об ограничениях сайта можно получить у администратора
CA Dataquery
.) Присоединитесь к более чем десяти таблицам базы данных или таблицам результатов.
Базовая процедура создания запроса
На следующей диаграмме показаны этапы создания запроса с помощью функции СОЗДАТЬ в главном меню. В нем представлен обзор шагов, описанных в следующем разделе. По мере накопления опыта вы можете изменить порядок некоторых шагов.
3 | Отобразите шаблон SQL и выберите предложения, необходимые для запроса, чтобы создать настраиваемый шаблон. Подробности см. В разделе Шаг 3. Использование шаблона SQL. | |
4 | Измените шаблон запроса, который вы create | Используйте строковые команды и клавиши клавиатуры для изменения предложений шаблона при создании запроса. См. Подробности с 1 по Edit ORDER BY Clause. |
6 | Сохраните запрос | Сохраните запрос с указанным именем, чтобы его можно было использовать позже. (Вы также можете изменить его позже и обновить свои изменения, если это необходимо.) |
7 | Заполните панель ONLINE EXECUTION и определите отчет, который вы хотите, если вы не хотите использовать значения по умолчанию . Затем выполните запрос. См. Шаг 7: Форматирование отчета и Выполнение запроса для получения дополнительной информации. |
Написание образца SQL-запроса
Используйте этот раздел, чтобы получить общее представление о том, как работает функция CREATE. Когда вы закончите, вы поймете, как создать базовый запрос с помощью РЕДАКТОРА, а также узнаете некоторые основные факты оCA Dataquery
.В этом разделе представлен обзор процедуры, задействованной при создании планового запроса. В руководстве представлены основные концепции построения запросов, введение в SQL и перечислены дополнительные концепции и функции.
Вы можете следовать руководству и создать свой собственный запрос. Просто выберите в своей базе данных таблицу, содержащую как символьные, так и числовые данные, и следуйте инструкциям на следующих страницах (используя правильные имена для ваших данных).
Предположим, вы менеджер по продажам и хотите увеличить количество заказов от существующих клиентов. Вы рассматриваете идею предложения скидок на заказы, превышающие 1000 долларов США. Вы хотите знать, сколько таких заказов было размещено в 2010 году. Имея эту информацию, вы можете оценить, во что обойдется компания.Вы также хотите знать, какие продавцы получили эти заказы. Вы хотите встретиться с ними, чтобы обсудить идею.
Ниже описаны общие этапы решения предыдущей бизнес-проблемы.
-
Определить потребность
Создайте запрос, который создает отчет, содержащий эту информацию:Какие клиенты разместили заказы на сумму более 1000 долларов в 1987 году?
Какие продавцы должны присутствовать на встрече?
-
Визуализировать отчет
Определите, как должен выглядеть отчет. -
Определить таблицы
Узнайте, какие таблицы содержат необходимые данные. -
Определить столбцы
Узнайте, на какие столбцы следует ссылаться, чтобы найти данные. -
Принять решение
Определите, может ли существующий запрос или диалоговое окно создать отчет. Если нет, решите, хотите ли вы скопировать и отредактировать существующий запрос (или диалоговое окно) или написать свой собственный. Если вы хотите написать свой собственный, решите, использовать ли GUIDE, CREATE или DRAW.Если существующий запрос был создан вами, вы можете обновить его. Обязательно внесите соответствующие изменения в формат отчета. -
Начать создание запроса
Выберите СОЗДАТЬ в главном меню. -
Определить отчет
Доступ к панели ОНЛАЙН ИСПОЛНЕНИЕ для созданного запроса. Выберите ФОРМАТИРОВАТЬ ОТЧЕТ и введите параметры печати. Эти спецификации печати сохраняются и становятся значениями по умолчанию для запроса при каждом его выполнении.
Ниже приведен пример того, как должен выглядеть ваш отчет:
=> 21.06.11 15:25:00 REP_ID ORD_AMT NAME -------- ------- ------------------------------ 34222 1021.89 DRISCOLL CO. 34222 1919.11 DRISCOLL CO. 34222 2001.95 ПРИБОРЫ FOX И СЫН 34222 2112.00 INGERSOLL DIE CO. 35111 1311.00 АБЕРНАТИЧЕСКАЯ САНТЕХНИКА 35111 1578.90 WILSON TOOLS CO 44123 1477.00 AUSTIN TOOLS CO. 44123 1230.00 МАКСВЕЛЛ ИНСТРУМЕНТЫ CO 44222 7329.34 BENTLEY ПРОИЗВОДСТВО 44222 1778.00 ФАРБЕРНЫЙ ИНСТРУМЕНТ И ПЛАСТИНА
Сравните пронумерованные элементы в образце отчета, чтобы получить описание каждого элемента, о котором вы хотите знать.
REP_ID | Отсортируйте соответствующие данные, найденные по идентификатору продавца, и распечатайте этот идентификатор в качестве первого столбца в отчете. |
ORD_AMT | Отсортируйте соответствующие данные для каждого продавца по сумме заказа. Выведите соответствующие суммы заказа во второй столбец отчета. |
НАЗВАНИЕ | Напечатайте имя клиента для каждого заказа в третьем столбце отчета. |
Создание образца запроса
В следующем разделе описывается создание запроса, который создает образец отчета о целях.Ниже приведен пример того, как запрос выглядит на панели редактора:
=> -------------------------------------------------- ------------------------ DQD10 ЗАПРОС: ТЕКУЩАЯ ТАБЛИЦА РЕДАКТОРА: ________________________________ -------------------------------------------------- ----------------------------- ИМЯ: ТИП SQLBASIC: СОСТОЯНИЕ SQL: ПУБЛИЧНЫЙ ОПИСАНИЕ: ОБРАЗЕЦ БАЗОВОГО ЗАПРОСА .... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 ....+ .... 5 .... + .... 6 .... + .... 7 .... +. .. ================================ TOP =============== ====================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ GLS_CUST_TABLE, GLS_ACCTS_TABLE 03 ГДЕ GLS_CUST_TABLE.CUST_ID = GLS_ACCTS_TABLE.CUST_ID 04 И GLS_ACCTS_TABLE.ORD_AMT> = 01000.00 05 ЗАКАЗ ПО REP_ID, ORD_AMT, NAME .. =========================== ВНИЗ ==================== ============== -------------------------------------------------- -----------------------------
ПОМОЩЬ ВОЗВРАТ ДИСПЛЕЙНЫЕ КОЛОНКИ ДИСПЛЕЙНЫЕ КЛАВИШИ ПОКАЗАТЬ ВСЕ СПИСОК ТАБЛИЦ НАЗАД ВПЕРЕД ШАБЛОН ПРОВЕРЬТЕ ВПРАВО / ВЛЕВО РЕЖИМ ПРОЦЕССА
В следующей таблице дается краткое описание четырех основных предложений SQL.
SELECT | Имена столбцов | Имена столбцов, содержащих данные, необходимые для отчета. Задает порядок выходных столбцов. |
ИЗ | Имена таблиц | Задает имена таблиц, в которых находятся столбцы, указанные в предложении SELECT. |
Условия поиска | Задает критерии, которым должны соответствовать данные, чтобы их можно было использовать для объединения таблиц или выбора строк. | |
ORDER BY | Имена столбцов | Задает порядок сортировки данных в том виде, в котором они отображаются в отчете. |
CA Dataquery
позволяет использовать ряд ключевых слов SQL:ALTER
КОММЕНТАРИЙ
СОЗДАТЬ ИНДЕКС
СОЗДАТЬ СИНОНИМ
СОЗДАТЬ ТАБЛИЦУ
СОЗДАТЬ ПРОСМОТР
ПРОСМОТР
УДАЛИТЬ ВИД
УДАЛИТЬ ВИД
DROP VIEW
GRANT
INSERT
REVOKE
SELECT
UPDATE
CA Dataquery
, и дополнительное форматирование не требуется.Если для решения бизнеса требуются промежуточные итоги, контрольные перерывы или математические функции, эти спецификации могут быть сделаны во время выполнения. Подробности см. В шаге 2: определение отчета в режиме SQL.Шаг 1 Отображение панели РЕДАКТОРА
В этом разделе описывается, как отобразить панель РЕДАКТОР.
Выберите СОЗДАТЬ в главном меню, чтобы отобразитьCA Dataquery
EDITOR.Вы можете изменить существующий запрос вместо того, чтобы начинать с пустой панели РЕДАКТОР. Чтобы отобразить запрос, введите команду EDIT, а затем имя запроса в командной строке.При изменении записи в поле NAME это новый запрос, созданный вами. Затем вы можете изменить любую часть запроса и сохранить ее как свою.
Вы также можете ввести команду DRAW и имя таблицы в командной строке, нажать Enter и увидеть отображение панели EDITOR, содержащей простой запрос с предложением SELECT, перечисляющим все имена столбцов, и предложением FROM с именем таблицы. Затем вы можете отредактировать основной запрос. См. Подробности в разделе «Выбор метода создания запроса».Шаг 2 Определите запрос
В этом разделе описывается, как дать запросу имя, статус библиотеки и описание.
После того, как вы выберете СОЗДАТЬ в главном меню, вы увидите следующую панель РЕДАКТОРА (DQD10).
=> ПАНЕЛЬ СОЗДАНИЯ -------------------------------------------------- ------------------------ DQD10 ЗАПРОС: ТЕКУЩАЯ ТАБЛИЦА РЕДАКТОРА: ________________________________ -------------------------------------------------- ----------------------------- ИМЯ: _______________ ТИП: ______ СТАТУС: _______ ОПИСАНИЕ: ___________________________________________________________ .... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 .... + .... 5. ... + .... 6 .... + .... 7 .... +. .. ================================ TOP =============== ====================== .. .. .. .. .. .. .. .. .. =========================== ВНИЗ ====================== ============ -------------------------------------------------- -----------------------------
ПОМОЩЬ ВОЗВРАТ ДИСПЛЕЙНЫЕ КОЛОНКИ ДИСПЛЕЙНЫЕ КЛАВИШИ ПОКАЗАТЬ ВСЕ СПИСОК ТАБЛИЦ НАЗАД ВПЕРЕД ШАБЛОН ПРОВЕРЬТЕ ВПРАВО / ВЛЕВО РЕЖИМ ПРОЦЕССА
Вам не нужно называть запрос, пока вы его не сохраните.Однако, если вы хотите проверить или выполнить его, вы должны указать ему тип. С таким же успехом вы можете определить запрос в качестве первого шага.
Вот что вам следует знать об идентификации запроса:
-
НАИМЕНОВАНИЕ:
Имя запроса должно быть уникальным в пределах назначенной ему библиотеки и должно состоять из одного слова, содержащего от 1 до 15 буквенных символов, цифр, подчеркиваний или специальных символов. Обязательно ознакомьтесь с разделом «Ограничения имен», чтобы ознакомиться с важными ограничениями для имен. -
ТИП:
Допустимые записи: QUERY или DIALOG.Диалог позволяет пользователям заменять переменные в запросе. Для получения информации об использованииCA Dataquery
EDITOR для создания диалоговых окон см.. -
СТАТУС:
Допустимые записи: ЧАСТНАЯ и ОБЩЕСТВЕННАЯ. Вы можете обновлять и удалять запросы, сохраненные в вашей частной библиотеке. Если вы назначаете запрос публичной библиотеке, вы не можете изменить или удалить его после сохранения запроса, если ваш сайт не разрешает автору публичного запроса изменять его. Свяжитесь с администраторомCA Dataquery
для получения дополнительной информации.Если вы решили обновить принадлежащий вам запрос, вам также может потребоваться обновить формат отчета. Некоторые изменения вызывают появление сообщения об ошибке с предупреждением о том, что формат не соответствует запросу. Другие, такие как добавление новых столбцов или новых операторов ORDER BY, не повлияют на процесс проверки формата отчета и, следовательно, не вызовут появление сообщения. Дополнительные сведения об изменении формата отчета по умолчанию при изменении запроса см. В разделе Изменение формата отчета SQL.
-
ОПИСАНИЕ:
Описание должно указывать на цель запроса и отмечать все, что делает его уникальным.Его длина не может превышать 60 символов.
Используйте клавишу Tab для перемещения курсора по очереди к каждому полю: ИМЯ, ТИП, СОСТОЯНИЕ и ОПИСАНИЕ. На следующей диаграмме показаны соответствующие записи для образца запроса.
ИМЯ | SQLSAMPLE01 | Имя указывает, что это запрос SQL и что это первый созданный образец запроса. |
ТИП | ЗАПРОС | Не требует пояснений. |
СОСТОЯНИЕ | ОБЩЕСТВЕННОЕ | Запрос должен быть доступен другим пользователям. |
ОПИСАНИЕ | ОБРАЗЕЦ БАЗОВОГО ЗАПРОСА | Описывает цель запроса, когда его имя указано в каталоге. |
На следующем рисунке показаны заполненные поля идентификации для образца запроса.
ЗАПРОС ДАННЫХ: ТЕКУЩАЯ ТАБЛИЦА РЕДАКТОРА: ________________________________ -------------------------------------------------- ----------------------------- ИМЯ: SQLSAMPLE01____ ТИП: ЗАПРОС_ СТАТУС: ПУБЛИКА_ ОПИСАНИЕ: ОБРАЗЕЦ БАЗОВОГО ЗАПРОСА _________________________________________ .... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 .... + .... 5. ... + .... 6 .... + .... 7 .... +. .. ================================ TOP =============== ======================
В описание можно включить дополнительную информацию о самом запросе. Например, вы можете перечислить отчетные столбцы или назвать таблицы, к которым осуществляется доступ, в описании запроса. Вы также можете сделать свои запросы ЧАСТНЫМИ, пока не будете уверены, что хотите поделиться ими с другими пользователями.
Шаг 3 Используйте шаблон SQL
В этом разделе описывается, как отобразить шаблон SQL и скопировать из него синтаксис на панель РЕДАКТОР, чтобы создать настраиваемый шаблон для запроса.После отображения панели РЕДАКТОР в режиме создания и определения нового запроса вы можете приступить к созданию запроса.
На этом шаге вы узнаете, как отобразить шаблон SQL и скопировать из него необходимый синтаксис на панель РЕДАКТОРА.
Ниже описаны шаги, необходимые для отображения и копирования синтаксиса на панель РЕДАКТОРА в режиме создания.
-
Шаг 1
На панели РЕДАКТОР (режим создания) переместите курсор в первую позицию в области ввода текста. -
Шаг 3
Просмотрите панель шаблона запроса (DQD50), показанную ниже:
=> Поместите непустое поле рядом с каждым утверждением, которое должно быть включено в запрос. -------------------------------------------------- ------------------------ DQD50 ЗАПРОС ДАННЫХ: ШАБЛОН ЗАПРОСА -------------------------------------------------- ----------------------------- Слова в нижнем регистре представляют записи, которые должен быть заменен пользователем. Скобки указывают на необязательные записи: их можно включить, удалив только круглые скобки или удалить, удалив как скобки, так и данные.-------------------------------------------------- ----------------------------- _ ВЫБРАТЬ столбец1, столбец2, счетчик (столбец3) _ ИЗ таблицы1, таблицы2 _ ГДЕ table1.column1 = table2.column2 и column3> 0 _ ГРУППА ПО столбцу 1, столбцу 2 _ ORDER BY column1 -------------------------------------------------- -----------------------------
ПОМОЩЬ ВОЗВРАТ НЕ ИСПОЛЬЗУЕТСЯ НЕ ИСПОЛЬЗУЕТСЯ НЕ ИСПОЛЬЗУЕТСЯ НЕ ИСПОЛЬЗУЕТСЯ НАЗАД ВПЕРЕД
-
Шаг 4
Поместите символ в поле перед каждым ключевым словом, необходимым для нового запроса.
В следующем примере показано, как выглядит панель РЕДАКТОР (DQD10) при копировании синтаксиса из панели «Шаблон SQL».
=> -------------------------------------------------- ------------------------ DQD10 ЗАПРОС: ТЕКУЩАЯ ТАБЛИЦА РЕДАКТОРА: ________________________________ -------------------------------------------------- ----------------------------- ИМЯ: SQLSAMPLE01 ТИП: СОСТОЯНИЕ SQL: ПУБЛИЧНЫЙ ОПИСАНИЕ: ОБРАЗЕЦ БАЗОВОГО ЗАПРОСА __________________________________________ .... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 .... + .... 5. ... + .... 6 .... + .... 7 .... +. .. ================================ TOP =============== ====================== 01 ВЫБРАТЬ столбец1, столбец2, счетчик (столбец3) 02 ИЗ table1, table2 03 ГДЕ table1.column1 = table2.column2 и column3> 0 04 ORDER BY column1 .. =========================== ВНИЗ ==================== ============== -------------------------------------------------- -----------------------------
ПОМОЩЬ ВОЗВРАТ ДИСПЛЕЙНЫЕ КОЛОНКИ ДИСПЛЕЙНЫЕ КЛАВИШИ ПОКАЗАТЬ ВСЕ СПИСОК ТАБЛИЦ НАЗАД ВПЕРЕД ШАБЛОН ПРОВЕРЬТЕ ВПРАВО / ВЛЕВО РЕЖИМ ПРОЦЕССА
Ниже приводится руководство по другим вещам, которые вы можете делать при использовании шаблона SQL.
-
Посмотрите на синтаксис
Вы можете использовать шаблон только как панель справки, ничего не вводя в поля шаблона. -
Копировать по одному пункту за раз
Вы можете обращаться к шаблону столько раз, сколько захотите, и копировать каждое предложение отдельно, где и когда вы решите, что оно вам нужно. -
Не использовать шаблон
Вы можете просто ввести свой запрос в область ввода текста, не отображая шаблон.
Шаг 4 Использование ключевых слов SQL
Когда пункты панели «Шаблон SQL», необходимые для запроса, копируются в панель «РЕДАКТОР», существует шаблон для нового запроса. Следующим шагом является использование РЕДАКТОРА для изменения шаблона и ввода определенных имен таблиц и столбцов для завершения написания запроса.
В оставшихся разделах этого шага обсуждается создание предложений, выбранных для примера запроса: SELECT, FROM, WHERE и ORDER BY. Информация, представленная в руководстве, обеспечивает хорошую основу для создания простых запросов.
Предложение GROUP BY создает результаты запроса, где каждая строка в таблице результатов состоит из результатов математических функций, примененных к группе данных. GROUP BY требуется только в том случае, если вы применяете математические функции к одним столбцам, а не к другим. Определения формата отчета, которые создаются во время выполнения запроса, могут предоставлять результаты, аналогичные GROUP BY, а также предоставлять подробные строки в выходных данных запроса; поэтому пример запроса и этот раздел не ссылаются на GROUP BY.
Ниже приводится общая информация о написании запросов.
-
Правила размещения:
Неважно, сколько пробелов вы вводите между словами в предложении. Также не имеет значения, хотите ли вы вводить все предложения в одной строке (если они подходят) или расположить их в виде списка. Примеры в этом руководстве показывают форматированные запросы с одним пробелом между каждым словом, потому что их легче читать большинству людей. -
Правила заказа:
Порядок, в котором вы используете ключевые слова SQL, важен.Если вы не соблюдаете соглашения об упорядочивании, запрос не будет понятCA Dataquery
илиCA Datacom® / DB
. Для предложений SQL используйте этот порядок:ВЫБРАТЬ
ИЗ
ГДЕ
ГРУППА ПО
ЗАКАЗАТЬ ПО
CA Dataquery
имена столбцов, которые содержат данные, которые должны быть найдены запросом. В этом разделе представлены основные правила и использование предложения SELECT, а также обсуждается создание предложения SELECT в примере запроса..... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 .... + ... .5 .... + .... 6 .... + .... 7 .... +. .. ================================ TOP =============== ====================== 01 ВЫБРАТЬ столбец1, столбец2, счетчик (столбец3) 02 ИЗ table1, table2 03 ГДЕ table1.column1 = table2.column2 и column3> 0 04 ORDER BY column1 .. =========================== ВНИЗ ==================== ==============
В следующих таблицах представлена основная информация об операторах SELECT и определениях предложений SELECT, а также правилах предложений SELECT.
Ниже приводится общая информация о ключевом слове SELECT.
-
Операторы SELECT
Запросы SQL всегда начинаются с оператора SELECT. Первое предложение оператора SELECT - это предложение SELECT. Оператор SELECT также может содержать дополнительные предложения, начиная с ключевых слов FROM, WHERE, GROUP BY и ORDER BY. -
Назначение статьи SELECT
Предложение SELECT называет столбцы, содержащие данные, которые должны появиться в отчете.
Ниже перечислены основные правила для предложений SELECT.
-
Пунктуация
После слова SELECT ставьте пробел и название столбца. При необходимости добавьте дополнительные имена столбцов, разделив их запятыми. Пример: ВЫБРАТЬ столбец1, столбец2, столбец3, столбец4 -
Идентификатор таблицы
Нет необходимости прикреплять идентификатор таблицы к имени столбца, если у вас нет повторяющихся имен столбцов (в нескольких таблицах) и вы хотите распечатать только одно из них.Чтобы прикрепить идентификатор таблицы, введите имя таблицы, точку и имя столбца как одно слово. Пример: ВЫБРАТЬ column1, column2, table2.column3, column4 -
Дублирующиеся строки
Если запрос обнаруживает повторяющиеся строки и вам нужна только одна из них в таблице результатов, после слова SELECT следует слово DISTINCT перед перечислением имен столбцов. Пробел должен предшествовать DISTINCT и следовать за ним. Пример: SELECT DISTINCT column1, column2, column3 -
Вернуть все строки
Чтобы явно указать, что все найденные строки должны быть включены в отчет, вставьте слово ALL между SELECT и именем первого столбца.Ставьте перед ВСЕМ пробелом и после него. Пример: ВЫБРАТЬ ВСЕ столбец1, столбец2, столбец3 -
Выбрать все столбцы
Чтобы выбрать данные из всех столбцов в ссылочных таблицах в отчете, используйте звездочку (*) вместо перечисления имен столбцов. Пример: ВЫБЕРИТЕ * -
Столбцы отчета о заказе
Порядок, в котором вы перечисляете столбцы в предложении SELECT, определяет порядок столбцов в отчете. При выборе из более чем одной таблицы (указанной в предложении FROM) вы можете перечислить столбцы без учета их имен таблиц.
Это шаги для редактирования предложения SELECT в соответствии с запросом:
-
Шаг 1
Переместите курсор на букву c в слове column1. Нажмите клавишу EOF или используйте клавишу Delete, чтобы удалить оставшуюся часть строки. -
Шаг 2
Чтобы показать, где найти данные и указать порядок их представления в отчете, введите эти символы, начиная с позиции курсора:REP_ID, ORD_AMT, NAME
Вот часть панели, показывающая, как теперь выглядит предложение SELECT.
ОПИСАНИЕ: ОБРАЗЕЦ БАЗОВОГО ЗАПРОСА __________________________________________ .... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 .... + .... 5 .... + .... 6 .... + .... 7 .... +. .. ================================ TOP =============== ====================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ table1, table2
Ниже приводится руководство по другим вещам, которые вы можете делать при создании собственных запросов.
-
Используйте онлайн-списки таблиц и столбцов.
Вы можете отобразить список таблиц для вашего текущего идентификатора авторизации, если курсор находится в текстовой области. Вы также можете увидеть имена столбцов для любой из перечисленных таблиц. Вы можете использовать списки для информации или скопировать имена из них в текстовую область в точке курсора. См. Раздел Отображение имен и структур баз данных. -
Используйте поле ТЕКУЩАЯ ТАБЛИЦА.
Если поле ТЕКУЩАЯ ТАБЛИЦА содержит имя, вы можете отображать информацию о столбцах в этой таблице при создании запроса.Есть два способа получить имя в поле ТЕКУЩАЯ ТАБЛИЦА. Вы можете ввести его или поместить курсор в область ввода текста, нажать СПИСОК ТАБЛИЦ и выбрать имя таблицы, которое будет вставлено как в область ввода текста, так и в поле ТЕКУЩАЯ ТАБЛИЦА. См. Раздел Отображение имен и структур баз данных. -
Изменить идентификатор авторизации.
Если вы перейдете на другой известный идентификатор авторизации на панели «ПРОФИЛЬ ПОЛЬЗОВАТЕЛЯ» (команда «ПРОФИЛЬ»), вы сможете отображать списки таблиц и столбцов в других схемах. -
Задайте математические функции для столбцов.
Вы можете запросить, чтобыCA Dataquery
возвращал результаты математической функции, указанной вами для одного или нескольких числовых столбцов, а не сами данные. Вы можете получить суммы, средние, минимальные и максимальные значения или количество значений в любом столбце таблицы результатов. -
Укажите временные результаты.
Вы можете написать выражение, состоящее из имен столбцов и арифметических выражений, и включить это выражение в качестве имени столбца в предложение SELECT.Результат отображается в виде данных столбца.
CA Dataquery
, в какой таблице или таблицах следует искать столбцы, перечисленные в предложении SELECT. В этом разделе представлены основные правила предложения FROM, а также использование и обсуждение создания предложения FROM примера запроса... ================================ TOP ============= ======================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ table1, table2 03 ГДЕ table1.column1 = table2.column2 и column3> 0 04 ORDER BY column1 .. =========================== ВНИЗ ====================== ============
Ниже перечислены правила, касающиеся основных предложений FROM.
-
ИЗ Назначение статьи
Предложение FROM называет таблицы, содержащие данные, которые должны быть прочитаны при создании отчета. -
Пунктуация
После слова FROM поставьте пробел и укажите имя таблицы. При необходимости добавьте дополнительные имена таблиц через запятую. Примеры: ИЗ table1, table2, table3, table4 FROM table1, table2, table3, table4 -
Идентификатор авторизации
Нет необходимости прикреплять идентификатор авторизации к имени таблицы, если он не указан в текущей схеме.Чтобы прикрепить идентификатор авторизации, введите его перед именем таблицы и разделите точкой. Пример: FROM table1, table2, public.table3, table4 -
Порядок имен таблиц
Порядок, в котором вы перечисляете таблицы в предложении FROM, не имеет значения. -
Количество названий таблиц
Вы можете перечислить до десяти имен таблиц в одном предложении FROM. Вы также можете использовать SQL для объединения и присвоения имен таблицам результатов илипросмотров
. Всего можно ссылаться не более чем на десять таблиц, то есть ваше общее количество должно включать количество таблиц, составляющих представление.
Это шаги для редактирования предложения FROM в соответствии с образцом запроса:
-
Шаг 1
Переместите курсор к букве t в слове table1. Нажмите EOF или используйте клавишу Delete, чтобы удалить оставшуюся часть строки. -
Шаг 2
Введите эти символы, начиная с позиции курсора:GLS_CUST_TABLE, GLS_ACCTS_TABLE
Это сообщаетCA Dataquery
, что данные для печати в отчете берутся из двух названных таблиц.
Ниже приведен образец части панели, показывающей, как теперь выглядит предложение SELECT:
ОПИСАНИЕ: ОБРАЗЕЦ БАЗОВОГО ЗАПРОСА __________________________________________ .... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 .... + .... 5 .... + .... 6 .... + .... 7 .... +. .. ================================ TOP =============== ====================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ GLS_CUST_TABLE, GLS_ACCTS_TABLE
Ниже приводится руководство по другим вещам, которые вы можете делать при создании собственных запросов.
-
Используйте онлайн-списки таблиц и столбцов.
Вы можете отобразить список таблиц для вашего текущего идентификатора авторизации, чтобы скопировать нужные имена таблиц прямо в текстовую область. Все, что вам нужно сделать, это поместить курсор в то место, куда вы хотите ввести имя, и нажать LIST TABLES. Из появившегося списка вы выбираете одно или несколько имен таблиц. См. Раздел Отображение имен и структур баз данных. -
Изменить идентификатор авторизации.
Если вы перейдете на другой известный идентификатор авторизации на панели «ПРОФИЛЬ ПОЛЬЗОВАТЕЛЯ» (команда «ПРОФИЛЬ»), вы сможете отображать списки таблиц в других схемах.
CA Dataquery
критерии выбора данных для вывода запроса. Он также может указывать отношения, которые объединяют таблицы, перечисляя условия, которые должны быть найдены в двух или более таблицах. В этом разделе представлены основные правила и использование предложения WHERE, а также обсуждается создание предложения WHERE в примере запроса... ================================ TOP ============= ======================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ GLS_CUST_TABLE, GLS_ACCTS_TABLE 03 ГДЕ table1.column1 = table2.column2 и column3> 0 04 ORDER BY column1 .. =========================== ВНИЗ ==================== ==============
Ниже приводится основная информация о назначении пунктов WHERE и правилах их использования. Для комплексного использования существуют дополнительные правила.
-
Назначение
Цель предложения WHERE:Объединяйте таблицы, называя столбцы, содержащие данные, связанные, как показано оператором сравнения, даже если имена столбцов могут отличаться.
Определите найденные данные, указав одно или несколько условий поиска, по которым проверяются строки.
-
Расположение
Предложения WHERE всегда следуют за оператором FROM. -
Количество пунктов WHERE
Вы можете использовать несколько предложений WHERE и объединять их с помощью AND, OR и круглых скобок для создания логических выражений. -
Пунктуация
После слова WHERE поставьте пробел и предикат.Используйте пробелы между словами и символами в предикате. -
Основные предикаты
Базовые предикаты сравнивают два значения и состоят из одного значения, за которым следует оператор сравнения и другое значение. Значение может быть именем столбца или выражением. (Второе значение также может быть SUBSELECT.) Результатом сравнения является либо истина, либо ложь. Если результат верен для данной строки, эта строка выбирается для таблицы результатов. Типы основных предикатов:Объединения на основе логических выражений, включая операторы сравнения, сравнивающие два значения.
- НЕ предшествует предикату, что означает, что
CA Dataquery
должен находить только строки, в которых найден предикат, а не
. - Несколько выражений, которые представляют собой смесь вышеперечисленного, связанные с помощью логических операторов И и ИЛИ. Пример: ГДЕ table1.name-column = table2.name-column И (СУММА> = 100 ИЛИ СУММА OR (CURRENT_DATE_YEAR
-
Основные операторы сравнения предикатов
Операторы сравнения определяют тип сравнения одного выражения с другим.Допустимые операторы в базовом предикате предложения SQL WHERE:= (равно)
<(меньше)
> (больше)
<> (не равно)
<= (меньше или равно)
> = (Больше или равно)
¬ = (Не равно)
¬ <(Не меньше)
¬> (Не больше)
-
Выражения
Выражения могут быть простыми или сложными, с использованием арифметических операторов (+ - / * =) и круглых скобок.Используйте круглые скобки, чтобы указать, какие операции должны выполняться первыми в сложном вычислении (до 5 уровней вложенных выражений). -
Другие типы предикатов
Вы можете использовать другие типы предикатов в предложении WHERE:ВСЕ
ЛЮБЫЕ
МЕЖДУ
СУЩЕСТВУЕТ
IN
КАК
NULL
5000
Это шаги для редактирования предложения WHERE в примере запроса:
-
Шаг 1
Переместите курсор к букве t в слове table1.столбец1. Нажмите EOF или используйте клавишу Delete, чтобы удалить оставшуюся часть строки. -
Шаг 2
Чтобы указать, что столбец CUST_ID в обеих таблицах должен использоваться для объединения таблиц и что должны быть выбраны только строки, в которых ORD_AMT больше 1000,00 долларов США, введите эти символы, начиная с позиции курсора:GLS_CUST_TABLE.CUST_ID = GLS_ACCTS_TABLE.CUST_ID AND ORD_AMT> 1000.00
Ниже приведен образец части панели, показывающей, как теперь выглядит оператор SELECT:
ОПИСАНИЕ: ОБРАЗЕЦ БАЗОВОГО ЗАПРОСА __________________________________________ .... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 .... + .... 5. ... + .... 6 .... + .... 7 .... +. .. ================================ TOP =============== ====================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ GLS_CUST_TABLE, GLS_ACCTS_TABLE 03 ГДЕ GLS_CUST_TABLE.CUST_ID = GLS_ACCTS_TABLE.CUST_ID И ORD_AMT> 1000.00
Ниже приводится руководство по другим вещам, которые вы можете делать при создании собственных запросов.
-
Объедините более двух таблиц с помощью предложения WHERE.
Вы можете объединить до десяти таблиц (или таблиц результатов) в свои запросы, используя предложение WHERE. -
Используйте ключевое слово UNION для объединения таблиц.
Вы можете создавать более сложные объединения, используя ключевое слово UNION для объединения таблиц результатов, созданных двумя или более операторами SELECT. -
Используйте различные операторы сравнения.
Доступны операторы для создания очень специфических условий поиска. -
Используйте особые условия поиска.
Специальные ключевые слова, такие как BETWEEN, IN, LIKE и IS NULL, доступны для создания специализированных условий поиска. -
Используйте круглые скобки.
Создавайте сложные условия поиска, используя круглые скобки и И и ИЛИ, чтобы написать логическое выражение. -
Используйте другой запрос в качестве объекта предложения WHERE.
Например: ВЫБЕРИТЕ * ОТ ОПЛАТЫ, ГДЕ КОЛОНКА = (ВЫБЕРИТЕ * ИЗ PER)
CA Dataquery
порядок, в котором данные должны быть представлены в выходных данных запроса.Если предложение ORDER BY не используется, порядок строк соответствует порядку строк в таблице результатов. (Порядок столбцов всегда соответствует порядку имен столбцов в операторе SELECT.) В этом разделе представлены основные правила предложения ORDER BY, а также использование и обсуждение создания предложения ORDER BY в примере запроса... ================================ TOP =============== ====================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ GLS_CUST_TABLE, GLS_ACCTS_TABLE 03 ГДЕ GLS_CUST_TABLE.CUST_ID = GLS_ACCTS_TABLE.CUST_ID И ORD_AMT> 1000.00 04 ORDER BY column1 .. =========================== ВНИЗ ==================== ==============
Предложение ORDER BY позволяет вам сортировать строки таблицы результатов в любом необходимом порядке на основе значений данных, найденных в определенных столбцах. Назовите столбцы, содержимое которых должно быть отсортировано, и эти столбцы определяют порядок, в котором строки должны быть расположены в отчете. Например, рассмотрите следующие три группы данных.
Упорядочивание предыдущих выборочных строк по ИМЕНИ и ORD-ID дает следующие результаты.
Упорядочивание предыдущих выборочных строк по ORD_ID и NAME дает следующий результат:
Ниже перечислены основные правила использования ключевого слова ORDER BY.
-
Расположение
Предложение ORDER BY должно быть последним предложением в запросе SELECT. -
Срок действия столбцов заказа
Вы можете использовать любой столбец в любой таблице, на которую ссылается запрос, в качестве столбца упорядочивания, независимо от того, включен он в предложение SELECT или нет. -
Направление сортировки
Строки сортируются по возрастанию, если иное не указано с ключевым словом DESC для сортировки по убыванию. -
Пунктуация
После слов ORDER BY поставьте пробел и укажите одно или несколько имен столбцов. Используйте запятые между именами столбцов. -
Указать идентификатор таблицы
Если в запросе объединены две или более таблиц и существует дубликат столбца ORDER BY, прикрепите идентификатор таблицы к имени столбца, чтобы указать, какой столбец будет использоваться при упорядочивании.Пример:ЗАКАЗАТЬ ПО ACCT_TABLE.ORDER_DATE, CUST_ID
Это шаги для редактирования предложения ORDER BY в соответствии с образцом запроса:
-
Шаг 1
Переместите курсор на букву c в слове column1. Нажмите EOF или используйте клавишу Delete, чтобы удалить оставшуюся часть строки. -
Шаг 2
Введите эти символы, начиная с позиции курсора:REP_ID, ORD_AMT, NAME
указатьCA Dataquery
, чтобы все строки в отчете были разделены на группы по REP_ID.В каждой группе REP_ID данные должны быть расположены в порядке возрастания по сумме заказа (ORD_AMT). Если существуют повторяющиеся суммы заказа, данные должны быть расположены в порядке возрастания по имени клиента (ИМЯ).
Ниже приведен образец части панели, показывающей, как теперь выглядит оператор SELECT:
ОПИСАНИЕ: ОБРАЗЕЦ БАЗОВОГО ЗАПРОСА __________________________________________ .... + .... 1 .... + .... 2 .... + .... 3 .... + .... 4 .... + .... 5 .... + ....6 .... + .... 7 .... +. .. ================================ TOP =============== ====================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ GLS_CUST_TABLE, GLS_ACCTS_TABLE 03 ГДЕ GLS_CUST_TABLE.CUST_ID = GLS_ACCTS_TABLE.CUST_ID И ORD_AMT> 1000.00 04 ORDER BY REP_ID, ORD_AMT, NAME
Ниже приводится руководство по другим вещам, которые вы можете делать при создании собственных запросов.
-
Заказ данных отчета по столбцам, которые не печатаются.
Вы можете сгруппировать данные в отчете в соответствии с данными в столбце, который вам неинтересно видеть в распечатанном виде.Например, вы можете не захотеть видеть одну и ту же дату в каждой строке вывода, даже если вы хотите, чтобы данные были упорядочены по дате. Вы можете использовать столбец даты в предложении ORDER BY, опуская его в предложении SELECT. -
Изменить порядок столбцов в предложении SELECT.
Возможно, вы захотите распечатать столбцы отчета в том же порядке, что и столбцы в предложении ORDER BY.
Шаги 5 и 6 Проверка и сохранение запроса
Перед сохранением проверьте свои запросы (и диалоговые окна) на наличие синтаксических ошибок и ошибок именования.Для этого вы нажимаете клавишу, чтобыCA Dataquery
подтвердил запрос
.После проверки запроса его следует сохранить, если он будет использоваться повторно.
Ниже приведен пример того, как отображается текстовая область панели РЕДАКТОР после завершения процедур на предыдущем шаге:
.. ================================ TOP =============== ====================== 01 ВЫБРАТЬ REP_ID, ORD_AMT, NAME 02 ИЗ GLS_CUST_TABLE, GLS_ACCTS_TABLE 03 ГДЕ GLS_CUST_TABLE.CUST_ID = GLS_ACCTS_TABLE.CUST_ID И ORD_AMT> 1000.00 04 ORDER BY REP_ID, ORD_AMT, NAME .. =========================== ВНИЗ ==================== ==============
Ниже приводится информация о процессе проверки.
-
Насколько безопасен мой текущий запрос?
Запрос находится в активной области запроса до тех пор, пока вы не используете команду или выбор для активации другого запроса. Вам следует сохранить любой запрос, над которым вы, возможно, захотите работать позже или выполнить более одного раза.После сохранения запроса вы можете изменить его и нажать ОБНОВЛЕНИЕ в режиме обработки, чтобы сохранить изменения. Если вы уже создали формат отчета, вы должны определить, нужно ли также изменить формат. Если вы не сохранили запрос, над которым работаете, и покидаете панель РЕДАКТОР для выполнения другой функции, вы можете использовать команду EDIT *, чтобы вызвать его, если другой запрос не был активирован. -
Сроки?
Вы можете проверить запрос или диалог в любой момент во время строительства.ХотяCA Dataquery
проверяет наличие ошибок, он не проверяет, завершен ли запрос. - Что проверяется
CA Dataquery
?CA Dataquery
проверяет, авторизован ли пользователь для выполнения функции, например, SELECT, DROP, CREATE.CA Dataquery
затем передает запросCA Datacom® / DB
, который проверяет синтаксис. Если обнаружена синтаксическая ошибка,CA Dataquery
отображает сообщение, начинающееся с букв DQ.Вы исправляете ошибку и снова подтверждаете.CA Dataquery
затем передает запросCA Datacom® / DB
. - Что произойдет, если
CA Datacom® / DB
обнаружит ошибку?CA Datacom® / DB
возвращает сообщение с кодом, который начинается сDQ093
и описывает ошибку (например,DQ093 ILLEGAL TABLE NAME
). Вы исправляете ошибку и снова подтверждаете. Обратитесь к администраторуCA Dataquery
за помощью в случае возникновения ошибокCA Datacom® / DB
.
Рассмотрите возможность сохранения и обновления запросов по мере их роста, чтобы не потерять свою работу в случае ошибки.
Ниже приводится информация о сохранении запросов.
-
Сроки?
Вы должны сохранить любой запрос, который хотите использовать снова. Если вы создаете сложный запрос и тратите на него много времени, подумайте о его сохранении, прежде чем закончить. Если вы это сделаете, вы можете использовать кнопку UPDATE PF, чтобы сохранить его снова. Вы можете сохранить без предварительной проверки. -
На чем сохраняется?
CA Dataquery
сохраняет все, что написано в текстовой области панели РЕДАКТОР. Перед сохранением элемент должен иметь имя, тип (запрос или диалоговое окно) и статус (общедоступный или частный). -
Что произойдет, если я выйду из панели РЕДАКТОР без сохранения?
Запрос или диалоговое окно находится в активной области запроса до тех пор, пока вы не получите доступ к другому запросу или диалоговому окну. Вы можете вызвать активный запрос на панель РЕДАКТОРА с помощью команды РЕДАКТИРОВАТЬ *. -
Как удалить ненужный запрос?
Когда вам больше не нужен сохраненный запрос, вы можете удалить его из своей частной библиотеки или, если вы авторизованы, из публичной библиотеки. После удаления запроса вы можете вспомнить его только в том случае, если он в настоящее время находится в активной области запроса, потому что вы его отобразили, проверили или выполнили.
Это шаги для проверки и сохранения образца запроса.
-
Шаг 1
Нажмите в любом режиме во время отображения запроса. -
Шаг 2
Исправьте ошибки, если они есть, и повторяйте шаг 1 до тех пор, пока не появится сообщение ЗАПРОС ПРОВЕРКИ УСПЕШНО. -
Шаг 3
В режиме создания нажмите PROCESS MODE, чтобы изменить меню клавиши PF. -
Шаг 4
В режиме обработки нажмите СОХРАНИТЬ, если запрос не был сохранен ранее. Если запрос уже существует, нажмите ОБНОВЛЕНИЕ, чтобы сохранить изменения.
Шаг 7 Форматирование отчета и выполнение запроса
Меню клавиши PF режима процесса предоставляет клавишу PF для выполнения запроса.Рекомендуем выполнять новые запросы и проверять результаты. Вы можете изменить и обновить сохраненный запрос. Инструкции по выполнению отображаются в разделе «Выполнение в режиме SQL».
Выполнение в режиме SQL позволяет указать спецификации отчета, который вы хотите создать во время выполнения. Эти характеристики:
Заголовок
Столбец или представление списка
Последовательность сортировки столбцов ORDER BY и контрольные разрывы для столбцов ORDER BY
Начало новой страницы
Порядок столбцов
Математические функции AVG , MAX, MIN, SUM, CNT и TOT
Обозначения результатов функции
Редактировать шаблоны результатов функции
Двухстрочные имена столбцов
Для использования контрольных разрывов и сортировки с форматом отчета спецификации во время выполнения, запрос должен содержать предложение ORDER BY, чтобы строки извлекались в отсортированном порядке.
Вы можете установить значения по умолчанию для этих спецификаций для создаваемого вами запроса. Панель «Выполнение» предоставляет дополнительный набор панелей, которые любой пользователь, имеющий доступ к вашему запросу, может использовать для определения спецификаций отчета. Когда вы выполняете запроссохраненный
в первый раз и вводите спецификации, они сохраняются и становятся значениями по умолчанию. Если вы не вводите никаких спецификаций,CA Dataquery
устанавливает значения по умолчанию.Дополнительные сведения и информацию об определении отчета, созданного на основе запроса SQL, см. В разделе Получение отчета.Следуйте инструкциям по заполнению панелей определения отчетов. При первом выполнении запроса спецификации сохраняются.
ОсновыSQL - Практическое руководство по SQL для начинающих Анализирование совместного использования велосипедов
В этом руководстве мы будем работать с набором данных из службы проката велосипедов Hubway, который включает данные о более чем 1,5 миллионах поездок, совершенных с помощью этой службы.
Прежде чем приступить к написанию некоторых собственных запросов на SQL, мы начнем с небольшого изучения баз данных, того, что они такое и почему мы их используем.
Если вы хотите продолжить, вы можете загрузить файл hubway.db здесь (130 МБ).
Основы SQL: реляционные базы данных
Реляционная база данных - это база данных, которая хранит связанную информацию в нескольких таблицах и позволяет запрашивать информацию в нескольких таблицах одновременно.
Проще понять, как это работает, на примере. Представьте, что вы работаете в бизнесе и хотите отслеживать информацию о продажах.Вы можете настроить электронную таблицу в Excel со всей информацией, которую вы хотите отслеживать, в виде отдельных столбцов: номер заказа, дата, сумма к оплате, номер для отслеживания отгрузки, имя клиента, адрес клиента и номер телефона клиента.
Эта установка отлично подойдет для отслеживания информации, которая вам нужна для начала, но когда вы начнете получать повторные заказы от одного и того же клиента, вы обнаружите, что их имя, адрес и номер телефона хранятся в нескольких строках вашей электронной таблицы.
По мере роста вашего бизнеса и увеличения количества отслеживаемых заказов эти избыточные данные будут занимать ненужное место и в целом снизят эффективность вашей системы отслеживания продаж. Вы также можете столкнуться с проблемами с целостностью данных. Например, нет гарантии, что каждое поле будет заполнено правильным типом данных или что имя и адрес будут вводиться каждый раз точно так же.
С реляционной базой данных, подобной той, что показана на диаграмме выше, вы избегаете всех этих проблем.Вы можете настроить две таблицы, одну для заказов и одну для клиентов. Таблица «клиенты» будет включать уникальный идентификационный номер для каждого клиента, а также имя, адрес и номер телефона, которые мы уже отслеживаем. Таблица «заказы» будет включать номер вашего заказа, дату, сумму к оплате, номер отслеживания и, вместо отдельного поля для каждого элемента данных о клиенте, в ней будет столбец для идентификатора клиента.
Это позволяет нам получить всю информацию о клиенте для любого конкретного заказа, но нам нужно сохранить ее в нашей базе данных только один раз, а не выводить ее повторно для каждого отдельного заказа.
Наш набор данных
Начнем с рассмотрения нашей базы данных. В базе есть две таблицы, поездок и станций . Для начала просто посмотрим на таблицу поездок и . Он содержит следующие столбцы:
-
id- Уникальное целое число, которое служит ссылкой для каждой поездки -
duration- Продолжительность поездки, измеряется в секундах -
start_date- Дата и время начала поездки -
start_station- Целое число, которое соответствует столбцуidв таблицестанцийдля станции, с которой началась поездка -
end_date- Дата и время окончания поездки -
end_station- 'id' станции, на которой завершилась поездка на -
bike_number- Уникальный идентификатор Hubway для велосипеда, использованного в поездке -
sub_type- Тип подписки пользователя.«Зарегистрированный»для пользователей с членством,«Обычный»для пользователей без членства -
zip_code- Почтовый индекс пользователя (доступен только для зарегистрированных пользователей) -
Birth_date- Год рождения пользователя (доступно только для зарегистрированных участников) -
пол- Пол пользователя (доступно только для зарегистрированных пользователей)
Наш анализ
С этой информацией и командами SQL, которые мы вскоре узнаем, вот несколько вопросов, на которые мы попытаемся ответить в ходе этого поста:
- Какова была самая длинная поездка?
- Сколько поездок совершили «зарегистрированные» пользователи?
- Какая была средняя продолжительность поездки?
- У зарегистрированных или случайных пользователей более длительные поездки?
- Какой велосипед использовался для большинства поездок?
- Какова средняя продолжительность поездок пользователей старше 30 лет?
Для ответа на эти вопросы мы будем использовать следующие команды SQL:
-
ВЫБРАТЬ -
ГДЕ -
ПРЕДЕЛ -
ЗАКАЗАТЬ ПО -
ГРУППА ПО -
И -
ИЛИ -
МИН -
МАКС -
СРЕДНЕЕ -
СУММ -
СЧЕТ
Установка и настройка
Для целей этого руководства мы будем использовать систему баз данных под названием SQLite3.SQLite входит в состав Python начиная с версии 2.5, поэтому, если у вас установлен Python, у вас почти наверняка будет SQLite. Python и библиотеку SQLite3 можно легко установить и настроить с помощью Anaconda, если у вас их еще нет.
Использование Python для запуска нашего кода SQL позволяет нам импортировать результаты в фреймворк Pandas, чтобы упростить отображение наших результатов в удобном для чтения формате. Это также означает, что мы можем выполнять дальнейший анализ и визуализацию данных, которые мы извлекаем из базы данных, хотя это выходит за рамки данного руководства.
В качестве альтернативы, если мы не хотим использовать или устанавливать Python, мы можем запустить SQLite3 из командной строки. Просто загрузите «предварительно скомпилированные двоичные файлы» с веб-страницы SQLite3 и используйте следующий код для открытия базы данных:
~ $ sqlite hubway.db Версия SQLite 3.14.0 2016-07-26 15: 17: 14 Введите ".help" для использования hints.sqlite> Отсюда мы можем просто ввести запрос, который хотим выполнить, и увидеть данные, возвращенные в окне терминала.
Альтернативой использованию терминала является подключение к базе данных SQLite через Python.Это позволит нам использовать записную книжку Jupyter, чтобы мы могли видеть результаты наших запросов в аккуратно отформатированной таблице.
Для этого мы определим функцию, которая принимает наш запрос (сохраненный в виде строки) в качестве входных данных и отображает результат в виде отформатированного фрейма данных:
импорт sqlite3
импортировать панд как pd
db = sqlite3.connect ('hubway.db')
def run_query (запрос):
вернуть pd.read_sql_query (запрос, БД) Конечно, нам не обязательно использовать Python с SQL. Если вы уже являетесь программистом R, наш курс «Основы SQL для пользователей R» станет отличным местом для начала.ВЫБРАТЬ
Первая команда, с которой мы будем работать, - это SELECT . SELECT будет основой почти каждого написанного нами запроса - он сообщает базе данных, какие столбцы мы хотим видеть. Мы можем указать столбцы по имени (через запятую) или использовать подстановочный знак * для возврата каждого столбца в таблице.
Помимо столбцов, которые мы хотим получить, мы также должны указать базе данных, из какой таблицы их получить. Для этого мы используем ключевое слово FROM , за которым следует имя таблицы.Например, если бы мы хотели видеть start_date и bike_number для каждой поездки в таблице trips , мы могли бы использовать следующий запрос:
ВЫБРАТЬ start_date, bike_number ИЗ поездок; В этом примере мы начали с команды SELECT , чтобы база данных знала, что мы хотим, чтобы она нашла нам некоторые данные. Затем мы сообщили базе данных, что нас интересуют столбцы start_date и bike_number .Наконец, мы использовали FROM , чтобы сообщить базе данных, что столбцы, которые мы хотим видеть, являются частью таблицы trips .
Одна важная вещь, о которой следует помнить при написании SQL-запросов, заключается в том, что мы хотим заканчивать каждый запрос точкой с запятой (; ). Не каждая база данных SQL на самом деле требует этого, но некоторые требуют, поэтому лучше сформировать эту привычку.
ПРЕДЕЛ
Следующая команда, которую нам нужно знать, прежде чем мы начнем выполнять запросы в нашей базе данных Hubway, - это LIMIT . LIMIT просто сообщает базе данных, сколько строк вы хотите вернуть.
Запрос SELECT , который мы рассмотрели в предыдущем разделе, будет возвращать запрошенную информацию для каждой строки в таблице поездок , но иногда это может означать большой объем данных. Мы можем не захотеть всего этого. Если бы вместо этого мы хотели видеть start_date и bike_number для первых пяти поездок в базе данных, мы могли бы добавить LIMIT к нашему запросу следующим образом:
ВЫБРАТЬ start_date, bike_number ИЗ поездок LIMIT 5; Мы просто добавили команду LIMIT , а затем число, представляющее количество строк, которые мы хотим вернуть.В этом случае мы использовали 5, но вы можете заменить его любым числом, чтобы получить соответствующий объем данных для проекта, над которым вы работаете.
Мы будем часто использовать LIMIT в наших запросах к базе данных Hubway в этом руководстве - таблица поездок содержит более 1,5 миллионов строк данных, и нам, конечно, не нужно отображать их все!
Давайте запустим наш первый запрос к базе данных Hubway. Сначала мы сохраним наш запрос в виде строки, а затем воспользуемся функцией, которую мы определили ранее, чтобы запустить его в базе данных.Взгляните на следующий пример:
query = 'ВЫБРАТЬ * ИЗ ОТКЛЮЧЕНИЙ LIMIT 5;'
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 9 | 28.07.2011 10:12:00 | 23 | 28.07.2011 10:12:00 | 23 | B00468 | Зарегистрировано | '97217 | 1976.0 | Мужской |
| 1 | 2 | 220 | 28.07.2011 10:21:00 | 23 | 28.07.2011 10:25:00 | 23 | B00554 | Зарегистрировано | '02215 | 1966,0 | Мужской |
| 2 | 3 | 56 | 28.07.2011 10:33:00 | 23 | 28.07.2011 10:34:00 | 23 | B00456 | Зарегистрировано | '02108 | 1943 г.0 | Мужской |
| 3 | 4 | 64 | 28.07.2011 10:35:00 | 23 | 28.07.2011 10:36:00 | 23 | B00554 | Зарегистрировано | '02116 | 1981,0 | Женский |
| 4 | 5 | 12 | 28.07.2011 10:37:00 | 23 | 28.07.2011 10:37:00 | 23 | B00554 | Зарегистрировано | '97214 | 1983.0 | Женский |
В этом запросе * используется как подстановочный знак вместо указания возвращаемых столбцов. Это означает, что команда SELECT дала нам каждый столбец в таблице trip . Мы также использовали функцию LIMIT , чтобы ограничить вывод первыми пятью строками таблицы.
Вы часто будете видеть, что люди используют ключевые слова команды в своих запросах (соглашение, которому мы будем следовать в этом руководстве), но это в основном вопрос предпочтений.Использование заглавных букв упрощает чтение кода, но на самом деле никоим образом не влияет на работу кода. Если вы предпочитаете писать запросы с командами в нижнем регистре, запросы по-прежнему будут выполняться правильно.
В нашем предыдущем примере возвращались все столбцы в таблице поездок . Если бы нас интересовали только столбцы duration и start_date , мы могли бы заменить подстановочный знак именами столбцов следующим образом:
query = 'ВЫБЕРИТЕ длительность, начальную_дату ИЗ ПРЕДЕЛ 5 поездок'
run_query (запрос) | продолжительность | start_date | |
|---|---|---|
| 0 | 9 | 28.07.2011 10:12:00 |
| 1 | 220 | 28.07.2011 10:21:00 |
| 2 | 56 | 28.07.2011 10:33:00 |
| 3 | 64 | 28.07.2011 10:35:00 |
| 4 | 12 | 28.07.2011 10:37:00 |
ЗАКАЗАТЬ ПО
Последняя команда, которую нам нужно знать, прежде чем мы сможем ответить на первый из наших вопросов, - это ORDER BY .Эта команда позволяет нам отсортировать базу данных по заданному столбцу.
Чтобы использовать его, мы просто указываем имя столбца, по которому хотим выполнить сортировку. По умолчанию ORDER BY сортируется в порядке возрастания. Если мы хотим указать, в каком порядке база данных должна быть отсортирована, мы можем добавить ключевое слово ASC для возрастания или DESC для убывания.
Например, если мы хотим отсортировать таблицу поездок от самой короткой продолжительности до самой длинной, мы могли бы добавить следующую строку в наш запрос:
ЗАКАЗАТЬ ПО продолжительности ASC С помощью команд SELECT , LIMIT и ORDER BY в нашем репертуаре, мы можем теперь попытаться ответить на наш первый вопрос: Какова была продолжительность самой продолжительной поездки?
Чтобы ответить на этот вопрос, полезно разбить его на разделы и определить, какие команды нам нужно будет адресовать каждой части.
Сначала нам нужно извлечь информацию из столбца длительности таблицы поездок . Затем, чтобы определить, какая поездка самая длинная, мы можем отсортировать столбец продолжительность в порядке убывания. Вот как мы можем проработать это, чтобы придумать запрос, который получит информацию, которую мы ищем:
- Используйте
SELECTдля получения продолжительностиFROMотключаеттаблица - Используйте
ORDER BYдля сортировки столбцадлительностии используйте ключевое словоDESC, чтобы указать, что вы хотите отсортировать в порядке убывания - Используйте
LIMIT, чтобы ограничить вывод одной строкой
Использование этих команд таким образом вернет единственную строку с самой длинной продолжительностью, которая даст нам ответ на наш вопрос.
Еще одно замечание: по мере того, как ваши запросы добавляют больше команд и усложняются, вам может быть легче читать, если вы разделите их на несколько строк. Это, как и использование заглавных букв, зависит от личных предпочтений. Это не влияет на выполнение кода (система просто считывает код от начала до точки с запятой), но может сделать ваши запросы более понятными и понятными. В Python мы можем разделить строку на несколько строк, используя тройные кавычки.
Давайте продолжим и запустим этот запрос и выясним, как долго длилась самая длинная поездка.
запрос = '' '
ВЫБРАТЬ ДЛИТЕЛЬНОСТЬ ИЗ поездок
ЗАКАЗАТЬ ПО длительности DESC
LIMIT 1;
'' '
run_query (запрос) Теперь мы знаем, что самая длинная поездка длилась 9999 секунд, или чуть более 166 минут. Однако при максимальном значении 9999 мы не знаем, действительно ли это длина самой длинной поездки или база данных была настроена только для четырехзначного числа.
Если правда, что база данных сокращает особенно длинные поездки, то мы можем ожидать увидеть много поездок на 9999 секундах, где они достигают предела.Давайте попробуем выполнить тот же запрос, что и раньше, но отрегулируем LIMIT , чтобы вернуть 10 самых высоких значений длительности, чтобы убедиться, что это так:
запрос = '' '
ВЫБЕРИТЕ ДЛИТЕЛЬНОСТЬ ОТ поездок
ЗАКАЗАТЬ ПО длительности DESC
ПРЕДЕЛ 10
'' '
run_query (запрос) | продолжительность | |
|---|---|
| 0 | 9999 |
| 1 | 9998 |
| 2 | 9998 |
| 3 | 9997 |
| 4 | 9996 |
| 5 | 9996 |
| 6 | 9995 |
| 7 | 9995 |
| 8 | 9994 |
| 9 | 9994 |
Что мы видим здесь, так это то, что на 9999 не так много поездок, поэтому не похоже, что мы сокращаем верхний предел нашей продолжительности, но все еще трудно сказать, является ли это реальная длина поездка или просто максимально допустимое значение.
Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут (кто-то, кто держит велосипед в течение 9999 секунд, должен будет заплатить дополнительные 25 долларов США), поэтому вполне вероятно, что они решили, что 4 цифры будет достаточно для отслеживания большинства поездок.
ГДЕ
Предыдущие команды отлично подходят для извлечения отсортированной информации для определенных столбцов, но что, если есть определенное подмножество данных, которые мы хотим просмотреть? Вот где приходит WHERE . Команда WHERE позволяет нам использовать логический оператор, чтобы указать, какие строки должны быть возвращены.Например, вы можете использовать следующую команду, чтобы возвращать информацию о каждой поездке на велосипеде B00400 :
ГДЕ bike_number = "B00400" Вы также заметите, что в этом запросе используются кавычки. Это потому, что bike_number хранится в виде строки. Если столбец содержит числовые типы данных, в кавычках нет необходимости.
Давайте напишем запрос, который использует WHERE для возврата каждого столбца в таблице поездок для каждой строки с продолжительностью дольше 9990 секунд:
запрос = '' '
ВЫБРАТЬ * ИЗ поездок
ГДЕ длительность> 9990;
'' '
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4768 | 9994 | 2011-08-03 17:16:00 | 22 | 2011-08-03 20:03:00 | 24 | B00002 | Повседневный | |||
| 1 | 8448 | 9991 | 2011-08-06 13:02:00 | 52 | 2011-08-06 15:48:00 | 24 | B00174 | Повседневный | |||
| 2 | 11341 | 9998 | 2011-08-09 10:42:00 | 40 | 2011-08-09 13:29:00 | 42 | B00513 | Повседневный | |||
| 3 | 24455 | 9995 | 2011-08-20 12:20:00 | 52 | 2011-08-20 15:07:00 | 17 | B00552 | Повседневный | |||
| 4 | 55771 | 9994 | 14.09.2011 15:44:00 | 40 | 14.09.2011 18:30:00 | 40 | B00139 | Повседневный | |||
| 5 | 81191 | 9993 | 2011-10-03 11:30:00 | 22 | 2011-10-03 14:16:00 | 36 | B00474 | Повседневный | |||
| 6 | 89335 | 9997 | 2011-10-09 02:30:00 | 60 | 2011-10-09 05:17:00 | 45 | B00047 | Повседневный | |||
| 7 | 124500 | 9992 | 2011-11-09 09:08:00 | 22 | 2011-11-09 11:55:00 | 40 | B00387 | Повседневный | |||
| 8 | 133967 | 9996 | 2011-11-19 13:48:00 | 4 | 2011-11-19 16:35:00 | 58 | B00238 | Повседневный | |||
| 9 | 147451 | 9996 | 23.03.2012 14:48:00 | 35 | 23.03.2012 17:35:00 | 33 | B00550 | Повседневный | |||
| 10 | 315737 | 9995 | 03.07.2012 18:28:00 | 12 | 03.07.2012 21:15:00 | 12 | B00250 | Зарегистрировано | '02120 | 1964 | Мужской |
| 11 | 319597 | 9994 | 05.07.2012 11:49:00 | 52 | 05.07.2012 14:35:00 | 55 | B00237 | Повседневный | |||
| 12 | 416523 | 9998 | 15.08.2012 12:11:00 | 54 | 15.08.2012 14:58:00 | 80 | B00188 | Повседневный | |||
| 13 | 541247 | 9999 | 26-09-2012 18:34:00 | 54 | 26.09.2012 21:21:00 | 54 | T01078 | Повседневный |
Как мы видим, этот запрос вернул 14 различных поездок, каждая длительностью 9990 секунд или более.Что выделяется в этом запросе, так это то, что все результаты, кроме одного, имеют sub_type из «Случайный» . Возможно, это показатель того, что «зарегистрированных» пользователей больше осведомлены о дополнительных сборах за дальние поездки. Возможно, Hubway сможет лучше донести свою структуру ценообразования до обычных пользователей, чтобы помочь им избежать дополнительных расходов.
Мы уже видим, как команда SQL даже для начинающих может помочь нам ответить на бизнес-вопросы и найти понимание в наших данных.
Возвращаясь к WHERE , мы также можем объединить несколько логических тестов в нашем предложении WHERE , используя AND или OR . Если, например, в нашем предыдущем запросе мы хотели вернуть только поездки с длительностью за 9990 секунд, которые также имели подтип Зарегистрированный, мы могли бы использовать И , чтобы указать оба условия.
Вот еще одна личная рекомендация: используйте круглые скобки для разделения каждого логического теста, как показано в блоке кода ниже.Это не является строго обязательным для работы кода, но круглые скобки упрощают понимание ваших запросов по мере увеличения сложности.
Теперь давайте запустим этот запрос. Мы уже знаем, что он должен возвращать только один результат, поэтому будет легко проверить, что все правильно:
запрос = '' '
ВЫБРАТЬ * ИЗ поездок
ГДЕ (продолжительность> = 9990) И (sub_type = "Зарегистрировано")
ЗАКАЗАТЬ ПО длительности DESC;
'' '
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 315737 | 9995 | 03.07.2012 18:28:00 | 12 | 03.07.2012 21:15:00 | 12 | B00250 | Зарегистрировано | '02120 | 1964 г.0 | Мужской |
Следующий вопрос, который мы задали в начале поста, - «Сколько поездок совершили« зарегистрированные »пользователи?» Чтобы ответить на него, мы могли бы выполнить тот же запрос, что и выше, и изменить выражение WHERE , чтобы вернуть все строки, в которых подтип равен «Зарегистрировано» , а затем подсчитать их.
Однако на самом деле в SQL есть встроенная команда для этого подсчета: COUNT .
COUNT позволяет перенести вычисления в базу данных и избавить нас от необходимости писать дополнительные скрипты для подсчета результатов. Чтобы использовать его, мы просто включаем COUNT (имя_столбца) вместо (или в дополнение к) столбцов, которые вы хотите SELECT , например:
ВЫБРАТЬ СЧЕТЧИК (id)
ИЗ поездок В этом случае не имеет значения, какой столбец мы выбираем для подсчета, потому что в каждом столбце должны быть данные для каждой строки в нашем запросе.Но иногда в запросе могут отсутствовать (или быть "нулевые") значения для некоторых строк. Если мы не уверены, содержит ли столбец нулевые значения, мы можем запустить наш COUNT для столбца id - столбец id никогда не будет нулевым, поэтому мы можем быть уверены, что наш счетчик ничего не пропустил.
Мы также можем использовать COUNT (1) или COUNT (*) для подсчета каждой строки в нашем запросе. Стоит отметить, что иногда нам может потребоваться запустить COUNT для столбца с нулевыми значениями.Например, нам может потребоваться узнать, сколько строк в нашей базе данных имеют отсутствующие значения для столбца.
Давайте взглянем на запрос, чтобы ответить на наш вопрос. Мы можем использовать SELECT COUNT (*) для подсчета общего количества возвращенных строк и WHERE sub_type = "Registered" , чтобы убедиться, что мы подсчитываем только поездки, совершенные зарегистрированными пользователями.
запрос = '' '
ВЫБРАТЬ КОЛИЧЕСТВО (*) ИЗ поездок
ГДЕ sub_type = "Зарегистрировано";
'' '
run_query (запрос) Этот запрос сработал и вернул ответ на наш вопрос.Но заголовок столбца не особо описательный. Если бы кто-то другой взглянул на эту таблицу, он не смог бы понять, что это значит. Если мы хотим сделать наши результаты более читабельными, мы можем использовать AS , чтобы дать нашему выводу псевдоним (или псевдоним). Давайте повторно выполним предыдущий запрос, но дадим заголовку нашего столбца псевдоним Всего поездок по зарегистрированным пользователям :
запрос = '' '
ВЫБЕРИТЕ СЧЕТЧИК (*) КАК "Общее количество поездок зарегистрированных пользователей"
ИЗ поездок
ГДЕ sub_type = "Зарегистрировано";
'' '
run_query (запрос) | Всего поездок по зарегистрированным пользователям | |
|---|---|
| 0 | 1105192 |
Агрегатные функции
COUNT - не единственный математический трюк, который есть у SQL.Мы также можем использовать SUM , AVG , MIN и MAX для возврата суммы, среднего, минимума и максимума столбца соответственно. Они, наряду с COUNT , известны как агрегатные функции.
Итак, чтобы ответить на наш третий вопрос, «Какова была средняя продолжительность поездки?» , мы можем использовать функцию AVG в столбце duration (и, опять же, использовать AS , чтобы дать нашему выходному столбцу более информативное имя):
запрос = '' '
ВЫБЕРИТЕ СРЕДНЮЮ (продолжительность) КАК "Средняя продолжительность"
ОТ поездок;
'' '
run_query (запрос) | Средняя продолжительность | |
|---|---|
| 0 | 912.409682 |
Получается, что средняя продолжительность поездки составляет 912 секунд, то есть примерно 15 минут. В этом есть смысл, поскольку мы знаем, что Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут. Услуга предназначена для пассажиров, совершающих короткие поездки в одну сторону.
А как насчет следующего вопроса: , зарегистрированные или случайные пользователи совершают более длительные поездки? Мы уже знаем один способ ответить на этот вопрос - мы могли бы запустить два запроса SELECT AVG (duration) FROM trips с предложениями WHERE , которые ограничивают один до "зарегистрированных" и один до "случайных" пользователей.
Но давайте по-другому. SQL также включает способ ответить на этот вопрос в одном запросе с помощью команды GROUP BY .
ГРУППА ПО
GROUP BY разделяет строки на группы в зависимости от содержимого определенного столбца и позволяет нам выполнять агрегированные функции для каждой группы.
Чтобы лучше понять, как это работает, давайте взглянем на столбец , пол . Каждая строка может иметь одно из трех возможных значений в столбце пол , «Мужской» , «Женский» или Нулевой (отсутствует; у нас нет данных пол для случайных пользователей).
Когда мы используем GROUP BY , база данных разделяет каждую из строк в другую группу на основе значения в столбце , пол , почти так же, как мы могли бы разделить колоду карт на разные масти. . Мы можем представить себе две стопки, одну из самцов, одну из самок.
Когда у нас есть две отдельные стопки, база данных будет выполнять любые агрегатные функции в нашем запросе для каждой из них по очереди. Если бы мы использовали, например, COUNT , запрос подсчитал бы количество строк в каждой стопке и вернул бы значение для каждой отдельно.
Давайте подробно рассмотрим, как написать запрос, чтобы ответить на наш вопрос о том, совершают ли более длительные поездки зарегистрированные или случайные пользователи.
- Как и в случае с каждым из наших запросов, мы начнем с
SELECT, чтобы сообщить базе данных, какую информацию мы хотим видеть. В этом случае нам понадобитсяsub_typeиAVG (продолжительность). - Мы также включим
GROUP BY sub_type, чтобы разделить наши данные по типу подписки и отдельно вычислить средние значения зарегистрированных и случайных пользователей.
Вот как выглядит код, если собрать все вместе:
запрос = '' '
ВЫБЕРИТЕ sub_type, AVG (продолжительность) AS "Средняя продолжительность"
ИЗ поездок
GROUP BY sub_type;
'' '
run_query (запрос) | подтип | Средняя продолжительность | |
|---|---|---|
| 0 | Повседневный | 1519.643897 |
| 1 | Зарегистрировано | 657.026067 |
Вот это большая разница! В среднем зарегистрированные пользователи совершают поездки продолжительностью около 11 минут, тогда как обычные пользователи тратят почти 25 минут на поездку.Зарегистрированные пользователи, вероятно, будут совершать более короткие и частые поездки, возможно, по дороге на работу. С другой стороны, обычные пользователи тратят примерно вдвое больше времени на поездку.
Возможно, что случайные пользователи, как правило, происходят из демографических групп (например, туристов), которые более склонны совершать длительные поездки, убедитесь, что они передвигаются и видят все достопримечательности. Как только мы обнаружим эту разницу в данных, компания сможет исследовать ее разными способами, чтобы лучше понять, что ее вызывает.
Однако для целей этого урока давайте продолжим. Наш следующий вопрос был , какой велосипед использовался для большинства поездок? . Мы можем ответить на этот вопрос, используя очень похожий запрос. Взгляните на следующий пример и посмотрите, сможете ли вы выяснить, что делает каждая строка - позже мы рассмотрим это шаг за шагом, чтобы вы могли убедиться, что все правильно:
запрос = '' '
ВЫБЕРИТЕ bike_number как "Номер велосипеда", COUNT (*) как "Количество поездок"
ИЗ поездок
ГРУППА ПО номеру велосипеда
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ (*) УДАЛЕНИЕ
LIMIT 1;
'' '
run_query (запрос) | Номер велосипеда | Количество поездок | |
|---|---|---|
| 0 | B00490 | 2120 |
Как видно из выходных данных, наибольшее количество поездок ездил на велосипеде B00490 .Давайте разберемся, как мы туда попали:
- Первая строка - это предложение
SELECT, чтобы сообщить базе данных, что мы хотим видеть столбецbike_numberи количество каждой строки. Он также используетAS, чтобы указать базе данных отображать каждый столбец с более удобным именем. - Во второй строке используется
ИЗ, чтобы указать, что данные, которые мы ищем, находятся в таблицепоездок. - В третьей строке все становится немного сложнее.Мы используем
GROUP BY, чтобы указать функцииCOUNTв строке 1 для отдельного подсчета каждого значения дляbike_number. - В четвертой строке у нас есть предложение
ORDER BY, чтобы отсортировать таблицу в порядке убывания и убедиться, что наш наиболее часто используемый велосипед находится наверху. - Наконец, мы используем
LIMIT, чтобы ограничить вывод первой строкой, которая, как мы знаем, будет велосипедом, который использовался в наибольшем количестве поездок, из-за того, как мы отсортировали данные в четвертой строке.
Арифметические операторы
Наш последний вопрос немного сложнее остальных. Мы хотим знать средней продолжительности поездок зарегистрированных участников старше 30 лет .
Мы могли бы просто вычислить год, в котором 30-летние родились в нашей голове, а затем подключить его, но более элегантное решение - использовать арифметические операции непосредственно в нашем запросе. SQL позволяет нам использовать + , - , * и / для выполнения арифметической операции сразу над всем столбцом.
запрос = '' '
ВЫБРАТЬ СРЕДНЕЕ (длительность) ИЗ поездок
ГДЕ (2017 - дата рождения)> 30;
'' '
run_query (запрос) | AVG (продолжительность) | |
|---|---|
| 0 | 923.014685 |
ПРИСОЕДИНЯЙТЕСЬ
До сих пор мы рассматривали запросы, которые извлекают данные только из таблицы , переходящей в таблицу . Однако одна из причин, по которой SQL является настолько мощным, заключается в том, что он позволяет нам извлекать данные из нескольких таблиц в одном запросе.
Наша база данных по прокату велосипедов содержит вторую таблицу, станций . Таблица станций содержит информацию о каждой станции в сети Hubway и включает столбец id , на который ссылается таблица поездок .
Прежде чем мы начнем работать с некоторыми реальными примерами из этой базы данных, давайте вернемся к гипотетической базе данных отслеживания заказов из ранее. В этой базе данных у нас было две таблицы: заказов и клиентов , и они были связаны столбцом customer_id .
Допустим, мы хотели написать запрос, который возвращал бы номер заказа и имя для каждого заказа в базе данных. Если бы они оба хранились в одной таблице, мы могли бы использовать следующий запрос:
ВЫБРАТЬ номер_заказа, имя
ОТ заказов; К сожалению, столбец order_number и столбец name хранятся в двух разных таблицах, поэтому нам нужно добавить несколько дополнительных шагов. Давайте поразмышляем над дополнительными вещами, которые должна знать база данных, прежде чем она сможет вернуть нужную нам информацию:
- В какой таблице находится столбец
order_number? - В какой таблице находится столбец
name? - Как информация в таблице
ordersсвязана с информацией в таблицеcustomers?
Чтобы ответить на первые два из этих вопросов, мы можем включить имена таблиц для каждого столбца в нашу команду SELECT .Мы делаем это просто, записывая имя таблицы и имя столбца, разделенные . . Например, вместо SELECT order_number, name мы должны написать SELECT orders.order_number, customers.name . Добавление сюда имен таблиц помогает базе данных находить нужные столбцы, сообщая ей, в какой таблице искать каждый.
Чтобы сообщить базе данных, как связаны таблицы заказов и клиентов , мы используем JOIN и ON . JOIN указывает, какие таблицы должны быть связаны, а ON указывает, какие столбцы в каждой таблице связаны.
Мы собираемся использовать внутреннее соединение, что означает, что строки будут возвращаться только тогда, когда есть совпадения в столбцах, указанных в ON . В этом примере мы захотим использовать JOIN для той таблицы, которую мы не включили в команду FROM . Таким образом, мы можем использовать FROM заказов INNER JOIN клиентов или FROM клиентов INNER JOIN orders .
Как мы обсуждали ранее, эти таблицы связаны по столбцу customer_id в каждой таблице. Следовательно, мы захотим использовать ON , чтобы сообщить базе данных, что эти два столбца относятся к одному и тому же, например:
ON orders.customer_ID = customers.customer_id Мы снова используем . , чтобы убедиться, что база данных знает, в какой таблице находится каждый из этих столбцов. Итак, когда мы сложим все это вместе, мы получим запрос, который выглядит следующим образом:
ВЫБРАТЬ заказы.order_number, customers.name
ИЗ заказов
INNER JOIN клиенты
ON orders.customer_id = customers.customer_id Этот запрос вернет порядковый номер каждого заказа в базе данных вместе с именем клиента, который связан с каждым заказом.
Возвращаясь к нашей базе данных Hubway, теперь мы можем написать несколько запросов, чтобы увидеть JOIN в действии.
Прежде чем мы начнем, мы должны взглянуть на остальные столбцы в таблице станций . Вот запрос, показывающий нам первые 5 строк, чтобы мы могли увидеть, как выглядит таблица станций :
запрос = '' '
ВЫБРАТЬ * ИЗ станций
LIMIT 5;
'' '
run_query (запрос) | id | станция | муниципалитет | шир. | lng | |
|---|---|---|---|---|---|
| 0 | 3 | Колледжи Фенуэй | Бостон | 42.340021 | -71.100812 |
| 1 | 4 | Тремонт-стрит, Беркли-стрит, | Бостон | 42.345392 | -71.069616 |
| 2 | 5 | Северо-Восточный U / Северная парковка | Бостон | 42,341814 | -71.0 |
| 3 | 6 | Кембридж-стрит, Джой-стрит, | Бостон | 42,361284999999995 | -71.06514 |
| 4 | 7 | Причал вентилятора | Бостон | 42,35 3412 | -71.044624 |
-
id- Уникальный идентификатор для каждой станции (соответствует столбцамstart_stationиend_stationв таблицепоездок) -
станция- Название станции -
муниципалитет- муниципалитет, в котором находится станция (Бостон, Бруклин, Кембридж или Сомервилль) -
lat- Широта станции -
lng- Долгота станции - Какие станции чаще всего используются для поездок туда и обратно?
- Сколько поездок начинается и заканчивается в разных муниципалитетах?
Как и раньше, мы попытаемся ответить на некоторые вопросы в данных, начиная с , какая станция является наиболее частой отправной точкой? Давайте поработаем пошагово:
- Сначала мы хотим использовать
SELECTдля возврата столбцаstationиз таблицыstationиCOUNTколичества строк. - Затем мы указываем таблицы, которые хотим
JOIN, и говорим базе данных подключить ихONстолбецstart_stationв таблицепоездоки столбецidв таблицестанций. - Затем мы переходим к сути нашего запроса - мы
GROUP BYстолбецstationв таблицеstation, чтобы нашCOUNTподсчитывал количество поездок для каждой станции отдельно - Наконец, мы можем
ЗАКАЗАТЬ ПОнашимCOUNTиLIMITвывод на управляемое количество результатов
запрос = '' '
ВЫБЕРИТЕ станции.станция AS "Станция", COUNT (*) AS "Count"
ИЗ поездок INNER JOIN станции
ВКЛ. Trips.start_station = station.idGROUP BY station.station ORDER BY COUNT (*) DESC
LIMIT 5;
'' '
run_query (запрос) | Станция | Счетчик | |
|---|---|---|
| 0 | Южный вокзал - 700 Атлантик авеню, | 56123 |
| 1 | Публичная библиотека Бостона - 700 Boylston St. | 41994 |
| 2 | Charles Circle - Charles St.на Кембридж-стрит | 35984 |
| 3 | Beacon St / Mass Ave | 35275 |
| 4 | MIT на Mass Ave / Amherst St | 33644 |
Если вы знакомы с Бостоном, вы поймете, почему это самые популярные станции. Южный вокзал - одна из главных станций пригородной железной дороги в городе, Чарльз-стрит проходит вдоль реки рядом с красивыми живописными маршрутами, а улицы Бойлстон и Бикон находятся в самом центре города, рядом с несколькими офисными зданиями.
Следующий вопрос, который мы рассмотрим, - это , какие станции наиболее часто используются для поездок туда и обратно? Мы можем использовать тот же запрос, что и раньше. Мы будем ВЫБРАТЬ те же выходные столбцы и JOIN таблицы таким же образом, но на этот раз мы добавим предложение WHERE , чтобы ограничить наш COUNT поездками, где start_station совпадает с конечная станция .
query = '' 'ВЫБРАТЬ станции. Станция КАК "Станция", СЧЁТ (*) КАК "Счетчик"
ИЗ поездок INNER JOIN станции
ПО поездкам.start_station = station.id
ГДЕ trips.start_station = trips.end_station
ГРУППА ПО станциям. Станции
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ (*) УДАЛЕНИЕ
LIMIT 5;
'' '
run_query (запрос) | Станция | Счетчик | |
|---|---|---|
| 0 | Эспланада - Бикон-стрит на Арлингтон-стрит | 3064 |
| 1 | Чарльз Серкл - Чарльз-стрит, Кембридж-стрит, | 2739 |
| 2 | Публичная библиотека Бостона - 700 Boylston St. | 2548 |
| 3 | Бойлстон-стрит на Арлингтон-стрит | 2163 |
| 4 | Beacon St / Mass Ave | 2144 |
Как мы видим, количество этих станций такое же, как и в предыдущем вопросе, но их количество намного меньше. Самые загруженные станции по-прежнему остаются самыми загруженными, но в целом более низкие цифры говорят о том, что люди обычно используют велосипеды Hubway, чтобы добраться из точки A в точку B, а не какое-то время кататься на велосипеде, прежде чем вернуться туда, откуда они начали.
Здесь есть одно существенное отличие - Esplande, которая не была одной из самых загруженных станций из нашего первого запроса, кажется, самая загруженная для поездок туда и обратно. Почему? Что ж, картинка стоит тысячи слов. Это определенно похоже на хорошее место для велосипедной прогулки:
Переходим к следующему вопросу: сколько поездок начинается и заканчивается в разных муниципалитетах? Этот вопрос продвигает дальше. Мы хотим знать, сколько поездок начинается и заканчивается в другом районе .Чтобы достичь этого, нам нужно JOIN , чтобы дважды переходил от таблицы к таблице станций . После ON столбец start_station , а затем ON столбец end_station .
Для этого мы должны создать псевдоним для таблицы станций , чтобы мы могли различать данные, относящиеся к start_station , и данные, относящиеся к end_station . Мы можем сделать это точно так же, как мы создавали псевдонимы для отдельных столбцов, чтобы они отображались с более интуитивно понятным именем, используя AS .
Например, мы можем использовать следующий код для JOIN таблицы станций к таблице поездок , используя псевдоним «start». Затем мы можем объединить «начало» с именами столбцов, используя . для ссылки на данные, которые поступают из этого конкретного JOIN (вместо второго JOIN мы будем делать ON в столбце end_station ):
ВНУТРЕННЕЕ СОЕДИНЕНИЕ станций КАК запускается в системе trips.start_station = start.id Вот как будет выглядеть окончательный запрос, когда мы его запустим. Обратите внимание, что мы использовали <> для обозначения «не равно», но ! = также подойдет.
запрос =
'' '
ВЫБЕРИТЕ COUNT (trips.id) КАК "Счетчик"
ИЗ поездок ВНУТРЕННИЕ СОЕДИНЯЙТЕ станции КАК старт
ВКЛ. Trips.start_station = start.id
INNER JOIN станции как конец
ВКЛ. Trips.end_station = end.id
ГДЕ start.municipality <> end.municipality;
'' '
run_query (запрос) Это показывает, что около 300000 из 1.5 миллионов поездок (или 20%) закончились в другом муниципалитете, чем начали, - еще одно свидетельство того, что люди в основном используют велосипеды Hubway для относительно коротких поездок, а не для длительных поездок между городами.
Если вы зашли так далеко, поздравляем! Вы начали осваивать основы SQL. Мы рассмотрели ряд важных команд, SELECT , LIMIT , WHERE , ORDER BY , GROUP BY и JOIN , а также агрегатные и арифметические функции.Это даст вам прочную основу для дальнейшего развития SQL.
Вы освоили основы SQL. Что теперь?
После завершения этого учебника по SQL для начинающих вы сможете выбрать базу данных, которая вам интересна, и написать запросы для получения информации. Хорошим первым шагом может быть продолжение работы с базой данных Hubway, чтобы посмотреть, что еще вы можете узнать. Вот еще несколько вопросов, на которые вы, возможно, захотите ответить:
- За сколько поездок взимается дополнительная плата (продолжительностью более 30 минут)?
- Какой велосипед использовался дольше всего?
- Были ли у зарегистрированных или случайных пользователей больше поездок туда и обратно?
- Какой муниципалитет имел самую длинную среднюю продолжительность жизни?
Если вы хотите сделать еще один шаг вперед, ознакомьтесь с нашими интерактивными курсами SQL, которые охватывают все, что вам нужно знать, от начального уровня до SQL продвинутого уровня для работы аналитиком и специалистом по данным.
Вы также можете прочитать наш пост об экспорте данных из ваших SQL-запросов в Pandas или просмотрите нашу шпаргалку по SQL и нашу статью о сертификации SQL.
Что такое запрос в SQL? - Видео и стенограмма урока
Как создать запрос
Давайте построим запрос на основе данных примера. Мы хотим выбирать альбомы с рейтингом 9 или выше. Проще говоря, мы запрашиваем у базы данных следующее:
- Дайте нам названия альбомов из базы данных, где рейтинг больше или равен 9.
В SQL у нас действительно есть ключевые слова, которые соответствуют нашему оператору. Мы скажем ВЫБРАТЬ , (получить из базы данных), ИЗ (на какую таблицу вы смотрите?) И ГДЕ (какие критерии?).
Следовательно, наш SQL-запрос будет довольно близок к тому простому оператору, который у нас был ранее:
SELECT albumTitle FROM tblAlbums
WHERE rating> = 9;
Мы выбираем (ВЫБРАТЬ) данные из (FROM) таблицы tblAlbums, где (WHERE) рейтинг альбома 9 или выше.Оператор WHERE - это наш фильтр, и он может быть очень сложным (с большим количеством вложенной логики) или очень простым.
При выполнении запроса будут отображаться следующие данные:
| albumTitle |
|---|
| Симфония ре минор |
| Сердце поэта |
Это довольно короткий список! Куда делись все поля? Помните, что компьютеры будут делать только то, что вы им прикажете. Мы только попросили вытащить название альбома и больше ничего.Давайте немного переработаем этот запрос, чтобы получить больше данных. Фактически, нам нужны все поля.
Чтобы получить все данные, используйте звездочку ( * ) в коде. Звездочка указывает на подстановочный знак, что означает, что нам нужно все. Это то же самое, что спросить у библиотекаря все книги в здании. Однако есть одно ключевое отличие: нам нужны альбомы только с рейтингом 9 или выше.
ВЫБРАТЬ *
ИЗ tblAlbums
ГДЕ рейтинг> = 9;
Поскольку мы вытащили все поля, но ограничили наши критерии предложением WHERE, мы получили следующее:
| albumID | альбом Название | Год выпуска | artistID | рейтинг |
|---|---|---|---|---|
| 100 | Симфония ре минор | 1888 | 5 | 10 |
| 110 | Сердце поэта | 1985 | 15 | 9 |
Помните, вам нужен оператор SELECT и FROM, иначе SQL не поймет, что делать.Предложение WHERE настоятельно рекомендуется, особенно если у вас много данных - например, все книги в библиотеке!
Пример: две таблицы
Давайте рассмотрим другой пример, но с двумя таблицами. Напомним, что в нашей таблице альбомов был идентификатор исполнителя, но не было имени исполнителя. В нашей базе есть еще одна таблица, таблица исполнителей:
| artistID | имя исполнителя |
|---|---|
| 5 | Цезарь Франк |
| 10 | Путешествие |
| 15 | Кейт Вольф |
| 20 | Гнилой Рольф |
Для этого следующего оператора мы будем использовать наш предыдущий запрос SQL, но выберем поля из обеих таблиц и объединим их в предложении WHERE.Сосредоточьтесь на ключевых словах: SELECT, FROM, WHERE. Они все здесь и работают вместе, чтобы объединить две таблицы.
ВЫБЕРИТЕ имя исполнителя, название альбома, рейтинг
ИЗ tblArtist, tblAlbum
ГДЕ tblArtist.artistID = tblAlbum.albumID И
tblAlbum.rating> = 9;
Дополнительная информация в предложении WHERE указывает SQL, чтобы убедиться, что идентификатор исполнителя совпадает в обеих таблицах. Мы поговорим о соединениях и расширенном SQL в других уроках.
При выполнении этого запроса мы получаем следующие данные:
| artistName | альбом Название | рейтинг |
|---|---|---|
| Цезарь Франк | Симфония ре минор | 10 |
| Кейт Вольф | Сердце поэта | 9 |
Итоги урока
Давайте рассмотрим.Запрос - это вопрос или запрос о наборе данных. Мы используем язык структурированных запросов (SQL) для извлечения значимой и актуальной информации из баз данных. При построении структуры мы извлекаем данные из таблиц и полей. Поля являются столбцами в таблице базы данных, а фактические данные составляют строки. Оператору SQL требуется предложение SELECT , чтобы указать ему начать поиск данных, предложение FROM , чтобы указать, из какой таблицы (таблиц) извлекать данные, и предложение WHERE для ограничения / фильтрации результатов.Если вы выберете SELECT * FROM Library, вы получите все!
Выучите SQL за 7 дней
Краткое изложение учебного курса по SQL
Базы данных можно найти практически во всех программных приложениях. SQL - это стандартный язык для запросов к базе данных. Это руководство по SQL для начинающих научит вас проектированию баз данных. Кроме того, он учит от базового до продвинутого SQL.
Что я должен знать?
Курс предназначен для начинающих SQL. Предварительный опыт работы с БД не требуется.
Программа SQL
Основы базы данных
Проектирование базы данных
Основы SQL
Сортировка данных
Функции
Что нужно знать!
Самые страшные темы!
Что дальше!
Что такое СУБД?
Система управления базами данных (СУБД) - это программное обеспечение, используемое для хранения и управления данными. Это гарантирует качество, надежность и конфиденциальность информации. Самым популярным типом СУБД являются системы управления реляционными базами данных или СУБД.Здесь база данных состоит из структурированного набора таблиц, и каждая строка таблицы представляет собой запись.
Что такое SQL?
Язык структурированных запросов (SQL) - это стандартный язык для работы с данными в СУБД. Проще говоря, он используется для общения с данными в СУБД. Ниже приведены типы операторов SQL.
- Язык определения данных (DDL) позволяет создавать такие объекты, как схемы, таблицы в базе данных.
- Язык управления данными (DCL) позволяет манипулировать и управлять правами доступа к объектам базы данных
- Управление данными Язык (DML) используется для поиска, вставки, обновления и удаления данных, который будет частично рассмотрен в этом руководстве по SQL.
Что такое запрос?
Запрос - это набор инструкций, передаваемых системе управления базой данных. Он сообщает любой базе данных, какую информацию вы хотели бы получить из базы данных. Например, чтобы получить имя студента из таблицы базы данных STUDENT, вы можете написать запрос SQL следующим образом:
SELECT Student_name from STUDENT;
Процесс SQL
Если вы хотите выполнить команду SQL для любой системы СУБД, вам необходимо найти лучший метод выполнения вашего запроса, и механизм SQL определяет, как интерпретировать эту конкретную задачу.
Важными компонентами, включенными в этот процесс SQL, являются:
- Механизм запросов SQL
- Механизмы оптимизации
- Диспетчер запросов
- Классический механизм запросов
Классический механизм запросов позволяет управлять всеми не-SQL запросами.
Процесс SQL
Оптимизация SQL
Знать, как составлять запросы, не так уж сложно, но вам нужно действительно изучить и понять, как работает хранилище данных и как читаются запросы, чтобы оптимизировать производительность SQL.Оптимизация основана на двух ключевых факторах:
- Правильный выбор при определении структуры базы данных
- Применение наиболее подходящих методов для чтения данных.
Что вы узнаете в этом курсе SQL?
Это руководство по основам SQL предназначено для всех, кто планирует работать с базами данных, особенно в роли системных администраторов и разработчиков приложений. Учебники помогают новичкам изучить основные команды SQL, включая SELECT, INSERT INTO, UPDATE, DELETE FROM и другие.Каждая команда SQL поставляется с ясными и краткими примерами.
В дополнение к списку команд SQL в руководстве представлены карточки с функциями SQL, такими как AVG (), COUNT () и MAX (). Наряду с этим, тесты помогают подтвердить ваши базовые знания языка.
Этот курс SQL поможет вам справиться с различными аспектами языка программирования SQL.
Почему вы должны изучать SQL?
SQL - это простой в освоении язык, специально разработанный для работы с базами данных.Растет спрос на профессионалов, умеющих работать с базами данных. Почти каждая крупная компания использует SQL. Он широко используется в различных секторах, таких как бронирование билетов, банковское дело, платформы социальных сетей, обмен данными, электронная коммерция и т. Д., Поэтому для разработчика SQL доступны широкие возможности.
13 навыков SQL, которые, вероятно, сделают вас лучшим инженером
Если вы уже знаете основы того, что делает SQL и как запрашивать базу данных, вы можете повысить свои навыки с помощью некоторых более продвинутых функций и более глубоких знаний теории.Эти навыки немного сложнее, и, как и в случае со всем более сложным, может потребоваться больше времени, чтобы полностью овладеть ими.
5. ОбъединяетНе все данные, с которыми вам нужно работать, всегда будут в одной таблице; на самом деле, чаще всего это не так. Освоив объединения, вы можете объединить данные из нескольких таблиц вместе. Это значительно упрощает анализ различных наборов данных.
Существует четыре типа объединений: внутреннее, левое, правое и полное. Вам нужно будет узнать, что и когда использовать, и какой код необходим для их выполнения.
6. ПодзапросыПодзапрос, иногда называемый вложенным запросом, - это запрос, вложенный в другой оператор. Как и объединения, они используются для связывания данных между разными таблицами, но при правильном выполнении они работают быстрее и эффективнее, чем объединения, поскольку исключают дополнительные шаги при извлечении данных.
7. Как работают индексыИндексы базы данных ускоряют запросы. Наводя порядок в таблицах данных, индексы упрощают поиск нужной информации для запросов.
Знание того, как (и почему) создаются индексы, а также различных типов, поможет вам лучше понять, как их эффективно использовать. Изучите разницу между кластеризованными и некластеризованными индексами, способы добавления структуры данных при индексировании и правила создания эффективных индексов.