Редактор запросов SSMS — SQL Server Management Studio (SSMS)
- Статья
Применимо к: SQL Server Azure SQL DatabaseУправляемый экземпляр SQL AzureAzure Synapse Analytics
В этой статье описываются возможности и функции редактора запросов SQL Server Management Studio (SSMS).
Примечание
Если вы хотите узнать, как использовать справку F1 по Transact-SQL (T-SQL), ознакомьтесь с разделом Справка F1 по Transact-SQL.
Если вы хотите узнать о задачах, которые можно выполнять с помощью редактора, перейдите к разделу Задачи редактора.
Редакторы в среде SSMS совместно используют стандартную архитектуру. Текстовый редактор реализует базовые функциональные возможности и может быть использован в качестве базового редактора для текстовых файлов. Другие редакторы (редакторы запросов) расширяют эти функциональные возможности, подключая языковую службу, определяющую синтаксис одного из языков, поддерживаемых в SQL Server. В редакторах запросов также присутствуют различные уровни поддержки таких функций редактора, как IntelliSense или отладка. В набор редакторов запросов входят редактор запросов компонента ядра СУБД, используемый для создания скриптов, содержащих инструкции T-SQL и XQuery, редактор многомерных выражений для работы с языком многомерных выражений, редактор расширений интеллектуального анализа данных для работы с языком расширений интеллектуального анализа данных и редактор XML/A для работы с языком XML для аналитики.
Вы можете использовать редактор запросов, чтобы создавать и выполнять скрипты, содержащие инструкции Transact-SQL.
Текстовый редактор реализует базовые функциональные возможности и может быть использован в качестве базового редактора для текстовых файлов. Другие редакторы (редакторы запросов) расширяют эти функциональные возможности, подключая языковую службу, определяющую синтаксис одного из языков, поддерживаемых в SQL Server. В редакторах запросов также присутствуют различные уровни поддержки таких функций редактора, как IntelliSense или отладка. В набор редакторов запросов входят редактор запросов компонента ядра СУБД, используемый для создания скриптов, содержащих инструкции T-SQL и XQuery, редактор многомерных выражений для работы с языком многомерных выражений, редактор расширений интеллектуального анализа данных для работы с языком расширений интеллектуального анализа данных и редактор XML/A для работы с языком XML для аналитики.
Вы можете использовать редактор запросов, чтобы создавать и выполнять скрипты, содержащие инструкции Transact-SQL.
Панель инструментов редактора SQL
Если открыт редактор запросов, отображается панель инструментов редактора SQL со следующими кнопками.
Можно также добавить панель инструментов редактора SQL, выбрав меню Вид , Панели инструментов, а затем выбрав Редактор SQL. Если добавить панель инструментов редактора SQL, когда окно редактора запросов не открыто, все кнопки будут недоступны.
Кнопка «Подключиться» на панели инструментов редактора
Открывает диалоговое окно Соединение с сервером . Используйте это диалоговое окно, чтобы установить соединение с сервером.
Подключиться к базе данных можно также с помощью контекстного меню.
Кнопка «Изменить подключение» на панели инструментов редактора
Открывает диалоговое окно Соединение с сервером . Используйте это диалоговое окно, чтобы установить соединение с другим сервером.
Изменить подключение можно также с помощью контекстного меню.
Кнопка «Доступные базы данных» на панели инструментов редактора
Изменяет подключение и соединяет с другой базой данных того же сервера.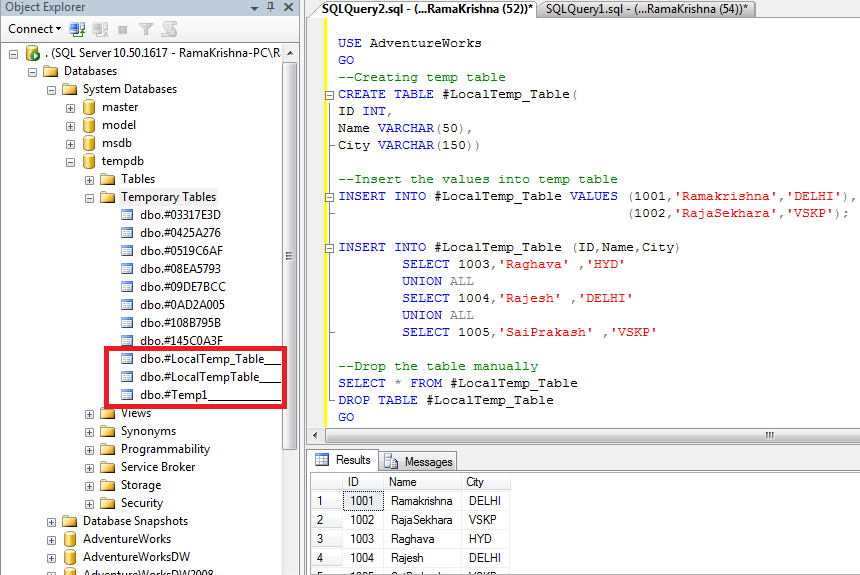
Кнопка «Выполнить» на панели инструментов редактора
Выполняет выбранный код или, если код не выбран, выполняет весь код редактора запросов.
Запрос можно выполнить также с помощью клавиши F5 или контекстного меню.
Кнопка «Отменить выполнение запроса» на панели инструментов редактора
Отправляет на сервер запрос отмены. Отмена выполнения некоторых запросов занимает некоторое время, так как необходимо дождаться подходящих условий отмены. После отмены транзакций могут происходить задержки на время отката транзакций.
Отменить выполнение запроса можно также с помощью клавиш ALT+BREAK.
Кнопка «Анализ» на панели инструментов редактора
Проверяет синтаксис выбранного кода. Если код не выбран, проверяется весь синтаксис кода в окне редактора запросов.
Проверить код в редакторе запросов можно также с помощью клавиш CTRL+F5.
Кнопка «Показать предполагаемый план выполнения» на панели инструментов редактора
Запрашивает план выполнения запроса у обработчика запросов, не выполняя этот запрос, и выводит план в окне План выполнения. Этот план использует статистику индексов для оценки ожидаемого числа строк, возвращаемых на каждом этапе выполнения запроса. Фактически используемый план запроса может отличаться от предполагаемого плана выполнения. Это может происходить, если количество возвращаемых строк расходится с оценкой, поэтому обработчик запросов вносит изменения в план в целях повышения его эффективности.
Этот план использует статистику индексов для оценки ожидаемого числа строк, возвращаемых на каждом этапе выполнения запроса. Фактически используемый план запроса может отличаться от предполагаемого плана выполнения. Это может происходить, если количество возвращаемых строк расходится с оценкой, поэтому обработчик запросов вносит изменения в план в целях повышения его эффективности.
Отобразить предполагаемый план выполнения можно также с помощью клавиш CTRL+L или контекстного меню.
Кнопка «Параметры запроса» на панели инструментов редактора
Открывает диалоговое окно Параметры запроса . С помощью этого диалоговое окно можно настроить параметры по умолчанию для выполнения запроса и для получения результатов запроса.
Открыть окно Параметры запроса можно также с помощью контекстного меню.
Кнопка «Функция Intellisense включена» на панели инструментов редактора
Указывает, доступны ли функциональные возможности технологии IntelliSense в редакторе запросов ядра СУБД. По умолчанию этот параметр активирован.
По умолчанию этот параметр активирован.
Вызвать команду Функция Intellisense включена можно также с помощью клавиш CTRL+B > CTRL+I или контекстного меню.
Кнопка «Включить действительный план выполнения» на панели инструментов редактора
Выполняет запрос, возвращает результаты запроса и использует план выполнения для запроса. Запросы отображаются в виде графического плана запроса в окне План выполнения.
Вызвать команду Включить действительный план выполнения можно также с помощью клавиш CTRL+M или контекстного меню.
Кнопка «Включить статистику активных запросов» на панели инструментов редактора
Позволяет анализировать процесс выполнения запроса в режиме реального времени по мере передачи управления от одного оператора плана запроса другому.
Вызвать команду Включить статистику активных запросов можно также с помощью контекстного меню.
Кнопка «Включить статистику клиента» на панели инструментов редактора
Включает окно Статистика клиента , содержащее статистические данные по запросу и сетевым пакетам, а также по времени выполнения запроса.
Вызвать команду Включить статистику активных запросов можно также с помощью клавиш SHIFT+ALT+S или контекстного меню.
Кнопка «Результаты в текст» на панели инструментов редактора
Возвращает результаты запроса в текстовом виде в окне Результаты .
Вывести результаты в текст можно также с помощью клавиш CTRL+T или контекстного меню.
Кнопка «Результаты в сетку» на панели инструментов редактора
Возвращает результаты запроса в виде одной или нескольких сеток в окне Результаты . По умолчанию параметр включен.
Вывести результаты в сетку можно также с помощью клавиш CTRL+D или контекстного меню.
Кнопка «Результаты в виде файла» на панели инструментов редактора
По завершении выполнения запроса открывается диалоговое окно Сохранить результаты . В поле Сохранить ввыберите папку, в которой необходимо сохранить файл. В поле Имя файла введите имя файла, а затем нажмите кнопку Сохранить, чтобы сохранить результаты запроса в файл отчета с расширением RPT. Для настройки дополнительных параметров выберите стрелку вниз на кнопке Сохранить, а затем пункт Выбор кодировки для сохранения.
Для настройки дополнительных параметров выберите стрелку вниз на кнопке Сохранить, а затем пункт Выбор кодировки для сохранения.
Вывести результаты в текст можно также с помощью клавиш CTRL+SHIFT+F или контекстного меню.
Преобразует текущую строку в комментарий, добавляя оператор комментария (—) в начало строки.
Закомментировать строку можно также с помощью клавиш CTRL+K > CTRL+C.
Преобразует текущую строку в активную инструкцию исходного кода, удаляя оператор комментария (—) в начале строки.
Раскомментировать строку можно также с помощью клавиш CTRL+K > CTRL+U.
Кнопка «Уменьшить отступ» на панели инструментов редактора
Перемещает текст строки влево, удаляя пробелы в начале строки.
Кнопка «Увеличить отступ строки» на панели инструментов редактора
Перемещает текст строки вправо, добавляя пробелы в начале строки.
Кнопка «Задание значений для параметров шаблона» на панели инструментов редактора
Открывает диалоговое окно, которое можно использовать, чтобы задать значения параметров в хранимых процедурах и функциях.
Чтобы вызвать контекстное меню, щелкните правой кнопкой мыши любую область редактора запросов. В контекстном меню отображаются те же команды, что и на панели инструментов редактора SQL. В контекстном меню, помимо команд Подключиться
Фрагмент кода T-SQL — это шаблон, который можно использовать в качестве отправной точки при написании новых инструкций Transact-SQL в редакторе запросов.
Фрагмент кода, который можно использовать в качестве отправной точки при включении набора инструкций Transact-SQL в блок BEGIN, IF или WHILE.
В отличие от панели инструментов SSMS в контекстном меню есть больше вариантов подключения.
Подключиться — открывает диалоговое окно «Соединение с сервером». Используйте это диалоговое окно, чтобы установить соединение с сервером.

Отключить — отключает текущее окно редактора запросов от сервера.
Отключить все запросы — отключает все соединения запросов.
Изменить соединение — открывает диалоговое окно «Соединение с сервером». Используйте это диалоговое окно, чтобы установить соединение с другим сервером.
В обозревателе объектов представлен иерархический пользовательский интерфейс для просмотра и управления объектами в каждом экземпляре SQL Server. Панель сведений обозревателя объектов предлагает табличное представление объектов экземпляра и возможность поиска указанных объектов. Возможности обозревателя объектов могут незначительно различаться в зависимости от типа сервера, но в общем случае включают функции разработки для баз данных, а также функции управления для всех типов серверов.
Выполняет выбранный код или, если код не выбран, выполняет весь код в редакторе запросов.
Запрашивает план выполнения запроса у обработчика запросов, не выполняя этот запрос, и выводит план в окне План выполнения . Этот план использует статистику индексов для оценки ожидаемого числа строк, возвращаемых на каждом этапе выполнения запроса. Фактически используемый план запроса может отличаться от предполагаемого плана выполнения. Это может происходить, если количество возвращаемых строк расходится с оценкой, поэтому обработчик запросов вносит изменения в план в целях повышения его эффективности.
Этот план использует статистику индексов для оценки ожидаемого числа строк, возвращаемых на каждом этапе выполнения запроса. Фактически используемый план запроса может отличаться от предполагаемого плана выполнения. Это может происходить, если количество возвращаемых строк расходится с оценкой, поэтому обработчик запросов вносит изменения в план в целях повышения его эффективности.
Указывает, доступны ли функциональные возможности технологии IntelliSense в редакторе запросов ядра СУБД. По умолчанию этот параметр активирован.
SQL Server Profiler — это интерфейс для создания трассировок и управления ими, а также для анализа и воспроизведения полученных результатов. События сохраняются в файле трассировки, который затем может быть проанализирован или использован для воспроизведения определенных последовательностей шагов для выявления возникших проблем.
Помощник по настройке ядра СУБД (Майкрософт) анализирует базы данных и составляет рекомендации по оптимизации производительности запросов. Помощник по настройке ядра СУБД используется для выбора и создания оптимальных наборов индексов, индексированных представлений и секций таблицы, не обладая экспертным уровнем понимания структуры баз данных или внутренних процессов SQL Server. Помощник по настройке ядра СУБД позволяет выполнять следующие задачи.
Помощник по настройке ядра СУБД используется для выбора и создания оптимальных наборов индексов, индексированных представлений и секций таблицы, не обладая экспертным уровнем понимания структуры баз данных или внутренних процессов SQL Server. Помощник по настройке ядра СУБД позволяет выполнять следующие задачи.
Конструктор запросов и представлений открывается при открытии определения представления, показе результатов запроса или представления, при создании или открытии запроса.
Выполняет запрос, возвращает результаты запроса и использует план выполнения для запроса. Запросы отображаются в виде графического плана запроса в окне План выполнения.
Позволяет анализировать процесс выполнения запроса в режиме реального времени по мере передачи управления от одного оператора плана запроса другому.
Включает окно Статистика клиента , содержащее статистические данные по запросу и сетевым пакетам, а также по времени выполнения запроса.
В контекстном меню можно выбрать любой вариант вывода 
Результаты в текст — отображает результаты запроса в текстовом виде в окне Результаты.
Результаты в сетку — отображает результаты запроса в виде одной или нескольких сеток в окне Результаты.
Результаты в виде файла — после выполнения запроса открывается диалоговое окно Сохранить результаты. В поле Сохранить ввыберите папку, в которой необходимо сохранить файл. В поле Имя файла
Окно свойств описывает состояние элемента в SQL Server Management Studio, например подключение или оператор Showplan, и сведения об объектах базы данных, таких как таблицы, представления и конструкторы.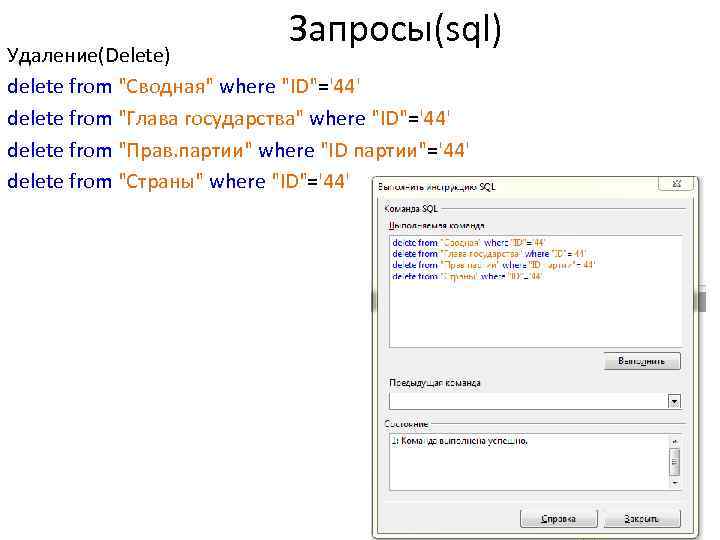
Окно свойств используется для просмотра свойств текущего соединения. Многие свойства в окне свойств доступны только для чтения, однако могут быть изменены другими средствами Management Studio. Например, свойство «База данных» запроса в окне свойств доступно только для чтения, но может изменяться на панели инструментов.
Открывает диалоговое окно Параметры запроса . С помощью этого диалогового окна можно настроить параметры по умолчанию для выполнения запроса и получения результатов запроса.
Справка F1 по Transact-SQL
При нажатии клавиши F1 редактор запросов открывает раздел справки по нужной вам инструкции Transact-SQL. Чтобы сделать это, выделите имя инструкции Transact-SQL и нажмите клавишу F1. После этого поисковая система справки выполнит поиск раздела, имеющего атрибут справки F1, соответствующий выделенной строке.
Если поисковой системе справки не удастся найти раздел с ключевым словом справки F1, точно соответствующим выделенной строке, будет отображен этот раздел. В этом случае есть два способа поиска нужной информации:
В этом случае есть два способа поиска нужной информации:
Скопируйте и вставьте из буфера редактора строку, выделенную на вкладке поиска электронной документации по SQL Server, и воспользоваться функцией поиска.
Выделите только ту часть инструкции Transact-SQL, которая вероятнее всего совпадет с ключевым словом справки F1, относящимся к разделу, и повторно нажмите клавишу F1. Средству поиска справки необходимо полное соответствие между выделенной строкой и ключевым словом справки F1, назначенным для раздела. Если выделенная строка содержит элементы, уникальные для вашей среды, например имена столбцов или параметров, поисковая система не сможет найти совпадение. Примерами строк для выделения могут служить следующие:
Имя инструкции Transact-SQL, такое как SELECT, CREATE DATABASE или BEGIN TRANSACTION.
Имя встроенной функции, такой как SERVERPROPERTY или @@VERSION.
Имя системной хранимой процедуры, таблицы или представлений, такое как sys.
data_spaces или sp_tableoption.
 data_spaces или sp_tableoption.
data_spaces или sp_tableoption.Задачи редактора
| Описание задачи | Раздел |
|---|---|
| Описывает различные способы открытия редакторов в среде SSMS. | Открытие редактора |
| Настройка параметров для различных редакторов, например нумерация линий или параметры IntelliSense. | Настройка редакторов |
| Управление режимом просмотра, например переносом по словам, разделением окна или вкладками. | Управление режимами редактирования и просмотра |
| Настройка параметров форматирования, например скрытый текст или выступы. | управлять форматированием кода |
| Способы навигации по тексту в окне редактора, например функции добавочного поиска или перехода. | Перемещение по коду и тексту |
| Настройка параметров присвоения цветов различным классам синтаксиса, что облегчает чтение сложных инструкций. | Выделение цветом в редакторах запросов |
Перетаскивание текста с одного места в скрипте в другое. | Перетаскивание текста |
| Установка закладок для более легкого поиска важных элементов кода. | Управление закладками |
| Вывод скриптов или результатов в окно или сетку. | Печать кода и результаты |
| Просмотр и использование базовых функций редактора запросов многомерных выражений. | Создание скриптов Analysis Services |
| Просмотр и использование базовых функций редактора запросов расширения интеллектуального анализа данных. | Создание DMX-запроса |
| Просмотр и использование базовых функций редактора запросов XML/A. | Редактор XML |
| Использование функций sqlcmd в редакторе запросов ядра СУБД. | Изменение скриптов SQLCMD |
Использование фрагментов кода в редакторе запросов ядра СУБД. Фрагменты кода — это шаблоны часто используемых инструкций или блоков. Их можно настроить или расширить, включив в них фрагменты, специфичные для сайта. | Фрагменты кода T-SQL |
| Использование отладчика Transact-SQL для пошагового просмотра кода и просмотра отладочных данных, например значений переменных и параметров. | Отладчик T-SQL. |
См. также раздел
- Настройка меню и сочетаний клавиш
- Сочетания клавиш среды SQL Server Management Studio
ТОП-5 способов выполнения SQL-запрос в PySpark
Если вы знаете SQL, но еще не освоились с фреймворком Apache Spark, то вы можете выполнять запросы различными способами. В этой статье вы узнаете, как писать SQL-выражения в PySpark, какие способы выполнения запросов существуют, как конкатенировать строки, фильтровать данные и работать с датами.
Способы выполнения в SQL-запросов в Apache Spark
Выполнять SQL-запросы можно выполнять различным образом, но все они в итоге дают тот же результат. Причем только один из них является полноценным запросом, все остальные является вызов функции, принимающей SQL-выражение. Вот некоторые из них:
Вот некоторые из них:
- напрямую через
spark.sql("QUERY"); - выборка столбцов через метод
selectв связке с функциейexprизpyspark.sql.functions; - выборка столбцов через метод
selectExpr; - добавление результата вычисления SQL-выражения к исходной таблице через метод
withColumn; - фильтрация данных через методы
whereилиfilterв связке с функциейexprизpyspark.sql.functions;.
Допустим, имеется следующий DataFrame:
df = spark.createDataFrame([
('py', 'Anton', 'Moscow', 23),
('c', 'Anna', 'Omsk', 27),
('py', 'Andry', 'Moscow', 24),
('cpp', 'Alex', 'Moscow', 32),
('cpp', 'Boris', 'Omsk', 55),
('py', 'Vera', 'Moscow', 89), ],
['lang', 'name', 'city', 'salary'])
Тогда чтобы напрямую выполнить SQL-запрос (1-способ), нужно создать так называемое представление (view). Это делается для того чтобы Spark знал о созданной таблице. Представление создается вызовом метода, в который нужно передать желаемое имя таблицы:
Это делается для того чтобы Spark знал о созданной таблице. Представление создается вызовом метода, в который нужно передать желаемое имя таблицы:
df.createOrReplaceTempView("prog_info")
Теперь можно выполнять запросы, так же, как это делается при работе с базами данных:
spark.sql("select lang from prog_info").show()
"""
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
"""
Этот способ наиболее универсален, поскольку не нужно знать о различных функциях, а просто нужно дать необходимый запрос.
Второй способ заключается в использовании метода select в связке с функцией expr. Она уже не требует создания представления. Однако она применяется к конкретному DataFrame, поэтому операторы SELECT FROM должны быть опущены. В этом случае следует говорить о SQL-выражении, ведь не является полным запросом. Например, вот так выглядит тот же самый запрос, что и выше, но только с использованием функции
Например, вот так выглядит тот же самый запрос, что и выше, но только с использованием функции expr:
# На самом деле именно для этого случая, `expr` может быть опушен,
# но далее вы увидите, что его обязательно нужно использовать
import pyspark.sql.functions as F
df.select(F.expr('lang')).show()
"""
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
"""
Далее следуют метод selectExpr. Второй метод точно такой же, как и select, но принимает на вход SQL-выражения, поэтому не нужно отдельно вызывать функцию expr.
df.selectExpr('lang').show()
# Или что то же самое:
df.select('lang').show()
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
Различие заключается в том, что в select передаются именно столбцы, поэтому такая запись неправильная:
# Ошибка selectExpr(df.
 lang).show()
# А вот так можно:
select(df.lang).show()
lang).show()
# А вот так можно:
select(df.lang).show()
Самый последний способ использования SQL-выражений — это метод withColumn в связке с функцией expr. В отличие от предыдущих он добавляет к имеющейся таблице новый столбец, полученный на основе SQL-выражения. Его можно рассматривать как оператор SELECT * FROM.
Анализ данных с Apache Spark
Конечно, на примере операции выборки столбца всю силу SQL-выражений не показать, поэтому рассмотрим более интересные операции, включая фильтрацию данных, о которой мы еще не поговорили.
Конкатенация строк с использованием ||
Самый простой способ объединения нескольких строк в одну — это использование SQL-выражения со знаком ||. Такая операция называется конкатенация строк. Итак, чтобы конкатенировать строки используйте один из вышеперечисленных способов.
spark.sql('SELECT name || "_" || lang AS name_lang FROM lang_info'). show()
df.select(F.expr('name || "_" || lang AS name_lang')).show()
df.selectExpr('name || "_" || lang AS name_lang').show()
"""
+---------+
|name_lang|
+---------+
| Anton_py|
| Anna_c|
| Andry_py|
| Alex_cpp|
|Boris_cpp|
| Vera_py|
+---------+
"""
# Возвращает всю таблицу
df.withColumn('name_lang', F.expr('name || "_" || lang')).show()
"""
+----+-----+------+------+---------+
|lang| name| city|salary|name_lang|
+----+-----+------+------+---------+
| py|Anton|Moscow| 23| Anton_py|
| c| Anna| Omsk| 27| Anna_c|
| py|Andry|Moscow| 24| Andry_py|
| cpp| Alex|Moscow| 32| Alex_cpp|
| cpp|Boris| Omsk| 55|Boris_cpp|
| py| Vera|Moscow| 89| Vera_py|
+----+-----+------+------+---------+
"""
 show()
df.select(F.expr('name || "_" || lang AS name_lang')).show()
df.selectExpr('name || "_" || lang AS name_lang').show()
"""
+---------+
|name_lang|
+---------+
| Anton_py|
| Anna_c|
| Andry_py|
| Alex_cpp|
|Boris_cpp|
| Vera_py|
+---------+
"""
# Возвращает всю таблицу
df.withColumn('name_lang', F.expr('name || "_" || lang')).show()
"""
+----+-----+------+------+---------+
|lang| name| city|salary|name_lang|
+----+-----+------+------+---------+
| py|Anton|Moscow| 23| Anton_py|
| c| Anna| Omsk| 27| Anna_c|
| py|Andry|Moscow| 24| Andry_py|
| cpp| Alex|Moscow| 32| Alex_cpp|
| cpp|Boris| Omsk| 55|Boris_cpp|
| py| Vera|Moscow| 89| Vera_py|
+----+-----+------+------+---------+
"""
show()
df.select(F.expr('name || "_" || lang AS name_lang')).show()
df.selectExpr('name || "_" || lang AS name_lang').show()
"""
+---------+
|name_lang|
+---------+
| Anton_py|
| Anna_c|
| Andry_py|
| Alex_cpp|
|Boris_cpp|
| Vera_py|
+---------+
"""
# Возвращает всю таблицу
df.withColumn('name_lang', F.expr('name || "_" || lang')).show()
"""
+----+-----+------+------+---------+
|lang| name| city|salary|name_lang|
+----+-----+------+------+---------+
| py|Anton|Moscow| 23| Anton_py|
| c| Anna| Omsk| 27| Anna_c|
| py|Andry|Moscow| 24| Andry_py|
| cpp| Alex|Moscow| 32| Alex_cpp|
| cpp|Boris| Omsk| 55|Boris_cpp|
| py| Vera|Moscow| 89| Vera_py|
+----+-----+------+------+---------+
"""
Фильтрация данных в PySpark
Для фильтрации существуют методы filter и where (это синонимы, они делают то же самое). Фильтрация данных может быть выражена двумя способами: в виде SQL-выражения или так, как это делается в библиотеке Pandas. Например, найдем те записи, которые содержат одинаковые значения.
Фильтрация данных может быть выражена двумя способами: в виде SQL-выражения или так, как это делается в библиотеке Pandas. Например, найдем те записи, которые содержат одинаковые значения.
# В виде SQL-выражения
df.filter('salary > 30 AND city like "Moscow"').show()
# Как в Pandas:
df.filter((df.salary > 30) & (df.city == 'Moscow')).show()
"""
+----+----+------+------+
|lang|name| city|salary|
+----+----+------+------+
| cpp|Alex|Moscow| 32|
| py|Vera|Moscow| 89|
+----+----+------+------+
"""
При использовании Pandas-стиля выражения заключается в скобки; если требуется произвести логические операции между ними, то ставится знак & (AND, побитовое И) или | (OR, побитовое ИЛИ). В нашем примере мы использовали знак И. Также стоит отметить, что его использование ограничено использованием имен с латинскими буквами и цифрами (как например, обратиться к имени столбца, содержащий пробел).
Также можно использовать обычный SQL-запрос в spark.sql.
spark.sql('SELECT * FROM lang_info WHERE salary > 30 AND city like "Moscow"')
Использование CASE WHEN в PySpark
В PySpark эквивалентом оператор CASE WHEN является использование функций when().otherwise(). Он необходим для выбора того или иного результата в зависимости от выполнения условия. Аналогичный оператор можно встретить в Python, который состоит if\elif\eles. Синтаксис у оператора `CASE WHEN в SQL такой:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
Допустим из неполных названий языков мы хотим получить полные. В этом случае можно поступить таким образом:
sql = """
CASE
WHEN (lang LIKE 'c') OR (lang LIKE 'cpp') THEN 'C/C++'
WHEN (lang LIKE 'py') THEN 'Python'
ELSE 'unknown'
END"""
df. withColumn('FullLang', F.expr(sql)).show()
"""
+----+-----+------+------+--------+
|lang| name| city|salary|FullLang|
+----+-----+------+------+--------+
| py|Anton|Moscow| 23| Python|
| c| Anna| Omsk| 27| C/C++|
| py|Andry|Moscow| 24| Python|
| cpp| Alex|Moscow| 32| C/C++|
| cpp|Boris| Omsk| 55| C/C++|
| py| Vera|Moscow| 89| Python|
+----+-----+------+------+--------+
"""
 withColumn('FullLang', F.expr(sql)).show()
"""
+----+-----+------+------+--------+
|lang| name| city|salary|FullLang|
+----+-----+------+------+--------+
| py|Anton|Moscow| 23| Python|
| c| Anna| Omsk| 27| C/C++|
| py|Andry|Moscow| 24| Python|
| cpp| Alex|Moscow| 32| C/C++|
| cpp|Boris| Omsk| 55| C/C++|
| py| Vera|Moscow| 89| Python|
+----+-----+------+------+--------+
"""
withColumn('FullLang', F.expr(sql)).show()
"""
+----+-----+------+------+--------+
|lang| name| city|salary|FullLang|
+----+-----+------+------+--------+
| py|Anton|Moscow| 23| Python|
| c| Anna| Omsk| 27| C/C++|
| py|Andry|Moscow| 24| Python|
| cpp| Alex|Moscow| 32| C/C++|
| cpp|Boris| Omsk| 55| C/C++|
| py| Vera|Moscow| 89| Python|
+----+-----+------+------+--------+
"""
Опять же мы могли бы вызвать select, но получили бы только один столбец, также в этом случае следует добавить оператор AS или метод alias, иначе название столбца будет состоять из всего оператора CASE WHEN. Например, так:
df.select(F.expr(sql).alias('FullLang')).show()
"""
+--------+
|FullLang|
+--------+
| Python|
| C/C++|
| Python|
| C/C++|
| C/C++|
| Python|
+--------+
"""
Либо, как уже говорили, и вовсе сделать с помощью функций when-otherwise.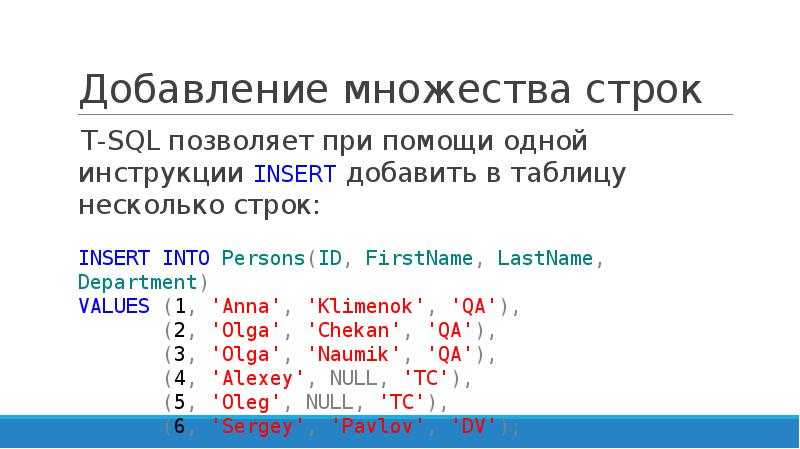 Советуем при этом соблюдать структурные отступы для читабельности кода:
Советуем при этом соблюдать структурные отступы для читабельности кода:
case_when = (
F.when(F.expr('lang LIKE "c" OR lang LIKE "cpp"'), 'C/C++')
.when(F.expr('lang LIKE "py"'), 'Python')
.otherwise('uknown')
)
df.withColumn('FullLang', case_when)
Работаем с датой и временем
Одними только числовыми и строковыми не отделаешься, иногда приходится работать с датами и временем. Для них тоже имеются различные функции, похожие на те, которые встречаются в SQL. Например, вот так можно найти разницу между датами в днях в Spark:
df2 = spark.createDataFrame([
('2020-01-01', '2022-10-25'),
('2021-05-12', '2022-05-12'),],
['before', 'after'])
df2.withColumn('diff', F.expr('DATEDIFF(after, before)')).show()
"""
+----------+----------+----+
| before| after|diff|
+----------+----------+----+
|2020-01-01|2022-10-25|1028|
|2021-05-12|2022-05-12| 365|
+----------+----------+----+
"""
Заметим, что мы могли бы не писать так, как это делается в SQL, а могли бы использовать функции из pyspark.. Более того, это хороший способ узнать, есть ли такая-то функция, заглянув в документацию. Однако полностью полагаться на документацию не стоит, так как есть еще незадокументированные функции, которые нет в языке SQL, но могут в некоторых случаях пригодится(например,  sql.functions
sql.functionsstack — обратная операция функции pivot, см. [5]).
Еще больше подробностей об SQL-операциях в PySpark вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Записаться на курс
Смотреть раcписание
Источники
- expr
- select
- selectExpr
- withColumn
- Как развернуть таблицу
Лучшие практики написания SQL-запросов
- Корректность, удобочитаемость, затем оптимизация: в таком порядке
- Сделайте свои стога как можно меньше, прежде чем искать иголки
- Сначала узнайте свои данные
- Разработка вашего запроса
- Общий порядок выполнения запроса
- Некоторые рекомендации по запросам (не правила)
- Прокомментируйте свой код, особенно почему
- лучшие практики SQL для FROM
- Соединение таблиц с использованием ключевого слова ON
- Псевдоним нескольких таблиц
- лучшие практики SQL для WHERE
- Фильтр с WHERE до HAVING
- Избегайте функций для столбцов в предложениях WHERE
- Предпочтение
= отдоНРАВИТСЯ - Избегайте подстановочных знаков в операторах WHERE
- Предпочитаю СУЩЕСТВУЕТ вместо IN
- рекомендации SQL для GROUP BY
- Упорядочить несколько групп по убыванию мощности
- лучших практик SQL для HAVING
- Используйте только HAVING для агрегатов фильтрации
- рекомендации SQL для SELECT
- SELECT столбцы, а не звезды
- лучших практик SQL для UNION
- Предпочесть UNION All вместо UNION
- рекомендации SQL для ORDER BY
- По возможности избегайте сортировки, особенно в подзапросах
- рекомендации SQL для INDEX
- Добавление индексов
- Использовать частичные индексы
- Использовать составные индексы
- ОБЪЯСНИТЬ
- Поиск узких мест
- С
- Организуйте свои запросы с помощью Common Table Expressions (CTE)
- С метабазой вам даже не нужно использовать SQL
- Вопиющие ошибки или упущения?
В этой статье рассматриваются некоторые рекомендации по написанию SQL-запросов для аналитиков и специалистов по данным. Большая часть нашего обсуждения будет касаться SQL в целом, но мы включим некоторые заметки о функциях, специфичных для Metabase, которые упрощают написание SQL.
Большая часть нашего обсуждения будет касаться SQL в целом, но мы включим некоторые заметки о функциях, специфичных для Metabase, которые упрощают написание SQL.
Правильность, удобочитаемость, затем оптимизация: в таком порядке
Здесь применяется стандартное предупреждение о преждевременной оптимизации. Избегайте настройки SQL-запроса, пока не будете уверены, что ваш запрос возвращает нужные вам данные. И даже в этом случае оптимизируйте запрос в первую очередь только в том случае, если он выполняется часто (например, при включении популярной информационной панели) или если запрос проходит большое количество строк. В общем, прежде чем беспокоиться о производительности, отдайте предпочтение точности (выдает ли запрос ожидаемые результаты) и удобочитаемости (могут ли другие легко понять и изменить код).
Сделайте свои стога как можно меньше, прежде чем искать иголки
Возможно, здесь мы уже приступаем к оптимизации, но цель должна заключаться в том, чтобы указать базе данных сканировать минимальное количество значений, необходимых для получения ваших результатов.
Частью красоты SQL является его декларативный характер. Вместо того, чтобы сообщать базе данных, как извлекать записи, вам нужно только сообщить базе данных, какие записи вам нужны, и база данных должна определить наиболее эффективный способ получения этой информации. Следовательно, большая часть советов по повышению эффективности запросов сводится просто к тому, чтобы показать людям, как использовать инструменты SQL для более точного формулирования своих потребностей.
Мы пересмотрим общий порядок выполнения запросов и добавим советы по сокращению пространства поиска. Затем мы поговорим о трех основных инструментах, которые можно добавить в пояс: INDEX, EXPLAIN и WITH.
Сначала узнайте свои данные
Прежде чем писать хоть одну строку кода, ознакомьтесь со своими данными, изучив метаданные, чтобы убедиться, что столбец действительно содержит ожидаемые данные. Редактор SQL в Metabase имеет удобную справочную вкладку данных (доступную через значок книги ), где вы можете просматривать таблицы в своей базе данных и просматривать их столбцы и соединения (рис. 1):
1):
Вы также можете просмотреть примеры значений для определенных столбцов (рис. 2).
Рис. 2 . Используйте боковую панель Data Reference , чтобы просмотреть образцы данных. Метабазапредоставляет вам множество различных способов изучения ваших данных: вы можете просматривать таблицы, составлять вопросы с помощью построителя запросов и редактора записной книжки, преобразовывать сохраненный вопрос в код SQL или создавать из существующего собственного запроса. Мы расскажем об этом в других статьях; а пока давайте рассмотрим общий рабочий процесс запроса.
Разработка запроса
Методы у всех разные, но вот пример рабочего процесса, которому нужно следовать при разработке запроса.
- Как и выше, изучите метаданные столбца и таблицы. Если вы используете собственный редактор запросов Metabase, вы также можете искать фрагменты SQL, содержащие код SQL для таблицы и столбцов, с которыми вы работаете. Фрагменты позволяют увидеть, как другие аналитики запрашивали данные. Или вы можете начать запрос из существующего вопроса SQL.
- Чтобы получить представление о значениях таблицы, ВЫБЕРИТЕ * из таблиц, с которыми вы работаете, и ОГРАНИЧЬТЕ результаты. Применяйте LIMIT по мере уточнения столбцов (или добавляйте дополнительные столбцы с помощью объединений).
- Сократите столбцы до минимального набора, необходимого для ответа на ваш вопрос.
- Применить любые фильтры к этим столбцам.
- Если вам нужно агрегировать данные, агрегируйте небольшое количество строк и убедитесь, что агрегирование соответствует вашим ожиданиям.
- Когда у вас есть запрос, возвращающий нужные вам результаты, найдите разделы запроса, чтобы сохранить их как Common Table Expression (CTE) для инкапсуляции этой логики.
- С помощью Metabase вы также можете сохранять код в виде фрагмента SQL для совместного использования и повторного использования в других запросах.
 Фрагменты позволяют увидеть, как другие аналитики запрашивали данные. Или вы можете начать запрос из существующего вопроса SQL.
Фрагменты позволяют увидеть, как другие аналитики запрашивали данные. Или вы можете начать запрос из существующего вопроса SQL.
Общий порядок выполнения запроса
Прежде чем мы перейдем к отдельным советам по написанию кода SQL, важно иметь представление о том, как базы данных будут выполнять ваш запрос. Это отличается от порядка чтения (слева направо, сверху вниз), который вы используете для составления запроса. Оптимизаторы запросов могут изменить порядок следующего списка, но этот общий жизненный цикл SQL-запроса следует помнить при написании SQL. Мы будем использовать порядок выполнения, чтобы сгруппировать следующие советы по написанию хорошего SQL.
Эмпирическое правило здесь таково: чем раньше в этом списке вы сможете удалить данные, тем лучше.
- FROM (и JOIN) получает(ют) таблицы, на которые есть ссылки в запросе. Эти таблицы представляют максимальное пространство поиска, указанное вашим запросом. По возможности ограничьте это пространство поиска, прежде чем двигаться дальше.
- ГДЕ фильтрует данные.
- GROUP BY объединяет данные.
- HAVING отфильтровывает агрегированные данные, которые не соответствуют критериям.
- SELECT захватывает столбцы (затем дедуплицирует строки, если вызывается DISTINCT).
- UNION объединяет выбранные данные в набор результатов.
- ORDER BY сортирует результаты.

И, конечно же, всегда будут случаи, когда оптимизатор запросов для вашей конкретной базы данных разработает другой план запроса, так что не зацикливайтесь на этом порядке.
Некоторые рекомендации по запросам (не правила)
Следующие советы являются рекомендациями, а не правилами, призванными уберечь вас от неприятностей. Каждая база данных обрабатывает SQL по-своему, имеет немного отличающийся набор функций и использует разные подходы к оптимизации запросов. И это еще до того, как мы приступим к сравнению традиционных транзакционных баз данных с аналитическими базами данных, которые используют форматы хранения столбцов, которые имеют совершенно разные характеристики производительности.
Помогите людям (включая себя через три месяца), добавив комментарии, поясняющие различные части кода. Самое важное, что здесь нужно уловить, — это «почему». Например, очевидно, что приведенный ниже код отфильтровывает заказы с
Самое важное, что здесь нужно уловить, — это «почему». Например, очевидно, что приведенный ниже код отфильтровывает заказы с ID больше 10, но это происходит потому, что первые 10 заказов используются для тестирования.
ВЫБЕРИТЕ идентификатор, продукт ОТ заказы -- отфильтровать тестовые заказы ГДЕ идентификатор заказа> 10
Загвоздка здесь в том, что вы вносите небольшие накладные расходы на обслуживание: если вы меняете код, вам нужно убедиться, что комментарий по-прежнему актуален и актуален. Но это небольшая цена за читаемый код.
Лучшие практики SQL для FROM
Соединение таблиц с помощью ключевого слова ON
Хотя можно «объединить» две таблицы с помощью предложения WHERE (то есть выполнить неявное соединение, например, SELECT * FROM a,b WHERE a.foo = b.bar ), вместо этого следует предпочесть явное ПРИСОЕДИНЕНИЕ:
ВЫБЕРИТЕ о.ид, о.общий, стр. поставщик ОТ заказы КАК О ПРИСОЕДИНЯЙТЕСЬ к продуктам КАК p ON o.
 product_id = p.id
product_id = p.id
В основном для удобства чтения, так как JOIN + 9Синтаксис 0032 ON отличает объединения от предложений WHERE , предназначенных для фильтрации результатов.
Псевдоним нескольких таблиц
При запросе нескольких таблиц используйте псевдонимы и применяйте эти псевдонимы в своем операторе выбора, чтобы базе данных (и вашему читателю) не нужно было анализировать, какой столбец принадлежит какой таблице. Обратите внимание, что если у вас есть столбцы с одинаковыми именами в нескольких таблицах, вам нужно будет явно ссылаться на них либо по имени таблицы, либо по псевдониму.
Избегать
ВЫБЕРИТЕ заголовок, фамилия, имя ИЗ художественных_книг ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ ПО fiction_books.author_id = fiction_authors.id
Предпочтение
ВЫБЕРИТЕ книги.название, авторы.фамилия, авторы.first_name ИЗ художественных_книг КАК книги ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ к авторам фикции КАК авторам ПО books.
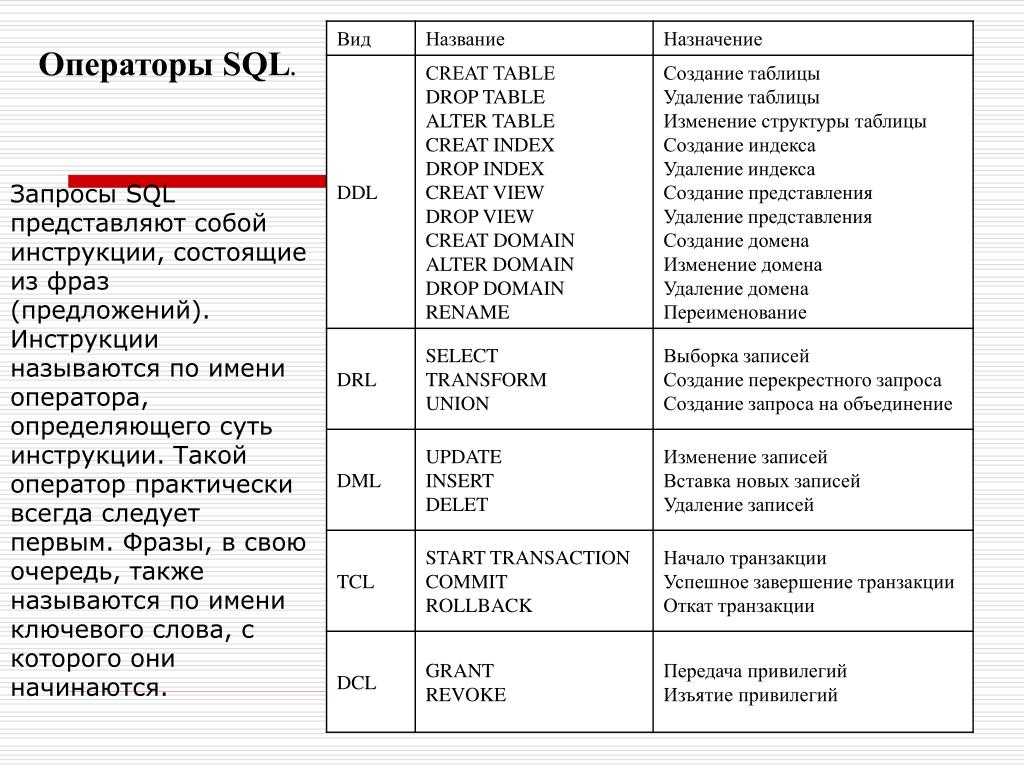 author_id = author.id
author_id = author.id
Это тривиальный пример, но когда количество таблиц и столбцов в вашем запросе увеличивается, вашим читателям не нужно будет отслеживать, какой столбец находится в какой таблице. Это и ваши запросы могут сломаться, если вы присоединитесь к таблице с неоднозначным именем столбца (например, обе таблицы включают поле с именем Создан_В .
Обратите внимание, что фильтры полей несовместимы с псевдонимами таблиц, поэтому вам потребуется удалить псевдонимы при подключении виджетов фильтров к вашим фильтрам полей.
Лучшие практики SQL для WHERE
Фильтр с WHERE перед HAVING
Используйте предложение WHERE для фильтрации лишних строк, чтобы вам не приходилось вычислять эти значения в первую очередь. Только после удаления ненужных строк, а также после объединения этих строк и их группировки следует включать Предложение HAVING для фильтрации агрегатов.
Избегайте функций для столбцов в предложениях WHERE
Использование функции для столбца в предложении WHERE может существенно замедлить ваш запрос, поскольку эта функция делает запрос недоступным для анализа (т. е. не позволяет базе данных использовать индекс для ускорения запроса). Вместо того, чтобы использовать индекс для перехода к соответствующим строкам, функция для столбца заставляет базу данных запускать функцию для каждой строки таблицы.
е. не позволяет базе данных использовать индекс для ускорения запроса). Вместо того, чтобы использовать индекс для перехода к соответствующим строкам, функция для столбца заставляет базу данных запускать функцию для каждой строки таблицы.
И помните, оператор конкатенации || — это тоже функция, так что не пытайтесь объединить строки для фильтрации нескольких столбцов. Вместо этого предпочесть несколько условий:
Избегать
ВЫБЕРИТЕ героя, помощника ОТ супергероев ГДЕ герой || помощник = 'БэтменРобин'
Предпочтение
ВЫБЕРИТЕ героя, помощника ОТ супергероев ГДЕ герой = «Бэтмен» И помощник = 'Робин'
Предпочтение
= от до НРАВИТСЯ Это не всегда так. Приятно знать, что LIKE сравнивает символы и может сочетаться с операторами подстановки, такими как % , тогда как оператор = сравнивает строки и числа для точного совпадения.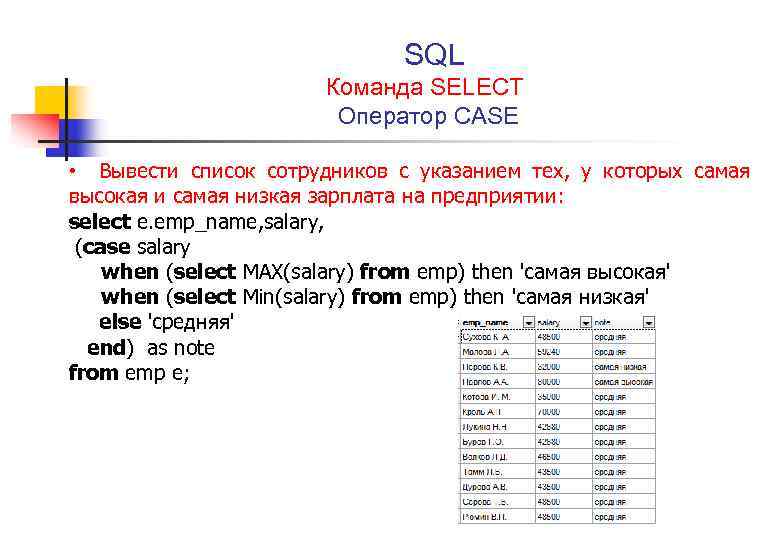
= могут использовать индексированные столбцы. Это не относится ко всем базам данных, поскольку LIKE может использовать индексы (если они существуют для поля), если вы избегаете префикса поискового запроса с оператором подстановки, % . Что подводит нас к следующему пункту:
Избегайте подстановочных знаков в операторах WHERE
Использование подстановочных знаков для поиска может быть дорогостоящим. Предпочитаю добавлять подстановочные знаки в конец строк. Префикс строки с подстановочным знаком может привести к полному сканированию таблицы.
Избегать
ВЫБЕРИТЕ столбец ИЗ таблицы WHERE col LIKE "%wizar%"
Предпочтение
SELECT столбец FROM table WHERE col LIKE "wizar%"
Предпочитает СУЩЕСТВУЕТ, а не В
Если вам просто нужно проверить существование значения в таблице, выберите EXISTS 9От 0033 до IN , поскольку процесс EXISTS завершается, как только он находит искомое значение, тогда как IN просматривает всю таблицу.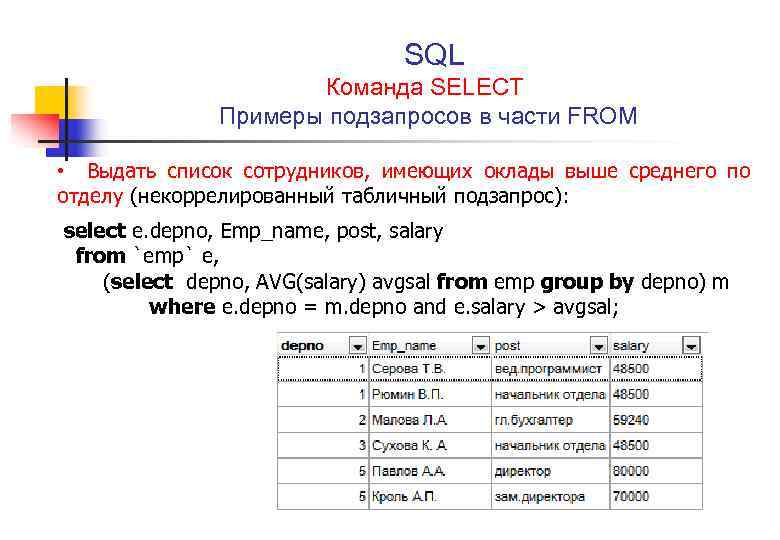
IN следует использовать для поиска значений в списках.
Аналогично, предпочтите НЕ СУЩЕСТВУЕТ вместо НЕ В .
Рекомендации по SQL для GROUP BY
Упорядочить несколько групп по убыванию мощности
Где возможно, СГРУППИРОВАТЬ НА столбца в порядке убывания кардинальности. То есть сначала группируйте по столбцам с более уникальными значениями (например, идентификаторы или номера телефонов), а затем группируйте по столбцам с меньшим количеством различных значений (например, штат или пол).
Лучшие практики SQL для HAVING
Используйте только HAVING для агрегатов фильтрации
А до HAVING отфильтруйте значения с помощью предложения WHERE перед агрегированием и группировкой этих значений.
Рекомендации по SQL для SELECT
ВЫБЕРИТЕ столбцы, а не звезды
Укажите столбцы, которые вы хотите включить в результаты (хотя можно использовать * при первом просмотре таблиц — только не забудьте LIMIT ваши результаты).
Рекомендации по SQL для UNION
Предпочесть UNION All вместо UNION
Если дубликаты не являются проблемой, UNION ALL не будет отбрасывать их, а поскольку UNION ALL не занимается удалением дубликатов, запрос будет более эффективным.
Рекомендации по SQL для ORDER BY
По возможности избегайте сортировки, особенно в подзапросах
Сортировка стоит дорого. Если вам необходимо выполнить сортировку, убедитесь, что ваши подзапросы не сортируют данные без необходимости.
Рекомендации по SQL для INDEX
Этот раздел предназначен для администраторов баз данных в толпе (тема слишком велика, чтобы поместиться в этой статье). Одна из наиболее распространенных проблем, с которыми сталкиваются люди при возникновении проблем с производительностью в запросах к базе данных, — это отсутствие адекватной индексации.
То, какие столбцы следует индексировать, обычно зависит от столбцов, по которым вы фильтруете (т. е. от того, какие столбцы обычно заканчиваются в предложениях
е. от того, какие столбцы обычно заканчиваются в предложениях WHERE ). Если вы обнаружите, что всегда фильтруете по общему набору столбцов, вам следует подумать об индексации этих столбцов.
Добавление индексов
Индексация столбцов внешнего ключа и часто запрашиваемых столбцов может значительно сократить время запроса. Вот пример оператора для создания индекса:
CREATE INDEX product_title_index В продуктах (название)
Доступны различные типы индексов, наиболее распространенный тип индекса использует B-дерево для ускорения поиска. Ознакомьтесь с нашей статьей о том, как сделать информационные панели быстрее, и ознакомьтесь с документацией по вашей базе данных, чтобы узнать, как создать индекс.
Использовать частичные индексы
Для особенно больших наборов данных или неравномерных наборов данных, где определенные диапазоны значений появляются чаще, рассмотрите возможность создания индекса с предложением WHERE , чтобы ограничить количество индексируемых строк. Частичные индексы также могут быть полезны для диапазонов дат, например, если вы хотите индексировать данные только за последнюю неделю.
Частичные индексы также могут быть полезны для диапазонов дат, например, если вы хотите индексировать данные только за последнюю неделю.
Использовать составные индексы
Для столбцов, которые обычно используются вместе в запросах (например, last_name, first_name), рассмотрите возможность создания составного индекса. Синтаксис аналогичен созданию одного индекса. Например:
CREATE INDEX full_name_index ON клиентов (last_name, first_name)
ОБЪЯСНИТЬ
Поиск узких мест
Некоторые базы данных, такие как PostgreSQL, предлагают информацию о плане запроса на основе вашего кода SQL. Просто добавьте к своему коду префикс ключевых слов EXPLAIN ANALYZE . Эти команды можно использовать для проверки планов запросов и поиска узких мест или для сравнения планов одной версии запроса с другой, чтобы определить, какая версия более эффективна.
Вот пример запроса с использованием образца базы данных dvdrental , доступного для PostgreSQL.
EXPLAIN ANALYZE SELECT название, выпуск_год ИЗ фильма ГДЕ выпуск_год > 2000;
И вывод:
Seq Scan на пленке (стоимость=0,00..66,50 рядов=1000 ширина=19) (фактическое время=0,008..0,311 рядов=1000 петель=1) Фильтр: ((release_year)::integer > 2000) Время планирования: 0,062 мс Время выполнения: 0,416 мс
Вы увидите миллисекунды, необходимые для планирования времени, времени выполнения, а также стоимости, строк, ширины, времени, циклов, использования памяти и т. д. Чтение этих анализов — своего рода искусство, но вы можете использовать их для выявления проблемных областей в ваших запросах (таких как вложенные циклы или столбцы, индексация которых может быть полезна) по мере их уточнения.
Вот документация PostreSQL по использованию EXPLAIN.
С
Организуйте свои запросы с помощью общих табличных выражений (CTE)
Используйте предложение WITH для инкапсуляции логики в общем табличном выражении (CTE). Вот пример запроса, который ищет продукты с самым высоким средним доходом на единицу, проданную в 2019 году, а также максимальные и минимальные значения.
Вот пример запроса, который ищет продукты с самым высоким средним доходом на единицу, проданную в 2019 году, а также максимальные и минимальные значения.
С product_orders КАК (
ВЫБЕРИТЕ o.created_at AS order_date,
p.title КАК product_title,
(o.subtotal / o.quantity) КАК доход_на_единицу
ОТ заказов КАК o
LEFT JOIN products AS p ON o.product_id = p.id
-- Отфильтровывать заказы, размещенные службой поддержки клиентов, для взимания платы с клиентов.
ГДЕ о.количество > 0
)
ВЫБЕРИТЕ product_title КАК продукт,
AVG(доход_на_единицу) AS avg_revenue_per_unit,
MAX(доход_на_единицу) AS max_revenue_per_unit,
MIN(доход_на_единицу) AS min_revenue_per_unit
ОТ product_orders
ГДЕ order_date МЕЖДУ 2019 г.-01-01" И "31-12-2019"
СГРУППИРОВАТЬ ПО продукту
ЗАКАЗАТЬ ПО avg_revenue_per_unit DESC
Предложение WITH делает код читабельным, поскольку основной запрос (то, что вы на самом деле ищете) не прерывается длинным подзапросом.
Вы также можете использовать CTE, чтобы сделать ваш SQL более читабельным, если, например, в вашей базе данных есть поля с неудобными именами или которые требуют небольшой обработки данных для получения полезных данных. Например, CTE могут быть полезны при работе с полями JSON. Вот пример извлечения и преобразования полей из большого двоичного объекта JSON пользовательских событий.
С исходными_данными КАК (
ВЫБЕРИТЕ события->'данные'->>'имя' КАК событие_имя,
CAST(события->'данные'->>'ts' AS timestamp) AS event_timestamp
CAST(события->'данные'->>'cust_id' AS int) AS customer_id
ОТ пользовательской_активности
)
ВЫБЕРИТЕ имя_события,
event_timestamp,
Пользовательский ИД
ИЗ source_data
Кроме того, вы можете сохранить подзапрос как фрагмент SQL (рис. 3 — обратите внимание на круглые скобки вокруг фрагмента), чтобы легко повторно использовать этот код в других запросах.
Рис. 3 . Сохранение подзапроса во фрагменте и его использование в предложении FROM.
И да, как и следовало ожидать, аэродинамический кожаный тукан приносит самый высокий средний доход на проданную единицу.
С метабазой вам даже не нужно использовать SQL
SQL потрясающий. Но то же самое можно сказать и о построителе запросов Metabase и редакторе блокнотов. Вы можете составлять запросы с помощью графического интерфейса Metabase для объединения таблиц, фильтрации и суммирования данных, создания настраиваемых столбцов и многого другого. А с помощью пользовательских выражений вы можете справиться с подавляющим большинством аналитических вариантов использования, даже не прибегая к SQL. Вопросы, составленные с использованием Notebook Editor также имеет преимущества автоматической детализации, которая позволяет зрителям ваших диаграмм щелкать и исследовать данные, функция, недоступная для вопросов, написанных на SQL.
Вопиющие ошибки или упущения?
Существуют библиотеки книг по SQL, так что здесь мы коснемся только поверхности. Вы можете поделиться секретами своего SQL-колдовства с другими пользователями метабазы на нашем форуме.
Вы можете поделиться секретами своего SQL-колдовства с другими пользователями метабазы на нашем форуме.
« Предыдущая Далее »
Вам помогла эта статья?
Спасибо за отзыв!
Учебное пособие по T-SQL: создание операторов Transact-SQL — SQL Server
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
Применяется к: SQL Server База данных SQL Azure Azure Synapse Analytics Платформа аналитики (PDW)
Примечание
Путь обучения «Начало работы с запросами с помощью Transact-SQL» содержит более подробные сведения, а также практические примеры.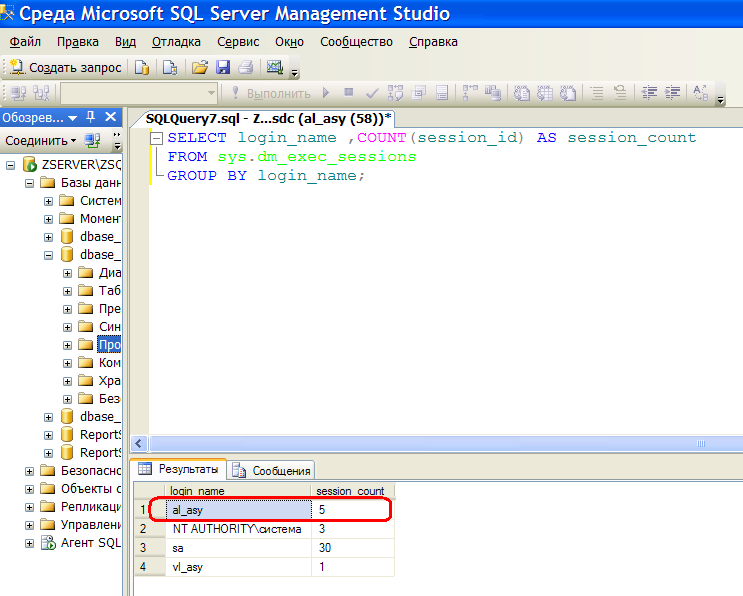
Добро пожаловать в учебник по написанию операторов Transact-SQL. Этот учебник предназначен для пользователей, которые плохо знакомы с написанием операторов SQL. Он помогает новым пользователям начать работу, ознакомившись с некоторыми основными операторами для создания таблиц и вставки данных. В этом руководстве используется Transact-SQL, реализация Microsoft стандарта SQL.
Это руководство предназначено для краткого ознакомления с языком Transact-SQL, а не для замены класса Transact-SQL. Операторы в этом руководстве намеренно сделаны простыми и не предназначены для представления сложности типичной производственной базы данных.
Примечание
Если вы новичок, вам может быть проще использовать SQL Server Management Studio вместо написания операторов Transact-SQL.
Чтобы найти дополнительные сведения о каком-либо конкретном операторе, выполните поиск оператора по имени или используйте содержимое для просмотра языковых элементов, перечисленных в алфавитном порядке в разделе Справочник по Transact-SQL (механизм базы данных). Другой хорошей стратегией поиска информации является поиск ключевых слов, связанных с интересующей вас темой. Например, если вы хотите знать, как вернуть часть даты (например, месяц), выполните поиск по указателю. на дат [SQL Server] , а затем выберите dateparts . Это приведет вас к статье DATEPART (Transact-SQL). В качестве другого примера, чтобы узнать, как работать со строками, найдите строковых функций . Вы перейдете к статье Строковые функции (Transact-SQL).
Другой хорошей стратегией поиска информации является поиск ключевых слов, связанных с интересующей вас темой. Например, если вы хотите знать, как вернуть часть даты (например, месяц), выполните поиск по указателю. на дат [SQL Server] , а затем выберите dateparts . Это приведет вас к статье DATEPART (Transact-SQL). В качестве другого примера, чтобы узнать, как работать со строками, найдите строковых функций . Вы перейдете к статье Строковые функции (Transact-SQL).
Что вы узнаете
В этом учебном пособии показано, как создать базу данных, создать таблицу в базе данных, вставить данные в таблицу, обновить данные, прочитать данные, удалить данные, а затем удалить таблицу. Вы создадите представления и хранимые процедуры и настроите пользователя для работы с базой данных и данными.
Этот учебник разделен на три урока:
Урок 1: Создание объектов базы данных
На этом уроке вы создадите базу данных, создадите таблицу в базе данных, вставите данные в таблицу, обновите данные и прочитаете данные.
