Как работает Git / Habr
В этом эссе описана схема работы Git. Предполагается, что вы знакомы с Git достаточно, чтобы использовать его для контроля версий своих проектов.Эссе концентрируется на структуре графа, на которой основан Git, и на том, как свойства этого графа определяют поведение Git. Изучая основы, вы строите своё представление на достоверной информации, а не на гипотезах, полученных из экспериментов с API. Правильная модель позволит вам лучше понять, что сделал Git, что он делает и что он собирается сделать.
Текст разбит на серии команд, работающих с единым проектом. Иногда встречаются наблюдения по поводу структуры данных графа, лежащего в основе Git. Наблюдения иллюстрируют свойство графа и поведение, основанное на нём.
После прочтения для ещё более глубокого погружения можно обратиться к обильно комментируемому исходному коду моей реализации Git на JavaScript.
Создание проекта
~ $ mkdir alpha
~ $ cd alphaПользователь создаёт директорию alpha
~/alpha $ mkdir data
~/alpha $ printf 'a' > data/letter.txtОн перемещается в эту директорию и создаёт директорию data. Внутри он создаёт файл letter.txt с содержимым «а». Директория alpha выглядит так:
alpha
└── data
└── letter.txtИнициализируем репозиторий
~/alpha $ git init
Initialized empty Git repositorygit init вносит текущую директорию в Git-репозиторий. Для этого он создаёт директорию .git и создаёт в ней несколько файлов. Они определяют всю конфигурацию Git и историю проекта. Это обычные файлы – никакой магии. Пользователь может их читать и редактировать. То есть – пользователь может читать и редактировать историю проекта так же просто, как файлы самого проекта.
Теперь директория alpha выглядит так:
alpha ├── data | └── letter.txt └── .git ├── objects etc...
Директория .git с её содержимым относится с Git. Все остальные файлы называются рабочей копией и принадлежат пользователю.
Добавляем файлы
~/alpha $ git add data/letter.txtПользователь запускает git add на data/letter.txt. Происходят две вещи.
Во-первых, создаётся новый блоб-файл в директории .git/objects/. Он содержит сжатое содержимое data/letter.txt. Его имя – сгенерированный хэш на основе содержимого. К примеру, Git делает хэш от а и получает 2e65efe2a145dda7ee51d1741299f848e5bf752e. Первые два символа хэша используются для имени директории в базе объектов: .git/objects/2e/. Остаток хэша – это имя блоб-файла, содержащего внутренности добавленного файла: .git/objects/2e/65efe2a145dda7ee51d1741299f848e5bf752e.
Заметьте, что простое добавление файла в Git приводит к сохранению его содержимого в директории objects. Оно будет храниться там, если пользователь удалит data/letter.txt из рабочей копии.
Во-вторых, git add добавляет файл в индекс. Индекс – это список, содержащий все файлы, за которыми Git было наказано следить. Он хранится в .git/index. Каждая строка даёт в соответствие отслеживаемому файлу хэш его содержимого и время добавления. Вот таким получается содержимое индекса после команды git add:
data/letter.txt 2e65efe2a145dda7ee51d1741299f848e5bf752eПользователь создаёт файл data/number.txt содержащий 1234.
~/alpha $ printf '1234' > data/number.txt
Рабочая копия выглядит так:
alpha
└── data
└── letter.txt
└── number.txtПользователь добавляет файл в Git.
~/alpha $ git add dataКоманда git add создаёт блоб-файл, в котором хранится содержимое data/number.txt. Он добавляет в индекс запись для data/number.txt, указывающую на блоб. Вот содержимое индекса после повторного запуска git add:
data/letter.txt 2e65efe2a145dda7ee51d1741299f848e5bf752e
data/number.txt 274c0052dd5408f8ae2bc8440029ff67d79bc5c3Заметьте, что в индексе перечислены только файлы из директории data, хотя пользователь давал команду git add data. Сама директория data отдельно не указывается.
~/alpha $ printf '1' > data/number.txt ~/alpha $ git add data
Когда пользователь создал data/number.txt, он хотел написать 1, а не 1234. Он вносит изменение и снова добавляет файл к индексу. Эта команда создаёт новый блоб с новым содержимым. Она обновляет запись в индексе для data/number.txt с указанием на новый блоб.
Делаем коммит
~/alpha $ git commit -m 'a1'
[master (root-commit) 774b54a] a1Пользователь делает коммит a1. Git выводит данные о нём. Мы вскоре объясним их.
У команды commit есть три шага. Она создаёт граф, представляющий содержимое версии проекта, которую коммитят. Она создаёт объект коммита. Она направляет текущую ветку на новый объект коммита.
Создание графа
Git запоминает текущее состояние проекта, создавая древовидный граф из индекса. Этот граф записывает расположение и содержимое каждого файла в проекте.
Граф состоит из двух типов объектов: блобы и деревья. Блобы сохраняются через git add. Они представляют содержимое файлов. Деревья сохраняются при коммите. Дерево представляет директорию в рабочей копии. Ниже приведён объект дерева, записавший содержимое директории data при новом коммите.
100664 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt
100664 blob 56a6051ca2b02b04ef92d5150c9ef600403cb1de number.txtПервая строка записывает всё необходимое для воспроизводства data/letter.txt. Первая часть хранит права доступа к файлу. Вторая – что содержимое файла хранится в блобе, а не в дереве. Третья – хэш блоба. Четвёртая – имя файла.
Ниже указан объект-дерево для alpha, корневой директории проекта:
040000 tree 0eed1217a2947f4930583229987d90fe5e8e0b74 dataЕдинственная строка указывает на дерево data.
В приведённом графе дерево root указывает на дерево data. Дерево data указывает на блобы для data/letter.txt и data/number.txt.
Создание объекта коммита
git commit создаёт объект коммита после создания графа. Объект коммита – это ещё один текстовый файл в .git/objects/:
tree ffe298c3ce8bb07326f888907996eaa48d266db4 author Mary Rose Cook <[email protected]> 1424798436 -0500 committer Mary Rose Cook <[email protected]> 1424798436 -0500 a1
Первая строка указывает на дерево графа. Хэш – для объекта дерева, представляющего корень рабочей копии. То бишь, директории alpha. Последняя строчка – комментарий коммита.
Направить текущую ветку на новый коммит
Наконец, команда коммита направляет текущую ветку на новый объект коммита.
Какая у нас текущая ветка? Git идёт в файл HEAD в .git/HEAD и видит:
ref: refs/heads/masterЭто значит, что HEAD указывает на master. master – текущая ветка.
HEAD и master – это ссылки. Ссылка – это метка, используемая Git, или пользователем, для идентификации определённого коммита.
Файла, представляющего ссылку master, не существует, поскольку это первый коммит в репозитории. Git создаёт файл в .git/refs/heads/master и задаёт его содержимое – хэш объекта коммит:
74ac3ad9cde0b265d2b4f1c778b283a6e2ffbafd(Если вы параллельно чтению вбиваете в Git команды, ваш хэш a1 будет отличаться от моего. Хэш объектов содержимого – блобов и деревьев – всегда получаются теми же. А коммитов – нет, потому что они учитывают даты и имена создателей).
Добавим в граф Git HEAD и master:
HEAD указывает на master, как и до коммита. Но теперь master существует и указывает на новый объект коммита.
Делаем не первый коммит
Ниже приведён граф после коммита a1. Включены рабочая копия и индекс.
Заметьте, что у рабочей копии, индекса и коммита одинаковое содержимое data/letter.txt и data/number.txt. Индекс и HEAD используют хэши для указания на блобы, но содержимое рабочей копии хранится в виде текста в другом месте.
~/alpha $ printf '2' > data/number.txtПользователь меняет содержимое data/number.txt на 2. Это обновляет рабочую копию, но оставляет индекс и HEAD без изменений.
~/alpha $ git add data/number.txtПользователь добавляет файл в Git. Это добавляет блоб, содержащий 2, в директорию objects. Указатель записи индекса для data/number.txt указывает на новый блоб.
~/alpha $ git commit -m 'a2' [master f0af7e6] a2
Пользователь делает коммит. Шаги у него такие же, как и раньше.
Во-первых, создаётся новый древовидный граф для представления содержимого индекса.
Запись в индексе для data/number.txt изменилась. Старое дерево data уже не отражает проиндексированное состояние директории data. Нужно создать новый объект-дерево data.
100664 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt
100664 blob d8263ee9860594d2806b0dfd1bfd17528b0ba2a4 number.txtХэш у нового объекта отличается от старого дерева data. Нужно создать новое дерево root для записи этого хэша.
040000 tree 40b0318811470aaacc577485777d7a6780e51f0b data
Во-вторых, создаётся новый объект коммита.
tree ce72afb5ff229a39f6cce47b00d1b0ed60fe3556
parent 774b54a193d6cfdd081e581a007d2e11f784b9fe
author Mary Rose Cook <[email protected]> 1424813101 -0500
committer Mary Rose Cook <[email protected]> 1424813101 -0500
a2Первая строка объекта коммита указывает на новый объект root. Вторая строка указывает на a1: родительский коммит. Для поиска родительского коммита Git идёт в HEAD, проходит до master и находит хэш коммита a1.
В третьих, содержимое файла-ветви master меняется на хэш нового коммита.
Коммит a2
Граф Git без рабочей копии и индекса
Свойства графа:
• Содержимое хранится в виде дерева объектов. Это значит, что в базе хранятся только изменения. Взгляните на граф сверху. Коммит а2 повторно использует блоб, сделанный до коммита а1. Точно так же, если вся директория от коммита до коммита не меняется, неё дерево и все блобы и нижележащие деревья можно использовать повторно. Обычно изменения между коммитами небольшие. Это значит, что Git может хранить большие истории коммитов, занимая немного места.
• У каждого коммита есть предок. Это значит, что в репозитории можно хранить историю проекта.
• Ссылки – входные точки для той или иной истории коммита. Это значит, что коммитам можно давать осмысленные имена. Пользователь организовывает работу в виде родословной, осмысленной для своего проекта, с ссылками типа fix-for-bug-376. Git использует символьные ссылки вроде HEAD, MERGE_HEAD и FETCH_HEAD для поддержки команды редактирования истории коммитов.
• Узлы в директории objects/ неизменны. Это значит, что содержимое редактируется, но не удаляется. Каждый кусочек содержимого, добавленный когда-либо, каждый сделанный коммит хранится где-то в директории objects.
• Ссылки изменяемы. Значит, смысл ссылки может измениться. Коммит, на который указывает master, может быть наилучшей версией проекта на текущий момент, но вскоре его может сменить новый коммит.
• Рабочая копия и коммиты, на которые указывают ссылки, доступны сразу. Другие коммиты – нет. Это значит, что недавнюю историю легче вызвать, но и меняется она чаще. Можно сказать, что память Git постоянно исчезает, и её надо стимулировать всё более жёсткими тычками.
Рабочую копию легче всего вызвать из истории, поскольку она находится в корне репозитория. Её вызов даже не требует команды Git. Но также это и самая непостоянная точка в истории. Пользователь может сделать десяток версий файла, но Git не запишет ни одну из них, пока они не добавлены.
Коммит, на который указывает HEAD, очень легко вызвать. Он находится на конце подтверждённой ветви. Чтобы просмотреть его содержимое, пользователь может просто сохранить и затем изучить рабочую копию. И в то же время, HEAD – самая часто изменяющаяся ссылка.
Коммит, на который указывает конкретная ссылка, легко вызвать. Пользователь просто подтвердит эту ветку. Конец ветки меняется реже, чем HEAD, но достаточно для того, чтобы смысл названия ветки можно было менять.
Сложно вызвать коммит, на который не указывают ссылки. Чем дальше пользователь уходит от ссылки, тем тяжелее ему воссоздать смысл коммита. Но чем дальше в прошлое он идёт, тем меньше вероятность, что кто-либо изменил историю с момента их предыдущего просмотра.
Подтверждение (check out) коммита
~/alpha $ git checkout 37888c2
You are in 'detached HEAD' state...Пользователь подтверждает коммит а2, используя его хэш. (Если вы запускаете эти команды, то данная команда у вас не сработает. Используйте git log, чтобы выяснить хэш вашего коммита а2).
Подтверждение состоит из четырёх шагов.
Во-первых, Git получает коммит а2 и граф, на который тот указывает.
Во-вторых, он делает записи о файлах в графе в рабочей копии. В результате изменений не происходит. В рабочей копии уже есть содержимое графа, поскольку HEAD уже указывал на коммит а2 через master.
В-третьих, Git делает записи о файлах в граф в индексе. Тут тоже изменений не происходит. В индексе уже содержится коммит а2.
В-четвёртых, содержимому HEAD присваивается хэш коммита а2:
f0af7e62679e144bb28c627ee3e8f7bdb235eee9Запись хэша в HEAD приводит репозиторий в состоянии с отделённым HEAD. Обратите внимание на графе ниже, что HEAD указывает непосредственно на коммит а2, а не на master.
~/alpha $ printf '3' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'a3'
[detached HEAD 3645a0e] a3Пользователь записывает в содержимое data/number.txt значение 3 и коммитит изменение. Git идёт к HEAD для получения родителя коммита а3. Вместо того, чтобы найти и последовать по ссылке на ветвь, он находит и возвращает хэш коммита а2.
Git обновляет HEAD, чтобы он указывал на хэш нового коммита а3. Репозиторий по-прежнему находится в состоянии с отделённым HEAD. Он не на ветви, поскольку ни один коммит не указывает ни на а3, ни на любой из его потомков. Его легко потерять.
Далее мы будем опускать деревья и блобы из диаграмм графов.
Создать ответвление (branch)
~/alpha $ git branch deputyПользователь создаёт новую ветвь под названием deputy. В результате появляется новый файл в .git/refs/heads/deputy, содержащий хэш, на который указывает HEAD: хэш коммита а3.
Ветви – это только ссылки, а ссылки – это только файлы. Это значит, что ветви Git весят очень немного.
Создание ветви deputy размещает новый коммит а3 на ответвлении. HEAD всё ещё отделён, поскольку всё ещё показывает непосредственно на коммит.
Подтвердить ответвление
~/alpha $ git checkout master
Switched to branch 'master'Пользователь подтверждает ответвление master.
Во-первых, Git получает коммит а2, на который указывает master, и получает граф, на который указывает коммит.
Во-вторых, Git вносит файловые записи в граф в файлы рабочей копии. Это меняет контент data/number.txt на 2.
В-третьих, Git вносит файловые записи в граф индекса. Это обновляет вхождение для data/number.txt на хэш блоба 2.
В-четвёртых, Git направляет HEAD на master, меняя его содержимое с хэша на
ref: refs/heads/masterПодтвердить ветвь, несовместимую с рабочей копией
~/alpha $ printf '789' > data/number.txt
~/alpha $ git checkout deputy
Your changes to these files would be overwritten
by checkout:
data/number.txt
Commit your changes or stash them before you
switch branches.Пользователь случайно присваивает содержимому data/number.txt значение 789. Он пытается подтвердить deputy. Git препятствует подтверждению.
HEAD указывает на master, указывающий на a2, где в data/number.txt записано 2. deputy указывает на a3, где в data/number.txt записано 3. В версии рабочей копии для data/number.txt записано 789. Все эти версии различны, и разницу нужно как-то устранить.
Git может заменить версию рабочей копии версией из подтверждаемого коммита. Но он всеми силами избегает потери данных.
Git может объединить версию рабочей копии с подтверждаемой версией. Но это сложно.
Поэтому Git отклоняет подтверждение.
~/alpha $ printf '2' > data/number.txt
~/alpha $ git checkout deputy
Switched to branch 'deputy'Пользователь замечает, что он случайно отредактировал data/number.txt и присваивает ему обратно 2. Затем он успешно подтверждает deputy.
Объединение с предком
~/alpha $ git merge master
Already up-to-date.Пользователь включает master в deputy. Объединение двух ветвей означает объединение двух коммитов. Первый коммит – тот, на который указывает deputy: принимающий. Второй коммит – тот, на который указывает master: дающий. Для объединения Git ничего не делает. Он сообщает, что он уже «Already up-to-date».
Серия объединений в графе интерпретируется как серия изменений содержимого репозитория. Это значит, что при объединении если коммит дающего получается предком коммита принимающего, Git ничего не делает. Эти изменения уже внесены.
Объединение с потомком
~/alpha $ git checkout master
Switched to branch 'master'Пользователь подтверждает master.
~/alpha $ git merge deputy
Fast-forwardОн включает deputy в master. Git обнаруживает, что коммит принимающего, а2, является предком коммита дающего, а3. Он может сделать объединение с быстрой перемоткой вперёд.
Он берёт коммит дающего и граф, на который он указывает. Он вносит файловые записи в графы рабочей копии и индекса. Затем он «перематывает» master, чтобы тот указывал на а3.
Серия коммитов на графе интерпретируется как серия изменений содержимого репозитория. Это значит, что при объединении, если дающий является потомком принимающего, история не меняется. Уже существует последовательность коммитов, описывающих нужные изменения: последовательность коммитов между принимающим и дающим. Но, хотя история Git не меняется, граф Git меняется. Конкретная ссылка, на которую указывает HEAD, обновляется, чтобы указывать на коммит дающего.
Объединить два коммита из разных родословных
~/alpha $ printf '4' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'a4'
[master 7b7bd9a] a4Пользователь записывает 4 в содержимое number.txt и коммитит изменение в master.
~/alpha $ git checkout deputy
Switched to branch 'deputy'
~/alpha $ printf 'b' > data/letter.txt
~/alpha $ git add data/letter.txt
~/alpha $ git commit -m 'b3'
[deputy 982dffb] b3Пользователь подтверждает deputy. Он записывает «b» в содержимое data/letter.txt и коммитит изменение в deputy.
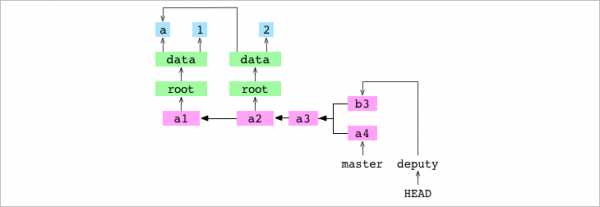
У коммитов могут быть общие родители. Это значит, что в истории коммитов можно создавать новые родословные.
У коммитов может быть несколько родителей. Это значит, что разные родословные можно объединить коммитом с двумя родителями: объединяющим коммитом.
~/alpha $ git merge master -m 'b4'
Merge made by the 'recursive' strategy.Пользователь объединяет master с deputy.
Git обнаруживает, что принимающий, b3, и дающий, a4, находятся в разных родословных. Он выполняет объединяющий коммит. У этого процесса восемь шагов.
1. Git записывает хэш дающего коммита в файл alpha/.git/MERGE_HEAD. Наличие этого файла сообщает Git, что он находится в процессе объединения.
2. Во-вторых, Git находит базовый коммит: самый новый предок, общий для дающего и принимающего коммитов.
У коммитов есть родители. Это значит, что можно найти точку, в которой разделились две родословных. Git отслеживает цепочку назад от b3, чтобы найти всех его предков, и назад от a4 с той же целью. Он находит самого нового из их общих предков, а3. Это базовый коммит.
3. Git создают индексы для базового, дающего и принимающего коммита из их древовидных графов.
4. Git создаёт diff, объединяющий изменения, которые принимающий и дающий коммиты произвели с базовым. Этот diff – список путей файлов, указывающих на изменения: добавление, удаление, модификацию или конфликты.
Git получает список всех файлов, имеющихся в индексах базового коммита, получающего и дающего. Для каждого он сравнивает записи в индексах и решает, каким образом нужно менять файл. Он пишет соответствующую запись в diff. В нашем случае в diff попадают две записи.
Первая запись для data/letter.txt. Содержимое этого файла – «a» в базовом, «b» в получающем и «a» в дающем. Содержимое у базового и получающего различается. Но у базового и дающего – совпадает. Git видит, что содержимое изменено получающим, а не дающим. Запись в diff для data/letter.txt – это изменение, а не конфликт.
Вторая запись в diff – для data/number.txt. В этом случае, содержимое совпадает у базового и получающего, а у дающего оно другое. Запись в diff для data/number.txt — также изменение.
Есть возможность найти базовый коммит объединения. Это значит, что если файл отличается от базового только в получающем или дающем, Git может автоматически провести объединение файла. Это уменьшает работу, которую должен проделать пользователь.
5. Изменения, описанные записями в diff, применяются к рабочей копии. Содержимому data/letter.txt присваивается значение b, а содержимому data/number.txt – 4.
6. Изменения, описанные записями в diff, применяются к индексу. Запись, относящаяся к data/letter.txt, указывает на блоб b, а запись для data/number.txt – на блоб 4.
7. Подтверждается обновлённый индекс:
tree 20294508aea3fb6f05fcc49adaecc2e6d60f7e7d
parent 982dffb20f8d6a25a8554cc8d765fb9f3ff1333b
parent 7b7bd9a5253f47360d5787095afc5ba56591bfe7
author Mary Rose Cook <[email protected]> 1425596551 -0500
committer Mary Rose Cook <[email protected]> 1425596551 -0500
b4Обратите внимание, что у коммита два родителя.
8. Git направляет текущую ветвь, deputy, на новый коммит.
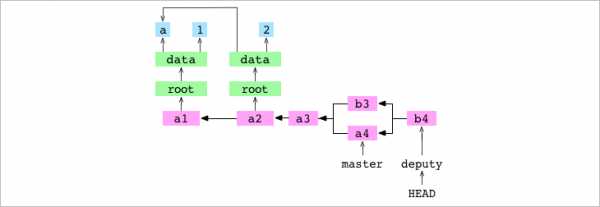
Объединение двух коммитов из разных родословных, изменяющих один и тот же файл
~/alpha $ git checkout master
Switched to branch 'master'
~/alpha $ git merge deputy
Fast-forwardПользователь подтверждает master. Он объединяет deputy и master. Это приводит к перемотке master до коммита b4. Теперь master и deputy указывают на один и тот же коммит.
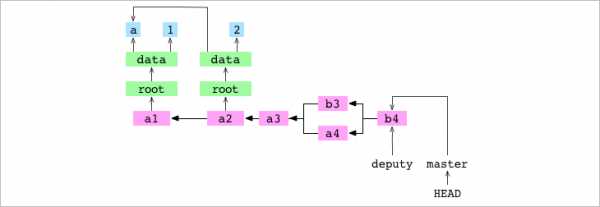
~/alpha $ git checkout deputy
Switched to branch 'deputy'
~/alpha $ printf '5' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'b5'
[deputy bd797c2] b5Пользователь подтверждает deputy. Он устанавливает содержимое data/number.txt в 5 и подтверждает изменение в deputy.
~/alpha $ git checkout master
Switched to branch 'master'
~/alpha $ printf '6' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'b6'
[master 4c3ce18] b6Пользователь подтверждает master. Он устанавливает содержимое data/number.txt в 6 и подтверждает изменение в master.
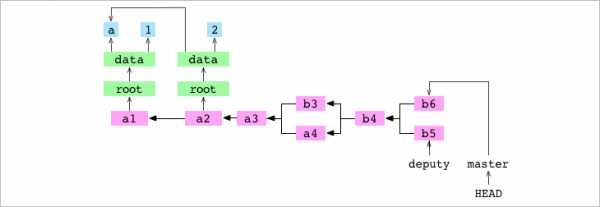
~/alpha $ git merge deputy
CONFLICT in data/number.txt
Automatic merge failed; fix conflicts and
commit the result.Пользователь объединяет deputy и master. Выявляется конфликт и объединение приостанавливается. Процесс объединения с конфликтом делает те же шесть первых шагов, что и процесс объединения без конфликта: определить .git/MERGE_HEAD, найти базовый коммит, создать индексы для базового, принимающего и дающего коммитов, создать diff, обновить рабочую копию и обновить индекс. Из-за конфликта седьмой шаг с коммитом и восьмой с обновлением ссылки не выполняются. Пройдём по ним заново и посмотрим, что получается.
1. Git записывает хэш дающего коммита в файл .git/MERGE_HEAD.
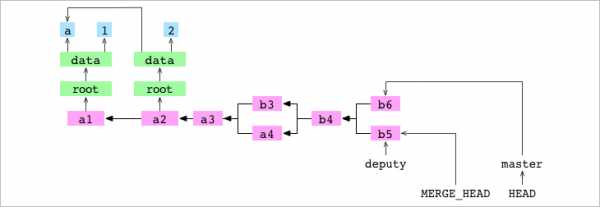
2. Git находит базовый коммит, b4.
3. Git генерирует индексы для базового, принимающего и дающего коммитов.
4. Git генерирует diff, комбинирующий изменения базового коммита, произведённые получающим и дающим коммитами. Этот diff – список путей к файлам, указывающим на изменения: добавление, удаление, модификацию или конфликт.
В данном случае diff содержит только одну запись: data/number.txt. Она отмечена как конфликт, поскольку содержимое data/number.txt отличается в дающем, принимающем и базовом коммитах.
5. Изменения, определяемые записями в diff, применяются к рабочей копии. В области конфликта Git выводит обе версии в файл рабочей копии. Содержимое файла ata/number.txt становится следующим:
<<<<<<< HEAD
6
=======
5
>>>>>>> deputy6. Изменения, определённые записями в diff, применяются к индексу. Записи в индексе имеют уникальный идентификатор в виде комбинации пути к файлу и этапа. У записи файла без конфликта этап равен 0. Перед объединением индекс выглядел так, где нули – это номера этапов:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
0 data/number.txt 62f9457511f879886bb7728c986fe10b0ece6bcbПосле записи diff в индекс тот выглядит уже так:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
1 data/number.txt bf0d87ab1b2b0ec1a11a3973d2845b42413d9767
2 data/number.txt 62f9457511f879886bb7728c986fe10b0ece6bcb
3 data/number.txt 7813681f5b41c028345ca62a2be376bae70b7f61Запись data/letter.txt на этапе 0 такая же, какая и была до объединения. Запись для data/number.txt с этапом 0 исчезла. Вместо неё появились три новых. У записи с этапом 1 хэш от базового содержимого data/number.txt. У записи с этапом 3 хэш от содержимого дающего data/number.txt. Присутствие трёх записей говорит Git, что для data/number.txt возник конфликт.
Объединение приостанавливается.
~/alpha $ printf '11' > data/number.txt
~/alpha $ git add data/number.txtПользователь интегрирует содержимое двух конфликтующих версий, устанавливая содержимое data/number.txt равным 11. Он добавляет файл в индекс. Git добавляет блоб, содержащий 11. Добавление конфликтного файла говорит Git о том, что конфликт решён. Git удаляет вхождения data/number.txt для этапов 1, 2 и 3 из индекса. Он добавляет запись для data/number.txt на этапе 0 с хэшем от нового блоба. Теперь индекс содержит записи:
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
0 data/number.txt 9d607966b721abde8931ddd052181fae905db503
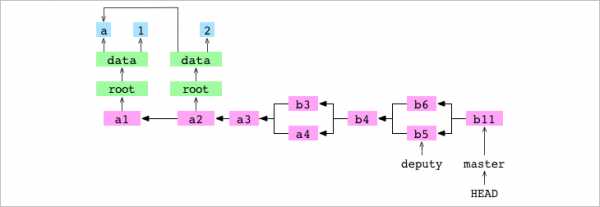
~/alpha $ git commit -m 'b11'
[master 251a513] b117. Пользователь коммитит. Git видит в репозитории .git/MERGE_HEAD, что говорит ему о том, что объединение находится в процессе. Он проверяет индекс и не обнаруживает конфликтов. Он создаёт новый коммит, b11, для записи содержимого разрешённого объединения. Он удаляет файл .git/MERGE_HEAD. Это и завершает объединение.
8. Git направляет текущую ветвь, master, на новый коммит.
Удаление файла
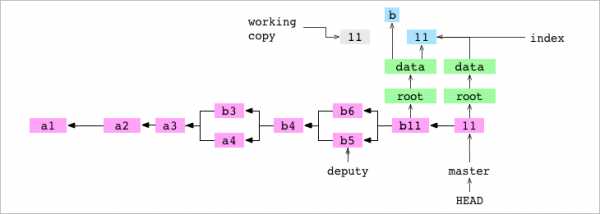
Диаграмма для графа Git включает историю коммитов, деревья и блобы последнего коммита, рабочую копию и индекс:
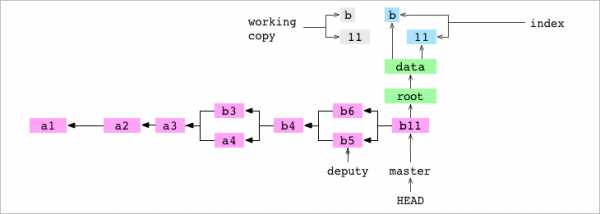
~/alpha $ git rm data/letter.txt
rm 'data/letter.txt'Пользователь указывает Git удалить data/letter.txt. Файл удаляется из рабочей копии. Из индекса удаляется запись.
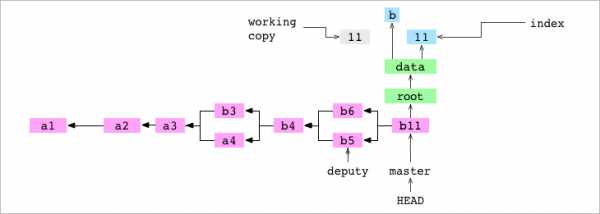
~/alpha $ git commit -m '11'
[master d14c7d2] 11Пользователь делает коммит. Как обычно при коммите, Git строит граф, представляющий содержимое индекса. data/letter.txt не включён в граф, поскольку его нет в индексе.
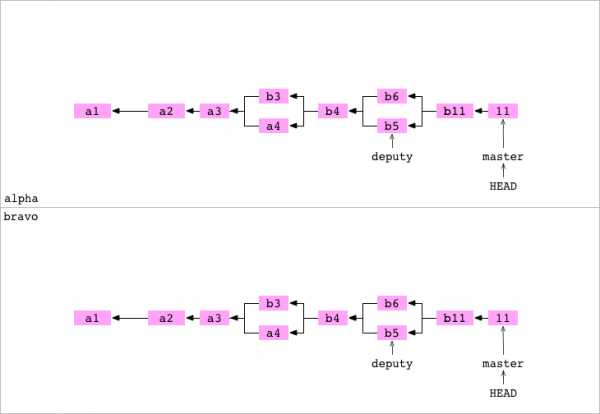
Копировать репозиторий
~/alpha $ cd ..
~ $ cp -R alpha bravoПользователь копирует содержимое репозитория alpha/ в директорию bravo/. Это приводит к следующей структуре:
~
├── alpha
| └── data
| └── number.txt
└── bravo
└── data
└── number.txtТеперь в директории bravo есть новый граф Git:
Связать репозиторий с другим репозиторием
~ $ cd alpha
~/alpha $ git remote add bravo ../bravoПользователь возвращается в репозиторий alpha. Он назначает bravo удалённым репозиторием для alpha. Это добавляет несколько строк в файл alpha/.git/config:
[remote "bravo"]
url = ../bravo/Строки говорят, что существует удалённый репозиторий bravo в директории ../bravo.
Получить ветвь с удалённого репозитория
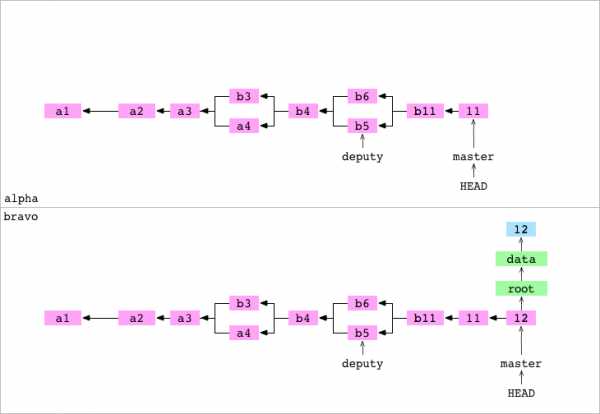
~/alpha $ cd ../bravo
~/bravo $ printf '12' > data/number.txt
~/bravo $ git add data/number.txt
~/bravo $ git commit -m '12'
[master 94cd04d] 12Пользователь переходит к репозиторию bravo. Он присваивает содержимому data/number.txt значение 12 и коммитит изменение в master на bravo.
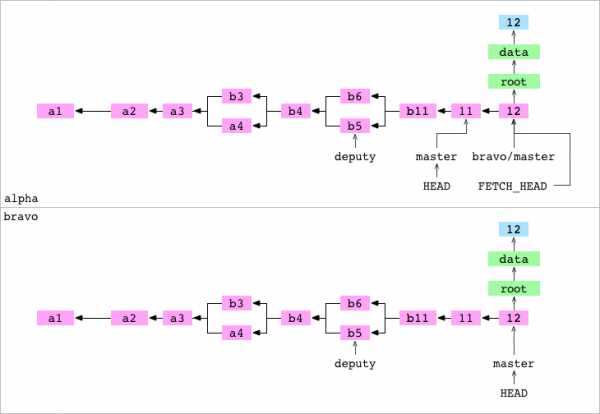
~/bravo $ cd ../alpha
~/alpha $ git fetch bravo master
Unpacking objects: 100%
From ../bravo
* branch master -> FETCH_HEADПользователь переходит в репозиторий alpha. Он копирует master из bravo в alpha. У этого процесса четыре шага.
1. Git получает хэш коммита, на который в bravo указывает master. Это хэш коммита 12.
2. Git составляет список всех объектов, от которых зависит коммит 12: сам объект коммита, объекты в его графе, коммиты предка коммита 12, и объекты из их графов. Он удаляет из этого списка все объекты, которые уже есть в базе alpha. Остальное он копирует в alpha/.git/objects/.
3. Содержимому конкретного файла ссылки в alpha/.git/refs/remotes/bravo/master присваивается хэш коммита 12.
4. Содержимое alpha/.git/FETCH_HEAD становится следующим:
94cd04d93ae88a1f53a4646532b1e8cdfbc0977f branch 'master' of ../bravoЭто значит, что самая последняя команда fetch достала коммит 12 из master с bravo.
Объекты можно копировать. Это значит, что у разных репозиториев может быть общая история.
Репозитории могут хранить ссылки на удалённые ветви типа alpha/.git/refs/remotes/bravo/master. Это значит, что репозиторий может локально записывать состояние ветви удалённого репозитория. Он корректен во время его копирования, но станет устаревшим в случае изменения удалённой ветви.
Объединение FETCH_HEAD
~/alpha $ git merge FETCH_HEAD
Updating d14c7d2..94cd04d
Fast-forwardПользователь объединяет FETCH_HEAD. FETCH_HEAD – это просто ещё одна ссылка. Она указывает на коммит 12, дающий. HEAD указывает на коммит 11, принимающий. Git делает объединение-перемотку и направляет master на коммит 12.
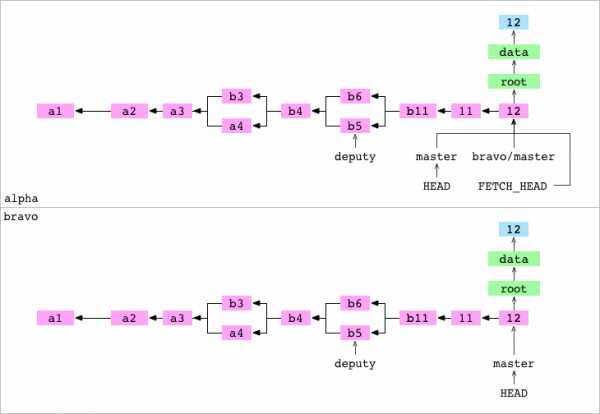
Получить ветвь удалённого репозитория
~/alpha $ git pull bravo master
Already up-to-date.Пользователь переносит master из bravo в alpha. Pull – это сокращение для «скопировать и объединить FETCH_HEAD». Git выполняет обе команды и сообщает, что master «Already up-to-date».
Клонировать репозиторий
~/alpha $ cd ..
~ $ git clone alpha charlie
Cloning into 'charlie'Пользователь переезжает в верхний каталог. Он клонирует alpha в charlie. Клонирование приводит к результатам, сходным с командой cp, которую пользователь выполнил для создания репозитория bravo. Git создаёт новую директорию charlie. Он инициализирует charlie в качестве репозитория, добавляет alpha в качестве удалённого под именем origin, получает origin и объединяет FETCH_HEAD.
Разместить (push) ветвь на подтверждённой ветви на удалённом репозитории
~ $ cd alpha
~/alpha $ printf '13' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m '13'
[master 3238468] 13Пользователь возвращается в репозиторий alpha. Присваивает содержимому data/number.txt значение 13 и коммитит изменение в master на alpha.
~/alpha $ git remote add charlie ../charlieОн назначает charlie удалённым репозиторием alpha.
~/alpha $ git push charlie master
Writing objects: 100%
remote error: refusing to update checked out
branch: refs/heads/master because it will make
the index and work tree inconsistentОн размещает master на charlie. Все объекты, необходимые для коммита 13, копируются в charlie.
В этот момент процесс размещения останавливается. Git, как всегда, сообщает пользователю, что пошло не так. Он отказывается размещать на ветви, которая подтверждена удалённо. Это имеет смысл. Размещение обновило бы удалённый индекс и HEAD. Это привело бы к путанице, если бы кто-то ещё редактировал рабочую копию на удалённом репозитории.
В этот момент пользователь может создать новую ветвь, объединить коммит 13 с ней и разместить эту ветвь на charlie. Но пользователям требуется репозиторий, на котором можно размещать, что угодно. Им нужен центральный репозиторий, на котором можно размещать, и с которого можно получать (pull), но на который напрямую никто не коммитит. Им нужно нечто типа удалённого GitHub. Им нужен чистый (bare) репозиторий.
Клонируем чистый (bare) репозиторий
~/alpha $ cd ..
~ $ git clone alpha delta --bare
Cloning into bare repository 'delta'Пользователь переходит в верхнюю директорию. Он создаёт клон delta в качестве чистого репозитория. Это обычный клон с двумя особенностями. Файл config говорит о том, что репозиторий чистый. И файлы, обычно хранящиеся в директории .git, хранятся в корне репозитория:
delta
├── HEAD
├── config
├── objects
└── refs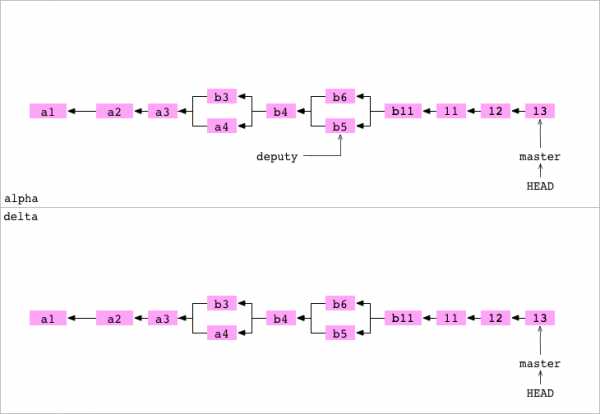
Разместить ветвь в чистом репозитории
~ $ cd alpha
~/alpha $ git remote add delta ../deltaПользователь возвращается в репозиторий alpha. Он назначает delta удалённым репозиторием для alpha.
~/alpha $ printf '14' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m '14'
[master cb51da8] 14Он присваивает содержимому значение 14 и коммитит изменение в master на alpha.
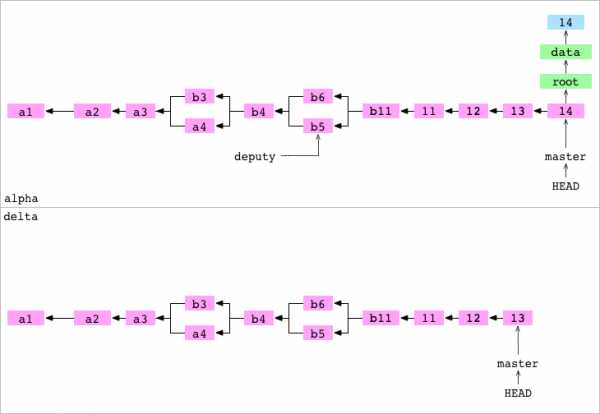
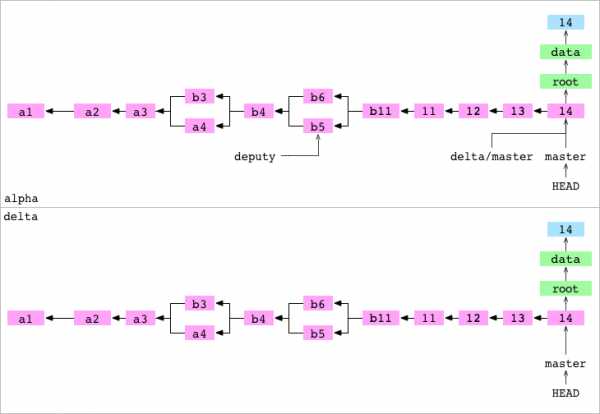
~/alpha $ git push delta master
Writing objects: 100%
To ../delta
3238468..cb51da8 master -> masterОн размещает master в delta. Размещение проходит в три этапа.
1. Все объекты, необходимые для коммита 14 на ветви master, копируются из alpha/.git/objects/ в delta/objects/.
2. delta/refs/heads/master обновляется до коммита 14.
3. alpha/.git/refs/remotes/delta/master направляют на коммит 14. В alpha находится актуальная запись состояния delta.
Итог
Git построен на графе. Почти все команды Git манипулируют этим графом. Чтобы понять Git, сконцентрируйтесь на свойствах графа, а не процедурах или командах.
Чтобы узнать о Git ещё больше, изучайте директорию .git. Это не страшно. Загляните вовнутрь. Измените содержимое файлов и посмотрите, что произойдёт. Создайте коммит вручную. Попробуйте посмотреть, как сильно вы сможете сломать репозиторий. Затем почините его.
habr.com
Еще одна инструкция по пользованию git / Habr
До того, как я начал работать в одноклассниках я думал, что знаю как пользоваться системой контроля версий. Но там мне дали ссылку на документацию по git. Эту книгу можно читать бесконечно, но на мой взгляд для того, чтобы начать пользоваться git она абсолютно бесполезна. Это не проблема скажете вы и будете совершенно правы. На том же хабре есть куча статей на тему как пользоваться git. Но пару дней назад один мой товарищ попросил объяснить ему некоторые непонятые им моменты. Я объяснил, как смог и хочу поделиться просто еще одной шпаргалкой на тему «10 простых действий по использованию git в повседневной работе». Не такой уж и маленькой она получилась, поэтому я пока напишу только как работать с git для вашего рабочего проекта, а потом, отдельно, что делать если вы хотите вносить изменения в чужой проект.Не хотелось бы описывать как настраивать аутентификацию для git.
Насколько я знаю можно настроить либо ssh ключи, либо использовать логин/пароль и ввести их в глобальных или локальных настройках git. Думаю когда заводишь аккаунт на github там про все про это написано. Лично у меня стоит Linux и настроены pub/priv ssh ключи для github. Для windows я обычно пользовался cygwin и использовал там те же ssh ключи.
И еще. Я по какой-то непонятной причине почти не пользуюсь IDE для работы с git. Если использовать IDE, то думаю все равно с какой системой контроля версий работать.
10 шагов для работы с проектом
Хочу написать что нужно делать если вы работаете в компании в которой используется git. Как правило для каждой задачи, которую вы делаете вам надо будет заводить отдельную ветку (branch), называть ее по имени задачи в вашей системе управления задач (например по имени задачи в JIRA), а после завершения выполнения задачи и прохождения процедуры проверки кода другими работниками объединять вашу ветку с общим кодом.
- Создаем локальную копию вашего проекта
# git clone "project_url"
Для github project_url можно найти нажав зеленую кнопку «Clone or download» на странице проекта. - Обновляем локальную копию — подгружаем изменения, которые внесли другие участники в эту ветку
# git pull
Примечание — git ругается, что не знает откуда обновлятьсяЕсли вы сами создали ветку при настройках по умолчанию git скажет, что не знает точно откуда обновить ветку, но догадывается и предложит вариант. Просто воспользуйтесь его подсказкой.
Примечание — произошел конфликтgit тупо не разрешит сделать pull если у вас есть локально измененные файлы и update их модифицирует. Можно тут использовать git stash / git pull / git shash pop.
Допустим вы внесли изменения и сделали commit. Есть 2 варианта — если ваши изменения и удаленные не конфликтуют, то git создаст еще один дополнительный сommit и предложит вам отредактировать сообщение этого вновь созданного комита.Если есть конфликты, то я делаю так.
Смотрим какие файлы конфликтуют (both modified)
# git status
, правим их, добавляем# git add "conflict_file_name"
, комитим# git commit -m "Merge master" - Узнаем название вашей текущей ветки, смотрим какие файлы были изменены локально, смотрим какие комиты (commits) вы не отправили на общий сервер
# git status - Выкидываем все ваши локальные изменения. Применять осторожно, можно выстрелить в ногу.
# git reset --hard
Примечание: современные IDE хранят историю изменения файлов локально, так что ничего страшного. Стреляйте. - Создаем ветку, обычно по имени задачи в JIRA. Примечание: ветка создается от той ветки в которой вы в настоящий момент находитесь (см. предыдущий пункт), поэтому как правило надо сначала переключиться в ветку master. Если есть измененный файлы, то ничего страшного — они никуда не пропадут.
Переключаемся в ветку master:
# git checkout master
Создаем новую ветку:# git checkout -b "task_name" - Если вы хотите внести изменения в ветку, которую пилит ваш товарищ, то надо сначала обновиться, а потом переключиться в его ветку
# git fetch # git checkout "task_name" - Периодически подсасываем изменения, которые другие участники внесли в основную ветку, чтобы потом не огрести проблем с несостыковками
# git fetch# git merge origin/master - После внесения локальных изменений их надо так сказать «закомитить». Надо отметить, что git вносит изменения (создает новый commit) в вашу локальную версию, на сервер ничего не отправляет. Для отправки на сервер есть другая команда. Лично я комичу из IDE. Но можно и руками.
Сообщаем git какие файлы мы хотим закомитить:
# git add file_list
Или сразу все файлыКоммитим:
# git commit -m "Commit message" - Отправляем файлы в репозиторий на сервере
# git push
Примечание — git ругается, что не знает куда отправлять — смотри примечание к пункту 2.Примечание — git ругается, что файлы не обновленыОбычно настройки git server такие, что вы не можете отправить свои изменения если кто-то отправил свои изменения в вашу ветку. Поэтому нужно обновить состояние вашей ветки — смотри пункт 2.
- Отправляем изменения на просмотр (review) другим участникам. Это UI штука, к git отношения не имеет. В github, например, надо просто в UI перейти в свою ветку и создать Pull request (PR)
- Сливаем ваши изменения в основную ветку. Тут есть несколько вариантов. По умолчанию git просто встроит все ваши комиты в общую ветку. То есть все увидят ваши нелепые попытки исправить несобирающийся билд, падающие тесты и просто вечерние комиты, которые вы сделали, чтобы не потерять результаты кропотливого дневного труда. Это хорошо, если вы эксбиционист, но как правило жедательно все комиты собрать в один и встроить в общую ветку именно одним комитом (т.н. squash commit) — так другим будет легче разобраться что же вы сделали перед тем, как что-то пошло не так и откатить ваши изменения. Поэтому желательно делать squash:
github ui magic
В интерфейсе github есть зеленая кнопочка «squash & commit». Через UI переходим в свою ветку, создаем Pull request (PR), а потом в интерфейсе PR выбираем и жмете «squash & commit».squash commit
Переходим в основную ветку (master)# git checkout master
, обновляемся# git pull
, делаем squash commit
. Все изменения, из нашей ветки появятся как локальные, но уже в основной ветке. Смотрим что мы наваяли. Посмотреть изменения — пункт 3. Комитим — пункт 8, отправляем на сервер — пункт 9. Можно делать squash commit не в основную ветку, а завести новую, сделать в нее squash commit и из нее сделать merge в основную (смотри следующий пункт).# git merge "branch name" --squashmerge
Ваши комиты в этом случае не склеятся в один. Переходим в основную ветку (master)# git checkout master
, обновляемся# git pull
, делаем обычный commit# git merge "branch name"
, отправляем на сервер — пункт 9.rebase
Можно сделать rebase ветки и, например, склеить все ваши комиты в один. Лично я так не делаюПотому что там нужна магия по выбиранию всех ваших комитов и отделению ваших от неваших (от тех, которые были добавлены из мастера) и тут во время rebase еще можно нарваться на изменение комита, который был подтянут из мастера. Можно делать rebase каждый раз, когда вы подтягиваете изменения из мастера. Так я тоже не делаю потому что если вы как чай работаете вдвоем над одной веткой и делаете rebase, то велика вероятность конфликтов.
Примечания:
- Ветка с общим кодом обычно называется master.
- Можно спрятать все ваши локальные изменения — смотри команду git stash.
- Можно применить комит в вашу ветку из какой-нибудь другой — смотри git cherry-pick.
- Магия. rebase. Склеить несколько комитов в один или переместить комиты из локальной ветки в начало списка — чтобы потом было легко их склеить — git rebase.
habr.com
Как пользоваться GitHub | Losst
Github — это очень известная платформа для хранения, распространения и управления исходным кодом открытых проектов. Этот сервис используют множество разработчиков по всему миру, среди которых есть и крупные компании, такие как Microsoft, RedHat и множество других, также сотни разработчиков многих популярных проектов.
Платформа предоставляет возможности не только по просмотру кода и его распространения, но также историю версий, инструменты совместной разработки, средства для предоставления документации, выпуска релизов и обратной связи. И самое интересное, что вы можете размещать на Gihub как открытые, так и приватные проекты. В этой статье мы рассмотрим как пользоваться Github для размещения своего проекта. Так сказать, github для начинающих.
Содержание статьи:
Как пользоваться GitHub
Итак, допустим, у вас есть свой проект и вы хотите разместить его код на Github в открытом доступе чтобы другие пользователи могли его посмотреть и участвовать в разработке. Первое что вам нужно сделать — создать аккаунт.
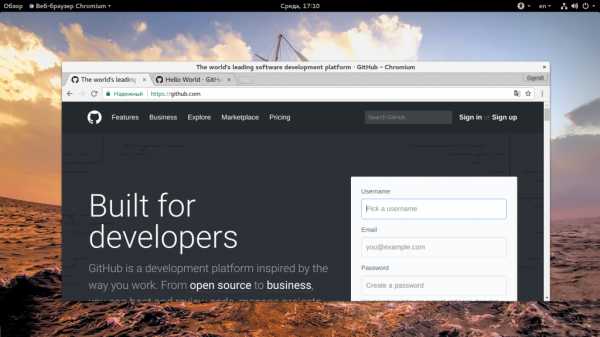
1. Создание аккаунта
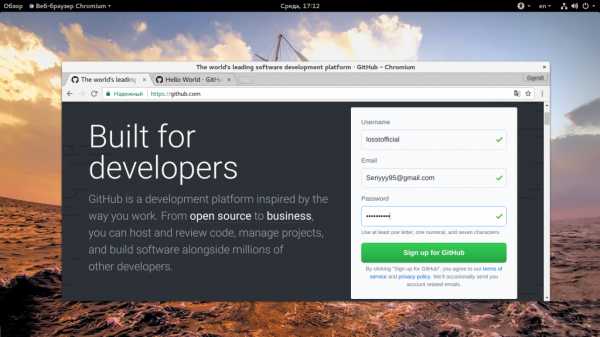
Чтобы создать новый аккаунт на сайте откройте главную страницу GitHub и тут же сразу вы можете ввести данные для новой учетной записи. Вам нужно указать имя пользователя, Email и пароль:
Когда завершите ввод, нажмите кнопку «Sign Up Free»:
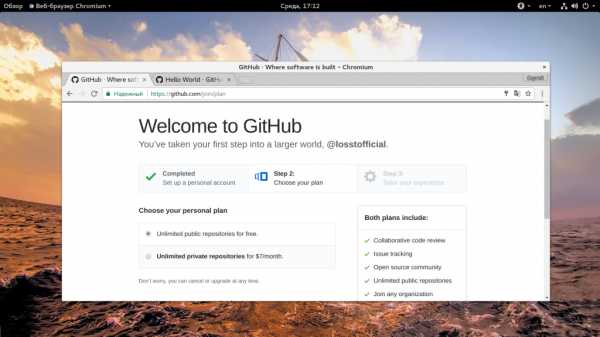
На следующем шаге вам нужно выбрать тип репозитория. Публичные репозитории бесплатны, но если вы хотите создать частный репозиторий, код из которого будет доступен только вам, то придется платить $7 в месяц.
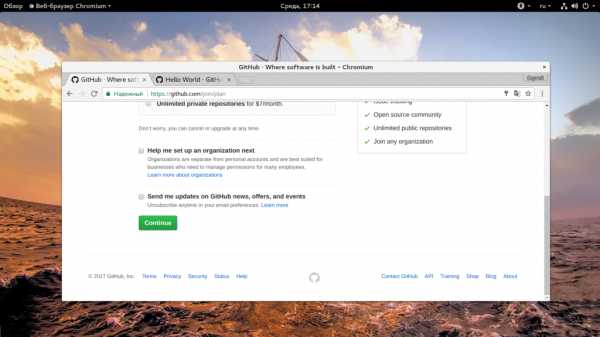
Аккаунт готов, и вы будете перенаправлены на страницу, где сможете создать свой первый проект. Но перед тем как вы сможете это сделать, нужно подтвердить свой Email адрес. Для этого откройте ваш почтовый ящик и перейдите по ссылке в письме от Github.
Никакая настройка github не нужна, достаточно лишь несколько кликов мышкой.
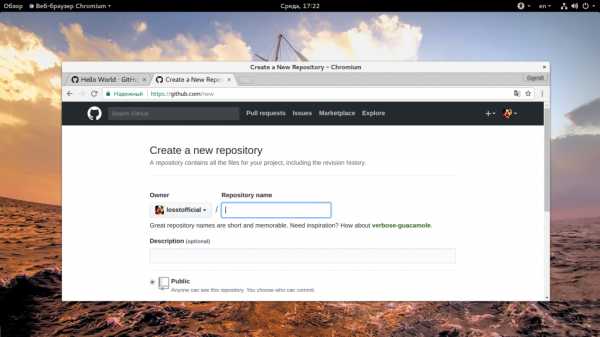
2. Создание репозитория
На открывшейся странице, это главная страница для авторизованных пользователей, нажмите кнопку «Start a project»:
Дальше введите имя и описание будущего репозитория:
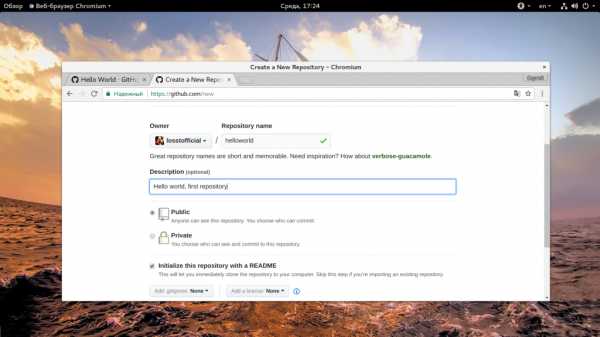
Вы можете сразу же инициализировать репозиторий, создав файл Readme, для этого нужно отметить галочку «Initialize this repository with a README» внизу страницы. Также можно выбрать лицензию:
Когда все будет готово, выберите «Create project», будет создан новый проект с файлом README, в котором находится описание и файлом лицензии.
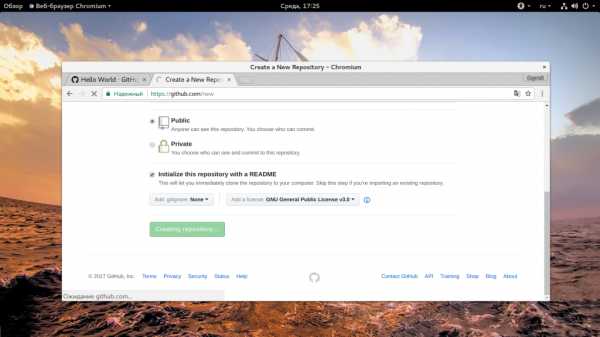
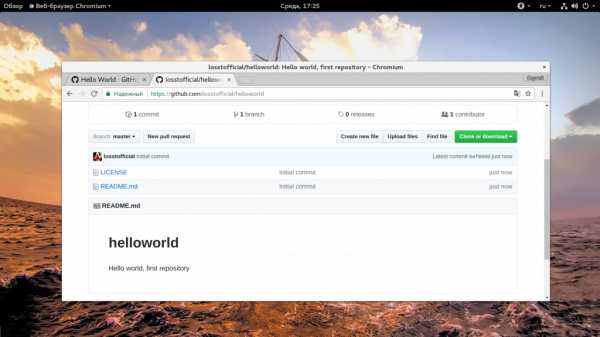
Дальше все самое интересное как работать с github.
3. Добавление веток
Ветки Github позволяют работать с несколькими версиями проекта одновременно. По умолчанию при создании репозитория создается ветка master, это основная рабочая ветка. Можно создать дополнительные ветки, например, для того, чтобы тестировать программное обеспечение перед тем, как оно будет опубликовано в ветке master. Таким образом, можно одновременно разрабатывать продукт и предоставлять пользователям стабильную версию. Также можно создавать отдельные ветки для версии программы для разных систем.
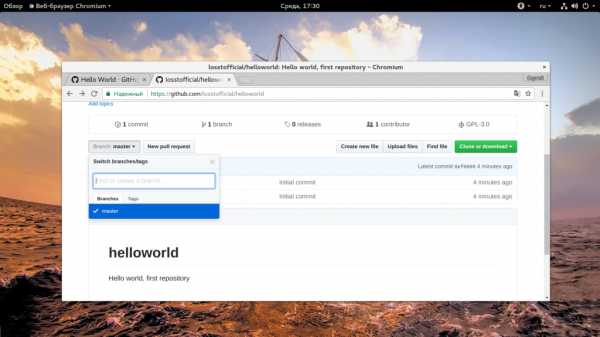
Текущая ветка обозначена в верхнем левом углу после слова «Branch». Чтобы создать новую ветку просто разверните этот список и начните набирать ее имя:
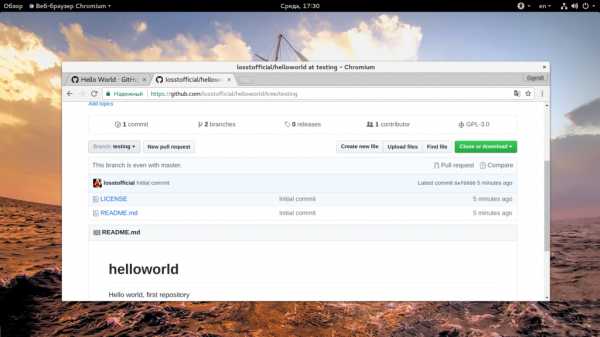
Сайт сам предложит вам создать новую ветку, выберите «Create branch».
Сразу же после создания вы будете работать с только что созданной веткой.
4. Изменение файлов и коммиты
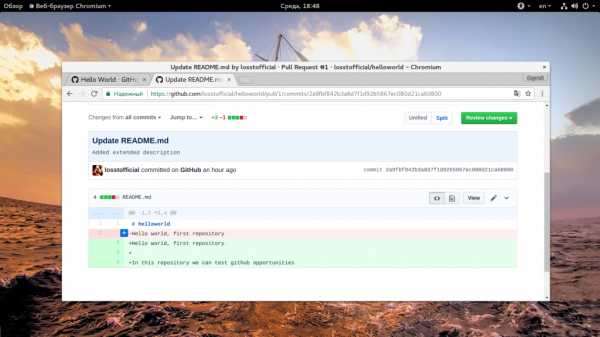
Любые изменения файлов на Github делаются с помощью коммитов. Коммит выполняется путем внесения самих исправлений и описания этих исправлений. Это необходимо для того, чтобы вы знали что и когда вы меняли, а также позволяет легко отслеживать работу команды. Слово коммит можно перевести как «фиксировать». То есть мы можем внести изменения в несколько файлов, а затем их зафиксировать. Давайте для примера изменим файл README. Для этого найдите в в правой стороне панели кнопку с кисточкой и нажмите на нее:
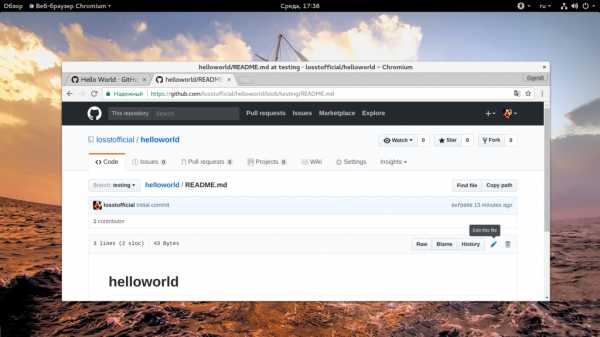
Откроется текстовый редактор, где вы можете ввести нужные вам исправления:
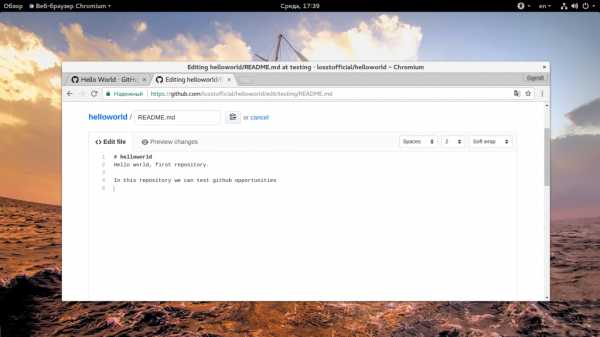
После того как вы сделаете все что вам нужно, необходимо заполнить поле «Commit» внизу страницы. Кратко опишите что было изменено, а затем нажмите кнопку «Commit changes»:
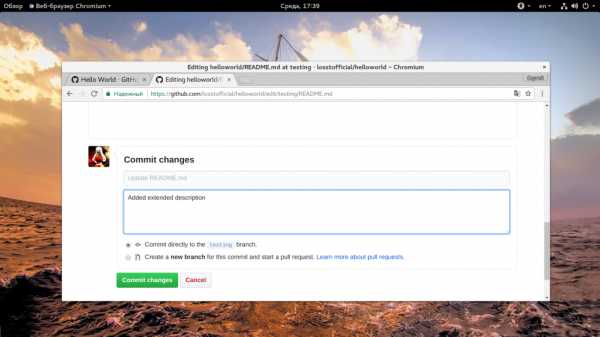
Эти изменения будут внесены в текущую ветку проекта, поскольку мы сейчас работаем с testing, то и изменения будут отправлены именно туда.
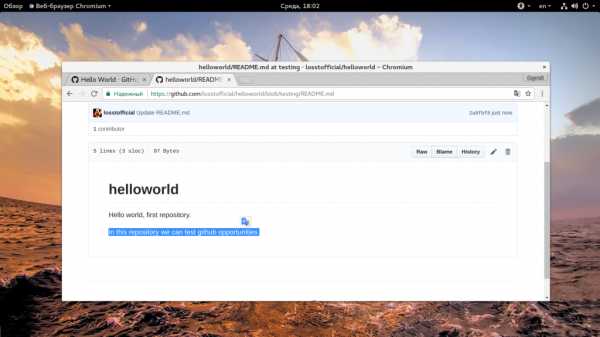
5. Создание запросов слияния (Pull Request)
GitHub для начинающих может показаться очень сложным именно из-за таких возможностей, но это очень удобно если разобраться. Запрос слияния или Pull Request — это возможность, благодаря которой любой разработчик может попросить другого, например, создателя репозитория просмотреть его код и добавить его в основной проект или ветку. Инструмент работы с запросами слияния использует инструмент сравнения diff, поэтому вы можете увидеть все изменения, они будут подчеркнуты другим цветом. Pull Request можно создать сразу же после создания коммита. Давайте отправим Pull Request из нашей testing ветки в основную. Сначала откройте вкладку «Pull Request».
Здесь нажмите кнопку «Create Pull Request»:
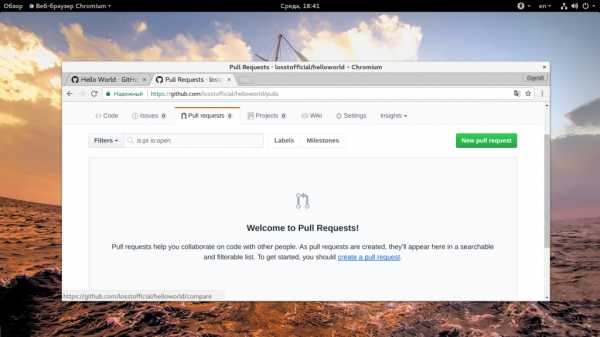
Дальше вам нужно будет выбрать ветку, которую нужно слить с основной, в нашем случае «testing».
В этом окне вы можете просмотреть все изменения, сейчас мы видим, что была добавлена строчка:
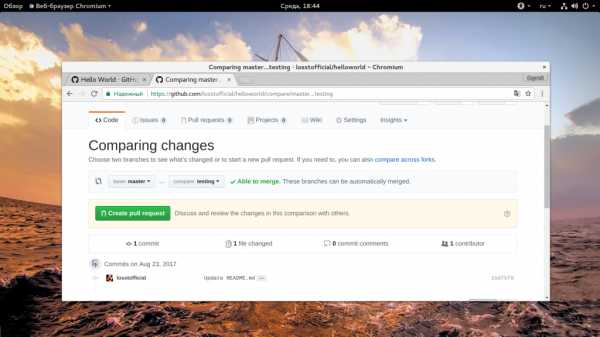
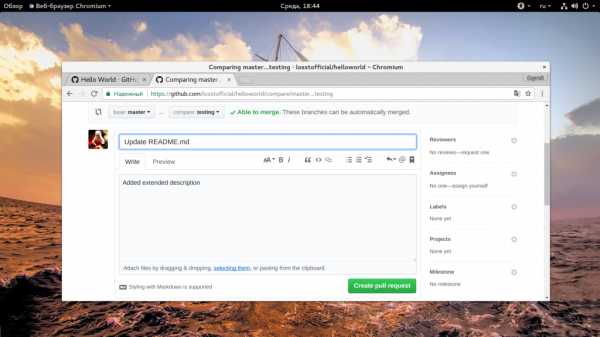
Дальше нажмите зеленую кнопку «Create Pull Request» и введите описание, как и для коммита:
6. Просмотр и одобрение запросов на слияние
Теперь, на той же вкладке Pull Requests мы видим только что созданный запрос на слияние и нам остается только принять его нажав «Merge Pull Request»:
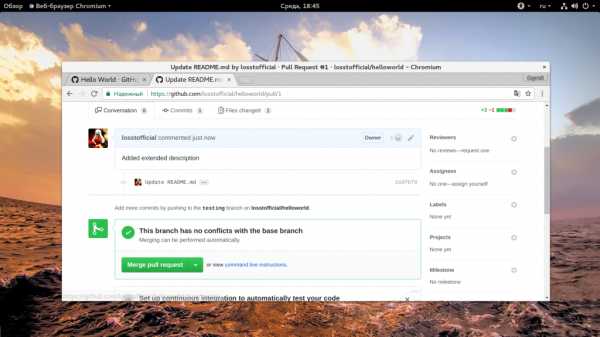
Но если этот запрос пришел от другого человека, вы должны проверить что он там изменил и нужно ли это, для этого просто нажмите на описание запроса и увидите уже знакомое окно просмотра изменений:
Дальше можно подтвердить Pull Request:
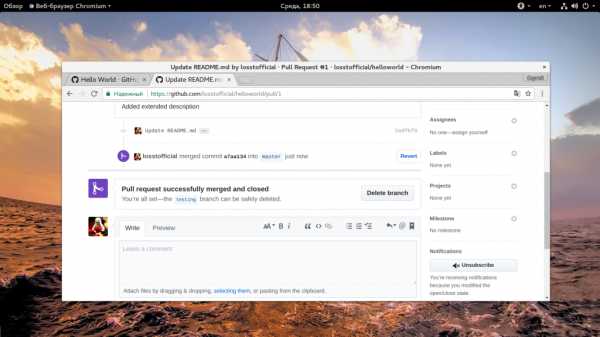
Затем код будет импортирован в основную ветку, а ветка testing может быть безопасно удалена.
7. Отчеты об ошибках
Удобно еще то, что возможно использование GitHub не только для разработки и управления кодом, но и для обратной связи с пользователями. На вкладке «Issue» пользователи могут оставлять сообщения о проблемах, с которыми они столкнулись при использовании вашего продукта. Откройте вкладку «Issues», и нажмите на кнопку «New issue»:
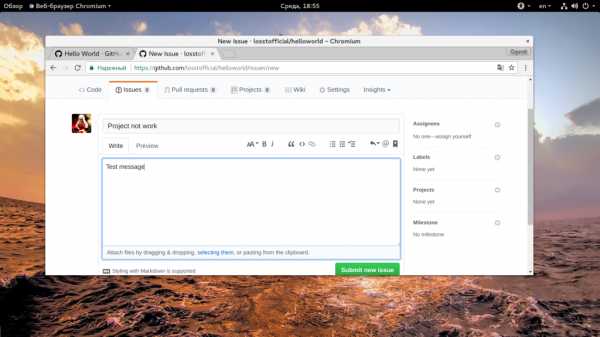
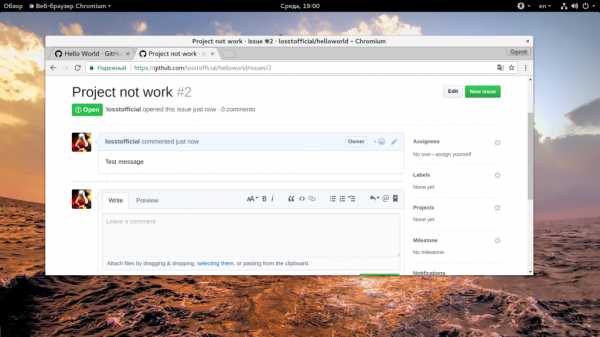
Дальше вам осталось ввести заголовок, текст и нажать «Create new issue».
8. Релизы
Последнее что мы сегодня рассмотрим — это релизы. Когда продукт достиг определенной стадии можно выпустить релиз, чтобы пользователи и вы могли быть уверенны что там все стабильно и никто ничего не сломал неверным Pull Request в Master. Сначала нужно перейти на главную страницу проекта, затем на вкладку «Releases»:
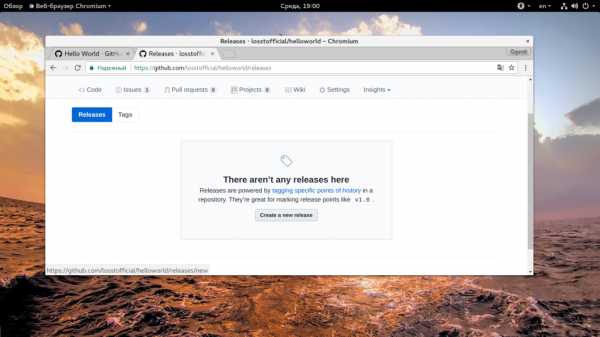
Дальше нажмите кнопку «Create New Release»:
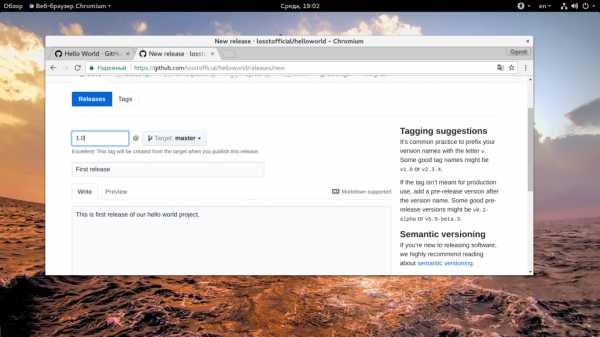
На этой странице нужно указать версию в поле «Tag Version», затем имя релиза и небольшое описание. Если у вас есть скомпилированные архивы с бинарниками то их тоже нужно прикрепить сюда. Затем нажмите «Create Release»:
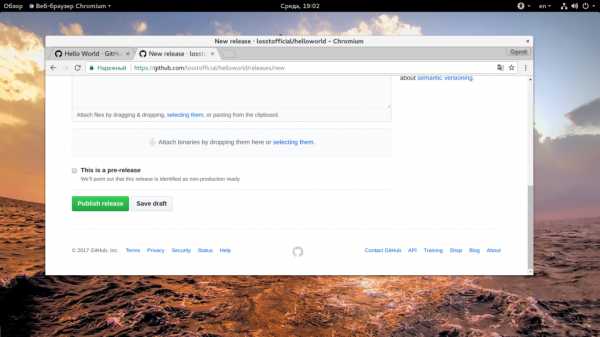
После создания релиза будет создана такая страничка:
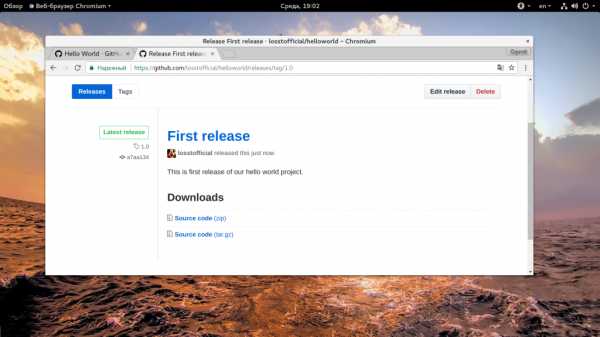
Ссылки на исходный код в tar.gz и zip будут созданы автоматически, все остальные файлы вам придется добавлять вручную.
Выводы
В этой статье мы рассмотрели как пользоваться GitHub для размещения и управления своим проектом. Вся система на английском, так что базовые знания языка очень желательны но даже без них работа с github будет не очень трудной. Надеюсь, эта информация была полезной для вас. Если вас интересует как работать с Git из командной строки, смотрите статью как пользоваться git для начинающих.
losst.ru
Git на практике / Habr
Существует замечательная книга Pro Git, в которой подробно описаны все команды и возможности гита. Но после ее прочтения у многих остается непонимание того, как это все использовать на практике. В частности, у программистов разного уровня часто возникают вопросы о том, как работать с ветками в Git, когда их заводить и как мержить между собой. Порой мне попадались очень «оригинальные» и неоправданно усложненные схемы работы с гитом. В то время как в сообществе программистов уже сформировалась схема работы с гитом и ветками в нем. В этой статье я хочу дать краткий обзор основных моментов при работе с Git, и описать «классическую» схему работы с ветками. Многое из того что описано в этой статье будет справедливо и для других систем управления версиями.Эта статья может быть полезна для программистов, которые только начинают осваивать Git, или какую-то другую систему управления версиями. Для опытных программистов эта статья покажется очень простой и банальной.
Для начала давайте разберемся с тем что такое ветка и коммит.
Коммит
Можно сказать, что коммит это основной объект в любой системе управления версиями. В нем содержится описание тех изменений, которые вносит пользователь в код приложения. В Git коммит состоит из нескольких так называемых объектов. Для простоты понимания можно считать, что коммиты это односвязный список, состоящий из объектов в которых содержаться измененные файлы, и ссылка на предыдущий коммит.
У коммита есть и другие свойства. Например, дата коммита, автор, комментарий к коммиту и т.п.
В качестве комментария обычно указывают те изменения, которые вносит этот коммит в код, или название задачи которую он решает.
Git это распределенная система управления версиями. Это значит, что у каждого участника проекта есть своя копия репозитория, которая находиться в папке “.git”, которая расположена в корне проекта. Именно в этой папке хранятся все коммиты и другие объекты Git. Когда вы работаете с Git, он в свою очередь работает с этой папкой.
Завести новый репозиторий очень просто, это делается командой
git init
Таким образом у вас получиться новый пустой репозиторий. Если вы хотите присоединиться к разработке уже имеющегося проекта, то вам нужно будет скопировать этот репозиторий в свою локальную папку с удаленного репозитория. Делается это так:
git clone <url удаленного репозитория>
После чего в текущей папке появляется директория .git в которой и будет содержаться копия удаленного репозитория.
Существует несколько основных областей в которых находиться код.
- Рабочая директория – это файлы в корне проекта, тот код с которым вы работаете.
- Локальный репозиторий — она же директория “.git”. В ней хранятся коммиты и другие объекты.
- Удаленный репозиторий – тот самый репозиторий который считается общим, в который вы можете передать свои коммиты из локального репозитория, что бы остальные программисты могли их увидеть. Удаленных репозиториев может быть несколько, но обычно он бывает один.
- Есть еще одна область, с пониманием которой обычно бывают проблемы. Это так называемая область подготовленных изменений (staging area). Дело в том, что перед тем как включить какие-то изменения в коммит, нужно вначале отметить что именно вы хотите включить в этот коммит. В своей рабочей директории вы можете изменить несколько файлов, но в один конкретный коммит включать не все эти изменения.
В целом работа с гитом выглядит так: вы меняете файлы в своей рабочей директории, затем добавляете эти изменения в staging area используя команду
git add <имя/файла>
При этом можно использовать маски со звездочкой.
Потом вы делаете коммит в свой локальный репозиторий
git commit –m “Комментарий к коммиту”
Когда коммитов накопиться достаточно много, чтобы ими можно было поделиться, вы выполняете команду
git push
После чего ваши коммиты уходят в удаленный репозиторий.
Если нужно получить изменения из удаленного репозитория, то нужно выполнить команду
git pull
После этого, в вашем локальном репозитории появятся те изменения, которые были отправлены другими программистами.
Код в рабочей области проекта образуется применением тех изменений, которые содержаться в коммитах. У каждого коммита есть свое имя, которое представляет собой результат хеш функции sha-1 от содержимого самого коммита.
Просмотреть коммиты можно при помощи команды
git log
Формат ответа этой команды по дефолту не очень удобен. Вот такая команда выведет ответ в более читаемом виде
git log --pretty=format:"%H [%cd]: %an - %s" --graph --date=format:%c
Что бы закончить просмотр нужно нажать на клавишу q
Посмотреть, что находиться в рабочей директории и staging area можно командой
git status
Рабочую директорию можно переключить на предыдущее состояние выполнив команду
git checkout <hash коммита>
Только перед тем как это делать выполните git status и убедитесь, что у вас нет никаких локальных и не зафиксированных изменений. Иначе Git не поймет, как ему переключаться. git status подскажет вам что можно сделать с локальными изменениями что бы можно было переключиться. Этого правила следует придерживаться и при всяких других переключениях рабочей области.
Ветка
Ветка в Git это подвижный указатель на один из коммитов. Обычно ветка указывает на последний коммит в цепочке коммитов. Ветка берет свое начало от какого-то одного коммита. Визуально это можно представить вот так.
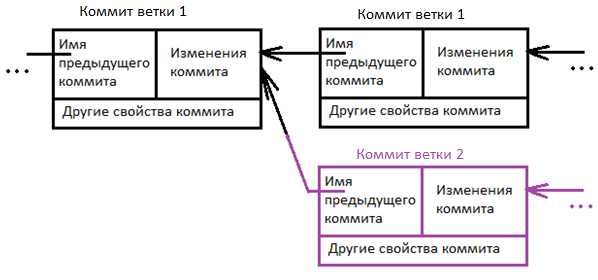
Сделать новую ветку и переключиться на нее можно выполнив команды
git pull
git checkout –b <имя новой ветки>
Просто сделать ветку, не переключаясь на нее можно командой
git branch <имя ветки>
переключиться на ветку
git checkout <имя ветки>
Важно понимать, что ветка берет свое начало не от ветки, а от последнего коммита который находиться в той ветке, в которой вы находились.
Ветка обычно заканчивается специальным merge коммитом, который говорит, что ветку нужно объединить с какой-то другой веткой. В merge коммите содержатся две ссылки на два коммита которые объединяются в одну ветку.
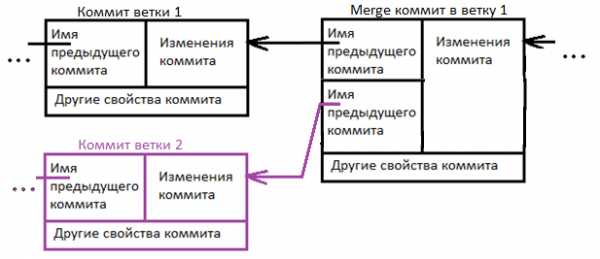
Существует другая ситуация при объединении веток, в которой merge может произойти без merge commit. Дело в том, что если в одной из веток не произошло никаких изменений, то необходимость в merge commit с двумя предками отпадает. В таком случае, при слиянии веток, Git просто сделает пометку о том, что дальше будут идти коммиты той ветки с которой эта ветка была объединена. Такая схема merge называется слияние-перемотка (fast-forward merge), визуально это можно представить вот так.
Во всех этих случаях, после того, как ветка объединяется с другой веткой, все коммиты сделанные в ней, попадают в ветку с которой она была объединена. Так же важно понимать, что merge это не двунаправленная операция. Если смержить ветку задачи в мастер ветку, то в мастер ветке появится код, который находился в ветке задачи, а в ветке задачи не появиться новый код из мастер ветки. Если нужно что бы это произошло, нужно смержить мастер ветку в ветку задачи.
Что бы смержить одну ветку в другую нужно вначале переключиться на ту ветку, в которую вы хотите смержить
git checkout <имя ветки>
Потом получить последние изменения сделанные в этой ветке выполнив
git pull
Затем выполнить команду
git merge <имя ветки>
Так выглядит работа с ветками в общих чертах.
Обратите внимание на то, что перед тем как заводить новую ветку нужно выполнить git pull. Делается это по нескольким причинам.
- Другой программист мог изменить код, в том числе внести такие изменения, которые повлияют на решение задачи, для которой вы заводите новую ветку. Эти изменения могут вам пригодиться при решении своей задачи.
- Из-за этих изменений вы можете получить конфликт при мерже.
- Больше шанс что у вас получится merge commit. Это не так плохо, как два предыдущих пункта. Но если можно избежать лишнего коммита, то почему бы этого не сделать?
Популярные схемы работы с ветками в Git
Теперь можно описать популярные схемы работы с ветками в гите.
Ветки нужны для того, чтобы программисты могли вести совместную работу над проектом и не мешать друг другу при этом. При создании проекта, Git создает базовую ветку. Она называется master веткой. Она считается центральной веткой, т.е. в ней содержится основной код приложения.
Классическая схема работы с ветками
Обычно перед тем как взяться за решение какой-то задачи, программист заводит новую ветку от последнего рабочего коммита мастер ветки и решает задачу в этой новой ветке. В ходе решения он делает ряд коммитов, после этого тестирует код непосредственно в ветке задачи. А после того как задача решена, делают merge обратно в мастер ветку. Такую схему работы часто используют с юнит тестами и автоматизированным деплоем. Если юнит тесты будут покрывать весь код, то можно настроить деплой так, что вначале будут прогоняться все тесты в ветке задачи. А после этого, если они прошли успешно, будет происходить merge и деплой. При такой схеме можно добиться полной автоматизации при тестировании и деплои.
Именная ветка
Неопытные программисты заводят себе именную ветку и работают всегда в ней. Они решают по одной задачи за раз, и когда заканчивают решение одной из задач, делают новый Pull запрос через Web интерфейсе (об этом чуть ниже). Недостаток этого подхода в том, что так можно решать только одну задачу и нельзя быстро переключиться на решение другой задачи. Еще один недостаток в том, что ветки так со временем будут все сильнее расходиться и код в ветке программиста рано или поздно устареет относительно мастер ветки и его придется обновить. Для этого можно либо смержить мастер ветку в ветку программиста, либо завести новую ветку для этого программиста от последнего рабочего состояния в мастер ветке. Правда к тому времени, как это произойдет программист уже может освоить гит в достаточной мере что бы перейти на “классическую” схему работы. Таким образом эта схема имеет место быть для неопытных пользователей Git.
Схема с dev веткой
Другая схема очень похожа на классическую, только в ней помимо мастер ветки есть еще девелоперская ветка, которая деплоится на тестовый сервер. Такую ветку обычно называют dev. Схема работы при этом такая. Программист перед выполнением новой задачи заводит для нее ветку от последнего рабочего состояния в мастер ветке. Когда он заканчивает работу над задачей, то мержит ветку задачи в dev ветку самостоятельно. После этого, совместными усилиями задача тестируется на тестовом сервере вместе с остальными задачами. Если есть ошибки, то задачу дорабатывают в той же ветке и повторно мержат с dev веткой. Когда тестирование задачи заканчивается, то ВЕТКУ ЗАДАЧИ мержат с мастер веткой. Важно заметить, что в этой схеме работы с мастер веткой нужно мержить ветку задачи, а не dev ветку. Ведь в dev ветке будут содержаться изменения, сделанные не только в этой задаче, но и в других и не все эти изменения могут оказаться рабочими. Мастер ветка и dev ветка со временем будут расходиться, поэтому при такой схеме работы периодически заводят новую dev ветку от последнего рабочего состояния мастер ветки. Недостатком этого подхода является избыточность, по сравнению с классической схемой. Такую схему работы с ветками часто используют если в проекте нет автоматизированных тестов и все тестирование происходит вручную на сервере разработки.
Так же следует отметить что эти схемы работы можно комбинировать между собой, если в этом есть какая-то необходимость.
Pull запросы
С этим понятием имеется путаница. Дело в том, что в Git есть две совершенно разные вещи, которые можно назвать Pull запросом. Одна из них, это консольная команда git pull. Другая это кнопка в web интерфейсе репозитория. На github.com она выглядит вот так
Про эту кнопку и пойдет речь дальше.
Если программист достаточно опытный и ответственный, то он обычно сам сливает свой код в мастер ветку. В противном случае программист делает так называемый Pull запрос. Pull запрос это по сути дела запрос на разрешение сделать merge. Pull запрос можно сделать из web интерфейса Git, или при помощи команды git request-pull. После того как Pull запрос создан, остальные участники могут увидеть это, просмотреть тот код который программист предлагает внести в проект, и либо одобрить этот код либо нет. Merge через pull запросы имеет свои плюсы и минусы. Минус в том, что для тесной команды опытных программистов такой подход будет лишним. Это будет только тормозить работу и вносить в нее оттенки бюрократии.
С другой стороны, если в проекте есть не опытные программисты, которые могут сломать код, то Pull запросы могут помочь избежать ошибок, и быстрее обучить этих программистов наблюдая за тем какие изменения они предлагают внести в код.
Так же Pull запросы подходят для широкого сообщества программистов, работающих с открытым исходным кодом. В этом случае нельзя заранее сказать что-то о компетенции таких разработчиков и о том, что они хотят изменить в коде.
Конфликты
Конфликты возникают при мердже веток если в этих ветках одна и та же строка кода была изменена по-разному. Тогда получается, что Git не может сам решить какое из изменений нужно применить и он предлагает вручную решить эту ситуацию. Это замедляет работу с кодом в проекте. Избежать этого можно разными методами. Например, можно распределять задачи так, чтобы связанные задачи не выполнялись одновременно различными программистами.
Другой способ избежать этого, это договориться о каком-то конкретном стиле кода. Тогда программисты не будут менять форматирование кода и вероятность того, что они изменят одну и ту же строчку станет ниже.
Еще один хороший совет, который поможет вам избежать конфликтов при работе в команде, это вносить минимум изменений в код при решении задач. Чем меньше строчек вы поменяли, тем меньше вероятность что вы измените ту же самую строку что и другой программист в другой задаче.
После того, как в мастер ветке достигается состояние, которое можно считать стабильным оно отмечается тегом с версией этого состояния. Это и есть то что называют версией программы.
Делается это вот так
git tag -a v1.0
Что бы передать ветки в удаленный репозиторий нужно выполнить команду
git push –tags
Теги удобны еще и тем, что можно легко переключиться на то состояние кода которое отмечено тегом. Делается это с помощью все той же команды
git checkout <имя тега>
Различные системы деплоя и автоматизированной сборки используют теги для идентификации того состояния, которое нужно задеплоить или собрать. Так сделано потому, что если мы будем собирать или деплоить код последней версии, то есть риск, что какой-то другой программист в этот момент внесет какие-то изменения в мастер ветку, и мы соберем не то что хотели. К тому же так будет проще переключаться между рабочими и проверенными состояниями проектов.
Если вы будете придерживаться этих правил и “классической” схемы работы с ветками, то вам будет проще интегрировать ваш Git с другими системами. Например, с системой непрерывной интеграции или с репозиторием пакетов, таким как packagist.org. Обычно сторонние решения и всякие расширения рассчитаны именно на такую схему работы с гитом, и если вы сразу начнете делать все правильно, то это может стать большим плюсом для вас в дальнейшем.
Это обзор основных моментов при работе с Git. Если вы хотите узнать про Git больше, то я вам посоветую прочитать книгу Pro Git. Вот здесь.
В этой статье была приведена упрощенная схема представления коммитов. Но перед тем как ее написать я решил разобраться как именно хранятся коммиты на диске. Если вас тоже заинтересует этот вопрос, то вы можете прочитать об этом вот здесь.
habr.com
Git и Github. Простые рецепты / Habr
При разработке собственного проекта, рано или поздно, приходится задуматься о том, где хранить исходный код и как поддерживать работу с несколькими версиями. В случае работы на компанию, обычно это решается за вас и необходимо только поддерживать принятые правила. Есть несколько общеупотребимых систем контроля версий, и мы рассмотрим одну из самых популярных — это Git и сервис Github.Система Git появилась, как средство управления исходными текстами в операционной системе Linux и завоевала множество поклонников в среде Open Source.
Сервис Github предоставляет хостинг (хранение) исходных текстов как на платной, так и на бесплатной основе. Это одна из крупнейших систем, которую любят Open Source пользователи. Основное отличие платной версии — это возможность создания частных репозиториев (хранилищ) исходных текстов и если вам скрывать нечего, то можете спокойно пользоваться бесплатной версией.
После того, как вы начали работу над проектом и написали какой-то работающий прототип, у вас появится желание сохранить результаты работы. Это так же может быть полезно в случае, если вы захотите продолжить работу на другом компьютере. Самое простое решение — это сохранить все на флешке. Этот вариант неплохо работает, но если есть подключение к интернету (а сейчас у кого его нет), то удобно воспользоваться системами Git/Github.
В этой статье будут описаны базовые сценарии использования систем Git/Github при работе над проектом в среде Linux с помощью командной строки. Все примеры проверялись на системе с Linux Ubuntu 14.04 и Git 1.9.1. Если вы пользуетесь другим дистрибутивом, то возможны отличия.
Создание локального репозитория
Предположим, что ваш проект находится в папке /home/user/project. Перед тем, как сохранять исходники, можно посмотреть, нет ли временных файлов в папке с проектом и по возможности их удалить.
Для просмотра папки удобно воспользоваться командой tree, которая покажет не только содержимое каждой папки, но и древовидную структуру директорий.
Часто временные файлы содержат специфические суффиксы, по которым их легко обнаружить и в последствии удалить. Для поиска таких файлов можно воспользоваться командой find. В качестве примера посмотрим, как найти все файлы, которые генерируются компилятором Python и имеют расширение .pyc
Переходим в папку с проектом /home/user/project:
cd /home/user/project
И показываем список файлов с расширением .pyc:
find . -name *.pyc
Эта команда выведет список всех файлов с расширением .pyc в текущей директории и в ее поддиректориях. Для удаления найденных файлов, достаточно добавить ключ -delete к этой команде:
find . -name *.pyc -delete
Очень рекомендуется не спешить и сразу ключ этот не добавлять. Первый раз вызвать команду для просмотра файлов и только убедившись, что в список не попало ничего полезного добавить ключ удаления.
Создадим локальный репозиторий в папке с проектом:
git init
После выполнения этой команды появится новая папка с именем .git. В ней будет несколько файлов и поддиректориев. На данный момент система управления версиями еще не видит наших файлов.
Добавление файлов в локальный репозиторий
Для добавления файлов используется команда:
git add readme
После выполнения команды, файл readme будет добавлен в систему управления версий (конечно если он уже был то этого в проекте). При добавлении файла генерируется хеш значение, которое выглядит примерно так:
9f2422325cef705b7682418d05a538d891bad5c8
Добавленные файлы хранятся в папке .git/objects/xx/yyyyyyyy, при этом первые 2 цифры хеша ипользуются для указания директории, а остальное хеш значение является именем файла. Наш добавленный файл будет находится здесь:
.git/objects/9f/2422325cef705b7682418d05a538d891bad5c8
Что легко увидеть с помощью команды:
ls .git/objects
Сам файл является архивом, который легко распаковать и вывести на экран, указав полное значение хеша.
git cat-file -p 9f2422325cef705b7682418d05a538d891bad5c8
Для того, чтобы добавить все файлы из текущей директории введите:
git add .
Если нужно добавить файлы из текущей директории и из всех поддиректориев, то используйте:
git add --all
Для того, чтобы в систему не попадали временные файлы, можно их занести в файл .gitignore, который нужно создать самостоятельно и разместить в корневом каталоге проекта (на том же уровне, что и .git директория).
Например, если в в файл .gitignore добавить следующую строчку *.pyc, то все файлы с расширением .pyc не будут добавляться в репозиторий.
После добавления файлов, все изменения находятся в так называемой staging (или cached) area. Это некоторое временнное хранилище, которое используется для накопления изменений и из которого создаются собственно версии проектов (commit).
Для просмотра текущего состояния можно воспользоваться командой:
git status
После выполнения команды мы увидим, что в stage area находится наш файл:
new file: readme
Если вы продолжите вносить изменения в файл readme, то после вызова команды git status вы увидите две версии файла.
new file: readme
modified: readme
Чтобы добавить новые изменения достаточно повторить команду. Команда git add не только добавляет новые файлы, но и все изменения файлов, которые были добавлены ранее.
git add readme
Можно отменить добавления файла readme в staging area с помощью команды:
git rm --cached readme
После выполнения команды, файл readme отметится, как неизмененный системой.
Создание версии проекта
После того, как мы добавили нужные файлы в staging area мы можем создать версию проекта. С помощью команды:
git commit -m "comment"
Каждая новая версия сопровождается комментарием.
После коммита, мы сможем найти два новых объекта внутри .git репозитория.
.git/objects/9f/2422325cef705b7682418d05a538d891bad5c8
.git/objects/65/7ab4c07bd3914c7d66e4cb48fe57f5c3aa7026
.git/objects/da/c6721c3b75fcb3c9d87b18ba4cef2e15e0a3d3
Посмотрим, что внутри:
git cat-file -t 657ab4c07bd3914c7d66e4cb48fe57f5c3aa7026
Ключ -t показывает тип объекта. В результате мы видим:
commit
Для второго объекта:
git cat-file -t dac6721c3b75fcb3c9d87b18ba4cef2e15e0a3d3
Результат:
tree
Для самого первого файла:
git cat-file -t 9f2422325cef705b7682418d05a538d891bad5c8
Мы видим:
blob
Если мы будем дальше изучать содержимое этих файлов, то обнаружим древовидную структуру. От каждого коммита можно по ссылкам пройти по всем измененным файлам. Для практического применения это не очень нужно, но возможно так будет легче понять, что происходит при работе с системой Git.
Самую первую версию отменить нельзя. Ее можно только исправить. Если вы хотите добавить изменения в последнюю версию, то после выполнения команды commit, добавляете необходимые изменения и вызываете:
git commit -m "comment" --amend
Или так:
git commit --amend --no-edit
Ключ —no-edit нужен, чтобы не вводить заново комментарий.
Можно просмотреть изменения, которые вы внесли последним коммитом:
git show
Или так:
git show --name-only
Ключ —name-only нужен, чтобы показывать только имена измененный файлов. Без него по каждому измененнному файлу будет выдан список всех изменений.
Если вы продолжили работать и изменили только те файлы, которые были уже добавлены в систему командой git add, вы можете сделать коммит одной командой:
git commit -a -m "comment"
Для просмотра списка всех коммитов, воспользуйтесь командой:
git log
Или так:
git log --oneline
Ключ —oneline нужен, чтобы уменьшить количество информации выдаваемой на экран. С этим ключем каждый коммит показывается в одну строчку. Например:
2b82e80 update
657ab4c first
Для того, чтобы просмотреть изменения по конкретному коммиту, достаточно в команду git show добавить хеш значение коммита, которое можно получить с помощью предыдущей команды.
git show 657ab4c
Для отмены последнего коммита (кроме самого первого) можно воспользоваться следующей командой:
git reset HEAD~1
Для того чтобы удалить все файлы в папке, которые не относятся к проекту и не сохранены в репозитории, можно воспользоваться командой:
git clean -df
Создание репозитория на Github
До текущего момента мы работали с локальным репозиторием, который сохранялся в папке на компьютере. Если мы хотим иметь возможность сохранения проекта в интернете, создадим репозиторий на Github. Для начала нужно зарегистрироваться на сайте github.com под именем myuser (в вашем случае это может быть любое другое имя).
После регистрации нажимаем кнопочку «+» и вводим название репозитория. Выбираем тип Public (репозиторий всегда Public для бесплатной версии) и нажимаем Create.
В результате мы создали репозиторий на сайте Github. На экране мы увидим инструкцию, как соединить наш локальный репозиторий со вновь созданным. Часть команд нам уже знакома.
Добавляем удаленный репозиторий (по протоколу SSH) под именем origin (вместо origin можно использовать любое другое имя).
git remote add origin [email protected]:myuser/project.git
Можем просмотреть результат добавления с помощью команды:
git remote -v
Если все было правильно сделано, то увидим:
origin [email protected]:myuser/project.git (fetch)
origin [email protected]:myuser/project.git (push)
Для того, чтобы отменить регистрацию удаленного репозитария введите:
git remote rm origin
Это может понадобиться, если вы захотите поменять SSH доступ на HTTPS. После этого можно добавить его опять, например под именем github и протоколом HTTPS.
git remote add github https://github.com/myuser/project.git
Следующей командой вы занесете все изменения, которые были сделаны в локальном репозитории на Github.
git push -u github master
Ключ -u используется для того, чтобы установить связь между удаленным репозиторием github и вашей веткой master. Все дальнейшие изменения вы можете переносить на удаленный репозиторий упрощенной командой.
git push
Перенос репозитория на другой компьютер
После того, как репозиторий был создан на Github, его можно скопировать на любой другой компьютер. Для этого применяется команда:
git clone https://github.com/myuser/project.git
Результатом выполнения этой команды будет создание папки project в текущем каталоге. Эта папка также будет содержать локальный репозиторий (то есть папку .git).
Так же можно добавить название папки, в которой вы хотите разместить локальный репозиторий.
git clone https://github.com/myuser/project.git <myfolder>
Работа с одним репозиторием с разных компьютеров
С одним репозиторием с разных компьютеров может работать несколько разработчиков или вы сами, если например работаете над одним и тем же проектом дома и на работе.
Для получения обновлений с удаленного репозитория воспользуйтесь командой:
git pull
Если вы изменили ваши локальные файлы, то команда git pull выдаст ошибку. Если вы уверены, что хотите перезаписать локальные файлы, файлами из удаленного репозитория то выполните команды:
git fetch --all
git reset --hard github/master
Вместо github подставьте название вашего удаленного репозитория, которое вы зарегистрировали командой git push -u.
Как мы уже знаем, для того чтобы изменения выложить на удаленный репозиторий используется команда:
git push
В случае, если в удаленном репозитории лежат файлы с версией более новой, чем у вас в локальном, то команда git push выдаст ошибку. Если вы уверены, что хотите перезаписать файлы в удаленном репозитории несмотря на конфликт версий, то воспользуйтесь командой:
git push -f
Иногда возникает необходимость отложить ваши текущие изменения и поработать над файлами, которые находятся в удаленном репозитории. Для этого отложите текущие изменения командой:
git stash
После выполнения этой команды ваша локальная директория будет содержать файлы такие же, как и при последнем коммите. Вы можете загрузить новые файлы из удаленного репозитория командой git pull и после этого вернуть ваши изменения которые вы отложили командой:
git stash pop
Заключение
Мы рассмотрели базовые сценарии работы с системами Git и Github. Каждая приведенная выше команда имеет значительно больше ключей и соответственно возможностей. Постепенное их изучение даст вам возможность легко оберегать свои иходники и больше концентрироваться непосредственно на разработке.
habr.com
Как научить людей использовать Git / Habr
По работе приходится участвовать в разных проектах, поэтому я хорошо знаю, как работают все мои коллеги. Помню, что компания начала использовать Git буквально за пару недель до моего прихода. На мониторах разработчиков кругом висели наклейки с напоминанием: сначала add, потом коммит, затем пуш.
Они не знали, зачем. Программистам просто сказали строго следовать инструкции, иначе беда. Но проблемы возникали так часто, что я решила провести семинар по Git.
Мне нравится составлять карту в голове. Я не говорю «ментальные карты», потому что это хорошо известный тип диаграмм. Речь о неких картинках, структурах или любом графическом представлении в уме. Например, в детстве я учила арифметику, представляя игральные кубики.
Поэтому я подготовила несколько рисунков. Не обязательно их смотреть, чтобы понять текст. Для каждого есть пояснение.
Кроме того, очень важно научить человека терминам. Иначе он не поймёт сообщения от Git. Рисунки — хороший способ.
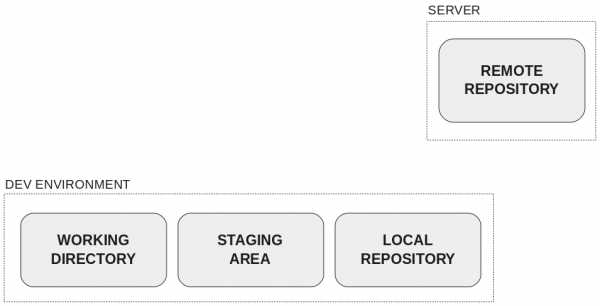
На рисунке четыре области распределены следующим образом:
- Среда разработки:
- Рабочий каталог
- Промежуточная область (staging) или индекс
- Локальный репозиторий
- Сервер:
- Удалённый репозиторий
Здесь можно объяснить преимущества распределённой системы управления версиями.
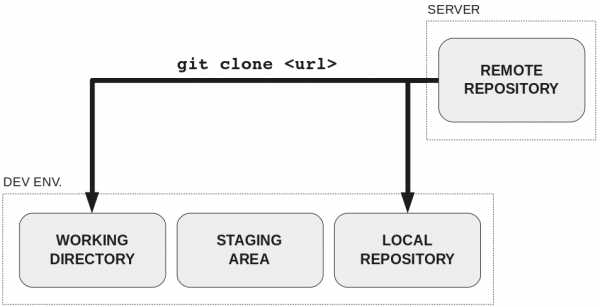
При клонировании данные из удалённого репозитория перемещаются в две области:
- Рабочий каталог
- Локальный репозиторий
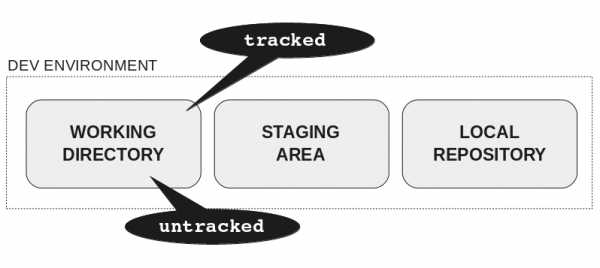
В рабочем каталоге два типа файлов:
- Отслеживаемые: файлы, о которых знает Git.
- Неотслеживаемые: которые ещё не были добавлены, поэтому Git не знает о них.
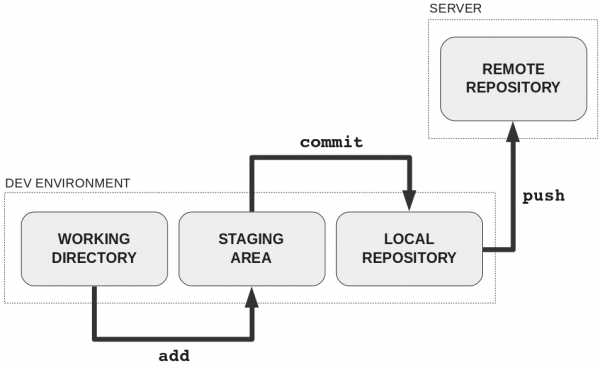
После подготовки изменений в рабочем каталоге их необходимо добавить в промежуточную область (staging area).
Когда там накопился ряд изменений с общей целью, самое время создать в локальном репозитории коммит с сообщением об этой цели.
Если в локальном репозитории есть один или несколько коммитов, готовых к совместному использованию всем остальным миром, они отправляются в удалённый репозиторий.
В этот момент можно говорить о различных состояниях файла в среде разработки: изменённом, промежуточном (staged) и зафиксированном (commited).
Далее вы можете объяснить:
- как показать изменения файла в рабочем каталоге:
git diff - как показать изменения файла в промежуточной области:
git diff --staged - как изменить файл в рабочем каталоге после добавления в промежуточную область
- и т. д.
Получение (fetching)
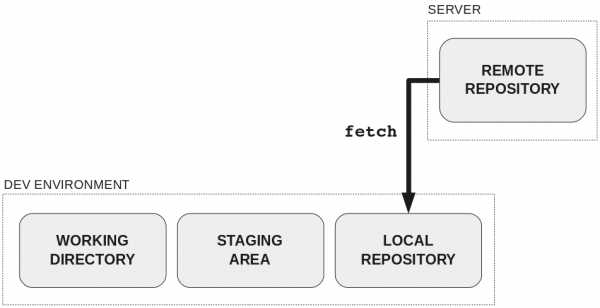
При выполнении git fetch данные из удалённого репозитория перемещаются только в локальный репозиторий.
Вытягивание (pulling)
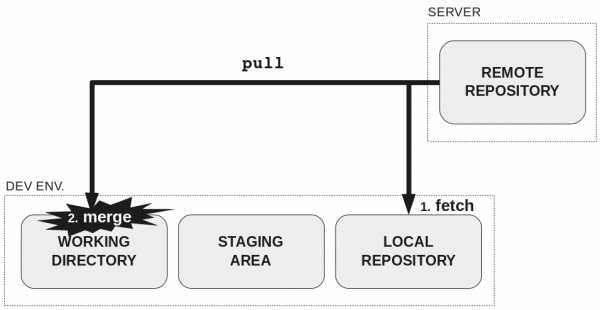
При выполнении git pull данные из удалённого репозитория перемещаются в две области:
- В локальный репозиторий:
fetch - В рабочий каталог:
merge
Если важна история коммитов, рассмотрите возможность использования
git pull --rebase. Тогда вместо команд fetch + merge выполняются команды fetch + rebase. Ваши локальные коммиты будут воспроизведены, так что вы не увидите в истории коммитов известную форму бриллианта.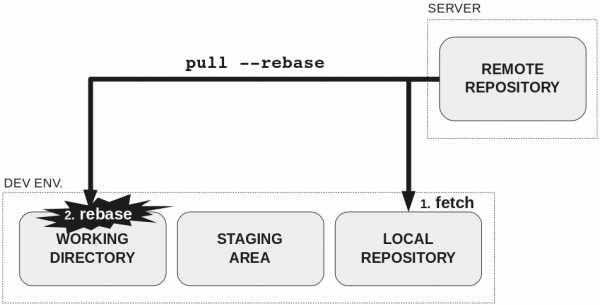
Можете добавить в среду разработки ещё одну область, чтобы проще прятать накопленные изменения: грязный рабочий каталог.
Когда люди усвоят эти понятия, вам будет легче объяснить дальнейшее: ветви, историю коммитов, перебазировку и так далее, потому что прочный фундамент уже заложен.
Я работала с другими системами управления версиями (Visual SourceSafe, TFS и Subversion): по моему скромному опыту, недостаток знаний вредит и со старым инструментом, и с новым. Сосредоточьтесь не только на выборе инструмента, но и на его освоении.
Мой друг Марк Виллаграса напомнил, что очень полезно решить задачки Git и делиться с коллегами решением.
Ресурсы из комментариев на Hacker News:
Прочитав комментарии на Reddit, я подумала, что более точным названием этой статьи было бы «Идея, как научить людей использовать Git», потому что это только идея, которая появилась в моей голове, когда я сама несколько лет назад изучала Git по книге Pro Git. Статья не является полным руководством, лишь отправная точка. Уверена, что все эти ресурсы будут очень полезны. Спасибо!
И спасибо Стюарту Максвеллу, который поделился ссылкой на Hacker News, и u/cryptoz, который запостил её на Reddit!
habr.com
Командная работа в Git / Habr
Во всем множестве статей по git’у, которые я смог найти в сети, не хватает одного существенного момента — описания командной работы. То, что обычно описывают как командную работу, на самом деле является просто работой с удаленным репозиторием.Ниже я хочу описать свой опыт командной работы над проектом с использованием git’а.
1. Общий принцип
Рабочий процесс у меня организован следующим образом.
Я ведущий разработчик тире руководитель отдела тире проджект менеджер. У меня в команде есть несколько разработчиков.
Моя работа заключается в следующем:
1) поговорить с заказчиком
2) превратить смутное и путанное пожелание заказчика в четко сформулированную задачу
3) поставить эту задачу разработчику
4) проверить результат выполнения задачи разработчиком
5) неудовлетворительный результат вернуть разработчику на доработку
6) удовлетворительный результат представить заказчику на утверждение или сразу отправить в продакшн
7) утвержденный заказчиком результат отправить в продакшн
8) неутвержденный заказчиком результат вернуть разработчику на доработку
Работа разработчика, соответственно, заключается в следующем:
1) получить от меня задачу
2) выполнить ее
3) отправить мне результат
4) если задача вернулась на доработку — доработать и снова отправить мне
Для управления задачами я использую Trac. Так же в Trac’е ведется документация по проекту, как программерская, так и пользовательская.
Сформулировав задачу, я записываю ее в Trac и назначаю какому-то разработчику. Разработчик, выполнив задачу, переназначает ее мне. Я проверяю результат и, либо снова переназначаю ее разработчику, либо отмечаю как выполненную.
Алгоритм работы с git’ом и общая картина происходящего схематически представлены на картинке:
Теперь от теоретической части перейдем к практической и разберемся, что все это значит и как работает.
2. Git
Установите Git. Прочитайте какой-нибудь мануал. Разберитесь с локальным репозиторием.
Обратите внимание — эта статья не про команды git’а, а про то, как увязать эти команды в нужную последовательность. Поэтому далее я буду приводить команды git’а без подробных объяснений, предполагая, что назначение отдельных команд вам известно.
3. Доступ к репозиторию
При командной работе потребуется обеспечить доступ к репозиторию нескольким пользователям. Для удобного разруливания прав доступа к репозиторию я использую gitosis.
Gitosis — это набор скриптов, реализующих удобное управление git-репозиториями и доступом к ним. Работает это так:
— на сервере заводится пользователь, которому будут принадлежать все репозитории
— все обращения к репозиториям происходят по SSH, под именем этого пользователя, авторизация пользователей производится по ключам
— при входе по SSH автоматически запускаются скрипты gitosis, которые, в зависимости от настройки, разрешают или запрещают дальнейшие действия с репозиториями
Скрипты и конфиги gitosis сами хранятся в репозитории и настраиваются путем отправки коммитов в этот репозиторий. Звучит безумно, но на деле ничего особо хитрого, вполне просто и удобно.
4. Установка gitosis
Для установки gitosis’а нужно (сюрприз!) вытянуть установочный репозиторий gitosis’а с сервера разработчика gitosis’а:
$ git clone git://eagain.net/gitosis.git
Установить gitosis:
$ cd gitosis
$ su
# python setup.py install
Установочный репозиторий больше не понадобится, его можно удалить.
Теперь нужно создать в системе пользователя, которому будут принадлежать все репозитории:
$ su
# adduser gituser
А затем инициализировать gitosis в домашнем каталоге созданного пользователя, с открытым ключом того, кто будет администратором gitosis’а. Открытый ключ, понятно, нужно положить куда-то, откуда его сможет прочитать пользователь gituser:
# su gituser
$ cd ~
$ gitosis-init < id_rsa.pub
Обратите внимание — пользователь gituser и администратор gitosis’а — это не одно лицо. Пользователь gituser является просто «хранителем» репозиториев и сам никаких действий вообще никогда не выполняет.
Я в качестве администратора gitosis’а использую другого зарегистрированного в системе пользователя. Но, вообще говоря, администратору вовсе не обязательно быть зарегистрированным в системе пользователем. Главное, указать при инициализации gitosis’а открытый ключ администратора.
После инициализации gitosis’а в домашнем каталоге пользователя gituser появится каталог repositories, в котором и будут храниться все репозитории. Сначала там будет только репозиторий gitosis-admin.git, в котором хранятся настройки самого gitosis’а.
Обратите внимание — по некоторым причинам, связанным с особенностями разных версий Питона, может понадобиться прописать права на исполнение скрипту post-update, находящемуся в репозитории gitosis’а:
$ chmod 755 ~/repositories/gitosis-admin.git/hooks/post-update
На этом установка gitosis’a закончена и начинается настройка.
5. Настройка gitosis’а и создание репозиториев
Настройка gitosis’а заключается в изменении администратором содержимого репозитория gitosis’а.
Становимся администратором gitosis’а (если администратор — зарегистрированный в системе пользователь) или вообще выходим из системы и логинимся там, где администратор зарегистрирован (например, на своем ноутбуке).
Теперь вытягиваем настроечный репозиторий gitosis’а:
$ git clone gituser@githost:gitosis-admin.git
Где githost — это имя сервера, на котором мы установили gitosis (и где будем хранить репозитории).
Обратите внимание — какое бы имя не имел администратор, обращение к серверу всегда выполняется под именем пользователя gituser.
После этого в домашнем каталоге администратора появится каталог gitosis-admin. В этом каталоге нас интересует файл gitosis.conf, именно в нем производится настройка всех репозиториев.
По умолчанию в нем будет нечто такое:
[group gitosis-admin]
writable = gitosis-admin
members = admin@host
Что означает «пользователю admin разрешена запись в репозиторий gitosis-admin».
Создание нового репозитория заключается в добавлении в конфиг новой группы. Название группы может быть любым, оно просто для понятности. Нам для работы потребуются два репозитория:
[group project-write]
writable = project
members = superdeveloper
[group project-read]
readonly = project
members = developer1 developer2 developer3 user1 user2
[group dev]
writable = dev
members = superdeveloper developer1 developer2 developer3
где superdeveloper — ведущий разработчик, developer* — разработчики, user* — прочие интересующиеся
Этот конфиг означает следующее:
1) ведущему разработчику позволено писать в главный репозиторий
2) всем позволено читать из главного репозитория
3) ведущему разработчику и всем разработчикам позволено писать в рабочий репозиторий
Все эти пользователи, как и администратор gitosis’а, вовсе не обязательно должны быть зарегистрированными в системе пользователями. Главное, чтобы у них были открытые ключи.
Открытые ключи указанных в конфиге пользователей нужно скопировать в каталог gitosis-admin/keydir. Файлы ключей должны иметь имена вида имя_пользователя.pub. В данном примере это будут имена superdeveloper.pub, developer1.pub, user1.pub и.т.д.
После правки конфига и копирования ключей нужно закоммитить изменения в локальный репозиторий:
$ git add.
$ git commit -am ‘Add project Project’
И отправить коммит в центральный репозиторий, где сделанные настройки подхватит gitosis:
$ git push
Все, теперь наш сервер репозиториев настроен и нужные репозитории созданы (вру, репозитории еще не созданы, но будут созданы автоматически при первом коммите).
6. Назначение репозиториев
Если в предыдущем разделе у вас возник вопрос — почему для одного проекта нужно два репозитория — то вот ответ.
Первый репозиторий, он же главный — это продакшн. На коде из этого репозитория будет работать боевая копия проекта. Второй репозиторий, он же рабочий — это разработка. В этом репозитории ведется, понятно, разработка проекта.
Я пробовал разные схемы командной работы и наиболее удобной на данный момент мне представляется «двухрепозиторная» схема. Работа в ней ведется примерно следующим образом:
1) я ставлю задачу разработчику
2) разработчик берет актуальную ветку проекта из главного репозитория и делает с нее локальный бранч
3) в этом бранче разработчик решает поставленную задачу
4) бранч с выполненной задачей разработчик отправляет в рабочий репозиторий
5) я беру из рабочего репозитория этот бранч и проверяю его
6) если задача выполнена правильно, я сливаю этот бранч с актуальной веткой проекта в главном репозитории
Эта схема имеет два ключевых отличия от широко описанной схемы, когда вся разработка идет в ветке master одного репозитория.
Во-первых, в моей схеме разработчики не могут вносить несанкционированные изменения (как случайные, так и намеренные) в актуальную ветку, т.е. в продакшн.
Во-вторых, актуальная ветка у меня никогда не бывает в нерабочем состоянии.
Вторая причина, на самом деле, является более важной. Несанкционированные изменения в любой момент можно откатить, на то и система контроля версий. А вот разрулить нерабочее состояние актуальной ветки может быть весьма затруднительно.
Поясню на примере.
Допустим, разработчик Р1 сделал правку П1 и отправил ее в ветку master. Я проверил эту правку и нашел ее плохой. Плохую правку нужно переделывать.
Пока я проверял, разработчик Р2 сделал правку П2 и тоже отправил ее в master. Эта правка оказалась хорошей. Хорошую правку нужно отправлять в продакшн.
Но теперь в ветке master находятся две правки, хорошая и плохая. Хорошую правку нужно бы отправить в продакшн, но присутствие плохой правки не позволяет это сделать. Придется ждать, пока плохая правка будет исправлена.
Или другой пример — все правки хорошие, но некоторые не утверждены заказчиком. Неутвержденные правки не дают попасть в продакшн утвержденным, а утверждение может происходить довольно долго.
В общем, нужно сделать так, чтобы правками можно было рулить по отдельности друг от друга, не сваливая их все кучей в ветку master.
Для этого разработчики отправляют в репозиторий все свои бранчи по отдельности, не сливая их с master’ом. Сливанием занимаюсь я. Соответственно, в актуальную ветку попадают только проверенные мной правки. Плохие правки отправляются на доработку, а правки, ждущие утверждения заказчика, отправляются в тестовую ветку и просто… ждут. И никому не мешают.
Таким образом, актуальная ветка всегда находится в рабочем состоянии.
В принципе, отправку бранчей по отдельности можно производить и в одном репозитории. Но в одном репозитории нельзя разделить доступ к отдельным бранчам, т.е. нельзя разрешить писать в репозиторий новые бранчи и при этом запретить изменять актуальную ветку. Поэтому нужен второй репозиторий — в одном находится актуальная ветка, в другом — все новые рабочие ветки, появляющиеся по мере решения отдельных задач.
На самом деле, в больших проектах у каждого разработчика вообще должен быть свой отдельный репозиторий. Но мне пока вполне удобно живется с двумя репозиториями — один мой (продакшн), другой — общий для всех разработчиков (разработка).
7. Первичная загрузка проекта в репозиторий
Обратите внимание — первичную загрузку делает ведущий разработчик, так как только у него есть право писать в главный репозиторий.
Создаем локальный репозиторий в каталоге проекта и загоняем в него файлы проекта:
$ cd /старый/каталог/проекта
$ git init
$ git add.
$ git commit -am ‘poehali!’
Сообщаем локальному репозиторию о том, где находится главный репозиторий:
$ git remote add origin gituser@githost:project.git
Теперь оправляем коммит в главный репозиторий:
$ git push origin master
Все, проект отправлен в главный репозиторий. Теперь старый каталог проекта можно смело грохнуть и начать работу уже в новом каталоге (или вообще на другом компе), под управлением git’а.
8. Репозиторий ведущего разработчика
Переходим в новый каталог (или вообще на другой комп) и вытягиваем главный репозиторий:
$ cd /новый/каталог/проекта
$ git clone gituser@githost:project.git
Это мы получили копию главного репозитория. В ней находится актуальная ветка. Теперь нужно создать тестовую ветку.
Просто скопируем актуальную ветку в главный репозиторий под именем тестовой:
$ git push origin master:stage
А затем вытянем тестовую ветку из главного репозитория уже под собственным именем:
$ git checkout -b stage origin/stage
Теперь локальный репозиторий содержит две ветки, master и stage. Обе ветки связаны с одноименными ветками в главном репозитории.
В этом локальном репозитории ведущий разработчик будет проверять бранчи, присланные другими разработчиками, и сливать проверенны бранчи с ветками главного репозитория.
Кроме того, нужно указать местонахождение рабочего репозитория dev:
$ git remote add dev gituser@githost:dev.git
9. Инфраструктура проекта
Проект у нас включает не только репозитории, но и «исполняющие» узлы — продакшн и отладку.
Продакшн и отладка — суть локальные репозитории, обновляющиеся с главного репозитория. Разница между продакшном и отладкой заключается в том, что продакшн обновляется с актуальной ветки, а отладка с тестовой.
Запуск продакшна, не вдаваясь в детали, был таким:
1) зарегистрировать в системе нового пользователя, из-под которого будет работать продакшн
2) добавить этого пользователя в gitosis (см. раздел 5, в моем примере это user*)
3) клонировать главный репозиторий project в каталог этого пользователя
4) Настроить виртуальный хост Apache (или что там вам больше нравится) на каталог проекта
И теперь для обновления продакшна достаточно просто зайти в этот каталог и выполнить одну-единственную команду:
$ git pull
Все обновления, находящиеся в актуальной ветке, во мгновение ока окажутся в продакшне.
Отладочная копия проекта устроена идентично, за исключением того, что после клонирования главного репозитория было сделано переключение с актуальной ветки master на тестовую ветку stage:
$ git checkout -b stage origin/stage
Теперь pull в отладке будет вытягивать обновления из тестовой ветки.
10. Репозиторий разработчика
Приступая к работе над проектом, разработчик должен предварительно настроить свой локальный репозиторий. Разработчик будет иметь дело с двумя удаленными репозиториями — главным и рабочим.
Главный репозиторий нужно склонировать:
$ git clone gituser@githost:project.git
А рабочий репозиторий просто добавить в конфиг:
$ git remote add dev gituser@githost:dev.git
Эта настройка выполняется только один раз. Вся дальнейшая работа выполняется по стандартной схеме (распечатать памятку и прилепить на монитор).
11. Памятка разработчика
Проверить почту. Если пришло уведомление из Trac’а о новой задаче — начать работать:
$ quake exit
Создать новый бранч на основе актуальной ветки из главного репозитория (мы у себя договорились называть бранчи номерами тикетов из Trac’а):
$ git checkout -b new_branch origin/master
Или вернуться к работе над старым бранчем из рабочего репозитория
$ git checkout -b old_branch dev/old_branch
Вытянуть последние изменения:
$ git pull
--- Выполнить задачу в новом бранче. Тут происходит работа с кодом. ---
Если в процессе работы были созданы новые файлы — добавить их в бранч:
$ git add .
Сохранить изменения в локальном репозитории:
$ git commit -am ‘komment’
Отправить новый бранч в рабочий репозиторий:
$ git push dev new_branch
Или повторно отправить туда же старый бранч:
$ git push
Выполненную задачу переназначить в Trac’е ведущему разработчику. Обратно разработчику она вернется либо с указанием на то, что нужно переделать, либо со статусом closed.
10 goto проверить почту;
Тут надо сказать еще о паре тонкостей. Состояние локального репозитория каждого конкретного разработчика меня, в общем, не беспокоит, но все-таки, чтобы люди не путались лишний раз, я рекомендую им делать две вещи.
Во-первых, бранчи, отправленные в рабочий репозиторий, более не нужны локально и могут быть смело удалены:
$ git branch -D new_branch
Во-вторых, список бранчей в удаленных репозиториях, выдаваемый командой
$ git branch -r
со временем устаревает, поскольку я удаляю оттуда проверенные и слитые с актуальной веткой бранчи. Чтобы обновить сведения об удаленных репозитория нужно выполнить команду
$ git remote prune dev
которая удалит из локального кеша отсутствующие в удаленном репозитории бранчи. Обратите внимание — обновлять сведения нужно только о рабочем репозитории. В главном репозитории никаких изменений никогда не происходит, там всегда находятся одни и те же бранчи — master и stage.
12. Действия ведущего разработчика
Получив уведомление из Trac’а о переназначенной мне задаче, я открываю эту задачу и смотрю, про что там вообще было, чтобы знать, что проверять.
Затем я обновляю данные об удаленных репозиториях:
$ git remote update
Теперь мне будут видны новые бранчи в рабочем репозитории, в том числе бранч, соответствующий проверяемой задаче:
$ git branch -r
Затем я вытягиваю проверяемый бранч из рабочего репозитория к себе (поскольку название бранча соответствует номеру тикета, то я всегда точно знаю, какой бранч вытягивать):
$ git checkout -b branch dev/branch
Если это не новый бранч, а исправление старого, то нужно еще вытянуть обновления:
$ git pull
Теперь я могу проверить работоспособность и правильность сделанной разработчиком правки.
Допустим, правка прошла проверку. Дальше действия зависят от того, является ли эта правка простой, такой, которую можно отправить в продакшн без согласования с заказчиком, или же это большая правка, которую надо согласовать.
Если правка простая, то я просто сливаю проверенный бранч с актуальной веткой и отправляю обновленную актуальную ветку в главный репозиторий:
$ git checkout master
$ git merge branch
$ git push
После этого я удаляю бранч у себя локально и из рабочего репозитория, больше этот бранч никому и никогда не понадобится:
$ git branch -D branch
$ git push dev :branch
Тут такой момент — сначала я хотел поручить удаление бранчей из рабочего репозитория разработчикам, чтобы каждый из них удалял свои бранчи. Но потом решил не усложнять людям жизнь. Т.е. подход такой — если разработчик прислал бранч, который меня устроил, то больше этот бранч не должен разработчика беспокоить.
Если же правка требует согласования, то проверяемый бранч сливается не с актуальной веткой, а с тестовой:
$ git checkout stage
$ git merge branch
$ git push
После отправки обновленной тестовой ветки в главный репозиторий я удаляю проверяемый бранч только у себя локально:
$ git branch -D branch
В рабочем же репозитории этот бранч остается. Вполне возможно, что заказчик захочет что-то переделать и тогда этот бранч понадобится разработчику для исправления.
В тестовой ветке проверяемый бранч лежит и есть не просит. Когда заказчик доберется до него и утвердит, тогда я снова вытяну этот бранч из рабочего репозитория и солью с актуальной веткой.
После того, как все бранчи слиты с нужными ветками и все это дело отправлено в главный репозиторий, я иду в продакшн и отладку и обновляю их.
(оригинал статьи)
habr.com