теория, инструменты и советы от практика
Рассказывает программист Вильям В. Вольд
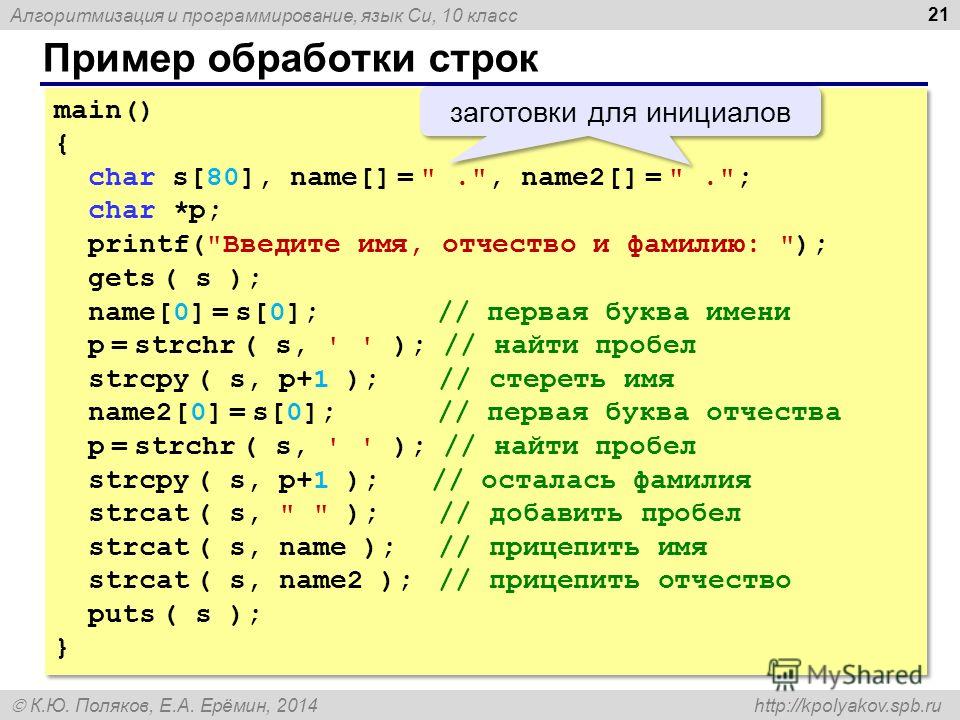
На протяжении последних шести месяцев я работал над созданием языка программирования (ЯП) под названием Pinecone. Я не рискну назвать его законченным, но использовать его уже можно — он содержит для этого достаточно элементов, таких как переменные, функции и пользовательские структуры данных. Если хотите ознакомиться с ним перед прочтением, предлагаю посетить официальную страницу и репозиторий на GitHub.
Введение
Я не эксперт. Когда я начал работу над этим проектом, я понятия не имел, что делаю, и всё еще не имею. Я никогда целенаправленно не изучал принципы создания языка — только прочитал некоторые материалы в Сети и даже в них не нашёл для себя почти ничего полезного.
Тем не менее, я написал абсолютно новый язык. И он работает. Наверное, я что-то делаю правильно.
В этой статье я постараюсь показать, каким образом Pinecone (и другие языки программирования) превращают исходный код в то, что многие считают магией. Также я уделю внимание ситуациям, в которых мне приходилось искать компромиссы, и поясню, почему я принял те решения, которые принял.
Также я уделю внимание ситуациям, в которых мне приходилось искать компромиссы, и поясню, почему я принял те решения, которые принял.
Текст точно не претендует на звание полноценного руководства по созданию языка программирования, но для любознательных будет хорошей отправной точкой.
Первые шаги
«А с чего вообще начинать?» — вопрос, который другие разработчики часто задают, узнав, что я пишу свой язык. В этой части постараюсь подробно на него ответить.
Компилируемый или интерпретируемый?
Компилятор анализирует программу целиком, превращает её в машинный код и сохраняет для последующего выполнения. Интерпретатор же разбирает и выполняет программу построчно в режиме реального времени.
Технически любой язык можно как компилировать, так и интерпретировать. Но для каждого языка один из методов подходит больше, чем другой, и выбор парадигмы на ранних этапах определяет дальнейшее проектирование. В общем смысле интерпретация отличается гибкостью, а компиляция обеспечивает высокую производительность, но это лишь верхушка крайне сложной темы.
Я хотел создать простой и при этом производительный язык, каких немного, поэтому с самого начала решил сделать Pinecone компилируемым. Тем не менее, интерпретатор у Pinecone тоже есть — первое время запуск был возможен только с его помощью, позже объясню, почему.
Прим. перев. Кстати, у нас есть краткий обзор серии статей по созданию собственного интерпретатора — это отличное упражнение для тех, кто изучает Python.
Выбор языка
Своеобразный мета-шаг: язык программирования сам является программой, которую надо написать на каком-то языке. Я выбрал C++ из-за производительности, большого набора функциональных возможностей, и просто потому что он мне нравится.
Но в целом совет можно дать такой:
- интерпретируемый ЯП крайне рекомендуется писать на компилируемом ЯП (C, C++, Swift). Иначе потери производительности будут расти как снежный ком, пока мета-интерпретатор интерпретирует ваш интерпретатор;
- компилируемый ЯП можно писать на интерпретируемом ЯП (Python, JS).
 Возрастёт время компиляции, но не время выполнения программы.
Возрастёт время компиляции, но не время выполнения программы.
 Возрастёт время компиляции, но не время выполнения программы.
Возрастёт время компиляции, но не время выполнения программы.Проектирование архитектуры
У структуры языка программирования есть несколько ступеней от исходного кода до исполняемого файла, на каждой из которых определенным образом происходит форматирование данных, а также функции для перехода между этими ступенями. Поговорим об этом подробнее.
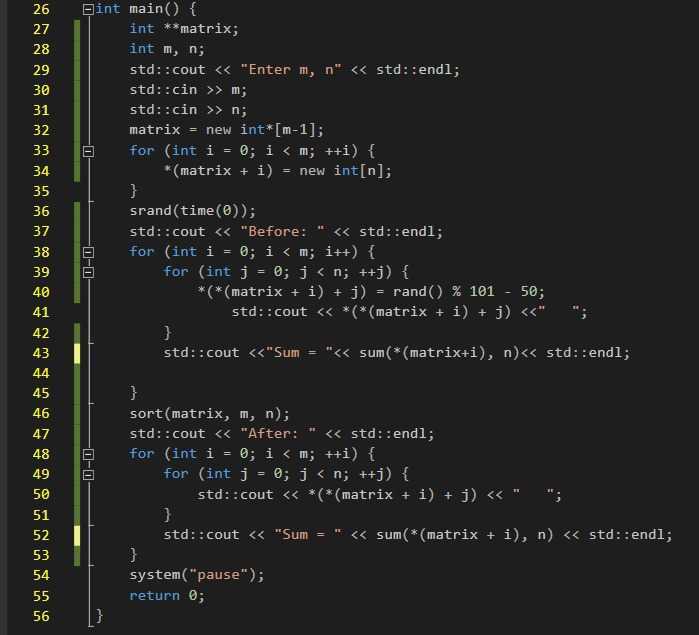
Лексический анализатор / лексер
Строка исходного кода проходит через лексер и превращается в список токенов.
Первый шаг в большинстве ЯП — это лексический анализ. Говоря по-простому, он представляет собой разбиение текста на токены, то есть единицы языка: переменные, названия функций (идентификаторы), операторы, числа. Таким образом, подав лексеру на вход строку с исходным кодом, мы получим на выходе список всех токенов, которые в ней содержатся.
Обращения к исходному коду уже не будет происходить на следующих этапах, поэтому лексер должен выдать всю необходимую для них информацию.
Flex
При создании языка первым делом я написал лексер. Позже я изучил инструменты, которые могли бы сделать лексический анализ проще и уменьшить количество возникающих багов.
Позже я изучил инструменты, которые могли бы сделать лексический анализ проще и уменьшить количество возникающих багов.
Одним из основных таких инструментов является Flex — генератор лексических анализаторов. Он принимает на вход файл с описанием грамматики языка, а потом создаёт программу на C, которая в свою очередь анализирует строку и выдаёт нужный результат.
Моё решение
Я решил оставить написанный мной анализатор. Особых преимуществ у Flex я в итоге не увидел, а его использование только создало бы дополнительные зависимости, усложняющие процесс сборки. К тому же, мой выбор обеспечивает больше гибкости — например, можно добавить к языку оператор без необходимости редактировать несколько файлов.
Синтаксический анализатор / парсер
Список токенов проходит через парсер и превращается в дерево.
Следующая стадия — парсер. Он преобразует исходный текст, то есть список токенов (с учётом скобок и порядка операций), в абстрактное синтаксическое дерево, которое позволяет структурно представить правила создаваемого языка. Сам по себе процесс можно назвать простым, но с увеличением количества языковых конструкций он сильно усложняется.
Сам по себе процесс можно назвать простым, но с увеличением количества языковых конструкций он сильно усложняется.
Bison
На этом шаге я также думал использовать стороннюю библиотеку, рассматривая Bison для генерации синтаксического анализатора. Он во многом похож на Flex — пользовательский файл с синтаксическими правилами структурируется с помощью программы на языке C. Но я снова отказался от средств автоматизации.
Преимущества кастомных программ
С лексером моё решение писать и использовать свой код (длиной около 200 строк) было довольно очевидным: я люблю задачки, а эта к тому же относительно тривиальная. С парсером другая история: сейчас длина кода для него — 750 строк, и это уже третья попытка (первые две были просто ужасны).
Тем не менее, я решил делать парсер сам. Вот основные причины:
- минимизация переключения контекста;
- упрощение сборки;
- желание справиться с задачей самостоятельно.
В целесообразности решения меня убедило высказывание Уолтера Брайта (создателя языка D) в одной из его статей:
Я бы не советовал использовать генераторы лексических и синтаксических анализаторов, а также другие так называемые «компиляторы компиляторов».
 Написание лексера и парсера не займёт много времени, а использование генератора накрепко привяжет вас к нему в дальнейшей работе (что имеет значение при портировании компилятора на новую платформу). Кроме того, генераторы отличаются выдачей не релевантных сообщений об ошибках.
Написание лексера и парсера не займёт много времени, а использование генератора накрепко привяжет вас к нему в дальнейшей работе (что имеет значение при портировании компилятора на новую платформу). Кроме того, генераторы отличаются выдачей не релевантных сообщений об ошибках.Абстрактный семантический граф
Переход от синтаксического дерева к семантическому графу
В этой части я реализовал структуру, по своей сути наиболее близкую к «промежуточному представлению» (intermediate representation) в LLVM. Существует небольшая, но важная разница между абстрактным синтаксическим деревом (АСД) и абстрактным семантическим графом (АСГ).
АСГ vs АСД
Грубо говоря, семантический граф — это синтаксическое дерево с контекстом. То есть, он содержит информацию наподобие какой тип возвращает функция или в каких местах используется одна и та же переменная. Из-за того, что графу нужно распознать и запомнить весь этот контекст, коду, который его генерирует, необходима поддержка в виде множества различных поясняющих таблиц.
Запуск
После того, как граф составлен, запуск программы становится довольно простой задачей. Каждый узел содержит реализацию функции, которая получает некоторые данные на вход, делает то, что запрограммировано (включая возможный вызов вспомогательных функций), и возвращает результат. Это — интерпретатор в действии.
Варианты компиляции
Вы, наверное, спросите, откуда взялся интерпретатор, если я изначально определил Pinecone как компилируемый язык. Дело в том, что компиляция гораздо сложнее, чем интерпретация — я уже упоминал ранее, что столкнулся с некоторыми проблемами на этом шаге.
Написать свой компилятор
Сначала мне понравилась эта мысль — я люблю делать вещи сам, к тому же давно хотел изучить язык ассемблера. Вот только создать с нуля кроссплатформенный компилятор — сложнее, чем написать машинный код для каждого элемента языка. Я счёл эту идею абсолютно не практичной и не стоящей затраченных ресурсов.
LLVM
LLVM — это коллекция инструментов для компиляции, которой пользуются, например, разработчики Swift, Rust и Clang. Я решил остановиться на этом варианте, но опять не рассчитал сложности задачи, которую перед собой поставил. Для меня проблемой оказалось не освоение ассемблера, а работа с огромной многосоставной библиотекой.
Я решил остановиться на этом варианте, но опять не рассчитал сложности задачи, которую перед собой поставил. Для меня проблемой оказалось не освоение ассемблера, а работа с огромной многосоставной библиотекой.
Транспайлинг
Мне всё же нужно было какое-то решение, поэтому я написал то, что точно будет работать: транспайлер (transpiler) из Pinecone в C++ — он производит компиляцию по типу «исходный код в исходный код», а также добавил возможность автоматической компиляции вывода с GCC. Такой способ не является ни масштабируемым, ни кроссплатформенным, но на данный момент хотя бы работает почти для всех программ на Pinecone, это уже хорошо.
Дальнейшие планы
Сейчас мне не достаёт необходимой практики, но в будущем я собираюсь от начала и до конца реализовать компилятор Pinecone с помощью LLVM — инструмент мне нравится и руководства к нему хорошие. Пока что интерпретатора хватает для примитивных программ, а транспайлер справляется с более сложными.
Заключение
Надеюсь, эта статья окажется кому-нибудь полезной. Я крайне рекомендую хотя бы попробовать написать свой язык, несмотря на то, что придётся разбираться во множестве деталей реализации — это обучающий, развивающий и просто интересный эксперимент.
Я крайне рекомендую хотя бы попробовать написать свой язык, несмотря на то, что придётся разбираться во множестве деталей реализации — это обучающий, развивающий и просто интересный эксперимент.
Вот общие советы от меня (разумеется, довольно субъективные):
- если у вас нет предпочтений и вы сомневаетесь, компилируемый или интерпретируемый писать язык, выбирайте второе. Интерпретируемые языки обычно проще проектировать, собирать и учить;
- с лексерами и парсерами делайте, что хотите. Использование средств автоматизации зависит от вашего желания, опыта и конкретной ситуации;
- если вы не готовы / не хотите тратить время и силы (много времени и сил) на придумывание собственной стратегии разработки ЯП, следуйте цепочке действий, описанной в этой статье. Я вложил в неё много усилий и она работает;
- опять же, если не хватает времени / мотивации / опыта / желания или ещё чего-нибудь для написания классического ЯП, попробуйте написать эзотерический, типа Brainfuck.

Я делал довольно много ошибок по ходу разработки, но большую часть кода, на которую они могли повлиять, я уже переписал. Язык сейчас неплохо функционирует и будет развиваться (на момент написания статьи его можно было собрать на Linux и с переменным успехом на macOS, но не на Windows).
О том, что ввязался в историю с созданием Pinecone, ни в коем случае не жалею — это отличный эксперимент, и он только начался.
Перевод статьи: «I wrote a programming language. Here’s how you can, too»
11 шагов и реальные перспективы
В статье рассказывается:
- Зачем нужны новые языки программирования
- 11 шагов создания своего языка программирования с нуля
- Книги про создание языка программирования с нуля
- Реально ли в одиночку написать язык программирования
- Онлайн-курсы по изучению и созданию языков программирования
-
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Про создание языка программирования мечтает каждый второй разработчик, причем, как правило, новичок. Цели преследует каждый свои. Одни желают улучшить уже существующий язык, другие — привнести в этот мир что-то ультрановое и экзотическое, а третьи – заработать миллионы на своей разработке.
Давайте вместе разбираться, реально ли в одиночку с нуля создать свой язык программирования даже на базе уже существующего, какие действия придется совершить, что проанализировать и самое главное – сколько по времени займет весь этот процесс. Хотя вы, наверное, и так уже понимаете, что за полчаса второй Python не создать, но давайте все равно предположим.
Зачем нужны новые языки программирования
На данный момент существуют уже сотни различных языков программирования, и их количество неуклонно растет. Они становятся популярными, широко востребованными. От чего это зависит? Тут влияют самые разные факторы, не всегда постоянные, меняющиеся с течением времени.
На заре развития компьютерных технологий новые языки программирования были крайне необходимы в первую очередь потому, что писать программы с помощью машинных кодов, да и на ассемблере тоже было очень затруднительно, процесс получался слишком сложным.
Требования к созданию языков программирования постепенно менялись по мере того, как стали появляться компьютеры помощнее, более простые и удобные в использовании. К примеру, Fortran придумывался больше для ведения математических вычислений, Basic и Pascal были «заточены» под учебные цели и отличались легкостью изучения, а другие (вроде Си) были хороши своей универсальностью и скоростью работы.
Как только в программировании свершались некие значимые достижения, тут же появлялась куча новых языков. Например, языки C++, Objective C, Java были разработаны в 1980-1990-е годы на фоне открытия парадигмы объектно-ориентированного программирования. Скриптовые языки (вроде PHP, JavaScript, Python) стали бурно развиваться в связи с появившейся необходимостью в создании веб-приложений. Да и сейчас тоже продолжают появляться отличные языки, они быстро пишутся, и программы на них работают просто молниеносно (примеры — Go, Swift, Rust).
Да и сейчас тоже продолжают появляться отличные языки, они быстро пишутся, и программы на них работают просто молниеносно (примеры — Go, Swift, Rust).
Разумеется, современные новые языки программирования – это не просто «модное» веяние. Часто в них возникает конкретная необходимость, когда требуется решение неких особых задач. К примеру, для автоматической обработки логических суждений создавался Prolog. А Erlang принят как стандарт в сфере разработки ПО для сетевых коммуникаций.
11 шагов создания своего языка программирования с нуля
Для чего и по каким причинам может понадобиться создание собственного языка программирования? Кому-то просто нечем заняться, другие пишут для упрощения своей же работы, а кто-то ставит целью решение конкретных задач. Ниже перечислены 11 шагов по созданию языка программирования, следуя которым, вы можете попробовать написать свой. Кто знает, вдруг это окажется шедевр, который прославит вас на весь мир?
Шаг 1. Ознакомьтесь с устройством компьютера.
Ознакомьтесь с устройством компьютера.
Это обязательное действие для всех, кто решил заняться программированием, не только при написании новых языков. Тут очень важно понимать, как компьютер преобразует коды и затем их исполняет. Вы не сможете принимать адекватные решения, если не исследуете функционал машины.
Шаг 2. Разберитесь в терминах.
Вам придется иметь дело с такими понятиями, как парсеры, лексеры, компиляторы, интерпретаторы, синтаксические деревья и еще много всего прочего. Если вы не будете четко понимать, о чем идет речь, то как сможете вообще этим заниматься, советоваться с другими разработчиками, искать нужные сведения в Интернете? Создание любого языка программирования начинается со знания терминологии и технологий.
Шаг 3. Обозначьте специализацию языка.
То есть определитесь, создаете вы инструмент для решения конкретных задач или это будет язык с широким профилем применения в самых разных областях IT. Прикиньте общий объём работ, обозначьте цели.
Шаг 4. Определитесь с основными концептуальными моментами.
Вот вопросы, на которые вам следует дать ответ:
- Задействовать компиляцию или интерпретацию? Компилируемый код пишется так, что машина сразу его «понимает» и исполняет. Интерпретируемый код работает построчно. Что именно использовать – выбирать вам, рассмотрите оба варианта с точки зрения удобства, функциональности, производительности, защищенности и т. п.
- Задавать статическую или динамическую типизацию? При статической пользователь сам указывает типы данных, а для динамической нужно будет создать систему, определяющую типы.
- Для памяти будет предусмотрено ручное управление или автоматическая очистка?
- Какую модель вы собираетесь задействовать: ООП, логическое, структурное или функциональное программирование? Или вы вообще планируете придумать нечто новое, чего раньше еще не было?
- Будет ли ваш язык интегрироваться с другими?
- Предусмотрен ли в языке базовый функционал или всё будет работать за счет внешних библиотек?
- Каким будет архитектурное построение программы?
Продумав все эти моменты, вы сформируете общий вид нового языка. В процессе возникнут и иные важные вопросы, с ними тоже нужно будет разобраться.
В процессе возникнут и иные важные вопросы, с ними тоже нужно будет разобраться.
Шаг 5. Продумайте синтаксис.
Служебные спецсимволы позволят машине работать быстрее, но потенциальных пользователей они могут спугнуть. Это касается и функциональных возможностей, придется выбирать между интуитивно понятными и самыми производительными.
Шаг 6. Придумайте название.
Пожалуй, один из самых простых шагов. Не пытайтесь заложить в название некий углубленный смысл, дайте короткое и простое имя, которое легко запомнится. Именно так, кстати, чаще всего и поступают разработчики. Заумные необычные аббревиатуры и длинные названия быстро забываются и для пользователей выглядят непривлекательно.
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
pdf 3,7mb
doc 1,7mb
Уже скачали 20270
Шаг 7. Определитесь с языком написания языка.
Определитесь с языком написания языка.
Помешанные на высоких технологиях гики готовы задействовать для этого машинные коды или язык ассемблера. Но в современных реалиях есть смысл заниматься созданием языков программирования на компилируемых языках Pascal, C, C++, C#, Swift (для интерпретируемого кода) и на интерпретируемых языках Java, JavaScript, Python, Ruby (для написания компилируемого кода). Это на выходе дает максимальную производительность.
Язык написания языка программированияШаг 8. Создайте лексер и парсер.
Это специальные инструменты в коде. Лексер проводит анализ лексики, следит за разбиением программы на токены (специальные составляющие). Парсер анализирует синтаксис, определяет иерархию токенов и порядок их взаимодействия. На графической схеме всё это выглядит понятнее.
Только не пугайтесь данного шага. Лексеры и парсеры создаются с помощью готовых приложений и библиотек, так что процесс получается не таким сложным, как может показаться на первый взгляд.
Шаг 9. Сформируйте стандартную библиотеку.
В ней необходимо собрать функции, с помощью которых будет возможна примерная демонстрация имеющихся программных возможностей. При этом неважно, предусмотрены в языке встроенные опции для задействования базового функционала или для этого нужно обращаться к внешним библиотекам.
Шаг 10. Напишите громадное количество текстов.
Мало создать язык, важно еще добиться от него корректной работы. А для этого понадобятся специальные тексты, которые будут указывать системе допустимые и недопустимые действия. Еще их задача – исключение возможности возникновения тупиковых для программы ситуаций.
Только до 6.04
Скачай подборку тестов, чтобы определить свои самые конкурентные скиллы
Список документов:
Тест на определение компетенций
Чек-лист «Как избежать обмана при трудоустройстве»
Инструкция по выходу из выгорания
Чтобы получить файл, укажите e-mail:
Подтвердите, что вы не робот,
указав номер телефона:
Уже скачали 7503
Шаг 11. Представьте язык миру.
Представьте язык миру.
Не прячьте свое детище. Пусть вы не ставили перед собой глобальных целей, но публикация откроет перед вами новые возможности. Откликнутся единомышленники, пользователи оставят отзывы, вы поймете, какие места требуют доработок, улучшений. Да и вообще, вы почувствуете свою полезность в качестве программиста.
Книги про создание языка программирования с нуля
Возможно, и есть книги с четким описанием процесса создания языка программирования, но пока что не нашлось таких материалов, которые можно было бы привести здесь в качестве примеров. Тут следует понимать, что каждый опыт разработки по-своему уникален, такие процессы просто не бывают абсолютно одинаковыми. Есть все же описания, так или иначе затрагивающие тему проектирования языков.
Например, работа А. В. Хохлова под названием «Как создать язык программирования и транслятор». Книга хорошая, но тут всё же больше про транслятор. Процессам выбора тех или иных решений внимания не уделено, а между тем, было бы интересно проследить за ходом мыслей автора.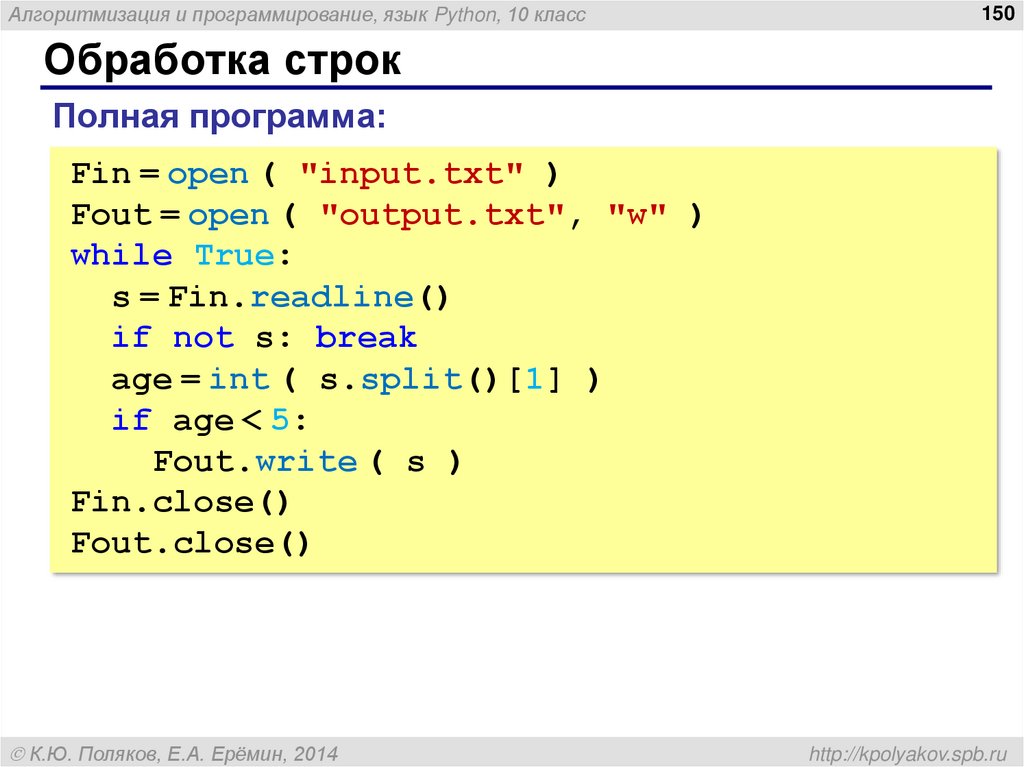 Может быть в скором времени он об этом еще расскажет.
Может быть в скором времени он об этом еще расскажет.
Если говорить об иностранных авторах, то можно привести в пример «Концепцию языков программирования» от Роберта Себесты. Книга, безусловно, хорошая, ее нужно прочесть. Но опять же, содержание здесь целиком соответствует названию, то есть речь идет не конкретно про создание языков программирования.
Для тех, кто задумался о создании языка программирования, есть неплохая книга «Теоретические основы разработки и реализации языков программирования». Авторы – отечественные разработчики М. М. Гавриков, А. Н. Иванченко, Д. В. Гринченков. Но и здесь следует сделать уточнение, что книга больше не про «разработку», а про «реализацию».
Она состоит из следующих глав: «Способы задания формальных языков», «Основы теории перевода и её применение к синтаксическому анализу», «Конструирование сканеров», «Применение КС-языков и грамматик в разработке языков программирования». Как можно понять по названиям, тематика в полной мере раскрывает процесс создания компиляторов.
Работы интересные, полезные, раскрывающие важные темы, но именно процесс проектирования языков детально в них не описывается.
А реально ли в одиночку написать язык программирования?
Тут стоит упомянуть об одном парадоксальном моменте: как правило, язык с самым простым описанием в применении может оказаться самым сложным. Существуют эзотерические языки с сотнями байт дистрибутива. Их практическое использование вообще не представляется возможным, но в качестве творческой площадки – вполне. С их помощью можно учиться разбираться в создании более сложных кодов.
Написать что-то такое, чем потом можно будет реально пользоваться, очень трудно, и уж тем более – в одиночку. К примеру, неслучайно в Microsoft долгие годы был в ходу язык Си, созданный еще в далеком 1973 году. Да, безусловно, можно привести примеры людей, самостоятельно создававших шедевры. Но процесс разработки ПО за последние десятки лет очень усложнился, и подобные подвиги уже вряд ли возможны. Язык без удобной среды разработки поддерживать никто не станет.
В создании качественных продуктов обычно участвуют целые команды профессионалов-энтузиастов. При необходимости вы найдете их на GitHub. Став членом одной из таких команд, вы найдете практическое применение своим знаниям, попробуете себя в деле.
Онлайн-курсы по изучению и созданию языков программирования
В нынешнее время с учетом эпидемиологической обстановки все большую актуальность приобретает удаленное обучение, причем это работает во многих областях. Данный формат набирает популярность во всем мире, и, пожалуй, это только начало.
Чем хорош удаленный процесс обучения? Тем, что не нужно никуда ехать или идти. На качестве знаний это никак не отражается, главное – самодисциплина и грамотное распределение времени.
Кроме того, здесь вы сами выбираете, кто станет вашим преподавателем. Хотите поменять – пожалуйста. Есть возможность общения с другими слушателями курса. По сути – это такое же обучение, как и офлайн.
Сфера ПО и, в частности, создание языков программирования – тематика сложная, требующая очень серьезного отношения. Айтишники в процессе работы занимаются решением серьезных логических задач, пишут уникальные сложнейшие коды.
И если вы только начинаете осваивать данную тему, вам понадобится всё ваше внимание и сосредоточенность. Обязательно переспрашивайте непонятные моменты, не стесняйтесь активно общаться с преподавателем.
Большое количество курсов и мастер-классов собрано на образовательном портале GeekBrains. Есть и возможность стажировки после обучения.
Продвижение блога — Генератор продаж
Рейтинг: 2
( голосов 4 )
Поделиться статьей
Как создать новый язык программирования
Вы устали от того, что просто использует языка программирования для работы, не зная, как он работает? Хотите знать, что происходит внутри машины после того, как вы закончите писать свой код?
Ну, ты не один такой. И вы узнаете об этом все, прочитав эту статью.
И вы узнаете об этом все, прочитав эту статью.
Как оказалось, есть три концепции, каждая из которых очень близка к другой:
- Как работает язык программирования, изнутри.
- Как работает компилятор.
- Как создать новый язык программирования.
В конечном счете, я думаю, что третий пункт — это то, что интересует каждого любопытного студента, такого как мы. Так что нам повезло, что это все похожие понятия!
Как создать новый язык программирования
Начну с забавного вопроса. По данным Google, в мире насчитывается около 26 миллионов разработчиков программного обеспечения. Как вы думаете, сколько из них знают, как создать новый язык программирования?
Бьюсь об заклад, их очень мало. На самом деле, я не проходил обучение по этому поводу, когда был студентом колледжа.
Причина в том, что очень немногие разработчики являются настоящими учеными-компьютерщиками , и даже среди последней группы лишь немногие из них изучали формальные языки и компиляторы.
Программисты люди практичные: компилируется ли? Кажется, это работает? Хорошо, тогда нажимай.
Немногие программисты обучены мыслить формально . Кроме того, создание языка программирования — это задача, гораздо более близкая к науке и искусству, чем к чистому кодированию (хотя, конечно, кодить тоже нужно много).
А ведь это так многому учит! Здесь так много увлекательных шагов и возможностей узнать о:
- Разработка программного обеспечения высокого уровня,
- Расширенные алгоритмы и структуры данных,
- Шаблоны программирования,
, все из которых, несомненно, будут чрезвычайно полезны в карьере разработчика. И ученый-компьютерщик. И инженер-программист.
Шаги по созданию языка программирования
С очень высокой точки зрения создание нового языка программирования включает в себя три основных этапа.
- Определение грамматики.
- Создайте интерфейсный компилятор для исходного кода.
- Создайте внутренний генератор кода.
Итак, вы начинаете с ручкой и листком бумаги, где вы определяете Грамматику вашего языка. Если вы не знаете, что такое формальная грамматика, то просто подумайте об этом как о грамматике человеческого языка (и прочитайте мою статью об этом).
Например, на человеческом языке можно сказать: «Предложение состоит из артикля, существительного и глагола». Затем естественная двусмысленность языка, в основном данная разговорной частью и человеческой природой, отбрасывает это правило.
На формальном языке, если ваша грамматика гласит: «Присвоение производится с помощью имени переменной, знака равенства (=) и числа», то это будет единственный способ, которым кто-то может создать экземпляр переменной в исходном коде программы. , иначе код не скомпилируется (или возникнет ошибка, если вы создаете интерпретируемый язык).
Короче говоря, формальная грамматика определяет, как должен выглядеть исходный код программы на этом языке.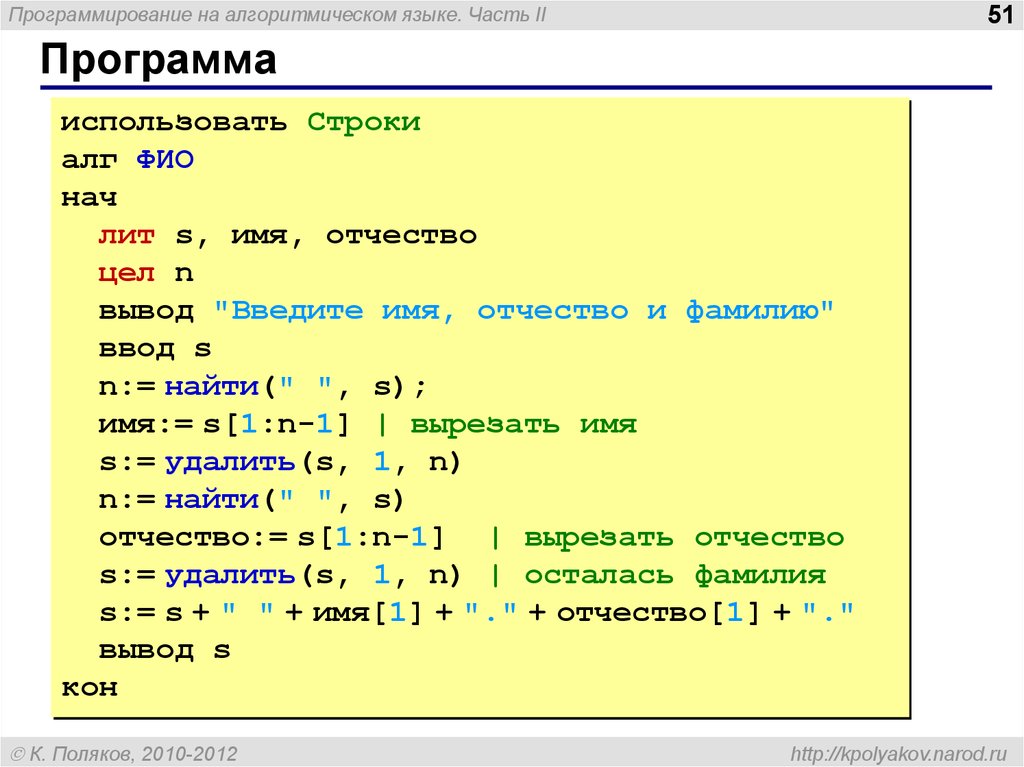 Речь идет о синтаксических правилах, которые программистам придется соблюдать для того, чтобы написать программу на вашем языке.
Речь идет о синтаксических правилах, которые программистам придется соблюдать для того, чтобы написать программу на вашем языке.
Front-End Compiler — это программа, которая берет исходный код и создает странную структуру данных. Подробнее об этом далее в статье.
Наконец, Генератор внутреннего кода — это еще одна часть программного обеспечения, которая берет все, что было создано внешним интерфейсом, и создает код, который действительно можно запустить.
Подождите. Это… можно запустить? Итак, все дело в том, что берет первоначальный исходный код и создает новый исходный код 9.0036 (что можно запустить)?
Да. Но тот, который машина может понять, часто называют Target Machine Code . Строго говоря, это означает, что в результате вы должны предоставить ассемблерный код, отдать его ассемблеру, который будет работать вместе с линкером/загрузчиком, а затем они вернут вам машинный код.
Тем не менее, многие сообразительные люди уже прошли через это в прошлом.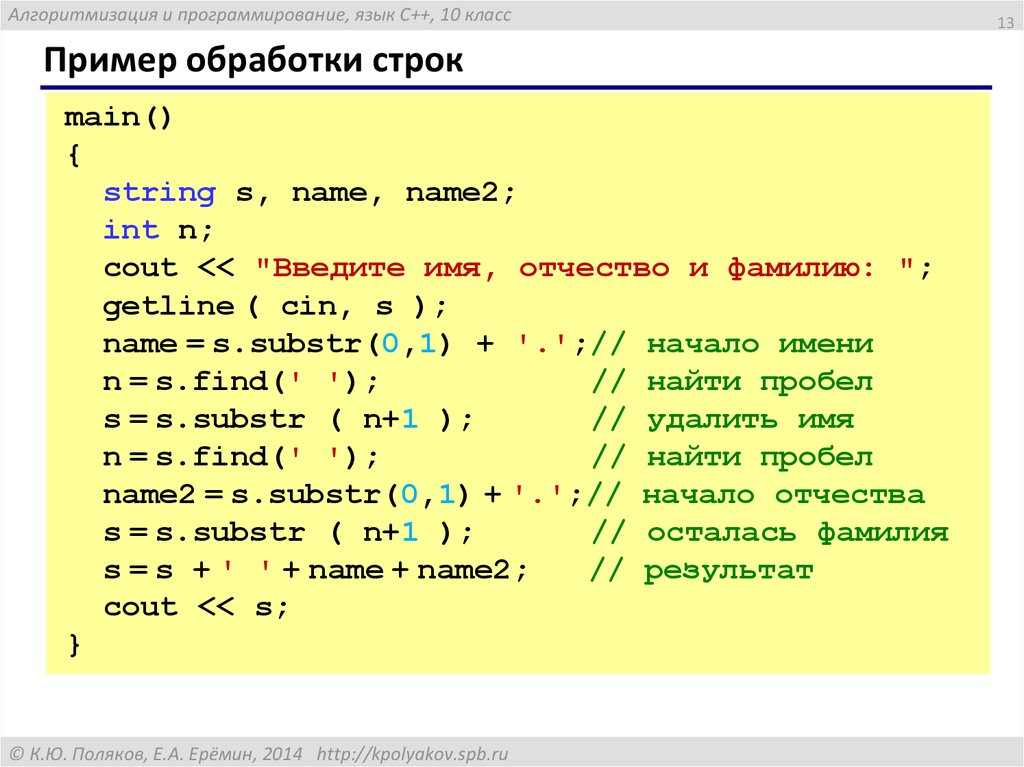 Таким образом, очень часто новые языки программирования просто переводятся на существующие языки программирования, для которых уже существует компилятор.
Таким образом, очень часто новые языки программирования просто переводятся на существующие языки программирования, для которых уже существует компилятор.
Например, при разработке нового языка вы можете решить, что ваш компилятор вместо создания машинного кода генерирует код C, который затем передается компилятору C. Это стандартный подход, и он не отнимет у вас ни одной забавной части написания компилятора: вам все равно нужно будет его собрать.
Но тогда что значит написать компилятор? Давайте посмотрим.
Шаги по созданию компилятора для языка программирования
Создание серьезного компилятора для сложного языка программирования — адская задача. Нужна большая команда квалифицированных специалистов.
Например, для компилятора FORTRAN 1 потребовалось около 3 лет. Созданный для научных вычислений, язык FORTRAN изменил правила игры в этой области и до сих пор широко используется. Они проделали хорошую работу и в значительной степени изменили историю вычислительной техники.
Несмотря на пугающую сложность, у компиляторов всего 5 основных частей:
- Лексический анализ . Распознавайте ключевые слова языка, операторы, константы и каждый токен, который определяет грамматика.
- Разбор . Поток токенов «понятен» в том смысле, что отношение между каждой парой токенов закодировано в древовидной структуре данных. Такое дерево предназначено для описания значения операций в каждой строке исходного кода.
- Семантический анализ . Вероятно, самый неясный из всех шагов. В основном включает в себя понимание типов и проверку несоответствий в «значении» исходного кода (не только в синтаксисе). Жесткий.
- Оптимизация . Независимо от того, насколько хорош исходный код до компиляции, есть вероятность, что при переходе на более низкие уровни кодирования (до машинного кода) можно реализовать несколько оптимизаций. Такие вещи, как оптимизация памяти или даже оптимизация энергопотребления. И, конечно же, оптимизация времени выполнения.
- Генерация кода . Оптимизированная версия исходного кода, наконец, преобразуется в исполняемый код.
 И, конечно же, оптимизация времени выполнения.
И, конечно же, оптимизация времени выполнения.Несмотря на то, что эти пять шагов по созданию компилятора не изменились за несколько десятилетий, сложность и время, затрачиваемое на каждый из них, сильно изменились.
Первый компилятор для FORTRAN создавался с 1954 по 1957 год. В то время все шаги, кроме семантического анализа, были очень сложными, что также объясняет, почему на получение результата ушло 3 года.
В настоящее время, вместо этого, несколько шагов стали почти автоматическими. Если вы определяете свою собственную формальную грамматику и делаете это хорошо, вы можете использовать программное обеспечение, которое автоматически выполняет лексический анализ, синтаксический анализ и генерацию кода.
Сегодня команды, которые создают и поддерживают компилятор, в основном сосредоточены на шаге оптимизации. Это стало чрезвычайно важным, особенно учитывая большой прогресс в области аппаратного обеспечения. Шаги семантического анализа также достаточно сложны, хотя и не так сильно, как оптимизация.
Это стало чрезвычайно важным, особенно учитывая большой прогресс в области аппаратного обеспечения. Шаги семантического анализа также достаточно сложны, хотя и не так сильно, как оптимизация.
Рассмотрим подробнее каждый шаг.
Лексический анализ
Этот шаг начинается непосредственно с формальной грамматики.
Допустим, вы хотите создать язык для представления минималистичных арифметических операций. Ваша грамматика может выглядеть следующим образом:
программа: [выражение";"]*
выражение: присваивание
присваивание : результат "=" операция
операция: переменная оператор переменная
оператор: "+" | "-" | "*" | "/"
переменная: "1" | "2" | "3" | "4" | "5"
| "6" | "7" | "8" | "9" | "0"
результат: "L" | "О" Это действительно плохой пример, но он полезен для иллюстрации. Вы можете прочитать приведенную выше грамматику как:
Программа состоит из нуля или более Выражений , за которыми следует точка с запятой (фигурные скобки означают «ноль или более» того, что находится внутри них). Выражение может быть только Присвоением . Назначение выполняется с помощью Результата , за которым следует знак Равно , за которым следует Операция . Операция выполняется Переменной , за которой следует Оператор , затем еще одна Переменная. Оператор должен быть символом из четырех вариантов: «+», «-», «*», «/» (символы в двойных кавычках являются терминальными токенами). Переменная должна быть символом из десяти вариантов (десять цифр). Результатом должен быть либо символ «L», либо символ «O».
Выражение может быть только Присвоением . Назначение выполняется с помощью Результата , за которым следует знак Равно , за которым следует Операция . Операция выполняется Переменной , за которой следует Оператор , затем еще одна Переменная. Оператор должен быть символом из четырех вариантов: «+», «-», «*», «/» (символы в двойных кавычках являются терминальными токенами). Переменная должна быть символом из десяти вариантов (десять цифр). Результатом должен быть либо символ «L», либо символ «O».
Если вы сейчас остановитесь всего на одну минуту и подумаете, то поймете, что с помощью этой глупой грамматики можно представить только последовательность сложений, вычитаний, умножений и делений между двумя маленькими целыми числами (от 0 до 9).включены). Последовательность также может быть пустой, а если это не так, то элементы в ней должны быть разделены точкой с запятой. Да, и результат каждой операции может быть назван только либо «L», либо «O».
Да, и результат каждой операции может быть назван только либо «L», либо «O».
Действительный «исходный код» может выглядеть как
.О = 2 + 3; Л = 5*2; …
Он тупой и с ним ничего не сделаешь. Но я могу объяснить, как работает шаг лексического анализа! Ваш лексический анализатор просматривает исходный код и идентифицирует каждый токен вместе с его типом в соответствии с грамматикой. Таким образом, результат лексического анализатора для 2-х строк выше будет:
"О" - результат "2" - вар "+" - оператор "3" - вар "Л" - результат "5" - вар "*" - оператор "2" - вар
Должно быть легко понять, почему существуют программные инструменты, которые выполняют эту задачу для любой четко определенной грамматики. На самом деле, если вы сделали это вручную один раз, то становится скучно делать это снова.
Разбор
Парсер возьмет список токенов (результат предыдущего шага) и создаст древовидную структуру, предназначенную для описания «значения» исходного кода. В предыдущем примере (глупые арифметические операции) дерево отражает реальные операции:
В предыдущем примере (глупые арифметические операции) дерево отражает реальные операции:
С некоторым упрощением можно предположить, что дерево на самом деле не нужно. Простого знания листьев дерева может быть достаточно для общей цели компиляции исходного кода. В любом случае, каждый парсер может действовать по-разному, но многие из них не хранят в памяти фактическое дерево.
Семантический анализ
Если вы строите язык со статическими типами или другими нюансами, то на этом шаге вам нужно будет проверить, не делает ли пользователь глупостей. Имейте в виду, что пользователь также является программистом!
Этот шаг очень сложен, особенно если речь идет о привязке переменных. Рассмотрим следующий фрагмент кода на Python.
по определению foo(foo):
вернуть фу + фу
значение = 5
print(foo(val)) # >> 10
защита foo2 (foo2):
вернуть foo + foo2
фу = вал
print(foo2(7)) # >> 12 Это явно нехороший код . Но давайте теперь посмотрим на это более внимательно.
Можете ли вы представить, какой беспорядок для интерпретатора Python, чтобы понять, что вы делаете, называя ваши переменные foo, подпрограмму foo, аргумент этой подпрограммы foo и, конечно же, используя идентификатор foo внутри области действия подпрограммы с именем foo .
Связывание — это присвоение правильного значения (5, 7 или даже всего тела функции) правильному идентификатору ( foo , val , foo2 ) в соответствии с текущей областью. Семантический анализ заключается в том, чтобы понять, если вы что-то напутали.
Оптимизация
Этот шаг немного похож на редактирование текста после того, как он был написан первоначальным автором.
Однако у каждого редактора свои цели. Итак, как оптимизатор кода, вы можете сосредоточиться на сокращении использования памяти или времени выполнения. Но это также может быть связано с уменьшением количества обращений к базе данных. Или для снижения энергопотребления, или сетевых сообщений.
С таким количеством специализированного оборудования и множеством различных сетей, баз данных и архитектур неудивительно, что компиляторы могут довольно сильно варьировать способы оптимизации кода.
Отдельного упоминания в этой теме заслуживает так называемая Оптимизация потока данных .
В каждом осмысленном исходном коде интенсивно используются агрегированные структуры данных, такие как массивы, доступ к которым осуществляется на протяжении всей программы. Оптимизация потока данных — это термин, используемый для улучшения того, что программист делал со структурами данных в своей программе, чтобы сделать общее выполнение более эффективным.
Генерация кода
Последний шаг, неофициально называемый CodeGen, в настоящее время также обычно автоматизируется. На самом деле, перевод из дерева синтаксического анализа на потенциально любой существующий язык является своего рода решенной проблемой.
Тем не менее, могут быть особые потребности или некоторые инновации в вашем компиляторе, которые заставят вас создать собственный генератор кода. Чаще всего вы переводите дерево синтаксического анализа либо в код ассемблера, либо в код C, который затем можно скомпилировать с помощью существующего компилятора C.
Чаще всего вы переводите дерево синтаксического анализа либо в код ассемблера, либо в код C, который затем можно скомпилировать с помощью существующего компилятора C.
Что дальше
Когда вы закончите внешний компилятор и внутренний генератор кода, вы будете более или менее готовы к работе. На GitHub существует забавный проект по созданию компилятора для Lisp на всех возможных языках (см. ссылки внизу).
По моему мнению, изучение теории языков и компиляторов стоит потраченного времени, потому что оно учит очень многому о реальной природе одной вещи, которую программисты часто используют: языков программирования.
Кроме того, это хороший повод узнать о шаблонах синтаксического анализа, алгоритмах рекурсивного спуска, области действия переменных и привязках (о которых вы уже должны знать!). Если вам когда-нибудь понадобится повод, чтобы чему-то научиться.
Как обычно в технике, практическая часть тоже имеет первостепенное значение. Подробнее об этом в следующих статьях.
Каталожные номера
Моя статья Что такое грамматика языка программирования?
Книга Дракона. Компиляторы: принципы, методы и инструменты. Страница в Википедии (книги).
Шаблоны языковой реализации. Книга профессора Терренса Парра.
Компиляторы класса Алекса Эйкена в Стэнфордском университете. Доступен в виде бесплатного онлайн-курса MOOC.
Проект GitHub, упомянутый в статье: https://github.com/kanaka/mal.
Как мне создать язык программирования?
Как мне создать язык программирования?Инструмент
Веб-сайт tomassetti.me изменился: теперь он является частью strumenta.com. Вы по-прежнему будете находить все новости в обычном качестве, но в новом оформлении.
Название этой статьи отражает вопрос, который я снова и снова слышу на форумах или в электронных письмах.
Думаю, все любознательные разработчики хотя бы раз его спрашивали.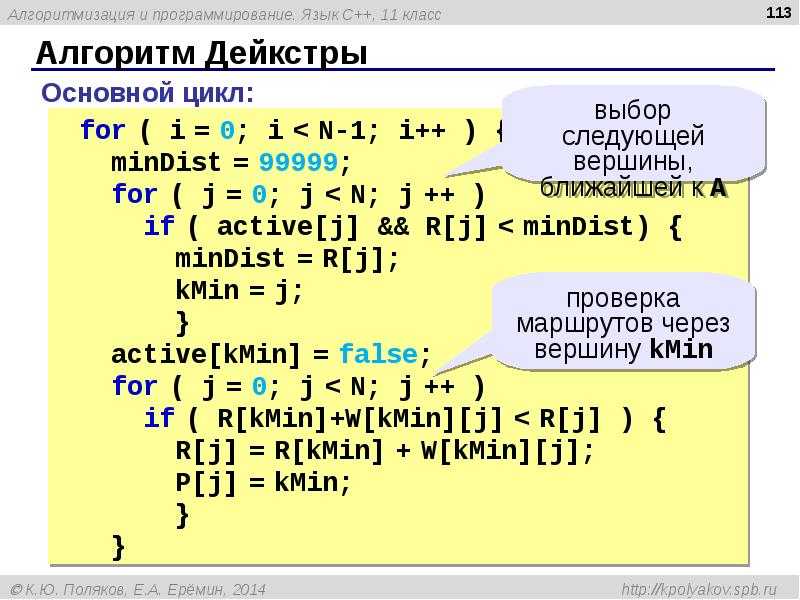 Это нормально быть очарованным тем, как работают языки программирования. К сожалению, большинство ответов, которые мы читаем, носят академический или теоретический характер. Некоторые другие содержат слишком много деталей реализации. Прочитав их, мы до сих пор удивляемся, как все работает на практике .
Это нормально быть очарованным тем, как работают языки программирования. К сожалению, большинство ответов, которые мы читаем, носят академический или теоретический характер. Некоторые другие содержат слишком много деталей реализации. Прочитав их, мы до сих пор удивляемся, как все работает на практике .
Итак, мы собираемся ответить на него. Да, мы увидим, каков процесс создания вашего собственного полного языка с компилятором для него, а что нет.
Обзор
Большинство людей, которые хотят научиться «создавать язык программирования», фактически ищут информацию о том, как создать компилятор. Они хотят понять механику, позволяющую выполнять новый язык программирования.
Компилятор является фундаментальной частью головоломки, но для создания нового языка программирования требуется нечто большее:
1) Язык должен быть разработан : создатель языка должен принять некоторые фундаментальные решения относительно используемых парадигм и синтаксис языка
2) Должен быть создан компилятор
3) Должна быть реализована стандартная библиотека
4) Должны быть предоставлены вспомогательные инструменты, такие как редакторы и системы сборки
Давайте подробнее рассмотрим, что влечет за собой каждый из этих пунктов.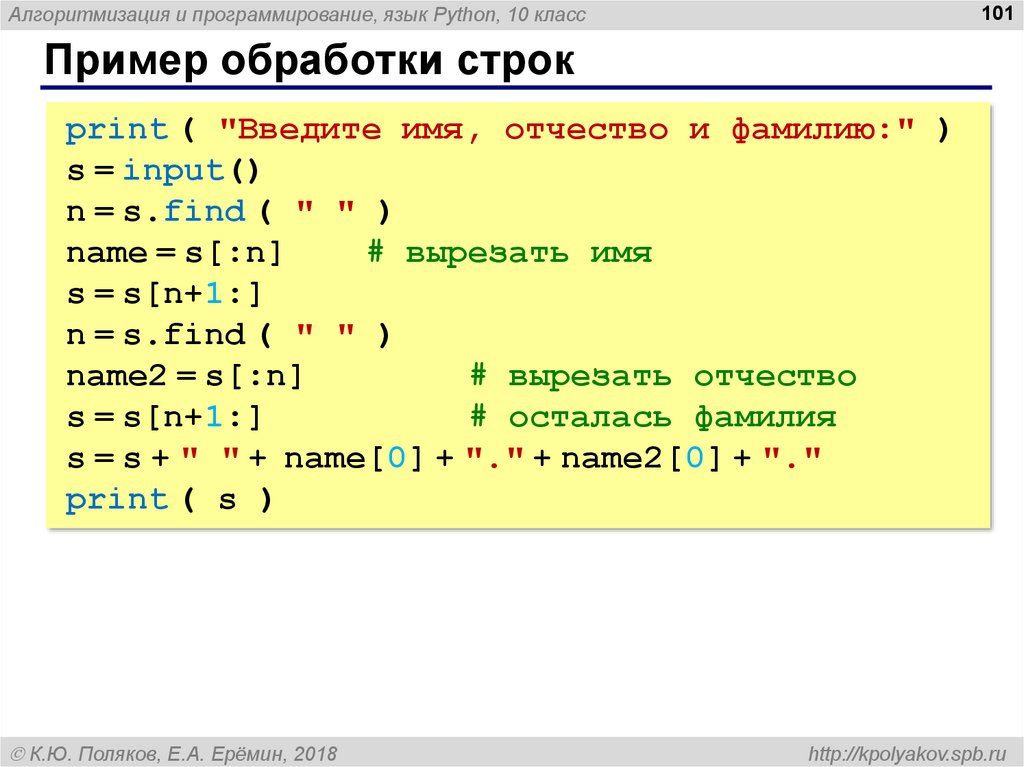
Разработка языка программирования
Если вы хотите просто написать свой собственный компилятор, чтобы узнать, как все это работает, вы можете пропустить этот этап. Вы можете просто взять подмножество существующего языка или придумать его простую вариацию и приступить к работе. Однако, если у вас есть планы по созданию собственного языка программирования, вам придется подумать об этом.
Я думаю, что проектирование языка программирования можно разделить на две фазы:
- Фаза общей картины
- Фаза уточнения
На первой фазе мы отвечаем на основные вопросы о нашем языке.
- Какую парадигму выполнения мы хотим использовать? Будет ли он императивным или функциональным? Или, может быть, на основе автоматов состояний или бизнес-правил?
- Нам нужна статическая или динамическая типизация?
- Для каких программ лучше всего подходит этот язык? Будет ли он использоваться для небольших сценариев или больших систем?
- Что для нас важнее всего: производительность? Читаемость?
- Хотим ли мы, чтобы он был похож на существующий язык программирования? Будет ли он предназначен для разработчиков C или будет простым в освоении для тех, кто пришел из Python?
- Хотим ли мы, чтобы он работал на определенной платформе (JVM, CLR)?
- Какие возможности метапрограммирования мы хотим поддерживать, если таковые имеются? Макросы? Шаблоны? Отражение?
На втором этапе мы продолжим развивать язык по мере его использования. Мы столкнемся с проблемами, с вещами, которые очень трудно или невозможно выразить на нашем языке, и в конечном итоге мы будем его развивать. Второй этап может быть не таким гламурным, как первый, но это этап, на котором мы продолжаем настраивать наш язык, чтобы сделать его пригодным для использования на практике, поэтому мы не должны его недооценивать.
Мы столкнемся с проблемами, с вещами, которые очень трудно или невозможно выразить на нашем языке, и в конечном итоге мы будем его развивать. Второй этап может быть не таким гламурным, как первый, но это этап, на котором мы продолжаем настраивать наш язык, чтобы сделать его пригодным для использования на практике, поэтому мы не должны его недооценивать.
Создание компилятора
Создание компилятора — самый захватывающий шаг в создании языка программирования. Когда у нас есть компилятор, мы действительно можем воплотить наш язык в жизнь. Компилятор позволяет нам начать играть с языком, использовать его и определить, что нам не хватает в первоначальном дизайне. Это позволяет увидеть первые результаты. Трудно превзойти радость выполнения первой программы, написанной на нашем совершенно новом языке программирования, какой бы простой она ни была.
Но как построить компилятор?
Как и все сложное, мы делаем это пошагово:
- Строим парсер : парсер — это часть нашего компилятора, которая берет текст наших программ и понимает, какие команды они выражают. Он распознает выражения, операторы, классы и создает внутренние структуры данных для их представления. Остальная часть парсера будет работать с этими структурами данных, а не с исходным текстом
- (необязательно) Мы переводим дерево разбора в абстрактное синтаксическое дерево . Обычно структуры данных, создаваемые синтаксическим анализатором, имеют низкоуровневый уровень, поскольку содержат множество деталей, не являющихся критическими для нашего компилятора. Из-за этого мы хотим часто переставлять структуры данных во что-то чуть более высокого уровня
- Разрешаем символы . В коде мы пишем что-то вроде
a + 1. Наш компилятор должен выяснить, на что ссылаетсяи. Это поле? Это переменная? Это параметр метода? Мы изучаем код, чтобы ответить, что - Проверяем дерево . Нам нужно проверить, не допустил ли программист ошибок. Он пытается суммировать логическое значение и целое число? Или доступ к несуществующему полю? Нам нужно выдать соответствующие сообщения об ошибках
- Генерируем машинный код . На этом этапе мы переводим код во что-то, что машина может выполнить. Это может быть правильный машинный код или байт-код для какой-нибудь виртуальной машины
- (опционально) Выполняем линковку . В некоторых случаях нам нужно объединить машинный код, созданный для наших программ, с кодом статических библиотек, которые мы хотим включить, чтобы сгенерировать один исполняемый файл 9.0012
 Он распознает выражения, операторы, классы и создает внутренние структуры данных для их представления. Остальная часть парсера будет работать с этими структурами данных, а не с исходным текстом
Он распознает выражения, операторы, классы и создает внутренние структуры данных для их представления. Остальная часть парсера будет работать с этими структурами данных, а не с исходным текстом На этом этапе мы переводим код во что-то, что машина может выполнить. Это может быть правильный машинный код или байт-код для какой-нибудь виртуальной машины
На этом этапе мы переводим код во что-то, что машина может выполнить. Это может быть правильный машинный код или байт-код для какой-нибудь виртуальной машиныВсегда ли нам нужен компилятор? Нет. Мы можем заменить его другими средствами для выполнения кода:
- Мы можем написать интерпретатор: интерпретатор — это, по сути, программа, которая выполняет шаги 1-4 компилятора, а затем непосредственно выполняет то, что указано в абстрактном синтаксическом дереве.
- Мы можем написать транспилятор: транспилятор будет делать то, что указано в шагах 1-4, а затем выводить код на каком-то языке, для которого у нас уже есть компилятор (например, C++ или Java)
Эти два варианта вполне допустимы, и часто имеет смысл выбрать один из них, потому что требуемые усилия обычно меньше.
Мы написали статью, объясняющую, как написать транспилятор. Взгляните на него, если хотите увидеть практический пример с кодом.
В этой статье мы более подробно объясняем разницу между компилятором и интерпретатором.
Стандартная библиотека для вашего языка программирования
Любой язык программирования должен делать несколько вещей:
- Печать на экране
- Доступ к файловой системе
- Использование сетевых подключений
- Создание графических интерфейсов
Это основные функции для взаимодействия с остальной системой. Без них язык практически бесполезен. Как мы предоставляем эти функции? Создав стандартную библиотеку. Это будет набор функций или классов, которые можно вызывать в программах, написанных на нашем языке программирования, но которые будут написаны на каком-то другом языке. Например, многие языки имеют стандартные библиотеки, хотя бы частично написанные на C.
Стандартная библиотека может содержать гораздо больше. Например, классы для представления основных коллекций, таких как списки и карты, или для обработки распространенных форматов, таких как JSON или XML. Часто он будет содержать расширенные функции для обработки строк и регулярных выражений.
Например, классы для представления основных коллекций, таких как списки и карты, или для обработки распространенных форматов, таких как JSON или XML. Часто он будет содержать расширенные функции для обработки строк и регулярных выражений.
Другими словами, написание стандартной библиотеки требует много работы. Это не гламурно, концептуально не так интересно, как написание компилятора, но по-прежнему является фундаментальным компонентом, делающим язык программирования жизнеспособным.
Есть способы обойти это требование. Один из них — заставить язык работать на какой-то платформе и сделать возможным повторное использование стандартной библиотеки другого языка. Например, все языки, работающие на JVM, могут просто повторно использовать стандартную библиотеку Java.
Вспомогательные инструменты для нового языка программирования
Чтобы язык можно было использовать на практике, нам часто приходится писать несколько вспомогательных инструментов.
Наиболее очевидным является редактор. Специализированный редактор с подсветкой синтаксиса, встроенной проверкой ошибок и автозавершением в настоящее время необходим любому разработчику.
Специализированный редактор с подсветкой синтаксиса, встроенной проверкой ошибок и автозавершением в настоящее время необходим любому разработчику.
Но сегодня разработчики избалованы и будут ожидать всевозможных других вспомогательных инструментов. Например, отладчик может быть очень полезен для устранения неприятной ошибки. Или система сборки, похожая на maven или gradle, может быть чем-то, что пользователи спросят позже.
В самом начале редактора может быть достаточно, но по мере роста вашей пользовательской базы будет расти и сложность проектов, и потребуется больше вспомогательных инструментов. Надеюсь, к тому времени найдется сообщество, готовое помочь в их создании.
Резюме
Создание языка программирования — процесс, который многим разработчикам кажется загадочным. В этой статье мы попытались показать, что это всего лишь процесс. Это увлекательно и не просто, но это можно сделать.
Вы можете захотеть создать язык программирования по разным причинам.